
Фундаментальные алгоритмы на C++ часть 1-4 (Роберт Седжвик) 2001

1 В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
В.Е. Снитюк
ПРОГНОЗИРОВАНИЕ. Модели, Методы, Алгоритмы
Учебное пособие
Киев - 2008

2 В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
ББК 32.97я73 УДК 004.89 (075.8) С 53 Рецензенты: академик НАН Украины (Международный на-
учно-учебный центр информационных технологий и систем НАН Ук-раины и Министерства образования и науки Украины);
доктор технических наук, профессор Зайченко Ю.П. (Институт при-кладного системного анализа НТУУ “КПИ”);
доктор технических наук, профессор Куссуль Н.Н. (Институт косми-ческих исследований НАН Украины).
С н и т ю к В. Е. Прогнозирование. Модели, методы, алгоритмы:
учебное пособие. – К.: «Маклаут», 2008. – 364 с. ISBN 978-966-2200-09-6 Аннотация Пособие является первым изданием в серии "Интеллектуальные ин-
формационные системы", в котором приведены элементы классических и современных технологий прогнозирования, базирующиеся на дедуктив-ном и индуктивном подходах. Его логическая структура предусматривает сквозное сопровождение процессов прогнозирования: от формирования исходной информации, определения значимых факторов, увеличения их информативности – к выбору методов прогнозирования и их реализации в информационно-аналитических системах. Элементный базис пособия составляют регрессионные методы, которые, кроме самостоятельного зна-чения, лежат в основании других методов; нейросетевые, эволюционные методы и методы теории нечетких множеств как составляющие техноло-гии Soft Computing; задачи восстановления информации и кластеризации как самостоятельные задачи прогнозирования, а также как такие, реше-ние которых является необходимым условием эффективного прогнози-рования; методы препроцессинга данных и композиционные методы.
Каждую структурную единицу учебного пособия формируют мо-дели, методы и алгоритмы, оптимизирующие процесс разработки или использования систем анализа данных и прогнозирования. Его особенно-стью является наличие в каждой главе заданий для самостоятельной ра-боты, практических задач, в т.ч. и проблемного характера, библиографии, а также информации справочного характера в приложениях, что способ-ствует более полному изучению изложенных технологий и знакомству с новыми.
Пособие рассчитано на студентов, изучающих курсы, связанные с ин-теллектуальными информационными системами, аналитической обра-боткой информации, распознаванием образов, другими задачами искус-ственного интеллекта. Оно будет также полезно социологам, экономи-стам, специалистам в области теории и практики прогнозирования.
Ивахненко А.Г.

3 В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
Тем, Кто помнит, мечтает и верит… Содержание
Предисловие 8 Введение 13
Глава 1
Классические методы
1.1. Метод наименьших квадратов. Парная линейная регрессия
17
1.2. Множественная линейная регрессия 20 1.3. Тестирование и устранение мультиколлинеарно-
сти
23 1.4. Тестирование и устранение гетероскедастичнос-
ти
31 1.5. Автокорреляция. Причины и следствия 35 1.6. Множественная нелинейная регрессия 38
Практические задания 40 Контрольные вопросы и задания для самопроверки 41 Темы рефератов и расчетно-графических работ 42 Темы для самостоятельной работы
42
Глава 2
Нейросетевые методы
2.1. Основные понятия 45 2.2. Алгоритм обратного распространения ошибки и
прогнозирование
48 2.3. Алгоритм обучения RBF-сети и ее использование
для прогнозирования
56 2.4. Сети встречного распространения–инструмента-
рий предварительного прогнозирования
60 Практические задания 65 Контрольные вопросы и задания для самопроверки 68 Темы рефератов и расчетно-графических работ 69 Темы для самостоятельной работы 70

4 В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
Глава 3
Эволюционное моделирование и методы самоорганизации
3.1. Метод группового учета аргументов. Общие поло-жения
75
3.2. Многорядный метод группового учета аргументов 76 3.3. Критерий регулярности 78 3.4. Критерий несмещенности 80 3.5. Критерий баланса переменных 83 3.6. Алгоритм разделения начальной выборки данных 85 3.7. Ретроспектива эволюционного моделирования 86 3.8. Генетический алгоритм. Историческая справка и
базовые элементы
88 3.9. Основные понятия и пример задачи 90
3.10. Элементный и функциональный базис генетичес-кого алгоритма
91
3.11. Эволюционные стратегии 97 3.12. Сравнительный анализ эволюционных алгоритмов 100 3.13. Мировые научные школы эволюционного моделиро-
вания 101
Практические задания 103 Контрольные вопросы и задания для самопроверки 104 Темы рефератов и расчетно-графических работ 107 Темы для самостоятельной работы 107
Глава 4
Методы обработки нечеткой информации
4.1. Основные понятия и определения 114 4.2. Нечеткие отношения и нечеткий логический вывод 119 4.3. Анализ нечетких экспертных заключений 126
4.4. Принятие решений в нечетких условиях 128 Практические задания 130 Контрольные вопросы и задания для самопроверки 131 Темы рефератов и расчетно-графических работ 132 Темы для самостоятельной работы 133

5 В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
Глава 5
Препроцессинг информации
5.1. Энтропия и количество информации 136 5.2. Нормализация и стандартизация начальных зна-
чений
138 5.3 Аналитико-эвристические алгоритмы определения
информативных признаков
140 5.4. Алгоритм “выбеливания” входов 143 5.5. Нейросетевое определение значимых факторов 145 5.6. Методика “box-counting” 147
Практические задания 150 Контрольные вопросы и задания для самопроверки 151 Темы рефератов и расчетно-графических работ 152 Темы для самостоятельной работы 153
Глава 6
Методы кластеризации
6.1. Постановка задачи и ее предварительный анализ 156 6.2. Характеристика методов кластерного анализа 158 6.3. Алгоритмы, базирующиеся на гипотезе компакт-
ности
164 6.4. Алгоритмы, базирующиеся на гипотезе лямбда-
компактности
165 6.5. Растущие пирамидальные сети 168 6.6. Эволюционная кластеризация 176
Практические задания 182 Контрольные вопросы и задания для самопроверки 185 Темы рефератов и расчетно-графических работ 186 Темы для самостоятельной работы 188
Глава 7
Восстановление информации
7.1. Математическая постановка задачи восстановления пропусков в таблицах данных
191

6 В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
7.2. Эвристические методы обработки некомплектных данных
193
7.3. Восстановление пропусков значений зависимой пе-ременной
195
7.4. Локальные методы восстановления пропусков 198 7.5. Итерационный метод главных компонент для дан-
ных с пропусками
203 7.6. ЕМ-алгоритм 207 7.7. Эволюционный метод восстановления пропусков 208
Практические задания 213 Контрольные вопросы и задания для самопроверки 215 Темы рефератов и расчетно-графических работ 216 Темы для самостоятельной работы 217
Глава 8
Гибридные методы. Практические приложения
8.1. Нечеткие нейросетевые парадигмы 222 8.2. Обучение нечетких нейросетей 228
8.3. Эволюционно-параметрическая оптимизация RBF-сети
233
8.4. «Синтетическая» оптимизация структуры сельсько-хозяйственного производства
243
8.5. Композиционный метод эволюционного модели-рования в проектных задачах
252
8.6. Композиционный метод уменьшения неопределенности
259
Контрольные вопросы и задания для самопроверки 264 Темы рефератов и расчетно-графических работ 265 Темы для самостоятельной работы 266
Глава 9
Другие методы Soft Computing
9.1. Муравьиные алгоритмы 269 9.2. Программирование генетических выражений 280 9.3. Нечеткие системы как универсальные аппрок-
симаторы 323

7 В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
Практические задания 336 Контрольные вопросы и задания для самопроверки 337 Темы рефератов и расчетно-графических работ 338
Темы для самостоятельной работы 338 Приложение А. Темы курсового проектирова-ния
340
Приложение Б. Базовые программные модули 347 Приложение В. Формирование пирамидальной растущей сети
353
Приложение Д. Статистические таблицы 360

8
От статистики – к анализу, от анализа – к прогнозированию, от прогнозирования – к планированию.
«Народная» мудрость
Предисловие
Процессы создания, функционирования и развития слож-ных природных и искусственных систем сопровождаются не-определенностью, которая является следствием размытости целей, неполноты исходной информации, субъективности представлений о будущих процессах и критериях их оценки. Уменьшение неопределенности достигается путем предвиде-ния и прогнозирования и, как следствие, объективизацией субъективных решений. В известной монографии Л. Фогеля, А. Оуэнса, М. Уолша "Искусственный интеллект и эволюци-онное моделирование" указано на то, что разумное поведение можно рассматривать как сочетание возможности предвидеть состояния внешней среды с преобразованием каждого пред-сказания в адекватную реакцию в соответствии с заданной целью. Такой вывод определяет роль прогнозирования как необходимого условия целенаправленной деятельности чело-века при решении задач анализа и синтеза, а также выбора оптимальных альтернатив.
Концепции и парадигмы, элементы которых представ-лены в пособии, базируются на определенных логико-фило-софских категориях, в том числе на индукции и дедукции. Понятие дедукции встречаем еще у Аристотеля и в широком смысле оно означает совокупность процессов научного мыш-ления, включающих в себя разделение и определение поня-тий, доказательство положений. Термин «индукция» впервые встречается у Сократа, где она интерпретируется как нахож-дение общего определения путем сравнения частных случаев и исключения ложных определений. Аристотель различал полную и неполную индукцию. Родоначальником современ-ного понятия индукции считают Ф. Бэкона, который указы-вал на то, что при обобщении необходимо соблюдать сле-дующее правило: сделать три обзора всех известных случаев

9
проявления известного свойства у различных предметов – обзор положительных и отрицательных случаев; обзор слу-чаев, в которых свойство проявляется в разной степени, и только тогда делать обобщения. Дальнейшее развитие поня-тие индукции получило в работах Дж. Ст. Милля.
Дедукция и индукция инцидентны понятиям анализа и синтеза. Сходство дедукции и анализа очевидно, поскольку анализ – прием мышления, через который происходит раз-ложение на составные части того, что является целым. Состав процесса дедукции включает следующие элементы: по-ложение, из которого делается вывод; собственно процесс вы-вода из указанного положения; заключение или положение, полученное из исходного положения. Положения, из которых делают выводы, сводятся к двум типам: очевидные истины и обобщения, полученные путем опытов.
Элементы обеих рассматриваемых категорий присутст-вуют в методах обработки информации и прогнозирования, которые рассмотрены в пособии. В частности, большинство приведенных задач решается с помощью дедуктивных схем, приоритетным в которых является изучение сущности отно-шений "причина-следствие". Представляют такой подход ме-тоды предварительной обработки данных, идентификация зависимости результирующей характеристики от входных факторов, если заданы ее структура и априорная информа-ция. Индуктивный подход реализован в методе группового учета аргументов и методе Брандона построения уравнения нелинейной множественной регрессии. Применение индук-тивной и дедуктивной парадигм наталкивается на опреде-ленные проблемы, основные из которых определены ниже. В частности, дедуктивный подход часто "коррелирует" с "про-клятием размерности".
В учебном пособии рассмотрены теоретические и при-кладные аспекты технологий прогнозирования, в основе ко-торых лежат классические и современные парадигмы. Заме-тим, что изучение задач прогнозирования, моделей, методов и средств их решения составляют часть учебного курса "Ин-формационные интеллектуальные системы". В частности, это модели, методы и алгоритмы, основанные на использовании

10
статистического анализа и метода наименьших квадратов, нейросетевые технологии, методы теории нечетких множеств, эволюционное и гибридное моделирование.
В первой главе представлен метод наименьших квадратов, который широко используется в подавляющем большинстве методов прогнозирования. Изложены проблемы, сопровож-дающие его применение при построении уравнений парной и множественной линейной регрессии, алгоритмы тестиро-вания таких явлений как мультиколлинеарность, гетероске-дастичность и автокорреляция. Для построения множествен-ной нелинейной регрессии рассмотрены аспекты примене-ния метода Брандона.
Основные нейросетевые парадигмы представлены в сле-дующей главе. Главная их особенность - минимальные тре-бования к составу и структуре исходной информации. Рас-смотрены квинтэссенция нейросетевых технологий - метод обратного распространения ошибки, а также сети встречного распространения и сети с радиально-базисными функциями активации.
Третья глава содержит описание технологий, базирую-щихся на идеях и принципах функционирования природных систем – естественного отбора, селекции и самоорганизации. В частности, это метод группового учета аргументов, с помо-щью которого получают сколь угодно сложные зависимости при минимальном априорном информационном обеспече-нии. Другую группу составляют эволюционные модели и ме-тоды. Определены аспекты применения генетического алго-ритма при решении задач оптимизации сложных зависимо-стей.
Третьей составляющей – представителем концепции "мяг-кой вычислений" по определению профессора Л. Заде явля-ется исчисление субъективных суждений с использованием методов теории нечетких множеств. В четвертой главе пред-ставлены основные понятия, алгоритмы нечеткого вывода и анализа нечетких экспертных заключений.
В пятой главе приведены методы и алгоритмы препроцес-синга данных, использование которых позволит повысить точность и скорость прогнозирования. Составляющими эле-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
11
ментами предварительной обработки данных является стан-дартизация и нормализация значений факторов, определе-ние наиболее информативных и значимых факторов. На уменьшение информационной энтропии направлены методы главных компонент, "выбеливания" входов и расчета кросс-энтропии.
Эффективность идентификации неизвестных зависимо-стей определяется качеством решения задачи кластеризации. В шестой главе представлены следующие группы методов кластеризации: классические, базирующиеся на методе пар-ных сравнений; методы, в основе которых лежит гипотеза компактности; эволюционные методы.
Еще одной из задач прогнозирования является восстанов-ление пропущенных значений. Ее особенность – интерполя-ционный характер, поскольку, зачастую, пропущенные зна-чения находятся внутри области исследования. В седьмой главе приведены эмпирические и локальные методы восста-новления пропусков; вероятностно-статистические методы и методы, в основе которых лежит построение уравнений ли-нейной регрессии, в частности, метод Бартлетта и resampling-методы; методы, разработанные Новосибирской школой ана-лиза данных под руководством профессора Н.Г. Загоруйко, а также эволюционные методы.
В восьмой главе изложены основы разработки и примене-ния гибридных моделей и методов. Композиция нейросете-вых парадигм, методов эволюционного моделирования и не-четкого вывода определяет формирование новых направле-ний исследования, что позволит увеличить точность прогно-зирования, повысить интерпретируемость его результатов, оптимизировать процессы принятия решений.
Девятая глава содержит адаптированные авторские пере-воды статей авторов известных современных методов Soft Computing. В частности, представлены муравьиные алго-ритмы как метаэвристики, которые предназначены для ре-шения задач дискретной оптимизации. Другую технологию представляет программирование генетических выражений, являющееся дальнейшим развитием и определенной комби-нацией элементов генетических алгоритмов и генетического

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
12
программирования. Указаны его преимущества при решении задач классификации и аппроксимации неизвестных за-висимостей. Далее приведена классическая теорема о нечет-кой аппроксимации, на которой базируется большинство ут-верждений о возможности аппроксимации функций с помо-щью нечетких экспертных заключений.
Пособие содержит практические задания к каждой теме, контрольные вопросы и задания для самопроверки, темы ре-фератов и расчетно-графических работ, а также темы для са-мостоятельной работы. Оно будет полезно студентам, обу-чающимся по направлениям "Компьютерные науки", "Ком-пьютерная инженерия", "Прикладная математика", эко-номистов, социологов, других специалистов в области ана-лиза информации, а также аспирантов и специалистов в на-правлении искусственного интеллекта, теории и практики прогнозирования.
В пособии, кроме известных методов прогнозирования, представлены оригинальные разработки автора по оптими-зации нейросетевых технологий, эволюционному моделиро-ванию и их прикладному применению.
Автор благодарен рецензентам: академику НАН Украины Ивахненко А.Г., профессорам Зайченко Ю.П. и Куссуль Н.Н. за указанные пожелания и замечания, подавляющее боль-шинство которых в данном издании пособия учтены.
Выражаю благодарность Говорухину С., Атамасю А. и Гарбуз О. за помощь в подготовке электронного варианта по-собия.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
13 Если вы не думаете о будущем,
у вас его и не будет. Джон Ґолсуорси
Введение
Информационная неопределенность жизненного цикла сложных систем, к которым относится и человек, является оп-ределяющим фактором процесса их существования. Поведе-ние людей, их судьба, в основном, связаны с принятием реше-ний на различных этапах жизненного цикла. Известно, что эти процессы, как диалектическая категория, должны иметь начало и завершение. Для задачи прогнозирования началом является сбор и анализ априорной информации. И хотя каж-дый человек принимает решения каждый день, почти никто не задумывается о том, какие предпосылки того или иного решения, как зависит время от возникновения идеи или необ-ходимости до их реализации от полноты, характера и формы представления исходных данных.
История математики свидетельствует о том, что первые попытки подвести научную базу под процессы принятия ре-шений осуществлялись еще в 17-м столетии, когда делались попытки вычисления частоты успеха в азартных играх. Для двадцатого столетия было характерно доминирование клас-сической интегро-дифференциальной парадигмы, которая является основой методов, используемых для поддержки при-нятия решений. Однако ее сторонники не акцентировали внимание на значительных ограничениях и завышенных тре-бованиях к априорной информации.
Тенденция к гумманизации общества во второй половине 20-го столетия привела к росту количества альтернативных методов принятия решений, базирующихся на различных научных парадигмах. К этому времени относится возникно-вение теории нечетких множеств, которая позволила осуще-ствлять оценивание субъективных суждений в категориях воз-можности и необходимости, что расширило представления о числовых множествах. Разработка теории нейронных сетей и методов эволюционного моделирования явилась причиной бурного развития нового направления в искусственном ин-теллекте, базирующегося на принципах естественного отбора и особенностях функционирования головного мозга чело-века. Важную роль для развития теории и практики прогно-зирования сыграл индуктивный метод моделирования - ме-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
14 тод группового учета аргументов. Он позволил осуществлять качественное прогнозирование на «коротких» выборках дан-ных.
Движение в направлении создания информационного общества и общества, основанного на знаниях, обуславливает расцвет современных технологий автоматизированного ин-теллектуального анализа данных. Это связано главным обра-зом с потоком новых идей в области компьютерных наук, об-разовавшихся на пересечении предметных областей искусст-венного интеллекта, статистики и теории баз данных. Эле-менты автоматизированной обработки и анализа данных ста-новятся неотъемлемой частью электронных хранилищ дан-ных (Data Warehouses) и имеют в этом контексте, в зависимо-сти от особенностей применения, названия: data mining (по-лучение знаний из данных), KDD (knowledge discovery in databases - открытия знаний в базах данных), text mining (по-лучение знаний из обработки текстов, что особенно акту-ально в связи с развитием сети Internet).
Компьютерные системы поддержки принятия решений, реализующие указанные направления обработки данных, ба-зируются на двух подходах. Первый, более традиционный, заключается в том, что в системе фиксируется опыт эксперта, и он используется для получения оптимального в данной си-туации решения. Для второго подхода характерно нахожде-ние решения на основе анализа ретроспективных данных, описывающих поведение объекта, принятые в прошлом ре-шения, их результаты и т.п. Внедрение таких систем в Ук-раине наталкивается на препятствия, главные из которых – сравнительно небольшой срок существования предприятий с определенной формой хозяйствования и нестабильность эко-номики. Статистической информации, накопившейся за это время, недостаточно для выработки на ее основе эффектив-ной стратегии принятия решений с помощью систем data mining. Названные факторы в значительной степени устанав-ливают и формируют тенденции разработки и применения информационных интеллектуальных систем.
Основными понятиями, которые определяют предмет изучения курса "Информационные интеллектуальные сис-темы", являются: интеллект, искусственный интеллект, ин-формация. Определение интеллекта в различных энцикло-педиях и справочниках позволяет характеризовать его как

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
15 объект, способ и процесс. Приведем несколько из них, на наш взгляд, наиболее содержательных.
Интеллект (intelligence) – от латинского intellectus – ум, способность человека мыслить, набор определенным образом упорядоченной информации о среде; понятие, объединяю-щее в себе память, мышление и позволяющее рациональное познание и возможность предсказания будущих результатов.
Интеллект является высшим способом решения практиче-ских и познавательных проблем, чем и отличается от других форм поведения – инстинкта и навыков.
Интеллектом называется способность мозга решать (ин-теллектуальные) задачи путем приобретения, запоминания и целенаправленного преобразования знаний в процессе обу-чения, исходя из опыта и адаптации к разнообразным обстоя-тельствам.
Искусственный интеллект - раздел информатики, изу-чающий алгоритмическую реализацию способов решения за-дач человеком. Иными словами, в рамках искусственного ин-теллекта изучают способы решения компьютером задач, не имеющих явного алгоритмического решения.
Искусственный интеллект (artificial intelligence) трактуют как способность автоматических систем брать на себя отдель-ные функции интеллекта человека, а именно, выбирать и принимать оптимизированные решения на основе ранее по-лученного опыта и рационального анализа внешних воз-действий.
Информацией называют набор символов (запись на неко-тором материальном носителе), для которого существует в природе хотя бы одно устройство (человек, машина, прибор), для которого этот набор может быть использован для дости-жения определенной цели.
Базируясь на основных понятиях, определяем цель курса - изучение структурных элементов новых информационных технологий, основой которых является теория искусственного интеллекта, а именно, основных способов представления зна-ний, моделей и методов их обработки, алгоритмов логиче-ского вывода на знаниях, которые, в конечном итоге, ведут к приобретению способности самостоятельного проектирова-ния интеллектуальных информационных систем для под-держки принятия решений и прогнозирования.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
16
Глава 1
Классические методы
Предвидеть − значит управлять. Блез Паскаль
Основные понятия и термины Идентификация Прогнозирование Производная Оптимизационные задачи Система линейных уравнений Методы оптимизации Операции матричной алгебры Определитель Математическое ожидание Линейная зависимость факторов Дисперсия Обратная матрица Коэффициент корреляции Критерий Стьюдента Критерий Фишера Критерий 2 Характеристическое уравнение Собственные числа и векторы Среднеквадратическая погреш-
ность Оценка параметра
Обучающая и контрольная по-следовательность данных
Степень свободы
Содержательная оценка Несмещенная оценка Временной ряд Дисперсионный анализ Спецификация модели Тренд Корреляционный момент Авторегрессия
Методы идентификации и прогнозирования, которые бу-
дут рассмотрены в главе "Классические методы", чаще всего не являются самостоятельными методами, которые применя-ются при решении слабоструктурированных и плохо форма-лизованных задач искусственного интеллекта. Вместе с тем, большинство методов, которые используются при решении таких задач, базируются на регрессионных моделях и методах или используют их в качестве составных элементов. Важной их особенностью является развитый математический аппарат, с помощью которого можно оценивать качество построенных моделей, в частности, их точность и адекватность.
Построение и исследование трех видов моделей: парной линейной регрессии, множественной линейной регрессии и некоторых типов нелинейной парной и множественной рег-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
17
рессии базируется на использовании метода наименьших квадратов. Вместе с тем, заметим, что адекватное его приме-нение требует выполнения определенного ряда предпосылок, которые будут рассмотрены ниже.
В этой главе детально изложен метод наименьших квадра-тов для случая парной линейной регрессии, приведены выра-жения для вычисления коэффициентов уравнения множест-венной линейной регрессии. Показано, при каких условиях наблюдаются неадекватные результаты применения метода наименьших квадратов, а также определены критерии тести-рования мультиколлинеарности, гетероскедастичности, авто-корреляции и рассмотрены методы их устранения.
Значительные преимущества при анализе информации для решения практических задач предоставляет метод Бран-дона, с помощью которого строят уравнения множественной нелинейной регрессии. Заметим, что приведенные модели и методы используются для анализа как статической, так и ди-намической информации и являются внутренними элемен-тами многих систем аналитической обработки информации.
1.1. Метод наименьших квадратов. Парная линейная регрессия Метод наименьших квадратов (МНК), вне всяких сомне-
ний, является тем классическим методом, с которого рацио-нально начинать представление и обоснование методов про-гнозирования. Он предназначен для оценки неизвестных ве-личин по результатам измерений или экспериментов, содер-жащих случайные ошибки, и применяется для приближен-ного представления заданной функции другими (более про-стыми) функциями при обработке данных наблюдений. МНК предложен К. Гауссом и А. Лежандром.
Таблица 1.1. Начальные данные X 1x 2x … nx Y 1y 2y … ny
Пусть имеются статистические данные или данные экспе-риментов (табл. 1.1). Если фактор X интерпретируют как время, то имеем динамический ряд (где ix расположены в воз-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
18
растающем порядке). Необходимо получить аналитическую зависимость
( ),Y f X (1.1)
которая наилучшим образом описывает начальные данные. Словосочетание "наилучшим образом" понимаем в смысле минимума суммы квадратов отклонений значений iy , приве-денных в табл. 1.1, от рассчитанных iy по (1.1):
2
1
( ) ,n
i ii
E y y
(1.2)
где ( ).i iy f x Идентификация зависимости (1.1) необходима, в том числе, и для нахождения 1 1( )n ny f x , что уже является задачей прогнозирования. Заметим, что кроме функционала (1.2) применяются и другие критерии оценки, в частности,
1
min,n
i ii
E y y
1max .i ii n
E y y
Применение первого из них направлено на уменьшение влияния отдельных "выбросов", а второго – приводит к более равномерному приближению во всех точках. Иное объясне-ние состоит в том, что они отвечают наблюдениям в условиях помех с разными статистическими свойствами. Если значения исходной характеристики определяются с точностью до нор-мально распределенного случайного слагаемого, то для оце-нивания коэффициентов используется первый функционал. Его применение оправдано также в условиях, если ошибка измерений распределена по закону Лапласа (это отвечает на-блюдениям при переменных условиях). Если слагаемое (ошибка измерений) распределено нормально в некотором интервале, то для оценки параметров регрессии необходимо использовать второй функционал.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
19
Нанесем точки из табл. 1.1 на координатную плоскость (рис. 1.1) и предположим, что зависимость (1.1) является ли-нейной, то есть Y a bX , а отклонения от прямой вызваны случайными факторами. Идентифицируем уравнения пря-мой (найдем значения коэффициентов a и b ) так, чтобы по-лучить решение задачи
min,E (1.3)
т.е. необходимо найти минимум функционала 2
1
( ( )) .n
i ii
E y a bx
(1.4) y 3y 3
y … … … . 0 1x 2x 3x 4x 1nx nx 1nx x
Рис. 1.1. Парная регрессия
Для того, чтобы найти минимум (1.4), приравняем к нулю частные производные в точках a a и b b , где ,a b – соответ-ствующие оценки параметров и упростим систему
1 1 1 1 1
2 2
1 1 1 1 1 1 1
2 ( ( )) 0, 0, ,
2 ( ( )) 0, 0, .
n n n n n
i i i i i ii i i i in n n n n n n
i i i i i i i i i i ii i i i i i i
y a bx y na b x na b x y
y a bx x x y a x b x a x b x x y
Последнюю систему можно представить в матричном виде

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
20
1 1
2
1 1 1
.
n n
i ii i
n n n
i i i ii i i
n x ya
bx x x y
Решая ее, получим значения коэффициентов
1 1 1
2 2
1 1
,( )
n n n
i i i ii i i
n n
i ii i
n x y x yb
n x x
,a y bx
где 1 1
1 1,n n
i ii i
y y x xn n
− средние значения.
Вычислив a и ,b получим функцию ,Y a bX которая в классе линейных функций наилучшим образом описывает табличную зависимость в смысле минимума суммы квадратов отклонений. Находим значения прогноза
1 1.n ny a bx
1.2. Множественная линейная регрессия Пусть начальные данные приведены в табл. 1.2, где
1 ,..., nX X - вектор входных факторов, Y - результирующая ха-рактеристика, m - количество статистических наблюдений или экспериментов. Уравнение линейной множественной регрессии является таким:
0 1 1 2 2 ... ,n nY a a X a X a X U (1.5) где U – остаток, обусловленный случайными факторами.
Таблица 1.2. Начальные данные для многофакторной линейной регрессии
1X 2X 3X ... 1nX nX Y 11x 12x 13x ... 1 1nx 1nx 1y 21x 22x 23x ... 2 1nx 2nx 2y
... ... ... ... ... ... ... 1 1mx 1 2mx 1 3mx ... 1 1m nx
1m nx 1my
1mx 2mx 3mx ... 1m nx m nx my Перепишем (1.5) в матричном виде

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
21 ,Y AX U (1.6)
где 0 1 2 n( , , ,..., ),A a a a a 1 2 n(1, , ,..., ) ,TX X X X 1 2( , ,..., ),mU u u u знаком “T ” обозначено вектор-столбец. Из уравнения (1.6) получаем, что U Y AX . Рассмотрим функцию
2
1
,m
Ti
iE u UU
(1.7)
которую необходимо минимизировать. Поскольку ( )( ) 2 ,T T T T T TUU Y AX Y AX YY AXY AXX A (1.8)
продифференцировав последнее выражение по ,A получим ( ) 2 2 0,
TT T TUU XY XX A
A
или .T T TXX A XY
Отсюда 1( ) ,T T TA XX XY где 111 21
12 22 2
1 2
11 1 ......
....... ... ... ...
...
m
m
n n mn
xx xX x x x
x x x
Пример 1.1. Пусть начальные данные заданы в табл. 1.3.
Предположим, что они описывают зависимость 1 1 2 2 ,Y a X a X а отклонения рассчитанных значений исход-
ной характеристики от табличных значений вызваны случай-ными факторами. Необходимо найти коэффициенты зави-симости.
Таблица 1.3. Начальные данные
1X 2X Y 1 2 4 2 3 5 4 6 9 7 8 17 1 5 7 4 2 6
Решение. На первом шаге находим произведение

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
22
1 22 3
1 2 4 7 1 4 4 6 87 101,
7 8 101 1422 3 6 8 5 21 54 2
TXX
обратную матрицу 1 0,07598 0,054( )
0,054 0,04548TXX
и произведение 1 0,07598 0,054 1 2 4 7 1 4
( )0,054 0,04548 2 3 6 8 5 2
TXX X
0,0321 0,0102 0,0203 0,1 0,1942 0,196.
0,0369 0,02836 0,0567 0,0567 0,014 0,1252
Получим значение 1 1,144997( )
1,016586T T TA XX XY
. Таким обра-
зом 1 21,145 1,017 .Y X X (1.9)
Если в модели (1.9) предполагалось наличие свободного члена, то необходимо было бы матрицу X рассматривать в
виде 1 1 1 1 1 11 2 4 7 1 42 3 6 8 5 2
X
, а дальнейшие вычисления про-
изводить аналогично. Метод наименьших квадратов в предложенном изложе-
нии можно использовать лишь при выполнении следующих условий: 1. Математическое ожидание остатков 0.MU Это означает, что сумма отклонений табличных значений от значений, рас-считанных по найденной зависимости, равняется нулю. Если это условие не выполняется, то выбрана неправильная форма зависимости 1 2( , ,..., )nY F X X X или в модели не учтен важ-ный фактор. Тем не менее, математическая модель (1.5), кото-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
23
рая имеет свободный член, поддается коррекции так, что все-гда можно добиться того, чтобы 0.MU 2. Дисперсия остатков должна оставаться постоянной
.DU const Невыполнение этого условия свидетельствует о влиянии факторов, не учтенных в модели. 3. Все входные факторы должны быть независимыми между собою. Существование линейной зависимости между факто-рами называется мультиколлинеарностью. Поскольку это ус-ловие часто не выполняется, то необходимо определить уро-вень влияния спецификации зависимости на оценку пара-метров модели. 4. Входные факторы и остатки должны быть взаимно незави-симыми. Невыполнение этого условия указывает на наличие факторов, для которых характерной является зависимость
1 ( ),n ni iX f X где n – номер эксперимента, iX – i -й фактор.
1.3. Тестирование и устранение мультиколлинеарности
Алгоритмом полного исследования мультиколлинеарно-сти является алгоритм Фаррара-Глобера. С его помощью тес-тируют три вида мультиколлинеарности: 1. В совокупности всех факторов (критерий Пирсона 2 – хи-квадрат). 2. Каждого фактора с другими (критерий Фишера). 3. Каждой пары факторов (критерий Стьюдента).
Для оценки параметров модели, в которую входят муль-тиколлинеарные переменные, используют также метод глав-ных компонент.
Алгоритм Фаррара-Глобера. Шаг 1. Нормируем и центрируем значения факторов
.H ik kik
k
x xx
(1.10)
Шаг 2. Находим выборочную корреляционную матрицу 1 ( ) .H T HR X X
n
(1.11)
Шаг 3. Рассчитываем значения критерия 2

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
24
2 1( 1 (2 5)) ln ,6
m n R (1.12)
где n – количество факторов, m – количество наблюдений.
Сравниваем его с табличным значением при 1 ( 1)2
n n степе-
нях свободы и уровне значимости . Если 2 2 ,табл то в век-торе входных факторов есть мультиколлинеарность. Шаг 4. Определяем обратную матрицу
1.D R
(1.13)
Шаг 5. Вычисляем значение F – критерия Фишера
1 ,1k kk
m nF dn
(1.14)
где kkd – диагональные элементы матрицы .D Рассчитанные значения критериев сравниваются с табличными при ( )m n и ( 1)n степенях свободы и уровне значимости . Если
,k таблF F то k -й фактор мультиколлинеарен с другими. Шаг 6. Находим выборочные частные коэффициенты корре-ляции
.kjkj
kk jj
dP
d d
(1.15)
Шаг 7. Вычисляем значения t – критерия Стьюдента
2.
1
kjkj
kj
P m ntP
(1.16)
Рассчитанные значения kjt сравниваются с табличными при ( )m n степенях свободы и уровне значимости . Если
kj таблt t , то между kX и jX существует мультиколлинеар-ность.
Алгоритм метода главных компонент На практике часто приходится иметь дело с задачами, в которых количество факторов превышает границы адекват-ного анализа и интерпретации. Поэтому вместо множества

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
25
исходных факторов 1,..., nX X рассматривают другое множе-ство 1,..., mZ Z , где .m n Причинами этого являются: – необходимость наглядного представления исходных дан-
ных, что достигается их проецированием на специальным образом определенное одно-, двух- или трехмерное про-странство:
– стремление к лаконизму исследуемых моделей, которое од-новременно позволит упростить расчеты и интерпретацию моделей;
– необходимость сжатия объемов статистической информа-ции.
Процедура определения факторов 1,..., mZ Z базируется на двух критериях: первый – максимальное сохранение исход-ной информации, которая сосредоточена в значениях факто-ров 1,..., nX X , второй – максимальное использование инфор-мации, которая находится в этих факторах относительно дру-гих, внешних показателей. Формально задача перехода к новому набору факторов будет такой. Пусть ( )Z Z X – некоторая k -мерная вектор-функция начальных факторов и ( ( ))kI Z X – определенным образом заданная мера информативности системы факторов
1( ) ( ( ),Z X Z X 2( ),..., ( ))kZ X Z X . Задача состоит в определении та-
кого набора факторов ~Z , найденного в классе F допустимых
преобразований начальных факторов X , которые являются решением задачи поиска
~( ( )) max ( ( )).m mZ F
I Z X I Z X
Предположим, что преобразование F определяет возможные линейные ортогональные нормированные комбинации на-чальных факторов, то есть
1 1 1( ) ( ) ... ( );j j jn n nZ X c X MX c X MX
2
1
1, 1, ;n
jii
c j n
1
0, , 1, , .n
ji kii
c c j k n j k
Мерой информативности является отношение

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
26
1
1
...( ( )) ,...
mm
n
DZ DZI Z XDX DX
где D – это знак дисперсии. Тогда вектор ~Z определяется как
линейная комбинация ~
,Z AX где строки матрицы A удов-летворяют условию ортогональности. Конструктивное по-строение элементов матрицы A рассмотрено ниже. Первой главной компонентой 1( )Z X называется такая нормировано-центрированная линейная комбинация на-чальных факторов, которая среди всех других таких комби-наций имеет наибольшую дисперсию. k -й главной компонентой исследуемой системы факто-ров 1,..., nX X называется такая нормировано-центрированная линейная комбинация этих факторов, которая не коррелиро-вана с ( 1k )-й предшествующими главными компонентами, и среди всех других таких комбинаций, которые не коррели-рованы с предшествующими ( 1k )-й главными компонента-ми линейных комбинаций, имеет наибольшую дисперсию. Шаг 1. Нормируем и центрируем значения факторов
.ij jHij
x Xx
(1.17)
Шаг 2. Вычисляем выборочную корреляционную матрицу
1 ( ) .H T HR X Xn
(1.18)
Шаг 3. Находим характеристические числа матрицы R из уравнения
0.R E (1.19)
Шаг 4. Упорядочиваем собственные числа k по абсолютному вкладу главной компоненты в общую дисперсию. Шаг 5. Вычисляем соответствующие собственные векторы .ka Шаг 6. Находим главные компоненты-векторы
,Hk kZ X a 1, .k m
Главные компоненты должны удовлетворять таким условиям:

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
27
,1
0,n
k ii
z
1, ,i n
1 ,Tk k kZ Z
n 1, ,k m
0,Tj kZ Z 1, ,k m .j k
Шаг 7. Определяем параметры модели ^
1 .b Z Y (1.20)
Шаг 8. Находим параметры модели ^ ^
Y X ^ ^
.a b (1.21)
Пример 1.2. Пусть есть некоторая система, имеющая три входа и один выход или три входных фактора и одну резуль-тирующую характеристику. Между ними существует зависи-мость, в нашем случае предполагаем, что она линейная, то есть 1 1 2 2 3 3Y a X a X a X . Необходимо решить задачу пара-метрической идентификации. Начальные данные находятся в табл. 1.4.
Таблица 1.4. Начальные данные
1X 2X 3X Y 1 9 12 23 3 8 23 43 5 3 34 12 7 2 29 26 9 5 38 76
12 6 45 43 15 7 54 23 18 11 56 76 21 1 67 18 23 5 78 44
Решение. Исследуем начальные данные на мультиколли-
неарность по критерию Фаррара-Глобера. На первом шаге нормируем начальные данные и получим данные табл. 1.5.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
28
Транспонируем матрицу значений входных факторов из табл. 1.5 и умножим транспонированную матрицу на началь-ную матрицу из табл. 1.5. Получим выборочную корреляци-онную матрицу
1 0,146 0,9830,146 1 0,21
0,983 0,21 1R
.
Таблица 1.5. Нормированные начальные данные
–0,45243 0,34765 –0,51572 –0,36542 0,2423 –0,3362 –0,27842 –0,2845 –0,15668 –0,19141 –0,3898 –0,23828 –0,10441 –0,0738 –0,09139 0,0261 0,0316 0,02285 0,15661 0,13696 0,16973 0,28711 0,55835 0,20237 0,41762 –0,4952 0,38189 0,50463 –0,0738 0,56142
Найдем ее определитель 0,0284R и вычислим значение критерия 2 11,8 . Сравниваем вычисленное значение с таб-личным 2 7,8табл при 3-х степенях свободы и уровне значи-мости 0,05 . Поскольку вычисленное значение больше табличного, то в массиве факторов существует мультиколли-неарность.
Определим мультиколлинеарность каждого фактора с ос-тальными. Для этого находим обратную матрицу
1
33,61 2,14 33,52,14 1,18 2,35
33,5 2,35 34,41C R
и вычислим значения F -
критерия. Так, 1 114,1,F 2 0,638,F 3 116,9.F Поскольку таб-личное значение критерия при 7 и 2 степенях свободы
19,36,таблF то, сравнивая вычисленные значения и таблич-ное, делаем вывод о том, что первый и третий факторы муль-тиколлинеарны с другими факторами.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
29
Для выяснения мультиколлинеарности каждой пары фак-торов находим частные коэффициенты корреляции:
12 0,339,r 13 0,029,r 23 0,368r и вычисляем значения t -критерия: 12 0,953,t 13 14,94,t 23 1,049.t Вычисленные зна-чения сравниваем с табличным 2,45таблt при 7 степенях сво-боды и уровне значимости 0,05. Мультиколлинеарность существует между первым и третьим факторами.
Далее, для поиска коэффициентов линейной регрессии используем метод главных компонент. Сначала нормируем матрицу значений факторов (начальную), результат нахо-дится в табл. 1.6. Вычислим выборочную корреляционную
матрицу 1 0,14 0,983
0,14 1 0,21 .0,983 0,21 1
r
Таблица 1.6. Нормированные данные
1X 2X 3X –1,431 1,099 –1,631 –1,156 0,766 –1,063 –0,88 –0,9 –0,495
–0,605 –1,23 –0,753 –0,33 –0,23 –0,289 0,083 0,1 0,0723 0,495 0,433 0,5367 0,908 1,766 0,64 1,321 –1,57 1,2077 1,596 –0,23 1,7754
Находим собственные (характеристические) числа мат-
рицы .r Получаем 2,0450,012 .0,943
el
Вычисляем собственные век-
торы 0,682 0,701 0,1890,237 0,045 0,974 .
0,692 0,711 0,128ev

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
30
Упорядочив собственные числа, получим массив (2,045; 0,943; 0,012) . Соответственно, массив собственных век-
торов будет таким: 0,682 0,189 0,7010,237 0,974 0,045 .
0,692 0,128 0,711
Вычислим векторы значений главных компонент 1 2,32; 1,76; 0,75; 0,68; 0,36; 0,08; 0,61; 0,64; 2,12; 2,37 ,Z
2 0,6; 0,38; 1,11; 1,38; 0,29; 0,12; 0,58; 1,98; 1,15; 0,33 ,Z
3 0,11; 0,09; 0,23; 0,2; 0,01; 0,01; 0,05; 0,1; 0,14; 0,13 .Z На следующем шаге определим параметры модели Y Zb по формуле 1( ) .T Tb Z Z Z Y Получим результат: (1,431; 12,992;b
32,11) . Остается вычислить параметры модели Y X по фор-
муле ,a b где a – массив собственных векторов. Результат: 25,94; 10,87; 20,17 . Таким образом, искомая зависимость
1 2 325,94 10,87 20,17 .Y X X X Прерывистая линия, которая ей отвечает, изображена на рис. 1.2.
-40
-20
0
20
40
60
80
1 2 3 4 5 6 7 8 9 10
Начальные данные (Y) Линия Z Линия регрессии
Рис.1.2. Графики аппроксимируемых зависимостей
То, что линия исходных данных размещена выше, чем ли-ния модели Y Zb , объясняется отсутствием коэффициента смещения в модели главных компонент.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
31
1.4. Тестирование и устранение гетероскедастичности Применение МНК ведет к негативным последствиям, если
не выполняются условия независимости остатков и постоян-ности их дисперсии. Пример, приведенный на рис. 1.3, пока-зывает, что прогноз значения характеристики 1ny в точке 1nx значительно отличается от истинного значения. Исходя из критерия минимума среднеквадратичной ошибки на точках обучающей последовательности, наилучшим приближением экспериментальной зависимости является прямая линия. В то же время, очевидно, что дисперсии остатков изменяются по некоторому закону (квадратичному, или типа квадратного корня).
В общем случае, такое явление приводит к тому, что оценки параметров, полученные по МНК, будут несмещен-ными, содержательными, но неэффективными и формулу для стандартной ошибки оценки адекватно применять нель-зя. Напомним, что: − оценка параметра называется несмещенной, если
,M где (*)M − математическое ожидание;
Y 1ny * 0 1nx X Рис. 1.3. Следствие гетероскедастичности

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
32
− оценка параметра называется состоятельной, если P (сходимость по вероятности);
− оценка параметра называется эффективной в некото-ром классе оценок, если она имеет минимальную диспер-сию в этом классе оценок.
Если дисперсия остатков изменяется для каждого наблю-дения или группы наблюдений, то есть ' 2 ,UMUU S где, в об-щем случае, 2
U − неизвестный параметр, а S − известная сим-метричная положительно определенная матрица, то такое яв-ление называется гетероскедастичностью. Если же ' 2 ,UMUU E то имеет место гомоскедастичность.
В случае простой однофакторной модели 0 1Y a a X uX устранить гетероскедастичность просто. Достаточно левую и правую часть модели разделить на .X Для модели многофак-торной регрессии такое преобразование значительно услож-няется.
Для проверки наличия гетероскедастичности чаще всего используют четыре метода, в зависимости от природы на-чальных данных: критерий , параметрический тест Гольд-фельда-Квандта, непараметрический тест Гольдфельда-Кван-дта, тест Глейсера. Рассмотрим алгоритмы каждого из этих методов и укажем особенности их применения.
Критерий (применяется в случае множества начальных данных значительной мощности). Шаг 1. Значения результирующей характеристики Y разбива-ются на k групп, соответственно изменениям уровня вели-чины (например, по возрастанию). Шаг 2. Для каждой группы данных вычисляем сумму квадра-
тов отклонений 2
1
( ) , 1, ,rn
r ir ri
S y y r k
где rn − количество
элементов в r -й группе. Шаг 3. Определим сумму квадратов отклонений в целом по
совокупности наблюдений 2
1 1 1
( ) ,rnk k
r ir rr r i
S S y y
где rn −
количество элементов в r -й группе.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
33
Шаг 4. Вычислим значение параметра 2 2
1( ) ( ) ,
rn nkr
r r
S Sn n
где n − количество наблюдений. Шаг 5. Вычислим значение критерия 2ln , приблизи-тельно отвечающему распределению 2 со степенью свободы
1k , если дисперсия всех наблюдений однородная. Таким образом, если значение не меньше табличного зна-чения 2 при выбранном уровне доверия и степени свободы
1k , то принимается гипотеза о наличии гетероскеда-стичности.
Параметрический тест Гольдфельда-Квандта (применяется, если количество наблюдений невелико и сделано предполо-жение о том, что дисперсия остатков возрастает пропорцио-нально квадрату одной из независимых переменных, то есть
' 2 2 .U ijMUU x Шаг 1. Отсортировать наблюдения соответственно величине элементов вектора kX , для которого вероятно выполняется вышеприведенное равенство.
Шаг 2. Исходя из соотношения 4 ,15
cn предложенного авто-
рами метода, где n − количество элементов kX , изъять c на-блюдений, которые находятся в середине вектора. Шаг 3. Согласно МНК построить две эконометрические мо-дели по двум полученным совокупностям наблюдений раз-
мерностью ,2
n c естественно, при условии, что ,2
n c m где
m − количество независимых факторов, присутствующих в модели. Шаг 4. Найти сумму квадратов остатков для первой и второй модели
^2' 1 1 2
11
( )
n c
i ii
S uu y y
и ^2
' 2 2 22
1
( )
n c
i ii
S uu y y
.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
34
Шаг 5. Вычислить значения критерия * 2
1
SRS
, что отвечает
F − критерию со 2 2( , )2 2
n c m n c m степенями свободы.
Таким образом, если *таблR F , то гипотеза об отсутствии гете-
роскедастичности принимается. Тест Глейсера. Шаг 1. В соответствии с МНК находим параметры линейной регрессии и для каждого отдельного наблюдения определяем ошибки .i Шаг 2. Строим регрессию, которая связывает абсолютные зна-чения ошибок, найденных на первом шаге ,i с независимой переменной ix . Форма регрессии подбирается из разных форм кривых 2
0 1 ,i i ib b x u 10 1 ,i i ib b x u 1/ 2
0 1 ,i i ib b x u
0 1 ,i i ib b x u 20 1 .i i ib b x u
Шаг 3. Если 0 0b и 1 0b , то имеет место "чистая" гетероске-дастичность, если 0 0b и 1 0,b то такая гетероскедастич-ность называется "смешанной".
Проводим любой тест на значимость параметров 0b и 1b . Если они значительно отличаются от нуля, то i являются ге-тероскедастичными.
1.5. Автокорреляция. Причины и следствия Автокорреляция − это взаимосвязь последовательных эле-
ментов временного или пространственного ряда данных. В эконометрических исследованиях возникают ситуации, когда дисперсия остатков постоянная, но имеет место их ковариа-ция. Это явление называют автокорреляцией остатков.
Автокорреляция остатков чаще всего наблюдается тогда, когда эконометрическая модель строится на основе времен-ных рядов. Если существует корреляция между последова-тельными значениями некоторой независимой переменной,

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
35
то будет присутствовать и корреляция последовательных зна-чений остатков.
Автокорреляция может быть также следствием ошибоч-ной спецификации эконометрической модели. Кроме того, наличие автокорреляции остатков может означать, что необ-ходимо ввести в модель новую независимую переменную.
Проиллюстрируем проблему существования автокорре-ляции остатков на примере эконометрической модели с дву-мя переменными. Пусть
0 1 ,t t ty a a x u (1.22)
где мы предполагаем, что остатки tu удовлетворяют схеме ав-торегрессии первого порядка, то есть зависят только от ос-татков предшествующего периода
1 ,t t tu u (1.23)
для которой 1 , а t имеют такие свойства:
( ) 0;tM 2( ) , 0;
( ) 0, 0.t t s s
t t s
M sM s
Величина характеризует уровень связи каждого следую-щего значения с предшествующим, то есть ковариацию ос-татков.
Модель (1.22) содержит индекс t , что свидетельствует о ее динамическом характере, то есть t ‒ период времени, для ко-торого строится такая модель динамических (временных) ря-дов начальных данных.
Рассмотрим остатки модели tu , учитывая (1.23), 2
1 2 1 1 2( ) ... ...t t t t t t t t tu u u . Отсюда
0
.rt t r
ru
(1.24)
Поскольку ( ) 0,tM то ( ) 0.tM u Тогда 2 2 2 2 4 2
1 2( ) ( ) ( ) ( ) ...t t t tM u M M M .

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
36
Учитывая, что последовательные значения t независимы, запишем
2 2 4 2( ) (1 ...) .tM u Тогда
22
2 .1u
(1.25)
Ковариация последовательных значений остатков запи-шется в виде
2 2 21 2( ) , ( ) ,t t u t t uM u u u M u u
и в общем случае 2( ) ,s
t t s uM u u (1.26)
т.е. для модели (1.22) не выполняется гипотеза о независи-мости последовательных значений остатков. Выражение (1.26) можно записать так:
2
( ) .st t s
u
M u u
(1.27)
Это означает, что при наличии автокорреляции остатков второе необходимое условие имеет такой вид:
' 2( ) ,uM uu S где S – матрица коэффициентов автокорреляции s -го по-рядка для ряда tu , или
'( ) ,M uu V (1.28)
т.е.
2 3 1
2 2
' 2 2 3
1 2 3 4
1 ...1 ...
( ) .1 ...... ... ... ... ... ...
... 1
n
n
nu
n n n n
M uu V
Сравнив матрицу, которую имеем в данном случае, с мат-рицей, полученной при наличии гетероскедастичности, убе-ждаемся в том, что они существенным образом отличаются одна от другой. Это связано с тем, что нарушается второе ус-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
37
ловие для применения метода МНК при наличии гетероске-дастичности и автокорреляции.
Итак, для гетероскедастичных остатков существует одна форма нарушения стандартной гипотезы, в соответствии с которой ' 2( ) ,uM uu S для автокорреляционных остатков мы сталкиваемся со второй формой нарушения этой гипотезы.
Если пренебречь автокорреляцией остатков и оценить па-раметры модели с помощью МНК, то получим такие три следствия: 1. Оценки параметров модели могут быть несмещенными, но неэффективными, то есть выборочные дисперсии вектора оценок A могут быть неоправданно велики. 2. Поскольку выборочные дисперсии вычисляются не по уточненным формулам, то статистические критерии t - и F - статистики, которые найдены для линейной модели, практи-чески не могут быть использованы в дисперсионном анализе. 3. Неэффективность оценок параметров эконометрической модели приводит, как правило, к неэффективным прогнозам, то есть прогнозов с очень большой выборочной дисперсией.
Критерий Дарбина-Уотсона. (Тест проверки модели на на-личие корреляции). Шаг 1. Рассчитываем значения d - статистики по формуле
21
2
2
1
( ).
n
t tt
n
tt
e ed
e
(1.29)
Шаг 2. Задаем уровень значимости и по таблице значений критерия Дарбина-Уотсона для количества факторов k и ко-личества наблюдений n находим значения Ld и .Ud Шаг 3. Если выполняется неравенство 0 Ld d , то имеет ме-сто положительная автокорреляция. Если 4 4Ld d , то де-лаем вывод об отрицательной автокорреляции. В случае вы-полнения неравенства L Ud d d или 4 4U Ld d d вы-вода о существовании автокорреляции сделать нельзя. Если
4U Ud d d , то автокорреляции нет.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
38
1.6. Множественная нелинейная регрессия Построение моделей множественной нелинейной рег-
рессии с помощью аналитических методов математической статистики, в большинстве случаев, невозможно. Для выхода из этой тупиковой ситуации прибегают к помощи эмпириче-ских методов, которые дают адекватные результаты. Одним из таких методов является метод, предложенный американ-ским экономистом Брандоном. Приведем его алгоритм, счи-тая, что начальные данные представлены в табл. 1.2.
На подготовительном этапе определяется перечень нели-нейных функций, которые с помощью определенных преоб-разований разрешают использовать МНК для идентифика-ции своих параметров. Базовые зависимости будут такими:
;y a bx ln ;y a b x ;xy a be ;y a b x
2 ;y a bx ;py a bx 1 ;y
a bx
1 ;xya be
;xy ab
;bxy ae ;bxy ae ;by ax
;bxy ax ;xya bx
2 3 ...;y a bx cx dx
01
( cos( ) sin( )).m
i ii
y a a ix b ix
Коэффициенты всех этих моделей можно определить, ис-пользуя МНК.
Алгоритм Брандона. Шаг 1. Вычислить среднее значение исходной характеристики
1
1 ,m
ii
y ym
0.iy
Шаг 2. Выполнить преобразования
0 ,ii
yyy
1, .i m
Шаг 3. Для пары переменных 0 1( ; )y x построить все зависимо-сти, которые приведены выше, и по критерию Дарбина-Уот-сона (DW) или по значению корреляционного отношения

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
39
(для линейной зависимости берут коэффициент корреля-ции r ), или с использованием некоторого значения как ре-зультата их композиции выбирается зависимость, которая имеет максимальный уровень спецификации r ,
0 1 1( ).y f x Шаг 4. Выполнить преобразования
01
0
,ii
i
yyy
1, .i m
Шаг 5. Для пары переменных 1 2( ; )y x выбрать вид зависимо-сти, которая имеет максимальный уровень спецификации
1 2 2( ).y f x Процесс вычислений продолжать до исчерпания всех факто-ров, которые влияют на исходную характеристику. После оп-ределения
1 ( )n n ny f x строим общую формулу множественной регрессии
1
0 1
( )n n
k k kk k
y y y y f x
.
Корреляционное отношение рассчитываем по формуле
2
1
2
1
( )1
( )
m
i iim
i ii
y y
y y
.
Если, например, 0,7, то это означает, что средняя относи-тельная ошибка аппроксимации равняется 30%.
Пусть .i i il y y Тогда значение критерия Дарбина-Уотсона определяют по формуле
21
1
2
1
( ).
m
i ii
m
ii
l lDW
l
Если 2,DW то автокорреляция отсутствует, если 0DW или 4,DW то имеет место полная автокорреляция. Проме-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
40
жуточные результаты проверяют с помощью специальных таблиц (см. приложения).
Практические задания 1.1. Парная линейная регрессия. По данным табл. 1.7 построить уравнение парной линей-
ной регрессии, осуществить прогнозирование, построить графики и выполнить интерпретацию коэффициентов мо-дели.
Таблица 1.7 X 24,32 28,34 34,56 39,45 44,76 50,32 55,34 60,43 65,87 88,98 43,34 Y 76,33 70,34 65,82 60,23 54,99 50,22 45,74 40,34 34,84 30,23 ?
1.2. Множественная линейная регрессия. По данным табл. 1.8 построить уравнение множественной
линейной регрессии, исследовать его на адекватность, осуще-ствить прогнозирование, построить графики и найти коэф-фициенты эластичности.
Таблица 1.8 1X 1 5 12 23 34 53 66 69 78 33
2X 88 77 66 56 43 34 31 23 22 50
3X 11 32 34 45 48 65 77 88 96 54 Y 2 4 8 12 17 32 54 65 77 ?
1.3. Мультиколлинеарность. По критерию Фаррара-Глобера выполнить тестирование
факторов табл. 1.8 на мультиколлинеарность. Если она при-сутствует, то выполнить процедуры ее удаления и построить адекватное уравнение регрессии.
1.4. Гетероскедастичность. Применить параметрический тест Гольдфельда-Квандта
для исследования наличия гетероскедастичности при по-строении эконометрической модели по данным табл. 1.8.
1.5. Метод Брандона. По данным табл. 1.8 построить уравнение нелинейной
регрессии, оценить ее адекватность и выполнить интерпрета-цию.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
41
Контрольные вопросы и задания для самопроверки
1. Какие математические принципы положены в основу ме-тода наименьших квадратов?
2. Какие задачи решаются с помощью построенного уравне-ния парной линейной регрессии?
3. Какое соотношение лежит в основе определения коэффи-циентов модели множественной линейной регрессии?
4. Назовите предпосылки применения метода наименьших квадратов.
5. Какие отрицательные последствия имеет линейная зави-симость факторов при применении метода наименьших квадратов?
6. Опишите алгоритм Фаррара-Глобера как метод последо-вательного тестирования мультиколлинеарности.
7. Назовите особенности применения метода главных ком-понент.
8. Какие отрицательные последствия имеет гетероскедастич-ность при применении метода наименьших квадратов?
9. Определите ситуации, в которых применение того ли дру-гого метода тестирования гетероскедастичности является оптимальным.
10. В каких случаях применяется критерий ? 11. Изложите алгоритм применения критерия . 12. Каковы особенности применения параметрического теста
Гольдфельда-Квандта? 13. Как объяснить соотношения между общим количеством
элементов и количеством изъятых элементов, которое по-ложено в основу теста Гольдфельда-Квандта?
14. Какие субъективные предпосылки лежат в основе теста Глейсера?
15. Объясните на примере явление автокорреляции. 16. В каких случаях возникает автокорреляция и к каким по-
следствиям она приводит? 17. Изложите алгоритм реализации критерия Дарбина-Уот-
сона.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
42
18. Какие преимущества предоставляет метод Брандона при анализе информации?
Темы рефератов и расчетно-графических работ
1. Сравнительный анализ применения в методе Брандона критерия Дарбина-Уотсона и корреляционного отноше-ния.
2. Дистрибутивно-лаговые модели. Подход Койка. 3. Использование dummy-переменных в сезонном анализе. 4. Одновременная зависимость экономических переменных. 5. Примеры эконометрических симультативных моделей. 6. Рекурсивные модели. 7. Процедуры изъятия гетероскедастичности. 8. Выбор "наилучшего" уравнения регрессии. 9. Экспоненциальная модифицированная кривая. Примеры
применения. 10. Информационная база эконометрических моделей.
Теми для самостоятельного изуче-
ния
1. Обобщенный метод наименьших квадратов. 2. Dummy-переменные. 3. Методы оценивания неизвестных параметров в моделях
симультативных уравнений. 4. Метод непрямых наименьших квадратов. 5. Метод двухшаговых наименьших квадратов. 6. Авторегрессионные и дистрибутивно-лаговые модели. 7. ANOVA-дисперсионный анализ. 8. Метод всех возможных регрессий. 9. Метод трех точек вычисления неизвестных параметров
нелинейных моделей. 10. Системы структурных уравнений. 11. Особенности оценивания методом Бартлетта.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
43
Литература
Основные источники 1. Айвазян С.А., Енюков И.С., Мешалкин Л.Д. Прикладная ста-
тистика. Исследование зависимостей. − М.: Финансы и статистика, 1985. − 432 с.
2. Грубер Й. Эконометрия. − К., 1996. − Т. 1. − Введение в эко-нометрию. − 400 с.
3. Дрейпер Н., Смит Г. Прикладной регрессионный анализ: В 2-х кн. − М.: Финансы и статистика, 1987-88. − Т. 1.− 366 с., Т. 2. − 351 с.
4. Лукьяненко И., Красникова Л. Эконометрика. − К.: Знання, 1998. − 494 с.
5. Наконечный С.И., Терещенко Т.О., Романюк Т.П. Экономет-рия. − К.: КНЕУ, 1997. − 352 с.
6. Рассел С., Норвиг П. Искусственный интеллект. Современ-ный подход. − М.: Вильямс, 2006. – 1408 с.
7. Толбатов Ю.А. Эконометрика. – К.: Четверта хвиля,1997. − 320 с.
Дополнительные источники 1. Бородич С.А. Эконометрика.− М.: Эконом. образование,
2001.− 408 с. 2. Гайдышев И. Анализ и обработка данных. − СПб.: Питер,
2001. − 752 с. 3. Доугерти К. Введение в эконометрику. − М.: ИНФРА-М,
1997. − 402 с. 4. Кремер Н.Ш., Путко Б.А. Эконометрика. − М.: ЮНИТИ,
2002. − 311 с. 5. Прикладная статистика: Классификация и снижение размер-
ности: Справ. изд. /C.А. Айвазян, В.М. Бухштабер, И.С. Енюков, Л.Д. Мешалкин; Под ред. С.А. Айвазяна. – М.: Финансы и статистика, 1989. – 607 c.
6. Тархов Д.А. Нейронные сети. Модели и алгоритмы. – М.: Радиотехника, 2005. – 256 с.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
44
Глава 2 Нейросетевые методы
Если тяжело понять всю бесконечность, пытайся понять ее хотя бы наполовину.
Славомир Врублевский
Основные понятия и термины Парадигма, концепция, идея Параметрическая идентификация Оптимизация функций Самоорганизация Обусловленность матриц Рекурсия Дифференцирование функций Градиентные методы Обратная матрица Метод главных компонент Интерполяция Метод “выбеливания” входов
По мнению российского ученого, профессора А.Н. Гор-
баня с помощью искусственных нейронных сетей (neural networks) можно решить едва ли не все задачи, которые ре-шаются другими методами. Такое концептуальное утвержде-ние на самом деле является основанием того значительного интереса, который наблюдается сегодня как в Украине, так и в мире к изучению теории и практики нейросетевого моде-лирования. Растущая мировая научная активность, изучение основ функционирования нейросетей студентами естествен-нонаучных специальностей свидетельствует в пользу "уни-версальности" парадигм, реализованных в нейронных сетях. В то же время, рядом с романтическим восприятием и изуче-нием концептуальных идей, в них реализованных, нельзя не указать на проблемы, которые сопровождают процессы при-менения нейросетей при решении практических задач.
Таким образом, в пользу использования нейросетей свиде-тельствуют: − наследование определенных механизмов работы мозга; − возможность универсальной аппроксимации непрерывных
зависимостей; − способность к восстановлению информации при разруше-
нии или удалении некоторой части нейросети;

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
45
− параллельная обработка информации. К недостаткам нейросетей относят:
− отсутствие четкой теории и механизмов интерпретации функционирования и результатов работы;
− низкая скорость обучения и необходимость разработки ал-горитмов избежания "паралича", переобучения и попадания в локальные оптимумы;
− необходимость выбора нейросетевых парадигм и разра-ботки соответствующих формализаций для решения кон-кретных задач.
Указанные обстоятельства являются причиной того, что нейросетевые технологии довольно привлекательны для изу-чения, исследования и усовершенствования, а также разра-ботки систем, в которых интегрированы нейронные сети и другие методы, но их практическое применение является еще довольно ограниченным. В значительной мере это определя-ется качеством программного обеспечения, которое базиру-ется на реализации нейропарадигм, а также необходимостью выполнения значительного объема работ, связанного с пред-варительной подготовкой априорных данных и определе-нием архитектуры и структуры нейронных сетей. Поэтому прогнозирование будущих процессов не может быть эффек-тивно осуществлено лишь путем использования нейросетевых технологий, необходимым является и знание их "инфра-структуры".
2.1. Основные понятия Искусственные нейронные сети (НС) относят к биокибер-
нетическому направлению в науке, сущность которого за-ключается в адаптации принципов функционирования при-роды к методам решения практических задач, в частности, задач искусственного интеллекта. От представителей класси-ческой интегро-дифференциальной парадигмы часто можно слышать, что результаты, которые получают с помощью НС, являются необоснованными и недоказуемыми. Но нельзя ос-порить и тот факт, что значительное количество теоретиче-ских результатов не нашло своего применения, а НС имеют практическое значение, подтвержденное экспериментально в

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
46
результате внедрения и использования. В пособии не будем детально описывать теорию и методы функционирования се-тей. Главное внимание обратим на то, как та или другая сеть может быть использована для прогнозирования. Сжато пред-ставим основные алгоритмы.
Приведем некоторые сведения и замечания. Как известно, клетки мозга называются нейронами. Каждый нейрон имеет приблизительно 100-1000 входов (дендритов) и один выход (аксон), который разветвляется. Таким образом, один нейрон взаимодействует с множеством других. Взаимодействующие нейроны образовывают скопления и отвечают за определен-ные функции.
Обычные компьютеры осуществляют последовательные вычисления. Многопроцессорные системы в сравнении с функционированием мозга человека все еще неэффективны из-за проблемы управления распараллеливанием потоков данных. Реализация по-настоящему параллельных вычисле-ний возможна исключительно аппаратно, программно – лишь последовательно, или иллюзорно параллельно. Вследствие такой причины компьютер не может восстановить образ че-ловека по одному или нескольким характерным признакам за приемлемое время, в отличие от самого человека. Главным фактором быстрого распознавания является параллелизм вы-числений, осуществляемый мозгом человека, и последова-тельные вычисления компьютером.
Основой функционирования биологического нейрона яв-ляются электрохимические реакции. Достижение порогового значения потенциала нейрона позволяет генерировать им-пульс (спайк), передаваемый по аксону. Потенциал нейрона изменяется под влиянием сигналов от других нейронов, кото-рые усиливаются синапсами, а также окружающей средой. Имеет место дуальность непознанности механизмов функ-ционирования мозга и аналитической неинтерпретированно-сти механизмов и результатов работы НС.
Краткий исторический экскурс. В 1943 году Маккалок и Питс (McCulloch и Pіtts) описывают искусственный нейрон. В 1957 году Розенблат (Rosenblatt) рассматривает персецтрон - некоторое объединение искусственных нейронов.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
47
Невозможность моделирования функции "исключающее ИЛИ" (XOR) однослойным перцептроном строго доказана в 1969 году математиком М. Минским (M.L. Mіnsky, http://web.medіa.mіt.edu/~mіnsky). В 1986 году Д. Руммель-харт, Д. Хинтон и Р. Вильямс (D.E. Rummelhart, G.E. Hіnton и R.J. Wіllіams) предлагают алгоритм обратного распростране-ния ошибки – квинтэссенцию теории нейронных сетей, и в том же году году Дж. Хопфилд (J.J. Hopfіeld, http://genomіcs.prіnceton.edu/hopfіeld предложил сети с об-ратными связями, чем и осуществил прорыв в методах реали-зации НС.
Искусственный нейрон (рис. 2.1) является упрощенной моделью биологического нейрона. Роль ден-дритов играют входы 1 2, ,..., ,nx x x синапсов – весовые коэффициенты
1 2, ,..., ,nw w w аксона – выход Y , пре-образования, которые происходят в теле биологического нейрона, - ак-тивация (actіvatіon) A и активаци-онная пороговая функция (actіvіty threshold functіon), значением ко-торой является Y .
Искусственные нейроны являются составными элементами нейросетей. На сегодня известно несколько десят-ков основных нейросетевых парадигм, которые определяют разную нейросе-тевую архитектуру, методы обучения и направленность на решение опреде-ленных задач. Традиционно наиболее часто используются такие архитекту-ры НС и методы обучения:
- прямосвязные НС (входы нейрона следующего шара являются выходами нейронов предыдущего шара),
- полносвязные НС (все нейроны связаны со всеми);
Marvin Minsky
John J. Hopfield

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
48
- НС с обратными связями (выходы НС подаются на ее вхо-ды);
- методы, в основе которых лежит использование дельта-правила;
- градиентные методы (такие, которые базируются на вы-числениях и применениях градиентов);
- стохастические методы (предусмотрено использования ве-роятностных конструкций для модификации весовых ко-эффициентов).
Некоторые из этих методов и архитектур рассмотрены ни-же.
2.2. Алгоритм обратного распространения ошибки
Алгоритм обратного распространения ошибки (АОРО) – квинтэссенция всей теории нейронных сетей. Именно он дал решающий толчок к возвращению внимания ученых мира к нейронным сетям после известной работы Минского и Пай-перта "Перцептроны". Алгоритм имеет много преимуществ и применяется для решения разнообразных задач. Выясним, как АОРО используется при решении задач прогнозирова-ния.
Рассмотрим некоторую сложную систему (экономиче-скую, техническую, социальную) (рис.2.2). Обозначим
1 2( , ,.., )nX X X X − вектор входных факторов, 1 2( , ,.., )mY Y Y Y –
1 Y
Y
A
2 2..........x w
n nx w
1 nx w
1
n
i ii
A x w
Рис. 2.1. Искусственный нейрон

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
49
вектор результирующих характеристик (показателей), F – функциональное преобразование, осуществляемое системой S . Например, 1X – количество ресурсов, 2X – фондовоору-женность, 3X – энергоемкость производства, 4X – квалифика-ция сотрудников и т.д., 1Y – количество выработанной про-дукции, 2Y − себестоимость продукции, 3Y – валовой доход. Очевидно, что 1 2( , ,.., )i i nY f X X X , 1, ,i m а прибыль, как инте-гральный показатель эффективности
1 2 1 1 2 2 1 2 1 2( , ,.., ) ( ( , ,.., ), ( , ,.., ),.., ( , ,.., )).m n n m nZ F Y Y Y F f X X X f X X X f X X X (2.1) Структурная и па-
раметрическая иден-тификация последней зависимости известны-ми классическими ме-тодами – задача, ко-торая в большинстве случаев не имеет реше-ния. Нейронная сеть может "решить" эту за-дачу понятным лишь ей одной способом самоорганизации значений весовых коэффициентов, но по указанному алго-ритму. Поэтому такую идентификацию, методология кото-рой выходит за классические теоретические границы, назы-вают «синтетической». Это означает, что зависимость (2.1) в виде математического выражения (функции) не будет полу-чена. Но по заданным значениям вектора X можно вычис-лять Y и даже определять чувствительность изменения зна-чения Z к приращению значений каждой компоненты .X
Алгоритм АОРО (back propagatіon) приведен ниже с выде-лением этапов обучения и использования НС. Рассмотрим НС следующего вида (рис. 2.3).
Слой A содержит n нейронов, слой S – l нейронов, слой R – m нейронов. Нейроны слоя A никаких функций не вы-полняют, кроме распределения сигналов. Начальные данные находятся в табл. 2.1, строки которой отвечают образам (на-блюдениям, экспериментам). Вектор 1 2( , ,.., )nX X X X содержит
1X 1Y 2X 2Y ………. ……. nX mY
Рис. 2.2. Сложная система
S F

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
50
значения входных факторов, 1 2( , ,.., )mD D D D − реальные ис-ходные величины, полученные в результате наблюдений, экспериментов или являются данными статистики.
В качестве примера рассмотрим данные, приведенные в табл. 2.2. В ней {1,2,..,9}kix , 1,2,i 1 1 2D X X , 2 1 2D X X ,
3 1 2D X X , 4 1 2/D X X . Обученная НС по двум числам, пред-ставленным на вход, должна определять их сумму, разность, произведение и частное. Итак, первое, что необходимо сде-лать, это выполнить инициализацию весовых коэффициентов
1ijw , 1,i n , 1,j l и 2
ijw , 1,i l , 1,j m случайными числами из интервала (0,1).
Для приведения начальных данных к единой шкале их необходимо нормировать. Чаще всего используют одно из та-ких преобразований:
Таблица 2.1Начальные данные… …… …… …
… … … … … … … …… …
1X 2X nX 1D 2D mD
11x 11x nx 1 11d 12d md 1
21x 22x nx 2 21d 22d md 2
1kx 2kx knx 1kd 2kd kmd
Таблица 2.2Пример данных
1 1 2 0 1 11 2 3 -1 2 0.5… … … … … …9 9 18 0 81 1
1X 2X 1D
2D *3D /
4D
… X … ….. … Y …
1W 2W
A S R Рис. 2.3. Искусственная нейронная сеть

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
51
min
max minij ijk i
ijij ijii
x xx
x x
,
max
max minij ijk i
ijij ijii
x xx
x x
,
max minij jk
ijij ijii
x xx
x x
, ij jkij
j
x xx
, 1 .1 ij
kij xx
e
У каждого из этих выражений есть свои преимущества и недостатки. Чаще всего используют первую и четвертую фор-мулу. Далее, для каждого нейрона скрытого слоя S вычисля-
ется сумма 1
n
ij i ji
w x z
, 1,j l , которую называют активацией
(асtіvatіon). На выходе нейронов слоя S получаем 1 ( )j jy f z , где (*)f – активационная функция (actіvіty functіon). Для на-шего примера и для большинства других рационально ис-
пользовать такие функции: 1( )x x
x x
e ef x thxe e
(гиперболиче-
ский тангенс) и 21( )
1 xf xe
(классический сигмоид). По-
скольку область значений 1( ) ( 1, 1)E f , то вместе с 1f целесо-образно использовать четвертое выражение для нормирова-ния, а с 2f , где 2( ) (0, 1),E f − первый, второй или пятый. Кроме того, при необходимости используют смещение (bіas) нейронов для получения нужной области на их выходе.
Рассчитаем выходы нейронов слоя R по формуле 2 2 1
1
l
j ij ii
y w y
, 1,j m . Они и являются рассчитанными НС выхо-
дами. Естественно, что полученные величины будут отли-чаться от реальных выходов jD , 1,j m . Процесс обучения НС состоит в преобразованиях весовых коэффициентов с це-лью приближения реальных значений на выходе сети рас-считанными. Для этого необходимо минимизировать функ-цию
2 2
1 1
( ) ( )k m
ij iji j
E w d y
(2.2)

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
52
и, используя метод градиентного спуска, скорректировать весовые коэффициенты послед-него слоя. Как оказалось позднее, такой алгоритм ранее был разра-ботан Полом Вербосом (Paul Werbos, www.werbos.com) и при-веден в его магистерской диссер-тации еще в 1974 году. Далее, ис-пользуя тот факт, что входы ней-ронов следующего слоя являются выходами нейронов предшест-вующего слоя, вычислить ошиб-ки и скорректировать весовые ко-эффициенты других, пре-дыдущих слоев.
Рассмотрим АОРО для сети с произвольным конечным количеством скрытых слоев. Тогда целевая функция будет такой:
2
1 1
1( ) ( ) ,2
k mp
ij iji j
E w d y
(2.3)
где p – количество слоев нейронов. Целью обучения НС явля-ется минимизация функции ( ).E w Осуществим ее за счет на-стройки весовых коэффициентов , 1, ,q
ijw q p которая реализу-ется путем корректирования
( ) ( 1) ( ),q q qij ij ijw t w t w t (2.4)
где t – номер итерации. Определение ( )qijw t происходит в со-
ответствии с методом градиентного спуска и является таким: qij q
ij
Eww
,
(2.5)
где – коэффициент, который определяет скорость сходимо-сти метода. Напомним, что выход нейрона q -го слоя, 1, ,q p опреде-ляется активационной функцией. В АОРО такая функция должна быть гладкой. Рассмотрим, без ограничения общно-
Paul Werbos

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
53
сти, в качестве активационной функции классический сигмо-ид
1 , 1, ,1
qj
qj s
y j me
(2.6)
где qjs – активация j -го нейрона q -го слоя,
1
1
,qk
q q qj ij i
is w x
(2.7)
1qk – количество нейронов в ( 1)q -м слое. Учитывая (2.6) и (2.7), получим
.q qj j
q q q qij j j ij
dy sE Ew y ds w
(2.8)
Заметим, что выражения (2.5) - (2.8) записаны в предполо-жение, что на вход сети подается один образ. Из (2.3) следует, что
,pj jp
j
E d yy
(2.9)
где jd – табличное значение j -го выхода сети, pjy – рассчитан-
ное и полученное значение как выход j -го нейрона послед-него слоя. Второй множитель в (2.8) находим из выражения (2.6), используя свойства классического сигмоида,
(1 ).qj q q
j jqj
dys s
ds
(2.10)
Разложим первый множитель из (2.8) таким способом: 1 1
1 1 .q qk k
q q q qkj k k j
dy sE Ey y ds y
(2.11)
Из формулы (2.11) следует, что суммирование выполня-ется среди нейронов ( 1)q -го слоя. Введем новую перемен-ную
.qjq
j q qj j
dyEy ds
(2.12)
Учитывая, что

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
54 1 1 ,q q q
k ik ii
s w y (2.13)
получим 1
1.q
qkjkq
j
s wy
(2.14)
Тогда из (2.11) – (2.14) получаем рекурсивную формулу
1 1 .qjq q q
j k jk qk j
dyw
ds
(2.15)
Для последнего слоя ( ) (1 ).p p p p
j j j j jd y y y (2.16)
Формулу (2.5) перепишем в таком виде: 1.q q q
ij j iw y (2.17) Иногда, для придания процессу коррекции весовых коэф-
фициентов некоторой инерционности, сглаживающей вспле-ски при перемещении по поверхности целевой функции, (2.17) дополняется значением изменения веса на предшест-вующей итерации
1( ) ( ( 1) (1 ) ),q q q qij ij j iw t w t y
где – коэффициент инерционности, t – номер текущей ите-рации.
Приведем алгоритм обратного распространения ошибки для сети с тремя входами, двумя выходами и тремя нейро-нами скрытого слоя. Шаг 1. Инициализируем весовые коэффициенты случай-ными значениями. Нормируем исходные значения. Шаг 2. Подаем на вход обучающий образ и рассчитываем вы-ход сети (описано выше). Шаг 3. Рассчитываем ошибки на выходе последнего слоя. В на-шем случае
( 2 ) 2 2 21 1 1 1 1 1( ) (1 )( ) ,y d y y
( 2 ) 2 2 22 2 1 2 2 2( ) (1 ) ( ) .y d y y
Шаг 4. Рассчитываем ошибки предыдущего слоя по формуле:

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
55
( ) ( 1 ) ( 1 )[ ] .jn n nj k jk
k j
d yd z
Предыдущий слой имеет индекс 1. Тогда: (1 ) ( 2 ) ( 2 ) ( 2 ) ( 2 ) 1 1
1 1 1 1 2 1 2 1 1( ) (1 ) ,w w y y ( 1 ) ( 2 ) ( 2 ) ( 2 ) ( 2 ) 1 1
2 1 2 1 2 2 2 2 2( ) (1 ) ,w w y y ( 1 ) ( 2 ) ( 2 ) ( 2 ) ( 2 ) 1 1
3 1 3 1 2 3 2 3 3( ) (1 ) .w w y y Осуществляем коррекцию весовых коэффициентов таким об-разом: − для последнего (второго) слоя
( ) ( ) ( )( ) ( 1) ( ) ,n n nij ij i jw t w t w t (2.18)
где ( 2 ) ( 2 ) 111 1 1 ;w y ( 2 ) ( 2 ) 1
12 2 1 ;w y ( 2 ) ( 2 ) 121 1 2 ;w y
( 2 ) ( 2 ) 122 2 2 ;w y ( 2 ) ( 2 ) 1
31 1 3 ;w y ( 2 ) ( 2 ) 132 2 3 .w y
− для предпоследнего слоя (1) (1)11 1 1 ;w x (1) (1)
12 2 1 ;w x (1) (1)13 3 1 ;w x
(1) (1)21 1 2 ;w x (1) (1)
22 2 2 ;w x (1) (1)23 3 2 ;w x
(1) (1)31 1 3 ;w x (1) (1)
32 2 3 ;w x (1) (1)33 3 3 .w x
С целью сглаживания резких изменений весовых коэффи-циентов (2.18) рекомендуется использовать следующее выра-жение: ( ) ( ) ( ) ( 1 )( ) ( ( ) (1 ) ) ,n n n n
i j i j j iw t t y где – коэффициент инерционности, t – номер текущей ите-рации, – коэффициент обучения, , (0;1). Шаг 5. Если представлены все обучающие образы, то переход на шаг 6, иначе переход на шаг 2 (подать следующий образ). Шаг 6. Если ( )E w , то выполнить переход на шаг 7, в про-тивном случае перейти на шаг 2 (подать первый образ). Шаг 7. Подать на вход обученной сети контрольный вектор X и найти Y (решается задача прогнозирования). Шаг 8. Вывод результатов.
Замечание 2.1. Образы желательно подавать в случайном порядке для того, чтобы сам порядок их поступления не стал еще одним виртуальным входом сети и, соответственно, не внес смещения в результат.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
56
Таким образом, нейронная сеть с АОРО или родствен-ными алгоритмами является едва ли не единственно прием-лемым средством для решения задачи прогнозирования в случае сложной зависимости между входными факторами и результирующими характеристиками, в особенности, если последние имеют векторное представление.
2.3. Алгоритм обучения RBF-сети и ее использование для прогнозирования
Сеть RBF, как и большинство других нейросетей, предна-значена для аппроксимации функций, заданных в неявном виде набором шаблонов (обучающих образов). Далее рассмот-рим один из методов обучения RBF-сети, не содержащий ре-курсии. Нейросеть характеризуется такими особенностями: имеет единственный скрытый слой, нейроны скрытого слоя имеют нелинейную активационную функцию, синаптиче-ские веса всех нейронов скрытого слоя равняются единице. Рассмотрим следующие обозначения (рис. 2.4): − 1 2( , ,..., )nc c c c – вектор координат центров активационных функций нейронов скрытого слоя; − j – «ширина окна» активационной функции j -го нейрона скрытого слоя;
−
2
12
( )
( , )
n
j jj
X c
f X c e
– радиально-симметричная активацион-ная функция нейрона скрытого слоя (см. рис. 2.4); − ,i j – вес связи между i -м нейроном начального слоя и j -м нейроном скрытого слоя. Приведем алгоритм обучения RBF-сети. Шаг 1. Выбрать размер скрытого слоя H равным количеству обучающих образов Q . Синаптические веса нейронов скры-того слоя принять равными 1. Шаг 2. Разместить центры активационных функций нейронов скрытого слоя в точках пространства входных сигналов сети, которые входят в набор обучающих образов : , 1,j jc X j H .
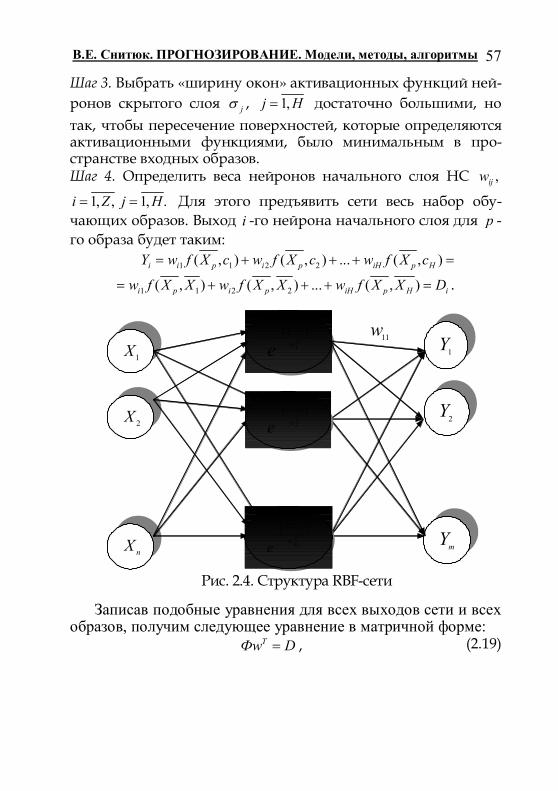
В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
57
Шаг 3. Выбрать «ширину окон» активационных функций ней-ронов скрытого слоя j , 1,j H достаточно большими, но так, чтобы пересечение поверхностей, которые определяются активационными функциями, было минимальным в про-странстве входных образов. Шаг 4. Определить веса нейронов начального слоя НС ,ijw
1, , 1, .i Z j H Для этого предъявить сети весь набор обу-чающих образов. Выход i -го нейрона начального слоя для p -го образа будет таким:
1 1 2 2( , ) ( , ) ... ( , )i i p i p iH p HY w f X c w f X c w f X c
1 1 2 2( , ) ( , ) ... ( , )i p i p iH p H iw f X X w f X X w f X X D .
Записав подобные уравнения для всех выходов сети и всех образов, получим следующее уравнение в матричной форме:
TФw D , (2.19)
11w
nmw
Рис. 2.4. Структура RBF-сети
1X
2X
nX
21
1
cX
е
1Y
2Y
mY
22
2
cX
е
21
1
k
kcX
е

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
58
где
11 1
21 2
1
...
...... ... ...
...
H
H
H HH
f ff f
Ф
f f
− интерполяционная матрица,
11 1
1
.... .. .
...
H
Z ZH
w ww
w w
− матрица начальных значений синаптиче-
ских весовых коэффициентов; 11 1
1
.... . .
...
Z
H HZ
D DD
D D
− матрица начальных образов.
Найдя произведение 1Tw Ф D , (2.20)
получим искомые начальные значения синаптических весо-вых коэффициентов, что обеспечивает прохождение интер-поляционной поверхности через обучающие образы в про-странстве входных образов.
Замечание 2.2. Сеть RBF чувствительна к значениям «ши-рины окон» активационной функции . Двухмерный аналог активационной функции изображен на рис. 2.5. Для адекват-ного обучения и использования наученной сети RBF необхо-димо провести некоторые подготовительные операции. Во-первых, максимизировать совместную энтропию начальных образов, например, с помощью известных методов главных компонент или "выбеливания входов" (об этом методе – ни-же).
Преобразованные данные обеспечат качественное и бы-строе обучения на множестве данных минимальной мощ-ности. Поскольку указанные методы достаточно трудоемки, можно выбирать из всего множества входных образов те, ко-торые имеют максимальное попарное евклидово расстояние. Следующим шагом должно быть нормирование. Далее, для того, чтобы избегнуть "паралича" сети (см. рис. 2.5) и не было бы больших ошибок при аппроксимации, требуем выполне-ния следующего условия:

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
59
2
12 ( ) / 2
n
ij ii
x c
(выбор границ интервала достаточно произволен, но его ра-циональность подтверждена экспериментами) или, ограни-чившись выбором положительного ,
2
10 ( ) / 2
n
ij ii
x c
.
Учитывая, что после нормирования , 0;1ij ix c , получим
2
1
0 ( )n
ij ii
x c n
для всех обучающих образов. Тогда .2n
Но при увеличении значения уменьшается эксцесс и рас-тут "хвосты" графика активационной функции, которая снова таки приводит к "параличу" сети. Приемлемые результаты были получены в реальных задачах при
32 2n n .
Неитерационный метод обучения RBF-сети не всегда яв-ляется оптимальным методом обучения. В частности, если ко-личество входных образов большое, то применение гради-
Рис.2.5. Активационная функция

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
60
ентных методов обучения позволяет уменьшить количество нейронов скрытого слоя. Главным отличием между RBF-сетью и нейросетями, которые обучаются с помощью алгоритма АОРО, является то, что первые обеспечивают глобальную ап-проксимацию нелинейного отображения, в то время как вто-рые – локальную.
Процесс функционирования сети RBF имеет еще много особенностей. Но одну следует вспомнить: с помощью такой сети лучше всего решать задачу интерполяции (прогнозиро-вание внутри области исследования).
2.4. Сети встречного распространения – инст-рументарий предварительного прогнозирова-ния
В отличие от НС с АОРО сети встречного распростране-ния (СВР) предназначены для на-чального быстрого моделирова-ния. Автор СВР Роберт Хехт-Нільсен (R. Hecht-Nіelsen, www.r.ucsd.edu) удачно объеди-нил в одной архитектуре пре-имущества способности к обоб-щению сети Тейво Кохонена (T. Kohonen, www.cіs.hut.fі/teuvo) и простоту обучения звезды С. Гроссберга (S.Grossberg, www.cns.bu.edu/Profіles/Grossberg), вследствие чего сеть СВР по-лучила свойства, которых нет у ни одной из них в отдельности. Прежде всего, СВР способна к обобщению и используется для распознавания и восстановления образов, а также усиления сигна-лов.
СВР (рис. 2.6) работает с век-торами, значениями которых яв-
Robert Hecht-Nielsen
Teuvo Kohonen

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
61
ляются непрерывные величины или двоичные, то есть такие, которые состоят из нулей и единиц.
В результате обучения входные векторы ассоциируются с векторами на выходе сети и, если сеть обучена, подача вход-ных образов приводит к получению результирующих обра-зов.
Правильный выход может быть получен и в случае непол-ноты или случайной модификации входного образа. Гипер-поверхность, которую получают в результате функцио-нирования СВР, вследствие принципа непрерывности дает возможность осуществлять прогнозирование. Естественно, что внутри гиперпараллелепипеда обучающих образов прогно-зирование будет более точным, а при решении задачи экст-раполяции ошибка будет значительно большей.
Подобно остальным НС, СВР работает в двух режимах: обучения и использования. В первом случае на входы подаем и вектор X , и вектор Y , корректируем весовые коэф-фициенты; во втором режиме на вход уже обученной сети по-даем X или Y , а на выходе получаем значения и X , и Y . В общем, функционирование сети будет таким: на вход подают
Слой Кохонена Слой Гроссберга 1X 11w 11v '
1X
12w 12v
2X '2X
nX '
nX 1Y '
1Y 2Y '
2Y mY '
mY kmnw mnkv
Рис. 2.6. Сеть встречного распространения

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
62
первый образ X , в каждом нейроне слоя Кохонена рассчиты-
вается активация 1
nT
j ij ii
A w x W X
. Только на выходе одно-
го нейрона будет единица, а именно 1, max ,
0, .
j pK pj
если A AOUT
в противном случае
Очевидно, что веса, инцидентные нейрону, который «вы-играл», являются максимально близкими к компонентам входного вектора.
На следующем шаге выполня-ем коррекцию весовых коэф-фициентов, инцидентных «выиг-равшему» нейрону. Слой Гросс-берга функционирует подобно слою Кохонена. Активация нейро-
нов его слоя 1
.m
Kj ij i
iB v OUT
На
выходе нейронов слоя Гроссберга будут веса, инцидентные нейрону слоя Кохонена, который "выиграл",
.Gj jOUT B Далее корректируем веса, инцидентные этому
нейрону, и подаем следующий образ. В результате много-кратного выполнения такой процедуры весовые коэффици-енты слоя Гроссберга должны совпадать или быть близкими к входным образам. Но все оказывается не так просто.
Рассмотрим некоторые аспекты алгоритма функциониро-вания СВР. Начальные данные представлены в табл. 2.3 и один входной образ отвечает одной строке этой таблицы.
Таблица 2.3. Начальные данные для обучения СВР 1X 2X … nX 1Y 2Y … mY
11x 1
2x … 1nx 1
1y 12y … 1
my 21x 2
2x … 2nx 2
1y 22y … 2
my … … … … … … … …
qx1 qx2 … qnx qy1 qy2 … q
my
Stephen Grossberg

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
63
Шаг 1. Нормируем каждый элемент таблицы. Так, например, нормированный аналог второго элемента первой строки рас-считываем по формуле
11 22
1 2 1 2
1 1( ) ( )
n m
j jj j
xzx y
и заменяем в табл. 2.3 каждый элемент на его нормированный аналог. Шаг 2. Генерируем случайным образом весовые коэффици-енты и обязательно их нормируем, тем самым, сокращая про-цесс обучения. Здесь существует несколько нюансов, о них можно прочитать, например, в известной книге Ф. Уоссер-мена, а также частично ниже. Шаг 3. Подаем на вход сети строку матрицы Z и рассчиты-ваем скалярные произведения с векторами весовых коэффи-циентов, которые связаны со всеми нейронами слоя Кохонена. Шаг 4. Среди всех скалярных произведений выбираем произ-ведение с максимальным значением и настраиваем вес соот-ветствующего нейрона в соответствии с выражением
( ),н c cW W X W где cW – предыдущее значение весового коэффициента, hW – его новое значение, – коэффициент обучения, который сна-чала приблизительно равен 0,7 и постепенно уменьшается в процессе обучения. Выход нейрона, который "выиграл", рав-няется единице, все остальные – нулю. Шаг 5. Значения выходного вектора слоя Кохонена подаются на слой нейронов Гроссберга. В каждом нейроне слоя Гросс-берга обычным способом рассчитывается активация. Шаг 6. Корректируем все веса слоя Гроссберга соответственно выражению
( ) ,Kijн ijc j ijc iV V Y V
где jY – j -ая компонента реального вектора выхода, ijcV – ста-рое значение весового коэффициента слоя Гроссберга, ijнV − новое значение,

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
64
1, " ",0, .
Ki
если i й нейрон слоя Кохонена выигралв противном случае
Шаг 7. Вывод результатов. Окончание алгоритма. Сделаем ряд замечаний к алгоритму и его реализации.
Применение такого алгоритма обучения является проблема-тичным, если значительное количество обучающих шаблонов образует совокупность незначительных размеров в области обучения. В таком случае результат работы классического ал-горитма будет правильным и необходимо применять предва-рительную обработку данных. Некоторой оптимизацией предложенного алгоритма является использование метода выпуклой комбинации, в одном из вариантов которого пред-лагается приравнять все весовые коэффициенты одной и той
же величине 1 .ijwn
Кроме того, приравнять каждую компо-
ненту входного вектора 1 .i ix xn
В начале обучения
0 и входные векторы совпадают с весовыми коэффициен-тами. В процессе обучения растет, постепенно приближа-ясь к единице. Этот метод приводит к правильному распре-делению входных векторов и является достаточно эффектив-ным.
В другом подходе предлагается к истинным значениям входного вектора прибавлять шум (смещение). В третьем на-страивают все весовые коэффициенты, а не только инцидент-ные нейрону, который "выиграл".
Возможным является и такой вариант: если один из нейро-нов слоя Кохонена чаще других становится «победителем», то порог его срабатывания увеличивается.
Все методы, рассмотренные выше, относятся к функцио-нированию сети в режиме аккредитации. СВР может функ-ционировать также в режиме интерполяции. Такой вариант отвечает случаю настройки весовых коэффициентов несколь-ких нейронов, которые имеют наибольшее значение актива-ции. При этом, выходы нейронов слоя Кохонена необходимо нормировать, используя, например, функцию SOFTMAX. То-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
65
гда значения выходов этих нейронов будут ин-терпретироваться как вероятности принадлежности входного вектора к этому или другому классу.
Сеть встречного распространения рекомендуется исполь-зовать для предварительного прогнозирования (для этого достаточно на входы обученной сети подать только вектор X и получить на выходе и ,X и Y ). По сравнению с НС с АОРО сеть СВР учится значительно быстрее, но точность результата ниже.
Применение нейронных сетей для прогнозирования явля-ется перспективным в случае существования сложных нели-нейных зависимостей со значениями факторов, на которые не наложено ни одного ограничения. Вместе с тем, необходимо заметить, что получение высокоточных результатов возможно только при наличии квалифицированных специалистов, по-скольку необходимым условием эффективного функциони-рования нейросети является формализация задачи, предвари-тельная подготовка данных и обеспечение избежания исклю-чительных ситуаций ("паралича", переобучения, попадания в локальные оптимумы).
В этой главе представлено только несколько основных нейросетевых парадигм, в частности без внимания остались стохастические методы обучения нейросетей, структура и принципы функционирования АRТ-сети и ее разновидно-стей, когнитрон, неокогнитрон и т.п. Надеемся, что читатели при желании заполнят информационный вакуум, воспользо-вавшись, в первую очередь, интересной и содержательной книгой С. Хайкина.
Практические задания 2.1. Моделирование логических функций с помощью
искусственного нейрона Разработать алгоритм и его программную реализацию для
моделирования логических функций с использованием искус-ственного нейрона. Начальные данные находятся в табл. 2.4. Результат представить в виде табл. 2.5. Выполнить сравни-тельный анализ скорости сходимости алгоритма для разных

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
66
значений коэффициента обучения. Выполнить мо-дификацию алгоритма, в которой предусмотреть введение смещения, изменение порогового значения и вывод решения о невозможности решения задачи в случае наличия проблемы с линейным разделением области исследования.
2.2. Реализация и исследование АОРО Выполнить программную реализацию АОРО для трех-
слойной нейронной сети с тремя нейронами первого слоя, тремя нейронами второго слоя и двумя нейронами третьего слоя или воспользоваться прикладными пакетами. Используя данные табл. 2.6, написать программный фрагмент для вы-числения 20 значений функции по заданным значениям ар-гументов и их вариациях с шагом 1 и найти их среднее зна-чение.
Таблица 2.4. Начальные данные № варианта
Логическая функция
Возможные значения коэффициента
1 1 2 3x x x 0,2 0,4 0,6 2 1 2 3( )x x x 0,2 0,04 0,08 3 1 2 3( )x x x 0,05 0,1 0,3 4 1 2 3x x x 0,07 0,1 0,3 5 1 2 3(| )x x x 0,02 0,05 0,4 6 1 2 3( )x x x 0,1 0,5 0,7 7 1 2 3( )x x x 0,2 0,02 0,002 8 1 2 3| ( )x x x 0,3 0,4 0,5 9 1 2 3(| )x x x 0,7 0,01 0,06
Таблица 2.5. Шаблон таблицы результатов 1w 2w 3w 1x 2x 3x a Y T ( )T Y iw
Подать заданные значения аргументов на вход нейронной
сети. Выходом 1d считать вычисленное значение функции; выходом 2d – 1, если полученное значение 1d больше среднего значения и 0, если меньше.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
67
Задать контрольные примеры и оценить скорость и точ-ность алгоритма. В результате обучения и тестирования ней-росети необходимо построить график зависимости вероятно-сти (частотности) правильного ответа от: - количества нейронов в скрытом слое при заданном количе-
стве входных нейронов; - количества входных нейронов при заданном количестве ней-
ронов в скрытом слое; - количества примеров в обучающей выборке при заданном
количестве нейронов во входном и скрытом слоях; - порогового значения нейронов при фиксированных значе-
ниях других параметров.
Таблица 2.6 № вари-анта
1x 2x 3x Функция
1 1 2 3 2 2 21 2 3x x x
2 5 4 3 1 2 3sin sin sinx x x
3 9 8 7 1 2 3sin sintgx x x
4 8 5 3 1 2 3sin sin cosx x x
5 5 6 7 1 2 3sintgx x tgx
6 1 8 7 1 2 3sin x tgx tgx
7 2 5 4 1 2 3cos cos sinx x x
8 5 7 8 1 2 3ln cos x tgx ctgx
9 2 3 6 12 32 cos sinx x x
10 7 4 5 2 22 1 3sin x x tgx
2.3. Исследование функционирования сети RBF Осуществить программную реализацию сети RBF. Обеспе-
чить возможность динамических изменений количества ней-ронов скрытого слоя и "ширины" активационных окон, а так-же вывод информации в файл и в виде графиков.
Для функциональных преобразований из п. 2.2 подобрать такие "ширины окон», при которых аппроксимация будет наилучшей, в чем убедиться на контрольных шаблонах. Про-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
68
верить, как изменяется качество аппроксимации при увели-чении количества обучающих шаблонов и изменении их дис-персии. Установить, что RBF-сеть выполняет точнее: интерпо-ляцию или экстраполяцию. Объяснить результаты.
Контрольные вопросы и задания для самопроверки
1. Определить главное отличие применения нейронних се-тей и методов классической парадигмы при решении за-дач прогнозирования.
2. Какие принципы функционирования мозга положены в основу функционирования искусственных нейронных се-тей?
3. Какие проблемы сопровождают процесс применения ней-ронных сетей в решении практических задач?
4. Опишите хронологию развития теории и методов функ-ционирования нейросетей.
5. Опишите архитектуру и структурные элементы перцеп-трона.
6. Для чего используется нормализация данных и какие осо-бенности имеет применение каждого из выражений для нормализации?
7. Перечислите основные этапы функционирования искус-ственного нейрона.
8. Опишите алгоритм обратного распространения ошибки. 9. Какие проблемы сопровождают процесс применения алго-
ритма обратного распространения ошибки? 10. В чем состоит главное отличие обучения прямосвязной
сети с алгоритмом обратного распространения ошибки и RBF-сети?
11. Опишите алгоритм обучения RBF-сети. 12. Какие проблемы сопровождают процесс обучение RBF-
сети? 13. Какие преимущества предоставляет RBF-сеть при прогно-
зировании? 14. Каким образом решается задача определения "ширины
окон" RBF-сети?

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
69
15. К какому классу нейросетей принадлежит сеть встречного распространения?
16. Элементы каких сетей и с какими функциями объединены в сеть встречного распространения?
17. Опишите алгоритм обучение сети встречного распростра-нения.
18. В чем состоит сущность метода выпуклой комбинации? 19. Назовите особенности использования сети встречного рас-
пространения? 20. Какие проблемы сопровождают процессы применения
нейросетевых технологий? 21. Назовите преимущества нейронных сетей при их приме-
нении к решению задач прогнозирования, класси-фикации и диагностики.
Темы рефератов и расчетно-графических работ
1. Проблема Минского. 2. Методы обучения нейросетей, уменьшающие возмож-
ность их "паралича". 3. Методы обучения нейросетей, минимизирующие вероят-
ность попадания в локальные оптимумы. 4. Анализ эффективности прогнозирования с помощью пря-
мосвязной сети с алгоритмом обратного распространения ошибки, RBF-сети, сети встречного распространения для функциональной зависимости и статистических данных.
5. Исследование эффективности обучения RBF-сети для слу-чая плохо обусловленной матрицы начальных данных.
6. Определение класса задач, для решения которых приме-нение сети АРТ является наиболее адекватным.
7. Особенности реализации когнитрона и неокогнитрона. 8. Новые нейросетевые парадигмы и архитектуры. 9. Применение нейросетей для решения задач математиче-
ского программирования. 10. Нейронные сети и самоорганизация систем. 11. Применение нейроинформатики в медицине, экономике
и технике.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
70
12. Применение нейронных сетей для обработки данных, рас-познавания образов и управления.
13. Практическое применение нейроматематики. 14. Аппаратная реализация нейросетевых технологий. 15. Пути оптимизации методов стохастического обучения
нейросетей. 16. (Задача проблемного типа). Концепция "искусственной жиз-
ни" и нейросетевое обучение агентов.
Теми для самостоятельной работы
1. Проблема линейного разделения исследуемой области с
помощью искусственного нейрона. 2. Особенности реализации алгоритма АОРО и проблемы,
которые ее сопровождают. 3. Стохастические методы обучения нейросетей. Метод от-
жига металла. Машины Больцмана и Коши. 4. Нейронные сети с обратными связями. 5. Двунаправленная ассоциативная память. 6. Алгоритмы обучения сети АРТ. 7. Особенности разработки и применения ядерных нейрон-
ных сетей. 8. Модели эволюции нейронных сетей. 9. Решение систем линейных уравнений с помощью нейро-
сетей. 10. Задачи искусственного интеллекта и нейросети. 11. Нейросетевое управление. 12. Вероятностная нейронная сеть. 13. Обобщенно-регрессионная нейронная сеть. 14. Задача нейросетевой кластеризации при известном коли-
честве кластеров. 15. Оптимизация количества кластеров при нейросетевой кла-
стеризации.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
71
Литература
Основные источники 1. Хайкин С. Нейронные сети: полный курс. М.: “Вильямс”,
2006. 1104 с. 2. Люгер Ф. Дж. Искусственный интеллект. Стратегии и ме-
тоды решения сложных проблем. М.: “Вильямс”, 2003. – 864 с.
3. Генетические алгоритмы, искусственные нейронные сети и проблеми виртуальной реальности. /Вороновский Г.К., Ма-хотило К.В., Петрашев С.Н., Сергеев С.Н. – Харьков: Ос-нова, 1997. – 112 с.
4. Уоссермен Ф. Нейрокомпьютерная техника: теория и прак-тика. – М.: Мир, 1992. – 240 с.
5. Заенцев И.В. Нейронные сети. Основные модели. – Воро-неж: ВГУ, 1999. – 76 с.
6. Нейроматематика. Кн. 6. Под ред. А.И. Галушкина. – М.: ИПРЖР, 2002. – 448 с.
7. Снитюк В.Е., Шарапов В.М. Эволюционно-параметрическая оптимизация RBF-сети // Донецк: Искусственный интел-лект. – 2003. – № 4. – С. 493-501.
Дополнительные источники
1. Holland J. H. Adaptation in natural and artificial systems. An introductory analysis with арplication to biology, control and artificial intelligence. – London: Bradford book edition, 1994. – 211 p.
2. Rumelhart D.E., Hinton G.E., Williams R.J. Learning representa-tion back-propagation errors // Nature. – 1986. – Vol. 323. – P. 533-536.
3. Hecht-Nielsen R. А. Counterpropagation networks. In Proceed-ings IEEE First International Conference on Neural Networks, eds. M. Caudill and Z. Butler. – San Diego, CA: SOS Printing.– 1987. − Vol. 2. – P. 19-32.
4. Kohonen T. Self-organization and associative memory. Series in Information Sciences. – Berlin: Springer Verlag, 1984. – Vol. 8.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
72
5. Grossberg S. Some networks that can learn, remember and re-produce any number complicated space-time patterns // Journal Mathematics and Mechanics. – 1969. – Vol. 19. – P. 53-91.
6. Рассел С., Норвиг П. Искусственный интеллект. Современ-ный подход. – М.: Вильямс, 2006. – 1408 с.
7. Минский М., Пайперт С. Перцептроны. – М.: Мир, 1971. – 261 с.
8. Методы нейроинформатики / Под ред. А.Н. Горбаня. – КГТУ, Красноярск, 1998. – 205 с.
9. Снитюк В.Е. Нейросетевое планирование процесса проек-тирования с использованием аппарата теории нечетких множеств // Херсон: Вестник ХГТУ. 2003. № 2(18). С. 249-253.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
73
Глава 3
Эволюционное модели-рование и методы само-
организации
Никаким количеством экспериментов нельзя доказать теорию; но достаточно одного
эксперимента, чтобы ее опровергнуть. Альберт Эйнштейн
Основные понятия и термины
Структурная и параметриче-
ская идентификация Теорема Вейерштрасса о при-
ближении непрерывной функ-ции полиномом
Адекватность модели Самоорганизация Теорема Геделя Принцип свободы выбора Активный и пассивный экс-
перименты Критерии внешнего дополне-
ния Спецификация модели Тренд Корреляционный момент Авторегрессия Интерполяция Экстраполяция Опорная функция Коэффициент корреляции Метод наименьших квадратов Контрольная выборка Учебная выборка Несмещенная оценка Ковариация Ортогональные векторы Критерии регулярности Дисперсия
Границы познания процессов современного мира являют-
ся размытыми и стремительно расширяются. Возникновение новых предметных областей, новых проблем является еще одним подтверждениям принципа „новых задач” академика В.М. Глушкова. Ниже выполним анализ методов решения та-ких задач, базирующиеся на эволюционных принципах. По-кажем их преимущества и недостатки при решении задач оп-тимизации в сравнении с классическими методами. Рассмот-рим аспекты научных исследований эволюционных техноло-гий в известных мировых школах. Обсудим проблемы сходи-мости и границы применимости.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
74
Существуют разные варианты классификации классиче-ских методов, которые используются для принятия решений. Значительную их часть составляют методы оптимизации, ко-торые используются при решении задач линейного, нели-нейного, целочисленного, выпуклого, динамического, стохас-тичного, геометрического программирования и т.п. До сего-дняшнего дня не разработаны методы, которые были бы инва-риантными к размерности и содержанию области данных, структуре и параметрам целевой функции. Двигаясь в этом направлении, независимо разными учеными были предложе-ны парадигмы, базирующиеся на идеях и принципах при-родной эволюции. К ним относят известные методы эволю-ционного моделирования, которые еще называют эволюци-онными алгоритмами (ЭА): - эволюционное программирование (ЭП); - эволюционные стратегии (ЭС); - генетические алгоритмы (ГА); - генетическое программирование (ГП).
Особенности каждого из указанных эволюционных алгорит-мов: - генетические алгоритмы, в основном, предназначены для
оптимизации функций дискретных переменных, в них ак-центируется внимание на рекомбинациях геномов;
- методы эволюционного программирования ориентированы на оптимизацию непрерывных функций без использования рекомбинаций;
- эволюционные стратегии ориентированы на оптимизацию непрерывных функций с использованием рекомбинаций;
- генетическое программирование использует эволюционный метод для оптимизации компьютерных программ.
Такая классификация предложена профессором В.Г. Редько. Однако сегодняшние реалии указывают на то, что каждый из эволюционных алгоритмов применяется для решения и других задач. Кроме того, появились методы, которые также считают представителями эволюционной парадигмы. Это муравьиные и меметические алгоритмы, программирование генетических выражений и другие.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
75
Поскольку каждый эволюционный алгоритм является итера-ционным методом, то для его реализации необходимо при-менять вычислительную технику. Неизбежно возникают во-просы сходимости каждого из них, скорости сходимости (для эволюционных алгоритмов она, как и раньше, является акту-альной), проведение препроцессинга данных. Эффективный выбор и использование эволюционного алгоритма зависят от правильного соотношения формализованной задачи, сущности метода ее решения и ожидаемых результатов.
Элементы эволюционного подхода присутствуют и в методе группового учета аргументов.
3.1. Метод группового учета аргументов. Общие положения
Автором метода группового учета аргументов (МГУА) явля-ется академик Национальной академии наук Украины Алексей Григорьевич Ивахненко. Свое применение МГУА нашел в разных областях знаний, в которых осуществляется структур-ная, параметрическая идентификация и прогнозирование. Он базируется на самоорганизации моделей и, в отличие от регрессионного анализа, где структура модели задана, направ-лен на определение структуры модели оптимальной сложности. Построение адекватного уравнения линейной регрессии и его уточнение требуют все большей и большей ретроспективы (пе-риода рассмотрения статистических данных), что чаще всего является невозможным. Увеличение количества факторов со-провождается „проклятьем размерности”, сущность которого состоит в накоплении суммарной ошибки и вычислительной сложности. Количество структурных элементов модели огра-ничено, что вследствие теоремы Геделя о неполноте (одна из ее формулировок: „Для любой системы существует теорема, которая не может быть ни доказана, ни опровергнута с по-мощью аксиом этой системы”) свидетельствует о существова-нии такой таблично заданной зависимости, которая не может быть аппроксимирована с помощью композиции данного на-бора структурных элементов.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
76
Метод группового учета аргументов реализован во мно-гих алгоритмах для решения разных задач. В него входят па-раметрические алгоритмы, алгоритмы кластеризации, ком-плексирование аналогов, ребинаризация и вероятностные алгоритмы. Подход самоорганизации, реализованный в МГУА, базируется на переборе моделей, которые постепенно усложняются, и выборе наилучшего решения, исходя из ми-нимального значения внешнего критерия. В качестве базис-ных моделей используются не только полиномы, но и другие нелинейные функции. С помощью перебора разных решений в индуктивном подходе к моделированию стараются миними-зировать роль влияния аналитика на результаты моделиро-вания. Компьютер находит структуру модели и законы, по ко-торым функционирует объект, и используется как руководство для отыскания новых решений в задачах искусственного интел-лекта.
Направление исследований, реализованное в МГУА, в част-ности, является эффективным и потому, что: - находится оптимальная сложность структуры модели, аде-
кватная уровню шумовых помех в выборке данных (для ре-шения проблем с зашумленными или “короткими” данны-ми упрощенные прогнозирующие модели оказываются бо-лее точными);
– количество шаров и нейронов в скрытых шарах, структура модели и другие оптимальные значения параметров нейро-сетей находятся автоматически.
Автор МГУА предложил использовать принцип внешнего дополнения. Базируясь на теореме Вейерштрасса о том, что лю-бую непрерывную функцию можно как угодно точно прибли-зить полиномом, он предложил следующую схему.
3.2. Многорядный метод группового учета аргументов
Пусть в качестве начальных данных выбрана матрица 1 2( , ,.., , ),nA X X X Y где , 1, ,iX i n и Y – векторы-столбцы раз-
мерностью ,m iX – входные факторы, Y – результирующая

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
77
характеристика. Задача состоит в идентификации зависимо-сти
1 2( , ,.., )nY F X X X (3.1) полиномом Колмогорова-Габора
01
...n
i i ij i j ijk i j ki i j i j k
Y a a x a x x a x x x
. (3.2)
Известно, что при увеличении порядка полинома точ-ность приближения им функции ( )F x возрастает, а затем убы-вает. Если точность является максимальной, то процесс услож-нения полинома заканчивается. Особенностью МГУА есть то, что он может быть применен в случае малого количества то-чек экспериментов, даже значительно меньшей, чем количе-ство членов полинома.
На первом этапе реализации МГУА выбирается опорная функция. Чаще всего используются зависимости вида: 1. 0 1 .i jy a a x x 2. 0 1 2 .i jy a a x a x 3. 0 1 2 3 .i j i jy a a x a x a x x 4. 2 2
0 1 2 3 4 5 .i j i j i jy a a x a x a x a x a x x Для первой функции необходимы данные хотя бы трех
экспериментов, для (2) – 4, для (3) – 5, для (4) – 7. Такой вывод объясняется тем, что для определения коэффициентов будет использован метод наименьших квадратов. Обозначим
( , ),k i jy f x x где f – одна из указанных зависимостей или, возможно, подобная.
На следующем шаге с помощью МНК определяют коэф-фициенты уравнений
1 1 2( , ),y f x x 2 1 3( , ),y f x x …, 1 1( , ),n ny f x x ),( 32 xxfyn ,…, 1( , ),p n ny f x x
(3.3)
где 2np C – количество сочетаний из n элементов по 2 . Объяс-
нить формулу расчетов p можно, исходя из таких соображе-ний. Все возможные пары индексов образуют матрицу (табл.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
78
3.1). Те пары, которые мы используем, находятся над главной
диагональю. Количество таких элементов 2( 1) .2 n
n n C
Таблица 3.1. Пары возможных индексов
(1,1) (1,2) (1,3) (1,4) … (1,n–1) (1,n) (2,1) (2,2) (2,3) (2,4) … (2,n–1) (2,n) (3,1) (3,2) (3,3) (3,4) … (3,n–1) (3,n) … … … … . … …
(n,1) (n,2) (n,3) (n,4) ... (n,n–1) (n,n)
После того, как все зависимости ,iy 1, ,i p идентифици-рованы, по внешнему критерию отбирают лучшие. Определе-ние их количества относят на свободу выбора, чаще всего это 40-60%. Те зависимости, которые остались, перенумеровывают и получают 1 2, ,.., ,sy y y где s – количество отобранных зависи-мостей. Первый шаг селекции окончен.
На следующем шаге с помощью МНК определяют коэф-фициенты таких зависимостей:
1 1 2( , ),z f y y 2 2 3( , ),z f y y … , 1( , ),r s sz f y y 2 .sr C (3.4) Дальнейшая процедура аналогична вышеизложенной. Ес-
ли значения внешнего критерия улучшаются, то селекция продолжается, в противном случае модель оптимальной сложности получена.
3.3. Критерий регулярности Опишем внешние критерии, использования которых бази-
руется на принципе внешнего дополнения. Этот принцип по-сле работ А.Г. Тихонова и В.К. Иванова получил название принципа регуляризации. В зависимости от типа задачи А.Г. Ивахненко предложил рассматривать такие критерии: регу-лярности, несмещенности и баланса переменных. Известны два критерия регулярности: - минимум среднеквадратичной ошибки на новых точках от-
дельной контрольной последовательности; - максимум коэффициента корреляции на тех же точках.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
79
Рассмотрим процедуру их применения. Начальные дан-ные находятся в выделенной части табл. 3.2.
Таблица 3.2. Начальные данные для идентификации с
помощью МГУА
1x 2x . nx y 1y 2y ... py 11x 12x . 1nx 1y 11y 12y . 1 py 21x 22x . 2nx 2y 21y 22y . 2 py . ... . . . . . . .
1mx 2mx ... mnx my 1my 2my . mpy
Разделим ее строки на две части (приблизительно 60% на 40%), тогда ,m l k где l – количество точек эксперимента в первой (обучающей) выборке, k – во второй (контрольной). Значение l должно быть больше числа слагаемых в опорной функции ( ).f x
Используя элементы обучающей выборки, определяем ко-эффициенты зависимостей (3.3). Далее рассчитываем значе-ние критерия регулярности на точках контрольной выборки, после чего упорядочиваем iy по увеличению значения кри-терия и выбираем из них определенное количество с наи-меньшим его значением. После перенумерации они составят множество функций следующего ряда селекции. Условия окончания итераций не „канонизированы” и могут быть, на-пример, такими: - среднее значение ошибки для следующего ряда селекции
есть большим, чем самое большое (среднее) значение ошиб-ки для предыдущего ряда;
- минимальное значение ошибки следующего ряда больше минимального значения ошибки предыдущего ряда;
- максимальное значение ошибки следующего ряда больше максимального значения ошибки предыдущего ряда;
- модуль отклонения ошибок следующего и предыдущего ряда меньше некоторого числа.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
80
Критерий регулярности, который состоит в минимизации среднеквадратичной ошибки на точках контрольной последова-тельности, будет таким:
1
2
1
( )min,
k
k
N
i ii
N
ii
y y
y
(3.5)
где kN – количество точек в контрольной последовательности,
iy рассчитанное значение искомой зависимости в i -и точке контрольной последовательности. Другой вариант критерия регулярности состоит в максимизации коэффициента корреля-ции
1
2
1
( )1.
k
k
N
i ii
N
ii
y yk
y
(3.6)
Для получения результатов, сопоставимых для разных мо-делей, величины в (3.5) и (3.6) необходимо нормировать:
,i
нy yy
y
.y yy
y
Преимуществом критерия регулярности является плавность изменения его значения при увеличении сложности модели. Недостатком его использования есть низкая точность при решении экстраполяционных задач. Поэтому критерий регу-лярности рационально применять для идентификации и крат-косрочного прогноза.
3.4. Критерий несмещенности Известные три вида критерия несмещенности, ба-
зирующиеся на анализе решений, на анализе коэффициентов и „критерий относительной несмещенности ”.
Критерий несмещенности, базирующийся на анализе решений (КН1). Для расчетов КН1 необходимо ранжировать все точки экспериментов по увеличению или уменьшению значения

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
81
дисперсии. Процедура ранжирования описана ниже. После ранжирования точки экспериментов нумеруют и делят на две последовательности: – к первой относят точки с четными номерами, их количество
1;N – ко второй – с нечетными, их количество 2 ;N 1 2 .N N n
На первом ряде селекции первая последовательность явля-ется обучающей, вторая – контрольной. Полученные на обу-чающей последовательности 1N уравнения регрессии обозна-чим 1 ( , ).k i jy f x x Далее первую последовательность считают контрольной, вторую – обучающей. На обучающей последова-тельности находят уравнения регрессии 2 ( , ).k i jy f x x Коли-чество уравнений 1
ky и 2ky должны совпадать, случай невы-
полнения этого условия не рассматриваем. Для каждого k рассчитывают среднеквадратичное отклонение
1 2 2 1/ 2
1
1( ( ) ) ,i i
m
k k ki
n y ym
(3.7)
где ik – номер i -го уравнения. Выбирают p уравнений, кото-рые отвечают меньшей оценке kn (можно из 1
ky или 2ky ).
Среднее значение критерия несмещенности на первом ряду селекции вычисляют по такой формуле:
11
1 .p
ii
N np
(3.8) На втором и следующих рядах селекции процедура оста-
ется такой же. Селекция длится до того времени, пока среднее значение критерия несмещенности уменьшается.
Критерий несмещенности, базирующийся на анализе коэффи-циентов (КН2). Точки экспериментов ранжируем по величине дисперсии и делим на обучающую и контрольную последова-тельности наполовину. Точки с большим значением диспер-сии попадают в обучающую последовательность, с меньшим – в контрольную. Особенность критерия заключается в том, что на каждом ряду селекции ранжирование и разделение точек эксперимента выполняется заново. Кроме того, уменьшается свобода выбора согласно формуле ,F m S где F – число

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
82
переменных, пропущенных на этом ряду селекции, S – номер ряда, m число входных переменных, 1..5, 0,1..0,2. Формула и процедура, которая с ней связана, дают возмож-ность скорейшего решения задач большой размерности.
Значение критерия несмещенности оценок коэффициентов модели рассчитывают по формуле
2
1
2 2
1 1
( ),
p
i i ii
k p p
i ii i
a b an
a b
(3.9)
где p – общее число коэффициентов, ia – коэффициенты, полу-ченные до изменения последовательностей, ib – после. В сле-дующий ряд пропускают F моделей, которые имеют боль-шее значение kn . Селекция длится до тех пор, пока, напри-мер, среднее значение kn в ряду селекции увеличивается.
Критерий несмещенности необходимо применять или вместе с критерием регулярности, или в алгоритмах с полным перебором моделей.
Критерий относительной несмещенности. В этом случае используют только линейные частные описания (напр.
0 1 2k i jy a a x a x ), но во избежание потери точности про-странство начальных аргументов включает и ковариации (на-пример, 1 ,x 2 ,x 1 2x x ). Присваивая значение ковариаций но-вым переменным, получим обобщенные аргументы (например,
1 ,x 2 ,x 3x ). Поскольку частное описание на втором ряду есть таким:
0 1 2 ,i jz a a y a y то ортогонализированное частичное описание –
,i jz y A у (3.10) где jу – вектор, ортогональный по отношению к .ix
Если в частных описаниях значения переменных центри-рованы и нормированы по среднему значению, то в орто-гонализированных частных описаниях свободный член
0 0,a а другие коэффициенты имеют такие значения: 1 1,a

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
83
12
2
1
( ).
N
i ji
N
ii
y ya A
y
(3.11)
Ортогонализация является преобразованием jу по отно-шению к базовому iy , в результате которого получаем:
1
0.N
i ji
y у
Для этого достаточно, чтобы ,j ijу y Ay где A определяет-ся по (3.11).
Таким образом, алгоритм МГУА с использованием крите-рия относительной несмещенности имеет такие базовые ша-ги:
Шаг 1. Начальные данные делим на две части (описано выше).
Шаг 2. На первой последовательности определяем значе-ния коэффициентов *A в уравнении регрессии, на второй – ко-эффициенты **.A
Лучшими считаем те описания, в которых * **
зм зм* min .i i
i
A An nA
Ряды описаний будут такими:
1 ;iy a x ;i jz y Aу ;jit z Az ..... .
3.5. Критерий баланса переменных Критерий баланса переменных является самым эффектив-
ным критерием при средне- и долгосрочном прогнозировании. Его определение может быть эмпирическим и искусственным.
При эмпирическом определении критерия баланса пере-менных из перебора исключаются модели, которые дают яв-ным образом неверный прогноз (то есть, прогнозируемое значение Y не принадлежит той области, которой должно принадлежать по своему определению). Кроме того, на Y может быть наложено множество других условий. Например,

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
84
в зависимости ( , )k i jy f x x 1 ,l lk ky y 1, 1,l n где n – количе-
ство точек, которые учитываются при построении ,ky или
[1;3], 1, 1.lkli
y l ny
Искусственные условия баланса не является следствием принципа физической реализуемости модели и определяют-ся исследователем. Чаще всего это функции, которые являют-ся комбинациями сумм и разностей значений входных фак-торов. При этом в систему входных факторов добавляются независимые переменные, которые обычно не имеют физиче-ского смысла.
В одном из примеров в задачу прогнозирования трех пе-ременных 1 2 3, ,X X X вводятся новые переменные
1 1 2 3 2 1 2 3 3 1 2 3, , ,S X X X S X X X S X X X 4 1 2 3 ,S X X X 5 1 2 3.S X X X 6 1 2 3.S X X X
(3.12)
Эти переменные вместе с начальными переменными 1 2 3, ,X X X образуют вектор входных факторов, рассчитанные
значения заносятся в таблицу начальных данных (табл. 3.3) и в дальнейшем прогнозируются вместе с другими переменны-ми.
Таблица 3.3. Начальные данные для МГУА t
1X 2X 3X 1S 2S … 6S
1t 11x 12x 13x 11s 12s … 16s
2t 21x 22x 23x 21s 22s … 26s … … … … … … …
nt 1nx 2nx 3nx 1ns 2ns … 6ns Предположим, что в результате постепенного усложнения
моделей и применения МНК получены уравнения трендов
01
( ) , 1,3, 1, .k
k k k ij j ij
iX t a a t j k m
(3.13)
Наилучшей предполагается такая система трендов, ко-торая имеет минимальное рассеяние в интервале времени наблюдения

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
85
1
31 2
1 1 2 3
6 62 2
1 1
62
1 2 31 , , 1
( ( ) ( ))
( ( ) ( ( ), ( ), ( ))) min,
n
n
t
l l ll l t t
t mkk k
l ll t t k k k
Ф E S t S t
S t S X t X t X t
(3.14)
где (*)lS
зависимости типа (3.12). Тренды – решения вышеупомянутой задачи, являются опти-
мальными зависимостями. Вид задачи указывает на значительную трудоемкость про-
цесса ее решения. Поэтому необходимо использовать эмпири-ческие процедуры уменьшения количества комбинаций пере-бора, в том числе учитывать принцип возможности физической реализуемости. Число m определяется исследователем и зави-сит, в общем случае, от мощности вычислительной машины.
По полученным трендам * * *1 2 3( ), ( ), ( )X t X t X t осуществляется
прогнозирование. Важно заметить, что довольно часто крите-рий несмещенности и критерий баланса переменных являют-ся одним и тем же критерием.
3.6. Алгоритм разделения начальной выборки данных
Реализация МГУА, в большинстве случаев, связана с необ-ходимостью разделения генеральной совокупности данных на две выборки – обучающую и контрольную. Наиболее рас-пространенным, но не единственным, является подход, при котором в обучающую последовательность выбирают точки экспериментов с большим значением дисперсии, а в кон-трольную – с меньшим. Это объясняется тем, что область обуче-ния должна быть наиболее широкой, а контрольные точки, в большинстве своем, находиться внутри нее.
Алгоритм разделения будет таким: Шаг 1. Определить процентное соотношение между количест-вом элементов в обучающей и контрольной последовательно-стях. Шаг 2. Для каждого столбца ,iX 1, ,i n рассчитать среднее значение его элементов

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
86
сeр1
1 m
i jij
x xm
(3.15)
и получить среднее значение множества образов (сeр1 ,x
сeр2 ,...,x
сeрnx ). Шаг 3. Найти выборочные дисперсии для каждой строки таб-лицы по формуле
2
1
1 ( ) ,1 ср
n
i ij jj
D x xn
1, .i m (3.16)
Шаг 4. Для упорядочения элементов таблицы переставить строки так, чтобы первой была строка с наибольшим значе-нием дисперсии, а последней – с наименьшим. Шаг 5. В соответствии с результатом шага 1 разделить данные таблицы на обучающую и контрольную последовательности.
Если решается задача краткосрочного прогноза (на один такт времени вперед), то ищут еще и оптимальное соотноше-ние количества образов в обучающей последовательности к количеству образов в контрольной последовательности с це-лью получения простейшей и достоверной модели.
3.7. Ретроспектива эволюционного моделирования
Ingo Rechenberg
В 60-ые годы прошлого столетия Инго Рехенберг (I. Rechenberg), нахо-дясь под впечатлением метода „орга-нической эволюции”, выдвинул идею применения мутации к вектору дейст-вительнозначных параметров при ре-шении оптимизационных проблем в аэродинамике. Реализованная техно-логия стала известной под названием „эволюционная стратегия” (evolution strategie).
В 1981 году Ханс-Пауль Швефель (H-P. Schwefel) при иссле-
довании гидродинамических задач ввел рекомбинации в эво-люционные стратегии и выполнил их сравнительный анализ

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
87
с классическими методами оптимизации. Приблизительно в то же время в США независимо выполнялись исследования Лоуренсом Фогелем (Lawrence Fogel) эволюции искусственно-го интеллектуального автомата с конечным числом состояний с использованием метода, который назвали эволюционным программированием (evolutionary programming).
Джон Холланд (John Holland, www.cscs.umich.edu/~crshalizi/notabene/evol-comp.html) ана-лизировал класс репродуктивных систем методом, который нам известен как генетический алгоритм (genetic algorithm). Такая классификация эволюционных алгоритмов была бы не полной без работ Лин Крамер (Lynn Cramer), Джека Хайкли-на (Jac Hicklin), Гори Фуджики (Gory Fujiki), результаты кото-рых обобщил и расширил Джон Коза (John Koza). Предло-женный метод назвали генетическим программированием.
Эволюционные алгоритмы отличаются один от другого. Но все они базируются на принципах эволюции: 1. Индивиды имеют конечное время жизни; размножение не-
обходимо для продолжения рода. 2. В определенной степени потомки отличаются от родите-
лей. 3. Индивиды существуют в среде, в которой выживание яв-
ляется борьбой за существование, и их изменения содейст-вуют лучшей адаптации к условиям внешней среды.
4. С помощью естественной селекции лучше адаптированные индивиды имеют тенденцию к более продолжительной жизни и большему количеству потомков.
5. Потомкам свойственно наследовать полезные характери-стики своих родителей, что влияет на увеличение приспо-собленности индивидов во времени.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
88
3.8. Генетический алгоритм. Историческая справка и базовые элементы
John Holland
Из биологии известно, что гене-тический код организма называется его генотипом, а физическая реализация организма – фенотипом. Эти и другие определения являются базовыми в тер-минологии ГА, что вовсе не означает точного наследования ими биологиче-ских процессов, и только в некотором приближении ГА можно считать их мо-делью. В биологической хромосоме информация кодируется цепочкойДНК, состоящей из длинной последова-тельности четырех элементов: аденина, цитозина, гуанина и тимина.
Начальный генетический код организма записывают, ис-пользуя четыре буквы (А, С, G, T) алфавита. В ГА хромосома представлена рядом, записанным в двухэлементном алфа-вите, состоящем из нуля и единицы.
К базовым операторам ГА относят кроссовер (рекомбина-ции, кроссинговер), мутации и инверсии. С их помощью осу-ществляется доминирующее размножение лучше адаптиро-ванных к внешней среде особей, а также получение особей с характеристиками, которые отсутствовали у особей в преды-дущих поколениях. В оптимизационных задачах, таким обра-зом, реализуется приближение к оптимальному решению и «выбивание» целевой функции из локальных экстремумов.
Генетический алгоритм является одним из методов нахо-ждения экстремумов сложных функций и составляющей ча-стью эволюционного моделирования как научного направле-ния, которое базируется на принципах естественного отбора по Ч. Дарвину. Название «генетический алгоритм» впервые было предложено в 1975 году в Мичиганском университете Джоном Холландом (John Holland). Сам алгоритм называли еще репродуктивным планом Холланда и он в дальнейшем

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
89
активно использовался как базовый алгоритм в эволюцион-ных вычислениях.
David. E. Goldberg Kenneth A. De Jong
Дальнейшее развитие ГА получил в роботах других уче-
ных, в частности Девида Голдберга (Goldberg D.E., www.illigal.uiuc.edu/web, www.davidegoldberg.com) в лабора-тории генетических алгоритмов Иллинойского университета, Кеннета де Йонга (De Jong K.A., www.cs.gmu.edu/ kdejong/) в университете Джорджа Мейсона и их учеников.
Рассмотрим базовый ГА. Шаг 1. Инициализировать начальный момент времени 0.t Шаг 2. Случайным образом сформировать начальную попу-ляцию, составленную из k особей. 0 1 2{ , ,..., }.kB A A A Шаг 3. Вычислить приспособленность каждой особи ( )
iA iF fit A ,
1, ,i k и популяции в целом, ( )t tF fit B (ее еще называют фитнесс-функцией (fitness-function)). Значение этой функции указывает на то, насколько оптимальной является особь, ко-торая описывается данной хромосомой, для решения задачи. Шаг 4. Выбрать особь
1cA из популяции. 1
( ).c tA Get B Шаг 5. Выбрать вторую особь из популяции
2( )c tA Get B и с оп-
ределенной вероятностью (вероятностью кроссовера cP ) выпол-нить кроссовер. Шаг 6. С вероятностью 0,5 из
1cA и 2cA выбрать одну особь.
1 2( , ).c c cA Get A A

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
90
Шаг 7. С определенной вероятностью (вероятностью мутации mP ) выполнить оператор мутации. ( ).c cA mutation A
Шаг 8. С определенной вероятностью (вероятностью инвер-сии iP ) выполнить оператор инверсии. ( ).c cA inversion A Шаг 9. Поместить полученную особь в новую популяцию.
1( , )t cinsert B A . Шаг 10. Повторить операции, начиная с шага 3, k раз. Шаг 11. Увеличить номер текущей эпохи. 1t t . Шаг 12. Если выполняется условие остановки алгоритма, то завершить работу, иначе перейти на шаг 3.
3.9. Основные понятия и пример задачи Пусть S – некоторая система или процесс. Ее атрибутами
являются: X – вектор входных и внутренних параметров, Y – вектор результирующих характеристик. Предположим, что преобразование ( )Y f X идентифицировано и зависимость
(*)f достаточно сложная. Известны также границы возмож-ных изменений значений составляющих вектора X . Необхо-димо найти такие значения вектора X , чтобы значение Y было оптимальным (квазиоптимальным).
В общем случае нельзя утверждать, что такая задача не может быть решенной другими методами, но в случае доста-точно сложной, возможно разрывной, полиэкстремальнои функции (*)f решить ее очень и очень сложно.
Как решается указанная задача с использованием ГА? Функция (*)f и является фитнесс-функцией. Возможные значения элементов вектора X составляют его фенотип. Дво-ичным представлением фенотипа является генотип (напри-мер, 34 100010). Генотип имеет определенное количество элементов (генов, битов). Один или несколько генотипов (по количеству элементов в X ) образовывают хромосому. Крос-совером называют разделение двух хромосом и обмен частя-ми (например, родители – 1100 и 1010 потомки – 1110 и 1000). Мутация – инвертирование одного из элементов хромо-сомы (например, 0000 0100). Инверсия – изменение порядка

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
91
местоположение частей хромосомы (например, 1100 0011).
Предположим, что некоторая переменная Y зависит от других переменных из множества 1 2( , ,..., )nX X X X . Началь-ные данные находятся в табл. 3.4. Рассмотрим случай, когда зависимость 1 2( , ,..., )nY f X X X достаточно сложная и нели-нейная. Сделаем маловероятное предположение: зависимость f установлена и она является, например, такой:
21 2 1 3 2 34,5 sin( ) ln( / )exp(13,4 ).Y X X X X X X
Таблица 3.4. Начальные данные
X1 X2 X3 Y 5 6 8 10 13 4 6 17 . ..... ..... .....
10 5 4 13 То, что получено такое выражение, означает решение за-
дачи структурной и параметрической идентификации. Структурной – потому, что определен вид зависимости
( 21 2 1 3 2 3sin( ) ln( / ) exp( )Y a X X X X b X X ),
а параметрической – потому, что установлены значения пара-метров ( 4,5, 13,4)a b . Имея такую зависимость, сложно определить, значения которого из факторов 1 2,X X или 3X осуществляют наибольшее или наименьшее влияние на зна-чение результирующего показателя .Y
3.10. Элементный и функциональный базис генетического алгоритма
В искусственной системе некоторая часть факторов может быть управляемой в том смысле, что их значения задаются в определенных границах аналитиком с целью минимизации или максимизации Y . Без ограничения общности будем счи-тать все факторы управляемыми, а также известными гра-ницы изменения их значений, то есть интервалы ( , )i ia b ,

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
92
1, .i n Если эти условия не выполнены, то задача будет иметь другую постановку.
В нашем случае задача состоит в нахождении максимума функции f с точностью , при известных предположениях об управляемости факторов и известных интервалах их зна-чений.
Указанная точность решения свидетельствует об априор-ном допущении о том, что полученное решение будет отли-чаться от точного решения на величину и это не противо-речит цели решения задачи. Такую задачу можно решить и методом полного перебора, но комбинаторная сложность та-кого подхода часто делает его непригодным из-за времени расчетов, например, сравнимого со временем существования человечества или Вселенной. Поэтому предлагается более компактный алгоритм поиска решения на базе ГА.
Его начальные шаги: Шаг 1. Выбираем такой интервал, для которого справедливым будет равенство: max( ).j j i ii
b a b a Пусть его длина равна d . Шаг 2. Для того, чтобы точность решения была , необхо-димо разбить этот интервал и все другие на 1 /k d отрез-ков. Длина каждого отрезка равна , что при попадании ре-шения на некоторый отрезок и будет гарантировать необхо-димую точность.
Замечание 3.1. Значение факторов можно нормировать, используя разные выражения, но в таком случае необходимо пересчитывать точность результата , а затем и сам результат.
Пусть, например, 0, 8, 8, 0,4,a b d тогда 21.k В результате разбиения получим точки отрезка [0,8] :{0;0,4;0,8;...;8} . Такое множество возможных значений называется фенотипом. Поставим в соответствие фенотипу его целочисленный аналог таким образом:
{0;0,4;0,8;...;8} {0; 1; 2;...;21}. Целочисленному аналогу нужно сопоставить также его
двоичный генотип. Для этого заранее необходимо определить количество разрядов двоичного представления, поскольку все

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
93
его элементы для корректной работы ГА должны иметь оди-наковую длину, например, 2[log ] 1.p k Неизбежно возни-кает избыточность, поскольку возможных генотипов будет больше, чем реальных фенотипов. Некоторые авторы предла-гают считать значение функции f в таких точках равным нулю. Тогда возникают дополнительные шаги ГА и время вы-числений возрастает. Традиционно разбивают начальный интервал на 2 1p интервалов, тем самым увеличивая точ-ность. В результате выполнения таких процедур получим на-боры фенотипов, целочисленных аналогов и генотипов. Все подготовительные операции для ГА закончены.
Кратко остановимся на особенностях реализации составляю-щих ГА. Заметим, что кроссовер может быть как одноточеч-ным, так и двухточечным, и многоточечным (вариантов мно-готочечного кроссовера существует достаточно много), и иным. Выбор родительских пар тоже может осуществляться по-разному. Известны следующие основные методы: – панмиксия – родители выбираются из популяции случайным образом, поэтому один родитель может составлять пару с самым собой, или принимать участие в нескольких парах; – селекция – выбираются такие родители, у которых значения функции приспособленности выше среднего значения по по-пуляции; – инбридинг – первый родитель выбирается случайным обра-зом, а вторым родителем с большей вероятностью является особь популяции ближайшая к первой (заметим, что расстоя-ние может определяться как между генотипами, так и между фенотипами); – аутбридинг – первый родитель выбирается случайным обра-зом, а вторым родителем с большей вероятностью является особь популяции наиболее отдаленная от первой (имеет ме-сто то же замечание, что и для инбридинга); – пропорциональный – родители выбираются с вероятностями, пропорциональными их значениям функции приспособлен-ности.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
94
В зависимости от реализации функции расстояния между индивидами инбридинг и аутбридинг могут быть генотипным или фенотипным.
Существует также два механизма отбора индивидов новой популяции: элитный и отбор с вытеснением. В первом случае новая популяция формируется из наилучших особей репро-дукционной группы, которая объединяет в себе родителей, детей и „мутантов”. При отборе с вытеснением то, будет ли особь репродукционной группы входить в новую популяцию, определяется не только величиной ее приспособленности, но и тем, есть ли в новой популяции особь с аналогичным набо-ром хромосом.
Следует упомянуть о том, что еще одной процедурой, ко-торая оптимизирует процесс работы ГА, является использо-вание кода Грея. Его особенностью является обеспечение не-прерывности, то есть, если фенотипы отличаются на единицу, то и соответствующие генотипы будут отличаться значением одного гена. Для перехода от обычного бинарного представ-ления к коду Грея используют такое правило: если преобра-зование начинается со стороны старшего разряда, то старший разряд остаются неизменными; значения элементов в каждом следующем разряде остаются неизменными, если соседний старший разряд равняется нулю, или инвертируются, если он равняется единице; если преобразование начинается с млад-шего разряда, достаточно записать каждый разряд без изме-нений, если элемент следующего старшего разряда в комби-нации начального кода – 0, или инвертировать его, если сле-дующий разряд – 1. Пользуясь таким правилом для комбина-ции начального кода 1011011, получим код Грея – 1110110.
Другой способ преобразования. Добавим начальный код по mod 2 к этому же коду, но смещенному на один разряд вправо, причем младший разряд сдвинутой комбинации от-брасываем.
Преобразование из кода Грея в обычный бинарный код осуществляем таким образом. Оставляя старший разряд неиз-менным, инвертируем элементы в каждом следующем разря-де столько раз, сколько единиц предшествует ему в пройден-ных разрядах комбинаций рефлексного кода.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
95
Пример 3.1. Преобразуем код Грея 1110100 в обычный код. Старший разряд записываем без изменений – 1. Значение сле-дующего элемента изменится на нуль, поскольку перед ним – нечетное количество единиц (другими словами, он инверти-руется нечетное количество раз). Значение следующего раз-ряда останется неизменным, четвертый и пятый слева эле-менты меняются на противоположные: шестой и седьмой разряды записываем без изменений: 1011000.
Вариантов реализации ГА существует довольно много, но с каждым годом появляются все новые и новые. Наверное, предложение оптимального варианта остается все еще впереди. Известно, что:
1. Поиск эволюционного алгоритма, который превосходит все конкурирующие с ним алгоритмы, не имеет смысла без точного описания конкретных задач и целевых функций, для которых эволюционный алгоритм имеет преимущества перед другими алгоритмами. Нельзя рассчитывать найти один алго-ритм, который будет результативнее других для любых целевых функций оптимизации, что подтверждает и известная теорема NFL (No Free Lunch).
2. Для того чтобы найти приемлемое решение для задан-ного класса задач, необходимо сначала идентифицировать характерные особенности класса задач и потом на их основе искать соответствующий алгоритм (может оказаться, что ал-горитм, с помощью которого успешно решается одна задача, абсолютно не годится для другой).
Учитывая вышеизложенное, эволюционные вычисления имеют такие преимущества и недостатки:
1. Преимущества: - широкая область применения; - возможность проблемно-ориентированного кодирования ре-шений, подбора начальной популяции, комбинирование эво-люционных вычислений с неэволюционными алгоритмами, продолжение процесса эволюции при условии наличия необхо-димых ресурсов; - пригодность для поиска в сложном пространстве решений большой размерности; - отсутствие ограничений на тип целевой функции;

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
96
- ясность схемы и базовых принципов эволюционных вы-числений; - интеграция эволюционных вычислений с другими некла-ссическими парадигмами искусственного интеллекта, такими как искусственные нейросети и нечеткая логика.
2. Недостатки: - эвристический характер эволюционных вычислений не га-рантирует оптимальности полученного решения (на прак-тике, чаще всего, важно за заданное время получить одно или несколько субоптимальных альтернативных решений, тем бо-лее, что начальные данные в задаче могут динамично изме-няться, быть неточными или неполными); - относительно высокая вычислительная трудоемкость, ко-торая преодолевается за счет распараллеливания на уровне организации эволюционных вычислений и на уровне их не-посредственной реализации в вычислительной системе; - относительно невысокая эффективность на заключительных фазах моделирования эволюции (операторы поиска в эво-люционных алгоритмах не ориентированы на быстрое попа-дание в локальной оптимум); - нерешенность проблемы самоадаптации.
Таким образом, сравнительный анализ показывает, что эволюционные вычисления наименее пригодны для решения задач, в которых: - требуется найти глобальный оптимум; - есть эффективный, не эволюционный алгоритм; - переменные, от которых зависит решение, независимы; - существует высокая степень эпистазии (одна переменная подавляет другую); - значения целевой функции во всех точках, за исключением оптимума, являются приблизительно одинаковыми.
Принципиально соответствующими для решения с помо-щью эволюционных вычислений являются: - задачи многомерной оптимизации с мультимодальными це-левыми функциями, для которых нет соответствующих неэво-люционных методов решения; - стохастические задачи; - динамические задачи с блуждающим оптимумом;

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
97
- задачи комбинаторной оптимизации; - задачи прогнозирования и распознавания образов.
Как и для других ЭА, для ГА остро стоит вопрос сходимости. При выполнении определенных условий сходимость имеет место.
Теорема. Пусть выполняются такие условия: 1. Последовательность популяций 0 1, ,...P P , которая генериру-ется алгоритмом, − монотонна, то есть:
1:min{ ( ) } min{ ( ) }.t ti N f a a P f a a P 2. ',a a элемент 'a достижим из a с помощью мутации и кроссовера, то есть через последовательность переходов в ря-де структур.
Тогда глобальный оптимум *a функции f находится с вероятностью 1:
*lim { } 1.ttp a P
Очевидно, что в практических реализациях ГА второе ус-ловие теоремы выполняется всегда. Монотонность мини-мального значения fitness-function – достаточно строгое усло-вие, поскольку в существующих ГА реализуются многочис-ленные операторы выбора родителей и формирования новой популяции. Теоретическое обоснование монотонности для разных комбинаций генетических операторов является со-временной актуальной научной задачей.
3.11. Эволюционные стратегии Тогда как ГА моделирует эволюцию, в основном, на уров-
не геномов, ЭС и другие ЭА направлены на эволюцию фено-типов. Поскольку ЭС развивались специально для числовой оптимизации, в них фенотипы представлены действительно-значными векторами.
Оригинальная (в начальном варианте) ЭС была двухэле-ментной схемой, которую составляли родитель и потомок. В ба-зовом алгоритме родитель, мутируя, создает потомка и один из этих двух индивидов с лучшим значением fitness-function переходит в популяцию следующего поколения. Этот алго-ритм был обобщен позднее на двухэлементную схему – так на-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
98
зываемые ( ) и ( , )-стратегии. Параметры и опре-деляют количество родителей и потомков, соответственно. В форме ( ) родители и потомки принимают участие в общем селекционном пуле, лучших индивидов переходят в следующую популяцию. В ЭС ( , ) в следующую популя-цию переходят индивидов из множества потомков. Как следствие, родители не переходят из популяции в популя-цию.
Коэффициент
по обыкновению равен или больше
семи. Чем большим будет его значение, тем больше шансов, что у каждого родителя будет, по меньшей мере, один потомок, лучший, чем он сам. Однако отличия между ( ) и ( , ) ЭС уменьшаются, если значение достаточно большое.
Каноническая ЭС представлена таким алгоритмом: Шаг 1. 0.t Шаг 2. Инициализировать популяцию tP случайными ин-дивидами из .nR Шаг 3. Пока не справедливо условие остановки алгоритма вы-полнять: Шаг 3.1. Определить индивидов из tP с равной вероятно-стью для получения потомков. Шаг 3.2. Выполнить мутации над потомками. Шаг 3.3. Вычислить fitness-function потомков. Шаг 3.4. Выбрать лучших потомков, базируясь на значения fitness-function, и создать 1.tP Шаг 3.5. 1.t t Шаг 4. Вывод результатов. Окончание алгоритма. В результате сравнительного анализа ЭC и ГА установле-но, что их главное отличие заключается в том, что в ГА выби-раются индивиды для рекомбинации пропорционально их fitness-function и они заменяют индивидов из предыдущей популяции, в ЭС действуют наоборот. В этом случае индиви-ды для репродукции выбираются с равными вероятностями, а формирование следующей популяции базируется на значе-ниях fitness-function. На самом деле и ЭС, и ГА являются “дву-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
99
мя сторонами одной и той же монеты” и, как показывают экс-перименты, их результаты эквивалентны. Мутация, которая часто является единственным эволюци-онным оператором, состоит в изменении каждого элемента вектора весов-связей на величину, которая имеет нормальное распределение, дисперсия которого адаптируется во времени. В стратегии (1+1) так называемое правило “20% успеха” ис-пользуется для адаптации дисперсии. Швефель так сформу-лировал это правило: “Периодически во время поиска полу-чают частоту успеха, то есть отношение количества успехов
ко всему числу попыток (мутаций). Если оно больше 1 ,5
то
дисперсия возрастает, иначе − убывает”. Правило “20% успеха” было развито І. Рехенбергом в ре-
зультате теоретических исследований стратегии (1+1), приме-ненной к двум целевым функциям – моделям сферы и кори-дора. С помощью правила было показано, как получить высо-кую скорость сходимости для этих и других целевых функ-ций.
Если используют многоэлементную стратегию для эволю-ции популяции из родителей и потомков, то каждая особь состоит из 2-х действительнозначных векторов. Первый вектор содержит переменные значения, а второй – соответст-вующие среднеквадратичные отклонения (СКО), которые ис-пользуются для оператора мутации. Оптимальнее правила „20% успеха” при осуществлении мутации в многоэлементных стратегиях считают изменение СКО с использованием логнор-мального распределения:
'(0, )1 ,Gauss
t t e
где t – дискретность времени генерации. Коэффициент схо-димости ЭС чувствительный к выбору ' и начальным значе-ниям вектора СКО. Заметим, что метода их получение не-зависимо от целевой функции пока что не существует. Шве-фель рекомендует принимать
' ,C

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
100
где C зависит от и . Он считает, что 1,0C для ЭС (10, 100). Для инициализации
используется равенство
kk
R
для 1,2,..., ,k
где константа kR – максимальный ранг неопределенности со-ответствующей переменной.
Для ( ) ЭС доказана сходимость по вероятности, для ЭС ( , ) проблема сходимости остается открытой.
3.12. Сравнительный анализ эволюционных алгоритмов
Одним из главных отличий ГА от других ЭА, используе-мых сегодня, есть то, что ГА моделирует эволюцию на уровне геномов, в других методах эволюционируют фенотипы. Мно-го модификаций ЭА используют разные представления для по-пуляции эволюционирующих особей, которые являются на-чальными данными и результатами. Если в ГА используют, в общем случае, бинарные строки для представления особей, то в ЭС базируются на более общих действительнозначных представлениях. В ГП используют представление в виде деревь-ев, ЭП сначала базировалось на представлениях в виде графов, а в дальнейшем используют представление фенотипов, адекват-ных решаемой задаче.
Другие особенности разных ЭА состоят в использовании генетических операторов. В отличие от инверсии битов в ГА, в большинстве ЭС гены мутируют с помощью добавления гаусовского шума. ЭП применяется для автоматов с конечным числом состояний, мутируют индивиды при добавлении и изъятии, изменении переходов из состояния в состояние и т.п. Заметим, что в ГА и ГП определяющим является оператор кроссовера, в ЭС и ЭП – мутации.
Существуют отличия и в базовых процессах ЭА. В ГА и ГП выбираются особи для репродукции пропорционально зна-чению fitness-function и они заменяют элементы предыдущей популяции одинаково (равновероятно). ЭА и ЭП предпола-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
101
гают противоположную стратегию, которая заключается в том, что с равными вероятностями выбираются особи для ре-продукции и процесс выживания базируется на значениях fitness-function. Как ранее замечено, вариации порядка ука-занных операций имеют малое влияние на процесс эволю-ции.
Ключевой точкой является то, что все ЭА базируются на фундаментальных дарвиновских принципах естественной се-лекции. Преимущества одного ЭА над другим являются пред-метом дискуссии.
3.13. Мировые научные школы эволюционного моделирования
Известной мировой школой, которая представляет новое на-правление в эволюционном моделировании, есть школа док-тора Кандиды Ферейры (Candida Ferreira, www.gene-expression-programming.com, см. главу 9) в Великобритании. Ее исследо-вания сосредоточены на программировании генетических выражений. Новые алгоритмы, которые разрабатываются представителями школы, используют специфические опера-торы комбинаторного поиска, включая инверсию, вставку и изъятие генов и их последовательностей, ограничение и обоб-щение перестановок, которые увеличивают их эффектив-ность. Автор определяет программирование генетических выражений (ПГВ) как мультигенное (генотип/фенотип) коди-рование деревьев выражений, связанных частичным взаимо-действием. Известно, что в простейшем случае при единич-ной длине хромосомы ПГВ эквивалентно ГА.
Наиболее известной школой, в которой исследуют генетиче-ские алгоритмы, эволюционные стратегии, генетическое про-граммирование и эволюционное программирование, является лаборатория эволюционных вычислений Департамента компь-ютерных наук в университете Джорджа Мейсона в США (http://www. cs.gmu. edu). Руководство школой осуществляет ученик Джона Холланда профессор Кеннет Де Йонг (Kenneth A. De Jong). В лаборатории работают над проектами и приме-нением моделей эволюции (в дарвиновском смысле). Такие

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
102
модели необходимы для лучшего понимания эволюционных систем, они используются для обеспечения робастности, гиб-кости и адаптивности вычислительных систем. Главное зна-чение специалисты лаборатории уделяют решению сложных научных и технических проблем, таких как инновационное проектирование, оптимизация и машинное обучение.
В аналогичном направлении, но с акцентом на ГА, рабо-тает научная школа профессора Дэвида Голдберга. Лабора-тория генетических алгоритмов находится в Иллинойском университете США.
В отличие от классических методов оптимизации, парадигма эволюционного моделирования позволяет по-иному рас-сматривать оптимизационные задачи и процессы принятия ре-шений, но не дает ответа на многочисленные вопросы. Какие необходимые и достаточные условия сходимости каждого из методов? Насколько инвариантными являются ЭА по отно-шению к виду fitness-function, структур и вида начальных данных? Какие ЭА более эффективно использовать для ре-шения известных задач оптимизации?
Ответы на эти вопросы являются необходимыми для по-строения теории эволюционного моделирования. Современ-ные исследования, к сожалению, ориентированы на решение конкретных задач и содержат исключительно эксперимен-тальные подтверждения эффективного использования того или иного ЭА.
ПРАКТИЧЕСКИЕ ЗАДАНИЯ
3.1. Реализация и исследования многорядного МГУА. Необходимо получить математическую модель по методу
МГУА, осуществить прогнозирование и сравнить результат МГУА с результатом, полученным любым другим методом, используя контрольные точки известной функции. Для этого выполнить такие шаги:
1. Разработать программный фрагмент, который реализу-ет метод наименьших квадратов для линейной функции n переменных.
2. Если согласно варианту (см. табл. 3.5) критерием селек-ции есть критерий регулярности, то необходимо разделить

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
103
выборку данных на обучающую и контрольную последова-тельности.
Таблица 3.5. Начальные данные для реализации много-рядного МГУА
№
1x 2x 3x y Критерий селекции
Опорная функция
1 4 5 9 12 Баланса перемен-ных
0 1 i jy a a x x
2 7 3 8 13 Регулярности (1) 0 1 2i jy a a x a x 3 5 4 5 15 Несмещенности 0 1 2 3i j i jy a a x a x a x x 4 2 2 6 18 Регулярности (2) 0 1 i jy a a x x 5 3 1 4 32 Несмещенности 0 1 2i jy a a x a x 6 8 3 7 54 Баланса перемен-
ных 0 1 2 3i j i jy a a x a x a x x
7 9 6 8 21 Несмещенности 0 1 i jy a a x x 8 2 8 2 75 Регулярности (1) 0 1 2i jy a a x a x 9 1 9 1 35 Регулярности (2) 0 1 2 3i j i jy a a x a x a x x
10 3 7 3 65 Баланса перемен-ных
0 1 2i jy a a x a x
3. Определить опорную функцию. 4. Рассчитать с помощью МНК коэффициенты опорных
функций. 5. По соответствующим критериям селекции оставить оп-
ределенный процент таких функций для дальнейших итера-ций.
6. При увеличении значения критерия итерации прекра-тить и определить прогнозное значение функции, сравнить его с истинным.
7. * Вывести полином в аналитическом виде на печать. 3.2. Оптимизация сложных зависимостей. Задача состоит в поиске extr ( ),F x x D
, где D – ограничен-ная область. Вид функции F , тип кроссовера, вероятность му-тации, механизм отбора родителей для кроссовера и выбора по-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
104
томков приведены в табл. 3.5. Предварительные соображения приведены ниже.
Пусть, например, необходимо найти 1 2max ( , )f x x , где
1 21 , 1x x и 1 2 1 2( , ) 3 cos sinf x x x x . Для решения этой за-дачи разобьем отрезок [-1;1] на 255 отрезков.
11 0,992 Будем кодировать:
1 00000000, 0,992 00000001,...., 1 11111111 . Поскольку переменных две, то хромосома будет состоять
из 16 генов, первая половина которых отвечает 1x , вторая – 2x . Всего таких хромосом – 65536. Случайным чином выберем
среди них 100 – начальную популяцию. Для фенотипов попу-ляции вычислим значение 1 100( , , )F F . Каждому значению iF
сопоставим вероятность 100
1
ii
ii
FpF
. Дальнейшие шаги выпол-
няются согласно данным табл. 3.5.
Контрольные вопросы и задачи для самопроверки
1. К какому классу методов принадлежит метод группово-го учета аргументов?
2. Какие принципы положены в основу реализации МГУА?
3. Как в МГУА используется принцип неполноты Геде-ля?
4. В чем состоит принцип свободы выбора при определе-нии множества моделей?
5. Дайте характеристику принципа полноты в МГУА. 6. Какие вариации имеет критерий регулярности? 7. Какими могут быть критерии окончания итерацион-
ного процесса в МГУА?

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
105
8. Опишите сущность критерия несмещенности, базирующе-гося на анализе решений.
Таблица 3.5. Начальные данные для реализации ГА: mP – ве-
роятность мутации; –− механизм выбора родителей: E – элитный, I – с вытеснением; K – кроссовер: O – одноточечный, D – двухто-чечный; B – выбор родителей: P – панмиксия, S – селективный, In – инбридинг, Au – аутбридинг
№ Функция K mP B M 1 2 3 4 5 6 1
1 2 2 21 2 1
100( , )100( ) (1 ) 1
F x xx x x
,
1,21,28 1,28x .
O
0,01
P
E
2 5
1 2 51
( , , , ) [ ]ii
F x x x x
,
1,2,3,4,55,12 5,12x .
D
0,02
S
I
3
25
1 2 261
1
1( , ) 0,002( )j
i ii
F x xj x a
,
1 216[( mod5) 2], 16[( %5) 2]j ja j a j
O
0,015
In
E
4 2 21 2 1 2 1
2 1,2
( , ) 20 10cos210cos 2 , 5,12 5,12.
F x x x x xx x
D 0,01 Au I
1 2 3 4 5 6
5 10
21 2
1
( , , ) (10cos(2 ) ) 100i ii
F x x x x
,
1,2, 105,12 5,12x .
O
0,015
P
E
6
5
1 2 51
( , , , ) [ ]ii
F x x x x
, 1,2,3,4,55,12 5,12x .
O
0,01 P
E
7 2 21 2 1 2 1
2 1,2
( , ) 20 10cos210cos 2 , 5,12 5,12.
F x x x x xx x
O 0,02 P E
8
5
1 2 51
( , , , ) [ ]ii
F x x x x
, 1,2,3,4,55,12 5,12x .
D
0,015 P
E

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
106
9. Какова роль обучающей и контрольной последователь-ностей в алгоритмах МГУА?
10. Опишите критерий несмещенности, базирующийся на анализе коэффициентов.
11. Какие особенности применения критерия относитель-ной несмещенности?
12. Приведите примеры эмпирического и искусственного формирования критерия баланса переменных.
13. К решению каких задач целесообразно применять критерий баланса переменных?
14. Приведите алгоритм разделения генеральной сово-купности на обучающую и контрольную последовательности по величине дисперсии.
15. Назовите известные мировые школы эволюционного моделирования и опишите основные направления их работы.
16. Опишите классический вариант генетического алго-ритма и объясните основные его этапы.
17. Приведите пример задачи, где применение генетическо-го алгоритма является рациональным.
18. Каким образом в алгоритмах МГУА реализованы эле-менты самоорганизации?
19. Опишите особенности выбора и применения опорных функций.
20. В чем состоит реализация принципа внешнего допол-нения?
21. В чем состоит сущность кроссовера и какие он имеет модификации?
22. Опишите назначение мутации и инверсии. Для чего они предназначены?
23. Какое отличие существует между генотипом и феноти-пом?
24. Какие предварительные процедуры необходимо вы-полнить для применения генетического алгоритма?
25. Приведите главные особенности методов выбора роди-тельских пар.
26. Укажите особенности элитного отбора и отбора с вы-теснением.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
107
Темы рефератов и расчетно- графических работ
1. Сравнительный анализ применения множественной ли-нейной регрессии и метода группового учета аргументов для статистических данных и данных, полученных по функцио-нальным зависимостям.
2. Исследование эффективности многорядного МГУА для разного разделения генеральной совокупности данных и про-центного соотношения отбора моделей.
3. Исследование глубины горизонта прогнозирования по разным критериям внешнего дополнения в практических зада-чах энергопотребления.
4. Определение оптимальной опорной функции при ап-проксимации зависимостей.
5. Исследование эффективности ГА при решении задач оптимизации аналитических функций в сравнении с класси-ческими методами оптимизации.
6. Сравнительный анализ механизмов отбора родитель-ских пар на примере поиска решения задачи оптимизации зависимости, заданной рядом.
7. Определение оптимального варианта формирования новой популяции на примере решения задачи дискретной оптимизации.
8. Сравнительный анализ эффективности поиска оптиму-ма функции для значений, кодированных с помощью кода Грея, и обычного бинарного кодирования.
9. Решение задач оптимизации с помощью генетического программирования.
10. Концептуальные отличия эволюционных теорий Ч. Дарвина, Ж.Б. Ламарка, Ж. Кювье, К. Мазера, С. Райта.
Темы для самостоятельного
изучения 1. Методы регуляризации исходных данных. 2. Генетическое программирование, модели, методы и алго-
ритмизация процесса решения соответствующих задач.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
108
3. Муравьиные алгоритмы, их применение для решения задач дискретной оптимизации.
4. Меметические алгоритмы. Особенности алгоритмиза-ции и применения.
5. Особенности алгоритмической реализации эволюцион-ных стратегий.
6. Эволюционное программирование и его основные эле-менты.
7. Метод группового учета аргументов и его композиция с нейронными сетями.
8. Аналитический обзор результатов, полученных сотруд-никами школы профессора Д. Голдберга в направлении про-гнозирования.
9. Аналитический обзор результатов, полученных сотруд-никами школы профессора Кеннета Де Йонга в направлении разработки новых эволюционных методов.
10. Современное состояние, проблемы, задачи, модели, ме-тоды, алгоритмы и программно-алгоритмические средства эво-люционного моделирования. Короткий обзор.
11. Особенности применения - и - стратегий. 12. (Задача проблемного характера). Применение эволюци-
онного моделирования на начальных этапах создания техниче-ских и социально-экономических систем.
13. (Задача проблемного характера). Сравнительный ана-лиз методов эволюционного моделирования при решении оптимизационных задач. Установление аспектов, определе-ние преимуществ и недостатков генетических и муравьиных алгоритмов, эволюционных стратегий и генетического про-граммирования на примере решения задачи поиска крат-чайшего пути.
Литература
Основные источники 1. Ивахненко А.Г. Долгосрочное прогнозирование и управле-
ние сложными системами. – К.: Техніка, 1975. – 312 с.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
109
2. Люгер Ф. Дж. Искусственный интеллект. Стратегии и ме-тоды решения сложных проблем. – М.: “Вильямс”, 2003. – 864 с.
3. Генетические алгоритмы, искусственные нейронные се-ти и проблеми виртуальной реальности /Вороновский Г.К., Махотило К.В., Петрашев С.Н., Сергеев С.Н. – Харьков: Осно-ва, 1997. – 112 с.
4. Божич В.И., Лебедев О.Б., Шницер Ю.Л. Разработка гене-тического алгоритма обучения нейронных сетей // Таганрог: Перспективные информационные технологии и интеллек-туальные системы. – 2002. – № 1. – С. 21–24.
5. Батищев Д.И., Исаев С.А. Оптимизация многоэкстре-мальных функций с помощью генетических алгоритмов / Межвуз. сборник. – ВГТУ: Воронеж, 1997. – С. 4–17.
6. Снитюк В.Е., Шарапов В.М. Эволюционно-параметриче-ская оптимизация RBF-сети // Донецк: Искусственный ин-теллект. –2003. – № 4. – С. 493–501.
Дополнительные источники
1. Рассел С., Норвиг П. Искусственный интеллект. Совре-менный подход. – М.: Вильямс, 2006. – 1408 с.
2. Редько В.Г. Эволюционная кибернетика. – М.: Наука, 2001. – 156 с.
3. Курейчик В.М., Родзин С.И. Эволюционные вычисления: ге-нетическое и эволюционное программирование //Новости ис-кусственного интеллекта. – 2003. – № 5. – С. 13–20.
4. Rechenberg I. Cybernetic solution path of an experimental problem. Library Translation 1122, August 1965. Farnborough Hants: Royal Aircraft Establishment. English translation of lecture given at the Annual Conference of the WGLR at Berlin in Septem-ber. – 1964.
5. Schwefel H.P. Numerical Optimization of Computer Models. – John Wiley&Sons, 1981.
6. Fogel L.J., Owens, A.J., Walsh, M.J. Artificial Intelligence Through Simulated Evolution. – John Wiley&Sons, 1966.
7. Фогель Л., Оуенс А., Уолш М. Искусственный интеллект и эволюционное моделирование. – М.: Мир, 1969. – 230 с.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
110
8. Holland J. Adaptation in natural and artificial systems. – University of Michigan Press, 1975.
9. Cramer N.L. A representation for the adaptive generation of simple sequential programs. In J.J. Grefenstette (Ed.). – Proc. of an International Conference on Genetic Algorithms and Their Appli-cations: Lawrence Erlbaum Associates. – 1985. − P. 105–118.
10. Hicklin J.F. Application of the genetic algorithm to auto-matic program generation. Masters thesis. – University of Idaho: Department of Computer Science, 1986.
11. Fujiki C., Dickinson, J. Using the genetic algorithm to gener-ate lisp source code to solve the prisoner’s dilemma. In J.J. Grefen-stette (Ed.). – Proceedings of the Second International Conference on Genetic Algorithms. – Lawrence Erlbaum Associates. – 1987. – P. 236–240.
12. Koza J.R. Hierarchical genetic algorithms operating on populations of computer programs. In N.S. Sridharan (Ed.). – Eleventh International Joint Conference on Artificial Intelligence. – Morgan Kaufmann. – 1989. – P. 768–774.
13. Koza J.R. Genetic Programming: On the Programming of Computers by means of Natural Selection. – Cambridge MA, MIT Press, 1992.
14. Potter M. A. The design and analysis of a computional model of cooperative coevolution. PhD Thesis.− George Mason University: Fairfax, Virginia. – 1997. – 153 p.
15. Harti R.E. A global convergence proof for class of genetic algorithms. − Technische Universitaet Wien, 1990.
16. Исаев С.А. Разработка и исследование генетических ал-горитмов для принятия решений на основе многокрите-риальных нелинейных моделей / Автореф. дисс. к.т.н. – Н. Новгород: НГУ, 2000. – 18 с.
17. Rechenberg I. Evolutionsstrategie – Optimierung technischer Systeme nach Prinzipien der biologischen Evolution. – Stuttgart-Bad CannStatt: Frommann-Halzboog, 1973.
18. Ferreira C. Combinatorial Optimization by Gene Expres-sion Programming: Inversion Revisited. In J.M. Santos and A. Zapico edc. – Proceedings of the Argentine Symposium an Artifi-cial Intelligence. – Santa Fe, Argentina. – 2002. – P. 160-174.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
111
19. De Jong K.A. Analysis of behavior of a class of genetic adaptive systems. PhD Thesis. – University of Michigan: Ann Ar-bor, MI. – 1975. – 256 p.
20. Spears W.M. The Role of Mutation and Recombination in Evolutionary Algorithms. PhD Thesis. – George Mason University: Fairfax, Virginia. – 1998. – 240 p.
21. Rechenberg, I. Cybernetic solution path of an expe-rimental problem. Library Translation 1122, August 1965. Farn-borough Hants: Royal Aircraft Establishment. English translation of lecture given at the Annual Conference of the WGLR at Berlin in September, 1964.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
112
Глава 4
Методы обработки нечеткой информации
Субъективизм – обычное дело при
отыскании объективных причин. Лешек Кумор
Основные понятия и термины Активный и пассивный эксперименты
Виды критериев внешнего дополнения
Интерполяция Экстраполяция Вероятность Идентификация Ковариация Ортогональные векторы Корреляционный момент Авторегрессия Критерий регулярности Дисперсия Метод наименьших квадра-тов
Контрольная выборка
Неопределенность данных Неполнота данных Нейронные сети Эволюционное моделирование Опорная функция Коэффициент корреляции Ряд селекции Несмещенная оценка Спецификация модели Тренд
Методы теории нечетких множеств вместе с нейронными
сетями и методами эволюционного моделирования принад-лежат к парадигме „Soft Computing”. Такое название для ука-занных технологий определил профессор Калифорнийского университета Лотфи Заде (Lotfi A. Zadeh), который и дал на-чальный толчок анализу нечеткой и неполной информации, опубликовав в 1965 году статью „Fuzzy Sets” в восьмом номере журнала „Information and Control”.
Л. Заде расширил классическое понятие множества, пред-положив, что функция-индикатор принадлежности элемента множеству может приобретать не только значения из множе-ства {0;1} , а и любые значения из отрезка [0;1] . Такие множе-ства он назвал нечеткими (fuzzy). Были предложены опера-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
113
ции над нечеткими множествами, а также обобщенные мето-ды логического вывода modus ponens и modus tollens. Необхо-димо также вспомнить теорему FAT (Fuzzy Approximation Theorem, см. главу 9), доказанную Бартоломеем Коско (B. Kosko) в 1993 году. Сущность ее состоит в том, что любая математи-ческая система может быть аппроксимирована системой, ко-торая базируется на нечеткой логике.
Lotfi A. Zadeh
Bart Kosko Теория нечетких множеств направлена на обработку сужде-
ний человека, которые, как известно, в подавляющем большин-стве случаев являются нечеткими, расплывчатыми. Ее методы образовывают основу для описания процессов интеллекту-альной деятельности, поддержки процессов принятия реше-ний в условиях неопределенности и неполноты исходной информации.
При изучении теории нечетких множеств необходимо помнить, что ( ) ( )A A не обязательно равняется единице, где (*) – мера возможности, A – противоположное событие к событию A , в отличие от теории вероятностей, где
( ) ( ) 1,P A P A здесь ( )P A – вероятность события .A Рассмот-рим основные определения, операции над нечеткими и лин-гвистическими переменными, методы фаззификации и де-фаззификации, аспекты идентификации системами, которые базируются на нечетких продукционных правилах.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
114
4.1. Основные понятия и определения Пусть – универсальное множество, которое описывает
предметную область, элемент .x Подмножество A яв-
ляется набором пар {( , ( ))},AA x x где 1, ,
( )0, .A
x Ax
x A
Определение 4.1. Нечеткое подмножество A является набором пар {( , ( ))},AA x x где x и : [0;1]A – функ-ция принадлежности, которая есть субъективной мерой соот-ветствия элемента x нечеткому подмножеству .A
Определение 4.2. Упуская некоторые предельные случаи, высотой нечеткого множества будем считать max ( ).Ax
h x
Определение 4.3. Нечеткое множество называют нор-
мальным, если 1,h в противном случае – субнормальным. Определение 4.4. Нечеткое множество называется унимо-
дальным, если ( ) 1A x только для одного x . Определение 4.5. Носителем нечеткого множества A яв-
ляется обычное множество suрр( ) { , ( ) 0}.AA x x x Нечеткие множества и соответствующие функции принад-
лежности могут иметь дискретную, непрерывную и кусочно-непрерывную форму записи. Так, дискретная форма записи чаще всего является такой:
1 2
1 2
( )( ) ( ){ , ,..., },A nA A
n
xx xAx x x
где ( ), 1, ,A ix i n – значение функции принадлежности эле-мента ix нечеткому множеству .A Непрерывная форма записи, в общем случае, будет такой:
1
2
1
2
, ,, ,
( )...
, ,m
A
AA
A m
x Ax A
x
x A
где 1 2 ... , , ,im i j AA A A A A A i j – непрерывная функ-
ция принадлежности элемента x множеству , 1, .iA i m

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
115
Такие непрерывные функции принадлежностей могут быть треугольными (параметры a и c ), трапециевидными (в общем случае 5 параметров – , , , ,m m h ), колоколообразными ( с двумя параметрами a и b ), гауссовскими ( с двумя парамет-рами m и ) (рис. 4.1) и другими.
0 a c x 0 m m x 0 m x Рис. 4.1. Наиболее распространенные функции принадлежности
Нечеткие множества имеют такие свойства: 1. Если ( ) 0A x x , то A – пустое. 2. Если ( ) ( )A Bx x x , то A и B – эквивалентные не-
четкие множества. 3. Если ( ) ( )A Bx x x , то ,A B где A и .B Операции над нечеткими множествами: 4. Дополнением A нечеткого множества A называется не-
четкое множество с функцией принадлежности ( ) 1 ( ) .AA x x x
5. Пересечением A B нечетких множеств A и B называ-ется нечеткое множество с функцией принадлежности
( ) ( ) ( ) .A B A Bx x x x 6. Объединением A B нечетких множеств называется не-
четкое множество с функцией принадлежности ( ) ( ) ( ) .A B A Bx x x x
Определение 4.6. Нечетким числом называется выпуклое нормальное нечеткое множество с кусочно-непрерывной функцией принадлежности, которая задана на множестве действительных чисел.
Принцип обобщения Заде. Если 1 2( , ,..., )nu f x x x – функция от n независимых переменных и аргументы 1 2, ,..., nx x x заданы

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
116
нечеткими числами ^ ^ ^1 2, ,..., ,nx x x соответственно, то значением
функции ^ ^ ^1 2( , ,..., )nu f x x x есть нечеткое действительное чис-
ло u с функцией принадлежности ^
* * * *1 2
* ^
* *
1,( , ,..., )( ), 1,
( ) sup min ( ).i
n
i i
iu xi nu f x x xx suрр x i n
u x
(4.1)
Согласно этому принципу можно найти функцию при-надлежности нечеткого числа, которое отвечает значению четкой функции от нечетких аргументов. Его реализация осуществляется по такому алгоритму: Шаг 1. Зафиксировать значение * .u u Шаг 2. Найти все наборы * * *
1 2( , ,..., ), 1, ,j j njx x x j k удовлетворяю-щие условиям * * * *
1 2( , ,..., )j j nju f x x x и * ^( ), 1, .ij ix supp x i n
Шаг 3. Меру принадлежности элемента *u нечеткому числу u вычислить по формуле ^
* *
1,1,( ) max min ( ).
iiju xi nj k
u x
(4.2)
Шаг 4. Проверить условие “выбраны ли все элементы u ?” Ес-ли да, то перейти на шаг 5. В противном случае зафиксиро-вать новое значение *u и перейти на шаг 2. Шаг 5. Окончание алгоритма.
Определение 4.7. Лингвистической переменной называют пятерку , , , ,I T S P , где I – идентификатор лингвистиче-ской переменной; T – терм-множество, которое является сово-купностью наименований нечетких переменных, каждая из которых определена в ; S – синтаксическая процедура, что позволяет генерировать новые термы; P – семантическая про-цедура, которая предназначена для преобразования значений лингвистической переменной в нечеткие переменные.
Определение 4.8. Множеством уровня , или -сечением нечеткого множества A называют четкое множество
{ ( ) }, [0;1].AA x x

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
117
Пример 4.1. Пусть 1 2 3 4{ , , , },x x x x A – нечеткое множество, для которого 1( ) 0,1;A x 2( ) 0,4;A x 3( ) 0;A x 4( ) 0,7.A x Тогда A можно записать так:
1 2 3 4
0,1 0,4 0 0,7; ; ;Ax x x x
или 1 2 3 4{0,1/ 0,4 / 0 / 0,7 / }.A x x x x Знак „+” здесь содержа-тельно обозначает объединение.
Пример 4.2. Пусть {0,1,2,...,240}. Тогда нечеткое множе-ство A {человек высокого роста (в см)} может быть представ-лено так:
{0 /0 0 /1 ... 0,001/151 ... 0,7 /180 ... 1/ 240}.A Пример 4.3. Нечеткие числа 1x и 2x заданы такими тра-
пециевидными функциями принадлежностей (рис. 4.2, 4.3):
1
0, если 2 или 6,2, если [2;3],
( ) 1, если (3;4),1 3, если [4;6],2
x
x xx x
x x
x x
2
0, если 4 или 7,4, если [4;5],
( )1, если (5;6),
7, если [6;7].
x
x xx x
xx
x x
1
42 3 6
1
64 5 7
Рис. 4.2 Рис. 4.3
Найдем нечеткое число 1 2y x x с использованием прин-
ципа обобщения. Зададим нечеткие аргументы на четырех точках: 2,3,4,6 для
1x и 4,5,6,7 для 2 .x Тогда
1
0 1 1 02 3 4 6
x и 20 1 1 0 .4 5 6 7
x Результаты операций ум-
ножения сведем в табл. 4.1.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
118
Таблица 4.1. Результаты реализации принципа обобще-ния
* * *
1 2y x x 8 10 12 14 15 16 18 20 21 24 28 30 36 42
*1x 2 2 2 3 2 3 4 3 4 3 4 6 4 6 2 2
*2x 4 5 6 4 7 3 4 6 5 7 6 4 7 5 4 5
1
*1( )x x 0 0 0 1 0 1 1 1 1 1 1 0 1 0 0 0
2
*2( )x x 0 1 1 0 0 1 0 1 1 0 1 0 0 1 0 1
1 2
* *1 2min( ( ), ( ))x xx x 0 0 0 0 0 1 0 1 1 0 1 0 0 0 0 0
*( )y y 0 0 0 0 1 0 1 1 0 1 0 0 0 0
Результирующее нечеткое множество задано в первых и последних строках таблицы. Первая строка содержит элемен-ты универсального множества, последняя – меру их принад-лежности к значениям выражения 1 2.x x Получим результат: 0 1 1 0 .8 15 24 42 Предположим, что тип функции принадлеж-
ности y будет таким же, как и аргументов 1x и 2x , т.е. трапе-циевидным. В этом случае функция принадлежности задается выражением
0 , если 8 или 42,1 8 , если [8;15],7 7( )
1, если (15; 24 ),1 7 , если [24; 42].
18 3
y
y y
x yy
y
x y
Результаты расчетов изображены на рис. 4.4.
*- нечеткое произведение на 4-х дискретах; - огибающая сверху Рис.4.4. Функция принадлежности нечеткого произведения

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
119
Пример 4.4. (Определение лингвистической переменной). Пусть эксперты классифицируют автомобили по значе-
нию максимальной скорости движения с помощью понятий „Малая скорость”, „Средняя скорость”, „Большая скорость”, при этом наибольшее значение максимальной скорости – 300 км/ч. Формализация такого описания осуществляется с по-мощью лингвистической переменной , , , , ,I T S P где I – максимальная скорость автомобиля; T – {„Малая скорость”, „Средняя скорость”, „Большая скорость”}; [140;300]; S – процедура образования новых термов с помощью логических связок &, , и модификаторов типа „очень”, „значитель-но”,…, например, „не очень большая скорость”; P – процеду-ра определения на [140;300] нечетких подмножеств
1A ”Малая скорость”, 2A = „Средняя скорость”, 3A = „Боль-шая скорость”.
4.2. Нечеткие отношения и нечеткий логический вывод
Известно, что булевый логический вывод базируется на та-ких тавтологиях:
– модус поненс: ( & ( )) ;A A B B – модус толленс: (( ) & ) ;A B B A – силлогизм: (( ) & ( )) ( );A B B C A C – контрапозиция: ( ) ( ).A B B A Определение 4.9. Нечетким логическим выводом называется
получения вывода в виде нечеткого множества, которое отве-чает текущим значением входов с использованием нечеткой базы знаний и нечетких операций.
Композиционное правило вывода Заде. Если известно нечеткое отношение R между входной ( )X и результирующей ( )Y пе-ременными, то при нечетком значении входной переменной
,x A нечеткое значения результирующей переменной опре-деляется так: ,y A R где – знак максиминной композиции.
Определение 4.10. Максиминной композицией нечетких отношений A и ,B заданных на X Z и ,Z Y называется от-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
120
ношение G A B на множестве X Y с функцией принад-лежности ( , ) supmin ( , ), ( , ) ,BG A
z Zx y x z z y
( , ) ,x y X Y
( , ) ,x z X Z ( , ) .z y Z Y В случае конечных множеств , ,X Y Z матрицу нечеткого
отношения G A B получают как максиминное произведе-ние матриц A и B . Эта операция выполняется как обычное произведение матриц, при этом операция поэтапного произ-ведения заменена на нахождение минимума, а расчет суммы – на нахождение максимума.
Пример 4.5. Пусть заданное нечеткое правило „Если ,x A это y B ” с нечеткими множествами
0,1 0,2 0,4 0,8 ,1 2 4 8
A 0,3 0,5 0,8 .10 20 30
B
Необходимо определить значение результирующей пере-менной ,y если
0,2 0,6 0,7 0,3.1 2 4 8
x C
Рассчитаем нечеткое отношение, которое отвечает прави-лу „Если ,x A это y B ”, применяя операцию нахождения минимума
0,1 0,1 0,10, 2 0, 2 0, 20, 3 0, 3 0, 40, 3 0, 5 0,8
R
.
Дальше по формуле y C R рассчитаем нечеткое значение результирующей переменной
0,3/10 0,4 / 20 0,4 / 30.y Элементной базой нечеткого логического вывода является
совокупность нечетких предикатных правил 1 : Если 1 ,x A то 1;y B 2 : Если 2 ,x A то 2 ;y B
…………………………….. :n Если ,nx A то ,ny B

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
121
где x – входная переменная, y – переменная вывода, ,iA ,iB 1, ,i n – функции принадлежности.
В общем случае логический вывод осуществляется в четы-ре этапа. На первом этапе строят функции принадлежности, которые определяют меру истинности каждой предпосылки каждого правила. Дальше осуществляется логический вывод, который состоит в том, что исходя из значений истинности для предпосылок правила, вычисляют вывод каждого прави-ла. На третьем этапе осуществляют композицию всех нечет-ких подмножеств, которые отвечают каждой переменной вы-вода. На последнем этапе выполняют дефаззификацию не-четкого набора выводов в четкое число.
Известно несколько алгоритмов логического вывода, рас-смотрим их детально.
Алгоритм Мамдани (Маmdani).
Ebrahim Mamdani
Для упрощения записи алгоритма предположим, что базу знаний со-ставляют два нечетких правила вида:
1 :P если 1x A и 1 ,y B то 1 ,Z C 2 :P если 2x A и 2y B то 2 .Z C Шаг 1. Находим меры истинности
1 0( ),A x 2 0( ),A x 1 0( ),B y 2 0( )B y (рис. 4.5). Шаг 2. Находим уровни „отсече-
ния” для предпосылок каждого из пра-вил
1 1 0 1 0( ) ( ),A x B y 2 2 0 2 0( ) ( ).A x B y
Шаг 3. Находим функции принадлежности '1 1 1( ) ( ( )),C Z C Z '2 2 2( ) ( ( )).C Z C Z
Шаг 4. Выполняем объединение найденных функций и находим результирующее нечеткое множество для выходной переменной с функцией принадлежности
' '1 2 1 1 2 2( ) ( ) ( ) ( ) ( ( )) ( ( )).Z C Z C z C Z C Z C Z

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
122
Шаг 5. Выполняем дефаззификацию, например, по методу
центра масс и находим четкое значение 0
( ),
( )
z
z
z
z
z z dzZ
z dz
где
интервал [ , ]z z является носителем функции принадлежно-сти.
1А1В 1С
2А 2В 2Сх у z
х у z0х 0y
1
1c
z
0z
Рис. 4.5. Реализация алгоритма Мамдани Алгоритм Цукамото (Tsukamoto). Исходные предпосылки аналогичные алгоритму Мамдани
при условии, что функции 1( )C z и 2 ( )C z являются монотон-ными.
Шаг 1. Находим меры истинности 1 0 2 0 1 0( ), ( ), ( ),A x A x B y 2 0( )B y (рис. 4.6).
Шаг 2. Находим уровни “отсечения” 1 да 2 и через ре-шение уравнений 1 1 1 2 2 2( ), ( )C z C z – четкие значения 1(z и 2z ) для каждого из исходных правил.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
123
1A 1B
1C x y 1z z
2A 2B
2C 0x x 0y y 2z z
Рис. 4.6. Реализация алгоритма Цукамото
Шаг 3. Определяем четкое значение переменных вывода
(как взвешенное среднее 1z и 2z ): 1 1 2 20
1 2
z zz
(в общем слу-
чае 01 1
n n
i i ii i
z z
).
Алгоритм Сугено и Такажи (Sugeno i Takagi).
Hideyuki Takagi
Используется набор правил в такой форме:
1П : если 1x A и 1y B , то 1 1 1 ,Z a x b y
2П : если 2x A и 2y B , то 2 2 2 .Z a x b y
Шаг 1. Находим меры истинности1 0 2 0 1 0 2 0( ), ( ), ( ), ( )A x A x B y B y (рис. 4.7).
Шаг 2. Рассчитываем 1 1 0 1 0( ) ( ),A x B y
2 2 0 2 0( ) ( )A x B y и
1 1 0 1 0 ,z a x b y
2 2 0 2 0 .z a x b y
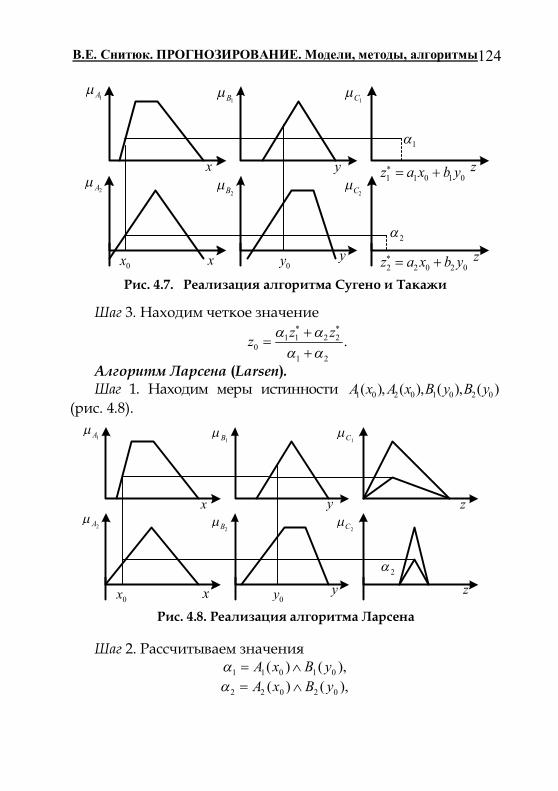
В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
124
1А1В 1С
2А2В 2С
х у z
х у z0х 0y
1
2
1 1 0 1 0z a x b y
2 2 0 2 0z a x b y
Рис. 4.7. Реализация алгоритма Сугено и Такажи
Шаг 3. Находим четкое значение 1 1 2 2
01 2
.z zz
Алгоритм Ларсена (Larsen). Шаг 1. Находим меры истинности 1 0 2 0 1 0 2 0( ), ( ), ( ), ( )A x A x B y B y
(рис. 4.8).
1А1В 1С
2А2В 2С
х у z
х у z0х 0y
2
Рис. 4.8. Реализация алгоритма Ларсена
Шаг 2. Рассчитываем значения
1 1 0 1 0( ) ( ),A x B y 2 2 0 2 0( ) ( ),A x B y

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
125
вычисляем 1 1 ( )C z и 2 2 ( )C z . Шаг 3. Находим результирующее нечеткое подмножество
с функцией принадлежности 1 1 2 2( ) ( ) ( ( )) ( ( ))z C z C z C z
( в общем случае 1
( ) ( ( ))n
i iiz C z
.
Шаг 4. Находим четкое значение. Упрощенный алгоритм. Начальные правила такие:
1П : если 1x A и 1y B , то 1 1Z C , 2П : если 2x A и 2y B , то 2 2Z C , где iC – четкие числа,
1,2,i Шаг 1. Находим меры истинности 1 0 2 0 1 0 2 0( ), ( ), ( ), ( )A x A x B y B y
(рис. 4.9).
1А1В 1С
2А2В 2С
х у z
х у z0х0y
2
11c
2c Рис. 4.9. Реализация упрощенного алгоритма
Шаг 2. Рассчитываем значения
1 1 0 1 0( ) ( )A x B y , 2 2 0 2 0( ) ( )A x B y .
Шаг 3. Находим четкое число 1 1 2 20
1 2
C CZ
.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
126
4.3. Анализ нечетких экспертных заключений Проиллюстрируем особенности анализа нечетких эксперт-
ных выводов на примере расчета возможного финансирования некоторого проекта, в котором принимают участие 4 органи-зации, о которых известно следующее:
Организация А– абсолютно надежная и стабильная, сумма финансирования составит 100 ед.
Организация В– стабильная, возможно финансирование проекта в сумме от 70 до 140 ед., причем существует большая уверенность в том, что будет предоставлено от 100 до 120 ед.
Организация С– стабильная, но ненадежная, наибольшая уверенность в том, что финансирование будет предоставлено в сумме от 100 до 200 ед., но возможно и полное его отсутст-вие.
Организация Д− ненадежная и нестабильная, скорее все-го проект не профинансирует, а если профинансирует, то в размере 20–30 ед., с уменьшением уверенности в предостав-ления средств по мере роста суммы.
Необходимо установить наиболее возможную общую сумму финансирования, наименее возможную и т.п.
Разные источники финансирования представим с помо-щью нечетких величин, которые будем интерпретировать как нечеткие интервалы, заданные пятеркой элементов ( , , , ,m m h ) (порядок следования элементов важен), где: m – левое модальное значение, m – правое модальное значение, – левый коэффициент скошенности, – правый коэффи-циент скошенности, h − высота.
Нечеткую величину изобразим с помощью функции при-надлежности (см. рис. 4.1). Заметим, что нечеткой величиной
i jM M , где iM и jM – два трапециевидных нечетких интер-
вала, есть также трапециевидный интервал ( , , , ,m m h ), где
min( , )i jh h h , ( )ji
i j
hh h
, ( )ji
i j
hh h
,
,i j i jm m m .i j i jm m m
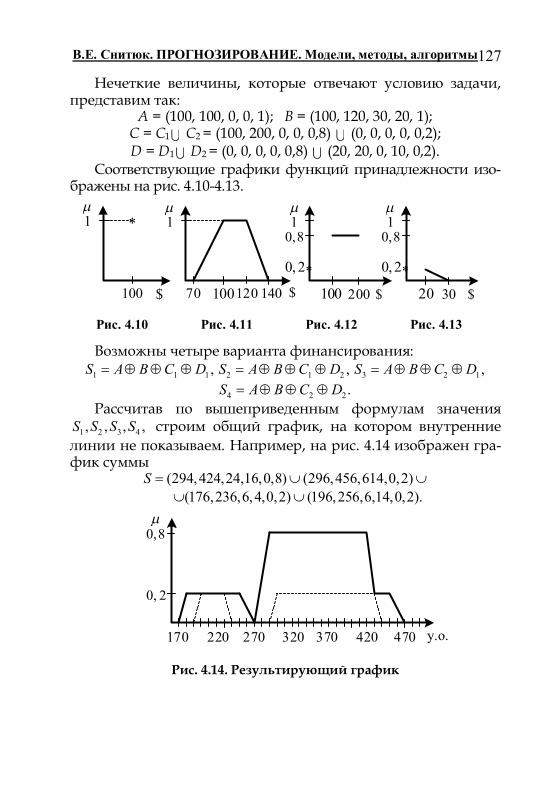
В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
127
Нечеткие величины, которые отвечают условию задачи, представим так:
А = (100, 100, 0, 0, 1); В = (100, 120, 30, 20, 1); С = С1 С2 = (100, 200, 0, 0, 0,8) (0, 0, 0, 0, 0,2); D = D1 D2 = (0, 0, 0, 0, 0,8) (20, 20, 0, 10, 0,2).
Соответствующие графики функций принадлежности изо-бражены на рис. 4.10-4.13.
$
1
100
$
1
10070 120 140
$
1
100
0,8
0, 2
200
$
1
20
0,8
0, 2
30
Рис. 4.10 Рис. 4.11 Рис. 4.12 Рис. 4.13
Возможны четыре варианта финансирования: 1 1 1 ,S A B C D 2 1 2 ,S A B C D 3 2 1 ,S A B C D
4 2 2 .S A B C D Рассчитав по вышеприведенным формулам значения
1 2 3 4, , , ,S S S S строим общий график, на котором внутренние линии не показываем. Например, на рис. 4.14 изображен гра-фик суммы
(294,424,24,16,0,8) (296,456,614,0,2)S (176,236,6,4,0,2) (196,256,6,14,0,2).
у.о.220
0,8
0, 2
170 270 320 370 420 470
Рис. 4.14. Результирующий график

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
128
В соответствии с полученным результатом область наибо-лее возможного финансирования находится в диапазоне 294-424 ед.; превышение суммы в 424 ед. возможно, но уверен-ность в этом уменьшается с ростом суммы; небольшая уве-ренность существует в том, что поступления не составят больше, чем 176-256 ед. (уровень 0,2); в любом случае они не могут опуститься ниже 170 ед. и подняться выше 470 ед.
4.4. Принятие решений в нечетких условиях В работе Беллмана Р. и Заде Л. „Принятие решений в не-
четких условиях” определены особенности процессов приня-тия решений в условиях нечеткости, составными частями ко-торых являются множество альтернатив; множество ограни-чений, которые необходимо учитывать при выборе между различными альтернативами; функция выбора, которая ста-вит в соответствие каждой альтернативе выигрыш или проиг-рыш, который будет получен в результате выбора этой аль-тернативы. Авторы отмечают, что элементы нечеткости ниве-лируют отличия между целями и ограничениями, и позволя-ют упростить процесс формирования решения на них основе.
Предположим, что 1 2{ , ,..., }nA a a a – множество альтерна-тив. Нечеткая цель Z отождествляется с фиксированным не-четким множеством Z в A . Если A является действительной прямой, то нечеткую цель „ a должно быть значительно больше 5” представим нечетким множеством с функцией принадлежности
2 1
0, 10,( )
(1 ( 5) ) , 10.Z
aa
a x
При обычном подходе функция выбора, которая исполь-зуется в процессе выбора, необходима для установления ли-нейной упорядоченности на множестве альтернатив. В нечет-ких условиях такую же задачу выполняет функция принад-лежности нечеткой цели. Важным аспектом является то, что цель и ограничения рассматриваются как нечеткие множест-ва в пространстве альтернатив и это дает возможность не раз-личать их при формировании решений.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
129
Предположим, что нечеткая цель Z и нечеткое ограниче-ние R заданы так: :Z a ‒ должно быть значительно больше 10 и :R a ‒ должно быть в окрестности 15.
Заметим, что цель и ограничения соединены между собой при помощи частицы „и”, а, как известно, „и” означает пере-сечение нечетких множеств. Это указывает на то, что сово-купное влияние цели и ограничений на выбор альтернатив может быть представленным пересечением .Z R Функция принадлежности для пересечения будет такой:
( ) ( ) ( ),Z R Z Ra a a или в развернутой форме
2 1 4 1min{(1 ( 10) ) , (1 ( 15) ) }, 10,( )
0, , 10.Z Ra a a
aa
Авторы выдвигают идею, согласно которой нечеткое ре-шение является нечетким множеством в пространстве альтер-натив, получаемое в результате пересечения заданных целей и ограничений, и формализуют это в виде определения.
Определение 4.11. Пусть в пространстве альтернатив за-даны нечеткая цель Z и нечеткое ограничение .R Тогда не-четкое множество ,D которое образовывается как пересече-ние Z и R , называется решением, т.е. .D Z R
Определение 4.11 можно обобщить на случай многих це-лей и ограничений.
Пример 4.5. Пусть {1,2,3,4,5,6,7,8,9,10},A а 1 2 1 2, , ,Z Z R R определены в табл. 4.2. Образовывая конъюнкцию для
1 2, ,Z Z
1 2, ,R R получим таблицу значений для ( )D a (табл.
4.3). Таблица 4.2
a 1 2 3 4 5 6 7 8 9 10
1Z 0 0,1 0,4 0,8 1,0 0,7 0,4 0,2 0 0
2Z 0,1 0,6 1,0 0,9 0,8 0,6 0,5 0,3 0 0
1R 0,3 0,6 0,9 1,0 0,8 0,7 0,5 0,3 0,2 0,1
2R 0,2 0,4 0,6 0,7 0,9 1,0 0,8 0,6 0,4 0,2

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
130
Таблица 4.3 a 1 2 3 4 5 6 7 8 9 10
( )D a 0 0,1 0,4 0,7 0,8 0,6 0,4 0,2 0 0 Заметим, что никакое значение a не принадлежит реше-
нию D полностью. Это является следствием того, что цели и ограничения вступают в конфликт между собой, исключая тем самым возможность существования альтернативы, кото-рая бы полностью им удовлетворяла.
В определении нечеткого решения D как пересечения целей и ограничений полагают, что все цели и ограничения имеют одинаковую важность. Но встречаются ситуации, в ко-торой одни цели и ограничения являются более важными, чем другие. В таком случае решение D выражается выпуклой комбинацией целей и ограничений с весовыми коэффициен-тами, которые характеризуют относительную важность состав-ных элементов. Таким образом, получим
1 1
( ) ( ) ( ) ( ) ( ),i j
n m
D i Z j Ri j
a a a a a
(4.3)
где i и j – функции принадлежности, такие, что
1 1
( ) ( ) 1.n m
i ji j
a a
(4.4)
С учетом этого ограничения функции ( )i a и ( )j a мо-гут быть подобраны таким образом, чтобы передать относи-тельную важность целей 1 2, ,..., nZ Z Z и ограничений
1 2, ,..., .mR R R Формулы (4.3)–(4.4) напоминают известный спо-соб приведения векторного критерия к скалярному с помощью образования линейной комбинации компонент векторной функции цели.
Практические задания 4.1. Определение объема возможного финансирования инвестиционного проекта
Известно, что в финансировании проекта принимают участие пять финансовых учреждений, о которых известно следующее:

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
131
1. Учреждение А надежное и стабильное, сумма финанси-рования составит 300 ед.
2. Учреждение Б надежное, но сумма финансирования за-висит от времени предоставления средств. Так, с полной уве-ренностью можно утверждать о том, что сумма финансирова-ния составит от 250 до 400 ед., причем наиболее возможно по-лучить сумму от 300 до 350 ед.
3. Учреждение В планирует финансирование проекта в сумме 200-300 ед. с увеличением уверенности в предоставле-ния суммы с ростом объема выплаты.
4. Учреждение Г определяют как нестабильное, но с воз-можностью предоставления значительных сумм средств. Так, существует большая уверенность в том, что проект будет профинансирован, в частности, в объеме 2000-2400 ед., но бо-лее надежно получить 2100-2200 ед.
5. Учреждение Д ненадежное и нестабильное, проект на-верное не будет финансировать, но если предоставит средст-ва, то в объеме 300-500 ед. с уменьшением уверенности в по-лучении средств по мере роста их суммы.
Определить, наиболее возможную сумму финансирова-ния, невозможные объемы финансирования и т.п. 4.2. Логический вывод
Пусть базу знаний составляют два правила: 1 :P если 1x A и 1 ,y B то 1 ,Z C 2 :P если 2x A и 2y B то 2 ,Z C
где 1 2 1 2 1 2, , , , ,A A B B C C – нечеткие множества с трапециевидны-ми функциями принадлежности
1100,200,30,40,1A ,
2200,300,20,60,1A ,
1140,240,30,40,1B ,
2240,320,50,40,1B ,
150,100,10,30,1C ,
2100,150,20,50,1C .
Найти 0Z , если 0 220x и 0 200.y
Контрольные вопросы и задачи для самопроверки
1. Что является объектом изучения в теории нечетких множеств?

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
132
2. В чем состоят отличия теории нечетких множеств от теории вероятностей?
3. Дайте определение нечеткого множества и объясните его сущность.
4. Какие существуют типы представления для записи не-четких множеств и соответствующих функций принадлежно-сти?
5. Какие вы знаете типы функций принадлежности? В чем заключаются их отличия?
6. Какие свойства имеют нечеткие множества? 7. Приведите примеры операций над нечеткими множест-
вами. 8. Для решения каких задач может быть использован
принцип обобщения Заде? 9. Опишите алгоритм обобщения Заде. 10. Дайте определение лингвистической переменной и
приведите примеры. 11. Приведите пример применения алгоритма обобщения
Заде. 12. Для решения каких задач используется композицион-
ное правило вывода Заде? 13.Приведите пример использования композиционного
правила Заде. 14. Опишите алгоритм логического вывода Maмдани и
приведите пример. 15. Опишите алгоритм логического вывода Ларсена и при-
ведите пример. 16. Опишите алгоритм логического вывода Цукамото и
приведите пример. 17. Опишите алгоритм логического вывода Сугенo и при-
ведите пример. 18. Приведите пример решения задачи с анализом экс-
пертных нечетких заключений.
Темы рефератов и расчетно-графических работ
1. Системы управления на базе нечеткой логики.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
133
2. Сравнительный анализ результатов применения мето-дов дефаззификации.
3. Сравнительный анализ применения алгоритмов Цукамото, Ларсена и Мамдани.
4. Алгоритм функционирования ANFIS. 5. Нечеткая кластеризация. 6. Сравнительный анализ четкой и нечеткой кластериза-
ции. 7. Аспекты горной кластеризации. 8. Нечеткий многокритериальный анализ вариантов. 9. Нечеткий многокритериальный анализ инновационных
объектов. 10. Реализация элементов теории нечетких множеств в паке-
тах прикладных программ.
Темы для самостоятельного
изучения 1. Построение функции принадлежности на основе экс-
пертной кластеризации. 2. Построение функции принадлежности на основе парных
сравнений. 3. Построение функции принадлежности по методу класте-
ризации экспериментальных данных. 4. Построение функций принадлежности с помощью ме-
тода потенциалов. 5. Принятие решений в нечетких условиях по схеме Белл-
мана-Заде.
Литература
Основные источники 1. Заде Л. Понятие лингвистической переменной и ее при-
менение к принятию приближенных решений. - М.: Мир, 1976. - 167 с.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
134
2. Нечеткие множества в моделях управления и искусствен-ного интеллекта / Под. ред. Д.А. Поспелова. - М.: Наука, 1986. - 312 с.
3. Круглов В.В., Дли М.І., Голунов Р.Ю. Нечеткие логики и искусственные нейронные сеты. - М.: Издательство физ.-мат. лит., 2001. - 224 с.
4. Ротштейн А.П. Интеллектуальные технологии иденти-фикации: нечеткая логика, генетические алгоритмы, неи-ронные сеты. - Винница: Универсум-Винница, 1999. - 320 с.
5. Дюбуа Р., Прад П. Теория возможностей. - М.: Радио и связь, 1990. - 288 с.
6. Люгер Ф. Дж. Искусственный интеллект. Стратегии и ме-тоды решения сложных проблем. – М.: “Вильямс”, 2003. - 864 с.
7. Зайченко Ю.П. Основы проектирования интеллектуаль-ных систем. - К.: “Слово”, 2004. - 352 с.
Дополнительные источники 1. Zadeh L. Fuzzy sets // Information and Control. - 1965. - №
8. - P. 338-353. 2. Беллман Р., Заде Л. Принятие решений в расплывчатых
условиях: В кн.: Вопросы анализа и процедуры принятия ре-шений. - М.: Мир, 1976. - С. 172-215.
3. Кофман А. Введение в теорию нечетких множеств. - М.: Радио и связь, 1982. – 432 с.
4. Прикладные нечеткие системы / Под ред. Т.Терано, К. Асаи, М. Сугэно. - М.: Мир, 1993. - 368 с.
5. Борисов А.Н., Крумберг О.А., Федоров І.П. Принятие реше-ний на основе нечетких моделей: примеры использования. - Рига: Зинатне, 1990. - 184 с.
6. Нечеткие множества и теория возможностей: последние дос-тижения / Под ред. Р.Р. Ягера. - М.: Радио и связь, 1986. - 408 с.
7. Kosko B. Fuzzy systems as universal approximations // IEEE Transactions on Computers. - 1994. - Vol. 43. - № 11. - P. 1329-1333
8. Mamdani E. H. Application of fuzzy algorithm for simple dynamic plant // Proceedings IEEE. - 1974. - № 12. - P. 1585-1588.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
135
Глава 5
Препроцеcсинг информации
Четыре закона теории информации: 1. Информация, которая есть, – не та, которая нужна. 2. Информация, которую хотелось бы получить, – не та, которая на
самом деле нужна. 3. Информация, которая на самом деле нужна, – недоступна. 4. Информация, которая доступна, стоит больше, чем можно запла-
тить.
Основные понятия и термины Вероятность. Классическое и аксиоматическое определение
Собственные числа и векторы
Информативность Корреляция Нормализация Мультиколлинеарность Линейная множественная регрессия
Неопределенность
Дисперсия Ковариация Перцептрон Статистическая зависимость
Успешное решение задач идентификации, прогнозирова-
ния и диагностики невозможно без предварительной формали-зации задачи и предварительной подготовки данных. Препро-цессингу априорной информации посвящены многочислен-ные монографии и статьи. В большинстве случаев он сво-дится к определению информативных или значимых пара-метров (признаков), выравниванию их распределения и при-ведение к безразмерному виду. Внимание к релевантным за-дачам вызвано несколькими аспектами:
- „проклятье размерности” предопределяет необходи-мость сокращения количества входных факторов;
- влияние шумовых эффектов на входные факторы иска-жает их значения и, соответственно, значения результирую-щих характеристик, поэтому необходимо удалять наиболее зашумленные факторы без снижения общей информативно-сти, определять и уменьшать присутствие шумов;

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
136
- необходимость обработки разнотипных факторов опре-деляет необходимость нормализации и стандартизации их значений;
- неравномерное распределение значений факторов умень-шает точность идентификации и прогнозирования, поэтому актуальной является задача выравнивания их распределения.
Информативность факторов определяется тем, насколько они влияют на точность идентификации искомых зависимо-стей. Очевидно, что состав множества информативных фак-торов зависит от конкретной задачи. В общем случае зависи-мости можно разделить на линейные и нелинейные. И если для линейных зависимостей информативные факторы опре-деляются с использованием известных методов (см. главу 1), то для нелинейных зависимостей такие процедуры чаще все-го являются эмпирическими.
Почти парадоксальным является утверждение о том, что максимальная энтропия значений входных факторов явля-ется необходимым условием минимальной энтропии значе-ний результирующей характеристики. В пятой главе рас-смотрены модели, методы и алгоритмы, указывающие на конструктивные элементы реализации такого условия, вклю-чающие в себя нормализацию значений факторов, установ-ление значимых факторов и увеличение их информативно-сти. Именно реализация такого комплекса задач сопровождает процесс максимально эффективного решения задач идентифи-кации и прогнозирования.
5.1. Энтропия и количество информации Появление теории информации связывают с фундамен-
тальной работой американского ученого К. Шеннона «Матема-тическая теория связи» (1948 г). Им была предложена, а совет-ским ученым Л.Я. Хинчиным доказана единственность функ-ционала
1
( ) log
n
i ii
H U C p p , (5.1)
названного энтропией, C положительная константа. Этот функционал указывает на меру неопределенности выбора

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
137
дискретного состояния из ансамбля .U Если есть n состояний 1 2, ,..., nu u u и известные вероятности этих состояний 1 2, ,..., np p p
(табл. 5.1), то мера неопределенности имеет такие атрибуты: Таблица 5.1. Ряд распределения
U 1u 2u nu P 1p 2p np
1. ( )H U – непрерывная функция вероятностей состояний,
1
1.n
ii
p
2. max( )H U H , если 1 1, , .ip i nn
3. 0 min( ) ,H U H если : 1 ii p и 0 . jp j i 4. ( )H U R (действительнозначная, неотрицательная
функция). 5. ( ) ( ) ( ), H X Y H X H Y если X и Y статистически неза-
висимы. 6. Энтропия характеризует среднюю неопределенность вы-
бора одного состояния из ансамбля. Меру снятой неопределенности называют количеством ин-
формации ( )I U и вычисляют как разность ( ) ( ) ( )apriori aposterioriI U H U H U , (5.2) где ( )aprioriH U энтропия до проведения опыта, ( )aposterioriH U – энтропия после проведения опыта. Значение ( )I U может быть как положительным, так и отрицательным.
Таблица 5.2. Начальные данные 1x 2x nx y
11x 12x 1nx 1y 21x 22x 2nx 2y
1mx 2mx ... mnx my 11mx 12mx ... 1m nx ?

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
138
Если начальные данные находятся в табл. 5.2, где 1 2( , ,..., ) nX X X X вектор входных факторов и Y результи-
рующая характеристика, то точность прогнозирования зна-чения 1my будет зависеть от информативности m обучаю-щих образов, которая в свою очередь определяется существо-ванием зависимостей между факторами и выполнением оп-ределенных операций, которые составляют содержание про-цедуры препроцессинга исходной информации.
5.2. Нормализация и стандартизация исходных значений
Поскольку значения векторов 1 2( , ,..., )nX X X , в общем слу-чае, разнотипны, то приведем их к единой шкале. Это необ-ходимо для адекватного применения математических мето-дов и компьютерных расчетов при вычислениях, связанных с большими и малыми абсолютными величинами, а также для того, чтобы установить соответствие между количественными и качественными значениями. Например, как Вы ответите на вопрос: „Что более естественно для парня в 25 лет: иметь 60 кг веса или 165 см роста?”. А тем временем ответы на вопросы такого типа и их комбинации важны при оценке склонности человека к определенным заболеваниям.
Важным шагом, который предоставляет возможность сравнения, является нормирование. Основными формулами, которые реализовывают нормирование и стандартизацию, есть такие:
' ' 'maxmin
max min max min
' 'min
max min
(1) , (2) , (3) ,
2( ) 1(4) 1, (5) .1 x
x xx x x xx x xx x x x
x xx xx x e
Дадим им короткую характеристику. Преобразование 1. Область значений – отрезок [0,1]. Реко-
мендуется использовать, если значения начальных данных равномерно заполняют область исследования. Для некоторых методов прогнозирования формула неэффективна в случае

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
139
равенства значений нулю или их концентрации возле концов отрезка [0,1].
Преобразование 2. Аналогичное первому. Преобразование 3. Отличается тем, что значения, полученные
в результате его применения, являются безразмерными, нахо-
дятся на отрезке maxmin[ , ]
x xx x преимущественно в окрест-
ности нуля, x – выборочное среднее значение, – выбороч-ное среднеквадратическое отклонение. Для использования такого преобразования, в частности, при обучении нейрон-ных сетей необходимо применять дополнительные преобра-зования, например,
1
1( )
.x xx xx
e
(5.3)
Последнее преобразование, кроме принадлежности зна-чений интервалу (0,1), гарантирует и более равномерное рас-пределение значений.
Преобразование 4. Область значений – отрезок [-1,1]. Фор-мула удобная для использования при прогнозировании с ис-пользованием нейронных сетей, в которых активационной функцией есть гиперболический тангенс. Имеет все те же свойства, что и преобразования 1 и 2.
Преобразование 5. Область значений – интервал (0,1) . Исполь-зуется редко, в основном для значительного усиления реакции на изменения значений в окрестности нуля. Функция является вспомогательной, поскольку значения факторов не становятся безразмерными.
Без ограничения общности будем считать, что использо-вание функций нормирования ведет к отображению входных значений в единичный гиперкуб. Если они будут неравно-мерно распределены и сосредоточены в небольших гипер-сферах, то такие данные являются малоинформативными и прогнозирование будет неточным (рис. 5.1).
Самую большую информативность (в смысле получения более точного прогноза) имеют данные с равномерным рас-пределением (известно, что они имеют самую большую эн-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
140
тропию) (рис. 5.2). Таким образом, одной из главных задач по-сле получения безразмерных величин и нормализации является максимизация энтропии.
1x 1x * * * ** * ** * *** * * * * *** * * * * ** *** 2x 2x
Рис. 5.1 Рис. 5.2
5.3. Аналитико-эвристические алгоритмы определения информативных признаков Новосибирской школой анализа данных под руково-
дством профессора Н.Г. Загоруйко разработаны методы оп-ределения информативных признаков, базирующиеся на эв-ристических суждениях и аналитических расчетах. Некото-рые из них рассмотрим дальше.
Алгоритм Del. Шаг 1. Пусть 0,i 1.j На обучающей последовательно-
сти выполняем идентификацию зависимости 1 2( , ,..., ) nY F X X X и на контрольной последовательности на-
ходим ошибку .iE Шаг 2. Удаляем jX и аналогично шагу 1 выполняем
идентификацию зависимости 1 1 1( ,..., , ,..., ) j j nY F X X X X , на-ходим ошибку .ijE
Шаг 3. Если ,j n то осуществляем переход на шаг 4, в противном случае положим 1 j j и переходим на шаг 2.
Шаг 4. Из множества факторов удаляем ,kX где k является решением задачи поиска arg max ,ij
jE 1, .j n Выполняем пере-
нумерацию факторов.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
141
Шаг 5. Если n равняется заданному числу ,N то выпол-няем переход на шаг 6, в противном случае – 1, 1 n n i i и переходим к шагу 1.
Шаг 6. Окончание алгоритма. Алгоритм Add. Шаг 1. Положим 1.i Шаг 2. На обучающей последовательности выполняем
идентификацию зависимостей ( ), , . j j jY F X j i n На кон-трольной последовательности определяем ошибки .jE
Шаг 3. В информативную подсистему включаем фактор ,kX где k – решение задачи arg min ,j
jE 1, .j n Выполняем пере-
нумерацию факторов, 1.k Шаг 4. 1. i i Если ,i N то переходим на шаг 7, иначе −
переход на шаг 5. Шаг 5. На обучающей последовательности выполняем
идентификацию зависимостей 1( , ), , . j j jY F X X j i n На кон-трольной последовательности определяем ошибки .jE
Шаг 6. Аналогичный шагам 3-5 с увеличением значения k на единицу.
… Шаг 7. Окончание алгоритма. Комбинированные алгоритмы. Комбинированными называются такие алгоритмы, в ко-
торых происходит композиция элементов алгоритмов Add и Del. В первом из них удаляем определенное количество фак-торов согласно алгоритму Del, потом некоторую часть факто-ров прибавляем согласно алгоритму Add. Такую последова-тельность операций повторяем заданное количество раз. Во втором случае последовательность чередования алгоритмов Add и Del выполняется наоборот: сначала алгоритм Add, по-том − Del.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
142
Экспериментально доказано, что комбинированные алго-ритмы имеют более высокую точность. Наиболее низкую точность имеют результаты применения алгоритма Del.
Алгоритм случайного поиска с адаптацией (ВПА). Шаг 1. Положим 1.k Пусть количество признаков, кото-
рые будем считать информативными, равно N . Разобьем ин-тервал (0,1) на N одинаковых отрезков: i -му отрезку отвечает i -й признак, 1, ,i N 1.j
Шаг 2. Генерируем равномерно распределенное случайное число из интервала (0,1).
Шаг 3. Если число принадлежит i -му интервалу, то i -й признак включается в множество информативных признаков, если там такого признака нет. Если такой признак есть, то множество информативных признаков оставляем без измене-ний, 1.j j
Шаг 4. Если ,j N то переходим на шаг 5, иначе − 1 j j и выполняем переход на шаг 2.
Шаг 5. Выполняем идентификацию зависимости 1 2
( , ,..., )Nk k k k kY F X X X и на контрольной выборке находим
ошибку .kE Шаг 6. Если ,k r то осуществляем переход на шаг 7, в
противном случае – 1 k k , 1j и переходим на шаг 2. Шаг 7. Находим значение mink и maxk , решая задачи поиска
min arg min kk
k E и max arg max . kk
k E
Шаг 8. Для факторов, которые входят в зависимость с но-мером max ,k увеличиваем на величину d соответствующие интервалы, а для факторов, входящих в зависимость с номером
mink , уменьшаем их на ту же величину 1 .dN
Суммарная
длина интервалов остается равной единицы. Шаг 9. Если в последовательность информативных призна-
ков несколько раз подряд попадают одни и те же признаки, то процесс их подбора закончен и переходим на шаг 10, иначе –
1j , 1k и выполняем переход на шаг 2. Шаг 10. Окончание алгоритма.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
143
Особенностью алгоритма является субъективизм при вы-боре значения .d Если d является сравнительно большим, то процесс поиска информативной подсистемы будет быстрым, но точность – низкой. В противоположном случае точность будет выше. В литературе указано, что практически прием-лемые результаты получены при 10r и количестве итера-ций от 10 до 15.
Алгоритм направленного таксономического поиска при-
знаков (НТПО). Шаг 1. Решить задачу кластеризации n признаков на m
кластеров. Шаг 2. Выбрать типичный признак в каждом кластере. Та-
кие признаки будут максимально независимыми один от дру-гого.
Шаг 3. Определить число ' .m m Выполняя перебор факто-ров из m по 'm (всего
'mmC раз), идентифицируя на обучаю-
щей выборке соответствующие зависимости и проверяя их точность на контрольной выборке, делаем вывод о составе множества информативных признаков.
5.4. Алгоритм „выбеливания” входов
Как уже определено выше, нормирование и приведение к единой шкале увеличивают информативность данных. Од-нако этого оказывается недостаточно. Известно, что если фак-торы статистически зависимы, то их совместная энтропия меньше суммы энтропий отдельных факторов, то есть
1 2 1 2( ) ( ) ( )H X X H X H X . (5.4) Тривиальным примером этого является процесс покупки
телевизора и DVD-проигрывателя. Очевидно, что неопреде-ленность при одновременном приобретении комплекта ви-деотехники одной марки меньшая, чем, если бы они были разных марок или покупались в разное время. В качестве оп-ределяющих факторов здесь выступают потребительские свойства.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
144
Достижение статистической независимости входов тем самым будет обеспечивать максимальную информационную насыщенность каждого из входных факторов отдельно. Ста-тистическая независимость – условие, выполнить которое до-вольно сложно, поэтому на первом шаге осуществим декорре-ляцию входов по следующему алгоритму “выбеливания” входов.
Шаг 1. Для каждого входного фактора (см. табл. 5.2) най-дем его среднее значение
1
1 , 1, .m
j iji
x x j nm
(5.5)
Шаг 2. Вычислим ковариационную матрицу ,K элементы которой рассчитаем по формуле
1
1 ( )( ), , 1, .1
m
ij li i lj jl
k x x x x i j nm
(5.6)
Шаг 3. Определяем линейное преобразование, которое бу-дет диагонализировать ковариационную матрицу. Это по-зволит сделать матрица, составленная из столбцов, являю-щихся собственными векторами матрицы ,K такой, что
,KV V где собственные числа матрицы K . Шаг 4. Выполним преобразование
~
/nX X V , (5.7) где матрицу nX получают из X вычитанием от элементов каждого столбика их средних значений.
Шаг 5. Окончание алгоритма. В результате применения “выбеливания” входов все вход-
ные факторы будут некоррелированными с единичной диспер-сией. Очевидно, что вследствие такого преобразования совмест-ная энтропия увеличивается, поскольку распределение элемен-тов в выборке выравнивается и становится близким к равномер-ному. Легко осуществить и обратное преобразование.
В приложении Б приведен текст модуля для прямого и обратного преобразований. Для того, чтобы не обременять читателя подробностями расчетов обратной матрицы, собст-венных векторов и чисел, модуль написан на внутреннем языке пакета Matlab.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
145
5.5. Нейросетевое определение значимых факторов
Продолжая оптимизировать структуру начальной ин-формации, необходимо решить две задачи:
1. Удаление линейно зависимых среди входных факторов. 2.Выбор значимых входных факторов. Рассматривая первую задачу, заметим, что один из спосо-
бов ее решения был приведен в п. 1.3. Он посвящен удалению мультиколлинеарности и базируется на критерии Фаррара-Глобера. Одним из традиционных методов устранения муль-тиколлинеарности является изъятие из множества входных факторов линейно зависимых. Другой метод состоит в замене одного из линейно зависимых факторов на линейную комби-нацию факторов (наиболее распространенной есть разность входов). Еще один метод состоит в следующем.
Вычисляем матрицу ковариаций , , 1( )ni j i jK k и ее собст-
венные числа 1{ }ni i из равенства ,Kx x где x – соб-
ственный вектор. Известно, что собственные числа являются квадратами дисперсий матрицы K вдоль ее главных осей. Ес-ли собственные числа достаточно малы, то это будет свиде-тельствовать о том, что значение дисперсии является малым, и, соответственно, гиперповерхность, которая описывает входные данные, теряет измерение (превращает его в кон-станту регрессионного уравнения) и, как следствие, указывает на то, что реальная размерность входного множества меньше заданной. Тогда размерность входов снижаем, исключая вхо-ды, которым отвечают собственные числа, имеющие абсо-лютные значения меньшие некоторого заданного 0. Точ-ность модели при этом, в большинстве случаев, теряется не-значительно.
Задача выбора значимых факторов также может быть ре-шена разными методами. Так, если предположить, что осуще-ствляется преобразование : ,F X Y причем 1 2( , ,..., )nX X X X ,
1 2( , ,..., )mY Y Y Y и зависимости 1 2( , ,..., ),i i nY f X X X 1, ,i m линей-ные, то необходимо действовать таким образом. Для иденти-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
146
фикации зависимости F используем однослойный (по коли-честву слоев весовых коэффициентов) перцептрон (рис. 5.3). Обучая его на известной матрице начальных данных (табл. 5.3), получим матрицу весовых коэффициентов
11 12 1
21 22 2
1 2
...
....
... ... ... ......
m
m
n n nm
w w ww w w
W
w w w
1X 1Y11W1H
12W21W
22W2X 2Y2H
nX mYnH nmW
1nW 2nW
Рис. 5.3. Однослойный перцептрон Тогда значимость элементов вектора X определяется при
помощи вычисления нормы строк матрицы .W Норма может быть, например, одной из таких:
12 21
1
* ( ) ,m
iij
j
w
2
1
* ,m
iij
jw
1, .i n
Таблица 5.3. Таблица начальных данных
1Х 2X ... nX 1Y 2Y ... mY 11x 12x ... 1nx 11y 12y ... 1my 21x 22x ... 2nx 21y 22y ... 2my
... ... ... ... ... ... ... ... 1kx 2kx ... knx 1ky 2ky ... kmy
Факторы, в которых соответствующие значения * боль-ше некоторого 0, полагают значимыми. Заметим, что

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
147
предложенный метод эффективен в предположении о ли-нейной зависимости if и выполнении предварительного «выбеливания» входов.
Однако в случае линейной зависимости совсем не обяза-тельно обучать нейронную сеть. Достаточно известными ме-
тодами получить модель 1 01
n
i ii
Y a a X
для случая 1{ }.Y Y
Если Y – вектор-функция, то эта процедура будет сложнее. Более содержательным является случай нелинейной зависи-мости. Одним из известных методов, инвариантных к специ-фикации зависимости, есть „box-counting”.
5.6. Методика „Box-counting” Развитая теория линейной множественной регрессии не
оставляет и капли сомнения в правильности полученных ре-зультатов и разработанных методов. Несомненным есть и тот факт, что большинство естественных процессов носит нели-нейный характер, а потому применение линейных регресси-онных моделей является ограниченным, а сами они, их раз-витие и усовершенствование служат средством преимущест-венно научно-теоретического поиска.
Теория нелинейных процессов, в части их идентифика-ции, оценки качества, статистических оценок, применения для прогнозирования развита слабо. Для такого состояния дел есть объективные и субъективные причины. Не углубляясь в них, сделаем анализ одного из методов определения значимо-сти входных факторов, как аспекта уменьшения начальной энтропии, играющего особенно важную роль при прогнози-ровании на „коротких” выборках.
Рассмотрим методику „box-counting”. Ее сущность состоит в следующем. Есть входные факторы 1 2, ,..., ,nX X X значе-ния каждого из них находятся в ограниченной области, то есть ,ij ix ,i ijX x 1, .j m
Согласно положениям теории информации и теории ве-роятностей, мерой предсказуемости значения фактора kX яв-ляется его энтропия, которая определяется по формуле (5.1).

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
148
Энтропия будет максимальной, если все значения фактора равновероятны. В методике „box-counting” энтропия оцени-вается по количеству заполненных ячеек, на которые разбива-ется интервал его возможных значений (рис. 5.4). Таким обра-зом, количественно энтропия является логарифмом эффек-тивного числа заполненных ячеек
( ) log .k XH X N
minXmaxX X
Рис. 5.4. Распределение значений по ячейкам
Очевидно, что энтропия увеличивается с увеличением ко-личества заполненных ячеек. Рост энтропии (меры неопреде-ленности) приводит к уменьшению меры предсказуемости значений фактора. Если все значения сосредоточены в одной ячейке, то энтропия фактора равняется нулю (имеет место полная определенность). Равномерному заполнению ячеек отвечает максимальная энтропия.
Предсказуемость результирующей характеристики ,Y ко-торая определяется знанием значений фактора ,X рассчиты-вается как кросс-энтропия (количество информации) ( , ) ( ) ( ) ( / ).I X Y H X H Y H Y X (5.8)
Кросс-энтропия является логарифмом отношения рассея-ния значений переменной Y к типичному рассеянию этой переменной при известном значении переменной X
( , ) log ,x y
xy
N NI X Y
N (5.9)
где xyN – количество ячеек, в которых находятся точки с коорди-натами ( , )i iX Y (рис. 5.5). На рис. 5.5 8.xyN Количество столб-цов, в которых есть значения ,X обозначено xN и для рис. 5.5
5.xN Аналогично, количество столбцов, в которых есть зна-чения ,Y обозначено yN и 5.yN Таким образом,

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
149
5 5( , ) log log3,125 1,64.8
I X Y
Заметим, что расчеты приведены для логарифма с осно-ванием 2.
X
Y Рис. 5.5. Исходные данные для расчетов ( , )I X Y
Чем большим будет значение кросс-энтропии, тем больше
определенности вносит знание значений X в прогноз значения .Y Подводя итог, предложим алгоритм реализации методики
„box-counting”. Шаг 1. Предположим, что существует зависимость
1 2( , ,..., ),nY F X X X вид которой является неизвестным. По-скольку априорно факторы , 1, ,iX i n имеют разную размер-ность, то их необходимо нормировать и привести к [0,1]–шкале, которая позволит проводить адекватный анализ.
Шаг 2. Выберем единицу дискретности , определяемую точностью исследований. Область определения каждого фак-тора ([0,1]-отрезок) разбиваем на интервалы длиной и рас-считываем .xN
Шаг 3. В двухмерном пространстве (см. рис. 5.5) опреде-ляем xyN для каждого фактора.
Шаг 4. Для каждой пары ( ,iX Y ) рассчитываем значение отношения (5.9) и упорядочиваем последовательность
1( , ),I X Y 2( , ),..., ( , )nI X Y I X Y по увеличению значений.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
150
Шаг 5. Исходя из начальных данных и опыта, определен-ное количество факторов с наименьшими значениями кросс-энтропии отбрасываем. Остаются значимые факторы.
Шаг 6. Окончание алгоритма. Замечание 5.1. На шаге 2 единицы дискретности могут
быть разными для каждого фактора. Замечание 5.2. Единицы дискретности для входных фак-
торов на шагах 2 и 3 являются одинаковыми.
Практические задачи 5.1. Информативность факторов Данные табл. 5.4 используются для идентификации зависи-
мости 1 2 10( , ,..., ).Y F X X X Отдельно по методам Del, Add, комбинированным AddDel и DelAdd, ВПА, НТПО опреде-лить информативные факторы, провести сравнительный ана-лиз их точности. Изъяв неинформативные факторы по каж-дому из методов, выполнить идентификацию указанной за-висимости и оценить ее адекватность по критерию минимума среднеквадратической погрешности. Сравнить результаты.
Таблица 5.4. Начальные данные
1X 2X 3X 4X 5X 6X 7X 8X 9X 10X Y 1 2 3 4 5 6 7 8 9 10 11
71,2 54,7 128 38995 10,43 412,8 3436 101,6 21,0 17,9 287 71,6 55,56 120,1 13636 14,920 452,7 3899 130,408 19,00 18,26 282,56
74,25 55,49 114,4 12905 12,11 410,2 4644 101,306 18,00 18,71 281,05 74,25 56,12 113,9 13271 18,67 458,6 2051 141,993 26,00 19,69 283,68 78,38 61,78 116,8 26785 56,83 518,6 2562 385,409 36,00 20,19 299,65 82,20 64,22 115,3 30437 80,62 555,9 2855 482,030 15,30 20,42 307,13 84,28 65,32 120,1 42156 18,65 458,6 2855 141,932 16,25 20,89 316,85 86,08 68,48 121,0 12936 34,30 483,1 2891 222,110 17,64 20,90 324,33 87,94 71,80 125,8 23894 41,60 494,6 3512 274,297 19,23 21,48 336,90 89,43 74,24 127,8 25355 34,31 483,2 1251 222,196 19,74 21,53 343,80
Продолжение таблицы 5.4
1 2 3 4 5 6 7 8 9 10 11 90,93 75,87 129,3 31929 8,994 443,4 3402 117,285 20,36 22,35 349,66 86,29 76,69 128,7 39058 71,66 541,9 3878 459,166 21,18 22,83 346,86 86,05 76,90 128,9 13332 34,20 483,0 4720 221,451 21,28 22,71 347,53 84,28 78,41 128,7 24289 23,87 466,8 1141 162,880 38,00 23,94 349,32 86,27 79,18 130,5 46600 78,43 552,5 1798 477,721 22,41 24,15 355,32

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
151 88,87 80,24 133,3 20302 37,43 488,1 2346 243,742 23,26 25,34 364,23 88,92 83,99 136,6 27973 64,67 530,9 2967 430,234 39,00 25,79 372,98 92,15 84,2 140,5 34547 54,29 514,6 3332 368,392 23,88 38,00 380,75 90,86 85,9 143,1 42979 60,34 524,1 3259 407,016 24,32 34,00 384,39 90,43 87,8 140,7 17411 90,85 572,0 3896 494,201 38,00 26,56 385,32 91,36 91,3 146,5 32021 17,01 456,0 1290 136,536 25,66 44,00 397,13 96,89 93,7 145,3 11963 22,91 465,2 4577 158,583 26,39 26,39 404,30 97,05 96,7 143,1 19633 40,07 492,2 2130 262,944 26,68 26,44 406,12 104,6 98,9 147,9 38759 28,25 473,6 3299 185,061 26,45 26,83 421,71
5.2. Статистическая независимость входов К факторам, значение которых приведены в табл. 5.4,
применить „выбеливание” входов (см. приложение Б). Прове-рить точность процедуры путем обратного преобразования, а также некоррелированность входов и равенство дисперсии единице. Использовать нейросетевые методы для идентифи-кации искомой зависимости с исходными данными табл. 5.4 и „выбеленными” входами.
5.3. Методика „box-counting” Используя методику „box-counting”, по данным табл. 5.4
определить наиболее информативные факторы. Сравнить полученные результаты с результатами метода главных компо-нент, метода „выбеливания” входов и результатами решения задачи 5.1.
Контрольные вопросы и задачи для самопроверки
1. Короткая теоретическая справка о возникновении и
развитии теории информации. 2. Какие свойства определяют энтропию? 3. Что называют количеством информации и как его вычис-
ляют? 4. Каким требованиям удовлетворяет мера неопределен-
ности? 5. Для чего нормируют начальные данные? 6. Какие свойства имеют функции нормирования? 7. Для чего применяют снижение размерности пространства
входных факторов?

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
152
8. В каких случаях используют и каких результатов дости-гают с помощью алгоритма „выбеливания” входов?
9. Метод удаления линейной зависимости среди входных факторов, базирующийся на критерии Фаррара-Глобера.
10. Методы определения мультиколлинеарности. 11. Какими методами решается задача выбора значимых
факторов? 12. В чем состоит сущность метода „box-counting”? 13. Как оценивается энтропия в методе „box-counting”? 14. В каком случае энтропия будет максимальной? 15. Что такое кросс-энтропия и как она определяется? 16. Алгоритм реализации метода „box-counting”. 17. Какие особенности имеет нейросетевое определение
значимых факторов? 18. Приведите пример рационального применения мето-
дики „box-counting”. 19. Какие преимущества и недостатки имеет методика
„box-counting” в сравнении с другими методами определения значимых факторов?
Темы рефератов и расчетно-графи-ческих работ
1. Исследование свойства сохранения метрики для разных
методов нормализации. 2. Сравнительный анализ результатов применения метода
главных компонент и нейросетевых технологий для определе-ния значимых факторов.
3. Исследование зависимости точности определения зна-чимых факторов от размера ячейки в методе „box-counting”.
4. Исследование эффективности методов увеличения ин-формативности данных в зависимости от их количества и на-личия линейной зависимости.
5. Критерии информативности признаков. 6. Теоретическое обоснование метода „box-counting”. 7. Применение нейронных сетей к отбору информатив-
ных признаков в моделях линейной регрессии.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
153
8. Применение нейронных сетей к отбору информатив-ных признаков в моделях нелинейной регрессии.
Темы для самостоятельного
изучения 1. Отбор информативных признаков в моделях дискри-
минантного анализа. 2. Отбор информативных признаков в моделях регрессии. 3. Нелинейное отображение многомерных данных в про-
странство низшей размерности по критерию стресса. 4. Быстрое нелинейное отображение с помощью опорных
точек. 5. Быстрый алгоритм нелинейного проектирования мно-
гомерных данных. 6. Модель Фишера с дополнительными предположениями
о структуре зависимости признаков. 7. Схема последовательного анализа наборов признаков.
Литература
Основные источники
1. Ежов А.А., Шумский С.А. Нейрокомпьютинг и его при-менение в экономике и бизнесе. - М.: МИФИ, 1998. - 224 с.
2. Люгер Ф. Дж. Искусственный интеллект. Стратегии и методы решения сложных проблем. – М.: “Вильямс”, 2003. – 864 с.
3. Наконечный С.І., Терещенко Т.О., Романюк Т.П. Эконо-мет-рия. - К.: КНЭУ, 1997. - 352 с.
4. Прикладная статистика: Классификация и снижение раз-мерности: Дел. изд. / С.А. Айвазян, В.М. Бухштабер, І.С. Еню-ков, Л. Д. Мешалкин; Под ред. С.А. Айвазяна. - М.: Финансы и статистика, 1989. - 607 с.
5. Загоруйко Н.Г. Прикладные методы анализа данных и знаний. - Новосибирск: Изд-во И-та математики, 1999. - 270 с.
6. Айвазян С.А., Енюков І.С., Мешалкин Л.Д. Прикладная ста-тистика. Основы моделирования и первичная обработка дан-ных. - М.: Финансы и статистика, 1983. - 471 c.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
154
7. Вапник В.Н., Червоненкис А.Я. Теория распознавания об-разов. - М.: Наука, 1974. - 416 c.
8. Загоруйко Н.Г., Елкина В.Н., Лбов Г.С. Алгоритмы обна-ружения эмпирических закономерностей. - Новосибирск: Наука, 1985. - 110 с.
Дополнительные источники
1. Вапник В.Н. Восстановление зависимостей по эмпири-
ческим данным. - М.: Наука, 1979. - 447 с. 2. Браверман Э.Г. Структурные методы обработки эмпи-
рических данных. - М.: Наука, 1983. - 464 с. 3. Алгоритмы и программы восстановления зависимостей /
Под ред. В.Н. Вапника. - М.: Наука, 1984. - 816 с. 4. Факторный, дискриминантный и кластерный анализ: Пер. с
англ. /Дж.-О. Кем, Ч.У. Мьюллер, У.Р. Клекка и др.; Под ред. І.С. Енюкова. - М.: Финансы и статистика, 1989. - 215 с.
5. Рассел С., Норвиг П. Искусственный интеллект. Совре-менный подход. - М.: „Вильямс”, 2006. - 1408 с.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
155
Глава 6
Методы кластеризации
Лев, царь зверей, решил разделить своих подчиненных на умных и кра-
сивых. Приказал выстроиться в две шеренги: умные – налево, красивые – направо. Выстроил всех. И лишь одна обезьянка продолжала метаться ме-жду шеренгами, решая – красивая она или все-таки умная.
Народный фольклор
Не в совокупности ищи единства, но более – в единообразии разделения.
Козьма Прутков
Основные понятия и термины
Базы данных и знаний Энтропия Метрика Корреляция Карта Кохонена Информативность Генетический алгоритм Функция приспособленности Нормальное распределение Равномерное распределение Математическое ожидание Дисперсия
Процесс поступательного движения к созданию инфор-
мационного общества сопровождают проблемы, связанные с хранением и обработкой больших массивов данных. Необхо-димым условием их решения есть интеллектуальный анализ данных, технологии которого формируются на пересечении теории искусственного интеллекта, статистики и теории баз данных. К ним принадлежат KDD (knowledge discovery in databases) – выявление знаний в базах данных, data mining („раскопка данных”), OLAP (on-line analytical processing) – „добыча информации” в реальном времени из многомерных баз данных и другие. Элементы указанных технологий стано-вятся неотъемлемой частью электронных хранилищ данных (warehouses). Значительную часть информации составляют данные, которые являются социально-экономическими пока-зателями функционирования сложных систем.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
156
Большим массивам информации свойственно присутствие шумовых эффектов, их обработка приводит к накоплению совокупной ошибки. Для преодоления указанной проблемы необходимо установить значимые факторы и осуществить их анализ. Уменьшение информационной энтропии может быть также достигнуто путем группирования объектов и выявле-ния знаний в меньших, функционально связанных совокуп-ностях. Такие процедуры направлены на последовательное преодоление неопределенности. Их первым шагом является решение задачи кластеризации.
Обоснованием актуальности решения задачи кластериза-ции является необходимость устранения усреднения при идентификации неизвестных зависимостей, поскольку в этом случае прогнозные оценки являются смещенными, и их нель-зя считать адекватными. Поэтому идентификацию необходи-мо осуществлять в классе однотипных объектов или процессов, предпосылкой чего есть предварительная кластеризация.
Важно заметить, что кластеризация и классификация яв-ляется основой как повседневной деятельности человека, так и фундаментальным процессом научной практики, посколь-ку даже дети классифицируют объекты окружающего мира, а система классификаций содержит понятия, которые являются необходимым условием разработки теорий и методов науки.
6.1. Постановка задачи и ее предварительный анализ
Задача кластеризации состоит в определении групп объ-ектов (процессов), которые являются ближайшими один к другому по некоторому критерию. При этом никаких пред-положений об их структуре, как правило, не делается. Боль-шинство методов кластеризации базируется на анализе зна-чений матрицы коэффициентов подобия, к которым относят-ся расстояние, корреляция и другие. Если критерием или метрическим свидетельством выступает расстояние, то кла-стером называют группу точек , такую, что средний квадрат внутригруппового расстояния до центра группы меньше сред-него расстояния к общему центру в начальном наборе объек-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
157
тов, то есть 2 2 ,d d где
2 21 1( ) , ,i i
i iX X
d X X X XN N
N – количество точек в кластере . . В общем случае, критерия-ми есть:
1. Расстояние Евклида 1
2 2
1
1( , ) ( ( ) )m
k l kj ljj
d X X X Xm
.
2. Максимальное расстояние по признакам (расстояние Че-бышева)
1( , ) max .k l kj ljj m
d X X X X
3. Расстояние Махаланобиса 1
1 2( , ) [( ) ( ) ] ,Tk l k l k ld X X X X R X X
где 1R – обратная к ковариационной матрице;
4. Расстояние Хемминга 1
1( , ) .m
k l kj ljj
d X X X Xm
Решение задачи минимизации расстояния между объектами равносильно решению задачи минимизации расстояния до объекта, имеющего усредненные характеристики, поскольку, например, для расстояния Хемминга
1 1 1 1
{ , }1 1 1
2 max ,
m m m m
kj lj kj j j lj kj j lj jj j j jk l k l k l k lm m m
kj j lj j pj jp k lj j j
X X X X X X X X X X
X X X X X X
где 1 2{ , ,..., }mX X X X – объект с усредненными значениями характеристик.
Задачи кластеризации сопровождаются двумя проблема-ми: определение оптимального количества кластеров и расчет их центров. Начальными данными для задачи кластеризации есть значения параметров объектов исследования. Чаще всего определение оптимального количества кластеров является прерогативой исследователя. Предположим, что число кла-стеров K задано и ,K m где m − количество объектов. По-лучим задачу

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
158
1 1
min,imK
iji j
X X
(6.1)
где , 1, ,im i K – количество объектов в i -м кластере, , 1, ,iX i K – среднее значение в кластере, ijX X – расстоя-
ние между объектами. Решением задачи (6.1) есть центры кластеров ,iX которые могут содержаться среди данных объ-ектов, что является достаточно строгим условием, и могут быть представленными любыми точками области исследования.
К традиционным методам кластерного анализа относят древовидную кластеризацию, двухвходовое объединение, ме-тод K -средних, метод дендритов, метод корреляционных плеяд, метод пластов и другие. Преимуществами указанных ме-тодов является простота, инвариантность техники реализации относительно характера начальных данных и используемых метрик. К недостаткам относят слабую формализуемость, что усложняет применение вычислительной техники, а также низкую точность, следствием чего являются предварительные оценки структуры пространства факторов и их информатив-ности. Еще один метод решения задачи кластеризации бази-руется на применении самоорганизующей карты Кохонена. Проблемой использования такой нейронной сети есть выбор начальных весовых коэффициентов, непрерывный характер функционирование и эффективность, оценка которой на сего-дняшний день остается актуальной задачей.
6.2. Характеристика методов кластерного анализа
Известно, что главная цель кластерного анализа – поиск групп подобных объектов в выборке данных. Кластер опреде-ляется такими характеристиками: плотность, дисперсия, раз-меры, форма и отделимость. Рассматривая метрические про-странства, плотность определим как свойство, которое позво-ляет считать кластер сгущением точек в пространстве дан-ных, относительно плотное в сравнении с другими областями пространства, которые содержат малое количество точек или не содержат вообще. Дисперсия определяет меру рассеяния

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
159
точек в пространстве относительно центра кластера. Размеры кластера тесно связаны с дисперсией: если кластер иденти-фицирован, то и его радиус можно измерить. Это свойство полезно только тогда, когда кластер является гиперсферой. Форма – размещение точек кластера в пространстве. Отдели-мость характеризует меру перекрытия кластеров и то, на-сколько далеко один от другого они размещены.
Разработанные классические кластерные методы образо-вывают такие группы: - иерархические агломеративные методы; - иерархические дивизимные методы; - иерархические методы группирования; - методы поиска модальных значений плотности; - факторные методы; методы сгущений; - методы, использующие теорию графов.
Иерархические агломеративные (объединяющие) методы. Метод одиночной связи. Пусть имеем матрицу подобия, при-
мер которой приведен в табл. 6.1. Анализ значений коэффици-ентов подобия свидетельствует о том, что наиболее подобны-ми есть объекты 4O и 5O , объединяем их (рис. 6.1). Следую-щим по абсолютному значению является коэффициент 0,7, что определяет подобие между 3O и 6O , их тоже объединяем. Далее рассматриваем значение 0,6, которое определяет подо-бие между парами 4O и 5O , 3O и 6O , как наибольшее значе-ние подобия между их элементами, а также подобие между
1O и парой 4O и 5O . Соединяем их. На последнем шаге со-единяем объект 2O с другими объектами на уровне 0,4.
Таблица 6.1. Коэффициенты подобия
1O 2O 3O 4O 5O 6O 1O – 0 0,2 0,6 0,24 0,45
2O – – 0,3 0,4 0,35 0,3
3O – – – 0,5 0,42 0,7
4O – – – – 0,8 0,5
5O – – – – – 0,6
6O – – – – – –

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
160
Сделаем некоторые замечания относительно метода оди-ночной связи. Во-первых, необходимо просматривать матрицу подобия и последовательно объединять подобные объекты. Во-вторых, последовательность объединения кластеров пред-ставляется в виде древоподобной диаграммы (дендрограммы). В-третьих, для полной кластеризации необходимо осущест-вить 1n шаг, где n – количество объектов. В-четвертых, вследствие выполнения достаточно простой процедуры по-лучаем вложенные кластеры.
Метод одиночной связи имеет как преимущества, так и не-достатки. Он один из немногих методов, результаты приме-нения которого не меняются при любых преобразованиях данных, которые оставляют без изменения относительное упорядочение элементов матрицы сходства. Главным недос-татком является то, что метод приводит к появления „цепо-чек”, то есть больших продолговатых кластеров, что делает почти невозможным адекватное определение количества кла-стеров.
0,3 0,4 0,5 0,6 0,7 0,8 1O 4O 5O 3O 6O 2O
Рис. 6.1. Дендрограмма
Метод полных связей. В отличие от метода одиночной свя-зи, согласно правилу объединения коэффициент сходства между кандидатами на включение в кластер и элементами этого кластера должен быть не меньше некоторого порогово-го значения. Дерево, полученное в результате применения ме-тода, дает лучшее представление о кластерной структуре дан-ных.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
161
Метод средней связи имеет несколько вариантов примене-ния. В первом из них вычисляется среднее подобие объекта, ко-торый нужно кластеризировать, со всеми объектами кластера. Если найденное среднее значение подобия достигает или пре-вышает некоторое заданное пороговое значение, объект при-соединяется к кластеру. Во втором варианте вычисляют коэф-фициент подобия между центрами весов кластеров, которые подлежат объединению.
Метод Уорда предназначен для определения кластеров та-ким образом, чтобы оптимизировать минимальную диспер-сию внутри кластеров. Целевая функция такая:
2 2
1
1 ( )n
i i jij
F X Xn
.
На первом шаге ее значение равняется нулю. Дальше объе-диняются те объекты, для которых значения указанной функ-ции имеет наименьшее приращение. Метод имеет тенденцию к нахождению кластеров приблизительно одинаковых разме-ров.
Итеративные методы группирования. В основе применения итеративных методов группирова-
ния лежит базовый алгоритм: Шаг 1. Эмпирически разбить объекты на указанное число кла-стеров. Вычислить центр каждого кластера. Шаг 2. Поместить каждую точку данных в кластер с наиболее близким центром масс. Шаг 3. Вычислить новые центры масс кластеров. Кластеры не меняются до тех пор, пока не будут пересмотрены все объек-ты. Шаг 4. Шаги 2 и 3 повторяются до тех пор, пока не перестанут изменяться кластеры.
Применение итеративных методов группирования связа-но с рядом проблем вычислительного характера, поэтому ис-пользуют подготовительные процедуры для выбора исходно-го деления, типа итераций, статистических критериев.
Выбор начальной разбивки осуществляется двумя путями: первый состоит в том, что определяются начальные точки –

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
162
центры кластеров и дальше вычисляется расстояние от каждого объекта до центров кластеров. Объект принадлежит тому кла-стеру, расстояние до центра которого является наименьшим. Согласно второму способу объекты произвольно разбивают на кластеры и находят их центры как средние значения.
Существует два основных типа итераций: по принципу „k-средних” и по принципу „восхождения на гору”. Итерации по принципу „k-средних” состоят в перемещении объекта в кластер с ближайшим центром веса. Они могут быть комби-наторными или некомбинаторными. В первом случае пере-расчет центра кластера осуществляется после каждого изме-нения его состава, во втором − только после того, как будет завершено просмотр всех данных. Кроме того, итерации по принципу „k-средних” бывают включающими и исключаю-щими. Во включающих итерациях после вычисления центра кластера объект включается в состав кластера, в исключаю-щих – удаляется из кластера. В итерациях, реализуемых по принципу „восхождения на гору”, перемещение объектов происходит, исходя из того, будет ли такое перемещение оп-тимизировать значение некоторого статистического крите-рия.
К функциям, которые определяют качество кластериза-ции (статистические критерии), принадлежат 1, , dettrW trW B W и наибольшее собственное число матрицы 1W B , где W – объ-единенная внутригрупповая ковариационная матрица, B – объединенная межгрупповая ковариационная матрица. Ис-пользуя каждый из статистических критериев, находят класте-ры определенного вида. Так, критерий trW ориентирован на образование гиперсферических однородных кластеров. По критерию detW предполагается, что у кластеров будет одина-ковая форма, не обязательно гиперсферическая.
Проблема всех итеративных методов – при решении зада-чи кластеризации имеют место и субоптимальные решения.
Другие методы кластеризации. Реализация методов факторного анализа начинается с
формирования корреляционной матрицы подобия объектов. По ее элементам определяются факторные нагрузки и вы-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
163
полняется распределение объектов по кластерам. К недостат-кам таких методов относят: необходимость обоснования при-менения линейной множественной регрессии; проблема множественных факторных нагрузок, поскольку существует проблема принятия решений, если объект имеет высокую на-грузку больше чем для одного фактора.
В основе иерархических дивизимных (разделяющих) мето-дов лежит идея деления: сначала все объекты принадлежат одному кластеру, а потом они делятся на большее количество кластеров. При этом возможна реализация двух вариантов: монотетического и политетического. В первом варианте кла-стеры определяются по одинаковости или близости значений одного признака, во втором – к кластеру принадлежат объек-ты, которые имеют определенные соотношения значений из некоторого множества признаков.
В методах поиска модальных значений плотности кла-стер определяют как область пространства с высокой плотно-стью образов в сравнении с окружающей средой. Различают два подхода: в первом подходе базируются на методе одиноч-ной связи, во втором – на делении „смесей” многомерных ве-роятностных распределений. Особенностью первого подхода является то, что при появлении нового образа он с опреде-ленным приоритетом образовывает новый кластер, чем при-соединяется к уже существующему кластеру. Второй подход базируется на статистической модели, в которой элементы разных групп или кластеров имеют разное распределение значений признаков.
Такие методы являются чувствительными к проблеме су-боптимальных решений, компоненты “смесей” являются многомерными нормальными распределениями, что и опре-деляет их недостатки.
Методы сгущения позволяют образовывать кластеры, ко-торые перекрываются. Они требуют вычисления матрицы подобия между образами и установление оптимального зна-чения стратегического критерия. Поскольку эти методы вна-чале образовывают лишь две группы, то рационально пред-лагать несколько конфигураций, каждая из которых оценива-ется на пригодность. Недостатком методов является то, что

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
164
через неудачную поисковую процедуру происходит повтор-ное нахождение одних и тех же групп, что не предоставляет новой информации.
Сравнительно новым направлением в разработке методов кластеризации есть методы, базирующиеся на теории графов. Развитый математический аппарат является альтернативой многочисленным эвристическим методам. Значительное рас-пространение приобрели методы, базирующиеся на расту-щих пирамидальных сетях. Такие сети позволяют выполнять кластеризацию в режиме реального времени.
6.3. Алгоритм, базирующийся на гипотезе компактности
Гипотеза компактности заключается в том, что реализации одного и того же образа отображаются в пространстве призна-ков в геометрически близких точках, образовывая „компактные” сгустки в предположении, что проведена предварительная об-работка образов. Мера компактности может быть разной, чаще всего эту роль играет евклидово расстояние. Различают унимо-дальную, полимодальную и локальную компактность. Гипо-теза унимодальной компактности лежит в основе многочис-ленных алгоритмов таксономии, с помощью которой полу-чают кластеры в виде гиперсфер или гиперпараллелепипе-дов. Использование гипотезы локальной компактности связа-но с критерием информативности, в качестве которого вы-ступают значения опорных точек, количество которых необ-ходимо для безошибочного распознавания обучающей по-следовательности. Для прогнозирования значений пропу-щенных элементов в таблицах „объект-признак” применяется гипотеза полимодальной компактности.
Алгоритм Forel Шаг 1. Признаки объектов нормируются так, чтобы их значе-ния находились на отрезке [0, 1], например,
min'
max min
. 0.ij jij
j j
x xx k
x x
Шаг 2. Строим гиперсферу минимального радиуса, которая охватывает все m точек. При нормировании, предложенном

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
165
на шаге 1, такой радиус равняется ,2knR где n – количество
факторов или признаков объекта. Шаг 3. Уменьшаем радиус гиперсферы по формуле 1kR
110k k
kR R и центр сферы размещаем в одной из точек (вы-
бранной случайно). Шаг 4. Определяем точки, расстояние от которых до центра гиперсферы меньше 1kR , и вычисляем координаты их центра масс. Шаг 5. Переносим центр сферы в центр масс и снова опреде-ляем внутренние точки. Эта операция циклически повторяет-ся. Шаг 6. Если состав множества внутренних точек и, как следст-вие, координаты центра масс не меняются, то сфера остано-вилась в области локального максимума плотности точек в пространстве признаков. Шаг 7. Удаляем из рассмотрения точки, которые принадлежат сфере (таксону 1). Шаг 8. Если еще остались „свободные” точки, то шаги 2-7 повторить, иначе – перейти на шаг 9. Шаг 9. Если количество таксонов меньше, чем задано, то
1k k и перейти на шаг 3, иначе – на шаг 10. Шаг 10. Окончание алгоритма.
Существует модификация приведенного базового алго-ритма Forel, которую называют Forel-2. В ней предусмотрено изменение радиуса на определенную величину на каждой ите-рации. Вместе с тем, отметим значительный субъективизм вы-бора как радиуса, так и его приращения, который часто при-водит к неоптимальной кластеризации. Алгоритм Forel-2 по-зволяет получить точно заданное число кластеров.
6.4. Алгоритм, который базируется на лямбда-компактности
Во многих задачах важную роль играют не сами расстоя-ния между объектами, а отношение между ними. Алгоритмы,

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
166
которые рассматриваются ниже, имеют в своей основе осо-бенность человеческого восприятия кластеров – внимание обращают не на абсолютные расстояния, а на отношение рас-стояний между несколькими соседними точками. Сделаем предварительные предположения. Пусть все точки генераль-ной совокупности соединены между собой ребрами полного графа. Обозначим длину между точками A и B индексом . Среди всех ребер, которые являются инцидентными этому ребру, найдем кратчайшее и его длину обозначим min . От-ношение
min
называют длиной ребра ( ,A B ). Оче-
видно, что большие значения имеют ребра, которые со-единяют отдаленные одна от другой точки, окруженные близкими соседями. Именно такие локальные всплески плот-ности точек наилучше замечает человеческий глаз при эмпи-рической кластеризации.
Алгоритм KRAB Шаг 1. Найти пару точек с минимальным значением -
расстояния между ними и соединить их ребром нового графа. Шаг 2. Соединить следующие наиболее -близкие точки
из тех, которые еще не присоединены к построенному графу. Шаг 3. Если все точки исчерпаны, то переход на шаг 4,
иначе – на шаг 2. Замечание 6.1. Полученный граф не имеет циклов и сум-
марная длина всех его ребер будет минимальной. Граф с та-кими свойствами называют кратчайшим незамкнутым путем (КНП) и обозначают –КНП. Решаем задачу разбития ис-ходного множества точек на два кластера.
Шаг 4. Для каждого ребра найдем характеристику его на-пряженности
22 ,ji mmCm m
где ,i jm m – количество точек, которые находятся по разные стороны от данного ребра.
Шаг 5. Обозначим длину разорванного ребра ,d рассчита-ем среднее значение длины внутренних ребер таксонов .v

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
167
Если кластер содержит один объект, то 0,v два объекта – 1,v при объединении всех точек в один кластер – 0.d Замечание 6.2. Разрыв наиболее напряженного ребра
обеспечивает выполнение таких условий: – граница между кластерами проходит по наиболее на-
пряженным ребрам -КНП; - средняя напряженность внутренних ребер в кластерах
будет минимальной; - кластеры будут иметь одинаковое число точек. Замечание 6.3. Критерием качества кластеризации считают
величину ,cdFcr V
где cd – средняя напряженность гра-
ничных ребер, cr – средняя напряженность внутренних ребер кластеров. Коэффициент V будет большим или равным ну-лю для того, чтобы при увеличении числа единичных класте-ров значение F не стремилось к бесконечности.
Рационально приравнять ,V например, среднему значению
напряженности ( )c полного -КНП и тогда .cdFcr c
Если
все точки объединены в один кластер, то 0.F В промежутке между этими крайностями значение F может быть как меньшим, так и большим 1, но всегда большим 0. Характери-стика F инвариантна по отношению к абсолютным значени-ям длин ребер графа -КНП, что позволяет сравнивать меж-ду собой качество кластеризации разных множеств при раз-ном количестве объектов ,m разном числе кластеров ,k разном среднем –расстоянии между объектами.
Если желательное число кластеров задано диапазоном от mink до max ,k то, наблюдая за значениями функции ( ),F f k
можно найти такое число кластеров, при котором F достига-ет максимума, который отвечает оптимальной кластеризации.
Важным этапом реализации алгоритма KRAB есть построе-ние -КНП. Если количество начальных точек превышает не-сколько сотен, то этап построения является очень трудоемким. Для ускорения выполнения процедуры необходимо осущест-вить предварительную подготовку данных (см. главу 5).

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
168
6.5. Растущие пирамидальные сети Эффективным инструментарием решения задач класси-
фикации, прогнозирования и диагностики являются расту-щие пирамидальные сети (РПС), предложенные профессором В.П. Гладуном в Институте кибернетики в Киеве. Сети РПС реализуют гипотезу о закономерностях структурирования информации при ее восприятии. Применение РПС в разных областях науки и техники подтвердило их репутацию как эф-фективного средства структуризации больших объемов ин-формации.
Определение 6.1. Ациклический ориентированный граф, в котором нет вершин с одной входной дугой (IN), называется растущей пирамидальной сетью.
Определение 6.2. Вершины, которые не имеют IN-дуг, назы-ваются рецепторами, другие вершины – концепторами.
Определение 6.3. Подграф РПС, включающий вершину A и вершины, от которых есть путь к вершине A , называется пирамидой вершины A .
Определение 6.4. Вершины, которые входят в пирамиду вершины A , образовывают ее субмножество. Множество вер-шин, к которым есть пути от вершины A , называется ее су-пермножеством.
Определение 6.5. Вершины, которые связаны с вершиной A в субмножестве и супермножестве, называются, соответст-венно, O –субмножеством и O –супермножеством.
Рецепторы РПС отвечают признакам объектов, концепто-ры – описаниям объектов в целом и пересечению понятий. В начальном состоянии сеть состоит только из рецепторов, кон-цепторы формируются в процессе работы алгоритма ее по-строения.
Разработка и использования РПС состоит из нескольких этапов:
1. Построение РПС. 2. Формирование в РПС структур, которые представляют
понятия. 3. Формирование кластерной базы данных. Рассмотрим их детальнее.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
169 Этап 1. Приведем алгоритм построения сети с возможностью
включения в существующие пирамиды объектов новых при-знаков в режиме реального времени, без замены пирамид в целом. Обозначим: AF – подмножество возбужденных вершин O -субмножества вершины A ; G -множество возбужденных вершин сети, которые не имеют других возбужденных вер-шин в своих супермножествах. При введении описания при-знаков объекта соответствующие рецепторы возбуждаются. Концептор возбуждается, если возбуждаются все вершины его O -субмножества. Введение новых вершин происходит по та-ким правилам:
А1. Если вершина A не возбуждена и множество AF содер-жит больше чем один элемент, то дуги, которые соединяют вершины множества AF с вершиной A , ликвидируются и в сеть вводится новый концептор, который соединяется IN-дугами с вершинами множества AF и исходной (OUT) дугой с вершиной A .
Интерпретация А1. Условием введения новой вершины есть ситуация, когда некоторая вершина сети является не полностью возбужденой (то есть возбуждено не меньше двух вершин ее O –субмножества, но не все). Новые вершины вводят-ся в субмножество не полностью возбужденных вершин. Они репрезентуют в сети пересечения описаний объектов (рис. 6.2).
Сеть на рис. 6.3 формируется после возбуждения в сети на рис. 6.2 рецепторов 2, 3, 4, 5.
А2. Если множество G содержит больше чем один элемент и не включает вершины, помеченные именем введенного объекта, к сети присоединяется новый концептор, который соединяется IN-дугами со всеми вершинами множества G . Новая вершина будет находиться в возбужденном состоянии. Сеть на рис. 6.4 формируется из сети на рис. 6.3 после возбуж-дения рецепторов 2, 3, 4, 5, 6.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
170 A
1 2 3 4 5 6 7
AF
A
1 2 3 4 5 6 7
G
Рис. 6.2 Рис. 6.3
А3. Если подмножество G содержит больше чем один элемент и включает вершину, помеченную именем введенно-го объекта, то эта вершина соединяется IN-дугами с теми вершинами из множества G , которые с ней не соединены. Сеть на рис. 6.5 получаем из сети на рис. 6.4 при условии, что возбуждены рецепторы 2, 3, 4, 5, 6, 7 и они отвечают описанию объекта B .
A
1 2 3 4 5 6 7
G
B
A
1 2 3 4 5 6 7
B
Рис. 6.4 Рис. 6.5 Определение 6.6. Элемент системы знаний, являющийся обобщенной логической признаковой моделью класса объек-тов, с помощью которой реализуются процессы распознава-ния и генерации моделей конкретных объектов, называется понятием.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
171 Этап 2.
Определение 6.7. Множество обобщенных в понятии объек-тов составляет его объем.
Рассмотрим задачу индуктивного формирования поня-тий. Пусть , 1, ,iV i n – множество объектов, ,i jV V .i j Обозначим L – множество объектов, которое является обу-чающей выборкой. Имеют место соотношения iL V и
1,i iV L n , которые свидетельствуют о том, что из каждо-го множества хотя бы один объект представлен в обучающей выборке и никакое множество не входит полностью в обу-чающую выборку. Путем анализа необходимо сформировать n понятий с объемами 1 2, , , nV V V , достаточными для пра-вильного распознавания всех объектов из L . Пусть есть РПС, которая представляет все объекты обу-чающей выборки L . Для формирования понятий 1 2, , , nP P P , которые отвечают множествам 1 2, , , nV V V , последовательно просматривают пирамиды всех объектов обучающей выборки. В РПС выделяют специальные вершины, с помощью которых должно осуществляться распознавание объектов из объема понятия. Их называют контрольными вершинами данного понятия. При выборе используют две характеристики вер-шин сети:
1 2, , , nm m m , где im – число объектов объема понятия iA , в пирамиды кото-рых входит данная вершина; k – число рецепторов в пирами-де, которая отвечает вершине. При просмотре пирамиды выполняются преобразования по таким правилам: В1. Если в пирамиде объекта из объема понятия iP вершина, которая имеет наибольшее k из всех вершин с наибольшим
im , не является контрольной вершиной понятия iP , то она помечается как контрольная вершина понятия. Если в группе вершин с наибольшим im значение k всех вершин равны, в качестве контрольной вершины понятия iP обозначается лю-бая из них.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
172
В2. Если в пирамиде объекта из объема понятия iP есть контрольные вершины других понятий, которые не содержат в своих супермножествах возбужденных контрольных вершин понятия iP , в каждом из этих супермножеств вершина, имеющая наибольшее k из всех возбужденных вершин с наибольшим im , обозначается как контрольная вершина по-нятия iP . Примеры применения правил В1 и В2 изображены на рис. 6.6, 6.7, 6.8. Так, на рис. 6.6 при возбуждении пирамиды вер-шины 2 контрольной вершиной является вершина 6, поскольку она имеет наибольшее k из всех вершин, которые имеют наи-большее 6,12,13 .im Числа в кружочках являются значения-ми im для концепторов, а в квадратиках – значение im для рецепторов. В соответствии с правилом В2 возбуждение пирамиды вершины 2 (рис. 6.7) при условии, что она представляет объект из объема понятия iP , приводит к выделению в качестве кон-трольной вершины понятия iP вершины 5 (рис. 6.8).
1
3
2 1
4 17
206
10 11 12 1317 20 20 10 10 14
14 15 16 17 18
15 15
149
8 12107
45
Рис. 6.6
Если при рассмотрении всех объектов обучающей выбор-ки появилась хотя бы одна новая контрольная вершина, то есть хотя бы один раз выполнились условия, которые содер-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
173
жатся в правилах В1 и В2, осуществляется новый просмотр всех объектов обучающей выборки. Работа алгоритма заканчи-вается, если при очередном просмотре обучающей выборки не возникает никакой новой контрольной вершины.
Рис. 6.7 Рис. 6.8
На следующем шаге применяется такое правило распо-знавания. Объект входит в объем iP , если в его пирамиде есть контрольные вершины понятия iP и нет никакой контрольной вершины любого другого понятия, которая не содержит воз-бужденных контрольных вершин понятия iP в своем супер-множестве. Если это условие не выполняется для всех понятий, объект считается неопределенным.
Рассмотрим пример построения РПС и формирования понятий. Пусть исходная информация содержится в табл. 6.2, где 1 2 12{ , ,..., }O O O – множество объектов, 1 2 8{ , ,..., }X X X – сово-купность их характеристик. Промежуточные этапы построе-ния РПС приведены в приложении В. Так, на рис. В.1 изобра-жена РПС после поступления одного объекта, на рис. В.2 – РПС, которая отвечает двум объектам, В.3 – сеть с тремя объ-ектами, последний, рис. В.8, отвечает полностью построенной РПС для двенадцати объектов.
- контрольные вершины понятия i A - контрольные вершины других понятий
20 - концепторы с 20 im
1 2
3
4 5
5
6 7 8
9
20
10 11 12 13 14 15 16 17 18
1 2
3
4 5
5
6 7 8
9
10 11 12 13 14 15 16 17 18

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
174
После того, как РПС построена, осуществляется процесс формирования понятий, результаты которого изображены на рис. 6.9, где серые вершины отвечают классу А, черные – классу В. Таким образом, получаем обобщенную модель ис-следуемого класса объектов, которая включает наиболее ха-рактерные свойства этих объектов. Она имеет вид логическо-го выражения, которое наглядно и легко интерпретируется. Обозначим серым цветом конъюнкцию, которая характеризу-ет объекты исследуемого класса, черным жирным – конъюнк-цию, которая характеризует объекты других классов, черным – конъюнкцию, которая характеризует отдельные объекты. То-гда получим:
Класс A:
7 3 2 5
5 1 4
1 4
3 2 1 4 5
6
7 6 8
8
&{ }
& { _ 6& _8& _9 & _ & _ & _1}
_8& _9 & _ & _1& _ & _1&
_ & _ & _1
_1& _10
_1& _10.
X X X X D X S X
X X X S X X S X X
X D X S X
X
X
X
3 2X _8&X _9
Класс B:
3 2 5 7 6 8
7
1 4
3 2 5
3 6 8 2 5 1
1 4
4
_S & _1
_8 & _9 & _D & _S & _1
& { } & { _8 & _9 & _S & _1 & _1 & _10}
_6 & _8 & _1 & _10 & _9 & _D & _S & _1.
X X X X
X X X
X X X X
X X X X X X X X
X X
5X _D
Таблица 6.2
OBJECT CLASS 1X 2X 3X 4X 5X 6X 7X 8X 1 2 3 4 5 6 7 8 9 10
1O A S 3 4 1 D 3 5 7
2O A P 6 10 3 S 1 1 10
3O A S 3 4 1 D 6 5 7
4O A S 3 4 1 D 1 6 10
5O A S 9 8 1 S 1 1 10
6O A S 9 10 1 D 6 8 6
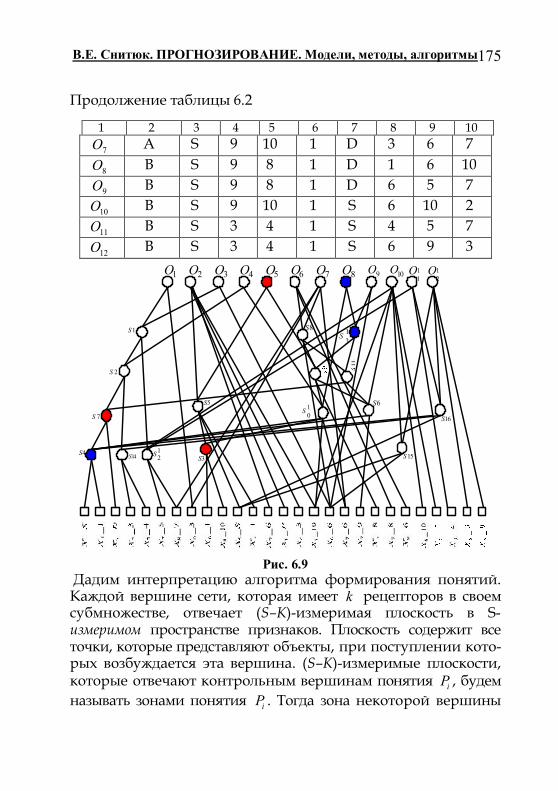
В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
175
Продолжение таблицы 6.2
1 2 3 4 5 6 7 8 9 10
7O A S 9 10 1 D 3 6 7
8O B S 9 8 1 D 1 6 10
9O B S 9 8 1 D 6 5 7
10O B S 9 10 1 S 6 10 2
11O B S 3 4 1 S 4 5 7
12O B S 3 4 1 S 6 9 3
1O 2O 3O 4O 5O 6O 7O 8O
1S
2S
3S4S
5S 6S
7S
8S
10
S
9O 10O
13
S
12S14S 15S
16S
11
O 12
O
Рис. 6.9
Дадим интерпретацию алгоритма формирования понятий. Каждой вершине сети, которая имеет k рецепторов в своем субмножестве, отвечает (S–K)-измеримая плоскость в S-измеримом пространстве признаков. Плоскость содержит все точки, которые представляют объекты, при поступлении кото-рых возбуждается эта вершина. (S–K)-измеримые плоскости, которые отвечают контрольным вершинам понятия iP , будем называть зонами понятия iP . Тогда зона некоторой вершины

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
176
РПС целиком принадлежит к зоне вершин ее субмножества и целиком включает зоны вершин ее супермножества. Точка, которая представляет объект в пространстве признаков, нахо-дится внутри области, которая образована в результате пере-сечения зон контрольных вершин, возбуждаемых при вос-приятии этого объекта.
Результатом работы алгоритма есть область из зон про-странства признаков, построенная для каждого из сформиро-ванных понятий, содержащая все точки объектов соответст-вующего класса и не содержащая никакой точки, которая представляет объекты других классов. Эта область аппрокси-мирует область распределения объектов соответствующего класса. Таким образом, алгоритм осуществляет кусочно-линейное разложение объектов, которые отвечают разным понятиям.
Объекты можно классифицировать, вычисляя значения приведенного выше типа, которые представляют соответст-вующие логические понятия.
Существует определенная аналогия между РПС и нейрон-ными сетями. Преимуществом РПС есть то, что структура сети априори не задана и формируется в зависимости от входных данных, чем уменьшается информационная избыточность. Кроме того, знания полученные в результате функциониро-вания РПС, являются явным образом представленными и до-пускают интерпретацию.
6.6. Эволюционная кластеризация Альтернативным методом решения задачи кластеризации
есть использования идей, которые лежат в основе эволюци-онного моделирования и, в частности, генетического алго-ритма. Базовой операцией является формирования фитнесс–функции.
Напомним, что начальными данными задачи кластериза-ции являются значения факторов-параметров объектов (табл. 6.3). Заранее, выполним их нормирование, например, по формуле

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
177
min'
max min
.ij jij
j j
x xx
x x
Таблица 6.3. Значения факторов исследования 1 11x 12x ... 1nx 2 21x 22x ... 2nx ... ... ... ... ... m 1mx 2mx ... mnx
Вследствие такого преобразования значения всех факто-ров будут принадлежать единичному гиперкубу [0,1] .n
Реализация фитнесс-функции осуществляется по такому ал-горитму (EvoСlast): Шаг 1. Значение фитнесс-функции положить равным нулю ( 0F ). Шаг 2. Задать количество кластеров K и указать значение .m Шаг 3. Выполнить инициализацию матрицы принадлежности элементов к кластерам .kT Шаг 4. Для всех объектов выполнить следующие шаги. Пусть
1.n Шаг 5. Вычислить расстояния от n -го объекта до центров всех K кластеров, которые являются особями выборочной популя-ции. Шаг 6. Среди всех расстояний , 1, ,jd j K выбрать минимальное
qd и отнести n -и объект к q -му кластеру. Внести соответст-венную запись в матрицу .kT .qF F d 1.n n Шаг 7. Если шаги 5–6 выполнены для всех объектов, то полу-чено значения фитнесс-функции ,F в противном случае пе-рейти на шаг 5. Шаг 8. Окончание алгоритма.
Очевидно, что алгоритм получения фитнесс-функции мож-но оптимизировать. Повышение эффективности является его внутренним атрибутом. Многообразие вариантов операций ге-нетического алгоритма определяет множество внешних свойств процесса получения фитнесс-функции. Возможность решения задачи ее оптимизации также предполагает двоичное и деся-тичное представления начальных данных. И если в первом

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
178
случае в процедурах генетического алгоритма доминирующим является равномерное распределение, то во втором – при по-иске оптимального решения преимущество отдается значе-ниям, которые имеют нормальное распределение с математи-ческим ожиданием, совпадающем с центром кластера. Опре-деление оптимальной дисперсии – еще одна задача, которая остается нерешенной.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
179
Пример 6.1. (кластеризация об-ластей по социально-экономичес-ким признакам). Для проверки эф-фективности эволюционного мето-да кластеризации были выбраны области Украины. Кластеризация осуществлялась, исходя из значений социально-экономических показа-телей. В результате предваритель-ного анализа установлены наиболее значимые показатели:
1X – валовая добавочная стои-мость в расчете на одного человека (в фактических ценах, грн.);
2X – территория (тыс. кв. км); 3X – инвестиции в основной ка-
питал на одного человека (в сравни-тельных ценах, грн.);
4X – прямые иностранные инве-стиции на одного человека (долл. США);
5X – занятость населения на 10 тыс. чел.;
6X – денежные доходы населе-ния на одного человека (грн.);
7X – кредиты, предоставленные субъектам хозяйствования на одно-го человека;
8X – количество полученных па-тентов на изобретения на 10 тыс. чел.
Для сравнительного анализа выбраны классические методы – древовидная кластеризация и метод средних. Количество кла-стеров априорно задано и равняется 2. По методу средних
Таблица 6.4Область Кластер
1 2 2 2 3 2 4 1 5 1 6 2 7 2 8 1 9 2
10 2 11 2 12 2 13 2 14 1 15 1 16 1 17 2 18 2 19 2 20 1 21 2 22 2 23 2 24 2 25 2

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
180
полученные такие результаты (табл. 6.4). К первому кластеру отнесены Днепропетровская, Донецкая, Запорожская, Никола-евская, Одесская, Полтавская и Харьковская области. Соглас-но древовидной кластеризации (рис. 6.10) к первому кластеру отнесенные те же области, кроме Донецкой, хотя она и является близкой к элементам первого кластера.
Рис. 6.10. Результаты
древовидной кластеризации
Рис. 6.11. Значение фитнесс-
функции
Рис. 6.12. Расстояние между
центрами кластеров
Рис. 6.13. Координаты цен-
тров кластеров Кластеризация проводилась также с использованием эво-
люционного моделирования. Критерием окончания вычис-лительного процесса выбрано максимальное количество ите-раций, равняющееся 1000. Для тех же двух кластеров и восьми

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
181
факторов количество переменных (хромосома), для которых проводилась оптимизация фитнесс-функции, составила 16. В выборочную популяцию вошло двадцать элементов. Учиты-вая то, что фитнесс-функция есть полиэкстремальной, значе-ние вероятности мутации увеличено и равнялось 0,4. Такое значение продлило время вычислений, но и значительно вы-росла точность расчетов за счет участившегося выбивания целе-вой функции из локальных минимумов. Для контроля за про-цессом вычислений в режиме реального времени выводилась информация о значении фитнесс-функции на каждой итера-ции (рис. 6.11); о среднем расстоянии между центрами кла-стеров (рис. 6.12); значение центров кластеров (рис. 6.13). Зна-чение фитнесс-функции уменьшилось с 96 10 до 11351587, причем на начальных этапах уменьшение происходило гипер-болически, а на последних – линейно. Среднее расстояние между центрами кластеров уменьшалась линейно, с диспер-сией, которая постоянно уменьшалась.
В результате вычисления получены два центра кластеров. Координаты первого –
1 2 3 4 5 6 7 84553, 0,01, 915, 99, 4623, 2554, 791, 1,34.X X X X X X X X Координаты второго –
1 2 3 4 5 6 72952, 0,02, 530, 58, 4288, 1555, 297,X X X X X X X 8 0,59.X К первому кластеру относятся Днепропетровская, До-
нецкая, Николаевская, Одесская, Полтавская и Харьковская области. Результаты трех рассмотренных методов близки, что свидетельствует об адекватности эволюционного моделиро-вания. Также его преимуществом есть определение центров кластеров и формализация вычислительного процесса. Как было указано выше, такая технология может быть усовершен-ствованной.
Предложенный метод эволюционного моделирования, ба-зирующийся на использовании генетического алгоритма, эффективно функционирует при обработке массивов боль-шой размерности, поскольку в нем оптимально сочетаются целенаправленный поиск и элементы случайности, направ-ленные на выбивание целевой функции из локальных мини-мумов. Никаких предварительных условий для его использо-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
182
вания не требуется. Главным условием оптимизации вычис-лений есть правильная алгоритмизация расчета значений це-левой функции. Многовекторность процесса увеличения ско-рости алгоритма (для генетических алгоритмов это особенно необходимо) и его точности (поиска глобального минимума фитнесс-функции), а также его актуальность свидетельствуют о необходимости решения задачи оптимизации эволюционного метода.
Практические задания
6.1. Классическая кластеризация. Используя методы классического кластерного анализа, вы-
полнить кластеризацию 56 объектов, каждый из которых имеет 8 признаков (табл. 6.5). Определить информативные факторы. Сравнить точность результатов, наполнение кластеров, цен-тры кластеров и значения целевой функции.
Таблица 6.5. Начальные данные
№ 1X 2X 3X 4X 5X 6X 7X 8X 1 6 150 1,8 24 30 120 3,4 15 2 7 150 1,8 24 30 120 9,7 5 3 6 170 1,8 24 30 120 7,4 23 4 7 170 1,8 24 30 120 10,6 8 5 6 150 2,4 24 30 120 6,5 20 6 7 150 2,4 24 30 120 7,9 9 7 6 170 2,4 24 30 120 10,3 13 8 7 170 2,4 24 30 120 9,5 5 9 6 150 1,8 36 30 120 14,3 23 10 7 150 1,8 36 30 120 10,5 1 11 6 170 1,8 36 30 120 7,8 11 12 7 170 1,8 36 30 120 17,2 5 13 6 150 2,4 36 30 120 9,4 15 14 7 150 2,4 36 30 120 12,1 8 15 6 170 2,4 36 30 120 9,5 15

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
183
Продолжение табл. 6.5 № 1X 2X 3X 4X 5X 6X 7X 8X 16 7 170 2,4 36 30 120 15,8 1 17 6 150 1,8 24 42 120 8,3 22 18 7 150 1,8 24 42 120 8 8 19 6 170 1,8 24 42 120 7,9 16 20 7 170 1,8 24 42 120 10,7 7 21 6 150 2,4 24 42 120 7,2 25 22 7 150 2,4 24 42 120 7,2 5 23 6 170 2,4 24 42 120 7,9 17 24 7 170 2,4 24 42 120 10,2 8 25 6 150 1,8 36 42 120 10,3 10 26 7 150 1,8 36 42 120 9,9 3 27 6 170 1,8 36 42 120 7,4 22 28 7 170 1,8 36 42 120 10,5 6 29 6 150 2,4 36 42 120 9,6 24 30 7 150 2,4 36 42 120 15,1 4 31 6 170 2,4 36 42 120 8,7 10 32 7 170 2,4 36 42 120 12,1 5 33 6 150 1,8 24 30 130 12,6 32 34 7 150 1,8 24 30 130 10,5 10 35 6 170 1,8 24 30 130 11,3 28 36 7 170 1,8 24 30 130 10,6 18 37 6 150 2,4 24 30 130 8,1 22 38 7 150 2,4 24 30 130 12,5 31 39 6 170 2,4 24 30 130 11,1 17 40 7 170 2,4 24 30 130 12,9 16 41 6 150 1,8 36 30 130 14,6 38 42 7 150 1,8 36 30 130 12,7 12 43 6 170 1,8 36 30 130 10,8 34 44 7 170 1,8 36 30 130 17,1 19 45 6 150 2,4 36 30 130 13,6 12 46 7 150 2,4 36 30 130 14,6 14 47 6 170 2,4 36 30 130 13,3 25 48 7 170 2,4 36 30 130 14,4 16

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
184
Продолжение табл. 6.5 № 1X 2X 3X 4X 5X 6X 7X 8X 49 6 150 1,8 24 42 130 11 31 50 7 150 1,8 24 42 130 12,5 14 51 6 170 1,8 24 42 130 8,9 23 52 7 170 1,8 24 42 130 13,1 23 53 6 150 2,4 24 42 130 7,6 28 54 7 150 2,4 24 42 130 8,6 20 55 6 170 2,4 24 42 130 11,8 18 56 7 170 2,4 24 42 130 12,4 11
6.2. Сравнительный анализ результатов. По значениям целевой функции выполнить сравнитель-
ный анализ эффективности каждого из классических методов кластеризации и эволюционного метода.
6.3. Эволюционная кластеризация. Используя эволюционный метод кластеризации, выпол-
нить кластеризацию объектов (табл. 6.5). Осуществить про-верку алгоритма эволюционного метода на устойчивость, ис-пользуя методы регуляризации данных. Исследовать точ-ность результата как зависимости от параметров генетическо-го алгоритма.
6.4. Кластеризация с помощью растущих пирамидаль-
ных сетей. По данным табл. 6.6 сформировать растущую пирами-
дальную сеть. Выполнить процесс формирования понятий и сформировать обобщенную модель исследуемых классов объ-ектов. На тестовых примерах выполнить распознавание обра-зов.
Таблица 6.6
Признаки объектов 1X 2X 3X 4X 5X
6X
1O 1 2 A 2 3 C Объекты
2O 1 4 B 3 2 C

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
185
Продолжение табл. 6.6 Признаки объектов
1X 2X 3X 4X 5X 6X
3O 3 4 A 2 4 D
4O 2 2 B 2 3 D
5O 1 2 B 2 3 D
6O 3 4 B 3 2 C
7O 1 4 B 3 2 C
Объекты
8O 1 4 A 2 3 D
Контрольные вопросы и задачи для самопроверки
1. Какие основные группы образовывают классические ме-тоды кластеризации?
2. Какие характеристики являются главными при опреде-лении кластеров?
3. Какие особенности определяют применение метода одиночной связи?
4. Какие недостатки сопровождают процесс кластериза-ции методами полной и средней связи?
5. Какая цель преследуется при применении метода Уорда? 6. Опишите особенности реализации классического алго-
ритма итеративных методов группирования. 7. Какое главное отличие применения иерархических аг-
ломеративных методов и итеративных методов группирова-ния?
8. Опишите методы выбора начального разбиения про-странства данных в иерархических методах группирования.
9. Опишите типы итерационных процессов, которые при-меняются в иерархических методах группирования.
10. Дайте характеристику статистическим критериям, ко-торые применяются в иерархических методах группирова-ния.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
186
11. Какие кластеры – монотетические или политетические образовываются при работе иерархических, агломеративных и итеративных методов?
12. Для решения каких задач используют растущие пирами-дальные сети?
13. В чем состоит гипотеза компактности? 14. Какие метрики используют при кластеризации и в чем
их особенности? 15. Какие проблемы сопровождают процесс кластериза-
ции функционально связанных объектов? 16. Укажите преимущества применения растущих пира-
мидальных сетей при решении задачи кластеризации. 17. Какие проблемы сопровождают процесс решения за-
дачи кластеризации с помощью алгоритма Forel? 18. Опишите сущность гипотезы лямбда-компактности. 19. Какие особенности сопровождают решение задачи
кластеризации с помощью алгоритма KRAB ? 20. Для решения каких задач используются растущие пи-
рамидальные сети? 21. Укажите преимущества и недостатки растущих пира-
мидальных сетей в сравнении с нейронными сетями. 22. Какая парадигма лежит в основе эволюционного мето-
да кластеризации? 23. Приведите алгоритм эволюционного метода кластериза-
ции. 24. Какие проблемы и перспективы сопровождают эволю-
ционный метод кластеризации?
Темы рефератов и расчетно-графических работ
1. Особенности реализации и применение „Вроцлавской таксономии”.
2. Сущность и алгоритм метода корреляционных плеяд Терентьева.
3. Метод Уорда для решения задачи кластеризации. 4. Отличия алгоритмов средней связи Кинга и близкой связи.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
187
5. Аналитический обзор иерархических агломеративных методов кластерного анализа.
6. Сравнительный анализ эффективности иерархических агломеративных методов на примере решения задачи класте-ризации (на выбор студента).
7. Исследование устойчивости метода одиночной связи при преобразовании начальных данных.
8. Сравнительный анализ применения вариантов метода средней связи на примере решения задачи кластеризации (на выбор студента).
9. Способы сравнения иерархических агломеративных ме-тодов кластеризации.
10. Выполнить алгоритмизацию иерархического метода группирования с разными вариантами разбиения начального множества данных, типами итераций, статистическими кри-териями и сравнить их результаты на примере решения ти-пичной задачи кластеризации.
11. Выполнить исследование работы иерархических мето-дов группирования методом Монте-Карло.
12. Осуществить реализацию алгоритма кластеризации на основе факторного анализа и выполнить сравнительный ана-лиз результатов его применения с результатами, полученны-ми другими методами.
13. Выполнить разработку и анализ эффективности моно-тетического алгоритма кластеризации.
14. Показать преимущества растущих пирамидальных се-тей при решении задачи кластеризации образов в сравнении с эвристическими методами.
15. Выполнить реализацию алгоритмов Forel и Forel-2 и сравнительный анализ на примере решения прикладной зада-чи.
16. Осуществить реализацию модуля для формирования растущей пирамидальной сети.
17. Разработать алгоритм формирования понятий по сформированной пирамидальной сети и реализовать его.
18. (Задача проблемного характера). Разработать и реали-зовать фитнесс-функцию для определения модального зна-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
188
чения плотности данных в эволюционном методе кластери-зации.
Темы для самостоятельного
изучения 1. Эффективность применения формулы Ланса и Вильям-
са для определения расстояния между кластерами. 2. Применение факторного анализа для кластеризации. 3. Технологии определения оптимального числа класте-
ров. 4. Изучить особенности и осуществить анализ алгоритма
SKAT, предназначенного для решения задачи кластеризации с “неустойчивыми” таксонами.
5. Выполнить программную реализацию и анализ эффек-тивности функционирования алгоритма BIGFOR.
6. Кластеризация с помощью нейросетей. Формализирoванные постановки задач для нейросетей с раз-ными архитектурами и принципами функционирования.
7. Кластеризация в неметрических пространствах. 8. Аспекты кластеризации объектов с признаками, кото-
рые имеют функциональные зависимости. 9. Применение растущих пирамидальных сетей к анализу
непрерывной информации.
Литература
Основные источники 1. Мендель І.Д. Кластерный анализ. - М.: Финансы и стати-
стика, 1988. - 176 с. 2. Факторный, дискриминантный и кластерный анализ/ Кем
Дж.-О., Мьюллер Ч.У., Клекка У.Р. и др. – М.: Финансы и ста-тистика, 1989. - 215 с.
3. Люгер Ф. Дж. Искусственный интеллект. Стратегии и методы решения сложных проблем. - М.: „Вильямс”, 2003. - 864 с.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
189
4. Гайдышев І. Анализ и обработка данных: специальный справочник. - Спб.: Питер, 2001. - 752 с.
5. Загоруйко Н.Г. Методы распознавания и их применение. - М.: Сов. радио, 1972. - 216 с.
6. Гладун В.П. Планирование решений. - К.: Наук. думка, 1987. - 186 с.
7. Снитюк В.Е. Эволюционная кластеризация сложных объектов и процессов // Bulgaria, Varna. Proc. XI-th Int. Conf. "Knowledge-Dialogue-Solution”, 2005. - P. 232-237.
Дополнительные источники
1. Ту Дж., Гонсалес Р. Принципы распознавания образов. - М.: Мир, 1978. - 411 с.
2. Дюран Б., Оделл П. Кластерный анализ. - М.: Статистика, 1977. - 128 с.
3. Фор А. Восприятие и распознавание образов. - М.: Ма-шиностроение, 1989. - 272 с.
4. A.N. Gorban, Zinovyev A.Yu. Method of Elastic Maps and its Applications in Data Visualization and Data Modeling // Int. Journal of Computing Anticipatory Systems, CHAOS. - 2002. - Vol. 12. - P. 353-369.
5. Фогель Л., Оуенс А., Уолш М. Искусственный интеллект и эволюционное моделирование. - М.: Мир, 1969. - 230 с.
6. Плюта В. Сравнительный многомерный анализ в эконо-метрическом моделировании. - Москва: Финансы и статис-тика, 1989. - 175 c.
7. Kohonen Т. Self-organization and associative memory. - New-York, 2d. ed., Springer Verlag, 1988.
8. Гладун В.П. Растущие пирамидальные сеты // Новости искусственного интеллекта. - 2004. - № 1. - С. 30-40.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
190
Глава 7
Восстановление информации
Нас этот заменит и тот –
Природа не терпит пустот. Андрей Вознесенский
Основные понятия и сроки
Методы оптимизации Множественная линейная рег-рессия
Идентификация Cмещенность оценки Мультиколлинеарность Гетероскедастичность Метод главных компонент Корреляция Функция плотности вероятно-сти
Метод наименьших квадратов
Адекватность модели Основы программирования Современные научные и практические исследования ба-
зируются на обработке текущей и ретроспективной инфор-мации. От того, насколько она является качественной (ин-формативной, точной, достоверной и т.п.), зависит точность результатов. Особый интерес представляет ситуация, когда часть данных отсутствует. Это возможно из-за отказов обору-дования, потери информации по техническим причинам, а также субъективных обстоятельств.
Задача восстановления пропусков имеет несколько вари-антов постановки, что определяется структурой пропущен-ных данных. В частности, пропуски могут быть среди значений входных факторов, результирующих характеристик, входных факторов и результирующих характеристик одновременно, а также среди значений признаков определенного объекта, где такие факторы и характеристики явным образом не выделены.
Методы, которыми решаются задачи восстановления про-пусков в данных, тоже имеют свою классификацию. Рассматри-вают методы, базирующиеся на элементарных вычислениях, статистические методы, вероятностные методы, нейросете-вые, эволюционные методы. Определяя, какой метод приме-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
191
нять, необходимо знать особенности и ограничения его ис-пользования. Так, методы, которые базируются на элементар-ных вычислениях, рационально применять тогда, когда ко-личество пропусков незначительно. Полученные оценки, ча-ще всего, являются смещенными.
Статистические методы, чаще всего, применяют, если предполагается существование линейной зависимости между входными факторами и результирующими характеристика-ми. Необходимость априорных знаний о вероятностных ха-рактеристиках определяет аспекты применения вероятност-ных методов. Нейросетевые методы, в общем случае, позво-ляют обрабатывать разные структуры пропусков, но точность полученных оценок будет определяться информативностью и полнотой данных для обучения нейросетей, а также их ар-хитектурой и законами функционирования. Аспекты приме-нения нейросетей рассматривались в главе 2. Поскольку зада-ча восстановления пропусков имеет оптимизационный ха-рактер, то для ее решения предложено использовать эволю-ционные методы, интегрирующие в себе нейросетевую иден-тификацию и генетическую оптимизацию. Анализ результа-тов экспериментов указывает на сравнительно высокую точ-ность результатов. Недостатком является необходимость ис-пользования значительных вычислительных ресурсов.
7.1. Математическая постановка задачи вос-становления пропусков в таблицах данных
В общей постановке задача восстановления пропусков в таблицах данных является такой: Пусть 1 2( , ,..., )nX X X X – вектор входных факторов, 1 2( , ,..., )mY Y Y Y – вектор результи-рующих характеристик, p – количество экспериментов или пе-риодов ретроспективы, 1 1( ) p n m
ij i jA a – матрица исходных дан-
ных. Среди ее элементов есть пропуски, которые обозначены звездочками (табл. 7.1).
Предположим, что между входными факторами и резуль-тирующими характеристиками существуют зависимости
1 2( , ,..., ), 1, .i i nY F X X X i m (7.1)

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
192
Таблица 7.1. Структура исходной информации
№ 1X 2X 3X … 1nX nX 1Y 2Y … mY 1 11a 12a 13a … * 1na 1 1na 1 2na … 1n ma 2 21a 22a * … 2 1na 2na 2 1na * … 2n ma 3 31a * 33a … 3 1na 3na 3 1na 3 2na … * … … … … … … … … … … …
1p 11pa 12pa 13pa … 1 1p na * 1 1p na 1 2p na … 1p n ma p
1pa 2pa 3pa … 1pna p na 1p na 2p na … p n ma Тогда задача восстановления пропусков в данных состоит
в поиске
*
min ( ) ,Y F X (7.2)
где 1 2( , ,..., )mF F F F и 1 2( , ,..., )mY Y Y Y – векторы значений, которые получены по идентифицированным зависимостям и приведены в табл. 7.1, соответственно. Задачу (7.2) детализи-руем и перепишем в виде
21 2* 1 1
1min ( ( , ,..., )) ,p m
i i iij j n
i jY F X X X
pm
(7.3)
или
^
2
* 1 1
1min ( )) .p m
ij iji j
Y apm
(7.4)
Если предположить, что зависимости (7.1) линейные, т.е.
0 1 1 2 2 ... ,i i i i in nY b b X b X b X (7.5) тогда задача восстановления пропусков состоит в поиске
*min ,Y BX (7.6)
где 1 1( ) ,p n mij i j nY a
11 1( ) ,m n
ij i jB b 1 1( ) .p n
ij i jX a Решение задач (7.2)–(7.5) имеет первый этап, который, в
общем случае, состоит в идентификации зависимостей iF , 1, .i m Заметим, что в задаче восстановления пропусков в

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
193
таблицах данных процедуры идентификации и оптимизации итеративно повторяются.
7.2. Эвристические методы обработки некомплектных данных
Выполним анализ методов восстановления утраченных данных, применяемых в большинстве случаев. Матрица, строка или столбец, имеющие пропуски данных, называются некомплектными.
1. Метод заполнения средним значением. Согласно этому методу отсутствующее значение на пе-
ресечении i -ой строки и j -го столбца рассчитывается по формуле:
*
1*
1 ,
ij
p
ij iji
a
a aq
(7.7)
где q – количество заполненных элементов в j -м столбце. Преимуществом метода является простота. Недостатки: в од-ном столбце может быть большое количество пропусков и все они будут заполнении одинаковыми значениями; не учиты-вается связь некомплектной строки с другими строками, что приводит к смещению и недостоверной оценке неизвестного значения. Этот вывод справедлив и для случая осуществления перерасчета с учетом каждого заполненного пропуска.
2. Метод исключения некомплектных строк. Применяется в случае незначительного количества про-
пусков. Метод является простым, но изъятие данных увели-чивает энтропию прогнозных значений и ведет к смещенно-сти параметров модели.
3. Метод подстановки. Метод имеет несколько модификаций. Рассмотрим одну
из них. Предположим, что на пересечении i -ой строки и j -го столбца есть отсутствующее значение. Тогда, среди всех дру-гих строк выбираем те, в которых только в j -м столбце про-пуск, или строки, которые являются некомплектными. Нахо-дим их расстояние до целевой строки по формуле

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
194
1
2 2
1
( ( ) ) ,n m
ki kl illl i
d a a
1, ,k Z (7.8)
где Z – количество строк, которые определяются вышеука-занным условием. Упорядочиваем значения kd по убыванию и задаем некоторое число 0d . Среди всех kd , 1, ,k Z выби-раем первые ,h для которых kd d . Находим значение про-пуска
11
1 1
11 .1
1
hh
ljlj lll li
ij h h
ll l li
aa Cda
Cd
(7.9)
Идея метода базируется на гипотезе существования зави-симостей между факторами, что, чаще всего, не соответствует действительности. Значительные вычислительные затраты уменьшают и так низкую эффективность метода, поскольку для адекватных вычислений расстояний между строками данные необходимо нормировать.
4. Метод множественной линейной регрессии. Применяется в предположении, что зависимость (7.1) яв-
ляется линейной. Для ее идентификации используют только комплектные данные и с использованием МНК получают (7.5). Очевидно, что в дальнейшем зависимости (7.5) исполь-зуются для восстановления пропусков, но адекватно это мож-но делать только в случае одного пропуска среди значений строки 1 2( , ,..., , )i i i
n iX X X Y . Если таких пропусков два и больше, то задача решается при дополнительных предположениях и ограничениях. Метод требует выполнения ряда предусловий и проверок входных факторов на мультиколлинеарность, ге-тероскедастичность, автокорреляцию и применения моди-фицированных версий МНК (см. главу 1).
5. Метод множественной нелинейной регрессии. Алгоритм метода приведен в главе 1. В отличие от ли-
нейной регрессии его применяют только в случае пропуска значений результирующей характеристики.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
195
7.3. Восстановление пропусков значений зависимой переменной
Рассмотрим случай, когда проводится активный экспери-мент и значения факторов 1 2( , ,..., )nX X X X заданы исследо-вателем, а Y – зависимая от этих факторов переменная. Оче-видно, что тогда пропусков среди значений входных факто-ров намного меньше, чем среди значений результирующей характеристики.
5. Метод Бартлетта заполнения пропусков. Предположим, что пропущенные значения есть только
среди значений результирующей характеристики Y и стро-ки, которые им отвечают, находятся вверху таблицы исход-ных данных. Каждый пропуск ,iy 01, ,i m заполним началь-ными значениями .iy Построим матрицу Z сопутствующих значений переменных пропусков. По определению i -я сопут-ствующая переменная пропусков является индикатором i -го пропущенного значения, то есть всегда есть ноль, за исклю-чением случая, если пропущено i -е значение, и тогда она равняется единице. Первая строка матрицы Z −
1 (1,0,0,...,0),Z 0m -я строка –0
(0,0,...,1).mZ Строки, начиная с
0 1m до n -ой, равны (0,0,...,0). Таким образом, имеем выра-жение
0
1
211 12 1 1
21 22 2 2
1 2
1 0 0 ... 00 1 0 ... 0...... ... ... ... ... ......0 0 0 ... 1
... ... ... ... ...0 0 0 ... 0
... ...... ... ... ... ...0 0 0 ... 0
p
p
m
n n np p
p
x x xx x x
x x x
0
0
1
21
2
1
...
,...
...
m
mn
n
yy
y
y
y
или в матричном виде .Y X Z (7.10)

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
196
В модели (7.10) 1 2( , , , )Тn – вектор остатков, которые
являются независимыми, одинаково распределенными, с ну-левым средним и одинаковой дисперсией, – оцениваемый параметр – вектор длиной .p
Считая, что выполняются все предпосылки применения МНК, классическая оценка будет такой (Y есть комплект-ным):
1( ) .x x x y (7.11) Для каждой задачи согласно МНК целевая функция
0
0
2 2
1 1
( , ) ( ) ( ) .m n
i i i i i ii i m
y x z y x z
(7.12)
Необходимо найти ,
min ( , ).
Используя определение матрицы Z из (7.12), получим
0
0
2 2
1 1
( , ) ( ) ( ) .m n
i i i i ii i m
y x z y x
(7.13)
Предположим, что – оценка, полученная по МНК по
формуле (7.11) для существующих значений ,Y то есть по по-следним 0m n m строкам. Она минимизирует вторую сум-
му в выражении (7.13). Если при
положить
01 2( , , , ) ,m где ,ii iy x
01, ,i m то минимизиру-ется и равняется нулю первая сумма в (7.13), получим функ-цию
0
2
1
( , ) ( ) .n
i ii m
y x
Таким образом, ( , )
минимизирует ( , ) и является оценкой МНК, полученной по модели (7.10). Уравнение (7.13) означает также, что точечная оценка МНК отсутствующего значения ,iy то есть
ii x
, есть i iy или: прогноз i -го
пропущенного значения по МНК является начальным значе-нием для i -го пропуска минус коэффициент для сопутст-вующей переменной i -го пропуска.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
197
Известны два способа инициализации пропущенных зна-чений: по первому из них они равняются нулю, по второму– являются средним известных значений. К преимуществам ме-тода относят его неитеративность; если структура пропусков является вырожденной, то результат отсутствует.
7. Resampling-метод. Метод восстановления пропусков resampling является
разновидностью известного метода “bootstrap”, предложенно-го американским статистиком Бредли Эфроном. Его сущ-ность состоит в многократной обработке разных частей одних и тех же данных, что позволяет осуществит их разностороний анализ и сопоставить полученные результаты.
Предположим, что данные и пропуски имеют ту же структуру, что и для метода Бартлетта. Применение метода resampling может быть выполнено двумя способами:
Resampling–1. Шаг 1. Формируем матрицу полных наблюдений H
1 2( , , , , ),pX X X Y количество строк в которой равно 0 .m Шаг 2. Случайным образом выбираем j -ю строку из мат-
рицы H и заменяем i -ю строку начальной матрицы, 0 01, 2, , .i m m n Эта строка может выбираться случайно
или по порядку, начиная с 0( 1)m -й. Шаг 3. Если все пропуски заполнены, то по МНК находим
коэффициенты регрессионного уравнения ,k 0, ,k p в про-тивном случае выполняем переход на шаг 2.
Шаг 4. Если получено r векторов 0 1( , , , ),q q q qp
1, ,q r то находим средние значения коэффициентов регрес-
сионной модели: 1
1 ,r
qk k
qr
0, .k p
Resampling–2. Шаг 1. По матрице H строим регрессионную модель и на-
ходим оценки коэффициентов ,i 0,i p . Шаг 2. Рассчитываем оценку iY по регрессионной модели
для 01, .i m

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
198
Шаг 3. Находим ошибки ,ii iY Y 01, .i m Шаг 4. Для каждого пропуска, подставляя значения сопут-
ствующих переменных 1 2, , , pX X X в полученное регресси-
онное уравнение, находим оценку ,iY 0 1, .i m n Шаг 5. Значения, которыми заменяют пропуска, получаем
по формуле: ,ii iY Y 0 ,i m n где i выбирают случайным образом из результатов шага 3.
Шаг 6. По данным, полученным после заполнения, строим регрессионную модель и находим оценки коэффициентов
i , 0, .i p Шаг 7. Аналогичен шагу 4 из resampling-1. Преимуществом метода resampling является полное ис-
пользование исходной информации, вместе с тем ее повтор-ное использование уменьшает информативность данных.
7.4. Локальные методы восстановления пропусков
8. Алгоритм ZET Сущность алгоритма состоит в том, что каждое пропу-
щенное значение оценивают по „компетентной” матрице, ко-торая состоит из определенного числа строк и столбцов ис-ходной матрицы. Пропущенное значение в строке находят, используя вычисление расстояний, в столбце – вычисление коэффициентов корреляции. Окончательную оценку опре-деляют, усредняя предыдущие оценки с весовыми коэффи-циентами, значения которых определяются некоторыми па-раметрами.
Шаг 1. Выполним нормирование значений матрицы A по
формуле ' ij jij
j
a aa
, где ja – среднее значение j -го столбца,
j – среднеквадратическое отклонение для комплектных дан-ных.
Шаг 2. Предположим, что *.ija Зададим коэффициент влияния компетентности на результат прогнозирования.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
199
Шаг 3. Находим расстояния от всех комплектных строк матрицы A до i -й строки по формуле:
1
2 2
1
( ( ) ) , 1, , .n m
ki kl illl j
d a a k p k i
(7.14)
Шаг 4. Определяем q строк, для которых kid будет наи-меньшими, из них и i -й строки формируем матрицу qA (поря-док размещения строк сохраняется, i -я строка становится ii - й).
Шаг 5. Находим модули коэффициентов корреляции всех столбцов матрицы qA с j -м столбцом
1
2 2
1 1
1 ( )( ),
1 1( ) ( )
q
lj j lk kl
jk q q
lj j lk kl l
a a a aqr
a a a aq q
1, ,k n m k j . (7.15)
Шаг 6. Определим v столбцов, для которых значения jkr являются наибольшими, из них и j -го столбца формируем „компетентную” матрицу ,qvA при этом порядок размещения столбцов сохраняется, а j -й столбец становится jj -м. Таким образом, *.ii jja
Шаг 7. Вычисляем „компетентности” строк ,plk 1, ,l q как
величины обратно пропорциональные расстояниям до стро-ки, которая содержит отсутствующее значение
1 .1
pl
l ii
kd
Шаг 8. Вычисляем „компетентности” столбцов ,clk 1,l v ,
как величины прямо пропорциональные (или равные) моду-лям .jkr
Шаг 9. Для каждой i -й строки, 1, ,i q и ii -й строки по мето-ду МНК находим уравнение парной линейной регрессии
ii i i ia k a b

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
200
и, приравнивая ,i i jja a находим оценку пропущенного значе-
ния pia , 1, .i q
Шаг 10. Аналогичен шагу 9, но для столбцов находим оценку
cja , 1,j v .
Шаг 11. Для компетентной матрицы находим прогнозные величины для строки и столбца
1
1
( ),
( )
q p pl lp l
qp
ll
a ka
k
1
1
( ).
( )
v с cl lc l
vcl
l
a ka
k
Шаг 12. Находим пропущенное значение 1 ( ).2
p с
ija a a
Шаг 13. Окончание алгоритма. Алгоритм ZET применяется в предположении о выполне-
нии 3-х гипотез: избыточности, аналогичности и локальной компетентности, согласно которым предполагают, что в таб-лицах данных есть подобные строки и зависимые столбцы; если пара объектов имеет подобные значения ( 1n )-го пара-метра, то и значения n -го параметра подобны; нет смысла использовать для заполнения отсутствующего пропуска всех строк и столбцов матрицы, а достаточно брать только их „компетентную” часть.
К недостаткам алгоритма ZET можно отнести определен-ный „волюнтаризм” исследователя, который состоит в субъ-ективном определении размеров „компетентной” матрицы и коэффициента „компетентности”, что влияет на присутствие шумового эффекта при прогнозировании пропущенного значения и точность вычислений результата.
9. Алгоритм Zetbraid. В отличие от алгоритма ZET, в Zetbraid реализована идея
постепенного добавления в „компетентную” матрицу строк и столбцов. Сущность алгоритма состоит в специфическом под-счете расстояний между строками и столбцами.
Расстояние между строками вычисляем по формуле

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
201
2
1
( ) ,n
ij k ik jkk
r b a a
где kb весовой коэффициент, значение которого зависит от того, входит ли i -й столбец в „компетентную” матрицу.
При вычислении коэффициентов ,kb 1, ,k n соблюдают-ся три принципы:
1. Все весовые коэффициенты столбцов, которые входят в „компетентную” матрицу, равны.
2. Все весовые коэффициенты столбцов, которые не вхо-дят в „компетентную” матрицу, равны.
3. Сумма весовых коэффициентов столбцов, которые вхо-дят в „компетентную” матрицу, разделенная на сумму весо-вых коэффициентов, не входящих в „компетентную” матри-цу, является константой (параметр алгоритма).
Если из n столбцов p принадлежат „компетентной” мат-рице, то весовой коэффициент столбца
1, если ,
1 ( 1), nw nC
p
столбец не принадлежит "компетентной" матрице
в противном случае.
Для нахождения расстояния между столбцами необходимо строить уравнение линейной регрессии. Пусть
1 2( , ,..., )mX x x x и 1 2( , ,..., )mY y y y – столбцы, тогда необходимо получить уравнение .y a bx
Для нахождения коэффициентов a и b минимизируем функцию
2
1
( , ) ( ) ,m
i i ii
D D a b b y a bx
(7.16)
где весовые коэффициенты строк ,ib 1, ,i m находятся анало-гично весовым коэффициентам столбцов, то есть

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
202
1, если ,
1 ( 1), W mC
q
столбец не придналежит "компетентной" матрице
в противном случае,
где q – количество строк, принадлежащих „компетентной” мат-рице.
Важной задачей остается подбор размера „компетентной” матрицы. Критерием оценки адекватности этой матрицы есть оценка качества прогнозирования неизвестного элемента. Та-ким образом, при построении „компетентной” матрицы строки и столбцы добавляются до тех пор, пока значение критерия (абсо-лютное отклонение точного и прогнозируемого значения) уменьшается.
Известны два варианта расчетов этого критерия. Согласно первому, методу „креста”, по уравнению линейной регрессии рассчитывают все известные значения строки и (или) столбца, содержащие неизвестный элемент и находят среднюю ошиб-ку. Эта средняя ошибка и является оценкой прогнозирования данной „компетентной” матрицы.
Второй вариант, дисперсионный метод, состоит в вычис-лении дисперсии прогнозирования неизвестного элемента. Для этого по уравнению линейной регрессии для каждого столбца прогнозируют значение неизвестного элемента и находят дисперсию этих ( 1)n -го прогнозов, которая и является ис-комой оценкой.
„Компетентная” матрица по построению является квад-ратной или количество строк и столбцов отличаются на еди-ницу. Для того, чтобы размерность матрицы могла быть про-извольной, но адекватной, выполним такие шаги:
Шаг 1. Находим наиболее близкую строку, которая не вхо-дит в „компетентную” матрицу, к целевой строке. Если до-бавление этой строки не ухудшает ее оценку, то прибавляем ее к “компетентной” матрице.
Шаг 2. Аналогичен шагу 1 для столбца. Шаги 1 и 2 повторяют до момента ухудшения оценки
“компетентной” матрицы и для строки, и для столбца. Для того, чтобы избежать ошибок при начальном по-
строении „компетентной” матрицы, на первых K шагах

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
203
(обычно, 6K ) прибавляют строки и столбцы в „компетент-ную” матрицу, не считаясь с ее оценкой.
7.5. Итерационный метод главных компонент для данных с пропусками
Методы, которые представляют данное направление, раз-работаны учеными Красноярской школы нейроматематики под руководством профессора А.Н. Горбаня. Их главная идея заключается в том, что набор точек, который является много-образием при наличии пропусков, позволяет строить линей-ные и нелинейные приближения – модели, с помощью кото-рых восстанавливают пропущенные значения. Результаты ал-горитмизации этих методов и экспериментальных проверок удостоверили достаточно высокую точность. Проведенные исследования указывают на удовлетворительное функциони-рование алгоритмов при 10-15% пропусков. В то же время, ма-тематические выкладки базируются на достаточно сильных предположениях о распределении исходных данных, гладко-сти функций и обусловленности матрицы начальных значе-ний. К недостаткам нужно также отнести сложность реализа-ции и верификации алгоритма.
Предположим, что задана прямоугольная таблица, клетки которой заполнены действительными числами, или символом @ , который означает отсутствие данных. Необходимо прав-доподобным образом восстановить отсутствующие данные. При более детальном рассмотрении возникают три задачи:
- заполнить пропуски в таблице; - отредактировать таблицу – изменить значение известных
данных так, чтобы наилучшим образом работали модели, кото-рые используются при восстановлении пропущенных данных;
- построить по таблице вычислительную процедуру, ко-торая будет заполнять пропуски в текущей строке данных (в предположении, что данные в этой строке связаны теми же соотношениями, что и в строках таблицы).
Для решения этих задач предлагается использовать метод последовательного приближения множества векторов данных (строк таблицы) прямыми. Основная процедура – поиск наи-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
204
лучшего приближения таблицы с пропусками ( )ijA a матрицей вида .i j jx y b Необходимо найти наилучшее приближение A матрицей вида i j jx y b по МНК
2
,@
( ) min.
ij
ij i j ji j
a
a x y b
(7.17)
Если два из трех векторов ,i jx y или jb фиксированы, то тре-тий легко находится по явным формулам. Задаваясь практи-чески произвольными начальными приближениями для двух из них, ищем значение третьего, далее объявляем неизвест-ным второй вектор из трех, находим его значение, наконец, на-ходим третий и т.д. (по кругу) – эти простые итерации, очевид-но, сходятся. Более того, по фиксированному значению ix , можно сразу по явным формулам вычислить значения jy и jb – таким образом расщепление проводится не на три, а на две составляющих.
При фиксированных векторах jy и jb значения ix , ми-нимизирующие (7.17), определяются из равенства / 0iФ x таким образом:
2
@ @
( ) ( ) .
ij ij
i ij j j jj j
a a
x a b y y
При фиксированном векторе ix значения jy и jb , мини-мизирующие (7.17), определяются из двух равенств / 0jФ y и / 0jФ b таким образом. Для каждого j имеем систему из двух уравнений относительно jy и jb
01 00
11 10 1
j j jj j o
j j jj j
y A b A B
y A b A B
, где
@
,
ij
j k lkl i
ia
A x
@
,
ij
j kk ij i
ia
B a x
0..1, 0..1.k l Находя из первого уравнения jb и подставляя полученное
значение во второе уравнение, получим

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
205
101 0
00
1011 01
00
,
jj j
j
j jj j
j
AB BAyAA AA
0 01
00
.j j
jj j
B y Ab
A
Начальные значения: y – случайный вектор, нормированный к 1 (т.е. 2 1j
jy ),
@
1 ,
ij
j ijij
a
b an
где @
1,
ij
ji
a
n
(число известных данных в j -м
столбце), т.ее jb определяется как среднее значение столбца. Критерием остановки является незначительность относи-
тельно улучшения / ,Ф Ф где Ф – полученное за цикл уменьшение значения Ф , а Ф – текущее значение. Второй критерий – достаточно малое значение Ф . Окончательно: процедура останавливается, если /Ф Ф или Ф для некоторых , 0 .
Последовательное исчерпание матрицы .A Для данной матрицы A ищем наилучшее приближение
матрицей 1P вида .i j jx y b Далее, для 1A P находим наи-лучшее приближение такого же вида 2P и т.д. Контроль ведет-ся, например, по остаточной дисперсии столбцов.
Q -факторное заполнение пропусков есть их определение из суммы Q полученных матриц вида ,i j jx y b Q -факторный „ремонт” таблицы – замена ее на сумму Q полу-ченных матриц вида .i j jx y b
Пусть в результате описанного процесса построена после-довательность матриц qP вида i j jx y b ( q q q
q i j jP x y b ), исчер-пывающая начальную матрицу A с заданной точностью. Опишем операцию восстановления данных в строке ja с про-пусками, поступающей на обработку (некоторые @ja ). Для каждого q по заданной строке определим число ( )qx a и век-тор q
ja

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
206 0j ja a ( @);ja
1 0 1 1 1 2
@ @
( ) ( ) ( ) ;
j j
j j j jj j
a a
x a a b y y
1 0 1 1 1( )j j j ja a b x a y ( @);ja ....... (7.18)
1 2
@ @
( ) ( ) ( ) ;
j j
q q q q qj j j j
j ja a
x a a b y y
1 ( )q q q q qj j j ja a b x a y ( @);ja
....... Здесь многообразие M – прямая, координаты точек на M
задаются параметрическим уравнением ,j j jz ty b а проек-ция Pr ( )M a определяется согласно (7.18)
Pr( ) ( ) ;j ja t a y b
2
@ @
( ) ( ) ( ) .
j j
j j j jj j
a a
t a a b y y
(7.19)
Для Q - факторного восстановления данных положим
1
( )Q
q q qj j j
qa x a y b
( @).ja (7.20)
Если пропуски отсутствуют, то описанный метод приво-дит к обычным главным компонентам – сингулярному разло-жению начальной таблицы данных. В этом случае, начиная с
2,q q qq i jP x y ( 0b ). В общем случае, это не так и центри-
рование для данных с пропусками является непригодным. Также следует учесть, что при отсутствии пропусков по-
лученные прямые будут ортогональными, т.е., получим орто-гональную систему факторов (прямых). Исходя из этого, при неполных данных возможен процесс ортогонализации полу-ченной системы факторов, который заключается в том, что начальная таблица восстанавливается с помощью полученной

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
207
системы, после чего эта система перечитывается снова, но уже при полных данных.
7.6. ЕМ-алгоритм Алгоритм ЕМ базируется на максимизации математиче-
ского ожидания, чем и обосновывается его название – expectation-maximization approach, которое он получил в 1977 году. В алгоритме реализована итерационная процедура вычисления оценки максимального правдоподобия и состоит он из двух ша-гов:
Шаг 1. Множество данных неполной задачи и текущее значение вектора параметров используются для получения расширенного полного набора данных.
Шаг 2. Вычисляется новая оценка вектора параметров пу-тем максимизации функции логарифмического правдоподо-бия полного множества данных.
Шаги 1 и 2 повторяются до полной сходимости. Приведем математическую запись алгоритма ЕМ. Пусть r – полный вектор данных, которым он должен был
бы быть, но не является; ( )d d r – вектор неполных данных, который фактически наблюдается. Таким образом, векторы r и d являются элементами соответствующих пространств: r R , d D . Обозначим ( / )cf r – функцию плотности услов-ной вероятности r для данного вектора параметров . Отсюда следует, что функция плотности условной вероятности слу-чайной переменной d для данного вектора определяется следующим образом:
( )
( / ) ( / )D cR d
f d f r dr ,
где ( )R d – подпространство R , которое определяется равенст-вом ( )d d r .
Необходимо найти значение , которые максимизирует функцию логарифмического правдоподобия на неполных данных
( ) log ( / )DL f d .

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
208
Эта задача решается итеративным применением функций логарифмического правдоподобия на полных данных
( ) log ( / )C CL f r , которая является случайной переменной, поскольку отсутст-вующие данные являются неизвестными.
Если предположить, что ( )n значение вектора парамет-ров на n -й итерации, то на первом ее шаге находим матема-тическое ожидание ( , ( )) ( ( ))CQ n M L по ( )n . На втором шаге вычисляем максимум функции
( , ( ))Q n по в пространстве параметров таким образом, чтобы найти оценку вектора ( 1)n ( 1) arg max ( , ( 1))n Q n
.
Алгоритм начинается заданием некоторого начального значения (0) вектора параметров . Шаги алгоритма итера-тивно повторяются, пока различие между ( ( 1))L n и ( ( ))L n не станет меньшим некоторого заведомо малого заданного значения. Тогда работа алгоритма завершается.
Для понимания математических выкладок и нюансов ал-горитма ЕМ отсылаем читателя к учебникам по теории веро-ятностей и математической статистике.
7.7. Эволюционный метод восстановления пропусков
Предположим, что пропуски есть только среди значений входных факторов 1 2( , ,..., ),nX X X X результирующая харак-теристика Y одна и существует зависимость 1 2( ) ( , ,..., ).nY F X F X X X (7.21)
А.Н. Колмогоров и В.І. Арнольд доказали теорему о том, что каждая непрерывная функция n переменных, заданная на единичном кубе n - измеримого пространства, может быть представлена в виде

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
209
2 1
1 21 1
( , ,..., ) ( ) ,n n
pn q q p
q pf x x x h x
где функции ( )qh u непрерывные, а функции ( )pq px , кроме
того, еще и стандартные, т.е. не зависят от выбора функции f . В терминах теории нейронных сетей теорема указывает на
то, что любая непрерывная функция идентифицируется се-тью с одним, как минимум, скрытым слоем нейронов с нели-нейными функциями активации. Для идентификации (7.21) в качестве модели выберем прямосвязную нейросеть с порого-вым алгоритмом обратного распространения ошибки. В дальнейшем структура сети и ее элементный базис в экспе-риментах остаются постоянными.
Поскольку входные образы для обучения нейронной сети имеют пропуски значений, то необходимо решить задачу па-раметрической оптимизации. В качестве метода оптимизации предложено использовать генетический алгоритм. Для гаран-тирования его сходимости используем теорему (см. разд. 3), доказанную Р. Харти (R.E. Harti).
Если использовать бинарное представление решений и для формирования их популяции − элитный отбор, то теорема ука-зывает на сходимость ГА по вероятности.
Для работы ГА необходимо сформировать генеральную и выборочную совокупности хромосом-решений. Хромосома со-ставляется из фрагментов, которые отвечают пропускам в таб-лице данных:
пропуск 1, пропуск 2,...,пропуск .Xr К Данные в таблице без учета пропущенных значений нор-
мируем. Если активационной функцией будет выбрано гипер-болический тангенс, то нормирование рациональнее осуще-ствлять в отрезок [ 1;1]. Количество хромосом в генеральной совокупности определяется заданной точностью результата, в выборочной – исследователем. На следующем шаге формируем обучающую и контроль-ную последовательность для обучения нейросети. Предлага-ется все образы с пропусками считать элементами обучающей последовательности. Для контрольной последовательности их

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
210
использование является проблематическим, поскольку невоз-можно применять для верификации недостоверные или от-сутствующие значения. Соотношение мощности множеств образов обучающей и контрольной последовательности мо-жет быть разным, на что влияет соотношение количества об-разов с пропусками и без пропусков в начальной таблице.
Алгоритм восстановления пропусков (EvoGap) будет таким: Шаг 1. Инициализация maxK хромосом-решений обучаю-
щей последовательности. Шаг 2. 1.K Шаг 3. Обучение нейросети на точках обучающей после-
довательности, где значения пропусков заполнены значения-ми K -й хромосомы. При этом решается задача поиска
21 1
1
1min ( ) ,2
oP
i nK i nW iM a a
где W – матрица весовых коэффициентов нейросети, oP – ко-личество образов в обучающей последовательности.
Шаг 4. Вычисление целевой функции ГА (fitness-function) 2
1 11
1 ( ) ,2
CP
i nK i ni
G a a
где cP – количество образов контрольной последовательности. Если min ,KG G то переход на шаг 7.
Шаг 5. 1.K K Если max ,K K где maxK – количество эле-ментов в обучающей последовательности, то переход на шаг 6, иначе переход на шаг 3.
Шаг 6. Выполнение процедур кроссовера, мутации, опре-деление и отбор хромосом следующей эпохи. Переход на шаг 2.
Шаг 7. Окончание алгоритма. Пример 7.1. Для верификации эволюционного метода
проведено экспериментальное моделирование с использова-нием Matlab 7.0. В качестве начальных данных для моделирова-ния определены две выборки. Данные первой выборки генери-ровались искусственно, значение входных факторов имели равномерное распределение, а результирующая характеристи-ка получена по формуле
1
23Y X 2 1 2 32 4 7sin .X X X X Вто-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
211
рая выборка являлась данными официальной статистики на-ционального информационного центра энергетики США и со-держала данные с 1949 по 2004 год, которые включают произ-водство твердого топлива, ядерной и другой энергии, импорт нефти и других энергоносителей, экспорт угля, газа, кокса и электроэнергии, потребление твердого топлива, ядерной и дру-гой энергии, а также общее потребление.
Первая выборка насчитывала 25 образов, из которых 20 от-несено к обучающей последовательности и 5 – к контрольной. Моделирование проводилось для разного количества пропус-ков при неизменных других условиях. Так, количество итера-ций обучения нейронной сети было ограничено 50, а значе-ние целевой функции составило 10. При моделировании ус-тановлено, что такая точность достигнута не была, и процесс обучения прекращался из-за ограничения на количество ите-раций. Результаты приведены в табл. 7.2, где N – количество пропусков, NP – процентное соотношение количества про-пусков, F – значение целевой функции, Er – относительная погрешность (в процентах). Зависимость значения относитель-ной погрешности от количества пропусков представлена на рис. 7.4.
Статистическая информация, которая характеризует па-раметры энергетики США, состоит из 11 входных факторов, одной результирующей характеристики и насчитывает 40 об-разов. Из них 35 отнесено в обучающую последовательность и 5 – в контрольную. Количество итераций установлено равным 150, значение целевой функции − 1. На второй выборке итера-ции прекращались из-за достижения указанного значения ошибки. Максимального количества итераций, в отличие от первого случая, достигнуто не было. Результаты моделирова-ния приведены в табл. 7.3 и на рис. 7.5.
При моделировании для работы ГА использовалась выбо-рочная популяция из 20 элементов, количество эпох равня-лось 100. Время моделирования на компьютере Intel Pentium M 2,0 Ггц составило в среднем 30 минут и от количества про-пусков значимо не зависело. Полученные результаты свиде-тельствуют о достаточно высокой точности метода, которую можно еще и повысить, если увеличить количество итераций

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
212
обучения нейронной сети. Динамика относительной по-грешности, которая приведена на рис. 7.4 и рис. 7.5, характе-ризует пластичность метода, то есть способность нейросети к обобщению, и свидетельствует о том, что она возрастает при увеличении количества пропусков (до некоторой границы). Такая тенденция является необычной, ее объяснение требует дополнительных исследований.
Т а б л и ц а 7 . 2Р е з у л ь т а т ы э к с п е р и м е н т о в
N N P F E r3 0 5 0 , 0 0 1 4 7 4 1 , 0 2 82 8 4 6 , 6 7 4 6 3 0 , 0 92 6 4 3 , 3 3 4 1 7 0 , 0 8 12 4 4 0 , 0 0 1 6 4 0 , 0 3 32 2 3 6 , 6 7 4 4 3 0 , 0 8 82 0 3 3 , 3 3 7 7 6 0 , 0 1 51 8 3 0 , 0 0 1 4 1 0 0 , 2 8 41 6 2 6 , 6 7 1 3 1 7 0 , 2 6 61 4 2 3 , 3 3 2 5 7 0 , 0 4 91 2 2 0 , 0 0 1 1 5 7 0 , 2 3 61 0 1 6 , 6 7 1 0 5 6 0 , 2 0 9
8 1 3 , 3 3 3 3 5 0 , 0 6 56 1 0 , 0 0 2 0 5 0 , 0 4 44 6 , 6 7 5 5 4 0 , 1 0 93 5 , 0 0 1 3 8 0 , 0 2 72 3 , 3 3 1 2 1 0 , 0 2 61 1 , 6 7 2 4 8 0 , 0 5 3
Т а б л и ц а 7 .3Р е з у л ь т а т ы э к с п е р и м е н т о в
N N P F E r5 1 ,1 4 0 ,9 3 0 ,0 0 9 6
1 0 2 ,2 7 0 ,8 8 0 ,0 0 9 11 5 3 ,4 1 0 ,3 9 0 ,0 0 42 0 4 ,5 5 0 ,3 5 0 ,0 0 3 62 5 5 ,6 8 0 ,1 7 4 0 ,0 0 1 83 0 6 ,8 2 0 ,6 6 5 0 ,0 0 73 5 7 ,9 5 0 ,2 6 5 0 ,0 0 2 74 0 9 ,0 9 0 ,5 0 8 0 ,0 0 5 34 5 1 0 ,2 3 0 ,8 0 6 0 ,0 0 8 35 0 1 1 ,3 6 0 ,6 1 1 0 ,0 0 6 35 5 1 2 ,5 0 0 ,5 2 3 0 ,0 0 5 46 0 1 3 ,6 4 0 ,9 6 5 0 ,0 16 5 1 4 ,7 7 0 ,6 1 1 0 ,0 0 6 37 0 1 5 ,9 1 0 ,8 2 9 0 ,0 0 8 67 5 1 7 ,0 5 0 ,9 0 2 0 ,0 0 9 38 0 1 8 ,1 8 0 ,7 9 1 0 ,0 1 9 5
0,01
0,21
0,41
0,61
0,81
1,01
30 28 26 24 22 20 18 16 14 12 10 8 6 4 3 2 1
Отн
осит
ельн
ая
погр
ешно
сть,
%
Количество пропусков
Рис. 7.4. Динамика относительной погрешности

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
213
0,001
0,003
0,005
0,007
0,009
0,011
0,013
0,015
0,017
0,019
5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80
Отн
осит
ельн
ая п
огре
шно
сть,
%
Количество пропусков
Рис. 7.5. Динамика относительной погрешности Эволюционный метод восстановления пропусков в дан-
ных имеет ряд преимуществ. Так, его использование не тре-бует выполнения ограничений на исходную информацию. Таблица начальных данных может иметь произвольную раз-мерность и структуру пропусков. Перспективным является ис-следование эффективности использования нейросети с не-итеративными алгоритмами обучения. Необходимо выяснить влияние распределения значений факторов на точность вос-становления пропусков. Дополнительные исследования в ука-занных направлениях позволят сформировать методику восста-новления пропусков с использованием эволюционного подхода.
Практические задачи
7.1. Восстановление пропусков среди значений результи-рующей характеристики
Восстановить пропущенные значения среди данных, при-веденных в табл. 7.4, используя методы resampling-1, resampling-2 и метод Бартлетта. Сравнить полученные ре-зультаты. Для их контроля и верификации считать, что в таб-лице представлена зависимость
1 3 2 1 1 33 exp( ) sin( ).Y X X X X X X

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
214
Таблица 7.4
№ 1X 2X 3X Y 1 1 3 4 18,43013 2 3 2 4 37,02487 3 5 6 4 * 4 8 7 6 145,3585 5 5 4 3 46,35724 6 4 3 4 49,35724 7 5 4 5 * 8 3 4 2 19,75936 9 2 3 1 8,859402
10 5 4 3 46,35724 7.2. Восстановление пропусков среди значений входных
факторов Восстановить пропущенные значения среди значений
входных факторов. Исходные данные (табл. 7.5) являются ста-тистической информацией о производстве и потреблении разных видов энергии. Использовать эмпирические методы и эволюционное моделирование. Сравнить полученные резуль-таты.
Таблица 7.5
№ 1X 2X 3X 4X 5X 6X 7X 8X 9X Y 1 2,97 31,72 1,43 1,45 0,88 1,59 29,00 0,00 2,97 31,98 2 2,98 35,54 1,89 * 0,79 1,47 31,63 0,00 2,98 34,62 3 2,78 40,15 2,75 2,79 1,46 2,29 37,41 0,00 2,78 40,21 4 2,93 * 4,00 4,19 1,02 * 42,14 0,01 2,93 45,09 5 3,40 50,68 5,40 5,89 1,38 1,83 50,58 0,04 3,40 54,02
6 4,08 63,50 7,47 8,34 1,94 2,63 63,52 0,24 4,08 67,84 7 4,27 62,72 8,54 9,53 1,55 2,15 * 0,41 4,27 69,29 8 4,40 63,92 10,30 11,39 1,53 2,12 67,70 0,58 4,40 72,70 9 * 63,58 13,47 14,61 1,43 2,03 70,32 0,91 4,43 75,71 10 4,77 62,37 13,13 14,30 1,62 2,20 67,91 1,27 4,77 73,99 11 4,72 61,36 * 14,03 1,76 2,32 65,35 1,90 4,72 72,00 12 4,77 61,60 15,67 16,76 1,60 2,17 * 2,11 4,77 76,01 13 4,25 62,05 18,76 19,95 1,44 2,05 70,99 2,70 4,25 78,00 14 5,04 63,14 17,82 19,11 1,08 1,92 71,86 3,02 5,04 79,99 15 5,17 65,95 17,93 19,46 1,75 2,86 72,89 2,78 5,17 80,90

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
215
Продолжение табл. 7.5 № 1X 2X 3X 4X 5X 6X 7X 8X 9X Y 16 5,49 * 14,66 15,80 2,42 3,69 69,98 2,74 5,49 78,29 17 5,47 67,01 12,64 13,72 2,94 4,31 67,75 3,01 5,47 76,34 18 5,99 66,57 10,78 11,86 2,79 4,61 64,04 3,13 5,99 73,25 19 6,49 64,11 10,65 11,75 2,04 3,69 63,29 3,20 6,49 73,10 20 6,43 68,83 11,43 12,47 2,15 3,79 66,62 3,55 6,43 76,74 21 6,03 67,65 * 11,78 2,44 4,20 66,22 4,08 6,03 76,47 22 6,13 67,09 13,20 * 2,25 4,02 66,15 4,38 6,13 76,78 23 5,69 67,61 14,16 15,40 2,09 * 68,63 4,75 5,69 79,23 24 5,49 68,95 15,75 17,30 2,50 4,37 71,66 * 5,49 82,84 25 6,29 69,36 17,16 18,77 * 4,66 73,02 5,60 6,29 84,96 26 6,13 70,77 17,12 18,82 2,77 4,75 72,46 6,10 6,13 84,70 27 6,16 70,41 16,35 18,33 2,85 5,14 72,00 6,42 6,16 84,64 28 5,91 69,98 16,97 19,37 2,68 4,94 73,52 6,48 * 85,99 29 6,16 68,30 18,51 21,27 1,96 4,26 75,05 6,41 6,16 87,622 30 6,06 70,71 19,24 22,39 1,88 4,06 76,48 6,69 6,06 89,28 31 6,67 71,18 18,88 22,26 2,32 4,51 77,49 * 6,67 91,25 32 * 72,50 * 23,70 2,37 4,63 79,98 7,09 7,14 94,26 33 7,08 72,43 21,74 25,22 2,19 4,51 81,09 6,60 7,08 94,77 34 6,56 72,83 22,91 26,58 2,09 4,30 81,59 7,07 6,56 95,19 35 6,60 71,71 23,13 27,25 1,53 3,71 82,65 7,61 6,60 96,84 36 6,16 71,27 * 28,97 1,53 4,01 84,96 7,86 6,16 98,96 37 5,33 71,88 25,40 30,16 1,27 3,77 3,18 8,03 5,33 96,47 38 5,84 70,76 24,68 29,41 1,03 3,66 3,99 8,14 5,84 97,88 39 6,08 70,01 26,22 * 1,12 4,07 4,49 ,96 6,08 98,31
Контрольные вопросы и задачи для самопроверки
1. Выполните математическую постановку задачи восстанов-ления пропусков в данных.
2. Укажите на особенности ее решения, исходя из разной структуры пропусков.
3. В чем состоят особенности применения метода запол-нения средними значениями?
4. Приведите алгоритмические особенности реализации метода подстановки и укажите гипотезы, при которых воз-можно его адекватное применение.
5. Опишите преимущества и недостатки применения метода множественной регрессии для восстановления пропусков?

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
216
6. Укажите особенности применения метода множествен-ной нелинейной регрессии.
7. Каким образом осуществляется предварительная подго-товка данных в методе Бартлетта?
8. Приведите алгоритм метода Бартлетта. 9. Какие преимущества и недостатки имеет применение
метода Бартлетта при восстановлении пропусков? 10. Какие гипотезы лежат в основе метода resampling? 11. Определите особенности реализации алгоритма
resampling-1. 12. Какие преимущества в сравнении с алгоритмом
resampling-1 имеет resampling-2? 13. Какая матрица называется комплектной? 14. Приведите алгоритм метода ZET. 15. При каких предположениях возможно применение ме-
тода ZET? 16. Какая идея реализована в алгоритме Zetbraid? 17. По каким критериям оценивают адекватность „компе-
тентной” матрицы? 18. В чем состоит основное отличие в применении EМ-
алгоритма по сравнению с другими алгоритмами? 19. Приведите математическую запись EМ-алгоритма. 20. Какие главные идеи положены в основу итерационного
метода главных компонентов? 21. Укажите теоретические предпосылки, на которых ба-
зируется эволюционный метод восстановления данных. 22. Опишите особенности реализации эволюционного мето-
да. 23. Опишите алгоритмические особенности метода восста-
новления данных многообразиями.
Темы рефератов и расчетно-графических работ
1. Метод восстановления данных с помощью кривых. 2. Исследование тенденции к увеличению точности вос-
становления данных с ростом количества пропусков (до 60 %) в эволюционном методе.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
217
3. Определение точности восстановления пропусков раз-ными методами, если их количество составляет 50% всех зна-чений в таблице данных.
4. Исследование условий, наложенных на входные факторы, с целью определения процента пропусков, при которых точ-ность восстановления информации будет максимальной.
5. Исследование возможности эффективного применения методов линейной и нелинейной регрессии для восстановления пропусков среди значений входных факторов.
6. Исследование особенностей практической реализации ЕМ-алгоритма.
7. Определение особенностей применения метода Барт-летта и метода resampling.
8. Нейросетевое восстановление пропусков в данных. 9. Сравнительный анализ применения методов ZET и
Zetbraid. 10. Сравнительный анализ методов формирования ком-
плектной матрицы в алгоритме Zetbraid. 11. Реализация и исследования EМ-технологии восстанов-
ления данных.
Темы для самостоятельного
изучения 1. Нейронные сети встречного распространения – модели
восстановления пропусков в данных. 2. Применение кусочно-линейной регрессии для восстанов-
ления пропущенных значений. 3. Композиционное применение методов разных пара-
дигм при восстановлении пропущенных значений в табли-цах.
4. (Задача проблемного характера). Укажите на особенно-сти разработки и реализации метода восстановления пропу-щенных данных при условии, что пропуски есть и среди зна-чений входных факторов, и среди значений результирующей или результирующих характеристик; количество пропусков довольно значительно; существует предположение о нели-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
218
нейности связи между входными факторами и результирую-щими характеристиками.
5. (Задача проблемного характера). Можно ли утверждать о том, что оценки пропущенных значений нестатистически-ми методами имеют их свойства: несмещенность, содержа-тельность и эффективность.
6. (Задача проблемного характера). Можно ли и если мож-но, то каким образом применить эволюционное моделирова-ние для оптимизации оценок пропущенных значений, полу-ченных разными методами на основании разных парадигм?
Литература
Основные источники
1. Злоба Е., Яцкив І. Статистические методы восстановления
пропущенных меченный // Computer Modelling & New Technologies. - 2002. - Vol. 6. - № 1. - P. 51-61.
2. Литтл Р. Дж. А., Рубин Д.Б. Статистический анализ дан-ных с пропусками. - М.: Финансы и статистика, 1991. - 336 с.
3. Айвазян С.А., Енюков І.С., Мешалкин Л.Д. Прикладная ста-тистика. Исследование зависимостей. - М.: Финансы и стати-стика, 1985. - 487 с.
4. Эфрон Б. Нетрадиционные методы многомерного стати-стического анализа. - М.: Финансы и статистика, 1988. - 264 с.
5. Дрейпер Н., Смит Г. Прикладной регрессионный анализ. Т. 1,2. - М.: Машиностроение, 1988. - 352 с.
6. Загоруйко Н.Г. Методы распознавания и их применение. - М.: Сов. радио, 1972. - 216 с.
7. Россиев А.А. Моделирование данных при помощи кри-вых для восстановления пробелов в таблицах // В сб. „Методы нейроинформатики”. Под ред. А.Н. Горбуна. - Красноярск: КГТУ, 1998. -С. 6-22.
8. Снитюк В.Е. Эволюционный метод восстановления про-пусков в данных // Сб. трудов VI-И Межд. конф. „Интеллек-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
219
туальный анализ информации”. - Киев. (2006. - С. 262-271. 9. Загоруйко Н.Г., Елкина В.Н., Лбов Г.С. Алгоритмы обна-
ружения эмпирических закономерностей. – Новосибирск: Наука, 1985. – 110 с.
Вспомогательные источники
1. Арнольд В.І. О функциях трех переменных // Докл. АН
СССР. - 1957. - Т. 114. - № 4. - С. 679-681. 2. Колмогоров А.Н. О представлении непрерывных функ-
ций нескольких переменных в виде суперпозиции непрерыв-ных функций одной переменной // Докл. АН СССР. - 1957. - Т. 114. - № 5. - С. 953-956.
3. Harti R.E. A global convergence proof for class of genetic al-gorithms. - Wien: Technische Universitaet, 1990. - 136 p.
4. Annual Energy Report 2004 / Energy Information Admini-stration USA: Washington, 2004. – 435 p. -http://www.eia.doe. gov/aer.
5.Люгер Ф. Дж. Искусственный интеллект. Стратегии и ме-тоды решения сложных проблем. - М.: “Вильямс”, 2003. - 864 с.
6. Рассел С., Норвиг П. Искусственный интеллект. Совре-менный подход. - М.: Вильямс, 2006. - 1408 с.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
220
Глава 8
Гибридные методы. Практические при-
ложения Сколь бы сложной не казалась проблема на первый взгляд, она, если правильно к ней подойти, окажется еще более сложной.
Пол Андерсен
Основные понятия и термины
Импликация Лингвистическая переменная Функция принадлежности Нейронные сети Фаззификация Дефаззификация Методы обучения нейросетей Критерии внешнего дополнения Спецификация модели Правила логического вывода Многофакторная оптимиза-
ция Многокритериальная оптимиза-
ция Методы оптимизации Нормальное распределение Глобальные экстремумы Локальные экстремумы Системная модель Код Грея
Выполняя анализ научной активности в мире, невозможно
не заметить лавиноподобный рост количества публикаций и конференций в области, названной Л. Заде „мягкими вычис-лениями (soft computing)”. Благодаря глобальной сети Internet сегодня появилась возможность изучать работы ученых ве-дущих научных центров. Во многих из них существует прак-тика электронных публикаций своих работ на страницах ор-ганизаций, кроме того, защите диссертации в обязательном порядке предшествует ее размещение в Internet с уведомле-нием заинтересованных лиц через специализированные дай-джесты.
Искусственные нейронные сети, эволюционное модели-рование, теория нечетких множеств являются компонентами soft computing, каждый из которых имеет приоритетное на-правление использования для решения задач в определенной

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
221
предметной области. Так, нейронные сети рационально ис-пользовать при решении задач идентификации и кластери-зации, эволюционное моделирование – задач оптимизации и машинного обучения, нечеткие множества – для исчисления субъективных суждений. Последние годы отмечены отсутстви-ем новых фундаментальных открытий и разработок, в связи с чем научная деятельность сосредоточена на усовершенствова-нии известных методик, а также на разработке моделей, методов и средств, которые базируются на взаимопроникновении эле-ментов одной теории в другую теорию. В качестве примеров можно привести использование нечеткой логики при проек-тировании нейронных сетей и их оптимизацию с помощью эволюционных алгоритмов.
Известно, что композиционное использование нейронных сетей и методов эволюционного моделирования может иметь как вспомогательный, так и равноправный характер. В первом случае одна из указанных компонент необходима для подго-товки данных, которые используются для реализации другой компоненты. В частности, с помощью нейросетей формируют генеральные популяции для генетического алгоритма, а гене-тические алгоритмы используются для подбора параметров и правил обучения нейросетей. Равноправное объединение пре-дусматривает одновременное функционирование двух ком-понент, например, с помощью генетических алгоритмов оп-тимизируют весовые коэффициенты и подбирают топологию сети, а нейросети используют для выполнения операций ге-нетического алгоритма. Интеграция нейронных сетей и пра-вил нечеткого вывода также имеет свои преимущества, по-скольку способность к обучению и адаптации нейросетей и возможность интерпретации нечетких правил позволят аргу-ментировано принимать интеллектуальные решения в усло-виях неопределенности. Оптимизация параметров функций принадлежности и других параметров нечетких нейросетей является одним из аргументов в пользу объективизации субъ-ективных суждений экспертов.
В этой главе будут приведены элементы вышеприведен-ных парадигм, в ней также нашли свое отображение и неко-торые практические применения гибридных методов.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
222
8.1. Нечеткие нейросетевые парадигмы Рассмотрим композиционное применение нейронных сетей
и систем нечеткого вывода для решения задач прогнозирова-ния. При этом построим изложение по такой схеме:
- основные понятия и обозначения; - архитектура нечеткой нейросети (ННС); - метод функционирования ННС; - обучение ННС. Определение 8.1. Нечеткой импликацией лингвистических
переменных A B называют правило логического вывода если ,x A то .y B
Определение 8.2 (обобщение). Если 1 2( , , , ) nx x x x – мно-гомерный вектор, то правило вывода является таким:
если 1 1x A , и 2 2x A ,и …, и n nx A , то B.y Для многомерного случая функцию принадлежности
( )A x интерпретируют как: – логическое произведение ( ) min ( ); A A ii
x x
– алгебраическое произведение 1
( ) ( ).
n
A A ii
x x
Каждая импликация A B имеет функцию принад-лежности ( , ) : A B x y
– в форме логического произведения min ( ), ( ) ; A B A Bx y
– в форме алгебраического произведения ( ) ( ). A B A Bx y
В простейшем случае логический вывод изображен на рис. 8.1.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
223 x y
Рис. 8.1. Система нечеткого вывода
то
то
то
------------------------------------------------
Если x это 1A
Если x это 2A
Если x это mA y это mB
y это 2B
y это 1B
Агрегация Дефаззифика-ция
Нечеткое множество
Четкое множество
Напомним, что наиболее используемыми функциями принадлежности являются:
1. Гауссовская функция 2 2( ) exp( ( ) / ), A x x c где c и параметры, определяющие ее размещение и форму.
2. Симметричная треугольная функция 1 / , если , ,
( )0, в противном случае,A
x a c x a c a cx
где a – центр, c – ширина. 3. Трапециевидная функция
0
1
, ,, ( , ),
( ) , ( , ),
, ( , ),
A
x m або x mx m x m m
x x m mm x x m m
где m и m – нижнее и верхнее модальные значения, и – левый и правый коэффициенты скошенности.
Опишем одну из первых нечетких нейронных сетей, пред-ложенную Янгом (J.-S.R. Jang) в 1993 году. Сеть получила на-звание ANFIS (Adaptive – Network – Based Inference System). Рассмотрим сеть ANFIS, в которой реализована система нечет-кого вывода Сугено (см. главу 4).
Пусть правила вывода имеют вид: 1 : если 1x A и 1 ,y B то 1 1 1 , Z a x b y
2 : если 2x A и 2 ,y B то 2 2 2 . Z a x b y

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
224
Соответствующую сеть ANFIS изображено на рис. 8.2.
1
1
1
1
2
2
3 4
3 4
5 Z
y
x
Рис. 8.2. Структура сети ANFIS с выводом Ларсена
В нейронах первого шара выполняется операция фаззи-фикации, т.е. каждому входному значению ставится в соот-ветствие значение функции принадлежности
( ), ( ), 1,2. k kA Bx x y x k
Количество нейронов первого шара равняется сумме мощностей терм-множеств входных переменных. Каждый вход соединен только со своими термами.
Второй шар содержит такое количество нейронов, которое отвечает количеству правил. В нашем случае их 2. Выходами нейронов есть произведения входных сигналов. Для первого нейрона это
1 11 ( ) ( ), A Bw x y для второго −
2 22 ( ) ( ). A Bw x y Количество нейронов третьего шара совпа-дает с количеством нейронов в предыдущем шаре. В этом ша-ре рассчитывается относительная важность каждого нечеткого правила
.
ii
i
www
Особенностью нейронов четвертого шара есть то, что они кроме соответствующего нейрона предыдущего шара связаны еще и со входами сети. Согласно алгоритму Сугено эти нейроны определяют вклад одного правила в выход сети. Для первого нейрона 1 1 1 1( ), q w a x b y для второго − 2 2 2 2( ). q w a x b y
В выходном нейроне рассчитывается сумма 1 2 . Z q q

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
225
Рассмотрим несколько более сложную задачу и использу-ем алгоритм логического вывода Цукамото и сеть ANFIS. Пусть правила будут такими:
1 : если 1 1x A , и 2 1x B , и 3 1 ,x C то 1;y D 2 : если 1 2x A , и 2 2x B , и 3 2 ,x C то 2 ;y D 3 : если 1 3x A , и 2 3x B , и 3 3 ,x C то 3 ,y D
где 1 2 3, ,x x x – входные переменные, y результирующая ха-рактеристика, , , , ,i i i iA B C D 1,3i , – нечеткие множества со своими функциями принадлежности. Соответствующая сеть ANFIS изображена на рис. 8.3.
1
1
1
1
1
1
1
1
1
2
5
4
4
4
3
3
3
2
2
y
1x
2x
3x
Рис. 8.3. Структура сети ANFIS с алгоритмом вывода Цукамото
На вход сети подаем значения 1 2 3( , , ). x x x В нейронах пер-вого шара находим значения функций принадлежности
1 2 3( ), ( ), ( ), 1,3. i i iA x B x C x i
Таким образом, количество нейронов первого шара (их 9) совпадает с суммарной мощностью терм-множеств. В нейро-нах второго шара рассчитываются значения мер истинности каждого правила базы знаний:

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
226
1 1 1 1 2 1 3
2 2 1 2 2 2 3
3 3 1 3 2 3 3
( ) ( ) ( ),
( ) ( ) ( ),
( ) ( ) ( ).
A x B x C xA x B x C xA x B x C x
Количество нейронов этого шара (их 3) совпадает с коли-чеством правил. Такое же количество нейронов содержит и следующий шар, в них вычисляется относительная важность правил
31 21 2 3
1 2 3 1 2 3 1 2 3
, , .
Нейроны 4-го шара выполняют операции 1 1 1
1 1 2 2 3 31 1 1 2 2 2 3 3 3( ), ( ), ( ).Z D x Z D x Z D x Один нейрон последнего шара предназначен для нахож-
дения суммы 1 2 31 2 3.y Z Z Z
Чаще всего в практических приложениях применяется не-четкая нейронная сеть TSK (Takagi, Sugeno, Kang'a), которая яв-ляется обобщением сети ANFIS. В ней система правил является такой:
1 1 2 2: ( , , ),k k kk n nесли x A и x A и и x A то
1
,
n
ko kj jj
y p p x где 1, .k M
Нейронная сеть, реализующая соответствующий вывод, изображена на рис. 8.4. В первом шаре нейронов выполняется фаззификация входных значений, т.е. для каждого значения каждой переменной и каждого значения терм-множества на-ходятся значения функции принадлежности
( ), 1, , 1, . kj
jAx k M j n
Количество нейронов второго шара отвечает количеству входов сети. В них происходит агрегация функций принадлеж-ности отдельных переменных и для каждого правила рассчиты-вается
1,
min ( ) , 1, .
ki
kiAi n
w x k M

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
227
)( 111
xA
)( 121
xA
)( 11
xmA
)( 212
xA
)( 222
xA
)( 22xmA
)(1 nA xn
)(2 nA xn
)( nA xmn
1x
2x
nx
)(xy
x
x
x )(xym
)(1 xy
)(2 xy
Рис. 8.4. Структура нечеткой нейронной сети TSK
В нейронах третьего шара рассчитываются, собственно,
значения функций TSK, которые умножаются на выходы нейронов предыдущего шара, то есть
1( ).
ni
i io ij jj
g w p p x
Очевидно, что количество нейронов совпадает с количест-вом нейронов предыдущего шара.
Четвертый шар образуют два нейрона. В первом из них
рассчитывается сумма 11
,
n
ii
f g во втором – 21
.
n
i
if W Резуль-
тирующий, единственный нейрон пятого шара выполняет де-
ление 1
2
.fYf
Общее выражение для функционирования сети TSK будет таким:

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
228
1 1 1
1 1
1( ) ( ) ( ).( )
kj
kj
nM n
ko kj jnM Ak j j
jAk j
y x p p x xx
8.2. Обучение нечетких нейросетей Рассмотрим алгоритм обучения сети ANFIS с алгоритмом
нечеткого вывода Сугено. Из п. 8.1 следует, что выход нечет-кой нейросети рассчитывается согласно выражения:
1 1 2 2
1 1 2 2
1 21 2 1 1 1 2 2 2 1 1 2 2
1 2 1 2
1 1 1 2 2 21 2
1 1 2 2
( ) ( ) ( ) ( )
1 1( ( ) ( ))( ) ( ) ( ) ( )
[ ( ) ( )( ) ( ) ( )( )]. (8.1)A B A B
A B A B
w wZ q q w a x b y w a x b y a x b y a x b yw w w w
w a x b y w a x b yw w x y x y
x y a x b y x y a x b y
Предположим, что функциями принадлежности есть гауссов-ские функции
2 2
( ) exp , ( ) exp , 1,2.
i i
A Bi i
A BA Bi i
x x y yx x i (8.2)
Величины 1 2 1 2 1 2 1 2 1 2 1 2, , , , , , , , , , , A A B B A A B Bx x y y a a b b (8.3) являются параметрами алгоритма вывода и подлежат опти-мизации путем обучения нечеткой нейросети.
Предположим, что нечеткой нейросетью реализовано не-известное отображение ( , ).Z F x y (8.4) Есть обучающая выборка 1 1 1( , , ), ,( , , ) .n n nx y z x y z Заметим, что
, , ,i i ix y z 1, ,i n являются действительными числами. Целевая функция для k -го образа будет такой:
21 ( ( ) ) , 1, ,2
k kkE Z Z k n (8.5)
где ( )kZ – рассчитанные значения выхода нейросети, kZ – значения, заданные таблично. Как и для обучения обычных

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
229
нейронных сетей, используем градиентный метод, который позволит осуществить настройку параметров (8.3), миними-зируя функцию (8.5), которая детализировано имеет такой вид:
2
1 2 1 2 1 2 1 2 1 2 1 2
2
1 2 1 2 1 2 1 2 1 2 1 2
1( ) , , , , , , , , , , , ( )2
1 , , , , , , , , , , , , 1, . (8.6)2
kA A B B A A B B kk k k
k A A B B A A B B k
E E E x x y y a a b b Z Z
Z x x y y a a b b Z k n
Корректировка значений параметров, в частности, 1 ,Ax будет осуществляться по формуле:
1 11
1( ) ( ) ,( )
A A kA
Ex t x tx t
(8.7)
где 1 ( )Ax t – значение параметра 1Ax на итерации ,t
1 1
1 1 1 2 21 1
( ) ( )( ) ( ( ) )( ) ( ) ( ) ( ) ( )( )( )
kA Bkk k
kA k AA A B A B
x xE E Z Z Zx x y x yx x tZ
1 1 2 2 1
11 1 2 2
1
2( )( ( ) ( ) 1)( ) ( ) ( )( ) ( ).A
A B A B AA
x xx y a x b y x y a x b y x
Аналогичные преобразования имеют место для ,i в ча-стности,
1 11
( 1) ( ) ,
A A kA
Et t (8.8)
1 1
1 1 1 2 2
1 1 2 2 1
1 1
2
1 1 2 2 3
( ) ( )( ) ( ( ) )( ) ( ) ( ) ( ) ( ) ( ) ( )( )
2( )( ( ) ( ) 1)( ) ( ) ( )( ) ( ).
kA Bkk k
kkA AA A B A B
A B A B A
x xE E Z Z Zt x t x y x yZ
x mx y a x b y x y a x b y x
Преобразование для 1a будет таким:
1 11
( 1) ( ) ,( )
kEa t a ta t
(8.9)
1 1
1 1 2 21 1
( ) ( )( ) ( ( ) ) .( ) ( ) ( ) ( ) ( ) ( )( )
k A Bkk kk
k A B A B
x x yE E Z Z Za t a t x y x yZ

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
230
Аналогично получают выражения для корректировки значений других параметров. Формально, алгоритм обуче-ния ННС есть таким: Шаг 1. Определить структуру и элементный базис ННС. Шаг 2. Выполнить инициализацию значений параметров (8.3). Шаг 3. Случайным образом выбрать обучающий образ, подать его на вход ННС и рассчитать выход. Шаг 4. Рассчитать значение целевой функции. Шаг 5. Выполнить корректировку значений параметров по формулам (8.7)–(8.9). Шаг 6. Если представлены n образов и выполнена соответст-вующая корректировка, то еще раз представить их в опреде-ленном порядке без корректировки и найти суммарное зна-
чение целевой функции 1
.
n
kk
E E Выполнение условия
,E где 0 − некоторое заданное число означает переход на шаг 7, если же условие не выполняется, то выполнить обну-ление счетчиков и перейти на шаг 3. Также на шаг 3 необходи-мо переходить, если представлено меньше чем n образов. Шаг 7. Окончание алгоритма.
Если функции принадлежности являются недифференци-рованными, применение градиентных методов обучения ННС невозможно. В частности, такими функциями есть треуголь-ные и трапециевидные. Одной из техник обучения ННС с та-кими функциями принадлежности является стохастический метод. Рассмотрим его применение при обучении сети ANFIS с алгоритмом логического вывода Цукамото. Известно, что вы-ход ННС (см. п. 8.1) рассчитывается по такой формуле
1 2 3
1 2 3
1 1 1 1 2 2 2 2
1 1 11 2 3 1 2 31 2 3 1 2 3
1 2 3
1 1 11 1 2 2 3 3 3
1 2 31
1 11 2 3 1 1 2 3 2
1( ) ( ) ( )
1( ) ( ) ( )( ) ( ) ( )
( ) ( ) ( ) ( ) ( ) ( ) ( ) ( )
i i i
D D D
D D D
A B Ci
A B C D A B C D
A
Y Z Z Z
x x x
x x x x x x
3 3 3 3
11 2 3 3( ) ( ) ( ) ( )]. (8.10)B C Dx x x

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
231
Таким образом, (8.10) составляют 12 функций принадлежно-сти. Без ограничения общности будем считать их симметрич-ными треугольными функциями. Тогда вектор параметров ННС будет таким:
1 2 3 1 2 3 1 2 3 1 2 3
1 2 3 1 2 3 1 2 3 1 2 3
( , , , , , , , , , , , ,, , , , , , , , , , , ).
A A A B B B C C C D D D
A A A B B B C C C D D D
a a a a a a a a a a a ac c c c c c c c c c c c
(8.11)
Для обучения ННС используем распределение Коши
( )f x 2 2
( ) ,( )T t
T t x
где ( )T t – искусственная температура, t –
номер итерации. Приведем алгоритм стохастического обучения ННС:
Шаг 1. 0.t Придать значению температуры T большое на-чальное значение. Шаг 2. Инициализировать значения вектора параметров . Шаг 3. Подать обучающий образ и вычислить значение целевой функции. Шаг 4. Случайным образом выбрать параметр w из (8.11), ра-зыграть равномерно распределенное случайное число из
интервала 2 2
, ,
вычислить ( ) tg ( ( ))w T t f и придать
коэффициенту w смещение ,w то есть . w w w Шаг 5. Вычислить снова значение целевой функции. Если оно уменьшилось, то изменение значения параметра w сохраня-ется. Если целевая функция ухудшилась, то необходимо ра-зыграть случайное равномерно распределенное на (0,1) число и сравнить с ( ).f w Если ( ) f w , то изменение значе-ния параметра сохранить, в противном случае изменение отме-няется. Шаг 6. Если все обучающие образы исчерпаны, то подаем их поочередно на вход ННС и рассчитываем суммарное значе-ние целевой функции E . Если ,E то переходим на шаг 8. Если не все образы исчерпаны, то осуществим переход на шаг 3. Шаг 7. Если все параметры были подвергнуты коррекции, то подаем все обучающие образы и рассчитываем суммарную це-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
232
левую функцию .E Если ,E то переходим на шаг 8, в про-тивном случае – на шаг 4.
Шаг 8. Окончание алгоритма. Рассмотрим алгоритм обучения сети TSK. В значительной
степени он аналогичен алгоритму обучения сети ANFIS. Пусть 1 2, , , nx x x – входы нейросети. Их фаззификация осуществля-
ется с использованием функций принадлежности
( )
1( ) , 1, , 1, ,1
j j ji ii i
iA b x ax i n j m
e
где m – количество правил. Тогда вектор параметров нейросети (см. п. 8.1), которые подлежат оптимизации, будет таким:
1 1 2 2 1 11 1 1 1 1 1 2 2 2 2 10 11 12
1 0 1 2
( , , , , , , , , , , , , , , , , , , ,, , , , , , ). (8.12)
n n n n n nm m
n m m m mn
a b a b a b a b a b a b p p pp p p p p
Приведем основные выражения для обучения модели TSK:
( 1) ( ) , 1, ,( )
j j ki i j
i
Ea t a t k pa t
где p – количество обучающих образов;
1 1
( )( ) 1( ( ) )( )( ) ( )
ji
ji j
i
kiA kk k
kk nj j mi i iA
iAj i
xE E Z Z Za x aZ x
1
0 021 1 11 1
1 1
( )
( ) 2
( )
( ) ( ) ( ) ( )( ( ))
;(1 )
ji
j ji i
ji
j ji i i
j ji i i
n
iAin nm m mi j
j ji i i j ji i inmA Ai j ii i
i j iAj i
b x aji
b x a
x
p p x x p P x xx
b ee
1 1
k( ) ( ) , , .( )
j ji i j
i
Eb t b t k pb t
В этом случае выражение для вычисления производной отличается от предыдущего только последним множителем:

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
233 ( )
( ) 2
( ) ( ) .(1 )
j ji i ij
ij j
i i i
b x ajiA i i
j b x ai
x a x eb e
Для совокупности параметров , 1, , 0, , ijp j m i n коррек-тировка осуществляется так:
( 1) ( ) ,
kij ij
ij
Ep t p tp
1
1 1
( )( ) ( ( ) ) ,
( ) ( )
ji
ji
n
k i iAk kk k ik nm
ji ijiA
j i
x xZE E Z Z
p pZ x
1
0
1 1
( )( ( ) ) .
( )
ji
ji
n
iAk kk inm
jiA
j i
xE Z Zp x
8.3. Эволюционно-параметрическая оптими-
зация RBF-cети Исходная информация. Задача аппроксимации сложной не-
линейной зависимости возникает при проектировании слож-ных систем, идентификации законов их функционирования, „добыче" знаний из баз данных, прогнозировании. Базируясь на классической теореме Вейерштрасса о приближении не-прерывной функции полиномом, одним из направлений ре-шения этой задачи есть построение временных рядов, поли-номов Колмогорова-Габора, Чебышева и других. Представи-телями такого подхода есть МГУА (см. главу 2) и метод пре-дельных упрощений (МПУ). Авторы этих методов указывают на то, что проблемой, которая сопровождает процесс их при-менения, есть определение оптимального соотношения сложности модели с объемом обучающей выборки. Кроме то-го, принцип свободы выбора, реализуемый при определении параметров метода, приводит к некоторой неопределенности, что является предпосылкой его адекватного применения

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
234
только опытными специалистами. Временные ряды, выбор их модели, как и ее усовершенствование ограничивают исследо-вателя одним экзогенным фактором модели.
Другое направление связано с «синтетическим» подходом к получению аппроксимационной зависимости. Типичным его представителем являются нейронные сети. Базируясь на том, что НС с непрерывными функциями активации являют-ся универсальными аппроксиматорами и теореме Колмого-рова о возможности получения любой непрерывной функции n переменных с помощью операций сложения, умножения и суперпозиции непрерывных функций одной переменной, их активно используют при решении задач восстановления зави-симостей и пропущенных данных, классификации, кластери-зации, ассоциативного поиска и многих других. Нейросети не ограничены требованиями непрерывности, дифференци-руемости функций, но синергетический эффект их обучения требует решения задач структурной и параметрической оп-тимизации.
Как было указано в главе 2, типичными представителями нейросетей с прямым алгоритмом обучения являются RBF-сети, которые хорошо аппроксимируют зависимости в облас-ти изменения данных, на которых происходит их обучение. Вне этой области функционирование НС дает самые неожи-данные результаты. Используем для увеличения предсказуе-мости поведения НС генетический алгоритм. Эта идея не яв-ляется новой, однако большая часть релевантных работ со-держит только теоретические предположения, в них отсутст-вует формализация задачи, экспериментальные результаты и, кроме того, они ориентированы на НС, функционирующие на основе алгоритма обратного распространения ошибки или подобных. Известно, что такой алгоритм имеет медленную скорость сходимости и низкую точность. Рассмотрим функ-ционирование RBF-сети по точному и прямому алгоритму. Оптимизируя ее параметры, можно получить эффективный механизм восстановления аппроксимирующей зависимости.
Постановка задачи. Пусть 1, 1 2, 2 1 2 1 1 2 1, k n m
i j i j i i j jA x y – матри-
ца обучающих образов, k – их количество, 1 2( , ,..., )
nX X X X –

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
235
вектор входных факторов, 1 2( , ,..., )
mY Y Y Y – вектор результи-рующих характеристик. Матрицу A разделим на две части: матрицу 1A и матрицу 2 .A Методы выполнения этой проце-дуры приведены в многочисленных научных источниках. Пусть количество строк в 1A равняется 1 ,k в 2A – 2 ,k причем
1 2 k k k и 2 1.k k Необходимо решить такую задачу:
2
2
1 12
1 ( ) min,
km
ij ijj i
y dmk
(8.13)
где ijd – результат, полученный обученной сетью на j -м выходе при поданном i -м образе из контрольной матрицы 2 .A По-скольку обучение RBF-сети (см. рис. 2.3) состоит в вычислении матрицы весовых коэффициентов 1TW F Q, где F – матрица значений выходов скрытого шара, 1
1 1{ } k mij i jQ y – значения
матрицы 1 ,A и учитывая то, что функционирование сети за-висит от вектора
11 2( , ,..., ),
k получим уточненную задачу:
2
2
1 12
1 ( ( , )) min.
km
Tij ij
j iy d W
mk (8.14)
Решение задачи (8.14) предваряет определение области , в которой изменяются значения вектора .
Такая процедура
необходима для адекватного использования генетического алгоритма, поскольку задача оптимизации (8.14) может быть решенной только в компактной области. Заметим, что чем меньшей она будет, тем более эффективным будет процесс ре-шения и точнее результат.
Определение области изменения параметров нейросети. До-пустим, что начальные данные нормированы и их значения находятся на отрезке 0;1 . Адекватное функционирование НС возможно и в противном случае, но является более трудо-емким при определении параметров и требует отдельного рассмотрения. „Центры окон” активационных функций kc совпадают с обучающими образами из матрицы 1.A Тогда зна-чения нормы, присутствующее в активационной функции, будет не меньшим нуля и не превышающим .n Значение

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
236
функции 2
,
X c
e соответственно, находится на отрезке
2 , 1 .
n
e Учитывая, что при 2
0 xx e , а также опасность
„паралича” сети, необходимо требовать выполнения неравен-ства
20,1 1.
n
e (8.15)
Тогда получим 2ln 0,1 0
n или 2ln 0,1 0.
n Отсюда
2
ln 0,1 1 0n
или 2 .ln0,1
n Предполагая, без ограничения
всеобщности, что 0, получим - .ln0,1
n Включая воз-
можность „перепрыгивания” сетью через оптимум, будем счи-
тать, что 2 0,9.
n
e Тогда, окончательно получим оценку для области изменения значений :
( ; ).ln0,1 ln 0,9
n n (8.16)
Например, при десяти обучающих образах получим та-кую оценку: (2,08;9,74).
Композиция RBF-сети и ГА. Оптимизируя работу RBF-сети, используем следующие процедуры: кроссовер одноточечный (ОТ) и двухточечный (ДТ); выбор родителей пропорциональ-ный (ПР), методом панмиксии (ПА), селективный (СЕ), мето-дами инбридинга (ИН) и аутбридинга (АУ); отбор потомков – обычный (ОБ), элитный (ЭЛ), с вытеснением (ВТ).
Композиционный алгоритм работы ГА с RBF-сетью требу-ет предварительной подготовки данных. Ее простейший этап состоит в нормировании начальных данных. Если использу-
ется преобразование ' min
max min
,
x xx
x x то в данных для нормиро-
вания необходимо включать элементы матриц 1A и 2 ,A а так-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
237
же элементы данных, содержащихся в векторе ,X и для кото-
рых необходимо рассчитывать прогнозные значения .Y Такая
операция необходима для того, чтобы и прогнозные данные попадали в единичный гиперкуб.
Размерность вектора ,
как и количество нейронов скры-того шара, совпадает с количеством тренировочных образов
1.k Каждая его компонента принадлежит области (8.16) и применение ГА состоит в получении таких значений элемен-тов ,
при которых получаем решение (8.14). Функцией при-
способленности будем считать среднеквадратичную ошибку на контрольных образах (элементах матрицы 2A ), обученной на элементах матрицы 1A RBF-сети.
Заметим, что на одном шаге ГА кроссовер можно проводить как для одного элемента вектора ,
так и для всех. Алгоритм
пропорционального выбора заключается в том, что родители выбираются пропорционально значениям их функции при-способленности; панмиксия не предполагает никаких огра-ничений на выбор; селективный отбор позволяет включать в пару только особей, приспособленность которых является не ниже средней по популяции при равных шансах всех; в ре-зультате инбридинга первая особь пары случайна, а вторая выбирается максимально близкой к первой по расстоянию Хемминга; в результате аутбридинга выбираются максималь-но отдаленные по тому же критерию особи. Обычный выбор потомка из двух и включение его в новую популяцию осуще-ствляется с вероятностью 0,5; элитный отбор предполагает включение в новую популяцию лучших родителей и потом-ков, а при отборе с вытеснением в новой популяции будут только разные особи.
Алгоритм оптимизации работы RBF-сети с помощью ГА бу-дет таким: Шаг 1. Нормируем начальные данные. Шаг 2. Формируем обучающий и контрольный массивы. Шаг 3. Определяем границы изменения оптимизируемых пара-метров. Шаг 4. Задаем параметры генетического алгоритма.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
238
Шаг 5. Вычисляем количество элементов в генеральной сово-купности (зависит от предварительной точности результата eps ). Шаг 6. Определяем количество бинарных элементов в геноти-пе. Шаг 7. Случайным образом формируем начальную популя-цию в двоичном, действительном и целом эквивалентах. Шаг 8. Положим _ 0S Fit и будем интерпретировать значе-ния этой переменной как среднюю приспособленность на предыдущем шаге. Шаг 9. Для всех элементов начальной популяции
поочередно
обучаем RBF-сеть и находим среднеквадратичную ошибке на контрольных образах ( ).Fit i Шаг 10. Находим значение средней приспособленности
_ .S Pop Если выполняется неравенство _ _ , S Fit S Pop eps то переходим на шаг 20. Шаг 11. Находим максимальное _Max Fit и минимальное
_Min Fit значения приспособленности в популяции. Если _ _ , Max Fit Min Fit eps то переходим на шаг 20.
Шаг 12. Нормируем значение ( )Fit i и формируем соответст-вующий массив вероятностей. Замечание 8.1. Шаги 13–16 выполняются 1k раз. Шаг 13.Выбираем родителей (по одной из схем ПР, ПА, СИ, ИН, АУ). Шаг 14.Осуществляем кроссовер (по одной из схем ОТ, ДТ). Шаг 15. Осуществляем мутацию с заданной вероятностью. Шаг 16. Формируем множество кандидатов в новую популя-цию. Шаг 17. Отбираем индивидов в новую популяцию по одной из схем ОБ, ЭЛ, ВТ. Шаг 18. Положим _ _ .S Fit S Pop Шаг 19. Переход на шаг 9. Шаг 20. Вычисляем прогнозные значения для полученных массивов весовых коэффициентов W и параметров .
Шаг 21. Окончание алгоритма.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
239
Экспериментальная верификация. Этот алгоритм реализован как составная часть программной системы идентификации и прогнозирования “Alternative S”. Проведенное тестирование дало возможность сделать определенные выводы. Для простоты функцией, которую необходимо аппроксимировать, выбрана
2 .y x Обучающие образы приведены в табл. 8.1. Таблица 8.1. Начальные данные для аппроксимации
x 1 3 5 7 9 11 13 15 17 19 y 1 9 25 49 82 120 169 223 290 361
Точки прогнозирования 1 24, 20 x x . Отношение коли-
чества тренировочных образов к контрольным было взято как 4:1, то есть в контрольную матрицу попали два образа, в тре-нировочную − восемь. Несмотря на то, что в начальных дан-ных присутствовали шумы, НС достаточно эффективно их обошла. Так, среднеквадратичные ошибки на контрольных образах составляли 8 610 10 . Результаты работы программ-ной системы представлены в табл. 8.2.
Анализ результатов показывает, что среднее количество итераций составило 13,5. Прогнозные значения: для
4 16,04; x y для 20x – 399,96.y Абсолютные ошибки составили 1 0,043 и 2 0,037, что свидетельствует о высо-кой точности прогнозирования. Тестирование проводилось с 14 представителями в популяции и заканчивалось, если абсо-лютное значение разности средней приспособленности в данной и предыдущей популяции или абсолютные значения минимальной и максимальной приспособленности в популя-ции было меньше 810 . Вероятность мутации составляла 0,02. Небольшое среднее количество итераций свидетельствует о том, что НС достаточно точно отслеживает закономерности в данных. Наибольшее количество итераций отвечает варианту, где механизмом формирования новой популяции является от-бор с вытеснением. Этому же варианту отвечает большинство случаев, когда прогнозирование осуществляется с некоторым по-ложительным смещением.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
240
Таблица 8.2. Результаты оптимизации RBF-сети и прогноза
Крос- совер
Выбор родите-
лей
Выбор потом-
ков
Прогноз для 4
Прогноз для 20
К-во итера-
ций
Относи-тельная
ошибка, % 1 2 3 4 5 6 7
ВОТ ПР ОБ 15,999 399,9494 4 0,0126 ВОТ ПР ЭЛ 16,000 399,9729 6 0,0076 ВОТ ПР ВТ 15,999 399,9737 6 0,0065 ВОТ ПН ОБ 16,000 399,7087 3 0,0739 ВОТ ПН ЭЛ 15,999 399,9872 8 0,0032 ВОТ ПН ВТ 16,000 399,9829 45 0,0043 ВОТ СИ ОБ 16,999 399,9633 4 6,2589 ВОТ СИ ЭЛ 16,000 399,9855 4 0,0037 ВОТ СИ ВТ 16,000 399,9951 10 0,0013 ВОТ ИН ОБ 15,999 399,9358 5 0,0161 ВОТ ИН ЭЛ 15,999 399,9824 6 0,0044 ВОТ ИН ВТ 16,000 399,9798 60 0,0050 ВОТ АУ ОБ 15,999 399,9310 6 0,0181 ВОТ АУ ЭЛ 16,000 399,9759 5 0,0060 ВОТ АУ ВТ 15,999 399,9707 9 0,0074 ДТ ПР ОБ 16,000 399,9589 4 0,0105 ДТ ПР ЭЛ 16,000 399,9636 4 0,0092 ДТ ПР ВТ 15,999 399,9957 13 0,0011 ДТ ПН ОБ 15,999 399,9672 3 0,0082 ДТ ПН ЭЛ 15,999 399,9736 12 0,0066 ДТ ПН ВТ 16,291 400,0651 21 1,8411 ДТ СИ ОБ 15,999 399,9825 3 0,0051 ДТ СИ ЭЛ 16,000 399,9813 5 0,0046 ДТ СИ ВТ 15,999 400,0047 13 0,0012 ДТ ИН ОБ 15,999 399,9465 5 0,0145 ДТ ИН ЭЛ 16,000 399,9749 20 0,0064 ДТ ИН ВТ 16,000 399,9743 50 0,0065 ДТ АУ ОБ 15,999 399,7864 6 0,0536 ДТ АУ ЭЛ 15,999 400,0183 5 0,0046 ДТ АУ ВТ 16,000 399,9721 61 0,0073
Анализ данных позволил установить ряд интересных
фактов. Так, средняя ошибка в популяции (рис. 8.5) не зави-сит от выбора варианта кроссовера. Для одноточечного крос-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
241
совера наибольшая ошибка отвечает селективному варианту выбора родителей и обычному принципу формирования но-вой популяции. Для двухточечного кроссовера – это пропор-циональный выбор родителей и отбор в новую популяцию с вытеснением.
Рис. 8.5. Cредняя ошибка в популяции
График зависимости средней ошибки в популяции от ва-рианта выбора родителей (рис. 8.6) свидетельствует о том, что оптимальным вариантом, дающим наибольшую скорость сходимости, есть селективный метод, самым медленным – аутбридинг. При формировании новой популяции наиболее эффективным оказывается выбор с вытеснением, незначи-тельно ему уступает элитный метод выбора потомков (рис. 8.7). Таким образом, оптимальной комбинацией является композиция селективного метода выбора родителей и фор-мирование новой популяции методом вытеснения. Результа-ты табл. 8.2 это подтверждают.
0,000 0,010 0,020 0,030 0,040 0,050 0,060 0,070 0,080
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Одноточечный кроссовер Двухточечный кроссовер

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
242
Рис. 8.6. Средняя ошибка в популяции
Рис. 8.7. Средняя ошибка в популяции
Прогнозирование было проведено и для других значений
(табл. 8.3). Величины абсолютных ошибок имеют квадратич-ную тенденцию к росту, однако, их величина при прогнозиро-вании в области, которая значительно отдалена от области обучения RBF-сети, свидетельствует о точности и эффективно-сти метода.
Если прогнозные значения попадают на границу гипер-куба, а остальные значения сосредоточены в некоторой не-большой его области, то точность прогноза будет уменьшаться по мере отдаления этой области от соответствующей границы
0,00 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08
1 2 3 4 5 6 пропорциональный панмиксия селективный инбридинг аутбридинг

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
243
гиперкуба. Эффективность алгоритма будет выше, если для бинарного кодирования использовать не простое двоичное представление числа, а его код Грея, поскольку он имеет свойство „непрерывности”, т.е., если числа в десятичной за-писи отличаются на единицу, то и в записи их кодом Грея бу-дут разными значения только в одном разряде.
Таблица 8.3
x y y y y 4 16 16,0021 0,00207
20 400 400 0,00027 25 625 624,997 0,0028 30 900 899,978 0,02163 35 1225 1224,89 0,1106 40 1600 1599,57 0,4263 45 2025 2023,66 1,3362 50 2500 2496,42 3,5784 55 3025 3016,52 8,4756 60 3600 3581,81 18,1889
Композиция прямого метода получения весовых коэффи-
циентов RBF-сети и итерационного ГА дает возможность по-лучения оптимальных значений параметров сети, которая, в свою очередь, позволяет решить задачу идентификации це-левой функции и осуществить прогнозирование с минималь-ными ошибками. В отличие от других НC, RBF-сеть в компо-зиции с ГА требует значительно меньших вычислительных ресурсов. И одним из главных преимуществ использования RBF-сети вместе с ГА при установлении аппроксимационных зависимостей есть возможность идентификации векторов-функций.
8.4. «Синтетическая» оптимизация структуры сельскохозяйственного производства
Постановка задачи. Пусть S – некоторая социально-экономическая система, функционирование которой опреде-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
244
ляется векторами входных 1 2( , ,..., )nX X X X и внутренних
1 2( , ,..., )mZ Z Z Z параметров, а также вектором результирующих характеристик 1 2( , ,..., ).pY Y Y Y Параметры являются числовы-
ми, причем значение ,xi iX 1, ,i n а , 1, , z
j jZ j m где xi и z
j являются известными ограниченными областями (от-резками). Считаем, что производственная функция
1 2( ) ( , ,..., ) pE G Y G Y Y Y (8.17) структурно и параметрически идентифицирована. Неизвест-ными являются зависимости
1 2 1 2( , ,... , , ,..., )i i n mY g X X X Z Z Z , 1, ,i p (8.18) без которых вычисления (8.17) невозможны. Необходимо ре-шить задачу поиска
, ,
arg max arg max ( )X Z X Z
E G Y (8.19)
в области
1 1
( ) ( )
n m
x zi ii j
. (8.20)
Полагаем известными статистические данные или данные экспериментов, количество которых .l n m Задача (8.17)–(8.20) в общей постановке декомпозируется на две отдельные задачи:
- первая – идентификация зависимостей (8.18); - вторая – нахождение решения (8.19) в области (8.20). Эволюционная идентификация. Сложность задачи (8.17)-
(8.20), в общем случае, определяется такими аспектами: - количество точек экспериментов меньше количества пе-
ременных; – между составляющими векторов ,X Z существует муль-
тиколлинеарность; - зависимости (8.18) являются нелинейными. Их композиция не позволяет использовать известные ме-
тоды статистического анализа. То обстоятельство, что количе-ство факторов, которые включены в (8.18), является недоста-точным и при этом не учтены субъективные выводы, которые объективно присутствуют в зависимостях (8.17)-(8.18), а также

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
245
взаимозависимость входных факторов и внутренних пара-метров делает невозможным использование МГУА, являюще-гося, как известно, одним из наиболее точных аппроксимаци-онных методов на „коротких” выборках. Для решения про-блемы выбора метода решения задачи предлагается исполь-зовать эволюционные принципы функционирования слож-ных систем.
Идентификацию (8.18) осуществим, используя нейронные сети. Учитывая то, что в основу большинства из них положе-ны итерационные методы функционирования, которые не дают достаточной точности при малом количестве начальных данных, используем сеть RBF (см. рис. 2.3). Указанная НС под-вергается простому, не содержащему итераций, обучению, кроме того, доказано, что она является универсальным средством аппроксимации любой функции с заданной величиной точно-сти. На вход сети подаем значения векторов начальных дан-ных ( , ) , 1, ,iX Z i l ( , ). X Z Каждый вектор координат цен-тра активационной функции нейронов скрытого шара совпа-дает с одним из векторов начальных данных, то есть
( , ) ,j jc X Z 1, .j l Предъявив сети значения всех векторов на-чальных данных и рассчитав значения выходов, получим уравнение (см. главу 3)
, ТФ Y (8.21)
где 1,( ) ,lij i jФ f 2 1( , ) , , , ,
i jc
ij i jf f c e i j l
– матрица вы-ходных синаптических весов, Y – известный вектор результи-рующих характеристик. Решение (8.21)
1Т Ф Y (8.22) дает нам искомые значения весовых коэффициентов, что будет означать прохождения интерполяционной поверхности через l точек начальных данных.
Значения известной матрицы позволяют вычислять значение функций 1, , ,iY i p во внутренних точках области исследования. Точность вычисления зависит от того, насколь-ко удачно выбранным будет вектор „ширины” окон и яв-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
246
ляется ли адекватным количество начальных точек сложности функциональных преобразований .iY
Очевидно, что элементы вектора должны быть вели-чинами одного порядка со значениями функции с =
= 2
1
( )l
i ii
c
, и такими их необходимо априорно задавать.
В противном случае элементы матрицы Ф будут близкими к нулю или единице, что не позволит адекватно вычислять ве-совые коэффициенты вследствие ее плохой обусловленности. Разделим начальные данные на две последовательности: пер-вая – обучающая размерностью 1l используется для вычисле-ния (8.22); вторая контрольная, размерностью 2l используется для проверки, 1 2 ,l l l 1 2 .l l Задача (8.18) трансформиру-ется в (8.22)–(8.23), где задача поиска
точн. розр.min Y Y (8.23) состоит в поиске такого вектора , который бы с заданной точностью позволял вычислять по (8.22) значение Y на контрольной последовательности начальных данных. Полу-чение решения (8.22) означает решение задачи структурной и параметрической идентификации. Несмотря на то, что в яв-ном виде зависимости (8.18) и не получены, по заданным век-торам ( , )X Z из (8.21) всегда можно вычислить ,iY 1, .i p Та-кую идентификацию называют «синтетической».
Эволюционная оптимизация. Согласно соображениям, при-веденным выше, зададим начальный вектор и ограниченную область , такую, что . Будем искать решение (8.23) в области . Требования к высокой точности результата и значительная размерность превращают задачу (8.23) в NP-полную. Для ее решения используем идеи и принципы, по-ложенные в основу ГА. Исходя из известных подходов дис-кретизируем область так, чтобы полученный результат удовлетворял заданной точности. Каждую точку дискретно-сти (фенотип) превратим в бинарный формат (генотип). К генотипам, являющимся отобранными представителями в начальной популяции, применяем процедуры рекомбина-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
247
ции, мутации и инверсии. В результате получим популяцию, которая будет иметь представителей с оптимальным значени-ем функции приспособленности, роль которой, в нашем слу-чае, будет выполнять НС, реализующая преобразование (8.21). Получение решения (8.23) будет свидетельствовать о том, что задача (8.18) полностью решена, а также с покомпо-нентной точностью «синтетически» построена производст-венная функция (8.17).
Следующий шаг – нахождение решения задачи (8.19). Считаем, что задана точность результата 0 и должно выпол-нятся неравенство
0 розр. opt( , ) ( , ) ,X Z X Z (8.24)
где розр.( , )X Z – рассчитанный вектор, opt( , )X Z – оптимальный вектор. Используем еще один раз процедуры ГА. Для этого осуществим дискретизацию области , учитывая то, что не-равенство (8.24) должно выполняться для каждой компоненты векторов X и ,Z что эквивалентно выполнению совокупно-сти неравенств 0 розр. optmax i ii
X X , 0 розр. optmax ,j jjZ Z (8.25)
1 1, , , .i n j m Кроме того, точность только повысится, если увеличить дискретность так, чтобы количество точек разбие-ния было кратным 2 для каждой подобласти . Это позволит выполнять преобразование фенотипа в генотип и наоборот максимально эффективно. Поскольку НС уже обучена, то по-давая на ее вход модифицированные значения вектора на-чальных данных ( , )X Z (рис. 8.7), получим значения
1 2, , ..., pY Y Y и по (8.17) вычисляем значение .E Согласно прин-ципу обратной связи формируем новую последовательность представителей вектора ( , ),X Z на которых производственная функция имеет максимальное значение. Проводим среди них рекомбинации, мутации и инверсии. Отбор наилучших представителей позволяет приблизиться сколь угодно близко к оптимуму. А инверсии и мутации не позволят остановку алгоритма в точках локального максимума.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
248
Таким образом, полученный вектор розр.( , )X Z является решением задачи (8.17)–(8.20). НС позволяет сделать выводы о чувствительности исходной характеристики к изменению значений каждого из входных факторов и внутренних пара-метров, а также выполнить прогнозирование, давая ответа на вопрос типа „а если.., то…?”.
подбор параметров (2) обучение контроль (1) F (3) ( ,X X Z Z ) ,opt optX Z Процедуры: (1)-дифузия элементов контрольной и обучающей последовательности; (2)-идентификация; (3)-оптимизация.
ГА
RBF-сеть
ГА
Начальные
данные
Начальные
данные
Рис. 8.7. Задачи и модели синтетической оптимизации
Пример применения «синтетической» оптимизации. При
предварительном анализе эффективности сельскохозяйст-венного производства в одном из регионов установлено, что наибольшее влияние на объем валовой продукции растение-водства ( )Y осуществляли такие факторы (табл. 8.4):
– структура посевных площадей (га), элементами которой являются: озимые зерновые ( 1X ), яровые зерновые ( 2X ), са-харная свекла ( 3X ), подсолнух ( 4X ), овощи ( 5X );
– затратные составляющие (тыс. грн.): горючее ( 6X ), ми-неральные удобрения ( 7X ), семена ( 8X ), запасные части ( 9X ).

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
249
Таблица 8.4. Начальные данные
Год 1X 2X 3X 4X 5X 6X 7X 8X 9X Y 1996 266858 264847 70880 61784 24290 45430 33120 37674 25861 365080 1997 206362 340564 85786 59360 21017 50643 34727 50701 27043 416899 1998 217299 303565 107997 68257 3612 46818 31946 45379 22423 361555 1999 270616 288578 75392 59605 19543 57332 40890 46502 22948 287735 2000 249832 335604 48463 79943 22028 104742 47250 73761 35272 379351
Задача состоит в нахождении таких значений факторов, которые максимизировали бы показатель ,Y минимизирова-ли затратные составляющие, при этом выполнялись ограни-чения, которые известны под названием критерия баланса переменных. Формально задача состоит в поиске
( )max ,
XY
9
6
min , ii
X (8.26)
5
1min max ,i
iS X S
9
6max ,i
iX R
0 1 9, , ,iX i (8.27)
где minS и maxS – минимальная и максимальная площади, кото-рые могут быть заняты под указанные культуры, maxR – мак-симальные затраты. minS и maxS определяются, исходя из того, что не все культуры учтены при постановке задачи (8.26)–(8.27), а засеянной должна быть максимальная площадь.
Решению задачи предшествовал предварительный эври-стический анализ, который показал, что имеет место ряд инте-ресных тенденций, которые в дальнейшем получили подтвер-ждение. Так, значение корреляционной матрицы (табл. 8.5) свидетельствуют о значимой линейной зависимости затрат-ных показателей, что указывает на равномерность и пропор-циональность использования хозяйствами области средств на горючее, семена, удобрения и запчасти.
Были сделаны предположения о том, что области xi опре-
деляются интервалами ( 0 5 1 5 сер. сер., , ,i iX X ), 1 9,i . В струк-туру нейронной сети включено 9 входных нейронов, 1 выход-ной нейрон и 4 нейрона скрытого шара. Выполнено норми-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
250
рование исходных данных. Начальный вектор „ширины” окна выбран таким: = (1000000, 2100000, 1500000, 1250000). При таком ошибка сети (СКО) на контрольном примере составляла 17%. Приемлемым положено значение =1% вследствие значительной размерности величин. Используя ГА, получили оптимизированные значения элементов векто-ра =(1000000, 1500000, 1500000, 1200000) и усредненная ошибка сети составила 0,28%. Количество итераций ГА в его наиболее простом варианте (с одноточечным кроссовером, про-порциональным отбором родителей, вероятностью мутации 0,01 и без инверсий) составило 28.
Таблица 8.5. Матрица парной корреляции
1X 2X 3X 4X 5X 6X 7X 8X 9X Y 1X 1 2X –0,66 1 3X –0,59 –0,12 1 4X 0,002 0,418 –0,462 1 5X 0,498 –0,02 –0,799 –0,113 1 6X 0,197 0,528 –0,775 0,851 0,29 1 7X 0,404 0,400 –0,814 0,623 0,41 0,924 1 8X –0,08 0,748 –0,620 0,824 0,17 0,957 0,84 1 9X 0,054 0,570 –0,808 0,753 0,50 0,893 0,73 0,875 1
Y –0,70 0,597 0,018 0,207 0,09 0,09 –0,2 0,262 0,459 1 Следующим шагом является решение задачи (8.26)-(8.27).
Для оптимизации используется уже обученная НС. Покажем применение ГА на примере первого фактора. По вышеприве-денной формулой 1 121096 3632897( , ).X Согласно (8.25) точ-ность результата выберем 0 =100 га или 0,04%. Дальше необ-ходимо разбить отрезок вариации 1X на (3632897–121096)/100 = 2455 интервалов. Точность результата только увеличится, если дискретность установить в 122 4096 точек. Тогда каждая точка (особь) будет иметь 12-битовое бинарное представление (генотип). Из 4096 генотипов выберем случайным образом 10. Для них вычислим с помощью НС производственную функ-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
251
цию. Используя рекомбинации и мутации, найдем наилучшего представителя, который и будет решением задачи (8.19)-(8.20):
235452 361254 131241 60142 18342 52314 32652 42563 21412( , , , , , , , , )X , значение производственной функции 444214.Y Именно на такие значения X необходимо ориентироваться для получе-ния оптимального значения Y в области .
С помощью обученной НС можно также исследовать чув-ствительность исходного показателя к изменению значений входных параметров. Так, увеличивая на 1% значения факто-ров, получаем проценты изменения результирующего показа-теля, которые приведены в табл. 8.6.
Таблица 8.6. Процент изменения Y при изменении зна-
чения фактора на 1%
Фактор 1X 2X 3X 4X 5X 6X 7X 8X 9X Процент –0,32 0,04 2,43 –0,21 0,06 –0,1 –0,02 –0,07 –0,13
Такие значения свидетельствуют о значительных затратах
на выращивание озимых культур, а также то, что значитель-ная часть урожая используется для собственных нужд хо-зяйств или используется не для денежных расчетов. Сахар-ная свекла, наоборот, приносит самые большие денежные по-ступления. Увеличение значений всех затратных факторов, а особенно горючего и запчастей, не приводит к соответствую-щему росту валовой продукции. НС позволяет исследовать динамику и тенденции в выращивании сельскохозяйствен-ных культур. На рис. 8.8 показано, как меняется показатель ,Y если увеличивать площади посевов озимых и яровых культур.
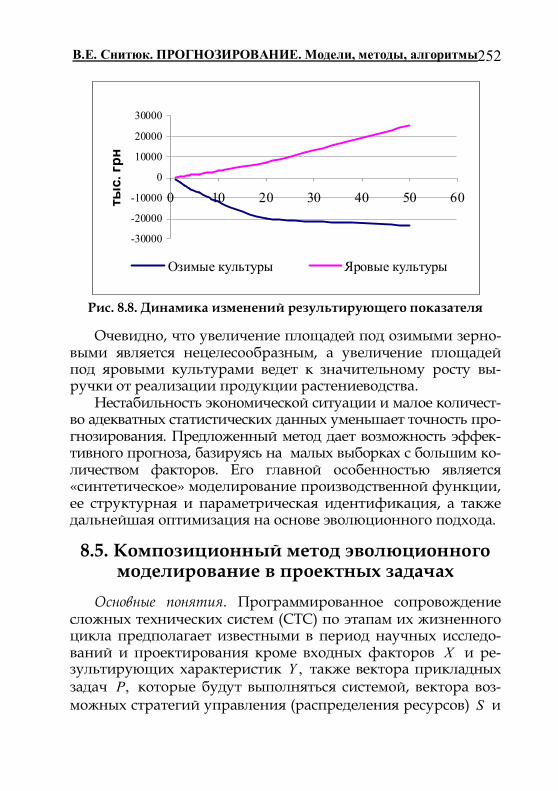
В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
252
-30000
-20000
-10000
0
10000
20000
30000
0 10 20 30 40 50 60
Проценты
тыс.
грн
Озимые культуры Яровые культуры
Рис. 8.8. Динамика изменений результирующего показателя
Очевидно, что увеличение площадей под озимыми зерно-
выми является нецелесообразным, а увеличение площадей под яровыми культурами ведет к значительному росту вы-ручки от реализации продукции растениеводства.
Нестабильность экономической ситуации и малое количест-во адекватных статистических данных уменьшает точность про-гнозирования. Предложенный метод дает возможность эффек-тивного прогноза, базируясь на малых выборках с большим ко-личеством факторов. Его главной особенностью является «синтетическое» моделирование производственной функции, ее структурная и параметрическая идентификация, а также дальнейшая оптимизация на основе эволюционного подхода.
8.5. Композиционный метод эволюционного моделирование в проектных задачах
Основные понятия. Программированное сопровождение
сложных технических систем (СТС) по этапам их жизненного цикла предполагает известными в период научных исследо-ваний и проектирования кроме входных факторов X и ре-зультирующих характеристик ,Y также вектора прикладных задач ,P которые будут выполняться системой, вектора воз-можных стратегий управления (распределения ресурсов) S и

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
253
вектора возможных структур C (рис. 8.9). Формирование век-тора S в значительной мере зависит от инициативы руково-дителя и на этапе проектирования возможным есть только предположения о составе его компонентов и их целесообраз-ности. Одним из инструментов осуществления эффективного производства в современных рыночных условиях, которые не-прерывно меняются, являются системы с переменной структу-рой.
P=const
S,C = variable
X Y
Рис. 8.9. Элементы процесса функционирования СТС
Напомним, что при исследовании, проектировании и соз-
дании сложных систем используется системная модель, структура которой включает уровни целей, моделей, методов, средств и межуровневые отображения. На нижнем уровне де-рева целей системной модели СТС находятся результирую-щие характеристики, получение нужных значений которых – необходимое условие достижения глобальной цели создавае-мой системы. Очевидно, что каждая характеристика является функцией от ,P ,S C и количественно оценивается показате-лем эффективности. Интегральной оценкой СТС есть критерий эффективности
( ) ( ( ( , , ))), E Y P C S (8.28) где – показатели эффективности, – знак, который указы-вает на то, что интегральная функция может быть как сум-мой или произведением, так и любой другой композицион-ной зависимостью.
Предположим, что существует опыт проектирования по-добных систем и есть статистические данные об l прототи-пах, которые представлены в матрице

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
254
11 12 1 11 12 1
21 22 2 21 22 2
1 2 n 1 2
... ...
... ...... ... ... ... ... ... ... ...
... ...
n m
n m
l l l l l lm
x x xx x x
x x x
или
11 12 1 1
21 22 2 2
1 2 n
...
...,
... ... ... ... ......
n
n
l l l l
x x x Ex x x E
x x x E
(8.29)
где ij – показатель эффективности для i -й характеристики j -го прототипа, jE – значение его критерия эффективности, n – количество элементов входного вектора. Максимальное зна-чение E достигается на некотором наборе значений компо-нентов вектора .X Классический подход состоит в нахождении аналитической зависимости
1 2( , ,..., ) nf x x x или 1 2( , ,..., ) nE Ф (8.30)и определении методами дифференциального исчисления максимума функции .Ф Но если матрица начальных данных имеет первое представление (8.29) и f есть вектор-функцией, то достаточно точное аналитическое выражение получить не-возможно, поскольку значения входных параметров и резуль-тирующих характеристик зависимы между собой. В против-ном случае, если зависимость (8.30) является нелинейной, по-иск экстремума связан со значительными трудностями, осо-бенно, если поверхность, заданная функцией ,Ф имеет много локальных экстремумов. Решить эти проблемы предлагается не аналитическими методами, а с помощью «синтетического» подхода, используя нейронную сеть в композиции с генетиче-ским алгоритмом. Нейронная сеть позволит вычислить значение функции без ее аналити-ческого представления, а генетический алгоритм не позволит зациклиться в окрестности локального экстремума.
Постановка задачи. Предположим, что известны интервалы значений параметров
1 1 1 2 2 2, , , ,..., , . n n nx a b x a b x a b (8.31)Возможные такие случаи: 1. Известны законы распределения входных параметров. 2. Известны их функции принадлежности. 3. Для некоторых параметров известны функции распре-
деления, для других – функции принадлежности.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
255
4. Все значения параметров равновероятны. Рассмотрим четвертый случай. Необходимо решить зада-
чу поиска
1 21 2, , ...,
max (*)i i in
nx x xE (8.32)
с заданной точностью . То, что решение будет иметь такую точность, определяется неравенством
*max , i iix x (8.33)
где *ix – точное значение параметра, ix – вычисленное значе-
ние. Подготовка начальных данных. Для того, чтобы синтезиро-
вать функцию эффективности (целевую функцию) нейрон-ной сетью, необходимо подготовить начальные данные. Если среди значений входных параметров есть положительные и отрицательные, то в качестве активационной функции необ-ходимо использовать гиперболический тангенс или сигмоид со смещением 1 ,
2 если есть только положительные значение,
то классический сигмоид. Начальные данные для адекватной обработки нормируем. Чаще всего используют такие выра-жения:
*' min
max min
,
x xx
x x ' ,
x xx ' 1 ,
1
xxe
(8.34)
где x и – выборочные среднее и среднеквадратичное от-клонение, соответственно. Но, использование каждого из этих выражений имеет и недостатки (см. главу 5). Так, первое пре-образование можно использовать только в предположении, что оптимальное значение ни одного из параметров не вый-дет за пределы отрезка min max, .x x Для применения второго преобразования необходимо вычислять дополнительные ве-личины и нежелательно использовать классический сигмоид. В третьем случае возможно неверное отображение тенденций изменения нормированных данных в сравнении с начальными данными. Выбрав способ нормирования, необходимо соответст-венно откорректировать и значение ошибки.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
256
Композиционный метод. На нормированном наборе ( , ),X E предварительно разработав структуру нейронной сети и ис-пользуя алгоритм обратного распространения ошибки, осу-ществим ее обучение. Для использования генетического ал-горитма выполним разбиения отрезка 0,1 , в котором после нормирования находятся все данные. Количество узлов раз-биения m выберем таким, чтобы выполнялась неравность
'1 ,m
где ' – специальным образом нормированная ошибка.
Отсюда следует, что достаточно положить '
1 1.
m Норми-
рованный вектор входных данных представим в виде одной хромосомы длиной ,n p где p есть длина бинарного фраг-мента, который кодирует один входной параметр и опреде-ляется из соотношения
22 log . p m p m (8.35) Будем считать, что 2log 1. p m Хромосома будет такой
(при 5p ): 10111 11001 ..... 10110. '
1x '2x 'nx
Дискретностью представления данных будет 12 1p (рис. 8.10).
02 1p
12 1p
22 1p
2 22 1
p
p
2 12 1
p
p
0 1
Рис. 8.10. Разбивка отрезка
На следующем шаге создаем начальную популяцию. Оче-видно, что в генеральной совокупности 2 pn индивидов (то-чек). Это число достаточно большое, поэтому допустим, что мощность выборочной популяции равняется ,q где 2 . pnq Для того, чтобы ее получить, генерируем матрицу
1 1( ) q nij i jR r случайных чисел из отрезка [0,1], имеющих рав-
номерное распределение. Подадим на вход обученной сети

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
257
поочередно строки матрицы R и получим на выходе вектор ' ' ' '
1 2( , ,..., ). qE E E E Вычислим среднюю эффективность ' '1 , iE E
q рассчитаем элементы вектора
'''
' , ii
EEE
1, ,i q и
выполним их нормализацию '' '' '' . in i iE E E (8.36)
Разобьем отрезок 0,1 на q отрезков таким образом (рис. 8.11):
'' ''1 2n nE E''
1nE''inE
0 1
Рис. 8.11. Дискретизация отрезка [0,1] по значениям эффективности
Генерируем два случайных числа 1 2, 0,1 .z z Если 1
'' ''1
0 0, ,
j j
in ini i
z E E 0, 1, j q то первым родителем выбираем
1 ,jr предварительно преобразованным к бинарному виду та-
ким способом. Если 11, ,
2 1 2 1
j k p p
i ir то '1 1 j kr i в деся-
тичной системе исчисления. Преобразуем '1 ,j kr 1, ,k n к би-
нарному виду и сформируем первую родительскую хромосому. Аналогично формируется и вторая хромосома.
После определения родительских генотипов необходимо сформировать генотип потомка. Для этого задаем вероятно-сти: kP – кроссовера, iP – инверсии, mP – мутации. Исходя из механизмов естественного отбора, будем считать, что
. i m kP P P (8.37)

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
258 Рекомбинация
Рис. 8.12. Структурная схема композиционного метода
Статистические данные X E
Обучение нейронной сети
),( '' EXfW
Генерация начальной популяции: '' XZ
Мутация
0000000000001000
Определение области : X и 0 : optxx , Xxx opt ,
Подготовка начальных данных, синтез топологии и алгоритма функционирования нейронной сети
'X T A
Вычисление эффективности нейронной сетью
E
Кроссовер
3
5.0
21 , xxxP
Инверсия
0000111111110000
+
1tt EE
С вероятностью kP проведем кроссовер, далее с вероятно-
стью 0,5 выберем одного потомка и с соответствующими ве-роятностями осуществим инверсию и мутацию. Разыграем слу-чайное число из множества {0,1,2,..., }q и особь с таким номе-ром исключим из матрицы .R На ее место, осуществив предва-рительное преобразование пофрагментно к десятичному виду, запишем потомка. Данную последовательность операций (рис. 8.12) проводим до тех пор, пока средняя эффективность в одной

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
259
эпохе будет отличаться от средней эффективности в следующей эпохе на малое число.
При бинарном кодировании значений входных парамет-ров неизбежно возникает некоторая избыточность. Одним из способов ее преодоления есть приравнивание нулю целевой функции (критерия эффективности) в точках, значения ко-торой в них превышают максимально возможное. Заметим, что не рассмотренными остаются проблемы, связанные с на-личием другой априорной информации о начальных дан-ных, кроме предположения об их равномерном распределе-нии. Предложенный метод целесообразно использовать и для определения отдельных показателей эффективности, что представляет значительные трудности для классических ана-литических подходов.
8.6. Композиционный метод уменьшения неопределенности
Основные понятия. Рассмотрим новый подход к решению задачи нелинейной многофакторной оптимизации, который базируется на использовании идей и принципов теории ве-роятностей, теории неопределенности и эволюционного мо-делирования. Его преимуществом является отсутствие требо-ваний к оптимизируемой функции и нахождению ее гло-бального оптимума.
Процесс решения задачи нелинейной многофакторной оптимизации сопровождают проблемы оптимального выбора начальной точки поиска, выбора шага поиска решения по каждому фактору и прочие. Кроме того, функция, оптимум которой ищут, должна удовлетворять условиям гладкости по каждой переменной. Указанные аспекты не позволяют эф-фективно решать задачу, а чаще всего в процессе поиска по-лучают неверные решения. Причиной этого является нахож-дение локальных экстремумов, а не глобального оптимума.
Сложность задачи нелинейной многофакторной оптимиза-ции и ее соответствие сложности и многогранности окружаю-щего мира требует разработки эффективных методов поиска решений с использованием компьютерной техники, новых

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
260
идей, принципов, моделей и методов. Одним из таких подходов к рассмотрению указанной задачи и есть композиция эволюци-онного моделирования с элементами классической теории ве-роятностей и теории нечетких множеств или, как ее еще назы-вают, теории неопределенности. Концептуально имеет место композиция детерминированной, объективной и субъектив-ной неопределенности.
Постановка задачи. Рассмотрим модель типа „черного ящика”. Пусть X – вектор входных переменных (факторов),
1 2( , ,..., ), qX X X X Y – результирующая переменная (отклик).
Преобразование F
X Y задано по данным наблюдений или экспериментов таблично. Предположим, что в результате ре-шения задачи идентификации зависимость
1 2( ) ( , ,..., ) qY F X F X X X получена. Она может быть кусочно-непрерывной и должна быть ограниченной. Тогда, задача со-стоит в поиске 1 2( )
max ( , ,..., ), qx D F
F X X X (8.38)
где ( )D F – область определения функции .F Будем считать, что область ( )D F известна и ограничена. Задана также точ-ность прогнозируемого оптимального решения ,optx кото-
рая указывает на то, что , optx x где x – приемлемое ре-шение.
Модели и метод поиска глобального оптимума целевой функ-ции. Известно (см. главу 3), что методами, представляющими эволюционное моделирование, есть генетические алгоритмы, эволюционное программирование, эволюционные стратегии, генетическое программирование. Предварительный анализ показал, что чаще всего для решения задачи нелинейной многофакторной оптимизации используют ГА. Его сущность в классическом изложении, заключается в том, что значения функции приспособленности (fitness-function), оптимум ко-торой ищем, указывают на меру оптимальности аргумента, или, как меру приспособленности некоторого индивида к ок-ружающей среде. Согласно теории природного отбора Ч. Дарвина выживают и размножаются сильнейшие индивиды,

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
261
то есть те, в которых приспособленность выше. Допускаются также и мутации, но с небольшой вероятностью.
Рассмотрим задачу однофакторной оптимизации, т.е. за-дачу поиска
( )
max ( ),x D f
f x (8.39)
а также сделаем соответствующие обобщения. В задаче (8.39) областью определения функции есть отрезок ( ) [ , ].D f a b В со-ответствии с необходимой точностью результата опреде-лим разбиение отрезка [ , ]a b
0 1([ , ]) ... . na b x x x Количество точек разбиения ( ),n g где g − некоторая
функция. Точки разбиения 0 1{ , ,..., }nx x x образовывают гене-ральную совокупность решений. Определяем биекцию полу-ченных точек и подмножества целых чисел {1,2,..., },pZ n а также соответствующих двоичных представлений .pB Для эффективной работы случайным образом выбираем репре-зентативную популяцию равномерно распределенных пред-ставителей среди элементов .pZ Ее размерность .k n Осу-ществляя преобразование из pZ в соответствующие реальные значения ( ),ix D f вычисляем значение функции
( ), 1, .if x i k Далее в классическом варианте ГА среди всех решений-
представителей выбирают те, которые имеют наибольшие значения функции приспособленности. Их бинарные пред-ставления принимают участие в рекомбинациях, в результате которых получают по два решения-потомка. Один из них или два помещают в популяцию следующего поколения. Путем такого итерационного отбора получают популяцию со значе-ниями, близкими к оптимальному решению. Для того, чтобы процесс не сошелся к локальному минимуму, применяют оператор мутации. С его помощью с определенной вероятно-стью осуществляют инверсию одного или нескольких бит в двоичном представлении представителя-решения, тем самым уводя процесс поиска от точки локального оптимума. Если же

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
262
поиск заканчивается одной и той же точкой или близкими, то она, или среднее значение и будет считаться глобальным экс-тремумом.
Для ГА предложены многочисленные способы выбора ро-дителей и механизмы отбора потомков, исследованы их пре-имущества и недостатки, определена специфика их исполь-зования при решении разных задач. Такие модификации ГА имеют один общий недостаток, который заключается в том, что исследователь в процессе поиска принимает пассивное участие. Кроме того, постоянное использование исключительно рав-номерного распределения значительно увеличивает время решения задачи. Композиционное преодоление неопреде-ленности состоит в управлении процессом поиска оптималь-ного решения. Иллюстрация соответствующей процедуры приведена на рис. 8.13.
1 0 a b X
Y
Рис. 8.13. Элементная база процедуры поиска оптимального ре-
шения
Алгоритм поиска глобального максимума функции ( )y f x содержит такие шаги:
Шаг 1. Определить генеральную и выборочную популяции решений.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
263
Шаг 2. Установить соответствие между элементами выбороч-ной популяции как действительными числами, целыми чис-лами и их двоичными представлениями. Шаг 3. Определить процентное соотношение p количества то-чек, которые переходят на следующий шаг поиска экстремума. Шаг 4. Положить 1.i Шаг 5. Вычислить значение функции, оптимум которой ищем, в точках выборочной популяции. Шаг 6. Построить функцию принадлежности ( ),
opt
iy y
f x оп-
ределяющую меру уверенности в том, что решение-представитель x близко к оптимальному. Определим также h -срез множества ( )D f как множество { ( ) / ( ) }.
opt
i ih y y
M x D f f x h (8.40)
Шаг 7. С учетом результата шага 3 определяем множество то-чек { },ix принадлежащее множеству i
hM и для которых вы-полняется неравенство max , k l
i ix x где , .k l ii i hx x M
Шаг 8. Для соответствующих целых представлений { }ix генери-руем нормально распределенные последовательности { }j
iz с математическим ожиданием i iMz x и среднеквадратичным отклонением . i При этом необходимо требовать выполне-ние равенства . j
ii j
z k (Количество элементов выборочной
популяции я неизменной). Шаг 9. Из элементов последовательности { }j
iz формируем но-вую популяцию, допуская мутации каждого элемента с веро-ятностью 0,01. Шаг 10. Если , i
hM то переходим на шаг 11, иначе 1 i i и переход на шаг 5. Шаг 11. Выполнение дополнительных процедур для уточне-ния оптимального решения. Окончание алгоритма.
В случае многофакторной оптимизации алгоритм отлича-ется лишь количеством операций, а также выбором точности решения для каждого фактора или определением интеграль-ной точности, которая требует дополнительных исследова-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
264
ний. В общем случае при решении задачи многофакторной оптимизации остается еще ряд проблем и неисследованных вопросов. Так, неизвестно, как определять значение средне-квадратических отклонений при известном среднем значении для каждого локального оптимума. Необходимо также разра-ботать процедуру оптимального построения последователь-ности функций принадлежности.
Предложенные модели и алгоритм решения задачи не-линейной многофакторной оптимизации являются эффек-тивнее классического ГА. В отличие от последнего, все шаги разработанного алгоритма направлены на приближение к оптимальному решению. В классическом ГА значительные временные затраты вызваны случайным непроизводительным поиском. От попадания в локальный экстремум страхует применение мутации. Отметим, что в предложенном алго-ритме отсутствует оператор кроссовера.
Результаты проведенных экспериментов и сравнительный анализ классического ГА и разработанного метода показали сокращение времени поиска оптимального решения на 15-20% и увеличение точности результата.
Контрольные вопросы и задачи для самопроверки
1. Какие преимущества и недостатки сопровождают про-цесс использования нейронных сетей с нечеткой логикой?
2. Какую конструкцию имеют правила, определяющие знание экспертов?
3. Дайте определение нечетких нейросетей. 4. Какие операции выполняются в блоке вывода нечетких
нейросетей? 5. В чем заключается содержательная сущность блоков фаз-
зификации и дефаззификации нечетких нейросетей? 6. Опишите структуру сети ANFIS с алгоритмом вывода
Сугено. 7. Опишите структуру сети ANFIS с алгоритмом вывода
Цукамото. 8. Опишите структуру сети TSK.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
265
9. Каким образом при обучении нечетких нейросетей ис-пользуется алгоритм обратного распространения ошибки?
10. С использованием каких выражений выполняется оп-тимизация параметров нечетких нейросетей?
11. Опишите алгоритм обучения нечеткой нейросети. 12. Какие особенности имеет применение функций принад-
лежности в нечетких нейросетях? 13. Какие идеи и принципы лежат в основе оптимизации
RBF-сети с помощью генетического алгоритма? 14. Опишите особенности реализации композиционного
алгоритма оптимизации RBF-сети с помощью генетического алгоритма.
15. Какие идеи и принципы положены в основу эволюци-онной идентификации целевой функции?
16. Какие особенности имеет реализация эволюционной оптимизации целевой функции?
17. Какие этапы имеет оптимизация нейросети как модели целевой функции генетическим алгоритмом?
18. В чем сущность композиционного метода эволюцион-ного моделирования?
19. Какие преимущества предоставляет применение ком-позиционного метода уменьшения неопределенности при многофакторной оптимизации по сравнению с применением обычного генетического алгоритма?
Темы рефератов и расчетно-графических работ
1. Интеграция интеллектуальных парадигм анализа дан-ных.
2. Интеллектуальные информационные системы в усло-виях неопределенности и риска.
3. Аналитический обзор методов отдельного и композицион-ного применения нейронных сетей и генетических алгоритмов.
4. Разработка модуля нечеткого управления типа Такажи-Сугено для случая независимых лингвистических перемен-ных.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
266
5. Разработка модуля нечеткого управления типа Такажи-Сугено для случая зависимых лингвистических переменных.
6. „Мягкие” экспертные системы. 7. Нечеткие гибридные классификаторы.
Темы для самостоятельного
изучения 1. Метод нечеткого управления Такажи-Сугено. 2. Проектирование базы нечетких правил на основе чи-
словых данных. 3. Система нечеткого вывода Мамдани-Заде. 4. Гибридный алгоритм обучения нейронных сетей.
Литература
Основные источники 1. Рутковская Д., Пилиньский М., Рутковский М. Нейрон-
ные сети, генетические алгоритмы и нечеткие системы. - М.: Горячая линия – Телеком, 2006. - 452 с.
2. Круглов В.В., Дли М.І., Голунов Р.Ю. Нечеткая логика и искусственные нейронные сети. - М.: Физматлит, 2001. - 224 с.
3. Ротштейн А.П. Интеллектуальные технологии иден-тификации: нечеткая логика, генетические алгоритмы, неи-ронные сети. - Винница, Универсум-Винница, 1999. - 320 с.
4. Круглов В.В., Борисов В.В. Гибридные нейронные сети. - Смоленск: Русич, 2001. - 324 с.
5. Ивахненко А.Г. Долгосрочное прогнозирование и управ-ление сложными системами. - К.: Техника, 1975. - 312 с.
6. Люгер Ф. Дж. Искусственный интеллект. Стратегии и методы решения сложных проблем. – М.: “Вильямс”, 2003. – 864 с.
7. Снитюк В.Е., Шарапов В.М. Эволюционно-параметрическая оптимизация RBF-сети // Донецк: Искусст-венный интеллект.– 2003. – № 4. – С. 493-501.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
267 Вспомогательные источники
1. Васильев В.І., Шевченко А.І. Комбинированный алгоритм
оптимальной сложности // Искусственный интеллект. - 2002. - № 3. - С. 504-509.
2. Бриллинджер Д. Временные ряды. Обработка данных и теория. - М.: Мир, 1980. - 535 с.
3. Бидюк П.І., Зворыгина Т.Ф. Структурный анализ методик построения регрессионных моделей по временным рядам на-блюдений // УСиМ. - 2003. - № 2. - С. 93-99.
4. Крисилов В.А., Побережник С.М. Аппроксимация слож-ных зависимостей структурно-гибкими полиномиальными и гармоническими рядами // УСиМ. - 2003. - № 2. - С. 80-86.
5. Ляшенко І.М., Снитюк О.І. Синтетическая оптимизация структуры производства на примере агропромышленного комплекса Черкасской области // Экономическая киберне-тика. - 2002. - № 3-4. - С. 67-73.
6. Шарапов В.М., Снитюк В.Е. Биокибернетический метод определения оптимума целевой функции в условиях неопре-деленности //Искусственный интеллект. - 2002. - № 4. - С. 123-128.
7. Колмогоров А.Н. О представлении непрерывных функ-ций нескольких переменных в виде суперпозиции непре-рывных функций одного переменного // Докл. АН СССР. - 1957. - Т. 114. - № 5. - С. 95--956.
8. Генетические алгоритмы, искусственные нейронные сети и проблемы виртуальной реальности / Вороновский Г.К., Махотило К.В., Петрашев С.Н., Сергеев С.Н. – Харьков: Основа. - 1997. - 112 с.
9. Ротштейн А.П., Митюшкин Ю.І. Извлечение нечетких баз знаний из экспериментальных данных с помощью гене-тических алгоритмов // Кибернетика и системный анализ. - 2001. - № 4. - С. 45-53.
10. Курейчик В.В. Эволюционные методы принятия ре-шений с синергетическими и гомеостатическими принци-пами управления // Таганрог: Перспективные инфор-мационные технологии и интеллектуальные системы. - 2002. - № 1. - С. 6-10.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
268
11. Божич В.І., Лебедев О.Б., Шницер Ю.Л. Разработка ге-нетического алгоритма обучения нейронных сетей // Таган-рог: Перспективные информационные технологии и интел-лектуальные системы. - 2002. - № 1. - С. 21-24.
12. Батищев Д.І., Исаев С.А. Оптимизация многоэкст-ремальных функций с помощью генетических алгоритмов / Мужвуз. сборник, ВГТУ, Воронеж, 1997. - C. 4-17.
13. Рассел С., Норвиг П. Искусственный интеллект. Сов-ременный подход. - М.: „Вильямс”, 2006. - 1408 с.
14. Фогель Л., Оуенс А., Уолш М. Искусственный интеллект и эволюционное моделирование. - М.: Мир, 1969. - 230 с.
15. Загде Л. Понятие лингвистической переменной и его применение к принятию приближенных решений: Пер. с англ. – М.: Мир, 1976. - 165 с.
16. Борисов А.Н., Крумберг О.А., Федоров І.П. Принятие ре-шений на основе нечетких моделей. - Рига: Зинатне, 1990. - 184 с.
17. Park J., Sandberg I.W. Universal approximation using radial basis function networks// Neural Computation. - 1991. - Vol. 3. - P. 246-257.
18. Тимченко А.А., Родионов А.А. Основы информатики сис-темного проектирования объектов новой техники. - К.: Наук. думка, 1991. - 152 с.
19. Матвеевский С.Ф. Основы системного проектирования комплексов летательных аппаратов. - М.: Машиностроение, 1987. - 239 с.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
269
Глава 9
Другие методы Soft Computing
Самое непостижимое в мире – то, что он постижим.
Альберт Эйнштейн Основные понятия и термины
Генетическое программирова-ние
Искусственный интеллект
Вероятность Принцип обобщения Комбинаторная оптимизация Рекомбинация Кроссовер Эволюционные стратегии Локальный и глобальный оп-
тимумы Эволюционное программиро-
вание Методы оптимизации Генетические алгоритмы Мутация Информация, энтропия Селекция Функция принадлежности Фитнесс-функция Нечеткий вывод
Информация этой главы базируется на авторских перево-дах оригинальных статей специалистов Soft Computіng.
Метаэвристикой (metaheurіstіc) называют алгоритмиче-ский подход к аппроксимации оптимальных решений в зада-чах комбинаторной оптимизации.
9.1. Муравьиные алгоритмы Рассмотрим метаэвристику, которая называется оптими-
зацией муравьиных колоний (Ant Colony Optіmіzatіon (ACO)) и предложена проф. Марк Дориго (Marco Dorіgo, http://іrіdіa.ulb.ac.be/~mdorіgo/HomePageDorіgo) и коллега-ми в начале 90-х годов прошлого столетия как метод решения сложных комбинаторных оптимизационных задач.
Алгоритм АСО принадлежит к предметной области, ко-торую называют интеллектом роя (swarm іntellіgence), и в ней изучаются алгоритмы, которые разработаны вследствие на-блюдений над поведением роев насекомых, стай птиц, стада животных и т.п. Определяющей характеристикой такого по-ведения, которое некоторым образом реализуется в алгорит-мах, является кооперация индивидов через самоорганизацию

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
270 без централизованного управления извне.
АСО-метаэвристика возникла как результат наблюдений за колониями муравьев. Одним из первых ученых, который отметил определенное социальное поведение муравьев, был французский энтомолог Пьер-Пауль Грассэ (Pіerre-Paul Grasse). В 40-х годах прошлого столетия он наблюдал поведе-ние термитов, которые были способны реагировать на "важ-ные стимулы", и потом передавать эту информацию другим насекомым. Грассэ назвал это явление стигмерджентностью (stіgmergy) и определил, что от других видов коммуникаций ее отличают такие свойства: − физическая, не символьная сущ-ность информации, которая реали-зуется через коммуникацию насе-комых и отвечает изменениям ок-ружающей среды; − локальная природа такой инфор-мации, поскольку она достижима лишь для насекомых, которые на-ходятся в непосредственной близо-сти к источнику информации.
Примеры стигмерджентности наблюдаются в колониях муравьев. Большинство их типов, путешест-вуя до и от источников пищи, от-кладывают субстанцию, которую называют феромоном (pheromone). Другие муравьи способны ощущать феромон и его присутст-вие определяет выбор пути, причем того, где концентрация феромона наибольшая. Проведенные эксперименты, когда источник пищи и группу муравьев разделяли два моста, убеждают в этом выводе. Если длины мостов были одинако-выми, то по них двигалось приблизительно равное количест-во муравьев, если же длина одного моста была меньшей, то спустя некоторое время плотность муравьев на нем станови-лась большей. Рассмотрим модель, которая объясняет этот эксперимент.
Предположим, что после момента времени t от начала эксперимента 1m муравьев используют для движения первый мост и 2m − второй, 1 2 .m m m Тогда вероятность 1p для
Marko Dorigo

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
271
1m -го муравья выбрать первый мост вычисляется так:
1
1 11 2
,
h
m h h
m kp
m k m k
(9.1)
где параметры k и h определяются из экспериментальных данных. Вероятность, что тот же 1m -й муравей выберет второй мост
2 1 1 11 . m mp p (9.2)
Экспериментальные исследования удостоверили, что мо-дель (9.1)-(9.2) при использовании реальных данных была аде-кватной при 20k и 2.h
Эта базовая модель, которая объясняет поведение муравь-ев, может быть применена для решения оптимизационных задач. Используем аналогии с естественными муравьями, то-гда главные характеристики стигмерджентности могут быть расширены для искусственных агентов: − ассоциации переменных состояния с состояниями разных
задач; − когда агентам будет разрешен только локальный доступ к этим переменным.
Другим важным аспектом, который может быть использо-ван искусственными муравьями, является объединение авто-каталитического механизма и оценки решений. При (неяв-ной) оценке решений, замечаем факт, что кратчайшие пути (которые отвечают наименьшей цене решений в случае ис-кусственных муравьев) заканчиваются раньше, чем длинные и потому на них накапливается больше феромона. Неявная оценка решений в объединении с автокатализом может быть в самом деле эффективной: короче путь - быстрее откладывает-ся феромон - больше муравьев используют короткий путь. При соответствующем применении это мощный механизм в оптимизационных алгоритмах, которые базируются на ис-пользовании поведения популяций (например, в эволюцион-ных алгоритмах автокатализ используется в селекционно-репродукционных механизмах).
Стигмерджентность вместе с косвенной оценкой резуль-татов и автокаталитическим поведением позволяет сформи-ровать алгоритм функционирования муравьиной колонии (АСО). Базовая идея АСО близка к биологической идее. И ес-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
272 тественные, и искусственные колонии муравьев являются по-пуляциями индивидов, которые работают вместе для дости-жения конечной цели. Колония – это популяция простых, не-зависимых, асинхронных агентов, которые кооперируются для нахождения лучших решений задачи. В случае естествен-ных муравьев - это задача нахождения пищи, для искусствен-ных муравьев − нахождение лучших решений оптимизаци-онных задач. Простой муравей (и естественный, и искусст-венный) способны найти решение такой задачи, но только кооперация между многими индивидами через стигмерд-жентность позволяет находить лучшие решения. Искусствен-ные муравьи живут в виртуальном мире, поэтому они лишь модифицируют числовые значения (искусственный феро-мон), которые ассоциированы с разными состояниями задачи. Последовательность значений феромона, которая ассоцииро-вана с состояниями задачи, называется следом искусственного феромона. В АСО он – единственный коммуникационный фактор для муравьев. Механизм, аналогичный испарению физического феромона в естественных колониях муравьев, разрешает искусственным муравьям забывать историю и фо-кусироваться на новых перспективных направлениях поиска.
Подобно естественным, искусственные муравьи создают решения последовательно, двигаясь от одного состояния за-дачи к другому. Есть несколько отличий между реальными и искусственными муравьями: − искусственные муравьи живут в дискретном мире – они
двигаются последовательно через конечное множество со-стояний задачи;
− изменение концентрации феромона для естественных и ис-кусственных муравьев осуществляется неодинаково. Иногда изменение концентрации феромона осуществляется только некоторыми искусственными муравьями и часто только по-сле получения результата;
− предполагается использование механизмов, которых нет в природе.
АСО был формализован как метаэвристика комбинатор-ной оптимизации M. Дориго и с того времени активно ис-пользуется для решения задач комбинаторной оптимизации (ЗКО). Первый шаг применения АСО для решения ЗКО со-стоит в определении адекватной модели. Она будет использо-ваться для определения центральной компоненты АСО: мо-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
273 дели концентрации феромона.
Моделью ЗКО называется модель , ,P S f , которая состоит из: − пространства поиска ,S что определяется как конечное множество переменных дискретных решений и множества ограничений ; − целевой функции 0: ,f S R которую необходимо мини-мизировать.
Пространство поиска S определяется так: дано множество дискретных переменных ,іХ 1 , n,і со значениями
1 iDji i i iv D v v, ... , . То, что переменная іХ имеет значение jiv , обозначим .j
i iX v Решение s S, в котором каждая со-ставляющая переменная имеет значение, которое удовле-творяет всем ограничениям множества , является допусти-мым решением ЗКО. Если множество пустое, P называется моделью задачи без ограничений, в противном случае − мо-делью с ограничениями. Решение s S* называется глобаль-ным оптимумом тогда и только тогда, если f s f s* s S. Множество всех глобальных оптимальных решений обозна-чим * .S S Решение ЗКО требует нахождения хотя бы одного s S* * .
Модель ЗКО используется для получения модели феро-мона с использованием АСО. Вначале инициализированная переменная результата j
i iX v называется компонентом ре-шения и обозначается ijC . Множество всех возможных компо-нентов решения − C. Множество всех параметров следа фе-ромона − T. Значение параметра следа феромона ijT обозна-чим ij и назовем значением феромона. Это значение исполь-зуется и модифицируется во время поиска алгоритмом АСО, который разрешает моделировать вероятностное распределе-ние разных компонент решения.
В АСО искусственные муравьи строят решение ЗКО, пу-тешествуя конструктивным графом CG V E, . Связанный граф состоит из множества вершин V и множества ребер .E
Множество компонент C может быть ассоциированным с множеством вершин или с множеством ребер. Муравьи дви-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
274 гаются от вершины к вершине вдоль ребер графа, строя част-ные решения. Они также оставляют определенное количество феромона на компонентах: или в вершинах, или на ребрах, которые они проходят. Количество феромона зависит от качества найденных решений. Следующие муравьи исполь-зуют информацию о феромоне, как указание на более пер-спективные области пространства поиска.
Метаэвристика АСО содержит инициализацию и цикл из трех алгоритмических компонент. Простая итерация цикла состоит из построенных всеми муравьями решений, их улуч-шения с использованием локального алгоритма поиска и мо-дификации значения феромона. Объясним эти три алгорит-мические компоненты более детально.
АСО – метаэвристика: Инициализация параметров, следа феромона. Пока не выполнено условие остановки, выполнить: сконструировать решения (СР); применить локальный поиск (ПЛП); модифицировать концентрацию феромона (МКФ); Конец цикла. Рассмотрим элементы метаэвристики. Конструирование решений. Множество из m искусственных
муравьев конструирует решения из элементов конечного множества допустимых компонентов решения ijС с ,
1 , n,і 1j i, D . Конструирование решения начинается с пустого частного решения .ps Далее на каждом шаге ча-стное решение ps расширяется путем добавления случайной компоненты решения из множества вероятных соседей
pN S C. Процесс конструирования решений может рас-сматриваться как путь на конструктивном графе CG V E, . Такой путь в CG однозначно определяется механизмом кон-струирования решения, с помощью которого формируется множество pN S по отношению к частному решению ps .
Выбор компоненты решения из pN S выполняется слу-чайно на каждом шаге конструирования. Точные правила для случайного выбора компонент решения разные в разных ва-риантах АСО. Одно из наиболее известных правил:

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
275
p
il
ij ijpij
il ijc N S
cp c s
c,
(9.3)
где ij − значение концентрации феромона, отвечающее ком-поненте ijс , * − функция, с помощью которой назначается на каждом шаге конструирования эвристическое значение каждому случайному компоненту решения p
ijс N S . Зна-чение, которое возвращает эта функция, в общем случае на-зывают эвристической информацией, и − положитель-ные параметры, значения которых определяются относитель-ной важностью концентрации феромона и эвристической информации. Уравнение (9.3) – это обобщение (9.1) и свиде-тельствует о сходстве АСО с биологическими механизмами.
Применение локального поиска. Если некоторые решения уже получены, то перед изменением концентрации феромона не-обходимо выполнить определенные дополнительные дейст-вия. Их часто называют демонами-акциями и они являются специальными процедурами, поскольку не выполняются про-стыми муравьями. Чаще всего демон-акция – это применение локального поиска для построения решений – формирование множества локально оптимизированных решений для опре-деления того, как нужно изменить концентрацию феромона.
Модификация концентрации феромона. Целью изменения концентрации феромона является увеличение значения фе-ромона, что ассоциируется с перспективными решениями, и уменьшение - в противоположном случае. Обычно это дости-гается посредством уменьшения всех значений концентрации феромона вследствие его испарения и увеличения значений концентрации феромона, которые отвечают множеству пер-спективных решений updS
1upd ij
ij ijs S c s
F s
ф с ф с , (9.4)
где updS − множество решений, которые модифицируются, 0 1с ; − коэффициент испарения, 0F S R: − функция, для
которой f s f s F s F s , s s S' . F * называ-ется фитнесс-функцией.
Испарение феромона необходимо для избежания быстрой

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
276 сходимости алгоритма. Такая операция является определен-ной формой "забывания" и оказывает содействие появлению новых областей в пространстве поиска. Другие АСО-алгоритмы отличаются изменением концентрации феромона.
Модификации правила (9.4) получают, выполняя разные спецификации updS , которое во многих случаях является под-множеством ,iter bsS s где iterS − множество решений, полу-ченное на текущей итерации, bss − наилучшее решение, по-лученное, начиная с первой итерации. Хорошо известный пример – AS (ant system)-правило модификации, где
upd iterS S . (9.5) Зачастую на практике используют ІВ-правило (iteration
best):
iter
upds S
S arg F smax . (9.6)
Правилом ІВ вводится более строгое смещение для нахож-дения перспективного решения, чем AS-правилом. Хотя это увеличивает скорость его поиска, но одновременно увеличи-вается и вероятность преждевременной сходимости. Более сильное смещение вводится ВS-правилом, где используется лучшее решение из первой итерации bss . В этом случае updS – это множество sbs . На практике АСО-алгоритм, который ис-пользует ІВ или BS-правила модификации и дополнительно включает механизм предотвращения преждевременной схо-димости, дает лучшие результаты, чем при использовании AS-правила.
Главные модификации АСО. В научной литературе предло-жено несколько вариантов АСО. Рассмотрим три из их: AS (Ant System) - первую реализацию АСО алгоритма, MMAS (Max-Mіn Ant System) и ACS (Ant Colony System) вместе с их дополнениями. Для иллюстрации отличий между ними ис-пользуем пример задачи коммивояжера.
AS – первый АСО-алгоритм. Его главной особенностью яв-ляется то, что концентрация феромона изменяется после того, как все муравьи осуществят полный тур. Для ребра, которое соединяет вершины i и j концентрация феромона изменяет-ся по закону

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
277
1
1
m
kij ij ij
k,
(9.7)
где − коэффициент испарения, m – количество муравьев и k
ij − количество феромона на единицу длины, отложенного на ребре i j, k -м муравьем:
0
, если k-й муравей использует ребро , в своем маршруте,
, в противоположном случае,
kkij
Q i jL
где Q − константа, kL − длина маршрута k -го муравья. Строя решения в AS-алгоритме, муравьи двигаются по
конструктивному графу и с определенной вероятностью принимают решение в каждой вершине. Вероятность перехо-да k
ijp k -го муравья из точки i в точку j такая:
0
k
ij ijk
k il ilij l A
j Ap
, якщо ,
, в іншому випадку,
(9.8)
где kA − список мест, которые k -й муравей еще не посетил, и − параметры, которые определяют относительную важ-ность концентрации феромона и эвристической информа-ции, заданной выражением
1 ijijd
, (9.9)
где ijd − длина пути i j, . Некоторые реализации AS-алгоритма применялись для
разных задач ЗКО. Наиболее известным является его приме-нение для решения ЗК (задачи коммивояжера), квадратичной задачи о назначении, задач теории расписаний, транспорт-ной задачи и других.
Алгоритм MMAS. В алгоритме MMAS усовершенствованы идеи AS-алгоритма. Он предложен Т. Штютцлем и Х. Хусом (T. Stützle і H. Hoos), которые ввели определенные изменения, такие как: − только наилучший муравей может изменять след феромона;

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
278 − минимальная и максимальная концентрации феромона – это ограниченные величины.
Преобразование (9.7) имеет такую форму: 1 ,best
ij ij ij (9.10)
где bestij − значение модификации концентрации феромона,
определенное как
1
, если наилучший муравей использовал , -
ребро в своем маршруте,0, в противном случае,
bestbestij
i jL
(9.11)
где bestL – длина маршрута наилучшего муравья. Это может быть маршрут, найденный на последней итерации ,ibL или наилучший маршрут, найденный с начала работы алгоритма
,bsL или их комбинация. Что касается ограничений на минимальное и максималь-
ное значения min и max , соответственно, то Т. Штютцль и Х. Хус предлагали определять их экспериментально в отдельно-сти для каждой задачи. Максимальное значение max вычис-ляется аналитически в предположении, что длина маршрута наилучшего муравья известна. В случае ЗК это
1 1max * ,
L
(9.12)
где *L − длина оптимального маршрута. Если значение *L не-известно, то оно может быть аппроксимировано значением
.bsL Минимальное значение min выбирают с предосторожно-стью, поскольку оно имеет значительно большее влияние на процесс выполнения алгоритма. Т. Штютцль и Х. Хус пред-ложили аналитический подход для нахождения этого значе-ния, базируясь на вероятности ,bestp в соответствии со значе-нием которой муравьи конструируют наилучший маршрут. Это осуществляется таким образом. Сначала предполагается, что на каждом шаге конструкции муравей имеет постоянное число k доступных опций. Тогда вероятность того, что мура-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
279 вей выберет правильное решение (решение, которое принад-лежит к последовательности лидирующих решений, полу-чаемых при конструировании наилучшего маршрута) на лю-бом из n шагов 1 .n
dec bestp p Аналитическая формула, кото-рую они предложили для нахождения min , такова:
1maxmin
dec
dec
pk p
.
(9.13)
Заметим, что найти min иногда легче экспериментально, чем аналитически. Процесс изменения значения концентра-ции феромона в MMAS заканчивается проверкой, все ли эти значения находятся в указанных границах:
min min
min max
max max
, если ,, если ,
, если .
ij
ij ij ij
ij
(9.14)
MMAS обеспечивает существенное улучшение решения в сравнении с базовым AS.
Алгоритм ACS. Другим улучшением оригинального AS является алгоритм ACS, предложенный Л. Гамбарделлой и М. Дориго (L. Gambardella и M. Dorіgo). Целесообразным в ACS является введение модификации значения концентрации ло-кального феромона в дополнение к модификации значения концентрации феромона в конце процесса конструирования (которое называется здесь модификацией offlіne).
Модификация значения концентрации локального феро-мона выполняется всеми муравьями после каждого шага кон-струирования. Каждый муравей применяет эту модифика-цию только к последнему пройденному ребру
01 ,ij ij (9.15) где 0 1, – это коэффициент распада феромона и 0 − на-чальное значение концентрации феромона.
Главная цель локальной модификации – это создание разнообразия поиска, выполняемого следующими муравьями во время одной итерации. На самом деле, уменьшение кон-центрации феромона на ребрах, которые они проходят на протяжении одной итерации, заставит следующих муравьев выбирать другие ребра и таким образом продуцировать дру-гие решения. Вследствие этого также уменьшается количество

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
280 муравьев, которые продуцируют одинаковые решения.
Изменение концентрации offlіne, как и в MMAS, осущет-свляется в конце каждой итерации только одним муравьем (или тем, который найдет лучшее решение в данной итера-ции, или во всех итерациях). Но формула модификации от-личается:
1- , если ребро , принадлежит к маршруту лучшего муравья,
, в противном случае.
ij ij
ij
ij
i j
(9.16)
В случае ЗК 1ij
bestL (как и в MMAS, bestL может быть ibL
или bsL ). Другое важное отличие между AS и ACS состоит в правиле
принятия решения, которое применяют муравьи во время процесса конструирования. Муравьи в ACS используют псев-дослучайное пропорциональное правило: вероятность для муравья пройти от точки i к точке j зависит от значения случайной величины q равномерно распределенной на 0 1; и параметра 0 ;q если 0 ,q q то
max ,
pil il
l N Sargj
в против-
ном случае используем (9.8). Современные направления исследований. На сегодня разра-
ботка и исследование муравьиных алгоритмов остаются акту-альными. Они включают применения АСО-алгоритмов к ре-шению новых задач оптимизации в реальном мире или из-вестных типов задач, таких как динамическая оптимизация, многокритериальная оптимизация, стохастические задачи, непрерывная и смешанная оптимизация. С ростом популяр-ности параллельных архитектур компьютеров (мультиядер-ных процессоров и GRID-технологий), значительное количе-ство исследований сосредоточено на создании параллельных реализаций АСО, которые способны использовать преимуще-ства такой архитектуры.
9.2. Программирование генетических выражений
Рассмотрим новое направление - программирование гене-тических выражений (ПГВ), сфокусировавшись на его приме-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
281
нении для решения задач. Автором ПГВ является Кандида Феррейра (Candіda Ferreіra, www.gene-expressіon-programmіng.com). Далее, кроме простого начального приме-ра, рассмотрим две относительно сложных тестовых задачи символьной регрессии. Одна из этих задач была выбрана при попытке пролить свет на проблемы получения моделей с по-мощью обучающих алгоритмов и обеспечения приемлемой точности эволюционных моделей и эффективности алгорит-мов. Указанные задачи также показывают, каким образом ПГВ применяется для моделирования сложных зависимостей с вы-сокой точностью, позволяя в то же время "добывание" знаний из эволюционных моделей.
Рассмотрим основные отличия между ПГВ и его предше-ственниками – генетическими алгоритмами и генетическим программированием (ГП).
В соответствии с роботами М. Митчел (М. Mіtchell) ПГВ, подобно ГА и ГП, является также эволюцион-ным алгоритмом, поскольку исполь-зует популяцию индивидов, выбира-ет их по значению функции приспо-собленности и вводит генетические изменения, используя один или больше генетических операторов. Основное отличие между тремя ал-горитмами - в природе индивидов: в ГА индивиды - символьные строки фиксированной длины (хромосомы); в ГП индивиды - нелинейные сущно-сти разных размеров и форм (деревья анализа); в ПГВ индивиды кодируются как символьные строки фиксированной длины (хромосомы), которые определяются как нелинейные сущности разных размеров и форм (деревья выражений).
Идея генетических алгоритмов состояла в применении био-логической теории эволюции к вычислительным системам. По-добно ко всем эволюционным вычислительным системам, ГА – упрощение биологической эволюции. В данном случае, потен-циальные решения задачи кодируются строками символов (в основном 0 и 1) и совокупность этих решений эволюционирует
Candida Ferreira

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
282
для того, чтобы найти решение задачи. Популяция, а следова-тельно и решения эволюционируют потому, что отдельные ре-шения (хромосомы) воссоздаются с определенными модифика-циями. Это необходимое условие для того, чтобы эволюция происходила. Модификации в оригинальном ГА осуществля-ются путем мутации, скрещивания и инверсии. В дополнение, к индивидам применяется еще и селективный отбор. Они выби-раются в соответствии со значениями функции приспособлен-ности, если она определена, и ее значение используется для пропорциональной репродукции. Чем больше значение функ-ции приспособленности, тем больше вероятность дать потомст-во.
Хромосомы ГА - простые репликаторы, как указал Р. Дов-кинс (R. Dawkіns), поэтому они приспосабливаются к условиям внешней среды и выживают благодаря своим свойствам. Можно утверждать, что они функционируют одновременно как геном и феном. Итак, хромосомы не только сохраняют генетическую информацию, которая повторяется и передается с модифика-цией к следующему поколению, но также являются объектом выбора. Разнообразие функций хромосом в ГА может быть серьезно ограничено этой двойной ролью и их структурной ор-ганизацией, а именно простым представлением хромосом и их фиксированной длиной. Это очень напоминает простой мир рибонуклеиновой кислоты (РНК-мир), где линейный геном РНК также способен к демонстрации структурного разнообра-зия. В данном случае полная структура молекулы РНК опреде-ляет функциональность и, как следствие, приспособленность индивида. Например, это было бы невозможно в таких системах, которые используют только частичную область генома как ре-шение задачи: целый геном - всегда решение. Очевидно, что применение таких систем ограничено.
Генетическое программирование. Генетическое программиро-вание, предложенное Л. Крамер (L. Cramer) в 1985 году и даль-ше развитое Дж. Козой (J. Koza) (www.genetіc-programmіng.com/johnkoza.html) решило проблему фиксиро-ванной длины решений, создав нелинейные сущности с раз-ными размерами и формами. Алфавит, использованный для создания этих сущностей, был также разнообразен, образуя многогранную систему представления. Тем не менее, создан-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
283
ным индивидам не хватало простого, автономного генома, ко-торый функционировал бы одновременно как геном и феном. Снова, на жаргоне эволюционной теории сущности ГП явля-ются простыми репликаторами и адаптируются благодаря их собственным свойствам. Нелинейные сущности (деревья ана-лиза) ГП напоминают использование молекул белка в своем алфавите и их сложное иерархическое представление. Поэтому ГП-сущности способны к демонстрации широкой функцио-нальности. Но эти сущности очень сложны для воспроизведе-ния с модификацией, так как генетические модификации вы-полняются непосредственно на дереве анализа. Как следствие, большинство модификаций генерируют структурные несоот-ветствия. Для сравнения следует заметить, что в природе вы-ражение любого гена белка всегда имеет место в соответст-вующей действительной структуре белка (в природе нет такой сущности как структурно некорректный белок).
Итак, в ГП генетические опера-торы действуют непосредственно на дереве анализа, которое, на первый взгляд, кажется выгодным, но очень ограничивает эту технологию (не-возможно заставить апельсиновое дерево продуцировать плоды манго, только привив и обрезав ветви). И вдобавок, основа применения гене-тических операторов, доступных в ГП, очень ограничена, так как боль-шинство из них приводили бы к не-корректным деревьям анализа. По-этому в ГП используются почти экс-клюзивная специальная рекомбинация, которая действует на уровне деревьев анализа. В этом ГП-специфическом кроссовере отобранные ветви обмениваются между родительскими деревь-ями анализа для создания новой популяции. Идея состоит в об-мене меньших, математически кратких блоков для того, чтобы развивать более сложные, иерархические решения, составлен-ные из меньших блоков.
Оператор мутации в ГП также отличается от точечных естест-венных мутаций для того, чтобы гарантировать создание синтак-
John Koza

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
284
сически правильных программ. Оператор мутации выбирает узел в дереве анализа и заменяет ветвь внизу этого узла случайно созданной ветвью. Полная форма дерева незначительно изменя-ется в результате такой мутации.
Перестановка – третий оператор, который используется в ГП, и подобно рекомбинации и мутации значительно ограни-чен: выбирают два структурно эквивалентных узла (два тер-минала или две функции с одинаковым числом аргументов) и их позиции обмениваются. В данном случае полная форма де-рева остается неизменной.
Несмотря на то, что Дж. Коза описал эти три операторы, как основные операторы ГП, кроссовер – практически единст-венный генетический оператор, который используется в большинстве реализаций ГП. Не удивительно, что в ГП боль-шие популяции деревьев анализа используются с целью соз-дания всех составных блоков, с проверкой начальной популя-ции для того, чтобы гарантировать нахождение решения, только перемещая эти начальные блоки.
В конце концов, благодаря дуальной функции деревьев анализа (геномов и феномов), в ГА и в ГП невозможно про-стое, рудиментарное выражение: во всех случаях полное дере-во анализа является решением.
Программирование генетических выражений. Программирова-ние генетических выражений является естественным развити-ем ГА и ГП.
ПГВ использует такой же вид диаграммы представления как в ГП, но сущности, созданные ПГВ (деревья выражений), являются выражениями геномов. Поэтому с ПГВ второй эво-люционный порог - порог фенотипа - был преодолен, обеспе-чивая новые и эффективные решения для эволюционных вы-числений.
Особенностью ПГВ является использование хромосом, способных к представлению любого дерева выражений. Для этого был создан новый язык (Karva), чтобы читать и "добы-вать" информацию из ПГВ-хромосом. И вдобавок, структура хромосом проектировалась для того, чтобы разрешить созда-ние множества генов, каждый из которых кодирует поддерево выражения. Гены структурно организованы в начале и в кон-це, и это та структурная и функциональная организация ге-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
285
нов ПГВ, которая всегда гарантирует создание валидных про-грамм, несмотря на то, сколько или как глубоко модифици-руются хромосомы.
В следующем параграфе описана структурная и функ-циональная организация ПГВ хромосомы: как хромосомы превращаются в деревья выражений; как функцию хромосом понимают как генотип и деревья выражений – как фенотип; как создаются, развиваются и воссоздаются индивидуальные программы, оставляя потомков с новыми свойствами и по-этому способными к адаптации.
Программирование генетических выражений: вступление. В отличие от известного аналогичного клеточного генетическо-го выражения ПГВ является более простым. Главных игроков в ПГВ лишь два: хромосомы и деревья выражений (ДВ), по-следние - выражения генетической информации, которая ко-дируется в хромосомах. Как и в природе, процесс декодиро-вания информации называется трансляцией. И эта трансля-ция, очевидно, предусматривает своего рода код и набор правил. Генетический код очень простой: это взаимоотноше-ние между символами хромосомы и функций или термина-лов. Правила также простые: они определяют пространствен-ную организацию функций и терминалов в ДВ и типы взаи-модействия между под-ДВ.
В ПГВ есть два языка: язык генов и язык ДВ, зная последова-тельность или структуру одного, – знаем и другой. В природе, не считаясь с возможностью сделать вывод о последовательно-сти белков, представленной последовательностью генов и на-оборот, мы практически ничего не знаем о правилах, которые определяют трехмерную структуру белков. Но в ПГВ, благода-ря простым правилам, которые определяют структуру ДВ и их взаимодействие, возможно сделать вывод о фенотипе, пред-ставленным последовательностью генов и наоборот. Эта дву-язычная и недвусмысленная система названа языком Karva.
Геном. В ПГВ геном или хромосома состоит из линейной символьной строки фиксированной длины, составленной из одного или более генов. Несмотря на их фиксированную дли-ну, мы убедимся в том, что в ПГВ хромосомы кодируют ДВ разных размеров и форм.
Открытые для чтения фреймы и гены. Структурную орга-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
286
низацию генов ПГВ лучше понять в строках фреймов, откры-тых для чтения (ФОЧ). В биологии ФОЧ или кодированная последовательность генов начинается со "стартового" кодона, продолжается кодонами аминокислоты и заканчивается за-ключительным кодоном. Тем не менее, ген больше чем соот-ветствующий ФОЧ, с последовательностями вверх от старто-вого кодона и последовательностями вниз от кодона останов-ки. Несмотря на то, что в ПГВ стартовая страница - всегда первая позиция гена, точка остановки не всегда совпадает с последней позицией гена. В основном гены ПГВ имеют неза-кодированные регионы вниз от точки остановки. Пока что мы не будем рассматривать эти незакодированные регионы, так как это не препятствует созданию выражений.
Рассмотрим, например, алгебраическое выражение a b d ec . (9.17)
Оно может быть также представлено диаграммой (рис. 9.1), где "Q" играет роль функции квадратного корня.
Этот вид диаграммных представлений - фактически фе-нотип хромосом ПГВ, из которого легко записать генотип, как показано ниже:
0 1 2 3 4 5 6 7 8 9+/ Q * c - a b d e
(9.18)
который получается вследствии чтения ДВ слева направо и сверху вниз (точно так, как мы читаем страницу текста). Вы-ражение (9.18) – ФОЧ, который начинается с "+" (позиция 0) и заканчивается в "e" (позиция 9). К. Ферейра назвала эти ФОЧ K-выражениями (исходя из Karva-нотаций).

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
287
+
/ Q
a
c *
b
–
d e
Рис. 9.1
Рассмотрим другой ФОЧ, следующее K-выражение: 0 1 2 3 4 5 6 7 8 9 0 1* - / Q b+ b + a a a b (9.19)
Он тоже простой. Чтобы правильно представить ФОЧ, мы должны придерживаться правил управления пространствен-ным распределением функций и терминалов. Во-первых, на-чало гена отвечает корню ДВ, формируем этот узел в первой линии. Во-вторых, в зависимости от числа аргументов каждого элемента (функции, возможно, имеют разное количество аргу-ментов, тогда как терминалы имеют ноль операндов) в сле-дующей линии размещены много узлов, которые являются ар-гументами функций предшествующей линии. В-третьих, слева направо заполняем узлы в том же порядке элементами генов. В-четвертых, процесс повторяется, пока линия, которая содержит только терминалы, не будет сформирована. Поскольку для K-выражения (9.19) корень ДВ - символ в позиции 0, то получим:
*
Функция произведения имеет два аргумента, поэтому сле-
дующая линия будет иметь два узла, в данном случае символы в позициях 1 и 2 (рис. 9.2).

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
288
*
– /
Рис. 9.2
Вычитание и деление - функции двух аргументов и потому в следующей линии размещены еще четыре узла. В данном случае это символы в позициях 3, 4, 5 и 6 (рис. 9.3).
Таким образом, мы имеем две разные функции в третьей линии: одна - функция одного аргумента (Q), другая - функ-ция двух аргументов (+). Поэтому, еще три узла нужно по-строить в следующей линии. В данном случае они заполнены элементами в позициях 7, 8 и 9 (рис. 9.4). В этой новой линии, не-смотря на то, что есть три узла, только один из них - функция (+). Поэтому соответствующие узлы размещены ниже этой функции и заполнены следующими элементами в ФОЧ (позиции 10 и 11). Получаем рис. 9.5.
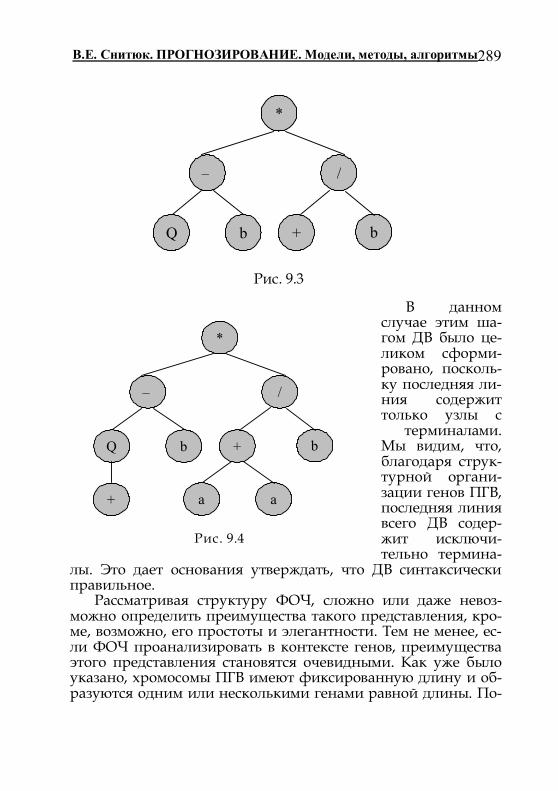
В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
289
В данном случае этим ша-гом ДВ было це-ликом сформи-ровано, посколь-ку последняя ли-ния содержит только узлы с
терминалами. Мы видим, что, благодаря струк-турной органи-зации генов ПГВ, последняя линия всего ДВ содер-жит исключи-тельно термина-
лы. Это дает основания утверждать, что ДВ синтаксически правильное.
Рассматривая структуру ФОЧ, сложно или даже невоз-можно определить преимущества такого представления, кро-ме, возможно, его простоты и элегантности. Тем не менее, ес-ли ФОЧ проанализировать в контексте генов, преимущества этого представления становятся очевидными. Как уже было указано, хромосомы ПГВ имеют фиксированную длину и об-разуются одним или несколькими генами равной длины. По-
*
– /
b Q + b
Рис. 9.3
*
– /
b Q + b
Рис. 9.4
a a +

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
290
этому длина гена также фиксирована. Тогда в ПГВ изменяется не длина генов, которая является постоянной, а длина ФОЧ. Действительно, длина ФОЧ является равной или меньшей чем длина гена. В первом случае точка остановки совпадает с концом гена, а в последнем – точка остановки размещена где угодно сверху от конца гена.
Выполним анализ структурной организации генов ПГВ для того, чтобы понять, как они неизменно кодируются для синтаксически правильных программ и почему они допуска-ют применения любого генетического оператора без ограни-чений.
Гены ПГВ. Гены ПГВ состоят из "головы" и "хвоста". "Голова" содержит символы, которые представляют как функции, так и терминалы, тогда как "хвост" содержит только терминалы. Для каждой задачи, длина "головы" h выбирается, тогда как длина "хвоста" t - это функция от h и количества аргументов функции с наибольшим количеством аргументов n и вычисляется так:
t=h(n-1)+1 . (9.20)
Рассмотрим ген, для которого набор функций { , *,/, , }F Q и набор терминалов − { , }.T a b В данном слу-
*
– /
b Q + b
Рис. 9.5
a a +
a b

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
291
чае 2n и, если мы выбрали 15,h то 16.t Поэтому длина гена g составляет 15+16=31. Ниже показан один такой ген ("хвост" изображен жирным):
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 /a Q/ b * a b /Q a * b * - a b a b a a b a b b a b b b b a
(9.21) Он кодируется ДВ (рис. 9.6). В данном случае ФОЧ заканчи-
вается в позиции 7, тогда как ген заканчивается в позиции 30. Предположим, что мутация происходит в позиции 2, и
изменим "Q" на "+". Тогда получим следующий ген: 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 / a + / b * a b / Q a * b * - a b a b a a b a b b a b b b b a
(9.22)
Его представление будет таким (рис. 9.7). В этом случае точка остановки перемещается на 10 позиций вправо (пози-ция 17).
Очевидно, что может случиться и противоположное, и ФОЧ сократится. Например, рассмотрим снова ген (9.21) и допустим, что мутация происходила в 5-й позиции, заменяя "*" на "b":
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 / aQ/ b b a b/Q a * b * - a b a b a a b a b b a b b b b a
(9.23)
Его выражение приводит к такому ДВ (рис. 9.8). В данном случае ФОЧ заканчивается в 5-й позиции, сокращая родитель-ское ДВ в 2 узлах.
Итак, несмотря на его фиксированную длину, каждый ген имеет потенциал для кодирования ДВ разных размеров и форм, будучи проще всего составленным только из одного уз-ла (если первый элемент гена - терминал) и сложно составлен-ным из такого количества узлов, которое равняется длине гена (если все элементы "головы" есть функцией с максимальным числом аргументов).

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
292
Как видно из примеров выше, любая модификация, сде-ланная в геноме, несмотря на ее глубину, дает в результате структурно правильную ДВ.
Единственное, с чем нужно быть осторожным, состоит в не-
/
a Q
*
b
Рис. 9.6
/
a
b
/
a +
*
b
Рис. 9.7
/
a
b /
a Q
*
b *
– a
b a
/
a Q
b
Рис. 9.8
/
b

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
293 зыблемости структурной организации генов при определении границы между "головой" и "хвостом". Нельзя также разрешать символам представлять функции в "хвосте". Эти вопросы рас-сматриваются ниже, где и будет выполнен анализ механизмов и эффекта применения разных генетических операторов.
Мультигенные хромосомы. Хромосомы ПГВ в основном со-
стоят из более чем одного гена фиксированной длины. Для каждой задачи или запуска программы, количество генов, как и длина «головы», выбираются априорно. Каждый ген коди-рует под-ДВ и они взаимодействуют, формируя более слож-ные мультиэлементы ДВ. Детали такого взаимодействия будут полностью объяснены ниже.
Рассмотрим, например, хромосому длиной 45, составленную из трех генов ("хвосты" показаны жирным):
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4Q/ * b+Q a - a b Q/* + * * - * b b /
b a b a a b a ab a b a b b a bb a b a a a a b
(9.24)
Она имеет три ФОЧ и каждый ФОЧ кодирует под-ДВ ((9.25) и рис. 9.9). Нулевая позиция обозначает начало каждого гена. Тем не менее,
012345 6789012340123456789 01234012345678901234Q/*b+Qa -abQ/*+ **-*bb/babaabaa bababbab babaaaab (9.25)
поддерево 1 поддерево 2 поддерево 3
Q –
Q
*
b
Рис. 9.9. Выражения для GEP- генов как поддеревьев
/
a
b
a
+
a b
*
– *
* b b /
a b b a
конец каждого ФОЧ становится очевидным только при по-строении соответствующего под-ДВ. Как показано на рис. 9.9,

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
294 первый ФОЧ заканчивается в позиции 8 (поддерево 1); второй ФОЧ заканчивается в позиции 2 (поддерево 2); последний ФОЧ заканчивается в позиции 10 (поддерево 3). Таким обра-зом, хромосомы ПГВ содержат несколько ФОЧ и любой ФОЧ кодирует структурно и функционально уникальное под-ДВ. В зависимости от задачи, эти под-ДВ могут выбираться инди-видуально в соответствии с их пригодностью (например, в за-дачах с множественными выходами) или они могут формиро-вать более сложные мультипод-ДВ и быть выбранными со-гласно пригодности целого мульти-под-ДВ. Ниже представ-лены образцы выражений и детали селекции. Тем не менее, нужно учитывать, что любое под-ДВ является отдельной сущ-ностью и частью более сложной иерархической структуры, и как во всех сложных системах, целое есть большим, чем сумма его частей.
Послетрансляционные взаимодействия и соединительные функ-ции. В ПГВ от простейшего индивида к более сложному пред-ставление генетической информации начинается с трансля-ции, преобразования информации от гена в ДВ. Раньше пока-зано, что трансляция приводит к формированию под-ДВ раз-ных размеров и форм, но, в большинстве случаев, полное вы-ражение генетической информации требует взаимодействия этих под-ДВ одного с другим. Одно из наиболее простых взаи-модействий - соединение под-ДВ с использованием специаль-ной функции. Этот процесс подобен объединению разных элементов белка в многоэлементный белок. Если под-ДВ явля-ются алгебраическими или логическими выражениями, то лю-бая алгебраическая или логическая функция с более чем од-ним аргументом может использоваться, чтобы связать под-ДВ в финальное мультиэлементное ДВ. Функции, которые чаще всего выбираются, является суммой или произведением алгеб-раических под-ДВ и логическими функциями Or или Іf для булевих под-ДВ.
Выражение (9.26) и рис. 9.10 отображают соединения трех под-ДВ с использованием сложения. 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 +b Q * * b + - - b/ b a / * Q * a * - / b a b a b b b b a a a b a b a b a b a a a a a b (9.26)
Отметим, что финальное ДВ может линейно кодироваться, как следующее K-выражение:

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
295
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 + + * +- Q * b Q- b a * - * / b / a b a * b a / a a+ b a a a b (9.27)
поддерево 1 поддерево 2 поддерево 3
+ –
b
*
b b
a
Q –
*
+ b
*
a
* Q
a
* /
a
b
/
a b a b
a a
Рис . 9.10. Алгебраические мультигенные хромосомы ка к многэлементные де ревья выражений. ДВ - результат послетрансляционной с вязи с доба влением. Функции связи показанные темным цветом
Q
+
Q
+
b a –
b a
+
b
*
–
/ b
a
b
а a
+
/
* –
/
a
b a a
a
ДВ

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
296 Тем не менее, решение сложных задач будет более эффек-
тивным, если использовать мультигенные хромосомы, для кото-рых разрешена модульная конструкция сложных иерархических структур, где каждый ген кодирует маленький строительный блок. Эти маленькие строительные блоки отделены один от дру-гого и каждый из них эволюционирует независимо. И вдобавок, эти мультигенные системы более эффективны, чем унигенные. Действительно, ПГВ – это эффективная иерархическая система, способная к выявлению простых блоков и использованию их для формирования более сложных структур.
Рис. 9.11. Выражения булевых мультигенных хромосом как мультиэлементные деревья выражений. Под-ДВ кодируют любой ген. Результат посттрансляции связан функцией Іf.
Функция связи выделенная темным цветом
поддерево 1
дерево
поддерево 3
O I
c A
N c I A
b
a a a
A
a
b I a
A
b c
a b
b
I
поддерево 2
O I
c A
N c I A
b
a a a
A
a
b I a
A
b c
a b
b

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
297 На рис. 9.11 и в выражении (9.29) показан другой пример по-слетрансляционного взаимодействия, где три булевых под-ДВ связывает функция Іf(x,y,z) (если x = 1, то вернуть y; иначе вер-нуть z).
Снова, мульти-подэлемент ДВ может быть линеаризиро-ван в следующее K-выражение:
012345678901234567890123IOIAcIANAcbbAc Ibba a a a a a b (9.28)
где "N" обозначает функцию NOT, "A" − AND, "O" − OR, "I" − If.
Итак, для каждой задачи вид функции связи, как и число ге-нов и длина каждого гена является априорным выбором. Пытаясь решить задачу, мы можем всегда начать с использования хромо-сомы, которая состоит из простого гена, а потом продолжать, уве-личивая длину ее "головы". Если она становится очень большой, мы можем увеличить количество генов и очевидно выбираем функцию для связи под-ДВ. Мы можем начать с добавления ал-гебраических выражений или использования OR для логических выражений, но в некоторых случаях другая функция соедине-ния, возможно, была бы более оптимальной (подобно умноже-нию или ІF, например). Идея - найти приемлемое или оптималь-ное решение и ПГВ обеспечивает его поиск эффективно.
012345678901234501234567890123450123456789012345OcIbAcaabcbc caaaIANAIbbaaaabaaabAcbcI caaaac accaa . (9.29)
Генетические операторы и эволюция. Генетические операто-ры - ядро всех генетических алгоритмов и два из них являются общими для всех эволюционных систем: селекция и репро-дукция. Фактически, они могут только вызвать генетический дрейф, делая популяции меньшими и менее разнообразными с течением времени, пока все индивиды не станут одинаковы-ми (см. (9.30)-(9.32) ниже). Итак, основа всех эволюционных систем – модификация, или точнее, генетические операторы, которые являются базой вариаций. Но в разных алгоритмах модификации выполняются по-разному. Например, в ГА, в основном, используются мутация и рекомбинация; ГП базиру-ется на почти эксклюзивной ГП-специфической рекомбина-ции; а в ПГВ имеет место мутация, рекомбинация и переме-щение.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
298
Покоління №: 001234567890120123456789012*+- /a* aaaaa aa/ /+*aaa aaaaaa -[0] = 10.64033/ - /a/ / aaaaa aa+*+a/+a aaaaaa -[1] = 16.2117*+a-+a aaaaa aa- - -// / a aaaaaa- [2] = 13.81953+a*/- a aaaaa aa**+a*aa aaaaaa- [3] = 18.32701*-+a/ - aaaaa aa /aa +a/a aaaaaa- [4] = 11.13926+*//a / aaaaa aa- - - aa-a aaaaaa- [5] = 13.88255*-*-*a aaaaa aa/ - a // /a aaaaaa- [6] = 7.777691/++a-*aaaaa aa/ + a*+-a aaaaaa- [7] = 13.14786// +*aaaaaaa aa*+ -/ - -a aaaaaa- [8] = 7.713599-**+- /aaaaa aa*/ /a a /a aaaaaa- [9] = 8.73985
(9.30)
Покоління №: 101234567890120123456789012*+a- +aaaaaaaa - - -/ / / aaaaaaa -[0] = 13.81953/- /a / / aaaaaaa +*+a/ +aaaaaaa -[1] = 16.2117*-+a/ - aaaaaaa / aa+a / aaaaaaa- [2] = 11.13926+*//a / aaaaaaa - - -aa - aaaaaaa- [3] = 13.88255+a*/- aaaaaaaa ** +a*a aaaaaaa- [4] = 18.32701-**+- / aaaaaaa */ / aa/ aaaaaaa- [5] = 8.73985-**+-/ aaaaaaa */ / aa/ aaaaaaa- [6] = 8.73985//+*aa aaaaaaa *+- / -- aaaaaaa- [7] = 7.713599/++a-*aaaaaaa /+a*+- aaaaaaa- [8] = 13.14786/- / a/ /aaaaaaa +*+a/+ aaaaaaa- [9] = 16.2117
(9.31)
Покоління №: 8 01234567890120123456789012/ -/ a // aaaaa aa+*+a/+ aaaaaaa -[0] = 16.2117/- / a // aaaaa aa+*+a/+ aaaaaaa- [1] = 16.2117/- / a // aaaaa aa+*+a/+ aaaaaaa- [2] = 16.2117/- / a // aaaaa aa+*+a/+ aaaaaaa- [3] 16.2117/- / a // aaaaa aa+*+a/+ aaaaaaa- [4] = 16.2117/- / a // aaaaa aa+*+a/+ aaaaaaa- [5] = 16.2117/- / a // aaaaa aa+*+a/+ aaaaaaa- [6] = 16.2117/- / a // aaaaa aa+*+a/+ aaaaaaa- [7] = 16.211
7/- / a // aaaaa aa+*+a/+ aaaaaaa- [8] = 16.2117/- / a // aaaaa aa+*+a/+ aaaaaaa- [9] = 16.2117
(9.32)
За исключением ГП, которое серьезно ограничено средст-
вами генетической модификации, в ГА и ПГВ возможно осуще-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
299 ствлять последовательность генетических операторов, способ-ных служить причиной генетической диверсификации потому, что хромосомы обоих алгоритмов легко разрешают свою им-плементацию. Фактически несколько генетических операторов выполняются в ПГВ, проливая свет на динамику эволюционных систем, но что важно - они разрешают предусмотреть необхо-димую степень генетической диверсификации, чтобы состоя-лась эволюция. Мутация сама по себе (безусловно, главнейший оператор) способная удивлять. Тем не менее, использование мутации и других генетических операторов не только разреша-ет эффективную эволюцию, но и дублирование строительных блоков, их циркуляцию в генетическом пуле, создание после-довательностей, которые повторяются, и т.д., делая результаты действительно интересными.
Ниже мы рассмотрим, как работают генетические операто-ры (включая селекцию и репродукцию) и как они легко могут быть имплементированы в ПГВ.
Селекция и репродукция. Все искусственные системы ис-пользуют схему отбора индивидов в соответствии со значе-ниями их приспособленности. Несколько схем - полностью детерминированы, тогда как другие включают элемент не-предсказуемости. Для ПГВ выбрано одну из последних, а именно пропорциональную схему колеса рулетки пригодно-сти, связанную с клонированием лучших индивидов (про-стой эллитизм), что точно имитирует естественные механиз-мы и продуцирует приемлемые результаты.
В соответствии со значением приспособленности и дви-жением рулетки, индивиды выбираются для размножения. Несмотря на жизненную ценность, размножение - наиболее неинтересный оператор. Во время размножения хромосомы определенным образом копируются в следующее поколение. Наиболее приспособленные индивиды с большей вероятно-стью оставляют больше потомков. Во время размножения ге-номы отобранных индивидов копируются столько раз, сколь-ко "разрешит" рулетка. Рулетка раскручивается столько раз, сколько есть индивидов в популяции, поддерживая размер популяции постоянным.
Выражения (9.30) и (9.31) демонстрируют как размножают-ся отобранные индивиды (другие операторы и эллитизм не учитываются, чтобы лучше понять размножение и выбор ко-леса рулетки). Начальная популяция показана в (9.30), ее не-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
300 посредственные потомки – в (9.31). Значения, указанные после каждой хромосомы, являются ее пригодностью. Например, хромосома 3 - лучший индивид поколения 0 оставляет лишь одного потомка (хромосома 4 из поколения 1); хромосома 1 - вторая лучшая хромосома из поколения 0 оставляет два по-томка (хромосомы 1 и 9 из поколения 1); хромосома 0 - сред-ний индивид, гибнет, не оставляя потомков; и, несмотря на то, что одна, наиболее непригодная хромосома 6 из поколе-ния 0 не размножается; посредственный индивид - хромосома 9 оставляет одно из наибольших потомств (хромосомы 5 и 6 из поколения 1). Результат такого эволюционного процесса по-казан в (9.32), где мы можем видеть, что в поколении 8 все ин-дивиды - потомки только одного индивида: в данном случае хромосомы 1 из начальной популяции (см. (9.30 и (9.31)). Дейст-вительно, размножение и селекция самостоятельно способны к порождению генетического дрейфа. После 8-ми итераций по-пуляция теряет разнообразие и все ее индивиды являются по-томками хромосомы 1 из начальной популяции.
Мутация. Мутации могут происходить где угодно в хро-мосоме. Тем не менее, структурная организация хромосом должна остаться неповрежденной. В "головах" любой символ может измениться на другой (функцию или терминал); в "хвостах" терминалы могут только измениться на терминалы. Таким образом, структурная организация хромосом сохраня-ется и все новые индивиды, порожденные вследствие мута-ций, - структурно правильные программы.
В основном используется коэффициент мутации ( mp ) эк-вивалентный двухточечным мутациям в хромосоме. Рассмот-рим следующую трехгенную хромосому:
012345678900123456789001234567890Q+bb*bbbaba-** -- abbbaaQ*a*Qbbbaab
(9.33)
Предположив, что мутация заменила "*" в позиции 4 в гене 1 на "/"; "-" в позиции 0 в гене 2 на "Q"; "a" в позиции 2 в гене 3 на "+", получим:
012345678900123456789001234567890Q+bb/bbbabaQ**--abbbaaQ*+*Qbbbaab
(9.34)
Отметим, что, если функция вследствие мутации становится терминалом или наоборот, или функция одного аргумента превращается в функцию двух аргументов или наоборот, ДВ значительно изменяется. Заметим также, что мутация в гене 1

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
301 служит примером нейтральной мутации, поскольку она про-исходила в некодированном регионе гена. Следует подчерк-нуть, что некодированные регионы хромосом ПГВ являются идеальными местами для накопления нейтральных мутаций. В результате в ПГВ нет никаких ограничений ни на вид мута-ции, ни на число мутаций в хромосоме: во всех случаях ново-образованные индивиды - синтаксически правильные про-граммы.
Перемещение и вставка последовательности элементов. Взаи-мозаменяемые элементы ПГВ - фрагменты генома, которые мо-гут быть активированы и способны осуществить прыжок на другое место в хромосоме. В ПГВ есть три вида взаимозаменяе-мых элементов: − короткие фрагменты с функцией или терминалом на первой позиции, которые перемещаются к "голове" генов кроме корня (вставка последовательности элементов или - ІS-элементов); − короткие фрагменты с функцией на первой позиции, кото-рые перемещаются к корню генов (корень - ІS-элементы или элементы RІS); − полные гены, которые перемещаются к началу хромосом.
Перемещение ІS-элементов. Любая последовательность в ге-номе может стать ІS-элементом, будучи при этом элементами, случайно выбранными из хромосомы. Копия транспозона сделана и вставлена в любую позицию в "голове" гена, кроме первой позиции. В основном коэффициент перемещения ( isp ) равняется 0,1 и используется множество из трех ІS-элементов разной длины. Оператор перемещения случайно выбирает хромосому, начало ІS-элемента, целевую сторону и длину транспозона.
Рассмотрим следующую двухгенную хромосому: 0123456789012345601234567890123456- aba+Q-baabaabaabQ*+*+- /aa babbaaaa
(9.35)
Предположим, что последовательность "a+Q" в гене 1 (пози-ции 3-5) была случайно выбрана, чтобы стать ІS-элементом и перемещена между позициями 2-3 в гене 2, тогда получим:
0123456789012345601234567890123456-aba+Q-baabaabaabQ*+a+Q*+ababbaaaa
(9.36)
Отметим, что с одной стороны, последовательность транспо-зона становится такой, что дублируется, но, с другой стороны, последовательность многих символов как ІS-элемент была

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
302 изъята в конце "головы" целевого гена (в данном случае по-следовательность "-/a" была изъята). Поэтому, несмотря на вставку, структурная организация хромосом сохраняется и поэтому все новые индивиды, созданные при перемещении, - синтаксически правильные программы.
Корневое перемещение. Все RIS-элементы начинаются с функций и потому выбираются среди последовательностей "голов". Для этого случайно выбирается точка в "голове" и ген просматривается сверху вниз, пока функция не будет найде-на. Эта функция становится стартовой позицией RIS-элемента. Если никакие функции не найдены, оператор не выполняет никаких действий.
В основном используется коэффициент перемещения ( risp ), который равняется 0,1, и множество из трех RІS-элементов разной длины. Этот оператор случайно выбирает хромосому, ген, который подлежит мутации, начало RІS-элемента и его длину. Рассмотрим двухгенную хромосому:
0123456789012345601234567890123456*-bQ/ ++/babbabbba / /Q*baa+bbbabbbbb
(9.37)
Предположим, что последовательность 'Q/+' в гене 1 была случайно выбрана, чтобы стать RIS-элементом. Далее копия транспозона размещается в корне гена и получим:
0123456789012345601234567890123456 Q/+*-bQ/babbabbba / /Q*baa+bbbabbbbb
(9.38)
Заметим, что на протяжении транспозиции, "голова" переме-щается, чтобы приспособить RIS-элемент, теряя, в то же вре-мя, последние символы "головы" (столько, какой есть длина транспозона). В данном случае последовательность '++/' была изъята и транспозон только частично продублирован. Как и с ІS-элементами, "хвост" гена подвергнут перемещению, и все соседние гены остались неизменными. Заметим, что новооб-разованные программы синтаксически правильные, так как структурная организация хромосомы сохраняется.
Генное перемещение. В генном перемещении полные генные функции как и транспозон перемещают себя на начало хро-мосомы. В отличие от других форм перемещения, в генном перемещении транспозон (ген) изымается из начального мес-та.
Очевидно, что перемещение гена способно только к пере-становке генов, и для ДВ, связанных коммутативными функ-циями, это не способствует адаптации при коротком запуске.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
303 Тем не менее, перемещение генов очень важно, если объеди-няется с другими операторами (всеми видами ПГВ-рекомбинации; смотрите ниже), для которых можно не толь-ко дублировать гены, но и обобщить рекомбинацию генов или меньших строительных блоков.
Хромосома, которая подлежит генному перемещению, вы-бирается случайно и один из ее генов (кроме первого, в ос-новном) случайно выбирается для перемещения. Рассмотрим следующую хромосому, которая состоит из 3-х генов:
012345678901201234567890120123456789012/+Qa*bbaaabaa *a*/Qbbbbbabb /Q-aabbaaa bbb
(9.39)
Предположим, что был выбран ген 3 для генного перемеще-ния. Получим следующую хромосому:
012345678901201234567890120123456789012/Q-aab baaabbb /+Qa*bbaaabaa*a* /Qbbbbbabb
(9.40)
Отметим, что для многих приложений, где функция, выби-раемая для связи генов, является коммутативной, выражение, оцениваемое хромосомой, не изменяется. Но ситуация отли-чается в других приложениях, где функция связи не является коммутативной, например, функция ІF, выбранная, чтобы связать некоторые под-ДВ в булевых задачах (см. рис. 9.11). Заметим, что в данном случае перемещение гена производит сильный эффект, генерируя большую часть времени нежиз-неспособных индивидов.
Рекомбинация. В ПГВ есть три вида рекомбинации: одното-чечная рекомбинация, двухточечная рекомбинация и генная рекомбинация гена. Во всех видах рекомбинации две случай-но выбранных хромосомы обмениваются определенным ма-териалом между собою, создавая две новых дочерних хромо-сомы. Обычно дочерние хромосомы отличаются одна от дру-гой и от своих родителей.
Одноточечная рекомбинация. При одноточечной рекомби-нации пары хромосом разделяются в определенной точке. Материал, зависимо от точки рекомбинации, обменивается между двумя хромосомами.
Рассмотрим следующие хромосомы родителей: 0123456789012345601234567890123456+*-b-Qa*aab bbbaaa -Q-/ /b /*aa bbabbab ++//b/ / - bbbbbbbbb -* -ab/ b+bbbaabbaa
(9.41)
Предположим, что точка разрыва находится в точке 6 гена 1 (между позициями 5 и 6). Она была случайно выбрана точкой

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
304 кроссовера. Потом две хромосомы разрезаются в этой точке и соответствующие фрагменты обмениваются, формируя по-томков как показан ниже:
0123456789012345601234567890123456+*-b-Q/ -bbbbbbbbb -*- ab/ b+bbbaabbaa++//b/ a*aabbbbaaa -Q-/ / b/ *aabbabbab
(9.42)
Следует заметить, что при такой рекомбинации большинство потомков будут иметь свойства, отличные от родительских. Подобно вышеупомянутым операторам, одноточечная ре-комбинация – важный источник генетических изменений, будучи после мутации одним из операторов, которые зачас-тую выбирают в ПГВ. В зависимости от значений коэффици-ентов видов рекомбинации, которые остаются, используют коэффициент одноточечной рекомбинации ( lrp ) со значени-ем между 0,3 и 0,7. Приемлемо правило, согласно которому используют коэффициент глобального кроссовера, который равен 0,7 (сумма коэффициентов трех видов рекомбинации).
Двухточечная рекомбинация. В двухточечной рекомбина-ции выбирается пара хромосом, и случайным образом две точки выбираются точками кроссовера. Материал, который находится между точками рекомбинации, обменивается меж-ду двумя родительскими хромосомами, и формируются две новых дочерних хромосомы
01234567890123456 01234567890123456*-+Q/Q*QaaabbbbabQQab*++-aabbabaabQ/-b -+/ a baabbbaab / * -aQa*babbabbabb
(9.43)
Предположим, что точка разрыва находится в точке 5 гена 1 (между позициями 4 и 5) и точка разрыва находится в точке 7 гена 2 (между позициями 6 и 7). Они были выбраны как точки кроссовера. Тогда будут созданы такие хромосомы:
0123456789012345601234567890123456 *-+Q/+ /abaa bbbaab /*- aQa*-aabbabaab Q/-b-Q*QaaabbbbabQQab*++babbabbabb
(9.44)
Следует заметить, что некодированные регионы хромосом ПГВ - идеальные регионы, где хромосомы могут быть разде-лены, не считаясь с ФОЧ и фактически на протяжении поиска эти регионы - наилучшие для скрещения.
Одноточечная или двухточечная рекомбинация, которая происходит после мутации, - операторы, которые чаще всего используются в ПГВ. Действительно, взаимодействие мутации

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
305 и одноточечной или двухточечной рекомбинации – это ис-точники генетического разнообразия, и этого более чем доста-точно, чтобы решать практически любые задачи.
Генная рекомбинация. В третьем виде ПГВ-рекомбинации - генной рекомбинации полные гены обмениваются между двумя родительскими хромосомами, формируя две дочерних хромосомы, которые содержат гены обоих родителей. Обме-ненные гены случайно выбираются и занимают свои позиции в родительских хромосомах. Рассмотрим следующие роди-тельские хромосомы:
012345678901201234567890120123456789012 /+/ ab- aabbbbb -aa**+ aaabaaa -+-- babbbbaab +baQaaaabaaba *-+a-a abbabbb/ ab/ +bbbabaaa
(9.45)
Предположим, что ген 2 был выбран для обмена. В данном случае потомки будут такими:
012345678901201234567890120123456789012 /+/ ab- aabbbbb* -+a- aabbabbb -+-- babbbbaab +baQaaaabaaba- aa**+aaabaaa /ab/ +bbbabaaa
(9.46)
Дочерние хромосомы содержат полные гены от обоих ро-дителей. Отметим, что при этом виде рекомбинации подоб-ные гены могут быть обменены, но, в основном, обмененные гены являются совсем разными и в популяцию вводится но-вый материал.
Следует заметить, что этот оператор не может создать но-вые гены: созданные индивиды являются разным размещени-ем существующих генов. Понятно, что если генная рекомби-нация используется как уникальный источник генетического разнообразия, более сложные задачи могут быть разрешимы лишь с использованием очень больших начальных популя-ций для того, чтобы обеспечить необходимое разнообразие генов. Тем не менее, креативная сила ПГВ базируется не толь-ко на перестановке генов или строительстве блоков, но и в по-стоянном создании нового генетического материала.
Решение простой задачи с помощью ПГВ. Целью этого пара-графа является изучение того, как популяции индивидов ПГВ эволюционируют в направлении получения оптимального или приемлемого решения.
В символьной регрессии или идентификации функции це-лью является нахождение выражения, которое удовлетвори-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
306 тельно объясняет зависимую переменную. Вход системы – это множество обучающих образов в форме ( ( ,0) ( ,1) ( , 1), , ..., , )i i i n ia a a y , где ( ,0) ( , 1),...,i i na a − независимые пе-ременные и iy – зависимая переменная. Множество обучаю-щих образов состоит из среды адаптации, где решения адапти-руются, определяя в этом процессе решения задачи.
В примере этого параграфа выбрана простая тестовая функция с помощью компьютерной генерации обучающих образов. Поэтому, в данном случае, мы знаем точно, какая функция является целевой (тем не менее, помним, что в ре-альных задачах функция, очевидно, неизвестна). Итак, пред-положим, что мы получаем выборку числовых значений кри-вой
2y=3a 2 1. a (9.47)
Имеем больше 10 случайно выбранных действительных точек в интервале [-10, 10] и нам необходимо найти функцию, ко-торая отвечает этим значением в границах определенной ошибки. В данном случае набор данных определяется 10-ю парами ( ,i ia y ), где ia – значение независимой переменной в данном интервале, а iy – соответствующее значение зависи-мой переменной (табл. 9.1). Эти 10 пар – обучающие образы (вход), которые будут использоваться как среда адаптации. При-годность специфической программы будет зависеть от того, как хорошо она будет выполняться в этой среде.
Таблица 9.1. Множество из 10 значений пригодно-сти, которые используются в простой задаче сим-
вольной регрессии a ( )f a -4,2605 46,9346 -2,0437 9,44273 -9,8317 271,324 2,7429 29,0563 0,7328 4,07659 -8,6491 208,123 -3,6101 32,8783 -1,8999 8,02906 -4,8852 62,8251 7,3998 180,071

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
307 Есть пять главных шагов при подготовке использования
ПГВ и первый - это выбрать функцию пригодности. Для этой задачи мы могли бы определить пригодность if i -й индиви-дуальной программы по такому выражению:
( , )1
tC
i i j jj
f M C T ,
(9.48)
где M – коэффициент селекции, ( , )i jC – значение, возвращенное индивидуальной хромосомой i для значения пригодности j (вне обучающих образов tC ) и jT – целевое значение для зна-чения пригодности j . Если ( , ) i j jC T (точность) меньше или равна 0,01, то точность равняется нулю, а max . i tf f C M Для этой задачи будем использовать 100M и потому max 1000.f Преимущество этого вида функции пригодности это то, что система может найти оптимальное решение для самой себя.
Второй главный шаг состоит в выборе множества терми-налов T и множества функций F для того, чтобы создать хромосомы. В этой задаче терминальное множество состоит из независимой переменной, то есть { }.T a Выбор соответст-вующего множества функций не такой очевидный, но опреде-ленное предположение всегда может быть сделано для того, чтобы включить все необходимые функции. В данном случае для упрощения будем использовать четыре основные арифме-тические операторы. Итак, F ={+,-,*,/}.
Третий главный шаг - выбрать архитектуру хромосомы, то есть длину "головы" и количество генов. В этой задаче мы будем использовать 6h и три гена в хромосоме.
Четвертый главный шаг в подготовке использования ПГВ- выбрать функцию соединения. Свяжем под-ДВ посредством сложения.
И заключительный пятый главный шаг - выбрать совокуп-ность генетических операторов, которые создают вариации и их степень. В данном случае мы будем использовать комбина-цию всех генетических операторов (мутация, три вида пере-мещения и три вида рекомбинации) ( табл. 9.2).
Параметры, которые будут использоваться для работы, све-дены в табл. 9.2. Для этой задачи выбрана маленькая популяция из 20 индивидов для того, чтобы упростить анализ эволюцион-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
308 ного процесса и не наполнять страницы текстом кодированных индивидов. Тем не менее, одно из преимуществ ПГВ - это спо-собность решать относительно сложные задачи с использовани-ем популяций маленьких размеров, и благодаря компактным Karva-нотациям возможно полностью проанализировать эволю-ционную историю работы.
Таблица 9.2. Параметры задачи для простой символьной
регрессии a ( )f a
Число поколений 50 Размер популяции 20 Количество начальных значений 10 (табл. 9.1) Совокупность функций + - * / Длина гена 13 Число генов 3 Функция соединения + Длина хромосомы 39 Коэффициент мутации 0,051 Коэффициент одноточечной реком-бинации
0,3
Коэффициент двухточечной реком-бинации
0,3
Коэффициент генной реком-бинации
0,1
Коэффициент ІS-перемещения 0,1 Длина ІS-элементов 1,2,3 Коэффициент RІ-перемещения 0,1 Длина RІ-элементов 1,2,3 Коэффициент генного перемеще-ния
0,1
Степень селекции 100 Точность 0,01
Начальная популяция для успешного запуска программы вместе с пригодностью каждого индивида показана в (9.49). Для каждой задачи генерируется такая начальная полностью случайная популяция.
Отметим, что три из 20 индивидов нежизнеспособны и по-этому имеют нулевое значение пригодности. Лучший инди-вид поколения - хромосома 19, имеет пригодность 661,5933. Ее

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
309 выражение и соответствующая запись показаны на (9.50) и рис. 9.12. Отметим, что ген 2 возвращает ноль и поэтому мо-жет рассматриваться как псевдоген. Заметим также, как имен-но алгоритм создал константы во всех под-ДВ.
Потомки индивидов начальной популяции показаны в (9.51). Отметим, что хромосома 0 - это клон лучшего индивида предшествующего поколения. В этом поколении новый ин-дивид, который был создан, хромосома 7, намного лучше, чем лучший индивид начальной популяции.
Generation №: 0 012345678901201234567890120123456789012+**/ */ aaaaaaa / +a/a* aaaaa aa/ a- *a+aaaaaaa -[ 0]=577.3946- -aa++aaaaaaa + - /a*/ aaaaaaa / -- a-aaaaaaaa -[ 1]=0/***/+ aaaaaaa* + /+- aaaaaaaa++ aa/aaaaaaaa- [ 2]=463.6533-/ + /++aaaaaaa+-/ / + /aaaaaaa+-/ a / *aaaaaaa- [ 3]=546.4241++a/*aaaaaaaa+-+a*-aaaaaaa-a/-*aaaaaaaa-[ 4] =460.8625*+*a-*aaaaaaa*a/aa/aaaaaaa//+*a/aaaaaaa-[ 5] =353.2168*/**+aaaaaaaa+a/**+aaaaaaa -f/aaaaaaa-[ 6]=492.6827*aa-+-aaaaaaa+a/-+/aaaaaaa***/-*aaaaaaa- [ 7] =560.9289+/-*//aaaaaaa*+*//+aaaaaaa-/**+*aaaaaaa-[ 8] =363.4358--a+*/aaaaaaa+a++--aaaaaaa+a+aa+aaaaaaa-[ 9] =386.7576+-*-**aaaaaaa*/-+**aaaaaaa*+--++aaaaaaa- [10]=380.6484/a-**/aaaaaaa/-a/a/aaaaaaa+/a/-*aaaaaaa-[11] =0+--+//aaaaaaa+*+/*-aaaaaaa/*-a-+aaaaaaa-[12] =551.2066-a/+a/aaaaaaa*/--/aaaaaaaa*-+/a+aaaaaaa-[13] =308.1296/+/- + -aaaaaaa+-a/aaaaaaaaa** + -*-aaaaaaa- [14]=0//-*+/aaaaaaa//*a+aaaaaaaa/a++a*aaaaaaa-[15] =489.5392*a-a*-aaaaaaa+*+-a/aaaaaaa*/*aa*aaaaaaa-[16] =399.2122-a++*/aaaaaaa+/aa-*aaaaaaa /**aaaaaaa-[17] =317.6631--a/*aaaaaaaa++* + -aaaaaaaa+-/*-i--aaaaaaa-[18]=597.8777*+++-/aaaaaaa/--///aaaaaaa+-+aaaaaaaaaa-[19] =661.5933
(9.49)
012345678901201234567890120123456789012 *+++-/aaaaaaa / - -/ / / aaaaaaa +-+aaaaaaaaaa (9.50)
В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
310
Generation №: 1012345678901201234567890120123456789012*+++-/aaaaaaa/--///aaaaaaa+-+aaaaaaaaaa-[ 0] = 661.5933-a-n-*/aaaaaaa+//a--aaaaaaa /**aaaaaaa-[ 1] = 0+-*-**aaaaaaa*/-+**aaaaaaa*+--++aaaaaaa-[ 2] = 380.6484+ -*-**aaaaaaa*/--i-**aaaaaaa*/*a**aaaaaaa- [ 3]= 356.9471+-+aaaaaaaaaa*+++-/aaaaaaa/--///aaaaaaa-[ 4] = 661.5933*aa- + -aaaaaaa+a/++/aaaaaaa***-i--*aaaaaaa- [ 5]= 567.9289*a-a*-aaaaaaa+/*-a/aaaaaaa* + -*+-t-aaaaaaa- [ 6]= 449.802*aa- + -aaaaaaa+a/--i-/aaaaaaa* + --++aaaaaaa- [ 7]= 961.8512/***/+aaaaaaa*+/+-aaaaaaaa-a/-*aaaaaaaa-[ 8] = 470.5862+--+//aaaaaaa+*+/*-aaaaaaa/*-a-+aaaaaaa-[ 9] = 551.2066*+++-/aaaaaaa-//--/aaaaaaa+-+aaaaaaaaaa-[10] = 0~-+a*-aaaaaaa++a/*aaaaaaaa-a/-*aaaaaaaa-[11] = 487.3099-a-n-*/aaaaaaa+/aa-*aaaaaaa /**aaaaaaa-[12] = 317.6631++a/*aaaaaaaa+-+a*-aaaaaaa++aa/aaaaaaaa-[13]= 451.464+ ---t-/-aaaaaaa+a/**+aaaaaaa +/aaaaaaa- [14] = 493.5336*/-a++aaaaaaa+/aa-*aaaaaaa /**aaaaaaa-[15] = 356.4241+/-*//aaaaaaa*+a//+aaaaaaa-/+*+*aaaaaaa-[16] = 493.9218*/**+aaaaaaaa+*+/*aaaaaaaa***/-*aaaaaaa-[17] = 448.4805+-*-**aaaaaaa*/-+**aaaaaaa*+--++aaaaaaa-[18] = 380.6484++a/*aaaaaaaa+--fa*+aaaaaaa--/-*aaaaaaaa-[19] = 380.8585
(9.51)
012345678901201234567890120123456789012 *+++-/aaaaaaa / - -/ / / aaaaaaa +-+aaaaaaaaaa (9.52)
У этой хромосомы пригодность 961,8512 и ее выражение показано в (9.52) и на рис. 9.13.
Рис. 9.12. Наилучшие индивиды начальной популяции
+
– +
a a a a
/
– –
/ / / a
*
+ +
– + / a
a a a a a a a a a a a a
aaay 2022 2
поддерево 1 поддерево 2 поддерево 3

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
311
Потомки индивидов этого поколения показаны в (9.53) (поколение 2). Отметим, что, несмотря на глобальное улуч-шение пригодности, ни один из потомков не превосходил лучшего индивида предшествующего поколения.
В следующем поколении (см. (9.54)) индивид с максималь-ной пригодностью был создан. Отметим, что эта хромосома яв-ляется потомком вследствие мутации хромосомы 18 из преды-дущего поколения: их хромосомы отличаются только в одной позиции ("-" в позиции 2 гена 1 заменен на "*"). Выражение этой хромосомы показывает, что она кодирует наилучшее решение (см. (9.55) и рис. 9.14).
поддерево 1 поддерево 2 поддерево 3
* +
a
+
а
Рис. 9.14. Перспективные решения, найденные в 3 поколении
/
a
*
/
*
a
a
*
– +
– + +
a a a a a a
*
a 12321 222 aaaaaay
* / / a
a a a a a a
a
поддерево 1 поддерево 2 поддерево 3
+ *
a
–
а
Рис. 9.13. Наилучшие индивиды первой популяции
/
a
+
a
/
a
a
*
– +
– + + a
a a a a a a
а
a 22 22
1 aaaaay

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
312
Generation №: 2012345678901201234567890120123456789012*aa-+-aaaaaaa+a/-+/aaaaaaa*+--++aaaaaaa-[ 0] = 961.8512*/**+aaaaaaaa*/-+**aaaaaaa***/-*aaaaaaa-[ 1] = 446.2061+-*-**aaaaaaa*+a//-aaaaaaa-/+*+*aaaaaaa-[ 2] = 323.1036+--+//aaaaaaa+*+/*-aaaaaaa/*-*-+aaaaaaa-[ 3] = 551.2066*aa-+-aaaaaaa+a/++/aaaaaaa***+-*aaaaaaa-[ 4] = 567.9289++a/*aaaaaaaa*/- + -*aaaaaaa* + --++aaaaaaa- [ 5] = 0+-*-**aaaaaaa+*+/*aaaaaaaa*/*a**aaaaaaa-[ 6] = 386.6484++a/*aaaaaaaa+-+/*-aaaaaaa+aa++aaaaaaaa- [ 7] =466.1533+-*-a*aaaaaaa*/-+**aaaaaaa*a*a**aaaaaaa-[ 8] = 194.0452/***/+aaaaaaa*+/+-aaaaaaaa-a--*aaaaaaaa-[ 9] = 541.4829+-*-+*aaaaaaa+-+a*-aaaaaaa***/-*aaaaaaa- [10]= 346.2235--*+*-aaaaaaa*aa-+-aaaaaaaaa/-+/aaaaaaa-[11] = 467.0862*/-+**aaaaaaa+-*-*+aaaaaaa*/*a**aaaaaaa- [12]= 672.877*aa+*/aaaaaaa4-a/- + /aaaaaaa* + -- ++aaaaaaa-[13] =961.8512*+++/+aaaaaaa*++/+-aaaaaaa-a/-*aaaaaaaa-[14] = 395.858/***-/aaaaaaa/--///aaaaaaa+-+a-aaaaaaaa- [15] = 467.0862*aa-+-aaaaaaa+a/++/aaaaaaa***+-*aaaaaaa-[16] = 567.9289+ -+aaaaaaaaaa*+++-/aaaaaaa/--///aaaaaaa-[17] = 661.5933+/-*//aaaaaaa*/a+**aaaaaaa*+--++aaaaaaa-[18] = 903.8886*/**+aaaaaaaa+*+/*aaaaaaaa+/aa/aaaaaaaa- [19]= 423.885
(9.53)
Generation № : 3012345678901201234567890120123456789012*aa+*/aaaaaaa+a/-+/aaaaaaa*+--++aaaaaaa-[ 0] = 961.8512*aa-+-aaaaaaa+a/-+/aaaaaaa/--///aaaaaaa-[ 1]= 560.9289*aa- + -aaaaaaa-++/-i--aaaaaaa-a/-*aaaaaaaa- [ 2]= 558.2066*++-f/4-aaaaaaa*+a/-+aaaaaaa++-- + +aaaaaaa-[ 3]= 569.0469/+++/+aaaaaaa*++/+-aaaaaaa-a/-*aaaaaaaa-[ 4] = 699.5153+-+aa/aaaaaaa++++-/aaaaaaa***+-*aaaaaaa-[ 5] = 466.1533*aa-+-aaaaaaaaa--**aaaaaaa*+--++aaaaaaa-[ 6] = 957.9443--++*-aaaaaaa*a+/*-aaaaaaa+aa+-t-aaaaaaaa- [ 7]= 337.7807*aaa*/aaaaaaa+a+-+/aaaaaaa*+-/++aaaaaaa-[ 8] = 953.9443/***/-aaaaaaa*+/+-aaaaaaaa-a--*aaaaaaaa- [ 9] = 0*aa- + ~aaaaaaa-i-a/--t-/aaaaaaa*/--++aaaaaaa- [10]= 560.9289*aa--"--aaaaaaa+a/++/aaaaaaa/--///aaaaaaa- [11] = 567.9289+-+a-aaaaaaaa/***-/aaaaaaa*+--++aaaaaaa-[12] = 676.0663+ /**//aaaaaaa*/a+**aaaaaaa* + --++aaaaaaa- [13]= 1000*/-+**aaaaaaa+-*-*+aaaaaaa*/*a**aaaaaaa- [14]= 672.877/***/+aaaaaaa/+*+/+aaaaaaa-a*/--aaaaaaa-[15] = 498.3734+/-*//aaaaaaa*/a+-*aaaaaaa* + --++aaaaaaa- [16] = 0--*+--aaaaaaa*/a-+-aaaaaaa/a/-+/aaaaaaa-[17] = 506.1233++a/*aaaaaaaa+-a- + -aaaaaaa-a*- + /aaaaaaa- [18]= 815.7772*+a//-aaaaaaa+a/-+/aaaaaaa-/ + *+*aaaaaaa- [19] = 412.5237
(9.54)
а) 012345678901201234567890120123456789012 +/**//aaaaaaa*/a+**aaaaaaa*+--++aaaaaaa . (9.55)

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
313 Поиск функции. Мы увидели, как ПГВ может использоваться
для выполнения символьной регрессии на простом примере Тем не менее, хотя целевая функция содержит простые числовые константы (3, 2 и 1), их было нелегко сгенерировать: алгоритм создал их сам.
В этом параграфе будет показано, как ПГВ решает задачу яв-ной генерации констант при выполнении символьной регрес-сии. И вдобавок определим, что явного использования констант лучше избежать, поскольку с помощью ПГВ получаем лучшие результаты, когда числовые константы не явным образом ис-пользуются и в системе находятся новые пути их представле-ния.
Функция поиска и создания числовых констант. Рассмотрим два разных подхода к задаче создания констант: один – без использования эфемерных случайных констант, а другой – с использованием эфемерных случайных констант. В первом подходе используются специальные условия для получения числовых констант. В втором подходе система создает их или находит альтернативные пути представления.
Числовые константы могут быть легко определенными в ПГВ. Для этого создается дополнительная область cD . Струк-турно cD находится после "хвоста", имеет длину равную t и состоит из символов, которые используются для представления эфемерных случайных констант. Таким образом, в хромосоме создается другой регион с его границами и собственным алфа-витом.
Для каждого гена константы случайно генерируются в на-чале запуска, но их циркуляция гарантируется генетически-ми операторами. Кроме того, создан специальный оператор мутации, который разрешает перманентное введение вариа-ции во множество случайных констант. ІS-перемещение со специфической областью также создано для того, чтобы га-рантировать эффективную перестановку констант. Отметим, что базовые генетические операторы не влияют на cD : нужно только придерживаться границ каждого региона и не смеши-вать разные алфавиты.
Рассмотрим хромосому, которая содержит один ген с 11h ( cD показана жирным):
01234567890123456789012345678901234 *?+?/ *a -* /* a???? a??a?? a 281983874486 (9.56)

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
314 где "?" обозначены эфемерные случайные константы. Выра-жение для такой хромосомы (рис. 9.15) получаем аналогично представленному выше.
Изменив "?" в ДВ слева направо и сверху вниз символами в cD , получим рис. 9.16:
Значения, которые отвечают этим символам, сохраняются в массиве. Например, для 10-элементного массива А={-2,83; 2,55; 2,40; 2,98; 2,44; 0,66; 1,80; -1,27; 2,83; 1,62}, хромосома (9.56), представленная выше, отвечает рис. 9.17.
В дальнейшем осуществим сравнительный анализ двух подходов к поиску решения относительно сложной задачи. Для теста выбрана следующая "V"-подобная функция:
2 24,25 ln( ) 7,243 ay a a e , (9.57)
где a − независимая переменная, e − иррациональное число 2,71828183. Для обоих подходов мы сравним результаты, кото-рые получены для 100 независимых запусков по 5000 поколе-ний каждый (табл. 9.3).
*
2 +
*
/
Рис. 9.16
8
a
– *
a 1
*
/
a 8 3 9
*
? +
*
/
Рис. 9.15
?
a
– *
a ?
*
/
a ? ? ?

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
315
Таблица 9.3. Значение общих параметров, использованных при поиске "V"-подобной функции со случайными констан-
тами и без них Со случай-
ными кон-стантами
Без слу-чайных констант
Количество запусков 100 100 Количество поколений 5000 5000 Размер популяции 100 100 Количество начальных значений 20 (см. табл.
9.4) 20 (см. табл. 9.4)
Множество функций +-/LEK~SC +-/LEK~SC Длина «головы» 6 6 Количество генов 4 5 Функция связи + + Длина хромосомы 80 65 Коэффициент мутации 0,044 0,044
*
2.399 +
*
/
Рис. 9.17
2.826
a
– *
a 2.55
*
/
a 2.826 2.979 1.618

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
316
Коэфф. одноточ. рекомбинации 0,3 0,3 Коэфф. двухточ. рекомбинации 0,3 0,3 Коэффициент генной рекомбина-ции
0,1 0,1
Коэффициент IS-транспозиции 0,1 0,1 Длина IS-элементов 1,2,3 1,2,3 Коэфф. RIS-транспозиции 0,1 0,1 Длина RIS-элементов 1,2,3 1,2,3 Коэфф. генной транспозиции 0,1 0,1 Коэфф. случайной константной мутации
0,01 0,01
Коэффициент ДС специальной ІS-транспозиции
0,1 −
Длина ДС специального ІS-элемента
1,2,3 −
Ранг селекции 100% 100% Погрешность 1% 1% Средняя наилучшая пригодность по всем запускам
1850,476 1934,619
Первый подход: прямое манипулирование рациональными кон-
стантами. В этом случае множество функций содержит, кро-ме ожидаемых функций, некоторое количество внешних функций { , ,*, /, , , , , , } F L E K ~ S C (' L ' обозначает натураль-ный логарифм, " E " – xe , " K " – логарифм с основанием 10, "~" – 10x , " S "– синус и " C " – косинус), { ,?}T a , набор случай-ных констант R = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} и эфемерная случай-ная константа "? " ранжирует сверху интервал [-1,1].
Набор 20 случайных обучающих образов из интервала [-1,1] показан в табл. 9.4 и пригодность оценена по (9.48):
( , )
1
100 .
tCi j j
ij j
C Tf M
T
(9.58)
Если значение 100),(
j
jji
TTC
(точность) меньше или рав-
няется 0,01%, то точность равняется нулю и ( , ) .i jf M Для на-шей задачи 100%M и 20;tC тогда max 2000.f

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
317
Таблица 9.4. Набор 20 случайных обучающих обра-зов, которые использованы в поиске функции "V"-
подобной формы a ( )f a -0,2639725157548009 3,194980662652764 0,0578905532656938 1,990520017259985 0,3340252901096346 8,396637039972868 -0,2363345775644623 3,070889769728257 -0,8557443825668047 5,879467636957033 -0,0194437136332785 -0,7753263223284588 -0,1921343881833043 2,834702257744086 0,5293079101246271 12,21547266421373 -0,007889741187284598 -2,498039834186359 0,4389698049506311 10,40717348588088 -0,1075592926980396 2,094136356459081 -0,2745569943771633 3,239272780108398 -0,05953332196045281 1,197012847673475 0,3844929939583523 9,355807691898551 -0,8749230207363339 6,006424530013026 -0,236546636250546 3,071897290438372 -0,1678759417045577 2,674400531309863 0,9506821818220914 22,48196398441491 0,9469791595773622 22,37501611873555 0,6393399100595915 14,5701285332337
В этом эксперименте было сделано 100 идентичных запусков программы. Параметры, которые использованные в запусках, показаны в первом столбике табл. 9.3. Лучшее решение было найдено при 79 запуске после 3619 поколений. Лучшее решение по значению 2R показано ниже (под-ДВ связываются сложением):
0
1
Ген 0: L*~*+/aa?a??a2132990 A = {0,565;0,203;0,613;0,219;0,28;
0,25;0,48;0,427;0,821;0,127} Ген 1: E-+-*?aaaaaaa7332660
А = {0,031;0,046;0,696;0,643;0,528; 0,417;0,978;0,811;0,637;0,988}
2
3
Ген 2: ~Saaa+??aa??a9109969А = {0,515;0,466;0,254;0,219;0,425;
0,942;0,306;0,619;0,821;0,262} Ген 3: ~SSaES?????aa5420661
А = {0,595;0,547;0,525;0,219;0,2970,387;0,508;0,695;0,728;0,415}
.
(9.59)

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
318
Он имеет пригодность 1975,264 и 2R =0,9999439, которые вы-числены на множестве 20 обучающих образов против значения
2R =0,9999075, полученного на тестовом наборе из 100 обучаю-щих образов. Его выражение показано на рис. 9.18.
Эта модель - лучше всего приближена к целевой функции как по значению 2R , так и в результате сравнения графиков це-левой функции и модели.
Следует заметить, что, несмотря на объединение констант в вычисленных результатах, полученные константы очень отлича-ются от ожидаемых. Действительно с помощью ПГВ (и всех гене-тических алгоритмов) можно найти ожидаемые константы с точ-ностью до третьего или четвертого знака после запятой, если це-левые функции - простые полиномиальные функции с рацио-нальными коэффициентами и/или, если мы можем предполо-жить довольно точно функциональное множество, в противном случае будут получены очень "креативные" решения.
Второй подход: создание рациональных констант. Для второго подхода эволюция модели непосредственно без использова-ния случайных констант, множество начальных значений и функциональное множество такие же, как и раньше, и
{ }.N a Параметры, использованные при запуске программы, по-
казаны во втором столбце табл. 9.3. В этом эксперименте с 100
*
~ *
+
a
/ a
Рис. 9.18. Модель (9.59) получена с использованием способности к манипуляции случайными константами. Под-ДВ кодируются каждым геном. Соответствующие математические выражения после соединения путем
сложения (вклад каждого под-ДВ показан в квадратных скобках)
L
0,613 a 0,203
–
+ –
+
a
a a
E
0,613
a
~
S
a
~
S
S
a
поддерево 1 поддерево 2 поддерево 3 поддерево 4
2
0,613210
0,8110,203 sin sinsinln 10 10a a
a aay e

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
319 идентичными запусками, лучший результат был найден в 1210 поколении при 63 запусках программы:
0 1 2 3 4 5 6 7 8 9 0 1 2+E L - * / a a a a a a a~a +E / L a a a a a a a+C+C+E a a a a a a a*C ~+ aS a a a a a a a~a - L ~+ a a a a a a a
(9.60)
Он имеет пригодность 1982,488 и значение 2R =0,9996922, вычисленное на множестве 20 начальных значений против
2R =0,9999460, вычисленного на приведенном выше тестовом на-боре, и потому лучше, чем модель (9.59) эволюционировал со спо-собностью к созданию случайных констант. Эта модель также больше отвечает целевой функции. Ее выражение показано в (9.61) и на рис. 9.19. 012 3456789012012345678901201 2345678901201234567890120123456789012 +EL-*/ aaaa aaa~a+E/ Laaaa aaa+C+C+Eaaaa aaa*C~+aSaaa aaaa~a -L~+aaaa aaa
(9.61)
E
– *
+
/ a a
Рис. 9.19. Модель получена без явного использования случайных констант
L
a
+
+
E +
a a a
*
a
~
a
~
a
поддерево 1 поддерево 2 поддерево 4 поддерево 5
aaaaa aaeaaaey 1010sincos2coscos10ln 21
поддерево 3
~ C
a +
a S
a
C
C
a
a
Сравним результаты, полученные в обоих подходах. Не
только модель (9.60), которая эволюционировала без случай-ных констант, была лучшей, чем модель, которая эволюцио-нировала со случайными константами, но и среднее значение наилучших в запуске образов было большим во втором под-ходе: 1934,619 против 1850,476 (см. табл. 9.3). Поэтому в прак-тических задачах, где моделируется сложная действитель-ность, где невозможно сделать вывод ни о типе, ни о ряде чи-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
320 словых констант, где в большинстве случаев мы не можем ус-тановить точный функциональный набор, более рациональ-но разрешить системе моделировать действительность без ис-пользования случайных констант. Возможно, модели были бы не совсем стандартными в сравнении с созданными челове-ком, но они разрешают, тем не менее, "добывать знания", так как программы, которые эволюционируют в ПГВ, просты и доступны. Следует заметить, что некоторые обучающие алго-ритмы, которые подобные нейросетевым, не разрешают до-бывать знания из своих моделей, тогда как анализ других ус-ложненных моделей является значительно ограниченным.
Поиск функции в пятимерном пространстве параметров. Цель этого параграфа – показать, как ПГВ может использо-ваться для моделирования сложной действительности с высо-кой точностью. Для тестирования выбрана функция, которая содержит пять параметров:
)tan(10
)cos()sin( edbayc
,
(9.62)
где b, c, d, и e – независимые переменные. Предположим, что мы имеем выборку числовых значений
этой функции в 100 случайных точках из интервала [-1,1] и хо-тели бы найти функцию, которая приближает эти значения в границах 0,01% от правильного значения. Пригодность оцени-вали по уравнению (9.58) при 100%.M Тогда для
max100 10000. tC f Предметная область этой задачи предусматривает, кроме
арифметических функций, использование ( ),sqrt x log( ),x 10 ,x sin( ),x cos( ),x и tan( )x в наборе функции, которой отве-чает Q, K ~, S, C и G. Поэтому для этой задачи F = {+,-,* /, Q, K ~, S, C, G} и T состоит из независимых переменных {а, b, c, d, e}.
Далее выбраны 3-генные хромосомы, которые кодируют под-ДВ с максимальным количеством – 19 узлов.
Под-ДВ после трансляции связывают сложением. Парамет-ры, которые используются при запусках программы, приведе-ны в табл. 9.5. Для моделирования этой функции использовано программное обеспечение Automatіc Problem Solver (APS), так как это разрешает осуществлять легкую оптимизацию проме-жуточных решений и легкое тестирование эволюционирую-щих моделей на тестовом наборе. При одном запуске прием-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
321
лемый результат с 2R =0,9999913, вычисленный на тестовом множестве с 200 случайных точек, был найден:
01 2345 6789012345678SS *-GKcaCbbccbeabdbaC--SKaeGceadddabadG-de*add+adedabdeaa
(9.63)
Рис. 9.20. Модель развитая ПГВ к пятипараметрической функции
S
S
a
*
C
– G
C K a
b
G
–
e d
поддерево 1 поддерево 3 поддерево 2
edaacby tantancoslogsinsin
Его выражение показано в (9.64) и на рис. 9.20. Эта модель
является приемлемым приближением к целевой функции (9.62), на что указывает значение 2R (почти 1). С APS можно преобразовать эволюционные программы на языке Karva в соответствующую компьютерную программу. Например, приведенная выше модель (9.63) может быть автоматически транслированной в следующую функцию C++:

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
322 double APSCfunction(double d[ ]) {
double dblTemp=0; dblTemp+=sin(sin(((log10(cos(d[l]))-d[2])*tan(d[0])))); dblTemp+=d[0]; dblTemp+=tan((d[3]-d[4]));
return dblTemp; }
012345678901234567801234567890123456780123456789012345678 SS*-GKcaCbbccbeabdbaC--SKaeGceadddabadG-de * add+adedabd eaa (9.64)
Отметим, что элемент, кодированный в последнем гене, точно отвечает второму элементу целевой функции. Тем не менее, очень непривычной и неэкономной альтернативой является выражение для первого элемента целевой функции. Но модель, которая эволюционирует в ПГВ, чрезвычайно точна, поскольку указывает на верхнее значение для 2R .
Таблица 9.5. Параметры для задания поиска функции
в пятимерном параметрическом пространстве Число поколений 1000 Размер популяции 100 Количество начальных значений 100 Набор функций +-*/QK-SCG Длина гена 19 Число генов 3 Функции соединения + Длина хромосомы 57 Коэффициент мутации 0,044 Коэффициент одноточечной рекомбина-ции
0,3
Коэффициент двухточечной рекомбина-ции
0,3
Коэффициент генной рекомбинации 0,1 Коэффициент ІS-перемещения 0,1 Длина ІS-элемента 1,2,3 Коэффициент RIS-перемещения 0,1 Длина RIS -элемента 1,2,3 Коэффициент генного перемещения 0,1 Степень селекции 100% Точность 0%

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
323 Выводы. С одной стороны, выше приведены детали выпол-нения алгоритма ПГВ, которые разрешают его легкое пони-мание и использование. С другой стороны, функционирова-ние алгоритма было проанализировано шаг за шагом для простой задачи символьной регрессии. И вдобавок вопрос о создании констант в символьной регрессии обсуждался со сравнением двух разных подходов к решению этой задачи: одним с явным использованием рациональных констант, а второй – без него. Представленные результаты свидетельст-вуют, что второй вариант лучше не только в терминах точно-сти эволюционных моделей и полной работы, оцененной в сроках средней пригодности, полученной при запуске про-граммы, но также потому, что область поиска значительно уменьшается, уменьшая тем самым сложность задач. Кроме того, отмечено как с помощью ПГВ рационально находить решения комплексной проблемы в пятимерном параметриче-ском пространстве с некоторым количеством внешних функ-ций, определяя почти наилучший результат со значением
2 0,9999913R .
9.3. Нечеткие системы как универсальные аппроксиматоры
Аддитивная нечеткая система может равномерно аппрок-симировать любую действительно определенную функцию в компактном пространстве с любой точностью. Аддитивная нечеткая система аппроксимирует функцию, покрывая ее график нечеткими сгустками во "вход-выход" пространстве состояний и усредняя сгустки, которые перекрываются. Если рассматривать нечеткие множества как случайные множества, то нечеткой системой вычисляется условное математическое ожидание E ( YX ). Каждое нечеткое правило определяет не-четкий сгусток и соединяет общесмысловые знания геометри-ей в пространстве состояний. Нейронные или статистические системы кластеризации могут аппроксимировать неизвестные нечеткие сгустки, исходя из тренировочных данных. Такие адаптивные нечеткие системы аппроксимируют функцию на 2-х уровнях. На локальном уровне нейронная система ап-проксимирует и настраивает нечеткие правила. На глобаль-ном уровне правила или сгустки аппроксимируют функцию.
Нечеткая аппроксимация как нечеткое покрытие. Нечеткая

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
324 система аппроксимирует функцию, покрывая ее график не-четкими сгустками и усредняя сгустки, которые перекрыва-ются. Точность аппроксимации улучшается при увеличении количества сгустков и уменьшении их размеров. На рис. 9.21 показано как нечеткие сгустки в пространстве "вход-выход"
YХ покрывают точно определенную функцию YXf : . На рис. 9.21а несколько больших сгустков аппроксимируют f . На рис. 9.21б меньшие сгустки лучшее аппроксимируют f . Точность аппроксимации увеличивается, если прибавить
больше маленьких сгустков, но тогда необходимо больше па-мяти и возрастает сложность. Эти короткие условия опреде-ляют алгебраические детали нечеткой аппроксимации.
Y f
X
f Y
X а) б)
(а) Четыре больших нечетких сгустка покрывают часть графика неизвестной функции : .f X Y Незначительное количество сгустков уменьшает вычислительную сложность и точность аппроксимации. (б) Меньшие нечеткие сгустки лучшее покрывают f , но значительно возрастает необходимое количество вычислений. Каждое нечеткое правило определяет сгусток в пространстве .X Y Большое, но конечное количество нечетких правил или четких правил покрывает график с достаточной точностью.
Рис. 9.21. Аппроксимация функции нечеткими сгустками
Нечеткая система является множеством нечетких правил "если-то", которые отображают входы в выходы. Каждое не-четкое правило определяет нечеткий сгусток во "вход-выход" пространстве состояний функции. На рис. 9.22 показано не-четкое правило "Если Х – отрицательное маленькое, то Y – позитивное маленькое" как декартово произведение PSNS "нечетких" или мультизначных множеств NS и PS . 3-Д ри-сунок показал бы нечеткий сгусток PSNS как параллеле-пипедоподобную структуру, которая нависает над своей пря-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
325 моугольной основой. Каждый вход относится в определенной степени к каждому входному нечеткому множеству. Так, каж-дый вход в определенной степени влияет на все нечеткие пра-вила. Эксперты формируют нечеткие правила, нейронные или статистические системы, исходя из данных выборки. Экс-перты и алгоритмы могут определить разные множества не-четких правил и таким образом получают разные аппрокси-мации функции.
Далее будет показано, что нечеткая система может ап-проксимировать любую непрерывную действительнозначную функцию, определенную на компакте (замкнутом и ограни-ченном множестве в nR ), а также установлено, что даже двух-валентная экспертная система может равномерно аппрокси-мировать ограниченную измеримую функцию. Нечеткая сис-тема имеет архитектуру с прямым распространением сигнала, подобную мультислойной нейронной системе с прямым рас-
NL
PL
PM
PS
ZE
NS
NM
NL y
NM NS ZE PS PM PL
x
If X = NS, then Y = PS
Рис. 9.22. Нечеткое правило как сгусток в пространстве или декартово произведение нечетких множеств. Произведение сгустков NS PS определяется нечетким правилом "Если Х отрицательное маленькое, то Y – попложительное маленькое". Здесь трапеции и треугольники определяют нечеткие или мультизначные множества.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
326 пространением сигнала, которой пользуются для аппрокси-мации функций. Равномерная аппроксимация непрерывных функций разрешает нам заменить каждое непрерывное не-четкое множество конечной дискретизацией, точкой в еди-ничном гиперкубе или "нечетким кубом" высокой размерно-сти.
К. Хорник, Х. Уайт (K. Hornіk, H. Whіte) и другие использовали теорему функционального анализа Стоуна-Вейэрштрасса (Stone-Weіerstrass), чтобы показать равномерную сходимость при нейросетевой аппроксимации. Теорема Стоуна-Вейэрштрасса указывает на то, что, если хС является sup-нормированным пространством непрерывных функций на компактном хаусдорфовом множестве Х и, если
( )A C x является замкнутой алгеброй, и А содержит отдель-ные точки и функции-константы, тогда xCA . Это являет-ся значительным результатом, но не указывает на то, как по-строить или исследовать реальную систему. Радиально-базисные нейросети, в которых вычисляются гауссовские функции, также равномерно аппроксимируют непрерывные функции на компактных множествах. Аддитивные нечеткие системы с гауссовскими нечеткими множествами определяют радиально-базисные сети, которые тоже являются равномер-ными аппроксиматорами. Ниже в теореме это прямо доказано для всех аддитивных систем. Конструктивное доказательство показывает, как использовать нейронные системы для обуче-ния правилам и как разрешить правилам или сгусткам изме-няться во времени, отслеживая поведение нестационарных функций.
Аддитивные нечеткие системы. Подавая на входы "если"-части jA всех нечетких правил "если jAX , то jBY », по-лучают взвешенную сумму jB на выходе. Раньше нечеткие системы вычисляли результирующие нечеткие множества jB как попарный максимум в соответствии с так называемым "принципом обобщения". Аддитивные нечеткие системы рас-считывают суммы выходов (рис. 9.23)
1
.m
j jj
B w B
(9.65)
Сначала положим значения весовых адаптационных ко-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
327
эффициентов 1jw . Предельные теоремы показывают, как работают разные комбинационные схемы. Комбинации сумм часто имеют тенденцию определять симметричное унимо-дальное распределение как исходное нечеткое множество В . Это представляет глобальный исходный центроид в (9.67) как простую выпуклую сумму множества центроидов в (9.70).
If 1A, then 1B
If 2A, then 2B
If nA , then mB
A ix
1B
mB
2B
1w
2w
тw
B Centroidal Deffuzzier jy
Рис. 9.23. Архитектура адитивной нечеткой системы.
Комбинируя результирующие нечеткие множества mBBB ,...,, 21 (рис. 9.24) и используя попарный максимум, по-
лучим огибающую нечетких множеств и тенденцию к равно-мерному распределению. В общем, лемма Бореля-Кантелли из теории вероятностей указывает на то, что по "принципу обобщения"теории нечетких множеств значения функции принадлежности стремится к бинарному значению конечной точки
1 2limsup ... ni i i ix x x b , (9.66)
которую получают с вероятностью 1 для попарно независи-мых, невырожденных последовательностей случайных пере-менных j
ix , которые принимают значения в ba, . Символ « » означает операцию попарного минимума. Так, в общем, "принцип обобщения" не обобщает нечеткое множество во-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
328 обще. Он дефаззифицирует нечеткое множество к бинарному распределению. На практике в нечетких системах 1n b . Если количество ненулевых выходов нечетких правил возрас-тает, огибающая локально возрастает к постоянному значе-нию 1. Глобально выход стремится к прямоугольному им-пульсу.
Комбинация максимумов игнорирует перекрытие нечет-ких множеств jB . Комбинация сумм прибавляет перекрытие к остроконечности B . Если значительно изменяется вход, значительно изменяется аддитивный выход B . В полученном как комбинация максимумов выходе могут быть проигнори-рованы такие входные изменения, поскольку для больших множеств правил большие изменения случаются в области перекрытия нечетких множеств jB . Проблема перекрытия возникает, поскольку центроид имеет тенденцию оставаться таким же для незначительных изменений входов. Но центро-ид сглаживает изменения в сумме нечетких множеств.
Центроидная дефаззификация сглаживает проблему мак-симума. Интегральная мультизначная функция 1;0: YmB дает центроидный выход jy или xF как
.
B
j
B
ym y dyy
m y dy
(9.67)
Мы можем заменить интегралы в (9.67) суммами с малень-кой дискретизацией индексированными только по количест-ву нечетких множеств, дискретизирующих нечеткие пере-менные (см. (9.69) ниже). Это исключает необходимость ап-проксимации центроида и ее вычислительную сложность. Ес-ли число комбинируемых исходных множеств jB возрастает, центроидная дефаззификация имеет тенденцию к совпаде-нию с модальной дефаззификацией, поскольку центроид и мода совпадают для симметричного унимодального распре-деления.
Нечеткая аппроксимация функции. Суммарный вывод сво-дится к взвешенной сумме

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
329
m
jj
jij BawB
1
,
(9.68)
где jia – это степень, с которой вход ix принадлежит к нечет-
кому множеству iA в правиле или области jj BA . Аддитив-ные нечеткие системы могут аппроксимировать функцию
YXf : , уменьшая сгустки в размере и увеличивая их ко-личество. Для доказательства не предусматриваем обучения и правила являются равновероятными: 1...21 mwww .
Уравнение (9.68) – это простая аппроксимационная теоре-ма. Предположим, что YXf : является измеримой и ог-раниченной. Тогда B – простая функция, если множества jB не являются нечеткими множествами. Заменим треугольники, трапеции и прочие нечеткие множества прямоугольниками. Простая функция YXs : отображает X в конечное мно-жество значений Y . Простая функция есть конечной суммой взвешенных функций-индикаторов. Выберем соответствую-щие значения ia как весовые коэффициенты и рассмотрим не нечеткие множества или прямоугольное разбиение X . Тогда s это простая функция, -близкая к f на .X Ограничения на f гарантируют равномерную аппроксимацию. Это пока-зывает, что достаточно большая экспертная система искусст-венного интеллекта может аппроксимировать любую ограни-ченную измеряемую функцию, и напоминает нам, что нечет-кие правила редуцируют в двухвалентном случае к правилам экспертной системы. Это не показывает, что аддитивная не-четкая система с мультизначными множествами сходится равномерно к f . Но на практике результат может иметь не-ограниченную ошибку. Эта проблема возникает потому, что треугольники, трапеции и прочие нечеткие множества не обязательно сходятся равномерно к прямоугольникам.
Равномерная сходимость имеет место, если учитывать не-прерывность вместо измеримости. Теорема ниже требует, чтобы YXf : была непрерывной и множество X было компактом (замкнутым и ограниченным множеством) в R . Теорема показывает, что в принципе аддитивная нечеткая система с конечными нечеткими правилами может аппрок-симировать любую непрерывную функцию с любой точно-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
330 стью. Это включает и гауссов результат как специальный слу-чай.
Теорема FAT. Аддитивная нечеткая система F равномер-но аппроксимирует YXf : , если X является компактом и f - непрерывная функция.
Доказательство. Возьмем некоторую маленькую константу 0 . Мы
должны показать, что xfxF Xx . X является компактным подмножеством в nR . xF – центроидный выход (9.67) или (9.70) аддитивной нечеткой системы F в (9.68).
Непрерывность f на компакте X дает равномерную не-прерывность. Пусть фиксированное расстояние является таковым, что для всех x и z из X , 4
zfxf , если
zx . Мы можем сконструировать множество открытых кубов mMMM ,...,, 21 , которые покрывают X и имеют упоря-доченные перекрытия своих n координат так, что угол каж-дого куба совпадает со средней точкой jc его соседа jM . За-даны симметричные исходные нечеткие множества jB цен-трированные относительно jf c . Так центроидом jB являет-ся jf c .
Пусть Xu . Тогда по построению u лежит в более чем n2 перекрытых открытых кубах jM . Пусть некоторое w при-
надлежит тому же множеству кубов. Если jMu и kMw , то для всех kj MMv : vu и v w . Из равномер-ной непрерывности следует, что 2
wfvfvfufwfuf . Тогда для цен-
тров кубов jc и kc , ( ) ( ) / 2.j kf c f c Пусть Xx . Тогда x также лежит в более чем n2 откры-
тых кубах с центрами jc и 2jf c f x . По всей длине k -й координаты ранжированного пространства pR k -я ком-понента центроида аддитивной системы xF лежит как и в

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
331
(9.70) на или между k -ми компонентами центроидов jB -
множеств. Тогда 2j kf c f c для всех jf c ,
2jF x f c и
2 2j jF x f x F x f c f c f x . Доказательство может требовать симметричных исходных
нечетких множеств jB , если минимум корреляции кодирует правила jj BA . Кодирование по произведению корреляций не требует симметрии, поскольку jj Ba имеет тот же центро-ид jB , если 0ja .
Доказательство показывает, что можно заменить нечеткие множества jA и jB конечной дискретизацией или соответст-вующими векторами j
njj aaa ,...,, 21 и j
njj bbb ,...,, 21 . Дискрет-
ная версия jB должна иметь центроид около или близко к центроиду jB . Так всегда можно работать с многомерными единичными кубами и видеть нечеткие правила или сгустки как матричные соответствия (или нечеткую ассоциативную память между гиперкубами, или как точки в даже большем гиперкубе.).
Доказательство является неверным для В , полученного как комбинация максимумов. В доказательстве центроидный выход ВС или jy в (9.67) размещается между центроидами 1BC и mBC , если mBCBCBC ...21 :
1
1
m
j jj
j jm
jj
A B C BС B c C B
A B
,
(9.69)-(9.70)
для объема или области j BX
A B m x dx и для выпуклой об-
ласти коэффициентов mccc ,...,, 21 . Л. Ванг (L. Wang) назвал эти элементы "функциями нечеткого базиса". Доказательство справедливо для любого комбинированного исходного мно-жества mBBB ,...,1 , такого, что mBCBC 1 . В об-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
332
щем, для комбинации максимумов 1m
jjB не выполняется
1 j mj
C B C B C B . Неравенство выполняется в триви-
альном случае, если maxsum . Поскольку yxyxyx ,max,min , то max , x y x y .
Если 0x или 0y , то комбинированные множества mBB ,...,1 являются разделенными. Доказательство также ра-
ботает для нецентроидных дефаззификаторов BD , для ко-торых mBCBDBC 1 . В общем, дефаззификатор су-премума или максимума функции принадлежности не удов-летворяет это неравенство.
Нечеткие системы как условные ожидания. Почему "fuzzy" аппроксимационная теорема? Почему "fuzzy" – это нечеткая система? Простая нечеткость происходит от пересечения свойств или множества A и его дополнения cA . A − нечеткое множество, если cAA . Нечеткие системы могут не быть нечеткими в этом простом смысле. Конечная область BA исходного множества B означает, что BA нормализу-
ет B , чтобы получить B как плотность условной вероятно-сти xyp :
.BB p Y X xA B
(9.71)-(9.72)
Можно считать нечеткие множества iA и jB случайными множествами или геометрическим местом точек двухточеч-ной плотности условной вероятности. Мера множества xmA равна xXAp , т.е. вероятности события A при условии, что случайная величина X принимает значение x из облас-ти или является индексом. Очевидно, что соответствующее значение xmPM – это вероятность того, что x является По-ложительным Средним, если X x . Равенство PMX озна-чает, что случайная величина X будет на всем случайном множестве Положительным Средним как значение из слу-чайного множества. Тогда для входа x каждое правило вы-полняется с определенной условной вероятностью. Система

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
333 связывает каждый выход с некоторой условной вероятностью. Выход равняется локальному среднему или условному мате-матическому ожиданию. Если выход – это значение максиму-ма вероятности, система вычисляет максимум а posterіorі.
Центроид (9.67) дает тот же результат, как и (9.72) и озна-чает, что выход нечеткой системы xF равняется реализации условного математического ожидания:
xXYExF . (9.73)
С такой точки зрения нечеткая система – вероятностная система. Она вычисляет случайную величину XYE или PLNMNLXYE ,...,, . Просуммированные сгустки дают
независимую от модели оценку YXf : . Это условное ожидание является среднеквадратичным оптимумом среди всех нелинейных оценок f , которые зависят от "множеств" или плотностей PLNMNL ,...,, . В аппроксимационной теоре-ме утверждается, что аддитивные нечеткие системы форми-руют -окрестность (условных математических ожиданий) вокруг f .
Адаптивные нечеткие системы. Адаптивная нечеткая сис-тема – это нечеткая система, которая изменяется с течением времени. Множества или правила изменяются по форме и ко-личеству. Обучающая система изменяет весовые коэффици-енты нечетких правил 1 2, ,..., m для набора входных-выходных данных ,...,,, 2211 yxyx . На практике весовые ко-эффициенты ограничивают нулем и единицей. Если весовые коэффициенты j равняются или превышают пороговое значение, положим 1j и прибавим нечеткое правило к нечеткой системе или "базе знаний". Если j – меньшее по-роговое значение, 0j и j -е правило игнорируется и не включается в нечеткую систему.
Адаптивные нечеткие системы оценивают нечеткие пра-вила, исходя из обучающих данных. Это сводится к оценке сгустков или кластеров в пространстве YX , которое назы-вают произведением пространств кластеризации. Нейронные или статистические кластеризационные алгоритмы конвер-тируют обучающие данные ii yx , в оценки кластеров. Обу-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
334 чающие данные определяются экспертами или физическими процессами. Кластеризационные алгоритмы ищут скрытые правила, которые эксперт или физический процесс "исполь-зует" для генерации данных.
Вектор количественно оценивает кластеры. Фиксирован-ное множество количественных векторов vmmm ,...,, 21 отсле-живает распределение обучающих данных. В нейронных сис-темах каждый количественный вектор jm определяет вход-ной (возбуждающий) синаптический вектор для нейрона се-ти, который функционирует в режиме "победитель забирает все". Нейронная система учится адаптироваться, тогда и толь-ко тогда, когда количественный (синаптический) вектор jm изменяется в пространстве YX входных-выходных значе-ний. В действительности, каждый количественный вектор jm оценивает локальный кластер в YX и, в оптимальном смысле, базирующемся на среднеквадратичной ошибке, стре-мится к кластерному центроиду экспоненциально быстро. Глобально, количественный вектор оценивает неизвестную совместную плотность вероятности yxp , , которая опреде-ляет приближение к парам данных наблюдения ii yx , . Ко-личественный вектор v оценивает вероятность любого ре-
гиона C как vnc , где количество количественных векторов в
C делится на общее количество количественных векторов. Кластеры количественных векторов оценивают нечеткие
сгустки. В любое время в обучающем процессе нечеткий сгу-сток ji BA содержит cn количественных векторов. Это ука-зывает на следование к адаптивной гистограмме или распре-делению частоты количественных векторов в rs перекрытом нечетком сгустке или ячейке. На практике мы можем считать ячейку занятой 1j , если она содержит определенный количественный вектор. Обучающие выборки, в общем, зна-чительно превышают фиксированные количественные векто-ры. В экстремальном случае мы можем считать каждый образ количественным вектором. В этом неограниченном случае не фильтруется шум и не сжимаются обучающие данные. На рис. 9.24 показано произведение пространств кластеризации

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
335 с количественным вектором после обучения, которое замед-лилось или закончилось. Малые точки на рис. 9.24а являются наблюдаемыми данными ii yx , . Большие точки на рис. 9.24б– это количественные векторы jm . Если установить по-роговое значение в два количественных вектора на ячейку, тогда произведение пространств кластеризирует поля 10 не-четких правил или сгустков. Другие обучающие схемы могут изменять кластерные регионы, группируя ковариационные эллипсоиды количественных векторов, и тогда могут изме-няться формы правил и множеств.
PL
PMPS
ZENSNM
NL
PLPMPSZENSNMNL
PLPMPSZENSNMNL
PL
PMPS
ZENSNM
NL
Рис. 9.24
Приведенная выше теорема о равномерной аппроксима-
ции указывает на то, что конечное количество векторов 1 2, ,..., m m m может обучить любую непрерывную функцию,
если обучающая система использует достаточно функцио-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
336
нальных примеров ,i iX f x и если количественные векторы сходятся к локальному центроиду. Некоторые типы конкури-рующего обучения гарантируют эту сходимость. В общем, это требует обучения с очень большим количеством векторов. В случае маленьких примеров можно уменьшить нечеткие сгу-стки и увеличить их количество, если использовать больше данных и увеличить количество адаптивных количественных векторов.
Выводы. Функционирование нечеткой системы или ап-проксиматора сводится к покрытию графика с локальным ус-реднением. Это не уникально. Аддитивная нечеткая система с гауссовскими множествами сводится к радиально-базисной нейросети, которая является тоже одним из многих покрытий графика. "Нечеткость" или мультизначность множеств имеет место, если сгустки или исходные множества пересекаются. Не нечеткие множества могут также "взвешивать" или усред-нять пересечения. Нечеткая система уникальна в том, что она старается неопределенные понятия, такие как "маленький" и "средний" привязать к математике кривых и соответствующих векторов (точек в единичном кубе). В ней сводится естествен-ный язык и правила общего содержания к "состояние-пространство" геометрии. Но "нечеткие" множества являются эквивалентными случайным множествам или геометрическо-му месту точек двухточечной условной вероятности. Нечет-кие системы дают независимую от модели оценку некоторого неизвестного условного математического ожидания / .E Y X Аппроксимационная сила нечетких систем состоит в их сво-боде от модели больше, чем в их нечеткой интерпретации. Заметим, что не нечеткие множества и сгустки правил также могут быть сведены к независимой от модели универсальной аппроксимации.
Практические задания
1. Разработать муравьиный алгоритм для задачи коммивоя-жера. Выполнить его верификацию.
2. Разработать муравьиный алгоритм для оптимизации по-лиэкстремальной функции. Выполнить его верификацию.
3. Разработать алгоритм AS и выполнить его верификацию на примере одной из известных задач.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
337
4. Разработать алгоритм MMAS и выполнить его исследова-ние и оптимизацию параметров.
5. Разработать алгоритм ACS и выполнить его верификацию на примере одной из известных задач.
6. Решите задачу генерации символьной регрессии по таб-личным данным (табл. 9.6).
Таблица 9.6 x 1 2 3 4 5 6 7 8 9 10 Y 5 15 29 47 69 95 125 159 197 239 x 1 2 3 4 5 6 7 8 9 10 Y 1 6 17 34 57 86 121 162 209 262 x 1 2 3 4 5 6 7 8 9 10 Y 2 -1 -2 -1 2 7 14 23 34 47 7. Для предшествующей задачи выполнить параметриче-
скую оптимизацию генетических операторов. 8. Исследовать эффективность алгоритмов ПГВ в зависимо-
сти от вариантов выбора рекомбинаций и мутации.
Контрольные вопросы и задачи для самопроверки
1. Что называется метаэвристикой? 2. Какие главные идеи, заимствованные у природы, лежат в
основе муравьиного алгоритма? 3. Назовите главные составные элементы муравьиного алго-
ритма и объясните их сущность. 4. Какие главные отличия ПГВ от других эволюционных ал-
горитмов? 5. Назовите особенности реализации разных вариантов ре-
комбинации и мутации в ПГВ и укажите их особенности. 6. Сформулируйте теорему FAT и укажите ограничения ее
применения. 7. Какую содержательную нагрузка имеют операторы
транспозиции в ПГВ? 8. Какие преимущества и при решении каких оптимизаци-
оннных задач предоставляют генетические алгоритмы?

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
338
Темы рефератов и расчетно-графических работ
1. Аналитический обзор современных метаэвристик. 2. Аналитический обзор практического применения ПГВ. 3. Особенности применения генетических операторов ПГВ. 4. Роль теоремы FAT при решении задач идентификации и
прогнозирования по нечетким экспертным заключениям.
Темы для самостоятельного
изучения 1. Применение генетического программирования для реше-
ния задач оптимизации. 2. Технологии поиска последовательностей. 3. Методы ассоциативного поиска.
Литература
Основные источники К параграфу 9.1: 1. Dorigo M., Gambardella L.M. Ant Colony System: A cooperative
learning approach to the traveling salesman problem. – IEEE Transactions on Evolutionary Computation. – 1(1):53–66, 1997.
2. Dorigo M., Maniezzo V., Colorni A. Ant System: Optimization by a colony of cooperating agents. – IEEE Transactions on Sys-tems, Man, and Cybernetics – Part B, 26(1):29–41, 1996.
3. Gambardella L.M., Dorigo M. Solving symmetric and asymmet-ric TSPs by ant colonies. – Proc. 96 IEEE Int. Conf. on Evolu-tionary Computation (ICEC'96). – IEEE Press: New York. – 1996. – P. 622.
4. Stützle T., Hoos H.H. MAX-MIN Ant System. – Future Genera-tion Comput. Syst. – 16(8). – 889. – 2000.
К параграфу 9.2: 1. Cramer N.L. A representation for the adaptive generation of sim-
ple sequential programs. – In J.J. Grefenstette, ed., Proceedings of

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
339
the First International Conference on Genetic Algorithms and Their Applications. – Erlbaum, 1985.
2. Dawkins R. River out of Edem. – Weidenfeld&Nicolson, 1995. 3. Ferreira C. 2001. Gene Expression Programming: A New
Adaptive Algorithm for Solving Problems. – Complex Systems. – 13(2). – 2001. – P. 87-129.
4. Goldberg D.E. Genetic Algorithms in Search, Optimization, and Machine Learning. – Addison-Wesley, 1989.
5. Holland J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence. – University of Michigan Press, 1975 (second edition: MIT Press, 1992).
6. Koza J.R. Genetic Programming: On the Programming of Computers by Means of Natural Selection. – Cambridge, MA: MIT Press, 1992.
7. Mitchell M. An Introduction to Genetic Algorithms. – MIT Press, 1996.
К параграфу 9.3.
1. Dickerson J.A., Kosko B. Fuzzy Function approximation with supervised ellipsoidal learning // INNS WCNN-93.: In Proc. World Congress on Neural Networks. − Vol. 2. − 1993. − P. 9-17.
2. Dubois D., Prade H. Fuzzy Sets and Systems: Theory and Ap-plications. − Orlando, FL: Academic Press, 1980. − 394 p.
3. Hartman E., Keeler J.D., Kowalski J. Layered neural networks with Gaussian hidden units as universal approximators // Neural Computation. − 1990. − Vol. 2. − P. 210-215.
4. Hornik K., Stinchombe M., White H. Multilayer feedforward networksare universal approximators // Neural Networks. − 1989. − Vol. 2. − P. 359-366.
5. Kosko B. Fuzzy knowledge combination // Int. J. Intell. Syst. − 1986. − Vol. 1. − P. 293-320.
6. Kosko B. Stochastic competitive learning // IEEE Trans. Neu-ral Netw. − 1991. − Vol. 2. − № 5. − P. 522-529.
7. Kosko B. Neural Networks and Fuzzy Systems: A Dynamical Systems Approach to Machine Intelligence. − Englewood Cliffs, NJ: Prentice Hall, 1991. − 452 p.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
340
8. Mead C. Analog VLSI and Neural Systems. − Reading, MA: Addison-Wesley, 1989. − 371 p.
9. Functional Analysis. − New York: McGraw-Hill, 1973. − 448 p. 10. Rudin W. Real and Complex Analysis, second ed. − New York:
McGraw-Hill, 1974. − 483 p. 11. Wang L., Mendel J.M. Fuzzy basis functions, universal ap-
proximation, and orthogonal least-squares learning // IEEE Trans. Neural Netw. − 1992. − Vol. 3. − № 5. −P. 807-814.
12. Zadeh L.A. Fuzzy sets // Information and Control. − 1965. − Vol. 8. − P. 338-353.
ПРИЛОЖЕНИЯ
Приложение А
ТЕМЫ КУРСОВОГО ПРОЕКТИРОВАНИЯ Курсовой проект предназначен для углубленного изуче-
ния теоретического материала, закрепления полученных зна-ний, приобретения практических навыков в создании интел-лектуальных информационных систем.
1. Моделирование работы многослойного бинарного перцептрона ( МБП ).
Задача: Разработать алгоритм и создать программное приложение, которое моделирует логические функции с по-мощью МБП. Предусмотреть введение логической функции, порогового значения, коэффициента обучения с клавиатуры, печать отчета о работе МБП. Исследовать работу МБП при различных значениях коэффициента обучения, порогового значения, количества нейронов в скрытом слое. Построить соответствующие отчеты.
2. Многослойный персептрон ( МП ). Алгоритм обрат-ного распространения ошибки ( АОРО ).
Задача: Разработать алгоритм и создать программное приложение, которое моделирует работу МП. Предусмотреть интерактивное введение количества входящих, исходящих нейронов, нейронов скрытого слоя, коэффициента обучения, точности результата, начальных значений. Исследовать рабо-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
341
ту МП при различных значениях коэффициента обучения, количества слоев, количества в них нейронов, функций акти-вации разных видов, типов нормализации. Построить графи-ки. Рассмотреть обобщение механизма функционирования МП на случай прогнозирования.
3. Многослойный персептрон. Задача классификации. Задача: На базе АОРО разработать алгоритм и создать программное приложение для классификации различных объектов. Предусмотреть описание и формализованную по-становку задачи, нормирования данных, вариацию внутрен-них параметров. Построить графики и отчеты. 4 . Применение АОРО для распознавания букв. Задача: Разработать алгоритм и создать программное приложение для ввода различных вариантов написания букв и их распознавания. Провести исследование эффективности функционирования АОРО при различных параметрах сети. Построить графики и отчеты. 5. Нейронная сеть с линейным поощрением ( НСЛП ). Задача: Разработать алгоритм и программный модуль, моделирующий работу НСЛП и предназначенный для реше-ния задачи прогнозирования. Исследовать ее эффективность. Построить графики и отчеты.
6. Задача классификации. Сеть Кохонена. Задача: Разработать алгоритм и создать программное
приложение для классификации различных объектов. Фор-мализовать задачу и исследовать эффективность функциони-рования НС в зависимости от значений внутренних парамет-ров. Построить графики и отчеты.
7. Задача классификации. Метод выпуклой комбина-ции.
Задача: Разработать алгоритм и создать программное приложение для классификации различных объектов. Фор-мализовать задачу и исследовать эффективность функциони-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
342
рования НС в зависимости от значений внутренних парамет-ров. Построить графики и отчеты. Разработать алгоритмы с такими опциями как "ощущение справедливости" и коррек-цией весов пропорционально значению выхода.
8. Задача распознавания образов. Сеть встречного рас-пространения ( СВР ). Задача: Разработать алгоритм и программное приложе-ние функционирования СВР, состоящий из слоев Кохонена и Гроссберга. Исследовать эффективность функционирования СВР в зависимости от внутренних параметров. Формализо-вать задачу. Построить графики и отчеты. 9. Задача многомерной оптимизации. Генетические ал-горитмы ( ГА ). Задача: Разработать алгоритм и создать программное приложение, в котором предусмотреть введение точности ре-зультата, количества представителей популяции, вероятность мутации. Исследовать зависимость между количеством ите-раций и различными методами образования новых эпох, вы-бора родителей ... Предусмотреть создание функции приспо-собленности в отдельном модуле и его компиляцию отдельно от основной программы. 10. Генетические алгоритмы. Обучение нейронных се-тей на их базе. Задача: Разработать алгоритм и программное приложе-ние для оптимизации параметров нейронной сети. Преду-смотреть использование нейронной сети любой конфигура-ции и инкапсулировать его в отдельную процедуру. Исследо-вать эффективность такого алгоритма в зависимости от зна-чений параметров ГА. Построить графики и отчеты. 11. Ассоциативная память. Сеть Хопфилда. Задача: Разработать алгоритм и создать программное приложение, которое моделирует работу сети Хопфилда. Ис-следовать ее эффективность в зависимости от значений внут-ренних параметров. Построить графики и отчеты.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
343 12. Векторный классификатор. Сеть АРТ. Задача: Разработать алгоритм и создать программное приложение, которое моделирует работу сети АРТ. Исследо-вать ее эффективность в зависимости от значений внутрен-них параметров. Построить графики и отчеты.
13. Прогнозирование на базе машины Больцмана ( МБ ) и машины Коши (МК ). Задача: Разработать алгоритм и создать программный модуль, моделирующий работу МБ и МК. Сравнить их эф-фективность. Исследовать эффективность каждой из них в зависимости от значений внутренних параметров. Построить графики и отчеты. 14. Аппроксимация функций на базе сети RBF. Задача: Разработать алгоритм и создать программное приложение, которое моделирует работу сети RBF. Преду-смотреть нормализацию исходных данных, настройку "ши-рины окон" активационной функции. Построить графики и отчеты. 15. Анализ данных на основе метода группового учета аргументов ( МГУА ) с использованием критерия регуляр-ности. Задача: Разработать алгоритм и создать программное приложение, которое моделирует работу МГУА с указанным критерием и продемонстрировать его использование для про-гнозирования. Исследовать эффективность алгоритма. По-строить графики и отчеты.
16. Анализ данных на основе метода группового учета аргументов с использованием критерия несмещенности . Задача: Разработать алгоритм и создать программное приложение, которое моделирует работу МГУА с указанным критерием и продемонстрировать его использование для про-гнозирования. Исследовать эффективность алгоритма. По-строить графики и отчеты.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
344 17. Анализ данных на основе метода группового учета аргументов ( МГУА ) с использованием критерия баланса переменных. Задача: Разработать алгоритм и создать программное приложение, которое моделирует работу МГУА с указанным критерием и продемонстрировать его использование для про-гнозирования. Исследовать эффективность алгоритма. По-строить графики и отчеты. 18. Экспертная система определения компетентности экспертов на базе аксиомы несмещенности. Задача: Создать программное приложение, в котором предусмотреть создание базы данных (текстовые файлы ), со-держащей вопросы и ответы. Разработать алгоритм их анали-за. Предусмотреть вывода результатов в файл и на экран. 19. Интегрированная экспертная система для тестиро-вания знаний студентов. Задача: Создать программное приложение, разработать алгоритмы формирования базы данных тестов, их анализа на основе аксиомы несмещенности. Предусмотреть разработку форм отчетности. 20. Исследование эффективности работы нейронной сети при динамическом добавлении нейронов скрытых слоев. Задача: Разработать алгоритм и создать программное приложение, которое моделирует работу нейронной сети. Предусмотреть интерактивное задание количества слоев и других параметров сети. Построить графики и отчеты об эф-фективности работы нейронной сети при динамическом до-бавлении нейронов скрытого слоя как в начале его обучения, так и по его окончании. 21. Сравнительный анализ модификации алгоритма обучения сети Кохонена (алгоритм справедливости и алго-ритм коррекции ) на примере распознавания букв. Задача: Разработать указанные алгоритмы и программ-

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
345
ное приложение для ввода различных вариантов написания букв и их распознавания. Провести исследование эффектив-ности функционирования сети Кохонена по различным ал-горитмам. Построить графики и отчеты. 22. Сравнительный анализ режимов аккредитации и интерполяции сети Кохонена на примере распознавания прямых линий. Задача: Разработать алгоритмы для режимов аккредита-ции и интерполяции и программное приложение для ввода или задания вариантов прямых линий и их распознавания. Провести сравнительное исследование эффективности режи-мов. Построить графики и отчеты. 23. Решение линейных уравнений с помощью нейрон-ных сетей. Задача: Осуществить формальную постановку задачи, разработать алгоритм и программное приложение для реше-ния линейных алгебраических уравнений. Провести исследо-вания эффективности алгоритма. Построить графики и отче-ты. 24. (* ) Решение дифференциальных уравнений с по-мощью нейронных сетей. Задача: Осуществить формальную постановку задачи, разработать алгоритм и программное приложение для реше-ния дифференциальных уравнений. Провести исследования эффективности алгоритма. Построить графики и отчеты. 25. Сравнительный анализ эффективности генетиче-ского алгоритма на базе гаплоидной и диплоидной попу-ляций. Задача: Разработать генетические алгоритмы с рекомби-нациями гаплоидной и диплоидной популяций и соответст-вующее программное приложение для оптимизации сложных функций. Провести сравнительное исследование эффектив-ности алгоритмов. Построить графики и отчеты.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
346 26. Модификация сети АРТ с непрерывными значе-ниями входных сигналов. Задача: Разработать алгоритм функционирования сети АРТ с непрерывными функциями активации и соответст-вующее программное приложение. Провести исследование ее эффективности. Построить графики и отчеты. 27. Аппроксимация функций (параметрическая иден-тификация ) с помощью генетического алгоритма. Задача: Осуществить формальную постановку задачи, разработать алгоритм и программное приложение для ап-проксимации полиномов. Провести исследования эффектив-ности алгоритма. Построить графики и отчеты. 28. Кластеризация сложных объектов и процессов с помощью пирамидальных растущих сетей. Задача: Исходя из начальных данных, выполнить фор-мализованную постановку задачи кластеризации. Разработать алгоритм и программный модуль для создания пирамидаль-ной растущей сети. Предусмотреть ввод информации о но-вых объектах в режиме реального времени и вывод промежу-точных результатов построения сети. Провести исследование адекватности построенной сети с использованием обучающих и контрольных примеров. 29. Кластеризация сложных непрерывных процессов с помощью пирамидальной растущей сети. Задача: Выполнить формализованную постановку задачи кластеризации для непрерывных процессов. Предложить ал-горитм сведения задачи непрерывной кластеризации к дис-кретной постановке. Разработать алгоритм и программный модуль для построения пирамидальной растущей сети. Раз-работать и алгоритмизировать процедуру формирования по-нятий на базе созданной сети. Выполнить проверку результа-тов на адекватность, используя обучающие и контрольные примеры. Построить графики и отчет.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
347 Приложение Б
БАЗОВЫЕ ПРОГРАММНЫЕ МОДУЛИ
Процедура преобразования генотипа в целочисельный
десятичный аналог {ss – переменная-строка, представляющая генотип; s − ее
десятичный целочисленный аналог; kk – количество бинар-ных розрядов в ss}
Procedure Tgenetic.Str_bin_to_dec(var ss:string;var s:integer;var kk:byte);
var s1:string; к,c1,l,i,p:integer; begin s:=0;p:=1; for i:=0 to kk-1 do begin s1:=copy(ss,kk-i,1); val(s1,c1,k); s:=s+c1*p; p:=p*2; end; end; Процедура преобразования целого неотрицательного
числа в бинарную форму {a – целое положительное число; b – генотип-строка; l –
длина строки} Procedure Tgenetic.Dec_to_bin_str(var а:integer;var b:string; var
l:byte); var с,v:string; i,d:byte;aa:integer; begin b:='';aa:=a; while aa>1 do begin d:=aa mod 2; aa:=aa div 2; str(d,c); b:=concat(с,b); end; str(aa,c); b:=concat(с,b); if length(b)<l then

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
348
for i:=1 to l-length(b) do b:=concat('0',b); end; Процедура одноточечного кроссовера {Par_1,Par_2 – родители-генотипы, Son – потомок, raz –
длина бинарной строки, kk – случайное число, указывающее на точку деления}
Procedure Tgenetic.Crossover(var Par_1,Par_2,Son:string;var raz:integer;var kk:byte); var l:integer;c1,c2,P_1,P_2:string;r1:real; begin l:=length(Par_1); kk:=random(raz-1)+1; P_1:=Par_1; P_2:=Par_2; c1:=copy(P_1,kk,l-kk+1); c2:=copy(P_2,1,kk-1); delete(P_1,kk,l-kk+1); delete(P_2,1,kk-1); P_2:=concat(P_1,P_2); P_1:=concat(c2,c1); r1:=random; if r1<0.5 then Son:=P_1 else Son:=P_2; end.
Процедура мутации {P – вероятность мутации, Str_Mut1 – начальная бинарная
строка, Str_Mut2 − результат мутации, raz − длина бинарной строки}
Procedure Tgenetic.Mutation(var Str_Mut1,Str_Mut2:string;raz:integer); var r1:real;sm1,s3:string;k:integer; begin r1:=random; sm1:=Str_Mut1; if r1<P_mutation then begin k:=random(raz-1)+1; s3:=copy(sm1,k,1);

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
349
delete(sm1,k,1); if s3='0' then insert('1',sm1,k) else insert('0',sm1,k); Str_Mut2:=sm1; end else Str_Mut2:=Str_Mut1; end;
Процедура “выбеливания” входов (прямой и обратный
ход) Начальные данные: матрица Х (три входных факторы,
пять наблюдений). x=[1 2 3; 2 4 7; 3 6 10; 4 8 15; 6 10 20]; % Вычисление ковариационной матрицы y=cov(x) % v – матрица, состоящая из собственных вектров; d – ма-
трица, на диагонали которой находятся собственные числа [v,d]=eig(y) % с – вектор средних значений входов c=mean(x) % Вычисляем матрицу nX for i=1:5 for j=1:3 z(i,j)=x(i,j)-c(j); end end
% Вычисляем матрицу ~X
l=z*v for i=1:5 for j=1:3 m(i,j)=l(i,j)/sqrt(d(j,j)); end end % Печатаем результат и его характеристики

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
350
m mean(m) corrcoef(m) var(m) % Преобразование в обратном направлении – для провер-
ки for i=1:5 for j=1:3 l(i,j)=m(i,j)*sqrt(d(j,j)); end end z=l*inv(v); for i=1:5 for j=1:3 x(i,j)=z(i,j)+c(j); end end x Процедура обучения и функционирования RBF-сети % Матрица значений входных факторов x=[0.834155453 –0.284317925 –1.592346695 –0.836322427
0.605244645; 0.627867084 0.10724084 –0.459995444 –1.014304382 –
1.058807143; 0.657744538 –0.646738376 –1.076962562 1.179108047
1.081966183; 0.526364678 –0.31178781 –1.647055666 –0.73885231
1.016044823; –0.235521366 –0.635306682 –0.459321452 0.825237912
1.756027116]; % Транспонирование матрицы x='; % Значения результирующей характеристики y=[–0.711169262; –1.058722236; –0.994462002; 1.173640605;
1.404361706]; % Вектор “ширины” окон активационных функций si=[0.5 0.5 1.0 1.7 1.5];

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
351
% Вычисление матрицы f for i=1:5 for j=1:5 s=0; for k=1:5 s=s+(x(i,k)-x(j,k))^2; end f(i,j)=exp(-s/si(i)); end end % Вычисление обратной матрицы к f c=inv(f); % Расчет весовых коэффициентов w=c*y; % Тестовые значения входных факторов ll=[1.273586949 1.797999046 –1.195117831 1.155286285 –
1.251115529]; % Расчет результирующего значения for i=1:5 s=0; for k=1:5 s=s+(ll(k)-x(i,k))^2; end f_re(i)=exp(-s/si(i)); end % Печатаем результат re=f_re*w
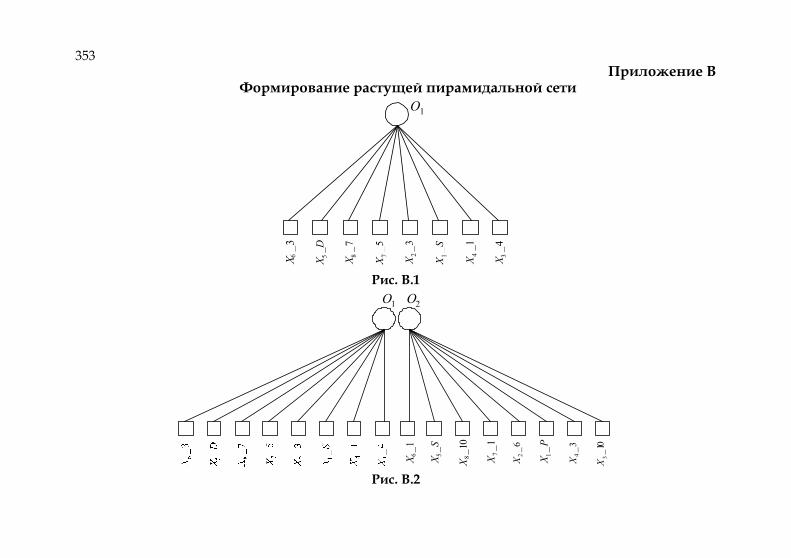
353 Приложение В
Формирование растущей пирамидальной сети 1O
3_6X
DX
_5
7_8X
5_7X
3_2X
SX
_1
1_4X
4_3X
Рис. В.1 1O 2O
1_6X
SX
_5
10_8X
1_7
X
6_2
X
PX
_1
3_4
X
10_3
X Рис. В.2

354
1S
1O 2O 3OS
X_
1
3_2X
4_3X
1_4X
DX
_5
5_7X
7_8X
3_ 6X
1_6X
SX
_ 5
10_8X
1_7X
6_2X
PX
_ 1
3_4X
10_3X
6_ 6X
Рис. В.3
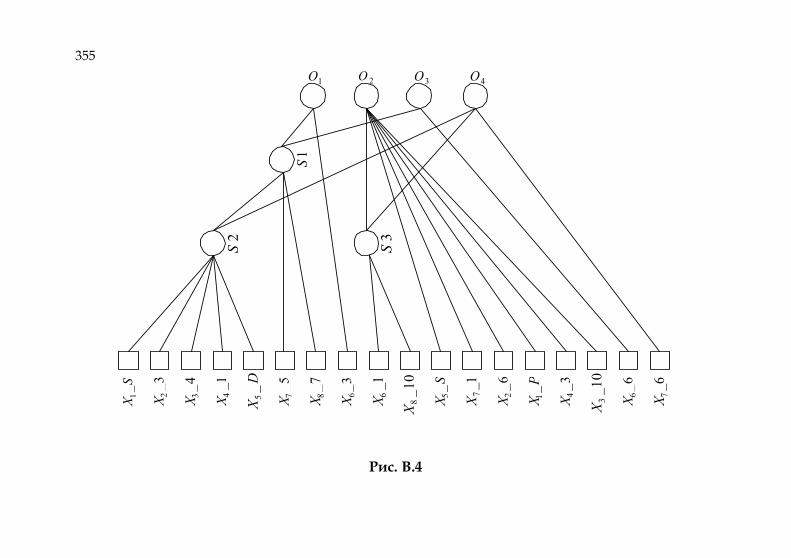
355
1S
1O 2O 3O
SX
_1
3_2X
4_3X
1_4X
DX
_5
5_7X
7_8X
3_ 6X
1_6X
SX
_ 510_8X
1_7X
6_2X
PX
_ 1
3_4X
10_3X
6_ 6X
4O
2S
3S
6_7X
Рис. В.4

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
356
1S
1O 2O 3OS
X_ 1
1_4
X
3_2X
4_3X
DX
_5
5_7X
7_8X
3_ 6X
1_6X
SX
_ 510_8X
1_7
X
6_2X
PX
_ 1
3_4X
10_3X
6_ 6X
4O
2S
3S
6_7X
4S
5S 6S
7S
5O 6O
9_ 2X
8_3X
8_7X
6_8X
Рис. В.5

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
357 1O 2O 3O 4O 5O 6O 7O 8O
1S
2S
3S4S
5S6S
7S
8S
9S
10S
11S
Рис. В.6

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
358
1O 2O 3O 4O 5O 6O 7O 8O
1S
2S
3S4S
5S
6S7S
8S
9S
10S
11S
9O 10O
13S
12S
10_6X
2_8X
Рис. В.7
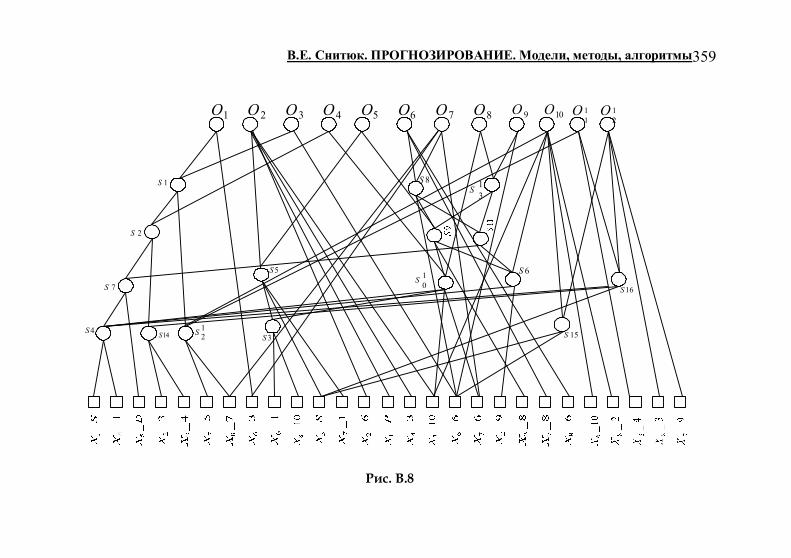
В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
359
1O 2O 3O 4O 5O 6O 7O 8O
1S
2S
3S4S
5S 6S
7S
8S
10
S
9O 10O
13
S
12S14S 15S
16S
11
O 12
O
Рис. В.8

360 Приложение Д
Таблица Д.1. Процентили t - распределения
df 0,60t 0,70t 0,80t 0,90t 0,95t 0,975t 0,99t 0,995t 1 0,325 0,727 1,376 3,078 6,314 12,706 31,821 3,657 2 0,289 0,617 1,061 1,886 2,920 4,303 6,965 9,925 3 0,277 0,584 0,978 1,638 2,353 3,182 4,541 5,841 4 0,271 0,569 0,941 1,533 2,132 2,776 3,747 4,604 5 0,267 0,559 0,920 1,476 2,015 2,571 3,365 4,032 6 0,265 0,553 0,906 1,440 1,943 2,447 3,143 3,707 7 0,263 0,549 0,896 1,415 1,895 2,365 2,998 3,499 8 0,262 0,546 0,889 1,397 1,860 2,306 2,896 3,355 9 0,261 0,543 0,883 1,383 1,833 2,262 2,821 3,250 10 0,260 0,542 0,879 1,372 1,812 2,228 2,764 3,169 11 0,260 0,540 0,876 1,363 1,796 2,201 2,718 3,106 12 0,259 0,539 0,873 1,356 1,782 2,179 2,681 3,055 13 0,259 0,538 0,870 1,350 1,771 2,160 2,650 3,012 14 0,258 0,537 0,868 1,345 1,761 2,145 2,624 2,977 15 0,258 0,536 0,866 1,341 1,753 2,131 2,602 2,947 16 0,258 0,535 0,865 1,337 1,746 2,120 2,583 2,921 17 0,257 0,534 0,863 1,333 1,740 2,110 2,567 2,898 18 0,257 0,534 0,862 1,330 1,734 2,101 2,552 2,878 19 0,257 0,533 0,861 1,328 1,729 2,093 2,539 2,861 20 0,257 0,533 0,860 1,325 1,725 2,086 2,528 2,845 21 0,257 0,532 0,859 1,323 1,721 2,080 2,518 2,831 22 0,256 0,532 0,858 1,321 1,717 2,074 2,508 2,819 23 0,256 0,532 0,858 1,319 1,714 2,069 2,500 2,807 24 0,256 0,531 0,857 1,318 1,711 2,064 2,492 2,797 25 0,256 0,531 0,856 1,316 1,708 2,060 2,485 2,787 26 0,256 0,531 0,856 1,315, 1,706 2,056 2,479 2,779 27 0,256 0,531 0,855 1,314 1,703 2,052 2,473 2,771 28 0,256 0,530 0,855 1,313 1,701 2,048 2,467 2,763 30 0,256 0,530 0,854 1,310 1,697 2,042 2,457 2,750 60 0,254 0,527 0,848 1,296 1,671 2,000 2,390 2,660
120 0,254 0,526 0,845 1,289 1,658 1,980 2,358 2,617 0,253 0,524 0,842 1,282 1,645 1,960 2,326 2,576

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алго-ритмы
361
Таблица Д.2 . Процентили 2 - распределения
df 0,5 1 2,5 5 10 90 95 97,5 99 99,5 1 0,000 0,000 0,001 0.004 0,016 2,71 3,84 5,02 6,63 7,88 2 0,010 0,020 0,052 0,103 0,211 4,61 5,99 7,38 9,21 10,60 3 0,072 0,115 0,216 0,352 0,584 6,25 7,81 9,35 11,34 12,84 4 0,207 0,297 0,484 0,711 1,064 7,78 9,49 11,14 13,28 14,86 5 0,412 0,554 0,831 1,15 1.61 9,24 11,07 12,83 15,09 16,75 6 0,676 0,872 1,24 1,64 2,20 10,64 12,59 14,45 16,81 18,55 7 0,989 1,24 1,69 2,17 2,83 12,02 14,07 16,01 18,48 20,28 8 1,34 1,65 2,18 2,73 3,49 13,36 15,51 17,53 20,09 21,96 9 1,73 2,09 2,70 3,33 4,17 14,68 16,92 19,02 21,67 23,59 10 2,16 2,56 3,25 3,94 4,87 15,99 18,31 20,48 23,21 25,19 11 2,60 3,05 3,82 4,57 5,58 17,28 19,68 21,92 24,73 26,76 12 3,07 3,57 4,40 5,23 6,30 18,55 21,03 23,34 26,22 28,30 13 3,57 4,11 5,01 5,89 7,04 19,81 22,36 24,74 27,69 29,82 14 4,07 4,66 5,63 6,57 7,79 21,06 23,68 26,12 29,14 31,32 15 4,60 5,23 6,26 7,26 8,55 22,31 25,00 27,49 30,58 32,80 16 5,14 5,81 6,91 7,96 9,31 23,54 26,30 28,85 32,00 34,27 IS 6,26 7,01 8,23 9,39 10,86 25,99 28,87 31,53 34,81 36,17 20 7,43 8,26 9,59 10,85 12,44 28,41 31,41 34,17 37,57 40,00 24 9,89 10,86 12,40 13,85 15,66 33,20 36,42 39,36 42,98 45,56 30 13,79 14,95 16,79 18,49 20,60 40,26 43,77 46,98 50,89 53,67 40 20,71 22,16 24,43 26,51 29,05 51,81 55,76 59,34 63,69 66,77 60 35.53 37,48 40,48 43,19 46,46 74,40 79,08 83,30 88,38 91,95 120 83,85 86,92 91,58 95,70 100,6 140,2 146,5 152,2 159 163,6
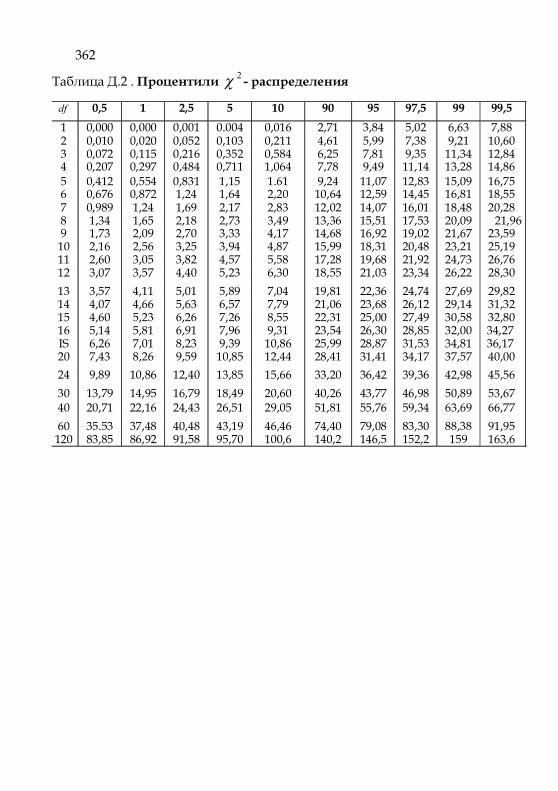
362
Таблица Д.2 . Процентили 2 - распределения
df 0,5 1 2,5 5 10 90 95 97,5 99 99,5 1 0,000 0,000 0,001 0.004 0,016 2,71 3,84 5,02 6,63 7,88 2 0,010 0,020 0,052 0,103 0,211 4,61 5,99 7,38 9,21 10,60 3 0,072 0,115 0,216 0,352 0,584 6,25 7,81 9,35 11,34 12,84 4 0,207 0,297 0,484 0,711 1,064 7,78 9,49 11,14 13,28 14,86 5 0,412 0,554 0,831 1,15 1.61 9,24 11,07 12,83 15,09 16,75 6 0,676 0,872 1,24 1,64 2,20 10,64 12,59 14,45 16,81 18,55 7 0,989 1,24 1,69 2,17 2,83 12,02 14,07 16,01 18,48 20,28 8 1,34 1,65 2,18 2,73 3,49 13,36 15,51 17,53 20,09 21,96 9 1,73 2,09 2,70 3,33 4,17 14,68 16,92 19,02 21,67 23,59 10 2,16 2,56 3,25 3,94 4,87 15,99 18,31 20,48 23,21 25,19 11 2,60 3,05 3,82 4,57 5,58 17,28 19,68 21,92 24,73 26,76 12 3,07 3,57 4,40 5,23 6,30 18,55 21,03 23,34 26,22 28,30 13 3,57 4,11 5,01 5,89 7,04 19,81 22,36 24,74 27,69 29,82 14 4,07 4,66 5,63 6,57 7,79 21,06 23,68 26,12 29,14 31,32 15 4,60 5,23 6,26 7,26 8,55 22,31 25,00 27,49 30,58 32,80 16 5,14 5,81 6,91 7,96 9,31 23,54 26,30 28,85 32,00 34,27 IS 6,26 7,01 8,23 9,39 10,86 25,99 28,87 31,53 34,81 36,17 20 7,43 8,26 9,59 10,85 12,44 28,41 31,41 34,17 37,57 40,00 24 9,89 10,86 12,40 13,85 15,66 33,20 36,42 39,36 42,98 45,56 30 13,79 14,95 16,79 18,49 20,60 40,26 43,77 46,98 50,89 53,67 40 20,71 22,16 24,43 26,51 29,05 51,81 55,76 59,34 63,69 66,77 60 35.53 37,48 40,48 43,19 46,46 74,40 79,08 83,30 88,38 91,95 120 83,85 86,92 91,58 95,70 100,6 140,2 146,5 152,2 159 163,6
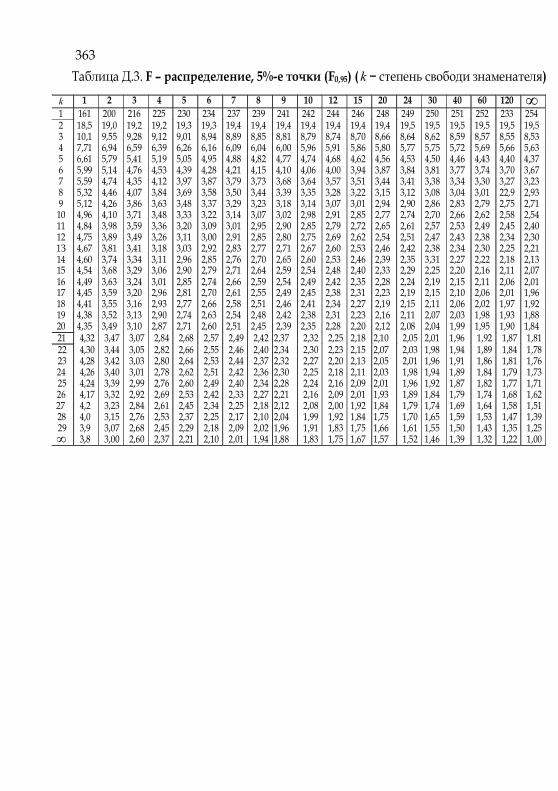
363 Таблица Д.3. F – распределение, 5%-е точки (F0,95) ( k − степень свободи знаменателя)
k 1 2 3 4 5 6 7 8 9 10 12 15 20 24 30 40 60 120 1 161 200 216 225 230 234 237 239 241 242 244 246 248 249 250 251 252 233 254 2 18,5 19,0 19,2 19,2 19,3 19,3 19,4 19,4 19,4 19,4 19,4 19,4 19,4 19,5 19,5 19,5 19,5 19,5 19,5 3 10,1 9,55 9,28 9,12 9,01 8,94 8,89 8,85 8,81 8,79 8,74 8,70 8,66 8,64 8,62 8,59 8,57 8,55 8,53 4 7,71 6,94 6,59 6,39 6,26 6,16 6,09 6,04 6,00 5,96 5,91 5,86 5,80 5,77 5,75 5,72 5,69 5,66 5,63 5 6,61 5,79 5,41 5,19 5,05 4,95 4,88 4,82 4,77 4,74 4,68 4,62 4,56 4,53 4,50 4,46 4,43 4,40 4,37 6 5,99 5,14 4,76 4,53 4,39 4,28 4,21 4,15 4,10 4,06 4,00 3,94 3,87 3,84 3,81 3,77 3,74 3,70 3,67 7 5,59 4,74 4,35 4,12 3,97 3,87 3,79 3,73 3,68 3,64 3,57 3,51 3,44 3,41 3,38 3,34 3,30 3,27 3,23 8 5,32 4,46 4,07 3,84 3,69 3,58 3,50 3,44 3,39 3,35 3,28 3,22 3,15 3,12 3,08 3,04 3,01 22,9 2,93 9 5,12 4,26 3,86 3,63 3,48 3,37 3,29 3,23 3,18 3,14 3,07 3,01 2,94 2,90 2,86 2,83 2,79 2,75 2,71 10 4,96 4,10 3,71 3,48 3,33 3,22 3,14 3,07 3,02 2,98 2,91 2,85 2,77 2,74 2,70 2,66 2,62 2,58 2,54 11 4,84 3,98 3,59 3,36 3,20 3,09 3,01 2,95 2,90 2,85 2,79 2,72 2,65 2,61 2,57 2,53 2,49 2,45 2,40 12 4,75 3,89 3,49 3,26 3,11 3,00 2,91 2,85 2,80 2,75 2,69 2,62 2,54 2,51 2,47 2,43 2,38 2,34 2,30 1З 4,67 3,81 3,41 3,18 3,03 2,92 2,83 2,77 2,71 2,67 2,60 2,53 2,46 2,42 2,38 2,34 2,30 2,25 2,21 14 4,60 3,74 3,34 3,11 2,96 2,85 2,76 2,70 2,65 2,60 2,53 2,46 2,39 2,35 3,31 2,27 2,22 2,18 2,13 15 4,54 3,68 3,29 3,06 2,90 2,79 2,71 2,64 2,59 2,54 2,48 2,40 2,33 2,29 2,25 2,20 2,16 2,11 2,07 16 4,49 3,63 З,24 3,01 2,85 2,74 2,66 2,59 2,54 2,49 2,42 2,35 2,28 2,24 2,19 2,15 2,11 2,06 2,01 17 4,45 3,59 3,20 2,96 2,81 2,70 2,61 2,55 2,49 2,45 2,38 2,31 2,23 2,19 2,15 2,10 2,06 2,01 1,96 18 4,41 3,55 3,16 2,93 2,77 2,66 2,58 2,51 2,46 2,41 2,34 2,27 2,19 2,15 2,11 2,06 2,02 1,97 1,92 19 4,38 3,52 3,13 2,90 2,74 2,63 2,54 2,48 2,42 2,38 2,31 2,23 2,16 2,11 2,07 2,03 1,98 1,93 1,88 20 4,35 3,49 3,10 2,87 2,71 2,60 2,51 2,45 2,39 2,35 2,28 2,20 2,12 2,08 2,04 1,99 1,95 1,90 1,84 21 4,32 3,47 3,07 2,84 2,68 2,57 2,49 2,42 2,37 2,32 2,25 2,18 2,10 2,05 2,01 1,96 1,92 1,87 1,81 22 4,30 3,44 3,05 2,82 2,66 2,55 2,46 2,40 2,34 2,30 2,23 2,15 2,07 2,03 1,98 1,94 1,89 1,84 1,78 23 4,28 3,42 3,03 2,80 2,64 2,53 2,44 2,37 2,32 2,27 2,20 2,13 2,05 2,01 1,96 1,91 1,86 1,81 1,76 24 4,26 3,40 3,01 2,78 2,62 2,51 2,42 2,36 2,30 2,25 2,18 2,11 2,03 1,98 1,94 1,89 1,84 1,79 1,73 25 4,24 3,39 2,99 2,76 2,60 2,49 2,40 2,34 2,28 2,24 2,16 2,09 2,01 1,96 1,92 1,87 1,82 1,77 1,71 26 4,17 3,32 2,92 2,69 2,53 2,42 2,33 2,27 2,21 2,16 2,09 2,01 1,93 1,89 1,84 1,79 1,74 1,68 1,62 27 4,2 3,23 2,84 2,61 2,45 2,34 2,25 2,18 2,12 2,08 2,00 1,92 1,84 1,79 1,74 1,69 1,64 1,58 1,51 28 4,0 3,15 2,76 2,53 2,37 2,25 2,17 2,10 2,04 1,99 1,92 1,84 1,75 1,70 1,65 1,59 1,53 1,47 1,39 29 3,9 3,07 2,68 2,45 2,29 2,18 2,09 2,02 1,96 1,91 1,83 1,75 1,66 1,61 1,55 1,50 1,43 1,35 1,25 3,8 3,00 2,60 2,37 2,21 2,10 2,01 1,94 1,88 1,83 1,75 1,67 1,57 1,52 1,46 1,39 1,32 1,22 1,00

364
Таблица Д.4 Критерий Дарбина–Уотсона (d).
Значения Ld и Ud при 5% -м уровне значимости
' 1К ' 2K ' 3K ' 4K ' 5K n
Ld Ud Ld Ud Ld Ud Ld Ud Ld Ud 15 1,08 1,36 0,95 1,54 0,82 1,75 0,69 1,97 0,56 2,21 16 1,10 1,37 0,98 1,54 0,86 1,73 0,74 1,93 0,62 2,15 17 1,13 1,38 1,02 1,54 0,90 1,71 0,78 1,90 0,67 2,10 19 1,18 1,40 1,08 1,53 0,97 1,68 0,86 1,85 0,75 2,02 20 1,20 1,41 1,10 1,54 1,00 1,68 0,90 1,83 0,79 1,99 22 1,24 1,43 1,15 1,54 1,05 1,66 0,96 1,80 0,86 1,94 23 1,26 1,44 1,17 1,54 1,08 1,66 0,99 1,79 0,90 1,92 25 1,29 1,46 1,21 1,55 1,12 1,66 1,04 1,77 0,95 1,89 26 1,30 1,47 1,22 1,55 1,14 1,65 1,06 1,76 0,98 1,88 29 1,34 1,49 1,27 1,56 1,20 1,65 1,12 1,74 1,05 1,84 30 1,35 1,50 1,28 1,57 1,21 1,65 1,14 1,74 1,07 1,83 31 1,36 1,50 1,30 1,57 1,23 1,65 1,16 1,74 1,09 1,83 32 1,37 1,51 1,31 1,57 1,24 1,65 1,18 1,73 1,11 1,82 33 1,38 1,51 1,32 1,58 1,26 1,65 1,19 1,73 1,13 1,81 35 1,40 1,52 1,34 1,58 1,28 1,65 1,22 1,73 1,16 1,80 36 1,41 1,52 1,35 1,59 1,29 1,65 1,24 1,73 1,18 1,80 37 1,42 1,53 1,36 1,59 1,31 1,66 1,25 1,72 1,19 1,80 38 1,43 1,54 1,37 1,59 1,32 1,66 1,26 1,72 1,21 1,79 40 1,44 1,54 1,39 1,60 1,34 1,66 1,29 1,72 1,23 1,79 45 1,48 1,57 1,43 1,62 1,38 1,67 1,34 1,72 1,29 1,78 50 1,50 1,59 1,46 1,63 1,42 1,67 1,38 1,72 1,34 1,77 60 1,55 1,62 1,51 1,65 1,48 1,69 1,44 1,73 1,41 1,77 65 1,57 1,63 1,54 1,66 1,50 1,70 1,47 1,73 1,44 1,77 75 1,60 1,65 1,57 1,68 1,54 1,71 1,51 1,74 1,49 1,77 80 1,61 1,66 1,59 1,69 1,56 1,72 1,53 1,74 1,51 1,77 85 1,62 1,67 1,60 1,70 1,57 1,72 1,55 1,75 1,52 1,77 90 1,63 1,68 1,61 1,70 1,59 1,73 1,57 1,75 1,54 1,78 100 1,65 1,69 1,63 1,72 1,61 1,74 1,59 1,76 1,57 1,78
П р и м е ч а н и е. n – количество наблюдений; 'K – коли-
чество независимых переменных.

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
365
Предметний указатель Modus ponens, 80 Modus tollens, 80 RBF-сеть, 37 Активация, 33 Алгоритм – „выбеливания” входов, 97 – Add, 95 – Del, 95 – Forel, 112 – случайного поиска с адаптацией, 96 – генетический, 59 − ЕМ, 135 – обратного распростране-ния ошибки, 34 – комбинированный, 96 – Ларсена, 83 – Мамдани,81 – упрощенный, 84 – Сугено и Такажи, 83 – таксономического поиска признаков, 97 – Фаррара-Глобера, 15 – Цукамото, 82 – -Krab, 113 Гетероскедастичность, 20 Гомоскедастичность, 20 Гипотеза – компактности, 112 – лямбда-компактности, 113 Дефаззификация, 81 Значимый фактор, 95 Переменная – лингвистическая, 78 – нечеткая, 77 – Бартлетта, 126
– Брандона, 25 – исключения некомплект-ных строк, 125 – главных компонент, 17 – группового учета аргументов, 50 – эволюционный для восста-новления пропусков, 136 – еволюционной кластериза-ции, 114 – заполнения средним значением, 125 – сгущения, 111 – иерархический дивизим-ный,111 – наименьших квадратов, 12 – одиночной связи, 108 – выпуклой комбинации, 42 – подстановки, 125 – полных связей, 109 – поиска модальных значе-ний плотности, 111 – средней связи, 110 – Уорда, 110 – факторного анализа, 111 Множественная линейная ре-грессия, 13 Мультиколинеарность, 15 Мутация, 60 Нечеткий логический вывод, 80 Нечеткое число, 77 Нормирование, 94 Оценка – эффективная, 20 – состоятельная, 20 Энтропія, 93

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
366
Продолжение таблицы Идентификация – параметрическая, 92 – структурная, 92 Инверсия, 60 Информативность призна-ков, 92 Итеративные методы груп-пирования, 110 Классификация, 107 Кластеризация, 106 Код Грея, 63 „Компетентная” матрица Композиционное правило вывода Заде,80 Контрапозиция, 80 Критерий – , 21 – баланса переменных, 56 – Дарбина-Уотсона, 24 – несмещенности, 54 – Пирсона хи-квадрат, 15 – регулярности, 52 – Стьюдента, 15 – Фишера, 15 Кросс-энтропия, 101 Кроссовер, 60 Сеть встречного распрост-ранения, 41 Метод – box-counting, 100 – resampling-1, 128 – resampling-2, 128 – Zet, 129 – Zet-1, 130
– ZetBraid, 131 – несмещенная, 20 „Паралич” нейросети, 43 Парная линейная регрес-сия, 12 Переобучение нейросети, 43 Пирамидальные растущие сети, 112 Популяция, 60 Принцип обобщения Заде, 77 Силлогизм, 80 Спецификация модели, 22 Теорема – Вейерштрасса – Геделя о неполноте, 50 – Колмогорова – FAT, Тест – Глейсера, 22 – непараметрический Гольдфельда-Квандта, 21 – параметрический Гольдфельда-Квандта, 21 Фаззификация, 76 Фитнесс-функция, 59 Функция – активационная, 33 – принадлежности, 76 – опорная Слой – Гросберга, 40 – Кохонена, 40

В.Е. Снитюк. ПРОГНОЗИРОВАНИЕ. Модели, методы, алгоритмы
367
Copyright © 2022 FDOKUMEN




















