
naacl 2022 - ACL Anthology
151
NAACL 2022 The 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies Proceedings of the Demonstrations Session July 10-15, 2022
-
Upload
khangminh22 -
Category
Documents
-
view
2 -
download
0
Transcript of naacl 2022 - ACL Anthology

NAACL 2022
The 2022 Conference of the North American Chapter of theAssociation for Computational Linguistics: Human Language
Technologies
Proceedings of the Demonstrations Session
July 10-15, 2022

The NAACL organizers gratefully acknowledge the support from the followingsponsors.
Diamond
Platinum
Gold
G-Research is Europe's leading quantitative finance research firm.
We hire the brightest minds in the world to tackle some of the biggestquestions in finance.
View our ML, NLP and Quantitative Research vacancies today.
CREATE TODAY.PREDICT TOMORROW.
IMAGINE DISCOVERING SOMETHING UNDISCOVERED.
gresearch.co.uk
ii

6
Logotype: Modernizing a classic
Primary logoOur logo is made up of two elements: the window shape and the type. These should not be altered or recreated. Send requests for the .eps artwork to [email protected].
6
Silver
Magic Data provides high quality training datasets for ML and customized AI training data labelilng services to enterprises and academic institutions engaged in artificial intelligence R&D and application research to natural language processing (NLP), voice recognition (ASR), speech synthesis (TTS), and computer vision (CV).
We provide data total solutions which cover automo-bile, finance, social networks, smart home automation, and end-user device, involving smart customer service, virtual assistant, machine translation, and many other AI scenarios.
www.magicdatatech.com
Contact Us
Bronze
D&I Champions
D&I Contributors
G-Research is Europe's leading quantitative finance research firm.
We hire the brightest minds in the world to tackle some of the biggestquestions in finance.
View our ML, NLP and Quantitative Research vacancies today.
CREATE TODAY.PREDICT TOMORROW.
IMAGINE DISCOVERING SOMETHING UNDISCOVERED.
gresearch.co.uk
iii

D&I Allies
iv

©2022 Association for Computational Linguistics
Order copies of this and other ACL proceedings from:
Association for Computational Linguistics (ACL)209 N. Eighth StreetStroudsburg, PA 18360USATel: +1-570-476-8006Fax: [email protected]
ISBN 978-1-955917-74-2
v

Introduction
Welcome to the proceedings of the system demonstration track of NAACL-HLT 2022 on Jul 10–15.NAACL-HLT 2022 will be a hybrid conference.
The system demonstration track invites submissions ranging from early prototypes to mature production-ready systems. This year we received 35 submissions, of which 14 were selected for inclusion in the pro-gram (acceptance rate 40%) after being reviewed by at least three members of the program committee.
This is the second year NAACL-HLT incorporated ethical considerations in the review process. In thestandard review stage, members of the program committee are given the option to flag a paper as needingseparate ethics reviews. Papers flagged as needing separate ethics reviews by at least one member fromthe program committee are subsequently reviewed by two members from the NAACL-HLT 2022 ethicscommittee. This year, compared to last year, had none that raised an ethics flag.
This year was the first year that the demo track at NAACL-HLT had different types of reproducibilitybadge(s). There were 6 papers that decided to participate and all of them successfully earned at least onebadge.
We would like to thank the members of the program committee for their timely help in reviewing thesubmissions. We also thank the many authors who submitted their work to the demonstration track. Thedemonstration papers will be presented through pre-recorded talks and one live online Q&A session.
Best,Qiang Ning, Hannaneh Hajishirzi and Avi Sil NAACL-HLT 2022 Demonstration Track Chairs
vi

Program Committee
Demonstration Chairs
Qiang Ning, AmazonHannaneh HajishirziAvi Sil, IBM Research
Program Committee
Akari Asai, University of WashingtonAmeet Deshpande, Princeton UniversityDavid Wadden, Department of Computer Science, University of WashingtonJaydeep Sen, International Business MachinesTiancheng Zhao, Carnegie Mellon UniversityAhmed Abdelali, Hamad Bin Khalifa UniversityAldrian Obaja Muis, Carnegie Mellon UniversityAles Horak, Masaryk UniversityAlexandros Papangelis, AmazonAli Hürriyetoglu, Koc UniversityAljoscha Burchardt, German Research Center for AIAlok Debnath, Trinity College, DublinAndrea Varga, Theta Lake LtdChengzhi Zhang, Nanjing University of Science and TechnologyCarl Edwards, Allen Institute for Artificial IntelligenceChanghan Wang, Meta AIChenchen Ding, National Institute of Information and Communications Technology (NICT)Chenkai Sun, University of Illinois, Urbana ChampaignChi Han, University of Illinois, Urbana ChampaignChien-Sheng Wu, Salesforce AIChristos Christodoulopoulos, AmazonChung-Chi Chen, National Tsing Hua UniversityConstantine Lignos, Brandeis UniversityDaniel F Campos, University of Illinois, Urbana ChampaignDaniel Hershcovich, University of CopenhagenDaniel Cer, GoogleDanilo Croce, University of Roma Tor VergataDavid Wadden, Department of Computer Science, University of WashingtonDenis Newman-Griffis, University of SheffieldDian Yu, GoogleDiane Napolitano, The Associated PressDiego Antognini, International Business MachinesDimitris Galanis, Institute for Language and Speech ProcessingDjamé Seddah, Inria ParisDong-Ho Lee, University of Southern CaliforniaEleftherios Avramidis, German Research Center for AIErion Çano, University of ViennaEugene Kharitonov, MetaFederico Fancellu, Samsung AI TorontoFeifei Pan, Rensselaer Polytechnic Institute
vii

Guangyou Zhou, Institute of Automation, Chinese Academy of SciencesGuanyi Chen, Utrecht UniversityGábor Berend, University of SzegedHamada M Zahera, Paderborn UniversityHamdy Mubarak, Qatar Computing Research InstituteHarshit Kumar, International Business MachinesHen-Hsen Huang, Institute of Information Science, Academia SinicaHongshen Chen, JD.comImed Zitouni, GoogleJames Fan, University of Texas, AustinJeff Jacobs, Columbia UniversityJhih-Jie , National Tsing Hua UniversityJian SUN, Alibaba Group, DAMO AcademyJiarun Cao, University of ManchesterJingjing Wang, Soochow UniversityJohn Heyer, Massachusetts Institute of TechnologyJohn Sie Yuen Lee, City University of Hong KongJoo-Kyung Kim, Amazon Alexa AIKhalid Al Khatib, University of GroningenLei Shu, GoogleLeonhard Hennig, German Research Center for AILiang-Chih Yu, Yuan Ze UniversityMamoru Komachi, Tokyo Metropolitan University, JapanManling Li, University of Illinois, Urbana ChampaignMargot Mieskes, University of Applied Sciences DarmstadtMarina Danilevsky, International Business MachinesMarina Litvak, Ben-Gurion University of the NegevMark Last, Ben-Gurion University of the NegevMichael Desmond, International Business MachinesMichal Shmueli-Scheuer, University of California, IrvineMiguel A. Alonso, Universidade da CoruñaMiruna Clinciu, Heriot-Watt UniversityMohaddeseh Bastan, State University of New York at Stony BrookMozhdeh Gheini, USC/ISINatalia Vanetik, SCENikola Ljubešic, Jožef Stefan InstituteOmri Abend, Hebrew University of Jerusalem, TechnionOren Pereg, IntelPablo Ruiz, Université de StrasbourgPaulo Fernandes, Roberts Wesleyan CollegePengfei Yu, University of Illinois at Urbana-ChampaignPhilipp Koehn, MetaPhilippe Laban, SalesForce.comPhilippe Muller, IRIT, University of ToulousePierre Nugues, Lund UniversityProkopis Prokopidis, Institute for Language and Speech Processing, Athena Research CenterQi Zeng, University of Illinois, Urbana ChampaignQi Zhang, Fudan UniversityQian Liu, Beihang UniversityQingyun Wang, University of Illinois, Urbana ChampaignRafael Anchiêta, Federal Institute of Piauí
viii

Rahul Aralikatte, University of CopenhagenRidong Jiang, National University of SingaporeRodrigo Agerri, University of the Basque CountryRoee Aharoni, GoogleRui Wang, Vipshop (China) Co., Ltd.Saarthak Khanna, AmazonSaurav Sahay, IntelSebastin Santy, University of WashingtonSeid Muhie Yimam, Universität HamburgSha Li, University of Illinois, Urbana ChampaignShaobo Cui, EPFL - EPF LausanneStella Markantonatou, ATHENA RICSudeep Gandhe, GoogleSudipta Kar, AmazonSumit Bhatia, Adobe SystemsSven Schmeier, German Research Center for AIThierry Declerck, German Research Center for AITsuyoshi Okita, Kyushu Institute of TechnologyTuan Lai, University of Illinois, Urbana ChampaignWenlin Yao, Tencent AI LabWolfgang Maier, Mercedes Benz Research & DevelopmentXianchao Wu, NVIDIAXianpei Han, Institute of Software, CASXiaodan Hu, University of Illinois, Urbana-ChampaignXintong Li, BaiduXuan Wang, University of Illinois, Urbana ChampaignXutan Peng, University of SheffieldYada Pruksachatkun, New York University Center for Data ScienceYanran Li, The Hong Kong Polytechnic UniversityYixin Cao, Singapore Management UniversityYoungsoo Jang, Korea Advanced Institute of Science and TechnologyYujiu Yang, Graduate School at Shenzhen,Tsinghua UniversityYun He, Texas A&M UniversityYuntian Deng, Harvard UniversityYusuke Miyao, The University of TokyoYusuke Oda, LegalForceZeljko Agic, Unity TechnologiesZeynep Akkalyoncu, University of WaterlooZhen Xu, PCG TencentZhenhailong Wang, University of Illinois at Urbana-ChampaignZhongqing Wang, Soochow University, ChinaZhuoxuan Jiang, Tencent Inc.Zixuan Zhang, University of Illinois at Urbana-ChampaignCarl Strathearn, Napier University
ix

Table of Contents
textless-lib: a Library for Textless Spoken Language ProcessingEugene Kharitonov, Jade Copet, Kushal Lakhotia, Tu Anh Nguyen, Paden Tomasello, Ann Lee,
Ali Elkahky, Wei-Ning Hsu, Abdelrahman Mohamed, Emmanuel Dupoux and Yossi Adi . . . . . . . . . . . 1
Web-based Annotation Interface for Derivational MorphologyLukáš Kyjánek . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
TurkishDelightNLP: A Neural Turkish NLP ToolkitHuseyin Alecakir, Necva Bölücü and Burcu Can . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
ZS4IE: A toolkit for Zero-Shot Information Extraction with simple VerbalizationsOscar Sainz, Haoling Qiu, Oier Lopez De Lacalle, Eneko Agirre and Bonan Min . . . . . . . . . . . . 27
Flowstorm: Open-Source Platform with Hybrid Dialogue ArchitectureJan Pichl, Petr Marek, Jakub Konrád, Petr Lorenc, Ondrej Kobza, Tomáš Zajícek and Jan Šedivý
39
Contrastive Explanations of Text Classifiers as a ServiceLorenzo Malandri, Fabio Mercorio, Mario Mezzanzanica, Navid Nobani and Andrea Seveso. .46
RESIN-11: Schema-guided Event Prediction for 11 Newsworthy ScenariosXinya Du, Zixuan Zhang, Sha Li, Pengfei Yu, Hongwei Wang, Tuan Lai, Xudong Lin, Ziqi Wang,
Iris Liu, Ben Zhou, Haoyang Wen, Manling Li, Darryl Hannan, Jie Lei, Hyounghun Kim, Rotem Dror,Haoyu Wang, Michael Regan, Qi Zeng, Qing Lyu, Charles Yu, Carl Edwards, Xiaomeng Jin, YizhuJiao, Ghazaleh Kazeminejad, Zhenhailong Wang, Chris Callison-Burch, Mohit Bansal, Carl Vondrick,Jiawei Han, Dan Roth, Shih-Fu Chang, Martha Palmer and Heng Ji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
A Human-machine Interface for Few-shot Rule Synthesis for Information ExtractionRobert Vacareanu, George C.G. Barbosa, Enrique Noriega-Atala, Gus Hahn-Powell, Rebecca
Sharp, Marco A. Valenzuela-Escárcega and Mihai Surdeanu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
SETSum: Summarization and Visualization of Student Evaluations of TeachingYinuo Hu, Shiyue Zhang, Viji Sathy, Abigail Panter and Mohit Bansal . . . . . . . . . . . . . . . . . . . . . 71
Towards Open-Domain Topic ClassificationHantian Ding, Jinrui Yang, Yuqian Deng, Hongming Zhang and Dan Roth . . . . . . . . . . . . . . . . . . 90
SentSpace: Large-Scale Benchmarking and Evaluation of Text using Cognitively Motivated Lexical,Syntactic, and Semantic Features
Greta Tuckute, Aalok Sathe, Mingye Wang, Harley Yoder, Cory Shain and Evelina Fedorenko 99
PaddleSpeech: An Easy-to-Use All-in-One Speech ToolkitHui Zhang, Tian Yuan, Junkun Chen, Xintong Li, Renjie Zheng, Yuxin Huang, Xiaojie Chen,
Enlei Gong, Zeyu Chen, Xiaoguang Hu, Dianhai Yu, Yanjun Ma and Liang Huang . . . . . . . . . . . . . . 114
DadmaTools: Natural Language Processing Toolkit for Persian LanguageRomina Etezadi, Mohammad Karrabi, Najmeh Zare, Mohamad Bagher Sajadi and Mohammad
Taher Pilehvar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
FAMIE: A Fast Active Learning Framework for Multilingual Information ExtractionMinh Van Nguyen, Nghia Trung Ngo, Bonan Min and Thien Huu Nguyen . . . . . . . . . . . . . . . . . 131
x

Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies: System Demonstrations, pages 1 - 9July 10-15, 2022 ©2022 Association for Computational Linguistics
textless-lib: a Library forTextless Spoken Language Processing
Eugene Kharitonov⋆, Jade Copet⋆, Kushal Lakhotia, Tu Anh Nguyen⋆, Paden Tomasello⋆
Ann Lee⋆, Ali Elkahky⋆, Wei-Ning Hsu⋆, Abdelrahman Mohamed⋆, Emmanuel Dupoux⋆†, Yossi Adi⋆⋆ Meta AI Research, † EHESS
Outreachkharitonov, jadecopet, [email protected]
Abstract
Textless spoken language processing researchaims to extend the applicability of standardNLP toolset onto spoken language and lan-guages with few or no textual resources. Inthis paper, we introduce textless-lib, aPyTorch-based library aimed to facilitate re-search in this research area. We describe thebuilding blocks that the library provides anddemonstrate its usability by discuss three dif-ferent use-case examples: (i) speaker prob-ing, (ii) speech resynthesis and compression,and (iii) speech continuation. We believethat textless-lib substantially simpli-fies research the textless setting and will behandful not only for speech researchers butalso for the NLP community at large. Thecode, documentation, and pre-trained modelsare available at https://github.com/facebookresearch/textlesslib/.
1 IntroductionTextless spoken language modeling (Lakhotia et al.,2021) consists in jointly learning the acoustic andlinguistic characteristics of a natural language fromraw audio samples without access to textual su-pervision (e.g. lexicon or transcriptions). Thisarea of research has been made possible by con-verging progress in self-supervised speech repre-sentation learning (Schneider et al., 2019; Baevskiet al., 2020; Oord et al., 2018; Hsu et al., 2021;Chorowski et al., 2021; Chen et al., 2021; Chunget al., 2021; Wang et al., 2021; Ao et al., 2021), lan-guage modeling (Peters et al., 2018; Devlin et al.,2019; Liu et al., 2019; Brown et al., 2020; Lewiset al., 2020), and speech synthesis (Ren et al., 2019;Kumar et al., 2019; Yamamoto et al., 2020; Renet al., 2020; Kong et al., 2020; Morrison et al.,2021).
Lakhotia et al. (2021) presented a GenerativeSpoken Language Modeling (GSLM) pipelinetrained from raw audio, consisting in a speech en-
Figure 1: A visual description for textless modeling ofspoken language. One can perform language modelingfor speech continuations (Lakhotia et al., 2021) or adirect speech resynthesis (Polyak et al., 2021).
coder (converting speech to discrete units), a lan-guage model (based on units) and a decoder (con-verting units back to speech). These componentsenabled the generation of new speech by samplingunits from the language model. Polyak et al. (2021)proposed an improved encoder/decoder workingfrom disentangled quantized content and F0 unitsand showed how such a system could be usedfor efficient audio compression. Kharitonov et al.(2021a) proposed a modified language model sys-tem capable of jointly modelling content units andF0 yielding expressive generations. Lastly, Kreuket al. (2021) demonstrated that the language modelcan be replaced by a sequence to sequence modelachieving the first high quality speech emotion con-version system (including laughter and yawning).
The textless approach has several advantages.First, it would be beneficial for the majority of theworld’s languages that do not have large textual re-sources or even a widely used standardized orthog-raphy (Swiss German, dialectal Arabic, Igbo, etc.).Despite being used by millions of people, these lan-guages have little chance of being served by current
1

text-based technology. Moreover, “high-resource”languages can benefit from such modeling wherethe oral and written forms are mismatched in termsof lexicon and syntax. Second, directly model-ing spoken language from raw audio allows us togo beyond lexical content and also model linguis-tically relevant signals such as prosodic features,intonation, non-verbal vocalizations (e.g., laughter,yawning, etc.), speaker identity, etc. All of theseare virtually absent in text.
Although great progress has been made in mod-eling spoken language, it still requires domain ex-pertise and involves a complicated setting. Forinstance, the official implementation of the GSLMpipeline (Lakhotia et al., 2021) consists of roughlyfour different launching scripts with a few dozensof checkpoints. Similarly, running the official im-plementation of Polyak et al. (2021), requires usingfour scripts from two different repositories.
We present textless-lib, a PyTorch libraryfor textless spoken language processing. It makesprocessing, encoding, modeling, and generating ofspeech as simple as possible. With a few lines ofcode, one can perform speech continuation, audio-book compression, representation analysis by prob-ing, speech-to-speech translation, etc. We pro-vide all the necessary building blocks, examplepipelines, and example tasks. We believe such asimple to use API will encourage both speech andNLP communities to deepen and extend the re-search work on modeling spoken language withouttext and unlock potential future research directions.
2 BackgroundBelow we provide an overview of the commontextless spoken language modeling pipeline. In anutshell, such pipeline is usually comprised of: i)Speech-to-Units (S2U) encoders that automaticallydiscover discrete representations or units whichcan be used to encode speech into "pseudo-text"; ii)Units-to-Units (U2U) models that are used for unitsmodeling. This can take a form as Unit-Language-Model (uLM) for speech continuation (Lakhotiaet al., 2021; Kharitonov et al., 2021a), sequence-to-sequence models for speech emotion conver-sion (Kreuk et al., 2021) or translation tasks (Leeet al., 2021a,b); iii) Units-to-Speech (U2S) modelsto reconstruct back the speech signals.
Alternatively, one could drop the U2U com-ponent and perform a direct speech resynthe-sis (Polyak et al., 2021). This can be used forspeech compression, voice conversion, or develop-
Type Model Dataset
EncodersHuBERT LS-960CPC LL-6k
Quantizers k-means
LS-960 w. 50 unitsLS-960 w. 100 unitsLS-960 w. 200 unitsLS-960 w. 500 units
F0 extract. YAAPT -
DecodersTacotron2 LJ SpeechWaveGlow LJ Speech
Table 1: Summary of the pre-trained models providedin textless-lib. We denote LibriSpeech and Libri-Light as LS-960 and LL-6k accordingly. All quantizerswere trained on “dev-clean” partition of LibriSpeech.
ing a better understanding of the learned represen-tation using probing methods. See Figure 1 for a vi-sual description of the full system. We provide a de-tailed description for each of the above-mentionedcomponents in the following subsections.
2.1 Speech to UnitsConsider the domain of audio samples as X ⊂ R.The representation for an audio waveform is there-fore a sequence of samples x = (x1, . . . , xT ),where each xi ∈ X for all 1 ≤ t ≤ T . Wedenote the S2U encoder as, E(x) = z, wherez = (z1, . . . ,zL) is a spectral representationof x sampled at a lower frequency, each zi for1 ≤ i ≤ L is a d-dimensional vector, and L < T .
Next, as the representations obtained by Eare continuous, an additional quantization stepis needed. We define a quantization function Q,which gets as input dense representations and out-puts a sequence of discrete tokens correspond-ing to the inputs’ quantized version. Formally,Q(z) = zq, where zq = (z1q , . . . , z
Lq ) such that
ziq ∈ 1, . . . ,K and K is the size of the vocabu-lary. After quantization one can either operate onthe original discrete sequences (duped) or collapserepeated units (e.g., 0, 0, 1, 1, 2 → 0, 1, 2), we re-fer to such sequences as “deduped”. Working withthe deduped sequences simplifies modeling longsequences, however, the tempo information is lost.
2.2 Units to SpeechConverting a sequence of units to audio is akinto the Text-to-Speech (TTS) problem, where weconsider the discrete units as “pseudo-text”. Thiscan be solved by adopting a standard TTS architec-ture. For instance, Lakhotia et al. (2021) traineda Tacotron2 model (Shen et al., 2018) to performunits to mel-spectrogram conversion followed by
2

Figure 2: We represent speech as three aligned, synchronised streams: discrete pseudo-units, duration, and pitch.
a WaveGlow (Prenger et al., 2019) neural vocoderfor time-domain reconstruction.
Formally, to reconstruct a time-domain speechsignal from a sequence of discrete units, zq wedefine the composition as, V (G(zq)) = x, whereG is a mel-spectrogram estimation module (e.g.,Tacotron2), and V is a phase vocoder module re-sponsible for time-domain synthesis (e.g., Wave-Glow). The input sequence zq can be either theoriginal sequence or its deduped version.
Interestingly, one can simplify the synthesis pro-cess when working with the duped unit sequences.As we have a direct mapping between the dupeddiscrete unit sequence to the time domain signal(e.g., each unit corresponds to a 20ms window)one can remove G, and directly feed zq to V .This was successfully done in (Polyak et al., 2021)for speech resynthesis using the HiFi-GAN neuralvocoder (Kong et al., 2020). Alternatively, as sug-gested by (Kreuk et al., 2021; Lee et al., 2021b)one can train a unit duration prediction model anduse the predicted durations to inflate the sequenceand feed the discrete sequence directly to V .
2.3 Unit to UnitsEquipped with the models to encode spoken lan-guage into discrete unit sequences and convert themback to speech samples, one can conveniently usecommon NLP architectures to model spoken lan-guage. Consider M to be a sequence modelingfunction that gets as input a discrete unit sequencezq and outputs another discrete units sequence, de-noted as zq. Generally, zq can represent differentgenerations, depending on the modeling task. Forinstance, Lakhotia et al. (2021) and Kharitonovet al. (2021a) setM to be a Transformer and traineda generative spoken language model. Similarly,Kreuk et al. (2021) set M to be a sequence-to-sequence model, hence can cast the emotion con-version problem as a translation task.1
1Examples are provided at speechbot.github.io/.
3 Library OverviewIn this section, we present the textless-liblibrary, intending to simplify future research ontextless spoken language modeling. Additionally,the proposed package will remove the main bar-rier of processing and synthesizing speech, whichrequires domain expertise, for other language re-searchers (e.g., NLP researchers) who are inter-ested in modeling spoken language, analyzing thelearned representations, etc.
To support the above, it is essential to providethe main building blocks described in Section 2,together with pre-trained models, with minimalcoupling between them (a list of the supported pre-trained models can be seen on Table 1). This willallow researchers to flexibly use the provided pre-trained building blocks or develop new buildingblocks and use them anywhere in their pipeline.We decided to exclude both U2U models as wellas evaluation metrics from the core functionalityof the library as we believe these models shouldbe an example usage. There are plenty of waysto evaluate the overall pipeline (Lakhotia et al.,2021; Dunbar et al., 2019, 2020; Nguyen et al.,2020) and different ways to model the “pseudo-text”units (Shi et al., 2021; Kharitonov et al., 2021a;Polyak et al., 2021; Kreuk et al., 2021; Lee et al.,2021a), hence including them as an integral part ofthe library will make it overcomplicated.
3.1 InterfacesThe pipeline presented in Figure 1 hints a straight-forward way to decouple elements of the libraryinto two principal blocks: (i) encoding speech;and (ii) decoding speech, with the only inter-dependence being the format of the data in-between(e.g., vocabulary size). Such interfaces enable in-teresting mix-and-match combinations as well asconducting research on each component indepen-dently. We firstly present those two interfaces, thenwe discuss helpers for dataloading.
3

Figure 3: textless-lib provides an “encoded”view for standard datasets, such as LibriSpeech.
Encoders and Vocoders. We denote the encodersas SpeechEncoder. These modules encompassall steps required to represent raw audio as discreteunit sequences (i.e., pseudo-text units and, option-ally duration and pitch streams).SpeechEncoder obtains a dense vector repre-
sentation from a given self-supervised model, dis-cretizes the dense representation into units, extractspitch, aligns it with the unit streams, and poten-tially, applies run-length encoding with per-framepitch averaging. See Fig. 2 for a visual description.
For each sub-model, a user might choose touse a pre-trained model or provide a customtorch.nn.Module module instead. An exam-ple of the former is demonstrated in lines 7-12 inFigure 3, in which a HuBERT model and a corre-sponding k-means codebook with a pre-defined K(i.e., vocabulary size) are automatically retrieved.
Conversely, vocoders take as input a discretizedsequence and convert it back to the audio domain.As with SpeechEncoder, we can retrieve a pre-trained model by setting the expected input specifi-cation (model, quantizer, and the size of the code-book), see Figure 4 lines 17-21.Datasets, Dataloaders, and Preprocessing.Apart from encoders and vocoders, in thetextless-lib we provide several componentsaimed to simplify frequent data loading use-cases.First, we provide a set of standard datasets (e.g.,LibriSpeech) wrapped to produce quantized repre-sentations (see Fig. 3 lines 14-15). Those datasetsare implemented via a QuantizeDatasetwrapper which can be used to wrap any map-stylePyTorch dataset, containing raw waveform data.
Figure 4: Fully functioning code for discrete audioresynthesis. An audio file is loaded, coverted into asequence of pseudo-units and transformed back intoaudio with Tacotron2. The model setup code will down-load required checkpoints and cache them locally.
The QuantizeDataset runs an instance of adense representation model, which can be compu-tationally heavy (e.g., the HuBERT-base model has7 convolutional layers and 12 Transformer layers).Unfortunately, such heavy preprocessing can starvethe training loop. Hence, we provide two possiblesolutions: (i) as part of the textless-lib weprovide a way to spread QuantizeDataset andDataLoader preprocessing workers (each withits copy of a dense model) across multiple GPUs,hence potentially balancing training and prepro-cessing across different devices; (ii) in cases whereon-the-fly preprocessing is not required (e.g., thereis no randomized data augmentation (Kharitonovet al., 2021b)), an alternative is to preprocess the en-tire dataset in advance. textless-lib providesa tool for preprocessing arbitrary sets of audio filesinto a stream of pseudo-unit tokens and, optionally,streams of per-frame tempo and F0 values, alignedto the token stream. The tool uses multi-GPU andmulti-node parallelism to speed up the process.
4

Model Quantized? Vocab. size Accuracy
HuBERT - - 0.99HuBERT 50 0.11HuBERT 100 0.19HuBERT 200 0.29HuBERT 500 0.48
CPC - - 0.99CPC 50 0.19CPC 100 0.32CPC 200 0.34CPC 500 0.40
Table 2: Speaker probing. Test accuracy on predictingspeaker based on HuBERT & CPC representations.
3.2 Pre-trained ModelsAs part of textless-lib we provide severalpre-trained models that proved to work best in priorwork (Lakhotia et al., 2021; Polyak et al., 2021).In future, we will maintain the list of the models tobe aligned with state-of-the-art.Dense representations. We support two denserepresentation models: (i) HuBERT base-960hmodel (Hsu et al., 2021) trained on LibriSpeech960h dataset, with a framerate of 50 Hz; (ii)Contrastive Predictive Coding (CPC) model (Riv-ière and Dupoux, 2020; Oord et al., 2018) trainedon the 6K hours subset from LibriLight (Kahn et al.,2020) with a framerate of 100 Hz. Both modelsprovided the best overall performance accordingto (Lakhotia et al., 2021; Polyak et al., 2021).Pitch extraction. Following Polyak et al. (2021)we support F0 extraction using the YAAPT pitchextraction algorithm (Kasi and Zahorian, 2002).We plan to include other F0 extraction models,e.g. CREPE (Kim et al., 2018).Quantizers. With the textless-lib we pro-vide several pre-trained quantization functions forboth HuBERT and CPC dense models using a vo-cabulary sizes K ∈ 50, 100, 200, 500. For thequantization function, we trained a k-means algo-rithm using the “dev-clean” part in the LibriSpeechdataset (Panayotov et al., 2015).Pitch normalization. Following Kharitonov et al.(2021a), we applied per-speaker pitch normaliza-tion to reduce inter-speaker variability. For singlespeaker datasets, we do not perform F0 normal-ization and the span of pitch values is preserved.Under the textless-lib we provide two pitch-normalization methods: per-speaker and prefix-based. In the per-speaker normalization, we assumethe mean F0 value per speaker is known in advance.While in the prefix-based normalization method a
Model Vocab. size Bitrate, bit/s WER
Topline - 512 ·103 2.2
HuBERT 50 125.5 24.2HuBERT 100 167.4 13.5HuBERT 200 210.6 7.9
Table 3: Bitrate/ASR WER trade-off. Topline corre-sponds to the original data encoded with 32-bit PCM.
part of the audio is used to calculate the mean pitch.Those two options provide useful trade-offs. In thefirst case, we need to have a closed set of speakersbut have a better precision while in the second wesacrifice quality but gain flexibility.Vocoder. In the initial release of the library, weprovide Tacotron2 as a mel-spectrogram estimationmodule (i.e., the G function) followed by Wave-Glow (Prenger et al., 2019) neural vocoder (i.e.,the V function) as used by Lakhotia et al. (2021).2
These operate on deduplicated pseudo-unit streamswith vocabulary sizes of 50, 100, and 200. In afollow-up release, we aim to include HiFi-GAN-based vocoders similarly to Polyak et al. (2021);Kharitonov et al. (2021a). We found those to gener-ate better audio quality with higher computationalperformance. However, as described in Section 2,the main drawback of droppingG and directly feed-ing the discrete units to V is the need for a unitduration prediction model. We plan to include suchmodels as well in the next release.
4 ExamplesAlongside the core functionality of the library, weprovide a set of illustrative examples. The goalof these examples is two-fold: (a) to illustrate theusage of particular components of the library, and(b) to serve as a starter code for a particular type ofapplication. For instance, a probing example (Sec-tion 4.1) can be adapted for better studying usedrepresentations, while discrete resynthesis (Sec-tion 4.2) could provide a starter code for an appli-cation operating on units (e.g., language modelingor a high-compression speech codec).
4.1 Speaker ProbingA vibrant area of research studies properties of“universal” pre-trained representations, such asGLoVE (Pennington et al., 2014) and BERT (De-vlin et al., 2018). Examples span from probing forlinguistic properties (Adi et al., 2017b; Ettinger
2WaveGlow is used as a part of TacotronVocoder.Both Tacotron2 and WaveGlow were trained on LJ speech (Itoand Johnson, 2017).
5

HE PASSES ABRUPTLY FROM PERSONS OF ABRUPT ACID FROM WHICH HE PROCEEDS ARIGHT BY ...HE PASSES ABRUPTLY FROM PERSONS AND CHARCOAL EACH ONE OF THE CHARCOAL ...HE PASSES ABRUPTLY FROM PERSONS FEET AND TRAY TO A CONTENTION OF ASSOCIATION THAT ...
Table 4: Three continuations of the same prompt (in pink), generated by the speech continuation example underdifferent random seeds. Sampled from a language model trained trained on HuBERT-100 units.
et al., 2016; Adi et al., 2017a; Conneau et al.,2018; Hewitt and Manning, 2019) to discovering bi-ases (Bolukbasi et al., 2016; Caliskan et al., 2017).
In contrast, widely used pre-trained representa-tions produced by HuBERT (Hsu et al., 2021) andwav2vec 2.0 (Baevski et al., 2020) are relativelyunderstudied. Few existing works include (vanNiekerk et al., 2021; Higy et al., 2021).
We believe our library can provide a convenienttool for research in this area. Hence, as the first ex-ample, we include a probing experiment similar tothe one proposed in (van Niekerk et al., 2021; Adiet al., 2019). We study whether the extracted rep-resentations contain speaker-specific information.In this example, we experiment with quantizedand continuous representations provided by CPCand HuBERT. We randomly split LibriSpeech dev-clean utterances into train/test (90%/10%) sets3
and train a two-layer Transformer for 5 epochs topredict a speaker’s anonymized identifier, basedon an utterance they produced. From the resultsreported in Table 2 we see that the continuous rep-resentations allow identifying speaker on hold-oututterances. In contrast, the quantization adds somespeaker-invariance, justifying its use.
4.2 Speech Resynthesis
The next example is the discrete speech resynthe-sis, i.e., the speech audio→ deduplicated units→speech audio pipeline. Fig. 4 illustrates how simpleits implementation is with textless-lib.
The discrete resynthesis operation can be seenas a lossy compression of the speech. Indeed, if asequence of n units (from a vocabulary U ) encodesa speech segment of length l, we straightforwardlyobtain a lossy codec with bitrate n
l ⌈log2 |U|⌉ bitsper second. Further, the token stream itself canbe compressed using entropy encoding and, as-suming a unigram token model, the compressionrate becomes: −n
l ·∑
u∈U P(u) log2 P(u). In Ta-ble 3 we report compression rate/word error rate(WER) trade-off achievable with the HuBERT-derived unit systems, as a function of the vocabu-lary size. WER is calculated using the wav2vec 2.0-
3We have to create a new split as the standard one hasdisjoint sets of speakers, making this experiment impossible.
based Automatic Speech Recognition (ASR) w.r.t.and uses the ground-truth transcripts. To calculatethe compression rate, the unigram token distribu-tion was fitted on the transcript of LibriLight 6Kdataset (Rivière and Dupoux, 2020). From Table 3we observe that discretized HuBERT representa-tions have a strong potential for extreme speechcompression (Polyak et al., 2021).4 Our providedimplementation reports the bitrate.
4.3 Speech Continuation
Finally, we include a textless-lib re-implementation of the full GSLM speech continua-tion pipeline (Lakhotia et al., 2021), as depicted inFigure 1. Table 4 presents ASR transcripts of threedifferent continuations of the same prompt, gener-ated using different random seeds. We use a LARGE
wav2vec 2.0 model, trained on LibriSpeech-960hwith CTC loss. Its decoder uses the standardKenLM 4-gram language model.
5 Discussion and Future Work
We introduced textless-lib, a Pytorch libraryaimed to advance research in textless modelingof spoken language, by simplifying textless pro-cessing and synthesizing spoken language. We de-scribed the main building blocks used to preprocess,quantize, and synthesize speech. To demonstratethe usability of the library, we provided three usageexamples related to (i) representation probing, (ii)speech compression, and (iii) speech continuation.The proposed library greatly simplifies researchin the textless spoken language processing, hencewe believe it will be a handful not only for speechresearchers but to the entire NLP community.
As a future work for textless-lib we envi-sion improving performance of the existing build-ing blocks, adding new example tasks (e.g., trans-lation (Lee et al., 2021b) or dialog (Nguyen et al.,2022)), extending the set of provided pre-trainedmodels, and introducing the possibility of trainingthe different components.
4In contrast to our setup, Polyak et al. (2021) worked withnon-deduplicated streams, hence obtained different bitrates.
6

ReferencesYossi Adi, Einat Kermany, Yonatan Belinkov, Ofer Lavi,
and Yoav Goldberg. 2017a. Analysis of sentenceembedding models using prediction tasks in naturallanguage processing. IBM Journal of Research andDevelopment, 61(4/5):3–1.
Yossi Adi, Einat Kermany, Yonatan Belinkov, Ofer Lavi,and Yoav Goldberg. 2017b. Fine-grained analysisof sentence embeddings using auxiliary predictiontasks.
Yossi Adi, Neil Zeghidour, Ronan Collobert, NicolasUsunier, Vitaliy Liptchinsky, and Gabriel Synnaeve.2019. To reverse the gradient or not: An empiri-cal comparison of adversarial and multi-task learn-ing in speech recognition. In ICASSP 2019-2019IEEE International Conference on Acoustics, Speechand Signal Processing (ICASSP), pages 3742–3746.IEEE.
Junyi Ao, Rui Wang, Long Zhou, Shujie Liu, ShuoRen, Yu Wu, Tom Ko, Qing Li, Yu Zhang, ZhihuaWei, et al. 2021. Speecht5: Unified-modal encoder-decoder pre-training for spoken language processing.arXiv preprint arXiv:2110.07205.
Alexei Baevski, Henry Zhou, Abdelrahman Mohamed,and Michael Auli. 2020. wav2vec 2.0: A frameworkfor self-supervised learning of speech representations.arXiv preprint arXiv:2006.11477.
Tolga Bolukbasi, Kai-Wei Chang, James Y Zou,Venkatesh Saligrama, and Adam T Kalai. 2016. Manis to computer programmer as woman is to home-maker? debiasing word embeddings. Advancesin neural information processing systems, 29:4349–4357.
Tom B. Brown et al. 2020. Language models are few-shot learners. In Proc. of NeurIPS.
Aylin Caliskan, Joanna J Bryson, and Arvind Narayanan.2017. Semantics derived automatically from lan-guage corpora contain human-like biases. Science,356(6334):183–186.
Sanyuan Chen, Chengyi Wang, Zhengyang Chen,Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, NaoyukiKanda, Takuya Yoshioka, Xiong Xiao, et al. 2021.Wavlm: Large-scale self-supervised pre-trainingfor full stack speech processing. arXiv preprintarXiv:2110.13900.
Jan Chorowski, Grzegorz Ciesielski, JarosławDzikowski, Adrian Lancucki, Ricard Marxer,Mateusz Opala, Piotr Pusz, Paweł Rychlikowski, andMichał Stypułkowski. 2021. Aligned contrastivepredictive coding. arXiv preprint arXiv:2104.11946.
Yu-An Chung, Yu Zhang, Wei Han, Chung-ChengChiu, James Qin, Ruoming Pang, and YonghuiWu. 2021. W2v-bert: Combining contrastivelearning and masked language modeling for self-supervised speech pre-training. arXiv preprintarXiv:2108.06209.
Alexis Conneau, German Kruszewski, Guillaume Lam-ple, Loïc Barrault, and Marco Baroni. 2018. Whatyou can cram into a single vector: Probing sentenceembeddings for linguistic properties. arXiv preprintarXiv:1805.01070.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, andKristina Toutanova. 2018. Bert: Pre-training of deepbidirectional transformers for language understand-ing. arXiv preprint arXiv:1810.04805.
Jacob Devlin et al. 2019. BERT: Pre-training of deepbidirectional transformers for language understand-ing. In Proc. of NAACL.
Ewan Dunbar, Robin Algayres, Julien Karadayi, Math-ieu Bernard, Juan Benjumea, Xuan-Nga Cao, LucieMiskic, Charlotte Dugrain, Lucas Ondel, Alan W.Black, Laurent Besacier, Sakriani Sakti, and Em-manuel Dupoux. 2019. The Zero Resource SpeechChallenge 2019: TTS without T. In Proc. INTER-SPEECH, pages 1088–1092.
Ewan Dunbar, Julien Karadayi, Mathieu Bernard, Xuan-Nga Cao, Robin Algayres, Lucas Ondel, LaurentBesacier, Sakriani Sakti, and Emmanuel Dupoux.2020. The Zero Resource Speech Challenge 2020:Discovering discrete subword and word units. InProc. INTERSPEECH, pages 4831–4835.
Allyson Ettinger, Ahmed Elgohary, and Philip Resnik.2016. Probing for semantic evidence of compositionby means of simple classification tasks. In Proceed-ings of the 1st Workshop on Evaluating Vector-SpaceRepresentations for NLP, pages 134–139.
John Hewitt and Christopher D Manning. 2019. A struc-tural probe for finding syntax in word representations.In Proceedings of the 2019 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics: Human Language Technologies,Volume 1 (Long and Short Papers), pages 4129–4138.
Bertrand Higy, Lieke Gelderloos, Afra Alishahi, andGrzegorz Chrupała. 2021. Discrete representationsin neural models of spoken language. arXiv preprintarXiv:2105.05582.
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai,Kushal Lakhotia, Ruslan Salakhutdinov, and Abdel-rahman Mohamed. 2021. Hubert: Self-supervisedspeech representation learning by masked predictionof hidden units. arXiv preprint arXiv:2106.07447.
Keith Ito and Linda Johnson. 2017. The ljspeech dataset. https://keithito.com/LJ-Speech-Dataset/.
J. Kahn, M. Rivière, W. Zheng, E. Kharitonov, Q. Xu,P. E. Mazaré, J. Karadayi, V. Liptchinsky, R. Col-lobert, C. Fuegen, T. Likhomanenko, G. Synnaeve,A. Joulin, A. Mohamed, and E. Dupoux. 2020. Libri-light: A benchmark for ASR with limited or no super-vision. In IEEE International Conference on Acous-tics, Speech and Signal Processing (ICASSP), pages7669–7673.
7

Kavita Kasi and Stephen A Zahorian. 2002. Yet anotheralgorithm for pitch tracking. In 2002 ieee interna-tional conference on acoustics, speech, and signalprocessing, volume 1, pages I–361. IEEE.
Eugene Kharitonov, Ann Lee, Adam Polyak, Yossi Adi,Jade Copet, Kushal Lakhotia, Tu-Anh Nguyen, Mor-gane Rivière, Abdelrahman Mohamed, EmmanuelDupoux, et al. 2021a. Text-free prosody-aware gen-erative spoken language modeling. arXiv preprintarXiv:2109.03264.
Eugene Kharitonov, Morgane Rivière, Gabriel Syn-naeve, Lior Wolf, Pierre-Emmanuel Mazaré, MatthijsDouze, and Emmanuel Dupoux. 2021b. Data aug-menting contrastive learning of speech representa-tions in the time domain. In 2021 IEEE Spoken Lan-guage Technology Workshop (SLT), pages 215–222.IEEE.
Jong Wook Kim, Justin Salamon, Peter Li, andJuan Pablo Bello. 2018. Crepe: A convolutionalrepresentation for pitch estimation. In ICASSP.
Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. 2020.HiFi-GAN: Generative adversarial networks for effi-cient and high fidelity speech synthesis. In Proc. ofNeurIPS.
Felix Kreuk, Adam Polyak, Jade Copet, EugeneKharitonov, Tu-Anh Nguyen, Morgane Rivière, Wei-Ning Hsu, Abdelrahman Mohamed, EmmanuelDupoux, and Yossi Adi. 2021. Textless speech emo-tion conversion using decomposed and discrete rep-resentations. arXiv preprint arXiv:2111.07402.
Kundan Kumar, Rithesh Kumar, Thibault de Boissiere,Lucas Gestin, Wei Zhen Teoh, Jose Sotelo, Alexandrede Brébisson, Yoshua Bengio, and Aaron Courville.2019. Melgan: Generative adversarial networksfor conditional waveform synthesis. arXiv preprintarXiv:1910.06711.
Kushal Lakhotia, Evgeny Kharitonov, Wei-Ning Hsu,Yossi Adi, Adam Polyak, Benjamin Bolte, Tu-AnhNguyen, Jade Copet, Alexei Baevski, AdelrahmanMohamed, et al. 2021. Generative spoken lan-guage modeling from raw audio. arXiv preprintarXiv:2102.01192.
Ann Lee, Peng-Jen Chen, Changhan Wang, Jiatao Gu,Xutai Ma, Adam Polyak, Yossi Adi, Qing He, YunTang, Juan Pino, and Wei-Ning Hsu. 2021a. Di-rect speech-to-speech translation with discrete units.arXiv preprint arXiv:2107.05604.
Ann Lee, Hongyu Gong, Paul-Ambroise Duquenne,Holger Schwenk, Peng-Jen Chen, Changhan Wang,Sravya Popuri, Juan Pino, Jiatao Gu, and Wei-NingHsu. 2021b. Textless speech-to-speech translationon real data. arXiv preprint arXiv:2112.08352.
Mike Lewis et al. 2020. BART: Denoising sequence-to-sequence pre-training for natural language gener-ation, translation, and comprehension. In Proc. ofACL.
Yinhan Liu et al. 2019. RoBERTa: A robustly opti-mized BERT pretraining approach. arXiv preprintarXiv:1907.11692.
Max Morrison, Rithesh Kumar, Kundan Kumar,Prem Seetharaman, Aaron Courville, and YoshuaBengio. 2021. Chunked autoregressive gan forconditional waveform synthesis. arXiv preprintarXiv:2110.10139.
Tu Anh Nguyen, Maureen de Seyssel, PatriciaRozé, Morgane Rivière, Evgeny Kharitonov, AlexeiBaevski, Ewan Dunbar, and Emmanuel Dupoux.2020. The Zero Resource Speech Benchmark 2021:Metrics and baselines for unsupervised spoken lan-guage modeling. In Advances in Neural Informa-tion Processing Systems (NeurIPS) – Self-SupervisedLearning for Speech and Audio Processing Work-shop.
Tu Anh Nguyen, Eugene Kharitonov, Jade Copet, YossiAdi, Wei-Ning Hsu, Ali Elkahky, Paden Tomasello,Robin Algayres, Benoit Sagot, Abdelrahman Mo-hamed, and Dupoux Emmanuel. 2022. Generativespoken dialogue language modeling. arXiv preprintarXiv:2203.16502.
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2018.Representation learning with contrastive predictivecoding. arXiv preprint arXiv:1807.03748.
Vassil Panayotov, Guoguo Chen, Daniel Povey, andSanjeev Khudanpur. 2015. Librispeech: an asr cor-pus based on public domain audio books. In 2015IEEE international conference on acoustics, speechand signal processing (ICASSP), pages 5206–5210.IEEE.
Jeffrey Pennington, Richard Socher, and Christopher DManning. 2014. Glove: Global vectors for word rep-resentation. In Proceedings of the 2014 conferenceon empirical methods in natural language processing(EMNLP), pages 1532–1543.
Matthew Peters et al. 2018. Deep contextualized wordrepresentations. In Proc. of NAACL.
Adam Polyak, Yossi Adi, Jade Copet, EugeneKharitonov, Kushal Lakhotia, Wei-Ning Hsu, Ab-delrahman Mohamed, and Emmanuel Dupoux.2021. Speech resynthesis from discrete disentan-gled self-supervised representations. arXiv preprintarXiv:2104.00355.
Ryan Prenger, Rafael Valle, and Bryan Catanzaro. 2019.Waveglow: A flow-based generative network forspeech synthesis. In ICASSP 2019-2019 IEEE Inter-national Conference on Acoustics, Speech and SignalProcessing (ICASSP), pages 3617–3621. IEEE.
Yi Ren, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao,Zhou Zhao, and Tie-Yan Liu. 2020. Fastspeech2: Fast and high-quality end-to-end text to speech.arXiv preprint arXiv:2006.04558.
8

Yi Ren, Yangjun Ruan, Xu Tan, Tao Qin, Sheng Zhao,Zhou Zhao, and Tie-Yan Liu. 2019. Fastspeech: Fast,robust and controllable text to speech. arXiv preprintarXiv:1905.09263.
Morgane Rivière and Emmanuel Dupoux. 2020. To-wards unsupervised learning of speech features in thewild. In IEEE Spoken Language Technology Work-shop (SLT), pages 156–163.
Steffen Schneider, Alexei Baevski, Ronan Collobert,and Michael Auli. 2019. wav2vec: Unsupervisedpre-training for speech recognition. arXiv preprintarXiv:1904.05862.
Jonathan Shen, Ruoming Pang, Ron J Weiss, MikeSchuster, Navdeep Jaitly, Zongheng Yang, ZhifengChen, Yu Zhang, Yuxuan Wang, Rj Skerrv-Ryan,et al. 2018. Natural tts synthesis by conditioningwavenet on mel spectrogram predictions. In 2018IEEE International Conference on Acoustics, Speechand Signal Processing (ICASSP), pages 4779–4783.IEEE.
Jing Shi, Xuankai Chang, Tomoki Hayashi, Yen-JuLu, Shinji Watanabe, and Bo Xu. 2021. Discretiza-tion and re-synthesis: an alternative method tosolve the cocktail party problem. arXiv preprintarXiv:2112.09382.
Benjamin van Niekerk, Leanne Nortje, Matthew Baas,and Herman Kamper. 2021. Analyzing speakerinformation in self-supervised models to improvezero-resource speech processing. arXiv preprintarXiv:2108.00917.
Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani,Shujie Liu, Furu Wei, Michael Zeng, and XuedongHuang. 2021. Unispeech: Unified speech representa-tion learning with labeled and unlabeled data. arXivpreprint arXiv:2101.07597.
Ryuichi Yamamoto, Eunwoo Song, and Jae-Min Kim.2020. Parallel wavegan: A fast waveform generationmodel based on generative adversarial networks withmulti-resolution spectrogram. In ICASSP 2020-2020IEEE International Conference on Acoustics, Speechand Signal Processing (ICASSP), pages 6199–6203.IEEE.
9

Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies: System Demonstrations, pages 10 - 16
July 10-15, 2022 ©2022 Association for Computational Linguistics
Web-based Annotation Interface for Derivational Morphology
Lukáš KyjánekCharles University, Faculty of Mathematics and Physics
Institute of Formal and Applied LinguisticsPrague, Czechia
AbstractThe paper presents a visual interface formanual annotation of language resources forderivational morphology. The interface is web-based and created using relatively simple pro-gramming techniques, and yet it rapidly facil-itates and speeds up the annotation process,especially in languages with rich derivationalmorphology. As such, it can reduce the costof the process. After introducing manual an-notation tasks in derivational morphology, thepaper describes the new visual interface anda case study that compares the current anno-tation method to the annotation using the in-terface. In addition, it also demonstrates theopportunity to use the interface for manual an-notation of syntactic trees. The source codesare freely available under the MIT License onGitHub.
1 Introduction
Making manual annotations is a common task whena high-quality language resource is created. Themore complex the annotation task, the more timeconsuming it is for an annotator, an expert ina linguistic field captured by the resource. Con-sequently, the cost of creating such resource can behigh. The simplest approach is to simplify the task;however, it is not possible in many cases.
This paper presents such task and how to ap-proach it in the field of annotating language re-sources of derivational morphology. When annotat-ing derivational data, annotators must make manydecisions at once. This complexity leads not only tothe prolongation of the annotation process but alsoto mistakes that must be additionally re-annotated.As the simplification of these decisions is out ofthe question, a freely available web-based visualinterface has been created to make the annotationprocess easier for annotators. The fact that annotat-ing derivational morphology using the interface isfaster than the currently used annotation method isalso validated by real annotators.
read
reading reader readable
readability readableness readably
Figure 1: A derivational family of the verb read.
The paper is structured as follows. Section 2 de-scribes the current state of annotating derivationalmorphology. Section 3 focuses on the new inter-face as well as its applicability to other annotationtasks. Section 4 provide a comparison of the cur-rent annotation method versus the utilisation of theinterface. Section 5 concludes the paper.
2 Related Work
2.1 Linguistic BackgroundMorphological derivation is a process of formingnew lexemes by modifying the already existingones. For instance, the noun reader is derived byattaching the lexical affix -er to the morphologicalbase of the verb read. Štekauer et al. (2012) docu-ment this process across many world languages.
One of the widely known approaches to deriva-tional morphology (cf. Dokulil 1962; Buzássyová1974; Horecký et al. 1989; Furdík 2004; Štekauer2005) models all derivationally related lexemes(DERIVATIONAL FAMILY) on the basis of:
(i) a system of directly derivationally related lex-emes grouped around a single base lexeme,e.g., read > read-ing, read-er, and read-able;
(ii) a sequence of consecutive derivatives,e.g., read > read-able > read-abil-ity.
If these parts are applied recursively to a singleunderived lexeme, it results in derivational familiesstructured in rooted trees, see Figure 1.
10

2.2 Data Resources
There is a lot of lexical resources of derivationalmorphology (cf. Kyjánek 2018),1 many of whichmodel derivational families in rooted trees, con-curring with the above-mentioned theory.2 Mostof the other existing resources that capture deriva-tional families in non-tree-shaped data structureshave been harmonised into the rooted trees and areavailable in the Universal Derivations collection(Kyjánek et al., 2020; Kyjánek et al., 2021).3
The reasons why some resources do not modelderivational families in rooted trees cover a wholerange from technical to theoretical reasons.4 For ex-ample, DErivBase for German (Zeller et al., 2013)has been created by exploiting so-called deriva-tional rules extracted from grammars in a formof sophisticated regular expressions which the au-thors have utilised to search derivationally relatedlexemes in a given lexeme set. Consequently, theresulting resource violates the main constraint ofthe rooted tree structure that each lexeme can haveat most one base lexeme, e.g., the adjective glatt(smooth) and the verb glätten (to smooth) are cap-tured as bases for the noun Glätte (smoothness).The manual annotation is thus necessary not onlybefore the creation of a high-quality resource butalso after that for its harmonisation, for example.
2.3 Manual Annotation Process
Annotators in the field of derivational morphologyhave to make many small decisions at once, even ifthey are only supposed to annotate Boolean deci-sion like whether a given derivational relation is ac-ceptable, e.g., glatt (smooth)>Glätte (smoothness)vs. glätten (to smooth) > Glätte (smoothness). Tofulfil the conditions of the linguistic approach de-scribed in Section 2.1, they must decide (i) whethera given derived lexeme is really a derivative; ifyes, then (ii) from which base lexeme it is derived;and (iii) whether the final decision does not violateconstraints of the rooted tree structure with otherderivationally related lexemes; and (iv) whetherthey decide consistently across derivational fami-
1Perhaps the earliest modern case of a large-scale resourceis CELEX2 (Baayen et al., 1995) with its annotations of deriva-tional morphology of Dutch, English, and German.
2For example: DeriNet for Czech (Vidra et al., 2021),Spanish (Faryad, 2021), Persian (Haghdoost et al., 2019), andRussian (Kyjánek et al., 2021), Polish and Spanish Word-Formation Networks (Mateusz et al., 2018a,b), and WordFormation Latin (Litta et al., 2016).
3https://ufal.mff.cuni.cz/universal-derivations
4They are described in the text on the harmonisation.
1 + glatt_A Glätte_Nf2 + glatt_A glätten_V3 + glätten_V glättend_A4 - glätten_V Glätte_Nf
Figure 2: Example of a common .tsv file format formanual annotation. The data is stored in columns (an-notator’s mark, base lexeme, and derivative; lexemesare equipped with part-of-speech tags: A for adjectives,V for verbs, Nf for feminine nouns).
lies. As these questions are interrelated, their sim-plification seems to be out of the question.
One of the common ways of making manual an-notation of derivational relations is to list them ina file and assign each of them with a mark repre-senting the presence/absence of the relation in theresulting rooted tree, see Figure 2. The annota-tion task seems easy if the data for annotation issmall; however, the data is relatively large in prac-tice. For instance, you can see manual annotationsof one thousand relations from Wiktionary anno-tated before their addition into DeriNet for Czech.5
Moreover, individual derivational families can berelatively large, especially in languages with richderivational morphology, which even complicatesthe annotation process.
2.4 Tools for Linguistic Annotation
To the best of our knowledge, there is no availabletool for making manual annotation of derivationalmorphology. The previous cases have relied oneither non-public software developed solely for theannotation project or on simple text-based methods.There are few visualisation tools that at least dis-play the data, e.g., WFL explorer6 (Passarotti andMambrini, 2012), DeriNet viewer7 (Žabokrtskýet al., 2016), DeriSearch v18 and v29 (Vidra andŽabokrtský, 2017, 2020), and Canoonet.10 How-ever, none of them allows editing the data.
There are also no case studies for annotation ofderivational morphology neither in the ACL An-thology nor in the recent Handbook of Linguis-tic Annotation (Ide and Pustejovsky, 2017). How-ever, the handbook and other similar cases from
5https://github.com/vidraj/derinet/blob/
master/data/annotations/cs/2018_04_wiktionary/hand-annotated/der0001-1000.tsv
6http://wfl.marginalia.it/
7https://ufal.mff.cuni.cz/derinet/derinet-viewer
8https://ufal.mff.cuni.cz/derinet/derinet-search
9https://quest.ms.mff.cuni.cz/derisearch2/v2/
databases/10https://www.lehrerfreund.de/schule/1s/
online-grammatik-canoo/2319
11

Figure 3: Screenshot of the freely available online Inter-face for manual annotation of derivational morphology.It captures the same derivational family as Figure 2.
the fields of annotating data resources of syntax(cf. Tyers et al. (2017)) and inflectional morphol-ogy (cf. Obeid et al. (2018); Alosaimy and Atwell(2018)) suggest that visualisation of the deriva-tional data and a possibility to edit it in the vi-sualisation interface is one of the best options tofacilitate the annotation process.
3 Interface for Manual Annotations
The new interface should visualise the annotateddata (cf. Figure 2) and allow annotators to edit it,leading to the facilitation of the annotation pro-cess. In this case, the process should lead to thedata of derivational morphology annotated into thetree-shaped structure presented in Section 2.1. Thefunctionality and design of the interface have al-ready been tested by real annotators. They providedfeedback for re-designing the interface to the cur-rent state, see Figure 3. Validation of the interfaceis presented in Section 4.
The development of such tools however neverends, as many things can be still improved. There-fore, the interface is distributed as open-source (onGitHub)11 with a detailed manual that includes alsoexample data. It is possible to run the interface bothlocally and online.12
3.1 Technical Properties
The interface is made as a web application thanksto which annotators can run it in any web browser,e.g., Microsoft Edge, Google Chrome, MozillaFirefox, and Safari. It prevents problems with
11https://github.com/lukyjanek/
uder-annotation-interface12https://lukyjanek.github.io/subpages/
uder-annotation-interface/UDerAnnotation.html
1 [2 3 "nodes":4 [5 "data":6 "name":"glättend_A","id":"glättend_A"7 ,8 "data":9 "name":"Glätte_Nf","id":"Glätte_Nf"
10 ,11 "data":12 "name":"glatt_A","id":"glatt_A"13 ,14 "data":15 "name":"glätten_V","id":"glätten_V"16 17 ],18 "edges":19 [20 "data":21 "target":"glatt_A","source":"Glätte_Nf",22 "intoTree":"solid"23 ,24 "data":25 "target":"glatt_A","source":"glätten_V",26 "intoTree":"solid"27 ,28 "data":29 "target":"glätten_V","source":"Glätte_Nf",30 "intoTree":"dotted"31 ,32 "data":33 "target":"glätten_V","source":"glättend_A",34 "intoTree":"solid"35 36 ]37 38 ]
Figure 4: Input and output .json format of the annota-tion data for the interface from Figure 3.
users’ installation of any programming environ-ments. The interface is responsive by default (with-out implementing the interface separately for in-dividual types of devices), so the annotators canannotate not only on their computers but also ontouchscreens of their mobile devices. The inter-face is programmed using HTML5, CCS3, andJavaScript with the libraries jQuery, CytoScape.js,and Notify.js. These technologies runs the inter-face on the client’s side/user’s device that bringsthe mention benefit, but, on the other hand, theinterface suffers from the limits of web browsers.13
As for the input/output file formats, the interfaceis ready to process derivational families stored inthe .json format; see Figure 4. There is also a func-tion implemented to convert the .tsv file into the.json file and vice versa (the TSV_to_JSON andJSON_to_TSV buttons).
3.2 Design and FunctionalityThe interface screen consists of top and bottom but-ton bars and a central canvas for data visualisation
13For instance, Google Chrome has a memory limit of512MB for 32-bit and 1.4GB for 64-bit systems. However, itis still enough memory for common manual annotation.
12

and annotation. While the top bar includes supportbuttons, such as a link to the source codes storedon GitHub and manual, the bottom bar containsbuttons for manual annotation.
The data is loaded using the Upload_JSONbutton. The annotator can zoom in/out the screenand move the displayed nodes and their relations.Positions of nodes on canvas are stored in the .jsonfile. Annotators can thus return quickly to alreadyannotated derivational families. During the annota-tion process, they select relations to be annotatedand change their state by one of the followingbuttons: Restore_edge (draws the relation bya solid line representing that it should be presentin the resulting family) or Remove_edge (dottedline, should be absent). The annotators can switchbetween families using the green arrow buttons orthe text box. At the end of the annotation, the workis saved with the Save_JSON button.
Several functionalities have been added basedon the annotators’ feedback. If the annotator writesa word or its substring to the text box, the interfacesearches for the family containing the word/sub-string and visualises it. To facilitate the annotationof families with many relations, there are two but-tons that remove and restore all derivational rela-tions in the displayed derivational family. For an-notators, it is sometimes easier to remove all edgesand build such a large tree from scratch by restor-ing individual edges. Some buttons list all lexemesfrom the visualised family and check whether thesolid lines in the annotated family are organisedin a rooted tree. In addition, keyboard shortcutshave been introduced for all the functions. Afterall these changes, the annotators confirmed that theinterface makes their work easier and faster.
3.3 Applicability to Different Tasks
To show the robustness of the new interface forannotation of data in tree-shaped structures, a briefexperiment with annotating syntactic data has beenperformed. The harmonised syntactic data fromthe Universal Dependencies collection (Zemanet al., 2021) was selected for this experiment. Theonly thing in need was to create a script thatwould convert the input .conllu format into the.json format required by the annotation interface.Figure 5 displays the German sentence ’Absolutempfehlenswert ist auch der Service.’ (The serviceis also highly recommended.) from the corpus GSD(McDonald et al., 2013) in the annotation interface.
Figure 5: Screenshot of the freely available online In-terface for manual annotation of derivational morphol-ogy applied to the data from syntactic treebank fromUniversal Dependencies. The underscores separate id,token, lemma, part-of-speech category.
4 Human Validation
To validate the usefulness of the newly created in-terface for manual annotation of derivational mor-phology, as described in the Section 2.3, a simpleannotation experiment has been done with humanannotators. Two methods of manual annotation arecompared: (a) the currently used method when an-notators work in the traditional text processor withthe .tsv format, and (b) the annotation by using thenewly created visual interface with the .json format.The main expectation is that annotating the samedata by using the interface should be faster. The in-dividual parts of this experiment, such as the inputsample as well as the annotated ones, are stored onthe GitHub repository with the source codes.
4.1 Annotation Experiment
The experiment involved 12 human annotators (uni-versity students of other than linguistic studies).They all annotated the same sample of derivationalfamilies; however, six of the annotators did it in thetext processor with the .tsv file format, i.e., the cur-rently used method of annotation such data, whilethe other six annotators used the newly createdvisual interface with the .json file format.
The annotators were instructed to annotate thegiven data in a such way that it concurs with theapproach to model derivational families in rootedtrees (Section 2.1), i.e., that each lexeme can haveat most one base lexeme and that the morpholog-ical complexity should grow from the root to theleaves. They also got the instructions related to theindividual annotation methods, e.g., all functionali-ties and buttons of the interface were explained tothe annotators who would use the interface.
13

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20ANNOTATED FAMILY
0
100
200
300
400
500
600
700TI
ME
[s]
Way of annotation.tsv.json
Figure 6: Time spent by annotators on annotating individual 20 derivational families in the .tsv file format andusing the new visual interface with the .json file format.
.tsv .jsonWAY OF ANNOTATION
1000
1500
2000
2500
3000
3500
TIM
E [s
]
Figure 7: Total time spent by annotators on annotating20 derivational families in the .tsv file format and usingthe new visual interface with the .json file format.
4.2 Annotation Sample
The annotation sample consisted of two similar setsof ten different derivational (sub-)families selectedfrom Czech DeriNet with respect to their numbersof lexemes, derivational relations, depths (morpho-logical complexity) of the original trees, and thepart-of-speech categories of the tree roots. Eachset of the sample thus includes four families withthe noun and verbal tree roots and two familieswith the adjective tree roots; it has the followingranges: for the number of lexemes from 6 to 20, forrelations from 6 to 24, for depth from 2 to 5.
A few random incorrect connections (from 2 to5 relations) were made in all families in the sample.The annotators were supposed to annotate theseerrors and let the other correct relations.
The division of the sample into two sets of tenfamilies can provide an overview of how the an-notators’ experience with the annotation using theassigned method influence the time spent on theannotation of individual families. The assumptionassociated with this is that the time spent over thesecond set should be less than for the first set be-cause the annotators learn the annotation processwith each annotated family. On the other hand, ifthe visual interface is useful, then the time spent onannotating the .json file format by using the inter-face should be still lower than on the annotation ofthe .tsv file format.
As for the specific properties of the individualfamilies in the sample, the smallest families interms of the number of lexemes are numbered as1, 2, 9, 10, 11, 12, 19, 20; and the families 9 and19 includes a complete graph which the annotatorshave to annotate into the rooted tree structure.
4.3 ResultsThe main hypothesis that the annotation process isfaster if the newly created visual interface is used(with .json format) instead of the current annota-tion method (with .tsv format) was proved, at leastfor Czech, a language that has rich derivationalmorphology. Annotators with the visual interfaceannotated faster in the case of all annotated deriva-tional families; see Figure 6. However, the differ-ence in time was small for smaller families, whichindicates that the current .tsv annotation methodis comparably good as the annotation using theinterface in the case of derivational families withfew tens of relations. If the family is bigger, then
14

the annotators were much faster when using thevisual interface. In total, Figure 7 illustrates thatthe annotation process with visual interface takesnoticeably fewer seconds than the currently usedannotation method.
The secondary hypothesis that the annotatorsare faster in the second half of the sample, espe-cially when this half shares the same parametersin terms of numbers of lexemes and relations, wasnot proved so conclusively as the main hypothesis.There is such trend in the second half of the sample,but the differences are not so radical.
5 Conclusion
When developing high-quality data, especially datathat contains more complicated structures, develop-ers often ask for manual annotations. They need theannotations when they create, extend, test, or eval-uate the data. Annotation of complex phenomenais time-consuming and increases data productioncosts. Therefore, it seems worth spending time tosimplify the annotation process.
In this paper, a case study about manual anno-tation of complex phenomena from derivationalmorphology has been presented. As a way of sim-plifying the annotation process, a web-based visualannotation interface in which annotators can editthe displayed data has been created. The interfaceis freely available (cf. Footnote 11). It was cre-ated in direct collaboration with several annotatorswho tested the interface on data of real derivationalfamilies and provided useful feedback. The anno-tators have also rated the annotation process withthe created interface as more attractive, easier, andfaster, which led to greater savings of time (andpotentially money spent on the development of theresulting resource while still achieving high qual-ity). Their feedback has led to the addition of sev-eral new functionalities, such as keyboard shortcutsand the button for checking treeness, that signifi-cantly speed up the annotation process. In addition,the desired benefits of the interface have been val-idated by annotators, and the paper describes thisvalidation. It confirms that usage of the new in-terface rapidly speeds up the annotation processcompared to the current method of annotating datafor derivational morphology.
In general, this paper underlines that a tool/inter-face can be created by relatively basic techniquesbut can still save a lot of annotators’ time and ef-fort. One of the crucial points is, however, to be
open-minded and to communicate with annotators.Since the annotators know how they must thinkduring the annotating, they can specify their needsand provide informed feedback. There is still (andalways will be) a lot of ways in which such inter-face can be improved or extended; they remain forfuture work. The important message is that evena simple interface can greatly facilitate the manualannotation process. While a programmer createssuch interface in a few hours, annotators can savedays of work.
Acknowledgements
This work was supported by the Grant No. GA19-14534S of the Czech Science Foundation, and theGrant No. START/HUM/010 of Grant schemes atCharles University (reg. No. CZ.02.2.69/0.0/0.0/19_073/0016935). It was using language resourcesdeveloped, stored, and distributed by the LINDAT/CLARIAH-CZ project.
ReferencesAbdulrahman Alosaimy and Eric Atwell. 2018. Web-
based Annotation Tool for Inflectional Language Re-sources. In Proceedings of the 11th InternationalConference on Language Resources and Evaluation(LREC 2018), pages 3933–3939.
Harald R. Baayen, Richard Piepenbrock, and Leon Gu-likers. 1995. CELEX2. Linguistic Data Consortium,Catalogue No. LDC96L14.
Klára Buzássyová. 1974. Sémantická struktúra sloven-ských deverbatív. Veda, Bratislava.
Miloš Dokulil. 1962. Tvorení slov v ceštine 1: Teorieodvozování slov. Academia, Prague.
Ján Faryad. 2021. DeriNet.ES 0.6. Institute of Formaland Applied Linguistics (ÚFAL), Faculty of Mathe-matics and Physics, Charles University; included inthe UDer collection.
Juraj Furdík. 2004. Slovenská slovotvorba. NÁUKA,Prešov.
Hamid Haghdoost, Ebrahim Ansari, Zdenek Žabokrt-ský, and Mahshid Nikravesh. 2019. DeriNet.FA 0.5.Institute of Formal and Applied Linguistics (ÚFAL),Faculty of Mathematics and Physics, Charles Uni-versity; included in the UDer collection.
Ján Horecký, Klára Buzássyová, Ján Bosák, et al. 1989.Dynamika slovnej zásoby súcasnej slovenciny. Veda,Bratislava.
Nancy Ide and James Pustejovsky. 2017. Handbook ofLinguistic Annotation, 1st edition. Springer Publish-ing Company, Incorporated.
15

Lukáš Kyjánek, Zdenek Žabokrtský, Jonáš Vidra, andMagda Ševcíková. 2021. Universal Derivations v1.1.LINDAT/CLARIAH-CZ digital library at the Insti-tute of Formal and Applied Linguistics (ÚFAL), Fac-ulty of Mathematics and Physics, Charles Univer-sity.
Lukáš Kyjánek, Zdenek Žabokrtský, Magda Ševcíková,and Jonáš Vidra. 2020. Universal Derivations1.0, A Growing Collection of Harmonised Word-Formation Resources. The Prague Bulletin of Math-ematical Linguistics, 115:5–30.
Lukáš Kyjánek. 2018. Morphological Resources ofDerivational Word-Formation Relations. TechnicalReport TR-2018-61, Faculty of Mathematics andPhysics, Charles University.
Lukáš Kyjánek, Olga Lyashevskaya, AnnaNedoluzhko, Daniil Vodolazsky, and ZdenekŽabokrtský. 2021. DeriNet.RU 0.5. Institute ofFormal and Applied Linguistics (ÚFAL), Facultyof Mathematics and Physics, Charles University;included in the UDer collection.
Eleonora Litta, Marco Passarotti, and Chris Culy. 2016.Formatio Formosa est. Building a Word FormationLexicon for Latin. In Proceedings of the 3rd Ital-ian Conference on Computational Linguistics, pages185–189.
Lango Mateusz, Magda Ševcíková, and ZdenekŽabokrtský. 2018a. Polish Word-Formation Net-work 0.5. Institute of Formal and Applied Linguis-tics (ÚFAL), Faculty of Mathematics and Physics,Charles University; included in the UDer collection.
Lango Mateusz, Magda Ševcíková, and ZdenekŽabokrtský. 2018b. Spanish Word-Formation Net-work 0.5. Institute of Formal and Applied Linguis-tics (ÚFAL), Faculty of Mathematics and Physics,Charles University; included in the UDer collection.
Ryan McDonald, Joakim Nivre, Yvonne Quirmbach-Brundage, Yoav Goldberg, Dipanjan Das, Kuz-man Ganchev, Keith Hall, Slav Petrov, HaoZhang, Oscar Täckström, Claudia Bedini, NúriaBertomeu Castelló, and Jungmee Lee. 2013. Univer-sal Dependency Annotation for Multilingual Parsing.In Proceedings of the 51st Annual Meeting of the As-sociation for Computational Linguistics (Volume 2:Short Papers), pages 92–97, Sofia, Bulgaria. Associ-ation for Computational Linguistics.
Ossama Obeid, Salam Khalifa, Nizar Habash, HoudaBouamor, Wajdi Zaghouani, and Kemal Oflazer.2018. MADARi: A web interface for joint Arabicmorphological annotation and spelling correction.In Proceedings of the 11th International Confer-ence on Language Resources and Evaluation (LREC2018).
Marco Passarotti and Francesco Mambrini. 2012. FirstSteps towards the Semi-automatic Development of
a Wordformation-based Lexicon of Latin. In Pro-ceedings of the 8th International Conference onLanguage Resources and Evaluation (LREC 2012),pages 852–859.
Pavol Štekauer. 2005. Onomasiological Approach toWord-Formation. In Pavol Štekauer and RochelleLieber, editors, Handbook of Word-Formation,pages 207–232. Springer, Dordrecht.
Pavol Štekauer, Salvador Valera, and Lívia Körtvé-lyessy. 2012. Word-Formation in the World’s Lan-guages: A Typological Survey. Cambridge Univer-sity Press, New York.
Francis Tyers, Mariya Sheyanova, and Jonathan Wash-ington. 2017. UD Annotatrix: An annotation toolfor Universal Dependencies. In Proceedings of the16th International Workshop on Treebanks and Lin-guistic Theories, pages 10–17.
Jonáš Vidra, Zdenek Žabokrtský, Lukáš Kyjánek,Magda Ševcíková, Šárka Dohnalová, Emil Svo-boda, and Jan Bodnár. 2021. DeriNet 2.1.LINDAT/CLARIAH-CZ digital library at the Insti-tute of Formal and Applied Linguistics (ÚFAL), Fac-ulty of Mathematics and Physics, Charles Univer-sity; included in the UDer collection.
Jonáš Vidra and Zdenek Žabokrtský. 2017. OnlineSoftware Components for Accessing DerivationalNetworks. In Proceedings of the Workshop on Re-sources and Tools for Derivational Morphology (De-riMo 2017), pages 129–139. EDUCatt.
Jonáš Vidra and Zdenek Žabokrtský. 2020. NextStep in Online Querying and Visualization of Word-Formation Networks. In Proceedings of the 23rdInternational Conference on Text, Speech and Dia-logue (TSD 2020), pages 144–152. Springer.
Britta Zeller, Jan Šnajder, and Sebastian Padó. 2013.DErivBase: Inducing and Evaluating a DerivationalMorphology Resource for German. In ACL, vol-ume 1, pages 1201–1211. Proceedings of the 51stAnnual Meeting of the Association for Computa-tional Linguistics (Volume 1: Long Papers).
Daniel Zeman, Joakim Nivre, Mitchell Abrams,et al. 2021. Universal Dependencies 2.9.LINDAT/CLARIAH-CZ digital library at theInstitute of Formal and Applied Linguistics (ÚFAL),Faculty of Mathematics and Physics, CharlesUniversity.
Zdenek Žabokrtský, Magda Ševcíková, Milan Straka,Jonáš Vidra, and Adéla Limburská. 2016. Merg-ing Data Resources for Inflectional and DerivationalMorphology in Czech. In Proceedings of the 10th In-ternational Conference on Language Resources andEvaluation (LREC 2016), pages 1307–1314.
16

Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies: System Demonstrations, pages 17 - 26
July 10-15, 2022 ©2022 Association for Computational Linguistics
TurkishDelightNLP: A Neural Turkish NLP Toolkit
Hüseyin AleçakırAfiniti
Necva BölücüComputer EngineeringHacettepe University
Burcu CanRGCL
University of WolverhamptonWolverhampton
Abstract
We introduce a neural Turkish NLP toolkitcalled TurkishDelightNLP that performs com-putational linguistic analyses from morpholog-ical level to semantic level that involves taskssuch as stemming, morphological segmenta-tion, morphological tagging, part-of-speech tag-ging, dependency parsing, and semantic pars-ing, as well as high-level NLP tasks such asnamed entity recognition. We publicly sharethe open-source Turkish NLP toolkit througha web interface that allows an input text to beanalysed in real-time, as well as the open sourceimplementation of the components providedin the toolkit, an API, and several annotateddatasets such as word similarity test set to eval-uate word embeddings and UCCA-based se-mantic annotation in Turkish. This will be thefirst open-source Turkish NLP toolkit that in-volves a range of NLP tasks in all levels. We be-lieve that it will be useful for other researchersin Turkish NLP and will be also beneficial forother high-level NLP tasks in Turkish.
1 Introduction
Turkish is one of the low-resource languages with arich morphology. Although still limited, there hasbeen an increasing interest in Turkish NLP in thelast decade. Being a morphologically productivelanguage is the main drawback of the Turkish NLPresearch. Current deep learning models are notori-ously data-hungry. When it comes to morpholog-ically productive languages, the data requirementsubstantially increases compared to other morpho-logically poor languages. This is due to the numberof different word forms that can be generated via in-flection and/or derivation. Although current wordembedding models such as BERT (Devlin et al.,2019) rely on tokenization that considers sub-wordtokens rather than word tokens, the recent research(Haley, 2020) still shows that the performance ofsuch models degrades with novel words.
We introduce a new neural Turkish NLP toolkitthat involves the following linguistic and NLP tasksin Turkish: Stemming, morphological segmenta-tion, morphological tagging, part-of-speech tag-ging, dependency parsing, semantic parsing, andnamed entity recognition. Morphological segmen-tation, morphological tagging, part-of-speech tag-ging, and dependency parsing are learned jointlyusing a multi-task learning approach. Most of theprevious work on Turkish morphology and syntaxconsiders morphological and syntactic tasks as in-dependent problems. However, syntax is stronglydefined by morphology and vice versa, especiallyin agglutinative languages. Therefore, in this study,we benefit from the mutual interaction betweenmorphological and syntactic layers in the language.
All components apart from semantic parsingmodel are built on LSTMs that are capable of learn-ing especially long distance relations. The modelsalso utilise a Bahdanau (Bahdanau et al., 2015)attention mechanism in various layers for an ef-ficient learning of the valuable contextual infor-mation within the sentence/word. Moreover, weinvestigate cross-level information flow betweenthe layers by incorporating information betweenwords in different time steps. As distinct from theother components, semantic parsing model adoptsan encoder-decoder model where the encoder isbased on self-attention mechanism (Vaswani et al.,2017).
TurkishDelightNLP is available at http://rgcl.wlv.ac.uk/TurkishNLP/ and thesource codes of all components are also publiclyavailable, which are specified in each section be-low. We also provide API to allow users to processtheir data using HTTP requests1. In addition tothe NLP toolkit, we provide few datasets; that arean UCCA-based semantic annotation for Turkish,
1The REST API for the TurkishDelightNLP toolkitis available at https://github.com/halecakir/turkish-delight-nlp-api.
17

a Turkish stemming training set based on METU-Sabanci Turkish Treebank (Oflazer et al., 2003b),and a word similarity test set along with the hu-man judgements for assessing morphologically richTurkish word embeddings.
2 Related Work and Tools on TurkishNLP
Despite being a low-resource language, Turkish hasbeen one of the actively studied languages amongother low-resource languages especially in the lastdecade. Numerous models have been recently re-leased for Turkish. However, most of them werenot released publicly available, and they were notshared as tools that facilitate generating a resultin real time. The earlier studies on Turkish mor-phology include morphological analyzers such asthe two-level description of Turkish morphology(Oflazer, 1993), the stochastic morphological ana-lyzer based on finite state transducers (Sak et al.,2009), paradigmatic approaches (Can and Man-andhar, 2009, 2012, 2018), and few other opensource analyzers such as Zemberek (Akın and Akın,2007), TRmorph (Çöltekin, 2010), and the syn-tactically expressive morphological analyzer byOzturel et al. (2019). The earlier studies also in-volve dependency parsers such as the probabilis-tic and deterministic dependency parser by Ery-igit et al. (2008), the two-phase statistical parserbased on Conditional Random Fields (CRFs) byDurgar El-Kahlout et al. (2014), and the recentneural parser by Tuç and Can (2020). There area couple of Turkish stemmers introduced such asthe probabilistic stemmer by Dincer and Karaoglan(2003), and the finite state machine-based Govde-Turk by Yücebas and Tintin (2017); a few part-of-speech taggers were also proposed such as theHidden Markov Model-based PoS tagger by Dinçeret al. (2008), the deterministic tagger using thetwo-level morphological description by Oflazerand Kuruoz (1994), and unsupervised Bayesian ap-proaches (Bölücü and Can, 2019, 2021). The firstsemantic parsing annotation for Turkish (Azinand Eryigit, 2019) has been presented for AbstractMeaning Representation (AMR) (Flanigan et al.,2014) and there is not any other semantic parserintroduced for Turkish yet, to our knowledge.
As seen, most of the linguistic analysis taskson Turkish are based on either statistical or deter-ministic approaches. Currently, the Turkish NLPresearch focuses more on NLP applications such
as named entity recognition (Günes and Tantug,2018; Güngör et al., 2019; Esref and Can, 2019),text classification (Tokgoz et al., 2021), sentimentanalysis (Gezici et al., 2019; Demirci et al., 2019),offensive language identification (Ozdemir andYeniterzi, 2020), text summarisation (Ertam andAydin, 2021), text normalisation (Göker and Can,2018) with especially the availability of the largepretrained neural word embeddings in almost anylanguage.
Most of the NLP tools in Turkish were releasedbefore the deep learning era and they still have notbeen replaced by the neural network approachesand the researchers in the field still use the old-fashioned statistical and deterministic models formorphological or syntactic processing. We aim tofill this gap with our Turkish NLP toolkit by intro-ducing better performing neural-based methods forTurkish linguistic analysis and NLP. The most sim-ilar one to our toolkit is ITU NLP Toolkit (Eryigit,2014) that also involves a wide range of NLP toolssuch as normalization, spell correction, morpho-logical analysis, dependency parsing, and namedentity recognition. However, all of their modelsare independent from each other and they are builton either deterministic or statistical machine learn-ing algorithms. Our toolkit deviates from theirs byadopting neural models and analysing morphologyand syntax jointly by considering the interactionbetween them. Moreover, their toolkit does notinvolve any semantic parsing as ours.
3 About Turkish
Turkish is an agglutinating language with a richmorphology. The morphological rules are quiteregular in Turkish that define the order of the mor-phemes in a word, as well as the morphophonemicprocesses such as consonant mutation and vowelharmony, which lead the suffix and the final con-sonant and vowel in a word to be harmonised witheach other mutually. Therefore, a morpheme canhave tens of different surface forms in Turkish,which are allomorphs of the same morpheme. InTurkish, syntactic information is encoded in in-flectional morphemes. For example, the word ‘yapabilecegim’ (in English, ‘ I will be able to do’)involves the following inflectional morphemes thateach correspond to a syntactic role: ‘ -abil’ (’beable’), ‘ -eceg’ ( ‘ will’), and ‘ -im’ ( ‘ I’).
In this paper, we propose to process every wordconsidering its left and right context through a
18

cross-level information from morphological seg-ments up to dependencies in a moving window, sothat morphological information of the contextualwords help to analyse the PoS tags, and the PoSinformation of the contextual words help to analysethe dependency relations in a sentence.
4 A Neural Turkish NLP Toolkit
The introduced toolkit involves different compo-nents that are all described thoroughly below.
4.1 Stemmer
The stemmer is built on an encoder-decoder modelthat employs a bidirectional LSTM (Can, 2019).The model has two versions, one without an at-tention mechanism considering all characters withequal probability and another version with Bah-danau attention (Bahdanau et al., 2015) over char-acters of a given word in both directions to learncharacter-based contextual information. The modelis trained on a dataset with 17025 word types alongwith their stems obtained from Metu-Sabanci Tree-bank (Oflazer et al., 2003b). Both the model thatis implemented in DyNet (Neubig et al., 2017) andthe dataset are publicly available2. The accuracy ofthe stemmer is 85% and comparable to that of Zem-berek (Akın and Akın, 2007), and outperforms theother open-source Turkish stemmers (Zafer, 2015).
4.2 Joint Morphology and Syntax Model
A multi-task learning model is proposed for jointlearning of morphology and syntax (Can et al.,2022). The model is built upon a multi-layer LSTMstructure where each layer contributes to the overallloss in a joint learning framework and the errorsfrom all layers backpropagate from top layer to thebottom. LSTM structure has been preferred bothdue its low size data requirement compared to trans-formers and the flexibility of processing sequentialinformation by controlling the vertical informationflow between the layers. The model is trained onIMST Turkish Treebank (Sulubacak et al., 2016).The model involves 4 layers where each of themadopts a bidirectional LSTM that is specialisedin either morphology or syntax. The layers arededicated for morphological segmentation, mor-phological tagging, part-of-speech tagging, and de-pendency parsing. The order of the layers has beendesigned based on the direction of the information
2https://github.com/burcu-can/Stemmer
flow and the size of the units (from smaller to big-ger). A separate component for morph2vec (Üstünet al., 2018) that is used to pretrain the morphemeembeddings is also involved.
The joint model is trained and evaluated onUD Turkish Treebank, which is called IMSTTreebank (Sulubacak and It, 2018) and it isa re-annotated version of the METU-SabanciTreebank (Oflazer et al., 2003a). For the pre-trained word embeddings, we use pre-trained 200-dimensional word embeddings trained on BounWeb Corpus (Sak et al., 2008) provided by CoNLL2018 Shared Task. The overall architecture ofthe joint model is given in Figure 1, where eachcoloured component belongs to a different level ofprocessing that starts from morphological segmen-tation till dependency parsing. Each level is builton LSTMs that sequentially process every unit (i.e.character, morpheme, word, or syntactic informa-tion) in a given sentence by utilising the contex-tual information as well (see Section 4.2.6 for thedetails of the cross-level information flow). Anexample analysis is also provided in Figure 2 andFigure 3. All layers are described in detail below.The open-source implementation in DyNet (Neubiget al., 2017) is publicly available3.
4.2.1 Morpheme-based Word Embeddings:morph2vec
Morph2vec (Üstün et al., 2018) is a morpheme-based word embedding model that learns wordembeddings as a weighted sum of word embed-dings each of which are obtained from a particu-lar morphological segmentation of a word. It isassumed that the correct morphological segmen-tation of a word is not known apriori; therefore,each potential morphological segmentation of aword is predicted before training the model. Eachmorphological segmentation is fed into a bidirec-tional LSTM with each LSTM unit being fed with amorpheme embedding that is randomly initialised.So each LSTM generates a word embedding forthat particular morphological segmentation. Fi-nally, Bahdanau attention mechanism (Bahdanauet al., 2015) is employed to learn the weight ofeach segmentation-specific word embedding. Themorpheme-based embeddings give a better Spear-man correlation with the human judgements inword similarity tasks compared to both char2vec(Cao and Rei, 2016) and fasttext (Bojanowski et al.,
3https://github.com/halecakir/JointParser
19

Figure 1: The layers of the proposed joint learning framework. The sentence “Ali okula gitti.” (“Ali went to school”)is processed from morphology up to dependencies (Can et al., 2022).
2017). The source code in DyNet is publicly avail-able4, and the datasets for syntactic analogy andword similarity along with the human judgementscores are also publicly available5.
Morph2vec is pre-trained on METU-Sabanci4https://github.com/burcu-can/
morph2vec_dynet5https://nlp.cs.hacettepe.edu.tr/
projects/morph2vec/
Turkish Treebank (Oflazer et al., 2003b) beforetraining the joint morphology and syntax model.Therefore, pretrained morpheme embeddings areused during joint learning.
4.2.2 Morphological Segmentation
The lowest layer of the joint model performs mor-phological segmentation through a bidirectional
20

O iyi insanlar o güzel atlara binip çekip gittilero iyi insan-lar o güzel atlar-a binip çekip git-ti-ler
DET ADJ NOUN DET ADJ ADJ VERB VERB VERB- - people-nom-3p - - horse-dat-3p got on-conv go away-conv go-3p-plu-past
det
amod
det
amod
amod
nmod nmod
nsubj
root
‘Those good people got on those beautiful horses and left.’
Figure 2: An example analysis of the toolkit for a sentence in Turkish. First line: The orthographic form. Second line:morphological segments. Third line: PoS tags. Fourth line: morphological features (’-’ is for null). Dependencies inthe article are arrowed (head to dependent) and labeled UD dependencies (de Marneffe et al., 2021).
Figure 3: The UCCA-based semantic parse tree of the sentence, O iyi insanlar o güzel atlara binip çekip gittiler. (inEnglish, “Those good people got on those beautiful horses and left")
LSTM that encodes each character of a given wordwith one hot encoding. The output at each time stepis reduced to a single dimension using a multilayerperceptron (MLP) with sigmoid function to predictwhether there is a morpheme boundary after thatcharacter or not. Each value above 0.6 refers to amorpheme boundary, and below means that thereis not a morpheme boundary at that time step afterthe current character. Binary cross entropy is usedfor this layer that contributes to the overall loss ofthe joint model.
We obtain the gold segments from the rule-basedmorphological analyser Zemberek (Akın and Akın,2007) to train the segmentation component sincethe IMST Treebank does not involve morpholog-ical segmentations but only morphological tags.Our joint model performs 98.97% of accuracy onmorphological segmentation task6.
4.2.3 Morphological TaggingWe adopt an encoder-decoder model for the mor-phological tagging layer. To encode the relevant
6It should be noted that the test set is also obtained fromZemberek.
contextual information both within the word andwithin the sentence, we use a character encoder andword encoder respectively. The character encoderprocesses the characters within the given word thatwill be analysed and the word encoder processesthe contextual words in that sentence to better pre-dict the morphological tagging of the given word ina particular context, which can also help to disam-biguate the word in a particular context. Both of theencoders are built on bidirectional LSTMs and bothof them adopt a Bahdanau attention (Bahdanauet al., 2015) to learn the weights over charactersand words. The input to the decoder is the con-catenation of the weighted outputs obtained fromboth character and context encoders. The decoderis also built on a bidirectional LSTM that gener-ates morpheme tags using a softmax function ateach time step. Our joint model performs 87.59%FEATS score on morphological tagging, and com-parable to a recently introduced neural Turkish mor-phological tagger that performs 89.54% FEATSscore (Dayanık et al., 2018).
21

4.2.4 Part-of-Speech TaggingThe PoS tagging layer is built upon a bidirectionalLSTM that is fed with the concatenation of word-level (i.e. word2vec embeddings), character-level(learned through a character BiLSTM for eachword), morpheme-level (i.e. morph2vec), and mor-pheme tag encodings of each particular word in asentence. Morpheme-level word embeddings areobtained from pretrained morph2vec as mentionedbefore. However, the other embeddings are all ran-domly initialised and learned during training. Theoutput at each time step is passed through an MLPwith softmax activation function to predict the PoStag of the word at that time step. Our joint modelperforms exactly the same with the state-of-art PoStagger by Che et al. (2018) with an accuracy of94.78%.
4.2.5 Dependency ParsingThe dependency parsing is also built on BiLSTMthat is fed with the same embeddings used in PoStagging layer, and in addition, we concatenate thePoS encodings of the words that are obtained fromthe previous layer. PoS encodings are randomlyinitialised and learned during training. The arcsare scored by an MLP that involves a pointer net-work that predicts whether there is an arc betweenthe given two words or not. Once the scores arepredicted by the MLP, the projective trees are gen-erated using Eisner’s decoding algorithm (Eisner,1996). Labels are analogously predicted using an-other MLP with a softmax function. Our jointmodel gives comparable results with the state-of-art dependency parsing results of Straka (2018)with 71% UAS and 63.92% LAS (whereas Straka(2018) achieves 72.25% UAS and 66.44% LAS).
4.2.6 Cross-Level Information FlowThe custom in such a multi-layered and multi-taskmodels is to feed the obtained information regard-ing the current word from the previous layers topass it over to the upper layers for the same word(Nguyen and Nguyen, 2021). However, to ourknowledge, we are the first to analyse cross-levelinformation flow between the layers by allowinginformation flow across different words in differentlayers. For this, we incorporate contextual infor-mation from the previous word to the current wordin different layers, by adding contextual informa-tion obtained from morpheme tagging encodingand morpheme encoding of the previous word toPOS and dependency layers of the current word.
Similarly, we incorporate POS tagging encodingof the previous word into the dependency layerof the current word. This is shown in Figure 1with PoSVerticalFlow, MorphTagVerticalFlow, andMorphVerticalFlow. The results show that suchcross-level information flow improves the perfor-mance of the model especially in upper layers.
4.3 Semantic Parsing
We use the Universal Conceptual Cognitive Annota-tion (UCCA) (Abend and Rappoport, 2013) frame-work for semantic annotation, which is a cross-lingual semantic annotation framework. Sincethere is no Turkish UCCA dataset, the model istrained using a combination of English, Germanand French datasets (Hershcovich et al., 2017)7,and the Turkish annotations are obtained in a zero-shot setting and manually revised. We annotated50 sentences obtained from METU-Sabaci TurkishTreebank that is also publicly available8.
We adopt an encoder/decoder model that tack-les the semantic parsing task in the form of achart-based constituency parsing (Bölücü and Can,2021)9. Self-attention layers (Vaswani et al., 2017)are used in the encoder where the encoding is fedinto an MLP with two fully-connected layers withReLU activation function, and the CYK (Cocke-Younger-Kasami) algorithm (Chappelier and Ra-jman, 1998) is used within the decoder that gen-erates the tree with the maximum score using thescores obtained from the encoder. Our TurkishUCCA-based semantic parser performs 81.11% F1score on labeled evaluation and 90.24% F1 scoreon unlabeled evaluation in few shot learning.
4.4 Named Entity Recognition (NER)
We use a BiLSTM-CRF model where each wordis encoded through a BiLSTM and decoded witha CRF layer to learn the named entities in a giventext (Kagan Akkaya and Can, 2021). We feed theBiLSTM with character-level (learned through acharacter-level BiLSTM), character n-gram-level(fasttext), morpheme-level (morph2vec), and word-level word embeddings (word2vec), as well as or-thographic embeddings that are learned either witha CNN or BiLSTM by encoding alphabetic charac-ters similar to that of Aguilar et al. (2017).
7https://github.com/UniversalConceptualCognitiveAnnotation
8https://github.com/necvabolucu/semantic-dataset9https://github.com/necvabolucu/ucca-parser
22

Figure 4: The user interface of the TurkishDelightNLP. The user selects a task from the dropdown menu on the leftand populates an input sentence. The output is displayed on the right.
Since the particular target domain for NER inour study is noisy text especially obtained fromsocial media, we use transfer learning to utiliseany available information in a formal but possiblylarger text to learn the named entities in an informalbut usually a smaller text. Therefore, we adopt twoCRF layers one of which is trained on the formaltext (i.e. Turkish news corpus) and the other oneis trained on an informal text (i.e. tweets) (Sekerand Eryigit, 2017). Training is performed alter-nately between the two CRF layers which sharethe same BiLSTM layer. Our named entity recog-nition model outperforms the current state-of-artmodel on noisy text by Seker and Eryigit (2017)with 67.39% F1 score on DS-1 v4 (Seker and Ery-igit, 2017). All source code and related material onNER are publicly available10.
5 Web Interface
TurkishDelightNLP is a Streamlit application thatprovides a simple user interface for producing pre-dictions for different tasks. We selected Stream-lit since it is a low-code web framework that en-ables researchers to easily create a data-drivenapp. Streamlit has a relatively simple applicationprogramming interface and it is specifically de-signed for data science applications. In TurkishDe-lightNLP, in the backend, query and model are
10https://github.com/emrekgn/turkish-ner
cached to avoid repeated calculations of the sameinput. Docker is used to increase portability andto be deployed in different operating systems andhardware platforms.
Figure 4 shows the user interface. In the leftpanel, there is a menu for the models. Wheneverthe user selects a model and populates a sentence,the result is displayed on the right panel.
We also provide a REST API that allows usersto access the toolkit with HTTP requests. To beable to use the API, we provide an API token, soa user can access it from clients such as cURLand Postman. Moreover, with the help of Swaggerand Redoc documentation, users can see how toconsume API endpoints.
6 Conclusion and Future Work
We introduce a new Neural Turkish NLP toolkitthat performs different levels of linguistic analysisfrom morphology to semantics, as well as otherNLP applications such as NER. All source codesand relevant datasets are publicly available and webelieve that this framework for Turkish NLP willbe beneficial for other researchers in the area, andwill eventually expedite the Turkish NLP research.
Acknowledgements
The joint model was funded by Scientific and Tech-nological Research Council of Turkey (TUBITAK),project number EEEAG-115E464.
23

ReferencesOmri Abend and Ari Rappoport. 2013. UCCA: A
semantics-based grammatical annotation scheme. InProceedings of the 10th International Conference onComputational Semantics (IWCS 2013)–Long Papers,pages 1–12.
Gustavo Aguilar, Suraj Maharjan, Adrian Pastor LópezMonroy, and Thamar Solorio. 2017. A multi-task ap-proach for named entity recognition in social mediadata. In Proceedings of the 3rd Workshop on NoisyUser-generated Text, pages 148–153.
Ahmet Afsın Akın and Mehmet Dündar Akın. 2007.Zemberek, an open source nlp framework for Turkiclanguages.
Zahra Azin and Gülsen Eryigit. 2019. Towards TurkishAbstract Meaning Representation. In Proceedingsof the 57th Annual Meeting of the Association forComputational Linguistics: Student Research Work-shop, pages 43–47, Florence, Italy. Association forComputational Linguistics.
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben-gio. 2015. Neural machine translation by jointlylearning to align and translate. In 3rd InternationalConference on Learning Representations, ICLR 2015,San Diego, CA, USA, May 7-9, 2015.
Piotr Bojanowski, Edouard Grave, Armand Joulin, andTomas Mikolov. 2017. Enriching Word Vectors withSubword Information. Transactions of the Associa-tion for Computational Linguistics, 5:135–146.
Necva Bölücü and Burcu Can. 2019. Unsupervisedjoint PoS tagging and stemming for agglutinative lan-guages. ACM Transactions on Asian Low-ResourceLanguage Information Processing, 18(3).
Necva Bölücü and Burcu Can. 2021. A cascaded unsu-pervised model for PoS tagging. ACM Transactionson Asian Low-Resource Language Information Pro-cessing, 20(1).
Necva Bölücü and Burcu Can. 2021. Self-attentive con-stituency parsing for UCCA-based semantic parsing.CoRR, 2110(621).
Burcu Can. 2019. Stemming Turkish words with lSTMnetworks. Bilisim Teknolojileri Dergisi, 12:183 –193.
Burcu Can, Hüseyin Aleçakır, Suresh Manandhar, andCem Bozsahin. 2022. Joint learning of morphologyand syntax with cross-level contextual informationflow. Natural Language Engineering, page 1–33.
Burcu Can and Suresh Manandhar. 2009. Clusteringmorphological paradigms using syntactic categories.In Proceedings of the 10th Cross-Language Evalu-ation Forum Conference on Multilingual Informa-tion Access Evaluation: Text Retrieval Experiments,CLEF’09, page 641–648. Springer-Verlag.
Burcu Can and Suresh Manandhar. 2012. Probabilistichierarchical clustering of morphological paradigms.In Proceedings of the 13th Conference of the Euro-pean Chapter of the Association for ComputationalLinguistics, pages 654–663, Avignon, France. Asso-ciation for Computational Linguistics.
Burcu Can and Suresh Manandhar. 2018. Tree struc-tured Dirichlet processes for hierarchical morpho-logical segmentation. Computational Linguistics,44(2):349–374.
Kris Cao and Marek Rei. 2016. A joint model for wordembedding and word morphology. In Proceedingsof the 1st Workshop on Representation Learning forNLP, pages 18–26, Berlin, Germany. Association forComputational Linguistics.
J-C Chappelier and Martin Rajman. 1998. A gener-alized CYK algorithm for parsing stochastic CFG.In Proceedings of 1st Workshop on Tabulation inParsing and Deduction (TAPD’98), CONF, pages133–137.
Wanxiang Che, Yijia Liu, Yuxuan Wang, Bo Zheng,and Ting Liu. 2018. Towards better UD parsing:Deep contextualized word embeddings, ensemble,and treebank concatenation. In Proceedings of theCoNLL 2018 Shared Task: Multilingual Parsing fromRaw Text to Universal Dependencies, pages 55–64.Association for Computational Linguistics.
Çagrı Çöltekin. 2010. A freely available morphologicalanalyzer for Turkish. In Proceedings of the SeventhInternational Conference on Language Resourcesand Evaluation (LREC’10), Valletta, Malta. Euro-pean Language Resources Association (ELRA).
Erenay Dayanık, Ekin Akyürek, and Deniz Yuret. 2018.MorphNet: A sequence-to-sequence model that com-bines morphological analysis and disambiguation.CoRR, abs/1805.07946.
Marie-Catherine de Marneffe, Christopher D. Man-ning, Joakim Nivre, and Daniel Zeman. 2021. Uni-versal Dependencies. Computational Linguistics,47(2):255–308.
Gözde Merve Demirci, Seref Recep Keskin, and Gülüs-tan Dogan. 2019. Sentiment analysis in Turkish withdeep learning. In 2019 IEEE International Confer-ence on Big Data (Big Data), pages 2215–2221.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, andKristina Toutanova. 2019. BERT: pre-training ofdeep bidirectional transformers for language under-standing. In Proceedings of the 2019 Conference ofthe North American Chapter of the Association forComputational Linguistics: Human Language Tech-nologies, NAACL-HLT 2019, Minneapolis, MN, USA,June 2-7, 2019, Volume 1 (Long and Short Papers),pages 4171–4186. Association for ComputationalLinguistics.
24

Bekir Dincer and Bahar Karaoglan. 2003. Stemming inagglutinative languages: A probabilistic stemmer forTurkish. In Lecture Notes in Computer Science bookseries, volume 2869, pages 244–251. Springer.
Bekir Taner Dinçer, Bahar Karaoglan, and Tarik Kisla.2008. A suffix based part-of-speech tagger for Turk-ish. Fifth International Conference on InformationTechnology: New Generations (itng 2008), pages680–685.
Ilknur Durgar El-Kahlout, Ahmet Afsın Akın, andErtugrul Yılmaz. 2014. Initial explorations in two-phase Turkish dependency parsing by incorporatingconstituents. In Proceedings of the First Joint Work-shop on Statistical Parsing of Morphologically RichLanguages and Syntactic Analysis of Non-CanonicalLanguages, pages 82–89, Dublin, Ireland. DublinCity University.
Jason M. Eisner. 1996. Three new probabilistic modelsfor dependency parsing: An exploration. In Pro-ceedings of COLING 1996 Volume 1: The 16th Inter-national Conference on Computational Linguistics,pages 340–345.
Fatih Ertam and Galip Aydin. 2021. Abstractive textsummarization using deep learning with a new Turk-ish summarization benchmark dataset. Concurrencyand Computation: Practice and Experience.
Gülsen Eryigit. 2014. ITU Turkish NLP web service. InProceedings of the Demonstrations at the 14th Con-ference of the European Chapter of the Associationfor Computational Linguistics (EACL), Gothenburg,Sweden. Association for Computational Linguistics.
Gülsen Eryigit, Joakim Nivre, and Kemal Oflazer. 2008.Dependency parsing of Turkish. Computational Lin-guistics, 34:627.
Yasin Esref and Burcu Can. 2019. Using morpheme-level attention mechanism for Turkish sequence la-belling. In 2019 27th Signal Processing and Com-munications Applications Conference (SIU), pages1–4.
Jeffrey Flanigan, Sam Thomson, Jaime Carbonell, ChrisDyer, and Noah A. Smith. 2014. A discriminativegraph-based parser for the Abstract Meaning Repre-sentation. In Proceedings of the 52nd Annual Meet-ing of the Association for Computational Linguistics(Volume 1: Long Papers), pages 1426–1436, Bal-timore, Maryland. Association for ComputationalLinguistics.
Bahar Gezici, Necva Bölücü, Ayça Tarhan, and BurcuCan. 2019. Neural sentiment analysis of user reviewsto predict user ratings. In 2019 4th InternationalConference on Computer Science and Engineering(UBMK), pages 629–634.
Onur Güngör, Tunga Güngör, and Suzan üsküarlı. 2019.The effect of morphology in named entity recognitionwith sequence tagging. Natural Language Engineer-ing, 25(1):147–169.
Sinan Göker and Burcu Can. 2018. Neural text nor-malization for Turkish social media. In 2018 3rdInternational Conference on Computer Science andEngineering (UBMK), pages 161–166.
Asim Günes and A. Cüneyd Tantug. 2018. Turkishnamed entity recognition with deep learning. In 201826th Signal Processing and Communications Appli-cations Conference (SIU), pages 1–4.
Coleman Haley. 2020. This is a BERT. Now there areseveral of them. Can they generalize to novel words?In Proceedings of the Third BlackboxNLP Workshopon Analyzing and Interpreting Neural Networks forNLP, pages 333–341, Online. Association for Com-putational Linguistics.
Daniel Hershcovich, Omri Abend, and Ari Rappoport.2017. A Transition-Based Directed Acyclic GraphParser for UCCA. In Proceedings of the 55th AnnualMeeting of the Association for Computational Lin-guistics (Volume 1: Long Papers), pages 1127–1138.
Emre Kagan Akkaya and Burcu Can. 2021. Trans-fer learning for Turkish named entity recognitionon noisy text. Natural Language Engineering,27(1):35–64.
Graham Neubig, Chris Dyer, Yoav Goldberg, AustinMatthews, Waleed Ammar, Antonios Anastasopou-los, Miguel Ballesteros, David Chiang, Daniel Cloth-iaux, Trevor Cohn, Kevin Duh, Manaal Faruqui,Cynthia Gan, Dan Garrette, Yangfeng Ji, LingpengKong, Adhiguna Kuncoro, Gaurav Kumar, Chai-tanya Malaviya, Paul Michel, Yusuke Oda, MatthewRichardson, Naomi Saphra, Swabha Swayamdipta,and Pengcheng Yin. 2017. Dynet: The dynamic neu-ral network toolkit.
Linh The Nguyen and Dat Quoc Nguyen. 2021. Phonlp:A joint multi-task learning model for Vietnamesepart-of-speech tagging, named entity recognition anddependency parsing. CoRR, abs/2101.01476.
Kemal Oflazer. 1993. Two-level description of Turkishmorphology. In Proceedings of the Sixth Conferenceon European Chapter of the Association for Com-putational Linguistics, EACL ’93, page 472, USA.Association for Computational Linguistics.
Kemal Oflazer and Ilker Kuruoz. 1994. Tagging andmorphological disambiguation of Turkish text. InFourth Conference on Applied Natural Language Pro-cessing, pages 144–149, Stuttgart, Germany. Associ-ation for Computational Linguistics.
Kemal Oflazer, Bilge Say, Dilek Zeynep Hakkani-Tür,and Gökhan Tür. 2003a. Building a Turkish Treebank,pages 261–277. Springer Netherlands, Dordrecht.
Kemal Oflazer, Bilge Say, Dilek Zeynep, and GokhanTur. 2003b. Building a turkish treebank. Abeillé.
Anil Ozdemir and Reyyan Yeniterzi. 2020. SU-NLPat SemEval-2020 task 12: Offensive language Iden-tifiCation in Turkish tweets. In Proceedings of the
25

Fourteenth Workshop on Semantic Evaluation, pages2171–2176, Barcelona (online). International Com-mittee for Computational Linguistics.
Adnan Ozturel, Tolga Kayadelen, and Isin Demirsahin.2019. A syntactically expressive morphological an-alyzer for Turkish. In Proceedings of the 14th In-ternational Conference on Finite-State Methods andNatural Language Processing, pages 65–75, Dresden,Germany. Association for Computational Linguistics.
Hasim Sak, Tunga Güngör, and Murat Saraçlar. 2008.Turkish language resources: Morphological parser,morphological disambiguator and web corpus. InAdvances in Natural Language Processing, pages417–427, Berlin, Heidelberg. Springer Berlin Heidel-berg.
Hasim Sak, Tunga Güngör, and Murat Saraçlar. 2009. Astochastic finite-state morphological parser for Turk-ish. In Proceedings of the ACL-IJCNLP 2009 Con-ference Short Papers, pages 273–276, Suntec, Singa-pore. Association for Computational Linguistics.
Gökhan Akın Seker and Gülsen Eryigit. 2017. Extend-ing a CRF-based named entity recognition model forTurkish well formed text and user generated content1. Semantic Web, 8(5):625–642.
Milan Straka. 2018. UDPipe 2.0 prototype at CoNLL2018 UD shared task. In Proceedings of the CoNLL2018 Shared Task: Multilingual Parsing from RawText to Universal Dependencies, pages 197–207,Brussels, Belgium. Association for ComputationalLinguistics.
Umut Sulubacak, Memduh Gokirmak, Francis Tyers,Çagrı Çöltekin, Joakim Nivre, and Gülsen Eryigit.2016. Universal Dependencies for Turkish. In Pro-ceedings of COLING 2016, the 26th InternationalConference on Computational Linguistics: TechnicalPapers, pages 3444–3454, Osaka, Japan. The COL-ING 2016 Organizing Committee.
Umut Sulubacak and G. It. 2018. Implementing uni-versal dependency, morphology, and multiword ex-pression annotation standards for turkish languageprocessing. Turkish Journal of Electrical Engineer-ing and Computer Sciences, 26:1662–1672.
Meltem Tokgoz, Fatmanur Turhan, Necva Bolucu, andBurcu Can. 2021. Tuning language representationmodels for classification of Turkish news. In 2021International Symposium on Electrical, Electronicsand Information Engineering, ISEEIE 2021, page402–407, New York, NY, USA. Association for Com-puting Machinery.
Salih Tuç and Burcu Can. 2020. Self attended stackpointer networks for learning long term dependen-cies. In Proceedings of the 17th International Confer-ence on Natural Language Processing, pages 90–100.NLP Association of India.
Ahmet Üstün, Murathan Kurfalı, and Burcu Can. 2018.Characters or morphemes: How to represent words?In Proceedings of The Third Workshop on Represen-tation Learning for NLP, pages 144–153, Melbourne,Australia. Association for Computational Linguistics.
Ashish Vaswani, Noam Shazeer, Niki Parmar, JakobUszkoreit, Llion Jones, Aidan N Gomez, ŁukaszKaiser, and Illia Polosukhin. 2017. Attention is allyou need. In Advances in neural information pro-cessing systems, pages 5998–6008.
Sait Can Yücebas and Rabia Tintin. 2017. Gövde-Türk:A Turkish stemming method. 2017 InternationalConference on Computer Science and Engineering(UBMK), pages 343–347.
Harun Resit Zafer. 2015. Resha stem-mer. https://github.com/hrzafer/resha-turkish-stemmer/. [Online; ac-cessed 6-Feb-2022].
26

Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies: System Demonstrations, pages 27 - 38
July 10-15, 2022 ©2022 Association for Computational Linguistics
ZS4IE: A toolkit for Zero-Shot Information Extractionwith simple VerbalizationsOscar Sainz1,*, Haoling Qiu2,*,
Oier Lopez de Lacalle1, Eneko Agirre1, and Bonan Min2
1HiTZ Basque Center for Language Technologies - Ixa NLP GroupUniversity of the Basque Country (UPV/EHU)
2Raytheon BBN [email protected], [email protected]
Abstract
The current workflow for Information Extrac-tion (IE) analysts involves the definition ofthe entities/relations of interest and a train-ing corpus with annotated examples. In thisdemonstration we introduce a new workflowwhere the analyst directly verbalizes the enti-ties/relations, which are then used by a Tex-tual Entailment model to perform zero-shotIE. We present the design and implementationof a toolkit with a user interface, as well asexperiments on four IE tasks that show thatthe system achieves very good performanceat zero-shot learning using only 5–15 min-utes per type of a user’s effort. Our demon-stration system is open-sourced at https://github.com/BBN-E/ZS4IE. A demon-stration video is available at https://vimeo.com/676138340.
1 Introduction
Information Extraction (IE) systems are very costlyto build. The current define-then-annotate-and-train workflow uses supervised machine learning,where the analyst first defines the schema with theentities and relations of interest and then builds atraining corpus with annotated examples. Unfor-tunately, each new domain and schema requiresstarting from scratch, as there is very little transferbetween domains.
We present an alternative verbalize-while-defining workflow where the analyst defines theschema interactively in a user interface using natu-ral language verbalizations of the target entity andrelation types. Figure 1 shows sample verbaliza-tion templates for a simple schema involving an em-ployee relation and a passing away event, as well asa sample output annotated with the schema. The an-notation of the EMPLOYEEOF relation requires per-forming Named Entity Recognition (NER) (TjongKim Sang and De Meulder, 2003) and Relation
*Denotes equal contribution.
Extraction (RE) (Zhang et al., 2017), while anno-tating the LIFE.DIE event involves NER, EventExtraction (EE), and Event Argument Extraction(EAE) (Walker et al., 2006). Our toolkit is able toperform those four IE tasks using a single user inter-face, allowing the analyst to easily model and testthe schema without the need to annotate examples.
Our toolkit leans on recent work which has suc-cessfully recast several IE tasks as Textual Entail-ment (TE) tasks (White et al., 2017; Poliak et al.,2018; Levy et al., 2017; Sainz et al., 2021). For in-stance, Sainz et al. (2021) model relation types be-tween entity pairs using type-specific verbalizationtemplates that describe the relation, generates a ver-balization (hypothesis) automatically using thosetemplates and then uses a pre-trained TE model topredict if the premise (the sentence where the pairappears) entails the hypothesis, therefore leadingto a prediction of the relation or “no relation”.
In this paper we thus present ZS4IE, a toolkit forzero-shot IE. We show that the four mainstream IEtasks mentioned above can be reformulated as TEproblems, and that it is possible to achieve strongzero-shot performances leveraging pre-trained TEmodels and a small amount of templates curated bythe user. Our toolkit allows a novice user to curatetemplates for each new types of entities, relations,events, and event argument roles, and validate theireffectiveness online over any example. We alsopresent strong results on widely used datasets withonly 5-15 minutes per type of a user’s effort.
2 Related Work
Textual Entailment has been shown to be a rea-sonable proxy for classification tasks like topicor sentiment analysis (Yin et al., 2019; Sainz andRigau, 2021; Zhong et al., 2021). To reformulatea classification problem as TE, it often starts withdefining templates to describe each class label, lead-ing to a natural language text (a “verbalization” ofa hypothesis) for each possible label. Inference is
27

Figure 1: Verbalization templates for a sample schema involving four tasks (from left to right, NER, EE, RE,EAE), with example output (bottom). The schema contains a EMPLOYEEOF relation between PERSON andORGANIZATION entities and a LIFE.DIE event with three argument types (VICTIM, PLACE and TIME) and PERSON,DATE and GPE entities as fillers. Due to space constraints, at most two verbalizations per task shown.
Figure 2: Three steps for entailment-based NER. The steps for the other IE tasks is analogous.
performed by selecting the most probable candi-date hypothesis entailing the premise. TE is usuallyimplemented with pre-trained language model fine-tuned on TE datasets, such as MNLI (Williamset al., 2018), SNLI (Bowman et al., 2015), FEVER(Thorne et al., 2018), ANLI (Nie et al., 2020) orXNLI (Conneau et al., 2018). The results on classi-fication have been particularly strong for zero-shotand few-shot learning, with Wang et al. (2021b)hypothesizing that entailment is a true languageunderstanding task, where a model that performsentailment well is likely to succeed on similarly-framed tasks.
Sainz et al. (2021) reformulated relation extrac-tion as a TE task surpassing the state-of-the-art inzero- and few-short learning. A similar approachwas previously explored by Obamuyide and Vla-chos (2018), using TE models that are not based onpre-trained language models. Similar to TE, (Clarket al., 2019) performs yes/no Question Answering,in which a model is asked about the veracity ofsome fact given a passage. Lyu et al. (2021) re-cast the zero-shot event extraction as a TE task,using TE model to check whether a piece of textis about a type of event. Lastly, Sainz et al. (2022)showed that TE allows to leverage the knowledgefrom other tasks and schemas.
3 IE via Textual Entailment
We first describe how to recast each of the IE tasks(NER, RE, EE, EAE) as TE independently, and
leave the workflow between the tasks for the nextsection. At a high level, the zero-shot TE reformu-lation consists of three steps: candidate generation,label verbalization and TE inference (Figure 2 illus-trates the steps for NER). The first step, candidategeneration, identifies text spans (e.g., proper nounsfor NER) or span pairs (a pair of entity mentionsfor relation extraction) in the input sentence as thefocus of the prediction. Taking a text span (or spanpair) as input, the label verbalization step appliesa verbalization template to generate a hypothesis,which is a natural language sentence describingthe span (or span pair) being an instance of a typeof entity, relation, event, or event argument. Theverbalization generates hypothesis for each of thetarget types. Finally, the TE inference step takesthe original sentence (the premise) and each hy-pothesis as input, and uses a pre-trained TE modelto predict if the premise entails, contradicts, or isneutral to the hypothesis. The type with the verbal-ization having the highest entailment probability isselected. We next describe each step in detail.
3.1 Candidate Generation
We describe the candidate generation for each ofthe task below.
Named Entity Recognition (NER): Candidatesare extracted using specific patterns of PoS tags asreturned by Stanza (Qi et al., 2020). For instance,for the simple example in Figure 1 it suffices to
28

select proper nouns (shown in Figure 2), which areeasily extended with other PoS patterns if needed.The toolkit also allows the usage of a constituencyparser (Kitaev and Klein, 2018).
Relation Extraction (RE): Each relation re-quires a pair of entities that satisfy specific typeconstraints, e.g. the EMPLOYEEOF relation re-quires a PERSON and an ORGANIZATION. A NERmodule is used to extract all candidate entities thatfollow the required entity types according to thetarget schema. The toolkit uses the TE based NERmodule, although it also allows usage of a super-vised NER system (Qi et al., 2020).
Event (Trigger) Extraction (EE): The maingoal of this task is to detect whether the input sen-tence contains a mention of any of the target eventtypes in the schema, e.g. LIFE.DIE. This task canbe formulated as a multi-label text classificationtask, and in this case the full sentence is the candi-date. Alternatively, the textual span that most likelyexpresses the event (the so-called trigger) can beextracted. In this case, the candidates are generatedusing specific PoS tags, e.g. verbs like died (cf.Figure 1). Our toolkit allows both options.
Event Argument Extraction: Given a sentencecontaining an event type (as detected by EE above),the goal is to extract entity mentions that are fillersof the target arguments in the schema. For exam-ple, the schema in Figure 1 involves three targetarguments. Each of the arguments requires spe-cific entity types, e.g. PERSON for the VICTIM
argument. The candidates of the required types areextracted using the same NER module as for RE.
3.2 Label Verbalization
For each of the IE tasks, the label verbalization pro-cess takes a sentence, a set of candidates and theset of target types (e.g. NER types), and generatesa natural language text (the hypothesis) describ-ing the existence of the type in the sentence (thepremise) using verbalization templates. Each can-didate is a span (or pair of spans) that can belongto a specific type (e.g. being a PERSON in NER).Therefore, the textual verbalization is generatedto express each potential type for the span or thepair of spans. For the NER and event extractiontasks, each verbalization expresses one potentialentity (or event type) for the target candidate. Forthe relation and event argument extraction tasks,the verbalization template combines the informa-
tion from the text spans of the candidate pair andproduces a text that expresses a relation (or eventargument role). The analyst just needs to write theverbalization templates for each target type, andthey are applied to the candidates to generate thehypothesis, as shown in the second step in Figure 2for NER.
Figure 1 shows sample TE verbalization tem-plates for entity, relation, event, and event argu-ment types corresponding to the 4 IE tasks, as wellas sample example as output. The templates forNER and event extraction (leftmost part of thefigure) are applied over a single candidate as ex-tracted in the previous step (the candidate entityor event trigger, respectively). Note that for eventextraction it is also possible to produce hypothe-sis using templates with no slots, e.g. "A persondied" for LIFE.DIE. In the case of relation ex-traction, the verbalization templates contain twoslots for the two entity spans potentially holdingthe relation. Finally, templates for event argumentextraction can be more varied. The figure showstwo examples: a template using a single slot for thecandidate filler, and a template which, in additionto the filler slot, uses the trigger ("died" in this case,for PLACE).
3.3 Inference
Given a premise (the original sentence) and a hy-pothesis (an verbalization generated by label verbal-ization templates), we use a pre-trained TE modelto decide whether the hypothesis is entailed by, con-tradicted with, or is neutral to the premise. In prin-ciple, any model trained on an entailment datasetcan be used. The inference is mainly determinedby three key factors: the TE probabilities for theverbalizations of all templates for all labels, thetype-specific input span constraints, and a thresh-old that decides if the probability is high enoughto consider the candidate a positive instance. Thetype-specific input span constraints are enforced tomake sure we don’t have candidates that violatesthe constraints. We return the class label of thehypothesis with highest entailment probability. Ifnone of the hypothesis is higher than the threshold,we return the negative class, that is the class thatrepresents that there is not a valid entity, relation,event, or event argument role type for the inputcandidate. The threshold for minimal entailmentprobability is set by default to 0.5.
29

4 ZS4IE toolkit
ZS4IE comprises a pipeline and a user interface.
4.1 The ZS4IE Pipeline
As described in Section 3.1 and illustrated in Figure3, there are inter-task dependencies between thefour IE tasks (e.g., relation extraction requires thatentity mentions have already been tagged in theinput sentence). Some task also require externalNLP tools for generating candidates. To addressthese issues and to allow maximal flexibility forthe users, we support the following two workflows.
The End-to-End (E2E) Mode: This mode willrun the ZS4IE modules in a pipeline: we allowthe users to start from raw text, and perform cus-tomization (e.g., develop templates for new typesof interest) for all four IE tasks. The user has tofollow the inter-task dependencies as illustrated inFigure 3: the user must finish NER customizationbefore moving on to relation extraction or the eventargument extraction task, because the later twotasks needs NER to generate their input candidates.Similarly, the user must finish customization forthe event trigger classification task, before workingon the event argument extraction task.
The end-to-end pipeline also runs a customiz-able pre-processing step including a POS taggerand a constituency parser, before any of the latermodules.
The Task Mode: In this mode, the user canchoose to work on each of the four IE tasks indepen-dently. In order to address the inter-dependencies,the user can choose to run an independent NERmodule instead, as part of the pre-processing step.The user interface allows the user to tag any spansfor entity or event trigger types, before runningcustomization for the more complex tasks such asrelation extraction or event argument extraction.This option allows to explore additional entity andevent trigger types before actually implementingthem
4.2 User Interface (UI)
Figure 4 shows the User Interface. It allows theuser to add new types of entities, relations, eventsand event argument roles, and then develop tem-plates (along with input type constraints for eachtype). Figure 5 shows the NER extraction resultson an user-input sentence. It also displays the like-lihood scores produced by the TE model of those
Figure 3: An illustration of the dependencies betweenthe four IE tasks.
templates that are above the threshold, to allow theuser to validate templates.
To show why it extracts each entity, it displays aranked list of likely entity types, the template thatled to that type, along with the entailment probabil-ity produced by the pre-trained TE model. The usercan click on "+" and "-" sign next to each extractionto label its correctness. Our system will track thetotal number of extractions and and accuracy foreach task, each type and each template, to allowthe user to quickly validate the effectiveness of thetemplates and to spot any low-precision template.
Supplying Input Text: The user can supply atext snippet, one at a time, to test writing templates.As described in Section 4.1, when using the taskmode, the user can label spans in the input textfor the more complex relation extraction and eventargument extraction tasks, so that the text alreadyhas the right entity or event trigger spans and typesto begin with.
Develop Templates for New Types: The usercan add new types of entities, relations, events, andevent argument role. For each type, the user cancreate templates along with the input span typeconstraints, and then run inference interactivelyon the input text, to see whether these templates
30

Figure 4: The UI for curating templates for types ofinterests for NER, relation extraction, event extractionand event argument extraction tasks. The NER tab ispartially shown with two types.
Figure 5: The UI for displaying NER extraction resultson an user-input sentence. We show the extractionsand the likelihood scores of the templates above thethreshold (e.g. T = 0.5).
can be used for extract the instances. The usercan label the correctness of the extracted instances,resulting a small development dataset (the dev set)to help measuring the precision and relative recallfor each template, and to tune the threshold for theTE inference.
Display Metrics: The UI displays the accuracyand yield for each template and each type in real-time, to allow the user to monitor the progress andmake adjustments on the fly.
More screenshots and details of our UI are de-scribe in Appendix A.
5 Experiments
We evaluated our system using publicly availabledatasets. We use CoNLL 2003 (Tjong Kim Sang
and De Meulder, 2003) for NER evaluation, TA-CRED (Zhang et al., 2017) for RE, and ACE forEE and EAE (Walker et al., 2006). We evaluateeach task independently (not as a pipeline) to makeas comparable as possible to existing zero-shot sys-tems. In order to apply our toolkit we made someadaptations as follows: We consider only propernouns as candidates for NER, and we ignore theMISC label because it is not properly defined inthe task 1. We evaluate EE as event classification,where the task is to output the events mentioned inthe sentence without extracting the trigger words,as we found that deciding which is the trigger wordis in many cases an arbitrary decision 2. In the caseof RE we used the templates from (Sainz et al.,2021), which are publicly available. We will re-lease the templates used on the experiments as ad-ditional material along with the paper. The analystsspent between 5-15 minutes per type, dependingon the task, with NER and EE being the fastest.
Table 1 shows the zero-shot results for NER, RE,EE, and EAE tasks. We report the results of threeentailment models: RoBERTa (Liu et al., 2019)trained on MNLI, RoBERTa* trained on MNLI,SNLI, FEVER and ANLI; and DeBERTa (He et al.,2021) trained on MNLI. The main results (top threerows) use the default threshold (T = 0.5), we se-lected the T blindly, without checking any devel-opment result.
The results show strong zero-shot performance.Note that there is no best entailment model, sug-gesting that there still exists margin for improve-ment. However, we see that RoBERTa* performsrelatively well in all scenarios except EE (see Sec-tion 6 for further discussion).
The table also shows in the middle three rows theresults where we optimize the threshold on develop-ment. The results improve in most of the cases, andallow comparison to other zero-shot systems whichsometimes optimize a threshold in developmentdata.
Furthermore, we compare our system with zero-shot task specific approaches from other authorswhen available. For RE, Wang et al. (2021a) pro-pose a text-to-triple translation method that givena text and a set of entities returns the existing re-lations. For EE, Lyu et al. (2021) propose, similar
1More specifically, we re-labeled the MISC instances to Olabel.
2Note that EAE can be addressed without an explicit men-tion of the trigger since we used templates that do not requirethe trigger
31

NER RE EE EAE AVGModel Pre Rec F1 Prec Rec F1 Prec Rec F1 Prec Rec F1 F1
RoBERTa 53.3 54.5 53.9 32.8 75.5 45.7 23.8 63.0 34.5 20.5 60.9 30.7 46.7RoBERTa* 73.5 76.3 74.9 36.8 76.7 49.8 23.5 60.8 33.9 30.1 63.2 40.8 49.0DeBERTa 58.0 50.2 53.8 40.3 77.7 53.0 12.9 60.3 21.2 20.0 31.9 24.6 45.1
RoBERTa (+ T opt) 49.3 61.8 ↑ 54.9 56.1 55.8 ↑ 55.9 32.0 52.9 ↑ 39.9 25.8 40.1 ↑ 31.4 ↑ 50.9
RoBERTa* (+ T opt) 71.9 77.8 ↓ 74.8 54.2 59.5 ↑ 56.8 25.1 58.6 ↑ 35.1 31.1 58.3 ↓ 40.6 ↑ 51.9
DeBERTa (+ T opt) 56.3 63.1 ↑ 59.5 66.3 59.7 ↑ 62.8 13.0 55.8 ↓ 21.1 28.9 17.5 ↓ 21.8 ↑ 51.3
Other authors - - - - - 49.2 36.2† 69.1† 47.5† 38.2 35.8 37.0 -
Table 1: Results for NER, RE, EE and EAE experiments results. Three top rows for zero-shot systems with defaultparameters. Middle rows for threshold optimized on development. The best scores among our results obtained withdefault thresholds are marked in bold. The † indicates non-comparable results due to additional SRL preprocessing.
to us, the use of an entailment model, but in theircase the input sentence is split in clauses accordingto the output of a Semantic Role Labelling sys-tem. In order to compare their results with ours, weonly use the event types, not the trigger informa-tion3. The results from our system can be seen asan ablation where we do not make use of any SRLpreprocessing. For EAE, Liu et al. (2020) performzero-shot EAE by recasting the task as QA. Someof these approaches also optimize a threshold ondevelopment data, although it is not always clear.We show that our toolkit with default threshold ob-tains excellent results despite being an all-in-onemethod.
6 Discussion
Towards post-editing on IE. Our internal evalu-ation suggest that verbalizing-while-defining work-flow can have similar impact as post-editing ma-chine translated text, where human translators ob-tain quality translations with less effort (Toral et al.,2018). The idea of this new framework will bringdown the effort required to create larger and higherquality datasets. Current IE system are subjectto a predefined schema and are useless to classifynew types of entities, relations and events. Theuse interface of ZS4IE brings to the annotators theopportunity of defining the schema interactivelyand manually annotating the dataset with the helpof the entailment model. In the future we wouldlike to use the manual annotations to fine-tune theTE model, which would further improve the perfor-mance, as shown by the excellent few-shot resultsof Sainz et al. (2021).
Implicit events extraction. During the develop-ment of the EE verbalizations we found out that the
3Output kindly provided by the authors.
entailment model is prone to predict implicit eventsthat are implied by other events. For example, anevent type of JUSTICE:JAIL implies an event ofJUSTICE:CONVICT where as the same time it im-plies event type of JUSTICE:TRIAL-HEARING. Asthe entailment models are not specifically trainedfor a particular IE task (e.g. EE) they are not limitedto the extraction of explicit mentions of types (e.g.event types) annotated in the dataset. We thinkthat this phenomenon might have penalized theRoBERTa* model on the EE task, as ACE datasetonly contains annotations of explicit events. On thecontrary, rather than a limitation of our approach,we believe that this is a positive feature that can beexploited by the users.
7 Conclusions
The ZS4IE toolkit allows a novice user to modelcomplex IE schemas, curating simple yet effectivetemplates for a target schema with new types of en-tities, relations, events, and event arguments. Em-pirical validation showed that reformulating the IEtasks as an entailment problem is easy and effective,as spending only 5-15 minutes per type allows toachieve very strong zero-shot performance. ZS4IEbrings to the users the opportunity of defining thedesired schema on the fly. In addition it allowsto annotate examples, similar to post editing MToutput. Rather than being a finalized toolkit, weenvision several exciting directions, such as includ-ing further NLP tasks, allowing the user to selectcustom pre-processing steps for candidate genera-tion and allowing the user to interactively improvethe system annotating examples that are used tofine-tune the TE model.
More generally, we would like to extend the in-ference capability of our models, perhaps acquiredfrom other tasks or schemas (Sainz et al., 2022),
32

in a research avenue where entailment and taskperformance improve in tandem.
Acknowledgements
Oscar is funded by a PhD grant from the BasqueGovernment (PRE_2020_1_0246). This workis based upon work partially supported via theIARPA BETTER Program contract No. 2019-19051600006 (ODNI, IARPA), and by the BasqueGovernment (IXA excellence research groupIT1343-19).
ReferencesSamuel R. Bowman, Gabor Angeli, Christopher Potts,
and Christopher D. Manning. 2015. A large anno-tated corpus for learning natural language inference.In Proceedings of the 2015 Conference on Empiri-cal Methods in Natural Language Processing, pages632–642, Lisbon, Portugal. Association for Compu-tational Linguistics.
Christopher Clark, Kenton Lee, Ming-Wei Chang,Tom Kwiatkowski, Michael Collins, and KristinaToutanova. 2019. BoolQ: Exploring the surprisingdifficulty of natural yes/no questions. In Proceedingsof the 2019 Conference of the North American Chap-ter of the Association for Computational Linguistics:Human Language Technologies, Volume 1 (Long andShort Papers), pages 2924–2936, Minneapolis, Min-nesota. Association for Computational Linguistics.
Alexis Conneau, Ruty Rinott, Guillaume Lample, AdinaWilliams, Samuel Bowman, Holger Schwenk, andVeselin Stoyanov. 2018. XNLI: Evaluating cross-lingual sentence representations. In Proceedings ofthe 2018 Conference on Empirical Methods in Nat-ural Language Processing, pages 2475–2485, Brus-sels, Belgium. Association for Computational Lin-guistics.
Pengcheng He, Xiaodong Liu, Jianfeng Gao, andWeizhu Chen. 2021. Deberta: Decoding-enhancedbert with disentangled attention. In InternationalConference on Learning Representations.
Nikita Kitaev and Dan Klein. 2018. Constituency pars-ing with a self-attentive encoder. In Proceedingsof the 56th Annual Meeting of the Association forComputational Linguistics (Volume 1: Long Papers),pages 2676–2686, Melbourne, Australia. Associationfor Computational Linguistics.
Omer Levy, Minjoon Seo, Eunsol Choi, and LukeZettlemoyer. 2017. Zero-shot relation extraction viareading comprehension. In Proceedings of the 21stConference on Computational Natural LanguageLearning (CoNLL 2017), pages 333–342, Vancouver,Canada. Association for Computational Linguistics.
Jian Liu, Yubo Chen, Kang Liu, Wei Bi, and XiaojiangLiu. 2020. Event extraction as machine reading com-prehension. In Proceedings of the 2020 Conferenceon Empirical Methods in Natural Language Process-ing (EMNLP), pages 1641–1651, Online. Associationfor Computational Linguistics.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Man-dar Joshi, Danqi Chen, Omer Levy, Mike Lewis,Luke Zettlemoyer, and Veselin Stoyanov. 2019.Roberta: A robustly optimized bert pretraining ap-proach. arXiv preprint arXiv:1907.11692.
Qing Lyu, Hongming Zhang, Elior Sulem, and DanRoth. 2021. Zero-shot event extraction via transferlearning: Challenges and insights. In Proceedingsof the 59th Annual Meeting of the Association forComputational Linguistics and the 11th InternationalJoint Conference on Natural Language Processing(Volume 2: Short Papers), pages 322–332, Online.Association for Computational Linguistics.
Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal,Jason Weston, and Douwe Kiela. 2020. AdversarialNLI: A new benchmark for natural language under-standing. In Proceedings of the 58th Annual Meet-ing of the Association for Computational Linguistics,pages 4885–4901, Online. Association for Computa-tional Linguistics.
Abiola Obamuyide and Andreas Vlachos. 2018. Zero-shot relation classification as textual entailment. InProceedings of the First Workshop on Fact Extractionand VERification (FEVER), pages 72–78, Brussels,Belgium. Association for Computational Linguistics.
Adam Poliak, Aparajita Haldar, Rachel Rudinger, J. Ed-ward Hu, Ellie Pavlick, Aaron Steven White, and Ben-jamin Van Durme. 2018. Towards a unified naturallanguage inference framework to evaluate sentencerepresentations. CoRR, abs/1804.08207.
Peng Qi, Yuhao Zhang, Yuhui Zhang, Jason Bolton, andChristopher D. Manning. 2020. Stanza: A pythonnatural language processing toolkit for many humanlanguages. In Proceedings of the 58th Annual Meet-ing of the Association for Computational Linguistics:System Demonstrations, pages 101–108, Online. As-sociation for Computational Linguistics.
Oscar Sainz, Itziar Gonzalez-Dios, Oier Lopez de La-calle, Bonan Min, and Agirre Eneko. 2022. Textualentailment for event argument extraction: Zero- andfew-shot with multi-source learning. In Findingsof the Association for Computational Linguistics:NAACL-HLT 2022, Online and Seattle, Washington.Association for Computational Linguistics.
Oscar Sainz, Oier Lopez de Lacalle, Gorka Labaka,Ander Barrena, and Eneko Agirre. 2021. Label ver-balization and entailment for effective zero and few-shot relation extraction. In Proceedings of the 2021Conference on Empirical Methods in Natural Lan-guage Processing, pages 1199–1212, Online andPunta Cana, Dominican Republic. Association forComputational Linguistics.
33

Oscar Sainz and German Rigau. 2021.Ask2Transformers: Zero-shot domain labellingwith pretrained language models. In Proceedingsof the 11th Global Wordnet Conference, pages44–52, University of South Africa (UNISA). GlobalWordnet Association.
James Thorne, Andreas Vlachos, ChristosChristodoulopoulos, and Arpit Mittal. 2018.FEVER: a large-scale dataset for fact extractionand VERification. In Proceedings of the 2018Conference of the North American Chapter ofthe Association for Computational Linguistics:Human Language Technologies, Volume 1 (LongPapers), pages 809–819, New Orleans, Louisiana.Association for Computational Linguistics.
Erik F. Tjong Kim Sang and Fien De Meulder.2003. Introduction to the CoNLL-2003 shared task:Language-independent named entity recognition. InProceedings of the Seventh Conference on NaturalLanguage Learning at HLT-NAACL 2003, pages 142–147.
Antonio Toral, Martijn Wieling, and Andy Way. 2018.Post-editing effort of a novel with statistical and neu-ral machine translation. Frontiers in Digital Humani-ties, 5:9.
Christopher Walker, Stephanie Strassel, Julie Medero,and Kazuaki Maeda. 2006. Ace 2005 multilin-gual training corpus. Linguistic Data Consortium,Philadelphia, 57:45.
Chenguang Wang, Xiao Liu, Zui Chen, Haoyun Hong,Jie Tang, and Dawn Song. 2021a. Zero-shot informa-tion extraction as a unified text-to-triple translation.In Proceedings of the 2021 Conference on Empiri-cal Methods in Natural Language Processing, pages1225–1238, Online and Punta Cana, Dominican Re-public. Association for Computational Linguistics.
Sinong Wang, Han Fang, Madian Khabsa, Hanzi Mao,and Hao Ma. 2021b. Entailment as few-shot learner.
Aaron Steven White, Pushpendre Rastogi, Kevin Duh,and Benjamin Van Durme. 2017. Inference is every-thing: Recasting semantic resources into a unifiedevaluation framework. In Proceedings of the EighthInternational Joint Conference on Natural LanguageProcessing (Volume 1: Long Papers), pages 996–1005, Taipei, Taiwan. Asian Federation of NaturalLanguage Processing.
Adina Williams, Nikita Nangia, and Samuel Bowman.2018. A broad-coverage challenge corpus for sen-tence understanding through inference. In Proceed-ings of the 2018 Conference of the North AmericanChapter of the Association for Computational Lin-guistics: Human Language Technologies, Volume1 (Long Papers), pages 1112–1122, New Orleans,Louisiana. Association for Computational Linguis-tics.
Wenpeng Yin, Jamaal Hay, and Dan Roth. 2019. Bench-marking zero-shot text classification: Datasets, eval-uation and entailment approach. In Proceedings ofthe 2019 Conference on Empirical Methods in Natu-ral Language Processing and the 9th InternationalJoint Conference on Natural Language Processing(EMNLP-IJCNLP), pages 3914–3923, Hong Kong,China. Association for Computational Linguistics.
Yuhao Zhang, Victor Zhong, Danqi Chen, Gabor Angeli,and Christopher D. Manning. 2017. Position-awareattention and supervised data improve slot filling.In Proceedings of the 2017 Conference on Empiri-cal Methods in Natural Language Processing, pages35–45, Copenhagen, Denmark. Association for Com-putational Linguistics.
Ruiqi Zhong, Kristy Lee, Zheng Zhang, and Dan Klein.2021. Adapting language models for zero-shot learn-ing by meta-tuning on dataset and prompt collections.In Findings of the Association for ComputationalLinguistics: EMNLP 2021, pages 2856–2878, PuntaCana, Dominican Republic. Association for Compu-tational Linguistics.
A User Interface
We present more details on our user interface (UI)in this section. Our system supports all 4 IE tasksinto a single integrated interface.
Template development. Figure 6a shows themain template development UI, in which each tabon the top represents one of the entity, relation,event, and event argument tasks. The user switchbetween tasks by simply clicking on a differenttab (the tabs for the other 3 tasks are shown inFigure 6b, 6c, and 6d, respectively).
Take the NER task as an example (Figure 6a), itshows an overview of all entity types along withthe templates defined for each type (e.g., “X is aperson” for the type PERSON, in which “X” is aplaceholder that can be replaced with a noun phrase“New York City”). If the user clicks on the editbutton (the pen-shaped button), the pop-up windowfor adding a new entity type (the right-hand sidefigure in Figure 6a) shows up. The user can add atemplate by clicking on "+" sign, and then input thetemplate to the left (the user can repeat this severaltimes to add more templates). The user can removea template by clicking on "-". The user can alsoclick on the big "+" card to the left to add a newentity type.
Template development for the relation extractiontask is similar to NER, except for two differences:first, as shown in Figure 6b (right), we can furtheradd a set of "allowed type" pairs, that are the set of
34

entity pairs each relation is defined over. For exam-ple, the “per:date_of_death” relation is only validbetween a pair of PERSON and DATE mentions.Our UI allows the user to specify the “LeftEntity-Type” (left entity type) and the “RightEntityType”(right entity type) for each relation type under "al-lowed type". These type constraints are show onthe top box for each relation card on the left fig-ure in Figure 6b (e.g., "PERSON->DATE" under“per:date_of_death”). Second, a relation involvesa pair of entity mentions. Therefore, each patternhas two placeholders, “X” and “Y”, which can bereplaced with two entity candidates that are likelyto participate in the relationship.
Template development for the event extractiontask (Figure 6c) is also similar to NER, exceptthat the template may not contain any trigger. Forexample, “Someone died” is a template for the“Death” event (Figure 6c). This template wouldallow the TE approach to classify whether an extent(e.g., a sentence) expresses a type of event.
Template development for the event argumentextraction task (Figure 6d) is similar to relation ex-traction, except that the template can include eithertwo placeholders “X” and “Y” in which “X” is anevent trigger and “Y” is an event argument candi-date filler (an entity), or only one placeholder “Y”which is the event argument candidate filler. Thelater would require the template to implicitly de-scribes the event type as well (for example, “Some-one died in Y” for the LOCATION event argumentrole in Figure 6d).
Template validation. We developed an interac-tive workflow to allow the user to quickly developtemplates and validate their effectiveness in our TE-based framework. To support this workflow, our UIallows the user to run inference over any free textsupplied by the user herself/himself. For simplicity,we omit the UI where we allow the user type in freetext. We show the UI that displays the extractionoutput on the free text, that also allows the user tolabel the correcness of the extractions. Based onthose labeled examples, the UI also automaticallycalculate a few metrics to help the user to find theeffectiveness of the templates curated so far.
Figure 7 shows the UI for displaying NER ex-traction outputs (left) and automatically calculatedmetrics (right). Taken the user-supplied sentence“John Smith, an executive at XYZ Corp., died inFlorida on Sunday” as input, the UI on the left-handside shows the extracted named entities. It shows
extractions such as “John Smith is a/an PERSON”,“Sunday is a/an DATE”, and so on. To provide ra-tionale for each extraction, it displays a rank list ofpossible entity types, the template led to that type,along with the entailment probability produced bythe pre-trained TE model. The user can click on"+" and "-" sign next to each extraction to label itscorrectness. In Figure 7, all extractions are green(labeled by the user as correct) except that “Floridais a/an CITY” is in red (labeled as incorrect by theuser). Based on these user-labeled extractions, thesystem calculated a number of metrics to facilitatetemplate validation: the total number of extractednamed entities (shown under “total”), the numberof correct and incorrect extractions under “correct”and “incorrect”, respectively (the accuracy numberis also shown in the parenthesis next to “correct”)for the overall task, each type, and each pattern.The right-hand side UI in Figure 7 displays thesemetrics, and allows the user to sort patterns/typesby each of the metric. The user can quickly iden-tify some templates are low-precision (e.g., “X is alocation” for the entity type CITY), and can revisethem to improve precision.
Figure 8a, 8b, and 8c shows the UI for display-ing extraction results for the relation extraction,event extraction, and event argument extraction,respectively. Similar to the NER task. Similarly,our system also includes metric board (the met-rics above) for the other 3 IE tasks. To view themetric boards for these tasks, please refer to ourdemonstration video.
35

(a) NER
(b) Relation extraction
(c) Event extraction
(d) Event argument extraction
Figure 6: The UI for developing templates for the 4 IE tasks. For each task, we show the overall UI on the left, andthe pop-up window for adding a new entity type PERSON on the right.
36
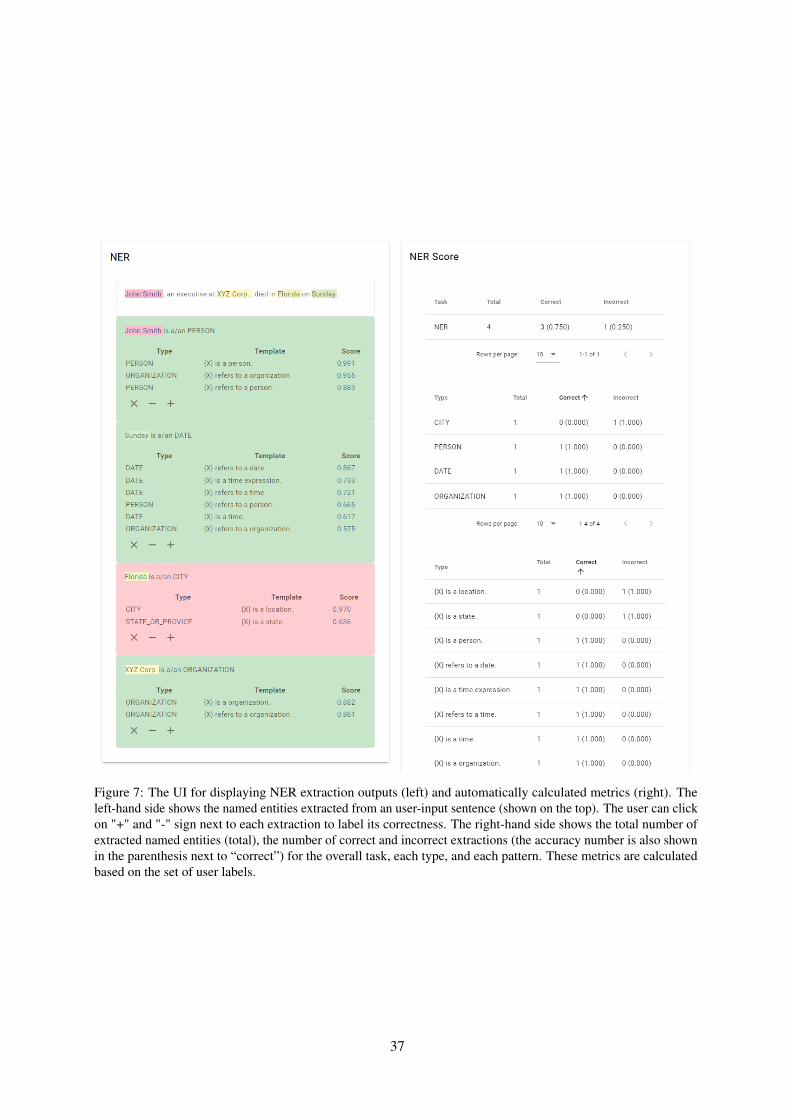
Figure 7: The UI for displaying NER extraction outputs (left) and automatically calculated metrics (right). Theleft-hand side shows the named entities extracted from an user-input sentence (shown on the top). The user can clickon "+" and "-" sign next to each extraction to label its correctness. The right-hand side shows the total number ofextracted named entities (total), the number of correct and incorrect extractions (the accuracy number is also shownin the parenthesis next to “correct”) for the overall task, each type, and each pattern. These metrics are calculatedbased on the set of user labels.
37

(a) Relation extraction
(b) Event extraction
(c) Event argument extraction
Figure 8: The UI for displaying extractions for relationextraction, event extraction, and event argument extrac-tion, respectively. The user an click on the "+" or "-"sign next to each extraction to label the extraction ascorrect or incorrect.
38

Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies: System Demonstrations, pages 39 - 45
July 10-15, 2022 ©2022 Association for Computational Linguistics
Flowstorm: Open-Source Platform with Hybrid Dialogue ArchitectureJan Pichl,12 Petr Marek, 12 Jakub Konrád 12 Petr Lorenc 12
Onrej Kobza1 Tomáš Zajícek 2 Jan Šedivý 32
1 Faculty of Electrical Engineering, Czech Technical University, Prague, Czech Republic2 PromethistAI, Prague, Czech Republic
3 CIIRC, Czech Technical University, Prague, Czech Republicpichljan,marekp17,konrajak,lorenpe2,[email protected],
tomas.zajicek,[email protected]
Abstract
This paper presents a conversational AI plat-form called Flowstorm. Flowstorm is an open-source SaaS project suitable for creating, run-ning, and analyzing conversational applications.Thanks to the fast and fully automated buildprocess, the dialogues created within the plat-form can be executed in seconds. Furthermore,we propose a novel dialogue architecture thatuses a combination of tree structures with gen-erative models. The tree structures are alsoused for training NLU models suitable for spe-cific dialogue scenarios. However, the gener-ative models are globally used across applica-tions and extend the functionality of the dia-logue trees. Moreover, the platform function-ality benefits from out-of-the-box components,such as the one responsible for extracting datafrom utterances or working with crawled data.Additionally, it can be extended using a customcode directly in the platform. One of the essen-tial features of the platform is the possibilityto reuse the created assets across applications.There is a library of prepared assets where eachdeveloper can contribute. All of the features areavailable through a user-friendly visual editor.
1 Introduction
With the increasing popularity of conversationalsystems in various areas, there is an increasing de-mand for human-like aspects of the systems. Thehuman-like aspects cover not only the content ofthe conversation but also the conversational styleand tone of voice. Moreover, many conversationalconstructs are applicable to various situations andare therefore suitable for sharing and reusing. Weintroduce the Flowstorm platform1, where conver-sational designers can easily design an applicationusing shared assets created by a community, createan application on their own, or use a combinationof both approaches. The platform does not requireany installation as it can be used as a web app.
1https://app.flowstorm.ai
However, advanced developers can use the open-source code2 to run and modify their own versionof the platform.
Our platform works with a novel dialogue archi-tecture we have proposed. It uses a combination ofdialogue trees/graphs (scenarios) specific to a do-main (or only a part of the domain) and generativemodels handling the aspects of the conversationthat are not domain-specific. The Flowstorm plat-form targets users with limited coding skills andconversational AI knowledge as well as the expertsin the area who can easily extend an out-of-the-box functionality with custom logic. Using theprovided tools, documentation3, and library of theshared assets, one can create a dialogue applica-tion in minutes. The Alquist (Konrád et al., 2021)socialbot, which was the first place winner in theAlexa Prize Socialbot Grand Challenge 4 (Hu et al.,2021), was created using the Flowstorm platform,proving the platform to be suitable even for such acomplex system.
Flowstorm platform supports English, Czech,German and Spanish languages.
2 Related Work
There are two categories of related software: open-source frameworks or libraries and online plat-forms. Rasa (Bocklisch et al., 2017) and Deep-Pavlov (Burtsev et al., 2018) are the most famousrepresentatives of the framework category. Theyprovide the developer with a set of programmaticand declarative interfaces for defining and train-ing natural language understanding (NLU) and dia-logue management (DM) models. They also allowcreating a pipeline of the components where thedeveloper can create a sequence of models or com-ponents for utterance processing. Both librariesrequire a local installation and, in addition, inte-
2https://gitlab.com/promethistai/flowstorm
3https://docs.flowstorm.ai/
39

grating either of them with the rest of the conversa-tional application requires considerable effort.
Alexa Skills Kit (ASK)4, Google Dialogflow5,and Voiceflow6 are representatives of the categoryof online platforms. ASK and Dialogflow offer anonline application for the definition of NLU mod-els (intents and slots/entities). For dialogue man-agement, ASK introduced Alexa Conversations(Acharya et al., 2021) allowing the developer tospecify the conversation flow using sample conver-sations. Dialogflow CX (a part of Dialogflow pro-viding a new way of working with conversationalagents) offers a visual view of the conversationagents to see the possible flows of the conversa-tion. Voiceflow uses a visual dialogue editor as anapproach to building a conversational application.Dialogue blocks can be connected via transitions tocreate a flow of blocks where each block representsa specific functionality such as keyword matchingor API calls.
The comparison of the key aspects of the de-scribed libraries and platforms is shown in Table 1.
Flowsto
rm
Rasa DeepP
avlov
Amazon
ASK
Dialog
flow
Voicefl
ow
SaaS Open-source pVisual editor p pCustom code ML-based NLU Sub-dialogues Sharing assets Built-in NRG Analytic tools
Table 1: Comparison of frameworks and online conver-sational platforms, p means partial functionality.
3 Architecture
The Flowstorm platform combines two sets offunctions—design and analytics. The design func-tions allow users to create individual sub-dialogues,train entity models, write shared code, and com-bine the sub-dialogues into complex conversationalapplications. Each of the created assets can then beshared with the community. The analytic functions
4https://developer.amazon.com/alexa/alexa-skills-kit
5https://cloud.google.com/dialogflow6https://www.voiceflow.com/
can be used to inspect the applications’ traffic andshow basic metrics such as session transcripts orvisualizations of specific parameters.
The following sections describe a novel conver-sational system architecture. The novel aspect con-sists of a combination of manually created sub-dialogues (that can be easily combined into a com-plex dialogue structure) and neural generative mod-els. First, we describe the blocks essential for cre-ating an application, and then we describe eachcomponent used in runtime in detail.
3.1 Conversational Application
Conversational application is a set of dialogue treeswe call sub-dialogues. Each sub-dialogue is fo-cused on a small subset of a domain (e.g., in themovie domain, one sub-dialogue can be focusedon a user’s favorite movie). Each application hasat least one sub-dialogue, but typically consists ofseveral sub-dialogues. The sub-dialogue which istriggered when the application is launched is called“main”. The other sub-dialogues are triggered whena specific situation occurs during the conversation.It depends on the specific design of the applica-tion, and it is described in detail in the followingsubsection.
Additionally, each application has configurableparameters such as language, Skimmer rules, orvoice.
3.2 Sub-dialogue
Sub-dialogue is a graph structure consisting of con-nected nodes representing the flow of the conver-sation. The key node types are described in thefollowing list. The basic structure and node typesare shown in Figure 1.
Enter – Entry point of the sub-dialogue. Eachsub-dialogue must have exactly one Enter.
Speech – Speech node contains one or more nat-ural language responses that are presented to a user.If there are multiple responses, one is randomlyselected. It can also contain slots that are eventu-ally filled with variables based on the context. Theresponses can be customized using Kotlin-basedDSL language.
User Input – Point in a conversation where thebot waits for the user utterance. It is typicallyconnected to multiple intent nodes. Each UserInput node has its own underlying intent recog-nition model trained separately. It has as manyintent classes as there are intent nodes connected
40

Figure 1: Nodes connected to the sub-dialogue struc-ture. The names of the node types are shown in thecorresponding boxes in the picture.
to it. The default behavior can be customized usingKotlin-based DSL language.
(Global) Intent – Intent node contains examplesof the users’ possible utterances which serve astraining data for the intent recognition model. Eachintent represents a single class in the intent recog-nition model. There are two types of intent nodes:contextual Intent and Global Intent. Contextualintents can be recognized only at a specific pointof the conversation—when the conversation flowreaches the User Input node they are connected to.Global Intents, however, can be recognized at anypoint of the conversation.
Function – Function node contains code writtenin the Kotlin language (JetBrains, 2011). The codecan contain arbitrary logic (usually working withattributes — see the attributes subsection). Thefunction returns the transition to the next dialoguenode. It is suitable for branching the dialogue basedon the attribute values, API results, etc.
(Global) Action – Actions represent specific sit-uations in the conversation flow. There are severalpredefined situations: Silence, Error and Out ofdomain. Silence action is triggered when no speechis recognized. Error action is triggered when thelogic written in the Function nodes fails (connec-tion errors or bad design). Out of domain actionrepresents the utterance that does not belong to anyof the intent classes. This will be described in detailin the following sections.
Sub-dialogue – Sub-dialogue node introducesthe ability to reference another sub-dialogue. When
the conversation flow reaches this node, it triggersthe referenced sub-dialogue, processing its logicfrom the Enter node to the Exit.
Exit – Exit node represents the end of the sub-dialogue flow. If the sub-dialogue is the “main”dialogue, the session is ended. If it is a lower-levelsub-dialogue, the conversation flow jumps to theparent sub-dialogue (i.e., the one where the currentsub-dialogue was referenced).
Init code – Each sub-dialogue has a declarativecode part that typically serves as a place to define at-tributes (see below) and methods that can be calledfrom the function nodes. As the code is written inthe Kotlin language, the type control is done in thebuild phase, which lowers runtime errors.
Attributes – There are four scopes of the at-tributes that can be defined in the Init code. Theattribute stores values that can be used to modifythe conversation flow, or they can be presented di-rectly as part of a response. Each attribute musthave its default value which is used to initialize theattribute based on its scope.
1. Turn – the value is reset to default at the be-ginning of each turn.
2. Session – the value is reset to default at thebeginning of each session.
3. User – the default value is used for each newuser. Once the value of a user attribute is set,it is valid for all sessions of the user.
4. Community – the default value is used for eachcommunity namespace. Once the value of acommunity attribute is set, it is valid for allusers using the same community namespace.
4 System Components
The Flowstorm conversational platform consists ofseveral components crucial for processing the userutterance and driving the dialogue. First, NLU gath-ers the information required by the DM. Afterward,DM traverses the corresponding sub-dialogue treestructure based on the NLU output.
4.1 Natural Language UnderstandingThe NLU consists of the main components—entityrecognition and intent recognition—that are com-monly used in conversational systems. Addition-ally, the out-of-domain detection enhances the in-tent recognition, allowing the system to handle asituation that was not expected during dialoguedesign.
41

4.1.1 Entity RecognitionThere are two modules used for Entity Recognition.Regex-based tool Duckling7 and a sequence label-ing neural network. The neural network uses theBi-LSTM-CRF architecture (Huang et al., 2015).The architecture is simple enough to provide rea-sonable response time when run on CPU. Ducklingis used to recognize such entities that have a spe-cific structure and can be easily described usingregular expressions (date, time, numbers, URLs,amount of money, etc.). Additionally, it parses (notonly) the date and time values from natural lan-guage representation into a structured format. Weenhanced the Duckling component with rules fornumbers and time values in the Czech language.
During the process of dialogue creation, onecan define custom entity types that can berecognized in the conversation. The enti-ties are defined using example sentences wherethey can occur, e.g. My favorite movieis [Matrix]movie, meaning the wordMatrix is an entity with type movie. These ex-amples are used as training data for the sequencelabeling model.
4.1.2 Entity MaskingThe recognized entities are masked out in theuser utterance prior to the intent recognitionphase. This step allows the intent recognitionmodel to focus only on the types of entitiesrather than the actual values. The intent recog-nition module receives, for example, the sentenceMy favorite movie is movie insteadof My favorite movie is Matrix. Onlythe entity types included in the intent examples (inthe intent nodes) are masked out.
4.1.3 Intent RecognitionA key part of each sub-dialogue are the intent nodes.Each sub-dialogue may contain multiple global in-tents and multiple user input nodes with variousnumbers of local intents connected to it. Let theG = (g1, . . . , gn) be a set of global intents of thesub-dialogue S and let the U = (u1, . . . , um) bethe set of User Input nodes where each node uihas its own set of local intents Li = (l1, . . . , lki).There is one model trained for each ui ∈ U thatclassifies the user utterance into |Li| classes. Addi-tionally, there is one extra model trained for globalintents which has |G| classes.
7https://github.com/facebook/duckling
When the conversation flow reaches the UserInput node, the system starts listening to the user(or waits for a text input). Then the actual intentrecognition process consists of two steps:
First, the user utterance is embedded using theUniversal Sentence Encoder (Cer et al., 2018) andthe embedding is compared with the training exam-ples from both global and local intent classes. Thisstep only decides whether the final intent will be se-lected from local intents, global intents or whetherthe utterance is out of domain given the context ofthe current User Input node (see Subsection Outof Domain Detection and Figure 2). Note that notonly global intents from the current sub-dialogueare considered but also the global intents from allparent sub-dialogues which are on the path fromthe current sub-dialogue to the main dialogue.
Second, the corresponding model (either globalintent model or a model corresponding to the cur-rent User Input node) is selected. This model clas-sifies the utterance into the final class.
The intent recognition experiments and a com-parison with other NLU tools is described in thepaper by Lorenc et al. (2021).
4.1.4 Out of Domain DetectionDuring each dialogue turn, the utterance is classi-fied into one of the intent classes. However, theutterance does not have to correspond to either ofthe classes. We call such utterances out of domain(OOD). Whether the utterance is OOD or not de-pends purely on the sample utterances in the globalintents and the corresponding local intent classesgiven in the current User Input node. The OOD istriggered using the confidences of the correspond-ing intent classes and the empirically estimatedthreshold. When the OOD is recognized, the dia-logue flow continues with a local OOD action (ifconnected to the current User input node) or with aglobal OOD action.
4.2 Skimmer
The Skimmer is a component that extracts relevantdata from the user utterance and stores it for laterusage. It is done on a turn basis regardless of thedialogue context. An example of such informa-tion is: the information about the user having abrother mentioned “by the way” in the conversa-tion (e.g., in a movie-related conversation, the usermay mention “I went to the cinema with my brotheryesterday.”). The component skims through eachutterance and saves the values into the attributes.
42

Intent 2Intent 1 Intent 3
Local intents
Logistic regressionLogistic regression
Cosine
G.Intent1 G.Intent2
Global intents
OOD
Utterance
Figure 2: Classification algorithm for intent and OODdetection. The utterance is first classified by a cosinesimilarity into a class of local intents or a class of globalintents. Next, the corresponding logistic regressionmakes the final intent classification. Additionally, co-sine similarity can predict the OOD class if the similarityscore falls below the threshold.
The dialogue creator can then use the informationin the conversation. The Skimmer is defined by aset of rules containing the following attributes:
• Regular expression - a set of patterns whichmust be contained in the utterance.
• Attribute name - the name of the attributewhere the value will be stored.
• Value - the value stored in the attribute, typ-ically true, false, or a matched group of theregular expression.
This component is inspired by a similar function-ality used in the Alquist socialbot (Konrád et al.,2021).
4.3 Dialogue Management
Dialogue management (DM) of a conversationalapplication created in Flowstorm is divided intotwo stages: Sub-dialogue DM and Dialogue se-lection. The former stage operates on the graphstructure of the corresponding sub-dialogue. TheDM simply follows the directed edges beginningin the Start node. There are two types of nodes thatmay have multiple outgoing edges: User Inputs andFunctions. In the User Input nodes, the next edgeis selected using Intent Recognition results, i.e., theedge leading to the most probable intent or globalintent is selected. The Function nodes contain codethat returns one of the connected edges.
4.3.1 Dialogue selectorThe dialogue selector stage is triggered whenevera previous sub-dialogue is ended, and there is nota direct transition to a different one. The overall
goal is to select a sub-dialogue that is related tothe context of the conversation. The most suitablesub-dialogue is selected from a list of eligible sub-dialogues, which is defined by the developer whocreates the dialogue application. Each sub-dialoguehas several properties that are considered duringthe process of the dialogue selection.
• Label – one or more labels can be assigned toeach sub-dialogue.
• Entity – a sub-dialogue can use the informa-tion about an entity and work with the entityattributes. E.g., a sub-dialogue works withthe information about a person, including theinformation about their birth date, occupation,etc. In that case, the sub-dialogue is taggedwith the entity type Person.
• Starting conditions is a custom logic that tellswhether the corresponding sub-dialogue canbe selected given the current context. E.g.,in the case of the sub-dialogue discussingthe user’s favorite movie, it needs to checkwhether the information about the favoritemovie is already stored. Additionally, most ofthe sub-dialogue can be triggered only onceper session. Hence, the starting condition typ-ically checks that as well.
The intuition behind the dialogue selector is tochoose a dialogue whose starting condition is met,and its label and entity sets have the biggest over-lap with the label and entity sets currently beingdiscussed in the session. Formally, let D be a setof eligible sub-dialogues, S be the current session.label(d, S) returns the overlapping labels betweenthe dialogue d and session S, and, analogically,entity(d, S) returns overlapping entities, and C isa set of starting conditions. Then the dialogue se-lector selects a sub-dialogue as follows:
argmaxd∈D
| label(d, S) ∪ entity(d, S)|
s.t. ∀ condi ∈ C : condi(d, S)
4.4 Neural Response GenerationAll the principles described in the previous sectionsare suitable for creating high-quality content forvarious scenarios with maximum control over theconversation flow. A natural language conversationcan, however, easily deviate from these scenarios.The Flowstorm platform comes with a novel ap-proach using a combination of manually created
43

content and generated content for this type of sit-uation. During the dialogue creation process, theuser may plug the generated response into any partof the sub-dialogue.
The platform currently uses a GPT-2-based (Rad-ford et al., 2019) architecture for generating re-sponses. The model takes a sequence of user ut-terances and bot responses as input. Additionally,the input contains the information about the dia-logue act of the desired response. Since the modelexpects only natural language as the input, it issuitable for situations where the next response can-not be determined using only the tree-like dialoguestructure.
Figure 3: Two basic NRG usage scenarios. The upperpart uses NRG response when OOD is detected. NRGgenerates a statement and a question, and then the sys-tem waits for the user’s utterance. Afterward, anotherNRG statement is used, and the flow is returned to thedialogue graph. The lower part illustrates the scenariowhere the crawled text or information from a DB isused. A single NRG generated question follows it. Thenext turn starts with the NRG statement, and the flow isreturned to the dialogue graph.
A typical use case for a generative model is touse it whenever an out-of-domain utterance is rec-ognized. Since the dialogue designer cannot eas-ily predict all out-of-domain variants and design aproper reaction, the generative approach is a suit-able solution as it operates purely with the dialoguehistory.
In Figure 3, we show two typical use cases ofthe generative model—generating response after anout-of-domain utterance is detected and asking ad-ditional questions based on free text (news article,fun-fact, etc.).
5 Analytics
The set of analytic tools allows developers to in-spect the traffic on their conversational applications.There are tools for inspecting session transcripts,community and user attributes, and creating metricvisualizations. The Session transcripts contains alist of the dialogue turns of each session with allthe annotations and log messages. One can easily
watch the NLU results, identify a weak part of thecorresponding application, inspect the AutomaticSpeech Recognition (ASR) hypotheses, duration ofeach turn, and session attributes stored during theconversation. The community and user attributescan be viewed in individual tables to watch thevalues gathered during conversations.
The metric visualization tool allows creatingplots of values defined as a metric. One can easilyfilter the specific values, time ranges, applications,users and specify the granularity of the visualiza-tion. An example visualization is shown in Figure4.
Figure 4: Example metric visualization. The columnsshow the count of sessions per client (Android, iOS,web and total).
6 Conclusion
The open-source platform Flowstorm allows usersto easily create conversational applications withlow effort while allowing them to modify each partwith custom functionality. Developers can visuallydesign an application and extend it with customcode thanks to an easy-to-use interface. A library ofshared assets contains common dialogue structuresthat can be used in various use cases. A novelhybrid architecture allows the system to handleunexpected utterances and make the conversationmore robust. Analytic tools show the conversationtranscripts, attributes, and metrics directly in theFlowstorm app. Based on the analytic data, thedeveloper can quickly identify the weak parts of theapplication and fix them by modifying the dialoguestructure or intent examples.
The Flowstorm platform is in active develop-ment, and we are primarily focusing on the gener-ative part of the dialogue architecture to make itmore suitable for various dialogue situations.
44

ReferencesAnish Acharya, Suranjit Adhikari, Sanchit Agarwal,
Vincent Auvray, Nehal Belgamwar, Arijit Biswas,Shubhra Chandra, Tagyoung Chung, Maryam Fazel-Zarandi, Raefer Gabriel, et al. 2021. Alexa con-versations: An extensible data-driven approach forbuilding task-oriented dialogue systems. In Proceed-ings of the 2021 Conference of the North AmericanChapter of the Association for Computational Lin-guistics: Human Language Technologies: Demon-strations, pages 125–132, Online. Association forComputational Linguistics.
Tom Bocklisch, Joey Faulkner, Nick Pawlowski, andAlan Nichol. 2017. Rasa: Open source languageunderstanding and dialogue management.
Mikhail Burtsev, Alexander Seliverstov, RafaelAirapetyan, Mikhail Arkhipov, Dilyara Baymurz-ina, Nickolay Bushkov, Olga Gureenkova, TarasKhakhulin, Yurii Kuratov, Denis Kuznetsov, et al.2018. Deeppavlov: Open-source library for dia-logue systems. In Proceedings of ACL 2018, SystemDemonstrations, pages 122–127.
Daniel Cer, Yinfei Yang, Sheng-yi Kong, Nan Hua,Nicole Limtiaco, Rhomni St John, Noah Constant,Mario Guajardo-Céspedes, Steve Yuan, Chris Tar,et al. 2018. Universal sentence encoder. arXivpreprint arXiv:1803.11175.
Shui Hu, Yang Liu, Anna Gottardi, Behnam Hedayatnia,Anju Khatri, Anjali Chadha, Qinlang Chen, PankajRajan, Ali Binici, et al. 2021. Further advances inopen domain dialog systems in the fourth alexa prizesocialbot grand challenge. In 4th Proceedings ofAlexa Prize (Alexa Prize 2021).
Zhiheng Huang, Wei Xu, and Kai Yu. 2015. Bidirec-tional lstm-crf models for sequence tagging. arXivpreprint arXiv:1508.01991.
JetBrains. 2011. Kotlin programming language.https://kotlinlang.org/. Accessed on14.09.2021.
Jakub Konrád, Jan Pichl, Petr Marek, Petr Lorenc,Van Duy Ta, Ondrej Kobza, Lenka Hýlová, and JanŠedivý. 2021. Alquist 4.0: Towards social intelli-gence using generative models and dialogue person-alization. In 4th Proceedings of Alexa Prize (AlexaPrize 2021).
Petr Lorenc, Petr Marek, Jan Pichl, Jakub Konrád, andJan Šedivý. 2021. Benchmark of public intent recog-nition services. Language Resources and Evaluation,pages 1–19.
Alec Radford, Jeff Wu, Rewon Child, David Luan,Dario Amodei, and Ilya Sutskever. 2019. Languagemodels are unsupervised multitask learners.
45

Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies: System Demonstrations, pages 46 - 53
July 10-15, 2022 ©2022 Association for Computational Linguistics
Contrastive Explanations of Text Classifiers as a Service
Lorenzo Malandri1,3, Fabio Mercorio1,3, Mario Mezzanzanica1,3, Navid Nobani2, Andrea Seveso2,3
1Dept of Statistics and Quantitative Methods, University of Milano Bicocca, Italy2Dept of Informatics, Systems and Communication, University of Milano Bicocca, Italy
3CRISP Research Centre crispresearch.eu, University of Milano Bicocca, Italy
Abstract
The recent growth of black-box machine-learning methods in data analysis has increasedthe demand for explanation methods and toolsto understand their behaviour and assist human-ML model cooperation. In this paper, wedemonstrate ContrXT , a novel approach thatuses natural language explanations to helpusers to comprehend how a back-box modelworks. ContrXT provides time contrastive (t-contrast) explanations by computing the differ-ences in the classification logic of two differenttrained models and then reasoning on their sym-bolic representations through Binary DecisionDiagrams. ContrXT is publicly available atContrXT.ai as a python pip package.
1 Introduction and Contribution
Consider a text classifier ψ1, retrained with newdata and resulting into ψ2. The underlying learningfunction of the newly trained model might leadto outcomes considered as contradictory by theend users when compared with the previous ones,as the system does not explain why the logic ischanged. Hence, such a user might wonder "whydo the criteria used by ψ1 result in class c, but ψ2
does not classify on c anymore?". This is posed asa T-contrast question, namely, "Why does object Ahave property P at time ti, but property Q at timetj?" (Miller, 2019; Van Bouwel and Weber, 2002).
1.1 ContributionIn this paper we demonstrate ContrXT as aservice, built on top of the approach we pre-sented in (Malandri et al., 2022). ContrXT(Contrastive eXplainer for Text classifier) is a toolthat computes model-agnostic global T-contrastexplanations from any black box text classifiers.ContrXT, as a novelty, (i) encodes the differencesin the classification criteria over multiple trainingphases through symbolic reasoning, and (ii) esti-mates to what extent the retrained model is con-
gruent with the past. ContrXT is available as anoff-the-shelf Python tool on Github, a pip package,and as a service through REST-API.1 We present asystem to deliver ContrXT as a service, togetherwith detailed insights and metrics. Among them,we introduce an explanation of how - and to whatextent - the single classification rules differ throughtime, along with examples of instances with the therules used by classifiers highlighted in the text.
To date, there is no work (other than ContrXT )that the authors are aware of that computes T-contrast explanation globally, as clarified by themost recent state-of-the-art surveys on XAI forsupervised ML (see (Burkart and Huber, 2021;Mueller et al., 2019)).
2 ContrXT in a nutshell
ContrXT aims at explaining how a classifierchanges its predictions through time. Belowwe describe the five building blocks composingContrXT, as in Fig.1: (A) the two text classifiers,(B) their post-hoc interpretation using global, rule-based surrogate models, (C) the Trace step, (D) theeXplain step and, finally, (E) the generation of thefinal explanations through indicators and NaturalLanguage Explanations (NLE).
(A) Text classifiers. ContrXT takes as inputtwo text classifiers ψ1,2 on the same target classset C, and the corresponding training datasetsD1,2.As clarified in (Sebastiani, 2002), classifyingDi under C consists of |C| independent problemsof classifying each d ∈ Di under a class ci fori = 1, . . . , |C|. Hence, a classifier for ci is a func-tion ψ : D × C → B approximating an unknowntarget function ψ.Output: Two black-box classifiers on the sameclass set.
(B) Post-hoc interpretation. Following thestudy about ML post-hoc explanation methods
1http://ContrXT.ai
46

of (Burkart and Huber, 2021), one of the ap-proaches consists in explaining a black box modelglobally by approximating it to a suitable inter-pretable model (i.e., the surrogate) solving the fol-lowing:
pg∗ = argmaxpg∈I
1
X
∑
x∈XS(pg(x), ψ(x))
s.t.Ω(pg) ≤ Γ
(1)
where I represents a set of possible white boxmodels to be chosen as surrogates, and S is thefidelity of the surrogate pg, that measures how wellit fits the predictions of the black box model ψ. Inaddition to (Burkart and Huber, 2021), ContrXTadds Ω(pg) ≤ Γ as a constraint to Eq. 1 to keepthe surrogate simple enough to be understandablewhile maximising the fidelity score. The constraintmeasures the complexity of the model whilst Γis a bounding parameter. In the global case, thesurrogate model pg approximates ψ over the wholetraining setX taken fromD which is representativeof the distribution of the predictions of ψ.2
Output: Two white-box, rule based surrogates p1,2of ψ1,2
08/11/21, 11:42 Senza nome.drawio
1/1
Black-box Classifier
Generate Global
Surrogate
Generate Global
Surrogate
Compute t-contrast
explanations
Indicators
BDDs
Data Process I/O Object
Step 1: Trace
BDDencoding
over
BDDencoding
over
Black-boxClassifier
Natural LanguageExplanations
(via BDD2Text)
Step 2: Explain
Figure 1: Overview of ContrXT, taken from (Malandriet al., 2022)
(C) Trace. This step aims at tracing the logic of themodels p1,2 while working on a datasets D1,2. Itgenerates the classifiers’ patterns through a globalinterpretable predictor (i.e., the surrogate), thenit is encoded into the corresponding Binary Deci-sion Diagram (BDD) (Bryant, 1986). A BDD isa rooted, directed acyclic graph with one or twoterminal nodes of out-degree zero, labelled 0 or 1.BDDs are usually reduced to canonical form, whichmeans that given an identical ordering of input vari-ables, equivalent Boolean functions will alwaysreduce to the same BDD. Reduced ordered BDDsallow ContrXT to (i) compute compact represen-tations of Boolean expressions, (ii) apply efficient
2in case the surrogate is a decision tree, Ω(pg) might bethe number of leaf nodes whilst it could be the number ofnon-zero coefficients in case of a logistic regression
algorithms for performing all kinds of logical op-erations, and (iii) guarantee that for any functionf : Bn → B there is one BDD representing it,testing whether it is true or false in constant time.Output: two BDDs b1,2 representing the logic ofpg1,2.
(D) eXplain. This step takes as input the BDDsb1,2, that formalise the logic of the surrogates pg1,2,and computes the BDDs encoding the differencesbetween the two. Step D manipulates the BDDsgenerated from the Trace step to explain how ψ1
and ψ2 differ (i) quantitatively by calculating thedistance metric defined below (aka, Indicators),and (ii) qualitatively by generating the BDDs of theadded/deleted patterns over multiple datasets Dti .As this is the key idea of ContrXT, we formalisethe following.
Definition: T-contrast explanations using BDDsGiven f1 : Bn → B and f2 : Bm → B we define:
f1 = f2 = ¬f1 ∧ f2 (2) f1 < f2 = f1 ∧ ¬f2 (3)
The goal of the operator < (=) is to obtain aboolean formula that is true iff a variables assign-ment that satisfies (falsifies) f1 is falsified (satis-fied) in f2 given f1 (f2). Let b1 and b2 be twoBDDs generated from f1 and f2 respectively, wesynthesise the following BDDs:
bb1,b2= = b1 = b2 (4) bb1,b2< = b1 < b2 (5)
where b= (b<) is the BDD that encodes the reducedordered classification paths that are falsified (satis-fied) by b1 and satisfied (falsified) by b2. We alsodenote as• var(b) the variables of b;• sat(bb1,b2= ) all the true (satisfied) paths of bb1,b2=
removing var(b1) \ var(b2);• sat(bb1,b2< ) all the true (satisfied) paths of bb1,b2<
removing var(b2) \ var(b1).Both bb1,b2= and bb1,b2< encode the differences in
the logic used by b1 and b2 in terms of featurepresence (i.e., classification paths). Indeed, bb1,b2=(bb1,b2< ) can be queried to answer a T-contrast ques-tion like "Why did a path on b1 have a true (false)value, but now it is false (true) in b2?". Clearly,features discarded (added) by b2 are removed frompaths of bb1,b2= (bb1,b2< ) as they are used by ψ1.
Output: Two BDDs bb1,b2= and bb1,b2< encoding therules used by b2 but not by b1 and vice-versa.
47

(E) Generation of final explanations: Startingfrom bb1,b2= and bb1,b2< , the final explanations areprovided through a set of indicators and NaturalLanguage Explanations.
Indicators estimate the differences between theclassification paths of the two BDDs through theAdd and Del values (see Eq. 6 and 7). To com-pare add and del across classes, we compute theAdd_Global (Del_Global) as the number of pathsto true in b= (b<) over the corresponding maximumamong all the bc= (bc<) with c ∈ C.
In the case of a multiclass classifier, as for20newsgroup, ContrXT suggests focusing onclasses that changed more with respect the indi-cators distribution.
Add(bb1,b2= ) =|sat(bb1,b2= )|
|sat(bb1,b2= )|+ |sat(bb1,b2< )|(6)
Del(bb1,b2< ) =|sat(bb1,b2< )|
|sat(bb1,b2= )|+ |sat(bb1,b2< )|(7)
Natural Language Explanations (NLE) exhibits theadded/deleted paths derived from b= and b< to finalusers through natural language. ContrXT uses thelast four steps of six NLG tasks described by (Gattand Krahmer, 2018), responsible for microplanningand realisation. In our case, the structured output ofBDDs obviates the necessity of document planningwhich is covered by the first two steps.
The explanation is composed of two main parts,corresponding to Add and Del paths. Content ofeach part is generated by parsing the BDDs, ex-tracting features, aggregating them using FrequentItemsets technique (Rajaraman and Ullman, 2011)to reduce the redundancy, inserting the related partsin the predefined sentences (Rosenthal et al., 2016).
2.1 ContrXT as a Service
ContrXT has been implemented through Pythonas a pip package, using scikit-learn for generatingsurrogates and pyEDA package for synthesisingBDDs. It takes as input the training data and thepredicted labels by the classifier.
The user can specify (i) the coverage of thedataset to be used (default: 100%), otherwise asampling procedure is used; (ii) to obtain explana-tions either for the multiclass case (default: oneclass vs all) or the two-class case (class vs class,by restricting the surrogate generation to thoseclasses); (iii) the Γ value as a measure of com-plexity of the surrogate.
ContrXT can be used either as a pip Pythonpackage3 or as a service through REST API. Inthe former case, ContrXT can be easily installedvia pip install contrxt. Then, it can beexecuted as in Code 1. A python notebook readyto use is available on the Google Colab platform.4
1 from contrxt.contrxt import ContrXT2 exp = ContrXT(3 X_t1, predicted_labels_t1,4 X_t2, predicted_labels_t2,5 save_path=’results/’,6 hyperparameters_selection=True,7 )8 exp.run_trace()9 exp.run_explain()
10 exp.explain.BDD2Text()
Code 1: Invoke ContrXT with few lines of code.
The API is written using Python and the Flask li-brary (Grinberg, 2018) and can be invoked using afew lines code shown in Code 3. Users are requiredto upload two csv files for time 1 and 2 Each csvis expected to have two columns respectively forcorpus (texts to be classified) and predicted (theoutcome of the classifier) for which the schema isshown in the following JSON.
1 schema = 2 "type": "csv",3 "columns": 4 "corpus": "type": "string",5 "predicted": "type": "string",6 ,7
Code 2: API schema
A load testing has been performed using lo-cust.io to measure the quality of service of theContrXT’s API, adding a virtual user every 10seconds, executing the whole ContrXT processfor the 20newsgroups dataset for each. Timeneeded to upload/download datasets and to gen-erate PDF versions of the BDDs are not consid-ered. We followed (Menascé, 2002) to determinethe number of users/requests our API web servercan tolerate in order to guarantee an acceptable re-sponse time (set to 5 minutes) while increasing thethroughput, i.e., requests per second.
Our architecture reached a throughput of 2.55users per second, as seen in Fig. 2. Beyond thisvalue, the API service keeps working, putting addi-tional requests into a queue.
1 import requests, io2 from zipfile import ZipFile
3https://pypi.org/project/contrxt/4https://tinyurl.com/ContrXT-pyn
48

Figure 2: Load testing provided by Locust.io: MRT (median response time, green), Request per Seconds (throughput,green) and the number of failures (requests reached the 5 min timeout, red).
3 files = 4 ’time_1’: open(t1_csv_path, ’rb’),5 ’time_2’: open(t2_csv_path, ’rb’)6 7 r = requests.post(’[see details on
github repo]’,files=files)8 result = ZipFile(io.BytesIO(r.content))
Code 3: Complete Python code to call ContrXT API
3 Experimental Evaluation
ContrXT was evaluated in terms of approxima-tion quality to the input model to be explained (i.e.,the fidelity of the surrogate) on 20newsgroups, awell-known benchmark used in (Jin et al., 2016) tobuild a reproducible text classifier, and in (Ribeiroet al., 2016), to evaluate LIME’s effectiveness inproviding local explanations.
We ran ContrXT over different classifiers,trained using popular classifiers such as linear re-gression (LR), random forest (RF), support vectormachines (SVM), Naive Bayes (NB), BidirectionalGated Recurrent Unit (bi-GRU) (Cho et al., 2014),and BERT (Devlin et al., 2019) (bert-base-uncased)with a sequence classification layer on top. Re-sults are shown in Table 1. We considered andevaluated all the global surrogate models surveyedby (Burkart and Huber, 2021), representing thestate of the art. Approaches falling outside the goalof ContrXT (e.g., SP-LIME (Ribeiro et al., 2016)and k-LIME (Hall et al., 2017) whose outcome islimited to the feature importance values) and pa-pers that did not provide the code were discarded.
To date, ContrXT relies on decision trees tobuild the surrogate, though it can employ any sur-rogate algorithms.
3.1 Results Comment for 20newsgroup
One might inspect how the classification changesfrom ψ1 to ψ2 for each class, i.e., which are thepaths leading to class c at time t1 (before) that leadto other classes at time t2 (now) (added paths) andthose who lead to c at t2 that were leading to other
Table 1: ContrXT on 20newgroups (Dt1 , Dt2 from(Jin et al., 2016)) varying the ML algorithm. • indicatesthe best surrogate.
ML Model F1-w Surrogate Fidelity F1-wAlgo Dt1 Dt2 Dt1 Dt2
LR .88 .83 .76 (±.06) .78 (±.07)RF .78 .74 .77 (±.06) .79 (±.07)
SVM .89 .84 .76 (±.06) .78 (±.06)NB .91 .87 .76 (±.06) .78 (±.06)
bi-GRU .79 .70 .77 (±.06) .78 (±.06)BERT .84 .72 .78 (±.05) • .83 (±.06) •
Figure 3: Indicators for the changes in classificationpaths from t1 to t2 for each 20newsgroup class. On thex-axis, we present the classification classes, and on they-axis the ADD/DEL indicators
classes at time t1 (deleted paths). Focusing onthe class atheism of Fig. 3 the number of deletedpaths is higher than the added ones. Fig. 4 revealsthat the presence of the word bill leads the ψ2 toassign the label atheism whilst the presence of sucha feature was not a criterion for ψ1. Conversely, ψ1
used the feature keith to assign the label, whilst ψ2
discarded this rule. Actually, both terms refer tothe name of the posts’ authors.
The example of Fig. 4 sheds light on the goalof ContrXT, which is providing to the final usera way to investigate why ψ2 classified documentsto a different class with respect to ψ1, as well asmonitoring future changes. NLE allows the user todiscover that -though the accuracy of ψ1 and ψ2 ishigh5- the underlying learning functions (i) learned
5The Spearman correlation test revealed the accuracy isnot correlated with the ADD/DEL indicators, confirming they
49

terms that should have been discarded during thepreprocessing, (ii) ψ2 persists in relying on thoseterms, which are changed after retraining (using billinstead of keith), and (iii) having political_atheistis no longer enough to classify in the class.
Figure 4: NLE for alt.atheism using the BERT modelof Tab. 1
Get Rule Examples. The NLE shows the differ-ences between the two models. However, a usermight also wish to see example instances in thedatasets where these rules apply.
To do so, ContrXT provides theget_rule_examples function, which requiresthe user to specify a rule to be applied and thenumber of examples to show. ContrXT appliesthe rule to D1 and D2, specifying the number ofdocument classified by that rule and provides someexamples, highlighting in the text the portion inwhich the rule applies, as in Fig. 5.
Notice this function is also useful to check theconsistency of a specific rule, that is, for an addrule, its prevalence should be higher inD1, for a delrule the opposite, while for a still rule the shouldbe roughly equivalent in both D1 and D2.
3.2 Evaluation through Human SubjectsWe designed a study to assess if - and to whatextent - final users can understand and describewhat differs in the classifiers’ behaviour by look-ing at NLE outputs. We recruited 15 participantsfrom prolific.co (Palan and Schitter, 2018), an on-line service that provides participants for research
provide additional insights beyond the quality of the trainedmodels
Figure 5: ContrXT shows examples in which a ruleapplies for the class alt.atheism.
studies. Participants were asked to look at NLEtextual explanations and to select one (or more)statements according to the meaning they catchfrom NLEs. Results showed that the participantsunderstood the NLE format and answered with an89% accuracy on average, and an F1-score of 87%.Finally, we computed Krippendorff’s alpha coeffi-cient, a statistical measure of the extent of agree-ment among users. We reached an alpha value of0.7, which Krippendorff (2004) considers as accept-able to positively assess the subjects consensus.
Figure 6: NLE for 2511, Systems Analysts using the RFmodel.
Figure 7: ContrXT shows examples in which a ruleapplies for the class 2511, Systems Analysts .
50

3.3 ContrXT in a real-life scenario
In the last years, the problem of extracting knowl-edge from online job ads (OJA, aka, online jobvacancies) in terms of occupations and skills isgrowing in interest in academic, industrial, andgovernment organisations to monitor and under-standing labour market changes (i) timely and (ii)at a very fine-grained geographical level, (iii) catch-ing novelties in terms of novel occupations andskills as soon as they emerge in the real-labour mar-ket. This is the goal of labour market intelligence(aka, skill intelligence) which refers to the use anddesign of AI algorithms and frameworks to analyselabour market data for supporting decision making(see, e.g., (Giabelli et al., 2021a,c; Turrell et al.,2018; Zhang et al., 2019)).
From a statistical perspective, in late 2020 EU-ROSTAT and Cedefop have joined forces announc-ing a call for tender (EuroStat, 2020) aimed at estab-lishing results from (CEDEFOP, 2016a,b) fosteringAI and Statistics to build up the European Hub ofOnline Job Ads. In such a scenario, training an MLmodel would be helpful to support questions suchas: Which occupations will grow in the future andwhere? What skills will be demanded the most inthe next years? However, once such an ML modelhas been trained and deployed (see, e.g., (Colomboet al., 2019; Boselli et al., 2018)) it needs to be pe-riodically re-trained as the labour market demandconstantly changes through time, mainly due to riseof new emerging occupations and skills (Giabelliet al., 2021a,b). This, in turn, leads policy makersto ask if - and to what extent - the re-trained modelis coherent in classifying new job ads with respectto the past criteria.
As an example, let us consider the systems ana-lysts, an occupation that changed a lot in the lastyears driven by technological progresses (Malan-dri et al., 2021). A policy maker might ask: "howsystems analysts are now classified by the updatedmodel, and how the updated model differs withrespect to the previous one?"
Figure 6 shows the difference in the criteria be-tween the two classifiers for the class "Systems An-alysts". The Figure shows that the updated modelconsiders business analysts as Systems Analysts.Furthermore, the user can easily discover that anovel occupation, i.e., "data scientist", is consid-ered as a system analyst by the updated model. Onthe other side, Fig. 6 clarifies to the user that theupdated model changed its criterion in regard to the
term "test analyst", that now does not characterisethe class anymore. Being able to catch those dif-ferences -class by class- is helpful to end users asit allows understanding to what extent the updatedmodel is coherent with past predictions, as well asits ability to catch the novelty in the domain andterms that might lead the model to misclassifica-tion. Furthermore, the Get Rule function providessamples to the user, as shown in Fig. 7.
4 Conclusion, Limitations and FutureWork
In this demonstration we presented a system todeliver contrastive explanations of text classifiersas a service. The system is built on top ofContrXT (Malandri et al., 2022), a novel model-agnostic tool to globally explain how a black boxtext classifier change its learning criteria with re-gard to the past (T-contrast) by manipulating BDDs.Given two classifiers trained on the same targetclass set, the system we presented provides timecontrastive explanations of their behaviour, to-gether with detailed insights and metrics. Amongthem, we presented the possibility to highlight howand how much the classification rules differ alongtime. A load test demonstrated that our architecturehas a throughput of 2.55 users per second. Beyondthis value, the API service puts the additional re-quests into a queue but keeps working.
To date, ContrXT is bounded to explain textclassifiers. We are working to extend ContrXT totabular classifiers.
4.1 Demonstration of ContrXTVideo to see ContrXT in action through a
video demonstration at https://tinyurl.com/ContrXT-NAACL.
Google Colab to run ContrXT directly on apython notebook, using Google Colab re-sources at at https://tinyurl.com/ContrXT-pyn
REST-API to embed ContrXT into a third-party application. Notice, it is requiredto ask for credential at https://tinyurl.com/contrxt-request-form
GitHub to download as well as to contribute tothis project, at https://ContrXT.ai
51

Impact Statement and EthicalConsiderations
AI-based decision systems interact with humans inmany application domains, including sensitive oneslike credit-worthiness, education and law enforce-ment. An unmitigated data-driven decision-makingalgorithm can systematically make unfair decisionsagainst certain population subgroups with specificattributes (e.g. race or gender) due to the inheritedbiases encoded in the data. Even a system whichhas been carefully trained in order to mitigate sucheffects can change its behaviour over time, due tochanges in the underlying data. The opaque natureof machine learning models can hide those unfairbehaviours to the end user.
In this context, ContrXT might reveal itselfextremely useful in tracing and explaining howthe model, which was designed to be fair at time1, changed its behaviour and rules after being re-trained at time 2. This allows one to check whetherthe model kept fair over time.
An interesting example of application in suchsense is the paper Towards Fairness ThroughTime (Castelnovo et al., 2021), presented at the2nd Workshop on Bias and Fairness in AI (BIAS)6
at ECML-PKDD, which uses ContrXT to observethe evolution of a ML model for credit lending overtime. Understanding the changing of the gaps be-tween different population subgroups, like genderor race, allows observing whether the mitigationstrategies in place are bringing benefits to society,favoring the convergence between individual andgroup fairness.
ReferencesRoberto Boselli, Mirko Cesarini, Stefania Marrara,
Fabio Mercorio, Mario Mezzanzanica, Gabriella Pasi,and Marco Viviani. 2018. Wolmis: a labor marketintelligence system for classifying web job vacancies.Journal of Intelligent Information Systems, 51(3).
Randal E Bryant. 1986. Graph-based algorithms forboolean function manipulation. IEEE Transactionson Computers.
Nadia Burkart and Marco F Huber. 2021. A surveyon the explainability of supervised machine learning.JAIR, 70:245–317.
Alessandro Castelnovo, Lorenzo Malandri, Fabio Mer-corio, Mario Mazzanzanica, and Andrea Cosentini.2021. Towards fairness through time. ECML PKDD,CCIS 1524, page 1–17.6https://sites.google.com/view/bias2021/
CEDEFOP. 2016a. Real-time labour market informa-tion on skill requirements: Setting up the eu systemfor online vacancy analysis. https://goo.gl/5FZS3E.
CEDEFOP. 2016b. Real-time labour market informa-tion on skill requirements: Setting up the eu systemfor online vacancy analysis. https://goo.gl/5FZS3E.
Kyunghyun Cho, Bart Van Merriënboer, Dzmitry Bah-danau, and Yoshua Bengio. 2014. On the propertiesof neural machine translation: Encoder-decoder ap-proaches. arXiv preprint arXiv:1409.1259.
Emilio Colombo, Fabio Mercorio, and Mario Mezzan-zanica. 2019. AI meets labor market: exploring thelink between automation and skills. Information Eco-nomics and Policy, 47.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, andKristina Toutanova. 2019. Bert: Pre-training of deepbidirectional transformers for language understand-ing. In NAACL, pages 4171–4186.
EuroStat. 2020. Towards the european web intelligencehub — european system for collection and analysisof online job advertisement data (wih-oja), availableat https://tinyurl.com/y3xqzfhp.
Albert Gatt and Emiel Krahmer. 2018. Survey of thestate of the art in natural language generation: Coretasks, applications and evaluation. JAIR, 61.
Anna Giabelli, Lorenzo Malandri, Fabio Mercorio,Mario Mezzanzanica, and Andrea Seveso. 2021a.NEO: A system for identifying new emerging oc-cupation from job ads. In Thirty-Fifth AAAI Con-ference on Artificial Intelligence, AAAI 2021, pages16035–16037. AAAI Press.
Anna Giabelli, Lorenzo Malandri, Fabio Mercorio,Mario Mezzanzanica, and Andrea Seveso. 2021b.Neo: A system for identifying new emerging occupa-tion from job ads. In AAAI - Demo track.
Anna Giabelli, Lorenzo Malandri, Fabio Mercorio,Mario Mezzanzanica, and Andrea Seveso. 2021c.Skills2job: A recommender system that encodes joboffer embeddings on graph databases. Appl. SoftComput., 101:107049.
Miguel Grinberg. 2018. Flask web development: de-veloping web applications with python. " O’ReillyMedia, Inc.".
Patrick Hall, Navdeep Gill, Megan Kurka, andWen Phan. 2017. Machine learning inter-pretability with h2o driverless ai. H2O. ai.URL: http://docs. h2o. ai/driverless-ai/latest-stable/docs/booklets/MLIBooklet. pdf.
Peng Jin, Yue Zhang, Xingyuan Chen, and Yunqing Xia.2016. Bag-of-embeddings for text classification. InIJCAI, pages 2824–2830.
Klaus Krippendorff. 2004. Reliability in content analy-sis: Some common misconceptions and recommen-dations. Human communication research, 30(3).
52

Lorenzo Malandri, Fabio Mercorio, Mario Mezzanzan-ica, and Navid Nobani. 2021. MEET-LM: A methodfor embeddings evaluation for taxonomic data in thelabour market. Comput. Ind., 124:103341.
Lorenzo Malandri, Fabio Mercorio, Mario Mezzanzan-ica, Navid Nobani, and Andrea Seveso. 2022. Con-trXT: Generating contrastive explanations from anytext classifier. Information Fusion, 81:103–115.
Daniel A Menascé. 2002. Load testing of web sites.IEEE internet computing, 6(4):70–74.
Tim Miller. 2019. Explanation in artificial intelligence:Insights from the social sciences. Artificial Intelli-gence, 267.
Shane T Mueller, Robert R Hoffman, William Clancey,Abigail Emrey, and Gary Klein. 2019. Explanation inhuman-ai systems: A literature meta-review, synopsisof key ideas and publications, and bibliography forexplainable ai. arXiv preprint arXiv:1902.01876.
Stefan Palan and Christian Schitter. 2018. Prolific.ac—a subject pool for online experiments. Journalof Behavioral and Experimental Finance, 17:22–27.
Anand Rajaraman and Jeffrey David Ullman. 2011.Mining of massive datasets. Cambridge UniversityPress.
Marco Tulio Ribeiro, Sameer Singh, and CarlosGuestrin. 2016. Why should i trust you?: Explainingthe predictions of any classifier. In ACM-SIGKDD.
Stephanie Rosenthal, Sai P Selvaraj, and Manuela MVeloso. 2016. Verbalization: Narration of au-tonomous robot experience. In IJCAI, volume 16,pages 862–868.
Fabrizio Sebastiani. 2002. Machine learning in auto-mated text categorization. CSUR, 34(1).
Arthur Turrell, Bradley Speigner, Jjyldy Djumalieva,David Copple, and James Thurgood. 2018. Using jobvacancies to understand the effects of labour marketmismatch on uk output and productivity.
Jeroen Van Bouwel and Erik Weber. 2002. Remotecauses, bad explanations? JTSB, 32(4).
Denghui Zhang, Junming Liu, Hengshu Zhu, YanchiLiu, Lichen Wang, Pengyang Wang, and Hui Xiong.2019. Job2vec: Job title benchmarking with collec-tive multi-view representation learning. In CIKM.
53

Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies: System Demonstrations, pages 54 - 63
July 10-15, 2022 ©2022 Association for Computational Linguistics
RESIN-11: Schema-guided Event Prediction for 11 Newsworthy ScenariosXinya Du1, Zixuan Zhang1, Sha Li1, Ziqi Wang1, Pengfei Yu1, Hongwei Wang1,
Tuan Manh Lai1, Xudong Lin2, Iris Liu3, Ben Zhou4, Haoyang Wen1, Manling Li1,Darryl Hannan5, Jie Lei5, Hyounghun Kim5, Rotem Dror4, Haoyu Wang4,
Michael Regan3, Qi Zeng1, Qing Lyu4, Charles Yu1, Carl Edwards1,Xiaomeng Jin1, Yizhu Jiao1, Ghazaleh Kazeminejad3, Zhenhailong Wang1,
Chris Callison-Burch4, Carl Vondrick2, Mohit Bansal5, Dan Roth4,Jiawei Han1, Shih-Fu Chang2, Martha Palmer3, Heng Ji1
1 University of Illinois Urbana-Champaign 2 Columbia University 3 University of Colorado, Boulder4 University of Pennsylvania 5 University of North Carolina at Chapel Hill
xinyadu2,zixuan11,shal2,[email protected]
Abstract
We introduce RESIN-11, a new schema-guidedevent extraction and prediction system thatcan be applied to a large variety of newswor-thy scenarios. The framework consists of twoparts: (1) an open-domain end-to-end multime-dia multilingual information extraction systemwith weak-supervision and zero-shot learning-based techniques. (2) a schema matching andschema-guided event prediction system basedon our curated schema library. We build a demowebsite1 based on our dockerized system andschema library publicly available for installa-tion2. We also include a video demonstratingthe system.3
1 Introduction
If the evening news discusses a migration of peopledue to drought and the infrastructure cannot han-dle the population influx, what will happen next?While annotated datasets have fueled progress inmachine intelligence, the knowledge required forevent forecasting is vast and potentially ambiguous.For example, to predict that a rebellion is likely inthe future, models need to integrate backgroundevents (drought), abstractions (strained infrastruc-ture causes unrest), and event schemas (structureand duration of rebellion). Existing link predic-tion (Zhang and Chen, 2018; Wang et al., 2018; Leiet al., 2019) or knowledge graph completion meth-ods (Zhang et al., 2019; Goel et al., 2020; Wanget al., 2021a) cannot meet this goal because theevent instance graphs extracted from news are of-ten incomplete and noisy. Recent work (Li et al.,2020b, 2021a) proposes to leverage complex event
1Demo: http://18.221.187.153:110002Github: https://github.com/RESIN-KAIROS/RESI
N-113Video: https://screencast-o-matic.com/watch
/c3nlhnVbeyg
schemas (stereotypical evolution pattern of com-plex events) for event prediction. However, thesemethods are often limited to a few scenarios dueto the lack of high-quality, open-domain informa-tion extraction systems to construct event instancegraphs needed for schema induction.
To tackle these challenges, in this paper we usethe event schemas discovered at scale to guide thelearning of predictive models. We first identify 11newsworthy scenarios, and construct comprehen-sive hierarchical schemas through the combinationof automatic schema induction and manual cura-tion. Then we develop an open-domain end-to-endmultimedia multilingual information extraction sys-tem that can extract entities, relations, events, andtemporal orders for all of these scenarios, based ona series of weak supervision based methods, includ-ing few-shot learning and lifelong learning. Com-pared with previous event tracking systems (Wenet al., 2021) that conduct graph matching on a lin-earized sequence, we propose a new schema match-ing algorithm that directly operates on graphs. Wealso proposed a event prediction model trained withself-supervision to predict possible missing eventsto form a coherent story. Our contributions include:
• We induce and curate hierarchical schemas for11 scenarios, capturing a wide coverage of news-worthy events.
• We extend our multi-lingual multi-media infor-mation extraction techniques (Wen et al., 2021)to handle the open-domain extraction setting.
• We develop a new schema matching and pre-diction algorithm that is capable of recoveringmissing events and predicting events that willlikely to happen in the future.
54

2 Methodology
Overview Figure 1 illustrates the overall architec-ture of our framework. It includes three parts: (1)schema library construction (Section 2.1); (2) open-domain multimedia multilingual Information Ex-traction (IE) system (Section 2.2-2.3) ; (3) schemamatching and prediction component (Section 2.4).
We first perform schema induction and curationfor 11 identified newsworthy scenarios. Specifi-cally, we use GPT-3 generated results as an outline,enrich the schema with the help of the WikiDataontology and expand the steps for better coverage.
On the IE side, we assume our input consists ofmultilingual multimedia document clusters abouta specific scenario (e.g., disease outbreak). Eachdocument cluster contains documents about a spe-cific complex event scenario (e.g., COVID-19 pan-demic). Our textual IE pipeline takes documentsand transcribed speech as input and extracts entity,relation and event mentions (Section 2.2). In or-der to extend IE to open-domain, we have adoptedweak supervision and zero-shot transfer learningtechniques. Then we perform cross-documentcross-lingual entity and event coreference resolu-tion, and link them to WikiData. The extractedevents are then ordered by temporal relation extrac-tion. Our visual pipeline extracts events and argu-ments from visual signals (i.e., images and videos),and link the extracted knowledge elements to ourextracted graph using cross-media event corefer-ence resolution (Section 2.3). Finally, our systemautomatically selects the schema from a schemalibrary that best matches the extracted IE graph andnew events are predicted (Section 2.4).
2.1 Schema Induction and CurationFor our schema library creation, we first start withcreating schemas with a zero-shot approach utiliz-ing GPT-3. Given a scenario for which we wantto create a schema, we generate multiple texts thatdiscuss the topically-related complex events usingthe OpenAI GPT-3 API4 with the Davinci-instruct-beta-v3 model. We use three prompting methodsto generate documents of diverse genres such asnews articles, Wikihow-style documents, and step-by-step event description. One example of such aprompt and the generated output is shown in Figure2. Then we identify the events mentioned in thetexts and link the events to WikiData Qnodes. Weuse generated documents instead of real documents
4https://openai.com/blog/openai-api/
because we observe that generated documents aregenerally cleaner and contain a higher percentageof events that can be linked. For instance, compar-ing the generated text and the crawled news articlesfor IED attacks, the generated text contains 0.13events per token and the news articles only contain0.06 events per token. From there we add argu-ments to the events, and identify the temporal andhierarchical relations between the events effectivelyconverting each text into a graph structure (Figure3).
Note that the automatic induced schema is oftennoisy and has limited coverage. Some of suchmistakes come from the GPT3 generation, e.g., inthe generated output in Figure 2, it omits how thedisease was discovered. Other mistakes root fromincorrect prediction of temporal relations, such asthe “Kill”→ “Come (Attack)” edge in Figure 3.
To improve coverage, human curators furthercheck Wikipedia and news articles on the relatedtopics and add more events. Three other crucial as-pects of human curation are (1) entity coreferenceresolution, (2) temporal ordering and (3) hierar-chical structure construction. Entity coreferencechains in schemas often involve implicit entities,such as the “area where the sick live” in step 2.This location entity is futher coreferential with the“contaminated areas” entity mentioned later in step4. The generated output is a list of steps, which canbe converted to a linear ordering of events. How-ever, some events can happen concurrently such asthe “Educate” event in step 4 and all other events.In addition, some events have strong semantic co-herence involving the same set of entities and thuscan be grouped together. For example, this chainof “Identify-Quarantine-Disinfect” can be seen asa medical response to one batch of infections. Werefer to this as a sub-schema and this medical re-sponse sub-schema can be repeated with a differentset of patients and medical agents. An example ofthe human curated schema is shown in Figure 4.
In the curation process, we use a web-basedgraphical interface (Mishra et al., 2021) to helpvisualize and assess schemas.
2.2 Open Domain IE from Speech and Text
We first convert speech data into text using theAmazon Transcribe API5. When the language isnot specified, it is automatically detected from theaudio signal. It returns the transcription with start-
5https://aws.amazon.com/transcribe/
55

ASR
English Entity/Relation/Event Mention Extraction
OneIE
Fine-grained Entity Extraction
Weak Supervision
TriggerLabeling
ArgumentLabeling
SpanishOneIE
Cross-document Cross-lingualCoreference Resolution and
Qnode Linking
Machine Translation
Schema Matching and Prediction
Historical News
Schema Induction
Schema Curation
Schema Library
Multilingual Multimedia
Document ClustersDoc-level
Event Argument Extraction
Visual IE
Cross-media Matching and Enrichment
Final output
Temporal Ordering
Figure 1: The architecture of RESIN-11 framework: including (1) open-domain multimedia multilingual informationextraction; and (2) schema matching and prediction.
1. Monitor and track disease spread.2. Identify and isolate the sick.3. Quarantine the sick and those who have been in contact with them.4. Disinfect and clean contaminated areas.5. Educate the public about the disease and how to prevent it.
Prompt: What are the steps involved in a disease outbreak?
GPT-3
TracingQ322229
A0_pag_thing_following:Medical Agent
A1_ppt_thing_followed:Pathogen
WikiData Ontology
Figure 2: An illustration of the schema curation process.The steps are actual output from GPT-3.
ing and ending times for each detected words, aswell as potential alternative transcriptions.
To achieve wide coverage of event types from11 scenarios, our information extraction systemconsists of 3 components: (1) the supervisedjoint entity, relation and event extraction modelOneIE (Lin et al., 2020); (2) weakly supervisedkeyword-guided event extraction; and (3) zero-shotgeneration-based argument extraction (Li et al.,2021b).
OneIE is a joint neural model for sentence-levelinformation extraction. Given a sentence, the goalof this module is to extract an information graphG = (V,E), where V is the node set contain-ing entity mentions and event triggers and E isthe edge set containing entity relations and event-argument links. In order to capture the interac-
Kill Injure
Detonate
Come(Attack) Open fire
Wound
Strike
Claim responsibility
Leave
Choose
Select Method
Acquire Weapon
Carry out (Attack)
Attack
AND
Figure 3: An automatically induced schema for the ter-rorist attack scenario with model predicted temporalorder, hierarchical relations and logical relations. Argu-ments are omitted for clarity.
tions among knowledge elements, we incorporateschema-guided global features when decoding in-formation graphs. After we extract these men-tions, we apply a syntactic parser (Honnibal et al.,2020) to extend mention head words to their extents.Based on OneIE relations output, we perform rule-based relation enrichment to obtain fine-grainedrelation subsubtypes. We collect keywords for vari-ous fine-grained types, then we construct rules bychecking keywords in Shortest Dependency Paths(SDP) between two relation entities.
To extract emergent event types for which wedo not have large-scale annotation, we employ akeyword-based event detection system. Specifi-cally, we select a list of keywords for each new
56

Medical Response I
Infection Illness
Diagnosis
Treatment
Gather DataIdentify Outbreak
Alert AuthoritiesRecover
DieXOR
Quarantine Funeral
Testing
Tracing
Contaminate
XOR
Eat
Drink
ConsumeThroughAir
Spread
Disease Outbreak
Contributory Factors Onset Outbreak
Authority Response
Research Response
Society Response
Investigation Justice
Figure 4: The curated schema for the disease outbreak scenario. Blue diamond shapes represent sub-schemas andyellow circles represent primitive events. Black arrows between primitive events represent temporal order, light bluelines between the primitive events and the sub-schema node represent event-subevent hierarchical relationship. Herewe only show the primitive events under the Onset sub-schema.
event type, and search for the occurrences of thesekeywords in a text corpus. We compute keywordrepresentations by averaging the contextualized rep-resentations from BERT (Devlin et al., 2019) ofkeyword occurrences, and cluster keyword repre-sentations for the same event type to get a set ofcluster representations for each event type. Forevent trigger detection, we first compute BERT rep-resentations of all the tokens in a sentence, andconsider a token as an event trigger if its cosinesimilarity with some cluster representations of anevent type is larger than a threshold. We tuned thethreshold using a few example event mentions.
After identifying the event triggers, we furtheremploy a document-level event argument extrac-tion model (Li et al., 2021b) to improve the recallof event argument role labeling. This model for-mulates the argument extraction problem as con-ditional text generation. The condition consists ofthe original document and a blank event template.For example, the template for Transportationevent type is arg1 transported arg2 in arg3 fromarg4 place to arg5 place. To apply this model in azero-shot setting, we create new templates for theemerging event types and use them as input.
For entity linking over Wikidata, we directly usethe EPGEL system proposed in Lai et al. (2022).For cross-document cross-lingual coreference res-olution, we follow the approach of (Wen et al.,2021). After the coreference resolution/entity link-ing stage, we conduct temporal ordering for allof the extracted events. First we provide twoindependent temporal ordering results from twolearning-based pairwise event order classification
systems (Zhou et al., 2021; Wen and Ji, 2021). Tomake the prediction consistent and valid over eachdocument cluster, we use a greedy algorithm thatselects conflict-free predicted temporal relations tothe final instance graph sequentially based on theirconfidence scores. Similar to Wen et al. (2021),these two results will be used for schema matchingand event prediction and only the best predictionwill be used in the final output.
2.3 Cross-media Info Grounding and Fusion
Visual event and argument role extraction Ourgoal is to extract structured visual events and en-tities. Specifically, given an image or a video seg-ment, the desired output are its event type and theassociated argument roles. Due to the expensivecost of event annotation for images and videos, itis not feasible to perform annotation for each newtype. Unlike existing systems leveraging super-vised training (Chen et al., 2021a), we propose anopen-domain framework to enable the visual eventextraction for a broader spectrum of event types.
Our proposed system is composed of two com-plementary models. The first model is a supervisedmodel based on a large-scale image dataset, Situa-tion with Groundings (SWiG) (Pratt et al., 2020).We manually define the mapping that covers 16event types and use the model pretrained on theSWiG dataset to extract event and argument roles.The second model is an unsupervised model byleveraging large-scale vision-language pretrainedmodel (Li et al., 2022; Radford et al., 2021). Weconduct further pretraining on an event-rich cor-pus (Li et al., 2022) by adding an additional pre-
57

training task of event structure alignment betweentwo modalities. In detail, we extract event struc-tures from captions and utilize them as the super-vision for image event extraction. The pretrain-ing corpus comprises multiple scenarios, providingsupport for the extraction of events for a wide rangeof scenarios. To process images and videos in a uni-fied manner, we follow Wen et al. (2021) to sampleframes at a frame rate of 1 frame per second fromvideos and process these key-frames as individualimages.
Cross-media event coreference resolution Toaugment the text event graph, we leverage a weakly-supervised coreference resolution model (Chenet al., 2021a) that is trained based on the align-ment between video frames and speech texts on alarge collection of news videos to predict the rel-evance between a textual event and the extractedvisual event. Once the relevance is higher than athreshold, we leverage a rule-based approach to de-cide whether the visual event mention and a textualevent mention are coreferential: (1) Matched eventtypes; (2) No contradiction of entity types for thesame argument role in different modalities. Thispipeline enables adding provenance of visual-onlyarguments into the event graph, which providesmore comprehensive event understanding.
2.4 Schema Matching and PredictionAfter obtaining a large-scale library of schemagraphs for various scenarios, our goal is to instan-tiate the schema graphs with extracted events, andthen use it for schema-guided event prediction.
Schema Matching To match the event nodes be-tween the IE graphs and schema graphs, previouswork (Wen et al., 2021) first linearizes graphs intoevent sequences and then conducts event matchingusing longest common subsequences (LCS). How-ever, such a sequence-based matching algorithmcannot well capture some global dependencies ina graph point of view, and the performance largelydepends on the quality of event temporal order-ing results. Also, the LCS based matching algo-rithm can only handle the cases where the events inschema graph and IE graph use an identical ontol-ogy (i.e., the same category of event types), whichis however not applicable for open-domain settingssince the names of events could be diverse andmultifarious.
To tackle these problems, we propose a newschema matching algorithm that directly operates
on each pair of instance graph I and schema graphS. We formulate schema matching as an integerprogramming problem, where we can use an assign-ment matrix X ∈ R|I|×|S| to represent the match-ing results. To enable matching between eventswith different names, we compute the pairwiseSynsets similarities from WordNet6 and store itinto a node similarity matrix A. For each event eiin a given instance graph I , we obtain the set of allreachable event nodes RI(i) = e | PI(ei, e) =1, e ∈ I, where PI(ei, e) denotes whether thereexists a path from ei to e in the instance graph I .Similarly, we can also obtain the reachable eventsetsRS and PS for the schema graph S. For edgesimilarity between each pair of events ei and ej , in-stead of strictly judging whether they are temporalneighbors (i.e., whether there exists an event-eventtemporal link between ei and ej) , we only use thereachability as temporal constraints (i.e., whetherej ∈ RI(i)) to mitigate the high dependence on thequality of event temporal ordering results. Specif-ically, we aim to find the optimal solution Xopt
Xopt = argmaxX
∑
i,j
Ai,jXi,j − c · Q(X), (1)
where c is a hyper-parameter and Q(X) denotesthe penalty term for the violation of temporal con-straints. The penalty term Q(X) is defined as thetotal number of event pairs that violates the tempo-ral constraints.
Schema-guided Event Prediction After schemamatching, an instance graph I is mapped to a sub-graph of the schema graph, i.e., I ′ ⊆ S. The nextstep is to determine whether a candidate event nodee ∈ S\I ′ is a missing node for I ′. Specifically, weaim to learn a function f(e, I ′) : S × 2S 7→ [0, 1],which outputs the probability that event node e ismissing for subgraph I ′. We consider two factorswhen designing the function f(e, I ′): (1) Neigh-bors of e and I ′. We use a graph neural network(GNN) to aggregate neighbor information and learnembedding vectors for nodes in S, then aggregateembeddings of nodes in I ′ to obtain the embeddingof I ′. The embeddings of e and I ′ are concate-nated, followed by an MLP to output the predictedprobability. (2) Paths. We identify all paths thatconnect e and each node in I ′ in the schema graphS, then aggregate the paths together to obtain thebag-of-path feature for the pair of (e, I ′). The bag-of-path feature is fed into another MLP to output
6https://www.nltk.org/howto/wordnet.html
58

Scenario # Episodes # Events # Ents # Rels
Business Change 18 81 24 54Civil Unrest 6 34 18 24Disease Outbreak 19 102 27 93Election 8 35 14 33International Conflict 17 95 56 50Kidnapping 9 66 15 56Mass Shooting 8 37 13 31Sports Events 4 17 14 19Terrorist Attacks 8 36 11 26Disaster/Manmade Disaster 8 38 10 29Disaster/Natural Disaster 4 23 8 18IED/General Attack 19 52 40 22IED/General IED 10 48 18 39IED/Drone Strikes 10 50 19 43IED/Backpack IED 10 49 18 40IED/Roadside IED 10 48 19 39IED/Car IED 10 50 19 43
Table 1: Statistics of our schema library.
the predicted probability. Finally, the outputs ofthe above two modules are averaged as the finalprediction.
3 Schema and Experiments
The overall statistics of our schema library are pre-sented in Table 1. The performance of each com-ponent is shown in Table 2. We evaluate the perfor-mance of our full system on a complex event cor-pus (LDC2022E02), which contains multi-lingualmulti-media document clusters. We train ourmention extraction component on ACE05 (Walkeret al., 2006) and ERE (Song et al., 2015);document-level argument extraction on ACE05 andRAMS (Ebner et al., 2020); coreference compo-nent on ACE05, EDL 2016 (LDC2017E03), EDL2017 (LDC2017E52), OntoNotes (Pradhan et al.,2012), ERE, CoNLL 2002 (Tjong Kim Sang, 2002),DCEP (Dias, 2016) and SemEval10 (Recasenset al., 2010); temporal ordering component on MA-TRES (Ning et al., 2018); weakly supervised eventextraction on ACE05; schema matching and predic-tion on LDC2022E03; visual event and argumentextraction on M2E2 (Li et al., 2020a) and cross-media event coreference on Video M2E2 (Chenet al., 2021a). For coreference resolution, similarto previous work (Wen et al., 2021), we use theCoNLL metric.
4 Related Work
Event Schema Induction and Curation Eventschemas, or otherwise known as scripts, arestructures that represent typical event progres-sions (Schank and Abelson, 1975). Prior to thiswork, there has been some effort in creating schema
Component Benchmark Metric Score
Weakly-supervised IETrigger ACE F1 63.3
Argument ACE F1 41.5
MentionExtraction
EnTrigger ACE+ERE F1 64.1
Argument ACE+ERE F1 49.7Relation ACE+ERE F1 49.5
EsTrigger ACE+ERE F1 63.4
Argument ACE+ERE F1 46.0Relation ACE+ERE F1 46.6
Document-levelArgument Extraction
ACE F1 66.7RAMS F1 48.6
CoreferenceResolution
EnEntity OntoNotes CoNLL 92.4Event ACE CoNLL 84.8
EsEntity SemEval 2010 CoNLL 67.6Event ERE-ES CoNLL 81.0
Wikidata QNode Linking TACKBP-2010 Acc. 90.9
TemporalOrdering
RoBERTa MATRES F1 81.7T5 MATRES-b Acc. 89.6
Visual Event Extraction M2E2 F1 52.7Cross-media Event Coreference Video M2E2 F1 51.5
Benchmark Metric Score
Schema Matching LDC2022E03 Recall 63.2Schema Prediction WikiEvents F1 45.5
Table 2: Performance (%) of each component our open-domain multimedia multilingual IE system (upper) andschema matching and prediction component (bottom).
databases through crowdsourcing (Regneri et al.,2010; Modi et al., 2016; Wanzare et al., 2016; Sak-aguchi et al., 2021). The key characteristics thatseparate our schema library from exiting resourcesinclude (1) focus on diverse newsworthy scenariosinstead of everyday events; (2) highly structuredmulti-level schema organization.
In addition to schema resources, there has alsobeen work on automating the schema inductionprocess, through the use of probabilistic graphi-cal models (Chambers, 2013; Cheung et al., 2013;Nguyen et al., 2015; Weber et al., 2018) and event-based language models (Pichotta and Mooney,2016; Modi and Titov, 2014; Rudinger et al., 2015;Li et al., 2020b, 2021a). We hope that our schemalibrary can serve as a resource for the developmentof better automatic schema induction methods.
Weakly-Supervised Event Extraction Due tothe high cost of annotating event instances, low re-source event extraction has received much attentionin recent years. There are a variety of settings ex-plored, including zero-shot transfer learning (Lyuet al., 2021; Huang et al., 2018), cross-lingual trans-
59

fer (Subburathinam et al., 2019), inducing eventtypes (Huang et al., 2016; Wang et al., 2021b),keyword-based supervision (Zhang et al., 2021)and few-shot learning (Peng et al., 2016; Lai et al.,2020; Shen et al., 2021; Cong et al., 2021; Chenet al., 2021b).
Schema-Guided Event Prediction Our schema-guided event prediction model is also related tolink prediction (Zhang and Chen, 2018; Wanget al., 2018; Lei et al., 2019) and graph completion(Zhang et al., 2019; Goel et al., 2020; Wang et al.,2021a) methods. The advantages of our schema-guided method are that: (1) Our method is speciallydesigned for multiple small event graphs, ratherthan a single large graph as studied in previouswork. Therefore, using event schema enables usto model the common pattern of instance eventgraphs. (2) An event schema can be seen as apool of inter-connected candidate events, whichprovides new event nodes that can be added into anincomplete instance event graph. However, exist-ing work can only predict missing links rather thanmissing nodes.
5 Conclusions and Future Work
We build an open-domain schema-guided eventprediction system that is capable of extracting andpredicting structured information regarding eventsfrom various scenarios. In the future, we plan to fur-ther improve both the extraction quality and porta-bility to cover even more scenarios, and use theautomatic zero-shot schema induction algorithm toiteratively extend our curated schemas. The hier-archy structure of our event schemas can also befurther utilized to improve future event prediction.
6 Broader Impact
The goal of this project is to advance the state-of-the-art schema-guided information extraction andevent prediction from real-world multi-modal newssources. We believe that grounding our work inreal-world applications will help us make progressin event-centric natural language understanding.However, this work is not void of possible improperuse that may have adverse social impacts.
One major distinction between beneficial use andharmful use depends on the data sources. Properuse of the technology requires that input sourcesare legally and ethically obtained. As an instanceof beneficial use, our demo may contribute to dis-ease outbreak monitoring and disaster emergency
response, which is included in our chosen scenarios.Besides, we should also be aware of the possiblebiases that may exists in the datasets. Our systemcomponents, as well as pretrained language modelsthat we use, are trained and evaluated on specificbenchmark datasets, which could be affected bysuch biases. For example, as is observed in Abidet al. (2021), the text generated by GPT-3 mightinclude undesired social biases. Our careful hu-man curators’ effort involved in the schema librarybuilding can mitigate this issue.
Generally, increasing transparency and explain-ability of models can help prevent social harm, suchas over-estimation of the model ability. We planto make our software fully open source for pub-lic audition and verification. We are also opento explore countermeasures to prevent unintendedconsequences.
The event prediction part of our model is ableto forecast the future trend of the current complexevent, which enables us to better understand thestructure and semantics of complex events. More-over, it is particularly helpful for us to analyze andpredict the public opinion.
Acknowledgement
We thank the anonymous reviewers helpful sug-gestions. This research is based upon work sup-ported by U.S. DARPA KAIROS Program No.FA8750-19-2-1004, U.S. DARPA AIDA ProgramNo. FA8750-18-2-0014 and LORELEI ProgramNo. HR0011-15-C-0115. The views and conclu-sions contained herein are those of the authors andshould not be interpreted as necessarily represent-ing the official policies, either expressed or implied,of DARPA, or the U.S. Government. The U.S. Gov-ernment is authorized to reproduce and distributereprints for governmental purposes notwithstand-ing any copyright annotation therein.
ReferencesAbubakar Abid, Maheen Farooqi, and James Zou. 2021.
Large language models associate muslims with vio-lence. Nature Machine Intelligence, 3(6):461–463.
Nathanael Chambers. 2013. Event schema inductionwith a probabilistic entity-driven model. In Proceed-ings of the 2013 Conference on Empirical Methodsin Natural Language Processing (EMNLP2013), vol-ume 13, pages 1797–1807.
Brian Chen, Xudong Lin, Christopher Thomas, Man-ling Li, Shoya Yoshida, Lovish Chum, Heng Ji, and
60

Shih-Fu Chang. 2021a. Joint multimedia event ex-traction from video and article. In Findings of theAssociation for Computational Linguistics: EMNLP2021, pages 74–88, Punta Cana, Dominican Republic.Association for Computational Linguistics.
Jiawei Chen, Hongyu Lin, Xianpei Han, and Le Sun.2021b. Honey or poison? solving the trigger cursein few-shot event detection via causal intervention.EMNLP.
Jackie Chi Kit Cheung, Hoifung Poon, and Lucy Van-derwende. 2013. Probabilistic frame induction. InProceedings of the 2013 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics: Human Language Technologies,pages 837–846, Atlanta, Georgia. Association forComputational Linguistics.
Xin Cong, Shiyao Cui, Bowen Yu, Tingwen Liu, WangYubin, and Bin Wang. 2021. Few-Shot Event Detec-tion with Prototypical Amortized Conditional Ran-dom Field. In Findings of the Association for Com-putational Linguistics: ACL-IJCNLP 2021, pages28–40, Online. Association for Computational Lin-guistics.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, andKristina Toutanova. 2019. BERT: Pre-training ofdeep bidirectional transformers for language under-standing. In Proceedings of the 2019 Conference ofthe North American Chapter of the Association forComputational Linguistics: Human Language Tech-nologies, Volume 1 (Long and Short Papers), pages4171–4186, Minneapolis, Minnesota. Association forComputational Linguistics.
Francisco Dias. 2016. Multilingual Automated TextAnonymization. Msc dissertation, Instituto SuperiorTécnico, Lisbon, Portugal, May.
Seth Ebner, Patrick Xia, Ryan Culkin, Kyle Rawlins,and Benjamin Van Durme. 2020. Multi-sentenceargument linking. In Proceedings of the 58th An-nual Meeting of the Association for ComputationalLinguistics.
Rishab Goel, Seyed Mehran Kazemi, Marcus Brubaker,and Pascal Poupart. 2020. Diachronic embedding fortemporal knowledge graph completion. In Proceed-ings of the AAAI Conference on Artificial Intelligence,volume 34, pages 3988–3995.
Matthew Honnibal, Ines Montani, Sofie Van Lan-deghem, and Adriane Boyd. 2020. spaCy: Industrial-strength Natural Language Processing in Python.Zenodo.
Lifu Huang, Taylor Cassidy, Xiaocheng Feng, HengJi, Clare R. Voss, Jiawei Han, and Avirup Sil. 2016.Liberal event extraction and event schema induction.In Proceedings of the 54th Annual Meeting of theAssociation for Computational Linguistics (Volume1: Long Papers), pages 258–268, Berlin, Germany.Association for Computational Linguistics.
Lifu Huang, Heng Ji, Kyunghyun Cho, Ido Dagan, Se-bastian Riedel, and Clare Voss. 2018. Zero-shottransfer learning for event extraction. In Proceedingsof the 56th Annual Meeting of the Association forComputational Linguistics (Volume 1: Long Papers),pages 2160–2170, Melbourne, Australia. Associationfor Computational Linguistics.
Tuan Manh Lai, Heng Ji, and ChengXiang Zhai. 2022.Improving candidate retrieval with entity profile gen-eration for wikidata entity linking. arXiv preprintarXiv:2202.13404.
Viet Dac Lai, Thien Huu Nguyen, and Franck Dernon-court. 2020. Extensively matching for few-shot learn-ing event detection. In Proceedings of the First JointWorkshop on Narrative Understanding, Storylines,and Events, pages 38–45, Online. Association forComputational Linguistics.
Kai Lei, Meng Qin, Bo Bai, Gong Zhang, and MinYang. 2019. Gcn-gan: A non-linear temporal linkprediction model for weighted dynamic networks. InIEEE INFOCOM 2019-IEEE Conference on Com-puter Communications, pages 388–396. IEEE.
Manling Li, Sha Li, Zhenhailong Wang, Lifu Huang,Kyunghyun Cho, Heng Ji, Jiawei Han, and ClareVoss. 2021a. The future is not one-dimensional:Complex event schema induction by graph modelingfor event prediction. In Proceedings of the 2021 Con-ference on Empirical Methods in Natural LanguageProcessing, pages 5203–5215.
Manling Li, Ruochen Xu, Shuohang Wang, LuoweiZhou, Xudong Lin, Chenguang Zhu, Michael Zeng,Heng Ji, and Shih-Fu Chang. 2022. Clip-event: Con-necting text and images with event structures. arXivpreprint arXiv:2201.05078.
Manling Li, Alireza Zareian, Qi Zeng, Spencer White-head, Di Lu, Heng Ji, and Shih-Fu Chang. 2020a.Cross-media structured common space for multime-dia event extraction. In Proceedings of the 58th An-nual Meeting of the Association for ComputationalLinguistics, pages 2557–2568, Online. Associationfor Computational Linguistics.
Manling Li, Qi Zeng, Ying Lin, Kyunghyun Cho, HengJi, Jonathan May, Nathanael Chambers, and ClareVoss. 2020b. Connecting the dots: Event graphschema induction with path language modeling. InProceedings of the 2020 Conference on EmpiricalMethods in Natural Language Processing (EMNLP),pages 684–695.
Sha Li, Heng Ji, and Jiawei Han. 2021b. Document-level event argument extraction by conditional gen-eration. In Proc. The 2021 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics - Human Language Technologies(NAACL-HLT2021).
Ying Lin, Heng Ji, Fei Huang, and Lingfei Wu. 2020. Ajoint end-to-end neural model for information extrac-tion with global features. In Proc. The 58th Annual
61

Meeting of the Association for Computational Lin-guistics (ACL2020).
Qing Lyu, Hongming Zhang, Elior Sulem, and DanRoth. 2021. Zero-shot event extraction via transferlearning: Challenges and insights. In Proceedingsof the 59th Annual Meeting of the Association forComputational Linguistics and the 11th InternationalJoint Conference on Natural Language Processing(Volume 2: Short Papers), pages 322–332, Online.Association for Computational Linguistics.
Piyush Mishra, Akanksha Malhotra, Susan WindischBrown, Martha Palmer, and Ghazaleh Kazeminejad.2021. A graphical interface for curating schemas. InProceedings of the 59th Annual Meeting of the Asso-ciation for Computational Linguistics and the 11thInternational Joint Conference on Natural LanguageProcessing: System Demonstrations, pages 159–166,Online. Association for Computational Linguistics.
Ashutosh Modi, Tatjana Anikina, Simon Ostermann,and Manfred Pinkal. 2016. InScript: Narrative textsannotated with script information. In Proceedingsof the Tenth International Conference on LanguageResources and Evaluation (LREC’16), pages 3485–3493, Portorož, Slovenia. European Language Re-sources Association (ELRA).
Ashutosh Modi and Ivan Titov. 2014. Inducing neuralmodels of script knowledge. In Proceedings of theEighteenth Conference on Computational NaturalLanguage Learning, pages 49–57.
Kiem-Hieu Nguyen, Xavier Tannier, Olivier Ferret, andRomaric Besançon. 2015. Generative event schemainduction with entity disambiguation. In Proceedingsof the 53rd Annual Meeting of the Association forComputational Linguistics and the 7th InternationalJoint Conference on Natural Language Processing(Volume 1: Long Papers), pages 188–197.
Qiang Ning, Hao Wu, and Dan Roth. 2018. A multi-axis annotation scheme for event temporal relations.In Proceedings of the 56th Annual Meeting of theAssociation for Computational Linguistics (Volume1: Long Papers), pages 1318–1328, Melbourne, Aus-tralia. Association for Computational Linguistics.
Haoruo Peng, Yangqiu Song, and Dan Roth. 2016.Event detection and co-reference with minimal su-pervision. In Proceedings of the 2016 Conferenceon Empirical Methods in Natural Language Process-ing, pages 392–402, Austin, Texas. Association forComputational Linguistics.
Karl Pichotta and Raymond J Mooney. 2016. Learningstatistical scripts with lstm recurrent neural networks.In Thirtieth AAAI Conference on Artificial Intelli-gence.
Sameer Pradhan, Alessandro Moschitti, Nianwen Xue,Olga Uryupina, and Yuchen Zhang. 2012. Conll-2012 shared task: Modeling multilingual unrestrictedcoreference in ontonotes. In Joint Conference on
Empirical Methods in Natural Language Process-ing and Computational Natural Language Learn-ing - Proceedings of the Shared Task: ModelingMultilingual Unrestricted Coreference in OntoNotes,EMNLP-CoNLL 2012, July 13, 2012, Jeju Island,Korea, pages 1–40. ACL.
Sarah Pratt, Mark Yatskar, Luca Weihs, Ali Farhadi,and Aniruddha Kembhavi. 2020. Grounded situationrecognition. In European Conference on ComputerVision, pages 314–332. Springer.
Alec Radford, Jong Wook Kim, Chris Hallacy, AdityaRamesh, Gabriel Goh, Sandhini Agarwal, Girish Sas-try, Amanda Askell, Pamela Mishkin, Jack Clark,et al. 2021. Learning transferable visual modelsfrom natural language supervision. In InternationalConference on Machine Learning, pages 8748–8763.PMLR.
Marta Recasens, Lluís Màrquez, Emili Sapena, M. Antò-nia Martí, Mariona Taulé, Véronique Hoste, MassimoPoesio, and Yannick Versley. 2010. Semeval-2010task 1: Coreference resolution in multiple languages.In Proceedings of the 5th International Workshop onSemantic Evaluation, SemEval@ACL 2010, UppsalaUniversity, Uppsala, Sweden, July 15-16, 2010, pages1–8. The Association for Computer Linguistics.
Michaela Regneri, Alexander Koller, and ManfredPinkal. 2010. Learning script knowledge with webexperiments. In ACL.
Rachel Rudinger, Pushpendre Rastogi, Francis Ferraro,and Benjamin Van Durme. 2015. Script induction aslanguage modeling. In Proceedings of the 2015 Con-ference on Empirical Methods in Natural LanguageProcessing, pages 1681–1686.
Keisuke Sakaguchi, Chandra Bhagavatula, RonanLe Bras, Niket Tandon, Peter Clark, and Yejin Choi.2021. proScript: Partially ordered scripts generation.In Findings of the Association for ComputationalLinguistics: EMNLP 2021, pages 2138–2149, PuntaCana, Dominican Republic. Association for Compu-tational Linguistics.
Roger C Schank and Robert P Abelson. 1975. Scripts,plans, and knowledge. In IJCAI, volume 75, pages151–157.
Shirong Shen, Tongtong Wu, Guilin Qi, Yuan-Fang Li,Gholamreza Haffari, and Sheng Bi. 2021. Adap-tive knowledge-enhanced Bayesian meta-learning forfew-shot event detection. In Findings of the Associa-tion for Computational Linguistics: ACL-IJCNLP2021, pages 2417–2429, Online. Association forComputational Linguistics.
Zhiyi Song, Ann Bies, Stephanie Strassel, Tom Riese,Justin Mott, Joe Ellis, Jonathan Wright, Seth Kulick,Neville Ryant, and Xiaoyi Ma. 2015. From light torich ere: annotation of entities, relations, and events.In Proceedings of the the 3rd Workshop on EVENTS:Definition, Detection, Coreference, and Representa-tion, pages 89–98.
62

Ananya Subburathinam, Di Lu, Heng Ji, Jonathan May,Shih-Fu Chang, Avirup Sil, and Clare Voss. 2019.Cross-lingual structure transfer for relation and eventextraction. In Proceedings of the 2019 Conference onEmpirical Methods in Natural Language Processingand the 9th International Joint Conference on Natu-ral Language Processing (EMNLP-IJCNLP), pages313–325, Hong Kong, China. Association for Com-putational Linguistics.
Erik F. Tjong Kim Sang. 2002. Introduction to theCoNLL-2002 shared task: Language-independentnamed entity recognition. In COLING-02: The 6thConference on Natural Language Learning 2002(CoNLL-2002).
Christopher Walker, Stephanie Strassel, Julie Medero,and Kazuaki Maeda. 2006. Ace 2005 multilin-gual training corpus. Linguistic Data Consortium,Philadelphia, 57.
Hongwei Wang, Hongyu Ren, and Jure Leskovec.2021a. Relational message passing for knowledgegraph completion. In Proceedings of the 27th ACMSIGKDD Conference on Knowledge Discovery &Data Mining, pages 1697–1707.
Hongwei Wang, Fuzheng Zhang, Min Hou, Xing Xie,Minyi Guo, and Qi Liu. 2018. Shine: Signed hetero-geneous information network embedding for senti-ment link prediction. In Proceedings of the EleventhACM International Conference on Web Search andData Mining, pages 592–600.
Ziqi Wang, Xiaozhi Wang, Xu Han, Yankai Lin, LeiHou, Zhiyuan Liu, Peng Li, Juanzi Li, and Jie Zhou.2021b. CLEVE: Contrastive Pre-training for EventExtraction. In Proceedings of the 59th Annual Meet-ing of the Association for Computational Linguisticsand the 11th International Joint Conference on Natu-ral Language Processing (Volume 1: Long Papers),pages 6283–6297, Online. Association for Computa-tional Linguistics.
Lilian D. A. Wanzare, Alessandra Zarcone, StefanThater, and Manfred Pinkal. 2016. A crowdsourceddatabase of event sequence descriptions for the acqui-sition of high-quality script knowledge. In Proceed-ings of the Tenth International Conference on Lan-guage Resources and Evaluation (LREC’16), pages3494–3501, Portorož, Slovenia. European LanguageResources Association (ELRA).
Noah Weber, Leena Shekhar, Niranjan Balasubrama-nian, and Nathanael Chambers. 2018. Hierarchicalquantized representations for script generation. ACL.
Haoyang Wen and Heng Ji. 2021. Utilizing relativeevent time to enhance event-event temporal relationextraction. In Proceedings of the 2021 Conferenceon Empirical Methods in Natural Language Process-ing, pages 10431–10437, Online and Punta Cana,Dominican Republic. Association for ComputationalLinguistics.
Haoyang Wen, Ying Lin, Tuan Lai, Xiaoman Pan, ShaLi, Xudong Lin, Ben Zhou, Manling Li, Haoyu Wang,Hongming Zhang, et al. 2021. Resin: A dockerizedschema-guided cross-document cross-lingual cross-media information extraction and event tracking sys-tem. In Proceedings of the 2021 Conference of theNorth American Chapter of the Association for Com-putational Linguistics: Human Language Technolo-gies: Demonstrations, pages 133–143.
Hongming Zhang, Haoyu Wang, and Dan Roth. 2021.Zero-shot Label-aware Event Trigger and Argu-ment Classification. In Findings of the Associationfor Computational Linguistics: ACL-IJCNLP 2021,pages 1331–1340, Online. Association for Computa-tional Linguistics.
Muhan Zhang and Yixin Chen. 2018. Link predictionbased on graph neural networks. Advances in NeuralInformation Processing Systems, 31:5165–5175.
Shuai Zhang, Yi Tay, Lina Yao, and Qi Liu. 2019.Quaternion knowledge graph embeddings. In Ad-vances in Neural Information Processing Systems,pages 2735–2745.
Ben Zhou, Kyle Richardson, Qiang Ning, Tushar Khot,Ashish Sabharwal, and Dan Roth. 2021. Temporalreasoning on implicit events from distant supervision.In Proceedings of the 2021 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics: Human Language Technologies,pages 1361–1371, Online. Association for Computa-tional Linguistics.
63

Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies: System Demonstrations, pages 64 - 70
July 10-15, 2022 ©2022 Association for Computational Linguistics
A Human-machine Interface for Few-shot Rule Synthesis forInformation Extraction
Robert Vacareanu, George C. G. Barbosa, Enrique Noriega-Atala, Gus Hahn-Powell,Rebecca Sharp, Marco A. Valenzuela-Escárcega, Mihai Surdeanu
University of ArizonaTucson, AZ, USA
rvacareanu, gcgbarbosa, enoriega, hahnpowell, [email protected], [email protected]
Abstract
We propose a system that assists a userin constructing transparent informationextraction models, consisting of patterns(or rules) written in a declarative lan-guage, through program synthesis. Usersof our system can specify their require-ments through the use of examples, whichare collected with a search interface. Therule-synthesis system proposes rule can-didates and the results of applying themon a textual corpus; the user has the op-tion to accept the candidate, request an-other option, or adjust the examples pro-vided to the system. Through an inter-active evaluation, we show that our ap-proach generates high-precision rules evenin a 1-shot setting. On a second evalua-tion on a widely-used relation extractiondataset (TACRED), our method generatesrules that outperform considerably man-ually written patterns. Our code, demo,and documentation is available at https://clulab.github.io/odinsynth/.
1 IntroductionRule-based methods for information extractionaddress the opacity of neural architectures byproducing models that are completely transpar-ent, i.e., they are usually a collection of ruleswritten in a declarative language. Such modelsare better suited for incremental improvements,as each individual rule can be explicitly inter-preted. However, these benefits do not comefor free: users of such systems must be familiarwith the underlying declarative rule language,and, potentially, with representations of syntaxsuch as syntactic dependencies. None of theseare trivial to users outside of natural languageprocessing (NLP), which, we argue, should bethe target users of these systems.
To mitigate the above limitation, we proposea human-machine interface (HMI) that: (a) lets
users synthesize rules from natural languageexamples, and correct them without necessarilyunderstanding the rule syntax (although expertusers who do have access to the actual ruleproduced), (b) generates rules in a few-shot set-ting, i.e., from a very small number of examples.The latter contribution is possible because ourrule synthesis engine has been pretrained on alarge collection of rules that were automaticallygenerated from a large text corpus (Vacareanuet al., 2022). In other words, our rule synthe-sis approach is akin to prompting for languagemodels (Liu et al., 2021). That is, we first trainan open-domain rule synthesis model, and thenwe guide its predictions to the task of inter-est using a small number of examples of thedesired extractions (the “prompt”).
We include two types of evaluations thatprove the value of the proposed approach. Thefirst evaluation focuses on interactive sessionswhere users generate rules that extract men-tions of named entity classes, e.g., CITY orACADEMIC INSTITUTION from a single exam-ple extraction. Using six different users, weshow that, despite the minimal supervision,the tool produces named entities in the corre-sponding classes with high precision, e.g., pre-cision at 20 (P@20) at over 75% for the CITYclass. This suggests that the proposed HMI isuseful to domain scientists that need to per-form information extraction quickly, withoutunderstanding the underlying NLP technology.For completeness, we also include a traditional,non-interactive evaluation, on the TACREDdataset (Zhang et al., 2017), through whichwe show that the rules synthesized by our ap-proach outperform the manually-written rulesby over 4 F1 points, even though our synthesiscomponent is not re-trained on the TACREDdata.
64

Figure 1: The architecture of our proposed system.
2 ArchitectureAt a high level, the proposed system consistsof two main modules: a rule synthesis com-ponent, and an UI module to facilitate rapidrule prototyping with minimal programmingor linguistic knowledge. The rule synthesiscomponent consists of: (a) a searcher that ex-plores the possible rule space, and (b) a neuralscorer that prioritizes next steps during rulegeneration. Figure 1 summarizes the overallarchitecture. The user selects a handful of ex-amples after an initial query. Then, our systemproposes a rule, together with its potential ex-tractions. The user then decides if this ruleis satisfactory. If not, the user can either askfor a new rule or add new examples (positiveor negative). This process repeats until thegenerated rule is accepted. We describe thesecomponents in detail in the next two sections.
3 Rule SynthesisOur proposed approach for rule generation fol-lows closely the method proposed in (Vacare-anu et al., 2022). For completeness, we summa-rize it here as well. Our rule synthesis methoduses enumerative search that is guided by atransformer-based scoring mechanism, and isoptimized using search-space pruning heuris-tics. Our transformer model scores each po-tential next state (where a state contains theincompletely generated rule up to this point),given the current state, such that the number ofstates to be explored is minimized. Specifically,our system consists of two main components:A searcher, with Branch and Bound (Landand Doig, 1960) as the underlying algorithm.The searcher uses the scores assigned by thescorer (below) to determine the order of ex-ploration, choosing the state with the highestscore, regardless of its position in the search
tree. As such, it is important for the scorerto assign high scores to states that are in thesub-tree that leads to the desired final rule,and lower scores to all other states;
A scorer, with a transformer backbone thatis initialized with a pretrained model, but fine-tuned through self-supervision, i.e., over auto-matically generated rules (see Section 3.2). Thescorer uses the current state and the specifica-tion, i.e., the natural language examples to bematched by the generated rule, to score eachpotential next state.
The searcher is responsible for exploring thestates in priority order (as determined by thescorer), and deciding if a given state is suc-cessful (i.e., it is a valid query and correctlyextracts the requested highlighted words andnothing more). The search space can be inter-preted as a tree, where the root is the initialcandidate solution and the children of a noden are the candidate solutions that the node ncould expand into. Given this, the searchercan be seen as iteratively applying a sequenceof three operations: (a) Expand the currentstate according to the domain-specific languagegrammar, (b) Score each expanded candidatenext state and insert them into the priorityqueue, and (c) Select from the queue the statewith the highest score to be the next state. Werepeat this process until we find a solution orwe reach our step limit.
The scorer assigns a numerical value to statesto establish the order of exploration. We ex-plore two variants: a static variant, whichassigns static weights to states based on theircomponents, and a contextual neural variantbased on a self-supervised method that assignscontextual state scores based on the currentcontext.
As a simple example, consider a user thatwants to learn named entities belonging to theclass CITY. She may start with a specifica-tion based on the sentence “Regina Romerois the mayor of Tucson, Arizona, havingbeen elected after. . . ”, in which she high-lights “mayor of” as the relevant context rep-resentative of this class, and “Tucson” asthe desired entity to be extracted. Fromthis specification, our method would generatethe rule: [lemma=mayor] [tag=IN] (?<arg>
65

[tag=NNP]+),1 which picks up “mayor” fol-lowed by a preposition (part-of-speech tag IN)as the context, and a sequence of 1 or moreproper nouns as the entity to be extracted.
3.1 Multiple sentencesOur system can handle specifications that con-tain multiple sentences and their highlights.We require the enumerative searcher to find arule that would satisfy all the constraints forall sentences in the specification. When scoring,we score a (current state, next potential state,single-sentence specification) triple, and thenaverage over all sentences in the specificationto obtain a final score for the (current state,next potential state) transition.
3.2 Training the neural scorerUnlike the static scorer, the neural guidingfunction of the contextual scorer needs to betrained, which we do with self-supervision.Because there is no large corpus of Odinsonrules, we artificially generate one with randomspans of text that we randomly manipulateinto rules. Our random-length text spans arechosen from the UMBC corpus (Han et al.,2013). Each token in this span is then ran-domly manipulated into an Odinson token con-straint based on either word, lemma, or part-of-speech. For example, a span such as thedog barked might be converted to [tag=DT][word=dog] [lemma=bark]. Then, to exposethe model to additional rule components (e.g.,alternation, quantifiers), we add further ma-nipulations, again with randomization. To addalternations, we build a temporary query byreplacing one of the token constraints witha wildcard that can match any token andquery the corpus for an additional sentencethat has different content in that position.This new content is added as an alternation.For example, with the temporary version ofthe above query [tag=DT] [word=dog] [],2we might find A dog runs, resulting in thefollowing alternation: [tag=DT] [word=dog]([lemma=bark]|[lemma=run]). To add aquantifier (i.e., *, +, or ?), we select a tokento modify and a quantifier to add, and check
1Our rules are generated in the Odinson rule lan-guage (Valenzuela-Escárcega et al., 2020).
2The Odinson wildcard, [], matches any token.
the corpus to ensure that the addition of thequantifier yields additional results.
After generating each random rule, we builda corresponding specification by querying theUMBC corpus: the retrieved sentences andtheir matched spans constitute specifications.However, having a specification and the corre-sponding rule is not enough to train our model.We also need a correct sequence of transitionsfrom the initial placeholder to the final rule.For this, we use an Oracle to generate the short-est sequence of transitions, which we considerto be the correct sequence for our purposes.This sequence of transitions, together with thespecification, forms the training data for ourmodel. Note that we train only on this data,i.e., after this self-supervised training processthe transformer’s weights are fixed. We trainusing the cross-entropy loss and with a cyclicallearning rate, as suggested by (Smith, 2017).Further, we employ a curriculum learning ap-proach (Bengio et al., 2009; Platanios et al.,2019), splitting the training data by sentencelength and by pattern length. We did not tuneour hyperparameters.
4 User Interface
We accompany the above rule synthesis com-ponent with a user interface (UI) to facilitaterapid prototyping with minimal programmingor linguistic knowledge. We showcase the UI inFigure 2, split into 5 blocks (a–e). Initially, theuser has to do an initial search for sentencesof interest (a). Then, she selects any relevantsentence, highlighting the parts for which shewishes to obtain a rule, e.g., highlighting thecapital city of as the context and Amman asthe entity of interest (b). The system thenreturns a potential rule which satisfies the cur-rent constraints, together with what the ruleextracts (c). Note that we display the rule forthe benefit of expert users, but most users arenot required to understand the format of therule. That is, a user can understand the rule’simpact by analyzing what such a rule extracts.She may add negative examples (a negativeexample is a sentence on which the output ruleshould not match anything), or ask for a newrule (d). This process is repeated until the useris satisfied with the given rule (e).
66

Figure 2: Walkthrough example of the user interface.
67

5 Evaluation5.1 Interactive Evaluation
Figure 3: Example of a specification annotated by auser in the interactive evaluation. The entity is high-lighted in orange and its context in gray.
We evaluated the performance of the sys-tem in an interactive scenario with a humanin the loop. The purpose of the interactiveevaluation is to quantify the performance ofrules generated with the interface to extractspecific entity types using a limited amountof examples. The user is tasked with usingthe interface to synthesize a rule to extract aspecific named entity type, and then manuallyverify that the extractions indeed belong tothe intended entity type. Given an entity type,the user queries an index of the UMBC corpusto pinpoint and select a pattern in one of theretrieved sentences. This pattern works as theuser’s specification, composed of the contextand an entity of the relevant type (See section3). Figure 3 depicts an example of a patternselection.
Once the specification is selected, it is usedto synthesize a candidate rule and retrieve asample sentences with matches. We restrict theevaluation to contain a single specification, toemulate a one-shot learning scenario, where themodel generates rules using a limited amountof information. The user inspects the rule andits matches to determine whether the candidaterule faithfully represents the original intent. Ifit does not, the next candidate rule is generatedand the process is repeated. We encouragedusers to repeat this process up to three times,but allowed them to repeat it a fourth time attheir discretion.
The interactive evaluation is carried outfor the following entity pairs: CITY/CAPITAL,PERSON/ACTOR, and ORGANIZATION/ACADEMICINSTITUTION. Each pair represents two differ-ent levels of granularity of the same concept.
One to two users were assigned to each pairand each user was instructed to use the inter-face to synthesize three rules per entity type.For every rule, they retrieved and manuallyverified precision at 10 (P@10) and precisionat 20 (P@20) on the most frequent entities inthe matches from the UMBC corpus.
Table 1 contains precision at 10 and precisionat 20 for each of the entity types. We canobserve that using minimal supervision, i.e.using a single specification to synthesize a rulefor a named entity type, the system generatesrules that have high precision (P@20 ≥ .77)for coarse grained named entities and similar,albeit slightly lower precision (P@20 ≥ .63), forfiner grained named entities. This is achievedwith no more than three or four iterations,highlighting how domain experts can readilybenefit from our proposed HMI.
Entity Type P@10 P@20CITY .85 .85CAPITAL .83 .75PERSON .78 .77ACTOR .71 .72ORGANIZATION .93 .85ACADEMIC INSTITUTION .70 .63
Table 1: P@10 and P@20 of our rule synthesis on6 different named entity types. CITY, PERSON andORGANIZATION are coarse types. CAPIITAL, ACTOR andACADEMIC INSTITUTION are fine grained types.
5.2 Non-interactive EvaluationTo facilitate a comparison with other ap-proaches, we also include an evaluation on theTACRED dataset, a widely-used relation clas-sification dataset (Zhang et al., 2017). In thissetting, we cluster the training sentences togenerate specifications. In particular, for eachsentence, we compute an embedding by aver-aging the embeddings of the words in betweenthe two given entities.3 Then, we compare thesimilarity of two sentences by cosine similarity,and cluster similar sentences together; eachcluster becomes one specification. Then, foreach cluster we run our system to generate arule, considering the words in-between the twoentities as the highlighted part.
We compare our approach against sev-eral state-of-the-art approaches, as well asthree baselines. Our first baseline isa traditional sequence-to-sequence approach(Sutskever et al., 2014) with transformers(Vaswani et al., 2017). We train it to decodethe rule using the specification as input, akin
3We used GloVe (Pennington et al., 2014).
68

to a traditional machine translation task. Oursecond baseline (Patterns) is a rule-based sys-tem that uses the hand-made rules compiled forTACRED (Zhang et al., 2017). Our third base-line No Learning consists of directly returninga rule for trivial cases (e.g. no words or onlyon word in between the two entities). Whenthere is no word, the final rule is empty. Whenthere is one word, the final rule consists of aword, lemma, or tag constraint, depending onwhich will result in a shorter rule. We presentour results in Table 2.
We note that both variants of our scorer(static and dynamic) perform better than theseq2seq and no-scorer baselines (34 F1 vs 28F1). Of particular relevance for our compar-ison is the baseline that relies on the hand-crafted patterns for TACRED. Our contextu-alized weights model obtains a higher F1 score(41.4 F1 vs 36.6 F1), although at the cost ofprecision, but with much higher recall. Our re-sults add evidence that it might be possible toreplace the human expert with a neural expert.When comparing our contextualized-scoringapproach to the supervised baselines, we notethat while we do not match their performance,there are two important factors to consider.First, our proposed approach is trained on do-main agnostic data that we automatically gen-erated, and then applied on TACRED as is,without fine-tuning. On the other hand, thesupervised approaches that we compare withtrain/fine-tune on the TACRED splits. Sec-ond, the output of our approach is a set ofhuman-interpretable rules, while the output ofthe other approaches is a statistical model thatproduces only the final label. In other words,previous work is much more opaque and thusmore difficult to interpret, debug, adjust, main-tain, and protect from hidden biases presentin the training data (e.g., Kurita et al., 2019;Sheng et al., 2019).
6 Conclusion and Future Work
We introduced a human-machine interface thatlets users synthesize rules from natural lan-guage examples, and correct them withoutnecessarily understanding the rule syntax. Inan interactive evaluation, we showed that ourmethod is capable to rapidly generate high-precision rules for the extraction of named enti-
Model P R F1Baselines
Seq2Seq with Transformers 53.0 19.0 28.0Patterns 86.9 23.2 36.6No Learning 53.0 19.0 28.0
Supervised ApproachesJoshi et al. (2020) 70.8 70.9 70.8Zhou and Chen (2021) – – 74.6Cohen et al. (2020) 74.6 75.2 74.8
Our approachStatic weights 54.9 24.6 34.0Contextual weights (BERT-Tiny) 57.6 29.6 39.1Contextual weights (BERT-Mini) 57.2 32.5 41.4Contextual weights (BERT-Small) 57.3 32.2 41.2Contextual weights (BERT-Medium) 55.0 31.8 40.3Contextual weights (BERT-Base) 55.6 32.4 41.0
Table 2: Results of our rule synthesis on the testingpartition of TACRED (given as precision (P), recall(R), and F1 scores), compared with 3 baselines andprevious supervised approaches. We include variants ofour contextualized method using different transformerbackbones.
ties from a single example in natural language.We also demonstrated that in a traditional,non-interactive evaluation on the TACREDdataset, our method produces rules that out-perform manually-written rules, despite thefact that our rule synthesis engine is not re-trained on the TACRED data.
While these initial results are exciting, thereis plenty of work left to do. First, the rulesgenerated by the system are “surface” rules,i.e., they act over sequences of tokens. Addingsupport for the generation of rules over syntaxwould allow for capturing more complicated re-lations and over greater distances. Second, thesystem is configured to generate a single rulethat captures the whole specification, whichmay include multiple (positive or negative) ex-amples. This may force the system to producecomplicated rules. A better alternative wouldbe to produce several simpler rules that to-gether capture the whole specification. Lastly,the system generates a sequence of rule candi-dates that are presented to the user one-by-one,which may bias the user’s perspective and im-pact usability. For example, the current systemtends to initially propose rules that are overlygeneral, which yield low-precision results. Tobetter understand users’ preferences (i.e., dousers prefer high-precision or high-recall rulesinitially?) user studies must be carried out.
69

ReferencesYoshua Bengio, Jérôme Louradour, Ronan Col-
lobert, and Jason Weston. 2009. Curriculumlearning. In Proceedings of the 26th Annual Inter-national Conference on Machine Learning, ICML’09, page 41–48, New York, NY, USA. Associa-tion for Computing Machinery.
Amir DN Cohen, Shachar Rosenman, andYoav Goldberg. 2020. Relation classificationas two-way span-prediction. arXiv preprintarXiv:2010.04829.
Lushan Han, Abhay L. Kashyap, Tim Finin,James Mayfield, and Jonathan Weese. 2013.UMBC_EBIQUITY-CORE: Semantic textualsimilarity systems. In Second Joint Confer-ence on Lexical and Computational Semantics(*SEM), Volume 1: Proceedings of the Main Con-ference and the Shared Task: Semantic TextualSimilarity, pages 44–52, Atlanta, Georgia, USA.Association for Computational Linguistics.
Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S.Weld, Luke Zettlemoyer, and Omer Levy. 2020.SpanBERT: Improving pre-training by represent-ing and predicting spans. Transactions of theAssociation for Computational Linguistics, 8:64–77.
Keita Kurita, Nidhi Vyas, Ayush Pareek, Alan WBlack, and Yulia Tsvetkov. 2019. Measuring biasin contextualized word representations. arXivpreprint arXiv:1906.07337.
Ailsa H. Land and Alison G. Doig. 1960. An auto-matic method of solving discrete programmingproblems. Econometrica, 28(3):497–520.
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zheng-bao Jiang, Hiroaki Hayashi, and Graham Neu-big. 2021. Pre-train, prompt, and predict: Asystematic survey of prompting methods innatural language processing. arXiv preprintarXiv:2107.13586.
Jeffrey Pennington, Richard Socher, and Christo-pher Manning. 2014. GloVe: Global vectors forword representation. In Proceedings of the 2014Conference on Empirical Methods in Natural Lan-guage Processing (EMNLP), pages 1532–1543,Doha, Qatar. Association for Computational Lin-guistics.
Emmanouil Antonios Platanios, Otilia Stretcu, Gra-ham Neubig, Barnabás Póczos, and Tom M.Mitchell. 2019. Competence-based curriculumlearning for neural machine translation. CoRR,abs/1903.09848.
Emily Sheng, Kai-Wei Chang, Prem Natarajan, andNanyun Peng. 2019. The woman worked as ababysitter: On biases in language generation. InProceedings of the 2019 Conference on EmpiricalMethods in Natural Language Processing and the
9th International Joint Conference on NaturalLanguage Processing (EMNLP-IJCNLP), pages3398–3403.
Leslie N. Smith. 2017. Cyclical learning rates fortraining neural networks. In 2017 IEEE WinterConference on Applications of Computer Vision(WACV), pages 464–472.
Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. 2014.Sequence to sequence learning with neural net-works. In Proceedings of the 27th InternationalConference on Neural Information ProcessingSystems - Volume 2, NIPS’14, page 3104–3112,Cambridge, MA, USA. MIT Press.
Robert Vacareanu, Marco A Valenzuela-Escarcega,George CG Barbosa, Rebecca Sharp, and MihaiSurdeanu. 2022. From examples to rules: Neuralguided rule synthesis for information extraction.arXiv preprint arXiv:2202.00475.
Marco A Valenzuela-Escárcega, Gus Hahn-Powell,and Dane Bell. 2020. Odinson: A fast rule-basedinformation extraction framework. In Proceed-ings of the 12th Language Resources and Evalua-tion Conference, pages 2183–2191.
Ashish Vaswani, Noam Shazeer, Niki Parmar,Jakob Uszkoreit, Llion Jones, Aidan N. Gomez,undefinedukasz Kaiser, and Illia Polosukhin.2017. Attention is all you need. In Proceedingsof the 31st International Conference on NeuralInformation Processing Systems, NIPS’17, page6000–6010, Red Hook, NY, USA. Curran Asso-ciates Inc.
Yuhao Zhang, Victor Zhong, Danqi Chen, Ga-bor Angeli, and Christopher D. Manning. 2017.Position-aware attention and supervised dataimprove slot filling. In Proceedings of the 2017Conference on Empirical Methods in Natural Lan-guage Processing (EMNLP 2017), pages 35–45.
Wenxuan Zhou and Muhao Chen. 2021. An im-proved baseline for sentence-level relation extrac-tion. arXiv preprint arXiv:2102.01373.
70

Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies: System Demonstrations, pages 71 - 89
July 10-15, 2022 ©2022 Association for Computational Linguistics
SETSUM: Summarization and Visualizationof Student Evaluations of Teaching
♠Yinuo Hu∗ ♠Shiyue Zhang∗ ♣Viji Sathy ♣A. T. Panter ♠Mohit Bansal♠Department of Computer Science, UNC Chapel Hill
♣Department of Psychology and Neuroscience, UNC Chapel HillOffice of Undergraduate Education, UNC Chapel Hillhuyinuo, shiyue, [email protected];
viji.sathy, [email protected]
AbstractStudent Evaluations of Teaching (SETs) arewidely used in colleges and universities. Typ-ically SET results are summarized for instruc-tors in a static PDF report. The report oftenincludes summary statistics for quantitative rat-ings and an unsorted list of open-ended stu-dent comments. The lack of organization andsummarization of the raw comments hindersthose interpreting the reports from fully uti-lizing informative feedback, making accurateinferences, and designing appropriate instruc-tional improvements. In this work, we intro-duce a novel system, SETSUM, that leveragessentiment analysis, aspect extraction, summa-rization, and visualization techniques to pro-vide organized illustrations of SET findings toinstructors and other reviewers. Ten univer-sity professors from diverse departments serveas evaluators of the system and all agree thatSETSUM help them interpret SET results moreefficiently; and 6 out of 10 instructors preferour system over the standard static PDF report(while the remaining 4 would like to have both).This demonstrates that our work holds the po-tential of reforming the SET reporting conven-tions in the future.
1 Introduction
Colleges and universities rely on student evalua-tions of teaching (SETs) to assess students’ per-ceptions about their courses (Chen and Hoshower,2003; Zabaleta, 2007). These evaluations about thecourse consist of both quantitative ratings usingLikert-type scales and open-ended comments thatdescribe student experiences. In many universities,SETs are a standard component of evaluations ofteaching and have multiple functions. First, theyhelp individual faculty members examine their ownteaching performance in a diagnostic way so theycan work to improve their approach in subsequentofferings of the course. Second, SETs allow institu-tion leaders to review and describe the educational
∗ Equal contribution.
quality of course offerings and the performanceof instructors. Third, though controversial, SETsummaries often are used as part of an instructor’slarger portfolio to demonstrate their teaching his-tory during high-stakes settings. Finally, in somecolleges and universities, SET summaries are re-leased to students to help guide them with courseselections. Given this wide range of uses for theSET summaries, it is important that thoughtful, ac-curate, and well-designed representations are pro-vided to draw accurate inferences about teachingquality, course design, and student learning (seeethics Sec. 7 for more details).
Usually, at the end of each semester, SET resultsare summarized into a PDF report for instructorsor other reviewers. As shown in a sample standardSET report in Fig. 5 of Appendix, quantitative rat-ings are summarized using basic statistics, such asmean and median, while students’ comments fromopen-ended questions are simply listed as raw text –without adequate organization and analyses. Whena college course is particularly large (e.g., withmore than 100 students), the final SET report canbe longer than 10 pages, which is time-consumingto read and analyze (Alhija and Fresko, 2009). Inaddition, instructors’ or other reviewers’ own cog-nitive biases may lead to inaccurate inferences andanalyses, e.g., people tend to pay more attentionto negative than positive comments (Kanouse andHanson Jr, 1987).
Therefore, the goal of our work is to provide anew dynamic presentation of SET results to facili-tate more efficient and less biased interpretationscompared to the standard PDF report. After obtain-ing institutional SET data of four semesters fromthe University of North Carolina (UNC) at ChapelHill, for demonstration we select two quantitativeand two open-ended questions from the total num-ber of questions (Sec. 3). We develop a system,SETSUM, to summarize and visualize the resultsof these four questions. For quantitative ratings
71

(Sec. 4.1), we visualize two statistics: response rateand sentiment distribution. For open-ended com-ments (Sec. 4.2), we develop a sentiment analysismodel to predict whether each comment sentenceis positive or negative. We use an aspect extractionapproach to help instructors quickly know the popu-larly discussed topics by students, e.g., assignment,and the corresponding topic sentiments. Finally, wepropose an unsupervised extractive summarizationmethod that extracts top sentences with high cen-trality, low redundancy, and balanced sentimentsas a summary of each aspect.
Automatic evaluations (Sec. 5.1) demonstratethat our sentiment prediction and aspect extractionmodules achieve good accuracy, and our summa-rization method produces more diverse and lessbiased summaries than simply picking top cen-tral sentences. More critically, the effectivenessof SETSUM should be judged by its main users –instructors. Thus, we begin by conducting humanevaluations (Sec. 5.2) with 10 professors from 8different academic departments at UNC. Note thatSETSUM is continuously under development, andour human evaluations were conducted on our veryfirst version: SETSUM V1.0. After evaluating thetwo SET presentation approaches, instructors areasked to complete a survey comparing the useful-ness of SETSUM to the standard SET report. Ac-cording to their responses, most of the new featuresintroduced on SETSUM are perceived as useful tovery useful by most instructors (on average, 8.8 outof 10), compared to the standard report. All 10instructors agree that SETSUM helps them inter-pret their ratings and comments more efficiently;while 4 out of 10 think the new system also sup-ports less biased interpretations. Finally, 6 of 10favor SETSUM more than the standard approach;the remaining 4 think both reports could be help-ful. Overall, for our first evaluation, instructorshold a positive attitude towards SETSUM and offervaluable and constructive suggestions to us.
Lastly, in Sec. 7, we discuss if machine-involvedrepresentations of SETs may introduce new errorsor bias and if so, what improvement needs to bemade before the “demonstration” can transitionto an “application”. Our system aims to provideaccurate, efficient, and visualized SET results toinstructors or other reviewers. It does not directlymake any value judgments or evaluations about theinstructor’s skills, the course design, or the amountof student learning during the term.
To the best of our knowledge, despite itswidespread use, we are among the few researchersto develop a pilot system that presents student-reported evaluations of teaching by using naturallanguage processing (NLP) techniques. In addition,we are the first to apply the system for a SET instru-ment and evaluate it using actual SET data from alarge public university. Though more developmentwork is in progress, our results demonstrate thatour approach is promising to reform the SET reportconventions in the future. Our SETSUM V1.1 web-site requires credentials to login, please contact usfor an access to the website. We provide a YouTubevideo to walk you through SETSUM V1.1. Ourcode is hosted at SETSum Github Repo.
2 Background & Related Work
As mentioned, SETs are widely used in higher edu-cation (Chen and Hoshower, 2003; Zabaleta, 2007).SET studies have shown that they can capture stu-dents’ opinions about instruction (Balam and Shan-non, 2010), enhance course design, can be used asa tool for assessing teaching performance (Pennyand Coe, 2004; Chen and Hoshower, 2003), andreflect institutional accountability about teaching(Spooren et al., 2013). Many instructors view SETsas valuable feedback to improve their teaching qual-ity (Griffin, 2001; Kulik, 2001). Many studies fo-cus on instrument design (i.e., which questions toask), reliability and validity of SET results (i.e., arethe scores consistent across contexts; are scoresrelated to other key constructs), and potential con-founding variables that affect SETs (e.g., do scoresdiffer by discipline, instructor race/ethnicity andgender, student grade) (Simpson and Siguaw, 2000;Spooren et al., 2013).
Typical SET instruments include quantitativeLikert-scale ratings. They are supplemented byopen-ended comments (Stupans et al., 2016; Mar-shall, 2021). Therefore, compared to quantitativeratings, open-ended comments are often under-analyzed or ignored completely due to labor re-quired to provide an adequate summary (Alhijaand Fresko, 2009; Hujala et al., 2020), raising theneed for contemporary methods in automated textanalysis. Recent works start to analyze studentcomments via text mining and machine learningmethods such as sentiment analysis (Wen et al.,2014; Azab et al., 2016; Cunningham-Nelson et al.,2018; Baddam et al., 2019; Sengkey et al., 2019;Hew et al., 2020), and identify topics, themes, or
72

Figure 1: The distribution of comments across prevalent topics (aspects). On the left, it shows the aspect bubblechart, and on the right, it shows the summary of the “assignment” aspect.
suggestions from student comments (Ramesh et al.,2014; Stupans et al., 2016; Gottipati et al., 2018;Unankard and Nadee, 2019; Hynninen et al., 2019).The common goal of these works is to answer someresearch questions (e.g., what are sentiment differ-ences across courses and students). In contrast, weprovide a demonstration tool of SET results to helpinstructors gain insights on their own and to allowothers have access to organized summaries.
The most relevant works to ours are SUFAT(Pyasi et al., 2018) and Palaute (Grönberg et al.,2021) – two analytic tools for student comments.They both support sentiment analysis and LDAtopic models (Blei et al., 2003), while we use moreadvanced RoBERTa-based sentiment analysis andweakly-supervised aspect extraction models. SU-FAT requires users to install the tool and load SETfiles locally, while our online website directly readsthe data from the SET instrument. More impor-tantly, none of them conducts human evaluations,which makes it unclear if their tools are useful fromthe actual users’ perspectives. Therefore, we de-velop the first demonstration system that uses anactual university SET instrument and is evaluatedby university instructors who are interpreting theirown evaluations.
3 SET Data
We use Student Evaluations of Teaching (SETs)data of over four academic terms (Fall 2017, Spring2018, Fall 2018, Spring 2019) collected at UNC
Chapel Hill. We utilize “semester + course number”as the specific identity of each course. We assumeeach course has just one instructor.1 In total, thereare about 5.6K courses and 298K SETs. Each SETis an evaluation questionnaire assigned to a studentfor a specific course they enrolled in, includingboth quantitative and open-ended questions.
UNC’s SET instrument includes a series of eval-uation questions assessing different aspects of thecourse and instructor. For demonstration, we selectfour representative questions – two quantitative andtwo open-ended items. For quantitative items, wechoose Overall, this course was excellent (CourseRate) and Overall, this instructor was an effectiveteacher (Instructor Rate), showing students’ over-all ratings on the course and instructor performance.Both items are based on a 5-point Likert scale (1= Strongly Disagree to 5 = Strongly Agree). Foropen-ended items, we choose Comments on overallassessment of this course (Course Comments) andComments on overall assessment of this instructor(Instructor Comments). Our system can be easilyextended to the full set of SET questions.
Because completing the SET form is not manda-tory, the average response rates of the two quantita-tive items we choose are 46% and 43% respectively,and even lower response rates are observed for thetwo open-ended items: 17% and 16%, respectively.
1This is not always true, and we will deal with co-teachingsituations in the next version of our system.
73

4 System Description
After logging in, instructors can select to displaytheir SET results of which semester and whichcourse. The dashboard shows two main sections:Rating Analysis and Comment Analysis. See screen-shots of our demo in Fig. 6 (SETSUM V1.0) andFig. 7 (SETSUM V1.1) in Appendix.
4.1 Rating AnalysisFor each of the two quantitative questions, we showthe following statistics.
Response Rate. Since students do not always re-spond to every SET question, knowing how manystudents responded is critical for interpreting thegeneralizability and representativeness of the re-sults. The standard report (Fig. 5) provides thenumber of responses for each question. To makethis information stand out, we use a circular pack-ing chart to describe the proportion of students whoanswered the question in comparison to the totalenrollment of the course (Fig. 2).
Sentiment Distribution. The standard SET re-port summarizes quantitative ratings by mean, me-dian, standard deviation, and percentages of the 5rating options. Instead, in SETSUM V1.0, we sim-plify ratings to be either positive (4 and 5) or nega-tive (3 or lower). We show the positive vs. negativeratings via a pie chart (Fig. 3 in Appendix). How-ever, after conducting human evaluations on SET-SUM V1.0, we received feedback from instructorspreferring the original 5-point scale distribution.Thus, in SETSUM V1.1, we include a detailedbreakdown of all scores.
4.2 Comment AnalysisFor open-ended questions, besides the option toview all raw comments as the standard report (byclicking the “View Raw Comments” button in SET-SUM V1.0 or the “Table View” button in SETSUM
V1.1), we provide the following new features.
4.2.1 Basic StatisticsWe present the Response Rate of open-ended ques-tions also by a circular packing chart. Studentcomments are raw texts without sentiment labels.Therefore, we develop a sentiment analysis model(Sec. 4.2.2) and get the sentiment of each commentsentence. Then, we display the Sentiment Distri-bution (positive vs. negative ratio) via a pie chartfor instructors to acquire an overview of students’sentiments expressed in comments.
4.2.2 Sentiment AnalysisAs mentioned in Sec. 2, many existing works haveconducted sentiment analysis on SET data (Wenet al., 2014; Azab et al., 2016; Baddam et al., 2019).In UNC’s SET instrument, no sentiment labels areexplicitly related to student comments. To traina sentiment analysis model, we pair Course Com-ments with the Course Rate since they are bothoverall assessment of the course. Similarly, we pairInstructor Comments with Instructor Rate.
We want to get sentence-level sentimentsto compute the overall sentiment of each as-pect (Sec. 4.2.3) and conduct summarization(Sec. 4.2.4). However, ratings are comment-levelsentences. Thus, we first train a comment-levelsentiment analysis model, and then we use it topredict the sentiments of each comment sentence.
4.2.3 Aspect ExtractionStudents usually comment on some common as-pects of the course, e.g., grade, assignment. Previ-ous works resort to LDA (Blei et al., 2003) to learntopics from student comments (Ramesh et al., 2014;Pyasi et al., 2018; Grönberg et al., 2021). We arguethat each topic learned from LDA is a set of wordsthat is hard to be assigned a post hoc name, andtopics sometimes lack distinctions (Ramesh et al.,2014). Therefore, we apply a weakly-supervisedaspect extraction model, MATE (Angelidis and La-pata, 2018), that can extract aspects from commentsusing a set of pre-defined aspects.
MATE. Multi Seed Aspect Extractor (MATE)(Angelidis and Lapata, 2018) is derived fromAspect-Based Autoencoder (ABAE) (He et al.,2017). ABAE learns a sentence-level aspect pre-dictor without supervision by reconstructing thesentence embedding as a linear combination ofaspect embeddings. Assume vs is the sentenceembedding and A is a matrix of aspect embed-dings, ABAE first predicts aspects: paspect
s =softmax(Wvs + b), and then reconstructs thesentence vector: rs = A⊤paspect
s . The objective isa max-margin loss using random sentences ni asnegative examples:
L =∑
s
∑
i
max(0, 1− rsvs + rsvni)
Similar to LDA, ABAE has to interpret the learnedaspects post hoc. To address this, MATE pre-defines a set of aspects by humans, and each aspectis given a set of seed words. Concatenating seed
74

word embeddings together forms an aspect seedmatrix Ai, and the final aspect embedding matrixA = [A⊤
1 z1, ...,A⊤KzK ], where zi is a weight vec-
tor of seed words.
Aspect Annotation. To pre-label aspects of stu-dent comments and get seed words for each aspect,we randomly sample 100 comments for each of thetwo open-ended questions from the entire corpusand split them into sentences. Two human anno-tators (two authors) work together, attribute oneor more aspects to each sentence, and label thecorresponding aspect sentiments (positive or nega-tive). Table 3 in Appendix shows two examples. Inthe end, we obtain 14 and 10 aspects of commentson course and instructor, respectively, and theirterminology is defined in Table 5, 6 in Appendix.With the annotations, we calculate clarity scores(Cronen-Townsend et al., 2002) of each word w.r.t.each aspect (see details in Appendix A). The higherthe clarity score, the more likely the word will ap-pear in sentences of a specific aspect. We manuallyselect 5 top-scored words for each aspect whileremoving noise (stopwords, names). Their scoresare re-normalized to add up to 1. Table 4 shows the5 seed words (plus weights) for each aspect.
Visualization. After training the MATE model,we predict the aspects of each comment sentence.We select all aspects that have paspects > 0.4. Thethreshold (0.4) is tuned on the subset with aspectannotations. Then, for each open-ended question ofeach course, we visualize its aspect distribution viaa bubble chart (Fig. 1). Bubble size represents thenumber of sentences of this aspect. While bubblecolor denotes the aspect sentiment – the averageof sentence-level sentiments, we chose accessiblecolor palette (the more blue the more positive, themore yellow the more negative).
4.2.4 Extractive SummarizationAfter clustering comments by aspects, we want toprovide a summary of each aspect. We first obtainthe “centrality” of each sentence and then proposea method to extract summaries with high centrality,low redundancy, and balanced sentiments.
LexRank. For all the comment sentences under acertain aspect, we use LexRank (Erkan and Radev,2004) to get the graph-based “centrality” of eachsentence, where we use the cosine similarity of sen-tence embeddings from Sentence-BERT (Reimersand Gurevych, 2019). Intuitively, if a sentence is
Algorithm 1: SummarizationInput: Sa,KOutput: S′
S′ ← ∅, S′a ← Sa, k ← 1;
while k ≤ K dos← argmaxs∈S′
aJ(s, S′, Sa);
S′ ← S′ ∪ s;S′a ← S′
a − s;k ← k + 1
end
similar to many other sentences, it will be close tothe “center” of the graph and thus it is prominent.
Sentence Extraction Algorithm. Naively, wecould extract the top central sentences as the sum-mary. However, such summary sometimes includesredundant information and tends to only select pos-itive sentences as they are more common. Inspiredby Hsu and Tan (2021), we propose a greedy sen-tence extraction algorithm that optimizes three ob-jectives on sentence selection: (1) maximizes cen-trality; (2) maximizes the difference between thesentence and other sentences extracted from previ-ous steps; (3) minimizes the difference between thesummary sentiment and the overall sentiment ofthe aspect. Algorithm 1 demonstrates our unsuper-vised extractive summarization algorithm, in whichSa represents all sentences under an aspect a, K isthe number of sentences we want to extract (K=5),and S′ is the target summary. Our learning objec-tive (we want to maximize it) at each extractionstep is written as:
J(s, S′, Sa) = centralitys − cosine_sim(s, S′)
−senti_diff(S′ ∪ s, Sa)
Essentially, we want to extract a summary withhigh centrality, low redundancy, and a balancedsentiment. centralitys is the centrality of sentences. Following Hsu and Tan (2021), we definecosine_sim(s, S′) as follows:
cosine_sim(s, S′) = maxs′∈S′
cosine(vs, vs′)
where vs and vs′ are sentence embeddings fromSentence-BERT (Reimers and Gurevych, 2019).And we define senti_diff(S′ ∪ s, Sa), as the fol-lowing:
senti_diff = |∑
s′∈S′∪s p(s′)
|S′ ∪ s| −∑
s′∈Sap(s′)
|Sa||
where p is the probability of positive sentimentpredicted by our sentiment analysis model.
75

Visualization. Hovering any bubble in the aspectbubble chart will display its summary on the right(Fig. 1). Clicking on the aspect tab will displaylisted summary sentences within their the originalcomments to provide contextual information. Atable of all sentences is on the bottom.
5 Evaluation & Results
5.1 Automatic Evaluation
Sentiment Analysis. We train two comment-level sentiment analysis models for Course Com-ments and Instructor Comments respectively. Wesplit our data into training (90%) and development(10%) sets, and about 6.3K and 5.8K examplesare in Course and Instructor development sets re-spectively. We first report comment-level sentimentprediction performance on the dev sets. Second, weuse the comment-level sentiment analysis modelsto predict sentence-level sentiments during infer-ence. To evaluate this, we use our aspect annotationdata (Table 3 in Appendix), and we only use sen-tences with just one sentiment (i.e., all aspects arepositive or negative), resulting in 202 and 230 test-ing examples for Course and Instructor. We reportmicro F1 (=accuracy) and macro F1. Table 1 showsthe results. It can be seen that our models achievereasonably good sentiment prediction performance,though they perform worse on predicting sentence-level sentiments than the comment level.
Aspect Extraction. Similarly, we also train twoaspect extraction models for Course Comments andInstructor Comments separately. We evaluate theirperformance by comparing to human annotated as-pects using F1 score. In total, we have 213 and 234testing examples for course and instructor mod-els, and the average number of aspects is 1.38and 1.31, respectively. We achieve F1 score of48.6 for the course model and 48.9 for the instruc-tor model, which are similar to the results of theMATE paper (Angelidis and Lapata, 2018). Wealso explore another approach by treating aspectextraction as a multi-label aspect classification task.We use half of the annotated data to finetune aRoBERTa-base (Liu et al., 2019) model and teston the other half annotated aspects. Our exper-iment shows improved F1 scores of 62.6 for thecourse model and 64.9 for the instructor model. Weplan to combine RoBERTa and MATE to deploy aweakly-supervised RoBERTa-based MATE in ournext version of website.
Sentiment Analysis Course Instructor
Comment-level micro F1 0.87 0.94Comment-level macro F1 0.83 0.86
Sentence-level micro F1 0.83 0.90Sentence-level macro F1 0.84 0.85
Table 1: Sentiment analysis results.
Summarization Course Instructor
Base. Ours Base. Ours
Centrality↑ 1.13 1.09 1.14 1.10Redundancy↓ 0.05 0.03 0.05 0.02Sentiment Diff↓ 0.41 0.34 0.43 0.36
Table 2: Summarization results.
Summarization. Due to the lack of gold sum-maries, we use three metrics (Centrality, Redun-dancy, and Sentiment Difference) to evaluate oursummarization approach and compare it to the base-line of extracting the top 5 central sentences. Pleaserefer to Appendix C for detailed definitions of thesethree metircs. We randomly sampled 100 coursesas the testing set to report the performance. Table 2shows the results. As expected, our method leadsto lower redundancy and sentiment difference thanthe baseline, though it scarifies some centrality.
5.2 Human EvaluationIt is critical to evaluate how our demonstration sys-tem is perceived by its primary users: instructors.
5.2.1 Evaluation SetupDesign a Survey. We design an evaluation surveyusing Qualtrics. Our complete survey can be foundat SETSum Github Repo. In the survey, we firstintroduce the background and purpose. We definethe standard PDF report Usual Approach and ourSETSUM V1.0 as Comparison Approach, and thenwe ask instructors to compare the two approaches.The main survey body contains 5 parts of questions:
(1) Rate the Usual Approach: Without compar-ing to SETSUM, we ask how they rate the useful-ness of standard SET reports in a 5-point scale:not at all, slightly, moderately, very, or extremelyuseful;
(2) Rate SETSUM (Rating Analysis): Comparedto the usual approach, instructors rate our new fea-tures of summarizing ratings in a slightly different5-point scale: not at all useful, not useful, equallyuseful, useful, or very useful;
(3) Rate SETSUM (Comments Analysis): Com-pared to the usual approach, we ask how usefuleach of our new features of summarizing commentsis (using the same response anchors as (2)).
76

(4) Rate the overall experience with SETSUM:We ask if our website helps them interpret SETresults more efficiently and/or with less bias (defi-nitely not, probably not, might or might not, proba-bly yes, definitely yes) as well as if they prefer thestandard SET report or our website or both.
(5) Comments: Instructors may leave additionalcomments on the website under development.
Invite Instructors. We invited 15 professors atUNC, who taught large introductory courses withinthe studied period (4 semesters). We estimated thesurvey to take 20-30 minutes, and each participantwas offered a $25 gift card to a campus coffeeshop. In the end, 10 instructors from 8 differentdepartments completed the survey successfully.
5.2.2 Results AnalysisFig. 4 shows the survey results, and the Qualtricsreport can be found at SETSum Github Repo. Here,we summarize some main takeaways.
Instructors have positive opinions about thestandard SET report. 8 out of 10 (and 6 outof 10) instructors think the PDF report is moder-ately to extremely useful in summarizing students’ratings (and comments), respectively. This demon-strates the well-perceived usefulness of existingSET reports by instructors, though they are lesssatisfied with the comment summarization.
New features introduced on SETSUM are per-ceived to be useful or very useful. On average,for rating analysis, 7 out of 10 instructors thinkeach of the 2 new features (response rate and sen-timent distribution) is useful or very useful, andfor comments analysis, 8.8 out of 10 instructorson avg. think each of the 5 new features (responserate, sentiment distribution, topic bubbles, sum-mary sentences, showing original comments foreach summary sentence) is useful or very useful,while fewer instructors (5.5 out of 10 on avg.) thinkthe scatter plot2 and the table showing all commentsentences are useful or very useful. Overall, mostinstructors perceive our SETSUM as being useful.
SETSUM helps all instructors interpret SET re-sults more efficiently, and it helps some instruc-tors interpret SET results with less bias. All in-structors agree that SETSUM helps them interpretSETs more efficiently (i.e., probably to definitely
2We had a scatter plot showing all comment sentences inSETSUM V1.0, which was removed from SETSUM V1.1.
yes). 4 out of 10 instructors think it helps themunderstand SETs with less bias.
Instructors prefer SETSUM than the standardreport or would like to have both. Lastly, 6 outof 10 instructors prefer SETSUM compared to theusual approach, while 4 instructors would like tohave both approaches.
Constructive suggestions. We identify the fol-lowing suggestions from instructors’ comments forimproving our future version: (1) The accuracy ofthe sentiment analysis and aspect extraction modelscan still be improved. (2) Many instructors preferthe complete display of ratings in the 5-point scale,rather than presenting only a positive v.s. negativeratio. (3) Instructors without a computer sciencebackground had difficulty understanding conceptslike “centrality”. So far, we addressed (2) and (3)in SETSUM V1.1 by providing the 5-point scalerating distribution and adding detailed explanationsfor each Machine Learning related modules.
Overall, instructors show a very positive attitudetowards our SETSUM demonstration system andprovided important suggestions and direction forour future work.
6 Conclusion
In this work, we propose SETSUM, a system tosummarize and visualize results from student eval-uations of teaching. We integrate NLP, statistical,visualization, and web service techniques. We areamong the few researchers to build a tool for in-structor use and are the first to evaluate the toolby university professors. Our results demonstratethat our system is promising at improving the SETreport paradigm and helps instructors gain insightsfrom their SETs more efficiently. In the future, wewill keep improving the sentiment analysis and as-pect extraction models to provide more accuratesummarization of SET results. The instructor eval-uation offered key recommendations for the nextiterations of the system. We will incorporate morefunctions to our system, including allowing instruc-tors to compare different courses and track theirown teaching history of their courses as well asdeveloping a separate administrator dashboard toidentify themes across academic courses, depart-ments, and programs.
77

7 Ethical Considerations
As mentioned earlier, SETs have multiple functionssuch as (1) faculty members examining their teach-ing performance in a diagnostic way, (2) allow-ing institution leaders to review and describe thequality of course offerings, (3) part of an instruc-tor’s larger portfolio to demonstrate their teachinghistory during high-stakes settings, and (4) sum-maries being released to students to guide themwith course selections. Given this wide range ofuses for the SET summaries, our work’s purposeis to take initial steps towards developing thought-ful, accurate, and well-designed representationsthat can be provided to draw accurate inferencesabout teaching quality, course design, and studentlearning. However, it is also critical to examine allaspects of SETs through an ethical lens. Errors inNLP-based analysis could lead to misinterpretationand inaccurate judgments in high-stakes settings.Therefore in the following, we discuss how eachmodule of our SETSum website affects the inter-pretation of SET results.
For quantitative items, we provide visualizationsof two statistics that are directly computed fromSET data. Therefore, no errors or biases should beintroduced compared to the standard PDF report.In fact, some instructors who participated in ourevaluations say that the response rate feature foreach individual question helps them understand theresults with less bias.
For open-ended items, to obtain their sentimentdistributions, we develop sentiment analysis mod-els to obtain sentence-level sentiments. Thoughwe obtain good sentiment prediction performance(Table 1), errors are inevitable. We use these fea-tures to demonstrate the relative number of positiveto negative comments (ratio). In general, unlessvery few students evaluate a course (low responserate for comments), the system can still conveythe information fairly well. Another important fea-ture that we develop as part of this system is togroup comment sentences by aspects. Although weachieve similar aspect prediction F1 scores consis-tent with past research, we find that the results arenot precise enough yet for widespread use. Our hu-man evaluators notice that some sentences from theopen-ended comments are inaccurately clustered.Therefore, in future iterations of this system, we be-lieve it is very important to develop a more accurateaspect extraction model. The final important fea-ture is the unsupervised extraction summarization
module. We choose an extraction method becauseit does not suffer from faithfulness (not stayingtrue to the source) issues as abstractive methods(Cao et al., 2018). Meanwhile, our algorithm ex-tracts summaries with more balanced sentiments(Table 2). Nonetheless, we hope to find a summa-rization approach that aligns more closely with thesentiments underlying the students’ comments.
Though instructors express positive attitudes to-wards our system and 4 instructors think it helpthem understand SETs with less bias, we believethat additional thorough evaluations need to be con-ducted in the future. Outside of SETs, our workrecognizes the different ways, reporters, and meth-ods that could be used to assess teaching effec-tiveness, including but not limited to peer reports,analysis of classroom sound, student learning, andan instructor’s own teaching portfolio.
Finally, at this time our system is designed tobe used and reviewed by instructors or other re-viewers, and it does not directly make any broadjudgments or decisions (e.g., whether the instructoris qualified for promotion). The primary end-usersof the system should be instructors who wish toanalyze their SET findings more thoroughly andacquire the main takeaways more efficiently. Otherreviewers and administrators can use the systemto view the SET findings in a broader scope, suchas reading the report summary per department orper division. Overall, the goal of SETSUM is tohelp instructors and other reviewers to understandmore of students’ needs and make improvementsto future course design.
Acknowledgments
We thank the reviewers for their helpful comments.We thank the UNC instructors who participated inour human evaluations. We would also like to thankHeather Thompson from the Office of Undergradu-ate Curricula for providing the data and Rob Ricksfrom the Office of Institutional Research and As-sessment for additional data preparation activities.This work was supported by NSF-CAREER Award1846185, NSF-AI Engage Institute DRL-2112635,a Bloomberg Data Science Ph.D. Fellowship, andthe Howard Hughes Medical Institute Inclusive Ex-cellence 3 Grant.
ReferencesFadia Nasser-Abu Alhija and Barbara Fresko. 2009. Stu-
dent evaluation of instruction: What can be learned
78

from students’ written comments? Studies in Educa-tional evaluation, 35(1):37–44.
Stefanos Angelidis and Mirella Lapata. 2018. Sum-marizing opinions: Aspect extraction meets senti-ment prediction and they are both weakly supervised.In Proceedings of the 2018 Conference on Empiri-cal Methods in Natural Language Processing, pages3675–3686, Brussels, Belgium. Association for Com-putational Linguistics.
Mahmoud Azab, Rada Mihalcea, and Jacob Abernethy.2016. Analysing ratemyprofessors evaluations acrossinstitutions, disciplines, and cultures: The tell-talesigns of a good professor. In International Confer-ence on Social Informatics, pages 438–453. Springer.
Swathi Baddam, Prasad Bingi, and Syed Shuva. 2019.Student evaluation of teaching in business education:Discovering student sentiments using text miningtechniques. e-Journal of Business Education andScholarship of Teaching, 13(3):1–13.
Esenc M Balam and David M Shannon. 2010. Studentratings of college teaching: A comparison of fac-ulty and their students. Assessment & Evaluation inHigher Education, 35(2):209–221.
David M Blei, Andrew Y Ng, and Michael I Jordan.2003. Latent dirichlet allocation. Journal of machineLearning research, 3(Jan):993–1022.
Ziqiang Cao, Furu Wei, Wenjie Li, and Sujian Li. 2018.Faithful to the original: Fact aware neural abstractivesummarization. In Proceedings of the AAAI Confer-ence on Artificial Intelligence, volume 32.
Yining Chen and Leon B Hoshower. 2003. Studentevaluation of teaching effectiveness: An assessmentof student perception and motivation. Assessment &evaluation in higher education, 28(1):71–88.
Steve Cronen-Townsend, Yun Zhou, and W Bruce Croft.2002. Predicting query performance. In Proceedingsof the 25th annual international ACM SIGIR confer-ence on Research and development in informationretrieval, pages 299–306.
Sam Cunningham-Nelson, Mahsa Baktashmotlagh, andWageeh Boles. 2018. Visually exploring sentimentand keywords for analysing student satisfaction data.Proceedings of the 29th Australasian Association ofEngineering Education (AAEE 2018), pages 1–7.
Günes Erkan and Dragomir R Radev. 2004. Lexrank:Graph-based lexical centrality as salience in text sum-marization. Journal of artificial intelligence research,22:457–479.
Swapna Gottipati, Venky Shankararaman, andJeff Rongsheng Lin. 2018. Text analytics approachto extract course improvement suggestions fromstudents’ feedback. Research and Practice inTechnology Enhanced Learning, 13(1):1–19.
Bryan W Griffin. 2001. Instructor reputation and stu-dent ratings of instruction. Contemporary educa-tional psychology, 26(4):534–552.
Niku Grönberg, Antti Knutas, Timo Hynninen, andMaija Hujala. 2021. Palaute: An online text miningtool for analyzing written student course feedback.IEEE Access, 9:134518–134529.
Ruidan He, Wee Sun Lee, Hwee Tou Ng, and DanielDahlmeier. 2017. An unsupervised neural attentionmodel for aspect extraction. In Proceedings of the55th Annual Meeting of the Association for Compu-tational Linguistics (Volume 1: Long Papers), pages388–397.
Khe Foon Hew, Xiang Hu, Chen Qiao, and Ying Tang.2020. What predicts student satisfaction with moocs:A gradient boosting trees supervised machine learn-ing and sentiment analysis approach. Computers &Education, 145:103724.
Chao-Chun Hsu and Chenhao Tan. 2021. Decision-focused summarization. In Proceedings of the 2021Conference on Empirical Methods in Natural Lan-guage Processing, pages 117–132.
Maija Hujala, Antti Knutas, Timo Hynninen, and HeliArminen. 2020. Improving the quality of teachingby utilising written student feedback: A streamlinedprocess. Computers & Education, 157:103965.
Timo Hynninen, Antti Knutas, Maija Hujala, and HeliArminen. 2019. Distinguishing the themes emerg-ing from masses of open student feedback. In 201942nd International Convention on Information andCommunication Technology, Electronics and Micro-electronics (MIPRO), pages 557–561. IEEE.
David E Kanouse and L Reid Hanson Jr. 1987. Neg-ativity in evaluations. In Preparation of this papergrew out of a workshop on attribution theory heldat University of California, Los Angeles, Aug 1969.Lawrence Erlbaum Associates, Inc.
Diederik P Kingma and Jimmy Ba. 2015. Adam: Amethod for stochastic optimization. In ICLR (Poster).
James A Kulik. 2001. Student ratings: Validity, utility,and controversy. New directions for institutionalresearch, 2001(109):9–25.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Man-dar Joshi, Danqi Chen, Omer Levy, Mike Lewis,Luke Zettlemoyer, and Veselin Stoyanov. 2019.Roberta: A robustly optimized bert pretraining ap-proach. arXiv preprint arXiv:1907.11692.
Ilya Loshchilov and Frank Hutter. 2018. Decoupledweight decay regularization. In International Confer-ence on Learning Representations.
Pablo Marshall. 2021. Contribution of open-ended ques-tions in student evaluation of teaching. Higher Edu-cation Research & Development, pages 1–14.
79

Jeffrey Pennington, Richard Socher, and Christopher DManning. 2014. Glove: Global vectors for word rep-resentation. In Proceedings of the 2014 conferenceon empirical methods in natural language processing(EMNLP), pages 1532–1543.
Angela R Penny and Robert Coe. 2004. Effectivenessof consultation on student ratings feedback: A meta-analysis. Review of educational research, 74(2):215–253.
Siddhant Pyasi, Swapna Gottipati, and VenkyShankararaman. 2018. Sufat-an analytics tool forgaining insights from student feedback comments. In2018 IEEE Frontiers in Education Conference (FIE),pages 1–9. IEEE.
Arti Ramesh, Dan Goldwasser, Bert Huang, HalDaumé III, and Lise Getoor. 2014. Understandingmooc discussion forums using seeded lda. In Pro-ceedings of the ninth workshop on innovative useof NLP for building educational applications, pages28–33.
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert:Sentence embeddings using siamese bert-networks.In Proceedings of the 2019 Conference on EmpiricalMethods in Natural Language Processing and the 9thInternational Joint Conference on Natural LanguageProcessing (EMNLP-IJCNLP), pages 3982–3992.
Daniel Febrian Sengkey, Agustinus Jacobus, andFabian Johanes Manoppo. 2019. Implementing sup-port vector machine sentiment analysis to students’opinion toward lecturer in an indonesian public uni-versity. Journal of Sustainable Engineering: Pro-ceedings Series, 1(2):194–198.
Penny M Simpson and Judy A Siguaw. 2000. Studentevaluations of teaching: An exploratory study of thefaculty response. Journal of Marketing Education,22(3):199–213.
Pieter Spooren, Bert Brockx, and Dimitri Mortelmans.2013. On the validity of student evaluation of teach-ing: The state of the art. Review of EducationalResearch, 83(4):598–642.
Ieva Stupans, Therese McGuren, and Anna Marie Babey.2016. Student evaluation of teaching: A study ex-ploring student rating instrument free-form text com-ments. Innovative Higher Education, 41(1):33–42.
Sayan Unankard and Wanvimol Nadee. 2019. Topicdetection for online course feedback using lda. InInternational Symposium on Emerging Technologiesfor Education, pages 133–142. Springer.
Miaomiao Wen, Diyi Yang, and Carolyn Rose. 2014.Sentiment analysis in mooc discussion forums: Whatdoes it tell us? In Educational data mining 2014.
Thomas Wolf, Lysandre Debut, Victor Sanh, JulienChaumond, Clement Delangue, Anthony Moi, Pier-ric Cistac, Tim Rault, Remi Louf, Morgan Funtow-icz, Joe Davison, Sam Shleifer, Patrick von Platen,
Figure 2: A circular packing chart describes the re-sponse rate.
Figure 3: A pie chart describes the sentiment distribu-tion.
Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu,Teven Le Scao, Sylvain Gugger, Mariama Drame,Quentin Lhoest, and Alexander Rush. 2020. Trans-formers: State-of-the-art natural language processing.In Proceedings of the 2020 Conference on EmpiricalMethods in Natural Language Processing: SystemDemonstrations, pages 38–45, Online. Associationfor Computational Linguistics.
Francisco Zabaleta. 2007. The use and misuse of stu-dent evaluations of teaching. Teaching in highereducation, 12(1):55–76.
Appendix
A Clarity Score
To identify seed words for each aspect. We com-pute the clarity score (Cronen-Townsend et al.,2002; Angelidis and Lapata, 2018) of each wordwith respect to each aspect. The score measureshow likely it is to observe word w in commentsof aspect a: scorea(w) = ta(w)log
ta(w)t(w) , where
ta(w) is the tf-idf score ofw in comments of aspecta and t(w) is that in all comments.
B Implementation Details
Sentiment Analysis. We finetuned a RoBERT-large model (Liu et al., 2019) using HuggingFace’sTransformers (Wolf et al., 2020) for 5 epochs andchose the best performed checkpoint on the de-velopment set. We used the AdamW optimizer
80

(Loshchilov and Hutter, 2018) with learning rate1e-5 and batch size 16.
Aspect Extraction. We used NLTK to conductsentence and word segmentation. We initializedthe MATE model using GloVe embeddings (Pen-nington et al., 2014). During the training, the wordembeddings, seed word matrices, and seed weightvectors were fixed and we trained the model for10 epochs using Adam optimizer (Kingma and Ba,2015) with learning rate 10−1 and batch size 50.We also experimented the multi-label classificationapproach by finetuning a RoBERTa-base model(Liu et al., 2019) for 10 epochs using AdamW opti-mizer (Loshchilov and Hutter, 2018) with learningrate 2e-5 and batch size 16.
Website. We developed the website using theReact framework for the front-end interface. Forthe back-end, we set up a database with Firebaseand created a RESTful API with Firebase CloudFunctions. Our website is deployed to Netlify.comfor an online demonstration.
C Summarization Evaluation Metrics
We define the Centrality metric as the average cen-trality of summary sentences. The higher the metricis, the better. Assume the summary to evaluate isS′.
Centrality(S′) =
∑s∈S′ centralitys|S′|
We compute the information Redundancy withina summary S′ by taking the average of cosinesimilarity among sentences. We use sentenceembeddings from Sentence-BERT (Reimers andGurevych, 2019) to compute cosine similarities.The lower the metric is, the better.
Redun(S′) =
∑s∈S′ max
s′∈S′−scosine(vs, vs′)
|S′|
We first compute the average sentiments for thesummary S′ and all sentences under the aspect Sa,respectively. Then, we take their absolute differ-ence as the final score of Sentiment Difference. Thelower the metric is, the better.
Senti_diff = |∑
s∈S′ p(s)
|S′| −∑
s∈Sap(s)
|Sa||
where p is the probability of positive sentimentpredicted by our sentiment analysis model.
81

0 1 2 3 4 5 6 7 8 9 10
Number of Evaluators
Rate the Usual Approach - Quantitative ratings ofyour course and teaching?
Rate the Usual Approach - Open-ended commentsabout your course and teaching?
Moderately useful3
Moderately useful5
Extremely useful2
Slightly useful3
Slightly useful2
Very useful3
Not at all useful Slightly useful Moderately useful Very useful Extremely useful
(a) How useful is the Usual Approach in summarizing students’ quantitative ratings and open-ended comments of your courseand teaching?
0 1 2 3 4 5 6 7 8 9 10
Number of Evaluators
Rate the Comparison Approach - The responserate for each quantitative question is displayed.
Rate the Comparison Approach - The ratio ofpositive to negative comments is shown.(quantitative)
Equally useful and not useful3
Very useful3
Very useful3
Not useful1
Useful4
Useful4
Not at all useful Not useful Equally useful and not useful Useful Very useful
(b) How useful is the Comparison Approach in summarizing students’ quantitative comments about your course and teaching?
0 1 2 3 4 5 6 7 8 9 10
Number of Evaluators
Rate the Comparison Approach - The response rate for theopen-ended comments is displayed.
Rate the Comparison Approach - The ratio of positive tonegative comments is shown (open-ended)
Rate the Comparison Approach - Comments are clusteredinto bubbles by topic areas.
Rate the Comparison Approach - Hovering over topicbubbles shows the top comment sentences
Rate the Comparison Approach - When you click into thebubbles, you can see original comments of the topsentences related to topic bubbles by clicking thedropdown.
Rate the Comparison Approach - You can see a scatterplotand table with all comment sentences related to thespecific topics when you click into the bubbles
Rate the Comparison Approach - You can choose to rankthe comments from most positive to most negative orfrom negative to positive in the list of all comments
Equally useful and not useful4
Very useful4
Very useful5
Very useful4
Not useful2
Useful8
Useful8
Useful5
Useful3
Useful5
Useful6
Useful5
Not at all useful Not useful Equally useful and not useful Useful Very useful
(c) How useful is the Comparison Approach in summarizing students’ open-ended comments about your course and teaching?
0 1 2 3 4 5 6 7 8 9 10
Number of Evaluators
Rate the Comparison Approach - interpret my SET resultsmore efficiently.
Rate the Comparison Approach - interpret my SET resultswith less bias.
Might or might not5
Definitely yes2
Probably yes8
Probably yes4
Definitely not Probably not Might or might not Probably yes Definitely yes
(d) Overall, how useful is the Comparison Approach in summarizing students’ opinions about your course and teaching?
0 1 2 3 4 5 6 7 8 9 10
Number of Evaluators
Please select your initialpreferences about how youreceive your SET findings.
I will like to have both approaches I prefer the Comparison Approach
I will like to have both approaches I prefer to use the Usual Approach I prefer the Comparison Approach
(e) Overall, please select your initial preference about how you receive your SET findings.
Figure 4: Results of human evaluation comparing the standard SET report (the Usual Approach) and the SETSUMV1.0 website (the Comparison Approach).
82

SET Question Comment Sentence (Aspect, Sentiment)
Comments on overall assess-ment of this course
Because, even though the lecture was fine the exams were brutalor was just wrong because of the answer key being wrong.
(content, positive); (exam,negative)
Comments on overall assess-ment of this instructor
The instructor was clear at explaining information and fairlyevaluating all assignments.
(delivery, positive);(grade, positive)
Table 3: Two examples of Aspect Annotation.
University of North Carolina at Chapel Hill, [College]
[COURSE] - [NAME] - Report Issue Date [DATE] 1
Student Evaluation of Teaching, [TERM]
[NAME], [COURSE]
Raters Students
Responded 120
Invited 169
Response Ratio 71.0%
Overall
Mean Median SD N Strongly
Disagree Neutral Agree Strongly
Comments on Overall Assessment of This Course.
Comments
I did not think I would take what I learned from this class and be able to apply it to any of my other studies or interests in
school/life/career, but I am very surprised and happy that I've learned so much and feel way more comfortable and proficient with
numbers and data. These are important skills that I am happy to have now.
I think it could have been structured better. We spent so much time on the relatively easy stuff in the beginning and then spent hardly
any time working through the harder topics in the end.
Everything was great about this course, however I felt very overwhelmed by the group project at the end of the semester and felt like it
had been thrown in as an afterthought. If we would have been given more time to complete it, it wouldn't have been as bad. Given the
timing in the semester was at the very end and my motivation was already lacking, the project just seemed like a little too much in a
short span of time.
This course, while very challenging, was taught well. While i think the flipped classroom technique is not the most beneficial, Dr.
[NAME] was really passionate about the class and tried to make information understood by all.
Comments on Overall Assessment of This Instructor.
Comments
She did an excellent job. You can see how passionate she is about the subject which made it more entertaining in class
Professor [NAME] was incredible. She worked hard to help her students succeed, and took into account our opinions as students in
order to better design the course. Professor [NAME] made herself available to help her students, and showed interest in our
success in the class, as well as outside of the class.
One of the best instructors I have had at UN
Dr. [NAME] cares so much about her students and at it made students want to learn more in the course.
Ms. [NAME] is a great instructor. She really loves what she is teaching, and tries to create a close community between the students.
I really felt seen and heard by Dr. [NAME]. I appreciate the format of the class and the personalized feed back she gave me at office
hours. I like how she encouraged us to share events on campus that are going on, and how she shared about her life as well.
Dr. [NAME] is obviously very passionate about her work and it shows every day. She does all that she can to cater to the needs of
her students individually and as a whole. She goes out of her way to provide ample resources to everyone to make sure we all learn
course materials to the best of our ability. I specifically appreciated the videos she provided and the notes and tables. I don't believe
there is anything I would change as everything worked ideally for me.
I enjoyed the polleverywhere questions we did in class; although I would like to see more questions similar to exam questions.
Disagree Agree
1. Overall, this course was excellent. 4.09 4.00 0.97 120 3.3 % 3.3 % 12.5 % 42.5 % 38.3 %
2. Overall, this instructor was an effective teacher. 4.52 5.00 0.78 117 1.7 % 1.7 % 2.6 % 30.8 % 63.2 %
I think she is an intelligent woman who clearly cares a great deal about her students, but I think she made the course too
complicated. There were too many resources, and I didn't find the assignments to be a great help. I also found that "review" before
exams was a waste of time and didn't help me at all.
One of the best professors I have had at UNC. She was very understanding and so excited to share her knowledge with us. The
videos were so so helpful –– I knew/understand almost everything we did in class because of watching the videos beforehand.
Figure 5: The standard PDF SET report.
83

(a) A page shows the Rating Analysis (Quantitative Questions) part.
Figure 6: Screenshots of SETSUM v1.0 (Part1, see Part2 in the next page).
84

(b) A page shows the Comments Analysis (Open-ended Questions) part.
Figure 6: Screenshots of SETSUM v1.0 (Part2).85

(a) A page shows the Rating Analysis (Quantitative Questions) part.
Figure 7: Screenshots of SETSUM v1.1 (Part1, see Part2 in the next page).
86

(b) A page shows the Comments Analysis (Open-ended Questions) part.
Figure 7: Screenshots of SETSUM v1.1 (Part2).
87
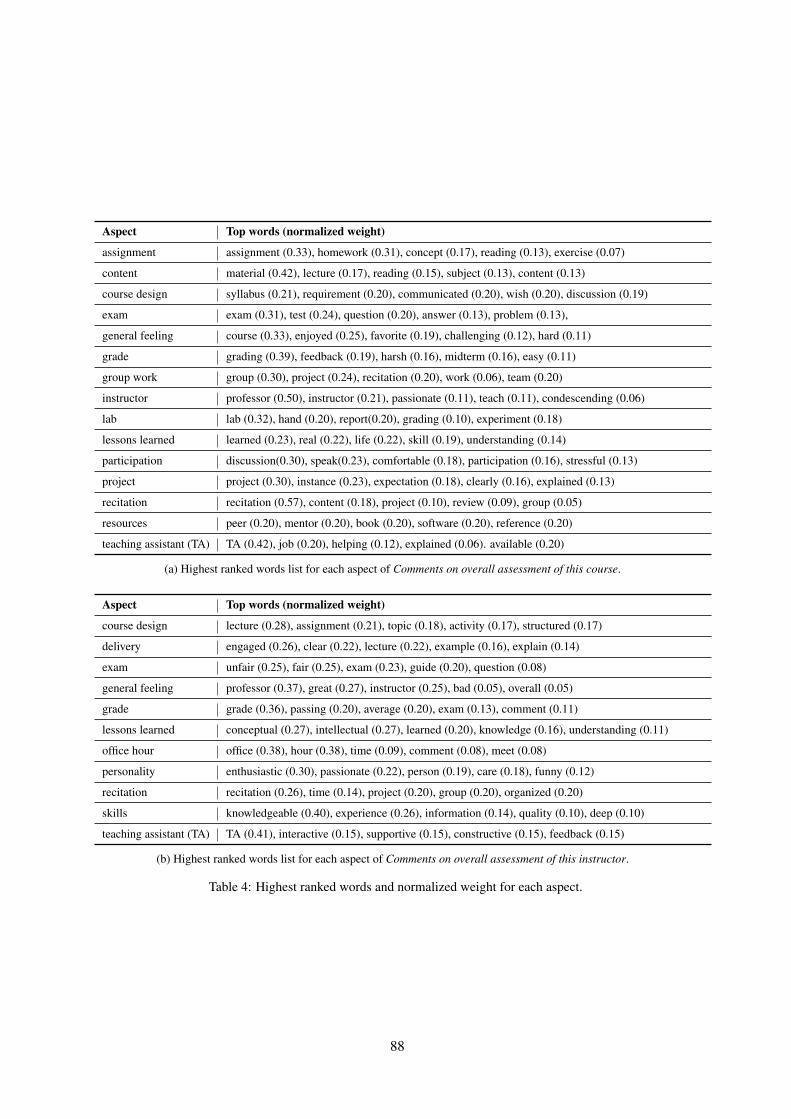
Aspect Top words (normalized weight)
assignment assignment (0.33), homework (0.31), concept (0.17), reading (0.13), exercise (0.07)
content material (0.42), lecture (0.17), reading (0.15), subject (0.13), content (0.13)
course design syllabus (0.21), requirement (0.20), communicated (0.20), wish (0.20), discussion (0.19)
exam exam (0.31), test (0.24), question (0.20), answer (0.13), problem (0.13),
general feeling course (0.33), enjoyed (0.25), favorite (0.19), challenging (0.12), hard (0.11)
grade grading (0.39), feedback (0.19), harsh (0.16), midterm (0.16), easy (0.11)
group work group (0.30), project (0.24), recitation (0.20), work (0.06), team (0.20)
instructor professor (0.50), instructor (0.21), passionate (0.11), teach (0.11), condescending (0.06)
lab lab (0.32), hand (0.20), report(0.20), grading (0.10), experiment (0.18)
lessons learned learned (0.23), real (0.22), life (0.22), skill (0.19), understanding (0.14)
participation discussion(0.30), speak(0.23), comfortable (0.18), participation (0.16), stressful (0.13)
project project (0.30), instance (0.23), expectation (0.18), clearly (0.16), explained (0.13)
recitation recitation (0.57), content (0.18), project (0.10), review (0.09), group (0.05)
resources peer (0.20), mentor (0.20), book (0.20), software (0.20), reference (0.20)
teaching assistant (TA) TA (0.42), job (0.20), helping (0.12), explained (0.06). available (0.20)
(a) Highest ranked words list for each aspect of Comments on overall assessment of this course.
Aspect Top words (normalized weight)
course design lecture (0.28), assignment (0.21), topic (0.18), activity (0.17), structured (0.17)
delivery engaged (0.26), clear (0.22), lecture (0.22), example (0.16), explain (0.14)
exam unfair (0.25), fair (0.25), exam (0.23), guide (0.20), question (0.08)
general feeling professor (0.37), great (0.27), instructor (0.25), bad (0.05), overall (0.05)
grade grade (0.36), passing (0.20), average (0.20), exam (0.13), comment (0.11)
lessons learned conceptual (0.27), intellectual (0.27), learned (0.20), knowledge (0.16), understanding (0.11)
office hour office (0.38), hour (0.38), time (0.09), comment (0.08), meet (0.08)
personality enthusiastic (0.30), passionate (0.22), person (0.19), care (0.18), funny (0.12)
recitation recitation (0.26), time (0.14), project (0.20), group (0.20), organized (0.20)
skills knowledgeable (0.40), experience (0.26), information (0.14), quality (0.10), deep (0.10)
teaching assistant (TA) TA (0.41), interactive (0.15), supportive (0.15), constructive (0.15), feedback (0.15)
(b) Highest ranked words list for each aspect of Comments on overall assessment of this instructor.
Table 4: Highest ranked words and normalized weight for each aspect.
88

Terminology Description Example
general feeling General high-level comments or over-all feelings about the course
The course is really interesting for me as a CS major and Ilearned a lot form it.
instructor Any comments towards the instructor Professor [NAME] is a joy, and is incredibly understanding,passionate, and enjoyable to simply listen to in class!
teaching assistant(TA)
Any comments related to TA Resources are always available, the instructors and TAs wereeasily accessible and always friendly, the material was challeng-ing, and examples were always fun and engaging.
lab Any comments related to lab I thought this course was very engaging and I liked that it wasvery hands on, like a lab should be.
recitation Any comments related to recitation This recitation was a bit odd.
course design Any comments on the organization andstructure of the course
I thought this course was excellently structured and formatted.
assignment Any comments related to home-work/assignments
The assignment is really, really well designed that it builds uponeach other from assignment 2 through assignment 9 and it helpedme exercise various topics/concepts that I learned from class.
exam Any comments related to exam/test This class is extremely hard and the second test is expected tobe failed by most students, which is ridiculous.
content Any comments related to course mate-rials or specific contents of the course
The material was very useful for our course although the profes-sors could have made a better connection with the techniqueslearned in the lab.
participation Talk about the participation / atten-dance / engagement / discussion
Needs more class participation and discussion.
grade Comments on the grading of the course Harsh grading on lab reports.
group work Any comments related to group work All of the recitations consisted of group work towards a finalproject, though the early recitations seemed largely irrelevant tothe project.
resources Resources provided by course such asreadings, textbooks, peer tutors etc.
I did however get all the help I needed from the peer mentors.
lessons learned Learning outcomes or skills acquiredfrom the course
The professor is really good, I learned a lot of interesting andclassic dramas this semester.
Table 5: Aspect Annotation Terminology for Comments on overall assessment of this course.
Terminology Description Example
general feeling General high-level comments or over-all feelings about the instructor
Awesome Professor.
teaching assistant(TA)
Any comments related to TA One of the best TAs I have had so far at UNC
recitation Any comments related to recitation Recitation felt like a waste of time.
office hour Any comments related to office hour She was great during her office hours and was always concernedthat we understood the material.
personality Describe personality of the instructor She cares a lot about the subject material and her students.
skills Describe the skill sets or experiencesof the instructor
The instructor had a deep understanding of the course materialand provided many real world examples built from her ownexperience and previous work.
grade Comments on the grading style The instructor was clear at explaining information and fairlyevaluating all assignments.
delivery How the instructor delivers the infor-mation and explains concepts
I really enjoyed her teaching style, she helped us through toughtopics by breaking them down into more digestible chunks andwas really positive overall, which helped for class moral.
course design Comments on the organization andstructure of the course
I didn’t really get to know the TA because we didn’t have a lotof recitations.
lessons learned Learning outcomes or skills acquiredfrom the course
I now have a greater understanding of the German language andof Swiss;German literature and culture.
Table 6: Aspect Annotation Terminology for Comments on overall assessment of this instructor.
89

Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies: System Demonstrations, pages 90 - 98
July 10-15, 2022 ©2022 Association for Computational Linguistics
Towards Open-Domain Topic Classification
Hantian Ding1, Jinrui Yang1,2, Yuqian Deng1, Hongming Zhang1, Dan Roth1
1University of Pennsylvania, 2University of Melbournehantian2, jinruiy, yuqiand, hzhangal, [email protected]
Abstract
We introduce an open-domain topic classifica-tion system that accepts user-defined taxonomyin real time. Users will be able to classify atext snippet with respect to any candidate la-bels they want, and get instant response fromour web interface. To obtain such flexibility,we build the backend model in a zero-shot way.By training on a new dataset constructed fromWikipedia, our label-aware text classifier caneffectively utilize implicit knowledge in thepretrained language model to handle labels ithas never seen before. We evaluate our modelacross four datasets from various domains withdifferent label sets. Experiments show thatthe model significantly improves over exist-ing zero-shot baselines in open-domain scenar-ios, and performs competitively with weakly-supervised models trained on in-domain data.12
1 Introduction
Text classification is a fundamental natural lan-guage processing problem, with one of its major ap-plications in topic labeling (Lang, 1995; Wang andManning, 2012). Over the past decades, supervisedclassification models have achieved great successin closed-domain tasks with large-scale annotateddatasets (Zhang et al., 2015; Tang et al., 2015; Yanget al., 2016). However, they are no longer effectivein open-domain scenarios where the taxonomy isunbounded. Retraining the model for every newlabel set often incurs prohibitively high cost in thesense of both annotation and computation. By con-trast, having one classifier that is flexible with un-limited labels can save such tremendous effortswhile keeping the solution simple. Therefore, inthis work, we build a system for open-domain topicclassification that can classify a given text snippetinto any categories defined by users.
1Interactive online demo at https://cogcomp.seas.upenn.edu/page/demo_view/ZeroShotTC
2Code and data available at http://cogcomp.org/page/publication_view/980
At the core of our system is a zero-shot textclassification model. While supervised models aretypically insensitive to class names, a zero-shotmodel is usually label-aware, meaning that it canunderstand label semantics directly from the nameor definition of the label, without accessing anyannotated examples. Our model TE-Wiki com-bines a Textual Entailment (TE) formulation withWikipedia finetuning. Specifically, we constructa new dataset that contains three million article-category pairs from Wikipedia’s subcategory graph,and finetune a pretrained language model (e.g.BERT) to predict the entailment relations betweenarticles and their associated categories. We simu-late the diversity in open-domain classification withthe wide coverage of Wikipedia, while preservinglabel-awareness through an entailment framework.
In our benchmarking experiments, TE-Wiki out-performs all previous zero-shot methods on fourbenchmarks from different domains. It alsoshows competitive performance against weakly-supervised models trained on in-domain data. Bylearning from Wikipedia, our method does not re-quire any data that is specifically collected fromthe evaluation domains. On the other hand, sinceour model is label-aware, it can flexibly classifytext pieces into any labels outside Wikipedia.
Finally, we compare our system against humansfor further insights. We show that even humans aresometimes confused by ambiguous labels througha crowdsourcing study, which explains the perfor-mance gap between open-domain and supervisedclassification. The gap is reduced significantlywhen label meanings are clear and well alignedwith the semantics of text. We also use an exam-ple to illustrate the negative effect of a bad labelname. Through the analysis, we demonstrate theimportance of choosing proper label names in open-domain classification.
90

Figure 1: An overview of our open-domain topic classification system. Users can choose multiple models (top), anddefine their own text input and candidate labels (middle). Prediction results from different models are displayed inthe bar chart and the table (bottom).
2 Related Work
Open-domain zero-shot text classification was firststudied in the NLP domain in (Chang et al., 2008)(under the name “dataless classification") as amethod that classifies solely based on a generalknowledge source and does not require any in-domain data, whether labeled or not. It was pro-posed to embed both the text and labels into thesame semantic space, via Explicit Semantic Anal-ysis, or ESA (Gabrilovich and Markovitch, 2007),and pick the label with the highest relevance score.This idea was further extended to hierarchical(Song and Roth, 2014) and cross-lingual (Songet al., 2016) text classification. Later on, (Yin et al.,2019) called this protocol “label fully unseen" andproposed an entailment approach to transfer knowl-edge from textual entailment to text classification.It formulates an n-class classification problem asn binary entailment problems by converting labelsinto hypotheses and the text into the premise, andselects the premise-hypothesis pair with highestentailment score. More recently, another concur-rent work (Chu et al., 2021) proposed to exploreresources from Wikipedia for zero-shot text classi-fication, but with a different formulation.
There are many other methods that also requireless labeling than supervised classification, thoughin slightly different settings. For example, previ-ous works have explored to generalize from a setof known classes (with annotation) to unknownclasses (without annotation) using word embed-
dings of label names (Pushp and Srivastava, 2017;Xia et al., 2018; Liu et al., 2019), class correlationon knowledge graphs (Rios and Kavuluru, 2018;Zhang et al., 2019), or joint embeddings of doc-uments and labels (Nam et al., 2016). Besides,Weakly supervised approaches (Mekala and Shang,2020; Meng et al., 2020) learn from an unlabeled,but in-domain training set. Given a set of pre-defined labels, a label-aware knowledge miningstep is first applied to find class-specific indicatorsfrom the corpus, followed by another self trainingstep to further enhance the model by propagatingthe knowledge to the whole corpus. However, noneof these approaches are suitable for building anopen-domain classification system. They either re-quire domain-specific annotation or knowing testlabels beforehand.
3 System Description
We present details about our open-domain topicclassification system, starting with an overview ofour web interface, followed by the backend model.
3.1 User Interface
Figure 1 is a snapshot of our online demo. The sys-tem is supported by multiple backend models fortest and comparison. Among them, “Bert-Wiki",corresponding to TE-Wiki in this paper, is the best-performing one in our evaluation. After selectingthe model(s), users can create their own taxonomyin the “Labels" column, and input the text snippet.
91

Figure 2: An overview of our proposed TE-Wiki. Left: the data collection process. For each of the top-levelcategories, we run DFS to find its descendant categories as well as their member articles. These articles are pairedwith the root category for model input. Right: the model architecture. We use BERT for sequence classification.The article text is concatenated with the category name to feed into a BERT encoder. The classification head takesthe output embedding of the "[CLS]" token to classify the input text-category pair.
The system will then classify the text with the user-defined taxonomy. Results are presented in twoformats: a bar chart and a ranking table. The tableon the right provides a clear view of rankings byeach model, while the bar chart on the left is usefulto compare the scale of the scores from differentmodels for different labels. These scores, rangingfrom 0 to 1, are probabilities of the label beingrelevant to the text, which we will explain furtherin the next section.
Consider the example in Figure 1. The input textis most relevant to lifestyle, somewhat relevant totechnology, and irrelevant to children, which alignswith the prediction of our “Bert-Wiki" model.
3.2 TE-WikiWe now describe our best performing model TE-Wiki. Previous work (Yin et al., 2019) has demon-strated that an n-way classification problem canbe converted into n binary entailment problems.Specifically, we can use the text as the premise,and candidate labels as the hypotheses, to generaten statements “[Text] Entails [Labeli]" for i ∈ [n].The motivation is that classification is essentiallya special kind of entailment. Suppose we want toclassify a document into 3 classes: politics, busi-ness, sports. We can ask three binary questions:“Is it about politics?”, “Is it about business?”, “Is itabout sports?”. By doing so, the model is no longerconstrained to a fixed label set, as we can alwaysask more questions to handle new labels.
With the above framework, it is straightforwardto train a model on an entailment dataset (e.g.MNLI (Williams et al., 2018), FEVER (Thorne
et al., 2018), RTE (Dagan et al., 2005; Wang et al.,2019).) and use it for classification. However, thismay not be the optimal choice as topic classifi-cation only focuses on high-level concepts, whiletextual entailment has a much wider scope and in-volves many other aspects (e.g., see (Dagan et al.,2013)). Therefore, we propose to construct a newdataset from Wikipedia with articles as premises,and categories as hypotheses. Our desired trainingpair should meet the following two criteria:
1. The hypothesis is consistent with the premise,i.e. the categorization is correct.
2. The hypothesis should be abstract and concise toreflect the high-level idea of the premise, ratherthan focus on certain details.
Directly using all the categories associated with anarticle satisfies the first criterion, but fails with thesecond, as some of them do not represent the articlewell. For example, the page Bill Gates is assignedCategory:Cornell family, which is correct aboutthe person but probably not a suitable label for thewhole article. To resolve the issue, we instead usehigher-level categories on Wikipedia’s subcategorygraph to yield better hypotheses.
The overview of TE-Wiki is illustrated in Fig-ure 2. Specifically, we start with a set of 700 top-level categories from Wikipedia’s overview page3
as roots. For each of them, we run a depth-firstsearch (DFS) to find its subcategories. In our ex-periment, we set the max depth to 2 to ensure thesubcategories found are strongly affiliated with the
3https://en.wikipedia.org/wiki/Wikipedia:Contents/Categories
92

Algorithm 1: Collect training dataInput :Top-level category set S,
Wikipedia subcategory graph G,max search depth r = 2;
Initialize d(x, c) =∞ for any article x ∈ X andc ∈ S. M = ;
for c in S doT = DFS(c,G, r);for t in T .nodes do
for x in t.articles dod(x, c) = mind(x, c), 1 + depth(t);
endend
endfor x in X do
if minc∈S d(x, c) <∞ thenP = argminc∈Sd(x, c);for c in P do
Add (x, c, 1) to M ;endSample c′ from S − P ;Add (x, c′,−1) to M ;
endendOutput :M
root. We collect all member articles of categoriesin the DFS tree, including both leaves and internalnodes, and pair them with the root to construct pos-itive examples. In case an article can be reachedfrom multiple root categories, we only pair it withthe root(s) that has the smallest tree distance tothe article to ensure supervision quality. Then foreach article, we randomly choose a different cat-egory to construct a negative example. While wehave tried more sophisticated negative samplingstrategies with the aim to confuse the model, noneof them makes a significant improvement. Thus,we keep to this simple version. The final trainingset D = (xi, ci, pi)ni=1 consists of 3-tuples suchthat xi is a Wikipedia article, ci is the correspond-ing high-level category name, and pi ∈ +1,−1is the label. The procedure for constructing thetraining set is summarized in Algorithm 1.
We then fine-tune the pre-trained BERT model(Devlin et al., 2019) with the collected dataset.Given a tuple (xi, ci, pi), the concatenation of xiand ci is passed to a BERT encoder, followed by aclassification head to predict whether the article xibelongs to the category ci. During test, (i) for thesingle-labeled case, we pick the label with the high-est predicted probability, (ii) for the multi-labeledcase, we pick all labels predicted as positive (i.e.probability > 0.5). We do not use any hypothesistemplate to convert label names into sentences asin (Yin et al., 2019), for consistency with training.
Dataset #Classes #samplesYahoo (Zhang et al., 2015) 10 100,000Situation (Mayhew et al., 2019) 12 3525AG News (Zhang et al., 2015) 4 7,600DBPedia (Lehmann et al., 2015) 14 70,000
Table 1: Dataset Statistics.
4 Evaluation
We evaluate all the backend models of our sys-tem on four classification benchmarks to comparetheir performance. We also compare them againstweakly-supervised and supervised models to quan-tify how much we can achieve without any domain-specific training data.
4.1 Experiment setupDatasets: We summarize all test datasets in Table1. For Yahoo! Answers, we use the reorganizedtrain/test split by (Yin et al., 2019). All datasets arein English. Among the four, Situation Typing is amulti-labeled dataset with imbalanced classes, forwhich we report the weighted average of per-classF1 score. We refer readers to (Yin et al., 2019) forthe class distribution statistics. The other three aresingle-labeled and class-balanced, and we reportthe classification accuracy.Models: Apart from TE-Wiki, we run five zero-shot models for open-domain evaluation, as wellas a weakly-supervised and a supervised model forclose-domain comparison.
• Word2Vec (Mikolov et al., 2013): To measurecosine similarity between the embedding vectorsof text and label.
• ESA (Chang et al., 2008): Same as above, exceptusing embeddings in Wikipedia title space
• TE-MNLI, TE-FEVER, TE-RTE (Yin et al.,2019): Textual entailment models by finetuningBERT on MNLI, FEVER, and RTE respectively.4
• LOTClass (Meng et al., 2020): A weakly-supervised method that learns label informationfrom unlabeled, but in-domain training data.
• BERT (Devlin et al., 2019): We finetune a su-pervised BERT on training data for each dataset.
Implementation: We finetune the bert-base-uncased model on the Wikipedia article-categorydataset to train TE-Wiki. We removed 26 cate-gories whose name starts with "List of" from the700 top-level categories, resulting in 674 categories
4In experiments, we always use bert-base-uncased.
93

Supervision Type Methods Yahoo Situation AG News DBPedia
Zero-shot
Word2Vec (Mikolov et al., 2013) 35.7 15.6 71.1 69.7ESA (Chang et al., 2008) 40.4 30.2 71.1 64.7TE-MNLI (Yin et al., 2019) 37.9 15.4 68.8 55.3TE-FEVER (Yin et al., 2019) 40.1 21.0 78.0 73.0TE-RTE (Yin et al., 2019) 43.8 37.2 60.5 65.9TE-Wiki 57.3 41.7 79.6 90.2
Weakly-supervised LOTClass (Meng et al., 2020) 54.7 N/A 86.4 91.1Supervised BERT (Devlin et al., 2019) 75.3 58.0 94.4 99.3
Table 2: Test results of all methods on four datasets. Compared with Word2Vec and ESA, ESA-WikiCate is overallthe best among the three embedding-based methods. TE-WikiCate outperforms all other zero-shot methods acrossall four datasets, and performs competitively against the weakly-supervised LOTClass.
as hypotheses and 1,367,784 articles as premises.The final training set contains 3,387,028 article-category pairs. We set the max sequence length tobe 128 tokens and the training batch size to be 64.The model is optimized with AdamW (Loshchilovand Hutter, 2019) with initial learning rate as 5e-5. Since we do not have a development set in thezero-shot setting, we train the model for 1500 stepsto prevent overfitting. For all zero-shot methods,we train once and evaluate the model on all testdatasets. For supervised and weakly-supervisedmethods, we train a different model for each differ-ent dataset.
4.2 Result Analysis
The main results are presented in Table 2. We ob-serve that TE-Wiki performs the best among allzero-shot methods on all four datasets with differ-ent labels and from different domains, demonstrat-ing its effectiveness as an open-domain classifier. Italso performs closely with the weakly-supervisedLOTClass which is trained on in-domain data withknown taxonomy, showing that an open-domainzero-shot model can achieve similar accuracy asthose domain-specific classifiers. In particular, TE-Wiki outperforms LOTClass on Yahoo, whosetraining set contains quite a few ambiguous ex-amples. These examples can have negative impacton self-training. On the other hand, our zero-shotmodel does not rely on any domain-specific data,making it more robust against imperfect data.
It is possible that some of the testing labels alsoappear in the Wikipedia categories used for train-ing.5 To ensure the quality and fairness of ourzero-shot evaluation, we remove the overlappingcategories from Wikipedia training data, and retrainthe TE-Wiki model for each test set. Specifically,we normalize labels and categories by their lower-cased, lemmatized names, and perform a token-
5Throughout this subsection, we use the word "category"for the training set and "label" for the testing sets.
based matching. We report in Table 3 the perfor-mance before and after deduplication. We find thatdeduplication has little or even positive influenceon performance, which shows that TE-Wiki doesnot rely on seeing test labels during training. In par-ticular, the performance on Yahoo gets improvedwith deduplication. We suspect that exact matchbetween training and testing labels can lead to over-fitting, since the same label may have differentmeanings under different context. Notice that thisstudy is only for justifying our zero-shot evaluation.For real-word applications, excluding overlappingcategories is neither necessary nor feasible as usersdo not know the test labels beforehand in zero-shotscenarios.
4.3 Early stopping and knowledge transferTo study the convergence of our model, we sam-ple a small dev set of 1000 examples from Yahoo’soriginal validation set. During training, we find thatwith 25 steps the TE-Wiki model already achievesa reasonably good performance on the dev set. Fur-ther training for longer steps yields some, but notsignificant gains. Since the model has only seen25 × 64 = 1600 examples at that point, there islittle chance for the model to acquire label spe-cific knowledge with such a small amount of data.Hence, we believe that during the early steps, themodel actually learns “what topic classificationis about", while the knowledge specific to differ-ent labels has already been implicitly stored in thepretrained BERT encoder. The category predic-tion task takes a minor role in transferring worldknowledge. Rather, it teaches the model how to useexisting knowledge to make a good inference.
5 Importance of label names
Since zero-shot classifiers understand a label by itsname, the quality of label names can be a importantperformance bottleneck in designing open-domaintext classification systems. To study this, We con-
94

Yahoo Situation AG News DBPediaTE-Wiki 57.3 41.7 79.6 90.2- Overlapping categories 59.4(+2.1) 38.8(-2.9) 79.7(+0.1) 88.9(-1.3)Removed training categories 15 2 4 10Overlapping test examples (%) 100.0 24.0 100.0 50.0
Table 3: Performance before and after removing the overlapping categories, as well as their difference. We alsoshow the number of removed categories, and the percentage of test documents that belong to the overlapping labels.
TE-Wiki Human SupervisedYahoo 58.9 64.8 77.4
Yahoo-5 82.1(+23.2) 88.1(+23.3) 89.4(+12.0)AG News 79.0 80.2 94.7
AG News-5 86.4(+7.4) 90.8(+10.6) 96.4(+1.7)
Table 4: Classification accuracy on crowdsourcingdatasets. Yahoo-5 and AG News-5 count only examplesfor which all five workers choose the same label.
duct crowdsourcing surveys on subsets of Yahooand AG News. For each dataset, we randomly sam-ple 1,000 documents while preserving class bal-ance. Every document is independently annotatedby five workers. In the survey question, we onlyprovide the document to be classified and namesof candidate labels, without giving workers exam-ples for each class. We consider an example to becorrectly classified by humans only if at least threeworkers choose the gold label. Details about thesurvey are in Appendix.
We summarize the results in Table 4. Row 1&3are classification accuracy on the whole crowd-sourcing datasets, and row 2&4 are on subsets of ex-amples where all 5 workers choose the same label.We observe that when including all examples, bothTE-Wiki and humans perform much worse thanthe supervised method. The supervised approachhas the advantage that it learns data-specific fea-tures to resolve ambiguity among different classes.On the other hand, humans only make judgementsbased on their understanding of the labels and astand-alone test document, and so does our zero-shot algorithm. Ideally, this task should not bedifficult for humans as long as the labels properlydescribe the text topics. However, in some cases thelabels could be ambiguous and confusing. Figure3 shows an example of a bad label name leadingto a mistake. The word “Reference" in the cor-rect label actually means “quoting other people’swords". However, it is hard for an ordinary personto understand the meaning without any exampleas illustration. 4 out of 5 annotators instead chose“Entertainment & Music" due to the movie “StarWars". By contrast, the supervised model has nodifficulty in making the correct decision becauseit has seen plenty of quotation examples during
Figure 3: An example with a bad label name. Annota-tors are confused by the word “Reference".
training and can easily capture the useful patternlike “Who said XXX". The main reason for hu-mans’ confusion here is that the label name doesnot directly reflect the semantics of the text. A bet-ter description of the class should be provided forclassification without examples.
We also calculate the accuracy on exampleswhere all 5 workers agree, as in row 2&4 in Ta-ble 4. We believe the high inter-annotator agree-ment here indicates a better alignment betweenthe semantics of text and label. We find a signifi-cant improvement of human performance on theseless ambiguous cases. The same happens to ourzero-shot model, but the supervised method bene-fits much less. Consequently, the performance gapbetween humans and the supervised model is alsogetting closer, which demonstrates that ambiguouslabels have a strongly negative impact on classifi-cation. Therefore, we believe picking good labelsis crucial for open-domain topic classification.
6 Conclusion
We introduce a system for open-domain topic clas-sification. The system allows users to define cus-tomized taxonomy and classify text with respect tothat taxonomy at real time, without changing theunderlying model. To build a powerful model, wepropose to utilize Wikipedia articles and categoriesand adopt an entailment framework for zero-shotlearning. The resulting TE-Wiki outperforms allexisting zero-shot baselines in open-domain evalu-ations. Finally, we demonstrate the importance ofchoosing proper label names in open-domain topicclassification through a crowdsourcing study.
95

Acknowledgements
This work was supported by Contracts FA8750-19-2-1004 and FA8750-19-2-0201 with the USDefense Advanced Research Projects Agency(DARPA). Approved for Public Release, Distribu-tion Unlimited. The views expressed are those ofthe authors and do not reflect the official policy orposition of the Department of Defense or the U.S.Government.
ReferencesMing-Wei Chang, Lev Ratinov, Dan Roth, and Vivek
Srikumar. 2008. Importance of Semantic Representa-tion: Dataless Classification. In Proc. of the Confer-ence on Artificial Intelligence (AAAI).
Zewei Chu, Karl Stratos, and Kevin Gimpel. 2021. NAT-CAT: Weakly supervised text classification with nat-urally annotated resources. In 3rd Conference onAutomated Knowledge Base Construction.
I. Dagan, O. Glickman, and B. Magnini. 2005. Thepascal recognising textual entailment challenge. InProceedings of PASCAL first Workshop on Recognis-ing Textual Entailment.
Ido Dagan, Dan Roth, Mark Sammons, and Fabio Mas-simo Zanzoto. 2013. Recognizing Textual Entail-ment: Models and Applications.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, andKristina Toutanova. 2019. BERT: Pre-training ofdeep bidirectional transformers for language under-standing. In Proceedings of the 2019 Conference ofthe North American Chapter of the Association forComputational Linguistics: Human Language Tech-nologies, Volume 1 (Long and Short Papers), pages4171–4186, Minneapolis, Minnesota. Association forComputational Linguistics.
E. Gabrilovich and S. Markovitch. 2007. Computingsemantic relatedness using wikipeida-based explicitsemantic analysis. In Proc. of the International JointConference on Artificial Intelligence (IJCAI).
Ken Lang. 1995. NewsWeeder: learning to filter net-news. In Proc. of the International Conference onMachine Learning (ICML).
Jens Lehmann, Robert Isele, Max Jakob, Anja Jentzsch,Dimitris Kontokostas, Pablo N. Mendes, SebastianHellmann, Mohamed Morsey, Patrick van Kleef,Sören Auer, and Christian Bizer. 2015. Dbpedia -A large-scale, multilingual knowledge base extractedfrom wikipedia. Semantic Web, 6(2):167–195.
Han Liu, Xiaotong Zhang, Lu Fan, Xuandi Fu, QimaiLi, Xiao-Ming Wu, and Albert Y.S. Lam. 2019. Re-constructing capsule networks for zero-shot intent
classification. In Proceedings of the 2019 Confer-ence on Empirical Methods in Natural Language Pro-cessing and the 9th International Joint Conferenceon Natural Language Processing (EMNLP-IJCNLP),pages 4799–4809, Hong Kong, China. Associationfor Computational Linguistics.
Ilya Loshchilov and Frank Hutter. 2019. Decoupledweight decay regularization. In 7th InternationalConference on Learning Representations, ICLR 2019,New Orleans, LA, USA, May 6-9, 2019. OpenRe-view.net.
Stephen Mayhew, Tatiana Tsygankova, FrancescaMarini, Zihan Wang, Jane Lee, Xiaodong Yu,Xingyu Fu, Weijia Shi, Zian Zhao, Wenpeng Yin,Karthikeyan K, Jamaal Hay, Michael Shur, JenniferSheffield, and Dan Roth. 2019. University of Penn-sylvania LoReHLT 2019 Submission. Technical re-port.
Dheeraj Mekala and Jingbo Shang. 2020. Contextu-alized weak supervision for text classification. InProceedings of the 58th Annual Meeting of the Associ-ation for Computational Linguistics, pages 323–333,Online. Association for Computational Linguistics.
Yu Meng, Yunyi Zhang, Jiaxin Huang, Chenyan Xiong,Heng Ji, Chao Zhang, and Jiawei Han. 2020. Textclassification using label names only: A languagemodel self-training approach. In Proceedings of the2020 Conference on Empirical Methods in NaturalLanguage Processing (EMNLP), pages 9006–9017,Online. Association for Computational Linguistics.
Tomas Mikolov, Ilya Sutskever, Kai Chen, Gregory S.Corrado, and Jeffrey Dean. 2013. Distributed repre-sentations of words and phrases and their composi-tionality. In Advances in Neural Information Process-ing Systems 26: 27th Annual Conference on NeuralInformation Processing Systems 2013. Proceedingsof a meeting held December 5-8, 2013, Lake Tahoe,Nevada, United States.
Jinseok Nam, Eneldo Loza Mencía, and JohannesFürnkranz. 2016. All-in text: Learning document, la-bel, and word representations jointly. In Proceedingsof the Thirtieth AAAI Conference on Artificial Intel-ligence, February 12-17, 2016, Phoenix, Arizona,USA, pages 1948–1954. AAAI Press.
Pushpankar Kumar Pushp and Muktabh MayankSrivastava. 2017. Train once, test anywhere:Zero-shot learning for text classification. CoRR,abs/1712.05972.
Anthony Rios and Ramakanth Kavuluru. 2018. Few-shot and zero-shot multi-label learning for structuredlabel spaces. In Proceedings of the 2018 Confer-ence on Empirical Methods in Natural LanguageProcessing, pages 3132–3142, Brussels, Belgium.Association for Computational Linguistics.
Yangqiu Song and Dan Roth. 2014. On Dataless Hierar-chical Text Classification. In Proc. of the Conferenceon Artificial Intelligence (AAAI).
96

Yangqiu Song, Shyam Upadhyay, Haoruo Peng, andDan Roth. 2016. Cross-lingual Dataless Classifi-cation for Many Languages. In Proc. of the Inter-national Joint Conference on Artificial Intelligence(IJCAI).
Duyu Tang, Bing Qin, and Ting Liu. 2015. Documentmodeling with gated recurrent neural network forsentiment classification. In Proceedings of the 2015Conference on Empirical Methods in Natural Lan-guage Processing, pages 1422–1432, Lisbon, Portu-gal. Association for Computational Linguistics.
James Thorne, Andreas Vlachos, ChristosChristodoulopoulos, and Arpit Mittal. 2018.FEVER: a large-scale dataset for fact extractionand VERification. In Proceedings of the 2018Conference of the North American Chapter ofthe Association for Computational Linguistics:Human Language Technologies, Volume 1 (LongPapers), pages 809–819, New Orleans, Louisiana.Association for Computational Linguistics.
Alex Wang, Amanpreet Singh, Julian Michael, FelixHill, Omer Levy, and Samuel R. Bowman. 2019.GLUE: A multi-task benchmark and analysis plat-form for natural language understanding. In 7th In-ternational Conference on Learning Representations,ICLR 2019, New Orleans, LA, USA, May 6-9, 2019.OpenReview.net.
Sida Wang and Christopher Manning. 2012. Baselinesand bigrams: Simple, good sentiment and topic clas-sification. In Proceedings of the 50th Annual Meet-ing of the Association for Computational Linguistics(Volume 2: Short Papers), pages 90–94, Jeju Island,Korea. Association for Computational Linguistics.
Adina Williams, Nikita Nangia, and Samuel Bowman.2018. A broad-coverage challenge corpus for sen-tence understanding through inference. In Proceed-ings of the 2018 Conference of the North AmericanChapter of the Association for Computational Lin-guistics: Human Language Technologies, Volume1 (Long Papers), pages 1112–1122, New Orleans,Louisiana. Association for Computational Linguis-tics.
Congying Xia, Chenwei Zhang, Xiaohui Yan, Yi Chang,and Philip Yu. 2018. Zero-shot user intent detectionvia capsule neural networks. In Proceedings of the2018 Conference on Empirical Methods in NaturalLanguage Processing, pages 3090–3099, Brussels,Belgium. Association for Computational Linguistics.
Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He,Alex Smola, and Eduard Hovy. 2016. Hierarchicalattention networks for document classification. InProceedings of the 2016 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics: Human Language Technologies,pages 1480–1489, San Diego, California. Associa-tion for Computational Linguistics.
Wenpeng Yin, Jamaal Hay, and Dan Roth. 2019. Bench-marking Zero-shot Text Classification: Datasets,
Evaluation, and Entailment Approach. In Proc. ofthe Conference on Empirical Methods in NaturalLanguage Processing (EMNLP).
Jingqing Zhang, Piyawat Lertvittayakumjorn, and YikeGuo. 2019. Integrating semantic knowledge to tacklezero-shot text classification. In Proceedings of the2019 Conference of the North American Chapter ofthe Association for Computational Linguistics: Hu-man Language Technologies, Volume 1 (Long andShort Papers), pages 1031–1040, Minneapolis, Min-nesota. Association for Computational Linguistics.
Xiang Zhang, Junbo Jake Zhao, and Yann LeCun. 2015.Character-level convolutional networks for text clas-sification. In Advances in Neural Information Pro-cessing Systems 28: Annual Conference on Neural In-formation Processing Systems 2015, December 7-12,2015, Montreal, Quebec, Canada, pages 649–657.
97

A Crowdsourcing Setup
We conduct crowdsourcing annotations for 1000documents sampled from the Yahoo! Answersdataset and another 1000 from the AG News onAmazon Mechanical Turk (AMTurk). Both crowd-sourcing subsets preserve the class-balance as inthe original datasets. We avoid using long doc-uments so that each document contains no morethan 512 characters. The 1000 samples are splitinto 40 assignments, each containing 25 examples.We request 5 AMTurk workers for multiple-choicequestions on each assignment. In order to ensurethe response quality, we use anchor examples andgold annotations from the original datasets to filterout low-quality answers. Specifically, in each as-signment we insert two anchor examples that webelieve are easy enough for workers to choose thecorrect answer as long as they pay attention. Wereject a submission if a worker’s classification ac-curacy against gold annotations is below 30%, orboth anchor examples are wrongly classified. Witha small initial pilot, we estimate the average work-ing time for labeling 25 examples to be 22 minutes,and we set the pay rate to be $1.5 per assignmentfor each valid submission. The overall cost is $300for 200 valid submissions for each dataset.
98

Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies: System Demonstrations, pages 99 - 113
July 10-15, 2022 ©2022 Association for Computational Linguistics
| SentSpace: Large-Scale Benchmarking and Evaluation of Text usingCognitively Motivated Lexical, Syntactic, and Semantic Features
Greta Tuckute∗ Aalok Sathe∗ Mingye Wang Harley YoderCory Shain Evelina Fedorenko
gretatu,asathe,mingyew,hyoder,cshain,evelina9 @ mit.edu
Dept. of Brain and Cognitive Sciences McGovern Institute for Brain ResearchMassachusetts Institute of Technology, Cambridge, MA, USA
Abstract
SentSpace is a modular framework forstreamlined evaluation of text. SentSpacecharacterizes textual input using diverse lexi-cal, syntactic, and semantic features derivedfrom corpora and psycholinguistic experiments.Core sentence features fall into three primaryfeature spaces: 1) Lexical, 2) Contextual, and3) Embeddings. To aid in the analysis of com-puted features, SentSpace provides a webinterface for interactive visualization and com-parison with text from large corpora. The mod-ular design of SentSpace allows researchersto easily integrate their own feature computa-tion into the pipeline while benefiting from acommon framework for evaluation and visual-ization. In this manuscript we will describe thedesign of SentSpace, its core feature spaces,and demonstrate an example use case by com-paring human-written and machine-generated(GPT2-XL) sentences to each other. We findthat while GPT2-XL-generated text appears flu-ent at the surface level, psycholinguistic normsand measures of syntactic processing reveal keydifferences between text produced by humansand machines. Thus, SentSpace providesa broad set of cognitively motivated linguisticfeatures for evaluation of text within naturallanguage processing, cognitive science, as wellas the social sciences.
1 Introduction
Natural Language Processing (NLP) researchersand language scientists alike rely heavily on nu-meric representations of text in order to better un-derstand how machines and humans process lan-guage. Consider the following text generated by alarge pre-trained language model, GPT2:
The scientist named the population, af-ter their distinctive horn, Ovid’s Unicorn.These four-horned, silver-white unicornswere previously unknown to science.
∗Equal contribution Equal contribution
The passage demonstrates a remarkable facilitywith language, but also some potentially non-human aspects, both syntactic (e.g., an unnatu-ral forward shifting of the phrase “after their dis-tinctive horn”) and semantic (describing a four-horned animal as a unicorn). It is of growinginterest to researchers to be able to characterizehow any text compares to that from another source,be it generated by humans or artificial languagemodels. For example, NLP practitioners are in-terested in understanding and improving languagemodel output, and bringing it closer to human gen-erated text e.g., Ettinger (2020); Hollenstein et al.(2021); Meister et al. (2022); similarly, languagescientists are highly interested in using large-scalelanguage models to develop and test hypothesesabout language processing in the mind and brain,e.g., Schrimpf et al. (2021); Caucheteux and King(2022); Goldstein et al. (2022).
To support these shared goals, we developedSentSpace, an open source application for char-acterizing textual input using diverse lexical, syn-tactic, and semantic features. These features arederived from sources such as large, constructedcorpora, behavioral psycholinguistic experiments,human judgment norms, and models based on theo-ries of human sentence processing. We also devel-oped functionality to compare textual inputs to oneanother and to large normative distributions basedon natural language corpora. We envision the usecases of SentSpace to be diverse: (i) comparisonof machine-generated text to human-generated text;(ii) comparison of text produced by different humanpopulations (e.g., native and non-native speakers,neurotypical individuals and individuals with devel-opmental or acquired communication disorders);(iii) comparison of different genres of text; (iv)evaluation of the normativity of stimuli/datasets tobe used in psycholinguistic experiments or experi-ments with language models; and (v) investigationof sentences that present particular comprehension
99

Figure 1: An overview of SentSpace data flow: userscan supply text in a number of formats. The text is batch-processed in each selected module containing variousfeatures. The features computed from each module arethen outputted in the specified output file format. Theseresults can be readily plugged into the visualizationmodule out of the box.
difficulties for humans and/or language models,e.g., eliciting a strong neural response in an electro-physiological or neuroimaging study, or producingnon-typical or undesired behavior in the case oflanguage models.
We make SentSpace publicly available viahttps://sentspace.github.io/sentspace in the follow-ing two forms: (i) an open source API implementedin Python (Figure 1), installable via the Pythonpackage index (PyPI) or as a self-contained Dockerimage; (ii) a hosted web interface for computingand visualizing features, thus making SentSpaceaccessible without running locally (Figures 2, 3, 4).
2 Structure and Design
At the core of SentSpace there are features asso-ciated with a sentence: f : sentence → Rd
where Rd can be any feature or representationspace. The core features are organized into threecore modules based on the nature of their char-acterization of a sentence. (1) The Lexical mod-ule acts at the individual lexical item (token) level.Sentence-level lexical features are computed byaggregating over the tokens of a sentence. (2) Con-textual features are sentence-level features and areobtained as a result of some computation at the sen-tence level, such as, constructing and then process-ing a syntax parse tree. Finally, (3) Embeddingscomputes pooled vector representations from oneof many popular embedding models, from GloVE(Pennington et al., 2014) to Transformer architec-
tures (Radford et al., 2019; Devlin et al., 2019;Wolf et al., 2020). These three modules cover awide range of features—derived from text corporaor behavioral experiments—that have some demon-strated relevance to language processing.
Figure 2: Public-facing hosted interface where userscan input text and obtain features by downloading themfrom the same website. Each request gets a correspond-ing ID which is temporarily cached to enable repeateddownloading and visualization of the same data.
The Lexical module consists of features that per-tain to individual lexical items, words, regardlessof the context in which they appear. These fea-tures include, for example, lexical frequency, con-creteness, and valence. Because SentSpace isbuilt to work with sentences, lexical-level featuresare aggregated across the sentence (cf. Gao et al.(2021)). As a default, SentSpace aggregatesover all words with available norms in the sentenceby computing the arithmetic mean across words.
The Contextual module consists of features thatquantify contextual and combinatorial inter-wordrelations that are not captured by individual lexicalitems. This module encompasses features that re-late to the syntactic structure of the sentence (Con-textual_syntax features) and features that apply tothe sentence context but are not (exclusively) re-lated to syntactic structure (Contextual_misc fea-tures). Contextual_syntax include features relatedto syntactic complexity, instantiated as e.g., sur-prisal or integration cost, based on leading theoret-ical proposals (Gibson, 2000; Shain et al., 2016;Rasmussen and Schuler, 2018). Some syntactic fea-tures are computed for each word in the sentenceand then subsequently aggregated; other featuresare computed for multi-word sequences or the en-tire sentence. Contextual_misc include features
100

Figure 3: An example of multiple corpora visualized alongside each other for the feature “Age of Acquisition”.Sentences from the Wall Street Journal and the Colossal Cleaned Common Crawl (C4) show a tendency of higherage of acquisition on average than other sources. Mouseover on dots enables users to see example sentences andtheir corresponding values. The ‘x axis value’ dropdown allows users to pick the feature to plot. The ‘y’ and ‘z’axis values are used for a 3D scatter plot, which can be enabled using the ‘Plot type’ selector.
like lexical density or sentence sentiment.The Embedding module consists of high-
dimensional vectors derived from pre-trained lan-guage models.SentSpace also provides functionality that al-
lows users to contribute novel features and mod-ules. A user may design their own features andplug-and-play into SentSpace to achieve a morestreamlined analysis pipeline and integrated bench-marking and visualization (Figure 1). In order tocontribute a module, users must adhere to the mod-ule call API, accepting a sentence batch and return-ing a dataframe whose columns consist of features.Users may make use of parallelism and other utilsprovided as a part of SentSpace. Users may alsoplug in their computed features in the visualizationmodule and use the web interface.
2.1 Feature Modules
2.1.1 Lexical
Lexical features have been shown to affect lan-guage comprehension at the level of individualwords. For instance, lexical features affect how
people recognize and recall words, such as wordfrequency (e.g., Gorman (1961); Kinsbourne andGeorge (1974)), concreteness/imageability (e.g.,Gorman (1961); Rubin and Friendly (1986)), andvalence/arousal (e.g., (Rubin and Friendly, 1986;Danion et al., 1995; Kensinger and Corkin, 2003).Moreover, lexical features have been shown to af-fect language processing when words are presentedin context as measured by eye tracking and self-paced reading, such as surprisal (e.g., Levy (2015);Demberg and Keller (2008); Singh et al. (2016)),polysemy (e.g., Pickering and Frisson (2001)), am-biguity (e.g., Frazier and Rayner (1987); Raynerand Duffy (1986)), word frequency (e.g., Raynerand Duffy (1986)), and age of acquisition (e.g.,Singh et al. (2016)). We implement these featuresusing lookup tables for each token. In case the fea-ture is unavailable for a token, we use a lemmatizerto obtain the feature corresponding to the word’slemma. We observe the various features are onlymoderately correlated with one another, thus eachadding new information to the analysis (Figure 5).See Appendix A.1 for supported lexical features.
101

Figure 4: A zoomed-in view of a 3D scatterplot showsmouseover on a point in space revealing the sentenceat that location and its features being plotted. A topbar (not displayed) allows the users to change the fea-tures to plot. A side bar (not displayed) enables se-lecting/deselecting corpora and files uploaded by theuser to the visualization module. (Abbreviations are‘num_morpheme_poly’: Number of Morphemes; ‘aoa’:Age of Acquisition.)
2.1.2 Contextual
Several properties of a sentence cannot be at-tributed to its individual lexical items (words).These features broadly fall into two categories: syn-tactic (denoted by Contextual_syntax) and miscella-neous (denoted by Contextual_misc). The syntacticfeatures include measures of storage and integra-tion cost as predicted by both the Dependency Lo-cality Theory (DLT; Gibson (2000)) and left-cornertheories of sentence processing (Rasmussen andSchuler, 2018). In brief, the Dependency LocalityTheory is an influential theory of word-by-wordcomprehension difficulty during human languageprocessing, with difficulty hypothesized to arisefrom working memory demand related to storingitems in working memory (storage cost) and retriev-ing items from working memory (integration cost)as required by the dependency structure of the sen-tence. Memory costs derived from the DLT havebeen associated with self-paced reading (Grodnerand Gibson, 2005), eye-tracking (Demberg andKeller, 2008), and fMRI (Shain et al., 2021b) mea-sures of comprehension difficulty. Left-corner pars-ing models also posit storage and integration costs,but these costs are thought to derive not from depen-dency locality but from the number of unconnectedfragments of phrase structure trees that must bemaintained and combined in memory throughout
Figure 5: Pearson correlation among features fromthe Lexical and Contextual modules obtained fromSentSpace for text written by humans and GPT2-XL (described in Section 4).
parsing, word-by-word. Probabilistic left-cornerparsers can also be used to define a probability dis-tribution over the next word that conditions solelyon hypotheses about the syntactic structure of thesentence, providing a critical tool for evaluatingthe degree to which syntax might influence bothhuman and language model predictions of futurewords (Shain et al., 2020). See Appendix A.2.1 forsupported contextual features.
2.1.3 EmbeddingsEmbeddings provide representations of wordsor sentences in high-dimensional, learned vectorspaces. The information contained in these spacesdepend on the objective function of the algorithmused to derive the vectors, but could be of seman-tic nature (e.g., Grand et al. (2022)). We providea decontextualized embedding space (words havethe same vector representation independent of con-text), GloVe (Pennington et al., 2014), as well asseveral commonly used contextualized embeddingspaces (words have different vector representationsbased on the context in which they appear) from theHuggingFace framework (Wolf et al., 2020). SeeAppendix A.3 for supported embedding models.
3 Benchmarking Against Large Corpora
To understand where a sentence stands relative toother text, we facilitate comparison with sentences
102
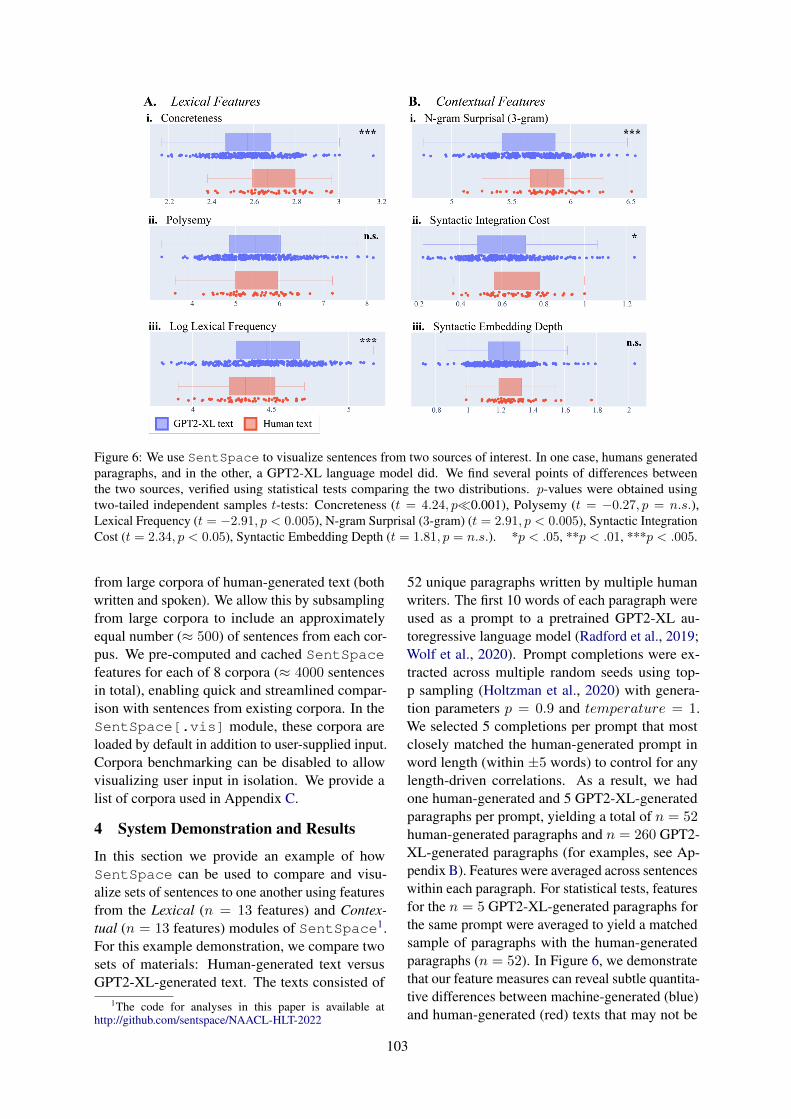
Figure 6: We use SentSpace to visualize sentences from two sources of interest. In one case, humans generatedparagraphs, and in the other, a GPT2-XL language model did. We find several points of differences betweenthe two sources, verified using statistical tests comparing the two distributions. p-values were obtained usingtwo-tailed independent samples t-tests: Concreteness (t = 4.24, p≪0.001), Polysemy (t = −0.27, p = n.s.),Lexical Frequency (t = −2.91, p < 0.005), N-gram Surprisal (3-gram) (t = 2.91, p < 0.005), Syntactic IntegrationCost (t = 2.34, p < 0.05), Syntactic Embedding Depth (t = 1.81, p = n.s.). *p < .05, **p < .01, ***p < .005.
from large corpora of human-generated text (bothwritten and spoken). We allow this by subsamplingfrom large corpora to include an approximatelyequal number (≈ 500) of sentences from each cor-pus. We pre-computed and cached SentSpacefeatures for each of 8 corpora (≈ 4000 sentencesin total), enabling quick and streamlined compar-ison with sentences from existing corpora. In theSentSpace[.vis] module, these corpora areloaded by default in addition to user-supplied input.Corpora benchmarking can be disabled to allowvisualizing user input in isolation. We provide alist of corpora used in Appendix C.
4 System Demonstration and Results
In this section we provide an example of howSentSpace can be used to compare and visu-alize sets of sentences to one another using featuresfrom the Lexical (n = 13 features) and Contex-tual (n = 13 features) modules of SentSpace1.For this example demonstration, we compare twosets of materials: Human-generated text versusGPT2-XL-generated text. The texts consisted of
1The code for analyses in this paper is available athttp://github.com/sentspace/NAACL-HLT-2022
52 unique paragraphs written by multiple humanwriters. The first 10 words of each paragraph wereused as a prompt to a pretrained GPT2-XL au-toregressive language model (Radford et al., 2019;Wolf et al., 2020). Prompt completions were ex-tracted across multiple random seeds using top-p sampling (Holtzman et al., 2020) with genera-tion parameters p = 0.9 and temperature = 1.We selected 5 completions per prompt that mostclosely matched the human-generated prompt inword length (within ±5 words) to control for anylength-driven correlations. As a result, we hadone human-generated and 5 GPT2-XL-generatedparagraphs per prompt, yielding a total of n = 52human-generated paragraphs and n = 260 GPT2-XL-generated paragraphs (for examples, see Ap-pendix B). Features were averaged across sentenceswithin each paragraph. For statistical tests, featuresfor the n = 5 GPT2-XL-generated paragraphs forthe same prompt were averaged to yield a matchedsample of paragraphs with the human-generatedparagraphs (n = 52). In Figure 6, we demonstratethat our feature measures can reveal subtle quantita-tive differences between machine-generated (blue)and human-generated (red) texts that may not be
103

subjectively apparent.
Figure 6A demonstrates three features from theLexical module: i) Concreteness (Brysbaert et al.,2014); a behavioral measure of the extent to whichthe concept denoted by the word refers to a per-ceptible entity, ii) Polysemy (Miller, 1992), andiii) Log lexical frequency from the SUBTLEX-usdatabase (Brysbaert and New, 2009). As evident,GPT2-XL produces sentences that on average haveless concrete words compared to human sentences(p≪.001). Lexical frequency reflects how oftena given word is used in language. Lexical fre-quency is known to affect language comprehen-sion, for instance more frequent words are readfaster (e.g., Rayner and Duffy (1986); Singh et al.(2016) and articulated faster (e.g., Jescheniak andLevelt (1994)). We can see this as being a trendtowards GPT2-XL’s use of more frequent wordingcompared to humans (p≪.001).
Figure 6B demonstrates three Contextual fea-tures: i) N-gram surprisal (3-gram), ii) Average syn-tactic integration cost according to the DependencyLocality Theory (DLT, (Gibson, 2000); integrationcost is roughly proportional to dependency length),and iii) Average syntactic center-embedding depthin a left-corner phrase-structure parser (van Schi-jndel et al., 2013). Although GPT2-XL usuallygenerates sentences that are syntactically well-formed, their syntactic features differ on averagefrom human-generated text. As shown, texts gen-erated by GPT2-XL show lower 3-gram surprisal(t=2.91, p≪.001), tend to be less syntactically com-plex on average than human-generated ones, withshorter syntactic dependencies (t=2.33, p=0.02)and numerically shallower center-embedded treestructures (t=1.8, p=0.09, n.s.). So, these findingsmight suggest GPT2-XL makes use of ‘simpler’wording compared to humans.
The remaining SentSpace features obtainedfor the comparison between human- and GPT2-XL-generated text (n = 26 features in total) are summa-rized in the Appendix, Table 2. More features arein the progress of being added to the SentSpaceframework (see Appendix A.1, A.2).
The comparison between human- and machine-generated text is a demonstration of one of theuse cases of SentSpace: comparing and visu-alizing texts to one another. The SentSpaceframework streamlines the process of obtainingcorpora-backed features, parsing and syntacticallyanalyzing texts, simplifying and accelerating such
analyses for natural language generation.
5 Related work
Related work include Balota et al. (2007) whocollected behavioral visual lexical decision andspeeded naming reaction times and provided thesealong with a set of word-level, psycholinguisticfeatures (The English Lexicon Project). Gao et al.(2021) provide a meta-base of word-level, psy-cholinguistic features. A different alley of re-lated work includes visualization tools for high-dimensional embeddings obtained from pre-trainedlanguage models (e.g., van Aken et al. (2020); Ope-nAI).
A large body of work focuses on characterizingbias in text, particularly that either used in traininglanguage models, or that generated by languagemodels (Sun et al., 2019). Related work also fo-cuses on methods to mitigate bias in existing lan-guage models using debiasing methods. In thefuture we hope to include norms that character-ize bias as one of the many features that will beadded to SentSpace. We also hope that outputsfrom SentSpace will inform what data goes intotraining large language models to make them morehuman-like.
6 Conclusion
SentSpace is a system for obtaining numeri-cal representations of sentences. Our core featuremodules span lexical, semantic, and syntactic fea-tures from corpora and behavioral experiments. Weprovide an interface for comparing textual inputsto one another or to large normative distributionsbased on natural language corpora.
Within the last few years, contextualized em-beddings obtained from large pre-trained languagemodels have revolutionized and dominated the fieldof natural language processing. However, despitethese embeddings being useful for diverse applica-tions, it is unclear precisely which information isembedded in these high-dimensional feature repre-sentations. We view SentSpace as a complemen-tary resource that can provide interpretability andgrounding to these pre-trained high-dimensionalembeddings.
A major limitation of SentSpace is that wecurrently only support English. Part of the lim-iting factor is the relative lack of behavioral andpsycholinguistic experimental data for other lan-guages, as well as mature linguistic features tai-
104

lored to other languages.We envision SentSpace as a dynamic plat-
form with continuous collaboration across researchlabs for the addition of new features and we hopeto make this framework valuable for a number ofapplications within natural language processing,cognitive science, psychology, linguistics, and so-cial sciences.
Acknowledgements
We thank the authors of publicly available datasetsthat we have been able to use in SentSpace.We thank Adil Amirov, Alvincé Le Arnz Pon-gos, Benjamin Lipkin, and Josef Affourtit fortheir assistance towards developing the softwarefor SentSpace. We thank Hannah Small andMatthew Siegelman for their assistance with thehuman- and GPT-generated texts.
ReferencesDavid A. Balota, Melvin J. Yap, Keith A. Hutchi-
son, Michael J. Cortese, Brett Kessler, Bjorn Loftis,James H. Neely, Douglas L. Nelson, Greg B. Simp-son, and Rebecca Treiman. 2007. The English Lexi-con Project. Behavior Research Methods, 39(3):445–459.
Thorsten Brants and Alexander Franz. 2009. Web 1t5-gram, 10 european languages version 1. Philadel-phia, Pa.: Linguistic Data Consortium, Computerfile.
Marc Brysbaert, Paweł Mandera, Samantha F. Mc-Cormick, and Emmanuel Keuleers. 2019. Wordprevalence norms for 62,000 English lemmas. Be-havior Research Methods, 51(2):467–479.
Marc Brysbaert and Boris New. 2009. Moving beyondKucera and Francis: A critical evaluation of currentword frequency norms and the introduction of a newand improved word frequency measure for AmericanEnglish. Behavior Research Methods, 41(4):977–990.
Marc Brysbaert, Boris New, and Emmanuel Keuleers.2012. Adding part-of-speech information to theSUBTLEX-US word frequencies. Behavior Re-search Methods, 44(4):991–997.
Marc Brysbaert, Amy Beth Warriner, and Victor Ku-perman. 2014. Concreteness ratings for 40 thousandgenerally known English word lemmas. BehaviorResearch Methods, 46(3):904–911.
Charlotte Caucheteux and J. R. King. 2022. Brainsand algorithms partially converge in natural languageprocessing. Communications Biology, 5.
J.-M. Danion, Françoise Kauffmann-Muller, Danielle Grange, M A Zimmermann, and Ph. Greth. 1995.Affective valence of words, explicit and implicitmemory in clinical depression. Journal of affectivedisorders, 34 3:227–34.
Mark Davies. 2009. The 385+ million word corpus ofcontemporary american english (1990–2008+): De-sign, architecture, and linguistic insights. Interna-tional journal of corpus linguistics, 14(2):159–190.
Simon De Deyne, Danielle J. Navarro, Amy Perfors,Marc Brysbaert, and Gert Storms. 2019. The “SmallWorld of Words” English word association norms forover 12,000 cue words. Behavior Research Methods,51(3):987–1006.
Vera Demberg and Frank Keller. 2008. Data from eye-tracking corpora as evidence for theories of syntacticprocessing complexity. Cognition, 109(2):193–210.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, andKristina Toutanova. 2019. Bert: Pre-training of deepbidirectional transformers for language understand-ing. ArXiv, abs/1810.04805.
Allyson Ettinger. 2020. What bert is not: Lessons froma new suite of psycholinguistic diagnostics for lan-guage models. Transactions of the Association forComputational Linguistics, 8:34–48.
W Nelson Francis and Henry Kucera. 1979. Browncorpus manual. Letters to the Editor, 5(2):7.
Lyn Frazier and Keith Rayner. 1987. Resolution ofsyntactic category ambiguities: Eye movements inparsing lexically ambiguous sentences. Journal ofMemory and Language, 26(5):505–526.
Chuanji Gao, Svetlana V. Shinkareva, and Rutvik H.Desai. 2021. Scope: The south carolina psycholin-guistic metabase.
Edward Gibson. 2000. The dependency locality theory:A distance-based theory of linguistic complexity. InImage, Language, Brain, pages 95–106. MIT Press.
Ariel Goldstein, Zaid Zada, Eliav Buchnik, MarianoSchain, Amy Rose Price, Bobbi Aubrey, Samuel A.Nastase, Amir Feder, Dotan Emanuel, Alon Co-hen, Aren Jansen, Harshvardhan Gazula, Gina Choe,Aditi Rao, Catherine Kim, Colton Casto, Lora Fanda,Werner K. Doyle, Daniel Friedman, Patricia Dugan,Lucia Melloni, Roi Reichart, Sasha Devore, AdeenFlinker, Liat Hasenfratz, Omer Levy, Avinatan Has-sidim, Michael Brenner, Y. Matias, Kenneth A. Nor-man, Orrin Devinsky, and Uri Hasson. 2022. Sharedcomputational principles for language processing inhumans and deep language models. Nature Neuro-science, 25:369 – 380.
Anna M. Gorman. 1961. Recognition memory fornouns as a function of abstractness and frequency.Journal of experimental psychology, 61:23–9.
105

Gabriel Grand, Idan Asher Blank, Francisco Pereira,and Evelina Fedorenko. 2022. Semantic projectionrecovers rich human knowledge of multiple objectfeatures from word embeddings. Nature human be-haviour.
Daniel Grodner and Edward Gibson. 2005. Conse-quences of the serial nature of linguistic input forsentenial complexity. Cognitive science, 29 2:261–90.
Paul Hoffman, Matthew A. Lambon Ralph, and Timo-thy T. Rogers. 2013. Semantic diversity: A measureof semantic ambiguity based on variability in the con-textual usage of words. Behavior Research Methods,45(3):718–730.
Nora Hollenstein, Federico Pirovano, Ce Zhang, Lena A.Jäger, and Lisa Beinborn. 2021. Multilingual lan-guage models predict human reading behavior. InNAACL.
Ari Holtzman, Jan Buys, Maxwell Forbes, and YejinChoi. 2020. The curious case of neural text degener-ation. ArXiv, abs/1904.09751.
Jörg D. Jescheniak and Willem J. M. Levelt. 1994.Word frequency effects in speech production: Re-trieval of syntactic information and of phonologicalform. Journal of Experimental Psychology: Learn-ing, Memory and Cognition, 20:824–843.
Elizabeth A. Kensinger and Suzanne Corkin. 2003.Memory enhancement for emotional words: Are emo-tional words more vividly remembered than neutralwords? Memory & Cognition, 31:1169–1180.
Marcel Kinsbourne and James W. George. 1974. Themechanism of the word-frequency effect on recogni-tion memory. Journal of Verbal Learning and VerbalBehavior, 13:63–69.
Victor Kuperman, Hans Stadthagen-Gonzalez, andMarc Brysbaert. 2012. Age-of-acquisition ratingsfor 30 thousand English words. page 39.
Roger Levy. 2015. Memory and surprisal in humansentence comprehension. page 36.
Matthew H. C. Mak and Hope Twitchell. 2020. Ev-idence for preferential attachment: Words that aremore well connected in semantic networks are betterat acquiring new links in paired-associate learning.Psychonomic Bulletin & Review, 27(5):1059–1069.
Mitchell P. Marcus, Beatrice Santorini, and Mary AnnMarcinkiewicz. 1993. Building a large annotatedcorpus of english: The penn treebank. Comput. Lin-guistics, 19:313–330.
Marco Marelli and Simona Amenta. 2018. A databaseof orthography-semantics consistency (OSC) esti-mates for 15,017 English words. Behavior ResearchMethods, 50(4):1482–1495.
D.A. Medler and J.R. Binder. 2005. Mcword: An on-line orthographic database of the english language.volume http://www.neuro.mcw.edu/mcword/.
Clara Meister, Tiago Pimentel, Gian Wiher, and RyanCotterell. 2022. Typical decoding for natural lan-guage generation. ArXiv, abs/2202.00666.
George A. Miller. 1992. Wordnet: A lexical databasefor english. Commun. ACM, 38:39–41.
Saif Mohammad. 2018. Obtaining Reliable Human Rat-ings of Valence, Arousal, and Dominance for 20,000English Words. In Proceedings of the 56th AnnualMeeting of the Association for Computational Lin-guistics (Volume 1: Long Papers), pages 174–184,Melbourne, Australia. Association for ComputationalLinguistics.
Luan Nguyen, Marten van Schijndel, and WilliamSchuler. 2012. Accurate unbounded dependency re-covery using generalized categorial grammars. InCOLING.
OpenAI. Openai embeddings. https://beta.openai.com/docs/guides/embeddings.Accessed: 2022-02-11.
Douglas B Paul and Janet Baker. 1992. The design forthe wall street journal-based csr corpus. In Speechand Natural Language: Proceedings of a WorkshopHeld at Harriman, New York, February 23-26, 1992.
Jeffrey Pennington, Richard Socher, and ChristopherManning. 2014. Glove: Global Vectors for WordRepresentation. In Proceedings of the 2014 Confer-ence on Empirical Methods in Natural Language Pro-cessing (EMNLP), pages 1532–1543, Doha, Qatar.Association for Computational Linguistics.
Penny M. Pexman, Emiko Muraki, David M. Sidhu,Paul D. Siakaluk, and Melvin J. Yap. 2019. Quan-tifying sensorimotor experience: Body–object inter-action ratings for more than 9,000 English words.Behavior Research Methods, 51(2):453–466.
Steven T. Piantadosi, Harry Tily, and Edward Gibson.2011. Word lengths are optimized for efficient com-munication. Proceedings of the National Academy ofSciences, 108(9):3526–3529.
Martin J. Pickering and Steven Frisson. 2001. Pro-cessing ambiguous verbs: Evidence from eye move-ments. Journal of Experimental Psychology: Learn-ing, Memory, and Cognition, 27(2):556–573.
Alec Radford, Jeff Wu, Rewon Child, David Luan,Dario Amodei, and Ilya Sutskever. 2019. Languagemodels are unsupervised multitask learners.
Colin Raffel, Noam Shazeer, Adam Roberts, Kather-ine Lee, Sharan Narang, Michael Matena, YanqiZhou, Wei Li, and Peter J. Liu. 2020. Exploring thelimits of transfer learning with a unified text-to-texttransformer. Journal of Machine Learning Research,21(140):1–67.
106

Nathan Rasmussen and William Schuler. 2018. Left-corner parsing with distributed associative memoryproduces surprisal and locality effects. Cognitivescience, 42 Suppl 4:1009–1042.
Keith Rayner and Susan A. Duffy. 1986. Lexical com-plexity and fixation times in reading: Effects of wordfrequency, verb complexity, and lexical ambiguity.Memory & Cognition, 14(3):191–201.
David C. Rubin and Michael Friendly. 1986. Predictingwhich words get recalled: Measures of free recall,availability, goodness, emotionality, and pronuncia-bility for 925 nouns. Memory & Cognition, 14:79–94.
Martin Schrimpf, Idan Asher Blank, Greta Tuckute, Ca-rina Kauf, Eghbal A. Hosseini, Nancy Kanwisher,Joshua B. Tenenbaum, and Evelina Fedorenko. 2021.The neural architecture of language: Integrativemodeling converges on predictive processing. Pro-ceedings of the National Academy of Sciences,118(45):e2105646118.
Cory Shain, Idan A Blank, Evelina Fedorenko, EdwardGibson, and William Schuler. 2021a. Robust effectsof working memory demand during naturalistic lan-guage comprehension in language-selective cortex.bioRxiv.
Cory Shain, Idan Asher Blank, Evelina Fedorenko, Ed-ward Gibson, and William Schuler. 2021b. Robusteffects of working memory demand during natural-istic language comprehension in language-selectivecortex. bioRxiv.
Cory Shain, Idan Asher Blank, Marten van Schijndel,Evelina Fedorenko, and William Schuler. 2020. fmrireveals language-specific predictive coding duringnaturalistic sentence comprehension. Neuropsycholo-gia, 138.
Cory Shain, Marten van Schijndel, Richard Futrell, Ed-ward Gibson, and William Schuler. 2016. Memoryaccess during incremental sentence processing causesreading time latency. In CL4LC@COLING 2016.
Abhinav Singh, Poojan Mehta, Samar Husain, and Ra-jkumar Rajakrishnan. 2016. Quantifying sentencecomplexity based on eye-tracking measures. InCL4LC@COLING 2016.
Tony Sun, Andrew Gaut, Shirlyn Tang, Yuxin Huang,Mai ElSherief, Jieyu Zhao, Diba Mirza, ElizabethBelding, Kai-Wei Chang, and William Yang Wang.2019. Mitigating gender bias in natural languageprocessing: Literature review. In Proceedings of the57th Annual Meeting of the Association for Computa-tional Linguistics, pages 1630–1640, Florence, Italy.Association for Computational Linguistics.
Betty van Aken, Benjamin Winter, Alexander Löser,and Felix A. Gers. 2020. Visbert: Hidden-state visu-alizations for transformers. Companion Proceedingsof the Web Conference 2020.
Walter J. B. van Heuven, Pawel Mandera, EmmanuelKeuleers, and Marc Brysbaert. 2014. Subtlex-UK:A New and Improved Word Frequency Database forBritish English. Quarterly Journal of ExperimentalPsychology, 67(6):1176–1190.
Marten van Schijndel, Andrew Exley, and WilliamSchuler. 2013. A model of language processing ashierarchic sequential prediction. Topics in cognitivescience, 5 3:522–40.
Sami Virpioja, Peter Smit, Stig-Arne Grönroos, andMikko Kurimo. 2013. Morfessor 2.0: Python imple-mentation and extensions for morfessor baseline.
WordNet Wikipedia. Wordnet. https://en.wikipedia.org/wiki/WordNet. Accessed:2022-02-11.
Thomas Wolf, Lysandre Debut, Victor Sanh, JulienChaumond, Clement Delangue, Anthony Moi, Pier-ric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz,Joe Davison, Sam Shleifer, Patrick von Platen, ClaraMa, Yacine Jernite, Julien Plu, Canwen Xu, Teven LeScao, Sylvain Gugger, Mariama Drame, QuentinLhoest, and Alexander M. Rush. 2020. Transform-ers: State-of-the-art natural language processing. InProceedings of the 2020 Conference on EmpiricalMethods in Natural Language Processing: SystemDemonstrations, pages 38–45, Online. Associationfor Computational Linguistics.
Yukun Zhu, Ryan Kiros, Rich Zemel, Ruslan Salakhut-dinov, Raquel Urtasun, Antonio Torralba, and SanjaFidler. 2015. Aligning books and movies: Towardsstory-like visual explanations by watching moviesand reading books. In Proceedings of the IEEE in-ternational conference on computer vision, pages19–27.
107

A Feature Descriptions
A.1 Lexical Features
Lexical features are ordered alphabetically.Age of Acquisition Age of acquisition is a met-
ric that estimates when a person acquired (i.e., un-derstood) a given word. Participants were asked foreach word to enter the age at which they thoughtthey had learned the word even if they could notuse, read, or write it at the time. The norms werecollected by (Kuperman et al., 2012).
Norms were available for 30,124 unique words.Obtained from: http://crr.ugent.be/
archives/806.Arousal Arousal quantifies each word on a scale
of active–passive. The norms were collected basedon human ratings by (Mohammad, 2018) usingBest-Worst scaling, where participants are pre-sented with four words at a time and asked to selectthe word with the highest arousal. The two ends ofthe arousal dimension were: MOST arousal, active-ness, stimulation, frenzy, jitteriness, alertness ORLEAST unarousal, passiveness, relaxation, calm-ness, sluggishness, dullness, sleepiness.
Norms were available for 20,007 unique words.Obtained from: https://saifmohammad.
com/WebPages/nrc-vad.html.Concreteness Concreteness quantifies the extent
to which the concept denoted by the word refers toa perceptible entity. Concrete words were definedas something that exists in reality and can be expe-rienced directly through the five senses or actions.Conversely, abstract words refer to something onecannot experience directly through your senses oractions. The norms were collected based on humanratings by (Brysbaert et al., 2014).
Norms were available for 37,058 unique words.Obtained from http://crr.ugent.be/
archives/1330.Log Contextual Diversity Contextual diversity
(CD) is the number of contexts in which a wordhas been seen [cite Adelman 2005]. The metricavailable here was computed based on the SUB-TLEXus database based on American subtitles (51million words in total) (Brysbaert and New, 2009)and thus denotes the number of films in whichthe word appears. The CD metric is computed aslog10(CDcount+1).
Norms were available for 74,286 unique words.Obtained from the SUBTLEXus
database: https://www.ugent.be/pp/
experimentele-psychologie/en/research/documents/subtlexus).
Log Lexical Frequency Lexical frequency de-notes how frequent a word occurs in a given cor-pus/sets of corpora. The frequency metric availablehere was computed as log10(FREQcount+1) basedon American subtitles (51 million words in total)from the SUBTLEXus database (Brysbaert andNew, 2009).
Norms were available for 74,286 unique words.Obtained from the SUBTLEXus
database: https://www.ugent.be/pp/experimentele-psychologie/en/research/documents/subtlexus).
Lexical Connectivity Lexical connectivity is ametric for how connected a given word is to otherwords based on association judgments. The metricviews the mental lexicon as a semantic networkwhere words are linked together by semantic relat-edness. Lexical connectivity is computed as thetotal degree centrality of a given word node in thesemantic graph. Norms were obtained from (Makand Twitchell, 2020) who computed the total de-gree centrality based on free association normscollected by (De Deyne et al., 2019) (specifically,the first recalled word).
Norms were available for 12,215 unique words.Obtained from: https://osf.io/
7942s/.Lexical Decision Reaction Time (RT) Lexical
decision latency measures how quickly people clas-sify strings as words or non-words. The lexicaldecision latency provides a proxy for how quicklya given word is extracted from the mental lexi-con/semantic memory. The norms were collectedby (Balota et al., 2007).
Norms were available for 40,482 unique words.Obtained from the English Lexicon Project:
https://elexicon.wustl.edu/.Number of Morphemes A morpheme denotes
the smallest meaningful lexical unit in a language.The number of morphemes quantifies how manymorphemes a given word has. The primary mor-pheme counter available here is Morfessor (Vir-pioja et al., 2013) which uses machine learningto find morphological segmentations of words. Ifdependency issues arise with Morfessor, the mor-pheme count is obtained from the English LexiconProject Database (Balota et al., 2007).
Orthographic Neighbor Frequency Ortho-graphic neighbor frequency is a metric that quan-
108

tifies the number of orthographic neighbors that astring has. The metric was computed by (Medlerand Binder, 2005) and an orthographic neighborwas defined as a word of the same length that dif-fers from the original string by only one letter. Thefrequency metric denotes the averaged frequency(per million) of orthographic neighbors.
Norms were available for 66,371 unique words.Obtained from http://www.neuro.mcw.
edu/mcword/.Orthography-Semantics Consistency (OSC)
Orthography–semantics consistency is a metric thatquantifies the degree of semantic relatedness be-tween a word and other words that are orthographi-cally similar. The metric was computed by (Marelliand Amenta, 2018) as the frequency-weighted av-erage semantic similarity between the meaning ofa given word and the meanings of all the wordscontaining that very same orthographic string.
Norms were available for 15,017 unique words.Obtained from: http://www.
marcomarelli.net/resources/osc.Polysemy Polysemy provides a metric of how
many distinct meanings a word has. Polysemywas measured by the number of definitions ofa word in WordNet (Miller, 1992). Polysemywas implemented using NLTK’s word_net library(synsets() function) which accepts a word and apart-of-speech tag as input and returns a list ofsynonyms. Parts-of-speech tags were taken fromNLTK’s pos_tag, then mapped to the four POS tagsaccepted by word_net. If a POS tag could not bemapped to one of word_net’s ADJ, VERB, NOUN,or ADV then the tag given was an empty string.The number of synonyms for a given word werecounted.
Norms were available for 155,327 words orga-nized in 175,979 synsets for a total of 207,016word-sense pairs (Wikipedia).
Obtained from the NLTK interface: https://www.nltk.org/howto/wordnet.html.
Prevalence Word prevalence is a metric thatquantifies the number of people who know a givenword. The norms were collected by (Brysbaertet al., 2019) based on human ratings of whether ornot they knew the word.
Norms were available for 61,855 unique words.Obtained from: https://osf.io/
g4xrt/.Valence Valence quantifies each word on a scale
of positiveness–negativeness. The norms were col-
lected based on human ratings by (Mohammad,2018) using Best-Worst scaling, where participantsare presented with four words at a time and askedto select the word with the highest valence. Thetwo ends of the valence dimension were: MOSThappiness, pleasure, positiveness, satisfaction, con-tentedness, hopefulness OR LEAST unhappiness,annoyance, negativeness, dissatisfaction, melan-choly, despair.
Norms were available for 20,007 unique words.Obtained from: https://saifmohammad.
com/WebPages/nrc-vad.html.
The following features were not analyzed in thecurrent work, but in the future we plan to add sup-port for these features in the SentSpace frame-work:
Body-Object Interaction Body-object interac-tion quantifies the ease with which the human bodycan interact with what a word represents. Thenorms were collected using behavioral ratings on ascale from 1 to 7 with a value of 7 indicating a highbody-object interaction rating by (Pexman et al.,2019).
The norms were available for 9,349 uniquewords.
Obtained from: https://link.springer.com/article/10.3758%2Fs13428-018-1171-z#Sec9.
Dominance Dominance quantifies each wordon a scale of dominant–submissive. The normswere collected based on human ratings by (Mo-hammad, 2018) using Best-Worst scaling, whereparticipants are presented with four words at a timeand asked to select the word with the highest domi-nance. The two ends of the dominance dimensionwere: MOST dominant, in control of the situation,powerful, influential, important, autonomous ORLEAST submissive, controlled by outside factors,weak, influenced, cared-for, guided.
Norms were available for 20,007 unique words.Obtained from: https://saifmohammad.
com/WebPages/nrc-vad.html.Part-of-Speech Ambiguity Parts-of-speech
(POS) ambiguity is a metric to quantify how fre-quent the dominant POS of a given word is given allpossible POS a word has. The value is a fraction be-tween 0 and 1 where 1 denotes that the word alwaysoccurs in its most dominant POS form. POS val-ues were obtained from the SUBTLEXus database(Brysbaert et al., 2012).
Norms were available for 74,286 unique words.
109

Obtained from the SUBTLEXusdatabase: https://www.ugent.be/pp/experimentele-psychologie/en/research/documents/subtlexus).
Semantic Diversity Semantic diversity is a met-ric that quantifies semantic ambiguity based onvariability in the contextual usage of words. Themetric was computed by (Hoffman et al., 2013) andtakes a step beyond simply summing the numberof definitions that a word has. The underlying as-sumption is that words that appear in a wide rangeof contexts on diverse topics are more variable inmeaning than those that appear in a restricted set ofsimilar contexts. Hoffman et al. thus quantify thedegree to which the different contexts associatedwith a given word vary in their meanings.
Norms were available for 31,739 English words.Obtained from: https://link.
springer.com/article/10.3758/s13428-012-0278-x#SecESM1.
Word Length Word length as measured by char-acters.
Zipf Lexical Frequency The Zipf lexical fre-quency is a metric of word frequency, but on adifferent scale than standard frequency. The Zipfscale was proposed by (van Heuven et al., 2014) asa scale that is easier to interpret than the usualfrequency scales. Zipf values range from 1 to7, with the values 1-3 indicating low-frequencywords (with frequencies of 1 per million words andlower) and the values 4-7 indicating high-frequencywords (with frequencies of 10 per million wordsand higher). Norms were based on American sub-titles (51 million words in total) from the SUB-TLEXus database (Brysbaert and New, 2009).
Norms were available for 74,286 unique words.Obtained from the SUBTLEXus
database: https://www.ugent.be/pp/experimentele-psychologie/en/research/documents/subtlexus).
A.2 Contextual Features
The contextual features broadly fall into two cate-gories: syntactic (denoted by Contextual_syntax)and miscellaneous (denoted by Contextual_misc).Contextual features are ordered alphabetically.
A.2.1 Contextual Features — SyntaxContent Word Ratio — Misc Lexical density isthe proportion of content words to function wordsin a sentence. It is a proxy for how much infor-mation a sentence contains. Content words were
defined as nouns, verbs, adjectives, and adverbsand were defined using the NLTK part-of-speechtagger.
Dependency Locality Theory (DLT) VariantsThe Dependency Locality Theory (DLT) (Gibson,2000) features are measures of storage and integra-tion costs during sentence processing. The DLT isa theory of word-by-word comprehension difficultyduring human language processing, with difficultyhypothesized to arise from working memory de-mand related to storing items in working memory(storage cost) and retrieving items from workingmemory (integration cost) as required by the de-pendency structure of the sentence. We include thetraditional DLT metrics, as well as modificationsas described in (Shain et al., 2016).
Left-Corner Features — Syntax The left-corner features are based on left-corner theoriesof sentence processing as described in (Rasmussenand Schuler, 2018). Similar to DLT, left-cornerparsing models also posit storage and integrationcosts, but these costs are thought to derive notfrom dependency locality but from the number ofunconnected fragments of phrase structure treesthat must be maintained and combined in mem-ory throughout parsing, word-by-word. See (Shainet al., 2021a) for detailed description of these fea-tures, but in brief they include: end of constituent,length of constituent (3 variants), end of center em-bedding, start of multi-word center-embedding, endof multi-word center embedding, length of multi-word center embedding (3 variants), and syntacticembedding depth. Features are derived from auto-matic parse trees generated by the van Schijndelet al. (2013) parser trained on a generalized catego-rial grammar reannotation (Nguyen et al., 2012) ofthe Penn Treebank corpus (Marcus et al., 1993).
N-gram Surprisal — Misc N-gram surprisalprovides a metric of how surprising a word is givenits context. The norms were computed by (Pianta-dosi et al., 2011) based on Google (Brants andFranz, 2009) using a standard probabilistic N-grammodel which treats the context as consisting onlyof the local linguistic context containing the pre-vious N − 1 words. The norms are available forN = 2, 3, 4, i.e. 2-grams, 3-grams and 4-grams.
Norms were available for 3,297,629 (2-grams),2,133,709 (3-grams) and 1,600,987 (4-grams)unique words. Obtained from colala.berkeley.edu/data/PiantadosiTilyGibson2011/Google10L-1T.
Pronoun Ratio — Misc The pronoun ratio is
110

the proportion of pronoun words to all words ina sentence. It is a proxy for how much discourseis assumed in a sentence. Pronoun words weredefined using the NLTK part-of-speech tagger.
The following features were not analyzed in thecurrent work, but are in the process of being addedto the SentSpace framework:
Language Model Surprisal Language modelsurprisal provides a metric for how surprising (i.e.,likely) a given sentence is by using the probabilitydistribution obtained from pre-trained state-of-the-art language models. The default probability iscomputed as the product of individual tokens’ logprobabilities.
The language models were obtained using theHuggingFace Transformers framework (Wolf et al.,2020).
Sentence-Level Sentiment — Misc Sentence-level sentiment provides a metric for how positiveor negative a given sentence is. The feature wasderived using a pre-trained transformer model fine-tuned to perform sentiment prediction from a largedataset of human-annotated sentiment norms. Thecode framework used to compute the feature wasby HuggingFace (Wolf et al., 2020).
Syntactic Rule Frequency — Syntax The syn-tactic rule frequencies consist of counts of n-aryand binary syntactic rules. For both n-ary (n is anarbitrary number larger than two) and binary rules,the sentence is dependency parsed (CoNLL format).The n-ary version gets all heads, along with its partof speech and its dependency relations. So if thereis a verb with a subject and object, an n-ary rulewould be: nsubj-V-dobj. The binary version is sim-ilar, but takes each head/dependency relationshipseparately. So the rules would be nsubj-V, V-dobj,etc. Thus, the syntactic rule frequency featuresconsists of the number of times each n-ary and bi-nary rules occur. The code framework to computethe features was obtained from Kyle Mahowald(preprint to appear).
A.3 EmbeddingsEmbeddings provide representations of sentencesin high-dimensional, learned vector spaces. Weprovide a context-independent embedding space(words have the same vector representation in-dependent of context), GloVe (Pennington et al.,2014), as well as several commonly used contextu-alized embedding spaces (words have different vec-tor representations based on the context in which
they appear) from the HuggingFace framework(Wolf et al., 2020). These can be invoked usingthe corresponding model identifier from Hugging-Face model hub as an argument to SentSpace.
B Materials Used in Demonstration
B.1 Example human-written paragraphMontreal has a unique bagel traditionthat dates back to at least 1919. The Mon-treal bagel is chewier, smaller, and lessdense, but has a much bigger hole thanits American cousin. Boiled in honeywater and then baked in a wood-burningoven, it’s a little sweet and has a harderexterior. It is hand-rolled in the shape ofan oval hoop; you can wear one aroundyour wrist like a bracelet.
B.2 Examples of GPT2-XL generated text1 Montreal has a unique bagel tradi-tion that dates back to the mid-nineteenthcentury. In the early days of the morn-ing, tourists would arrive in Montreal inlarge numbers for a morning sandwichand coffee. You could be guaranteed tofind several dozen different varieties ina pastry case. When the “Cappuccino”was introduced in 1894, the bagels camewith it. You had to order your espressoand and your bagel separately.
2 Montreal has a unique bagel traditionthat dates back to 1766, when an English-man named J.D. Bagel opened the firstof what would become five bakeries. To-day, there are more than 70 Bagel East St.Laurent and 15 Bagel Central St. Lau-rent. It’s not just the flavors of bagelsthat separate Montreal bagel restaurantsfrom the rest of Canada. What also setsthem apart are the quality ingredients.
3 Montreal has a unique bagel traditionthat dates back to 1876, when the cityhosted the Olympic Games. The tradi-tion is still alive today. Because the bagelis such an American food, you won’t findbagels being served in many Chineserestaurants, as French food in Franceis considered food that originated fromthe Americas. Desserts Although bagelshave many tastes, you don’t need to try
111

every flavor to enjoy bagel ice cream orbagel sandwiches.
4 Montreal has a unique bagel tradi-tion that dates back to 1917. In 2017,the Bagel Corner will open its doorsagain to celebrate Montreal’s uniquebagel heritage. This May, the BagelCorner will offer a variety of bagels,bagel sandwiches and doughnuts, sold inMontreal and Montreal-area food trucks.With bags of fresh fruit, grapes, pickledveggies and other delicious bagels, thisyear’s sale will be a great opportunity toindulge your taste buds.
5 Montreal has a unique bagel traditionthat dates back to the early 1900’s. Thebagels that we now associate with Mon-treal are greatly influenced by the placethat spawned them the Sea Route Bagel.This famous bagel began its long journeyto Montreal with a group of Jewish im-migrants arriving from Eastern Europein the early 1900’s. To say that they werefortunate would be an understatement.
C Corpora Benchmarks
As mentioned in the manuscript, we subsam-ple a collection of corpora for use as bench-marks to compare against. We list thesecorpora in Table 1. These include: theBrown Corpus (Francis and Kucera, 1979),the Toronto Books Corpus Adventure genre(Zhu et al., 2015), Wall Street Journal corpus(Paul and Baker, 1992), Universal Dependen-cies https://universaldependencies.org/#download, Colossal Cleaned CommonCrawl (C4) (Raffel et al., 2020), Corpus of Contem-porary American English (Spoken) — 1991, 2001,2012 (Davies, 2009).
112
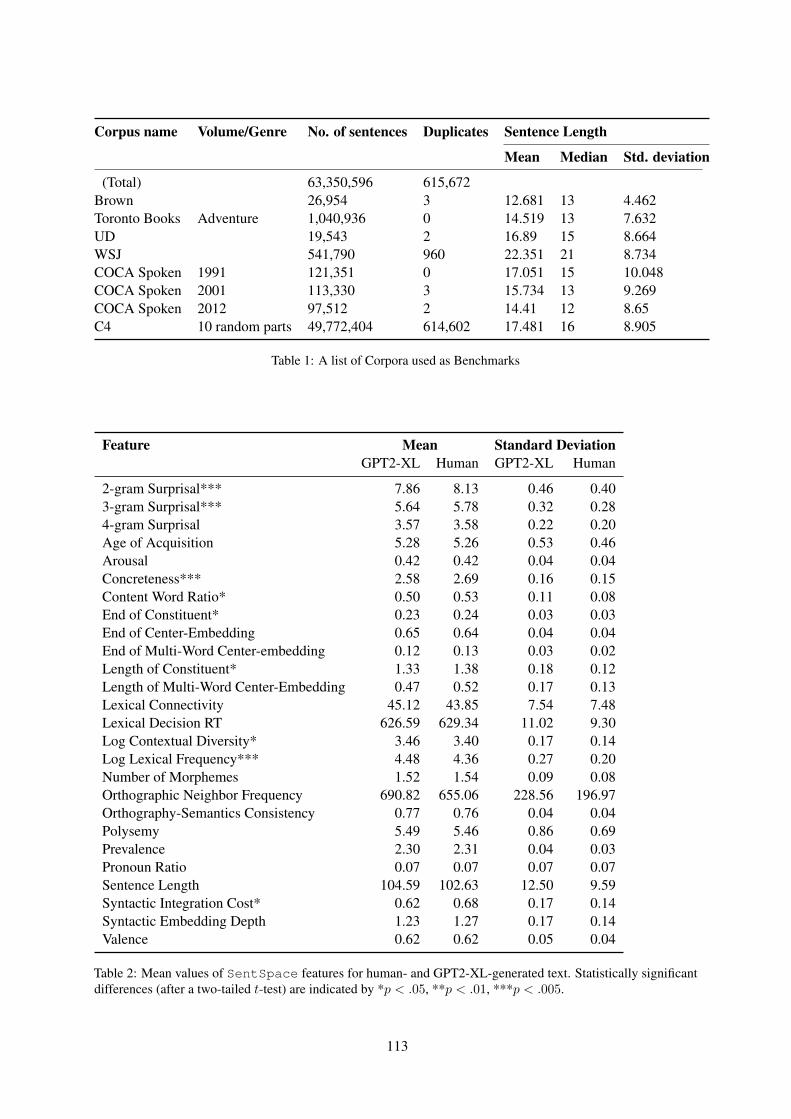
Corpus name Volume/Genre No. of sentences Duplicates Sentence Length
Mean Median Std. deviation
(Total) 63,350,596 615,672Brown 26,954 3 12.681 13 4.462Toronto Books Adventure 1,040,936 0 14.519 13 7.632UD 19,543 2 16.89 15 8.664WSJ 541,790 960 22.351 21 8.734COCA Spoken 1991 121,351 0 17.051 15 10.048COCA Spoken 2001 113,330 3 15.734 13 9.269COCA Spoken 2012 97,512 2 14.41 12 8.65C4 10 random parts 49,772,404 614,602 17.481 16 8.905
Table 1: A list of Corpora used as Benchmarks
Feature Mean Standard DeviationGPT2-XL Human GPT2-XL Human
2-gram Surprisal*** 7.86 8.13 0.46 0.403-gram Surprisal*** 5.64 5.78 0.32 0.284-gram Surprisal 3.57 3.58 0.22 0.20Age of Acquisition 5.28 5.26 0.53 0.46Arousal 0.42 0.42 0.04 0.04Concreteness*** 2.58 2.69 0.16 0.15Content Word Ratio* 0.50 0.53 0.11 0.08End of Constituent* 0.23 0.24 0.03 0.03End of Center-Embedding 0.65 0.64 0.04 0.04End of Multi-Word Center-embedding 0.12 0.13 0.03 0.02Length of Constituent* 1.33 1.38 0.18 0.12Length of Multi-Word Center-Embedding 0.47 0.52 0.17 0.13Lexical Connectivity 45.12 43.85 7.54 7.48Lexical Decision RT 626.59 629.34 11.02 9.30Log Contextual Diversity* 3.46 3.40 0.17 0.14Log Lexical Frequency*** 4.48 4.36 0.27 0.20Number of Morphemes 1.52 1.54 0.09 0.08Orthographic Neighbor Frequency 690.82 655.06 228.56 196.97Orthography-Semantics Consistency 0.77 0.76 0.04 0.04Polysemy 5.49 5.46 0.86 0.69Prevalence 2.30 2.31 0.04 0.03Pronoun Ratio 0.07 0.07 0.07 0.07Sentence Length 104.59 102.63 12.50 9.59Syntactic Integration Cost* 0.62 0.68 0.17 0.14Syntactic Embedding Depth 1.23 1.27 0.17 0.14Valence 0.62 0.62 0.05 0.04
Table 2: Mean values of SentSpace features for human- and GPT2-XL-generated text. Statistically significantdifferences (after a two-tailed t-test) are indicated by *p < .05, **p < .01, ***p < .005.
113

Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies: System Demonstrations, pages 114 - 123
July 10-15, 2022 ©2022 Association for Computational Linguistics
PaddleSpeech: An Easy-to-Use All-in-One Speech ToolkitHui Zhang1, Tian Yuan1, Junkun Chen3, Xintong Li2, Renjie Zheng2,
Yuxin Huang1, Xiaojie Chen1, Enlei Gong1, Zeyu Chen1, Xiaoguang Hu1,Dianhai Yu1, Yanjun Ma1, Liang Huang2,3
1Baidu Inc., Beijing, China2Baidu Research, Sunnyvale, CA, USA
3Oregon State University, Corvallis, OR, USAzhanghui41, yuantian01, xintongli, renjiezheng,
huangyuxin, chenxiaojie06, gongenlei, chenzeyu01baidu.com
AbstractPaddleSpeech is an open-source all-in-onespeech toolkit. It aims at facilitating the devel-opment and research of speech processing tech-nologies by providing an easy-to-use command-line interface and a simple code structure. Thispaper describes the design philosophy and corearchitecture of PaddleSpeech to support sev-eral essential speech-to-text and text-to-speechtasks. PaddleSpeech achieves competitive orstate-of-the-art performance on various speechdatasets and implements the most popular meth-ods. It also provides recipes and pretrainedmodels to quickly reproduce the experimentalresults in this paper. PaddleSpeech is publiclyavaiable at https://github.com/PaddlePaddle/PaddleSpeech.1
1 Introduction
Speech processing technology enables humans todirectly communicate with computers, which isan essential part of enormous applications suchas smart home devices (Hoy, 2018), autonomousdriving, and simultaneous translation (Zheng et al.,2020). Open-source toolkits boost the develop-ment of speech processing technology by lower-ing the barrier of application and research in thisarea (Young et al., 2002; Lee et al., 2001; Huggins-Daines et al., 2006; Rybach et al., 2011; Poveyet al., 2011; Watanabe et al., 2018; Han et al., 2019;Wang et al., 2020; Ravanelli et al., 2021; Zhao et al.,2021).
However, the current prevailing speech process-ing toolkits presume that their users are experi-enced practitioners or researchers, so beginnersmight feel baffled when developing their excitingapplications. For example, to prototype new speechapplications with Kaldi (Povey et al., 2011), theusers have to be comfortable reading and revis-ing the provided recipes written in Bash, Perl, and1Demo video: https://paddlespeech.readthedocs.io/en
/latest/demo_video.html
Python scripts and be proficient at C++ to hack itsimplementation. The more recent toolkits, suchas Fairseq S2T (Wang et al., 2020) and NeurST(Zhao et al., 2021), become more flexible by build-ing on general-purpose deep learning libraries. Buttheir complicated code styles also make it time-consuming to learn and hard to migrate from one toanother. So, we have developed PaddleSpeech, pro-viding a command-line interface and portable func-tions to make the development of speech-relatedapplications accessible to everyone.
Notably, the Chinese community has many de-velopers eager to contribute to the community.However, nearly all deep learning libraries, suchas Pytorch (Paszke et al., 2019) and Tensorflow(Abadi et al., 2016), target the English commu-nity mainly, so it significantly increases the dif-ficulty for Chinese developers. PaddlePaddle, asthe only fully-functioning open-source deep learn-ing platform targeting both the English and Chi-nese community, has accumulated more than 500kcommits, 476k models, and is used by 157k en-terprises. So, we expect PaddleSpeech, developedwith PaddlePaddle can remove the barriers betweenthe English and Chinese communities to boost thedevelopment of speech technologies and applica-tions.
Developing speech applications for the industryis not the same scenario as conducting research inacademia. The research papers mainly focus on de-veloping novel models to perform better on specificdatasets. However, a clean dataset usually does notexist when applying a speech product. So, Paddle-Speech provides on-the-fly preprocessing for theraw audios to make PaddleSpeech directly usable inproduct-oriented applications. Notably, some pre-processing methods are exclusive in PaddleSpeech,such as rule-based Chinese text-to-speech frontend,which can significantly benefit the performance ofsynthesized speech.
Performance is the cornerstone of all applica-
114

Task Description Techniques Datasets
SoundClassification Label sound class Finetuned PANN (Kong et al., 2020b) ESC-50 dataset (Piczak, 2015)
SpeechRecognition
Transcribe speechto text
Deepspeech2 (Amodei et al., 2016)Conformer (Zhang et al., 2020)Transformer (Zhang et al., 2020)
Librispeech (Panayotov et al., 2015)AISHELL-1 (Bu et al., 2017)
PunctuationRestoration
Post-add punctuationto transcribed text Finetuned ERNIE (Sun et al., 2019) IWSLT2012-zh (Federico et al., 2012)
SpeechTranslation
Translate speechto text Transformer (Vaswani et al., 2017) MuST-C (Di Gangi et al., 2019)
TextTo Speech
Synthesis speechfrom text
Acoustic ModelTacotron 2 (Shen et al., 2018)Transformer TTS (Li et al., 2019)SpeedySpeech (Vainer and Dušek, 2020)FastPitch (Łancucki, 2021)FastSpeech 2 (Ren et al., 2020)
VocoderWaveFlow(Ping et al., 2020)Parallel WaveGAN (Yamamoto et al., 2020)MelGAN (Kumar et al., 2019)Style MelGAN (Mustafa et al., 2021)Multi Band MelGAN (Yang et al., 2021)HiFi GAN (Kong et al., 2020a)
CSMS (DataBaker)AISHELL-3 (Shi et al., 2020)LJSpeech (Ito and Johnson, 2017)VCTK (Yamagishi et al., 2019)
Table 1: List of speech tasks and corpora that are currently supported by PaddleSpeech.
tions. PaddleSpeech achieves state-of-the-art orcompetitive performers on various commonly usedbenchmarks, as shown in Table 1.
Our main contributions in this paper are two-folds.
• We introduce how we designed PaddleSpeechand what features it supports.
• We provide the implementation and repro-ducible experimental details that result instate-of-the-art or competitive performanceon various tasks.
2 Design of PaddleSpeech
Figure 1 shows the software architecture of Pad-dleSpeech. As an easy-to-use speech processingtoolkit, PaddleSpeech provides many completerecipes to perform various speech-related tasks anddemo usage of the command line interface. Gettingfamiliar with the top level should be enough forbuilding speech-related applications.
The second level faces researchers in speechand language processing. The design philosophyof PaddleSpeech is model-centric to simplify thelearning and development of speech processingmethods. For a specific method, all computationsof a specific model are included in two files under
Fundamental Platforms
Common Modules
Models & Updaters & Datasets
Recipes
PaddlePaddleOther Libraries
Kaldi, Sclite, Sox, Openblas
PaddleAudiopaddleaudio.features.Spectrogrampaddleaudio.features.LogMelSpectrogram
Utilsutils/build_vocab.pyutils/parse_options.sh
PaddleSpeechcli/asr/infer.pyt2s/exps/fastspeech2/train.pyt2s/models/fastspeech2/fastspeech2.pyt2s/models/fastspeech2/fastspeech2_updater.py
Datasets
dataset/aishell/aishell.pydataset/librispeech/librispeech.py
Examples/Demosexamples/aishell/run.shdemos/metaverse/run.sh
Figure 1: Software architecture of PaddleSpeech.
PaddleSpeech/<task>/models/<model>.2
PaddleSpeech has implemented most of the com-monly used and well-performing models. A modelarchitecture is implemented in a standalone filenamed by the method. Its corresponding train-ing step and evaluation step are implementedin another updater file. Generally, reading orhacking these two files is enough to understandor design a model. More advanced hackingon more fine data processing or more compli-2<task> includes s2t and t2s which stands for speech-to-text and text-to-speech respectively.
115

cated training/evaluation loop is also available atPaddleSpeech/<task>/exps/<model>. The orig-inal datasets can be obtained by scripts in cor-responding dataset/<dataset>/. PaddleSpeechsupports distributed multi-GPU training with goodefficiency.
The standard modules, such as audio and textfeature transformation and utility scripts, are imple-mented as libraries in the third level . The backendof PaddleSpeech is mainly PaddlePaddle with somefunctions from third-party libraries as shown inthe fourth level . PaddleSpeech provides multiple
ways to extract multiple types of speech featuresfrom raw audios using PaddleAudio and Kaldi,such as spectrogram and filterbanks, which canbe varied according to the needs of the tasks.
3 Experiments
In this section, we compare the performance ofmodels in PaddleSpeech with other popular imple-mentations in five speech-related tasks, includingsound classification, speech recognition, punctua-tion, speech translation, and speech synthesizing.The toolkit can reach SOTA on most tasks. Allexperiments in this section include details on datapreparation, evaluation metrics, and implementa-tion to enhance reproducibility.3
3.1 Sound Classification
Sound Classification is a task to recognize particu-lar sounds, including speech commands (Warden,2018), environment sounds (Piczak, 2015), iden-tifying musical instruments (Engel et al., 2017),finding birdsongs (Stowell et al., 2018), emotionrecognition (Xu et al., 2019) and speaker verifica-tion (Liu et al., 2018).
Datasets In this section, we analyze the perfor-mance of PaddleSpeech in Sound Classificationon ESC-50 dataset (Piczak, 2015). The ESC-50dataset is a labeled collection of 2000 environ-mental 5-second audio recordings consisting of 50sound events, such as "Dog", "Cat", "Breathing"and "Fireworks", with 40 recordings per event.
Data Preprocessing First, we resample all audiorecordings to 32 kHz, and convert them to mono-phonic to be consistent with the PANNs trained onAudioSet (Kong et al., 2020b). And then, we trans-form the recordings into log mel spectrograms by3https://github.com/PaddlePaddle/PaddleSpeech/tree/
develop/examples
Model Accuracy
AST-P (Gong et al., 2021) 95.6± 0.4
PANNs-CNN14 95.00PANNs-CNN10 89.75PANNs-CNN6 88.25
Table 2: 5-fold cross validation accuracy of ESC-50.
applying short-time Fourier transform on the wave-forms with a Hamming window of size 1024 and ahop size of 320 samples. This configuration leadsto 100 frames per second. Following Kong et al.(2019), we apply 64 mel filter banks to calculatethe log mel spectrogram.
Implementation PANNs (Kong et al., 2020b)is one of the pre-trained CNN models for audio-related tasks, which is characterized in terms ofbeing trained with the AudioSet (Gemmeke et al.,2017). PANNs are helpful for tasks where only alimited number of training clips are provided. Inthis case, we fine-tune all parameters of a PANN forthe environment sounds classification task. All pa-rameters are initialized from the PANN, except thefinal fully-connected layer which is randomly ini-tialized. Specifically, we implement CNNs with 6,10 and 14 layers, respectively (Kong et al., 2020b).
Results We report 5-fold cross validation accu-racy values on ESC-50 dataset. As shown in Table2, PANNs-CNN14 achieves 0.9500 5-fold crossvalidation accuracy that is comparable to the cur-rent state-of-the-art method (Gong et al., 2021).
3.2 Automatic Speech Recognition
Automatic Speech Recognition (ASR) is a task totranscribe the audio content to text in the samelanguage.
Datasets We conduct the ASR experiments ontwo major datasets including Librispeech4 (Panay-otov et al., 2015) and Aishell-15 (Bu et al., 2017).Librispeech contains 1000 hours speech data. Thewhole dataset is divided into 3 training sets (100hclean, 360h clean, 500h other), 2 validation sets(clean, other), and 2 test sets (clean, other). Aishellcontains 178 hours speech data. 400 speakers fromdifferent accent areas in China participate in therecording. The dataset is divided into the training
4http://www.openslr.org/12/
5http://www.aishelltech.com/kysjcp
116

Data Model Streaming Test Data Language Model CER WERA
ishe
llWeNet Conformer†∗ (Yao et al., 2021) 5.45 -WeNet Conformer† (Yao et al., 2021) 4.61 -WeNet Transformer† (Yao et al., 2021) 5.30 -ESPnet Conformer† (Inaguma et al., 2020) 5.10 -ESPnet Transformer† (Inaguma et al., 2020) 6.70 -SpeechBrain Transformer† (Ravanelli et al., 2021) 5.58 -
Deepspeech 2 char 5-gram 6.66 -Deepspeech 2 char 5-gram 6.40 -Transformer 5.23 -Conformer∗ 5.44 -Conformer 4.64 -
Lib
risp
eech
WeNet Conformer† (Yao et al., 2021) test-clean - 2.85SpeechBrain Transformer† (Ravanelli et al., 2021) test-clean TransformerLM - 2.46ESPnet Transformer† (Inaguma et al., 2020) test-clean TransformerLM - 2.60
Deepspeech 2 test-clean word 5-gram - 7.25Conformer test-clean - 3.37Transformer test-clean TransformerLM - 2.40
†denotes the results are reported in their public repositories.
∗denotes the results are streaming with chunk size 16.
Table 3: WER/CER on Aishell, Librispeech for ASR Tasks.
set (340 speakers), validation set, (40 speakers) andtest set (20 speakers).
Data Preprocessing Deepspeech 2 takescharacter-level vocabularies for both Englishand Mandarin tasks. For other models, we usecharacter-level vocabulary for Mandarin. AndEnglish text is preprocessed with SentencePiece(Kudo and Richardson, 2018). Both two kindsof datasets are added four additional characters,which are <’>, <space>, <blank> and <eos>.For cepstral mean and variance normalization(CMVN), a subset of or full of the training setis selected and be used to compute the featuremean and standard error. For feature extraction,we have several methods implemented, such aslinear spectrogram, filterbank, and mfcc. Currently,the Deepspeech 2 model uses linear spectrogramor filterbank, but Transformer and Conformermodels use filterbank. For a fair comparison, wetake additional 3 dimensional pitch features intoTransformer to be consistent with ESPnet.
Implementation We implement both streamingand non-streaming Deepspeech 2 (Amodei et al.,2016). The non-streaming model has 2 convolu-tion layers and 3 LSTM layers. The streamingmodel has 2 convolution layers and 5 LSTM lay-ers. The Conformer and Transformer models areimplemented following Zhang et al. (2020) with 12encoder layers and 6 decoder layers.
Results We report word error rate (WER) andcharacter error rate (CER) for Librispeech (En-glish) and Aishell (Mandarin) speech recognition,respectively. As shown in Table 3, Conformer andTransformer are better than Deepspeech 2. Ourbest models achieve comparable performance onboth datasets compared with related works.
3.3 Punctuation RestorationPunctuation restoration is a post-processing prob-lem for ASR systems. It is crucial to improve thereadability of the transcribed text for the humanreader and facilitate down-streaming NLP tasks.
Datasets We conduct experiments onIWSLT2012-zh6 dataset, which contains 150kChinese sentences with punctuation. We selectcomma, period, and question marks as restoretargets in this task, so we replace other punctuationwith these three marks before training a model. Wesplit the data into training, validation and testingsets with 147k, 2k, and 1k samples, respectively.
Implementation We formulate the problem ofpunctuation restoration as a sequence labeling taskwith four target classes including EMPTY, COMMA,PERIOD, and QUESTION (Nagy et al., 2021b).ERNIE (Sun et al., 2019), as a pretrained languagemodel, achieves new state-of-the-art results on fiveChinese natural language processing tasks, includ-ing natural language inference, semantic similarity,6https://hltc.cs.ust.hk/iwslt/
117

Frameworks De Es Fr It Nl Pt Ro Ru
ESPnet-ST (Inaguma et al., 2020) 22.9 28.0 32.8 23.8 27.4 28.0 21.9 15.8fairseq-ST (Wang et al., 2020) 22.7 27.2 32.9 22.7 27.3 28.1 21.9 15.3NeurST (Zhao et al., 2021) 22.8 27.4 33.3 22.9 27.2 28.7 22.2 15.1
PaddleSpeech 23.0 27.4 32.9 22.9 26.7 28.8 22.2 15.4
Table 4: Case-sensitive detokenized BLEU scores on MuST-C tst-COMMON.
model COMMA PERIOD QUESTION Overall
BERTLinear† 0.4646 0.4227 0.7400 0.5424BERTBiLSTM† 0.5190 0.5707 0.8095 0.6330
ERNIELinear 0.5142 0.5447 0.8406 0.6331†
denotes the results come from our reproduced models.
Table 5: F1-score values on IWSLT2012-zh dataset.
named entity recognition, sentiment analysis, andquestion answering. So, we finetune an ERNIEmodel for this task. More specifically, all param-eters are initialized from the ERNIE pretrainedmodel, except the final shared fully-connectedlayer, which is randomly initialized.
Results We report F1-score values onIWSLT2012-zh dataset. As shown in Table5, our ERNIELinear model achieves 0.6331 overallF1-score, which is comparable with the previouswork (Nagy et al., 2021a).
3.4 Speech Translation
Speech translation, where translating speech in asource language to text in another language, is ben-eficial in human communications.
Datasets In this section, we analyze the perfor-mance of speech-to-text translation with Paddle-Speech on MuST-C dataset (Di Gangi et al., 2019)with 8 different language translation pairs, whichtake the English speech as the source input.
Implementation We process the raw audioswith Kaldi (Povey et al., 2011) and extract 80-dimensional log-mel filterbanks stacked with 3-dimensional pitch feature using a 25ms windowsize and a 10ms step size. Text is firstly tokenizedwith Moses tokenizer7 and then processed by Sen-tencePiece (Kudo and Richardson, 2018) with ajoint vocabulary whose size is 8K for each languagepair. We employ Transformer (Vaswani et al., 2017)as the base architecture for the speech translationexperiments. In detail, the Transformer model has7https://github.com/moses-smt/mosesdecoder
12 encoder layers that follow 2 layers of 2D convo-lution with kernel size of 3 and stride size of 2, and6 decoder layers. Each layer contains 4 attentionheads with a size of 256. The encoder is initializedfrom a pretrained ASR model.
Results We report detokenized case-sensitiveBLEU8. As shown in Table 4, PaddleSpeech canachieve competitive results compared with otherframeworks.
3.5 Text-To-Speech
A Text-To-Speech (TTS) system converts givenlanguage text into speech. PaddleSpeech’s TTSpipeline includes three steps. We first convert theoriginal text into the characters/phonemes throughthe text frontend module. Then, through an Acous-tic model, we convert the characters or phonemesinto acoustic features, such as mel spectrogram, Fi-nally, we generate waveform from the acoustic fea-tures through a Vocoder. In PaddleSpeech, the textfrontend is a rule-based model inspired by expertknowledge. The Acoustic models and Vocoders aretrainable.
Datasets In PaddleSpeech, we mainly focus onMandarin and English speech synthesis. Wehave benchmarks on CSMSC9, AISHELL-310,LJSpeech11, VCTK12. Due to the limit of space,we only list the experimental results on CSMSC,which includes 12 hours speech audio correspond-ing to 10k sentences.
Text Frontend A text frontend module is used toextract linguistic features, characters and phonemesfrom given text. It mainly includes: Text Segmenta-tion, Text Normalization (TN), Word Segmentation(WS), Part-of-Speech Tagging, Prosody Predictionand Grapheme-to-Phoneme (G2P) (see Table 6).
8https://github.com/mjpost/sacrebleu
9https://www.data-baker.com/open_source.html
10http://www.aishelltech.com/aishell_3
11https://keithito.com/LJ-Speech-Dataset/
12https://datashare.ed.ac.uk/handle/10283/3443
118

Module ResultPa
ddle
Spee
ch
jın tian shì zuì dı wen dù shìText 今天 是 2020/10/29 , 最低 温度 是 -3°C 。
today is lowest temperature is
èr líng èr líng nían shí yùe èr shí jiu rì líng xià san dùTN 今天 是 二零 二 零 年 十 月 二十九 日 , 最低 温度 是 零下 三 度 。
2 0 0 2 year 10 month 29 day negative three degree
WS 今天 / 是 / 二零二零年 /十月 /二十九日 , /最低 温度 / 是 / 零下 /三度 。
G2P jin1 tian1 shi4 er4 ling2 er4 ling2 nian2 shi4 yue4 er4 shi2 jiu3 ri4 zui4 di1 wen1 du4 shi4 ling2 xia4 san1 du4
ESPnet jin1 tian1 shi4 2020/10/29 zui4 di1 wen1 du4 shi4 -3°C
Table 6: An example of the text preprocessing pipeline for Mandarin TTS of PaddleSpeech and ESPnet. TNstands for the text normalization module, WS stands for the word segmentation module, G2P stands for thegrapheme-to-phoneme module. The text normalization module for mandarin of ESPnet is not able to correctlyhandle dates (2020/10/29) and temperatures (-3°C).
For Mandarin, our G2P system consists of a poly-phone module, which uses pypinyin and g2pM, anda tone sandhi module which uses rules based onchinese word segmentations. To the best of ourknowledge, our Mandarin text frontend system isthe most complete one compared with other pub-licly released works.
Data Preprocessing PaddleSpeech TTS uses thefollowing modules for data preprocessing13: First,we use Montreal-Forced-Aligner to get the durationfor corresponding phonemes. Second, we extractmel spectrograms as the features (additional pitchand energy features for Fastspeech 2). Last, weconduct the statistical normalization for each fea-ture.
Acoustic Model Acoustic models can bemainly classified into autoregressive and non-autoregressive models. The decoding of the au-toregressive model relies on previous predictionsat each step, which leads to longer inferencetime but relatively better quality. While the non-autoregressive model generates the outputs in par-allel, so the inference speed is faster, but the qualityof generated result is relatively poor.
As shown in Table 1, PaddleSpeech has im-plemented the following commonly used autore-gressive acoustic models: Tacotron 2 and Trans-former TTS, and non-autoregressive acoustic mod-els: SpeedySpeech, FastPitch and FastSpeech 2.
Vocoder As shown in Table 1, PaddleSpeechhas implemented the following vocoders: Wave-Flow, Parallel WaveGAN, MelGAN, Style Mel-
13https://github.com/PaddlePaddle/PaddleSpeech/blob/
develop/examples/csmsc/tts3/local/preprocess.sh
Acoustic Model Vocoder MOS ↑ESPnet Fastspeech 2 PWGAN 2.55 ± 0.19
Tacotron 2 PWGAN 3.69 ± 0.11Speedyspeech PWGAN 3.79 ± 0.09Fastspeech 2 PWGAN 4.25 ± 0.09
PaddleSpeech Fastspeech 2 Style MelGAN 4.32 ± 0.10Fastspeech 2 MB MelGAN 4.43 ± 0.09Fastspeech 2 HiFi GAN 4.72 ± 0.08
Table 7: The MOS evaluation with 95% confidenceintervals for TTS models trained using CSMSC dataset.PWGAN stands for Parallel WaveGan, MB MelGANstands for Multi-Band MelGAN.
GAN, Multi Band MelGAN, and HiFi GAN.
Implementation The PadddleSpeech TTS imple-mentation of FastSpeech 2 adopts some improve-ment from FastPitch and uses MFA to obtain theforced alignment (the original FastSpeech paperuses Tacotron 2). Notably, the speech feature pa-rameters of the acoustic model and the vocoder ofone TTS pipeline should be the same. Detailedsettings can be found in the sample config file14 onCSMSC dataset.
Results We report the mean opinion score (MOS)for naturalness evaluation in Table 7. We use thecrowdMOS toolkit (Ribeiro et al., 2011), where 14Mandarin samples (see Appendix A) from these7 different models were presented to 14 workerson Mechanical Turk. As shown in Table 7, Pad-dleSpeech can largely outperform ESPnet on Man-darin TTS. The main reason is that PaddleSpeechTTS has a better text frontend as shown in Table6. Compared with other models, Fastspeech 2 with
14https://github.com/PaddlePaddle/PaddleSpeech/blob/
develop/examples/csmsc/tts2/conf/default.yaml
119

HiFi GAN can achieve the best results.
4 Conclusion
This paper introduces PaddleSpeech, an open-source, easy-to-use, all-in-one speech processingtoolkit. We illustrated the main design philosophybehind this toolkit to conduct development and re-search on various speech-related tasks accessible.A number of reproducible experiments and com-parisons show that PaddleSpeech achieves state-of-the-art or competitive performance with the mostpopular models on standard benchmarks.
5 Acknowledgment
We sincerely thank the anonymous reviewersfor their valuable comments and suggestions.This work was supported by the National KeyResearch and Development Project of China(2020AAA0103503).
ReferencesMartín Abadi, Paul Barham, Jianmin Chen, Zhifeng
Chen, Andy Davis, Jeffrey Dean, Matthieu Devin,Sanjay Ghemawat, Geoffrey Irving, Michael Isard,et al. 2016. Tensorflow: A system for large-scale ma-chine learning. In 12th USENIX symposium on op-erating systems design and implementation (OSDI16), pages 265–283.
Dario Amodei, Sundaram Ananthanarayanan, RishitaAnubhai, Jingliang Bai, Eric Battenberg, Carl Case,Jared Casper, Bryan Catanzaro, Qiang Cheng, Guo-liang Chen, et al. 2016. Deep speech 2: End-to-endspeech recognition in english and mandarin. In In-ternational conference on machine learning, pages173–182. PMLR.
Hui Bu, Jiayu Du, Xingyu Na, Bengu Wu, and HaoZheng. 2017. Aishell-1: An open-source mandarinspeech corpus and a speech recognition baseline. In2017 20th Conference of the Oriental Chapter ofthe International Coordinating Committee on SpeechDatabases and Speech I/O Systems and Assessment(O-COCOSDA), pages 1–5. IEEE.
Mattia A Di Gangi, Roldano Cattoni, Luisa Bentivogli,Matteo Negri, and Marco Turchi. 2019. Must-c: amultilingual speech translation corpus. In 2019 Con-ference of the North American Chapter of the Asso-ciation for Computational Linguistics: Human Lan-guage Technologies, pages 2012–2017. Associationfor Computational Linguistics.
Jesse Engel, Cinjon Resnick, Adam Roberts, SanderDieleman, Mohammad Norouzi, Douglas Eck, andKaren Simonyan. 2017. Neural audio synthesis ofmusical notes with wavenet autoencoders. In ICML.
Marcello Federico, Mauro Cettolo, Luisa Bentivogli,Paul Michael, and Stüker Sebastian. 2012. Overviewof the iwslt 2012 evaluation campaign. In IWSLT-International Workshop on Spoken Language Trans-lation, pages 12–33.
Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman,Aren Jansen, Wade Lawrence, R. Channing Moore,Manoj Plakal, and Marvin Ritter. 2017. Audio set:An ontology and human-labeled dataset for audioevents. 2017 IEEE International Conference onAcoustics, Speech and Signal Processing (ICASSP),pages 776–780.
Yuan Gong, Yu-An Chung, and James R. Glass.2021. Ast: Audio spectrogram transformer. ArXiv,abs/2104.01778.
Kun Han, Junwen Chen, Hui Zhang, Haiyang Xu, Yip-ing Peng, Yun Wang, Ning Ding, Hui Deng, YonghuGao, Tingwei Guo, Yi Zhang, Yahao He, BaochangMa, Yulong Zhou, Kangli Zhang, Chao Liu, YingLyu, Chenxi Wang, Cheng Gong, Yunbo Wang, WeiZou, Hui Song, and Xiangang Li. 2019. DELTA:A DEep learning based Language Technology plAt-form. arXiv e-prints.
Matthew B Hoy. 2018. Alexa, siri, cortana, and more:an introduction to voice assistants. Medical referenceservices quarterly, 37(1):81–88.
David Huggins-Daines, Mohit Kumar, Arthur Chan,Alan W Black, Mosur Ravishankar, and Alexander IRudnicky. 2006. Pocketsphinx: A free, real-timecontinuous speech recognition system for hand-helddevices. In 2006 IEEE International Conference onAcoustics Speech and Signal Processing Proceedings,volume 1, pages I–I. IEEE.
Hirofumi Inaguma, Shun Kiyono, Kevin Duh, ShigekiKarita, Nelson Yalta, Tomoki Hayashi, and ShinjiWatanabe. 2020. Espnet-st: All-in-one speech trans-lation toolkit. In Proceedings of the 58th AnnualMeeting of the Association for Computational Lin-guistics: System Demonstrations, pages 302–311.
Keith Ito and Linda Johnson. 2017. The lj speechdataset. https://keithito.com/LJ-Speech-Dataset/.
Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. 2020a.Hifi-gan: Generative adversarial networks for ef-ficient and high fidelity speech synthesis. arXivpreprint arXiv:2010.05646.
Qiuqiang Kong, Yin Cao, Turab Iqbal, Yuxuan Wang,Wenwu Wang, and Mark D. Plumbley. 2020b. Panns:Large-scale pretrained audio neural networks for au-dio pattern recognition. IEEE/ACM Transactions onAudio, Speech, and Language Processing, 28:2880–2894.
Qiuqiang Kong, Yin Cao, Turab Iqbal, Yong Xu, WenwuWang, and Mark D. Plumbley. 2019. Cross-tasklearning for audio tagging, sound event detection andspatial localization: Dcase 2019 baseline systems.ArXiv, abs/1904.05635.
120

Taku Kudo and John Richardson. 2018. Sentencepiece:A simple and language independent subword tok-enizer and detokenizer for neural text processing. InProceedings of the 2018 Conference on EmpiricalMethods in Natural Language Processing: SystemDemonstrations, pages 66–71.
Kundan Kumar, Rithesh Kumar, Thibault de Boissiere,Lucas Gestin, Wei Zhen Teoh, Jose Sotelo, Alexandrede Brébisson, Yoshua Bengio, and Aaron Courville.2019. Melgan: Generative adversarial networksfor conditional waveform synthesis. arXiv preprintarXiv:1910.06711.
Adrian Łancucki. 2021. Fastpitch: Parallel text-to-speech with pitch prediction. In ICASSP 2021-2021IEEE International Conference on Acoustics, Speechand Signal Processing (ICASSP), pages 6588–6592.IEEE.
Akinobu Lee, Tatsuya Kawahara, and Kiyohiro Shikano.2001. Julius—an open source real-time large vocab-ulary recognition engine. EUROSPEECH2001: the7th European Conference on Speech Communicationand Technology.
Naihan Li, Shujie Liu, Yanqing Liu, Sheng Zhao, andMing Liu. 2019. Neural speech synthesis with trans-former network. In Proceedings of the AAAI Con-ference on Artificial Intelligence, volume 33, pages6706–6713.
Bin Liu, Shuai Nie, Yaping Zhang, Shan Liang, andWenju Liu. 2018. Deep segment attentive embeddingfor duration robust speaker verification.
Ahmed Mustafa, Nicola Pia, and Guillaume Fuchs.2021. Stylemelgan: An efficient high-fidelity adver-sarial vocoder with temporal adaptive normalization.In ICASSP 2021-2021 IEEE International Confer-ence on Acoustics, Speech and Signal Processing(ICASSP), pages 6034–6038. IEEE.
Attila Nagy, Bence Bial, and Judit Ács. 2021a. Au-tomatic punctuation restoration with bert models.arXiv preprint arXiv:2101.07343.
Attila Matyas Nagy, Bence Bial, and Judit Ács. 2021b.Automatic punctuation restoration with bert models.ArXiv, abs/2101.07343.
Vassil Panayotov, Guoguo Chen, Daniel Povey, andSanjeev Khudanpur. 2015. Librispeech: an asr cor-pus based on public domain audio books. In 2015IEEE international conference on acoustics, speechand signal processing (ICASSP), pages 5206–5210.IEEE.
Adam Paszke, Sam Gross, Francisco Massa, AdamLerer, James Bradbury, Gregory Chanan, TrevorKilleen, Zeming Lin, Natalia Gimelshein, LucaAntiga, et al. 2019. Pytorch: An imperative style,high-performance deep learning library. Advancesin neural information processing systems, 32:8026–8037.
Karol J. Piczak. 2015. Esc: Dataset for environmentalsound classification. Proceedings of the 23rd ACMinternational conference on Multimedia.
Wei Ping, Kainan Peng, Kexin Zhao, and Zhao Song.2020. Waveflow: A compact flow-based model forraw audio. In International Conference on MachineLearning, pages 7706–7716. PMLR.
Daniel Povey, Arnab Ghoshal, Gilles Boulianne, LukasBurget, Ondrej Glembek, Nagendra Goel, MirkoHannemann, Petr Motlicek, Yanmin Qian, PetrSchwarz, et al. 2011. The kaldi speech recognitiontoolkit. In IEEE 2011 workshop on automatic speechrecognition and understanding, CONF. IEEE SignalProcessing Society.
Mirco Ravanelli, Titouan Parcollet, Peter Plantinga,Aku Rouhe, Samuele Cornell, Loren Lugosch, CemSubakan, Nauman Dawalatabad, Abdelwahab Heba,Jianyuan Zhong, et al. 2021. Speechbrain: Ageneral-purpose speech toolkit. arXiv preprintarXiv:2106.04624.
Yi Ren, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao,Zhou Zhao, and Tie-Yan Liu. 2020. Fastspeech2: Fast and high-quality end-to-end text to speech.arXiv preprint arXiv:2006.04558.
Flávio Ribeiro, Dinei Florêncio, Cha Zhang, andMichael Seltzer. 2011. Crowdmos: An approach forcrowdsourcing mean opinion score studies. In 2011IEEE international conference on acoustics, speechand signal processing (ICASSP), pages 2416–2419.IEEE.
David Rybach, Stefan Hahn, Patrick Lehnen, DavidNolden, Martin Sundermeyer, Zoltan Tüske, SimonWiesler, Ralf Schlüter, and Hermann Ney. 2011.Rasr-the rwth aachen university open source speechrecognition toolkit. In Proc. ieee automatic speechrecognition and understanding workshop.
Jonathan Shen, Ruoming Pang, Ron J Weiss, MikeSchuster, Navdeep Jaitly, Zongheng Yang, ZhifengChen, Yu Zhang, Yuxuan Wang, Rj Skerrv-Ryan,et al. 2018. Natural tts synthesis by conditioningwavenet on mel spectrogram predictions. In 2018IEEE International Conference on Acoustics, Speechand Signal Processing (ICASSP), pages 4779–4783.IEEE.
Yao Shi, Hui Bu, Xin Xu, Shaoji Zhang, and MingLi. 2020. Aishell-3: A multi-speaker mandarintts corpus and the baselines. arXiv preprintarXiv:2010.11567.
Dan Stowell, Yannis Stylianou, Mike Wood, HannaPamula, and Hervé Glotin. 2018. Automatic acousticdetection of birds through deep learning: the first birdaudio detection challenge. ArXiv, abs/1807.05812.
Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, XuyiChen, Han Zhang, Xin Tian, Danxiang Zhu, HaoTian, and Hua Wu. 2019. Ernie: Enhanced rep-resentation through knowledge integration. ArXiv,abs/1904.09223.
121

Jan Vainer and Ondrej Dušek. 2020. Speedyspeech:Efficient neural speech synthesis. arXiv preprintarXiv:2008.03802.
Ashish Vaswani, Noam Shazeer, Niki Parmar, JakobUszkoreit, Llion Jones, Aidan N Gomez, ŁukaszKaiser, and Illia Polosukhin. 2017. Attention is allyou need. In Advances in neural information pro-cessing systems, pages 5998–6008.
Changhan Wang, Yun Tang, Xutai Ma, Anne Wu,Dmytro Okhonko, and Juan Pino. 2020. FairseqS2T: Fast speech-to-text modeling with fairseq. InProceedings of the 1st Conference of the Asia-PacificChapter of the Association for Computational Lin-guistics and the 10th International Joint Conferenceon Natural Language Processing: System Demon-strations, pages 33–39, Suzhou, China. Associationfor Computational Linguistics.
Pete Warden. 2018. Speech commands: A datasetfor limited-vocabulary speech recognition. ArXiv,abs/1804.03209.
Shinji Watanabe, Takaaki Hori, Shigeki Karita, TomokiHayashi, Jiro Nishitoba, Yuya Unno, Nelson En-rique Yalta Soplin, Jahn Heymann, Matthew Wiesner,Nanxin Chen, et al. 2018. Espnet: End-to-end speechprocessing toolkit. arXiv preprint arXiv:1804.00015.
Haiyang Xu, Hui Zhang, Kun Han, Yun Wang, YipingPeng, and Xiangang Li. 2019. Learning alignmentfor multimodal emotion recognition from speech.CoRR, abs/1909.05645.
Junichi Yamagishi, Christophe Veaux, Kirsten MacDon-ald, et al. 2019. Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit (ver-sion 0.92). University of Edinburgh. The Centre forSpeech Technology Research (CSTR).
Ryuichi Yamamoto, Eunwoo Song, and Jae-Min Kim.2020. Parallel wavegan: A fast waveform generationmodel based on generative adversarial networks withmulti-resolution spectrogram. In ICASSP 2020-2020IEEE International Conference on Acoustics, Speechand Signal Processing (ICASSP), pages 6199–6203.IEEE.
Geng Yang, Shan Yang, Kai Liu, Peng Fang, Wei Chen,and Lei Xie. 2021. Multi-band melgan: Faster wave-form generation for high-quality text-to-speech. In2021 IEEE Spoken Language Technology Workshop(SLT), pages 492–498. IEEE.
Zhuoyuan Yao, Di Wu, Xiong Wang, Binbin Zhang,Fan Yu, Chao Yang, Zhendong Peng, Xiaoyu Chen,Lei Xie, and Xin Lei. 2021. Wenet: Produc-tion oriented streaming and non-streaming end-to-end speech recognition toolkit. arXiv preprintarXiv:2102.01547.
Steve Young, Gunnar Evermann, Mark Gales, ThomasHain, Dan Kershaw, Xunying Liu, Gareth Moore,Julian Odell, Dave Ollason, Dan Povey, et al. 2002.The htk book. Cambridge university engineeringdepartment, 3(175):12.
Binbin Zhang, Di Wu, Zhuoyuan Yao, Xiong Wang,Fan Yu, Chao Yang, Liyong Guo, Yaguang Hu, LeiXie, and Xin Lei. 2020. Unified streaming andnon-streaming two-pass end-to-end model for speechrecognition. arXiv preprint arXiv:2012.05481.
Chengqi Zhao, Mingxuan Wang, Qianqian Dong, RongYe, and Lei Li. 2021. NeurST: Neural speech transla-tion toolkit. In Proceedings of the 59th Annual Meet-ing of the Association for Computational Linguisticsand the 11th International Joint Conference on Nat-ural Language Processing: System Demonstrations,pages 55–62, Online. Association for ComputationalLinguistics.
Renjie Zheng, Mingbo Ma, Baigong Zheng, Kaibo Liu,Jiahong Yuan, Kenneth Church, and Liang Huang.2020. Fluent and low-latency simultaneous speech-to-speech translation with self-adaptive training. InFindings of the Association for Computational Lin-guistics: EMNLP 2020, pages 3928–3937.
122

A TTS Examples
We use the following sentences as the MOS evalua-tion test set in Table 7.
• 早上好,今天是2020/10/29,最低温度是-3°C。
• 你好,我的编号是37249,很高兴为您服务。
• 我们公司有37249个人。
• 我出生于2005年10月8日。
• 我们习惯在12:30吃中午饭。
• 只要有超过3/4的人投票同意,你就会成为我们的新班长。
• 我要买一只价值999.9元的手表。
• 我的手机号是18544139121,欢迎来电。
• 明天有62%的概率降雨。
• 手表厂有五种好产品。
• 跑马场有五百匹很勇敢的千里马。
• 有一天,我看到了一栋楼,我顿感不妙,因为我看不清里面有没有人。
• 史小姐拿着小雨伞去找她的老保姆了。
• 不要相信这个老奶奶说的话,她一点儿也不好。
123

Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies: System Demonstrations, pages 124 - 130
July 10-15, 2022 ©2022 Association for Computational Linguistics
DadmaTools: a Natural Language Processing Toolkitfor the Persian Language
Romina Etezadi, Mohammad Karrabi, Najmeh Zare Maduyieh,Mohammad Bagher Sajadi, and Mohammad Taher Pilehvar
Dadmatech, Tehran, Iranroetezadi,karrabi,n zare,[email protected]
Abstract
We introduce DadmaTools, an open-sourcePython Natural Language Processing toolkitfor the Persian language. The toolkit is a neu-ral pipeline based on spaCy for several textprocessing tasks, including normalization, to-kenization, lemmatization, part-of-speech, de-pendency parsing, constituency parsing, chunk-ing, and ezafe detecting. DadmaTools relieson fine-tuning of ParsBERT using the PerDTdataset for most of the tasks. Dataset moduleand embedding module are included in Dad-maTools that support different Persian datasets,embeddings, and commonly used functions forthem. Our evaluations show that DadmaToolscan attain state-of-the-art performance on mul-tiple NLP tasks. The source code is freely avail-able at https://github.com/Dadmatech/DadmaTools.
1 Introduction
With the increased accessibility of open-source nat-ural language processing toolkits, users are nowable to more easily develop tools that perform so-phisticated linguistic tasks. There are several Per-sian NLP toolkits, such as Stanza (Qi et al., 2020),Hazm1, Parsivar2, and jPTDP (Nguyen and Ver-spoor, 2018). However, they suffer from severallimitations. First, most Persian toolkits are basedon conventional non-neural models which preventsthem from taking full advantage of the recent de-velopments in the filed. Examples include Parsi-var (Mohtaj et al., 2018), STeP1 (Shamsfard et al.,2010), Virastar3, Virastyar4, and ParsiAnalyzer5.
1https://github.com/sobhe/hazm2https://github.com/ICTRC/Parsivar3https://github.com/aziz/virastar4https://github.com/alishakiba/
virastyar5https://github.com/NarimanN2/
ParsiAnalyzer
Second, most Persian toolkits either do not coverall the basic processing tools (e.g., Perstem6 andfarsiNLPTools) or are not open-source (e.g., Farsi-Yar7). Third, there is no single toolkit that providesstate-of-the-art results across different basic tasks.Table 1 lists the toolkits available for Persian NLPalong with their task coverage.
We introduce DadmaTools, an open-sourcePython Natural Language Processing toolkit forPersian. DadmaTools provides the following ad-vantages compared to existing toolkits:
• Using the DadmaTools framework, users caneasily download various standard Persiandatasets and perform a variety of operationson them.
• Several pre-trained static word embeddingsexits for the Persian language. Many of theseembeddings are integrated in the DadmaToolstoolkit.
• We evaluated DadmaTools on different Per-sian datasets, reporting state-of-the-art orcompetitive performance at each step of thepipeline.
Moreover, DadmaTools is based on the spaCyframework which allows users to integrate ourtoolkit with other piplelines implemented in spaCy.We note that Stanza is a widely used Persian toolkit.Hence, we mainly compare DadmaTools to Stanza.Many of the standard tasks, such as constituencyparsing, chunking, and ezafe detection8, are notsupported by Stanza for Persian. In addition to cov-ering these tasks, our toolkit also provides supportfor datasets and word embeddings. DadmaTools is
6https://github.com/jonsafari/perstem7https://www.text-mining.ir/8Ezafe is a grammatical particle in Pesrsian language that
links two words together
124

Toolkit Normalizer Lemma POS dependency Constintuency Chunker Ezafe
Stanza
spaCy
Hazm
farsiNLPTools (Feely et al., 2014)
Perstem
persianp Toolbox
UM-wtlab pos tagger
RDRPOSTagger
jPTDP
Parsivar
text mining
DadmaTools
Table 1: Persian NLP toolkits and the corresponding tasks they support.
fully open-source. We hope it can facilitate NLPresearch and application for the Persian language.
2 System Design
DadmaTools is a neural NLP pipeline, but it alsoincludes modules for embeddings and datasets. Inthis section, we first describe these modules, fol-lowed by the main pipeline.
2.1 Dataset Module
Popular text processing libraries such as Transform-ers9, NLTK (Bird and Loper, 2004), and PyTorch-text have poor support for low-resource languagedatasets such as Persian. The dataset module ofDadmaTools provides a convenient solution for au-tomatic downloading and utilizing of some popularPersian NLP datasets. Each available dataset can becalled by a function of the same name and loadedas a generator object. For instance, the Arman(Poostchi et al., 2018) dataset can be loaded withthe following lines of code:
import dadmatools
# load datasetarman = dadmatools.datasets.ARMAN()
# working with datasetlen_train = len(arman.train)test_sample = next(arman.test)
DadmaTools allows users to load differentsets (e.g., train, test, or dev), if there areany, by using the <DATASET>.<SET> for-mat (e.g., arman.train). Moreover, thedetails of the selected dataset can be viewedby using <DATASET>.info. DadmaTools
9https://github.com/huggingface/transformers
comes with a set containing the most commonlyused Persian datasets for various tasks, suchas text summarization, named entity recogni-tion (NER), spell checking, textual entailment,text classification, sentiment classification, texttranslation, and universal dependency. Thereis also a search operation in DadmaTools forfinding datasets that belong to specific tasksby using get all datasets info(tasks=[’<task1>’, ’<task2>’,...]). The listof datasets that are currently included in Dadma-Tools is shown in Table 2. We will keep integratingnew datasets to the toolkit.
2.2 Embedding Module
One of the challenges in developing NLP tools forthe Persian language is the lack of a library to sup-port different pre-trained embedding models. Inorder to overcome this challenge, we have devel-oped an embedding module in DadmaTools whichprovides a variety of public Persian embeddings.For any given embedding space, an object is cre-ated which provides a wide range of functions.
# download and load embeddingem_name = ’glove-wiki’embedding = get_embedding(em_name)
# word embeddingvec = embedding(<your_word>)
# sentence embeddingtext = <your_text>t_vec = embedding.embedding_text(text)
# embedding functionsw1 = <word_1>w2 = <word_2>similarity_rateembedding.similarity(w1,w2)top = embedding.top_nearest(10, w1)
125

Dataset Task
PersianNER8 NERARMAN (Poostchi et al., 2018) NERPEYMA (Shahshahani et al., 2018) NERFarsTail (Amirkhani et al., 2020) Textual EntailmentFaSpell9 Spell CheckingPersianNews (Farahani et al., 2020) Text ClassificationPerDT Universal DependencyPnSummary (Farahani et al., 2021) Text SummarizationSnappfoodSentiment (Farahani et al., 2020) Sentiment ClassificationTEP (Pilevar et al., 2011) Text Translation(eng-fa)WikipediaCorpus CorpusPersianTweets (Khojasteh et al., 2020) Corpus
Table 2: Persian Datasets that are currently integrated in the DadmaTools toolkit.
The details of the correspond-ing embeddings can be shown withget embedding info(<EMBEDDING>).Several functions are present in DadmaTools thatcan be used for word embeddings, such as findingtop nearest neighbours, finding similarity scoresbetween two given words, or getting sentenceembedding of a text. Word embeddings that arecurrently included in DadmaTools are listed inTable 3. Similarly to the datasets module, wewill keep updating the list when new embeddingmodels are available.
2.3 NLP Pipeline
The pipeline consists of models that range fromtokenizing raw text to performing syntactic parsingand high-level task such as NER. The artchitec-ture of models employed in DadmaTools is mostlybased on Stanza (Qi et al., 2020) and ACE (Wanget al., 2021).
Normalization. Each sentence can be passed to anormalizer so that different optional procedures canbe applied to it, such as whitespace correction, char-acter unification, stopwords/punctuations removal,and email/number/URL replacement. As different
8https://github.com/Text-Mining/Persian-NER
9https://lindat.mff.cuni.cz/repository/xmlui/handle/11372/LRT-1547
10https://github.com/Text-Mining/Persian-Wikipedia-Corpus/tree/master/models/glove
11https://fasttext.cc/docs/en/crawl-vectors.html
12http://vectors.nlpl.eu/repository/13https://commoncrawl.org/
settings can be used, this task can be used indepen-dently of the pipeline. However, the pipeline uses adefault normalizer, which only corrects whitespaceand unifies the character.
Tokenization, Sentence Splitting, and MWT.As for tokenization and sentence splitting, Dad-maTools uses a similar seq2seq architecture to thatof Stanza trained on the PerDT dataset.
The tokenizer also identifies whether or not atoken is a multi-word token (MWT). Once a wordis detected as an MWT, the word is expanded intothe underlying syntactic subwords using the MWTExpander.
Lemmatization. Lemmatization is the task ofconverting the input word to its canonical form.For this purpose, we also utilize the seq2seq modelpresented in the Stanza for lemmatization. How-ever, we manually validate the training dataset andremove wrong or empty instances which results ina better performance (cf. Table 5).
Part of Speech Tagging. For each word in agiven input text DadmaTools assign a POS tag. Topredict the POS tag, we used the ACE model basedon ParsBERT pre-trained model (Mehrdad Fara-hani, 2021) fine-tunned on the PerDT dataset forthe sequence labeling task.
Dependency Parsing. Similarly to POS tagging,our dependency parsing module is based on theACE model. In this case, we fine-tuned ParsBERTfor dependency parsing on the PerDT dataset.
Constituency Parsing. A constituency parse treebreaks a text into sub-phrases. Non-terminals in
126

Embedding Model Training corpus
glove-wiki10 GloVe Wikipediafasttext-commoncrawl-bin11 FastText CommonCrawl12
fasttext-commoncrawl-vec11 FastText CommonCrawlword2vec-conll13 word2vec Persian CoNLL17 corpus
Table 3: Persian word embeddings currently supported by DadmaTools.
Dataset # of Instances Lemma POS Tags Dependency Tags Constituency parses
Seraji 6,000
PerDT (Rasooli et al., 2020) 29,107
Bijankhan 83,991
Dorsa Treebank (Dehghan et al., 2018) 30,000
Table 4: Persian datasets that are currently included in the toolkit.
the tree are types of phrases, the terminals are thewords in the sentence, and the edges are unlabeled.To construct the constituency parser, we used theSupar library CRFConstituencyParser14 using theconstituency dataset provided by Dorsa Treebank(Dehghan et al., 2018). It is worth mentioning thatthe output parse tree tags are different from the tagsproduced by the POS tagger.
Chunking. Chunking is the process of separatingand segmenting a sentence into its sub constituents,such as nouns, verbs, etc. We implemented a rule-based chunker. The rules have been written basedon words, POS tags, and Dependency tags. Thechunking module functions based on around sixtyrules.
Ezafe Detecting. Ezafe is a grammatical particlein Pesrsian language that links two words together.Ezafe carries valuable information about the gram-matical structure of sentences. However, it is notexplicitly written in Persian scripts. To create amodel to detect ezafe we used the Bijankhan cor-pus, as it includes ezafe as one of its POS tags.Therefore, we trained the sequence labeling model,ParsBERT, on reprocessed Bijankhan corpus fordetecting the ezafe.
3 System Usage
It is possible to use the Normalizer directly with-out triggering the pipeline using the normalizerclass. The DadmaTools pipline can be also initial-ized with pipline class. By default, only thetokenizer with sentence splitting and MWT are
14https://parser.yzhang.site/en/latest/parsers/const.html
loaded. However, it is possible to load custom pro-cessors by adding their names as arguments. Thepipeline will generate a Doc instance, whichcontains all the raw text’s properties regarding theprocesses that have been called, in the form of thespaCy Doc. The following code snippet shows aminimal usage example of DadmaTools.
import datamatools.pipeline as pipe
# pipes gets the models e.g.# pips = ’lem’ will only contain# lemmatizer in pupelinepips = ’lem,pos,dep,cons’nlp = pipe.language.Pipeline(pips)
# you can see the pipeline# with this codeinfo = nlp.analyze_pipes(pretty=True)print(info)# doc is an SpaCy pbjectdoc = nlp(<your_text>)
DadmaTools is designed to run on different typesof hardware (CUDA and CPU). Priority is given toCUDA devices, if available.
4 Training Datasets
There are multiple Persian datasets that providetraining data for various NLP tasks. Table 4 pro-vides details about some of these dataset. We exper-imented with these datasets, both in isolation andwhen combined. Taking these results as our basis,we chose the best models as default for Dadma-Tools. The merging of different datasets for POStags and dependencies was carefully evaluated bylinguists.
• Seraji. This dataset has 6K instances. Ourmanual validation revealed noisy lemmas in
127

ToolkitSeraji PerDT PerDT + Seraji
Dependency POS Lemm. Dependency POS Lemm. Dependency POS Lemm.Stanza 87.20 / 83.89 97.43 93.34 / 91.05 97.35 98.97 84.95 / 80.55 88.53 96.92jPTDP – / 84.07 96.66 – – – –Hazm – – 86.93 – – 89.01 – – 87.95DadmaTools 92.5 / 89.23 97.83 – 95.36 / 92.54 97.52 99.14 92.3 / 88.79 96.15 97.86
Table 5: F1 score percentage for various models on different Persian datasets. For dependency we report two scores,for UAS (Unlabeled Attachment Score) and LAS (Labeled Attachment Score), as UAS/LAS.
the dataset which might be due to its auto-matic construction procedure.
• PerDT. This dataset has almost 30K instances.Thanks to its manual curation by linguists, thedataset is relatively free of annotation errorsand mistakes.
• PerDT + Seraji. Combining these twodatasets was challenging in the case of de-pendency parsing and POS tagging. We triedto unify tags based on some rules. However,the dataset was not fully unified. Therefore,we did not train the final DadmaTools modelbased on this combination.
• Bijankhan. This dataset has almost 80Kinstances. The tokenized sentences in thisdataset is completely different from the pre-vious ones. However, it has the ezafe tage inits tagset which we used for training the ezafedetection.
• Dorsa Treebank. This dataset is a Persianconstituency treebank. The treebank was de-veloped by using a bootstrapping approachwhich converts a dependency structure tree toa phrase structure tree. The annotations arethen manually verified. The treebank consistsof approximately 30,000 sentences.
5 Experiments
Models presented in Table 5 are separately trainedon Seraji, PerDT, and combination of both. Theevaluations are carried out on corresponding testsets of each dataset. We carried out a set of experi-ments to compare DadmaTools with other populartoolkits. We opted for Stanza as our main competi-tor, given that it is the most widely used toolkit forthe Persian language. We were limited to compareour toolkit only with those models that were trainedon the same datasets (or had public source codes al-lowing us to train and test on specific datasets). It is
worth mentioning that the final models (lemmatizer,POS tagger, and dependacny parser) presented inDadmaTools is based on the PerDT dataset only.
Lemmatizer. We compare DadmaTools againstStanza and hazm on the lemmatization task. Asshown in Table 5, DadmaTools outperforms theother two tools.
POS Tagger. For this experiment, we comparedDadmaTools against Stanza given that both modelsuse the same dataset for their training. As shownin Table 5, DadmaTools achieved a better result inpredicting the universal tags.
Dependency Parser. Similarly to the previoussetting, Stanza is our main baseline for dependencyparsing, given their training on the same dataset. Asshown in Table 5, DadmaTools outperforms Stanza(+1.5% for LAS and +2% in UAS) in predictingthe universal tags.
Constituency Parser. To train the constituencyparser model we used the Dorsa Treebank. Onefifth of the treebank was split for testing and theF-score percentage on the test dataset was 82.88.There is no other similar constituency parser modelto compare the results with.
Chunker. Our chunker is rule-based model thatemploys nearly eighty rules. There is no golddataset in the Persian language that would allow usto evaluate the chunking module.
5.1 Speed
In order to test the speed of DadmaTools, we com-bined PerDT and Seraji (PerDT + Seraji) to have alarge dataset which would allow us to draw reliableconclusions. Table 6 shows the average run timeof models on PerDT + Seraji, computed based onrunning the models on GPU. Hazm is faster forPOS tagging and lemmatizing due to its rule-basednature (as opposed to our neural model).
128

Toolkit Dependency parser POS tagger LemmatizerStanza 0.065 0.051 0.032Hazm 2.404 0.001 0.000DadmaTools 0.027 0.029 0.038
Table 6: Average run time (in seconds) per instance in the PerDT test set, using an Nvidia GeForce RTX 3090 GPU.
6 Conclusion and Future Work
We introduced DadmaTools, an open-sourcePython Natural Language Processing toolkit forthe Persian language. DadmaTools supports dif-ferent NLP tasks. Moreover, it is based on thespaCy framework which allows users to integratethe toolkit with other processors in a pipeline. Asfuture work, we intend to extend the supportedtasks by adding high-level NLP tasks, such as senti-ment analysis, entailment, and summarization. Wealso plan to provide users with the ability to addnew datasets and models to the toolkit. We hopethat the toolkit can pave the way for research anddevelopment for the Persian language.
ReferencesHossein Amirkhani, Mohammad AzariJafari, Zohreh
Pourjafari, Soroush Faridan-Jahromi, ZeinabKouhkan, and Azadeh Amirak. 2020. FarsTail: APersian Natural Language Inference Dataset. arXivpreprint arXiv:2009.08820.
Steven Bird and Edward Loper. 2004. NLTK: The natu-ral language toolkit. In Proceedings of the ACL In-teractive Poster and Demonstration Sessions, pages214–217, Barcelona, Spain. Association for Compu-tational Linguistics.
Mohammad Hossein Dehghan, Mohammad Molla-Abbasi, and Heshaam Faili. 2018. Toward a multi-representation persian treebank. In 2018 9th Inter-national Symposium on Telecommunications (IST),pages 581–586. IEEE.
Mehrdad Farahani, Mohammad Gharachorloo, MarziehFarahani, and Mohammad Manthouri. 2020. Pars-BERT: Transformer-based model for persian lan-guage understanding. ArXiv, abs/2005.12515.
Mehrdad Farahani, Mohammad Gharachorloo, andM. Manthouri. 2021. Leveraging ParsBERT and pre-trained mT5 for persian abstractive text summariza-tion. 2021 26th International Computer Conference,Computer Society of Iran (CSICC), pages 1–6.
Weston Feely, Mehdi Manshadi, Robert Frederking, andLori Levin. 2014. The cmu metal farsi nlp approach.In Proceedings of the Ninth International Conferenceon Language Resources and Evaluation (LREC’14),pages 4052–4055.
Hadi Abdi Khojasteh, Ebrahim Ansari, and MahdiBohlouli. 2020. LSCP: Enhanced large scale collo-quial persian language understanding. arXiv preprintarXiv:2003.06499.
Marzieh Farahani Mohammad ManthouriMehrdad Farahani, Mohammad Gharachorloo.2021. Parsbert: Transformer-based model forpersian language understanding. Neural ProcessingLetters.
Salar Mohtaj, Behnam Roshanfekr, Atefeh Zafarian,and Habibollah Asghari. 2018. Parsivar: A languageprocessing toolkit for persian. In Proceedings ofthe Eleventh International Conference on LanguageResources and Evaluation (LREC 2018).
Dat Quoc Nguyen and Karin Verspoor. 2018. An im-proved neural network model for joint POS taggingand dependency parsing. In Proceedings of theCoNLL 2018 Shared Task: Multilingual Parsing fromRaw Text to Universal Dependencies, pages 81–91,Brussels, Belgium. Association for ComputationalLinguistics.
Mohammad Taher Pilevar, Heshaam Faili, and Ab-dol Hamid Pilevar. 2011. Tep: Tehran english-persian parallel corpus. In International Conferenceon Intelligent Text Processing and ComputationalLinguistics, pages 68–79. Springer.
Hanieh Poostchi, Ehsan Zare Borzeshi, and MassimoPiccardi. 2018. BiLSTM-CRF for persian named-entity recognition ArmanPersoNERCorpus: the firstentity-annotated persian dataset. In LREC.
Peng Qi, Yuhao Zhang, Yuhui Zhang, Jason Bolton, andChristopher D. Manning. 2020. Stanza: A Pythonnatural language processing toolkit for many humanlanguages. In Proceedings of the 58th Annual Meet-ing of the Association for Computational Linguistics:System Demonstrations.
Mohammad Sadegh Rasooli, Pegah Safari, AmirsaeidMoloodi, and Alireza Nourian. 2020. The persiandependency treebank made universal. arXiv preprintarXiv:2009.10205.
Mahsa Sadat Shahshahani, Mahdi Mohseni, AzadehShakery, and Heshaam Faili. 2018. PEYMA: Atagged corpus for persian named entities. arXivpreprint arXiv:1801.09936.
Mehrnoush Shamsfard, Hoda Sadat Jafari, and MahdiIlbeygi. 2010. STeP-1: A set of fundamental toolsfor persian text processing. In LREC.
129

Xinyu Wang, Yong Jiang, Nguyen Bach, Tao Wang,Zhongqiang Huang, Fei Huang, and Kewei Tu. 2021.Automated Concatenation of Embeddings for Struc-tured Prediction. In the Joint Conference of the59th Annual Meeting of the Association for Compu-tational Linguistics and the 11th International JointConference on Natural Language Processing (ACL-IJCNLP 2021). Association for Computational Lin-guistics.
130

Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies: System Demonstrations, pages 131 - 139
July 10-15, 2022 ©2022 Association for Computational Linguistics
FAMIE: A Fast Active Learning Framework for Multilingual InformationExtraction
Minh Van Nguyen1, Nghia Trung Ngo1, Bonan Min2, and Thien Huu Nguyen1
1 Dept. of Computer and Information Science, University of Oregon, Eugene, OR, USA2 Raytheon BBN Technologies, USA
minhnv@cs,nghian@,[email protected],[email protected]
Abstract
This paper presents FAMIE, a comprehensiveand efficient active learning (AL) toolkit formultilingual information extraction. FAMIE isdesigned to address a fundamental problem inexisting AL frameworks where annotators needto wait for a long time between annotationbatches due to the time-consuming nature ofmodel training and data selection at each ALiteration. This hinders the engagement, produc-tivity, and efficiency of annotators. Based onthe idea of using a small proxy network for fastdata selection, we introduce a novel knowledgedistillation mechanism to synchronize theproxy network with the main large model (i.e.,BERT-based) to ensure the appropriatenessof the selected annotation examples forthe main model. Our AL framework cansupport multiple languages. The experimentsdemonstrate the advantages of FAMIE in termsof competitive performance and time efficiencyfor sequence labeling with AL. We publiclyrelease our code (https://github.com/nlp-uoregon/famie) and demo website(http://nlp.uoregon.edu:9000/).A demo video for FAMIE is provided at:https://youtu.be/I2i8n_jAyrY.
1 Introduction
Information Extraction (IE) systems provide im-portant tools to extract structured information fromtext (Li et al., 2014; Nguyen and Nguyen, 2019;Lai et al., 2021; Veyseh et al., 2021; Nguyen et al.,2021a). At the core of IE involves sequence la-beling tasks that aim to recognize word spans andsemantic types for some objects of interest (e.g., en-tities and events) in text. For example, two typicalsequence labeling tasks in IE feature Named En-tity Recognition (NER) to find names of entities ofinterest, and Event Detection (ED) to identify trig-gers of specified event types (Walker et al., 2006).Despite extensive research effort for sequence la-beling (Lafferty et al., 2001; Ma and Hovy, 2016;
Pouran Ben Veyseh et al., 2021b), a major bottle-neck of existing IE methods involves the require-ment for large-scale human-annotated data to buildhigh-quality models. As annotating data is oftenexpensive and time-consuming, large-scale labeleddata is not practical for various domains and lan-guages.
To address the annotation cost for IE, previ-ous work has resorted to active learning (AL) ap-proaches (Settles and Craven, 2008; Settles, 2009)where only a selective set of examples are anno-tated to minimize the annotation effort while max-imizing the performance. Starting with a set ofunlabeled data, AL methods train and improve a se-quence labeling model via multiple human-modelcollaboration iterations. At each iteration, threemajor steps are performed in order: (i) training themodel on the current labeled data, (ii) using thetrained model to select the most informative ex-amples in the current unlabeled set for annotation,and (iii) presenting the selected examples to hu-man annotators to obtain labels. In AL, the numberof annotated samples or annotation time might belimited by a budget to make it realistic.
Unfortunately, despite much potentials, existingAL methods and frameworks are still not appliedwidely in practice due to their main focus on devis-ing the most effective example selection algorithmfor human annotation, e.g., based on the diversityof the examples (Shen et al., 2017; Yuan et al.,2020) and/or the uncertainty of the models (Rothand Small, 2006; Wang and Shang, 2014; Shel-manov et al., 2021). Training and selection time inthe first and second steps of each AL interactionis thus not considered in prior work for sequencelabeling. This is a critical issue that limits the ap-plication of AL: annotators might need to wait fora long period between annotation batches due tothe long training and selection time of the modelsat each AL iteration. Given the widespread trendof using large-scale pre-trained language models
131

(e.g., BERT), this problem of long waiting or train-ing/selection time in AL can only become worse.On the one hand, the long idle time of annotatorsreduces the number of annotated examples givenan annotation budget. Further, the engagement ofannotators in the annotation process can drop sig-nificantly due to the long interruptions betweenannotation rounds, potentially affecting the qual-ity of their produced annotation. In all, currentAL frameworks are unable to optimize the avail-able time of annotators to maximize the annotationquantity and quality for satisfactory performance.
To this end, we demonstrate a novel AL frame-work (called FAMIE) that leverages large-scale pre-trained language models for sequence labeling toachieve optimal modeling capacity while signifi-cantly reducing the waiting time between annota-tion rounds to optimize annotator time. Instead oftraining the full/main large-scale model for data se-lection at each AL iteration, our key idea is to trainonly a small proxy model on the current labeleddata to recommend new examples for annotationin the next round. In this way, the training anddata selection time can be reduced significantly toenhance annotation engagement and quality. Animportant issue in this idea is to ensure that theexamples selected by the proxy model are also op-timal for the main large model. To this end, weintroduce a novel knowledge distillation mecha-nism for AL that encourages the synchronizationbetween the proxy and main models, and promotesthe fitness of selected examples for the main model.To update the main model with new annotated datafor effective distillation, we propose to train themain large model on current labeled data duringthe annotation time, thus not adding to the wait-ing time of annotators between annotation rounds.This is in contrast to previous AL frameworks thatleave the computing resources unused during an-notation time. Our approach can thus efficientlyexploit both human and computer time for AL.
To evaluate the proposed AL framework FAMIE,we conduct experiments for multilingual sequencelabeling problems, covering two important IE tasks(i.e., NER and ED) in three languages (i.e., English,Spanish, and Chinese). The experiments demon-strate the efficiency and effectiveness of FAMIEthat can achieve strong performance with signif-icantly less human-computer collaboration time.Compared to existing AL systems such as Ac-tiveAnno (Wiechmann et al., 2021) and Paladin
(Nghiem et al., 2021), our system FAMIE featuresimportant advantages. First, FAMIE introduces anovel approach to reduce model training and dataselection time for AL via a small proxy modeland knowledge distillation while still benefitingfrom the advances in large-scale language mod-els. Second, while previous AL systems only focuson some specific task in English, FAMIE can sup-port different sequence labeling tasks in multiplelanguages due to the integration of our prior mul-tilingual toolkit Trankit (Nguyen et al., 2021b) toperform fundamental NLP tasks in 56 languages.Third, in contrast to previous AL systems that onlyimplement one data selection algorithm, FAMIEcovers a diverse set of AL algorithms. Finally,FAMIE is the first complete AL system that allowsusers to define their sequence labeling problems,work with the models to annotate data, and eventu-ally obtain a ready-to-use model for deployment.
2 System Description
In AL, we are given two initial datasets, a smallseed set of labeled examplesD0 = (w, y) and anunlabeled example set U0 = w (the seed set D0
is optional and our system can work directly withonly U0). For sequence labeling, models consumea sequence of K words w = [w1, w2, . . . , wK ](i.e., a sentence/example) to output a tag sequencey = [y1, y2, . . . , yK ] (yi is the label tag for wi).The tag sequence is represented in the BIO schemeto capture spans and types of objects of interest.
A typical AL process contains multiplerounds/iterations of model training, data selection,and human annotation in a sequential manner. LetD and U be the overall labeled and unlabeled setof examples at the beginning of the current t-th it-eration (initialized with D0 and U0). At the currentiteration, a sequence labeling model is first trainedon the current labeled set D. A sample selection al-gorithm then employs the trained model to suggestthe most informative subset of examples U t in U(i.e., U t ⊂ U ) for annotation. Afterwards, a humanannotator will provide labels for the sentences inthe selected set U t, leading to the labeled examplesDt for U t. The labeled and unlabeled sets can thenbe updated via: D ← D ∪Dt and U ← U \ U t.
2.1 Model
We employ the typical Transformer-CRF archi-tecture for sequence labeling (Nguyen et al.,2021b). In particular, given the input sentence
132

Figure 1: The overall Proxy Active Learning process.
w = [w1, w2, . . . , wK ], the state-of-the-art mul-tilingual language model XLM-Roberta (Conneauet al., 2020) is used to obtain contextualized em-beddings for the words: X = x1, . . . , xK =XLMR(w1, . . . , wK) (i.e., to support multiple lan-guages). Afterwards, the word embeddings aresent to a feed-forward network with softmax in theend to obtain the score vectors: zi = softmax(hi)where hi = FFN(xi). Here, each value inzi represents a score for a tag in the tag setV . The score vectors are then fed into a Con-ditional Random Field (CRF) layer to computea distribution for possible tag sequences for w:P (y|w) = exp(s(y,w))∑
y′∈Y (w) exp(s(y′,w))where Y (w) is the
set of all possible tag sequences for w. Also,s(y,w) is the score for a tag sequence y =[y1, . . . , yK ]: s(y,w) =
∑i zi[yi] +
∑i πyi→yi+1
.Here, πyi→yi+1
is the transition score from thetag yi to the tag yi+1. The model is trained byminimizing the negative log likelihood: Ltask =− logP (y|w). For inference, the Viterbi algorithmis used for decoding: y∗ = maxy′P (y
′|w).
Adapter-based Finetuning To further improvethe memory and time efficiency, we incorporatelight-weight adapter networks (Houlsby et al.,2019; Peters et al., 2019) into our model. In form ofsmall feed-forward networks, adapters are injectedin between the transformer layers of XLM-Roberta.For training, we only update the adapters whilethe parameters of XLM-Roberta are fixed. Thissignificantly reduces the amount of learning param-eters while sacrificing minimal extraction loss, orin case of low-resource learning even surpassingperformance of fully fine-tuned models.
2.2 Data Selection Strategies
To improve the flexibility to accommodate differ-ent problems, our AL framework supports a wide
range of data selection strategies for choosing thebest batch of examples to label at each iterationfor sequence labeling. These algorithms are cate-gorized into three groups, i.e., uncertainty-based,diversity-based, and hybrid. For each group, weexplore its most popular methods as follows.
Uncertainty-based. These methods select exam-ples for annotation according to the main model’sconfidence over the predicted tag sequences for un-labeled examples. Early methods sort the unlabeledexamples by the uncertainty of the main model.To avoid the preference over longer examples, themethod Maximum Normalized Log-Probability(MNLP) (Shen et al., 2017) proposes to normalizethe likelihood over example lengths. In particular,MNLP selects examples with the highest MNLPscores: MNLP (w) = −maxy′
1K logP (y′|w).
Diversity-based. Algorithms in this category as-sume that a representative set of examples can actas a good surrogate for the whole dataset. BERT-KM (Yuan et al., 2020) uses K-Means to clusterthe examples in unlabeled data based on the con-textualized embeddings of the sentences (i.e., therepresentations for the [CLS] tokens in the trainedBERT-based models). The nearest neighbors to theK cluster centers are then chosen for labeling.
Hybrid. Recently, several works have proposeddata selection strategies for BERT-based AL tobalance between uncertainty and diversity. TheBADGE method (Ash et al., 2019; Kim, 2020)chooses examples from clusters of gradient embed-dings, which are formed with the token represen-tations hi from the penultimate layer of the mainmodel and the gradients of the cross-entropy losswith respect to such token representations. The gra-dient embeddings are then sent to the K-Means++to find the initial K cluster centers that are distantfrom each other, serving as the selected examples(Kim, 2020).
In addition, we implement the AL frameworkALPS (Yuan et al., 2020) that does not requiretraining the main model for data section. ALPSemploys the surprisal embedding of w, which is ob-tained from the likelihoods of masked tokens frompre-trained language models (i.e., XLM-Roberta).The surprisal embeddings are also clustered to se-lect annotation examples as in BERT-KM.
133

2.3 Proxy Active Learning
As discussed in the introduction, model trainingand data selection at each iteration of traditionalAL methods might consume significant time (espe-cially with the current trend of large-scale languagemodels), thus introducing a long idle time for an-notators that might reduce annotation quality andquantity. To this end, (Shelmanov et al., 2021) haveexplored approaches to accelerate training and dataselection steps for AL by leveraging smaller andapproximate models during the AL iterations. Tomake it more efficient, the main large model isonly trained once in the end over all the annotatedexamples in AL. Unfortunately, this approach suf-fers from the mismatch between the approximateand main models as they are separately trained inAL, thus limiting the effectiveness of the selectedexamples for the main model (Lowell et al., 2019).
To overcome these issues, our AL frameworkFAMIE trains a small proxy network at each iter-ation to suggest new unlabeled samples. Dealingwith the mismatch between the proxy-selected ex-amples and the main model, FAMIE proposes toinvolve the main model in the training and dataselection for the proxy model. In particular, at eachAL iteration, the main model will still be trainedover the latest labeled data. However, to avoid theinterference of the main large model with the wait-ing time of annotators, we propose to train the mainmodel during the annotation time of the annotators(i.e., main model training and data annotation aredone in parallel). Given the main model trained atprevious iteration, knowledge distillation will beemployed to synchronize the knowledge betweenthe main and proxy models at the current iteration.
The complete framework for FAMIE is pre-sented in Figure 1. At iteration t, a proxy acquisi-tion model is trained on the current labeled data setDt−1
0 = D0 ∪D1 . . . ∪Dt−1. The trained proxymodel at the current step is called M t
prx. Also,we use knowledge distillation signals Kt−2
0 that iscomputed from the main model M t−1
main trained atthe previous iteration t−1 to synchronize the proxymodel M t
prx and the main model M t−1main (M1
prx istrained only on D0). Afterwards, a data selectionalgorithm is used to select a batch of examples U t
from the current unlabeled set U for annotation,leveraging the feedback from M t
prx. Next, a hu-man annotator will label U t to produce the labeleddata batch Dt for the next iteration t+ 1. Duringthis annotation time, the main model will also be
trained again over the current labeled data Dt−10 to
produce the current version M tmain of the model.
The distillation signal Kt−10 for the next step will
also be computed after the training of M tmain. This
process is repeated over multiple iterations and thelast version of Mmain will be returned for users.
To improve the fitness of the proxy-based se-lected examples for Mmain, we leverage the dis-tilled version miniLM of XLM-Roberta (Wanget al., 2021) that employs similar stacks of trans-former layers for the proxy model Mprx. Note thatMprx also includes a CRF layer on top of miniLM.
2.4 Uncertainty Distillation
Although the proxy and main model Mprx andMmain are trained on similar data, they might stillexhibit large mismatch, e.g., regarding decisionboundaries. This prompts a demand for regulariz-ing the proxy model’s predictions to be consistentwith those of a trained main model to improve thefitness of the selected examples forMmain. Ideally,we expect the tag sequence distribution Pprx(y|w)learned by the proxy model to mimic the tag se-quence distribution Pmain(y|w) learned by themain model. To this end, we propose to minimizethe difference between the intermediate outcomes(i.e., the unary and transition scores) of the two dis-tributions. In particular, we introduce the followingdistillation objective for each sentence w at one ALiteration: Ldist = −
∑i
∑v p
maini [v] log pprxi [v] +∑
i(πmainyi→yi+1
− πprxyi→yi+1)2 where pmain
i and pprxi
are the tag distributions computed by the main andproxy models respectively for the word wi ∈ w(i.e., the scores zi). Note that pmain
i and πmainyi→yi+1
serve as the knowledge distillation signal that isobtained once the main model finishes its train-ing at each iteration. Here, we will use the newlyselected examples for the current annotation tocompute the distillation signals. The overall ob-jective to train Mprx at each AL iteration is thus:L = Ltask + Ldist.
3 Usage
Detailed documentation for FaMIE is provided at:https://famie.readthedocs.io/. Thecodebase is written in Python and Javascript, whichcan be easily installed through PyPI at : https://pypi.org/project/famie/.Initialization. To initialize a project, users firstchoose a data selection strategy and upload a labelset to define a sequence labeling problem. Next,
134

0 5 10 15 20 250.70
0.75
0.80
0.85
0.90
F1 sc
ore
a) Performance comparison on CoNLL03-English
All DataMNLPALPSBADGEBertKMRandom
0 5 10 15 20 250
25
50
75
100
125
150
Min
utes
b) Time comparison on CoNLL03-EnglishAll DataMNLPALPSBADGEBertKMRandom
0 5 10 15 20 25Iterations
0.575
0.600
0.625
0.650
0.675
0.700
0.725
0.750
F1 sc
ore
c) Performance comparison on ACE-English
All DataMNLPALPSBADGEBertKMRandom
0 5 10 15 20 25Iterations
0
50
100
150
200
Min
utes
d) Time comparison on ACE-EnglishAll DataMNLPALPSBADGEBertKMRandom
Figure 2: Comparison among data selection strategies.
the dataset U with unlabeled sentences should besubmitted. FAMIE then allows users to interactwith the models and annotate data over multiplerounds with a web interface. Also, FAMIE can de-tect languages automatically for further processing.Annotating procedure. Given one annotationbatch in an iteration, annotators label one sentenceat a time as illustrated in Figure 3. In particular, theannotators annotate the word spans for each labelby first choosing the label and then highlightingthe appropriate spans. Also, FAMIE designs thesize of the annotation batches to allow enough timeto finish the training of the main model during theannotation time at each iteration.Output. Unlike previous AL toolkits which fo-cus only on their web interfaces to produce labeleddata, FAMIE provides a simple and intuitive codeinterface for interacting with the resulting labeleddataset and trained main models after the AL pro-cesses. The code snippet in Figure 4 presents aminimal usage of our famie Python package to usethe trained main model for inference over new data.This allows users to immediately evaluate theirmodels and annotation efforts on data of interest.
Figure 3: Annotation interface in FAMIE.
4 Evaluation
Datasets and Hyper-parameters. To compre-hensively evaluate our AL framework FAMIE,
import famie# access a project via its namep = famie.get_project('NewProject')# access the project's labeled datadata = p.get_labeled_data()
# access the project's trained target modelmodel = p.get_trained_model()# make predictions with the trained modeldoc = '''Nick is happy.'''output = model.predict(doc)print(output)# [('Nick', 'B-Person'), ('is', 'O'), ('happy', 'O'), ('. ', 'O')]
12345678910111213
Figure 4: Accessing the labeled dataset and the trained mainmodel returned by an AL project.
we conduct experiments on two IE tasks (i.e.,NER and ED) for three languages using fourdatasets: CoNLL03-English (Tjong Kim Sang andDe Meulder, 2003) and CoNLL02-Spanish (TjongKim Sang, 2002) for NER, and ACE-English andACE-Chinese for ED (i.e., using the multilingualACE-05 dataset (Walker et al., 2006; Nguyen andGrishman, 2015, 2018)). The CoNLL datasetscover 4 entity types while 33 event types are an-notated in ACE-05 datasets. We follow the stan-dard data splits for train/dev/test portions for eachdataset (Li et al., 2013; Lai et al., 2020; PouranBen Veyseh et al., 2021a).
For the main target model Mmain, the full-scaleXLM-Robertalarge model is used as the encoder.Our framework for AL thus inherits the ability ofXLM-Roberta to support more than 100 languages.Also, we employ the compact miniLM architecture(distilled from the pre-trained XLM-Roberta) forthe proxy model Mprx. In all experiments, themain model is trained for 40 epochs while the proxymodel is trained for 20 epochs at each iteration. Weuse the Adam optimizer with batch size of 16 andlearning rate of 1e-5 to train the models.
We follow the AL settings in previous work toachieve consistent evaluation (Kim, 2020; Shel-manov et al., 2021; Liu et al., 2022). Specifically,the unlabeled pool is created by discarding labelsfrom the original training data of each dataset; 2%of which (∼ 242 sentences) is selected for labelingat each iteration for a total of 25 iterations (exam-ples of the first iteration are randomly sampled toserve as the seed D0). The annotation is simulatedby recovering the ground-truth labels of the cor-responding instances. The model performance ismeasured on the test datasets by taking averageover 3 runs with different random seeds.
Comparing Data Selection Strategies. In thisexperiment, we aim to determine the best data se-lection strategy for our AL framework. To this end,we perform the standard AL process (i.e., trainingthe full transformer-CRF model with no adapters,
135

Idle CoNLL03-English CoNLL02-Spanish ACE-English ACE-Chinesemins/iter 10% 20% 30% 40% 50% 100% 10% 20% 30% 40% 50% 100% 10% 20% 30% 40% 50% 100% 10% 20% 30% 40% 50% 100%
Full Data x x x x x x 92.4 x x x x x 89.6 x x x x x 71.9 x x x x x 69.1Large 41.6 90.3 92.4 93.0 92.4 92.4 x 86.9 88.6 89.4 89.3 89.0 x 67.8 71.1 70.0 72.4 71.3 x 64.8 67.6 71.3 68.7 71.5 xFaMIE 3.4 90.1 91.7 91.8 91.7 92.7 x 86.5 88.2 88.5 88.1 89.4 x 67.0 69.3 69.5 68.9 70.6 x 61.3 67.9 68.5 69.8 69.6 xFaMIE-A 5.7 89.7 90.8 91.3 91.9 91.7 x 87.4 87.2 89.0 87.7 89.1 x 67.2 68.0 69.5 68.9 70.6 x 62.8 66.5 67.9 66.3 69.4 xFaMIE-AD 5.6 87.0 90.1 90.5 90.7 90.5 x 85.5 86.9 87.7 88.8 88.6 x 64.9 65.4 67.7 66.8 69.1 x 58.1 65.4 66.5 64.8 70.3 xRandom x 86.0 89.1 90.6 91.4 91.9 x 80.8 85.3 88.1 88.7 88.6 x 60.4 64.1 66.9 69.0 67.5 x 48.4 58.2 65.1 65.4 66.6 x
Table 1: Main model’s performance on multilingual NER and ED tasks. “Idle” indicate average waiting time of annotators.
selecting data, and annotating data at each itera-tion) for different data selection strategies to mea-sure performance and time. We focus on Englishdatasets in this experiment. Figure 2 reports theperformance across AL iterations of the model fordifferent data selection methods. As can be seen,“MNLP” is the overall best method for data selec-tion in AL. We will thus leverage MNLP as thedata section strategy for the evaluation of FAMIE.
Also, Figure 2 shows the annotators’ idle time(the combined time for model training and data se-lection) across iterations for each selection strategy.The major difference comes from ALPS that hassignificantly less waiting time than other methodsas it does not require model training. However,ALPS’s performance is considerably worse thanMNLP as a result, especially in early iterations.This demonstrates the importance of training andincluding the main model during the AL iterationsfor data section. Importantly, we find that the wait-ing time of annotators at each iteration is very highin current AL methods (e.g., more than 30 minutesafter the first 8 iterations with the MNLP strategy),thus affecting the annotators’ productivity.
Performance and Time Efficiency. To evaluatethe performance and time efficiency of FAMIE,Table 1 compares our full proposed frameworkFAMIE (with proxy model, knowledge distilla-tion, and adapters) with the following baselines: (i)“Large”: the best AL baseline from the previous ex-periment employing the full-scale transformer en-coder and MNLP for data selection; (ii) “Random”:this is the same as “Large”, but replaces MNLPwith random selection; (iii) “FAMIE-A”: this isthe proposed framework FAMIE without adapter-based tuning (all parameters from the main modelare fine-tuned); and (iv) “FAMIE-AD”: we fur-ther remove the knowledge distillation loss from“FAMIE-A” in this method. The experiments aredone for all four datasets of NER and ED.
The first observation is that FAMIE’s perfor-mance is only marginally below that of Large de-spite only using the small proxy network for dataselection. Importantly, annotators only have to waitfor about 3.4 minutes per AL iteration before they
can annotate the next data batch in FAMIE. This isover 10 times faster compared to the standard ALapproaches (e.g., in Large). Second, the adaptersin FAMIE not only boost the overall performancefor AL but also reduce the waiting time for annota-tors. Also, we note that using adapters, the trainingtime of Mmain only takes 32 minutes at each iter-ation (on average). This is reasonable to fit intothe time that an annotator needs to spend to labelan annotation batch at each AL iteration, thus ac-commodating our proposal for training the mainmodel during annotation time. Finally, FAMIE-ADperforms worst (i.e., similar or even worse thanRandom) in most cases, which confirms the neces-sity of our distillation component in FAMIE.
5 Related Work
Despite the potential of AL in reducing annota-tion cost for a target task, most previous AL workfocuses on developing data selection strategiesto maximize the model performance (Wang andShang, 2014; Sener and Savarese, 2017; Ash et al.,2019; Kim, 2020; Liu et al., 2022; Margatina et al.,2021). As such, previous AL methods and frame-works tend to ignore the necessary time to trainmodels and perform data selection at each AL iter-ation that can be significantly long and hinder an-notators’ productivity and model performance. Tomake AL frameworks practical, few recent workshave attempted to minimize the model training anddata selection time by leveraging simple and nonstate-of-the-art architectures as the main model,e.g., ActiveAnno (Wiechmann et al., 2021) andPaladin (Nghiem et al., 2021). However, an issuewith these approaches is the inability to exploit re-cent advances in large-scale language models toachieve optimal performance. In addition, some re-cent works have also explored large-scale languagemodels for AL (Shelmanov et al., 2021; Yuan et al.,2020); however, to reduce waiting time for anno-tators, such methods need to exclude the trainingof the large models in the AL iterations or employsmall models for data selection, thus suffering froma harmful mismatch between the annotated exam-ples and the main models (Lowell et al., 2019).
136

6 Conclusion
We introduce FAMIE, a comprehensive AL frame-work that supports model creation and data anno-tation for sequence labeling in multiple languages.FAMIE optimizes the annotators’ time by leverag-ing a small proxy network for data selection anda novel knowledge distillation to synchronize theproxy and main target models for AL. As FAMIEis task-agnostic, we plan to extend FAMIE to coverother NLP tasks in future work.
Acknowledgement
This research has been supported by the Army Re-search Office (ARO) grant W911NF-21-1-0112and the NSF grant CNS-1747798 to the IU-CRC Center for Big Learning. This research isalso based upon work supported by the Officeof the Director of National Intelligence (ODNI),Intelligence Advanced Research Projects Activ-ity (IARPA), via IARPA Contract No. 2019-19051600006 under the Better Extraction from TextTowards Enhanced Retrieval (BETTER) Program.The views and conclusions contained herein arethose of the authors and should not be interpretedas necessarily representing the official policies, ei-ther expressed or implied, of ARO, ODNI, IARPA,the Department of Defense, or the U.S. Govern-ment. The U.S. Government is authorized to re-produce and distribute reprints for governmentalpurposes notwithstanding any copyright annotationtherein. This document does not contain technol-ogy or technical data controlled under either theU.S. International Traffic in Arms Regulations orthe U.S. Export Administration Regulations.
ReferencesJordan T Ash, Chicheng Zhang, Akshay Krishnamurthy,
John Langford, and Alekh Agarwal. 2019. Deepbatch active learning by diverse, uncertain gradientlower bounds. arXiv preprint arXiv:1906.03671.
Alexis Conneau, Kartikay Khandelwal, Naman Goyal,Vishrav Chaudhary, Guillaume Wenzek, FranciscoGuzmán, Edouard Grave, Myle Ott, Luke Zettle-moyer, and Veselin Stoyanov. 2020. Unsupervisedcross-lingual representation learning at scale. In Pro-ceedings of the 58th Annual Meeting of the Asso-ciation for Computational Linguistics, pages 8440–8451, Online. Association for Computational Lin-guistics.
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski,Bruna Morrone, Quentin De Laroussilhe, Andrea
Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019.Parameter-efficient transfer learning for nlp. In Pro-ceedings of the International Conference on MachineLearning.
Yekyung Kim. 2020. Deep active learning for sequencelabeling based on diversity and uncertainty in gradi-ent. In Proceedings of the 2nd Workshop on Life-longLearning for Spoken Language Systems, pages 1–8,Suzhou, China. Association for Computational Lin-guistics.
John Lafferty, Andrew McCallum, and Fernando CNPereira. 2001. Conditional random fields: Proba-bilistic models for segmenting and labeling sequencedata.
Viet Dac Lai, Minh Van Nguyen, Thien Huu Nguyen,and Franck Dernoncourt. 2021. Graph learning reg-ularization and transfer learning for few-shot eventdetection. In Proceedings of the 44th InternationalACM SIGIR Conference on Research and Develop-ment in Information Retrieval, pages 2172–2176.
Viet Dac Lai, Tuan Ngo Nguyen, and Thien HuuNguyen. 2020. Event detection: Gate diversity andsyntactic importance scores for graph convolutionneural networks. In Proceedings of the 2020 Con-ference on Empirical Methods in Natural LanguageProcessing (EMNLP).
Qi Li, Heng Ji, Yu Hong, and Sujian Li. 2014. Con-structing information networks using one singlemodel. In Proceedings of the 2014 Conference onEmpirical Methods in Natural Language Processing.
Qi Li, Heng Ji, and Liang Huang. 2013. Joint eventextraction via structured prediction with global fea-tures. In Proceedings of the 51th Annual Meeting ofthe Association for Computational Linguistics.
Mingyi Liu, Zhiying Tu, Tong Zhang, Tonghua Su, Xi-aofei Xu, and Zhongjie Wang. 2022. Ltp: A newactive learning strategy for crf-based named entityrecognition. Neural Processing Letters, pages 1–22.
David Lowell, Zachary C. Lipton, and Byron C. Wal-lace. 2019. Practical obstacles to deploying activelearning. In Proceedings of the 2019 Conference onEmpirical Methods in Natural Language Processingand the 9th International Joint Conference on Natu-ral Language Processing (EMNLP-IJCNLP), pages21–30, Hong Kong, China. Association for Computa-tional Linguistics.
Xuezhe Ma and Eduard Hovy. 2016. End-to-end se-quence labeling via bi-directional lstm-cnns-crf. InProceedings of the 54th Annual Meeting of the Asso-ciation for Computational Linguistics.
Katerina Margatina, Giorgos Vernikos, Loïc Barrault,and Nikolaos Aletras. 2021. Active learning byacquiring contrastive examples. arXiv preprintarXiv:2109.03764.
137

Minh-Quoc Nghiem, Paul Baylis, and Sophia Anani-adou. 2021. Paladin: an annotation tool based onactive and proactive learning. In Proceedings ofthe 16th Conference of the European Chapter of theAssociation for Computational Linguistics: SystemDemonstrations, pages 238–243, Online. Associationfor Computational Linguistics.
Minh Van Nguyen, Viet Lai, and Thien Huu Nguyen.2021a. Cross-task instance representation interac-tions and label dependencies for joint informationextraction with graph convolutional networks. InProceedings of the 2021 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics: Human Language Technologies,pages 27–38, Online. Association for ComputationalLinguistics.
Minh Van Nguyen, Viet Dac Lai, Amir Pouran BenVeyseh, and Thien Huu Nguyen. 2021b. Trankit: Alight-weight transformer-based toolkit for multilin-gual natural language processing. In Proceedings ofthe 16th Conference of the European Chapter of theAssociation for Computational Linguistics: SystemDemonstrations.
Thien Huu Nguyen and Ralph Grishman. 2015. Eventdetection and domain adaptation with convolutionalneural networks. In The 53rd Annual Meeting ofthe Association for Computational Linguistics andthe 7th International Joint Conference on NaturalLanguage Processing.
Thien Huu Nguyen and Ralph Grishman. 2018. Graphconvolutional networks with argument-aware pool-ing for event detection. In Proceedings of the AAAIConference on Artificial Intelligence.
Trung Minh Nguyen and Thien Huu Nguyen. 2019. Onefor all: Neural joint modeling of entities and events.In Proceedings of the AAAI Conference on ArtificialIntelligence.
Matthew E Peters, Sebastian Ruder, and Noah A Smith.2019. To tune or not to tune? adapting pretrained rep-resentations to diverse tasks. In RepL4NLP@ACL.
Amir Pouran Ben Veyseh, Viet Lai, Franck Dernon-court, and Thien Huu Nguyen. 2021a. Unleash GPT-2 power for event detection. In Proceedings of the59th Annual Meeting of the Association for Compu-tational Linguistics and the 11th International JointConference on Natural Language Processing (Vol-ume 1: Long Papers).
Amir Pouran Ben Veyseh, Minh Van Nguyen, NghiaNgo Trung, Bonan Min, and Thien Huu Nguyen.2021b. Modeling document-level context for eventdetection via important context selection. In Proceed-ings of the 2021 Conference on Empirical Methodsin Natural Language Processing.
Dan Roth and Kevin Small. 2006. Margin-based activelearning for structured output spaces. In EuropeanConference on Machine Learning, pages 413–424.Springer.
Ozan Sener and Silvio Savarese. 2017. Active learn-ing for convolutional neural networks: A core-setapproach. arXiv preprint arXiv:1708.00489.
Burr Settles. 2009. Active learning literature survey.
Burr Settles and Mark Craven. 2008. An analysis ofactive learning strategies for sequence labeling tasks.In Proceedings of the 2008 Conference on Empiri-cal Methods in Natural Language Processing, pages1070–1079, Honolulu, Hawaii. Association for Com-putational Linguistics.
Artem Shelmanov, Dmitri Puzyrev, LyubovKupriyanova, Denis Belyakov, Daniil Larionov,Nikita Khromov, Olga Kozlova, Ekaterina Artemova,Dmitry V. Dylov, and Alexander Panchenko. 2021.Active learning for sequence tagging with deeppre-trained models and Bayesian uncertaintyestimates. In Proceedings of the 16th Conferenceof the European Chapter of the Association forComputational Linguistics: Main Volume, pages1698–1712, Online. Association for ComputationalLinguistics.
Yanyao Shen, Hyokun Yun, Zachary C Lipton, YakovKronrod, and Animashree Anandkumar. 2017. Deepactive learning for named entity recognition. arXivpreprint arXiv:1707.05928.
Erik F. Tjong Kim Sang. 2002. Introduction to theCoNLL-2002 shared task: Language-independentnamed entity recognition. In COLING-02: The 6thConference on Natural Language Learning 2002(CoNLL-2002).
Erik F. Tjong Kim Sang and Fien De Meulder.2003. Introduction to the CoNLL-2003 shared task:Language-independent named entity recognition. InProceedings of the Seventh Conference on NaturalLanguage Learning at HLT-NAACL 2003, pages 142–147.
Amir Pouran Ben Veyseh, Minh Van Nguyen, BonanMin, and Thien Huu Nguyen. 2021. Augmentingopen-domain event detection with synthetic data fromgpt-2. In Joint European Conference on MachineLearning and Knowledge Discovery in Databases,pages 644–660. Springer.
Christopher Walker, Stephanie Strassel, Julie Medero,and Kazuaki Maeda. 2006. Ace 2005 multilingualtraining corpus. In Technical report, Linguistic DataConsortium.
Dan Wang and Yi Shang. 2014. A new active labelingmethod for deep learning. In 2014 International jointconference on neural networks (IJCNN), pages 112–119. IEEE.
Wenhui Wang, Hangbo Bao, Shaohan Huang, Li Dong,and Furu Wei. 2021. MiniLMv2: Multi-head self-attention relation distillation for compressing pre-trained transformers. In Findings of the Associationfor Computational Linguistics: ACL-IJCNLP 2021,pages 2140–2151, Online. Association for Computa-tional Linguistics.
138

Max Wiechmann, Seid Muhie Yimam, and ChrisBiemann. 2021. ActiveAnno: General-purposedocument-level annotation tool with active learningintegration. In Proceedings of the 2021 Conferenceof the North American Chapter of the Association forComputational Linguistics: Human Language Tech-nologies: Demonstrations, pages 99–105, Online.Association for Computational Linguistics.
Michelle Yuan, Hsuan-Tien Lin, and Jordan Boyd-Graber. 2020. Cold-start active learning through self-supervised language modeling. In Proceedings of the2020 Conference on Empirical Methods in NaturalLanguage Processing (EMNLP), pages 7935–7948,Online. Association for Computational Linguistics.
139

Author Index
Adi, Yossi, 1Agirre, Eneko, 27Alecakir, Huseyin, 17
Bansal, Mohit, 54, 71Barbosa, George C.G., 64Bölücü, Necva, 17
Callison-Burch, Chris, 54Can, Burcu, 17Chang, Shih-Fu, 54Chen, Junkun, 114Chen, Xiaojie, 114Chen, Zeyu, 114Copet, Jade, 1
Deng, Yuqian, 90Ding, Hantian, 90Dror, Rotem, 54Du, Xinya, 54Dupoux, Emmanuel, 1
Edwards, Carl, 54Elkahky, Ali, 1Etezadi, Romina, 124
Fedorenko, Evelina, 99
Gong, Enlei, 114
Hahn-Powell, Gus, 64Han, Jiawei, 54Hannan, Darryl, 54Hsu, Wei-Ning, 1Hu, Xiaoguang, 114Hu, Yinuo, 71Huang, Liang, 114Huang, Yuxin, 114
Ji, Heng, 54Jiao, Yizhu, 54Jin, Xiaomeng, 54
Karrabi, Mohammad, 124Kazeminejad, Ghazaleh, 54Kharitonov, Eugene, 1Kim, Hyounghun, 54Kobza, Ondrej, 39
Konrád, Jakub, 39Kyjánek, Lukáš, 10
Lacalle, Oier Lopez De, 27Lai, Tuan, 54Lakhotia, Kushal, 1Lee, Ann, 1Lei, Jie, 54Li, Manling, 54Li, Sha, 54Li, Xintong, 114Lin, Xudong, 54Liu, Iris, 54Lorenc, Petr, 39Lyu, Qing, 54
Ma, Yanjun, 114Malandri, Lorenzo, 46Marek, Petr, 39Mercorio, Fabio, 46Mezzanzanica, Mario, 46Min, Bonan, 27, 131Mohamed, Abdelrahman, 1
Ngo, Nghia Trung, 131Nguyen, Minh Van, 131Nguyen, Thien Huu, 131Nguyen, Tu Anh, 1Nobani, Navid, 46Noriega-Atala, Enrique, 64
Palmer, Martha, 54Panter, Abigail, 71Pichl, Jan, 39Pilehvar, Mohammad Taher, 124
Qiu, Haoling, 27
Regan, Michael, 54Roth, Dan, 54, 90
Sainz, Oscar, 27Sajadi, Mohamad Bagher, 124Sathe, Aalok, 99Sathy, Viji, 71Seveso, Andrea, 46Shain, Cory, 99Sharp, Rebecca, 64
140

Surdeanu, Mihai, 64Šedivý, Jan, 39
Tomasello, Paden, 1Tuckute, Greta, 99
Vacareanu, Robert, 64Valenzuela-Escárcega, Marco A., 64Vondrick, Carl, 54
Wang, Haoyu, 54Wang, Hongwei, 54Wang, Mingye, 99Wang, Zhenhailong, 54Wang, Ziqi, 54Wen, Haoyang, 54
Yang, Jinrui, 90
Yoder, Harley, 99Yu, Charles, 54Yu, Dianhai, 114Yu, Pengfei, 54Yuan, Tian, 114
Zajícek, Tomáš, 39Zare, Najmeh, 124Zeng, Qi, 54Zhang, Hongming, 90Zhang, Hui, 114Zhang, Shiyue, 71Zhang, Zixuan, 54Zheng, Renjie, 114Zhou, Ben, 54
141




















