
Orientado: Francis Carlos dos Santos Orientador
16
Orientado: Francis Carlos dos Santos Orientador: William Robson Schwartz Coorientador: Jefersson Alex dos Santos [email protected], [email protected], [email protected] Departamento de Ciˆ encia da Computa¸c˜ ao Universidade Federal de Minas Gerais 31270-901 Belo Horizonte MG, Brasil 12 de agosto de 2014 1 Introdu¸ c˜ ao O termo sensoriamento remoto ´ e geralmente utilizado para se referir ` a aquisi¸ c˜ ao de imagens a partir de um sensor remotamente localizado, por exemplo, em um avi˜ ao ou sat´ elite. Enquanto fotografias convencionais geralmente possuem trˆ es canais de cor no espectro vis´ ıvel (R, G, B), imagens hiperespectrais, obtidas a partir desses sensores, diferenciam-se por possu´ ırem at´ e centenas de bandas cobrindo v´ arias faixas do espectro. Imagens hiperespectrais podem ser compostas de dezenas ou at´ e centenas de bandas espectrais. Cada banda espectral ´ e resultado da reflectˆ ancia do material em um determinado comprimento de onda. O agrupamento de todas as bandas obtidas, como um cubo, forma a imagem hiperespectral. Em uma imagem hiperespectral, cada pixel possui v´ arias assinaturas espectrais. Como mostrado na Figura 1. 1
Transcript of Orientado: Francis Carlos dos Santos Orientador

Orientado: Francis Carlos dos Santos
Orientador: William Robson Schwartz
Coorientador: Jefersson Alex dos Santos
[email protected], [email protected], [email protected]
Departamento de Ciencia da Computacao
Universidade Federal de Minas Gerais
31270-901 Belo Horizonte MG, Brasil
12 de agosto de 2014
1 Introducao
O termo sensoriamento remoto e geralmente utilizado para se referir a aquisicao de imagens a
partir de um sensor remotamente localizado, por exemplo, em um aviao ou satelite. Enquanto
fotografias convencionais geralmente possuem tres canais de cor no espectro visıvel (R, G, B),
imagens hiperespectrais, obtidas a partir desses sensores, diferenciam-se por possuırem ate centenas
de bandas cobrindo varias faixas do espectro.
Imagens hiperespectrais podem ser compostas de dezenas ou ate centenas de bandas espectrais.
Cada banda espectral e resultado da reflectancia do material em um determinado comprimento de
onda. O agrupamento de todas as bandas obtidas, como um cubo, forma a imagem hiperespectral.
Em uma imagem hiperespectral, cada pixel possui varias assinaturas espectrais. Como mostrado
na Figura 1.
1

Figura 1: Extracao de assinatura espectral de vetor de pixels. Modificado de [8].
Essas imagens sao muito utilizadas como fonte de informacao em estudos sobre uso, ocupacao
e monitoramento do solo. Nessas aplicacoes, e comum o uso de tecnicas de classificacao supervisi-
onada e nao supervisionada para identificar objetos de interesse baseadas em classes pre-definidas
por um especialista.
Apesar de bastante desenvolvida nos ultimos anos, a tarefa de identificar materiais na superfıcie
da Terra por meio de imagens hiperespectrais ainda oferece grandes desafios computacionais. Al-
guns desses problemas sao relacionados a extracao e combinacao de caracterısticas espectrais e
espaciais [1] e reducao de dimensionalidade devido ao grande numero de bandas [10]. Esse estudo
tem como objetivo a utilizacao do algoritmo Floresta de Caminhos Otimos [12] na classificacao de
imagens hiperespectrais. O OPF e um framework que fornece metodos de classificacao supervisio-
nada e nao supervisionada. Nesse trabalho utilizaremos o metodo de classificacao supervisionado
que modela o problema de classificacao em um grafo, em que os nos sao as amostras e as arestas
sao definidas por uma relacao de adjacencia. Essa relacao de adjacencia (ou custo) e definida por
uma funcao baseada na distancia das amostras no espaco de caracterısticas. Trabalhos recentes
tem mostrado que o classificador OPF e mais rapido e alcanca acuracias similares ao tradicional
SVM usando kernel Gaussiano [11]. Este trabalho tem como objetivo comparar o classificador
OPF com outros classificadores ja conhecidos na literatura
2

2 Trabalhos Relacionados
Essa secao apresenta o estudo realizado com finalidade de conhecer o estado da arte e os principais
conceitos aplicados a reconhecimento de padroes em imagens hiperespectrais.
Nos ultimos anos o desenvolvimento tecnologico facilitou a obtencao de imagens hiperespectrais.
Esse progresso influenciou na criacao de diversas aplicacoes para classificacao de tais imagens.
Inicialmente a classificacao era feita apenas com base na informacao espectral e cada pixel era
considerado uma amostra, o conjunto de caracterısticas dos pixels e conhecido como espectro[13].
Cada pixel e representado por um vetor que corresponde a sua reflectancia em diferentes faixas
do espectro eletromagnetico[5]. As imagens hiperespecrais apresentam elevada dimensionalidade,
por isso sao necessarios algoritmos que sejam capazes tanto de reduzir o tamanho dados, quanto
capazes de trabalhar nesse cenario[4]. Nesse aspecto, tem se observado que algoritmos baseados
em kernel sao mais eficazes que os tradicionais metodos de aprendizagem. Metodos baseados em
kernel transformam os dados em um novo espaco de caracterısticas onde se torna possıvel uma
melhor separacao entre as classes[13]. Outra forma de melhorar o desemprenho da classificacao de
imagens hiperespectrais consiste em acrescentar informacao espacial a espectral, isso significa que
agora a classificacao leva em conta a caracterıstica do pixel vizinho e nao somente a informacao
espectral obtida.
3 Metodologia
Este estudo foi dividido em duas partes, a primeira utilizando o classificador OPF e segunda utili-
zando o WEKA[9]. Os resultados da classificacao foram validados utilizando o protocolo conhecido
como k fold-cross validation[7]. Esse metodo funciona da seguinte forma: o dataset e divido em k
partes, k-1 para treinamento e uma para teste. O algoritmo e entao executado k vezes, mas para
cada vez um conjunto diferente e utilizado para teste. Neste estudo o valor cinco foi atribuıdo a k.
A Figura 2 mostra os passos seguidos nesse estudo.
Figura 2: Diagrama do processo realizado nesse estudo.
3.1 Classificador OPF
Esta etapa do trabalho sera realizada por meio da biblioteca LIBOPF [12]. O OPF, (Optimum
path forest) interpreta a imagem como um grafo. Cada amostra e um no do grafo, e as arestas
sao definidas por uma relacao de adjacencia. Uma funcao de maximizacao/minimizacao do valor
3

da distancia de cada caminho gera uma floresta de caminhos otimos, ou seja, uma particao em
grupos de diferentes caracterısticas (prototipos). A escolha de um prototipo pode ser feita de
forma supervisionada e nao supervisionada. Na etapa de teste, os prototipos competem entre
si para conquistar a amostra que se liga a ele mais fortemente, formando assim uma arvore de
caminhos otimos tendo como raiz um prototipo[11] . A etapa de classificacao e feita como se segue:
1. Normalizacao dos dados.
2. Divisao do dataset em cinco partes iguais.
3. Treinamento do classificador, utilizando quatro conjuntos, etapa de aprendizado.
4. Teste do classificador obtido no conjunto restante.
5. Calculo da acuracia obtida no conjunto de treinamento. Nesse estudo, o calculo da acuracia
foi feito no conjunto de teste. A precisao e medida levando em conta que as classes podem ter
tamanho diferente . Caso contrario se existem duas classes com tamanhos muito diferentes
e o classificador sempre atribuısse a etiqueta a classe de maior tamanho, a acuracia poderia
cair drasticamente.
3.2 Weka
Para a utilizacao dos algoritmos K-nearest Neighbor e Suport Vector Machine foi utilizada o Weka
que e uma biblioteca de algoritmos de aprendizado de maquina.
3.2.1 K-nearest Neighbor(KNN)
O KNN e um algoritmo de reconhecimento de padroes que usa a distancia euclidiana normalizada
para atribuir uma determinada amostra a um grupo. Neste caso um foi atribuido ao valor de K.
Foi utilizada a funcao IB1, disponibilizada pela WEKA.
3.2.2 Suport Vector Machine(SVM)
O SVM e um metodo de aprendizado supervisionado que analisa os dados e reconhece padroes.
Esse algoritmo se baseia na separacao das classes atraves de margens de erro maximo[3]. O kernel
gaussiano foi o escolhido para esse estudo. Foi utilizada a biblioteca LIBsvm disponibilizada pela
ferramenta WEKA.
4 Experimentos e resultados
Neste topico serao descritas as bases de dados utilizadas nesse estudo assim como os criterios de
avaliacao e resultados obtidos.
4

4.1 Bases de Dados
Para uma maior confiabilidade nos experimentos realizados iremos utilizar tres bases de dados
hiperespectrais diferentes. Duas dessas imagens, base de dados, representam areas de cultivo e
outra uma area tıpicamente urbana. As bases de dados Indian Pines e Salinas foram obtidas pelo
sensor AVIRIS e a imagem hiperespectral Pavia University foi obitida pelo sensor ROSIS.
4.1.1 Indian Pines
A base de dados Indian Pines corresponde a uma area de cultivo e vegetacao no noroeste de Indiana,
EUA. Possuindo dimensoes de 145 × 145, com resolucao espacial de 20m e 200 bandas que que
cobrem uma faixa espectral de 0, 4µm a 2, 5µm [6]. A Figura 3 mostra o Ground-truth dessa cena.
(a) Ground-truth Indian Pines
Figura 3: Ground-truth da base de dados Indian Pines. A Tabela 1 mostra as classes de interesseassim como o numero de amostras por classe.
5

Identificador Classe Numero de amostras
1 Alfalfa 46
2 Corn-notill 1428
3 Corn-mintill 830
4 Corn 237
5 Grass-pasture 483
6 Grass-trees 730
7 Grass-pasture-mowed 28
8 Hay-windrowed 478
9 Oats 20
10 Soybean-notill 972
11 Soybean-mintill 2455
12 Soybean-clean 593
13 Wheat 205
14 Woods 1265
15 Buildings-Grass-Trees-Drives 386
16 Stone-Steel-Towers 93
Tabela 1: Classes de interesse para o Indian Pines.
4.1.2 Salinas
Essa Base de dados corresponde a uma regiao de cultivo e vegetacao no Salinas Valley situado no
estado da California, EUA. Possui dimensoes 217 × 512 e possui alta resolucao espacial (3.7m por
pixel) [6]. A Figura 4 mostra o Ground truth da imagem.
6

(a) Ground-truth Salinas
Figura 4: Ground-truth da base de dados Salinas. A tabela 2 mostra todas as classes de interessebem como a numero de amostras para cada classe.
7

Identificador Classe Numero de amostras
1 Brocoli green weeds 1 2009
2 Brocoli green weeds 2 3726
3 Fallow 1976
4 Fallow rough plow 1394
5 Fallow smooth 2678
6 Stubble 3959
7 Celery 3579
8 Grapes untrained 11271
9 Soil vinyard develop 6203
10 Corn senesced green weeds 3278
11 Lettuce romaine 4wk 1068
12 Lettuce romaine 5wk 1927
13 Lettuce romaine 6wk 916
14 Lettuce romaine 7wk 1070
15 Vinyard untrained 7268
16 Vinyard vertical trellis 1807
Tabela 2: Classes de interesse para o Salidas dataset.
4.1.3 Pavia University
A base de dados Pavia University diferentemente das outras representa uma regiao urbana, referente
a Universidade de Pavia, Italia. Essa imagem possui cento e tres bandas espectrais e dimensao
340× 610pixels e resolucao espacial de 1.3m por pixel [6]. A Figura 5 mostra o Ground truth para
essa base.
8

(a) Ground-truth Pavia University
Figura 5: Ground-truth da base de dados Pavia University. A tabela 3 mostra as nove classes deinteresse da cena assim como a quantidade de amostras por classe.
Identificador Classe Numero de amostras
1 Asphalt 6631
2 Meadows 18649
3 Gravel 2099
4 Trees 3064
5 Painted metal sheets 1345
6 Bare Soil 5029
7 Bitumen 1330
8 Self-Blocking Bricks 3682
9 Shadows 947
Tabela 3: Classes de interesse para o Pavia University dataset.
4.2 Resultados
Nesta secao sao apresentados resultados obtidos aplicando os metodos de classificacao apresentados
na secao 3.
9

4.2.1 Base de dados Indian Pines
Neste experimento o OPF e comparado com os metodos tradicionais ja mencionados. As abodagens
foram avaliadas variando-se a porcentagem de amostras para teste e utilizando-se k-cross validation
como mencionado na secao 3. A figura 6 mostra os resultas obtidos em todos os cenarios.
Figura 6: Acuracia do conjunto de testes para a base de dados Indian Pines. Conjunto de treina-mento de 10% ,20%,30%,40%,50%,60% e 70% de amostras.
Um dos objetivos da classificacao e a obtencao de mapas tematicos. Na figura 7 estao represen-
tados mapas tematicos obtidos atraves da classificacao com o OPF , O mapa com 10% das amostras
possui acuracia igual a 75,58% para todas as classes. O mapa com 30% das mostras possui acuracia
igual a 78,28% para todas as classes. O ultimo possui acuracia de 81,98% para todas as classes
com 70% das amostras utilizadas na etapa de treinamento.
10
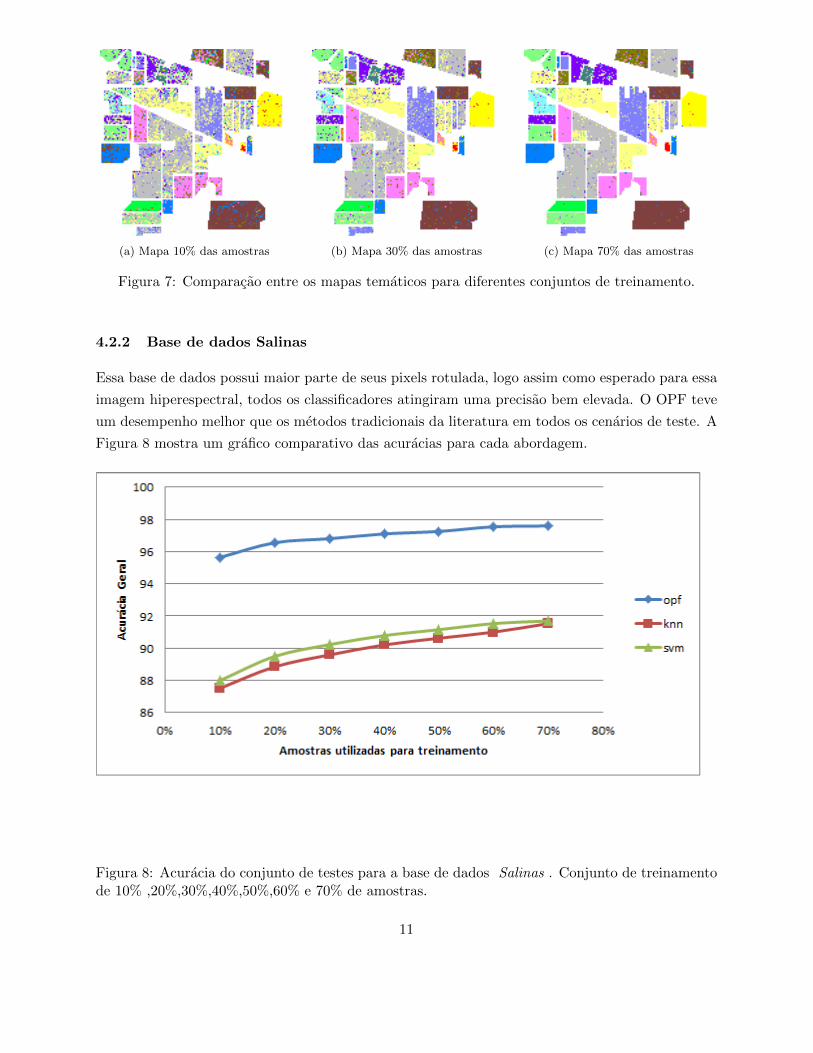
(a) Mapa 10% das amostras (b) Mapa 30% das amostras (c) Mapa 70% das amostras
Figura 7: Comparacao entre os mapas tematicos para diferentes conjuntos de treinamento.
4.2.2 Base de dados Salinas
Essa base de dados possui maior parte de seus pixels rotulada, logo assim como esperado para essa
imagem hiperespectral, todos os classificadores atingiram uma precisao bem elevada. O OPF teve
um desempenho melhor que os metodos tradicionais da literatura em todos os cenarios de teste. A
Figura 8 mostra um grafico comparativo das acuracias para cada abordagem.
Figura 8: Acuracia do conjunto de testes para a base de dados Salinas . Conjunto de treinamentode 10% ,20%,30%,40%,50%,60% e 70% de amostras.
11

Assim como para a primeira base de dados, foram gerados mapas tematicos a fim de visualizar
a acuracia do classificador obtido pelo OPF. Utilizando 10% das amostras, o classificador obteve
95,67% de precisao. Para 30% das amostras 96,8% e para 70% das amostras o classificador atingiu
97,59% de precisao.
(a) Mapa 10% das amostras para
treino
(b) Mapa 30% das amostras (c) Mapa 70% das amostras
Figura 9: Comparacao entre os mapas tematicos para diferentes conjuntos de treinamento.
4.2.3 Base de Dados Pavia University
As acuracias obtidas em todas as abordagens para conjuntos com 10%, 20%, 30%, 40%,50%, 60% e
70% de amostras estao mostradas na Figura 10. Essa imagem apresenta maior parte dos pixels nao
rotulados , logo os resultados dessa classificacao foram mais baixos que das outras bases de dados.
O classificador OPF obteve o melhor desempenho, quando comparado aos metodos tradicionais
KNN e SVM, em todos os cenarios.
12

Figura 10: Acuracia do conjunto de testes para a base de dados Pavia University . Conjunto detreinamento de 10% ,20%,30%,40%,50%,60% e 70% de amostras.
Na Figura 11 pode ser visualizada atraves dos mapas tematicos o resuldado da classificacao
utilizando o classificador OPF. Foram usadas para a montagem do mapas os resultados dos expe-
rimentos para o numero de amostras igual a 10%, 30% e 70%, As precisoes obtidas em cada caso
sao respectivamente, 68,47%, 70,80% e 74,33% para todas as classe.
13

(a) Mapa 10% das amostras para
treino
(b) Mapa 30% das amostras (c) Mapa 70% das amostras
Figura 11: Comparacao entre os mapas tematicos para diferentes conjuntos de treinamento.
5 Conclusao e Trabalhos Futuros
5.1 Conclusao
Nesse trabalho foi apresentado e avaliado o algoritmo Floresta de Caminhos Otimos (OPF), como
um novo metodo para classificacao de imagens hiperespectrais. Com o objetivo de obter um
parametro de comparacoes o OPF foi comparado com outros dois metodos ja bem difundidos na
literatura sao estes o K-nearest Neigborh (KNN) e o Suport Vector Machines (SVM) com kernel
gaussiano [11]. Foram realizados experimentos em diferentes cenarios de treino e teste, em ambos
os casos o OPF se mostrou superior ao KNN e SVM. Foram realizados testes com 10%, 20%, 30%,
40%, 50%, 60% e 70% de dados no conjunto de treinamento. O OPF foi mais rapido nas etapas de
aprendizado e teste em todos os cenarios.
Ao termino desse trabalho temos alguns pontos a ressaltar:
• O primeiro e que obtivemos exito na conclusao das tarefas propostas inicialmente.
• Segundo, a quantidade de novos conhecimentos adquiridos durante a realizacao desse trabalho
pelo orientado, sendo que a maior parte desses conhecimentos nao e abordado nas disciplinas
da graduacao em Engenharia de Sistemas.
14

5.2 Trabalhos Futuros
Os proximos passos da pesquisa sao:
• A Aplicacao do OPF em tarefas mais complexas de classificacao, como seu uso na fusao de
dados de multiplos sensores.
• Utilizar o OPF na competicao1 de classificacao utilizando diferentes tipos de ISRs [2]. Essa
competicao e feita pela IEEE Geoscience and Remote Sensing Society (GRSS), visando o
desenvolvimento de novas tecnicas de fusao de dados.
Referencias
[1] A. Alonso-Gonzalez, S. Valero, J. Chanussot, C. Lopez-Martınez, and P. Salembier. Processing
multidimensional sar and hyperspectral images with binary partition tree. Proceedings of the
IEEE, PP(99):1 –25, 2012.
[2] C. Berger, M. Voltersen, R. Eckardt, J. Eberle, T. Heyer, N. Salepci, S. Hese, C. Schmullius,
J. Tao, S. Auer, R. Bamler, K. Ewald, M. Gartley, J. Jacobson, A. Buswell, Q. Du, and
F. Pacifici. Multi-modal and multi-temporal data fusion: Outcome of the 2012 grss data
fusion contest. Selected Topics in Applied Earth Observations and Remote Sensing, IEEE
Journal of, 6(3):1324–1340, 2013.
[3] Chih-Chung Chang and Chih-Jen Lin. Libsvm: a library for support vector machines. ACM
Transactions on Intelligent Systems and Technology (TIST), 2(3):27, 2011.
[4] Yang-Lang Chang, Jin-Nan Liu, Chin-Chuan Han, and Ying-Nong Chen. Hyperspectral image
classification using nearest feature line embedding approach. Geoscience and Remote Sensing,
IEEE Transactions on, 52(1):278–287, Jan 2014.
[5] Yi Chen, N.M. Nasrabadi, and T.D. Tran. Hyperspectral image classification via kernel sparse
representation. Geoscience and Remote Sensing, IEEE Transactions on, 51(1):217–231, Jan
2013.
[6] Grupo de Inteligencia Computacional GIC. Hyperspectral remote sensing scenes, 2011.
[7] Ron Kohavi et al. A study of cross-validation and bootstrap for accuracy estimation and
model selection. In IJCAI, volume 14, pages 1137–1145, 1995.
[8] A. A. Araujo J. A. dos Santos L. C. B. dos Santos, S. J. F. Guimaraes. Unsupervised hypers-
pectral band selection based on spectral rhythm analysis. In SIBGRAPI 2014, Rio de Janeiro,
Brazil, May 2014.
1http://www.grss-ieee.org/community/technical-committees/data-fusion/
15

[9] Geoffrey Holmes Bernhard Pfahringer Peter Reutemann Ian H. Witten Mark Hall, Eibe Frank.
The weka data mining software: An update. SIGKDD Explorations, 2009.
[10] R. Nakamura, J. P. Papa, L. Fonseca, J. A. dos Santos, and R. da S. Torres. Hyperspectral
band selection through optimum-path forest and evolutionary-based algorithms. In Geoscience
and Remote Sensing Symposium, IEEE International, Munich, Germany, July 2012.
[11] J. P. Papa, A. X. Falcao, and Celso T. N. Suzuki. Supervised pattern classification based on
optimum-path forest. International Journal of Imaging Systems and Technology, 19:120–131,
2009.
[12] J.P. Papa, A.X. Falcao, and C.T.N. Suzuki. LibOPF: A library for the design of optimum-
path forest classifiers, 2009. Software version 2.0 available at http://www.ic.unicamp.br/
\~{}afalcao/LibOPF.
[13] Y. Tarabalka, J. Chanussot, J.A Benediktsson, J. Angulo, and M. Fauvel. Segmentation
and classification of hyperspectral data using watershed. In Geoscience and Remote Sensing
Symposium, 2008. IGARSS 2008. IEEE International, volume 3, pages III – 652–III – 655,
July 2008.
16




















