
Pic-A-Topic: Efficient Viewing of Informative TV Contents on Travel, Cooking, Food and More
20
Pic-A-Topic: Efficient Viewing of Informative TV Contents on Travel, Cooking, Food and More Tetsuya Sakai ‡ Tatsuya Uehara † Taishi Shimomori † Makoto Koyama ∗ Mika Fukui ∗ ‡ NewsWatch, Inc. † Multimedia Laboratory, Toshiba Corporate R&D Center ∗ Knowledge Media Laboratory, Toshiba Corporate R&D Center [email protected] Abstract Pic-A-Topic is a prototype system designed for enabling the user to view topical segments of recorded TV shows selectively. By analysing closed captions and eletronic program guide texts, it performs topic segmentation and topic sentence selection, and presents a clickable table of contents to the user. Our pre- vious work handled TV shows on travel, and included a user study which suggested that Pic-A-Topic’s average segmentation accuracy at that point was possibly indistinguishable from that of manual seg- mentation. This paper shows that the latest version of Pic-A-Topic is capable of effectively segmenting several TV genres related to travel, cooking, food and talk/variety shows, by means of genre-specific strategies. According to an experiment using 26.5 hours of real Japanese TV shows (25 clips) which subsumes the travel test collection we used earlier (10 clips), Pic-A-Topic’s topic segmentation results for non-travel genres are as accurate as those for travel. We adopt an evaluation method that is more demanding than the one we used in our previous work, but even in terms of this strict measurement, Pic-A-Topic’s accuracy is around 82% of manual performance on average. Moreover, the fusion of cue phrase detection and vocabulary shift detection is very successful for all the genres that we have targeted. Introduction Nowadays, hard disk recorders that can record more than one thousand hours of TV shows are on the market, so that people can watch TV shows at the time of their convenience. But there is a problem: Nobody can spend one thousand hours just watching TV! Thus, unless there are ways to let the user handle recorded TV contents efficiently, the recorded contents will eventually be deleted or forgotten before put to use in any way. Many researchers have tackled the problem of efficient information access for broadcast news [3, 4, 5, 6, 9, 13, 19, 21], by means of news story segmentation, segment/shot retrieval, topic labelling (i.e., assigning a closed-class category) and so on. Broadcast news is clearly an important type of video contents, especially for professionals and for organisations such as companies and governments. Both timely access to incoming news and retrospective access to news archives are required for such applications. Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France
Transcript of Pic-A-Topic: Efficient Viewing of Informative TV Contents on Travel, Cooking, Food and More

Pic-A-Topic: Efficient Viewing of Informative TV Contentson Travel, Cooking, Food and More
Tetsuya Sakai‡ Tatsuya Uehara† Taishi Shimomori†
Makoto Koyama∗ Mika Fukui∗
‡ NewsWatch, Inc.† Multimedia Laboratory, Toshiba Corporate R&D Center
∗ Knowledge Media Laboratory, Toshiba Corporate R&D [email protected]
Abstract
Pic-A-Topic is a prototype system designed for enabling the user to view topical segments of recordedTV shows selectively. By analysing closed captions and eletronic program guide texts, it performs topicsegmentation and topic sentence selection, and presents a clickable table of contents to the user. Our pre-vious work handled TV shows on travel, and included a user study which suggested that Pic-A-Topic’saverage segmentation accuracy at that point was possibly indistinguishable from that of manual seg-mentation. This paper shows that the latest version of Pic-A-Topic is capable of effectively segmentingseveral TV genres related to travel, cooking, food and talk/variety shows, by means of genre-specificstrategies. According to an experiment using 26.5 hours of real Japanese TV shows (25 clips) whichsubsumes the travel test collection we used earlier (10 clips), Pic-A-Topic’s topic segmentation resultsfor non-travel genres are as accurate as those for travel. We adopt an evaluation method that is moredemanding than the one we used in our previous work, but even in terms of this strict measurement,Pic-A-Topic’s accuracy is around 82% of manual performance on average. Moreover, the fusion of cuephrase detection and vocabulary shift detection is very successful for all the genres that we have targeted.
Introduction
Nowadays, hard disk recorders that can record more than one thousand hours of TV showsare on the market, so that people can watch TV shows at the time of their convenience. Butthere is a problem: Nobody can spend one thousand hours just watching TV! Thus, unlessthere are ways to let the user handle recorded TV contents efficiently, the recorded contents willeventually be deleted or forgotten before put to use in any way.
Many researchers have tackled the problem of efficient information access for broadcastnews [3, 4, 5, 6, 9, 13, 19, 21], by means of news story segmentation, segment/shot retrieval,topic labelling (i.e., assigning a closed-class category) and so on. Broadcast news is clearlyan important type of video contents, especially for professionals and for organisations such ascompanies and governments. Both timely access to incoming news and retrospective access tonews archives are required for such applications.
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France

However, at the personal level, there are many other TV genres that need to be considered:drama, comedy, quiz, sport, music, wildlife, cookery, education, and so on. In fact, one couldargue that these types of contents are more important than news for general consumers, as theseare the kinds of contents that tend to accumulate in hard disks, waiting to be accessed by theuser some day, often in vain.
Among the aforementioned “entertaining” kinds of TV genres, we are currently interested inseparable contents. By “separable”, we casually mean that a TV show can be broken down intoseveral segments, where each segment is independent enough to provide the user with a usefulpiece of information. Thus, according to our definition, most factual TV shows are separable,while most dramas and films are not.
For separable TV contents, we believe that topic segmentation is useful for solving the afore-mentioned “hard disk information overload” problem. For example, suppose that there is arecorded TV show that is two-hour long, which contains several distinct topics. If it is possibleto segment the TV show according to topics and provide the user with a clickable table-of-contents interface from which he can select an interesting topic or two, then the user may beable to obtain useful information by viewing the selected segments only, which may only lastfor several minutes.
As a first step to enabling selective viewing of separable contents, we introduced Pic-A-Topicthat can handle TV shows on travel in [17]. The present study reports on its latest version, whichcan handle a wider variety of TV genres that are related to travel, cooking, food and talk/varietyshows by means of genre-specific topic segmentation strategies. According to an experimentusing 26.5 hours of real Japanese TV shows (25 clips) which subsumes the travel test collectionwe used earlier (10 clips), Pic-A-Topic’s topic segmentation results for non-travel genres areas accurate as those for travel. We adopt an evaluation method that is more demanding thanthe one we used in our previous work, but even in terms of this strict measurement, Pic-A-Topic’s accuracy is around 82% of manual performance on average. Moreover, the fusion ofcue phrase detection and vocabulary shift detection is very successful for all the genres that wehave targeted.
Figure 1 provides a couple of screendumps of Pic-A-Topic’s interface. To avoid copyrightproblems, the figure shows a travel video clip created at Toshiba rather than a real TV show.The green bar at the top of each screen is a static area that displays the title of the clip: “Yumeno Tabi (Travel of Dreams)”. The other blue bars represent topics automatically generated byPic-A-Topic, where a topic is casually defined as a video segment that is informative on itsown. (This loose definition essentially implies that what constitutes a topic differs from personto person. Thus the evaluation of our topic segmentation task is harder than that of, say, newsstory segmentation, as we shall see later in this paper.) Each topic is represented by a thumbnailimage and a couple of topic sentences extracted automatically from closed caption texts. Forexample, Topic 5 in Figure 1 discusses a dinner featuring Koshu beef; Topic 6 discusses a walkalong a valley; Topic 7 discusses a place called Kakuenho Peak and the famous rocks nearby;Topic 9 discusses a castle and so on: Rough English translations are provided just for theconvenience of the reader. When a topic is selected by the user, three extra thumbnails (selectedusing simple heuristics) are shown in order to provide more details of that topic. Then, when hepresses an “enter” key, Pic-A-Topic starts playing the video segment. The user can also movedirectly from Topic N to Topic N + 1 or N − 1 by pressing “skip” buttons.
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France

Figure 1. Sample screendumps of Pic-A-Topic.
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France

The remainder of this paper is organised as follows. First, we discuss some previous workrelated to Pic-A-Topic. Next, we describe the TV genres and the Japanese TV shows that wehave targeted. Next, we describe how the latest version of Pic-A-Topic handles these differentgenres. Then, we evaluate Pic-A-Topic’s topic segmentation accuracy using the aforementioneddata. Finally, we provide conclusions and directions for future research.
Related Work
As mentioned earlier, many researchers have tackled the problem of efficient informationaccess from broadcast news video. Below, we briefly mention some studies that handled TVgenres other than news, and point out how our approach differs from them.
Extracting highlights from sports TV programs is a popular research topic, for which audiofeatures [14] or manually transcribed commentaries [22] are often utilised. Aoki, Shimotsujiand Hori [1] used colour and layout analysis for selecting unique keyframes from movies. Morerecently, Aoki [2] reported on a system that can structuralise variety shows based on shot inter-activity, while Hoashi et al. also tackled the topic segmentation problem for news and varietyshows using generic audio and video features [8]. Although these approaches are very interest-ing, we believe that nontextual features alone are not sufficient for identifying topics within aseparable and informative TV content. Lack of language analysis also implies that providingtopic words or topic sentences [17] to the user is difficult. Zhang et al. [23] handled non-newsvideo contents such as travelogue material to perform video parsing, but their method is basedon shot boundary detection, not topic segmentation. As we argued in our previous work [17],we feel that shot boundaries are not suitable for the purpose of viewing a particular topicalsegment.
There exist approaches that effectively combine audio, video and textual evidence. Jasinschiet al. [10] report on a combination-of-evidence system that can deal with talk shows. However,what they refer to as “topic segmentation” appears to be to segment closed captions based onspeaker change markers for the purpose of labelling each “closed caption unit” with either fi-nancial news or talk show. Nitta and Babaguchi [12] structuralise sports programs by analysingboth closed captions and video. Smith and Kanade [20] also combine image and textual evi-dence to handle news and non-news contents: They first select keyphrases from closed captionsbased on tf -idf values, and use them as the basis of a video skim. While their keyphrase ex-traction involves detection of breaks between utterances, it is clear that this does not necessarilycorresond to topical boundaries. Thus, even though their Video Skimming interface may beuseful for viewing the entire “summary” of a TV program, whether it is also useful for selectingand viewing a particular topical segment or two is arguably an open question. More recently,Shibata and Kurohashi [18] reported on a “topic identification” system for the cooking domainusing linguistic features and color distribution. However, their “topics” are closed-class statesof Hidden Markov Models, namely, preparation, sauteing, frying, baking, simmering, boiling,dishing up and steaming. This definition is clearly narrower (or rather, more focused) than ours.It remains to be seen, moreover, how their approach extends to other TV genres.
Target TV Genres and Test Data
In our previous study [17], we used 10 clips of travel TV shows to evaluate Pic-A-Topic’stopic segmentation accuracy and user satisfaction. In order to expand Pic-A-Topic’s scope, wegathered 15 new representative Japanese TV shows, covering several genres that involve talking
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France

in the studio, cooking and eating. In contrast to cooking shows, a TV show on eating is to dowith visiting good restaurants or obtaining good foodstuff, and is not about how to cook dishes.Together with travel TV shows, these TV genres are very popular in Japan, and most of themare separable: small segments of the entire show can often be of use to the user.
Table 1 provides a description of nine well-known Japanese TV series A-I that we selected forcontructing our topic segmentation test collection. A total of 25 clips, each lasting between 30minutes and 2 hours, were collected by recording the broadcast shows and decoding the closedcaption information. This collection subsumes the travel collection we used earlier: Series E-H,containing 10 clips.
The second column of Table 1 shows the EPG “genres” provided by TV stations, where eachprogram can have up to three genre tags. The EPG genres form a two-level hierarchy: Forexample, Series B has only one genre tag: “gourmet/cooking” which is categorised under “in-formation/long variety”. We quickly discovered, however, that the EPG genres are not alwaysuseful. For example, while both Series B and C are tagged with “gourmet/cooking” only, theyin fact have very little in common: Series B is a typical cooking show consisting almost entirelyof studio shots, while Series C is a “countdown” show which not only concerns food and restau-rants but also “must-visit” spots such as parks and memorials in a particular city in Japan. Notealso that Series H and I are tagged with “subtitles”, which indicates that subtitle information isavailable with the programs: The tag has nothing to do with genres. Because of this nature ofthe EPG genres, Pic-A-Topic uses its own genre taxonomy which is a little more fine-grained,and classifies a given TV program based on both the EPG genres and the closed caption textusing simple pattern-matching heuristics. We shall describe this feature in the next section.
The third column of Table 1 briefly describes each TV series. It can be observed that weare handling a relatively diverse range of TV shows, which suggests that genre-specific topicsegmentation strategies may be effective.
How Pic-A-Topic Works
Overview
Figure 2 provides an overview of the Pic-A-Topic system. As can be seen, in addition to thetopic segmentation, topic sentence selection and table-of-contents creation modules [17], wenow have a pilot genre identification module to handle several different TV genres.
The input to the genre identification module are Japanese closed captions and ElectronicProgram Guide (EPG) text. It identifies the genre of a given TV program according to Pic-A-Topic’s own genre taxonomy. Details will follow.
The input to the topic segmentation component are Japanese closed captions and EPG text, aswell as the result of genre identification. Currently, the EPG data (if available) is used only forthe purpose of extracting names of TV celebrities, in order to automatically augment our namedentity recognition dictionaries used in vocabulary shift detection. This is because celebritiessuch as comedians tend to have anomalous names, which named entity recognition tend tooverlook (e.g., “Beat Takeshi” and “Papaya Suzuki”). The topic segmentation component per-forms both cue phrase detection and vocabulary shift detection, and then finally fuses the tworesults. Details will follow.
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France
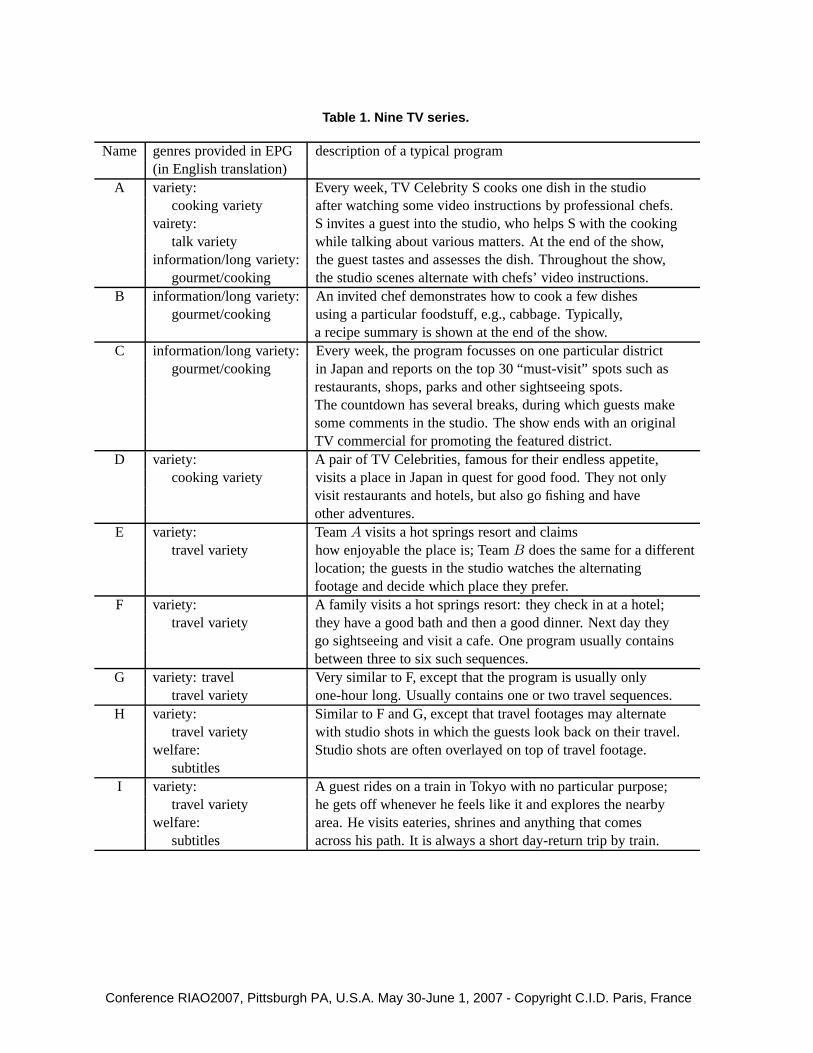
Table 1. Nine TV series.
Name genres provided in EPG description of a typical program(in English translation)
A variety: Every week, TV Celebrity S cooks one dish in the studiocooking variety after watching some video instructions by professional chefs.
vairety: S invites a guest into the studio, who helps S with the cookingtalk variety while talking about various matters. At the end of the show,
information/long variety: the guest tastes and assesses the dish. Throughout the show,gourmet/cooking the studio scenes alternate with chefs’ video instructions.
B information/long variety: An invited chef demonstrates how to cook a few dishesgourmet/cooking using a particular foodstuff, e.g., cabbage. Typically,
a recipe summary is shown at the end of the show.C information/long variety: Every week, the program focusses on one particular district
gourmet/cooking in Japan and reports on the top 30 “must-visit” spots such asrestaurants, shops, parks and other sightseeing spots.The countdown has several breaks, during which guests makesome comments in the studio. The show ends with an originalTV commercial for promoting the featured district.
D variety: A pair of TV Celebrities, famous for their endless appetite,cooking variety visits a place in Japan in quest for good food. They not only
visit restaurants and hotels, but also go fishing and haveother adventures.
E variety: Team A visits a hot springs resort and claimstravel variety how enjoyable the place is; Team B does the same for a different
location; the guests in the studio watches the alternatingfootage and decide which place they prefer.
F variety: A family visits a hot springs resort: they check in at a hotel;travel variety they have a good bath and then a good dinner. Next day they
go sightseeing and visit a cafe. One program usually containsbetween three to six such sequences.
G variety: travel Very similar to F, except that the program is usually onlytravel variety one-hour long. Usually contains one or two travel sequences.
H variety: Similar to F and G, except that travel footages may alternatetravel variety with studio shots in which the guests look back on their travel.
welfare: Studio shots are often overlayed on top of travel footage.subtitles
I variety: A guest rides on a train in Tokyo with no particular purpose;travel variety he gets off whenever he feels like it and explores the nearby
welfare: area. He visits eateries, shrines and anything that comessubtitles across his path. It is always a short day-return trip by train.
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France

Figure 2. Pic-A-Topic configuration.
The input to the topic sentence selection component are the result of topic segmentation andthe raw closed caption text. For each topical segment, this component first selects topic wordsbased on a relevance feedback algorithm used widely in information retrieval. Subsequently,it selects topic sentences based on the weights of the aforementioned topic words. Note thatthis functionality is different from “topic labelling” [5] which assigns a closed-class category to(say) a news story. Topic Sentence Selection can assign any text extracted from closed captions,and are more flexible. As the focus of the present study is topic segmentation rather than topicsentence selection, we refer the reader to our previous work [17] for more details on this module.
The input to the table-of-contents creation component are the results of topic segmentationand topic sentence selection. This component performs several postprocessing functions, in-cluding keyframe selection, thumbnail creation and start/end time adjustment [17]. Becausethere may be a time lag between the closed-caption timestamps and the actual audio/video, thetimestamps output by topic segmentation are heuristically (but automatically) adjusted. An ex-ample heuristic would be to avoid playing the video from the middle of an utterance, since thiswould be neither informative nor user-friendly.
Genre Identification
As we mentioned earlier, we found that the EPG genres provided by the TV stations donot sufficiently reflect the nature of the TV show contents. We therefore devised our ownpreliminary TV genre taxonomy, shown in Table 2. As can be seen, we set up individual genresfor TV series A-E, as their characteristics were quite different from one another. In constrast,we found that the travel shows are quite similar in nature to one another, despite the fact thatthey come from different TV stations. (Series I is perhaps an exception, in that it is more aboutexploring one’s neighbourhood in just one day rather than travel. However, we did not set upan individual genre for I, as we found that it was difficult to automatically separate I from theother travel shows using our simple genre identication heuristics described below.)
Our current genre identification module is a simple set of hand-crafted if-then rules that relyon the more coarse-grained EPG genres and closed caption text. Some of the rules are shown in
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France

Table 2. Pic-A-Topic’s preliminary genre taxnonomy.genre name TV series descriptionCOOK/TALK A a cross between a cooking show and a talk showCOOK B traditional cooking showEAT/COUNTDOWN C countdown show on foodEAT D show on food and restaurantsTRAVEL/COMPETE E travel show involving two competing teamsTRAVEL F,G,H,I travel show
if EPGgenre includes “gourmet/cooking”if EPGgenre includes “talk variety”
genre=COOK/TRAVELelse genre=COOK
if EPGgenre includes “cooking variety”if closed caption text contains countdown-type expressions (e.g., “No. 1”, “Top 30”)
genre=EAT/COUNTDOWNelse genre=EAT
Figure 3. Sample rules for genre identification.
Figure 3. Because of the limited scale of our data set, the classification accuracy of this simpleset of rules is currently 100%. However, if we expand our target TV genres, we will have toexpand our genre taxonomy accordingly and to devise more sophisticated ways to classify TVshows into genres. This issue will be pursued in our future work.
Topic Segmentation
The task of topic segmentation is to take the timestamps in the closed captions as candidatesand output a list of selected timestamps that are likely to represent topical boundaries, togetherwith confidence scores. We assume that the number of required topical segments will be givenfrom outside, based on constraints such as the size and the resolution of the TV screen. Asmentioned earlier, our topic segmentation module can perform both cue phrase detection andvocabulary shift detection.
Our first approach to topic segmentation, cue phrase detection, relies on Semantic Role Anal-ysis (SRA) [15, 16]. SRA first performs morphological analysis, breaks the text into fragments(which in our case are sentences), and assigns one or more fragment labels to each fragmentbased on hand-written pattern-matching rules. A heuristically-determined weight is assigned toeach rule.
We have devised a separate set of cue phrase detection rules for each genre. For example, ourfragment labels for the TRAVEL genre include [17]:
CONNECTIVE This covers expressions such as “as a starter”, “at last” and “furthermore”.(Hereafter, all examples of Japanese words and phrases will be given in English transla-tions.)
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France

MOVEMENT This covers verbs such as “head for” and “visit”.
TIME ELAPSED This covers expressions that refer to the passage of time, such as “nextmorning” and “lunchtime”.
Whereas, our fragment labels for COOK includes:
CONNECTIVE This is similar to that for travel.
NEWDISH This covers expressions that introduce a new dish, such as “main course”, “dessert”and “next dish”.
RECIPE This covers expressions that indicate recipes and foodstuff.
For each candidate boundary (i.e., timestamp), cue phrase detection calculates the raw con-fidence score by summing up the weights of all rules that matched the corresponding sentence.Finally, it obtains the normalised confidence scores c by dividing the raw confidence scoreswith the maximum one among all candidates.
The result of cue phrase detection may be used on its own for defining topical segments.In this case, we sieve the topical boundary timestamps before handing them to topic sentenceselection: For each timestamp s (in milliseconds) obtained, we examine all its “neighbours”(i.e., timestamps that lie within [s − 30000, s + 30000]), and overwrite its confidence score cwith zero if any of the neighbours has a higher confidence score than s. This is for obtaining“local optimum” timestamps which are at least 30 seconds apart from one another.
Our second approach to topic segmentation, vocabulary shift detection, is similar in spirit tostandard topic segmentation algorithms such as TextTiling [7]. Although these algorithms orig-inally designed for “written” text are often directly applied to closed captions (e.g., [11]), ourpreliminary experiments suggested that they are not satisfactory for analysing closed-captionswhich mainly consist of dialogues. Since closed captions contain timestamps, our algorithmuses timestamps explicitly and extensively. Moreover, as our preliminary experiments showedthat domain specific knowledge is effective for some of our TV genres, we use named entityrecognition tuned specifically for each of these genres. Our algorithm is described below.
We first analyse the closed-caption text and extract morphemes and named entities, which wecollectively refer to as terms. We have over one hundred generic named entity classes coveringperson names, place names, organization names, numbers and so on, originally developed foropen-domain question answering [15]. In addition, we have some domain-specific named entityclasses for some of the genres. For example, for TRAVEL, we have [17]:
TRAVEL ACTIVITY This class covers typical activities of a tourist, such as “dinner”, “walk”and “rest”.
TRAVEL ATTRACTION CLASS This class covers concepts that represent tourist attrac-tions and events such as “sightseeing spot”, “park”, “show” and “festival”. Note that thisis not for detecting specific instances such as “Tokyo Disneyland”.
TRAVEL HOTEL CLASS This class covers words such as “hotel” and “inn”.
TRAVEL BATH CLASS This class covers words such as “hot spring” and “bath”.
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France

Let t denote a term in a given closed-caption text, and s denote a candidate topical boundary(represented by a timestamp in milliseconds). For a fixed widow size S, let WL denote the setof terms whose timestamps (by which we actually mean start times) lie within [s − S, s), andWR denote the set of terms whose timestamps lie within [s, s + S). For each t ∈ WL∪WR−WL∩WR (i.e., term included in either WL or WR but not both), we define a downweightingfactor dw(t) as follows:
dw(t) = max{dwdomain(t), dwgeneric(t), dwmorph(t)} (1)
wheredwdomain(t) = DWdomain if t is a domain-specific named entity; otherwise 0;dwgeneric(t) = DWgeneric if t is a generic named entity; otherwise 0;dwmorph(t) = DWmorph if t is a single morpheme; otherwise 0.
Here, DWdomain, DWgeneric and DWmorph are tuning constants between 0 and 1.Next, for each t ∈ WL ∪ WR − WL ∩ WR whose timestamp is s(t), we compute:
f(t) = 0.5 − 0.5 cosπ(s(t) − s
S+ 1) . (2)
f(t) takes the maximum value of 1 when s(t) = s and the minumum value of 0 when |s(t)−s| =S. That is, f(t) gets smaller as the term moves away (along the timestamp) from the candidateboundary.
Meanwhile, for each t ∈ WL ∩ WR, let sWL(t) and sWR(t) denote the timestamps of t thatcorrespond to WL and WR. (If there are multiple occurrences within the interval covered byWL or WR, then we take the timestamp that is closest to s.) Then we compute:
g(t) = 0.5 − 0.5 cosπ(sWR(t) − sWL(t)
2S+ 1) . (3)
If sWL(t) and sWR(t) are close (i.e., the term occurs just before the candidate boundary and justafter it), then g(t) is close to 1. If sWR(t) − sWL(t) is close to 2S (i.e., the two occurrences ofthe same term are far apart), then g(t) is close to 0.
The term weighting functions f(t) and g(t) have been designed in order to make the algorithmrobust to the choice of window size S, which is currently fixed at 30 seconds. We currently donot use global statistics such as idf (e.g., [20]). Thus our vocabulary shift detection algorithmis theoretically applicable to real-time processing of stream data as well.
Based on dw(t), f(t) and g(t) as well as two positive parameters α and β, we compute thenovelty of each candidate boundary s as follows:
novelty =∑
t∈WR−WL
dw(t) ∗ f(t) + α ∗ ∑
t∈WL−WR
dw(t) ∗ f(t) − β ∗ ∑
t∈WL∩WR
g(t) (4)
Thus, a candidate boundary receives a high novelty score if WR has many terms that are notin WL (and vice versa) and if WL and WR have few terms in common. Using α < 1 impliesthat WR and WL are not treated symmetrically, unlike the cosine-based segmentation methods(e.g., [7, 9]). This corresponds to the intuition that terms that occur after the candidate boundarymay be more important than those that occur before it. This feature proved effective for someof our genres.
The final confidence score v based on vocabulary shift is given by:
v =novelty − minnovelty
maxnovelty − minnovelty(5)
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France
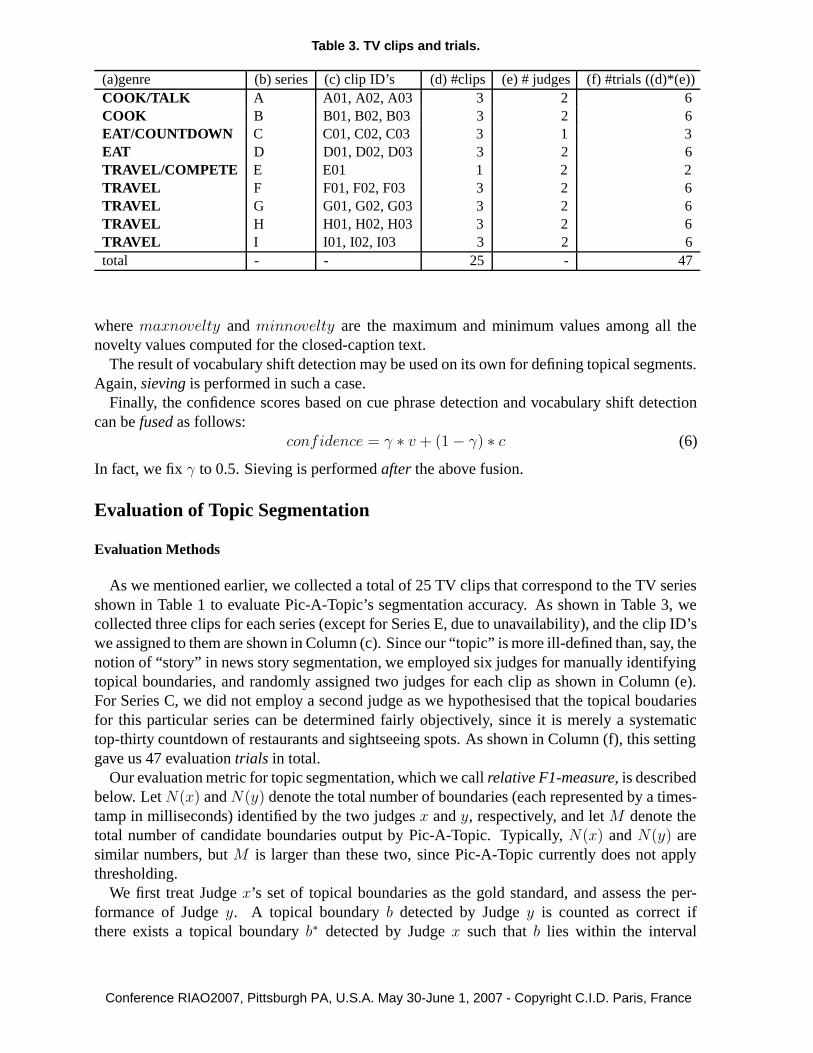
Table 3. TV clips and trials.
(a)genre (b) series (c) clip ID’s (d) #clips (e) # judges (f) #trials ((d)*(e))COOK/TALK A A01, A02, A03 3 2 6COOK B B01, B02, B03 3 2 6EAT/COUNTDOWN C C01, C02, C03 3 1 3EAT D D01, D02, D03 3 2 6TRAVEL/COMPETE E E01 1 2 2TRAVEL F F01, F02, F03 3 2 6TRAVEL G G01, G02, G03 3 2 6TRAVEL H H01, H02, H03 3 2 6TRAVEL I I01, I02, I03 3 2 6total - - 25 - 47
where maxnovelty and minnovelty are the maximum and minimum values among all thenovelty values computed for the closed-caption text.
The result of vocabulary shift detection may be used on its own for defining topical segments.Again, sieving is performed in such a case.
Finally, the confidence scores based on cue phrase detection and vocabulary shift detectioncan be fused as follows:
confidence = γ ∗ v + (1 − γ) ∗ c (6)
In fact, we fix γ to 0.5. Sieving is performed after the above fusion.
Evaluation of Topic Segmentation
Evaluation Methods
As we mentioned earlier, we collected a total of 25 TV clips that correspond to the TV seriesshown in Table 1 to evaluate Pic-A-Topic’s segmentation accuracy. As shown in Table 3, wecollected three clips for each series (except for Series E, due to unavailability), and the clip ID’swe assigned to them are shown in Column (c). Since our “topic” is more ill-defined than, say, thenotion of “story” in news story segmentation, we employed six judges for manually identifyingtopical boundaries, and randomly assigned two judges for each clip as shown in Column (e).For Series C, we did not employ a second judge as we hypothesised that the topical boudariesfor this particular series can be determined fairly objectively, since it is merely a systematictop-thirty countdown of restaurants and sightseeing spots. As shown in Column (f), this settinggave us 47 evaluation trials in total.
Our evaluation metric for topic segmentation, which we call relative F1-measure, is describedbelow. Let N(x) and N(y) denote the total number of boundaries (each represented by a times-tamp in milliseconds) identified by the two judges x and y, respectively, and let M denote thetotal number of candidate boundaries output by Pic-A-Topic. Typically, N(x) and N(y) aresimilar numbers, but M is larger than these two, since Pic-A-Topic currently does not applythresholding.
We first treat Judge x’s set of topical boundaries as the gold standard, and assess the per-formance of Judge y. A topical boundary b detected by Judge y is counted as correct ifthere exists a topical boundary b∗ detected by Judge x such that b lies within the interval
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France

[b∗ − 10000, b∗ + 10000]. (At most one boundary can be counted as correct for each gold-standard interval: If there are two or more boundaries that lie within a single gold-standardinterval, then only the one that is closest to the center of the interval is counted as correct.)Let nx(y) denote the number of “correct” boundaries counted in this way. Then, we computeprecision, recall and F1-measure of Judge y as follows:
precisionx(y) = nx(y)/N(y)
recallx(y) = nx(y)/N(x)
F1-measurex(y) =2 ∗ precisionx(y) ∗ recallx(y)
precisionx(y) + recallx(y)
As we mentioned earlier, however, N(x) and N(y) are generally very similar numbers, if notalways identical. Thus, in practice, precision and recall values are very similar, and thereforeF1-measure, which is the harmonic mean of precision and recall, is also very similar to thesevalues. For this reason, this paper focusses on F1-measure. For short, we may refer to F1-measure as “F1”.
The above F1-measure represents the performance of Judge y when the topical boundariesset by Judge x is assumed to be the gold standard. This can be regarded as a performance upper-bound for our system, although our system may possibly outperform it especially if the degreeof inter-judge agreement is low. To see how well Pic-A-Topic does in comparison to Judge ywhen Judge x is the gold standard, we first compute the absolute F1-measure of the system asfollows. Recall that Pic-A-Topic outputs M (> N(x), N(y)) candidate boundaries with differ-ent confidence values. Hence, in order to compare Pic-A-Topic directly with Judge y, we sortthe M candidates in decreasing order of confidence and take the top N(y). Then we evaluatethese N(y) boundaries in exactly the same way as described above. Thus, let nx(system) de-note the number of “correct” boundaries among the top N(y) candidates output by Pic-A-Topic.Then, its absolute F1 is computed as:
precisionx(system) = nx(system)/N(y)
recallx(system) = nx(system)/N(x)
F1-measurex(system) =2 ∗ precisionx(system) ∗ recallx(system)
precisionx(system) + recallx(system)
Finally, we directly compare Pic-A-Topic with Judge y, assuming that Judge x defines thegold standard, by computing the relative F1-measure:
RelativeF1-measurex(system) = F1-measurex(system)/F1-measurex(y)
Similarly, RelativeF1-measurey(system) can be computed, by treating Judge y’s boundariesas the gold standard instead. Note that if the two judges agree perfectly with each other, thentheir absolute F1 values would equal one, and therefore Pic-A-Topic’s relative F1 would equalits absolute F1.
We use macroaveraging rather than microaveraging: That is, we compute performance valuesfor each clip first, and then take the average across all data. This is because we prefer to weightall clips equally rather than to weight all topical boundaries equally.
In our previous work using travel TV shows [17], we employed four judges per clip, andcounted a candidate boundary as correct if it agreed with at least one of three judges. Our new
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France

evaluation method is arguably more intuitive and substantially more demanding: According toour previous lenient measurement, Pic-A-Topic’s mean relative F1 was 82% for travel data [17];however, according to our new strict measurement, the mean relative F1 of the same system forthe same data is only 62%. As we shall see in the next section, the latest version of Pic-A-Topicachieves 82% mean relative F1 even though we use the strict measurement and cover severalgenres.
It should also be noted that lack of standard test collections for diverse TV genres currentlyprevents us from conducting more large-scale experiments, although, to our knowlegdge, ourown data set covers more genres than those used in most studies.
Results and Discussions
Figure 4 shows the absolute per-trial F1 values for our data set, using cue phrase detection(c), vocabulary shift detection (v) and a fusion of the two (c+v). For example, A01x representsthe trial using Clip A01 with Judge x as the gold standard. The benefit of fusion is clear: thefusion performance is better than either of the pre-fusion performances (i.e., c or v) for as manyas 32 trials out of 47. According to a two-tailed sign test, fusion is significantly better than thecue phrase detection and vocabulary shift detection components at α = 0.011.
Figure 5 shows the absolute and relative per-trial F1 values for our data after fusion, togetherwith the absolute F1 values of manual segmentation. It can be observed that Pic-A-Topic ac-tually outperforms Judge y for clips B03, D01 and E01 when Judge x is treated as the goldstandard. (Note that Judge y is generally a different person for different clips.) Moreover,Pic-A-Topic’s relative F1 values for non-travel genres (series A-D) are comparable to those fortravel (series E-I). Also, recall that we assigned only one judge per clip for Series C: The man-ual performance for this particular series is always 100%, and therefore Pic-A-Topic’s relativeF1 equals absolute F1 for this series.
Table 4 summarises the above figures from the viewpoint of genres. For example, for theCOOK/TALK genre, the mean absolute F1 of cue phrase detection (c) is only 30%, which is33% in mean relative F1; vocabulary shift detection (v) achieves 57% in mean absolute F1 and62% in mean relative F1; fusion (c + v) achieves 69% in mean absolute F1 and 74% in meanrelative F1. Note that the fusion performance is higher than either of the pre-fusion ones for allgenres. For the entire data set, cue phrase detection achieves 49% in mean absolute F1 and 67%in mean relative F1; vocabulary shift detection achieves 39% in mean absolute F1 and 51% inmean relative F1; and fusion achieves 61% in mean absolute F1 and 82% in mean relative F1.Thus the overall performance has also been boosted substantially through fusion.
On the other hand, it can be observed that the performance of vocabulary shift detection forthe EAT genre is very low. Moreover, the absolute F1 for this genre is only 50%, even thoughthe corresponding relative F1 is 95%. The discrepancy between these two values arises fromconsiderable inter-judge disagreements for the EAT genre (i.e., Series D): Figure 5 shows thatit is very hard even for a man to produce a topic segmentation output that agrees well with the“gold standard” for Series D. In each episode of Series D, two TV celebrities keep travellingfrom one place to another looking for something good to eat, and where the boundary liesbetween Food 1 and Food 2 or Place 1 and Place 2 is indeed controversial. For this kind of TVshow, we should probably aim for user-biased topic segmentation rather than for perfect generic
1The use of two judges per clip violates the i.i.d. assumption for our data, so significance tests should probablybe performed using those based on only one of the judges. We have a total of 25 trials based on the first judge:Fusion outperforms the two components for 17 trials while hurting only three trials, which is still statisticallyhighly significant.
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France

topic segmentation, as our ultimate goal is to aid every user in efficient viewing of recorded TVshows. We would like to tackle this problem in our future work.
We now take a closer look at some of our successful and unsuccessful trials.Table 5 provides the details of our most successful trials, whose relative F1 values were
100% or even higher. The table includes the aforementioned three trials for which Pic-A-Topicactually outperformed manual performance. For example, for Trial B03y, the absolute F1 ofJudge x is 77%; the relative F1 of cue phrase detection is 81%, while that of vocabulary shiftdetection is only 19%; after fusion, Pic-A-Topic’s relative F1 for this trial is 100%.
Figure 6 shows how fusion worked for Trial B03y shown in Table 5: The top left graphcompares cue phrase detection with Judge y (i.e., the gold standard); the bottom left graphcompares vocabulary shift detection with Judge y; the top right graph compares Judge x withJudge y; finally, the bottom right graph compares fusion with Judge y. The vertical axis ofeach graph represents the timestamps, and the horizontal axis represents the number of topicalboundaries identified. For this clip, Judge y identified six boundaries, while Judge x identifiedseven boundaries, as shown in the top right graph. The two judged agreed on five trials, whichare indicated by circles on Judge y’s graph. Hence, Judge x’s recall and precision are 5/6 and5/7, respectively, and therefore his F1 is 77% as shown in Table 5. The top left graph of Figure 6shows that cue phrase detection successfully detected Judge y’s boundaries No.1, No.3, No.5and No.6; the bottom left graph shows that vocabulary shift detection detected boundary No.4only; finally, the bottom right graph shows that, after fusion, all of these five boundaries weresuccessfully detected. As a result, Pic-A-Topic is on a par with Judge x. This example suggeststhat cue phrase detection and vocabulary shift detection can be complementary: They can finddifferent correct boundaries.
Table 6 provides the details of our trials for which fusion failed. Let c, v and c + v denotethe performance of cue phrase detection, vocabulary shift detection and fusion, respectively; wesay that “fusion failed” if c + v < max(c, v). However, the last column of this table shows thatfusion is never a disaster: Even when it fails, the difference between the fusion performanceand max(c, v) is very small. For example, for Trial A03y, the absolute F1 of vocabulary shiftdetection is 73%, while the corresponding fusion performance is only 67%, which is only 6%lower. Note that the corresponding cue phrase detection performance is only 27%. In summary,fusion rarely hurts performance, and even when it does, it hurts very little.
Figure 7 depicts how fusion fails for Trial D02y shown in Table 6, in a way similar to Figure 6.As the top right graph shows, Judge y (the gold standard) identified as many as 20 topicalboundaries, while Judge x identified only 11. Thus, as mentioned earlier, there are many inter-judge disagreements for Series D. The top left graph shows that cue phrase detection managedto detect boundaries No.1, No.2, No.5, No.12, No.13, No.14 and No.15, and therefore its recalland precision are 7/20 and 7/11, respectively. On the other hand, vocabulary shift detectionwas no good for this clip: it only detected boundary No.2, and therefore its recall and precisionare 1/20 and 1/11, respectively. Finally, as the bottom right graph shows, Pic-A-Topic missedboundary No.5 as a result of fusion, and therefore its final recall and precision are 6/20 and6/11. Hence the absolute F1 for this trial is 39%, as shown in Table 6. In this example, thereis clearly too much noise in the vocabulary shift detection output. There certainly is room forimprovement for this module.
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France
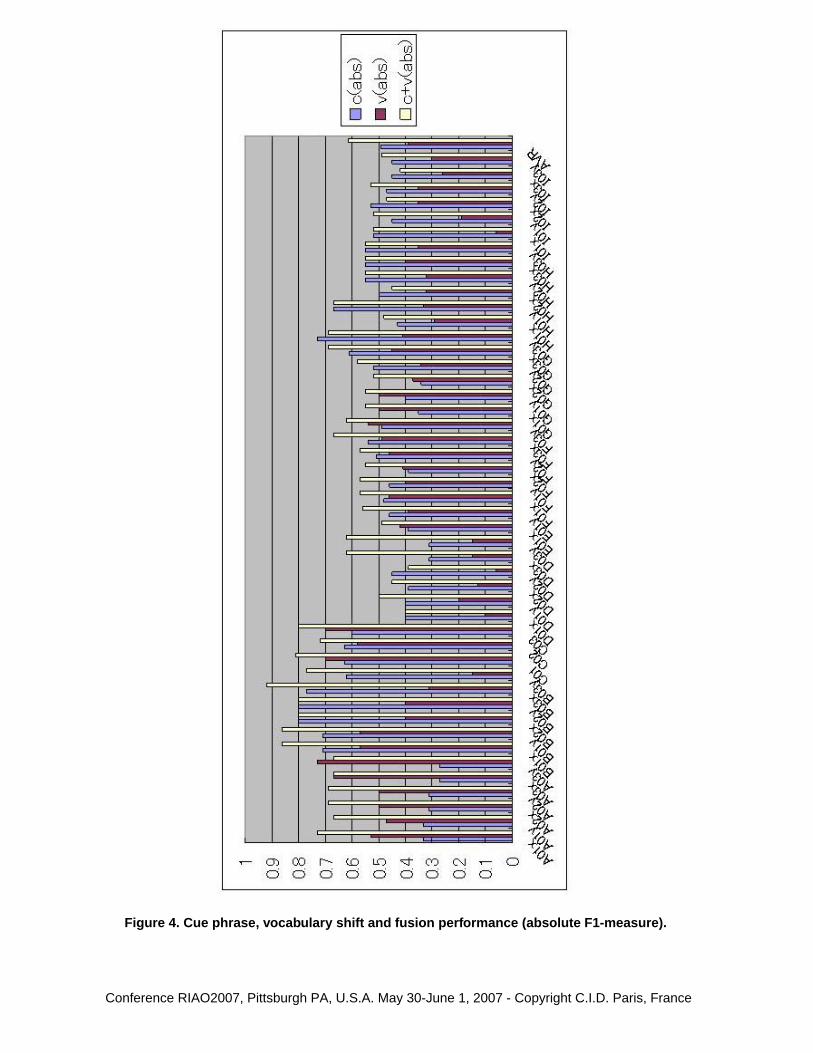
Figure 4. Cue phrase, vocabulary shift and fusion performance (absolute F1-measure).
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France
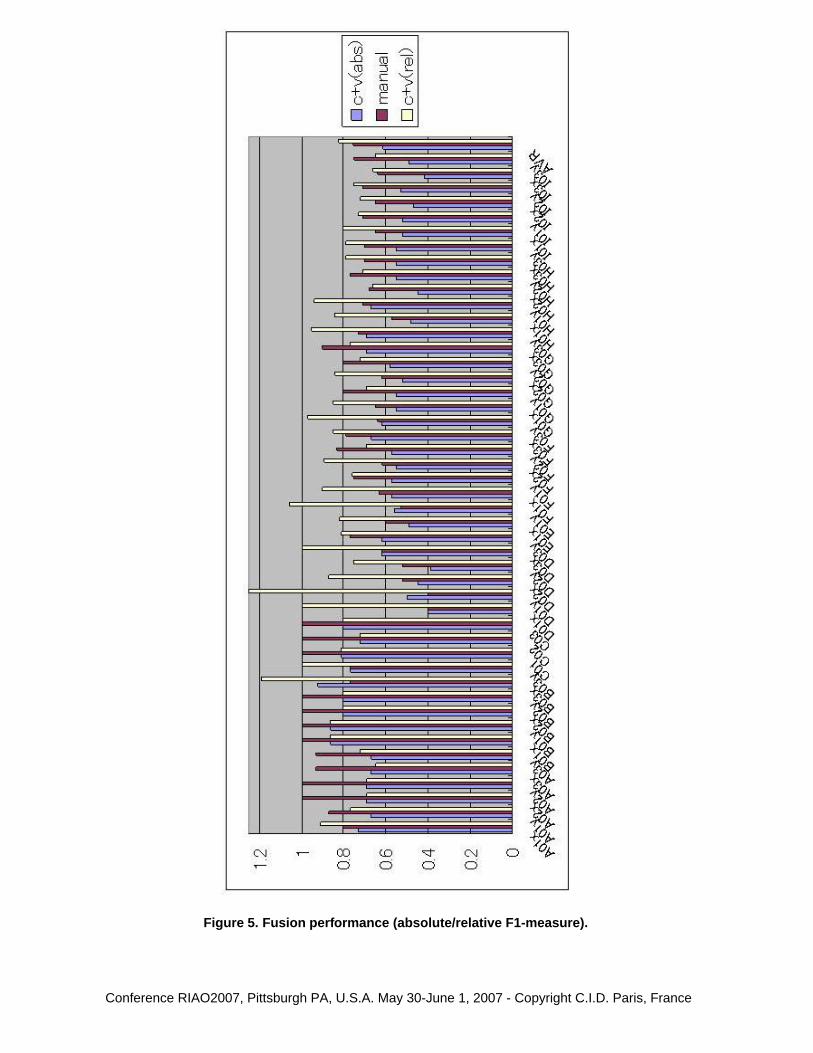
Figure 5. Fusion performance (absolute/relative F1-measure).
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France
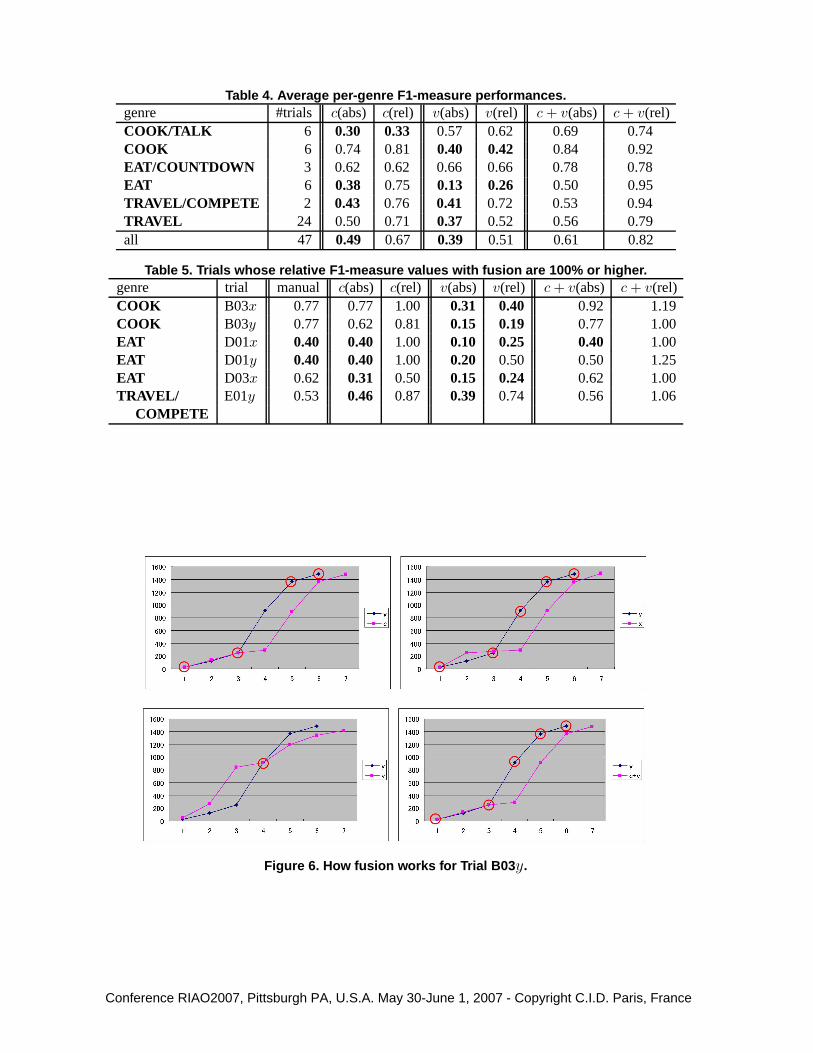
Table 4. Average per-genre F1-measure performances.genre #trials c(abs) c(rel) v(abs) v(rel) c + v(abs) c + v(rel)COOK/TALK 6 0.30 0.33 0.57 0.62 0.69 0.74COOK 6 0.74 0.81 0.40 0.42 0.84 0.92EAT/COUNTDOWN 3 0.62 0.62 0.66 0.66 0.78 0.78EAT 6 0.38 0.75 0.13 0.26 0.50 0.95TRAVEL/COMPETE 2 0.43 0.76 0.41 0.72 0.53 0.94TRAVEL 24 0.50 0.71 0.37 0.52 0.56 0.79all 47 0.49 0.67 0.39 0.51 0.61 0.82
Table 5. Trials whose relative F1-measure values with fusion are 100% or higher.genre trial manual c(abs) c(rel) v(abs) v(rel) c + v(abs) c + v(rel)COOK B03x 0.77 0.77 1.00 0.31 0.40 0.92 1.19COOK B03y 0.77 0.62 0.81 0.15 0.19 0.77 1.00EAT D01x 0.40 0.40 1.00 0.10 0.25 0.40 1.00EAT D01y 0.40 0.40 1.00 0.20 0.50 0.50 1.25EAT D03x 0.62 0.31 0.50 0.15 0.24 0.62 1.00TRAVEL/ E01y 0.53 0.46 0.87 0.39 0.74 0.56 1.06
COMPETE
Figure 6. How fusion works for Trial B03y.
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France

Table 6. Fusion failures (Absolute F1-measure).genre trial c(abs) v(abs) c + v(abs) c + v −max(c, v)COOK/TALK A03y 0.27 0.73 0.67 −0.06EAT D02y 0.45 0.06 0.39 −0.06TRAVEL G03y 0.73 0.41 0.69 −0.04TRAVEL H02x 0.50 0.32 0.45 −0.05TRAVEL I02x 0.53 0.35 0.47 −0.06TRAVEL I03x 0.45 0.26 0.42 −0.03
Figure 7. How vocabulary shift and fusion fail for Trial D02y.
Conclusions and Future Work
This paper showed that the latest version of Pic-A-Topic is capable of segmenting severalTV genres related to travel, cooking, food and talk/variety shows using genre-specific strate-gies. Using 26.5 hours of real Japanese TV shows (25 clips), we showed that Pic-A-Topic’stopic segmentation results for non-travel genres are as accurate as those for travel. We adoptedan evaluation method that is more demanding than the one we used in our previous work, buteven in terms of this strict measurement, Pic-A-Topic’s accuracy is around 82% of manualperformance on average. In our previous work, we used a substantially less effective versionof Pic-A-Topic (62% in mean relative F1-measure according to our strict measurement), andconducted a preliminary user evaluation which suggested that Pic-A-Topic’s average topic seg-mentation performance at that point was possibly indistinguishable from a manual one. It istherefore possible that the latest version of Pic-A-Topic provides accuracy that is practically
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France

more than sufficient on average, although more extensive user studies are required to verify thisclaim. Moreover, it is clear that the fusion of cue phrase detection and vocabulary shift detectionis very successful for all the genres that we have targeted, although we need to make vocabularyshift detection more robust to change of genres.
Our current list of future work includes:
• Expanding our TV genres further and to build a genre identification module with a widercoverage;
• Incorporating video and audio features to our topic segmentation algorithm;
• Automatic per-genre, per-user optimisation of topic segmentation parameters, especiallythose for vocabulary shift detection;
• A large-scale user evaluation of topic segmentation, topic sentence selection and the entiretable-of-contents interface;
• Applying Pic-A-Topic modules to other applications, such as selective downloading ofvideo contents for mobile phones.
References
[1] Aoki, H., Shimotsuji, S. and Hori, O. (1996). A Shot Classification Method of SelectingKey-Frames for Video Browsing. In Proceedings of ACM Multimedia ’96.
[2] Aoki, H. (2006). High-Speed Topic Organizer of TV Shows Using Video Dialog Detec-tion. Systems and Computers in Japan, 37(6), 44–54.
[3] Boykin, S. and Merlino, A. (2000). Machine Learning of Event Segmentation for Newson Demand. Communications of the ACM, 43(2), 35–41.
[4] Chua, T.-S. et al. (2004). Story Boundary Detection in Large Broadcast News VideoArchives - Techniques, Experience and Trends. In Proceedings of ACM Multimedia 2004.
[5] Hauptmann, A. G. and Lee, D. (1998). Topic Labeling of Broadcast News Stories in theInformedia Digital Video Library. In Proceedings of ACM Digital Libraries ’98.
[6] Hauptmann, A. G. and Witbrock, M. J. (1998). Story Segmentation and Detection of Com-mercials in Broadcast News Video. Advances in Digital Libraries ’98.
[7] Hearst, M. A. (1994). Multi-Paragraph Segmentation of Expository Text. In Proceedingsof ACL ’94, 9–16.
[8] Hoashi, K. et al. (2006). Video Story Segmentation Based on Generic Low-Level Features.IEICE Transactions on Information and Systems, J86-D-II-8, 2305–2314.
[9] Ide, I. et al. (2003). Threading News Video Topics. ACM SIGMM Workshop on MultimediaInformation Retrieval (MIR 2003), 239–246.
[10] Jasinschi, R. S. et al. (2001). Integrated Multimedia Processing for Topic Segmentationand Classification. In Proceedings of IEEE ICIP.
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France

[11] Miyamori, H. and Tanaka, K. (2005). Webified Video: Media Conversion from TV Pro-gram to Web Content and their Integrated Viewing Method. In Proceedings of ACM WWW2005.
[12] Nitta, N. and Babaguchi, N. (2003). Story Segmentation of Broadcasted Sports Videosfor Semantic Content Acquisition (in Japanese). IEICE Transactions on Information andSystems, J86-D-II-8, 1222–1233.
[13] Over, P., Kraaij, W. and Smeaton, A. F. (2005). TRECVID 2005 - An Introduction. InProceedings of TREC 2005 Proceedings.
[14] Rui, Y., Gupta, A. and Acero, A. (2000). Automatically Extracting Highlights for TVBaseball Programs. In Proceedings of ACM Multimedia 2000.
[15] Sakai, T. et al. (2004). ASKMi: A Japanese Question Answering System based on Se-mantic Role Analysis. In Proceedings of RIAO 2004, 215–231.
[16] Sakai, T. (2005). Advanced Technologies for Information Access. International Journalof Computer Processing of Oriental Languages, 18(2), 95–113.
[17] Sakai, T., Uehara, T., Sumita, K. and Shimomori, T. (2006). Pic-A-Topic: Gathering In-formation Efficiently from Recorded TV Shows on Travel. AIRS 2006, Lecture Notes inComputer Science 4182, 374–389, Springer-Verlag.
[18] Shibata, T. and Kurohashi, S. (2006). Unsupervised Topic Identification by IntegratingLinguistic and Visual Information Based on Hidden Markov Models, COLING/ACL 2006Main Conference Poster Sessions, 755–762.
[19] Smeaton, A. F. et al. (2004). The Fıschlar-News-Stories System: Personalised Access toan Archive of TV News. In Proceedings of RIAO 2004.
[20] Smith, M. A. and Kanade, T. (1998). Video Skimming and Characterization through theCombination of Image and Language Understanding. In Proceedings IEEE ICCV ’98 Pro-ceedings.
[21] Uehara, T., Horikawa, M. and Sumita, K. (2000). Navigation System for News ProgramsFeaturing Direct Access to Desired Scenes (in Japanese). Toshiba Review 55(10).
[22] Yamada, I. et al. (2006). Automatic Generation of Segment Metadata for Football GamesUsing Announcer’s and Commentator’s Commentaries (in Japanese). IEICE Transactions,Vol. J89-D, No. 10, 2328–2337.
[23] Zhang. H.-J. et al. (1995). Video Parsing, Retrieval and Browsing: An Integrated andContent-Based Solution. In Proceedings of ACM Multimedia ’95, 15–24.
Conference RIAO2007, Pittsburgh PA, U.S.A. May 30-June 1, 2007 - Copyright C.I.D. Paris, France




















