
Small-ruleset regular expression matching on GPGPUs
12
Small-Ruleset Regular Expression Matching on GPGPUs: Quantitative Performance Analysis and Optimization Jamin Naghmouchi 1,2 Daniele Paolo Scarpazza 1 Mladen Berekovic 2 1 IBM T.J. Watson Research Center Business Analytics & Math Dept. Yorktown Heights, NY, USA [email protected], [email protected] 2 Institut für Datentechnik und Kommunikationsnetze Technische Universität Braunschweig Braunschweig, Germany [email protected] ABSTRACT We explore the intersection between an emerging class of archi- tectures and a prominent workload: GPGPUs (General-Purpose Graphics Processing Units) and regular expression matching, re- spectively. It is a challenging task because this workload –with its irregular, non-coalesceable memory access patterns– is very differ- ent from the regular, numerical workloads that run efficiently on GPGPUs. Small-ruleset expression matching is a fundamental building block for search engines, business analytics, natural language pro- cessing, XML processing, compiler front-ends and network secu- rity. Despite the abundant power that GPGPUs promise, little work has investigated their potential and limitations with this workload, and how to best utilize the memory classes that GPGPUs offer. We describe an optimization path of the kernel of flex (the popular, open-source regular expression scanner generator) to four nVidia GPGPU models, with decisions based on quantitative micro-benchmarking, performance counters and simulator runs. Our solution achieves a tokenization throughput that exceeds the results obtained by the GPGPU-based string matching solutions presented so far, and compares well with solutions obtained on any architecture. Categories and Subject Descriptors D.1.3 [Programming Techniques]: Concurrent Programming— Parallel Programming; F.2.2 [Analysis of Algorithms]: Nonnu- merical Algorithms—Pattern matching General Terms Algorithms, Design, Performance 1. INTRODUCTION With the advent of “Web 2.0” applications, the volume of un- structured data that Internet and enterprises applications produce and consume has been growing at extraordinary rates. The tools we use to access, transform and protect these data are search Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. ICS’10, June 2–4, 2010, Tsukuba, Ibaraki, Japan. Copyright 2010 ACM 978-1-4503-0018-6/10/06 ...$10.00. engines, business analytics suites, Natural-Language Processing (NLP) tools, XML processors and Intrusion Detection Systems (IDSs). These tools rely crucially on some form of Regular Ex- pression (regexp) scanning. We focus on tokenization: a form of small-ruleset regexp match- ing used to divide a character stream into tokens like English words, E-mail addresses, company names, URLs, phone numbers, IP ad- dresses, etc. Tokenization is the first stage of any search engine indexer (where it consumes between 14 and 20% of the execu- tion time [1]) and any XML processing tool (where it can absorb 30% [2, 3]). It is also part of NLP tools and programming language compilers. The further growth of unstructured-data applications depends on whether fast, scalable tokenizers are available. Architectures are offering more cores per socket [4, 5] and wider SIMD units (Single- Instruction Multiple-Data). For example, Intel is increasing per- chip core counts from the current 4–8 to the 16–48 of Larrabee [6], and SIMD width from the current 128 bits of SSE (Streaming SIMD Extension [7]) to the 256 bits of AVX (Advanced Vector eXtensions [8]) and the 512 bits of LRBni [9]. nVidia GPGPUs [10] employ hundreds of light-weight cores that juggle thousands of threads, in an attempt to mask the latency to an uncached main memory. Despite this promising amount of paral- lelism, little work has explored the potential of GPGPUs for text processing tasks, whereas traditional multi-core architectures have received abundant attention [11, 12, 13, 14, 15]. Filling this gap is the objective with this paper. It is a challeng- ing task because tokenization is far from the numerical, array-based applications that traditionally map well to GPGPUs. Unlike nu- merical kernels that aim at fully coalesced memory accesses, our workload never enjoys coalescing. Also, automaton-based algo- rithms have been named embarrassingly sequential [16] for their inherent lack of parallelism. Our optimization reasoning relies on performance figures that are not available from the manufacturer or independent publica- tions. We determine these figures with micro-benchmarks specifi- cally designed for the purpose. We start our optimization from a naïve port to GPGPUs of a to- kenizer kernel produced by flex [17]. We analyze compute opera- tions and memory accesses, and explore data-layout improvements on a quantitative basis, with the help of benchmarks, profiling, per- formance counters, static analysis of the disassembled bytecode, and simulator [18] runs. On a GTX280 device, we achieve a typical tokenizing through- put on realistic (Wikipedia) data of 1.185 Gbyte/s per device, and a peak scanning throughput of 6.92 Gbyte/s (i.e., 3.62× and 8.59× speedups over naïve GPGPU ports, respectively). This perfor- mance is 20.1× faster than the original, unmodified flex tokenizer
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Small-ruleset regular expression matching on GPGPUs

Small-Ruleset Regular Expression Matching on GPGPUs:Quantitative Performance Analysis and Optimization
Jamin Naghmouchi1,2 Daniele Paolo Scarpazza1 Mladen Berekovic2
1 IBM T.J. Watson Research CenterBusiness Analytics & Math Dept.
Yorktown Heights, NY, [email protected], [email protected]
2 Institut für Datentechnik und KommunikationsnetzeTechnische Universität Braunschweig
Braunschweig, [email protected]
ABSTRACTWe explore the intersection between an emerging class of archi-tectures and a prominent workload: GPGPUs (General-PurposeGraphics Processing Units) and regular expression matching, re-spectively. It is a challenging task because this workload –with itsirregular, non-coalesceable memory access patterns– is very differ-ent from the regular, numerical workloads that run efficiently onGPGPUs.
Small-ruleset expression matching is a fundamental buildingblock for search engines, business analytics, natural language pro-cessing, XML processing, compiler front-ends and network secu-rity. Despite the abundant power that GPGPUs promise, little workhas investigated their potential and limitations with this workload,and how to best utilize the memory classes that GPGPUs offer.
We describe an optimization path of the kernel of flex (thepopular, open-source regular expression scanner generator) tofour nVidia GPGPU models, with decisions based on quantitativemicro-benchmarking, performance counters and simulator runs.
Our solution achieves a tokenization throughput that exceeds theresults obtained by the GPGPU-based string matching solutionspresented so far, and compares well with solutions obtained on anyarchitecture.
Categories and Subject DescriptorsD.1.3 [Programming Techniques]: Concurrent Programming—Parallel Programming; F.2.2 [Analysis of Algorithms]: Nonnu-merical Algorithms—Pattern matching
General TermsAlgorithms, Design, Performance
1. INTRODUCTIONWith the advent of “Web 2.0” applications, the volume of un-
structured data that Internet and enterprises applications produceand consume has been growing at extraordinary rates. The toolswe use to access, transform and protect these data are search
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copies arenot made or distributed for profit or commercial advantage and that copiesbear this notice and the full citation on the first page. To copy otherwise, torepublish, to post on servers or to redistribute to lists, requires prior specificpermission and/or a fee.ICS’10, June 2–4, 2010, Tsukuba, Ibaraki, Japan.Copyright 2010 ACM 978-1-4503-0018-6/10/06 ...$10.00.
engines, business analytics suites, Natural-Language Processing(NLP) tools, XML processors and Intrusion Detection Systems(IDSs). These tools rely crucially on some form of Regular Ex-pression (regexp) scanning.
We focus on tokenization: a form of small-ruleset regexp match-ing used to divide a character stream into tokens like English words,E-mail addresses, company names, URLs, phone numbers, IP ad-dresses, etc. Tokenization is the first stage of any search engineindexer (where it consumes between 14 and 20% of the execu-tion time [1]) and any XML processing tool (where it can absorb30% [2, 3]). It is also part of NLP tools and programming languagecompilers.
The further growth of unstructured-data applications depends onwhether fast, scalable tokenizers are available. Architectures areoffering more cores per socket [4, 5] and wider SIMD units (Single-Instruction Multiple-Data). For example, Intel is increasing per-chip core counts from the current 4–8 to the 16–48 of Larrabee [6],and SIMD width from the current 128 bits of SSE (StreamingSIMD Extension [7]) to the 256 bits of AVX (Advanced VectoreXtensions [8]) and the 512 bits of LRBni [9].
nVidia GPGPUs [10] employ hundreds of light-weight cores thatjuggle thousands of threads, in an attempt to mask the latency to anuncached main memory. Despite this promising amount of paral-lelism, little work has explored the potential of GPGPUs for textprocessing tasks, whereas traditional multi-core architectures havereceived abundant attention [11, 12, 13, 14, 15].
Filling this gap is the objective with this paper. It is a challeng-ing task because tokenization is far from the numerical, array-basedapplications that traditionally map well to GPGPUs. Unlike nu-merical kernels that aim at fully coalesced memory accesses, ourworkload never enjoys coalescing. Also, automaton-based algo-rithms have been named embarrassingly sequential [16] for theirinherent lack of parallelism.
Our optimization reasoning relies on performance figures thatare not available from the manufacturer or independent publica-tions. We determine these figures with micro-benchmarks specifi-cally designed for the purpose.
We start our optimization from a naïve port to GPGPUs of a to-kenizer kernel produced by flex [17]. We analyze compute opera-tions and memory accesses, and explore data-layout improvementson a quantitative basis, with the help of benchmarks, profiling, per-formance counters, static analysis of the disassembled bytecode,and simulator [18] runs.
On a GTX280 device, we achieve a typical tokenizing through-put on realistic (Wikipedia) data of 1.185 Gbyte/s per device, anda peak scanning throughput of 6.92 Gbyte/s (i.e., 3.62× and 8.59×speedups over naïve GPGPU ports, respectively). This perfor-mance is 20.1× faster than the original, unmodified flex tokenizer

running in 4 threads on a modern commodity processor, and 49.8×faster than a single-threaded flex.
The limitations of our approach are the size of the rule set and theneed for a large number of independent input streams. The first lim-itation derives from our mapping of automata state tables to (small)core-local memories and caches. This constraint does not fit appli-cations requiring large state spaces like IDS or content-based trafficfiltering. The second constraint is due to the high number of threads(approx. 4,000–6,000) necessary to reach good GPGPU utilizationthreads at any time. Traditional CPUs that have fewer cores andthreads, and reach full utilization with fewer input streams.
2. THE GPGPU ARCHITECTURE ANDPROGRAMMING MODEL
We briefly introduce the architecture and programming modelof nVidia GPGPUs of the CUDA (Compute-Unified Device Archi-tecture) family. We focus primarily on the GTX280 device, butthese concepts apply broadly to the other devices we consider (Ta-ble 2). For more detailed information, see the technical documen-tation [19] and the relevant research papers [10, 20, 21, 22, 18].
2.1 Compute cores and memory hierarchyA CUDA GPGPU is a hierarchical collection of cores as in Fig-
ure 1. Cores are called Scalar Processors (SP). A Streaming Mul-tiprocessor (SM) contains 8 SPs and associated resources (e.g., acommon instruction unit, shared memory, a common register file,and an L1 cache). Three SMs, together with texture units and L2caches constitute a Thread Processing Cluster (TPC). The GTX280has 10 TPCs, connected to memory controllers and an L3 cache.
Part of the internals we report are unofficial and derive from Pa-padopoulou et al. [22]. nVidia often does not disclose the internalsof its devices, possibly in an attempt to discourage non-portable op-timizations. Nevertheless, the high-performance computing com-munity pursues efficiency even at the cost of device-specific, low-level optimizations.
The memory hierarchy includes a shared register file, a block ofshared memory and a global memory. The register file is staticallypartitioned among threads at compile time.
In the general case, GPGPUs do not mitigate memory latency byusing caches (except for the Fermi models, not available at the timethis article was composed). Rather, they maintain a large number ofthreads, and mask latencies by switching to a different, ready groupof threads. The cores are designed to perform inexpensive contextswitches. The L1–L3 caches are used only for instructions, con-stants and caches. In detail, the constant memory is a programmer-designated area of global memory, up to 64 kbytes, initialized bythe host and not modifiable by code running on the device; accessesto this area are cached. A visual representation of memory classesand latencies is in Figure 2. In Section 4, we analyze quantitativelythe performance of these classes of memory.
2.2 Programming ModelThe CUDA programming model does not explicitly associate
threads to cores. Rather, the programmer provides a kernel of codethat describes the operations of a single thread, and a rectangulargrid that defines the thread count and numbering.
Threads are organized in a hierarchy: a grid of blocks of warpsof threads. A warp is a collection of 32 threads that run on the8 SPs of an SM concurrently (each SP runs 4 threads). A blockis a collection of threads, of programmer-defined size (up to 512).We found no convenience in defining blocks of non-multiple-of-32threads, therefore we regard a block as a group of warps. A grid is
an array of blocks, having 1, 2 or 3 dimensions. Image processingand physics kernels map naturally to 2D and 3D grids, but our text-based workload does not need more than 1D. Therefore we treatthis grouping as a linear array of blocks and refer to this degree offreedom only as “number of blocks” from now on.
2.3 Compilation and Execution ModelWith CUDA, GPGPUs are coprocessor devices where to offload
portions of the code called kernels. The programmer can writesingle-source C/C++ hybrid applications, where the kernels arelimited to a subset of the C language with no recursion and no func-tion pointers. The NVCC compiler separates host code from devicecode and it forwards host code to an external compiler like GNUGCC. The device source code is compiled to a virtual instruction setcalled PTX [23]. At program startup, the device driver applies finaloptimizations and translates PTX code into real binary code. Thereal instruction set and the compilation process are undocumented.
Threads in a warp execute in lockstep (with a shared programcounter) and therefore have no independent control flows. Controlflow statements in the source map to predicated instructions: thehardware nullifies the instructions of non-taken branches.
The memory accesses of the threads in each half-warp can co-alesce into one, that serves 16 threads concurrently, provided thatthe target addresses respect constraints of stride and continuity. Un-coalesced accesses are much more inefficient than coalesced ones.Due to the lack of regularity of our workload, its memory accessesnever coalesce.
3. REGULAR-EXPRESSION MATCHINGAND TOKENIZATION
A regular expression describes a set of strings in terms of an al-phabet and operators like choice ‘|’, optionality ‘?’, and unboundedrepetition ‘*’. Regexps are a powerful abstraction: one expressioncan denote an infinite class of strings with desired properties.
Finding matches between a stream of text and a set of regexps isa common task. Antivirus scanners find matches between user filesand a set of regexps that denote the signatures of malicious content.IDSs do the same on live network traffic. These examples exhibitlarge rule sets (since threat signatures can be tens of thousands) andlow match rates (because the majority of traffic and files are usuallylegitimate). In this work, we rather focus on the small-ruleset, high-match-rate regexp matching involved in the tokenization stage ofsearch engines, XML and NLP processors, and compilers. Also,tokenizers implement a different matching semantics: they onlyaccepts non-overlapping, maximum length matches.
Regexp matching is performed with a Deterministic Finite Au-tomaton (DFA), often generated automatically with tools likeflex [17]. Flex takes as an input a rule set like the one in Fig-ure 3, and produces the C code of an automaton that matches thoserules, as in Figure 4. Our GPGPU-based tokenizer implements thisexample. The size of the flex-generated DFA is 174 states, whichillustrates practically what we mean by small rule set.
In the listing, the while loop scans the input. At each iteration,the automaton reads one input character, determines the next stateand whether it is an accepting one, it performs associated semanticactions, and transitions to the new state. In tokenizers, the usualsemantic actions add the accepted token to an output table.
The memory accesses of this DFA are illustrated in Figure 5. TheDFA reads sequentially characters from the input (1) with no reuse,except for backup transitions, discussed below; the input is read-only and not bound in size. The automaton accesses the STT (2)and the accept table (3); both accesses are, at a first approximation,
TP
C
TP
C
TP
C
TP
C
TP
C
Interconnect
Me
mo
ry
GPGPU card
SM SM SM
Thread Processing Cluster (TPC) Streaming Multiprocessor (SM)
L332k
TP
C
TP
C
TP
C
TP
C
TP
C
Textureunits
L28 k
SP
SP
SP
SP
SF
U
SP
SP
SP
SP
SF
U
RegisterFile
SharedMemory
DPU
InstructionUnit
L1 2k
Figure 1: A GTX280 contains 10 Thread Processing Clusters (TPCs), each of which groups 3 Streaming Multiprocessors (SMs).One SM contains 8 Scalar Processors (SPs), i.e., 10×3×8 = 240 cores. An SM also contains Special Function Units (SFUs) andDouble-Precision Units (DPUs) which we do not use in this work.
Table 1: Architectural characteristics of the compute devices we employ in our experiments.Architecture Number Total Clock Global Constant Shared Registers
Revision of SMs cores Rate Memory Memory Memory per Block
GeForce GTX280 1.3 30 240 1.30 GHz 1.00 Gbytes 64 kbytes 16 kbytes 16,384GeForce GTX8800 1.0 16 128 *1.40 GHz 0.75 Gbytes 64 kbytes 16 kbytes 8,192Tesla C870 1.1 16 128 1.35 GHz 1.50 Gbytes 64 kbytes 16 kbytes 8,192Quadro FX3700 1.0 14 112 1.24 GHz 0.50 Gbytes 64 kbytes 16 kbytes 8,192
In all devices a warp is 32 threads and the maximum number of threads per block is 512. (* Overclocked specimen; factory clock rate was 1.35 GHz).
Scalar Processor (SP)Streaming Multiprocessor (SM)Thread Processing Cluster (TPC)
L1 2k
L2 8k
L3 32k
Global Memory1 Gbyte
SharedMemory
16k
>406 cycles~220 cycles
~81 cycles6 cycles
6 cycles
Figure 2: Round-trip read latencies to the memories on a GTX280 GPGPU, from the point of view of a Scalar Processor (SP),expressed in clock cycles for a 1.30 GHz device [22]. Color coding is consistent with Fig. 1, but some blocks were omitted for clarity.

LETTER [a-z]DIGIT [0-9]P ("_"|[,-/])HAS_DIGIT ({LETTER}|{DIGIT})*{DIGIT}({LETTER}|{DIGIT})*ALPHA {LETTER}+ALPHANUM ({LETTER}|{DIGIT})+APOSTROPHE {ALPHA}("’"{ALPHA})+ACRONYM {ALPHA}"."({ALPHA}".")+COMPANY {ALPHA}("&"|"@"){ALPHA}EMAIL {ALPHANUM}(("."|"-"|"_"){ALPHANUM})*"@"
{ALPHANUM}(("."|"-"){ALPHANUM})+HOST {ALPHANUM}("."{ALPHANUM})+NUM {ALPHANUM}{P}{HAS_DIGIT}|{HAS_DIGIT}{P}{ALPHANUM}|
{ALPHANUM}({P}{HAS_DIGIT}{P}{ALPHANUM})+|{HAS_DIGIT}({P}{ALPHANUM}{P}{HAS_DIGIT})+|{ALPHANUM}{P}{HAS_DIGIT}({P}{ALPHANUM}{P}{HAS_DIGIT})+|{HAS_DIGIT}{P}{ALPHANUM}({P}{HAS_DIGIT}{P}{ALPHANUM})+
STOPWORD "a"|"an"|"and"|"are"|"as"|"at"|"be"|"but"|"by"|"for"|"if"|"in"|"into"|"is"|"it"|"no"|"not"|"of"|"on"|"or"|"s"|"such"|"t"|"that"|"the"|"their"|"then"|"there"|"these"|"they"|"this"|"to"|"was"|"will"|"with"
KEPT_AS_IS {ALPHANUM}|{COMPANY}|{EMAIL}|{HOST}|{NUM}
%%{STOPWORD}|.|\n /* ignore */;{KEPT_AS_IS} emit_token (yytext);{ACRONYM} emit_acronym (yytext);{APOSTROPHE} emit_apostrophe (yytext);%%
Figure 3: An example tokenizer rule set, specified in flex, sim-ilar to the one of Lucene [24], the open-source search enginelibrary. The rules accept words, company names, email ad-dresses, host names and numbers as a class of tokens; theyalso recognize acronyms and apostrophe expressions as distinctclasses.
const flex_int16_t yy_nxt[][...] = { ... }; /* next-state table */const flex_int16_t yy_accept[ ] = { ... } ; /* accept table */
/* ... */while ( 1 ) {
yy_bp = yy_cp;yy_current_state = yy_start; /* initial state */
while ( (yy_current_state =yy_nxt[ yy_current_state ][ *yy_cp ]) > 0 )
{if ( yy_accept[yy_current_state] ) {(yy_last_accepting_state) = yy_current_state;(yy_last_accepting_cpos) = yy_cp;
}++yy_cp;
}yy_current_state = -yy_current_state;
yy_find_action:yy_act = yy_accept[yy_current_state];
switch ( yy_act ){case 0: /* back-up transition */
yy_cp = (yy_last_accepting_cpos) + 1;yy_current_state = (yy_last_accepting_state);goto yy_find_action;
case 1: /* ignore */ break;case 2: emit_token(yytext); break;case 3: emit_acronym(yytext); break;case 4: emit_apostrophe(yytext); break;/* ... */}
}
Figure 4: The core of the tokenizer generated by flex, corre-sponding to the rule set of Figure 3. In the code, yy_nxt containsthe State Transition Table (STT). Array yy_accept marks the ac-cepting states and the semantic actions (rule numbers) associ-ated with them. At any time, the characters between pointersyy_bp and yy_cp are the input partial match candidate that theautomaton is considering.
... its biggest annual gain since 2003, ...
Input text
yy_bp yy_cp
1: *yy_cp
State transition table Accept table
Output token table
2: yy_nxt [yy_current_state][*yy_cp]
3: yy_accept [yy_current_state]
4: (*token_table_p) = ...
Automaton
yy_current_state
yy_bp
yy_cp
token_table_p
start_p stop_p file_id rule_id
Figure 5: The memory accesses of a tokenizing automaton. Ac-cess 1 is a mostly-linear read with no reuse. Accesses 2 and 3are mostly-random accesses. Access 4 is a linear write with noreuse. Reads are drawn in green, writes in red, computation inblue.
random, and both tables are limited in size. The uncompressed 16-bit STT for the example above, with ASCII-128 inputs occupies|states| × |input alphabet| × (16 bits) =174×128×2 bytes = 44kbytes.
Since flex-based tokenizers implement the longest-of-the-leftmost matching semantics, upon a valid match, the DFA canpostpone the action in search of a longer match. If the attempt fails,the automaton backs up to the last valid match and re-processes therest of the input again.
Accesses (1–4) never coalesce because, at any time, the DFAsrunning in the different threads find themselves in uncorrelatedstates, accessing independent portions of the STT. Not even theinput pointers advance with constant strides, since each DFA mightat any time incur a backup state and jump back to an arbitrary inputlocation.
STTs naturally contain redundant information. One STT com-pression technique consists in removing duplicate columns, bymapping the input characters into a smaller number of equivalenceclasses. The number of classes needed depends on the rule set. Ourexample above needs 29 classes, thus reducing the STT size by afactor of 128/29 = 4.4. Equivalence classes come at the price of oneadditional lookup, since each input character must now be mappedto the class it belongs to.
4. A TOKENIZATION-ORIENTED PER-FORMANCE CHARACTERIZATION
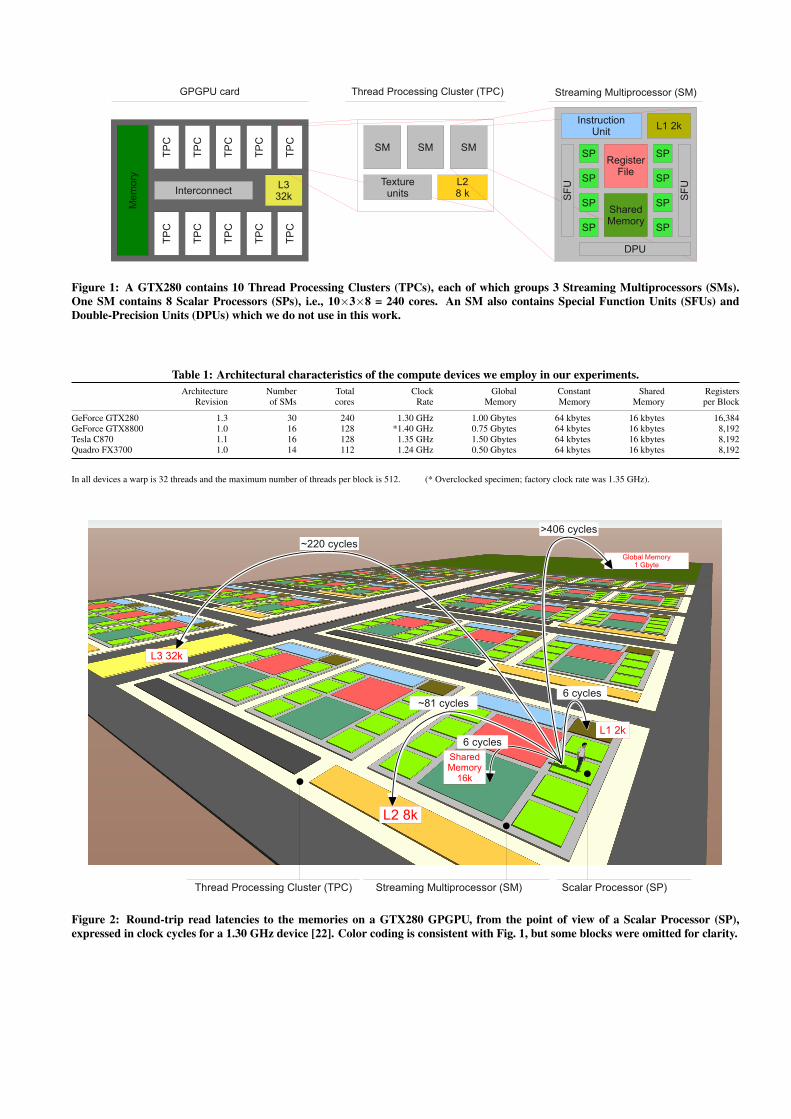
On a GPGPU, the different memory classes have significantlydifferent performance, that varies depending on the characteristicsof its accesses: coalescing, stride, block size, caching, spread, lo-cality, alignment, bank and controller congestion, etc.. Actual per-formance can be significantly lower than peak values advertised bythe manufacturer or measured in ideal conditions. For example, theGTX280 is advertised with a bandwidth of a 120 Gbyte/s, and theBWtest benchmark in the SDK reports 114 Gbyte/s. In practice,parallel threads accessing single contiguous characters from devicememory experience <1% of that (Figure 6, right).
We measure the throughput of the GPGPU memories with ac-cess patterns relevant to tokenization, with the use of micro-benchmarks. We also measure gaps: sustained operation inter-arrival times at the device level. E.g., if the read gap is 1 ns,
0
2
4
6
8
10
0 2000 4000 6000 8000 10000 12000 14000 16000
Read g
ap in n
anoseconds
Total number of threads
Gap of parallel, single-byte, linear reads from global memory
Blocksof warps
1
4
6
8
12
18
20
24
28
30
0
2
4
6
8
10
12
14
16
0 2000 4000 6000 8000 10000 12000 14000 16000
Read thro
ughput in
Gbyte
s/s
econd
Total number of threads
Throughput of parallel, single-byte, linear reads from global memory
Blocksof warps
1
4
6
8
12
16
20
24
28
30
Figure 6: When threads access their individual, linear input streams with single-byte reads to global memory, they experience avery low bandwidth (0.87 Gbyte/s), much lower than the ideal (120 Gbyte/s). Each line connects experiments with the same numberof blocks, and growing number of warps per block (1...16); e.g., the rightmost data point represents 30 blocks × 16 warps × 32threads/warp = 15,360 threads.
0
2
4
6
8
10
0 2000 4000 6000 8000 10000 12000 14000 16000
Read g
ap in n
anoseconds
Total number of threads
Gap of parallel, aligned, 16-byte, linear reads from global memory
Blocksof warps
1
4
6
8
12
18
20
24
28
30
0
2
4
6
8
10
12
14
16
0 2000 4000 6000 8000 10000 12000 14000 16000
Read thro
ughput in
Gbyte
s/s
econd
Total number of threads
Throughput of parallel, aligned, 16-byte, linear reads from global memory
Blocksof warps
1
4
6
8
12
16
20
24
28
30
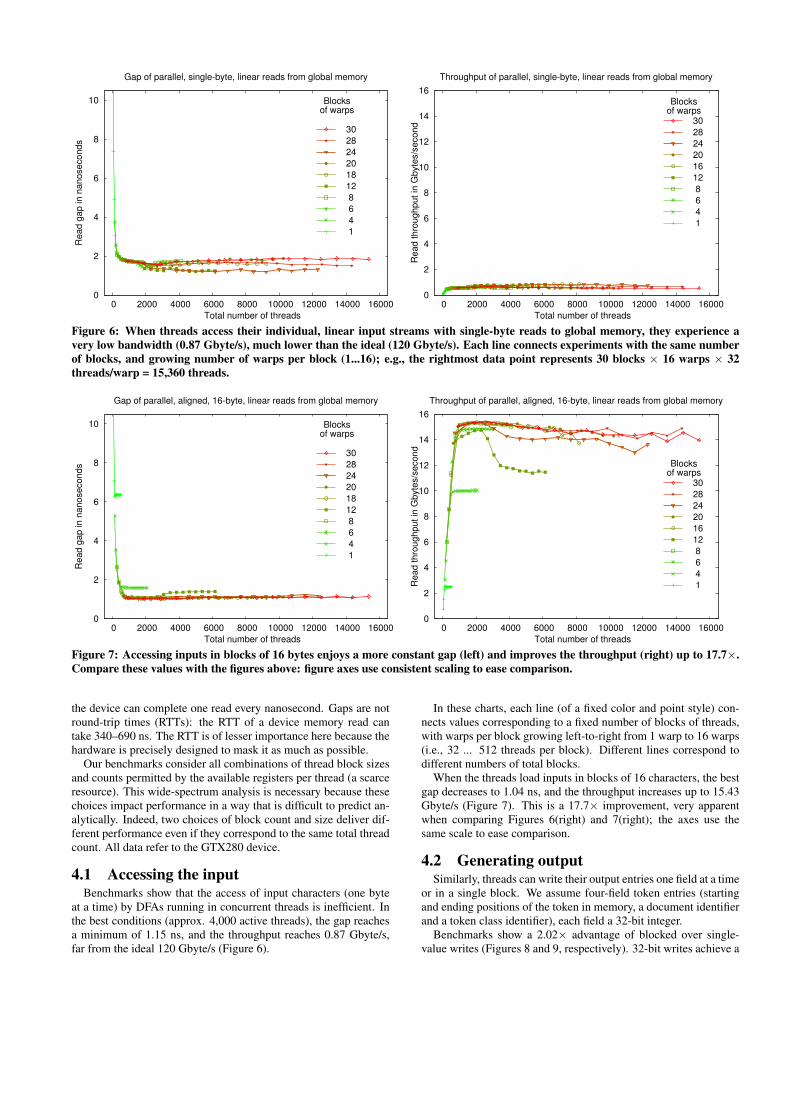
Figure 7: Accessing inputs in blocks of 16 bytes enjoys a more constant gap (left) and improves the throughput (right) up to 17.7×.Compare these values with the figures above: figure axes use consistent scaling to ease comparison.
the device can complete one read every nanosecond. Gaps are notround-trip times (RTTs): the RTT of a device memory read cantake 340–690 ns. The RTT is of lesser importance here because thehardware is precisely designed to mask it as much as possible.
Our benchmarks consider all combinations of thread block sizesand counts permitted by the available registers per thread (a scarceresource). This wide-spectrum analysis is necessary because thesechoices impact performance in a way that is difficult to predict an-alytically. Indeed, two choices of block count and size deliver dif-ferent performance even if they correspond to the same total threadcount. All data refer to the GTX280 device.
4.1 Accessing the inputBenchmarks show that the access of input characters (one byte
at a time) by DFAs running in concurrent threads is inefficient. Inthe best conditions (approx. 4,000 active threads), the gap reachesa minimum of 1.15 ns, and the throughput reaches 0.87 Gbyte/s,far from the ideal 120 Gbyte/s (Figure 6).
In these charts, each line (of a fixed color and point style) con-nects values corresponding to a fixed number of blocks of threads,with warps per block growing left-to-right from 1 warp to 16 warps(i.e., 32 ... 512 threads per block). Different lines correspond todifferent numbers of total blocks.
When the threads load inputs in blocks of 16 characters, the bestgap decreases to 1.04 ns, and the throughput increases up to 15.43Gbyte/s (Figure 7). This is a 17.7× improvement, very apparentwhen comparing Figures 6(right) and 7(right); the axes use thesame scale to ease comparison.
4.2 Generating outputSimilarly, threads can write their output entries one field at a time
or in a single block. We assume four-field token entries (startingand ending positions of the token in memory, a document identifierand a token class identifier), each field a 32-bit integer.
Benchmarks show a 2.02× advantage of blocked over single-value writes (Figures 8 and 9, respectively). 32-bit writes achieve a
0
2
4
6
8
10
0 2000 4000 6000 8000 10000 12000 14000 16000
Write
gap in n
anoseconds
Total number of threads
Gap of parallel, single 32-bit value, linear writes to global memory
Blocksof warps
1
4
6
8
12
18
20
24
28
30
0
2
4
6
8
10
12
14
16
0 2000 4000 6000 8000 10000 12000 14000 16000
Write
thro
ughput in
Gbyte
s/s
econd
Total number of threads
Throughput of parallel, single 32-bit value, linear writes to global memory
Blocksof warps
1
4
6
8
12
16
20
24
28
30
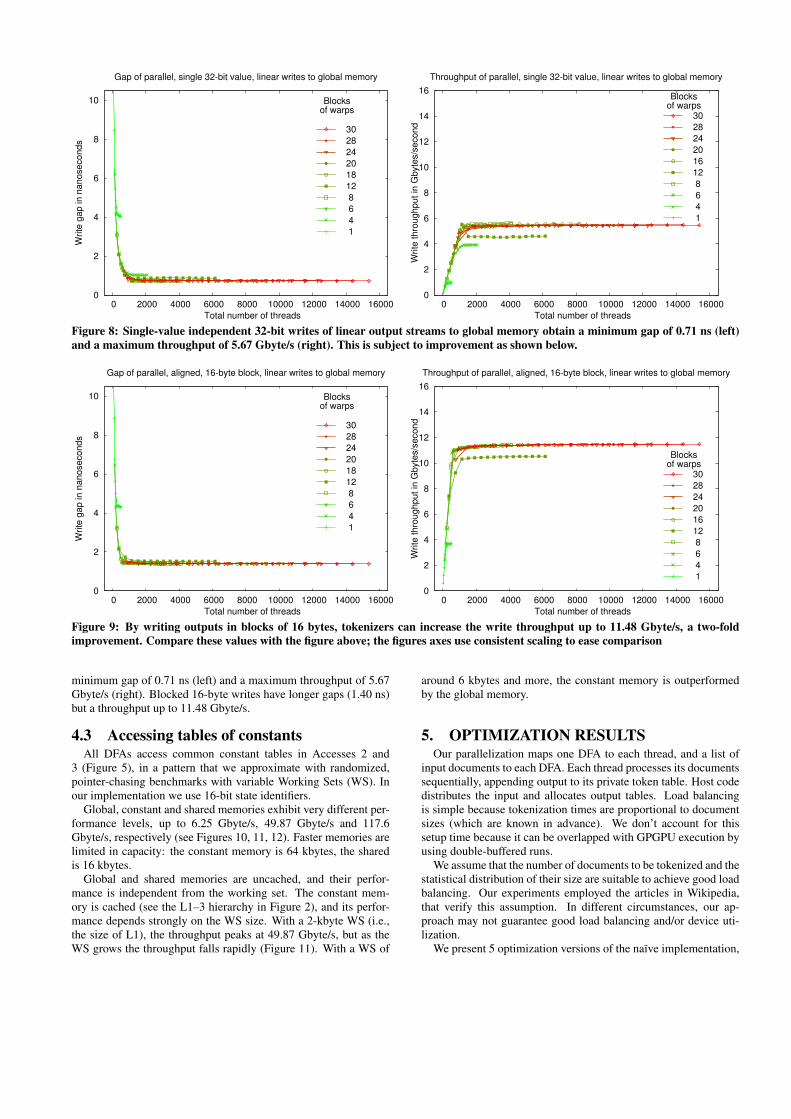
Figure 8: Single-value independent 32-bit writes of linear output streams to global memory obtain a minimum gap of 0.71 ns (left)and a maximum throughput of 5.67 Gbyte/s (right). This is subject to improvement as shown below.
0
2
4
6
8
10
0 2000 4000 6000 8000 10000 12000 14000 16000
Write
gap in n
anoseconds
Total number of threads
Gap of parallel, aligned, 16-byte block, linear writes to global memory
Blocksof warps
1
4
6
8
12
18
20
24
28
30
0
2
4
6
8
10
12
14
16
0 2000 4000 6000 8000 10000 12000 14000 16000
Write
thro
ughput in
Gbyte
s/s
econd
Total number of threads
Throughput of parallel, aligned, 16-byte block, linear writes to global memory
Blocksof warps
1
4
6
8
12
16
20
24
28
30
Figure 9: By writing outputs in blocks of 16 bytes, tokenizers can increase the write throughput up to 11.48 Gbyte/s, a two-foldimprovement. Compare these values with the figure above; the figures axes use consistent scaling to ease comparison
minimum gap of 0.71 ns (left) and a maximum throughput of 5.67Gbyte/s (right). Blocked 16-byte writes have longer gaps (1.40 ns)but a throughput up to 11.48 Gbyte/s.
4.3 Accessing tables of constantsAll DFAs access common constant tables in Accesses 2 and
3 (Figure 5), in a pattern that we approximate with randomized,pointer-chasing benchmarks with variable Working Sets (WS). Inour implementation we use 16-bit state identifiers.
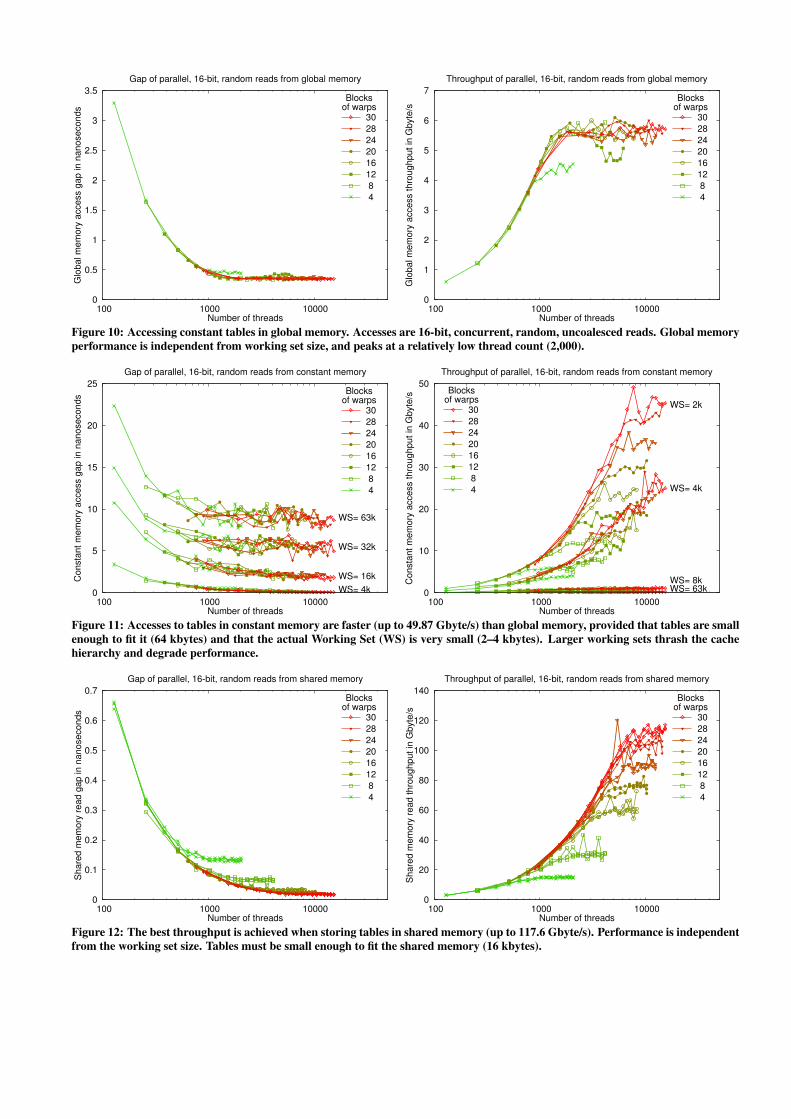
Global, constant and shared memories exhibit very different per-formance levels, up to 6.25 Gbyte/s, 49.87 Gbyte/s and 117.6Gbyte/s, respectively (see Figures 10, 11, 12). Faster memories arelimited in capacity: the constant memory is 64 kbytes, the sharedis 16 kbytes.
Global and shared memories are uncached, and their perfor-mance is independent from the working set. The constant mem-ory is cached (see the L1–3 hierarchy in Figure 2), and its perfor-mance depends strongly on the WS size. With a 2-kbyte WS (i.e.,the size of L1), the throughput peaks at 49.87 Gbyte/s, but as theWS grows the throughput falls rapidly (Figure 11). With a WS of
around 6 kbytes and more, the constant memory is outperformedby the global memory.
5. OPTIMIZATION RESULTSOur parallelization maps one DFA to each thread, and a list of
input documents to each DFA. Each thread processes its documentssequentially, appending output to its private token table. Host codedistributes the input and allocates output tables. Load balancingis simple because tokenization times are proportional to documentsizes (which are known in advance). We don’t account for thissetup time because it can be overlapped with GPGPU execution byusing double-buffered runs.
We assume that the number of documents to be tokenized and thestatistical distribution of their size are suitable to achieve good loadbalancing. Our experiments employed the articles in Wikipedia,that verify this assumption. In different circumstances, our ap-proach may not guarantee good load balancing and/or device uti-lization.
We present 5 optimization versions of the naïve implementation,
0
0.5
1
1.5
2
2.5
3
3.5
100 1000 10000
Glo
ba
l m
em
ory
acce
ss g
ap
in
na
no
se
co
nd
s
Number of threads
Gap of parallel, 16-bit, random reads from global memory
Blocksof warps
4
8
12
16
20
24
28
30
0
1
2
3
4
5
6
7
100 1000 10000
Glo
ba
l m
em
ory
acce
ss t
hro
ug
hp
ut
in G
byte
/s
Number of threads
Throughput of parallel, 16-bit, random reads from global memory
Blocksof warps
4
8
12
16
20
24
28
30
Figure 10: Accessing constant tables in global memory. Accesses are 16-bit, concurrent, random, uncoalesced reads. Global memoryperformance is independent from working set size, and peaks at a relatively low thread count (2,000).
0
5
10
15
20
25
100 1000 10000
Co
nsta
nt
me
mo
ry a
cce
ss g
ap
in
na
no
se
co
nd
s
Number of threads
Gap of parallel, 16-bit, random reads from constant memory
WS= 4k
WS= 16k
WS= 32k
WS= 63k
Blocksof warps
4
8
12
16
20
24
28
30
0
10
20
30
40
50
100 1000 10000
Co
nsta
nt
me
mo
ry a
cce
ss t
hro
ug
hp
ut
in G
byte
/s
Number of threads
Throughput of parallel, 16-bit, random reads from constant memory
WS= 2k
WS= 4k
WS= 8kWS= 63k
Blocksof warps
4
8
12
16
20
24
28
30
Figure 11: Accesses to tables in constant memory are faster (up to 49.87 Gbyte/s) than global memory, provided that tables are smallenough to fit it (64 kbytes) and that the actual Working Set (WS) is very small (2–4 kbytes). Larger working sets thrash the cachehierarchy and degrade performance.
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
100 1000 10000
Sh
are
d m
em
ory
re
ad
ga
p in
na
no
se
co
nd
s
Number of threads
Gap of parallel, 16-bit, random reads from shared memory
Blocksof warps
4
8
12
16
20
24
28
30
0
20
40
60
80
100
120
140
100 1000 10000
Sh
are
d m
em
ory
re
ad
th
rou
gh
pu
t in
Gb
yte
/s
Number of threads
Throughput of parallel, 16-bit, random reads from shared memory
Blocksof warps
4
8
12
16
20
24
28
30
Figure 12: The best throughput is achieved when storing tables in shared memory (up to 117.6 Gbyte/s). Performance is independentfrom the working set size. Tables must be small enough to fit the shared memory (16 kbytes).
Global memory
Constant memory
Shared memory
Registers
Thread
Input Output STT
State
Version 0
Global memory
Constant memory
Shared memory
Registers
Thread
Input Output
STT
State
Version 1
Global memory
Constant memory
Shared memory
Registers
Thread
Input Output
STT
State
Version 2
Global memory
Constant memory
Shared memory
Registers
Thread
Input Output
STT
State
Version 3
Input
16-b
yte
blo
ck
Global memory
Constant memory
Shared memory
Registers
Thread
Input Output
STT
State
Version 4,5
Input Output
16-byte block
16-b
yte
bloc
k
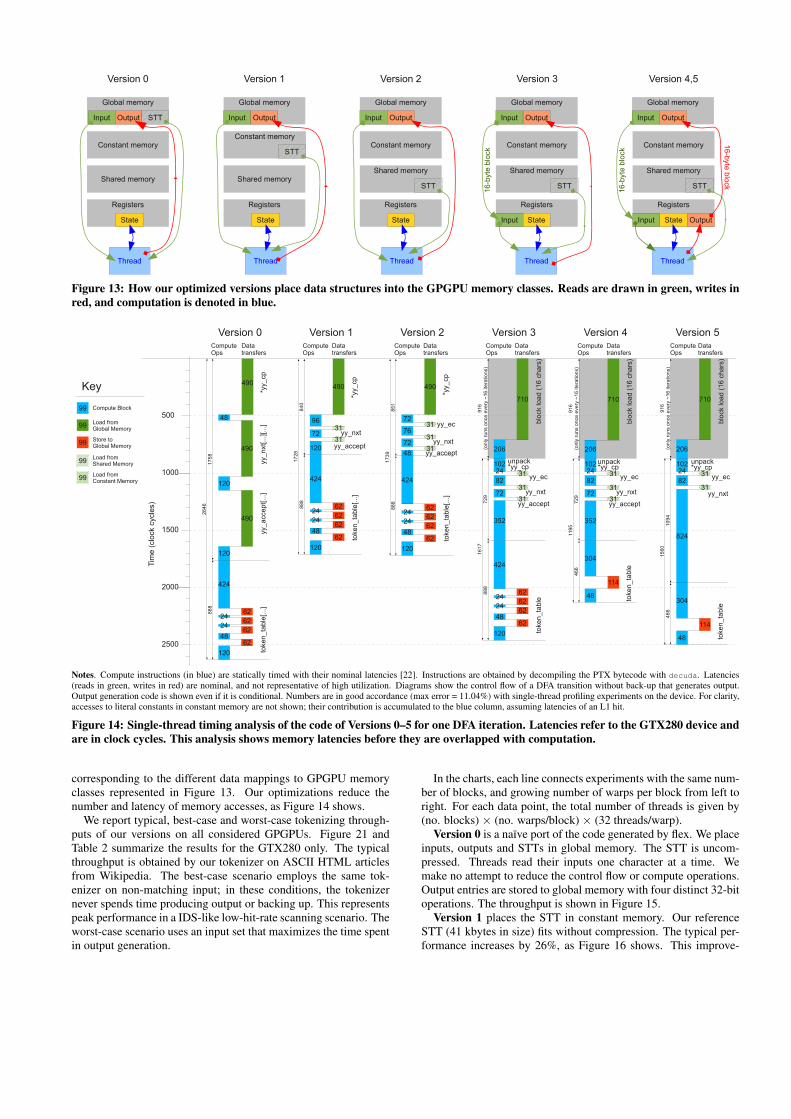
Figure 13: How our optimized versions place data structures into the GPGPU memory classes. Reads are drawn in green, writes inred, and computation is denoted in blue.
175
888
8
yy_ n
x t[..
. ][...
]*y
y _cp
yy_ a
c cep
t[.. .]
264
6
424
626262
4862
120
2424
48
120
490
490
490
toke
n_ta
b le[
...]
120
500
1000
1500
2000
2500
Tim
e (c
lock
cy c
les)
840
172
8
31
96
120
31
490
yy_nxt
*yy_
cp
yy_accept
72
888
424
626262
4862
120
2424
toke
n_ta
b le[
...]
Version 0 Version 1
851
173
9
76
72
490
72
48
yy_ec
*yy_
cpyy_accept
yy_nxt
888
424
626262
4862
120
2424
toke
n_ta
b le[
...]
31
31
31
Version 2 Version 3 Version 4 Version 5
99 Load from Global Memory
99 Store to Global Memory
99 Compute Block
99 Load fromConstant Memory
Key
99 Load fromShared Memory
729
161
782
206
710
72
352
yy_ec
bloc
k lo
a d (
1 6 c
hars
)
yy_accept
yy_nxt
916
(on
ly r
un
s o
nce
eve
r y ~
16
ite
ratio
ns)
10224
unpack*yy_cp
888
424
626262
4862
120
2424
toke
n_ta
b le
31
31
31
109
415
60
82
206
710
824
yy_ec
bloc
k lo
a d (
1 6 c
hars
)
yy_nxt
916
(on
ly r
un
s o
nce
eve
r y ~
16
ite
ratio
ns)
10224
unpack*yy_cp
466
304
48
114
toke
n_ta
b le
31
31
ComputeOps
Data transfers
ComputeOps
Data transfers
ComputeOps
Data transfers
ComputeOps
Data transfers
ComputeOps
Data transfers
466
729
119
5
82
206
304
48
710
114
72
352
yy_ec
bloc
k lo
a d (
1 6 c
hars
)to
k en_
tab l
e
yy_accept
yy_nxt
916
(on
ly r
un
s o
nce
eve
r y ~
16
ite
ratio
ns)
10224
unpack*yy_cp
31
31
31
ComputeOps
Data transfers
Notes. Compute instructions (in blue) are statically timed with their nominal latencies [22]. Instructions are obtained by decompiling the PTX bytecode with decuda. Latencies(reads in green, writes in red) are nominal, and not representative of high utilization. Diagrams show the control flow of a DFA transition without back-up that generates output.Output generation code is shown even if it is conditional. Numbers are in good accordance (max error = 11.04%) with single-thread profiling experiments on the device. For clarity,accesses to literal constants in constant memory are not shown; their contribution is accumulated to the blue column, assuming latencies of an L1 hit.
Figure 14: Single-thread timing analysis of the code of Versions 0–5 for one DFA iteration. Latencies refer to the GTX280 device andare in clock cycles. This analysis shows memory latencies before they are overlapped with computation.
corresponding to the different data mappings to GPGPU memoryclasses represented in Figure 13. Our optimizations reduce thenumber and latency of memory accesses, as Figure 14 shows.
We report typical, best-case and worst-case tokenizing through-puts of our versions on all considered GPGPUs. Figure 21 andTable 2 summarize the results for the GTX280 only. The typicalthroughput is obtained by our tokenizer on ASCII HTML articlesfrom Wikipedia. The best-case scenario employs the same tok-enizer on non-matching input; in these conditions, the tokenizernever spends time producing output or backing up. This representspeak performance in a IDS-like low-hit-rate scanning scenario. Theworst-case scenario uses an input set that maximizes the time spentin output generation.
In the charts, each line connects experiments with the same num-ber of blocks, and growing number of warps per block from left toright. For each data point, the total number of threads is given by(no. blocks) × (no. warps/block) × (32 threads/warp).
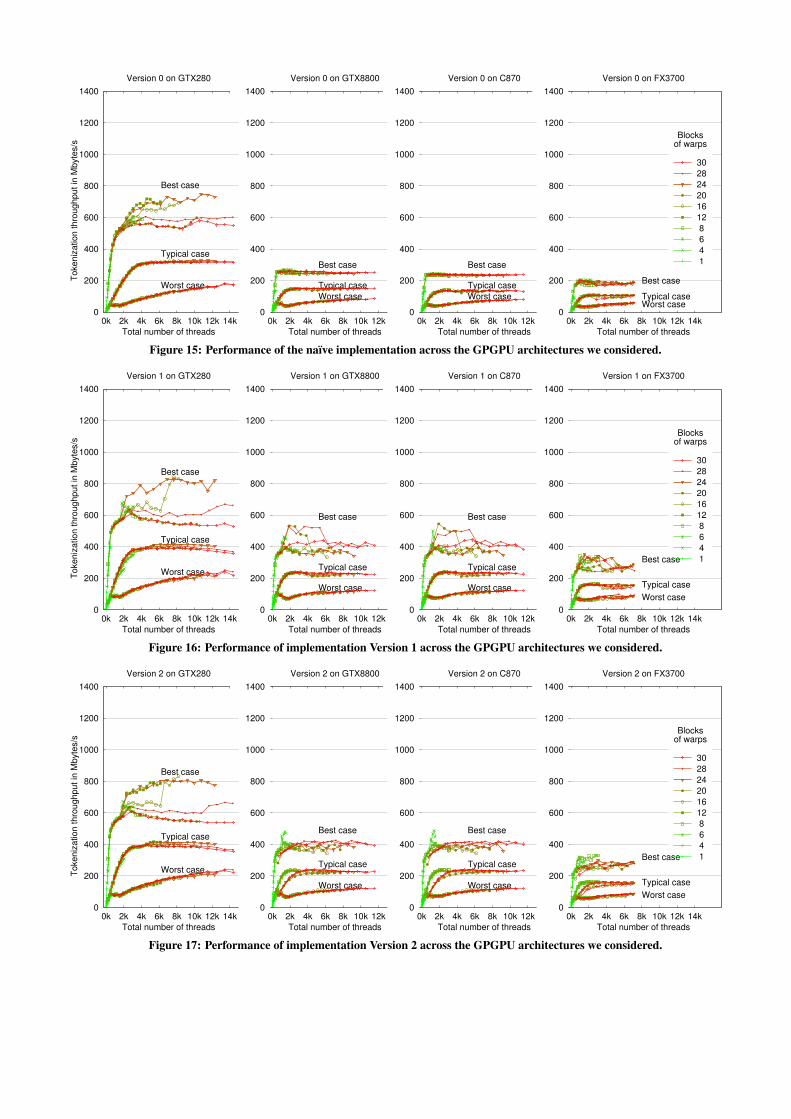
Version 0 is a naïve port of the code generated by flex. We placeinputs, outputs and STTs in global memory. The STT is uncom-pressed. Threads read their inputs one character at a time. Wemake no attempt to reduce the control flow or compute operations.Output entries are stored to global memory with four distinct 32-bitoperations. The throughput is shown in Figure 15.
Version 1 places the STT in constant memory. Our referenceSTT (41 kbytes in size) fits without compression. The typical per-formance increases by 26%, as Figure 16 shows. This improve-
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Tokeniz
ation thro
ughput in
Mbyte
s/s
Total number of threads
Version 0 on GTX280
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 0 on GTX8800
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 0 on C870
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 0 on FX3700
Best case
Typical caseWorst case
Blocksof warps
1
4
6
8
12
16
20
24
28
30
Figure 15: Performance of the naïve implementation across the GPGPU architectures we considered.
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Tokeniz
ation thro
ughput in
Mbyte
s/s
Total number of threads
Version 1 on GTX280
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 1 on GTX8800
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 1 on C870
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 1 on FX3700
Best case
Typical case
Worst case
Blocksof warps
1
4
6
8
12
16
20
24
28
30
Figure 16: Performance of implementation Version 1 across the GPGPU architectures we considered.
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Tokeniz
ation thro
ughput in
Mbyte
s/s
Total number of threads
Version 2 on GTX280
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 2 on GTX8800
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 2 on C870
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 2 on FX3700
Best case
Typical case
Worst case
Blocksof warps
1
4
6
8
12
16
20
24
28
30
Figure 17: Performance of implementation Version 2 across the GPGPU architectures we considered.
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Tokeniz
ation thro
ughput in
Mbyte
s/s
Total number of threads
Version 3 on GTX280
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 3 on GTX8800
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 3 on C870
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 3 on FX3700
Best case
Typical case
Worst case
Blocksof warps
1
4
6
8
12
16
20
24
28
30
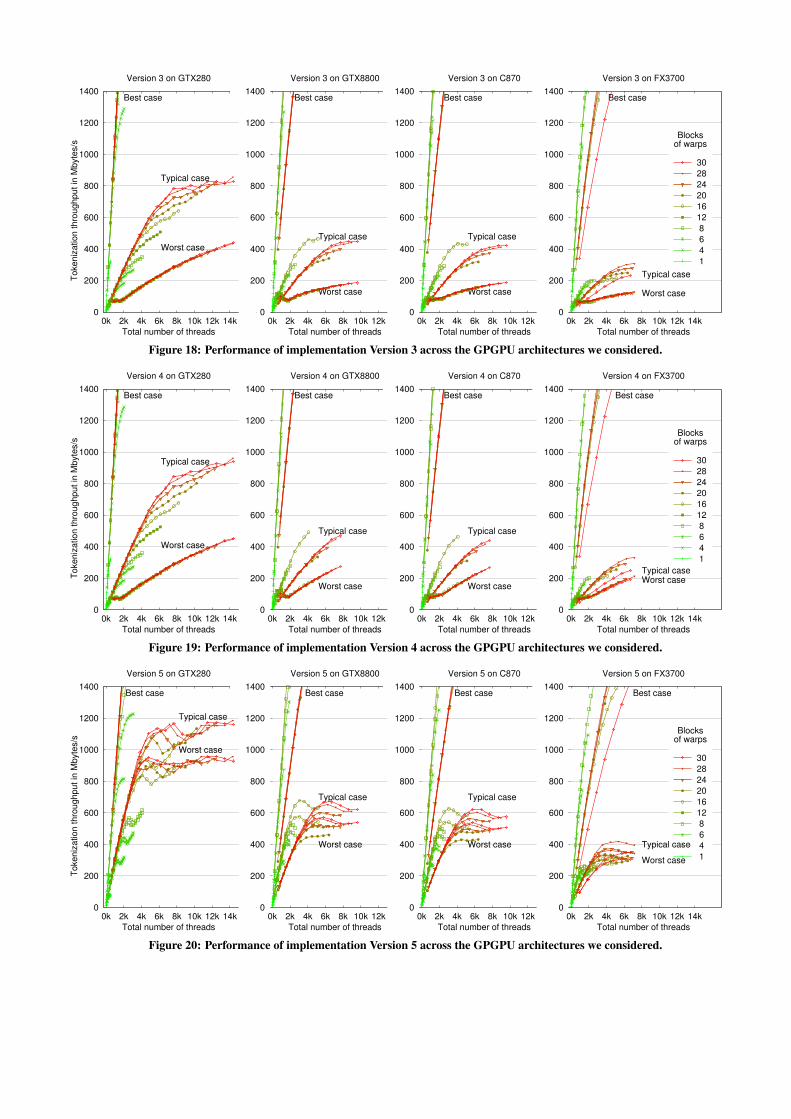
Figure 18: Performance of implementation Version 3 across the GPGPU architectures we considered.
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Tokeniz
ation thro
ughput in
Mbyte
s/s
Total number of threads
Version 4 on GTX280
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 4 on GTX8800
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 4 on C870
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 4 on FX3700
Best case
Typical caseWorst case
Blocksof warps
1
4
6
8
12
16
20
24
28
30
Figure 19: Performance of implementation Version 4 across the GPGPU architectures we considered.
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Tokeniz
ation thro
ughput in
Mbyte
s/s
Total number of threads
Version 5 on GTX280
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 5 on GTX8800
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 5 on C870
Best case
Typical case
Worst case
0
200
400
600
800
1000
1200
1400
0k 2k 4k 6k 8k 10k 12k 14k
Total number of threads
Version 5 on FX3700
Best case
Typical case
Worst case
Blocksof warps
1
4
6
8
12
16
20
24
28
30
Figure 20: Performance of implementation Version 5 across the GPGPU architectures we considered.
0
200
400
600
800
1000
1200
Version 0 Version 1 Version 2 Version 3 Version 4 Version 5
Thro
ughput (M
byte
/s)
Typical performance across the optimization steps on GTX280
0
1000
2000
3000
4000
5000
6000
7000
Version 0 Version 1 Version 2 Version 3 Version 4 Version 5
Thro
ughput (M
byte
/s)
Best-, Typical and Worst-case performance on GTX280
Worst caseTypical caseBest case
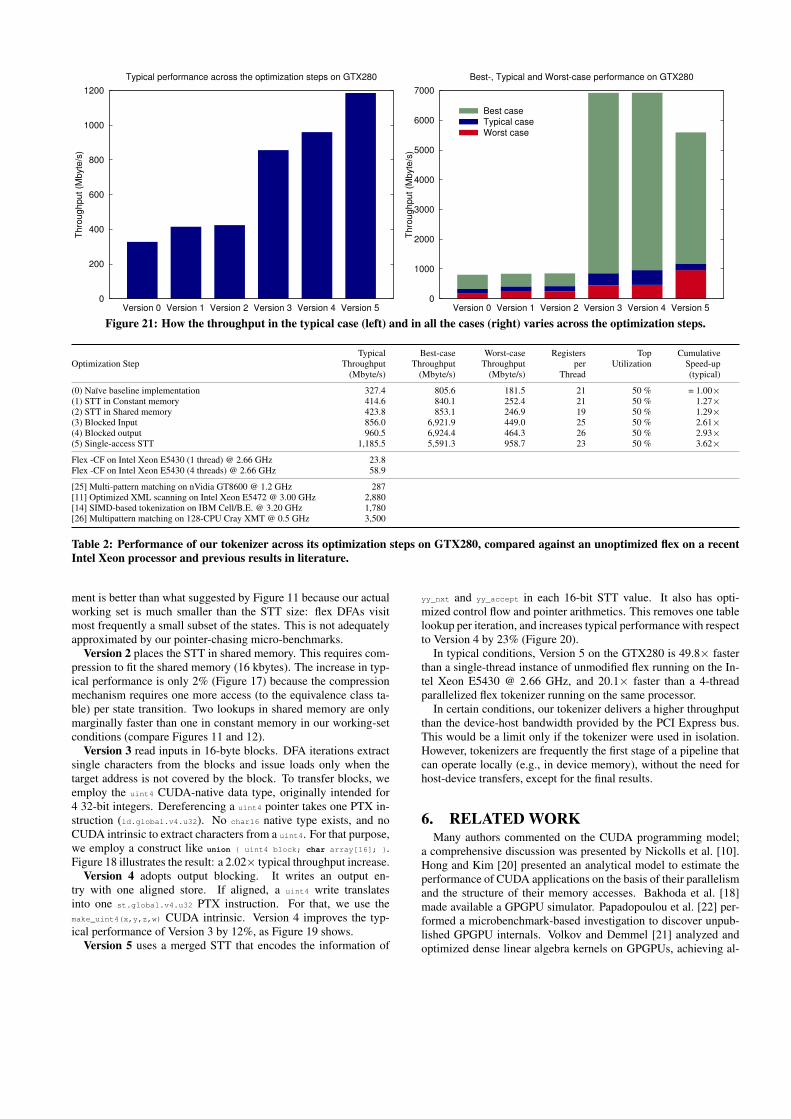
Figure 21: How the throughput in the typical case (left) and in all the cases (right) varies across the optimization steps.
Typical Best-case Worst-case Registers Top CumulativeOptimization Step Throughput Throughput Throughput per Utilization Speed-up
(Mbyte/s) (Mbyte/s) (Mbyte/s) Thread (typical)
(0) Naïve baseline implementation 327.4 805.6 181.5 21 50 % = 1.00×(1) STT in Constant memory 414.6 840.1 252.4 21 50 % 1.27×(2) STT in Shared memory 423.8 853.1 246.9 19 50 % 1.29×(3) Blocked Input 856.0 6,921.9 449.0 25 50 % 2.61×(4) Blocked output 960.5 6,924.4 464.3 26 50 % 2.93×(5) Single-access STT 1,185.5 5,591.3 958.7 23 50 % 3.62×
Flex -CF on Intel Xeon E5430 (1 thread) @ 2.66 GHz 23.8Flex -CF on Intel Xeon E5430 (4 threads) @ 2.66 GHz 58.9
[25] Multi-pattern matching on nVidia GT8600 @ 1.2 GHz 287[11] Optimized XML scanning on Intel Xeon E5472 @ 3.00 GHz 2,880[14] SIMD-based tokenization on IBM Cell/B.E. @ 3.20 GHz 1,780[26] Multipattern matching on 128-CPU Cray XMT @ 0.5 GHz 3,500
Table 2: Performance of our tokenizer across its optimization steps on GTX280, compared against an unoptimized flex on a recentIntel Xeon processor and previous results in literature.
ment is better than what suggested by Figure 11 because our actualworking set is much smaller than the STT size: flex DFAs visitmost frequently a small subset of the states. This is not adequatelyapproximated by our pointer-chasing micro-benchmarks.
Version 2 places the STT in shared memory. This requires com-pression to fit the shared memory (16 kbytes). The increase in typ-ical performance is only 2% (Figure 17) because the compressionmechanism requires one more access (to the equivalence class ta-ble) per state transition. Two lookups in shared memory are onlymarginally faster than one in constant memory in our working-setconditions (compare Figures 11 and 12).
Version 3 read inputs in 16-byte blocks. DFA iterations extractsingle characters from the blocks and issue loads only when thetarget address is not covered by the block. To transfer blocks, weemploy the uint4 CUDA-native data type, originally intended for4 32-bit integers. Dereferencing a uint4 pointer takes one PTX in-struction (ld.global.v4.u32). No char16 native type exists, and noCUDA intrinsic to extract characters from a uint4. For that purpose,we employ a construct like union { uint4 block; char array[16]; }.Figure 18 illustrates the result: a 2.02× typical throughput increase.
Version 4 adopts output blocking. It writes an output en-try with one aligned store. If aligned, a uint4 write translatesinto one st.global.v4.u32 PTX instruction. For that, we use themake_uint4(x,y,z,w) CUDA intrinsic. Version 4 improves the typ-ical performance of Version 3 by 12%, as Figure 19 shows.
Version 5 uses a merged STT that encodes the information of
yy_nxt and yy_accept in each 16-bit STT value. It also has opti-mized control flow and pointer arithmetics. This removes one tablelookup per iteration, and increases typical performance with respectto Version 4 by 23% (Figure 20).
In typical conditions, Version 5 on the GTX280 is 49.8× fasterthan a single-thread instance of unmodified flex running on the In-tel Xeon E5430 @ 2.66 GHz, and 20.1× faster than a 4-threadparallelized flex tokenizer running on the same processor.
In certain conditions, our tokenizer delivers a higher throughputthan the device-host bandwidth provided by the PCI Express bus.This would be a limit only if the tokenizer were used in isolation.However, tokenizers are frequently the first stage of a pipeline thatcan operate locally (e.g., in device memory), without the need forhost-device transfers, except for the final results.
6. RELATED WORKMany authors commented on the CUDA programming model;
a comprehensive discussion was presented by Nickolls et al. [10].Hong and Kim [20] presented an analytical model to estimate theperformance of CUDA applications on the basis of their parallelismand the structure of their memory accesses. Bakhoda et al. [18]made available a GPGPU simulator. Papadopoulou et al. [22] per-formed a microbenchmark-based investigation to discover unpub-lished GPGPU internals. Volkov and Demmel [21] analyzed andoptimized dense linear algebra kernels on GPGPUs, achieving al-

most optimal utilization of the arithmetic units. Their workload haslittle similarity with ours, but we believe we share their white-box,bottom-up analysis approach.
While no work has explicitly explored information indexingor retrieval algorithms onto GPGPUs, the work performed onautomaton-based string matching is related to ours and worth men-tioning. Vasiliadis et al. have presented Gnort [25], a network in-trusion detection engine based on the Aho-Corasick [27] algorithm.Gnort delivers an end-to-end filtering throughput of 287 Mbyte/sonto an nVidia GT8600 device, with a dictionary of a few thou-sands signatures. The authors store STTs in texture memory, inan attempt to leverage the caches. Smith et al. [28] also presentedan intrusion detection solution, which relies on XFA, a DFA vari-ant designed to recognize regexps compactly. Their implementa-tion delivers a throughput of 156 Mbyte/s. Goyal et al. [29] pro-poses a DFA-based regexp matching implementation that delivers50 Mbyte/s.
We now compare our result with relevant ones on traditionalmulti-core architectures. Pasetto et al. [11] have presented aflexible tool that can perform small-ruleset regexp matching at2.88 Gbyte/s per chip on an Intel Xeon E5472. Scarpazza andRussell [14] presented a SIMD tokenizer that delivers 1.00–1.78Gbyte/s on one IBM Cell/B.E. chip, and extended their approach toIntel Larrabee [15]. Villa et al. [26] demonstrated a large-dictionaryAho-Corasick-based string matcher that delivers 3.5 Gbyte/s on aCray XMT. Iorio and van Lunteren [12] proposed a BFSM [30]string matcher for automata whose STT fits in the register file,achieving 4 Gbyte/s on an IBM Cell chip.
Not only some of these solutions outperform ours; one additionaladvantage they have is that they do not need a high number of in-dependent input streams to achieve high device utilization.
7. CONCLUSIONSWe have found that the workload of automaton-based tokeniza-
tion with small rule sets maps to GPGPUs better than its irregularmemory access patterns suggest. This irregularity prevents the taskfrom exploiting coalesced memory accesses,
We have characterized the performance of the different GPGPUmemory classes when subject to the typical access patterns of to-kenizers. We have showed how software designers can speed uptheir workloads significantly by mapping each data structures tothe most appropriate GPGPU memory classes, and restructuringaccesses to use larger blocks.
We have employed this knowledge to craft an optimized tok-enizer implementation that compares well with the results reportedin literature.
AcknowledgmentsWe thank Rajesh Bordawekar of IBM T.J. Watson, for his sup-port and valuable suggestions; we thank Oreste Villa of the PacificNorthwest National Laboratory for his helpful comments.
8. REFERENCES[1] Daniele Paolo Scarpazza and Gordon W. Braudaway. Workload characterization
and optimization of high-performance text indexing on the Cell processor. InIEEE Intl. Symposium on Workload Characterization (IISWC’09), Austin,Texas, USA, October 2009.
[2] M. Nicola and J. John. XML parsing: A threat to database performance. InCIKM. ACM, 2003.
[3] Eric Perkins, Margaret Kostoulas, Abraham Heifets, Morris Matsa, and NoahMendelsohn. Performance analysis of XML APIs. In XML 2005 Conferenceand Exposition, November 2005.
[4] Intel Corp. Tera-scale research prototype – connecting 80 simple cores on asingle test chip, October 2006.
[5] Intel Corp. Single-chip cloud computer;techresearch.intel.com/articles/tera-scale/1826.htm, December 2009.
[6] Larry Seiler, Doug Carmean, Eric Sprangle, Tom Forsyth, Michael Abrash,Pradeep Dubey, Stephen Junkins, Adam Lake, Jeremy Sugerman, Robert Cavin,Roger Espasa, Ed Grochowski, Toni Juan, and Pat Hanrahan. Larrabee: Amany-core x86 architecture for visual computing. In ACM SIGGRAPH 2008,pages 1–15, New York, NY, USA, 2008. ACM.
[7] Intel Corp. Intel SSE4 Programming Reference, Reference Number:D91561-001, April 2007.
[8] Nadeem Firasta, Mark Buxton, Paula Jinbo, Kaveh Nasri, and Shihjong Kuo.Intel AVX: New Frontiers in Performance Improvements and EnergyEfficiency, March 2008.
[9] Michael Abrash. A first look at the Larrabee new instructions (LRBni). The Dr.Dobb’s Journal, April 2009.
[10] John Nickolls, Ian Buck, Michael Garland, and Kevin Skadron. Scalableparallel programming with CUDA. ACM Queue, 6(2):40–53, 2008.
[11] Davide Pasetto, Fabrizio Petrini, and Virat Agarwal. Tools for very fast regularexpression matching. IEEE Computer, 43(3):50–58, March 2010.
[12] Francesco Iorio and Jan Van Lunteren. Fast pattern matching on the CellBroadband Engine. In 2008 Workshop on Cell Systems and Applications(WCSA), affiliated with the 2008 Intl. Symposium on Computer Architecture(ISCA’08), Beijing, China, June 2008.
[13] Robert D. Cameron and Dan Lin. Architectural support for SWAR textprocessing with parallel bit streams: the inductive doubling principle. In 14thIntl. Conference on Architectural support for programming languages andoperating systems (ASPLOS’09), pages 337–348, New York, NY, USA, 2009.ACM.
[14] Daniele Paolo Scarpazza and Gregory F. Russell. High-performance regularexpression scanning on the Cell/B.E. processor. In 23rd Intl. Conference onSupercomputing (ICS’09), Yorktown Heights, New York, USA, June 2009.
[15] Daniele Paolo Scarpazza. Is Larrabee for the rest of us? – Can non-numericalapplication developers take advantage from the new LRBni instructions? Dr.Dobb’s Journal ; http://www.ddj.com/architect/221601028, Nov 2009.
[16] Krste Asanovic, Ras Bodik, Bryan Christopher Catanzaro, Joseph James Gebis,Parry Husbands, Kurt Keutzer, David A. Patterson, William Lester Plishker,John Shalf, Samuel Webb Williams, and Katherine A. Yelick. The landscape ofparallel computing research: A view from berkeley. Technical ReportUCB/EECS-2006-183, EECS Department, University of California, Berkeley,Dec 2006.
[17] Vern Paxson. flex – a fast lexical analyzer generator, 1988.[18] Ali Bakhoda, George Yuan, Wilson W. L. Fung, Henry Wong, and Tor M.
Aamodt. Analyzing CUDA workloads using a detailed GPU simulator. In IEEEIntl. Symposium on Performance Analysis of Systems and Software(ISPASS’09), Boston, MA, April 2009.
[19] nVidia. nVidia CUDA programming guide, version 2.3, August 2009.[20] Sunpyo Hong and Hyesoon Kim. An analytical model for a GPU architecture
with memory-level and thread-level parallelism awareness. SIGARCH Comput.Archit. News, 37(3):152–163, 2009.
[21] Vasily Volkov and James W. Demmel. Benchmarking GPUs to tune denselinear algebra. In ACM/IEEE Intl. Conference for High PerformanceComputing, Networking, Storage and Analysis (SuperComputing’08), pages1–11, Austin, TX, November 2008.
[22] Misel-Myrto Papadopoulou, Maryam Sadooghi-Alvandi, and Henry Wong.Micro-benchmarking the GT200 GPU. Technical report, Computer Group,ECE, University of Toronto, 2009.
[23] nVidia. nVidia compute, PTX : Parallel thread execution, ISA version 1.4,September 2009.
[24] The Apache Software Foundation. Lucene, http://lucene.apache.org.[25] Giorgos Vasiliadis, Spyros Antonatos, Michalis Polychronakis, Evangelos P.
Markatos, and Sotiris Ioannidis. Gnort: High performance network intrusiondetection using graphics processors. In 11th Intl. Symposium on RecentAdvances in Intrusion Detection (RAID’08), volume 5230 of Lecture Notes inComputer Science, pages 116–134, Cambridge, MA, September 2008. Springer.
[26] Oreste Villa, Daniel Chavarria, and Kristyn Maschhoff. Input-independent,scalable and fast string matching on the Cray XMT. In 23nd IEEE Intl. Parallel& Distributed Processing Symposium (IPDPS’09), 2009.
[27] Alfred V. Aho and Margaret J. Corasick. Efficient string matching: an aid tobibliographic search. Communications of the ACM, 18(6):333–340, 1975.
[28] Randy Smith, Neelam Goyal, Justin Ormont, Karthikeyan Sankaralingam, andCristian Estan. Evaluating GPUs for Network Packet Signature Matching. InIEEE Intl. Symposium on Performance Analysis of Systems and Software(ISPASS’09), Boston, MA, April 2009.
[29] Neelam Goyal, Justin Ormont, Randy Smith, Karthikeyan Sankaralingam, andCristian Estan. Signature matching in network processing using SIMD/GPUarchitectures. Technical Report 1628, University of Wisconsin at Madison,January 2008.
[30] Jan van Lunteren. High-performance pattern-matching for intrusion detection.In 25th IEEE Intl. Conference on Computer Communications (INFOCOM2006), pages 1–13, April 2006.



















