
Sentiment learning on product reviews via sentiment ontology tree
10
Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, pages 404–413, Uppsala, Sweden, 11-16 July 2010. c 2010 Association for Computational Linguistics Sentiment Learning on Product Reviews via Sentiment Ontology Tree Wei Wei Department of Computer and Information Science Norwegian University of Science and Technology [email protected] Jon Atle Gulla Department of Computer and Information Science Norwegian University of Science and Technology [email protected] Abstract Existing works on sentiment analysis on product reviews suffer from the following limitations: (1) The knowledge of hierar- chical relationships of products attributes is not fully utilized. (2) Reviews or sen- tences mentioning several attributes asso- ciated with complicated sentiments are not dealt with very well. In this paper, we pro- pose a novel HL-SOT approach to label- ing a product’s attributes and their asso- ciated sentiments in product reviews by a Hierarchical Learning (HL) process with a defined Sentiment Ontology Tree (SOT). The empirical analysis against a human- labeled data set demonstrates promising and reasonable performance of the pro- posed HL-SOT approach. While this pa- per is mainly on sentiment analysis on re- views of one product, our proposed HL- SOT approach is easily generalized to la- beling a mix of reviews of more than one products. 1 Introduction As the internet reaches almost every corner of this world, more and more people write reviews and share opinions on the World WideWeb. The user- generated opinion-rich reviews will not only help other users make better judgements but they are also useful resources for manufacturers of prod- ucts to keep track and manage customer opinions. However, as the number of product reviews grows, it becomes difficult for a user to manually learn the panorama of an interesting topic from existing online information. Faced with this problem, re- search works, e.g., (Hu and Liu, 2004; Liu et al., 2005; Lu et al., 2009), of sentiment analysis on product reviews were proposed and have become a popular research topic at the crossroads of infor- mation retrieval and computational linguistics. Carrying out sentiment analysis on product re- views is not a trivial task. Although there have al- ready been a lot of publications investigating on similar issues, among which the representatives are (Turney, 2002; Dave et al., 2003; Hu and Liu, 2004; Liu et al., 2005; Popescu and Etzioni, 2005; Zhuang et al., 2006; Lu and Zhai, 2008; Titov and McDonald, 2008; Zhou and Chaovalit, 2008; Lu et al., 2009), there is still room for improvement on tackling this problem. When we look into the de- tails of each example of product reviews, we find that there are some intrinsic properties that exist- ing previous works have not addressed in much de- tail. First of all, product reviews constitute domain- specific knowledge. The product’s attributes men- tioned in reviews might have some relationships between each other. For example, for a digital camera, comments on image quality are usually mentioned. However, a sentence like “40D han- dles noise very well up to ISO 800”, also refers to image quality of the camera 40D. Here we say “noise” is a sub-attribute factor of “image quality”. We argue that the hierarchical relationship be- tween a product’s attributes can be useful knowl- edge if it can be formulated and utilized in product reviews analysis. Secondly, Vocabularies used in product reviews tend to be highly overlapping. Es- pecially, for same attribute, usually same words or synonyms are involved to refer to them and to de- scribe sentiment on them. We believe that labeling existing product reviews with attributes and cor- responding sentiment forms an effective training resource to perform sentiment analysis. Thirdly, sentiments expressed in a review or even in a sentence might be opposite on different attributes and not every attributes mentioned are with senti- ments. For example, it is common to find a frag- ment of a review as follows: Example 1: “...I am very impressed with this cam- era except for its a bit heavy weight especially with 404
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Sentiment learning on product reviews via sentiment ontology tree

Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, pages 404–413,Uppsala, Sweden, 11-16 July 2010. c©2010 Association for Computational Linguistics
Sentiment Learning on Product Reviews via Sentiment Ontology Tree
Wei WeiDepartment of Computer and
Information ScienceNorwegian University of Science
Jon Atle GullaDepartment of Computer and
Information ScienceNorwegian University of Science
AbstractExisting works on sentiment analysis onproduct reviews suffer from the followinglimitations: (1) The knowledge of hierar-chical relationships of products attributesis not fully utilized. (2) Reviews or sen-tences mentioning several attributes asso-ciated with complicated sentiments are notdealt with very well. In this paper, we pro-pose a novel HL-SOT approach to label-ing a product’s attributes and their asso-ciated sentiments in product reviews by aHierarchical Learning (HL) process with adefined Sentiment Ontology Tree (SOT).The empirical analysis against a human-labeled data set demonstrates promisingand reasonable performance of the pro-posed HL-SOT approach. While this pa-per is mainly on sentiment analysis on re-views of one product, our proposed HL-SOT approach is easily generalized to la-beling a mix of reviews of more than oneproducts.
1 Introduction
As the internet reaches almost every corner of thisworld, more and more people write reviews andshare opinions on the World Wide Web. The user-generated opinion-rich reviews will not only helpother users make better judgements but they arealso useful resources for manufacturers of prod-ucts to keep track and manage customer opinions.However, as the number of product reviews grows,it becomes difficult for a user to manually learnthe panorama of an interesting topic from existingonline information. Faced with this problem, re-search works, e.g., (Hu and Liu, 2004; Liu et al.,2005; Lu et al., 2009), of sentiment analysis onproduct reviews were proposed and have becomea popular research topic at the crossroads of infor-mation retrieval and computational linguistics.
Carrying out sentiment analysis on product re-views is not a trivial task. Although there have al-ready been a lot of publications investigating onsimilar issues, among which the representativesare (Turney, 2002; Dave et al., 2003; Hu and Liu,2004; Liu et al., 2005; Popescu and Etzioni, 2005;Zhuang et al., 2006; Lu and Zhai, 2008; Titov andMcDonald, 2008; Zhou and Chaovalit, 2008; Lu etal., 2009), there is still room for improvement ontackling this problem. When we look into the de-tails of each example of product reviews, we findthat there are some intrinsic properties that exist-ing previous works have not addressed in much de-tail.
First of all, product reviews constitute domain-specific knowledge. The product’s attributes men-tioned in reviews might have some relationshipsbetween each other. For example, for a digitalcamera, comments on image quality are usuallymentioned. However, a sentence like “40D han-dles noise very well up to ISO 800”, also refersto image quality of the camera 40D. Here we say“noise” is a sub-attribute factor of “image quality”.We argue that the hierarchical relationship be-tween a product’s attributes can be useful knowl-edge if it can be formulated and utilized in productreviews analysis. Secondly, Vocabularies used inproduct reviews tend to be highly overlapping. Es-pecially, for same attribute, usually same words orsynonyms are involved to refer to them and to de-scribe sentiment on them. We believe that labelingexisting product reviews with attributes and cor-responding sentiment forms an effective trainingresource to perform sentiment analysis. Thirdly,sentiments expressed in a review or even in asentence might be opposite on different attributesand not every attributes mentioned are with senti-ments. For example, it is common to find a frag-ment of a review as follows:Example 1: “...I am very impressed with this cam-era except for its a bit heavy weight especially with
404

camera +
camera
design and usability image quality lens camera -
design and usability + weight interface design and usability - image quality + noise resolution image quality - lens + lens -
weight + weight - interface + menu button interface -
menu + menu - button + button -
noise + noise - resolution + resolution -
Figure 1: an example of part of a SOT for digital camera
extra lenses attached. It has many buttons and twomain dials. The first dial is thumb dial, locatednear shutter button. The second one is the biground dial located at the back of the camera...”In this example, the first sentence gives positivecomment on the camera as well as a complaint onits heavy weight. Even if the words “lenses” ap-pears in the review, it is not fair to say the cus-tomer expresses any sentiment on lens. The sec-ond sentence and the rest introduce the camera’sbuttons and dials. It’s also not feasible to try toget any sentiment from these contents. We ar-gue that when performing sentiment analysis onreviews, such as in the Example 1, more attentionis needed to distinguish between attributes that arementioned with and without sentiment.
In this paper, we study the problem of senti-ment analysis on product reviews through a novelmethod, called the HL-SOT approach, namely Hi-erarchical Learning (HL) with Sentiment Ontol-ogy Tree (SOT). By sentiment analysis on prod-uct reviews we aim to fulfill two tasks, i.e., label-ing a target text1 with: 1) the product’s attributes(attributes identification task), and 2) their corre-sponding sentiments mentioned therein (sentimentannotation task). The result of this kind of label-ing process is quite useful because it makes it pos-sible for a user to search reviews on particular at-tributes of a product. For example, when consider-ing to buy a digital camera, a prospective user whocares more about image quality probably wants tofind comments on the camera’s image quality inother users’ reviews. SOT is a tree-like ontologystructure that formulates the relationships betweena product’s attributes. For example, Fig. 1 is a SOTfor a digital camera2. The root node of the SOT is
1Each product review to be analyzed is called target textin the following of this paper.
2Due to the space limitation, not all attributes of a digi-tal camera are enumerated in this SOT; m+/m- means posi-
a camera itself. Each of the non-leaf nodes (whitenodes) of the SOT represents an attribute of a cam-era3. All leaf nodes (gray nodes) of the SOT rep-resent sentiment (positive/negative) nodes respec-tively associated with their parent nodes. A for-mal definition on SOT is presented in Section 3.1.With the proposed concept of SOT, we manage toformulate the two tasks of the sentiment analysisto be a hierarchical classification problem. We fur-ther propose a specific hierarchical learning algo-rithm, called HL-SOT algorithm, which is devel-oped based on generalizing an online-learning al-gorithm H-RLS (Cesa-Bianchi et al., 2006). TheHL-SOT algorithm has the same property as theH-RLS algorithm that allows multiple-path label-ing (input target text can be labeled with nodes be-longing to more than one path in the SOT) andpartial-path labeling (the input target text can belabeled with nodes belonging to a path that doesnot end on a leaf). This property makes the ap-proach well suited for the situation where com-plicated sentiments on different attributes are ex-pressed in one target text. Unlike the H-RLS algo-rithm , the HL-SOT algorithm enables each clas-sifier to separately learn its own specific thresh-old. The proposed HL-SOT approach is empiri-cally analyzed against a human-labeled data set.The experimental results demonstrate promisingand reasonable performance of our approach.
This paper makes the following contributions:
• To the best of our knowledge, with the pro-posed concept of SOT, the proposed HL-SOTapproach is the first work to formulate thetasks of sentiment analysis to be a hierarchi-cal classification problem.
• A specific hierarchical learning algorithm is
tive/negative sentiment associated with an attribute m.3A product itself can be treated as an overall attribute of
the product.
405

further proposed to achieve tasks of senti-ment analysis in one hierarchical classifica-tion process.
• The proposed HL-SOT approach can be gen-eralized to make it possible to perform senti-ment analysis on target texts that are a mix ofreviews of different products, whereas exist-ing works mainly focus on analyzing reviewsof only one type of product.
The remainder of the paper is organized as fol-lows. In Section 2, we provide an overview ofrelated work on sentiment analysis. Section 3presents our work on sentiment analysis with HL-SOT approach. The empirical analysis and the re-sults are presented in Section 4, followed by theconclusions, discussions, and future work in Sec-tion 5.
2 Related Work
The task of sentiment analysis on product reviewswas originally performed to extract overall senti-ment from the target texts. However, in (Turney,2002), as the difficulty shown in the experiments,the whole sentiment of a document is not neces-sarily the sum of its parts. Then there came upwith research works shifting focus from overalldocument sentiment to sentiment analysis basedon product attributes (Hu and Liu, 2004; Popescuand Etzioni, 2005; Ding and Liu, 2007; Liu et al.,2005).
Document overall sentiment analysis is to sum-marize the overall sentiment in the document. Re-search works related to document overall senti-ment analysis mainly rely on two finer levels senti-ment annotation: word-level sentiment annotationand phrase-level sentiment annotation. The word-level sentiment annotation is to utilize the polar-ity annotation of words in each sentence and sum-marize the overall sentiment of each sentiment-bearing word to infer the overall sentiment withinthe text (Hatzivassiloglou and Wiebe, 2000; An-dreevskaia and Bergler, 2006; Esuli and Sebas-tiani, 2005; Esuli and Sebastiani, 2006; Hatzi-vassiloglou and McKeown, 1997; Kamps et al.,2004; Devitt and Ahmad, 2007; Yu and Hatzivas-siloglou, 2003). The phrase-level sentiment anno-tation focuses sentiment annotation on phrases notwords with concerning that atomic units of expres-sion is not individual words but rather appraisalgroups (Whitelaw et al., 2005). In (Wilson et al.,
2005), the concepts of prior polarity and contex-tual polarity were proposed. This paper presenteda system that is able to automatically identify thecontextual polarity for a large subset of sentimentexpressions. In (Turney, 2002), an unsupervisedlearning algorithm was proposed to classify re-views as recommended or not recommended byaveraging sentiment annotation of phrases in re-views that contain adjectives or adverbs. How-ever, the performances of these works are not goodenough for sentiment analysis on product reviews,where sentiment on each attribute of a productcould be so complicated that it is unable to be ex-pressed by overall document sentiment.
Attributes-based sentiment analysis is to ana-lyze sentiment based on each attribute of a prod-uct. In (Hu and Liu, 2004), mining product fea-tures was proposed together with sentiment polar-ity annotation for each opinion sentence. In thatwork, sentiment analysis was performed on prod-uct attributes level. In (Liu et al., 2005), a systemwith framework for analyzing and comparing con-sumer opinions of competing products was pro-posed. The system made users be able to clearlysee the strengths and weaknesses of each prod-uct in the minds of consumers in terms of variousproduct features. In (Popescu and Etzioni, 2005),Popescu and Etzioni not only analyzed polarityof opinions regarding product features but alsoranked opinions based on their strength. In (Liuet al., 2007), Liu et al. proposed Sentiment-PLSAthat analyzed blog entries and viewed them as adocument generated by a number of hidden sen-timent factors. These sentiment factors may alsobe factors based on product attributes. In (Lu andZhai, 2008), Lu et al. proposed a semi-supervisedtopic models to solve the problem of opinion inte-gration based on the topic of a product’s attributes.The work in (Titov and McDonald, 2008) pre-sented a multi-grain topic model for extracting theratable attributes from product reviews. In (Lu etal., 2009), the problem of rated attributes summarywas studied with a goal of generating ratings formajor aspects so that a user could gain differentperspectives towards a target entity. All these re-search works concentrated on attribute-based sen-timent analysis. However, the main differencewith our work is that they did not sufficiently uti-lize the hierarchical relationships among a prod-uct attributes. Although a method of ontology-supported polarity mining, which also involved
406

ontology to tackle the sentiment analysis problem,was proposed in (Zhou and Chaovalit, 2008), thatwork studied polarity mining by machine learn-ing techniques that still suffered from a problemof ignoring dependencies among attributes withinan ontology’s hierarchy. In the contrast, our worksolves the sentiment analysis problem as a hierar-chical classification problem that fully utilizes thehierarchy of the SOT during training and classifi-cation process.
3 The HL-SOT Approach
In this section, we first propose a formal defini-tion on SOT. Then we formulate the HL-SOT ap-proach. In this novel approach, tasks of sentimentanalysis are to be achieved in a hierarchical classi-fication process.
3.1 Sentiment Ontology TreeAs we discussed in Section 1, the hierarchial rela-tionships among a product’s attributes might helpimprove the performance of attribute-based senti-ment analysis. We propose to use a tree-like ontol-ogy structure SOT, i.e., Sentiment Ontology Tree,to formulate relationships among a product’s at-tributes. Here,we give a formal definition on whata SOT is.
Definition 1 [SOT] SOT is an abbreviation forSentiment Ontology Tree that is a tree-like ontol-ogy structure T (v, v+, v−, T). v is the root nodeof T which represents an attribute of a given prod-uct. v+ is a positive sentiment leaf node associ-ated with the attribute v. v− is a negative sen-timent leaf node associated with the attribute v.T is a set of subtrees. Each element of T is alsoa SOT T ′(v′, v′+, v′−, T′) which represents a sub-attribute of its parent attribute node.
By the Definition 1, we define a root of a SOT torepresent an attribute of a product. The SOT’s twoleaf child nodes are sentiment (positive/negative)nodes associated with the root attribute. The SOTrecursively contains a set of sub-SOTs where eachroot of a sub-SOT is a non-leaf child node of theroot of the SOT and represent a sub-attribute be-longing to its parent attribute. This definition suc-cessfully describes the hierarchical relationshipsamong all the attributes of a product. For example,in Fig. 1 the root node of the SOT for a digital cam-era is its general overview attribute. Comments ona digital camera’s general overview attribute ap-pearing in a review might be like “this camera is
great”. The “camera” SOT has two sentiment leafchild nodes as well as three non-leaf child nodeswhich are respectively root nodes of sub-SOTs forsub-attributes “design and usability”, “image qual-ity”, and “lens”. These sub-attributes SOTs re-cursively repeat until each node in the SOT doesnot have any more non-leaf child node, whichmeans the corresponding attributes do not haveany sub-attributes, e.g., the attribute node “button”in Fig. 1.
3.2 Sentiment Analysis with SOT
In this subsection, we present the HL-SOT ap-proach. With the defined SOT, the problem of sen-timent analysis is able to be formulated to be a hi-erarchial classification problem. Then a specifichierarchical learning algorithm is further proposedto solve the formulated problem.
3.2.1 Problem FormulationIn the proposed HL-SOT approach, each targettext is to be indexed by a unit-norm vector x ∈X ,X = Rd. Let Y = {1, ..., N} denote the fi-nite set of nodes in SOT. Let y = {y1, ..., yN} ∈{0, 1}N be a label vector to a target text x, where∀i ∈ Y :
yi =
{1, if x is labeled by the classifier of node i,0, if x is not labeled by the classifier of node i.
A label vector y ∈ {0, 1}N is said to respectSOT if and only if y satisfies ∀i ∈ Y , ∀j ∈A(i) : if yi = 1 then yj = 1, where A(i)represents a set ancestor nodes of i, i.e.,A(i) ={x|ancestor(i, x)}. Let Y denote a set of labelvectors that respect SOT. Then the tasks of senti-ment analysis can be formulated to be the goal of ahierarchical classification that is to learn a functionf : X → Y , that is able to label each target textx ∈ X with classifier of each node and generatingwith x a label vector y ∈ Y that respects SOT. Therequirement of a generated label vector y ∈ Y en-sures that a target text is to be labeled with a nodeonly if its parent attribute node is labeled with thetarget text. For example, in Fig. 1 a review is tobe labeled with “image quality +” requires that thereview should be successively labeled as related to“camera” and “image quality”. This is reasonableand consistent with intuition, because if a reviewcannot be identified to be related to a camera, it isnot safe to infer that the review is commenting acamera’s image quality with positive sentiment.
407

3.2.2 HL-SOT AlgorithmThe algorithm H-RLS studied in (Cesa-Bianchi etal., 2006) solved a similar hierarchical classifica-tion problem as we formulated above. However,the H-RLS algorithm was designed as an online-learning algorithm which is not suitable to be ap-plied directly in our problem setting. Moreover,the algorithm H-RLS defined the same value asthe threshold of each node classifier. We arguethat if the threshold values could be learned sepa-rately for each classifiers, the performance of clas-sification process would be improved. Thereforewe propose a specific hierarchical learning algo-rithm, named HL-SOT algorithm, that is able totrain each node classifier in a batch-learning set-ting and allows separately learning for the thresh-old of each node classifier.
Defining the f function Let w1, ..., wN beweight vectors that define linear-threshold classi-fiers of each node in SOT. Let W = (w1, ..., wN )⊤
be an N ×d matrix called weight matrix. Here wegeneralize the work in (Cesa-Bianchi et al., 2006)and define the hierarchical classification functionf as:
y = f(x) = g(W · x),
where x ∈ X , y ∈ Y . Let z = W · x. Then thefunction y = g(z) on an N -dimensional vector zdefines:∀i = 1, ..., N :
yi =
B(zi ≥ θi), if i is a root node in SOT
or yj = 1 for j = P(i),
0, else
where P(i) is the parent node of i in SOT andB(S) is a boolean function which is 1 if and onlyif the statement S is true. Then the hierarchicalclassification function f is parameterized by theweight matrix W = (w1, ..., wN )⊤ and thresholdvector θ = (θ1, ..., θN )⊤. The hierarchical learn-ing algorithm HL-SOT is proposed for learningthe parameters of W and θ.
Parameters Learning for f function Let D de-note the training data set: D = {(r, l)|r ∈ X , l ∈Y}. In the HL-SOT learning process, the weightmatrix W is firstly initialized to be a 0 matrix,where each row vector wi is a 0 vector. The thresh-old vector is initialized to be a 0 vector. Each in-stance in the training set D goes into the trainingprocess. When a new instance rt is observed, each
row vector wi,t of the weight matrix Wt is updatedby a regularized least squares estimator given by:
wi,t = (I + Si,Q(i,t−1)S⊤i,Q(i,t−1) + rtr
⊤t )−1
×Si,Q(i,t−1)(li,i1 , li,i2 , ..., li,iQ(i,t−1))⊤
(1)where I is a d × d identity matrix, Q(i, t − 1)denotes the number of times the parent of node iobserves a positive label before observing the in-stance rt, Si,Q(i,t−1) = [ri1 , ..., riQ(i,t−1)
] is a d ×Q(i, t−1) matrix whose columns are the instancesri1 , ..., riQ(i,t−1)
, and (li,i1 , li,i2 , ..., li,iQ(i,t−1))⊤ is
a Q(i, t−1)-dimensional vector of the correspond-ing labels observed by node i. The Formula 1 re-stricts that the weight vector wi,t of the classifier iis only updated on the examples that are positivefor its parent node. Then the label vector yrt iscomputed for the instance rt, before the real labelvector lrt is observed. Then the current thresholdvector θt is updated by:
θt+1 = θt + ϵ(yrt − lrt), (2)
where ϵ is a small positive real number that de-notes a corrective step for correcting the currentthreshold vector θt. To illustrate the idea behindthe Formula 2, let y′t = yrt − lrt . Let y′i,t denotean element of the vector y′t. The Formula 2 correctthe current threshold θi,t for the classifier i in thefollowing way:
• If y′i,t = 0, it means the classifier i made aproper classification for the current instancert. Then the current threshold θi does notneed to be adjusted.
• If y′i,t = 1, it means the classifier i made animproper classification by mistakenly identi-fying the attribute i of the training instancert that should have not been identified. Thisindicates the value of θi is not big enough toserve as a threshold so that the attribute i inthis case can be filtered out by the classifieri. Therefore, the current threshold θi will beadjusted to be larger by ϵ.
• If y′i,t = −1, it means the classifier i made animproper classification by failing to identifythe attribute i of the training instance rt thatshould have been identified. This indicatesthe value of θi is not small enough to serve asa threshold so that the attribute i in this case
408

Algorithm 1 Hierarchical Learning Algorithm HL-SOT
INITIALIZATION:1: Each vector wi,1, i = 1, ..., N of weight ma-
trix W1 is set to be 0 vector2: Threshold vector θ1 is set to be 0 vector
BEGIN3: for t = 1, ..., |D| do4: Observe instance rt ∈ X5: for i = 1, ...N do6: Update each row wi,t of weight matrix
Wt by Formula 17: end for8: Compute yrt = f(rt) = g(Wt · rt)9: Observe label vector lrt ∈ Y of the in-
stance rt
10: Update threshold vector θt by Formula 211: end for
END
can be recognized by the classifier i. There-fore, the current threshold θi will be adjustedto be smaller by ϵ.
The hierarchial learning algorithm HL-SOT ispresented as in Algorithm 1. The HL-SOT al-gorithm enables each classifier to have its ownspecific threshold value and allows this thresh-old value can be separately learned and correctedthrough the training process. It is not only a batch-learning setting of the H-RLS algorithm but alsoa generalization to the latter. If we set the algo-rithm HL-SOT’s parameter ϵ to be 0, the HL-SOTbecomes the H-RLS algorithm in a batch-learningsetting.
4 Empirical Analysis
In this section, we conduct systematic experimentsto perform empirical analysis on our proposed HL-SOT approach against a human-labeled data set.In order to encode each text in the data set by ad-dimensional vector x ∈ Rd, we first remove allthe stop words and then select the top d frequencyterms appearing in the data set to construct the in-dex term space. Our experiments are intended toaddress the following questions:(1) whether uti-lizing the hierarchical relationships among labelshelp to improve the accuracy of the classification?(2) whether the introduction of separately learn-ing threshold for each classifier help to improvethe accuracy of the classification? (3) how doesthe corrective step ϵ impact the performance of the
proposed approach?(4)how does the dimensional-ity d of index terms space impact the proposed ap-proach’s computing efficiency and accuracy?
4.1 Data Set PreparationThe data set contains 1446 snippets of customerreviews on digital cameras that are collected froma customer review website4. We manually con-struct a SOT for the product of digital cameras.The constructed SOT (e.g., Fig. 1) contains 105nodes that include 35 non-leaf nodes representingattributes of the digital camera and 70 leaf nodesrepresenting associated sentiments with attributenodes. Then we label all the snippets with corre-sponding labels of nodes in the constructed SOTcomplying with the rule that a target text is to belabeled with a node only if its parent attribute nodeis labeled with the target text. We randomly dividethe labeled data set into five folds so that each foldat least contains one example snippets labeled byeach node in the SOT. For each experiment set-ting, we run 5 experiments to perform cross-foldevaluation by randomly picking three folds as thetraining set and the other two folds as the testingset. All the testing results are averages over 5 run-ning of experiments.
4.2 Evaluation MetricsSince the proposed HL-SOT approach is a hier-archical classification process, we use three clas-sic loss functions for measuring classification per-formance. They are the One-error Loss (O-Loss)function, the Symmetric Loss (S-Loss) function,and the Hierarchical Loss (H-Loss) function:
• One-error loss (O-Loss) function is definedas:
LO(y, l) = B(∃i : yi = li),
where y is the prediction label vector and l isthe true label vector; B is the boolean func-tion as defined in Section 3.2.2.
• Symmetric loss (S-Loss) function is definedas:
LS(y, l) =
N∑i=1
B(yi = li),
• Hierarchical loss (H-Loss) function is definedas:
LH(y, l) =
N∑i=1
B(yi = li ∧ ∀j ∈ A(i), yj = lj),
4http://www.consumerreview.com/
409

Table 1: Performance Comparisons (A Smaller Loss Value Means a Better Performance)
Metrics Dimensinality=110 Dimensinality=220H-RLS HL-flat HL-SOT H-RLS HL-flat HL-SOT
O-Loss 0.9812 0.8772 0.8443 0.9783 0.8591 0.8428S-Loss 8.5516 2.8921 2.3190 7.8623 2.8449 2.2812H-Loss 3.2479 1.1383 1.0366 3.1029 1.1298 1.0247
0 0.02 0.04 0.06 0.08 0.10.838
0.84
0.842
0.844
0.846
0.848
0.85
0.852
Corrective Step
O−
Loss
d=110d=220
(a) O-Loss
0 0.02 0.04 0.06 0.08 0.12.15
2.2
2.25
2.3
2.35
2.4
Corrective Step
S−
Loss
d=110d=220
(b) S-Loss
0 0.02 0.04 0.06 0.08 0.1
1.02
1.025
1.03
1.035
1.04
1.045
1.05
Corrective Step
H−
Loss
d=110d=220
(c) H-Loss
Figure 2: Impact of Corrective Step ϵ
where A denotes a set of nodes that are an-cestors of node i in SOT.
Unlike the O-Loss function and the S-Loss func-tion, the H-Loss function captures the intuitionthat loss should only be charged on a node when-ever a classification mistake is made on a node ofSOT but no more should be charged for any ad-ditional mistake occurring in the subtree of thatnode. It measures the discrepancy between theprediction labels and the true labels with consider-ation on the SOT structure defined over the labels.In our experiments, the recorded loss function val-ues for each experiment running are computed byaveraging the loss function values of each testingsnippets in the testing set.
4.3 Performance Comparison
In order to answer the questions (1), (2) in thebeginning of this section, we compare our HL-SOT approach with the following two baseline ap-proaches:
• HL-flat: The HL-flat approach involves an al-gorithm that is a “flat” version of HL-SOTalgorithm by ignoring the hierarchical rela-tionships among labels when each classifieris trained. In the training process of HL-flat,the algorithm reflexes the restriction in theHL-SOT algorithm that requires the weightvector wi,t of the classifier i is only updatedon the examples that are positive for its parentnode.
• H-RLS: The H-RLS approach is imple-mented by applying the H-RLS algorithmstudied in (Cesa-Bianchi et al., 2006). Un-like our proposed HL-SOT algorithm that en-ables the threshold values to be learned sepa-rately for each classifiers in the training pro-cess, the H-RLS algorithm only uses an iden-tical threshold values for each classifiers inthe classification process.
Experiments are conducted on the performancecomparison between the proposed HL-SOT ap-proach with HL-flat approach and the H-RLS ap-proach. The dimensionality d of the index termspace is set to be 110 and 220. The corrective stepϵ is set to be 0.005. The experimental results aresummarized in Table 1. From Table 1, we can ob-serve that the HL-SOT approach generally beatsthe H-RLS approach and HL-flat approach on O-Loss, S-Loss, and H-Loss respectively. The H-RLS performs worse than the HL-flat and the HL-SOT, which indicates that the introduction of sepa-rately learning threshold for each classifier did im-prove the accuracy of the classification. The HL-SOT approach performs better than the HL-flat,which demonstrates the effectiveness of utilizingthe hierarchical relationships among labels.
4.4 Impact of Corrective Step ϵ
The parameter ϵ in the proposed HL-SOT ap-proach controls the corrective step of the classi-fiers’ thresholds when any mistake is observed inthe training process. If the corrective step ϵ is settoo large, it might cause the algorithm to be too
410
50 100 150 200 250 300
0.84
0.841
0.842
0.843
0.844
0.845
0.846
Dimensionality of Index Term Space
O−
Loss
(a) O-Loss
50 100 150 200 250 3002.26
2.27
2.28
2.29
2.3
2.31
2.32
2.33
2.34
2.35
Dimensionality of Index Term Space
S−
Loss
(b) S-Loss
50 100 150 200 250 3001.01
1.015
1.02
1.025
1.03
1.035
1.04
1.045
Dimensionality of Index Term Space
H−
Loss
(c) H-Loss
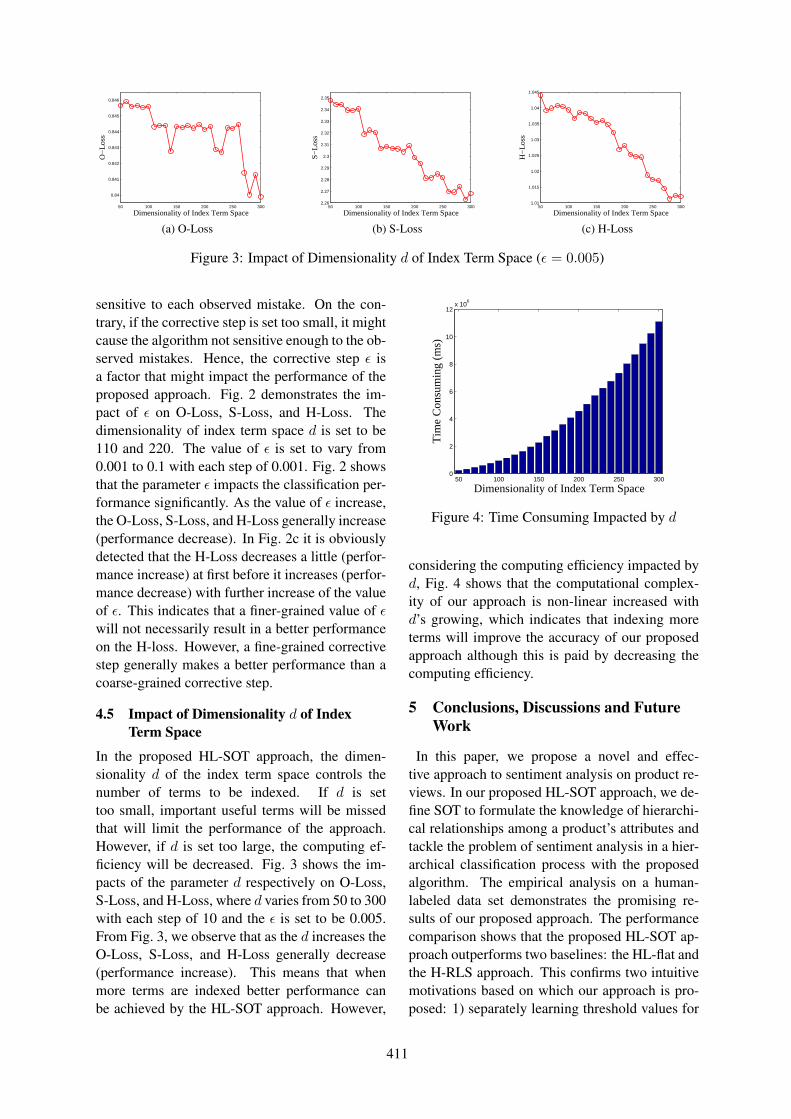
Figure 3: Impact of Dimensionality d of Index Term Space (ϵ = 0.005)
sensitive to each observed mistake. On the con-trary, if the corrective step is set too small, it mightcause the algorithm not sensitive enough to the ob-served mistakes. Hence, the corrective step ϵ isa factor that might impact the performance of theproposed approach. Fig. 2 demonstrates the im-pact of ϵ on O-Loss, S-Loss, and H-Loss. Thedimensionality of index term space d is set to be110 and 220. The value of ϵ is set to vary from0.001 to 0.1 with each step of 0.001. Fig. 2 showsthat the parameter ϵ impacts the classification per-formance significantly. As the value of ϵ increase,the O-Loss, S-Loss, and H-Loss generally increase(performance decrease). In Fig. 2c it is obviouslydetected that the H-Loss decreases a little (perfor-mance increase) at first before it increases (perfor-mance decrease) with further increase of the valueof ϵ. This indicates that a finer-grained value of ϵwill not necessarily result in a better performanceon the H-loss. However, a fine-grained correctivestep generally makes a better performance than acoarse-grained corrective step.
4.5 Impact of Dimensionality d of IndexTerm Space
In the proposed HL-SOT approach, the dimen-sionality d of the index term space controls thenumber of terms to be indexed. If d is settoo small, important useful terms will be missedthat will limit the performance of the approach.However, if d is set too large, the computing ef-ficiency will be decreased. Fig. 3 shows the im-pacts of the parameter d respectively on O-Loss,S-Loss, and H-Loss, where d varies from 50 to 300with each step of 10 and the ϵ is set to be 0.005.From Fig. 3, we observe that as the d increases theO-Loss, S-Loss, and H-Loss generally decrease(performance increase). This means that whenmore terms are indexed better performance canbe achieved by the HL-SOT approach. However,
50 100 150 200 250 3000
2
4
6
8
10
12x 10
6
Dimensionality of Index Term Space
Tim
e C
onsu
min
g (m
s)
Figure 4: Time Consuming Impacted by d
considering the computing efficiency impacted byd, Fig. 4 shows that the computational complex-ity of our approach is non-linear increased withd’s growing, which indicates that indexing moreterms will improve the accuracy of our proposedapproach although this is paid by decreasing thecomputing efficiency.
5 Conclusions, Discussions and FutureWork
In this paper, we propose a novel and effec-tive approach to sentiment analysis on product re-views. In our proposed HL-SOT approach, we de-fine SOT to formulate the knowledge of hierarchi-cal relationships among a product’s attributes andtackle the problem of sentiment analysis in a hier-archical classification process with the proposedalgorithm. The empirical analysis on a human-labeled data set demonstrates the promising re-sults of our proposed approach. The performancecomparison shows that the proposed HL-SOT ap-proach outperforms two baselines: the HL-flat andthe H-RLS approach. This confirms two intuitivemotivations based on which our approach is pro-posed: 1) separately learning threshold values for
411

each classifier improve the classification accuracy;2) knowledge of hierarchical relationships of la-bels improve the approach’s performance. The ex-periments on analyzing the impact of parameterϵ indicate that a fine-grained corrective step gen-erally makes a better performance than a coarse-grained corrective step. The experiments on an-alyzing the impact of the dimensionality d showthat indexing more terms will improve the accu-racy of our proposed approach while the comput-ing efficiency will be greatly decreased.
The focus of this paper is on analyzing reviewtexts of one product. However, the framework ofour proposed approach can be generalized to dealwith a mix of review texts of more than one prod-ucts. In this generalization for sentiment analysison multiple products reviews, a “big” SOT is con-structed and the SOT for each product reviews isa sub-tree of the “big” SOT. The sentiment analy-sis on multiple products reviews can be performedthe same way the HL-SOT approach is applied onsingle product reviews and can be tackled in a hier-archical classification process with the “big” SOT.
This paper is motivated by the fact that therelationships among a product’s attributes couldbe a useful knowledge for mining product reviewtexts. The SOT is defined to formulate this knowl-edge in the proposed approach. However, whatattributes to be included in a product’s SOT andhow to structure these attributes in the SOT is aneffort of human beings. The sizes and structuresof SOTs constructed by different individuals mayvary. How the classification performance will beaffected by variances of the generated SOTs isworthy of study. In addition, an automatic methodto learn a product’s attributes and the structureof SOT from existing product review texts willgreatly benefit the efficiency of the proposed ap-proach. We plan to investigate on these issues inour future work.
Acknowledgments
The authors would like to thank the anonymousreviewers for many helpful comments on themanuscript. This work is funded by the ResearchCouncil of Norway under the VERDIKT researchprogramme (Project No.: 183337).
ReferencesAlina Andreevskaia and Sabine Bergler. 2006. Min-
ing wordnet for a fuzzy sentiment: Sentiment tag
extraction from wordnet glosses. In Proceedings of11th Conference of the European Chapter of the As-sociation for Computational Linguistics (EACL’06),Trento, Italy.
Nicolo Cesa-Bianchi, Claudio Gentile, and Luca Zani-boni. 2006. Incremental algorithms for hierarchi-cal classification. Journal of Machine Learning Re-search (JMLR), 7:31–54.
Kushal Dave, Steve Lawrence, and David M. Pennock.2003. Mining the peanut gallery: opinion extractionand semantic classification of product reviews. InProceedings of 12nd International World Wide WebConference (WWW’03), Budapest, Hungary.
Ann Devitt and Khurshid Ahmad. 2007. Sentimentpolarity identification in financial news: A cohesion-based approach. In Proceedings of 45th AnnualMeeting of the Association for Computational Lin-guistics (ACL’07), Prague, Czech Republic.
Xiaowen Ding and Bing Liu. 2007. The utility oflinguistic rules in opinion mining. In Proceedingsof 30th Annual International ACM Special Inter-est Group on Information Retrieval Conference (SI-GIR’07), Amsterdam, The Netherlands.
Andrea Esuli and Fabrizio Sebastiani. 2005. Deter-mining the semantic orientation of terms throughgloss classification. In Proceedings of 14th ACMConference on Information and Knowledge Man-agement (CIKM’05), Bremen, Germany.
Andrea Esuli and Fabrizio Sebastiani. 2006. Senti-wordnet: A publicly available lexical resource foropinion mining. In Proceedings of 5th InternationalConference on Language Resources and Evaluation(LREC’06), Genoa, Italy.
Vasileios Hatzivassiloglou and Kathleen R. McKeown.1997. Predicting the semantic orientation of ad-jectives. In Proceedings of 35th Annual Meetingof the Association for Computational Linguistics(ACL’97), Madrid, Spain.
Vasileios Hatzivassiloglou and Janyce M. Wiebe.2000. Effects of adjective orientation and grad-ability on sentence subjectivity. In Proceedingsof 18th International Conference on ComputationalLinguistics (COLING’00), Saarbruken, Germany.
Minqing Hu and Bing Liu. 2004. Mining and sum-marizing customer reviews. In Proceedings of 10thACM SIGKDD Conference on Knowledge Discoveryand Data Mining (KDD’04), Seattle, USA.
Jaap Kamps, Maarten Marx, R. ort. Mokken, andMaarten de Rijke. 2004. Using WordNet to mea-sure semantic orientation of adjectives. In Proceed-ings of 4th International Conference on LanguageResources and Evaluation (LREC’04), Lisbon, Por-tugal.
412

Bing Liu, Minqing Hu, and Junsheng Cheng. 2005.Opinion observer: analyzing and comparing opin-ions on the web. In Proceedings of 14th Inter-national World Wide Web Conference (WWW’05),Chiba, Japan.
Yang Liu, Xiangji Huang, Aijun An, and Xiaohui Yu.2007. ARSA: a sentiment-aware model for predict-ing sales performance using blogs. In Proceedingsof the 30th Annual International ACM Special Inter-est Group on Information Retrieval Conference (SI-GIR’07), Amsterdam, The Netherlands.
Yue Lu and Chengxiang Zhai. 2008. Opinion inte-gration through semi-supervised topic modeling. InProceedings of 17th International World Wide WebConference (WWW’08), Beijing, China.
Yue Lu, ChengXiang Zhai, and Neel Sundaresan.2009. Rated aspect summarization of short com-ments. In Proceedings of 18th International WorldWide Web Conference (WWW’09), Madrid, Spain.
Ana-Maria Popescu and Oren Etzioni. 2005. Extract-ing product features and opinions from reviews. InProceedings of Human Language Technology Con-ference and Empirical Methods in Natural Lan-guage Processing Conference (HLT/EMNLP’05),Vancouver, Canada.
Ivan Titov and Ryan T. McDonald. 2008. Modelingonline reviews with multi-grain topic models. InProceedings of 17th International World Wide WebConference (WWW’08), Beijing, China.
Peter D. Turney. 2002. Thumbs up or thumbs down?semantic orientation applied to unsupervised classi-fication of reviews. In Proceedings of 40th AnnualMeeting of the Association for Computational Lin-guistics (ACL’02), Philadelphia, USA.
Casey Whitelaw, Navendu Garg, and Shlomo Arga-mon. 2005. Using appraisal taxonomies for senti-ment analysis. In Proceedings of 14th ACM Confer-ence on Information and Knowledge Management(CIKM’05), Bremen, Germany.
Theresa Wilson, Janyce Wiebe, and Paul Hoffmann.2005. Recognizing contextual polarity in phrase-level sentiment analysis. In Proceedings of Hu-man Language Technology Conference and Empir-ical Methods in Natural Language Processing Con-ference (HLT/EMNLP’05), Vancouver, Canada.
Hong Yu and Vasileios Hatzivassiloglou. 2003. To-wards answering opinion questions: Separating factsfrom opinions and identifying the polarity of opin-ion sentences. In Proceedings of 8th Conference onEmpirical Methods in Natural Language Processing(EMNLP’03), Sapporo, Japan.
Lina Zhou and Pimwadee Chaovalit. 2008. Ontology-supported polarity mining. Journal of the AmericanSociety for Information Science and Technology (JA-SIST), 59(1):98–110.
Li Zhuang, Feng Jing, and Xiao-Yan Zhu. 2006.Movie review mining and summarization. In Pro-ceedings of the 15th ACM International Confer-ence on Information and knowledge management(CIKM’06), Arlington, USA.
413



















