
Network Security 10EC832 - ATME College of Engineering
154
Network Security 10EC832 Department Of ECE, ATMECE Page 1 ATME COLLEGE OF ENGINEERING Approved by AICTE, Affiliated to VTU, Recognized by Govt. of Karnataka 13 th KM, Mysuru-Bannur road, Mysuru-570028 Subject: Network Security Subject Code: 10EC832 VIII Semester B.E DEPARTMENT OF ELECTRONICS & COMMUNICATION ENGINEERING ACADEMIC YEAR 2016-17
-
Upload
khangminh22 -
Category
Documents
-
view
2 -
download
0
Transcript of Network Security 10EC832 - ATME College of Engineering

Network Security 10EC832
Department Of ECE, ATMECE Page 1
ATME COLLEGE OF ENGINEERING
Approved by AICTE, Affiliated to VTU, Recognized by Govt. of Karnataka
13th
KM, Mysuru-Bannur road, Mysuru-570028
Subject: Network Security
Subject Code: 10EC832
VIII Semester B.E
DEPARTMENT OF ELECTRONICS & COMMUNICATION ENGINEERING
ACADEMIC YEAR 2016-17

Network Security 10EC832
Department Of ECE, ATMECE Page 2
ATME COLLEGE OF ENGINEERING
DEPT. OF ELECTRONICS & COMMUNICATION ENGINEERING
Institute Vision and Mission
VISION
Development of academically excellent,culturally vibrant,socially responsible and globally competent
human resources.
MISSION
To keep pace with advancements in knowledge and make the students competitive and capable at the
global level. To create an environment for the students to acquire the right physical, intellectual,
emotional and moral foundations and shine as torch bearers of tomorrow's society. To strive to attain
ever-higher benchmarks of educational excellence.
DEPARTMENT OF ELECTRONICS & COMMUNICATION
VISION
To develop highly skilled and globally competent professionals in the field of Electronics and
Communication Engineering to meet industrial and social requirements with ethical responsibility.
MISSION
To provide State-of-art technical education in Electronics and Communication at undergraduate and
post-graduate levels to meet the needs of the profession and society.
To adopt the best educational methods and achieve excellence in teaching-learning and research.
To develop talented and committed human resource, by providing an opportunity for innovation,
creativity and entrepreneurial leadership with high standards of professional ethics, transparency
and accountability.
To function collaboratively with technical Institutes/Universities/Industries and offer opportunities
for long-term interaction with academia and industry.

Network Security 10EC832
Department Of ECE, ATMECE Page 3
To facilitate effective interactions among faculty and students, and promote networking with
alumni, industries, institutions and other stake-holders.
PROGRAMME EDUCATIONAL OBJECTIVES
PE01. Graduates will have a successful professional career and will be able to pursue higher
education and research globally in the field of Electronics and Communication Engineering thereby
engaging in lifelong learning.
PE02. Graduates will be able to analyse, design and create innovative products by adapting to the
current and emerging technologies while developing a conscience for environmental/ societal
impact.
PE03. Graduates with strong character backed with professional attitude and ethical values will
have the ability to work as a member and as a leader in a team.
PE04. Graduates with effective communication skills and multidisciplinary approach will be able
to redefine problems beyond boundaries and develop solutions to complex problems of today‘s
society.
PROGRAMME OUTCOMES
Engineering Graduates will be able to:
PO1. Engineering knowledge: Apply the knowledge of mathematics, science, engineering
fundamentals, and an engineering specialization to the solution of complex engineering problems.
PO2. Problem analysis: Identify, formulate, review research literature, and analyze complex
engineering problems reaching substantiated conclusions using first principles of mathematics,
natural sciences, and engineering sciences.
PO3. Design/development of solutions: Design solutions for complex engineering problems and
design system components or processes that meet the specified needs with appropriate
consideration for the public health and safety, and the cultural, societal, and environmental
considerations.
PO4. Conduct investigations of complex problems: Use research-based knowledge and research
methods including design of experiments, analysis and interpretation of data, and synthesis of the
information to provide valid conclusions.
PO5. Modern tool usage: Create, select, and apply appropriate techniques, resources, and modern
engineering and IT tools including prediction and modeling to complex engineering activities with
an understanding of the limitations.

Network Security 10EC832
Department Of ECE, ATMECE Page 4
PO6. The engineer and society: Apply reasoning informed by the contextual knowledge to assess
societal, health, safety, legal and cultural issues and the consequent responsibilities relevant to the
professional engineering practice.
PO7. Environment and sustainability: Understand the impact of the professional engineering
solutions in societal and environmental contexts, and demonstrate the knowledge of, and need for
sustainable development.
PO8. Ethics: Apply ethical principles and commit to professional ethics and responsibilities and
norms of the engineering practice.
PO9. Individual and team work: Function effectively as an individual, and as a member or leader
in diverse teams, and in multidisciplinary settings.
PO10. Communication: Communicate effectively on complex engineering activities with the
engineering community and with society at large, such as, being able to comprehend and write
effective reports and design documentation, make effective presentations, and give and receive
clear instructions.
PO11. Project management and finance: Demonstrate knowledge and understanding of the
engineering and management principles and apply these to one‘s own work, as a member and
leader in a team, to manage projects and in multidisciplinary environments.
PO12. Life-long learning: Recognize the need for, and have the preparation and ability to engage
in independent and life-long learning in the broadest context of technological change.

Network Security 10EC832
Department Of ECE, ATMECE Page 5
Course Syllabi with CO’s
Faculty Name/s : JUSLIN F Academic Year: 2016 - 2017
Department: Electronics and Communication Engineering
Course
Code Course Title Core/Elective Prerequisite
Contact
Hours Total Hrs/
Sessions L T P
10EC83
2 Network Security Elective
Computer terminology.
Basic mathematics
concept like mod
operation and matrix
multiplication.
OSI layers.
4 - 52
Objectiv
es
After studying this course, you should be able to:
1. Identify some of the factors driving the need for network security
2. Identify and classify particular examples of attacks
3. Define the terms vulnerability, threat and attack
4. Identify physical points of vulnerability in simple networks
5. Compare and contrast symmetric and asymmetric encryption systems and their
vulnerability to attack, and explain the characteristics of hybrid systems.
Topics Covered as per Syllabus
UNIT - 1
Services, mechanisms and attacks, The OSI security architecture, A model for network security.
UNIT - 2
SYMMETRIC CIPHERS: Symmetric Cipher Model, Substitution Techniques, Transposition Techniques,
Simplified DES, Data encryption standard (DES), The strength of DES, Differential and Linear
Cryptanalysis,
Block Cipher Design Principles and Modes of Operation, Evaluation Criteria for Advanced Encryption
Standard, The AES Cipher.
UNIT - 3
Principles of Public-Key Cryptosystems, The RSA algorithm, Key Management, Diffie - Hellman Key
Exchange, Elliptic Curve Arithmetic, Authentication functions, Hash Functions.
UNIT - 4
Digital signatures, Authentication Protocols, Digital Signature Standard.
UNIT - 5
Web Security Consideration, Security socket layer (SSL) and Transport layer security, Secure Electronic
Transaction.
ATME COLLEGE OF ENGINEERING DEPT OF ELECTRONICS AND COMMUNICATIONENGINEERING

Network Security 10EC832
Department Of ECE, ATMECE Page 6
UNIT – 6
Intruders, Intrusion Detection, Password Management.
UNIT - 7
MALICIOUS SOFTWARE: Viruses and Related Threats, Virus Countermeasures.
UNIT - 8
Firewalls Design Principles, Trusted Systems.
List of Text Books
1. Cryptography and Network Security, William Stalling, Pearson Education, 2003.
List of Reference Books
1. Cryptography and Network Security, Behrouz A. Forouzan, TMH, 2007.
2. Cryptography and Network Security, Atul Kahate, TMH, 2003.
List of URLs, Text Books, Notes, Multimedia Content, etc
1. Ellis, J. and Speed, T. (2001) The Internet Security Guidebook, Academic Press.
2. ISO/IEC 17799 (2000) Information Technology – Code of Practice for Information
Security Management, International Organization for Standardization.
Course
Outco
mes
1. Understood the basic need of security issues and Studied the classical encryption and
decryption methods
2. Analysed the symmetric and asymmetric encryption
3. Understood the concepts of malicious softwares, firewalls
4. Able to analyze the web security issues present in secure electronic transaction
Internal Assessment Marks: 25 (3 Session Tests are conducted during the semester and marks
allotted based on average of best performances).
The Correlation of Course Outcomes (CO’s) and Program Outcomes (PO’s) Subject
Code: 10EC832 TITLE: Network Security
Faculty
Name: Juslin F
List of
Course
Outcomes
Program Outcomes
Total PO1 PO2 PO3 PO4 PO5 PO6 PO7 PO8 PO9 PO10 PO11 PO12
CO-1 4 3 2 2 2 2 1 1 1 2 1 1 22
CO-2 3 3 2 2 3 2 3 2 2 2 1 1 26
CO-3 4 4 4 4 3 3 2 3 3 3 2 2 37
CO-4 3 3 3 2 2 2 2 2 2 2 1 2 26
Total 14 13 11 10 10 9 8 8 8 9 5 6 111 Note: 4 = Strong Contribution 3 = Average Contribution 2 = Weak Contribution 1 = No Contribution
The Correlation of Course Outcomes (CO’s) and Program Specific Outcomes (PSO’s) Subject
Code: 10EC832 TITLE: Network Security
Faculty
Name: Juslin F
List of
Course
Outcomes
Program Specific Outcomes
Total PSO1 PSO2 PSO3 PSO4
CO-1 3
3
3
1
2
3
1
1
1
1
1
1
6
CO-2 3
3
3
2
2
3
2
1
2
2
1
1
9
CO-3 4
3
3
2
2
3
2
3
2
3
1
1
10
CO-4 4
3
3
3
2
2
2
2
2
4
1
2
14
Total 14
12
12
8
8
11
7
7
7
10
4
5
39
Note: 4 = Strong Contribution 3 = Average Contribution 2 = Weak Contribution 1 = No Contribution

Network Security 10EC832
Department Of ECE, ATMECE Page 7
NETWORK SECURITY
Subject Code : 10EC832 IA Marks : 25
No. of Lecture Hrs/Week : 04 Exam Hours : 03
Total no. of Lecture Hrs. : 52 Exam Marks : 100
UNIT 1:
Services, Mechanisms, Mechanism Attacks, The OSI security architecture, A model for network
security. 6 Hours
UNIT 2: Symmetric Ciphers:
Symmetric Ciphers model, Substitution Techniques, Transposition Techniques, Simplified DES, Data
encryption Standard (DES),The strength of DES, Differential and Linear Cryptanalysis, Block Cipher
Design Principles and modes of operation,Evaluation Criteria for Advanced Encryption Standard, The
AES Cipher. 7 Hours
UNIT 3:
Principles of public key Cryptosystem, The RSA algorithms, Key management, Diffie – Hellman key
exchange, Elliptic Curve Arithmetic, Authentication functions, Hash functions 6 Hours
UNIT 4:
Digital Signatures, Authentication protocols, Digital signature standard. 7 Hours
UNIT 5:
Web security consideration, Secure Socket layer, Transport layer security, secure electronic transaction.
6 Hours
UNIT 6:
Intruders, Intrusion Detection, Password Management. 6 Hours
UNIT 7: Malicious software
Malicious software programs: Viruses and related Threats, Virus Countermeasures 6 Hours
UNIT 8:
Firewall Design Principles, Trusted Systems 6 Hours

Network Security 10EC832
Department Of ECE, ATMECE Page 8
Text Book:
1. Cryptography and network Security. William Stalling, Pearson Education, 2003
References books:
1. Cryptography and network security, Behrouz A Forouzan, TMH, 2007.
2. Cryptography and network security, Atul kahate, TMH, 2003.

Department Of ECE, SJBIT Page 10
Unit-1
Unit Structure:
1.0 Introduction
1.1 Objectives
1.2 Services
1.3 Mechanisms
1.4 Mechanism Attacks
1.5 The OSI security architecture,
1.6 A model for network security.
1.0 INTRODUCTION
Access control is the ability to limit and control the access to host systems and applications via
communications links. A security service as a service that is provided by a protocol layer of
communicating open systems and that ensures adequate security of the systems or of data transfers.
1.1 OBJECTIVES
After studying the unit, Student should be able to
• Understand Basic issues in computer network security
• Learn about Services, mechanism and attacks
• Understand OSI Security Architecture and model for network security
1.2 SECURITY SERVICES
A security service as a service that is provided by a protocol layer of communicating open
systems and that ensures adequate security of the systems or of data transfers. Or a processing or
communication service that is provided by a system to give a specific kind of protection to system
resources.
X.800 divides these services into five categories and fourteen specific services.
Authentication
The authentication service is concerned with assuring that a communication is authentic. In the
case of a single message, such as a warning or alarm signal, the function of the authentication service is
to assure the recipient that the message is from the source that it claims to be from. In the case of an

Department Of ECE, SJBIT Page 10
ongoing interaction, such as the connection of a terminal to a host, two aspects are involved. First, at the
time of connection initiation, the service assures that the two entities are authentic, that is, that each is
the entity that it claims to be. Second, the service must assure that the connection is not interfered with
in such a way that a third party can masquerade as one of the two legitimate parties for the purposes of
unauthorized transmission or reception.
Two specific authentication services are defined in X.800:
Peer entity authentication: Peer entity authentication is provided for use at the establishment
of, or at times during the data transfer phase of, a connection. It attempts to provide confidence that an
entity is not performing either a masquerade or an unauthorized replay of a previous connection.
Data origin authentication: Provides for the corroboration of the source of a data unit. It does
not provide protection against the duplication or modification of data units. This type of service
supports applications like electronic mail, where there are no prior interactions between the
communicating entities.
Access Control
Access control is the ability to limit and control the access to host systems and applications via
communications links. To achieve this, each entity trying to gain access must first be identified, or
authenticated, so that access rights can be tailored to the individual.
Data Confidentiality
Confidentiality is the protection of transmitted data from passive attacks. With respect to the
content of a data transmission, several levels of protection can be identified. The broadest service
protects all user data transmitted between two users over a period of time. Narrower forms of this
service can also be defined, including the protection of a single message or even specific fields within a
message.
The other aspect of confidentiality is the protection of traffic flow from analysis. This requires
that an attacker not be able to observe the source and destination, frequency, length, or other
characteristics of the traffic on a communications facility.
Data Integrity
As with confidentiality, integrity can apply to a stream of messages, a single message, or
selected fields within a message. A connection-oriented integrity service, one that deals with a stream of
messages, assures that messages are received as sent with no duplication, insertion, modification,
reordering, or replays. The connection-oriented integrity service addresses both message stream
modification and denial of service. A connectionless integrity service, one that deals with individual
messages without regard to any larger context, generally provides protection against message
modification only.

Department Of ECE, SJBIT Page 10
We can make a distinction between service with and without recovery. Because the integrity
service relates to active attacks, we are concerned with detection rather than prevention. If a violation of
integrity is deteed, then the service may simply report this violation, and some other portion of software
or human intervention is required to recover from the violation. There are mechanisms available to
recover from the loss of integrity of data; the incorporation of automated recovery mechanisms is, in
general, the more attractive alternative.
Data Integrity
As with confidentiality, integrity can apply to a stream of messages, a single message, or
selected fields within a message. A connection-oriented integrity service, one that deals with a stream of
messages, assures that messages are received as sent with no duplication, insertion, modification,
reordering, or replays. The connection-oriented integrity service addresses both message stream
modification and denial of service. a connectionless integrity service, one that deals with individual
messages without regard to any larger context, generally provides protection against message
modification only.
We can make a distinction between service with and without recovery. Because the integrity
service relates to active attacks, we are concerned with detection rather than prevention. If a violation of
integrity is detected, then the service may simply report this violation, and some other portion of
software or human intervention is required to recover from the violation. there are mechanisms
available to recover from the loss of integrity of data, The incorporation of automated recovery
mechanisms is, in general, the more attractive alternative.
Non repudiation
Nonrepudiation prevents either sender or receiver from denying a transmitted message. Thus,
when a message is sent, the receiver can prove that the alleged sender in fact sent the message.
Similarly, when a message is received, the sender can prove that the alleged receiver in fact received the
message.
1.3 SECURITY MECHANISMS
SPECIFIC SECURITY MECHANISMS May be incorporated into the appropriate protocol
layer in order to provide some of the OSI security services.
Encipherment
The use of mathematical algorithms to transform data into a form that is not readily intelligible.

Department Of ECE, SJBIT Page 10
The transformation and subsequent recovery of the data depend on an algorithm and zero or
more encryption keys.
Digital Signature
Data appended to, or a cryptographic transformation of, a data unit that allows a recipient of the
data unit to prove the source and integrity of the data unit and protect against forgery (e.g., by
the recipient).
Access Control
A variety of mechanisms that enforce access rights to resources.
Data Integrity
A variety of mechanisms used to assure the integrity of a data unit or stream of data units.
Authentication Exchange
A mechanism intended to ensure the identity of an entity by means of information exchange.
Traffic Padding
The insertion of bits into gaps in a data stream to frustrate traffic analysis attempts.
Routing Control
Enables selection of particular physically secure routes for certain data and allows routing
changes, especially when a breach of security is suspected.
Notarization
The use of a trusted third party to assure certain properties of a data exchange.
PERVASIVE SECURITY MECHANISMS: Mechanisms that is not specific to any particular OSI
security service or protocol layer.
Trusted Functionality
That which is perceived to be correct with respect to some criteria (e.g., as established by a security
policy).
Security Label
The marking bound to a resource (which may be a data unit) that names or designates the security
attributes of that resource.
Event Detection
Detection of security-relevant events.
Security Audit Trail
Data collected and potentially used to facilitate a security audit, which is an independent review and
Department Of ECE, SJBIT Page 10
examination of system records and activities.
Security Recovery
Deals with requests from mechanisms, such as event handling and management functions,
and takes recovery actions.
Table 1.3 Relationships between Security Services and Mechanisms
Mechanisms
Services Encipher
-ment
Digital
Signature
Access
control
Data
Integrity
Authenti
-cation
Exchange
Traffic
Padding
Routing
Control
Notari
z
ation
Peer Entity
Authentication
Y
Y
Y
Data Origin
Authentication
Y
Y
Access Control Y
Confidentiality Y Y Traffic Flow
Confidentiality
Y
Y
Y
Data Integrity Y Y Y
Nonrepudiation Y Y Y
Availability Y Y
1.4 SECURITY ATTACKS
A useful means of classifying security attacks is in terms of passive attacks and active attacks. A
passive attack attempts to learn or make use of information from the system but does not affect system
resources. An active attack attempts to alter system resources or affect their operation.
Passive Attacks
Passive attacks are in the nature of eavesdropping on, or monitoring of, transmissions. The goal
of the opponent is to obtain information that is being transmitted. Two types of passive attacks are the
release of message contents and traffic analysis.
The release of message contents is easily understood (Figure 1.1a).A telephone conversation,
an electronic mail message, and a transferred file may contain sensitive or confidential information. We
would like to prevent an opponent from learning the contents of these transmissions.
A second type of passive attack, traffic analysis, is subtler (Figure 1.1b). Suppose that we had a
way of masking the contents of messages or other information traffic so that opponents, even if they
captured the message, could not extract the information from the message. The common technique for
masking contents is encryption. If we had encryption protection in place, an opponent might still be
able to observe the pattern of these messages. The opponent could determine the location and identity of
communicating hosts and could observe the frequency and length of messages being exchanged. This
information might be useful in guessing the nature of the communication that was taking place.
Passive attacks are very difficult to detect, because they do not involve any alteration of the data.

Department Of ECE, SJBIT Page 10
Typically, the message traffic is not sent and received in an apparently normal fashion and the sender
nor receiver is aware that a third party has read the messages or observed the traffic pattern. However, it
is feasible to prevent the success of these attacks, usually by means of encryption. Thus, the emphasis in
dealing with passive attacks is on prevention rather than detection.
(a) Release of message contents
(b) Traffic analysis
Figure 1.1 Passive Attack
Department Of ECE, ATMECE Page 15
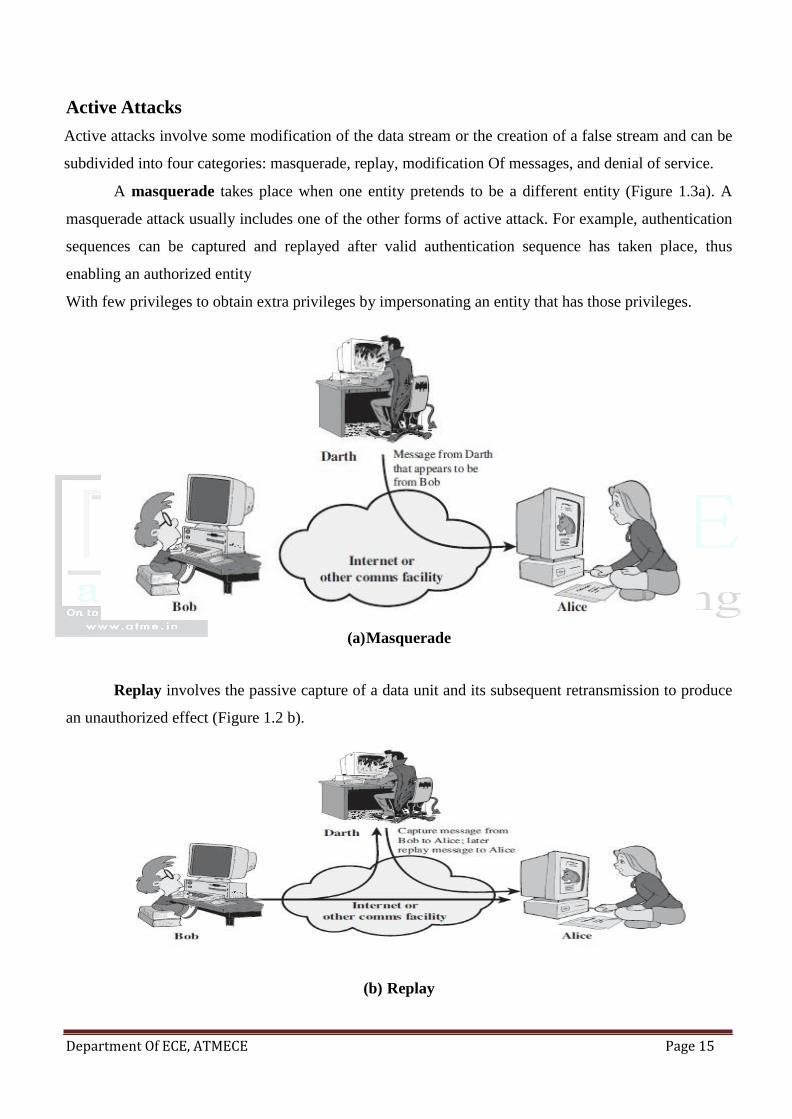
Active Attacks
Active attacks involve some modification of the data stream or the creation of a false stream and can be
subdivided into four categories: masquerade, replay, modification Of messages, and denial of service.
A masquerade takes place when one entity pretends to be a different entity (Figure 1.3a). A
masquerade attack usually includes one of the other forms of active attack. For example, authentication
sequences can be captured and replayed after valid authentication sequence has taken place, thus
enabling an authorized entity
With few privileges to obtain extra privileges by impersonating an entity that has those privileges.
(a) Masquerade
Replay involves the passive capture of a data unit and its subsequent retransmission to produce
an unauthorized effect (Figure 1.2 b).
(b) Replay

Department Of ECE, ATMECE Page 16
Modification of messages simply means that some portion of a legitimate message is altered, or
that messages are delayed or reordered, to produce an unauthorized effect (Figure 1.3c). For example, a
message meaning ―Allow John Smith to read confidential file accounts‖ is modified to mean ―Allow
Fred Brown to read Confidential file accounts.‖
(c) Modification of messages
The denial of service prevents or inhibits the normal use or management of communications
facilities (Figure 1.3d). This attack may have a specific target; for example, an entity may suppress all
messages directed to a particular destination.
Another form of service denial is the disruption of an entire network, either by disabling the
network or by overloading it with messages so as to degrade performance.
Active attacks present the opposite characteristics of passive attacks. Whereas passive attacks
are difficult to detect, measures are available to prevent their success.
(d) Denial of service
Figure 1.2 Active Attacks

Department Of ECE, ATMECE Page 17
It is quite difficult to prevent active attacks absolutely because of the wide variety of potential
physical, software, and network vulnerabilities. Instead, the goal is to detect active attacks and to
recover from any disruption or delays caused by them. If the detection has a deterrent effect, it may also
contribute to prevention.
1.5 THE OSI SECURITY ARCHITECTURE
The OSI security architecture is useful to managers as a way of organizing the task of providing
security. The OSI security architecture focuses on security attacks, mechanisms, and services. These
can be defined briefly as
• Security attack: Any action that compromises the security of information owned by an organization.
• Security mechanism: A process (or a device incorporating such a process) that is designed to detect,
prevent, or recover from a security attack.
• Security service: A processing or communication service that enhances the security of the data
processing systems and the information transfers of an organization. The services are intended to
counter security attacks, and they make use of one or more security mechanisms to provide the service.
1.6 A MODEL FOR NETWORK SECURITY
A message is to be transferred from one party to another across some sort of Internet service. The two
parties, who are the principals in this transaction, must cooperate for the exchange to take place. A
logical information channel is established by defining a route through the Internet from source to
destination and by the cooperative use of communication protocols (e.g., TCP/IP) by the two principals.
Security aspects come into play when it is necessary or desirable to protect the information transmission
from an opponent who may present a threat to confidentiality, authenticity, and so on. All the
techniques for providing security have two components:
• A security-related transformation on the information to be sent. Examples include the encryption of
the message, which scrambles the message so that it is unreadable by the opponent, and the addition of
a code based on the contents of the message, which can be used to verify the identity of the sender.
•Some secret information shared by the two principals and, it is hoped, unknown to the opponent. An
example is an encryption key used in conjunction with the transformation to scramble the message
before transmission and unscramble it on reception.

Department Of ECE, ATMECE Page 18
A trusted third party may be needed to achieve secure transmission. For example, a third party
may be responsible for distributing the secret information to the two principals while keeping it from
any opponent. Or a third party may be needed to arbitrate disputes between the two principals
concerning the authenticity of a message transmission.
This general model shows that there are four basic tasks in designing a particular security service:
1. Design an algorithm for performing the security-related transformation. The algorithm should be
such that an opponent cannot defeat its purpose.
2. Generate the secret information to be used with the algorithm.
3. Develop methods for the distribution and sharing of the secret information.
4. Specify a protocol to be used by the two principals that makes use of the security algorithm and the
secret information to achieve a particular security service.
Figure 1.3 Models for Network Security
The security mechanisms needed to cope with unwanted access fall into two broad categories
(see Figure 1.4).The first category might be termed a gatekeeper function. It includes password-based
login procedures that are designed to deny access to all but authorized users and screening logic that is
designed to detect and reject worms, viruses, and other similar attacks. Once either an unwanted user or
unwanted software gains access, the second line of defense consists of a variety of internal controls that
monitor activity and analyze stored information in an attempt to detect the presence of unwanted
intruders.

Department Of ECE, ATMECE Page 19
Figure 1.4 Network Access Security Model
OUTCOMES
• Define Basic issues in computer network security
• Understand Services, mechanism and attacks in Computer network
• Understand OSI Security Architecture and model for network security
RECOMMENDED QUESTIONS:
1. Distinguish between passive and active attacks.
2. Explain the different categories of security services.
3. Draw the block diagram of network security model and explain it. Mention basic tasks in
Designing a particular security service.
4. Explain X-800 security mechanisms, in detail.
5. Differentiate between active and passive attacks.
6. With a neat diagram, explain network access security model with gate keeper function.
7. Classify and explain different type of attacks

Department Of ECE, ATMCE, Mysuru Page 20
UNIT 2
Structure:
2.0 Introduction
2.1 Objective
2.2 Symmetric Ciphers model
2.3 Substitution Techniques
2.4 Transposition Techniques
2.5 Simplified DES
2.6 Data encryption Standard (DES)
2.7 The strength of DES
2.8 Differential and Linear Cryptanalysis
2.9 Block Cipher Design Principles and modes of operation,
2.10 Evaluation Criteria for Advanced Encryption Standard
2.11 The AES Cipher.
2.0 INTRODUCTION
Symmetric encryption, also referred to as conventional encryption or single-key encryption, was the only
type of encryption in use prior to the development of public key encryption in the 1970s. It remains by far
the most widely used of the two types of encryption. Part One examines a number of symmetric ciphers.
In this chapter, we begin with a look at a general model for the symmetric encryption process; this will
enable us to understand the context within which the algorithms are used. Next, we examine a variety of
algorithms in use before the computer era.
Finally, we look briefly at a different approach known as steganography. Chapters 3 and 5 examine the
two most widely used symmetric cipher: DES and AES. Before beginning, we define some terms. An
original message is known as the plaintext, while the coded message is called the ciphertext. The
process of converting from plaintext to cipher text is known as enciphering or encryption; restoring the
plaintext from the cipher text is deciphering or decryption. The many schemes used for encryption
constitute the area of study known as cryptography. Such a scheme is known as a cryptographic
system or a cipher. Techniques used for deciphering a message without any knowledge of the

Department Of ECE, ATMCE, Mysuru Page 21
enciphering details fall into the area of cryptanalysis. Cryptanalysis is what the layperson calls ―breaking
the code.‖The areas of cryptography and cryptanalysis together are called cryptology.
2.1 OBJECTIVES
After studying the unit, Student should be able to
• Illustrate the principles of modern symmetric ciphers.
• Analyze various Encryption and decryption Technique
• Learn Data encryption Standard (DES) and its strength and also AES cipher
• Learn Block Cipher Design Principles and modes of operation
2.2 SYMMETRIC CIPHER MODEL
Figure 2.1 Simplified Model of Symmetric Encryption
A symmetric encryption scheme has five ingredients (Figure 2.1):
• Plaintext: This is the original intelligible message or data that is fed into the algorithm as input.
• Encryption algorithm: The encryption algorithm performs various substitutions and transformations
on the plaintext.
• Secret key: The secret key is also input to the encryption algorithm. The key is a value independent of
the plaintext and of the algorithm. The algorithm will produce a different output depending on the
specific key being used at the time. The exact substitutions and transformations performed by the
algorithm depend on the key.
• Cipher text: This is the scrambled message produced as output. It depends on the plaintext and the
secret key. For a given message, two different keys will produce two different cipher texts. The cipher

Department Of ECE, ATMCE, Mysuru Page 22
text is an apparently random stream of data and, as it stands, is unintelligible.
• Decryption algorithm: This is essentially the encryption algorithm run in reverse. It takes the cipher
text and the secret key and produces the original plaintext.
There are two requirements for secure use of conventional encryption:
1. We need a strong encryption algorithm. The algorithm to be such that an opponent who
knows the algorithm and has access to one or more cipher texts would be unable to decipher
the cipher text or figure out the key. The opponent should be unable to decrypt ciphertext or
discover the key even if he or she is in possession of a number of ciphertexts together with
the plaintext that produced each ciphertext.
2. Sender and receiver must have obtained copies of the secret key in a secure fashion and must
keep the key secure. If someone can discover the key and knows the algorithm, all
communication using this key is readable.
We assume that it is impractical to decrypt a message on the basis of the cipher text plus
knowledge of the encryption/decryption algorithm. We do not need to keep the algorithm secret; we
need to keep only the key secret.
Let us take a closer look at the essential elements of a symmetric encryption scheme, using
Figure 2.2. A source produces a message in plaintext, . The M elements of
X are letters in some finite alphabet. Traditionally, the alphabet usually consisted of the 26 capital
letters. Nowadays, the binary alphabet {0, 1} is typically used. For encryption, a key of
the form is generated. If the key is generated at the message source, then it
must also be provided to the destination by means of some secure channel. Alternatively, a third party
could generate the key and securely deliver it to both source and destination.
Figure 2.2 Model of Symmetric Cryptosystem
With the message X and the encryption key K as input, the encryption algorithm forms the cipher text
we can write this as

Department Of ECE, ATMCE, Mysuru Page 23
This notation indicates that Y is produced by using encryption algorithm E as a function of the plaintext
X , with the specific function determined by the value of the key K.
The intended receiver, in possession of the key, is able to invert the transformation:
An opponent, observing but not having access to X or K , may attempt to recover X or K or
both X and K. It is assumed that the opponent knows the encryption (E) and decryption (D)
algorithms. If the opponent is interested in only this particular message, then the focus of the effort is
to recover by generating a plaintext estimate. Often, however, the opponent is interested in being able
to read future messages as well, in which case an attempt is made to recover by generating an estimate.
Cryptography
Cryptographic systems are characterized along three independent dimensions:
1. The type of operations used for transforming plaintext to ciphertext. All encryption algorithms
are based on two general principles: substitution, in which each element in the plaintext (bit, letter,
group of bits or letters) is mapped into another element, and transposition, in which elements in the
plaintext are rearranged. The fundamental requirement is that no information be lost (that is, that all
operations are reversible). Most systems, referred to as product systems, involve multiple stages of
substitutions and transpositions.
2. The number of keys used. If both sender and receiver use the same key, the system is referred to as
symmetric, single-key, secret-key, or conventional encryption. If the sender and receiver use different
keys, the system is referred to as asymmetric, two-key, or public-key encryption.
3. The way in which the plaintext is processed. A block cipher processes the input one block of
elements at a time, producing an output block for each input block. A stream cipher processes the input
elements continuously, producing output one element at a time, as it goes along.
Cryptanalysis and Brute-Force Attack
Typically, the objective of attacking an encryption system is to recover the key in use rather than simply
to recover the plaintext of a single cipher text. There are two general approaches to attacking a
conventional encryption scheme:
• Cryptanalysis: Cryptanalytic attacks rely on the nature of the algorithm plus perhaps some
knowledge of the general characteristics of the plaintext or even some sample plaintext–cipher text
pairs. This type of attack exploits the characteristics of the algorithm to attempt to deduce a specific
plaintext or to deduce the key being used.
• Brute-force attack: The attacker tries every possible key on a piece of cipher text until an intelligible

Department Of ECE, ATMCE, Mysuru Page 24
translation into plaintext is obtained. On average, half of all possible keys must be tried to achieve
success.
Table 2.1 summarizes the various types of cryptanalytic attacks based on the amount of information
known to the cryptanalyst.
Table 2.1 Types of Attacks on Encrypted Messages
Types of Attack Known to cryptanalyst Cipher text Only • Encryption algorithm
• Cipher text Known Plaintext • Encryption algorithm
• Cipher text
• One or more plaintext–cipher text pairs formed with the
secret key Chosen Plaintext • Encryption algorithm
• Cipher text
• Plaintext message chosen by cryptanalyst, together
with its corresponding cipher text generated with the
secret key Chosen
Cipher text • Encryption algorithm • Cipher text • Cipher text chosen by cryptanalyst, together with its
corresponding decrypted plaintext generated with the secret
key Chosen Text • Encryption algorithm • Cipher text
• Plaintext message chosen by cryptanalyst, together
with its corresponding cipher text generated with the
secret key
• Cipher text chosen by cryptanalyst, together with its
corresponding decrypted plaintext generated with the secret
key
2.3 SUBSTITUTION TECHNIQUES
The two basic building blocks of all encryption techniques are substitution and transposition. A
substitution technique is one in which the letters of plaintext are replaced by other letters or by
numbers or symbols.1 If the plaintext is viewed as a sequence of bits, then substitution involves
replacing plaintext bit patterns with cipher text bit patterns.
Caesar Cipher
The earliest known, and the simplest, use of a substitution cipher was by Julius Caesar. The
Caesar cipher involves replacing each letter of the alphabet with the letter standing three places further
down the alphabet. For example,
plain: meet me after the toga party
cipher: PHHW PH DIWHU WKH WRJD SDUWB
Note that the alphabet is wrapped around, so that the letter following Z is A. We can define the

Department Of ECE, ATMCE, Mysuru Page 25
transformation by listing all possibilities, as follows:
Plain: a b c d e f g h i j k l m n o p q r s t u v w x y z
cipher: D E F G H I J K L M N O P Q R S T U V W X Y Z A B C
Let us assign a numerical equivalent to each letter:
Then the algorithm can be expressed as follows. For each plaintext letter , substitute the ciphertext letter
A shift may be of any amount, so that the general Caesar algorithm is
Where takes on a value in the range 1 to 25.The decryption algorithm is simply
If it is known that a given ciphertext is a Caesar cipher, then a brute-force cryptanalysis is easily
performed: simply try all the 25 possible keys.
Three important characteristics of this problem enabled us to use a brute force cryptanalysis:
1. The encryption and decryption algorithms are known.
2. There are only 25 keys to try.
3. The language of the plaintext is known and easily recognizable.
Playfair Cipher
The best-known multiple-letter encryption cipher is the Playfair, which treats diagrams in the
plaintext as single units and translates these units into ciphertext diagrams. The Playfair algorithm is
based on the use of a 5 X 5 matrix of letters constructed using a keyword. Here is an example,
In this case, the keyword is monarchy. The matrix is constructed by filling in the letters of the
keyword (minus duplicates) from left to right and from top to bottom, and then filling in the remainder
of the matrix with the remaining letters in alphabetic order. The letters I and J count as one letter.
Plaintext is encrypted two letters at a time, according to the following rules:

Department Of ECE, ATMCE, Mysuru Page 26
1. Repeating plaintext letters that are in the same pair are separated with a filler letter, such as x, so that
balloon would be treated as ba lx lo on.
2. Two plaintext letters that fall in the same row of the matrix are each replaced by the letter to the right,
with the first element of the row circularly following the last. For example, ar is encrypted as RM.
3. Two plaintext letters that fall in the same column are each replaced by the letter beneath, with the top
element of the column circularly following the last. For example, mu is encrypted as CM.
4. Otherwise, each plaintext letter in a pair is replaced by the letter that lies in its own row and the
column occupied by the other plaintext letter. Thus, hs becomes BP and ea becomes IM (or JM, as the
encipherer wishes).
The Playfair cipher is a great advance over simple monoalphabetic ciphers. For one thing,
whereas there are only 26 letters, there are 26 X 26 = 676 diagrams, so that identification of individual
diagrams is more difficult. Furthermore, the relative frequencies of individual letters exhibit a much
greater range than that of diagrams, making frequency analysis much more difficult. For these reasons,
the Playfair cipher was for a long time considered unbreakable.
Hill Cipher
Another interesting multiletter cipher is the Hill cipher, developed by the mathematician Lester
Hill in 1929. CONCEPTS FROM LINEAR ALGEBRA Before describing the Hill cipher, let us briefly
review some terminology from linear algebra. In this discussion, we are concerned with matrix
arithmetic modulo 26.
We define the inverse of a square matrix M by the equation , where I is
the identity matrix. I is a square matrix that is allzeros except for ones along the main diagonal from
upper left to lower right. The inverse of a matrix does not always exist, but when it does, it satisfies the
preceding equation. For example,
To explain how the inverse of a matrix is computed, we begin by with the concept of
determinant. For any square matrix (m × ), the determinant equals the sum of all the products that can
be formed by taking exactly one element from each row and exactly one element from each column,
with certain of the product terms preceded by a minus sign. For a 2X2 matrix,

Department Of ECE, ATMCE, Mysuru Page 27
THE HILL ALGORITHM This encryption algorithm takes successive plaintext letters and
substitutes for them cipher text letters. The substitution is determined by linear equations in which each
character is assigned a numerical value
Where C and P are row vectors of length 3 representing the plaintext and ciphertext, and K is a 3
X 3matrix representing the encryption key. Operations are performed mod 26. For example, consider
the plaintext ―paymoremoney‖ and use the encryption key

Department Of ECE, ATMCE, Mysuru Page 28
It is easily seen that if the matrix is applied to the cipher text, then the plaintext is recovered.
In general terms, the Hill system can be expressed as
As with Playfair, the strength of the Hill cipher is that it completely hides single-letter
frequencies. Indeed, with Hill, the use of a larger matrix hides more frequency information. Thus, a 3
X3 Hill cipher hides not only single-letter but also two-letter frequency information.
The inverse of X can be computed:
This result is verified by testing the remaining plaintext–ciphertext pairs.

Department Of ECE, ATMCE, Mysuru Page 29
Polyalphabetic Ciphers
Another way to improve on the simple monoalphabetic technique is to use different
monoalphabetic substitutions as one proceeds through the plaintext message. The general name for this
approach is polyalphabetic substitution cipher. All these techniques have the following features in
common:
1. A set of related monoalphabetic substitution rules is used.
2. A key determines which particular rule is chosen for a given transformation.
VIGEN`ERE CIPHER The best known, and one of the simplest, polyalphabetic ciphers is the Vigenère
cipher. In this scheme, the set of related monoalphabetic substitution rules consists of the 26 Caesar
ciphers with shifts of 0 through 25. Each cipher is denoted by a key letter, which is the ciphertext letter
that substitutes for the plaintext letter a. Thus, a Caesar cipher with a shift of 3 is denoted by the key
value .
We can express the Vigenère cipher in the following manner. Assume a sequence of plaintext
letters and a key consisting of the sequence of letters
where typically is calculated as follows:
Thus, the first letter of the key is added to the first m letter of the plaintext, mod 26, the second
m letters are added, and so on through the first letters of the plaintext. For the next letters of the
plaintext, the key letters are repeated. This process continues until all of the plaintext sequence is
encrypted. A general equation of the encryption process is
Compare this with Equation (2.1) for the Caesar cipher. In essence, each plaintext character is
encrypted with a different Caesar cipher, depending on the corresponding key character. Similarly,
decryption is a generalization is
To encrypt a message, a key is needed that is as long as the message. Usually, the key is a
repeating keyword. For example, if the keyword is deceptive, the message ―we are discovered save
yourself‖ is encrypted as

Department Of ECE, ATMCE, Mysuru Page 30
The strength of this cipher is that there are multiple cipher text letters for each plaintext letter,
one for each unique letter of the keyword. Thus, the letter frequency information is obscured. However,
not all knowledge of the plaintext structure is lost. For example, Figure 2.6 shows the frequency
distribution for a Vigenère cipher with a keyword of length 9. An improvement is achieved over the
Playfair cipher, but considerable frequency information remains.
It is instructive to sketch a method of breaking this cipher, because the method reveals some of
the mathematical principles that apply in cryptanalysis.
First, suppose that the opponent believes that the ciphertext was encrypted using either
monoalphabetic substitution or a Vigenère cipher. A simple test can be made to make a determination.
If a monoalphabetic substitution is used, then the statistical properties of the ciphertext should be the
same as that of the language of the plaintext. Thus, referring to Figure 2.5, there should be one
cipherletter with a relative frequency of occurrence of about 12.7%, one with about9.06%, and so on. If
only a single message is available for analysis, we would not expect an exact match of this small
sample with the statistical profile of the plaintext language. Nevertheless, if the correspondence is close,
we can assume a monoalphabetic substitution.
If, on the other hand, a Vigenère cipher is suspected, then progress depends on determining the
length of the keyword, as will be seen in a moment. For now, let us concentrate on how the keyword
length can be determined. The important insight that leads to a solution is the following: If two identical
sequences of plaintext letters occur at a distance that is an integer multiple of the keyword length, they
will generate identical ciphertext sequences. In the foregoing example, two instances of the sequence
―red‖ are separated by nine character positions. Consequently, in both cases, r is encrypted using key
letter, e is encrypted using key letter, and d is encrypted using key letter .Thus, in both cases, the

Department Of ECE, ATMCE, Mysuru Page 31
ciphertext sequence is VTW. We indicate this above by underlining the relevant ciphertext letters and
shading the relevant ciphertext numbers. An analyst looking at only the ciphertext would detect the
repeated sequences VTW at a displacement of 9 and make the assumption that the keyword is either
three or nine letters in length. The appearance of VTW twice could be by chance and not reflect
identical plaintext letters encrypted with identical key letters. However, if the message is long enough,
there will be a number of such repeated ciphertext sequences. By looking for common factors in the
displacements of the various sequences, the analyst should be able to make a good guess of the keyword
length.
Solution of the cipher now depends on an important insight. If the keyword length is m, then the
cipher, in effect, consists of m monoalphabetic substitution ciphers. For example, with the keyword
DECEPTIVE, the letters in positions 1, 10, 19, and so on are all encrypted with the same
monoalphabetic cipher. Thus, we can use the known frequency characteristics of the plaintext language
to attack each of the monoalphabetic ciphers separately.
The periodic nature of the keyword can be eliminated by using a nonrepeating keyword that is
as long as the message itself. Vigenère proposed what is referred to as an auto key system, in which a
keyword is concatenated with the plaintext itself to provide a running key. For our example,
VERNAM CIPHER The ultimate defense against such a cryptanalysis is to choose a keyword
that is as long as the plaintext and has no statistical relationship to it. Such a system was introduced by
an AT&T engineer named Gilbert Vernam in 1918. His system works on binary data (bits) rather than
letters. The system can be expressed succinctly as follows (Figure 2.7):

Department Of ECE, ATMCE, Mysuru Page 32
Figure 2.3 Vernam Cipher
Thus, the ciphertext is generated by performing the bitwise XOR of the plaintext and the key.
Because of the properties of the XOR, decryption simply involves the same bitwise operation:
which compares with Equation (2.4).
The essence of this technique is the means of construction of the key. Vernam proposed the use
of a running loop of tape that eventually repeated the key, so that in fact the system worked with a very
long but repeating keyword. Although such a scheme, with a long key, presents formidable
cryptanalytic difficulties, it can be broken with sufficient ciphertext, the use of known or probable
plaintext sequences, or both.
One-Time Pad
An Army Signal Corp officer, Joseph Mauborgne, proposed an improvement to the Vernam
cipher that yields the ultimate in security. Mauborgne suggested using a random key that is as long as
the message, so that the key need not be repeated. In addition, the key is to be used to encrypt and
decrypt a single message, and then is discarded. Each new message requires a new key of the same
length as the new message. Such a scheme, known as a one-time pad, is unbreakable. It produces
random output that bears no statistical relationship to the plaintext. Because the ciphertext contains no
information whatsoever about the plaintext, there is simply no way to break the code. An example
should illustrate our point. Suppose that we are using a Vigenère scheme with 27 characters in which
the twenty-seventh character is the space character, but with a one-time key that is as long as the
message. Consider the ciphertext

Department Of ECE, ATMCE, Mysuru Page 33
Suppose that a cryptanalyst had managed to find these two keys. Two plausible plaintexts are
produced. How is the cryptanalyst to decide which is the correct decryption (i.e., which is the correct
key)? If the actual key were produced in a truly random fashion, then the cryptanalyst cannot say that
one of these two keys is more likely than the other. Thus, there is no way to decide which key is correct
and therefore which plaintext is correct.
In fact, given any plaintext of equal length to the ciphertext, there is a key that produces that
plaintext. Therefore, if you did an exhaustive search of all possible keys, you would end up with many
legible plaintexts, with no way of knowing which was the intended plaintext. Therefore, the code is
unbreakable. The security of the one-time pad is entirely due to the randomness of the key. If the stream
of characters that constitute the key is truly random, then the stream of characters that constitute the
ciphertext will be truly random. Thus, there are no patterns or regularities that a cryptanalyst can use to
attack the ciphertext. The one-time pad offers complete
security but, in practice, has two fundamental difficulties:
1. There is the practical problem of making large quantities of random keys. Any heavily used
system might require millions of random characters on a regular basis. Supplying truly random
characters in this volume is a significant task.
2. Even more daunting is the problem of key distribution and protection. For every message to
be sent, a key of equal length is needed by both sender and receiver. Thus, a mammoth key
distribution problem exists.
Because of these difficulties, the one-time pad is of limited utility and is useful primarily for
low-bandwidth channels requiring very high security.
The one-time pad is the only cryptosystem that exhibits what is referred to as perfect secrecy.

Department Of ECE, ATMCE, Mysuru Page 34
2.4 TRANSPOSITION TECHNIQUES
All the techniques examined so far involve the substitution of a ciphertext symbol for a plaintext
symbol. A very different kind of mapping is achieved by performing some sort of permutation on the
plaintext letters. This technique is referred to as a transposition cipher.
The simplest such cipher is the rail fence technique, in which the plaintext is written down as a
sequence of diagonals and then read off as a sequence of rows. For example, to encipher the message
―meet me after the toga party‖ with a rail fence of depth 2, we write the following:
The encrypted message is
This sort of thing would be trivial to cryptanalyze. A more complex scheme is to write the
message in a rectangle, row by row, and read the message off, column by column, but permute the order
of the columns. The order of the columns then becomes the key to the algorithm. For example,
Thus, in this example, the key is 4312567.To encrypt, start with the column that is labeled 1, in
this case column 3.Write down all the letters in that column. Proceed to column 4, which is labeled 2,
then column 2, then column 1, then columns 5, 6, and 7.
A pure transposition cipher is easily recognized because it has the same letter frequencies as the
original plaintext. For the type of columnar transposition just shown, cryptanalysis is fairly
straightforward and involves laying out the ciphertext in a matrix and playing around with column
positions. Diagram and trigram frequency tables can be useful.
The transposition cipher can be made significantly more secure by performing more than one
stage of transposition. The result is a more complex permutation that is not easily reconstructed. Thus,
if the foregoing message is re encrypted using the same algorithm,

Department Of ECE, SJBIT Page 30
To visualize the result of this double transposition, designate the letters in the original plaintext
message by the numbers designating their position. Thus, with 28 letters in the message, the original
sequence of letters is
After the first transposition, we have
which has a somewhat regular structure. But after the second transposition, we have
This is a much less structured permutation and is much more difficult to cryptanalyze
2.5 DES ENCRYPTION
The overall scheme for DES encryption is illustrated in Figure 3.5. As with any encryption
scheme, there are two inputs to the encryption function: the plaintext to be encrypted and the key. In
this case, the plaintext must be 64 bits in length and the key is 56 bits in length.
Looking at the left-hand side of the figure, we can see that the processing of the plaintext
proceeds in three phases. First, the 64-bit plaintext passes through an initial permutation (IP) that
rearranges the bits to produce the permuted input. This is followed by a phase consisting of sixteen
rounds of the same function, which involves both permutation and substitution functions. The output of
the last (sixteenth) round consists of 64 bits that are a function of the input plaintext and the key. The
left and right halves of the output are swapped to produce the preoutput. Finally, the preoutput is passed
through a permutation that is the inverse of the initial permutation function, to produce the 64-bit cipher
text. With the exception of the initial and final permutations.

Department Of ECE, SJBIT Page 31
Figure 2.4 General Depiction of DES Encryption Algorithm
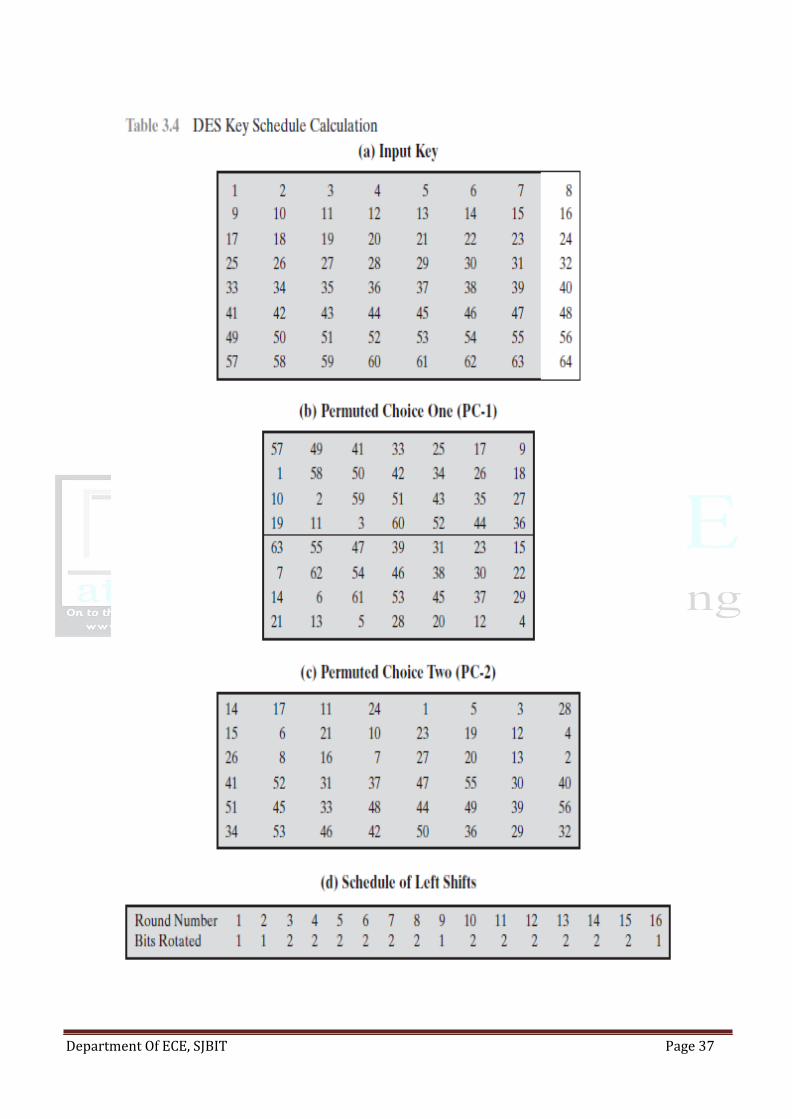
The right-hand portion of Figure 2.5 shows the way in which the 56-bit key is used. Initially, the
key is passed through a permutation function. Then, for each of the sixteen rounds, a subkey (Ki ) is
produced by the combination of a left circular shift and a permutation. The permutation function is the
same for each round, but a different subkey is produced because of the repeated shifts of the key bits.
Initial permutation The initial permutation and its inverse are defined by tables, as shown in Tables
3.2a and 3.2b, respectively. The tables are to be interpreted as follows. The input to a table consists of
64 bits numbered from 1 to 64.The 64 entries in the permutation table contain a permutation of the
numbers from 1 to 64. Each entry in the permutation table indicates the position of a numbered input bit
in the output, which also consists of 64 bits.

Department Of ECE, SJBIT Page 32
To see that these two permutation functions are indeed the inverse of each other, consider the following 64-bit input M

Department Of ECE, SJBIT Page 33
:
If we then take the inverse permutation, it can be seen that the
original ordering of the bits is restored.
DETAILS OF SINGLE ROUND Figure 2.5 shows the internal structure of a single round.
Again, begin by focusing on the left-hand side of the diagram. The left and right halves of each 64-bit
intermediate value are treated as separate 32-bit quantities, labelled L (left) and R (right). As in any
classic Feistel cipher, the overall processing at each round can be summarized in the following
formulas:
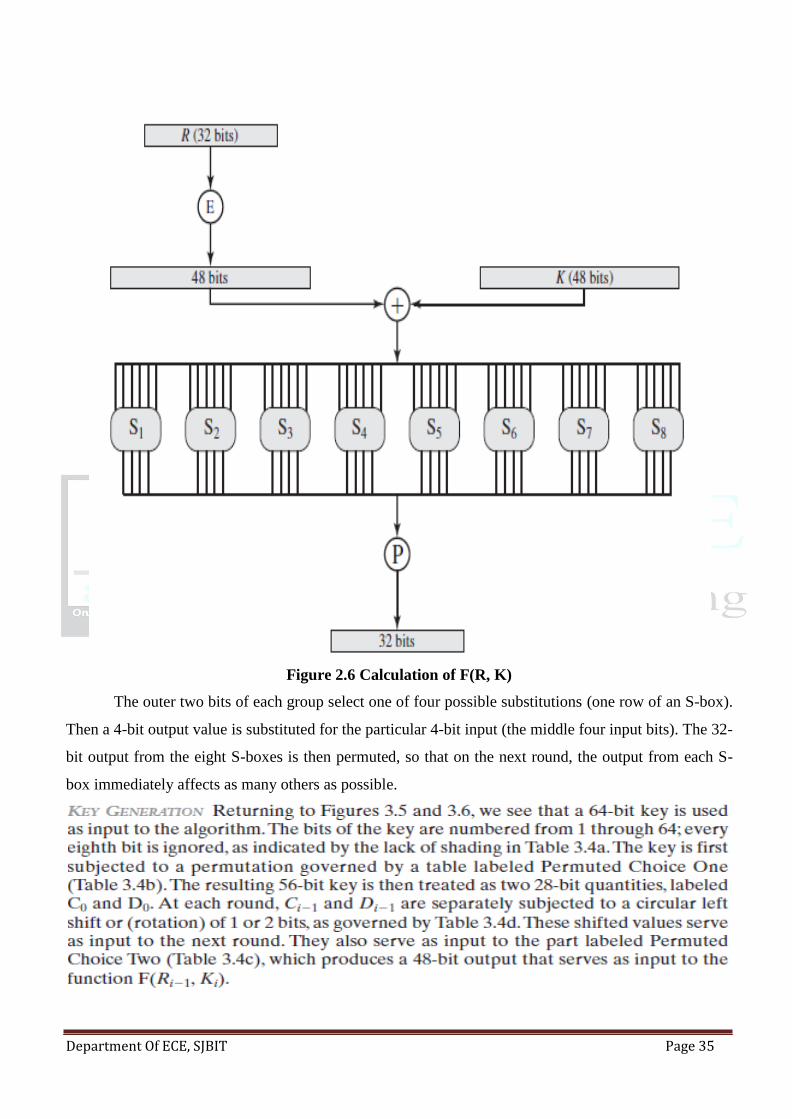
The round key Ki is 48 bits. The R input is 32 bits. This R input is first expanded to 48 bits by
using a table that defines a permutation plus an expansion that involves duplication of 16 of the R bits
(Table 3.2c).The resulting 48 bits are XORed with Ki. This 48-bit result passes through a substitution
function that produces a 32-bit output, which is permuted as defined by Table 3.2d.
The role of the S-boxes in the function F is illustrated in Figure 3.7.The substitution consists of
a set of eight S-boxes, each of which accepts 6 bits as input and produces 4 bits as output. These
transformations are defined in Table 3.3, which is interpreted as follows: The first and last bits of the
input to box form a 2-bit binary number to select one of four substitutions defined by the four rows in
the table for. The middle four bits select one of the sixteen columns. The decimal value in the cell

Department Of ECE, SJBIT Page 34
selected by the row and column is then converted to its 4-bit representation to produce the output. For
example, in S1, for input 011001, the row is 01 (row 1) and the column is 1100 (column 12).The value
in row 1, column 12 is 9, so the output is 1001. Each row of an S-box defines a general reversible
substitution. Figure 3.2 may be useful in understanding the mapping. The figure shows the substitution
for row 0 of box S1.
The operation of the S-boxes is worth further comment. Ignore for the moment the contribution
of the key ( ). If you examine the expansion table, you see that the 32 bits of input are split into groups
of 4 bits and then become groups of 6 bits by taking the outer bits from the two adjacent groups. For
example, if part of the input word is
Figure 2.5 Single Round of DES Algorithm
Department Of ECE, SJBIT Page 35
Figure 2.6 Calculation of F(R, K)
The outer two bits of each group select one of four possible substitutions (one row of an S-box).
Then a 4-bit output value is substituted for the particular 4-bit input (the middle four input bits). The 32-
bit output from the eight S-boxes is then permuted, so that on the next round, the output from each S-
box immediately affects as many others as possible.

Department Of ECE, SJBIT Page 36
DES Decryption
As with any Feistel cipher, decryption uses the same algorithm as encryption, except that the
application of the subkeys is reversed.
Department Of ECE, SJBIT Page 37

Department Of ECE, SJBIT Page 38
2.6 THE STRENGTH OF DES
Since its adoption as a federal standard, there have been lingering concerns about the level of
security provided by DES. These concerns, by and large, fall into two areas: key size and the nature of
the algorithm.
The Use of 56-Bit Keys
With a key length of 56 bits, there are possible keys, which are approximately keys. Thus, on
the face of it, a brute-force attack appears impractical. Assuming that, on average, half the key space
has to be searched, a single machine performing one DES encryption per microsecond would take more
than a thousand years (see Table 2.2) to break the cipher.
However, the assumption of one encryption per microsecond is overly conservative. As far
back as 1977, Diffie and Hellman postulated that the technology existed to build a parallel machine
with 1 million encryption devices, each of which could perform one encryption per microsecond
[DIFF77]. This would bring the average search time down to about 10 hours. The authors estimated that
the cost would be about $20 million in 1977 dollars.
DES finally and definitively proved insecure in July 1998, when the Electronic Frontier
Foundation (EFF) announced that it had broken a DES encryption using a special-purpose ―DES
cracker‖ machine that was built for less than $250,000. The attack took less than three days. The EFF
has published a detailed description of the machine, enabling others to build their own cracker
[EFF98].And, of course, hardware prices will continue to drop as speeds increase, making DES
virtually worthless.
It is important to note that there is more to a key-search attack than simply running through all
possible keys. Unless known plaintext is provided, the analyst must be able to recognize plaintext as
plaintext. If the message is just plain text in English, then the result pops out easily, although the task of
recognizing English would have to be automated. If the text message has been compressed before
encryption, then recognition is more difficult. And if the message is some more general type of data,
such as a numerical file, and this has been compressed, the problem becomes even more difficult to
automate. Thus, to supplement the brute-force approach, some degree of knowledge about the expected
plaintext is needed, and some means of automatically distinguishing plaintext from garble is also
needed. The EFF approach addresses this issue as well and introduces some automated techniques that
would be effective in many contexts.

Department Of ECE, SJBIT Page 39
The Nature of the DES Algorithm
Another concern is the possibility that cryptanalysis is possible by exploiting the characteristics
of the DES algorithm. The focus of concern has been on the eight substitution tables, or S-boxes, that
are used in each iteration. Because the design criteria for these boxes, and indeed for the entire
algorithm, were not made public,
There is a suspicion that the boxes were constructed in such a way that cryptanalysisis possible
for an opponent who knows the weaknesses in the S-boxes. This assertion is tantalizing, and over the
years a number of regularities and unexpected behaviours of the S-boxes have been discovered. Despite
this, no one has so far succeeded in discovering the supposed fatal weaknesses in the S-boxes.9
Timing Attacks
We discuss timing attacks in more detail in Part Two, as they relate to public-key algorithms.
However, the issue may also be relevant for symmetric ciphers. In essence, a timing attack is one in
which information about the key or the plaintext is obtained by observing how long it takes a given
implementation to perform decryptions on various ciphertexts. A timing attack exploits the fact that an
encryption or decryption algorithm often takes slightly different amounts of time on different inputs.
[HEVI99] reports on an approach that yields the Hamming weight (number of bits equal to one) of the
secret key. This is a long way from knowing the actual key, but it is an intriguing first step. The authors
conclude that DES appears to be fairly resistant to a successful timing attack but suggest some avenues
to explore. Although this is an interesting line of attack, it so far appears unlikely that this technique
will ever be successful against DES or more powerful symmetric ciphers such as triple DES and AES.
2.7 DIFFERENTIAL AND LINEAR CRYPTANALYSIS
For most of its life, the prime concern with DES has been its vulnerability to brute-force attack
because of its relatively short (56 bits) key length. However, there has also been interest in finding
cryptanalytic attacks on DES. With the increasing popularity of block ciphers with longer key lengths,
including triple DES, brute-force attacks have become increasingly impractical. Thus, there has been
increased emphasis on cryptanalytic attacks on DES and other symmetric block ciphers. In this section,
we provide a brief overview of the two most powerful and promising approaches: differential
cryptanalysis and linear cryptanalysis.
Differential Cryptanalysis
One of the most significant advances in cryptanalysis in recent years is differential
cryptanalysis. In this section, we discuss the technique and its applicability to DES.

Department Of ECE, SJBIT Page 40
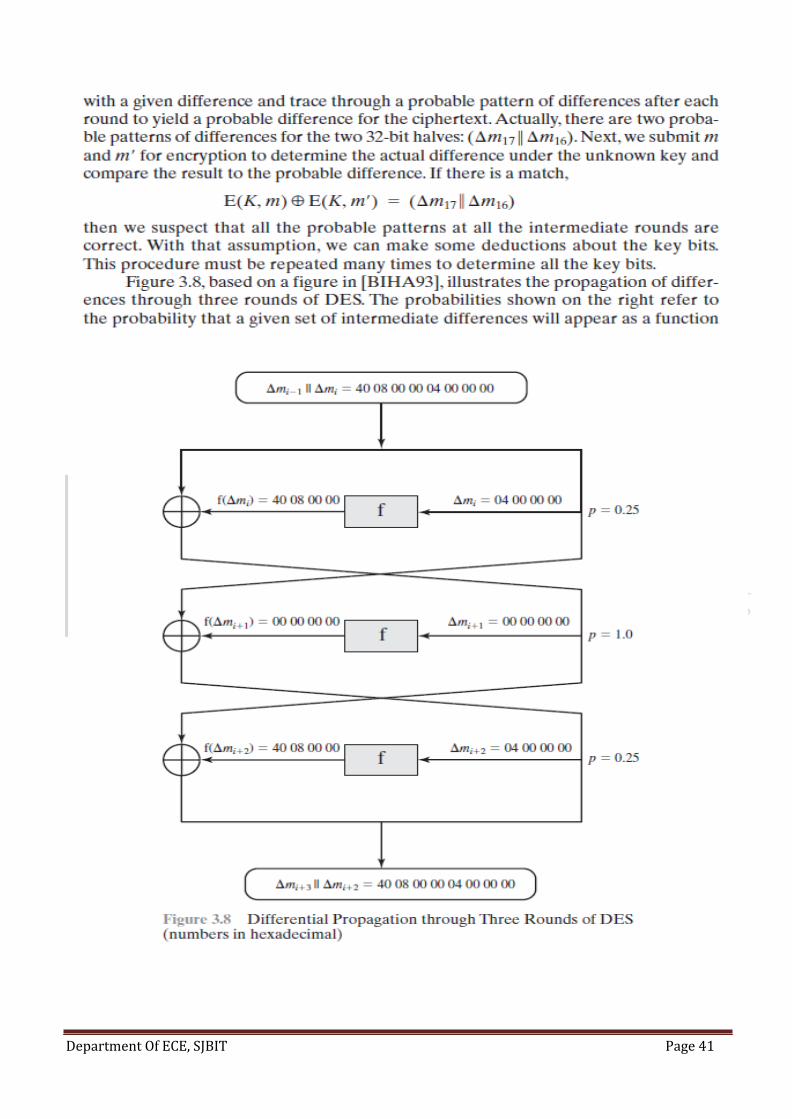
Department Of ECE, SJBIT Page 41

Department Of ECE, SJBIT Page 42
2.8 BLOCK CIPHER DESIGN PRINCIPLES
Although much progress has been made in designing block ciphers that are cryptographically
strong, the basic principles have not changed all that much since the work of Feistel and the DES design
team in the early 1970s. It is useful to begin this discussion by looking at the published design criteria
used in the DES effort. Then we look at three critical aspects of block cipher design: the number of
rounds, design of the function F, and key scheduling.
DES Design Criteria
The criteria used in the design of DES, as reported in [COPP94], focused on the design of the S-
boxes and on the P function that takes the output of the S-boxes (Figure 3.8).The criteria for the S-
boxes are as follows.

Department Of ECE, SJBIT Page 43
1. No output bit of any S-box should be too close a linear function of the input bits. Specifically, if we
select any output bit and any subset of the six input bits, the fraction of inputs for which this output bit
equals the XOR of these input bits should not be close to 0 or 1, but rather should be near 1/2.
2. Each row of an S-box (determined by a fixed value of the leftmost and rightmost input bits) should
include all 16 possible output bit combinations.
3. If two inputs to an S-box differ in exactly one bit, the outputs must differ in at least two bits.
4. If two inputs to an S-box differ in the two middle bits exactly, the outputs must differ in at least two
bits.
5. If two inputs to an S-box differ in their first two bits and are identical in their last two bits, the two
outputs must not be the same.
6. For any nonzero 6-bit difference between inputs, no more than eight of the 32 pairs of inputs
exhibiting that difference may result in the same output difference.
7. This is a criterion similar to the previous one, but for the case of three S-boxes.
Coppersmith pointed out that the first criterion in the preceding list was needed because the S-
boxes are the only on linear part of DES. If the S-boxes were linear (i.e., each output bit is a linear
combination of the input bits), the entire algorithm would be linear and easily broken. We have seen
this phenomenon with the Hill cipher, which is linear. The remaining criteria were primarily aimed at
thwarting differential cryptanalysis and at providing good confusion properties.
The criteria for the permutation P are as follows.
Number of Rounds
The cryptographic strength of a Feistel cipher derives from three aspects of the design: the
number of rounds, the function F, and the key schedule algorithm. Let us look first at the choice of the
number of rounds.

Department Of ECE, SJBIT Page 44
The greater the number of rounds, the more difficult it is to perform cryptanalysis, even for a
relatively weak F. In general, the criterion should be that the number of rounds is chosen so that known
cryptanalytic efforts require greater effort than a simple brute-force key search attack. This criterion
was certainly used in the design of DES. Schneier [SCHN96] observes that for 16-round DES, a
differential cryptanalysis attack is slightly less efficient than brute force: The differential cryptanalysis
attack requires operations,10 whereas brute force requires . If DES had 15 or fewer rounds, differential
cryptanalysis would require less effort than a brute-force key search.
This criterion is attractive, because it makes it easy to judge the strength of an algorithm and to
compare different algorithms. In the absence of a cryptanalytic breakthrough, the strength of any
algorithm that satisfies the criterion can be judged solely on key length.

Department Of ECE, SJBIT Page 45
2.9 Evaluation criteria for advanced encryption standard

Department Of ECE, SJBIT Page 46

Department Of ECE, SJBIT Page 47
2.10 THE AES CIPHER

Department Of ECE, SJBIT Page 48
Fig:2.6.

Department Of ECE, SJBIT Page 51
Fig : 2.7.

Department Of ECE, SJBIT Page 52
OUTCOMES
• Know the principles of modern symmetric ciphers.
• understand various Encryption and decryption Technique
• Describe Data encryption Standard (DES) and its strength and also AES cipher
• Define Block Cipher Design Principles and modes of operation
Related questions
1. Encrypt the plaintext ―PAY MOREMONEY‖ using hill cipher with the key.
Show the calculations and cipher text.
2. Draw a single round DES algorithm and express the process in detail.
3. In S-DES, 10bit key is 1011010011. Find the sub keys K and K if : P=35274101986 ;
P=6374855109
4. Decrypt the cipher text ―CQSUBJNR‖ using hill cipher technique with the key : . find the plain
text [Hint : a=0, b=1, …………..z=25]
5. Using the keyword ―ENCRYPT‖ create playfair matrix and obtain ciphertext for the message
―MATCHFIXED‖. Also write the rules used.
6. Explain single round of DES along with the key generation.
7. Explain the working of counter mode of blax cipher operation.
8. Discuss the final evaluation criteria of AES

Department Of ECE, SJBIT Page 53
UNIT 3
Unit Structure:
3.0 Introduction
3.1 Objective
3.2 The RSA algorithms
3.3 Key management
3.4 Diffie – Hellman key exchange
3.5 Elliptic Curve Arithmetic
3.6 Authentication functions
3.7 Hash functions
3.0 INTRODUCTION
The concept of public-key cryptography evolved from an attempt to attack two of the most
difficult problems associated with symmetric encryption. The first problem is that of key distribution,
which is examined in some detail in Chapter 14.As Chapter 14 discusses, key distribution under
symmetric encryption requires either (1) that two communicants already share a key, which somehow
has been distributed to them; or (2) the use of a key distribution centre. Whitfield Diffie, one of the
discoverers of public-key encryption (along with Martin Hellman, both at Stanford University at the
time), reasoned that this second requirement negated the very essence of cryptography: the ability to
maintain total secrecy over your own communication. As Diffie put it [DIFF88], ―what good would it
do after all to develop impenetrable cryptosystems, if their users were forced to share their keys with a
KDC that could be compromised by either burglary or subpoena?‖ The second problem that Diffie
pondered, and one that was apparently unrelated to the first, was that of digital signatures. If the use of
cryptography was to become widespread, not just in military situations but for commercial and private
purposes, then electronic messages and documents would need the equivalent of signatures used in
paper documents. That is, could a method be devised that would stipulate, to the satisfaction of all
parties, that a digital message had been sent by a particular person. Diffie and Hellman achieved an
astounding breakthrough in 1976[DIFF76 a, b] by coming up with a method that addressed both
problems and was radically different from all previous approaches to cryptography, going back over
four millennia. In the next subsection, we look at the overall framework for public-key cryptography.
Then we examine the requirements for the encryption/decryption algorithm that is at the heart of the

Department Of ECE, SJBIT Page 54
scheme
3.1 OBJECTIVE
After studying the unit, Student should be able to
4.0 Illustrate the principles of Principles of public key Cryptosystem
5.0 Analyze The RSA algorithms and Diffie – Hellman key exchange
6.0 Learn Elliptic Curve Arithmetic, Authentication functions and Hash functions
Public-Key Cryptosystems
Asymmetric algorithms rely on one key for encryption and a different but related key for
decryption. These algorithms have the following important characteristic.
• It is computationally infeasible to determine the decryption key given only knowledge of the
cryptographic algorithm and the encryption key.
In addition, some algorithms, such as RSA, also exhibit the following characteristic.
• Either of the two related keys can be used for encryption, with the other used for decryption.
A public-key encryption scheme has six ingredients.
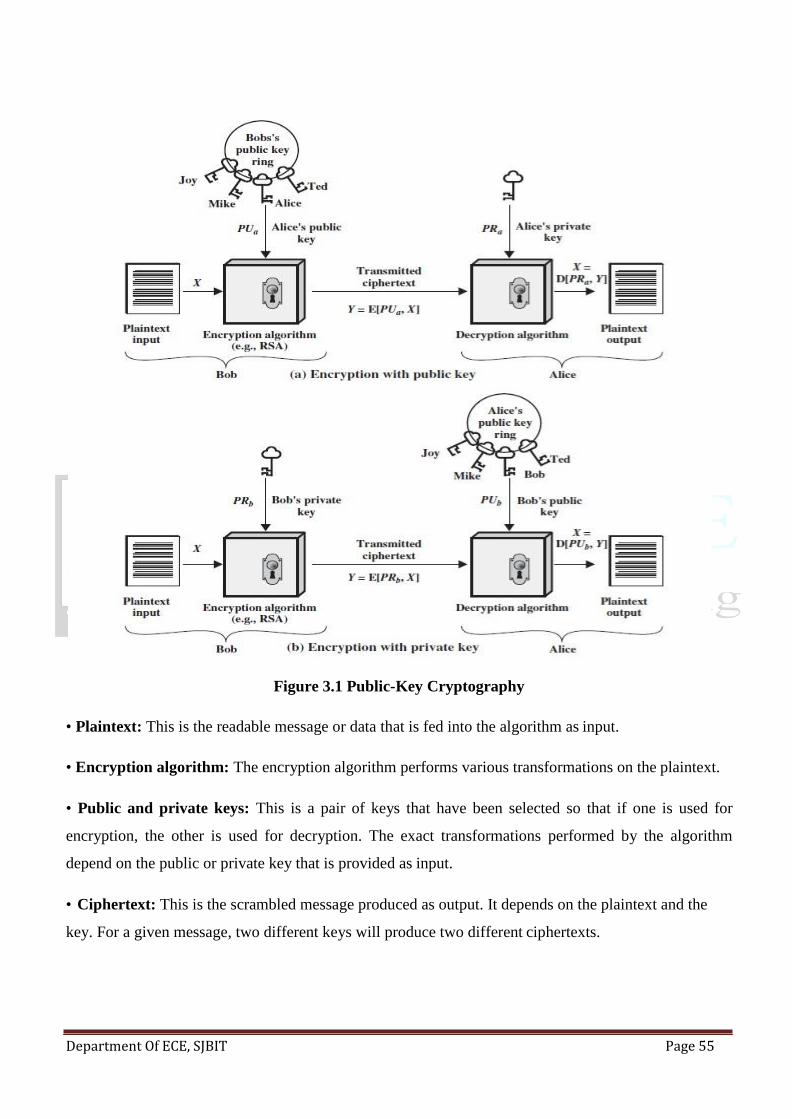
Department Of ECE, SJBIT Page 55
Figure 3.1 Public-Key Cryptography
• Plaintext: This is the readable message or data that is fed into the algorithm as input.
• Encryption algorithm: The encryption algorithm performs various transformations on the plaintext.
• Public and private keys: This is a pair of keys that have been selected so that if one is used for
encryption, the other is used for decryption. The exact transformations performed by the algorithm
depend on the public or private key that is provided as input.
• Ciphertext: This is the scrambled message produced as output. It depends on the plaintext and the
key. For a given message, two different keys will produce two different ciphertexts.

Department Of ECE, SJBIT Page 56
• Decryption algorithm: This algorithm accepts the ciphertext and the matching key and produces the
original plaintext.
The essential steps are the following.
1. Each user generates a pair of keys to be used for the encryption and decryption of messages.
2. Each user places one of the two keys in a public register or other accessible file. This is the public
key. The companion key is kept private. As Figure 3.1a suggests, each user maintains a collection of
public keys obtained from others.
3. If Bob wishes to send a confidential message to Alice, Bob encrypts the message using Alice‘s public
key.
4. When Alice receives the message, she decrypts it using her private key. No other recipient can
decrypt the message because only Alice knows Alice‘s private key.
With this approach, all participants have access to public keys, and private keys are generated
locally by each participant and therefore need never be distributed. As long as a user‘s private key
remains protected and secret, incoming communication is secure. At any time, a system can change its
private key and publish the companion public key to replace its old public key. Table 3.2 summarizes
some of the important aspects of symmetric and public key encryption. To discriminate between the
two, we refer to the key used in symmetric encryption as a secret key. The two keys used for
asymmetric encryption are referred to as the public key and the private key.2 Invariably, the private
key is kept secret, but it is referred to as a private key rather than a secret key to avoid confusion with
symmetric encryption.
Let us take a closer look at the essential elements of a public-key encryption scheme, using Figure 3.
There is some source A that

Department Of ECE, SJBIT Page 57
Table 9.2 Conventional and Public-Key Encryption
Figure 3.2 Public-Key Cryptosystem: Secrecy
The intended receiver, in possession of the matching private key, is able to invert the
transformation:

Department Of ECE, SJBIT Page 58
An adversary, observing Y and having access to PUb, but not having access to PRbor X, must
attempt to recover X and/or PRb. It is assumed that the adversary does have knowledge of the
encryption (E) and decryption (D) algorithms. If the adversary is interested only in this particular
message, then the focus of effort is to recover X by generating a plaintext estimate X ˆ . Often, however,
the adversary is interested in being able to read future messages as well, in which case an attempt is
made to recover PRb by generating an estimate PRˆb. We mentioned earlier that either of the two
related keys can be used for encryption, with the other being used for decryption. This enables a rather
different cryptographic scheme to be implemented. Whereas the scheme illustrated in Figure 932
provides confidentiality, Figures 9.1b and 9.3 show the use of public-key encryption to provide
authentication:
In this case, A prepares a message to B and encrypts it using A‘s private key before transmitting
it. B can decrypt the message using A‘s public key. Because the message was encrypted using A‘s
private key, only A could have prepared the message. Therefore, the entire encrypted message serves as
a digital signature. In addition, it is impossible to alter the message without access to A‘s private key,
so the message is authenticated both in terms of source and in terms of data integrity.
Figure 3.3 Public-Key Cryptosystem: Authentication
In the preceding scheme, the entire message is encrypted, which, although validating both
author and contents, requires a great deal of storage. Each document must be kept in plaintext to be
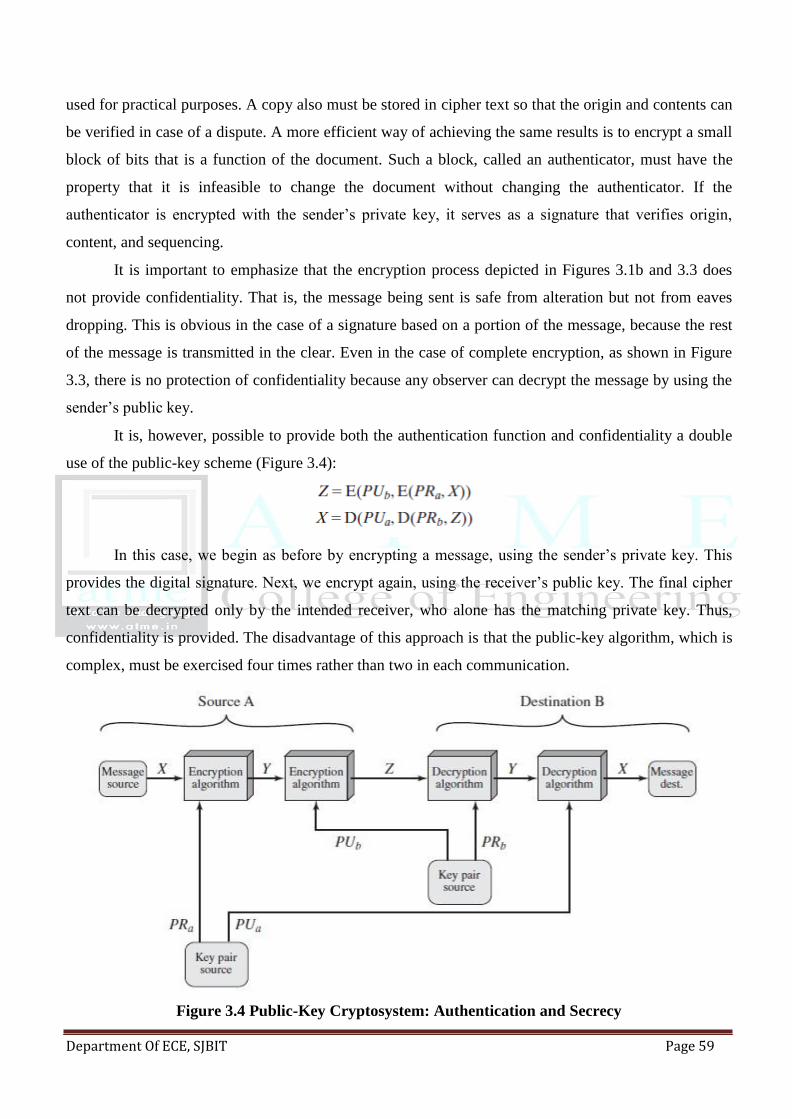
Department Of ECE, SJBIT Page 59
used for practical purposes. A copy also must be stored in cipher text so that the origin and contents can
be verified in case of a dispute. A more efficient way of achieving the same results is to encrypt a small
block of bits that is a function of the document. Such a block, called an authenticator, must have the
property that it is infeasible to change the document without changing the authenticator. If the
authenticator is encrypted with the sender‘s private key, it serves as a signature that verifies origin,
content, and sequencing.
It is important to emphasize that the encryption process depicted in Figures 3.1b and 3.3 does
not provide confidentiality. That is, the message being sent is safe from alteration but not from eaves
dropping. This is obvious in the case of a signature based on a portion of the message, because the rest
of the message is transmitted in the clear. Even in the case of complete encryption, as shown in Figure
3.3, there is no protection of confidentiality because any observer can decrypt the message by using the
sender‘s public key.
It is, however, possible to provide both the authentication function and confidentiality a double
use of the public-key scheme (Figure 3.4):
In this case, we begin as before by encrypting a message, using the sender‘s private key. This
provides the digital signature. Next, we encrypt again, using the receiver‘s public key. The final cipher
text can be decrypted only by the intended receiver, who alone has the matching private key. Thus,
confidentiality is provided. The disadvantage of this approach is that the public-key algorithm, which is
complex, must be exercised four times rather than two in each communication.
Figure 3.4 Public-Key Cryptosystem: Authentication and Secrecy

Department Of ECE, SJBIT Page 60
Applications for Public-Key Cryptosystems
Before proceeding, we need to clarify one aspect of public-key cryptosystems that is otherwise
likely to lead to confusion. Public-key systems are characterized by the use of a cryptographic
algorithm with two keys, one held private and one available publicly. Depending on the application, the
sender uses either the sender‘s private key or the receiver‘s public key, or both, to perform some type of
cryptographic function. In broad terms, we can classify the use of public-key cryptosystems into three
categories
• Encryption /decryption: The sender encrypts a message with the recipient‘s public key.
• Digital signature: The sender ―signs‖ a message with its private key. Signing is achieved by
a cryptographic algorithm applied to the message or to a small block of data that is a function of the
message.
• Key exchange: Two sides cooperate to exchange a session key. Several different approaches are
possible, involving the private key(s) of one or both parties. Some algorithms are suitable for all three
applications, whereas others can be used only for one or two of these applications.
Requirements for Public-Key Cryptography
The cryptosystem illustrated in Figures 9.2 through 9.4 depends on a cryptographic algorithm
based on two related keys. Diffie and Hellman postulated this system without demonstrating that such
algorithms exist.
1. It is computationally easy for a party B to generate a pair (public key PUb,private key PRb).
2. It is computationally easy for a sender A, knowing the public key and themessage to be
encrypted, to generate the corresponding cipher text:
Table 3.3 Applications for Public-Key Cryptosystems
1. It is computationally easy for the receiver B to decrypt the resulting cipher text using the
private key to recover the original message:
2. It is computationally infeasible for an adversary, knowing the public key, PUb, to determine
the private key PRb.

Department Of ECE, SJBIT Page 61
3. It is computationally infeasible for an adversary, knowing the public key, PUb, and a cipher
text, C, to recover the original message M. We can add a sixth requirement that, although
useful, is not necessary for all public-key applications:
4. The two keys can be applied in either order:
These are formidable requirements, as evidenced by the fact that only a few algorithms (RSA,
elliptic curve cryptography, Diffie-Hellman, DSS) have received widespread acceptance in the several
decades since the concept of public-key cryptography was proposed.
Before elaborating on why the requirements are so formidable, let us first recast them. The
requirements boil down to the need for a trap-door one-way function. A one-way function3 is one that
maps a domain into a range such that every function value has a unique inverse, with the condition that
the calculation of the function is easy, whereas the calculation of the inverse is infeasible:
Generally, easy is defined to mean a problem that can be solved in polynomial time as a
function of input length. Thus, if the length of the input is n bits, then the time to compute the function
is proportional to na, where a is a fixed constant. Such algorithms are said to belong to the class P. The
term infeasible is a much fuzzier concept. In general, we can say a problem is infeasible if the effort to
solve it grows faster than polynomial time as a function of input size. For example, if the length of the
input is n bits and the time to compute the function is proportional to 2n, the problem is considered
infeasible. Unfortunately, it is difficult to determine if a particular algorithm exhibits this complexity.
Furthermore, traditional notions of computational complexity focus on the worst-case or average-case
complexity of an algorithm. These measures are inadequate for cryptography, which requires that it be
infeasible to invert a function for virtually all inputs, not for the worst case or even average case.
We now turn to the definition of a trap-door one-way function, which is easy to calculate in
one direction and infeasible to calculate in the other direction unless certain additional information is
known. With the additional information the inverse can be calculated in polynomial time. We can
summarize as follows: A trapdoor one-way function is a family of invertible functions fk, such that
Thus, the development of a practical public-key scheme depends on discovery of a suitable trap-
door one-way function.

Department Of ECE, SJBIT Page 62
3.2. THE RSA ALGORITHM
The Rivest-Shamir-Adleman (RSA) scheme is a block cipher in which the plaintext and cipher
text are Integers between 0 and n - 1 for some n. A typical size for n is 1024 bits, or 309 decimal digits.
That is, n is less than 21024.We examines RSA in this section in some detail, beginning with an
explanation of the algorithm. Then we examine some of the computational and crypt analytical
implications of RSA.
Description of the Algorithm
RSA makes use of an expression with exponentials. Plaintext is encrypted in blocks, with each
block having a binary value less than some number n. That is, the block size must be less than or equal
to log2(n) + 1; in practice, the block size is i bits, where 2i 6 n ≤ 2i+1. Encryption and decryption are of
the following form, for some plaintext block M and cipher text block C.
Both sender and receiver must know the value of n. The sender knows the value of e, and only
the receiver knows the value of d. Thus, this is a public-key encryption algorithm with a public key of
PU = {e, n} and a private key of PR = {d, n}.For this algorithm to be satisfactory for public-key
encryption, the following requirements must be met.
1. It is possible to find values of e, d, n such that Med mod n = M for all M <n.
2. It is relatively easy to calculate Me mod n and Cd mod n for all values of M <n.
3. It is infeasible to determine d given e and n. For now, we focus on the first requirement and
consider the other questions later. We need to find a relationship of the form
This is equivalent to saying
That is, e and d are multiplicative inverses mod f(n). Note that, according to the rules of modular
arithmetic, this is true only if d is relatively prime t of(n). Equivalently, gcd(f(n), d) = 1.

Department Of ECE, SJBIT Page 63
We are now ready to state the RSA scheme. The ingredients are the following:
The private key consists of {d, n} and the public key consists of {e, n}. Suppose that user A has
published its public key and that user B wishes to send the message M to A. Then B calculates C = Me
mod n and transmits C. On receipt of this ciphertext, user A decrypts by calculating M = Cd mod n.
Figure 3.5 summarizes the RSA algorithm. It corresponds to Figure 3.1a: Alice generates a
public/private key pair; Bob encrypts using Alice‘s public key; and Alice decrypts using her private
key. An example from [SING99] is shown in Figure 3.6.For this example; the keys were generated as
follows.
We now look at an example from [HELL79], which shows the use of RSA to process multiple
blocks of data. In this simple example, the plaintext is an alphanumeric string. Each plaintext symbol is
assigned a unique code of two decimal digits (e.g., a = 00, A = 26).6 A plaintext block consists of four
decimal digits, or two alphanumeric characters. Figure 9.7a illustrates the sequence of events for the
encryption of multiple blocks, and Figure 3.7b gives a specific example. The circled numbers indicate
the order in which operations are performed.

Department Of ECE, SJBIT Page 60

Department Of ECE, SJBIT Page 61
Figure 3.7 RSA Processing of Multiple Blocks
Computational Aspects
We now turn to the issue of the complexity of the computation required to use RSA. There are
actually two issues to consider: encryption/decryption and key generation. Let us look first at the
process of encryption and decryption and then consider key generation.
EXPONENTIATION IN MODULAR ARITHMETIC Both encryption and decryption in RSA
involve raising an integer to an integer power, mod n. If the exponentiation is done over the integers
and then reduced modulo n, the intermediate values would be gargantuan. Fortunately, as the preceding
example shows, we can make use of a property of modular arithmetic:
Thus, we can reduce intermediate results modulo n. This makes the calculation practical.
Another consideration is the efficiency of exponentiation, because with RSA, we are dealing with

Department Of ECE, SJBIT Page 62
potentially large exponents. To see how efficiency might be increased, consider that we wish to
compute x16. A straightforward approach requires 15 multiplications:
EFFICIENT OPERATION USING THE PUBLIC KEY To speed up the operation of the RSA
algorithm using the public key, a specific choice of e is usually made. The most common choice is
65537 (216 + 1); two other popular choices are 3 and 17. Each of these choices has only two 1 bits, so
the number of multiplications required to perform exponentiation is minimized.

Department Of ECE, SJBIT Page 63
However, with a very small public key, such as e = 3, RSA becomes vulnerable to a simple
attack. Suppose we have three different RSA users who all use the value e = 3 but have unique values
of n, namely (n1, n2, n3). If user A sends the same encrypted message M to all three users, then the
three cipher texts are C1 =M3 mod n1, C2 = M3 mod n2, and C3 = M3 mod n3. It is likely that n1, n2,
and n3 are pair wise relatively prime. Therefore, one can use the Chinese remainder theorem (CRT) to
computeM3 mod (n1n2n3). By the rules of the RSA algorithm, M is less than each of then i; therefore
M3 <n1n2n3. Accordingly, the attacker need only compute the cube root of M3. This attack can be
countered by adding a unique pseudorandom bit string as padding to each instance of M to be
encrypted. This approach is discussed subsequently.
The reader may have noted that the definition of the RSA algorithm (Figure 3.5)requires that
during key generation the user selects a value of e that is relatively prime to f(n).Thus, if a value of e is
selected first and the primes p and q are generated, it may turn out that gcd(f(n), e) . In that case, the
user must reject the p, q values and generate a new p, q pair.
Table 3.4 Result of the Fast Modular Exponentiation Algorithm for ab mod n, where a = 7,
b = 560 = 1000110000, and n = 561
EFFICIENT OPERATION USING THE PRIVATE KEY We cannot similarly choose a small
constant value of d for efficient operation. A small value of d is vulnerable to a brute force attack and to
other forms of cryptanalysis [WIEN90]. However, there is a way to speed up computation using the
CRT. We wish to compute the value M = Cd mod n. Let us define the following intermediate results:
Furthermore, we can simplify the calculation of Vp and Vq using Fermat‘s theorem, which states
that ap-1 K 1 (mod p) if p and a are relatively prime. Some thought should convince you that the
following are valid.

Department Of ECE, SJBIT Page 64
The quantities d mod (p - 1) and d mod (q - 1) can be precalculated. The end result is that the
calculation is approximately four times as fast as evaluating M= Cd mod n directly.
KEY GENERATION Before the application of the public-key cryptosystem, each participant
must generate a pair of keys. This involves the following tasks.
• Determining two prime numbers, p and q.
• Selecting either e or d and calculating the other.
First, consider the selection of p and q. Because the value of n = pq will be known to any
potential adversary, in order to prevent the discovery of p and q by exhaustive methods, these primes
must be chosen from a sufficiently large set (i.e., p and q must be large numbers). On the other hand,
the method used for finding large primes must be reasonably efficient.
At present, there are no useful techniques that yield arbitrarily large primes, so some other
means of tackling the problem is needed. The procedure that is generally used is to pick at random an
odd number of the desired order of magnitude and test whether that number is prime. If not, pick
successive random numbers until one is found that tests prime.
A variety of tests for primarily have been developed. Almost invariably, the tests are
probabilistic. That is, the test will merely determine that a given integer is probably prime. Despite this
lack of certainty, these tests can be run in such a way as to make the probability as close to 1.0 as
desired. As an example, one of the more efficient and popular algorithms, With this algorithm and most
such algorithms, the procedure for testing whether a given integer n is prime is to perform some
calculation that involves n and a randomly chosen integer a. If n ―fails‖ the test, then n is not prime. If
n
―passes‖ the test, then n may be prime or nonprime. If n passes many such tests with many different
randomly chosen values for a, then we can have high confidence that n is, in fact, prime.
In summary, the procedure for picking a prime number is as follows.
1. Pick an odd integer n at random (e.g., using a pseudorandom number generator).
2. Pick an integer a <n at random.
3. Perform the probabilistic primarily test, such as Miller-Rabin, with a as a parameter. If n fails
the test, reject the value n and go to step 1.
4. If n has passed a sufficient number of tests, accept n; otherwise, go to step 2.
This is a somewhat tedious procedure. However, remember that this process is performed
relatively infrequently: only when a new pair (PU, PR) is needed.
It is worth noting how many numbers are likely to be rejected before a prime number is found.
A result from number theory, known as the prime number theorem, states that the primes near N are
spaced on the average one every (ln N) integers. Thus, on average, one would have to test on the order

Department Of ECE, SJBIT Page 65
of ln(N) integers before a prime is found. Actually, because all even integers can be immediately

Department Of ECE, SJBIT Page 66
rejected, the correct figure is ln(N)/2. For example, if a prime on the order of magnitude of 2200were
sought, then about ln(2200)/2 = 70 trials would be needed to find a prime.
Having determined prime numbers p and q, the process of key generation is completed by
selecting a value of e and calculating d or, alternatively, selecting a value of d and calculating e.
Assuming the former, then we need to select an e such that gcd(f(n), e) = 1 and then calculate d K e-1
(mod f(n)). Fortunately, there is a single algorithm that will, at the same time, calculate the greatest
common divisor of two integers and, if the gcd is 1, determine the inverse of one of the integers modulo
the other. The algorithm, referred to as the extended Euclid‘s algorithm, is explained in Chapter 4.Thus,
the procedure is to generate a series of random numbers, testing each against f(n) until a number
relatively prime to f(n) is found. Again, we can ask the question: How many random numbers must we
test to find a usable number, that is, a number relatively prime to f(n)? It can be shown easily that the
probability that two random numbers are relatively prime is about 0.6; thus, very few tests would be
needed to find a suitable integer.
The Security of RSA
Four possible approaches to attacking the RSA algorithm are
• Brute force: This involves trying all possible private keys.
• Mathematical attacks: There are several approaches, all equivalent in effort to factoring the
product of two primes.
• Timing attacks: These depend on the running time of the decryption algorithm.
• Chosen cipher text attacks: This type of attack exploits properties of the RSA algorithm.
The defence against the brute-force approach is the same for RSA as for other cryptosystems,
namely, to use a large key space. Thus, the larger the number of bits in d, the better. However, because
the calculations involved, both in key generation and in encryption/decryption, are complex, the larger
the size of the key, the slower the system will run. In this subsection, we provide an overview of
mathematical and timing attacks.
3.3. DIFFIE-HELLMAN KEY EXCHANGE
The first published public-key algorithm appeared in the seminal paper by Diffie and Hellman
that defined public-key cryptography [DIFF76b] and is generally referred to as Diffie-Hellman key
exchange.1 A number of commercial products employ this key exchange technique.
The purpose of the algorithm is to enable two users to securely exchange a key that can then be
used for subsequent encryption of messages. The algorithm itself is limited to the exchange of secret
values.

Department Of ECE, SJBIT Page 67
The Diffie-Hellman algorithm depends for its effectiveness on the difficulty of computing
discrete logarithms. Briefly, we can define the discrete logarithm in the following way. Recall from
Chapter 8 that a primitive root of a prime number as one whose powers modulo generate all the integers
from 1 to p-1.That is, if isa primitive root of the prime number, then the numbers
are distinct and consist of the integers from 1 through p-1 in some permutation.
For any integer b and a primitive root a of prime number, we can find a unique exponent such that
The exponent is referred to as the discrete logarithm of for the base , mod .We express this value as
The Algorithm
Figure summarizes the Diffie -Hellman key exchange algorithm. For this scheme, there are two
publicly known numbers: a prime number and an integer α that is a primitive root of Suppose the users
A and B wish to exchange a key.

Department Of ECE, SJBIT Page 68
Figure 3.9 The Diffie-Hellman Key Exchange Algorithm
The security of the Diffie-Hellman key exchange lies in the fact that, while it is relatively easy
to calculate exponentials modulo a prime, it is very difficult to calculate is crete logarithms. For large
primes, the latter task is considered in feasible. Here is an example. Key exchange is based on the use of
the prime number
In this simple example, it would be possible by brute force to determine the secret key 160. In
particular, an attacker E can determine the common key by discovering a solution to the equation

Department Of ECE, SJBIT Page 69
or the equation . The brute-force approach is to calculate powers
of 3 modulo 353, stopping when the result equals either 40 or 248. The desired answer is reached with
the exponent value of 97, which provides .With larger numbers, the problem becomes impractical.
Key Exchange Protocols
Figure 3.10 shows a simple protocol that makes use of the Diffie-Hellman calculation. Suppose
that user wishes to set up a connection with user B and use a secret key to encrypt messages on that
connection. User A can generate a one-time private key, calculate, and send that to user B. User B
responds by generating a private value, calculating, and sending to user A. Both users can now calculate
the key. The necessary public values and would need to be known ahead of time. Alternatively, user A
could pick values for and include those in the first message. As an example of another use of the Diffie-
Hellman algorithm, suppose that a group of users each generate a long-lasting private value and
calculate a public value. These public values, together with global public values for and α, are stored in
some central directory. At any time, user can access user‘s public value, calculate a secret key, and use
that to send an encrypted message to user A. If the central directory is trusted, then this form of
communication provides both confidentiality and a degree of authentication.
Because only and can determine the key, no other user can read the message. Recipient knows
that only user could have created a message using this key However, the technique does not protect
against replay attacks.
Figure 3.10 Diffie-Hellman Key Exchange

Department Of ECE, SJBIT Page 70
3.4. ELLIPTIC CURVE ARITHMETIC
Most of the products and standards that use public-key cryptography for encryption and digital
signatures use RSA. As we have seen, the key length for secure RSA use has increased over recent
years, and this has put a heavier processing load on applications using RSA. This burden has
ramifications, especially for electronic commerce sites that conduct large numbers of secure
transactions. A competing system challenges RSA: elliptic curve cryptography (ECC). ECC is showing
up in standardization efforts, including the IEEE P1363 Standard for Public-Key Cryptography.
The principal attraction of ECC, compared to RSA, is that it appears to offer equal security for a
far smaller key size, thereby reducing processing overhead. On the other hand, although the theory of
ECC has been around for some time, it is only recently that products have begun to appear and that
there has been sustained cryptanalytic interest in probing for weaknesses. Accordingly, the confidence
level in ECC is not yet as high as that in RSA.ECC is fundamentally more difficult to explain than
either RSA or Diffie-Hellman, and a full mathematical description is beyond the scope of this book.

Department Of ECE, SJBIT Page 70
This section and the next give some background on elliptic curves and ECC. We begin with a
brief review of the concept of abelian group. Next, we examine the concept of elliptic curves defined
over the real numbers. This is followed by a look at elliptic curves defined over finite fields. Finally, we
are able to examine elliptic curve ciphers.

Department Of ECE, SJBIT Page 71
Figure 3.11 Example of Elliptic Curves

Department Of ECE, SJBIT Page 72
3.5. MESSAGE AUTHENTICATION FUNCTIONS
Any message authentication or digital signature mechanism has two levels of functionality. At
the lower level, there must be some sort of function that produces an authenticator: a value to be used to
authenticate a message. This lower-level function is then used as a primitive in a higher-level
authentication protocol that enables a receiver to verify the authenticity of a message. This section is
concerned with the types of functions that may be used to produce an authenticator. These may be
grouped into three classes.
• Hash function: A function that maps a message of any length into a fixed length hash value,
which serves as the authenticator
• Message encryption: The cipher text of the entire message serves as its authenticator
• Message authentication code (MAC): A function of the message and a secretkey that
produces a fixed-length value that serves as the authenticator

Department Of ECE, SJBIT Page 73
Figure 3.12.Basic Uses of Message Encryption

Department Of ECE, SJBIT Page 74
Figure 3.13 Internal and External Error Control
Decrypts the incoming block and treats the results as a message with an appended FCS. B
applies the same function F to attempt to reproduce the FCS. If the calculated FCS is equal to the
incoming FCS, then the message is considered authentic. It is unlikely that any random sequence of bits
would exhibit the desired relationship.

Department Of ECE, SJBIT Page 75
3.6. HASH FUNCTIONS:

Department Of ECE, SJBIT Page 76
Outcomes:
Describe the principles of Principles of public key Cryptosystem
Explain The RSA algorithms and Diffie – Hellman key exchange
Study Elliptic Curve Arithmetic, Authentication functions and Hash functions
Recommended questions:
1. a. in a RSA algorithms system it is given that p=3, q=11, e=7 and m=5. Find the cipher text ‗C‘ and
decrypt ‗C‘ to get plain text M.
b. explain diffie –Hellman key exchange algorithm with example
c. what is key management ? Explain distribution of secret key using public key cryptography.
2. a. perform encryption and decryption using RSA if p=7, q=11, e=13 and m=5.
b. explain the public key distribution of secret key with confidentiality and authentication.
c. with neat schematics, explain message authentication code.
3. a. justify how both confidentiality and authentication are obtained in public key cryprosystems.
b. write RSA algorithm.
c. in diffie Hellman key exchange q=71, its primitive root =7, A‘s private key is 5 B‘s private key
is 12. Find : ) A‘s public key ; ) B‘s public key ; ) shared secret key.
d. explain the distribution of secret key the public key cryptography with confidentiality and
authentication.
4. a. in a RSA algorithm system, the cipher text received is c=10 with a public key P = {5,35}, deduse
the plain text . verify the answer by encryption process.
b. explain Diffie-Hellman key exchange algorithm. Also calculate the Y, Y and secret key (K) for
q=23, =07, X=3 and X=6.

Department Of ECE, SJBIT Page 77
UNIT 4 - DIGITAL SIGNATURES
Unit Structure
4.0 Introduction of Digital Signatures
4.1 Objective
4.2 Authentication protocols
4.3 Digital signature standard.
4.0 INRODCUTION OF DIGITAL SIGNATURES
Message authentication protects two parties who exchange messages from any third party.
However, it does not protect the two parties against each other. Several forms of dispute between the
two are possible.
For example, suppose that John sends an authenticated message to Mary, using one of the
schemes of Figure 4.1. Consider the following disputes that could arise.
1. Mary may forge a different message and claim that it came from John. Mary would simply
have to create a message and append an authentication code using the key that John and Mary
share.
2. John can deny sending the message. Because it is possible for Mary to forge a message, there
is no way to prove that John did in fact send the message.
Both scenarios are of legitimate concern. Here is an example of the first scenario: An electronic
funds transfer takes place, and the receiver increases the amount of funds transferred and claims that the
larger amount had arrived from the sender. An example of the second scenario is that an electronic mail
message contains instructions to a stockbroker for a transaction that subsequently turns out badly. The
Sender pretends that the message was never sent.
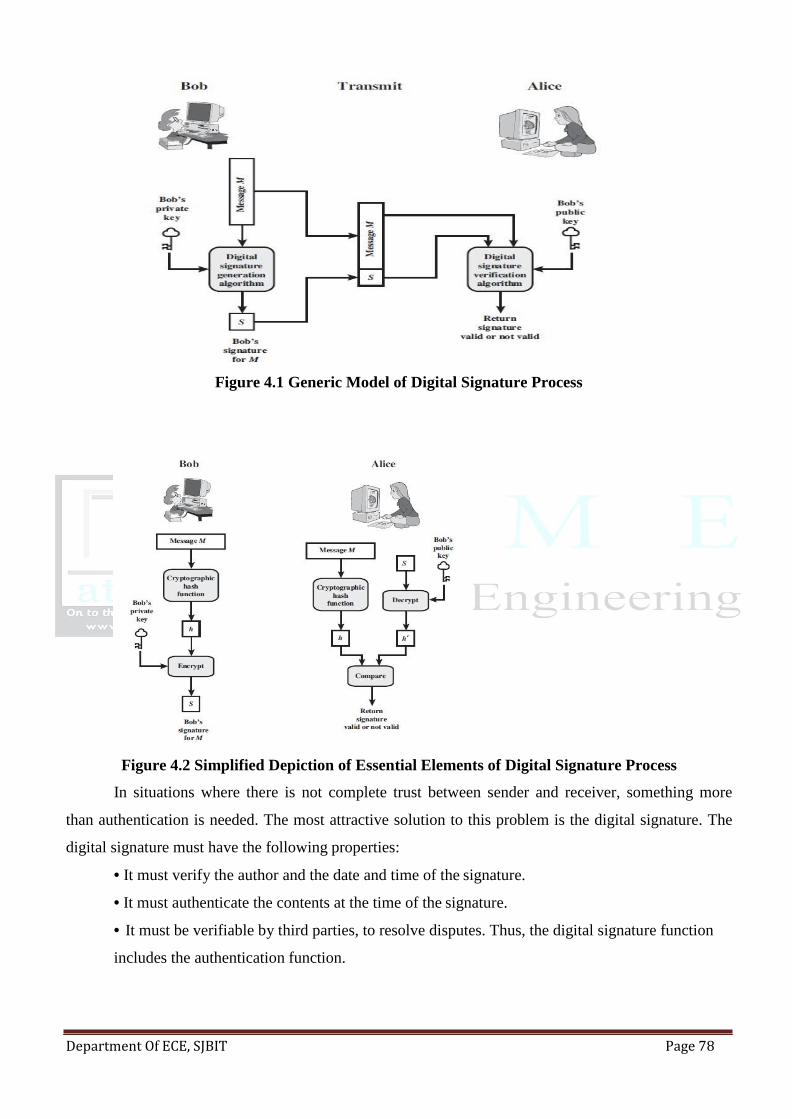
Department Of ECE, SJBIT Page 78
Figure 4.1 Generic Model of Digital Signature Process
Figure 4.2 Simplified Depiction of Essential Elements of Digital Signature Process
In situations where there is not complete trust between sender and receiver, something more
than authentication is needed. The most attractive solution to this problem is the digital signature. The
digital signature must have the following properties:
• It must verify the author and the date and time of the signature.
• It must authenticate the contents at the time of the signature.
• It must be verifiable by third parties, to resolve disputes. Thus, the digital signature function
includes the authentication function.

Department Of ECE, SJBIT Page 79
Attacks and Forgeries
Lists the following types of attacks, in order of increasing severity. Here A denotes the user whose
signature method is being attacked, and C denotes the attacker.
• Key-only attack: C only knows A‘s public key.
• Known message attack: C is given access to a set of messages and their signatures.
• Generic chosen message attack: C chooses a list of messages before attempting to breaks A‘s
signature scheme, independent of A‘s public key. C then obtains from A valid signatures for the chosen
messages. The attack is generic, because it does not depend on A‘s public key; the same attack is used
against everyone.
• Directed chosen message attack: Similar to the generic attack, except that the list of messages to be
signed is chosen after C knows A‘s public key but before any signatures are seen.
• Adaptive chosen message attack: C is allowed to use A as an ―oracle.‖ This means the A
may request signatures of messages that depend on previously obtained message–signature pairs. then
defines success at breaking a signature scheme as an outcome in which C can do any of the following
with a non-negligible probability:
• Total break: C determines A‘s private key.
• Universal forgery: C finds an efficient signing algorithm that provides an equivalent way of
constructing signatures on arbitrary messages.
• Selective forgery: C forges a signature for a particular message chosen by C.
• Existential forgery: C forges a signature for at least one message. C has no control over the message.
Consequently, this forgery may only be a minor nuisance to A.
Digital Signature Requirements
On the basis of the properties and attacks just discussed, we can formulate the following
requirements for a digital signature.
• The signature must be a bit pattern that depends on the message being signed.
• The signature must use some information unique to the sender to prevent both forgery and
denial.
• It must be relatively easy to produce the digital signature.
• It must be relatively easy to recognize and verify the digital signature.
• It must be computationally infeasible to forge a digital signature, either by constructing a new
message for an existing digital signature or by constructing a fraudulent digital signature for a
given message.
• It must be practical to retain a copy of the digital signature in storage. A secure hash function,

Department Of ECE, SJBIT Page 80
embedded in a scheme such as that of Figure 4.2, provides a basis for satisfying these
requirements. However, care must be taken in the design of the details of the scheme.
Direct Digital Signature
The term direct digital signature refers to a digital signature scheme that involves only the
communicating parties (source, destination). It is assumed that the destination knows the public key of
the source.
Confidentiality can be provided by encrypting the entire message plus signature with a shared
secret key (symmetric encryption). Note that it is important to perform the signature function first and
then an outer confidentiality function. In case of dispute, some third party must view the message and
its signature. If the signature is calculated on an encrypted message, then the third party also needs
access to the decryption key to read the original message. However, if the signature is the inner
operation, then the recipient can store the plaintext message and its signature for later use in dispute
resolution.
The validity of the scheme just described depends on the security of the sender‘s private key. If
a sender later wishes to deny sending a particular message, the sender can claim that the private key was
lost or stolen and that someone else forged his or her signature. Administrative controls relating to the
security of private keys can be employed to thwart or at least weaken this ploy, but the threat is still
there, at least to some degree. One example is to require every signed message to include a timestamp
(date and time) and to require prompt reporting of compromised keys to a central authority.
Another threat is that some private key might actually be stolen from X at time T. The opponent
can then send a message signed with X‘s signature and stamped with a time before or equal to T.
The universally accepted technique for dealing with these threats is the use of a digital certificate and
certificate authorities.
4.1 OBJECTIVE:
Understand the use of Digital Signatures.
Learn authentication protocol and Digital signature standard
4.2 AUTHENTICATION PROTOCOLS:
In most computer security contexts, user authentication is the fundamental building block and
the primary line of defence. User authentication is the basis for most types of access control and for user
accountability. RFC 2828 defines user authentication as shown on the following page.

Department Of ECE, SJBIT Page 81
For example, user Alice Toklas could have the user identifier ABTOKLAS. This information
needs to be stored on any server or computer system that Alice wishes to use and could be known to
system administrators and other users. A typical item of authentication information associated with this
user ID is a password, which is kept secret (known only to Alice and to the system). If no one is able to
obtain or guess Alice‘s password, then the combination of Alice‘s user ID and password enables
administrators to set up Alice‘s access permissions and audit her activity. Because Alice‘s ID is not
secret, system users can send her e-mail, but because her password is secret, no one can pretend to be
Alice.
In essence, identification is the means by which a user provides a claimed identity to the system;
user authentication is the means of establishing the validity of the claim. Note that user authentication is
distinct from message authentication. Message authentication is a procedure that allows communicating
parties to verify that the contents of a received message have not been altered and that the source is
authentic. This chapter is concerned solely with user authentication.
There are four general means of authenticating a user‘s identity, which can be used alone or in
combination:
• Something the individual knows: Examples include a password, a personal identification number
(PIN), or answers to a prearranged set of questions.
• Something the individual possesses: Examples include cryptographic keys, electronic key cards,
smart cards, and physical keys. This type of authenticator is referred to as a token.
• Something the individual is (static biometrics): Examples include recognition by fingerprint, retina,
and face.
• Something the individual does (dynamic biometrics): Examples include recognition by voice
pattern, handwriting characteristics, and typing rhythm.
All of these methods, properly implemented and used, can provide secure user authentication.
However, each method has problems. An adversary may be able to guess or steal a password. Similarly,
an adversary may be able to forge or steal a token. A user may forget a password or lose a token.
Furthermore, there is a significant administrative overhead for managing password and token
information on systems and securing such information on systems. With respect to biometric
authenticators, there are a variety of problems, including dealing with false positives and false
negatives, user acceptance, cost, and convenience. For network-based user authentication, the most
important methods involve cryptographic keys and something the individual knows, such as a
password.

Department Of ECE, SJBIT Page 82
4.3. DIGITAL SIGNATURE STANDARD:
The DSS Approach
The DSS uses an algorithm that is designed to provide only the digital signature function.
Unlike RSA, it cannot be used for encryption or key exchange. Nevertheless, it is a public-key
technique.
Figure 4.3 contrasts the DSS approach for generating digital signatures to that used with RSA.
In the RSA approach, the message to be signed is input to a hash function that produces a secure hash
code of fixed length. This hash code is then encrypted using the sender‘s private key to form the
signature. Both the message and the signature are then transmitted. The recipient takes the message and
produces a hash code. The recipient also decrypts the signature using the sender‘s public key. If the
calculated hash code matches the decrypted signature, the signature is accepted as valid. Because only
the sender knows the private key, only the sender could have produced a valid signature.
The DSS approach also makes use of a hash function. The hash code is provided as input to a signature
function along with a random number generated for this particular signature. The signature function also
depends on the sender‘s private key and a set of parameters known to a group of communicating
principals. We can consider this set to constitute a global public key .1 The result is a signature consisting
of two components, labelled s and r.
Figure 4.3 Two Approaches to Digital Signatures
At the receiving end, the hash code of the incoming message is generated. This plus the
signature is input to a verification function. The verification function also depends on the global public

Department Of ECE, SJBIT Page 83
key as well as the sender‘s public key, which is paired with the sender‘s private key. The output of the
verification function is a value that is equal to the signature component if the signature is valid. The
signature function is such that only the sender, with knowledge of the private key, could have produced
the valid signature.
We turn now to the details of the algorithm.
The Digital Signature Algorithm
Figure 4.4 summarizes the algorithm. There are three parameters that are public and can be
common to a group of users. A 160-bit prime number is chosen. Next, a prime number is selected with
a length between 512 and 1024 bits such that divides (p - 1). Finally, g is chosen to be of the form h(p-
1)/qmod p, where h is an p qqr(PUa)2In number-theoretic terms, g is of order q modp; integer between
1 and with the restriction that must be greater than 1.2
Thus, the global public-key components of DSA have the same for as in the Schnorr signature scheme.
With these numbers in hand, each user selects a private key and generates a public key. The private key
must be a number from 1 to and should be chosen randomly or pseudo randomly. The public key is
calculated from the private key as .The calculation of given is relatively straightforward. However, given
the public key , it is believed to be computationally infeasible to determine ,which is the discrete
logarithm of y to the base g, modp.

Department Of ECE, SJBIT Page 84
Figure 4.4 Digital Signature Algorithm (DSA)
To create a signature, a user calculates two quantities, and, that are functions of the public key
components , the user‘s private key , the hash code of the message , and an additional integer that
should be generated randomly or pseudo randomly and be unique for each signing.
At the receiving end, verification is performed using the formulas shown in Figure 4.4.The
receiver generates a quantity that is a function of the public key components, the sender‘s public key,
and the hash code of the incoming message. If this quantity matches the component of the signature,
then the signature is validated.
Figure 4.5 depicts the functions of signing and verifying.
The structure of the algorithm, as revealed in Figure 4.5, is quite interesting. Note that the test at
the end is on the value, which does not depend on the message at all. Instead, is a function of and the
three global public-key components. The multiplicative inverse of is passed to a function that also has
as inputs the message hash code and the user‘s private key. The structure of this function is such that
the receiver can recover using the incoming message and signature, the public key of the user, and the
global public key. It is certainly not obvious from Figure 4.4 or Figure 4.5 that such a scheme would
work.
Given the difficulty of taking discrete logarithms, it is infeasible for an opponent to recover
from or to recover from .Another point worth noting is that the only computationally demanding task in
signature generation is the exponential calculation. Because this value does not depend on the message
to be signed, it can be computed ahead of time.
Figure 4.5 DSS Signing and Verifying

Department Of ECE, SJBIT Page 85
OUTCOME:
Learn Digital Signature
Describe authentication Protocol and Digital Signal Standard
Recommended questions:
1. what is digital signature
2. what is authentication protocol
3. what is hash function and replay attacks.

Department Of ECE, SJBIT Page 86
PART B
UNIT 5-WEB SECURITY
Unit Structure
5.0 Introduction
5.1 Objective
5.2 Web security consideration
5.3 Secure Socket layer
5.4 Transport layer security
5.5 Secure electronic transaction
5.0 INTRODUCTION OF WEB SECURITY CONSIDERATIONS
The World Wide Web is fundamentally a client/server application running over the Internet and
TCP/IP intranets. As such, the security tools and approaches discussed so far in this book are relevant to
the issue of Web security. But, as pointed out in, the Web presents new challenges not generally
appreciated in the context of computer and network security.
• The Internet is two-way. Unlike traditional publishing environments even electronic publishing
systems involving tele text, voice response, or fax-back—the Web is vulnerable to attacks on the Web
servers over the Internet.
• The Web is increasingly serving as a highly visible outlet for corporate and product information and
as the platform for business transactions. Reputations can be damaged and money can be lost if the Web
servers are subverted.
• Although Web browsers are very easy to use, Web servers are relatively easy to configure and
manage, and Web content is increasingly easy to develop, the underlying software is extraordinarily
complex. This complex software may hide many potential security flaws. The short history of the Web
is filled with examples of new and upgraded systems, properly installed, that are vulnerable to a variety
of security attacks.
• A Web server can be exploited as a launching pad into the corporation‘s or agency‘s entire computer
complex. Once the Web server is subverted, an attacker may be able to gain access to data and systems
not part of the Web itself but connected to the server at the local site.
• Casual and untrained (in security matters) users are common clients for Web-based services. Such

Department Of ECE, SJBIT Page 87
users are not necessarily aware of the security risks that exist and do not have the tools or knowledge to
take effective countermeasures.
Web Security Threats
Table 5.1 provides a summary of the types of security threats faced when using the Web. One
way to group these threats is in terms of passive and active attacks. Passive attacks include
eavesdropping on network traffic between browser and server and gaining access to information on a
Web site that is supposed to be restricted. Active attacks include impersonating another user, altering
messages in transit between client and server, and altering information on a Web site. Another way to
classify Web security threats is in terms of the location of the threat: Web server, Web browser, and
network traffic between browser and server. Issues of server and browser security fall into the category of
computer system security; Part Four of this book addresses the issue of system security in general but is
also applicable to Web system security. Issues of traffic security fall into the category of network security
and are addressed in this chapter.
Web Traffic Security Approaches
A number of approaches to providing Web security are possible. The various approaches that
have been considered are similar in the services they provide and to some extent, in the mechanisms
that they use, but they differ with respect to their scope of applicability and their relative location within
the TCP/IP protocol stack. Figure 5.1 illustrates this difference. One way to provide Web security is to
use IP security (IP sec) (Figure 5.1a).The advantage of using IP sec is that it is transparent to end users
and applications and provides a general-purpose solution. Furthermore, IP sec includes a filtering
capability so that only selected traffic need incur the overhead of IP sec processing. Another relatively
general-purpose solution is to implement security just above TCP (Figure 5.1b). The foremost example
of this approach is the Secure Sockets Layer (SSL) and the follow-on Internet standard known as
Transport Layer Security (TLS). At this level, there are two implementation choices. For full generality,
SSL (or TLS) could be provided as part of the underlying protocol suite and therefore be transparent to
applications. Alternatively, SSL can be embedded in specific packages. For example, Netscape and
Microsoft Explorer browsers come equipped with SSL, and most Web servers have implemented the
protocol. Application-specific security services are embedded within the particular application.
Figure 5.1c shows examples of this architecture. The advantage of this approach is that the service can
be tailored to the specific needs of a given application.
Table 5.1 A Comparison of Threats on the Web

Department Of ECE, SJBIT Page 88
Figure 5.1 Relative Locations of Security Facilities in the TCP/IP Protocol Stack
5.1 OBJECTIVE:
Student will be able to,
Understand the need of Web security
Learn different Transport layer security, Secure Socket layer and secure electronic transaction
5.2 SECURE SOCKET LAYER:
SSL Architecture
SSL is designed to make use of TCP to provide a reliable end-to-end secure service.SSL is not a
single protocol but rather two layers of protocols, as illustrated in Figure 5.2.The SSL Record Protocol

Department Of ECE, SJBIT Page 89
provides basic security services to various higher layer protocols. In particular, the Hypertext Transfer
Protocol (HTTP), which provides the transfer service for Web client/server interaction, can operate on
top of SSL. Three higher-layer protocols are defined as part of SSL: the Handshake Protocol, The
Change Cipher Spec Protocol, and the Alert Protocol. These SSL-specific protocols are used in the
management of SSL exchanges and are examined later in this section. Two important SSL concepts are
the SSL session and the SSL connection, which are defined in the specification as follows.
• Connection: A connection is a transport (in the OSI layering model definition) that provides a
suitable type of service. For SSL, such connections are peer-to-peer relationships. The
connections are transient. Every connection is associated with one session.
• Session: An SSL session is an association between a client and a server. Sessions are created
by the Handshake Protocol. Sessions define a set of cryptographic.
Figure 5.2 SSL Protocol Stack
Security parameters which can be shared among multiple connections. Sessions are used to
avoid the expensive negotiation of new security parameters for each connection.
Between any pair of parties (applications such as HTTP on client and server), there may be
multiple secure connections. In theory, there may also be multiple simultaneous sessions between
parties, but this feature is not used in practice.
There are a number of states associated with each session. Once a session is established, there is
a current operating state for both read and write (i.e., receive and send). In addition, during the
Handshake Protocol, pending read and writes states are created. Upon successful conclusion of the
Handshake Protocol, the pending states become the current states.
A session state is defined by the following parameters.
• Session identifier: An arbitrary byte sequence chosen by the server to identify an active or
resumable session state.
• Peer certificate: An X509.v3 certificate of the peer. This element of the state may be null.
• Compression method: The algorithm used to compress data prior to encryption.

Department Of ECE, SJBIT Page 90
• Cipher spec: Specifies the bulk data encryption algorithm (such as null, AES, etc.) and a hash
algorithm (such as MD5 or SHA-1) used for MAC calculation. It also defines cryptographic attributes
such as the hash size.
• Master secret: 48-byte secret shared between the client and server.
• Is resumable: A flag indicating whether the session can be used to initiate new connections.
A connection state is defined by the following parameters.
• Server and client random: Byte sequences that are chosen by the server and client for each
connection.
• Server write MAC secret: The secret key used in MAC operations on data sent by the server.
• Client write MAC secret: The secret key used in MAC operations on data sent by the client.
• Server write key: The secret encryption key for data encrypted by the server and decrypted by
the client.
• Client write key: The symmetric encryption key for data encrypted by the client and
decrypted by the server.
• Initialization vectors: When a block cipher in CBC mode is used, an initialization vector (IV)
is maintained for each key. This field is first initialized by the SSL Handshake Protocol. Thereafter, the
final cipher text block from each record is preserved for use as the IV with the following record.
• Sequence numbers: Each party maintains separate sequence numbers for transmitted and
received messages for each connection. When a party sends or receives a change cipher spec message,
the appropriate sequence number is set to zero. Sequence numbers may not exceed 264
– 1.
SSL Record Protocol
The SSL Record Protocol provides two services for SSL connections:
• Confidentiality: The Handshake Protocol defines a shared secret key that is used for
conventional encryption of SSL payloads.
• Message Integrity: The Handshake Protocol also defines a shared secret key that is used to
form a message authentication code (MAC).Figure 5.3 indicates the overall operation of the SSL
Record Protocol. The Record Protocol takes an application message to be transmitted, fragments the
data into manageable blocks, optionally compresses the data, applies a MAC, encrypts, adds a header,
and transmits the resulting unit in a TCP segment. Received data are decrypted, verified, decompressed,
and reassembled before being delivered to higher-level users.

Department Of ECE, SJBIT Page 91
The first step is fragmentation. Each upper-layer message is fragmented into blocks of 214
bytes (16384 bytes) or less. Next, compression is optionally applied. Compression must be lossless and
may not increase the content length by more than 1024 bytes.1In SSLv3 (as well as the current version
of TLS), no compression algorithm is specified, so the default compression algorithm is null.
The next step in processing is to compute a message authentication code over the compressed
data. For this purpose, a shared secret key is used. The calculation is defined as
Figure 5.3 SSL Record Protocol Operations

Department Of ECE, SJBIT Page 90
Note that this is very similar to the HMAC algorithm defined in Chapter 12.Thedifference is that
the two pads are concatenated in SSLv3 and are XORed in HMAC. The SSLv3 MAC algorithm is
based on the original Internet draft for HMAC, which used concatenation. The final version of HMAC
(defined in RFC 2104) uses the XOR. Next, the compressed message plus the MAC are encrypted
using symmetric encryption. Encryption may not increase the content length by more than 1024bytes,
so that the total length may not exceed 214 + 2048. The following encryption algorithms are permitted:
Fortezza can be used in a smart card encryption scheme.
For stream encryption, the compressed message plus the MAC are encrypted. Note that the
MAC is computed before encryption takes place and that the MAC is then encrypted along with the
plaintext or compressed plaintext.
For block encryption, padding may be added after the MAC prior to encryption. The padding is
in the form of a number of padding bytes followed by a one-byte indication of the length of the
padding. The total amount of padding is the smallest amount such that the total size of the data to be
encrypted (plaintext plus MAC plus padding) is a multiple of the cipher‘s block length. An example is a
plaintext (or compressed text if compression is used) of 58 bytes, with a MAC of 20 bytes (usingSHA-
1), that is encrypted using a block length of 8 bytes (e.g., DES). With the padding-length byte, this
yields a total of 79 bytes. To make the total an integer multiple of 8, one byte of padding is added.
The final step of SSL Record Protocol processing is to prepare a header consisting of the
following fields:
• Content Type (8 bits): The higher-layer protocol used to process the enclosed fragment.
• Major Version (8 bits): Indicates major version of SSL in use. For SSLv3, the value is 3.
• Minor Version (8 bits): Indicates minor version in use. For SSLv3, the value is 0.
• Compressed Length (16 bits): The length in bytes of the plaintext fragment (or compressed
fragment if compression is used).The maximum value is the content types that have been
defined are change_cipher_spec, alert, handshake, and application_data. The first three are the
SSL-specific

Department Of ECE, ATMECE Page 91
protocols, discussed next. Note that no distinction is made among the various applications (e.g., HTTP)
that might use SSL; the content of the data created by such applications is opaque to SSL.
5.3 TRANSPORT LAYER SECURITY
TLS is an IETF standardization initiative whose goal is to produce an Internet standard version
of SSL. TLS is defined as a Proposed Internet Standard in RFC5246. RFC 5246 is very similar to
SSLv3. In this section, we highlight the differences.
Version Number
The TLS Record Format is the same as that of the SSL Record Format (Figure 5.4), and the
fields in the header have the same meanings. The one difference is in version values. For the current
version of TLS, the major version is 3 and the minor version is 3.
Message Authentication Code
There are two differences between the SSLv3 and TLS MAC schemes: the actual algorithm and
the scope of the MAC calculation. TLS makes use of the HMAC algorithm defined in RFC 2104.
Recall from Chapter 12 that HMAC is defined as
SSLv3 uses the same algorithm, except that the padding bytes are concatenated with the secret key
rather than being XORed with the secret key padded to the block length. The level of security should be
about the same in both cases.
For TLS, the MAC calculation encompasses the fields indicated in the following expression:

Department Of ECE, ATMECE Page 92
Pseudorandom Function
TLS makes use of a pseudorandom function referred to as PRF to expand secrets into blocks of
data for purposes of key generation or validation. The objective is to make use of a relatively small
shared secret value but to generate longer blocks of data in a way that is secure from the kinds of
attacks made on hash functions and MACs. The PRF is based on the data expansion function.
Figure 5.4 TLS Function P_hash (secret, seed)

Department Of ECE, ATMECE Page 93
The data expansion function makes use of the HMAC algorithm with either MD5or SHA-1 as
the underlying hash function. As can be seen, P_hash can be iterated as many times as necessary to
produce the required quantity of data. For example, if P_SHA-1 was used to generate 64 bytes of data,
it would have to be iterated four times, producing 80 bytes of data of which the last 16 would be
discarded.
In this case, P_MD5 would also have to be iterated four times, producing exactly 64 bytes of
data. Note that each iteration involves two executions of HMAC—each of which in turn involves two
executions of the underlying hash algorithm.
To make PRF as secure as possible, it uses two hash algorithms in a way that should guarantee
its security if either algorithm remains secure. PRF is defined as
PRF(secret, label, seed) = P_hash(S1,label || seed)PRF takes as input a secret value, an identifying label,
and a seed value and produces an output of arbitrary length.
Alert Codes
TLS supports all of the alert codes defined in SSLv3 with the exception of no_certificate. A
number of additional codes are defined in TLS; of these, the following are always fatal.
• record_overflow: A TLS record was received with a payload (cipher text) whose length exceeds
bytes, or the cipher text decrypted to a length of greater than bytes.
• unknown_ca: A valid certificate chain or partial chain was received, but the certificate was not
accepted because the CA certificate could not be located or could not be matched with a known,
trusted CA.
• access_denied: A valid certificate was received, but when access control was applied, the sender
decided not to proceed with the negotiation.
• decode_error: A message could not be decoded, because either a field was out of its specified
range or the length of the message was incorrect.
• protocol_version: The protocol version the client attempted to negotiate is recognized but not
supported.
• insufficient_security: Returned instead of handshake_failure when a negotiation has failed
specifically because the server requires ciphers more secure than those supported by the client.
• unsupported_extension: Sent by clients that receive an extended server hello containing an
extension not in the corresponding client hello.
• internal_error: An internal error unrelated to the peer or the correctness of the protocol makes it
impossible to continue.

Department Of ECE, ATMECE Page 94
• decrypt_error: A handshake cryptographic operation failed, including being unable to verify a
signature, decrypt a key exchange, or validate a finished message.
• user_canceled: This handshake is being cancelled for some reason unrelated
to a protocol failure.
• no_renegotiation: Sent by a client in response to a hello request or by the server in response to a
client hello after initial handshaking. Either of these messages would normally result in
renegotiation, but this alert indicates that the sender is not able to renegotiate. This message is
always a warning.
Cipher Suites
There are several small differences between the cipher suites available under SSLv3 and under TLS:
• Key Exchange: TLS supports all of the key exchange techniques of SSLv3 with the exception
of Fortezza.
• Symmetric Encryption Algorithms: TLS includes all of the symmetric encryption algorithms
found in SSLv3, with the exception of Fortezza.
Client Certificate Types
TLS defines the following certificate types to be requested in a certificate_request message:
rsa_sign, dss_sign, rsa_fixed_dh, and dss_fixed_dh. These are all defined in SSLv3. In addition, SSLv3
includes rsa_ephemeral_dh, dss_ephemeral_dh, and fortezza_kea. Ephemeral Diffie-Hellman involves
signing the Diffie-Hellman parameters with either RSA or DSS. For TLS, the rsa_sign and dss_sign
types are used for that function; a separate signing type is not needed to sign Diffie-Hellman
parameters. TLS does not include the Fortezza scheme.
certificate_verify and Finished Messages
In the TLS certificate_verify message, the MD5 and SHA-1 hashes are calculated only over
handshake_messages. Recall that for SSLv3, the hash calculation also included the master secret and
pads. These extra fields were felt to add no additional security.
As with the finished message in SSLv3, the finished message in TLS is a hash based on the
shared master_secret, the previous handshake messages, and a label that identifies client or server. The
calculation is somewhat different. For TLS, we have

Department Of ECE, ATMECE Page 95
5.4 SECURE ELECTRONIC TRANSACTION
COMPRESSION: As a default, PGP compresses the message after applying the signature but
before encryption. This has the benefit of saving space both for e-mail transmission and for file storage.
The placement of the compression algorithm, indicated by Z for compression and Z–1 for
decompression is critical.
1. The signature is generated before compression for two reasons:
a. It is preferable to sign an uncompressed message so that one can store only the uncompressed
message together with the signature for future verification. If one signed a compressed document,

Department Of ECE, ATMECE Page 96
then it would be necessary either to store a compressed version of the message for later verification
or to recompress the message when verification is required.
b. Even if one were willing to generate dynamically a recompressed message or verification, PGP‘s
compression algorithm presents a difficulty. The algorithm is not deterministic; various
implementations of the algorithm achieve different tradeoffs in running speed versus compression
ratio and, as a result, produce different compressed forms. However, these different compression
algorithms are interoperable because any version of the algorithm can correctly decompress the
output of any other version. Applying the hash function and signature after compression would
constrain all PGP implementations to the same version of the compression algorithm.
2. Message encryption is applied after compression to strengthen cryptographic security. Because the
compressed message has less redundancy than the original plaintext, cryptanalysis is more difficult.
E-M AIL COMPATIBILITY: When PGP is used, at least part of the block to be transmitted is
encrypted. If only the signature service is used, then the message digest is encrypted (with the sender‘s
private key). If the confidentiality service is used, the message plus signature (if present) are encrypted
(with a one-time symmetric key).Thus, part or the entire resulting block consists of a stream of arbitrary
8-bit octets. However, many electronic mail systems only permit the use of blocks consisting of ASCII
text. To accommodate this restriction, PGP provides the service of converting the raw 8-bit binary
stream to a stream of printable ASCII characters.
The scheme used for this purpose is radix-64 conversion. Each group of three octets of binary
data is mapped into four ASCII characters. This format also appends a CRC to detect transmission
errors.
The use of radix 64 expands a message by 33%. Fortunately, the session key and signature
portions of the message are relatively compact, and the plaintext message has been compressed. In fact,
the compression should be more than enough to compensate for the radix-64 expansion. For example,
[HELD96] reports an average compression ratio of about 2.0 using ZIP. If we ignore the relatively
small signature and key components, the typical overall effect of compression and expansion of a file of
length would be .Thus, there is still an overall compression of about one-third.
One noteworthy aspect of the radix-64 algorithm is that it blindly converts the input stream to
radix-64 format regardless of content, even if the input happens to be ASCII text. Thus, if a message is
signed but not encrypted and the conversion is applied to the entire block, the output will be unreadable
to the casual observer, which provides a certain level of confidentiality. As an option, PGP can be
configured to convert to radix-64 format only the signature portion of signed plain text messages. This

Department Of ECE, ATMECE Page 97
enables the human recipient to read the message without using PGP.PGP would still have to be used to
verify the signature.
On transmission (if it is required), a signature is generated using a hash code of the
uncompressed plaintext. Then the plaintext (plus signature if present) is compressed. Next, if
confidentiality is required, the block (compressed plaintext or compressed signature plus plaintext) is
encrypted and prepended with the public-key encrypted symmetric encryption key. Finally, the entire
block is converted toradix-64 format.
On reception, the incoming block is first converted back from radix-64 format to binary. Then,
if the message is encrypted, the recipient recovers the session key and decrypts the message. The
resulting block is then decompressed. If the message is signed, the recipient recovers the transmitted
hash code and compares it to its own calculation of the hash code.
OUTCOME
Learn web security Considerations
Learn SSL and Secure electronic transaction
Recommended questions:
1. what is web security?
2. What is the use of wed security?
3. Write the issues related to web secutity?
4. what are the protocols required to maintain security?

Department Of ECE, SJBIT Page 98
UNIT 6- INTRUDERS
Unit Structure:
6.0 Introduction
6.1 Objective
6.2 Intrusion Detection
6.3 Password Management.
6.0 INTRODUCTION
One of the two most publicized threats to security is the intruder (the other is viruses), often referred to
as a hacker or cracker. In an important early study of intrusion, Anderson[ANDE80] identified three
classes of intruders:
Masquerade: An individual who is not authorized to use the computer and who penetrates a
system‘s access controls to exploit a legitimate user‘s account
Misfeasor: A legitimate user who accesses data, programs, or resources for which such access
is not authorized, or who is authorized for such access but misuses his or her privileges
Clandestine user: An individual who seizes supervisory control of the system and uses this
control to evade auditing and access controls or to suppress audit collection
The masquerader is likely to be an outsider; the misfeasor generally is an insider; and the
clandestine user can be either an outsider or an insider.
Intruder attacks range from the benign to the serious. At the benign end of the scale, there are
many people who simply wish to explore internets and see what is out there. At the serious end are
individuals who are attempting to read privileged data, perform unauthorized modifications to data, or
disrupt the system.
Lists the following examples of intrusion:
Performing a remote root compromise of an e-mail server
Defacing a Web server
Guessing and cracking passwords
Copying a database containing credit card numbers
Viewing sensitive data, including payroll records and medical information,
without authorization
Running a packet sniffer on a workstation to capture usernames and passwords
Using a permission error on an anonymous FTP server to distribute pirated

Department Of ECE, SJBIT Page 99
software and music files
Dialling into an unsecured modem and gaining internal network access
Posing as an executive, calling the help desk, resetting the executive‘s e-mail
password, and learning the new password
Using an unattended, logged-in workstation without permission
Intruder Behaviour Patterns
The techniques and behaviour patterns of intruders are constantly shifting, to discovered
weaknesses and to evade detection and countermeasures. Even so, intruders typically follow one of a
number of recognizable behaviour patterns, and these patterns typically differ from those of ordinary
users. In the following, we look at three broad examples of intruder behaviour patterns, to give the
reader some feel for the challenge facing the security administrator. Table 6.1, summarizes the
behaviour.
HACKERS Traditionally, those who hack into computers do so for the thrill of it or for status.
The hacking community is a strong meritocracy in which status is determined by level of competence.
Thus, attackers often look for targets of opportunity and then share the information with others. A
typical example is a break-in at a large financial institution reported in [RADC04]. The intruder took
advantage of the fact that the corporate network was running unprotected services, some of which were
not even needed. In this case, the key to the break-in was the pc anywhere application. The
manufacturer, Symantec, advertises this program as a remote control solution that enables secure
connection to remote devices. But the attacker had an easy time gaining access to pc anywhere; the
administrator used the same three-letter username and password for the program. In this case, there was
no intrusion detection system on the 700-node corporate network. The intruder was only discovered
when a vice president walked into her office and saw the cursor moving files around on her Windows
workstation.
Some Examples of Intruder Patterns of Behaviour
(a) Hacker
Select the target using IP lookup tools such as NS Lookup, Dig, and others.
Map network for accessible services using tools such as NMAP.
Identify potentially vulnerable services (in this case, pc anywhere).
Brute force (guess) pc anywhere password.
Install remote administration tool called Dame Ware.
Wait for administrator to log on and capture his password.
Use that password to access remainder of network.

Department Of ECE, SJBIT Page 100
(b) Criminal Enterprise
Act quickly and precisely to make their activities harder to detect.
Exploit perimeter through vulnerable ports.
Use Trojan horses (hidden software) to leave back doors for re-entry.
Use sniffers to capture passwords.
Do not stick around until noticed.
Make few or no mistakes.
(c) Internal Threat
Create network accounts for themselves and their friends.
Access accounts and applications they wouldn‘t normally use for their daily jobs.
E-mail former and prospective employers.
Conduct furtive instant-messaging chats.
Visit Web sites that cater to disgruntled employees, such as f‘dcompany.com.
Perform large downloads and file copying.
Access the network during off hours.
Benign intruders might be tolerable, although they do consume resources and may slow
performance for legitimate users. However, there is no way in advance to know whether an intruder will
be benign or malign. Consequently, even for systems with no particularly sensitive resources, there is a
motivation to control this problem.
Intrusion detection systems (IDSs) and intrusion prevention systems (IPSs) are designed to
counter this type of hacker threat. In addition to using such systems, organizations can consider
restricting remote logons to specific IP addresses and/or use virtual private network technology.
One of the results of the growing awareness of the intruder problem has been the establishment
of a number of computer emergency response teams (CERTs).These cooperative ventures collect
information about system vulnerabilities and disseminate it to systems managers. Hackers also routinely
read CERT reports. Thus, it is important for system administrators to quickly insert all software patches
to discovered vulnerabilities. Unfortunately, given the complexity of many IT systems, and the rate at
which patches are released, this is increasingly difficult to achieve without automated updating. Even
then, there are problems caused by incompatibilities resulting from the updated software. Hence the
need for multiple layers of defence in managing security threats to IT systems.
CRIMINALS Organized groups of hackers have become a widespread and common threat to
Internet-based systems. These groups can be in the employ of a corporation or government but often are

Department Of ECE, SJBIT Page 101
loosely affiliated gangs of hackers. Typically, these gangs are young, often Eastern European, Russian,
or southeast Asian hackers who do business on the Web. They meet in underground forums with names
like DarkMarket.org andtheftservices.com to trade tips and data and coordinate attacks. A common
target is a credit card file at an e-commerce server. Attackers attempt to gain root access. The card
numbers are used by organized crime gangs to purchase expensive items and are then posted to carder
sites, where others can access and use the account numbers; this obscures usage patterns and
complicates investigation.
Whereas traditional hackers look for targets of opportunity, criminal hackers usually have
specific targets or at least classes of targets in mind. Once a site is penetrated, the attacker acts quickly,
scooping up as much valuable information as possible and exiting.
IDSs and IPSs can also be used for these types of attackers, but may be less effective because of
the quick in-and-out nature of the attack. For e-commerce sites, database encryption should be used for
sensitive customer information, especially credit cards. For hosted e-commerce sites (provided by an
outsider service), the e-commerce organization should make use of a dedicated server (not used to
support multiple customers) and closely monitor the provider‘s security services.
INSIDER ATTACKS Insider attacks are among the most difficult to detect and prevent.
Employees already have access and knowledge about the structure and content of corporate databases.
Insider attacks can be motivated by revenge or simply a feeling of entitlement. An example of the
former is the case of Kenneth Patterson, fired from his position as data communications manager for
American Eagle Outfitters. Patterson disabled the company‘s ability to process credit card purchases
during five days of the holiday season of 2002. As for a sense of entitlement, there have always been
many employees who felt entitled to take extra office supplies for home use, but this now extends to
corporate data. An example is that of a vice president of sales for a stock analysis firm who quit going
to a competitor. Before she left, she copied the customer database to take with her. The offender
reported feeling no animus toward her former employee; she simply wanted the data because it would
be useful to her.
Although IDS and IPS facilities can be useful in countering insider attacks, other more direct
approaches are of higher priority. Examples include the following:
Enforce least privilege, only allowing access to the resources employees need to do their job.
Set logs to see what users access and what commands they are entering.
Protect sensitive resources with strong authentication.
Upon termination, delete employee‘s computer and network access.
Upon termination, make a mirror image of employee‘s hard drive before reissuing it. That
evidence might be needed if your company information turns up at a competitor.

Department Of ECE, SJBIT Page 102
Intrusion Techniques
The objective of the intruder is to gain access to a system or to increase the range of
privileges accessible on a system. Most initial attacks use system or software vulnerabilities that
allow a user to execute code that opens a back door into the system. Alternatively, the intruder
attempts to acquire
information that should have been protected. In some cases, this information is in the form of a user
password. With knowledge of some other user‘s password, an intruder can log in to a system and
exercise all the privileges accorded to the legitimate user.
Typically, a system must maintain a file that associates a password with each authorized user.
If such a file is stored with no protection, then it is an easy matter to gain access to it and learn
passwords. The password file can be protected in one of two ways:
One-way function: The system stores only the value of a function based on the user‘s password.
When the user presents a password, the system transforms that password and compares it with the
stored value. In practice, the system usually performs a one-way transformation (not reversible) in
which the password is used to generate a key for the one-ay function and in which a fixed-length
output is produced.
Access control: Access to the password file is limited to one or a very few accounts. If one or
both of these countermeasures are in place, some effort is needed for a potential intruder to learn
passwords. On the basis of a survey of the literature and interviews with a number of password
crackers, reports the following techniques for learning passwords:
Try default passwords used with standard accounts that are shipped with the system. Many
administrators do not bother to change these defaults.
Exhaustively try all short passwords (those of one to three characters).
Try words in the system‘s online dictionary or a list of likely passwords. Examples of the
latter are readily available on hacker bulletin boards.
Collect information about users, such as their full names, the names of their spouse and
children, pictures in their office, and books in their office that are related to hobbies.
Try users‘ phone numbers, Social Security numbers, and room numbers.
Try all legitimate license plate numbers for this state.
Use a Trojan to bypass restrictions on access.
Tap the line between a remote user and the host system.

Department Of ECE, SJBIT Page 103
6.1 OBJECTIVE
Student should be able to,
Need for intrusion detection
Learn Password management
6.2 INTRUSION DETECTION
Inevitably, the best intrusion prevention system will fail. A system‘s second line of defence is
intrusion detection, and this has been the focus of much research in recent years. This interest is
motivated by a number of considerations, including the following:
If an intrusion is detected quickly enough, the intruder can be identified and ejected from the
system before any damage is done or any data are compromised. Even if the detection is not
Sfficiently timely to pre-empt the intruder, the sooner that the intrusion is detected, the less the
amount of damage and the more quickly that recovery can be achieved.
An effective intrusion detection system can serve as a deterrent, so acting to prevent Intrusions.
Intrusion detection enables the collection of information about intrusion techniques that can be
used to strengthen the intrusion prevention facility.
Intrusion detection is based on the assumption that the behaviour of the intruder differs from that of
a legitimate user in ways that can be quantified. Of course, we cannot expect that there will be a crisp,
exact distinction between an attack by an intruder and the normal use of resources by an authorized
user. Rather, we must expect that there will be some overlap.
Figure 6.1 suggests, in very abstract terms, the nature of the task confronting the designer of an
intrusion detection system. Although the typical behaviour of an intruder differs from the typical
behaviour of an authorized user, there is an overlap in these behaviours. Thus, a loose interpretation of
intruder behaviour, which will catch more intruders, will also lead to a number of ―false positives,‖ or
authorized user identified as intruders. On the other hand, an attempt to limit false positives by a tight
interpretation of intruder behaviour will lead to an increase in false negatives, or intruders not identified
as intruders. Thus, there is an element of compromise an dart in the practice of intrusion detection.
In Anderson‘s study, it was postulated that one could, with reasonable confidence, distinguish
between a masquerade and a legitimate user. Patterns of legitimate user behaviour can be established by
observing past history, and significant deviation from such patterns can be detected. Anderson suggests
that the task of detecting a misfeasor (legitimate user performing in an unauthorized fashion) is more
difficult, in that the distinction between abnormal and normal behaviour maybe small. Anderson
concluded that such violations would be undetectable solely through the search for anomalous
behaviour. However, misfeasor behaviour might nevertheless be detectable by intelligent definition of

Department Of ECE, SJBIT Page 104
the class of conditions that suggest unauthorized use. Finally, the detection of the clandestine user was
felt to be beyond the scope of purely automated techniques. These observations, which were made in
1980, remain true today.

Department Of ECE, SJBIT Page 105
Figure 6.1: Profiles of Behaviour of Intruders and Authorized Users
Identifies the following approaches to intrusion detection:
1. Statistical anomaly detection: Involves the collection of data relating to the behaviour of
legitimate users over a period of time. Then statistical tests are applied to observed behaviour to
determine with a high level of confidence whether that behaviour is not legitimate user
behaviour.
Threshold detection: This approach involves defining thresholds, independent of user, for
the frequency of occurrence of various events.
Profile based: A profile of the activity of each user is developed and used to detect changes
in the behaviour of individual accounts.
2. Rule-based detection: Involves an attempt to define a set of rules that can be used to decide
that a given behaviour is that of an intruder.
Anomaly detection: Rules are developed to detect deviation from previous usage patterns.
Penetration identification: An expert system approach that searches for suspicious
behaviour.
Audit Records
A fundamental tool for intrusion detection is the audit record. Some record of ongoing activity
by users must be maintained as input to an intrusion detection system. Basically, two plans are used:
Native audit records: Virtually all multiuser operating systems include accounting software that
collects information on user activity. The advantage of using this information is that no additional
collection software is needed. The disadvantage is that the native audit records may not contain
the needed information or may not contain it in a convenient form.

Department Of ECE, SJBIT Page 106
Detection-specific audit records: A collection facility can be implemented that generates audit
records containing only that information required by the intrusion detection system. One
advantage of such an approach is that it could be made vendor independent and ported to a variety
of systems. The disadvantage is the extra overhead involved in having, in effect, two accounting
packages running on a machine.
A good example of detection-specific audit records is one developed by Dorothy Denning. Each audit
record contains the following fields:
Subject: Initiators of actions. A subject is typically a terminal user but might also be process
acting on behalf of users or groups of users. All activity arises through commands issued by
subjects. Subjects may be grouped into different access classes, and these classes may overlap.
Action: Operation performed by the subject on or with an object; for example, login, read,
perform I/O, execute.
Object: Receptors of actions. Examples include files, programs, messages, records, terminals,
printers, and user- or program-created structures. When a subject is the recipient of an action, such
as electronic mail, then that subject is considered an object. Objects may be grouped by type.
Object granularity may vary by object type and by environment. For example, database actions
may be audited for the database as a whole or at the record level.
Exception-Condition: Denotes which, if any, exception condition is raised on return.
Resource-Usage: A list of quantitative elements in which each element gives the amount used of
some resource (e.g., number of lines printed or displayed, number of records read or written,
processor time, I/O units used, session elapsed time).
Time-Stamp: Unique time-and-date stamp identifying when the action took place.
Most user operations are made up of a number of elementary actions. For example, a file copy
involves the execution of the user command, which includes doing access validation and setting up the
copy, plus the read from one file, plus the write to another file. Consider the command
COPY GAME.EXE TO <Libray>GAME.EXE
Issued by Smith to copy an executable file GAME from the current directory to the<Library> directory.
The following audit records may be generated:
In this case, the copy is aborted because Smith does not have write permission to<Library>.

Department Of ECE, SJBIT Page 107
The decomposition of a user operation into elementary actions has three advantages:
Because objects are the protectable entities in a system, the use of elementary actions enables an
audit of all behaviour affecting an object. Thus, the system can detect attempted subversions of
access controls (by noting an abnormality in the number of exception conditions returned) and can
detect successful subversions by noting an abnormality in the set of objects accessible to the
subject.
Single-object, single-action audit records simplify the model and the implementation.
Because of the simple, uniform structure of the detection-specific audit records, it may be
relatively easy to obtain this information or at least part of it by a straightforward mapping from
existing native audit records to the detection-specific audit records.
Statistical Anomaly Detection
As was mentioned, statistical anomaly detection techniques fall into two broad categories:
threshold detection and profile-based systems. Threshold detection involves counting the number of
occurrences of a specific event type over an interval of time. If the count surpasses what is considered a
reasonable number that one might expect to occur, then intrusion is assumed.
Threshold analysis, by itself, is a crude and ineffective detector of even moderately sophisticated
attacks. Both the threshold and the time interval must be determined. Because of the variability across
users, such thresholds are likely to generate either a lot of false positives or a lot of false negatives.
However, simple threshold detectors may be useful in conjunction with more sophisticated techniques.
Profile-based anomaly detection focuses on characterizing the past behaviour of individual users
or related groups of users and then detecting significant deviations. A profile may consist of a set of
parameters, so that deviation on just a single parameter may not be sufficient in itself to signal an alert.
The foundation of this approach is an analysis of audit records. The audit records provide input
to the intrusion detection function in two ways. First, the designer must decide on a number of
quantitative metrics that can be used to measure user behaviour. An analysis of audit records over a
period of time can be used to determine the activity profile of the average user. Thus, the audit records
serve to define typical behaviour. Second, current audit records are the input used to detect intrusion.
That is, the intrusion detection model analyzes incoming audit records to determine deviation from
average behaviour.
Examples of metrics that are useful for profile-based intrusion detection are the following:
Counter: A nonnegative integer that may be incremented but not decremented until it is reset by
management action. Typically, a count of certain event types is kept over a particular period of
time. Examples include the number of logins by a single user during an hour, the number of times

Department Of ECE, SJBIT Page 108
a given command is executed during a single user session, and the number of password failures
during a minute.
Gauge: A nonnegative integer that may be incremented or decremented. Typically, a gauge is
used to measure the current value of some entity. Examples include the number of logical
connections assigned to a user application and the number of outgoing messages queued for a user
process.
Interval timer: The length of time between two related events. An example is the length of time
between successive logins to an account.
Resource utilization: Quantity of resources consumed during a specified period. Examples
include the number of pages printed during a user session and total time consumed by a program
execution.
Given these general metrics, various tests can be performed to determine whether current activity fits
within acceptable limits. [DENN87] lists the following approaches that may be taken:
Mean and standard deviation
Multivariate
Markov process
Time series
Operational
The simplest statistical test is to measure the mean and standard deviation of a parameter over
some historical period. This gives a reflection of the average behaviour and its variability. The use of
mean and standard deviation is applicable to a wide variety of counters, timers, and resource measures.
But these measures, by themselves, are typically too crude for intrusion detection purposes.
A multivariate model is based on correlations between two or more variables. Intruder behavior
may be characterized with greater confidence by considering such correlations (for example, processor
time and resource usage, or login frequency and session elapsed time).
A Markov process model is used to establish transition probabilities among various states. As an
example, this model might be used to look at transitions between certain commands.
A time series model focuses on time intervals, looking for sequences of events that happen too
rapidly or too slowly. A variety of statistical tests can be applied to characterize abnormal timing.
Finally, an operational model is based on a judgment of what is considered abnormal, rather than an
automated analysis of past audit records. Typically, fixed limits are defined and intrusion is suspected
for an observation that is outside the limits. This types of approach works best where intruder behavior

Department Of ECE, SJBIT Page 109
can be deduced from certain types of activities. For example, a large number of login attempts over a
short period suggest an attempted intrusion.
As an example of the use of these various metrics and models, Table 6.2 shows various
measures considered or tested for the Stanford Research Institute(SRI) intrusion detection system
(IDES) .The main advantage of the use of statistical profiles is that a prior knowledge of security flaws
is not required. The detector program learns what ―normal‖ behaviour is and then looks for deviations.
The approach is not based on system-dependent characteristics and vulnerabilities. Thus, it should be
readily portable among a variety of systems.
Table 6.1: Measures That May Be Used for Intrusion Detection

Department Of ECE, SJBIT Page 110
System administrators and security analysts to collect a suite of known penetration scenarios and key
events that threaten the security of the target system. A simple example of the type of rules that can be
used is found in NIDX, a nearly system that used heuristic rules that can be used to assign degrees of
suspicion to activities Example heuristics are the following:
Users should not read files in other users‘ personal directories.
Users must not write other users‘ files.
Users who log in after hours often access the same files they used earlier.
Users do not generally open disk devices directly but rely on higher-level operating system utilities.
Users should not be logged in more than once to the same system.
Users do not make copies of system programs.

Department Of ECE, SJBIT Page 110
The Base-Rate Fallacy
To be of practical use, an intrusion detection system should detect a substantial percentage of
intrusions while keeping the false alarm rate at an acceptable level. If only a modest percentage of
actual intrusions are detected, the system provides a false sense of security. On the other hand, if the
system frequently triggers an alert when there is no intrusion (a false alarm), then either system
managers will begin to ignore the alarms, or much time will be wasted analyzing the false alarms.
Unfortunately, because of the nature of the probabilities involved, it is very difficult to meet the
standard of high rate of detections with a low rate of false alarms. In general, if the actual numbers of
intrusions is low compared to the number of legitimate uses of a system, then the false alarm rate will
be high unless the test is extremely discriminating. A study of existing intrusion detection systems,
reported in [AXEL00], indicated that current systems have not overcome the problem of the base-rate
fallacy. See Appendix 20A for a brief background on the mathematics of this problem.
Distributed Intrusion Detection
Until recently, work on intrusion detection systems focused on single-system stand alone
facilities. The typical organization, however, needs to defend a distributed collection of hosts supported
by a LAN or internetwork. Although it is possible to mount a defence by using stand-alone intrusion
detection systems on each host, a more effective defense can be achieved by coordination and
cooperation among intrusion detection systems across the network. Pores points out the following major
issues in the design of a distributed intrusion detection system.
A distributed intrusion detection system may need to deal with different audit record formats. In a
heterogeneous environment, different systems will employ different native audit collection
systems and, if using intrusion detection, may employ different formats for security-related audit
records.
One or more nodes in the network will serve as collection and analysis points for the data from the
systems on the network. Thus, either raw audit data or summary data must be transmitted across
the network. Therefore, there is a requirement to assure the integrity and confidentiality of these
data. Integrity is required to prevent an intruder from masking his or her activities by altering the
transmitted audit information. Confidentiality is required because the transmitted audit
information could be valuable.

Department Of ECE, SJBIT Page 111
Either a centralized or decentralized architecture can be used. With a centralized architecture,
there is a single central point of collection and analysis of all audit data. This eases the task of
correlating incoming reports but creates a potential bottleneck and single point of failure. With a
decentralized architecture, there are more than one analysis centers, but these must coordinate
their activities and exchange information.
Figure 20.2 shows the overall architecture, which consists of three main components:
• Host agent module: An audit collection module operating as a background process on a
monitored system. Its purpose is to collect data on security related events on the host and transmit
these to the central manager.
• LAN monitor agent module: Operates in the same fashion as a host agent module except that it
analyzes LAN traffic and reports the results to the central manager.
• Central manager module: Receives reports from LAN monitor and host agents and processes
and correlates these reports to detect intrusion.
The scheme is designed to be independent of any operating system or system auditing
implementation. Figure 20.3 [SNAP91] shows the general approach that is taken. The agent captures
each audit record produced by the native audit collection system. A filter is applied that retains only
those records that are of security interest. These records are then reformatted into a standardized format
referred to as the host audit record (HAR). Next, a template-driven logic module analyzes the records
for suspicious activity. At the lowest level, the agent scans for notable events that are of interest
independent of any past events. Examples include failed file accesses, accessing system files, and

Department Of ECE, SJBIT Page 112
changing a file‘s access control. At the next higher level, the agent looks for sequences of events, such
as known attack patterns (signatures). Finally, the agent looks for anomalous behaviour of an individual
user based on a historical profile of that user, such as number of programs executed, number of files
accessed, and the like.
Figure 6.3: Agent Architecture
When suspicious activity is detected, an alert is sent to the central manager. The central manager
includes an expert system that can draw inferences from received data. The manager may also query
individual systems for copies of HARs to correlate with those from other agents.
The LAN monitor agent also supplies information to the central manager. The LAN monitor
agent audits host-host connections, services used, and volume of traffic. It searches for significant
events, such as sudden changes in network load, the use of security-related services, and network
activities such as rlogin.
The architecture depicted in Figures 7.2 and 7.3 is quite general and flexible. It offers a
foundation for a machine-independent approach that can expand from stand-alone intrusion detection to
a system that is able to correlate activity from a number of sites and networks to detect suspicious
activity that would otherwise remain undetected.

Department Of ECE, SJBIT Page 113
Honey pots
A relatively recent innovation in intrusion detection technology is the honey pot. Honey pots are
decoy systems that are designed to lure a potential attacker away from critical systems. Honey pots are
designed to
Divert an attacker from accessing critical systems
Collect information about the attacker‘s activity
Encourage the attacker to stay on the system long enough for administrators to respond
These systems are filled with fabricated information designed to appear valuable but that a
legitimate user of the system wouldn‘t access. Thus, any access to the honey pot is suspect. The system
is instrumented with sensitive monitors and event loggers that detect these accesses and collect
information about the attacker‘s activities. Because any attack against the honey pot is made to seem
successful, administrators have time to mobilize and log and track the attacker without ever exposing
productive systems.
Initial efforts involved a single honey pot computer with IP addresses designed to attract
hackers. More recent research has focused on building entire honey pot networks that emulate an
enterprise, possibly with actual or simulated traffic and data. Once hackers are within the network,
administrators can observe their behaviour in detail and figure out defences.
Intrusion Detection Exchange Format
To facilitate the development of distributed intrusion detection systems that can function across a
wide range of platforms and environments, standards are needed to support interoperability. Such
standards are the focus of the IETF Intrusion Detection Working Group. The purpose of the working
group is to define data formats and exchange procedures for sharing information of interest to intrusion
detection and response systems and to management systems that may need to interact with them. The
outputs of this working group include:
A requirements document, which describes the high-level functional requirements for
communication between intrusion detection systems and requirements for communication
between intrusion detection systems and with management systems, including the rationale for
those requirements. Scenarios will be used to illustrate the requirements.
A common intrusion language specification, which describes data, formats that satisfy the
requirements.
A framework document, which identifies existing protocols best used for communication between

Department Of ECE, SJBIT Page 114
intrusion detection systems, and describes how the devised data formats relate to them. As of this
writing, all of these documents are in an Internet-draft document stage.
6.3. PASSWORD MANAGEMENT
Password Protection
The front line of defence against intruders is the password system. Virtually all multiuser
systems require that a user provide not only a name or identifier (ID) but also a password. The
password serves to authenticate the ID of the individual logging on to the system. In turn, the ID
provides security in the following ways:
The ID determines whether the user is authorized to gain access to a system. In some systems,
only those who already have an ID filed on the system are allowed to gain access.
The ID determines the privileges accorded to the user. A few users may have supervisory or
―super user‖ status that enables them to read files and perform functions that are
especially protected by the operating system. Some systems have guest or anonymous accounts,
and users of these accounts have more limited privileges than others.
The ID is used in what is referred to as discretionary access control. For example, by listing the
IDs of the other users, a user may grant permission to them to read files owned by that user.
THE VULNERABILITY OF PASSWORDS to understand the nature of the threat to password-
based systems let us consider a scheme that is widely used on UNIX, in which passwords are never
stored in the clear. Rather, the following procedure is employed (Figure 7.4a). Each user selects a
password of up to eight printable characters in length. This is converted into a 56-bit value (using 7-bit
ASCII) that serves as the key input to an encryption routine. The encryption routine, known as crypt, is
based on DES. The DES algorithm is modified using a 12-bit ―salt‖ value. Typically, this value
is related to the time at which the password is assigned to the user. The modified DES algorithm is
exercised with a data input consisting of a 64-bit block of zeros. The output of the algorithm then serves
as input for a second encryption. This process is repeated for a total of 25 encryptions. The resulting 64-
bit output is then translated into an 11-character sequence. The hashed password is then stored, together
with a plaintext copy of the salt, in the password file for the corresponding user ID. This method has
been shown to be secure against a variety of cryptanalytic attacks.
The salt serves three purposes:
It prevents duplicate passwords from being visible in the password file. Even if two users choose
the same password, those passwords will be assigned at different times. Hence, the
―extended‖ passwords of the two users will differ.
It effectively increases the length of the password without requiring the user to remember two
additional characters. Hence, the number of possible passwords is increased by a factor of 4096,

Department Of ECE, SJBIT Page 115
increasing the difficulty of guessing a password.
prevents the use of a hardware implementation of DES, which would ease the difficulty of a brute-
force guessing attack.
When a user attempts to log on to a UNIX system, the user provides an ID and a password. The
operating system uses the ID to index into the password file and retrieve the plaintext salt and the
encrypted password. The salt and user-supplied password are used as input to the encryption routine. If
the result matches the stored value, the password is accepted.
The encryption routine is designed to discourage guessing attacks. Software implementations of DES
are slow compared to hardware versions, and the use of25 iterations multiplies the time required by 25.
However, since the original designof this algorithm, two changes have occurred. First, newer
implementations of thealgorithm itself have resulted in speedups.
(a) Loading a new password
(b) Verifying a password
Fig 6.4: UNIX Password Scheme
In a reasonably short time by using a more efficient encryption algorithm than the standard one
stored on the UNIX systems that it attacked. Second, hardware performance continues to increase, so
that any software algorithm executes more quickly.
Thus, there are two threats to the UNIX password scheme. First, a user can gain access on a
machine using a guest account or by some other means and then run a password guessing program,
called a password cracker, on that machine. The attacker should be able to check hundreds and perhaps

Department Of ECE, SJBIT Page 116
thousands of possible passwords with little resource consumption. In addition, if an opponent is able to
obtain a copy of the password file, then a cracker program can be run on another machine at leisure.
This enables the opponent to run through many thousands of possible passwords in a reasonable period.
As an example, a password cracker was reported on the Internet in August 1993 [MADS93].
Using a Thinking Machines Corporation parallel computer, a performance of 1560 encryptions per
second per vector unit was achieved. With four vector units per processing node (a standard
configuration), this works out to 800,000 encryptions per second on a 128-node machine (which is a
modest size) and 6.4 million encryptions per second on a 1024-node machine. Even these stupendous
guessing rates do not yet make it feasible for an attacker to use a dumb brute-force technique of trying
all possible combinations of characters to discover a password. Instead, password crackers rely on the
fact that some people choose easily guessable passwords.
Some users, when permitted to choose their own password, pick one that is absurdly short. The
results of one study at Purdue University are shown in Table 20.4. The study observed password change
choices on 54 machines, representing approximately 7000 user accounts. Almost 3% of the passwords
were three characters or fewer in length. An attacker could begin the attack by exhaustively testing all
possible passwords of length 3 or fewer. A simple remedy is for the system to reject any password
choice of fewer than, say, six characters or even to require that all passwords be exactly eight characters
in length. Most users would not complain about such a restriction.
Password length is only part of the problem. Many people, when permitted to choose their own
password, pick a password that is guessable, such as their own name, their street name, a common
dictionary word, and so forth. This makes the job of password cracking straightforward. The cracker
simply has to test the password file against lists of likely passwords. Because many people use
guessable passwords, such a strategy should succeed on virtually all systems.
One demonstration of the effectiveness of guessing is reported in [KLEI90]. From a variety of
sources, the author collected UNIX password files, containing nearly 14,000 encrypted passwords. The
result, which the author rightly characterizes.
Table 7.3: Passwords Cracked from a Sample Set of 13,797 Accounts [KLEI90]

Department Of ECE, SJBIT Page 117
Try various permutations on the words from step 2. This included making the first letter uppercase
or a control character, making the entire word uppercase, reversing the word, changing the letter
―o‖ to the digit ―zero,‖ and so on. These permutations added another 1 million words to the list.
Try various capitalization permutations on the words from step 2 that were not considered in
step3. This added almost 2 million additional words to the list. Thus, the test involved in the
neighbourhood of 3 million words. Using the fastest Thinking Machines implementation listed
earlier, the time to encrypt all these words for all possible salt values is under an hour. Keep in
mind that such a thorough search could produce a success rate of about 25%, whereas even a
single hit may be enough to gain a wide range of privileges on a system.
Access Control:

Department Of ECE, SJBIT Page 118
One way to thwart a password attack is to deny the opponent access to the password file. If the
encrypted password portion of the file is accessible only by a privileged user, then the opponent cannot
read it without already knowing the password of a privileged user. [SPAF92a] points out several flaws
in this strategy:• Many systems, including most UNIX systems, are susceptible to unanticipated break-
ins. Once an attacker has gained access by some means, he or she may wish to obtain a collection of
passwords in order to use different accounts for different logon sessions to decrease the risk of
detection. Or a user with an account may desire another user‘s account to access privileged data or to
sabotage the system.
An accident of protection might render the password file readable, thus compromising all the
accounts.
Some of the users have accounts on other machines in other protection domains, and they use the
same password. Thus, if the passwords could be read by any one on one machine, a machine in
another location might be compromised. Thus, a more effective strategy would be to force users to
select passwords that are difficult to guess.
Password Selection Strategies
The lesson from the two experiments just described (Tables 20.4 and 20.5) is that, left to their
own devices, many users choose a password that is too short or too easy to guess. At the other extreme,
if users are assigned passwords consisting of eight randomly selected printable characters, password
cracking is effectively impossible. But it would be almost as impossible for most users to remember
their passwords. Fortunately, even if we limit the password universe to strings of characters that are
reasonably memorable, the size of the universe is still too large to permit practical cracking. Our goal,
then, is to eliminate guessable passwords while allowing the user to select a password that is
memorable. Four basic techniques are in use:
User education
Computer-generated passwords
Reactive password checking
Proactive password checking
Users can be told the importance of using hard-to-guess passwords and can be provided with
guidelines for selecting strong passwords. This user education strategy is unlikely to succeed at most
installations, particularly where there is a large user population or a lot of turnover. Many users will
simply ignore the guidelines. Others may not be good judges of what is a strong password. For
example, many users (mistakenly) believe that reversing a word or capitalizing the last letter makes a
password unguessable.

Department Of ECE, SJBIT Page 119
Computer-generated passwords also have problems. If the passwords are quite random in
nature, users will not be able to remember them. Even if the password is pronounceable, the user may
have difficulty remembering it and so be tempted to write it down. In general, computer-generated
password schemes have a history of poor acceptance by users. FIPS PUB 181 defines one of the best-
designed automated password generators. The standard includes not only a description of the approach
but also a complete listing of the C source code of the algorithm. The algorithm generates words by
forming pronounceable syllables and concatenating them to form a word. A random number generator
produces a random stream of characters used to construct the syllables and words.
A reactive password checking strategy is one in which the system periodically runs its own
password cracker to find guessable passwords. The system cancels any passwords that are guessed and
notifies the user. This tactic has a number of drawbacks. First, it is resource intensive if the job is done
right. Because a determined opponent who is able to steal a password file can devote full CPU time to
the task for hours or even days, an effective reactive password checker is at a distinct disadvantage.
Furthermore, any existing passwords remain vulnerable until the reactive password checker finds them.
The most promising approach to improved password security is a proactive password checker.
In this scheme, a user is allowed to select his or her own password. However, at the time of selection,
the system checks to see if the password is allowable and, if not, rejects it. Such checkers are based on
the philosophy that, with sufficient guidance from the system, users can select memorable passwords
from a fairly large password space that are not likely to be guessed in a dictionary attack.
The trick with a proactive password checker is to strike a balance between user acceptability and
strength. If the system rejects too many passwords, users will complain that it is too hard to select a
password. If the system uses some simple algorithm to define what is acceptable, this provides guidance
to password crackers to refine their guessing technique. In the remainder of this subsection, we look at
possible approaches to proactive password checking.
The first approach is a simple system for rule enforcement. For example, the following rules
could be enforced:
All passwords must be at least eight characters long.
In the first eight characters, the passwords must include at least one each of uppercase, lowercase,
numeric digits, and punctuation marks.
These rules could be coupled with advice to the user. Although this approach is superior to
simply educating users, it may not be sufficient to thwart password crackers. This scheme alerts
crackers as to which passwords not to try but May still make it possible to do password cracking.

Department Of ECE, SJBIT Page 120
Another possible procedure is simply to compile a large dictionary of possible ―bad‖ passwords.
When a user selects a password; the system checks to make sure that it is not on the disapproved list.
There are two problems with this approach:
Space: The dictionary must be very large to be effective. For example, the dictionary used in the
Purdue study [SPAF92a] occupies more than 30 megabytes of storage.
Time: The time required to search a large dictionary may itself be large. In addition, to check for
likely permutations of dictionary words, either those words most be included in the dictionary,
making it truly huge, or each search must also involve considerable processing.
Two techniques for developing an effective and efficient proactive password checker that is
based on rejecting words on a list show promise. One of these develops a Markov model for the
generation of guessable passwords [DAVI93]. Figure 20.5shows a simplified version of such a model.
This model shows a language consisting of an alphabet of three characters. The state of the system at
any time is the identity of the most recent letter. The value on the transition from one state to another
represents the probability that one letter follows another. Thus, the probability that the next letter is b,
given that the current letter is a, is 0.5.
Figure 7.4: An Example Markov Model

Department Of ECE, SJBIT Page 121
The result is a model that reflects the structure of the words in the dictionary. With this model,
the question ―Is this a bad password?‖ is transformed into the question ―Was this string
(password) generated by this Markov model?‖ For a given password, the transition probabilities of all
its trigrams can be looked up. Some standard statistical tests can then be used to determine if the
password is likely or unlikely for that model. Passwords that are likely to be generated by the model are
rejected. The authors report good results for a second-order model. Their system catches virtually all the
passwords in their dictionary and does not exclude so many potentially good passwords as to be user
unfriendly. A quite different approach has been reported by Spafford [SPAF92a,SPAF92b]. It is based
on the use of a Bloom filter [BLOO70]. To begin, we explain the operation of the Bloom filter. A
Bloom filter of order consists of a set of independent hash functions, where each function maps a
password into a hash value in the range 0 to.
OUTCOME:
Learn password management
Describe Intrusion Detection
Recomended questions:
1. what is an intruder?
2. Mention intrusion detection system.
3. Explain briefly password management?

Department Of ECE, SJBIT Page 122
UNIT 7- MALICIOUS SOFTWARE
Unit Structure:
7.0 Introduction
7.1 Objective
7.2 Malicious software programs
7.3 Viruses and related Threats
7.4 Virus Countermeasures
7.0 Introduction
The terminology in this area presents problems because of a lack of universal agreement on all of the
terms and because some of the categories overlap.
Malicious software can be divided into two categories: those that need a host program, and those
that are independent. The former, referred to as parasitic, are essentially fragments of programs that
cannot exist independently of some actual application program, utility, or system program. Viruses,
logic bombs, And backdoors are examples. Independent malware is a self-contained program that can
be scheduled and run by the operating system. Worms and boot programs are examples.
We can also differentiate between those software threats that do not replicate and those that do.
The former are programs or fragments of programs that are activated by a trigger. Examples are logic
bombs, backdoors, and boot programs. The latter consist of either a program fragment or an
independent program that, when executed, may produce one or more copies of itself to be activated
later on the same system or some other system. Viruses and worms are examples.
In the remainder of this section, we briefly survey some of the key categories of malicious
software, deferring discussion on the key topics of viruses and worms until the following sections.

Department Of ECE, SJBIT Page 123
Table 7.1 Terminology of Malicious Programs

Department Of ECE, SJBIT Page 124
Backdoor
A backdoor, also known as a trapdoor, is a secret entry point into a program that allows
someone who is aware of the backdoor to gain access without going through the usual security access
procedures. Programmers have used backdoors legitimately for many years to debug and test programs;
such a backdoor is called a maintenance hook. This usually is done when the programme is developing
an application that has an authentication procedure, or a long setup, requiring the user to enter many
different values to run the application. To debug the program, the developer may wish to gain special
privileges or to avoid all the necessary setup and authentication. The programmer may also want to
ensure that there is a method of activating the program should something be wrong with the
authentication procedure that is being built into the application. The backdoor is code that recognizes
some special sequence of input or is triggered by being run from a certain user ID or by an unlikely
sequence of events.
Backdoors become threats when unscrupulous programmers use them to gain unauthorized
access. The backdoor was the basic idea for the vulnerability portrayed in the movie War Games.
Another example is that during the development of Multics, penetration tests were conducted by an Air
Force ―tiger team‖ (simulating adversaries). One tactic employed was to send a bogus operating system
update to a site running Multics. The update contained a Trojan horse (described later) that could be
activated by a backdoor and that allowed the tiger team to gain access. The threat was so well
implemented that the Multics developers could not find it, even after they were informed of its presence
[ENGE80].
It is difficult to implement operating system controls for backdoors. Security measures must
focus on the program development and software update activities.

Department Of ECE, SJBIT Page 125
Logic Bomb
One of the oldest types of program threat, predating viruses and worms, is the logic bomb. The
logic bomb is code embedded in some legitimate program that is set to ―explode‖ when
certain conditions are met. Examples of conditions that can be used as triggers for a logic bomb are the
presence or absence of certain files, a particular day of the week or date, or a particular user running the
application.
Once triggered, a bomb may alter or delete data or entire files, cause a machine halt, or do some
other damage. A striking example of how logic bombs can be employed was the case of Tim Lloyd,
who was convicted of setting a logic bomb that cost his employer, Omega Engineering, more than $10
million, derailed its corporate growth strategy, and eventually led to the layoff of 80workers
[GAUD00]. Ultimately, Lloyd was sentenced to 41 months in prison and ordered to pay $2 million in
restitution.
Trojan Horses
A Trojan horse1 is a useful, or apparently useful, program or command procedure containing
hidden code that, when invoked, performs some unwanted or harmful function.
Trojan horse programs can be used to accomplish functions indirectly that an unauthorized user
could not accomplish directly. For example, to gain access to the files of another user on a shared
system, a user could create a Trojan horse program that, when executed, changes the invoking user‘s
file permissions so that the files are readable by any user. The author could then induce users to run the
program by placing it in a common directory and naming it such that it appears to be a useful utility
program or application. An example is a program that ostensibly produces a listing of the user‘s files in
a desirable format. After another user has run the program, the author of the program can then access
the information in the user‘s files. An example of a Trojan horse program that would be difficult to
detect is a compiler that has been modified to insert additional code into certain programs as they are
compiled, such as a system login program. The code creates a backdoor in the login program that
permits the author to log on to the system using a special password. This Trojan horse can never be
discovered by reading the source code of the login program.
Another common motivation for the Trojan horse is data destruction. The program appears to be
performing a useful function (e.g., a calculator program), but it may also be quietly deleting the user‘s
files. For example, a CBS executive was victimized by a Trojan horse that destroyed all information
contained in his computer‘s memory The Trojan horse was implanted in a graphics routine offered on
an electronic bulletin board system.
Trojan horses fit into one of three models:

Department Of ECE, SJBIT Page 126
Continuing to perform the function of the original program and additionally performing a
separate malicious activity
Continuing to perform the function of the original program but modifying the function to
perform malicious activity (e.g., a Trojan horse version of a login program that collects
passwords) or to disguise other malicious activity (e.g., a Trojan horse version of a process
listing program that does not display certain processes that are malicious)
Performing a malicious function that completely replaces the function of the original program
Mobile Code
Mobile code refers to programs (e.g., script, macro, or other portable instruction) that can be
shipped unchanged to a heterogeneous collection of platforms and execute with identical semantics
[JANS01]. The term also applies to situations involving a large homogeneous collection of platforms
(e.g., Microsoft Windows).Mobile code is transmitted from a remote system to a local system and then
executed on the local system without the user‘s explicit instruction. Mobile code often acts as a
mechanism for a virus, worm, or Trojan horse to be transmitted to the user‘s workstation. In other
cases, mobile code takes advantage of vulnerabilities to perform its own exploits, such as unauthorized
data access or root compromise. Popular vehicles for mobile code include Java applets, ActiveX,
JavaScript, and VB Script. The most common ways of using mobile code for malicious operations on
local system are cross-site scripting, interactive and dynamic Web sites, e-mail attachments, and
downloads from untrusted sites or of untrusted software.
Multiple-Threat Malware
Viruses and other malware may operate in multiple ways. The terminology is far from uniform;
this subsection gives a brief introduction to several related concepts that could be considered multiple-
threat malware.
A multipartite virus infects in multiple ways. Typically, the multipartite virus is capable of
infecting multiple types of files, so that virus eradication must deal with all of the possible sites of
infection.
A blended attack uses multiple methods of infection or transmission, to maximize the speed of
contagion and the severity of the attack. Some writer‘s characterize a blended attack as a package that
includes multiple types of malware. An example of a blended attack is the Nimda attack, erroneously
referred to as simply a worm. Nimda uses four distribution methods:

Department Of ECE, SJBIT Page 127
E-mail: A user on a vulnerable host opens an infected e-mail attachment; Nimda looks for e-
mail addresses on the host and then sends copies of itself to those addresses.
Windows shares: Nimda scans hosts for unsecured Windows file shares; it can then use
NetBIOS86 as a transport mechanism to infect files on that host in the hopes that a user will run
an infected file, which will activate Nimda on that host.
Web servers: Nimda scans Web servers, looking for known vulnerabilities in Microsoft IIS. If
it finds a vulnerable server, it attempts to transfer a copy of itself to the server and infect it and
its files.
Web clients: If a vulnerable Web client visits a Web server that has been infected by Nimda,
the client‘s workstation will become infected.
Thus, Nimda has worm, virus, and mobile code characteristics. Blended attacks may also spread
through other services, such as instant messaging and peer-to-peer file sharing.
7.1 OBJECTIVE:
Student will be able to,
Learn about Malwares
Understand Virus and its threats
Study Countermeasures
7.2. VIRUSES AND RELATED ATTACKS:
The Nature of Viruses
A computer virus is a piece of software that can ―infect‖ other programs by modifying them;
the modification includes injecting the original program with a routine to make copies of the virus
program, which can then go on to infect other programs. Computer viruses first appeared in the early
1980s, and the term itself is attributed to Fred Cohen in 1983. Cohen is the author of a groundbreaking
book on the subject
Biological viruses are tiny scraps of genetic code—DNA or RNA—that can take over the
machinery of a living cell and trick it into making thousands of flawless replicas of the original virus.
Like its biological counterpart, a computer virus carries in its instructional code the recipe for making
perfect copies of itself. The typical virus becomes embedded in a program on a computer. Then,
whenever the infected computer comes into contact with an uninfected piece of software, a fresh copy
of the virus passes into the new program. Thus, the infection can be spread from computer to computer
by unsuspecting users who either swap disks or send programs to one another over a network. In a
network environment, the ability to access applications and system services on other computers
provides a perfect culture for the spread of a virus.

Department Of ECE, SJBIT Page 128
A virus can do anything that other programs do. The difference is that a virus attaches itself to
another program and executes secretly when the host program is run. Once a virus is executing, it can
perform any function, such as erasing files and programs that is allowed by the privileges of the current
user.
A computer virus has three parts :
Infection mechanism: The means by which a virus spreads, enabling it to replicate. The
mechanism is also referred to as the infection vector.
Trigger: The event or condition that determines when the payload is activated or delivered.
Payload: What the virus does, besides spreading. The payload may involve damage or may
involve benign but noticeable activity.
During its lifetime, a typical virus goes through the following four phases:
Dormant phase: The virus is idle. The virus will eventually be activated by some event, such as
a date, the presence of another program or file, or the capacity of the disk exceeding some limit.
Not all viruses have this stage.
Propagation phase: The virus places a copy of itself into other programs or into certain system
areas on the disk. The copy may not be identical to the propagating version; viruses often morph
to evade detection. Each infected program will now contain a clone of the virus, which will
itself enter a propagation phase.
Triggering phase: The virus is activated to perform the function for which it was intended. As
with the dormant phase, the triggering phase can be caused by a variety of system events,
including a count of the number of times that this copy of the virus has made copies of itself.
Execution phase: The function is performed. The function may be harmless, such as a message
on the screen, or damaging, such as the destruction of programs and data files. Most viruses
carry out their work in a manner that is specific to a particular operating system and, in some
cases, specific to a particular hardware platform. Thus, they are designed to take advantage of
the details and weaknesses of particular systems.
VIRUS STRUCTURE A virus can be prepended or postpended to an executable program, or it can be
embedded in some other fashion. The key to its operation is that the infected program, when invoked,
will first execute the virus code and then execute the original code of the program.
A very general depiction of virus structure is shown in Figure 7.1 In this case, the virus code, V,
is prepended to infected programs, and it is assumed that the entry point to the program, when invoked,
is the first line of the program.
The infected program begins with the virus code and works as follows. The first line of code is a

Department Of ECE, SJBIT Page 129
jump to the main virus program. The second line is a special marker that is used by the virus to
determine whether or not a potential victim program has already been infected with this virus. When the
program is invoked, control is immediately transferred to the main virus program. The virus program
may first seek out uninfected executable files and infect them. Next, the virus may perform some action,
usually detrimental to the system. This action could be performed every time the program is invoked, or
it could be a logic bomb that triggers only under certain conditions. Finally, the virus transfers control
to the original program. If the infection phase of the program is reasonably rapid, a user is unlikely to
notice any difference between the execution of an infected and an uninfected program.
A virus such as the one just described is easily detected because an infected version of a
program is longer than the corresponding uninfected one. A way to thwart such a simple means of
detecting a virus is to compress the executable file so that both the infected and uninfected versions are
of identical length. Figure 7.2 shows in general terms the logic required. The key lines in this virus are
numbered, illustrates the operation. We assume that program P1 is infected with the virus CV. When
this program is invoked, control passes to its virus, which performs the following steps:
1. For each uninfected file P2 that is found, the virus first compresses that file to produce , which is
shorter than the original program by the size of the virus.
2. A copy of the virus is prepended to the compressed program.
3. The compressed version of the original infected program, , is uncompressed.
4. The uncompressed original program is executed.
Figure 7.2 Logic for a Compression Virus

Department Of ECE, SJBIT Page 130
Figure 7.3 A Compression Virus
Viruses Classification
There has been a continuous arms race between virus writers and writers of antivirus software
since viruses first appeared. As effective countermeasures are developed for existing types of viruses,
newer types are developed. There is no simple or universally agreed upon classification scheme for
viruses, In this section, classify viruses along two orthogonal axes: the type of target the virus tries to
infect and the method the virus uses to conceal itself from detection by users and antivirus software.
A virus classification by target includes the following categories:
• Boot sector infector: Infects a master boot record or boot record and spreads when a system is
booted from the disk containing the virus.
• File infector: Infects files that the operating system or shell consider to be executable.
• Macro virus: Infects files with macro code that is interpreted by an application. A virus
classification by concealment strategy includes the following categories:
• Encrypted virus: A typical approach is as follows. A portion of the virus creates a random
encryption key and encrypts the remainder of the virus. The key is stored with the virus. When an
infected program is invoked, the virus uses the stored random key to decrypt the virus. When the
virus replicates, a different random key is selected. Because the bulk of the virus is encrypted with
a different key for each instance, there is no constant bit pattern to observe.
• Stealth virus: A form of virus explicitly designed to hide itself from detectionby antivirus
software.Thus, the entire virus, not just a payload is hidden.
• Polymorphic virus: A virus that mutates with every infection, making detectionby the
―signature‖ of the virus impossible.
• Metamorphic virus: As with a polymorphic virus, a metamorphic virus mutateswith every
infection.The difference is that a metamorphic virus rewrites itself completely at each iteration,
increasing the difficulty of detection.
Metamorphic viruses may change their behavior as well as their appearance.One example of a stealth

Department Of ECE, SJBIT Page 131
virus was discussed earlier: a virus that uses compressionso that the infected program is exactly the
same length as an uninfectedversion. Far more sophisticated techniques are possible. For example, a
virus canplace intercept logic in disk I/O routines, so that when there is an attempt to readsuspected
portions of the disk using these routines, the virus will present back theoriginal, uninfected
program.Thus, stealth is not a term that applies to a virus as suchbut, rather, refers to a technique used
by a virus to evade detection.
A polymorphic virus creates copies during replication that are functionallyequivalent but have
distinctly different bit patterns. As with a stealth virus, the purposeis to defeat programs that scan for
viruses. In this case, the ―signature‖ of thevirus will vary with each copy. To achieve this variation,
the virus may randomlyinsert superfluous instructions or interchange the order of independent
instructions. A more effective approach is to use encryption.The strategy of the encryption virusis
followed. The portion of the virus that is responsible for generating keys andperforming
encryption/decryption is referred to as the mutation engine. The mutationengine itself is altered with
each use.
Virus Kits
Another weapon in the virus writers‘ armory is the virus-creation toolkit. Such a toolkit enables a
relative novice to quickly create a number of different viruses. Although viruses created with toolkits
tend to be less sophisticated than viruses designed from scratch, the sheer number of new viruses that
can be generated using a toolkit creates a problem for antivirus schemes.
Macro Viruses
In the mid-1990s, macro viruses became by far the most prevalent type of virus.Macro viruses are
particularly threatening for a number of reasons:
1. A macro virus is platform independent. Many macro viruses infect MicrosoftWord documents or
other Microsoft Office documents. Any hardware platformand operating system that supports these
applications can be infected.
2. Macro viruses infect documents, not executable portions of code. Most of theinformation
introduced onto a computer system is in the form of a documentrather than a program.
3. Macro viruses are easily spread.A very common method is by electronic mail.
4. Because macro viruses infect user documents rather than system programs, traditionalfile system
access controls are of limited use in preventing their spread.
Macro viruses take advantage of a feature found in Word and other officeapplications such as
Microsoft Excel, namely the macro. In essence, a macro is anexecutable program embedded in a word

Department Of ECE, SJBIT Page 132
processing document or other type of file.Typically, users employ macros to automate repetitive tasks
and thereby savekeystrokes. The macro language is usually some form of the Basic
programminglanguage.A user might define a sequence of keystrokes in a macro and set it up sothat the
macro is invoked when a function key or special short combination of keysis input.
Successive releases of MS Office products provide increased protectionagainst macro viruses. For
example, Microsoft offers an optional Macro VirusProtection tool that detects suspicious Word files
and alerts the customer to thepotential risk of opening a file with macros.Various antivirus product
vendors havealso developed tools to detect and correct macro viruses. As in other types ofviruses, the
arms race continues in the field of macro viruses, but they no longer arethe predominant virus threat.
E-M ail Viruses
A more recent development in malicious software is the e-mail virus. The firstrapidly spreading
e-mail viruses, such as Melissa, made use of a Microsoft Wordmacro embedded in an attachment. If the
recipient opens the e-mail attachment, theWord macro is activated.Then
1. The e-mail virus sends itself to everyone on the mailing list in the user‘s e-mailpackage.
2. The virus does local damage on the user‘s system.
In 1999, a more powerful version of the e-mail virus appeared. This newerversion can be activated
merely by opening an e-mail that contains the virus ratherthan opening an attachment. The virus uses
the Visual Basic scripting languagesupported by the e-mail package.
Thus we see a new generation of malware that arrives via e-mail and uses e-mailsoftware features to
replicate itself across the Internet. The virus propagates itself assoon as it is activated (either by opening
an e-mail attachment or by opening thee-mail) to all of the e-mail addresses known to the infected host.
As a result, whereasviruses used to take months or years to propagate, they now do so in hours.This
makesit very difficult for antivirus software to respond before much damage is done.Ultimately, a
greater degree of security must be built into Internet utility and applicationsoftware on PCs to counter
the growing threat.
7.3. VIRUS COUNTERMEASURES
Antivirus Approaches
The ideal solution to the threat of viruses is prevention: Do not allow a virus to getinto the
system in the first place, or block the ability of a virus to modify any filescontaining executable code or
macros.This goal is, in general, impossible to achieve,although prevention can reduce the number of
successful viral attacks.The next best approach is to be able to do the following:
• Detection: Once the infection has occurred, determine that it has occurredand locate the virus.

Department Of ECE, SJBIT Page 133
• Identification: Once detection has been achieved, identify the specific virusthat has infected a
program.
• Removal: Once the specific virus has been identified, remove all traces of thevirus from the infected
program and restore it to its original state. Remove thevirus from all infected systems so that the virus
cannot spread further.If detection succeeds but either identification or removal is not possible, then the
alternative is to discard the infected file and reload a clean backup version.Advances in virus and
antivirus technology go hand in hand. Early viruseswere relatively simple code fragments and could be
identified and purged withrelatively simple antivirus software packages. As the virus arms race has
evolved,both viruses and, necessarily, antivirus software have grown more complex andsophisticated.
[STEP93] identifies four generations of antivirus software:
• First generation: simple scanners
• Second generation: heuristic scanners
• Third generation: activity traps
• Fourth generation: full-featured protection
A first-generation scanner requires a virus signature to identify a virus. Thevirus may contain
―wildcards‖ but has essentially the same structure and bit patternin all copies. Such signature-
specific scanners are limited to the detection of knownviruses. Another type of first-generation scanner
maintains a record of the length ofprograms and looks for changes in length.
A second-generation scanner does not rely on a specific signature. Rather, thescanner uses
heuristic rules to search for probable virus infection. One class of suchscanners looks for fragments of
code that are often associated with viruses. Forexample, a scanner may look for the beginning of an
encryption loop used in a polymorphicvirus and discover the encryption key. Once the key is
discovered, the scanner can decrypt the virus to identify it, then remove the infection and returnthe
program to service.
Another second-generation approach is integrity checking. A checksum canbe appended to each
program. If a virus infects the program without changing thechecksum, then an integrity check will
catch the change. To counter a virus that issophisticated enough to change the checksum when it infects
a program, anencrypted hash function can be used. The encryption key is stored separately fromthe
program so that the virus cannot generate a new hash code and encrypt that. Byusing a hash function
rather than a simpler checksum, the virus is prevented fromadjusting the program to produce the same
hash code as before.
Third-generation programs are memory-resident programs that identify avirus by its actions
rather than its structure in an infected program. Such programshave the advantage that it is not
necessary to develop signatures and heuristics for awide array of viruses. Rather, it is necessary only to

Department Of ECE, SJBIT Page 134
identify the small set of actionsthat indicate an infection is being attempted and then to intervene.
Fourth-generation products are packages consisting of a variety of antivirustechniques used in
conjunction. These include scanning and activity trap components.In addition, such a package includes
access control capability, which limits theability of viruses to penetrate a system and then limits the
ability of a virus to updatefiles in order to pass on the infection.
The arms race continues.With fourth-generation packages, a more comprehensivedefense strategy is
employed, broadening the scope of defense to moregeneral-purpose computer security measures.
OUTCOME:
Define various Malcious Softwares
Describe Virus Strucuture, and its counter measures
Recommended questions:
1. what is virus?
2. Explain Virus structure.
3. Explain virus counter measures.

Department Of ECE, SJBIT Page 135
UNIT 8-FIREWALL
Unit Structure:
8.0 Introduction
8.1 Objective
8.2 Firewall Design Principles
8.3 Trusted Systems
8.0 INTRODUCTION
Firewalls are seen evolution of information systems and now everyone want to be on the
Internet and to interconnect networks .It has persistent security concerns and can‘t easily secure every
system in org and so typically use a Firewall to provide perimeter defence as part of comprehensive
security strategy.
8.1 OBJECTIVE:
Student will be able to,
Study Firewalls
Understand Trusted Systems
8.2 FIREWALL DESIGN PRINCIPLES
What is a Firewall?
A firewall is inserted between the premises network and the Internet to establish a controlled
link and to erect an outer security wall or perimeter, forming a single choke point where security and
audit can be imposed. A firewall is defined as a single choke point that keeps unauthorized users out of
the protected network, prohibits potentially vulnerable services from entering or leaving the network,
and provides protection from various kinds of IP spoofing and routing attacks. It provides a location for
monitoring security-related events and is a convenient platform for several Internet functions that are
not security related, such as NAT and Internet usage audits or logs. A firewall can serve as the platform
for IPSec to implement virtual private networks. The firewall itself must be immune to penetration,
since it will be a target of attack.

Department Of ECE, SJBIT Page 136
The Figure below illustrates the general model of firewall use on the security perimeter, as a
choke point for traffic between the external less-trusted Internet and the internal more trusted private
network.
Firewalls have their limitations, including that they cannot protect against attacks that bypass the
firewall, eg PCs with dial-out capability to an ISP, or dial-in modem pool use. They do not protect
against internal threats, eg disgruntled employee or one who cooperates with an attacker. An improperly
secured wireless LAN may be accessed from outside the organization. An internal firewall that
separates portions of an enterprise network cannot guard against wireless communications between
local systems on different sides of the internal firewall. A laptop, PDA, or portable storage device may
be used and infected outside the corporate network, and then attached and used internally.
Firewalls Packet Filters:
Have three common types of firewalls: packet filters, application-level gateways, & circuit-level
gateways. A packet-filtering router applies a set of rules to each incoming and outgoing IP packet to
forward or discard the packet. Filtering rules are based on information contained in a network packet
such as src & dest IP addresses, ports, transport protocol & interface. Some advantages are simplicity,
transparency & speed. If there is no match to any rule, then one of two default policies are applied that
which is not expressly permitted is prohibited (default action is discard packet), conservative policy and
that which is not expressly prohibited is permitted (default action is forward packet), permissive policy

Department Of ECE, SJBIT Page 137
Figure illustrates the packet filter firewall role as utilising information from the transport,
network & data link layers to make decisions on allowable traffic flows, and its placement in the border
router between the external less-trusted Internet and the internal more trusted private network
Attacks on Packet Filters:
Some of the attacks that can be made on packet-filtering routers & countermeasures are:
• IP address spoofing: where intruder transmits packets from the outside with internal host source
IP addr, need to filter & discard such packets
• Source routing attacks: where source specifies the route that a packet should take to bypass
security measures, should discard all source routed packets
• Tiny fragment attacks: intruder uses the IP fragmentation option to create extremely small
fragments and force the TCP header information into a separate fragments to circumvent filtering
rules needing full header info, can enforce minimum fragment size to include full header.
In IP address spoofing fake source address to be trusted and we can add filters on router to block .In
source routing attacks attacker sets a route other than default and block source routed packets.In tiny
fragment attacks split header info over several tiny packets either discard or reassemble before check .
Firewalls – Stateful Packet Filters
A traditional packet filter makes filtering decisions on an individual packet basis and does not
take into consideration any higher layer context. In general, when an application that uses TCP creates a
session with a remote host, it creates a TCP connection in which the TCP port number for the remote
(server) application is a number less than 1024 and the TCP port number for the local (client)
application is a number between 1024 and 65535. A simple packet filtering firewall must permit
inbound network traffic on all these high- numbered ports for TCP-based traffic to occur. This creates a
vulnerability that can be exploited by unauthorized users. A stateful inspection packet filter tightens up
the rules for TCP traffic by creating a directory of outbound TCP connections, and will allow incoming
traffic to high-numbered ports only for those packets that fit the profile of one of the entries in this
directory. Hence they are better able to detect bogus packets sent out of context. A stateful packet
inspection firewall reviews the same packet information as a packet filtering firewall, but also records
information about TCP connections. Some stateful firewalls also keep track of TCP sequence numbers
to prevent attacks that depend on the sequence number, such as session hijacking. Some even inspect
limited amounts of application data for some well-known protocols like FTP, IM and SIPS commands,
in order to identify and track related connections.
A traditional packet filters do not examine higher layer context i.e. matching return packets with

Department Of ECE, SJBIT Page 138
outgoing flow stateful packet filters address this need they examine each IP packet in context and keep
track of client-server sessions and check each packet validly belongs to one . Hence are better able to
detect bogus packets out of context and may even inspect limited application data.
Firewalls - Application Level Gateway (or Proxy):
These have application specific gateway / proxy and have full access to protocol and the user
requests service from proxy. The proxy validates request as legal and then actions request and returns
result to user so that can log / audit traffic at application level. We need separate proxies for each
service and some services naturally support proxying and others are more problematic
Firewalls - Circuit Level Gateway
A fourth type of firewall is the circuit-level gateway or circuit-level proxy. This can be a stand-
alone system or it can be a specialized function performed by an application-level gateway for certain
applications. A circuit-level gateway relays two TCP connections, one between itself and an inside
TCP user, and the other between itself and a TCP user on an outside host. Once the two connections are
established, it relays TCP data from one connection to the other without examining its contents. The
security function consists of determining which connections will be allowed. It is typically used when
internal users are trusted to decide what external services to access.
One of the most common circuit-level gateways is SOCKS, defined in RFC 1928. It consists of
a SOCKS server on the firewall, and a SOCKS library & SOCKS-aware applications on internal clients.
When a TCP-based client wishes to establish a connection to an object that is reachable only via a
firewall (such determination is left up to the implementation), it must open a TCP connection to the
appropriate SOCKS port on the SOCKS server system. If the connection request succeeds, the client
enters a negotiation for the authentication method to be used, authenticates with the chosen method, and
then sends a relay request. The SOCKS server evaluates the request and either establishes the
appropriate connection or denies it. UDP exchanges are handled in a similar fashion.
It relays two TCP connections which impose security by limiting which such connections are
allowed and once created usually relays traffic without examining contents. These typically used when
trust internal users by allowing general outbound connections and SOCKS is commonly used
Bastion Host
It is common to base a firewall on a stand-alone machine running a common operating system,
such as UNIX or Linux. Firewall functionality can also be implemented as a software module in a
router or LAN switch.

Department Of ECE, SJBIT Page 139
A bastion host is a critical strong point in the network‘s security, serving as a platform for an
application-level or circuit-level gateway, or for external services. It is thus potentially exposed to
"hostile" elements and must be secured to withstand this. Common characteristics of a bastion host
include that it executes a secure version of its O/S, making it a trusted system and • has only essential
services installed on the bastion host. It may require additional authentication before a user may access
to proxy services configured to use only subset of standard commands, access only specific hosts which
maintains detailed audit information by logging all traffic. Each proxy module a very small software
package designed for network security and has each proxy independent of other proxies on the bastion
host who have a proxy performs no disk access other than read its initial configuration file. They also
have each proxy run as a non-privileged user in a private and secured directory
Host-Based Firewalls
A host-based firewall is a software module used to secure an individual host. Such modules are
available in many operating systems or can be provided as an add-on package. Like conventional stand-
alone firewalls, host-resident firewalls filter and restrict the flow of packets. A common location for
such firewalls is a server. There are several advantages to the use of a server-based or workstation-
based firewall:
• Filtering rules can be tailored to the host environment. Specific corporate security policies for
servers can be implemented, with different filters for servers used for different application.
• Protection is provided independent of topology. Thus both internal and external attacks must pass
through the firewall.
• Used in conjunction with stand-alone firewalls, the host-based firewall provides an additional
layer of protection. A new type of server can be added to the network, with its own firewall, without
the necessity of altering the network firewall configuration.
Software module used to secure individual host are available in many operating systems or can be
provided as an add-on package often used on servers
Advantages:
can tailor filtering rules to host environment
protection is provided independent of topology
provides an additional layer of protection

Department Of ECE, SJBIT Page 140
Personal Firewalls
A personal firewall controls the traffic between a personal computer or workstation on one side
and the Internet or enterprise network on the other side. Personal firewall functionality can be used in
the home environment and on corporate intranets. Typically, the personal firewall is a software module
on the personal computer. In a home environment with multiple computers connected to the Internet,
firewall functionality can also be housed in a router that connects all of the home computers to a DSL,
cable modem, or other Internet interface.
Personal firewalls are typically much less complex than either server-based firewalls or stand-
alone firewalls. The primary role of the personal firewall is to deny unauthorized remote access to the
computer. The firewall can also monitor outgoing activity in an attempt to detect and block worms and
other malware. It controls traffic between PC/workstation and Internet or enterprise network. It is a
software module on personal computer or in home/office DSL/cable/ISP router typically much less
complex than other firewall types whose primary role to deny unauthorized remote access to the
computer and monitor outgoing activity for malware
In today's distributed computing environment, the virtual private network (VPN) offers an
attractive solution to network managers. The VPN consists of a set of computers that interconnect by
means of a relatively unsecure network and that make use of encryption and special protocols to
provide security. At each corporate site, workstations, servers, and databases are linked by one or more
local area networks (LANs). The Internet or some other public network can be used to interconnect
sites, providing a cost savings over the use of a private network and offloading the wide area network
management task to the public network provider. That same public network provides an access path for
telecommuters and other mobile employees to log on to corporate systems from remote sites.
A logical means of implementing an IPSec is in a firewall. If IPSec is implemented in a separate
box behind (internal to) the firewall, then VPN traffic passing through the firewall in both directions is
encrypted. In this case, the firewall is unable to perform its filtering function or other security functions,
such as access control, logging, or scanning for viruses. IPSec could be implemented in the boundary
router, outside the firewall. However, this device is likely to be less secure than the firewall and thus
less desirable as an IPSec platform.
A distributed firewall configuration involves stand-alone firewall devices plus host-based
firewalls working together under a central administrative control. It suggests a distributed firewall
configuration. Administrators can configure host-resident firewalls on hundreds of servers and
workstation as well as configure personal firewalls on local and remote user systems. Tools let the

Department Of ECE, SJBIT Page 141
network administrator set policies and monitor security across the entire network. These firewalls
protect against internal attacks and provide protection tailored to specific machines and applications.
Stand-alone firewalls provide global protection, including internal firewalls and an external firewall, as
discussed previously. With distributed firewalls, it may make sense to establish both an internal and an
external DMZ. Web servers that need less protection because they have less critical information on
them could be placed in an external DMZ, outside the external firewall. What protection is needed is
provided by host-based firewalls on these servers. An important aspect of a distributed firewall
configuration is security monitoring. Such monitoring typically includes log aggregation and analysis,
firewall statistics, and fine-grained remote monitoring of individual hosts if needed.
The following alternatives can be identified:
• Host-resident firewall: incl. personal firewall software and firewall software on servers, used
alone or as part of an in-depth firewall deployment.
• Screening router: A single router between internal and external networks with stateless or full
packet filtering. Typical for small office/home office (SOHO) use.
• Single bastion inline: A single firewall device between an internal and external router. The
firewall may implement stateful filters and/or application proxies. This is the typical firewall
appliance configuration for small to medium-sized organizations.
• Single bastion T: Similar to single bastion inline but has a third network interface on bastion to a
DMZ where externally visible servers are placed. Again, this is a common appliance configuration
for medium to large organizations.
• Double bastion inline: In this configuration, where the DMZ is sandwiched between bastion
firewalls. This configuration is common for large businesses and government organizations.
• Double bastion T: The DMZ is on a separate network interface on the bastion firewall. This
configuration is also common for large businesses and government organizations and may be
required. For example, this configuration is required for Australian government use.
• Distributed firewall configuration: This configuration is used by some large businesses and
government organizations.
8.3 TRUSTED SYSTEMS:
In the security engineering subspecialty of computer science, a trusted system is a system that
is relied upon to a specified extent to enforce a specified security policy. As such, a trusted system is

Department Of ECE, SJBIT Page 142
one whose failure may break a specified security policy. Trusted systems are used for the processing,
storage and retrieval of sensitive or classified information. Central to the concept of U.S. Department of
Defense-style "trusted systems" is the notion of a "reference monitor", which is an entity that occupies
the logical heart of the system and is responsible for all access control decisions. Ideally, the reference
monitor is (a) tamperproof, (b) always invoked, and (c) small enough to be subject to independent
testing, the completeness of which can be assured. Per the U.S. National Security Agency's
1983 Trusted Computer System Evaluation Criteria (TCSEC), or "Orange Book", a set of "evaluation
classes" were defined that described the features and assurances that the user could expect from a
trusted system.
The highest levels of assurance were guaranteed by significant system engineering directed
toward minimization of the size of the trusted computing base (TCB), defined as that combination of
hardware, software, and firmware that is responsible for enforcing the system's security policy. Because
failure of the TCB breaks the trusted system, higher assurance is provided by the minimization of the
TCB. An inherent engineering conflict arises in higher-assurance systems in that, the smaller the TCB,
the larger the set of hardware, software, and firmware that lies outside the TCB. This may lead to some
philosophical arguments about the nature of trust, based on the notion that a "trustworthy"
implementation may not necessarily be a "correct" implementation from the perspective of users'
expectations.
One way to enhance the ability of a system to defend against intruders and malicious programs
is to implement trusted system technology.
Data Access Control
Through the user access control procedure (log on), user is identified to the system. Associated
with each user, there is a profile that specifies permissible operations and file accesses. The operating
system can enforce rules based on the user profile.
Access Control List: An access control list lists users and their permitted access right. The list
may contain a default or public entry. This is how Unix handles security, and is the only mechanism
available in Unix. Everything in Unix looks like a text file. All files have 9-bit permissions in the in ode
pointer
Trusted Systems Concept:
Trusted Systems protect data and resources on the basis of levels of security (e.g. military).
Users can be granted clearances to access certain categories of data. Trusted systems need not discern

Department Of ECE, SJBIT Page 143
levels of permissions; they can operate ―system high‖ . Telephone systems Security Levels:
Multilevel security: multiple categories or levels of data. Multilevel secure system must enforce. No
read up: A subject can only read an object of lower or equal security level (BLP Simple Security
Property). No write down: A subject can only write into an object of greater or equal security level
(BLP *-Property). May enforce discretionary security (BLP DS property). Security levels may be linear
or latticed.
Trusted Systems Implementation: Reference Monitor provides multilevel security for a data
processing system. Reference Monitor is a concept, not a thing
Reference Monitor: Controlling element in the security kernel of a computer that regulates
access of subjects to objects on basis of security parameters. The monitor has access to a file
(security kernel database). The monitor enforces the security rules (no read up, no write down)
Reference Monitor Properties: Complete mediation: Security rules are enforced on every
access Isolation: Reference monitor and database protected from unauthorized modification.
Verifiability: reference monitor‘s correctness must be mathematically provable this may be
where we bend the rules!
Trusted Systems: A system that can provide such verifications (properties) is referred to as a
trusted system
OUTCOMES:
Describe Firewall design principles
Understand trusted Systems
Recommended questions:
1. what is firewall.
2. What are different types of firewalls
3. what is access control.




















