
Psychology of Programming Interest Group (PPIG) Work-in-Progress Workshop 2013 Proceedings
43
Psychology of Programming Interest Group (PPIG) Work-in-Progress Workshop 2013 School of Computing and Mathematics Keele University, UK 8 – 9 July 2013 Proceedings Edited by Louis Major
-
Upload
manchester -
Category
Documents
-
view
3 -
download
0
Transcript of Psychology of Programming Interest Group (PPIG) Work-in-Progress Workshop 2013 Proceedings

Psychology of Programming Interest Group
(PPIG) Work-in-Progress Workshop 2013
School of Computing and Mathematics
Keele University, UK
8 – 9 July 2013
Proceedings
Edited by Louis Major

ii
Message from the Organiser
Welcome to the Psychology of Programming Interest Group (PPIG) Work-in-Progress
Workshop 2013, taking place in the School of Computing and Mathematics at Keele
University (Staffordshire, UK).
The Psychology of Programming Interest Group (PPIG) was established in 1987 in order to
bring together people from diverse communities to explore common interests in the
psychological aspects of programming and/or in computational aspects of psychology. The
group attracts cognitive scientists, psychologists, computer scientists, software engineers,
software developers, HCI people et al., in both universities and industry.
As always at PPIG, this year’s workshop involves discussion on a range of topics. Presenters
have travelled from countries including Australia, Canada, Germany, the United States and
the United Kingdom.
On the second day of the workshop we welcome Gordon Rugg as a Guest Speaker. Gordon is
a former timberyard worker, archaeologist and English lecturer. His PhD was in experimental
social psychology. He subsequently worked in knowledge elicitation for expert systems, then
in expert systems for information retrieval, after which he moved into requirements
engineering and HCI/human factors. His recent work has mainly involved development of a
framework for identifying errors in expert reasoning about long-standing problems. Gordon is
a senior lecturer in computing at Keele University, and a company director.
We are grateful to the members of the technical committee, organising committee and the
reviewers for their hard work preparing for this workshop. Finally, we would like to thank the
authors and speakers, without whom such a high quality technical program would not be
possible.
Louis Major

iii
Contents
Computer Anxiety and the potential for mitigation Page 3
Sarah Crabbe and Peter Andras
Neo-Piagetian Preoperational Reasoning in a Novice Programmer Page 10
Donna Teague and Raymond Lister
Increasing Student Confidence throughout the Computer Science Curriculum Page 12
John A. Trono
The cognitive difficulties of Description Logics Page 18
Paul Warren, Trevor Collins and Paul Mulholland
Towards Defining a Cognitive Linguistics of Programming and Using Eye Tracking to Verify Its Claims Page 24
Sebastian Lohmeier
Representational Formality in Computational Thinking Page 27
Alistair Stead and Alan Blackwell
Towards a Mechanism for Prompting Undergraduate Students to Consider Motivational Theories Page 30
when Designing Games for Health
Monica M. McGill
Analysing the effect of Natural Language Descriptions as a support for novice programmers Page 34
Edgar Cambranes, Judith Good and Benedict du Boulay
Workshop: Psychological Impact of 3D Intelligent Environments on Pedagogy Page 36
Martin Loomes, Georgios Dafoulas and Noha Saleeb
Tools to Support Systematic Literature Reviews in Software Engineering: Protocol for a Feature Analysis Page 37
Christopher Marshall and Pearl Brereton
Bringing Heterogeneous Computing to the End User Page 39
Gordon Inggs & David B. Thomas and Wayne Luk
Integrating Connectivist Pedagogy with Context Aware Interactions for the Interlinked Learning of Page 41
Debugging and Programming
Xiaokun Zhang

Computer Anxiety and the potential for mitigation
Sarah Crabbe York St John Business School
York St John University [email protected]
Peter Andras School of Computing Science
Newcastle University [email protected]
Abstract This paper sets out the findings and further research about potential links between personality, computer anxiety and the mitigation strategies that can be used to alleviate the level of anxiety felt by an individual. Having found that, while there is a correlation between openness and emotional stability and computer anxiety this is not enough to successfully predict those who would be likely to suffer. Given that a significant minority of people will suffer from computer anxiety at some point and that this is often hidden or ignored, potentially leading to reduced performance or even stress related illness, mitigation of this would seem to be important. The research is investigating the various ways that people like to be supported and seeing if there is a link between this and their personality type. Index Terms—computer anxiety, technophobia, personality
Introduction The use of computers is an everyday occurrence for the majority of people at work, home and in education. While for many this is an enjoyable experience for a sizeable minority this interaction causes anxiety. How this anxiety manifests and can be mitigated efficiently and effectively is worthy of investigation. Prior research (Crabbe & Andras, 2012) indicated that there was a weak link between low scores in both emotional stability and agreeableness and a high level of computer anxiety. However this was not enough to confidently predict an individual’s level of computer anxiety. Building on this we set out a research strategy to identify the level of computer anxiety and identify the range of support strategies to deal with this. The possibility that the preference for strategy is linked to personality type is also explored.
What knowledge is needed? There are several aspects of a person that need to be assessed in order to arrive at a suggestion for mitigation and then to verify that this was the correct intervention.
• Personality
• Level of anxiety
• Support strategy preference
• Success of preferred strategy
Personality
While there are several different ways of describing personality, most researchers are agreed that personality does not change very much over time (Maltby, Day, & Macaskill, 2007; Nettle, 2007) and there are a range of tools designed to measure the different factors that make a person who they are. Many of these are self-reporting questionnaires which expect the person to have some emotional intelligence i.e. can use emotive vocabulary to describe themselves.
For many questionnaires there are large bodies of research that justify the approach taken.(Bradley & Russell, 1997; Ceyhan, 2006; Choi, Deek, & Im, 2008; Durndell & Haag, 2002; Kaiser, McGinnis, &
3

Overfield, 2012; Korobili, Togia, & Malliari, 2010; Korukonda, 2007; Livingston, Jennings, Reynolds, & Gray, 2003; McCreery, Kathleen Krach, Schrader, & Boone, 2012; Moldafsky, 1994)
Many of these questionnaires can be administered by a researcher or even at a distance using an electronic survey tool.
Often the results of the test are numeric and based on scales. The individual is not described as this or that, but as being strongly or weakly this or that. This gives rise to a profile that is unique for each individual and is not so likely to classify people as one type or another. This is part of their attraction alongside the relatively low cost or open access to the tools and the research that they support.
There are other tools like MBTI (Briggs Myers, 2000) which have to be administered by trained psychologists. There is a cost in purchasing the tests and the mark schemes. Although the results are often interesting and the test has been around for a long time there are beginning to be some questions about its validity (Boyle, 1995; “Myers-Briggs Widely Used But Still Controversial,” n.d.)The usefulness in classifying people into one of only 16 pigeon holes is also quite debatable given the complexity of humans.
The group of factors called the Big Five (Nettle, 2007) are more accessible and there are open-source, well researched questionnaires based on this model that are available for general use. These can be administered by a researcher without psychological training and are completed by the subject at a time of their own convenience as they do not require the presence of the researcher. The completed results can be quickly marked and the response given back to the subject.
Level of computer anxiety The level of computer anxiety can be measured in a variety of ways. Among the most popular seem to be:
The Computer Anxiety Rating Scale (Rosen & Weil, 1992) which has been used in many research projects (Abd-el-fattah, 2005; Anderson, 1996; Anthony, Clarke, & Anderson, 2000; M. Brosnan, Gallop, Iftikhar, & Keogh, 2010; M J Brosnan, 1999; Heinssen, 1987; Hvelka, Beasley, & Broome, 2004; Karal, 2009; Korobili et al., 2010; Maurer, 1994; Meier, 1988; Rahimi & Yadollahi, 2011; Rosen & Weil, 1995a; Tekinarslan, 2008). This 20 item questionnaire with 5 point Likert Scales results in a single rating which indicates the level of anxiety suffered,
The Computer Attitude Scale (Nickell & Pinto, 1987). This was analyzed by Ceyhan and Nalum to suggest three factors, and has been used in a range of research projects too. (Agyei & Voogt, 2011; Altinkurt & Yilmaz, 2012; Celik & Yesilyurt, 2013; Karal, 2009; Kurt & Gürcan, 2010; Rahimi & Yadollahi, 2011; Tekinarslan, 2008).
The Computer Anxiety Scale developed by George A Marcoulides in 1989 which seems to be among the most popular scale in use at the moment (Powell, 2013) and has been revalidated many times. This uses a two pronged approach with equipment anxiety being separated from general computer anxiety. (John J. Beckers, Wicherts, & Schmidt, 2007; M J Brosnan & Thorpe, 2006; M. J. Brosnan, 1998; Chua, Chen, & Wong, 1999; Hewson & Brosnan, 2002; López-Bonilla & López-Bonilla, 2012; Marcoulides, Emrich, & Marcoulides, 2011; Morris, Hall, Davis, Davis, & Walton, 2003; Namlu, 2003; Rosen & Weil, 1995b; Schulenberg & Melton, 2008; Terzis & Economides, 2011; Torkzadeh, Chang, & Demirhan, 2006; van Raaij & Schepers, 2008; Weil & Rosen, 1995; Wicherts & Zand Scholten, 2010)
The six-factor model (J.J Beckers & Schmidt, 2001) recognizes that computer anxiety is complex and influenced by the experiences of the user and how these are perceived and internalized. An identical experience can cause quite different reactions in different people and give rise to different levels of computer anxiety. This has been used to support work in a range of studies (Hvelka et al., 2004; Korobili et al., 2010; Teo, 2008).
4

Support Strategy Preference People are complex and there are many reasons for computer anxiety which may have an impact on how support should be given which can be organized into four different areas.
1 Not knowing how to start the application for example gives rise to operational anxiety
2 Conditioning such as being told that computers are difficult to use is a sociological cause
3 A deep mistrust of technology can give rise to a more psychological anxiety
4 Bad prior experience such as being taught badly can cause experiential anxiety
Three of the types of anxiety identified above: Operational, sociological and psychological were noted as long ago as 1986 (Howard, 1986).
Operational computer anxiety is potentially the easiest to mitigate as it is caused by a lack of skills knowledge This can be addressed with appropriate training. (Anthony et al., 2000; Blazhenkova & Kozhevnikov, 2010; Cowan & Jack, 2011; Gravill & Compeau, 2008; Gupta, Bostrom, & Anson, 2010; Heinssen, 1987; van Raaij & Schepers, 2008)
Helping the user to know what to do can mitigate some of the anxiety that they feel. How this help is actually delivered is also an interesting issue as people have different learning preferences. As an example, some may prefer to have a manual, while others prefer to be taught by an expert. This could be discovered by asking the user what their preference is or it may be linked to the personality type of the user.
Sociological computer anxiety is a bit more difficult to address as it can include cultural issues, gender stereotypes and peer pressure. This could perhaps be mitigated through the use of coaching, positive role-models and more general education about the purposes and uses of the specific application increasing the desire to acquire the skill.
Psychological computer anxiety may only be successfully addressed through professional counseling although perhaps the impacts can be reduced using similar methods to those suggested above.
The fourth, experiential anxiety was noted more recently (Cowan & Jack, 2011) . This is also difficult to completely mitigate as an experience has happened and cannot be undone. However it may be possible to reframe the response of the affected party using coaching techniques, or to reduce the impact of a bad experience by overlaying it with many positive experiences.
There is also much discussion about self-efficacy (Bandura, 1994) and its impact on the level of computer anxiety (John J. Beckers et al., 2007; M. J. Brosnan, 1998; Celik & Yesilyurt, 2013; Chou, 2001; Durndell & Haag, 2002; Karsten, Mitra, & Schmidt, 2012; Lindblom, Gregory, Wilson, Flight, & Zajac, n.d.; Mcilroy, Sadler, & Boojawon, 2007; Torkzadeh & Van Dyke, 2002). Self-efficacy is tied up with people’s idea of their own skill level as well as their actual skill level. It would seem to be sensible to assume that increasing self-efficacy would reduce computer anxiety but it seems more likely that reducing computer anxiety increases self-efficacy (M. J. Brosnan, 1998)
People have their own ways of learning and if this is not addressed effectively it can have a negative impact on performance and may feed into increased anxiety levels. (Altinkurt & Yilmaz, 2012; Austin, Nolan, & Donnell, 2009; Beckwith & Burnett, 2004; Bennett, Maton, & Kervin, 2008; Chien, 2008; Furnham, Monsen, & Ahmetoglu, 2009; Kurt & Gürcan, 2010; Margaryan, Littlejohn, & Vojt, 2011; Tulbure, 2011) While it can be seen that training is most successful when it matches the learning style of the user (Gupta et al., 2010)
One way of finding out how people want to be supported in their learning is to ask them. A brief questionnaire can ascertain what support has been used before and which support the user thinks would work for them best in the future.
Success of preferred strategy How successful the intervention has been could be ascertained by repeating the measurement of the initial computer anxiety level and seeing if this has altered.
5

Plan for data collection Three different cohorts will be assessed in September
1 York St John University Business School Level 1 Business Management Undergraduates
2 York University Social Science Level 1 Undergraduates
3 Robert Kennedy College Masters Level Students across several programmes (MALIC, MBA, MBA Sustainability etc.)
Cohorts 1 and 2 will be predominantly under 25 years old, first degree students based on campus in the UK. Cohort 3 will be predominantly over 35 years old, accessing a Masters course on-line as distance learners and will be based around the world.
The questionnaires about the three areas: computer anxiety, personality and support preference, will be collated into one questionnaire in order to collect a comprehensive picture of each respondent. The results should clarify which are the most popular methods of support to enable the development and application of appropriate support strategies.
The results may indicate whether on campus students have different needs from distance learners and different levels of computer anxiety. Distance Learners have often chosen this way of learning because other options are limited, but anecdotally it seems that they would prefer to learn in a more social environment.
It would be interesting to see if different academic disciplines present with differing levels of anxiety or have different requirements for support, and if there is any personality differential between the cohorts.
Students with high levels of computer anxiety in Cohort A will be given the option to access a range of support strategies that have been identified as to being appropriate for them.
At the end of the first semester all the participants will be re-tested using the first computer anxiety measure to see if their anxiety level has changed.
Analysis The questionnaires will return two sets of quantitative data and a mixed set of qualitative and qualitative. This data pool can be analysed for correlations between results. The level of change of computer anxiety will be checked for the whole group and the difference analysed to see if the students who had interventions reduced their anxiety levels.
As there are three sets of students there it will be interesting to compare the scores across the cohorts and see if there are any correlations between age groups, gender, levels of experience, nationality and programme being studied.
Conclusion The project is an exploration. There is no hypothesis to be proven or challenged. It is a moment to collect data and see if anything interesting emerges. The opportunity to access a large and varied population is exceptional and the information gleaned may help all students to achieve better results.
The expectation is that this may lead to a novel approach to predicting the most appropriate intervention strategy for mitigating computer anxiety.
Acknowledgment SC acknowledges the support of the staff at YSJU Business School especially Doug who will help to implement the project, to Matt Cox at YU for sharing the questionnaires with the students there and for RKC for allowing access to their students. Also the students who are going to give their time to take part in this work
6

References Abd-el-fattah, S. M. (2005). The effect of prior experience with computers , statistical self-efficacy ,
and computer anxiety on students ’ achievement in an introductory statistics course : A partial least squares path analysis. I Can, 5(5), 71–79.
Agyei, D. D., & Voogt, J. M. (2011). Exploring the potential of the will, skill, tool model in Ghana: Predicting prospective and practicing teachers’ use of technology. Computers & Education, 56(1), 91–100. doi:10.1016/j.compedu.2010.08.017
Altinkurt, Y., & Yilmaz, K. (2012). Prospective science and mathematics teachers ’ computer anxiety and learning styles, 4(2), 933–942.
Anderson, A. (1996). Predictors of computer anxiety and performance in information systems. Computers in Human Behavior, 12(1), 61–77. doi:10.1016/0747-5632(95)00019-4
Anthony, L. M., Clarke, M. C., & Anderson, S. J. (2000). Technophobia and personality subtypes in a sample of South African university students. Computers in Human Behavior, 16.
Austin, R. D., Nolan, R. L., & Donnell, S. O. (2009). The Technology Manager ’ s Journey : An Extended Narrative Approach to Educating Technical Leaders. Management, 8(3), 337–355.
Bandura, A. (1994). Self-efficacy. Encyclopedia of mental health. Retrieved July 7, 2011, from http://des.emory.edu/mfp/BanEncy.html
Beckers, J.J, & Schmidt, H. . (2001). The structure of computer anxiety: a six-factor model. Computers in Human Behavior, 17(1), 35–49. doi:10.1016/S0747-5632(00)00036-4
Beckers, John J., Wicherts, J. M., & Schmidt, H. G. (2007). Computer Anxiety: “Trait” or “State”? Computers in Human Behavior, 23(6), 2851–2862. doi:10.1016/j.chb.2006.06.001
Beckwith, L., & Burnett, M. (2004). Gender: An Important Factor in End-User Programming Environments? 2004 IEEE Symposium on Visual Languages - Human Centric Computing, 107–114. doi:10.1109/VLHCC.2004.28
Bennett, S., Maton, K., & Kervin, L. (2008). The “digital natives” debate: A critical review of the evidence. British Journal of Educational Technology, 39(5), 775–786. doi:10.1111/j.1467-8535.2007.00793.x
Blazhenkova, O., & Kozhevnikov, M. (2010). Visual-object ability: a new dimension of non-verbal intelligence. Cognition, 117(3), 276–301. doi:10.1016/j.cognition.2010.08.021
Boyle, G. J. (1995). Myers-Briggs Type Indicator (MBTI): Some Psychometric Limitations. Australian Psychologist, 30(1), 71–74. doi:10.1111/j.1742-9544.1995.tb01750.x
Bradley, G., & Russell, G. (1997). Computer Experience , School Support and Computer Anxieties. Educational Psychology, 17(3), 267–284. doi:10.1080/0144341970170303
Briggs Myers, I. (2000). Introduction to Type. Oxford: OUP. Brosnan, M J. (1999). Modeling technophobia : a case for word processing. Computers in Human Behavior, 15,
105–121. Brosnan, M J, & Thorpe, S. J. (2006). An evaluation of two clinically-derived treatments for technophobia.
Computers in Human Behavior, 22, 1080–1095. doi:10.1016/j.chb.2006.02.001 Brosnan, M., Gallop, V., Iftikhar, N., & Keogh, E. (2010). Digit ratio ( 2D : 4D ), academic performance in
computer science and computer-related anxiety. PERSONALITY AND INDIVIDUAL DIFFERENCES. doi:10.1016/j.paid.2010.07.009
Brosnan, M. J. (1998). The impact of computer anxiety and self-efficacy upon performance. Journal of Computer Assisted Learning, 14(3), 223–234. doi:10.1046/j.1365-2729.1998.143059.x
Celik, V., & Yesilyurt, E. (2013). Attitudes to technology, perceived computer self-efficacy and computer anxiety as predictors of computer supported education. Computers & Education, 60(1), 148–158. doi:10.1016/j.compedu.2012.06.008
Ceyhan, E. (2006). Computer anxiety of teacher trainees in the framework of personality variables. Computers in Human Behavior, 22, 207–220. doi:10.1016/j.chb.2004.07.002
Chien, T. (2008). Factors Influencing Computer Anxiety and Its Impact on E-Learning Effectiveness : A Review of Literature. Journal of Psychology, (2001).
Choi, K., Deek, F., & Im, I. (2008). Exploring the underlying aspects of pair programming: The impact of personality. Information and Software Technology, 50(11), 1114–1126. doi:10.1016/j.infsof.2007.11.002
Chou, H. (2001). Effects of training method and computer anxiety on learning performance and self-efficacy. Computers in Human Behavior, 17, 51–69.
Chua, S. L., Chen, D., & Wong, A. F. L. (1999). Computer anxiety and its correlates : a. Computers in Human Behavior, 15, 609–623.
Cowan, B. R., & Jack, M. A. (2011). Interacting with Computers Exploring the wiki user experience : The effects of training spaces on novice user usability and anxiety towards wiki editing. Interacting with Computers, 23(2), 117–128. doi:10.1016/j.intcom.2010.11.002
Crabbe, S., & Andras, P. (2012). Computer Anxiety. PPIG 2012.
7

Durndell, A., & Haag, Z. (2002). Computer self efficacy , computer anxiety , attitudes towards the Internet and reported experience with the Internet , by gender , in an East European sample. Computers in Human Behavior, 18, 521–535.
Furnham, A., Monsen, J., & Ahmetoglu, G. (2009). Typical intellectual engagement, Big Five personality traits, approaches to learning and cognitive ability predictors of academic performance. The British journal of educational psychology, 79(Pt 4), 769–82. doi:10.1348/978185409X412147
Goldberg, L. R. (1992). International Personality Item Pool. Psychological Assessment. Gravill, J., & Compeau, D. (2008). Self-regulated learning strategies and software training. Information &
Management, 45(5), 288–296. doi:10.1016/j.im.2008.03.001 Gupta, S., Bostrom, R. P., & Anson, R. (2010). Do I Matter ? The Impact of Individual Differences on Training
Process. SIGMIS-CPR’10 (pp. 112–120). Heinssen, R. (1987). Assessing computer anxiety: Development and validation of the Computer Anxiety Rating
Scale. Computers in Human Behavior, 3(1), 49–59. doi:10.1016/0747-5632(87)90010-0 Hewson, C., & Brosnan, M. (2002). Comparing online and offline administration of multiple choice question
assessments to psychology undergraduates : do assessment modality or computer attitudes influence performance ? Psychology Learning and Teaching, 6(1), 37–46.
Howard, G. S. (1986). Computer Anxiety and the Use of Microcomputers in Management. Michigan: UMI Research Press.
Hvelka, D., Beasley, F., & Broome, T. (2004). American Journal of Business » Blog Archive » A Study of Computer Anxiety Among Business Students. American Journal of Business, 19(1).
Kaiser, R. B., McGinnis, J. L., & Overfield, D. V. (2012). The how and the what of leadership. Consulting Psychology Journal: Practice and Research, 64(2), 119–135. doi:10.1037/a0029331
Karal, H. (2009). Assessing Pre-Service Teachers ’ Computer Phobia Levels in terms of Gender and Experience , Turkish. Sciences-New York, 90(462), 71–75.
Karsten, R., Mitra, A., & Schmidt, D. (2012). Computer-self-efficacy-a-meta-analysis. Journal of organizational and end user computing, 24(4), 54–80.
Korobili, S., Togia, A., & Malliari, A. (2010). Computers in Human Behavior Computer anxiety and attitudes among undergraduate students in Greece. Computers in Human Behavior, 26(3), 399–405. doi:10.1016/j.chb.2009.11.011
Korukonda, A. R. (2007). Differences that do matter : A dialectic analysis of individual characteristics and personality dimensions contributing to computer anxiety. Computer, 23, 1921–1942. doi:10.1016/j.chb.2006.02.003
Kurt, A. Ag., & Gürcan, A. (2010). The comparison of learning strategies, computer anxiety and success states of students taking web-based and face-to-face instruction in higher education. Procedia - Social and Behavioral Sciences, 9, 1153–1157. doi:10.1016/j.sbspro.2010.12.299
Lindblom, K., Gregory, T., Wilson, C., Flight, I. H. K., & Zajac, I. (n.d.). The impact of computer self-efficacy, computer anxiety, and perceived usability and acceptability on the efficacy of a decision support tool for colorectal cancer screening. Journal of the American Medical Informatics Association : JAMIA, 19(3), 407–12. doi:10.1136/amiajnl-2011-000225
Livingston, R. B., Jennings, E., Reynolds, C. R., & Gray, R. M. (2003). Multivariate analyses of the profile stability of intelligence tests: high for IQs, low to very low for subtest analyses. Archives of clinical neuropsychology : the official journal of the National Academy of Neuropsychologists, 18(5), 487–507. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/14591445
López-Bonilla, J. M., & López-Bonilla, L. M. (2012). Validation of an information technology anxiety scale in undergraduates. British Journal of Educational Technology, 43(2), E56–E58. doi:10.1111/j.1467-8535.2011.01256.x
Maltby, J., Day, L., & Macaskill, A. (2007). Introduction to Personality, Individual Difference and Intelligence. Harlow: Pearson Education Ltd.
Marcoulides, G. A., Emrich, C., & Marcoulides, L. D. (2011). Educational and Psychological Measurement Testing for Multigroup Anxiety Scale. Educational and Psychological Measurement. doi:10.1177/0013164407308469
Margaryan, A., Littlejohn, A., & Vojt, G. (2011). Are digital natives a myth or reality? University students’ use of digital technologies. Computers & Education, 56(2), 429–440. doi:10.1016/j.compedu.2010.09.004
Maurer, M. M. (1994). Computer anxiety correlates and what they tell us: A literature review. Computers in Human Behavior, 10(3), 369–376. doi:10.1016/0747-5632(94)90062-0
McCreery, M. P., Kathleen Krach, S., Schrader, P. G., & Boone, R. (2012). Defining the virtual self: Personality, behavior, and the psychology of embodiment. Computers in Human Behavior. doi:10.1016/j.chb.2011.12.019
8

Mcilroy, D., Sadler, C., & Boojawon, N. (2007). Computer phobia and computer self-efficacy : their association with undergraduates use of university computer facilities. Computers in Human Behavior, 23, 1285–1299. doi:10.1016/j.chb.2004.12.004
Meier, S. T. (1988). Predicting Individual Differences in Performance on Computer-Administered Tests and Tasks : Development of the Computer Aversion Scale, 4, 175–187.
Moldafsky, N. (1994). Attributes Affecting Computer-Aided Decision Making - A Literature Survey. Science, 10(3), 299–323.
Morris, M. G., Hall, M., Davis, G. B., Davis, F. D., & Walton, S. M. (2003). U SER A CCEPTANCE OF I NFORMATION T ECHNOLOGY : T OWARD A U NIFIED V IEW 1. MIS Quarterly, 27(3), 425–478.
Myers-Briggs Widely Used But Still Controversial. (n.d.). Retrieved from http://www.psychometric-success.com/personality-tests/personality-tests-popular-tests.htm
Namlu, A. G. (2003). The effect of learning strategy on computer anxiety. Computers in Human Behavior, 19, 565–578. doi:10.1016/S0747-5632(03)00003-7
Nettle, D. (2007). Personality. Oxford: Oxford University Press. Nickell, G. S., & Pinto, J. N. (1987). The Computer Attitude Scale, 2, 301–306. Powell, A. L. (2013). Computer anxiety: Comparison of research from the 1990s and 2000s. Computers in
Human Behavior, 29(6), 2337–2381. doi:10.1016/j.chb.2013.05.012 Rahimi, M., & Yadollahi, S. (2011). Computer anxiety and ICT integration in English classes among Iranian
EFL teachers. Procedia Computer Science, 3, 203–209. doi:10.1016/j.procs.2010.12.034 Rosen, L. D., & Weil, M. M. (1992). Measuring technophobia, (June 1992), 1–51. Rosen, L. D., & Weil, M. M. (1995a). Computer Availability , Computer Experience and Technophobia Among
Public School Teachers. Education, 11(1), 9–31. Rosen, L. D., & Weil, M. M. (1995b). Computer Anxiety : A Cross-Cultural Comparison of University Students
in Ten Countries. Science, 11(1), 45–64. Schulenberg, S. E., & Melton, A. M. A. (2008). The Computer Aversion , Attitudes , and Familiarity Index (
CAAFI ): A validity study. Computer, 24, 2620–2638. doi:10.1016/j.chb.2008.03.002 Tekinarslan, E. (2008). Computer anxiety : A cross-cultural comparative study of Dutch and Turkish university
students. Computer, 24, 1572–1584. doi:10.1016/j.chb.2007.05.011 Teo, T. (2008). Assessing the computer attitudes of students : An Asian perspective. Technology, 24, 1634–
1642. doi:10.1016/j.chb.2007.06.004 Terzis, V., & Economides, A. a. (2011). The acceptance and use of computer based assessment. Computers &
Education, 56(4), 1032–1044. doi:10.1016/j.compedu.2010.11.017 Torkzadeh, G., Chang, J. C.-J., & Demirhan, D. (2006). A contingency model of computer and Internet self-
efficacy. Information & Management, 43(4), 541–550. doi:10.1016/j.im.2006.02.001 Torkzadeh, G., & Van Dyke, T. P. (2002). Effects of training on Internet self-efficacy and computer user
attitudes. Computers in Human Behavior, 18(5), 479–494. doi:10.1016/S0747-5632(02)00010-9 Tulbure, C. (2011). Do different learning styles require differentiated teaching strategies? Procedia - Social and
Behavioral Sciences, 11, 155–159. doi:10.1016/j.sbspro.2011.01.052 Van Raaij, E. M., & Schepers, J. J. L. (2008). The acceptance and use of a virtual learning environment in
China. Computers & Education, 50(3), 838–852. doi:10.1016/j.compedu.2006.09.001 Weil, M. M., & Rosen, L. D. (1995). The Psychological Impact of Technology From a Global Perspective : A
Study of Technological Sophistication and Technophobia in University Students From Twenty-Three Countries. Science, 11(1), 95–133.
Wicherts, J. M., & Zand Scholten, A. (2010). Test anxiety and the validity of cognitive tests: A confirmatory factor analysis perspective and some empirical findings. Intelligence, 38(1), 169–178. doi:10.1016/j.intell.2009.09.008
9

Neo-Piagetian Preoperational Reasoning in a Novice Programmer
Donna Teague
Queensland University of Technology, Australia
Raymond Lister
University of Technology, Sydney, Australia
Keywords: POP-II.A. novices; POP-V.A. Neo-Piagetian. POP-V.B. protocol analysis.
Extended Abstract Using neo-Piagetian theory, Lister (2011) conjectured there were four main stages of cognitive development in the novice programmer, which are (from least mature to most mature):
• Sensorimotor: The novice programmer cannot reliably manually execute a piece of code and determine the final values in the variables, due to both the well known novice misconceptions about language semantics and their inability to organize a written manual execution of the code.
• Preoperational: The novice can manually execute code reliably, but struggles to “see the forest for the trees”. That is, the novice struggles to understand how several lines of code work together to perform some computational process. When trying to understand a piece of code, such novices tend to use an inductive approach. That is, they manually execute the code, perhaps more than once with differing initial values, and make an educated guess based on the input/output behaviour.
• Concrete operational: The novice programmer is capable of deductive reasoning. That is, the novice can understand short pieces of code by simply reading the code, rather than executing the code with specific values. When reading code, they tend to reason in terms of constraints on the set of possible values that each variable may have. The concrete operational stage is the first stage at which novices can reason with abstractions of code, such as diagrams.
• Formal Operational: As this most advanced stage does not figure in this paper, we refer the reader to Lister (2011) for a description of it.
It is well known that researchers since Piaget have conducted experiments that call into question aspects of his “classical” Piagetian theory. Neo-Piagetians have proposed modifications to address problematic aspects of the classical theory. One of the problematic aspects is the conception of stages. For example, in classical Piagetian theory, a person spends an extended period in one stage, before undergoing a rapid change to the next stage. This is commonly referred to as the “stair case metaphor”. Instead, some neo-Piagetian researchers have found evidence for the “overlapping wave” metaphor (e.g. Siegler, 1996), where a person exhibits a changing mix of reasoning strategies from the different Piagetian stages. Initially, the sensorimotor stage of reasoning is dominant, but its frequency of use declines as the use of preoperational styles of reasoning increases, and so on. Our think aloud data supports the overlapping wave model.
Corney et al. (2012) provided indirect evidence that novice programmers pass through the preoperational and concrete operational stages, by analyzing student answers to exam questions. They found that (a) within individual exam questions, there were students who could provide a preoperational answer but not a concrete operational answer, and (b) across exam questions, students tended to consistently provide either a preoperational answer or a concrete operational answer. However, such indirect evidence does not indicate the actual thought processes of a student.
In the study reported here, we had several volunteer students complete programming related tasks while "thinking aloud". We found direct evidence that students progress though these neo-Piagetian stages. We met approximately once each week with these students, so we could follow their progress over the course of a semester. In this abstract, we briefly describe a single think aloud session with
10

one representative student, with the pseudonym "Donald". He is 22 years old, speaks English as his first language and at the time of the think aloud described below he was in his 9th week of semester.
In one exercise, Donald (and other participants) were asked to read the mix of python code and pseudocode shown below and then, in one sentence, “describe the purpose of that code”: if (y1 < y2):
Code to swap the values in y1 and y2 goes here.
if (y2 < y3): Code to swap the values in y2 and y3 goes here.
if (y1 < y2): Code to swap the values in y1 and y2 goes here.
Donald (and some other participants) used the inductive approach of a novice at the preoperational stage. That is, Donald selected some initial values for the variables (y1 = 1, y2 = 2 and y3 = 3), manually executed the code with those values, and then inferred what the code did from the input/output behaviour. In his think aloud, Donald initially showed remnant attributes of the sensorimotor stage, as his first attempt at manual execution was unorthodox and poorly organised. After he gave up on that initial attempt, he then spontaneously adopted a more orthodox and better organised approach to manual execution, and quickly completed a correct manual execution. However, he then made an incorrect inductive inference, which led him to write the following incorrect answer: “To reverse the values stored in y1, y2 and y3 ...” The person conducting the think aloud (the first author) then provided Donald with alternate initial values for the variables (y1 = 2, y2 = 1 and y3 = 3). Donald then performed a successful manual execution with those values. On completing that execution, Donald exclaimed, “Oh! It’s ordering them … um … so, it’s more about, it’s not to rev … hang on … oh [indecipherable]… rather than to reverse, it would be to, place them from highest to lowest.” In summary, Donald manifested behaviour consistent with someone who, in terms of the overlapping wave metaphor, is transitioning from the sensorimotor stage being dominant to the preoperational stage being dominant. In this think aloud, he did not manifest concrete operational reasoning. Elsewhere (Teague et al., 2013), we have described think aloud sessions where students do manifest more sophisticated modes of reasoning than Donald exhibited.
Our think aloud study has pedagogical implications. From the earliest lessons, the traditional approach to teaching programming places heavy emphasis on code writing and code design. In so doing, the traditional approach effectively skips across the sensorimotor and preoperational stages and assumes that all students can immediately reason about code at the concrete operational stage. Our think aloud with Donald, and think alouds with other students, suggests that the traditional approach skips too quickly across the sensorimotor and preoperational stages.
References Corney, M., Teague, D., Ahadi, A. and Lister, R. (2012) Some Empirical Results for Neo-Piagetian
Reasoning in Novice Programmers and the Relationship to Code Explanation Questions. 14th Australasian Computing Education Conference (ACE2012), Melbourne, Australia. pp. 77-86. http://www.crpit.com/confpapers/CRPITV123Corney.pdf
Lister, R. (2011) Concrete and Other Neo-Piagetian Forms of Reasoning in the Novice Programmer. 13th Australasian Computer Education Conference (ACE 2011), Perth, Australia. pp. 9-18. http://crpit.com/confpapers/CRPITV114Lister.pdf
Siegler, R. S. (2006). Microgenetic analyses of learning. In W. Damon & R. M. Lerner (Series Eds.) & D. Kuhn & R. S. Siegler (Vol. Eds.) Handbook of Child Psychology, Vol. 2: Cognition, Perception and Language (6th ed) pp. 464-510). Hoboken, NJ: Wiley.
Teague, D., Corney, M., Ahadi, A. and Lister, R. (2013) A Qualitative Think Aloud Study of the Early Neo-Piagetian Stages of Reasoning in Novice Programmers. 15th Australasian Computing Education Conference (ACE2013), Adelaide, Australia. pp 87-95.
11

Increasing Student Confidence throughout the Computer Science Curriculum
John A. Trono
Computer Science Department Saint Michael's College
[email protected] Keywords: POP-I.B. barriers to programming, POP-II.B. program comprehension, POP-IV.A concurrency
Abstract As educators, we all try to do our best to help the students enrolled in our classes learn/understand the concepts, techniques and strategies pertinent to those courses. One effective methodology to aid this pursuit is to devise a semester-long plan of activities that will attempt to increase each student’s level of confidence that they are adequately learning the course’s contents. Experience has shown that students who are confident about their knowledge competency tend to stay more focused and motivated about the subject matter, which tends to improve their retention of this knowledge obtained therein well beyond the course’s duration. The remainder of this report will describe some of the specific, course-related activities that have been used to bolster student confidence in many different computer science courses.
1. Introduction The basic premise upon which this work is built is something that this author has been incorporating since his first few years as an educator (almost thirty years ago). From those early days as a novice, assistant professor, to the present day evolution of this ‘sage on the stage’, one thing has always been clear to me as I’ve looked at the faces of those attending my course presentations: students who believe that they are understanding the concepts being described are more engaged, active learners while attending course lectures than those whose facial expressions actually remind me of ‘a deer caught in the headlights’.
It is unimaginable that one could meet a teacher, at any level – in any system of education, who can say that they have never seen that look of sheer terror that is concomitant with the realization that what the speaker is trying to convey makes no sense whatsoever to that person who is listening to them. Once that feeling of being lost has been recognized by the listener’s brain, one of two things usually occurs: either a hand is raised, and a question is asked (to rectify the situation), or, that student continues to sit there, only listening passively while taking notes, hopeful that a revelation will occur to them at a later time – perhaps while they are reading passages from the assigned, course textbook.
Unfortunately, many students who realize that they are in a course which appears to them to be beyond their ability to completely comprehend, sadly acquiesce into ‘survival mode’, if it is too late to withdraw from this course. In this mode, the student will work as hard as they can, and they will hope that they will receive at least a passing grade in the course so that they will receive the credits for completing the course, and it will therefore not have been a total waste of their time. How sad is it that some students must rely on this approach at all, especially since becoming a more informed citizen is one important outcome of higher education – not just the semester’s grade point average, or the eventual diploma that may be earned.
Thankfully, many intelligent, motivated students resist this temptation and persevere past such roadblocks. It has become clear to me over the years that all those who do overcome such temporary setbacks typically seem to share one common trait: they all believe in themselves, and are confident in their ability to learn new ideas. For some students, their confidence can be lessened during their time in a course, and if it is, their level of engagement slowly ebbs towards passivity, and their internal push to ask clarifying questions during class decreases until it is non-existent (for that course).
12

This self-defeating, reinforcing behaviour is usually supported by two faulty student assumptions. First, ”… the teacher will think that I am stupid because I have to ask them questions”; students have said that they believe the teacher will also “… assume that I think that they are a terrible teacher since I can’t follow what they are doing in class.” Secondly, “If I ask a stupid question”, it will allow “… the teacher to become aware how low my IQ is, and I am hoping to hide that fact from them.”
Some students have such strong identities and personalities that it would be difficult for one teacher (in one course) to alter their self-esteem at such a late developmental stage. However, many students are not so strongly aware of their own inherent capabilities, and those are the ones who would benefit the most from the techniques and methodologies suggested in this paper.
Subsequent sections will outline strategies (to increase student confidence) fthat have been integrated into courses on software development, operating systems, computer architecture, and computer networks, and hopefully this report will inspire those who read it to develop more of the same.
2. Introductory Level Programming Courses Many universities did not have programming courses in the 1960’s, but now that the information revolution has taken hold, such courses are available to many high school students – or even younger individuals, if they wish to learn about how to instruct a computer (to do what they want it to do) either by reading a book on that topic, or by some online, educational experience.
Most college curricula now have incoming students enrol in a basic course that introduces them to problem solving on the computer, implementing their software artifacts in some high level, programming language, e.g. Java, C++ or Python. Some students may test out of this course in some fashion, most popularly in the United States by having successfully scored high enough on an Advanced Placement (AP) test, after having completed an AP course in high school. (Many colleges state-side will give college credit if a student earns a 4 or 5 – out of 5 – on an AP exam.) Most institutions then follow this course with one where data structures and algorithm analysis are the primary topics of interest.
At Saint Michael's College, our computer science (CS) curriculum has three courses in the introductory software development sequence. Our first programming course (CS111) is essentially open to all students, so we enrol quite a variety of students in it, from many different backgrounds and majors, as CS111 also fulfils the quantitative reasoning, graduation component within the College’s, required Liberal Studies Curriculum. The following course, CS113, focuses more on ‘programming in the large’ since the largest program a student will complete in our CS111 course will most likely be between 50 and 100 lines of Java code (not counting comments). Hence, the two primary goals of CS113 are: to expose our students to some of the software engineering techniques that are used by many professionals when they develop software; and to help our students reinforce (and extend) their own problem solving skills as they are designing (and implementing) programs composed of hundreds of lines of code (and possibly many, distinct Java classes/objects).
CS113 also provides the students (who take it) with an opportunity to increase their confidence in the programming skills that they acquired in CS111 since those skills are now going to be reinforced (and enhanced) by the completion of more challenging and intricate programming projects in CS113 (than those that can reasonably be assigned to students taking CS111). This curricular decision has been an important building block that was instituted back when our department was created (1982), and we believe that it has been a very valuable, pedagogically sound choice that has aided many students – especially those who came to our program with no prior programming experience whatsoever.
One technique that I’ve always found to be quite effective with regards to reinforcing student understanding, when I am teaching our CS111 course, is illustrating how the values of the variables change (over time) while a program is executing. Mayer (1981) cites the results from an earlier study of his where students, that were exposed to his “concrete model”, performed better on questions pertaining to basic program understanding that those in the control group. More recently, Msele (2010) has verified that the use of his RAM diagrams have likewise been a valuable methodology for enhancing comprehension (when teaching programming).
13

Both of these approaches are slightly different manifestations of having students carefully trace a program in a step by step manner. I also demonstrate this technique during my lectures, though I simply list each declared variable in a horizontal fashion, with a ‘?’ underneath each one, to show that its value is currently unassigned. Then, each time a variable is updated during an assignment statement, the value in the corresponding column is modified to indicate that current value (which has been placed into that memory location, for that specific variable).
Because repetition is a very powerful tool for those attempting to master the skills in CS111, my students will trace (and write) programs on weekly quizzes as well as during the three, in class exams given each semester; there are also weekly programming assignments that will help them to internalize the art and science of computer programming. Both skills – tracing and creating software – are fundamentally what CS111 is all about. However, learning how to correctly trace a program is quite an important skill since it allows the students to determine why their program’s output is incorrect, which can help them when creating a program on a quiz or exam, since it provides them a technique to discover any logic errors – and rectify them before the result is assessed.
Another useful tool in these introductory CS courses is the concept of an extended, or multi-phase, assignment. Huggins et al (2003) describe several places where having a project contain several phases, which may be given as consecutive assignments, or can be spread out throughout the semester, can be beneficial. Student confidence seems to build during the time these related assignments are being worked on (whenever I’ve utilized this approach).
More recently, Chen and Hall (2013) have also used the last month of a first programming course to expose their students to a lengthy, cumulative programming project, with several deadlines and milestones spread throughout that time period. A student quote indicates how positive this assignment was for them: “This project was a great learning experience … I now realize that I’m capable of making fairly complex programs … and because of that, I feel confident and excited to program more.” The course instructors also seem to concur with this belief: “We observed an increase in confidence amongst the students as they progressed through the project.”
Textbooks have a great impact on what students learn during their courses, and many books at the introductory level attempt to build their reader’s confidence regarding their internalization of those particular concepts. One popular strategy to accomplish this is to sprinkle review/’self-help’ questions throughout each chapter rather than place them at the end of each chapter. Using the former approach, students can gain immediate feedback and assess their level of understanding while they try to comprehend the material. This self-assessment strategy is facilitated by incorporating the answers to these questions in an easily accessible place so students can validate their newly acquired knowledge, or, they can return to previous sections in the book to uncover what they missed during their initial pass over those ideas. (I’ve noticed recently that some upper level CS textbooks are beginning to do likewise as well.)
This section has included several strategies that may help to augment each student’s learning of the desired, basic programming skills. Because these skills must be retained for subsequent CS courses, it is important that they are not forgotten. The more hands on experiences that each student successfully completes, the more likely it is that these skills will become like ‘second nature’ to those students who complete the course.
To make the more abstract concepts of advanced, upper level CS courses as crystal clear as possible, to all the students enrolled in those classes, it is also important to provide many hands on exercises and projects to bolster their understanding as well. The following three sections will enumerate what approaches seem to have benefited my students the most over the years (in this regard).
3. Understanding the Mechanisms inside an Operating System Mayer (1981) stated “… understanding is defined as the ability to use learned information in problem-solving tasks that are different from what was explicitly taught … ability to transfer learning to new situations.” This is a point that I stress at the first meeting of a required junior/senior level course that focusses on operating systems (O/S) concepts. As an example, I show them how to add
14

two three digit numbers, illustrating the process of propagating the carries, e.g. 468 + 795. I then proceed to say that I now expect that they could add two seven digit numbers in the same manner, if they truly understand the process, even though I have not ever explicitly demonstrated a specific example of that size.
As advanced, upper level undergraduates, these students need to be prepared to become lifelong learners, and to be more independent in advanced courses like this one since they will be expected to continue to develop professionally, on their own, after graduation. That is why I tell them that they can’t rely only on memorization, for the same reason that that strategy doesn’t work when trying to learn how to program; one must understand what each statements does, and how to select the right ones – in the correct order – to solve the problem at hand. Remembering the exact statements in one program may be useless when solving an entirely different problem.
To emphasize this point, there must be less hand holding in courses like this one, than in CS111: typically, upper level students are provided one opportunity to demonstrate proficiency on a topic, unlike in CS111, where quiz questions are a preparatory step for similar questions on upcoming exams, and these exams are weighted more heavily, since students should be rewarded if they’ve finally learned the material even if initially they were ‘not quite getting it’. (This approach seems reasonable because the student mix in CS111 is also more heterogeneous than in an advanced course like one investigating O/S concepts.)
Homework assignments, quizzes and programming projects are all certainly quite helpful tools as students attempt to understand the O/S topics presented, but besides exercises on short term scheduling strategies, local page replacement algorithms and deadlock avoidance techniques, for example, several other useful instructional aids will now be described.
Concurrency, the concept of more than one program being necessary (to efficiently solve a problem), has always been an important topic that ties together many of the underlying O/S concepts (after those concepts have been described earlier in the course). To help students gain confidence in this area, one that is quite different from the straightforward, sequential programming that they’ve been exposed to up to this point in time, I provide them with many homework problems to solve, all of which require them to construct process pairs (via paper design) that utilize semaphore operations to control their independent (and possibly parallel) execution.
These homework problems are assigned in such a way that one is due at the beginning of every class for roughly six lectures. Students are also informed that the first few of these assignments will be graded more leniently than the ones that follow, since concurrent programming is probably new to them. Problems that are handed out in one class period aren’t due the next period (when they can ask for clarification on the problem), but their solution must be turned during the class after that one.
Students are told that for each such homework, one submission will be selected randomly, and it will be copied onto the board for inspection. (Students will only have at most one of their submissions publically displayed in this manner.) My experience is that students certainly learn from how a correct solution solves the posed, concurrent programming problem, but they learn more from recognizing what does not work in someone else’s proposed solution. Using this approach, many students can also learn what to avoid by seeing such demonstrative examples. Students will also be asked to solve a similar problem on a quiz (and on the final exam), and one of these exercises will be chosen for direct implementation, using the semaphore primitives that are available on our Linux-based workstations (in our upper level, computer lab).
One final piece of the ‘concurrency learning experience’ is to have the students be exposed to other related topics. One strategy that I’ve found to be beneficial is to discuss how general counting semaphores can be implemented using the binary semaphore primitives if they are available on the underlying hardware, and the problems in one such implementation have been documented. I have distributed the relevant articles that have described the problem, and the debate that followed, and then require the students to determine which of the arguing authors view is most correct, and why, and to place their views on this debate in a paper of their own creation. (A brief introduction to the problem, and the articles that compose this debate, can be found in Trono and Taylor (2000).)
15

4. Computer Architecture: Enhancing Understanding through Performance Analysis Our CS majors typically enrol in our required computer architecture course in the semester following the O/S course, which is also roughly one year after our students complete our machine organization course. Back in the 1980’s, there were truly no outstanding computer architecture textbooks, but when the first edition of the popular Hennessy and Patterson book (Computer Architecture: A Quantitative Approach) was released in 1990, I adopted it, and have used it ever since. Even though many topics that I consider essential to what I emphasize in this course have been moved into the book’s appendices, I believe it is still the top text for exposing CS students to the level of detail necessary to understand how a processor executes the program’s instructions, and what techniques are used to reduce the time it takes for the programs to complete.
Though this book includes many pertinent exercises at the end of each chapter, I’ve created my own extended assignment that illustrates how much time is saved by the architectural changes that have been incorporated into microprocessors over the years. More specifics about this collection can be found in Trono (1999), but the basic outline is as follows. A typical program in the SPEC (Standard Performance Evaluation Corporation) benchmark suite was chosen, written as a C program, and then translated into a reasonably well optimized, MIPS assembly language (where MIPS is the instruction set architecture described in Appendix C of the 5th edition of Hennessey and Patterson’s book).
The first assignment is to familiarize the students with the C program, one that they will continue to analyse throughout the semester, and to simply calculate the total number of machine cycles it will take to execute this iterative code stub (64K iterations, i.e. 65,536 executions of the code within that loop) with two underlying, instruction execution models. This basic architecture is then improved upon in the next assignment, using the same MIPS code, by first adding a two stage pipeline, and then adding a finite, instruction look-ahead buffer, and the performance improvements can then be quantified using the relevant formulas from the book’s opening chapter.
Next, the inclusion of a data cache, and then an additional instruction cache, reduce the memory bottleneck’s impact on the program’s performance. Finally, the C code is once again translated to MIPS, this time utilizing the available vector instructions present, and only 1024 iterations are needed since each iteration now processes data vectors of 64 elements at a time. The CPI (average number of cycles per instruction) is measured for the architecture in each of these assignment extensions, and the resultant speedup values can be computed, for comparison purposes, after each hardware improvement is introduced. Students do become more confident as this assignment unfolds during the semester, and their performance on these homework problems improve over time even though each subsequent problem is more complex than its predecessor.
Several other possible hardware improvements could be used for subsequent assignments after caches are added, like including a scoreboard, or reservation stations, to facilitate an out of order execution strategy that could extract more instruction level parallelism from this program. However, since the students are also performing research on a topic from a paper chosen from a recent International Symposium on Computer Architecture (ISCA) at that time, I have chosen not to overload them with more homework assignments in the last quarter of the semester when they are feverishly working on their paper, which they could only begin in earnest after the midterm exam. (Their topic was selected early in the semester, so they could collect the relevant references during the first half of this course. This assignment comprises 20% of their overall grade, and must be submitted in written form.)
5. Computer Networks: Packet Flow Activities The primary objectives I have, when teaching this particular course, is for the students to come away with a deeper understanding concerning how packets travel over the Internet, especially during the transmission of large music or picture files, as well as how basic mechanisms within the protocol stack actually work. Following one idea that permeates this paper – that repetition is one major key to learning, and retaining, how to do something, especially because reinforcing the steps needed to accomplish a task helps to cement those steps in one’s mind – the principle that ‘if you don’t use it, you lose it’ is one that seems to be worth keeping at the forefront of one’s plan for the semester, when
16

establishing a timeline for what should occur during the limited amount of time allotted to enlighten the enrolled students about the topics to be covered.
Error detection (and correction) is an important concept to convey, and cyclic redundancy check (CRC) codes, as implemented in the data link layer, are probably the primary methodology to accomplish this task in many popular protocols. CRC codes also can be efficiently implemented in hardware, using shift registers, and exclusive-or operations, so this topic combines and revisits ideas presented in the machine organization course that students have recently completed. CRC codes also lend themselves to repetition in homework, quiz and exam questions, for reinforcement purposes, and they allow for the investigation of one way to create an error-free conduit for packets/frames to travel.
How packets are routed (between the original and final destination nodes) is another area where each student’s confidence (of the knowledge they are acquiring) can be increased through opportunities that reinforce what they have learned via assessment tools like homework, quiz and exam questions. Several different, distance vector problems are assigned as homework, and once these algorithms have been mastered, the next idea to investigate is how congestion control in the Internet is accomplished. (Congestion occurs if too many packets are attempting to be sent, and the available bandwidth is not high enough to prevent packets from being dropped, due to insufficient space to buffer the excess packets that are queued up for transmission to the next node – in their journey to the final destination specified.)
Many examples of how TCP Tahoe works are presented in class, and as homework/quiz problems, and then other implementations like TCP Reno, and/or other more recent modifications to this basic strategy can be covered, like Selective Acknowledgements (SACK), allowing students to get a better sense of what is going on behind the scenes.
6. Conclusion While no strategy will work perfectly with every student, my experience has been that the in class strategies, and individual assignments, described here have been reasonably successful in helping students recognize that they have acquired the basic understanding of the related, specific topics (in their respective computer science courses). Ensuring that each student’s confidence in their ability (at a high level) seems to help them remain engaged learners in the classroom. This in turn, I believe, helps them to stay focussed and alert during class meetings and eventually gives them the best chance to successfully complete the course – and to maximize their understanding of the concepts and techniques presented.
7. References Chen, W.K., and Hall, B.R. (2013) Applying software engineering in CS1. Proceedings of the 18th
Innovation and Technology in Computer Science Education conference.
Huggins, J., Kumar, A., Kussmaul, C. and Trono, J. (2003) Multi-phase homework assignments in CS1 and CS2. The Journal of Computing in Small Colleges, 19(2), 182-184.
Mayer, R.E. (1981) The psychology of how novices learn computer programming. ACM Computing Surveys, 13(1) 121-141.
Msele, L.J. (2010) Enhancing comprehension by using Random Access Memory (RAM) diagrams in teaching programming; class experiment. Proceedings of the 22nd Annual Psychology of Programming Interest Group workshop.
Trono, J.A. (1999) A quantitative examination of computer architecture evolution. The Journal of Computing in Small Colleges, 14(4), 190-201.
Trono, J.A., and Taylor, W. E. (2000) Further comments on “A correct and unrestrictive implementation of general semaphores”. Operating Systems Review, 34(3), 5-10.
17

PPIG, Keele University, 2013 www.ppig.org
The cognitive difficulties of Description Logics
Paul Warren*
Trevor Collins*
Paul Mulholland*
*Knowledge Media Institute, The Open University, UK
Keywords: POP-I.A Description Logics, POP-II.B program comprehension, POP-III.B OWL, POP-V.A mental
models
Abstract
This paper describes work-in-progress investigating the difficulties experienced in using Description
Logic constructs. In particular it views these difficulties from the standpoints of cognitive
dimensions, mental models and relational complexity. It outlines how the latter two theories might be
applied to estimate the cognitive complexity of individual Description Logic constructs and patterns
of constructs. The paper also describes some initial feedback obtained from users of ontologies and
Description Logics.
1. Introduction
The use of ontologies based on Description Logics, in particular the various profiles of the Web
Ontology Language (OWL), is now prevalent in a variety of domains, including biomedicine, e.g.,
SNOMED1; engineering, e.g., the Semantic Sensor Network Ontology (Compton et al., 2012); and
business, e.g., Good Relations2. OWL is also one of the languages standardized by the World Wide
Web Consortium for use in the Semantic Web. Description Logics have been studied extensively
from the viewpoints of ensuring decidability and also of their general computational tractability, e.g.,
see Donini et al. (1997). However, there has been much less work to investigate their usability by the
producers and consumers of ontologies. In particular, little has been done to understand the cognitive
difficulties encountered in using Description Logics. This paper will describe work-in-progress
investigating the difficulties experienced with Description Logic constructs and seeking to explain
those difficulties in terms of cognitive science.
The next section describes some related work in this area. Section 3 then briefly describes the results
of a survey of ontology users. Sections 4, 5 and 6 in turn apply the frameworks of cognitive
dimensions, mental models and relational complexity. Finally, section 7 draws some conclusions and
outlines future work.
2. Related Work
There has been some related work by those who are interested in helping ontology builders debug
their ontologies. Typically in this situation, when automatic reasoning is applied, errors in ontology
design lead to unexpected and unwanted inferences. To aid debugging, users are presented with a set
of axioms selected from the ontology to justify the inference.
Horridge et al. (2011) undertook experiments with computer science students to study their
understanding of justifications expressed using logical symbolism, as they might be presented to aid
debugging. They compared their results with their own model of complexity, which was not
grounded in any cognitive theory. They found that in most cases there was a significant difference in
student errors between justifications ranked easy and hard by the model.
Nguyen et al. (2012) were similarly motivated to understand how to best explain inferences to
ontology builders. They did not propose a model of complexity but undertook experiments to
establish, for a set of 51 deduction rules, the probability of each rule being correctly understood.
1 http://www.ihtsdo.org/snomed-ct/
2 http://www.heppnetz.de/projects/goodrelations/
18

2
PPIG, Keele University, 2013 www.ppig.org
These deduction rules were regarded as single inference steps, and the intention was that the
probabilities could be used to decide between different proof trees. A subsequent experiment
confirmed that the model worked relatively well for predicting the probability of correctly
understanding proofs consisting of two inference steps (Nguyen, Power, Piwek, & Williams, 2013).
In this work, unlike that of Horridge et al., the deduction rules were presented in English and the
experimental participants were drawn from a general sample of the population.
3. Ontology Users’ Survey
As an initial study, a survey has been undertaken of ontology users (Warren, 2013). The survey was
aimed at ontology users in general but included questions specifically relating to Description Logics.
Over a hundred responses were received. The survey responses include information about the size of
ontologies; use of visualization tools; use of ontology patterns and pattern tools; Description Logic
features and OWL profiles in use; and the choice of ontology tools. The response to a question about
ontology editors indicated that the most popular editors were based on the use of Description Logics.
This indicates a shift from an earlier frame paradigm. In the frame paradigm the ontology developer
defines classes and relations between instances of classes; using Description Logics relations can also
be used to define classes. Some of the comments received suggest that whilst there are a number of
people skilled in the use of sophisticated Description Logic constructs there are also others who find
this difficult; e.g., one respondent commented “The rigor of the languages exceeds the rigor of the
typical user by a wide margin”.
4. Cognitive Dimensions
The cognitive dimensions framework was developed to assess the cognitive difficulties inherent in a
wide range of cognitive artifacts, e.g., see Green and Blackwell (1998) for a tutorial and Green and
Petre (1996) for an example of an application of the framework. Figure 1 illustrates, in broad terms,
how this framework might describe the use of Description Logics to create ontologies. Some of these
comments relate to ontologies generally, e.g., the limited features for abstraction. A number of the
comments relate to the available tools. In general the state-of-the-art in ontology development tools
lags that of software development tools; the need for improved tool functionality was a comment
made by respondents to the ontology users’ survey mentioned above.
There are four dimensions which are specifically relevant to the use of Description Logics, as
distinguished from ontologies generally or current tools:
Hard mental operations. Description Logics are based on subsets of first order logic. This raises
two problems. Firstly, humans are not adept at handling logic. Secondly, the usage of language
does not always correspond to everyday usage. The most commonly used linguistic
representation is Manchester OWL Syntax (Horridge et al., 2006). Whilst apparently English-
like, this syntax can lead to confusion.
Hidden dependencies. Even relatively small sets of axioms may contain hidden dependencies.
Typically these are not apparent until an automatic reasoner is executed, when unexpected and
possibly unwanted inferences become apparent, as noted in section 2.
Diffuseness, role expressiveness and error-proneness. The language used is very terse, being
based on logic. This avoids ambiguity but, combined with the unusual English usage, creates
difficulties of comprehension. For example, the expression ‘X SubClassOf R some Y’, where X
and Y are classes, R is a relation, and ‘some’ is a keyword, is equivalent to the more normal
English usage ‘every member of X has the relation R to some member of Y’. The latter, more
verbose usage, may be regarded by some people as more intelligible. The use of the ‘only’
keyword to represent the universal quantifier, combined with the use of relations in Description
Logic to define classes, demonstrates the tendency to error-proneness . The difficulty here is that
in logic the universal quantifier can be trivially satisfied, i.e. ‘∀x ∈ X: P(x)’ is true for all predicates P when X is the empty set; this does not correspond to the normal English usage.
This difficulty can be illustrated with an example taken from Nguyen et al. (2013). The statement
19
3
PPIG, Keele University, 2013 www.ppig.org
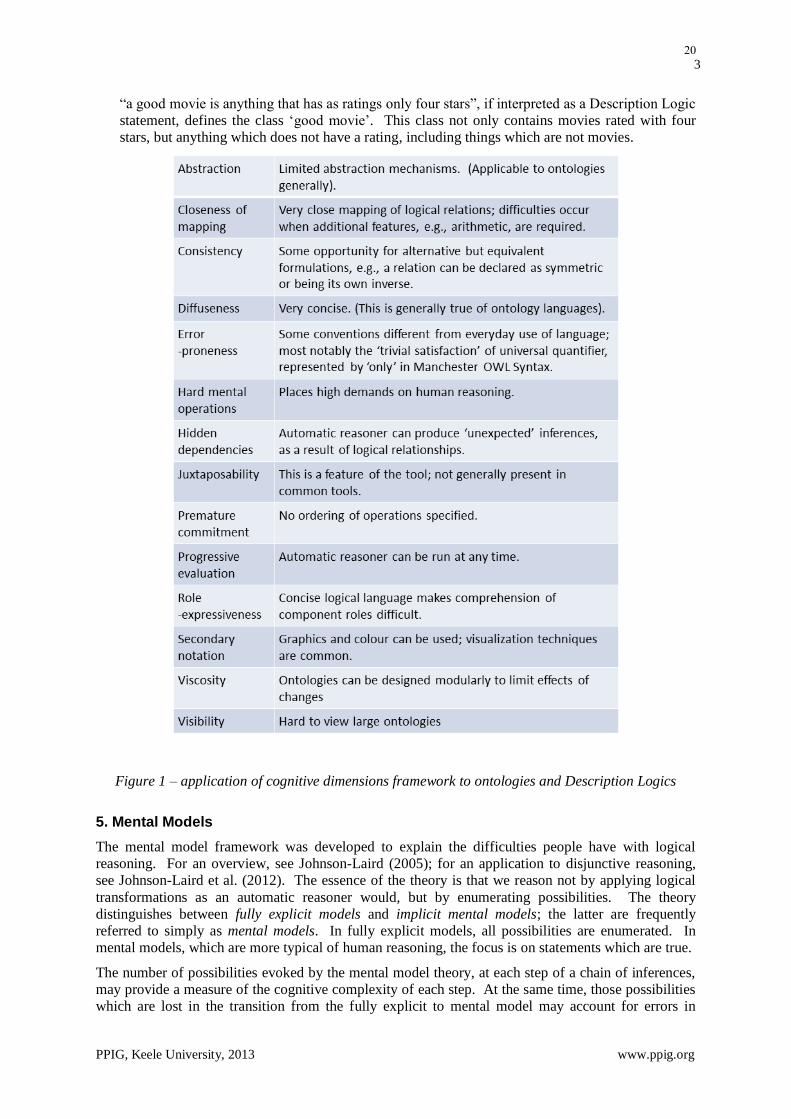
“a good movie is anything that has as ratings only four stars”, if interpreted as a Description Logic
statement, defines the class ‘good movie’. This class not only contains movies rated with four
stars, but anything which does not have a rating, including things which are not movies.
Figure 1 – application of cognitive dimensions framework to ontologies and Description Logics
5. Mental Models
The mental model framework was developed to explain the difficulties people have with logical
reasoning. For an overview, see Johnson-Laird (2005); for an application to disjunctive reasoning,
see Johnson-Laird et al. (2012). The essence of the theory is that we reason not by applying logical
transformations as an automatic reasoner would, but by enumerating possibilities. The theory
distinguishes between fully explicit models and implicit mental models; the latter are frequently
referred to simply as mental models. In fully explicit models, all possibilities are enumerated. In
mental models, which are more typical of human reasoning, the focus is on statements which are true.
The number of possibilities evoked by the mental model theory, at each step of a chain of inferences,
may provide a measure of the cognitive complexity of each step. At the same time, those possibilities
which are lost in the transition from the fully explicit to mental model may account for errors in
20

4
PPIG, Keele University, 2013 www.ppig.org
reasoning. Figure 2, which is taken from Johnson-Laird (2005), illustrates the two types of models for
a conditional statement. The tendency is to focus on the case in which A and B are true and neglect,
for example, that B can be true when A is false.
Figure 2 – fully explicit model and mental models; from Johnson-Laird (2005)
Figure 3 illustrates how the mental model approach might be applied to a simple example from
Description Logics. The left-hand side represents the fully explicit model for each axiom; the right-
hand side represents the mental models and shows how they can be combined. In the figure X, Y and
Z are classes and x, y, z are representative members of those classes. R represents a relation. The
first axiom is ‘X SubClassOf R some Y’. The significance of this statement was explained in section
4. This gives rise to two possibilities; that the representative element x of X is in relation R to a
representative element y of Y; and that there is another representative element of Y for which there is
no X in relation R. This second possibility may be omitted by the human reasoner because it is not
the focus of attention. The second axiom is similar. The third axiom is the transitivity of R. This
axiom is applicable to all individuals in the domain of discourse, not just the elements of X, Y and Z.
However, here the focus is on these three classes. If we consider two relations a R b and c R d, where
a, b, c and d can be individuals in any of X, Y, Z, then we have 81 (34) possibilities in the fully
explicit model. To simplify, in the figure we ignore ordering (so that a R b c R d and c R d a R b are
equivalent), omit the repetition of identical relations (a R b a R b) and omit the repetition of an
individual in any particular relation (a R a). This gives a total of ten possibilities3, as illustrated. The
right-hand side of the figure shows the simplification when we focus on the apparently most
significant possibilities, i.e. those for which the transitive relation leads to a conclusion.
Figure 3 – fully explicit models and mental models for a Description Logic inference
3 Without loss of generality, we assume that the first relation relates x and y (x R y and y R x). Then there are
five possibilities for the second relation: the unused relation between x and y plus x R z, y R z, z R x and z R y.
This gives rise to 2 x 5 = 10 possibilities.
21

5
PPIG, Keele University, 2013 www.ppig.org
6. Relational Complexity
Halford et al. (2010) argue that each step in a reasoning process is characterised by an n-ary relation.
Formally an n-ary relation is a set of ordered n-tuples. Thus the statement ‘Bob is taller than Tom
who is taller than Peter’ is an instance of a ternary relation which contains the 3-tuple (Bob, Tom,
Peter), amongst others. Proportion, e.g. ‘3/5 > 4/7’, entails a quaternary relation, see Halford et al.
(1998). It is argued that human processing capacity is limited to one quaternary relation in parallel.
When confronted with relations for which n>4, we have recourse to strategies such as chunking
variables together and breaking complex relations down to be processed in sequential stages, rather
than concurrently. In their ‘method for analysis of relational complexity’, Halford et al. (2007)
propose that the processing complexity of a multi-step task is determined by the relational complexity
of the most complex step.
Figure 4 shows how this might be applied to the example of the previous section. The statement ‘X
SubClassOf R some Y’ is an instance of a ternary relation which can be represented by S(X, R, Y).
The second axiom can similarly be represented by S(Y, R, Z), and the conclusion by S(X, R, Z). The
third axiom represents a ternary relation because there are three slots in a transitive relation. It is also
possible that it will be perceived by many people as a unary relation, T(R); this is an example of
chunking to reduce dimensionality of a relation.
Part of the difficulty with expressions of the form ‘X SubClassOf R some Y’ is that ‘R some Y’ is to
be understood as the anonymous class containing all individuals that are in the relation R with an
individual in Y. A more natural English usage is ‘every x R y’. Here the focus is on the individuals x
and y rather than the classes they represent. Perhaps more importantly, by chunking the ‘every’ and
the ‘R’ this statement can be perceived as a binary relation either between the representative
individuals x and y or the classes X and Y, written P(X, Y). The latter is illustrated in figure 5.
Figure 4 – Description Logic inference regarded as a set of n-ary relations
Figure 5 – the effect of language on relational complexity
A graphical representation can be used to compare the complexity of the approaches of figures 4 and
5, in line with a long history of representing logic graphically, e.g. see Stenning and Oberlander
(1995). When represented graphically, the introduction of the anonymous classes in the approach of
figure 4 can be seen to lead to extra complexity.
7. Conclusions and Future Work
This paper has described how the problem of understanding the cognitive complexity of Description
Logics can be viewed from three different frameworks. Cognitive dimensions provides a general
view of where the difficulties lie in interpreting Description Logics, and set this in the context of the
problems experienced with ontologies generally and of the current state-of-the-art of available tools.
Mental models provide a means of interpreting Description Logic statements as sets of possibilities.
22

6
PPIG, Keele University, 2013 www.ppig.org
Relational complexity focuses on the complexity inherent in the relations employed at each step of the
inference chain. In both cases the predicted limitations on reasoning have their roots in what can be
held concurrently in working memory. The mental model and relational complexity theories now
need to be applied to predict the difficulty of a range of Description Logic inferences; these
predictions can then be investigated by experiment. Graphical models can also be applied to help
understand logical complexity. It is hoped that this will lead to a model of the comprehensibility of
Description Logic statements which will have a number of benefits: a clearer understanding of where
the problems lie, and how they can be avoided by choice of logical constructs; better representation of
these logical statements in a more natural language; and improved tools, methodologies and training.
8. References
Compton, M., Barnaghi, P., Bermudez, L., García-Castro, R., Corcho, O., Cox, S., Graybeal, J.,
Hauswirth, M., Henson, C., Herzog, A. (2012). The SSN ontology of the W3C semantic sensor
network incubator group. Web Semantics: Science, Services and Agents on the World Wide Web.
Retrieved from http://www.sciencedirect.com/science/article/pii/S1570826812000571
Donini, F. M., Lenzerini, M., Nardi, D., & Nutt, W. (1997). The complexity of concept languages.
Information and Computation, 134(1), 1–58.
Green, T., & Petre, M. (1996). Usability Analysis of Visual Programming Environments: A
`Cognitive Dimensions’ Framework. Journal of Visual Languages & Computing, 7(2), 131–174.
Green, Thomas, & Blackwell, A. (1998). Cognitive dimensions of information artefacts: a tutorial. In
BCS HCI Conference. Retrieved from
http://128.232.0.20/~afb21/CognitiveDimensions/CDtutorial.pdf
Halford, G. S, Wilson, W. H., & Phillips, S. (1998). Processing capacity defined by relational
complexity: Implications for comparative, developmental, and cognitive psychology. Behavioral
and Brain Sciences, 21(06), 803–831.
Halford, Graeme S., Cowan, N., & Andrews, G. (2007). Separating cognitive capacity from
knowledge: A new hypothesis. Trends in cognitive sciences, 11(6), 236–242.
Halford, Graeme S., Wilson, W. H., & Phillips, S. (2010). Relational knowledge: The foundation of
higher cognition. Trends in cognitive sciences, 14(11), 497–505.
Horridge, M., Bail, S., Parsia, B., & Sattler, U. (2011). The cognitive complexity of OWL
justifications. The Semantic Web–ISWC 2011, 241–256.
Horridge, M., Drummond, N., Goodwin, J., Rector, A., Stevens, R., & Wang, H. H. (2006). The
manchester owl syntax. OWL: Experiences and Directions, 10–11.
Johnson-Laird, P. N., Lotstein, M., & Byrne, R. M. (2012). The consistency of disjunctive assertions.
Memory & cognition, 1–10.
Johnson-Laird, Philip N. (2005). Mental models and thought. The Cambridge handbook of thinking
and reasoning, 185–208.
Nguyen, Power, Piwek, & Williams. (2012). Measuring the understandability of deduction rules for
OWL. Presented at the First international workshop on debugging ontologies and ontology
mappings, Galway, Ireland. Retrieved from http://oro.open.ac.uk/34591/
Nguyen, T. A. T., Power, R., Piwek, P., & Williams, S. (2013). Predicting the understandability of
OWL inferences. Retrieved from http://oro.open.ac.uk/36692/
Stenning, K., & Oberlander, J. (1995). A cognitive theory of graphical and linguistic reasoning: Logic
and implementation. Cognitive science, 19(1), 97–140.
Warren, P. (2013). Ontology Users’ Survey - Summary of Results (KMi Tech Report No. kmi-13-01).
Retrieved from http://kmi.open.ac.uk/publications/techreports/year/2013
23

Towards Defining a Cognitive Linguistics of Programming andUsing Eye Tracking to Verify Its Claims
Sebastian Lohmeier
Technische Universitat [email protected]
Keywords: POP-II.B program comprehension, POP-V.A cognitive linguistics, POP-V.B eyetracking
1 A Cognitive Linguistics of Programming
There are cognitive models that explain programming (Parnin, 2010) and psychological exper-iments based on models from cognitive psycholinguistics (Burkhardt, Detienne, & Wiedenbeck,1997). In computer science, attempts have been made to enhance programming languages basedon knowledge of natural languages (Knoll, Gasiunas, & Mezini, 2011; Knoll & Mezini, 2006;Lopes, Dourish, Lorenz, & Lieberherr, 2003). Combining these three relations, I propose acognitive linguistics of programming that is based on three-level semantics, a theory of textcomprehension from cognitive linguistics (Schwarz, 1992; Schwarz-Friesel, 2007). The cog-nitive linguistics of programming enables psychological experiments and is used to enhanceprogramming languages.
Three-level semantics was chosen as the basis of the cognitive linguistics of programming,because it specifies structures and processes that can be implemented computationally andare comparable to those found in object-oriented programming languages. Furthermore, three-level semantics is suitable for generating testable psychological hypotheses and incorporatesthe reader. That is why I describe a cognitive linguistics of programming, not of programminglanguages: three-level semantics assumes an active role of the reader – she constructs meaningwhile reading. Using such a reader-centric model of language, it becomes possible to explainproblems related to programming language understanding during the act of programming.
To make a start, the cognitive linguistics of programming is realized by adding indirectanaphors known from linguistics to the Java programming language (Lohmeier, 2011).
2 Indirect Anaphors in Linguistics
How are indirect anaphors described in linguistics? Example (1) contains the indirect anaphorthe Expression whose definite article the signals that the Expression is known, either due toworld knowledge or prior mention.
(1) An if-then statement is executed by first evaluating the Expression. If the result is of typeBoolean, it is subject to unboxing conversion (Gosling et al., 2005, 372)
According to Schwarz-Friesel (2007), the indirect anaphor the Expression is understood in re-lation to its antecedent An if-then-expression and based on the knowledge that if-then state-ments contain an expression. Using conceptual schemata, this fact is expressed as a part-wholerelation between EXPRESSION and IF-THEN-STATEMENT (upper case denotes concepts).Reading the sentence can then be described as follows: While reading the antecedent An if-then-statement, the default EXPRESSION part of the IF-THEN-STATEMENT concept is activatedin the mind and is still active when the Expression is read. The definite article the signals thatthe expression refers to a known EXPRESSION and since the default EXPRESSION part ofthe IF-THEN-STATEMENT is the only active referent of a matching concept, the expressionrefers to it. During reading, the reader retrieves from memory the part-whole-relation that is
24

underspecified in the text, but available from long-term memory. Likewise, she reconstructsthat the result is the result of the Expression. By resolving the underspecification of the indirectanaphors the Expression and the result, the reader understands a text that would be longerotherwise:
(2) An if-then statement is executed by first evaluating its Expression. If the result of theExpression is of type Boolean, it is subject to unboxing conversion
If the underspecified relations are well known to the reader, underspecification shortens texts andimproves learning of new relations explicated in the text (McNamara, Kintsch, Butler-Songer,& Kintsch, 1996).
3 Indirect Anaphors in Programming
Knowledge of part-whole and other semantic relations is encoded in object-oriented programs.It is thus desireable to shorten source code by introducing indirect anaphors to programminglanguages in order to improve programmers’ learning from source code. This requires compilersthat are able to process indirect anaphors similar to programmers. Listing 1 shows an exampleof an indirect anaphor in programming.
Listing 1. Indirect anaphor .Result in a modified org.junit.runner.JUnitCore (JUnit 4.8.2)
52 public static void runMainAndExit(JUnitSystem system , String ...
args) {
53 new JUnitCore ().runMain(system , args);
54 system.exit(.Result.wasSuccessful () ? 0 : 1);
55 }
The indirect anaphor .Result in line 54 refers to the Result returned by the invocation ofrunMain, eliminating a local variable from the original source code shown in Listing 2.
Listing 2. Original snippet from org.junit.runner.JUnitCore (JUnit 4.8.2)
52 public static void runMainAndExit(JUnitSystem system , String ...
args) {
53 Result result= new JUnitCore ().runMain(system , args);
54 system.exit(result.wasSuccessful () ? 0 : 1);
55 }
4 Claims
Experienced programmers should not have difficulty understanding both listings. While it is notclear whether they would take less time to read the code, if the findings for underspecificationin natural language hold for indirect anaphors in programming languages, programmers canbe expected to better recall new information from source code underspecified with indirectanaphors. Like in the case of underspecification in natural language, indirect anaphors will ofcourse impede understanding for those programmers who do not possess the underspecifiedknowledge. Identifying what knowledge is available to programmers so as to be able to presentcode with or without indirect anaphors would require use of a cognitive architecture (Hansen,Lumsdaine, & Goldstone, 2012; Lohmeier & Russwinkel, 2013) and is beyond the scope ofthis work.
5 Eye Tracking
To test whether source code with indirect anaphors is slower or faster to comprehend thantraditional source code, eye tracking could be applied relatively naturally by integrating eye
25

tracking into an existing IDE (see http://monochromata.de/eyeTracking). This would allowa comparison of eye movements and reading times for indirect anaphors in natural language texts(Garrod & Terras, 2000) and source code. Presenting programmers source code with varyingnumbers of indirect anaphors would permit comprehension studies in the fashion performed fornatural language texts (McNamara et al., 1996). For both reading times and comprehension ofindirect anaphors in source code, the effect of a reader’s possession or lack of knowledge requiredto overcome underspecification will be of interest.
References
Burkhardt, J.-M., Detienne, F., & Wiedenbeck, S. (1997). Mental representations constructedby experts and novices in object-oriented program comprehension. In S. Howard, J. Ham-mond, & G. Lingaard (Eds.), Human-computer interaction: INTERACT ’97. Chapman& Hall.
Garrod, S., & Terras, M. (2000). The contribution of lexical and situational knowledge toresolving discourse roles: Bonding and resolution. Journal of Memory and Language, 42 ,526–544.
Gosling, J., Joy, B., Steele, G., & Bracha, G. (2005). The Java language specification (3rd ed.).Boston: Addison Wesley.
Hansen, M. E., Lumsdaine, A., & Goldstone, R. L. (2012). Cognitive architectures: A wayforward for the psychology of programming. In Onward! 2012: Proceedings of the ACMinternational symposium on New ideas, new paradigms, and reflections on programmingand software (pp. 27–37).
Knoll, R., Gasiunas, V., & Mezini, M. (2011). Naturalistic types. In Onward ’11: Proceed-ings of the 10th SIGPLAN symposium on New ideas, new paradigms, and reflections onprogramming and software (pp. 33–47).
Knoll, R., & Mezini, M. (2006). Pegasus: first steps toward a naturalistic programming language.In OOPSLA ’06: Companion to the 21st ACM SIGPLAN symposium on Object-orientedprogramming systems, languages, and applications (pp. 542–559). New York: ACM.
Lohmeier, S. (2011). Continuing to shape statically-resolved indirect anaphora for naturalisticprogramming: A transfer from cognitive linguistics to the Java programming language.
Lohmeier, S., & Russwinkel, N. (2013). Issues in implementing three-level semantics with ACT-R. In Proceedings of the 12th international conference on cognitive modeling (ICCM).
Lopes, C. V., Dourish, P., Lorenz, D. H., & Lieberherr, K. (2003). Beyond AOP: towardnaturalistic programming. SIGPLAN Notices, 38 (12), 34–43.
McNamara, D. S., Kintsch, E., Butler-Songer, N., & Kintsch, W. (1996). Are good texts alwaysbetter? Interactions of text coherence, background knowledge and levels of understandingin learning from text. Cognition and Instruction, 14 (1), 1–43.
Parnin, C. (2010). A cognitive neuroscience perspective on memory for programming tasks. InPPIG 2010, 22nd annual workshop.
Schwarz, M. (1992). Kognitive Semantiktheorie und neuropsychologische Realitat: reprasentatio-nale und prozedurale Aspekte der semantischen Kompetenz. Tubingen: Niemeyer.
Schwarz-Friesel, M. (2007). Indirect anaphora in text: A cognitive account. In M. Schwarz-Friesel, M. Consten, & M. Knees (Eds.), Anaphors in text : cognitive, formal and appliedapproaches to anaphoric reference (pp. 3–20). Amsterdam: Benjamins.
26

The eighth PPIG Work-in-Progress Workshop, Keele University, UK, July 2013 www.ppig.org
Representational Formality in Computational Thinking
Alistair G. Stead
Computer Laboratory Cambridge University
Alan F. Blackwell
Computer Laboratory Cambridge University
Keywords: POP-II.A. novices, POP-VI.E. computer science education research
Abstract This paper describes our thoughts on a new addition to the set of Computational Thinking abilities: Representation Expertise.
1. Background The notion of Computational Thinking (CT), defined first by Jeanette Wing (2006) led to spirited discussions within several research communities on the origins of problem solving, what exactly constitutes thinking computationally, and whether the term has any real world value. The various lists of CT “abilities” (The National Academy of Sciences, 2011) (ISTE, 2013) (Google, 2013) cover many activities related to thinking computationally, such as data representation, problem decomposition, visualisation, parallelisation and others.
Despite being a core component of computer science, Wing (2006) (2008) intentionally avoided describing “programming” as an ability of CT. Although this is consistent with the original aims of CT: to teach skills and strategies that are transferrable to other disciplines, the exclusion of programming conveniently avoids inheritance of any stigma associated with the term.
2. Representational Expertise as a CT ability Despite the exclusion of programming as an ability in the original definition of CT (Wing, 2006), Resnick (2011) has argued that to truly master CT, one must be able to express themselves and their ideas in computational terms and therefore have “fluency” with computational media.
We agree with this view of CT. However, we think there is a missing CT ability that has yet to be addressed: Representation Expertise. If one takes the view, as we do, that all computer users are programmers to varying degrees, where “programming” is the interaction with abstractions mediated by some representational notation (Blackwell, 2002), then to express computation fluently, one must master the use of (a range of) notations.
As with representations in other disciplines, such as mathematics and logic, several representations can specify the same result. It is therefore important that users are able to recognise, interpret, and identify correspondences between notations to allow them to achieve competence with representational systems. In mathematics, representational knowledge was found to correlate highly with success in mathematics education (Gagatsis & Shiakalli, 2004). Representational knowledge is also thought to mediate complex problem solving, transfer of knowledge to novel situations, and understanding of high-level concepts (Heritage & Niemi, 2011). The ability to translate between different representations is also thought to contribute towards success in problem solving in mathematics (Gagatsis & Shiakalli, 2004).
3. Current Teaching Practices The UK National Curriculum is changing its emphasis from application-oriented “ICT”, towards more technical Computer Science based curriculums. Our interviews with teachers in the past eight months
27

2
The eighth PPIG Work-in-Progress Workshop, Keele University, UK, July 2013 www.ppig.org
suggest that in response to this, Scratch is being introduced at the end of Key Stage 2. Other imperative programming languages such as Alice and Python are introduced later, becoming more similar to professional software development tools as the students move through Key Stage 3 and 4 to ultimately meet qualification requirements for GCSE and A-Level. We are concerned that the focus on purely imperative languages may conflict with the need to establish broader representational expertise; students’ ability to recognise and understand new representations is limited, if such a narrow range of visual formalisms (Nardi., 1993) is used, simply offering varying degrees of block syntax. To increase competence with computational representations, students could experience multiple approaches to programming, including visual formalisms that support imperative, declarative and programming by demonstration paradigms.
The degree of formality in computational representations may also vary (Blackwell, Church, Plimmer, & Gray, 2008). For example, a student could express a computational concept as a sketch with pen and paper, which although an informal representation, might be easily decoded by other human readers. We suspect that a major barrier to programming, and to representation expertise, is to understand that computers “think” in a formal manner, and that the specifically formal attributes of mathematical or programming representations may be hard to acquire for this reason. A key skill that has not yet been emphasised as a CT ability is the need to translate one or more informal representations (on paper, or even expressed verbally) into a formal representation the computer can process.
4. Proposed Research We propose to take standard web technologies as a starting point to investigate these questions. Standard website construction typically involves a mix of declarative and imperative representations, and website design practice often moves from informal sketches to executable models or code. We are creating a tool that can be used in classrooms to provide a far more structured experience, scaffolding the development of formal representation skills.
5. Bibliography
Blackwell, A. F. (2002). What is programming? 14th workshop of the Psychology of Programming Interest Group (pp. 204–218).
Blackwell, A. F., Church, L., Plimmer, B., & Gray, D. (2008). Formality in Sketches and Visual Representation : Some Informal Reflections. Creativity Research Journal, 11–18.
Gagatsis, A., & Shiakalli, M. (2004). Ability to Translate from One Representation of the Concept of Function to Another and Mathematical Problem Solving. Educational Psychology, 24(5), 645–657.
Google. (2013). What is Computational Thinking. Retrieved January 2, 2013, from http://www.google.com/edu/computational-thinking/what-is-ct.html
Heritage, M., & Niemi, D. (2011). Toward a Framework for Using Student Mathematical Representations as Formative Assessments Toward a Framework for Using Student Mathematical Representations as Formative Assessments, (May 2013), 37–41.
ISTE. (2013). Computational Thinking Vocabulary and Progression Chart. The International Society for Technology in Education. Retrieved January 5, 2013, from http://www.iste.org/docs/ct-documents/ct-teacher-resources_2ed-pdf.pdf?sfvrsn=2
Nardi., B. A. (1993). A Small Matter of Programming: Perspectives on End User Computing. The MIT Press.
28

3
The eighth PPIG Work-in-Progress Workshop, Keele University, UK, July 2013 www.ppig.org
The National Academy of Sciences. (2011). Report of a Workshop of Pedagogical Aspects of Computational Thinking Committee for the Workshops on Computational Thinking.
Wing, J. M. (2006). Computational thinking. Communications of the ACM, 49(3), 33.
Wing, J. M. (2008). Computational thinking and thinking about computing. Philosophical transactions. Series A, Mathematical, physical, and engineering sciences, 366(1881), 3717–3725.
29

Towards a Mechanism for Prompting Undergraduate Students to Consider Motivational Theories when Designing Games for Health
Monica M. McGill Department of Interactive Media
Bradley University Peoria, Illinois USA [email protected]
Keywords: POP-V.A. theories of design, POP-I.B. teaching design
1. Introduction Games are increasingly being used for more than entertainment and educational purposes, and the spread of games into advertising, marketing, and healthcare continues to grow (Gartner 2011). This latter area is often referred to as serious games, or games that are designed with specific outcomes in mind (Engelfeldt-Nielson, Smith, Tosca 2008). In the area of games for health, these outcomes are often patient-centred.
Due to the recent changes to healthcare and the provisions for which physicians in the United States (US) will be paid in the future, there is a particular emphasis on improving patient outcomes (Report on the National Commission on Physician Payment Reform 2013). The new healthcare initiative is highly focused on patient-outcomes, and physicians will be reimbursed at a higher percentage for achieving better outcomes. Towards this end, the medical community is exploring new and innovative ways to improve patient outcomes, including the potential of games for improving and managing health (Institute for the Future 2012).
2. Problem statement and scope of work Over the last decade, post-secondary institutions in the United Kingdom and the United States have implemented and started to refine game degree curriculum and instruction (Entertainment Software Association 2012, McGill 2011). These programs and their corresponding courses and modules vary considerably in scope and focus and include areas of focus such as Game Design, Game Technology, Game Programming, and Game Art. Given the various types of games that can be created as well as their multi-disciplinary nature, teaching games purely for entertainment is challenging. Designing for serious games adds a layer of complexity to the process by specifying targeted outcomes that the game must meet for it to be considered successful.
Motivational design in software applications is not new, with many underlying theories being researched and evaluated in this context (Rieber 1996). Cognitive load theory, for example, which evaluates the ability for an individual to process information and interactions, has been reviewed within multimedia learning environments (Kilic et al 2012). Other theories, including self-determination theory and Skinner’s behavior theory, have been evaluated in web-based learning software, preventive health care software, and online community software (Gurzick 2009, Matsuo 2008, Sundar 2012). Skinner’s behavior model has also been recognized as a means for effective results in wellness and health care applications, and is identifiable in effective systems like Weight Watchers weight loss programs (Freedman 2012).
Fogg’s Behavior Model, Behavior Grid and Persuasive Systems Design (PSD) are explored in terms of persuasive design of software systems, including behaviour change support systems, ecology, and more (Ferebee 2010, Fogg 2009, Oinas-Kukkonen 2010, Räisänen et al 2010). Other persuasive design theories draw from many theories of motivation and have been explored in areas such as interactive mannequins, exercise coaching, autism, and managing work-related stress (Harjumaa 2009, Ploug 2010, Ranfelt 2009, Reitberger 2009). Using the acronym OCEAN, VandenBerghe
30

proposes five elements of motivation that should be considered when developing games: openness, conscientiousness, extraversion, agreeableness, and neuroticism (VandenBerghe 2012).
Motivational theories have been an important part of the game design scene over the last 40 years (Baranowski et al 2008, Engelfeldt-Nelson 2006, Malone 1980). Much of the research that has been performed has focused on evaluating games post-production against various theories and frameworks, including the Player Experience of Need Satisfaction (PENS), which is based on self-determination theory (Ryan et al 2006). Considering these theories earlier in the design process is becoming more commonplace, with game designers from LucasFilm Games and WB Games recently describing at the 2013 Game Developers Conference how self-determination theory has drastically changed their approach to game design (Rocchia 2013).
One of the more interesting and potentially most impactful areas of motivational design in software is in the area of individual and community wellness (Yim et al 2007). Social cognitive theory has been evaluated in light of serious games for health (Bandura 2004), but Bandura does not directly propose a method for use in game design. In this work, Bandura notes that:
Human health is a social matter, not just an individual one. A comprehensive approach to health promotion also requires changing the practices of social systems that have widespread effects on human health…. Interactive computer-assisted feedback provides a convenient means for informing, enabling, motivating, and guiding people in their efforts to make lifestyle changes…. These systems need to be structured in ways that build motivational and self-management skills as well as guide habit changes. Otherwise, those who need the guidance most will use this tool least. (p. 149)
Other research evaluates games post-production against theories of motivation and does not provide a mechanism for novice game designers to consider these theories when designing serious games for health.
3. Proposed Methodology The author recently proposed a set of prompts for use in teaching motivation in serious game design based on Self-Determination Theory. The prompts were introduced near the end of the design phase, as development was already being undertaken. After testing these prompts with undergraduate research students, the author noticed that some students were more likely to defend the current design rather than take a deep look at how the design might be improved based on the prompts.
The author proposes that a more comprehensive approach to motivational design be explored and that a full set of prompts and instructional materials based on this design be created to teach motivational design in serious games. The most critical part of this will be the creation of a set of prompts that can be used as a tool for instructing novice game designers to consider player motivation within the game. By developing these resources, novice designers will be able to actively and fully consider the motivational aspects of gameplay in serious games to improve patient outcomes in the crucial early stages of design.
The author proposes to review Svinicki’s (2010) Combined Motivation Theory (CMT), a theory that was created as a framework for research in engineering education. CMT draws from six theories (self-determination theory, expectancy/value theory, behavior theory, social cognitive theory, attribution theory and achievement goal orientation theory), and has three basic pillars emphasizing the perceived value of the targeted task the learner’s beliefs about who controls the outcome and the learner’s self-efficacy for the task—that is, the belief in one’s own ability to succeed.
Svinicki postulates that the motivation of a learner is affected by (p. 16): • The value of the targeted task, which is influenced by:
o How interested the individual is in the task o How challenged the individual is o How influential others see it o The value that peers place on the task
31

o Relationship to long-range goals of the individual o The task’s immediate usefulness or payoff
• The individual’s beliefs about who controls the outcome o The amount of control given to the individual o The likelihood that the outcome can change given different circumstances o The ability to control the change in the outcome
• The individual’s self-efficacy o Past success at same or similar tasks o Having most skills required by the task o Being persuaded by someone else that success is possible o Seeing someone like themselves be successful o How difficult the individual perceives the task to be
Though these have been framed as learner needs, it is interesting to review these components as they apply to motivation in games, particular games for health which attempt engage the player in the game in order to promote behavior changes and/or learning.
The author proposes to review literature to define each of the theories in CMT, to evaluate how they have been previously applied to games, and to incorporate CMT in the creation of instructional materials. The instructional materials, including prompts, will also be created based on this theory and then tested with undergraduate students studying game design in Spring 2014.
4. Conclusion The author proposes that a set of prompts rooted in various motivational theories would serve as a valuable resource for students in the early stages of game design. Though the intent of this research is to provide a tool based on motivational theories for the use by undergraduate students studying game design, the prompts may also serve as a resource for the larger design community. The research proposed in this abstract is the next logical step in establishing these prompts. For the purposes of the Psychology of Programming Interest Group (PPIG) Work-in-progress Workshop, the author seeks feedback on the proposed methodology.
5. References Bandura, A. (2004) Health Promotion by Social Cognitive Mean. Health Education & Behavior, Vol
31(2):143-164.
Baranowski, T., Buday, R., Thompson, D.I., Baranowski, J. (2008) Playing for Real: Video Games and Stories for Health-Related Behavior Change. Am J Prev Med. 2008 January; 34(1): 74–82.e10.
Engelfeldt-Nielson, S. (2006) Overview of research on the educational use of video games. Nordic Journal of Digital Literacy. March 2006. Nr 3., pp. 185-214.
Engelfeldt-Nielson, S., Smith, J.H., and Tosca S.P. 2008. Understanding video games: The essential introduction. Routledge: New York, USA.
Entertainment Software Association. (2012) Video Game Courses and Degree Programs Hit All-Time High at U.S. Colleges in All 50 States. Retrieved October 19, 2012 from http://www.theesa.com/newsroom/release_detail.asp?releaseID=179
Gartner. 2011. Gartner Says By 2015, More Than 50 Percent of Organizations That Manage Innovation Processes Will Gamify Those Processes. Retrieve June 2013 from http://www.gartner.com/newsroom/id/1629214
Institute for the Future. 2012. Innovations in Games: Better Health and Healthcare. Office of the National Coordinator for Health IT and the White House Office of Science and Technology Policy. Retrieved May 29, 2013 from http://www.healthit.gov/sites/default/files/IFTF_SR-1494_Innovations_in_Games.pdf
32

Malone, T.W. (1980) What Makes Things Fun to Learn? A Study of Intrinsically Motivating Computer Games. Xerox, Palo Alto Research Center, Cognitive and Instructional Sciences Series, CIS-7, SSL-801-11.
McGill, M.M. 2011. Motivations and informing frameworks of game degree programs in the United Kingdom and the United States. In Proceedings of the 2011 conference on Information technology education (SIGITE '11). ACM, New York, NY, USA, 67-72. DOI=10.1145/2047594.2047613 http://doi.acm.org/10.1145/2047594.2047613
Svinicki, M.A. (2010) Guidebook on conceptual frameworks for research in engineering education. Retrieved February 2012 from http://www.ce.umn.edu/~smith/docs/RREE-Research_Frameworks-Svinicki.pdf
Report on the National Commission on Physician Payment Reform. 2013. Retrieved May 17, 2013 from http://physicianpaymentcommission.org/wp-content/uploads/2012/02/physician_payment_report.pdf
Ryan, R.M., Rigby, C.S., Przybylski, A. (2006) The Motivational Pull of Video Games: A Self-Determination Theory Approach. Motiv Emot. Springer. DOI 10.1007/s11031-006-9051-889.
Report on the National Commission on Physician Payment Reform. (2013) Retrieved May 17, 2013 from http://physicianpaymentcommission.org/wp-content/uploads/2012/02/physician_payment_report.pdf
Rocchia, G. (2013) Self-determination theory at GDC. Retrieved April 26, 2013 from http://gamasutra.com/blogs/GabrielRecchia/20130329/189588/Selfdetermination_theory_at_GDC.php
VandenBerghe, J. 2012. Making psychology work for you in game design. 2012 Game Developers Conference. Retrieved June 7, 2013 from http://www.gamasutra.com/view/news/193906/Video_Making_psychology_work_for_you_in_game_design.php?utm_source=twitterfeed&utm_medium=twitter&utm_campaign=Feed%3A+GamasutraNews+%28Gamasutra+News%29
33

PPIG, Keele University, 2013 www.ppig.org
Analysing the effect of Natural Language Descriptions as a support for novice programmers.
Edgar Cambranes, Judith Good, Benedict du Boulay Human-Centred Technology Group
School of Engineering and Informatics. University of Sussex.
Brighton, United Kingdom. [email protected]
Keywords: POP-I.A. learning to program; POP-II.A. novices; POP-II.B. debugging, program comprehension, design.
Abstract
This paper describes an experiment that has explored the effect to integrate natural language (NL) descriptions into a visual language (VL) designed for novice programmers. The experiment compared three conditions: the VL with NL representation, the VL with pseudo-code representation and the VL without second representation. The initial analysis measured the learning gain (LG) using the pre-tes and post-test scores. Comparison of overall LG scores revealed no significant difference between the groups. However, the two groups with a secondary representation, and particularly the NL group, might be better assisted with some of their programming tasks.
1. Introduction
This research proposes to explore the usefulness of providing a second representation to support a visual language (based on flowcharts) designed for novice programmers. In particular, the second representation uses Natural Language to describe the current solution. The aim of the research is to assess the beneficial effects (if any) of a second representation on the comprehension, creation and debugging of programs. Specifically, the research will try to answer to what extent does the second representation affect these different aspects of the programming process?
My proposal considered a tool called Origami (Rodríguez-Cámara, Ku-Quintana, & Cambranes-Martínez, 2009), which is used to teach basic programming concepts to novices. This tool enables students to create, test and debug programs using a visual language based on flowcharts. The programs produced are syntactically error-free, however, students may input instructions into each flowchart block that are semantically incorrect. Origami logs interaction data during the problem solving process: time taken to complete an exercise, the blocks used, the inner blocks’ instructions and any compilation messages. Each interaction is associated with a timestamp that preserves the chronology of the problem solving process. The Origami tool was improved using some design ideas from Flip (Good, 2011) and now combines a visual language based on interlocking blocks with natural language
2. Study
Since the major consideration for this research is to examine the effect of providing secondary NL descriptions to support novice programmers, a comparative study was carried out with three conditions: the earlier version of Origami (with no secondary representation), a version with an secondary NL description, and a version with a secondary pseudo-code representation. This three-way comparison was an attempt to partial out the effects of providing a secondary representation of any kind from the particular effects of using NL in that role. Origami logs provide the main quantitative data source; whereas qualitative data has been gathered via semi-structured interviews.
34
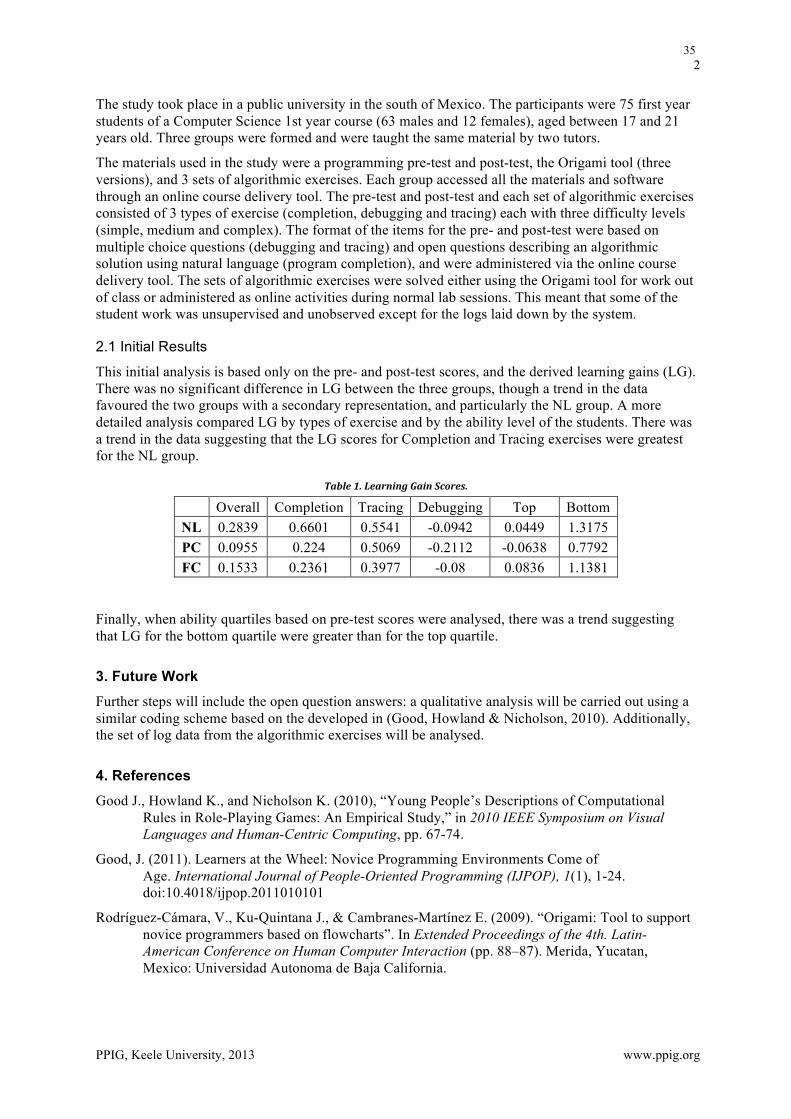
2
PPIG, Keele University, 2013 www.ppig.org
The study took place in a public university in the south of Mexico. The participants were 75 first year students of a Computer Science 1st year course (63 males and 12 females), aged between 17 and 21 years old. Three groups were formed and were taught the same material by two tutors.
The materials used in the study were a programming pre-test and post-test, the Origami tool (three versions), and 3 sets of algorithmic exercises. Each group accessed all the materials and software through an online course delivery tool. The pre-test and post-test and each set of algorithmic exercises consisted of 3 types of exercise (completion, debugging and tracing) each with three difficulty levels (simple, medium and complex). The format of the items for the pre- and post-test were based on multiple choice questions (debugging and tracing) and open questions describing an algorithmic solution using natural language (program completion), and were administered via the online course delivery tool. The sets of algorithmic exercises were solved either using the Origami tool for work out of class or administered as online activities during normal lab sessions. This meant that some of the student work was unsupervised and unobserved except for the logs laid down by the system.
2.1 Initial Results
This initial analysis is based only on the pre- and post-test scores, and the derived learning gains (LG). There was no significant difference in LG between the three groups, though a trend in the data favoured the two groups with a secondary representation, and particularly the NL group. A more detailed analysis compared LG by types of exercise and by the ability level of the students. There was a trend in the data suggesting that the LG scores for Completion and Tracing exercises were greatest for the NL group.
!"#$%&'(&)%"*+,+-&.",+&/01*%2(&
Overall Completion Tracing Debugging Top Bottom NL 0.2839 0.6601 0.5541 -0.0942 0.0449 1.3175 PC 0.0955 0.224 0.5069 -0.2112 -0.0638 0.7792 FC 0.1533 0.2361 0.3977 -0.08 0.0836 1.1381
Finally, when ability quartiles based on pre-test scores were analysed, there was a trend suggesting that LG for the bottom quartile were greater than for the top quartile.
3. Future Work
Further steps will include the open question answers: a qualitative analysis will be carried out using a similar coding scheme based on the developed in (Good, Howland & Nicholson, 2010). Additionally, the set of log data from the algorithmic exercises will be analysed.
4. References
Good J., Howland K., and Nicholson K. (2010), “Young People’s Descriptions of Computational Rules in Role-Playing Games: An Empirical Study,” in 2010 IEEE Symposium on Visual Languages and Human-Centric Computing, pp. 67-74.
Good, J. (2011). Learners at the Wheel: Novice Programming Environments Come of Age. International Journal of People-Oriented Programming (IJPOP), 1(1), 1-24. doi:10.4018/ijpop.2011010101
Rodríguez-Cámara, V., Ku-Quintana J., & Cambranes-Martínez E. (2009). “Origami: Tool to support novice programmers based on flowcharts”. In Extended Proceedings of the 4th. Latin-American Conference on Human Computer Interaction (pp. 88–87). Merida, Yucatan, Mexico: Universidad Autonoma de Baja California.
35

Workshop: Psychological Impact of 3D Intelligent Environments on Pedagogy
Martin Loomes, Georgios Dafoulas and Noha Saleeb
Middlesex University, UK [email protected], [email protected], [email protected]
Abstract
The ultimate goal of this research is to enhance students’ blended learning experiences comprising of both face-to-face and online courses. This is by investigating educational methods, factors, and procedures that can psychologically affect students to help achieve maximum engagement using Artificial Intelligence for e-learning within 3D Virtual Learning Environments (VLEs). The enhanced student engagement aspired for includes increased academic retention (assimilation), participation and overall enjoyment. 3D Virtual Learning Environments (3DVLEs) have been a host for many virtual campuses of universities, e.g. Harvard and Cambridge, since their offset more than a decade ago. These virtual media offer innovative opportunities for technologically supported pedagogy and e-learning for many fields of sciences and arts which has reaped noticeable participation, satisfaction and hence achievement from students. This supports the developmental perspective of teaching and transmission of knowledge by adopting the constructivist paradigm/approach to teaching and learning.
There is a challenge to integrate contributions from a number of different disciplines into a single learning support offering that will (i) take under consideration the psychological and pedagogic needs associated with the use of 3D VLEs, (ii) address usability and web 2.0 issues from the use of a social learning network and (iii) investigate 3D VLE interactions with the mediums used to access learning platforms. So far the creation of intelligent 3D VLEs is primarily concerned with the design of content for virtual learning tasks.
This workshop researches the opportunities available to use 3DVLEs, such as Second Life, to create e-learning Project Innovation for students using 3D Virtual and Generative Intelligent concepts. This entails the use of programming and coding to create bots (artificial intelligence robotic avatars) that can be used to direct interactive teaching and learning activities inside a 3DVLE, hence affecting the psychology of pedagogy offered within it. Moreover, through the creation and coding of holographic platforms (holodecks) inside 3DVLEs, diverse classroom and environment settings can be created to aid in the e-learning process and help the students themselves to use this technique to create immersive 3D projects e.g. 3D catalogues and exhibitions. This is in addition to the prospects of using these holodecks for educational role-play activities, modelling activities and interactive discussions and seminars.
The workshop session will consist of (i) an initial presentation explaining how the integration of virtual worlds and traditional physical environments lends an innovative approach to the enhancement of Higher Education Institutes provision, (ii) a strategic perspective on supporting teaching and learning via activities, assessment, feedback provision, pastoral services & student support, employer engagement, (iii) a hands on activity of the Middlesex virtual learning villages and, (iv) a brainstorming session on the future of blended learning using Artificial Intelligence, it’s psychological impact, and further institutional enhancement. Furthermore there are recommendations for possible applications of the technology through the use of a variety of educational scenarios in 3D Virtual Learning Environments. The key contribution is to initiate discussions, trigger debates and offer brainstorming opportunities related to enhancing the psychological effects of 3D Intelligent Environments on e-learning opportunities. The session is highly interactive and requires engagement in a series of activities, including hands on experience for all willing to access the Virtual Campus and participate in a 3D learning session.
36

PPIG-WIP, Keele University, 2013 www.ppig.org
Tools to Support Systematic Literature Reviews in Software Engineering:
Protocol for a Feature Analysis
Christopher Marshall & Pearl Brereton
School of Computing and Mathematics
Keele University
Staffordshire, UK
[email protected] / [email protected]
Keywords: systematic literature review, automated tool, mapping study, software engineering, feature analysis
Extended Abstract
Systematic literature reviews (SLRs) have become an established methodology in software
engineering research (Kitchenham et al., 2009). SLRs are concerned with rigorously evaluating
empirical evidence from a variety of relevant literature, in an attempt to address a particular issue or
topic of interest (Kitchenham & Charters, 2007). SLRs differ from ordinary literature reviews in being
formally planned and methodically executed (Staples & Niazi, 2007). Undertaking an SLR comprises
several discrete stages that can be grouped into three core phases: planning, conducting and reporting.
Despite their usefulness, conducting an SLR remains a highly manual, error prone and labour
intensive process (Riaz et al., 2010; Babar & Zhang, 2009; Brereton et al., 2007). Automated support
to assist the various stages of the SLR process may help to overcome some issues and so we are
currently investigating the use and effectiveness of tools to support the conduct of SLRs in software
engineering.
A literature review, in the form of a mapping study, identified tools that have been developed or used
to provide automated support for the SLR process and established the extent to which the tools have
been evaluated. The mapping study, after applying inclusion/exclusion criteria, accepted 14 papers
into the final set. A variety of approaches and support tools which had been developed to assist the
conduct of an SLR were found. During the next phase of the research project, using the Feature
Analysis approach, four existing tools identified by the mapping study will be evaluated.
Feature Analysis is a qualitative form of evaluation involving a subjective assessment of the relative
importance of different features and how well features are implemented (Kitchenham et al., 1997). It
is based on the requirements that users have for a particular task/activity and mapping those
requirements to features that a tool aimed at supporting the task/activity should possess. (Kitchenham
& Jones, 1997; Kitchenham et al., 1997). Building on the results of the mapping study, a Feature
Analysis protocol (plan) is being developed. Four SLR tools will be subject to the Feature Analysis.
These tools have been developed from scratch, with the sole aim of supporting software engineering
researchers throughout the entirety of a SLRs undertaking. Table 1 lists the four candidate tools for
evaluation.
The Feature Analysis will be the first step toward the development of a rigorous evaluation
framework for tools that support SLRs. The aims of this activity are to produce an initial set of
features and user requirements for a tool of this type. Results generated will act as a foundation for
more complex evaluation exercises to be undertaken. The Feature Analysis will be organised as an
initial screening, and will only focus on evaluating simple features. Simple features relate to aspects
that are either present or absent and are assessed by a simple YES/PARTLY/NO nominal scale
(Kitchenham et al., 1997).
37

PPIG-WIP, Keele University, 2013 www.ppig.org
A protocol for the Feature Analysis is currently being developed and will be presented at PPIG-WIP
2013. The presentation will include an initial feature list, score sheet and judgment scales and a
discussion of future research aims and objectives.
Tool Description
“SLuRp” An open source web enabled database that supports the management of SLRs.
(Bowes et al., 2012)
“SLR-Tool” A freely-available tool for performing SLRs
(Fernández-Sáez et al., 2010)
“StArt” A tool that provides support to each of the activities, except the automated
support of primary studies. (Hernandes et al., 2012)
“SLRTOOL” An open-source, web-based, multi-user tool that supports the SLR process.
(http://www.slrtool.org)
Table 1. SLR support tools selected for the Feature Analysis
References
Babar, M. A., & Zhang, H. (2009). Systematic literature reviews in software engineering: Preliminary results from interviews with
researchers. In Proceedings of the 2009 3rd International Symposium on Empirical Software Engineering and Measurement, pp.
346-355. IEEE Computer Society.
Bowes, D., Hall, T., & Beecham, S. (2012). SLuRp: a tool to help large complex systematic literature reviews deliver valid and
rigorous results. In Proceedings of the 2nd international workshop on Evidential assessment of software technologies, pp. 33-36.
ACM.
Brereton, P., Kitchenham, B. A., Budgen, D., Turner, M., & Khalil, M. (2007). Lessons from applying the systematic literature
review process within the software engineering domain. Journal of Systems and Software, Vol. 80, no. 4, pp. 571-583.
Hernandes, E., Zamboni, A., Fabbri, S., & Di Thommazo, A. (2012). Using GQM and TAM to evaluate StArt–a tool that supports
Systematic Review. CLEI Electronic Journal, Vol. 15 no. 1, pp. 13-25.
Kitchenham, B. A. (1997). Evaluating software engineering methods and tools, part 7: planning feature analysis evaluation. ACM
SIGSOFT Software Engineering Notes, 22(4), 21-24.
Kitchenham, B. A., & Charters, S. (2007). Guidelines for performing systematic literature reviews in software engineering. Keele University and University of Durham, EBSE Technical Report
Kitchenham, B. A., & Jones, L. (1997). Evaluating SW Eng. methods and tools, part 8: analysing a feature analysis evaluation.
ACM SIGSOFT Software Engineering Notes, 22(5), 10-12.
Kitchenham, B., Brereton, O. P., Budgen, D., Turner, M., Bailey, J., & Linkman, S. (2009). Systematic literature reviews in
software engineering–a systematic literature review. Information and software technology, Vol. 51, no. 1, pp. 7-15.
Kitchenham, B., Linkman, S., & Law, D. (1997). DESMET: a methodology for evaluating software engineering methods and tools.
Computing & Control Engineering Journal, 8(3), 120-126.
Kitchenham, B., Pearl Brereton, O., Budgen, D., Turner, M., Bailey, J., & Linkman, S. (2009). Systematic literature reviews in software engineering–a systematic literature review. Information and software technology, 51(1), 7-15..
M. Fernández-Sáez, M. G. Bocco, F.P. Romero. (2010). SLR-tool - a tool for performing systematic literature reviews. In
Proceedings of the 2010 International Conference on Software and Data Technologies, pp. 144.
Riaz, M., Sulayman, M., Salleh, N., & Mendes, E. (2010). Experiences conducting systematic reviews from novices’ perspective. In
Proceedings. of EASE Vol. 10, pp. 1-10.
Staples, M., & Niazi, M. (2007). Experiences using systematic review guidelines. Journal of Systems and Software, 80(9), 1425-
1437.
38

Bringing Heterogeneous Computing to the End User
Gordon Inggs1 & David B. Thomas1, Wayne Luk2
1 Circuits & Systems Research Group, Dept. of Electrical & Electronic Engineering, Imperial College London[g.inggs11;d.thomas1]@imperial.ac.uk
2 Custom Computing Research Group, Dept. of Computing, Imperial College [email protected]
Heterogeneous Computers are computing platforms that are comprised of two or more ar-chitecturally distinct computing devices, such as Multicore Central Processing Units (CPUs),Graphics Processing Units (GPUs) and Field Programmable Gate Arrays (FPGAs). Increas-ingly commodity computational systems are comprised of up to several of these platforms, asthe power and memory walls continue to limit the capabilities of CPUs, and alternatives suchas GPUs and FPGAs continue to improve in functionality and efficiency.
This new paradigm offers opportunities, but also poses challenges. In fact, it has been shownthat applications can execute with better performance on a homogeneous architecture ratherthan a heterogeneous one, despite the heterogeneous configuration ostensibly having more com-puting resources [1].
We have identified three challenges in using Heterogeneous Computers effectively:
1. Predicting the runtime characteristics of applications tasks upon the constituent platformsof the system.
2. A better-than-homogeneous partitioning of tasks across the constituent platforms.3. Balancing end user objectives in the context of a large design space.
We believe that we can address the first two questions through automatic means [3], using adomain-specific toolflow [4]. Furthermore, we argue that domain specific heterogeneous com-puting represents an opportunity for the end user. By providing exponentially more potentialconfigurations, the user may then select one that more closely matches their desired outcomesfor the system, one of the goals of software engineering practice. However, this opportunity mayonly be realised if that choice is presented to the end-user in a form which is meaningful [2].
User inputs Task
Description
Result Returned
Generation of Pareto Optimal Design Space
User selects metric trade-off
Calculation is Performed
KSO 1KSU
IIKSO 2
KSO 4 KSU III
K=100, TK=5,S0=100, r=0.05, μ=0.09, κ=2, ξ=1, ρ=-0.3, V0=0.09
K=100, TK=5, H=120,
K=100, TK=5, HL=90,HU=110,
S0=100, r=0, μ=0.04, κ=0.5, ξ=1, ρ=-0, V0=0.04
Accuracy
Late
ncy
User selects desired trade-off point
Figure 1. Pareto Interface Flow Chart
We propose a two-stage input process to bring heterogeneous computing to the end user asis illustrated in Figure 1. Firstly, the end user describes the problem that they wish to solve in a
39

graphical manner specific to a particular application domain, and identifies the platforms uponwhich the application will be run. Secondly, the system executes a limited subset of the specifiedproblem to create a representation of the projected Pareto optimal tradeoff between the domainspecific metrics of interest, such as Latency and Accuracy in the context of ComputationalFinance. Then the end-user may select where on this Pareto frontier they wish the execution oftheir problem to lie, providing the configuration information to the system.
Figure 2. Optimal partitioning of example problem set
Figure 2 illustrates the key element that the end user uses to explore the design space as partof this approach - a Pareto curve-based interface for a small computational finance applicationof three option pricing tasks upon two platforms, an AMD Opteron Multicore CPU and AMDFirePro GPU. The purple line plotted illustrates the trade-off curve that the end-user wouldhave to select from in terms of absolute latency of the computation and minimum guaranteedaccuracy. Helping make the case for heterogeneous computing, the heterogeneous implementationoutperforms the homogeneous GPU implementation by 1.5 times, and the CPU one by 2.3 times,while delivering equivalent accuracy.
Further work will focus on an exhaustive elaboration of the design space of the Kaiserslatuarnbenchmark of Option Pricing tasks 1 upon a range of platforms. The aim of these experiments isto verify the efficacy of the prediction and partitioning infrastructure to use. Furthermore suchan elaboration will allow the benefit of greater user choice versus a balanced default options tobe quantified.
References1. Faraz Ahmad, Srimat T. Chakradhar, Anand Raghunathan, and T. N. Vijaykumar. Tarazu: optimizing
MapReduce on heterogeneous clusters. In Proceedings of the seventeenth international conference on Archi-tectural Support for Programming Languages and Operating Systems, ASPLOS ’12, pages 61–74, New York,NY, USA, 2012. ACM.
2. Alan F Blackwell and Cecily Morrison. A logical mind, not a programming mind: Psychology of a professionalend-user. In Proc. of the Workshop of Psychology of Programming Interest Group, pages 19–21, 2010.
3. Tracy Braun, Howard Siegel, and Anthony Maciejewski. Heterogeneous Computing: Goals, Methods, andOpen Problems. In Burkhard Monien, Viktor Prasanna, and Sriram Vajapeyam, editors, High PerformanceComputing, volume 2228 of Lecture Notes in Computer Science, pages 307–318. Springer Berlin/Heidelberg,2001.
4. Hassan Chafi, Arvind K. Sujeeth, Kevin J. Brown, HyoukJoong Lee, Anand R. Atreya, and Kunle Olukotun.A Domain-Specific Approach to Heterogeneous Parallelism. In PPOPP, pages 35–46, 2011.
1http://www.uni-kl.de/en/benchmarking/option-pricing/
40

Integrating Connectivist Pedagogy with Context Aware Interactions for the Interlinked Learning of Debugging and Programming
Xiaokun Zhang
School of Computing & Information Systems,
Athabasca University, Alberta, Canada [email protected]
Extended Abstract
Debugging and programming are important skills that remain to be challenge for beginner to learn and for instructors to teach. Research relating debugging ability to psychological factors or cognitive abilities has gained some successes, such as researches in learning styles [Goold & Rimmer 2000, Thomas, etc. 2002], visualisations enhanced multiple external representations [Pablo Romero, etc. 2008], visual-based independence tests (Mancy & Reid, 2004), and abstraction ability (Bennedsen & Caspersen, 2006]. One of the recent works in Collabode system developed in MIT [Max Goldman and Robert C. Miller 2012] demonstrates an approach of combining test-driven pair programming with micro-outsourcing mechanism to leverage error-mediated integration of pairs of both student and professional programmers. It appears that explicit relations between debugging success and individual factors [Rene´e McCauley, etc. 2008] within emergent interlinked social learning context need further investigation, even though social cognition implications have been observed in relevant researches in terms of pair programming, collaborative and heterogeneous knowledge representation and sharing between various granularity levels in debugging processes. On the one hand, social cognition enhanced learning methods have been gaining innovative success in learning paradigms by means of fast growing social computing and context-aware collaborative computing technology, that reveals opportunity to foster social intelligence enhanced learning of debugging and programming. On the other hand, it is non-trivial to ensure high quality services of such interlinked learning from various perspectives especially how innovative learning theory and pedagogy methods are engaged in the practical and domain dependent application framework in order to facilitate personalized, social and context aware learning and teaching in heterogeneous learning environments, especially in the situation in which students, teachers, and learning resources and services are geographically located in many different locations. To this end, this paper introduces our on-going project that aims at creating an integrated interlinked learning context model under which emergent connectivist pedagogy concept is embodied by three key technique components: hypergraph-based relation data model for representing interlinked learning context; functions of observing and facilitating teaching and learning activities (data or actions) in connectivist learning; and loosely coupled collaboration mechanism for imposing individual interlink context towards self-organized problem-solving group structures by dynamic changes to temporal or spatial proximity suggested by the former two components.
In this paper, interlinked learning context and domain knowledge of debugging and programming are selected as one of application frameworks to demonstrate how proposed interlink context model and relevant data representation can leverage multifaceted interlink analysis for fine-grained data-driven context observation and event-driven loosely-coupled learning management through heterogeneous interaction processes. The paper may not have enough space to detail algorithm description and analysis in terms of interlinked learning context in debugging and programming case, rather, the paper describes hypergraph-based interlink context model and explains how tensor method is applied to model and analyse multifaceted interlink context to uncover the underlying debugging problem structures, students interaction structure and behaviours in debugging by means of known types of knowledge and debugging strategies in connectivist learning perspective. The generic concept model of multifaceted interlink learning context model and multilevel collaboration mechanism based on data driven interlink observation and event-driven interaction engagement in terms of teaching presence (TP), cognition presence (CP), and social presence (SP) in connectivist learning perspective,
41

is shown in Figure 1. The connectivist pedagogy paradigm demonstrated in Figure 1 has multi-level granularity in terms of collaborative information framework for facilitating heterogeneous interactions and interlinked learning activities based on macro-level problem description, macro-level interaction structure description, micro-level problem observation, and micro-level interlinked learning status and activity structure in dealing with fine-grained learning tasks in debugging, concept components in programming, and learner generated contents and reflections. The paper addresses key issues on how heterogeneous interactions between those parts from various granularity levels are collaboratively observed and analyzed in practical way in terms of the concepts of cognitive present, teaching present, and social present within connectivist learning strategies [George Siemens 2005, Terry Anderson and Jon Dron 2011, Athabasca University in Canada] in order to manage and optimize interlinked learning and teaching activities in open and dynamic social learning environments, especially in the scenario of the learning of debugging and programming.
It is emphasized that my colleagues Professor Siemens initiated the concept of connectivist pedagogy in 2005 and Professors Anderson and Dron enriched the theory by embracing emergent social computing features. However, practical interlinked learning system and implementation need not only high level pedagogy and conceptual interaction mechanism, but also measurable, retrievable, and observable data representation and algorithm mechanism under certain collaborative framework and architecture to leverage appropriate learning analysis and management. The project demonstrated in this paper addresses these issues from implementation perspective and focuses on specific elearning system in the learning of debugging and programming.
F1. Multi-faceted connections between teaching presence (TP), cognition presence (CP), and social presence (SP)
Teaching Presence
Linked Data and Contents for Social
Networked Learning
Cognition Presence
Social Presence
Teaching Presence
Cognition Presence
Social Presence
Linked Data and Contents for Social
Networked LearningIndividuals
𝐶𝑃(2)
𝑇𝑃(2)
𝑆𝑃(2)
F3. Individual dynamic behavior projected alongTP, CP and SP dimensions at granularity level 2
Event-based interaction
Event-based interaction
Vertical multi-level (granularity) views of TP, CP, SP, linked data and contents
𝐶𝑃(1)
𝐶𝑃(2)
𝑇𝑃(1)
𝑇𝑃(2)
𝑆𝑃(1)
𝑆𝑃(2)
Data-basedinteraction
Event-basedinteraction
3 types of Individual
F2. Horizontal interactions for collaborating and integrating heterogeneous, multimodal observations and
operations via TP, CP, SP, and linked data and learning contents
Figure 1. Multi-faceted interlink learning context model and multilevel collaboration mechanism baseddata driven interlink observation and event-driven interaction in terms of teaching presence (TP),cognition presence (CP), and social presence (SP) in connectivist learning perspective
42




















