
Predicting synthetic voice style from facial expressions. An application for augmented conversations
13
Predicting synthetic voice style from facial expressions. An application for augmented conversations E ´ va Sze ´kely a,⇑ , Zeeshan Ahmed a , Shannon Hennig b , Joa ˜o P. Cabral a , Julie Carson-Berndsen a a CNGL, School of Computer Science and Informatics, University College Dublin, Dublin, Ireland b Pattern Analysis & Computer Vision, Istituto Italiano di Tecnologia, Genova, Italy Received 30 July 2013; accepted 10 September 2013 Available online 25 September 2013 Abstract The ability to efficiently facilitate social interaction and emotional expression is an important, yet unmet requirement for speech generating devices aimed at individuals with speech impairment. Using gestures such as facial expressions to control aspects of expressive synthetic speech could contribute to an improved communication experience for both the user of the device and the conversation partner. For this purpose, a mapping model between facial expressions and speech is needed, that is high level (utterance-based), versatile and personalisable. In the mapping developed in this work, visual and auditory modalities are connected based on the intended emotional salience of a message: the intensity of facial expressions of the user to the emotional intensity of the synthetic speech. The mapping model has been implemented in a system called WinkTalk that uses estimated facial expression categories and their intensity values to automat- ically select between three expressive synthetic voices reflecting three degrees of emotional intensity. An evaluation is conducted through an interactive experiment using simulated augmented conversations. The results have shown that automatic control of synthetic speech through facial expressions is fast, non-intrusive, sufficiently accurate and supports the user to feel more involved in the conversation. It can be concluded that the system has the potential to facilitate a more efficient communication process between user and listener. Ó 2013 Elsevier B.V. All rights reserved. Keywords: Expressive speech synthesis; Facial expressions; Multimodal application; Augmentative and alternative communication 1. Introduction 1.1. Motivation Text-to-speech synthesis systems in devices for people with speech impairment need to function effectively as a human communication tool. Millions of non-speaking individuals rely on speech generating devices (SGDs) to meet their everyday communication needs. SGDs currently face challenges with speed, naturalness, input strategies and the lack of ability to convey the personality and the emo- tions of the user. These may disrupt the natural flow of the conversation or they can lead to misunderstandings between speaker and listener. One of the most important enhancements required is the integration of expressive syn- thetic voices that are functional, easy to use, and help the user to express emotion and personality by providing the right tone of voice for the given social situation. Higginbotham (2010) emphasises the need for such syn- thetic voices, as well as the necessity for input strategies carefully designed to ensure that non-speaking individuals (AAC 1 users) are able to effectively access and control 0167-6393/$ - see front matter Ó 2013 Elsevier B.V. All rights reserved. http://dx.doi.org/10.1016/j.specom.2013.09.003 ⇑ Corresponding author. Tel.: +353 1 7162911. E-mail addresses: [email protected] (E ´ . Sze ´kely), zeeshan. [email protected] (Z. Ahmed), [email protected] (S. Hennig), [email protected] (J.P. Cabral), [email protected] (J. Carson- Berndsen). 1 Augmentative and alternative communication (AAC) refers to an area of research, clinical, and educational practice. AAC involves attempts to study and when necessary compensate for temporary or permanent impairments, activity limitations, and participation restrictions of indi- viduals with severe disorders of speech-language production and/or comprehension, including spoken and written modes of communication (ASHA, 2005). www.elsevier.com/locate/specom Available online at www.sciencedirect.com ScienceDirect Speech Communication 57 (2014) 63–75
-
Upload
independent -
Category
Documents
-
view
1 -
download
0
Transcript of Predicting synthetic voice style from facial expressions. An application for augmented conversations

Available online at www.sciencedirect.com
www.elsevier.com/locate/specom
ScienceDirect
Speech Communication 57 (2014) 63–75
Predicting synthetic voice style from facial expressions.An application for augmented conversations
Eva Szekely a,⇑, Zeeshan Ahmed a, Shannon Hennig b, Joao P. Cabral a,Julie Carson-Berndsen a
a CNGL, School of Computer Science and Informatics, University College Dublin, Dublin, Irelandb Pattern Analysis & Computer Vision, Istituto Italiano di Tecnologia, Genova, Italy
Received 30 July 2013; accepted 10 September 2013Available online 25 September 2013
Abstract
The ability to efficiently facilitate social interaction and emotional expression is an important, yet unmet requirement for speechgenerating devices aimed at individuals with speech impairment. Using gestures such as facial expressions to control aspects of expressivesynthetic speech could contribute to an improved communication experience for both the user of the device and the conversation partner.For this purpose, a mapping model between facial expressions and speech is needed, that is high level (utterance-based), versatile andpersonalisable. In the mapping developed in this work, visual and auditory modalities are connected based on the intended emotionalsalience of a message: the intensity of facial expressions of the user to the emotional intensity of the synthetic speech. The mapping modelhas been implemented in a system called WinkTalk that uses estimated facial expression categories and their intensity values to automat-ically select between three expressive synthetic voices reflecting three degrees of emotional intensity. An evaluation is conducted throughan interactive experiment using simulated augmented conversations. The results have shown that automatic control of synthetic speechthrough facial expressions is fast, non-intrusive, sufficiently accurate and supports the user to feel more involved in the conversation. Itcan be concluded that the system has the potential to facilitate a more efficient communication process between user and listener.� 2013 Elsevier B.V. All rights reserved.
Keywords: Expressive speech synthesis; Facial expressions; Multimodal application; Augmentative and alternative communication
1 Augmentative and alternative communication (AAC) refers to an area
1. Introduction
1.1. Motivation
Text-to-speech synthesis systems in devices for peoplewith speech impairment need to function effectively as ahuman communication tool. Millions of non-speakingindividuals rely on speech generating devices (SGDs) tomeet their everyday communication needs. SGDs currentlyface challenges with speed, naturalness, input strategies andthe lack of ability to convey the personality and the emo-tions of the user. These may disrupt the natural flow of
0167-6393/$ - see front matter � 2013 Elsevier B.V. All rights reserved.
http://dx.doi.org/10.1016/j.specom.2013.09.003
⇑ Corresponding author. Tel.: +353 1 7162911.E-mail addresses: [email protected] (E. Szekely), zeeshan.
[email protected] (Z. Ahmed), [email protected] (S. Hennig),[email protected] (J.P. Cabral), [email protected] (J. Carson-Berndsen).
the conversation or they can lead to misunderstandingsbetween speaker and listener. One of the most importantenhancements required is the integration of expressive syn-thetic voices that are functional, easy to use, and help theuser to express emotion and personality by providing theright tone of voice for the given social situation.Higginbotham (2010) emphasises the need for such syn-thetic voices, as well as the necessity for input strategiescarefully designed to ensure that non-speaking individuals(AAC1 users) are able to effectively access and control
of research, clinical, and educational practice. AAC involves attempts tostudy and when necessary compensate for temporary or permanentimpairments, activity limitations, and participation restrictions of indi-viduals with severe disorders of speech-language production and/orcomprehension, including spoken and written modes of communication(ASHA, 2005).

64 E. Szekely et al. / Speech Communication 57 (2014) 63–75
the synthetic voice during social interactions. One of thedirections recommended in the above paper to address this,is to investigate the possibility of coordinating gestures andfacial expressions with expressive speech output. Such anintegration of modalities has the potential to improve thecommunication experience for the user of a speech generat-ing device, as well as the conversation partner. This studyinvestigates the possibility of using a functional linking offacial expressions and expressive synthetic voices in orderto provide an alternative control strategy over the paralin-guistic aspects of the synthetic speech output.
When integrating expressive synthetic speech into an SGD,many aspects of the augmented communication process needto be considered. Any natural conversation involves the use ofsignificant linguistic, social-pragmatic, and discourse skills byboth communicators. This can be particularly challengingwhen using an AAC system, which demands additional skillsand knowledge as well as strong psychosocial capabilities,such as motivation and confidence, for competent communi-cation (Light, 2003). Further, it has been shown that manyAAC users struggle to effectively coordinate attentionbetween a conversation partner, the AAC system, and theactivity at hand (Light and Drager, 2007). Many challengesto both using, and learning how to use, current AAC systemshave been documented (Light and Drager, 2007) and it isanticipated that the advent of expressive speech synthesis willpose additional challenges. Specifically, AAC users will soonneed to coordinate the creation of linguistic content with theparalinguistic delivery of these messages. One of the advanta-ges when the voice style of the synthetic voice automaticallycorresponds to the user’s facial gestures would be an easierand more efficient delivery of the message, whilst reducingthe risk of being misunderstood.
While introducing the option of expressive speech into aspeech generating device adds freedom and flexibility ofexpression to the user, at the same time, the user now hasa new cognitive decision to make when composing a mes-sage: not only typing what to say, but also choosing howto say it. This kind of dual task and working memory haverecently been identified as core challenges to be consideredwhen designing AAC systems (Beukelman et al., 2012). Ifthe decision as to which expressive voice to use could bemade more automatically by analysing the emotional stateof the user, then the presence of the expressive voices wouldno longer imply an additional cognitive load to the user.
1.2. Relationship between facial gestures and voice
In the past, there has been considerable interest in inves-tigating the relationship between facial gestures such aseyebrow movements and acoustic prominence (focus) (Caveet al., 2002; Swerts and Krahmer, 2008; Moubayed et al.,2011). These studies have shown that there is a strongrelationship between auditory and visual modalities in per-ceiving prominence, and that appropriate accompanyingfacial gestures such as eyebrow movements aid the intelligi-bility and perceived naturalness of the message. Eyebrow
movements are, however, not always reliable cues for pros-ody and there are differing views on the temporal relation-ship between these gestures and the place of focus in anutterance (Cvejic et al., 2011). For the particular task of aug-mented interactions (where one of the conversation partnersuses speech synthesis as their communication tool), themapping model between facial gestures and synthetic voiceshas to meet a set of practical requirements. One should takeinto account for example, that during an augmented com-munication process, there is a temporal shift between thetext input and the acoustic realisation of the utterance bythe TTS system, which would make facial expression basedcontrol at a lower level such as syllables or even singlewords, problematic. The linking between gestures and voiceshould be at a high level, functional for entire utterances,and not dependent on short temporal relationships. More-over, the mapping needs to be easily personalisable, toaccount for individual needs and preferences. Lastly,because the mapping needs to be applicable in an automatedsystem, it is functionally restricted to features that have beenshown to produce robust and consistent results in bothstate-of-the art gesture recognisers and speech synthesisers.
Previous research has investigated a one-to-one mappingbetween facial expression and speech style for the applica-tion of speech-to-speech translation (Szekely et al., 2013).There, a straight-forward mapping has been impliedbetween facial and vocal expression such as from happy faceto cheerful voice, sad face to depressed voice, etc. The draw-back of this approach is the need for synthetic voices in spe-cific voice styles, and the fact that an erroneous classificationof a facial expression is magnified by a choice of a differentbasic emotion in the speech output. This means that if theuser is smiling but the system makes an error and classifiesthe face as angry, the output will be synthetic speech in a ste-reotypical angry voice, which is highly undesirable. Webelieve that this effect can be avoided by stepping away fromsynthetic voices representing categories of basic emotions,and approaching the visual-auditory emotion mappingspace from the viewpoint of emotional intensity instead.In this paper, we propose a high-level mapping betweenfacial expressions and expressive synthetic voice styles basedon intensity: how intense an emotion should be displayed inan utterance is determined by the intensity of the facialexpression detected. Emotional intensity is a measure thatis becoming more widely applied for facial expression recog-nition (Liao et al., 2012). The use of intensity as a feature offacial expressions is also supported by a study from the fieldof neuroscience which reports that the presence of cognitiveprocesses is responsive to increments of intensity in facialexpressions of emotion, but not sensitive to the type of emo-tion (Sprengelmeyer and Jentsch, 2006).
1.3. Challenges for speech technologies in assistive
communication
Probably the most fundamental need in a speech gener-ating device is the intelligibility of the synthetic voice.

E. Szekely et al. / Speech Communication 57 (2014) 63–75 65
Higher quality synthetic voices lower the cognitive require-ments of the conversation partners of having to listen tothe synthetic speech output (Mullennix and Stern, 2010),thus resulting in a more rewarding communication experi-ence. Besides intelligibility, there are many possibleenhancements that can contribute to the success of a com-munication experience between AAC user and listener.Personalisation of voice is often listed as a highly importantfeature (Creer et al., 2010). The synthetic voice can influ-ence a listener’s attitude towards the user of the voice(Stern et al., 2002) because people associate syntheticspeech with human-like attributes much like they do withnormal speech. Personalised voices have the potential toimprove the listener’s impression and attitudes towardsthe user. Customisability of text input strategies is also arelevant feature, AAC being an area where “one size doesnot fit all”. During an augmented communication process,the temporal dynamics and the collaborative nature of con-versation may be disrupted (Mullennix and Stern, 2010).An important goal for a speech generating device is toaim for fluid interaction, and to preserve normal conversa-tional rhythm, addressing the social dynamics between theaugmented speaker and the listener (Higginbotham, 2010).Higginbotham (2010) also highlights the need for the abil-ity to express emotions with voice, by means of alternativesolutions to control prosodic variations of utterance pro-ductions. The future of AAC technology is advancing withinnovative technologies involving brain-computer inter-faces (BCI’s) (Guenther et al., 2009), animated visual ava-tars (Massaro, 2004), and applications using naturallanguage processing such as word prediction and comple-tion algorithms, speech recognition and linguistic contextmining (Higginbotham et al., 2002).
1.4. The aim of this study
This paper describes the development and characteris-tics of three expressive synthetic voices, and the designand implementation of personalisable mapping rulesbetween these voices and the output of a facial expressionrecogniser. To help study the practical impact of a highlevel linking of visual and auditory cues based on the emo-tive-expressive intent of a message, the research prototypeof a multimodal speech synthesis platform called WinkTalkhas been developed. The WinkTalk system connects theresults of a facial expression recogniser to three syntheticvoices representing increasing degrees of emotional inten-sity. With the help of this system, an interactive evaluationhas been conducted to measure the efficiency of the map-ping between facial expressions and voice types, as wellas to investigate the pragmatic effects of using facial expres-sion control of synthetic speech in simulated augmenteddialogue situations.
The goal of this work is two-fold: firstly, to show thatintensity is a functional measure for mapping betweenfacial expressions and features of synthetic voices. Sec-ondly, to show that leveraging this type of correspondence
of face and voice has the potential to improve communica-tion experiences in situations where speech synthesis is usedas a human communication tool.
An SGD that incorporates automatic selection of voicestyles based on the facial expression of the user can be usedin two ways: firstly, when an AAC user is in a conversationwith another person and composes messages one utteranceat the time. The device would analyse the facial expressionof the user upon completion of the typing of the utteranceand output speech that corresponds to the user’s facial ges-tures. Secondly, it could be applied when delivering a pre-pared speech composed of several utterances, where thevoice style of each utterance would be adapted on-the-fly,to match the facial gestures of the user upon delivery ofthe speech, and hereby give the user of the device theopportunity to interact with the audience, maintain eyecontact, and at the same time influence the delivery ofthe speech by the TTS system. The software componentof such a device is implemented in this work. While inte-grated facial gesture analysis in a speech generating devicemay not be appropriate for all AAC users, we estimate thata significant number of users could benefit from it, espe-cially when detailed personalisation options are added forflexibility.
Fig. 1 outlines the main components of the augmentedcommunication process proposed in this work.
This paper is organised as follows: Sections 2,2,3,4 pres-ent the details of the underlying study to develop a mappingbetween facial gestures and synthetic voices. Section 5 intro-duces the system prototype called WinkTalk and Section 6describes an interactive experiment conducted to evaluatethe mapping model and the prototype system.
2. Expressive synthetic voices
2.1. Synthesising expressive speech – background
There has been significant recent interest in goingbeyond the neutral speaking style of traditional speech syn-thesisers and developing systems that are able to synthesiseemotional or expressive speech. As Taylor (2009) describes,the history of expressive speech synthesis systems datesback to formant synthesisers (Cahn, 1990; Murray andArnott, 1993), where different parameters could be variedto synthesise the same sentence with different types ofaffect. Later systems used data-driven approaches (Bulutet al., 2002) that essentially consisted of collecting andlabelling a database featuring certain emotions and recogn-ising patterns of fundamental frequency and timing thatcharacterise the emotions. Another approach is to usevoice transformation to convert a neutral-sounding speechsynthesiser to reflect a certain emotion (Kawanami et al.,2003). Later, a paradigm shift has been observed, from syn-thesising speech featuring distinct emotions (such as joy,sadness, fear, disgust, surprise and anger) to more flexible,dimensional approaches (Schroder, 2004) that describeemotion on continuous variables.

Fig. 1. Components of the communication process between AAC user and conversation partner involving facial expression-based automatic control overexpressive synthetic voices.
66 E. Szekely et al. / Speech Communication 57 (2014) 63–75
The current study uses an expressively read audiobookcorpus for the building of the synthetic voices. Synthesisingexpressive speech from audiobooks has been a target ofinterest for some time, for example for building voicesfocusing on prominence (Breuer et al., 2006) and usingtext-based approaches to categorise the reader’s imitationstyles of different characters (Zhao et al., 2006). In thisstudy, we use a novel unsupervised method based on voicequality parameters to take advantage of the natural vari-ability of voice styles within the corpus.
2.2. Audiobook corpus
The corpus used for the synthetic voices in this study is asection of an open source audiobook originally publishedon librovox.org, read by John Greenman. The segmentedaudio was made available for the Blizzard Challenge2012 by Toshiba Research Europe Ltd, CambridgeResearch Laboratory. The method used to segment theaudio and align the speech with the corresponding text isdescribed in Braunschweiler et al. (2010). The motivationfor using audiobooks was that they contain a wide varietyof unprompted, naturally sounding expressive voice styles,which makes them suitable for expressive speech synthesis.The challenge in using audiobooks for TTS is to detect thevariety of voice styles, as their occurrence is often notaccurately predictable from the text. Two Mark Twainbooks, A Tramp Abroad and The Man That Corrupted
Hadleyburg were selected for voice building. A 5.5 hourcorpus containing a variety of expressive speech styleswas formed from selected utterances of the books that wereno longer than 5 seconds, in order to obtain speech seg-ments which have small variation in voice style within theutterance.
2.3. Clustering expressive voice styles
Each synthetic voice was trained from different subsetsof the audiobook corpus obtained using an unsupervisedclustering technique based on glottal source parameters(Szekely et al., 2011). The method uses a Self-OrganisingFeature Map with input features calculated from glottalsource parameters (Cabral et al., 2007) of the LF-model(Fant and Lin, 1988) and fundamental frequency. Gobl(1989) and Childers and Ahn (1995) have shown correla-tions between the LF-model parameters and different typesof voice quality such as breathy, tense and creaky.
Therefore, they have the potential to characterise differentexpressive voice styles of one speaker. The input features ofthe clustering were calculated by taking the delta and meanvalues of the glottal source parameters OQ (open quotient),RQ (return quotient) and SQ (speed quotient), and themean values of f0 (fundamental frequency) for each speechsegment. Szekely et al. (2011) has shown through subjectivelistening tests, that this method is able to detect the varietyof expressive voice styles in a speech corpus and groupthem into a given number of clusters of in terms of voicestyle similarly sounding utterances. For the voices used inthe current work, this method was applied on the corpusdescribed in Section 2.2.
2.4. Voice building
For voice building, 36 voice style clusters were usedwhich were further grouped into 3 subcorpora of similarclusters with the help of informal listening tests conductedby the authors (Szekely et al., 2012b). The further groupingwas necessary to obtain enough speech data to build a syn-thetic voice for each voice style. The voices were built usingthe HTS speech engine 2.1. (2008). The HMM-basedspeech synthesiser used in the experiment uses theSTRAIGHT vocoder (Kawanami et al., 2003) similarlyto the speaker-dependent HMM-based speech synthesisercalled Nitech-HTS 2005 (Zen et al., 2007).
2.5. Evaluation of the synthetic voices
The three voices were given the non-descriptive namesA, B and C have been evaluated with perceptual listeningtests with the aim of assessing their voice style characteris-tics, and their capability to capture expressive intent in con-versational phrases in particular. It was found that each ofthe voices represent a different voice style that is consistent.In the evaluation, after a short familiarisation phase, listen-ers could make a reliable prediction of how a given sen-tence will sound in a chosen voice style (Szekely et al.,2012b). Consistency and predictability of voice style areindispensable characteristics of expressive synthetic voicesthat are used for augmenting human interaction in assistivetechnologies. The reason for this is that the user of a speechgenerating device often does not have the opportunity tolisten to the resulting synthetic speech ahead of a conversa-tion, but has to trust the known characteristics of the voicestyles to be able to use them during interaction. Results of

E. Szekely et al. / Speech Communication 57 (2014) 63–75 67
further perceptual experiments aimed at AAC applicationin particular (Hennig et al., 2012) have shown that thethree voices can be characterised on an expressiveness gra-dient representing different intensities of emotions: fromcalm (A voice), through intense (B voice) to very intense
(C voice). In this study, participants were asked to comparea set of sentences and decide which one sounds more emo-tionally intense. When comparing the same sentence syn-thesised with different voices, 89% of participants ratedthe sentences synthesised with voices higher on the inten-sity scale as sounding more emotionally intense (B vs. A,C vs. B and C vs. A, respectively). This percentage was79% when evaluating with sentences of different linguisticcontent. Listeners were also asked to assign descriptivelabels to the voices. A selection of these labels are:
Voice A:
standard, neutral, matter of fact, quiet, indifferent, bored,calm, unsure, resigned, basic, disinterested, apathetic;
Voice B:
somewhat emphatic, somewhat emotional, medium calm,brisk, fluent, agitated, modest, convincing, questioning,lively, interested, vigilant;
Voice C:
stressed, tense, nervous, panicked, agitated, enthusiastic,energetic, excitable, angry, alarmed, very interested.
Detailed sentiment analysis conducted on these descrip-tive labels gave support to the thesis that the voices arecharacterised with underlying emotions of differing levelsof intensity. The sentiment analysis was done usingLymbix2, an online tool that uses crowd-sourcing to anno-tate words and sentences with not only positive, negativeand neutral scores but also note the underlying basic emo-tion, and the intensity with which the given word reflectsthat emotion category. The results of the sentiment analysisare displayed in Appendix A. These results show that thelabels describe the emotional intensity of the voices on ascale of 0–10 as 2.8 for the A voice, 4.42 for the B voiceand 7.89 for the C voice. In terms of sentiment, all threevoices received both positive and negative sentiment labels.This indicates that they are suitable for synthesisingemotional utterances of both positive and negative senti-ment: the sentiment of the utterance will be decided bythe linguistic content of the sentence.
These results are further supported by another experi-ment, where the sentences in the original speech corpuswere labelled according to sentiment (positive, neutral ornegative) with the help of the Lymbix software. Prosodicfeatures such as F0 and voice quality parameters wereextracted from the recordings to compare the three groups,positive, neutral, and negative to each other. The analysis
2 See http://lymbix.com/supportcenter/docs for a documentation.Retreived on: 26.06.2012.
revealed that the three groups showed no significant differ-ences. This result could be due to the fact that it is extre-mely difficult to predict the artistic expression that theactor chooses for each sentence from the text alone. How-ever, it also indicates that – at least in the case of this par-ticular speaker – the intensity dimension of an emotionalexpression is perhaps more prominently carried in the vocalexpression than linguistic sentiment.
3. Facial expression analysis
One of the most well-known systems for analysing facialexpressions is the Facial Action Coding System proposedby Ekman and Friesen (1976). FACS measures facialexpressions in Action Units (AUs) related to musclechanges. FACS can be used to discriminate positive andnegative emotions, and to some extent indicate the intensityof the expressions. While FACS can offer a more detailedanalysis, for the purpose of using facial expression recogni-tion in augmented conversations, a method is required thatprovides automatic, robust, real time information of facialexpression categories and a reliable indication of intensityof expression. The facial expression analysis used in thisstudy is, therefore, performed by the Sophisticated High-speed Object Recognition Engine (SHORE) library (Kuebl-beck and Ernst, 2006). A software development kit of thesystem has been made available by Fraunhofer for aca-demic demonstration and evaluation purposes. Whendetecting faces and expressions, SHORE analyses localstructure features in an image (or series of images) thatare computed with a modified census transform (Kueblbeckand Ernst, 2006). This face detection system outputs scoresfor four distinct facial expressions, happy, sad, angry andsurprised, with an indication of the intensity of the expres-sion. The intensity ranges from 0-100, with a higher valueindicating a more intense expression within a category.
4. Mapping between facial expressions and synthetic voices
4.1. Theoretical foundations of the mapping
Theoretical foundations based on considerations aboutintensity levels of the underlying basic emotions of the fourfacial expression categories have been considered to initia-lise the mapping values. Cowie et al. (2000) proposed thesince widely applied two-dimensional disk-shaped activa-tion-evaluation space to model emotion dimensions. Theouter boundary of the disk represents maximally intenseemotions, while its centre represents a neutral state. Theradial distance of an emotion from the centre is themeasure of its intensity. We placed the four basic emotionsconsidered to be the underlying emotions happy, sad, angry
and surprised facial expressions on the activation-evalua-tion space (see Fig. 2). These are located on the wheel asfull-blown emotions (corresponding to a value of 100 inthe facial expression analysis in SHORE), while lowerintensity values are closer to the centre. The practical

68 E. Szekely et al. / Speech Communication 57 (2014) 63–75
implication of this is that when mapping the facial expres-sions onto voices of differing emotional intensity, the map-ping should take into consideration the intensity level ofthe corresponding (full-blown) emotion. The different emo-tions operate on different scales of intensity; therefore, theyneed to be considered separately, even when eventuallymapping them onto the same voices. This implies that inthis case of mapping of visual and auditory features, thedimensions activation and evaluation are not necessarilyoperating independently, but rather are scaled by eachother. The process of obtaining the mapping thresholdsfor the intensity values of each facial expression categoryto the different voices is explained in Section 4.2. Althougha two-dimensional representation of emotions is debated(Fontaine et al., 2007), and probably lacks the ability toaccurately describe all possible combinations of emotionand affect with any lexical content; it proves to be a usefulmodel for the current application, because both the charac-teristics of the synthetic voices, and the capabilities of thefacial expression recognition are well known and limitedto an extent.
4.2. Perceptual experiment to obtain mapping rules
A perceptual test was carried out to obtain initial map-ping values for mapping the facial expressions to the typesof synthetic voices, based on a majority of judgements col-lected by listeners. A dataset was prepared to contain 20sentences with linguistic content that implicitly suggest dif-ferent emotional sentiments and 20 photographs of facialexpressions. A male actor was asked to make a facialexpression that according to him matched the sentimentof a particular sentence. Then, the images were analysedwith the SHORE face detection engine, to create a bal-anced set of happy, angry, sad, surprised and neutral (nofacial expression detected) images. The dataset thereforecontained an equal number of stimuli from all facialexpression categories, each with differing degrees of inten-sity. In the perceptual test, participants were presented witha written sentence, a photo of the actor’s face and threesynthetic speech samples, one from each voice. The
Fig. 2. Adaptation of the disk-shaped activation-evaluation space pro-posed by Cowie et al. The location of the underlying emotions of the facialexpression categories considered in this work are indicated on thediagram.
participants’ task was to look at the picture and after lis-tening to all three samples, select the sample that accordingto them best matched the facial expression on the corre-sponding image. The test was completed by 25 participants.
The results show that the participants selected the voicesA, B and C in 39%, 23% and 38% of all cases, respectively.In 65% of the stimuli a majority (as defined here as at leasttwo thirds of participants) agreed on one voice choice.These results were used to set the initial thresholds for map-ping. The intensity thresholds for separating the voice styleswere selected to include 90% of these majority votings. Theanswers to 35% of the stimuli showed no majority favouringone particular voice style. These answers reflect individualdifferences and were, therefore, not taken into account insetting the initial mapping values. These individual differ-ences will be accommodated in a personalisation phasewhich will be introduced in Section 5.2. For neutral facialexpressions, voice A was preferred in 67% of all cases. Inthe initial mapping, therefore, if no facial expression isdetected, the utterance will be synthesised with voice A.
Fig. 3 illustrates these initial mapping values. The y axisshows the intensity values for the facial expressions, thebars represent the facial expression categories, colouredfor the corresponding voice choice depending on the value.For example, if the SHORE analysis of an image results inthe facial expression happy with an intensity of 25, the cor-responding utterance will be synthesised with the B voice,while an intensity of 80 will be synthesised with the C voice.Note that the values presented in Fig. 3 appear to corre-spond to the position of the underlying emotion displayedin Fig. 2, in that the distance from the centre and the posi-tion on the activation axis reflects the threshold changes inthe voice: low for sad and highest for surprised.
5. The WinkTalk system
5.1. System architecture and working modes
Fig. 4 provides an overview of the main components andthe operation modes of the WinkTalk system. The systemcan operate in one of three modes: automatic voice selec-tion (Mode 1), personalisation of voice selection (Mode3) and manual voice selection (Mode 2). Mode 1 is the prin-cipal mode which automatically selects a voice from theface expression of the user. Mode 3 can be performed ini-tially for the system to adapt the mapping rules betweenfacial parameters and voice types to the user and to his/her personal preference for the different voice types. Thismode is a combination of both the automatic and manualvoice selection modes. The manual voice selection mode(Mode 2) is also used in the experiment part of this workfor evaluating the system. In this mode the user selectsone of three buttons to synthesise speech, each button cor-responding to one of the voices.
The main components of the WinkTalk system are:SHORE for facial expression analysis, HMM-synthesisersand synthetic voices A, B, and C, presented in Section 2,

Fig. 3. Thresholds for mapping intensity values of facial expressions tosynthetic voices A, B and C.
E. Szekely et al. / Speech Communication 57 (2014) 63–75 69
and the mapping rules between intensity values of facialexpressions and the voices, described in Section 4.2. Areview of the system has been presented in the demo paperSzekely et al. (2012a).
5.2. Personalisation of voice selection
The system contains a personalisation component,which is performed using the operation Mode 3 illustratedin Fig. 4. In this mode, the mapping rules between facialexpressions and voice types are adjusted by the system totake into account individual differences between users.These differences could be two-fold: the facial expressiondetection may have slightly altered results for differentusers (because of individual facial characteristics), andthe preferences of individuals for the expressiveness ofspeech are also likely to differ as shown in Szekely et al.
Fig. 4. System Architecture.
(2012b). Both factors are accounted for by adjusting thesystem’s threshold for voice selection based on the user’smanual selection of the voices. In this adaptive thresholdadjustment phase, users rate a set of synthesised samplesthat match their current facial expression for each utter-ance. The mapping rules are updated after each utterance,by calculating the minimum and maximum value for eachfacial expression-voice pair. The thresholds for each pairare normalised so that there is no overlap between differentvoices for the same feature. The interface of the personali-sation phase is shown in Fig. 5.
6. Interactive experiment
6.1. Goal of the experiment
The interactive experiment had two general goals: first,to evaluate the intensity based mapping between users’facial expressions and the synthetic voices, and second, totest the functionality of the WinkTalk prototype systemby simulating dialogues between the user and a conversa-tion partner. More specifically, we were interested to studywhether the personalisation phase is successful in improv-ing the user experience, and, whether the system facilitatesa communication experience that is a step closer to livevoice communication than traditional speech generatingdevices. Additionally, the acquired information throughthe experiment can be used to inform future design andresearch with the target population, namely AAC users.
While the validity of the testing of a speech synthesis systemdesigned for disabled individuals through recruiting peoplewithout speech impairments might appear to be questionable,the use of healthy subjects - particularly in early stage ofresearch is widely accepted and frequently necessary becauseof ethical considerations (Bedrosian, 1995) (Higginbotham,1995). Examples in the literature of non-disabled people par-ticipating in AAC directed research such as speech outputpreferences and selection techniques include Wisenburn andHigginbotham (2008) and Wilkinson and Snell (2011).
6.2. Experiment design
An interactive experiment, involving users of the Wink-Talk system performing acted conversations with an
Fig. 5. Interface of the personalisation component.

Fig. 6. Photos obtained from different camera angles during the interac-
70 E. Szekely et al. / Speech Communication 57 (2014) 63–75
interlocutor, has been conducted with 10 participants: 7native speakers and 3 non-native speakers of English, agedbetween 22 and 46. The participants received a monetaryreward for their efforts. Participants were given a 10 minuteintroduction where they had the opportunity to familiarisethemselves with the use of speech synthesis in assistive tech-nologies and watched two video-clips of patients using text-to-speech systems to communicate. This was important sothat subjects could use this prior knowledge to answer oneof the questions regarding to how the WinkTalk systemcompares to a synthesiser equipped only with one neutralvoice.
The experiment involved participants acting out 8 shortscripted dialogues each with a conversation partner.3 Thedialogue session lasted 25–35 minutes. In this session, par-ticipants selected their part of the conversation from a rangeof pre-synthesised speech samples. The voice selection con-trol using the WinkTalk system was done in two conditions:manual voice selection (Mode 2) and automatic voice selec-tion from facial expressions (Mode 1). To provide a baselineof comparison, participants also acted out each conversa-tion once using their live speech. After each dialogue wascompleted in all conditions, participants were asked to indi-cate their preference for the control over the synthetic voices(manual or automatic through facial expressions) for thatparticular dialogue. They were also asked to rate on a scaleof 1–5, how important was the option for choosing betweenthree expressive voices for that dialogue, compared to theoption of having only one, neutral voice. The dialogueswere elaborated in this work to reflect a range of socialinteraction types, as well as to cover both negative and posi-tive emotional involvement to differing degrees of intensity.Topics involved short conversations amongst friends, col-leagues, strangers and peers. The order of the dialogueswas randomised in the experiment, as was the order of con-trol mode (manual or automatic).
Prior to the dialogue session, participants used the sys-tem in the personalisation mode to adapt it to their per-sonal face expression characteristics and preferences forthe different voices. The personalisation session was com-posed of 20 utterances and participants completed it in10–15 minutes. They were asked to make an appropriatefacial expression to a given sentence and consequently theywere presented with the system’s voice choice for theirfacial expression. If they did not agree with the system’schoice, they could indicate their preference which was thentaken into account to update the system’s rules for voiceselection in the next iteration.
At the end of the experiments, participants were askedto fill out a questionnaire about their experience with thesystem. In order to collect data for future analysis, the dia-logue sessions were recorded from three camera angles, andthe subjects were asked to wear skin conduction sensors.Fig. 6 illustrates the room set-up for the dialogue sessions.A short video clip from the experiment is available at
3 Two examples of the dialogues can be found in Appendix B.
http://muster.ucd.ie/%7Eeva/WinkTalkDemo. The view-ing of the video is highly recommended in order to aidthe understanding the process of the dialogue experiment.
In addition to the participant questionnaires betweeneach dialogue set and those completed at the end of theexperiment, participant electrodermal activity wasrecorded as a means of continuously and noninvasivelymonitoring participant reactions to three experimental con-ditions: live voice, manual control of the synthetic voice,and automatic control of the synthetic voice based on facialexpressions.
Electrodermal activity (EDA) varies with changes in thesympathetic branch of a person’s autonomic nervous sys-tem and is considered a reflection of one’s physiologicalarousal level (Dawson et al., 2000). One metric of EDAis the rate skin conductance responses (SCR), or localpeaks of EDA, which typically are observed 1–3 timesper minute. Changes in SCR are frequently used as an indi-rect measure of changes in cognitive effort, attention, and/or emotion (Critchley et al., 2000) and are also associatedwith social-emotional factors such as the degree of interac-tion with a conversational partner (MacWhinney et al.,1982) and presence of social support (Gallo et al., 2000).All of which are important factors in socialcommunication.
The experiment set-up is summarised below.
1. Signing of the consent form and short introductionto speech generating devices and AAC users.(10 min)
2. Putting on skin conductance sensors. (2 min)3. Familiarisation with the goal of the system and the
synthetic voices. (5 min)4. Personalisation session. (15 min, Mode 3)5. Dialogue sessions in 3 conditions (order random-
ised, 25 min):(a) Acting with live voice;(b) Using buttons to control the synthetic voice
choice of the system (Mode 2);(c) Using facial expressions for automatic control
of synthetic voice choice of the system (Mode 1);
tion of one user in the experiment. The SHORE analysis for the image onthe right is happy, with an intensity of 12.

Fig. 7. Relationship between voice control preference and importance ofaccess to three voices in a dialogue.
E. Szekely et al. / Speech Communication 57 (2014) 63–75 71
(d) Filling out a form indicating mode preferenceand importance of having three voices for thisdialogue.
6. Filling out the questionnaires and receiving reward.
6.3. Results
6.3.1. Personalisation sessions
In the personalisation process, the initial thresholdsbetween the voice styles, on the scale of 0 to 100, under-went significant changes. The results between users exhib-ited a standard deviation of 8.5 for the happy expression,9.6 for angry and 3.4 for surprised. The facial expressioncategory sad was assigned to the A voice in all instances,resulting in no deviation from the original thresholds.For images classified as neutral by the SHORE system,60% of participants preferred the A voice, whereas 40%preferred the B voice. This confirms the finding from theperceptual experiment described in Section 4.2 that foreach person, a single voice (either A or B) can be used atall times if no facial expression is detected.
The results from the personalisation sessions show thatin 53% of the cases users agreed with a selection that wouldhave been made by using the initial threshold. Using thepersonally adapted threshold results in 73% of the test sen-tences being classified according to the user’s preferencesbased on their facial expressions.
In order to test whether the mapping values obtained inthe personalisation sessions provide a better result in gen-eral, and that this is not merely due to a poor selectionof initial thresholds, we used the data from the personalisa-tion sessions to calculate one single threshold for all userswith the highest acceptance rate for each facial expression.For this purpose, the sentences from the personalisationphase were split into a training (first 80%) and a test set(last 20%). A logistic regression model was trained on thetraining set to find the optimal decision boundary betweenthe A and B voices and between the B and C voices. Thesuccess rate of applying this on the test set was 56%. Thisis not significantly higher than the results using the initialthresholds, which demonstrates that no single mappingwould have worked well for everybody. The success rateusing the adapted threshold on the test set is 80%. This sug-gests that a longer and more detailed personalisation ses-sion, which would be applicable if someone used thesystem for everyday communication, has the potential tofurther improve these results.
6.3.2. Results of automatic selection of voice types during
dialogue sessions
The dialogue sessions lasted approximately 25 minutesfor all participants. The voices, A, B and C were selected19%, 45%, and 37% of the times during the manual control,and 21%, 48% and 31% of the times during the automaticcontrol, respectively. A chi-squared test was performed to
test for equal multinomial distribution of the results ofthe two modi. This test supports the hypothesis that thedistribution of used voice types for both types of controlis not different (with a p-value of 0.47 > 0.05 significance).
The length of the dialogue sessions were measured foreach participant, to get a sense of the difficulty of the taskin both modes. Longer lasting sessions would suggest anincrease in task difficulty. While there was a significant dif-ference in length between acting the dialogues with ownvoice (28.8s on average), being the shorter one, and usinga synthetic voice; no significant difference could beobserved between Mode 2 (manual control, 43.1s on aver-age) and Mode 1 (automatic control, 45.9s on average). At-test supports the hypothesis that there is no significantdifference in time required to go through the dialoguebetween the two types of control (with a p-value of 0.36> 0.05 significance level).
Overall, participants indicated that they prefer manualcontrol in 64% of the cases. Some participants explainedin verbal feedback that the manual selection provided themwith a “hard sense of control” over the voice (see video ref-erence in Section 6.2). In the answer sheet that was filledout after each dialogue in manual and automatic voice con-trol conditions, participants’ opinion about the importanceof the access to three expressive voices differed per dia-logue. From Fig. 7 it appears that there is a correlationbetween indicating that the three expressive voices for aparticular dialogue were important and an increasing pref-erence for facial expression control. This may indicate thatin situations where a wide range of vocal expressiveness isneeded (perhaps for reasons of greater emotional involve-ment), facial control over the type of voice aids users’ abil-ity to express themselves better.
6.3.3. Questionnaires
The questionnaire began with a question about the over-all experience with the system on a scale of 1–5. 60% of theparticipants answered with 5: very nice, 40% with 4: nice,and 0% with 3: reasonable, 2: unpleasant and 1: awful. Next,one of 4 answers had to be selected for the followingquestion:
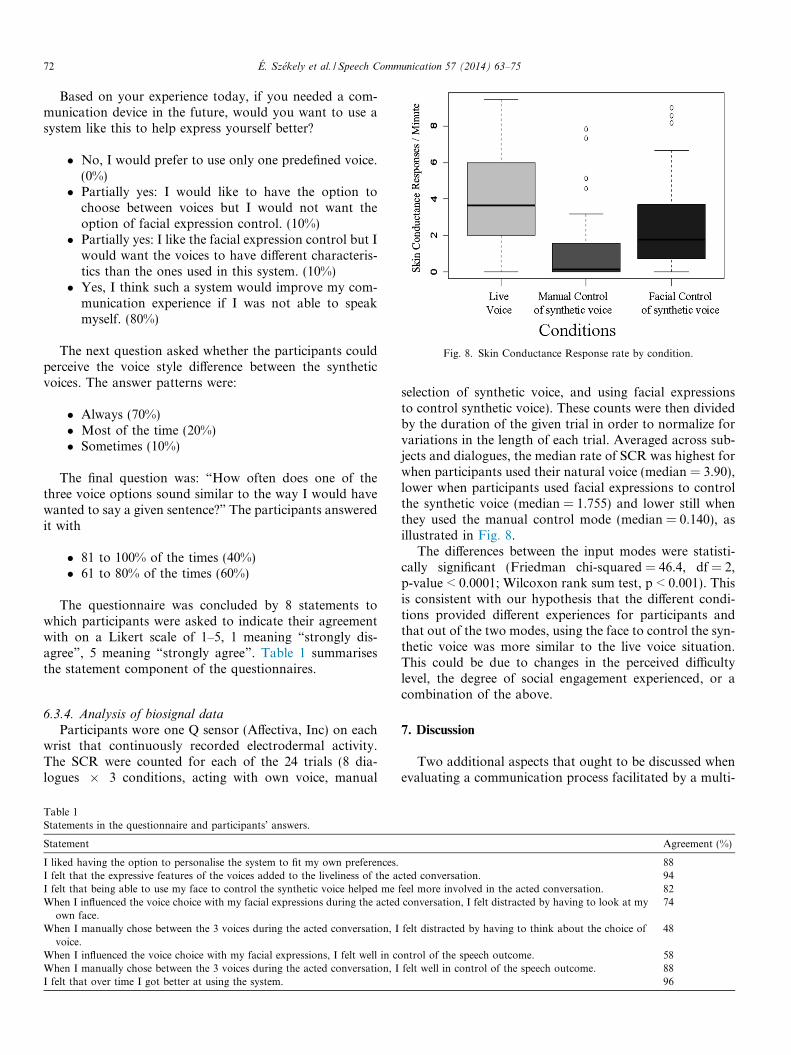
Fig. 8. Skin Conductance Response rate by condition.
72 E. Szekely et al. / Speech Communication 57 (2014) 63–75
Based on your experience today, if you needed a com-munication device in the future, would you want to use asystem like this to help express yourself better?
� No, I would prefer to use only one predefined voice.(0%)
� Partially yes: I would like to have the option tochoose between voices but I would not want theoption of facial expression control. (10%)
� Partially yes: I like the facial expression control but Iwould want the voices to have different characteris-tics than the ones used in this system. (10%)
� Yes, I think such a system would improve my com-munication experience if I was not able to speakmyself. (80%)
The next question asked whether the participants couldperceive the voice style difference between the syntheticvoices. The answer patterns were:
� Always (70%)� Most of the time (20%)� Sometimes (10%)
The final question was: “How often does one of thethree voice options sound similar to the way I would havewanted to say a given sentence?” The participants answeredit with
� 81 to 100% of the times (40%)� 61 to 80% of the times (60%)
The questionnaire was concluded by 8 statements towhich participants were asked to indicate their agreementwith on a Likert scale of 1–5, 1 meaning “strongly dis-agree”, 5 meaning “strongly agree”. Table 1 summarisesthe statement component of the questionnaires.
6.3.4. Analysis of biosignal data
Participants wore one Q sensor (Affectiva, Inc) on eachwrist that continuously recorded electrodermal activity.The SCR were counted for each of the 24 trials (8 dia-logues � 3 conditions, acting with own voice, manual
Table 1Statements in the questionnaire and participants’ answers.
Statement
I liked having the option to personalise the system to fit my own preferences.I felt that the expressive features of the voices added to the liveliness of the aI felt that being able to use my face to control the synthetic voice helped meWhen I influenced the voice choice with my facial expressions during the acted
own face.When I manually chose between the 3 voices during the acted conversation, I
voice.When I influenced the voice choice with my facial expressions, I felt well in coWhen I manually chose between the 3 voices during the acted conversation, II felt that over time I got better at using the system.
selection of synthetic voice, and using facial expressionsto control synthetic voice). These counts were then dividedby the duration of the given trial in order to normalize forvariations in the length of each trial. Averaged across sub-jects and dialogues, the median rate of SCR was highest forwhen participants used their natural voice (median = 3.90),lower when participants used facial expressions to controlthe synthetic voice (median = 1.755) and lower still whenthey used the manual control mode (median = 0.140), asillustrated in Fig. 8.
The differences between the input modes were statisti-cally significant (Friedman chi-squared = 46.4, df = 2,p-value < 0.0001; Wilcoxon rank sum test, p < 0.001). Thisis consistent with our hypothesis that the different condi-tions provided different experiences for participants andthat out of the two modes, using the face to control the syn-thetic voice was more similar to the live voice situation.This could be due to changes in the perceived difficultylevel, the degree of social engagement experienced, or acombination of the above.
7. Discussion
Two additional aspects that ought to be discussed whenevaluating a communication process facilitated by a multi-
Agreement (%)
88cted conversation. 94feel more involved in the acted conversation. 82conversation, I felt distracted by having to look at my 74
felt distracted by having to think about the choice of 48
ntrol of the speech outcome. 58felt well in control of the speech outcome. 88
96

Voice A labels Underlying emo�on Sen�ment Intensitystandard contentment / gratitude Neutral 1.29neutral contentment / gratitude Neutral 1.63matter of fact amusement / excitement Neutral 2.25quiet contentment / gratitude Positive 2.99indifferent anger / loat hing Neutral 0.3bored sadness / grief Neutral 0.57calm contentment / gratitude Positive 6.96unsure fear / uneasiness Negative 4.91resigned sadness / grief Negative 2.76basic contentment / gratitude Positive 5.66disinterested sadness / grief Negative 3.4a pathetic sadness / grief Neutral 0.97
Total score: 2.80
Voice B labels Underlying emo�on Sen�ment Intensitysomewhat emp hatic contentment / gratitude Neutral 1.61somewhat emotional contentment / gratitude Neutral 1.61medium calm contentment / gratitude Positive 6.96brisk enjoyment / elation Positive 2.82fluent anger / loathing Positive 5.42agitated anger / loathing Negative 4.85modest contentment / gratitude Positive 6.73convincing fear / uneasiness Positive 5.2questioning fear / uneasiness Neutral 1.08lively enjoyment / elation Positive 5.14interested enjoyment / elation Positive 6.14vigilant sadness / grief Negative 5.55
Total score: 4.42
Voice C labels Underlying emo�on Sen�ment Intensitystressed sadness / grief Negative 6.0tense fear / uneasine ss Negative 6.41nervous fear / uneasiness Negative 6.96excited amusement / excitement Positive 10.0panicked fear / uneasiness Positive 10.0agitated anger / loathing Negative 4.85enthusiastic amusement / excitement Positive 8.07energetic amusement / excitem ent Positive 8.65excitable amusement / excitement Positive 10.0angry anger / loathing Negative 10.0alarmed fear / uneasiness Negative 8.62very interested amusement / excitement Positive 5.13
Total score: 7.89
Fig. A.9.
E. Szekely et al. / Speech Communication 57 (2014) 63–75 73
modal speech synthesis system such as WinkTalk, are thedynamics and timing aspects of the assisted conversationand the role of attention in the communication process.With regard to dynamics and timing, one might argue thatduring a natural conversation, gestures and linguistic mes-sage operate in a tightly connected pattern. A speech syn-thesis system that uses visual and linguistic inputhowever, does not eliminate the necessary lag between typ-ing and the sound of the synthetic message, that is unfortu-nately typical of assisted conversations. This lag couldquite possibly interfere with the communication dynamicsin such a manner that would alter the timing and role ofthe gestural expression. To what extent this could mean acommunication barrier however, greatly depends on out-side factors such as the typing speed of the user of the sys-tem, or the relationship between the conversation partners.
When considering the problem of attention, it should benoted that composing a written message, listening to itsspoken output and at the same time maintaining connec-tion with the conversation partner already requires dividedattention to some degree. An additional active interfacecomponent of the SGD, such as voice style buttons wouldtake attention away from the conversation partner. On theother hand, both the volitional and the involuntary controlof facial expressions require a different type of cognitiveeffort. At the same time, facial expressions have an obviousrole in a conversation, outside of their function as a visualinput to the SGD, namely that they help maintain eye con-tact and help keep both conversation partners engaged inthe communication process.
8. Conclusion and future work
This paper presented an intensity based mapping offacial expressions and synthetic voices that is implementedin a multimodal speech synthesis platform, and evaluatedwith the help of interactive experiments. The aim of the sys-tem is to provide an alternative strategy to control thechoice of expressive synthetic voices by automatic selectionof voice types through expression analysis of the user’sface. The personalised, high-level mapping of facial expres-sions and synthetic voices resulted in a 73% accuracy interms of selecting the users’ preferred voice style. The par-ticipants of the interactive experiment provided very posi-tive feedback in the questionnaires about the system. Theexperiment showed that although participants mostly pre-ferred manual control over the automatic control ofexpressive synthetic speech output, most of them wouldlike to have the option of facial expression control as well.
Results also indicated that automatic control over syn-thetic voices through facial expressions helped the partici-pants to better express themselves, in particular inconversations with higher emotional involvement. Analysisof the length of the dialogue sessions showed that the addi-tional effort of selecting a voice type is the same for manualcontrol as for gesture based automatic control. The analy-sis of the biosensor data however indicates that during
automatic control, users’ engagement with the conversa-tion is closer to speaking with their natural voice. Animportant next step is facilitating the personalisation ofthe facial expression analysis to fit individual needs of aug-mented speakers who are physically limited with respect totheir gestural expressiveness. Future work also involvesmore detailed analysis of the collected data including vid-eos and biosensor data, as well as adding female syntheticvoices into the system.
Acknowledgements
This research is supported by the Science FoundationIreland (Grant 07/CE/I1142) as part of the Centre for NextGeneration Localisation (www.cngl.ie) at UniversityCollege Dublin (UCD). The opinions, findings, and conclu-sions or recommendations expressed in this material arethose of the authors and do not necessarily reflect the viewsof Science Foundation Ireland. This is research is furthersupported by the Istituto Italiano di Tecnologia and theUniversita degli Studi di Genova. The authors would alsolike to thank Nick Campbell and the Speech Communica-

74 E. Szekely et al. / Speech Communication 57 (2014) 63–75
tion Lab (TCD) for their invaluable help with the interac-tive evaluation.
Appendix A. Sentiment analysis on descriptive labels of
voices
See Fig. A.9.
Appendix B. Example scripted dialogues played during the
experiment
The parts played by the participant of the experimentare in italics.
Example 1
– Guess what, I’m getting married!– Congratulations! That’s wonderful news!
– Thank you.– Do you already have a date?
– Not yet, but it’ll probably be around the end of thissummer.
– You must be very excited!
– I am!
Example 2
– Excuse me, is this your wallet?!– Yes it is! Oh my gosh!
– I found it under the seat where you were sitting justa minute ago.
– I am so relieved! I thought it was stolen. I am very
grateful.
– You are welcome. I’m glad I could help.
References
Asha, 2005. Roles and responsibilities of speech-language pathologistswith respect to augmentative and alternative communication: positionstatement. American Speech-Language-Hearing Association <www.asha.org/policy>.
Bedrosian, J., 1995. Limitations in the use of nondisabled subjects inAAC research. Augmentative and Alternative Communication 11(1), 6–10.
Beukelman, D., Blackstone, S., Caves, K., De Ruyter, F., Fried-Oken, M.,Higginbotham, J., Jakobs, T., Light, J., McNaughton, D., Nelson-Bryen, D., Shane, H., Williams, M., Dec. 2012. 2012 state of thescience conference in AAC: AAC-RERC final report. In: Communi-cation Enhancement for People with Disabilities in the 21st Century.Partners of the Rehabilitation Engineering Research Center forCommunication Enhancement.
Braunschweiler, N., Gales, M.J.F., Buchholz, S., 2010. Lightly supervisedrecognition for automatic alignment of large coherent speech record-ings. In: Proceedings of Interspeech, Makuhari, pp. 2222–2225.
Breuer, S., Bergmann, S., Dragon, R., Moller, S., 2006. Set-up of a unit-selection synthesis with a prominent voice. In: Proceedings of LREC,Genoa.
Bulut, M., Narayanan, S.S., Syrdal, A.K., 2002. Expressive speechsynthesis using a concatenative synthesizer. In: Proceedings of Inter-national Conference on Spoken Language Processing, pp. 1265–1268.
Cabral, J., Renals, S., Richmond, K., Yamagishi, J., 2007. Towards animproved modeling of the glottal source in statistical parametricspeech synthesis. In: Proceedings of the 6th ISCA Workshop onSpeech Synthesis.
Cahn, J.E., 1990. Generation of affect in synthesized speech. Journal of theAmerican Voice I/O Society 8, 1–19.
Cave, C., Guaıtella, I., Santi, S., 2002. Eyebrow movements and voicevariations in dialogue situations: an experimental investigation. In:Proceedings of ICSLP, Denver.
Childers, D., Ahn, C., 1995. Modeling the glottal volume-velocitywaveform for three voice types. The Journal of the Acoustical Societyof America 97, 505.
Cowie, R., Douglas-Cowie, E., Savvidou, S., McMahon, E., Sawey, M.,Schroeder, M., 2000. ‘FEELTRACE’: An instrument for recordingperceived emotion in real time. In: Proceedings of the ISCA workshopon speech and emotion, Northern Ireland, pp. 14–29.
Creer, S.M., Green, P.D., Cunningham, S.P., Yamagishi, J., 2010.Building personalised synthetic voices for individuals with dysarthriausing the hts toolkit. In: Mullennix, J.W., Stern, S.E. (Eds.), ComputerSynthesized Speech Technologies: Tools for Aiding Impairment. IGIGlobal, pp. 92–115.
Critchley, H.D., Elliott, R., Mathias, C.J., Dolan, R.J., 2000. Neuralactivity relating to generation and representation of galvanic skinconductance responses: a functional magnetic resonance imagingstudy. Journal of Neuroscience 20 (8), 3033–3040.
Cvejic, I., Kim, J., Davis, C., 2011. Temporal relationship betweenauditory and visual prosodic cues. In: Proceedings of Interspeech,Florence.
Dawson, M.E., Schell, A.M., Filion, D.L., 2000. In: The electrodermalsystem, 2. Cambridge University Press, pp. 200–223.
Ekman, P., Friesen, W.V., 1976. Measuring facial movement. Journalof Nonverbal Behavior 1, 56–75. http://dx.doi.org/10.1007/BF01115465.
Fant, G., Lin, Q., 1988. Frequency domain interpretation and derivationof glottal flow parameters. STL-QPSR 29 (2–3), 1–21.
Fontaine, J., Scherer, K., Roesch, E., Ellsworth, P., 2007. The world ofemotions is not two-dimensional. Psychological Science 18 (12), 1050–1057.
Gallo, L.C., Smith, T.W., Kircher, J.C., 2000. Cardiovascular andelectrodermal responses to support and provocation: Interpersonalmethods in the study of psychophysiological reactivity. Psychophys-iology 37 (3), 289–301.
Gobl, C., 1989. A preliminary study of acoustic voice quality correlates.STL-QPSR, Royal Institute of Technology, Sweden 4, 9–21.
Guenther, F.H., Brumberg, J.S., Wright, E.J., Nieto-Castanon, A.,Tourville, J.A., Panko, M., Law, R., Siebert, S.A., Bartels, J.L.,Andreasen, D.S., Ehirim, P., Mao, H., Kennedy, P.R., 2009. A wirelessbrain-machine interface for real-time speech synthesis. PLoS ONE 4(12), e8218+.
Hennig, S., Szekely, E., Carson-Berndsen, J., Chellali, R., 2012. Listenerevaluation of an expressiveness scale in speech synthesis for conver-sational phrases: implications for AAC. In: Proceedings of ISAAC,Pittsburgh.
Higginbotham, D., 1995. Use of nondisabled subjects in AAC research:confessions of a research infidel. Augmentative and AlternativeCommunication 11 (1), 2–5.
Higginbotham, J., 2010. Humanizing vox artificialis: the role of speechsynthesis in augmentative and alternative communication. In: Mul-lennix, J.W., Stern, S.E. (Eds.), Computer Synthesized Speech Tech-nologies: Tools for Aiding Impairment. IGI Global, pp. 50–70.
Higginbotham, J., Leshner, G.W., Moulton, B.J., Roark, B., 2002. Theapplication of natural language processing to augmentative andalternative communication. Assistive Technology: The Official Journalof RESNA 24, 14–24.

E. Szekely et al. / Speech Communication 57 (2014) 63–75 75
HTS, 2008. Hts-2.1 toolkit,hmm-based speech synthesis system version2.1, <http://hts.sp.nitech.ac.jp>.
Kawanami, H., Iwami, Y., Toda, T., Saruwatarai, H., Shikano, K., 2003.Gmm-based voice conversion applied to emotional speech synthesis.In: Proceedings of Eurospeech, Geneva.
Kueblbeck, C., Ernst, A., 2006. Face detection and tracking in videosequences using the modified census transformation . Journal on Imageand Vision Computing, 0262-8856 24 (6), 564–572.
Liao, C., Chuang, H., Lai, S., 2012. Learning expression kernels for facialexpression intensity estimation. In: Proceedings of ICASSP, Kyoto.
Light, J., 2003. Shattering the silence: development of communicativecompetence by individuals who use AAC. Communicative Compe-tence for Individuals Who Use AAC: From Research to EffectivePractice, 3–38.
Light, J., Drager, K., 2007. AAC technologies for young children withcomplex communication needs: state of the science and future researchdirections. Augmentative and Alternative Communication 23 (3), 204–216.
MacWhinney, B., Keenan, J., Reinke, P., 1982. The role of arousal inmemory for conversation. Memory & Cognition 10, 308–317. http://dx.doi.org/10.3758/BF03202422.
Massaro, D.W., 2004. From Multisensory Integration to Talking Headsand Language Learning. The MIT Press.
Moubayed, S.A., Beskow, J., Granstrom, B., House, D., 2011. Audio-visual prosody: perception, detection, and synthesis of prominence.Lecture Notes in Computer Science 6456, 55–71.
Mullennix, J.W., Stern, S.E., 2010. Important issues for researchers andpractitioners using computer synthesized speech as an assistive aid. In:Mullennix, J.W., Stern, S.E. (Eds.), Computer Synthesized SpeechTechnologies: Tools for Aiding Impairment. IGI Global, pp. 1–8.
Murray, I.R., Arnott, J.L., 1993. Toward the simulation of emotion insynthetic speech: A review of the literature on human vocal emotion.Journal of the Acoustic Society of America 93, 1097–1108.
Schroder, M., 2004. Speech and emotion research: An overview ofresearch frameworks and a dimensional approach to emotional speechsynthesis. Ph.D. Thesis, PHONUS 7, Research Report of the Instituteof Phonetics, Saarland University.
SHORE, 2012. Shore face detection engine. Fraunhofer Institute, http://www.iis.fraunhofer.de/en/bf/bsy/fue/isyst retreived on: 27.01.2012.
Sprengelmeyer, R., Jentsch, I., 2006. Event related potentials and theperception of intensity in facial expressions. Neuropsychologia 44,2899–2906.
Stern, S.E., Mullennix, J.W., Wilson, S.J., 2002. Effects of perceiveddisability on persuasiveness of computer-synthesized speech. Journalof Applied Psychology 87 (2), 411–417.
Swerts, M., Krahmer, E., 2008. Facial expression and prosodic promi-nence: effects on modality and facial area. Journal of Phonetics 36,219–238.
Szekely, E., Ahmed, Z., Cabral, J.P., Carson-Berndsen, J., 2012. Wink-talk: a demonstration of a multimodal speech synthesis platformlinking facial expressions to expressive synthetic voices. In: Proceed-ings of SLPAT, Montreal.
Szekely, E., Cabral, J.P., Abou-Zleikha, M., Cahill, P., Carson-Berndsen,J., 2012. Evaluating expressive speech synthesis from audiobookcorpora for conversational phrases. In: Proceedings of LREC,Istanbul.
Szekely, E., Cabral, J.P., Cahill, P., Carson-Berndsen, J., 2011. Clusteringexpressive speech styles in audiobooks using glottal source parameters.In: Proceedings of Interspeech, Florence. ISCA, pp. 2409–2412.
Szekely, E., Steiner, I., Ahmed, Z., Carson-Berndsen, J., 2013. Facialexpression-based affective speech translation. Journal on MultimodalUser Interfaces special issue: From Multimodal Analysis to Real-TimeInteractions with Virtual Agents (in press).
Taylor, P., 2009. Text-to-Speech Synthesis. Cambridge University Press.Wilkinson, K., Snell, J., 2011. Facilitating children’s ability to distinguish
symbols for emotions: The effects of background color cues and spatialarrangement of symbols on accuracy and speed of search. AmericanJournal of Speech-Language Pathology 20 (4), 288.
Wisenburn, B., Higginbotham, D., 2008. An AAC application usingspeaking partner speech recognition to automatically produce contex-tually relevant utterances: objective results. Augmentative and Alter-native Communication 24 (2), 100–109.
Zen, H., Toda, T., Nakamura, M., Tokuda, K., 2007. Details of NitechHMM-based Speech Synthesis System for the Blizzard Challenge 2005.In: IEICE Transaction, V.E90-D, No1, pp. 325–333.
Zhao, Y., Peng, D., Wang, L., Chu, M., Chen, Y., Yu, P., Guo, J., 2006.Constructing stylistic synthesis databases from audio books. In:Proceedings of Interspeech, Pittsburgh.




















