
Parallel and Vector Problems on the FLEX/32 - Purdue e-Pubs
88
Purdue University Purdue University Purdue e-Pubs Purdue e-Pubs Department of Computer Science Technical Reports Department of Computer Science 1987 Parallel and Vector Problems on the FLEX/32 Parallel and Vector Problems on the FLEX/32 H S. McFaddin John R. Rice Purdue University, [email protected] Report Number: 87-661 McFaddin, H S. and Rice, John R., "Parallel and Vector Problems on the FLEX/32" (1987). Department of Computer Science Technical Reports. Paper 572. https://docs.lib.purdue.edu/cstech/572 This document has been made available through Purdue e-Pubs, a service of the Purdue University Libraries. Please contact [email protected] for additional information.
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of Parallel and Vector Problems on the FLEX/32 - Purdue e-Pubs

Purdue University Purdue University
Purdue e-Pubs Purdue e-Pubs
Department of Computer Science Technical Reports Department of Computer Science
1987
Parallel and Vector Problems on the FLEX/32 Parallel and Vector Problems on the FLEX/32
H S. McFaddin
John R. Rice Purdue University, [email protected]
Report Number: 87-661
McFaddin, H S. and Rice, John R., "Parallel and Vector Problems on the FLEX/32" (1987). Department of Computer Science Technical Reports. Paper 572. https://docs.lib.purdue.edu/cstech/572
This document has been made available through Purdue e-Pubs, a service of the Purdue University Libraries. Please contact [email protected] for additional information.

PARALLEL AND VECTOR PROBLEMS ON THE PLEX/32
H. S. McFaddinJ. R. Rice
CSD-TR-661Man;h 1987

PARALLEL AND VECTOR PROBLEMS ON THE FLEX/32
liS. McFaddin'"l.R. Rice"''''
Department of Computer SciencePurdue University
West Lafayette, Indiana 47907CSD-TR-661
March 2, 1987
ABSTRACT
Earlier we proposed [Rice,1985] sixteen problems to test the effectiveness of languages inexpressing parallel and vector computations. These problems were presented in ordinary notation(mathematics and English) plus four algorithmic fonns: A) Fortran 77, B) Fornan 77 with extensions (resembling Fortran 8X), C) PROTRAN with extensions and D) Cyber 205 Farnan. Wenow present these problems programmed for the FLEX/32 multiprocessor in a Concurrent Fortrnn. Our objectives are twofold: 1) to show how these problems appear in this language (whichis similar to those on several other multiprocessors), 2) to show the parallel efficiency achievedfor these problems.
.. This work was suppolUd by IMSL, Icc..
... This woek supported in part by ARO gnnt DAAL03-86-K-OI06

-2-
1. INTRODUCTION AND SUMMARY
The purpose of this report is explore two properties of the fLEX/32 multiprocessordescribed in derail in [Flexible, 1985] (see Section 3 for a brief description). First, we wish coevaluate its effectiveness as a parallel computer (see [Houstis,et.al., 1987] for some earlier work).Second, we wish to evaluate the programming methodology required by its Concurrent FortranLanguage. We have programmed sixteen problems on the FLEXI32 taken from [Rice, 1985]which are designed to test the effectiveness of programming languages for parallel and vectorapplications. These problems are also well suited to test the speedup obtained with parallel andvector computers.
The sixteen problems are summarized in the next section and the FLEXl32 and its Concurrent Fortran program.ming language are briefly described in Section 3. In Section 4 we presentspeedup curves for these problems using 2,3,4 and 5 processors of the FLEX/32. Each problem isparametrized so that both the amount of parallelism and the size of the computation can beincreased. The data is in the form of efficiency
E = Time with one processorN '" (Time with N processors)
verms computer time with one processor. The range of times are from 200 to 2200 ticks (or 4 to44 seconds), depending on the problem. A tick on the FLEXJ32 clock is 1150 second..
Appendix One contains the sixteen programs for the problems. These are complete programs just as used for the speedup evaluations. Each program stans with code for interactiveinput which is very similar from program to program.
The design of the FLEX/32 is best suited for one or a small number of applications that ronfor a long time. Such applications occur commonly in real-time conaot. The initiation of a set ofparallel processes is a substantial activity: programs are loaded into the local memories of theprocessors, data are placed in common memories, tables are set up for parallel synchronization,etc. It is somewhat analogous to the linklload step in a sequential computation and takes at leastone second of real time. The effect of this activity is magnified by the fact that some parts aresequential in the number of processors used.
"This simation has a direct impact on synchronizations that must occur in some of the six[Cen problems. The programs initiate the number of parallel processes to be used and then synchronization is carried out by traditional teChniques (semaphores, critical variables, etc.) withoutusing the parallel constructs of Concurrem Fortran.
An examination of the efficiency curves in Section 4 shows that they all stan off quite lowand one must have a 10 to 20 ticks sequential job for any of the programs to reach efficiencies of80 or 90 percent. TIlls is due to the start-up times for the parallel computations. Appendix Twocontains the data on timing and efficiency.
A visual examination of the efficiency curves suggests that, with five processors, no program reaches 95% efficiency for a job less than 800-1000 ticks (about 15-20 seconds). We summarize thaI observations for the 14 problems (excluding numbers 8 and 16), the job sizes aremeasured in ticks on a single FLEX/32 processor.

-3-
2 processors S processorsJob size to reach 75% efficiency
Minimum.TypicalMaximum
Job size to reach 95% efficiency
MinimumTypicalMaximum
1015-20100
100250
>2000
50200-300
3000
5002000-50007
7
The reason that efficiencies of 95% are difficult to achieve is thai: most of the problems havesome small "sequential" pan (such as forming a sum) or have some synchronization code whichis unneeded in a sequential computation.
Keep in mind that we have programmed most oftbese problems in the style that we think'istypical of-general program.ming: 1) some initial thought is given to the computations, 2) anapproach is chosen, 3) a code is written and. 4) some testing for correctness is made. We did notinvest the effon to obtain highly efficient codes for these problems.
Two problems, #8 (compute a divided difference table) and #16 (multiple linear equationsolutions). have low efficiences for all job sizes. Our program for problem #8 is essentiallysequential in behavior, we have not used an appropriate parallelization here. High parallelefficiency is only possible here when the problem size is very large compared. to the number ofprocessors. Our program for problem #16 also does not use an appropriate parallelization, a comparison with problem #10 shows this.
Writing efficient programs for tb: F1.EXI32 requires one to become familiar wim the detailsof the machine and to learn various synchronization techniques for parallel computations. Theprincipal suppon that Concurrent Fortran provides for synchronization is shared critical variables,the explicit synchronization facilities are too inefficient to be used often. We made a few experiment; of the effect of coarse grain vetses small grain parallelism. For example. a computationwith 3 processors with i going from 1 to 300 can be divided into 3 parts in two obvious ways:
1 S i, S 100, 101 S i 2 S 200, 201 Si, S3oo,
or
i l = I, 4. 7, ...• i 2 =2, 5, 8•...• i 3 =3, 6. 9, ...•.
If no further synchronization were required, then these [wo approaches give essentially equalefficiency. Of course. the coarse grain approach is mare efficient if there is much synchronizationrequired at all.

-4-
2. THE SIXTEEN PROBLEMS
Problem 1:
Problem 2:
Problem 3:
Problem 4:
Problem 5:
Problem 6:
Problem 7:
Evaluate the ttapezoidal rule estimate of an integral off (x):
H-ITH = h*('hf(a) + I,f(a + ih) + 'hf(b))
i-I
Compute Ihe value of
.. m .... = I, II(!. + ,H'-JIl)
i=l l"'l
• mCompute the value of S = 1: IIaij
j.-I i"'l
H 1Compute the value of R = L
;=\ Xi
.'"One has a table of the j -th student's score on the u·th test. One is to
(a) list the top score for each student = tOPi
(b) give the number ofscores above the average = NABOVE(e) increase all the above average scores by 10 percent(d) give the lowest score that is above average = BLOW_ABOVE(e) say whether any student has all scores above average = GENIUS
Solve the oidiagonal system Tx = y by the special, vector oriented algorithm of [Jordan, 1979]. The matrix T is represented by L,D and U, itslower diagonal, main diagonal and upper diagonal.
Compute polynomial interpolant values of I(x) at five points usingLagrange interpolation formulas:
Hp(x) = V(x,)I,(x)
i_I
NI,(x) = II(x - Xj)lII(xi - Xj)
j=1 j=tj~j i~j

Problem 8:
Problem 9:
Problem 10:
Problem 11:
Problem 12:
-5-
TIle divided difference table for a set of data Xi. :Ii = f (Xi) is defined bythe formulas
f[z;] =y,
.'..:[,,"',,'.,,',,'_....:.• .e%,,'":0.:.]_-.:.',-,=["',,'.:.''::""".:.Z.:.'"=]f[Xi. %i+l..... %i+.t] =-
Xi+.t - xi
The problem is to compute the first M columns of the divided differencetable
One has an anay Ilij of values on an N by M grid and wants to replaceeach value by the average of its value plus those of all its neighbors.This is expressed by
"i; = ( LUi;) / (Numbt!r of ~jghbors)N~i&Jrbon
This computation is typical of what one does in solving partial differen~
tia1 equations. image processing and geometric modeling.
W factorization of the N by N maaix A = ai; using Gauss elimin.aI:ionwith pivoting.
Read. sets of data d j I j = I ..... N, trim the negative values to zero andlarge values to 1000, do a logarithmic t:ransfonnation d j = log (1 + d i )
Nand compute the first four Fourier momems I:.dicos(7ti/(N + 1» then
i_Isave these moments and the data ID in a data base.
Given the m by m matrix A. the 1 by m vector R. the m by 1 vector Cand a number A • consmIet the anay
ABIG = [~ ~]

Problem 13:
-6-
For given vector 3, b, c, d compute the new vector
. b'OJ =OJ sm
If Qj < cos(c;) then OJ = OJ + Cj
else OJ = OJ - dj
and compute
Problem 13H: Modify Problem 13 for a machine that wants to have the computationsplit into 20 processes (e.g., such as the HEP ).
Problem 14: Cany out a test of four methods to integrate Ihree different functionswith 10 different levels of accuracy each. Print Out a table with all theresults including the number of function evaluations and in each integration. This problem comes from [Rice, 1983], page 204.
Problem 15: Carry out a comparison of [wo types of interpolation points (equispacedand chebyshev spaced) for Hermite interpolation using piece-wise cubicpolynomials. The inteI'JXlIant's value v aty can be expressed as
N
.(y) = I.f(xj)h1j(y) +!'(xj)h2j (y)j ..t
where h Ij (z) and h 2j (x) are suitable basis functions that depend on theN interpolation points Ij_ This problem comes from [Rice, 1983], pages93,98 and 380-381.
Problem 16: Solve a Mattix equation Ax = B where A is an N by N Hilben matrixand B is an N by 4 matrix. The matrix order N l:akes on the values 4, 8,12, 16 and 20 and the B column·vectoni are, respectively, the firstcolumn of the identity matrix, alI l's, a 0.01 random pertubation of alll's, and alternating +1,-1.

-7-
3. THE FLEX/32 MULTICOMPUTER AND ITS CONCURRENT FORTRAN
3.1. FLEX/32 Architecture
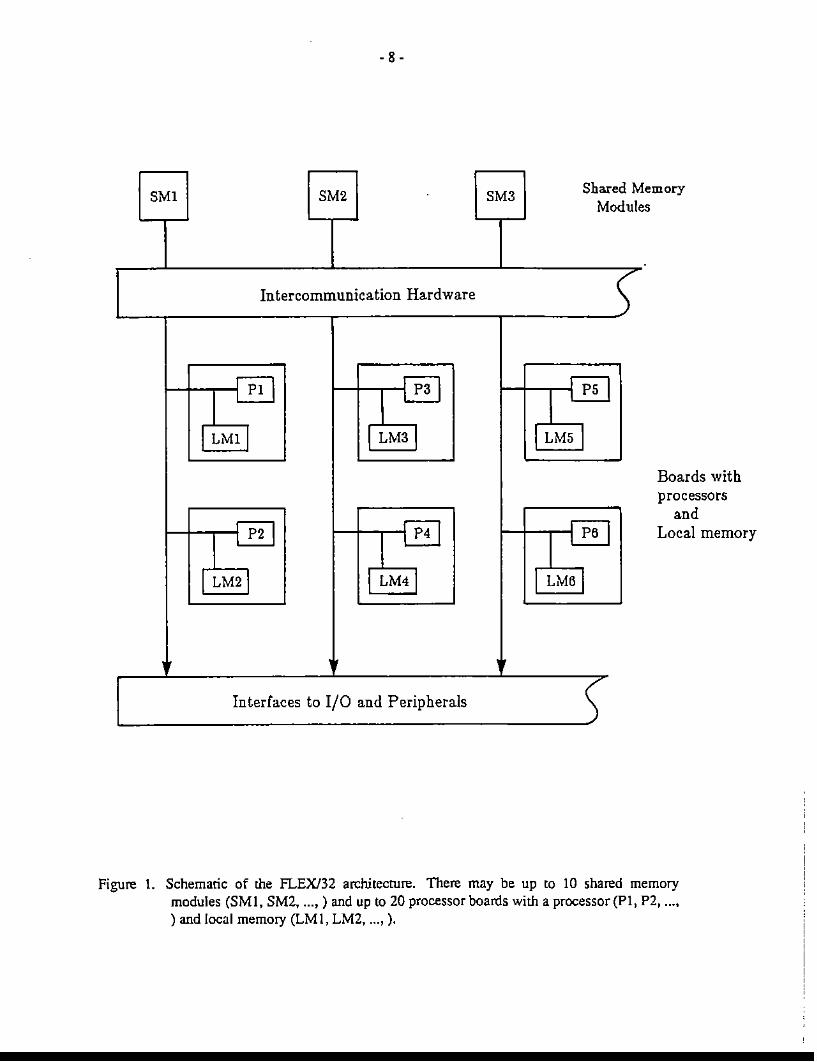
1bc FLEX/32 is a MIMD (Multiple Instruction Stream Multiple Data Stream) computingdevice which may be configured to operate up to 20 indepeodeDt processing units. Each processor may access a shared common memory via a common bus. as well as its own local memory.The programs iDcludcd in this report primarily use the shared memory -local memories are usedonly to store intermediate computatioas. An effort is made to reduce shared memory accesses,although the report [Houstis etal., 1987] indicale that the effect of memory coDtention is negligible. Figure 1 shews a block diagram of d:1e structure of the FLEX/32, see [flex,1985] for moredetails.
1be FLEXl32 operated by the Com~ter Science Department is currently configun:d wilh 7processors.. One processor runs multi-user UNIX for program development and has 4 Mbytes oflocal memory. The remaining six operate in batch-parallel mode under the MMOS operating system, each has 1 Mbyte of local memory. 1bere are six shared memory modules with 512 Kbytesof memory each.
3~ FLEX/32 Concurrent Fortran
3.2.1 Imple.menn"n.g ParalJe./ism on tM FLEX132
FLEX/32 Concurrent Fortran is an example of a parallel language constIUcted on top of anolder ODe. The new features range in functionality from high level (block struCbJres, conditionalwaits, etc.) to low level (explicit process forks).
A parallel program in Concurrent Fortran may be viewed as a main procedure which hasbeen downloaded from the UNIX development computer onto one of the MMOS computers.Eventually. the main program may fork into a collection of independent processes executing concunen.tly on one or more of the J\fMOS computers. The machine is then operating in parallel asillustrated in Figore 2.
The forking operation has been observed to be expensive, requiring as much as one secondof real time. Thus, it is a bad idea to write programs which repeatedly fork and join (i.e.• returnto MAIN) as a form. of imerprocess synchronization. For example, consider a program whichperforms Gaussian Elimination on a mani.x in sb.ared memory. We might cOOose to computeeach submattix in parallel, and rhus approach the problem as shown in Figure 3. This is a badapproach. Instead, me programmer should we a single fork (or a CODStiJOi number of them) perprogram run, aDd relegate synchronization duties to the processes spawned. In the programs ofthis report, for example, synchronization is implemented by incrementing iJnd inspecting integervariables (semaphores) in the shared memory.
From the viewpoint of the programmer, then. parallelism in Concurrent Foman should becoarse grained - the chu.nks of code parallelized are on the order of entire programs, instead of afew lines. Ifparallelization is synchronized and done at the "few lines of code" level, then it
- 8 -
Boards withprocessors
andLocal memory
Memoryes
8Ml 5M2 5M3 SharedModul
Intercommunication Hardware
PI I P3 PS I
I LMII I LM31 ,I LMSI
P6 IP2 I P4
I LM21 I LM41 I LM61
Interfaces to I/O and Peripherals S'
Figure 1. Schematic of me FLEX/32 architecture. There may be up [Q 10 shared memorymodules (8Ml, 8M2, ...• ) and up to 20 processor boards with a processor (PI, P2, ....) and local memory (LMl, LM2, ... ,).

- 9 -
MAIN fork
1time process process
1MAIN join
Figure 2. Schematic of me process fork. and join of Concurrent Fornan.
must be synchronized using shared variables which adds a significant but not overwhelming additional computation. This reflects the design intentions of the FLEXI32, as a general purposeindustrial machine capable of concurrently operating several dissimilar processes over longperiods of time.
3.2.2 Declaring Shared Memory
Shared memory must be made visible to every pro~ss wishing to access andlor change it.This is done by declaring shared variables. The syntax is to precede a normal FORTRANdeclaration by the word shared.
Example:
shared real I rll a(loo,100) pivotshared real I ill isynch, ipvt, row(lOO)
Shared blocks should be named (if there is more lhan one) and shared variable declarations maynot involve parameter values.

compute 1st pivot
- 10-
MAIN
compute 1stsubmatrix
time compute 2nd pivot
compute 2ndsubmatrix
compute 3rd pivot
•
•
MAIN
MAIN
Figure 3. Schmatic of an inefficient approach to Gauss Elimination because of excessive forkingwhich is very expensive in the FLEX/32.
3.2.3 Crearing Processes
To create a new process, a parent process, such as MAm, must supply an integer into whichthe process id of the child is to be written, provide code to begin executing (in the farm of a subroutine call) and specify the computer on which to operate. The synmx of me creation statementis
process ( proc_id, subroutine_name, computer_number)
The code to be mapped to the specified computer is determined by mimicking !:he given subroutine call - addresses (I-values of argument expressions) are placed in stacks, etc. However, the

- 11 -
!pawned process does DOt begin execution immediat::ly. R.ather, the p.m:nt proc::ss is fre= to executeo~ axl.e, possibly spawning o~r proc::s.ses, befo~ initiating actual execution.
Example:
do 50 i - 3,6lIg(i) _ ipr=ss (pid(i), c<>de(arg(i)), i)
SO coIllimle
-- DOW st3:rt above proc:esses--
He~, the programml;i must be careful. SiDe: ~sses (call by ~ferenc::) are passed to
wbrou.t:ines in For::ran. the programmer must bear in mind that the values at ti:los.e~ m:d.eerm:in::::i at the time ::xe:::w:ion begins, bur the location referen::es are establlihed. at me rime ofthe pn::c:ss statemCD.!... To fort:: the evaluation of arguments at the time of the proc:::s.s s:rat:ement,an i..n.t:rme:diate structlJl"e should be used.. such as ~ array "arg" above. Had 'We specified~(i) instead of co:ie.(arg(i)) as th: subrout:ine call, then the process would acc:ss the value inthe integer i I :DOt iU the ti.me of tile proc:::ss statement. but lat:t, at the time process execm:ion isiIIiti~ This would give i = 6 for all proc:sses.
1De process cons..-uct ~rferes with programme: abstraction on t'NO counts.. First. the progr2ID:!I1er must specify explicitly which computer is to ex~ the new~. This~kDowledg: of the current con.:figuration of the machine. SecoDdly, the prog:ra:mII1"'-I' must chronologically separate the det:'1'II1i.n.aIion of the address of a subroutine argument (the I-value of theargu:mem e~jon). oc=urri.ng at the time of !be proc:ss stal-*tJ1ent, and the ac:ua.l value (rvaJu:.) of the argument. determined larer, at proc:ss initiation. The child pn:x:::es.s cannot bevie-wed as a subrouti.ne call at th: poinl of the proc:ss statement, for the r-value is DOt c-~:mined..
Neither can it be viewed as a suh-rourine call at !he p::lint ofproces.s initiation, for the I-value wasd.ete':mined earlier.
3.2..4 Block S~ruresfor Process GeM.rtUion
As e:xplai.ned above, the pro~rmay choose to defer initiation ofone ormo~ spawnedproc::sscs, beginning them alI simultan.e:Ously. 'Ibis is accomplished by enzlosing the proc:ssstatements in a COBEGIN' block:
COBEGIN- - proc:ss statements and o~r code -ENDCOBEGIN
Initiation of alI processes v.idtin the block is deferred until the bottOm of the block is reached.The parent proc:ss may contim.Je c:xecuting ar that poinL
Another alternative is to have spawned process begin executing immediately, but force theparem proc.ess to wait until all children have ~ru.rned before proc:eding. TIlls constrUct is the
COEND block:

- 12-
COEND- - process statements and other code -ENDCOEND
The COBLOCK construct combines the above two, deferring initiation of child processes tothe bottom of the block., and forcing the parent process to wait until all child processes in theblock have terminated
COBLCOK- - process statements and other code-ENDCOBLOCK
3.2.5 Conditional Waiting
Concurrent Fornan provides a facilicy to have a process wait until a condition is satisfied:
'WHEN(cond)statemenrs
or
WHEN(cond)statemems- block of statements END WHEN
This is spin waiting.
3.2.6 en'tical Access
When several processes wish to update a shared memory location, it is often necessary thatonly one process have access at a time. Suppose. for example, several processes Pi have eachgenerated a local value Xi and we wish to form. the sum S ... Vi' Then while some process Pi
iexecutes S ... S + X no other process should read S. Process Pi must have exclusive access to S.Concurrent Fortran provides two facilities to ensure exclusive access to shared memory constructS.
The first is via the WHEN sttucture above. AU shared variables in lhe conditional pan of aWHEN statement are locked while the conditional is being evaluated and, if successful, while thecode within the WHEN block is executing. Thus, it is possible to implicitly generate a block ofcode having exclusive access to portions of shared memory. Notice in dlis example that processP j does not really want to wait on a condition - it simply wants exclusive access to S while itexecutes the (short) block of code
S-S+XWe must use a conditional which always evaluates [0 .TRUE. and contains the variable S. Thetypical technique, then, is to use a block such as
WHEN ( S .EQ. S ) THENS-S+X
END WHEN

- 13 -
The WHEN block implemems exclusive access by calling the M:MQS system routinesCFlock and CFulck. which lock and unlock., respectively. shared variables. The programmer maywish to explicitly perform locking by calling the routines ~If:
call CFlock{ ICFret, # of variable names, list of variable names )and
call CFuld( ICFIC£, # of variable DameS, list of variable names )
(ICF~t is aD integer through which error codes are returned) In our example, we would use thecode .
call CFlock( ICFre~ I, 's' )S-S+X
call CFulok( ICFret, I, 'S·)
We make two observations regarding dUs locking scheme. First, the programmer mustbear in mind that any shared variables mentioned in the conditional of a WHEN statement arelocked for the duration of the block, not just for the conditiooaI evaluation. Thus, the WHENblock should be as small as possible, so that the process does Dot tie up the shared variable anylonger than necessary. In fact. we suggest that !he block form of the WHEN structUre be usedonly when the programmer desires BOTH the "waitn functionality and the exclusive access functionality of the WHEN block. Otherwise, the si.mple~form. of the WHEN
WHEN( condition) contiDLIc
should be used when only waiting is required, and explicit lock: calls when only exclusive accessis required. Thus, we would classify the first locking scheme given above as bad.
'The second observation is that the locking routines tend to lock "too much". Since thelocking routine uses the variable name as a key, the programmer is not allowed to lock only portions of arrays. Here, caution is advised, for the programmer could inadvertantly create adeadlock situation by assuming only pan of an array was locked. This is especially likely if theprogrammer is in the habit of using WHEN structures to implicitly lock arrays.
3.2.7 Synchronization
Concurrent Fortran provides SfATIC communication channels which allow one process tobigger exceptions in another process. In the programs of this repon, we have chosen a moredynamic, and higher level, approach to synchronization, by implementing semaphores in sharedmemory.
Suppose we have a section of code C which we wish to be executed simultaneously on eachof N processors and we wish all processors to halt together before continuing. An example ofsuch a code fragment would be a single submaaix reduction in Gaussian elimination - no processor should proceed to the next submatrix reduction until all have finished Ehe current one.Assume there is an integer variable ISYNCH in shared memory (and lhus visible to all Nprocesses) which had value S before any of the processes began executing code C. To synchronize the processes we require that each increment the semaphore ISYNCH and then wait until theother processors have done so. A trPic.:J.I code fragment would be

- 14-
C (the code frllgment being synchrolliz.ed)
ca11.CF1ock(1CFre~ I, 'isynch')ISYNCH - ISYNCH + 1
ca11 CFuIck(ICFre~I, 'isynch')WHEN (ISYNCH .GE. S + N) CONTINUE
The system calls provide the locking functionality needed to correctly increment the semaphore,while the WHEN statement provides the waiting functionality.
4. THE PARALLEL EFTICIENCY CURVES
We plot efficiency E versus the job size (ticks for a sequential computation) for each of thesixteen problems. Four curves are given for each problem corresponding to using 2,3,4 Of 5 processors. As one would expect. the efficiency is generally decreasing as one increases Ihe numberaf processors. TIle timings are made using the standard FLEXl32 mechanism (one coums"licks" which are 20 milliseconds each). It has been found to be reliable (repeatable) and consistent with other timing data for mese NS32032 processors. Data from which these curves arederived is given in Appendix Two.
5. REFERENCES
Flexible Computer Corporation, FLEXJ32 Multicomputer System Overview, Doc. No. 0300000-002, (June, 1985).
C.E. Houstis. E.N. Houstis and J.R. Rice, Partitioning PDE Computations: Methods andperformance evaluation. Parallel Computing (1987).
IR. Rice, Numerical Methods. Software and Analysis, McGraw HilI, 1983.
l.R Rice, Problems to test parallel and vector languages, CSD-TR 516, Department ofCompua:rScience. Purdue University, (May, 1985), 95 pages.

-15-
Problem 1Integration I7y Trapezoidal rule
1
0.8
0.2
1000 5000 10000Number of evaluation POiTUS
25000 30000
ZP&
H~
0'---'-'-·;-°--i---+-----------j-----;---......J16 79 ~8 3~
Single processor time ( in ticks = 1150 sec. )
r:'~... (Si1lgle processor rime)J;;,JJ ...Je1lCY
N x ( N processor rime )
473
0.001
0.000/~::.~ 1e-QS
.§~ Je.06
1e.Q7-'-';---j-----;------------;-----j--__16 79 158 3~
Logarithmic plot o/integration erroras a junction ofsingle processor rime
( in ricks = 1150 sec.)
473

-16-
Problem 2E-STAR
Dimension ofdata array (assumed square)25 55 70 85
1
0.8
C 0.6.~<.>
~ 0.4
02
'__+---:c_;-;: 2 P&.: : ':..::3P&
;.'::4P&.. : .,: 5PE.r
•..!"
0YCjl0w in singleprecisiDn compUllJticn.
ofUPOM1UiaJprohibus largerprob~msiu
0...1..;--'---;-+-'-;-------- -1
11 48 77 114Single processor time ( in ricks = 1/50 sec. )
Efficiency = (Single processor time)N x (N processor time )

-17-
Problem 3Generalized E·STAR
100, 200,Value olN and M (here, equal)
250 300, , 400,I.
IK:: -j. -' - - -.;. .--.- ~~;;:~~~~.~~.~~.~.~~.~c.c.c.ccc.CC"
. ;. ..- ..; :O8'- : ': ..... : :. - . ,.... .., .. .. , : :r .. : : :, .
e-06- r ...J:::' I:·'~ I r(,J , :.
~ 0.4- 'f:02-
O--'--T-,-j-,--j-,--+,---+,----------;------28 64 112 175 251 446
Single processor time ( in ricks = 1150 sec. )
EfjUk (Single processor time)nr:y N X ( N proc~sor time )

1
10,000 50,000
-18-
Problem 4Sum ofinverses
Nwnber ofvector elemems100,000 150,000 200,000
0.8
~ 0.6.§"ifll 0.4
02
. . - - - - - - - - -::-;--.:-.:-. :-.:'.7.7.:.-:: ::."::-;: ----t.:::-.::::-:-- ....... -:"' :... ;...... :..': ... '
0-'--;'---+--+--+---;----+----+--------'20 51 102 1~ 2~ 3~ 4~
Single processor lime ( in n·cks == 1150 sec. )
Efficient:y (Single processor time)N x (N processor time )

-19-
Problem 5Grader program
1
0.8
25 100 150Nwnber ofstudellIS and lestS (here, equal)
200 250 300
: ..... ----_..:. - - - - - - :.:::::.-:::::~
~ 006.~~
~ 0.4
02
O...L;--i----;----;---;---;---------i-------l12 48 107 188 238 293 422
Single processor nOme (in ricks = 1150 sec.)
E~ncy= (Single processor rime)N X ( N processor rime )

-20-
Prob/em6Tritliagonal solver
50 250 500Manixsize
1,000 1,500 2,000
.. '
1
0.8
1:;>0.6.~<.>
~0.4
_i------:-=-i·~~-::=-=-=-=:-:~+, :_:_:-:_:-:_~-~_:---:-::- :_:_~-~-~-~-::-::-J~ ~~~--------- . .__ -:-- . . : 4P&------ :...... : sPes--- : ... -:-" ... . .....". ..'.. ....
~ ...., ., .
:./' : .....f .:.'
/" .".I : ,.":..:..'
02 .,'
O...l..j--+---+--------+----_+- ---+----.J21 55 113 241 356
Single processor nOme (in ticks = 1150 sec.)516
Efficiency (Single processor rime)
N x (N processor time )

-21-
Problem 7Polynomial inlerpolarion
25 50,
1
02-
1,000,
-i"
.:
Nwnber ofevaluation points2,000, 4,000
2 PE>J PE>HE>SfE>
O-L--;-----'--;-------;----------i- -.J-. r r I I
14 47 134 241 435Single processor rime (in ricks = 1/50 sec.)
EfM~ = (Single processor time)ncy N x ( N processor rime )

-22-
Problem 8Divided Difference Table
10 25Nwnber ofevaJuan·on rwdes
50, 70,1-
0.8-
e;. 0.6-.§"~0.4
. . :.' .·1' ~ .... : :
. .-----~------------------------~.;..--------------- :
2P&
JP&
4P&5P&
90-+---;-,---- -;-,----------_;-, ---.J
57 233 459Single processor rime (in ricks = 1150 sec.)
Effidency _ (Single processor time)N x (N processor rime )

-23-
Prob/em9Image Refinement
IOpasses
Grid size10 25 40 50 60
1
0.8
CO.6
~~0.4
l_-------t=-=-:~~:-:::-:j::::::::::::.::::.::~::;~~~· 2 PEl: ~-----_----------"3~g_ ... -------- ...•..•••• : ••.••.•.•••..•••.•..••...•.••.•••.. ;4
__ -: ............: :SPEl.. -- ,---- .... ;.... :~- .... - .... .... : :, . ......I: .
" .i······, .., .":, :" :" ..", .', .', .
.0.2
512223 352Single processor rime (in ricks == 1150 sec. )
86o+---;------;-----j-------;-
15
Efficient: = (Single processor rime)Y N X (N processor time)

-24-
Problem 10Gaussian EUminan'on
15
1-
25,MatTix size
35 40,
0.8
02-
-------------;--------;--------o _
-~-- .
3P&
4P&
SP&
O+-----j-,--------;-, -;-- --..J
56 158 327 441Single processor rime ( in "ocks = 1/50 sec,)
E'..<l': 0 (Single processor time)~J'C1e!ICY - 0
N x ( N processor tzme )

-25-
Problem 11DlUa Filtering
250500 2500Vector size
7500 12,500
1
0.8: -------------------~
ZP&JP&4P&5 P&
C;> 0.6~
~...®0.4
. .(" ..... ,.l' 1.·····
': ..":/.:
02
488298Single processor rime ( in ticks = 1150 sec. )
108O+'---i------r----------;----------i----.J
23 51
Effic~ru::y = (Single processor rirnt)N x (N processor time )

-26-
Problem 12Data Movement
50100 150" ,
200,
Matrix Dimension(Here, asswned square.)
250 300,
m:<PEsSPEs
..............
.j ...... :
1-•.• '-' "-' "-' "-' :.:...':':''':''':''':'':''':'':'':.':.!.... : : .
~"". --~--- ,.. ,,:.---- .....0.8 - . f ~ : ~ .
: .: i' .; .: ,::: I:
~ 0.6- r'/ >.~ : / .:.. :/::~ ./."® 0.4 - i, .... !, "
",.,02
o-'-i-'r-r--;-,---;----;-----r-r---------------.J8 33 74 131 205 296
Single processor time (in n"cks = 1150 sec.)
Effidency= (Single processor time)N x (N processor rime )
-27-
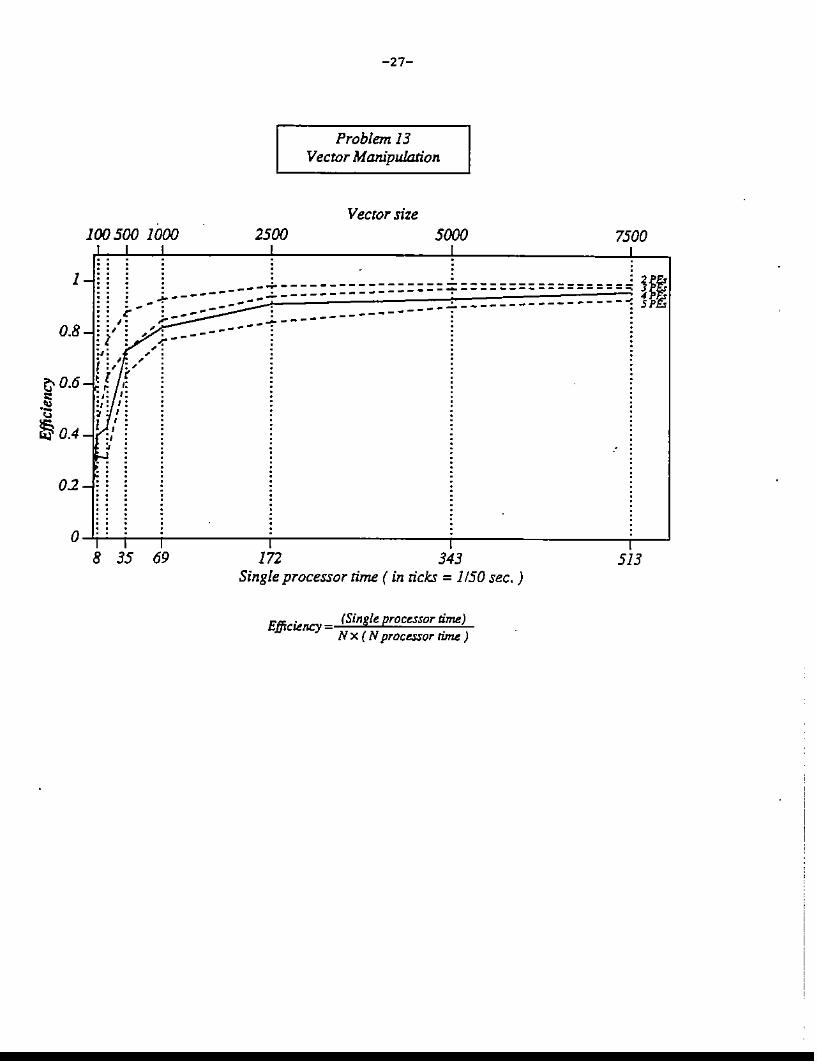
Problem 13Vector Manipulation
Vector size100500 1000
I I2500
I5000, 7500
I
1-. .::: : : 2f~: : -------~----::::::::::::::;:=================:::;: ~jO.: .. ~--- .. - .. ----- . .. ~ SP.... _- 0 •
t: • --- ------: ,. ;-- ---:----------08- :,: " __ ----. 1:' ;.--
o ,:,. ,.t :,':,' :'I (e- 0.6 - " "::: :j: ,.
Il,) :,: ,~ ;'0'
§ I,''" 0.4 - :,
~
02-: i
O--'j-'--j-,-;-,------;--,----- -j-, ;-,--J
8 35 69 172 343 513Single processor time ( in ticks = 1150 sec. )
E'~ 0 (Single. processor time)'JJ.cte.ncyN x ( Nproc~or riJM )

-28-
Problem 14Imegration rests
25 250 500, 1000,Number ofevaluan'on poinrs
2500, 3300,1- i .. ..
: ~ ~ .~::j::::':':':':'::::~:~~~~~:::~:~:~:~~ ~ ~~~~~~~:~:~~~:~:~~:~~~~ ~...."':; . - - ...!................ : :
08 . " .' . '.. - ~.... :,,/.: ' : ! ~.. r ' ....,. :...:; ': .';
O6 ::' ..' ;Q . :=/: ..' :.~ :: I ~., :
\,,) 1'-:
!§04_'i~"l. . .
I / :
02-
5o-Ji.--i--,--j--,---T-,-----------i----,-----T-,---1
37 74 148 369 488Single processor time (in ticks = 1150 sec.)
Effidency = (Single processor time)N x ( N processor time )

-29-
Problem 15Interpolation
50 250 500, 1,000Nwnber of interpolalion points
3,500
I -'w!!1 ;. -----------------~.~.~~.~~""~.. ; H~~ ~ ~ _-- .. -f----.~.~.~.~.~.~.~.~.~ ················.......... : SPEr
08.:' ;..-- :........ :· .~. .. .. . .' . .· . ~. ..' .: : ~~ :..... : :· l.~ ! !• I' ~. • •: ,: .' . :~/~./ ~
I· .<..~ .' .'~:.,.,'.
~ 0.6
~~ 0.4
0.2 -
o+'---+---i-,---_+_-------------------_+_,_....J
10 38 75 148 508Single processor n·me (in ticks = 1150 sec.)
E.I:1.... (Single processor rime),,-"'ncy N N .x ( processor rune )

-30-
Problem 16Hilbert Matrix System
5 10
1-
0.8
15, 20,
Matri.x size25 30
" 06-jr: : ~ i __ .i._ ------ -J~. : j L----------i------------ j ~'U : : __ -----: : :.;
.i;j :,~ : : ...•. :•......•.•..••.... :"'- :.- : : oo!'......................: :<:;' 0.4- :.-- ' ,..........: : :
/':',........: : : :.... ..,': ..... : . : : :
02_~...j-"'.. i : : : :.. . . . . ..': : : : : :· . .. .· . '. .· . . .· . . .· . . .· . . .
o i i . I I i15 46 101 178 279 407 496
Single processor rime (in ricks = 1150 sec.)
Efficiency _ (Single processor rime)N X ( N processor time )
2P&
3P&
4P&
SP&

problem! -J1-
APPENDIX ONE: THE FLEX/32 PROGRAMS
problem!
c: Problem 1c Trape:zoidal ,~ e.szim.au o{ a7J iJlkgral
pu-a.eter ( Uses "" 8 )
c Shared 1Iari4bla .• available to all proccsanahaftd. ru1 mw I sum., h, .. bahued blte&er fum! id(32}, Nfunc, N~ N
otenlal Idderlate&er procid(2)l.D.te&er msp(32)
IDtqer Npts( kases )integer c!ock.{32.kases)l.D.tev;er maxPEs
c Dio1Dg wun IUD' : Sa up D:puimuus by 8t:ltillg a sa of problemc sius and aHIIPlJJU card IUII1IMrS on which to aury Ol't 1M aper~rus:
1 writc(6,·) 'Maximum number of processors" 0 to stop.'IUd(5,·) maxPEsIf( maxPEs .le. 0 ) stop
do 10 i '" l,muPEswrile{6,7) i
7 format( 'Computer If", i.2, • '" ?" )rud(5,·) m8p{i)
10 cont:I.Dne
write(6,·) "a ::: l'read(5,·) •
write(6,·) " = 7"JUd(5,·) b
20 wri1c(6,·) "Numb=" of cases to try '" ?'read(5,·) Nkases
U( NOses .gt. kases ) thenwrite<6,·) 'Too many. Try again."&0 to 20..."
do 30 i '" 1. Nlca.se:swrite(6.27) i
27 fonnw:("How many eYalulllion poinl.S for casc"J3: 7}rud(5,·) Npts(i)
30 continue
c ChoU:t: of thru inJegrands:Vr'ritc(6,·) 'Function rrumbcr "" "t'read(5.·) Nftmc
kfar 3 21:01 1987 Pagt! 1 oj problonl

problem! -32- problem!
, Main apuimenJ. loop:do 900 Im :: 1, Nkascs
N :::: Npts(nn)h '" ( b-a ) I flo81(N)
do 800 Nprocs = I, maxPEs
call CFrtIc{istart)sum = 0.0
COBLOCKdo 50 i =: I, Nprocs
id(i) = iite:mp :;; IlUlp(i)process( procid(i), adder(id(i». itemp )
continueEND COBLOCK
50
sum = h .. ( .5 l11 f(a,Nfunc) + sum + S"f(b,Nfunc) )call CFrtk(istop)clock(Nprocs,rm) :::: istop - istanwritc(6,·) 'Sum = • ,sum
800 coatinue
,,812
123
8131
Prinz lahk giving peifornJlJJla remus so far:write(6.812) Nfunc, ( Npls(i), i = I, nn )fomw( "PROBLEM 1: TRAPEZOIDAL RULE ESTIMATE
'OF INTEGRAL Function number " i3, '.',1,/,'Number of -;> -> Numb=r of evaluation points _>->',
I, 'processors lOiS)wriLe(6.813)fomw( •
, )
,
837
847
848850
do 850 i '" 1, maxPEswriIc(6.837) i, ( clocll:(ij), j =. l,nn )fotlIl.a1(· 1', i3, 4x,1', lOiS)writc(6.&47) (float(clock(l,j)) Ifloat(j-clock(i,j»j= l,Tm)format(' v I', lOfS.5 )writc(6.848)fomw(' I)candnne
900 continuego to 1on.
Mar 3 21 :01 1987 Page 2 oj problem]

problem! -33- problem!
cc
o~ copy of t1Ii.! swb,.,,1lZiN. is mapped 10 each procr.ssor dLsigfIQUdill 1M o:puimenl:
nbraal:1De addc:I(myid)
.Ibred real Iruh I sum. h. .. baharecI 1D.te&er &'b./ id(32), Nfun.::. N~. N
tc::m.p E 0.0do 80 i :::; myid, N-l, Nproc~
x=a+i-htemp '" temp + f(x, Nftmc)
80 coat:lD.ue
c Swn is aa:lI/7Ill.lakd focally, so only onz. common. memory access f1Udd.c Note tN. nud to ~e acl/Lrive access to glabaJ SW7!.
call CFIock(lCF~t,l.·5UIIlJ
sum =sum + tempcall CFlIlck(lC'Fret.1."sum")
retarD..cd
real lal1ctloD f(x.n)If( n Je. 0 ) then
f '" x--2....II ( n .eq. 1) then
f = sin(x)....f '" cxp(x)
eadlrondJI
,"'"cond
Mar 3 21:01 1987 Page j of problGrl}

problem2 -34- problem2
cccc
c
cc
c
Problenu 2 and 3. GelU:7alized E-STAR .. 1M sum: of the products of1M~ in e«h row of a matri:r;, Strougy: divide. lM rows upas evOl1y as po~~ tJJMrzg 1M processors, each processor complllingthe pro4a for an 0Ilir1! row of 1M I1U1lrU:.
parameter ( kase.s '" 8 )
sbared re.al. Irulsf swnshared. Integer lint!.; I id(32), Nftmc, Nprocs, N.MatenW. wOIke:r
A process id and COmpll1U assig1lnlCll for each spawned prtXe.ss.Integer procid(32)lateger map(32)
lDteger Nsize( ka.ses )Integer Msize( kases )lnteger clock(32,kases)Integer maxPEs
User inplll portion of program .. Spedfy the apuimenls to run.
1 write(6,·) 'Maximwn numbc::r of processors? 0 to stop.'read(5,·) muPEsIt( maxPEs .Ie. 0 ) stop
do 10 i "" l.nu.xPEswrite(6,7) i
7 forma!( ·CompU1.er #', i2, • = l' )re:u:l(5,') map{i)
10 coatinu!!
20 write(6,·) "Number of cases to try = l'read(S.·) Nkases
If( Nlwe:s .gL kases ) thl:nwrile(6.*) 100 milJ1.Y. Try again.'go to 20
••d1t
do 30 i = 1, Nkaseswrile(6,27) i
27 formllJ:('Enter N and M for ease',i3: :)rc.ad(5,·) Nsi2e(i), Msize(i)
30 continue
wri[t:(6,') rWlCtion number = 7'read(S.·) Nfunc
===============================================================
Feb 22 17:07 1987 Page 1 oj problem2

problem2 -35- problem2
Loop (Ala aU Dpuimenls. colleaing riming daJa:
do 900 nn '" 1. NkasesN = Nsiu(nn)M :: Msizc(nn)
do 800 Nproc:s '" I, nuxPEs
call CFrtlc(istm)IUIIl = 0.0
cc
50
800
812I23
813
.14I
837
847
84.850
COBLOCKdo SO i '" 1. Npr0c3
id(i) = iitl:mp = map(i)process( procid(i), wod::el(id(i», itemp )
coatlnueEND COBLOCK
call CFrttc(istop)I:Jock(Nprocs.nn) = istop - iswtwrite(6,·) "Sum = • ..sum
coar:l.ntle
Prinl Ulbk of performance resulls so for:
write(6,812) Nfunc.(Nsiu(i),i=l,nn)fotmlJ:( "PROBLEMS 2 and 3 _. SUM OF PRODUcrS.'Function number', iJ, ·.·./.1,
\ -> -> Si2e of problem ->->', /,'II of \ N:', i6. 9ig )write(6, 813 ) ( Msiu(i), i = 1, M )fomw:('JrOCS \ M:', i6. 9iB )write(6.814)'emu« .
do 850 i = 1. muPEswri[t;(6.837) i. ( clock(iJ), j = 1.nn )fonnat(' I', i3, 4x,1', lOiS)write{6,847) (floll(clock(l,j)) lfloat(i*clock(iJ»J=I,JIIl)fonnat(· v I', lOfE.5 )write(6,848)formaIC 11cODliDue
. )
c
900 CODtinae
1:0 to 1
'D'
Feb 22 17:07 1987 Page 2 oj problDT12

problem2
subroutine worlrer(myid)
-36- problem2
shand realsbared integer
!=hI >Urn
linuJ id(32), Nfunc, Nprocs, NoM
70
real [e:mp
temp = 0.0do 80 i ::: myid, N. Nproc:s
prod :::r 1.0do70j=1.M
prod = prod·f(i,j,Nfunc)continue
80 continuetemp ::: temp + prcd
c Accwmdate sum ltx:a1Jy. tlIDI do only one write to common /7fJ:J7U}ry.c WHFN construct WIUU exclusive OJ:cess.
when( sum .cq. sum ) chensum = sum + tempend when
return.nd
feal (DuctloD f(i,j,n)
JI( n leo 1 ) thenf = 1.0 + exp( -1.0 • float(abs(i-j)) )
f '" 1.0001endll
return.nd
Feb 22 17:07 1987 Page 3 of problem2

problem4 -37- problem4
cccc
ccc
Problon 4 •• Sll17I o[ inYD'su of ~kmorls in a vt:t:wr.StI'auzy: DivitU EN! elDnmu up among 1M proassors ( as e\lUJiyas posible). EtJdI procus« will inYm and S"'71 his dmu:nu,and add WI to 1M global mm.
,.,...etu ( ka.ses "" 8 )
Ihared. re.al huhl sum. x(200000)aharecI blte&;eI" fs:rJ.uJ id(32), Nfimc, NJKOCS' N_ .... odda
Ia...... procirl(32)lIIte&er msp(32)
latee;er Ndim( kase.s )Integer clock(32.kases)lDteger maxPEs
-=:======================================::===========::==Ust'r Urplll .udion .. so up t::r:perUMIW on wuious \leaOTlDtgtJu and proc~or counLs:
write(6,·} 'Ma.timurn number of processors? 0 to stop.'read(S.·) muPEsIt( muPEs Je. 0 ) atop
do 10 i :: l,mnPEswrite(6,7) i
, fomw.( 'Computer /I', i2, • = ?' )read(5.·) mll:p(i)
10 contlnue
20 write(6,·) 'Number of cases to try = ?'read(S,·} Nkases
Ir( Nkascs .gt. kases ) thenwritc(6,·) 'Too many. Try again.'go to 20
end[(
do 30 i = I, Nkaseswrite{6,27) i
27 forma.t(1:Iow many VOClOT e.J.emenLS for case',i3: 1")re.ad(5.·) Ndim(i)
30
Mar 3 20:59 1987 Pagt! J of p,.ob/~

problem4 -38- problem4
c
cc
do 900 nn ;; 1, NkasesN '" Ndim(nn)
do 800 Nprocs '" 1, maxPEs
R~ vector:do40i=l.N
xci) ;; 1.01 (1,0 + float(i) )40 continue
x(11) = 0.0
c.all CFrtlc(istart)sum :: 0.0
COBLOCKdo 50 i ;; I, Nprocs
id(i) = iitemp =. map(i)process( procid(i), adder(id(i», itemp )
50 C'ODtlnueEND CORLOCK
calJ. CFrtlc(istop)clock:(Nprocs,nn) =. istep - istartIf(clock(Npmcs,Iin) le. 0 ) cIock(Nprocs.nn) = 1
writc(6,*) 'Sum;; • ,sum •800 contlnue
=~============================================================
PrinJ table of clUTenl performaru:e results.
write(6,812) ( Ndim(i), i ;; 1. nn )812 fonnat( "PROBLEM 4: MASKED SUMMATION:, 1,/,
I '# of \ ',20x: -> -> Number of vector elements ->->', I,2 'procs \', lOiS)
wri<c(6,813)
813 f<fco:,:mw(~~'----==============::-1-1 '- ' )
do 850 i ;; I, maxPEswrile(6.837) i. ( clock(iJ). j ;; l,nn )
837 format(· 1', i3, 4x, 'I', lOiS )write(6.847) (floa.t(clock(l.j)) Ifloat(i*clock(ij»j= l,nn)
847 [annal(' v r, lOfS.5 )write(6.&48)
848 fonnat(' I)850 continue
c ==============================================================
900 conl:tnuego to 1on.
Mar 3 20:59 1987 Page :2 of problem4

problem4
nbrout:l.a.e adder(myid)
-39- problem4
ahared. re:al 1reaJs/:nmL, x(I00000)shared Intqt!f Ii:r&/ id(32), Nfunc. Nprocs, N
ru1 ""'"
temp = 0.0do 80 i = myid. N. Nprocs
If( xCi) .ne. 0.0 ) temp '" temp + 1.0/x(i)80 coatlDue
calI CFlock(ICFret.l. 'swnjsum. = sum + tempcall CFulck(lCFrct,I, 'sum')
....nd
real fanctlon f(x,n)
It( n 1e. 0 ) lhenf'" x'''2....II' ( n .cq. 1) men
f = sin(x)....f '" cxp(x)
.ndlf.ndlf
roturn.nd
Mar 3 20:59 1987 Page 3 oj problem4

problemS -40- problemS
c
cc
10
Probkm 5 .. Compuu st4Ii.rtics 0'" a lable of grades
parameter(isizes=8)shared. real Ir I score(JOO,300), avg(300),top(300),lowabv(3OO)sharN lDteger IiI I id(32), Nprocs, nablve(300)shared. Integer luI Nlests, Nstudsshared logical l10gvar I geniusexternal avcaIc, stats
real pi1D.teger p(32),map(32),clockC32.isius)iIlteger itests(isizes),isrods(isizes)Integer tI, I2
dua pi I 3.141592654 I
::===============================================================Problem dejinitiM p~: COIISull with IUD" to 5el up experimDlrs.
write(6,·) "How many =es? 0 to stopreed(5.·) ka.sestr ( leases .g1. isizes ) then
write(6.·) TOO MANY. Must be <=', isiz.esgo to 12
'DdIf
If( kases lc. 0 ) stop
do 15 i = 1, kase:s13 write(6.14) i14 fOIIIlal(' Enter # tests and # SD.ldcnts for case',B,
I '. Must be <= 300: )=d(S.·) il.e:Sts(i), iswds(i)
lr ( (iswds(i) _gt. 300) .or. (itests(i) .gt. 300) ) lhenwrite(6, 'f) TOO LARGE. Try again.'1:0 to 13cadit
15 cODtinue
writc{6,·) 'Maximum nwnber of processors for this experimenr::read(S,·) nowPEs
c
17
20
do 20 i = I, nowPEswrite(6.17) i
[cona.te Enter computer # for process',i3)rc.ad(5,·) map(i)
cObtlnue
F~b 21 23:11 1987 Page I of problemS

problemS -41- problemS
c
c
Loop Oller erpuimLnls:
do 1000 un = I, kasesNleSts =. ileSts(nn)
Nswds = istuds(rm)
do 800 Nproc:s = I, tlOwPEs
lNlI'IALlZE SCORE TAlJLE:do 40 i :II I, NleSl!!do 30 j = I, Nswds
~iJ) =100.0 • sin( fiolll(i+ j) )
30 eGat1boe40 colltI.Dae
First paralld phase: compll1e avuagr: of uu:/r. TOW:
cc
50
call CFrtlc(tl)COBLOCKdo 50 i "" I, Nprocs
id(i) ::z ij .. map(i)process( P(i). lI.vcalc(id(i», j)
coattaaeEND COBLOC'K
S«ond parallel pJuue:Distribll1e cDmplllations for uu:::h studou among proassor.s:
genius = la1se.COBLOCKdo 100 i '" 1. Nprocs
id(i) =. ij = map(i)process( P(i), stalS(id(in, j )
100 contlDueEND COBLOCK
c.al.l CFrt1c:(C2)clock(Nprocs..nn) = a. - t1If( cloc:k(Nprocs,nn) Je. 0 ) clock(Nprocs,nn) = 1
cc
c
c
800
1000
contlDae
Prinl table of ruubs:
- Cotk fkkud for breoJizy -
cODdnneli:0 to 10
on'
Feb 21 23:11 1987 Page 2 of problemS

problemS
51Ibroatlne avcalc( istart )
-42- problemS
200
sband rcal Ir I S«lre(300,300), avg(300),top(300),lowabv(300)sha..n:d integer IiI f id(32), Nprocs, nabave(300)shared integer fill Ntests, Nsmdsshared 102;1ca1 flogvor I genius
nal t=pdo 250 i "" istart,Ntests, Nprocs
temp '" 0.0
do 200 j "" I, Nswdstt::mp "" temp + scorc(i..J)col1t1nue
temp '" temp I floal(NsDJds)llVg(i) = temp
250 contlnuere_.n.nbroatlDe stals(jstan)
shared real Ir I soore(300,300), avg(300),top(300),lowabv(300)sbat1!d Integer lill id(32), Npnx.s. nabove(300)sbared Integer luI Ntesls, Nsmdsshared logIcal Ilogvar I genius
real tIe:mp. lleInp, slemplnteger ntempI~cal anyge:n, allabv
anygen = .false.do 350 j = jstart,NStllds,Nprocs
ntemp '" 0ncmp ::::: 0.0ltemp = 50000.0allabv = .true..
do 300 i '" I, NteslSsternp '" score(i.J1ir( Slemp .gt.. oemp ) llemp = stemplIe SLemp .gt. avg(i) ) then
Ir( stemp 1t. ltemp ) Itemp = stempotemp = DUlmp + 1score(i..J1 = l.l·stemp
.Isoallabv = ialse.
cndit300 continue
anygen = anygen .or. .illabvtop(j) = ttcmplowabvG) '" Itempnabove(j) = nte:mp
350 continuegcmWl '" gcniw .ar. anygen
return.n'
Feb 2/ 23:11 1987 Page: 3 oj problemS

problem6 -43- problem6
,,
,,,,,
ProolDra 6Ttidia.gONJ1 SONU u.ring ileraLive 1N.thod of Jortkul.
pU1Ull.eter ( kases '" 8 )shared real hulstl u(lOOOO.2)J(lOOOO,1), limitshared real 1rea1s2/ d(lOOOO,2).x(lOOOO),y(lOOOO,1)abated Integer lints I id(32),Nprocs.N,isync:hme_ worl=
1II.tq:er pro:id(32)l.ate&er m1lp(32)
IIItqer Nsiz.c( kases )iIlter;er clock(32,kases)iD.~ muPEs
UKr di4.log pluJ#. Ga complllU 1UII7Thus andproblem .riu:r fer 1M. 1Iarit:Hls casu.
- C~ tkldui fol' brlNiJy -
LOOP OVER EXPERIMENTS:do 900 tID .. I, Nkases
N =Nsm(nrt)limit =. 1.44269504 • doge float( N ) ) + .1
~o 800 Nprocs = 1, maxPEs
,
,
40
lrUsitiliz.1!1 ~ors:
do 40 i :z I,N1(i,I) '" 1.0d(i,l) =1.0u(i.,l) '" 1.0y(i,l) = 15.0
coadDuey(I,I) '" 10.0y(N,l) = 10.0
call CFrtlc(iswt)"-" • 0
COBLOCKdo SO i = I, Nprocs
id(i) = iiternp '" IIU!p{i)process( procid(i), workenid(i», icemp )
SO CC1DtlnueEND CORLOCK
C8U CFrtfc(istop)clock(Nprocs.nn) = istop - istart
11( (Nproc:s .cq. 1) .and. ( N le. 50 ) } thendo 80 i = I, Nwrite(6,·) 'xc.i.1 = '. x(i), y(i..l),d(i,l)
80 coatlnue..dIt
,,,
800
900
coatiDue
===:z===============================================Prim table of poformmu:e raulLs. Code amkted.
condonego Ia 1.nd
Mar 3 21.-f.M 1987 Page 1 of problem6

problem6 -44- problem6
cccc
Each complllQ' aLCUle$ a copy of this rOUline. No~ that since
this is an: ileralive mahod.. syTJclronizalion. is necessary toWive lha1 all proce.I.fors art: on ~ same ilerarkJrl. Globalinugu IJalu.e.f seT1It: ar synchronizalion semaphores.
IJDbroutine WOIXer(myid)
sbllftd real /realsll u(loooo,2),1(loooo.2), limitshared. real Jreals2/ d(lOOOO,2).x(lOOOO).y(lOOOO,2)shared Integer lintsl id(32},Nprocs.,N,isynch
c TOP OF II'ERAI'ION WOP:10 coadDue
c U~ updMe is pQ'{ormed on. a suhSi!& of vecUJr eUmm1s:do 50 i = myid,N,Nprocs
If( d(i.,1) .ne. 0.0 ) then1(i..,2) = l(i.,l)fd(i,l)u(i.2) '" u(i,l)/d(i,l)y(i.2) '" y(i,l)/d(i.l)
,n<ill50 continue
cc SYNCHRONIZATION: Wait hue for feI/gw processors.
call CFIoclr.(ICFret,l, ~1S)'Ilch1isyD::h ::a isynch + 1
call CFulck(ICFrct,l.~lSYJlcb.')
wbea(is)nch. .ge. (2·mycnlZ-l)·Nprocs ) continuec
do 100 i '" myid,N,Nproesd(i,l) ::: 1. - 1(i,2)·u(i-k.2) - u(i,2)·I(i+k.2)y(i,l) '" y(U) - 1(i,2)·y(i-k,2) - u(i,2)·I(i+k,2)1(i,I) = -1(i,2)·1(i-k,2)u(i,I) = u(i,2)~(i+k.1)
100 continue
cc SYNCHRONlZATION: Agaill wait for fellows.
call CFlock(ICfut,l, ~l5)'1lcltlis)7\ch = isynch + 1
call CFulck(ICFret,l, 'isynch)wheo( is}'l\Ch .ge. Z·Nproc.s·mycnlr ) cODtlnue
mycnlr = mycnlr + 1k = 2-kIr( mycru:r .gt. limit ) then
do 150 i = myid,N,Nprocs:x(i) = y(i,l)/d(i,l)
150 cootlnue<ohm>
eodlf
go to 10,nd
Mar 3 21:04 1987 PQ.g~ 2 of problem6

problem7 -45- problem7
cc
ccc
c
Problem 7. Compuu. polynomial Wopolanl v~ tIl 5 poimswsing tM Lagrange inrUPOlaJioll fomw1a.s.
par:l.ID.eter ( Uses = 8 )
&hared real IrWs I sum(S), x(5), nade(lOOOO)eared 1Il.teger lints I id(32), Nprocs. N
utenW """"
• LDtq:u procid(32)IDteger map(32)
lllteeer Ndim( kases )lDtq:er clock(32,kases)1D.tq:er muPEs
.D=============================================================Q~ iLSO' to atablish aperimolUl.l parameters. Sa lip %(1 .• 5). COtk omiad.
LOOP OVER F:XPERIMFNTS:do 900 mt. = I, Nka.ses
N = Ndim(rm)
do40i=l,Nnode(i) ::::: .08 • i
40 continue
do 800 Nprocs = 1. maxPEs
call CFrtlc(istan)
do45i::l,5sum(i) = 0.0
45 COl1dnu.e
50
COBLOCKdo 50 i "" I, Nprocs
id(i) = iitemp = map(i)process( procid(i), adder(id(i», itemp )
coatlnueEND COBLOCK
call CFrtlc(istOp)cloci:.(Nprocs.rm) = islOp - istanIf(clock(Nprocs,nn) .Ie. 0 ) clock(Nprocs,nn) '" 1
ccc
800 CODl:1D.ne
writ.e(6.5S) muPEs. Ndim(nn)55 fomw(/,' Answer computed by', iJ, • procs for is,' nodes." )
do60i=l,5wrilC(6.5S) i..s:um(i). (xCi)), abs( (f(x(i)}-rom(i»/f(x(i» )
58 formaI( 'swnC.i1..., = ',eI2.5: acrual = ',el2.5,1 • rei e:rr =',elLS)
60 colltlnge
Prw 0111 p~rfoT'7TUUJCe resulJs for 1M t:rpuimeTW db~ so far. Code ekkted for brt:lliry
900 CODt1nnego to 1..d
Mar 3 21:{)5 1987 Page 1 of prob/em7

problem7 -46- problem7
ee
Etzdr. CDmprilu o:ecuus a: copy of this. The job is to compure an equolfUlI7l1JD' of 1M rums in tk lAgrQrlge Sll11I, and add thBe inla a global ~aritJb~.
mbrolltiae addc:r(myid)
shared re.al lreals I sum(5), x(5), node(lOOOO)shared Integer lints I id(32), Nprocs. N
c LOOP 0IIt:T IN 5 sll11V7WIions.do 300 k = 1,5
temp = 0.0
do 200 i :r myid,N,Nprocsprod = 1.0do 100 j = I,Nif G .ne. i) prod = prod·(x(k}-node(j) I(node(i}-node(j))
100 continae
temp = temp + f( node(i) ) • prod
200 continue
ec Writ/:' remit inro sluJred mDMry, arillg WHEN for exclusive access
call CFlock(ICF:ret,l,"sum;swn(k.) = sum(k) + tempcall CFulck(ICFret,l. ".rum,
e
300 canUnue"turn'Dd
real fnnct10D (x)f = cxp(x)return.Dd
Mar 3 21:05 1987 Page 3 oj problem7

problemS -47- problemS
, Problem 8. Co1lStT1ICt diIIide.d dijfco,u tab~.
paruteter ( kasc.s '" 8 )
shared real Ireals I x(300},d(300,:300)ahared: lDteger IUusI id(32), Nproc:s. N, mypos(32)external wO'l:kc:r
to..." p<Ocid(32)1b.tqu map(32)
to " N<llin< lu= )to " """'(32.0=)lDtee;er muPEs
,,,, LOOP OVER EXPERlMFNl'S:
do 900 :nn :: I, Nka.sc.sN '" Ndim(nn)
do 4() i '" l,NxCi) '" 2 • i + .01 • cos(Doal(i»dei-I) = (xCi»
40 contf.Due
do 800 Nprocs '" 1. maxPEs
do 4S i '" l,NprocsmyPOs(i) :::z 0
continueEND COBLOCK
call CFrdc(isr.op)clock(Nproes,nn) '" istop - 1slartIt(clock(Nproc:s,nn) .Ie. 0 ) clock(Nprocs,nn) -= 1
45 colltiDaemypos(Nprocs) '" N
call CFrtlc(istart)COBLOCKdo 50 i =. I, Nprocs
id(i) '" iitemp = map(i)pl"OCeS5( pTOCid(i), worker(id(i», ite:mp )
50
'00 continne
,,,
77'0
900
If( N le. 10) thendoSOi=l,Nwri~6.n) x(i),(d(U),k.=l.N-lc.+1)fomw:(11f13)
continueeadll
Display pufor~~ 'culls whid have been cofll!.ctt.d so for. COtk omined.
coadnuego to 1.nd
Feb 12 15:26 1987 Page 1 of problem&

problemS-48- problemS
ccccccc
Co1llmlls QTt: divided among proassors, each processor consrruairag 1M wholecollU7lll. EadI. processor is synchroniud wiJh tlw! proassor working to his left,worlting OM raw JUgh8 (beccut.re of tM da14 riependenc~). Syru::hronUalion.aw:rMad is o:trOM.ly high. Each entry in. tM table is associat~ wUh l2
nJJmber, specifically, (j-l)·N + i for tM (ij) tWry. Each pocessorrecords the n.umbu of 1M UIJry he most reunify COmpulM ill an array in sharedmemory calWi ~rrrypos"• .so tJuu proassars to his righl may synchronize on. him.
subroutine woIXer(myid)
shared real Ireals I x(300).d(300,300)shared Integer Imrsl id(32), Nprocs, N, mypos(32)
c This is the proc. id. of the proassar opealing 10 my immedime l£.ft.Integer mastermaster = Nprocs - mod(Nprocs-myid+l. Nprocs)
do 200 k :::z myid+l,N,Nprocs
when(mypos(rnaster) .8C. (k-2).N + 2) continued(l,k) '" ( d(2.k-l}-d(l,k-l) )/ (x(l+k}-x(l»mypos(myid) = N·(k-l) + 1
do 100 i = 2,N--k+lwhll!o(mypos(muste'f) .gc. mypos(myid}-N+l) continued(i,k) = ( d(i+l.k-l)-d(i.,k-l) )1 (x(i+k}-x(i»mypos(myid) = mypos(rnyid) + 1
100 continue
200 continue
return.nd
real functIon [(x)f = sin(x)return.nd
Feb 22 15:26 19PJ7 Page 2 oj problem&

problem9 -49- problem9
,,
,,,
,,"
Probl~m 0;1
lm4gt smoolhing 011 an N by M grid. Mild s.ynchrolli:arion.
shand real frew f :1.(300,300.2)RUed lateger Im[S/ id(32), Npwes. N. isynch. Kenenaal woli:cr
latecer procid(32lmtqer map{32l
llltecer Ndim( kase! )mtepo reps( kases )"'leger clock{32J:ascs)I_teeer maxPEs
----------------------------.-----------------------USl!r dill/og phast. Read if! tx~,imtllJal paramtrtrs. CtXk om;rud
----------------------------------------------------LOOP OVER EXPERIMENTS:do 90Cl M = L Nk:ases
N :::: Ndim(nn)K = rcPs(M)
do 800 Nprocs = 1. maxPEs
do 45 i = I.Ndo 40 j = I.N
a(i.j,l) = 125.0 • sm(float(i+j)J40 coadnue45 coaUaoe
isyn<:h :: 0all CFrUc(istanl
CORlOCKdo 50 i = 1. Nprocs
id(i) = iitemp = map(i}proce55( procid(il. wodtcI(id{iJ). itemp
SO coo.llnueEND COBLOCK
aU CFrtle(islOplclock{Nprocs.n.al '= istop - islarcIf(clock(Nprocs.nn) .Ie. 0 ) c!ock(Nprocs,MI =
300 coaUoae
11{ N .Ie. 10) mendo80i:::LNirog = ( + mod(K..21writc(6,771 (:l(i.jitogIJ=I.N1
77 forma.c(10f8.3180 coatloue
e8dl!
---------------------------------------_._--Prim pujoNtuzrru r~sul(s so far Cod~ omi(r~d.
._------------------------------------------900 cooliDue
1°10 I<od
Mar j 11 :09 /987 P<J~~ 1 oj prob/~",9

problem9
.Uar J' ~J:OQ 1987
-50- problem9
Page:! 0/ problcm9

problem9 -51- problem9
,,,
Rows ar~ dividtd ama"'g rht proctssors. Each prOCtssor lu1ndlts an tTIJirt ruw.Sylll:hrot!i=01ion is t1tCl:ssary ar Iht tnd of tach pass Qvtr Iht grid to insurtall processors ort: working all Iht SQm(! pass.
AbrotitLae wo.l±.ertmyid)
lre:lls I ;.(300.300.2)lints I idl32l. Nprc:cs. N. isynch. K
,,,
itog ::: 1dQ Soo mycntr :: LK
iold jlosilog = I + mod(ilog.2)
Wait htrt all fdlo .....s:....bea( isynch .~. Nprocs-tmycntr-lJJ c:ooC!ode
do 300 i =myid1' l.N-I.Nproc..do 200 j = 2.N-l
:l(i,j.uog) :::: ( a{i-l.j.ioldl + ;l(i+l.j.ioldl +a<i.j-Liold) + :l(i.j+ljold) )/4.0
,,
,
200JOO
500 cootlaue
rehlra<ad
cDQl!Jl;ae
coatlDue
Notify stt1ll1phort tlior I'm dont_all CFlocJ!:(lCFret.l.'isynch')isynch ::: isynch + (all CFulck(lCFn:t.l. 'isynch"J
,'rflJr J ~1 ,09 19~7 Pagr J of probltm9

problemlO -52- problemlO
c
ccc
c
c
ccc
4045
47
50
800
900
Problcrs 10. LU jaaori:aliml fly GtJJLISUm dimuuzMn willa partial pivoting.
parameter ( kases :::: 8 )
shand real /rc.als I a(300,300), pivotshared Integer Imrsl id(32), Nprocs, N, isynch.,i:pvt,row(300)
external wotkcr
Integer procid(32)Integer map(32)Intt:gu Ndim( kases )Jntezu clock(32"kases)IntegermaxPEs
QUDJI IlSC' for e:rperimt:nl sius. compulu 1WnIhus, DC_ C0d4 omitted.
WOP OYER EXPERIMENTS:do 900 IIll ::: I, Nkase.s
N "" Ndim(IUl)do 800 Nproc:s == I, maxPEs
do 45 i::: I,Nmw(i) '" i
do40j=l,Na(i...D :::: 125.0 • sin(f1oat(i+j»
contlDaecondnue
Go akad and (sequenria.Uy) jiNJ. tM. first pivot.call CFrtfc(istan)ipvt :: 1pivot::: 0.0do 47 i ::: I,N
Ir( abs(a(i,l» .gt. pivot) thenpivot = abs(a(i,l»ipvt '" ieDdlt
contlnae
isynch :::: Nprocs -1CORLOCKdo 50 i ;; I, Nprocs
id(i) ::: iitemp '" lTUIp(i)process( procid(i), workc:(id(i», itemp
continueEND COBLOCK
call CFrtlc(istop)clock(Nprocs,nn) ::: istop istanU(clock(Nprocs,nn) .Ie. 0 ) clock(Nprocs,nn) = 1
continue================================================================Display clUrOll pufOr7TU:JJ'la resulls. and. factored maua if small. Code omkted.
conUnaego to 1.Dd
Mar 3 21 :14 1987 Page 1 of problem10

problemlO-53- problemlO
nbrautlDe wotb:r(myid)
shared real Jreals I a(300,300). pivotllhared lIltqe:r Ifnfsl id(32), Nprocs, N. isynch,ipvt,row(300)
ccccc
~m========:==============================D=======================
LOOP OVER SUBMATRIX STEPS: AI lM ~ginniltg o[ each such sup, it i.r a.uumt:dIhDt tJse. piVOl dmtenl Welf~ 011 W prwwlU step. as tJwl swbmaJTa1oIW' compilld. (['Jtis aplains EM~ Us 1M mmn program).
do SOO k. _ I,N
Wair IUI1iI alI procs are d/)1JI!. wilh last SllbmQ/TU; ~p_whene is;nch .ge. k·N~ - 1 ) continue
itemp = I'tlw(k:)row(k) = roW(Ipvl)ro...-(ipvt) = itemp
Proccs 1 tJCtIIlJ1ly maU.s' 1M swap.Ir( myid .eq. 1 ) then
----------c
cc
c
pivot = 0.0ipvt "" k+l
cc SigrttJ1 SC1IQ{JJwre and. wait here for felJcw proc=ors.
call CFlock(ICFm.l,"""""hiisynch ;; isynch + 1call CFul,k(lCFm.l,""Y""hiWheD( isynch .ge. k-Nprocs ) continue
ccc
Rows of subm4rrU; arc disrribllud amDng processors. Compuu n£l:1 piYQrby looking Ql 1M mlT~ in W (k+l)st column C1f they are compurd.
do 400 i "" k+myid, N. Nproc;s
300
s(row(i),k) = a(row(i),k) Ia(row(k),k)do 300 j = k+l,Na(row(ilJ1 = a(mw(i),j) - a(row(i),k)-:i(row(k:),k)eoatlnue
c
c
caO CF!ock(ICFnlt,l, 'pivot}if( abs(a(row(i),k+l» .gt. pivot) lhe:npivot'" a.bs(a(row(i),k+l»ipvt :: iI!DdUcall CFlIlck(1CFret,I,'pivot')
400
500
contlDul!
cODUaue
"'_end
Mar 3 21:14 1987 Page 2 of probll!m10

problemll -54-problemll
, Problem. 11. Filler dma. in 4 vedar and write to a dmaba.se.
parameter ( kases = 8 )
shared rul treals I data(lOOOOO), sum(4)shared Integer lints I N. id(32), Nprocsexternal worlc.er
,,,
In....,. procid(32)Integer m.ap(32)
lateger Ndim( lcases )In....,. clook(32.ka=)lateger maxPEs
============================================================Qu.ery WSQ' for cperimenl sius, CompUlU ruunbes. ere. Code. omiJled.
do 900 Im = I, NkasesN = Ndim(rm)
do 800 Nproc$ = I, maxPEs
40 continue
do40i=l,Ndala(i) = -float(i)/.l + 1080.0 • sin(float(i+lO»
call CFrtlc(iswt)do 45 i = 1,4:rum(i) = 0.0
4S -' continue
COBLOCKdo 50 i = I, Nprocs
id(i) "" iitemp = map(i)process( procid(i), workenid(i». itemp )
continueEND COBLOCK
50
60 continue
Save dlJla in dtJJaba.se wiJlUn. timer scope:do 60 i "" 1,4
write{6,·) sum(i)
call CFrtIc(istop)clock(NPfOC.'.Iln) = istop - istartIt(clock(Nprocz,nn) .Ie. 0 ) clock(Nproc.s.nn) = 1
,,,
'00 continue==============~=====================Hue. prinl rab~ of perjormJJnJ::e re.sll.us====================================
900 condoucgo to 1.nd
Mar ] 21:37 ]987 Page ] of problem]]

problemll -55- problemll
c Pofonn filler 011 sda:t w:.c::tor dmrou.1, QCllII1I'tIJl1lJJg sums, alii! thmc add r1Iir 10 IN shmd. SII111S.
nbrautlne WOtkct(idenI).Iha.ted nal !reml da.ta(100000), sum(4)&baftd 1D.ter;er (mrsl N, id(32), Nprocs
ru.l lcesum.(4). pi, tempd.ata pi I 3.141.592654 I
do 50 i '" 1. 4Iocsam(i) '" 0.0
50 coatiDae
7S
do 100 i "" ident, N, Nprocs
temp '" mw:.H 0.0, amio.l( 1000.0, da1a(i) ) )data(i) "" temp
:Locsum(l) '" locsum(l) + temp
do7Sk=2,41oesum(k) = locsum.(k) + cos( floa.t(pi.*k.*i) Ifloat(N+l»*tempCODtlnue
100 conl:1nue
c Nou thM in tJU.s block. access to SUM enlTies wiUc be acWsiye.
call CFloc..t(lCFrcr.l. '.sum ')sum(l) = sum(l) + locsum(l)/Nsum(2) '" swn.(2) + locsum(2)swn(3) = sum(3) + loesum(3)sum(4) "" sum(4) + locsum(4)
caD CFalck,(ICFrct,l. 'swn")
..turn
<n'
Mar J 21:37 1987 Page 2 of problem!1

problem12 -56- problem12
50 coatinueEND CORLOCK
,c
ccc
3540
45
Problem 12. Simpk. data. mQIIU1JQJl. MOlle data from smaller array to forma. compos~ larger ~.
parameter ( Uses '" 8 )
shared real /rlf 1(300,300). c(300), I(300)sbared real lal &COm. abig(300,300)shared iDteger finlSl id(32), Nprocs, NoM:extern.al wenker
Integer procid(32)Intee;u map(32)
Integer Nsize( kasc.s )Integer Msize( kases )muger cIock(32,kases)Integer muPEs
QIU!ry ILSU for aperimenl sius, COnlpIllU TlJJnliJus. dc. Code omiIted.
do 900 1m '" 1. Nka.sesN ::l Nsiu(m)M ::: Msizc(nn)
do40i=l,Nc(i) "" float(l+i)
do35j=1,Ma(ij) '" floal(i+j)
conllDuecontinuedo45j=1,M
r(j) = float(l-J)continueICOITl. '" .5
do 800 Nprocs '" I, ·maxPEs
call CFrtlc(istan)CORLOCK
do 50 i '" I, Nprocsid(i) '" iilemp = map(i)process( procid(i). worker(id(i), itemp )
cc,
abig(N+l.M+l) = acorncall CFrdc{istop)clock(Nprocs.,nn) :::: istop - isurt
800 continue
Print table of pufor=t: r~uils
=========================900 contLaue
go to 1ond
Feb 22 '21 :'23 1987 Page 1 of problem12

problem12 -57- problem12
o
a.broatIDe workc'(myid)
ahared ruI 11'1 , -000,:300), c(300). r(300).bared ru.l Ir2 ( IlCOm, abig(300,300)
Ilhared latqer lints f id(32}, Nprocs. N,M
do 100 i ::: rnyid,N,Nprocsabig(i,M+l) '" c(i)
do 50j"" 1.M"",("'1 • >iiJ)
50 CODtlaue100 continue
do "200 j '" myid,M,Nprocsabig(N+IJ) "" r(j)
200 coatlnae
"turDDDd
Feb 22 21 :23 1987 Page 2 oj p,-oblunl2

probleml3 -58- problem13
parameter ( Uses '" 8 )
shand real Ireals I sum, a(50000),b(50000),c(50000).d(50000)Ibared Integer Jimsl id(32), Nprocs, N
_nul """
"'leg" pnxid(.l2)lbtqer ma:p(32)
lateger Ndim( kases )1D.teger clock(32.kases)Integer maxPEs
• Hue. read in ape.rimml sius. compu/er numbers, etc. from lL.l"eT. Cotk omkted.
do 900 IIIl :: I, NkasesN '" Ndim(nn)
do 800 Nprocs '" I, maxPEs
do40i=l,Na(i) '" i1float(lO) + l.O/flollt(i)b(i) '" alog(a(i» + .02c(i) '" (a(i) + b(i» • sin(a(i»d(i) '" a(i) + b(i) - 2-c(i)
4() contlbue
call CFrUc(istan)sum '" 0.0COBLOCK
do 50 i =. I, Nprocsid(i) = iitemp = map(i)process( procid(i), adder(id(i», itemp )
SO continueEND COBLOCKcall CFrdc(islDp)clock(Nprocs,nn) = istop - istanll(cloc.i::(Nprocs,nn) .Ie. 0 ) clock(Nprocs,nn) = I
wri~6.·) 'Swn = • ,sum800 coatlnue
c Hue, wri~ Qui inJ.erm.edilJle performmu:e resu./ts.
900 contiDuego to 1.nd
Mar 3 21:10 1987 Page 1 of problemJ3

problem13
nbroatlDe addc:r(myid)
-59- problem13
&hared real !Rab I sum, a(50000).b(SOOOO),e(50000),d(50000)ahared 1b~er linLs I id(32), Npnxs, N
rul,-temp "" 0.0do 80 i =myid, N, NIXOCS
I(i) '" lI(i)*"si:n(b(i»It( s:in(a(i» lL cos(c(i» ) lhcn.
a(i) "" a(i) ... e(i)
a(i) = a(i) - d(i)..d1f
cc eRfflCAL REGION: E:rdu.sively r~ and updau SUM
cal.I CFIoct(lCFrct.l, 'sum")rum '" sum + tempcall CFukk(ICFret,l. 'sum')
c
returnc.d
-re.a.I rtmctiOD f(x.,n)
cwit ( n .cq. 1) lhcn
f = sin(x)cw
f '" cxp(x)ndll
eadlt
...lUrn••d
Mar 3 21 :20 1987 Page 2 of problD71J3

problem14-60- problem14
, ProblDrJ. 14. /7IUgraJion luts.
parameter ( kases = 8 )
shared realshared realshared Integer
!R.alsll sum(3,3), a, b1re:JJs2/ h.,hgauss.,offsetlintsl id(32), Nfunc. Npmcs, N. Ngauss
,,,,,,,
aternl.1 adderInteger procid(32)Integer map(32)real cxlICt(3)Integer Ndim( ka.ses )integer c1ock(32.kascs)JntegermaxPEs
Hut:, T~ in pararn.etus for operimmls from user. This indutks tlu!tJC:uradc (110/ evaluations), o:act solution values willi which ardative errOl' may be compllld, the limi.ts of inlegTalion a and b,and 1hz computer numbers. CODE OMIITED.
WOP OVER EXPERiMENTS:do 900 IIIl '" I, Nkases
N '" Ndim(nn)h '" (b-1I.) Ifloa.t(N)Ngauss = NI3hgauss::: {b-Il.) Ifloal(Ngauss)offset'" .774596669241. hgll.uss I 20
do 800 Nprocs ::: I, maxPEs
call CFrtlc(istart)do45i=1,3do40j::::l.3
sum(i,j) = 0.0
contlbtleEND COBLOCK
COBLOCKdo 50 i '" 1. Nprocs
id(i) = iiternp '" map(i)process( proeid(i), adder(id(i», itemp )
50
40 continue45 continue
,
70
ADJUST SUMS:do70j=1,3surn(lJ) '" h"(sum(lj) + f(a.j) 12.0 + f(bJ112.0 )sum(2,j) '" h·Csum(3j) + f(a,j) + f(bJ) )13.0swn(3J) =. hgauss .. surn(3.j) I 18.0condnue
caU CFrtlc(istop)clock(Nprocs,nn) = islOP - istartil(clock(Nprocs,nn) .Ie. 0 ) clock(Nprocs.nn) = 1
,,,
800
900
continue
Prinl table of per[oTrN;UlCe Te.5ults. Code omiJted.
continuego to 1ond
Mar 3 '21:40 1987 Page. I of prob/em14

problem14
llIbroutlDe addcr(myid)
-61- problem14
ahared real heals! I sum(3.3), a. bshared real. Irealsl/ h,hglDl.Ss,offsctahared. iDteger lintsl id(32), Nfunc, Nprocs, N, Ngauss
do 1000 Nftm:: ZI 1.3
cc Compllle temporary .nm for tTapaoiJaJ ndt:..
tempI ... 0.0do 100 i .. myid,N-l"Nprocs
I"" i*htempI '" tempI + f{x,Nfunc)
100 contlDlNlcC Compllte mm for Simpson's Ride.
Icmp2 • 0.0do 200 i '" myid.N-l.Nprocs
x", i(lhlie mod(i.,l) .ge. 1 ) then
temp2 '" tcmp2 + 4.O*f(x.Ntlmc).be
temp2 '" ternp2 + 2~f(x,Nfunc)
.adIl:200 coDdaae
cc
1300
GawsrimI quadratwe.tanpJ '" 0.0do 300 i '" myid,Ngauss,Nproes
x '" ( flol1(i) - .5 ) • h&ausslcmp3 '" temp3 + S.O*f(x-olIset.Nlunc)
+ 8.0 • f(x,Nfunc) + 5.0 • f(x+offsct.Nfunc)continue
cc Ac= shared memory .swnf, using system Jocks.
call CFlock(lCFret,l. 'sum')sum(1.Nfunc.) '" surn(l,N'fImc) + temptsum(2.Nfwlc) '" sum(2,Nfunc) + temp2lIUmC3,Nfunc) '" surn(3,Nfunc) + temp3
caU CFulck(1CFret,l,'sum1c
1000 condnu.eromrn.n'real fllDdloD. f(x.n)11( n leo 1 ) thl:J1
f '" exp(x).be
If ( n .eq. 2) thlmf"" sqrt( abs(x-.2345) )
.Iso
cadUCll.dlfrerurD.n'
Mar 3 21:40 1987 Page 3 of problemJ4

problem15 -62- problem15
Qrury II.SeT for IlSJUl1 problem paramelos, pw a V«UJr t(1 •.•,K) of~ poinls. COtk omkted..
parameter ( kases :: 8 )shared re.aJ. Irealsl a,b,sum.x(0;50001.2),l(lO),approx(1O.2)shand Integer liIUs I id(32), Nproc.s, N. K, isynch....""" "'"'"'lDtet:er procid(32).lD.teger map(32)lntee;er Ndim( kase.s )lnte2er clock(32,kases)lnteg;ermaxPEs
eee
38 coatlDoe40 coatlane
e LOOP OVER EXPERIMENTS:do 900 Dn ::: 1. Nka.ses
N:::: Ndim(nn)do 800 Npmcs "" 1, maxPEs
call CFrtlc(istan)do40j '" 1,2
x(OJ) = a - .1x<N+IJ) = b + .1
do38i=1,Kapprox(i-j) :::: 0.0
SO contlnueEND COBLOCK
isynch == 0COBLOCK
do 50 i = I, Nprocsid(i) = iitcmp = mo:p(i)process( procid(i), adder(id(i», itemp )
58 continue60 coat:lD.ue
do60i=l,Kdo58j=1.2
approx(ij) = abs( (f(tei» - approx(iJ»/f(L(i» )
caD CFrtlc(istop)clock(Nprocs.m1) '" istop - istanIt'(clock:(Nprocs,nn) le. 0 ) clock(Nprocs,nn) '" 1
do 810 i :::: 1. Kwrite(6.808) t(i),approx(i,l),approx(i,2)fomuJ.(3clO.2)
800
8051
808810
continuewri[e(6,805)fOImat( I r t point rei error
unifonn
continue
rei error",chebyshev' )
eee
HU'~. prin.l pcforrtUJnJ:e ruults. CODE OMfITEn.
900 continuego to 1on.
Mar 3 21:23 1987 Page J of problemJ5

problem15-63- problem15
IIabroadne .ddc:r(myid)
Ab.aftd ru1 halsl ...b.sum.x(O:SOOOl,2),t(10),8ppItlx(lO,2)abared lIlte&er Jinls I id(32). Nprocs, N. K, i.s)nch
re.alh.pidw. pi 13.141592654 Ih ... (b-a)/floa.t(n-l)
do 100 i .. myid,N,NprocsXCi-I) '" a + (i-l)*hx(i,2) '" a + (a-b)·cos(f1oat( (Z*i-Wpi/(Z·N) ) )
100 contiDue
cc SYNCHRONlZAIION... Wait on feUows
c:aIJ. CFloclr.(ICFret,l, -lS}'I\ch")isyncb. =isynch + 1c:aIJ. CFulc.k(ICF:ret,l. ~1S)'IlchlwheB( iI)nl::h .ge. Nprocs ) continue
c
do 500 kk :II IXtempt", 0.0temp1 "" 0.0
do 400 i '" myid.N.NptOCstc:mpl "" tempt + ((xCi,I» • hcrm.c ([(kk),i,l) +
t fprirne(x(i,l» • henncl(t(kk),i,l)lcmp1 "" lcmp2 ... f(x(i,2» • benne (t(Id:),i,2) +
t fprirne(x(i,2» * hennc1(t(kk),i,2)400 cout1Due
c:.aD CF1ock(ICFret.l. 'approx13pprOx(kk.l) '" approx(kk.l) + templapprox(kk,.2) = approx(kk,2) + u:mp2
call CFukk(ICfut,l:approx)
SOO conttaoe
"''''~'Dd
Mar 3 21:23 /987 Page 2 of problem/5

problem15 -64- problem15
.'"
real ID.bctlOD hennc(tpt,i.it1ag)sb.llred real Irea1sI a,b.sum.x(0:50001.2),l(lO),approx(lO,2)sbRred Integer lintsl id(32). Nprocs. N, K., isynch
11( (tpt .le. x(i-unag» .or. (lpt .ge. x(i+l,illag) ) ) Ihc:nhcrmc :;; 0.0"turn
'DdIf
l!( rpt .gt. x(i,iflag) ) thendt :;; x(i+l,illag) - xCi,illag)dx '" x(i+l,iflag) - Ipt
dt = X(J.iflag) - x(i+l,iflag)dx = tpt - x(i,iflag)
'DdIf
hermc = ( 3.0 - 2.0 lIdx/dt) .. dJ;.~/dt·.2
return.Dd
real function hcrmcl(tpt,i,iflag)sband real IreaJsI a,b,sum.x(0:50001,2),t(lO),approx(lO,2)shared Integer /ml3/ id(32), Nprocs, N. K, isynch
U( (tpt .le. x(i-l,illag» .or. (lpt .ge. x(i+l,iflag) ) ) thenhennel = 0.0"tum
'DdIfdx =lpt - X(i,illag)lI( lpt .gt. x(i.illag) ) men
dI2 = ( x(i,iflag) - x(i+l,illag) )"2dx2 = ( !pt - x(i+l,iflag) ).·2
'DdIf
dr2 = ( x(i,if1ag) - x(i-l,iflag) )··2dx2 = ( tpt - x(i-l,illag) ).·2
henne! = dx2.dx Ida
"turn'Dd
real (unction rex)f = x"2 + 25.0"turn.Dd
real (eafoD fprime(x)fprirne = 20 .. x
"turn'Dd
Mar 3 21 :23 1987 Page 3 of prob/em15

problem16 -65- problem16
c Problem 16. Fal:tor tUJd badrolw: I/.Sing a Hilbert 17I41rix.
par-..eter ( kases '" 8 )
aJu:red real Irll a(lOO,lOO),hilb(lOO.100),morm(4)ahared real h!2/ b(lOO,4), x(lOO,4), pivot, wsid(lOO,4)ahared Inter;er lints I id(32), Nprocs, N, isy'nch.ipvt,mw(lOO)all:ued JoiIeaI /log I dane(lOO,1)ueeruJ flClOr'. solve
C _~S_.33_2_~::=~"':==================================
C Hen:, qwoy lI.!eT /0,.- problcrl sius. COmpUlu NU7lbus, ~.c ~==================================================
do 35 i = 1,100b(i,l) = 0.0b(i,2) = 1.0b(J..3) = 1.0 + .01 • sin( float( tOO·i) )b(i,4) = 0.0
do 34 j "" 1,100hilb(i,j) = l.Otfloat(i+j-l)b(i.,4) '" b(i,4) + hilb(i...11
34 eoDt1Jl.ue3:5 coablle
c WOP OVER EXPERIMENTS:do 900 un = I, Nka.ses
N = Ndim(raI)do 800 Nprocs :::: 1. maxPEs
do 45 i = t.NrtIw(i) '" idone(i.l) = ialse.done(i..2) = ialse.
do39j",l,4x(i..)) = b(i,J)resid(i,j) = b(i,j)
39 COI:ItiDoedo40j=l,N
r(i,j) = hilb(ij)40 coatlnue45 eoatlaue
c.all CFrtlc(iswt)
"""" = Nproa-Iipvt = 1pivot"" 0.0
do47i=1.N'if( abs(a(i.l» .gt. pivot) !henpivot = Bbs(a(i,l»ipvt = ieudll
47 continue
Mar 4 10:24 1987 Pagt! 1 of problem/6

problem16 -66- problem16
coatiDaeEND CORLOCK
In this COBWCK. tM mtJlrU: "a~ is jaaored in paralh/.CORLOCKdo 50 i = I, Nprocs
id(i) = iiranp = m.ap(i)process( procid(i), fllCtor(id(i», itemp )
50
c
contInueEND CORLOCK
/11 this COBLOCK. bacbJfving and residlml compUUJlion is daM in paraUeI.isyD.:h = 0COBLOCKdo 60 i = 1. Nprocs
id(i) "" iitemp "" m.ap(i)process( procid(i),solve(id(i», itemp )
60
c
cal.I CFrth:(istDp)cIock(Nprocs,nn) '" istop - is[axtIt(clock.(Nprocs,nn) leo a ) clock(Nprocs,nn) '" I
800 contiDue
c ============================================================C HUf!, prim l4ble of pufor11l(JJ'1(2 resu1Js so far, and prinJ soluribn \lerroI'.c ============================================================
900 conUnuego to 1.ad
subroutine f.1Ctor(myid)shared real Itl f a.(lOO,l00),hiIb(lOO,l00),monn(4)shared real Ir2I b(lOO,4), x(IOO,4), pivot, resid(lOO,4)shared Integer lines! id(32), Nprocs, N, is}11Ch,ipvt,row(IOO)shared logical /logl done(lOO,2)
c SEE CODE FOR ROUTINE "WORKER" OF PROBLEM 10
Mar 4 10:14 1987 Page 2 of problemJ6

problem!6-67- problem!6
1400 contlaue1500 COl:ltlaue
nbroatlDe solve(myid)shared real Irl J a(lOO.lOO).hilb(lOO.100),mmn(4)shared real ft2./ b(100,4), x(I00,4), pivot, ruid(lOO,4)ahand lategu lints I id(32), Npnx::s. N. isynch.ipvt,row(lOO)ahared. loe:1caI /log I done(lOO,1)rull<mp(4)
c FORWARD SUBSTITUTIONdo 500 i .. myid,N,Nprocsdo 400 j .. l,i-l
wheD( doneQ.l) ) coatlnu!!do 40 k :: 1,4z(raw(i),k) '" x(row(i)..k) - a(row(i)J).x(row(j),k)
40 contlDae400 coutlaae
done(i,l) = .true.sao C'DDdDae
c BACK SUBSTITUTIONdo 1000 ii = myid.N.Nprocsi "" N+l-iido 900 jj = 0, i-l
j=N-ijwhen( done(j,2) ) contiaul!do 800 .k = 1.4x(row(i),k) '" x(raw(i),k) - a(row(i)j)·X(TOWGJ,k)
800 COIltlnue -900 cont!.bge
do 920 k "" 1,4x(row(i),k) = x(row(i),k) Ia(row(i).i)
920 COIltlDal!_<.2) - .<roe.
do 950 j '" I,Ndo 940 k = 1,4
rcsid(row(j),k) =. ruid(rowCJ1.k:) - a(row(j),i).x{row(i),k)94() COlltlnue950 continue
1000 coatlaue
c Use $D7IlZphore ISYNCH to sigtuJ1 fellow processors tluJI YOIU work is r/J)~. so for.caU CFloclr.(ICful,l. ~lS)'Il.ch')isynch = isynch + 1c.all CFukk(lCFrel,l. ~lS)'IIchl
do 1100 k = 1,4<=p(k) • 0.0
1100 conUbIll!
c Wait 011 feUow:s to 86 dLJ~ wirh I~ work and :1101 compwe residllQl:when ( isync:h .ge. Nprocs ) ooDflnuedo 1500 i "" myid,N,Nprocsdo 1400 k '" 1.4
temp(k) "" temp(k) + :resid(i);)••2
call CFJock(ICF:ret.l:monn1do 2000 k: "" 1,4monn(k:) = morm(lc) + temp(k:)
2000 continuecall CFukk(ICfut,I,'morm1
return'Dd
Mar "10:24 1987 Page] of problunJ6

- 68-
APPENDIX TWO: MEASURED PERFORMANCE DATA
We present in tabular fOml the data sets plotted in Section 4. The entries are clock ticks (=to 1150 of a second) and, for more than 1 processor, the resulting efficiency.
Number of Integration Points
Processor,; 100 500 1,000 5,000 10,000 25,000 32,000
1 2 9 16 79 158 394 473
2 3 6 10 42 81 199 238.33 .75 .80 .94 .98 .99 .99
3 4 6 9 31 56 135 161.17 .50 .59 .85 .94 .97 .98
4 5 6 10 25 45 103 124.10 .38 .40 .79 .88 .96 .95
5 5 6 8 21 36 86 101.08 .30 .40 .75 .88 .92 .94
reIerror 2-10-' 8'10-0 2'10-0 2'10-7 4'10-7 8'10-7 3'10-7
Problem 1: Trapezoidal Rule forf (x) = e~.

- 69-
Number oCIndices
Processors 10 25 40 55 70 80 85
1 2 11 25 48 77 101 114
2 4 8 15 26 41 53 60.25 .69 .83 .92 .94 .95 .95
3 4 7 12 20 30 37 42.17 .52 .69 .80 .86 .91 .90
4 5 8 12 18 24 31 33.10 .34 .52 .67 .80 .81 .86
5 4 6 9 13 20 24 27.10 .37 .56 .74 .77 .84 .84
Problem 2: Compute sum of products of expression.

-70·
Array Size (square)
Processors 50 100 150 200 250 300 400 500
1 8 28 64 112 175 251 446 697
2 6 16 34 58 89 127 224 349.67 .88 .94 .97 .98 .99 1.0 1.0
3 7 13 25 41 63 87 153 235.38 .72 .85 .91 .93 .96 .97 .99
4 7 13 21 33 49 68 117 179.29 .54 .76 .85 .89 .92 .95 .97
5 6 13 17 29 39 56 96 145.27 .43 .75 .77 .90 .90 .93 .96
Problem 3: Compute sum. of products of array elements.

-71 -
Number Dr vector elements
Processo" 2,500 10,000 25,000 50,000 75,000 100,000 150,000 200,000
1 6 20 51 102 153 204 304 404
2 5 12 27 54 79 105 156 208.60 .83 .94 .94 .97 .97 .97 .97
3 5 11 21 38 55 72 106 141.40 .61 .81 .89 .93 .94 .96 .96
4 6 11 19 31 43 56 82 108.25 .45 .67 .82 .89 .91 .93 .94
5 5 8 17 28 37 45 69 89.24 50 .60 .73 .83 .91 .88 .91
Problem 4: Compute sum of reciprocols of non--zero elements.

-72 -
Number of Students and Grades
Processors 25><25 50><50 looX1oo 150x150 200><200 225><225 250><250 300><300
I 4 12 48 107 188 238 293 422
2 6 11 28 58 99 124 151 215.33 .55 .86 .92 .95 .96 .97 .98
3 7 12 24 43 70 87 106 148.17 .33 .67 .83 .90 .91 .92 .95
4 8 12 20 36 57 69 83 114.13 .25 .60 .74 .83 .86 .88 .93
5 9 II 18 35 48 58 70 96.09 .22 .53 .61 .78 .82 .84 .88
Problem 5: Grading Program -Pessimistic Version: Times include creating processes.

-73 -
Number of Students and Grades
Pro=sors 25><25 5OXSO 100xloo 15Ox150 200><200 225><225 250><250 300x300
1 4 12 47 106 186 236 291 416
2 5 9 27 55 96 122 148 212.4 .67 .87 .96 .97 .97 .98 .98
3 3 8 20 41 68 84 103 144.44 5 .78 .86 .91 .94 .94 .96
4 4 6 18 33 51 62 80 111.25 5 .65 .80 .91 .95 .91 .94
5 3 5 15 26 40 50 61 89.27 .48 .63 .82 .93 .94 .95 .94
Problem 5: Grading Program - Optimistic Version: Does not include creating processes.

-74-
Matrix Order
Processors 50 100 250 500 1,000 1,500 2,000 2,500 5,000 10,000
I 12 21 55 113 241 356 516 642 1384 2975
2 11 17 36 67 134 194 280 345 735 1571.55 .62 .76 .84 .90 .92 .92 .93 .94 .95
3 12 16 31 52 96 137 193 238 496 1056.33 .44 .59 .72 .84 .87 .89 .90 .93 .94
4 15 18 31 47 82 112 153 187 384 805.20 .29 .44 .60 .73 .79 .84 .86 .90 .92
5 19 20 32 46 73 97 133 159 318 655.13 .21 .34 .49 .66 .73 .78 .81 .87 .91
Problem 6: Tridiagonal Matrix Solver

-75 -
Number of evaluation points
Processors 2S 50 100 1,000 2,000 4,000 10,000
1 14 47 116 134 241 435 975
2 9 27 60 73 127 226 513.78 .87 .97 .92 .95 .96 .95
3 9 20 44 52 88 157 348.52 .78 .88 .86 .91 .92 .93
4 9 19 35 44 73 126 271.39 .62 .83 .76 .83 .86 .90
5 10 17 30 36 60 104 229.28 .55 .77 .74 .81 .84 .85
Problem 7: LaGrange polynomial interpolation.

·76 -
Number of Data Points
Processors 10 25 50 70 100 150 200
1 9 57 233 459 940 2122 3778
2 10 53 219 404 863 1933 3732.45 .54 .53 .57 .54 .55 .51
3 11 58 210 402 816 1831 3225.27 .33 .37 .38 .38 .39 .39
4 15 58 197 401 817 1746 3322.15 .25 .30 .29 .29 .30 .28
5 17 68 217 399 823 1784 3053.11 .17 .21 .23 .23 .24 .25
Problem 8: Divided difference, table - tightly synchronized version.

-77 -
Number or Data Points
Processors 10 15 SO 100 ISO 200 150 300
1 2 6 IS SI 103 17S 26S 371
2 4 8 20 S6 110 181 276 383.15 .38 .38 .46 .47 .48 .48 .48
3 S 11 21 S9 liS 189 281 393.13 .18 .24 .29 .30 .31 .31 .31
4 4 12 23 62 119 191 291 404.12 .12 .16 .21 .22 .23 .23 .23
5 5 11 15 64 121 202 298 416.08 .11 .12 .16 .17 .17 .18 .18
Problem 8: Divided difference table - naive version which results in almost sequenrial execution.Note that asympotic efficiency for N processor.; is approximately liN.

-78 -
Size or 2D Array (square)
Processors 10 25 40 SO 60 75 90 100
1 IS 86 223 352 512 807 1169 1449
2 13 49 116 181 261 414 589 72958 .88 .96 .97 .98 .97 .99 .99
3 14 38 85 126 184 285 407 496.36 .75 .87 .93 .93 .94 .96 .97
4 15 34 70 99 143 221 303 381.25 .63 .80 .88 .90 .91 .96 .95
5 19 34 63 88 119 180 254 310.16 51 .71 .80 .86 .90 .92 .93
Problem 9: Averaging neighbors in 2D array.10 Passes.

-79 -
Matrix Dimension
Processor.; 15 25 35 40 45 55 65 80 I()()
1 56 158 327 441 577 919 1369 2269 3961
2 38 95 186 246 317 495 726 1188 2049.74 .83 .88 .90 .91 .93 .94 .95 .97
3 34 79 144 186 236 360 519 836 1429.55 .67 .76 .79 .81 .85 .88 .90 .92
4 34 71 127 158 200 303 425 672 1124.41 .56 .64 .70 .72 .76 .81 .84 .88
5 32 73 117 148 175 271 367 567 950.35 .43 .56 .60 .66 .68 .75 .80 .83
Problem 10: Gaussian elimination with partial pivoting.

- 80-
# of Vector Elements
Processors 250 500 1.000 2,500 7.500 12,500 25,000 50,000
1 23 33 51 108 298 488 961 1907
2 19 25 34 63 159 252 489 963.61 .66 .75 .86 .94 .97 .98 .99
3 20 23 29 49 112 174 333 649.38 .48 .59 .73 .89 .93 .96 .98
4 20 23 28 42 90 137 256 492.29 .36 .46 .64 .83 .89 .94 .97
5 21 23 27 38 77 115 209 381.22 .29 .38 .57 .77 .85 .92 1.0
Problem 11: Data filtering.

- 81 -
Size of ABIG
Processors IOxIO 25><25 50xS0 lOOxlOO 15Oxl50 200x200 250><250 300><300
I I 2 8 33 74 131 205 296
2 2 3 7 18 39 69 106 151.25 .33 .57 .92 .95 .95 .97 .98
3 2 4 6 15 28 48 72 102.17 .17 .44 .73 .88 .91 .95 .97
4 3 5 8 14 24 37 57 80.08 .10 .25 .59 .77 .89 .90 .93
5 4 5 7 12 22 33 45 67.05 .08 .23 .55 .67 .79 .91 .88
Problem 12: CODStruction of a big array.

- 82-
Number of Vector Elements
Processors 50 100 250 500 1,000 2,500 5,000 7,500 10,000
1 4 8 17 35 69 172 343 513 683
2 24 6 11 20 37 88 174 259 343.50 .67 .77 .88 .93 .98 .99 . .99 1.0
3 5 6 9 16 27 61 118 175 231.27 .44 .63 .73 .85 .94 .97 .98 .99
4 5 5 10 12 21 47 92 134 177.20 .40 .43 .73 .82 .91 .93 .96 .96
5 5 5 11 11 18 41 76 110 144.16 .32 .31 .64 .77 .84 .90 .93 .95
Problem 13: Transform a vector, sum squares of elements.

- 83-
Number Dr Evaluation Points
Processors 10 25 50 100 250 500 1,000 2.500 3,300
1 2 5 7 15 37 74 148 369 488
2 3 4 7 10 21 39 77 187 247.33 .62 .5 .75 .88 .95 .96 .99 .99
3 4 5 6 9 17 29 53 128 166.17 .33 .39 .56 .73 .85 .93 .96 .98
4 4 6 8 9 15 22 41 98 128.13 .21 .22 .42 .62 .84 .90 .94 .95
5 5 5 6 11 14 22 38 81 106.08 .20 .23 .27 .53 .67 .78 .91 .92
Problem 14: Test 4 integrators on 10 functions.

- 84-
Number of Evaluation Nodes
Processors 50 100 250 500 1,000 3,500 5,000 10,000
1 10 17 38 75 148 508 726 1447
2 8 12 23 40 76 258 365 727.63 .71 .83 .94 .97 .98 .99 .99
3 9 11 18 30 55 174 248 487.37 .52 .70 .83 .90 .97 .97 .99
4 9 11 17 26 44 134 188 370.28 .39 .56 .72 .84 .95 .97 .98
5 11 12 16 24 38 110 154 298.18 .28 .48 .63 .78 .92 .94 .97
Problem 15: Comparison of inr.erpolation methods.

- 85-
Size of Matrix
Processors 5 10 15 20 2S 30 33 35 40
1 15 46 101 178 279 407 496 563 749
2 17 38 74 122 182 262 316 359 454.44 .61 .68 .73 .77 .78 .78 .78 .82
3 19 42 68 107 162 220 262 290 378.26 .37 .50 .55 .57 .62 .63 .65 .66
4 2S 48 74 106 154 217 243 271 346.15 .24 .34 .42 .45 .47 .51 .52 .54
5 28 48 74 112 164 202 241 270 339.11 .19 .27 .32 .34 .40 .41 .42 .44
Problem 16: Solve Hilbert problem with multiple right sides.





















