
ОЧЕРКИ ПО КОЛИЧЕСТВЕННОЙ ГЛОТТОЛОГИИ И ...
244
Б. И. Бартков ОЧЕРКИ ПО КОЛИЧЕСТВЕННОЙ ГЛОТТОЛОГИИ И ГЛОТТОГРАФИИ Казань Издательство «Бук» 2017
-
Upload
khangminh22 -
Category
Documents
-
view
2 -
download
0
Transcript of ОЧЕРКИ ПО КОЛИЧЕСТВЕННОЙ ГЛОТТОЛОГИИ И ...

Б. И. Бартков
ОЧЕРКИ ПО КОЛИЧЕСТВЕННОЙ ГЛОТТОЛОГИИ И ГЛОТТОГРАФИИ
КазаньИздательство «Бук»
2017

УДК 81’1ББК 81
Б26
Рецензент:Миронец Юрий Алексеевич, кандидат филологических наук, доцент
(Дальневосточный федеральный университет)
Бартков, Борис Ильич.Б26 Очерки по количественной глоттологии и глоттографии /
Б. И. Бартков. — Казань : Изд-во «Бук», 2017. — 244 с.
ISBN 978-5-906954-54-1.
Книга посвящена количественно-качественному рассмотрению основных вопросов языкознания: язык — речь, их двуплановые элемен-ты и уровни, полисемия, синонимия, антонимия, термины. Рассмотре-ны важные вопросы количественной дериватологии и дериватогра-фии, проблемы составления аффиксальных минимумов, количествен-ная фразеология и паремиология, а также наиболее важные лингвисти-ческие постулаты и курьезные ляпсусы.
Книга рассчитана на лингвистов, как теоретиков, так и практи-ков, включая преподавателей вузов и Академии наук.
УДК 81’1ББК 81
© Б. И. Бартков, 2017 © Оформление. ООО «Бук», 2017
ISBN 978-5-906954-54-1

ВВЕДЕНИЕ
В ходе 45-летних занятий глоттологией (лингвистикой) и глоттогра-фией (дериватогорафией) был разработан ряд новых подходов к опи-санию речи и языка, структуры и функции их элементов в синхронии и диахронии, а именно: описание аффиксов на количественной диахро-нической основе с использованием максимально крупных диахрониче-ских толковых, обратных и частотных словарей; введен ряд новых ко-личественных характеристик деривационных аффиксов, таких как диа-хроническая и синхроническая продуктивность, модельная и суммар-ная частотность, модельная и суммарная внутренняя и внешняя валент-ности и т. д.; были сформулированы новые, научно корректные дефи-ниции фразем и паремием, а также их семантических классов, что по-зволило впервые осуществить их количественное структурно-функцио-нальное описание. Впервые составлены количественно-качественные дериватарии английского (300 аффиксов), русского (100 аффиксов), украинского (100 аффиксов), немецкого (70 аффиксов) и французско-го (80 аффиксов) языков. Предложен ряд количественных частотных, продуктивных и частотно-продуктивных аффиксальных минимумов ан-глийского, русского, немецкого и французского языков.
В свете современных представлений о языке и речи как системе зна-ков, имеющих звучание и значение и передающих понятия, суждения и умозаключения, рассматриваются ляпсусные высказывания некото-рых лингвистов об элементах языковой системы, о ее структуре и функ-ции, изменяющихся синхронически и диахронически в пространстве. Показано, что причиной ошибок является отсутствие корректных дефи-ниций ряда терминов, а также слабое знание как лингвистических, так и философских законов и категорий.
Показано, что «фразеологические единицы» и так называемая «се-мантическая классификация» В. В. Виноградова не имеют строгих науч-ных определений. Поэтому за прошедшие 60 лет никто не смог исполь-зовать их для реального однозначного разбиения на классы единиц ка-
Альбине, которая стойко выносила тяготы и лишения семейной жизни с лингвистом-ученым,
успешно воспитав детей — Таню и Илью!

4
кого-либо фразеологического словаря. Анализ всех примеров В. В. Ви-ноградова в свете наших научно корректных дефиниций позволил выявить 101 фразему [непредикативное устойчивое словосочетание (УСС)] и 28 паремием [предикативных УСС]. Нами предложены новые лингвистические дефиниции семантических классов: (а) фраземные сращения — это фраземы, имеющие 2 значения: прямое — неизвестное говорящим из-за незнания значений ряда слов — архаизмов, имен соб-ственных и религионимов; переносное (образное) значение — извест-ное и высокочастотное (выявлено 8 единиц = 7,9 % фразем); (б) фра-земные единства — это фраземы, имеющие 2 значения: прямое — из-вестное, но низкочастотное; переносное — известное и высокочастот-ное (65 единиц = 64,4 %); (в) фраземные сочетания — это фраземы, имеющие пока одно значение — прямое, — известное и высокочастот-ное (28 единиц = 27,7 %). Установлено, что фраземы образованы по сле-дующим структурным моделям: ГС (30 %), ГпС (11 %), ПС (9 %), СГ (5 %), СнеГ (2 %), пСГ (2 %) и т. д. Впервые предложены научные дефиниции семантических классов паремием: (а) паремиемные сращения — это паремиемы, имеющие 2 значения: прямое — неизвестное говорящим из-за незнания значений ряда слов — архаизмов, имен собственных и религионимов; переносное (образное) значение — известное и высо-кочастотное (выявлена 1 единица = 3,6 % паремием); (б) паремиемные единства — это паремиемы, имеющие 2 значения: прямое, — извест-ное, но низкочастотное; переносное — известное и высокочастотное (26 единиц = 92,8 %); (в) паремиемные сочетания — это паремиемы, имеющие пока одно значение — прямое, — известное и высокочастот-ное (1 единица = 3,6 %). Установлено, что паремиемы, как предложе-ния, относится к изъявительному (27 единиц) и повелительному (1 еди-ница) наклонению; употребляются в настоящем (3 единицы), прошед-шем (7 единиц), будущем (3 единиц) времени; стоят в действительном (146 единиц) или страдательном (отсутствуют) залоге.
Количественный семантико-структурный анализ 168 паремием (предикативных устойчивых словосочетаний=пУСС) русского языка показал, что они распределяются по следующим семантическим клас-сам: а) сращения [пУСС, имеющие 2 значения: прямое — неизвестное говорящим из-за незнания значений ряда слов — архаизмов, имен соб-ственных и религионимов; переносное (образное) — известно и высо-кочастотно] — 3 единицы (1,8 %); б) единства [пУСС, имеющие 2 зна-чения: прямое — известное, но малочастотное; переносное — извест-ное и высокочастотное] — 130 единиц (77,4 %); сочетания [пУСС, имею-

5Введение
щие пока одно значение — прямое — известное и высокочастотное] — 35 единиц (20,8 %). Анализ выявил распределение паремием по накло-нению: а) изъявительное — 151 единиц (89,9 %); б) повелительное — 17 ед. (10,1 %); сослагательное — не представлено; по времени: а) на-стоящее время — 80 ед. (53,0 %); прошедшее — 55 ед. (36,4 %); буду-щее — 16 ед. (10,6 %); по залогу: а) действительный залог — 146 ед. (96,7 %); страдательный залог — 5 ед. (3,3 %).

Глава 1
СТРУКТУРА И ФУНКЦИЯ ЯЗЫКА И РЕЧИ
§ 1. Язык/речь — мышление — материальный мир
В головном мозгу человека существует две разных системы эле-ментов: 1) мыслительная (понятийная), состоящая из элементов сле-дующих уровней (ярусов): понятия — суждения — умозаключения; и 2) лингвистическая, элементами которой являются фонемы — мор-фемы — лексемы — фраземы — граммемы (в том числе: 1) части речи: 2) словесные формы; 3) члены предложения; 4) словесные конструкции (включая паремиемы).
Элементы каждой из этих 2-х систем располагаются в разных частях головного мозга и удерживаются разными структурно-функциональны-ми группами нейронов.
Известно, что понятия формируются в коре головного мозга с помо-щью 8 объективно существующих органов чувств (зрения, слуха, вку-са, обоняния, осязания тактильного, осязания термического, равнове-сия, мышечной усталости) (см. Рис. 1). Понятия могут объединяться в суждения, а суждения — в умозаключения. Вместе они образуют мыс-лительную систему (нестрого называемую сознанием, знанием, мыш-лением, памятью, информацией). Понятия, выражающие эмоции и так называемые душевные переживания, также являются частью этой си-стемы. Каждому элементу мыслительной системы (понятию, суждению или умозаключению) соответствуют элементы лингвистической систе-мы — языка и речи.
Как известно, сначала в мозгу (на основе работы органов чувств) формируется понятие о предмете окружающей действительности, а за-

7Структура и функция языка и речи
тем в другой части головного мозга создается соответствующий ему лингвистический знак (слово, словосочетание и т. п.). Связь между эле-ментами системы мышления и соответствующими элементами лингви-стической системы проходит от нейрона к нейрону через синапсы. Си-стема органов чувств называется 1-ой сигнальной системой. Однако, новые понятия, суждения и умозаключения можно формировать и с по-мощью лингвистической системы, называемой поэтому 2-й сигнальной системой.
Работу мыслительной системы изучает раздел философии, называе-мый теорией познания [147; 148], к которой пытается примкнуть так называемый когнитивизм — эклектичное заморское направление фи-лософии с туманными исходными посылками, неясными целями и ме-тодами решения неизвестно каких задач.
Элементы лингвистической системы (речи и языка) — изучает лин-гвистика (глоттология, языкознание, языковедение). Один из основа-телей современной лингвистики как научной дисциплины — Ферди-нанд де Соссюр [139] прямо говорил, что «единственным и истинным объектом лингвистики является язык, рассматриваемый в самом себе и для себя» [139, 269].
Правда, А. А. Холодович [139], редактор русского перевода трудов Ф. де Соссюра, который сам лично не слушал Ф. де Соссюра и не ви-дел лекции ВСЕХ слушателей, письменно высказывает предположение, что эти слова добавили Ш. Балли и А. Сеше — издатели курса. Но как бы то ни было, эта идея — верна!
Ф. де Соссюр [139] говорил, что существует также «внешняя лин-гвистика», задачей которой является изучение следующих проблем: (1) связь между языком и мышлением (сознанием); (2) связь между языком и обществом.
Следовательно, одной из важных проблем лингвистики (глоттоло-гии) является исследование связи между языком и окружающим миром.
История этого вопроса уходит корнями в античность [111; 33]. Еще в III в до н. э. греческий философ Секст Эмпирик предложил изо-бражать связь между Предметом (человеком) — Понятием о нем (обра-зом предмета) — Словом (именем) в виде треугольника (по-видимому, в душе он был пифагорейцем!). Он первый сообразил, что между «пред-метом» и его «образом в голове» существует связь. С другой стороны, между «образом предмета» и его «названием» также существует связь. С третьей стороны, между «предметом» и его «названием» («именем») также существует какая-то связь. Эта схема Секста Эмпирика имеет сле-дующий вид [33].

8 Глава 1
Отметим, что эта схема предполагает существование непосредствен-ной связи между предметом и словом (именем). Однако, в наше вре-мя стало известно, что прямой связи между предметом и словом (лин-гвистическим знаком) не существует. Если бы каждому предмету соот-ветствовало одно слово, то на Земле существовал бы только один язык (а не 6,5 тыс. разных языков, известных в наше время).
В начале XX в. американские лингвисты Ogden and Richards шумно объявили о том, что они нашли, наконец, связь между словом (word), вещью (thing) и мыслью (thought) о ней, изобразив ее с помощью сле-дующего треугольника («забыв», правда, упомянуть Секста Эмпирика).
Ясно, что американские лингвисты «позаимствовали» схему Секста Эмпирика, слегка модернизировав ее. Так, «образ Диона» они замени-ли на «Thought», что ухудшило картину, так как неясно, что это за мысль, о чем она. А у Секста Эмпирика «образ Диона» вполне соответствует современному термину «понятие» о предмете (например, о философе Дионе).
Слово «Word» является улучшением схемы Секста Эмпирика, так как в его времена еще не понимали, что лингвистический знак име-ет не только «звучание», но и «значение». Положительным является то, что американцы заменили сплошную линию (основание треугольни-ка), обозначающую непосредственную связь между словом и предме-том, на штриховую линию, что несколько улучшило схему. Если Секст

9Структура и функция языка и речи
Эмпирик рассматривал связь между человеком Дионом и его именем [ДИОН] как нечто реально существующее, то в ХХ в. н.э. лингвисты ста-ли поняли, что связь эта — опосредованная (через понятие), отсюда — штриховая линия.
Несколько позже появились изображения так называемого «семан-тического треугольника». Так, Ю. С. Степанов [140] предложил следую-щую схему этого «семантического треугольника».
Семантический треугольник
Общий случай Примерфонетическое слово петух [п´эиту́х]
отражаетсяПредмет или денотат, или референт
Смысл или сигнифинат
Домашняя птица, самец кур, с красным гребнем на голове и шпорами на ногах
Как видно, здесь изображена непосредственная связь между «пред-метом» и «звучанием», с одной стороны, и «сигнификатом», т. е. «зна-чением», с другой. Возникает вопрос, а где же на этой схеме находит-ся «понятие»? Ведь еще умеренные номиналисты (тысячу лет назад!) утверждали, что «предмету» соответствует «понятие», формирующееся в голове человека, а В. Гумбольдт 150 лет назад полагал [96], что «поня-тие» предшествует «слову». Ясно, что предложенную схему можно вос-принимать только, как предварительную попытку изобразить связь ме-жду «предметом», «понятием» и «словом».
Известна также попытка представить отношения между языком и окружающим миром в виде четырехугольника [34]. На рисунке изо-бражена связь между «понятием» и «значением», что является верным. Однако прямой связи между «предметом» и «звучанием» не существует, о чем говорит тот факт, что один и тот же предмет выражается разными звучаниями в разных языках.
назы
вает
имеет смысл

10 Глава 1
Хотя, как известно, «понятие» отражается «словом» (имеющим как звучание, так и значение), прямая связь между «понятием» и «звуча-нием» на этой схеме отсутствует.
Приходится констатировать, что и эту попытку следует рассматри-вать как предварительную.
Таким образом, остаются неясными следующие вопросы:1) каков характер связи между предметом и словом;2) почему связь между словом, понятием и предметом изображает-
ся треугольником?3) и, наконец, где же находятся эти «треугольники» и «прямоуголь-
ники»?Итак, современные представления отвергают существование непо-
средственной связи между предметом и словом. Доказано, что об опре-деленном «предмете» с помощью 8 органов чувств человек (и живот-ное) формирует в коре головного мозга «образ» этого предмета, то есть, выражаясь научно, «понятие» о предмете. В другой части коры головно-го мозга человек формирует «слово» (вообще говоря, лингвистический знак), которое отражает это «понятие».
В целом, процесс идет следующим образом: «предмет» восприни-мается органами чувств, и в мозгу формируется «понятие», которому в другой части мозга формируется «слово». С другой стороны, если мы воспринимаем «слово» (то есть, слышим его или видим написанным), то в мозгу возбуждается «понятие», которое соответствует «предме-ту». Следовательно, никакого «треугольника» не существует, а имеется прямая линия — «одноугольник» (то есть, развернутый угол в 180 гра-дусов), по которой и проходит этот процесс слева направо или справа налево.
Предмет Понятие Слово (лингвистический знак)
То есть на самом деле мы имеем не «треугольник», а «одноугольник»!

11Структура и функция языка и речи
Так, например, «понятию» о дереве соответствует «слово» дерево, а «понятию» об «избушке на курьих ножках» соответствует «словосоче-тание» избушка на курьих ножках.
Ни Секст Эмпирик, ни Огден вкупе с Ричардсом, ни их последовате-ли и улучшатели ничего не писали о том, где же находится этот пресло-вутый «треугольник», который на самом деле оказался «одноугольни-ком»! Как известно, «понятие» формируется в головном мозгу, соответ-ствующее ему «слово» также формируется в мозгу, но в другой его ча-сти. Поэтому мы предлагаем следующую схему, которая изображает эту связь в обобщенном виде.
Связь между языком и окружающим миром выглядит следующим об-разом: с помощью 8 органов чувств человек формирует в коре головно-го мозга «понятие» о «предмете». Этому «понятию» в другой части мозга формируется «слово» (или другой лингвистический знак).
Предмет Понятие Слово (лингвистический знак)
Заметим, что на этой схеме представлены простейшие отношения: предмет — понятие — слово. Аналогично можно построить схему связи между свойством предмета либо действием и его характером, с одной стороны, и лингвистическим знаком, с другой.
Специально отметим, что «информация» — это ничто иное, как мно-жество понятий, суждений и умозаключений, т. е. категорий мышле-ния; а «мышление» — это оперирование этими категориями, что яв-ляется предметом изучения раздела философии, называемого «теори-

12 Глава 1
ей познания», и которая, как известно, появилась задолго до возникно-вения так называемой «когнитивной лингвистики» с ее жонглировани-ем туманными представлениями о концептах, фреймах, скриптах, наив-ных «кусочках действительности» и прочей абракадаброй, чепухой, чу-шью и, говоря транслитерационно, рениксой.
Как известно, понятие о конкретном предмете у людей, говоря-щих на разных языках, практически одно и то же, но оно выражает-ся разными лингвистическими знаками (словами, словосочетаниями и т. п.). Следовательно, если у полиглота имеется «понятие» о каком-ли-бо «предмете», то этому «понятию» соответствует столько «слов», сколь-ко языков он знает (схема ниже).
Эта схема также иллюстрирует положение Ф. де Соссюра о «произ-вольности языкового знака», суть которого состоит в том, что каждое «понятие» вначале может быть названо любым словом или словослчета-нием (лингвистическим знаком вообще).
§ 2. Речь, язык. Их двусторонние элементы
Уточняя Ф. де Соссюра [139], можно сказать: «Единственным и ис-тинным объектом лингвистики является язык и речь во времени и про-странстве, а также их отношение к мышлению и обществу».
Хотя Фердинанд де Соссюр [139] и предложил различать «язык» и «речь», лингвистически корректных определений этих понятий он не дал.
Самое лучшее «гибридное» определение языка «по Соссюру» можно скомпоновать из нескольких его высказываний: «Язык есть система зна-ков, выражающих понятия, в которой единственно существенным явля-

13Структура и функция языка и речи
ется соединение плана выражения (звучания) и плана содержания (зна-чения)».
«Речь — сумма всего того, что говорят люди» [139, с. 57].Мы даем следующие дефиниции речи и языка.«Речь — это система, представляющая собой непрерывный поток
множества взаимосвязанных звуковых и значащих элементов, передаю-щих информацию (т. е. понятия, суждения и умозаключения) об окру-жающем мире». А ее элементами являются звуки, слова, непредикатив-ные и предикативные словосочетания.
Поскольку язык является обобщением речи, то, иными словами, «язык — это словари и грамматика» (если под «словарями» понимать упорядоченные собрания элементов языка — фонем, морфем, лексем, фразем и граммем).
Или: «Язык — это множество обобщенных речевых элементов (фо-нем, морфем, лексем, фразем, граммем) и правил их употребления в речи».
В настоящее время считается, что каждый лингвистический элемент (знак) является двуплановым, то есть имеет звучание и значение. Это подтверждается философией, утверждающей, что все, объективно су-ществующее, имеет «форму» и «содержание», чему в лингвистике соот-ветствуют «значение» и «звучание», т. е. план выражения и план содер-жания знака.
Известно, что «Палиндром (гр. palindromos = движущийся обрат-но) — слово или словосочетание, одинаково читающееся как слева на-право, так и справа налево (напр., казак, дом мод)» [87, 417]. Заметим, что ни слово «палиндром», ни примеров мы не найдем в программах, учебниках по «Введению в языкознание» или по «Общему языкозна-нию», по которым готовят будущих лингвистов. Считается, что место ему — в сборниках материалов для детей типа «Игры в рифмы» В. В. Во-линой (1997), предназначенных для развития языковой культуры и ху-дожественного вкуса.
Однако это не так. Когда начинающие лингвисты знакомятся с по-нятием речи, они узнают, что «речь — однонаправлена» и запоминают это на всю жизнь. Повседневный опыт говорит им, что это так. Но фи-лософский закон «единства и борьбы противоположностей» [147; 148] гласит о том, что если в мире вообще (а, следовательно, и в лингвисти-ке, в частности!) существует процесс, направленный в одну сторону, то вполне закономерно должен существовать и процесс, направленный в противоположную сторону. В письменном варианте речи — тексте — палиндром как раз и демонстрирует свойство речи «течь не только сле-

14 Глава 1
ва направо, но и в противоположном направлении, справа налево», на-пример: «А роза упала на лапу Азора», «поп», «шабаш» и т. д. Заметим, что палиндромами могут быть слова-лексемы («Анна», «поп», «шалаш», «кабак», «казак», “bib”, “dad”, “mom”, “nun”, “pop”, “poop”, “SOS”), не-предикативные словосочетания-фраземы («На доме чемодан», «Дом мод») и предложения-паремиемы («Я иду себе судия», «Кит на море ро-мантик», «Коту тащат уток», «Нажал кабан на баклажан», «Хорош шо-рох», «Уж я веники не вяжу», «Аргентина манит негра», «Лазер резал»,
“Madam, I’m Adam”, “A man, a plan, a canal: Panama”, “Able was I ere I saw Elba”).
Следовательно, палиндромы являются важным достоянием лин-гвистики, показывающим, что письменная речь может течь в двух направлениях: слева направо — в общем случае, и справа налево — в частности, лишний раз подтверждая как справедливость самой фи-лософии, так и ее применимость к объяснению сложных явлений лин-гвистики.
Лингвистические элементы, например, слова, по Соссюру [139], имеют, с одной стороны, «план выражения» и, с другой стороны, «план содержания», каковым следует считать «значение», которое является «отражением понятия» о предмете. И как, например, отражение яблока в зеркале отличается от самого яблока, так и «отражение понятия» (т. е. значение), хранимое нейронами одной части головного мозга, отлича-ется от самого «понятия», хранимого нейронами другой части мозга.
Следовательно, необоснованными следует считать высказывания о том, что «фонема имеет только звучание, но не имеет значения», так как они противоречат философии, из которой следует, что если фонема объективно существует, то она должна иметь как форму (в лингвисти-ке — это «звучание»), так и содержание (в лингвистике — это «значе-ние»). Поскольку фонема и лексема являются единицами разных уров-ней языка, то и их «значения» должны выражаться по-разному. Нет смысла у фонемы искать «лексемное значение», как нет смысла у лек-семы искать «фонемное значение». Глубоко мыслящие лингвисты [82] давно уже утверждали, что «значением» фонемы является набор ее диф-ференциальных признаков (ДП). В последнее время положение о том, что «фонема — двусторонняя единица», и что «фонемное значение — это набор ее ДП», подтверждается [82].
Семема, как единица значения (плана содержания), является, так сказать, «половинкой» знака, а не полноправной единицей языка, и по-этому не может рассматриваться «на равных» в одном ряду с лексемой, морфемой и фонемой.

15Структура и функция языка и речи
Слог также не является полноправной единицей языка; это всего лишь звучащая «половинка» знака, не имеющая значения.
Исходя из того, что язык является обобщением речи, современные представления об их элементах и отношениях между ними можно выра-зить следующим образом (Табл. 1).
Таблица 1Единицы речи и языка, расположенные иерархически
по возрастанию их сложности
Речь Язык Примеры
Звук Фонема [e], [u], [ou], [i:], [b], [p], [d], [k], [s], [t];[А], [У], [Б], [Б‘], [П], [П’], [Д], [К’], [Р]
Морф Морфема Be-, en-, dis-, over-; -dom, -ess, -ity, -al, -ic;Пере-, без- (бес-), дис-; -ость,
-ник, -окСлово Лексема I, bit, beat, cat, go, put, big, hardly, and,
outЯ, дом, есть, белый, быстро, у, или, эй
Непредикатив-ное словосоче-тание
Фразема Бить баклуши; у черта на куличках; белая кость; продуктовый магазин; синий чулок;A white horse; to kick the bucket; a blue bird, Achilles’ heel, etc.
Высказывание (предикатив-ное словосоче-тание)
ГраммемаА) Граммемы слов (лексем)Части речи: С, П, Г, Н, Ме,Чи, Ча, Меж, Пр, СоюзБ) Граммемы словесных форм(Сущ.: склонение; Глаг.:спряжение; Прил., Нареч.:степени сравнения)В) Граммемы словесныхпозиций (члены предл.: П, С, Д, Оп, Об, Со, Ча, Пр., Межд)Г) Граммемы словесныхконструкций (типы предложений)(в т. ч. паремиемы)
А) В английском=616 тыс.; в рус-ском=300 тыс; в чешском=250 тыс. лексемБ) Распределяются примерно так: су-ществительные=40 %; глаголы=15 %;Прилагательные 25 %; наречия=10 %; остальные=10 %В) Распределяются примерно так: подлежащее=40 %.; сказуемое=20 %.; определение=15 %; дополне-ние=10 %; обстоятельство=5 %; ча-стицы=5 %; союзы=3 %; междометия и проч.=2#Г) Типы предложений: утвердитель-ные, отрицательные; Повествова-тельные, вопросительные, восклица-тельные; и т.
Примечание. Разбиение граммем на 4 класса предложено Б. Н. Голо-виным [82, 182–193]

16 Глава 1
Как известно, рациональная терминология — основа любой науки, поэтому мы дадим определения речевым и языковым элементам. Сна-чала рассмотрим элементы речи.
Звук — это модулированные колебания выдыхаемого человеком воз-духа. Морф — минимальная значимая часть слова, состоящая из зву-ков. Слово — минимальная свободная единица словосочетания (непре-дикативного или предикативного). Непредикативное словосочетание (нСС) — два или более слов, связанных непредикативными связями (со-гласование, управление, примыкание). Высказывание — это предика-тивное словосочетание (предложение).
Рассмотрим элементы языка:Фонема — минимальная звуковая единица языка, служащая для по-
строения морфем и лексем. Морфема — это минимальная значимая часть лексемы, состоящая и фонем. Лексема — это минимальная сво-бодная единица непредикативного или предикативного СС (предло-жения). Фразема — это непредикативное устойчивое словосочетание. Предложение — это предикативное словосочетание, передающее ин-формацию об окружающем мире (законченную мысль). Граммема — единство грамматического значения и средств его выражения. Это определение является довольно общим, поскольку оно включает все из-вестные граммемы, содержащиеся в самых полных грамматиках, в том числе и паремиемы — устойчивые предложения).
§ 3. Теория языковых уровней
Важным для лингвистики является решение вопроса о том, из ка-ких единиц состоит речь, а из каких — язык, поскольку от этого зави-сит решение вопроса о том, что же следует изучать лингвистам. Целью «теории языковых уровней» как раз и является выявление единиц язык и речи, поскольку только выделив единицы, лингвист сможет начать их изучение. Однако вопрос о полном наборе таких единиц до сих пор не решен.
Как известно, еще 2,5 тыс. лет назад Аристотель [33] выделял в речи следующие единицы: звук, слог, имя, глагол, союз (включающий место-имение и артикль), член (прочие единицы), падеж, предложение [33; 111], то есть, звук — слог — слово — предложение. Падеж является од-ной из граммем (также, как и предложение). Сам Аристотель писал, что «слог» полноправной единицей не является [111].

17Структура и функция языка и речи
Американские дескриптивисты и трансформисты-генеративисты раз-личают всего 3 элемента в языке (кстати, специального строгого подраз-деления объекта своего исследования на «язык» и «речь» они не прово-дят): фонему, морфему и предложение. Причем под морфемой они могут понимать как корневые морфемы, так и слова (John, ran, away).
Французский лингвист Э. Бенвенист [80], например, выделяет сле-дующие единицы языка: фонемы — морфемы — лексемы.
Отметим, что фраземы (устойчивые непредикативные словосочета-ния) как самостоятельные языковые единицы американские лингви-сты специально не выделяют и, следовательно, не изучают. Вместо это-го американцы и некоторые «продвинутые» российские лингвисты ис-пользует туманное заморское слово «идиома», которое, как выясня-ется, не имеет строго научной дефиниции ни в английском, ни в рус-ском языках и поэтому понимается каждым «как заблагорассудится». Так, “A Book of English Idioms” [7] представляет собой лингвистическую «солянку» (smorgasbord) и в числе «идиом» содержит 23 лексемы (gaga; dotty, a nest-egg; hocus-pocus; potty; soft; to stomach; to wolf), 893 фра-земы (поговорки) — непредикативные устойчивые словосочетания (a Sisiphean task; to kick one’s heels; a wild goose chase; a white elephant) и 99 паремием (пословиц) — предикативных устойчивых словосочета-ний (A little bird told me; Even a worm will turn; It’s just one of those things; That is up to him; There is no smoke without fire).
Ясно, что нужно быть не лингвистом, а “gaga”, чтобы пользоваться та-ким псевдотермином, как «идиома», в потугах научного описания языка.
Б. А. Плотников [129] выделяет следующие уровни (то есть, наборы единиц) и ярусы (наборы знаков) (Табл. 2).
Таблица 2Основные уровни и ярусы языковой системы (по [129])
Уровень Ярус
Предложения Суперзнаковый
Слова Знаковый
Фонемы Субзнаковый
Он выделяет еще и промежуточные уровни, состоящие из таких еди-ниц, как «слоги» (субзнаковый ярус), а также «морфемы» и «словосоче-тания» (знаковый ярус)
Заметим, что по современным представлениям «слово» является единицей не языка, который имеет в виду автор схемы, а речи. Поэтому его следует заменить языковой единицей — «лексемой».

18 Глава 1
Неизвестно, по какому принципу выделяются «основные» и «проме-жуточные» уровни и их единицы? Поскольку без так называемых «про-межуточных» уровней [129] язык не может существовать, то они, следо-вательно, должны быть отнесены к так называемому «основному» уров-ню. Неясно, почему столь различные единицы, как «морфемы», «слова» и «словосочетания» относятся к одному ярусу — «знаковому»? Что же касается «слога», так это вообще не полноправная двуплановая едини-ца, а всего-навсего, так сказать, «половинка знака», о чем писал вели-кий Аристотель 2,5 тыс. лет назад.
Напомним, что Ф.де Соссюр [139] — основоположник учения о язы-ке, как о знаковой системе, все элементы считал знаками без дифферен-циации их на собственно знаки, субзнаки, суперзнаки, гипознаки, ги-перзнаки и проч.
Такое жонглирование различными произвольными названиями ярусов и единиц разных уровней ничего нового для понимания языка как системы знаков не дает, а только захламляет лингвистическую тер-минологию.
В. А. Звегинцев [104] выделяет следующие единицы языка, снаб-жая их соответствующими примерами, что позволяет точнее понять его концепцию.
Таблица 3Уровни и ярусы языка
Уровень (по [104]) Примеры из [104] Ярус (по [129])
Предложение Автор написал книгу Суперзнак
Словосочетание Автор написал, написал книгу Знак
Слово Автор, книга, написал Знак
Морфема Автор, нак-пис-а-л, книг-а Знак
Слог Ав-тор, на-пи-сал, кни-гу Субзнак
Фонема А-в-т-о-р, н-а-п’-и-с-а-л, к-н’-и-г-а Субзнак
Во-первых, отметим, что в этой таблице вперемешку приведены еди-ницы языка (предложение, морфема, фонема) и речи (словосочетание, слово).
Во-вторых, «слог», как известно, выделяется в речи, но не являет-ся полноправной единицей, так как имеет только звучание, но не име-ет значения. Например, в слове «фо-не-ма», все слоги имеют звучание, но ни один не имеет значения. Ясно, что можно изучать «слог» в спе-циальных просодических целях, но не следует забывать, что это всего лишь «половинка» полноправной лингвистической единицы.

19Структура и функция языка и речи
В. А. Звегинцев [104] не пишет, что он понимает под «словосочета-нием». В русском синтаксисе — это непредикативные («по умолчанию», как говорят программисты-компьюторщики) словосочетания. Предло-жение — это тоже словосочетание, но предикативное.
Однако, среди примеров «словосочетаний» у [104] мы видим такой, как «автор пишет». Но это же «предложение»(!) и место ему в верхней строке, содержащей «предложения».
Видимо, автор «слыхом не слыхивал» о принципиальном различии между «непредикативными связями» и «предикативными связями», ле-жащим в основе синтаксического деления на «словосочетания» и «пред-ложения». Налицо грубая лингвистическая ошибка.
Очевидно, что вклад В. А. Звегинцева [104] в так называемую «тео-рию языковых уровней» скорее отрицательный, чем положительный, поскольку он вводит в заблуждение начинающих лингвистов и, мягко говоря, удивляет профессионалов.
В 1931 г. Л. В. Щерба [153] опубликовал статью под названием «О трояком аспекте языковых явлений и об эксперименте в языкозна-нии», в которой, в частности, пишет: «Я буду называть процессы гово-рения и понимания «речевой деятельностью» (первый аспект языковых явлений)» [153, 39].
Но, как известно, о «речевой деятельности» Ф. де Соссюр [139] го-ворил намного ранее, и «акт речевого общения» он понимал только как часть «речевой деятельности». Отметим, что Ф. де Соссюр отде-лил «язык» от «речи», а под «речевой деятельностью» понимал их сум-му и ни о каких особых специальных элементах «речевой деятельности», отличных от «языка» или «речи», даже не упоминал [139].
Ф. де Соссюр рассматривает акт говорения как процесс передачи «понятий» с помощью «речи». Акт слушания представляет собой обрат-ный процесс, а именно: слушание «речи» и возбуждение соответствую-щих «понятий в коре головного мозга. Следовательно, как при гово-рении, так и при слушании мы имеет дело с «речью» и ее элементами, но никакой новой лингвистической системы или подсистемы не возни-кает. Обобщением «речи» и ее элементов, как известно, являются «язык» и его элементы.
Тем не менее, А. А. Гируцкий [93], решил реанимировать идею «троя-кого подхода к феномену языка», всуе, для красного словца сославшись на В. Гумбольдта и Л. В. Щербу [153], и рассматривает «Язык», «Речь» и «Речевую деятельность» как равноправные стороны этого трехсторон-него гибрида.

20 Глава 1
Таблица 4Элементы языка, речи и речевой деятельности [93, 234]
Язык Речь Речевая деятельность
Фонема Аллофон Звук
Морфема Алломорф Морф
Лексема Аллолекс Лекс
Семема Значение Сема
Слово Словоформа Словоупотребление
Предложение Высказывание Фраза
Обратим внимание на следующее.Во-первых, поскольку «речевая деятельность» в понимании Ф. Де
Соссюра представляет собой философскую категорию «общего» по от-ношению к «речи» и «языку», представляющими категорию «частного», то их рассмотрение в качестве трех равноправных сущностей противо-речит философии, а, следовательно, антинаучно.
Во-вторых, рассмотрение таких одноплановых семантических еди-ниц, как «семема», «значение» «сема» наравне с остальными двуплано-выми единицами неправомерно и антинаучно, поскольку каждый объ-ективно существующий элемент должен иметь форму и содержание, что в лингвистике соответствует звучанию и значению.
В-третьих, судя по тому, что фонема находится в верхней строке таб-лицы, а предложение — в нижней, делаем вывод, что перечисление единиц идет в направлении от простых к сложным. Тогда получается, что «лексема» является более простой единицей, чем «слово». Но всем лингвистам известно, что названия единиц «языка» образованы путем присоединения лингвистического суффикса -ема к греческим корням (фонема — морфема — лексема — фразема — граммема) и поэтому они называются «эмическими единицами языка». Однако А. А. Гируцкий [93] вводит в состав языковых единиц наряду с «лексемой» еще и «сло-во» как самостоятельную единицу более высокого порядка, никак не по-ясняя, чем они отличаются друг от друга.
Известно, что О. С. Ахманова [36] рассматривает «лексему» как эле-мент «языка» — слово-тип (в отличие от слова-члена как единицы речи) [36, 214]. «Слово» трактуется как «предельная составляющая предло-жения» [36, 422], а «предложение» как единица «речи». Отсюда следует, что «слово» — это единица «речи». Следовательно, «слово» как едини-ца речи, является частным по отношению к «лексеме», как единице язы-

21Структура и функция языка и речи
ка. То есть, речевая единица — «слово», будучи обобщенной, становится единицей языка — «лексемой». Однако по [93] обе эти единицы являют-ся единицами языка, но занимающими разные уровни в иерархии, при-чем «слово» занимает более высокий уровень, чем «лексема»!
В-четвертых, где в этой разношерстной компании элементов распо-лагается «непредикативное словосочетание» — единица, выделяемая и описываемая в синтаксисе?
В-пятых, может быть, автор под «лексемой» понимает только звуко-вую оболочку, а под «семемой» — значимую составляющую некой еди-ницы? Тогда что это за единица? В этом случае ни «лексема», ни «семе-ма» не имеют права стоять среди остальных двуплановых единиц!
В-шестых, если автор вслед за [36] речевые единицы снабжает пре-фиксом «алло-», то почему его содержат только три единицы, а не все шесть? Где же «аллозначение», «аллословоформа» и «аллопредложе-ние»?
В-седьмых, если все единицы языка — женского рода, а первые три мифические единицы «речевой деятельности» — мужского, то поче-му бы и остальные единицы не отнести к мужскому роду «по аналогии», как говаривали древние греки? «Сем», «словоупотреблен» и «фразем» вполне органично войдут в букет из прочих псевдоединиц этой псевдо-группы речеязыковых гибридов!
В целом, новация А. А. Гируцкого [93], выделившего некую «третью» подсистему вслед за Л. В. Щербой [153], у которого эта «третья» ипо-стась лингвистических явлений есть ничто иное, как ранее выделен-ная Ф. де Соссюром [139] «речь» говорящего или слушающего (которая в сумме с «языком» и составляет «речевую деятельность»), показыва-ет, что стремление к оригинальности надо согласовывать с научно про-веренными фактами и теоретическими представлениями, иначе мож-но «попасть впросак» или «пальцем в небо», а начинающих лингвистов «сбить с панталыку», говоря фразеологически. «Триединство» «языка», «речи» и «речевой деятельности» — это такая же научная ересь, ерунда и чушь собачья, как «триединство» «бога-отца», «бога-сына» и «святаго духа» у христианских попов!
Отметим, что лингвистически корректно, поступает Б. Н. Головин [82, 274–276], который выделяет 4 единицы «речи» и соответствующие им 4 единицы «языка», давая дефиниции каждому члену пар: «звук-фо-нема», «морф-морфема», «слово-лексема», «высказывание-предложе-ние». «Предложение» входит в обобщенную единицу — «граммему», ко-торая состоит, по его мнению, из следующих 4-х грамматических клас-сов: 1) граммемы слов; 2) граммемы словесных форм; 3) граммемы сло-

22 Глава 1
весных позиций; 4) граммемы словесных конструкций (т. е. предложе-ний) [82, 182–193].
Вот такой подход и является настоящим вкладом в лингвистическую теорию, поскольку он упорядочивает и углубляет наше понимание язы-ка и речи вообще и их единиц в частности.
К сожалению, здесь не хватает еще одной пары: «непредикативное словосочетание — фразема», которые должны располагаться на предпо-следнем месте его списка лингвистических единиц, поскольку как сво-бодные, так и устойчивые непредикативные словосочетания объектив-но существуют в русском языке. Традиционно синтаксисты-русисты не-предикативные словосочетания называются просто «словосочетания-ми», которые принципиально отличаются от предикативных словосоче-таний, называемых «предложениями».
В более общем случае Б. Н. Головин [82] выделяет следующие едини-цы языка: фонемы, морфемы, слова, словообразовательные типы, мор-фологические категории и синтаксические категории [82, 147] Объеди-нив элементы в подсистемы, он для наглядности предложил следующую схему связей между подсистемами языка.
ФОНЕТИКА
ЛЕКСИКА
МОРФЕ- МИКА
СИНТАКСИС
МОРФОЛО-ГИЯСЛОВО-
ОБРАЗОВА-НИЕ
Ценным здесь является то, что показана сложная взаимосвязь раз-личных подсистем языка: фонетика связана с лексикой и морфемикой; лексика связана с фонетикой, морфемикой, словообразованием; мор-фемика связана со всеми пятью подсистемами; словообразование свя-зано с лексикой, морфемикой и морфологией; морфология связана со словообразовакнием, морфемикой и синтаксисом. Итого: фонетика и синтаксис связаны с двумя подсистемами каждая; лексика, словооб-разование и морфология связаны с тремя подсистемами каждая; морфе-мика связана с пятью разными подсистемами.

23Структура и функция языка и речи
Отметим, что такое графическое представление соотношения под-систем языка очень важно для более глубокого понимания структуры и функции системы языка в целом.
В наше время [93], считающий «слово» центром «лингвистическо-го мироздания», предложил следующую «додекаэдрную» схему, демон-стрирующую связи слова с другими единицами языка.
Как известно, речь и ее единицы (слово, морф, звук и т. д.) являют-ся частными категориями по отношению к языку и его единицам (лек-семе, морфеме, фонеме и т. д.), которые представляют общие катего-рии.
Однако, автор пишет, «Структурными элементами слова, как едини-цы языка являются фонема, морфема, лексема и семема» [93, 207].
Заметим, что если в вершине пирамиды стоит «слово», то оно, надо полагать, является чем-то «общим», философски говоря, по отношению к единицам, лежащим в основании пирамиды, которые будут являться «частными» сущностями.
Конечно, можно считать «слово» важнейшей речевой единицей, но нельзя говорить и писать, во-первых, что слово состоит их языковых единиц (фонем и морфем), во-вторых, что оно состоит из такой языко-вой единицы, как лексема. Это является нарушением соотношения фи-лософских категорий «частное» и «общее», а, следовательно, антинауч-но вообще и антилингвистично в частности.
Что же касается «семемы», то это всего лишь половинка лингвисти-ческого знака, не имеющая звучания, и среди полноправных двусторон-них знаков стоять на равных не имеет права.

24 Глава 1
Следовательно, верхняя половина «додекаэдра А. А. Гируцкого» [93] вводит в заблуждение лингвистов из-за лингвистической и философ-ской путаницы в построениях его автора.
Хорошая схема речевых и языковых уровней, называемых им аспек-тами, предложена Ю. С. Степановым [140, 220].
Таблица 5Отношение единиц и уровней в языке
Конкретный, или наблюдаемый аспект Абстрактный аспект
Предложение Структурная схема предложения
Словосочетание Структурная схема словосочетания
Слово Слово
Морф Морфема
Аллофон Фонема
Отметим, что среди речевых единиц (конкретный аспект) «аллофон» обозначает «звук». Неясно, почему «по аналогии» более сложная едини-ца не названа «алломорфом» и т. п.?
Оказывается, среди языковых единиц (абстрактный аспект) и ре-чевых (конкретный аспект) есть единица с одинаковым названием — «слово»! Что это означает? Разные единицы с одинаковым названием-омонимом или одна и та же единица принадлежит как речи, так и язы-ку? Заметим, что для языковой единицы давно имеется свое собствен-ное название — «лексема» (Ахманова, [36, 214]. Зачем же вводить в за-блуждение лингвистов?
Таким образом, попытки создать «теорию языковых уровней» дали в конце концов определенные результаты. Правда, многие любители «потеоретизировать» оказались не на высоте, так как «не видят» раз-ницы между: (1) двусторонними единицами (морфемами, лексемами и т. п.) и односторонними «половинками» (слогами и семемами); (2) ре-чевыми и языковыми единицами; (3) словосочетаниями предикатив-ными (т. е. предложениями) и непредикативными (т. е. НЕ предложе-ниями).
Обобщенная иерархическая (лестничная) схема соотношения еди-ниц языка и соответствующих единиц речи может быть представлена следующим образом:Здесь представлены соотносимые единицы речи и языка, но недостат-ком иерархии (лестницы) является то, что она показывает связи толь-

25Структура и функция языка и речи
ко между непосредственно составляющи-ми этой схемы (а) в языке: Ф (фонема) — М (морфема); М (морфема) — Л (лексема); Л (лексема) — Фр (фразема); Фр (фразе-ма) — Гр (граммема); (б) в речи: З (звук) — М (морф); М (морф) — С (слово); С (сло-во) — СС (непредикактивное словосочета-ние); СС (непредикативное словосочета-ние) — В (высказывание, т. е. предикатив-ное словосочетание). Однако на этой схе-ме не отражена черезступенчатая связь как между единицами языка (Фразема — Лексема; Лексема — Граммема), так и речи (Звук — Слово; Слово — Высказывание).
ф
м
л
фр
гр
З
М
С
СС
В
Мы предлагаем следующую «схему речеязыковых уровней», учиты-вающую существование «черезступенчатых» связей между единицами. Она состоит из 2-х треугольников, в каждой вершине которых распола-гается по 2 единицы: речевая и соответствующая ей языковая, а имен-но: Ф (звук — фонема); М (морф — морфема); Л (слово — лексема); Фр (непредикативное свободное — непредикативное связанное словосоче-тание); Гр (высказывание — предложение (граммема).
Рисунок 1. Двухтреугольниковая схема речеязыковых уровней
Более детальная схема, включающая типы предложений, имеет сле-дующий вид.

26 Глава 1
Рисунок 2. Трехтреугольниковая схема речеязыковых уровней
Эти «треугольниковые» схемы, как отмечалось, демонстрируют свя-зи как между соседними (по иерархии) уровнями единиц речи-язы-ка, так и связи между «черезступенчатыми» иерархическими уровнями единиц, а именно: между З-Ф и С-Л; С-Л и В-П.
§ 4. Типы значений лингвистических единиц
Как известно, каждая единица языка и речи имеет звучание и значе-ние, а именно: [Зв/Зн]. Философские категории формы и содержания [Ф/С] надо понимать в том смысле, что все объективно существующее имеет форму, с одной стороны, и содержание, с другой, то есть [Ф/С] → [Зв/Зн].
Каждая единица относится к соответствующему уровню и имеет свой тип значении а именно: фонема имеет фонемное значение, морфе-ма — морфемное, лексема — лексемное, фразема — фраземное, паре-миема — паремиемное, граммема — граммемное значение. Возникает вопрос: как эти значения выражаются?
А) Лексемное (лексическое) значение — это отражение понятия о предмете. Раньше думали, что лексическое значение — это понятие о предмете [139]. Однако следует помнить, что понятие о конкретном предмете у носителей разных языков практически одинаковое, а слова, обозначающие это понятие, являются разными (причем не только их зву-чания, но и значения) в разных языках. Следовательно, понятие и зна-чение слова — это разные сущности. В «мыслительной» части головного мозга нейроны удерживают «понятие» о предмете, а в «лингвистической»

27Структура и функция языка и речи
части головного мозга «звучание» слова удерживается другой группой нейронов, а «значение» — третьей, соседней группой нейронов.
Предмет Понятие Слово (звуч./знач.)
Б) Морфемное значение выявляется в результате сравнения множе-ства пар «производное — производящее».
Рассмотрим, например, словообразовательную морфему -б- в рус-ском языке. Это относительно редко употребляющаяся морфема, и ее значение не сразу вспоминают даже носители русского языка.
Рассмотрим следующий ряд пар слов, связанных отношениями сло-вообразовательной деривации (с философской точки зрения — это при-чинно-следственные отношения, которые некоторые «продвинутые» лингвисты называют заморским словцом «мотивация»):
Косить — косьбаДружить — дружбаПалить — пальбаПросить — просьбаСлужить — службаСватать — свадьбаХодить — ходьбаИ т. д. и т. п.Анализ показывает, что у производных имеется повторяющаяся мор-
фема «-б-», имеющая звучание [Б] и значение «обобщенное действие».Таким образом, особенностью морфемного значения является то,
что оно вычленяется в результате сравнения пар: «производящая осно-ва — производное».
Рассмотрим пример пар слов, связанных отношениями словоизме-нительной деривации:
Брожу — бродилХожу — ходилНошу — носилВожу — водил

28 Глава 1
Скачу — скакалЧитаю — читалИ т. д. и т. п.Анализ примеров показывает, что все производные объединяются
наличием одинакового звучания [Л]. С другой стороны, все производ-ные объединены наличием одинакового значения «действие в прошед-шем времени», которое и является морфемным значением словоизме-нительного суффикса [Л].
Таким образом, грамматическое значение флексии глагола прошед-шего времени вычленяется в результате сравнения пар: производящая основа — производное.
В) Фонемное значение — это набор ее дифференциальных призна-ков (ДП). К такому выводу пришли думающие лингвисты [82]. В наше время считается, что «означаемое фонемы представлено составом ее дифференциальных признаков, устанавливаемых на основе противопо-ставления фонемы другим фонемам в одних и тех же фонетических по-зициях» [82, 96].
Рассмотрим русскую фонему [А] 1) гласная, 2) нижнего подъема, 3) среднего ряда. Ее звучанием являются модулированные колебания выдыхаемого человеком воздуха с частотами двух первых формант 620 гц и 1070 гц (Головин, 1983, с. 31). Ее значением являются выше указанные ДП.
Рассмотрим фонему [Б’] 1) согласная, 2) звонкая, 3) мягкая, 4) смыч-ная, 5) губно-губная, 6) неносновая. Этот набор ДП и есть ее фонемное значение.
Рассмотрим фонему [М’] 1) согласная, 2) звонкая, 3) мягкая, 4) смыч-ная, 5) губно-губная, 6) носовая.
Г) Фраземное значение — это образное (переносное) значение не-предикативного устойчивого словосочетания (являющегося результа-том семантической трансформации всего прямого значения в ходе дей-ствия метафоры, метонимии и т. п.).
Например, «Белая ворона» 1. (прямое значение) Ворона белого цве-та; 2) (образное, переносное значение) Человек, отличающийся от дру-гих людей экстравагантностью.
Это образное значение и является фраземным значением.Д) Паремиемное значение — это образное значение предикативного
устойчивого словосочетания (являющееся результатом семантической трансформации всего прямого значения в ходе действия метафоры, ме-тонимии и т. п.). Например, «Бабушка надвое сказала» 1. (прямое) Не-кая бабушка сказала, что данное конкретное дело может завершиться

29Структура и функция языка и речи
либо так, либо сяк; 2) (образное, переносное) Неизвестно еще, удаст-ся ли данное дело.
Еще один пример: «На безрыбье и рак рыба» 1) (прямое) Когда нет рыбы, то и рака можно считать рыбой; 2) (образное, переносное) О ком-л., о чем-л., высоко ценящемся при недостаточном количестве, при отсутствии.
Переносные значения этих двух паремием и являются их паремием-ными значениями
Е) Граммемное значение — это обобщенное значение множества од-нородных лингвистических элементов (морфем, лексем, фразем, пред-ложений), которое вычленяется в результате сравнения рядов однорож-ных единиц.
Рассмотрим следующий ряд: домов, котов, столов, потолков, дубов, псов и т. п. Все эти слова объединены наличием звукового комплекса [ов]. С другой стороны, все они объединены обобщенным значением: «кого, чего нет», как объясняется в школьной грамматике. Тем не менее, это значение точно отражает отношения склонения существительных мужского рода, единственного числа в родительном падеже.
§ 5. Количественная семантика. Причины возникновения полисемии
Полисемия — это наличие 2-х или более значений у языковой еди-ницы (лексемы, морфемы, фраземы, граммемы). Одной из причин по-явления полисемии является возраст, то есть время функциорнипрова-ния в речи.
Полисемия является результатом дублирования звучания в языкеРассмотрим английскую лексему HORSE. Она может быть представ-
лена, как набор слов: horse «Лошадь, конь»; horse «Кавалерия, конни-ца»; horse «спорт. Конь»; horse «шахм. Фигура»; horse «сленг. Шпаргал-ка». На рисунке слова изображены в виде схем, причем верхние элемен-ты каждой пары изображают «звучания», на нижние — «значения».
Звучание
Значение

30 Глава 1
Таким образом, полисемия представляет собой дублирование оди-наковых «звучаний». Но поскольку язык является надежной системой, то дублирование является закономерным. Следовательно, полисемия также является закономерной. Она всегда была, есть и будет существо-вать в любом языке.
§ 6. Законы Ципфа-Гиро
Количество значений и частность
В 1945 году К. Ципф [28], проанализировав частотный словарь ан-глийского языка Е. Торндайка [25], содержавший 30 тыс. слов из вы-борки в 18 млн словоупотреблений, показал, что «чем чаще слово встречается в речи, тем больше у него значений». Однако, его откры-тие осталось почти незамеченным. Позднее французский лингвист П. Гиро [10] нашел аналитическое выражение для этой закономер-ности, которую мы назвали семантическим законом Ципфа-Гиро [10; 28]: S=C2√f, где S — количество значений у лексемы, f — частота упо-требления соответствующего слова в речи, С2 — семантический коэф-фициент пропорциональности (подсчитано, для русского и английско-го языков С2 ≈ 1000).
«Количество значений (S) у лексемы прямо пропорционально ча-стотности (f) употребления соответствующего слова в речи», то есть «Чем чаще слово употребляется в речи, чем более многозначной (поли-семичной) стремится стать соответствующая лексема».
Таким образом, впервые была установлена одна из объективных причин возникновения полисемии (многозначности) лексем. Заметим, что ни в одной работе по семантике или семасиологии вопрос о причи-нах полисемии даже не ставится, так авторы не знают на него ответа.
[Не следует путать этот закон Ципфа-Гиро с шумно известной тавто-логической зависимостью между убывающей частотностью слов в ран-жированном списке и их рангом (порядковым номером) в том же спис-ке, именуемой «законом Ципфа-Эсту-Мандельброта», который, как вы-яснилось, ничего не дает лингвистике и поэтому бесполезен, что позд-нее было аргументированно доказано.
К. Ципф [28] обнаружил, а П. Гиро [10] придал аналитический вид еще двум лингвистическим законам.

31Структура и функция языка и речи
Фонетический закон Ципфа-Гиро: L=C1 / lg f, где L — количество фо-нем в лексеме, f — частотность употребления слова, С1 — семантиче-ский коэффициент пропорциональности (для русского, английского языков C1 ≈ –40).
«Фонетическая длина (L) лексемы обратно пропорциональна ча-стотности (f) употребления соответствующего слова в речи», то есть, «Чем выше частотность слова, тем оно стремится стать короче». Этот за-кон объясняет известные в фонетике явления диэрез и гаплологии.
К. Ципф [28] также обнаружил, что «Чем чаще употребляется слово, тем оно древнее».
П. Гиро [10] не описал аналитически этот закон, поэтому мы по ана-логии придали ему следующий вид:
Хронологический закон Ципфа-Гиро: Т=С3√f, где Т — возраст лексе-мы, — частотность употребления слова в речи, С3 — хронологический коэффициент пропорциональности.
«Возраст (T) лексемы прямо пропорционален частотности (f) соот-ветствующего слова в речи», т. е. «Чем выше частотность слова, тем оно старше (древнее), и наоборот».
Таким образом, эти три закона описывают связь основных характери-стик слов и лексем (звучание и значение) с частотностью употребления слов в речи, формируемой обществом, то есть связь между «внутренней» и «внешней» лингвистикой (в частности, социолингвистикой).
Обратим внимание на то, что аргумент во всех этих формулах один и тот же — частотность (f). Объединив попарно эти уравнения, мож-но решить получившиеся системы из двух уравнений с одним неизвест-ным в общем виде и получить три следствия из законов Ципфа-Гиро:
Фоносемантическое следствие из законов Ципфа-Гиро (в двух фор-мах).
L= C4/S «Фонетическая длина лексемы обратно пропорциональна ее многозначности (полисемичности), и наоборот».
S=C4/L «Многозначность (полисемичность) лексемы обратно про-порциональна ее фонетической длине, и наоборот».
Семантико-хронологическое следствие из законов Ципфа-Гиро [] (в двух формах).
S=C5T «Количество значений у лексемы прямо пропорционально ее возрасту, и наоборот».
[Отметим, что этот закон объясняет вторую причину многозначно-сти (полисемичности) лексем].
T=C6 S «Возраст лексемы прямо пропорционален ее многозначности (полисемичности), и наоборот».

32 Глава 1
Фонохронологическое следствие из законов Ципфа-Гиро (в двух фор-мах).
L=C7/T «Фонетическая длина лексемы обратно пропорциональна ее возрасту, и наоборот»
Это следствие объясняет известный факт существования огромно-го количества коротких исконных лексем в английском языке: древ-ние лексемы со временем сократились, что наглядно видно, если срав-нить их транскрипционное изображение с буквенным (которое отража-ет их звучание на момент письменной фиксации, начавшейся еще в VII–VIII вв.)
T= C7/L «Возраст лексемы обратно пропорционален ее фонетиче-ской длине, и наоборот».
Возраст как причина возникновения полисемии
Для решения проблемы полисемии важным является следствие из законов Ципфа-Гиро, гласящее: «Чем старше лексема, тем она мно-гозначнее», т. е. 2-й объективной причиной полисемии является возраст лексемы.
Еще в 1982 году, диахронически описывая высокочастотные дерива-ты с глагольным суффиксом -ify в английском языке, мы [67] впервые обнаружили следующую эмпирическую закономерность: лексемы, воз-никшие в XIII в., имеют в среднем по 7,0 значений на лексему (то есть, S*=7,0); лексемы, возникшие в XIV в. — S*=6,0 знач/лекс; в XV в. — S*= 6,5 знач/лекс; в XVI в. — S*=5,7 знач/лекс; в XVII в. — S*=2,0 знач/лекс; в XVIII в. — S*=1,0 знач/лекс; в XIX в. — S*=2,0 знач/лекс. (Табл. 2).
Таблица 6Изменение средней полисемичности частотных дериватов
с суффиксом -ify в диахронии
Век Fm S S* Примеры
XIII 1 7 7,0
XIV 9 54 6,0
XV 4 26 6,5
XVI 3 17 5,7
XVII 1 2 2,0
XVIII 1 1 1,0

33Структура и функция языка и речи
Век Fm S S* Примеры
XIX 1 2 2,0
XX - - -
Сумма 20 101 5,1
Среднее
Примечание: Среднюю полисемичность лексем (S*) подсчитывали по формуле: S*= S / Fm, где Fm — количество высокочастотных слов, возникших в данном веке; S — суммарное количество значений у этих лексем.
Анализ величин S* показал, что существует следующая зависимость: «Чем старше лексема, тем она многозначнее (полисемичнее)» [67]. Это явилось первым прямым экспериментальным подтверждением справед-ливости семантико-хронологического следствия из законов Ципфа-Гиро.
Приведем еще один пример зависимости полисемичности лек-сем от их возраста (Табл. 6). Так, было установлено, что в уни-кальном диахроническом словаре английского языка [22] объемом в 616 тыс. статей содержится 1316 лексем с заимствованным суффик-сом-ism. Анализ их семантики показал, что наиболее полисемичны-ми являются лексемы, возникшие в XIV и XV вв.: S*=4,4 знач/лекс и S*=3,3 знач/лекс соответственно. Лексемы, возникшие в начале но-воанглийского периода, в среднем имеют S* (XVI в.) =2,5 знач/лекс и S* (XVII в.) =2,1 знач / лекс. Лексемы, появившиеся в поздний ново-английский период, характеризуются следующей средней полисемич-ностью (S*): S* (XVIII в.) =1,8 знач/ лекс; S* (XIX в.) =2,1 знач/лекс; S* (XX в.) =1,1 знач/лекс. Следовательно, независимо от того, сколько лек-сем появилось в тот или иной век, четко прослеживается общая зависи-мость между возрастом и полисемичностью лексем: «Чем старше лексе-ма, тем она многозначнее (полисемичнее)».
Таблица 7Изменение средней полисемичности дериватов
с суффиксом -ism в диахронии
Век Ps S S* Примеры
XIV 5 22 4,4 Embolism, exorcism
XV 3 10 3,3 Graecism, Judaism
XVI 39 97 2,5 Gentilism, Puritanism
XVII 156 320 2,1 Nepotism, stoicism

34 Глава 1
Век Ps S S* Примеры
XVIII 121 220 1,8 Heroism, Sabianism
XIX 815 1161 1,4 Industrialism, nominalisn
XX 177 199 1,1 Gaullism, lettrism
Сумма 1316 2029 -
Среднее - - 1,5
Примечание: Средняя полисемичность лексемы (S*) подсчитывали по формуле: S*= S / Ps, где Ps — количество лексем, появившихся в те-чение века; S — сумма значений всех этих лексем.
Позднее эта закономерность многократно подтверждалась нами при полном количественном диахроническом описании каждого из 30 английских префиксальных и суффиксальных деривационных типов [48].
Заметим, что в 1974 году Р. А. Будагов в книге «Человек и его язык» [86] написал об открытии им «закона многозначности слов», сообщив, что если мы «раскроем большой Толковый словарь русского или поль-ского, французского или испанского, английского или немецкого языков и подсчитаем, сколько многозначных слов находится на той или иной странице, то получится, что около восьмидесяти процентов слов… предстанут перед нами как слова многозначные».
Отметим, что «слова», как единицы речи, всегда однозначны, а «лек-семы», которые мы находим в толковых словарях, в начале своей «лин-гвистической карьеры» всегда однозначны, но со временем, часто упо-требляясь в речи, могут стать многозначными. Известно, что в языках цивилизованных народов насчитывается более полумиллиона лексем (например, в «Новом большом русско-английском словаре» [127] содер-жится более 300 000 лексических единиц русского языка; в The Oxford English Dictionary [22] содержится 616 000 словарных статей). Если ка-кие-либо авторы собираются составить толковый словарь объемом, ска-жем, в 100–200 тыс. лексем, то они интуитивно отбирают, как выясняет-ся, самые частотные слова. Но, как гласит семантический закон Ципфа-Гиро, высокочастотные слова как раз и являются самыми многозначны-ми. Но Р. А. Будагову [86], по-видимому, это было неизвестно, и «по про-стоте душевной» он «открыл Америку наоборот», перепутав причину со следствием (что является философской и научной ошибкой!), и, так сказать, «сел в лингвистическую лужу»!

35Структура и функция языка и речи
Скорость изменения семантического поля
Диахронический подход к изучению семантики лексем английского языка, используя [22], содержащий даты первой письменной фиксации каждого значения, позволяет подсчитывать скорость изменения семан-тического поля любой лексемы по предложенной нами формуле [59]:
v=100 (S – 1) / (Tn – T1),
где S — количество значений у лексемы, T1 — дата появления (то есть, письменной фиксации) 1-го по времени значения лексемы, Tn — дата появления n-го (то есть, последнего по времени) значений.
Рассмотрим примеры. Так, лексема имеет 7 датированных значе-ний (все значения, кроме 1-го мы здесь не приводим за ненадобно-стью): horse 1. A large hoofed mamma having a long mane and tail (850); 2. (1200); 3 (1650); 4 (1300); 5 (1400); 6 (1800); 7 (1950). Согласно фор-муле имеем: v=100 (7–1) / (1950–850) = 600/1100=0,54 знач./век.
Итак, известны две объективные причины многозначности (полисе-мичности) лексем:
1) синхроническая причина многозначности: высокая частотность слов (в речи);
2) диахроническая причина многозначности: почтенный возраст лексемы (в языке).
Термины
Интенсивное изучение терминов и различных терминосистем нача-лось в середине ХХ века [90; 120; 132].
Рассмотрим определение термина в «Словаре лингвистических тер-минов» [36].
«ТЕРМИН. Слово или словосочетание специального (научного, тех-нического и т. п.) языка, создаваемое (принимаемое, заимствуемое и т. п.) для точного выражения специальных понятий и обозначения специальных предметов» [36, 474].
Отсюда следует, что другие речевые единицы (кроме слова и слово-сочетания), а также все языковые единицы не могут быть терминами! Неясно, что имеет в виду авторесса, говоря о «специальном (научном, техническом и т. п.) языке»? В настоящее время лингвистам известно, что нет никакого «специального языка», что все «специалисты (ученые,

36 Глава 1
техники и т. п.)» используют один и тот же общенародный язык/речь, правда, содержащий значительное количество «терминов».
Также известно, что термины (как и любые другие лингвистиче-ские единицы) передают «понятия», но вовсе не «обозначают специаль-ные предметы» (как, впрочем, и неспециальные предметы!). Напомним, как соотносятся «предметы», «понятия» о них и «слова», обозначающие эти «понятия» (Рис.):
Предмет Понятие Слово (лингвистический знак)
Необходимо помнить, что любая лингвистическая единица «точно» передает соответствующее понятие. Так, лексема «помидор» точно пе-редает понятие о нем, а не об апельсине или несъедобном камне. Слово «кошка» точно обозначает понятие о кошке, а слово «мышка» — не ме-нее точно обозначает понятие о мышке.
Что же касается использования терминов «для точного выражения специальных понятий», то, как отмечено выше, он столь же точно вы-ражает соответствующее понятие, известное узкому кругу говорящих — специалистов в какой-либо области деятельности.
Например, лексема «транзистор» передает (1) (спец.) понятие о ми-ниатюрном керамическом полупроводнике либо (2) (общелитер.) поня-тие о портативном радиоприемнике, в котором громоздкие радиолам-пы замены миниатюрными полупроводниковыми детальками.
При определении лингвистических единиц следует использовать их ингерентные характеристики — звучание и значение, а не апеллиро-вать к понятиям, которые они обозначают, так как понятия — это эле-менты «системы мышления», а «предметы» окружающего мира вообще напрямую не связаны с лингвистическими единицами. Основополагаю-щим свойством термина является наличие значения, известного узкому кругу говорящих (специалистов в какой-либо области теории или прак-тики). К тому же термины, как все лингвистические единицы, могут быть единицами либо речи, либо языка, поэтому мы даем следующие две дефиниции [75; 94; 107].
«Речевые термины — это слова, морфы или непредикативные сло-восочетания, имеющие значение, известное узкому кругу говорящих — специалистов в какой-либо области теоретической или практической деятельности».
«Языковые термины — это лексемы, морфемы или фраземы, имею-щие хотя бы одно значение, известное узкому кругу говорящих — спе-

37Структура и функция языка и речи
циалистов в какой-либо области теоретической или практической дея-тельности».
Что же касается «звучания» терминов, то в современных «рацио-нальных» терминологиях термины строятся из греческих и латинских корней, следовательно, они обладают характерным набором звуков, но сформулировать это свойство кратко и однозначно пока не удается.
Рассмотрим примеры лингвистических терминов.«Фонема — минимальная звуковая единица языка, служащая для по-
строения морфем и лексем».«Дифференциальный признак (ДП) — существенный признак, отли-
чающий одну фонему от другой» Например, русская фонема [Ы] харак-теризуется тремя ДП: 1) гласная, 2) верхнего подъема, 3) среднего ряда; согласная фонема [М’] характеризуется 6-ю ДП: 1) согласная, 2) звон-кая, 3) мягкая, 4) смычная, 5) губно-губная, 6) носовая); Фонема [Б']: 1) согласная, 2) звонкая, 3) мягкая, 4) смычная, 5) губно-губная, 6) не-носовая.
«-ИТ-1 (медицинский) суффикс, обозначающий понятие «о воспа-лительном процессе», например, в лексемах: бронхит, конъюнктивит, плеврит, ларингит, панкреатит, полиартрит и т. п.
«-ИТ-2 (геологический) суффикс, обозначающий «названия минера-лов», например: адамсит, вольфрамит, вулканит, лабрадорит, моноцит, уранит, родонит и т. п.
Рассмотрим несколько примеров, демонстрирующих терминологи-ческие процессы.
Проводник, -а, м. 1) Провожатый, 2) Железнодорожный служащий, сопровождающий пассажирский вагон и обслуживающий пассажиров, 3) Посредник при распространении каких-либо идей, взглядов и т. п. 4) (физич.) Вещество или среда, обладающие проводимостью.
В диахроническом плане первым появилось 1-е значение, затем 2-е и 3-е (неважно, какое раньше!). 4-е (физическое, электротехническое) значение появилось в конце ХIХ века с появлением электричества. За-метим, что в этот момент лексема ПРОВОДНИК и стала термином, так как приобрела «специальное значение, т. е. значение, известное узкому кругу говорящих». Этот процесс называется «терминологизацией» лек-семы.
В тех случаях, когда «чистый» термин, скажем, лексема со специаль-ным значением, приобретает значение, известное всем носителям язы-ка, термин «детерминологизируется». Например, когда был изобретен керамический полупроводник, авторы (получившие за это открытие Нобелевскую премию) назвали его «транзистором» [1. (физич.) Полу-

38 Глава 1
проводниковый диод или триод, а затем и прибор, их содержащий]. Ко-гда (крупные) электронные лампы в радиоприемниках заменили эти-ми миниатюрными детальками, то появились портативные приемни-ки (размером в несколько см.), получившие широкое распространение и названные «транзисторами» (по имени детальки). Это значение ста-ло известно всем говорящим, а лексема в словарях стала подаваться сле-дующим образом: ТРАНЗИСТОР, -а, м. 1. (физич.) Полупроводниковый диод или триод…; 2) Портативный радиоприемник.
Произошел процесс, называемый «детерминологизацией» термина.Заметим, что степень терминологизации можно подсчитывать
по следующей формуле:
Кt=St/S (0<Kt<1),
где St — количество специальных (так сказать, «терминологических») значений у лингвистической единицы; S — полное количество значе-ний у этой единицы.
Подсчитаем величины коэффициента терминологичности у ряда терминов.
Kt (проводник) = 1 / 4 = 0,25 (слабая терминологизация). Kt (тран-зистор) = 1/ 2 = 0,5 (средняя терминологизация).
§ 7. Синонимия
А) Синонимия как результат дублирования значений в языкеРассмотрим ряд русских синонимов: Лингвистика — Языкознание —
Языковедение, которые имеют одинаковое значение «Наука о язы-ке и речи». Представим этот ряд схематически на рисунке. Отметим, что каждая лексема изображена в виде пары связанных фигур, обозна-чающих «звучание» (верхняя часть каждой пары) и «значение» (нижняя часть пары).
звучание
значение

39Структура и функция языка и речи
Ясно видно, что значения повторяются, «дублируются». Но дублиро-вание — закономерное явления для надежно работающих систем. По-скольку язык является надежной системой, то и синонимия является за-кономерным явлением в языке. Она была, есть и всегда будет в каждом языке.
Академик Ю. П. Алтухов [154] однажды заметил: «Научная строгость терминологии является показателем уровня развития науки». Посмо-трим, на каком уровне находится лингвистическая наука, открыв «Сло-варь лингвистических терминов» [36].
«СИНОНИМЫ (равнозначащие слова, равнозначные слова). Те чле-ны тематической группы (во 2 знач.), которые (а) принадлежат к одной и той же части речи и (б) настолько близки по значению, что их пра-вильное употребление в речи требует точного знания различающих их семантических оттенков и стилистических свойств. Русск. Храб-рый, смелый, мужественный, стойкий; недурной, неплохой, удовлетво-рительный; карп, сазан; ива, ветла; англ. Broad, wide, large, extensive» (с. 407).
«Синонимы абсолютные (синонимы безотносительные, синонимы полные). Слова, полностью совпадающие по значению и употреблению. Русск. Языкознание — языковедение» (с. 407).
Заметим, что в определении упоминаются только «слова», как это де-лали древние греки 2,5 тысяч лет назад. А если «близкими по значению» окажутся, скажем, морфы, словосочетания, высказывания или другие единицы речи? И как быть с единицами языка — лексемами, морфе-мами, фраземами, граммемами? Видимо, по мнению авторессы, они не могут быть синонимами…
Что же касается «близости по значению», то в научном определении такие пассажи недопустимы, поскольку критерия «близости» авторесса не только не приводит, но даже не упоминает о нем.
Большой энциклопедический словарь «ЯЗЫКОЗНАНИЕ» [155] дает следующее определение.
«СИНОНИМЫ (от. греч. Synonymos — одноименный) — слова одной и той же части речи (а также, в более широком понимании, фразеоло-гизмы, морфемы, синтаксические конструкции), имеющие полностью или частично совпадающие значения. В качестве единицы смыслового сопоставления лексических синонимов выступает элементарное значе-ние слова, его лексико-семантический вариант» [155, 447].
Положительной характеристикой этого определения является то, что кроме «слов» (кстати, речевых единиц) упоминаются также «фра-зеологизмы», «морфемы», «синтаксические конструкции» — языковые

40 Глава 1
единицы. Отмечается, что синонимы «имеют полностью или частично совпадающие значения». Неясно, правда, что автор понимает под «ча-стично совпадающими значениями», поскольку далее он совершенно справедливо отмечает, что оперировать надо с «элементарными зна-чениями — лексико-семантическими вариантами». Если эти значения «элементарны», что ни о каком «частичном» их совпадении говорить не приходится: элементарные значения либо совпадают, либо не совпа-дают!
Как известно, все «лексическое» должно иметь «звучание» и «значе-ние» (то есть семантику). Поэтому термин «лексико-семантический ва-риант» неудачен, так как означает нечто «звуко-семантико-семантиче-ское».
Заметим, что древние греки, обнаружившие явление синонимии в III в. до н. э., изучали речь, в которой, как известно, все слова одно-значны в любом данном месте (контексте). Если значения этих одно-значных слов совпадали, то это и было явление синонимии. В древней-ших греческих литературных памятниках «Илиаде» и «Одиссее» [33; 110] содержится в сумме около 9 тыс. разных слов, причем практически все они были однозначны (поскольку только в этот период только нача-ли обнаруживать случаи полисемии — явления многозначности неко-торых слов). До тех пор, пока лингвисты имели дело с речью, никаких проблем с дефиницией этого явления не возникало: действительно ре-чевыми «синонимами были слова, одинаковые по значению». В наше время, когда стали изучать не только речь, но и язык, единицы которо-го по определению могут быть многозначными, древнегреческое опре-деление синонимии оказалось неприменимым к новым лингвистиче-ским реалиям. Термин «значение» применительно к словам означал ра-нее «одно значение». Но у лексемы, как известно, может быть несколько «элементарных значений», поэтому корректная дефиниция языковой синонимии обязательно должна учитывать это обстоятельство.
Под синонимией следует понимать «совпадение элементарных зна-чений», а не некие туманные свойства вроде «близость», «частичное сходство», «похожесть» и т. п.
В синонимическом ряду может насчитываться два или более членов одной части речи, но это является очевидной истиной, так как никакие «элементарные значения», скажем, существительного не могут совпасть с «элементарными значениями» прилагательного или глагола, посколь-ку каждое из них обозначают принципиально различающиеся понятия,

41Структура и функция языка и речи
соответственно, о предмете, или о свойстве предмета, либо о действии! (то есть, они различны, как говорят, по определению!).
Для лингвистической корректности в дефиниции также должна со-держаться информация о том, что члены ряда различаются по звучанию. Таким образом, мы предлагаем следующие дефиниции.
«Речевые синонимы — это два или более разно звучащих слова, мор-фа, словосочетания или высказывания, совпадающие по значению». Они всегда «абсолютно синонимичны», так как в речи каждая едини-ца является однозначной и если она совпадает по значению с другими, то налицо абсолютные синонимы.
«Языковые синонимы — это две или более разно звучащие лексемы, морфемы, фраземы, паремиемы, фонемы, граммемы, имеющие хотя бы одно значение, одинаковое для всего ряда».
Данное определение позволяет количественно оценивать степень синонимичности рядов с помощью формулы для подсчета коэффициен-та синонимичности, выведенной нами путем обобщения формулы Че-кановского на многомерный случай [53]:
Ксин= nS0/ (S1+S2+… Sn), (0≤ Ксин ≥1),
где n-количество членов в синонимическом ряду; S1, S2, Sn — количество значений у 1-го, 2-го,…, n-го членов ряда; S0 — количество значений, одинаковых для всего ряда. Если Ксин=1, то имеем ряд абсолютных сино-нимов; если Ксин=0, то синонимия отсутствует.
Рассмотрим, например, следующий синонимический ряд:Лингвистика («наука о языке») — глоттология («наука о языке») —
языкознание («наука о языке») — языковедение («наука о языке»)В этом случае имеем: n=4, S0=1, S1=1, S2=1, S3=1, S4=1. Подсчитаем
величину коэффициента синонимичности этого ряда:Ксин (Л, Г, Яз, Яв) =4х1/ (1+1+1+1) =4 / 4 = 1,0 (то есть, имеем аб-
солютные синонимы).Рассмотрим другой ряд синонимов: Спутник (4 значения, в том чис-
ле «тот, кто идет с тобой по одному пути») — Попутчик (2 значения, в том числе «тот, кто идет с тобой по одному пути»)
Здесь имеем следующие значения величин в формуле коэффициента синонимичности: n=2, S0=1, S1=4, S2=2. Подсчет дает следующую ве-личину коэффициента синонимичности этого ряда:
Ксин (С, П) = 2х1/ (4+2) =2/6 = 0,33 (то есть, имеем слабую степень синонимичности).

42 Глава 1
§ 8. Антонимия
Рассмотрим определения антонимов в «Словаре лингвистических терминов» [36].
«АНТОНИМЫ. 1. Слова, имеющие в своем значении качественный признак и потому способные противопоставляться друг другу как про-тивоположные по значению. Русск. Хороший — плохой, близкий — да-лекий, добро — зло, беднеть — богатеть» [36, 50].
Авторесса упоминает только «слова», «…имеющие в своем значе-нии качественный признак и потому способные противопоставляться… по значению». А как быть со словами-глаголами, не передающими «ка-чественных признаков»? И могут ли быть антонимами другие единицы речи — морфы, непредикативные и предикативные слососочетания? С другой стороны, могут ли быть антонимами единицы языка — лексе-мы, морфемы, фраземы, паремиемы, граммемы, фонемы? Согласно это-му, с позволения сказать, определению — не могут!
В «Большом энциклопедическом словаре «ЯЗЫКОЗНАНИЕ» [155] го-ворится:
«АНТОНИМИЯ — тип семантических отношений лексических еди-ниц, имеющих противоположные значения» [155, 35].
Следовательно, антонимы — это «лексические единицы» (то есть, лексемы?), имеющие «противоположные значения». Возникает вопро-сы: «Противоположные чему?» — значениям других лексем или своим собственным (как это имеет место, например, при энантиосемии [одол-жить (у кого, кому); преданный (кому, кем)])? А сколько этих «лексиче-ских единиц» может быть в антонимическом ряду? Могут ли быть анто-нимами другие языковые единицы — морфемы, фраземы, паремиемы, граммемы вообще?
«АНТОНИМЫ (от греч. anti- — против и onyma — имя) — слова од-ной части речи, имеющие противоположные значения» [155, 36].
В этом определении говорится уже не о «лексемах» — единицах языка, а о «словах» — единицах речи. И возникает вопрос, а как быть с остальными единицами речи — морфами, непредикативными слово-сочетаниями, высказываниями)?
Отметим, что антонимия — это распространенное явление, Напри-мер, «Словарь антонимов русского языка» М. Р. Львова (1996) содержит около 2500 антонимических пар. Поэтому для научного описания анто-нимов мы сформулировали следующие лингвистически корректные де-финиции.

43Структура и функция языка и речи
«Речевые антонимы — то два разно звучащих слова, морфа, непреди-кативного словосочетания или высказывания (предикативного слово-сочетания), противоположные по значению».
Поскольку каждая речевая единица всегда однозначна в контексте, то речевые антонимы всегда являются абсолютными антонимами.
«Языковые антонимы — это две разно звучащие лексемы, морфемы, фраземы, паремиемы, фонемы, граммемы, противоположные хотя бы по одному значению». Поскольку языковые единицы могут быть мно-гозначными, то языковая антонимия может быть абсолютной и отно-сительной.
Для количественной оценки степени языковой антонимичности мы впервые предложили использовать следующий коэффициент (Минина, Бартков, 1986): Кант=2S0 / (S1+S2), [ (0≤ Кант ≤1)], где S0 — количество пар противопоставленных значений, S1 и S2 — это количество значений у 1-го и 2-го членов ряда. Если Кант =0, то антонимия отсутствует; если Кант =1, то антонимы абсолютны.
Рассмотрим, например, пару лексем: Белый (11 значений) — Чер-ный (9 значений). Они противоположны по следующим 4-м значени-ям: 1) Цвета снега или мела — сажи или угля; 2) Светлый (например, хлеб) — темный (хлеб); 3) Светлокожий (человек) — темнокожий (че-ловек); 4) белая кость (аристократ) — черная кость (плебей). Следова-тельно, S0=4, S1=11, S2=9. Подсчитаем величину коэффициента анто-нимичности: Кант (Б, Ч) =2Х4 / (11+9) = 8 / 20 = 0,4. Это средняя анто-нимичность.
§ 9. Закономерность полисемии и синонимии (принцип дублирования)
Явления полисемии и синонимии обнаружены во многих описан-ных языках. С развитием интерлингвистики некоторые лингвисты по-ставили вопрос о том, закономерны ли эти явления, не исчезнут ли они со временем «за ненадобностью». Дело в том, что при создании искус-ственных универсальных языков кажется естественным следовать пра-вилу «экономии усилий»: «Одно слово — одно значение».
Однако в естественных языках этого не наблюдается. Почему?Как известно, естественные и искусственные системы характери-
зуются так называемой «надежностью», т. е. способностью сохранять

44 Глава 1
свою структуру и выполнять определенные функции в течение опре-деленного времени. Достигается это, среди прочего и за счет много-кратного повторения их элементов. Мы назвали это явление «принци-пом дублирования (мультиплирования)». Оно широко распростране-но в биологических системах». Так, сохранению вида в ходе эволюции способствует то, что особи производят множество потомков. Например, рыба-луна мечет за нерест около 300 млн икринок, треска — около 1 млн икринок, белуга — около 8 млн икринок и т. д. У теплокровных жи-вотных, которые в отличие от рыб могут защитить свое потомство, это проявляется не столь наглядно, но заметно. Так, мыши, свиньи за один приносят до 10–12 детенышей.
Растения, как известно, дают множество плодов. Некоторые тропи-ческие деревья дают несколько десятков тысяч цветочков. Дуб, напри-мер, производит несколько тысяч желудей, яблони, грущи, сливы, абри-косы — около тысячи и т. д.
С другой стороны, у древесных растений (например, дуба, липы, ясе-ня, а также ели, пихты, сосны и т. п.) имеется до несколько тысяч листь-ев, каждый из которых выполняет одну и ту же функцию — синтезиру-ет углеводы, которые распределяются затем по всему организму. Это — дублирование функций, которое сопровождается, естественно, дубли-рованием структур этих листьев.
У человека, например, принцип дублирования выражается в том, что мы имеем по два глаза, уха, почки, руки, ноги и т. д. Мультиплиро-вание можно проиллюстрировать существованием пяти пальцев на ру-ках и ногах, каждый из которых, в общем, выполняет одну и ту же функ-цию — хватательную.
В искусственных (технических) системах также выполняется «прин-цип дублирования». Как известно, можно ездить на одном колесе (на-пример, в цирке). Но на двухколесном велосипеде легче сохранять рав-новесие, то есть, ехать надежнее. Трехколесный велосипед еще надеж-нее для езды (существуют даже автомашины). Четырехколесные схемы шасси автомобилей, однако, еще надежнее для езды и распространены повсеместно. Надежность езды (особенно на поворотах) обеспечивает-ся дублированием (мультиплированием) колес.
Известно, что в самолетах фирмы «Боинг» имеется по три автоном-ных системы проводов, соединяющих кабину пилотов с системами ко-рабля: двигателями, элеронами, шасси и т. д. В космических кораблях некоторые наиболее важные детали устанавливаются также в тройном комплекте для надежности (на случай выхода из строя одной или даже двух из них, например, от удара метеорита).

45Структура и функция языка и речи
Поскольку язык является надежной системой, то в нем должно суще-ствовать дублирование элементов и/или их структур (форм) и функций (содержаний).
Более широко «принцип дублирования» в лингвистике следует пони-мать как «многократное повторение элементов системы, их форм (зву-чаний) или содержаний (значений)».
Примерами дублирования лингвистических элементов являются различные повторы, например: еле-еле, тихо-тихо, волей-неволей, ма-ло-помалу, перво-наперво и т. п. Заметим, что полисемия и синонимия являются примерами дублирования звучания и значения, соответствен-но. Это становится ясно, если их представить в виде предлагаемых нами схем.
Полисемия как явление дублирования звучания в языкеРассмотрим английскую лексему HORSE. Она может быть представ-
лена, как набор слов: horse «Лошадь, конь»; horse «Кавалерия, конни-ца»; horse «спорт. Конь»; horse «шахм. Фигура»; horse «сленг. Шпаргал-ка». На рисунке слова изображены в виде схем, причем верхние элемен-ты каждой пары изображают «звучания», на нижние — «значения».
Звучание
Значение
Таким образом, полисемия представляет собой дублирование оди-наковых «звучаний». Но поскольку язык является надежной системой, то дублирование является закономерным. Следовательно, полисемия также является закономерной. Она всегда была, есть и будет существо-вать в любом языке.
Синонимия как явление дублирования значений в языкеРассмотрим ряд русских синонимов: Лингвистика — Языкознание —
Языковедение, которые имеют одинаковое значение «Наука о язы-ке и речи». Представим этот ряд схематически на рисунке. Отметим, что каждая лексема изображена в виде пары связанных фигур, обозна-чающих «звучание» (верхняя часть каждой пары) и «значение» (нижняя часть пары).

46 Глава 1
звучание
значение
Ясно видно, что значения повторяются, «дублируются». Но дублиро-вание — закономерное явления для надежно работающих систем. По-скольку язык является надежной системой, то и синонимия является за-кономерным явлением в языке. Она была, есть и всегда будет в каждом языке.

Глава 2
КОЛИЧЕСТВЕННАЯ ДЕРИВАТОЛОГИЯ
§ 1. Способы словообразования
Словообразование как самостоятельный раздел науки в СССР начало формироваться в конце 30-х гг. ХХ века. Следует отметить важные рабо-ты [29; 32; 34; 89; 90; 91; 103; 105; 106; 108; 115; 116; 118; 123. 124; 128; 131; 135; 141; 142; 149; 151], авторы которых заложили основы этой об-ласти языкознания.
Однако ни в одной из работ по словообразованию нет определения того, что же такое «словообразование» вообще (кроме тавтологическо-го пояснения, даваемого некоторыми авторами: «Словообразование — это образование новых слов»).
Поскольку как исходные, как и конечные единицы этого процесса являются двусторонними лингвистическими знаками, то в самом об-щем виде термин «словообразование» можно сформулировать следую-щим образом.
Словообразование (деривация) — это процесс изменения звучания и/или значения исходных единиц, которыми могут быть лексемы, фразе-мы, паремиемы.
Мы исходим из априорного философского равноправия каждой из сторон лингвистических единиц — звучания и значения, поэтому из-менение любой из них дает иную единицу.
В свете этой дефиниции все основные способы можно представить в следующем виде (Табл. 8).

48 Глава 2
Таблица 8Способы словообразования
Что изменяется у исходных единиц
Звучание Значение Звучание и значение
1) аббревиацияА) лексемБ) фраземВ) паремием
2) конверсия3) семантический способ(транссемантизация)
А) метафораБ) метонимияВ) синекдоха
4) основосложение5) аффиксация
А) префиксацияБ) суффиксацияВ) конверсификсацияГ) циркумфиксация
6) псевдодезаффиксация7) заимствование
Отметим, что исходными единицами при аббревиации могут быть не только лексемы и фраземы (устойчивые непредикативные словосо-четания), но и паремиемы (устойчивые предложения), например: Save our Souls = SOS, Situation Normal All Fouled Up = SNAFU.
Заметим, что раньше «семантический способ» словообразования специально не рассматривался в курсах лексикологии [136]. С другой стороны, «метафора, метонимия, синкдоха и т. п.» рассматривались в лексикологии просто как «способы изменения значений слов» [1; 34], а не как способы словообразования!
Из выше приведенной дефиниции следует, что «Транссемантизация (семантический способ) — это процесс (акт) изменения значения лек-семы, точнее, приобретение очередного значения посредством метафо-ризации, метонимизации, синекдохизации и т. п.».
Известно, что «конверсия», как результат изменения частеречной принадлежности (а следовательно, категориального значения), давно признается способом словообразования в англистике.
Термин «лексико-семантическое словопроизводство» мы считаем неудачным по следующей причине: поскольку лексема имеет звучание и значение, то выше упомянутое выражение означает нечто «звуко-се-мантико-семантическое» и поэтому лингвистически неприемлемо.
Отметим также, что «транссемантизация» может происходить и с фраземами (по аналогии с лексемами), например: Синий чулок 1 (прямое). Чулок синего цвета; 2 (перен.). Человек, носящий синие чул-ки; 3 (перен.). Воспитательницы детских приютов носили такие чулки (как часть казенной униформы); 4 (перен.). Старая дева (каковыми эти воспитательницы часто со временем становились).

49Количественная дериватология
§ 2. Аффиксология
Задачей современной аффиксологии является исчерпывающее опи-сание качественных и количественных характеристик аффиксальных типов и моделей при выполнении следующих требований:
А) Полнота (исчерпывающая); Б) Учет как синхронии, так и диахро-нии; Г) Как качественное, так и количественное описание; Д) Описа-ние формирования моделей и типов в диахронии; Е) Формирование се-мем в диахронии; Ж) Описание средней полисемичности в диахронии; З) Изменение средней скорости изменения семантического поля лек-сем в диахронии; И) Учет этимологии производящих основ в диахро-нии; К) Описание стилистических пометы в диахронии; Л) Формиро-вание терминологических помет в диахронии; М) Фонемное тяготение (в том числе в диахронии); Н) Морфемное тяготение (в т. ч. в диахро-нии); О) Суффиксальная валентность в диахронии.
Таблица 9.Наборы характеристик деривационных аффиксов
Зятковская [105] Бартков [51; 54] Кубрякова, Харитончик [115] 4. Фонология темы 1. Транскрипция. Ударение1. Алломорфы2. Фонематический вариант
2. Алломорфы (в т. ч. фоне-матические варианты)
3*. Деривационный статус (объективный и субъективный) 4*. Стилевая принадлежность5*. Терминологическая принадлежность дериватов6. Этимология 1. Диахронические данные
(этимология) 7*. Время возникновения (T)
6. Грамматическая функция
8*.Деривационные моде-ли в диахронии (ПО+ аф-фикс = П)
4. Общекатегориальные свойства ПО и аффикса
7. Грамматическая совместимость

50 Глава 2
Зятковская [105] Бартков [51; 54] Кубрякова, Харитончик [115] 3. Типы швов: свобод-ные, полусвободные, несвободные
9*.Диахроническая продук-тивность (Pd) 10*.Синхроническая про-дуктивность (Ps) 11*. Модельное фонемное тяготение (PhM)
2. Фонетические и фоноло-гические данные
12*. Суммарное фонемное тяготение (PhS)
5. Дистрибуция 13*.Модельное морфемное тяготение (MrphM)
3. Морфемно-деривацион-ная структура
14*.Суммарное морфемное тяготение (MrphS) 15*.Модельный паралле-лизм (синонимия) (SynM) 16*.Суммарный паралле-лизм (синонимия) (SynS) 17*.Модельный паралле-лизм (антонимия) (AntM) 18*.Суммарный паралле-лизм (антонимия) (AntS) 19*.Модельная частотность (Fm) 18*.Суммарная частотность (Fs)
5. Дистрибуция 20*. Модельная внешняя валентность (Vm) 21*. Суммарная внешняя валентность (Vs)
8. Семантическая функция
22*.Поле деривационных значений23*Средняя полисемич-ность дериватов типа (S*=Pd/S) 24. Соответствующие рус-ские аффиксы

51Количественная дериватология
Зятковская [105] Бартков [51; 54] Кубрякова, Харитончик [115] 5. Лексические свойства ПО и суффикса (лексико-семантические подклас-сы ПО и их сочетаемость с суффиксом)
Описано 96 суффиксов английского языка
Описано 300 аффиксов ан-глийского языка
Рекомендации к описанию
Примечание. Нумерация характеристик аффиксов соответствует ав-торской. Звездочкой (*) обозначены количественные характеристики аффиксов и/или деривационных типов.
§ 3. Описание префиксов (SEMI-)
Источником описания послужила полная выборка лексем с препози-тивной морфемой SEMI- из [22] — уникального диахронического сло-варя, содержащего даты первой письменной фиксации каждого значе-ния лексемы, этимологию, стилистические и терминологические поме-ты, а также суффиксальные производные от лексем с префиксом SEMI-.
Здесь количественно описываются следующие характеристики. Мо-дель — все лексемы с аффиксом, образованные от ПО одной части речи, например: SEMI- + N = N. Количество этих лексем дает диахрониче-скую продуктивность модели: Pdm (N) =305. Общее количество лексем с аффиксом (т. е. сумма продуктивностей всех моделей) дает диахрони-ческую продуктивность типа: Pd=616.
Проанализировав даты возникновения всех производных с префик-сом SEMI-, мы получили следующие результаты (Табл. 10).
Таблица 10Формирование моделей с префиксом SEMI- в диахронии
ВекМодели
PsSEMI-+N=N SEMI-+A=A SEMI-+V=V
XIV 2 1 - 3XV 4 3 - 7XVI 13 4 - 17XVII 42 33 - 75XVIII 68 73 1 142
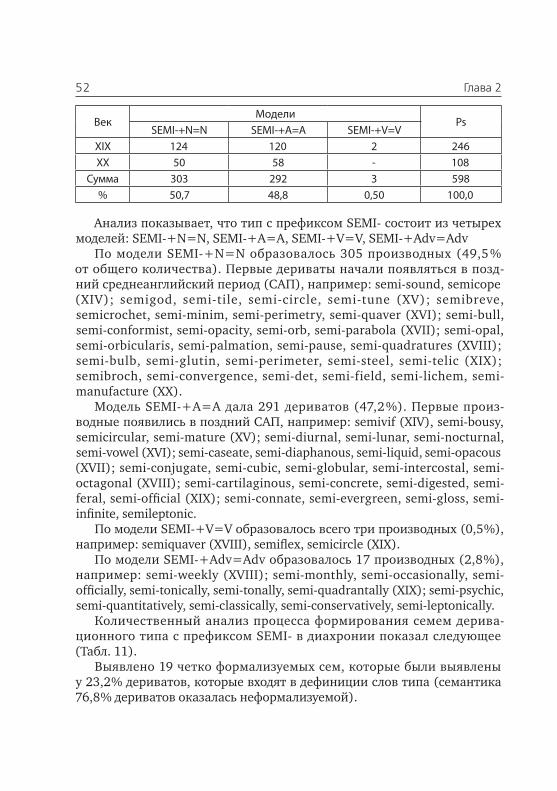
52 Глава 2
ВекМодели
PsSEMI-+N=N SEMI-+A=A SEMI-+V=V
XIX 124 120 2 246XX 50 58 - 108
Сумма 303 292 3 598% 50,7 48,8 0,50 100,0
Анализ показывает, что тип с префиксом SEMI- состоит из четырех моделей: SEMI-+N=N, SEMI-+A=A, SEMI-+V=V, SEMI-+Adv=Adv
По модели SEMI-+N=N образовалось 305 производных (49,5 % от общего количества). Первые дериваты начали появляться в позд-ний среднеанглийский период (САП), например: semi-sound, semicope (XIV); semigod, semi-tile, semi-circle, semi-tune (XV); semibreve, semicrochet, semi-minim, semi-perimetry, semi-quaver (XVI); semi-bull, semi-conformist, semi-opacity, semi-orb, semi-parabola (XVII); semi-opal, semi-orbicularis, semi-palmation, semi-pause, semi-quadratures (XVIII); semi-bulb, semi-glutin, semi-perimeter, semi-steel, semi-telic (XIX); semibroch, semi-convergence, semi-det, semi-field, semi-lichem, semi-manufacture (XX).
Модель SEMI-+A=A дала 291 дериватов (47,2 %). Первые произ-водные появились в поздний САП, например: semivif (XIV), semi-bousy, semicircular, semi-mature (XV); semi-diurnal, semi-lunar, semi-nocturnal, semi-vowel (XVI); semi-caseate, semi-diaphanous, semi-liquid, semi-opacous (XVII); semi-conjugate, semi-cubic, semi-globular, semi-intercostal, semi-octagonal (XVIII); semi-cartilaginous, semi-concrete, semi-digested, semi-feral, semi-official (XIX); semi-connate, semi-evergreen, semi-gloss, semi-infinite, semileptonic.
По модели SEMI-+V=V образовалось всего три производных (0,5 %), например: semiquaver (XVIII), semiflex, semicircle (XIX).
По модели SEMI-+Adv=Adv образовалось 17 производных (2,8 %), например: semi-weekly (XVIII); semi-monthly, semi-occasionally, semi-officially, semi-tonically, semi-tonally, semi-quadrantally (XIX); semi-psychic, semi-quantitatively, semi-classically, semi-conservatively, semi-leptonically.
Количественный анализ процесса формирования семем дерива-ционного типа с префиксом SEMI- в диахронии показал следующее (Табл. 11).
Выявлено 19 четко формализуемых сем, которые были выявлены у 23,2 % дериватов, которые входят в дефиниции слов типа (семантика 76,8 % дериватов оказалась неформализуемой).

53Количественная дериватология
Таблица 11Формирование семем в диахронии
Сема и ее услов-ное обозначение
Дата возникновения слов, век
XIV XV XVI XVII XVIII XIX XX Всего %
C1 Half- 1 3 3 6 2 10 - 25 3,98
C2 Half of - 1 3 7 7 2 1 21 3,34
C3 Partially - - - 2 3 3 3 11 1,75
C4 Of (of the form of, of the shape of ) - 1 1 1 7 - - 10 1,60
C5 Partly - - - 1 2 5 1 9 1,43
C6 Semi- - 1 - - 1 1 5 8 1,27
C7 Pertaining to - - 2 1 1 - 4 8 1,27
C8 Of - - - - 1 1 5 7 1,11
C9 Imperfect - - - 3 1 1 - 5 0,80
C10 Applied to - - - 1 - - 3 4 0,64
C11 Having - - - - 1 3 - 4 0,64
C12 Designating - - - - - 3 - 3 0,48
C13 Imperfectly - - - 1 1 - - 2 0,32
С14 Partial - - - 1 1 - - 2 0,32
C15 Consisting of - - 1 - 1 - - 2 0,32
C16 The condition or quality of being - - - 1 1 - - 2 0,32
C17 Incomplete - - - 2 - - - 2 0,32
C18 Performed in - - 1 - - - - 1 0,16
C19 Demi- - - - 1 - - - 1 0,16
C20 Others 2 1 7 39 78 209 85 421 67,01
Неформализуе-мые - 2 8 23 35 9 3 80 12,74
Сумма 3 9 26 90 143 247 110 628 100,0
% 0,48 1,43 4,14 14,33 22,77 39,3 17,5 100,0 -
Наиболее многочисленной является сема С1, которая дает 4,5 % всех зафиксированных сем нашего типа, например, semivif (XIV); semi-lousy, semi-mature, semicircle (XV); semilunar, semitaur, semi-

54 Глава 2
nocturnal (XVI); semi-demi, semi-caseate, semi-cardinal, semi-tint (XVII); semispheroid, semi-ped (XVIII), semi-feral, semi-formed, semi-difference, semi-nude (XIX).
Cема С2 употребляется в 3,8 % случаев: semi-tune (XV); semicircled, semidiameter (XVI); semi-cylinder, semiparabola, semi-brick, semi-tact (XVII); semi-globe, semi-axis, semi-column, semi-ellipse (XVIII); semi-major, semi-animate (XIX); semi-scale (XX).
Сема С3 дает 2,0 % всех случаев встречаемости, например, semi-Arian, semi-diaphanous (XVII); semi-combined, semi-vitreous, semicirculating (XVIII); semi-attached, semi-nomadic, semi-acquaintance (XIX); semi-automatic, semi-open, semi-detached (XX).
Сема С4 дает 1,8 % всех случаев встречаемости: semi-parabolic, semi-transparent, semi-metallic (XVIII); semi-rotary, semi-adjectively, semi-official, semi-aquatic (XIX); semi-quantitative (XX).
Сема С5 употребляется в 1,6 % случаев, например, semicircular (XV); semicircled (XVI); semi-annular (XVII); semi-columnar, semi-elliptical, semi-oval, semi-globous (XVIII).
Сема С6 употребляется в 1,4 % случаев: semi-Pelagian (XVII); semitonic (XVIII); semi-cursive, semi-Bantu, semi-intensive, semi-documentary (XX).
Семы С7 и С8 употребляются в 1,2 % всех случаев встречаемости: C7 semitune (XV), semifluid (XVIII), semi-officially (XIX), semi-lethal, semi-pro, semi-rigid (XX); C8 semi-double (XVIII), semi-hiant (XIX), semi-documentary, semi-diesel, semi-antique, semi-indirect (XX).
Сема С9 употребляется в 0,9 % случаев: semi-body, semi-allegiance, semi-perfect (XVII); semi-form (XVIII).
Семы С10 и С11 употребляются в 0,7 % случаев, например, C10 semi-concave (XVII), semi-submercible, semi-chemical, semi-portal (XX); C11 semi-reflecting, semi-coking, semi-gloss (XX).
Сема С12 употребляется в 0,5 % случаев: semi-coronated, semi-domed, semi-domical (XIX).
Следующие 5 сем употребляются в 0,3 % случаев. С13 semi-opacous (XVII), semi-transparent (XVIII); C14 semi-opaque (XVII), semi-transparency (XVIII); C15 semi-diurnal (XVI), semi-tonic (XVIII); C16 semi-opacity (XVII), semi-palmation (XVIII); C17 semi-allegiance, semi-perfect (XVII).
Остальные две семы употребляются только в 0,1 % случаев: C18 semiquaver (XVI); C19 semi-demi (XVII).
Приведем примеры лексем с неформализующимися семами: semicope, semi-sound (XIV); semigod (XV); semi-crotchet, semi-perimetry, semi-cipher (XVI); semi-diapason, semi-century, semicolon, semi-parabolical (XVII); semi-infidel, semi-oxygenated, semi-pupal, semi-quinquifid (XVIII);

55Количественная дериватология
semi-decussation, semi-parasitism, semi-sextile, semi-corneous (XIX); semi-reflector, semifinished, semi-conductivity, semi-empirical.
Еще в середине 70-х годов [77] мы начали использовать количе-ственный семантический показатель — среднюю полисемичность (S*) лексем, который подсчитывали путем деления суммы всех значений лексем, появившихся за столетие, на количество этих лексем. Анализ данных показал следующее (Табл. 3). Оказалось, что все лексемы с пре-фиксом SEMI-, возникшие в ХХ в. (за исключением двух), являются од-нозначными (S*=1,0 знач/лекс). Лексемы XIX в. имеют S*=1,02 знач/лекс; у лексем XVII в. S*=1,1 знач/лекс; у лексем XVI в. S*=1,6 знач/лекс; XV в. S*=1,2 знач/лекс.
В целом, наблюдается устойчивая, хотя и не очень сильно выражен-ная закономерность: «Чем старше лексема, тем она многозначнее». У суффиксов аналогичная закономерность проявляется значительно сильнее (Табл. 12).
Таблица 12Изменение средней полисемичности дериватов в диахронии
Век Ps S S/Ps Примеры
XIV 3 3 1,0 semi-vif, semi-sound, semi-cope
XV 7 9 1,3 semi-tile, semi-tune, semi-mature, semigod, semi-bousy, semicircle, semicircular
XVI 17 26 1,5 semibreve, semibrachiation, semivowel, semivocal, semi-time, semitaur, semi-perimetry, semi-nocturnal, semi-minim
XVII 75 90 1,2 semi-tact, semi-separatist, semi-rect, semi-periphery, semi-hoop, semi-divine, semi-deity, semi-atheist
XVIII 142 143 1,01 semi-weekly, semi-volcanic, semi-uncial, semi-transparent, semi-spinalis, semi-revolution
XIX 246 247 1,00 semi-vibration, semi-solid, semi-internal, semi-erect
XX 108 110 1,01 semi-truck, semi-synthetic, semi-predicative, semi-logarithm
Сумма 598 628 1,05
В целом, наблюдается заметная, хотя и не очень сильно выражен-ная закономерность: «Чем старше лексема, тем она многозначнее (по-лисемичнее)». У суффиксов аналогичная закономерность проявляет-ся значительно сильнее. Так, например, анализ дериватов с суффик-сом -ology показал следующую закономерность: лексемы, появившие-

56 Глава 2
ся в САП имеют в S*=2,62 знач/лекс; возникшие в ранний новоанглий-ский период (НАП) — S*=1,73 знач/лекс; лексемы позднего НАП име-ют S*=1,11 знач/лекс. [77].
Ранее было введено понятие скорости (v) изменения семантическо-го поля лексемы, которую мы предложили подсчитывать по следующей формуле: v= 100 (S-1) / (Tn-T1), где S — количество значений у лексе-мы; T1 и Tn — это даты появления первого и последнего по времени значений лексемы, извлекаемые из [22].
При исследовании типа с префиксом semi- выявлено 16 многознач-ных дериватов. Мы подсчитали среднюю скорость (v) изменения семан-тического поля с учетом их возраста и получили следующие результаты (Табл. 13).
Таблица 13Средняя скорость изменения семантического поля в диахронии
Век Vср Примеры
XIV 0,28 semicircular, semi-mature
XVI 1,22 semicircle, semilunar, semivocal, semi-diurnal, semi-breve
XVII 0,80 semiparabola, semitone
XVIII 1,06 semi-annual, semi-parabolic
XIX 4,74 semi-detached, semi-automatic, semi-conductor, semi-invariant, semi-nude
В целом, наблюдается следующая закономерность: «чем древнее сло-во, тем ниже у него скорость изменения семантического поля, чем мо-ложе, тем эта скорость выше».
Конечно, анализ 16-ти имеющихся многозначных дериватов демон-стрирует всего лишь тенденцию, но работа с полисемичными суффик-сальными типами показала, что такая тенденция существует у дерива-тов других аффиксальных типов.
В 50-х годах ХХ в. было обнаружено, что некоторые суффиксы демон-стрируют избирательность присоединения к определенным финаль-ным фонемам производящих основ (ПО) в немецком, русском и англий-ском языках [103; 106; 141]. Позднее мы показали, что наблюдается аналогичное «фонемное тяготение» английских префиксов к инициаль-ным фонемам производящих основ [58; 70].
Мы исследовали фонемное тяготение префикса SEMI- к инициалям производящих основ и получили следующие результаты (Табл. 14).

57Количественная дериватология
Таблица 14Тяготение префикса SEMI- к согласным инициалям ПО
Согласные инициали
Фонема Кол-во % Примеры
[k] 85 16,9 Semi-cup, semi-crustaceous, semi-caseate, semi-quinone, semi-comatose
[s] 74 14,7 semi-span, semi-spheroid, semicirculating, semicylinder, semi-sound
[p] 55 11,0 semi-pause, semi-purulent, semipedal, semi-perfect, semi-palmate, semi-pasty
[d] 47 9,4 semi-direct, semi-Darwinian, semi-daily, semi-ductile, semi-dole, semi-divine
[f ] 38 6,3 semi-fusion, semi-fistular, semifluid, semi-flosculose, semi-form, semi-ferous
[r] 31 5,2 semi-revolution, semi-reverse, semi-reduced, semi-regular, semi-relief
[t] 30 5,0 semi-transparency, semi-tint, semitaur, semi-tile, semitune, semi-tesseral
[b] 25 4,2 semi-bifid, semi-barbarian, semi-barbarism, semibreved, semi-bull, semi-body
[m] 23 3,8 semi-Manicheanism, semi-mensual, semi-molecule, semi-millenary
[l] 21 3,5 semi-looper, semi-logical, semi-lucent, semi-lens, semi-liquid, semi-lethal
[g] 15 2,5 semi-Gothic, semi-globe, semi-granulate, semi-grand, semi-grainy, semi-group
[v] 14 2,3 semi-vitreous, semivowel, semivocal, semi-variable, semi-vault, semi-volcanic
[h] 13 2,2 semi-hyaline, semi-heterocercal, semi-horny, semi-hexagon, semi-hexagonal
[n] 12 2,0 semi-nonconformist, semi-narcosis, semi-nude, semi-nymph, semi-nocturnal
[w] 4 0,8 semi-weekly, semi-dwarf, semi-works, semi-water-gas
Проч. 15 3,0
Сумма 502 100,0
Анализ данных показывает (Табл. 14, 15), что на фонемном стыке ис-пользуется 31 фонема (18 согласных и 13 гласных). Интересно, что пре-фикс SEMI- неодинаково тяготеет к разным инициальным фонемам. Так, инициальную фонему [k] имеет 13,6 % от общего количества лек-

58 Глава 2
сем лексем, [s] — 12,0 %, [p] — 9,0 %, [d] — 7,6 %), [f] –6,1 %, [r] — 5,0 %, [t] — 4,9 %, [b] — 4,1 %, [m] — 3,7 %, [l] — 3,4 %, что в сумме составля-ет 60,4 % согласных инициалей от общего количества лексем (Табл. 14).
Таблица 15Тяготение префикса SEMI- к гласным инициалям ПО
Гласные инициали
Фоне-ма
Кол- во
% Примеры
[æ] 25 26,1 semialdehyde, semi-albinism, semi-anthracite, semi-arid, semi-acid
[ı] 17 17,5 semi-ellips, semi-intensive, semi-invariant, semi-infinite
[ə] 13 13,5 semi-aluminous, semi-Apollinarism, semi-adherent, semi-attached
[əʊ] 12 12,5 semi-opaque, semi-opacity, semi-opacous, semi-opal, semi-opalescent
[ɔ:] 7 7,2 semi-Augustinian, semi-automatic, semi-orbicularis, semi-orbicular
[a:] 6 6,2 semi-arch, semi-armour-plercing, semi-armour-plercer, semi-arc
[ɒ] 5 5,2 semi-oxygenized, semi-oxidated, semi-oxigenated, semi-osseous
[e] 4 4,2 semi-Arianism, semi-evergreen, semi-equitant, semi-egg
[ı:] 2 2,08 semi-evening, semi-egret
[aı] 2 2,08 semi-island, semi-islet
[ʌ] 1 1,04 semi-uncial
[j] 1 1,04 semi-universalist
[eı] 1 1,04 semi-atheist
Sum 96 100,0
Было обнаружено 13 гласных инициалей, наиболее многочисленны-ми из которых являются следующие: [æ] (4,1 % от общего количества лексем), [ı] (2,8 %), [ə] (2,1 %), [əʊ] (1,9 %) (Табл. 15).
Таким образом, впервые для данного префикса установлено наличие фонемного тяготения к инициальным фонемам ПО.
Мы проанализировали формирование терминологической соотне-сенности типа с SEMI- и получили следующие результаты (Табл. 16).

59Количественная дериватология
Таблица 16Формирование терминологической соотнесенности дериватов
с semi- в диахронии
Терминосистема XVI XVII XVIII XIX XX Сум-ма
%
1. Mathematics 2 6 12 8 8 36 20,2
2. Chemistry - - 3 12 6 21 11,7
3. Geology, Mineralogy, Geography - 1 9 11 - 21 11,7
4. Building - - 6 8 2 16 8,8
5. Anatomy 1 1 8 5 - 15 8,4
6. Pathology, Therapeutics - - 2 12 1 15 8,4
7. Music 3 4 4 - - 11 6,1
8. Astronomy 2 1 3 1 - 7 3,8
9. Zoology 2 - 2 1 - 5 2,8
10. Crystallography - - - 5 - 5 2,8
11. Physics - - 1 - 3 4 2,2
12. Biology - - - - 3 3 1,6
11. Botany 1 - 2 2 - 3 1,6
14. Heraldry - - - 2 - 2 1,1
15. Paleography - - 1 - 1 2 1,1
16. Biochemistry - - - - 2 2 1,1
17. Natural History - - 2 - - 2 1,1
18. Typography - - - - 2 2 1,1
19. Printing - - 2 - - 2 1,1
Прочие (13 областей) 2 - 3 2 6 13 7,3
Сумма 11 13 62 57 35 178 100,0
% 6,2 7,3 34,8 32,0 19,6 100 -
Анализ терминологической соотнесенности дериватов с префиксом SEMI- позволил выявить 178 лексем, что составляет 29,8 % всех лексем типа с SEMI-. Эти термины относятся к 32 терминосистемам. К наибо-лее многочисленным терминосистемам относятся первые 10 (Табл. 16), которые включают 84,7 % терминов. Рассмотрим примеры терминоси-стем.

60 Глава 2
Mathematics semi-perimetry, semidiameter (XVI); semiparabola, semi-base, semidiametral, semi-cubical, semi-circumference, semi-periphery (XVII); semi-transverse, semi-segment, semi-ordinate, semi-angle, semi-parabolic (XVIII); semi-parameter, semi-perimeter, semi-regular, semi-quadrantally, semi-tangent, semi-sum (XIX); semi-convergence, semi-field, semi-group, semi-infinite, semi-logarithmic, semi-invariant (XX).
Chemistry semi-oxygenated, semi-acidified, semi-combined (XVIII); semi-acid, semi-glutin, semi-naphthalidine, semi-carbonate, semi-phlogisticated (XIX).
Geology, Mineralogy, Geography semi-metal (XVII); semi-volcanic, semi-granitic, semi-compacted, semi-indurated, semi-lapidified, semipromotolite, (XVIII); semi-delataic, semi-extinct, semi-fossil, semi-desert, semi-aluminous, semi-anthracite, semi-mineralized (XIX).
Building semi-vault, semi-transept, semi-rotunda, semi-relief, semi-girder, semi-channel, (XVIII); semi-cupola, semi-engaged, semi-groove, semi-roll, semi-shelf, semi-bay, semi-arch (XIX); semi-beam, semi-basement (XX).
Anatomy semi-spinalis, semi-tendinose, semi-orbicular, semi-orbicularis, semi-intercostal, semi-interroseus (XVIII); semi-membranous, semi-mucous, semi-tendonosus, semi-sarcodic, semi-bulb (XIX).
Pathology, Therapeutics semi-recumbent, semi-prime (XVIII); semi-luxation, semi-malignant, semi-supination, semi-pectoral, semi-pronation, semi-albinism, semi-coma, semi-comatose, semi-confluent, semi-fluctuating, semi-hepitization (XIX); semi-narcosis (XX).
Music semi-minim, semi-crotchet, semibreve (XVI); semi-choric, semiquaver, semitonic, semiditone (XVIII).
Astronomy semi-diurnal, semi-nocturnal, (XVI); semi-quintile (XVII); semi-quartile, seni-quadrate, semi-sixth (XVIII).
Zoology semibranchiation, semilunar (XVI); semi-palmation, semi-palmated (XVIII); semi-palmate (XIX).
Crystallography semi-tesseral, semi-tessular, semi-prismated, semi-form, semi-formed (XIX).
Следующие две пометы составляют 3,2 % от общего количества всех терминов:
Botany semilunar (XVI); semi-floret, semi-columnar (XVIII); semi-nude, semi-cell (XIX).
Терминологическая помета Biology составляет 1,6 % от общего коли-чества всех терминов, например, semispecies, semi-sterile, semi-sterility (XX).

61Количественная дериватология
Терминологическая помета Physics составляет 2,2 % от общего коли-чества всех терминов, например, semiconducting (XVIII); semiconductor, semiconduction, semiconductivity (XX).
Следующие 6 помет составляют 6,6 % от общего количества всех терминов: Heraldry semi-chevron, semi-saltire (XIX); Palaeography semi-uncial (XVIII), semi-cursive (XX); Biochemistry semi-conservative, semi-conservatively (XX); Natural History semi-oval, semi-ovate (XVIII); Typography semi-display, semi-displayed (XX); Printing semi-quotes, semi-quadratures (XVIII).
Целая группа терминологических помет используется очень редко: Entomology semi-diurnal (XVI); Logics semi-definite (XIX); Agriculture semi-intensive (XX); Statistics semi-invariant (XX); Genetics semi-lethal (XX); Aeronautics semi-monoccoque (XX); Anthropology semi-nomadic (XIX); Fortification semidiameter (XVI); Prosody semi-ped (XVIII); Architecture semi-column (XVIII); Archaeology semi-broch (XX); Art semitone (XVIII); Economics semi-variable (XX).
§ 4. Описание суффиксов (-MONGER)
В 1978 году мы начали отработку методики качественно-количе-ственного описания суффиксов и полусуффиксов английского языка [42; 47; 51; 54; 55], в основу которой были положены следующие прин-ципы:
1) максимально полная выборка лексем с данной деривационной морфемой с использованием крупнейших в мире обратных сло-варей [5; 13].
2) анализ значений и дат их первой письменной фиксации, этимо-логии, суффиксальной производности 2-го шага, извлекаемых из уникального диахронического толкового словаря [22] объе-мом в 616 тыс. статей.
3) использование целого набора переформулированных или за-ново сформулированных нами количественных характеристик (синхроническая и диахроническая продуктивность; модельная и суммарная частотность; модельная и суммарная внешняя ва-лентность; модельная и суммарная внутренняя (фонетическая) валентность). В дальнейшем количество количественных харак-теристик английских аффиксов дошло до 20 позиций.

62 Глава 2
Рассмотрим описание деривационной морфемы -monger, начатое нами в 1977 г. [54].
В дитературе его статус оценивают различно. Одни считают его кор-нем сложений [11; 22], другие — полусуффиксом [14; 91], а осталь-ные — корнем сложений [6; 14; 23; 105; 106; 122].
Существительное Monger, sb. «торговец» зафиксировано еще в 975 году [22]. Начиная с середины XVI в., оно все чаще употребляется в переносном значении — «dealer or trafficker in» — «делец, махинатор (неодобрительно)», например: ceremony-monger, fashion-monger, mass-monger, merit-monger, news-monger, pardon-monger, scandal-monger.
С 1000 года существительное Monger, sb. начинает употребляться в качестве второго компонента сложных слов в прямом значении «тор-говец», например: flesh-monger (1000), wood-monger (1260), timber-monger (1275), hair-monger (1300), garlic-monger (1393), horse-monger (1454), fish-monger (1464), сheese-monger (1510), apple-monger (1552), sheep-monger (1560), beer-monger (1522), cal-monger (1697), soap-monger (1756), water-monger (1865), machine-monger (1840), etc.
В [22] говорится, что, начиная с ХVI века, все чаще появляются сло-ва с -monger в переносном значении: «dealer or trafficker in» — «делец, махинатор (неодобрительно)», например: ceremony-monger, fashion-monger, mass-monger, merit-monger, news-monger, pardon-monger, scandal-monger.
Заметим, что в доступном Обратном словаре английского языка [13] объемом в 110 тыс. слов содержится всего 20 лексем со вторым компо-нентом -monger.
Walker’s Rhyming Dictionary [26] объемом в 54 000 слов содержит все-го 7 лексем с -monger: scare-, whore-, cheese-, fish-, iron-, coster-, news-monger. В крупнейшем частотном словарем [12] в выборке из 1 млн. СУ обнаружено только одно слово: fishmonger (f=1).
Поэтому мы воспользовались в три раза более полным Обратным словарем И. Брауна [5], который содержит 351 тыс. слов (он является «перевернутой версией» Словаря Вебстера [27] объемом в 600 тыс. ста-тей!). Этот словарь содержит 133 лексемы с -monger.
В результате объединения выборок из 3-х обратных словарей пол-ная выборка слов с -monger составила 172 лексемы! Ее анализ с ис-пользованием Большого Оксфордского словаря [22] позволил устано-вить, что первые лексемы с переносным значением начали появлять-ся еще в конце XIII века: hey-monger (1297), supersedias-monger (1475).
Анализ процесса формирования деривационной морфемы -monger в диахронии показал следующее (Табл. 17)

63Количественная дериватология
Таблица 17Формирование дериватов с морфемой -monger
ВекЛексемы с морфемой -monger В том числе в переносном значении
Ps Примеры Ps Примеры
XI–XII 2 Flesh-monger -
XIII–XIV 3 Wood-monger, timber-monger -
XV 6 Horse-monger, fish-monger 1 (16,7 %) Supersedias-monger
XVI 30 Cheese-monger, apple-monger 20 (66,7 %) Mass-monger,
whore-monger
XVII 35 Beer-monger, cal-monger 24 (68,6 %) States-monger
XVIII 22 Soap-monger 14 (63,6 %) Punctilio-monger
XIX 33 Water-monger, machine-monger 26 (78,8 %) Fiction-monger,
humanity-monger
XX 41 40 (97,6 %) Hero-monger
Сумма 172 125 (100,0 %)
Синхроническая продуктивность типа c -monger (Ps) (то есть количе-ство новообразований за данный век) постепенно возрастала. Причем если за средне английский период образовалось 11 лексем с -monger, то за ранний новоанглийский — уже 65 лексем, а за поздний новоан-глийский период — 96 лексем. В целом, за новоанглийский период по-явилась 161 лексема с -monger (93,6 %). Диахроническая продуктив-ность типа (Pd) (то есть сумма всех синхронических продуктивностей Ps) равна 172 лексемам.
Отметим, что в XV в. появилась первая лексема с переносным зна-чением (“dealer or trafficker in” — «делец, махинатор»), например, supersedias-monger «судейский чиновник-махинатор», а ее доля от об-щего количества лексем составила 16,7 % (Табл. 12).
В XVI веке доля лексем с переносным значением составила 66,7 % [например, mass-monger (1550), whore-monger (1526), news-monger (1596), fashion-monger (1599)]; в XVII веке — 68,6 % [например, merit-monger (1611), states-monger (1678)]; в XVIII веке — 63,6 % [например, punctilio-monger (1762)]; в XIX веке — 78,8 % [например, gossip-monger (1836), verbal-inspiration-monger (1869)]; в XX веке — 97,6 % [напри-мер, hero-monger (1900), strife-monger (1909), mystery-monger (1919), hysteria-monger (XX), revenge-monger (XX)]. Следовательно, идет нара-

64 Глава 2
стающий процесс перераспределения ролей прямого и переносного зна-чений.
Ранее было отмечено, что многие типичные суффиксы английско-го языка характеризуются наличием фонемного тяготения, т. е. избира-тельного присоединения к ПО с определенными фонемными исходами [141; 106].
Следует проверить, имеется ли фонемное тяготение у деривацион-ной морфемы -monger.
Результаты анализа приведены в Таблице 18.
Таблица 18Тяготение морфемы -monger к финальным фонемам
производящей основы
Фонема Кол-во % Примеры основ
[l] 26 15,1 Apple-, fell-, scandal-, shell-
[t] 20 11,6 Hate-, insect-, jest-, merit-
[n] 17 9,9 Emotion-, fashion-, fiction-, iron-, loan-, panic-
[s] 14 8,1 Horse-, mass-, verse-, states-
[нейтр.] 13 7,6 Coster-, timber-, water-
[I] 12 7,0 Ceremony-, expediency-, humanity-, money-
[d] 11 6,4 Ballad-, fad-, fund-, wood-
[ou] 9 5,2 Borough-, hero-, punctilio-
[k] 7 4,1 Book-, garlic-
[z] 7 4,1 Cheese-, lease-, news-
[p] 7 4,1 Gossip-, soap-, sheep-
[m] 4 2,3 Atom-, nostrum-
[sh] 4 2,3 Fish-, flesh-
[o:] 4 2,3 War-, whore-
[f ] 2 1,2 Strife
[r] 2 1,2 Horror-
Прочие 13 7,5 Beer-, hair-, hey-, hysteria-, revenge-, rumour-, scare-
Сумма 172 100,0
Анализ данных по фонемному тяготению показывает, что -monger тяготеет к 24 финальным фонемам ПО, в том числе к 7 гласным.

65Количественная дериватология
Заметим, что на 3 самых многочисленных фонемы приходится 36,6 % лексем; на 5 самых многочисленных фонемных исходов — 52,3 % лексем, а на 7 наиболее многочисленных фонемных исхода ПО — 65,7 % лексем. Все это указывает на существование резко выраженного фонем-ного тяготения морфемы -monger к определенным финальным фоне-мам ПО.
Как известно, фонемное тяготение представляет собой внутреннюю валентность морфемы.
Внешняя (суффиксальная) валентность показывает, какие суффиксы могут присоединяться к лексемам с -monger (Табл. 19).
Таблица 19Внешняя (суффиксальная) валентность морфемы -monger
СтолетиеВалентные суффиксы Всего
-ing -y Прочие Количество %
XVI 4 1 1 6 6,2
XVII - - 3 3 3,1
XVIII 1 1 3 5 5,2
XIX 33 10 4 47 48,4
XX 32 4 - 36 37,1
Сумма 70 16 11 97 100,0
% 72,2 16,5 11,3 100,0 -
Анализ данных показал, что первые суффиксальные производные от лексем с морфемой -monger (это и называетсмя «суффиксальной ва-лентностью — V») начали появляться в XVI в., а всего выявлено 97 ва-лентных дериватов, причем наиболее продуктивными моделями явля-ются следующие:
Модель N + -ing = N Обнаружено 70 валентных дериватов (72,2 % от общего количества), например: Fashionmongering (1955), jestmon-gering (1599) massmongering (1552), leasemongering, boroughmongering (1797), etc.
Продуктивность этой модели сильно возросла в XIX в. (до 33 про-изводных, например: Moneymongering (1816), fundmongering (1886), horrormongering (1887), meritmongering (1845), versemongering (1836), etc.
В XX в. добавилось еще 32 валентных деривата, например: Scaremongering (1902), warmongering (1907), boroughmongering (XX c.), salvation-mongering (1867).

66 Глава 2
Модель N + -y = N Продуктивность модели равна 16 дериватам, например: newsmongery (1592), fellmongery (1759), nostrummongery (1812), loanmongery (1822), costermongery (1865), bookmongery (1876), fadmongery (1890), etc.
Модель N + -dom = N (coster-mongerdom (1889), whore-mongerdom (1850)
Модель N + -ship = N (nostrum-mongership (1748)N + -ly = Adv (cheesemongerly).N – -er + -ing = N (hairmonging (1300).N – -er + -ing = A (fashionmonging, massmonging, meritmonging).Интересно, что еще в ХХ в. продолжал употреблялся глагол monger, v
(trans.) (to deal or traffic in) (образованный по конверсии от существи-тельного), например: “Both American and British opinion is laughing out of court those who monger their scares about the United States Navy” (1928); «I laughed at her and told her, that she cannot monger any money out of my pocket» (1962) [22].
Отметим, что деривационная морфема -monger вместе с такими, как -smith и -wright, обозначающими «деятеля», образует однокорен-ные ряды, например: versemonger=versesmith=versewright «стихоплет», playmonger=playwright «сочинитель пьес», wondermonger=wondersmith «чудотворец».
Параллелизмом называется явление, когда синонимические суф-фиксы или префиксы образуют однокоренные дериваты, обычно являю-щиеся синонимами, но не всегда.
Нами обнаружено 11 параллельных образований с морфемами -monger и -wright. Некоторые из них близки по значению, но отличают-ся стилистической окраской, например: playmonger (1593) «(ирон.) тот, кто пишет пьесы» — playwright (1687), «автор пьес»; witmonger (1620) «(презр.) остряк» — witwright (1655) «(ирон.) остряк», peacemonger (1808) «(презр. В устах поджигателей войны) сторонник мира» — peacewright (1855) «сторонник мира».
Было выявлено 7 однокоренных пар с -minger/-smith: wondermonger (1612) «чудодей, чудотворец» — wondersmith (?) «(ирон.) чудотворец», wordmonger (1590) «(презр.) фразер» — wordsmith (1896) «(ирон.) жон-глер красивыми словами».
Обнаружено также 2 тройки дериватов с исходами: — monger/-wright/-smith, а именно: versemonger (1634) «(презр.) версификатор, рифмоплет» — versewright (1729) «(ирон.) стихотворец» — versesmith (1820) «(ирон.) рифмач, стихоплет»; housemonger (1604) «тот, кто кра-

67Количественная дериватология
сит или украшает дома» — housesmith (?) «мастер, ремонтирующий до-мшнюю утварь» — housewright (1549) «столяр, строящий дома; плот-ник».
§ 5. Проблема статуса деривационных морфем
Проблема статуса деривационных формантов (морфем) интересу-ет многих исследователей, как теоретиков, так и практиков [7; 15; 23; 30; 34; 35; 122–124]. Однако традиционно статус морфем оценивали по дихотомической шкале интуитивно: аффикс — неаффикс (т. е. ко-рень сложения).
В 40–50-х годах в германистике была введена промежуточная града-ция статуса — полуаффиксы [141], и шкала статуса стала трихотомиче-ской: аффикс — полуаффикс — корень. Идея выделения морфем проме-жуточного статуса быстро приобрела сторонников в англистике [1; 14; 91] и русистике (аффиксоид) [119; 151].
Следует заметить, что составители больших толковых словарей ан-глийского языка [17; 22; 27] давно уже выделяют деривационные мор-фемы промежуточного статуса называя их «комбинирующимися фор-мами» (combining forms). Вскоре было установлено, что многие англий-ские «полуаффиксы» — это ничто иное, как «переименованные» комби-нирующиеся формы английского языка.
Как бы то ни было, статус и тех и других определялся интуитивно (на качественных основах).
С внедрением количественных критериев в дериватологию появи-лась возможность подойти к решению проблемы статуса на объектив-ной основе.
Ниже мы продемонстрируем разработанную нами методику опреде-ления субъективного статуса (СС) и объективного статуса (ОС) [56; 57].
Для нахождения субъективного статуса мы проанализировали ос-новные работы по словообразованию на предмет выявления статуса данной деривационной морфемы и (для сравнения) еще 12 морфем, ве-дущих свое происхождение от вторых компонентов сложений [1; 11; 14; 91; 106] (Табл. 20).

68 Глава 2
Таблица 20Качественные характеристики ряда деривационных морфем
английского языка
Аффиксы Ч. р. [22 [27] [24] [11] [91] [14] [34] 106 108 [105 СС
- - - - - - - - - - -
-dom n s s s s s s s s s s 1,00
-hood n s s s s s s s s s s 1,00
-ship n s s s s s s s s s s 1,00
-man n - cf - - ss ss ss ss s - 0,35
-land n - cf - - - ss ss ss - - 0,20
-monger n - cf - - ss ss ss - - - 0,20
-berry n - - - - ss ss Ss - - - 0,15
-wright n - cf - - ss ss - - - - 0,15
-house n - cf - - - — - ss - - 0,10
-stone n - cf - - - - - ss - - 0,10
-ware n - cf - - ss - - - - - 0,10
-wort n - cf - - ss - - - - - 0,10
-wood n - cf - - - - - - - 0,05
Средн. 0,35
Примечание. Приняты следующие обозначения: S — суффикс, SS — полусуффикс, cf — комбинирующаяся форма. СС — субъективный ста-тус
В основе методики лежит идея о «коллективном информанте», како-вым выступают авторитетные специалисты по словообразованию ан-глийского языка. Имплицитно предполагается, что описываемые де-ривационные морфемы авторы монографий или составители крупных толковых словарей считают аффиксами, а все не включенные в опи-сание морфемы — корнями. Некоторые морфемы «промежуточного» статуса некоторые авторы эксплицитно называют «полуаффиксами» и «комбинирующимися» формами.
Для нахождения усредненной величины субъективного статуса (СС) мы присваивали 1 балл суффиксу (S); 0,5 балла — полусуффиксу -SS или комбинирующейся форме (Сf). Затем все баллы каждой из описы-ваемых морфем складывали и делили на 10 (т. е. количество источни-

69Количественная дериватология
ков). Полученный усредненный статус (СС) представлен в последней графе (Табл. 5). Идеальный суффикс должен иметь величину СС, рав-ную единице (СС=1,00); а полусуффикс — 0,50 (т. е. СС=0,50); корень сложения имеет СС=0.
Видно, что морфема -monger имеет СС=0,20, то есть явно ниже «по-лусуффикса», оцениваемого субъективно.
С введением количественных характеристик деривационных мор-фем в практику описания аффиксов появилась возможность оценивать статус количественно следующим образом.
Пентахотомическая шкала статуса деривационных морфем имеет следующий вид [56]: Аффикс — Аффиксоид — Полуаффикс — Радиксо-ид — Радикс (корень).
Если суффиксы, описаны с помощью какой-либо количественной ха-рактеристики (например, диахронической продуктивности -Pd), то они ранжируются по убыванию этой величины (Табл. 21). Находится сум-ма всех величин и делится на количество описываемых морфем (N), что дает нам среднюю величину характеристики Pd, которую обозна-чим как X* (то есть, X*=SumPd/N). Затем разделив Х* на 2,7 (основа-ние натуральных логарифмов) и получим величину X** (Х**=X*/2,7). Далее находим величину Х*** (X***=X**/2,7).
Ранее было показано, что количественные характеристики аффик-сов (такие, как Pd, Ps, Fm, Fs, Vm, Vs) положительно коррелируют с де-ривационным статусом, в частности, все «типичные» суффиксы имеют максимальные величины каждой из количественных характеристик; «типичные» полусуффиксы имеют более низкие величины этих харак-теристик и т. д.
Все морфемы, у которых Pd выше Х*, как оказывается, являются «суффиксами». Те морфемы, у которых Pd находится между Х* и Х**, от-носятся к «суффиксоидами» (похожими на суффиксы!). Морфемы, у ко-торых Pd находится между Х** и Х*** считаются к «полусуффиксам», а те, у которых Pd меньше Х*** будут «радиксоидами».
Поскольку используется несколько объективных количественных характеристик аффиксов [такие, как длина деривационного ряда (Pd), количество неологизмов (Ps), способность присоединять другие суф-фиксы (валентность, Vm, Vs), частотность употребления слов с дан-ной деривационной морфемой (Fm, Fs)], то можно определить статус по каждому из них. Так как эти характеристики в большей или меньшей степени являются независимыми, то можно найти так называемый «ин-тегральный» объективный статус, являющийся суммарной характери-стикой.

70 Глава 2
Таблица 21Количественные характеристики продуктивности, частотности
и валентности ряда суффиксов, полусуффиксов и конвесификсов, их объективной (ОС) и субъективной (СС) статус
Морфема Частьречи ОС Pd Ps Fm Fs Vm Vs СС
-dom N 0,25 402 2 7 210 3 5 1,00
-hood N 0,25 328 3 18 192 2 2 1,00
-ship N 0,56 892 6 46 572 0 0 1,00
-man N 0,69 1300 45 218 640 5 54 0,35
-monger N 0,06 133 0 1 1 5 97 0,20
-land N 0,31 209 13 65 243 9 80 0,20
-berry N 0,25 200 1 7 114 5 10 0,15
-wright N 0,00 34 1 2 6 3 7 0,15
-house N 0,12 154 15 36 88 2 3 0,10
-ware N 0,12 69 8 2 4 2 3 0,10
-wort N 0,25 294 0 1 1 2 2 0,10
-stone N 0,12 191 1 22 29 1 1 0,10
-wood N 0,25 263 1 33 94 5 6 0,05
Сумма 4469 96 458 2094 44 270 4,50
Среднее (Х*) 343,8 7,4 35,2 161,1 3,4 20,8 0,346
Х*/е=Х** 127,3 2,74 13,1 60,8 1,26 7,7 0,128
Х**/ е 47,2 1,01 4,8 22,5 0,5 2,85 0,05
Результаты, представленные в таблице 6 показывают, что объектив-ный статус морфемы -monger оценивается величиной, равной 0,30. Со-гласно пентахотомической шкале это — радиксоид!
Таблица 22Ранжировка деривационных морфем по количественным
критериям
Ранг СС Pd Ps Fm Fs Vm Vs
1 -dom -man -man -man -man -land monger
2 -hood -ship -house -land -ship -berry -land
3 -ship -dom -land -ship -land -man -man

71Количественная дериватология
Ранг СС Pd Ps Fm Fs Vm Vs
4 -man -hood -ware -house -dom monger -berry
5 monger -wort -ship -wood -hood -wood -wright
6 -land -wood -hood -stone -wood -dom -wood
7 -berry -land -berry -hood -house -wright -dom
8 -wright -berry -stone -berry -stone -hood -house
9 -house -stone -wood -dom -berry -house -ware
10 -stone -house -house -ware -wright -ware -hood
11 -ware monger -wright -wright -ware -wort -wort
12 -wort -ware -monger -monger monger -stone -stone
13 -wood -wright -wort -wort -wort -ship -ship
Анализ количественных характеристик 13 деривационных морфем показывает (Табл. 22), что -monger уступает в статусе типичным суф-фиксам -dom, -hood, -ship по всем количественным характеристикам, за исключением Vm и Vs.
§ 6. Префиксальные гнезда (c pseudo- / quasi-)
В английском языке встречаются слова, включающие в себя боль-шое количество деривационных морфем — префиксов и/или суффик-сов. В качестве примера можно привести следующие, извлеченные из словаря [17]:
1) pseudo-pseudohypoparathyroidism, pseudo-Dantesque, pseudo-ar-tistically, pseudo-etymologically, pseudo-linguistically, pseudo-hyper-trophic, pseudo-multiseptate, pseudo-internationalistic, pseudo-Pres-byterian, etc.;
2) quasi-artistically, quasi-disgraced, quasi-educationally, quasi-fatalis-tically, quasi-disastrously, quasi-enthusiastically, quasi-extraterrito-rially, quasi-internationally, quasi-nationalistic, quasi-revolutionized, quasi-metaphysically, etc.
Словообразовательная система английского языка включает в себя как деривационные модели и типы [11; 14; 105; 108; 115; 116; 122; 119; 131; 151], так и словообразовательные цепочки и гнезда [136; 137].
Известно, что «гнездо — это группа слов, происходящих от одного корня или объединяемых современными морфологическими или се-

72 Глава 2
мантическими связями» [36, 109]. Существуют работы, посвященные исследованию аффиксальных гнезд [136; 137]
Кроме качественного реляционного описания словообразователь-ных гнезд в последнее время появились работы по их количественному описанию [114].
Целью данной работы является исследование не однокорневых, а од-нопрефиксальных гнезд слов современного английского языка. Мате-риалом для анализа послужили все слова с заимствованными префик-сами PSEUDO- (греч.) и QUASI- (лат.), извлеченные из второго издания словаря [17], содержащего 310 тыс. словарных статей.
Языковые характеристики префиксальных гнезд -pseudo- / quasi-
Были поставлены следующие задачи.А. Описать следующие языковые (словарные) характеристики двух
префиксальных гнезд (ПГ):1. Подсчитать количество дериватов с каждым из этих префиксов,
т. е. найти их диахроническую продуктивность (Pd);2. Установить наличие морфемного тяготения каждого из данных
префиксов к инициальным префиксальным морфемам производящих основ (ПО);
3. Выявить наборы суффиксов, использующихся на 1-м, 2-м и т. д. ша-гах деривации в гнездах слов с префиксами pseudo- и quasi-.
Б. Найти некоторые речевые (текстовые) характеристики этих гнезд:1. Найти модельную (Fm) и суммарную (Fs) частотность дериватов
из этих префиксальных гнезд по крупнейшему в мире 128; частотно-му словарю [12], содержащему 50 тыс. самых частотных слов (выборка равна 1 млн словоупотреблений)
2. Выявить наборы суффиксов, использующихся на 1-м, 2-м и т. д. ша-гах деривации высокочастотных слов ПГ с pseudo- и quasi-.
Аффиксальные морфемы идентифицировали, опираясь на работы [14; 105; 108; 122]. Количественные определения понятий диахрони-ческая продуктивность (Pd), модельная (Fm) и суммарная (Fs) частот-ность введены нами ранее [42; 47; 48; 54; 55].
Использование функции Шеннона и коэффициента сходства 2-х со-вокупностей по нескольким параметрам при исследовании словообра-зования также было описано ранее [48; 79].

73Количественная дериватология
Вначале было решено посмотреть, как количественные характе-ристики префиксальных гнезд (ПГ) зависят от свойств самих пре-фиксов.
Известно, что греческий префикс pseudo- был заимствован латин-ским языком, откуда в среднеанглийский период начал проникать в ан-глийский язык в составе заимствований. Согласно данным крупнейше-го исторического словаря [22] (далее БОС) префикс pseudo- в XIV в. на-чал присоединяться к существительным, а в XVII в. — к прилагатель-ным, формируя 2 модели:
1) pseudo- + N = N Например, pseudo-Christ (1380), pseudoprophet (1380);
2) pseudo- + A = A Например, pseudo-Christian (1664).Согласно [17] он имеет следующее значение: “false; pretended;
unreal”, которое в «Большом словаре иноязычнных слов» (2003) дает-ся как «ложь, вымысел», выражая понятия «недействительный, ложный, мнимый» [87, 475].
Латинский префикс quasi- начал проникать в английский язык в со-ставе заимствований в новоанглийский период. Согласно [22] в XVII в. он стал присоединяться к существительным, а в XIX в. — к прилагатель-ным и глаголам, формируя 3 следующие модели:
1) quasi- + N = N Например, quasi-dying (1676);2) quasi- + A = A Например, quasi-colloquial (1802);3) quasi- + V = V Например, quasi-deify (1826).Согласно [17] он обозначает «resembling; having some, but not all of
the features of», что переводится как «мнимый; ложный; ненастоящий» [87, 261].
Хотя мы везде для удобства называем обе эти препозитивные морфе-мы «префиксами», лингвисты оценивают их по-разному: как префиксы (pr), комбинирующиеся формы (cf) либо как корневые морфемы сложе-ний (R).
В Таблице 23 представлен их субъективный статус в настоящее вре-мя и подсчитана величина ОСС (относительного субъективного ста-туса) по следующей шкале: префикс (ОСС=1,0) — комбинирующаяся форма, или полуаффикс (ОСС=0,5) — корневой компонент сложений (ОСС=0,0) [51].
Было установлено, что производящие основы (ПО) дериватов двух исследуемых ПГ являются либо простыми (zero), либо суффиксальны-ми, содержащими или один суффикс (1-й шаг деривации), или два (2-й шаг), или три (3-й шаг), или четыре (4-й шаг), или пять (5-й шаг) суф-фиксов (Табл. 2).

74 Глава 2
Таблица 23Деривационный статус препозитивных морфем pseudo- и quasi-
по мнению различных авторов и составителей словарей
Аффикс OED 1933
Webster1934
March.1960
Каращук1965
Пиот.1971
RHD1987
Collins1991 ОСС
pseudo- pr cf pr pr R cf pr 0,71
quasi- pr R R R R cf pr 0,36
Чисто префиксальные дериваты ПГ с pseudo- (47 слов) образованы по следующим моделям:
1) pseudo- + A = A (16 дериватов)Например, pseudo-antique, pseudo-candid, pseudo-Dutch, pseudo-
French, pseudo-Greek, pseudo-human, pseudo-noble, pseudo-subtle, pseudo-modest, pseudo-modern, pseudo-genteel, pseudo-cleft, etc.
2) pseudo- + N = N (31 дериват)Например, pseudo-concha, pseudo-bulb, pseudo-carp, pseudo-cyphella,
pseudo-esthesia, pseudo-parenchyma, pseudo-podium, pseudo-scorpion, pseudo-symmetry, pseudo-sphere, pseudo-event, pseudo-Dionysius, etc.
3) pseudo- + A = A (16 дериватов)Например, pseudo-antique, pseudo-candid, pseudo-Dutch, pseudo-
French, pseudo-Greek, pseudo-human, pseudo-noble, pseudo-subtle, pseudo-modest, pseudo-modern, pseudo-genteel, pseudo-cleft, etc.
Чисто префиксальные дериваты с quasi- (84 слова) образованы по следующим моделям:
1) quasi- + A = A (75 дериватов)Например, quasi-absolute, quasi-antique, quasi-bad, quasi-blind, quasi-
candid, quasi-correct, quasi-deaf, quasi-dumb, quasi-empty, quasi-false, quasi-free, quasi-French, quasi-good, quasi-Greek, quasi-happy, quasi-honest, quasi-young, etc.
2) quasi- + N = N (4 деривата)Например, quasi-adult, quasi-contract, quasi-crystal, quasi-particle.3) quasi- + V = V (5 дериватов)Например, quasi-admire, quasi-adopt, quasi-attempt, quasi-determine,
quasi-pledge.Важной количественной характеристикой префиксов является
их морфемное тяготение, т. е. избирательное присоединение к опреде-ленным инициальным морфемам ПО (Бартков, 19980б). Анализ описы-ваемых ПГ показывает, в частности, что морфемное тяготение префик-са pseudo- характеризуется следующими 6 моделями, давшими в общей сложности 9 дериватов:

75Количественная дериватология
1) pseudo- + in- (im-) (pseudo-impartial, pseudo-independent, pseudo-insane, pseudo-invalid);
2) pseudo- + inter- (pseudo-international);3) pseudo- + re- (pseudo-reformed);4) pseudo- + di- (pseudo-dipteral);5) pseudo- + peri- (pseudo-peripteral);6) pseudo- + tri- (pseudo-tripteral).Таким образом, мы подсчитали величины модельного (MrphM=6)
и суммарного (MrphS=9) морфемного тяготения префикса pseudo-.Анализ морфемного тяготения префикса quasi- позволил выявить
следующие 9 моделей, давших в сумме 25 дериватов:1) quasi- + a- (quasi-aside, quasi-asleep);2) quasi- + dis- (quasi-disadvantageous, quasi-disastrous);3) quasi- + extra- (quasi-extraterritorial);4) quasi- + in- (im-, ir-) (quasi-immortal, quasi-impartial, quasi-inde-
pendent, quasi-indifferent, quasi-inevitable, quasi-infinite, quasi-innumera-ble, quasi-intolerable, quasi-intolerant, quasi-invisible, quasi-irregular);
5) quasi- + inter- (quasi-international, quasi-interviewed);6) quasi- + meta- (quasi-metaphysical);7) quasi- + re- (quasi-reformed, quasi-renewed, quasi-re-
stored, quasi-replaced);8) quasi- + super- (quasi-supervised);9) quasi- + un- (quasi-unconscious).Следовательно, мы получили следующие величины морфемного тя-
готения префикса quasi-: MrphM=9, MrphS=25.Сравнение показывает, что ПГ с латинским quasi- по обеим этим ко-
личественным характеристикам превосходит ПГ с греческим pseudo-.Анализ суффиксальных характеристик этих двух ПГ показывает сле-
дующее (Табл. 24).Таблица 24
Количество производных на разных шагах деривации в гнездах с префиксами pseudo- и quasi-
Префикс zero 1-й шаг 2-й шаг 3-й шаг 4-й шаг 5-й шаг Сумма
pseudo- 479,7 %
26755,2 %
12125,0 %
479,7 %
20,4 % 0 484
100 %
quasi- 847,3 %
56949,4 %
38333,2 %
1018,8 %
121,0 %
30,3 %
1152100 %
quasi- / pseudo- 1,8 2,1 3,2 2,1 6,0 - 2,4

76 Глава 2
В целом, диахроническая продуктивность ПГ с латинским префик-сом quasi- равна 1152 дериватам (т. е. Pd=1152), а ПГ с греческим пре-фиксом pseudo- — 484 дериватам (т. е. Pd=484).
Таким образом, ПГ с quasi- в 2,4 раза многочисленнее, чем ПГ с pseudo-.
Необходимо отметить, однако, что хотя доли (%) производных соот-ветствующих шагов деривации в обоих ПГ практически почти одинако-вы (Табл. 2), качественный состав суффиксов, использующихся в каждом из ПГ, и количество дериватов с ними сильно различаются (Табл. 24 и 25).
Сначала проанализируем количественные характеристики гнезда с греческим префиксом с pseudo- (Табл. 25).
Таблица 25Суффиксальные цепочки дериватов с префиксом PSEUDO-
Суффиксы (в обратном алфавитном порядке)
1 шаг 2 шаг 3 шаг 4 шаг
Кол-во % Кол-во % Кол-во % Кол-во %
Адъективные суффиксы
-ic, a 69 25,8 9 7,5 3 6,4 1 50,0
-ed, a 2 0,7 1 0,8
-oid, a 1 0,4
-(a, i) ble, a 1 0,4
-ile, a 2 0,7
-ine, a 1 0,4
-ese, a 2 0,7
-ate, a 6 2,2 1 0,8
-esque, a 1 0,4
-ive, a 7 2,6 1 0,8
-ing, a 1 0,4
-ish, a 8 3,0
-al, a 37 13,8 59 48,8 2 4,3
-ful, a 1 0,4
-an, a 48 18,0 1 0,8
-ar, a 8 3,0
-ous, a 17 6,4

77Количественная дериватология
Суффиксы (в обратном алфавитном порядке)
1 шаг 2 шаг 3 шаг 4 шаг
Кол-во % Кол-во % Кол-во % Кол-во %
-(a, e) nt, a 6 2,2
-ly, a 1 0,4
-(a, o) ry, a 5 1,9 1 0,8
Субстантивные суффиксы
-ia, n 4 1,5
-ance, n 1 0,4
-ite, n 1 0,4
-ism, n 2 0,7
-man, n 2 0,7
-ion, n 9 3,4 1 0,8
-osis, n 1 0,4
-itis, n 1 0,4
-ment, n 1 0,4
-ist, n 9 3,4 3 2,5 1 2,1
-y, n 1 0,4
-ity, n 0 0 1 0,8
Глагольные суффиксы
-ate, v 4 1,5
Наречные суффиксы
-ly, adv 7 2,6 43 35,6 41 87,2 1 50,0
Сумма дериватов 267 100 121 100 47 100 2 100
Среднее 8,1 11,0 11,7 1,0
Число суффиксов 33 11 3 2
ЗАМЕЧАНИЕ. Далее при серийном использовании терминов «дери-ват», «производное слово» мы будем употреблять аббревиатуру «Д» в це-лях экономии.
Для образования дериватов 1-го шага всего используется 33 суффик-са (давших 267 Д, т. е. дериватов), в том числе 20 адъективных (224 Д), 12 субстантивных (32 Д), 1 глагольный (4 Д) и 1 наречный (7 Д).
Отметим, что наиболее многочисленны дериваты с адъективными суффиксами -ic (69 Д), -an (48 Д), -al (37 Д), -(a, e) nt (17 Д).

78 Глава 2
На 2-м шаге используется 11 суффиксов (121 Д), в том числе 7 адъек-тивных (73 Д), 3 субстантивных (5 Д), 1 наречный (43 Д).
Здесь, однако, наиболее многочисленными являются дериваты с адъективными суффиксами -al (59 Д), -ic (9 Д) и наречным -ly (43 Д).
На 3-м шаге использовано всего 3 суффикса (давших 47 Д), в том числе 2 адъективных (5 Д), 1 субстантивный (1 Д) и 1 наречный (41 Д).
Наиболее многочисленным является наречный суффикс -ly (41 Д).На 4-м шаге использованы только 1 адъективный (1 Д) и 1 наречный
(1 Д) суффиксы.Таким образом, видно, что в гнезде с греческим префиксом pseudo-
наблюдается следующая закономерность: с увеличением номера шага деривации уменьшается количество как использующихся суффиксов, так и образованных с их помощью дериватов. Следует специально отме-тить, что количество дериватов с наречным суффиксом ly- на 2-м (43 Д) и 3-м (41 Д) шагах деривации очень велико, в 6 раз превышая количе-ство дериватов на 1-м шаге (7 Д).
Если качественно сравнить наборы суффиксов 1-го шага деривации со всеми остальными шагами, используя коэффициент Чекановского (К) (Czekanowski, 1913; Бартков, 1980б), то получим следующую кар-тину (при полном сходстве суффиксальных наборов мы получим К=1, а при отсутствии сходства К=0).
Сходство наборов суффиксов, использующихся на 1-м и 2-м шагах деривации, оценивается следующей величиной: К (1,2 шагов) =0,45 (т. е. сходство среднее).
Сходство наборов суффиксов 1-го и 3-го шагов деривации еще мень-ше: К (1,3 шагов) =0,22.
Сходство наборов суффиксов использующихся на 1-м и 4-м шагах де-ривации является самым небольшим: К (1,4 шагов) =0,11.
Данные Табл. 3 показывают, что количество дериватов с разными суффиксами резко различается на каждом шаге деривации.
Количественное сравнение долей участия каждого суффикса в об-разовании дериватов на 1-м, 2-м, и т. д. шагах деривации позволяет ис-пользование коэффициента Ренконена К* (Renkonen, 1939; Бартков, 1980б; Бартков, Парфенова, Каращук, Барткова, 1999) (при полном сходстве долей дериватов с каждым суффиксом К*=1, при отсутствии сходства К*=0).
Подсчеты дают следующие величины количественного сходства с учетом долей дериватов с каждым суффиксом:
К* (1,2 шагов) =0,31; К* (1,3 шагов) =0,15; К* (1,4 шагов) =0,28.

79Количественная дериватология
В целом, величины первых двух коэффициентов К* ниже, чем соот-ветствующих величины К, оценивающих только сходство наборов суф-фиксов.
Теперь проанализируем количественные характеристики суффик-сальных дериватов в гнезде с латинским префиксом quasi- (Табл. 26).
Таблица 26Суффиксальные цепочки дериватов с префиксом QUASI-
Суффиксы (в обратном алфавитном порядке)
1 шаг 2 шаг 3 шаг 4 шаг
Кол-во % Кол-во % Кол-во % Кол-во %
Адъективные суффиксы
-ic, a 58 10,2 5 1,3 4 4,0 3 25,0
-ed, a 97 17,0 20 5,2 4 4,0
-(a, i) ble, a 28 4,9 2 0,6
-ile, a 1 0,2
-ese, a 1 0,2
-ate, a 16 2,8 1 0,3
-ive, a 26 4,6 4 1,0
-ing, a 20 3,5 7 1,8
-ish, a 5 0,9
-al, a 68 11,9 79 20,6 6 5,9 3 25,0
-ful, a 20 3,5
-an, a 3 0,5
-ar, a 7 1,2
-ous, a 39 6,9
-(a, e) nt, a 43 7,6
-y, a 5 0,9
-ly, a 1 0,2
-(a, o) ry, a 11 1,9 3 0,8
Субстантивные суффиксы
-ance, n 1 0,2
-ure, n 4 0,7
-man, n 2 0,4 3 3,0
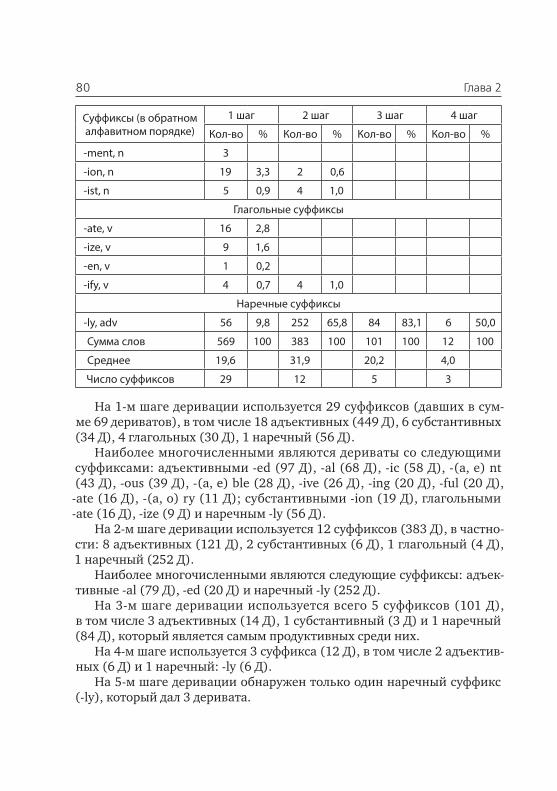
80 Глава 2
Суффиксы (в обратном алфавитном порядке)
1 шаг 2 шаг 3 шаг 4 шаг
Кол-во % Кол-во % Кол-во % Кол-во %
-ment, n 3
-ion, n 19 3,3 2 0,6
-ist, n 5 0,9 4 1,0
Глагольные суффиксы
-ate, v 16 2,8
-ize, v 9 1,6
-en, v 1 0,2
-ify, v 4 0,7 4 1,0
Наречные суффиксы
-ly, adv 56 9,8 252 65,8 84 83,1 6 50,0
Сумма слов 569 100 383 100 101 100 12 100
Среднее 19,6 31,9 20,2 4,0
Число суффиксов 29 12 5 3
На 1-м шаге деривации используется 29 суффиксов (давших в сум-ме 69 дериватов), в том числе 18 адъективных (449 Д), 6 субстантивных (34 Д), 4 глагольных (30 Д), 1 наречный (56 Д).
Наиболее многочисленными являются дериваты со следующими суффиксами: адъективными -ed (97 Д), -al (68 Д), -ic (58 Д), -(a, e) nt (43 Д), -ous (39 Д), -(a, e) ble (28 Д), -ive (26 Д), -ing (20 Д), -ful (20 Д), -ate (16 Д), -(a, o) ry (11 Д); субстантивными -ion (19 Д), глагольными -ate (16 Д), -ize (9 Д) и наречным -ly (56 Д).
На 2-м шаге деривации используется 12 суффиксов (383 Д), в частно-сти: 8 адъективных (121 Д), 2 субстантивных (6 Д), 1 глагольный (4 Д), 1 наречный (252 Д).
Наиболее многочисленными являются следующие суффиксы: адъек-тивные -al (79 Д), -ed (20 Д) и наречный -ly (252 Д).
На 3-м шаге деривации используется всего 5 суффиксов (101 Д), в том числе 3 адъективных (14 Д), 1 субстантивный (3 Д) и 1 наречный (84 Д), который является самым продуктивных среди них.
На 4-м шаге используется 3 суффикса (12 Д), в том числе 2 адъектив-ных (6 Д) и 1 наречный: -ly (6 Д).
На 5-м шаге деривации обнаружен только один наречный суффикс (-ly), который дал 3 деривата.

81Количественная дериватология
Таким образом, в гнезде с латинским префиксом quasi- наблюдает-ся следующая закономерность: с увеличением номера шага деривации уменьшается количество как использующихся суффиксов, так и образо-ванных с их помощью дериватов. Следует специально отметить, что ко-личество дериватов с наречным суффиксом ly- на 2-м (252 Д) и 3-м (84 Д) шагах деривации очень велико, превышая количество дериватов на 1-м (56 Д) соответственно в 4,5 и 1,5 раз.
Если мы качественно сравним с помощью коэффициента Чеканов-ского (К) наборы суффиксов, использующихся на разных шагах дерива-ции в ПГ с quasi-, то получим следующие величины:
К (1,2 шаги) =0,58; К (1,3 шаги) =0,29; К (1,4 шаги) =0,19; К (1,5 шаги) =0,07.Данные Табл. 4 показывают, однако, что количество дериватов с раз-
ными суффиксами резко различается на каждом шаге деривации.Количественное сравнение долей участия каждого суффикса в обра-
зовании дериватов на 1-м, 2-м, и т. д. шагах деривации с помощью коэф-фициента Ренконена (К*) показывает следующее:
К* (1,2 шагов) =0,35; К* (1,3 шагов) =0,24; К* (1,4 шагов) =0,32; К* (1,5 шагов) =0,10.
В целом, величины первых двух коэффициентов К* ниже, чем соот-ветствующих величины К, оценивающих только сходство наборов суф-фиксов.
Сопоставим величины коэффициентов качественного сходства на-боров суффиксов и количественного сходства долей дериватов с каж-дым суффиксом в каждом из гнезд (Табл. 27).
Таблица 27Величины коэффициентов качественного сравнения наборов
суффиксов, использующихся на 1-м и последующих шагах деривации (Чекановского, К), и количественного сравнения
долей дериватов с каждым суффиксом (Ренконена, К*) в префиксальных гнездах с pseudo- и quasi-
Шаги К pseudo- К quasi- К* pseudo- К* quasi-
1,2 шаги 0,45 0,58 0,31 0,35
1,3 шаги 0,22 0,29 0,15 0,24
1,4 шаги 0,11 0,19 0,28 0,32
1,5 шаги - 0,01 - 0,10

82 Глава 2
Анализ таблицы 5 показывает, что в каждом ПГ величины коэффици-ентов сходства наборов суффиксов (К) резко уменьшаются с увеличени-ем порядкового номера шага деривации.
Величины коэффициентов сходства долей производных с каждым суффиксом (К*) в целом уменьшаются более плавно.
Таблица 28Пошаговое количественное сравнение наборов суффиксов (К)
и долей дериватов с каждым из них (К*) в гнездах с префиксами pseudo- и quasi-
Шаги К pseudo-/ quasi- К* pseudo-/ quasi-
1 шаг 0,73 0,52
2 шаг 0,87 0,62
3 шаг 0,67 0,91
4 шаг 0,80 0,75
Анализ данных (Табл. 28) показывает, что наборы суффиксов, ис-пользующихся на любом соответствующем шаге деривации в обоих гнездах очень сходны, о чем говорят высокие величины коэффициента Чекановского (К). Если же учесть доли дериватов с каждым из суффик-сов (К*), то на 1-м шаге деривации сходство двух ПГ несколько ниже, чем на последующих шага.
Высокие значения К* на последующих шагах деривации говорит о том, что там используются почти одни и те же суффиксы, дающие мно-жество дериватов, в частности, наречный суффикс -ly.
Речевые (частотные) характеристики гнезд с префиксами PSEUDO- И QUASI-
Приведенные выше результаты анализа ПГ, извлеченных из тако-го крупного толкового словаря, как [17], являются языковой характе-ристикой гнезд. Известно, однако, что текстовые (частотные) характе-ристики лексем и морфем отличаются от языковых, так как представля-ют другую лингвистическую категорию — речь [82]. Поэтому мы про-анализировали высокочастотные слова, входящие в рассматриваемые ПГ, использовав для этого крупнейший частотный словарь английского

83Количественная дериватология
языка [12]. Результаты количественного описания структуры суффик-сальных дериватов представлены в Таблице 29.
Оказалось, что в число 50 тыс. самых частотных слов входит 17 дери-ватов из ПГ с pseudo- и 6 дериватов из ПГ с quasi-. Их суммарные стан-дартные частотные характеристики [51] можно выразить следующим образом: Fm=17; Fs=26 (ПГ с pseudo-); Fm=6; Fs=10 (ПГ с quasi-).
Анализ ПГ с pseudo- выявил всего 4 высокочастотных слова с про-стой ПО в гнезде. Все они образованы по модели:
pseudo- + N = N (pseudomonas, pseudonym, pseudynom, pseudo-phloem).
На 1-м шаге деривации было выявлено 6 суффиксов (давших 12 Д), в том числе: 3 адъективных (7 Д) и 3 субстантивных (5 Д), которые дали всего лишь по 1–3 деривата.
На 2-м шаге деривации обнаружено всего 2 суффикса (давшие 2 Д), а именно: 1 адъективный (1 Д) и 1 субстантивный (1 Д).
На 3-м шаге деривации используется только 1 адъективный суф-фикс: -al (1 Д).
Таблица 29Высокочастотные суффиксальные дериваты в гнездах
с префиксами pseudo- и quasi-
Суффиксы (в обратном алфавитном порядке)
1 шаг 2 шаг 3 шагpseudo- qua si- pseudo- qua si- pseudo- qua si-
Адъективные суффиксы-ic, a 3 - 1 1-ive, a - 1-ing, a 3 --al, a - - - 1 1 --ous, a 1 -
Субстантивные суффиксы-ism, n 2 --ion, n 2 - 1 --er, n - 1-ness, n 1 --ment, n - 1-ist, n - 1Сумма дериватов 12 4 2 2 1 -Среднее 2,0 1,0 1,0 1,0 1,0 -Число суффиксов 6 4 2 2 1 -

84 Глава 2
В гнезде с quasi- обнаружено 1 высокочастотное слово с простой ПО, которое образовано по модели: quasi- + N = N (Quasimodo)
В ПГ с quasi- на 1-м шаге деривации используется 4 суффикса (дав-ших 4 деривата), в том числе 1 адъективный (1 Д) и 3 субстантивных (3 Д).
На 2-м шаге деривации используется 2 суффикса (2 Д), причем оба они адъективные: -ic (1 Д), -al (1 Д).
На 3-м шаге обнаружен 1 адъективный суффикс: -al (1 Д).В целом, высокочастотные дериваты рассмотренных ПГ характери-
зуются как малочисленностью набора использующихся суффиксов, так и небольшим количеством дериватов.
Анализ таблицы 29 показывает, что у высокочастотных дериватов каждого из рассматриваемых ПГ нет ни одного суффикса на 2-м или 3-м шагах деривации, которые совпадали бы с суффиксами 1-го шага. Есте-ственно, что количественное сравнение наборов суффиксов и долей де-риватов с каждым из них дает везде одинаковые величины:
К (1,2 шагов) =0; К (1,3 шагов) =0; К* (1,2 шагов) =0; К* (1,3 шагов) =0.Таким образом, изучение языковых (словарных) характеристик суф-
фиксальных дериватов 2-х гнезд с парасемантическими префиксами (ПГ) pseudo- и quasi- показало следующее:
1) Количество дериватов в этих ПГ выражается следующими величи-нами: Pd (pseudo-) =484; Pd (quasi-) =1152.
2) Префиксальные слова с простыми ПО образованы по следующим моделям:
a) pseudo- + A = A (16 Д): pseudo- + N = N (31 Д);b) quasi- + A = A (75 Д); quasi- + N = N (4 Д); quasi- + V = V (5 Д).
3) Обнаружено наличие тяготения к инициальным морфемам ПО в составе ПГ
a) pseudo-: к префиксам in- (im-), inter-, re-, di-, peri-, tri-;b) quasi-: к префиксам a-, dis-, extra-, in- (im-, ir-), inter-, meta-, re-,
super-, un-.4) Определены наборы суффиксов, и количество дериватов (Д), ис-
пользующихся на разных шагах.На 1-м шаге деривации:
a) pseudo-: 33 (267 Д), в том числе: адъективных — 20 (224 Д), субстантивных — 11 (32 Д), глагольных — 1 (4 Д), наречных — 1 (7 Д);
b) quasi-: 29 (569 Д) (адъективных — 18 (449 Д), субстантив-ных — 6).

85Количественная дериватология
На 2-м шаге деривации:a) pseudo-: 11 (121 Д), в том числе: адъективных — 7 (73 Д), суб-
стантивных — 3 (5 Д), наречных — 1 (43 Д);b) quasi-: 12 (383 Д), в том числе: адъективных — 8 (121 Д), суб-
стантивных — 2 (6 Д), глагольных — 1 (4 Д), наречных — 1 (252 Д).
На 3-м шаге деривации:a) pseudo-: 3 (47 Д), в том числе: адъективных — 2 (5 Д), субстан-
тивных — 1 (1 Д), наречных — 1 (41 Д);b) quasi-: 5 (101 Д), в том числе: адъективных — 3 (14 Д), субстан-
тивных — 1 (3 Д), наречных — 1 (84 Д).На 4-м шаге деривации:
a) pseudo-: 1 адъективный (1 Д) и 1 наречный (1 Д):b) quasi-: 3 (12 Д), в том числе: адъективных — 2 (6 Д), нареч-
ный — 1 (6 Д).На 5-м шаге деривации:
a) pseudo-: отсутствуют.b) quasi-: 1 наречный (3 Д).
5) Количественное сравнение наборов суффиксов, использующихся на 1-м и последующих шагах деривации в каждом ПГ дало следующие величины коэффициентов сходства Чекановского (К):
a) pseudo-: К (1,2 шагов) =0,45; К (1,3 шагов) =0,22; К (1,4 ша-гов) =0,11.
b) quasi-: К (1,2 шагов) =0,58; К (1,3 шагов) =0,29; К (1,4 шагов) =0,19; К (1,5 шагов) =0,01.
6) Количественное сравнение долей дериватов с каждым суффик-сом, использующихся на 1-м и последующих шагах деривации в каждом ПГ дало следующие величины коэффициентов сходства Ренконена (К*):
a) pseudo-: К* (1,2 шагов) =0,31; К* (1,3 шагов) =0,15; К* (1,4 шагов) =0,28.
b) quasi-: К* (12 шагов) =0,35; К* (1,3) =0,24; К* (1,4 шагов) =0,32; К* (1,5 шагов) =0,10.
7) Попарное количественное сравнение наборов суффиксов, исполь-зующихся в гнездах с префиксами pseudo- и quasi- на 1-м и последую-щих шагах деривации, дало следущие величины коэффициентов сход-ства Чекановского (К): на 1-м шаге К (pseudo-/quasi-) =0,73; на 2-м шаге К (pseudo-/quasi-) =0,87; на 3-м шаге К (pseudo-/quasi-) =0,67; на 4-м шаге К (pseudo-/quasi-) =0,80.
8) Попарное количественное сравнение долей дериватов с каждым суффиксом, использующихся на 1-м и последующих шагах деривации

86 Глава 2
в гнездах с префиксами pseudo- и quasi- дало следующие величины ко-эффициентов сходства Ренконена (К*): на 1-м шаге К* (pesudo-/quasi-)
=0,52; на 2-м шаге К* (pseudo-/quasi-) =0,62; на 3-м шаге К* (pseudo-/quasi-) =0,91; на 4-м шаге К* (pseudo-/quasi-) =0,75.
II. Изучение речевых (частотных) характеристик суффиксальных дериватов 2-х гнезд с парасемантическими префиксами (ПГ pseudo- и quasi- показало следующее:
1) В число 50 тыс. самых частотных слов английского языка вхо-дит небольшое количество слов: для pseudo- Fm=17, Fs=26; для quasi- Fm=6, Fs=10.
2) Выявлены следующие модели строения префиксальных слов с простыми ПО: pseudo- + N = N (4 Д); quasi- + N = N (1 Д).
3) При образовании высокочастотных дериватов ПГ используются следующее количество суффиксов:
a) pseudo-: на 1-м шаге — 6 (12 Д), на 2-м шаге — 2 (2 Д), на 3-м шаге — 1 (1 Д).
b) quasi-: на 1-м шаге — 4 (4 Д), на 2-м шаге — 2 (2 Д).4) Сходство между наборами суффиксов, использующимися на раз-
ных шагах деривации, отсутствует.
§ 7. Суффиксальные цепочки
Цепочка -ive + -ness
Ранее было установлено, что с помощью аффиксации образовано около 70 % всех лексем одного из крупнейших в мире словаря [27].
1. Известно, что дерватология описывает не только деривационные типы [3; 4; 11; 14; 34; 41; 46; 48; 90; 103; 105; 108; 119; 122; 128; 131; 135; 141; 142; 149; 151], но и деривационные цепочки [92; 114; 136; 137]. Мы заинтересовались количественным исследованием некоторых цепочек, например: Root → Root + -less → Root + -Less + -Ness.
Под цепочкой мы понимаем ряд дериватов, образованных путем последовательного присоединения 2-х или более суффиксов к про-изводящей основе (ПО). Иногда встречаются дериваты, содержащие довольно длинные аффиксальные последовательности, например, antidisestablishmentarianism, beatificationistically, pseudoapprehensivelt, pseudoassertiveness, unputdownableness, etc.

87Количественная дериватология
Материалом для настоящего исследования послужили цепочки, со-стоящие из: ПО и производных 1-го и 2-го шагов деривации, содержа-щие суффиксы -ive и -iveness, которые извлекали сплошной выборкой из Обратного словаря М. Ленерта [13], например:
Adhere, v → Adhesive, a → Adhesiveness, nAgress, v → Agressive, a → Agressiveness, nCompete, v → Competitive, a → Competitiveness, nDeliberate, v → Deliberative, a → Deliberativeness, nSecret, n → Secretive, a → Secretiveness, nДефиниции и даты их первой письменной фиксации как для ПО, так
и для производных 1-го и 2-го шагов деривации извлекали из [22].Наша задача состояла в следующем:1. Описать процесс формирования 230 выявленных суффиксальных
цепочек типа Root → Root + -ive → Root + -ive + -ness в диахронии;2. Подсчитать среднее количество значений у каждого члена дерива-
ционной цепочки;3. Определить среднюю фонетическую длину каждого члена дерива-
ционной цепочки;4. Подсчитать скорость приобретения значений каждым членом це-
почки;5. Определить временной интервал между образованием корней (R)
производных 1-го (D-1) и 2-го шага (D-2) деривации;6. Определить среднюю длину (L*) ПО и ее изменение в диахронии;7. Найти среднюю полисемичность (S*) ПО и ее изменение в диахро-
нии;Диахрония появления корней (Root) и производных первого (Root +
-ive) и второго (Root + -ive + -ness) шагов деривации.
А) В ходе исследования 230 словообразовательных суффиксальных цепочек типа Root → Root + -ive → Root + -ive + -ness было установле-но, что корневые производящие основы (Root) начали формировать-ся в среднеанглийский период (XII–XV вв.) (САП): их количество со-ставляет в этот период 117 слов, например, Affront, v (1315); Depress, v (1325); Delude, v (1450); Dispute, v (1290); Impel, v (1470); Feast, v (1300) (Табл. 30).
За новоанглийский период (XVI–XIX) (НАП) образовалось 113 кор-ней, в том числе Fermentate, v (1598); Fugitate, v (1521); Convulse, v (1613); Inoperate, v (1720), etc.

88 Глава 2
Таблица 30Появление корней и дериватов первого
и второго шагов диахронии
ВЕК 10 11 12 13 14 15 16 17 18 19 20 SUM
ROOT 0 0 0 14 63 40 85 34 4 1 0 230
Root +-ive 0 0 0 0 20 24 53 95 19 15 0 230
Root +-ive+ness 0 0 0 0 0 8 6 70 32 103 0 230
Б) В случае с образованием дериватов первого шага с суффиксом –ive картина немного изменяется: за среднеанглийский период (XIV–XV вв) появляется 44 дериватов, например: Imitative, a (1484); Inactive, a (1447); Meditative, a (1356); Causative, a (1420), etc.
За новоанглийский период (XVI–XIX) образуется большее количе-ство производных первого шага — 186 дериватов, например: Curative, a (1533); Relative, a (1594); Cumulative, a (1605); Procreative, a (1634); Argumentative, a (1734); Attributive, a (1765), etc.
В) Производных второго шага с суффиксом -ness за среднеанглий-ский период было образовано всего лишь 8, в то время как в новоан-глийском периоде их насчитывается 222, среди них: Locomotiveness, n (1825), Lexativeness, n (1801); Meditativeness, n (1860); Irresponsiveness, n (1864); Pervasiveness, n (1879), etc. Таким образом, соотношение лек-сем между САП и НАП равно: Roots — 117: 113; дериваты 1-го шага (D-1) — 44: 186; дериваты 2-го шага (D-2) — 8: 222.
Средний временной интервал между появлением корней и произ-водных первого и второго шагов деривации.
А. Хронологический анализ 230 цепочек, образованных путем по-следовательного присоединения суффиксов -ive, -ness, обнаруженных в БОС позволил установить следующие закономерности (Таблицу 31): Производные первого шага появляются в среднем через 140 лет от даты первой фиксации корневой основы. Например, Pervade, v (1656) → Pervasive, a (1750); Persuade, v (1513) → Persuasive, a (1630); Invent, v (1475) → Inventive, a (1601).
Б. Дериваты второго шага с суффиксом -ness образуются от производ-ных с формантом –ive также примерно через 140 лет. Так, Insensitive, a (1610) → Insensitiveness, n (1738); Irrespective, a (1640) → Irrespectiveness, n (1798); Contractive, a (1624) → Contractiveness, n (1760);

89Количественная дериватология
Таблица 31Временной интервал между появлением ПО и производных
первого и второго шагов дериваци
Элемент цепочки Количество элементов Средний интервал (лет)
Root / Root + -ive 230 142
Root + -less /Root + -ive + -ness 230 141
Root / Root + -ive + -ness 230 283
В. Временной интервал между появлением производных второго порядка от корня составляет примерно 280 лет. Например, Contract, v (1548) → Contractiveness, n (1813); Compute, v (1601) → Computativeness, n (1869); Meditate, v (15800 → Meditative, a (1860).
Следовательно, в среднем Д-1 возникают через 140 лет, а Д-2 появля-ются после Д-1 также через 140 лет (Табл. 31).
Средняя полисемичность корня и производных первого и второго шагов деривации.
А. Исследование семантики корней показывает, что в среднем на одну корневую основу приходится 3,4 значения (S*=3,4 meanings/word). На-пример, Convulse, v (S=3); Corrosive, sb (S=4); Pervade, v (S=3); Mass, sb2 (S=4) (Таблица 32).
Таблица 32Средняя полисемичность корня и производных
первого и второго шагов деривации.
Элемент цепочки Количество элементов Средняя полисемичность
Root 230 3,4
Root + -ive 230 2,4
Root + -ive + -ness 230 1,1
Б. Среднее число значений у дериватов первого порядка с суффик-сом -ive составляет 2,3 значения (S8=2,3 meanings/word). Так, напри-мер: Convulsive, a (S=2); Corrosive, a (S=2); Pervasive, a (S=2); Massive, a (S=3).
В. У дериватов второго порядка с суффиксом -ness в среднем фик-сируется по 1,1 значению (S*=1,1 meanings/word). Например, Convulsiveness, n (S=1) Corrosivenes, n (S=1); Pervasiveness, n (S=1); Massiveness, n (S=1).

90 Глава 2
То есть, чем больше морфем содержит член деривационной цепочки, тем он менее полисемичен.
Средняя фонетическая длина корней и производных первого и вто-рого порядка в составе деривационных цепочек типа Root / Root + -ive / Root + -Ive + -Ness.
Как известно, каждая единица языка является двуплановой, т. е. она обладает как значением так и звучанием. Поэтому мы определим сред-нее количество фонем в составе каждого ряда цепочки (Таблица 33).
Таблица 33Средняя фонетическая длина корня и производных
первого и второго шагов деривации.
Элемент цепочки Количество элементов Среднее количество фонем
Root 230 4,6
Root + -ive 230 6,6
Root + -ive + -ness 230 9,6
А. Средняя фонетическая длина корней для всех 230 словообразова-тельных суффиксальных цепочек в основном составляет примерно 4,6 фонем в составе слова (Ph*=4,6 phonemes/word). Так, Correct, v (5 ph); Effuse, v (4ph); Effect, v (5ph); Digress, v (5ph).
Б. Дериваты первого порядка с суффиксом -ive в среднем состоят из 6,6 фонем (Ph*=6,6 phonemes/word). Например, Corrective, a (7ph); Effusive, a (7ph); Effective, a (7ph); Digressive, a (7ph).
В. Производные второго порядка с суффиксом -ness являются са-мыми продолжительными и в среднем включают в себя 9,6 фонем (Ph*=9,6 phonemes/word). Для примера представим следующие сло-ва: Correctiveness, n (10ph); Effusiveness, n (10ph); Effectiveness, (10ph); Digressiveness, n (10ph).
Следовательно, чем больше морфем содержит член цепочки, тем он фонетически длинее.
Скорость изменения семантического поля каждого ряда словообра-зовательных суффиксальных цепочек типа Root / Root + -Ive / Root +
-Ive + -Ness.Современная количественная семантика позволяет оперировать
скоростью изменения семантического поля слов в целом, которая на-ходится по формуле V= (S-1) x 100/ (tn -t1), где S — количество ЛСВ у слова, t1 и tn — даты фиксации последнего и первого зачения у слова. (Бартков, Жданович, Каращук, 1980) (Таблица34).

91Количественная дериватология
Таблица 34Средняя скорость (v*) изменения семантического поля
в деривационных цепочках
Chain Root Root + -ive Root + -ive + -ness
V* (velocity) 1,3 2,1 2,7
А. Подсчеты показывают (см. Таблицу 34), что средняя скорость из-менения семантического поля для корней в деривационной цепочке со-ставляет 1,3 ЛСВ/век (v*=1,3 meanings/century). Необходимо отметить, что индивидуальные скорости отдельных слов могут сильно варьиро-вать. Так, Digress, v (V=1,89 ЛСВ/век); Describe, v (V=0.93 ЛСВ/век); Distribute, v (V=1,7 ЛСВ/век); Motive, a (V=2,1 ЛСВ/век).
Б. Для группы производных первого шага деривации ско-рость изменения семантического поля составляет 2,1 ЛСВ/век (v*=2,1 meaning/century). Например, Locomotive, a (V=0, 89 ЛСВ/век); Distributive, a (V=1, 97 ЛСВ/век); Diminutive, a (V=2,6 ЛСВ/век); Concessive, a (V=0,66 ЛСВ/век).
В. Производные второго шага деривации имеют коэффициент равный примерно 2,7 ЛСВ/век (v*=2,7 meanings/century). Отметим, что большинство производных второго шага деривации однозначны, следовательно, имеют скорость изменения семантического поля рав-ную нулю, например: Extensiveness, n (V=0, 7 ЛСВ/век); Directiveness, n (V=0 ЛСВ/век); Pensiveness, n (V=0 ЛСВ/век).
В целом, однако, чем больше морфем содержит лексема, тем выше у нее скорость изменения семантического поля.
Временной интервал между образованием корней и производных первого и второго шагов деривации.
Распределением членов деривационных цепочек по временным классам показывает, что в среднем количество дериватов, образующих-ся через указанные промежутки времени для каждого ряда цепи различ-ны (Таблица 35).
Таблица 35Временной интервал между образованием дериватов в диахронии
Разница между датами появления
Элемент цепочки
Root / Root + -ive
Root + -ive / Root + -ive + -ness
Root / R + -ive + -ness
0–49 71 81 16
92 Глава 2
Разница между датами появления
Элемент цепочки
Root / Root + -ive
Root + -ive / Root + -ive + -ness
Root / R + -ive + -ness
50–99 45 20 16
100–149 37 42 30
150–199 32 43 34
200–249 29 40 56
250–299 16 4 78
300 и более 0 0 0
Сумма 230 230 230
А. От корневых основ образовалось 71 производных через 50 лет, 45 через 100 лет, 37 через 150 лет, 64 через 200 лет и 16 дериват через 250–300 лет.
Б. От производных первого шага с суффиксом -ive пошли дериваты второго шага с суффиксом -ness в среднем через 50 лет-81, через 100–20, через 150–42, через 200 лет-80.
В. Хронологическая картина образования дериватов второго шага деривации от корневых основ иная. По 16 производных образовались через 50–100 лет;30 через 150 лет, 34 через 200 лет и наибольшее коли-чество (79) появилось через 200–300 лет.
Отметим, что, например, за первые 100 лет образовалось 116 Д-1 (50 %), 101 Д-2 из Д-1 (44 %), 32 Д-2 из Корней (14 %); за 200 лет от К об-разовалось 185 Д-1 (80 %), от Д-1 образовалось 186 В-2 (80 %), от К обра-зовано 96 Д-2 (42 %).
Фонетическая длина корня в диахронии.В ходе своего исследования мы рассчитали количество фонем в со-
ставе корней для всех 230 словообразовательных суффиксальных це-почек типа Root / Root + -Ive / Root + -Ive + -Ness и ранжировали их в диахроническом порядке по датам их первой письменной фикса-ции (Табл. 36).
Хотя средняя фонетическая длина корней равна 4,6 фонемы.слово, наибольшее количество составляют 6-ти фонемные корни: их 64 еди-ницы, например: Contemplate, v; Concession, sb. Отметим, что 5-ти фо-немных слов насчитывается довольно много — 58 единиц, например: Cogitate, v; Progress, etc.

93Количественная дериватология
Таблица 36Фонетическая длина корня в диахронии
Кол-во фонем
СтолетиеВсего
X XI XII XIII XIV XV XVI XVII XVIII XIX
3 1 0 0 2 3 1 2 1 0 0 10
4 0 1 0 5 9 7 7 3 0 0 32
5 0 0 1 0 23 15 16 3 0 0 58
6 0 0 1 6 15 13 23 6 0 0 64
7 0 0 0 0 2 3 13 7 1 0 26
8 0 0 0 0 4 1 8 5 1 0 19
9 0 0 0 0 1 0 10 8 2 0 21
Всего 1 1 2 13 57 40 79 33 4 0 230
4-х фонемные слова составляют 32 единицы;. 7, 8, 9 фонемные корни в составе словообразовательных суффиксальных цепей составляют 26, 19 и 21 единиц соответственно. Наименьшее количество насчитывается 3-х фонемных корней — 10 единиц.
Полисемия корней и производных первого и второго шагов диахро-нии.
Исследование семантики (Табл. 37) словообразовательных суффик-сальных цепочек типа Root → Root + -ive → Root + -ive + -ness показыва-ет, что следующее.
Таблица 37Полисемия (S) производящих основ (корней) и цепочек
производных
Количе-ство значе-
ний (S)
СтолетиеВсего
X XI XII XIII XIV XV XVI XVII XVIII XIX
Root
1 0 0 1 2 7 5 16 14 3 1 49
2 5 0 0 0 5 4 11 11 0 0 31
3 0 0 0 0 14 7 25 5 1 0 52
4 0 1 1 2 12 15 15 3 0 0 49
5 0 0 0 0 13 7 6 1 0 0 30
6 1 0 0 0 6 2 4 1 0 0 14

94 Глава 2
Количе-ство значе-
ний (S)
СтолетиеВсего
X XI XII XIII XIV XV XVI XVII XVIII XIX
7 0 0 0 0 1 1 2 1 0 0 5
Root + -ive
1 0 0 0 0 1 4 8 33 12 16 74
2 0 0 0 0 2 7 16 28 8 2 63
3 3 0 0 0 3 6 15 27 2 1 54
4 0 0 0 0 7 6 10 6 0 0 29
5 0 0 0 0 2 1 5 2 0 0 10
Root + -ive + -ness
1 0 0 0 0 0 4 6 63 29 114 216
2 0 0 0 0 0 0 0 7 2 1 11
3 0 0 0 0 0 0 1 1 0 0 2
4 0 0 0 0 0 0 0 1 0 0 1
А. Среди корневых основ наибольшее место занимают 3-х значные слова-их общее количество 52. Например, 1 и 4-х значных слов в со-ставе этого ряда цепи 49, 2-х значных 31 и 30 слов с пятью значения-ми. Наименьшее количество 7 значных слов-5. Ранее было подсчитано, что S*=3,4 meanings/word.
Б. Среди производных первого порядка с суффиксом –Ive больше все-го слов 1- значных (74). Так, Кроме того 2-х значных слов мы насчита-ли 63; 3-х значных. — 54; 4-х значных дериват — 29; 5-ти значных — 10. Выше мы подсчитали, что S*=2,4 meanings/word.
В. В ряду дериватов второго шага картина следующая: 216 слов име-ют по одному значению, 11 слов являются 2-х значными и только 2 име-ет 3 значения; одно — 4 значения. Ранее было подсчитао, что S*=1,1 meanings/word.
Итак, количественный анализ 230 словообразовательных суффик-сальных цепочек типа Root → Root + -ive → Root + -ive + -ness показал следующее.
1. Синхроническая продуктивность по периодам равнялась: за САП — 117 корней, 44 и 8 дериватов первого и второго шагов деривации соот-ветственно. В НАП зарегистрировано 113 корня, 186 производных пер-вого шага деривации и 222 деривата второго шага.
2. Средний временной интервал появления производной первого шага от корневой основы составляет около 142,5 лет; примерно через

95Количественная дериватология
141,5 лет появились производные второго шага; временной интервал между появлением производной второго шага от корневой основы со-ставляет в среднем 284 года.
3. Средний коэффициент полисемичности корней равен 3,4 ЛСВ/сло-во, производных первого шага деривации — 2,4 ЛСВ/слово, второго шага — 1,1 ЛСВ/слово.
4. Средняя фонетическая длина корней составляет в среднем 4,6 фо-нем/слово; дериваты первого и второго шагов в деривации по 6,6 и 9,6 фонем/слово соответственно.
5. Средняя скорость изменения семантического поля корней и де-риватов первого и второго шагов в деривации равна: для корней 1,3 ЛСВ/век; производные первого и второго шагов 2,2 и 2,7 ЛСВ/век соответственно.
6. Фонетическая длина корней следующая: 3-х фонемных — 10, 4-х фонемных — 32, 5-ти фонемных — 58, 6-ти фонемных — 64, 7-ми фо-немных — 19, 8-ми фонемных — 21;
7. Было установлено, что в составе 230 суффиксально-образователь-ных цепей типа Root → Root + -ive → Root + iIve + -ness существует опред-ленное распределение по многозначности:
а) корни: однозначных — 49, двузначных — 31, 3-х значных — 52, 4-х значных — 49, 5-ти значных — 30, 6-ти значных — 14, 7-и значных — 5;
б) производные первого шага деривации: однозначных — 74, дву-значных — 63, 3-х значных — 54, 4-х значных — 29, 5-ти знач-ных — 10;
в) производные второго шага деривации: однозначных — 216, дву-значных — 11, 3-х значных –2, 4-х значных — 1.
Цепочка -less + -ness
Среди различных способов образования новых слов аффиксация играет важную роль. Однако многие словообразовательные морфе-мы, а также модели и типы, в которых они используются, исследованы еще недостаточно полно.
Большой интерес представляют деривационные цепочки суффиксов, например: Root → Root + -less → Root + -Less + -Ness.
Под цепочкой мы понимаем ряд дериватов, образованных путем последовательного присоединения 2-х или более суффиксов к про-изводящей основе (ПО). Иногда встречаются дериваты, содержащие

96 Глава 2
довольно длинные аффиксальные последовательности, например, antidisestablishmentarianism, beatificationistically, unputdownableness, nonrepresentationalism, etc.
Материалом для настоящего исследования послужили цепочки, со-стоящие из: ПО и производных 1-го и 2-го шагов деривации, содержа-щие суффиксы -less и -lessness, которые извлекали из Обратного словаря М. Ленерта [ (Lehnert, 1971)], например:
Sleeve, sb → Sleeveless, a → Sleevelessness, nMeaning, sb1 → Meaningless, a → Meaninglessness, nList, sb → Listless, a → Listlessness, nДефиниции и даты их первой письменной фиксации как для ПО,
так и для производных 1-го и 2-го шагов деривации, извлекали из [The Oxford English Dictionary (1933)].
Приведем пример рабочей карточки:
Deliberate, v1. To weight in mind, to consider carefully. (1510);2. To use consideration. (1561);3. To determine, resolve. (1550).
Deliberative, a[f. Deliberate, v+-ive]1. Pertaining to delibe- ration, having the function of deliberating (1533);2. Characterized by deliberation (1659).
Deliberativeness, n[f. As prec. + -Ness]1. The quality of being deliberative (1653).
Наша задача состояла в следующем:1. Описать процесс формирования 80 выявленных суффиксальных
цепочек типа Root → Root + -less → Root + -Less + -Ness в диахронии;2. Подсчитать среднее количество значений у каждого члена суф-
фиксальной словообразовательной цепочки;3. Определить среднюю фонетическую длину каждого составляюще-
го цепочки;4. Подсчитать скорость приобретения значений каждым членом це-
почки;5. Определить временной интервал между образованием производ-
ных 1-го и 2-го шага деривации в диахронии;6. Определить среднюю длину ПО (L*) и ее изменение в диахронии;7. Найти среднюю полисемичность ПО (S*) и ее изменение в диахро-
нии;

97Количественная дериватология
Диахрония появления корней и производных первого и второго шагов деривации.
В ходе исследования было установлено (Табл. 38), что первые ПО на-чали появляться в древне английский период (ДАП), который дал 36 лексем, например: Love, sb (925); Life, sb (1000); End, sb (905); Bleath, sb (923); Tear, sb1 (971), etc.
За средне английский период (САП) образовано 39 лексем, напри-мер: Art, sb (1225); Bound, sb1 (1206); Daunt, v (1298); Blame, sb (1230); Tone, sb (1340); Track, sb (1470), etc.
За ранний новоанглийский период (НАП) образовалось 5 лексем, в частности: Sense, sb (1526); Self, sb (1674); Plan, sb (1678); Rhyme, sb (1610); Result, sb (1626);
За поздний НАП — не возникла ни одна ПО.
Таблица 38Появление корней и дериватов первого
и второго шага в диахронии
ВЕК 10 11 12 13 14 15 16 17 18 19 20 SUM
ROOT 30 6 1 24 10 4 1 4 0 0 0 80
ROOT +-LESS 6 3 4 3 13 9 25 5 7 5 0 80
ROOT +-LESS ++-NESS
1 0 0 0 1 0 10 22 3 43 0 80
Образование дериватов первого шага с суффиксом -less (т. е. Root + -less) происходило следующим образом (Табл. 38).
В ДАП образовалось 9 дериватов, например: Sinless, a (927); Sleeveless, a (950); Reckless, a (975); Endless, a (900); Needless, a (1225); Lifeless, a (1100);
В САП образуется 29 производных первого шага, например, Loveless, a (1411); Thriftless, a (1400); Brainless, a (1440); Deathles, a (1598); Baseless, a (1616).
Максимальное количество производных 1-го шага образовалось в НАП — 42 деривата, например: Briefless, a (1824); Rhymeless, a (1789); Planless, (1880); Toneless, a (1773); Selfless, a (1768).
Производных второго шага с суффиксом -ness в древне английский период было образовано всего лишь 1 Recklessnes, n (1000).
За САП образовано 1 производное.

98 Глава 2
Наибольше количество производных 2-го шага появляется в НАП — 78 дериватов, например: Senselessness, n (1505); Sinlessness, (1661); Remedilessness, n (1601); Godlessness, a (1552); Regardlessnes, a (1601); Sleevelessnes, n (1882), Lifelessness, n (1727); Brieflessness, (1842); Tonelesnes, n (1873); Baselessness, n (1850); Aimlessness, n (1859); Tracklessness, n (1847).
Средний временной интервал (T) между появлением корней и производных первого и второго шага в деривации.
А. Хронологический анализ 80 цепочек, образованных путем после-довательного присоединения суффиксов -less, -ness, изъятых из [БОС] позволил установить следующую закономерность: производные пер-вого шага появляются в среднем через 3 века (T=317 years) от даты первой фиксации корневой основы. Например, Love (925) — Loveless (1311); Base (1325) — Baseless (1675); Life (1000) — Lifeless (1285); Need (929) — Needless (1225); Aim (1300) — Aimless (1859) (Табл. 39);
Таблица 39Временной интервал между появлением ПО и производных
первого и второго шага
Элемент цепочки Количество элементов Средний интервал (лет)
Root + -less 80 317
Root + -less /Root + -less + -ness
80 287
Root / Root + -less + -ness 80 603
Б. Дериваты второго шага с суффиксом -ness образуются от произ-водных с формантом -less примерно через 280 лет (T*=280 years). Так, Loveless (1311) — Lovelesness (1616); Baseless (1675) — Baselessness (1890); Lifeless (1285) — Lifelessness (1627); Needless (1225) — Needlessness (1607); Aimless (1627) — Aimlessness (1859);
В. Временной интервал между появлением ПО и производных вто-рого порядка составляет около 600 лет (T**=603 years). Например, Love (925) — Lovelessness (1616); Base (1325) — Baselessness (1890); Life (1000) — Lifelessness (1627); Need (929) — Needlessness (1607); Aim (1300) — Aimlessness (1859).

99Количественная дериватология
Средняя полисемичность (S) корня (ПО) и производных первого и второго шага в деривации.
А. Исследование семантики корней показывает (Таблица 40), что в среднем на одну производящую основу приходится примерно 3,46 значений (т. е. S=3,46). Например, Track, sb S=4; Result, sb S=4; Rhyme, sb S=3; Plan, sb S=3; Self, sb S=3; Sleep. sbS=4; Limit, sb S=3; End, sb S=4; Point, sb1S=3; Mind, sb S=4; Bleath, sb S=3;
Лексема Mind, sb1 имеет следующие значения:1. The faculty of memory. (1000);2. The state of being remembered. (1000);3. The action or state of thinking. (975);4. That which person thinks about smth. (1400).Лексема Point, sb имеет следующие значения:1. A separate article, item or clause. (1225);2. An important phrase or subject. (1597);3. A definite position in a scale of any kind. (1425).
Таблица 40Средняя полисемичность корня и производных
первого и второго шагов деривации.
Элемент цепочки Количество элементов Средняя полисемичность
Root 80 3,46
Root + -less 80 2,08
Root + -less + -ness 80 1,09
Б. Среднее число значений у дериватов первого порядка с суффик-сом -less составляет 2,08 значений (т. е. S*=2,08). Так, Sleepless, a S=2; Selfless, a S=2; Trackless, a S=2; Aimless S=2; Needless, a S=3; Blameless, a S=3; Reckless, S=3; Sleeveless, S=3. Нпример, Blameless, a имеет такие значения:
1. Exempt from censure or blame. (1377);2. Giving no cause for blame. (1535);3. Not imputing or containing blame. (15985).В. У дериватов второго порядка с суффиксом -ness в среднем фикси-
руется по одному значению (S**=1,09). Например, Sleeplessness, n S=1; Selflessness, n S=1; Tracklessness, n S=1; Aimlessness, n S=1; Needlessness, n S=1; Blamelessness, n S=1; Recklessness, n S=1; Sleevelessness, S=1.
Например, Needlessness 1. The fact of being needless, unnecessariness. (1607);

100 Глава 2
Средняя фонетическая длина (L) корней (ПО) и производных первого и второго порядка
Как известно, каждая лингвистическая единица является двуплано-вой, т. е. она обладает как значением так и звучанием. Учитывая это, мы определим среднее количество фонем в составе каждого ряда цепи (Таб-лица 41).
А. Средняя фонетическая длина корней для всех 80 суффиксаль-но-образовательных цепочек составляет примерно 3,9 фонем в лексе-ме (L=3,9). Так, Blame, sb (4); Taste, sb (4); Sleeve, sb (4); Sense, sb (4); Shape, sb (4); Plan, sb (4); Self, sb (4).
Таблица 41Средняя полисемичность корня и производных
первого и второго шагов деривации.
Элемент цепочки Количество элементов Среднее количество фонем
Root 80 3,9
Root + -less 80 9,9
Root + -less + -ness 80 1,09
Б. Дериваты первого порядка с суффиксом -less в среднем состоят из 6,9 фонем (L*=6,9). Например, Heedless, a (6); Sleepless (7); Planless, a (7); Senseless, a (7); Sinless, a (6); Sleepless, a (7); Sleeveless, a (7); Toneless, a (6); Reckless, a (6).
В. Производные второго порядка с суффиксом -ness являются са-мыми продолжительными и в среднем включают в себя 9,9 фонем (L**=9,9). Для примера представим следующие слова: Remedilessness, n (10); Limitlessness, n (10); Mindlessness, n (10); Helplessness, n (10); Homelessness, n (10); Pointlessness, n (10); Godlessness, n (9).
Скорость изменения семантического поля (v*) членов семанти-ческих цепочек
Современная количественная семантика позволяет оперировать скоростью изменения семантического поля слов в целом, которая нахо-дится по формуле V= (S-1) x 100/ (tn -t1), где S — количество ЛСВ у сло-ва, t1 и tn- даты фиксации последнего и первого зачения у слова. (Барт-ков, Жданович, Каращук, 1980).
А. Подсчеты показывают (Таблица 42), что средняя скорость изме-нения семантического поля для корневой основы в составе словообра-зовательной суффиксальной цепочке составляет 1,6 ЛСВ/век (v=1,6).

101Количественная дериватология
Необходимо отметить, что индивидуальные скорости отдельных слов могут сильно варьировать. Так, Love (sb) V=0,63 ЛСВ/век; God (sb), V=1,14 ЛСВ/век; Bleath, (sb), V=1,56 ЛСВ/век; Mind (sb), V=1,15 ЛСВ/век; Faith (sb), V=1,54 ЛСВ/век; Cheer (sb), V=0,98 ЛСВ/век; Comfort (sb), V=1,43 ЛСВ/век.
Таблица 42Средняя полисемичность корня и производных первого
и второго шагов деривации.
Элемент цепочки Количество элементов Средняя полисемичность
Root 80 1,6
Root + -less 80 1,1
Root + -less + -ness 80 0,9
Б. Для группы производных второго шага скорость изменения се-мантического поля составляет 1,1 ЛСВ/век. Например, Thoughtless (a), V=1,03 ЛСВ/век; Hopeless (a), V=1,02 ЛСВ/век; Remediless (a), V=0,98 ЛСВ/век; Reasonless (a), V=1,01 ЛСВ/век;
В. Производные второго шага деривации в составе суффиксально-образовательной цепи имеют коэффициент равны 0,1 ЛСВ/век. Напри-мер, Sleevelessness (n), V=0 ЛСВ/век; Recklessness (n), V=0,24 ЛСВ/век; Tastelessness (n), V=0,06 ЛСВ/век; Boundlessness (n), V=0 ЛСВ/век.
Временной интервал между появлением корней и производных первого и второго шага деривации
Распределением по классам показывает, что в среднем количество дериват, образующихся через указанные промежутки для каждого ряда цепи различны (Таблица 43):
Таблица 43Временной интервал между образованием дериватов
в диахронии
Разница между да-тами появления
Элемент цепочкиR / R + -less R + -less / R + -less + -ness R / R + -less + -ness
0–49 16 18 050–99 10 4 3100–149 17 13 3150–199 20 18 4

102 Глава 2
Разница между да-тами появления
Элемент цепочкиR / R + -less R + -less / R + -less + -ness R / R + -less + -ness
200–249 10 17 11250–299 7 10 39300 и более 0 0 20Сумма 80 80 80Среднее 30,3 32,1 40,2
А. От корневых основ образовалось 16 производных через 50 лет, 10 через 100 лет, 17 через 150 лет, 10 через 200 лет и 7 дериват через 250–300 лет.
Б. От производных первого шага с суффиксом -less пошли дерива-ты второго шага с суффиксом -ness в среднем через 50 лет-18, через 100, 150, 200 лет 17, 18 и 18 соответственно.
В. Хронологическая картина образования дериват второго шага де-ривации от корневых основ немного иная. По 3–4 производных образо-вались через 50–150 лет; наибольшее количество производных (70) по-явилось через 200–300 лет.
Фонетическая длина (L) корня в диахронииВ ходе своего исследования мы рассчитали количество фонем в со-
ставе корней для всех 80 словообразовательных суффиксальных цепо-чек типа Root+Less+Ness и ранжировали их в диахроническом порядке от даты фиксации первого значения. (см. Таблицу 44).
Таблица 44Фонетическая длина корня в диахронии
Кол-во фонем
СтолетиеВсего
X XI XII XIII XIV XV XVI XVII XVIII XIX
3 16 2 1 6 2 3 0 1 0 0 31
4 9 5 0 11 5 1 1 3 0 0 35
5 2 0 0 3 2 0 0 0 0 0 7
6 1 0 0 2 3 1 0 0 0 0 7
Сумма 28 7 1 22 12 5 1 4 0 0 80
А. Наибольшее количество составляют 4-х фонемные слова-35. На-пример, Blame, sb; Life, sb; Help, sb; Sleep, sb; Plan, sb; Self, sb; Shape, sb.
Б. 31 слово является 3-х фонемной единицей. Так, Hope, sb; Love, sb; God, sb; Reck, sb; Home, sb.

103Количественная дериватология
В. Наименьшее количество составляют 5–6 фонемные корни в соста-ве словообразовательных суффиксальных цепей: 7 и 6 соответственно. Приведем несколько примеров: Remedy, sb; Regasd, sb; Point, sb; Bound, sb; Result, sb.
Полисемия (S) корней и производных первого и второго шага в диахронии
Исследование семантики словообразовательных суффиксальных це-почек показывает следующее (Табл. 445).
Таблица 45Полисемия (S) производящих основ (корней) и цепочек
производных в диахронии
Кол-во знач. (S)
СтолетиеСумма
X XI XII XIII XIV XV XVI XVII XVIII XIX
Root
1 3 0 0 1 0 0 0 0 0 0 4
2 5 0 0 4 1 0 0 2 0 0 12
3 7 3 1 8 9 1 0 1 0 0 30
4 10 4 0 1 1 1 0 1 0 0 18
5 1 1 0 4 0 2 1 0 0 0 9
6 1 0 0 2 1 0 0 0 0 0 4
7 0 0 0 1 2 0 0 0 0 0 3
Root + -less
1 1 0 0 1 4 2 10 5 2 4 29
2 1 4 0 0 2 5 8 3 0 1 24
3 3 0 0 3 4 3 2 0 0 1 17
4 1 1 0 0 5 1 2 0 0 0 10
Root + -less + -ness
1 0 0 0 0 0 0 7 18 6 43 74
2 1 0 0 0 1 0 1 2 0 0 5
3 0 0 0 0 0 0 1 0 0 0 1
А. Среди корневых основ наибольшее место занимают 3-х значные слова — 29 лексем.

104 Глава 2
Например, Luck, sb (3); Bound, sb (3); Reck, sb (3); Так, у слова Plan, sbследующие значения:
1. A drawing or diagram showing the relative position of the parts of a building or any one floor (1678);
2. A design according to which things or parts of a thing are to be arranged (1732);
3. A formulated or organized method according to which smth is to be done (1706).
Лексема Sleep, sb:1. The unconscious state or condition reguraly and naturaly assumed by
man (825);2. The effects or signs of sleep (1864);3. The condition of being quite (1807).4-х значных слов в составе этого ряда цепи 18, такие как Result, sb
(4); End, sb (4); Shape, sb (4);
Blame, sb1. The action censuring, expression of dissapprobating (1230);2. The condition of being blamed (1256);3. A charge, an accusation (1340);4. Responsebility for anything wrong (1393).
2-х значных 12, например, Rhyme, sb (2); Sin, sb (2); и 9 слов с пятью значениями, среди ни Aim, sb (5); Track, sb (5); Наименьшее количество 1, 7 и 6 значных слов, а именно 4, 4 и 3 слова. Например:
Need, sb1. Violence, force,, compulsion, excersised by a person (825);2. Of or by necessity, avoidably (900);3. Necessaty arising from the facts (925);4. To be under a necessety (1010)5. A condition, marked by the lack or want of something necessary (1100);6. To require to smth (1200).
Б. Среди производных первого порядка с суффиксом -Less больше всего слов 2-значных (28 и 24). Так, Trackless, a; Remediless, Hopeless, a; Thoughtless, a; etc. Кроме того 3-х значных слов мы насчитали 17, среди них Selfless, a; Blameless, a; и 10 4-х значных, среди которых, Breathless, a; Senseless, a; etc.

105Количественная дериватология
В. В ряду дериватов второго порядка картина следующая: 74 лексе-мы имеют по одному значению, 5 слов являются 2-х значными и только одно имеет 3 значения. Например, Sinlessness, n. 1) The quality or state of being sinless, freedom from sin. (1846).
Breathlessnes, n. 1) Breathless condition, want of breath. (1615).Таким образом, в результате детального исследования 80 словообра-
зовательных суффиксальных цепочек типа Root → Root + -Less → Root +-less + -Ness, были установлены их количественные характеристики:
1. Синхроническая продуктивность по периодам равнялась: в д.а. пе-риод — 60 корней, 16 производных первого шага и 1 производная вто-рого шага в деривации. В с.а. период- 20 корней, 47 и 11 дериват пер-вого и второго шага в деривации соответственно. В н.а. период зареги-стрировано 16 корней, 17 производных первого шага в деривации и 68 дериват второго шага.
2. Средний временной интервал появления производной первого шага от корневой основы составляет около 300 лет; примерно через 280 лет появились производные второго шага; интервал между появле-нием производного второго шага от корневой основы составляет в сред-нем 600 лет.
3. Коэффициент полисемичности для корней в составе данных це-почек составляет примерно 3,5 ЛСВ/слово. Производные первого шага в деривации — в среднем 2 ЛСВ/слово и производные второго шага имеют коэффициент равный 1 ЛСВ/слово.
4. Средняя фонетическая длина корней составляет в среднем 3,5 фо-нем/слово; дериваты первого и второго шагов в деривации по 6,5 и 10,5 фонем/слово соответственно.
5. Средняя скорость изменения семантического поля корней и дери-ватов первого и второго шагов в деривации равна: для корней: 1, 6 ЛСВ/век; производные первого и второго шагов — 1,1 и 1 ЛСВ/век соответ-ственно.
6. Фонетическая длина корневых основ следующая: 35 корней состо-ят из 4 фонем, 31 слово имеет 3 фонемы и 13 слов имеют по 5 и 6 фонем в своем составе.
7. Было установлено: a) 29 корней — 3-х значные; 18 корней — 4 значные; 12 корней — 2-х значные; 9 корней — 5-и значные; b) Произ-водные первого шага деривации: 28 — 1-значные; 24 — 2-х значные; 17 — 3-х значные; 10 — 4-х значные; c) Производные второго шага в де-ривации: 74 деривата — 1-значные; 6 дериватов — 2-х значные.

Глава 3
КОЛИЧЕСТВЕННАЯ ДЕРИВАТОГРАФИЯ
§ 1. Аффиксография
Известно несколько «качественных» дериватариев (т. е. «словарей» аффиксов): русского [99; 131; 149], английского [105], немецкого [133] языков.
Начиная с 1978 г., мы стали осуществлять качественно-количествен-ное описание деривационных морфем английского [42; 51], русско-го [50], немецкого [43], украинского [39] и французского [44] языков по разработанной нами ментодике, заключающейся в анализе макси-мально полных выборок дериватов и использовании ряда современ-ных количественно сформулированных характеристик аффиксов (про-дуктивность синхроническая и диахроническая, частотность модельная и суммарная, валентность внутренняя и внешняя и т. д.), а также в ко-личественном определении субъективного и объективного статуса аф-фиксов по разработанной1 нами пентахотомической шкале.
ПараметрыМакет статьи качественно-количественного дериватария англий-
ского языка был разработан к 1979 году [42; 47; 51; 54; 55] после кри-тического анализа ряда качественных «словарей» деривационных мор-фем русского, английского и немецкого языков [99; 105; 131; 133; 149].
Количественных предшественником явился списов 90 суффиксов английского языка, снабженных количественной характеристикой — «(модельной) частотностью» [24].

107Количественная дериватография
§ 2. Параметры статьи дериватария
Статьи качественно-количественного дериватария содержат сле-дующие параметры [42; 51; 54; 55]:
0. Заголовочная деривационная морфема (прописными буквами)1. Транскрипция.2. Варианты:3. Деривационный статус: semisuffix (СС); suffix (ОС);4. Этимология:5. Время возникновения деривационной морфемы: OE [в сложениях
с VIII в.: alderman (725г]; Pd (OE)=; Pd (ME)=; Pd (eMoE)=; Pd (lMoE)=6. Стиль: Литературная норма (). Стилистические пометы (%), в том
числе: obsolete (40 % стил. окрашенных),7. Терминологичность:% терминов (Pd (termin.)8. Деривационные модели; время их возникновения и процесс фор-
мирования в диахронии:9. Диахроническая продуктивность типа: Pd (W-2), (L);10. Синхроническая продуктивность типа в наше время: Ps (XX в.)11. Модельное фонемное тяготение: Phm12. Суммарное фонемное тяготение: Phs13. Модельное морфемное тяготение: MrphM14. Суммарное морфемное тяготение: MrphS15. Модельная частотность морфемы: Fm16. Суммарная частотность морфемы: Fs17. Внешняя модельная валентность: Vm18. Внешняя суммарная валентность: Vs19. Синонимия модельная: SynМ20. Синонимия суммарная: SynS21. Словообразовательные значения (семемы)
а) «person, man» (лицо, деятель) (примеры)б) «object» (неодушевленный предмет) (примеры)в) «animal, bird, fly, fish»;г) «mythonym» (мифологические существа) (0,5 %)
22. Значение типа:

108 Глава 3
§ 3. Дериватография префикса Anti-
Продемонстрируем качественно-количественное описание префик-са современного английского языка ANTI-.
ANTI-1. Транскрипция. [‘entai], [‘enti]2. Варианты. Ant- (перед ПО, начинающимися с гласной или h]
(antacid, Antarctica),3. Деривационный статус. Префикс4. Этимология. Пришел из греческого языка с заимствованными сло-
вами.5. Время возникновения деривационной морфемы: с IX века.6. Стиль. Литературная норма.7. Терминологичность: мед. (antibody, antiseptic, antiserum,
anticoagulation).8. Деривационные модели;a) ANTI- + N = N (Pd=34) (например, antibody, anticlimax, anticyclone,antigene, antigravity, antimatter, antiparticle, anti-Semite, antitheism,
antitoxin, antitype);b) ANTI- + A = N (Pd=3) (например, anticlerical, antipyretic,
antiscorbutic);c) ANTI- + A = A (Pd=8) (например, antimonarchial, antiphlogistic,
antisocial);d) ANTI- + N = A (Pd=12) (anticoagulant, antiaircraft, anti-g, anti-
Jacobin, anti-Semite, antitrade);e) ANTI- + Adv = Adv (Pd=1) (например, anti-clockwise);f) ANTI- + S + sf = N (Pd=2) (например, antiperspirant, antivenin);g) Заимствовано: 16 лексем (например, antibiosis, antichrist, antidote,
antiphon, antirrhinum, antistrophe, antithesis, antionomasia, antionyma).9. Диахроническая продуктивность типа: Pd=1340 лексем (W-2).10. Синхроническая продуктивность типа в наше время: Ps
(XX в.) =85 (Ps*=45 (Nouns): anti-art, antiatom, antihero, antinovel; Ps*=40 (Adjectives): antiblack, anticonvulsive, antidumping, antiemetic, antiparasitic, antiwhite.
11. Модельное фонемное тяготение: Phm=18 фонемам (16 согласных + 2 гласных);
12. Суммарное фонемное тяготение: Phs: s (17 %), p (15 %), k (15 %), t (9 %), m (7 %), n (5 %).
13. Модельное морфемное тяготение: MrphM=2 (de-, mono-);

109Количественная дериватография
14. Суммарное морфемное тяготение: MrphS: antidepressant, antimonarchial.
15. Модельная частотность морфемы: Fm=57;16. Суммарная частотность морфемы: Fs=206 СУ (anti-trust=27; anti-
Semitism=23; antibody=21; anti-slavery=13; anti-communist=9; anti-submarine=8; antiseptic=6; anti-party=5; anti-Semite=5).
17. Синонимия модельная: SynМ=1 (NON-) /18. Синонимия суммарная: SynS=1 (anti-/non-hero).19. Антонимия модельная. AntM=1 (PRO-)20. Антонимия суммарная: AntS: anti-Communist#pro-Communist,
anti-market#pro-market.21. Словообразовательные значения (СЗ=5 семемам).
a) «opposite, against, preventing» (e. g. antibody, atntipope; antiair-craft, antitrust; Antarctic, anti-Semitic; antineutrino, antiproton);
b) «unlike conventional form» (e. g. anti-hero, anti-novel).
§ 4. Дериватография суффиксов: -man
MAN-1. Транскрипция. [m*n];2. Варианты: Во множественном числе: -men;3. Деривационный статус: semisuffix (СС=0,37; ОС=0,69);4. Этимология: германский суффикс (VIII c.);5. Время возникновения деривационной морфемы: OE [в сложениях
с VIII в.: alderman (725г];6. Стиль: Литературная норма (94,8 % лексем). Стилистические по-
меты имеют 224 лексемы (17,2 %), в том числе: obsolete (40 % стил. окра-шенных),
7. Терминологичность: 68 лексем являются терминами (Pd (termin.) =68 лексем (5,2 % лексем);
8. Деривационные модели; время их возникновения и процесс фор-мирования в диахронии:
a) N + -man = N (PdN (84,9 %);b) A + man = N (PdA (7,4 %);c) V + -man = N (PdV (2,0 %);d) Particle + -man = N (PdP (0,7 %),e) Num + -man = N (PdNum (0,5 %),f) Pron+ -man = N (PdPron (0,1 %),

110 Глава 3
9. Диахроническая продуктивность типа: Pd=1301 лексем (W-2), 440 лексем (L);
10. Синхроническая продуктивность типа в наше время: Ps (XX в.) =2
11. Модельное фонемное тяготение: Phm=36 фонем;12. Суммарное фонемное тяготение: Phs:13. Модельное морфемное тяготение: MrphM=214. Суммарное морфемное тяготение: MrphS=46, в том числе: -er
(52 %), — ingN (22 %).15. Модельная частотность морфемы: Fm=216;16. Суммарная частотность морфемы: Fs=640 СУ (chairman=67;
congressman=57)17. Внешняя модельная валентность: Vm=16;18. Внешняя суммарная валентность: Vs=153: N: -ship, -hood, -(e) ry,
-ism, -ate, -ingN, -cy, -ity, -ess; A: -ly, -like, -ish, -ic, -ical, -ed.19. Синонимия модельная: SynМ=1 (-man = -er) (hammer-, work-,
hunt-, signal-20. Синонимия суммарная: SynS= -man = -er (hammer-, work-, hunt-,
signal).21. Словообразовательные значения (семемы) (выявлено 5 семем):
а) «person, man» (лицо, деятель) (71,4 % лексем);б) «object» (неодушевленный предмет) (4,4 %);в) «animal, bird, fly, fish» (виды животных, птиц, насекомых, рыб)
(1,8 %);г) «mythonim» (мифологические существа) (0,5 %);д) «plant» (виды растений) (0,4 %).
22. Значение типа: деятель, человек (a freshman- студент, студентка первокурсница; Mrs Chairman — председатель (женщина)

Глава 4
АФФИКСАЛЬНЫЕ МИНИМУМЫ
§ 1. Продуктивные минимумы
Продуктивные аффиксальные минимумы составляются в результа-те количественного анализа «продуктивности» аффиксов, то есть под-счета количества лексем с каждым аффиксом в словаре. Затем аффик-сы аранжируются в порядке убывания величин их продуктивностей (П). Сложив П всех аффиксов и разделив полученную сумму на количество аффиксов, получают среднюю продуктивность (Х*) — важную характе-рис тику ряда аффиксов! Все аффиксы, у которых П >Х*, являются вы-соко продуктивными и изучаются в 1-ю очередь. Разделив Х* на е=2,71 (основание натуральных логарифмов), получим еще одну важную ха-рактеристику ряда аффиксов Х** Все аффиксы, у которых Х* > П > Х** (меньше Х*, но больше Х**) являются средне продуктивными и изуча-ются во 2-ю очередь. Все остальные аффиксы являются низко продук-тивными и изучаются в 3-ю (и последнюю) очередь! Ценность количе-ственного подхода к отбору аффиксов для изучения заключается в том, что в внутри каждой группы аффиксы располагаются в направлении уменьшения величины их продуктивности (П), поэтому всегда ясно, ка-кой следующий аффикс берется («за жабры») и изучается…
А) Продуктивный аффиксальный минимум (литературная норма)Словарный запас «среднего американца», то есть набор слов, кото-
рые он знает, но никогда не употребляет, составляет 10–20 тыс. слов [Flexn, viii). Это так называемый «пассивный запас» [Крупн].
Однако средний объем «письменного» вокабуляра, используемого интеллектуалами (писателями, учеными), оценивается в 50–100 тыс. слов [West, Kimb, I].

112 Глава 4
Именно с таким количеством слов сталкиваются аспиранты (как естественники, так и гуманитарии), когда начинают интенсив-но читать (и переводить!) оригинальную литературу по специальности. Но их «пассивный» запас английских слов, полученный в университете, в среднем равен 1–3 тыс. слов. В основном, это простые слова, широко использующиеся англоговорящей публикой для создания большого ко-личества производных слов с помощью префиксов и суффиксов. Нами подсчитано, что из 600 тыс. лексем, содержащихся в одном из крупней-ших толковых словарей английского языка [W-2], около 70 % составля-ют префиксальные и/или суффиксальные производные [Б, 84]. Инте-ресно, что некоторые слова содержат несколько аффиксов, например, такие, которые содержатся в толковом словаре объемом в 310 тыс. слов [RHUD]: anti-Americanism, anticapitalistically, antiestablismentarianism, antiimperialistic, antiintellectualistic, antimaterialistically, antisupernatu-lalistic [RH, 89–95]; nonauthorbiographically, noncapitalistically (p. 1307), nondisastrousness (p. 1310), noninstrumentalistically (p. 1313), noninter-changeability (p. 1313), nonmonogamously (p. 1314), nonopinionative-ness (p. 1315), nonrepresentationalist (p. 1316), predominatingly (p. 1523), prefigurativeness (p. 1524). Premisrepresentation (p. 1530), pseudointer-nationalistic (p. 1559), pseudomultilocular (p. 1560), unaxiomatically ( (p. 2054), uncharacteristically (p. 2056), unconventionality (p. 2058), undisin-heritable (p. 2062) RH [] [24]. Много примеров подобного рода можно найти в крупнейших толковых словарях [Ox, Web].
Заметим, что знание аффиксов позволяет понять значение произ-водных слов, если известны значения корней — путем «сложения значе-ний» [Зятк, Кар. Марч 1.
Каково значение аффиксов английского языка, можно узнать из ряда специальных работ по словообразованию [Зят, Кар, Меш, Пиот, Еспер, Марч 1; 11; 12; 14; 15; 17; 20; 21].
Однако, анализ крупнейших справочников по словообразованию по-казывает, что в английском языке используется от 252 аффиксов (123 префикса и 129 суффиксов) [RHPB] до 300 аффиксов (179 префиксов и 121 суффикс) [Coll].
Ранее в специальной работе было показано, что когда студентов ознакомили со способами словообразования, то они смогли перевести «без словаря» в 7 раз больше слов, чем контрольная группа [Крупн].
Однако детально ознакомиться с 300 английских аффиксов практи-чески нереально. Но специалистам известно, что не все аффиксы одина-ково важны. Некоторые из них встречаются в составе огромного коли-чества производных (это свойство называется «продуктивностью (П)»).

113Аффиксальные минимумы
Например, в [В-2] имеется 14,6 тыс. слов с префиксом un- и 5,5 тыс. слов с in- (il-, im-, ir-) [Б, 84, 17]. Высока, например продуктивность суф-фиксов прилагательных -ic (13,3 тыс. слов) и -al (11,6 тыс. слов) [Б, 84]. Следовательно, знакомство только с 4-мя выше упомянутыми аффикса-ми поможет определить значения 45 тысяч (!) производных (естествен-но, при знании корней, многие из которых являются высоко частотны-ми и поэтому известными аспирантам.
Итак, если знать продуктивность всех аффиксов, то можно отобрать наиболее продуктивные для изучения в 1-ю очередь, средне продуктив-ные — во 2-ю очередь, а низко продуктивные оставить «на потом».
Поэтому мы решили подсчитать «продуктивность» аффиксов в по-пулярном толковом словаре Web-conc] американского языка (как назы-вает его известный популяризатор [22]
Методика работы. Анализируемый Словарь [WConc] содержит око-ло 4600 слов. В ходе работы выписывали все слова с каждым аффиксом. Деривационную членимость уточняли по толковому словарю [24] объе-мом в 310 тыс. словарных статей.
Подсчитав величины «продуктивности» (П) аффиксов (то есть коли-чество производных с каждым из них в Словаре [WCon], мы использова-ли прием «ранжировки» [Б, — 45 лет, 16-№ 3–3 (27) 3; 6; 7], то есть рас-положили аффиксы по уменьшению величин их продуктивности. Затем сложили все величины П и полученную сумму разделили на количество аффиксов, получив среднюю арифметическую продуктивность (Х*) — важную характеристику нашего ряда аффиксов. После чего, разделив среднюю (Х*) на е=2,71 (основание натуральных логарифмов), полу-чаем еще одну важную для нас величину: Х**=Х*/е. Делается это пото-му, что ряд, состоящий из величин продуктивностей аффиксов, спада-ет (как говорят математики) по логарифмической кривой. Следующий шаг — это «разбиение» (известный математический термин!) аффиксов на группы продуктивности.
В 1-ю группу «высоко продуктивных» аффиксов попадают все те, у которых величина продуктивности (П) больше средней (Х*).
Во 2-ю группу» «средне продуктивных» аффиксов попадают те, у ко-торых величины продуктивности меньше средней (Х*), но больше Х**.
В 3-ю группу «низко продуктивных» аффиксов попадают все остав-шиеся аффиксы, у которых величины продуктивности меньше Х**.
Эту методику мы успешно использовали для получения ряда так на-зываемых «аффиксальных минимумов» для интенсификации процесса обучении аспирантов чтению (то есть переводу на русский язык) тек-стов на английском языке [4; 6; 8; 9; 10]. Заметим, что при перечисле-

114 Глава 4
нии суффиксов в случае наличия омонимов мы отмечаем частеречную принадлежность общепрнятыми буквенными обозначениями: A — при-лагательное; N — существительное; V — глагол; Adv — наречие, напри-мер: -ateN, -ateA, -ateV; -icN, -icA, etc.
В результате «сплошного» анализа словаря [WCon] установлено, что в нем содержится 2013 производных слов (что составляет 43,8 % во-кабуляра), образованных с помощью 142 аффиксов, что дает среднюю продуктивность аффикса, равную 5,2 деривата (Табл. 54).
Таблица 54Общая характеристика аффиксов
Аффикс Количество Сумма (П) Среднее (Х*) Х**=Х* / 2,7
Префиксы 49 229 4,7 1,7Суффиксысуществительных 57 841 16,5 6,1
Суффиксы прилагательных 25 553 22,1 8,2
Суффиксы глаголов 4 85 21,2 7,8
Суффиксы наречий 4 184 46,0 16,9
Суффиксы числительных 3 21 7,0 2,6
Сумма 142 2013 14,2 5,2
Анализ данных (Табл. 54) показывает, что хотя в составе 142 аффик-сов насчитывается 49 префиксов (34,5 %), по количеству производных префиксы составляют всего 11,4 %. Количество суффиксов имен суще-ствительных составляет 40,4 % от общего числа аффиксов, а доля их де-риватов равна 41,8 %. Количество суффиксов прилагательных равно 17,6 %, но сумма продуктивностей их дериватов составляет 24,5 %. В це-лом состав аффиксов разных грамматических классов и количество их дериватов дают довольно пеструю картину (Табл. 54).
Рассмотрим результаты анализа продуктивности аффиксов по клас-сам.
Отметим, что в Приложении Словаря [WCon] приведен список из 67 префиксов (и полупрефиксов), но не все они представлены дериватами в Словаре [WCo]. Реально продуктивные префиксы Словаря отмечены звездочками (Табл. 55).
Приступим к задаче разбиения списка префиксов на группы в соот-ветствии с их продуктивностью П. Отметим, что в среднем продуктив-ность префиксов составляет 4,7 деривата (Х*=4,7) (Табл. 55).

115Аффиксальные минимумы
Таблица 55Продуктивность 49 префиксов и полупрефиксов
Prefix П Examples
Un*- 47 -able, -easy, -conscious, -employed, -true, -wise
In*- (l, m, r-) 21 -legal, -polite, -patient, -correct, -regular, -visible
Dis*- 17 -abled, -cover, -ease, -honest, -like, -loyal, -solve
A- (adv) 13 -board, -head, -loud, -part, -side, shore, -way
Re*- 11 -act, -assure, -move, -new, -pay, -place, -view
In- (Im-) 10 -come, -habitant, -land, -side, -press, -prison
Over*- 9 -board, -coat, -flow, -look, -night, -seas, -take
Under*- 8 -go, -graduate, -ground, -growth, take, -wear
Out- 7 -door, -fit, -line, -side, -skirts, -standing,
Pre*- 6 -caution, -dict, -judice, -fix, -position, scription
Up- 6 -to-day, -hill, -right, -set, -side-down, -stairs
En*- (v) 5 -able, -brace, -close, -courage, -joy, -large
Micro*- 4 -chip, -computer, -phone, -scope
Step*- 4 -father, -mother, -brother, -sister
Astro*- 3 -naut, -nomy, -nomer
Co*- 3 -operete, -operation, -operative
Fore*- 3 -cast, -head, -man
Geo*- 3 -graphy, -logy, -metry
Mis*- 3 -behave, -fortune, -take
Be*- (v) 2 -come, ware
Bi*- 2 -cycle, -(n) ocular
Bio*- 2 -graphy, -logy
Centi*- 2 -grade, -meter
Down- 2 -hill, -stairs
Inter*- 2 -national, -view
Kilo*- 2 -gram, -meter
Mid*- 2 -day, -night
Mono*- 2 -tony, -tonous
Pro*- 2 -non, -verb

116 Глава 4
Prefix П Examples
Semi*- 2 -circle, -colon
Sub*- 2 -marine, -urb
Super*- 2 -market, -sonic
Sur- 2 -face, -name
Trans*- 2 -form, -port
Tri*- 2 -angle, -cycle
Arch*- 1 -bishop
Back- 1 -ground, -wards
Ex*- 1 -wife
Extra*- 1 -ordinary
Half- 1 -way
Hemi- 1 -sphere
Hydro*- 1 -gen
Ill- 1 -mannered
Mal*- 1 -nutrition
Milli*- 1 -meter
Non*- 1 -sense
Uni*- 1 -form
Vice*- 1 -president
Well- 1 -mannered
Сумма 229
X* 4,7
X** 1,7
В соответствии с методикой все префиксы с П > 4,7 считаются высо-ко продуктивными и изучаются в 1-ю очередь. Сюда попадают 12 сле-дующих морфем: un-, in- (il-, in-, ir-), dis-, a-, re-, in- (im-), over-, under-, out-, pre-, up-, en-.
Во 2-ю группу попадает 12 префиксов, у которых X* > П > X**, то есть следующие: micro-, step-, astro-, co-, fore-, geo-, mis-, be-, bi-, bio-, centi-, down-, inter-, kilo-, mid-, mono-, pro-, semi-, sub-, super-, sur-, trans-, tri-.
Остальные 14 префиксов мало продуктивны и изучаются в послед-нюю очередь.

117Аффиксальные минимумы
Такой подход к изучению аффиксов представляется более рацио-нальным, чем рассмотрение представленных по алфавиту префиксов в конце Словаря.
Поскольку традиционно суффиксы рассматриваются в соответствии с грамматическими классами их производных, проанализируем данные о продуктивности суффиксов существительных (Табл. 56).
Таблица 56Продуктивность 57 суффиксов и полусуффиксов имен
существительных
Suffix П Примеры
-ion, n 222 Act-, collect-, creat-, locat-, mot-, possess-, sensat-, vibrat
-er, n 112 Bak-, bomb-, box-, deal-, min-, office-, hunt-, lead-, post-
-(a, e) nce, n 61 Abse-, audie-, dista-, entra-, guida-, obedie-, refere-, sile-
-ment, n 59 Agree-, depart-, govern-, judge-, move-, pay-, regi-, treat-
-ing, n 51 Box-, cross-, feel-, fish-, land-, meet-, paint-, sew-, turn-
-ity, n 49 Abil-, char-, dign-, grav-, liber-, socie-, qunt-, qual-, varie-
-(a, e) nt, n 39 Age-, consta-, curree-, restaura-, mercha-, stude-, trua-
-or, n 37 Auth-, direct-, edit-, err-, govern-, sail-, tut-, tract-, visit-
-ure, n 35 Advent-, creat-, fail-, fig-, gest-, lect-, pickt-, struct-, tort-
-age, n 26 Bagg-, cabb-, dam-, host-, marri-, pass-, saus-, vill-, voy-
-(a, o) ry, n 19 Bounda-, dictiona-, facto-, libra-, memo-, secreta-, victo-
-ic, n 16 Cathol-, clin-, cosmet-, fabr-, lunat-, mag-, machan-, pan-
-(e) ry, n 15 Brav-, brew-, brib-, forg-, bak-, machin-, poet-, pott-, slav-
-ist, n 15 Art-, biology-, botan-, chem-, novel-, physic-, scient-
-th, n 15 Bread-, dea-, fil-, grow-, heal-, tru-, warm-, wid-, you-
-man, n 14 Chair-, crafts-, gentle-, post-, sales-, states, watch-, work-
-y, n 14 Assembl-, monarch-, flatter-, honest-, jelous-, recover-
-ness, n 12 Busi-, dark-, happi-, ill-, kind-, like-, sick-, weak-, wit-
-al, n 11 Approv-, arriv-, propos-, refus-, remov-, surviv-, tri-
-ate, n 10 Candid-, certific-, deb-, sen-, gradu-, pir-, undergradu-
-ess, n 10 Actr-, duch-, fortr-, god-, lion-, princ-, steward-, waitr-
-ian, n 10 Civil-, guard-, misic-, physic-, politic-, technic-, veterinar-
-ics, n 8 Athlete-, characterist-, gymnast-, mathemat-, phys-, trop-

118 Глава 4
Suffix П Примеры
-meter, n 6 Baro-, centi-, dia-, kilo-, milli-, thermo-
-(a, e) ncy, n 5 Constitue-, curre-, emerge-, tende-, vaca-
-logy, n 5 Archeo-, apo-, bio-, geo-, techno-
-ship, n 5 Champion-, friend-, relation-, scholar-, wor-
-dom, n 4 Bore-, free-, king-, wis-
-ism, n 4 Bapt-, critic-, journal-, juda-
-tude 4 Atti-, grati-, lati-, longi-
-ee, n 3 Employ-, refug-, refer-
-eer, n 3 Engine-, pion-, volunt-
-ful, n 3 Hand-, mouth-, spoon-
-graph, n 3 photo-, para-, tele-
-graphy, n 3 Bio-, geo-, photo-
-ine, n 3 Margar-, medic-, tanger-
-let, n 3 Brace-, leaf-, pig-
-fix, n 2 pre-, suf-
-gram, n 2 Kilo-, tele-
-hood, n 2 Child-, neighbor-
-ice, n 2 Just-, injust-
-in, n 2 Aspir-, paraff-
-ling, n 2 Dar-, duck-
-nomy, n 2 Astro-, eco-
-ade, n 1 Lemon-
-cracy, n 1 Demo-
-ene, n 1 Keros-
-ette, n 1 Cigar-
-metry, n 1 Geo-
-ock, n 1 Bull-
-on, n 1 Nyl-
-phone 1 Tele-
-red, n 1 Hat-
-scape, n 1 Land-

119Аффиксальные минимумы
Suffix П Примеры
-scope, n 1 Tele-
-sphere, n 1 Atmo-
-ule, n 1 Molec-
Сумма (57) 941
X* 16,5
X** 6,1
В 1-ю группу высоко продуктивных попадают суффиксы, у которых величины продуктивности (П) больше средней Х*. Это следующие 11 морфем: -ion, -er, -(a, e) nce, -ment, -ingN, -ity, -(a, e) ntN, -or, -ure, -age,
-(a, o) ry.Во 2-ю группу средне продуктивных суффиксов попадают те, у ко-
торых X* > П > X**. Это следующие 12 морфем: -icN, -ery, -ist, -th, -man, -yN, -ness, -alN, -ateN, -ess, -ianN, -ics.
В 3-ю группу низко продуктивных суффиксов попадают 34 морфемы, у которых Х** > П (Табл. 56).
Анализ продуктивности суффиксов прилагательных (Табл. 57) пока-зывает, что их средняя продуктивность равна Х*=23,0.
В 1-ю группу высоко продуктивных суффиксов попадает 9 морфем, у которых П > X*=22,1: -alA, -yA, -(a, e) ntA, -ous, -ed, -(a, i) ble, -ive, -icA,
-fulA.Во 2-ю группу средне продуктивных суффиксов попадают 6 морфем,
у которых X* > П > X**, а именно: -ateA, -(a, o) ryA, -ingA, -less, -lyA, -ar.В третью группу низко продуктивных суффиксов попадают осталь-
ные 10 морфем, у которых X** > П.
Таблица 57Продуктивность 25 суффиксов прилагательных
Suffix П Примеры
-al, a 102 Actu-, crimin-, fin-, magic-, raci-,- spir-, tropic-, usu-, vit-
-y, a 61
-(a, e) nt, a 50 Abse-, brillia-, evide-, ignora-, obedie-, patie-, significa-
-ous, a 42 Adventur-, danger-, envi-, gener-, hazard-, prosper-, vigor-
-ed, a 41 Advance-, crook-, drunken, nak-, shap-, talent-, tir-, worri-
-(a, i) ble, a 38 Awaila-, capa-, favora-, lova-, relia-, sensi-, suita-, value-

120 Глава 4
Suffix П Примеры
-ive, a 32 Adject-, detect-, explos-, nat-, posit-, relat-, sensit-, talkat-
-ic, a 31 Angel-, cub-, domest-, elast-, magnet-, metr-, plast-, publ-
-ful, a 27 Aw-, care-, grace-, harm-, law-, peace-, skill-, thank-, us-
-ate, a 21 Affection-, delic-, moder-, obstin-, passion-, priv-, separ-
-(a, o) ry, a 17 Contra-, milita-, necessa-, ordina-, prima-, seconda-, solita-
-ing, a 16 Amaz-, charm-, excit-, faith-, excit-, revolt-, starv-, will-
-less, a 16 Care-, end-, fault-, hope-, merci-, reck-, tact-, us-, wire-
-ly, a 15 Cost-, dead-, ghost-, heaven-, like-, lone-, month-, unfriend-
-ar, a 14 Circul-, family-, nucle-, popul-, regul-, simil-, sol-, vulg-
-id, a 7 Horr-, liqu-, rap-, sol-, splend-, stup-, viv-
-en, a 4 Gold-, rott-, wood-, wool-
-ern, a 4 East-, north-, south-, west-
-ish, a 4 Child-, fever-, fool-, self-
-(e, i) an, a 3 Christ-, magic-, Rom-
-ine, a 3 Femin-, genu-, mascul-
-ile, a 2 Fert-, host-
-proof, a 1 Water-
-some, a 1 Hand-
-worthy, a 1
Сумма 553
X* 22,1
X** 8,2
В 1-ю группу высоко продуктивных суффиксов попадает 9 морфем, у которых П > X*=22,1: -alA, -yA, -(a, e) ntA, -ous, -ed, -(a, i) ble, -ive, -icA,
-fulA.Во 2-ю группу средне продуктивных суффиксов попадают 6 морфем,
у которых X* > П > X**, а именно: -ateA, -(a, o) ryA, -ingA, -less, -lyA, -ar.В третью группу низко продуктивных суффиксов попадают осталь-
ные 10 морфем, у которых X** > П (Табл. 57).Известно, что в английском языке имеется 4 глагольных суффикса;
их продуктивность представлена ниже (Табл. 58).

121Аффиксальные минимумы
В результате анализа их продуктивности в Словаре мы видим, что са-мым продуктивным является суффикс -ateV. Во вторую очередб изуча-ются суффиксы -enV и –ize. А суффикс -ify остается «напоследок».
Таблица 58Продуктивность суффиксов глаголов
Suffix П Examples
-ate, v 44 Associ-, calcul-, educ-, migr-, oper-, rel-, rot-, transl-, vibr-
-en, v 18 Christ-, fatt-, happ-, less-, sharp-, soft-, strength-, threat-
-ize, v 15 Adv-, bapt-, civil-, fertile-, organ-, real-, recogn-, special-
-ify, v 8 Defy, horr-, ident-, magn-, qual-, satis-, simpl-, terr-
Сумма 85
X* 23,0
X** 8,5
В результате анализа их продуктивности в Словаре мы видим, что са-мым продуктивным является суффикс -ateV. Во вторую очередб изуча-ются суффиксы -enV и -ize. А суффикс -ify остается «напоследок».
Анализ продуктивности суффиксов наречий (Табл. 59) показывает, что доминирующей является морфема -lyAdv.
Суффиксы -ward, -wise, -ways изучаются во вторую очередь.
Таблица 59Продуктивность 7 суффиксов наречий
Suffix П Examples
-ly, adv 171 Active-, bad-, fair-, false-, nice-, quick-, sad-, tru-, wrong-
-ward, adv 9 After-, back-, east-, north-, south, out-, west-, up-
-wise, adv 3 Clock-, like-, other-
-ways, adv 1 Side-
Сумма 184
X* 46,0
X** 16,9
Суффиксы -ward, -wise, -ways изучаются во вторую очередь.Традиционно специалисты по словообразованию английского языка
суффиксы числительных не описывают [4; 6; 11; 14; 23; 106; 118], счи-

122 Глава 4
тая их грамматическими. Это не совсем верно, поэтому (по принципу «кашу маслом не испортишь») мы подсчитали их продуктивности и ряд других количественных характеристик [72] по методике, исползован-ной в работах [106] и [118].
В Словаре было обнаружено некоторое количество дериватов-числи-тельных (Табл. 60).
Однако ясно, что никакой особой очередности их изучения не требу-ется из-за замкнутости этой группы.
Таблиц 60Продуктивность трех суффиксов числительных
Suffix П Examples
-teen, nun 7 Eigh-, fif-, four-, nine-, seven-, six-, thir-
-ty, num 8 Eigh-, fif-, for-nine-, seven-, six-, thir-, twen-
-th, num 6 Eigh-, eleven-, fifteen-, fiftie-, ninrteen-, seven-, six-, twelf-
Сумма 21
X* 7,0
X** 2,6
Ясно, что никакой особой очередности их изучения не требуется из-за ограниченности этой группы (Табл. 60).
Как известно, в текстах аффиксы в составе дериватов могут встре-чаться в любой последовательности, независимо от их принадлежности к тому или иному грамматическому классу. Следовательно, встает во-прос о том, как аффиксы распределяются по продуктивности, так ска-зать, в глобальной картине. С этой целью мы составили сводный список аффиксов, ранжированных по убыванию их продуктивности (как един-ственной существенной характеристики) (Табл. 61).
Величина средней продуктивности (Х*) здесь будет своя, что учиты-вается при разбиении сводного списка на группы в соответствии с ме-тодикой работы.
В 1-ю сводную высоко продуктивную группу аффиксов попадает 36 морфем, у которых П > X*=14,2. Это следующие аффиксы, перечисляе-мые в соответствии с убыванием их продуктивности: -ion, -lyAdv, -er,
-alA, -(a, e) nce, -yA, -ment, -ingN, -(a, e) ntA, -ity, Un-, -ateV, -ous, -ed, -(a, e) ntA, -(a, i) ble, -or, -ure, -ive, -icA, -fulA, -age, -ateA, In (il-, im, -ir), -(a, o) ryN, -enV, -(a, o) ryA, Dis-, -icN, -ingA, -less, -ery, -ist, -ize, -lyA, -th.
123Аффиксальные минимумы
Во 2-ю сводную средне продуктивную группу попадает 24 аффикса, у которых X* > П, а именно: -ar, -man, -yN, A-, -ness, -alN, Re-, -ateN, -ess,
-ianN, In- (Im-), -over, -ward, -ics, -ify, -tyNum, Under-, -id, Out-, -teen, -meter, Pre-, thNum, Up-.
В 3-ю сводную низко продуктивную группу попадают остальные 82 аффикса, у которых X** > П (Табл. 61).
Следует напомнить, что в каждой группе аффиксы перечисляются в порядке убывания их продуктивности.
Таблица 61Сводный список 142-х аффиксов американского языка, ранжированных по уменьшению их панхронической
продуктивности (П)
Аффиксы П Примеры
-ion, n 222 Act-, collect-, creat-, locat-, mot-, possess-, sensat-, vibrat
-ly, adv 171 Active-, bad-, fair-, false-, nice-, quick-, sad-, tru-, wrong-
-er, n 112 Bak-, bomb-, box-, deal-, min-, office-, hunt-, lead-, post-
-al, a 102 Actu-, crimin-, fin-, magic-, raci-,- spir-, tropic-, usu-, vit-
-(a, e) nce, n 61 Abse-, audie-, dista-, entra-, guida-, obedie-, refere-, sile-
-y, a 61 Cloud-, fogg-, greed-, guilt-, luck-, nois-, sleep-, tid-, witt-
-ment, n 59 Agree-, depart-, govern-, judge-, move-, pay-, regi-, treat-
-ing, n 51 Box-, cross-, feel-, fish-, land-, meet-, paint-, sew-, turn-
-(a, e) nt, a 50 Abse-, brillia-, evide-, ignora-, obedie-, patie-, significa-
-ity, n 49 Abil-, char-, dign-, grav-, liber-, socie-, qunt-, qual-, varie-
Un- 47 -able,- easy,- conscious,- employed,- true,- wise
-ate, v 44 Associ-, calcul-, educ-, migr-, oper-, rel-, rot-, transl-, vibr-
-ous, a 42 Adventur-, danger-, envi-, gener-, hazard-, prosper-, vigor-
-ed, a 41 Advance-, crook-, drunken, nak-, shap-, talent-, tir-, worri-
-(a, e) nt, n 39 Age-, consta-, curree-, restaura-, mercha-, stude-, trua-
-(a, i) ble, a 38 Awaila-, capa-, favora-, lova-, relia-, sensi-, suita-, value-
-or, n 37 Auth-, direct-, edit-, err-, govern-, sail-, tut-, tract-, visit-
-ure, n 35 Advent-, creat-, fail-, fig-, gest-, lect-, pickt-, struct-, tort-
-ive, a 32 Adject-, detect-, explos-, nat-, posit-, relat-, sensit-, talkat-
-ic, a 31 Angel-, cub-, domest-, elast-, magnet-, metr-, plast-, publ-

124 Глава 4
Аффиксы П Примеры
-ful, a 27 Aw-, care-, grace-, harm-, law-, peace-, skill-, thank-, us-
-age, n 26 Bagg-, cabb-, dam-, host-, marri-, pass-, saus-, vill-, voy-
-ate, a 21 Affection-, delic-, moder-, obstin-, passion-, priv-, separ-
In- (l-, m-, r- 21 -legal,- polite,- patient,- correct,- regular,- visible
-(a, o) ry, n 19 Bounda-, dictiona-, facto-, libra-, memo-, secreta-, victo-
-en, v 18 Christ-, fatt-, happ-, less-, sharp-, soft-, strength-, threat-
-(a, o) ry, a 17 Contra-, milita-, necessa-, ordina-, prima-, seconda-, solita-
Dis- 17 -abled,- cover,- ease,- honest,- like,- loyal,- solve
-ic, n 16 Cathol-, clin-, cosmet-, fabr-, lunat-, mag-, machan-, pan-
-ing, a 16 Amaz-, charm-, excit-, faith-, excit-, revolt-, starv-, will-
-less, a 16 Care-, end-, fault-, hope-, merci-, reck-, tact-, us-, wire-
-(e) ry, n 15 Brav-, brew-, brib-, forg-, bak-, machin-, poet-, pott-, slav-
-ist, n 15 Art-, biology-, botan-, chem-, novel-, physic-, scient-
-ize, v 15 Adv-, bapt-, civil-, fertile-, organ-, real-, recogn-, special-
-ly, a 15 Cost-, dead-, ghost-, heaven-, like-, lone-, month-, unfriend-
-th, n 15 Bread-, dea-, fil-, grow-, heal-, tru-, warm-, wid-, you-
-ar, a 14 Circul-, family-, nucle-, popul-, regul-, simil-, sol-, vulg-
-man, n 14 Chair-, crafts-, gentle-, post-, sales-, states, watch-, work-
-y, n 14 Assembl-, monarch-, flatter-, honest-, jelous-, recover-
A (adv) 13 -board,- head,- loud,- part,- side, shore,- way
-ness, n 12 Busi-, dark-, happi-, ill-, kind-, like-, sick-, weak-, wit-
-al, n 11 Approv-, arriv-, propos-, refus-, remov-, surviv-, tri-
Re- 11 -act,- assure,- move,- new,- pay,- place,- view
-ate, n 10 Candid-, certific-, deb-, sen-, gradu-, pir-, undergradu-
-ess, n 10 Actr-, duch-, fortr-, god-, lion-, princ-, steward-, waitr-
-ian, n 10 Civil-, guard-, misic-, physic-, politic-, technic-, veterinar-
In- (Im-) 10 -come,- habitant,- land,- side,- press,- prison
Over- 9 -board,- coat,- flow,- look,- night,- seas,- take
-ward, adv 9 After-, back-, east-, north-, south, out-, west-, up-
-ics, n 8 Athlete-, characterist-, gymnast-, mathemat-, phys-, trop-
-ify, v 8 Defy, horr-, ident-, magn-, qual-, satis-, simpl-, terr-

125Аффиксальные минимумы
Аффиксы П Примеры
-ty, num 8 Eigh-, fif-, for-nine-, seven-, six-, thir=, twen-
Under- 8 -go,- graduate,- ground,- growth, take,- wear
-id, a 7 Horr-, liqu-, rap-, sol-, splend-, stup-, viv-
Out- 7 -door,- fit,- line,- side,- skirts,- standing,
-teen, nun 7 Eigh-, fif-, four-, nine-, seven-, six-, thir-
-meter, n 6 Baro-, centi-, dia-, kilo-, milli-, thermo-
Pre*- 6 -caution,- dict,- judice,- fix,- position, scription
-th, num 6 Eigh-, eleven-, fifteen-, fiftie-, ninrteen-, seven-, six-, twelf-
Up*- 6 -to-day,- hill,- right,- set,- side-down,- stairs
-(a, e) ncy, n 5 Constitue-, curre-, emerge-, tende-, vaca-
En*- (v) 5 -able,- brace,- close,- courage,- joy,- large
-logy, n 5 Archeo-, apo-, bio-, geo-, techno-
-ship, n 5 Champion-, friend-, relation-, scholar-, wor-
-dom, n 4 Bore-, free-, king-, wis-
-en, a 4 Gold-, rott-, wood-, wool-
-ern, a 4 East-, north-, south-, west-
-ish, a 4 Child-, fever-, fool-, self-
-ism, n 4 Bapt-, critic-, journal-, juda-
Micro- 4 -chip,- computer,- phone,- scope
Step*- 4 -father,- mother,- brother,- sister
-tude 4 Atti-, grati-, lati-, longi-
-(e, i) an, a 3 Christ-, magic-, Rom-
Astro*- 3 -naut,- nomy,- nomer
Co*- 3 -operete,- operation,- operative
-ee, n 3 Employ-, refug-, refer-
-eer, n 3 Engine-, pion-, volunt-
Fore*- 3 -cast,- head,- man
-ful, n 3 Hand-, mouth-, spoon-
Geo*- 3 -graphy,- logy,- metry
-graph, n 3 photo-, para-, tele-
-graphy, n 3 Bio-, geo-, photo-

126 Глава 4
Аффиксы П Примеры
-ine, a 3 Femen-, genu-, mascul-
-ine, n 3 Margar-, medic-, tanger-
-let, n 3 Brace-, leaf-, pig-
Mis- 3 -behave,- fortune,- take
-wise, adv 3 Clock-, like-, other-
Be*- (v) 2 -come, ware
Bi*- 2 -cycle,- (n) ocular
Bio*- 2 -graphy,- logy
Centi*- 2 -grade,- meter
Down- 2 -hill,- stairs
-fix, n 2 pre-, suf-
-gram, n 2 Kilo-, tele-
-hood, n 2 Child-, neighbor-
-ice, n 2 Just-, injust-
-ile, a 2 Fert-, host-
-in, n 2 Aspir-, paraff-
Inter- 2 -national,- view
Kilo*- 2 -gram,- meter
-ling, n 2 Dar-, duck-
Mid- 2 -day,- night
Mono*- 2 -tony,- tonous
-nomy, n 2 Astro-, eco-
Pro*- 2 -non,- verb
Semi- 2 -circle,- colon
Sub- 2 -marine,- urb
Super- 2 -market,- sonic
Sur- 2 -face,- name
Trans*- 2 -form,- port
Tri*- 2 -angle,- cycle
-ade, n 1 Lemon-
Arch*- 1 -bishop
Back- 1 -ground,- wards

127Аффиксальные минимумы
Аффиксы П Примеры
-cracy, n 1 Demo-
-ene, n 1 Keros-
-ette, n 1 Cigar-
Ex- 1 -wife
Extra- 1 -ordinary
Half- 1 -way
Hemi- 1 -sphere
Hydro*- 1 -gen
Ill- 1 -mannered
Mal- 1 -nutrition
-metry, n 1 Geo-
Milli*- 1 -meter
Non- 1 -sense
-ock, n 1 Bull-
-on, n 1 Nyl-
-phone, n 1 Tele-
-proof, a 1 Water-
-red, n 1 Hat-
-scape, n 1 Land-
-scope, n 1 Tele-
-some, a 1 Hand-
-sphere, n 1 Atmo-
-ule, n 1 Molec-
Uni- 1 -form
Vice- 1 -president
-ways, adv 1 Side-
Well- 1 -mannered
-worthy, a 1 Trust-
Сумма 2013
X* 14,2
X** 5,2
Примечание. Жирным шрифтом выделены границы между высоко, средне и низко продуктивными аффиксами.

128 Глава 4
Отметим, что 36 аффиксов 1-й группы дали 80,1 % производных про-анализированного Словаря, а 24 аффикса 2-й группы — 11,1 %. Остав-шиеся 82 аффикса в сумме дали всего 8,8 % дериватов. То есть, зная все-го 36 самых продуктивных аффиксов (из 142!), обучаемые смогут дога-даться о значении 80 % производных, содержащихся в Словаре [21].
Интересно, что еще нагляднее польза рационального отбора аффик-сов для изучения может быть проиллюстрирована следующими цифра-ми.
Ранее мы впервые подсчитали по [27] объемом в 600 тыс. статей, что префикс un- дал 14,6 тыс. дериватов; префикс in- (il-, im-, ir-) = 5,5 тыс.; re- = 5,4 тыс.; pre- = 3,5 тыс.; non- = 3,0 тыс.; over- = 2,1 тыс.; dis- = 1,8 тыс.; sub- = 1,7 тыс.; self- = 1,4 тыс.; inter- = 1,4 тыс.; anti- = 1,3 тыс.; pseudo- = 1,3 тыс. дериватов и т. д. Эти 12 префиксов в сумме находятся в составе 28,4 тыс. производных словаря [27].
Некоторые суффиксы тоже характеризуются высокой продуктив-ностью. Так, наши подсчеты по [Веб] показали, что наибольшую про-дуктивность имеют следующие суффиксы [5; 6]: -icA (13,3 тыс.); -alA (11,6 тыс.); -ed (9,5 тыс.); -ness (6,9 тыс.); -ous (6,9 тыс.); -er (5,5 тыс.);
-ingN (3,9 тыс.); -ive (2,1 тыс.); -less (1,7 тыс.); -like (1,3 тыс.); -ingA (1,3 тыс.); -man (1,3 тыс.); -ish (1,2 тыс.) и т. д. [Б, 1984; 2017, 15–16 мая]. В сумме эти 13 суффиксов находятся в составе 66,5 тыс. производных словаря [27].
Полученный список ранжированных по убыванию продуктивности аффиксов представляют собой «аффиксальный минимум» проанализи-рованного Словаря [21].
§ 2. Частотные аффиксальные минимумы
Известно, что первый большой частотный словарь (немецкого язы-ка), составленный Ф. Кедигом (1898) [98], содержит около 70 тыс. сло-воформ на основе анализа текстовой выборке объемом в 11 млн слово-употреблений.
Однако, менее известно, что самым первым частотным словарем русского языка был список, составленный еще в 1894 г. В. Н. Куницким [98], правда, содержит он всего 3370 разных слов (без ремарок и переч-ня действующих лиц) из 13 246 словоупотреблений в комедии А. С. Гри-боедова «Горе от ума» [98].

129Аффиксальные минимумы
В 20-х годах ХХ столетия в США появились небольшие частотные словари испанского и французского языков объемом в 5–6 тыс. наибо-лее частотных слов, которые стали использовать для написания рацио-нальных учебников этих языков для средней школы. Тогда же Е. Торн-дайк [25] начал составлять большие частотные словари американско-го варианта английского языка объемом сначала в 10 тыс. слов, затем в 20 тыс. слов и, наконец, в 30 тыс. слов [25]. Он же впервые отобрал список 90 наиболее частотных суффиксов английского языка (с указа-нием «(модельной) частотности» каждого) [24]. Позднее появились ра-боты, авторы которых, предлагали аффиксальные минимумы, состав-ленные в результате анализа различных текстов.
Отметим, что при использовании частотности употребления слов с каждым аффиксом следует четко разграничивать два критерия: 1) «мо-дельную частотность» (Fm) — количество разных слов с данным аффик-сом в тексте определенного объема; 2) «суммарную частотность» (Fs) — общее количество словоупотреблений с данным аффиксом. Проиллю-стрируем на примере, почему важно различать эти две частотные ха-рактеристики.
Пусть, в тексте встречено 100 разных слов с суффиксом — ist (каж-дое по одному разу), либо всего одно слово с -ist встретилось 100 раз. В первом случае имеем: Fm=100 СУ, Fs=100 СУ; во втором случае — Fm=1 СУ, Fs=100 СУ. Если, например, в тексте одно слово с суффиксом
–ist встретилось 50 раз и другоеслово c -ist- тоже 50 раз, тогда имеем сле-дующее: Fm=2 СУ, Fs=100 СУ. Видно, что это 2 различных частотных ха-рактеристики аффикса -ist.
Частотный аффиксальный минимум физической терминосистемыКак известно, в одном из крупнейших толковых словарей английско-
го языка [22] содержится 616 тыс. лексем [20, 324], а в другом [27] со-держится 600 тыс. словарных статей.
Но к счастью для учащихся каждый конкретный автор употребля-ет в своих произведениях далеко не все эти слова. Так, в сочинени-ях У. Шекспира насчитывается около 24 тыс. разных слов, а в поло-вине томов полного собрания (55 томов) сочинений В. И Ленина — 37 тыс. [110]. Но при чтении текстов специалисты обычно встреча-ются с 20–40 тыс. слов, причем многие из них содержат в своем со-ставе префиксы или суффиксы (иногда — по нескольку, например: antidisestablishmentarianism, beatificationistically, nonrepresentationalism, semihemidemisemiquaver, unputdownableness, etc.).

130 Глава 4
Количество производных (аффиксальных) лексем, как мы [51] ранее подсчитали, в словаре [27] довольно велико, причем 20 % лексем явля-ются префиксальными дериватами и 49 % слов — суффиксальными про-изводными [51]. Это составляет 69 % лексем словаря, то есть 414 тысяч аффиксальных слов!
Известно, что структурно простые слова обычно являются корот-кими и высоко частотными, поэтому многие из них, как правило, дав-но известны аспирантам, которых мы обучаем. Если значение аффикса также будет известно, то значение производного слова можно легко вы-вести путем «сложения» значений корня и аффикса.
В специальном исследовании ранее было показано, что студенты, которых обучили основам словообразования, особенно аффиксального, стали понимать значение в 7 раз большего количества слов, чем ранее, не заглядывая в словарь [113].
В последнее время проблема ознакомления студентов со способами словообразования для эффективного расширения их словарного запаса начинает интересовать педагогов [35].
Однако в английском языке имеется несколько сотен аффиксов, при-чем многие из них известны только специалистам-англистам. Так, в по-пулярном пособии описано около 300 английских префиксов и суффик-сов [6], которые запомнить не так легко… В другом справочнике [23] приведено 123 префикса и 129 суффиксов. В одной специальной моно-графии детально описано 80 префиксов, 78 суффиксов и 5 полусуффик-сов английского языка [14]. Советский автор [122] описал 37 префик-сов (93 модели) и 82 суффикса (164 модели) английского языка.
Ясно, что не-лингвисту трудно запомнить эти двести-триста аффик-сов.
Одним из путей решения проблемы является отбор самых необходи-мых аффиксов.
Когда в 1941 год известный методист и лексикограф [24] в каче-стве критерия отбора предложил использовать так называемую «(мо-дельную) частотность» суффиксов, то есть количество разных слов с каждым из 90 суффиксов в имевшейся у него картотеке, содержавшей 4,5 млн словоупотреблений. Ранжировав суффиксы по убыванию вели-чин их частотности, автор [24] разбил их на три группы: 1) восемь вы-сокочастотных [-(a, i) ble, -ian, -er, -ful, -less, -ness, -ion, -ity], которые сле-дует изучать в первую очередь; 2) шестнадцать среднечастотных [-age,
-al, -an, -ance, -ant, -ary, -ate, -ence. -ic, -ical, -ish, -ive, -ment, -or, -ous, -y], которые изучаются во вторую очередь; 3) остальные 66 суффиксов из-учаются в последнюю очередь [24].

131Аффиксальные минимумы
Отметим, что, во-первых, он [24] не подсчитывал частотность ан-глийских префиксов, во-вторых, частотность суффиксов он подсчиты-вал по общелитературным текстам.
Но, как известно, специальные тексты содержат большое количе-ство терминов, под которыми мы понимаем, в частности, слова (лексе-мы), имеющие хотя бы одно значение, известное только специалистам. Как термины, так и общенаучная лексика в значительной степен являют-ся аффиксальными производными. Поэтому, чем больше аффиксов зна-ют аспиранты, тем больше слов они будут понимать, не заглядывая в сло-варь, тем легче и быстрее будут читать литературу по специальности.
Ранее мы составили несколько частотных аффиксальных миниму-мов [3; 60; 61; 63; 74].
В данной работе мы поставили перед собой две задачи. Первая за-ключалась в том, чтобы получить частотный аффиксальный минимум, который поможет аспирантам читать литературу по физике на англий-ском языке. В качестве источника материала был взят «Частотный ан-гло-русский физический словарь-минимум» [150], содержащий около 4666. слов из выборки объемом в 600 тыс. СУ.
Методика работы заключалась в следующем. Сначала подсчитыва-лось количество слов с каждым аффиксом — этот показатель называет-ся «модельной частотностью» (Чм) аффикса. Затем подсчитывали сум-му всех частотностей слов с каждым аффиксом — «суммарную частот-ность» (Чс) аффикса. В пределах каждой группы аффиксов — префик-сов, суффиксов существительных, прилагательных, глаголов и наре-чий все величины Чм складывали и результат делили на количество аф-фиксов в группе. Полученная величина является арифметической сред-ней (X*): Чм (ср); затем ее делили на е=2,7 (основание натуральных логарифмов). Дело в том, что если аффиксы ранжировать по уменьше-нию величины Чм, то они распределяются по логарифмической кривой, на которой одной характерной точкой является арифметическая сред-няя Чм (ср), а второй будет величина Чм (ср), деленная на е=2,7 Чм (ср)*. Теперь разбиваем каждую группу аффиксов на 3 части: 1) все аф-фиксы группы, у которых Чм больше Чм (ср) (то есть самые высокоча-стотные аффиксы) следует изучать в первую очередь; 2) те аффиксы, у которых Чм меньше Чм (ср), но больше Чм (ср)* (это среднечастотные аффиксы) изучаются во вторую очередь; 3) оставшиеся аффиксы име-ют Чм меньше Чм (ср)*, поэтому их изучают в третью очередь. Таким образом можно научно обоснованно разбивать аффиксы на три группы, причем внутри каждой группы они располагаются по убыванию их ча-стотности, поэтому их изучать в том же порядке.

132 Глава 4
Аналогичным образом аффиксы разбиваются на три группы по дру-гому критерию — их суммарной частотности (Чс).
Вторая задача заключалась в том, чтобы строго научно установить, насколько сильно связаны друг с другом используемые характеристики:
Чм — модельная частотность, то есть количество разных слов с дан-ным аффиксом в анализируемом частотном Словаре;
Чс — суммарная частотность — это сумма частотностей всех слов с данным аффиксом в том же Словаре.
Мы подсчитывали величину знакового коэффициента корреляции Фехнера [39, 21] следующим образом. Сначала находили арифметиче-скую среднюю Чм (ср) группы аффиксов (префиксов или суффиксов су-ществительных, прилагательных и т. д.) и сравнивали ее с Чм каждого аффикса. Если Чм была больше Чм (ср), то возле аффикса ставили знак плюс (+), а если меньше — то знак минус (–). Затем аналогичную про-цедуру проделывали со значениями Чс, ставя знак плюс (+), если Чс аф-фикса больше Чс (ср), и знак минус (–), если Чс меньше Чс (ср). В ре-зультате каждый аффикс характеризовался 2-я знаками. Далее подсчи-тывали величину w — количество аффиксов с совпадающими знаками (два плюса, либо два минуса) и v — количество аффиксов с несовпадаю-щими знаками (то есть плюс и минус или минус и плюс). Найденные значения подставляли в формулу: Kф = (w-v) / (w + v). (если Кф=0, свя-зи между Чм и Чс нет; если Кф=1, то связь максимальная, а зависимость между Чм и Чс — прямо пропорциональная).
Кроме коэффициента корреляции между абсолютными значениями величин, используемого в математической статистике (с довольно гро-моздкими расчетами), используются ранговые (Спирмена и Кендела) и знаковый (Фехнера) [39, 21], которые вполне можно подсчитать вруч-ную при работе с длинными рядами коррелирующих пар (у нас это не-сколько десятков или даже 150 пар в сводной таблице аффиксов!).
Сначала представим результаты общего количественного анализа Словаря [150] (Табл. 57).
Ними было установлено, что в анализируемом Словаре насчитыва-ется 2770 аффиксально образованных слов (то есть 59,4 % по Чм), хотя по Чс они дают всего 17,6 % от общего количества словоупотреблений Словаря (т. е. 600 тыс. СУ). По количеству слов (т. е. по величине Чм) 65 префиксов дают 21,2 % дериватов; 47 суффиксов существительных — 38,0 %; 22 суффикса прилагательных — 25,0 %; 4 глагольных суффик-сов — 7,6 %; два суффикса наречий — 6,9 %; а 10 конверсификсов– всего 1,2 % производных слов.

133Аффиксальные минимумы
Таблица 57Количественный анализ деривационного состава Словаря
Word structure Чм Чс Кол-во аффикс Examples
Non-affixal 1896 494520 - Arrow, energy, mass, matter, spin, wave
Prefixes 587 10376 65 Antibond, multipole, re-check, unfold
Noun Suffixes 1054 64709 47 Density, equation, spacing, voltage, error
Adjectival suffixes 693 20630 22 Atomic, physical, active, nuclear, curved
Verbal Suff. 211 6181 4 Calculate, ionize, shorten, verify, widen
Adverbial Suffixes 190 3074 2 Directly, exactly, physically, sideways
Conversifixes 35 501 10 Breakup, built-in, cutoff, feedback
Sum of affixes 2770 105461 150
Sum Total 4666 600000 -
Среднее (X*) (аф.) 18,5 703,1 -
Среднее / 2,71 (X**) 6,8 260,4 -
Среднее / 7,34 (X***) 2,5 96,4
Примечание. Приняты следующие обозначения: Чм — модельная частотность, Чс — суммарная частотность.
Рассмотрим ранжированный по Чм список префиксов (Табл. 58). За-метим, что первые 3 самые частотные префикса (non-, un-, in- (neg.)) находятся в составе 25 % префиксальных слов анализируемого Слова-ря! Если мы подсчитаем долю слов, например, с 12 самыми частотными префиксами, то получим 57 % слов. Следовательно, если аспирантам бу-дет известно значение дюжины самых частотных префиксов (non-, un-, in- (neg.), photo-, re-, two-, inter-, dis-, co-, de-, semi-, sub-), то они поймут больше половины префиксальных слов в физических текстах!
Согласно разработанной ранее методике [63] все префиксы, у кото-рых Чм больше Чм (ср) =9,9; рекомендуется изучать в первую очередь. Это следующие 22 морфемы: non-, un-, in- (neg), photo-, re-, two-, inter-, dis-, co-, di-, semi-, sub-, single-, anti-, three, iso-, micro-, mono-, quasi-, self-, half-, mis-. То есть треть (33,8 %) от числа префиксов находится в соста-ве трех четвертей (73,4 %) количества префиксальных дериватов. За-

134 Глава 4
метим, что из классической монографии [122] в первую группу попало всего 11 префиксов (т. половина), давших только 50 % слов.
Таблица 59Частотность 65 префиксов
Префикс Чм Чс Примеры
Non*- 55 461 -rational, -linear, -uniform, -leptonic, -serial, -zero
Un*- 45 343 -certainty, -stable, -saturated, -physical, axial, -fold
In- (neg.) * 43 861 -dependent, -finite, -elastic, -variance, equality
Photo- 33 893 -electric, -multiplier, -voltaic, -current, -elastic
Re*- 33 448 -place, -combination, -move, -produce, -compute
Two- 22 192 -beam, -channel, -phonon, -pole, -nucleon, -vector
Inter*- 19 351 -face, -atomic, -band, change, -nuclear, -space
Dis*- 17 635 -charge, -location, -placement, -continuity, -play
Co*- 16 286 -ordinate, -incidence, -variant, -linear, -worker
De*- 16 189 -form, -magnetize, -couple, -gas, -bug, -press
Semi- 15 299 -conductor, -carbasone, -leptonic, -classical
Sub*- 15 126 -group, -section, -matrix, -system, -lattice, -divide
Single- 13 81 -address, -baryon, -crystal, -domain, -particle
Anti*- 12 85 -symmetric, -quark, -hermitian, -parallel, -phase
Three- 12 78 -particle, -magnon, -pion, -point, -quark, -vector
Iso- 11 257 -topic, -tropic, -thermal, -vector, -scalar, -meric
Micro- 11 166 -ampere, -second, -phone, -plasma, -volter, -wave
Mono- 11 61 -atomic, -chrome, -layer, -crystal, -valent, -pole
Quasi- 11 48 -elastic, -local, -invariant, -static, -steady, -boson
Self- 11 98 -consistent, -diffusion, -energy, -stress, -correction
Half- 10 62 -maximum, -crystal, -plane, -life, -cycle, -integer
Mis*- 10 43 -lead, -orientation, -interpret, -understanding, -pair
Poly- 9 82 -crystalline, -nomial, -thene, -ethylene, -crystal
Trans*- 9 421 -form, -mission, -port, -pose, -versal
En- (em-) * 8 43 -body, -circle, -close, -coder, compass, -large
Multi- 8 40 -vibrator, -channel, -group, -meson, -domain
Pre*- 8 58 -dominant, -set, -determine, -exponential, -select
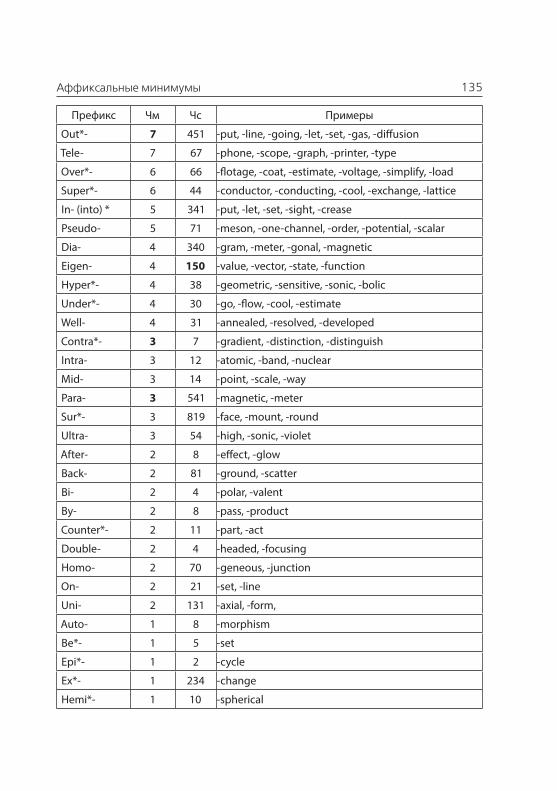
135Аффиксальные минимумы
Префикс Чм Чс Примеры
Out*- 7 451 -put, -line, -going, -let, -set, -gas, -diffusion
Tele- 7 67 -phone, -scope, -graph, -printer, -type
Over*- 6 66 -flotage, -coat, -estimate, -voltage, -simplify, -load
Super*- 6 44 -conductor, -conducting, -cool, -exchange, -lattice
In- (into) * 5 341 -put, -let, -set, -sight, -crease
Pseudo- 5 71 -meson, -one-channel, -order, -potential, -scalar
Dia- 4 340 -gram, -meter, -gonal, -magnetic
Eigen- 4 150 -value, -vector, -state, -function
Hyper*- 4 38 -geometric, -sensitive, -sonic, -bolic
Under*- 4 30 -go, -flow, -cool, -estimate
Well- 4 31 -annealed, -resolved, -developed
Contra*- 3 7 -gradient, -distinction, -distinguish
Intra- 3 12 -atomic, -band, -nuclear
Mid- 3 14 -point, -scale, -way
Para- 3 541 -magnetic, -meter
Sur*- 3 819 -face, -mount, -round
Ultra- 3 54 -high, -sonic, -violet
After- 2 8 -effect, -glow
Back- 2 81 -ground, -scatter
Bi- 2 4 -polar, -valent
By- 2 8 -pass, -product
Counter*- 2 11 -part, -act
Double- 2 4 -headed, -focusing
Homo- 2 70 -geneous, -junction
On- 2 21 -set, -line
Uni- 2 131 -axial, -form,
Auto- 1 8 -morphism
Be*- 1 5 -set
Epi*- 1 2 -cycle
Ex*- 1 234 -change
Hemi*- 1 10 -spherical

136 Глава 4
Префикс Чм Чс Примеры
Hetero- 1 5 -genous
Hypo*- 1 76 -thesis
Meta- 1 30 -stable
Off- 1 8 -line
Per*- 1 26 -mutation
Post*- 1 2 -amplifier
Pro*- 1 10 -long
Сумма (65 шт 587 10375
Ч (ср) 9,9 158,7
Ч (ср) * 3,7 58,5
Примечание. Звездочкой (*) отмечены префиксы, включенные в мо-нографию [122], Ч (ср) — это арифметическая средняя, Ч (ср) * — ариф-метическая средняя, деленная на 2,7.
Во вторую группу попадают префиксальные морфемы, у которых Чм меньше Чм (ср), но больше Чм (ср) * (то есть Чм (ср), деленной на е=2,7 — основание натуральных логарифмов, так как распределе-ние префиксов подчиняется логарифмическому закону). В нашем слу-чае Чм (ср) / е=3,7. Вот эти 16 морфем: trans-, poly-, pre-, en- (em-), multi-, out-, tele-, over-, super-, in-, pseudo-, dia-, eigen-, hyper-, well-, under-). Встречаются они в составе 98 слов (17 %). Заметим, что 9 из них, дав-ших 57 слов (9,8 %), рассматриваются в монографии [122].
Остальные морфемы, у которых Чм меньше Чм (ср) / е, изучаются в третью очередь. Это 27 префиксальных морфем: contra-, intra-, intra-, para-, sur-, ultra-, after-, back-, bi-, by-, counter-, double, homo-, on-, uni-
, auto-, be-, epi-, ex-, hemi-, hetero-, hypo-, meta-, off-, per-, post-, pro-. Они входят в состав 48 слов (8 %). Только 11 префиксов этой группы упоми-нается в монографии [122], а входят он в состав всего 2 % префиксаль-ных слов.
Анализ суффиксов имен существительных, ранжированных по кри-терию Чм, показывает следующее (Табл. 60). Первый суффикс (-ity) на-ходится в составе 12 % существительных, а первые пять суффиксов (-ity,
-ingN, -er, -(a, e) nce), -or) -в составе 45,6 % существительных!В первую очередь следует изучать суффиксы, у которых Чм больше
Чм (ср) =22,4. Это следующие 10 морфем: -ity, -ingN, -er, -(a, e) nce), -or, -ion, -ment, -on, -ure, -(a, e) nt N.

137Аффиксальные минимумы
В сумме они входят в состав 694 слов (66,1 %, то есть две трети!).
Таблица 60Частотность 47-и суффиксов существительных
Суффикс Чм Чс Examples
-(i) ty*, N 126 5069 Dens-, proper-, veloc-, conductive-, quant-, intens-
-ing*, N 103 1638 Scatter-, coupl-, split-, spac-, bind-, read-, heat-
-er*, N 95 2524 Carri-, count-, loayer, comput-, amplifi-, transmitt-
-(a, e) nce*, N 84 3494 Differe-, depende-, resiste-, resona-, dista-, refere-
-or, N 73 3083 Operat-, transist-, direct-, collect-, don-, generat-
-ion* N 70 24821 Equas-, funct-, reg-, sect-, condit-, dictribut-, emiss-
-ment*, N 46 2788 Experi-, mo-, agree-, treat-, arrange, argu-, require-
-on, N (физ.) 36 2138 Phot-, prot-, mes-, nucle-, neutr-, bari-, phon-, lept-
-ure*, N 32 4323 Temperat-, meas-, fig-, struct-, press-, proced-
-(a, e) nt*, N 32 3283 Curre-, consta-, compone-, coefficie-, gradie-
-meter, N 22 832 Para-, dia-, specrto-, thrmo-, potentio-, radio-, volt-
-age*, N 20 1139 Volt-, stor-, cleav-, pass-, percent-, langu-, cover-
-ide*, N 18 377 Ox-, sulpf-, carb-, selen-, arsen-, cglor-, tellur-
-ness*, N 18 270 Thick-, nright-, stiff-, complete-, effective-, sharp-
-(a, e) ncy*, N 14 996 Freque-, efficie-, vacan-, discrepa-, consiste-
-ics*, N 13 166 Dynam-, kinet-, electron-, mechan-, opt-, statist-
-ite, N 11 131 Graph-, satell-, crystal-, spherule-, bakel-, dendr-
-ode, N 10 1578 Cath-, an-, electr-, di-, tetr-, tri-, pent-, dyn-
-ism*, N 10 306 Mechan-, formal-, automorph-, magnet-, parallel-
-al*, N 9 1749 Potenti-, materi-, revers-, remov-, arriv-, dispos-,
-th*, N 9 831 Leng-, wid-, streng-, height, steal-, bread-, weight
-ate*, N 9 119 Substr-, aggreg-, precipit-, carbon-, sulph-, titan-
-tron, N 8 143 Cyclo-, magne-, posi-, thyro-, klys-, synchro-
-(a, o) ry*, N 7 403 Bounda-, laborato-, summa-, corolla-
-gen, N 7 267 Hydro-, oxy-, nitro-, halo-, glycol-
-acy*, N 7 188 Accur-, degener-, constan-, adequ-, interstitial-
-graph, N 6 45 Photo-, oscillo-, para-, micro-, phono-, tele-

138 Глава 4
Суффикс Чм Чс Examples
-ist*, N 6 44 Pacif-, special-, experimental-, psychology-
-ology, N 6 24 Techn-, top-, psych-, morph-, termin-
-ene, N (ch) 6 19 Polypropil-, benz-, polyethyl-, tolu-,
-metry, N 5 467 Dosi- stoichio-, spectro-, gea- sym-
-graphy, N 5 19 Photo-, radio-, biblio-, metallo-, strobo-
-gram, N 4 190 Dia-, histo-, oscillo-, stereo-
-oid*, N 4 77 Solen-, ellips-, sphere-, coll-
-ine*, N 4 11 Alkal- , brom-, tourmal-
-scope, N 3 125 Micro-, tele-, oscillo-
-an*, N 3 24 Technici-, rad-, mathematic-
-phone, N 3 17 Tele-, micro-, head-
-tude*, N 2 1002 Ampli-, magni-
-sphere, N 2 30 Atmo-, iono-
-y*, N 2 18 Entry, recovery
-ware, N 2 12 Hard-, soft-
-man, N 2 6 Rapair-, keyman
-ship*, N 1 121 Relation-
-eer, N 1 38 Engineer
-hood*, N 1 28 Neighbor-
-let*, N 1 3 Platelet
Сумма (47 шт.) 1054 64709
Ч (ср) 22,4 1376,8
Ч (ср) * 8,3 509,9
Во вторую группу входят суффиксы, у которых Чм меньше Чм (ср), но больше Чи (ср) *.
Это следующие 12 морфем: -meter-, -age, -ide, -ness, -(a, e) ncy, -ics, -ite, -ode, -ism, -al, -th, -ate. Они входят в состав всего 15,5 % существи-тельных. 9 суффиксов входят в [122].
Третью группу составляют 25 суффиксов, входящих в состав 194 су-ществительных (18,4 %). Отметим, что только 11 суффиксов этой груп-пы описывается в монографии [122]. Всего же из 47 суффиксов только 28 лописаны в классическом пособии [122].

139Аффиксальные минимумы
В ранжированном по Чс ряду суффиксов существительных наблюда-ется следующая картина. Так, первый суффикс (-ion) находится в соста-ве 31,1 % суффиксальных -существительных. Первые 5 суффиксов (-ion,
-ingN, -ity, -er, -(a, e) nce) дают 59,9 % существительных, а первые 11 суф-фиксов (добавим еще: -er, -ment, -tron, -or, -(a, t) ncy, -th) -это и есть группа самых высоко частотных суффикса существительных -находятся в составе 82,9 % существительных!
Коэффициент корреляции Фехнера между Чм и Чс суффиксов суще-ствительных равен 0,92 (Кф=0,92).
Посмотрим теперь, как распределяются суффиксы прилагательных (Табл. 61). Самый частотный суффикс прилагательных (-ic) находится в составе 23,5 % слов Словаря.
Первая группа суффиксов — это те, у которых Чм больше Чм (ср). Это следующие 7 суффиксов: -ic, -al, -ive, -(a, i) ble, -(a, e) nt, -ed, -ar. Они входят в состав 578 слов. Это 83,4 % производных прилагательных Сло-варя! Их изучают первыми, естественно.
Во вторую группу входит всего 3 суффикса с Чм меньше Чм (ср) и Чм (ср) *: -(a, o) ry, -ous, -ateA, которые входят в состав 60 прилагательных (8,6 % слов).
В третью группу входят остальные 12 суффиксов, давших 55 прила-гательных (7,9 %).
Таблица 61Частотность 22-х суффиксов прилагательных
Суффикс Чм Чс Examples
-ic*, A 163 4620 Magnet-, electr-, characterist-, class-, atom-, electron-
-al*, A 100 7159 Experiment-, tot-, therm-, equ-, physic-, optic-, norm-
-ive*, A 87 2128 Posit-, effect-, negat-, relat-, sensit-, act-, refract-
-(a, e) ble*, A 79 1139 Availa-, negligi-, varia-, visi-, compara-, applica-, relia-
-(a, e) nt*, A 69 1471 Incide-, const-, depende-, consiste-, equivale-, subseque
-ed*, A 41 192 Dash-, dott-, jump-, curv-, travers-, sophisticat-, assum-
-ar*, A 39 1790 Simil-, angul-, particul-, line-, nucle-, pol-, molecule-
-(a, o) ry*, A 23 592 Seconda-, arbitra-, unita-, elementa-, auxilia-, elementa-
-ous*, A 21 452 Analog-, homogene-, anomal-, continu-, gase-, aque-
-ate*, A 16 307 approxi-, accur-, adequ-, separ-, immedi-, altern-, ultim-

140 Глава 4
Суффикс Чм Чс Examples
-ing, A 10 65 Alternat-, neighbor-, tunnel-, steer-
-less*, A 10 10 Mass-, dimension-, stain-, spin-, colour-, radiation-
-ian*, A 7 173 Hamilton-, Hermit-, Maxwell-
-id*, A 6 315 Sol-, val-, flu-, rap-, ac-, rig-
-y*, A 6 21 Leak-, gass-, length-, cloud-, edd-, wav-
-like, A 4 26 Hydrogen-, time-, amorphous-, quark-
-fold*, A 3 26 Two-, three-, many-
-ile*, A 3 19 Tens-, fiss-, mob-
-free, A 3 10 Dislocation-, n-free, field-, quasi-
-rich, A 1 3 Sodium-rich
-proof, A 1 2 Damp-proof
-tight, A 1 2 Vacuum-tight
Сумма 22 шт 693 20620
Среднее 31,5 937,3
Средн./ е 11,7 342,2
Во вторую группу входит всего 3 суффикса с Чм меньше, чем Чм (ср), но больше Чм (ср) *: -(a, o) ry, -ous, -ateA, которые входят в состав 60 прилагательных (8,6 % слов).
В третью группу входят остальные 12 суффиксов, у которых Чм мень-ше Чм (ср) *
Они входят в состав 55 прилагательных (7,9 %).По критерию Чс в первой группе находится 5 суффиксов (-ed, -al, -ing,
-ic, -(a, e) nt), которые дают 85,6 % словоупотреблений. Во второй груп-пе имеется всего 4 суффикса (-(a, i) ble, -(a, e) nt, -ive, -ous), на которые приходится всего лишь 11,2 % словоупотреблений.
Для суффиксов прилагательных коэффициент корреляции Фехнера между Чм и Чс равен 0,91 (Кф=0,91), то есть очень высок.
В Словаре обнаружен 211 глагол, образованный с помощью одного из 4-х суффиксов.
Самым частотным является суффикс -ate, который входит в состав 128 глаголов Словаря,
А это 60 %. Формально в первую группу входит также суффикс -ize, давший 53 глагола (25 %). Менее частотны суффиксы -ify и -en.

141Аффиксальные минимумы
Таблица 62Частотность 4 суффиксов глаголов
Суффикс Чм Чс Examples
-ate*, V 128 4509 Calcul-, indic-, associ-, rel-, oper-, investing-, evalu-
-ize*, V 53 993 Ion-, analy-, normal-, character-, summar-, polar-, util-
-(i) fy*, V 18 622 Satis-, mod-, spec-, simpl-, ident-, ver-, electr-, ampl-
-en*, V 12 57 Broad-, hard-, sh0rt-, dark-, deep-, fast-, black-, damp-
Сумма 211 6181
Среднее 52,7 1545,2
Средн./ е 19,5 570,2
Коэффициент корреляции Фехнера между Чм и Чс суффиксов глаго-лов равен единице (Кф=1,0 (Табл. 62).
Всего было обнаружено 2 суффикса наречий. Самым высокочастот-ным является -ly, который входит в состав 189 наречий Словаря, и суф-фикс -ways, который встретился только в одном слове (Табл. 63).
Таблица 63Частотность 2-х суффиксов наречий
Суффикс Чм Чс Examples
-ly*, Adv 189 3072 Approximate-, direct-, complete-, relative-, experimental-
-ways*, |Adv 1 2 Sideways
Сумма 190 3074
Среднее 95 1537
Известно, что в литературной норме используются и другие нареч-ные суффиксы: -wise, -ward (s).
Конверсификсы — морфемы, восходящие к послелогам в составе глагольно-наречных сочетаний [45; 46]. Они обладают теми же свой-ствами, что и типичные суффиксы, поэтому они и рассматриваются в данной работе (Табл. 64).

142 Глава 4
Таблица 64Частотность 10-ти конверсификсов
Конверсификс Чм Чс Examples
-off, cv 7 130 Cut-, pinch-, shut-, switch-, round-, cut- (a)
-up, cv 6 78 Build-, set-, pick-, pile-, clean-
-out, cv 6 27 Bake-, lay-, print-, check-, fall-
-in, cv 5 18 Lock-, lead-, fall-, plug-, built- (a)
-over, cv 4 23 Spark-, cross-, change-, flash-
-back, cv 2 28 Feed-, play-
-through, cv 2 5 Punch-, leak-
-down, cv 1 185 Break-
-away, cv 1 4 Run-
-on, cv 1 3 Turn-
Сумма 35 501
Среднее 3,5 50,1
Среднее / е 1,3 18,6
Самыми высокочастотными являются первые пять конверсификсов: -off, -up, -out, -in, -over. Они входят в состав 80 % конверсификсов. Вторая группа включает в себя два конверсификса: -back, -through. Во третью группу входят три конверсификса: -down, -away, -on (Табл. 64).
Заметим, что традиционно аффиксы изучают по лексико-граммати-ческим разрядам: префиксы, суффиксы существительных, прилагатель-ных, глаголов, наречий, конверсификсов и даже числительных (-teen,
-ty).На практике все аффиксы встречаются в зависимости от их частот-
ности употребления в текстах. Поэтому мы решили составить сводный список аффиксов и ранжировать их по убыванию Чм (Табл. 65). Прав-да, можно ранжировать аффиксы и по критерию Чс. Формально говоря, читая текст, мы можем фиксировать свое внимание на повторяющихся аффиксах. В этом случае удобнее отбирать аффиксы для ознакомления из Списка, ранжированного по суммарной частотности — Чс.

143Аффиксальные минимумы
Таблица 65Частотность 150 аффиксов
Суффикс Чм Чс Examples
-ly*, Adv 189 3072 Approximate-, complete-, relative-, relative-
-ic*, A 163 4620 Magnet-, electr-, characterist-, atom-, electron-
-ate*, V 128 4509 Calcul-, indic-, associ-, oper-, investing-, evalu-
-(i) ty*, N 126 5069 Dens-, proper-, veloc-, conductive-, quant-, intens-
-ing*, N 103 1638 Scatter-, coupl-, split-, spac-, bind-, read-, heat-
-al*, A 100 7159 Experiment-, therm-, equ-, physic-, optic-, norm-
-er*, N 95 2524 Carri-, count-, loayer, comput-, amplifi-, transmitt-
-ive*, A 87 2128 Posit-, effect-, negat-, relat-, sensit-, act-, refract-
-(a, e) nce*, N 84 3494 Differe-, depende-, resiste-, resona-, dista-, refere-
-(a, e) ble*, A 79 1139 Availa-, negligi-, varia-, visi-, compara-, applica-
-or, N 73 3083 Operat-, transist-, direct-, collect-, tens-, generat-
-ion*, N 70 24821 Equas-, funct-, reg-, sect-, condit-, dictribut-
-(a, e) nt*, A 69 1471 Incide-, depende-, consiste-, equivale-, subseque
Non*- 55 461 -rational,- linear,- uniform,- leptonic,- serial,- zero
-ize*, V 53 993 Ion-, analy-, normal-, character-, summar-, polar-
-ment*, N 46 2788 Experi-, mo-, agree-, treat-, arrange, argu-, require-
Un*- 45 343 -certainty,- stable,- saturated,- physical,- axial
In (neg) * 43 861 -dependent,- finite,- elastic,- variance,- equality
-ed*, A 41 192 Dash-, jump-, curv-, travers-, sophisticat-, assum-
-ar*, A 39 1790 Simil-, angul-, particul-, line-, nucle-, molecule-
-on, N (физ.) 36 2138 Phot-, mes-, nucle-, neuutr-, bari-, phon-, lept-
Photo- 33 893 -electric,- multiplier,- voltaic,- current,- elastic
Re*- 33 448 -place,- combination,- move,- produce,- compute
-ure*, N 32 4323 Temperat-, meas-, fig-, struct-, press-, proced-
-(a, e) nt*, N 32 3283 Curre-, consta-, compone-, coefficie-, gradie-
-(a, o) ry*, A 23 592 Seconda-, arbitra-, elementa-, auxilia-, elementa-
-meter, N 22 832 Para-, dia-, specrto-, thrmo-, potentio-, radio-, volt-
Two- 22 192 -beam,- channel,- phonon,- pole,- nucleon,- verctor
-ous*, A 21 452 Analog-, homogene-, anomal-, continu-, gase-

144 Глава 4
Суффикс Чм Чс Examples
-age*, N 20 1139 Volt-, stor-, cleav-, pass-, percent-, langu-, cover-
Inter*- 19 351 -face,- act,- atomic,- change,- nuclear,- space
-(i) fy*, V 18 622 Satis-, mod-, spec-, simpl-, ident-, electr-, ampl-
-ide*, N 18 377 Ox-, hal-, sulpf-, carb-, selen-, arsen-, cglor-, tellur-
-ness*, N 18 270 Thick-, nright-, stiff-, complete-, effective-, sharp-
Dis*- 17 635 -charge,- location,- placement,- continuity,- play
-ate*, A 16 307 approxi- accur-, adequ-, separ-, immedi-, altern-
Co*- 16 286 -ordinate,- incidence,- variant,- linear,- worker
De*- 16 189 -form,- magnetize,- couple,- gas,- bug,- press
Semi- 15 299 -conductor,- carbasone,- leptonic,- classical
Sub*- 15 126 -group,- section,- matrix,- system,- lattice,- divide
-(a, e) ncy, N 14 996 Freque-, efficie-, vacan-, discrepa-, consiste-
-ics*, N 13 166 Dynam-, kinet-, electron-, mechan-, opt-, statist-
Single- 13 81 -address,- baryon,- crystal,- domain,- particle
Three- 12 78 -particle, magnon,- pion,- point,- quark,- vector
Anti*- 12 65 -symmetric,- quark,- hermitian,- parallel,- phase
-en*, V 12 57 Broad-, hard-, sh0rt-, dark-, deep-, black-, damp-
Iso- 11 257 -topic,- thermal,- tropic,- vector,- scalar,- metric
Micro- 11 166 -ampere,- second,- phone,- plasma,- volter,- wave
-ite, N 11 131 Graph-, satell-, crystal-, spherule-, dendr-, ferr-
Self- 11 98 -consistent,- diffusion,- energy,- stress,- correction
Mono- 11 61 -atomic,- chrome,- layer,- crystal,- valent,- pole
Quasi- 11 48 -elastic,- free,- local,- invariant,- steady,- boson
-ode, N 10 1578 Cath-, an-, electr-, di-, tetr-, tri-, pent-, dyn-
-ism,* N 10 306 Mechan-, formal-, automorph-, magnet-, parallel-
-ing, A 10 65 Alternat-, neighbor-, tunnel-, steer-
Half- 10 62 -maximum,- crystal,- plane,- life,- cycle,- integer
Mis*- 10 43 -lead,- orientation,- interpret,- understanding,- pair
-less*, A 10 10 Mass-, dimension-, stain-, spin-, colour-, radiation-
-al*, N 9 1749 Potenti-, materi-, revers-, remov-, arriv-, dispos-,
-th*, N 9 831 Leng-, wid-, streng-, height, steal-, bread-, weight

145Аффиксальные минимумы
Суффикс Чм Чс Examples
Trans*- 9 421 -form,- mission,- port,- pose,- versal
-ate*, N 9 119 Substr-, aggreg-, precipit-, carbon-, sulph-, titan-
Poly- 9 82 -crystalline,- nomial,- thene,- ethylene,- crystal
-tron, N 8 143 Cyclo-, magne-, posi-, thyro-, klys-, synchro-, ioni-
Pre*- 8 58 -dominant,- set,- determine,- exponential,- select
En- (em-) *, V 8 43 -body,- circle,- close,- coder.- compass,- large
Multi- 8 40 -vibrator,- channel,- group,- meson,- domain
Out*- 7 451 -put,- line,- going,- let,- set,- gas,- diffusion
-(a, o) ry*, N 7 403 Bounda-, laborato-, summa-, corolla-
-gen, N 7 267 Hydro-, oxy-, nitro-, halo-, glycol-
-acy*, N 7 188 Accur-, degener-, constan-, adequ-, interstitial-
-ian*, A 7 173 Hamilton-, Hermit-, Maxwell-
-off, cv 7 130 Cut-, pinch-, shut-, switch-, round-, cut- (a)
Tele- 7 67 -phone,- scop-e,- graph,- printer,- type
-id*, A 6 315 Sol-, val-, flu-, rap-, ac-, rig-
-up, cv 6 78 Build-, set-, pick-, pile-, clean-
Over*- 6 66 -flotage,- coat,- estimate,- voltage,- simplify,- load
-graph, N 6 45 Photo-, oscillo-, para-, micro-, phono-, tele-
Super*- 6 44 -conductor,- cool,- exchange,- lattice,- cell
-ist*, N 6 44 Pacif-, special-, experimental-, psychology-, scient-
-out, cv 6 27 Bake-, lay-, print-, check-, fall-
-ology, N 6 24 Techn-, top-, psych-, morph-, termin-
-y,* A 6 21 Leak-, gass-, length-, cloud-, edd-, wav-
-metry, N 5 467 Dosi- stoichio-, spectro-, gea- sym-
In (into) * 5 341 -put,- let,- set,- sight,- crease
Pseudo- 5 71 -meson,- one=channel,- order,- potential,- scalar
-graphy, N 5 19 Photo-, radio-, biblio-, metallo-, trobe-
-in, cv 5 18 Lock-, lead-, fall-, plug-, built- (a)
Dia- 4 340 -gram,- meter,- gonal,- magnetic
-gram, N 4 190 Dia-, histo-, oscillo-, stereo-
Eigen- 4 150 -value,- vector,- state,- function

146 Глава 4
Суффикс Чм Чс Examples
-oid*, N 4 77 Solen-, ellips-, sphere-, coll-
Hyper*- 4 38 -geometric,- sensitive,- sonic
Well- 4 31 -annealed,- resolved,- developed
Under*- 4 30 -go,- flow,- cool,- estimate
-like, A 4 26 Hydrogen-, time-, amorphous-, quark-
-over, cv 4 23 Spark-, cross-, change-, flash-
-ine*, N 4 11 Alkal- , brom-, tourmal-
Sur*- 3 819 -face,- mount,- round
Para- 3 541 -magnetic,- meter
-scope, N 3 125 Micro-, tele-, oscillo-
Ultra- 3 54 -high,- sonic,- violet
-fold*, A 3 26 Two-, three-, many-
-an*, N 3 24 Technici-, rad-, mathematic-
-ile*, A 3 19 Tens-, fiss-, mob-
-phone, N 3 17 Tele-, micro-, head-
Mid- 3 14 -point,- scale,- way
Intra- 3 12 -atomic,- band,- nuclear
-free, A 3 10 Dislocation-, n-free, field-, quasi-
Contra*- 3 7 -gradient,- distinction,- distinguish
-tude*, N 2 1002 Ampli-, magni-
Uni- 2 131 -axial,- form
Back- 2 81 -ground,- scatter
Homo- 2 70 -genous,- junction
-sphere, N 2 30 Atmo-, iono-
-back, cv 2 28 Feed-, play-
On- 2 21 -set,- line
-y*, N 2 18 Entry, recovery
-ware, N 2 12 Hard-, soft-
Counter*- 2 11 -part,- act
After- 2 8 -effect,- glow
By- 2 8 -pass,- product
-man, N 2 6 Rapair-, keyman
-through, cv 2 5 Punch-, leak-

147Аффиксальные минимумы
Суффикс Чм Чс Examples
Bi- 2 4 -polar,- valent
Double- 2 4 -heade,- focusing
Ex*- 1 234 -change
-down, cv 1 185 Break-
-ship*, N 1 121 Relation-
Hypo*- 1 76 -thesis
-eer, N 1 38 Engineer
Meta- 1 30 -stable
-hood*, N 1 28 Neighbor-
Per*- 1 26 -mutation
Hemi*- 1 10 -spherical
Pro*- 1 10 -long
Auto- 1 8 -morphism
Off- 1 8 -line
Be*- 1 5 -polar,- valent
Hetero- 1 5 -genous
-away, cv 1 4 Run-
-let*, N 1 3 Platelet
-rich, A 1 3 Sodium-rich
-on, cv 1 3 Turn-
Epi*- 1 2 -cycle
Post*- 1 2 -amplifier
-proof, A 1 2 Damp-proof
-tight, A 1 2 Vacuum-tight
-ways*, Adv 1 2 SidewaysСумма (150 единиц) 2770 105461
Ч (ср) 18,5 703,1
Ч (ср) * 6,8 260,4
Средн./ 7,34 2,5 96,4
Примечание. Звездочка (*) при аффиксе означает, что описывается в классическом пособии по словообразовании (Меш). Ч (ср) — ариф-метическое среднее, Ч (ср) * — арифметическое среднее, деленное

148 Глава 4
на е=2,71 (основание натуральных логарифмов), Ч (ср) ** — арифме-тическое среднее, деленное на 7,34 (квадрат основания натуральных ло-гарифмов.
Этот ранжированный по Чм список аффиксов (Табл. 65) позволяет получить частотный аффиксальный минимум физической терминоси-стемы, состоящий из 4-х частей.
СПИСОК № 1 представляет 31 самый высокочастотный аффикс [Чм > X*]: -ly, Adv; ic, A; -ate, V; -ity, N; -ing, N; -al, A; -er, N; -ive, A; -(a, e) nce, N; -(a, i) ble, A; -or, N; -ion, N; -(a, e) nt, A; Non-; -ize, V; -ment, N; Un-; In- (neg.); -ed, A; -ar, A; -on, N; Photo-; Re-; -ure, N; -(a, e) nt, N; -(a, o) ry, A; -meter, N; Two-; -ous, A; -age, N; Inter-.
СПИСОК № 2 представляет 43 среднечастотных аффикса [X* > Чм > X**]: -ify, V; -ide, N; -ness, N; Dis-; -ate, A; Co-; De-; Semi-, Sub-; -(a, e) ncy, N; -ics, N; Single-; Three-; Anti-; -en, V; Iso-; Micro-; -ite, N; Self-; Mono-; Quasi-; -ode, N; -ism, N; -ing, A; Half-; Mis-, -less, A; -al, N; -th, N; Trans-;
-ate, N; Poly-; -tron, N; Pre-; En- (em-); Multi-; Out-; -(a, o) ry, N; -gen, N; -acy, N; -ian, A; -off, cv; Tele-.
СПИСОК № 3: представляет 37 низкочастотных аффиксов [X* > Чм > X**]: -id, A; -up, cv; Over-; -graph, N; Super-; -ist, N; -out, cv; -ology, N; -y, A; -ate, N; -ene, N; -metry, N; In- (into); Pseudo-; -graphy, N; -in, cv; Dia-; -gramm, N; Eigen-; -oid, N; Hyper-; Well-; Under-; -like, A; -over, cv; -ine, N; Sur-; Para-; -scope, N; Ultra-, -fold-, A; -an, N; -ile, A; -phone, N; Mid-; Intra-;
-free, A; Contra-.СПИСОК № 4 представляет все остальные 39 аффиксов [X** > Чм]:
-tude, N; Uni-; Back-; Homo-; -sphere-, N; -back, cv; On-; -y, N; -ware-, N; Counter-; After-; By-; -man, N; -through, cv; Bi-; Double-; Ex-; -down, cv;
-ship, N; Hypo-; -eer, N; Meta-, hood, N; Per-; Hemi-; Pro-; Auto-; Off-; Be-; Hetero-; -away, cv; -let, N; -rich, A; -on, cv; Epi-; Post-; -proof, A; -tight, A;
-ways, Adv.Это наглядно демонстрирует пользу получения количественных ран-
жированных списков для отбора самых продуктивных аффиксов для по-следующего их изучения.
Коэффициент корреляции Фехнера между Чм и Чс всех 150 аффик-сов равен 0,813 (Кф=0,813), то есть существует сильная связь между такими количественными характеристиками, как модельная частот-ность и суммарная частотность аффиксов в физических текстах. Поэто-му списки частотных аффиксов, отобранных по Чм, будут не сильно от-личаться от списков, отобранных по Чс (из-за сильной корреляции ме-жду Чм и Чс).

149Аффиксальные минимумы
В общем, аффиксальные минимумы предназнаены для двух целей: 1) Способствовать расширению «активного» словарного запаса. Это — частотные аффиксальные мининмумы; 2) Способствовать расширению «пассивного» словарного запаса. Это — продуктивные аффиксальные минимумы.
Частотные аффиксальные минимумы получают в результате анали-за частотных словарей, причем параллельно можно составлять мини-мум, беря за основу «модельную частотность» (Чм), когда подсчитыва-ют количество «разных» слов с каждым аффиксом; либо за основу бе-рется подсчет «суммарной частотности» (Чс), то есть складываются ча-стотности каждого слова с определенным аффиксом. Величины Чм и Чс являются близкими по величине, «родственными», но не одинаковыми. Они коррелируют примерно на 50 %.
Частотные аффиксальные минимумы составляются как для литера-турной нормы [74], так и для различных терминосистем [60; 63], при-чем очевидно, что чем крупнее словарь (то есть чем больше объем текста, который использовался для составления частотного словаря), тем точнее полученные цифры отражают «речь» английского языка.

Глава 5
КОЛИЧЕСТВЕННАЯ ФРАЗЕОЛОГИЯ
§ 1. Семантическая классификация
Отметим, что фразеологизмы (фразеологические единицы, фразео-логические обороты и т. д.) представляют собой устойчивые словосо-четания (УСС), которые образовываются из свободных словосочета-ний, передающих важные для носителей языка понятия и потому ста-новятся высокочастотными и устойчивыми, приобретая при этом пере-носное (образное) значение, которое является результатом семантиче-ской трансформации (метафора, метонимия и т. п.) их прямого значе-ния (т. е. суммы значений слов, из которых оно состоит) [100].
Из синтаксиса известно, что свободные сочетания слов могут быть непредикативными (в русистике их называют просто «словосочета-ниями») и предикативными (то есть «предложениями»). Становясь устойчивыми, они сохраняют характер синтаксических связей, пре-вращаясь в непредикативные УСС (фраземы) и предикативные УСС (паремиемы).
Мы сформулировали следующие лингвистически корректные дефи-ниции этих единиц [52; 62; 65].
Фразема (поговорка, saying) — это непредикативное УСС, имеющее как прямое (сумма значений слов), так и переносное (образное) значе-ние, являющееся результатом семантического преобразования прямого (метафоризации, метонимизации и т. п.) [52; 62].
В «Большом словаре русских поговорок» [125] содержится 40 тыс. непредикативных устойчивых словосочетаний (фразем), которые авто-ры называют «поговорками. Следовательно, «фразема» означает то же, что и «поговорка»!.

151Количественная фразеология
Паремиема (пословица) — это предикативное УСС, имеющее как прямое (сумма значений слов), так и переносное (образное) значе-ние, являющееся результатом семантического преобразования прямого (метафоризации, метонимизации и т.п [52; 62].
В словаре В. И. Даля «Пословицы русского народа» [97] содержит-ся 30 тыс. устойчивых предикативных словосочетаний (т. е. предложе-ний). То есть, «паремиема» равна «пословице». А в «Большом слова-ре русских пословиц» [126] содержится около 70 тыс. предикативных устойчивых словосочетаний (паремием), которые авторы называют «пословицами». Следовательно, «паремиема» означает то же, что и «по-словица»!
Таким образом, соотнося научные термины (фраземы и паремиемы) с народными (поговорки и пословицы), мы опираемся на мнения круп-ных специалистов-практиков, которые сами собрали десятки тысяч УСС и, так сказать, «собаку съели» на этом деле. И мы категорически против так называемого «широкого» понимания «фразеологизмов», «фразео-логических единиц» и «фразеологических оборотов», «пословиц» и «по-говорок» так называемыми «теоретиками», которые подкрепляют свои лингвистически некорректные построения парой дюжин разношерст-ных примеров, среди которых без разбора, вперемешку идут как непре-дикативные, так и предикативные устойчивые словосочетания, что ука-зывает на их «нетвердость в синтаксической вере», говоря фразеологи-чески.
В свое время Ш. Балли [2; 37] впервые выделил три семантических класса фразеологизмов во французском языке, которые через 42 года В. В. Виноградов [89] использовал в русистике («забыв» сослаться на первоисточник [2; 37]!?), переведя их с французсеого как «фразео-логические сращения», «фразеологические единства» и «фразеологиче-ские сочетания».
К сожалению, ни Ш. Балли [2, 37], ни В. В. Виноградов [89] не дали строгих научных определений этих классов. Поэтому, хотя за пери-од с 1918 по 1986 гг. в СССР и было опубликовано более 15 тыс. ра-бот по фразеологии [117, 11)], ни одна из них не содержит результа-тов использования этой «классификации» для практического разбие-ния на 3 семантических класса какого-либо достаточно полного собра-ния «фразеологизмов» объемом, скажем, в пять, десять, двадцать, сорок или семдесят тысяч устойчивых словосочетаний.
В результате нам пришлось сформулировать собственные строго научные дефиниции семантических классов фразем, сохранив их по-пулярные названия: сращения, единства и сочетания [52].

152 Глава 5
«Фраземное сращение — это фразема, имеющая два значения: 1-е (прямое), которое неизвестно говорящим из-за незнания значений не-которых слов (антропонимов, топонимов, религионимов, архаизмов, заимствований); 2-е (переносное, образное), которое известно и высо-кочастотно».
Например: «Филькина грамота» 1) (прямое) Это значение неизвест-но, так как имя собственное «Филька» ничего нам не говорит (без спе-циальных разысканий); 2) (перенос., метонимич.) Пустая, ничего не значащая бумажка; не обладающий реальной ценностью документ.
«Фраземное единство — это фразема, имеющая два значения: 1-е (прямое) известное, но редко употребляемое; 2-е (переносное, образ-ное) — известно и высокочастотно».
Например: «Заварить кашу» 1) (прямое) Сварить кашу; 2) (перен., образное) Затевать какое-либо сложное, хлопотливое или дело непри-ятное дело.
«Фраземное сочетание — это фразема, имеющая пока только одно значение, которое известно и высокочастотно». Это утверждения обще-го, абстрактного или конкретного характера.
Например: «Без лишних слов» 1) не говоря много, не теряя времени на лишние разговоры.
Заметим, что заморское словечко «идиома» используется как за ру-бежом, так и в России (особенно некоторыми «продвинутыми» лингви-стами), но дефиниции его довольно туманны, например: “Idiom, n. 1. an expression whose meaning is not predictable from the usual meanings of its constituent elements, as kick the bucket or hang one’s head” [17, 951], то есть «Идиома — это выражение, значение которого нельзя предска-зать, зная обычные значения составляющих его элементов». Здесь не-ясно, что обозначает “expressioin”. Видимо, это словосочетание, но ка-кое, «предикативное» (то есть «предложение») или «непредикативное» (то есть «непредложение»), что является принципиально различным с синтаксической точки зрения.
Однако есть лингвисты, которые считают, что любая единица языка, имеющая «образное» значение, является «идиомой». В результате, на-пример, в “A Book of English Idioms› [7], строго говоря, содержится 893 фраземы (the lion’s share; to spoil the Egyptians, to turn over a new leaf; a wet blanket), 99 паремием (There is no smoke without fire; You can whistle for it) и 23 лексемы (bumbledom; dotty; gaga; to stomach; to wolf). То есть «идиома» «триедина»!
Мы полагаем, что слово «идиома», которое может обозначать и лек-сему, и фразему (поговорку), и паремиему (пословицу), давно уже сле-

153Количественная фразеология
дует исключить из лингвистического обращения, как бессмысленное (или «трехсмысленное») и захламляющее научный лексикон, посколь-ку оно вводит в заблуждение лингвистов и поэтому не может являться термином.
Материалом для данного количественного исследования семантиче-ских и структурных характеристик УСС послужили широко использую-щиеся в учебном процессе списки идиом и пословиц английского языка, а именно: «101 most popular American English idioms› (1987) и «101 most popular American English proverbs› (1987) [28].
Мы решили провести анализ этих двух списков УСС в соответствии с лингвистически строгими дефинициями как самих единиц (посло-виц=паремием и поговорок=фразем), так их семантических и струк-турных классов по методике, разработанной и используемой нами [52; 63].
Таблица 66Доля фразем (поговорок), паремием (пословиц) и лексем (слов)
среди «101 popular Idioms› и «101 popular Proverbs»
УСС Phraseme Paremieme Lexeme Всего
Кол. Примеры Кол. Примеры Кол. Приме-ры
101 MostPopularAmericanEnglishIdioms
86 All thumbs; a duck soup; to make a splash; on ice; to smell a rat; a snow job; in the hole
12 All’s well that ends well; Go fly a kite! Money talks. Cat got your tongue? Early bird catches the worm
3 Tongue-in-cheek; Fishy, Lemon
101
101 MostPopularAmericanEnglishProverbs
6 Better late than never; to spoil the broth; no pain, no gain; better safe than sorry
95 All that glitters is not gold; Look before you leap; Don’t cry over spilt milk; Birds of feather flock to
- - 101
Сумма 92 107 3 202
Ознакомление с примерами (Табл. 66) показывает, что 101 так назы-ваемая «идиома» (Idioms) представляет собой «солянку» из 86 phrasemes, 12 paremiemes и 3 lexemes; с другой стороны, собрание из 101 послови-цы (Proverbs) на самом деле состоит из 95 paremiemes и 6 phrasemes.
Поэтому мы объединили однородные единицы и получили 2 спис-ка, причем один содержит 92 фраземы (поговорки) и второй — 107 па-ремиемы (пословицы). Ниже представлены результаты количественно-

154 Глава 5
го семантико-структурного анализа фразем (Табл. 66 и 67) и паремием (Табл. 66–68).
Семантическая классификацмя фразем (поговорок)Результаты разбиения фразем на семантические классы показыва-
ют (Табл. 67), что фраземные сращения отсутствуют в проанализиро-ванном списке. Фраземные единства составляют 97,8 % всех фразем, на-пример: better a live coward than a dead hero; too many chiefs, not enough Indians; dressed to the teeth; different strokes for different folks; a snow job; a wet blanket; dressed to kill; a horse of a different color; for a song; on one’s last legs; no pain, no gain; to horse around; to stick to one’s guns; straight from the horse’s mouth; to spoil the broth; to mind one’s P’s and Q’s, to talk through one’s hat, etc.
Таблица 67Семантическая классификация фразем
Семантический класс фразем
Коли-чество
% Примеры
Сращения - - -
Единства 90 97,8 To let the cat out of the bag; a duck soup; to kick the bucket
Сочетания 2 2,2 Better late than never; better safe than sorry
Сумма 92 100,0
На фраземные сочетания приходится всего 2,2 % фразем, а именно: Better late than never. Better safe than sorry.
§ 2. Структурная классификацмя фразем (поговорок)
Структурный анализ позволил выявить 20 моделей фразем (Табл. 68). Отметим, что по модели VN образовано половина всех проанализиро-ванных фразем! Три самые продуктивные модели дали 73 % фразем, а на остальные 13 моделей приходится 27 %, то есть, одна четверть фра-зем!
В семантическом классе фраземных сочетаний обнаружена одна мо-дель: AdvAconjAdv. Она представлена всего двумя фраземами: better late than never; better safe than sorry.
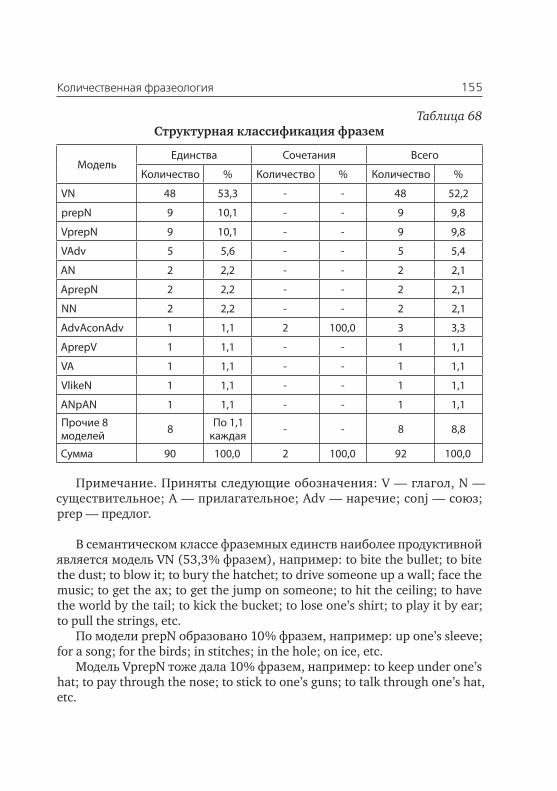
155Количественная фразеология
Таблица 68Структурная классификация фразем
МодельЕдинства Сочетания Всего
Количество % Количество % Количество %
VN 48 53,3 - - 48 52,2
prepN 9 10,1 - - 9 9,8
VprepN 9 10,1 - - 9 9,8
VAdv 5 5,6 - - 5 5,4
AN 2 2,2 - - 2 2,1
AprepN 2 2,2 - - 2 2,1
NN 2 2,2 - - 2 2,1
AdvAconAdv 1 1,1 2 100,0 3 3,3
AprepV 1 1,1 - - 1 1,1
VA 1 1,1 - - 1 1,1
VlikeN 1 1,1 - - 1 1,1
ANpAN 1 1,1 - - 1 1,1
Прочие 8 моделей 8 По 1,1
каждая - - 8 8,8
Сумма 90 100,0 2 100,0 92 100,0
Примечание. Приняты следующие обозначения: V — глагол, N — существительное; A — прилагательное; Adv — наречие; conj — союз; prep — предлог.
В семантическом классе фраземных единств наиболее продуктивной является модель VN (53,3 % фразем), например: to bite the bullet; to bite the dust; to blow it; to bury the hatchet; to drive someone up a wall; face the music; to get the ax; to get the jump on someone; to hit the ceiling; to have the world by the tail; to kick the bucket; to lose one’s shirt; to play it by ear; to pull the strings, etc.
По модели prepN образовано 10 % фразем, например: up one’s sleeve; for a song; for the birds; in stitches; in the hole; on ice, etc.
Модель VprepN тоже дала 10 % фразем, например: to keep under one’s hat; to pay through the nose; to stick to one’s guns; to talk through one’s hat, etc.

156 Глава 5
По модели VAdv образовано 5,5 % фразем: to horse around; to cough up; to hang on; to fork over, etc.
Три модели дали по 2,1 % фразем каждая: AN (wet blanket); AprepN (dressed to the teeth; hot under the collar); NN (duck soup; snow job).
По остальным моделям образовано по одной фраземе, например: NprepN (a horse of a different color); VlikeN (feel like a million dollars), etc.
Отметим, что наиболее популярными являются наиболее простые модели: VN; prepN; VprepN.

Глава 6
КОЛИЧЕСТВЕННАЯ ПАРЕМИОЛОГИЯ
§ 1. Семантическая классификация паремием (пословиц)
Известны «классические» определения пословиц [36; 101].Но мы сформулировали собственные строгие дефиниции семанти-
ческих классов фразем (то есть непредивативных устойчивых слововсо-четаний) [52; 63]. Однако о семантической классификации «паремием, пословиц» (то есть предикативных устойчивых словосочетаний) никто и нигде дажн не упоминает!
Поэтому, учитывая, что паремиемы (как и фраземы) являются устой-чивыми словосочетаниями, мы сформулировали следующие научно строгие дефиниции их семантических классов [52; 63].
«Паремиологическое сращение — это пословица, имеющая два зна-чения: прямое, которое неизвестно говорящим из-за незнания значе-ний некоторых слов (имен собственных, мифонимов, заимствований или архаизмов), и переносное — известное и высокочастотное».
When in Rome do as Romans do — 1 (прямое) Будучи в Риме, посту-пайтете так, как это делают римляне; 2 (перен.) Со своим уставом в чу-жой монастырь не ходи.
The devil is not so black as he is painted — 1. (прямое) Не так страшен черт, как его малюют; 2 (перен.) Ситуация не так страшна, как кажется.
«Паремиологическое единство — это пословица, имеющая два зна-чения: прямое — известное, но низкочастотное, и переносное — извест-ное и высокочастотное».
Например: Strike the iron while it is hot — 1 (прямое) Куй железо по горячо; 2 (перен.) Делай дело, пока ситуация благоприятна.

158 Глава 6
«Паремиологическое сочетание — это пословица, имеющая пока только одно значение — прямое, которое известно и высокочастотно».
Например: First impressions are most lasting — Первое впечатление — самое сильное. Practice makes perfect — Совершенство достигается прак-тикой.
Материалом для данного количественного исследования семантиче-ских и структурных характеристик УСС послужили широко использую-щиеся в учебном процессе списки идиом и пословиц английского языка, а именно: «101 most popular American English idioms› (1987) и «101 most popular American English proverbs› (1987) [28].
Мы решили провести анализ списков УСС в соответствии с лингви-стически строгими дефинициями как самих единиц (пословиц=паре-мием и поговорок=фразем), так их семантических и структурных клас-сов по методике, разработанной и используемой нами [52] /
Ознакомление с примерами (Табл. 69) показывает, что 101 так назы-ваемая «идиома» (Idioms) представляет собой «солянку» из 86 phrasemes, 12 paremiemes и 3 lexemes; с другой стороны, собрание из 101 послови-цы (Proverbs) на самом деле состоит из 95 paremiemes и 6 phrasemes.
Таблица 69Доля фразем (поговорок), паремием (пословиц) и лексем (слов)
среди “101 popular Idioms› и “101 popular Proverbs”
УСС Phraseme Paremieme Lexeme Всего
Кол. Примеры Кол. Примеры Кол. Приме-ры
101 MostPopularAmericanEnglishIdioms
86 All thumbs; a duck soup; to make a splash; on ice; to smell a rat; a snow job; in the hole
12 All’s well that ends well; Go fly a kite! Money talks. Cat got your tongue? Early bird catches the worm
3 Tongue-in-cheek; Fishy, Lemon
101
101 MostPopularAmericanEnglishProverbs
6 Better late than never; to spoil the broth; no pain, no gain; better safe than sorry
95 All that glitters is not gold; Look before you leap; Don’t cry over spilt milk; Birds of feather flock to
- - 101
Сумма 92 107 3 202
Поэтому мы объединили однородные единицы и получили 2 списка, причем один содержит 92 фраземы (поговорки) и второй — 107 пареми-

159Количественная паремиология
ем (пословиц). Ниже представлены результаты количественного семанти-ко-структурного анализа фразем (Табл. 66–68) и паремием (Табл. 69–74).
Семантический анализ 107 наиболее популярных паремием (посло-виц) показал, что наиболее продуктивным классом является следую-щий: паремиемные единства — 59,8 % паремием, например: All that glitters is not gold; Don’t judge a man until you’ve walked in his boots; He who laughs last, laughs best; if the shoe fits, wear it; If you can’t stand the heat, get out of the kitchen; It never rains but it pours; Make hay while the sun shines; People who live in glass houses shouldn’t throw stones; Strike the iron while it’s hot; The bigger they are, the harder they fall; When the cat’s away the mice will play; Where there’s smoke, there’s fire; You can lead a horse to water, but you can’t make him drink; You reap what you sow; Don’t count your chickens before they’re hatched; Don’t bite off more than you can chew; Don’t bite the hand that feeds you, etc. (Табл. 69).
Таблица 69Семантическая классификация паремием
Семантический класс паремием
Коли-чество
% Примеры
Сращения 3 2,8 Rome wasn’t built in a day; The road to hell is paved with good intentions; When in Rome do as Romans do
Сочетания 40 37,4 Familiarity breeds contempt; The spirit is willing, but the flesh is weak; A man is known by the company he keeps
Единства 64 59,8 If you can’t stand the heat, get out of the kitchen. When the cat is away the mice will play/ All that glitters is not gold
Сумма 107 100,0
Следующим по продуктивности идет класс паремиемных сочетаний — 37,4 %, например: A friend who shares is a friend who cares; A man is known by the company he keeps; All’s well that ends well; Don’t put off for tomorrow what you can do today; He who hesitates is lost; If at first turn you don’t succeed, try, try again; If you can’t beat them, join them; The spirit is willing, but the flesh is weak; Do as I say, not as I do; Leave well enough alone; Absence makes the heart grow fonder; Actions speak louder than words; Bad news travels fast; Beauty is in the eye of the beholder; Familiarity breeds contempt, etc.
Самым малочисленным является класс паремиемных сращений — 2,8 %, а именно: When in Rome do as the Romans do; Rome wasn’t built in a day; The road to hell is paved with good intentions.

160 Глава 6
§ 2. Структурная классификация паремием (пословиц)
Cтруктурный (точнее: синтаксический) анализ паремием каждого семантического класса проводили по следующим синтаксическим кате-гориям: 1) наклонение, 2) время, 3) аспект (вид), 4) залог.
Семантика паремием и наклонение
Граммема (грамматическая категория) наклонения представлена двумя классами (Табл. 70).
В изъявительном наклонении находятся 114 предложений (82,6 %), например: Cat got your tongue? Curiosity killed the cat; A friend in need is a friend indeed; A leopard cannot change his spots; A miss is as good as a mile; After the feast comes the reckoning; An apple a day keeps the doctor away; Barking dogs seldom bite, etc.
В повелительном наклонении находится 24 предложения (17,4 %), например: Don’t cry over spilt milk; Don’t judge a book by its cover; Don’t look a gift horse in the mouth; Don’t put all your eggs in one basket; Don’t put the cart before the horse; Go fly a kite! Let sleeping dogs lie; Look before you leap; Shape up or ship out! etc.
Сослагательное наклонение не представлено в рассматриваемой группе наиболее популярных УСС.
В семантическом классе паремиемных сращений в изъявительном наклонении имеется 3 предложения: Rome wasn’t built in a day; The road to hell is paved with good intentions; When in Rome do as the Romans do (то есть, второе простое предложение).
В повелительном наклонении стоит простое предложение в составе сложного: When in Rome do as the Romans do.
В классе паремиемных единств в изъявительном наклонении на-ходится 65 предложений (78,3 %), например: There is no honor among thieves; There’s more than one way to skin a cat; To put one’s money where one’s mouth is; Two’s company, but three’s a crowd; You can’t have your cake and eat it; You can’t teach an old dog new tricks; A bird in the hand is worth two in the bush; A bark (is) worse than one’s bite.
В повелительном наклонении находится 18 предложений (21,7 %), например: Don’t count your chickens before they’re hatched; Don’t bite off more than you can chew; Don’t bite the hand that feeds you; Don’t cry over spilt milk; Don’t judge a book by its cover; Don’t look a gift horse in the mouth.

161Количественная паремиология
Таблица 70Семантические классы паремием и наклонение
НаклонениеСращение Единство Сочетание Всего
Кол-во % Кол-во % Кол-во % Кол-во %
Изъявительное 3 75,0 65 78,3 46 90,2 114 82,6
Повелительное 1 25,0 18 21,7 5 9,8 24 17,4
Сослагательное - - - - - - - -
Сумма 4 100,0 83 100,0 51 100,0 138 100,0
% 2,9 - 60,1 - 37,0 - 100,0 -
Примечание. Сложные предложения делили на простые, которые за-тем анализировали.
В классе паремиемных сочетаний в изъявительном наклонении на-ходится 46 предложений (90,2 %), например: Absence makes the heart grow fonder; Actions speak louder than words; Bad news travels fast; Beauty is in the eye of the beholder; Familiarity breeds contempt; Good things come in small packages; Haste makes waste; Hindsight is better than foresight; Imitation is the sincerest form of flattery.
В повелительном наклонении стоит всего 5 предложений (9,8 %), например: If at first turn you don’t succeed, try, try again; If you can’t beat them, join them; Do as I say, not as I do; Leave well enough alone.
Таким образом, наиболее популярным среди паремием является граммема изъявительного наклонения.
Заметим, что дальнейшему синтаксическому анализу подвергались только пословицы-предложения в изъявительном наклонении.
Семантика паремием и время
Граммема времени представлена тремя классами (Табл. 71):1) настоящим (96,5 %), например: There’s no place like home; Two
heads are better than one; Variety is the spice of life; Way to a man’s heart is through his stomach; You have to take the good with the bad; You’re never too old to learn; The grass is always greener on the other side of the fence; You can’t have your cake and eat it; You can’t teach an old dog new tricks; Where there’s smoke, there’s fire, etc.
2) прошедшим (2,6 %): Rome wasn’t built in a day; Cat got your tongue? Curiosity killed the cat.
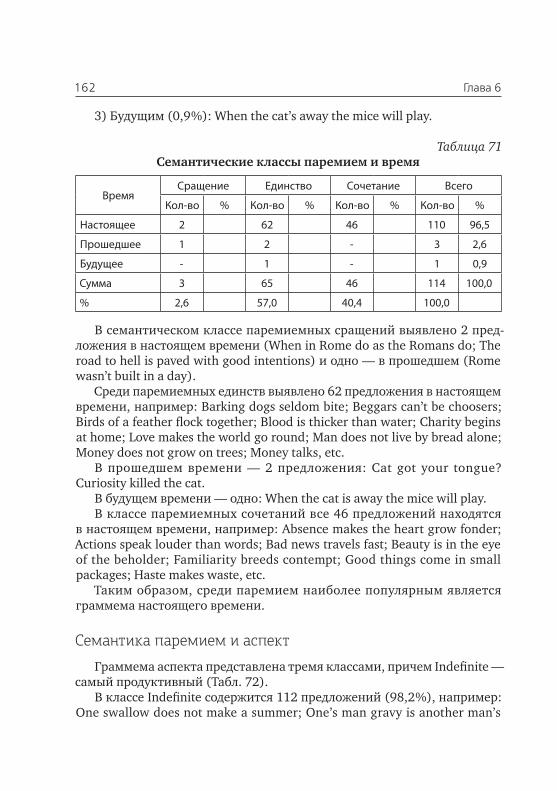
162 Глава 6
3) Будущим (0,9 %): When the cat’s away the mice will play.
Таблица 71Семантические классы паремием и время
ВремяСращение Единство Сочетание Всего
Кол-во % Кол-во % Кол-во % Кол-во %
Настоящее 2 62 46 110 96,5
Прошедшее 1 2 - 3 2,6
Будущее - 1 - 1 0,9
Сумма 3 65 46 114 100,0
% 2,6 57,0 40,4 100,0
В семантическом классе паремиемных сращений выявлено 2 пред-ложения в настоящем времени (When in Rome do as the Romans do; The road to hell is paved with good intentions) и одно — в прошедшем (Rome wasn’t built in a day).
Среди паремиемных единств выявлено 62 предложения в настоящем времени, например: Barking dogs seldom bite; Beggars can’t be choosers; Birds of a feather flock together; Blood is thicker than water; Charity begins at home; Love makes the world go round; Man does not live by bread alone; Money does not grow on trees; Money talks, etc.
В прошедшем времени — 2 предложения: Cat got your tongue? Curiosity killed the cat.
В будущем времени — одно: When the cat is away the mice will play.В классе паремиемных сочетаний все 46 предложений находятся
в настоящем времени, например: Absence makes the heart grow fonder; Actions speak louder than words; Bad news travels fast; Beauty is in the eye of the beholder; Familiarity breeds contempt; Good things come in small packages; Haste makes waste, etc.
Таким образом, среди паремием наиболее популярным является граммема настоящего времени.
Семантика паремием и аспект
Граммема аспекта представлена тремя классами, причем Indefinite — самый продуктивный (Табл. 72).
В классе Indefinite содержится 112 предложений (98,2 %), например: One swallow does not make a summer; One’s man gravy is another man’s

163Количественная паремиология
poison; The apple doesn’t fall far from the tree; The first step is always the hardest; The grass is always greener on the other side of the fence; Absence makes the heart grow fonder; Actions speak louder than words; Bad news travels fast; Beauty is in the eye of the beholder.
В классе Perfect выявлено 1 предложение: Don’t judge a man until you’ve walked in his boots.
В классе Continuous — также одно предложение: The spirit is willing, but the flesh is weak.
В семантическом классе сращений выявлено всего 3 предложения, причем все они находятся в синтаксическом классе Indefinite: When in Rome do as the Romans do; Rome wasn’t built in a day; The road to hell is paved with good intentions.
Среди паремиемных единств в Indefinite находится 63 предложения, например: The pen is mightier than the swordж The proof of the pudding is in the eatingж The squeaking wheel gets the oilж There is no honor among thievesж There’s more than one way to skin, etc.
Таблица 72Семантические классы паремием и аспект
АспектСращение Единство Сочетание Всего
Кол-во % Кол-во % Кол-во % Кол-во %
Indefinite 3 63 46 112 98,2
Perfect - 1 - 1 0,9
Continuous - 1 - 1 0,9
Сумма 3 65 46 114 100,0
% 2,6 57,0 40,4 100,0 -
В классе Perfect выявлено 1 предложение: Don’t judge a man until you’ve walked in his boots.
В классе Continuous обнаружено 1 предложение: The spirit is willing, but the flesh is weak.
В семантическом классе паремиемных сочетаний все 46 предложе-ний находятся в классе.
Indefinite: Good things come in small packagesж Haste makes waste; Hindsight is better than foresight; Imitation is the sincerest form of flattery; In unity there is strength; Love is blind; Might makes right (Табл. 72).
Таким образом, наиболее популярным аспектом среди паремием яв-ляется синтаксический класс Indefinite.

164 Глава 6
Семантика паремием и залог
В граммеме залога (Табл. 73) основным является действительный — 106 предложений (93 %), например: Necessity is the mother of invention; No news is good news; Nothing hurts like the truth; Old habits die hard; One good turn deserves another; Possession is nine-tenths of the law; Money does not grow on trees; Money talks; One swallow does not make a summer; One’s man gravy is another man’s poison; The apple doesn’t fall far from the tree; The first step is always the hardest; The grass is always greener on the oth-er side of the fence; The proof of the pudding is in the eating; The squeaking wheel gets the oil; There is no honor among thieves; There’s more than one way to skin a cat; To put one’s money where one’s mouth is; Two’s company, but three’s a crowd; You can’t have your cake and eat it; You can’t teach an old dog new tricks; A fool and his money are soon parted; A bird in the hand is worth two in the bush, etc.
В страдательном залоге находится всего 7 % предложений, на-пример: Rome wasn’t built in a day; The road to hell is paved with good intentions; Nothing (is) ventured, nothing (is) gained; A man is known by the company he keeps.
Таблица 73Семантические классы паремием и залог
ЗалогСращение Единство Сочетание Всего
Кол-во % Кол-во % Кол-во % Кол-во %
Действитель-ный 1 63 42 106 93,0
Страдательный 2 2 4 8 7,0
Сумма 3 65 46 114 100,0
% 2,6 - 57,0 - 40,4 - 100,0 -
В семантическом классе сращений выявлено 1 предложение в дей-ствительном залоге (When in Rome do as Romans do) и 2 предложения — в страдательном (Rome wasn’t built in a day; The road to hell is paved with good intentions).
Среди паремиемных единств в действительном залоге находится 63 предложения: The first step is always the hardest; The grass is always greener on the other side of the fence; The pen is mightier than the sword; The proof of the pudding is in the eating; The squeaking wheel gets the oil; You can’t teach an old dog new tricks; A fool and his money are soon parted; A bird in the hand is worth two in the bush, etc.

165Количественная паремиология
В страдательном залоге находится всего 2 предложения класса единств: Don’t count your chicken before they are hatched; A fool and his money are soon parted.
В семантическом классе сочетаний в действительном залоге на-ходится 42 предложения, например: A friend who shares is a friend who cares; All’s well that ends well; He who hesitates is lost; The spirit is willing, but the flesh is weak; Absence makes the heart grow fonder; One good turn deserves another; Possession is nine-tenths of the law; Practice makes perfect; The best things in life are free; There’s no fool like an old fool; There’s no place like home, etc.
В страдательном залоге — 4 предложения класса паремиемных соче-таний: A man is known by the company he keeps; Forewarned is forearmed; Nothing (is) ventured, nothing (is) gained.
Таким образом, среди паремием наиболее популярным является дей-ствительный залог.

Глава 7
ЛИНГВИСТИЧЕСКИЕ ПРИНЦИПЫ И ЛЯПСУСЫ
§ 1. Лингвистические принципы
Лингвистическая догма: «Язык происходит от языка»
В биологии известна догма: «Все живое происходит от живого», «клетка от клетки». В настоящее время практически невозможно воз-никновение живого из неживого, поскольку имеющиеся живые орга-низмы немедленно «съедят», утилизируют протоплазму на начальном этапе ее существования.
По аналогии сформулируем лингвистическую догму «Каждый язык происходит от языка» либо путем эволюционного развития языка-пред-ка, либо в результате разделения языка-предка на два диалекта, кото-рые, развиваясь независимо, дают родственные языки.
Необратимость развития языка
В ходе эволюции любого языка происходит его усложнение, как бла-годаря изменению звучания и/или значения единиц каждого уровня, и увеличению их количества с течением времени и в результате рассе-ления говорящих в пространстве. По мере познания окружающего мира увеличивается количество понятий, суждений и умозаключений о нем, а, следовательно, увеличивается и количество знаков языка, которые их отражают (обозначают). Направление развития языка идет в сторо-

167Лингвистические принципы и ляпсусы
ну усложнения лексической подсистемы за счет увеличения количества лексем, фразем и паремием. Например, английский язык в Х веке имел около 10 тыс. лексем, а в конце ХХ в. имел 616 тыс. литературных лексем и около 400 тыс. терминов. Никто не обнаружил обратного процесса — уменьшения количества единиц.
Изменение звучания слов в английском языке за тысячелетие приве-ло к тому, что почти каждое слово приходится снабжать транскрипци-ей. И никто не обнаружил примеров «возвращения» лексем к прежне-му звучанию. Искусственный язык Эсперанто, имевший простую систе-му грамматических и деривационных аффиксов, а также исходный сло-варь из 900 корней и 1200 слов, за 100 лет существования значитель-но усложнился. Так, его словарь составляет теперь более 70 тыс. лексем, появились многозначные лексемы, а также развивается синонимия. Ни-каких признаков его «обратного» развития не наблюдается.
Усложнение организации языка в диахронии
Биологами установлено что в ходе эволюции у большинства организ-мов всех таксонов происходит усложнение организации. Это является ре-зультатом усложнения геномов в ходе эволюции, так как при любых из-менениях среды выживают только те организмы, которые в дополнение к имевшимся получают дополнительные гены, позволяющие им выжить в новых условиях (паразитизм является исключением из правила).
В лингвистике постоянно происходит усложнение структуры и функ-ции языка и речи за счет увеличение количества лексем, морфем, фра-зем и паремием. Это происходит потому, что окружающий мир услож-няется и вместе с ним усложняется наша мыслительная система (т. е. увеличивается количество понятий, суждений и умозаключений), а, следовательно, усложняется лингвистическая система, отражающая ка-тегории мышления.
Количество языков максимально в центре происхождения группы или семьи языков
Известный советский биолог академик Н. И. Вавилов [] сформулиро-вал и доказал закон о центрах происхождения растений: «В центре про-исхождения предка какого-либо семейства или рода растений разнооб-разие родственных видов максимально». По аналогии с этим законом Н. И. Вавилова мы cформулируем закон о центрах происхождения язы-ков: «В центре происхождения языка-предка разнообразие родственных

168 Глава 7
групп и самих родственных языков является максимальным». Так, в Ев-ропе располагаются языки следующих групп языков: славянской, гер-манской, романской, кельтской, балтийской, греческой, албанской. Сле-дует добавить, что количество носителей языка также велико. На Кавка-зе, напротив, имеются языки только 2-х групп: армянской и иранской (осетинский, курдский). Причиной аналогии биологической и лингви-стической закономерностей является тот факт, что чем дальше в седую древность, тем в большей степени наши предки подчинялись законам расселения животных и растительных организмов.
В однородных условиях существования на ограниченной территории разнообразие видов минимально
По аналогии можно сформулировать лингвистический закон: «В од-нородных условиях существования народа на ограниченной террито-рии языковая группа представлена одним языком». В качестве приме-ров служат следующие моноязыковые группы: албанская, греческая, ар-мянская.
Ускорение развития языка в диахронии
Биологи обнаружили, что скорость эволюции живого мира посте-пенно увеличивается. Аналогичное явление обнаружено в лингвистике. Так, нами было экспериментально установлено, что средняя скорость изменения семантического поля лексем английского языка увеличива-ется, достигая максимальной в ХХ веке [59].
Закон гомологических рядов языков
«Закон гомологических рядов растений», открытый академиком Н. И. Вавиловым [8, 484], гласит, что у растений родственных видов или родов проявляются одинаковые свойства, например, одинаковые спектры окраски семян у злаковых. Сейчасизвестно, что в основе это-го явления лежит значительная общность геномов растений одного се-мейства.
По аналогии сформулируем «закон гомологических рядов языков», а именно: «Языки одной группы характеризуются наборами одинако-вых элементов, их форм и значений (например, во всех языках, образо-вавшихся из латинского, появились артикли, которых не было в латин-ском! Во всех этих языках определение стоит в постпозиции к опреде-

169Лингвистические принципы и ляпсусы
ляемому слову. Во всех германских языках определение стоит в препо-зиции, как это было в языке-предке и в готском языке.
Объясняется это тем, что родственные языки одной группы (ветви) произошли от одного языка-родоначальника, поэтому они сохранили основные структурно-семантические «гомологические» характеристи-ки этого языка-предка.
§ 2. Структура и функция языка и речи
В современной лингвистике имеется ряд понятий и обозначающих их терминов, которые являются либо неточными, либо абсолютно не-правильными (т. е. ляпсусами) в свете современных научных представ-лений, как самой лингвистики, так и философии.
Для того, чтобы разобраться с тем, что явилось причиной появле-ния ляпсуса, необходимо сначала напомнить некоторые важные научно корректные современные лингвистические представления.
Язык — мышление — окружающий мир
Знаки лингвистической системы передают «понятия» о предметах (явлениях, их свойствах и т. д.) окружающего мира, которые формиру-ются в головном мозгу с помощью 8 органов чувств (зрение, слух, обо-няние, вкус, осязание тактильное, осязание термическое, равновесие, мышечное чувство усталости — 1-я сигнальная система) и с помощью языка, как второй сигнальной системы.
В целом, мы представили это с помощью следующей схемы.
Процесс формирования лингвистического знака происходит следую-щим образом. С помощью 8 органов чувств в головном мозгу челове-

170 Глава 7
ка формируется представление (говоря научно, «понятие») о предмете. Этому «понятию» в другой части головного человек формирует лингви-стический «знак» — слово, словосочетание и т. п.
Предмет Понятие Слово (лингвистический знак)
С другой стороны, когда человек слышит (или видит написанное) «слово», то у него в мозгу возбуждается соответствующее «понятие», ко-торое он может соотнести с предметом окружающего мира.
Заметим, что на этой схеме представлены простейшие отношения: предмет — понятие — слово. Аналогично можно построить схему связи между свойством предмета либо действием и его характером, с одной стороны, и лингвистическим знаком, с другой.
Специально отметим, что «информация» — это ничто иное, как мно-жество понятий, суждений и умозаключений, т. е. категорий мышле-ния; а «мышление» — это оперирование этими категориями, что яв-ляется предметом изучения раздела философии, называемого «теори-ей познания», и которая, как известно, появилась задолго до возникно-вения так называемой «когнитивной лингвистики» с ее жонглировани-ем туманными представлениями о концептах, фреймах, скриптах, наив-ных «кусочках действительности» и прочей абракадаброй, чепухой, чу-шью и, говоря транслитерационно, рениксой.
Речь, язык и их единицы
Мы полагаем, что «ЛИНГВИСТИКА (глоттология, языкознание, язы-коведение) — это наука о языке и речи». «РЕЧЬ — это система, представ-ляющая собой непрерывный поток взаимосвязанных звуковых и знача-щих элементов (знаков), передающих информацию (т. е. понятия, сужде-ния и умозаключения)». «ЯЗЫК — это система обобщенных речевых эле-ментов (знаков) (фонем, морфем, лексем, фразем, граммем (включая па-ремиемы)». Как говорили древние римляне, знак — это что-то, стоящее вместо чего-то другого (quid pro quo). Лингвистические знаки, переда-ют категории мыслительной системы (понятия, суждения и умозаклю-чения); они являются двуплановыми: состоят из «звучания и значения» (что соответствует философским категориям «форма и содержание»). Само «звучание» — материально, так как это — модулированные колеба-ния выдыхаемого человеком воздуха. Кроме того, представление о «зву-чании» лингвистического знака удерживается нейронами коры головно-

171Лингвистические принципы и ляпсусы
го мозга, следовательно, материально. «Значение» знака также матери-ально, так как оно удерживается нейронами другой части коры головно-го мозга. Следовательно, лингвистическая система (язык + речь = рече-вая деятельность) в целом является материальной системой.
Вообще говоря, «СИСТЕМА — это множество взаимосвязанных эле-ментов, демонстрирующее новое качество, которое не является суммой качеств элементов». «Система» представляет собой единство «струк-туры» и «функции», являющихся «двумя сторонами одной медали». Как известно, система — это общая категория, а структура и функция — частные категории.
Основными дихотомиями лингвистики (по Ф. де Соссюру [139]) яв-ляются следующие: 1) язык — речь; 2) синхрония — диахрония; 3) син-тагматика — парадигматика; 4) знаки языка и речи состоят из планов выражения и планов содержания; 5) звучание — линейно, значение — ассоциативно (объемно); 6) внутренняя лингвистика (изучающая речь и язык во времени и пространстве) — Внешняя лингвистика [мента-лингвистика (психолингвистика) и социолингвистика].
Как известно, первичной является «речь», а «язык», как обобщение речи, является вторичным. Иначе говоря, «Язык — это обобщенная речь». Соотношение между знаками речи и языка представлены в Таб-лице 74.
Таблица 74Единицы речи и языка, расположенные иерархически
по возрастанию их сложности
Речь Язык Примеры
Звук Фонема [e], [u], [ou], [i:], [b], [p], [d], [k], [s], [t];[А], [У], [Б], [Б‘], [П], [П’], [Д], [К’], [Р]
Морф Морфема Be-, en-, dis-, over-; -dom, -ess, -ity, -al, -icПере-, без- (бес-), дис-; -ость, -ник, -ок
Слово Лексема I, bit, beat, cat, go, put, big, hardly, and, outЯ, дом, есть, белый, быстро, у, или, эй
Непредика-тивное cло-восочетание
Фразема Бить баклуши; у черта на куличках; белая кость; продуктовый магазин; синий чулок;A white horse; to kick the bucket; a blue bird
Высказыва-ние (преди-кативноесловосоче-тание)
ГраммемаА) Граммемы слов (лексем)Части речи: С, П, Г, Н, Ме, Чи, Ча, Меж, Пр, Союз
А) В английском=616 тыс.; в русском=300 тыс; в чешском=250 тыс. лексемБ) Распределяются примерно так: суще-ствительные=40 %; глаголы=15 %;Прилагательные=25 %; наречия=10 %; остальные=10 %

172 Глава 7
Б) Граммемы словесных форм(Сущ.: склонение; глаг.:спряжение; прил., нареч.:степени сравнения)В) Граммемы словесныхпозиций (члены предл.: П, С, Д, Оп, Об, Со, Ча, Пр., Меж)Г) Граммемы словесныхКонструкций (типы предложений (в т. ч. паремиемы)
В) Распределяются примерно так: под-лежащее=.; сказуемое=.; определение=; дополнение=; обстоятельство=; части-цы=5 %; союзы=3 %; междометия и проч.=
Примечание. Подразделение граммем на 4 класса было предложено Б. Н. Головиным [ (1979)].
Каждый лингвистический знак является единством «звучания» и «значения».
Научные дефиниции единиц языка и речи
Во избежание недоразумений в понимании терминов, обозначаю-щих единицы речи и языка, дадим их рабочие определения.
Существуют следующие единицы «речи».«Звуком речи являются модулированные колебания выдыхаемого
человеком воздуха».«Морф — это минимальная значимая часть слова, состоящая из зву-
ков».«Слово — это минимальная свободная единица непредикативного
словосочетания или высказывания».«Непредикативное словосочетание (НСС) — это два или более слов,
соединенных путем согласования, управления или примыкания».«Высказывание — это предикативное словосочетание (ПСС), т. е.
словосочетание, содержащее связь между подлежащим и сказуемым на-ряду с другими типами связи между остальными членами».
Соответствующие единицы «языка» имеют следующие дефиниции.«Фонема — минимальная звуковая единица языка, служащая для по-
строения морфем и лексем».«Морфема — это минимальная значимая часть лексемы, состоящая
из фонем».«Лексема — это минимальная свободная единица НСС или ПСС»

173Лингвистические принципы и ляпсусы
«Фразема — это устойчивое НСС, имеющее как прямое, так и пере-носное значения».
«Граммема» — это ндинство грамматического значения и средств его выражения.
«Паремиема — это устойчивое ПСС, имеющее как прямое, так и пе-реносное значения».
«Семема — это всего лишь «элемент» значения, не имеющий звуча-ния». Следовательно, она не является полноправной двуплановой еди-ницей ни речи, ни языка.
«Слог — это всего лишь «элемент» звучания, не имеющий значения». Следовательно, он не является полноправной двуплановой единицей ни речи, ни языка.
Единицы речи всегда однозначны, но их звучание может варь-ировать; единицы языка могут быть многозначны (полисемичны), но их звучание не изменяется.
Философия (законы и категории)
«Философия — это наука о наиболее общих закономерностях струк-туры и функции (и их изменений в пространстве и времени) материаль-ного мира (живого и неживого), общества, мышления и языка (а также других семиотических систем)» [147; 148]. Существуют следующие законы и категории философии: 1) «Закон единства и борьбы противо-положностей»; 2) «Закон перехода количества в качество, и наоборот»; 3) «Закон отрицания отрицания».
«КАТЕГОРИЯ (лат. сategoria, от гр. kategoria = высказывание, су-ждение) — научное понятие, выражающее наиболее общие и суще-ственные связи явлений действительности (напр. Категория причинно-сти)» [(Булыко, 2004, с. 259)]. В сущности, категории — это тоже зако-ны, но выраженные лаконично. Они объединяются в противоположные пары, отражая дуализм материального мира.
1) Материальность — идеальность; 2) Форма — содержание; 3) Структура — функция; 4) Внешнее — внутреннее; 5) Пространство — время; 6) Частное — общее (часть — целое); 7) Причина — следствие; 8) Количество — качество; 9) Индукция — дедукция; 10) Аналогия — гомология; 11) Анализ — синтез; 12) Дискретность — континуаль-ность; 13) Необходимость и случайность
Использование основных положений философии позволяет прове-рять, испытывать как на оселке, истинность лингвистических утвер-ждений. Все, что противоречит ФИЛОСОФИИ, — антинаучно.

174 Глава 7
§ 3. Лингвистические ляпсусы
В современной лингвистике имеется ряд понятий и обозначающих их терминов, которые являются либо неточными, либо абсолютно не-правильными (т. е. ляпсусами) в свете современных научных представ-лений как самой лингвистики, так и философии.
Для того, чтобы разобраться с этими ляпсусами, необходимо посмо-треть, какие лингвистические или философские принципы нарушены.
«Метаязык» (О. С. Ахманова) [36]
Чтобы не сбивать читателя с панталыку, мы сначала будем приво-дить дефиниции речи, языка, их основных единиц — двуплановых (дву-сторонних) знаков, системы, ее структуры и функции, а затем крити-чески рассмотрим различные лингвистические ляпсусы (абракадабру, ерунду, чушь).
Известно, что строгость терминологии определяет уровень развития науки. Отсюда следует, что термин должен однозначно и непротиворе-чиво обозначать понятия науки, а его дефиниция должна содержать ба-зисные категории этой науки. Посмотрим, как это реализуется в «Сло-варе лингвистических терминов» [36], содержащим 7 тыс. статей.
«МЕТАЯЗЫК. Язык «второго порядка», т. е. такой язык, на котором го-ворят о языке же (языке-объекте)» [36, 232]. То есть это некий «иной» язык, на котором говорят о «языке-объекте».
Возможно, в творческом процессе создания этого нового термина аналогом послужили следующие слова: «МЕТАКРИТИКА (от мета- + критика) — критический разбор критического отзыва» [87, 352]. «МЕ-ТАГАЛАКТИКА (от мета- + галактика) — совокупность всех космиче-ских объектов (галактик, квазаров и др.)» [87, 352].
В этих терминах префикс «мета-» означает процесс, объект более вы-сокого порядка, более сложный, чем обозначенный производящей ос-новой.
Но что касается «языка» как объекта исследования, то о нем лин-гвисты говорят и пишут на том же самом языке, который они описы-вают, просто при этом для обозначения специальных лингвистиче-ских понятий используют «термины». Аналогичным образом поступа-ют биологи, физики, химики, животноводы, растениеводы и т. д., кото-рые, как и лингвисты, говорят и пишут об объекте своего исследования не на «биологическом, физическом, химическом» языке, а на известном им литературном языке, используя при этом «термины» своей науки.

175Лингвистические принципы и ляпсусы
О. С. Ахманова [36] дает следующее определение: «ТЕРМИН. Слово или словосочетание специального (научного, технического и т. п.) язы-ка, создаваемое (принимаемое, заимствуемое и т. п.) для точного выра-жения специальных понятий и обозначения специальных предметов» [36, 417].
Как известно, не существует некоего «специального языка» ни в на-уке, ни в технике. Специалисты используют общеизвестный язык, до-полняемый «терминами», обозначающими специальные «понятия» (а не предметы!) своей области. Известно также, что не только термины, но и каждая лингвистическая единица «точно передает понятие о пред-мете, его свойстве и т. п.». Просто одни понятия известны ВСЕМ говоря-щим и обозначаются общеизвестными лингвистическими единицами, а другие понятия известны только специалистам и обозначаются спе-циальными лингвистическими единицами, называемыми терминами.
Лингвистам также известно, что «слова или словосочетания» обо-значают не «предметы» (специальные или неспециальные), а «понятия» и «суждения» о них.
Заметим, что если в дефиниции говорится о «языке», то следует опе-рировать не «речевыми единицами» (словами и словосочетаниями), а «языковыми единицами», а именно: лексемами, морфемами, фразе-мами и т. д. То, что «морфемы» тоже могут быть терминологическими, авторессе, видимо, неизвестно, хотя, кстати, все языковые единицы со-держат «лингвистический» суффикс « — ема», например: фонема, мор-фема, лексема, фразема, граммема, семема, синтаксема, дериватема.
Мы считаем, что «ТЕРМИН — это лексема, морфема или фразема, имеющая хотя бы одно значение, известное узкому кругу говорящих — специалистам в какой-нибудь области деятельности» [41, 20].
Например, термином-лексемой является «Фонема» — минималь-ная звуковая единица языка, служащая для построения морфем и лек-сем. Термин-фразема — «Дифференциальный признак» — минималь-ный существенный признак, отличающий одну фонему от другой. Тер-мин-морфема — «-ема»: суффикс, выделяющийся из состава таких тер-минов, как фонема, морфема, семема, семантема и т. п. со значением «структурный элемент языка».
Однако полагать, что слово «метаязык» обозначает некий «иной» язык не имеет смысла, поскольку никакого преобразования самого язы-ка или его единиц (фонем, морфем, лексем, фразем, граммем) не на-блюдается — просто лингвисты используют «термины» (лексемы, мор-фемы и фраземы), то есть единицы, имеющие значения, известные только лингвистам.

176 Глава 7
Таким образом, поскольку никакого «специального языка» нет, а лингвисты говорят и пишут о своем объекте на том же самом литера-турном языке, но при этом используют «термины» (в том числе из [36] для обозначения понятий своей области деятельности, то никакого «ме-таязыка» не существует, и этот неологизм следует выбросить на «лин-гвистическую свалку» как захламляющий корректную лингвистиче-скую терминологию, вводящий в заблуждение и «сбивающий с панта-лыку» начинающих лингвистов.
«Язык — это система произвольных знаков» (Ф. де Соссюр) [139]
Как известно, Ф. де Соссюр [139] первым выделил из «речевой дея-тельности» ее составные части: «речь» и «язык». «Язык» он определял следующим образом: (1) «Язык есть система, которая подчиняется толь-ко своему собственному порядку»; (2) «Язык — это система произволь-ных знаков»; (3) «Язык — это система, все части которой можно и дол-жно рассматривать в их синхроническом единстве»; (4) «Язык есть си-стема знаков, выражающих понятия, а следовательно, его можно срав-нивать с письменностью, азбукой для глухих…»; (5) «Язык — это систе-ма знаков, в которой единственно существенным является соединение смысла и акустического образа». «Речь — сумма всего того, что говорят люди» [139, 57].
Заметим, что приведенные выше формулировки «языка» неполны и фрагментарны, но из них можно скомпоновать гибридное определе-ние, которое более полно передает представление о нем:
«Язык есть система знаков, выражающих понятия, в которой един-ственно существенным является соединение смысла и акустического образа».
Отметим, что мысль Ф. де Соссюра [139] о том, что «знаки» представ-ляют собой «соединение смысла и акустического образа» неверна! Дело в том, что под «смыслом», «психическим образом» [139] (как и все лин-гвисты того времени) имел в виду «понятие».
Однако, в наше время известно, что «значением» лексемы является не «понятие» (т. е. единица системы «мышления» о предмете), а «отра-жение понятия», находящееся в другой, «лингвистической системе» го-ловного мозга (рядом со «звучанием» этой единицы).
Из философии [147; 148] следует, что все, что объективно существу-ет, в том числе и лингвистический знак, должно иметь «форму и содер-жание», называемые в лингвистике соответственно «звучанием» и «зна-

177Лингвистические принципы и ляпсусы
чением». Видимо, поэтому Ф. де Соссюр чаще употреблял термины «план выражения» и «план содержания» языкового знака.
Что же касается «речи», то Ф. де Соссюр [139] говорил, что «[рече-вая] единица — это отрезок звучания, который является означающим некоторого понятия» [139, 136].
Мы сформулировали следующие корректные определения: «Язык и речь — это система взаимосвязанных звуковых и значащих элементов, передающих понятия, суждения и умозаключения об окружающем мире».
Это то же самое, что соссюровская «речевая деятельность», представ-ляющая собой сумму «языка» и «речи», которые изучает лингвистика.
«Язык — это система, представляющая собой множество обобщен-ных речевых знаков [фонем, морфем, лексем, фразем, граммем (вклю-чая паремиемы)], передающих понятия, суждения и умозаключения об окружающем мире».
«Речь — это система, представляющая собой дискретный поток взаи-мосвязанных элементов (звуков, морф, слов, непредикативных слово-сочетаний и высказываний), передающих понятия, суждения и умоза-ключения об окружающем мире».
Итак, каждый лингвистический знак (как речевой, так и языковой) состоит из «звучания» и «значения».
«Язык… можно сравнить с письменностью, с азбукой для глухих…» (Ф. де Соссюр) [139]
Как известно, Ф. де Соссюр [139] писал, что «язык есть система зна-ков, выражающих понятия, а следовательно его можно сравнивать с письменностью, с азбукой для глухих» [139, 54]. Однако дефиниции термина «система» он не приводит, поэтому каждый может представ-лять себе эту «систему» «как черт (или бог) на душу положит».
Что же касается «письменности», то лингвистам известно, что это — ничто иное, как записанная устная «речь», а «речь — сумма всего того, что говорят люди» [139, 57].
Конечно, сравнивать «язык» с «письменностью», можно, но в ре-зультате ничего принципиально нового, отличающегося от результатов сравнения «языка» и «речи» мы не получим. Письменная речь переда-ет те же самые понятия, что и устная речь. Разница заключается в том, что устная речь воспринимается с помощью органов слуха, а письмен-ная — с помощью органов зрения, но и те, и другие сигналы приходят в одну и ту же область головного мозга, удерживающую лингвистиче-ские единицы.

178 Глава 7
Аналогичная ситуация наблюдается и в случае с «азбукой Брайля», которая придумана для того, чтобы передавать звуки устной речи дан-ного языка с помощью комбинаций из миниатюрного набора «выпук-лостей и вогнутостей», воспринимаемых кожей пальцев, т. е. органом чувств — осязанием. Затем сигналы идут в ту же самую область коры го-ловного мозга, что и в результате восприятия слуховых или зрительных сигналов. Следовательно, как письменная речь, так и азбука Брайля представляют собой то же самое, что и звуковая речь, т. е. одну и ту же «речевую систему», а не несколько разных систем, как представлял себе 100 лет назад Ф. де Соссюр [139].
В этой связи Л. Ельмслев в 1950 г. писал, что «… датский язык, будь то устный, или писаный, или телеграфированный при помощи азбуки Морзе, или переданный при помощи международной морской сигнали-зации флагами, остается во всех этих случаях все тем же датским язы-ком и не представляет четырех разных языков» [11, 103].
То есть, как азбука Морзе, так и флажковая сигнализация не являются какими-то новыми системами, так как они передают буквы (и звуки) кон-кретного языка с помощью наборов коротких и длинных звуковых сигна-лов или же точек и тире на письме, или разноцветных флажков, а эти бук-вы соответствуют определенным звукам устной речи того же языка.
Язык как системно-структурное образование [139]
Около 50 лет назад В. М. Солнцев [138] написал монографию, кото-рую озаглавил: «Язык как системно-структурное образование».
Заметим, что представление о системах было введено и широко ис-пользуется в биологии, где Л. Берталанфи [83] еще в 30-х гг. ХХ в. дал определение системы. С тех пор одни ученые отмечают наличие у си-стем «структуры» и «функции» [31], другие — только «структуры» — это лингвисты [138; 140], третьи — только «функции» [145]. Однако в био-логии прочно укоренилось представление о том, что любая система имеет «структуру», с одной стороны, и «функцию», с другой, о чем сви-детельствуют, например, монографии с такими названиями: «Структу-ра и функция клетки» [143]; «Структура и функция хромосом» и т. п.
Как известно, в философии [147; 148] говорится, что системы ха-рактеризуются двумя категориями: «структурой» и «функцией». Ясно, что лингвистические системы должны иметь как «структуру», так и «функцию». Поэтому авторы, ставящие псевдоглубокомыслен-ные вопросы о том, как соотносятся понятия «система» и «структура»,

179Лингвистические принципы и ляпсусы
что из них является общим, а что — частным, «ломятся в открытую дверь», выражаясь фразеологически. «Система» является общей катего-рией, а «структура» и «функция» — частными категориями, и путать эти вещи антинаучно. Поэтому монографию В. М. Солнцева [138] следова-ло бы назвать, например, так: «Языковая система как структурно-функ-циональное образование».
«Язык — система систем» (В. И. Кодухов) [109]
В. И. Кодухов [109] пишет, что «… особенностью языка как систе-мы является то, что он есть система систем, или гетерогенная система» [109, 136].
Известно, «ГЕТЕРОГЕННЫЙ (гр. heterogenes = инородный, разно-родный) — состоящий из различных по составу, свойствам, происхо-ждению частей» [87, 147]. Мы знаем, что язык состоит из различных как по звучанию, так и по значению элементов (знаков), следователь-но, он гетерогенен. Но гетерогенность — это одно из системообразую-щих свойств; все истинные системы состоят из гетерогенных элемен-тов. Из этого не следует, что гетерогенную «систему» следует называть «системой систем». «Система» может состоять из ряда более мелких объ-единений элементов, которые называются «подсистемами». Лингвисти-ческая система — язык — состоит из фонемной, морфемной, лексемной, фраземной и граммемной подсистем. Иногда для упрощения лингвисты говорят о «лексической системе», «фонетической системе» или «фразео-логической системе», имея в виду, естественно, соответствующие «под-системы». Поэтому в соответствии с «бритвой Оккама» будем считать, что «Язык — это система взаимосвязанных гетерогенных звуковых и зна-чащих элементов (знаков), состоящая из ряда подсистем, а именно: фо-немной, морфемной, лексемной, фраземной и граммемной». И «горо-дить огород» из систем, выстраивая из них «карточный домик» «системы систем» не имеет смысла, иначе «из-за деревьев леса не увидим».
«О трояком аспекте языковых явлений» (Л. В. Щерба) [153]
В 1931 году Л. В. Щерба [153], известный лексикограф-практик, ре-шил внести свой вклад в теорию и написал: «Я буду называть процессы говорения и понимания «речевой деятельностью» (первый аспект язы-ковых явлений)». «… словари и грамматики языков… мы будем назы-

180 Глава 7
вать «языковыми системами» (второй аспект языковых явлений)». «Все языковые величины, с которыми мы оперируем в словаре и граммати-ке, … могут выводиться нами лишь из процессов говорения и понима-ния, которые я называю в такой их функции «языковым материалом» (третий аспект языковых явлений). Под этим я понимаю … совокуп-ность всего говоримого и понимаемого… На языке лингвистов это «тек-сты»» [153, 39–40].
Отметим, что 1-й аспект включает «процессы говорения», но если проговоренное записать (а мы, слава Кириллу и Мефодию, можем это сделать!), то получим «текст», который сам же Л. В. Щерба [153] называ-ет 3-м аспектом языковых явлений!
Если процесс «говорения» представляет собой передачу «понятий» с помощью лингвистических знаков, т. е. «речь», то процесс «понима-ния» — это противоположно идущий процесс, т. е. преобразование услышанных (или увиденных) лингвистических знаков в «понятия»!
Воспроизведем схему, объясняющую эти процессы: при «говоре-нии» процесс идет слева направо, от понятия к лингвистическому знаку, а при «понимании» процесс идет справа налево, от лингвистического знака к соответствующему «понятию». В обоих случаях мы имеем дело с «речью» (3-й аспект по Л. В. Щербе) [153].
Таким образом, констатируем, что 1-й и 3-й аспекты — это один и тот же аспект, а именно: всем известная «речь», но Л. В. Щерба [153] этого «слона-то и не приметил». Следовательно, ему надо было пи-сать статью «о двояком аспекте языковых явлений». Да и с философ-ской точки зрения попытка представить «языковые явления» в виде не-коей «трехсторонней» сущности — затея явно антинаучная, так как, хо-тим мы этого или не хотим (volens nolens, так сказать), но живем мы в «дихотомической» Вселенной, где все объекты являются «двуплановы-ми», то есть имеют «форму» и «содержание», а те, что сложней устроены, имеют «структуру» и «функцию».

181Лингвистические принципы и ляпсусы
Кстати, все это было известно лингвистам еще с 1916 г., когда Ф. де Соссюр в книге «Le cours de linguistique general» [139] предложил разли-чать «язык» и «речь», которые в сумме и составляют «речевую деятель-ность». С философской точки зрения эта картина не вызывает возра-жений: «речь» и «язык» — это частные категории, а «речевая деятель-ность» — это общая категория.
«Язык как явление… представлен тремя аспектами: языком — речью — речевой деятельностью» (Гируцкий) [93]
Здесь мы видим практический результат, как сказали бы раньше, «вредительской лингвистической деятельности» Л. В. Щербы [153], ко-торого в 1943 г. избрали академиком (но, конечно, не за то, что он высказал антинаучную гипотезу «о трояком аспекте языковых явле-ний»). На эту «удочку «троякости», заброшенную академиком», и по-пался А. А. Гируцкий [93, c. 40, 89, 324)], который попытался развить далее идею «троякости» феномена языка и речи, предложив тройной набор элементов для этих аспектов (Табл. 74).
Таблица 74«Троякий» аспект языка как явления
Язык Речь Речевая деятельность
Фонема Аллофон Звук, или фон
Морфема Алломорф Морф
Лексема Аллелекс Лекс
Семема Значение Сема
Слово Словоформа Словоупотребление
Предложение Высказывание Фраза
Из таблицы следует, что язык, оказывается, содержит две разные единицы — лексему и слово. Но ведь лингвисты считают, что «слово» — единица речи, а «лексема» — это единица языка, соответствующая ей [36]. В этой таблице элементы расположены в порядке их усложне-ния: сверху вниз. Следовательно, слово — это более сложная единица, чем лексема! А между ними находится «семема», которая, как известно, не является полноправным двуплановым знаком. Это всего лишь «поло-винка», обозначающая «значение», то есть часть лингвистического зна-ка (кстати, какого?).

182 Глава 7
Во втором и третьем столбцах таблицы расположены элементы «речи» и «речевой деятельности». Отметим, что А. А. Гируцкому [93], видимо, невдомек, что «речевая деятельность» у Л. В. Щербы есть ни что иное, как обыкновенная «речь» — результат передачи «понятия» знаками речи (при говорении). Но если «речь» и «речевая деятельность» — это одно и то же, то почему тогда они состоят из разных элементов?
Как известно, мир, в котором мы живем, начиная с Галактики в це-лом и кончая лингвистической системой в частности, является дихото-мическим, дуалистическим. Философия [147; 148] (Царица наук!) гово-рит, что все сущее (т. е. объективно существующее) имеет «форму» и «со-держание», ни больше, ни меньше! Tertium non datur = Nihil tertium est, как говаривали древние латиняне. А всякие там «троякие» аспекты че-го-либо являются антифилософскими, следовательно, антинаучными, на-чиная с «бога-отца, бога-сына и святаго духа» у христиан и кончая три-единствами: язык — речь — речевая деятельность либо фонема — алло-фон — фон; морфема — алломорф — морф и т. п. у лингвистов.
Любителям порассуждать всуе на «общие темы» напомним, напри-мер, о следующих дихотомиях: материальный мир — духовный мир, южное полушарие — северное полушарие, низ — верх, правое полуша-рие — левое полушарие, речь — язык [93, 256].
Как известно, существует пара философских категорий «частное — общее»; в лингвистике — это «речь» и «язык» (которые представляют собой категорию «частного»), а «речевая деятельность» — это катего-рия «общего». Ставить их «на одну доску» на равных не полагается, так как это — антинаучно.
А ведь Ф. де Соссюр [139], который впервые ввел эти понятия, прямо говорил, что «речевая деятельность» состоит из «языка» и «речи» [ (Сос-сюр, 1977, с. 131). Зачем же «изобретать велосипед»?
Как известно, теория Ф. де Соссюра [139] состоит из дихотомий: «язык — речь», «синхрония — диахрония», «синтагматика — парадиг-матика», «акустический образ — психический образ», «план выраже-ния — план содержания», «лингвистика внутренняя — лингвистика внешняя», что является философски и научно корректным.
А выделение различных «трояких аспектов языковых явлений» Л. В. Щербой [153] и примкнувшим к нему А. А. Гируцким [93], пред-ложившим тройной комплект единиц «языка как явления», следует объ-яснить их «философской неграмотностью». Ну, а саму «троякую класси-фикацию» единиц надо выбросить на лингвистическую свалку, чтобы «не сбивать с панталыку» начинающих лингвистов и «не вешать мака-роны на уши» продолжающим наше дело.

183Лингвистические принципы и ляпсусы
«Речь течет в одном направлении». Палиндромы
Речь течет в одном направлении (в письменном ее варианте (тек-сте) — слева направо). Однако, как раз при анализе письменного вари-анта речи еще древними греками было обнаружено интересное явле-ние — течение речи в противоположном направлении, названное па-линдромом (гр. Palindromos — движущийся обратно).
Палиндромами могут быть слова (Dad, Mom, bib, bob, gag, did, pop, tit; поп, пуп, кабак, казак, шалаш), непредикативные словосочета-ния (дом мод) или предикативные словосочетания (предложения): («Able was I ere I saw Elba» (якобы слова Наполеона, подплывающего к о. Эльба. Заметим, что английского он не знал, а уж палиндромов даже на родном корсиканском не придумал ни одного, не говоря уже о фран-цузском, а тем более — английском!); A man, a plan, a canal: Panama; Madam, I’m Adam; SOS; А роза упала на лапу Азора; Аргентина манит негра; Кит на море романтик; Коту тащат уток; Лазер резал; На вилах ехал Иван; Нажал кабан на баклажан; «Не видно морд, ни лап, и палин-дромон дивен» (В. Брюсов); «Я иду себе судия» (Р. Г. Державин); Уж я ве-ники не вяжу).
Интересно, что в учебниках по «Введению в языкознание» или «Об-щему языкознанию» палиндромы вообще не упоминаются. Однако их можно найти, например, в книге В. В. Волиной «Игры в рифмы» (1997 [], которая «адресована не только детям, но и воспитателям, учителям, родителям, которые хотели бы развить в ребенке художественный вкус, языковую культуру…».
Философский закон «единства и борьбы противоположностей» озна-чает, что в каждой системе закономерно уживаются как одинаковые (элементы или их свойства), так и противоположные. Это относится и к речи в ее письменном варианте: наряду с течением «слева направо» вполне закономерным является и «движение в обратном направлении», т. е. «справа налево» — палиндромия!
«Двуплановость лингвистического знака» (Ф. де Соссюр) [139]
Ф. де Соссюр [139] считал лингвистический знак двуплановым, со-стоящим из «акустического образа» и «психического образа», которые называл соответственно «планом выражения» и «планом содержания». Отметим, что «психический образ» у него — это «понятие». Впрочем, не только в начале ХХ в., но и в наше время находятся лингвисты, ду-мающие также [104; 140].

184 Глава 7
Но Ф. де Соссюр [139] говорил: «Лингвистический знак (слово) име-ет план выражения и план содержания».
Так считал де Соссюр (и многие лингвисты до и после него!)
Современное представление о любом лингвисти-ческом знаке, как единстве «звучания» и «значе-ния».
Заметим, что «понятие» о конкретном предмете у людей, говоря-щих на разных языках, одинаково, потому что формируется с помощью одних и тех же 8 органов чувств. И во всех энциклопедиях «понятие» об этом предмете описывается одинаково. Однако «значение» в лин-гвистическом (толковом) словаре, соответствующее этому «понятию», в разных языках передается по-разному.
Было установлено, например, что лексемное «значение» — это отра-жение «понятия» о «предмете», а не само «понятие» (см. Схему в начале статьи). «Значение» и «понятие» так же различны, как отражение ябло-ка в зеркале отличается от самого яблока.
«Понятие» — это категория мыслительной системы, а «значение» и «звучание» — это категории лингвистической системы. Лингвисти-ческий знак не может состоять из элемента «лингвистической систе-мы» — «звучания» и из элемента «мыслительной системы» — «понятия», как думал сто лет назад Ф. де Соссюр [139] и иже с ним. Любая лингви-стическая единица является единством двух «лингвистических сторон»: «звучания» и «значения».
Знание философии помогает однозначно ответить на вопрос о дву-плановости лингвистического знака: если знак объективно существует, то он должен иметь «форму и содержание», а в лингвистике — это «зву-чание и значение».
Так же думает В. М. Солнцев [138], который пишет: «Слово как целое, как единство звучания и значения есть единица языка» [138, 115]. И да-лее: «С точки зрения тезиса двусторонности знака морфема и слово при-знаются знаками…» [138, 116]. И это есть хорошо!

185Лингвистические принципы и ляпсусы
В. И. Кодухов [109] также отмечает, что «языковыми знаками при-знаются значимые единицы языка — слова, морфемы и предложения» [109, 130].
Знаки, субзнаки, суперзнаки (Б. А. Плотников) [129]
Ф. де Соссюр [139], который первым ввел в лингвистику понятие о «языке, как системе знаков», все без различия единицы считал «знака-ми». Позднее появились «улучшатели», предложившие следующее «нов-шество»: выделять суперзнаки — знаки — субзнаки [129].
Таблица 75Соотношение между лингвистическими единицами
и знаками языка
Уровень предложений Суперзнаковый уровень
Уровень слов Знаковый уровень
Уровень фонем Субзнаковый уровень
В этой схеме неизвестно почему отсутствуют такие вполне закон-ные единицы языка, как морфемы и фраземы. Видимо, потому, что то-гда придется продолжить «номинационный процесс», назвав, например, морфему «суперсубзнаком», а фразему — «субсуперзнаком… А, может, наоборот?
Вряд ли эти новации Б. А. Плотникова 129] помогут глубже понять «язык как систему знаков», но вот дополнительную «головную боль» лингвистам, пожелавшим запомнить эту белиберду, они наверняка обеспечат, а ради чего?
Асимметрия знака (С. Карцевский) [111]
В 1929 году С. Карцевский [см. 1034; 111] поразил языковедов и «сде-лал себе имя», заявив «Об асимметричном дуализме лингвистического знака».
«Знак и значение не покрывают друг друга полностью». «Один и тот же знак имеет несколько функций, одно и то же значение выража-ется несколькими знаками». «Всякий знак является потенциально «омо-нимом» и «синонимом» одновременно».

186 Глава 7
Читая его статью, лингвист не может понять, что же С. Карцевский понимает под «знаком»?
Двуплановую единицу Ф. де Соссюра [139] или нечто одноплановое? Если знак двупланов, то как же следует понимать фразу «Знак и зна-чение не покрывают друг друга полностью», т. е. двуплановая едини-ца — знак — не покрывает значение, т. е. нечто одноплановое? Если же «знак» — это просто «звучание», то неясно, как «значение» может по-крывать (или не покрывать) «звучание»? Это же две разные философ-ские категории — «форма» и «содержание»! А как, интересно, называет-ся единица, состоящая из двупланового «знака» и «значения»?
Далее этот автор пишет: «Лингвистический знак по своей внутрен-ней структуре…». Отсюда можно заключить, что «знак» все-таки дву-планов и имеет «внутреннюю структуру» и, возможно, что-нибудь «вне-шнее».
С. Карцевский [104; 111] пишет, что «для иллюстрации асимметри-ческого характера знака можно было бы прибегнуть к следующей схе-ме» [104, 90].
← Омонимия: СМОЛЧИ ОН; и т. д.
Знак адекватный:МОЛЧИ!
←
→ МОЛЧАТЬ! И т. д. Синонимия →
«Обозначающее (звучание) и обозначаемое (функция) постоянно скользят по «наклонной плоскости реальности. Каждое «выходит» из ра-мок, назначенных для него его партнером: обозначающее стремится об-ладать иными функциями, нежели его собственная: обозначаемое стре-мится к тому, чтобы выразить себя иными средствами, нежели его соб-ственный знак. Они асимметричны: будучи парными, они оказываются в состоянии неустойчивого равновесия» (с. 90).
Понятие симметрии впервые было введено используется в матема-тике и кристаллографии для описания «формы» предметов. Известно, что «Симметрия — это способность фигуры ли ее частей совпадать друг с другом при следующих операциях: 1) повороте вокруг точки или оси; 2) зеркальном отражении; 3) параллельном смещении». Никто из ма-тематиков, кристаллографов или философов никогда даже не заикался о поисках «симметрии» между такими противоположными категория-ми, как «форма» и «содержание». А ведь «звучание» и «значение» — это лингвистическая реализация философских категорий «формы» и «со-держания».
Следовательно, «рассуждения» С. Карцевского [104; 111] и карцеви-стов о симметрии и асимметрии языкового знака — это попытки геоме-

187Лингвистические принципы и ляпсусы
трически-философских невежд, блуждающих в лингвистических потем-ках, «навести тень на плетень»…
Незнаковые свойства языка (Л. Ельмслев)
Л. Ельмслев [см. 111] считал, что фонема как знак языка состоит из дифференциальных признаков, которые, знаками уже не являются, и называл их фигурами. С ним согласен В. И. Кодухов [109], который до-бавляет, что «Родовые отличия существительных «перо» и «дыра» не об-разуют особых знаков.
Заметим, что в наше время считается, что фонема, как объективно существующая единица языка, должна иметь две стороны: «звучание» и «значение». Звучанием являетсянаше представление (т. е. понятие) о модулированном колебании выдыхаемого человеком воздуха, «значе-нием» — набор ее дифференциальных признаков [82]. На этом основа-нии следует считать, что компоненты значения фонемы — дифференци-альные признаки — также имеют знаковую природу.
Вообще, по определению (по умолчанию, как говорят программи-сты) в языке — «знаковой системе» — не может быть чего-либо «незна-кового».
Материален или идеален лингвистический знак?
Принципиально важным является вопрос о том, материален или идеален лингвистический знак?
Раньше считалось, что «язык идеален» так как находится в голо-ве и относится к психическим явлениям, которые понимали как нечто «идеальное» (как и саму душу). В. Гумбольдт [96] считал, что «деятель-ность мышления и язык представляют неразрывное единство» [см.: 111, 49]. А. А. Потебня [130] например, писал, что «язык есть форма мысли» [см.: 111, 90].
Следовательно, оба этих лингвиста не различали элементы, принад-лежащие к двум разным системам — мыслительной (элементами кото-рой являются понятия, суждения и умозаключение) и лингвистической (элементам речи и языка).
В ХХ в. некоторые лингвисты считали, что звуковая сторона языка — материальна, в значение — идеально, так как относится к психической деятельности человека [138].

188 Глава 7
Заметим, что «звучание» знака представляет собой модулирован-ные колебания выдыхаемого человеком воздуха, а информация о «зву-чании» удерживается вполне материальными нейронами коры голов-ного мозга.
С другой стороны, «значение» также удерживается, но уже други-ми нейронами коры головного мозга, а, следовательно, материаль-но. Поэтому высказывания «половинчатого» характера в том плане, что «звучание» знака материально, а «значение» — идеально явля-ются антинаучными и вредными, так как «наводят тень на плетень» и «сбивают с панталыку» начинающих лингвистов, плохо знающих философию.
Звук, слово, предложение (Аристотель) [33]
В IV в. до новой эры Аристотель писал: «Во всяком словесном изло-жении есть следующие части: элемент, слог, союз, имя, глагол, член, па-деж, предложение» [33, 62].
То есть в речи Аристотель выделял такие единицы, как звук, слог, слово, предложение. Но он сам говорил также, что слог не имеет значе-ния. Следовательно, еще в античности выделялись такие единицы речи, как: звук, слово и предложение.
«Фонема не имеет значения» (Ю. С. Маслов) [121]
Встречаются утверждения о том, что лексема и морфема — едини-цы двусторонние, имеющие как звучание, так и значение. А вот фоне-ма — единица односторонняя, имеющая только звучание, но не имею-щая значения.
По этому поводу следует заметить следующее. Философия гово-рит: все, что объективно существует, должно иметь форму и содержа-ние. Поскольку фонема, как обобщение звука, объективно cуществу-ет, то она должна быть двусторонней. Другой вопрос, как эти стороны выражены… Известно, что у разных языковых знаков «значение» вы-ражается по-разному. Так, у лексемы значение — это «отражение поня-тия» (а не само «понятие», как считали ранее, в том числе Ф. де Соссюр [139]). У морфемы значение выводится из сопоставления значений пар лексем: производящее — производное. У фонемы значением является набор ее дифференциальных признаков [82].

189Лингвистические принципы и ляпсусы
Рассмотрим примеры.[b] 1) английская согласная, 2) звонкая, 3) смычная, 4) губно-губная,
5) неносовая;[u:] 1) английская гласная, 2) долгая, 3) верхнего подъема, 4) задне-
го ряда;[Б’] 1) русская согласная, 2) звонкая, 3) мягкая, 4) смычная, 5) губ-
но-губная, 6) неносовая;[М’] 1) русская согласная, 2) звонкая, 3) мягкая, 4) смычная, 5) губ-
но-губная, 6) носовая.[У] 1) русская гласная, 2) верхнего подъема, 3) заднего ряда.
Семема — единица языка (А. А. Гируцкий) [93]
А. А. Гируцкий [93] среди таких единиц языка, как фонема, морфе-ма, лексема упоминает и семему. Известно, однако, что фонема, морфе-ма и лексема являются двусторонними единицами языка (то есть каж-дая имеет «звучание» и «значение»). «Семема» же является минималь-ной единицей «значения», то есть одноплановой единицей. О. С. Ахма-нова [36], в частности, пишет: «СЕМЕМА.
1. Наименьшая единица системы содержания… 2. Значение слова…» [36; 401]. Следовательно, поскольку семема не является двусторонней единицей, то она не может входить состав двуплановых единиц языка.
Слог — единица языка (Звегинцев) [104]
В. А. Звегинцев [104] среди языковых единиц разных уровней при-водит «слог» наравне с такими двусторонними единицами, как фонема, морфема, слово, словосочетание и предложение. Известно, что еще Ари-стотель [33] выделял в речи «слог», но он говорил, что слог не имеет зна-чения. За прошедшие 2,3 тыс. лет лингвистика сделала определенный прогресс, вследствие чего пришло понимание той философской исти-ны, что языковые единицы, как объективные сущности, имеют две сто-роны: план выражения (звучание) и план содержания (значение). По-скольку «слог» имеет только план выражения — «звучание», но не име-ет плана содержания — «значения», то он не является полноправной двуплановой единицей языка. Приведем примеры слогов из работы В. А. Звегинцева [104]: кни-га, ав-тор и т. д. Ясно, что слоги не имеют «значения». Кстати, Ф. де Соссюр [139] также говорил, что слог не име-

190 Глава 7
ет значения. «Бог (или черт?) его знает», как такого «слона-то и не при-метил» В. А. Звегинцев [104]!
Лексико-семантический вариант.
Поскольку «лексема» — состоит из звучания и значения («семанти-ки»), постольку все «лексическое» является «звучащим», с одной сто-роны, и «семантическим», с другой. Поэтому «лексико-семантический» вариант, по сути, означает «звуко-семантико-семантический» вариант, что тавтологично и напоминает «масляное масло».
Некоторые лингвисты-оригиналы понимают «лексему» как единицу «звучания», а «семему», как единицу «значения». Возникает вопрос, а ка-кую двуплановую лингвистическую единицу они составляют? Как назы-вается эта единица? Слово? Но «слово» — это единица речи, а суффикс –ема еще со времен Бодуэна де Куртенэ [84] используется для образования названий единиц языка: фонема, морфема, фразема, паремиема, грамме-ма. Зачем выхолащивать лексему, оставляя у нее только звучание, когда удобнее понимать ее как двуплановую единицу со звучанием и значени-ем, а слово — оставить единицей речи, также имеющей звучание и значе-ние. При этом «семему» как единицу значения вполне можно изучать спе-циально в семасиологии, но как лингвистическую «половинку»!
Внутренняя форма [96]
Некоторые лингвисты [116] использует это выражение, введенное в оборот еще В. Гумбольдтом [96] около двухсот лет назад. Оставляя в стороне туманные объяснения В. Гумбольдта [96], заметим, что в фи-лософии существуют следующие пары противоположных категорий: «Внешнее — внутреннее» и «Форма — содержание». Отметим, что ка-тегории «внешнее» и «форма» являются родственными, одного плана. «Внутренне» и «содержание» — это тоже две родственные категории, но противоположные им. Употребление пары противоположных кате-горий в одном ряду противоречит философии, а, следовательно, являет-ся ненаучным или даже антинаучным.
Выражение «внутренняя форма» столь же абсурдно, как и «внешнее содержание», и поэтому должно быть выброшено на свалку лингвисти-ческих ляпсусов «от греха подальше», чтобы не «сбивать с панталыку» лингвистов, «плавающих» в философии.

191Лингвистические принципы и ляпсусы
Идиоматичность, идиома (Баранов, Добровольский) [38]
Заметим, что научно корректных определений «идиомы» не существу-ет. Поэтому под «идиомой» понимают все, что угодно или как кому забла-горассудится. Но в классическом определении говорится: «ИДИОМА.
1. Словосочетание, обнаруживающее в своем синтаксическом и се-мантическом строении специфические и неповторимые свойства дан-ного языка. 2. То же, что фразеологическая единица (см. фразеологиче-ский). Собственно идиома (англ. idiom proper). Фразеологическая еди-ница, обладающая ярко выраженными стилистическими особенностя-ми, благодаря которым ее употребление вносит в речь элемент игры, шутки, нарочитости. [русск. взять быка за рога, приказать долго жить, через пень колоду (валить)]» [36, с. 165–166].
1) Заметим, что это определение не позволяет однозначно выделять «идиомы», так как: (1) в нем ничего не говорится о том, предикативное это словосочетание или непредикативное; (2) не сообщается, что же со-бой представляют «специфические и неповторимые свойства данного языка», и единственным утешением для лингвистов является лишь (3) упоминание о том, что речь идет о свойствах «данного языка», а не ка-кого-либо иного. …
О «собственно идиоме» говорится, что это «Фразеологическая еди-ница». Однако в приведенном далее определении самой «фразеологи-ческой единицы» ничего не говорится о том, предикативное это слово-сочетание или нет. Кроме того, все фразеологисты признают тот факт, что ФЕ имеют «образное значение». В свете этого неясно, чем же «соб-ственно идиома» отличается от «собственно фразеологической едини-цы».
В «Словаре лингвистических терминов» Ж. Марузо (1960, с. 114) есть французский термин Idiotisme (от гр. idios), который Н. Д. Андре-ев (переводчик) ошибочно передал как «идиома», хотя следовало бы «называть вещи своими именами» и транслитерировать его как «идио-тизм» (см. нем.: Idiotismus). Этот термин ранее использовала в своей классификации устойчивых словосочетаний И. М. Вульфиус (1929) [см.: 152, с. 6], которая выделила: (1) идиомы (смотреть сквозь пальцы, спу-стя рукава, собаку съел, задать перцу), (2) пословицы, (3) идиотизмы (ни зги не видно, сгореть дотла).
Есть лингвисты, которые считают, что любая единица языка, имею-щая «образное» значение, является «идиомой». Так, в словаре идиом В. Коллинза [7] дефиниции этого термина не приводится. Поэтому, как показал научный анализ, в нем содержится 893 фраземы (the lion’s

192 Глава 7
share; to spoil the Egyptians, to turn over a new leaf; a wet blanket), 99 паре-мием (There is no smoke without fire; You can whistle for it) и 23 лексемы (bumbledom; dotty; gaga; to stomach; to wolf). Таким образом, на практи-ке оказывается, что так называемые «идиомы» — это и (1) непредика-тивные устойчивые словосочетания (УСС) — фраземы, поговорки; и (2) предикативные УСС — паремиемы, пословицы; и (3) лексемы (т. е. даже не словосочетания!).
Есть и более «оригинальные» мнения. Так, Д. Глинберг в Предисло-вии к «Словарю американских идиом: 8 000 единиц» [123, III] пишет следующее: «Идиома — это новое, неожиданное значение группы слов, каждое из которых обладает своим собственным значением [с. III]». Итак, идиома, по ее мнению — это не двуплановая единица (единство звучания и значения!), а всего лишь значение, то есть, так сказать, по-ловинка лингвистической единицы. Обратим также внимание на сле-дующую часть высказывания авторессы Предисловия: «…группы слов, каждое из которых обладает своим собственным значением». Инте-ресно, как она себе представляет слова, которые НЕ «обладают своим собственным значением»? Далее авторесса пишет: «Не меньшее чис-ло идиоматических выражений — имена. Так, hot dog (сосиска в хле-бе), White House (Белый Дом) — имена существительные. Некоторые из идиом — имена прилагательные: так, в нашем примере pepper and salt…» [ (c. III)].
Заметим, что даже школьники должны знать, что “Hot dog” и “White House” — это не “имена существительные”, а словосочетания, состоя-щие из имени прилагательного (hot, White) и имени существитель-ного (dog, House), а “pepper and salt” — это не «имя прилагательное», как думает Глинберг, а словосочетание, состоящее их двух имен суще-ствительных (pepper, salt), соединенных союзом (and). Далее авторес-са пишет, что «словарь содержит лексемные идиомы, фразеологиче-ские единицы и поговорки (с. V)», причем «Лексемные идиомы» — это выше приведенные «имена существительные», «имена прилагатель-ные». А «фразеологические единицы» (to fly off the handle; to blow one’s stack; to kick the bucket) и «поговорки» (don’t count your chickens before they are hatched) — это словосочетания, то есть двуплановые единицы, имеющие как звучание (сумма звучаний слов), так и значения (прямое и переносное).
А. Н. Баранов и Д. О. Добровольский [38], проанализировав литера-туру, пишут, что «можно выделить общую часть большинства опреде-лений идиомы, которая сводится к трем основным идеям: неоднослов-ность, устойчивость и идиоматичность» [38, 27], и дают свое определе-

193Лингвистические принципы и ляпсусы
ние: «Идиомы — это сверхсловные образования, которым свойствен-на высокая степень идиоматичности и устойчивости» [38, 57]. Заме-тим, что определение «идиомы» через «идиоматичность» — это элемен-тарная тавтология. А туманные понятия «неоднословность» и «сверх-словность» включает в себя такие принципиально различные единицы, как непредикативное словосочетание и предикативное словосочетание (т. е. предложение!). Следовательно, вся «идиоматика» представляет со-бой синтаксическую солянку из УСС и является шагом назад по сравне-нию с выделением и дальнейшим раздельным семантическим и струк-турным описанием фразем (непредикативных УСС) и паремием (преди-кативных УСС).
Поэтому мы полагаем, что слово «идиома», которая у некоторых лингвистов может обозначать и лексему, и фразему (поговорку), и па-ремиему (пословицу), и даже просто «значение» [123, c. III] давно уже следует исключить из лингвистического обращения, как бессмыслен-ное (или «трехсмысленное») и захламляющее научный лексикон, по-скольку оно вводит в заблуждение лингвистов, не являясь термином в научном понимании этого слова.
Фразеологические единицы (обороты) — «широкое» понимание (Телия) [144]
В. Н. Телия [144] дает следующее определение: «ФРАЗЕОЛОГИЗМ (фразеологическая единица) — общее название семантически связан-ных сочетаний слов и предложений, которые… воспроизводятся в речи в фиксированном соотношении семантической структуры и определен-ного лексико-грамматического состава» [144, 559]. «Термин «Ф.» обо-значает несколько семантически разнородных типов сочетаний: идио-мы, сочетания-фразеосхемы, пословицы, поговорки и крылатые слова». «Переосмысление, или семантическая транспозиция, лексического со-става, устойчивость и воспроизводимость — основные и универсаль-ные признаки Ф.» — пишет авторесса определения.
Отметим, во-первых, излишнее многословие: нет смысла отмечать «семантическую связанность» сочетаний слов и предложений. Разве существуют семантически НЕ связанные сочетания слов и предложе-ния? Во-вторых, зачем нужен этот тавтологический период — «устойчи-вость и воспроизводимость»? Любому лингвисту ясно, что словосочета-ние устойчиво потому, что воспроизводимо, а если оно воспроизводимо, то оно — устойчиво! В-третьих, использование слов, которые, как ока-

194 Глава 7
зывается, не имеют лингвистически корректных дефиниций (идиома, фразеосхема, пословица, поговорка), недопустимо как в энциклопеди-ческом, так и в лингвистическом описании единиц.
Посмотрим, какие дефиниции предлагает нам «Словарь лингвисти-ческих терминов» О. С. Ахмановой [36].
«ФРАЗЕОЛОГИЧЕСКАЯ ЕДИНИЦА (автоматизированная фраза, ав-томатизированный элемент, идиома, идиоматизм, композита сополо-жения, фразеограмма, фразеологический оборот, фракционирован-ный знак — всего 23 синонима!). Словосочетание, в котором семан-тическая монолитность (цельность номинации) довлеет над структур-ной раздельностью составляющих его элементов (выделение призна-ков предмета подчинено его целостному обозначению), вследствие чего оно функционирует в составе предложения как эквивалент отдельного слова».
Авторесса не сообщает, каким способом можно определить, «до-влеет» ли «семантическая монолитность» над «структурной раздельно-стью», а если да, то в какой степени? И что означает эта «семантическая монолитность»?
В статье ничего не говорится о том, какой из 2-х принципиально от-личающихся видов словосочетаний имеется в виду — непредикативное или предикативное (т. е. предложение)?
Ничего не говорится также о том, что эти «фразеологические еди-ницы» имеют прямое значение и переносное значение, являющееся результатом семантической трансформации прямого метафорически или метонимически.
«ПОСЛОВИЦА. Образное законченное изречения, имеющее назида-тельный смысл и, обычно, специфическое ритмо-фонетическое оформ-лениие. Русск. Белые ручки чужие труды любят» [36, 341].
«ПОГОВОРКА. Образное иносказательное выражение, отличаю-щееся от пословицы своей синтаксической незаконченностью. Русск. Ни пава ни ворона» [36, 328]).
Итак, если под «законченным изречением» понимается предложе-ние, а «синтаксическая незаконченность» означает отсутствие преди-кативной связи между словами, то авторесса так должна была написать.
Другого мнения придерживается В. Жуков [102]: «Под поговорка-ми понимаются краткие народные изречения (нередко назидательного характера), имеющие только буквальный план и в грамматическом от-ношении представляющие собой законченное предложение» [103, 11].
Отметим, однако, что все авторы отмечают (1) устойчивость и (2) наличие образного значения у всех этих фразеологизмов, пословиц

195Лингвистические принципы и ляпсусы
и поговорок. С другой стороны, авторы «не замечают» следующего: 1) существование двух принципиально различных типов словосочетаний: непредикативных (непредложений) и предикативных (предложений) УСС; 2) устойчивые словосочетания имеют как прямое значение (сум-ма значений слов), так и переносное значение, образованное из прямо-го путем его семантической трансформации (метафорически, метони-мически и т. п.). Поэтому мы сформулировали следующие лингвистиче-ски корректные дефиниции.
«Фразема — это устойчивое непредикативное словосочетание, имеющее как прямое, так и переносное (образное) значения».
«Паремиема — это устойчивое предикативное словосочетание, имеющее как прямое, так и переносное (образное) значения».
Пословично-поговорочные выражения (В. П. Жуков) [103]
В. П. Жуков [104] пишет: «Между пословицами и поговорками раз-мещается обширный тип пословично-поговорочных выражений, кото-рые сочетают в себе признаки пословиц и поговорок» [103, 12]. Посмо-трим, что бы это могло означать.
В «Предисловии» к словарю В. П. Жуков [104] пишет, что «от фра-зеологизмов пословицы и поговорки отличаются в структурно-грамма-тическом отношении: они представляют собой законченное предложе-ние» [104, 9].
Далее он пишет: «Под пословицами в широком смысле мы понимаем краткие народные изречения, имеющие одновременно буквальный и пе-реносный (образный) план или только переносный план и составляющие в грамматическом отношении законченное предложение» [103, 11].
Неясно, как он себе представлял пословицы, имеющие «только пере-носный план».
Известно, что переносное значение, как у лексем, так и у устойчи-вых словосочетаний образуется от (переносится с) прямого значения путем его семантической трансформации в ходе метафорического, ме-тонимического или иного процесса. Поэтому, невозможно существова-ние устойчивого словосочетания (УСС), имеющего «только переносное» значение без «прямого», от которого оно образовано! Может быть, речь идет о том, что они употребляются «только в переносном значении». Та-кая иллюзия может возникнуть, но так как «прямое» значение имеется, то оно вполне может использоваться говорящими в определенных кон-текстах.

196 Глава 7
«Под поговорками понимаются краткие народные изречения (не-редко назидательного характера), имеющие только буквальный план и в грамматическом отношении представляющие собой законченное предложение» [103, 11].
«Между пословицами и поговорками размещается обширный тип пословично-поговорочных выражений, которые сочетают в себе при-знаки пословиц и поговорок».
Итак, если существуют пословицы, имеющие как буквальный, так и переносный (образный) план, и поговорки, имеющие только букваль-ный план, то какой «план» тогда могут иметь так называемые «посло-вично-поговорочные выражения»? Ведь третьего не дано, т. е. “tertium non datur” или “nihil tertium est”, как говаривал Цицерон пару тысяч лет назад.
Странно, что такие семантически туманные, можно сказать, мифи-ческие «пословично-поговорочные выражения» как-то ухитряются рас-сматривать в некоем «семантико-типологическом аспекте» новые по-коления лингвистов. Видимо, для рецензентов подобных опусов вопрос о том, чем же объективно отличаются так называемые «пословично-по-говорочные выражения» от собственно «пословиц» и «поговорок», оста-ется «тайной за семью печатями»…
Семантические классы: сращения, единства, сочетания [89]
В. Н. Телия [144] пишет: «В отечественном языкознании большин-ство ученых выделяет вслед за В. В. Виноградовым 4 типа фразеоло-гизмов: фразеологические сращения (идиомы, утратившие мотивиров-ку значения: «бить баклуши», «собаку съесть»), фразеологические един-ства (идиомы, сохраняющие прозрачную внутреннюю форму: «сидеть на мели», «кот наплакал», «стреляный воробей»), фразеологические соче-тания («оказывать помощь», «зло (досада, страх) берет», «твердый ха-рактер», «поле деятельности», фразеологические выражения, или устой-чивые фразы (предложения с переосмысленным составом: «Не имей сто рублей, а имей сто друзей» и т. п.).» [144, 559].
Заметим, что В. В. Виноградов [89] описал только 3 класса, а 4-й класс (фразеологические выражения) предложил Н. М. Шанский [152], который считает, что они «не только являются семантически членимы-ми, но и состоят целиком из слов со свободными значениями» [152, 44], причем он различает две группы «фразеологических» выражений: 1) коммуникативного характера (Человек — это звучит гордо; Хрен редь-

197Лингвистические принципы и ляпсусы
ки не слаще; Без труда — не вытащишь и рыбки из пруда; Суждены нам благие порывы и т. п.); 2) номинативного характера: трудовые успехи, на данном этапе, поджигатели войны, высшее учебное заведение и т. д. [152, 45].
Отметим также, что из трех «виноградовских» классов два класса предложил основоположник «фразеологии» Шарль Балли [2] на 40 лет раньше, а В. В. Виноградов [89] позаимствовал их (не сославшись на Ш. Балли [2]) и добавил всего один собственный класс — «фразеоло-гические сращения».
Представляя четыре класса фразеологизмов, В. Н. Телия [144] ис-пользует поэтизм «позрачная внутренняя форма». Заметим по этому по-воду следующее: словосочетание «внутренняя форма» с философской точки зрения столь же бессмысленно (а с лингвистической — катахрез-но!), сколь и «внешнее содержание», поскольку «внутренний» и «содер-жание» — это категории одного порядка, которые противоположны другой паре категорий: «внешний» и «форма» соответственно. А соеди-нять противоположные категории в одном периоде антифилософично и, следовательно, антинаучно.
В итоге, лингвист после прочтения этой статьи не получает ни одно-значного лингвистически корректного определения «фразеологизма», ни определений семантических классов, которые позволили бы одно-значно и непротиворечиво разбить любой большой массив устойчивых словосочетаний (УСС) на несколько семантических классов.
В статье о фразеологических единицах [36, 505], в частности, отме-чается, что Ф. сращение характеризуется наибольшей степенью семан-тической неделимости, спаянности, монолитности (глобальности) …
Ф. единство характеризуется меньшей по сравнению со сращением спаянности ее элементов…
Ф. сочетание не обладает в отличие от единства полной семантиче-ской слитностью…
Отсюда следует, что фразеологическое единство обладает полной се-мантической слитностью! Но выше говорилось о том, что фразеологи-ческое единство характеризуется «меньшей по сравнению со сращени-ем спаянностью…». Это означает, что сращение, а не единство облада-ет полной спаянностью!
Логика здесь отсутствует, но и лингвистика не присутствует, по-скольку НИГДЕ не говорится о том, как же эту «семантическую слит-ность, спаянность, неделимость, монолитность и глобальность» оце-нивать. А ведь это понятие является у авторессы основополагающим при выделении семантических классов фразеологизмов! Не удивитель-

198 Глава 7
но, что хотя «за период с 1918 по 1986 гг. в СССР было опубликовано 15255 работ по фразеологии» [117, 11] до сих пор нет ни одной серьез-ной работы, в которой кому-нибудь удалось бы однозначно и непроти-воречиво разбить большой массив фразеологических единиц на предло-женные три класса!
Поскольку семантической классификации пословиц ранее не суще-ствовало, мы предложили следующие дефиниции [52].
«Паремиологическое сращение — это пословица, имеющая два зна-чения: прямое, которое неизвестно говорящим из-за незнания значе-ний некоторых слов (имен собственных, мифонимов, заимствований или архаизмов), и переносное — известное и высокочастотное».
When in Rome do as Romans do — 1 (прямое) Будучи в Риме, посту-пайтете так, как это делают римляне; 2 (перен.) Со своим уставом в чу-жой монастырь не ходи.
The devil is not so black as he is painted — 1. (прямое) Не так страшен черт, как его малюют; 2 (перен.) Ситуация не так страшна, как кажется.
«Паремиологическое единство — это пословица, имеющая два зна-чения: прямое известное, но низкочастотное, и переносное — извест-ное и высокочастотное»
Например: Strike the iron while it is hot — 1 (прямое) Куй железо, пока горячо; 2 (перен.) Делай дело, пока ситуация благоприятна.
There is a snake in the grass — 1 (прямое) В траве змеи водятся; 2 (пе-рен.) В данной ситуации кроется опасность.
«Паремиологическое сочетание — это пословица, имеющая пока только одно значение — прямое, которое известно и высокочастотно».
Например: First impressions are most lasting — Первое впечатление — самое сильное.
Practice makes perfect — Совершенство доcтигается практикой.Live and learn — Век живи, век учись.
Язык находится между человеком и природой (В. Гумбольдт) [96]
Во времена В. Гумбольдта [96] и ранее считалось, что язык — это не-кий «организм», находящийся где-то вне человека. В настоящее время известно, что на самом деле язык находится в голове человека, в коре головного мозга. Известно также, что лингвистическая система (состоя-щая из речевых и языковых знаков) отличается от системы мышления (сознания) (состоящей из единиц: понятий, суждений и умозаключе-

199Лингвистические принципы и ляпсусы
ний). Располагаются системы мышления и лингвистическая в разных частях коры головного мозга (см. схему).
МЫШЛЕНИЕ ЯЗЫК / РЕЧЬ
ЯЗЫК (по В. Гумбольдту)
Итак, каждому «предмету» действительности (мира) в головном моз-ге человека с помощью органов чувств формируется «понятие» о пред-мете. Этому понятию в другой части головного мозга формируется «лингвистический знак» (слово, словосочетание и т. п.). Следовательно, «язык/речь» находится не где-то в пространстве, между человеком (т. е. мышлением, как сущности человека разумного) и предметом, а в голо-ве, так сказать, за системой «мышления»!

ПРИЛОЖЕНИЯ
Приложение 1ТАК НАЗЫВАЕМЫЕ «ФРАЗЕОЛОГИЧЕСКИЕ ЕДИНИЦЫ»
В. В. ВИНОГРАДОВА В НАУЧНОМ ОСВЕЩЕНИИ
Здесь будет показано, что «фразеологические единицы» и так назы-ваемая «семантическая классификация» В. В. Виноградова [89] не име-ют строгих научных определений. Поэтому за прошедшие 70 лет ни-кто не смог использовать их для реального однозначного разбиения на классы единиц какого-либо фразеологического словаря. Анализ всех примеров В. В. Виноградова [89] в свете наших научно корректных де-финиций позволил выявить 101 фразему [непредикативное устойчи-вое словосочетание (УСС)] и 28 паремием [предикативных УСС]. Нами предложены новые лингвистические дефиниции семантических клас-сов: (а) «Фраземные сращения» — это фраземы, имеющие 2 значения: прямое — неизвестное говорящим из-за незнания значений ряда слов — архаизмов, имен собственных и религионимов; переносное (образное) значение — известное и высокочастотное (выявлено 8 единиц = 7,9 % фразем); (б) «Фраземные единства» — это фраземы, имеющие 2 зна-чения: прямое — известное, но низкочастотное; переносное — извест-ное и высокочастотное (65 единиц = 64,4 %); (в) «Фраземные сочета-ния» — это фраземы, имеющие пока одно значение — прямое, — из-вестное и высокочастотное (28 единиц = 27,7 %). Установлено, что фра-земы образованы по следующим структурным моделям: ГС (30 %), ГпС (11 %), ПС (9 %), СГ (5 %), СнеГ (2 %), пСГ (2 %) и т. д. Впервые предло-жены научные дефиниции семантических классов паремием: (а) паре-миемные сращения — это паремиемы, имеющие 2 значения: прямое — неизвестное говорящим из-за незнания значений ряда слов — архаиз-мов, имен собственных и религионимов; переносное (образное) значе-ние — известное и высокочастотное (выявлена 1 единица = 3,6 % паре-мием); (б) паремиемные единства — это паремиемы, имеющие 2 зна-чения: прямое, — известное, но низкочастотное; переносное — извест-ное и высокочастотное (26 единиц = 92,8 %); (в) паремиемные сочета-ния — это паремиемы, имеющие пока одно значение — прямое, — из-вестное и высокочастотное (1 единица = 3,6 %). Установлено, что па-

201Приложения
ремиемы, как предложения, относится к изъявительному (27 единиц) и повелительному (1 единица) наклонению; употребляются в настоя-щем (3 единицы), прошедшем (7 единиц), будущем (3 единиц) време-ни; стоят в действительном (146 единиц) или страдательном (отсут-ствуют) залоге.
Часть 1. Теория устойчивых словосочетанийСначала рассмотрим историю вопроса, из чего станет ясно, что ни-
какой «семантической классификации фразеологизмов В. В. Виноградо-ва» на самом деле не существует.
Сто двенадцать лет назад Шарль Балли [2] выделил в лингвистике новую область «фразеологию» и описал следующие семантические груп-пы во французском языке: 1) «les groupement usuels› — обычные группы (une grave maladie «тяжелая болезнь»); 2) «les series phraseologiques› — фразеологические серии (remporter une victoire «одержать победу»); 3) «les unites phraseologiques› — фразеологические единства (faire table rase «очистить место»).
Как известно, В. В. Виноградов [89] заимствовал у Ш. Балли [] эту классификацию (кстати, не ссылаясь на него!) и использовал для опи-сания фразеологических единиц русского языка, предложив следую-щие русские названия: фразеологические сращения, фразеологические единства и фразеологические сочетания.
1) К сожалению, Ш. Балли [2] не дал эксплицитных дефиниций фра-зеологических классов, поэтому В. В. Виноградов [89] (попытался это сделать и описал «… тип словосочетаний, абсолютно неделимых, не-разложимых, значение которых совершенно независимо от их лекси-ческого состава, от значений их компонентов и так же условно и про-извольно, как значение немотивированного слова-знака. Фразеологи-ческие единицы этого рода могут быть названы ФРАЗЕОЛОГИЧЕСКИ-МИ СРАЩЕНИЯМИ. Они не мотивированы и непроизвольны. В их зна-чении нет никакой связи, даже потенциальной, со значением их компо-нентов» [89, 22]. В качестве примеров автор приводит следующие: «со-баку съел (и сучкой закусил), во всю Ивановскую, вверх тормашками, бить баклуши, точить лясы, точить балясы и т. д.» [89, 22–23]. Далее ав-тор пишет: «Основным признаком СРАЩЕНИЯ является его семантиче-ская неделимость, абсолютная невыводимость значений целого из ком-понентов. Фразеологическое сращение представляет собою семантиче-скую единицу, однородную со словом, лишенным внутренней формы. Оно есть ни произведение, ни сумма семантических элементов. Оно — химическое соединение каких-то растворившихся и с точки зрения со-

202
временного языка аморфных лексических частей». В качестве приме-ров приводятся такие: «как ни в чем не бывало, дело не терпит отлага-тельства, совесть зазрила, мозолить глаза, мертвецки пьян, положа руку на сердце, сидеть сложа руки, средь бела дня, на босу ногу, (пустить-ся) во все тяжкие, так себе, куда ни шло, была не была, то и дело, хоть куда, трусу праздновать, диву даться, выжить из ума, чем свет, как пить дать, мало ли какой, из рук вон (плохо), так и быть, шутка сказать, себе на уме» [89, 23–24)].
2) Далее В. В. Виноградов [89] пишет, что «если в тесной фразеоло-гической группе сохранились хотя бы слабые признаки семантической раздельности компонентов, если есть хотя бы глухой намек на моти-вировку общего значения, то о сращении говорить уже трудно. Напри-мер, в выражениях (держать камень за пазухой, выносить сор из избы, семь пятниц на неделе, стреляный воробей, мелко плавает, кровь с мо-локом, последняя спица в колеснице, плясать под чужую дудку, без ножа зарезать, язык чесать или языком чесать, из пальца высосать, первый блин комом, плыть по течению, плыть против течения, всплыть на по-верхность и т. д.) значение целого связано с пониманием внутреннего образного стержня фразы, потенциального смысла слов, образующих эти ФРАЗЕОЛОГИЧЕСКИЕ ЕДИНСТВА. Таким образом, многие крепко спаянные фразеологические группы легко расшифровываются как об-разные выражения. Они обладают свойством потенциальной образно-стью. Образный смысл, приписываемый им в современном языке, ино-гда вовсе не соответствует их фактической этимологии… Понимание производности, мотивированности значения такого фразеологическо-го единства связано с сознанием его лексического состава, с сознани-ем отношения значения целого к значению составных частей. Таким об-разом, от фразеологических сращений отличается другой тип устойчи-вых, тесных фразеологических групп, которые тоже семантически не-делимы и тоже являются выражением единого, целостного значения, но в которых это целостное значение мотивировано, являясь произве-дением, возникающим из слияния значений лексических компонентов. В таком фразеологическом единстве слова подчинены единству обще-го образа, единству реального значения… Значение целого здесь абсо-лютно неразложимо на отдельные лексические значения компонентов. Оно как бы разлито в них и вместе с тем оно как бы вырастает из их се-мантического слияния. ФРАЗЕОЛОГИЧЕСКИЕ ЕДИНСТВА являются по-тенциальными эквивалентами слов, и в этом отношении они несколь-ко сближаются с фразеологическими сращениями, отличаясь от них се-мантической сложностью своей структуры, потенциальной выводи-

203Приложения
мостью своего общего значения из семантической связи компонен-тов. Фразеологические единства по внешней, звуковой форме могут со-впадать со свободными сочетаниями слов. Ср. устно-фамильярные вы-ражения: вымыть голову, намылить голову (кому-нибудь) в значении: сильно побранить, пожурить, сделать строгий выговор — и омоними-ческие словосочетания в их прямом значении: вымыть голову, намы-лить голову». Приводится ряд примеров: «Ноль внимания, ему и го-рюшка мало! Плакали наши денежки! Держи карман или держи карман шире! Что ему делается? чего изволите? Час от часу не легче! Хорошень-кого понемножку (ирон.); туда ему и дорога! Ср.: жирно будет; чем черт не шутит? И пошел и пошел! Наша взяла! Ума не приложу! Над нами не каплет! И дешево и сердито! До тех пор пока; с тех пор как; в то вре-мя как; с того времени как; ввиду того что; по мере того как; между тем как; после того как; потому что; до того что; несмотря на то что; вместо того чтобы; подобно тому как; прежде чем; так что; так чтобы; даром что; едва только; лишь только; чуть лишь; не то чтобы; добро бы; как будто бы и т. п.» [89, 25].
3) Затем говорится, что «тип фраз, образуемых реализацией несво-бодных значений слов, целесообразнее всего назвать ФРАЗЕОЛОГИ-ЧЕСКИМИ СОЧЕТАНИЯМИ. Фразеологические сочетания не являются безусловными семантическими единствами. Они аналитичны. В них слова с несвободным значением допускают синонимическую подста-новку и замену, идентификацию». «Но бывают устойчивые фразеоло-гические группы, в которых значения слов-компонентов обособляют-ся гораздо более четко и резко, однако остаются несвободными. На-пример: щекотливый вопрос, щекотливое положение, щекотливое обстоятельство и т. д.; обдать презрением, злобой, взглядом; обдать взглядом ласкающего сочувствия и т. п.; страх берет, тоска берет, до-сада берет, злость берет, ужас берет, зависть берет, смех берет, разду-мье берет, охота берет и т. п.» [89, с. 26–27]. «Фразеологически связан-ное значение трудно определимо. В нем общее логическое ядро не вы-ступает так рельефно, как в свободном значении. Фразеологически связанное значение, особенно при узости и тесноте соответствующих контекстов, дробится на индивидуальные оттенки, свойственные от-дельным фразам». Приводятся иллюстративные примеры: «потупить взор, взгляд, глаза; потупить голову; беспросыпно пьянствовать; спать беспробудным сном; беспробудное пьянство». «Для фразеологическо-го сочетания характерно наличие синонимического, параллельно-го оборота, связанного с тем же опорным словом, характерно осозна-ние отделимости фразеологически несвободного слова. Например: за-

204
тронуть чувство чести, затронуть чьи-нибудь интересы, затронуть гор-дость и т. п.» [89, с. 26–27].
Отметим, что в этом описании, содержащем различные философ-ско-физико-математико-химические аллюзии («лишено внутренней формы», «потенциальная связь», «ни произведение, ни сумма семанти-ческих элементов», «химическое соединение каких-то растворивших-ся, аморфных частей»), а также так называемые «термины», которые, как выясняется, не имеют строгих научных дефиниций (идиоматич-ность, мотивированность, внутренняя форма), в сущности, отсутству-ет релевантная лингвистически корректная информация о сращениях, единствах и сочетаниях, которая позволила бы различать их и исполь-зовать для дальнейшего описания.
По этой причине за прошедшие 60 лет никому не удалось однознач-но расклассифицировать какое-либо достаточно полное собрание фра-зеологизмов (например, словарь объемом в несколько тысяч единиц) какого-либо языка. Видимо, поэтому находятся хитроумные лингвисты, которые заявляют, что они изучают не «фразеологические единицы», а нечто совершенно особенное, называя их «как бог на душу положит», например: автоматизированный элемент, автоматизированная фраза, идиоматизм, композита соположения, лексикализированное словосо-четание, фракционированный знак, фразеограмма и т. п. Подобные «ху-дожественные излишества» хотя и ласкают слух авторов этих экзотиз-мов, но не сдвигают дело изучения устойчивых словосочетаний (УСС) с мертвой точки, поэтому «воз нерасклассифицированных фразеологиз-мов и ныне там» [89, 27] …
Выскажем несколько критических замечаний с позиций современ-ной лингвистики.
А) Судя по иллюстративным примерам, В. В. Виноградов [89] «не ви-дит» принципиальных различий между непредикативными и предика-тивными УСС и приводит их подряд, недифференцированно. Рассмо-трим несколько его примеров: 1) во всю Ивановскую; 2) собаку съел и сучкой закусил; 3) бить баклуши; 4) куда ни шло; 5) точить лясы; 6) мелко плавает; 7) держать камень за пазухой; 8) первый блин комом; 9) выносить сор из избы; 10) плакали наши денежки; 11) брать в свои руки; 12) держи карман шире 13) ноль внимания; 14) чем чорт не шу-тит [здесь под нечетными цифрами мы приводим непредикативные УСС; под четными — предикативные УСС (то есть предложения)].
Б) Не учитывается тот важный факт, что УСС имеет как прямое зна-чение (сумма значений слов), так и переносное (метафорическое, мето-нимическое и т. п.) значение, являющееся результатом семантической

205Приложения
трансформации прямого значения целиком (а не каких-либо отдель-ных слов). Заметим, что еще 155 лет тому назад В. И. Даль [97] упоми-нал целый ряд различных способов образования переносного значения («окольного выражения») у пословиц: метафора, аллегория, гипербола, метонимия, синекдоха, ирония, противоположность, извращение, дву-смыслие, олицетворение, условность, опущение, недоговорка [97, 34].
Приведем примеры, иллюстрирующие наличие как прямого, так и переносного значений у УСС:
«Собаку съесть» 1) (прямое значение) употребить в пищу собаку; 2) (переносное значение) приобрести большой опыт, навык, основа-тельные знания о чем-либо.
«Показать кузькину мать» 1) (прямое значение) показать мать неко-его Кузьки (видимо, грозную даму!); 2) (переносное значение) угроза жестоко наказать кого-либо.
«Намылить голову» 1) (прямое значение) нанести мыло на голову (при мытье); 2) (переносное значение) Выругать, разбранить, сделать суровое внушение.
В свете выше сказанного, лингвистически некорректными являют-ся многократно повторяемые В. В. Виноградовым [89] рассуждения о типе словосочетаний, «… ЗНАЧЕНИЕ которых совершенно независи-мо от их лексического состава, от значений их компонентов и так же условно и ПРОИЗВОЛЬНО, как значение немотивированного слова-зна-ка» [89, 22].
Возникает закономерный вопрос: «От чего же это значение зави-сит?». Но ответ отсутствует…
Как известно, ПЕРЕНОСНОЕ значение является семантической транс-формацией ПРЯМОГО, от которого оно образовано. Следовательно, фра-зема «Собаку съесть» не имеет такого «ПРОИЗВОЛЬНОГО» значения, как, например: «Выругать, разбранить, сделать суровое внушение» либо «вы-ражать угрозу жестоко наказать кого-либо». Точно так же фразема «По-казать кузькину мать» не может иметь «ПРОИЗВОЛЬНОГО» значения, например: «Приобрести большой опыт, навык, основательные знания о чем-либо». В качестве примеров можно привести практически любую из 12 тыс. фразеологических единиц, приведенных в крупнейшем в мире «Фразеологическом словаре русского литературного языка» А. И. Федоро-ва [146]. ВСЕ переносные значения выводятся из прямых значений, яв-ляющимися суммой значений слов, из которых они состоят.
В) Что у В. В. Виноградова [89] означает «немотивированное слово-знак» остается только гадать, так как такого термина нет ни в лингви-стических словарях [36], ни в лингвистических энциклопедиях [155].

206
Г) Отличие «фразеологических единств» от «фразеологических сра-щений» В. В. Виноградов [89] описывает следующим образом: «Если в тесной фразеологической группе сохранились хотя бы СЛАБЫЕ ПРИ-ЗНАКИ семантической раздельности компонентов, если есть хотя бы ГЛУХОЙ НАМЕК на мотивировку общего значения, то о сращении гово-рить уже трудно» [89].
Поскольку неизвестно, как можно оценить степень «слабости при-знака» или «глухости намека», то пользоваться таким «объяснением» для практического различения семантических классов фразем невоз-можно. Невозможно также однозначно определить, чем же семантиче-ски отличаются друг от друга, например, следующие фразеологические единицы: 1) намылить голову, 2) держать камень за пазухой, 3) бить ключом, 4) плясать под чужую дудку, 5) взять за бока, 6) плыть по тече-нию, 7) брать в свои руки, 8) выносить сор из избы и т. д. Оказывается, В. В. Виноградов [], опираясь на свою интуицию, относит их к разным классам: СРАЩЕНИЯМ (они обозначены нечетными номерами: 1, 3, 5, 7) и ЕДИНСТВАМ (они обозначены четными числами: 2, 4, 6, 8).
Д) Далее он пишет: «Отличие фразеологического единства от фра-зеологического сочетания состоит в следующем. В фразеологическом сочетании значения сочетающихся слов в ИЗВЕСТНОЙ СТЕПЕНИ РАВ-НОПРАВНЫ И РЯДОПОЛОЖНЫ». Однако в чем же заключается это «равноправие и рядоположность», автор не объясняет, как не объяс-няет и способ оценки этой «степени равноправности и рядополож-ности». Подобное «объяснение» не позволяет найти разницу, напри-мер, между следующими фразеологическими единицами: 1) взять за бока, 2) выносить сор из избы, 3) положить зубы на полку, 4) затро-нуть чувство чести, 5) уйти в свою скорлупу, 6) спать беспробудным сном, 7) плясать под чужую дудку, 8) отвести глаза (от кого-нибудь). Но В. В. Виноградов [89] ничтоже сумняшеся относит одни из них к ЕДИНСТВАМ (мы обозначили их нечетными номерами), а другие — к СОЧЕТАНИЯМ (обозначены четными числами). А на каком основа-нии, позвольте спросить?
Таким образом, как показывает анализ, практически никакой «се-мантической классификации В. В. Виноградова» [89] не существует, так как предложенное им описание семантических классов не позволяет од-нозначно отделять один семантический класс фразеологических еди-ниц от другого. Фактически остаются только ТРИ НАЗВАНИЯ семанти-ческих классов: фразеологические единства и сочетания (предложен-ные Шарлем Балли [2]) и фразеологические сращения (предложенное В. В. Виноградовым [89]).

207Приложения
Часть 2Практика описания УССМы поставили перед собой задачу: извлечь все примеры «фразео-
логических единиц» из статьи В. В. Виноградова [89] и, рассмотрев их в свете научно корректных дефиниций, во-первых, разделить на фра-земы и паремиемы, во-вторых, разбить фраземы и паремиеы на семан-тические классы в соответствии с нашими дефинициями (этим мы про-иллюстрируем то, что дает строгий научный подход к классификациям лингвистических единиц любого уровня); в-третьих, выявить структур-ные модели, по которым они построены.
Поскольку в определениях фразем и их семантических классов у тео-ретиков-фразеологистов [89; 144; 152] практически отсутствует лин-гвистически релевантная информация о таких важнейших характери-стиках единиц, как «звучание» и «значение», «форма» и «содержание», «структура» и «функция», «предикативность» или «непредикативность» словосочетаний, их устойчивость, наличие у них «прямого» и «перенос-ного (образного)» значений, то, во избежание недоразумений, мы бу-дем пользоваться следующими лингвистически корректными определе-ниями устойчивых словосочетаний (УСС).
«Фразема» (поговорка) — непредикативное устойчивое словосоче-тание, имеющее как прямое, так и переносное (образное) значения [62; 64; 68; 71; 78].
«Паремиема» (пословица) — это предикативное устойчивое слово-сочетание (т. е. предложение), имеющее как прямое, так и переносное (образное) значения [52; 62; 64; 66; 69; 76].
Сразу же рассмотрим вопрос о соотношении между этими двумя на-учно выделенными группами и различными «народными» названиями: пословицами, поговорками, клише, крылатыми выражениями и проч. За основу мы возьмем мнения людей, которые на самом деле разбира-ются в так называемой «фразеологии» (то есть составителей больших словарей пословиц и поговорок), а не дилетантские упражнения так на-зываемых «теоретиков», неспособных даже дать научно строгие опреде-ления изучаемых единиц.
Так, В. И. Даль [97] лично собрал и опубликовал словарь «Пословицы русского народа», содержащий 30 тысяч единиц, которые являются пре-дикативными УСС. Следовательно, народный термин «пословица» соот-ветствует научному термину «паремиема». Кстати, «Большой словарь русских пословиц» [126] содержит около 70 тыс. единиц, являющихся предикативными устойчивыми словосочетаниями. То есть «пословица» означает то же, что и паремиема.

208
В. М. Мокиенко и Т. Г. Никитана [125] лично составили и опубли-ковали «Большой словарь русских поговорок», содержащий свыше 40 тысяч единиц, которые являются непредикативными УСС. Следова-тельно, народный термин «поговорка» соотвествует научному терми-ну «фразема».
Поэтому никаких других терминов, кроме «фразема=поговорка» и «паремиема=пословица» мы не используем, так как все эти «фразео-логические единицы», «фразеологические обороты», «идиомы», «идио-матизмы» и «идиотизмы» (это название заимствовала из французского языка И. Вульфиус [см.: 152], «автоматизированные фразы» и не менее «автоматизированные элементы», «композиты соположения», «фразео-граммы» и «фразеосхемы», «клише», «крылатые слова» и не менее «кры-латые фразы» в соотвествии с наличием или отсутствием предикатив-ной связи между словами являются либо фраземами, либо паремиема-ми «по определению».
Таким образом, в лингвистие существуют две разные области, из-учающие устойчивые словосочетания (УСС):
1) фразеология, изучающая семантику и структуру фразем (погово-рок);
2) паремиология, изучающая семантику и синтаксическую структу-ру паремием (пословиц).
Эти единицы различаются как семантически, так и структурно, как будет показано далее. Так, например, фраземы строятся по следую-щим моделям: П+С (прилагательное + существительное), например: белая ворона, старая дева, дубина стоеросовая, авгиевы конюшни, ва-вилонское столпотворение и т. п. Либо по модели Г+С (глагол + суще-ствительное): бить баклуши, валять дурака, тянуть кота за хвост, тянуть канитель и т. д. и т. п.
Паремиемы, являются предложениями, поэтому в структурно-син-таксическом плане могут быть классифицированы по таким категори-ям, например, как наклонение, время, залог и т. п. Так, паремиема «Ба-бушка надвое сказала» характеризуется граммемами изъявительного наклонения, настоящего времени, действительного залога и т. п. и т. д. «Черт возьми» — повелительным наклоненим.
Ниже мы приведем дефиниции семантических классов, использовав приводимые в каждом учебнике по «Введению в языкознание» и рабо-тах по фразеологии названия классов («сращений» «единств» и «сочета-ний»), но дав им наши лингвистически корректные определения.
«Фраземное сращение — это фразема, имеющая два значения: 1-е (прямое), которое неизвестно говорящим из-за незнания значений не-

209Приложения
которых слов (архаизмов, антропонимов, топонимов, религионимов, заимствований); 2-е (переносное, образное), которое известно и высо-кочастотно».
«Фраземное единство — это фразема, имеющая два значения: 1-е (прямое) известное, но редко употребляемое; 2-е (переносное, образ-ное) — известное и высокочастотное».
«Фраземное сочетание — это фразема, имеющая пока только одно значение, которое известно и высокочастотно».
«Паремиемное сращение — это паремиема, имеющая два значения: 1-е (прямое), которое неизвестно говорящим из-за незнания значений некоторых слов (антропонимов, топонимов, религионимов, архаизмов, заимствований)»; 2-е (переносное, образное), которое известно и высо-кочастотно».
Например: «Бог знает» 1) (прямое) Это значение неизвестно, так как имя собственное «Бог» ничего нам не говорит (а попы о нем гово-рят, «черт знает что»!); 2) (переносное, метонимич.) Нечто неизвестное говорящему.
«Не так страшен черт, как его малюют» 1 (прямое) Это значение не-известно из-за незнания значения слова черт (поскольку никто черта лично не видел, то любой поп наплетет «с три короба», а другой — наго-ворит «сорок бочек арестантов»). 2 (переносное, образное) Дело не так страшно в действительности, как представляется, как кажется.
«Паремиемное единство — это паремиема, имеющая два значения: 1-е (прямое), которое известно, но редко употребляемо; 2-е (перенос-ное, метафорическое, метонимическое) известное и высокочастотное». Например:
«Много воды утекло» 1) (прямое) Утекло много воды (на что требует-ся много времени); 2) (переносное, образное) Прошло много времени, произошло немало перемен с каких-либо пор.
«Паремиемное сочетание — это паремиема, имеющая пока только одно значение, которое известно и высокочастотно». Обычно, это утвер-ждения общего, абстрактного или конкретного характера.
Например: «Век живи, век учись» 1. (прямое) Учись всю жизнь (весь свой век).
§ 1. Семантическая классификация фраземКак известно, В. В. Виноградов [89] «не видит» различий между пре-
дикативными и непредикативныеми словосочетаниями. В результате сплошного анализа 129 так называемых «фразеологических единиц», извлеченных из его статьи, было установлено, что они распадаются

210
на 101 фразему (т. е. непредикативную УСС) и 28 паремием (т. е. преди-кативных УСС) (Табл. 75).
Приведем примеры фразем: Выносить сор из избы; Грудная жаба; Держать в ежовых рукавицах; Держать камень за пазухой; диву давать-ся; Железная дорога; задеть гордость; затронуть чьи-нибудь интересы; И дешево и сердито! Из пальца высосать; из рук вон (плохо); Кровь с мо-локом; Намылить голову кому-нибудь; Ни в зуб толкнуть; Ноль внима-ния; носу не казать; опустить глаза; Положить зубы на полку; Послед-няя спица в колесе; потупить взгляд; С боку припека; себе на уме; Семь пятниц на неделе; спать беспробудным сном; Стреляный воробей; труса праздновать; Уйти в свою скорлупу; шутка сказать.
К паремиемам относятся следующие УСС: (он) мелко плавает; (я) ума не приложу! держи; карман шире! досада берет; ему и горюшка мало! жирно будет! Как ни в чем не бывало; Над нами не каплет! наша взяла! охота берет; первый блин (бывает) комом; плакали наши денеж-ки! Собаку съел в чем-нибудь; страх берет).
Таблица 75Распределение фразем и паремием
по уточненным семантическим классам
Устойчивые словосочетания
Семантический класс
Сращения Единства Сочетания Всего
Фраземы=поговорки (непредикативные УСС)
8 (7,9 %) 65 (64,4 %) 28 (27,7 %) 101 (100 %)
Паремиемы=пословицы(предикативные УСС)
1 (3,6 %) 26 (92,8 %) 1 (3,6 %) 28 (100 %)
Сумма (по нашим данным)
9 (9,0 %) 91 (64,7 %) 29 (26,3 %) 129 (100 %)
Фразеологиче-ские ед-ницы В. В. Виноградова
26*+4**=30(23,3 %)
65*+15**=80(62,0 %)
10*+9**=19(14,7 %)
101* + 28** = 129
(100 %)
Примечание. Значки * и ** обозначают фразеологические едини-цы В. В. Виноградова [89], которые в синтаксическом плане оказались непредикативными (*) или предикативными (**). Приводимые ниже примеры из его статьи снабжены указаниями на семантические клас-сы, в которые он их интуитивно помещает: ср — сращения, е — един-ства, с — сочетания.
Семантический анализ фразем показывает, что, в соответствии с введенными нами дефинициями, к фраземным сращениям относит-

211Приложения
ся 8 единиц, например: бить баклуши — ср; вверх тормашками — ср; во всю Ивановскую — ср; Кузькина мать — ср; Показать кому-нибудь кузькину мать — ср; точить балясы — ср; точить лясы — ср; у черта на киличках — ср.
Отметим, что и В. В. Виноградов [89] интуитивно относит эти 8 ФЕ к сращениям! Это не случайно, так он «чувствовал, но не смог понять», что поскольку их прямое значение современным носителям русского языка неизвестно из-за незнания ими значений архаизмов или имен собственных (Ивановская, Кузька, баклуши, тормашки, балясы, лясы, черт, килички!), то их следует отнести к «сращениям».
Фраземные единства представляют самый многочисленный класс (64,4 %), например: Без ножа зарезать — е; беспробудное пьянство — е; беспросыпно пьянствовать — е; Бить ключом — е; Биться из-за кус-ка хлеба — е; Брать в свои руки — е; Взять за бока — е; Всплыть на по-верхность — е; выжить из ума — ср; Вымыть голову — е; Выносить сор из избы — е; глаз не казать — с; Грудная жаба — т-ср; Держать в ежо-вых рукавицах — ср; С боку припека (у) — ср; себе на уме — ср; Семь пятниц на неделе — е; спать беспробудным сном — е; Стреляный во-робей — е; то и дело — ср; трусу праздновать — ср; уйти в свою скор-лупу — е; чем свет — ср; шутка сказать — ср; щекотливое обстоятель-ство — с; щекотливое положение — с; щекотливый вопрос — с; Язык че-сать — е; Языком чесать — е).
Однако В. В. Виноградов интуитивно разделил эти 65 единиц на 14 сращений, 41 единство и 10 сочетаний. Напомним, что все едини-цы этого класса имеют по 2 значения — прямое и переносное, В. В. Ви-ноградов, видимо, «интуитивно чувствовал» это и поместил в «един-ства» хоть и не все, но все же 41 фразеологизм.
Фраземные сочетания насчитывают 27,7 % фразем, например: В то время как — е; Ввиду того что — е; вместо того чтобы — е; даром что — е; До тех пор пока — е; до того что — е; едва только — е; С того времени как — е; так как — ср; так что — е; Хорошенького понемнож-ку — е; так себе — ср; так чтобы — е; хоть куда — ср.
Отметим, что эти 28 единиц неизвестно почему были распределены В. В. Виноградовым [89] по следующим классам: сращения — 4 едини-цы, единства — 23 единицы, а в сочетания — ни одной! Такова цена его «туманных» определений классов…
Паремиемы распределяются по семантическим классам следующим образом.
К паремиемным сращениям относится одна единица — чем черт не шутит?! Но у В. В. Виноградова [89] она отнесена к единствам.

212
К паремиемным единствам относится 26 единиц (92,8 %), например: была не была-ср; держи карман шире! — е; досада берет-с; ему и горюш-ка мало! — е; жирно будет! — е; зависть берет — с; злость берет — с; и пошел и пошел! — е; над нами не каплет! — е; наша взяла! — е; охота берет — с; первый блин (бывает) комом — е; плакали наши денежки! — е; смех берет — с; Собаку съел в чем-нибудь — ср; страх берет — с; то-ска берет — с, туда ему (будет) и дорога! — е; ужас берет — с; час от часу не (становится) легче! — е; чего изволите? — е.
Отметим, что из 28 предикативных единиц В. В. Виноградов [89] только 4 интуитивно относит к сращениям, 15 — к единствам и 9 — к сочетаниям (не обратив, правда, внимания на такую «синтаксическую мелочь», как принадлежность их к предикативным устойчивым слово-сочетаниям, т. е. предложениям!).
К паремиемным сочетаниям относится 1 единица: «Что ему сдела-ется?».
§ 2. Структурная классификация фраземЕсли В. В. Виноградов [89] и пытался модифицировать семанти-
ческую классификацию Ш. Балли [2] (правда, без особого успеха!), то о структурной классификации в его статье нет и речи. Однако непре-дикативные устойчивые словосочетания, каковыми являются фраземы, состоят из слов различной частеречной принадлежности, что является одной из их структурных характеристик. Наш анализ показал, что фра-земы образуются по различным структурным моделям, причем отнюдь не по каким-либо особым, отличным от тех, которые существуют в со-временном языке, как думают некоторые фразеологи [144], а по впол-не обычным моделям языка. Объясняется это тем, что фраземы (и паре-миемы!) представляют собой обычные и вполне типичные словосочета-ния, которые настолько «понравились» носителям языка, что они стали их употреблять часто, «сплошь и рядом», т. е. превратили их в «устойчи-вые словосочетания».
Ниже представлены результаты структурного анализа «фразео-логических единиц», извлеченных из статьи В. В. Виноградова [89]. (Табл. 76).
Анализ распределения фразем по структурным классам показал сле-дующее (Табл. 76).
Наиболее многочисленны следующие модели:Модель ГС — 30 единиц (29,7 %), например: Выносить сор из избы —
е; Держать камень за пазухой — е; Класть зубы на полку — е; обдать взглядом ласкающего сочувствия — с; Положить зубы на полку — е; за-

213Приложения
деть чувство чести — е; затронуть чувство чести — е; Бить ключом — е; Вымыть голову — е; задеть гордость — е; затронуть гордость — е; На-мылить голову кому-нибудь — е; обдать взглядом — с; обдать злобой — с; обдать презрением — с; опустить глаза — е; опустить голову — е; от-вести глаза (кому-нибудь) — е; отвести глаза (от кого-нибудь) — с; по-тупить взгляд — е; потупить взор — е.
Таблица 76Структурные классы фраземных сращений
СтруктурнаяМодель
Коли-чество % Примеры
ГС 30 29,7 Показать Кузькину мать, положить зубы на полку, задеть чувство чести, обдать презрением, точить лясы, бить баклуши, бить ключом, опустить голову, точить балясы
ГпС 11 10,9 Брать в свои руки, держать в ежовых рукавицах, взять за бока, кричать во всю Ивановскую, плыть против течения
ПС 9 8,9 Грудная жаба, железная дорога, щекотливый во-прос, Кузькина мать, стреляный воробей, беспро-будное пьянство
СГ 5 4,9 Диву даваться, трусу праздновать, языком чесать
СнеГ 2 2,0 Глаз не казать, носу не казать
пСГ 2 2,0 Без ножа зарезать, из пальца высосать
Прочие 44 41,6 Вверх тормашками, ни в зуб толкнуть, себе на уме, у черта на киличках, хорошенького понемножку, ноль внимания, семь пятниц на неделе, из рук вон плохо, без ножа зарезать
Сумма 101 100,0
Примечание. Приняты обозначения: Г — глагол, С — существитель-ное, П — прилагательное, п — предлог, не — отрицательная частица.
Модель ГпС — 11 единиц (10,9 %): Брать в свои руки — е; Держать в ежовых рукавицах — ср; Плясать под чужую дудку — е; Уйти в свою скорлупу — е; Биться из-за куска хлеба — е; Взять за бока — е; Всплыть на поверхность — е; выжить из ума — ср; Плыть по течению — е; Плыть против течения — е; кричать во всю Ивановскую — ср.
Модель ПС — 9 единиц: Последняя спица в колесе — е; беспробуд-ное пьянство — е; Грудная жаба — т-ср; Железная дорога — т-ср; Стре-

214
ляный воробей — е; щекотливое обстоятельство — с; щекотливое поло-жение — с; щекотливый вопрос — с; Кузькина мать — ср.
Модель СГ — 5 единиц: диву даваться — ср; трусу праздновать — ср; шутка сказать — ср; Язык чесать — е; Языком чесать — е.
Модель СнеГ — 2 единицы: глаз не казать — с; носу не казать — с.Модель пСГ — 2 единицы: Без ножа зарезать — е; Из пальца высо-
сать — е.Прочие модели: 1) пСНН — 1 единица: из рук вон (плохо) — ср;
2) пСпС — 1 единица: у черта на киличках — ср; 3) пСС — 1 единица: с боку припека (у) — ср; 4) МСсС — 1 единица: то и дело — ср. и т. д.
§ 3. Семантическая классификация паремиемАнализ распределения паремием по семантическим классам показал
следующее (Табл. 77).Таблица 77
Семантическая классификация паремием
Семантиче-ский класс
Кол-во % Примеры
Сращения 1 3,6 Чем черт не шутит?
Единства 26 92,8 Собаку съел, наша взяла, ужас берет, мелко плава-ет, смех берет
Сочетания 1 3,6 Что ему сделается?
Сумма 28 100
Примечание. Приводимые примеры снабжены указанием на семан-тический класс, интуитивно присвоенный В. В. Виноградовым [89], а именно: ср — сращение, е — единство, с — сочетание.
Полученные данные свидетельствуют о том, что наиболее много-численным классом являются паремиемные единства — 26 единиц (92,8 %), например: ума не приложу! — е; жирно будет! — е; тоска бе-рет — с; страх берет — с; (он) мелко плавает — е; досада берет — с; ему и горюшка мало! — е; зависть берет — с; час от часу не (становит-ся) легче! — е; чего изволите? — е; Как ни в чем не бывало — ср; была не была — ср; и пошел и пошел! — е; Куда (бы это) ни шло — ср; плака-ли наши денежки! — е; держи карман шире! — е.
Паремиемные сращения представлены одной единицей: чем черт не шутит?

215Приложения
Паремиемные сочетания также представлены одной единицей: что ему сделается?
§ 4. Семантические классы паремием и наклонениеПаремиемы, как предложения, подчиняются совсем другим струк-
турным закономерностям, чем фраземы. Они могут принадлежать раз-личным грамматическим (синтаксическим) категориям, например: на-клонению, времени, залогу и т. д. Анализ принадлежности паремием к граммеме наклонения показал следующее (Табл. 78).
Таблица 78Семантические классы паремием и наклонение
НаклонениеСемантический класс
Сращения Единства Сочетания Всего
Изъявительное 1 25 1 27
Повелительное - 1 - 1
Сумма 1 26 1 28
Наш анализ показал, что 96 % паремием относятся к изъявительно-му наклонению, например: жирно будет! что ему сделается? тоска бе-рет; страх берет; (он) мелко плавает; досада берет; ему и горюшка мало! чем черт не шутит? Как ни в чем не бывало; собаку съел (в чем-нибудь); была не была; и пошел и пошел! Куда (бы это) ни шло; наша взяла! пла-кали наши денежки!
Обнаружена только одна паремиема в повелительном наклонении: держи карман шире!
Отметим, что из 27 паремием в изъявительном наклонении к сра-щениям относится 1 паремиема (чем черт не шутит?), к сочетани-ям — 1 (что ему сделается?), а остальные 25 — к семантическому клас-су единств, например: Над нами не каплет! охота берет; первый блин (бывает) комом; раздумье берет; смех берет; туда ему и дорога! ужас бе-рет; час от часу не (становится) легче! Куда (бы это) ни шло; наша взя-ла! плакали наши денежки!
Паремиема в повелительном наклонении относится к семантическо-му классу единств: держи карман шире!
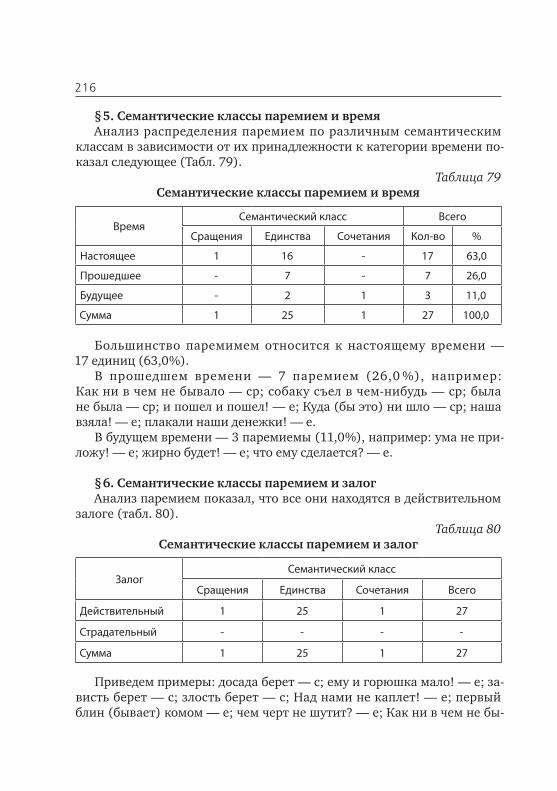
216
§ 5. Семантические классы паремием и времяАнализ распределения паремием по различным семантическим
классам в зависимости от их принадлежности к категории времени по-казал следующее (Табл. 79).
Таблица 79Семантические классы паремием и время
ВремяСемантический класс Всего
Сращения Единства Сочетания Кол-во %
Настоящее 1 16 - 17 63,0
Прошедшее - 7 - 7 26,0
Будущее - 2 1 3 11,0
Сумма 1 25 1 27 100,0
Большинство паремимем относится к настоящему времени — 17 единиц (63,0 %).
В прошедшем времени — 7 паремием (26,0 %), например: Как ни в чем не бывало — ср; собаку съел в чем-нибудь — ср; была не была — ср; и пошел и пошел! — е; Куда (бы это) ни шло — ср; наша взяла! — е; плакали наши денежки! — е.
В будущем времени — 3 паремиемы (11,0 %), например: ума не при-ложу! — е; жирно будет! — е; что ему сделается? — е.
§ 6. Семантические классы паремием и залогАнализ паремием показал, что все они находятся в действительном
залоге (табл. 80).Таблица 80
Семантические классы паремием и залог
ЗалогСемантический класс
Сращения Единства Сочетания Всего
Действительный 1 25 1 27
Страдательный - - - -
Сумма 1 25 1 27
Приведем примеры: досада берет — с; ему и горюшка мало! — е; за-висть берет — с; злость берет — с; Над нами не каплет! — е; первый блин (бывает) комом — е; чем черт не шутит? — е; Как ни в чем не бы-

217Приложения
вало — ср; собаку съел в чем-нибудь — ср; была не была — ср; и пошел и пошел! — е; Куда (бы это) ни шло — ср; наша взяла! — е.
Таким образом, в так называемой «семантической классифика-ции В. В. Виноградова», во-первых, названия классов представляют со-бой просто-напросто перевод французского названий, предложенных Ш. Балли (2) на полстолетия ранее; во-вторых, научно строгих опре-делений классов нет, а, следовательно, нет и классификации. Беспо-мощные аллюзии к философии, химии, физике вряд ли помогают разо-браться в сути этого лингвистического явления, а опора на «глухие на-меки на мотивировку», на «слабые признаки семантической раздельно-сти компонентов» демонстрирует отсутствие понимания того, что же представляет собой любая научная классификация. Это также прояв-ляется и в том, что В. В. Виноградов [89] «не замечает» того очевидного факта, что «фразеологические единицы» обладают прямым значением (сумма значений слов) и переносным значением, являющимся резуль-татом семантической трансформации прямого значения. Следователь-но, это переносное значение ФЕ не может быть «совершенно независи-мо от их лексического состава, от значений их компонентов». Антинауч-но поэтому писать, что «в их значении нет никакой связи, даже потен-циальной, со значением их компонентов».
Только учет прямого и переносного значений фразем и паремием по-зволяет создать их научную семантическую классификацию, позволяю-щую однозначно анализировать любые массивы УСС!

218
Приложение 2СЕМАНТИКО-СТРУКТУРНЫЕ ХАРАКТЕРИСТИКИ
1000 ФРАЗЕОЛОГИЗМОВ РУССКОГО ЯЗЫКА. ПАРЕМИЕМЫ
Кратко говоря, количественный семантико-структурный анализ 168 паремием (предикативных устойчивых словосочетаний=пУСС) русско-го языка показал, что они распределяются по следующим семантиче-ским классам: а) сращения [пУСС, имеющие 2 значения: прямое — не-известное говорящим из-за незнания значений ряда слов-архаизмов, имен собственных и религионимов; переносное (образное) — извест-но и высокочастотно] — 3 единицы (1,8 %); б) единства [пУСС, имею-щие 2 значения: прямое — известное, но малочастотное; переносное — известное и высокочастотное] — 130 единиц (77,4 %); сочетания [пУСС, имеющие пока одно значение — прямое — известное и высокочастот-ное] — 35 единиц (20,8 %). Анализ выявил распределение паремием по наклонению: а) изъявительное — 151 единиц (89,9 %); б) повели-тельное — 17 ед. (10,1 %); сослагательное — не представлено; по време-ни: а) настоящее время — 80 ед. (53,0 %); прошедшее — 55 ед. (36,4 %); будущее — 16 ед. (10,6 %); по залогу: а) действительный залог — 146 ед. (96,7 %); страдательный залог — 5 ед. (3,3 %).
Количественное описание характера распределения паремием (по-словиц=устойчивых предложений) по разным граммемам (наклоне-ние, время, залог и т. д.) из двух разных словарей [95; 102] позволило впервые получить точную картину этого явления, чему помогло два сле-дующих обстоятельства описания устойчивых словосочетаний (УСС): 1) впервые были предложены и использованы в работе лингвистиче-ски корректные дефиниции фразем-поговорок (непредикативных УСС) и паремием-пословиц (предикативных УСС), что позволило количе-ственно описывать структурные (синтаксические) модели построения, с одной стороны, фразем, а с другой стороны, паремием; 2) были пред-ложены дефиниции семантических классов фразем, названия кото-рых взяты из классификации В. В. Виноградова [89], но сами дефини-ции получили новые лингвистически корректные формулировки, впер-вые позволившие на практике однозначно и непротиворечиво разби-вать любые массивы фразем на три класса; позднее, по аналогии с опре-делениями фраземных семантических классов были сформулированы лингвистически корректные дефиниции паремиемных семантических классов [52; 62]. Одним из направлений дальнейшей работы является проведение количественного анализа соотношений долей семантиче-ских классов как фразем, так и паремием на различных и все увеличи-

219Приложения
вающихся массивах УСС; в ходе структурного анализа необходимо про-должать устанавливать наборы и доли моделей, по которым построены фраземы, а также синтаксические модели, по которым построены паре-миемы, включая грамматические категории, к которым они принадле-жат [52; 62; 64; 66; 71; 76; 78].
Настоящая работа находится в русле выше упомянутых исследова-ний фразем и паремием.
Материалом для анализа послужила сплошная выборка из «Фразео-логического словаря русского языка» [88], содержащего около 1000 еди-ниц.
Дефиниции единиц, отбираемых для включения в Словарь, являют-ся важнейшей частью работы, так как от этого зависит состав Словаря. Поэтому авторы во Введении пишут: «Фразеологический оборот — это воспроизводимая в готовом виде языковая единица, состоящая из двух или более ударных компонентов словного характера, фиксированная (т. е. постоянная) по своему значению, составу и структуре» [88, 3].
1) Итак, авторы говорят, что ФО — это языковая единица, состоящая из компонентов «словного характера»? Что это за компоненты? Если это не слова, а некие новые неизвестные лингвистике единицы, то сле-дует в определении прямо сказать, из каких же единиц состоят ФО.
Например, В. Н. Телия [144] пишет, что «Фразеологизм — это се-мантически связанное сочетание слов и предложений…» [144, 559)]. То есть, авторесса считает, что фразеологизм может состоять не толь-ко из слов, но и из целых предложений! Что представляет из себя это «сверхпредложениевое» образование, остается только гадать… А может речь идет о сочетании отдельных слов с целыми предложениями, так сказать, «на равных»?…
2) Авторы пишут, что ФО — это «воспроизводимая в готовом виде единица»,…«фиксированная (т. е. постоянная) по своему значению, составу и структуре». Если единица воспроизводима, то она является фиксированной (т. е. постоянной), и наоборот! Зачем эта тавтология в определении?
3) Авторы сообщают далее, что ФО — это единица, фиксированная (т. е. постоянная) по своему значению, составу и структуре». Если сопо-ложение двух общих категорий — «значение» и «структура» — у лингви-стов не вызывают возражений, так как они соответствуют философским категориям «структура — функция», то какова роль третьего члена это-го ряда — «состав»? Известно, что «Структура — взаиморасположение и связь составных частей чего-л.; строение» [87, 554)]. То есть, поня-тие «структура» включает в себя понятие «состав», как частную катего-

220
рию, но авторы, видимо, не различают философские категории «обще-го» и «частного» и ставят их на одну доску.
4) В определении авторов говорится, что «ФО — это … единица, со-стоящая из двух или более ударных компонентов…», но не сообщает-ся о том, какие же компоненты они считают «ударными». Приведем не-сколько примеров из Словаря: «лишь только» (состоит из частицы и ча-стицы); «вот еще» (частица + наречие); «между тем» (предлог + части-ца), «между делом» (предлог + имя существительное), «еще бы» (наре-чие + частица). Конечно, можно и предлоги, и частицы произносить «ударно», но…
5) Cерьезным недостатком данного определения является то, что ав-торы не считают нужным указать на такую принципиально важную де-таль, как характер синтаксической связи между словами в ФО. Одно дело — это непредикативное словосочетание типа «бить баклуши, иг-рать в прятки, альфа и омега, белый свет и т. п.». Структурно они по-строены по следующим моделям: «Г + С», «Г + предлог + С», «С + союз + С», «П + С» и т. п. И совсем другое дело, если между компонентами существует предикативная связь; тогда мы имеем дело с предложени-ем, например: «бог знает; собаку съел; не поминай лихом, много воды утекло; молоко на губах не обсохло, хоть пруд пруди и т. п.». Структурно, предложения характеризуются следующими грамматическими (син-таксическими) категориями: наклонением, временем, залогом и т. п. С синтаксической точки зрения наличие или отсутствие предикативной связи в словосочетании — это «две большие разницы», как сказали бы лингвисты-одесситы.
Известно, что устойчивые словосочетания произошли от свободных словосочетаний. Становясь устойчивыми, словосочетания сохраняют тип синтаксической связи между словами. Известно также, что часть грамматики, называемая «синтаксисом», состоит из 2-х разделов, при-чем в одном из них отдельно рассматриваются непредикативные слово-сочетания, а в другом — предикативные словосочетания, называемые предложениями [ (Русская грамматика, т. 2, 1982)].
Если не различать устойчивые непредикативные и предикативные «фразеологические обороты», то получим лингвистическую «солянку», «сморгасборд», в котором даже «лингвистический черт ногу сломит».
6) Авторы пишут, что «ФО — единица, фиксированная (т. е. постоян-ная) по своему значению…».
Неясно, о каком значении говорят авторы — о прямом или перенос-ном? Ведь и то и другое значения являются «фиксированными (т. е. по-стоянными)», так как зависят от набора значений входящих в них слов.

221Приложения
Прямое значение — это просто сумма значений слов, а переносное (образное) значение — это результат семантической трансформации (преобразования) прямого значения путем метафоризации, метони-мизации и т. п. Например: «Брать быка за рога» 1. (прямое) Взять быка за рога (что вполне возможно буквально); 2 (метафорич., перенос.) На-чинать действовать энергично, решительно и т. д. Отметим, что оба эти значения являются «фиксированными (т. е. постоянными)».
Другой пример: «Шнурки в стакане» 1. Шнурки (от башмаков) поме-щены в стакан (т. е. в некое ограниченное пространство); 2) (метафор., перенос.) родители дома (т. е. находятся в квартире — замкнутом про-странстве (как шнурки в стакане) (молодеж. жаргон). Оба эти значения также являются «фиксированными (т. е. постоянными)».
Интересно, как авторы представляют себе значения некоторого сло-восочетания, которые являются «нефиксированными, непостоянными»?
Первое, что мы сделали в своей работе по анализу всяческих «фра-зеологизмов», так это сформулировали четкие научно корректные де-финиции устойчивых словосочетаний (УСС), а именно:
«Фразема — это непредикативное УСС, имеющее как прямое, так и переносное (образное) значение, являющееся результатом семанти-ческого преобразования прямого значения (метафорически, метони-мически и т. п.)» [52; 62]. Фразема — это поговорка, как это понимают В. М. Мокиенко и Т. Г. Никитина [125] — создатели «Большого словаря русских поговорок» (2008), содержащего 40 тыс. непредикативных УСС.
«Паремиема — это предикативное УСС, имеющее как прямое, так и переносное (образное) значение, являющееся результатом семантиче-ского преобразования прямого значения метафорически, метонимиче-ски и т. п.» [52; 62]. Таким образом, паремиема — это устойчивое пред-ложение, или пословица, если следовать В. И. Далю [97], собравшему 30 тыс. русских пословиц — предикативных УСС.
Как известно, первым семантическую классификацию фразеоло-гических оборотов предложил Ш. Балли [2], который наряду со сво-бодными предложил выделять три класса УСС во французском языке:
“les groupement usuels› (une grave maladie), “les series phraseologiques› (remporter une victoire)? “les unites phraseologique” (faire table rase).
Позднее В. В. Виноградов [89] для описания русских УСС использо-вал эту классификацию, переведя названия классов на русский язык следующим образом: «фразеологические сращения», «фразеологиче-ские единства» и «фразеологические сочетания».
Однако его описание этих классов были настолько некорректны-ми с научной точки зрения, что за 70 лет, прошедших с того времени,

222
ни один лингвист не смог взять какой-нибудь словарь, содержащий не-сколько сотен (не говоря уже о тысячах!) фразем, и однозначно разбить его на 3 группы в соответствии с этой, так называемой «классификаци-ей В. В. Виноградова» [89]. Объясняется это тем, что из-за отсутствия лингвистически корректных дефиниций даже приводимые автором примеры можно помещать либо в тот, либо в другой класс. Попробуем угадать, чем же следующие фраземы отличаются семантически: 1) на-мылить голову, 2) держать камень за пазухой, 3) бить ключом, 4) пля-сать под чужую дудку, 5) взять за бока, 6) плыть по течению, 7) брать в свои руки, 8) выносить сор из избы. Оказывается, В. В. Виноградов [89] единицы, отмеченные нами нечетными цифрами, относит к «сра-щениям», а отмеченные нами четными цифрами — к «единствам»! А почему? На каком основании? Интуитивно! Приведем еще приме-ры: 1) взять за бока, 2) выносить сор из избы, 3) положить зубы на пол-ку, 4) затронуть чувство чести, 5) уйти в свою скорлупу, 6) спать беспро-будным сном, 7) плясать под чужую дудку, 8) отвести глаза. Оказывает-ся, УСС, отмеченные нами нечетными цифрами, В. В. Виноградов [89] относит к «единствам», а четными — к «сочетаниям»!. А на каком осно-вании? Опять интуитивно!
Ясно, что такой, с позволения сказать, «классификацией» невозмож-но пользоваться для однозначного, непротиворечивого разбиения мас-сива реальных УСС на семантические классы. Поэтому в своих рабо-тах [64–55; 76; 78] мы пользуемся следующими лингвистически кор-ректными дефинициями классов, названия которых мы заимствовали у В. В. Виноградова [89], но дали новые формулировки.
«Фраземное сращение — это фразема, имеющая два значения: 1-е (прямое), которое неизвестно говорящим из-за незнания значений не-которых слов (антропонимов, топонимов, религионимов, архаизмов, заимствований); 2-е (переносное, образное), которое известно и высо-кочастотно».
«Фраземное единство — это фразема, имеющая два значения: 1-е (прямое) известное, но редко употребляемое; 2-е (переносное, образ-ное) — известно и высокочастотно»
«Фраземное сочетание — это фразема, имеющая пока только одно значение, которое известно и высокочастотно». Это утверждения, исти-ны абстрактного или конкретного характера.
Заметим, что Н. М. Шанский [152], описывая три семантических класса В. В. Виноградова [89], вводит еще один, свой класс, который определяет следующим образом: «Фразеологическими выражениями следует называть такие устойчивые в своем составе и употреблении

223Приложения
фразеологические обороты, которые не только являются семантически членимыми, но и состоят целиком из слов со свободными значениями» [153, 44]. Эту группу он делит на две подгруппы:
(1) «Фразеологические выражения коммуникативного характера представляют собой предикативные словосочетания, равные предло-жению»» и (2) «Фразеологические выражения номинативного характе-ра являются сочетаниями слов, идентичными лишь определенной части предложения» [ (Шанский [152, 45].
Заметим, что группа (1) — это предложения, т. е. другой синтаксиче-ский класс, а не семантическая группа. Группа (2) — по сути совпадает с семантической группой «фразеологических сочетаний» Шарля Балли [2] и В. В. Виноградова [89].
Отметим, что ни у В. В. Виноградова [89], ни у Н. М. Шанского [152] никакой отдельной семантической классификации паремием (посло-виц) нет и в помине, поскольку они не видят разницы между предика-тивными УСС (т. е. предложениями) «собаку съел, (он) ни в зуб толк-нуть не умеет, убил бобра, плакали наши денежки, на вкус и цвет масте-ра нет, пиши пропало и т. п.» и непредикативными УСС «кузькина мать, у черта на киличках, во всю Ивановскую, попасть впросак, пули отли-вать…».
Но ведь паремиемы (пословицы), как и фраземы (поговорки), яв-ляются устойчивыми словосочетаниями. Поэтому мы решили «по ана-логии» сформулировать дефиниции семантических классов паремием [52; 62].
«Паремиемное сращение — это паремиема, имеющая два значения: 1-е (прямое), которое неизвестно говорящим из-за незнания значений некоторых слов (антропонимов, топонимов, религионимов, архаизмов, заимствований)»; 2-е (переносное, образное), которое известно и высо-кочастотно».
Например: «Бог знает» 1) (прямое) Это значение неизвестно, так как имя собственное «Бог» ничего нам не говорит (а попы о нем гово-рят, «черт знает что»!); 2) (перенос., антонимично-метафорич.) Нечто неизвестное.
«Сам черт не поймет» 1) (прямое) это значение неизвестно из-за не-знания значения слова «черт»; 2) (перенос.) никто не поймет.
«Паремиемное единство — это паремиема, имеющая два значения: 1-е (прямое), которое известно, но редко употребляется; 2-е (перенос-ное, метафорическое, метонимическое) известно и высокочастотно».
Например: «Медведь на ухо наступил» 1) (прямое) Медведь насту-пил на ухо (что привело, ясное дело, к потере слуха!); 2) (перен., образ-

224
ное) У кого-либо отсутствует музыкальный слух, кто-либо неспособен правильно воспроизвести музыкальные звуки.
«Много воды утекло» 1) (прямое) Утекло много воды (на что требует-ся много времени); 2) (переносное, образное) Прошло много времени, произошло немало перемен с каких-либо пор.
«Паремиемное сочетание — это паремиема, имеющая пока только одно значение, которое известно и высокочастотно». Обычно, это утвер-ждения общего, абстрактного или конкретного характера.
Например: «Так и быть» 1) (прямое) Пусть так и будет.«Будьте любезны» 1) (прямое) Вежливая просьба сделать что-либо.В ходе анализа Словаря мы сначала отделили фраземы от паремием,
так сказать, «чистых от нечистых», а затем проделали семантический и структурный анализ паремием, количество которых оказалось рав-ным 168 единицам (плюс 701 фразема, что в сумме дает 869 УСС — вот тебе и «около 1000 единиц», как авторы пишут на обложке Словаря!).
§ 1. Семантические классы паремиемВ ходе работы было установлено, что паремиемы распадаются на три
семантических класса в следующем соотношении (Табл. 81).
Таблица 81Семантические классы паремием
Семантиче-ский Класс
ВсегоПримеры
Кол. %
ПаремиемныеСращения 3 1,8 Бог с тобой. Бог весть. Бог его знает.
ПаремиемныеЕдинства 130 77,4
Руки не дойдут. Ума не приложу. Язык проглотишь. Извилины задымились. Кот наплакал. Много воды утекло. Глаза разбежались
ПаремиемныеСочетания 35 20,8
Как бы то ни было. Будь что будет. Представь себе. Давно бы так. Куда попало. Будьте любезны. В чем дело? Мало не покажется.
Сумма 168 100,0
Паремиемные сращения оказались самым малочисленным семан-тическим классом — 3 единицы (1,8 % всех паремием Словаря): Бог его знает; Бег весть (ведает); Бог (есть, будет) с тобой.
Паремиемные единства являются самым многочисленным семан-тическим классом — 130 единиц (77,4 %), например: Как в воду ка-

225Приложения
нул; Как воды в рот набрал; Как гора с плеч свалилась; Крыша поехала; Молоко на губах не обсохло; Мурашки забегали по спине; Палец в рот не клади; Поминай как (его) звали; Туши (те) свет; Хоть глаз выколи; Хоть пруд пруди; Хоть шаром покати и т. п.
Паремиемные сочетания представлены 35 единицами (20,8 %), на-пример: Дух захватило; Как бы то ни было; Как ни в чем не бывало; Чего бы это не стоило; Будь что будет; Представь себе; Все (есть) в по-рядке; Все (есть) равно; Дело идет; Конца-краю не видно; Кто на что го-ден; Куда глаза глядят; Не может быть и т. п.
Ранее мы установили, что во «Фразеологическом словаре-справоч-нике русского языка» Е. С. Грабчиковой [95] содержащем кроме 1063 фразем еще и 282 паремиемы, к паремиемным сращениям относится 8,9 %; к паремиемным единствам — 85,8 %, к паремиемным сочетани-ям — 5,3 % паремием (Бартков и соавт., 2007). Подсчет коэффициента сходства долей (%) семантических классов паремием двух словарей по-казал довольно высокое сходство этих распределений: Ксх=0,845 (из-вестно, что Ксх=1,0 получается при абсолютном сходстве двух распре-делений, а Ксх=0 при отсутствии сходства).
Некоторые различия в полученных величинах долей (%) разных семантических классов паремием в этих двух словарях показывают, что отбор материала производится несколько субъективно, поскольку авторы даже «не видят» различий между непредикативными УСС (фра-земами=поговорками) и предикативными УСС (паремиемами=посло-вицами).
§ 2. Семантические классы паремием и наклонениеРазбив паремиемы на семантические классы, мы решили посмо-
треть, по каким структурным, то есть, синтаксическим моделям по-строены (Табл. 82). Известно, что предложение состоит из множества граммем. На первых порах мы рассмотрим количественные соотноше-ния между наиболее простыми, однозначно выделяемыми синтаксиче-скими классами, а именно: 1) наклонением (изъявительным — повели-тельным — сослагательным), временем (настоящим — прошедшим — будущим), 3) залогом (действительным — страдательным), как это де-лалось нами в ранее опубликованных работах на материале русско-го (Бартков, 2006), украинского (Бартков и соавт., 2006), английского (Бартков, Гречко, 2004) и немецкого (Бартков, 2005) языков.
Исследование количественных отношений между категориями на-клонения в связи с принадлежностью паремием к определенным семан-тическим классам показало следующее (Табл. 82).
226
Все паремиемные сращения находятся в изъявительном наклоне-нии: Бог его знает; Бег весть (ведает); Бог с тобой. В целом, в изъяви-тельном наклонении находятся 90 % фразем Словаря.
Таблица 82Семантические классы паремием и наклонение
Синтаксиче-ский класс
Сращения Единства Сочетания Всего
Кол-во % Кол-во % Кол-во % Кол-во %
Изъявительное 3 100,0 118 90,8 30 85,7 151 89,9
Повелительное - - 12 9,2 5 14,3 17 10,1
Сослагательное - - - - - - - -
Сумма 3 100,0 130 100,0 35 100,0 168 100,0
% 21,0 - 78,1 - 19,9 - 100,0 -
Среди паремиемных единств 90,8 % стоят в изъявительном наклоне-нии, например: Душа не лежит; Жаба души; И глазом не ведет; И даже бровью не ведет; Как дважды два (есть) четыре; Кошки скребут на серд-це; Кружится голова; Крыша едет; Туши(те) свет; Хоть глаз выколи; Хоть отбавляй; Хоть пруд пруди; Хоть шаром покати; Кто его знает; Легок на подъем; Легок на помине и т. п.
В повелительном наклонении в классе единств обнаружено 12 паре-мием (9,2 % единств), например: Поминай как (его) звали (поминай); Того и гляди; Туши(те) свет; Хоть глаз выколи; Хоть отбавляй; Хоть пруд пруди; Хоть шаром покати; Шутки (уберите) в сторону и т. п.
Сослагательного наклонения не обнаружено вообще.В семантическом классе паремиемных сочетаний было обнару-
жено 30 паремием в изъявительном наклонении (85,7 %), например: Мало не покажется; Ничего не поделаешь; Что поделаешь; Все (есть) в порядке; Делать нечего; Дело идет; Дух захватывает; Конца-краю нет; Кто на что годен; Куда глаза глядят; Ничего не стоит; Во что бы то ни стало; Дух захватило; Как попало и т. п.
В повелительном наклонении обнаружено 5 паремием касса сочета-ний: Будь добр; Будь что будет; Будь (те) любезны; Будьте добры; Пред-ставь себе; и т. д.
В целом, паремиемы по наклонению распадаются на 2 группы: в изъ-явительном наклонении — 89,9 %; в повелительном — 10,1 %; в сослага-тельном наклонении паремием не обнаружено. Интересно, что в сло-варе Е. С. Грабчиковой [95] соотношение по подгруппам было следую-щим: в изъвительном наклонении — 83,7 %; в повелительном — 15,2 %;

227Приложения
в сослагательном наклонени — 1,1 % паремиием. Подсчет коэффициен-та сходства долей (%) Е. А. Быстровой с соавт. [88] показал, что в целом эти распределения очень паремием по семантическим классам слова-рей Е. С. Грабчиковой [95] и близки: Ксх=0,938.
§ 3. Семантические классы паремием и времяРаспределение паремием по граммемам времени показало
(Табл. 83), больше всего паремием стоит в настоящем времени — 80 единиц (53,0 %), например: Выеденного яйца не стоит; Где раки зимуют (показать); Глаза разбегаются; Глаза слипаются; Голова (есть) на пле-чах; Голова идет кругом; Голова кружится; Грош цена; Дела нет; Дом едет; Душа болит; Душа в пятки уходит; Чайник кипит и т. п.
В прошедшем времени стоит 36,4 % паремием Словаря, например: показать, где (тут) собака зарыта; (дело) горело в руках; (он) Глазом не моргнул; Была не была; В глаза не видал (я, он); Глаза слиплись; Гла-за слипались; Глазом не моргнул; Голова закружилась; И след простыл; И ухом не повел; Как в воду канул; Извилины задымились; Как воды в рот набрал; Как гора с плеч свалилась и т. п. (Табл. 83).
Таблица 83Семантические классы паремием и время
Синтаксиче-ский класс
Сращения Единства Сочетания Всего
Кол-во % Кол-во % Кол-во % Кол-во %
Настоящее 3 100,0 60 50,8 17 56,7 80 53,0
Прошедшее - - 46 39,0 9 30,0 55 36,4
Будущее - - 12 10,2 4 13,3 16 10,6
Сумма 3 100,0 118 100,0 30 100,0 151 100,0
% 2,0 - 78,1 - 19,9 - 100,0 -
Анализ показал, что все паремиемные сращения в количестве 3-х единиц стоят в настоящем времени: Бог с тобой (с вами, с ней и т. п.); Бог весть; Бог его знает.
В следующем семантическом классе — паремиемные единства — 50,8 % паремием стоят в настоящем времени: например: Крыша едет; Крыша не (есть) в порядке; Кто его знает; Легок на подъем (он); Мороз по коже дерет; Мурашки бегают по коже; На чем свет стоит; Не выходит из головы; Не лезет за словом в карман; Руки опускаются; Сам за себя говорит; Сердце болит; Сердце замирает; Не выходит из головы; Сердце болит; Сердце замирает; Мороз по коже дерет, и т. п.

228
В прошедшем времени стоит 39,0 % паремием этого семантиче-ского класса, например: Мурашки пошли по спине; Мухи не обидел; Не тут-то было; Немало воды утекло; Раз-два и обчелся; Сердце замерло; Сердце кровью облилось; Скворечник поехал; Сколько воды утекло; Со-баку съел; Только его и видели; Что было духу; В глаза не видал (я, он); Глаза разбежались; Глаза слиплись; Глазом не моргнул; Голова закружи-лась; Голова пошла кругом; Дом поехал и т. п.
В будущем времени стоит 10,2 % паремием, например: (это) даром не пройдет; Водой не разольешь; Воды не замутит; Выйдет толк; Далеко не уедешь; Каши не сваришь; Комар носа не подточит; Мухи не обидит; Не полезет за словом в карман; Руки не дойдут; Ума не приложу; Язык проглотишь и т. п.
Отметим, что паремиемы словаря Е. С. Грабчиковой [95] с категори-ей времени взаимодействуют следующим образом: в настоящем време-ни — 64,0 %; в прошедшем — 26,7 %; в будущем — 9,3 %. Величина ко-эффициента сходства этого распределения паремием с распределением в анализируемом Словаре равна: Ксх=0,890. Следовательно, сходство довольно высокое.
§ 3. Семантические классы паремием и залогВ целом, анализируемые паремиемы по залогу распределяются сле-
дующим образом (Табл. 84).В действительном залоге находится подавляющее большинство па-
ремием Словаря — 96,7 %, например: Выйдет толк; Далеко не уедешь; Каши не сваришь; Комар носа не подточит; Мухи не обидит; Не полезет за словом в карман; Руки не дойдут; Ума не приложу; Язык проглотил; (дело) горит в руках; (Его) нет и в помине; (он) звезд с неба не хвата-ет; (это) даром не проходит; (это) можно по пальцам пересчитать; Мало не покажется; Ничего не поделаешь; Что поделаешь и т. п.
Таблица 84Семантические классы паремием и залог
Синтаксический класс
Сращения Единства Сочетания Всего
Кол-во % Кол-во % Кол-во % Кол-во %
Действительный 3 100,0 114 96,6 29 96,7 146 96,7
Страдательный - - 4 3,4 1 3,3 5 3,3
Сумма 3 100,0 118 100,0 30 100,0 151 100,0
% 21,0 - 78,1 - 19,9 - 100,0 -

229Приложения
В страдательном залоге находится всего 3,3 % паремии ем Словаря: Язык (есть) неплохо подвешен; Язык (есть) хорошо подвешен; Как ве-тром сдуло; Язык здорово подвешен; Уму непостижимо.
Интересно, что все три паремиемы класса сращений находятся в дей-ствительном залоге: Бог с тобой (с вами, с ней и т. п.); Бог весть; Бог его знает.
В классе паремиемных единств 96,7 % паремием находятся в дей-ствительном залоге, например: Мурашки бегают по коже; На чем свет стоит; Не выходит из головы; Не лезет за словом в карман; Руки опуска-ются; Сердце болит; Сердце замирает; Сердце кровью обливается; Фай-лы не сходятся; Хлопот полон рот; Чайник кипит; Яблоку негде упасть; Яблоку некуда упасть; Язык (есть) хорошо подвешен. Где собака зарыта; Глазом не моргнул; Была не была и т. п.
Находящихся в страдательном залоге паремием обнаружено всего четыре: Язык неплохо подвешен; Язык хорошо подвешен; Как ветром сдуло; Язык здорово подвешен.
В семантическом классе паремиологических сочетаний обнаружено 146 паремием (96,7 %) в действительном залоге, например: Во что бы то ни стало; Давно бы (сделал) так!; Дух захватило; Как бы то ни было; Как ни в чем не бывало; Как попало; Куда (что-то) попало; Чего бы это не стоило; Будь что будет-2-е; Мало не покажется; Ничего не подела-ешь; Что поделаешь; Все (есть) в порядке; Все равно; Делать нечего; Дело в том, что и т. п.
В страдательном залоге пребывает одна паремиема: Уму непости-жимо.
Таким образом, в результате количественного анализа 168 пареми-ем, содержащихся в словаре, установлен ряд ранее неизвестных семан-тических и синтаксических характеристик паремием.

ЛИТЕРАТУРА
1. Arnold I. V. The English Word. М.: Высш. шк., 1986. 296 p.2. Bally Ch. Precis de stylistique. Geneve, 1905.3. Bartkov B., Larson D., Bartkova T., Golovatskaya Y., Strom N.,
Strom H. Frequent English Affixes for Students of Linguistics // Культур-но-языковые контакты, вып. 6. Владивосток: Изд-во Дальневост. Ун-та, 2004. С. 18–27.
4. Bauer L. English word-formation. Cambridge; Cambridge Univ. Press, 1983. 311 p.
5. Brown I. F. Normal and reverse English word list. Philadelphia, 1963. V. 1–8.
6. Collins Cobuild. English Guides. 2. Word Formation. L.: Harper Collins Publishers, 1991. 209 p.
7. Сollins V. H. A Book of English Idioms. London: Longmans, Green and Co., 1958. 258 p.
8. Smith H. The Russians. Ballantine Books. New York: 1976. — 775 p.9. Flexner S. B. Preface // Dictionary of American slang. Compiled and
edited by H. Wentworth and S. B. Flexner. N. Y.: T. Y. Crowell Company, 1960. P. vi — xv.
10. Guiraud P. Les characteres statistiques du vocabulaire francaise. P., 1954. 111 p.
11. Jespersen O. A Modern English Grammar on Historical Principles. Pt. 6. Morphology. Copeenhagen, 1942. 570
12. Kucera H., Francis W. N. Computational analysis of present-day American English. Providence, Rhode Island: Brown Univ. Press, 1967. 401 p.
13. Lehnert M. Reverse Dictionary of Present-Day English. Leipzig: VEB Verlag
14. Marchand H. The categories and types of preent –day English word-roramtion. Wiesbaden: O. Harrassowitz, 1960. 379 p.
15. Mencken H. L. The American language. Suppl. 1. N. Y.: Alfred A. Knopf, 1945. — 739 p.
16. Paul H. Prinzipien der Sprachgeschichte. Berlin, 1920. 147 S.17. Random House Unabridged Dictionary, 2 nd ed. New York: Random
House, 1993. — 2478 p.18. Spearman С Demonstration of formulae for true measurement of
correlation // Amer. J. Psychol. 1907. Vol. 18. P. 161–167.

231Литература
19. Spears R. A. Dictionary of American slang. Lincolnwood, 111.: National Textbook Co., 1991. — 528 р.
20. The Guinness Book of Records.N. Y., 1996. 774 p.21. The New Concise Webster’s Dictionary. A comprehensive guide to the
English language for home, office, and school. New York: Modern Publishing, 1989. — 352 p.
22. The Oxford English Dictionary (2-nd edition), Oxford University Press, 1989. Vols. 1–20.
23. The Random House Power Vocabulary Builder. N. Y.: Ballantine Books, 1996. 312 p.
24. Thorndike E. L. The Teaching of English Suffixes. N. Y.: Teacher’s College, Columbia Univ., 1941. — 81 p.
25. Thorndike E., Lorge J. The Teacher’s Word Book of 30,000 Words. N. Y., 1944.
26. Walker’s Rhyming Dictionary of the English Language. Routledge & Kegan Paul. London and Henley. 1979. — 549 pp. (54 thousand words).
27. Webster’s New International Dictionary of the English Language. 2 nd ed. Cambridge, Mass. G. & C. Merriam Co., 1934. — 3210 p.
28. West M., Kimber P. F. Deskbook of Correct English. Л.: Гоучпедгиз, 1963.192 p
29. Zipf G. K. The Meaning-Frequency Relationship of Words // J. General Psychol.1945. Vol. 33, Pt.2. P.251–256.
30. Алпатов В. М. Что следует считать исходной единицей морфоло-гического описания? // Морфемика. Принципы сегментации, отожде-ствления и классификации морфологических единиц. Санкт-Петербург: Издю С.-Петербург. Ун-та, 1997. С. 4–11.
31. Амосов Н. М. Моделирование сложных систем. Киев: Наук. Дум-ка, 1968. 87 с.
32. Амосова Н. Н. Основы английской фразеологии. Л.: Изд-во ЛГУ, 1963. 208 с.
33. Античные теории языка и стиля. М.; Л., 1936.34. Арнольд И. В. Лексикология современного английского языка.
М.: ИЛ, 1959. 351 с.35. Афанасьева О. В. Обучение деривационным моделям на уроках
английского языка // Иностр. яз. в школе. 2012. С. 53–57.36. Ахманова О. С. Словарь лингвистических терминов. М.: КомКни-
га, 2005.37. Балли Ш. Французская стилистика / Пер. с фр. К. А. Долинина. М.,
1961.

232
38. Баранов А. Н., Добровольский Д. О. Аспекты теории фразеологии. М.: Знак, 2008. 289 с.
39. Бартков Б. И. Дериватография украинского языка т квантита-тивный дприватарий 100 аффиксов, полуаффиксов и аффиксоидов на-учного стиля и литературной нормы // Полуаффиксация в терминоло-гия и литературной норме. Владивосток: ДВНЦ АН СССР, 1986. С. 8–58.
40. Бартков Б. И, Барткова Т. Б., Барткова А. Д., Бартков И. Б. и др. Продуктивный аффиксальный минимум для чтения философской ли-тературы на английском языке // Academic science — problems and achievements. V. Vol. 3. Spc Academic.North Charleston, USA, 2014. P. 150–163. Материалы V Научно-практ. конф. 1–2 декабря 2014 г
41. Бартков Б. И. 45 лет в глоттологии и глоттографии // Квантита-тивная дериватография, дериватология, фразеология и паремиология германских, славянских и романских языков. Владивосток: ПИППКРО, 2010. С. 3–51.
42. Бартков Б. И. Английские суффиксоиды, полусуффиксы, суффик-сы и словарь 100 словообразовательных формантов современного ан-глийского языка (научный стиль и литературная норма) // Аффиксои-ды, полуаффиксы и аффиксы в научном стиле и литературной норме. Владивосток: ДВНЦ АН СССР, 1980. С. 3–62.
43. Бартков Б. И. Количественная дериватография и дериватарий 70 немецких аффиксов (научный стиль и литературная норма) // Продук-тивность, частотность и валентность деривационных моделей. Влади-восток: ДВНЦ АН СССР, 1988. С. 51–81.
44. Бартков Б. И. Количественная дериватология и дериватарий французского языка (80 моделей префиксации, суффиксации, циркум-фиксации, основосложения, псевдоаффиксации, аббревиации и аббре-вификсации) // Омосемия и омография в естественных и машинных языках. Владивосток: ДВНЦ АН СССР, 1986. С.81–121
45. Бартков Б. И. Количественная дериватология и дериватография конверсификсов английского языка. Казань: Изд-во «БУК», 2016. 116 с.
46. Бартков Б. И. Конверсификсы как новые суффиксы английского языка. Казань: Изд-во «Бук», 2017. 150 с.
47. Бартков Б. И. Количественная морфемография (дериватография) английского, немецкого и русского языков // Основосложение и по-луаффиксация в научном стиле и литературной норме. Владивосток: ДВНЦ АН СССР, 1982а. С. 27–55.
48. Бартков Б. И. Количественная семантика английских дериваци-онных типов // Форма и содержание единиц языка и речи. Владиво-сток: Дальнаука, 1998. С. 3–12.

233Литература
49. Бартков Б. И. Количественная синсемия (синонимия) и антисе-мия (антонимия) лингвистических единиц (лексем, фразем, морфем, фонем, граммем) // Гуманитарные науки в контексте международного сотрудничества. Материалы 1-й Междунар. Научн. Конф. Владивосток: Изд-во ДВГТУ, 1999. С. 7–11.
50. Бартков Б. И. Количественное представление деривационной подсистемы и экспериментальный словарь 100 словообразовательных формантов русского языка (научный стиль и литературная норма) // Особенности словообразования в научном стиле и литературной норме. Владивосток: ДВНЦ АН СССР, 1982. С. 114–163.
51. Бартков Б. И. Количественный дериватарий английского языка (300 аффиксов научного стиля и литературной нормы). Препр. Влади-восток: ДВНЦ АН СССР, 1984. 63 с.
52. Бартков Б. И. О выделении семантических классов английских, немецких и русских паремием (пословиц): сращений, единств и сочета-ний в диахронии // Труды ДВГТУ, вып. 141. Владивосток: Изд-во «Уссу-ри», 2005. С.181–188.
53. Бартков Б. И. О коэффициентах сходства членов синонимических рядов (двумерный и многомерный простой и «взвешенный» случаи) // Структурная и математическая лингвистика. Вып. 9. Киев: Вища шко-ла, 1981. С. 6–13.
54. Бартков Б. И. О статусе некоторых постфиксальных словообразо-вательных формантов в современном английском языке // Особенно-сти аффиксального словообразования в терминосистемах и норме. Вла-дивосток: ДВНЦ АН СССР, 1979. С. 63–91.
55. Бартков Б. И. О статусе словообразовательных морфем типа -monger, -smith, -wright, -proof, -tight в английском языке // Словообра-зование и его место в курсе обучения иностранному языку. Владиво-сток, 1978, вып. 6, с. 42–51
56. Бартков Б. И. Пентахотомическая шкала статуса деривацион-ных морфем современного русского языка // Филология и культура. Лингвистика в XXI веке. Материалы международного научного форума (Владивосток, 19–20 октября 2004 г.). Владивосток: Изд-во Дальневост. Ун-та, 2006. С. 67–76.
57. Бартков Б. И. Проблема деривационного статуса исконных пост-фиксальных именных морфем английского языка // Современные ис-следования социальных проблем, № 3–3 (27), 2016. С. 44–52.
58. Бартков Б. И., Лейних И. Р. Синхронно-диахронное количествен-ное описание исконного английского префикса MIS- // Труды ДВГТУ. Вып. 128, 2004. С. 196–203.

234
59. Бартков Б. И. Скорость эволюции деривационной подсистемы ан-глийского языка // Актуальные вопросы английской филологии. Влади-восток: Изд-во Дальневост. Ун-та, 1995. С. 10–14.
60. Бартков Б. И. Частотный аффиксальный минимум для чтения текстов по оптоэлектронике и лазерной технике на английском язы-ке // Современные проблемы развития фундаментальных и приклад-ных наук. Мат. II междунар. Научно-практ. Конф. 25 февраля 2016 г. Том 2. Praha, Czech Republik. С. 100–118.
61. Бартков Б. И., Барткова А. Д., Бартков И. Б., Барткова Т. Б. Частот-ный аффиксальный минимум для чтения английской газеты // Труды ДВГТУ. Вып. 130, 2001. С. 50–60.
62. Бартков Б. И., Барткова Т. Б. Дифференциация идиом на фраземы и паремиемы // Россия — Восток — Запад. Проблемы межкультурной коммуникации. Тез. Регион. Научно-практ. Конф. Владивосток, 22 апре-ля 2005 г. Владивосток: Изд-во Дальневост. Ун-та, 2005. С. 9–10
63. Бартков Б. И., Барткова Т. Б. Частотный минимум аффиксов для чтения английских текстов по истории // Культурно-языковые кон-такты, вып. 4. Владивосток: Изд-во Дальневост. Ун-та, 2001. С. 3–12.
64. Бартков Б. И., Барткова Т. Б., Перешивкина О. Н. Устойчивые сло-восочетания английского языка и принципы их структурно-семантиче-ского описания // Материалы 49-й Всероссийской межвуз. Науч-техн конф. Т. 2. Психолого-педагогич. Проблемы обучения. Владивосток: ТОВМИ, 2006. C. 19–37.
65. Бартков Б. И., Барткова Т. Б., Логинова С. А., Степанова Ю. В. Диа-хронический анализ английских пословиц. Часть 1. Структурный анализ пословиц с опорными лексемами CAT, DOG, DEVIL, GOD, FIRE, WATER, MAN, WOMAN, MOON, SUN // Труды ДВГТУ. Вып. 128, 2001. С. 164–172.
66. Бартков Б. И., Барткова Т. Б., Перешивкина О. Н. Формирова-ние семантических и грамматических классов английских пословиц в диахронии // Культурно-языковые контакты, вып. 9. Владивосток: Изд-во Дальневост. Ун-та, 2006. С. 28–48.
67. Бартков Б. И., Бутенко Л. Д. Количественное описание английско-го глагольного словообразовательного типа с заимствованным суффик-сом -ify // Аффиксы и комбинирующиеся формы в научной терминоло-гии и норме. Владивосток: ДВНЦ АН СССР, 1982. С. 14–29.
68. Бартков Б. И., Гречко Н. С. Семантическая классификация 11 000 английских фразем // Труды ДВГТУ. Вып. 138, 2004. С. 32–39.
69. Бартков Б. И., Дмитриева И. В. Диахронический анализ англий-ских пословиц. Часть 2. Синтаксический анализ 8 000 пословиц англий-ского языка // Труды ДВГТУ. Вып. 138, 2004. С.3–14.

235Литература
70. Бартков Б. И., Сапегина Н. Г. Формирование деривационных ти-пов с антонимичными префиксами ILL- / WELL- в английском языке // Труды ДВГТУ. Вып. 128, 2004. С. 186–196.
71. Бартков Б. И., Игонина Т. Формирование семантических классов фразем (сращений, единств, сочетаний) в диахронии // Труды ДВГТУ, вып. 141. Владивосток: Изд-во «Уссури», 2005. С. 52–56.
72. Бартков Б. И., Куркович Е. П. Структурно-функциональные харак-теристики английских суффиксальных наречий и числительных // Сло-восочетание, словосложение и аффиксация как способы словообразова-ния. Владивосток: ДВО АН СССР, 1990. С. 12–29.
73. Бартков Б. И., Кушнир Н. В. Аффиксальные минимумы на основе продуктивности типов в экономической, медицинской и морской тех-нической терминосистемах современного английского языка // Труды ДВГТУ, вып. 127. Владивосток, 2000. С. 3–6.
74. Бартков Б. И. Дериватография и отбор минимума частотных и продуктивных аффиксов для эффективного обучения иностранцев русскому языку // Труды ДВГТУ, вып. 127. Владивосток,2000. С. 34–44
75. Бартков Б. И., Минина Л. И., Минина Л. В. Особенности словооб-разования в английской морской терминологии и в языке эсперанто // Особенности аффиксального словообразования в терминосистемах и норме.ю Владивосток: ДВНЦ АН СССР, 1979. С. 135–142.
76. Бартков Б. И., Позевич О. И. Количественный грамматический анализ русских паремием (пословиц) // Труды ДВГТУ, вып. 140. Влади-восток: Изд-во «Уссури», 2005. С. 60–64.
77. Бартков Б. И., Федюкина А. В. Возникновение, структура и функ-ция деривационной модели с суффиксом — (o) logy в английском язы-ке // Словообразовательная номинация в терминосистемах и норме. Владивосток: ДВО АН СССР, 1987. С. 20–48.
78. Бартков Б. И., Яночкина Г. И. Количественный семантический и структурный анализ русских фразем // Труды ДВГТУ, вып. 140. Влади-восток: Изд-во «Уссури», 2005. С. 17–22.
79. Бартков Б. И. Квантитативные методы исследования словообра-зовательной подсистемы современного английского языка // Аффик-соиды, полуаффиксы и аффиксы в научном стиле и литературной норме. Владивостоу: ДВНЦ АН СССР, 1980. С. 117–142.
80. Бенвенист Э. Общая лингвистика. М.: Прогресс, 1974. 447 с.81. Бережан С. Г. Семантическая эквивалентность лексических еди-
ниц. Кишинев: Штиинца, 1973. 372 с.82. Березин Ф. М., Головин Б. Н. Общее языкознание. М.: Просвеще-
ние, 1979. 416 с.

236
83. Берталанфи Л. фон. Общая теория систем — обзор проблемы и результатов // Системные исследования: Ежегодник. 1969. М.: На-ука, 1969.
84. Бодуэн де Куртенэ И. А. Избранные труды по общему языкозна-нию. В 2-х т. М., 1963.
85. Брускина Т. Л., Шитова Л. Ф. Краткий русско-английский фразео-логический словарь. СПб.: Изд-во «Лань», 1998. — 256 с.
86. Будагов Р. А. Что такое развитие и совершенствование языка? М.: Наука, 1977. 264 с.
87. Булыко А. Н. Большой словарь иноязычных слов. 35 тысяч слов. М.: Мартин, 2004. 704 с.
88. Быстрова Е. А., Окунева А. П., Шанский Н. М. Фразеологический словарь русского языка. Около 1000 единиц. М.: ООО «Издательство Астрель», 2008. — 413 с.
89. Виноградов В. В. Об основных типах фразеологических единиц в русском языке // История советского языкознания. Хрестоматия / Сост. Березин Ф. М. — М.: Выс. Шк., 1981. С. 230–235.
90. Винокур Г. О. О некоторых явлениях словообразования в русской технической терминологии // Тр. МИФЛИ. 1939. Т. 4. С. 3–54. Владиво-сток: ТОВМИ, 2006. С. 19–37.
91. Гальперин И. Р., Черкасская Е. Б. Лексикология английского язы-ка. М.: ИЯ, 1956. 105 с.
92. Гинзбург E. Л. Исследование структуры словообразовательных гнезд // Проблемы структурной лингвистики. 1972. М.: Наука, 1973. С. 54–136.
93. Гируцкий А. А. Общее языкознание. Минск: НТООО ТетраСи-стемс, 2001. 304 с.
94. Головин Б. Н., Кобрин Р. Ю. Лингвистические основы учения о терминах: Учебн. пособие для филол. спец. вузов. М.: Высш. шк., 1987. 104 с.
95. Грабчикова Е. С. Фразеологический словарь-справочник русского языка. Ростов-на-Дону: Феникс, 2001. 156 с.
96. Гумбольдт В. фон. О различии строения человеческих языков и его влиянии на духовное развитие человеческого рода // Звегин-цев В. А. История языкознания XIX и XX веков в очерках и извлечениях. М., 1960. Часть 1.
97. Даль В. И. Пословицы русского народа. Том 1. М.: Диамант, 1996. 480 с.
98. Ермоленко Г. В. Лингвистическая статистика. Алма-Ата: Казах. Гос. Ун-т, 1970. 155 с.

237Литература
99. Ефремова Т. Ф. Толковый словарь словообразовательных единиц русского языка. М.: Астрель-АСТ, 2й005. 636 с.
100. Жуков В. П. Поговорка // Языкознание. Большой энциклопеди-ческий словарь / Гл. ред. В. Н. Ярцева. М.: Большая Российская энцикло-педия, 1998. С. 379.
101. Жуков В. П. Пословица // Языкознание. Большой энциклопеди-ческий словарь / Гл. ред. В. Н. Ярцева. М.: Большая Российская энцикло-педия, 1998. С. 389.
102. Жуков В. П. Словарь русских пословиц и поговорок. М.: Рус. яз., 1993. 537 с.
103. Земская Е. А. Современный русский язык. Словообразование. М.: Просвещение, 1973. 304 с.
104. Звегинцев В. А. Очерки по общему языкознанию. М., 1962.105. Зятковская Р. Г. Суффиксальная система современного англий-
ского языка. М.: Просвещение, 1971. 181 с.106. Иванова И. П. (Ред.) Структура английского имени существи-
тельного. М: Высш. шк., 1975. 168 с.107. Ильиш Б. А. Современный английский язык. Теоретический
курс. М.: ИН-ЯЗ, 1948. — 348 с.108. Каращук П. Cловообразование английского языка.М.: Высш.
шк., 1977. 303 с.109. Кодухов В. И. Общее языкознание. М.: Выс. Шк., 1974. 303 с.110. Кондратов А. Звуки и знаки. Изд. 2-е, перераб. М.: Знание.
1978. — 208 с.111. Кондрашов Н. А. История лингвистических учений. М.: Просве-
щение, 1979. 224 с.112. Кочерган М. П. Загальне мовознавство. К.: «Академiя», 2006.
464 с.113. Крупник К. Н. К проблеме обучения чтению на иностранном
языке. Автореф. дис… канд. филол. наук. М.: Изд-во МГУ, 1968. — 24 с.114. Кочетков В. П. Параллельные суффиксальные образования при-
лагательных с одинаковой основой в английском языке (на примере прилагательных с исходами на -al и -ous): Автореф. Дис. … канд. Филол. Наук. Л., 1969. 23 с.
115. Кубрякова Е. С, Харитончик З. А. О словообразовательном зна-чении и описании смысловой структуры производных суффиксально-го типа// Принципы и методы семантических исследований. М.: На-ука,1976.356 с.
116. Кубрякова Е. С. Словообразование // Общее языкознание. Вну-тренняя структура языка. М.: Наука, 1972. С. 344–393.

238
117. Кунин А. В. Курс фразеологии современного английского язы-ка: Учебн. для ин-тов и фак. иностр. яз. — 2-е изд., перераб. — М.: Высш. шк., Дубна: Изд. центр «Феникс», 1996. — 381 с.
118. Лесина И. М., Меграбова Э. Г., Науменко Л. К. и др. Структурная характеристика производных суффиксальных прилагательных в совре-менном английском языке. Владивосток: Дальневост. гос. ун-т, 1978. — 92 с.
119. Лопатин В. В., Улуханов И. С. Основные понятия морфемики: словообразование // Русская грамматика: в 2-х т. Т. 1. М., 1980. С. 123–470.
120. Лотте Д. С. Основы построения научно-технической терминоло-гии. М.: Изд-во АН СССР, 1961. 158 с.
121. Маслов Ю. С. Введение в языкознание. М.: Выс. Шк., 1975. 327 с.122. Мешков О. Д. Словообразование современного английского
языка. М.: Наука, 1976. 246 с.123. Маккей А., Ботнер М. Т., Гейтс Дж. И. Словарь американских иди-
ом: 8000 единиц / Оформление. А. Лурье. СПб.: Изд-во «Лань», 1997. — 458 с.
124. Минина Л. И. Качественно-количественный дериватарий аф-фиксоидов и полуаффиксов современного русского языка // Дерива-ция в норме и терминосистемах. Владивосток: ДВО АН СССР, 1990. С. 74–94.
125. Мокиенко В. М., Никитина Т. Г. Большой словарь русских пого-ворок. Свыше 40 000 поговорок. М.: ЗАО «ОЛМА Медиа Групп», 2008. — 784 с.
126. Мокиенко В. М., Никитина Т. Г., Николаева Е. К. Большой сло-варь русских пословиц. Около 70 000 пословиц. М.: ЗАО «ОЛМА Медиа Групп», 2010. — 1024 с.
127. Новый большой русско-английский словарь: в трех томах, более 300 000 лексических единиц. Под общ. Рук. П. Н. Макурова, М. С. Мюл-лера, В. Ю. Петрова. М.: «Лингвистика», 1997. 3260 стр.
128. Пиоттух К. В. Система префиксальных структурно-семантиче-ских моделей в современном английском языке. Автореф. Дис… канд. наук. М.: 1971. 22 с.
129. Плотников Б. А. Общее языкознание: Семинарий. Минск, 1986.130. Потебня А. А. Мысль и язык. К., 1993.131. Потиха З. А. Как сделаны слова в русском языке. Справочник
служебных морфем. Л.: Просвещение, 1974.132. Реформатский А. А. Введение в языковедение. М., 1967.

239Литература
133. Словарь словообразовательных элементов немецкого язы-ка/А. Н. Зуев, И. Д. Молчанова, Р. З. Мурясов и др.; Под рук. М. Д. Степа-новой. М.: Рус. яз., 1979. 536 с.
134. Словарь употребительных английских пословиц: 326 статей / М. В. Буковская, С. И. Вяльцева, З. И. Дубянская и др. 2-е изд., стереотип. М.: Рус. яз., 1988. 240 с.
135. Смирницкий А. И. Лексикология английского языка. М. Ин. — яз., 1956. 260 с.
136. Соболева П. А. Моделирование словообразования // Проблемы структурной лингвистики. 1971. М.: Наука, 1972. С. 165–212.
137. Соболева П. А., Емельянова Н. В. Вершина словообразовательно-го гнезда и структура словообразовательного ряда // Словообразова-тельные типы и гнезда в индоевропейских языках. Владивосток: ДВНЦ АН СССР, 1986. С. 29–39.
138. Солнцев В. М. Язык как системно-структурное образование. М., 1977.
139. Соссюр Ф. де Труды по языкознанию. М.: Прогресс, 1977. 695 с.140. Степанов Ю. С. Основы общего языкознания. М.: Просвещение,
1975.272 с.141. Степанова М. Д. Словообразование современного немецкого
языка. М.: ИЛ, 1953.142. Структура английского имени существительного / Под ред.
И. П. Ивановой. М.; Высшая школа, 1975. 168 с.143. Структура и функция клетки. М.: ИЛ, 1964.144. Телия В. Н. Фразеологизм // Языкознание. Большой энциклопе-
дический словарь / Гл. ред. В. Н. Ярцева. — 2-е изд. — М.: Большая рос-сийская энциклопедия, 2000. С. 559–560.
145. Тюхтин В. С. Отражение, системы, кибернретика. Теория отра-жения в свете кибернетики и системного подхода.М.: Наука, 1972. 283 с.
146. Федоров А. И. Фразеологический словарь русского языка. Ново-сибирск: Наука, 1995. Т. 1–2.
147. Философия. Основные идеи и принципы: Популярный очерк. М.: Политиздат, 1985.
148. Философия: Учеб. пособие / Под ред. проф. В. Н. Лавриненко. М.: Юристъ, 1996.
149. Цыганенко Г. П. Словарь служебных морфем русского языка. Киев: Рад. шк., 1982. 241 с.
150. Частотный англо-русский словарь-минимум по электронике. Сост. П. М. Алексеев. М.: Воениздат, 1971. 304 с.

240
151. Шанский Н. М. Очерки по русскому словообразованию и лекси-кологии. М., 1959. 246 с 152. Шанский Н. М. Фразеология современного русского языка. М.: Выс. Шк., 1963. — 156 с.
153. Щерба Л. В. Языковая система и речевая деятельность. Л., 1974.154. Энон. Основные закономерности научной работы //Физики
продолжают шутить. М.: Мир,1968. С. 171–172.155. Языкознание. Больщой энциклопедический словарь / Гл. ред.
В. Н. Ярцева. 2-е изд. М.: Большая Российская энциклопедия, 1998. 685 с.

СОДЕРЖАНИЕ
Введение ...................................................................................................3
Глава 1СТРУКТУРА И ФУНКЦИЯ ЯЗЫКА И РЕЧИ ...............................................6
§ 1. Язык/речь — мышление — материальный мир ........................6§ 2. Речь, язык. Их двусторонние элементы ...................................12§ 3. Теория языковых уровней ........................................................16§ 4. Типы значений лингвистических единиц ................................26§ 5. Количественная семантика.
Причины возникновения полисемии ......................................29§ 6. Законы Ципфа-Гиро ................................................................. 30
Количество значений и частность .......................................... 30Возраст как причина возникновения полисемии....................32Скорость изменения семантического поля ..............................35Термины ....................................................................................35
§ 7. Синонимия .................................................................................38§ 8. Антонимия .................................................................................42§ 9. Закономерность полисемии и синонимии (принцип
дублирования) ..........................................................................43
Глава 2КОЛИЧЕСТВЕННАЯ ДЕРИВАТОЛОГИЯ ................................................47
§ 1. Способы словообразования ......................................................47§ 2. Аффиксология ...........................................................................49§ 3. Описание префиксов (SEMI-) ...................................................51§ 4. Описание суффиксов (-MONGER) ............................................61§ 5. Проблема статуса деривационных морфем .............................67§ 6. Префиксальные гнезда (c pseudo- / quasi-) ..............................71
Языковые характеристики префиксальных гнезд -pseudo- / quasi- .........................................................................72Речевые (частотные) характеристики гнезд с префиксами PSEUDO- И QUASI- .............................................82
§ 7. Суффиксальные цепочки ...........................................................86Цепочка -ive + -ness ..................................................................86Цепочка -less + -ness .................................................................95

242
Глава 3КОЛИЧЕСТВЕННАЯ ДЕРИВАТОГРАФИЯ ............................................106
§ 1. Аффиксография.......................................................................106§ 2. Параметры статьи дериватария .............................................107§ 3. Дериватография префикса Anti- .............................................108§ 4. Дериватография суффиксов: -man .........................................109
Глава 4АФФИКСАЛЬНЫЕ МИНИМУМЫ .........................................................111
§ 1. Продуктивные минимумы ......................................................111§ 2. Частотные аффиксальные минимумы ...................................128
Глава 5КОЛИЧЕСТВЕННАЯ ФРАЗЕОЛОГИЯ .................................................. 150
§ 1. Семантическая классификация ..............................................150§ 2. Структурная классификацмя фразем (поговорок) ................154
Глава 6КОЛИЧЕСТВЕННАЯ ПАРЕМИОЛОГИЯ ...............................................157
§ 1. Семантическая классификация паремием (пословиц) .........157§ 2. Структурная классификация паремием (пословиц) .............160
Семантика паремием и наклонение ......................................160Семантика паремием и время ................................................ 161Семантика паремием и аспект ...............................................162Семантика паремием и залог .................................................164
Глава 7ЛИНГВИСТИЧЕСКИЕ ПРИНЦИПЫ И ЛЯПСУСЫ................................166
§ 1. Лингвистические принципы ..................................................166§ 2. Структура и функция языка и речи ........................................169§ 3. Лингвистические ляпсусы ......................................................174
Приложения ......................................................................................... 200
Литература ........................................................................................... 230

Для заметок

Научное издание
Бартков Борис Ильич
ОЧЕРКИ ПО КОЛИЧЕСТВЕННОЙ ГЛОТТОЛОГИИ И ГЛОТТОГРАФИИ
Выпускающий редактор Г. А. КайноваПодготовка оригинал-макета О. В. Майер
Оформление обложки С. Р. Некрасова
Подписано в печать 10.10.2017. Формат 60х84 / 16. Усл.-печ. л. 14,2. Тираж 101 экз. Заказ 308.
Издательство «Бук». 420029, г. Казань, ул. Академика Кирпичникова, д. 25.Отпечатано в издательстве «Бук».




















