
PersonalNews - A nossa vida de relance
108
PersonalNews – A nossa vida de relance… Bruno Ricardo Tavares Antunes Dissertação para obtenção do Grau de Mestrado em Engenharia Informática e de Computadores Júri Presidente: Prof. Joaquim Armando Pires Jorge Orientador: Prof. Daniel Jorge Viegas Gonçalves Vogal: Prof. Carlos Alberto Pacheco dos Anjos Duarte Setembro 2008
-
Upload
independent -
Category
Documents
-
view
1 -
download
0
Transcript of PersonalNews - A nossa vida de relance

PersonalNews – A nossa vida de relance…
Bruno Ricardo Tavares Antunes
Dissertação para obtenção do Grau de Mestrado em
Engenharia Informática e de Computadores
Júri
Presidente: Prof. Joaquim Armando Pires Jorge
Orientador: Prof. Daniel Jorge Viegas Gonçalves
Vogal: Prof. Carlos Alberto Pacheco dos Anjos Duarte
Setembro 2008


I
Agradecimentos
Um grande obrigado à minha namorada Ana Cristina Ricardo. Sem o seu apoio, muito
dificilmente teria conseguido alcançar os objectivos a que me propus.
Agradeço também aos meus pais, irmã e o resto da família toda pelo constante apoio.
Ao co-orientador Joaquim Jorge e ao Engenheiro Tiago Guerreiro pela incansável
ajuda ao longo de todo o trabalho.
Aos meus amigos Bruno Anjos, Bruno Santos, Daniel Martins, David Rodrigues, Hugo
Alberto, João Inácio, Manuel Rosa, Nuno Tomás, Pedro Fiadeiro, Telmo Machado que
foram alguns dos utilizadores teste e todos deram uma ajuda à sua maneira.
Por fim, o maior agradecimento vai para o Professor Daniel Gonçalves, que ao longo
do último ano me guiou, aconselhou e incentivou, o que foi o principal combustível
para que este trabalho tivesse chegado ao fim.

II
Resumo
Com o aumento da quantidade de informação existente nos computadores pessoais,
existe cada vez mais a necessidade de desenvolver novas formas de gerir essa
informação. Em particular, as ferramentas existentes hoje em dia não possibilitam ao
utilizador visualizar, de forma eficaz, quais os seus interesses num dado período de
tempo e, a partir destes, recuperar informação pessoal para referência ou reutilização.
Apresentamos o PersonalNews, um sistema que fornece ao utilizador um jornal
pessoal da sua vida. As várias notícias descrevem os desenvolvimentos nos temas
que mais interessaram o utilizador num dado intervalo de tempo. Essas notícias,
criadas a partir dos documentos do utilizador. Com base nestes, conseguimos
automaticamente inferir os temas de interesse, obter passagens que os descrevem, e
criar o texto das notícias. Estas são dispostas no jornal de acordo com a sua
importância relativa, dando ao utilizador de uma ideia dos temas que mais o
interessaram e permite facilmente encontrar os documentos com eles relacionados. A
interface permite pois visualizar e navegar de forma eficaz na informação pessoal de
um utilizador, possibilitando a descoberta de padrões relevantes nessa informação.
Um conjunto de testes com utilizadores confirma que o PersonalNews consegue
identificar correctamente a maioria dos temas relevantes para os utilizadores, e até
mesmo alguns de que estes à partida não se recordam. Adicionalmente, mostra-se
que é possível encontrar eficazmente documentos pessoais com o auxílio do sistema.

III
Abstract
It is not uncommon for computer users to work on several things at once. However, to
the computer, all documents, emails and applications are considered equal, regardless
of why they were created or used. Little support is provided when trying to recall
important information about a particular project or subject at a later time. What is more,
there is no effective way to help users review their past activities to identify when a
particular subject was more important, what were their concerns at a given moment in
the past, or simply review at a glance their activities during a period of time.
In this paper we describe PersonalNews, a system in which users are presented with a
personal newspaper, in which the news articles report on the subjects they were
concerned with in a given period of time. Those articles are automatically generated
from the users‘ documents, grouped according to their subject and analyzed for
relevant passages describing them. We show that PersonalNews is able to help users
recognize the subjects and projects they were involved in, and even recall some they
had forgotten about. Also, it can be used effectively to help retrieve documents on
particular subjects, even when the usual hints of filename and location in the
filesystem.

IV
Palavras Chave
Gestão de Informação Pessoal, Metafora de Jornal, Visualização de Informação,
Recuperação de documentos pessoais
Keywords
Personal Information Management, Personal Document Retrieval, Newspaper
Metaphor, Information Visualization.

V
Índice
1. Introdução ............................................................................................................................. 1
1.1. Contribuições ................................................................................................................ 2
1.2. Publicações .................................................................................................................... 3
1.3. Estrutura do documento ............................................................................................... 3
2. Estado da Arte ....................................................................................................................... 4
2.1. Informação pessoal em E-mails..................................................................................... 4
2.1.1. Themail .................................................................................................................. 5
2.1.2. Email visualization to Aid Communications .......................................................... 5
2.1.3. Mailview ................................................................................................................ 7
2.1.4. PostHistory e Social Network Fragments .............................................................. 7
2.2. E-mail e tarefas .............................................................................................................. 9
2.2.1. TimeStore .............................................................................................................. 9
2.3. TaskView...................................................................................................................... 10
2.4. Dispositivos Físicos ...................................................................................................... 10
2.4.1. Storytelling with Digital Photographs ................................................................. 11
2.4.2. Personal Digital Historian: User interface Design ............................................... 11
2.4.3. Forgot-me-not ..................................................................................................... 12
2.5. Social Networks ........................................................................................................... 13
2.5.1. Newsgroup Crowds and AuthorLines .................................................................. 13
2.5.2. PeopleGarden ...................................................................................................... 15
2.6. Informação multimédia ............................................................................................... 15

VI
2.6.1. Milestones in Time .............................................................................................. 16
2.6.2. Time-Machine Computing ................................................................................... 16
2.6.3. LifeLines ............................................................................................................... 18
2.6.4. Lifestreams .......................................................................................................... 19
2.6.5. MyLifeBits ............................................................................................................ 19
2.7. Pesquisadores e Browsers ........................................................................................... 21
2.7.1. Stuff I’ve Seen ...................................................................................................... 21
2.7.2. Plath .................................................................................................................... 22
2.7.3. Personal Chronicling Tools .................................................................................. 23
2.7.4. FacetMap ............................................................................................................. 24
2.8. Discussão ..................................................................................................................... 25
3. Overview ............................................................................................................................. 29
4. Descoberta de Temas .......................................................................................................... 31
4.1. Motivação/Introdução ................................................................................................ 31
4.2. Método ........................................................................................................................ 31
4.3. Matriz de distâncias .................................................................................................... 32
4.4. LSA ............................................................................................................................... 32
4.5. Escolha das Keywords ................................................................................................. 35
4.6. Matriz de Distância LSA ............................................................................................... 36
4.7. Criação dos clusters ..................................................................................................... 36
4.8. Utilização do QT-Clust ................................................................................................. 38
4.9. Join clusters ................................................................................................................. 39
4.10. Avaliação ................................................................................................................. 39

VII
4.10.1. Medidas de avaliação .......................................................................................... 40
4.10.2. Conjuntos de testes usados ................................................................................ 41
4.10.3. Raio ...................................................................................................................... 42
4.10.4. Join Clusters......................................................................................................... 44
4.10.5. Número de keywords .......................................................................................... 48
4.10.6. Teste da Dimensão .............................................................................................. 51
4.10.7. Conclusões dos testes ......................................................................................... 53
4.11. Verificação manual dos clusters obtidos ................................................................. 53
4.12. Conclusão ................................................................................................................ 56
5. Geração das Notícias ........................................................................................................... 57
5.1. Extracção das palavras-chave dos Grupos .................................................................. 57
5.2. Extracção dos sumários ............................................................................................... 58
5.2.1. Algoritmo de extracção dos sumários ................................................................. 58
5.2.2. Tratamento das frases relevantes ....................................................................... 60
5.2.3. Classificação das frases ....................................................................................... 61
5.3. Criação das notícias ..................................................................................................... 62
5.3.1. Padrões de Notícias ............................................................................................. 63
5.3.2. Análise Lexical ..................................................................................................... 64
6. Interface .............................................................................................................................. 68
7. Resultados e avaliação ........................................................................................................ 72
7.1. Protocolo Experimental ............................................................................................... 72
7.1.1. Tarefas ................................................................................................................. 72
7.1.1.1 Lançamento da aplicação pela primeira vez pelo utilizador ............................... 73

VIII
7.1.1.2 Identificação de temas em intervalos de tempo diferentes ............................... 73
7.1.1.3 Identificação de tema único ................................................................................ 74
7.1.1.4 Pesquisa de ficheiros ........................................................................................... 74
7.1.2. Questionário ........................................................................................................ 75
7.2. Resultados obtidos ...................................................................................................... 75
7.2.1. Tarefas ................................................................................................................. 75
7.2.1.1 Tarefa 1 - Lançamento da aplicação pela primeira vez pelo utilizador ............... 76
7.2.1.2 Tarefa 2 - Identificação de temas em intervalos de tempo diferentes ............... 76
7.2.1.3 Tarefa 3 - Identificação de tema único ................................................................ 81
7.2.1.4 Tarefa 4 - Pesquisa de ficheiros ........................................................................... 82
7.2.2. Questionário ........................................................................................................ 83
7.3. Conclusão .................................................................................................................... 86
8. Conclusões e trabalho futuro .............................................................................................. 87
9. Bibliografia .......................................................................................................................... 89
10. Anexos ................................................................................................................................. 94

IX
Lista de Figuras
Figura 1 - Interface do Themail ..................................................................................................... 5
Figura 2 - Um e-mail thread .......................................................................................................... 6
Figura 3 - Message tree com timeline ........................................................................................... 6
Figura 4 - Reduced-Resulution vista geral de documentos. ......................................................... 6
Figura 5 - Interfaces do Mailview .................................................................................................. 7
Figura 6 - Interface do PostHistory................................................................................................ 8
Figura 7 - Social network e o da History. ...................................................................................... 8
Figura 8 - Interface do TimeStore. ................................................................................................ 9
Figura 9 - Interface do taskView.................................................................................................. 10
Figura 10 - Interface do dispositivo móvel em questão. ............................................................. 11
Figura 11 - Dispositivo em questão. ............................................................................................ 11
Figura 12 - Dispositivo móvel e interface. ................................................................................... 13
Figura 13 - Interface do AuthorLines. .......................................................................................... 13
Figura 14 - Interface do Newsgroup Crowds. ............................................................................. 14
Figura 15 - Um PeopleGarden .................................................................................................... 15
Figura 16 - Interface do Milestones in Time ................................................................................ 16
Figura 17 - Screenshot do TimeScape desktop. ......................................................................... 16
Figura 18 - Do lado esquerdo a timeline view e do direito a calendar view ................................ 17
Figura 19 - Interface do LifeLines................................................................................................ 18
Figura 20 - Interfaces do Lifestreams. ........................................................................................ 19
Figura 21 - Screenshots das vistas ............................................................................................. 20
Figura 22 - Screenshot do SIS, em Top view ............................................................................. 22
Figura 23 - Screenshot do Phlat.................................................................................................. 23
Figura 24 - Interface de browsing do PCT .................................................................................. 24
Figura 25 - Interface do Facetmap. ............................................................................................. 24
Figura 26 – Etapas seguidas ao longo do PersonalNews .......................................................... 29
Figura 27 - Resultados obtidos depois da aplicação do algoritmo LSA. .................................... 34
Figura 28 - Screenshot da janela de configuração. .................................................................... 68
Figura 29 – Screenshot de uma edição do jornal. ...................................................................... 69
Figura 30 – Selecção de data e alteração da configuração. ....................................................... 70
Figura 31 – Screenshot da barra temporal usada. ...................................................................... 71

X
Lista de Tabelas
Tabela 1 - Classificação dos trabalhos descritos ........................................................................ 27
Tabela 2 - Extractos de texto usados no exemplo de aplicação do algoritmo LSA .................... 33
Tabela 3 - Matriz term-document. ............................................................................................... 34
Tabela 4 - Resultados obtidos com o primeiro conjunto de dados. ............................................ 54
Tabela 5 - Resultados obtidos com o segundo conjunto de dados ............................................ 55
Tabela 6 – Resultados obtidos para o intervalo de tempo de uma semana. .............................. 77
Tabela 7 - Resultados obtidos para o intervalo de tempo de um mês........................................ 78
Tabela 8 - Resultados obtidos para o intervalo de tempo de um ano. ....................................... 79
Tabela 9 – Tabela resumo dos resultados obtidos no questionário ........................................... 86

XI
Lista de Gráficos
Gráfico 1 - Resultados obtidos para os conjuntos de dados (a e b) ........................................... 43
Gráfico 2 – Percentagem de acerto variando o raio ................................................................... 43
Gráfico 3 - Silhouette Coefficient variando o raio ........................................................................ 44
Gráfico 4 - Resultados para os conjuntos de dados - raio de 0.22 (a e b) ................................. 45
Gráfico 5 - Resultados obtidos para o 1º conjunto de dados - raio de 0.22 ............................... 45
Gráfico 6 - Resultados obtidos para o 2º conjunto de dados - raio de 0.22 ............................... 46
Gráfico 7 - Distância de junção para o raio 0.22, 1º conjunto de dados ..................................... 47
Gráfico 8 - Distância de junção para o raio 0.22, 2º conjunto de dados ..................................... 47
Gráfico 9 - Variação do número de clusters com a distância de junção. .................................... 48
Gráfico 10 – Gráfico para encontrar o número de keywords confirmando o raio 0.22. .............. 49
Gráfico 11 – Percentagem de acerto para o raio fixo em 0.22. .................................................. 50
Gráfico 12 - Gráfico para encontrar o número de keywords confirmando o raio 0.22. ............... 50
Gráfico 13 - Percentagem de acerto para o raio fixo em 0.22. ................................................... 51
Gráfico 14 - Variação da variável dimensão, 1º conjunto de dados ........................................... 52
Gráfico 15 - Variação da variável dimensão, 1º conjunto de dados ........................................... 52
Gráfico 16 - Relação de tempo com a variação da dimensão usa no algoritmo LSA. ............... 53
Gráfico 17 - Distribuição dos temas pela sua importância (semana) ......................................... 77
Gráfico 18 - Distribuição dos temas pela sua importância (mês) ............................................... 79
Gráfico 19 - Distribuição dos temas pela sua importância (ano) ................................................ 80
Gráfico 20 – Grau de satisfação obtido na identificação de tema único. .................................... 81
Gráfico 21 – Resultados obtidos na tarefa de pesquisa de ficheiro............................................ 82
Gráfico 22 – Facilidade de interacção com a aplicação ............................................................. 83
Gráfico 23 – Facilidade de Identificação dos temas em que trabalhou ...................................... 83
Gráfico 24 – Facilidade de encontrar ficheiros através dos temas ............................................. 83
Gráfico 25 – Qualidade dos resultados obtidos nas suas pesquisas ......................................... 84
Gráfico 26 – Facilidade em identificar o tema de uma noticia em particular .............................. 84
Gráfico 27 – Qualidade das frases .............................................................................................. 85
Gráfico 28 – Estética do jornal .................................................................................................... 85
Gráfico 29 – Legibilidade das notícias. ....................................................................................... 85
Gráfico 30 – Utilidade da aplicação ............................................................................................ 85

1
1. Introdução
Nos dias que decorrem, existem cada vez mais formas de guardar todo o tipo de
informação indexada num computador pessoal. Desde e-mails enviados/recebidos,
documentos criados/alterados, conversas em salas de chat e msn, etc. Esta
informação encontra-se disponível a qualquer utilizador comum no seu computador
pessoal. O grande problema, há já algum tempo, tem sido como procurar e visualizar
essa informação.
Com toda a informação que existe actualmente indexada no nosso computador
pessoal é fácil efectuar uma pesquisa acerca de um e-mail que recebemos num dado
momento em que se laborava num determinado trabalho de uma disciplina. O único
problema que se coloca é toda esta informação estar dispersa em vários locais,
programas, ficheiros, etc., o que torna bastante difícil ter uma percepção global sobre
esta e conseguir visualiza-la de forma integrada com as várias relações que existem.
Um outro problema, é quando não nos conseguimos lembrar do nome do documento,
sabendo apenas que foi editado numa determinada data, ao trabalhar num
determinado tema.
Um exemplo da grande quantidade de informação aglomerada e, por vezes, de forma
confusa, são os e-mails dos utilizadores. Estes, normalmente contêm informação de
variadíssimas áreas, desde informações e documentos dos empregos dos utilizadores,
tarefas e lembranças a executar, convites e outro tipo de informação, toda ela na
mesma pasta de Inbox do e-mail. Embora exista a possibilidade de criar novas pastas
e de filtrar a entrada de e-mails, esta solução não é suficiente. Existe assim a
necessidade de criar novos paradigmas e novas metáforas para gerir a informação
contida num simples e-mail.
Um outro exemplo é o da informação multimédia. Devido aos avanços tecnológicos,
todos os utilizadores comuns têm acesso a máquinas fotográficas digitais, câmaras de
filmar, telemóveis, etc. O conteúdo destes dispositivos normalmente vai parar ao
computador pessoal dos seus utilizadores, de forma não muito organizada, e quando o
é, é simplesmente dividida em pastas, não havendo qualquer informação adicional
acrescentada aos conteúdos. Assim, quando o utilizador quer efectuar uma dada
pesquisa ou simplesmente navegar nesses conteúdos, e caso não se lembre do nome
dos ficheiros ou do caminho para os mesmos, é como se esta informação estivesse
perdida, não existindo qualquer forma de pesquisa que encontre esses conteúdos,
perdendo-se muito tempo para a encontrar. Existe assim a necessidade de criar um

2
sistema que, de forma atraente, facilite estas pesquisas e a navegação nestes
conteúdos, sendo as pesquisas baseadas em informação indexada. Em particular,
deve ser possível ao utilizador visualizar informação dos temas em que este laborou,
temas que são reflectidos no conjunto de documentos do utilizador.
Como veremos no capítulo 2, a maioria dos sistemas que se preocupam com a
visualização de informação pessoal apenas se destinam a um tipo de informação
pessoal. Houve uma série de abordagens que tentaram fazer face ao problema
enunciado acima, mas nenhum conseguiu resolver o problema na totalidade.
Exemplos destas abordagens são os sistemas que têm como principal incidência a
informação contida nos emails dos utilizadores, no entanto, como é previsível, estes
sistemas deixam de parte muita informação pessoal dos utilizadores. Existem, por
outro lado, sistemas físicos, no entanto, estes sistemas acabam por servir de agenda,
registando os acontecimentos do dia-a-dia de um determinado utilizador. Existem
também aproximações à resolução do nosso problema através de Social Networks, no
entanto, como vermos no capítulo do estado da arte, estes tipos de sistemas já fogem
à nossa percepção do problema. Por fim, existem aproximações através de
pesquisadores e browsers, no entanto, o principal problema destes é mostrarem a
informação toda, sem criar padrões de notícias ao longo do tempo, não mostrando
assim o que o utilizador tem andado a fazer.
Neste trabalho propomos uma abordagem que possibilita aos utilizadores visualizarem
a sua informação pessoal de modo a revelar de forma imediata o contexto e interesses
do utilizador num dado intervalo temporal. Tal é conseguido pela criação automática
de grupos de documentos semanticamente relacionados de acordo com os vários
temas de interesse para o utilizador. Uma vez identificados os temas, estes são
apresentados ao utilizador sob a forma de notícias num jornal pessoal. Esta é uma
metáfora amplamente conhecida e fácil de compreender, adaptando-se à grande
quantidade de informação a mostrar. Cada ―edição‖ do jornal reporta-se a um
determinado período temporal, reflectindo as notícias, isto é, os interesses do
utilizador nesse período. O texto das notícias é gerado automaticamente a partir dos
documentos em cada tema, podendo estes ser recuperados directamente a partir do
PersonalNews.
1.1. Contribuições
Este trabalho mostra-nos que a organização de vários tipos de informação pessoal em
temas/grupos e a apresentação desta sob a forma de jornal tem claras vantagens, no

3
sentido em que possibilita ao utilizador recordar-se de temas, os quais já estavam
esquecidos, pesquisar ficheiros e verificar relações e padrões ao longo do tempo. As
nossas principais contribuições são:
Inferência automática de temas a partir de documentos.
Extracção de excertos relevantes e representativos dos documentos pessoais
dos utilizadores.
Criação de notícias que resumam os temas.
Criação de uma interface e sistema interactivo onde se aplica a biblioteca
desenvolvida.
1.2. Publicações
Até ao momento, foram publicados artigos acerca do PersonalNews em:
Interacção2008 – 3ª Conferência Nacional em Interacção Pessoa Máquina.
IUI2009 (Submetido) – 2009 International Conference on Intelligent User
Interfaces. Sanibel Island, Florida, 8 – 11 Fevereiro 2009.
1.3. Estrutura do documento
Para que os leitores se consigam enquadrar com o problema a que nos propomos
resolver, é necessária uma análise exaustiva das soluções já existentes, análise que
irá ser realizada na secção 2 seguido por um overview na secção 3. Na secção 4
estudamos as várias formas de criação de clusters para a formação dos temas da
informação pessoal contida nos computadores. Após estarmos na posse dos vários
temas, passamos então, na secção 5 a descrever a forma criada para a extracção de
sumários dos documentos e a geração de notícias. Por fim, na secção 6 descrevemos
a interface da nossa aplicação. Para terminar o documento, fazemos a avaliação e
discussão dos resultados obtidos no teste da aplicação, isto na secção 7.

4
2. Estado da Arte
Com o aumento da quantidade da informação nos computadores pessoais tem-se
notado uma crescente necessidade de melhorar e criar novas interfaces de
visualização para pesquisar e navegar por toda esta informação. Para além do
aumento de informação, tem-se notado um aumento da variedade de informação,
principalmente na área do multimédia, o que não facilita a sua visualização. Têm
surgido várias investigações e várias aplicações para fazer face ao crescente aumento
de informação, no entanto estes dirigem-se num sentido específico. Normalmente
apenas se dedicam a uma parte da informação pessoal contida no computador dos
utilizadores. De seguida são apresentados exemplos de sistemas que se dedicam a
esta a apresentação de vários tipos de informação pessoal, das mais variadíssimas
maneiras.
2.1. Informação pessoal em E-mails
O E-mail foi inicialmente desenhado como uma aplicação de comunicação, no entanto
nos dias que decorrem este está, e cada vez mais a ser usado para funções
adicionais, como é o exemplo da gerência de tarefas e personal archiving. A isto
chama-se email overload. Este email overload cria problemas para a gerência de
infomação pessoal, como é o caso das perdas de informação [Whittaker and Sidner
96]. O email overload é em parte gerado devido ao facto dos email clients terem
evoluído pouco desde a sua invenção, continuando com as mesmas funcionalidades e
organização estrutural: múltiplas pastas, uma listagem textual das mensagens dentro
de uma determinada pasta e a possibilidade de ver uma mensagem seleccionada.
Estudos mostram que sistemas de pastas depressa se degradam com a recepção de
muitas mensagens [Whittaker96].
Assim sendo surgiram várias aplicações para tentar resolver este problema de uma
forma eficaz e estética. A principal preocupação dos produtores destas aplicações
estavam relacionadas com as interfaces destas, de modo a conseguir convencer
qualquer tipo de utilizador a usar essas mesmas aplicações. Conclui-se que
actualmente o email é usado para mais tarefas do que fora desenhado inicialmente,
sendo as que se destacam mais: entrega e armazenamento de documentos, work task
delegation, task tracking, armazenamento de contactos e de respectivas direcções,
para o envio de lembranças, para pedir assistência e scheduling appointments
[Whittaker96].

5
2.1.1. Themail
Um dos primeiros trabalhos abordados em relação a este tema mencionado acima, é o
Themail (Figura 1) [Viégas et al. 06]. Este trabalho, bastante recente, diz respeito a um
sistema em que o grande objectivo era criar uma visualização para visualizar
informação preservada em arquivos e-mail dos seus utilizadores, onde a interface da
aplicação era de extrema importância. A aplicação foi desenhada de modo a ajudar os
seus utilizadores a responder a duas perguntas de extrema importância: ―de que
coisas falo com cada um dos meus contactos e-mail?‖ e ―como é que as minhas
conversas diferem das outras pessoas?‖. Assim sendo, o Themail mostra uma relação
entre o utilizador com um dos seus contactos e-mail, numa dada altura.
Figura 1 - Interface do Themail
Na interface destaca-se a existência de muitas camadas de informação, cada qual
com o seu significado. Por exemplo, a camada que se encontra mais abaixo diz
respeito aos termos mais usados ao longo de um ano de troca de e-mails. A maneira
que os criadores da aplicação encontraram para realçar as palavras mais importantes,
era fazendo variar o tamanho da letra, com a frequência com que essas palavras
apareciam. Como neste trabalho a noção de tempo também tinha grande importância,
criaram-se dois métodos para mostrar a informação desejada ao longo do tempo, a
collapsed view e a expanded view. A limitação deste trabalho é tratar apenas da
informação contida nos arquivos do e-mail do respectivo utilizador, restringindo assim
muito o seu campo de aplicação. Outro problema desta aplicação é tratar todas as
mensagens da mesma forma, não tendo em conta a importância destas, isto é, não
existem pesos diferentes entre as várias mensagens, não se podendo assim dar
especial atenção às que se destacam.
2.1.2. Email visualization to Aid Communications
Email visualization to Aid Communications é um artigo onde se descreve um trabalho
sobre e-mails, para melhorar a percepção e visualização através de várias técnicas de

6
visualização de informação (trees, timelines e low-resulution overviews) num novo
cliente e-mail [Rohall et al. 01]. Estas visualizações dão maior importância às relações
existentes entre as mensagens e entre as pessoas que fazem a troca de e-mails. A
este novo cliente e-mail deu-se especial atenção a três atributos que poderão ser
visualizados: message threads, tempo e o conteúdo do documento.
As message threads são threads de conversação em e-mail (Figura 2), que
representam uma série de respostas a uma mensagem e as respostas a essas
respostas. No sistema, os autores criaram uma árvore para representar estas trocas
de mensagens.
Os nós têm diferentes cores, para assim
mostrarem a relação do sender de cada
mensagem com o receptor das mensagens.
Outro atributo muito importante, que já foi referido acima, é o tempo aquando a
mensagem foi recebida. Em relação a este, a ideia dos autores foi combinar as
message tree referidas acima (Figura 3), que dá importância ao primeiro atributo, com
uma timeline, para produzir
assim uma melhor visualização,
como é perceptível abaixo. As
linhas verticais representam as
fronteiras dos dias. O texto no
meio é o subject da thread.
Por fim, o último atributo, que diz respeito ao conteúdo do documento, a ideia é
transmitir uma vista geral de reduced-resulution do conteúdo do e-mail (Figura 4). A
combinação destes três atributos base
deu origem ao cliente e-mail, criado pelos
autores do artigo.
O artigo dá especial importância a
threads de mensagens, no entanto a
técnica de visualização escolhida pode
levar ao caos quando estas threads de
mensagens começam a crescer demasiado. Embora os autores do artigo referiram
que esta situação seria pouco provável de acontecer, deveriam ter adoptado uma
técnica que conseguisse fazer face ao problema. É de referir que as cores, embora
sejam para ajudar os utilizadores, estas podem ter o efeito contrário, devido ao facto
Figura 2 - Um e-mail thread
Figura 3 - Message tree com timeline
Figura 4 - Reduced-Resulution vista geral de
documentos.

7
de serem muitas. A mais-valia deste artigo, é de facto a técnica de visualização
adoptada para o atributo ―conteúdo‖ do documento, podendo esta ser de enorme
utilidade, devido ao facto de dar uma boa vista geral.
2.1.3. Mailview
Mailview é uma aplicação que fornece uma ferramenta de visualização interactiva de
e-mail que utiliza filtros e técnicas de coordenação para explorar os seus dados
arquivados [Frau et al. 05]. Esta aplicação permite aos seus utilizadores analisar e
visualizar e-mails armazenados, distribuindo-os em plots dependentes do tempo,
permitindo assim que o utilizador tenha uma noção temporal entre os seus e-mails
(Figura 5).
Figura 5 - Interfaces do Mailview
Assim sendo o Mailview, fornece uma visualização de e-mails focados, mostrando-os
cronologicamente, usando as técnicas de focagem, de contexto e múltiplas vistas.
Inclui (a) uma vista geral dos múltiplos e-mails representados por glyphs, (b) duas
vistas coordenadas e zooming descrevendo o tempo de chegada, especificando
cronologicamente a ordem de chegada dos vários e-mails e o tamanho relativo dos
vários e-mails, e (c) descreve detalhes específicos de um e-mail seleccionado. No
entanto, tal como a aplicação anterior, esta aplicação também se restringe muito,
tratando apenas da informação pessoal contida no e-mail.
2.1.4. PostHistory e Social Network Fragments
No trabalho seguinte são analisadas duas visualizações diferentes: a PostHistory e
Social Network Fragments [Viégas et al. 04]. Estas visualizações são ferramentas que
permitem aos utilizadores aceder aos seus hábitos e-mail através de padrões de
elevado nível. O PostHistory (Figura 6) e Social Network Fragments (Figura 7)focam-
se nas duas dimensões mais importantes dos arquivos e-mail: tempo e pessoas. O
primeiro foca-se no mundo social de relações e-mail, por exemplo entre duas pessoas.

8
Assim sendo o PostHistory foca-se nas interacções directas entre utilizadores com
cada um dos seus contactos e-mail. O segundo explora o agrupamento de pessoas
que emergem entre a social network de uma pessoa, pela troca de e-mails. Ambos os
sistemas têm mecanismos para mostrar como os ―mundos sociais‖ evoluem ao longo
do tempo. O PostHistory cria o seu esquema de visualização à volta da noção de
tempo, mostrando ritmos de trocas de e-mail de longo tempo numa interface que é
estruturada por um calendário. O sistema mostra também como as mudanças de
ritmos de trocas de e-mail afecta a social landscape do utilizador. O Social Network
Fragments usa o tempo para mostrar como as conexões entre o utilizador e os seus
correspondentes surgem e se dissolvem.
Figura 6 - Interface do PostHistory.
Em relação à interface do PostHistory esta encontra-se dividida em duas partes: o
calendário na parte esquerda, o qual mostra a intensidade de trocas e-mail ao longo
do tempo e os contactos. O calendário mostra a actividade e-mail na base de um dia,
em que cada dia é representado por um quadrado. O tamanho do quadrado
representa a quantidade de e-mails recebidos nesse dia. A cor dos quadrados indica
se as mensagens são ―personal‖ ou ―directed‖. Em relação aos contactos, estes
podem ter três representações possíveis: vertical, circular e alfabética.
A interface do Social Network Fragments também é composta por dois painéis: o
painel da social network e o painel da história.
Figura 7 - Social network e o da History.

9
O painel da história descreve cada time slice com dois quadrados. O quadrado de fora
indica o número de conexões que ocorreram durante o período de tempo e o quadrado
de dentro indica o número de relações. O painel da social network mostra toda a rede.
Em relação às reacções a estas interfaces, no geral foram bastante positivas, porque
conseguiam captar a atenção do utilizador, através da sua estética e simplicidade. No
entanto, numa análise mais profunda e quando as interfaces eram sujeitas a testes
mais exaustivos pelos utilizadores, esta tinha vários problemas, como por exemplo a
fraca legibilidade no nível geral, isto antes de se fazer zooming. As cores da interface,
em vez de ajudarem os utilizadores, faziam exactamente o contrário, baralhando-os,
devido ao facto de não saberem o significado delas. Este trabalho fornece umas ideias
gerais de como representar informação acerca dos e-mails, combinando-a com os
contactos do utilizador, no entanto é apenas isso, não tendo qualquer vertente noutro
sentido, tratando assim pouca informação pessoal.
2.2. E-mail e tarefas
Para além dos simples e-mail clients, existem outros mais complexos que tentam gerir
as tarefas dos seus utilizadores. No entanto, ainda não existe nenhuma aplicação que
o faça de forma eficaz e atraente para os utilizadores, isto é, os utilizadores não se
sentem atraídos por estas aplicações. É por esta razão que surgiram os artigos
seguintes, que tentam resolver o problema mencionado.
2.2.1. TimeStore
TimeStore é um trabalho sobre um sistema e-mail, cuja principal característica é usar
o tempo de chegada para a exposição do e-mail [Yiu et al. 97]. Visualizações
baseadas no tempo podem complementar ou substituir a semântica tradicional em que
se baseia o e-mail usando aspectos da memória humana que a maioria dos e-mails
ignora: organização temporal em memória auto-
biográfica (Figura 8).
Para além de gerir o e-mail, TimeStore fornece
suporte integral para gerir tarefas assim como outra
informação pessoal, onde o tempo seja o primeiro
método para aceder. Fornece também a
possibilidade de ligar as mensagens às tarefas.
Figura 8 - Interface do TimeStore.

10
Toda a interface é baseada no tempo, sendo a área principal constituída por um
gráfico de duas dimensões onde se encontra a informação, em que o eixo dos xx diz
respeito ao tempo e o eixo dos yy aos contactos do utilizador. A parte superior da
janela da aplicação contém um calendário, uma lista de tarefas organizadas por data e
uma lista de notas, também organizada por tempo. Os utilizadores podem também
fornecer keywords específicas para efectuar pesquisas, sendo o resultado destas
pesquisas apresentado na vista principal do sistema, isto é, nas duas dimensões
referidas acima. No entanto este sistema é bastante incompleto por possuir vários
problemas. O primeiro é a aplicação não fornecer nenhum meio para organizar os
nomes. Embora o conceito do TimeStore seja interessante e até útil, é muito limitado
no que diz respeito a sua interface, complicando, a interacção do sistema com o
utilizador. Tal como nos trabalhos analisados anteriormente, também este se limita à
informação baseada no e-mail, tendo no entanto este já alguma informação pessoal,
como é o exemplo das tarefas.
2.3. TaskView
TaskView é um trabalho que tem
como preocupação principal a gestão
de tarefas pendentes em e-mail e
explora soluções que usam
representações externas diferentes
de mensagens e tarefas associadas
[Gwizdka02a] [Gwizdka02b]. No
desenho da interface foi tido especial atenção a relação entre o tempo e as
mensagens (Figura 9). A interface baseia-se nas mensagens serem automaticamente
organizadas por tempo e por remetente, e sendo dispostas numa grelha de duas
dimensões.
2.4. Dispositivos Físicos
Ao longo das pesquisas efectuadas para a realização deste survey apareceram alguns
artigos acerca de dispositivos móveis que estavam de alguma forma relacionados com
a apresentação de informação pessoal, por exemplo fotografias. Nestes dispositivos,
como é óbvio, o mais importante é a sua interface, dando-se a esta especial atenção,
não dando deste modo atenção à parte física do dispositivo.
Figura 9 - Interface do taskView

11
2.4.1. Storytelling with Digital Photographs
Storytelling with Digital Photographs descreve um dispositivo móvel fácil de usar que
permite visualizar fotografias e construir histórias com as fotografias contidas no
dispositivo [Balabanović et al. 00]. Combinando uma interface inovadora e user
friendly, o objectivo deste trabalho foi criar um dispositivo acessível a qualquer
utilizador para que este possa partilhar e formar histórias com as suas fotografias
(Figura 10). Com o resultado das histórias o utilizador pode formar um filme, ou antes
um slideShow, podendo em qualquer altura o utilizador acrescentar/remover
fotografias à sua história actual. Para além disso, no meio de uma visualização de uma
história, pode passar para outra.
A interacção do dispositivo como o utilizador é feita através de uma interface
relativamente simples. O display é dividido em três partes: a parte central, que ilustra o
thumbnail seleccionado, ou seja, é
onde se vêm as histórias e as
fotografias; a área de áudio, para
quando uma determinada história foi
criada com áudio; área de
navegação, no topo do ecrã, que é a
representação gráfica para procurar
e navegar entre as várias fotos.
Este trabalho está limitado no sentido em que trata apenas de fotografias. Em termos
de interface, o protótipo estava bem formado para os seus objectivos. Já em relação
ao dispositivo móvel, embora este já não seja área sobre a qual vamos trabalhar, era
de certa forma arcaico, dados os avanços tecnológicos nesta área na época em que
este sistema foi criado.
2.4.2. Personal Digital Historian: User interface Design
Personal Digital Historian: User interface Design é um
artigo que descreve o design de uma user interface para
interacções multi-user informais para storytelling [Shen et
al. 01]. O objectivo deste artigo era criar um dispositivo
físico com uma user interface de forma a permitir
storytelling entre várias pessoas, através de dados digitais
pessoais, como por exemplo fotografias, vídeos, entre
Figura 10 - Interface do dispositivo móvel em questão.
Figura 11 - Dispositivo em
questão.

12
outros. Para isso o dispositivo físico teria de ser de um tamanho razoável, isto é, uma
superfície de uma pequena mesa redonda touch sensitive (Figura 11).
Em relação ao layout do sistema seria constituído por: uma grande área do dispositivo
para a criação das histórias; vários painéis para os ―narradores‖ das histórias para
interagirem com o sistema. As fotografias e os dados seriam expostos à volta da
mesa, podendo os utilizadores organizar com estas as suas histórias, movendo-as e
reordenando-as. A navegação é feita através de perguntas essenciais para
storytelling: ―Quem?‖, ―Quando?‖, ―Onde?‖ e ―O que?‖. Através de botões que se
encontram à volta do perímetro da mesa com o nome de ―people‖, ―calendar‖,
―location‖ e ―events‖. Os utilizadores podem também formar Boolean queries, ou filtros,
seleccionando para isso os itens ou regiões nas diferentes vistas. Embora este
trabalho tenha algum interesse na área sobre a qual o meu se insere, pensamos que
não será muito viável devido ao facto de estar limitado a dados digitais e de ser
necessário um equipamento especial para as tarefas referidas acima, uma mesa touch
sensitive, isto pelo menos para utilizadores comuns.
2.4.3. Forgot-me-not
O ―Forgot-me-not‖ foi um dos primeiros dispositivos físicos a aplicar a ideia de
representar informação pessoal passada [Lamming and Flynn 94]. A ideia principal do
―Forgot-me-not‖ era criar um dispositivo móvel que ―ajudasse‖ a memória do seu
utilizador, isto é, que resolvesse alguns problemas do utilizador, nomeadamente
problemas de memória. Por exemplo, lembrar onde se encontra um determinado
documento, lembrar o nome de uma determinada pessoa. Este dispositivo usava um
modelo denominado Intimate Computing, que enunciava um dispositivo móvel que
andava sempre com o seu utilizador, em todas as actividades do seu dia-a-dia, este
poderia recolher informação ao longo do tempo, modelando assim o objecto para as
necessidades do seu utilizador. Este dispositivo poderia recolher informação de todos
os objectos que rodeiam o seu utilizador, por exemplo o carro, o fax, do posto de
trabalho, etc. O dispositivo recolheria esses dados acerca de aspectos das actividades
do utilizador e organizava-a numa biografia pessoal. Para o dispositivo móvel, os
criadores queriam uma interface fácil de aprender, fácil de usar, de confiança, etc.

13
Figura 12 - Dispositivo móvel e interface.
A interface deveria permitir procurar e mostrar toda essa informação reunida e que se
encontra armazenada. O display do dispositivo encontrava-se dividido em duas partes:
title line, que ocupava a parte superior do ecrã, que continha uma subject e um filter,
onde poderiam ser colocados ícones para o utilizador dizer quais os eventos que
deveriam aparecer na parte inferior do ecrã; a parte inferior do ecrã, que era a maior,
chamada a biography onde aparecia toda a biografia. Neste trabalho aborda-se muito
a questão do armazenamento, mas para esse problema actualmente já existe solução.
Nota-se que é um dos primeiros trabalhos a aparecer na área devido ao facto de ser
arcaico, toda a noção de interface que os seus autores abordaram já se encontra
ultrapassada. No entanto é um dos artigos que li que se assemelha mais ao trabalho
que vamos realizar, devido ao facto da informação poder surgir de variadíssimas
fontes, não se limitando a e-mails ou a fotografias.
2.5. Social Networks
Outra área onde surgiu a necessidade de sistemas de visualização sofisticados foi nas
redes sociais. Com a crescente actividade nestas redes, tanto em termos de
participantes, como em termos de quantidade de informação houve necessidade de
criar novas técnicas de visualização para facilitar a interacção dos utilizadores e para
os ajudar a ter uma percepção geral sobre o sistema.
2.5.1. Newsgroup Crowds and AuthorLines
No Newsgroup Crowds and AuthorLines discute-
se o desenho, a implementação e a evolução de
duas visualizações de actividades de authors em
Usenet newsgroup [Viégas and Smith 04].
Figura 13 - Interface do AuthorLines.

14
O primeiro a abordar é o Newsgroup Crowds,
que representa graficamente a população de
authors num particular newsgroup, por exemplo,
ao longo de um mês. Os authors são amostrados
de acordo com o número de mensagens com
que contribuem para cada thread e o número de
diferentes dias que eles aparecem no espaço,
ilustrando e contrastando desta forma os
padrões de interacção dos participantes. Em
relação ao AuthorLines visualiza a actividade de ―postagem‖ de um determinado
author em todos os newsgroups ao longo de um período de um ano.
A interface do Newsgroup Crowds (Figura 14) é constituída por uma parte central, que
pode ser considerada como a vista geral, onde cada author é representado por um
círculo. Este círculo é colocado no ecrã segundo dois eixos: o vertical, que indica o
número de dias que um author esteve activo num dado mês e a horizontal, que indica
a média de posts por thread no newsgroup. A cor do círculo mostra o quão recente o
author esteve activo no newsgroup e a sua total actividade de ―postagem‖ no Usenet
em geral.
A interface contém também uma outra parte, do lado direito do display, que contém os
endereços e-mail de todos os authors. Se o utilizador seleccionar o endereço e-mail, o
respectivo círculo na vista geral aparece destacado.
A interface do AuthorLines (Figura 13) mostra a intensidade da actividade de
―postagem‖ ao longo do tempo. Contém uma timeline horizontal com os meses na
vertical. Linhas verticais de círculos figuram a actividade semanal, representando cada
circulo uma thread de conversação para qual o author contribui. O tamanho do círculo
representa o número de mensagem com que o author contribui para essa thread.
É interessante ver como se apresenta a informação dos vários utilizadores do Usenet
e só de um em particular, daí o interesse neste trabalho. Embora não tenhamos um
sistema de pesquisas como os trabalhos anteriores, é bem visível a noção de tempo e
de informação guardada ao longo do tempo, com uma boa interface.
Figura 14 - Interface do Newsgroup Crowds.

15
2.5.2. PeopleGarden
O PeopleGarden [Xiong and Donath 99], tal como o artigo
anterior, refere-se a interacções online em ambientes com
um elevado número de participantes. Neste artigo propõe-
se uma nova representação gráfica dos utilizadores
baseada nas suas interacções passadas. Usa-se, para
isso, uma metáfora de flor para criar retratos de dados
individuais, retratos que apresentam uma representação
abstracta do histórico de interacções do utilizador, e uma
metáfora de jardim de forma a combinar esses retratos para representar um ambiente.
Em relação às flores (peopleFlower), estas indicam o tempo na ordem e na saturação
das pétalas. O número de pétalas cresce conforme cresce o número de mensagens
―postadas‖. As pétalas mais antigas movem-se para a esquerda à medida que novas
pétalas vão sendo adicionadas à direita. As pétalas desvanecem-se à medida que o
tempo passa. As respostas ao post também são representadas através de círculos
pistil-like.
Em relação ao jardim, o peopleGarden (Figura 15) mostra as peopleFlowers dos
diversos utilizadores, facilitando assim a percepção de uma vista geral e a
comparação entre os vários utilizadores. Assim, jardins com mais flores indicam bons
grupos, onde existe muita discussão. Utilizam também as propriedades das flores que
foram plantadas há mais tempo serem mais altas, isto é, a altura da peopleFlower
indica há quanto tempo o utilizador se encontra no ambiente. Este trabalho é
interessante devido ao facto de ter adoptado metáforas diferentes e inovadoras para
representar informação de diferentes utilizadores ao longo do tempo. Tal como no
trabalho anterior não existe a noção de pesquisa.
2.6. Informação multimédia
Muita da informação pessoal contida nos computadores pessoais dos seus utilizadores
é informação multimédia. Este tipo de informação surge cada vez mais por vários tipos
de meios, como é o caso das fotografias, vídeos, documentos, etc. Surgiu assim
também a necessidade de se criarem sistemas que permitem visualizar e procurar
informação ao longo do tempo.
Figura 15 - Um PeopleGarden

16
2.6.1. Milestones in Time
Milestones in Time descreve um sistema que foi
construído sobre um motor de pesquisa, motor
este que consegue indexar toda a informação
que o utilizador viu ao longo de um determinado
tempo [Ringel et al. 03]. Esta informação pode
ser sobre páginas na Web, emails e
documentos, entre outros.
Os resultados dessas pesquisas são apresentados com a ajuda de uma timeline, em
forma de vista geral ou em detalhe. A vista sumária permite ver a distribuição dos
resultados da pesquisa ao longo do tempo. A vista detalhada permite analisar com
mais detalhe um determinado resultado da pesquisa. Assim sendo, a visualização
interactiva fornece uma representação timeline-based de resultados de pesquisa
marcada por marcos pessoais (fotos, tarefas) e públicos (notícias, férias). Os
resultados das pesquisas são fornecidos por um sistema de indexação pessoal e
sistema de pesquisa chamado Stuff I’ve Seen (SIS).
A interface do sistema (Figura 16) é relativamente simples. Do lado esquerdo do
display está a timeline, cujos endpoints estão rotulados com as datas do primeiro e do
último resultado devolvido pela pesquisa. O tempo flui do topo para o fundo do ecrã,
com os resultados mais recentes no topo. A vista geral, que se encontra no centro do
display mostra uma vista geral dos resultados obtidos com a pesquisa. Perto da vista
geral, pode-se visualizar as datas e os marcos. Embora a interface fosse relativamente
simples, pelos testes realizados ao protótipo os utilizadores encontraram dificuldades
em navegar na timeline. Este trabalho é bastante parecido ao que iremos realizar,
devido ao facto de se conseguirem fazer pesquisas sobre dados indexados, sejam
estes documentos, emails ou outro tipo de ficheiros. No entanto as pesquisas são
pesquisas normais, sem grande semântica por detrás.
2.6.2. Time-Machine Computing
Time-Machine Computing (TMC) é uma
aproximação time-centric para organizar
informação em computadores
[Rekimoto99a] [Rekimoto99b]. Permite
aos utilizadores visitar os estados
Figura 16 - Interface do Milestones in Time
Figura 17 - Screenshot do TimeScape desktop.

17
passados e futuros de um computador. Quando um utilizador necessita de consultar
um documento onde este estava a trabalhar num dado momento, pode viajar numa
dimensão de tempo e o computador restaurando o seu estado para esse momento.
Um dos principais objectivos deste trabalho é explorar as vantagens da combinação
de informação espacial com mecanismos de navegação cronológicos. TMC é um novo
conceito de user interfaces que permite aos utilizadores visitar espaços de informação
passados e futuros. Existem quatro conceitos chave, que caracterizam este conceito:
lifelong archival os information history – que se resume a guardar toda a informação no
computador, seja esta o histórico das visitas realizadas na Web, documentos, etc.;
Time-traveling: chronological navigation over archived information – a informação
arquivada pode ser usada para recriar o estado do computador para um determinado
momento; visualizing time in varius ways – restaurar o passado simplesmente não é
suficiente, é necessário fornecer várias vistas para a visualização desta informação
(por exemplo timelines e calendários); time-casting: inter-applicational communication
of time – para além de se restaurar o estado dos documentos, é desejável restaurar o
estado das aplicações para essa altura.
O timescape fornece vários meios para mudar o tempo do desktop. Quando por
exemplo o utilizador muda o selector de tempo, o sistema restaura o estado do
desktop para o estado em que estava nesse momento seleccionado. A interface do
sistema consiste apenas na parte central, que é uma vista geral do resultado da
navegação no tempo e uma pequena barra, localizada na parte superior do display
onde o utilizador selecciona as datas desejadas para as suas viagens no tempo.
Existem várias técnicas de visualização dos resultados das viagens: em desktop, que
basicamente resume-se a visualizar o desktop, como estava na altura seleccionada;
timeline e vista de calendário (Figura 17 e 18).
Figura 18 - Do lado esquerdo a timeline view e do direito a calendar view
O TMC é particularmente apropriado para gerir informação pessoal porque o
processamento de informação e a história pessoal estão fortemente ligados nesse

18
domínio. No entanto, a ideia da nossa tese não é aceder a estados passados da
aplicação, mas sim, encontrar qualquer tipo de informação indexada no computador.
No entanto este artigo é interessante no sentido em que ajuda a visualizar
variadíssimos tipos de informação e em vários tipos de escalas e formas de tempo,
isto é, em vários tipos de timeline.
2.6.3. LifeLines
LifeLines é um sistema que fornece um ambiente
de visualização para histórias pessoais que pode
ser aplicado por exemplo a dados médicos,
registos de tribunal, histórias profissionais e outro
tipo de dados biográficos [Plaisant et al. 96]. Por
exemplo, a condição médica de um determinado
paciente é indicado com timelines individuais,
enquanto os ícones indicam eventos. A cor da linha e a sua espessura ilustram
relações ou outro determinado significado. Este sistema ajuda assim a que não seja
esquecida informação, tendo uma noção geral da situação ao qual o LifeLines é
aplicado. Para além disso, as metodologias gerais que o desenho da interface seguiu
foram: apresentar um registo visual geral num único ecrã; promover acesso directo a
toda a informação detalhada sobre a vista geral com apenas um ou dois clicks do rato;
colocar informação crítica ou alertas no nível geral.
Os grandes benefícios do LifeLines são: reduzir a possibilidade de perda de
informação; facilitar a detecção de anomalias e de tendências; facilitar o acesso a
dados. No entanto, a nível de interface tinha um problema, que era a representação de
muita informação no nível geral. O problema foi solucionado aproximando as linhas
umas das outras quando existe grande quantidade de informação, continuando assim
a ver-se toda a informação. Usaram também o denominado semantic zooming [22].
Para além disso o LifeLines está organizado em facets (Figura 19), podendo estas
expandir e contrair para desta forma aumentarem ou diminuírem o nível de detalhe.
Também existe a possibilidade de rescaling (zooming in) para quando os dados se
estendem ao longo de um grande período de tempo. As vantagens claras deste
sistema é ter-se sempre uma vista geral da informação e o fácil acesso aos detalhes.
No entanto, este trabalho também só serve para retirar algumas ideias para o nosso,
isto porque, embora possa tratar de uma grande variedade de dados, eram apenas
dados pessoais e não informação electrónica. Para além disso, neste trabalho não
existe a noção de pesquisa que é muito importante no nosso trabalho.
Figura 19 - Interface do LifeLines.

19
2.6.4. Lifestreams
O artigo Lifestreams é sobre um sistema que serve para, dinamicamente, se organizar
o workspace pessoal de um utilizador [Fertig et al. 96] [Freeman and Gelernter 96].
Lifestreams usa uma simples
metáfora organizacional, uma
stream de documentos
ordenada no tempo. Filtros
stream são usados para
organizar, monitorizar e
sumarizar informação acerca do utilizador. Assim sendo o Lifestreams é um sistema
para gerir informação electrónica pessoal (Figura 20).
Lifestreams é baseado nas seguintes observações: o armazenamento deve ser
transparente; directórios são inadequados como meio de organização; o
armazenamento deve ser automático; o sistema deve fornecer uma lógica sofisticada
para sumarizar ou comprimir um grande número de documentos relacionados, sobre o
qual o utilizador quer ter uma vista geral.
Em relação a interface deste sistema, é baseada numa representação da metáfora
stream. Existe uma grande combinação de cores e de animações para indicar
características especiais dos documentos. Por exemplo, uma margem vermelha indica
que o documento ainda não foi visto, e a bold significa que é writable. Os documentos
novos que chegam entretanto pelo lado esquerdo, e documentos criados entram na
stream vindos de cima, empurrando os restantes, fazendo um push numa pilha. Para
além disso contém vários botões e menus que facilitam aos utilizadores a interacção
com o sistema.
Este sistema, tal como os outros artigos já referidos anteriormente, contém alguma
informação que poderá vir a ser usada no nosso trabalho, no entanto o trabalho limita-
se ao tratamento de documentos. É interessante ver a metáfora usada na interface do
sistema e a importância destas metáforas, de uma forma geral, serem bastante
intuitivas para facilitar a interacção do sistema com o utilizador.
2.6.5. MyLifeBits
O artigo que se segue é o MyLifeBits [Gemmel et al.02] [Gemmel et al. 02] [Gemmel et
al.06]. Este trabalho é um projecto para aplicar a visão Memex, criada por Vannevar
Bush em 1945. É um sistema para guardar todos os media digitais de um utilizador,
Figura 20 - Interfaces do Lifestreams.

20
incluindo documentos, imagens, vídeos, etc. O sistema foi concebido sobre três
princípios: (1) colecções e pesquisas são a base para organização; (2) devem ser
suportadas muitas visualizações e (3) deve ser possível tirar anotações de forma
simples e eficaz. A visão Memex é a seguinte: ―a device in which an individual store all
His books, records, and communications, and which is mechanized so that it may be
consulted with exceeding speed and flexibility‖. Assim o objectivo do MyLifeBits é
implementar uma personal digital store.
De uma forma geral, o sistema é uma base de dados de recursos (media) e
hiperligações. Uma hiperligação indica que um recurso anota outro. O MyLifeBits usa
SQL Server com Índex Server, fornecendo assim pesquisas full-text. O schema da
base de dados é relativamente simples: existe uma tabela para recursos, uma para
hiperligações de anotação e outra para tabela para links de colecções. Na interface, os
resultados de uma pesquisa podem ser vistos de múltiplas formas: detail que é uma
lista dos resultados com as suas propriedades; thumbnail, onde se apresentam
imagens em miniatura dos recursos, numa espécie de grelha; timeline, onde se
mostram thumbnails numa escala de tempo linear; clustered-time faz o cluster de
thumbnails por tempos parecidos, e organiza-os numa ordem temporal.
O MyLifeBits inclui funcionalidades que permitem fazer anotações de forma simples.
Para além das funcionalidades referidas anteriormente, o sistema facilita também a
criação de histórias com ajuda de um método chamado Interactive Story by Query
(ISBQ). ISBQ permite aos utilizadores criarem queries e depois fazer drag and drop de
selecções numa história.
Figura 21 - Screenshots das vistas
Este survey enquadra-se no tema do nosso trabalho na medida em que este permite
pesquisar informação sobre vários tipos de ficheiros, visualizando o resultado destas
pesquisas de várias formas, variando estas no seu grau de detalhe. É interessante
analisar as interfaces escolhidas para as diferentes formas de representação dos
dados (Figura 21), podendo retirar destas várias ideias. No entanto, num nível mais

21
geral, a interface era relativamente limitada, a nível de outras opções, limitando-se a
apresentar as tais formas de representar os resultados das pesquisas de forma eficaz.
2.7. Pesquisadores e Browsers
Como já foi referido anteriormente, o aumento e a diversidade de informação pessoal
tem criado vários tipos de problemas aos utilizadores comuns de computadores
pessoais, devido ao facto destes estarem a perder a noção geral do seu sistema. Para
além disso, a grande quantidade de informação dificulta a navegação por esta e
também a sua pesquisa. Devido a estas razões, surgiram alguns sistemas com
visualizações interessantes, os quais iremos analisar de seguida.
2.7.1. Stuff I’ve Seen
Stuff I’ve Seen é um sistema que facilita a reutilização de informação [Dumais et al.
03]. Esta reutilização é feita de dois modos: o primeiro consiste num sistema que
guarda qualquer informação que o utilizador tenha visto, através da indexação, seja
esta referente ao seu e-mail pessoal, documentos criados/editados pelo utilizador ou
mesmo páginas acedidas na Web; o segundo é quando a informação já foi ―vista‖ e
indexada, é possível, através de uma interface de pesquisa, reencontrar essa
informação.
A interface permite ao utilizador especificar queries, visualizar e manipular os
resultados. Os utilizadores têm possibilidade de fazer uma pesquisa mais geral e de
seguida refinar a pesquisa, filtrando e sorteado interactivamente os resultados.
A interface, denominada Top View (Figura 22), é uma list view com filtros para refinar
atributos em cada coluna. Os resultados das pesquisas são mostrados na parte
inferior do display. Para cada resultado é apresentada informação adicional, como por
exemplo o título do documento, autor, etc. É também mostrado um ícone que identifica
o tipo de documento que é. Como já foi referido acima, depois de ser aplicado uma
pesquisa pode-se refinar esta mesma pesquisa, através da secção de filtros. Estes
filtros podem ser aplicados através da selecção de checkBoxes.

22
Figura 22 - Screenshot do SIS, em Top view
De forma geral, este sistema é semelhante ao sistema que vamos desenvolver ao
longo deste trabalho, daí o seu interesse. A nível de interface dá para retirar ideias
interessantes do SIS, como é o caso do refinamento das pesquisas através de filtros
de uma forma simples que são as checkboxes, permitindo assim aos utilizadores
encontrar informação desejada de forma simples e eficaz. Em relação ao resto da
interface, mesmo os próprios autores do artigo referiram que era uma das partes onde
podem efectuar alterações para melhorar o seu aspecto, devido ao facto de ainda ser
uma simples list view.
2.7.2. Plath
O próximo survey é o Plath (Personal Search and Organization Made Easy) [Cutrell et
al. 06]. Descreve-se o design de um sistema que faz a optimização de pesquisas para
informação pessoal com uma interface simples que junta a pesquisa e o browsing com
uma variedade de sugestões associativas e contextuais. Para além disso, o Plath
(Figura 23) suporta um esquema de tagging para organizar conteúdo pessoal por
sistema de armazenamento (por exemplo o e-mail). De uma forma geral, o Plath
permite aos utilizadores encontrar informação baseada no que o utilizador se lembra e
onde quer que esteja a informação. Em relação aos princípios de desenho que o
sistema seguiu, citamos os mais importantes: unify text entry and filtering, isto é, as
pesquisas tanto devem ser possíveis através da inserção do texto da query a
pesquisar, como só por filtro, ou mesmo ambos; os critérios actuais da busca devem
ser visíveis e salientes em todas as situações, isto significa que em qualquer altura o
utilizador tem de saber quais os critérios de uma pesquisa actual, os filtros aplicados
sobre a pesquisa, ou seja, uma noção geral do sistema em cada momento; promova a
interação rápida da query, isto é, as pesquisas têm de ser rápidas, ou pelo menos,
depois de o utilizador carregar em Enter, devem aparecer resultados assim que

23
possível; Permita a interacção baseada no reconhecimento. Em relação a Interface,
esta é composta por três áreas principais: área de query, onde estão os comandos
query (go, back, forward, etc.) e a query box, onde se coloca o texto da query; sob
esta, encontra-se a área de filtro; à direita destas duas últimas áreas encontra-se a
secção dos resultados.
De uma forma geral, os resultados do
sistema são bastante positivos. Entre
estes aspectos encontra-se o facto do
modelo de query ser simples, no
entanto muito eficaz. Outro aspecto
muito positivo é os utilizadores
poderem modificar as suas queries nos
resultados de uma pesquisa. No
entanto, existiam alguns problemas
com o sistema. O maior problema que o sistema tinha prendia-se com o tagging. A
nível da interface, era relativamente simples para o que era necessário, conseguindo
uma boa interacção com o utilizador, no entanto, é demasiado simplista para aplicar
ao nosso trabalho. No nosso ver, a mais-valia deste artigo são os princípios de
desenho em que se baseou, referidos anteriormente.
2.7.3. Personal Chronicling Tools
Neste artigo propõe-se um conjunto de ferramentas para guardar eventos pessoais
(PCT – Personal Chronicling Tools), para suportar trabalhadores de conhecimento da
empresa nos eventos digitais de armazenamento e de publicação [Kim et al. 04]. PCT
é composto por quatro ferramentas primárias: (1) monitorização de eventos –
capturam os eventos do utilizador como por exemplo e-mail, paginas Web,
documentos editados, etc.; (2) anotação interactiva – permite ao utilizador fazer
tagging e book marking de momentos interessantes; (3) browser/search – permite
pesquisas semânticas; (4) edição/publicação – facilita a publicação de eventos
importantes. Este trabalho é claramente orientado para pessoas num contexto
empresarial. Ora, neste contexto, existe uma grande perda de informação devido a
informação que não é capturada, informação que não é organizada eficientemente
para à posteriori ser pesquisada ou simplesmente, a informação não estar disponível
para pesquisa. Assim o principal objectivo do PCT (Figura 24) é fornecer ferramentas
que permitem aos empregados capturar, organizar, recuperar e partilhar registos das
suas actividades, interacções e interesses. Enquanto as ferramentas de monitorização
Figura 23 - Screenshot do Phlat.

24
de eventos captam toda a actividade do utilizador com o computador, as anotações e
tagging interactivo permite ao utilizador fazer tagging e anotações manuais. Para isso
o utilizador tem um tagging button.
Figura 24 - Interface de browsing do PCT
Relativamente ao browsing para a pesquisa e recuperação de informação, usa-se uma
interface de pesquisa como um aspecto comum a qualquer outra, como é observável
na figura acima. Na parte superior do layout encontra-se a caixa de texto onde se
insere a query para a pesquisa desejada. Existe também uma opção de More, que ao
ser seleccionada abre um sub-menu nesse sob a caixa de texto, onde podem ser
seleccionados alguns filtros através de check-boxes e onde também pode ser feita
uma selecção por data. Na parte inferior do layout surgem os resultados das
pesquisas. Em relação à publicação e partilha de informação, existe no layout, na
parte direita deste, um menu chamado PCT views and Access Control. Este trabalho
enuncia a elaboração de sistema guardar/recuperar informação vocacionado para as
empresas. É sempre interessante visualizar diferentes âmbitos aplicacionais da
recuperação e visualização de informação. No entanto, em relação à interface deste,
esta é limitada, na medida em que é um sistema de pesquisa comum, não existindo
uma profunda abordagem ao nível da visualização de informação.
2.7.4. FacetMap
A maioria dos sistemas de pesquisas
são baseados no texto, e a visualização
destes resultados limitam-se a
apresentar uma lista com um scroll. O
FacetMap (Figura 25) é um sistema de
visualização interactiva, guiado por
queries, generalizável para um grande
conjunto de informação através da sua
metadata [Smith et al. 06]. Figura 25 - Interface do Facetmap.

25
O FacetMap tentou ultrapassar o paradigma dominante para procuras e browsing
baseadas em texto através de visualizações interactivas e query-driven, generalizáveis
para uma grande quantidade de data stores ricas em informação metadata. O
objectivo inicial dos autores do artigo era explorar os designs para um sistema de
recuperação de informação pessoal que permitisse que os utilizadores tirassem
partido das suas capacidades visuais espaciais e que também desse prazer de usar.
Assim sendo, o FacetMap é uma visualização para interagir com grandes bases de
dados e ricas em metadata permitindo ao utilizador juntar queries complexas por
iteração e por interacção directa com o output gráfico do sistema.
O FacetMap permite aos utilizadores realizarem pesquisas e browse tarefas,
seleccionando iterativamente atributos para filtrar o conjunto de dados e refinar os
resultados no display. O princípio base por detrás do FacetMap é mostrar qualquer
conjunto de dados da maneira mais eficaz, dado a restrição do tamanho do ecrã, o
número de itens e os seus atributos. O sistema, em vez de começar com o ecrã vazio
e branco, mostra logo um conjunto de dados organizado (por tempo, autor, tipo, etc.).
Quando o conjunto de dados é demasiado grande para o display, o FacetMap junta-os
numa bolha oval, representando assim o conjunto de dados que partilham atributos,
oferecendo assim uma vista geral da distribuição dos itens ao utilizador. Para realizar
uma pesquisa ou um browse o utilizador simplesmente selecciona uma das bolhas,
clicando sobre ela, aplicando assim um filtro aos dados, reduzindo logo à partida o
conjunto de dados. O espaço do ecrã é dividido em duas partes: do lado esquerdo
têm-se as facets que ainda não foram usadas para filtrar os dados e do lado esquerdo
estão as facets com os valores que estão a ser usados no filtro.
Os autores deste artigo, de facto conseguem criar um novo paradigma para a
pesquisa e browse através da metáfora usada. Em termos de interface, esta é
bastante atraente e simples de usar, simplificando a visualização dos resultados ao
longo da pesquisa e permitindo uma boa interacção entre o sistema e o utilizador. Em
relação à escalabilidade do sistema, a forma como os autores resolveram o problema
(juntando dados com características iguais) também foi bem conseguida, tornando-se
assim o sistema escalável. Os utilizadores por vezes ficam confundidos, não sabendo
qual a facet correcta que devem seleccionar para a sua pesquisa.
2.8. Discussão
Depois de analisar todos os sistemas mencionados anteriormente, existe a
necessidade de os comparar entre si, para que desta forma se consiga aproveitar o

26
melhor de cada um, de uma forma geral, conseguir visualizar os prós e os contras dos
vários sistemas.
Embora todos os trabalhos tenham pontos interessantes para a resolução dos
problemas que existem na visualização de informação pessoal, nenhum consegue dar
resposta a todos eles, estando assim as respostas aos problemas repartidos entre os
vários artigos. Na tabela 1 encontra-se um resumo dos trabalhos segundo várias
dimensões que são relevantes para o meu trabalho.
No nosso trabalho e do nosso ponto de vista, a dimensão ―Overview‖ é a dimensão
mais importante. Os trabalhos que tentam uma aproximação ao problema referido,
deveriam todos fazer de esta a dimensão mais importante, isto porque assim a
utilização não perde a percepção geral do seu conteúdo, isto é, da sua informação
pessoal. Na realidade, praticamente todos os trabalhos analisados respeitam esta
dimensão, a excepção de dois. A ausência desta dimensão deve-se, no nosso ver, a
serem dispositivos físicos, sendo difícil manter uma ―Big Picture‖ do sistema.
Uma outra dimensão importante é a Time Navigation. Como a informação pessoal de
um utilizador se encontra dispersa no tempo e o utilizador trabalha em vários temas
tanto ao mesmo tempo como ao longo do tempo, existe a necessidade de permitir a
este a navegação no espaço temporal na sua informação. Dos trabalhos analisados
nem todos possuíam esta feature. Cerca de metade dos trabalhos não permitiam
qualquer navegação no tempo aos utilizadores na sua informação pessoal.
Em relação ao tipo de visualização utilizada, isto é, visualização 2D ou 3D, a grande
maioria dos trabalhos usava visualizações 2D, existindo apenas 3 trabalhos que
usavam a visualização 3D. Para o problema em questão a visualização 3D pode ser
usada para inserir mais uma dimensão na informação disponibilizada ao utilizador, e
não para meros aspectos decorativos.
Por fim encontramos as seguintes dimensões: zooming, filtering e details on demand.
Todos estes contribuem para melhorar alguns aspectos nos trabalhos, reflectindo a
maioria das vezes a granularidade com que os trabalhos analisam a informação em
questão.

27
Abordagem Organização Overview Vis.
3D
Vis.
2D
Time
navigation
Zoom-
ing
Fil-
tering
Details
on
demand
Themail Temporal
Visualization to
aid com-
munications
Temporal
MaiView Espacial
PostHistory e
Social Network
Fragments
Temporal e
especial
TimeStore Temporal
TaskView Temporal
Storytelling
with D.
Photographs
-
Personal Digital
Historian -
Forget-me-not -
Newsgroup
Crowds and
AuthorLines
Espacial
PeopleGarden Espacial
Milestones in
Time Temporal
Time-Machine
Computing
Temporal e
Espacial
LifeLines Temporal
Lifestreams Temporal
MyLifeBits Temporal e
Espacial
Stuff I’ve Seen Espacial
Plath Espacial
Personal
Chronicling
Tools
Espacial
FacetMap Espacial
Tabela 1 - Classificação dos trabalhos descritos
Todos os trabalhos, à excepção dos pesquisadores e navegadores, do Time-Machine
Computing e do Milestones in Time, dedicam-se apenas à representação de um tipo
de informação pessoal, não abrangendo toda a informação pessoal contida num
computador pessoal, daí as suas limitações. Os que conseguem abordar toda a
informação pessoal, não conseguem criar uma interface coerente e eficaz para
apresentar essa informação.
O nosso trabalho vai tentar reaproveitar os aspectos mais positivos dos trabalhos
analisados nesta secção, tentando responder a todas as dimensões referidas acima.

28
No entanto existe uma delas que à partida não irá ser tida em conta, que é a
visualização 3D, visto que a nossa interface vai ser em forma de jornal.
Uma dimensão, que de certa forma estava relacionada com a anterior, é a
organização da informação. Esta pode ser dividida em temporal e espacial. Também
nesta dimensão não há consenso, estando alguns trabalhos organizados
temporalmente e outros espacialmente. Existem mesmo alguns que têm em conta as
duas organizações, isto é, conseguem organizar-se espacialmente e temporalmente.

29
3. Overview
O nosso trabalho pode ser dividido numa série de blocos, todos estes interligados para
atingir o mesmo fim: permitir a um determinado utilizador visualizar a sua informação
pessoal como um todo, isto é, sem que este perca a percepção geral de toda a
informação. Para além disso, e como objectivo secundário, a identificação e respectiva
apresentação de padrões existente na informação pessoal do utilizador.
A figura 26 identifica as etapas seguidas para a resolução do nosso problema.
Figura 26 – Etapas seguidas ao longo do PersonalNews
Toda a aplicação é baseada em informação pessoal, nomeadamente documentos
pessoais dos utilizadores. Assim, a primeira etapa é a indexação desses documentos
pessoais e a extracção de imagens desses mesmos documentos, para que estas
possam ser utilizadas na fase da exposição das notícias. A fase que se segue é a
identificação dos temas. Nesta criam-se grupos de documentos pertencentes ao
mesmo tema. Realiza-se também nesta fase a extracção de palavras-chave destes
temas, para assim ficarmos na posse das palavras mais significativas do tema. Segue-
se a extracção de excertos das notícias. Esta, para além de usar os documentos da
primeira fase, usa as palavras-chave extraídas da fase anterior para a que desta forma
se possam extrair os excertos mais significativos dos documentos. Após a fase de
extracção dos excertos mais significativos dos documentos, segue-se a extracção dos
sumários. Nesta extracção, que tem por base os excertos da fase anterior, é, de uma
forma geral, a selecção da secção mais importante de um excerto, que passa deste
modo a ser considerado um sumário. Na quinta fase procede-se à geração das
notícias, onde se inclui todas as operações de língua natural.

30
Por fim, na última fase encontra-se a exposição das notícias. Para tal, elaborou-se
uma interface que usa a biblioteca criada ao longo do trabalho, isto é, nas etapas
anteriores. No geral, pode-se verificar que o trabalho é constituído por duas grandes
partes: a criação da biblioteca e a segunda que consiste na elaboração de uma
interface que aplique a biblioteca, sendo, no entanto, independentes. A biblioteca
engloba os 5 primeiros passos. Resta o último passo que é da elaboração da interface.

31
4. Descoberta de Temas
Uma vez apresentados os objectivos e o enquadramento do nosso trabalho,
começamos agora com a descoberta dos temas. Esta descoberta de temas incide
sobre a informação pessoal dos utilizadores, nomeadamente documentos.
4.1. Motivação/Introdução
Qualquer utilizador trabalha em várias áreas e vários temas ao longo do tempo. A
informação disponível na nossa base de indexação possibilita-nos a análise desta e a
organização da mesma em vários temas, que são representativos das áreas que um
determinado utilizador andou a trabalhar, como iremos ver de seguida.
De forma a se conseguir visualizar informação mais relevante para o utilizador em
temas, é necessário existir um pré-tratamento dessa informação antes de ser
apresentada ao utilizador. Da mesma forma, para que o conhecimento contido nas
várias fontes de informação possa ser apresentado ao utilizador através de padrões, é
necessário que seja organizada em grupos de forma a que, à posteriori, estes grupos
sejam apresentados aos utilizadores da aplicação em secções diferentes, ou de forma
claramente separável.
Cada grupo necessita de ter uma breve descrição, isto é, um sumário que descreva de
forma sucinta os vários tópicos mais relevantes do respectivo cluster, isto é, do tema.
4.2. Método
A forma escolhida para a descoberta de temas é através do agrupamento de fontes
através de clustering por tema.
Esta etapa de clustering pode ser decomposta em várias subsecções, subsecções que
vão ser explicadas de seguida. Numa primeira fase é necessário criar os corpii dos
ficheiros desejados para análise, isto é, dos dados que o utilizador vai ver. Os corpii
contêm as palavras e o número de vezes que essas palavras surgem nos ficheiros. O
objectivo da análise dos corpii é a obtenção das keywords dos respectivos ficheiros
usando o TF-IDF [Brooks and Montanez 06] [Liu et al. 04]. Depois de estar na posse
das keywords, inicia-se a fase referente ao algoritmo LSA, que serve para extracção e
representação do significado no uso contextual das palavras de grandes corpii de
texto.

32
Após o cálculo da matriz LSA estamos na posse das matrizes de distâncias, que pode
ser usado como input para o algoritmo de clustering (QT-Clust), o qual vai criar então
os grupos de dados agrupados em diferentes temas.
4.3. Matriz de distâncias
Para criar os clusters é necessário algum género de medida, com que se possa medir
a distância entre os dados que se desejam agrupar. O método escolhido para obter
esta medida foi através de uma matriz de distâncias. Esta mede a distância semântica
entre os documentos. Nas linhas a matriz contém os documentos e nas colunas
contém as keywords utilizadas. Assim sendo, as células da matriz contêm o número
de vezes que a keyword (coluna) se encontra no documento (linha). Cada linha pode
ser vista como um vector n-dimensional que nos dá a posição do documento no
espaço semântico. A distância entre os documentos é pois dada pela distância
euclidiana entre os respectivos vectores.
Para a criação da matriz de distância utilizou-se o algoritmo LSA, o qual será
apresentado da secção seguinte.
4.4. LSA
A Latent Sematic Analysis (LSA) pode ser aplicado para induzir e representar aspectos
do significado das palavras [Berry et al. 1995] [Berry92] [Landauer and Dumais 94].
LSA é uma variante do modelo vector space que converte documentos para uma
matriz termo-documento (term-document), em que cada célula da matriz indica a
frequência que cada termo (termos que estão representados nas linhas) ocorre em
cada documento (documentos que se encontram representados nas colunas). O LSA
é parecido com modelos de redes neuronais, no entanto é baseado no singular value
decomposition, uma técnica matemática de decomposição de uma matriz.
O LSA é uma teoria/método para extracção e representação do significado no uso
contextual das palavras de grandes corpii de texto. A ideia base deste algoritmo é que
o agregado de todos os contextos em que uma determinada palavra aparece fornece
um conjunto de restrições que largamente determinam a similaridade do significado
das palavras dos documentos. Este método não usa qualquer dicionário, base de
conhecimento ou qualquer outra ferramenta, utilizando apenas como input o texto em
análise, o que é adequado para o nosso caso, uma vez que nos é fácil prever os
temas prever os temas que podem ter interesse para o utilizador.

33
De uma forma geral, o algoritmo LSA permite a criação de uma matriz, que na linhas
representa os documentos em análise e nas colunas os documento-keywords dos
documentos em questão, criando assim uma matriz documento-keyword. Assim
sendo, seja li uma linha e cj uma coluna da matriz e Oij um elemento, Oij representa o
número de vezes que o termo j aparece no documento i. Depois de se ter a matriz
documento-keyword, é aplicado o SVD (Simple Value Decomposition). O SVD divide a
matriz documento-keyword em três matrizes: U, S e V. A matriz U diz respeito aos
termos, enquanto que a matriz S contém os valores mais representativos da matriz
documento. A matriz V contém os documentos. De seguida escolhe-se um tamanho
(nível k, ou simplesmente dimensão) para trabalhar com as três matrizes, obtendo-se
as matrizes U‘, S‘ e V‘, matrizes estas que agora contêm as keywords pesadas, isto é,
as keywords menos importantes não irão possuir qualquer peso ao contrário das mais
importantes. Finalmente, usam-se estas matrizes para reconstruir a original, matriz
esta que pode ter keywords que não ocorreram num determinado documento, isto
porque correspondem com o tema e keywords que antes de correr o LSA eram
importantes, mas que no entanto agora não vão ter qualquer peso por não ocorrerem
no tema, ou por terem sido eliminadas pela dimensão.
De seguida apresenta-se um exemplo de ilustração, onde é aplicado o LSA
[Deerwester et al. 90] (Tabela 2 e Tabela 3).
Titles
c1:
Human machine interface for Lab ABC computer
applications
c2:
A survey of user opinion of computer system response
time
c3: The EPS user interface management system
c4: System and human system engineering testing of EPS
c5:
Relation os user-perceived response time error
measurement
m1: the generation of random, binary, unordered trees
m2: the intersection graph of paths in trees
m3: Graph minors IV: widths of trees and well-quasi-ordering
m4: Graph minors: A survey
Tabela 2 - Extractos de texto usados no exemplo de aplicação do algoritmo LSA

34
Terms Documentos
c1 c2 c3 c4 c5 m1 m2 m3 m4
human 1 0 0 1 0 0 0 0 0
interface 1 0 1 0 0 0 0 0 0
computer 1 1 0 0 0 0 0 0 0
user 0 1 1 0 1 0 0 0 0
system 0 1 1 2 0 0 0 0 0
response 0 1 0 0 1 0 0 0 0
time 0 1 0 0 1 0 0 0 0
EPS 0 0 1 1 0 0 0 0 0
survey 0 1 0 0 0 0 0 0 1
trees 0 0 0 0 0 1 1 1 0
graph 0 0 0 0 0 0 1 1 1
minors 0 0 0 0 0 0 0 1 1
Tabela 3 - Matriz term-document.
Neste exemplo escolheu-se propositadamente termos em títulos de forma a conseguir-
se uma boa aproximação usando apenas duas dimensões. Assim na figura 27 é
apresentado um gráfico bidimensional dos termos e dos títulos dos documentos; as
suas coordenadas são simplesmente as duas primeiras colunas na matriz U e V
respectivamente.
Figura 27 - Resultados obtidos depois da aplicação do algoritmo LSA.
A partir da análise da figura 27, consegue-se facilmente verificar que os vários
documentos estão organizados segundo um tema, isto é, os documentos m

35
encontram-se bem separados dos documentos c, representando m e c dois temas
diferentes.
A matriz resultante do algoritmo LSA vai ser de extrema importância para a criação
dos clusters, isto porque para o algoritmo de clustering vamos necessitar uma matriz
de distância, que é criada com a ajuda da matriz resultante do LSA.
4.5. Escolha das Keywords
A escolha das keywords é um passo de elevada relevância por estas terem um papel
importante no algoritmo LSA, com que se vai criar a matriz de distâncias.
A extracção das keywords foi realizada de duas formas diferentes, isto porque ambas
produziam resultados diferentes, existindo assim a necessidade de verificar qual seria
a melhor. Numa primeira abordagem seleccionavam-se as N mais frequentes para ser
criada a matriz de distância. Esta forma era a maneira simples de extrair keywords, no
entanto poderia não ser o melhor método para o fazer.
Depois de uma análise inicial das keywords seleccionadas (resultados na tabela 3),
através deste primeiro método de selecção escolhido, conclui-se que este não era o
mais correcto, isto porque surgiam keywords sem qualquer interesse, como por
exemplo números. Após os testes efectuados, os resultados, numa primeira
aproximação continham stop words, que são palavras de ligação de frases, por
exemplo o the, to, or, entre outras. Era necessário ignorar estas stop words para se
obterem resultados mais interessantes. Na segunda aproximação foi usado o método
TFIDF [Brooks and Montanez 06] [Liu et al. 04] para a extracção de keywords. Assim
sendo, foi necessário remodelar a selecção de keywords. Optou-se pela selecção de
palavras através do algoritmo TFIDF, conseguindo-se assim obter melhores
resultados.
A função standard do TFIDF combina a frequência dos termos (Term frequency TF), o
qual mede o número de vezes que uma palavra ocorre no documento e a frequência
inversa do documento (inverse document frequency IDF).
idfa = log(N/df
a)
tfidfag=tf
ag x idf
a
Assim sendo o idfa é a frequência inversa do documento da palavra a, nos N
documentos, sendo dfa o número de documentos em que a palavra a aparece. Por fim,
tfag é o número de vezes que a palavra a aparece no documento g.

36
Com o TFIDF, as keywords vêm em forma de Stem (usando o Porter Stemmer
[Porter80]), isto é, as palavras já vêm reduzidas à sua forma base, sem ter em conta
as variações que a palavra pode ter. Um exemplo disso é a palavra drawings. Esta
palavra quando reduzida à sua forma stem fica draw, isto é, draw é a raiz da palavra
drawings.
4.6. Matriz de Distância LSA
Um dos objectivos para a utilização do algoritmo LSA era, depois de este ter devolvido
a matriz LSA, criar a uma matriz de distância. Esta matriz de distância vai ter enorme
importância, na medida em que os input‘s dos algoritmos de clustering é esta matriz e
outro factor, como veremos de seguida.
A matriz resultante do algoritmo LSA fornece as coordenadas para o cálculo da matriz
de distâncias, isto é, como esta matriz possui nas suas linhas os documentos, e nas
colunas, as várias keywords, que representam cada uma das coordenadas. Assim, a
matriz LSA é uma representação espacial, num espaço de dimensão igual ao número
de keywords existentes. Para o cálculo da matriz de distância bastava assim ter os
documentos nas linhas (i) e nas colunas (j) e em cada Dij ter a distância do documento
i ao documento j. O cálculo da distância foi realizado através da distância euclidiana.
4.7. Criação dos clusters
Para os humanos é relativamente fácil agrupar um conjunto de documentos em
diferentes grupos (bastando para tal a leitura destes). Como os computadores não têm
a mesma compreensão das palavras como os humanos, este agrupamento não é tão
trivial. Foram desenvolvidas algumas teorias e algoritmos de forma a facilitar esta
tarefa às máquinas, como é o caso de Machine Learning [Sebastiani02] [Yang and Liu
99] e clustering. Para o Machine Learning vários algoritmos podem ser utilizados,
como é o exemplo das redes neuronais, Naive Bayes, Support Vector Machines (SVM)
e k-Nearest Neighbours (kNN). Como é óbvio, cada um tem as suas vantagens e
desvantagens, variando o algoritmo usado conforme os dados e os resultados
desejados. No entanto, a grande desvantagem dos métodos de Machine Learning é
estes necessitarem de ser treinados, para que desta forma a máquina aprenda
realmente. Para que estes métodos produzam resultados significativos têm de ser
treinados com uma imensa quantidade de dados, existindo métodos que foram
treinados com 800.000 documentos.

37
Já em relação ao clustering, este pode ser dividido em duas partes: supervisionado e
não supervisionado. Os métodos de clustering supervisionados, normalmente são
referidos como métodos de classificação, isto porque usam um conjunto de dados
classificados e treinados para cada grupo. No entanto, esta é uma abordagem que não
interessa para o nosso caso, como já foi mencionado acima. Assim os métodos de
clustering que nos interessam são os não supervisionados.
Para além da separação clara dos métodos de clustering quanto ao
supervisionamento, ainda existe outra divisão: os hierárquicos e os particionais. Os
métodos de clusters hierárquicos usam clusters estabelecidos anteriormente para
conseguir criar os novos clusters. Assim sendo, o objectivo destes métodos de
clustering não é produzir uma única solução de clustering, mas um grupo de soluções,
conectadas umas às outras, criando um género de uma árvore. Nos métodos de
clustering particionais, o objectivo é chegar apenas a uma solução, ou seja, uma
partição dos dados. Estes métodos têm a vantagem de serem mais rápidos e
computacionalmente menos pesados, devido ao facto de só se produzir um conjunto
de clusters. No entanto, neste tipo de métodos é preciso saber o número de
grupos/clusters que vão ser criados à partida, como é o exemplo do K-means. [Xu and
Wunsch 05].
Devido aos problemas levantados pelos métodos de clustering referidos acima, tanto
do lado dos hierárquicos, como do lado dos particionais, começaram a surgir métodos
que tiram partido das potencialidades e evitam as desvantagens destes. Algoritmos
como o CBC (clustering by committee) [Pantel and Lin 02] e o QT_Clust [Heyer et al.
99] são exemplos deste tipo.
O algoritmo CBC constrói um centróide de um cluster calculando as médias de um
subconjunto de membros dos clusters. Este subconjunto pode ser visto como um
committee para determinar quais são os outros elementos que deveriam pertencer ao
cluster. Este algoritmo é composto por três fases: procura dos elementos top-similar,
encontrar os committees e por fim, atribuir os restantes elementos aos clusters. No
entanto, estudos feitos mostram que este algoritmo não cobre todos os objectos
[Hotho and Stumme 02].
Já em relação ao QT-Clust (Quality cluster algorithm) (Heyer et al., 1999) o objectivo
deste algoritmo é criar clusters com garantia de qualidade. Este algoritmo tem duas
vantagens a seu favor, dai ter sido escolhido para a implementação do clustering no
nosso caso: não é necessário saber o número de clusters à partida, como no caso do
K-Means e tem garantia de qualidade, como é explicado no artigo (Heyer et al., 1999).

38
4.8. Utilização do QT-Clust
O algoritmo funciona da seguinte maneira: um cluster candidato é criado com base no
primeiro elemento dos dados (que no nosso caso, um elemento irá corresponder a um
documento) e junta-se a este um outro elemento que tenha elevadas parecenças com
este elemento, ou seja, que esteja próximo. Vão-se juntando outros elementos a este
cluster candidato iterativamente, sendo que em cada elemento que se junta é menor
que um certo raio que é fornecido no input do algoritmo. Quando este raio é
ultrapassado, é criado um novo cluster candidato, começando com o segundo
elemento dos dados repetindo-se o procedimento, tendo novamente em conta todos
os elementos que formam o conjunto de dados, isto é, mesmo que um elemento já se
encontre no primeiro cluster candidato, é tido em conta para este segundo cluster
candidato. No fim deste processo, vai-se ter tantos clusters candidatos como
elementos do conjunto de dados. De seguida é escolhido o maior cluster candidato e
guardado, retirando-se os elementos, que fazem parte deste, do conjunto de dados e
repete-se o processo todo novamente. No algoritmo 1 está representado o pseudo-
código deste algoritmo.
Procedure QT_Clust(G,d)
if(|G| ≤ 1) then output G, else do
foreach i Є G
set flag = True; set Ai = {i} /* Ai cluster started by i*/
while ((flag = True) and (Ai≠G))
find j Є (G - Ai) such that diameter(Ai U {j}) is min
if (diameter(Ai U {j}) > d)
then set flag = False
else set Ai = Ai U {j} /* Add j to cluster Ai */
identify set C Є {A1, A2, …, A|G|} with maximum cardinality
output C
call QT_Clust(G - C, d)
Algoritmo 1 - Qt_clust
No entanto, depois de se perceber o algoritmo, foi necessário escolher um raio que iria
ser usado no algoritmo. Em relação ao número de keywords, era previsível que este
raio variasse, isto é, para um determinado conjunto de dados poderia ser um, e para
outro conjunto de dados poderia ser outro, completamente diferente do anterior. Este
problema foi atenuado, com a normalização da matriz resultante da aplicação do
algoritmo LSA. Foi necessário efectuar-se testes exaustivos para tentar escolher o
valor do raio que, em média, produz os melhores resultados.

39
4.9. Join clusters
Embora os resultados obtidos através do algoritmo de clustering geralmente fossem
completos, notava-se uma clara tendência a produzirem demasiados clusters, e alguns
com apenas um a dois elementos. Ora, esta situação é perfeitamente possível, no
entanto, geralmente o que se verificava era que esses clusters podem-se juntar com
outros clusters, visto que a distância entre estes é reduzida indicando que o clusters
são semelhantes, reduzindo assim o número de clusters, e por consequente o número
de temas, o que seria desejável. Foi pois necessário criar mais um algoritmo que junte
os clusters segundo um determinado parâmetro, e mais uma vez, este parâmetro não
era conhecido à partida, sendo necessário efectuar-se um conjunto de testes. O que
fazia mais sentido, para a junção dos clusters, era determinar o centro de cluster dos
clusters que se poderiam juntar e verificar a distância entre estes. Se esta distância for
menor do que um determinado valor, juntam-se os clusters.
O que levou à criação deste algoritmo de junção de cluster, foi a obtenção de
demasiados clusters através do algoritmo de clustering. Ora, este número era
demasiado elevado quando comparado com o que era esperado a partir dos nossos
conjuntos de dados de teste. Depois de se efectuar os conjuntos de teste após a
aplicação do algoritmo de junção, verificou-se que os resultados continuavam a ser
bons em termos de agrupamento concreto de documentos, e, o mais importante,
conseguiu-se aproximar o número de clusters produzidos pelo algoritmo ao número de
clusters que seria esperado para os conjuntos de dados.
Assim sendo, numa primeira fase foi necessário encontrar o centro do cluster, tarefa
esta, fácil de executar devido ao facto de cada linha da matriz LSA se poder
considerar as coordenadas de um espaço, de dimensão igual ao número de keywords
utilizado, bastando para tal efectuar a média dos vectores linha para que assim se
obtivesse o ponto médio. O único problema que se punha nesta fase era a distância a
utilizar para o caso de junção.
4.10. Avaliação
Para se conseguir verificar que os clusters gerados pela nossa aplicação são bons,
houve a necessidade de efectuar medidas e avaliações. Para além disso, foi
necessário estipular valores que funcionem bem no caso geral. As variáveis em causa
são: raio e keywords utilizados no algoritmo de clustering, dimensão usada no LSA e a
distância de junção dos clusters usada no Join Clusters.

40
4.10.1. Medidas de avaliação
Ao longo da criação dos clusters foi necessário efectuar um conjunto de testes e
comparar resultados, sendo assim necessário usar um conjunto de medidas para que
as comparações fossem efectuadas de maneira correcta e eficiente.
Usaram-se duas medidas principais de comparação: Silhouette Coefficient [Kaufman
and Rousseeuw 90] e a taxa de acerto. Com a ajuda destas duas medidas de
comparação entre clusters, conseguiram-se tirar conclusões.
O Silhouette Coefficient é uma medida própria dos algoritmos de clustering, que mede
a qualidade dos clusters, independente do número de clusters. Informalmente, mede a
qualidade de um determinado cluster através do cálculo das distâncias entre os vários
elementos desse mesmo cluster. O método de cálculo do Silhouette Coefficient é
constituído pelos seguintes passos:
Para um determinado objecto (i), calcular a distância média para todos os objectos
contidos no cluster onde o objecto em análise se insere. A este valor chama-se ai.
Para o mesmo objecto i e todos os clusters que não contenham o objecto i, calcular a
distância média a todos os objectos nesses clusters. Encontrar a menor distância,
chamando a esse valor bi.
Para o objecto i, o Silhouette Coefficient é calculado da seguinte forma:
si = (bi -ai)/max(ai,bi)
Este processo realiza-se para todos os objectos do cluster, e calcula-se a média dos
Silhouette Coefficient de todos os objectos, ficando assim com o Silhouette Coefficient
do cluster.
Depois de se estar na posse do valor do Silhouette Coefficient, verifica-se em qual dos
seguintes intervalos este se insere:
0.7 ≤ SC(P) ≤ 1.0 → separação excelente entre os clusters
0.5 ≤ SC(P) < 0.7 → separação média entre os clusters. Os vários dados que
compõem possuem um centro de cluster bem definido.
0.25 ≤ SC(P) < 0.5 → separação fraca entre clusters, continuando no entanto a ser
possível a encontrar o centro do cluster.

41
SC(P) < 0.25 → Separação sem estrutura, tornando-se impossível encontrar o centro
do cluster.
A outra medida é a taxa de acerto. ‗A‘ são os documentos relevantes para o utilizador
e ‗B‘ são os documentos recuperados pela aplicação.
Diagrama 1 – Ilustração da taxa de acerto
A B – Medida desejada, que evolui o número de documentos bem classificados.
A - (A B) – Avalia o número de documentos mal classificados.
4.10.2. Conjuntos de testes usados
Em todo o processo desta descoberta de temas foram utilizados dois conjuntos de
testes. Os documentos contidos nestes dois conjuntos de testes eram artigos
científicos de forma a serem relativamente fáceis de classificar, para que à posteriori
se conseguissem comprovar/comparar os resultados obtidos pelos métodos criados.
O primeiro conjunto de documentos para teste foi obtido com a ajuda do grupo de
multimédia VIMMI (grupo de investigação do INESC-ID - http://vimmi.inesc-id.pt/).
Encontram-se neste quase todos os artigos científicos escritos pelo grupo. Este
primeiro conjunto possuía 116 artigos que foram manualmente classificados e
agrupados em 8 grupos, podendo-se assim concluir que este primeiro conjunto de
documentos era constituído por 8 temas diferentes. Os temas deste conjunto de testes
são: eLearning, Accessibility, Mobile, CG, Improve, Multimedia Information Retrieval,
Sketch-Based e Narrative Baseed Document Retrieval. Estes artigos estão todos
escritos em inglês.
O segundo conjunto de documentos para teste também era constituído por artigos
científicos, que foram obtidos nas bibliotecas digitais ACM e IEEE. Para a obtenção
destes, arranjaram-se 11 temas diferentes, e com base no nome desse tema

42
efectuava-se a pesquisa nas bibliotecas. Assim consegui-se criar um segundo
conjunto de testes com 128 ficheiros agrupados em 11 temas diferentes. Os temas
deste conjunto de testes são: Collaborative Tagging, Consensus Algorithm, Data
Mining, Embedded Computation, Intelligent Environment, LSA, Network Protocols,
Parallel Computation, Speech Synthesis, Use cases e Sketch Based. Tal como no
conjunto de testes anterior, estes artigos estão todos escritos em inglês.
No primeiro conjunto de testes usaram-se temas que se inserem todos num grande
grupo (multimédia) e no segundo usamos temas completamente diferentes, para
assim se verificar se as conclusões retiradas dos testes, tanto num caso como no
outro, seriam parecidas.
Para testar os algoritmos utilizados e explicados acima, foi necessário arranjar dois
conjuntos de dados, que eram artigos científicos, por serem mais fáceis de classificar
à partida. Com estes dois conjuntos de testes devidamente classificados era possível
comparar os clusters obtidos com a classificação realizada manualmente, embora
nenhuma destas fosse completamente correcta. Não eram totalmente correctas devido
ao facto de, na classificação manual, os artigos não terem sido lidos na sua totalidade,
existindo a possibilidade de o artigo falar sobre várias áreas, e uma destas áreas se
poder enquadrar numa outra classificação. No caso dos resultados obtidos pelo nosso
algoritmo, estes nunca iriam ser perfeitos devido ao facto de o algoritmo depender de
várias variáveis que não podiam ser completamente definidas, como é o caso do raio.
Para além disso, as keywords dos vários documentos, poderiam aparecer nos outros
documentos, não tendo estes necessariamente pertencer à mesma classificação, mas
mesmo assim queremos o melhor possível e por isso fizemos os testes.
4.10.3. Raio
Um dos primeiros testes realizados ao algoritmo foi relativamente simples, e servia
apenas para se ter uma ideia do raio que poderíamos esperar como bom no QT-Clust.
No teste avaliava-se o tempo que o algoritmo demora a executar, o número de clusters
criados pelo algoritmo e o maior número de documentos num cluster, isto é o número
de documentos do maior cluster. Os resultados obtidos foram os seguintes:

43
Gráfico 1 - Resultados obtidos para os conjuntos de dados (a e b)
Podem-se tirar várias conclusões da análise dos gráficos. Em primeiro lugar, nota-se
que a medida que o raio vai aumentando, o algoritmo vai demorando mais tempo, e
vai-se aperfeiçoando até um certo ponto, isto é, até quando o raio é aproximadamente
0.3. Conclui-se que o raio que vai ser utilizado no algoritmo QT_Clust irá ser perto de
0.2. Retira-se esta conclusão a partir do gráfico 1, em que, até aos valores referidos, o
número de clusters, que no inicio é ridiculamente grande vai diminuindo, com base nos
conjuntos de testes usados. Já em relação ao tempo, este vai aumentando quase
exponencialmente à medida que o raio vai ficando maior, o que, mais uma vez, nos
levou a escolher um raio relativamente pequeno (0.3), para que desta forma o
algoritmo não fosse muito lento. No entanto, nota-se que ainda continuavam a existir
muitos clusters, o que indicava que iria de ter de utilizar um algoritmo adicional que, de
certa forma, juntasse os clusters mais parecidos, algoritmo este que irá ser referido
adiante.
Gráfico 2 – Percentagem de acerto variando o raio
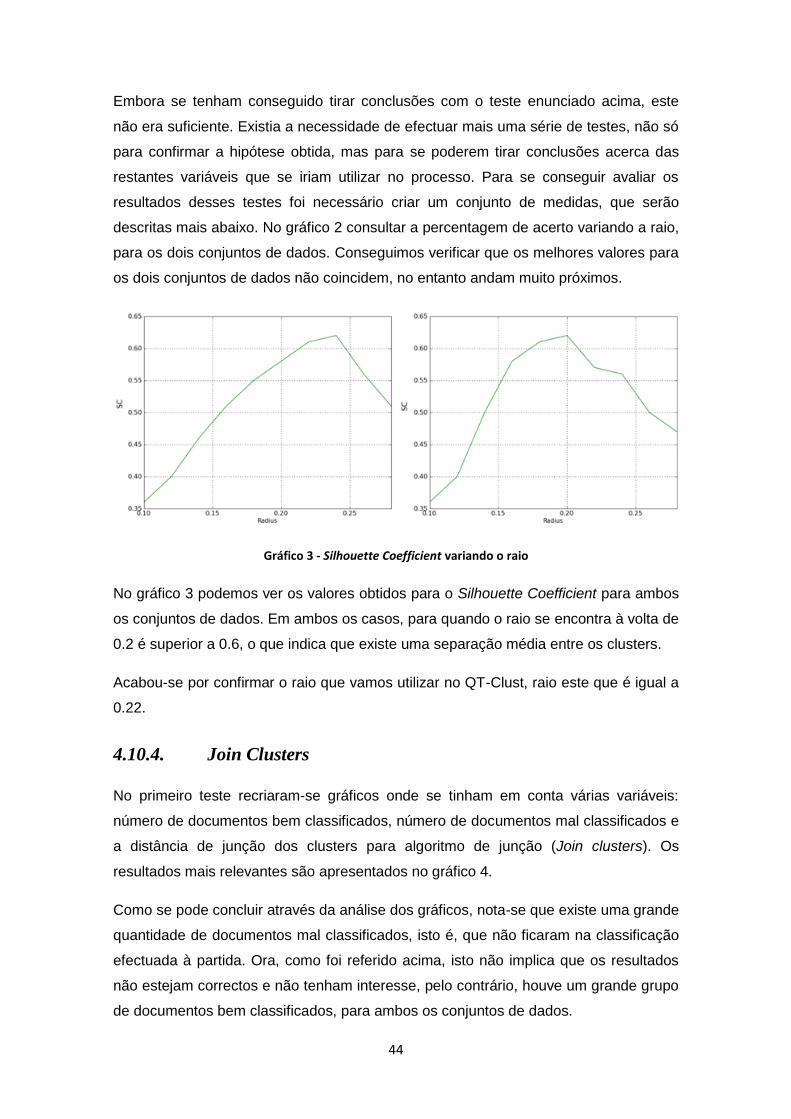
44
Embora se tenham conseguido tirar conclusões com o teste enunciado acima, este
não era suficiente. Existia a necessidade de efectuar mais uma série de testes, não só
para confirmar a hipótese obtida, mas para se poderem tirar conclusões acerca das
restantes variáveis que se iriam utilizar no processo. Para se conseguir avaliar os
resultados desses testes foi necessário criar um conjunto de medidas, que serão
descritas mais abaixo. No gráfico 2 consultar a percentagem de acerto variando a raio,
para os dois conjuntos de dados. Conseguimos verificar que os melhores valores para
os dois conjuntos de dados não coincidem, no entanto andam muito próximos.
Gráfico 3 - Silhouette Coefficient variando o raio
No gráfico 3 podemos ver os valores obtidos para o Silhouette Coefficient para ambos
os conjuntos de dados. Em ambos os casos, para quando o raio se encontra à volta de
0.2 é superior a 0.6, o que indica que existe uma separação média entre os clusters.
Acabou-se por confirmar o raio que vamos utilizar no QT-Clust, raio este que é igual a
0.22.
4.10.4. Join Clusters
No primeiro teste recriaram-se gráficos onde se tinham em conta várias variáveis:
número de documentos bem classificados, número de documentos mal classificados e
a distância de junção dos clusters para algoritmo de junção (Join clusters). Os
resultados mais relevantes são apresentados no gráfico 4.
Como se pode concluir através da análise dos gráficos, nota-se que existe uma grande
quantidade de documentos mal classificados, isto é, que não ficaram na classificação
efectuada à partida. Ora, como foi referido acima, isto não implica que os resultados
não estejam correctos e não tenham interesse, pelo contrário, houve um grande grupo
de documentos bem classificados, para ambos os conjuntos de dados.

45
Gráfico 4 - Resultados para os conjuntos de dados - raio de 0.22 (a e b)
Testou-se o Silhouette Coefficient, para verificar que os resultados obtidos, isto é, que
os clusters criados automaticamente com o nosso algoritmo faziam sentido (se existia
uma boa separação entre clusters). Os resultados obtidos encontram-se nos gráficos 5
e 6. A conclusão que se retira da análise dos gráficos acerca do Silhouette Coefficient
é que este é indicativo da qualidade dos clusters. Em ambos os casos é acima de
0.55, e escolhendo o join distance a 0.25, este valor passa acima de 0.6, o que indica
uma separação média entre os clusters. Os vários dados que compõem possuem um
centro de cluster bem definido. No entanto existem valores ainda melhores do
Silhouette Coefficient, com join distances maiores, no entanto diminuem os
documentos bem classificados e aumentam os documentos mal classificados, daí a
necessidade de escolher um valor que tirasse melhor partido de todos os valores.
Gráfico 5 - Resultados obtidos para o 1º conjunto de dados - raio de 0.22
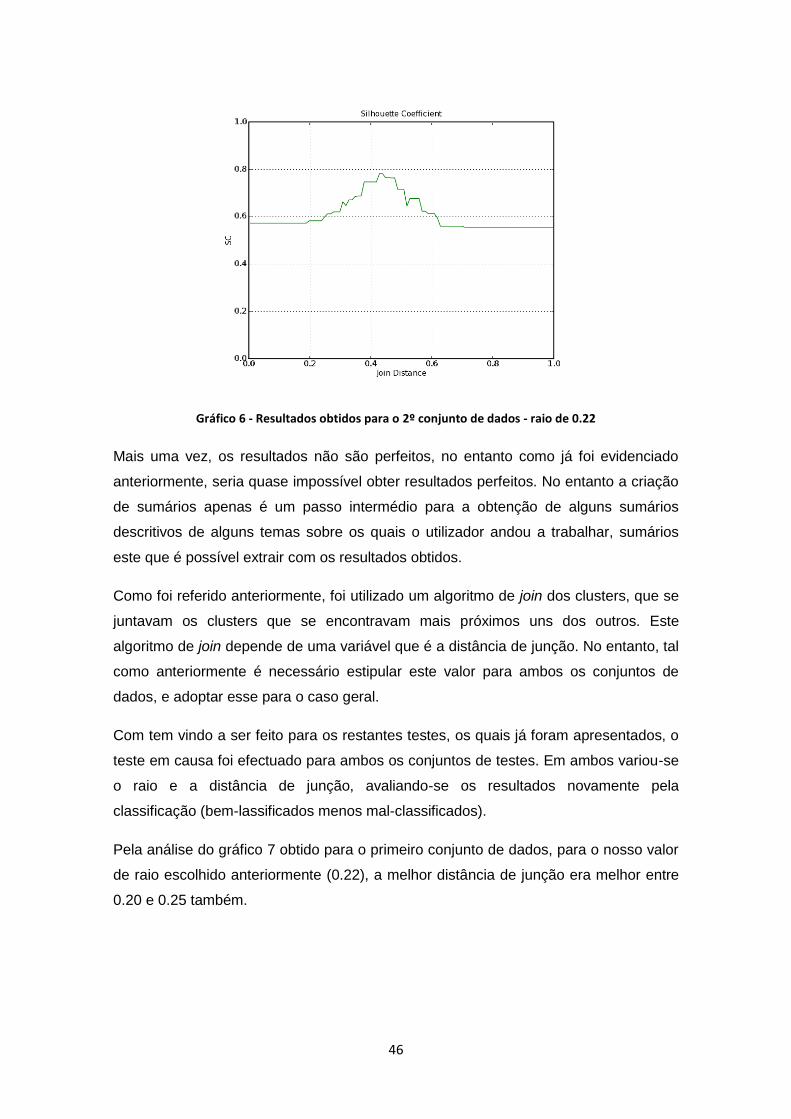
46
Gráfico 6 - Resultados obtidos para o 2º conjunto de dados - raio de 0.22
Mais uma vez, os resultados não são perfeitos, no entanto como já foi evidenciado
anteriormente, seria quase impossível obter resultados perfeitos. No entanto a criação
de sumários apenas é um passo intermédio para a obtenção de alguns sumários
descritivos de alguns temas sobre os quais o utilizador andou a trabalhar, sumários
este que é possível extrair com os resultados obtidos.
Como foi referido anteriormente, foi utilizado um algoritmo de join dos clusters, que se
juntavam os clusters que se encontravam mais próximos uns dos outros. Este
algoritmo de join depende de uma variável que é a distância de junção. No entanto, tal
como anteriormente é necessário estipular este valor para ambos os conjuntos de
dados, e adoptar esse para o caso geral.
Com tem vindo a ser feito para os restantes testes, os quais já foram apresentados, o
teste em causa foi efectuado para ambos os conjuntos de testes. Em ambos variou-se
o raio e a distância de junção, avaliando-se os resultados novamente pela
classificação (bem-lassificados menos mal-classificados).
Pela análise do gráfico 7 obtido para o primeiro conjunto de dados, para o nosso valor
de raio escolhido anteriormente (0.22), a melhor distância de junção era melhor entre
0.20 e 0.25 também.
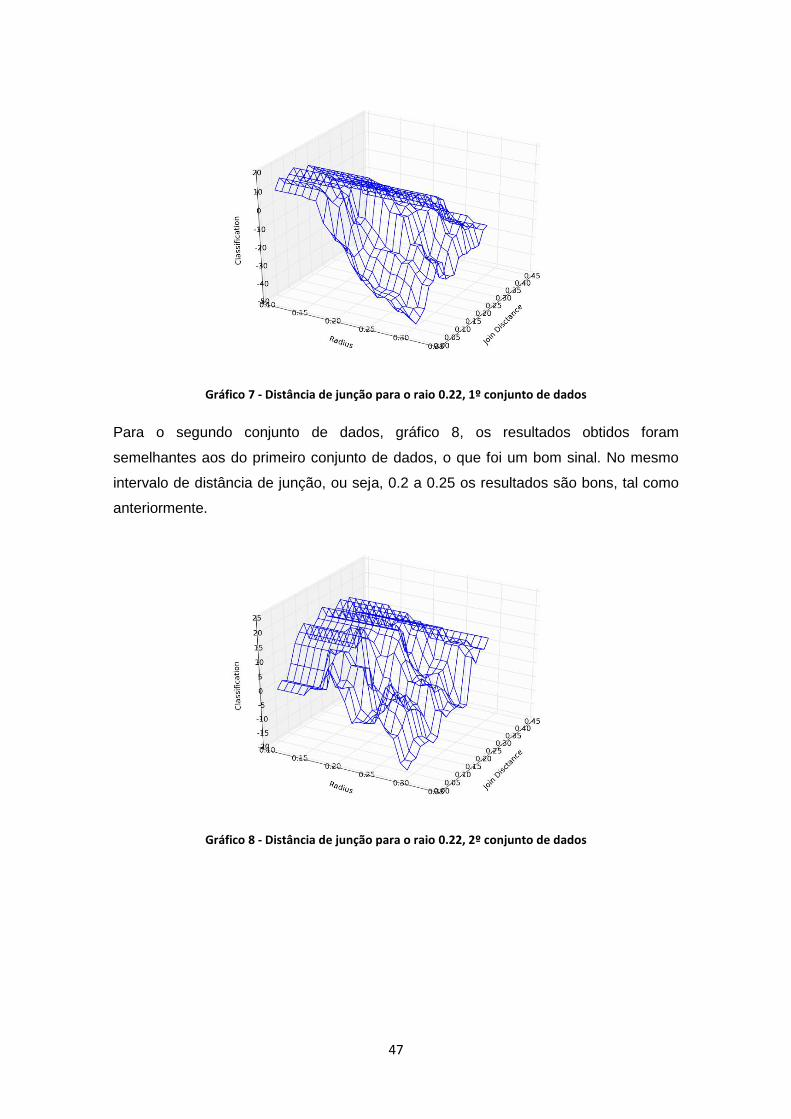
47
Gráfico 7 - Distância de junção para o raio 0.22, 1º conjunto de dados
Para o segundo conjunto de dados, gráfico 8, os resultados obtidos foram
semelhantes aos do primeiro conjunto de dados, o que foi um bom sinal. No mesmo
intervalo de distância de junção, ou seja, 0.2 a 0.25 os resultados são bons, tal como
anteriormente.
Gráfico 8 - Distância de junção para o raio 0.22, 2º conjunto de dados

48
Gráfico 9 - Variação do número de clusters com a distância de junção.
Assim sendo, escolheu-se um distância de junção por default de 0.22.
4.10.5. Número de keywords
Como tem vindo a ser referido, o algoritmo de clustering depende de um conjunto de
variáveis que são dinâmicas. Um exemplo disso é o número de keywords usado para
criar a term-document. O número de keywords vai ser fixo, isto devido ao facto de a
maioria dos utilizadores usarem os valores que nós iremos definir como default. no
entanto é necessário escolher um número com o qual se obtenham melhores
resultados e que seja indicado para praticamente todos os conjuntos de dados que
poderão ser usados na aplicação.
Para além do número de keywords, ainda existia a necessidade de verificar se o raio
considerado como indicado até a este ponto 0.22, continuava a produzir bons
resultados.
Assim, para que fosse possível estimar estes dois valores (número de keywords e o
raio usado no algoritmo de clustering) correu-se o algoritmo de clustering várias vezes
com vários valores para o raio e vários valores para as keywords. Para se
conseguirem avaliar os resultados obtidos, classificaram-se os resultados obtidos pelo
algoritmo de clustering. Esta classificação era simplesmente a subtracção dos
documentos bem-classificados menos os documentos mal-classificados. Assim, com

49
esta classificação, conseguia-se ter uma ideia se os resultados estavam a ser bons ou
não.
Para o primeiro conjunto de dados os resultados obtidos encontram-se abaixo:
Gráfico 10 – Gráfico para encontrar o número de keywords confirmando o raio 0.22.
Pela análise do gráfico 10, consegue-se verificar que existe um pico do gráfico, isto é,
uma classificação elevada, sendo este um bom resultado possível. No entanto o raio
deste pico é relativamente baixo ao esperado, obtendo-se muitos conjuntos de
documentos, isto é, muitos clusters a mais do que o que era esperado, admitindo
assim este resultado menos bom. Existia um outro pico no gráfico bastante
interessante, que é quando o raio se encontra acima de 0.2, que confirma o valor
obtido anteriormente. Assim, confirma-se que o raio anteriormente encontrado para o
algoritmo de clustering é de 0,22 é adequado.
Já em relação as keywords, consegue-se verificar, a partir do gráfico 11, que o número
de keywords que em média produz os melhores resultados é 20, em concreto, para o
raio escolhido anteriormente de 0.22. Os restantes valores não têm grande interesse,
devido ao facto de a classificação considerada ser muito baixa, sendo mesmo na
maioria dos casos negativa, o que indica que existem mais documentos mal
classificados do que bem classificados, isto pelo algoritmo de clustering com os dados
em causa.

50
Gráfico 11 – Percentagem de acerto para o raio fixo em 0.22.
Para o segundo conjunto de dados, os resultados obtidos foram relativamente
parecidos, embora neste conjunto de dados se tivessem obtido mais picos, ou seja,
mais variações ao logo dos vários valores testados.
Gráfico 12 - Gráfico para encontrar o número de keywords confirmando o raio 0.22.
Como é fácil de verificar a partir do gráfico 11, os valores escolhidos anteriormente
não batem certos com os picos do gráfico 13 para este conjunto de dados, no entanto
a classificação continua a ser boa para o conjunto de dados escolhidos.

51
Gráfico 13 - Percentagem de acerto para o raio fixo em 0.22.
Neste teste só se utilizaram raios entre 0.1 e 0.3 devido ao facto de para raios fora
deste intervalo os resultados já não possuírem interesse, teoria comprovada pela
análise do gráfico 2. Para raios menores que 0.1, obtinham-se muitos clusters, isto é,
muitos em relação ao número que seria esperado obter. Para valores de raio superior
a 0.3, o tempo despendido também já era muito elevado, e levava a obtenção de um
cluster com muitos documentos, o que também não tinha grande interesse.
Podemos concluir que, para ambos os conjuntos de testes, os melhores resultados
eram obtidos com keywords e raios diferentes, no entanto, ao escolher-se um raio e
um número de keywords que produzisse bons resultados para ambos os conjuntos de
dados, conseguia-se obter resultados bastante positivos.
4.10.6. Teste da Dimensão
No teste que se segue, o objectivo era verificar qual a dimensão indicada no algoritmo
LSA, dimensão esta que na realidade é o número de keywords que se retiram na
matriz.
Foram testadas várias dimensões para os dois conjuntos de dados e verificavam-se
novamente os resultados obtidos pelo algoritmo. Esses resultados eram novamente
indicados pela classificação, conseguindo-se assim verificar qual seria a melhor
dimensão.
Pela análise dos resultados obtidos para ambos os conjuntos de dados nos gráficos 14
e 15, conclui-se que a dimensão deveria ser 1, isto é devem ser mantidas todas as

52
dimensões menos 1. No primeiro conjunto de dados, existe um pico do gráfico 14 onde
se conseguem resultados melhores, no entanto esta a diferença não é significativa, e
não se verifica no segundo conjunto de dados, gráfico 15.
Gráfico 14 - Variação da variável dimensão, 1º conjunto de dados
Gráfico 15 - Variação da variável dimensão, 1º conjunto de dados
Pela análise do gráfico 16, verifica-se que essa dimensionalidade convinha ser
reduzida, porque quanto maior essa fosse, mais tempo se demorava na obtenção dos
clusters, para além dos resultados serem piores.

53
Gráfico 16 - Relação de tempo com a variação da dimensão usa no algoritmo LSA.
4.10.7. Conclusões dos testes
Após este conjunto de testes conseguimos chegar a conclusão que os resultados
nunca irão ser perfeitos, no entanto, conseguem-se boas aproximações com os
valores que vamos tomar por default e usar para o resto da aplicação e testes.
Assim, o raio do algoritmo de clustering com que se obtinham melhores resultados era
0.22. Para além disso, o algoritmo de clustering, para produzir clusters bons
necessitava de 20 keywords. Já em relação ao join distance usamos 0.22. A dimensão
da matriz LSA deveria ser 1.
4.11. Verificação manual dos clusters obtidos
Após a obtenção dos clusters com o algoritmo de QTClust existia a necessidade de
verificar manualmente a qualidade desses clusters obtidos, devido ao facto de
existirem muitas variáveis que influenciavam a obtenção de resultados. Também era
impossível obter resultados perfeitos porque, para além das muitas variáveis já
referidas, as keywords não são independentes, podendo documentos diferentes no
seus tema, possuírem keywords muito parecidas.
Para a verificação manual dos resultados criou-se uma tabela para ambos os
conjuntos de dados. Nas linhas destas tabelas encontram-se os clusters que o nosso
algoritmo criou, e nas colunas os vários temas que o conjunto de dados possuía.
Assim, cada célula da tabela diz respeito ao número de documentos que um

54
determinado cluster tem sobre um determinado tema. Por exemplo, na tabela 4, o
cluster 1 contém 1 documento de eLearning, entre outros.
O ideal seria existir o mesmo número de clusters que o número de temas, isto é, o
número de linhas ser igual ao número de colunas e só existir um tipo de documento
em cada cluster. No entanto, tal como já foi referido anteriormente, esta situação é
impossível de acontecer devido ao elevado número de variáveis que influenciam os
resultados, como por exemplo o número de keywords e os termos não serem
estanques.
eL
earn
ing
Ac
ce
ss
ibilit
y
Mo
bile
CG
Imp
rov
e
Mu
ltim
ed
iaIn
foR
etr
ieval
Sk
etc
h_
Ba
se
d
NB
DR
Mis
c
To
tal
1 1 - - 13 1 10 26 3 1 56
2 - - - 1 - - 1 - - 2
3 - - 4 - - - - - 4 8
4 10 - - - - - - - - 10
5 - 2 1 - - - - - 1 4
6 - - - - - 3 - - - 3
7 - - - 3 - - - - - 3
8 - - - 1 - - - - - 1
9 4 - - - - - - - - 4
10 - - - 3 - - - - - 3
11 - - - 3 - - - - - 3
12 2 - - - - - - - - 2
13 - - - - 4 - - - 1 3
14 - - - - 1 - 1 11 1 14
TOTAL 17 2 5 24 6 13 28 14 8
Tabela 4 - Resultados obtidos com o primeiro conjunto de dados.
Nas tabelas encontram-se diferenciadas algumas células, como cores diferentes,
indicando assim o possível tema correspondente ao cluster. A análise das tabelas 4 e
5 leva-nos a perceber que os clusters são criados de forma satisfatória. A cor diferente
de alguns campos da tabela significa que o cluster gerado tem mais documentos do
tema da coluna onde se insere o campo de cor diferente. Imaginemos o cluster 1 da
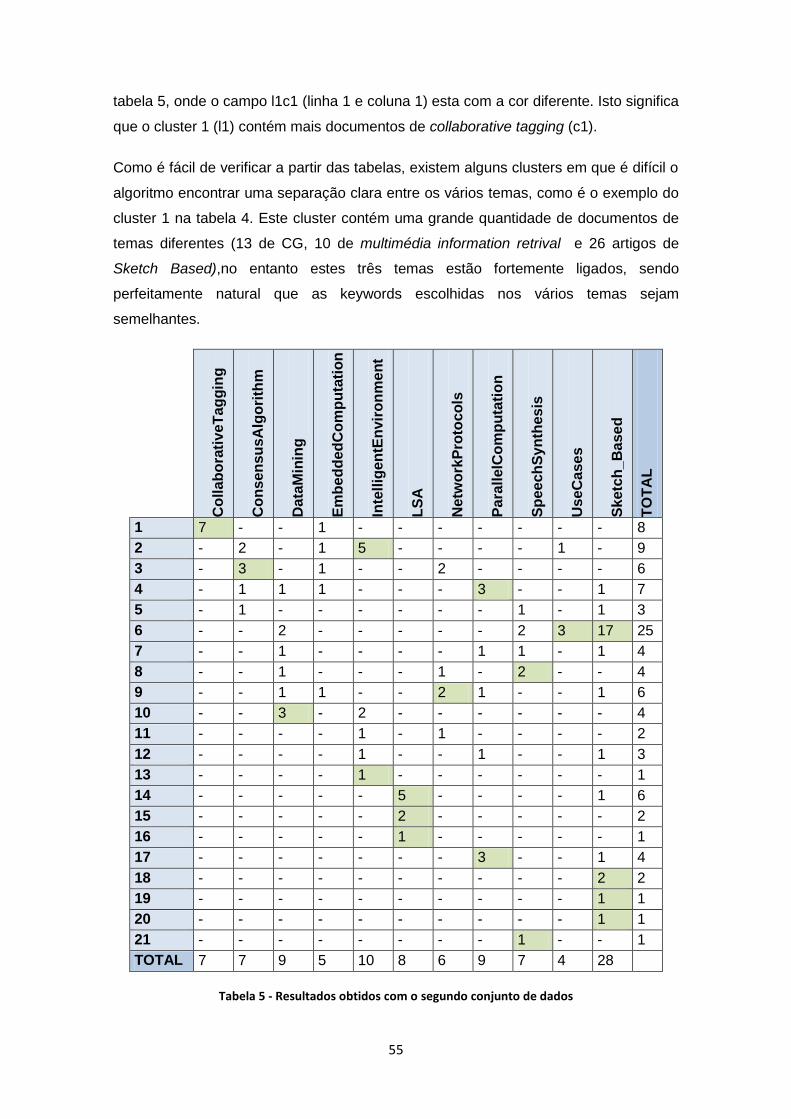
55
tabela 5, onde o campo l1c1 (linha 1 e coluna 1) esta com a cor diferente. Isto significa
que o cluster 1 (l1) contém mais documentos de collaborative tagging (c1).
Como é fácil de verificar a partir das tabelas, existem alguns clusters em que é difícil o
algoritmo encontrar uma separação clara entre os vários temas, como é o exemplo do
cluster 1 na tabela 4. Este cluster contém uma grande quantidade de documentos de
temas diferentes (13 de CG, 10 de multimédia information retrival e 26 artigos de
Sketch Based),no entanto estes três temas estão fortemente ligados, sendo
perfeitamente natural que as keywords escolhidas nos vários temas sejam
semelhantes.
Co
lla
bo
rati
veT
ag
gin
g
Co
ns
en
su
sA
lgo
rith
m
Da
taM
inin
g
Em
be
dd
ed
Co
mp
uta
tio
n
Inte
llig
en
tEn
vir
on
me
nt
LS
A
Ne
two
rkP
roto
co
ls
Pa
rall
elC
om
pu
tati
on
Sp
ee
ch
Sy
nth
es
is
Us
eC
ase
s
Sk
etc
h_
Ba
se
d
TO
TA
L
1 7 - - 1 - - - - - - - 8
2 - 2 - 1 5 - - - - 1 - 9
3 - 3 - 1 - - 2 - - - - 6
4 - 1 1 1 - - - 3 - - 1 7
5 - 1 - - - - - - 1 - 1 3
6 - - 2 - - - - - 2 3 17 25
7 - - 1 - - - - 1 1 - 1 4
8 - - 1 - - - 1 - 2 - - 4
9 - - 1 1 - - 2 1 - - 1 6
10 - - 3 - 2 - - - - - - 4
11 - - - - 1 - 1 - - - - 2
12 - - - - 1 - - 1 - - 1 3
13 - - - - 1 - - - - - - 1
14 - - - - - 5 - - - - 1 6
15 - - - - - 2 - - - - - 2
16 - - - - - 1 - - - - - 1
17 - - - - - - - 3 - - 1 4
18 - - - - - - - - - - 2 2
19 - - - - - - - - - - 1 1
20 - - - - - - - - - - 1 1
21 - - - - - - - - 1 - - 1
TOTAL 7 7 9 5 10 8 6 9 7 4 28
Tabela 5 - Resultados obtidos com o segundo conjunto de dados

56
Embora os resultados não sejam perfeitos, conseguimos obter uma boa aproximação,
obtendo bons resultados na junção dos documentos que estão relacionados com
keywords em comum, que era o objectivo primordial.
Existem alguns resultados curiosos da análise das duas tabelas. O primeiro é de os
resultados da tabela 5 serem mais expressivos do que os resultados da tabela 4. Isto
justifica-se com o facto de os documentos da tabela 5 estarem todos muito
interligados, pertencendo todos a área de multimédia, havendo assim um cluster que
contém muitos desses documentos (l1), enquanto que na tabela 5, os temas são muito
mais diversificados. Embora haja grande incidência de documentos no clutser 1 (l1) na
tabela 5, isto não quer dizer que esse cluster não esteja correcto. Se olharmos para os
temas (computer grafics, multimédia information retrieval e sketched based retrieval)
concluímos que estes temas estão fortemente ligados, daí a incidência de tantos
documentos nesse cluster.
4.12. Conclusão
Como já foi referido anteriormente os resultados obtidos não são perfeitos, no entanto
conseguem uma boa aproximação a realidade, aproximação que se torna melhor
ainda quando os temas são mais diversificados, por razões óbvias.
Vimos que, para o primeiro conjunto de dados, existia um cluster que continha muitos
documentos, no entanto, como foi referido acima, isto devia-se aos temas serem muito
semelhantes. Temas muito semelhantes contêm keywords muito parecidas,
explicando assim os clusters com maior número de documentos. No entanto este
problema é atenuado, como veremos nas secções seguintes, com a extração de um
segundo conjunto de keywords, não dos documentos apenas, mas do tema, isto é,
extraem-se as keywords do tema das keywords dos documentos desse tema.
Como o objectivo não era obter clusters perfeitos, pensamos que a solução atingida é
muito satisfatória, e, em conjunção com as restantes etapas antes da produção da
noticia em si, vai produzir bons resultados.
Assim os valores que vamos usar com predefinidos são: raio a 0.22, join distance a
0.22, dimensão 1 e o número de keywords a 20.

57
5. Geração das Notícias
No capítulo anterior estudaram-se as formas de criação dos grupos e de agrupamento
da informação pessoal de um dado utilizador em temas. Analisaram-se também as
formas de extracção de palavras-chave, tanto de documentos individuais como dos
grupos.
Neste capítulo vamos analisar a forma utilizada para a geração de notícias. Para tal,
decompôs-se o problema em questão em vários sub-problemas para que desta forma
a abordagem a estes fosse mais simples: extracção das palavras-chave dos grupos,
extracção dos sumários, análise lexical e padrões de notícias.
5.1. Extracção das palavras-chave dos Grupos
O objectivo de se criarem os clusters, é obter grupos de dados dos utilizador para, à
posteriori, serem criados sumários dos temas que representam um resumo da
actividade deste. Assim sendo, uma forma de criar estes sumários é com a ajuda das
keywords. Estas keywords já não vão ser apenas de um ficheiro, mas tem de existir
um conjunto de keywords que defina cada um dos clusters, até porque os clusters não
são perfeitos. Para isso criou-se um algoritmo de extracção de keywords do cluster.
Este algoritmo tem em conta, numa primeira fase, as keywords que aparecem em
mais ficheiros, e para os casos de empate o número de vezes que estas aparecem
nos ficheiros.
O algoritmo tem por base as palavras-chave já extraídas anteriormente de cada um
dos ficheiros pertencentes ao cluster através do algoritmo TFIDF, já descrito acima.
Assim garante-se que as palavras-chave extraídas dos clusters contém palavras-
chave que não são stopwords e não têm em conta apenas a frequência com que estas
aparecem no documento. Este método torna-se mais correcto do que voltar a aplicar
TF-IDF, porque se restringe só as palavras-chave que o grupo de documentos possui.
Imagine-se que num determinado grupo do tema X existem 5 documentos que
pertencem de facto a esse grupo e 2 documentos que não pertencem ao grupo, mas
que no entanto foram inseridos no grupo pelo algoritmo de clustering. Ora, os 5
documentos que pertencem mesmo ao grupo vão ter palavras-chave muito
semelhantes, enquanto que nos 2 documentos que não pertencem ao referido grupo,
as palavras-chave vão ser diferentes, pelo menos algumas delas. Com esta extracção
de palavras-chave as palavras que se encontram apenas em dois documentos não

58
vão ter tanta importância como as que se encontram nos restantes 5 que pertencem
realmente ao grupo. Se o TF-IDF voltasse a ser aplicado, é quase certo que as
keywords documentos ao serem frequentes nestes e raros nos demais não seriam
representativas do tema do cluster.
As keywords assim extraídas do cluster dão assim uma boa descrição do cluster. O
que pode variar é o número de keywords desejadas, no entanto este é um problema
menor, visto que este número afecta apenas o número de sumários extraídos. Como o
algoritmo a esse ponto era configurável, não havia qualquer problema.
5.2. Extracção dos sumários
As palavras-chave caracterizam correctamente os grupos. No entanto, para a geração
de notícias, as palavras-chave não são suficientes. Efectivamente, as palavras,
isoladamente, não possuem uma semântica suficiente para descrever de forma
articulada os temas a que se reportam. Assim, estas foram usadas como ponto de
partida para a obtenção de sumários.
A forma como isto foi feito foi através da extracção de excertos de texto contidos nos
documentos a analisar. Assim sendo, a ideia foi percorrer os ficheiros pertencentes a
um determinado cluster/grupo a procura de excertos onde se encontram as palavras-
chave encontradas no respectivo grupo. Depois de se encontrar um determinado
excerto onde ocorria mais do que uma palavra-chave, considerava-se este excerto
como um sumário relevante para o grupo.
5.2.1. Algoritmo de extracção dos sumários
O algoritmo criado para a extracção dos sumários é baseado numa ideia relativamente
simples: estando na posse das palavras-chave e do texto em si dos documentos, é
relativamente fácil encontrar extractos que possuam mais que uma palavra-chave e
passam-se a considerar estes extractos como relevantes para o grupo.
O algoritmo começa por um determinado documento do grupo de documentos criado
através do algoritmo de clustering. Ao percorrer o texto procuravam-se as palavras-
chave encontradas para o cluster. Quando se encontra uma, verifica-se se existia
outra palavra-chave num pré-determinado raio à volta da primeira. Este processo é
recursivo: se for encontrada uma outra palavra-chave dentro desse raio, procuram-se
outras tendo essa como base. O limite é quando não se encontravam mais palavras-
chave nos raio das anteriores ou se encontra um sinal de pontuação que termine a

59
frase, terminando-se o processo e considerando-se o extracto com um sumário
relevante para o grupo. Efectuava-se o mesmo processo para o restante texto do
documento e para os restantes documentos dos grupos.
Um raio de duas palavras-chave mostrou-se razoável, visto não fazer sentido
considerar todas as frases onde aparece uma única palavra-chave, e ao considerar
um número maior que dois, corríamos o risco de obter poucas frases.
Caso o algoritmo não encontrasse nenhum sumário relevante para um determinado
documento aumentava-se o raio pré-estabelecido à volta da primeira palavra-chave
encontrada até ao limite de 5, para que desta forma aumentasse a probabilidade de se
encontrar um sumário relevante para o grupo.
De seguida exemplifica-se o funcionamento do algoritmo.
Considerem-se as seguintes frases:
―A number of novel information visualization methods have been developed. In order to
facilitate the exploration of data across temporal contexts the application takes specific
time aspects into account.‖
Imagine-se agora que as palavras-chave extraídas são: information, visualization,
exploration, data e temporal.
O algoritmo começa com a primeira frase. Ao encontrar a palavra-chave information
verifica se existe outra palavra-chave num raio de 2 palavras (palavras que não sejam
stop-words). À esquerda da primeira palavra-chave estão as palavras novel e number,
palavras estas que não pertencem às palavras-chave encontradas nas frases. À direita
da palavra information está visualization e methods. Como a palavra visualization faz
parte das palavras-chave encontradas para o pequeno extracto de texto, somam-se
duas palavras-chave na mesma frase com um raio de 2 palavras. Repete-se o
processo para a palavra visualization, no entanto agora só para a direita, visto que a
parte da esquerda já está analisada. Como à direita da palavra visualization não existe
mais nenhuma palavra que pertença às palavras-chave com o raio de duas palavras o
algoritmo termina e conclui-se que a frase analisada é um sumário relevante para o
grupo, sendo o extracto resultante o seguinte:
“A number of novel information visualization methods have been developed”

60
Embora o algoritmo só necessite de encontrar duas palavras-chave numa frase com o
raio de duas palavras, este continua a identificar as restantes palavras-chave, para
que desta forma se consiga determinar a importância do sumário, isto é, quantas mais
palavras-chave existem numa determinada frase mais relevante é o sumário.
O algoritmo continuaria com a segunda frase do excerto de texto, e o processo seria o
mesmo. Muito resumidamente o algoritmo segue até à palavra exploration. Como à
direita existe a palavra data esta frase também é considerada um sumário relevante,
no entanto, este sumário é mais relevante que o da primeira frase porque à direita da
palavra-chave data ainda se encontra a palavra temporal, existindo assim 3 palavras-
chave juntas na frase.
Ao efectuar este processo para todos os documentos do grupo, ficamos na posse de
um vasto leque de informação semanticamente rica acerca do tema desse grupo. No
entanto, verificou-se que existiam documentos onde as palavras-chave se
encontravam muito separadas, não extraindo assim qualquer extracto deste. Era para
esses casos que se voltava a repetir o procedimento, no entanto incrementava-se o
raio, passando este a ser de 3. Caso o procedimento não voltasse a encontrar
extractos novamente, voltava-se a incrementar o raio, parando apenas quando o raio é
igual a 5.
5.2.2. Tratamento das frases relevantes
Após a extracção dos sumários para cada grupo é necessário tratar estas
orações/frases para que estas apenas possuam informação relevante, e não
necessariamente frases completas. Queremos também evitar situações em que o raio
usado cause a cisão indevida de orações com relevância. Assim sendo, as frases
passam por um conjunto de tratamentos para que estas ficassem mais simples e
possuíssem apenas a informação relevante. De seguida explicam-se os tratamentos a
que as frases foram sujeitas.
Um dos primeiros tratamentos efectuados à frase/oração é a simplificação desta
através das vírgulas. Como a maioria das frases/orações possuem vírgulas para
separar as várias partes da frase, retém-se apenas o texto até essas vírgulas (ou a
partir delas), dependendo de onde se encontra o maior número de palavras-chave,
para que desta forma obtenhamos a parte mais importante da frase. Verifica-se que a
maioria das vezes essa parte é suficiente para descrever toda a frase. Pode-se pensar
que se corre um grande risco de ficarmos com extractos de frases sem sentido
nenhum e sem qualquer significado semântico, no entanto, como a maioria das

61
palavras-chave são nomes, verifica-se que estes extractos, na maioria das vezes,
possui, para além das palavras-chave, verbos e orações que acabam por dar sentido
ao extracto. Imagine-se o seguinte sumário:
The work we have done is about information visualization, and in the last section, we
will analyze interfaces.
Imagine-se que agora as palavras-chave seriam apenas information e visualization. O
extracto resultante do tratamento da frase seria apenas o seguinte:
“The work we have done is about information visualization”
Com esta simples simplificação reduz-se significativamente o tamanho e a
complexidade das frases, conseguindo-se um bom tratamento para os sumários, visto
que a maioria das frases possuem várias vírgulas.
No entanto, houve o cuidado de deixar de ter em conta as vírgulas quando se tratava
de uma enumeração, como por exemplo a seguinte frase: […] we considered the
follow objects: spheres, squares, circles, triangles […].
Um outro tratamento às frases/sumários extraídos anteriormente é através da
identificação das preposições. Assim, um raciocínio semelhante foi usado como
fronteira as palavras como that e which indicam uma clara divisão na frase.
Foi criada uma pequena lista de preposições, à qual se podem juntar novas
preposições em qualquer altura, para simplificar as frases. Tal como no caso das
vírgulas, verificava-se a localização das palavras-chave relativamente à preposição
existente na frase, de modo a que se achasse o extracto da frase mais importante.
5.2.3. Classificação das frases
Após a extracção das frases/sumários e do respectivo tratamento ficamos na posse de
um vasto conjunto de informação. Cada grupo possui vários ficheiros e cada um
desses ficheiros possui vários sumários. No entanto, para a geração das notícias, são
necessários apenas alguns desses sumários, nomeadamente os mais relevantes e os
que caracterizam melhor o grupo. Para se saber quais os sumários mais relevantes é
importante que haja uma métrica, para estes serem classificados.
A métrica encontrada para a classificação foi a seguinte: Com o número de palavras-
chave existentes num determinado sumário e com o raio da ―janela‖ utilizado para a
extracção destes mesmos sumários conseguimos, dividindo o número de palavras-

62
chave pelo raio, obter um valor para ser usado como medida de comparação entre os
vários sumários. Isto é correcto porque, os extractos com mais palavras-chave e com
um raio menor são sempre melhor classificadas do que com menos palavras-chave.
Imaginem-se os seguintes exemplos:
Primeiro extracto: “A number of novel information visualization methods have been
developed.”
Palavras-chave: information e visualization. Raio usado: 2
Segundo extracto: “A number of novel information visualization methods with great
interfaces have been developed.”
Palavras-chave: information, visualization e interfaces. Raio usado: 2
Embora ambos os extractos sejam muito semelhantes, pelo nosso método o segundo
obtém uma melhor classificação que o primeiro, isto porque 3/2 é maior que 2/2. Neste
exemplo, ambos os extractos contém o raio igual a 2, no entanto para raios diferentes
também se verifica a regra: Um primeiro extracto de texto com duas palavras-chave e
com um raio de 2 e segundo com o mesmo número de palavras-chave, no entanto
com raio 3. Neste caso o primeiro vai ser melhor classificado porque necessitou de um
raio menor para encontrar o mesmo número de palavras-chave (2/2 é maior que 2/3),
Desta forma, depois de se extraírem as frases, de se efectuarem os respectivos
tratamentos às mesmas e depois da sua classificação, escolheram-se as que
classificassem melhor os grupos de documentos, através da escolha das frases
melhor classificadas.
5.3. Criação das notícias
Na secção anterior falámos da extracção dos sumários. Esta extracção tem como
objectivo a criação de notícias, que têm por sua vez o objectivo de reflectir a actividade
de um dado utilizador com o seu computador pessoal numa determinada altura. Assim
sendo, depois de estarmos na posse dos sumários, devidamente configurados e
classificados, é necessário passar à fase da criação das notícias.
As notícias deveriam descrever o grupo a que estas se referiam, e para que tal
deveriam usar os sumários extraídos dos grupos. No entanto, como já foi referido
apresentar apenas os sumários sem qualquer ligação entre estes e sentido semântico
não tinha qualquer interesse para o utilizador. Assim sendo, seria necessário criar uma
nova frase, com os sumários extraídos, e coloca-la na notícia gerada.

63
5.3.1. Padrões de Notícias
Para organizar os sumários obtidos num todo coerente, recorremos a padrões
(templates) de possíveis notícias, em que esses sumários são usados de forma
adequada. Como os sumários extraídos poderiam ser orações sob as mais diversas
formas, isto é, poderiam começar tanto com um nome ou com um verbo, é necessário
criar diferentes padrões de frases para que, depois de se juntar o texto contido no
template e a respectiva oração, o texto fizesse sentido. Visto não se saberem à priori,
os temas a reportar, o texto dos padrões é o mais abstracto possível.
Cada padrão possui obrigatoriamente um título da notícia e um corpo da notícia. Para
além destes, existem elementos opcionais, usados apenas se existirem sumários
relevantes para os preencher. É o caso de imagens e excertos de documentos.
Finalmente, é possível especificar elementos alternativos, a escolher aleatoriamente
durante a criação da notícia para enriquecer o jornal, mas também para serem usadas
em situações específicas. Por exemplo, uma palavra poderá ser usada se o sumário
seguinte estiver no passado, e outra se este estiver no presente. Os padrões são
descritos em XML. Um exemplo pode ser visto abaixo (Anexo1).
<newsTemplate importance ="1">
<title>
<alt>
<!-- as alternativas ficam aqui -->
<li>New advances in</li>
<li time="Present" number="plural">Developments on</li>
</alt>
<textExcerpt quoteSize="small" morphology="verb"> </textExcerpt>
</title>
<body>
We saw new developments in
<textExcerpt quoteSize="small" morphology="name"> </textExcerpt>,
having figured out that
<textExcerpt quoteSize="medium" morphology="name"> </textExcerpt>.
As a result, we
<alt>
<li time="present">studied how</li>
<li time="future">will study how</li>
<li time="past">had studied how</li>
</alt>
<textExcerpt quoteSize="medium" morphology="name"> </textExcerpt>
</body>
</newsTemplate>

64
A utilização destes padrões permite uma fácil adaptação e enriquecimento da
interface.
5.3.2. Análise Lexical
Não é possível usar directamente os sumários para a criação das notícias. É
necessário saber, por exemplo, em que tempo verbal se encontra a oração, se está no
singular ou plural, etc, para que os textos criados façam sentido. Assim sendo foi
necessário incluir nesta parte do trabalho a análise lexical, âmbito de Língua Natural, e
outros métodos desenvolvidos para encontrar o tempo verbal de uma determinada
frase.
A análise lexical propriamente dita foi realizada com a ajuda do NLTK, um toolkit de
língua natural em Python. Neste criaram-se uma série de expressões regulares para
identificar a morfologia das palavras, isto é, se uma determinada palavra é um nome,
verbo, adjectivo, etc. No nosso caso apenas interessavam os nomes, para saber se
uma determinada oração estava no plural ou no singular, e os verbos, para conhecer o
seu tempo verbal. Como só estamos a considerar documentos são escritos em inglês,
não foi muito difícil efectuar esta análise.
De forma a conseguir, construímos notícias que fizessem sentido, isto é, que fossem
semanticamente correctas, era necessário analisar a gramática das frases. Para tal,
depois de estarmos na posse das várias palavras que constituíam uma frase e da sua
morfologia, era fácil de criar gramáticas, embora esta pudesse não estar correcta.
Mais uma vez, para se conseguir verificar se a frase estava gramaticalmente correcta
seria preciso um sistema de língua natural muito sofisticado, com muita informação por
detrás. Embora já haja sistemas que conseguem uma boa aproximação a frases
correctas, estes ainda têm falhas. Para além disso nenhum destes se dedica
exclusivamente a notícias.
Assim sendo, foi necessário tentar uma nova aproximação a este problema.
Tínhamos, à partida, noção que a nossa aproximação não produzem resultados
perfeitos, já que nem os últimos sistemas que tentam uma aproximação a este
problema o são. A forma encontrada para a resolução do problema referido acima era
a seguinte: através da análise gramatical de cerca de 18000 notícias, construíamos a
nossa própria gramática, isto é, um conjunto de regras de várias notícias (recolhidas
na internet). A cada regra era atribuída um peso, que era o número de vezes que a
mesma regra aparecia no conjunto de notícias. Este número era importante para
verificar se a regra, para além de ser parecida com a nossa, se era frequente, e se era

65
verdadeiramente importante. Efectuava-se essa verificação também para o caso de
estarmos na posse de duas regras em que em ambas faltava apenas uma palavra na
nossa frase para que esta ficasse completa, escolhia-se a que aparecia mais vezes. O
conjunto de regras forma a gramática.
Depois de estarmos na posse da nossa regra, e após possuir a regra de uma dada
notícia criada pela nossa aplicação comparava-se a nossa regra com as das notícias
reais e verificamos qual delas se aproximava mais à nossa. Caso fossem as duas
iguais, não era necessário efectuar qualquer operação. Caso contrário, isto é, caso a
nossa gramática fosse uma aproximação à outra existente, completava-se a frase com
palavras da mesma morfologia. Essas palavras eram retiradas do contexto dos
sumários que eram usados para a geração das frases. Para se saber quão próximas
eram duas regras, utilizou-se a distância de Levenshtein.
Assim, após estas operações, ficávamos com uma frase bastante correcta e com uma
boa aproximação a uma frase criada de raiz correctamente.
Um exemplo das gramáticas que nos obtínhamos através do nosso método encontra-
se abaixo.
<NN> <VB> <PREP> <NN> <PREP> <VB> <NN> ->9
<NN> <VB> <AJ> <NN> <PREP> <VB> <NN> ->3
Tal como foi referido acima, o número 9 significa que essa gramática foi encontrada 9
vezes nas notícias analisadas. Podemos verificar que a frase começa por um nome
<NN> seguida por um verbo <VB>, seguindo-se as restantes preposições. Nas
gramáticas identificavam-se os seguintes tipos morfológicos: números (CD), advérbios
(AD), adjectivos (AJ), articles (ART - the, na, etc), preposições (PREP), pronomes
(SW), conjunções (CONJ) e nomes (NN).
Imagine-se agora que se deseja juntar um determinado excerto com o template. Após
essa junção ficaríamos com a seguinte gramática:
<NN> <VB> <NN> <PREP> <VB> <NN>
Ao verificar as gramáticas semelhantes extraídas das notícias chegávamos a
conclusão que as duas referidas acima eram as mais semelhantes, um com 9
ocorrências e outra com 3. Com o nosso algoritmo, era escolhida a gramática com
nove ocorrências. De seguida, juntava-se uma preposição à nossa, para que assim as
duas gramáticas ficassem iguais, tornando-se a frase assim o mais correcta possível.

66
Na análise lexical era dado especial atenção aos nomes e aos verbos, isto porque, nos
templates encontrava-se o tempo verbal de que o template estava à espera e se o
template estava no plural ou no singular. Para caso dos verbos, criou-se um pequeno
programa que identificava o tempo verbal do verbo. Como a aplicação estava
desenvolvida para o idioma inglês, não houve grande dificuldade em identificar os
tempos do verbo. Exemplo disso são os verbos irregulares, sendo as regras de
formação de tempos verbais com estes verbos muito simples. Já em relação aos
verbos regulares, também era trivial saber o tempo verbal destes mesmos, tirando
raras excepções, que também eram consideradas. Já em relação ao número dos
nomes, isto é, se o nome se encontrava no singular ou no plural também foi
relativamente fácil identificar o número deste. A regra trivial para verificar se um
determinado nome se encontrava no plural era verificar se esse mesmo número
terminava em ‗s‘. Como é possível de prever, também neste caso havia uma série
excepções que também foram devidamente consideradas, como é o exemplo de
palavras como ‗hippopotamus‘ e ‗bus.‘
Quando se juntavam os vários extractos com os templates era então verificar o tempo
verbal e o número de um e do outro verificando se ambos eram iguais. Caso estes
correspondam, pode-se passar de imediato à junção das partes da frase, isto é, do
template e do excerto. Caso não correspondessem, verifica-se se o template possuía
uma outra alternativa para o tempo verbal e para o número do verbo (elemento <li> no
template), verificando-se se este correspondia às condições desejadas. Em último
caso, isto é, quando as alternativas estivessem esgotadas sem no entanto se ter
encontrado correspondência, ignorava-se o extracto, passando-se ao extracto
seguinte.
Os extractos a usar obedeciam a uma determinada regra para que estes fossem
escolhidos. Antes de mais, todos os extractos se encontravam ordenados segundo a
sua importância, começando-se assim por considerar e tentar criar frases com os mais
relevantes. Para o título da notícia escolhia-se o extracto mais importante, para que
assim se conseguisse ―dizer tudo‖ com título. No resto da notícia era criada com os
extractos que se seguiam. Caso os extractos possuíssem igual importância, escolhia-
se um de forma aleatória.
Quando se juntavam os extractos extraídos dos documentos com os templates de
notícias existentes, havia necessidade de retocar a ligação entre estes. Depois de
analisar várias notícias geradas verificou-se que no início da frase, esta ligação não
batia certo, sendo necessário uma análise mais pormenorizada. Uma das regras que

67
se implementou foi que depois do texto do template, quando vinha um nome seguido
de imediato por um verbo, era necessário inserir a palavra that ou that is entre estes
dois para que frase fosse mais correcta. Esta regra, embora muito simples, produzia
bons resultados, conseguindo na maioria das vezes corrigir a frase e fazer com que
esta tivesse sentido.
Um exemplo de uma notícia (curta) criada automaticamente pelo sistema é:
Work in mesh quality and mesh accuracy
Recently we had new advances in partitioning techniques that are the most popular
methods for rendering implicit surfaces, by creating a polygonal mesh.

68
6. Interface
Nesta secção iremos falar de uma submódulo do trabalho de extrema importância, a
interface. Como o nosso trabalho tinha uma forte componente de multimédia e era
apenas direccionada para utilizadores comuns, os quais teriam de gostar da aplicação,
tanto ao nível funcional como da estética, houve a necessidade de dar especial a
elaboração desta.
A interface tem a forma de uma página web, com o aspecto tradicional de um jornal,
isto na janela principal. A aplicação, embora local, corre num navegador comum. O
uso de HTML e CSS dá-nos a versatilidade de incluir todo o tipo de texto e mesmo
imagens nas notícias. Com este tipo de tecnologia damos a possibilidade a qualquer
utilizador de usar a nossa aplicação, bastando para tal correr um executável e de
seguida lançar o browser.
Quando o utilizador lança a aplicação pela primeira vez, é-lhe pedido que configure
uma série de parâmetros (figura 28), sendo estes o nome, selecione uma pasta que
contanha ficheiros que quer indexar, o raio e o número de keywords usados para a
criação dos clusters. Nestes dois últimos parâmetros é indicado aos utilizadores os
valores com que o algoritmo funciona melhor, encontrando-se estes valores
seleccionados por omissão. Estes valores podem ser configurados à posteriori pelo
utilizador. A aplicação indexa todos os ficheiros que contenham texto.
Figura 28 - Screenshot da janela de configuração.

69
A indexação desses documentos pessoais e a extracção de imagens desses mesmos
documentos, para que estas possam ser utilizadas na fase da exposição das notícias
era assim feita logo de inicio, quando se lançava a aplicação pela primeira vez, não
sendo necessário à posteriori indexar novamente os documentos, a não ser que o
utilizador quisesse alterar os documentos usados. Também é referido explicitamente
nos templates das notícias se a respectiva notícia deve incluir uma imagem ou não.
Para se criar uma edição de um jornal, o utilizador necessita de seleccionar uma data
de incio e de fim, sendo assim criadas noticias relativas a esse intervalo de tempo.
Figura 29 – Screenshot de uma edição do jornal.
No topo, encontramos o título do jornal, seguido da data a que se reporta (Figura 29).
Em seguida, dispostas de acordo com a sua importância relativa (inferida a partir do
número de documentos de cada tema), surgem as várias notícias. Cada tema pode
resultar em uma notícia, de diferentes relevâncias. As notícias com mais destaque são
mostradas, tal como nos jornais reais, com um título maior e ocupando uma parte
maior do ecrã. Cada noticia contem no final um link no qual se podem ver os
documentos pertencentes ao tema da noticia em questão.
A disposição das notícias na página é decidida automaticamente com base na
quantidade de notícias a apresentar e a importância destas. É usado um algoritmo de
sub-divisão sucessiva do espaço para o fazer. A página começa por ser dividida em

70
duas, ficando logo uma das partes reservada para a notícia de maior importância. De
seguida, divide-se a parte ainda não reservada em mais duas, sendo novamente uma
das partes reservada para a segunda notícia mais relevante, e assim sucessivamente
até todas as notícias terem sido posicionadas. O tamanho reservado para cada uma
depende da sua importância relativamente às restantes. Ao dar mais destaque a
temas mais importantes, fornece-se imediatamente uma pista visual ao utilizador sobre
as suas actividades num determinado período de tempo.
O tamanho das colunas das notícias de certa forma era gerado de forma automática,
isto é, apenas se inserem as notícias desejadas numa linha horizontal imaginária e
depois esta adapta-se as notícias. A primeira notícia ocupava a largura toda do jornal,
visto que era a noticia mais importante. De seguida colocavam-se notícias de
importância 2 com notícias de importância 3 ou 5, conforme se desejasse preencher a
largura do jornal. O que diferenciava as notícias, para além dos diferentes tamanhos
de letra, quanto menos importante menor é o tamanho da letra, era a largura da
noticiam, à excepção das notícias de importância 4, que ocupavam toda a largura do
jornal, mas tinham o tamanho da letra muito reduzido.
Existiu da nossa parte o cuidado de as notícias que se encontravam na mesma linha
imaginária na vertical terem aproximadamente o mesmo tamanho, para que na mesma
linha não houvesse uma noticia muito grande e ao lado uma demasiado pequena.
Para tal, para além de se juntarem as colunas de tamanho semelhante, inseriam-se
imagens para preencherem os espaços em branco existentes. No entanto, esta tarefa
não era perfeita, devido ao facto de ser difícil de saber a altura de uma notícia e da
sua imagem, visto que é tudo gerado dinamicamente.
Figura 30 – Selecção de data e alteração da configuração.
Para navegar entre várias edições do jornal pessoal para seleccionar intervalos de
tempo diferentes a que o jornal se reporta, carrega-se sobre a data (Figura 30) o que
nos leva uma secção da interface onde se podem efectuar as operações referidas.
Esta contém uma barra temporal onde se encontram as edições do jornal já visitadas,
sob a forma de sub-barras nos respectivos intervalos de tempo (Figura 31). Consegue-
se assim ter uma percepção geral de todas as edições existentes. Para se criar uma

71
edição do jornal referente a um período novo, basta seleccionar um novo intervalo de
tempo em menus de selecção da data.
Figura 31 – Screenshot da barra temporal usada.
De notar que na geração da folha principal do jornal eram usados tipos de letra e
tamanhos de letra parecidos aos jornais verdadeiros, tornando assim o sistema mais
real. Para além disso, todas as notícias, para além de estarem diferenciadas pela
importância destas, encontram-se divididas por linhas verticais e horizontais, dando
assim a ideia de secções, o que também se verifica nos jornais reais.
No decorrer do desenvolvimento da aplicação verificou-se que a maioria dos
documentos continha várias imagens, o que poderia servir para enriquecer as nossas
notícias, e desta forma melhorar assim a aparência da nossa interface. Assim, ao
mesmo tempo que se indexava a informação, isto é, o texto, retiravam-se as imagens
dos documentos. Ao gerar-se uma nova notícia, verificavam-se quais os documentos
pertenciam ao grupo da notícia e inseria-se, junto com o texto, uma imagem desses
mesmos documentos, sempre que houvesse necessidade de preencher um espaço
em branco entre textos e que o grupo de documentos que constituía a noticia
possuísse imagens.

72
7. Resultados e avaliação
Neste capítulo de resultados e avalização descrevemos com foi efectuada a avaliação
da aplicação, através do protocolo experimental, passando depois para a análise de
todos os resultados obtidos na avaliação da nossa aplicação.
7.1. Protocolo Experimental
Para se avaliar a usabilidade, utilidade e a eficiência da nossa aplicação é necessário
efectuar testes com vários utilizadores, simulado assim várias situações possíveis de
utilização da aplicação. Para tal vamos tentar escolher um leque alargado de
utilizadores, para assim conseguirmos obter várias situações e avaliações diferentes
acerca do nosso sistema. No entanto, existe à partida uma pequena limitação aos
utilizadores a considerar: estes devem possuir um vasto conjunto de informação
pessoal em inglês, devido ao facto de a aplicação ter sido desenvolvida para essa
língua. Assim sendo, um público-alvo muito apetecível para os testes da aplicação é a
comunidade universitária, nomeadamente os alunos que se encontram a fazer tese de
mestrado, devido ao facto de estes alunos possuírem variadíssimos documentos
científicos, normalmente em inglês. Inicialmente os utilizadores teste seriam poderiam
ser quaisquer utilizadores, no entanto, como ao longo do trabalho nos focámos em
documentos pessoais do tipo artigo científico. Os utilizadores tinham entre 23 e 35
anos, todos eles com um curso académico e possuidores de grandes conhecimentos
em inglês. Todos ele possuiam documentos pessoais escritos em inglês.
Os testes com os utilizadores irão ser feitos no computador pessoal dos mesmos
devido ao facto de aí que se encontram os documentos pessoais destes. Sendo
assim, e para além de ser necessário combinar o local para efectuar os testes, é
necessário indexar os documentos dos utilizadores visto que é sobre estes mesmo
documentos pessoais indexados que a aplicação funciona.
Os testes com os utilizadores vão ser constituídos por duas partes principais: tarefas a
serem efectuadas pelos utilizadores e um questionário.
7.1.1. Tarefas
As tarefas elaboradas para os testes com os utilizadores encontram-se na secção
seguinte.

73
7.1.1.1 Lançamento da aplicação pela primeira vez pelo utilizador
Esta tarefa, como é a primeira, é a mais simples das tarefas, na medida em que o
utilizador necessita apenas de correr a aplicação e configurar os parâmetros a utilizar
na indexação dos documentos pessoais. Para tal o utilizador selecciona uma pasta
onde se encontram os documentos, que poderá ser a pasta MyDocuments. É também
dado ao utilizador algum tempo para que este se ambiente à aplicação, tanto ao
aspecto visual desta como ao modo de funcionamento. Para isso pode livremente
escolher um intervalo de tempo desejado e navegar nos resultados obtidos. Poderá
também escolher mais do que um intervalo de tempo, e deste modo ver diferentes
edições do seu jornal pessoal.
No decorrer da tarefa, o utilizador vai apenas ser observado, cabendo ao avaliador
apenas anotações acerca da experiência, pedindo que o utilizador comente o que está
a pensar e o que este vai fazendo. Existem também uns requisitos mínimos que o
utilizador tem de correr para que a experiencia tenha sucesso. São estes requisitos os
seguintes:
Lançamento da aplicação
Configuração da aplicação
Indexação de dados (documentos pessoais)
Inserção de intervalos de tempo (data de inicio e data de fim)
Navegação pelas notícias
Utilização da barra temporal
Reacções as notícias geradas
Para além destes requisitos, o avaliador deve anotar outros que surjam no decorrer da
experiência e outro tipo de reacções do utilizador.
7.1.1.2 Identificação de temas em intervalos de tempo diferentes
Esta tarefa consiste na identificação, por parte do utilizador, dos temas dos
documentos indexados de um determinado intervalo de tempo. Esta tarefa é repetida
por vários intervalos de tempo, começando pela semana, passado para o mês e por
fim o ano.
Os testes começam pela selecção de uma determinada semana. É pedido ao
utilizador que identifique os temas em que este trabalhou nessa semana e anotam-se.
Para além disso anota-se a importância dada pelo utilizador a esses temas. De

74
seguida efectua-se o mesmo processo, no entanto depois de o utilizador usar a
aplicação, isto é, pede-se ao utilizador que identifique os temas que a aplicação
reconheceu, pedindo também a importância dada por parte do utilizador a esses
temas. Para finalizar avaliam-se os dois conjuntos de temas e retiram-se as devidas
conclusões. De seguida efectua-se a mesma tarefa para os restantes intervalos de
tempo, isto é, para o mês e para o ano.
Como é fácil de prever seria importante que a aplicação identificasse os temas mais
relevantes para o utilizador, isto é, que esta identificasse os temas identificados pelos
utilizadores com maior importância. Seria também interessante que o utilizador
conseguisse recordar outros temas depois de utilizar a aplicação, ou seja, que a
aplicação relembrasse o utilizador de determinados temas em que este trabalhou e já
não se recorda.
7.1.1.3 Identificação de tema único
Esta tarefa consiste em o utilizador se recordar de um tema importante e seleccionar
um intervalo de tempo para verificar se esse tema faz parte do jornal. Esta tarefa
distingue-se da anterior no sentido em que não existe nenhum intervalo de tempo
predefinido nem nenhum limite para este, isto é, o utilizador pode seleccionar o
intervalo que bem entender e onde melhor se enquadra o tema escolhido.
O objectivo é verificar se aplicação consegue responder com notícias que o utilizador
está à espera, isto é, se a aplicação produzir um jornal onde esse tema se encontra
destacado, este resultado é considerado positivo.
7.1.1.4 Pesquisa de ficheiros
A última tarefa é a pesquisa de um determinado ficheiro contido no conjunto de
documentos pessoais indexados. É pedido ao utilizador que se recorde de um
determinado ficheiro, de um intervalo de tempo em que esse ficheiro tenha sido criado
e/ou alterado e o tema em que esse ficheiro se enquadra. De seguida o utilizador cria
o jornal com esse intervalo de tempo.
O utilizador deverá ser capaz de identificar a notícia/tema no jornal em qual o ficheiro
se encontra e de seguida verificar que o ficheiro se encontra nos ficheiros que servem
de base a essa notícia/tema. Durante a tarefa são contados também o número de
cliques para encontrar ficheiros e o número de retrocessos para a tarefa.

75
7.1.2. Questionário
Para finalizar a avaliação da aplicação com os utilizadores, é-lhes pedido que
preencham um questionário onde expressam uma opinião geral sobre o sistema.
Todas as questões do questionário relacionam-se com a usabilidade do sistema. As
perguntas são as seguintes:
Facilidade de interacção com a aplicação
Qualidade dos resultados obtidos nas suas pesquisas
Facilidade de identificação dos temas em que trabalhou
Facilidade de encontrar ficheiros através dos temas
Qualidade das frases
Facilidade em identificar o tema de uma notícia em particular
Estética do jornal (layout , tipos de texto, etc.)
Legibilidade das notícias
Utilidade da aplicação
As avaliações devem ser feitas numa escala de 1 a 5, sendo o 1 a pior avaliação e 5 a
melhor avaliação do tópico (1 - mau, 2 - razoável, 3 - bom, 4 - muito bom, 5 -
excelente).
Para finalizar é pedido aos utilizadores que dêem opiniões e sugestões acerca da
aplicação.
7.2. Resultados obtidos
Foram efectuados 18 testes com os utilizadores, tendo assim resultados válidos da
aplicação. A análise dos resultados irá ser feita por tarefa, tal como anteriormente para
a descrição destes.
7.2.1. Tarefas
Para se conseguir avaliar a utilidade e o funcionamento da aplicação foi necessário
elaborar um conjunto de tarefas a serem executadas à posteriori por utilizadores de
teste. Foram criadas 4 tarefas com diferentes graus de complexidade, avaliando vários
cenários e vários objectivos, como veremos de seguida.

76
7.2.1.1 Tarefa 1 - Lançamento da aplicação pela primeira vez pelo utilizador
Esta tarefa tinha como principal objectivo ambientar o utilizador a aplicação e ao
sistema em si, aproveitando-a também para que este pudesse esclarecer qualquer
dúvida que surgisse durante a execução da aplicação. Existiam um conjunto de metas
que os utilizadores deveriam atingir no decorrer da tarefa, como foi referido acima. De
forma geral, todos os utilizadores conseguiram atingir essas metas, não se registando
qualquer problema ao correr a aplicação pela primeira vez.
Já em relação à configuração da aplicação os utilizadores mostraram-se bastante
interessados em saber em como os valores de configuração (raio, números de
palavras-chave) escolhidos poderiam ser escolhidos, embora acabassem por utilizar
os valores que se encontravam seleccionados por default, isto é, os valores com os
quais obtivemos melhores resultados na secção 4.
Quando a indexação dos documentos, como os utilizadores já tinham os documentos
pré-seleccionados numa pasta e seria apenas necessário inserir o caminho para essa
pasta. Em relação ao tempo demorado na indexação dos ficheiros, não houve
qualquer tipo de reclamação a registar, chegando os utilizadores a considerar o tempo
de indexação razoável e compreensível. Os utilizadores possuíam, em média, 40
documentos, demorando a indexação destes e a respectiva extracção de imagens, em
média, 3 minutos.
Após a indexação dos ficheiros, os utilizadores inseriam um determinado intervalo de
tempo para que assim pudessem ver a primeira edição do PersonalNews. O decorrer
esta fase também se dava sem qualquer problema. Depois de estarem na presença da
edição do jornal, o utilizador navegava pelas notícias, verificando se os resultados
obtidos correspondiam aos esperados. As reacções às notícias, de uma forma geral,
eram muito boas, gostando assim da aplicação e dos resultados obtidos.
7.2.1.2 Tarefa 2 - Identificação de temas em intervalos de tempo diferentes
Nesta tarefa, o objectivo principal era testar se os temas que o utilizador ainda possuía
em mente correspondiam aos temas apresentados pela aplicação. Assim sendo,
pedia-se ao utilizador que, para cada intervalo de tempo (aproximadamente uma
semana, um mês e um ano) identificasse os temas de que se lembrava, temas estes
que eram apontados e aos quais era atribuída uma importância numa escala de 1 a 5,
sendo 1 o tema muito pouco importante e 5 muito importante para o utilizador. Após a
aplicação gerar a edição do jornal para o respectivo intervalo de tempo, o utilizador

77
verificava se todos os temas previamente recordados apareciam e ainda se, com a
ajuda da edição gerada, conseguia recordar de mais algum tema. Os intervalos de
tempo, isto é, a semana, o mês e o ano não eram necessários ser os mais recentes.
Não era necessário o utilizador seleccionar a semana anterior, podendo escolher uma
à escolha.
Em relação ao intervalo de tempo de um semana, os valores a reter são os
apresentados na tabela 6.
Intervalo de tempo de uma semana Média Desvio padrão
Max Min Total
Temas identificados antes da edição 3,67 2,11 8 1 66
Temas identificados correctamente pela aplicação 3 1,49 6 1 54
Temas não identificados pela aplicação 0,67 0,51 2 0 12
Temas identificados apenas pela aplicação 1,72 1,07 4 0 31
Percentagem de acerto 81,81%
Importância dos temas identificados pelo utilizador
3.45 1.17 5 1
Importância dos temas identificados pela aplicação
3,67 1,17 5 1
Importância dos temas não identificados pela aplicação
2,5 1 4 1
Importância dos temas identificados após correr a aplicação
2,45 1.03 5 1
Tabela 6 – Resultados obtidos para o intervalo de tempo de uma semana.
Como se pode verificar através da análise da tabela 6, os utilizadores, antes de
correrem a aplicação lembravam-se de em média de 3,67 temas. Destes, 3 temas
eram correctamente identificados pela aplicação, conseguindo assim uma taxa de
sucesso da aplicação na identificação dos
temas de 81.81%. Este resultado é muito
bom devido ao facto de a aplicação
conseguir reconhecer mais de 80% dos
temas identificados pelo utilizador. Para
além disso a aplicação identificava em
média mais 1,72 temas, isto é, ajudava o
utilizador a recordar-se de 1 – 2 temas.
Uma outra conclusão interessante que se
pode retirar da tabela, é que a aplicação Gráfico 17 - Distribuição dos temas pela sua
importância (semana)

78
conseguia identificar os temas mais importantes para o utilizador, isto é, a média de
importância dos temas identificados pela utilizador e reconhecidos correctamente pela
aplicação era de 3.67. Os temas que a aplicação não reconhecia mas que eram
identificados pelos utilizadores previamente era de 2,5. Assim sendo, os temas que a
aplicação não reconhecia tinham uma importância menor para o utilizador. Já em
relação a importância dos temas recordados pela aplicação ao utilizador era de 2.45.
Através da análise do gráfico 17 conseguimos verificar as importâncias dos vários
temas obtidos, o número de temas identificados pela aplicação e o número de temas
não identificados, isto para o total dos utilizadores, isto no intervalo de tempo de uma
semana. Verifica-se que para o tema de importância 1, houve 2 temas que o utilizador
teste identificou e que a aplicação não identificou. No entanto para os temas de maior
importância, por exemplo os de importância 5 a aplicação conseguiu identificar todos
os temas de que o utilizador se tinha recordado.
Já em quando o intervalo de tempo era um mês, os resultados obtidos encontram-se
na tabela 7.
Intervalo de tempo de um mês Média Desvio padrão
Max Min Total
Temas identificados antes da edição 3,78 2,05 9 1 68
Temas identificados correctamente pela aplicação 3,27 1,53 7 1 59
Temas não identificados pela aplicação 0,5 0.70 2 0 12
Temas identificados apenas pela aplicação 1,56 0.98 3 0 28
Percentagem de acerto 86,76%
Importância dos temas identificados pelo utilizador
3.44 1.08 5 1
Importância dos temas identificados pela aplicação
3,57 1.03 5 1
Importância dos temas não identificados pela aplicação
2,56 1.01 4 1
Importância dos temas identificados após correr a aplicação
2,39 1.00 5 1
Tabela 7 - Resultados obtidos para o intervalo de tempo de um mês.
Através da análise da tabela 7 podemos concluir que os resultados foram muito
parecidos aos do intervalo de tempo referente a uma semana. De referir apenas que o
taxa de acerto para o intervalo de tempo de um mês subiu, passando a ser de 86.76%.
Isto pode ser justificado na medida em que o temas identificados pelo utilizadores

79
relativamente ao intervalo de tempo em
questão são mais gerais e mais
abrangentes, sendo assim também mais
fácil à aplicação de os identificar.
Já em relação à distribuição dos temas por
importância, podemos verificar os resultados
obtidos no gráfico 18. Os resultados obtidos
para quando o intervalo de tempo era de um
mês, foram bastante semelhantes aos de
quando o intervalo de tempo era de uma
semana. Mais uma vez é realçar que a
aplicação conseguiu identificar todos os temas de importância 5 de que o utilizador
teste se tinha recordado. O único resultado menos bom, que no entanto continua a ser
um óptimo resultado, é para os temas de nível de importância 3, em que dos 18
temas, 5 não foram identificados pela aplicação.
Por fim, a tabela 8 indica os resultados obtidos quando o intervalo de tempo era um
ano.
Intervalo de tempo de um ano Média Desvio Padrão
Max Min Total
Temas identificados antes da edição 4,33 2,44 9 2 78
Temas identificados correctamente pela aplicação 3.78 1,85 8 2 68
Temas não identificados pela aplicação 0,56 0,77 2 0 10
Temas identificados apenas pela aplicação 1,67 0.84 3 0 30
Percentagem de acerto 87,17%
Importância dos temas identificados pelo utilizador
3.73 1.02 5 1
Importância dos temas identificados pela aplicação
3,7 1.07 5 1
Importância dos temas não identificados pela aplicação
2,5 1.08 4 1
Importância dos temas identificados após correr a aplicação
2,4 0.86 4 1
Tabela 8 - Resultados obtidos para o intervalo de tempo de um ano.
Na tabela podemos verificar que, tal como tinha acontecido para os restantes
intervalos de tempo, os resultados são muito semelhantes e voltando a aumentar a
taxa de sucesso na identificação dos temas pela aplicação.
Gráfico 18 - Distribuição dos temas pela sua
importância (mês)

80
Mais uma vez, com a análise da
distribuição dos temas pela importância
deste, concluímos que os temas mais
importantes eram todos identificados. Já
em relação aos de nível de importância 4,
dos 32 temas, houve apenas 2 que não
foram identificados pela aplicação.
Com os dados obtidos nesta tarefa,
podemos concluir que a aplicação se
comporta de maneira semelhante para
intervalos de tempo diferentes, o que é um
bom resultado. Para além disso, a taxa de sucesso na identificação dos temas
encontra-se sempre acima dos 80% chegando quase aos 90%. Assim a aplicação vai
em conta às expectativas dos utilizadores. A aplicação consegue também recordar em
média 1 a 2 temas ao utilizador. Concluímos também que a aplicação consegue
identificar os temas mais relevantes para o utilizador. Com a comparação dos
diferentes intervalos de tempo, verifica-se que quanto maior são os intervalos de
tempo, melhor é a taxa de acerto. Isto justifica-se com o facto de quanto maior os
intervalos de tempo, os utilizadores cada vez se recordam mais do geral e não tanto
dos pormenores, isto leva os utilizadores testes a identificar os temas mais relevantes
e importantes, para os quais a aplicação tem pouca dificuldade em identificar.
Gráfico 19 - Distribuição dos temas pela sua
importância (ano)
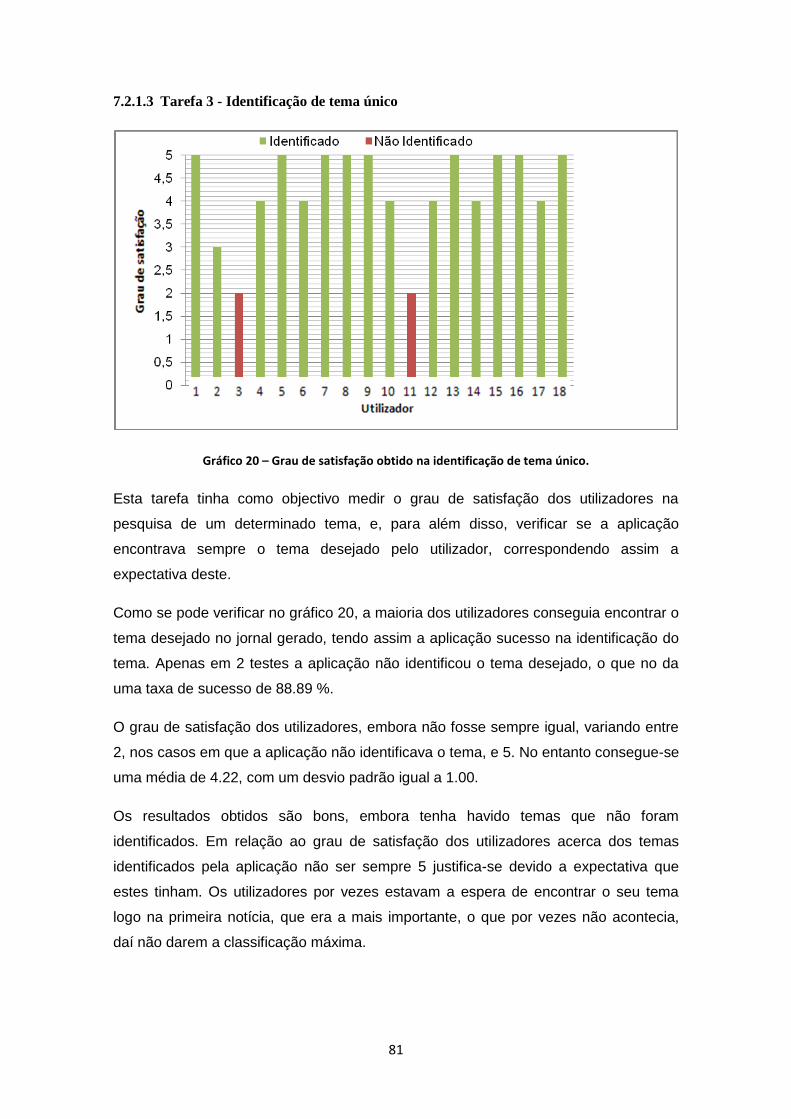
81
7.2.1.3 Tarefa 3 - Identificação de tema único
Gráfico 20 – Grau de satisfação obtido na identificação de tema único.
Esta tarefa tinha como objectivo medir o grau de satisfação dos utilizadores na
pesquisa de um determinado tema, e, para além disso, verificar se a aplicação
encontrava sempre o tema desejado pelo utilizador, correspondendo assim a
expectativa deste.
Como se pode verificar no gráfico 20, a maioria dos utilizadores conseguia encontrar o
tema desejado no jornal gerado, tendo assim a aplicação sucesso na identificação do
tema. Apenas em 2 testes a aplicação não identificou o tema desejado, o que no da
uma taxa de sucesso de 88.89 %.
O grau de satisfação dos utilizadores, embora não fosse sempre igual, variando entre
2, nos casos em que a aplicação não identificava o tema, e 5. No entanto consegue-se
uma média de 4.22, com um desvio padrão igual a 1.00.
Os resultados obtidos são bons, embora tenha havido temas que não foram
identificados. Em relação ao grau de satisfação dos utilizadores acerca dos temas
identificados pela aplicação não ser sempre 5 justifica-se devido a expectativa que
estes tinham. Os utilizadores por vezes estavam a espera de encontrar o seu tema
logo na primeira notícia, que era a mais importante, o que por vezes não acontecia,
daí não darem a classificação máxima.

82
7.2.1.4 Tarefa 4 - Pesquisa de ficheiros
Gráfico 21 – Resultados obtidos na tarefa de pesquisa de ficheiro
Esta tarefa tinha como principal objectivo verificar se os utilizadores eram capazes de
encontrar um determinado documento com a nossa aplicação. Para isso era pedido ao
utilizador que se lembrasse de um determinado documento e do respectivo tema e que
inserisse o intervalo de tempo desejado. Após o jornal estar criado contava-se o
número de cliques que o utilizador precisava para conseguir encontrar o ficheiro,
navegado apenas nas notícias e identificando o tema das notícias. Cada vez que o
utilizador seleccionava os documentos de uma dada noticia e o documento pretendido
não se encontrava no grupo de documentos dessa notícia, contava-se um retrocesso.
Os resultados obtidos estão ilustrados no gráfico 21. Todos os utilizadores
conseguiram identificar o ficheiro, no entanto, alguns necessitaram mais cliques que
outros, como se pode verificar através da análise do gráfico. Em média, cada utilizador
necessitava de 2.11 cliques para encontrar o seu ficheiro, com o desvio padrão a 1.41
cliques. No entanto a média para esta tarefa não é muito explicativa. Podemos
verificar que 10 utilizadores (mais de metade) encontraram o ficheiro à primeira,
necessitando de apenas um clique. Verifica-se também que apenas dois utilizadores
necessitaram mais de 3 cliques.
Em relação ao numero de retrocessos, estes numero é directamente proporcional ao
numero de cliques, isto é, se forem necessários 3 cliques, sabemos que houve um
retrocesso, 5 cliques 2 retrocessos e assim sucessivamente.
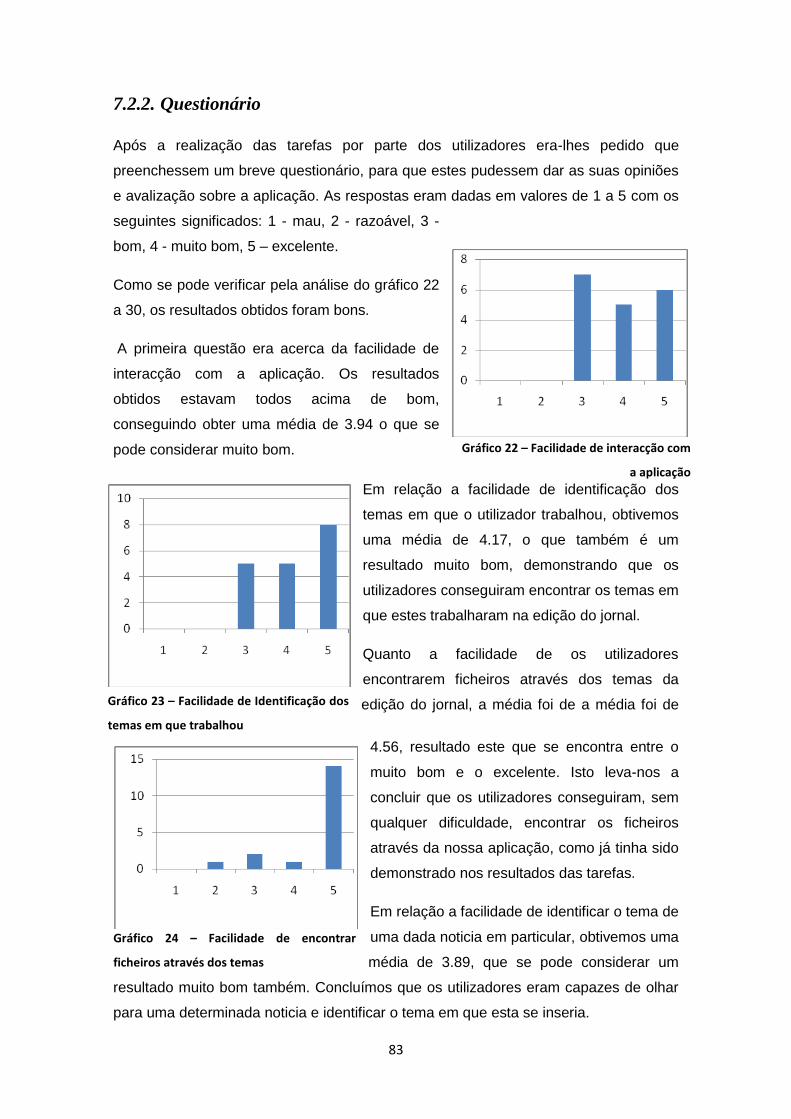
83
7.2.2. Questionário
Após a realização das tarefas por parte dos utilizadores era-lhes pedido que
preenchessem um breve questionário, para que estes pudessem dar as suas opiniões
e avalização sobre a aplicação. As respostas eram dadas em valores de 1 a 5 com os
seguintes significados: 1 - mau, 2 - razoável, 3 -
bom, 4 - muito bom, 5 – excelente.
Como se pode verificar pela análise do gráfico 22
a 30, os resultados obtidos foram bons.
A primeira questão era acerca da facilidade de
interacção com a aplicação. Os resultados
obtidos estavam todos acima de bom,
conseguindo obter uma média de 3.94 o que se
pode considerar muito bom.
Em relação a facilidade de identificação dos
temas em que o utilizador trabalhou, obtivemos
uma média de 4.17, o que também é um
resultado muito bom, demonstrando que os
utilizadores conseguiram encontrar os temas em
que estes trabalharam na edição do jornal.
Quanto a facilidade de os utilizadores
encontrarem ficheiros através dos temas da
edição do jornal, a média foi de a média foi de
4.56, resultado este que se encontra entre o
muito bom e o excelente. Isto leva-nos a
concluir que os utilizadores conseguiram, sem
qualquer dificuldade, encontrar os ficheiros
através da nossa aplicação, como já tinha sido
demonstrado nos resultados das tarefas.
Em relação a facilidade de identificar o tema de
uma dada noticia em particular, obtivemos uma
média de 3.89, que se pode considerar um
resultado muito bom também. Concluímos que os utilizadores eram capazes de olhar
para uma determinada noticia e identificar o tema em que esta se inseria.
Gráfico 22 – Facilidade de interacção com
a aplicação
Gráfico 23 – Facilidade de Identificação dos
temas em que trabalhou
Gráfico 24 – Facilidade de encontrar
ficheiros através dos temas
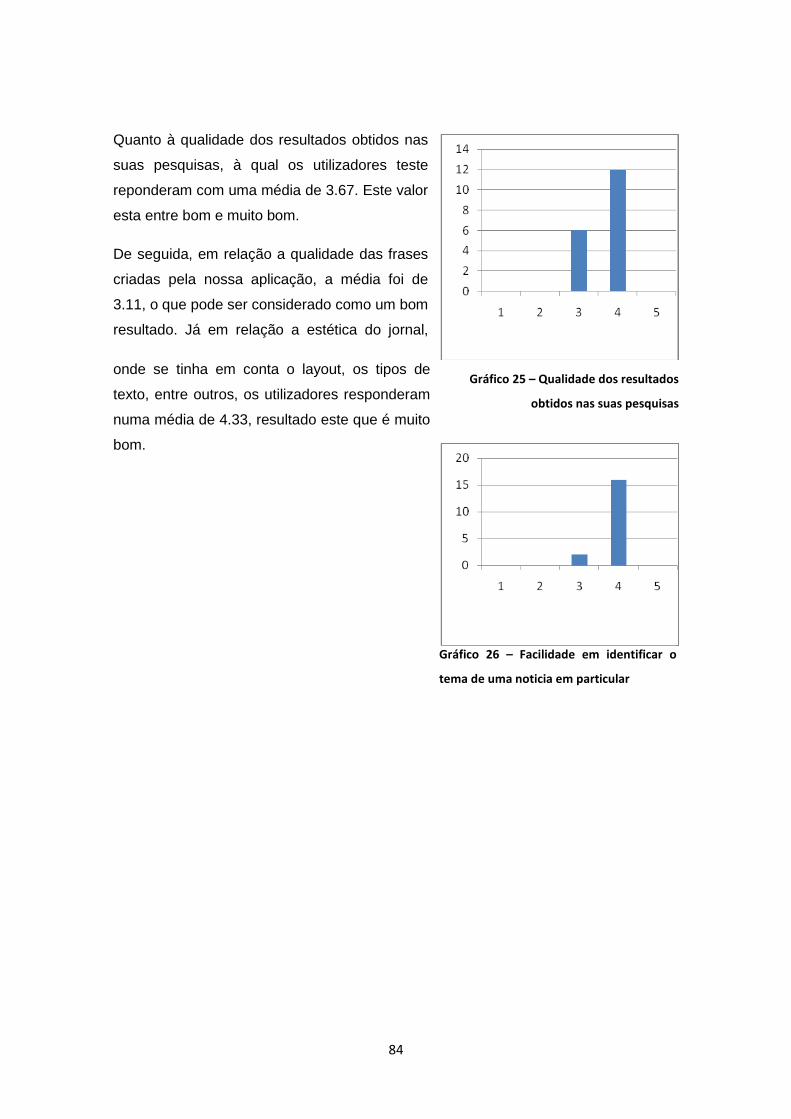
84
Quanto à qualidade dos resultados obtidos nas
suas pesquisas, à qual os utilizadores teste
reponderam com uma média de 3.67. Este valor
esta entre bom e muito bom.
De seguida, em relação a qualidade das frases
criadas pela nossa aplicação, a média foi de
3.11, o que pode ser considerado como um bom
resultado. Já em relação a estética do jornal,
onde se tinha em conta o layout, os tipos de
texto, entre outros, os utilizadores responderam
numa média de 4.33, resultado este que é muito
bom.
Gráfico 25 – Qualidade dos resultados
obtidos nas suas pesquisas
Gráfico 26 – Facilidade em identificar o
tema de uma noticia em particular
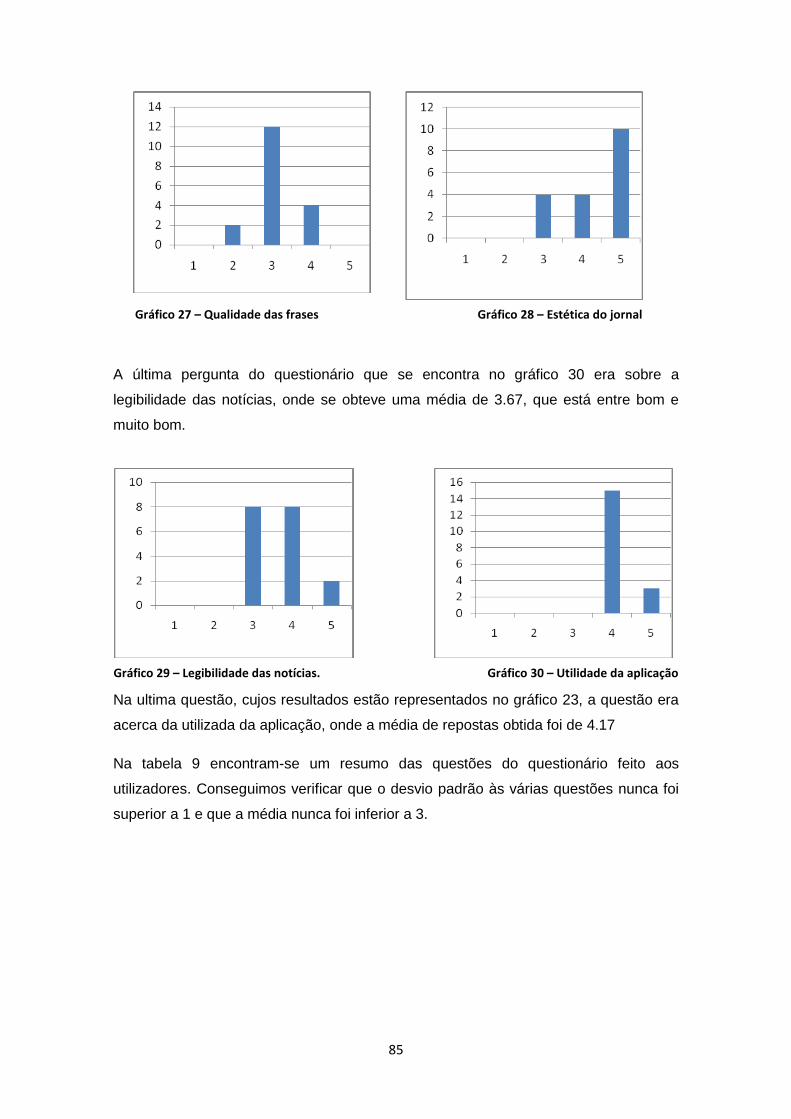
85
A última pergunta do questionário que se encontra no gráfico 30 era sobre a
legibilidade das notícias, onde se obteve uma média de 3.67, que está entre bom e
muito bom.
Na ultima questão, cujos resultados estão representados no gráfico 23, a questão era
acerca da utilizada da aplicação, onde a média de repostas obtida foi de 4.17
Na tabela 9 encontram-se um resumo das questões do questionário feito aos
utilizadores. Conseguimos verificar que o desvio padrão às várias questões nunca foi
superior a 1 e que a média nunca foi inferior a 3.
Gráfico 28 – Estética do jornal Gráfico 27 – Qualidade das frases
Gráfico 29 – Legibilidade das notícias. Gráfico 30 – Utilidade da aplicação
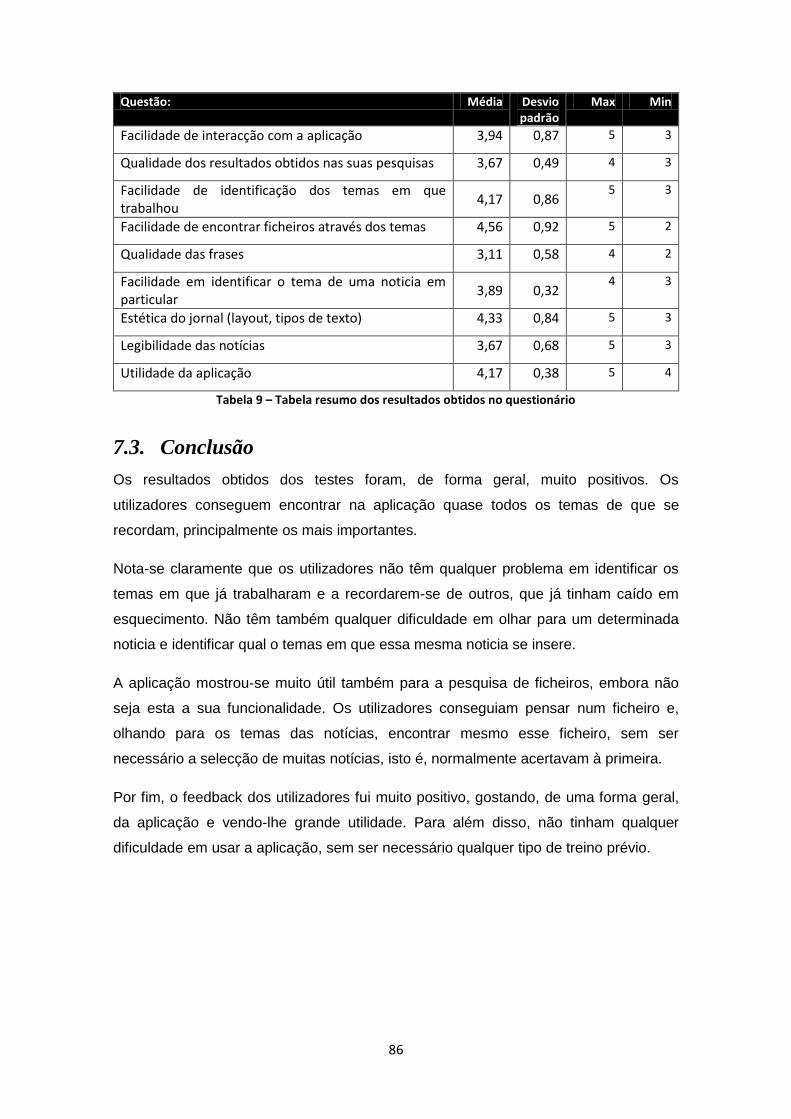
86
Questão: Média Desvio padrão
Max Min
Facilidade de interacção com a aplicação 3,94 0,87 5 3
Qualidade dos resultados obtidos nas suas pesquisas 3,67 0,49 4 3
Facilidade de identificação dos temas em que trabalhou
4,17 0,86 5 3
Facilidade de encontrar ficheiros através dos temas 4,56 0,92 5 2
Qualidade das frases 3,11 0,58 4 2
Facilidade em identificar o tema de uma noticia em particular
3,89 0,32 4 3
Estética do jornal (layout, tipos de texto) 4,33 0,84 5 3
Legibilidade das notícias 3,67 0,68 5 3
Utilidade da aplicação 4,17 0,38 5 4
Tabela 9 – Tabela resumo dos resultados obtidos no questionário
7.3. Conclusão
Os resultados obtidos dos testes foram, de forma geral, muito positivos. Os
utilizadores conseguem encontrar na aplicação quase todos os temas de que se
recordam, principalmente os mais importantes.
Nota-se claramente que os utilizadores não têm qualquer problema em identificar os
temas em que já trabalharam e a recordarem-se de outros, que já tinham caído em
esquecimento. Não têm também qualquer dificuldade em olhar para um determinada
noticia e identificar qual o temas em que essa mesma noticia se insere.
A aplicação mostrou-se muito útil também para a pesquisa de ficheiros, embora não
seja esta a sua funcionalidade. Os utilizadores conseguiam pensar num ficheiro e,
olhando para os temas das notícias, encontrar mesmo esse ficheiro, sem ser
necessário a selecção de muitas notícias, isto é, normalmente acertavam à primeira.
Por fim, o feedback dos utilizadores fui muito positivo, gostando, de uma forma geral,
da aplicação e vendo-lhe grande utilidade. Para além disso, não tinham qualquer
dificuldade em usar a aplicação, sem ser necessário qualquer tipo de treino prévio.

87
8. Conclusões e trabalho futuro
Neste capítulo vamos concluir esta dissertação. No inicio desta dissertação
propusemo-nos a criar uma nova forma de mostrar a informação pessoal que se
encontra encontrada indexada nos computadores aos seus utilizadores.
Um dos problemas encontrados hoje em dia ao gerir a grande quantidade de
informação pessoal ao nosso dispor no computador é conseguir visualizá-la de forma
suficientemente resumida e agrupada de forma a dar ao utilizador uma percepção
geral desta e de padrões acerca das suas actividades e interesses ao longo do tempo.
A nossa solução, o PersonalNews, permite obter essa percepção ao agrupar os
documentos do utilizador de acordo com os seus temas e apresentando esses temas
sob a forma de notícias num ―jornal pessoal‖. Conseguimos identificar correctamente
os temas em causa, bem como obter excertos relevantes dos documentos que
caracterizem esses temas. Esses excertos são então usados para a criação das
notícias propriamente ditas.
Existiram várias contribuições ao longo do nosso trabalho, destacando-se claramente
a inferência automática de temas a partir de documentos, a extracção de excertos
relevantes e representativos dos documentos pessoais dos utilizadores, a criação de
notícias que resumem os temas e, para finalizar, a criação de uma interface e sistema
interactivo onde se aplicou a biblioteca criada.
Depois de avaliar a aplicação com testes verificamos que obtivemos bons resultados.
Exemplo disso são os resultados obtidos na identificação dos temas pela aplicação.
Acima de 80% dos temas identificados pelos utilizadores foram também identificados
pela nossa aplicação, chegando este valor aos 87% quando o intervalo de tempo era
de aproximadamente 1 ano. É de realçar também os bons resultados obtidos nas
pesquisas de ficheiros. Todos o utilizadores conseguiram encontrar os ficheiros a
pesquisar, bastando para tal em média 2 cliques. Existam, no entanto, pontos onde se
pode melhorar. Exemplo disso, e onde obtivemos piores resultados, embora estes
ainda sejam bons, é a qualidade das frases. Os resultados obtidos justificam-se com a
não utilização de uma aplicação de língua natural já testada e em funcionamento,
sendo aplicada uma criada por nós. O valor mais importante a reter dos testes a
aceitação da aplicação por parte dos utilizadores. Também é de realçar a taxa de
identificação de temas pela aplicação dos quais os utilizadores estavam a espera e de
os relembrar certos temas que já tenham caído em esquecimento.

88
Em relação ao trabalho futuro, existem várias vertentes por onde este pode seguir.
Pode-se criar um algoritmo de clustering de raiz para aplicações parecidas com a
nossa, ou tentar adaptar os já existentes. Por outro lado, pode-se tentar melhorar a
estipulação dos valores usados no algoritmo de clustering, como é o caso das
keywords, raio e distância de junção, para diferentes conjuntos de dados. Uma outra
vertente por onde se pode continuar o trabalho é na língua natural. Neste, também
existem várias possibilidades, no entanto pensamos que a melhor seria aplicar uma
aplicação já existente e testada, de forma a que os resultados melhorassem
significativamente. Um outro caminho que se pode seguir como trabalho futuro prende-
se com a interface, podendo criar uma nova aplicação de visualização mais elaborado.
Por fim, a vertente mais interessante por onde este trabalho poderia evoluir era com a
integração de outras fontes de informação, como é o caso de informação pessoal
contida nos e-mails dos utilizadores, por exemplo.

89
9. Bibliografia
[Balabanović et al. 00] Balabanović, M., Chu, L. L., Wolff, G. J. 2000. Storytelling with
digital photographs, Proceedings of the SIGCHI conference on Human factors in
computing systems, p.564-571, April 01-06, 2000, The Hague, The Netherlands.
[Berry 92] Berry, M., W. 1992. Large-scale sparse singular value computations. The
International Journal of Supercomputer Applications, 6(1):13--49.
[Berry et al. 95] Berry, M., W., Dumais S.,T., O‘Brien, G. W. 1995. Using linear algebra
for intelligent information retrieval, SIAM Review, v.37 n.4, p.573-595, Dec. 1995
[Brooks and Montanez 06] Brooks, C. H., Montanez, N. 2006. An Analysis of the
Effectiveness of Tagging in Blogs, Proc 2006 AAAI Conf, 2006.
[Calvo and Ceccatto 00] Calvo A. R., Ceccatto H. A. 2000. Intelligent document
classification. In intelligent Data Analysis., p.411-420.
[Cutrell et al. 06] Cutrell, E., Robbins, D., Dumais, S., Sarin, R. 2006. Fast, flexible
filtering with phlat, Proceedings of the SIGCHI conference on Human Factors in
computing systems, April 22-27, 2006, Montréal, Québec, Canada.
[Deerwester et al. 90] Deerwester, S., Dumais S., Landauer, T., Furnas, G., Harshman,
R. 1990. Indexing by latent semantic analysis. In Journal of the American Society for
Information Science 41, 391-407.
[Dumais et al. 03] Dumais, S., Cutrell, E., Cadriz, JJ., Jancke, G., Sarin, R., Robbins,
C. D. 2003. Stuff I‘ve seen: A System for personal information retrieval and re-use.
Proceedings of the 26th annual international ACM SIGIR conference on Research
and development in information retrieval, July 28-August 01, 2003, Toronto,
Canada.
[Frau et al. 05] Frau, S., Roberts, J., & Boukhelifa, N. 2005. Dynamic Coordinated
Email Visualization. In WSCG.
[Fertig et al. 96] Fertig, S., Freeman, E., Gelernter, D. 1996. Lifestreams: an alternative
to the desktop metaphor, Conference companion on Human factors in computing
systems: common ground, p.410-411, April 13-18, 1996, Vancouver, British
Columbia, Canada.

90
[Freeman and Gelernter 96] Freeman, E., Gelernter, D. 1996. Lifestreams: a storage
model for personal data, ACM SIGMOD Record, v.25 n.1, p.80-86, March 1996.
[Gemmel et al. 02] Gemmel, J., Bell, G., Lueder, R., Drucker, S., Wong, C. 2002.
MyLifeBits: Fulfilling the Memex Vision. In Proceedings of the 10th ACM
international conference on Multimedia, December 01-06, 2002, Juan-les-Pins,
France.
[Gemmel et al. 06] Gemmel, J., Bell, G., Lueder, R. 2006. MyLifeBits: a personal
database for everything. In Communications of the ACM, v.49 n.1, p.88-95, January
2006.
[Gemmel et al. 03] Gemmel, J., Luder, R., Bell, G. 2003. The MyLifeBits Lifetime Store.
In proceedings of the 2003 ACM SIGMM workshop of experimental telepresence,
November 07, 2003, Berkeley, California.
[Gwizdka02a] Gwizdka, J., 2002. TaskView: design and evaluation of a task-based
email interface, Proceedings of the 2002 conference of the Centre for Advanced
Studies on Collaborative research, p.4, September 30-October 03, 2002, Toronto,
Ontario, Canada.
[Gwizdka02b] Gwizdka, J. 2002. Future Time in Email - Design and Evaluation of a
Task-Based Email Interface. Proceedings of IBM CASCON 2002, pp. 136--145.
[Heyer et al. 99] Heyer, L., J., Kruglyak, S., Yooseph, S. 1999. Exploring expression
data: identification and analysis of coexpressed genes. Genome Research, 9:1106-
1115, 1999.
[Hotho and Stumme 02] Hotho, A. Stumme, G. 2002. Conceptual clustering of text
clusters. In G. Kokai and J. Zeidler (Eds.), editors,Proc. Fachgruppentreffen
Maschinelles Lernen (FGML 2002), pages 37--45, Hannover, 2002.
[Kaufman and Rousseeuw 90] Kaufman, L., Rousseeuw, P., J. 1990. Finding Groups in
Data: An Introduction to Cluster Analysis. Wiley Series In Probability and Statistics.
John Wiley and Sons. New York: Wiley, 1990.
[Kim et al. 04] Kim, P., Podlaseck, M., Pingali, G. 2004. Personal chronicling tools for
enhancing information archival and collaboration in enterprises, Proceedings of the
the 1st ACM workshop on Continuous archival and retrieval of personal
experiences, October 15-15, 2004, New York, New York, USA.

91
[Lamming and Flynn 94] Lamming, M., Flynn, M. 1994. ―Forget-me-not‖ Intimate
computing in Support of Human Memory. In Proceedings of FRIEND 21:
International Symposium on Next Generation Human Interfaces (Tokyo, 1994), 125-
128.
[Landauer and Dumais 94] Landauer, T.,K., Dumais, S., T. 1994. Latent Semantic
analysis and the measurement of knowledge. In R. M. Kaplan and J. C. Burstein
(EDS) Education Testing Service Conference on Natural Language Processing
Techniques and Technology in Assessment and Education.
[Liu et al. 04] Liu, Y., Ciliax, B. J., Borges, K., Dasigi, V., Ram, A., Navathe, S.,
Dingledine, R. 2004. Comparison of two schemes for automatic keyword extraction
from MEDLINE for functional gene clustering. In Proceedings of the 2004 IEEE
Computational Systems Bioinformatics Conference (CSB'04), p.394-404, August 16-
19, 2004.
[Pantel and Lin 02] Pantel, P., Lin, D. 2002. Document clustering with committees. In
Proceedings of the 25th annual international ACM SIGIR conference on Research
and development in information retrieval, August 11-15, 2002, Tampere, Finland.
[Plaisant et al. 96] Plaisant, C., Milash, B., Rose, A., Widoff, S., Shneiderman, B. 1996.
LifeLines: visualizing personal histories, Proceedings of the SIGCHI conference on
Human factors in computing systems: common ground, p.221-ff., April 13-18, 1996,
Vancouver, British Columbia, Canada.
[Porter80] Porter, M. F. An algorithm for suffix stripping. Program,(14):130–137,1980.
[Rekimoto99a] Rekimoto, J. 1999. Time-machine computing: a time-centric approach
for the information environment, Proceedings of the 12th annual ACM symposium
on User interface software and technology, p.45-54, November 07-10, 1999,
Asheville, North Carolina, United States.
[Rekimoto99b] Rekimoto, J. 1999 TimeScape: a time machine for the desktop
environment, CHI '99 extended abstracts on Human factors in computing systems,
May 15-20, 1999, Pittsburgh, Pennsylvania.
[Ringel et al. 03] Ringel, M., Cutrell, E., Dumais, S. and Horvitz, E. 2003. Milestones in
time: The value of landmarks in retrieving information from personal stores. In
Proceedings of Interact 2003: Ninth International Conference on Human-Computer
Interaction, September 2003, Zürich, Switzerland.

92
[Rohall et al. 01] Rohall, S. L., Gruen, D., Moody, P., Kellerman, S. 2001. Email
Visualizations to Aid Communications. In Proceedings of InfoVis 2001 The IEEE
Symposium on Information Visualization, IEEE. 12--15.
[Sebastiani02] Sebastiani, F. 2002. Machine learning in automated text categorization.
ACM Computing Surveys (CSUR), v.34 n.1, p.1-47, March 2002.
[Shen et al. 01] Shen, C., Lesh, N., Moghaddam, B., Beardsley, P., Bardsley, R. S.
2001. Personal digital historian: user interface design, CHI '01 extended abstracts
on Human factors in computing systems, March 31-April 05, 2001, Seattle,
Washington .
[Smith et al. 06] Smith, G., Czerwinski, M., Mayers, B., Robbins, D., Robertson, G.,
Tan, D. S. 2006. FacetMap: A Scalable Search and Browse Visualization. In IEEE
Transactions on Visualization and Computer Graphics, v.12 n.5, p.797-804,
September 2006.
[Viégas et al. 04] Viégas, F. B., Boyd, D., Nguyen, N. B., Potter, J., Donath, J. 2004.
Digital Artifacts for Remembering and Storytelling: PostHistory and Social Network
Fragments, Proceedings of the Proceedings of the 37th Annual Hawaii International
Conference on System Sciences (HICSS'04) - Track 4, p.40109.1, January 05-08,
2004.
[Viégas and Smith 04] Viégas, F. B., Smith, M. 2004. Newsgroup Crowds and
AuthorLines: Visualizing the Activity of Individuals in Conversational Cyberspaces.
In Proceedings of the Proceedings of the 37th Annual Hawaii International
Conference on System Sciences (HICSS'04) - Track 4, p.40109.2, January 05-08,
2004.
[Viégas et al. 06] Viégas, F. B., Golder, S., Donath, J. 2006. Visualizing Email Content:
Portraying Relationships form Conversational Histories. Proceedings of the SIGCHI
conference on Human Factors in computing systems, April 22-27, 2006, Montréal,
Québec, Canada.
[Whittaker and Sidner 96] Whittaker, S., Sidner, C., 1996. Email overload: exploring
personal Information management of email. In Proceedings of the SIGCHI
conference on Human factors in computing systems: common ground, p.276-283,
April 13-18, 1996, Vancouver, British Columbia, Canada
[Xiong and Donath 99] Xiong, R., Donath, J. 1999. PeopleGarden: creating data
portraits for users, Proceedings of the 12th annual ACM symposium on User

93
interface software and technology, p.37-44, November 07-10, 1999, Asheville, North
Carolina, United States.
[Xu and Wunsch 05] Xu, R., Wunsch, D. 2005. Survey of clustering algorithms.
Transactions on neural networks. IEEE Transactions on neural networks 16 (3):
645—678.
[Yang and Liu 99] Yang, Y., Liu, X.. 1999. A re-examination of text categorization
methods. In Proceedings of the 22nd annual international ACM SIGIR conference
on Research and development in information retrieval, p.42-49, August 15-19, 1999,
Berkeley, California, United States.
[Yiu et al. 97] Yiu, K., R. Baecker, N. Silver and B. Long. 1997. A time-based interface
for electronic mail and task management. In Proc. HCI International ‗97.

94
10. Anexos
A1 – Estrutura dos padrões em XML
Como foi referido e explicado no capítulo 5, os padrões de notícias eram muito
importantes para a geração destas. Nesta secção iremos analisar e descrever
detalhadamente a estrutura dos documentos XML que continham estes padrões de
notícias. De seguida encontra-se um desses padrões:
<newsTemplate importance ="1">
<title>
<alt>
<!-- as alternativas ficam aqui -->
<li>New advances in</li>
<li time="Present" number="plural">Developments on</li>
</alt>
<textExcerpt quoteSize="small" morphology="verb"> </textExcerpt>
</title>
<body>
We saw new developments in
<textExcerpt quoteSize="small" morphology="name"> </textExcerpt>,
having figured out that
<textExcerpt quoteSize="medium" morphology="name"> </textExcerpt>.
As a result, we
<alt>
<li time="present">studied how</li>
<li time="future">will study how</li>
<li time="past">had studied how</li>
</alt>
<textExcerpt quoteSize="medium" morphology="name"> </textExcerpt>
</body>
</newsTemplate>
Como se pode ver, estes padrões são compostos para vários nós e elementos, que
analisaremos de seguida.
<newsTemplate importance ="1">
Marca o início de um novo template para as notícias. O atributo importance define a
importância da notícia, podendo estes assumir valores de 1 a 5, sendo o 1 a notícia
mais importante e a 5 a menos importante.

95
<title>
<alt>
<!-- as alternativas ficam aqui -->
<li>New advances in</li>
<li time="Present" number="plural">Developments on</li>
</alt>
<textExcerpt quoteSize="small" morphology="verb"> </textExcerpt>
</title>
Este submódulo de XML define o título da notícia. Dentro do elemento <alt> podem-se
inserir as diferentes alternativas par o inicio da notícia, sendo depois escolhido apenas
uma na geração da noticia. Essas alternativas estão dentro de um <li> que pode ter os
seguintes atributos: number que indica se o texto a inserir deve estar no plural ou no
singular e o time que indica o tempo verbal do texto a inserir. Assim, para o exemplo
fornecido se escolhêssemos a segunda alternativa, o tempo verbal do texto a inserir
deveria ser no presente. Depois do elemento <alt> vem o elemento <textExcerpt> que
contém o atributo morphology que indica a morfologia da primeira palavra a inserir
após o texto do temlate.
O XML que se segue é acerca do corpo da noticia:
<body>
We saw new developments in
<textExcerpt quoteSize="small" morphology="name"> </textExcerpt>,
having figured out that
<textExcerpt quoteSize="medium" morphology="name"> </textExcerpt>.
As a result, we
<alt>
<li time="present">studied how</li>
<li time="future">will study how</li>
<li time="past">had studied how</li>
</alt>
<textExcerpt quoteSize="medium" morphology="name"> </textExcerpt>
</body>
Tal como anteriormente para o título os elementos e os seus atributos do <body> são
semelhantes.
Com estes templates qualquer utilizador pode acrescentar novos templates e/ou
adaptar os já existentes para o formato desejado.




















