
Rapport PFE
56
Rapport de projet de fin d'études Logiciel de simulation de déroulement des algorithmes Universitaire HASSAN II Ain Chock CASABLANCA École Supérieur de Technologie Élaboré par : HAJI Soukaïna OUICHOUL Chaimaa CHACKCHAME Fatima-Zahra Encadré par : ANOUN Houda Département : Génie Informatique Année scolaire : 2013 - 2014
Transcript of Rapport PFE

Rapport de projet de fin d'études
Logiciel de simulation de déroulement des algorithmes
Universitaire HASSAN II Ain Chock CASABLANCA
École Supérieur de Technologie
Élaboré par : HAJI Soukaïna
OUICHOUL Chaimaa
CHACKCHAME Fatima-Zahra
Encadré par : ANOUN Houda
Département : Génie Informatique
Année scolaire : 2013 - 2014

1
Remerciements
Avant d’entamer ce travail, on tient tout d’abord à exprimer notre gratitude au corps
professoral et administratif de l'École Supérieur de Technologie de Casablanca, pour leur
formation et leur encadrement durant toute l'année.
De même, on adresse nos sincères remerciements dans un premier temps à Mr Larbi
HASSOUNI le chef du département de l’informatique.
On tient à présenter nos sincères et nos vifs remerciements à Mme Houda ANOUN, notre
encadrante, pour son aide, ses conseils inestimables, son encouragement et sa disponibilité
tout au long de la réalisation du projet.
On tient à leur exprimer toute notre gratitude pour ses précieux conseils et son grand effort
pour mettre en valeur notre projet.
On espère que vous trouvez ici l’expression de notre profond respect et notre
profonde reconnaissance.

2
Avant-propos
Dans le cadre de la formation à l’École Supérieure de Technologie de Casablanca
(ESTC) et afin de préparer l’entrée à la vie active, l’établissement cherche à améliorer les
compétences et le savoir-faire de ses étudiants par divers moyens tels que les mini-projets,
les stages et le projet de fin d’étude.
Le projet de fin d’études est une initiative parfaite qui ouvre la porte face à tous les
étudiants afin de tester et d’amplifier leurs connaissances, pour renforcer leur bagage et
leurs compétences professionnelles.
Le document ci-présent constitue le résumé de notre travail accompli dans le cadre de notre
projet de fin d’études et dont l’objectif est la réalisation d’un logiciel de simulation de
déroulement des algorithmes.
Ce logiciel a pour objectif d'aider les étudiants de la première année Génie Informatique à
assimiler toutes les instructions de base en algorithmique.

3
Table des matières
Remerciements .......................................................................................................................... 0
Avant-propos .............................................................................................................................. 2
Introduction .......................................................................................................... 5
Partie I : Généralités
I. Présentation de l’ESTC ........................................................................................................ 7
II. Organisation du travail en groupe: ..................................................................................... 8
Partie II : Présentation du projet
I. Cahier de charge ............................................................................................. 10
1. Contexte ........................................................................................................................ 10
2. Objectives du projet ...................................................................................................... 10
3. Public-cible du projet .................................................................................................... 11
II. Analyse de l’existant ........................................................................................ 11
III. Description de l’ interpréteur LSALGO-SIMULATOR ............................................... 11
1. Environnement de développement .............................................................................. 13
2. Utilité de l’interpréteur ................................................................................................. 13
3. Les composants de base ................................................................................................ 13
4. Structure d’un compilateur/interpréteur ..................................................................... 15
IV. Étape de réalisation de l’interpréteur .................................................................. 16
1. Analyse des besoins ...................................................................................................... 17
2. Conception .................................................................................................................... 18
2.1. Héritage .................................................................................................................. 18
2.2. Polymorphisme ...................................................................................................... 19
2.3. Diagramme de classes ............................................................................................ 20
3. Réalisation ..................................................................................................................... 24
3.1. Outils utilisés .......................................................................................................... 24
3.2. Spécification FLEX et CUP ...................................................................................... 25
3.3. Arbre syntaxique .................................................................................................... 32
3.4. Table de symboles .................................................................................................. 34
3.5. Grammaire ............................................................................................................. 34

4
3.6. Exécution ................................................................................................................ 34
3.7. Exécution pas-à-pas ............................................................................................... 37
3.8. Gestion d'erreur ..................................................................................................... 42
Partie III : Simulation
I. Site web LSALGO ............................................................................................................... 45
II. logiciel LSALGO .................................................................................................................. 45
1. Détails de l’interface ..................................................................................................... 46
Problèmes rencontrés et perspectives .................................................................................... 53
Conclusion ................................................................................................................................ 54
Bibliographie et webographie .................................................................................................. 55

5
Introduction
Au début de l’informatique, on développait des programmes en langage bas niveau (dit binaire). Cela s’est vite avéré fastidieux. On a très vite essayé d’utiliser les possibilités de l’informatique pour faciliter le travail de programmation.
L’étape suivante consiste à s’affranchir complètement de la machine en élaborant ce que l’on appelle des langages de haut niveau. Ces langages ont introduit un certain nombre de constructions qui n’existent pas dans le langage de la machine : expressions arithmétiques, variables locales, procédures et fonctions avec des paramètres qui retournent un résultat, structures de données (tableaux, énumération, record, objet,..), etc.
Pour cela il a fallu construire des programmes qui traduisent des énoncés exprimés dans le langage de haut niveau utilisé par les programmeurs, ce que l’on appelle le langage source, en instructions pour la machine cible. Les programmes effectuant ce genre d’opération s’appellent des compilateurs/interpréteurs- et qui s’avère être le sujet de notre projet - .
En tant que développeurs, nous utilisons fréquemment des compilateurs, pourtant avant de réaliser ce projet nous étions incapables d'expliquer le fonctionnement de ceux-ci.
Grâce à ce projet nous nous sommes intéressés aux outils que nous utilisons quotidiennement puisqu'il nous a été demandé de réaliser un logiciel permettant le déroulement et l'interprétation d'algorithmes écrits en pseudocode. Le compilateur permet de transformer un algorithme en un langage cible, c'est à dire un langage très proche de la machine. Ce langage machine sera par la suite interprété. Il en découlera différents états mémoires.
Ce rapport relate les procédures misent en place lors de la réalisation de ce projet, c'est-à-dire la mise en évidence de tâches ainsi que leurs répartitions, les différents choix adoptés ainsi que les méthodes de travail.

Partie I Généralités

Logiciel de simulation de déroulement des algorithmes
Partie I : Généralités
7
Présentation de l’ESTC
L’École supérieure de technologie de Casablanca (ESTC), créée en 1986 par le Ministère de
l'Enseignement Supérieur de la Formation des Cadres et de la Recherche Scientifique, est
une école d'enseignement supérieur public. Elle fait partie du réseau des écoles supérieures
de technologie et relève de l'université Hassan II - Ain Chock de Casablanca. Sa vocation est
de former des Techniciens Supérieurs polyvalents, hautement qualifiés et immédiatement
opérationnels après leur sortie de l'École en tant que collaborateurs d'ingénieurs et de
managers.
Sont admis à l'ESTC, les bacheliers de l'enseignement secondaire technique, scientifique et
tertiaire. L'admission à l'École se fait par présélection sur la base des notes obtenues au
baccalauréat. Les candidats doivent être âgés de 22 ans au plus au 31 Décembre de l'année
du concours et doivent déposer leurs dossiers avant le 30 Juin de chaque année.
Orientation appliquée de l’enseignement
La formation appliquée à l'ESTC est largement tournée vers l'industrie, c'est pourquoi ses
programmes sont fait afin de répondre aux exigences et aux attentes de l'environnement
économique et social de l'École et font appel à des méthodes pédagogiques actives et
évoluées. Les programmes d'enseignement comportent des Cours, des Travaux Pratiques,
des Travaux Dirigés et des Travaux de Réalisation ainsi que des projets de fin d'études.
L'ESTC dispense des formations dans les spécialités suivantes
- Génie mécanique (GM)
- Génie électrique (GE)
- Génie informatique (GI)
- Génie des procédés (GP)
- Techniques de management (TM)
Elle permet aussi la formation continue.

Logiciel de simulation de déroulement des algorithmes
Partie I : Généralités
8
Durée des études
La durée des études est de deux années universitaires :
- La première année s'étale sur 32 semaines suivies de quatre semaines de stage dans
l'entreprise en Juillet ou Aout.
- La deuxième année est de 36 semaines dont 8 semaines de stage qui débutent du 21
Avril jusqu’au 14 Juin.
I. Organisation du travail en groupe:
Le groupe étant divisé en plusieurs binômes et trinômes, les séances de travail étaient
gérées par nous-mêmes avec l’aide des encadrants ainsi que des doctorants.
Toutes se déroulant sous forme de séances TP dans lesquelles on avançait dans la
préparation de notre projet, en discutant les étapes à suivre afin de mieux les réaliser ainsi
qu’en se répartissant les tâches que chacun aura à effectuer.
On avait aussi une réunion avec notre encadrante une fois par semaine, le Mardi, afin qu’elle
puisse mieux nous guider et nous éclairer sur les points qu’on n’a pas réussi à comprendre
ou à réaliser, tout en nous corrigeant ce qu’on avait pu accomplir jusqu’à présent.
À la fin de chaque réunion notre encadrante nous donnait des renseignements sur les tâches
à réaliser pour la prochaine séance, chose qui nous permettra de mieux améliorer notre
projet.

9
Partie II Présentation du
projet

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
10
II. Cahier de charge
1. Contexte
L’interpréteur permet l’interprétation/simulation d’un code algorithme suivant la syntaxe
mentionnée par la suite.
Une bête à cornes pour résumé le fonctionnement de l’interpréteur:
2. Objectifs du projet
Les caractéristiques du projet sont les suivantes :
Un logiciel d’interprétation d’algorithme de base ouvert à tout public.
Facilité d’adaptation aux fonctionnalités du logiciel qui est destiné aux débutants en
programmation.
Déroulement pas-à-pas et vulgarisation de la RAM aide l’utilisateur à mieux assimiler
le fonctionnement des programmes développés.
Interface simple et riche de différents outils d’éditions pour faciliter la manipulation
du code.

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
11
Site web disponible sur internet pour plus d’accessibilité au logiciel avec divers
contenus pour une meilleure compréhensibilité aux utilisateurs.
3. Public-cible du projet
Le logiciel a été réalisé en étant destiné aux étudiants de première année en Génie
Informatique qui auront au début quelques difficultés à s’adapter au langage de
programmation.
Le logiciel peut être utile à toute personne souhaitant débuter en développement
informatique.
III. Analyse de l’existant
Il existe peu de logiciels permettant l’exécution d’algorithmes écrits en pseudocode. Il en
convient de les analyser pour définir les fonctionnalités intéressantes à réutiliser, et surtout
les fonctionnalités que nous aimerions pouvoir utiliser et qui manquent à ces logiciels ; car
nous sommes nous-mêmes des utilisateurs potentiels de notre logiciel.
Voici donc une analyse non exhaustive des points forts et points faibles d’un logiciel de
compilation:
Le logiciel LARP : est un logiciel gratuit les plus connus qui permet la compilation des codes
d’algorithme.
Ainsi, LSALGO a comme fonctionnalités de vulgariser la RAM afin d’avoir une idée plus claire
sur les opérations qui s’y effectuent, dont l’affectation des valeurs à des variables, sans
oublier l’exécution pas-à-pas des instructions afin d’avoir une meilleure idée sur la manière
dont on a obtenu le résultat, on pourra ainsi donc arriver à notre objectif final.
IV. Description de l’interpréteur LSALGO-SIMULATOR
LSALGO est en fait un interpréteur. Il vient de la compression de la phrase «Logiciel de
simulation d’algorithmes», Il est un langage de programmation permettant le prototypage
rapide d'algorithmes.
L'avantage de LSALGO est que le programme est un langage pseudocode à syntaxe flexible et
non un code source à compiler, ce qui permet de formuler des algorithmes en un langage
semi-naturel plutôt que de devoir adhérer à une syntaxe rigide et cryptique telle que celle
des langages de programmation traditionnels (C++, Pascal, Java, etc.…).
Voici un pseudo code LSALGO indiquant à l'écran si un nombre entré via le clavier de
l'ordinateur est positif ou négatif :

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
12
Comme on peut le constater, la syntaxe du langage LSALGO est simple et facile à
comprendre.
LSALGO offre un environnement de développement d'algorithmes simple et convivial
permettant à un utilisateur novice de se familiariser rapidement avec le logiciel.
L'utilisateur peut ainsi consacrer ses énergies à programmer des algorithmes plutôt qu'à se
familiariser avec une interface complexe ou une syntaxe de programmation aride.
La flexibilité du pseudocode supporté par LSALGO ainsi que la convivialité de
l'environnement de développement rend le logiciel particulièrement propice à
l'enseignement de la programmation.
En pratique, les étudiants peuvent exploiter l'environnement de développement de LSALGO
pour implémenter et expérimenter les algorithmes présentés par l'enseignant.
Afin de faciliter l'exploitation du langage dans un environnement éducatif, LSALGO est doté
d'un système d'aide contextuel présentant la syntaxe du langage LSALGO sous une forme
pédagogiquement des exemples explicatifs et simples de différentes instructions.
Ainsi, la documentation en ligne permet à l'utilisateur non seulement d'apprendre la syntaxe
de LSALGO afin de programmer des algorithmes, mais aussi d'apprendre à exploiter des
notions de programmation telles les variables, les structures conditionnelles et répétitives et
le stockage de données.
Ces notions de programmation sont expliquées et accompagnées d'exemples concrets
facilitant leur compréhension.
Le logiciel LSALGO est un outil pédagogique essentiel à l'enseignement de la programmation. Que ce soit en apprentissage autonome ou en classe, LSALGO rend l'apprentissage de la
programmation plus facile et agréable.

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
13
1. Environnement de développement
L'environnement de développement de LSALGO est constitué d'une interface graphique
conforme aux standards de Microsoft Windows.
L'utilisateur étant déjà familier avec le type d'environnement accompagnant les outils de
développement traditionnels n'aura aucune difficulté à maîtriser l'environnement de
développement de LSALGO.
Réciproquement, l'utilisateur s'initiant à la programmation avec LSALGO aura peu de
difficultés à transférer les aptitudes acquises à un produit plus traditionnel comme ceux cités
ci-haut.
L'environnement de développement de LSALGO est constitué de plusieurs composants, dont
les principaux sont la fenêtre principale, la console d'exécution et l'aide en ligne.
2. Utilité de l’interpréteur
Lors de la réalisation de notre interpréteur, nous avons eu l’idée de vulgariser la RAM afin
d’avoir une idée plus claire sur les variables déclarées ainsi que les valeurs qu’on leur a
attribué.
Nous avons aussi introduit à notre interpréteur la fonction de déroulement pas-à-pas, de
façon à voir le résultat d’exécution de chaque instruction.
Aussi la réalisation de l’interpréteur prend en compte la gestion des erreurs. Donc, au cas où
on finit par commettre des erreurs lorsqu’on écrit un algorithme, ces dernières ainsi que leur
numéro s’afficheront à l’écran.
3. Les composants de base
Les composants de base du pseudocode supporté par LSAGLO sont récapitulés ci-dessous :
- Déclaration
o Déclaration d’une ou plusieurs variables en une instruction.
- Types Simples :
o Entier
o Réel
o Caractère
o Booléen
- Affectation

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
14
- Entrée/ Sortie :
o Affichage dans l’Écran (ECRIRE)
o Scan des variables (LIRE)
- Les expressions Booléennes :
o VRAI
o FAUX
- Les opérations arithmétiques :
o Addition +
o Soustraction -
o Division /
o Multiplication *
- Les opérations logiques :
o ET
o OU
o NON
- Incrémentation, Décrémentation :
o Incrémentation ++
o Décrémentation --
- Les instructions conditionnelles :
o SI ALORS SINON
o SI ALORS
- Les instructions répétitives :
o Boucle TANTQUE
o Boucle REPETERTANTQUE
o Boucle POUR
- Sélection en choix :
o SELON
- Les fonctions primitives :
o Modulo
o Racine
- Le Cast
o ENTIER ->REEL
o REEL ->ENTIER

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
15
4. Structure d’un compilateur/interpréteur
La réalisation d'un compilateur/interpréteur peut être effectuée de façon modulaire car il est généralement structuré en plusieurs phases:
- l'analyseur lexical; - l'analyseur syntaxique; - l'analyseur sémantique; - le générateur de code; - l'optimisation du code généré.
Les fonctions de chacune de ces composantes sont:
l'analyseur lexical (scanner) inspecte le programme source, caractère par caractère, élimine les caractères superflus, reconnaît les unités lexicales (tokens), construit les lexèmes à partir de ces caractères et les fournit à l'analyseur syntaxique;
l'analyseur syntaxique (parser) effectue une analyse syntaxique du programme source en se basant sur les unités lexicales que lui fournit l'analyseur lexical. L'analyse syntaxique consiste à vérifier si le programme est syntaxiquement correct, c'est-à-dire si la séquence des symboles dans le programme source respecte les règles syntaxiques du langage. Les règles d'écriture (syntaxe) sont généralement données sous la forme de grammaire.
l'analyseur sémantique vérifie si le programme syntaxiquement correct l'est aussi sémantiquement. La sémantique est l'étude d'un langage du point de vue du sens. Dans le cadre de la compilation le sens d'un programme est matérialisé par son code généré. Cet analyseur sémantique effectue, principalement, l'analyse de la portée des identificateurs et l'analyse des types;
le générateur de code est la partie du compilateur qui s'occupe de la production du code. Le code généré peut être du code machine, un code intermédiaire, un autre langage de programmation. C'est la composante du compilateur qui réalise effectivement la traduction évoquée à la section. Le code généré peut être optimisé.

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
16
Un compilateur/interpréteur ne réalise donc pas seulement un travail de traduction, il vérifie aussi que le programme source fourni par le programmeur respecte les règles de construction du langage de programmation choisi. Il doit également gérer les erreurs éventuelles, ce qui est loin d'être une tâche aisée.
V. Étape de réalisation du interpréteur
Voici un schéma qui résume les principales étapes qu’on a dû suivre afin de réaliser LSALGO:

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
17
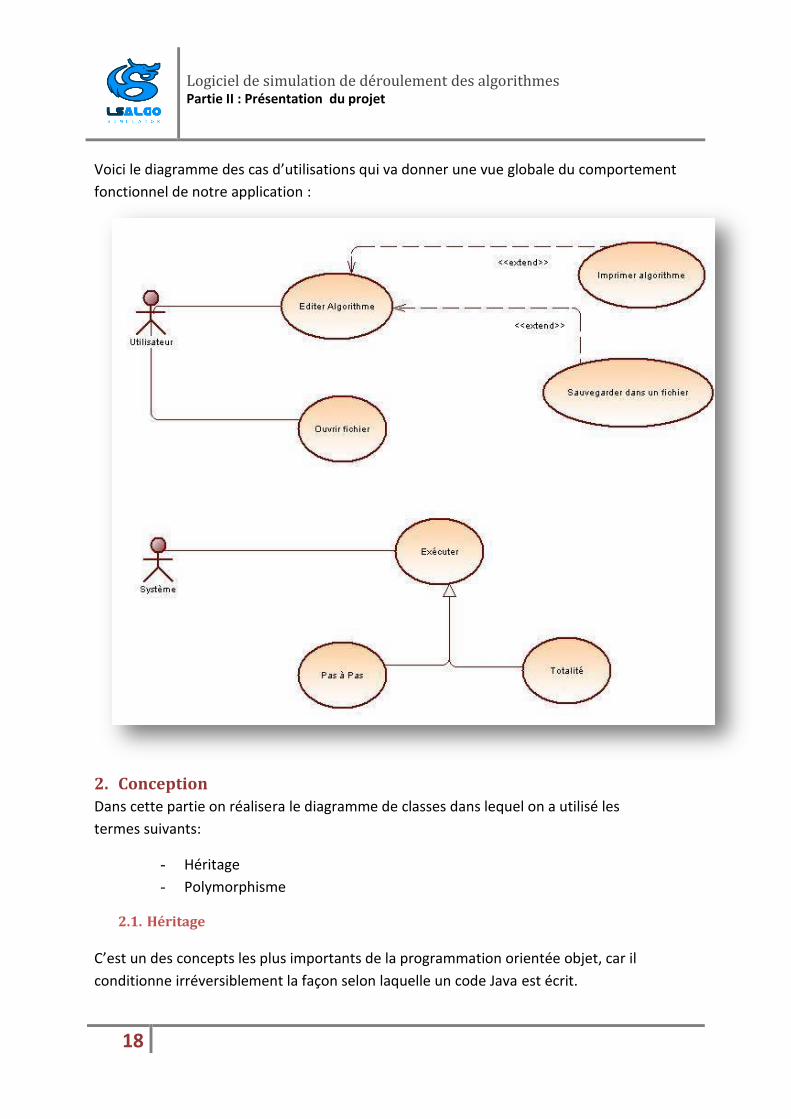
1. Analyse des besoins
Les diagrammes de cas d'utilisation sont des diagrammes UML utilisés pour donner une
vision globale du comportement fonctionnel d'un système logiciel. Ils sont utiles pour des
présentations auprès de la direction ou des acteurs d'un projet, mais pour le
développement, les cas d'utilisation sont plus appropriés. Un cas d'utilisation représente une
unité discrète d'interaction entre un utilisateur (humain ou machine) et un système.
UML définit une notation graphique pour représenter les cas d'utilisation, cette notation est
appelée diagramme de cas d'utilisation. UML ne définit pas de standard pour la forme écrite
de ces cas d'utilisation, et en conséquence il est aisé de croire que cette notation graphique
suffit à elle seule pour décrire la nature d'un cas d'utilisation.
Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
18
Voici le diagramme des cas d’utilisations qui va donner une vue globale du comportement
fonctionnel de notre application :
2. Conception
Dans cette partie on réalisera le diagramme de classes dans lequel on a utilisé les
termes suivants:
- Héritage
- Polymorphisme
2.1. Héritage
C’est un des concepts les plus importants de la programmation orientée objet, car il
conditionne irréversiblement la façon selon laquelle un code Java est écrit.

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
19
L'héritage est un mécanisme permettant de créer une nouvelle classe à partir d'une classe
existante en lui proférant ses propriétés et ses méthodes.
Ainsi, pour définir une nouvelle classe, il suffit de la faire hériter d'une classe existante et de
lui ajouter de nouvelles propriétés/méthodes.
De cette façon, les classes héritées forment une hiérarchie descendante, au sommet de
laquelle se situe la classe de base (superclasse).
Exemple de l'héritage dans le code source de LSALGO:
La classe Tdeclar et Taffect hérite de la classe abstraite Tinstr, dont la méthode
prepareInterp et interpret sont redéfinis
2.2. Polymorphisme
Le polymorphisme est un mécanisme par lequel un nom peut désigner des objets de
nombreuses classes différentes, tant qu’elles sont reliées par une superclasse commune.
Tout objet désigné par ce nom est alors capable de répondre de différentes manières à un
ensemble commun d’opérations.
Le polymorphisme est donc un concept qui complète parfaitement celui de l'héritage, il est
plus simple qu'il n'y paraît.
Pour faire court, nous pouvons le définir en disant qu'il permet de manipuler des objets sans
vraiment connaître leur type.

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
20
Exemple du polymorphisme dans le code source de LSALGO:
La méthode interpret de la classe Tinstr_list fait appel à la méthode interpret de chaque
objet instr suivant le mécanisme de polymorphisme pour exécuter la méthode interpret
équivalant au type de l'objet (Tdeclar, Taffect, Tfor...) :
2.3. Diagramme de classes
Le diagramme de classes est un schéma utilisé en génie logiciel pour présenter les classes et
les interfaces des systèmes ainsi que les différentes relations entre celles-ci. Ce
diagramme fait partie de la partie statique d'UML car il fait abstraction des aspects
temporels et dynamiques.
Une classe décrit les responsabilités, le comportement et le type d'un ensemble d'objets. Les
éléments de cet ensemble sont les instances de la classe. C’est un ensemble de fonctions et
de données (attributs) qui sont liées ensemble par un champ sémantique. Les classes sont
utilisées dans la programmation orientée objet. Elles permettent de modéliser
un programme et ainsi de découper une tâche complexe en plusieurs petits travaux simples.
Voici le diagramme de classes:
Tprogram regroupe toutes les instructions se trouvant entre les deux étiquettes "DEBUT" et "FIN".
Tinstrlist est une liste d'instructions (type Tinst) qui peut être soit une déclaration(Tdeclar),
affectation (Taffect), instruction de sélection en choix (Tswitch) ...
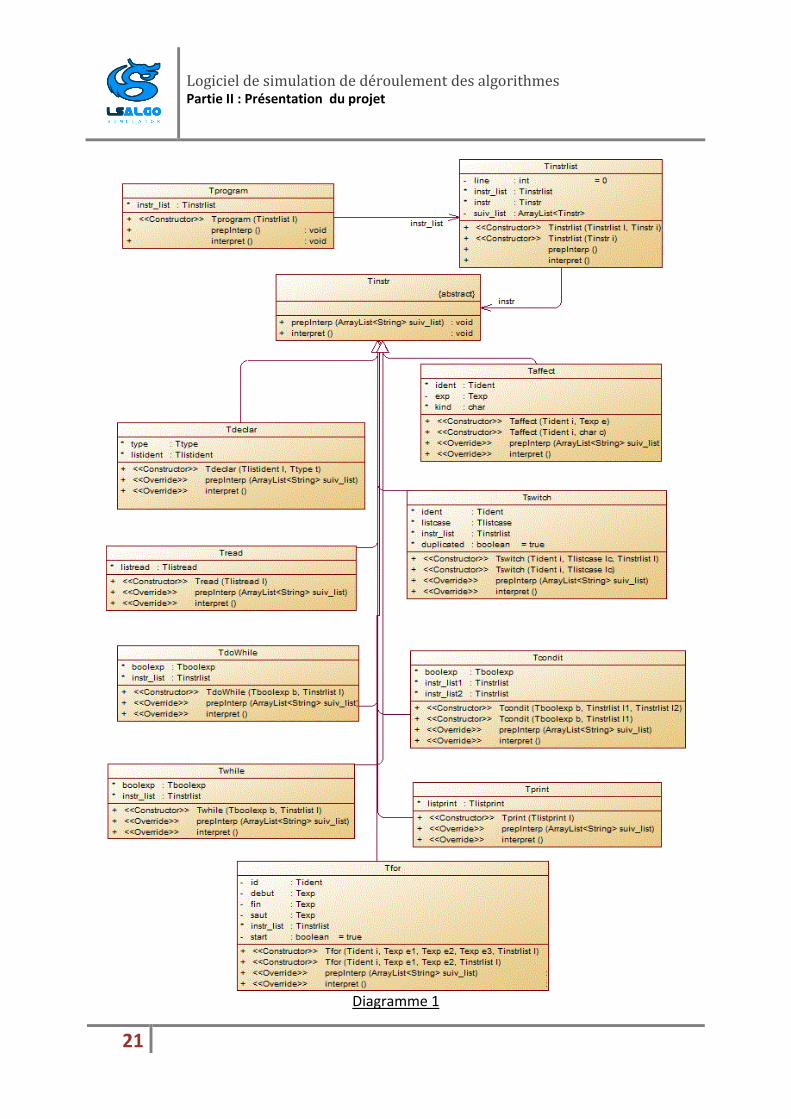
Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
21
Diagramme 1

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
22
Texp représente l'expression de Cast, les identifiants, les expressions booléennes ...
Diagramme 2

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
23
FirstForm contient la fonction main qui lance l'instance du MainInterface.
SymTab est la table de symbole qui contient les objets Variable, ainsi que les opérations de
manipulation de ce dernier.
MyError est une classe qui permet la gestion des erreurs.
Diagramme 3

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
24
3. Réalisation
3.1. Outils utilisés
Langage de programmation
Java est un langage de programmation informatique orienté objet, Le langage reprend en grande partie la syntaxe du langage C++, très utilisé par les informaticiens. Néanmoins, Java a été épurée des concepts les plus subtils du C++ et à la fois les plus déroutants, tels que les pointeurs
et références, ou l’héritage multiple contourné par l’implémentation des interfaces.
Swing est une bibliothèque graphique pour le langage de
programmation Java, faisant partie du package Java Foundation
Classes (JFC), inclus dans J2SE. Swing constitue l'une des principales
évolutions apportées par Java 2 par rapport aux versions
antérieures. Swing offre la possibilité de créer des interfaces
graphiques identiques quel que soit le système d'exploitation sous-jacent, au prix
de performances moindres qu'en utilisant Abstract Window Toolkit (AWT).
JTattoo se compose de plusieurs différents Look and Feel pour les
applications Swing. Chacun d'entre eux permet aux développeurs
d'améliorer leur application avec une excellente interface
utilisateur. Donc JTattoo ouvre des applications de bureau la porte
pour les utilisateurs finaux qui sont malheureux avec le regard et se sent livré avec
le JDK standard.
JFlex est un générateur d’analyseurs lexicaux pour Java : il génère des analyseurs lexicaux écrits en Java. Le F de JFlex signifie ‘’Fast’’ : JFlex est une réécriture du générateur d’analyseurs lexicaux Jlex. JFlex et Jlex diffèrent par leur mise en
œuvre mais les fichiers de spécification et les techniques d’analyse utilisées sont très similaires. Leur ancêtre commun est Lex, un générateur d’analyseur lexical pour le langage de programmation C.
JCup raccourci pour Java—Based Constructor of Useful Parsers — est un générateur d’analyseurs syntaxiques LALR (cas particulier d’analyseurs LR) à partir de spécifications.
Inspiré de Yacc, il est écrit en Java et génère des analyseurs écrits en Java. Il est conçu pour travailler avec le générateur d’analyseurs lexicaux JFlex2. Un fichier de spécification pour Cup décrit une grammaire algébrique LALR (analyse syntaxique) éventuellement décorée par des actions sémantiques (analyse sémantique).

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
25
logiciels utilisés
NetBeansIDE est un environnement de développement qui s'adapte aux langages de programmation (Javascript, Python, PHP, C/C++, etc.), aux outils et aux ressources dont on dispose. Le programme détecte automatiquement la présence de Java, JDK, MySQL, etc.
PowerAMC propose différentes techniques de modélisation, chacune accessible aux informaticiens de tout niveau, parmi elles : Merise, UML, Data Warehouse, et processus métiers.
EdrawMax est spécialement conçu pour créer et assembler les graphiques, diagrammes, schémas ou autres plans et organigrammes. Plusieurs modèles sont proposés avec la possibilité de personnaliser entièrement les couleurs, les symboles, les dispositions de texte, les formes, etc…
3.2. Spécification FLEX et CUP
3.2.1. Générateur d’analyseurs lexicaux JFLEX
Flex prend en entrée un fichier qui contient une description de l’analyseur lexical à générer.
Il génère un fichier .java.
Le cœur de l’analyseur est une méthode appelée par la suite ‘’méthode d’analyse’’, cette
méthode extrait du texte à analyser le prochain lexème.
JFlex permet de configurer le nom, le type de retour de cette méthode, et le type
d’exception levée. Il est aussi possible de configurer son corps en associant une action à une
description du lexème. Cette action sera effectuée dans l´état final correspondant au
lexème. Dans l’utilisation habituelle d’un analyseur lexical, la méthode d’analyse est destinée
à être appelée répétitivement par un analyseur syntaxique jusqu’à la fin du flot de
caractères. L’action consiste alors le plus souvent à retourner le lexème reconnu, ce qui
termine l’exécution de la méthode.
Dans d’autres utilisations, les actions pourront par exemple calculer une valeur qui sera
retournée à la fin de l’analyse.

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
26
Structuration d’un fichier de spécification Un fichier
JFlex est composé de trois sections séparées par des %% :
La suite de ce document décrit succinctement le contenu de
ces trois sections :
– section 1 : code utilisateur ;
– section 2 : options et déclarations ;
– section 3 : règles lexicales.
Voici une partie du code du fichier flex:
Chaque lexème est représenté par une expression régulière spécifique.

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
27
Le Lexer retourne au Parser un lexème parfois accompagné par un String représentant la
valeur du lexème.
Pour exécuter un fichier .flex il faut :
o Télécharger jflex.jar
o Modifier la variable d’environnement PATH.
o La commande d’exécution :
Pour réaliser un tel analyseur, il faut élaborer spécification dans un fichier portant
l'extension .flex, par exemple on peut l'appeler monanalyseur.flex.
Cette spécification fournie à FLex permet d'obtenir ensuite un analyseur lexical en langage
Java... Une fois obtenu cet analyseur sous la forme d'une seule classe de java il faut la
compiler et l'on a alors un .class que l'on peut exécuter et qui effectue l'analyse lexicale d'un
texte suivant les instructions données dans monanalyseur.flex. Ce fonctionnement peut être
schématisé par la figure suivante :

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
28
3.2.2. Générateur d’analyseurs syntaxiques JCUP
Quand on écrit une grammaire attribuée, on a l’habitude d’indiquer de manière globale le
nom des attributs associés aux lexèmes terminaux et non-terminaux de la grammaire, ainsi
que leur type. Le procédé de spécification de Cup est différent : on explicite globalement le
type des attributs lors de la déclaration des terminaux et non-terminaux, mais le nom des
attributs est local à chaque production.
Chaque terminal ou non-terminal ne peut posséder qu’un attribut, nécessairement de type
objet (on utilisera par exemple le type objet Java Integer et non le type primitif int).
La syntaxe de fichier JCup :
Le fonctionnement peut être schématisé par la figure suivante :

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
29
Pour exécuter un fichier .cup il faut :
o Télécharger JCup.jar
o Modifier la variable d’environnement PATH
o La commande d’exécution :
- Voici un extrait du fichier JCup:
Les instructions peuvent être soit une instruction de déclaration, affectation affichage,
entrée clavier …

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
30
La structure de déclaration
VAR : représente la chaine de caractère « VAR ».
DPT : représente la chaine « : ».

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
31
type : représente une chaine de caractère qui peut être soit « ENTIER », « REEL »,
« CARACTERE » et « BOOLEEN ».
La structure de l’affectation
ident : représente une variable déclarée.
EQUALS : représente la chaine « <- ».
expr_all : représente des expressions arithmétiques.
boolexp : représente des expressions booléennes.
3.2.3. Interfaçage du JFLEX et JCUP
JCup et JFlex sont prévus pour s’interfacer. Pour que Cup puisse exploiter un analyseur
lexical celui-ci doit satisfaire les conditions suivantes :
– la méthode d’analyse s’appelle next token et retourne des lexèmes de type java
cup.runtime.Symbol;
- Le symbole de fin de fichier s’appelle EOF ;
- La classe implémente l’interface java_cup.runtime.Scanner.
Les tokens qui sont reconnus par le fichier Flex modélisateur de l’analyse lexicale et dont
l’ordre n’est pas la priorité, ne peuvent être analysé qu’avec le fichier Cup qui modélise
l’analyse syntaxique, constituée de deux parties : Partie qui décrit les lexèmes terminaux et
non terminaux ainsi que les priorités et partie qui est dédiée à la définition de la grammaire.
Ainsi, en pratiquant une analyse ascendante, le parseur est en mesure de dire si le code qui lui est donné respecte la grammaire du langage.

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
32
3.3. Arbre syntaxique
Un arbre syntaxique abstrait (abstract syntax tree, ou AST, en anglais) est un arbre dont les
nœuds internes sont marqués par des opérateurs et dont les feuilles (ou nœuds externes)
représentent les opérandes de ces opérateurs. Autrement dit, généralement, une feuille est
une variable ou une constante.
Un arbre syntaxique abstrait est utilisé par un analyseur syntaxique comme un intermédiaire
entre un arbre d'analyse et une structure de données. On l'utilise comme la représentation
intermédiaire interne d'un programme informatique pendant qu'il est optimisé et à partir
duquel la génération de code est effectuée.
Un AST diffère d'un arbre d'analyse par l'omission des nœuds et des branches qui n'affectent
pas la sémantique d'un programme. Un exemple classique est l'omission des parenthèses de
groupement puisque, dans un AST, le groupement des opérandes est explicité par la
structure de l'arbre.
La création d'un arbre syntaxique abstrait pour un langage décrit par sa grammaire est
généralement facile : la plupart des règles de la grammaire créent un nouveau nœud dont
les branches sont les symboles de la règle. Les seules règles qui n'ajoutent pas de symboles à
l'arbre sont les règles de groupement, qui sont représentées par un nœud (parenthèses, par
exemple). Un analyseur syntaxique peut aussi créer un arbre complet, et faire une passe
ultérieure pour supprimer les nœuds non utilisés par l'arbre syntaxique abstrait.

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
33
Prenant l’exemple de :
Les trois étapes importantes pour générer le code ainsi que l’arbre syntaxique depuis cet
exemple sont :
- Analyse Lexical
- Analyse Syntaxique
- Générateur de code

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
34
3.4. Table de symboles
LSALGO utilise une table de symboles pour garder trace de la portée et des informations
concernant la liaison des noms.
De ce fait, chaque fois qu’un nom est rencontré dans le texte source, une recherche
s’effectue dans la table de symboles.
Cette table est modifiée si l’on rencontre une déclaration d’une nouvelle variable ou une
affectation d’une variable déjà déclarée.
Donc le mécanisme de la table de symboles doit nous permettre d’ajouter de nouvelles
entrées et de retrouver des entrées existantes de façon efficace.
La table de symboles est une classe qui contient les informations concernant la variable, ces
informations sont :
- Nom : le nom de la variable.
- Val : la valeur de la variable.
- Type : le type de la variable.
- Emp : l’emplacement de la variable dans la mémoire.
3.5. Grammaire
Instruction Syntaxe Déclaration VAR liste-
identifiant :{ENTIER|REEL|CARACTERE|BOOLEAN}
Affectation Id <- valeur
Incrémentation Décrémentation
Id++ Id--
Lecture Écriture
LIRE(liste identifiant ) ECRIRE(‘’chaine‘’ , valeur , ...)
Condition SI(condition) ALORS liste-instruction SI(condition) ALORS liste-instruction SINON liste-instruction
Boucle TANTQUE(condition) FAIRE liste-instruction FINTANTQUE REPETER TANTQUE(condition) liste-instruction FINREPETER POUR id ALLANT DE valeur A valeur [PAR PAS DE valeur] liste-instruction FINPOUR
SymTab
Nom String Val Object Type String Emp String

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
35
Sélection en choix SELON(valeur) CAS valeur1 :liste-instruction1 CAS valeur2 :liste-instruction2 ... [CAS SELON liste-instruction] FINSELON
Cast Id<- (ENTIER)valeur Id<- (REEL)valeur
Opération logique Valeur1[>|<|=|>=|<=| !=]valeur2 OU|ET ...
Fonctions primitives RACINE(valeur) Valeur1 MOD valeur2
3.6. Exécution
On a vu le rôle des analyseurs, Lexical et syntaxique (JFLEX et JCUP), et comment chacun
d’eux contribue pour la réalisation de l’arbre syntaxique mais que ce passe-t-il réellement
lors de l’exécution d’un code tapé sur l’interface de l’interpréteur ?
Quand un utilisateur clique sur le bouton « Exécuter », le code sera enregistré sous un fichier
texte qui sera interprété par le Lexer et le Parser. Juste après la création de l’arbre
syntaxique la méthode de l’exécution (interpret) sera exécutée sous forme de série d’appel.
La méthode appelée lors du clic sur le bouton « Exécuter ».
Génération de l’arbre syntaxique dont le nœud regroupant est Tprogram
Interprétation de l’arbre généré (tous les instructions du programme)
1
2
1
2

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
36
Prenant un exemple simple et suivant la démarche précédente pour mieux comprendre :
Après la génération de l’arbre syntaxique, la
méthode interpret sera appelé par l’objet instance
de Tprogram, la méthode interpret de Tprogram
n’est qu’un appel de la méthode interpret de l’objet
Tinstrlist qui était stocké lors de la génération de
l’arbre (Tprogram = DEBUT list_nstr FIN).
Ainsi de suite la méthode interpret de l’objet Tinstlist
est sous forme d’appels récursifs des objets Tinstrlist, qui à la fin de chaque appel, la
méthode interpret de l’objet Tinstr sera exécutée.
Voici le code de la méthode interpret de la class Tinstrlist.
NB : la class Tinstrlist possède deux attributs Tinstrlist et Tinstr.
La méthode interpret de Tinstr est abstraite donc, est grâce au polymorphisme, la méthode
interpret sera exécuter selon la nature de l’instruction Tinstr.
Pour la première instruction de déclaration (regarder l’exemple), c’est là où la vrai exécution
aura lieu à la fin de l’arbre, une liste d’identifiants sera stockée dans la table de symbole (un
autre appel de la méthode interpret de l’objet instance de la class Tlistident, puis de l’objet
instance de Tident).
La même chose pour la deuxième instruction d’affectation (NB : on est toujours au niveau de
Tinstrlist à l’appel récursive), cella contacte la table de symbole, si l’identifiant en question
est existant la valeur sera affecté sinon une exception sera levée.
Même concept pour les autres instructions jusqu’à ce que la liste d’instructions de l’objet
Tprogram sera NULL.

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
37
Voici un schéma qui résume les étapes de déroulement d’une instruction d’affectation :
3.7. Exécution pas-à-pas
Lors d’une exécution simple et après la génération de l’arbre syntaxique en suivant les
étapes expliquées auparavant, l’exécution des instructions aura lieu avec des arrêts
d’entrées /sorties ou de gestion des exceptions.
Pour le cas d’exécution pas-à-pas l’exécution va prendre une différente démarche ;
Prenant le même exemple de la partie exécution, quand l’utilisateur clique sur le bouton de
l’exécution pas-à-pas pour la première fois l’arbre syntaxique du code en général sera
générée et les instructions de l’arbre seront stockés sous forme de liste grâce à la méthode
en série (même principe que la méthode interpret) « prepareinterpret ».

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
38
Le code de génération de l’arbre et d’exécution de la méthode prepInterp() dans la méthode
appelé lors du clic sur le bouton d’exécution pas-à-pas :
Tout comme la méthode interpret, prepInterp de la classe Tprogram fait appel à prepInterp
de Tintrlist, cette dernière stock chaque instruction (par appel récursive) dans une liste
d’objet Tinstr, comme le montre le code suivant :
Dans la classe Tprogram la méthode prepInterp affecte la liste retournée par l’appel de
l’objet instr_list à la une liste d’instruction de la classe FirstForm pour pouvoir exécuter la
liste d’instruction par la suite lors d’autre click sur le bouton exécution pas-à-pas.
Toujours lors du premier click sur le bouton d’exécution pas-à-pas après la génération de
l’arbre, le stockage des instructions sous forme de liste d’objet Tinstr, la récupération de
cette liste au niveau de la classe FirstForm. La première instruction de la liste « suivant » sera
automatiquement exécutée (NB : chaque instruction exécutée sera supprimée de la liste
« suivant », donc l’instruction qui sera exécuter à chaque fois est à l’index 0 de la liste).

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
39
Dans l’exemple précédent il n’y a que des instructions simples non imbriquées (déclaration,
affectation..), le vrai défi de l’exécution pas-à-pas est l’exécution des instructions imbriquées
comme les conditions, les instructions répétitives comme les boucles POUR et TANTQUE,
encore pire ; les instructions répétitives contenants des instructions imbriquées comme les
conditions et les boucles etc. ...
Commençons par la logique suivi pour l’exécution pas-à-pas pour les instructions
conditionnelles, prenons l’exemple ci-dessous :
Supposons que l’utilisateur a entré le nombre « 120 », la première condition du premier bloc
SI-SINON n’est pas validé donc le bloc d’instruction (SI) ne sera pas exécuter c’est dans ce cas
le deuxième bloc (SINON) qui sera traité, même chose pour le deuxième bloc SI-SINON.
Pour qu’à la fin un seul bloc d’instruction sera exécuté.
Restons sur l’exemple du nombre « 120 », Pour l’exécution pas-à-pas quand l’utilisateur
clique sur le bouton, après l’instruction LIRE, l’instruction qui sera directement exécuter
c’est : ECRIRE(’’C’est de la vapeur ‘’).
Mais derrière cette exécution plusieurs appels récursive auront lieu au niveau de la
méthode « suivant » (la méthode appelé lors du clic sur le bouton d’exécution P-A-P).
En effet l’instruction exécutée au début (celle qui a été stocké lors de la génération de la liste
d’instruction « suivant ») est la suivante :
SI ... SINON SI ... SINON ... FINSI FINSI
Après l’exécution de l’instruction SI-SINON la liste « suivant » sera modifié :
- suppression de l’instruction SI-SINON général et ajout du bloc d’instruction SINON car
dans notre cas c’est le bloc SINON qui sera exécuté.

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
40
- la liste d’instruction « suivant » ne contiendra par la suite que la deuxième
instruction SI-SINON (en bleu).
Si l’instruction courante est une instance de la classe Tcondition, ce qui est le cas dans notre
exemple, un appel récursive aura lieu et la deuxième instruction sera exécuter.
Ainsi de suite l’instruction suivante est une condition, automatiquement l’instruction SI-
SINON sera supprimée et le bloc d’instruction validant la condition (dans notre cas SINON)
sera stocké dans la liste pour qu’il soit exécuter à son tour grâce à un autre appel récursive
(instruction exécuté à la fin : ECRIRE (’’C’est de la vapeur ‘’)).
L’imbrication est sans limite le plus important c’est que la première instruction du bloc qui
valide les conditions sera exécuter en un seul clique sur le bouton d’exécution pas-à-pas.
Le schéma suivante résume le fonctionnement du déroulement pas-à-pas pour les
instructions simples et imbriquées (conditions) :
NB : la suppression de l’instruction SI-SINON et l’ajout du bloc valide aura lieu avant
l’exécution de l’instruction suivante (précisément lors de l’appel de la méthode interpret de
Tcondition -sans entrer dans les détails du code-).

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
41

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
42
Même principe de récursivité pour les instructions répétitives sauf que cette fois les
instructions de type boucle ne seront pas supprimé pour des raisons (savoir le point de
rebouclage du bloc, tester la validité de la condition à chaque fois).
L’idée était que lors de l’exécution , le bloc Tinstrlist de l’instruction Twhile par exemple sera
ajouté avant l’instruction Twhile ,bien sûr si la condition est valide sinon la boucle sera
supprimé sans rien ajouté dans la liste « suivant » , ainsi chaque instruction du bloc sera
exécuter jusqu’à ce qu’on arrive à notre instruction Twhile qui signifie la fin de la boucle , si
la condition est toujours valide le bloc sera ajouté avant l’instruction Twhile et encore
exécuté.
Le rebouclage continuera jusqu’à ce que la condition n’est plus valide, c’est là où
l’instruction Twhile sera supprimée et l’exécution du reste de la liste « suivant » aura lieu.
NB : les instructions à l’intérieure de la boucle, même chose pour les conditions, sont
exécutées une par une après le clic sur le bouton pas-à-pas.
En combinant les deux logiques des conditions et des boucles l’exécution pas-à-pas est
généralisée ; En cas de boucle contenant des conditions le premier click « suivant »
permettra l’exécution de la première instruction du bloc valide de la première condition (en
cas où la première instruction dans le bloc interne de la boucle est une condition).
3.8. Gestion d'erreur
Tout programme en exécution peut être sujet à des erreurs pour lesquelles des stratégies de
détection et de réparation sont possibles. Ces erreurs ne sont pas des bugs mais des
conditions particulières (ou conditions exceptionnelles, ou exceptions) dans le déroulement
normal d'une partie d'un programme.
Par exemple, utilisation d’une variable non déclaré ou non initialisé;
LSALGO contient une classe MyError qui permet la gestion des erreurs.
Voici un tableau qui représente les codes des erreurs :
Code d’erreur Description 100 Une variable déjà déclarée.
101 Une variable non déclarée.
102 Une variable non initialisée.
103 Incompatibilité de type.
104 Caractère illégal.
105 Code vide.
106 Opérant invalide
107 Casting invalide.
108 Cas dupliqué.
109 Erreur de syntaxe.

Logiciel de simulation de déroulement des algorithmes
Partie II : Présentation du projet
43
Le programmeur doit considérer durant le développement tous les cas de figure relatifs à
l’exécution de son code, et en particulier les erreurs d’exécution pouvant survenir.
En traitant une erreur d’exécution, le développeur doit aussi s’assurer que le système repart
dans un état stable.
Ce travail est très fastidieux et il est fort probable que le développeur oublie de traiter
certains cas.
Prenons l’exemple suivant :
Dans le cas où la variable n’est pas déclarée, tenter d’exécuter le programme, ça va
provoquer une erreur.
Bien évidemment, il suffit au développeur de corriger ce problème en ajoutant une condition permettant de vérifier l’existence de la variable dans la table de symbole.

Partie III Simulation

Logiciel de simulation de déroulement des algorithmes
Partie III : Simulation
45
I. Site web LSALGO « En cours de construction »
II. logiciel LSALGO Pour ce projet, il faut offrir à l'utilisateur une interface intuitive et complète. En effet, elle doit permettre de réagir rapidement…
Pour cela nous avons décidé d'étudier plus particulièrement les parties suivantes :
La première Form à afficher lors du lancement d’une instance de LSALGO est la suivante :
Voici l’interface graphique telle qu'elle est au moment de la rédaction de ce rapport. Il se peut qu’elle évolue d’ici le rendu du projet étant donné que certains composants n’ont pas encore été intégrés, faute de temps.

Logiciel de simulation de déroulement des algorithmes
Partie III : Simulation
46
1. Détails de l’interface
Actions sur les fichiers
Comme sur la plupart des logiciels, il faut cliquer sur le bouton "Nouveau Fichier...".
Voici la première barre d’outils :
Elle contient :
- : en cliquant sur ce bouton un nouveau fichier sera créé mais après avoir notifié
l’utilisateur si ce dernier veut enregistrer le code ou non, par ce JDialog suivant :

Logiciel de simulation de déroulement des algorithmes
Partie III : Simulation
47
- Si on clique sur oui, le JFileChooser s’affiche :
LSALGO a sa propre extension .algo comme s’est afficher dans la figure précédente.
Une fois le choix fait, une page vierge s'ouvrira afin que vous puissiez commencer à taper votre code. Cette action peut être aussi réalisée en cliquant sur le menu "Fichier" puis "Nouveau" et en sélectionnant le langage que vous désirez.
- Ouvrir : Ouverture d’un fichier existant, Il permet de parcourir les dossiers et de choisir un fichier à ouvrir dans le logiciel LSALGO, le type de fichier (extension) est toujours .algo.

Logiciel de simulation de déroulement des algorithmes
Partie III : Simulation
48
- Annuler et refaire : En cliquant sur le bouton "Annuler", tout
simplement. On peut ainsi réparer l'erreur commise. Si on clique sur "Annuler" par
inadvertance et que toutes les modifications ont disparu, cela n’est pas un souci. On
clique juste sur le bouton "Refaire" et tout rentrera dans l'ordre.
- Imprimer : Le bouton imprimer permet l’impression du code.
- Web : Ce bouton permet l’accès directement au site officiel du LSALGO.
- l’indentation : Ces deux boutons permettent l’indentation qui est un procédé de retrait de texte qui permet d'organiser et de rendre plus lisibles le code et ils sont accessibles par des shortcut : TAB et Shift-TAB.
- Zoom en avant et en arrière du code et restauration de la taille par défaut.
En cliquant sur "Edition" puis sur " Remplacer". Tapez alors le texte à chercher et, si besoin est, le texte par lequel le remplacer.
Le nombre de la chaine trouvée est affiché, ainsi que highlighting les chaines dans le code :
Logiciel de simulation de déroulement des algorithmes
Partie III : Simulation
49
LSALGO contient deux thèmes :
Le premier thème LIGHT est celui par défaut :

Logiciel de simulation de déroulement des algorithmes
Partie III : Simulation
50
Le deuxième thème AngyDragon :
Ajout de la numérotation des lignes en utilisant Document Listener du package javax.swing.event:
Localisation du curseur en utilisant Listener CaretUpdate, ça sert à positionner le curseur pour faciliter la recherche des erreurs:

Logiciel de simulation de déroulement des algorithmes
Partie III : Simulation
51
- Ces boutons servent à l’édition du code : Couper, copier, coller et supprimer.
- Le premier bouton permet l’exécution du code, le deuxième l’exécution pas-à-pas et le troisième l’arrêt du déroulement pas-à-pas.
Afin de faciliter l'exploitation du langage dans un environnement éducatif, LSALGO est doté
d'un système d'aide contextuel présentant la syntaxe du langage LSALGO sous une forme
pédagogiquement des exemples explicatifs et simples de différentes instructions.

Logiciel de simulation de déroulement des algorithmes
Partie III : Simulation
52
Avant-propos du logiciel LSALGO :

53
Problèmes rencontrés et perspectives
Le problème majeur rencontré lors de l'implémentation de l'interface est la localisation des
instructions à exécuter dans le déroulement pas-à-pas. Plusieurs idées nous sont venues à
l'esprit parmi elle la fonction d’auto-complétion.
Nous ne pensions pas passer autant de temps sur la conception de la grammaire, qui nous a
valu de recommencer plusieurs fois et de passer de nombreuses heures à chercher la bonne
méthode pour lever les ambiguïtés, sans en soulever d'autres.
Malgré ces difficultés, une fois que notre AST était prêt et pensé sans ambiguïté pour le
parcours, nous avons été agréablement surpris de l'efficacité d'un tel travail pour les
contrôles sémantiques, la génération du code, qui se font naturellement en respectant les
différentes étapes.
Durant la réalisation de notre interpréteur, nous avions dû faire face à l’obstacle du temps,
ce qui nous a valu de faire notre travail à moitié, sans qu’on ait pu introduire les notions
suivantes :
- Fonctions et procédures,
- Type riches : tableaux, pointeurs, enregistrements…
- Variables locales,
- Localisation des instructions à exécuter dans le déroulement pas-à-pas,
- Auto-complétion,
Mais malgré cet obstacle, nous avons des perspectives futures concernant notre projet et ce,
en travaillons sur les notions qu’on n’a pas pu réaliser à temps. Car même si nous n’avions
pas eu l’occasion de présenter notre interpréteur au complet durant cette période, nous
espérons pouvoir le finaliser prochainement.

54
Conclusion
Satisfaits de n'être pas devenus fous à l'issu de ce projet, celui-ci nous aura permis de
parfaitement comprendre la chaîne de compilation d'un code.
L'expérience était très intéressante, et nous a donné l'occasion de découvrir énormément de
problèmes liés notamment à l'analyse, qui n'étaient pas aussi évidents durant la partie
théorique.
Cette unité d’enseignement de développer un interpréteur a tout d’abord été l’occasion de
montrer nos capacités à apprendre rapidement de nouvelles façons de travailler dans le
monde de l’informatique, notamment sur des projets de groupe. Ainsi, le résultat produit est
plus qu’un développement personnel, c’est le fruit d’une collaboration.
D’autre part, ce travail nous a permis de regarder vers l’avenir : le travail en équipe dans nos
futures carrières professionnelles.
Finalement, cette expérience ne s’arrête pas une fois ce rapport rendu. En effet, le projet est terminé mais son utilisation dans le temps définira de nouveaux besoins, et ainsi peut-être d’autres étudiants/développeurs prendront-ils la relève pour ajouter des modules, de nouvelles fonctionnalités et ainsi assurer la pérennité de notre interpréteur.

55
Bibliographie et webographie
Bien entendu, le résultat de ce projet n’aurait pas été tel qu’il est sans des ressources et des aides extérieures ! Voici une liste non exhaustive de nos principales sources d’information.
SWING - Livre Les Cahiers du Programmeur – Edition EYROLLES – Emmanuel Puybaret - http://stackoverflow.com/questions/13681977/jcombobox-autocomplete JAVA 1.4 ET 5.0 - Livre Les Cahiers du Programmeur – Edition EYROLLES – Emmanuel Puybaret
- http://www.java2s.com/Tutorial/Java
- http://stackoverflow.com/
- https://community.oracle.com/
JFLEX -
JCUP -




















