
Glossa: a Multilingual, Multimodal, Configurable User Interface
Upload
khangminh22Category
view
1download
0
Proceedings of the Sixth Conference on Machine Translation (WMT) pages 398ndash411November 10ndash11 2021 copy2021 Association for Computational Linguistics
398
MMTAfrica Multilingual Machine Translation for African Languages
Chris C EmezuelowastTechnical University of Munich
Mila Quebec AI Institutedagger
Masakhane
Bonaventure F P DossoulowastJacobs University BremenMila Quebec AI Institutedagger
Masakhane
AbstractIn this paper we focus on the task of mul-tilingual machine translation for African lan-guages and describe our contribution in the2021 WMT Shared Task Large-Scale Mul-tilingual Machine Translation We introduceMMTAfrica the first many-to-many multilin-gual translation system for six African lan-guages Fon (fon) Igbo (ibo) Kinyarwanda(kin) SwahiliKiswahili (swa) Xhosa (xho)and Yoruba (yor) and two non-African lan-guages English (eng) and French (fra) Formultilingual translation concerning Africanlanguages we introduce a novel backtransla-tion and reconstruction objective BTampRECinspired by the random online back trans-lation and T5 modelling framework respec-tively to effectively leverage monolingualdata Additionally we report improvementsfrom MMTAfrica over the FLORES 101benchmarks (spBLEU gains ranging from+058 in Swahili to French to +1946 inFrench to Xhosa)
In this paper we make use of the following nota-tions
bull ~ refers to any language in the seteng fra ibo fon swa kin xho yor
bull refers to any language in the seteng fra ibo fon
bull AL(s) refers to African language(s)
bull Xminusrarr Y refers to neural machine translationfrom language X to language Y
1 Introduction
Despite the progress of multilingual machine trans-lation (MMT) and the many efforts towards improv-ing its performance for low-resource languages
lowast_Authors contributed equally to this work Cor-respondence to chrisemezuegmailcom or femipan-cracedossougmailcom
dagger_Independent Research done while interning at Mila Que-bec AI Institute
African languages suffer from under-representationFor example of the 2000 known African lan-guages (Eberhard et al 2020) only 17 of themare available in the FLORES 101 Large-scaleMultilingual Translation Task as at the time ofthis research Furthermore most research thatlook into transfer learning of multlilingual mod-els from high-resource to low-resource languagesrarely work with ALs in the low-resource sce-nario While the consensus is that the outcomeof the research made using the low-resource non-African languages should be scalable to Africanlanguages this cross-lingual generalization is notguaranteed(Orife et al 2020) and the extent towhich it actually works remains largely under-studied Transfer learning from African languagesto African languages sharing the same languagesub-class has been shown to give better translationquality than from high-resource Anglo-centric lan-guages (Nyoni and Bassett 2021) calling for theneed to investigate ALlarrrarrAL multilingual trans-lation
This low representation of African languagesgoes beyond machine translation (Martinus andAbbott 2019 Joshi et al 2020 forall et al 2020)The analysis conducted by forall et al (2020) revealedthat low-resourcedness of African languages canbe traced to the poor incorporation of African lan-guages in the NLP research community (Joshi et al2020) All these call for the inclusion of moreAfrican languages in multilingual NLP researchand experiments
With the high linguistic diversity in Africa mul-tilingual machine translation systems are very im-portant for inter-cultural communication which isin turn necessary for peace and progress For ex-ample one widely growing initiative to curb thelarge gap in scientific research in Africa is to trans-late educational content and scientific papers tovarious African languages in order to reach farmore African native speakers (Abbott and Mart-
399
inus 2018 Nordling 2018 Wild 2021)We take a step towards addressing the under-
representation of African languages in MMT andimproving experiments by participating in the2021 WMT Shared Task Large-Scale Multilin-gual Machine Translation with a major target ofALslarrrarrALs In this paper we focused on 6African languages and 2 non-African languages(English and French) Table 1 gives an overview ofour focus African languages in terms of their lan-guage family number of speakers and the regionsin Africa where they are spoken (Adelani et al2021b) We chose these languages in an effort tocreate some language diversity the 6 African lan-guages span the most widely and least spoken lan-guages in Africa Additionally they have some sim-ilar as well as contrasting characteristics whichoffer interesting insights for future work in ALs
bull Igbo Yorugravebaacute and Fon use diacritics intheir language structure while KinyarwandaSwahili and Xhosa do not Various forms ofcode-mixing are prevalent in Igbo (Dossouand Emezue 2021b)
bull Fon was particularly chosen because there isonly a minuscule amount of online (parallel ormonolingual) corpora compared to the other5 languages We wanted to investigate andprovide valuable insights on improving trans-lation quality of very low-resourced Africanlanguages
bull Kinyarwanda and Fon are the only Africanlanguages in our work not covered in the FLO-RES Large-Scale Multilingual Machine Trans-lation Task and also not included in the pre-training of the original model framework usedfor MMTAfrica Based on this we were ableto understand the performance of multilingualtranslation finetuning involving languages notused in the original pretraining objective Wealso offered a method to improve the transla-tion quality of such languages
Our main contributions are summarized below
1 MMTAfrica ndash a many-to-many ALlarrrarrALmultilingual model for 6 African languages
2 Our novel reconstruction objective (describedin section 42) and the BTampREC finetuningsetting together with our proposals in sec-tion 51 offer a comprehensive strategy for
effectively exploiting monolingual data ofAfrican languages in ALlarrrarrAL multilingualmachine translation
3 Evaluation of MMTAfrica on theFLORES Test Set reports signifi-
cant gains in spBLEU over the M2MMMT (Fan et al 2020) benchmark modelprovided by Goyal et al (2021)
4 We further created a unique highly represen-tative test set ndash MMTAfrica Test Set ndashand reported benchmark results and insightsusing MMTAfrica
Language Lang ID(ISO 639-3)
Family Speakers Region
Igbo ibo Niger-Congo-Volta-Niger 27M West
Fon(Fongbe)
fon Niger-Congo-Volta-Congo-Gbe
17M West
Kinyarwanda kin Niger-Congo-Bantu 12M East
Swahili swa Niger-Congo-Bantu 98M Southern Central amp East
Xhosa xho Niger-Congo-NguniBantu
192M Southern
Yorugravebaacute yor Niger-Congo-Volta-Niger 42M West
Table 1 Language family number of speakers (Eber-hard et al 2020) and regions in Africa Adapted from(Adelani et al 2021b)
2 Related Work
21 Multilingual Machine Translation(MMT)
The great success of the encoder-decoder (Sutskever et al 2014 Cho et al2014) NMT on bilingual datasets (Bahdanauet al 2015 Vaswani et al 2017 Barrault et al2019 2020) inspired the extension of the originalbilingual framework to handle more languagespairs simultaneously ndash leading to multilingualneural machine translation
Works on multilingual NMT have progressedfrom sharing the encoder for one-to-many trans-lation (Dong et al 2015) many-to-one transla-tion (Lee et al 2017) sharing the attention mech-anism across multiple language pairs (Firat et al2016a Dong et al 2015) to optimizing a singleNMT model (with a universal encoder and decoder)for the translation of multiple language pairs (Haet al 2016 Johnson et al 2017) The universalencoder-decoder approach constructs a shared vo-cabulary for all languages in the training set anduses just one encoder and decoder for multilingualtranslation between language pairs Johnson et al(2017) proposed to use a single model and prepend
400
special symbols to the source text to indicate thetarget language We adopt their model approach inthis paper
The current state of multilingual NMT wherea single NMT model is optimized for the transla-tion of multiple language pairs (Firat et al 2016aJohnson et al 2017 Lu et al 2018 Aharoni et al2019 Arivazhagan et al 2019b) has become veryappealing for a number of reasons It is scalableand easy to deploy or maintan (the ability of asingle model to effectively handle all translation di-rections from N languages if properly trained anddesigned surpasses the scalability of O(N2) indi-vidually trained models using the traditional bilin-gual framework) Multilingual NMT can encour-age knowledge transfer among related languagepairs (Lakew et al 2018 Tan et al 2019) aswell as positive transfer from higher-resource lan-guages (Zoph et al 2016 Neubig and Hu 2018Arivazhagan et al 2019a Aharoni et al 2019Johnson et al 2017) due to its shared representa-tion improve low-resource translation (Ha et al2016 Johnson et al 2017 Arivazhagan et al2019b Xue et al 2021) and enable zero-shot trans-lation (ie direct translation between a languagepair never seen during training) (Firat et al 2016bJohnson et al 2017)
Despite the many advantages of multilingualNMT it suffers from certain disadvantages Firstlythe output vocabulary size is typically fixed regard-less of the number of languages in the corpus andincreasing the vocabulary size is costly in terms ofcomputational resources because the training andinference time scales linearly with the size of thedecoderrsquos output layer For example the trainingdataset for all the languages in our work gave a totalvocabulary size of 1 683 884 tokens (1 519 918with every sentence lowercased) but we were con-strained to a decoder vocabulary size of 250 000
Another pitfall of massively multilingual NMT isits poor zero-shot performance (Firat et al 2016bArivazhagan et al 2019a Johnson et al 2017Aharoni et al 2019) particularly compared topivot-based models (two bilingual models thattranslate from source to target language throughan intermediate language) Neural machine transla-tion is heavily reliant on parallel data and so with-out access to parallel training data for zero-shotlanguage pairs multilingual models face the spuri-ous correlation issue (Gu et al 2019) and off-targettranslation (Johnson et al 2017) where the model
ignores the given target information and translatesinto a wrong language
Some approaches to improve the performance(including zero-shot translation) of multilingualmodels have relied on leveraging the plentifulsource and target side monolingual data that areavailable For example generating artificial paral-lel data with various forms of backtranslation (Sen-nrich et al 2015) has been shown to greatly im-prove the overall (and zero-shot) performance ofmultilingual models (Firat et al 2016b Gu et al2019 Lakew et al 2018 Zhang et al 2020) aswell as bilingual models (Edunov et al 2018)Zhang et al (2020) proposed random online back-translation to enhance multilingual translation ofunseen training language pairs
Additionally leveraging monolingual data byjointly learning to reconstruct the input while trans-lating has been shown to improve neural machinetranslation quality (Feacutevry and Phang 2018 Lampleet al 2017 Cheng et al 2016 Zhang and Zong2016) Siddhant et al (2020) leveraged monolin-gual data in a semi-supervised fashion and reportedthree major results
1 Using monolingual data significantly booststhe translation quality of low resource lan-guages in multilingual models
2 Self-supervision improves zero-shot transla-tion quality in multilingual models
3 Leveraging monolingual data with self-supervision provides a viable path towardsadding new languages to multilingual models
3 Data Methodology
Table 2 presents the size of the gathered andcleaned parallel sentences for each language di-rection We devised preprocessing guidelines foreach of our focus languages taking their linguisticproperties into consideration We used a maximumsequence length of 50 (due to computational re-sources) and a minimum of 2 In the followingsections we will describe the data sources for thethe parallel and monolingual corpora
Parallel Corpora As NMT models are very re-liant on parallel data we sought to gather moreparallel sentences for each language direction inan effort to increase the size and domain of eachlanguage direction To this end our first source wasJW300 (Agic and Vulic 2019) a parallel corpus of
401
Target Languageibo fon kin xho yor swa eng fra
ibo - 3 179 52 685 58 802 134 219 67 785 85 358 57 458
fon 3 148 - 3 060 3 364 5 440 3 434 5 575 2 400
kin 53 955 3 122 - 70 307 85 824 83 898 77 271 62 236
xho 60 557 3 439 70 506 - 64 179 125 604 138 111 113 453
yor 133 353 5 485 83 866 62 471 - 117 875 122 554 97 000
swa 69 633 3 507 84 025 125 307 121 233 - 186 622 128 428
eng 87 716 5 692 77 148 137 240 125 927 186 122 - -
fra 58 521 2 444 61 986 112 549 98 986 127 718 - -
Table 2 Number of parallel samples for each language direction We highlight the largest and smallest parallelsamples We see for example that much more research on machine translation and data collation has been carriedout on swalarrrarreng than fonlarrrarrfra attesting to the under-representation of some African languages
over 300 languages with around 100 thousand bibli-cal domain parallel sentences per language pair onaverage Using OpusTools (Aulamo et al 2020)we were able to get only very trustworthy trans-lations by setting t = 15 (t is a threshold whichindicates the confidence of the translations) Wecollected more parallel sentences from Tatoeba1kde42 (Tiedemann 2012) and some English-basedbilingual samples from MultiParaCrawl3
Finally following pointers from the native speak-ers of these focus languages in the Masakhane com-munity (forall et al 2020) to existing research on ma-chine translation for African languages which open-sourced their parallel data we assembled moreparallel sentences mostly in the en frlarrrarrALdirection
From all this we createdMMTAfrica Test Set (explained in
more details in section 31) got 5 424 578 totaltraining samples for all languages directions (abreakdown of data size for each language directionis provided in Table 2) and 4 000 for dev
Monolingual Corpora Despite our efforts togather several parallel data from various domainswe were faced with some problems 1) there wasa huge imbalance in parallel samples across thelanguage directions In Table 2 we see that the~ larrrarrfon direction has the least amount of par-allel sentences while ~ larrrarrswa or ~ larrrarryor ismade up of relatively larger parallel sentences 2)
1httpsopusnlpleuTatoebaphp2httpshuggingfacecodatasetskde43httpswwwparacrawleu
the parallel sentences particularly for ALlarrrarrALspan a very small domain (mostly biblical internet)
We therefore set out to gather monolingual datafrom diverse sources As our focus is on Africanlanguages we collated monolingual data in onlythese languages The monolingual sources andvolume are summarized in Table 3
Language(ID) Monolingual source Size
Xhosa (xho) The CC100-Xhosa Dataset cre-ated by Conneau et al (2019) andOpenSLR (van Niekerk et al 2017)
158 660
Yoruba (yor) Yoruba Embeddings Corpus (Alabi et al2020) and MENYO20k (Adelani et al2021a)
45 218
FonFongbe(fon)
FFR Dataset (Dossou and Emezue2020) and Fon French Daily DialoguesParallel Data (Dossou and Emezue2021a)
42 057
SwahiliKiswahili(swa)
(Shikali and Refuoe 2019) 23 170
Kinyarwanda(kin)
KINNEWS-and-KIRNEWS (Niy-ongabo et al 2020)
7 586
Igbo (ibo) (Ezeani et al 2020) 7 817
Table 3 Monolingual data sources and sizes (numberof samples)
31 Data Set Types in our WorkHere we elaborate on the different categories ofdata set that we (generated and) used in our workfor training and evaluation
bull FLORES Test Set This refers to thedev test set of 1012 parallel sentences in all101 language directions provided by Goyal
402
et al (2021)4 We performed evaluation onthis test set for all language directions except~larrrarrfon and ~larrrarrkin
bull MMTAfrica Test Set This is a sub-stantial test set we created by taking out asmall but equal number of sentences fromeach parallel source domain As a result wehave a set from a wide range of domainswhile encompassing samples from many exist-ing test sets from previous research Althoughthis set is small to be fully considered as a testset we open-source it because it contains sen-tences from many domains (making it usefulfor evaluation) and we hope that it can be builtupon by perhaps merging it with other bench-mark test sets (Abate et al 2018 Abbott andMartinus 2019 Reid et al 2021)
bull Baseline TrainTest Set We firstconducted baseline experiments with FonIgbo English and French as explained in sec-tion 441 For this we created a special dataset by carefully selecting a small subset of theFFR Dataset (which already contained paral-lel sentences in French and Fon) first auto-matically translating the sentences to Englishand Igbo using the Google Translate API5and finally re-translating with the help of Igbo(7) and English (7) native speakers (we recog-nized that it was easier for native speakers toedittweak an existing translation rather thanwriting the whole translation from scratch)In so doing we created a data set of 13 878translations in all 4 language directions
We split the data set into 12 554 for trainingBaseline Train Set 662 for dev and662 for test Baseline Test Set
4 Model and Experiments
41 ModelFor all our experiments we used the mT5model (Xue et al 2021) a multilingual variant ofthe encoder-decoder transformer-based (Vaswaniet al 2017) ldquoText-to-Text Transfer Transformerrdquo(T5) model (Raffel et al 2019) In T5 pre-trainingthe NLP tasks (including machine translation) werecast into a ldquotext-to-textrdquo format ndash that is a task
4httpsdlfbaipublicfilescomflores101datasetflores101_datasettargz
5httpscloudgooglecomtranslate
where the model is fed some text prefix for contextor conditioning and is then asked to produce someoutput text This framework makes it straightfor-ward to design a number of NLP tasks like machinetranslation summarization text classification etcAlso it provides a consistent training objective bothfor pre-training and finetuning The mT5 modelwas pre-trained with a maximum likelihood objec-tive using ldquoteacher forcingrdquo (Williams and Zipser1989) The mT5 model was also pretrained witha modification of the masked language modellingobjective (Devlin et al 2018)
We finetuned the mt5-base model on ourmany-to-many machine translation task WhileXue et al (2021) suggest that higher versions ofthe mT5 model (Large XL or XXL) give betterperformance on downstream multilingual transla-tion tasks we were constrained by computationalresources to mt5-base which has 580M pa-rameters
42 SetupFor each language direction X rarr Y we have its setof n parallel sentences D = (xi yi)ni=1 wherexi is the ith source sentence of language X and yiis its translation in the target language Y
Following the approach of Johnson et al (2017)and Xue et al (2021) we model translation in atext-to-text format More specifically we createthe input for the model by prepending the targetlanguage tag to the source sentence Thereforefor each source sentence xi the input to the modelis ltYtaggt xi and the target is yi Taking a realexample letrsquos say we wish to translate the Igbosentence Daalu maka ikwu eziokwu nke Chineke toEnglish The input to the model becomes ltenggtDaalu maka ikwu eziokwu nke Chineke
43 TrainingWe have a set of language tags L for the lan-guages we are working with in our multilin-gual many-to-many translation In our baselinesetup (section 441) L = eng fra ibo fonand in our final experiment (section 442) L =eng fra ibo fon swa kin xho yor We car-ried out many-to-many translation using all thepossible directions from L except eng larrrarr fraWe skipped eng larrrarr fra for this fundamentalreason
bull our main focus is on AfricanlarrrarrAfrican oreng fra larrrarrAfrican Due to the high-
403
resource nature of English and French addingthe training set for eng larrrarr fra would over-shadow the learning of the other language di-rections and greatly impede our analyses Ourintuition draws from the observation of Xueet al (2021) as the reason for off-target trans-lation in the mT5 model as English-basedfinetuning proceeds the modelrsquos assigned like-lihood of non-English tokens presumably de-creases Therefore since the mt5-basetraining set contained predominantly English(and after other European languages) tokensand our research is about ALlarrrarrAL trans-lation removing the eng larrrarr fra directionwas our way of ensuring the model designatedmore likelihood to AL tokens
431 Our ContributionsIn addition to the parallel data between the Africanlanguages we leveraged monolingual data to im-prove translation quality in two ways
1 our backtranslation (BT) We designed amodified form of the random online backtrans-lation (Zhang et al 2020) where instead ofrandomly selecting a subset of languages tobacktranslate we selected for each languagenum_bt sentences at random from the mono-lingual data set This means that the modelgets to backtranslate different (monolingual)sentences every backtranslation time and inso doing we believe improve the modelrsquos do-main adaptation because it gets to learn fromvarious samples from the whole monolingualdata set We initially tested different values ofnum_bt to find a compromise between back-translation computation time and translationquality
Following research works which have shownthe effectiveness of random beam-search overgreedy decoding while generating backtrans-lations (Lample et al 2017 Edunov et al2018 Hoang et al 2018 Zhang et al 2020)we generated num_sample prediction sen-tences from the model and randomly selected(with equal probability) one for our back-translated sentence Naturally the value ofnum_sample further affects the computa-tion time (because the model has to producenum_sample different output sentences foreach input sentence) and so we finally settledwith num_sample = 2
2 our reconstruction Given a monolingualsentence xm from language m we appliedrandom swapping (2 times) and deletion (witha probability of 02) to get a noisy version xTaking inspiration from Raffel et al (2019)we integrated the reconstruction objective intoour model finetuning by prepending the lan-guage tag ltmgt to x and setting its target out-put to xm
44 ExperimentsIn all our experiments we initialized the pretrainedmT5-base model using Hugging Facersquos Auto-
ModelForSeq2SeqLM6 and tracked the trainingprocess with WeightsampBiases (Biewald 2020) Weused the AdamW optimizer (Loshchilov and Hutter2017) with a learning rate (lr) of 3eminus6 and trans-formerrsquos get_linear_schedule_with_warmup7
scheduler (where the learning rate decreases lin-early from the initial lr set in the optimizer to 0after a warmup period and then increases linearlyfrom 0 to the initial lr set in the optimizer)
441 BaselineThe goal of our baseline was to understand theeffect of jointly finetuning with backtranslationand reconstruction on the AfricanlarrrarrAfrican lan-guage translation quality in two scenarios whenthe AL was initially pretrained on the multilingualmodel and contrariwise Using Fon (which wasnot initially included in the pretraining) and Igbo(which was initially included in the pretraining) asthe African languages for our baseline training wefinetuned our model on a many-to-many translationin all directions of eng fra ibo foneng larrrarrfra amounting to 10 directions We used theBaseline Train Set for training and theBaseline Test Set for evaluation We
trained the model for only 3 epochs in three set-tings
1 BASE in this setup we finetune the modelon only the many-to-many translation task nobacktranslation nor reconstruction
2 BT refers to finetuning with our backtransla-tion objective described in section 42 For our
6httpshuggingfacecotransformersmodel_docautohtmltransformersAutoModelForSeq2SeqLM
7httpshuggingfacecotransformersmain_classesoptimizer_scheduleshtmltransformersget_linear_schedule_with_warmup
404
baseline where we backtranslate using mono-lingual data in ibo fon we set num_bt =500 For our final experiments we first triedwith 500 but finally reduced to 100 due to thegreat deal of computation required
For our baseline experiment we ran one epochnormally and the remaining two with back-translation For our final experiments we firstfinetuned the model on 3 epochs before con-tinuing with backtranslation
3 BTampREC refers to joint backtranslation andreconstruction (explained in section 42) whilefinetuning Two important questions were ad-dressed ndash 1) the ratio backtranslation re-construction of monolingual sentences to useand 2) whether to use the same or differentsentences for backtranslation and reconstruc-tion Bearing computation time in mind weresolved to go with 500 50 for our baselineand 100 50 for our final experiments Weleave ablation studies on the effect of the ra-tio on translation quality to future work Forthe second question we decided to randomlysample (with replacement) different sentenceseach for our backtranslation and reconstruc-tion
For our baseline we used a learning rate of 5eminus4a batch size of 32 sentences with gradient accumu-lation up to a batch of 256 sentences and an earlystopping patience of 100 evaluation steps To fur-ther analyse the performance of our baseline setupswe ran comparemt 8 (Neubig et al 2019) on themodelrsquos predictions
442 MMTAfricaMMTAfrica refers to our final experimentalsetup where we finetuned our model on all lan-guage directions involving all eight languagesL = eng fra ibo fon swa kin xho yor ex-cept englarrrarrfra Taking inspiration from our base-line results we ran our experiment with our pro-posed BTampREC setting and made some adjust-ments along the way
The long computation time for backtranslating(with just 100 sentences per language the modelwas required to generate around 3 000 translationsevery backtranslation time) was a drawback Tomitigate the issue we parallelized the process us-
8httpsgithubcomneulabcompare-mt
ing the multiprocessing package in Python9 Wefurther slowly reduced the number of sentences forbacktranslation (to 50 and finally 10)
Gradient descent in large multilingual modelshas been shown to be more stable when updatesare performed over large batch sizes are used (Xueet al 2021) To cope with our computational re-sources we used gradient accumulation to increaseupdates from an initial batch size of 64 sentencesup to a batch gradient computation size of 4096sentences We further utilized PyTorchrsquos DataParal-lel package10 to parallelize the training across theGPUs We used a learning rate (lr) of 3eminus6
5 Results and Insights
All evaluations were made using spBLEU (sen-tencepiece (Kudo and Richardson 2018) + sacre-BLEU (Post 2018)) as described in (Goyal et al2021) We further evaluated on the chrF (Popovic2015) and TER metrics
51 Baseline Results and InsightsFigure 1 compares the spBLEU scores for the threesetups used in our baseline experiments As a re-minder we make use of the symbol to refer toany language in the set eng fra ibo fon
BT gives strong improvement over BASE (ex-cept in engminusrarribo where itrsquos relatively the sameand framinusrarribo where it performs worse)
Figure 1 spBLEU scores of the 3 setups explained insection 441
When the target language is fon we observe aconsiderable boost in the spBLEU of the BT set-ting which also significantly outperformed BASE
9httpsdocspythonorg3librarymultiprocessinghtml
10httpspytorchorgdocsstablegeneratedtorchnnDataParallelhtml
405
and BTampREC BTampREC contributed very littlewhen compared with BT and sometimes even per-formed poorly (in engminusrarrfon) We attribute thispoor performance from the reconstruction objec-tive to the fact that the mt5-base model wasnot originally pretrained on Fon Therefore withonly 3 epochs of finetuning (and 1 epoch beforeintroducing the reconstruction and backtranslationobjectives) the model was not able to meaningfullyutilize both objectives
Conversely when the target language is iboBTampREC gives best results ndash even in scenarios
where BT underperforms BASE (as is the caseof framinusrarribo and engminusrarribo) We believe that thedecoder of the model being originally pretrainedon corpora containing Igbo was able to better useour reconstruction to improve translation quaity in minusrarribo direction
Drawing insights from fonlarrrarribo we offer thefollowing propositions concerning ALlarrrarrALmultilingual translation
bull our backtranslation (section 42) from mono-lingual data improves the cross-lingual map-ping of the model for low-resource Africanlanguages While it is computationally expen-sive our parallelization and decay of numberof backtranslated sentences are some potentialsolutions towards effectively adopting back-translation using monolingual data
bull Denoising objectives typically have beenknown to improve machine translation qual-ity (Zhang and Zong 2016 Cheng et al 2016Gu et al 2019 Zhang et al 2020 Xue et al2021) because they imbue the model withmore generalizable knowledge (about that lan-guage) which is used by the decoder to pre-dict better token likelihoods for that languageduring translation This is a reasonable ex-planation for the improved quality with theBTampREC over BT in the minusrarribo As we
learned from minusrarrfon using reconstructioncould perform unsatisfactorily if not handledwell Some methods we propose are
1 For African languages that were includedin the original model pretraining (aswas the case of Igbo Swahili Xhosaand Yorugravebaacute in the mT5 model) usingthe BTampREC setting for finetuning pro-duces best results While we did not per-form ablation studies on the data size
ratio for backtranslation and reconstruc-tion we believe that our ratio of 2 1(in our final experiments) gives the bestcompromise on both computation timeand translation quality
2 For African languages that were not orig-inally included in the original model pre-training (as was the case of Kinyarwandaand Fon in the mT5 model) reconstruc-tion together with backtranslation (espe-cially at an early stage) only introducesmore noise which could harm the cross-lingual learning For these languages wepropose(a) first finetuning the model on only
our reconstruction (described in sec-tion 42) for fairly long training stepsbefore using BTampREC This waythe initial reconstruction will help themodel learn that language represen-tation space and increase its the like-lihood of tokens
52 MMTAfrica Results and InsightsIn Table 4 we compared MMTAfrica with theM2M MMT(Fan et al 2020) benchmark resultsof Goyal et al (2021) using the same test set theyused ndash FLORES Test Set On all languagepairs except swararreng (which has a comparableminus276 spBLEU difference) we report an improve-ment from MMTAfrica (spBLEU gains rangingfrom +058 in swaminusrarrfra to +1946 in framinusrarrxho)The lower score of swararreng presents an intriguinganomaly especially given the large availability ofparallel corpora in our training set for this pair Weplan to investigate this in further work
In Table 5 we introduce benchmark results ofMMTAfrica on MMTAfrica Test Set Wealso put the test size of each language pair
Interesting analysis about Fon (fon) andYorugravebaacute (yor) For each language the lowest sp-BLEU scores in both tables come from the minusrarryordirection except fonlarrrarryor (from Table 5) whichinterestingly has the highest spBLEU score com-pared to the other fonminusrarr ~ directions We donot know the reason for the very low performancein the ~ minusrarryor direction but we offer below aplausible explanation about fonlarrrarryor
The oral linguistic history of Fon ties it to theancient Yorugravebaacute kingdom (Barnes 1997) Further-more in present day Benin where Fon is largely
406
spoken as a native language Yoruba is one of the in-digenuous languages commonly spoken 11 There-fore Fon and Yorugravebaacute share some linguistic charac-teristics and we believe this is one logic behind thefonlarrrarryor surpassing other fonminusrarr ~ directions
This explanation could inspire transfer learningfrom Yorugravebaacute which has received comparably moreresearch and has more resources for machine trans-lation to Fon We leave this for future work
Source Target spBLEU (FLORES)uarr spBLEU (Ours)uarr spCHRFuarr spTERdarr
ibo swa 438 2184 3738 7148
ibo xho 244 1397 3195 8137
ibo yor 154 1072 2655 7572
ibo eng 737 1362 3890 7623
ibo fra 602 1646 3510 7548
swa ibo 197 1980 3395 6822
swa xho 271 2171 3986 7316
swa yor 129 1168 2744 7523
swa eng 3043 2767 5612 5591
swa fra 2669 2727 4620 6347
xho ibo 380 1702 3130 7066
xho swa 614 2947 4468 6321
xho yor 192 1042 2677 7625
xho eng 1086 2077 4869 6409
xho fra 828 2148 4065 6931
yor ibo 185 1145 2526 7499
yor swa 193 1499 3049 7990
yor xho 194 931 2634 8608
yor eng 418 815 3065 8694
yor fra 357 1059 2760 8132
eng ibo 353 2149 3724 6568
eng swa 2695 4011 5313 5280
eng xho 447 2715 4493 6777
eng yor 217 1209 2834 7474
fra ibo 169 1948 3447 6850
fra swa 1717 3421 4895 5811
fra xho 227 2173 4006 7372
fra yor 116 1142 2767 7533
Table 4 Evaluation Scores of the Flores M2M MMTmodel and MMTAfrica on FLORES Test Set
6 Conclusion and Future Work
In this paper we introduced MMTAfrica a mul-tilingual machine translation model on 6 AfricanLanguages which outperformed the M2M MMTmodel Fan et al (2020) Our results and analy-ses including a new reconstruction objective giveinsights on MMT for African languages for fu-ture research Moreover we plan to launch themodel on Masakhane MT and FFRTranslate in or-der to get human evaluation feedback from theactual speakers of the languages in the Masakhanecommunity (Orife et al 2020) and beyond
In order to fully test the advantage ofMMTAfrica we plan to finish comparing it on
11httpsenwikipediaorgwikiBenin(Last Accessed 30082021)
direct and pivot translations with the Masakhanebenchmark models (forall et al 2020) We alsoplan to perform human evaluation All test setsresults code and checkpoints will be releasedat httpsgithubcomedaiofficialmmtafrica
7 Acknowledgments
The computational resources for running all ex-periments were provided by the FLORES com-pute grants12 as well as additonal computationalresources provided by Paco Guzman (FacebookAI) and Mila Quebec AI Institute We expressour profound gratitude to all who contributed inone way or the other towards the development ofMMTAfrica including (in no order)
Mathias Muumlller (University of Zurich) for giv-ing immense technical assistance in finetuning themodel and advising us on best hyperparameter tun-ing practises
Graham Neubig (Carnegie Mellon University)for explaining and setting up comparemt for usto better understand and evaluate the performanceof our baseline models
Angela Fan (FacebookAI) for guiding us duringthe shared task and taking the time to answer allour questions
Julia Kreutzer (GoogleAI) for advising us on use-ful model comparison and evaluation techniques
Colin Leong (University of Dayton) for painstak-ingly proof-reading the paper and helping us makeit more reader-friendly
Daria Yasafova (Technical University of Mu-nich) and Yeno Gbenou (Drexel University) foradditionally proof-reading the paper
Finally the entire Masakhane community13 foramong many other things 1) guiding us to exist-ing parallel and monolingual data set for the focusAfrican languages 2) explaining their (the focusAfrican languages) important linguistic charteris-tics which helped us work better with them (likein preprocessing) and 3) performing (in the future)human evaluation on MMTAfrica
Indeed it took a village to raise MMTAfrica1412httpwwwstatmtorgwmt21
flores-compute-grantshtml13httpswwwmasakhaneio14lsquoIt takes a village to raise a childrsquo is an African proverb
that means that an entire community of people with differentexpertise must provide for and interact positively with the childfor the child to actually develop and reach the best possiblepotential
407
Source Target Test size spBLEUuarr spCHRFuarr spTERdarr
ibo swa 60 3489 4738 6828
ibo xho 30 3669 5066 5965
ibo yor 30 1177 2954 12984
ibo kin 30 3392 4653 6773
ibo fon 30 3596 4314 6321
ibo eng 90 3728 6042 6205
ibo fra 60 3086 4409 6953
swa ibo 60 3371 4302 6001
swa xho 30 3728 5253 5586
swa yor 30 1409 2750 11363
swa kin 30 2386 4259 9467
swa fon 30 2329 3352 6511
swa eng 60 3555 6047 4732
swa fra 60 3011 4833 6338
xho ibo 30 3325 4536 6283
xho swa 30 3926 5375 5372
xho yor 30 2200 3806 7045
xho kin 30 3066 4619 7470
xho fon 30 2580 3487 6596
xho eng 90 3025 5512 6211
xho fra 30 2945 4572 6103
yor ibo 30 2511 3419 7480
yor swa 30 1762 3471 8518
yor xho 30 2931 4313 6682
yor kin 30 2516 3802 7267
yor fon 30 3181 3745 6339
yor eng 90 1781 4173 9300
yor fra 30 1544 3097 9057
kin ibo 30 3125 4236 6673
kin swa 30 3365 4634 7270
kin xho 30 2040 3971 8997
kin yor 30 1834 3353 7043
kin fon 30 2243 3249 6726
kin eng 60 1582 4310 9655
kin fra 30 1623 3351 9182
fon ibo 30 3236 4644 6182
fon swa 30 2984 4296 7228
fon xho 30 2882 4374 6698
fon yor 30 3045 4263 6072
fon kin 30 2388 3959 7806
fon eng 30 1663 4163 6903
fon fra 60 2479 4339 8215
eng ibo 90 4424 5489 6392
eng swa 60 4994 6145 4783
eng xho 120 3197 4974 7289
eng yor 90 2393 3619 8405
eng kin 90 4098 5600 7637
eng fon 30 2719 3686 6254
fra ibo 60 3647 4693 5991
fra swa 60 3653 5142 5594
fra xho 30 3435 4939 6030
fra yor 30 726 2554 12453
fra kin 30 3107 4226 8106
fra fon 60 3107 3872 7574
Table 5 Benchmark Evaluation Scores onMMTAfrica Test Set
ReferencesSolomon Teferra Abate Michael Melese Martha Yi-
firu Tachbelie Million Meshesha Solomon AtinafuWondwossen Mulugeta Yaregal Assabie HafteAbera Binyam Ephrem Tewodros Abebe Wondim-agegnhue Tsegaye Amanuel Lemma Tsegaye An-dargie and Seifedin Shifaw 2018 Parallel corporafor bi-lingual English-Ethiopian languages statisti-cal machine translation In Proceedings of the 27thInternational Conference on Computational Linguis-tics pages 3102ndash3111 Santa Fe New Mexico USAAssociation for Computational Linguistics
Jade Abbott and Laura Martinus 2019 Benchmarkingneural machine translation for Southern African lan-guages In Proceedings of the 2019 Workshop onWidening NLP pages 98ndash101 Florence Italy Asso-ciation for Computational Linguistics
Jade Z Abbott and Laura Martinus 2018 Towardsneural machine translation for african languages
David I Adelani Dana Ruiter Jesujoba O Al-abi Damilola Adebonojo Adesina Ayeni MofeAdeyemi Ayodele Awokoya and Cristina Espantildea-Bonet 2021a The effect of domain and diacritics inyorugravebaacute-english neural machine translation
David Ifeoluwa Adelani Jade Z Abbott GrahamNeubig Daniel Drsquosouza Julia Kreutzer Constan-tine Lignos Chester Palen-Michel Happy Buza-aba Shruti Rijhwani Sebastian Ruder StephenMayhew Israel Abebe Azime Shamsuddeen Has-san Muhammad Chris Chinenye Emezue JoyceNakatumba-Nabende Perez Ogayo Aremu An-uoluwapo Catherine Gitau Derguene Mbaye Je-sujoba O Alabi Seid Muhie Yimam Tajud-deen Gwadabe Ignatius Ezeani Rubungo An-dre Niyongabo Jonathan Mukiibi Verrah OtiendeIroro Orife Davis David Samba Ngom Tosin PAdewumi Paul Rayson Mofetoluwa Adeyemi Ger-ald Muriuki Emmanuel Anebi Chiamaka Chuk-wuneke Nkiruka Odu Eric Peter Wairagala SamuelOyerinde Clemencia Siro Tobius Saul BateesaTemilola Oloyede Yvonne Wambui Victor Akin-ode Deborah Nabagereka Maurice Katusiime Ayo-dele Awokoya Mouhamadane Mboup Dibora Ge-breyohannes Henok Tilaye Kelechi Nwaike De-gaga Wolde Abdoulaye Faye Blessing SibandaOrevaoghene Ahia Bonaventure F P DossouKelechi Ogueji Thierno Ibrahima Diop AbdoulayeDiallo Adewale Akinfaderin Tendai Marengerekeand Salomey Osei 2021b Masakhaner Namedentity recognition for african languages CoRRabs210311811
Željko Agic and Ivan Vulic 2019 JW300 A wide-coverage parallel corpus for low-resource languagesIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages3204ndash3210 Florence Italy Association for Compu-tational Linguistics
Roee Aharoni Melvin Johnson and Orhan Firat 2019Massively multilingual neural machine translation
408
In Proceedings of the 2019 Conference of the NorthAmerican Chapter of the Association for Compu-tational Linguistics Human Language Technolo-gies Volume 1 (Long and Short Papers) pages3874ndash3884 Minneapolis Minnesota Associationfor Computational Linguistics
Jesujoba Alabi Kwabena Amponsah-Kaakyire DavidAdelani and Cristina Espantildea-Bonet 2020 Mas-sive vs curated embeddings for low-resourced lan-guages the case of Yorugravebaacute and Twi In Proceed-ings of the 12th Language Resources and EvaluationConference pages 2754ndash2762 Marseille FranceEuropean Language Resources Association
Naveen Arivazhagan Ankur Bapna Orhan Firat RoeeAharoni Melvin Johnson and Wolfgang Macherey2019a The missing ingredient in zero-shot neuralmachine translation CoRR abs190307091
Naveen Arivazhagan Ankur Bapna Orhan FiratDmitry Lepikhin Melvin Johnson Maxim KrikunMia Xu Chen Yuan Cao George F Foster ColinCherry Wolfgang Macherey Zhifeng Chen andYonghui Wu 2019b Massively multilingual neuralmachine translation in the wild Findings and chal-lenges CoRR abs190705019
Mikko Aulamo Umut Sulubacak Sami Virpioja andJoumlrg Tiedemann 2020 OpusTools and parallel cor-pus diagnostics In Proceedings of The 12th Lan-guage Resources and Evaluation Conference pages3782ndash3789 European Language Resources Associ-ation
Dzmitry Bahdanau Kyunghyun Cho and Yoshua Ben-gio 2015 Neural machine translation by jointlylearning to align and translate In 3rd Inter-national Conference on Learning RepresentationsICLR 2015 San Diego CA USA May 7-9 2015Conference Track Proceedings
ST Barnes 1997 Africarsquos Ogun Old World andNew African systems of thought Indiana Univer-sity Press
Loiumlc Barrault Magdalena Biesialska Ondrej BojarMarta R Costa-jussagrave Christian Federmann YvetteGraham Roman Grundkiewicz Barry HaddowMatthias Huck Eric Joanis Tom Kocmi PhilippKoehn Chi-kiu Lo Nikola Ljubešic ChristofMonz Makoto Morishita Masaaki Nagata Toshi-aki Nakazawa Santanu Pal Matt Post and MarcosZampieri 2020 Findings of the 2020 conference onmachine translation (WMT20) In Proceedings ofthe Fifth Conference on Machine Translation pages1ndash55 Online Association for Computational Lin-guistics
Loiumlc Barrault Ondrej Bojar Marta R Costa-jussagraveChristian Federmann Mark Fishel Yvette Gra-ham Barry Haddow Matthias Huck Philipp KoehnShervin Malmasi Christof Monz Mathias MuumlllerSantanu Pal Matt Post and Marcos Zampieri 2019
Findings of the 2019 conference on machine transla-tion (WMT19) In Proceedings of the Fourth Con-ference on Machine Translation (Volume 2 SharedTask Papers Day 1) pages 1ndash61 Florence Italy As-sociation for Computational Linguistics
Lukas Biewald 2020 Experiment tracking withweights and biases Software available fromwandbcom
Yong Cheng Wei Xu Zhongjun He Wei He HuaWu Maosong Sun and Yang Liu 2016 Semi-supervised learning for neural machine translationIn Proceedings of the 54th Annual Meeting of the As-sociation for Computational Linguistics (Volume 1Long Papers) pages 1965ndash1974 Berlin GermanyAssociation for Computational Linguistics
Kyunghyun Cho Bart van Merrienboer CcedilaglarGuumllccedilehre Dzmitry Bahdanau Fethi Bougares Hol-ger Schwenk and Yoshua Bengio 2014 Learningphrase representations using RNN encoder-decoderfor statistical machine translation In Proceedings ofthe 2014 Conference on Empirical Methods in Nat-ural Language Processing EMNLP 2014 October25-29 2014 Doha Qatar A meeting of SIGDAT aSpecial Interest Group of the ACL pages 1724ndash1734ACL
Alexis Conneau Kartikay Khandelwal Naman GoyalVishrav Chaudhary Guillaume Wenzek FranciscoGuzmaacuten Edouard Grave Myle Ott Luke Zettle-moyer and Veselin Stoyanov 2019 Unsupervisedcross-lingual representation learning at scale
Jacob Devlin Ming-Wei Chang Kenton Lee andKristina Toutanova 2018 BERT pre-training ofdeep bidirectional transformers for language under-standing CoRR abs181004805
Daxiang Dong Hua Wu Wei He Dianhai Yu andHaifeng Wang 2015 Multi-task learning for mul-tiple language translation In Proceedings of the53rd Annual Meeting of the Association for Compu-tational Linguistics and the 7th International JointConference on Natural Language Processing (Vol-ume 1 Long Papers) pages 1723ndash1732 BeijingChina Association for Computational Linguistics
Bonaventure F P Dossou and Chris C Emezue 2020FFR V10 fon-french neural machine translationCoRR abs200312111
Bonaventure F P Dossou and Chris C Emezue 2021aCrowdsourced phrase-based tokenization for low-resourced neural machine translation The case offon language CoRR abs210308052
Bonaventure F P Dossou and Chris C Emezue 2021bOkwugbeacute End-to-end speech recognition for fonand igbo CoRR abs210307762
David M Eberhard Gary F Simons and CharlesD Fennig (eds) 2020 Ethnologue Languages ofthe world twenty-third edition
409
Sergey Edunov Myle Ott Michael Auli and DavidGrangier 2018 Understanding back-translation atscale CoRR abs180809381
Ignatius Ezeani Paul Rayson Ikechukwu E OnyenweChinedu Uchechukwu and Mark Hepple 2020Igbo-english machine translation An evaluationbenchmark CoRR abs200400648
Angela Fan Shruti Bhosale Holger Schwenk ZhiyiMa Ahmed El-Kishky Siddharth Goyal Man-deep Baines Onur Celebi Guillaume WenzekVishrav Chaudhary Naman Goyal Tom Birch Vi-taliy Liptchinsky Sergey Edunov Edouard GraveMichael Auli and Armand Joulin 2020 Be-yond english-centric multilingual machine transla-tion CoRR abs201011125
Thibault Feacutevry and Jason Phang 2018 Unsuper-vised sentence compression using denoising auto-encoders CoRR abs180902669
Orhan Firat Kyunghyun Cho and Yoshua Bengio2016a Multi-way multilingual neural machinetranslation with a shared attention mechanism InProceedings of the 2016 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 866ndash875 San Diego California Associationfor Computational Linguistics
Orhan Firat Baskaran Sankaran Yaser Al-onaizanFatos T Yarman Vural and Kyunghyun Cho 2016bZero-resource translation with multi-lingual neuralmachine translation In Proceedings of the 2016Conference on Empirical Methods in Natural Lan-guage Processing pages 268ndash277 Austin TexasAssociation for Computational Linguistics
forall Wilhelmina Nekoto Vukosi Marivate TshinondiwaMatsila Timi Fasubaa Tajudeen Kolawole TaiwoFagbohungbe Solomon Oluwole Akinola Sham-suddee Hassan Muhammad Salomon Kabongo Sa-lomey Osei et al 2020 Participatory research forlow-resourced machine translation A case study inafrican languages Findings of EMNLP
Naman Goyal Cynthia Gao Vishrav Chaudhary Peng-Jen Chen Guillaume Wenzek Da Ju Sanjana Kr-ishnan MarcrsquoAurelio Ranzato Francisco Guzmanand Angela Fan 2021 The flores-101 evaluationbenchmark for low-resource and multilingual ma-chine translation
Jiatao Gu Yong Wang Kyunghyun Cho and Vic-tor OK Li 2019 Improved zero-shot neural ma-chine translation via ignoring spurious correlationsIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages1258ndash1268 Florence Italy Association for Compu-tational Linguistics
Thanh-Le Ha Jan Niehues and Alexander H Waibel2016 Toward multilingual neural machine trans-lation with universal encoder and decoder CoRRabs161104798
Vu Cong Duy Hoang Philipp Koehn GholamrezaHaffari and Trevor Cohn 2018 Iterative back-translation for neural machine translation In Pro-ceedings of the 2nd Workshop on Neural MachineTranslation and Generation pages 18ndash24 Mel-bourne Australia Association for ComputationalLinguistics
Melvin Johnson Mike Schuster Quoc V Le MaximKrikun Yonghui Wu Zhifeng Chen Nikhil ThoratFernanda Vieacutegas Martin Wattenberg Greg CorradoMacduff Hughes and Jeffrey Dean 2017 Googlersquosmultilingual neural machine translation system En-abling zero-shot translation Transactions of the As-sociation for Computational Linguistics 5339ndash351
Pratik Joshi Sebastin Santy Amar Budhiraja KalikaBali and Monojit Choudhury 2020 The state andfate of linguistic diversity and inclusion in the NLPworld In Proceedings of the 58th Annual Meet-ing of the Association for Computational Linguisticspages 6282ndash6293 Online Association for Computa-tional Linguistics
Taku Kudo and John Richardson 2018 SentencePieceA simple and language independent subword tok-enizer and detokenizer for neural text processing InProceedings of the 2018 Conference on EmpiricalMethods in Natural Language Processing SystemDemonstrations pages 66ndash71 Brussels BelgiumAssociation for Computational Linguistics
Surafel Melaku Lakew Mauro Cettolo and MarcelloFederico 2018 A comparison of transformer andrecurrent neural networks on multilingual neural ma-chine translation In Proceedings of the 27th Inter-national Conference on Computational Linguisticspages 641ndash652 Santa Fe New Mexico USA Asso-ciation for Computational Linguistics
Guillaume Lample Ludovic Denoyer andMarcrsquoAurelio Ranzato 2017 Unsupervisedmachine translation using monolingual corporaonly CoRR abs171100043
Jason Lee Kyunghyun Cho and Thomas Hofmann2017 Fully Character-Level Neural Machine Trans-lation without Explicit Segmentation Transactionsof the Association for Computational Linguistics5365ndash378
Ilya Loshchilov and Frank Hutter 2017 Fixingweight decay regularization in adam CoRRabs171105101
Yichao Lu Phillip Keung Faisal Ladhak Vikas Bhard-waj Shaonan Zhang and Jason Sun 2018 A neu-ral interlingua for multilingual machine translationIn Proceedings of the Third Conference on MachineTranslation Research Papers pages 84ndash92 Brus-sels Belgium Association for Computational Lin-guistics
Laura Martinus and Jade Z Abbott 2019 A focuson neural machine translation for african languagesCoRR abs190605685
410
Graham Neubig Zi-Yi Dou Junjie Hu Paul MichelDanish Pruthi Xinyi Wang and John Wieting 2019compare-mt A tool for holistic comparison of lan-guage generation systems CoRR abs190307926
Graham Neubig and Junjie Hu 2018 Rapid adapta-tion of neural machine translation to new languagesIn Proceedings of the 2018 Conference on Empiri-cal Methods in Natural Language Processing pages875ndash880 Brussels Belgium Association for Com-putational Linguistics
Rubungo Andre Niyongabo Qu Hong Julia Kreutzerand Li Huang 2020 KINNEWS and KIRNEWSBenchmarking cross-lingual text classification forKinyarwanda and Kirundi In Proceedings ofthe 28th International Conference on Computa-tional Linguistics pages 5507ndash5521 BarcelonaSpain (Online) International Committee on Compu-tational Linguistics
Linda Nordling 2018 How decolonizationcould reshape south african science Nature554(7691)159ndash162
Evander Nyoni and Bruce A Bassett 2021 Low-resource neural machine translation for southernafrican languages CoRR abs210400366
Iroro Orife Julia Kreutzer Blessing Sibanda DanielWhitenack Kathleen Siminyu Laura MartinusJamiil Toure Ali Jade Z Abbott Vukosi Mari-vate Salomon Kabongo Musie Meressa Es-poir Murhabazi Orevaoghene Ahia Elan VanBiljon Arshath Ramkilowan Adewale AkinfaderinAlp Oumlktem Wole Akin Ghollah Kioko KevinDegila Herman Kamper Bonaventure DossouChris Emezue Kelechi Ogueji and Abdallah Bashir2020 Masakhane - machine translation for africaCoRR abs200311529
Maja Popovic 2015 chrF character n-gram F-scorefor automatic MT evaluation In Proceedings of theTenth Workshop on Statistical Machine Translationpages 392ndash395 Lisbon Portugal Association forComputational Linguistics
Matt Post 2018 A call for clarity in reporting BLEUscores In Proceedings of the Third Conference onMachine Translation Research Papers pages 186ndash191 Brussels Belgium Association for Computa-tional Linguistics
Colin Raffel Noam Shazeer Adam Roberts KatherineLee Sharan Narang Michael Matena Yanqi ZhouWei Li and Peter J Liu 2019 Exploring the limitsof transfer learning with a unified text-to-text trans-former CoRR abs191010683
Machel Reid Junjie Hu Graham Neubig and YutakaMatsuo 2021 Afromt Pretraining strategies andreproducible benchmarks for translation of 8 africanlanguages
Rico Sennrich Barry Haddow and Alexandra Birch2015 Improving neural machine translation modelswith monolingual data CoRR abs151106709
Shivachi Casper Shikali and Mokhosi Refuoe 2019Language modeling data for swahili
Aditya Siddhant Ankur Bapna Yuan Cao Orhan Fi-rat Mia Xu Chen Sneha Reddy Kudugunta NaveenArivazhagan and Yonghui Wu 2020 Lever-aging monolingual data with self-supervision formultilingual neural machine translation CoRRabs200504816
Ilya Sutskever Oriol Vinyals and Quoc V Le 2014Sequence to sequence learning with neural networksIn Proceedings of the 27th International Conferenceon Neural Information Processing Systems - Vol-ume 2 NIPSrsquo14 page 3104ndash3112 Cambridge MAUSA MIT Press
Xu Tan Jiale Chen Di He Yingce Xia Tao Qin andTie-Yan Liu 2019 Multilingual neural machinetranslation with language clustering In Proceedingsof the 2019 Conference on Empirical Methods inNatural Language Processing and the 9th Interna-tional Joint Conference on Natural Language Pro-cessing (EMNLP-IJCNLP) pages 963ndash973 HongKong China Association for Computational Lin-guistics
Joumlrg Tiedemann 2012 Parallel data tools and inter-faces in opus In Proceedings of the Eight Interna-tional Conference on Language Resources and Eval-uation (LRECrsquo12) Istanbul Turkey European Lan-guage Resources Association (ELRA)
Daniel van Niekerk Charl van Heerden Marelie DavelNeil Kleynhans Oddur Kjartansson Martin Janscheand Linne Ha 2017 Rapid development of TTS cor-pora for four South African languages In Proc In-terspeech 2017 pages 2178ndash2182 Stockholm Swe-den
Ashish Vaswani Noam Shazeer Niki Parmar JakobUszkoreit Llion Jones Aidan N Gomez LukaszKaiser and Illia Polosukhin 2017 Attention is allyou need CoRR abs170603762
Sarah Wild 2021 African languages to get more be-spoke scientific terms Nature 596(7873)469ndash470
Ronald J Williams and David Zipser 1989 A learn-ing algorithm for continually running fully recurrentneural networks Neural Computation 1(2)270ndash280
Linting Xue Noah Constant Adam Roberts Mi-hir Kale Rami Al-Rfou Aditya Siddhant AdityaBarua and Colin Raffel 2021 mT5 A massivelymultilingual pre-trained text-to-text transformer InProceedings of the 2021 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 483ndash498 Online Association for Computa-tional Linguistics
Biao Zhang Philip Williams Ivan Titov and RicoSennrich 2020 Improving massively multilingualneural machine translation and zero-shot translationCoRR abs200411867
411
Jiajun Zhang and Chengqing Zong 2016 Exploit-ing source-side monolingual data in neural machinetranslation In Proceedings of the 2016 Conferenceon Empirical Methods in Natural Language Process-ing pages 1535ndash1545 Austin Texas Associationfor Computational Linguistics
Barret Zoph Deniz Yuret Jonathan May and KevinKnight 2016 Transfer learning for low-resourceneural machine translation In Proceedings of the2016 Conference on Empirical Methods in Natu-ral Language Processing pages 1568ndash1575 AustinTexas Association for Computational Linguistics

399
inus 2018 Nordling 2018 Wild 2021)We take a step towards addressing the under-
representation of African languages in MMT andimproving experiments by participating in the2021 WMT Shared Task Large-Scale Multilin-gual Machine Translation with a major target ofALslarrrarrALs In this paper we focused on 6African languages and 2 non-African languages(English and French) Table 1 gives an overview ofour focus African languages in terms of their lan-guage family number of speakers and the regionsin Africa where they are spoken (Adelani et al2021b) We chose these languages in an effort tocreate some language diversity the 6 African lan-guages span the most widely and least spoken lan-guages in Africa Additionally they have some sim-ilar as well as contrasting characteristics whichoffer interesting insights for future work in ALs
bull Igbo Yorugravebaacute and Fon use diacritics intheir language structure while KinyarwandaSwahili and Xhosa do not Various forms ofcode-mixing are prevalent in Igbo (Dossouand Emezue 2021b)
bull Fon was particularly chosen because there isonly a minuscule amount of online (parallel ormonolingual) corpora compared to the other5 languages We wanted to investigate andprovide valuable insights on improving trans-lation quality of very low-resourced Africanlanguages
bull Kinyarwanda and Fon are the only Africanlanguages in our work not covered in the FLO-RES Large-Scale Multilingual Machine Trans-lation Task and also not included in the pre-training of the original model framework usedfor MMTAfrica Based on this we were ableto understand the performance of multilingualtranslation finetuning involving languages notused in the original pretraining objective Wealso offered a method to improve the transla-tion quality of such languages
Our main contributions are summarized below
1 MMTAfrica ndash a many-to-many ALlarrrarrALmultilingual model for 6 African languages
2 Our novel reconstruction objective (describedin section 42) and the BTampREC finetuningsetting together with our proposals in sec-tion 51 offer a comprehensive strategy for
effectively exploiting monolingual data ofAfrican languages in ALlarrrarrAL multilingualmachine translation
3 Evaluation of MMTAfrica on theFLORES Test Set reports signifi-
cant gains in spBLEU over the M2MMMT (Fan et al 2020) benchmark modelprovided by Goyal et al (2021)
4 We further created a unique highly represen-tative test set ndash MMTAfrica Test Set ndashand reported benchmark results and insightsusing MMTAfrica
Language Lang ID(ISO 639-3)
Family Speakers Region
Igbo ibo Niger-Congo-Volta-Niger 27M West
Fon(Fongbe)
fon Niger-Congo-Volta-Congo-Gbe
17M West
Kinyarwanda kin Niger-Congo-Bantu 12M East
Swahili swa Niger-Congo-Bantu 98M Southern Central amp East
Xhosa xho Niger-Congo-NguniBantu
192M Southern
Yorugravebaacute yor Niger-Congo-Volta-Niger 42M West
Table 1 Language family number of speakers (Eber-hard et al 2020) and regions in Africa Adapted from(Adelani et al 2021b)
2 Related Work
21 Multilingual Machine Translation(MMT)
The great success of the encoder-decoder (Sutskever et al 2014 Cho et al2014) NMT on bilingual datasets (Bahdanauet al 2015 Vaswani et al 2017 Barrault et al2019 2020) inspired the extension of the originalbilingual framework to handle more languagespairs simultaneously ndash leading to multilingualneural machine translation
Works on multilingual NMT have progressedfrom sharing the encoder for one-to-many trans-lation (Dong et al 2015) many-to-one transla-tion (Lee et al 2017) sharing the attention mech-anism across multiple language pairs (Firat et al2016a Dong et al 2015) to optimizing a singleNMT model (with a universal encoder and decoder)for the translation of multiple language pairs (Haet al 2016 Johnson et al 2017) The universalencoder-decoder approach constructs a shared vo-cabulary for all languages in the training set anduses just one encoder and decoder for multilingualtranslation between language pairs Johnson et al(2017) proposed to use a single model and prepend
400
special symbols to the source text to indicate thetarget language We adopt their model approach inthis paper
The current state of multilingual NMT wherea single NMT model is optimized for the transla-tion of multiple language pairs (Firat et al 2016aJohnson et al 2017 Lu et al 2018 Aharoni et al2019 Arivazhagan et al 2019b) has become veryappealing for a number of reasons It is scalableand easy to deploy or maintan (the ability of asingle model to effectively handle all translation di-rections from N languages if properly trained anddesigned surpasses the scalability of O(N2) indi-vidually trained models using the traditional bilin-gual framework) Multilingual NMT can encour-age knowledge transfer among related languagepairs (Lakew et al 2018 Tan et al 2019) aswell as positive transfer from higher-resource lan-guages (Zoph et al 2016 Neubig and Hu 2018Arivazhagan et al 2019a Aharoni et al 2019Johnson et al 2017) due to its shared representa-tion improve low-resource translation (Ha et al2016 Johnson et al 2017 Arivazhagan et al2019b Xue et al 2021) and enable zero-shot trans-lation (ie direct translation between a languagepair never seen during training) (Firat et al 2016bJohnson et al 2017)
Despite the many advantages of multilingualNMT it suffers from certain disadvantages Firstlythe output vocabulary size is typically fixed regard-less of the number of languages in the corpus andincreasing the vocabulary size is costly in terms ofcomputational resources because the training andinference time scales linearly with the size of thedecoderrsquos output layer For example the trainingdataset for all the languages in our work gave a totalvocabulary size of 1 683 884 tokens (1 519 918with every sentence lowercased) but we were con-strained to a decoder vocabulary size of 250 000
Another pitfall of massively multilingual NMT isits poor zero-shot performance (Firat et al 2016bArivazhagan et al 2019a Johnson et al 2017Aharoni et al 2019) particularly compared topivot-based models (two bilingual models thattranslate from source to target language throughan intermediate language) Neural machine transla-tion is heavily reliant on parallel data and so with-out access to parallel training data for zero-shotlanguage pairs multilingual models face the spuri-ous correlation issue (Gu et al 2019) and off-targettranslation (Johnson et al 2017) where the model
ignores the given target information and translatesinto a wrong language
Some approaches to improve the performance(including zero-shot translation) of multilingualmodels have relied on leveraging the plentifulsource and target side monolingual data that areavailable For example generating artificial paral-lel data with various forms of backtranslation (Sen-nrich et al 2015) has been shown to greatly im-prove the overall (and zero-shot) performance ofmultilingual models (Firat et al 2016b Gu et al2019 Lakew et al 2018 Zhang et al 2020) aswell as bilingual models (Edunov et al 2018)Zhang et al (2020) proposed random online back-translation to enhance multilingual translation ofunseen training language pairs
Additionally leveraging monolingual data byjointly learning to reconstruct the input while trans-lating has been shown to improve neural machinetranslation quality (Feacutevry and Phang 2018 Lampleet al 2017 Cheng et al 2016 Zhang and Zong2016) Siddhant et al (2020) leveraged monolin-gual data in a semi-supervised fashion and reportedthree major results
1 Using monolingual data significantly booststhe translation quality of low resource lan-guages in multilingual models
2 Self-supervision improves zero-shot transla-tion quality in multilingual models
3 Leveraging monolingual data with self-supervision provides a viable path towardsadding new languages to multilingual models
3 Data Methodology
Table 2 presents the size of the gathered andcleaned parallel sentences for each language di-rection We devised preprocessing guidelines foreach of our focus languages taking their linguisticproperties into consideration We used a maximumsequence length of 50 (due to computational re-sources) and a minimum of 2 In the followingsections we will describe the data sources for thethe parallel and monolingual corpora
Parallel Corpora As NMT models are very re-liant on parallel data we sought to gather moreparallel sentences for each language direction inan effort to increase the size and domain of eachlanguage direction To this end our first source wasJW300 (Agic and Vulic 2019) a parallel corpus of
401
Target Languageibo fon kin xho yor swa eng fra
ibo - 3 179 52 685 58 802 134 219 67 785 85 358 57 458
fon 3 148 - 3 060 3 364 5 440 3 434 5 575 2 400
kin 53 955 3 122 - 70 307 85 824 83 898 77 271 62 236
xho 60 557 3 439 70 506 - 64 179 125 604 138 111 113 453
yor 133 353 5 485 83 866 62 471 - 117 875 122 554 97 000
swa 69 633 3 507 84 025 125 307 121 233 - 186 622 128 428
eng 87 716 5 692 77 148 137 240 125 927 186 122 - -
fra 58 521 2 444 61 986 112 549 98 986 127 718 - -
Table 2 Number of parallel samples for each language direction We highlight the largest and smallest parallelsamples We see for example that much more research on machine translation and data collation has been carriedout on swalarrrarreng than fonlarrrarrfra attesting to the under-representation of some African languages
over 300 languages with around 100 thousand bibli-cal domain parallel sentences per language pair onaverage Using OpusTools (Aulamo et al 2020)we were able to get only very trustworthy trans-lations by setting t = 15 (t is a threshold whichindicates the confidence of the translations) Wecollected more parallel sentences from Tatoeba1kde42 (Tiedemann 2012) and some English-basedbilingual samples from MultiParaCrawl3
Finally following pointers from the native speak-ers of these focus languages in the Masakhane com-munity (forall et al 2020) to existing research on ma-chine translation for African languages which open-sourced their parallel data we assembled moreparallel sentences mostly in the en frlarrrarrALdirection
From all this we createdMMTAfrica Test Set (explained in
more details in section 31) got 5 424 578 totaltraining samples for all languages directions (abreakdown of data size for each language directionis provided in Table 2) and 4 000 for dev
Monolingual Corpora Despite our efforts togather several parallel data from various domainswe were faced with some problems 1) there wasa huge imbalance in parallel samples across thelanguage directions In Table 2 we see that the~ larrrarrfon direction has the least amount of par-allel sentences while ~ larrrarrswa or ~ larrrarryor ismade up of relatively larger parallel sentences 2)
1httpsopusnlpleuTatoebaphp2httpshuggingfacecodatasetskde43httpswwwparacrawleu
the parallel sentences particularly for ALlarrrarrALspan a very small domain (mostly biblical internet)
We therefore set out to gather monolingual datafrom diverse sources As our focus is on Africanlanguages we collated monolingual data in onlythese languages The monolingual sources andvolume are summarized in Table 3
Language(ID) Monolingual source Size
Xhosa (xho) The CC100-Xhosa Dataset cre-ated by Conneau et al (2019) andOpenSLR (van Niekerk et al 2017)
158 660
Yoruba (yor) Yoruba Embeddings Corpus (Alabi et al2020) and MENYO20k (Adelani et al2021a)
45 218
FonFongbe(fon)
FFR Dataset (Dossou and Emezue2020) and Fon French Daily DialoguesParallel Data (Dossou and Emezue2021a)
42 057
SwahiliKiswahili(swa)
(Shikali and Refuoe 2019) 23 170
Kinyarwanda(kin)
KINNEWS-and-KIRNEWS (Niy-ongabo et al 2020)
7 586
Igbo (ibo) (Ezeani et al 2020) 7 817
Table 3 Monolingual data sources and sizes (numberof samples)
31 Data Set Types in our WorkHere we elaborate on the different categories ofdata set that we (generated and) used in our workfor training and evaluation
bull FLORES Test Set This refers to thedev test set of 1012 parallel sentences in all101 language directions provided by Goyal
402
et al (2021)4 We performed evaluation onthis test set for all language directions except~larrrarrfon and ~larrrarrkin
bull MMTAfrica Test Set This is a sub-stantial test set we created by taking out asmall but equal number of sentences fromeach parallel source domain As a result wehave a set from a wide range of domainswhile encompassing samples from many exist-ing test sets from previous research Althoughthis set is small to be fully considered as a testset we open-source it because it contains sen-tences from many domains (making it usefulfor evaluation) and we hope that it can be builtupon by perhaps merging it with other bench-mark test sets (Abate et al 2018 Abbott andMartinus 2019 Reid et al 2021)
bull Baseline TrainTest Set We firstconducted baseline experiments with FonIgbo English and French as explained in sec-tion 441 For this we created a special dataset by carefully selecting a small subset of theFFR Dataset (which already contained paral-lel sentences in French and Fon) first auto-matically translating the sentences to Englishand Igbo using the Google Translate API5and finally re-translating with the help of Igbo(7) and English (7) native speakers (we recog-nized that it was easier for native speakers toedittweak an existing translation rather thanwriting the whole translation from scratch)In so doing we created a data set of 13 878translations in all 4 language directions
We split the data set into 12 554 for trainingBaseline Train Set 662 for dev and662 for test Baseline Test Set
4 Model and Experiments
41 ModelFor all our experiments we used the mT5model (Xue et al 2021) a multilingual variant ofthe encoder-decoder transformer-based (Vaswaniet al 2017) ldquoText-to-Text Transfer Transformerrdquo(T5) model (Raffel et al 2019) In T5 pre-trainingthe NLP tasks (including machine translation) werecast into a ldquotext-to-textrdquo format ndash that is a task
4httpsdlfbaipublicfilescomflores101datasetflores101_datasettargz
5httpscloudgooglecomtranslate
where the model is fed some text prefix for contextor conditioning and is then asked to produce someoutput text This framework makes it straightfor-ward to design a number of NLP tasks like machinetranslation summarization text classification etcAlso it provides a consistent training objective bothfor pre-training and finetuning The mT5 modelwas pre-trained with a maximum likelihood objec-tive using ldquoteacher forcingrdquo (Williams and Zipser1989) The mT5 model was also pretrained witha modification of the masked language modellingobjective (Devlin et al 2018)
We finetuned the mt5-base model on ourmany-to-many machine translation task WhileXue et al (2021) suggest that higher versions ofthe mT5 model (Large XL or XXL) give betterperformance on downstream multilingual transla-tion tasks we were constrained by computationalresources to mt5-base which has 580M pa-rameters
42 SetupFor each language direction X rarr Y we have its setof n parallel sentences D = (xi yi)ni=1 wherexi is the ith source sentence of language X and yiis its translation in the target language Y
Following the approach of Johnson et al (2017)and Xue et al (2021) we model translation in atext-to-text format More specifically we createthe input for the model by prepending the targetlanguage tag to the source sentence Thereforefor each source sentence xi the input to the modelis ltYtaggt xi and the target is yi Taking a realexample letrsquos say we wish to translate the Igbosentence Daalu maka ikwu eziokwu nke Chineke toEnglish The input to the model becomes ltenggtDaalu maka ikwu eziokwu nke Chineke
43 TrainingWe have a set of language tags L for the lan-guages we are working with in our multilin-gual many-to-many translation In our baselinesetup (section 441) L = eng fra ibo fonand in our final experiment (section 442) L =eng fra ibo fon swa kin xho yor We car-ried out many-to-many translation using all thepossible directions from L except eng larrrarr fraWe skipped eng larrrarr fra for this fundamentalreason
bull our main focus is on AfricanlarrrarrAfrican oreng fra larrrarrAfrican Due to the high-
403
resource nature of English and French addingthe training set for eng larrrarr fra would over-shadow the learning of the other language di-rections and greatly impede our analyses Ourintuition draws from the observation of Xueet al (2021) as the reason for off-target trans-lation in the mT5 model as English-basedfinetuning proceeds the modelrsquos assigned like-lihood of non-English tokens presumably de-creases Therefore since the mt5-basetraining set contained predominantly English(and after other European languages) tokensand our research is about ALlarrrarrAL trans-lation removing the eng larrrarr fra directionwas our way of ensuring the model designatedmore likelihood to AL tokens
431 Our ContributionsIn addition to the parallel data between the Africanlanguages we leveraged monolingual data to im-prove translation quality in two ways
1 our backtranslation (BT) We designed amodified form of the random online backtrans-lation (Zhang et al 2020) where instead ofrandomly selecting a subset of languages tobacktranslate we selected for each languagenum_bt sentences at random from the mono-lingual data set This means that the modelgets to backtranslate different (monolingual)sentences every backtranslation time and inso doing we believe improve the modelrsquos do-main adaptation because it gets to learn fromvarious samples from the whole monolingualdata set We initially tested different values ofnum_bt to find a compromise between back-translation computation time and translationquality
Following research works which have shownthe effectiveness of random beam-search overgreedy decoding while generating backtrans-lations (Lample et al 2017 Edunov et al2018 Hoang et al 2018 Zhang et al 2020)we generated num_sample prediction sen-tences from the model and randomly selected(with equal probability) one for our back-translated sentence Naturally the value ofnum_sample further affects the computa-tion time (because the model has to producenum_sample different output sentences foreach input sentence) and so we finally settledwith num_sample = 2
2 our reconstruction Given a monolingualsentence xm from language m we appliedrandom swapping (2 times) and deletion (witha probability of 02) to get a noisy version xTaking inspiration from Raffel et al (2019)we integrated the reconstruction objective intoour model finetuning by prepending the lan-guage tag ltmgt to x and setting its target out-put to xm
44 ExperimentsIn all our experiments we initialized the pretrainedmT5-base model using Hugging Facersquos Auto-
ModelForSeq2SeqLM6 and tracked the trainingprocess with WeightsampBiases (Biewald 2020) Weused the AdamW optimizer (Loshchilov and Hutter2017) with a learning rate (lr) of 3eminus6 and trans-formerrsquos get_linear_schedule_with_warmup7
scheduler (where the learning rate decreases lin-early from the initial lr set in the optimizer to 0after a warmup period and then increases linearlyfrom 0 to the initial lr set in the optimizer)
441 BaselineThe goal of our baseline was to understand theeffect of jointly finetuning with backtranslationand reconstruction on the AfricanlarrrarrAfrican lan-guage translation quality in two scenarios whenthe AL was initially pretrained on the multilingualmodel and contrariwise Using Fon (which wasnot initially included in the pretraining) and Igbo(which was initially included in the pretraining) asthe African languages for our baseline training wefinetuned our model on a many-to-many translationin all directions of eng fra ibo foneng larrrarrfra amounting to 10 directions We used theBaseline Train Set for training and theBaseline Test Set for evaluation We
trained the model for only 3 epochs in three set-tings
1 BASE in this setup we finetune the modelon only the many-to-many translation task nobacktranslation nor reconstruction
2 BT refers to finetuning with our backtransla-tion objective described in section 42 For our
6httpshuggingfacecotransformersmodel_docautohtmltransformersAutoModelForSeq2SeqLM
7httpshuggingfacecotransformersmain_classesoptimizer_scheduleshtmltransformersget_linear_schedule_with_warmup
404
baseline where we backtranslate using mono-lingual data in ibo fon we set num_bt =500 For our final experiments we first triedwith 500 but finally reduced to 100 due to thegreat deal of computation required
For our baseline experiment we ran one epochnormally and the remaining two with back-translation For our final experiments we firstfinetuned the model on 3 epochs before con-tinuing with backtranslation
3 BTampREC refers to joint backtranslation andreconstruction (explained in section 42) whilefinetuning Two important questions were ad-dressed ndash 1) the ratio backtranslation re-construction of monolingual sentences to useand 2) whether to use the same or differentsentences for backtranslation and reconstruc-tion Bearing computation time in mind weresolved to go with 500 50 for our baselineand 100 50 for our final experiments Weleave ablation studies on the effect of the ra-tio on translation quality to future work Forthe second question we decided to randomlysample (with replacement) different sentenceseach for our backtranslation and reconstruc-tion
For our baseline we used a learning rate of 5eminus4a batch size of 32 sentences with gradient accumu-lation up to a batch of 256 sentences and an earlystopping patience of 100 evaluation steps To fur-ther analyse the performance of our baseline setupswe ran comparemt 8 (Neubig et al 2019) on themodelrsquos predictions
442 MMTAfricaMMTAfrica refers to our final experimentalsetup where we finetuned our model on all lan-guage directions involving all eight languagesL = eng fra ibo fon swa kin xho yor ex-cept englarrrarrfra Taking inspiration from our base-line results we ran our experiment with our pro-posed BTampREC setting and made some adjust-ments along the way
The long computation time for backtranslating(with just 100 sentences per language the modelwas required to generate around 3 000 translationsevery backtranslation time) was a drawback Tomitigate the issue we parallelized the process us-
8httpsgithubcomneulabcompare-mt
ing the multiprocessing package in Python9 Wefurther slowly reduced the number of sentences forbacktranslation (to 50 and finally 10)
Gradient descent in large multilingual modelshas been shown to be more stable when updatesare performed over large batch sizes are used (Xueet al 2021) To cope with our computational re-sources we used gradient accumulation to increaseupdates from an initial batch size of 64 sentencesup to a batch gradient computation size of 4096sentences We further utilized PyTorchrsquos DataParal-lel package10 to parallelize the training across theGPUs We used a learning rate (lr) of 3eminus6
5 Results and Insights
All evaluations were made using spBLEU (sen-tencepiece (Kudo and Richardson 2018) + sacre-BLEU (Post 2018)) as described in (Goyal et al2021) We further evaluated on the chrF (Popovic2015) and TER metrics
51 Baseline Results and InsightsFigure 1 compares the spBLEU scores for the threesetups used in our baseline experiments As a re-minder we make use of the symbol to refer toany language in the set eng fra ibo fon
BT gives strong improvement over BASE (ex-cept in engminusrarribo where itrsquos relatively the sameand framinusrarribo where it performs worse)
Figure 1 spBLEU scores of the 3 setups explained insection 441
When the target language is fon we observe aconsiderable boost in the spBLEU of the BT set-ting which also significantly outperformed BASE
9httpsdocspythonorg3librarymultiprocessinghtml
10httpspytorchorgdocsstablegeneratedtorchnnDataParallelhtml
405
and BTampREC BTampREC contributed very littlewhen compared with BT and sometimes even per-formed poorly (in engminusrarrfon) We attribute thispoor performance from the reconstruction objec-tive to the fact that the mt5-base model wasnot originally pretrained on Fon Therefore withonly 3 epochs of finetuning (and 1 epoch beforeintroducing the reconstruction and backtranslationobjectives) the model was not able to meaningfullyutilize both objectives
Conversely when the target language is iboBTampREC gives best results ndash even in scenarios
where BT underperforms BASE (as is the caseof framinusrarribo and engminusrarribo) We believe that thedecoder of the model being originally pretrainedon corpora containing Igbo was able to better useour reconstruction to improve translation quaity in minusrarribo direction
Drawing insights from fonlarrrarribo we offer thefollowing propositions concerning ALlarrrarrALmultilingual translation
bull our backtranslation (section 42) from mono-lingual data improves the cross-lingual map-ping of the model for low-resource Africanlanguages While it is computationally expen-sive our parallelization and decay of numberof backtranslated sentences are some potentialsolutions towards effectively adopting back-translation using monolingual data
bull Denoising objectives typically have beenknown to improve machine translation qual-ity (Zhang and Zong 2016 Cheng et al 2016Gu et al 2019 Zhang et al 2020 Xue et al2021) because they imbue the model withmore generalizable knowledge (about that lan-guage) which is used by the decoder to pre-dict better token likelihoods for that languageduring translation This is a reasonable ex-planation for the improved quality with theBTampREC over BT in the minusrarribo As we
learned from minusrarrfon using reconstructioncould perform unsatisfactorily if not handledwell Some methods we propose are
1 For African languages that were includedin the original model pretraining (aswas the case of Igbo Swahili Xhosaand Yorugravebaacute in the mT5 model) usingthe BTampREC setting for finetuning pro-duces best results While we did not per-form ablation studies on the data size
ratio for backtranslation and reconstruc-tion we believe that our ratio of 2 1(in our final experiments) gives the bestcompromise on both computation timeand translation quality
2 For African languages that were not orig-inally included in the original model pre-training (as was the case of Kinyarwandaand Fon in the mT5 model) reconstruc-tion together with backtranslation (espe-cially at an early stage) only introducesmore noise which could harm the cross-lingual learning For these languages wepropose(a) first finetuning the model on only
our reconstruction (described in sec-tion 42) for fairly long training stepsbefore using BTampREC This waythe initial reconstruction will help themodel learn that language represen-tation space and increase its the like-lihood of tokens
52 MMTAfrica Results and InsightsIn Table 4 we compared MMTAfrica with theM2M MMT(Fan et al 2020) benchmark resultsof Goyal et al (2021) using the same test set theyused ndash FLORES Test Set On all languagepairs except swararreng (which has a comparableminus276 spBLEU difference) we report an improve-ment from MMTAfrica (spBLEU gains rangingfrom +058 in swaminusrarrfra to +1946 in framinusrarrxho)The lower score of swararreng presents an intriguinganomaly especially given the large availability ofparallel corpora in our training set for this pair Weplan to investigate this in further work
In Table 5 we introduce benchmark results ofMMTAfrica on MMTAfrica Test Set Wealso put the test size of each language pair
Interesting analysis about Fon (fon) andYorugravebaacute (yor) For each language the lowest sp-BLEU scores in both tables come from the minusrarryordirection except fonlarrrarryor (from Table 5) whichinterestingly has the highest spBLEU score com-pared to the other fonminusrarr ~ directions We donot know the reason for the very low performancein the ~ minusrarryor direction but we offer below aplausible explanation about fonlarrrarryor
The oral linguistic history of Fon ties it to theancient Yorugravebaacute kingdom (Barnes 1997) Further-more in present day Benin where Fon is largely
406
spoken as a native language Yoruba is one of the in-digenuous languages commonly spoken 11 There-fore Fon and Yorugravebaacute share some linguistic charac-teristics and we believe this is one logic behind thefonlarrrarryor surpassing other fonminusrarr ~ directions
This explanation could inspire transfer learningfrom Yorugravebaacute which has received comparably moreresearch and has more resources for machine trans-lation to Fon We leave this for future work
Source Target spBLEU (FLORES)uarr spBLEU (Ours)uarr spCHRFuarr spTERdarr
ibo swa 438 2184 3738 7148
ibo xho 244 1397 3195 8137
ibo yor 154 1072 2655 7572
ibo eng 737 1362 3890 7623
ibo fra 602 1646 3510 7548
swa ibo 197 1980 3395 6822
swa xho 271 2171 3986 7316
swa yor 129 1168 2744 7523
swa eng 3043 2767 5612 5591
swa fra 2669 2727 4620 6347
xho ibo 380 1702 3130 7066
xho swa 614 2947 4468 6321
xho yor 192 1042 2677 7625
xho eng 1086 2077 4869 6409
xho fra 828 2148 4065 6931
yor ibo 185 1145 2526 7499
yor swa 193 1499 3049 7990
yor xho 194 931 2634 8608
yor eng 418 815 3065 8694
yor fra 357 1059 2760 8132
eng ibo 353 2149 3724 6568
eng swa 2695 4011 5313 5280
eng xho 447 2715 4493 6777
eng yor 217 1209 2834 7474
fra ibo 169 1948 3447 6850
fra swa 1717 3421 4895 5811
fra xho 227 2173 4006 7372
fra yor 116 1142 2767 7533
Table 4 Evaluation Scores of the Flores M2M MMTmodel and MMTAfrica on FLORES Test Set
6 Conclusion and Future Work
In this paper we introduced MMTAfrica a mul-tilingual machine translation model on 6 AfricanLanguages which outperformed the M2M MMTmodel Fan et al (2020) Our results and analy-ses including a new reconstruction objective giveinsights on MMT for African languages for fu-ture research Moreover we plan to launch themodel on Masakhane MT and FFRTranslate in or-der to get human evaluation feedback from theactual speakers of the languages in the Masakhanecommunity (Orife et al 2020) and beyond
In order to fully test the advantage ofMMTAfrica we plan to finish comparing it on
11httpsenwikipediaorgwikiBenin(Last Accessed 30082021)
direct and pivot translations with the Masakhanebenchmark models (forall et al 2020) We alsoplan to perform human evaluation All test setsresults code and checkpoints will be releasedat httpsgithubcomedaiofficialmmtafrica
7 Acknowledgments
The computational resources for running all ex-periments were provided by the FLORES com-pute grants12 as well as additonal computationalresources provided by Paco Guzman (FacebookAI) and Mila Quebec AI Institute We expressour profound gratitude to all who contributed inone way or the other towards the development ofMMTAfrica including (in no order)
Mathias Muumlller (University of Zurich) for giv-ing immense technical assistance in finetuning themodel and advising us on best hyperparameter tun-ing practises
Graham Neubig (Carnegie Mellon University)for explaining and setting up comparemt for usto better understand and evaluate the performanceof our baseline models
Angela Fan (FacebookAI) for guiding us duringthe shared task and taking the time to answer allour questions
Julia Kreutzer (GoogleAI) for advising us on use-ful model comparison and evaluation techniques
Colin Leong (University of Dayton) for painstak-ingly proof-reading the paper and helping us makeit more reader-friendly
Daria Yasafova (Technical University of Mu-nich) and Yeno Gbenou (Drexel University) foradditionally proof-reading the paper
Finally the entire Masakhane community13 foramong many other things 1) guiding us to exist-ing parallel and monolingual data set for the focusAfrican languages 2) explaining their (the focusAfrican languages) important linguistic charteris-tics which helped us work better with them (likein preprocessing) and 3) performing (in the future)human evaluation on MMTAfrica
Indeed it took a village to raise MMTAfrica1412httpwwwstatmtorgwmt21
flores-compute-grantshtml13httpswwwmasakhaneio14lsquoIt takes a village to raise a childrsquo is an African proverb
that means that an entire community of people with differentexpertise must provide for and interact positively with the childfor the child to actually develop and reach the best possiblepotential
407
Source Target Test size spBLEUuarr spCHRFuarr spTERdarr
ibo swa 60 3489 4738 6828
ibo xho 30 3669 5066 5965
ibo yor 30 1177 2954 12984
ibo kin 30 3392 4653 6773
ibo fon 30 3596 4314 6321
ibo eng 90 3728 6042 6205
ibo fra 60 3086 4409 6953
swa ibo 60 3371 4302 6001
swa xho 30 3728 5253 5586
swa yor 30 1409 2750 11363
swa kin 30 2386 4259 9467
swa fon 30 2329 3352 6511
swa eng 60 3555 6047 4732
swa fra 60 3011 4833 6338
xho ibo 30 3325 4536 6283
xho swa 30 3926 5375 5372
xho yor 30 2200 3806 7045
xho kin 30 3066 4619 7470
xho fon 30 2580 3487 6596
xho eng 90 3025 5512 6211
xho fra 30 2945 4572 6103
yor ibo 30 2511 3419 7480
yor swa 30 1762 3471 8518
yor xho 30 2931 4313 6682
yor kin 30 2516 3802 7267
yor fon 30 3181 3745 6339
yor eng 90 1781 4173 9300
yor fra 30 1544 3097 9057
kin ibo 30 3125 4236 6673
kin swa 30 3365 4634 7270
kin xho 30 2040 3971 8997
kin yor 30 1834 3353 7043
kin fon 30 2243 3249 6726
kin eng 60 1582 4310 9655
kin fra 30 1623 3351 9182
fon ibo 30 3236 4644 6182
fon swa 30 2984 4296 7228
fon xho 30 2882 4374 6698
fon yor 30 3045 4263 6072
fon kin 30 2388 3959 7806
fon eng 30 1663 4163 6903
fon fra 60 2479 4339 8215
eng ibo 90 4424 5489 6392
eng swa 60 4994 6145 4783
eng xho 120 3197 4974 7289
eng yor 90 2393 3619 8405
eng kin 90 4098 5600 7637
eng fon 30 2719 3686 6254
fra ibo 60 3647 4693 5991
fra swa 60 3653 5142 5594
fra xho 30 3435 4939 6030
fra yor 30 726 2554 12453
fra kin 30 3107 4226 8106
fra fon 60 3107 3872 7574
Table 5 Benchmark Evaluation Scores onMMTAfrica Test Set
ReferencesSolomon Teferra Abate Michael Melese Martha Yi-
firu Tachbelie Million Meshesha Solomon AtinafuWondwossen Mulugeta Yaregal Assabie HafteAbera Binyam Ephrem Tewodros Abebe Wondim-agegnhue Tsegaye Amanuel Lemma Tsegaye An-dargie and Seifedin Shifaw 2018 Parallel corporafor bi-lingual English-Ethiopian languages statisti-cal machine translation In Proceedings of the 27thInternational Conference on Computational Linguis-tics pages 3102ndash3111 Santa Fe New Mexico USAAssociation for Computational Linguistics
Jade Abbott and Laura Martinus 2019 Benchmarkingneural machine translation for Southern African lan-guages In Proceedings of the 2019 Workshop onWidening NLP pages 98ndash101 Florence Italy Asso-ciation for Computational Linguistics
Jade Z Abbott and Laura Martinus 2018 Towardsneural machine translation for african languages
David I Adelani Dana Ruiter Jesujoba O Al-abi Damilola Adebonojo Adesina Ayeni MofeAdeyemi Ayodele Awokoya and Cristina Espantildea-Bonet 2021a The effect of domain and diacritics inyorugravebaacute-english neural machine translation
David Ifeoluwa Adelani Jade Z Abbott GrahamNeubig Daniel Drsquosouza Julia Kreutzer Constan-tine Lignos Chester Palen-Michel Happy Buza-aba Shruti Rijhwani Sebastian Ruder StephenMayhew Israel Abebe Azime Shamsuddeen Has-san Muhammad Chris Chinenye Emezue JoyceNakatumba-Nabende Perez Ogayo Aremu An-uoluwapo Catherine Gitau Derguene Mbaye Je-sujoba O Alabi Seid Muhie Yimam Tajud-deen Gwadabe Ignatius Ezeani Rubungo An-dre Niyongabo Jonathan Mukiibi Verrah OtiendeIroro Orife Davis David Samba Ngom Tosin PAdewumi Paul Rayson Mofetoluwa Adeyemi Ger-ald Muriuki Emmanuel Anebi Chiamaka Chuk-wuneke Nkiruka Odu Eric Peter Wairagala SamuelOyerinde Clemencia Siro Tobius Saul BateesaTemilola Oloyede Yvonne Wambui Victor Akin-ode Deborah Nabagereka Maurice Katusiime Ayo-dele Awokoya Mouhamadane Mboup Dibora Ge-breyohannes Henok Tilaye Kelechi Nwaike De-gaga Wolde Abdoulaye Faye Blessing SibandaOrevaoghene Ahia Bonaventure F P DossouKelechi Ogueji Thierno Ibrahima Diop AbdoulayeDiallo Adewale Akinfaderin Tendai Marengerekeand Salomey Osei 2021b Masakhaner Namedentity recognition for african languages CoRRabs210311811
Željko Agic and Ivan Vulic 2019 JW300 A wide-coverage parallel corpus for low-resource languagesIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages3204ndash3210 Florence Italy Association for Compu-tational Linguistics
Roee Aharoni Melvin Johnson and Orhan Firat 2019Massively multilingual neural machine translation
408
In Proceedings of the 2019 Conference of the NorthAmerican Chapter of the Association for Compu-tational Linguistics Human Language Technolo-gies Volume 1 (Long and Short Papers) pages3874ndash3884 Minneapolis Minnesota Associationfor Computational Linguistics
Jesujoba Alabi Kwabena Amponsah-Kaakyire DavidAdelani and Cristina Espantildea-Bonet 2020 Mas-sive vs curated embeddings for low-resourced lan-guages the case of Yorugravebaacute and Twi In Proceed-ings of the 12th Language Resources and EvaluationConference pages 2754ndash2762 Marseille FranceEuropean Language Resources Association
Naveen Arivazhagan Ankur Bapna Orhan Firat RoeeAharoni Melvin Johnson and Wolfgang Macherey2019a The missing ingredient in zero-shot neuralmachine translation CoRR abs190307091
Naveen Arivazhagan Ankur Bapna Orhan FiratDmitry Lepikhin Melvin Johnson Maxim KrikunMia Xu Chen Yuan Cao George F Foster ColinCherry Wolfgang Macherey Zhifeng Chen andYonghui Wu 2019b Massively multilingual neuralmachine translation in the wild Findings and chal-lenges CoRR abs190705019
Mikko Aulamo Umut Sulubacak Sami Virpioja andJoumlrg Tiedemann 2020 OpusTools and parallel cor-pus diagnostics In Proceedings of The 12th Lan-guage Resources and Evaluation Conference pages3782ndash3789 European Language Resources Associ-ation
Dzmitry Bahdanau Kyunghyun Cho and Yoshua Ben-gio 2015 Neural machine translation by jointlylearning to align and translate In 3rd Inter-national Conference on Learning RepresentationsICLR 2015 San Diego CA USA May 7-9 2015Conference Track Proceedings
ST Barnes 1997 Africarsquos Ogun Old World andNew African systems of thought Indiana Univer-sity Press
Loiumlc Barrault Magdalena Biesialska Ondrej BojarMarta R Costa-jussagrave Christian Federmann YvetteGraham Roman Grundkiewicz Barry HaddowMatthias Huck Eric Joanis Tom Kocmi PhilippKoehn Chi-kiu Lo Nikola Ljubešic ChristofMonz Makoto Morishita Masaaki Nagata Toshi-aki Nakazawa Santanu Pal Matt Post and MarcosZampieri 2020 Findings of the 2020 conference onmachine translation (WMT20) In Proceedings ofthe Fifth Conference on Machine Translation pages1ndash55 Online Association for Computational Lin-guistics
Loiumlc Barrault Ondrej Bojar Marta R Costa-jussagraveChristian Federmann Mark Fishel Yvette Gra-ham Barry Haddow Matthias Huck Philipp KoehnShervin Malmasi Christof Monz Mathias MuumlllerSantanu Pal Matt Post and Marcos Zampieri 2019
Findings of the 2019 conference on machine transla-tion (WMT19) In Proceedings of the Fourth Con-ference on Machine Translation (Volume 2 SharedTask Papers Day 1) pages 1ndash61 Florence Italy As-sociation for Computational Linguistics
Lukas Biewald 2020 Experiment tracking withweights and biases Software available fromwandbcom
Yong Cheng Wei Xu Zhongjun He Wei He HuaWu Maosong Sun and Yang Liu 2016 Semi-supervised learning for neural machine translationIn Proceedings of the 54th Annual Meeting of the As-sociation for Computational Linguistics (Volume 1Long Papers) pages 1965ndash1974 Berlin GermanyAssociation for Computational Linguistics
Kyunghyun Cho Bart van Merrienboer CcedilaglarGuumllccedilehre Dzmitry Bahdanau Fethi Bougares Hol-ger Schwenk and Yoshua Bengio 2014 Learningphrase representations using RNN encoder-decoderfor statistical machine translation In Proceedings ofthe 2014 Conference on Empirical Methods in Nat-ural Language Processing EMNLP 2014 October25-29 2014 Doha Qatar A meeting of SIGDAT aSpecial Interest Group of the ACL pages 1724ndash1734ACL
Alexis Conneau Kartikay Khandelwal Naman GoyalVishrav Chaudhary Guillaume Wenzek FranciscoGuzmaacuten Edouard Grave Myle Ott Luke Zettle-moyer and Veselin Stoyanov 2019 Unsupervisedcross-lingual representation learning at scale
Jacob Devlin Ming-Wei Chang Kenton Lee andKristina Toutanova 2018 BERT pre-training ofdeep bidirectional transformers for language under-standing CoRR abs181004805
Daxiang Dong Hua Wu Wei He Dianhai Yu andHaifeng Wang 2015 Multi-task learning for mul-tiple language translation In Proceedings of the53rd Annual Meeting of the Association for Compu-tational Linguistics and the 7th International JointConference on Natural Language Processing (Vol-ume 1 Long Papers) pages 1723ndash1732 BeijingChina Association for Computational Linguistics
Bonaventure F P Dossou and Chris C Emezue 2020FFR V10 fon-french neural machine translationCoRR abs200312111
Bonaventure F P Dossou and Chris C Emezue 2021aCrowdsourced phrase-based tokenization for low-resourced neural machine translation The case offon language CoRR abs210308052
Bonaventure F P Dossou and Chris C Emezue 2021bOkwugbeacute End-to-end speech recognition for fonand igbo CoRR abs210307762
David M Eberhard Gary F Simons and CharlesD Fennig (eds) 2020 Ethnologue Languages ofthe world twenty-third edition
409
Sergey Edunov Myle Ott Michael Auli and DavidGrangier 2018 Understanding back-translation atscale CoRR abs180809381
Ignatius Ezeani Paul Rayson Ikechukwu E OnyenweChinedu Uchechukwu and Mark Hepple 2020Igbo-english machine translation An evaluationbenchmark CoRR abs200400648
Angela Fan Shruti Bhosale Holger Schwenk ZhiyiMa Ahmed El-Kishky Siddharth Goyal Man-deep Baines Onur Celebi Guillaume WenzekVishrav Chaudhary Naman Goyal Tom Birch Vi-taliy Liptchinsky Sergey Edunov Edouard GraveMichael Auli and Armand Joulin 2020 Be-yond english-centric multilingual machine transla-tion CoRR abs201011125
Thibault Feacutevry and Jason Phang 2018 Unsuper-vised sentence compression using denoising auto-encoders CoRR abs180902669
Orhan Firat Kyunghyun Cho and Yoshua Bengio2016a Multi-way multilingual neural machinetranslation with a shared attention mechanism InProceedings of the 2016 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 866ndash875 San Diego California Associationfor Computational Linguistics
Orhan Firat Baskaran Sankaran Yaser Al-onaizanFatos T Yarman Vural and Kyunghyun Cho 2016bZero-resource translation with multi-lingual neuralmachine translation In Proceedings of the 2016Conference on Empirical Methods in Natural Lan-guage Processing pages 268ndash277 Austin TexasAssociation for Computational Linguistics
forall Wilhelmina Nekoto Vukosi Marivate TshinondiwaMatsila Timi Fasubaa Tajudeen Kolawole TaiwoFagbohungbe Solomon Oluwole Akinola Sham-suddee Hassan Muhammad Salomon Kabongo Sa-lomey Osei et al 2020 Participatory research forlow-resourced machine translation A case study inafrican languages Findings of EMNLP
Naman Goyal Cynthia Gao Vishrav Chaudhary Peng-Jen Chen Guillaume Wenzek Da Ju Sanjana Kr-ishnan MarcrsquoAurelio Ranzato Francisco Guzmanand Angela Fan 2021 The flores-101 evaluationbenchmark for low-resource and multilingual ma-chine translation
Jiatao Gu Yong Wang Kyunghyun Cho and Vic-tor OK Li 2019 Improved zero-shot neural ma-chine translation via ignoring spurious correlationsIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages1258ndash1268 Florence Italy Association for Compu-tational Linguistics
Thanh-Le Ha Jan Niehues and Alexander H Waibel2016 Toward multilingual neural machine trans-lation with universal encoder and decoder CoRRabs161104798
Vu Cong Duy Hoang Philipp Koehn GholamrezaHaffari and Trevor Cohn 2018 Iterative back-translation for neural machine translation In Pro-ceedings of the 2nd Workshop on Neural MachineTranslation and Generation pages 18ndash24 Mel-bourne Australia Association for ComputationalLinguistics
Melvin Johnson Mike Schuster Quoc V Le MaximKrikun Yonghui Wu Zhifeng Chen Nikhil ThoratFernanda Vieacutegas Martin Wattenberg Greg CorradoMacduff Hughes and Jeffrey Dean 2017 Googlersquosmultilingual neural machine translation system En-abling zero-shot translation Transactions of the As-sociation for Computational Linguistics 5339ndash351
Pratik Joshi Sebastin Santy Amar Budhiraja KalikaBali and Monojit Choudhury 2020 The state andfate of linguistic diversity and inclusion in the NLPworld In Proceedings of the 58th Annual Meet-ing of the Association for Computational Linguisticspages 6282ndash6293 Online Association for Computa-tional Linguistics
Taku Kudo and John Richardson 2018 SentencePieceA simple and language independent subword tok-enizer and detokenizer for neural text processing InProceedings of the 2018 Conference on EmpiricalMethods in Natural Language Processing SystemDemonstrations pages 66ndash71 Brussels BelgiumAssociation for Computational Linguistics
Surafel Melaku Lakew Mauro Cettolo and MarcelloFederico 2018 A comparison of transformer andrecurrent neural networks on multilingual neural ma-chine translation In Proceedings of the 27th Inter-national Conference on Computational Linguisticspages 641ndash652 Santa Fe New Mexico USA Asso-ciation for Computational Linguistics
Guillaume Lample Ludovic Denoyer andMarcrsquoAurelio Ranzato 2017 Unsupervisedmachine translation using monolingual corporaonly CoRR abs171100043
Jason Lee Kyunghyun Cho and Thomas Hofmann2017 Fully Character-Level Neural Machine Trans-lation without Explicit Segmentation Transactionsof the Association for Computational Linguistics5365ndash378
Ilya Loshchilov and Frank Hutter 2017 Fixingweight decay regularization in adam CoRRabs171105101
Yichao Lu Phillip Keung Faisal Ladhak Vikas Bhard-waj Shaonan Zhang and Jason Sun 2018 A neu-ral interlingua for multilingual machine translationIn Proceedings of the Third Conference on MachineTranslation Research Papers pages 84ndash92 Brus-sels Belgium Association for Computational Lin-guistics
Laura Martinus and Jade Z Abbott 2019 A focuson neural machine translation for african languagesCoRR abs190605685
410
Graham Neubig Zi-Yi Dou Junjie Hu Paul MichelDanish Pruthi Xinyi Wang and John Wieting 2019compare-mt A tool for holistic comparison of lan-guage generation systems CoRR abs190307926
Graham Neubig and Junjie Hu 2018 Rapid adapta-tion of neural machine translation to new languagesIn Proceedings of the 2018 Conference on Empiri-cal Methods in Natural Language Processing pages875ndash880 Brussels Belgium Association for Com-putational Linguistics
Rubungo Andre Niyongabo Qu Hong Julia Kreutzerand Li Huang 2020 KINNEWS and KIRNEWSBenchmarking cross-lingual text classification forKinyarwanda and Kirundi In Proceedings ofthe 28th International Conference on Computa-tional Linguistics pages 5507ndash5521 BarcelonaSpain (Online) International Committee on Compu-tational Linguistics
Linda Nordling 2018 How decolonizationcould reshape south african science Nature554(7691)159ndash162
Evander Nyoni and Bruce A Bassett 2021 Low-resource neural machine translation for southernafrican languages CoRR abs210400366
Iroro Orife Julia Kreutzer Blessing Sibanda DanielWhitenack Kathleen Siminyu Laura MartinusJamiil Toure Ali Jade Z Abbott Vukosi Mari-vate Salomon Kabongo Musie Meressa Es-poir Murhabazi Orevaoghene Ahia Elan VanBiljon Arshath Ramkilowan Adewale AkinfaderinAlp Oumlktem Wole Akin Ghollah Kioko KevinDegila Herman Kamper Bonaventure DossouChris Emezue Kelechi Ogueji and Abdallah Bashir2020 Masakhane - machine translation for africaCoRR abs200311529
Maja Popovic 2015 chrF character n-gram F-scorefor automatic MT evaluation In Proceedings of theTenth Workshop on Statistical Machine Translationpages 392ndash395 Lisbon Portugal Association forComputational Linguistics
Matt Post 2018 A call for clarity in reporting BLEUscores In Proceedings of the Third Conference onMachine Translation Research Papers pages 186ndash191 Brussels Belgium Association for Computa-tional Linguistics
Colin Raffel Noam Shazeer Adam Roberts KatherineLee Sharan Narang Michael Matena Yanqi ZhouWei Li and Peter J Liu 2019 Exploring the limitsof transfer learning with a unified text-to-text trans-former CoRR abs191010683
Machel Reid Junjie Hu Graham Neubig and YutakaMatsuo 2021 Afromt Pretraining strategies andreproducible benchmarks for translation of 8 africanlanguages
Rico Sennrich Barry Haddow and Alexandra Birch2015 Improving neural machine translation modelswith monolingual data CoRR abs151106709
Shivachi Casper Shikali and Mokhosi Refuoe 2019Language modeling data for swahili
Aditya Siddhant Ankur Bapna Yuan Cao Orhan Fi-rat Mia Xu Chen Sneha Reddy Kudugunta NaveenArivazhagan and Yonghui Wu 2020 Lever-aging monolingual data with self-supervision formultilingual neural machine translation CoRRabs200504816
Ilya Sutskever Oriol Vinyals and Quoc V Le 2014Sequence to sequence learning with neural networksIn Proceedings of the 27th International Conferenceon Neural Information Processing Systems - Vol-ume 2 NIPSrsquo14 page 3104ndash3112 Cambridge MAUSA MIT Press
Xu Tan Jiale Chen Di He Yingce Xia Tao Qin andTie-Yan Liu 2019 Multilingual neural machinetranslation with language clustering In Proceedingsof the 2019 Conference on Empirical Methods inNatural Language Processing and the 9th Interna-tional Joint Conference on Natural Language Pro-cessing (EMNLP-IJCNLP) pages 963ndash973 HongKong China Association for Computational Lin-guistics
Joumlrg Tiedemann 2012 Parallel data tools and inter-faces in opus In Proceedings of the Eight Interna-tional Conference on Language Resources and Eval-uation (LRECrsquo12) Istanbul Turkey European Lan-guage Resources Association (ELRA)
Daniel van Niekerk Charl van Heerden Marelie DavelNeil Kleynhans Oddur Kjartansson Martin Janscheand Linne Ha 2017 Rapid development of TTS cor-pora for four South African languages In Proc In-terspeech 2017 pages 2178ndash2182 Stockholm Swe-den
Ashish Vaswani Noam Shazeer Niki Parmar JakobUszkoreit Llion Jones Aidan N Gomez LukaszKaiser and Illia Polosukhin 2017 Attention is allyou need CoRR abs170603762
Sarah Wild 2021 African languages to get more be-spoke scientific terms Nature 596(7873)469ndash470
Ronald J Williams and David Zipser 1989 A learn-ing algorithm for continually running fully recurrentneural networks Neural Computation 1(2)270ndash280
Linting Xue Noah Constant Adam Roberts Mi-hir Kale Rami Al-Rfou Aditya Siddhant AdityaBarua and Colin Raffel 2021 mT5 A massivelymultilingual pre-trained text-to-text transformer InProceedings of the 2021 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 483ndash498 Online Association for Computa-tional Linguistics
Biao Zhang Philip Williams Ivan Titov and RicoSennrich 2020 Improving massively multilingualneural machine translation and zero-shot translationCoRR abs200411867
411
Jiajun Zhang and Chengqing Zong 2016 Exploit-ing source-side monolingual data in neural machinetranslation In Proceedings of the 2016 Conferenceon Empirical Methods in Natural Language Process-ing pages 1535ndash1545 Austin Texas Associationfor Computational Linguistics
Barret Zoph Deniz Yuret Jonathan May and KevinKnight 2016 Transfer learning for low-resourceneural machine translation In Proceedings of the2016 Conference on Empirical Methods in Natu-ral Language Processing pages 1568ndash1575 AustinTexas Association for Computational Linguistics

400
special symbols to the source text to indicate thetarget language We adopt their model approach inthis paper
The current state of multilingual NMT wherea single NMT model is optimized for the transla-tion of multiple language pairs (Firat et al 2016aJohnson et al 2017 Lu et al 2018 Aharoni et al2019 Arivazhagan et al 2019b) has become veryappealing for a number of reasons It is scalableand easy to deploy or maintan (the ability of asingle model to effectively handle all translation di-rections from N languages if properly trained anddesigned surpasses the scalability of O(N2) indi-vidually trained models using the traditional bilin-gual framework) Multilingual NMT can encour-age knowledge transfer among related languagepairs (Lakew et al 2018 Tan et al 2019) aswell as positive transfer from higher-resource lan-guages (Zoph et al 2016 Neubig and Hu 2018Arivazhagan et al 2019a Aharoni et al 2019Johnson et al 2017) due to its shared representa-tion improve low-resource translation (Ha et al2016 Johnson et al 2017 Arivazhagan et al2019b Xue et al 2021) and enable zero-shot trans-lation (ie direct translation between a languagepair never seen during training) (Firat et al 2016bJohnson et al 2017)
Despite the many advantages of multilingualNMT it suffers from certain disadvantages Firstlythe output vocabulary size is typically fixed regard-less of the number of languages in the corpus andincreasing the vocabulary size is costly in terms ofcomputational resources because the training andinference time scales linearly with the size of thedecoderrsquos output layer For example the trainingdataset for all the languages in our work gave a totalvocabulary size of 1 683 884 tokens (1 519 918with every sentence lowercased) but we were con-strained to a decoder vocabulary size of 250 000
Another pitfall of massively multilingual NMT isits poor zero-shot performance (Firat et al 2016bArivazhagan et al 2019a Johnson et al 2017Aharoni et al 2019) particularly compared topivot-based models (two bilingual models thattranslate from source to target language throughan intermediate language) Neural machine transla-tion is heavily reliant on parallel data and so with-out access to parallel training data for zero-shotlanguage pairs multilingual models face the spuri-ous correlation issue (Gu et al 2019) and off-targettranslation (Johnson et al 2017) where the model
ignores the given target information and translatesinto a wrong language
Some approaches to improve the performance(including zero-shot translation) of multilingualmodels have relied on leveraging the plentifulsource and target side monolingual data that areavailable For example generating artificial paral-lel data with various forms of backtranslation (Sen-nrich et al 2015) has been shown to greatly im-prove the overall (and zero-shot) performance ofmultilingual models (Firat et al 2016b Gu et al2019 Lakew et al 2018 Zhang et al 2020) aswell as bilingual models (Edunov et al 2018)Zhang et al (2020) proposed random online back-translation to enhance multilingual translation ofunseen training language pairs
Additionally leveraging monolingual data byjointly learning to reconstruct the input while trans-lating has been shown to improve neural machinetranslation quality (Feacutevry and Phang 2018 Lampleet al 2017 Cheng et al 2016 Zhang and Zong2016) Siddhant et al (2020) leveraged monolin-gual data in a semi-supervised fashion and reportedthree major results
1 Using monolingual data significantly booststhe translation quality of low resource lan-guages in multilingual models
2 Self-supervision improves zero-shot transla-tion quality in multilingual models
3 Leveraging monolingual data with self-supervision provides a viable path towardsadding new languages to multilingual models
3 Data Methodology
Table 2 presents the size of the gathered andcleaned parallel sentences for each language di-rection We devised preprocessing guidelines foreach of our focus languages taking their linguisticproperties into consideration We used a maximumsequence length of 50 (due to computational re-sources) and a minimum of 2 In the followingsections we will describe the data sources for thethe parallel and monolingual corpora
Parallel Corpora As NMT models are very re-liant on parallel data we sought to gather moreparallel sentences for each language direction inan effort to increase the size and domain of eachlanguage direction To this end our first source wasJW300 (Agic and Vulic 2019) a parallel corpus of
401
Target Languageibo fon kin xho yor swa eng fra
ibo - 3 179 52 685 58 802 134 219 67 785 85 358 57 458
fon 3 148 - 3 060 3 364 5 440 3 434 5 575 2 400
kin 53 955 3 122 - 70 307 85 824 83 898 77 271 62 236
xho 60 557 3 439 70 506 - 64 179 125 604 138 111 113 453
yor 133 353 5 485 83 866 62 471 - 117 875 122 554 97 000
swa 69 633 3 507 84 025 125 307 121 233 - 186 622 128 428
eng 87 716 5 692 77 148 137 240 125 927 186 122 - -
fra 58 521 2 444 61 986 112 549 98 986 127 718 - -
Table 2 Number of parallel samples for each language direction We highlight the largest and smallest parallelsamples We see for example that much more research on machine translation and data collation has been carriedout on swalarrrarreng than fonlarrrarrfra attesting to the under-representation of some African languages
over 300 languages with around 100 thousand bibli-cal domain parallel sentences per language pair onaverage Using OpusTools (Aulamo et al 2020)we were able to get only very trustworthy trans-lations by setting t = 15 (t is a threshold whichindicates the confidence of the translations) Wecollected more parallel sentences from Tatoeba1kde42 (Tiedemann 2012) and some English-basedbilingual samples from MultiParaCrawl3
Finally following pointers from the native speak-ers of these focus languages in the Masakhane com-munity (forall et al 2020) to existing research on ma-chine translation for African languages which open-sourced their parallel data we assembled moreparallel sentences mostly in the en frlarrrarrALdirection
From all this we createdMMTAfrica Test Set (explained in
more details in section 31) got 5 424 578 totaltraining samples for all languages directions (abreakdown of data size for each language directionis provided in Table 2) and 4 000 for dev
Monolingual Corpora Despite our efforts togather several parallel data from various domainswe were faced with some problems 1) there wasa huge imbalance in parallel samples across thelanguage directions In Table 2 we see that the~ larrrarrfon direction has the least amount of par-allel sentences while ~ larrrarrswa or ~ larrrarryor ismade up of relatively larger parallel sentences 2)
1httpsopusnlpleuTatoebaphp2httpshuggingfacecodatasetskde43httpswwwparacrawleu
the parallel sentences particularly for ALlarrrarrALspan a very small domain (mostly biblical internet)
We therefore set out to gather monolingual datafrom diverse sources As our focus is on Africanlanguages we collated monolingual data in onlythese languages The monolingual sources andvolume are summarized in Table 3
Language(ID) Monolingual source Size
Xhosa (xho) The CC100-Xhosa Dataset cre-ated by Conneau et al (2019) andOpenSLR (van Niekerk et al 2017)
158 660
Yoruba (yor) Yoruba Embeddings Corpus (Alabi et al2020) and MENYO20k (Adelani et al2021a)
45 218
FonFongbe(fon)
FFR Dataset (Dossou and Emezue2020) and Fon French Daily DialoguesParallel Data (Dossou and Emezue2021a)
42 057
SwahiliKiswahili(swa)
(Shikali and Refuoe 2019) 23 170
Kinyarwanda(kin)
KINNEWS-and-KIRNEWS (Niy-ongabo et al 2020)
7 586
Igbo (ibo) (Ezeani et al 2020) 7 817
Table 3 Monolingual data sources and sizes (numberof samples)
31 Data Set Types in our WorkHere we elaborate on the different categories ofdata set that we (generated and) used in our workfor training and evaluation
bull FLORES Test Set This refers to thedev test set of 1012 parallel sentences in all101 language directions provided by Goyal
402
et al (2021)4 We performed evaluation onthis test set for all language directions except~larrrarrfon and ~larrrarrkin
bull MMTAfrica Test Set This is a sub-stantial test set we created by taking out asmall but equal number of sentences fromeach parallel source domain As a result wehave a set from a wide range of domainswhile encompassing samples from many exist-ing test sets from previous research Althoughthis set is small to be fully considered as a testset we open-source it because it contains sen-tences from many domains (making it usefulfor evaluation) and we hope that it can be builtupon by perhaps merging it with other bench-mark test sets (Abate et al 2018 Abbott andMartinus 2019 Reid et al 2021)
bull Baseline TrainTest Set We firstconducted baseline experiments with FonIgbo English and French as explained in sec-tion 441 For this we created a special dataset by carefully selecting a small subset of theFFR Dataset (which already contained paral-lel sentences in French and Fon) first auto-matically translating the sentences to Englishand Igbo using the Google Translate API5and finally re-translating with the help of Igbo(7) and English (7) native speakers (we recog-nized that it was easier for native speakers toedittweak an existing translation rather thanwriting the whole translation from scratch)In so doing we created a data set of 13 878translations in all 4 language directions
We split the data set into 12 554 for trainingBaseline Train Set 662 for dev and662 for test Baseline Test Set
4 Model and Experiments
41 ModelFor all our experiments we used the mT5model (Xue et al 2021) a multilingual variant ofthe encoder-decoder transformer-based (Vaswaniet al 2017) ldquoText-to-Text Transfer Transformerrdquo(T5) model (Raffel et al 2019) In T5 pre-trainingthe NLP tasks (including machine translation) werecast into a ldquotext-to-textrdquo format ndash that is a task
4httpsdlfbaipublicfilescomflores101datasetflores101_datasettargz
5httpscloudgooglecomtranslate
where the model is fed some text prefix for contextor conditioning and is then asked to produce someoutput text This framework makes it straightfor-ward to design a number of NLP tasks like machinetranslation summarization text classification etcAlso it provides a consistent training objective bothfor pre-training and finetuning The mT5 modelwas pre-trained with a maximum likelihood objec-tive using ldquoteacher forcingrdquo (Williams and Zipser1989) The mT5 model was also pretrained witha modification of the masked language modellingobjective (Devlin et al 2018)
We finetuned the mt5-base model on ourmany-to-many machine translation task WhileXue et al (2021) suggest that higher versions ofthe mT5 model (Large XL or XXL) give betterperformance on downstream multilingual transla-tion tasks we were constrained by computationalresources to mt5-base which has 580M pa-rameters
42 SetupFor each language direction X rarr Y we have its setof n parallel sentences D = (xi yi)ni=1 wherexi is the ith source sentence of language X and yiis its translation in the target language Y
Following the approach of Johnson et al (2017)and Xue et al (2021) we model translation in atext-to-text format More specifically we createthe input for the model by prepending the targetlanguage tag to the source sentence Thereforefor each source sentence xi the input to the modelis ltYtaggt xi and the target is yi Taking a realexample letrsquos say we wish to translate the Igbosentence Daalu maka ikwu eziokwu nke Chineke toEnglish The input to the model becomes ltenggtDaalu maka ikwu eziokwu nke Chineke
43 TrainingWe have a set of language tags L for the lan-guages we are working with in our multilin-gual many-to-many translation In our baselinesetup (section 441) L = eng fra ibo fonand in our final experiment (section 442) L =eng fra ibo fon swa kin xho yor We car-ried out many-to-many translation using all thepossible directions from L except eng larrrarr fraWe skipped eng larrrarr fra for this fundamentalreason
bull our main focus is on AfricanlarrrarrAfrican oreng fra larrrarrAfrican Due to the high-
403
resource nature of English and French addingthe training set for eng larrrarr fra would over-shadow the learning of the other language di-rections and greatly impede our analyses Ourintuition draws from the observation of Xueet al (2021) as the reason for off-target trans-lation in the mT5 model as English-basedfinetuning proceeds the modelrsquos assigned like-lihood of non-English tokens presumably de-creases Therefore since the mt5-basetraining set contained predominantly English(and after other European languages) tokensand our research is about ALlarrrarrAL trans-lation removing the eng larrrarr fra directionwas our way of ensuring the model designatedmore likelihood to AL tokens
431 Our ContributionsIn addition to the parallel data between the Africanlanguages we leveraged monolingual data to im-prove translation quality in two ways
1 our backtranslation (BT) We designed amodified form of the random online backtrans-lation (Zhang et al 2020) where instead ofrandomly selecting a subset of languages tobacktranslate we selected for each languagenum_bt sentences at random from the mono-lingual data set This means that the modelgets to backtranslate different (monolingual)sentences every backtranslation time and inso doing we believe improve the modelrsquos do-main adaptation because it gets to learn fromvarious samples from the whole monolingualdata set We initially tested different values ofnum_bt to find a compromise between back-translation computation time and translationquality
Following research works which have shownthe effectiveness of random beam-search overgreedy decoding while generating backtrans-lations (Lample et al 2017 Edunov et al2018 Hoang et al 2018 Zhang et al 2020)we generated num_sample prediction sen-tences from the model and randomly selected(with equal probability) one for our back-translated sentence Naturally the value ofnum_sample further affects the computa-tion time (because the model has to producenum_sample different output sentences foreach input sentence) and so we finally settledwith num_sample = 2
2 our reconstruction Given a monolingualsentence xm from language m we appliedrandom swapping (2 times) and deletion (witha probability of 02) to get a noisy version xTaking inspiration from Raffel et al (2019)we integrated the reconstruction objective intoour model finetuning by prepending the lan-guage tag ltmgt to x and setting its target out-put to xm
44 ExperimentsIn all our experiments we initialized the pretrainedmT5-base model using Hugging Facersquos Auto-
ModelForSeq2SeqLM6 and tracked the trainingprocess with WeightsampBiases (Biewald 2020) Weused the AdamW optimizer (Loshchilov and Hutter2017) with a learning rate (lr) of 3eminus6 and trans-formerrsquos get_linear_schedule_with_warmup7
scheduler (where the learning rate decreases lin-early from the initial lr set in the optimizer to 0after a warmup period and then increases linearlyfrom 0 to the initial lr set in the optimizer)
441 BaselineThe goal of our baseline was to understand theeffect of jointly finetuning with backtranslationand reconstruction on the AfricanlarrrarrAfrican lan-guage translation quality in two scenarios whenthe AL was initially pretrained on the multilingualmodel and contrariwise Using Fon (which wasnot initially included in the pretraining) and Igbo(which was initially included in the pretraining) asthe African languages for our baseline training wefinetuned our model on a many-to-many translationin all directions of eng fra ibo foneng larrrarrfra amounting to 10 directions We used theBaseline Train Set for training and theBaseline Test Set for evaluation We
trained the model for only 3 epochs in three set-tings
1 BASE in this setup we finetune the modelon only the many-to-many translation task nobacktranslation nor reconstruction
2 BT refers to finetuning with our backtransla-tion objective described in section 42 For our
6httpshuggingfacecotransformersmodel_docautohtmltransformersAutoModelForSeq2SeqLM
7httpshuggingfacecotransformersmain_classesoptimizer_scheduleshtmltransformersget_linear_schedule_with_warmup
404
baseline where we backtranslate using mono-lingual data in ibo fon we set num_bt =500 For our final experiments we first triedwith 500 but finally reduced to 100 due to thegreat deal of computation required
For our baseline experiment we ran one epochnormally and the remaining two with back-translation For our final experiments we firstfinetuned the model on 3 epochs before con-tinuing with backtranslation
3 BTampREC refers to joint backtranslation andreconstruction (explained in section 42) whilefinetuning Two important questions were ad-dressed ndash 1) the ratio backtranslation re-construction of monolingual sentences to useand 2) whether to use the same or differentsentences for backtranslation and reconstruc-tion Bearing computation time in mind weresolved to go with 500 50 for our baselineand 100 50 for our final experiments Weleave ablation studies on the effect of the ra-tio on translation quality to future work Forthe second question we decided to randomlysample (with replacement) different sentenceseach for our backtranslation and reconstruc-tion
For our baseline we used a learning rate of 5eminus4a batch size of 32 sentences with gradient accumu-lation up to a batch of 256 sentences and an earlystopping patience of 100 evaluation steps To fur-ther analyse the performance of our baseline setupswe ran comparemt 8 (Neubig et al 2019) on themodelrsquos predictions
442 MMTAfricaMMTAfrica refers to our final experimentalsetup where we finetuned our model on all lan-guage directions involving all eight languagesL = eng fra ibo fon swa kin xho yor ex-cept englarrrarrfra Taking inspiration from our base-line results we ran our experiment with our pro-posed BTampREC setting and made some adjust-ments along the way
The long computation time for backtranslating(with just 100 sentences per language the modelwas required to generate around 3 000 translationsevery backtranslation time) was a drawback Tomitigate the issue we parallelized the process us-
8httpsgithubcomneulabcompare-mt
ing the multiprocessing package in Python9 Wefurther slowly reduced the number of sentences forbacktranslation (to 50 and finally 10)
Gradient descent in large multilingual modelshas been shown to be more stable when updatesare performed over large batch sizes are used (Xueet al 2021) To cope with our computational re-sources we used gradient accumulation to increaseupdates from an initial batch size of 64 sentencesup to a batch gradient computation size of 4096sentences We further utilized PyTorchrsquos DataParal-lel package10 to parallelize the training across theGPUs We used a learning rate (lr) of 3eminus6
5 Results and Insights
All evaluations were made using spBLEU (sen-tencepiece (Kudo and Richardson 2018) + sacre-BLEU (Post 2018)) as described in (Goyal et al2021) We further evaluated on the chrF (Popovic2015) and TER metrics
51 Baseline Results and InsightsFigure 1 compares the spBLEU scores for the threesetups used in our baseline experiments As a re-minder we make use of the symbol to refer toany language in the set eng fra ibo fon
BT gives strong improvement over BASE (ex-cept in engminusrarribo where itrsquos relatively the sameand framinusrarribo where it performs worse)
Figure 1 spBLEU scores of the 3 setups explained insection 441
When the target language is fon we observe aconsiderable boost in the spBLEU of the BT set-ting which also significantly outperformed BASE
9httpsdocspythonorg3librarymultiprocessinghtml
10httpspytorchorgdocsstablegeneratedtorchnnDataParallelhtml
405
and BTampREC BTampREC contributed very littlewhen compared with BT and sometimes even per-formed poorly (in engminusrarrfon) We attribute thispoor performance from the reconstruction objec-tive to the fact that the mt5-base model wasnot originally pretrained on Fon Therefore withonly 3 epochs of finetuning (and 1 epoch beforeintroducing the reconstruction and backtranslationobjectives) the model was not able to meaningfullyutilize both objectives
Conversely when the target language is iboBTampREC gives best results ndash even in scenarios
where BT underperforms BASE (as is the caseof framinusrarribo and engminusrarribo) We believe that thedecoder of the model being originally pretrainedon corpora containing Igbo was able to better useour reconstruction to improve translation quaity in minusrarribo direction
Drawing insights from fonlarrrarribo we offer thefollowing propositions concerning ALlarrrarrALmultilingual translation
bull our backtranslation (section 42) from mono-lingual data improves the cross-lingual map-ping of the model for low-resource Africanlanguages While it is computationally expen-sive our parallelization and decay of numberof backtranslated sentences are some potentialsolutions towards effectively adopting back-translation using monolingual data
bull Denoising objectives typically have beenknown to improve machine translation qual-ity (Zhang and Zong 2016 Cheng et al 2016Gu et al 2019 Zhang et al 2020 Xue et al2021) because they imbue the model withmore generalizable knowledge (about that lan-guage) which is used by the decoder to pre-dict better token likelihoods for that languageduring translation This is a reasonable ex-planation for the improved quality with theBTampREC over BT in the minusrarribo As we
learned from minusrarrfon using reconstructioncould perform unsatisfactorily if not handledwell Some methods we propose are
1 For African languages that were includedin the original model pretraining (aswas the case of Igbo Swahili Xhosaand Yorugravebaacute in the mT5 model) usingthe BTampREC setting for finetuning pro-duces best results While we did not per-form ablation studies on the data size
ratio for backtranslation and reconstruc-tion we believe that our ratio of 2 1(in our final experiments) gives the bestcompromise on both computation timeand translation quality
2 For African languages that were not orig-inally included in the original model pre-training (as was the case of Kinyarwandaand Fon in the mT5 model) reconstruc-tion together with backtranslation (espe-cially at an early stage) only introducesmore noise which could harm the cross-lingual learning For these languages wepropose(a) first finetuning the model on only
our reconstruction (described in sec-tion 42) for fairly long training stepsbefore using BTampREC This waythe initial reconstruction will help themodel learn that language represen-tation space and increase its the like-lihood of tokens
52 MMTAfrica Results and InsightsIn Table 4 we compared MMTAfrica with theM2M MMT(Fan et al 2020) benchmark resultsof Goyal et al (2021) using the same test set theyused ndash FLORES Test Set On all languagepairs except swararreng (which has a comparableminus276 spBLEU difference) we report an improve-ment from MMTAfrica (spBLEU gains rangingfrom +058 in swaminusrarrfra to +1946 in framinusrarrxho)The lower score of swararreng presents an intriguinganomaly especially given the large availability ofparallel corpora in our training set for this pair Weplan to investigate this in further work
In Table 5 we introduce benchmark results ofMMTAfrica on MMTAfrica Test Set Wealso put the test size of each language pair
Interesting analysis about Fon (fon) andYorugravebaacute (yor) For each language the lowest sp-BLEU scores in both tables come from the minusrarryordirection except fonlarrrarryor (from Table 5) whichinterestingly has the highest spBLEU score com-pared to the other fonminusrarr ~ directions We donot know the reason for the very low performancein the ~ minusrarryor direction but we offer below aplausible explanation about fonlarrrarryor
The oral linguistic history of Fon ties it to theancient Yorugravebaacute kingdom (Barnes 1997) Further-more in present day Benin where Fon is largely
406
spoken as a native language Yoruba is one of the in-digenuous languages commonly spoken 11 There-fore Fon and Yorugravebaacute share some linguistic charac-teristics and we believe this is one logic behind thefonlarrrarryor surpassing other fonminusrarr ~ directions
This explanation could inspire transfer learningfrom Yorugravebaacute which has received comparably moreresearch and has more resources for machine trans-lation to Fon We leave this for future work
Source Target spBLEU (FLORES)uarr spBLEU (Ours)uarr spCHRFuarr spTERdarr
ibo swa 438 2184 3738 7148
ibo xho 244 1397 3195 8137
ibo yor 154 1072 2655 7572
ibo eng 737 1362 3890 7623
ibo fra 602 1646 3510 7548
swa ibo 197 1980 3395 6822
swa xho 271 2171 3986 7316
swa yor 129 1168 2744 7523
swa eng 3043 2767 5612 5591
swa fra 2669 2727 4620 6347
xho ibo 380 1702 3130 7066
xho swa 614 2947 4468 6321
xho yor 192 1042 2677 7625
xho eng 1086 2077 4869 6409
xho fra 828 2148 4065 6931
yor ibo 185 1145 2526 7499
yor swa 193 1499 3049 7990
yor xho 194 931 2634 8608
yor eng 418 815 3065 8694
yor fra 357 1059 2760 8132
eng ibo 353 2149 3724 6568
eng swa 2695 4011 5313 5280
eng xho 447 2715 4493 6777
eng yor 217 1209 2834 7474
fra ibo 169 1948 3447 6850
fra swa 1717 3421 4895 5811
fra xho 227 2173 4006 7372
fra yor 116 1142 2767 7533
Table 4 Evaluation Scores of the Flores M2M MMTmodel and MMTAfrica on FLORES Test Set
6 Conclusion and Future Work
In this paper we introduced MMTAfrica a mul-tilingual machine translation model on 6 AfricanLanguages which outperformed the M2M MMTmodel Fan et al (2020) Our results and analy-ses including a new reconstruction objective giveinsights on MMT for African languages for fu-ture research Moreover we plan to launch themodel on Masakhane MT and FFRTranslate in or-der to get human evaluation feedback from theactual speakers of the languages in the Masakhanecommunity (Orife et al 2020) and beyond
In order to fully test the advantage ofMMTAfrica we plan to finish comparing it on
11httpsenwikipediaorgwikiBenin(Last Accessed 30082021)
direct and pivot translations with the Masakhanebenchmark models (forall et al 2020) We alsoplan to perform human evaluation All test setsresults code and checkpoints will be releasedat httpsgithubcomedaiofficialmmtafrica
7 Acknowledgments
The computational resources for running all ex-periments were provided by the FLORES com-pute grants12 as well as additonal computationalresources provided by Paco Guzman (FacebookAI) and Mila Quebec AI Institute We expressour profound gratitude to all who contributed inone way or the other towards the development ofMMTAfrica including (in no order)
Mathias Muumlller (University of Zurich) for giv-ing immense technical assistance in finetuning themodel and advising us on best hyperparameter tun-ing practises
Graham Neubig (Carnegie Mellon University)for explaining and setting up comparemt for usto better understand and evaluate the performanceof our baseline models
Angela Fan (FacebookAI) for guiding us duringthe shared task and taking the time to answer allour questions
Julia Kreutzer (GoogleAI) for advising us on use-ful model comparison and evaluation techniques
Colin Leong (University of Dayton) for painstak-ingly proof-reading the paper and helping us makeit more reader-friendly
Daria Yasafova (Technical University of Mu-nich) and Yeno Gbenou (Drexel University) foradditionally proof-reading the paper
Finally the entire Masakhane community13 foramong many other things 1) guiding us to exist-ing parallel and monolingual data set for the focusAfrican languages 2) explaining their (the focusAfrican languages) important linguistic charteris-tics which helped us work better with them (likein preprocessing) and 3) performing (in the future)human evaluation on MMTAfrica
Indeed it took a village to raise MMTAfrica1412httpwwwstatmtorgwmt21
flores-compute-grantshtml13httpswwwmasakhaneio14lsquoIt takes a village to raise a childrsquo is an African proverb
that means that an entire community of people with differentexpertise must provide for and interact positively with the childfor the child to actually develop and reach the best possiblepotential
407
Source Target Test size spBLEUuarr spCHRFuarr spTERdarr
ibo swa 60 3489 4738 6828
ibo xho 30 3669 5066 5965
ibo yor 30 1177 2954 12984
ibo kin 30 3392 4653 6773
ibo fon 30 3596 4314 6321
ibo eng 90 3728 6042 6205
ibo fra 60 3086 4409 6953
swa ibo 60 3371 4302 6001
swa xho 30 3728 5253 5586
swa yor 30 1409 2750 11363
swa kin 30 2386 4259 9467
swa fon 30 2329 3352 6511
swa eng 60 3555 6047 4732
swa fra 60 3011 4833 6338
xho ibo 30 3325 4536 6283
xho swa 30 3926 5375 5372
xho yor 30 2200 3806 7045
xho kin 30 3066 4619 7470
xho fon 30 2580 3487 6596
xho eng 90 3025 5512 6211
xho fra 30 2945 4572 6103
yor ibo 30 2511 3419 7480
yor swa 30 1762 3471 8518
yor xho 30 2931 4313 6682
yor kin 30 2516 3802 7267
yor fon 30 3181 3745 6339
yor eng 90 1781 4173 9300
yor fra 30 1544 3097 9057
kin ibo 30 3125 4236 6673
kin swa 30 3365 4634 7270
kin xho 30 2040 3971 8997
kin yor 30 1834 3353 7043
kin fon 30 2243 3249 6726
kin eng 60 1582 4310 9655
kin fra 30 1623 3351 9182
fon ibo 30 3236 4644 6182
fon swa 30 2984 4296 7228
fon xho 30 2882 4374 6698
fon yor 30 3045 4263 6072
fon kin 30 2388 3959 7806
fon eng 30 1663 4163 6903
fon fra 60 2479 4339 8215
eng ibo 90 4424 5489 6392
eng swa 60 4994 6145 4783
eng xho 120 3197 4974 7289
eng yor 90 2393 3619 8405
eng kin 90 4098 5600 7637
eng fon 30 2719 3686 6254
fra ibo 60 3647 4693 5991
fra swa 60 3653 5142 5594
fra xho 30 3435 4939 6030
fra yor 30 726 2554 12453
fra kin 30 3107 4226 8106
fra fon 60 3107 3872 7574
Table 5 Benchmark Evaluation Scores onMMTAfrica Test Set
ReferencesSolomon Teferra Abate Michael Melese Martha Yi-
firu Tachbelie Million Meshesha Solomon AtinafuWondwossen Mulugeta Yaregal Assabie HafteAbera Binyam Ephrem Tewodros Abebe Wondim-agegnhue Tsegaye Amanuel Lemma Tsegaye An-dargie and Seifedin Shifaw 2018 Parallel corporafor bi-lingual English-Ethiopian languages statisti-cal machine translation In Proceedings of the 27thInternational Conference on Computational Linguis-tics pages 3102ndash3111 Santa Fe New Mexico USAAssociation for Computational Linguistics
Jade Abbott and Laura Martinus 2019 Benchmarkingneural machine translation for Southern African lan-guages In Proceedings of the 2019 Workshop onWidening NLP pages 98ndash101 Florence Italy Asso-ciation for Computational Linguistics
Jade Z Abbott and Laura Martinus 2018 Towardsneural machine translation for african languages
David I Adelani Dana Ruiter Jesujoba O Al-abi Damilola Adebonojo Adesina Ayeni MofeAdeyemi Ayodele Awokoya and Cristina Espantildea-Bonet 2021a The effect of domain and diacritics inyorugravebaacute-english neural machine translation
David Ifeoluwa Adelani Jade Z Abbott GrahamNeubig Daniel Drsquosouza Julia Kreutzer Constan-tine Lignos Chester Palen-Michel Happy Buza-aba Shruti Rijhwani Sebastian Ruder StephenMayhew Israel Abebe Azime Shamsuddeen Has-san Muhammad Chris Chinenye Emezue JoyceNakatumba-Nabende Perez Ogayo Aremu An-uoluwapo Catherine Gitau Derguene Mbaye Je-sujoba O Alabi Seid Muhie Yimam Tajud-deen Gwadabe Ignatius Ezeani Rubungo An-dre Niyongabo Jonathan Mukiibi Verrah OtiendeIroro Orife Davis David Samba Ngom Tosin PAdewumi Paul Rayson Mofetoluwa Adeyemi Ger-ald Muriuki Emmanuel Anebi Chiamaka Chuk-wuneke Nkiruka Odu Eric Peter Wairagala SamuelOyerinde Clemencia Siro Tobius Saul BateesaTemilola Oloyede Yvonne Wambui Victor Akin-ode Deborah Nabagereka Maurice Katusiime Ayo-dele Awokoya Mouhamadane Mboup Dibora Ge-breyohannes Henok Tilaye Kelechi Nwaike De-gaga Wolde Abdoulaye Faye Blessing SibandaOrevaoghene Ahia Bonaventure F P DossouKelechi Ogueji Thierno Ibrahima Diop AbdoulayeDiallo Adewale Akinfaderin Tendai Marengerekeand Salomey Osei 2021b Masakhaner Namedentity recognition for african languages CoRRabs210311811
Željko Agic and Ivan Vulic 2019 JW300 A wide-coverage parallel corpus for low-resource languagesIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages3204ndash3210 Florence Italy Association for Compu-tational Linguistics
Roee Aharoni Melvin Johnson and Orhan Firat 2019Massively multilingual neural machine translation
408
In Proceedings of the 2019 Conference of the NorthAmerican Chapter of the Association for Compu-tational Linguistics Human Language Technolo-gies Volume 1 (Long and Short Papers) pages3874ndash3884 Minneapolis Minnesota Associationfor Computational Linguistics
Jesujoba Alabi Kwabena Amponsah-Kaakyire DavidAdelani and Cristina Espantildea-Bonet 2020 Mas-sive vs curated embeddings for low-resourced lan-guages the case of Yorugravebaacute and Twi In Proceed-ings of the 12th Language Resources and EvaluationConference pages 2754ndash2762 Marseille FranceEuropean Language Resources Association
Naveen Arivazhagan Ankur Bapna Orhan Firat RoeeAharoni Melvin Johnson and Wolfgang Macherey2019a The missing ingredient in zero-shot neuralmachine translation CoRR abs190307091
Naveen Arivazhagan Ankur Bapna Orhan FiratDmitry Lepikhin Melvin Johnson Maxim KrikunMia Xu Chen Yuan Cao George F Foster ColinCherry Wolfgang Macherey Zhifeng Chen andYonghui Wu 2019b Massively multilingual neuralmachine translation in the wild Findings and chal-lenges CoRR abs190705019
Mikko Aulamo Umut Sulubacak Sami Virpioja andJoumlrg Tiedemann 2020 OpusTools and parallel cor-pus diagnostics In Proceedings of The 12th Lan-guage Resources and Evaluation Conference pages3782ndash3789 European Language Resources Associ-ation
Dzmitry Bahdanau Kyunghyun Cho and Yoshua Ben-gio 2015 Neural machine translation by jointlylearning to align and translate In 3rd Inter-national Conference on Learning RepresentationsICLR 2015 San Diego CA USA May 7-9 2015Conference Track Proceedings
ST Barnes 1997 Africarsquos Ogun Old World andNew African systems of thought Indiana Univer-sity Press
Loiumlc Barrault Magdalena Biesialska Ondrej BojarMarta R Costa-jussagrave Christian Federmann YvetteGraham Roman Grundkiewicz Barry HaddowMatthias Huck Eric Joanis Tom Kocmi PhilippKoehn Chi-kiu Lo Nikola Ljubešic ChristofMonz Makoto Morishita Masaaki Nagata Toshi-aki Nakazawa Santanu Pal Matt Post and MarcosZampieri 2020 Findings of the 2020 conference onmachine translation (WMT20) In Proceedings ofthe Fifth Conference on Machine Translation pages1ndash55 Online Association for Computational Lin-guistics
Loiumlc Barrault Ondrej Bojar Marta R Costa-jussagraveChristian Federmann Mark Fishel Yvette Gra-ham Barry Haddow Matthias Huck Philipp KoehnShervin Malmasi Christof Monz Mathias MuumlllerSantanu Pal Matt Post and Marcos Zampieri 2019
Findings of the 2019 conference on machine transla-tion (WMT19) In Proceedings of the Fourth Con-ference on Machine Translation (Volume 2 SharedTask Papers Day 1) pages 1ndash61 Florence Italy As-sociation for Computational Linguistics
Lukas Biewald 2020 Experiment tracking withweights and biases Software available fromwandbcom
Yong Cheng Wei Xu Zhongjun He Wei He HuaWu Maosong Sun and Yang Liu 2016 Semi-supervised learning for neural machine translationIn Proceedings of the 54th Annual Meeting of the As-sociation for Computational Linguistics (Volume 1Long Papers) pages 1965ndash1974 Berlin GermanyAssociation for Computational Linguistics
Kyunghyun Cho Bart van Merrienboer CcedilaglarGuumllccedilehre Dzmitry Bahdanau Fethi Bougares Hol-ger Schwenk and Yoshua Bengio 2014 Learningphrase representations using RNN encoder-decoderfor statistical machine translation In Proceedings ofthe 2014 Conference on Empirical Methods in Nat-ural Language Processing EMNLP 2014 October25-29 2014 Doha Qatar A meeting of SIGDAT aSpecial Interest Group of the ACL pages 1724ndash1734ACL
Alexis Conneau Kartikay Khandelwal Naman GoyalVishrav Chaudhary Guillaume Wenzek FranciscoGuzmaacuten Edouard Grave Myle Ott Luke Zettle-moyer and Veselin Stoyanov 2019 Unsupervisedcross-lingual representation learning at scale
Jacob Devlin Ming-Wei Chang Kenton Lee andKristina Toutanova 2018 BERT pre-training ofdeep bidirectional transformers for language under-standing CoRR abs181004805
Daxiang Dong Hua Wu Wei He Dianhai Yu andHaifeng Wang 2015 Multi-task learning for mul-tiple language translation In Proceedings of the53rd Annual Meeting of the Association for Compu-tational Linguistics and the 7th International JointConference on Natural Language Processing (Vol-ume 1 Long Papers) pages 1723ndash1732 BeijingChina Association for Computational Linguistics
Bonaventure F P Dossou and Chris C Emezue 2020FFR V10 fon-french neural machine translationCoRR abs200312111
Bonaventure F P Dossou and Chris C Emezue 2021aCrowdsourced phrase-based tokenization for low-resourced neural machine translation The case offon language CoRR abs210308052
Bonaventure F P Dossou and Chris C Emezue 2021bOkwugbeacute End-to-end speech recognition for fonand igbo CoRR abs210307762
David M Eberhard Gary F Simons and CharlesD Fennig (eds) 2020 Ethnologue Languages ofthe world twenty-third edition
409
Sergey Edunov Myle Ott Michael Auli and DavidGrangier 2018 Understanding back-translation atscale CoRR abs180809381
Ignatius Ezeani Paul Rayson Ikechukwu E OnyenweChinedu Uchechukwu and Mark Hepple 2020Igbo-english machine translation An evaluationbenchmark CoRR abs200400648
Angela Fan Shruti Bhosale Holger Schwenk ZhiyiMa Ahmed El-Kishky Siddharth Goyal Man-deep Baines Onur Celebi Guillaume WenzekVishrav Chaudhary Naman Goyal Tom Birch Vi-taliy Liptchinsky Sergey Edunov Edouard GraveMichael Auli and Armand Joulin 2020 Be-yond english-centric multilingual machine transla-tion CoRR abs201011125
Thibault Feacutevry and Jason Phang 2018 Unsuper-vised sentence compression using denoising auto-encoders CoRR abs180902669
Orhan Firat Kyunghyun Cho and Yoshua Bengio2016a Multi-way multilingual neural machinetranslation with a shared attention mechanism InProceedings of the 2016 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 866ndash875 San Diego California Associationfor Computational Linguistics
Orhan Firat Baskaran Sankaran Yaser Al-onaizanFatos T Yarman Vural and Kyunghyun Cho 2016bZero-resource translation with multi-lingual neuralmachine translation In Proceedings of the 2016Conference on Empirical Methods in Natural Lan-guage Processing pages 268ndash277 Austin TexasAssociation for Computational Linguistics
forall Wilhelmina Nekoto Vukosi Marivate TshinondiwaMatsila Timi Fasubaa Tajudeen Kolawole TaiwoFagbohungbe Solomon Oluwole Akinola Sham-suddee Hassan Muhammad Salomon Kabongo Sa-lomey Osei et al 2020 Participatory research forlow-resourced machine translation A case study inafrican languages Findings of EMNLP
Naman Goyal Cynthia Gao Vishrav Chaudhary Peng-Jen Chen Guillaume Wenzek Da Ju Sanjana Kr-ishnan MarcrsquoAurelio Ranzato Francisco Guzmanand Angela Fan 2021 The flores-101 evaluationbenchmark for low-resource and multilingual ma-chine translation
Jiatao Gu Yong Wang Kyunghyun Cho and Vic-tor OK Li 2019 Improved zero-shot neural ma-chine translation via ignoring spurious correlationsIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages1258ndash1268 Florence Italy Association for Compu-tational Linguistics
Thanh-Le Ha Jan Niehues and Alexander H Waibel2016 Toward multilingual neural machine trans-lation with universal encoder and decoder CoRRabs161104798
Vu Cong Duy Hoang Philipp Koehn GholamrezaHaffari and Trevor Cohn 2018 Iterative back-translation for neural machine translation In Pro-ceedings of the 2nd Workshop on Neural MachineTranslation and Generation pages 18ndash24 Mel-bourne Australia Association for ComputationalLinguistics
Melvin Johnson Mike Schuster Quoc V Le MaximKrikun Yonghui Wu Zhifeng Chen Nikhil ThoratFernanda Vieacutegas Martin Wattenberg Greg CorradoMacduff Hughes and Jeffrey Dean 2017 Googlersquosmultilingual neural machine translation system En-abling zero-shot translation Transactions of the As-sociation for Computational Linguistics 5339ndash351
Pratik Joshi Sebastin Santy Amar Budhiraja KalikaBali and Monojit Choudhury 2020 The state andfate of linguistic diversity and inclusion in the NLPworld In Proceedings of the 58th Annual Meet-ing of the Association for Computational Linguisticspages 6282ndash6293 Online Association for Computa-tional Linguistics
Taku Kudo and John Richardson 2018 SentencePieceA simple and language independent subword tok-enizer and detokenizer for neural text processing InProceedings of the 2018 Conference on EmpiricalMethods in Natural Language Processing SystemDemonstrations pages 66ndash71 Brussels BelgiumAssociation for Computational Linguistics
Surafel Melaku Lakew Mauro Cettolo and MarcelloFederico 2018 A comparison of transformer andrecurrent neural networks on multilingual neural ma-chine translation In Proceedings of the 27th Inter-national Conference on Computational Linguisticspages 641ndash652 Santa Fe New Mexico USA Asso-ciation for Computational Linguistics
Guillaume Lample Ludovic Denoyer andMarcrsquoAurelio Ranzato 2017 Unsupervisedmachine translation using monolingual corporaonly CoRR abs171100043
Jason Lee Kyunghyun Cho and Thomas Hofmann2017 Fully Character-Level Neural Machine Trans-lation without Explicit Segmentation Transactionsof the Association for Computational Linguistics5365ndash378
Ilya Loshchilov and Frank Hutter 2017 Fixingweight decay regularization in adam CoRRabs171105101
Yichao Lu Phillip Keung Faisal Ladhak Vikas Bhard-waj Shaonan Zhang and Jason Sun 2018 A neu-ral interlingua for multilingual machine translationIn Proceedings of the Third Conference on MachineTranslation Research Papers pages 84ndash92 Brus-sels Belgium Association for Computational Lin-guistics
Laura Martinus and Jade Z Abbott 2019 A focuson neural machine translation for african languagesCoRR abs190605685
410
Graham Neubig Zi-Yi Dou Junjie Hu Paul MichelDanish Pruthi Xinyi Wang and John Wieting 2019compare-mt A tool for holistic comparison of lan-guage generation systems CoRR abs190307926
Graham Neubig and Junjie Hu 2018 Rapid adapta-tion of neural machine translation to new languagesIn Proceedings of the 2018 Conference on Empiri-cal Methods in Natural Language Processing pages875ndash880 Brussels Belgium Association for Com-putational Linguistics
Rubungo Andre Niyongabo Qu Hong Julia Kreutzerand Li Huang 2020 KINNEWS and KIRNEWSBenchmarking cross-lingual text classification forKinyarwanda and Kirundi In Proceedings ofthe 28th International Conference on Computa-tional Linguistics pages 5507ndash5521 BarcelonaSpain (Online) International Committee on Compu-tational Linguistics
Linda Nordling 2018 How decolonizationcould reshape south african science Nature554(7691)159ndash162
Evander Nyoni and Bruce A Bassett 2021 Low-resource neural machine translation for southernafrican languages CoRR abs210400366
Iroro Orife Julia Kreutzer Blessing Sibanda DanielWhitenack Kathleen Siminyu Laura MartinusJamiil Toure Ali Jade Z Abbott Vukosi Mari-vate Salomon Kabongo Musie Meressa Es-poir Murhabazi Orevaoghene Ahia Elan VanBiljon Arshath Ramkilowan Adewale AkinfaderinAlp Oumlktem Wole Akin Ghollah Kioko KevinDegila Herman Kamper Bonaventure DossouChris Emezue Kelechi Ogueji and Abdallah Bashir2020 Masakhane - machine translation for africaCoRR abs200311529
Maja Popovic 2015 chrF character n-gram F-scorefor automatic MT evaluation In Proceedings of theTenth Workshop on Statistical Machine Translationpages 392ndash395 Lisbon Portugal Association forComputational Linguistics
Matt Post 2018 A call for clarity in reporting BLEUscores In Proceedings of the Third Conference onMachine Translation Research Papers pages 186ndash191 Brussels Belgium Association for Computa-tional Linguistics
Colin Raffel Noam Shazeer Adam Roberts KatherineLee Sharan Narang Michael Matena Yanqi ZhouWei Li and Peter J Liu 2019 Exploring the limitsof transfer learning with a unified text-to-text trans-former CoRR abs191010683
Machel Reid Junjie Hu Graham Neubig and YutakaMatsuo 2021 Afromt Pretraining strategies andreproducible benchmarks for translation of 8 africanlanguages
Rico Sennrich Barry Haddow and Alexandra Birch2015 Improving neural machine translation modelswith monolingual data CoRR abs151106709
Shivachi Casper Shikali and Mokhosi Refuoe 2019Language modeling data for swahili
Aditya Siddhant Ankur Bapna Yuan Cao Orhan Fi-rat Mia Xu Chen Sneha Reddy Kudugunta NaveenArivazhagan and Yonghui Wu 2020 Lever-aging monolingual data with self-supervision formultilingual neural machine translation CoRRabs200504816
Ilya Sutskever Oriol Vinyals and Quoc V Le 2014Sequence to sequence learning with neural networksIn Proceedings of the 27th International Conferenceon Neural Information Processing Systems - Vol-ume 2 NIPSrsquo14 page 3104ndash3112 Cambridge MAUSA MIT Press
Xu Tan Jiale Chen Di He Yingce Xia Tao Qin andTie-Yan Liu 2019 Multilingual neural machinetranslation with language clustering In Proceedingsof the 2019 Conference on Empirical Methods inNatural Language Processing and the 9th Interna-tional Joint Conference on Natural Language Pro-cessing (EMNLP-IJCNLP) pages 963ndash973 HongKong China Association for Computational Lin-guistics
Joumlrg Tiedemann 2012 Parallel data tools and inter-faces in opus In Proceedings of the Eight Interna-tional Conference on Language Resources and Eval-uation (LRECrsquo12) Istanbul Turkey European Lan-guage Resources Association (ELRA)
Daniel van Niekerk Charl van Heerden Marelie DavelNeil Kleynhans Oddur Kjartansson Martin Janscheand Linne Ha 2017 Rapid development of TTS cor-pora for four South African languages In Proc In-terspeech 2017 pages 2178ndash2182 Stockholm Swe-den
Ashish Vaswani Noam Shazeer Niki Parmar JakobUszkoreit Llion Jones Aidan N Gomez LukaszKaiser and Illia Polosukhin 2017 Attention is allyou need CoRR abs170603762
Sarah Wild 2021 African languages to get more be-spoke scientific terms Nature 596(7873)469ndash470
Ronald J Williams and David Zipser 1989 A learn-ing algorithm for continually running fully recurrentneural networks Neural Computation 1(2)270ndash280
Linting Xue Noah Constant Adam Roberts Mi-hir Kale Rami Al-Rfou Aditya Siddhant AdityaBarua and Colin Raffel 2021 mT5 A massivelymultilingual pre-trained text-to-text transformer InProceedings of the 2021 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 483ndash498 Online Association for Computa-tional Linguistics
Biao Zhang Philip Williams Ivan Titov and RicoSennrich 2020 Improving massively multilingualneural machine translation and zero-shot translationCoRR abs200411867
411
Jiajun Zhang and Chengqing Zong 2016 Exploit-ing source-side monolingual data in neural machinetranslation In Proceedings of the 2016 Conferenceon Empirical Methods in Natural Language Process-ing pages 1535ndash1545 Austin Texas Associationfor Computational Linguistics
Barret Zoph Deniz Yuret Jonathan May and KevinKnight 2016 Transfer learning for low-resourceneural machine translation In Proceedings of the2016 Conference on Empirical Methods in Natu-ral Language Processing pages 1568ndash1575 AustinTexas Association for Computational Linguistics
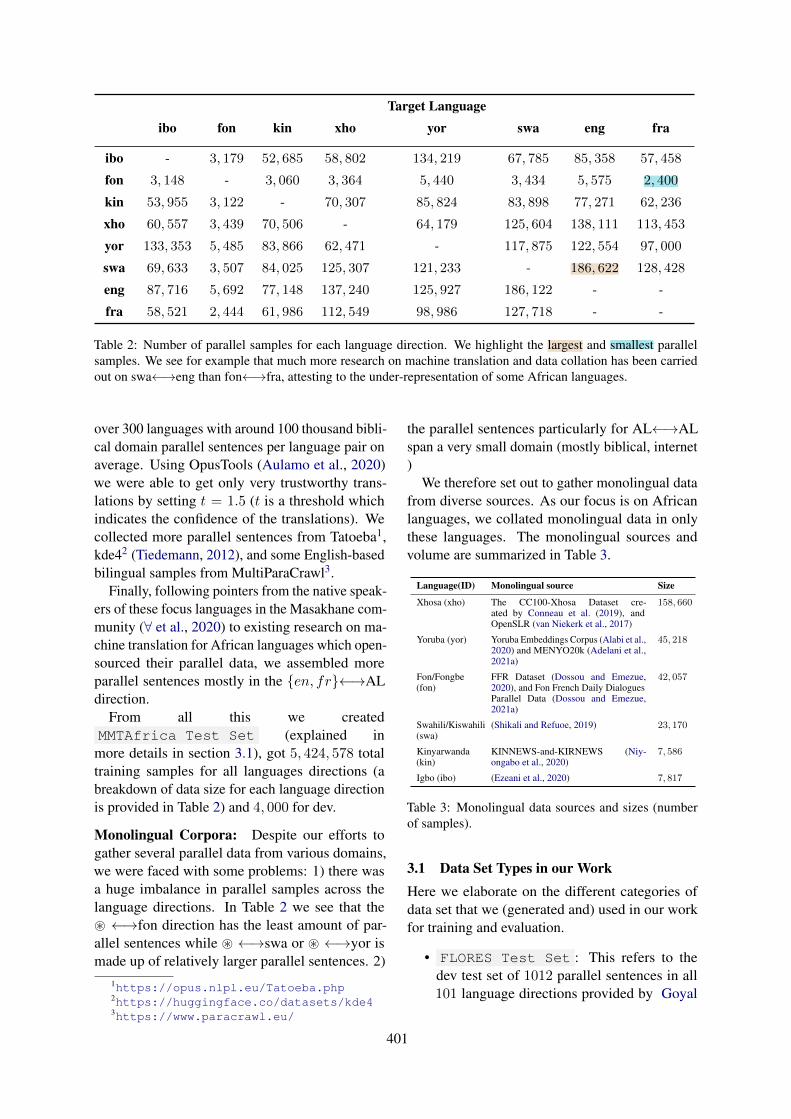
401
Target Languageibo fon kin xho yor swa eng fra
ibo - 3 179 52 685 58 802 134 219 67 785 85 358 57 458
fon 3 148 - 3 060 3 364 5 440 3 434 5 575 2 400
kin 53 955 3 122 - 70 307 85 824 83 898 77 271 62 236
xho 60 557 3 439 70 506 - 64 179 125 604 138 111 113 453
yor 133 353 5 485 83 866 62 471 - 117 875 122 554 97 000
swa 69 633 3 507 84 025 125 307 121 233 - 186 622 128 428
eng 87 716 5 692 77 148 137 240 125 927 186 122 - -
fra 58 521 2 444 61 986 112 549 98 986 127 718 - -
Table 2 Number of parallel samples for each language direction We highlight the largest and smallest parallelsamples We see for example that much more research on machine translation and data collation has been carriedout on swalarrrarreng than fonlarrrarrfra attesting to the under-representation of some African languages
over 300 languages with around 100 thousand bibli-cal domain parallel sentences per language pair onaverage Using OpusTools (Aulamo et al 2020)we were able to get only very trustworthy trans-lations by setting t = 15 (t is a threshold whichindicates the confidence of the translations) Wecollected more parallel sentences from Tatoeba1kde42 (Tiedemann 2012) and some English-basedbilingual samples from MultiParaCrawl3
Finally following pointers from the native speak-ers of these focus languages in the Masakhane com-munity (forall et al 2020) to existing research on ma-chine translation for African languages which open-sourced their parallel data we assembled moreparallel sentences mostly in the en frlarrrarrALdirection
From all this we createdMMTAfrica Test Set (explained in
more details in section 31) got 5 424 578 totaltraining samples for all languages directions (abreakdown of data size for each language directionis provided in Table 2) and 4 000 for dev
Monolingual Corpora Despite our efforts togather several parallel data from various domainswe were faced with some problems 1) there wasa huge imbalance in parallel samples across thelanguage directions In Table 2 we see that the~ larrrarrfon direction has the least amount of par-allel sentences while ~ larrrarrswa or ~ larrrarryor ismade up of relatively larger parallel sentences 2)
1httpsopusnlpleuTatoebaphp2httpshuggingfacecodatasetskde43httpswwwparacrawleu
the parallel sentences particularly for ALlarrrarrALspan a very small domain (mostly biblical internet)
We therefore set out to gather monolingual datafrom diverse sources As our focus is on Africanlanguages we collated monolingual data in onlythese languages The monolingual sources andvolume are summarized in Table 3
Language(ID) Monolingual source Size
Xhosa (xho) The CC100-Xhosa Dataset cre-ated by Conneau et al (2019) andOpenSLR (van Niekerk et al 2017)
158 660
Yoruba (yor) Yoruba Embeddings Corpus (Alabi et al2020) and MENYO20k (Adelani et al2021a)
45 218
FonFongbe(fon)
FFR Dataset (Dossou and Emezue2020) and Fon French Daily DialoguesParallel Data (Dossou and Emezue2021a)
42 057
SwahiliKiswahili(swa)
(Shikali and Refuoe 2019) 23 170
Kinyarwanda(kin)
KINNEWS-and-KIRNEWS (Niy-ongabo et al 2020)
7 586
Igbo (ibo) (Ezeani et al 2020) 7 817
Table 3 Monolingual data sources and sizes (numberof samples)
31 Data Set Types in our WorkHere we elaborate on the different categories ofdata set that we (generated and) used in our workfor training and evaluation
bull FLORES Test Set This refers to thedev test set of 1012 parallel sentences in all101 language directions provided by Goyal
402
et al (2021)4 We performed evaluation onthis test set for all language directions except~larrrarrfon and ~larrrarrkin
bull MMTAfrica Test Set This is a sub-stantial test set we created by taking out asmall but equal number of sentences fromeach parallel source domain As a result wehave a set from a wide range of domainswhile encompassing samples from many exist-ing test sets from previous research Althoughthis set is small to be fully considered as a testset we open-source it because it contains sen-tences from many domains (making it usefulfor evaluation) and we hope that it can be builtupon by perhaps merging it with other bench-mark test sets (Abate et al 2018 Abbott andMartinus 2019 Reid et al 2021)
bull Baseline TrainTest Set We firstconducted baseline experiments with FonIgbo English and French as explained in sec-tion 441 For this we created a special dataset by carefully selecting a small subset of theFFR Dataset (which already contained paral-lel sentences in French and Fon) first auto-matically translating the sentences to Englishand Igbo using the Google Translate API5and finally re-translating with the help of Igbo(7) and English (7) native speakers (we recog-nized that it was easier for native speakers toedittweak an existing translation rather thanwriting the whole translation from scratch)In so doing we created a data set of 13 878translations in all 4 language directions
We split the data set into 12 554 for trainingBaseline Train Set 662 for dev and662 for test Baseline Test Set
4 Model and Experiments
41 ModelFor all our experiments we used the mT5model (Xue et al 2021) a multilingual variant ofthe encoder-decoder transformer-based (Vaswaniet al 2017) ldquoText-to-Text Transfer Transformerrdquo(T5) model (Raffel et al 2019) In T5 pre-trainingthe NLP tasks (including machine translation) werecast into a ldquotext-to-textrdquo format ndash that is a task
4httpsdlfbaipublicfilescomflores101datasetflores101_datasettargz
5httpscloudgooglecomtranslate
where the model is fed some text prefix for contextor conditioning and is then asked to produce someoutput text This framework makes it straightfor-ward to design a number of NLP tasks like machinetranslation summarization text classification etcAlso it provides a consistent training objective bothfor pre-training and finetuning The mT5 modelwas pre-trained with a maximum likelihood objec-tive using ldquoteacher forcingrdquo (Williams and Zipser1989) The mT5 model was also pretrained witha modification of the masked language modellingobjective (Devlin et al 2018)
We finetuned the mt5-base model on ourmany-to-many machine translation task WhileXue et al (2021) suggest that higher versions ofthe mT5 model (Large XL or XXL) give betterperformance on downstream multilingual transla-tion tasks we were constrained by computationalresources to mt5-base which has 580M pa-rameters
42 SetupFor each language direction X rarr Y we have its setof n parallel sentences D = (xi yi)ni=1 wherexi is the ith source sentence of language X and yiis its translation in the target language Y
Following the approach of Johnson et al (2017)and Xue et al (2021) we model translation in atext-to-text format More specifically we createthe input for the model by prepending the targetlanguage tag to the source sentence Thereforefor each source sentence xi the input to the modelis ltYtaggt xi and the target is yi Taking a realexample letrsquos say we wish to translate the Igbosentence Daalu maka ikwu eziokwu nke Chineke toEnglish The input to the model becomes ltenggtDaalu maka ikwu eziokwu nke Chineke
43 TrainingWe have a set of language tags L for the lan-guages we are working with in our multilin-gual many-to-many translation In our baselinesetup (section 441) L = eng fra ibo fonand in our final experiment (section 442) L =eng fra ibo fon swa kin xho yor We car-ried out many-to-many translation using all thepossible directions from L except eng larrrarr fraWe skipped eng larrrarr fra for this fundamentalreason
bull our main focus is on AfricanlarrrarrAfrican oreng fra larrrarrAfrican Due to the high-
403
resource nature of English and French addingthe training set for eng larrrarr fra would over-shadow the learning of the other language di-rections and greatly impede our analyses Ourintuition draws from the observation of Xueet al (2021) as the reason for off-target trans-lation in the mT5 model as English-basedfinetuning proceeds the modelrsquos assigned like-lihood of non-English tokens presumably de-creases Therefore since the mt5-basetraining set contained predominantly English(and after other European languages) tokensand our research is about ALlarrrarrAL trans-lation removing the eng larrrarr fra directionwas our way of ensuring the model designatedmore likelihood to AL tokens
431 Our ContributionsIn addition to the parallel data between the Africanlanguages we leveraged monolingual data to im-prove translation quality in two ways
1 our backtranslation (BT) We designed amodified form of the random online backtrans-lation (Zhang et al 2020) where instead ofrandomly selecting a subset of languages tobacktranslate we selected for each languagenum_bt sentences at random from the mono-lingual data set This means that the modelgets to backtranslate different (monolingual)sentences every backtranslation time and inso doing we believe improve the modelrsquos do-main adaptation because it gets to learn fromvarious samples from the whole monolingualdata set We initially tested different values ofnum_bt to find a compromise between back-translation computation time and translationquality
Following research works which have shownthe effectiveness of random beam-search overgreedy decoding while generating backtrans-lations (Lample et al 2017 Edunov et al2018 Hoang et al 2018 Zhang et al 2020)we generated num_sample prediction sen-tences from the model and randomly selected(with equal probability) one for our back-translated sentence Naturally the value ofnum_sample further affects the computa-tion time (because the model has to producenum_sample different output sentences foreach input sentence) and so we finally settledwith num_sample = 2
2 our reconstruction Given a monolingualsentence xm from language m we appliedrandom swapping (2 times) and deletion (witha probability of 02) to get a noisy version xTaking inspiration from Raffel et al (2019)we integrated the reconstruction objective intoour model finetuning by prepending the lan-guage tag ltmgt to x and setting its target out-put to xm
44 ExperimentsIn all our experiments we initialized the pretrainedmT5-base model using Hugging Facersquos Auto-
ModelForSeq2SeqLM6 and tracked the trainingprocess with WeightsampBiases (Biewald 2020) Weused the AdamW optimizer (Loshchilov and Hutter2017) with a learning rate (lr) of 3eminus6 and trans-formerrsquos get_linear_schedule_with_warmup7
scheduler (where the learning rate decreases lin-early from the initial lr set in the optimizer to 0after a warmup period and then increases linearlyfrom 0 to the initial lr set in the optimizer)
441 BaselineThe goal of our baseline was to understand theeffect of jointly finetuning with backtranslationand reconstruction on the AfricanlarrrarrAfrican lan-guage translation quality in two scenarios whenthe AL was initially pretrained on the multilingualmodel and contrariwise Using Fon (which wasnot initially included in the pretraining) and Igbo(which was initially included in the pretraining) asthe African languages for our baseline training wefinetuned our model on a many-to-many translationin all directions of eng fra ibo foneng larrrarrfra amounting to 10 directions We used theBaseline Train Set for training and theBaseline Test Set for evaluation We
trained the model for only 3 epochs in three set-tings
1 BASE in this setup we finetune the modelon only the many-to-many translation task nobacktranslation nor reconstruction
2 BT refers to finetuning with our backtransla-tion objective described in section 42 For our
6httpshuggingfacecotransformersmodel_docautohtmltransformersAutoModelForSeq2SeqLM
7httpshuggingfacecotransformersmain_classesoptimizer_scheduleshtmltransformersget_linear_schedule_with_warmup
404
baseline where we backtranslate using mono-lingual data in ibo fon we set num_bt =500 For our final experiments we first triedwith 500 but finally reduced to 100 due to thegreat deal of computation required
For our baseline experiment we ran one epochnormally and the remaining two with back-translation For our final experiments we firstfinetuned the model on 3 epochs before con-tinuing with backtranslation
3 BTampREC refers to joint backtranslation andreconstruction (explained in section 42) whilefinetuning Two important questions were ad-dressed ndash 1) the ratio backtranslation re-construction of monolingual sentences to useand 2) whether to use the same or differentsentences for backtranslation and reconstruc-tion Bearing computation time in mind weresolved to go with 500 50 for our baselineand 100 50 for our final experiments Weleave ablation studies on the effect of the ra-tio on translation quality to future work Forthe second question we decided to randomlysample (with replacement) different sentenceseach for our backtranslation and reconstruc-tion
For our baseline we used a learning rate of 5eminus4a batch size of 32 sentences with gradient accumu-lation up to a batch of 256 sentences and an earlystopping patience of 100 evaluation steps To fur-ther analyse the performance of our baseline setupswe ran comparemt 8 (Neubig et al 2019) on themodelrsquos predictions
442 MMTAfricaMMTAfrica refers to our final experimentalsetup where we finetuned our model on all lan-guage directions involving all eight languagesL = eng fra ibo fon swa kin xho yor ex-cept englarrrarrfra Taking inspiration from our base-line results we ran our experiment with our pro-posed BTampREC setting and made some adjust-ments along the way
The long computation time for backtranslating(with just 100 sentences per language the modelwas required to generate around 3 000 translationsevery backtranslation time) was a drawback Tomitigate the issue we parallelized the process us-
8httpsgithubcomneulabcompare-mt
ing the multiprocessing package in Python9 Wefurther slowly reduced the number of sentences forbacktranslation (to 50 and finally 10)
Gradient descent in large multilingual modelshas been shown to be more stable when updatesare performed over large batch sizes are used (Xueet al 2021) To cope with our computational re-sources we used gradient accumulation to increaseupdates from an initial batch size of 64 sentencesup to a batch gradient computation size of 4096sentences We further utilized PyTorchrsquos DataParal-lel package10 to parallelize the training across theGPUs We used a learning rate (lr) of 3eminus6
5 Results and Insights
All evaluations were made using spBLEU (sen-tencepiece (Kudo and Richardson 2018) + sacre-BLEU (Post 2018)) as described in (Goyal et al2021) We further evaluated on the chrF (Popovic2015) and TER metrics
51 Baseline Results and InsightsFigure 1 compares the spBLEU scores for the threesetups used in our baseline experiments As a re-minder we make use of the symbol to refer toany language in the set eng fra ibo fon
BT gives strong improvement over BASE (ex-cept in engminusrarribo where itrsquos relatively the sameand framinusrarribo where it performs worse)
Figure 1 spBLEU scores of the 3 setups explained insection 441
When the target language is fon we observe aconsiderable boost in the spBLEU of the BT set-ting which also significantly outperformed BASE
9httpsdocspythonorg3librarymultiprocessinghtml
10httpspytorchorgdocsstablegeneratedtorchnnDataParallelhtml
405
and BTampREC BTampREC contributed very littlewhen compared with BT and sometimes even per-formed poorly (in engminusrarrfon) We attribute thispoor performance from the reconstruction objec-tive to the fact that the mt5-base model wasnot originally pretrained on Fon Therefore withonly 3 epochs of finetuning (and 1 epoch beforeintroducing the reconstruction and backtranslationobjectives) the model was not able to meaningfullyutilize both objectives
Conversely when the target language is iboBTampREC gives best results ndash even in scenarios
where BT underperforms BASE (as is the caseof framinusrarribo and engminusrarribo) We believe that thedecoder of the model being originally pretrainedon corpora containing Igbo was able to better useour reconstruction to improve translation quaity in minusrarribo direction
Drawing insights from fonlarrrarribo we offer thefollowing propositions concerning ALlarrrarrALmultilingual translation
bull our backtranslation (section 42) from mono-lingual data improves the cross-lingual map-ping of the model for low-resource Africanlanguages While it is computationally expen-sive our parallelization and decay of numberof backtranslated sentences are some potentialsolutions towards effectively adopting back-translation using monolingual data
bull Denoising objectives typically have beenknown to improve machine translation qual-ity (Zhang and Zong 2016 Cheng et al 2016Gu et al 2019 Zhang et al 2020 Xue et al2021) because they imbue the model withmore generalizable knowledge (about that lan-guage) which is used by the decoder to pre-dict better token likelihoods for that languageduring translation This is a reasonable ex-planation for the improved quality with theBTampREC over BT in the minusrarribo As we
learned from minusrarrfon using reconstructioncould perform unsatisfactorily if not handledwell Some methods we propose are
1 For African languages that were includedin the original model pretraining (aswas the case of Igbo Swahili Xhosaand Yorugravebaacute in the mT5 model) usingthe BTampREC setting for finetuning pro-duces best results While we did not per-form ablation studies on the data size
ratio for backtranslation and reconstruc-tion we believe that our ratio of 2 1(in our final experiments) gives the bestcompromise on both computation timeand translation quality
2 For African languages that were not orig-inally included in the original model pre-training (as was the case of Kinyarwandaand Fon in the mT5 model) reconstruc-tion together with backtranslation (espe-cially at an early stage) only introducesmore noise which could harm the cross-lingual learning For these languages wepropose(a) first finetuning the model on only
our reconstruction (described in sec-tion 42) for fairly long training stepsbefore using BTampREC This waythe initial reconstruction will help themodel learn that language represen-tation space and increase its the like-lihood of tokens
52 MMTAfrica Results and InsightsIn Table 4 we compared MMTAfrica with theM2M MMT(Fan et al 2020) benchmark resultsof Goyal et al (2021) using the same test set theyused ndash FLORES Test Set On all languagepairs except swararreng (which has a comparableminus276 spBLEU difference) we report an improve-ment from MMTAfrica (spBLEU gains rangingfrom +058 in swaminusrarrfra to +1946 in framinusrarrxho)The lower score of swararreng presents an intriguinganomaly especially given the large availability ofparallel corpora in our training set for this pair Weplan to investigate this in further work
In Table 5 we introduce benchmark results ofMMTAfrica on MMTAfrica Test Set Wealso put the test size of each language pair
Interesting analysis about Fon (fon) andYorugravebaacute (yor) For each language the lowest sp-BLEU scores in both tables come from the minusrarryordirection except fonlarrrarryor (from Table 5) whichinterestingly has the highest spBLEU score com-pared to the other fonminusrarr ~ directions We donot know the reason for the very low performancein the ~ minusrarryor direction but we offer below aplausible explanation about fonlarrrarryor
The oral linguistic history of Fon ties it to theancient Yorugravebaacute kingdom (Barnes 1997) Further-more in present day Benin where Fon is largely
406
spoken as a native language Yoruba is one of the in-digenuous languages commonly spoken 11 There-fore Fon and Yorugravebaacute share some linguistic charac-teristics and we believe this is one logic behind thefonlarrrarryor surpassing other fonminusrarr ~ directions
This explanation could inspire transfer learningfrom Yorugravebaacute which has received comparably moreresearch and has more resources for machine trans-lation to Fon We leave this for future work
Source Target spBLEU (FLORES)uarr spBLEU (Ours)uarr spCHRFuarr spTERdarr
ibo swa 438 2184 3738 7148
ibo xho 244 1397 3195 8137
ibo yor 154 1072 2655 7572
ibo eng 737 1362 3890 7623
ibo fra 602 1646 3510 7548
swa ibo 197 1980 3395 6822
swa xho 271 2171 3986 7316
swa yor 129 1168 2744 7523
swa eng 3043 2767 5612 5591
swa fra 2669 2727 4620 6347
xho ibo 380 1702 3130 7066
xho swa 614 2947 4468 6321
xho yor 192 1042 2677 7625
xho eng 1086 2077 4869 6409
xho fra 828 2148 4065 6931
yor ibo 185 1145 2526 7499
yor swa 193 1499 3049 7990
yor xho 194 931 2634 8608
yor eng 418 815 3065 8694
yor fra 357 1059 2760 8132
eng ibo 353 2149 3724 6568
eng swa 2695 4011 5313 5280
eng xho 447 2715 4493 6777
eng yor 217 1209 2834 7474
fra ibo 169 1948 3447 6850
fra swa 1717 3421 4895 5811
fra xho 227 2173 4006 7372
fra yor 116 1142 2767 7533
Table 4 Evaluation Scores of the Flores M2M MMTmodel and MMTAfrica on FLORES Test Set
6 Conclusion and Future Work
In this paper we introduced MMTAfrica a mul-tilingual machine translation model on 6 AfricanLanguages which outperformed the M2M MMTmodel Fan et al (2020) Our results and analy-ses including a new reconstruction objective giveinsights on MMT for African languages for fu-ture research Moreover we plan to launch themodel on Masakhane MT and FFRTranslate in or-der to get human evaluation feedback from theactual speakers of the languages in the Masakhanecommunity (Orife et al 2020) and beyond
In order to fully test the advantage ofMMTAfrica we plan to finish comparing it on
11httpsenwikipediaorgwikiBenin(Last Accessed 30082021)
direct and pivot translations with the Masakhanebenchmark models (forall et al 2020) We alsoplan to perform human evaluation All test setsresults code and checkpoints will be releasedat httpsgithubcomedaiofficialmmtafrica
7 Acknowledgments
The computational resources for running all ex-periments were provided by the FLORES com-pute grants12 as well as additonal computationalresources provided by Paco Guzman (FacebookAI) and Mila Quebec AI Institute We expressour profound gratitude to all who contributed inone way or the other towards the development ofMMTAfrica including (in no order)
Mathias Muumlller (University of Zurich) for giv-ing immense technical assistance in finetuning themodel and advising us on best hyperparameter tun-ing practises
Graham Neubig (Carnegie Mellon University)for explaining and setting up comparemt for usto better understand and evaluate the performanceof our baseline models
Angela Fan (FacebookAI) for guiding us duringthe shared task and taking the time to answer allour questions
Julia Kreutzer (GoogleAI) for advising us on use-ful model comparison and evaluation techniques
Colin Leong (University of Dayton) for painstak-ingly proof-reading the paper and helping us makeit more reader-friendly
Daria Yasafova (Technical University of Mu-nich) and Yeno Gbenou (Drexel University) foradditionally proof-reading the paper
Finally the entire Masakhane community13 foramong many other things 1) guiding us to exist-ing parallel and monolingual data set for the focusAfrican languages 2) explaining their (the focusAfrican languages) important linguistic charteris-tics which helped us work better with them (likein preprocessing) and 3) performing (in the future)human evaluation on MMTAfrica
Indeed it took a village to raise MMTAfrica1412httpwwwstatmtorgwmt21
flores-compute-grantshtml13httpswwwmasakhaneio14lsquoIt takes a village to raise a childrsquo is an African proverb
that means that an entire community of people with differentexpertise must provide for and interact positively with the childfor the child to actually develop and reach the best possiblepotential
407
Source Target Test size spBLEUuarr spCHRFuarr spTERdarr
ibo swa 60 3489 4738 6828
ibo xho 30 3669 5066 5965
ibo yor 30 1177 2954 12984
ibo kin 30 3392 4653 6773
ibo fon 30 3596 4314 6321
ibo eng 90 3728 6042 6205
ibo fra 60 3086 4409 6953
swa ibo 60 3371 4302 6001
swa xho 30 3728 5253 5586
swa yor 30 1409 2750 11363
swa kin 30 2386 4259 9467
swa fon 30 2329 3352 6511
swa eng 60 3555 6047 4732
swa fra 60 3011 4833 6338
xho ibo 30 3325 4536 6283
xho swa 30 3926 5375 5372
xho yor 30 2200 3806 7045
xho kin 30 3066 4619 7470
xho fon 30 2580 3487 6596
xho eng 90 3025 5512 6211
xho fra 30 2945 4572 6103
yor ibo 30 2511 3419 7480
yor swa 30 1762 3471 8518
yor xho 30 2931 4313 6682
yor kin 30 2516 3802 7267
yor fon 30 3181 3745 6339
yor eng 90 1781 4173 9300
yor fra 30 1544 3097 9057
kin ibo 30 3125 4236 6673
kin swa 30 3365 4634 7270
kin xho 30 2040 3971 8997
kin yor 30 1834 3353 7043
kin fon 30 2243 3249 6726
kin eng 60 1582 4310 9655
kin fra 30 1623 3351 9182
fon ibo 30 3236 4644 6182
fon swa 30 2984 4296 7228
fon xho 30 2882 4374 6698
fon yor 30 3045 4263 6072
fon kin 30 2388 3959 7806
fon eng 30 1663 4163 6903
fon fra 60 2479 4339 8215
eng ibo 90 4424 5489 6392
eng swa 60 4994 6145 4783
eng xho 120 3197 4974 7289
eng yor 90 2393 3619 8405
eng kin 90 4098 5600 7637
eng fon 30 2719 3686 6254
fra ibo 60 3647 4693 5991
fra swa 60 3653 5142 5594
fra xho 30 3435 4939 6030
fra yor 30 726 2554 12453
fra kin 30 3107 4226 8106
fra fon 60 3107 3872 7574
Table 5 Benchmark Evaluation Scores onMMTAfrica Test Set
ReferencesSolomon Teferra Abate Michael Melese Martha Yi-
firu Tachbelie Million Meshesha Solomon AtinafuWondwossen Mulugeta Yaregal Assabie HafteAbera Binyam Ephrem Tewodros Abebe Wondim-agegnhue Tsegaye Amanuel Lemma Tsegaye An-dargie and Seifedin Shifaw 2018 Parallel corporafor bi-lingual English-Ethiopian languages statisti-cal machine translation In Proceedings of the 27thInternational Conference on Computational Linguis-tics pages 3102ndash3111 Santa Fe New Mexico USAAssociation for Computational Linguistics
Jade Abbott and Laura Martinus 2019 Benchmarkingneural machine translation for Southern African lan-guages In Proceedings of the 2019 Workshop onWidening NLP pages 98ndash101 Florence Italy Asso-ciation for Computational Linguistics
Jade Z Abbott and Laura Martinus 2018 Towardsneural machine translation for african languages
David I Adelani Dana Ruiter Jesujoba O Al-abi Damilola Adebonojo Adesina Ayeni MofeAdeyemi Ayodele Awokoya and Cristina Espantildea-Bonet 2021a The effect of domain and diacritics inyorugravebaacute-english neural machine translation
David Ifeoluwa Adelani Jade Z Abbott GrahamNeubig Daniel Drsquosouza Julia Kreutzer Constan-tine Lignos Chester Palen-Michel Happy Buza-aba Shruti Rijhwani Sebastian Ruder StephenMayhew Israel Abebe Azime Shamsuddeen Has-san Muhammad Chris Chinenye Emezue JoyceNakatumba-Nabende Perez Ogayo Aremu An-uoluwapo Catherine Gitau Derguene Mbaye Je-sujoba O Alabi Seid Muhie Yimam Tajud-deen Gwadabe Ignatius Ezeani Rubungo An-dre Niyongabo Jonathan Mukiibi Verrah OtiendeIroro Orife Davis David Samba Ngom Tosin PAdewumi Paul Rayson Mofetoluwa Adeyemi Ger-ald Muriuki Emmanuel Anebi Chiamaka Chuk-wuneke Nkiruka Odu Eric Peter Wairagala SamuelOyerinde Clemencia Siro Tobius Saul BateesaTemilola Oloyede Yvonne Wambui Victor Akin-ode Deborah Nabagereka Maurice Katusiime Ayo-dele Awokoya Mouhamadane Mboup Dibora Ge-breyohannes Henok Tilaye Kelechi Nwaike De-gaga Wolde Abdoulaye Faye Blessing SibandaOrevaoghene Ahia Bonaventure F P DossouKelechi Ogueji Thierno Ibrahima Diop AbdoulayeDiallo Adewale Akinfaderin Tendai Marengerekeand Salomey Osei 2021b Masakhaner Namedentity recognition for african languages CoRRabs210311811
Željko Agic and Ivan Vulic 2019 JW300 A wide-coverage parallel corpus for low-resource languagesIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages3204ndash3210 Florence Italy Association for Compu-tational Linguistics
Roee Aharoni Melvin Johnson and Orhan Firat 2019Massively multilingual neural machine translation
408
In Proceedings of the 2019 Conference of the NorthAmerican Chapter of the Association for Compu-tational Linguistics Human Language Technolo-gies Volume 1 (Long and Short Papers) pages3874ndash3884 Minneapolis Minnesota Associationfor Computational Linguistics
Jesujoba Alabi Kwabena Amponsah-Kaakyire DavidAdelani and Cristina Espantildea-Bonet 2020 Mas-sive vs curated embeddings for low-resourced lan-guages the case of Yorugravebaacute and Twi In Proceed-ings of the 12th Language Resources and EvaluationConference pages 2754ndash2762 Marseille FranceEuropean Language Resources Association
Naveen Arivazhagan Ankur Bapna Orhan Firat RoeeAharoni Melvin Johnson and Wolfgang Macherey2019a The missing ingredient in zero-shot neuralmachine translation CoRR abs190307091
Naveen Arivazhagan Ankur Bapna Orhan FiratDmitry Lepikhin Melvin Johnson Maxim KrikunMia Xu Chen Yuan Cao George F Foster ColinCherry Wolfgang Macherey Zhifeng Chen andYonghui Wu 2019b Massively multilingual neuralmachine translation in the wild Findings and chal-lenges CoRR abs190705019
Mikko Aulamo Umut Sulubacak Sami Virpioja andJoumlrg Tiedemann 2020 OpusTools and parallel cor-pus diagnostics In Proceedings of The 12th Lan-guage Resources and Evaluation Conference pages3782ndash3789 European Language Resources Associ-ation
Dzmitry Bahdanau Kyunghyun Cho and Yoshua Ben-gio 2015 Neural machine translation by jointlylearning to align and translate In 3rd Inter-national Conference on Learning RepresentationsICLR 2015 San Diego CA USA May 7-9 2015Conference Track Proceedings
ST Barnes 1997 Africarsquos Ogun Old World andNew African systems of thought Indiana Univer-sity Press
Loiumlc Barrault Magdalena Biesialska Ondrej BojarMarta R Costa-jussagrave Christian Federmann YvetteGraham Roman Grundkiewicz Barry HaddowMatthias Huck Eric Joanis Tom Kocmi PhilippKoehn Chi-kiu Lo Nikola Ljubešic ChristofMonz Makoto Morishita Masaaki Nagata Toshi-aki Nakazawa Santanu Pal Matt Post and MarcosZampieri 2020 Findings of the 2020 conference onmachine translation (WMT20) In Proceedings ofthe Fifth Conference on Machine Translation pages1ndash55 Online Association for Computational Lin-guistics
Loiumlc Barrault Ondrej Bojar Marta R Costa-jussagraveChristian Federmann Mark Fishel Yvette Gra-ham Barry Haddow Matthias Huck Philipp KoehnShervin Malmasi Christof Monz Mathias MuumlllerSantanu Pal Matt Post and Marcos Zampieri 2019
Findings of the 2019 conference on machine transla-tion (WMT19) In Proceedings of the Fourth Con-ference on Machine Translation (Volume 2 SharedTask Papers Day 1) pages 1ndash61 Florence Italy As-sociation for Computational Linguistics
Lukas Biewald 2020 Experiment tracking withweights and biases Software available fromwandbcom
Yong Cheng Wei Xu Zhongjun He Wei He HuaWu Maosong Sun and Yang Liu 2016 Semi-supervised learning for neural machine translationIn Proceedings of the 54th Annual Meeting of the As-sociation for Computational Linguistics (Volume 1Long Papers) pages 1965ndash1974 Berlin GermanyAssociation for Computational Linguistics
Kyunghyun Cho Bart van Merrienboer CcedilaglarGuumllccedilehre Dzmitry Bahdanau Fethi Bougares Hol-ger Schwenk and Yoshua Bengio 2014 Learningphrase representations using RNN encoder-decoderfor statistical machine translation In Proceedings ofthe 2014 Conference on Empirical Methods in Nat-ural Language Processing EMNLP 2014 October25-29 2014 Doha Qatar A meeting of SIGDAT aSpecial Interest Group of the ACL pages 1724ndash1734ACL
Alexis Conneau Kartikay Khandelwal Naman GoyalVishrav Chaudhary Guillaume Wenzek FranciscoGuzmaacuten Edouard Grave Myle Ott Luke Zettle-moyer and Veselin Stoyanov 2019 Unsupervisedcross-lingual representation learning at scale
Jacob Devlin Ming-Wei Chang Kenton Lee andKristina Toutanova 2018 BERT pre-training ofdeep bidirectional transformers for language under-standing CoRR abs181004805
Daxiang Dong Hua Wu Wei He Dianhai Yu andHaifeng Wang 2015 Multi-task learning for mul-tiple language translation In Proceedings of the53rd Annual Meeting of the Association for Compu-tational Linguistics and the 7th International JointConference on Natural Language Processing (Vol-ume 1 Long Papers) pages 1723ndash1732 BeijingChina Association for Computational Linguistics
Bonaventure F P Dossou and Chris C Emezue 2020FFR V10 fon-french neural machine translationCoRR abs200312111
Bonaventure F P Dossou and Chris C Emezue 2021aCrowdsourced phrase-based tokenization for low-resourced neural machine translation The case offon language CoRR abs210308052
Bonaventure F P Dossou and Chris C Emezue 2021bOkwugbeacute End-to-end speech recognition for fonand igbo CoRR abs210307762
David M Eberhard Gary F Simons and CharlesD Fennig (eds) 2020 Ethnologue Languages ofthe world twenty-third edition
409
Sergey Edunov Myle Ott Michael Auli and DavidGrangier 2018 Understanding back-translation atscale CoRR abs180809381
Ignatius Ezeani Paul Rayson Ikechukwu E OnyenweChinedu Uchechukwu and Mark Hepple 2020Igbo-english machine translation An evaluationbenchmark CoRR abs200400648
Angela Fan Shruti Bhosale Holger Schwenk ZhiyiMa Ahmed El-Kishky Siddharth Goyal Man-deep Baines Onur Celebi Guillaume WenzekVishrav Chaudhary Naman Goyal Tom Birch Vi-taliy Liptchinsky Sergey Edunov Edouard GraveMichael Auli and Armand Joulin 2020 Be-yond english-centric multilingual machine transla-tion CoRR abs201011125
Thibault Feacutevry and Jason Phang 2018 Unsuper-vised sentence compression using denoising auto-encoders CoRR abs180902669
Orhan Firat Kyunghyun Cho and Yoshua Bengio2016a Multi-way multilingual neural machinetranslation with a shared attention mechanism InProceedings of the 2016 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 866ndash875 San Diego California Associationfor Computational Linguistics
Orhan Firat Baskaran Sankaran Yaser Al-onaizanFatos T Yarman Vural and Kyunghyun Cho 2016bZero-resource translation with multi-lingual neuralmachine translation In Proceedings of the 2016Conference on Empirical Methods in Natural Lan-guage Processing pages 268ndash277 Austin TexasAssociation for Computational Linguistics
forall Wilhelmina Nekoto Vukosi Marivate TshinondiwaMatsila Timi Fasubaa Tajudeen Kolawole TaiwoFagbohungbe Solomon Oluwole Akinola Sham-suddee Hassan Muhammad Salomon Kabongo Sa-lomey Osei et al 2020 Participatory research forlow-resourced machine translation A case study inafrican languages Findings of EMNLP
Naman Goyal Cynthia Gao Vishrav Chaudhary Peng-Jen Chen Guillaume Wenzek Da Ju Sanjana Kr-ishnan MarcrsquoAurelio Ranzato Francisco Guzmanand Angela Fan 2021 The flores-101 evaluationbenchmark for low-resource and multilingual ma-chine translation
Jiatao Gu Yong Wang Kyunghyun Cho and Vic-tor OK Li 2019 Improved zero-shot neural ma-chine translation via ignoring spurious correlationsIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages1258ndash1268 Florence Italy Association for Compu-tational Linguistics
Thanh-Le Ha Jan Niehues and Alexander H Waibel2016 Toward multilingual neural machine trans-lation with universal encoder and decoder CoRRabs161104798
Vu Cong Duy Hoang Philipp Koehn GholamrezaHaffari and Trevor Cohn 2018 Iterative back-translation for neural machine translation In Pro-ceedings of the 2nd Workshop on Neural MachineTranslation and Generation pages 18ndash24 Mel-bourne Australia Association for ComputationalLinguistics
Melvin Johnson Mike Schuster Quoc V Le MaximKrikun Yonghui Wu Zhifeng Chen Nikhil ThoratFernanda Vieacutegas Martin Wattenberg Greg CorradoMacduff Hughes and Jeffrey Dean 2017 Googlersquosmultilingual neural machine translation system En-abling zero-shot translation Transactions of the As-sociation for Computational Linguistics 5339ndash351
Pratik Joshi Sebastin Santy Amar Budhiraja KalikaBali and Monojit Choudhury 2020 The state andfate of linguistic diversity and inclusion in the NLPworld In Proceedings of the 58th Annual Meet-ing of the Association for Computational Linguisticspages 6282ndash6293 Online Association for Computa-tional Linguistics
Taku Kudo and John Richardson 2018 SentencePieceA simple and language independent subword tok-enizer and detokenizer for neural text processing InProceedings of the 2018 Conference on EmpiricalMethods in Natural Language Processing SystemDemonstrations pages 66ndash71 Brussels BelgiumAssociation for Computational Linguistics
Surafel Melaku Lakew Mauro Cettolo and MarcelloFederico 2018 A comparison of transformer andrecurrent neural networks on multilingual neural ma-chine translation In Proceedings of the 27th Inter-national Conference on Computational Linguisticspages 641ndash652 Santa Fe New Mexico USA Asso-ciation for Computational Linguistics
Guillaume Lample Ludovic Denoyer andMarcrsquoAurelio Ranzato 2017 Unsupervisedmachine translation using monolingual corporaonly CoRR abs171100043
Jason Lee Kyunghyun Cho and Thomas Hofmann2017 Fully Character-Level Neural Machine Trans-lation without Explicit Segmentation Transactionsof the Association for Computational Linguistics5365ndash378
Ilya Loshchilov and Frank Hutter 2017 Fixingweight decay regularization in adam CoRRabs171105101
Yichao Lu Phillip Keung Faisal Ladhak Vikas Bhard-waj Shaonan Zhang and Jason Sun 2018 A neu-ral interlingua for multilingual machine translationIn Proceedings of the Third Conference on MachineTranslation Research Papers pages 84ndash92 Brus-sels Belgium Association for Computational Lin-guistics
Laura Martinus and Jade Z Abbott 2019 A focuson neural machine translation for african languagesCoRR abs190605685
410
Graham Neubig Zi-Yi Dou Junjie Hu Paul MichelDanish Pruthi Xinyi Wang and John Wieting 2019compare-mt A tool for holistic comparison of lan-guage generation systems CoRR abs190307926
Graham Neubig and Junjie Hu 2018 Rapid adapta-tion of neural machine translation to new languagesIn Proceedings of the 2018 Conference on Empiri-cal Methods in Natural Language Processing pages875ndash880 Brussels Belgium Association for Com-putational Linguistics
Rubungo Andre Niyongabo Qu Hong Julia Kreutzerand Li Huang 2020 KINNEWS and KIRNEWSBenchmarking cross-lingual text classification forKinyarwanda and Kirundi In Proceedings ofthe 28th International Conference on Computa-tional Linguistics pages 5507ndash5521 BarcelonaSpain (Online) International Committee on Compu-tational Linguistics
Linda Nordling 2018 How decolonizationcould reshape south african science Nature554(7691)159ndash162
Evander Nyoni and Bruce A Bassett 2021 Low-resource neural machine translation for southernafrican languages CoRR abs210400366
Iroro Orife Julia Kreutzer Blessing Sibanda DanielWhitenack Kathleen Siminyu Laura MartinusJamiil Toure Ali Jade Z Abbott Vukosi Mari-vate Salomon Kabongo Musie Meressa Es-poir Murhabazi Orevaoghene Ahia Elan VanBiljon Arshath Ramkilowan Adewale AkinfaderinAlp Oumlktem Wole Akin Ghollah Kioko KevinDegila Herman Kamper Bonaventure DossouChris Emezue Kelechi Ogueji and Abdallah Bashir2020 Masakhane - machine translation for africaCoRR abs200311529
Maja Popovic 2015 chrF character n-gram F-scorefor automatic MT evaluation In Proceedings of theTenth Workshop on Statistical Machine Translationpages 392ndash395 Lisbon Portugal Association forComputational Linguistics
Matt Post 2018 A call for clarity in reporting BLEUscores In Proceedings of the Third Conference onMachine Translation Research Papers pages 186ndash191 Brussels Belgium Association for Computa-tional Linguistics
Colin Raffel Noam Shazeer Adam Roberts KatherineLee Sharan Narang Michael Matena Yanqi ZhouWei Li and Peter J Liu 2019 Exploring the limitsof transfer learning with a unified text-to-text trans-former CoRR abs191010683
Machel Reid Junjie Hu Graham Neubig and YutakaMatsuo 2021 Afromt Pretraining strategies andreproducible benchmarks for translation of 8 africanlanguages
Rico Sennrich Barry Haddow and Alexandra Birch2015 Improving neural machine translation modelswith monolingual data CoRR abs151106709
Shivachi Casper Shikali and Mokhosi Refuoe 2019Language modeling data for swahili
Aditya Siddhant Ankur Bapna Yuan Cao Orhan Fi-rat Mia Xu Chen Sneha Reddy Kudugunta NaveenArivazhagan and Yonghui Wu 2020 Lever-aging monolingual data with self-supervision formultilingual neural machine translation CoRRabs200504816
Ilya Sutskever Oriol Vinyals and Quoc V Le 2014Sequence to sequence learning with neural networksIn Proceedings of the 27th International Conferenceon Neural Information Processing Systems - Vol-ume 2 NIPSrsquo14 page 3104ndash3112 Cambridge MAUSA MIT Press
Xu Tan Jiale Chen Di He Yingce Xia Tao Qin andTie-Yan Liu 2019 Multilingual neural machinetranslation with language clustering In Proceedingsof the 2019 Conference on Empirical Methods inNatural Language Processing and the 9th Interna-tional Joint Conference on Natural Language Pro-cessing (EMNLP-IJCNLP) pages 963ndash973 HongKong China Association for Computational Lin-guistics
Joumlrg Tiedemann 2012 Parallel data tools and inter-faces in opus In Proceedings of the Eight Interna-tional Conference on Language Resources and Eval-uation (LRECrsquo12) Istanbul Turkey European Lan-guage Resources Association (ELRA)
Daniel van Niekerk Charl van Heerden Marelie DavelNeil Kleynhans Oddur Kjartansson Martin Janscheand Linne Ha 2017 Rapid development of TTS cor-pora for four South African languages In Proc In-terspeech 2017 pages 2178ndash2182 Stockholm Swe-den
Ashish Vaswani Noam Shazeer Niki Parmar JakobUszkoreit Llion Jones Aidan N Gomez LukaszKaiser and Illia Polosukhin 2017 Attention is allyou need CoRR abs170603762
Sarah Wild 2021 African languages to get more be-spoke scientific terms Nature 596(7873)469ndash470
Ronald J Williams and David Zipser 1989 A learn-ing algorithm for continually running fully recurrentneural networks Neural Computation 1(2)270ndash280
Linting Xue Noah Constant Adam Roberts Mi-hir Kale Rami Al-Rfou Aditya Siddhant AdityaBarua and Colin Raffel 2021 mT5 A massivelymultilingual pre-trained text-to-text transformer InProceedings of the 2021 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 483ndash498 Online Association for Computa-tional Linguistics
Biao Zhang Philip Williams Ivan Titov and RicoSennrich 2020 Improving massively multilingualneural machine translation and zero-shot translationCoRR abs200411867
411
Jiajun Zhang and Chengqing Zong 2016 Exploit-ing source-side monolingual data in neural machinetranslation In Proceedings of the 2016 Conferenceon Empirical Methods in Natural Language Process-ing pages 1535ndash1545 Austin Texas Associationfor Computational Linguistics
Barret Zoph Deniz Yuret Jonathan May and KevinKnight 2016 Transfer learning for low-resourceneural machine translation In Proceedings of the2016 Conference on Empirical Methods in Natu-ral Language Processing pages 1568ndash1575 AustinTexas Association for Computational Linguistics

402
et al (2021)4 We performed evaluation onthis test set for all language directions except~larrrarrfon and ~larrrarrkin
bull MMTAfrica Test Set This is a sub-stantial test set we created by taking out asmall but equal number of sentences fromeach parallel source domain As a result wehave a set from a wide range of domainswhile encompassing samples from many exist-ing test sets from previous research Althoughthis set is small to be fully considered as a testset we open-source it because it contains sen-tences from many domains (making it usefulfor evaluation) and we hope that it can be builtupon by perhaps merging it with other bench-mark test sets (Abate et al 2018 Abbott andMartinus 2019 Reid et al 2021)
bull Baseline TrainTest Set We firstconducted baseline experiments with FonIgbo English and French as explained in sec-tion 441 For this we created a special dataset by carefully selecting a small subset of theFFR Dataset (which already contained paral-lel sentences in French and Fon) first auto-matically translating the sentences to Englishand Igbo using the Google Translate API5and finally re-translating with the help of Igbo(7) and English (7) native speakers (we recog-nized that it was easier for native speakers toedittweak an existing translation rather thanwriting the whole translation from scratch)In so doing we created a data set of 13 878translations in all 4 language directions
We split the data set into 12 554 for trainingBaseline Train Set 662 for dev and662 for test Baseline Test Set
4 Model and Experiments
41 ModelFor all our experiments we used the mT5model (Xue et al 2021) a multilingual variant ofthe encoder-decoder transformer-based (Vaswaniet al 2017) ldquoText-to-Text Transfer Transformerrdquo(T5) model (Raffel et al 2019) In T5 pre-trainingthe NLP tasks (including machine translation) werecast into a ldquotext-to-textrdquo format ndash that is a task
4httpsdlfbaipublicfilescomflores101datasetflores101_datasettargz
5httpscloudgooglecomtranslate
where the model is fed some text prefix for contextor conditioning and is then asked to produce someoutput text This framework makes it straightfor-ward to design a number of NLP tasks like machinetranslation summarization text classification etcAlso it provides a consistent training objective bothfor pre-training and finetuning The mT5 modelwas pre-trained with a maximum likelihood objec-tive using ldquoteacher forcingrdquo (Williams and Zipser1989) The mT5 model was also pretrained witha modification of the masked language modellingobjective (Devlin et al 2018)
We finetuned the mt5-base model on ourmany-to-many machine translation task WhileXue et al (2021) suggest that higher versions ofthe mT5 model (Large XL or XXL) give betterperformance on downstream multilingual transla-tion tasks we were constrained by computationalresources to mt5-base which has 580M pa-rameters
42 SetupFor each language direction X rarr Y we have its setof n parallel sentences D = (xi yi)ni=1 wherexi is the ith source sentence of language X and yiis its translation in the target language Y
Following the approach of Johnson et al (2017)and Xue et al (2021) we model translation in atext-to-text format More specifically we createthe input for the model by prepending the targetlanguage tag to the source sentence Thereforefor each source sentence xi the input to the modelis ltYtaggt xi and the target is yi Taking a realexample letrsquos say we wish to translate the Igbosentence Daalu maka ikwu eziokwu nke Chineke toEnglish The input to the model becomes ltenggtDaalu maka ikwu eziokwu nke Chineke
43 TrainingWe have a set of language tags L for the lan-guages we are working with in our multilin-gual many-to-many translation In our baselinesetup (section 441) L = eng fra ibo fonand in our final experiment (section 442) L =eng fra ibo fon swa kin xho yor We car-ried out many-to-many translation using all thepossible directions from L except eng larrrarr fraWe skipped eng larrrarr fra for this fundamentalreason
bull our main focus is on AfricanlarrrarrAfrican oreng fra larrrarrAfrican Due to the high-
403
resource nature of English and French addingthe training set for eng larrrarr fra would over-shadow the learning of the other language di-rections and greatly impede our analyses Ourintuition draws from the observation of Xueet al (2021) as the reason for off-target trans-lation in the mT5 model as English-basedfinetuning proceeds the modelrsquos assigned like-lihood of non-English tokens presumably de-creases Therefore since the mt5-basetraining set contained predominantly English(and after other European languages) tokensand our research is about ALlarrrarrAL trans-lation removing the eng larrrarr fra directionwas our way of ensuring the model designatedmore likelihood to AL tokens
431 Our ContributionsIn addition to the parallel data between the Africanlanguages we leveraged monolingual data to im-prove translation quality in two ways
1 our backtranslation (BT) We designed amodified form of the random online backtrans-lation (Zhang et al 2020) where instead ofrandomly selecting a subset of languages tobacktranslate we selected for each languagenum_bt sentences at random from the mono-lingual data set This means that the modelgets to backtranslate different (monolingual)sentences every backtranslation time and inso doing we believe improve the modelrsquos do-main adaptation because it gets to learn fromvarious samples from the whole monolingualdata set We initially tested different values ofnum_bt to find a compromise between back-translation computation time and translationquality
Following research works which have shownthe effectiveness of random beam-search overgreedy decoding while generating backtrans-lations (Lample et al 2017 Edunov et al2018 Hoang et al 2018 Zhang et al 2020)we generated num_sample prediction sen-tences from the model and randomly selected(with equal probability) one for our back-translated sentence Naturally the value ofnum_sample further affects the computa-tion time (because the model has to producenum_sample different output sentences foreach input sentence) and so we finally settledwith num_sample = 2
2 our reconstruction Given a monolingualsentence xm from language m we appliedrandom swapping (2 times) and deletion (witha probability of 02) to get a noisy version xTaking inspiration from Raffel et al (2019)we integrated the reconstruction objective intoour model finetuning by prepending the lan-guage tag ltmgt to x and setting its target out-put to xm
44 ExperimentsIn all our experiments we initialized the pretrainedmT5-base model using Hugging Facersquos Auto-
ModelForSeq2SeqLM6 and tracked the trainingprocess with WeightsampBiases (Biewald 2020) Weused the AdamW optimizer (Loshchilov and Hutter2017) with a learning rate (lr) of 3eminus6 and trans-formerrsquos get_linear_schedule_with_warmup7
scheduler (where the learning rate decreases lin-early from the initial lr set in the optimizer to 0after a warmup period and then increases linearlyfrom 0 to the initial lr set in the optimizer)
441 BaselineThe goal of our baseline was to understand theeffect of jointly finetuning with backtranslationand reconstruction on the AfricanlarrrarrAfrican lan-guage translation quality in two scenarios whenthe AL was initially pretrained on the multilingualmodel and contrariwise Using Fon (which wasnot initially included in the pretraining) and Igbo(which was initially included in the pretraining) asthe African languages for our baseline training wefinetuned our model on a many-to-many translationin all directions of eng fra ibo foneng larrrarrfra amounting to 10 directions We used theBaseline Train Set for training and theBaseline Test Set for evaluation We
trained the model for only 3 epochs in three set-tings
1 BASE in this setup we finetune the modelon only the many-to-many translation task nobacktranslation nor reconstruction
2 BT refers to finetuning with our backtransla-tion objective described in section 42 For our
6httpshuggingfacecotransformersmodel_docautohtmltransformersAutoModelForSeq2SeqLM
7httpshuggingfacecotransformersmain_classesoptimizer_scheduleshtmltransformersget_linear_schedule_with_warmup
404
baseline where we backtranslate using mono-lingual data in ibo fon we set num_bt =500 For our final experiments we first triedwith 500 but finally reduced to 100 due to thegreat deal of computation required
For our baseline experiment we ran one epochnormally and the remaining two with back-translation For our final experiments we firstfinetuned the model on 3 epochs before con-tinuing with backtranslation
3 BTampREC refers to joint backtranslation andreconstruction (explained in section 42) whilefinetuning Two important questions were ad-dressed ndash 1) the ratio backtranslation re-construction of monolingual sentences to useand 2) whether to use the same or differentsentences for backtranslation and reconstruc-tion Bearing computation time in mind weresolved to go with 500 50 for our baselineand 100 50 for our final experiments Weleave ablation studies on the effect of the ra-tio on translation quality to future work Forthe second question we decided to randomlysample (with replacement) different sentenceseach for our backtranslation and reconstruc-tion
For our baseline we used a learning rate of 5eminus4a batch size of 32 sentences with gradient accumu-lation up to a batch of 256 sentences and an earlystopping patience of 100 evaluation steps To fur-ther analyse the performance of our baseline setupswe ran comparemt 8 (Neubig et al 2019) on themodelrsquos predictions
442 MMTAfricaMMTAfrica refers to our final experimentalsetup where we finetuned our model on all lan-guage directions involving all eight languagesL = eng fra ibo fon swa kin xho yor ex-cept englarrrarrfra Taking inspiration from our base-line results we ran our experiment with our pro-posed BTampREC setting and made some adjust-ments along the way
The long computation time for backtranslating(with just 100 sentences per language the modelwas required to generate around 3 000 translationsevery backtranslation time) was a drawback Tomitigate the issue we parallelized the process us-
8httpsgithubcomneulabcompare-mt
ing the multiprocessing package in Python9 Wefurther slowly reduced the number of sentences forbacktranslation (to 50 and finally 10)
Gradient descent in large multilingual modelshas been shown to be more stable when updatesare performed over large batch sizes are used (Xueet al 2021) To cope with our computational re-sources we used gradient accumulation to increaseupdates from an initial batch size of 64 sentencesup to a batch gradient computation size of 4096sentences We further utilized PyTorchrsquos DataParal-lel package10 to parallelize the training across theGPUs We used a learning rate (lr) of 3eminus6
5 Results and Insights
All evaluations were made using spBLEU (sen-tencepiece (Kudo and Richardson 2018) + sacre-BLEU (Post 2018)) as described in (Goyal et al2021) We further evaluated on the chrF (Popovic2015) and TER metrics
51 Baseline Results and InsightsFigure 1 compares the spBLEU scores for the threesetups used in our baseline experiments As a re-minder we make use of the symbol to refer toany language in the set eng fra ibo fon
BT gives strong improvement over BASE (ex-cept in engminusrarribo where itrsquos relatively the sameand framinusrarribo where it performs worse)
Figure 1 spBLEU scores of the 3 setups explained insection 441
When the target language is fon we observe aconsiderable boost in the spBLEU of the BT set-ting which also significantly outperformed BASE
9httpsdocspythonorg3librarymultiprocessinghtml
10httpspytorchorgdocsstablegeneratedtorchnnDataParallelhtml
405
and BTampREC BTampREC contributed very littlewhen compared with BT and sometimes even per-formed poorly (in engminusrarrfon) We attribute thispoor performance from the reconstruction objec-tive to the fact that the mt5-base model wasnot originally pretrained on Fon Therefore withonly 3 epochs of finetuning (and 1 epoch beforeintroducing the reconstruction and backtranslationobjectives) the model was not able to meaningfullyutilize both objectives
Conversely when the target language is iboBTampREC gives best results ndash even in scenarios
where BT underperforms BASE (as is the caseof framinusrarribo and engminusrarribo) We believe that thedecoder of the model being originally pretrainedon corpora containing Igbo was able to better useour reconstruction to improve translation quaity in minusrarribo direction
Drawing insights from fonlarrrarribo we offer thefollowing propositions concerning ALlarrrarrALmultilingual translation
bull our backtranslation (section 42) from mono-lingual data improves the cross-lingual map-ping of the model for low-resource Africanlanguages While it is computationally expen-sive our parallelization and decay of numberof backtranslated sentences are some potentialsolutions towards effectively adopting back-translation using monolingual data
bull Denoising objectives typically have beenknown to improve machine translation qual-ity (Zhang and Zong 2016 Cheng et al 2016Gu et al 2019 Zhang et al 2020 Xue et al2021) because they imbue the model withmore generalizable knowledge (about that lan-guage) which is used by the decoder to pre-dict better token likelihoods for that languageduring translation This is a reasonable ex-planation for the improved quality with theBTampREC over BT in the minusrarribo As we
learned from minusrarrfon using reconstructioncould perform unsatisfactorily if not handledwell Some methods we propose are
1 For African languages that were includedin the original model pretraining (aswas the case of Igbo Swahili Xhosaand Yorugravebaacute in the mT5 model) usingthe BTampREC setting for finetuning pro-duces best results While we did not per-form ablation studies on the data size
ratio for backtranslation and reconstruc-tion we believe that our ratio of 2 1(in our final experiments) gives the bestcompromise on both computation timeand translation quality
2 For African languages that were not orig-inally included in the original model pre-training (as was the case of Kinyarwandaand Fon in the mT5 model) reconstruc-tion together with backtranslation (espe-cially at an early stage) only introducesmore noise which could harm the cross-lingual learning For these languages wepropose(a) first finetuning the model on only
our reconstruction (described in sec-tion 42) for fairly long training stepsbefore using BTampREC This waythe initial reconstruction will help themodel learn that language represen-tation space and increase its the like-lihood of tokens
52 MMTAfrica Results and InsightsIn Table 4 we compared MMTAfrica with theM2M MMT(Fan et al 2020) benchmark resultsof Goyal et al (2021) using the same test set theyused ndash FLORES Test Set On all languagepairs except swararreng (which has a comparableminus276 spBLEU difference) we report an improve-ment from MMTAfrica (spBLEU gains rangingfrom +058 in swaminusrarrfra to +1946 in framinusrarrxho)The lower score of swararreng presents an intriguinganomaly especially given the large availability ofparallel corpora in our training set for this pair Weplan to investigate this in further work
In Table 5 we introduce benchmark results ofMMTAfrica on MMTAfrica Test Set Wealso put the test size of each language pair
Interesting analysis about Fon (fon) andYorugravebaacute (yor) For each language the lowest sp-BLEU scores in both tables come from the minusrarryordirection except fonlarrrarryor (from Table 5) whichinterestingly has the highest spBLEU score com-pared to the other fonminusrarr ~ directions We donot know the reason for the very low performancein the ~ minusrarryor direction but we offer below aplausible explanation about fonlarrrarryor
The oral linguistic history of Fon ties it to theancient Yorugravebaacute kingdom (Barnes 1997) Further-more in present day Benin where Fon is largely
406
spoken as a native language Yoruba is one of the in-digenuous languages commonly spoken 11 There-fore Fon and Yorugravebaacute share some linguistic charac-teristics and we believe this is one logic behind thefonlarrrarryor surpassing other fonminusrarr ~ directions
This explanation could inspire transfer learningfrom Yorugravebaacute which has received comparably moreresearch and has more resources for machine trans-lation to Fon We leave this for future work
Source Target spBLEU (FLORES)uarr spBLEU (Ours)uarr spCHRFuarr spTERdarr
ibo swa 438 2184 3738 7148
ibo xho 244 1397 3195 8137
ibo yor 154 1072 2655 7572
ibo eng 737 1362 3890 7623
ibo fra 602 1646 3510 7548
swa ibo 197 1980 3395 6822
swa xho 271 2171 3986 7316
swa yor 129 1168 2744 7523
swa eng 3043 2767 5612 5591
swa fra 2669 2727 4620 6347
xho ibo 380 1702 3130 7066
xho swa 614 2947 4468 6321
xho yor 192 1042 2677 7625
xho eng 1086 2077 4869 6409
xho fra 828 2148 4065 6931
yor ibo 185 1145 2526 7499
yor swa 193 1499 3049 7990
yor xho 194 931 2634 8608
yor eng 418 815 3065 8694
yor fra 357 1059 2760 8132
eng ibo 353 2149 3724 6568
eng swa 2695 4011 5313 5280
eng xho 447 2715 4493 6777
eng yor 217 1209 2834 7474
fra ibo 169 1948 3447 6850
fra swa 1717 3421 4895 5811
fra xho 227 2173 4006 7372
fra yor 116 1142 2767 7533
Table 4 Evaluation Scores of the Flores M2M MMTmodel and MMTAfrica on FLORES Test Set
6 Conclusion and Future Work
In this paper we introduced MMTAfrica a mul-tilingual machine translation model on 6 AfricanLanguages which outperformed the M2M MMTmodel Fan et al (2020) Our results and analy-ses including a new reconstruction objective giveinsights on MMT for African languages for fu-ture research Moreover we plan to launch themodel on Masakhane MT and FFRTranslate in or-der to get human evaluation feedback from theactual speakers of the languages in the Masakhanecommunity (Orife et al 2020) and beyond
In order to fully test the advantage ofMMTAfrica we plan to finish comparing it on
11httpsenwikipediaorgwikiBenin(Last Accessed 30082021)
direct and pivot translations with the Masakhanebenchmark models (forall et al 2020) We alsoplan to perform human evaluation All test setsresults code and checkpoints will be releasedat httpsgithubcomedaiofficialmmtafrica
7 Acknowledgments
The computational resources for running all ex-periments were provided by the FLORES com-pute grants12 as well as additonal computationalresources provided by Paco Guzman (FacebookAI) and Mila Quebec AI Institute We expressour profound gratitude to all who contributed inone way or the other towards the development ofMMTAfrica including (in no order)
Mathias Muumlller (University of Zurich) for giv-ing immense technical assistance in finetuning themodel and advising us on best hyperparameter tun-ing practises
Graham Neubig (Carnegie Mellon University)for explaining and setting up comparemt for usto better understand and evaluate the performanceof our baseline models
Angela Fan (FacebookAI) for guiding us duringthe shared task and taking the time to answer allour questions
Julia Kreutzer (GoogleAI) for advising us on use-ful model comparison and evaluation techniques
Colin Leong (University of Dayton) for painstak-ingly proof-reading the paper and helping us makeit more reader-friendly
Daria Yasafova (Technical University of Mu-nich) and Yeno Gbenou (Drexel University) foradditionally proof-reading the paper
Finally the entire Masakhane community13 foramong many other things 1) guiding us to exist-ing parallel and monolingual data set for the focusAfrican languages 2) explaining their (the focusAfrican languages) important linguistic charteris-tics which helped us work better with them (likein preprocessing) and 3) performing (in the future)human evaluation on MMTAfrica
Indeed it took a village to raise MMTAfrica1412httpwwwstatmtorgwmt21
flores-compute-grantshtml13httpswwwmasakhaneio14lsquoIt takes a village to raise a childrsquo is an African proverb
that means that an entire community of people with differentexpertise must provide for and interact positively with the childfor the child to actually develop and reach the best possiblepotential
407
Source Target Test size spBLEUuarr spCHRFuarr spTERdarr
ibo swa 60 3489 4738 6828
ibo xho 30 3669 5066 5965
ibo yor 30 1177 2954 12984
ibo kin 30 3392 4653 6773
ibo fon 30 3596 4314 6321
ibo eng 90 3728 6042 6205
ibo fra 60 3086 4409 6953
swa ibo 60 3371 4302 6001
swa xho 30 3728 5253 5586
swa yor 30 1409 2750 11363
swa kin 30 2386 4259 9467
swa fon 30 2329 3352 6511
swa eng 60 3555 6047 4732
swa fra 60 3011 4833 6338
xho ibo 30 3325 4536 6283
xho swa 30 3926 5375 5372
xho yor 30 2200 3806 7045
xho kin 30 3066 4619 7470
xho fon 30 2580 3487 6596
xho eng 90 3025 5512 6211
xho fra 30 2945 4572 6103
yor ibo 30 2511 3419 7480
yor swa 30 1762 3471 8518
yor xho 30 2931 4313 6682
yor kin 30 2516 3802 7267
yor fon 30 3181 3745 6339
yor eng 90 1781 4173 9300
yor fra 30 1544 3097 9057
kin ibo 30 3125 4236 6673
kin swa 30 3365 4634 7270
kin xho 30 2040 3971 8997
kin yor 30 1834 3353 7043
kin fon 30 2243 3249 6726
kin eng 60 1582 4310 9655
kin fra 30 1623 3351 9182
fon ibo 30 3236 4644 6182
fon swa 30 2984 4296 7228
fon xho 30 2882 4374 6698
fon yor 30 3045 4263 6072
fon kin 30 2388 3959 7806
fon eng 30 1663 4163 6903
fon fra 60 2479 4339 8215
eng ibo 90 4424 5489 6392
eng swa 60 4994 6145 4783
eng xho 120 3197 4974 7289
eng yor 90 2393 3619 8405
eng kin 90 4098 5600 7637
eng fon 30 2719 3686 6254
fra ibo 60 3647 4693 5991
fra swa 60 3653 5142 5594
fra xho 30 3435 4939 6030
fra yor 30 726 2554 12453
fra kin 30 3107 4226 8106
fra fon 60 3107 3872 7574
Table 5 Benchmark Evaluation Scores onMMTAfrica Test Set
ReferencesSolomon Teferra Abate Michael Melese Martha Yi-
firu Tachbelie Million Meshesha Solomon AtinafuWondwossen Mulugeta Yaregal Assabie HafteAbera Binyam Ephrem Tewodros Abebe Wondim-agegnhue Tsegaye Amanuel Lemma Tsegaye An-dargie and Seifedin Shifaw 2018 Parallel corporafor bi-lingual English-Ethiopian languages statisti-cal machine translation In Proceedings of the 27thInternational Conference on Computational Linguis-tics pages 3102ndash3111 Santa Fe New Mexico USAAssociation for Computational Linguistics
Jade Abbott and Laura Martinus 2019 Benchmarkingneural machine translation for Southern African lan-guages In Proceedings of the 2019 Workshop onWidening NLP pages 98ndash101 Florence Italy Asso-ciation for Computational Linguistics
Jade Z Abbott and Laura Martinus 2018 Towardsneural machine translation for african languages
David I Adelani Dana Ruiter Jesujoba O Al-abi Damilola Adebonojo Adesina Ayeni MofeAdeyemi Ayodele Awokoya and Cristina Espantildea-Bonet 2021a The effect of domain and diacritics inyorugravebaacute-english neural machine translation
David Ifeoluwa Adelani Jade Z Abbott GrahamNeubig Daniel Drsquosouza Julia Kreutzer Constan-tine Lignos Chester Palen-Michel Happy Buza-aba Shruti Rijhwani Sebastian Ruder StephenMayhew Israel Abebe Azime Shamsuddeen Has-san Muhammad Chris Chinenye Emezue JoyceNakatumba-Nabende Perez Ogayo Aremu An-uoluwapo Catherine Gitau Derguene Mbaye Je-sujoba O Alabi Seid Muhie Yimam Tajud-deen Gwadabe Ignatius Ezeani Rubungo An-dre Niyongabo Jonathan Mukiibi Verrah OtiendeIroro Orife Davis David Samba Ngom Tosin PAdewumi Paul Rayson Mofetoluwa Adeyemi Ger-ald Muriuki Emmanuel Anebi Chiamaka Chuk-wuneke Nkiruka Odu Eric Peter Wairagala SamuelOyerinde Clemencia Siro Tobius Saul BateesaTemilola Oloyede Yvonne Wambui Victor Akin-ode Deborah Nabagereka Maurice Katusiime Ayo-dele Awokoya Mouhamadane Mboup Dibora Ge-breyohannes Henok Tilaye Kelechi Nwaike De-gaga Wolde Abdoulaye Faye Blessing SibandaOrevaoghene Ahia Bonaventure F P DossouKelechi Ogueji Thierno Ibrahima Diop AbdoulayeDiallo Adewale Akinfaderin Tendai Marengerekeand Salomey Osei 2021b Masakhaner Namedentity recognition for african languages CoRRabs210311811
Željko Agic and Ivan Vulic 2019 JW300 A wide-coverage parallel corpus for low-resource languagesIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages3204ndash3210 Florence Italy Association for Compu-tational Linguistics
Roee Aharoni Melvin Johnson and Orhan Firat 2019Massively multilingual neural machine translation
408
In Proceedings of the 2019 Conference of the NorthAmerican Chapter of the Association for Compu-tational Linguistics Human Language Technolo-gies Volume 1 (Long and Short Papers) pages3874ndash3884 Minneapolis Minnesota Associationfor Computational Linguistics
Jesujoba Alabi Kwabena Amponsah-Kaakyire DavidAdelani and Cristina Espantildea-Bonet 2020 Mas-sive vs curated embeddings for low-resourced lan-guages the case of Yorugravebaacute and Twi In Proceed-ings of the 12th Language Resources and EvaluationConference pages 2754ndash2762 Marseille FranceEuropean Language Resources Association
Naveen Arivazhagan Ankur Bapna Orhan Firat RoeeAharoni Melvin Johnson and Wolfgang Macherey2019a The missing ingredient in zero-shot neuralmachine translation CoRR abs190307091
Naveen Arivazhagan Ankur Bapna Orhan FiratDmitry Lepikhin Melvin Johnson Maxim KrikunMia Xu Chen Yuan Cao George F Foster ColinCherry Wolfgang Macherey Zhifeng Chen andYonghui Wu 2019b Massively multilingual neuralmachine translation in the wild Findings and chal-lenges CoRR abs190705019
Mikko Aulamo Umut Sulubacak Sami Virpioja andJoumlrg Tiedemann 2020 OpusTools and parallel cor-pus diagnostics In Proceedings of The 12th Lan-guage Resources and Evaluation Conference pages3782ndash3789 European Language Resources Associ-ation
Dzmitry Bahdanau Kyunghyun Cho and Yoshua Ben-gio 2015 Neural machine translation by jointlylearning to align and translate In 3rd Inter-national Conference on Learning RepresentationsICLR 2015 San Diego CA USA May 7-9 2015Conference Track Proceedings
ST Barnes 1997 Africarsquos Ogun Old World andNew African systems of thought Indiana Univer-sity Press
Loiumlc Barrault Magdalena Biesialska Ondrej BojarMarta R Costa-jussagrave Christian Federmann YvetteGraham Roman Grundkiewicz Barry HaddowMatthias Huck Eric Joanis Tom Kocmi PhilippKoehn Chi-kiu Lo Nikola Ljubešic ChristofMonz Makoto Morishita Masaaki Nagata Toshi-aki Nakazawa Santanu Pal Matt Post and MarcosZampieri 2020 Findings of the 2020 conference onmachine translation (WMT20) In Proceedings ofthe Fifth Conference on Machine Translation pages1ndash55 Online Association for Computational Lin-guistics
Loiumlc Barrault Ondrej Bojar Marta R Costa-jussagraveChristian Federmann Mark Fishel Yvette Gra-ham Barry Haddow Matthias Huck Philipp KoehnShervin Malmasi Christof Monz Mathias MuumlllerSantanu Pal Matt Post and Marcos Zampieri 2019
Findings of the 2019 conference on machine transla-tion (WMT19) In Proceedings of the Fourth Con-ference on Machine Translation (Volume 2 SharedTask Papers Day 1) pages 1ndash61 Florence Italy As-sociation for Computational Linguistics
Lukas Biewald 2020 Experiment tracking withweights and biases Software available fromwandbcom
Yong Cheng Wei Xu Zhongjun He Wei He HuaWu Maosong Sun and Yang Liu 2016 Semi-supervised learning for neural machine translationIn Proceedings of the 54th Annual Meeting of the As-sociation for Computational Linguistics (Volume 1Long Papers) pages 1965ndash1974 Berlin GermanyAssociation for Computational Linguistics
Kyunghyun Cho Bart van Merrienboer CcedilaglarGuumllccedilehre Dzmitry Bahdanau Fethi Bougares Hol-ger Schwenk and Yoshua Bengio 2014 Learningphrase representations using RNN encoder-decoderfor statistical machine translation In Proceedings ofthe 2014 Conference on Empirical Methods in Nat-ural Language Processing EMNLP 2014 October25-29 2014 Doha Qatar A meeting of SIGDAT aSpecial Interest Group of the ACL pages 1724ndash1734ACL
Alexis Conneau Kartikay Khandelwal Naman GoyalVishrav Chaudhary Guillaume Wenzek FranciscoGuzmaacuten Edouard Grave Myle Ott Luke Zettle-moyer and Veselin Stoyanov 2019 Unsupervisedcross-lingual representation learning at scale
Jacob Devlin Ming-Wei Chang Kenton Lee andKristina Toutanova 2018 BERT pre-training ofdeep bidirectional transformers for language under-standing CoRR abs181004805
Daxiang Dong Hua Wu Wei He Dianhai Yu andHaifeng Wang 2015 Multi-task learning for mul-tiple language translation In Proceedings of the53rd Annual Meeting of the Association for Compu-tational Linguistics and the 7th International JointConference on Natural Language Processing (Vol-ume 1 Long Papers) pages 1723ndash1732 BeijingChina Association for Computational Linguistics
Bonaventure F P Dossou and Chris C Emezue 2020FFR V10 fon-french neural machine translationCoRR abs200312111
Bonaventure F P Dossou and Chris C Emezue 2021aCrowdsourced phrase-based tokenization for low-resourced neural machine translation The case offon language CoRR abs210308052
Bonaventure F P Dossou and Chris C Emezue 2021bOkwugbeacute End-to-end speech recognition for fonand igbo CoRR abs210307762
David M Eberhard Gary F Simons and CharlesD Fennig (eds) 2020 Ethnologue Languages ofthe world twenty-third edition
409
Sergey Edunov Myle Ott Michael Auli and DavidGrangier 2018 Understanding back-translation atscale CoRR abs180809381
Ignatius Ezeani Paul Rayson Ikechukwu E OnyenweChinedu Uchechukwu and Mark Hepple 2020Igbo-english machine translation An evaluationbenchmark CoRR abs200400648
Angela Fan Shruti Bhosale Holger Schwenk ZhiyiMa Ahmed El-Kishky Siddharth Goyal Man-deep Baines Onur Celebi Guillaume WenzekVishrav Chaudhary Naman Goyal Tom Birch Vi-taliy Liptchinsky Sergey Edunov Edouard GraveMichael Auli and Armand Joulin 2020 Be-yond english-centric multilingual machine transla-tion CoRR abs201011125
Thibault Feacutevry and Jason Phang 2018 Unsuper-vised sentence compression using denoising auto-encoders CoRR abs180902669
Orhan Firat Kyunghyun Cho and Yoshua Bengio2016a Multi-way multilingual neural machinetranslation with a shared attention mechanism InProceedings of the 2016 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 866ndash875 San Diego California Associationfor Computational Linguistics
Orhan Firat Baskaran Sankaran Yaser Al-onaizanFatos T Yarman Vural and Kyunghyun Cho 2016bZero-resource translation with multi-lingual neuralmachine translation In Proceedings of the 2016Conference on Empirical Methods in Natural Lan-guage Processing pages 268ndash277 Austin TexasAssociation for Computational Linguistics
forall Wilhelmina Nekoto Vukosi Marivate TshinondiwaMatsila Timi Fasubaa Tajudeen Kolawole TaiwoFagbohungbe Solomon Oluwole Akinola Sham-suddee Hassan Muhammad Salomon Kabongo Sa-lomey Osei et al 2020 Participatory research forlow-resourced machine translation A case study inafrican languages Findings of EMNLP
Naman Goyal Cynthia Gao Vishrav Chaudhary Peng-Jen Chen Guillaume Wenzek Da Ju Sanjana Kr-ishnan MarcrsquoAurelio Ranzato Francisco Guzmanand Angela Fan 2021 The flores-101 evaluationbenchmark for low-resource and multilingual ma-chine translation
Jiatao Gu Yong Wang Kyunghyun Cho and Vic-tor OK Li 2019 Improved zero-shot neural ma-chine translation via ignoring spurious correlationsIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages1258ndash1268 Florence Italy Association for Compu-tational Linguistics
Thanh-Le Ha Jan Niehues and Alexander H Waibel2016 Toward multilingual neural machine trans-lation with universal encoder and decoder CoRRabs161104798
Vu Cong Duy Hoang Philipp Koehn GholamrezaHaffari and Trevor Cohn 2018 Iterative back-translation for neural machine translation In Pro-ceedings of the 2nd Workshop on Neural MachineTranslation and Generation pages 18ndash24 Mel-bourne Australia Association for ComputationalLinguistics
Melvin Johnson Mike Schuster Quoc V Le MaximKrikun Yonghui Wu Zhifeng Chen Nikhil ThoratFernanda Vieacutegas Martin Wattenberg Greg CorradoMacduff Hughes and Jeffrey Dean 2017 Googlersquosmultilingual neural machine translation system En-abling zero-shot translation Transactions of the As-sociation for Computational Linguistics 5339ndash351
Pratik Joshi Sebastin Santy Amar Budhiraja KalikaBali and Monojit Choudhury 2020 The state andfate of linguistic diversity and inclusion in the NLPworld In Proceedings of the 58th Annual Meet-ing of the Association for Computational Linguisticspages 6282ndash6293 Online Association for Computa-tional Linguistics
Taku Kudo and John Richardson 2018 SentencePieceA simple and language independent subword tok-enizer and detokenizer for neural text processing InProceedings of the 2018 Conference on EmpiricalMethods in Natural Language Processing SystemDemonstrations pages 66ndash71 Brussels BelgiumAssociation for Computational Linguistics
Surafel Melaku Lakew Mauro Cettolo and MarcelloFederico 2018 A comparison of transformer andrecurrent neural networks on multilingual neural ma-chine translation In Proceedings of the 27th Inter-national Conference on Computational Linguisticspages 641ndash652 Santa Fe New Mexico USA Asso-ciation for Computational Linguistics
Guillaume Lample Ludovic Denoyer andMarcrsquoAurelio Ranzato 2017 Unsupervisedmachine translation using monolingual corporaonly CoRR abs171100043
Jason Lee Kyunghyun Cho and Thomas Hofmann2017 Fully Character-Level Neural Machine Trans-lation without Explicit Segmentation Transactionsof the Association for Computational Linguistics5365ndash378
Ilya Loshchilov and Frank Hutter 2017 Fixingweight decay regularization in adam CoRRabs171105101
Yichao Lu Phillip Keung Faisal Ladhak Vikas Bhard-waj Shaonan Zhang and Jason Sun 2018 A neu-ral interlingua for multilingual machine translationIn Proceedings of the Third Conference on MachineTranslation Research Papers pages 84ndash92 Brus-sels Belgium Association for Computational Lin-guistics
Laura Martinus and Jade Z Abbott 2019 A focuson neural machine translation for african languagesCoRR abs190605685
410
Graham Neubig Zi-Yi Dou Junjie Hu Paul MichelDanish Pruthi Xinyi Wang and John Wieting 2019compare-mt A tool for holistic comparison of lan-guage generation systems CoRR abs190307926
Graham Neubig and Junjie Hu 2018 Rapid adapta-tion of neural machine translation to new languagesIn Proceedings of the 2018 Conference on Empiri-cal Methods in Natural Language Processing pages875ndash880 Brussels Belgium Association for Com-putational Linguistics
Rubungo Andre Niyongabo Qu Hong Julia Kreutzerand Li Huang 2020 KINNEWS and KIRNEWSBenchmarking cross-lingual text classification forKinyarwanda and Kirundi In Proceedings ofthe 28th International Conference on Computa-tional Linguistics pages 5507ndash5521 BarcelonaSpain (Online) International Committee on Compu-tational Linguistics
Linda Nordling 2018 How decolonizationcould reshape south african science Nature554(7691)159ndash162
Evander Nyoni and Bruce A Bassett 2021 Low-resource neural machine translation for southernafrican languages CoRR abs210400366
Iroro Orife Julia Kreutzer Blessing Sibanda DanielWhitenack Kathleen Siminyu Laura MartinusJamiil Toure Ali Jade Z Abbott Vukosi Mari-vate Salomon Kabongo Musie Meressa Es-poir Murhabazi Orevaoghene Ahia Elan VanBiljon Arshath Ramkilowan Adewale AkinfaderinAlp Oumlktem Wole Akin Ghollah Kioko KevinDegila Herman Kamper Bonaventure DossouChris Emezue Kelechi Ogueji and Abdallah Bashir2020 Masakhane - machine translation for africaCoRR abs200311529
Maja Popovic 2015 chrF character n-gram F-scorefor automatic MT evaluation In Proceedings of theTenth Workshop on Statistical Machine Translationpages 392ndash395 Lisbon Portugal Association forComputational Linguistics
Matt Post 2018 A call for clarity in reporting BLEUscores In Proceedings of the Third Conference onMachine Translation Research Papers pages 186ndash191 Brussels Belgium Association for Computa-tional Linguistics
Colin Raffel Noam Shazeer Adam Roberts KatherineLee Sharan Narang Michael Matena Yanqi ZhouWei Li and Peter J Liu 2019 Exploring the limitsof transfer learning with a unified text-to-text trans-former CoRR abs191010683
Machel Reid Junjie Hu Graham Neubig and YutakaMatsuo 2021 Afromt Pretraining strategies andreproducible benchmarks for translation of 8 africanlanguages
Rico Sennrich Barry Haddow and Alexandra Birch2015 Improving neural machine translation modelswith monolingual data CoRR abs151106709
Shivachi Casper Shikali and Mokhosi Refuoe 2019Language modeling data for swahili
Aditya Siddhant Ankur Bapna Yuan Cao Orhan Fi-rat Mia Xu Chen Sneha Reddy Kudugunta NaveenArivazhagan and Yonghui Wu 2020 Lever-aging monolingual data with self-supervision formultilingual neural machine translation CoRRabs200504816
Ilya Sutskever Oriol Vinyals and Quoc V Le 2014Sequence to sequence learning with neural networksIn Proceedings of the 27th International Conferenceon Neural Information Processing Systems - Vol-ume 2 NIPSrsquo14 page 3104ndash3112 Cambridge MAUSA MIT Press
Xu Tan Jiale Chen Di He Yingce Xia Tao Qin andTie-Yan Liu 2019 Multilingual neural machinetranslation with language clustering In Proceedingsof the 2019 Conference on Empirical Methods inNatural Language Processing and the 9th Interna-tional Joint Conference on Natural Language Pro-cessing (EMNLP-IJCNLP) pages 963ndash973 HongKong China Association for Computational Lin-guistics
Joumlrg Tiedemann 2012 Parallel data tools and inter-faces in opus In Proceedings of the Eight Interna-tional Conference on Language Resources and Eval-uation (LRECrsquo12) Istanbul Turkey European Lan-guage Resources Association (ELRA)
Daniel van Niekerk Charl van Heerden Marelie DavelNeil Kleynhans Oddur Kjartansson Martin Janscheand Linne Ha 2017 Rapid development of TTS cor-pora for four South African languages In Proc In-terspeech 2017 pages 2178ndash2182 Stockholm Swe-den
Ashish Vaswani Noam Shazeer Niki Parmar JakobUszkoreit Llion Jones Aidan N Gomez LukaszKaiser and Illia Polosukhin 2017 Attention is allyou need CoRR abs170603762
Sarah Wild 2021 African languages to get more be-spoke scientific terms Nature 596(7873)469ndash470
Ronald J Williams and David Zipser 1989 A learn-ing algorithm for continually running fully recurrentneural networks Neural Computation 1(2)270ndash280
Linting Xue Noah Constant Adam Roberts Mi-hir Kale Rami Al-Rfou Aditya Siddhant AdityaBarua and Colin Raffel 2021 mT5 A massivelymultilingual pre-trained text-to-text transformer InProceedings of the 2021 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 483ndash498 Online Association for Computa-tional Linguistics
Biao Zhang Philip Williams Ivan Titov and RicoSennrich 2020 Improving massively multilingualneural machine translation and zero-shot translationCoRR abs200411867
411
Jiajun Zhang and Chengqing Zong 2016 Exploit-ing source-side monolingual data in neural machinetranslation In Proceedings of the 2016 Conferenceon Empirical Methods in Natural Language Process-ing pages 1535ndash1545 Austin Texas Associationfor Computational Linguistics
Barret Zoph Deniz Yuret Jonathan May and KevinKnight 2016 Transfer learning for low-resourceneural machine translation In Proceedings of the2016 Conference on Empirical Methods in Natu-ral Language Processing pages 1568ndash1575 AustinTexas Association for Computational Linguistics

403
resource nature of English and French addingthe training set for eng larrrarr fra would over-shadow the learning of the other language di-rections and greatly impede our analyses Ourintuition draws from the observation of Xueet al (2021) as the reason for off-target trans-lation in the mT5 model as English-basedfinetuning proceeds the modelrsquos assigned like-lihood of non-English tokens presumably de-creases Therefore since the mt5-basetraining set contained predominantly English(and after other European languages) tokensand our research is about ALlarrrarrAL trans-lation removing the eng larrrarr fra directionwas our way of ensuring the model designatedmore likelihood to AL tokens
431 Our ContributionsIn addition to the parallel data between the Africanlanguages we leveraged monolingual data to im-prove translation quality in two ways
1 our backtranslation (BT) We designed amodified form of the random online backtrans-lation (Zhang et al 2020) where instead ofrandomly selecting a subset of languages tobacktranslate we selected for each languagenum_bt sentences at random from the mono-lingual data set This means that the modelgets to backtranslate different (monolingual)sentences every backtranslation time and inso doing we believe improve the modelrsquos do-main adaptation because it gets to learn fromvarious samples from the whole monolingualdata set We initially tested different values ofnum_bt to find a compromise between back-translation computation time and translationquality
Following research works which have shownthe effectiveness of random beam-search overgreedy decoding while generating backtrans-lations (Lample et al 2017 Edunov et al2018 Hoang et al 2018 Zhang et al 2020)we generated num_sample prediction sen-tences from the model and randomly selected(with equal probability) one for our back-translated sentence Naturally the value ofnum_sample further affects the computa-tion time (because the model has to producenum_sample different output sentences foreach input sentence) and so we finally settledwith num_sample = 2
2 our reconstruction Given a monolingualsentence xm from language m we appliedrandom swapping (2 times) and deletion (witha probability of 02) to get a noisy version xTaking inspiration from Raffel et al (2019)we integrated the reconstruction objective intoour model finetuning by prepending the lan-guage tag ltmgt to x and setting its target out-put to xm
44 ExperimentsIn all our experiments we initialized the pretrainedmT5-base model using Hugging Facersquos Auto-
ModelForSeq2SeqLM6 and tracked the trainingprocess with WeightsampBiases (Biewald 2020) Weused the AdamW optimizer (Loshchilov and Hutter2017) with a learning rate (lr) of 3eminus6 and trans-formerrsquos get_linear_schedule_with_warmup7
scheduler (where the learning rate decreases lin-early from the initial lr set in the optimizer to 0after a warmup period and then increases linearlyfrom 0 to the initial lr set in the optimizer)
441 BaselineThe goal of our baseline was to understand theeffect of jointly finetuning with backtranslationand reconstruction on the AfricanlarrrarrAfrican lan-guage translation quality in two scenarios whenthe AL was initially pretrained on the multilingualmodel and contrariwise Using Fon (which wasnot initially included in the pretraining) and Igbo(which was initially included in the pretraining) asthe African languages for our baseline training wefinetuned our model on a many-to-many translationin all directions of eng fra ibo foneng larrrarrfra amounting to 10 directions We used theBaseline Train Set for training and theBaseline Test Set for evaluation We
trained the model for only 3 epochs in three set-tings
1 BASE in this setup we finetune the modelon only the many-to-many translation task nobacktranslation nor reconstruction
2 BT refers to finetuning with our backtransla-tion objective described in section 42 For our
6httpshuggingfacecotransformersmodel_docautohtmltransformersAutoModelForSeq2SeqLM
7httpshuggingfacecotransformersmain_classesoptimizer_scheduleshtmltransformersget_linear_schedule_with_warmup
404
baseline where we backtranslate using mono-lingual data in ibo fon we set num_bt =500 For our final experiments we first triedwith 500 but finally reduced to 100 due to thegreat deal of computation required
For our baseline experiment we ran one epochnormally and the remaining two with back-translation For our final experiments we firstfinetuned the model on 3 epochs before con-tinuing with backtranslation
3 BTampREC refers to joint backtranslation andreconstruction (explained in section 42) whilefinetuning Two important questions were ad-dressed ndash 1) the ratio backtranslation re-construction of monolingual sentences to useand 2) whether to use the same or differentsentences for backtranslation and reconstruc-tion Bearing computation time in mind weresolved to go with 500 50 for our baselineand 100 50 for our final experiments Weleave ablation studies on the effect of the ra-tio on translation quality to future work Forthe second question we decided to randomlysample (with replacement) different sentenceseach for our backtranslation and reconstruc-tion
For our baseline we used a learning rate of 5eminus4a batch size of 32 sentences with gradient accumu-lation up to a batch of 256 sentences and an earlystopping patience of 100 evaluation steps To fur-ther analyse the performance of our baseline setupswe ran comparemt 8 (Neubig et al 2019) on themodelrsquos predictions
442 MMTAfricaMMTAfrica refers to our final experimentalsetup where we finetuned our model on all lan-guage directions involving all eight languagesL = eng fra ibo fon swa kin xho yor ex-cept englarrrarrfra Taking inspiration from our base-line results we ran our experiment with our pro-posed BTampREC setting and made some adjust-ments along the way
The long computation time for backtranslating(with just 100 sentences per language the modelwas required to generate around 3 000 translationsevery backtranslation time) was a drawback Tomitigate the issue we parallelized the process us-
8httpsgithubcomneulabcompare-mt
ing the multiprocessing package in Python9 Wefurther slowly reduced the number of sentences forbacktranslation (to 50 and finally 10)
Gradient descent in large multilingual modelshas been shown to be more stable when updatesare performed over large batch sizes are used (Xueet al 2021) To cope with our computational re-sources we used gradient accumulation to increaseupdates from an initial batch size of 64 sentencesup to a batch gradient computation size of 4096sentences We further utilized PyTorchrsquos DataParal-lel package10 to parallelize the training across theGPUs We used a learning rate (lr) of 3eminus6
5 Results and Insights
All evaluations were made using spBLEU (sen-tencepiece (Kudo and Richardson 2018) + sacre-BLEU (Post 2018)) as described in (Goyal et al2021) We further evaluated on the chrF (Popovic2015) and TER metrics
51 Baseline Results and InsightsFigure 1 compares the spBLEU scores for the threesetups used in our baseline experiments As a re-minder we make use of the symbol to refer toany language in the set eng fra ibo fon
BT gives strong improvement over BASE (ex-cept in engminusrarribo where itrsquos relatively the sameand framinusrarribo where it performs worse)
Figure 1 spBLEU scores of the 3 setups explained insection 441
When the target language is fon we observe aconsiderable boost in the spBLEU of the BT set-ting which also significantly outperformed BASE
9httpsdocspythonorg3librarymultiprocessinghtml
10httpspytorchorgdocsstablegeneratedtorchnnDataParallelhtml
405
and BTampREC BTampREC contributed very littlewhen compared with BT and sometimes even per-formed poorly (in engminusrarrfon) We attribute thispoor performance from the reconstruction objec-tive to the fact that the mt5-base model wasnot originally pretrained on Fon Therefore withonly 3 epochs of finetuning (and 1 epoch beforeintroducing the reconstruction and backtranslationobjectives) the model was not able to meaningfullyutilize both objectives
Conversely when the target language is iboBTampREC gives best results ndash even in scenarios
where BT underperforms BASE (as is the caseof framinusrarribo and engminusrarribo) We believe that thedecoder of the model being originally pretrainedon corpora containing Igbo was able to better useour reconstruction to improve translation quaity in minusrarribo direction
Drawing insights from fonlarrrarribo we offer thefollowing propositions concerning ALlarrrarrALmultilingual translation
bull our backtranslation (section 42) from mono-lingual data improves the cross-lingual map-ping of the model for low-resource Africanlanguages While it is computationally expen-sive our parallelization and decay of numberof backtranslated sentences are some potentialsolutions towards effectively adopting back-translation using monolingual data
bull Denoising objectives typically have beenknown to improve machine translation qual-ity (Zhang and Zong 2016 Cheng et al 2016Gu et al 2019 Zhang et al 2020 Xue et al2021) because they imbue the model withmore generalizable knowledge (about that lan-guage) which is used by the decoder to pre-dict better token likelihoods for that languageduring translation This is a reasonable ex-planation for the improved quality with theBTampREC over BT in the minusrarribo As we
learned from minusrarrfon using reconstructioncould perform unsatisfactorily if not handledwell Some methods we propose are
1 For African languages that were includedin the original model pretraining (aswas the case of Igbo Swahili Xhosaand Yorugravebaacute in the mT5 model) usingthe BTampREC setting for finetuning pro-duces best results While we did not per-form ablation studies on the data size
ratio for backtranslation and reconstruc-tion we believe that our ratio of 2 1(in our final experiments) gives the bestcompromise on both computation timeand translation quality
2 For African languages that were not orig-inally included in the original model pre-training (as was the case of Kinyarwandaand Fon in the mT5 model) reconstruc-tion together with backtranslation (espe-cially at an early stage) only introducesmore noise which could harm the cross-lingual learning For these languages wepropose(a) first finetuning the model on only
our reconstruction (described in sec-tion 42) for fairly long training stepsbefore using BTampREC This waythe initial reconstruction will help themodel learn that language represen-tation space and increase its the like-lihood of tokens
52 MMTAfrica Results and InsightsIn Table 4 we compared MMTAfrica with theM2M MMT(Fan et al 2020) benchmark resultsof Goyal et al (2021) using the same test set theyused ndash FLORES Test Set On all languagepairs except swararreng (which has a comparableminus276 spBLEU difference) we report an improve-ment from MMTAfrica (spBLEU gains rangingfrom +058 in swaminusrarrfra to +1946 in framinusrarrxho)The lower score of swararreng presents an intriguinganomaly especially given the large availability ofparallel corpora in our training set for this pair Weplan to investigate this in further work
In Table 5 we introduce benchmark results ofMMTAfrica on MMTAfrica Test Set Wealso put the test size of each language pair
Interesting analysis about Fon (fon) andYorugravebaacute (yor) For each language the lowest sp-BLEU scores in both tables come from the minusrarryordirection except fonlarrrarryor (from Table 5) whichinterestingly has the highest spBLEU score com-pared to the other fonminusrarr ~ directions We donot know the reason for the very low performancein the ~ minusrarryor direction but we offer below aplausible explanation about fonlarrrarryor
The oral linguistic history of Fon ties it to theancient Yorugravebaacute kingdom (Barnes 1997) Further-more in present day Benin where Fon is largely
406
spoken as a native language Yoruba is one of the in-digenuous languages commonly spoken 11 There-fore Fon and Yorugravebaacute share some linguistic charac-teristics and we believe this is one logic behind thefonlarrrarryor surpassing other fonminusrarr ~ directions
This explanation could inspire transfer learningfrom Yorugravebaacute which has received comparably moreresearch and has more resources for machine trans-lation to Fon We leave this for future work
Source Target spBLEU (FLORES)uarr spBLEU (Ours)uarr spCHRFuarr spTERdarr
ibo swa 438 2184 3738 7148
ibo xho 244 1397 3195 8137
ibo yor 154 1072 2655 7572
ibo eng 737 1362 3890 7623
ibo fra 602 1646 3510 7548
swa ibo 197 1980 3395 6822
swa xho 271 2171 3986 7316
swa yor 129 1168 2744 7523
swa eng 3043 2767 5612 5591
swa fra 2669 2727 4620 6347
xho ibo 380 1702 3130 7066
xho swa 614 2947 4468 6321
xho yor 192 1042 2677 7625
xho eng 1086 2077 4869 6409
xho fra 828 2148 4065 6931
yor ibo 185 1145 2526 7499
yor swa 193 1499 3049 7990
yor xho 194 931 2634 8608
yor eng 418 815 3065 8694
yor fra 357 1059 2760 8132
eng ibo 353 2149 3724 6568
eng swa 2695 4011 5313 5280
eng xho 447 2715 4493 6777
eng yor 217 1209 2834 7474
fra ibo 169 1948 3447 6850
fra swa 1717 3421 4895 5811
fra xho 227 2173 4006 7372
fra yor 116 1142 2767 7533
Table 4 Evaluation Scores of the Flores M2M MMTmodel and MMTAfrica on FLORES Test Set
6 Conclusion and Future Work
In this paper we introduced MMTAfrica a mul-tilingual machine translation model on 6 AfricanLanguages which outperformed the M2M MMTmodel Fan et al (2020) Our results and analy-ses including a new reconstruction objective giveinsights on MMT for African languages for fu-ture research Moreover we plan to launch themodel on Masakhane MT and FFRTranslate in or-der to get human evaluation feedback from theactual speakers of the languages in the Masakhanecommunity (Orife et al 2020) and beyond
In order to fully test the advantage ofMMTAfrica we plan to finish comparing it on
11httpsenwikipediaorgwikiBenin(Last Accessed 30082021)
direct and pivot translations with the Masakhanebenchmark models (forall et al 2020) We alsoplan to perform human evaluation All test setsresults code and checkpoints will be releasedat httpsgithubcomedaiofficialmmtafrica
7 Acknowledgments
The computational resources for running all ex-periments were provided by the FLORES com-pute grants12 as well as additonal computationalresources provided by Paco Guzman (FacebookAI) and Mila Quebec AI Institute We expressour profound gratitude to all who contributed inone way or the other towards the development ofMMTAfrica including (in no order)
Mathias Muumlller (University of Zurich) for giv-ing immense technical assistance in finetuning themodel and advising us on best hyperparameter tun-ing practises
Graham Neubig (Carnegie Mellon University)for explaining and setting up comparemt for usto better understand and evaluate the performanceof our baseline models
Angela Fan (FacebookAI) for guiding us duringthe shared task and taking the time to answer allour questions
Julia Kreutzer (GoogleAI) for advising us on use-ful model comparison and evaluation techniques
Colin Leong (University of Dayton) for painstak-ingly proof-reading the paper and helping us makeit more reader-friendly
Daria Yasafova (Technical University of Mu-nich) and Yeno Gbenou (Drexel University) foradditionally proof-reading the paper
Finally the entire Masakhane community13 foramong many other things 1) guiding us to exist-ing parallel and monolingual data set for the focusAfrican languages 2) explaining their (the focusAfrican languages) important linguistic charteris-tics which helped us work better with them (likein preprocessing) and 3) performing (in the future)human evaluation on MMTAfrica
Indeed it took a village to raise MMTAfrica1412httpwwwstatmtorgwmt21
flores-compute-grantshtml13httpswwwmasakhaneio14lsquoIt takes a village to raise a childrsquo is an African proverb
that means that an entire community of people with differentexpertise must provide for and interact positively with the childfor the child to actually develop and reach the best possiblepotential
407
Source Target Test size spBLEUuarr spCHRFuarr spTERdarr
ibo swa 60 3489 4738 6828
ibo xho 30 3669 5066 5965
ibo yor 30 1177 2954 12984
ibo kin 30 3392 4653 6773
ibo fon 30 3596 4314 6321
ibo eng 90 3728 6042 6205
ibo fra 60 3086 4409 6953
swa ibo 60 3371 4302 6001
swa xho 30 3728 5253 5586
swa yor 30 1409 2750 11363
swa kin 30 2386 4259 9467
swa fon 30 2329 3352 6511
swa eng 60 3555 6047 4732
swa fra 60 3011 4833 6338
xho ibo 30 3325 4536 6283
xho swa 30 3926 5375 5372
xho yor 30 2200 3806 7045
xho kin 30 3066 4619 7470
xho fon 30 2580 3487 6596
xho eng 90 3025 5512 6211
xho fra 30 2945 4572 6103
yor ibo 30 2511 3419 7480
yor swa 30 1762 3471 8518
yor xho 30 2931 4313 6682
yor kin 30 2516 3802 7267
yor fon 30 3181 3745 6339
yor eng 90 1781 4173 9300
yor fra 30 1544 3097 9057
kin ibo 30 3125 4236 6673
kin swa 30 3365 4634 7270
kin xho 30 2040 3971 8997
kin yor 30 1834 3353 7043
kin fon 30 2243 3249 6726
kin eng 60 1582 4310 9655
kin fra 30 1623 3351 9182
fon ibo 30 3236 4644 6182
fon swa 30 2984 4296 7228
fon xho 30 2882 4374 6698
fon yor 30 3045 4263 6072
fon kin 30 2388 3959 7806
fon eng 30 1663 4163 6903
fon fra 60 2479 4339 8215
eng ibo 90 4424 5489 6392
eng swa 60 4994 6145 4783
eng xho 120 3197 4974 7289
eng yor 90 2393 3619 8405
eng kin 90 4098 5600 7637
eng fon 30 2719 3686 6254
fra ibo 60 3647 4693 5991
fra swa 60 3653 5142 5594
fra xho 30 3435 4939 6030
fra yor 30 726 2554 12453
fra kin 30 3107 4226 8106
fra fon 60 3107 3872 7574
Table 5 Benchmark Evaluation Scores onMMTAfrica Test Set
ReferencesSolomon Teferra Abate Michael Melese Martha Yi-
firu Tachbelie Million Meshesha Solomon AtinafuWondwossen Mulugeta Yaregal Assabie HafteAbera Binyam Ephrem Tewodros Abebe Wondim-agegnhue Tsegaye Amanuel Lemma Tsegaye An-dargie and Seifedin Shifaw 2018 Parallel corporafor bi-lingual English-Ethiopian languages statisti-cal machine translation In Proceedings of the 27thInternational Conference on Computational Linguis-tics pages 3102ndash3111 Santa Fe New Mexico USAAssociation for Computational Linguistics
Jade Abbott and Laura Martinus 2019 Benchmarkingneural machine translation for Southern African lan-guages In Proceedings of the 2019 Workshop onWidening NLP pages 98ndash101 Florence Italy Asso-ciation for Computational Linguistics
Jade Z Abbott and Laura Martinus 2018 Towardsneural machine translation for african languages
David I Adelani Dana Ruiter Jesujoba O Al-abi Damilola Adebonojo Adesina Ayeni MofeAdeyemi Ayodele Awokoya and Cristina Espantildea-Bonet 2021a The effect of domain and diacritics inyorugravebaacute-english neural machine translation
David Ifeoluwa Adelani Jade Z Abbott GrahamNeubig Daniel Drsquosouza Julia Kreutzer Constan-tine Lignos Chester Palen-Michel Happy Buza-aba Shruti Rijhwani Sebastian Ruder StephenMayhew Israel Abebe Azime Shamsuddeen Has-san Muhammad Chris Chinenye Emezue JoyceNakatumba-Nabende Perez Ogayo Aremu An-uoluwapo Catherine Gitau Derguene Mbaye Je-sujoba O Alabi Seid Muhie Yimam Tajud-deen Gwadabe Ignatius Ezeani Rubungo An-dre Niyongabo Jonathan Mukiibi Verrah OtiendeIroro Orife Davis David Samba Ngom Tosin PAdewumi Paul Rayson Mofetoluwa Adeyemi Ger-ald Muriuki Emmanuel Anebi Chiamaka Chuk-wuneke Nkiruka Odu Eric Peter Wairagala SamuelOyerinde Clemencia Siro Tobius Saul BateesaTemilola Oloyede Yvonne Wambui Victor Akin-ode Deborah Nabagereka Maurice Katusiime Ayo-dele Awokoya Mouhamadane Mboup Dibora Ge-breyohannes Henok Tilaye Kelechi Nwaike De-gaga Wolde Abdoulaye Faye Blessing SibandaOrevaoghene Ahia Bonaventure F P DossouKelechi Ogueji Thierno Ibrahima Diop AbdoulayeDiallo Adewale Akinfaderin Tendai Marengerekeand Salomey Osei 2021b Masakhaner Namedentity recognition for african languages CoRRabs210311811
Željko Agic and Ivan Vulic 2019 JW300 A wide-coverage parallel corpus for low-resource languagesIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages3204ndash3210 Florence Italy Association for Compu-tational Linguistics
Roee Aharoni Melvin Johnson and Orhan Firat 2019Massively multilingual neural machine translation
408
In Proceedings of the 2019 Conference of the NorthAmerican Chapter of the Association for Compu-tational Linguistics Human Language Technolo-gies Volume 1 (Long and Short Papers) pages3874ndash3884 Minneapolis Minnesota Associationfor Computational Linguistics
Jesujoba Alabi Kwabena Amponsah-Kaakyire DavidAdelani and Cristina Espantildea-Bonet 2020 Mas-sive vs curated embeddings for low-resourced lan-guages the case of Yorugravebaacute and Twi In Proceed-ings of the 12th Language Resources and EvaluationConference pages 2754ndash2762 Marseille FranceEuropean Language Resources Association
Naveen Arivazhagan Ankur Bapna Orhan Firat RoeeAharoni Melvin Johnson and Wolfgang Macherey2019a The missing ingredient in zero-shot neuralmachine translation CoRR abs190307091
Naveen Arivazhagan Ankur Bapna Orhan FiratDmitry Lepikhin Melvin Johnson Maxim KrikunMia Xu Chen Yuan Cao George F Foster ColinCherry Wolfgang Macherey Zhifeng Chen andYonghui Wu 2019b Massively multilingual neuralmachine translation in the wild Findings and chal-lenges CoRR abs190705019
Mikko Aulamo Umut Sulubacak Sami Virpioja andJoumlrg Tiedemann 2020 OpusTools and parallel cor-pus diagnostics In Proceedings of The 12th Lan-guage Resources and Evaluation Conference pages3782ndash3789 European Language Resources Associ-ation
Dzmitry Bahdanau Kyunghyun Cho and Yoshua Ben-gio 2015 Neural machine translation by jointlylearning to align and translate In 3rd Inter-national Conference on Learning RepresentationsICLR 2015 San Diego CA USA May 7-9 2015Conference Track Proceedings
ST Barnes 1997 Africarsquos Ogun Old World andNew African systems of thought Indiana Univer-sity Press
Loiumlc Barrault Magdalena Biesialska Ondrej BojarMarta R Costa-jussagrave Christian Federmann YvetteGraham Roman Grundkiewicz Barry HaddowMatthias Huck Eric Joanis Tom Kocmi PhilippKoehn Chi-kiu Lo Nikola Ljubešic ChristofMonz Makoto Morishita Masaaki Nagata Toshi-aki Nakazawa Santanu Pal Matt Post and MarcosZampieri 2020 Findings of the 2020 conference onmachine translation (WMT20) In Proceedings ofthe Fifth Conference on Machine Translation pages1ndash55 Online Association for Computational Lin-guistics
Loiumlc Barrault Ondrej Bojar Marta R Costa-jussagraveChristian Federmann Mark Fishel Yvette Gra-ham Barry Haddow Matthias Huck Philipp KoehnShervin Malmasi Christof Monz Mathias MuumlllerSantanu Pal Matt Post and Marcos Zampieri 2019
Findings of the 2019 conference on machine transla-tion (WMT19) In Proceedings of the Fourth Con-ference on Machine Translation (Volume 2 SharedTask Papers Day 1) pages 1ndash61 Florence Italy As-sociation for Computational Linguistics
Lukas Biewald 2020 Experiment tracking withweights and biases Software available fromwandbcom
Yong Cheng Wei Xu Zhongjun He Wei He HuaWu Maosong Sun and Yang Liu 2016 Semi-supervised learning for neural machine translationIn Proceedings of the 54th Annual Meeting of the As-sociation for Computational Linguistics (Volume 1Long Papers) pages 1965ndash1974 Berlin GermanyAssociation for Computational Linguistics
Kyunghyun Cho Bart van Merrienboer CcedilaglarGuumllccedilehre Dzmitry Bahdanau Fethi Bougares Hol-ger Schwenk and Yoshua Bengio 2014 Learningphrase representations using RNN encoder-decoderfor statistical machine translation In Proceedings ofthe 2014 Conference on Empirical Methods in Nat-ural Language Processing EMNLP 2014 October25-29 2014 Doha Qatar A meeting of SIGDAT aSpecial Interest Group of the ACL pages 1724ndash1734ACL
Alexis Conneau Kartikay Khandelwal Naman GoyalVishrav Chaudhary Guillaume Wenzek FranciscoGuzmaacuten Edouard Grave Myle Ott Luke Zettle-moyer and Veselin Stoyanov 2019 Unsupervisedcross-lingual representation learning at scale
Jacob Devlin Ming-Wei Chang Kenton Lee andKristina Toutanova 2018 BERT pre-training ofdeep bidirectional transformers for language under-standing CoRR abs181004805
Daxiang Dong Hua Wu Wei He Dianhai Yu andHaifeng Wang 2015 Multi-task learning for mul-tiple language translation In Proceedings of the53rd Annual Meeting of the Association for Compu-tational Linguistics and the 7th International JointConference on Natural Language Processing (Vol-ume 1 Long Papers) pages 1723ndash1732 BeijingChina Association for Computational Linguistics
Bonaventure F P Dossou and Chris C Emezue 2020FFR V10 fon-french neural machine translationCoRR abs200312111
Bonaventure F P Dossou and Chris C Emezue 2021aCrowdsourced phrase-based tokenization for low-resourced neural machine translation The case offon language CoRR abs210308052
Bonaventure F P Dossou and Chris C Emezue 2021bOkwugbeacute End-to-end speech recognition for fonand igbo CoRR abs210307762
David M Eberhard Gary F Simons and CharlesD Fennig (eds) 2020 Ethnologue Languages ofthe world twenty-third edition
409
Sergey Edunov Myle Ott Michael Auli and DavidGrangier 2018 Understanding back-translation atscale CoRR abs180809381
Ignatius Ezeani Paul Rayson Ikechukwu E OnyenweChinedu Uchechukwu and Mark Hepple 2020Igbo-english machine translation An evaluationbenchmark CoRR abs200400648
Angela Fan Shruti Bhosale Holger Schwenk ZhiyiMa Ahmed El-Kishky Siddharth Goyal Man-deep Baines Onur Celebi Guillaume WenzekVishrav Chaudhary Naman Goyal Tom Birch Vi-taliy Liptchinsky Sergey Edunov Edouard GraveMichael Auli and Armand Joulin 2020 Be-yond english-centric multilingual machine transla-tion CoRR abs201011125
Thibault Feacutevry and Jason Phang 2018 Unsuper-vised sentence compression using denoising auto-encoders CoRR abs180902669
Orhan Firat Kyunghyun Cho and Yoshua Bengio2016a Multi-way multilingual neural machinetranslation with a shared attention mechanism InProceedings of the 2016 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 866ndash875 San Diego California Associationfor Computational Linguistics
Orhan Firat Baskaran Sankaran Yaser Al-onaizanFatos T Yarman Vural and Kyunghyun Cho 2016bZero-resource translation with multi-lingual neuralmachine translation In Proceedings of the 2016Conference on Empirical Methods in Natural Lan-guage Processing pages 268ndash277 Austin TexasAssociation for Computational Linguistics
forall Wilhelmina Nekoto Vukosi Marivate TshinondiwaMatsila Timi Fasubaa Tajudeen Kolawole TaiwoFagbohungbe Solomon Oluwole Akinola Sham-suddee Hassan Muhammad Salomon Kabongo Sa-lomey Osei et al 2020 Participatory research forlow-resourced machine translation A case study inafrican languages Findings of EMNLP
Naman Goyal Cynthia Gao Vishrav Chaudhary Peng-Jen Chen Guillaume Wenzek Da Ju Sanjana Kr-ishnan MarcrsquoAurelio Ranzato Francisco Guzmanand Angela Fan 2021 The flores-101 evaluationbenchmark for low-resource and multilingual ma-chine translation
Jiatao Gu Yong Wang Kyunghyun Cho and Vic-tor OK Li 2019 Improved zero-shot neural ma-chine translation via ignoring spurious correlationsIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages1258ndash1268 Florence Italy Association for Compu-tational Linguistics
Thanh-Le Ha Jan Niehues and Alexander H Waibel2016 Toward multilingual neural machine trans-lation with universal encoder and decoder CoRRabs161104798
Vu Cong Duy Hoang Philipp Koehn GholamrezaHaffari and Trevor Cohn 2018 Iterative back-translation for neural machine translation In Pro-ceedings of the 2nd Workshop on Neural MachineTranslation and Generation pages 18ndash24 Mel-bourne Australia Association for ComputationalLinguistics
Melvin Johnson Mike Schuster Quoc V Le MaximKrikun Yonghui Wu Zhifeng Chen Nikhil ThoratFernanda Vieacutegas Martin Wattenberg Greg CorradoMacduff Hughes and Jeffrey Dean 2017 Googlersquosmultilingual neural machine translation system En-abling zero-shot translation Transactions of the As-sociation for Computational Linguistics 5339ndash351
Pratik Joshi Sebastin Santy Amar Budhiraja KalikaBali and Monojit Choudhury 2020 The state andfate of linguistic diversity and inclusion in the NLPworld In Proceedings of the 58th Annual Meet-ing of the Association for Computational Linguisticspages 6282ndash6293 Online Association for Computa-tional Linguistics
Taku Kudo and John Richardson 2018 SentencePieceA simple and language independent subword tok-enizer and detokenizer for neural text processing InProceedings of the 2018 Conference on EmpiricalMethods in Natural Language Processing SystemDemonstrations pages 66ndash71 Brussels BelgiumAssociation for Computational Linguistics
Surafel Melaku Lakew Mauro Cettolo and MarcelloFederico 2018 A comparison of transformer andrecurrent neural networks on multilingual neural ma-chine translation In Proceedings of the 27th Inter-national Conference on Computational Linguisticspages 641ndash652 Santa Fe New Mexico USA Asso-ciation for Computational Linguistics
Guillaume Lample Ludovic Denoyer andMarcrsquoAurelio Ranzato 2017 Unsupervisedmachine translation using monolingual corporaonly CoRR abs171100043
Jason Lee Kyunghyun Cho and Thomas Hofmann2017 Fully Character-Level Neural Machine Trans-lation without Explicit Segmentation Transactionsof the Association for Computational Linguistics5365ndash378
Ilya Loshchilov and Frank Hutter 2017 Fixingweight decay regularization in adam CoRRabs171105101
Yichao Lu Phillip Keung Faisal Ladhak Vikas Bhard-waj Shaonan Zhang and Jason Sun 2018 A neu-ral interlingua for multilingual machine translationIn Proceedings of the Third Conference on MachineTranslation Research Papers pages 84ndash92 Brus-sels Belgium Association for Computational Lin-guistics
Laura Martinus and Jade Z Abbott 2019 A focuson neural machine translation for african languagesCoRR abs190605685
410
Graham Neubig Zi-Yi Dou Junjie Hu Paul MichelDanish Pruthi Xinyi Wang and John Wieting 2019compare-mt A tool for holistic comparison of lan-guage generation systems CoRR abs190307926
Graham Neubig and Junjie Hu 2018 Rapid adapta-tion of neural machine translation to new languagesIn Proceedings of the 2018 Conference on Empiri-cal Methods in Natural Language Processing pages875ndash880 Brussels Belgium Association for Com-putational Linguistics
Rubungo Andre Niyongabo Qu Hong Julia Kreutzerand Li Huang 2020 KINNEWS and KIRNEWSBenchmarking cross-lingual text classification forKinyarwanda and Kirundi In Proceedings ofthe 28th International Conference on Computa-tional Linguistics pages 5507ndash5521 BarcelonaSpain (Online) International Committee on Compu-tational Linguistics
Linda Nordling 2018 How decolonizationcould reshape south african science Nature554(7691)159ndash162
Evander Nyoni and Bruce A Bassett 2021 Low-resource neural machine translation for southernafrican languages CoRR abs210400366
Iroro Orife Julia Kreutzer Blessing Sibanda DanielWhitenack Kathleen Siminyu Laura MartinusJamiil Toure Ali Jade Z Abbott Vukosi Mari-vate Salomon Kabongo Musie Meressa Es-poir Murhabazi Orevaoghene Ahia Elan VanBiljon Arshath Ramkilowan Adewale AkinfaderinAlp Oumlktem Wole Akin Ghollah Kioko KevinDegila Herman Kamper Bonaventure DossouChris Emezue Kelechi Ogueji and Abdallah Bashir2020 Masakhane - machine translation for africaCoRR abs200311529
Maja Popovic 2015 chrF character n-gram F-scorefor automatic MT evaluation In Proceedings of theTenth Workshop on Statistical Machine Translationpages 392ndash395 Lisbon Portugal Association forComputational Linguistics
Matt Post 2018 A call for clarity in reporting BLEUscores In Proceedings of the Third Conference onMachine Translation Research Papers pages 186ndash191 Brussels Belgium Association for Computa-tional Linguistics
Colin Raffel Noam Shazeer Adam Roberts KatherineLee Sharan Narang Michael Matena Yanqi ZhouWei Li and Peter J Liu 2019 Exploring the limitsof transfer learning with a unified text-to-text trans-former CoRR abs191010683
Machel Reid Junjie Hu Graham Neubig and YutakaMatsuo 2021 Afromt Pretraining strategies andreproducible benchmarks for translation of 8 africanlanguages
Rico Sennrich Barry Haddow and Alexandra Birch2015 Improving neural machine translation modelswith monolingual data CoRR abs151106709
Shivachi Casper Shikali and Mokhosi Refuoe 2019Language modeling data for swahili
Aditya Siddhant Ankur Bapna Yuan Cao Orhan Fi-rat Mia Xu Chen Sneha Reddy Kudugunta NaveenArivazhagan and Yonghui Wu 2020 Lever-aging monolingual data with self-supervision formultilingual neural machine translation CoRRabs200504816
Ilya Sutskever Oriol Vinyals and Quoc V Le 2014Sequence to sequence learning with neural networksIn Proceedings of the 27th International Conferenceon Neural Information Processing Systems - Vol-ume 2 NIPSrsquo14 page 3104ndash3112 Cambridge MAUSA MIT Press
Xu Tan Jiale Chen Di He Yingce Xia Tao Qin andTie-Yan Liu 2019 Multilingual neural machinetranslation with language clustering In Proceedingsof the 2019 Conference on Empirical Methods inNatural Language Processing and the 9th Interna-tional Joint Conference on Natural Language Pro-cessing (EMNLP-IJCNLP) pages 963ndash973 HongKong China Association for Computational Lin-guistics
Joumlrg Tiedemann 2012 Parallel data tools and inter-faces in opus In Proceedings of the Eight Interna-tional Conference on Language Resources and Eval-uation (LRECrsquo12) Istanbul Turkey European Lan-guage Resources Association (ELRA)
Daniel van Niekerk Charl van Heerden Marelie DavelNeil Kleynhans Oddur Kjartansson Martin Janscheand Linne Ha 2017 Rapid development of TTS cor-pora for four South African languages In Proc In-terspeech 2017 pages 2178ndash2182 Stockholm Swe-den
Ashish Vaswani Noam Shazeer Niki Parmar JakobUszkoreit Llion Jones Aidan N Gomez LukaszKaiser and Illia Polosukhin 2017 Attention is allyou need CoRR abs170603762
Sarah Wild 2021 African languages to get more be-spoke scientific terms Nature 596(7873)469ndash470
Ronald J Williams and David Zipser 1989 A learn-ing algorithm for continually running fully recurrentneural networks Neural Computation 1(2)270ndash280
Linting Xue Noah Constant Adam Roberts Mi-hir Kale Rami Al-Rfou Aditya Siddhant AdityaBarua and Colin Raffel 2021 mT5 A massivelymultilingual pre-trained text-to-text transformer InProceedings of the 2021 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 483ndash498 Online Association for Computa-tional Linguistics
Biao Zhang Philip Williams Ivan Titov and RicoSennrich 2020 Improving massively multilingualneural machine translation and zero-shot translationCoRR abs200411867
411
Jiajun Zhang and Chengqing Zong 2016 Exploit-ing source-side monolingual data in neural machinetranslation In Proceedings of the 2016 Conferenceon Empirical Methods in Natural Language Process-ing pages 1535ndash1545 Austin Texas Associationfor Computational Linguistics
Barret Zoph Deniz Yuret Jonathan May and KevinKnight 2016 Transfer learning for low-resourceneural machine translation In Proceedings of the2016 Conference on Empirical Methods in Natu-ral Language Processing pages 1568ndash1575 AustinTexas Association for Computational Linguistics

404
baseline where we backtranslate using mono-lingual data in ibo fon we set num_bt =500 For our final experiments we first triedwith 500 but finally reduced to 100 due to thegreat deal of computation required
For our baseline experiment we ran one epochnormally and the remaining two with back-translation For our final experiments we firstfinetuned the model on 3 epochs before con-tinuing with backtranslation
3 BTampREC refers to joint backtranslation andreconstruction (explained in section 42) whilefinetuning Two important questions were ad-dressed ndash 1) the ratio backtranslation re-construction of monolingual sentences to useand 2) whether to use the same or differentsentences for backtranslation and reconstruc-tion Bearing computation time in mind weresolved to go with 500 50 for our baselineand 100 50 for our final experiments Weleave ablation studies on the effect of the ra-tio on translation quality to future work Forthe second question we decided to randomlysample (with replacement) different sentenceseach for our backtranslation and reconstruc-tion
For our baseline we used a learning rate of 5eminus4a batch size of 32 sentences with gradient accumu-lation up to a batch of 256 sentences and an earlystopping patience of 100 evaluation steps To fur-ther analyse the performance of our baseline setupswe ran comparemt 8 (Neubig et al 2019) on themodelrsquos predictions
442 MMTAfricaMMTAfrica refers to our final experimentalsetup where we finetuned our model on all lan-guage directions involving all eight languagesL = eng fra ibo fon swa kin xho yor ex-cept englarrrarrfra Taking inspiration from our base-line results we ran our experiment with our pro-posed BTampREC setting and made some adjust-ments along the way
The long computation time for backtranslating(with just 100 sentences per language the modelwas required to generate around 3 000 translationsevery backtranslation time) was a drawback Tomitigate the issue we parallelized the process us-
8httpsgithubcomneulabcompare-mt
ing the multiprocessing package in Python9 Wefurther slowly reduced the number of sentences forbacktranslation (to 50 and finally 10)
Gradient descent in large multilingual modelshas been shown to be more stable when updatesare performed over large batch sizes are used (Xueet al 2021) To cope with our computational re-sources we used gradient accumulation to increaseupdates from an initial batch size of 64 sentencesup to a batch gradient computation size of 4096sentences We further utilized PyTorchrsquos DataParal-lel package10 to parallelize the training across theGPUs We used a learning rate (lr) of 3eminus6
5 Results and Insights
All evaluations were made using spBLEU (sen-tencepiece (Kudo and Richardson 2018) + sacre-BLEU (Post 2018)) as described in (Goyal et al2021) We further evaluated on the chrF (Popovic2015) and TER metrics
51 Baseline Results and InsightsFigure 1 compares the spBLEU scores for the threesetups used in our baseline experiments As a re-minder we make use of the symbol to refer toany language in the set eng fra ibo fon
BT gives strong improvement over BASE (ex-cept in engminusrarribo where itrsquos relatively the sameand framinusrarribo where it performs worse)
Figure 1 spBLEU scores of the 3 setups explained insection 441
When the target language is fon we observe aconsiderable boost in the spBLEU of the BT set-ting which also significantly outperformed BASE
9httpsdocspythonorg3librarymultiprocessinghtml
10httpspytorchorgdocsstablegeneratedtorchnnDataParallelhtml
405
and BTampREC BTampREC contributed very littlewhen compared with BT and sometimes even per-formed poorly (in engminusrarrfon) We attribute thispoor performance from the reconstruction objec-tive to the fact that the mt5-base model wasnot originally pretrained on Fon Therefore withonly 3 epochs of finetuning (and 1 epoch beforeintroducing the reconstruction and backtranslationobjectives) the model was not able to meaningfullyutilize both objectives
Conversely when the target language is iboBTampREC gives best results ndash even in scenarios
where BT underperforms BASE (as is the caseof framinusrarribo and engminusrarribo) We believe that thedecoder of the model being originally pretrainedon corpora containing Igbo was able to better useour reconstruction to improve translation quaity in minusrarribo direction
Drawing insights from fonlarrrarribo we offer thefollowing propositions concerning ALlarrrarrALmultilingual translation
bull our backtranslation (section 42) from mono-lingual data improves the cross-lingual map-ping of the model for low-resource Africanlanguages While it is computationally expen-sive our parallelization and decay of numberof backtranslated sentences are some potentialsolutions towards effectively adopting back-translation using monolingual data
bull Denoising objectives typically have beenknown to improve machine translation qual-ity (Zhang and Zong 2016 Cheng et al 2016Gu et al 2019 Zhang et al 2020 Xue et al2021) because they imbue the model withmore generalizable knowledge (about that lan-guage) which is used by the decoder to pre-dict better token likelihoods for that languageduring translation This is a reasonable ex-planation for the improved quality with theBTampREC over BT in the minusrarribo As we
learned from minusrarrfon using reconstructioncould perform unsatisfactorily if not handledwell Some methods we propose are
1 For African languages that were includedin the original model pretraining (aswas the case of Igbo Swahili Xhosaand Yorugravebaacute in the mT5 model) usingthe BTampREC setting for finetuning pro-duces best results While we did not per-form ablation studies on the data size
ratio for backtranslation and reconstruc-tion we believe that our ratio of 2 1(in our final experiments) gives the bestcompromise on both computation timeand translation quality
2 For African languages that were not orig-inally included in the original model pre-training (as was the case of Kinyarwandaand Fon in the mT5 model) reconstruc-tion together with backtranslation (espe-cially at an early stage) only introducesmore noise which could harm the cross-lingual learning For these languages wepropose(a) first finetuning the model on only
our reconstruction (described in sec-tion 42) for fairly long training stepsbefore using BTampREC This waythe initial reconstruction will help themodel learn that language represen-tation space and increase its the like-lihood of tokens
52 MMTAfrica Results and InsightsIn Table 4 we compared MMTAfrica with theM2M MMT(Fan et al 2020) benchmark resultsof Goyal et al (2021) using the same test set theyused ndash FLORES Test Set On all languagepairs except swararreng (which has a comparableminus276 spBLEU difference) we report an improve-ment from MMTAfrica (spBLEU gains rangingfrom +058 in swaminusrarrfra to +1946 in framinusrarrxho)The lower score of swararreng presents an intriguinganomaly especially given the large availability ofparallel corpora in our training set for this pair Weplan to investigate this in further work
In Table 5 we introduce benchmark results ofMMTAfrica on MMTAfrica Test Set Wealso put the test size of each language pair
Interesting analysis about Fon (fon) andYorugravebaacute (yor) For each language the lowest sp-BLEU scores in both tables come from the minusrarryordirection except fonlarrrarryor (from Table 5) whichinterestingly has the highest spBLEU score com-pared to the other fonminusrarr ~ directions We donot know the reason for the very low performancein the ~ minusrarryor direction but we offer below aplausible explanation about fonlarrrarryor
The oral linguistic history of Fon ties it to theancient Yorugravebaacute kingdom (Barnes 1997) Further-more in present day Benin where Fon is largely
406
spoken as a native language Yoruba is one of the in-digenuous languages commonly spoken 11 There-fore Fon and Yorugravebaacute share some linguistic charac-teristics and we believe this is one logic behind thefonlarrrarryor surpassing other fonminusrarr ~ directions
This explanation could inspire transfer learningfrom Yorugravebaacute which has received comparably moreresearch and has more resources for machine trans-lation to Fon We leave this for future work
Source Target spBLEU (FLORES)uarr spBLEU (Ours)uarr spCHRFuarr spTERdarr
ibo swa 438 2184 3738 7148
ibo xho 244 1397 3195 8137
ibo yor 154 1072 2655 7572
ibo eng 737 1362 3890 7623
ibo fra 602 1646 3510 7548
swa ibo 197 1980 3395 6822
swa xho 271 2171 3986 7316
swa yor 129 1168 2744 7523
swa eng 3043 2767 5612 5591
swa fra 2669 2727 4620 6347
xho ibo 380 1702 3130 7066
xho swa 614 2947 4468 6321
xho yor 192 1042 2677 7625
xho eng 1086 2077 4869 6409
xho fra 828 2148 4065 6931
yor ibo 185 1145 2526 7499
yor swa 193 1499 3049 7990
yor xho 194 931 2634 8608
yor eng 418 815 3065 8694
yor fra 357 1059 2760 8132
eng ibo 353 2149 3724 6568
eng swa 2695 4011 5313 5280
eng xho 447 2715 4493 6777
eng yor 217 1209 2834 7474
fra ibo 169 1948 3447 6850
fra swa 1717 3421 4895 5811
fra xho 227 2173 4006 7372
fra yor 116 1142 2767 7533
Table 4 Evaluation Scores of the Flores M2M MMTmodel and MMTAfrica on FLORES Test Set
6 Conclusion and Future Work
In this paper we introduced MMTAfrica a mul-tilingual machine translation model on 6 AfricanLanguages which outperformed the M2M MMTmodel Fan et al (2020) Our results and analy-ses including a new reconstruction objective giveinsights on MMT for African languages for fu-ture research Moreover we plan to launch themodel on Masakhane MT and FFRTranslate in or-der to get human evaluation feedback from theactual speakers of the languages in the Masakhanecommunity (Orife et al 2020) and beyond
In order to fully test the advantage ofMMTAfrica we plan to finish comparing it on
11httpsenwikipediaorgwikiBenin(Last Accessed 30082021)
direct and pivot translations with the Masakhanebenchmark models (forall et al 2020) We alsoplan to perform human evaluation All test setsresults code and checkpoints will be releasedat httpsgithubcomedaiofficialmmtafrica
7 Acknowledgments
The computational resources for running all ex-periments were provided by the FLORES com-pute grants12 as well as additonal computationalresources provided by Paco Guzman (FacebookAI) and Mila Quebec AI Institute We expressour profound gratitude to all who contributed inone way or the other towards the development ofMMTAfrica including (in no order)
Mathias Muumlller (University of Zurich) for giv-ing immense technical assistance in finetuning themodel and advising us on best hyperparameter tun-ing practises
Graham Neubig (Carnegie Mellon University)for explaining and setting up comparemt for usto better understand and evaluate the performanceof our baseline models
Angela Fan (FacebookAI) for guiding us duringthe shared task and taking the time to answer allour questions
Julia Kreutzer (GoogleAI) for advising us on use-ful model comparison and evaluation techniques
Colin Leong (University of Dayton) for painstak-ingly proof-reading the paper and helping us makeit more reader-friendly
Daria Yasafova (Technical University of Mu-nich) and Yeno Gbenou (Drexel University) foradditionally proof-reading the paper
Finally the entire Masakhane community13 foramong many other things 1) guiding us to exist-ing parallel and monolingual data set for the focusAfrican languages 2) explaining their (the focusAfrican languages) important linguistic charteris-tics which helped us work better with them (likein preprocessing) and 3) performing (in the future)human evaluation on MMTAfrica
Indeed it took a village to raise MMTAfrica1412httpwwwstatmtorgwmt21
flores-compute-grantshtml13httpswwwmasakhaneio14lsquoIt takes a village to raise a childrsquo is an African proverb
that means that an entire community of people with differentexpertise must provide for and interact positively with the childfor the child to actually develop and reach the best possiblepotential
407
Source Target Test size spBLEUuarr spCHRFuarr spTERdarr
ibo swa 60 3489 4738 6828
ibo xho 30 3669 5066 5965
ibo yor 30 1177 2954 12984
ibo kin 30 3392 4653 6773
ibo fon 30 3596 4314 6321
ibo eng 90 3728 6042 6205
ibo fra 60 3086 4409 6953
swa ibo 60 3371 4302 6001
swa xho 30 3728 5253 5586
swa yor 30 1409 2750 11363
swa kin 30 2386 4259 9467
swa fon 30 2329 3352 6511
swa eng 60 3555 6047 4732
swa fra 60 3011 4833 6338
xho ibo 30 3325 4536 6283
xho swa 30 3926 5375 5372
xho yor 30 2200 3806 7045
xho kin 30 3066 4619 7470
xho fon 30 2580 3487 6596
xho eng 90 3025 5512 6211
xho fra 30 2945 4572 6103
yor ibo 30 2511 3419 7480
yor swa 30 1762 3471 8518
yor xho 30 2931 4313 6682
yor kin 30 2516 3802 7267
yor fon 30 3181 3745 6339
yor eng 90 1781 4173 9300
yor fra 30 1544 3097 9057
kin ibo 30 3125 4236 6673
kin swa 30 3365 4634 7270
kin xho 30 2040 3971 8997
kin yor 30 1834 3353 7043
kin fon 30 2243 3249 6726
kin eng 60 1582 4310 9655
kin fra 30 1623 3351 9182
fon ibo 30 3236 4644 6182
fon swa 30 2984 4296 7228
fon xho 30 2882 4374 6698
fon yor 30 3045 4263 6072
fon kin 30 2388 3959 7806
fon eng 30 1663 4163 6903
fon fra 60 2479 4339 8215
eng ibo 90 4424 5489 6392
eng swa 60 4994 6145 4783
eng xho 120 3197 4974 7289
eng yor 90 2393 3619 8405
eng kin 90 4098 5600 7637
eng fon 30 2719 3686 6254
fra ibo 60 3647 4693 5991
fra swa 60 3653 5142 5594
fra xho 30 3435 4939 6030
fra yor 30 726 2554 12453
fra kin 30 3107 4226 8106
fra fon 60 3107 3872 7574
Table 5 Benchmark Evaluation Scores onMMTAfrica Test Set
ReferencesSolomon Teferra Abate Michael Melese Martha Yi-
firu Tachbelie Million Meshesha Solomon AtinafuWondwossen Mulugeta Yaregal Assabie HafteAbera Binyam Ephrem Tewodros Abebe Wondim-agegnhue Tsegaye Amanuel Lemma Tsegaye An-dargie and Seifedin Shifaw 2018 Parallel corporafor bi-lingual English-Ethiopian languages statisti-cal machine translation In Proceedings of the 27thInternational Conference on Computational Linguis-tics pages 3102ndash3111 Santa Fe New Mexico USAAssociation for Computational Linguistics
Jade Abbott and Laura Martinus 2019 Benchmarkingneural machine translation for Southern African lan-guages In Proceedings of the 2019 Workshop onWidening NLP pages 98ndash101 Florence Italy Asso-ciation for Computational Linguistics
Jade Z Abbott and Laura Martinus 2018 Towardsneural machine translation for african languages
David I Adelani Dana Ruiter Jesujoba O Al-abi Damilola Adebonojo Adesina Ayeni MofeAdeyemi Ayodele Awokoya and Cristina Espantildea-Bonet 2021a The effect of domain and diacritics inyorugravebaacute-english neural machine translation
David Ifeoluwa Adelani Jade Z Abbott GrahamNeubig Daniel Drsquosouza Julia Kreutzer Constan-tine Lignos Chester Palen-Michel Happy Buza-aba Shruti Rijhwani Sebastian Ruder StephenMayhew Israel Abebe Azime Shamsuddeen Has-san Muhammad Chris Chinenye Emezue JoyceNakatumba-Nabende Perez Ogayo Aremu An-uoluwapo Catherine Gitau Derguene Mbaye Je-sujoba O Alabi Seid Muhie Yimam Tajud-deen Gwadabe Ignatius Ezeani Rubungo An-dre Niyongabo Jonathan Mukiibi Verrah OtiendeIroro Orife Davis David Samba Ngom Tosin PAdewumi Paul Rayson Mofetoluwa Adeyemi Ger-ald Muriuki Emmanuel Anebi Chiamaka Chuk-wuneke Nkiruka Odu Eric Peter Wairagala SamuelOyerinde Clemencia Siro Tobius Saul BateesaTemilola Oloyede Yvonne Wambui Victor Akin-ode Deborah Nabagereka Maurice Katusiime Ayo-dele Awokoya Mouhamadane Mboup Dibora Ge-breyohannes Henok Tilaye Kelechi Nwaike De-gaga Wolde Abdoulaye Faye Blessing SibandaOrevaoghene Ahia Bonaventure F P DossouKelechi Ogueji Thierno Ibrahima Diop AbdoulayeDiallo Adewale Akinfaderin Tendai Marengerekeand Salomey Osei 2021b Masakhaner Namedentity recognition for african languages CoRRabs210311811
Željko Agic and Ivan Vulic 2019 JW300 A wide-coverage parallel corpus for low-resource languagesIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages3204ndash3210 Florence Italy Association for Compu-tational Linguistics
Roee Aharoni Melvin Johnson and Orhan Firat 2019Massively multilingual neural machine translation
408
In Proceedings of the 2019 Conference of the NorthAmerican Chapter of the Association for Compu-tational Linguistics Human Language Technolo-gies Volume 1 (Long and Short Papers) pages3874ndash3884 Minneapolis Minnesota Associationfor Computational Linguistics
Jesujoba Alabi Kwabena Amponsah-Kaakyire DavidAdelani and Cristina Espantildea-Bonet 2020 Mas-sive vs curated embeddings for low-resourced lan-guages the case of Yorugravebaacute and Twi In Proceed-ings of the 12th Language Resources and EvaluationConference pages 2754ndash2762 Marseille FranceEuropean Language Resources Association
Naveen Arivazhagan Ankur Bapna Orhan Firat RoeeAharoni Melvin Johnson and Wolfgang Macherey2019a The missing ingredient in zero-shot neuralmachine translation CoRR abs190307091
Naveen Arivazhagan Ankur Bapna Orhan FiratDmitry Lepikhin Melvin Johnson Maxim KrikunMia Xu Chen Yuan Cao George F Foster ColinCherry Wolfgang Macherey Zhifeng Chen andYonghui Wu 2019b Massively multilingual neuralmachine translation in the wild Findings and chal-lenges CoRR abs190705019
Mikko Aulamo Umut Sulubacak Sami Virpioja andJoumlrg Tiedemann 2020 OpusTools and parallel cor-pus diagnostics In Proceedings of The 12th Lan-guage Resources and Evaluation Conference pages3782ndash3789 European Language Resources Associ-ation
Dzmitry Bahdanau Kyunghyun Cho and Yoshua Ben-gio 2015 Neural machine translation by jointlylearning to align and translate In 3rd Inter-national Conference on Learning RepresentationsICLR 2015 San Diego CA USA May 7-9 2015Conference Track Proceedings
ST Barnes 1997 Africarsquos Ogun Old World andNew African systems of thought Indiana Univer-sity Press
Loiumlc Barrault Magdalena Biesialska Ondrej BojarMarta R Costa-jussagrave Christian Federmann YvetteGraham Roman Grundkiewicz Barry HaddowMatthias Huck Eric Joanis Tom Kocmi PhilippKoehn Chi-kiu Lo Nikola Ljubešic ChristofMonz Makoto Morishita Masaaki Nagata Toshi-aki Nakazawa Santanu Pal Matt Post and MarcosZampieri 2020 Findings of the 2020 conference onmachine translation (WMT20) In Proceedings ofthe Fifth Conference on Machine Translation pages1ndash55 Online Association for Computational Lin-guistics
Loiumlc Barrault Ondrej Bojar Marta R Costa-jussagraveChristian Federmann Mark Fishel Yvette Gra-ham Barry Haddow Matthias Huck Philipp KoehnShervin Malmasi Christof Monz Mathias MuumlllerSantanu Pal Matt Post and Marcos Zampieri 2019
Findings of the 2019 conference on machine transla-tion (WMT19) In Proceedings of the Fourth Con-ference on Machine Translation (Volume 2 SharedTask Papers Day 1) pages 1ndash61 Florence Italy As-sociation for Computational Linguistics
Lukas Biewald 2020 Experiment tracking withweights and biases Software available fromwandbcom
Yong Cheng Wei Xu Zhongjun He Wei He HuaWu Maosong Sun and Yang Liu 2016 Semi-supervised learning for neural machine translationIn Proceedings of the 54th Annual Meeting of the As-sociation for Computational Linguistics (Volume 1Long Papers) pages 1965ndash1974 Berlin GermanyAssociation for Computational Linguistics
Kyunghyun Cho Bart van Merrienboer CcedilaglarGuumllccedilehre Dzmitry Bahdanau Fethi Bougares Hol-ger Schwenk and Yoshua Bengio 2014 Learningphrase representations using RNN encoder-decoderfor statistical machine translation In Proceedings ofthe 2014 Conference on Empirical Methods in Nat-ural Language Processing EMNLP 2014 October25-29 2014 Doha Qatar A meeting of SIGDAT aSpecial Interest Group of the ACL pages 1724ndash1734ACL
Alexis Conneau Kartikay Khandelwal Naman GoyalVishrav Chaudhary Guillaume Wenzek FranciscoGuzmaacuten Edouard Grave Myle Ott Luke Zettle-moyer and Veselin Stoyanov 2019 Unsupervisedcross-lingual representation learning at scale
Jacob Devlin Ming-Wei Chang Kenton Lee andKristina Toutanova 2018 BERT pre-training ofdeep bidirectional transformers for language under-standing CoRR abs181004805
Daxiang Dong Hua Wu Wei He Dianhai Yu andHaifeng Wang 2015 Multi-task learning for mul-tiple language translation In Proceedings of the53rd Annual Meeting of the Association for Compu-tational Linguistics and the 7th International JointConference on Natural Language Processing (Vol-ume 1 Long Papers) pages 1723ndash1732 BeijingChina Association for Computational Linguistics
Bonaventure F P Dossou and Chris C Emezue 2020FFR V10 fon-french neural machine translationCoRR abs200312111
Bonaventure F P Dossou and Chris C Emezue 2021aCrowdsourced phrase-based tokenization for low-resourced neural machine translation The case offon language CoRR abs210308052
Bonaventure F P Dossou and Chris C Emezue 2021bOkwugbeacute End-to-end speech recognition for fonand igbo CoRR abs210307762
David M Eberhard Gary F Simons and CharlesD Fennig (eds) 2020 Ethnologue Languages ofthe world twenty-third edition
409
Sergey Edunov Myle Ott Michael Auli and DavidGrangier 2018 Understanding back-translation atscale CoRR abs180809381
Ignatius Ezeani Paul Rayson Ikechukwu E OnyenweChinedu Uchechukwu and Mark Hepple 2020Igbo-english machine translation An evaluationbenchmark CoRR abs200400648
Angela Fan Shruti Bhosale Holger Schwenk ZhiyiMa Ahmed El-Kishky Siddharth Goyal Man-deep Baines Onur Celebi Guillaume WenzekVishrav Chaudhary Naman Goyal Tom Birch Vi-taliy Liptchinsky Sergey Edunov Edouard GraveMichael Auli and Armand Joulin 2020 Be-yond english-centric multilingual machine transla-tion CoRR abs201011125
Thibault Feacutevry and Jason Phang 2018 Unsuper-vised sentence compression using denoising auto-encoders CoRR abs180902669
Orhan Firat Kyunghyun Cho and Yoshua Bengio2016a Multi-way multilingual neural machinetranslation with a shared attention mechanism InProceedings of the 2016 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 866ndash875 San Diego California Associationfor Computational Linguistics
Orhan Firat Baskaran Sankaran Yaser Al-onaizanFatos T Yarman Vural and Kyunghyun Cho 2016bZero-resource translation with multi-lingual neuralmachine translation In Proceedings of the 2016Conference on Empirical Methods in Natural Lan-guage Processing pages 268ndash277 Austin TexasAssociation for Computational Linguistics
forall Wilhelmina Nekoto Vukosi Marivate TshinondiwaMatsila Timi Fasubaa Tajudeen Kolawole TaiwoFagbohungbe Solomon Oluwole Akinola Sham-suddee Hassan Muhammad Salomon Kabongo Sa-lomey Osei et al 2020 Participatory research forlow-resourced machine translation A case study inafrican languages Findings of EMNLP
Naman Goyal Cynthia Gao Vishrav Chaudhary Peng-Jen Chen Guillaume Wenzek Da Ju Sanjana Kr-ishnan MarcrsquoAurelio Ranzato Francisco Guzmanand Angela Fan 2021 The flores-101 evaluationbenchmark for low-resource and multilingual ma-chine translation
Jiatao Gu Yong Wang Kyunghyun Cho and Vic-tor OK Li 2019 Improved zero-shot neural ma-chine translation via ignoring spurious correlationsIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages1258ndash1268 Florence Italy Association for Compu-tational Linguistics
Thanh-Le Ha Jan Niehues and Alexander H Waibel2016 Toward multilingual neural machine trans-lation with universal encoder and decoder CoRRabs161104798
Vu Cong Duy Hoang Philipp Koehn GholamrezaHaffari and Trevor Cohn 2018 Iterative back-translation for neural machine translation In Pro-ceedings of the 2nd Workshop on Neural MachineTranslation and Generation pages 18ndash24 Mel-bourne Australia Association for ComputationalLinguistics
Melvin Johnson Mike Schuster Quoc V Le MaximKrikun Yonghui Wu Zhifeng Chen Nikhil ThoratFernanda Vieacutegas Martin Wattenberg Greg CorradoMacduff Hughes and Jeffrey Dean 2017 Googlersquosmultilingual neural machine translation system En-abling zero-shot translation Transactions of the As-sociation for Computational Linguistics 5339ndash351
Pratik Joshi Sebastin Santy Amar Budhiraja KalikaBali and Monojit Choudhury 2020 The state andfate of linguistic diversity and inclusion in the NLPworld In Proceedings of the 58th Annual Meet-ing of the Association for Computational Linguisticspages 6282ndash6293 Online Association for Computa-tional Linguistics
Taku Kudo and John Richardson 2018 SentencePieceA simple and language independent subword tok-enizer and detokenizer for neural text processing InProceedings of the 2018 Conference on EmpiricalMethods in Natural Language Processing SystemDemonstrations pages 66ndash71 Brussels BelgiumAssociation for Computational Linguistics
Surafel Melaku Lakew Mauro Cettolo and MarcelloFederico 2018 A comparison of transformer andrecurrent neural networks on multilingual neural ma-chine translation In Proceedings of the 27th Inter-national Conference on Computational Linguisticspages 641ndash652 Santa Fe New Mexico USA Asso-ciation for Computational Linguistics
Guillaume Lample Ludovic Denoyer andMarcrsquoAurelio Ranzato 2017 Unsupervisedmachine translation using monolingual corporaonly CoRR abs171100043
Jason Lee Kyunghyun Cho and Thomas Hofmann2017 Fully Character-Level Neural Machine Trans-lation without Explicit Segmentation Transactionsof the Association for Computational Linguistics5365ndash378
Ilya Loshchilov and Frank Hutter 2017 Fixingweight decay regularization in adam CoRRabs171105101
Yichao Lu Phillip Keung Faisal Ladhak Vikas Bhard-waj Shaonan Zhang and Jason Sun 2018 A neu-ral interlingua for multilingual machine translationIn Proceedings of the Third Conference on MachineTranslation Research Papers pages 84ndash92 Brus-sels Belgium Association for Computational Lin-guistics
Laura Martinus and Jade Z Abbott 2019 A focuson neural machine translation for african languagesCoRR abs190605685
410
Graham Neubig Zi-Yi Dou Junjie Hu Paul MichelDanish Pruthi Xinyi Wang and John Wieting 2019compare-mt A tool for holistic comparison of lan-guage generation systems CoRR abs190307926
Graham Neubig and Junjie Hu 2018 Rapid adapta-tion of neural machine translation to new languagesIn Proceedings of the 2018 Conference on Empiri-cal Methods in Natural Language Processing pages875ndash880 Brussels Belgium Association for Com-putational Linguistics
Rubungo Andre Niyongabo Qu Hong Julia Kreutzerand Li Huang 2020 KINNEWS and KIRNEWSBenchmarking cross-lingual text classification forKinyarwanda and Kirundi In Proceedings ofthe 28th International Conference on Computa-tional Linguistics pages 5507ndash5521 BarcelonaSpain (Online) International Committee on Compu-tational Linguistics
Linda Nordling 2018 How decolonizationcould reshape south african science Nature554(7691)159ndash162
Evander Nyoni and Bruce A Bassett 2021 Low-resource neural machine translation for southernafrican languages CoRR abs210400366
Iroro Orife Julia Kreutzer Blessing Sibanda DanielWhitenack Kathleen Siminyu Laura MartinusJamiil Toure Ali Jade Z Abbott Vukosi Mari-vate Salomon Kabongo Musie Meressa Es-poir Murhabazi Orevaoghene Ahia Elan VanBiljon Arshath Ramkilowan Adewale AkinfaderinAlp Oumlktem Wole Akin Ghollah Kioko KevinDegila Herman Kamper Bonaventure DossouChris Emezue Kelechi Ogueji and Abdallah Bashir2020 Masakhane - machine translation for africaCoRR abs200311529
Maja Popovic 2015 chrF character n-gram F-scorefor automatic MT evaluation In Proceedings of theTenth Workshop on Statistical Machine Translationpages 392ndash395 Lisbon Portugal Association forComputational Linguistics
Matt Post 2018 A call for clarity in reporting BLEUscores In Proceedings of the Third Conference onMachine Translation Research Papers pages 186ndash191 Brussels Belgium Association for Computa-tional Linguistics
Colin Raffel Noam Shazeer Adam Roberts KatherineLee Sharan Narang Michael Matena Yanqi ZhouWei Li and Peter J Liu 2019 Exploring the limitsof transfer learning with a unified text-to-text trans-former CoRR abs191010683
Machel Reid Junjie Hu Graham Neubig and YutakaMatsuo 2021 Afromt Pretraining strategies andreproducible benchmarks for translation of 8 africanlanguages
Rico Sennrich Barry Haddow and Alexandra Birch2015 Improving neural machine translation modelswith monolingual data CoRR abs151106709
Shivachi Casper Shikali and Mokhosi Refuoe 2019Language modeling data for swahili
Aditya Siddhant Ankur Bapna Yuan Cao Orhan Fi-rat Mia Xu Chen Sneha Reddy Kudugunta NaveenArivazhagan and Yonghui Wu 2020 Lever-aging monolingual data with self-supervision formultilingual neural machine translation CoRRabs200504816
Ilya Sutskever Oriol Vinyals and Quoc V Le 2014Sequence to sequence learning with neural networksIn Proceedings of the 27th International Conferenceon Neural Information Processing Systems - Vol-ume 2 NIPSrsquo14 page 3104ndash3112 Cambridge MAUSA MIT Press
Xu Tan Jiale Chen Di He Yingce Xia Tao Qin andTie-Yan Liu 2019 Multilingual neural machinetranslation with language clustering In Proceedingsof the 2019 Conference on Empirical Methods inNatural Language Processing and the 9th Interna-tional Joint Conference on Natural Language Pro-cessing (EMNLP-IJCNLP) pages 963ndash973 HongKong China Association for Computational Lin-guistics
Joumlrg Tiedemann 2012 Parallel data tools and inter-faces in opus In Proceedings of the Eight Interna-tional Conference on Language Resources and Eval-uation (LRECrsquo12) Istanbul Turkey European Lan-guage Resources Association (ELRA)
Daniel van Niekerk Charl van Heerden Marelie DavelNeil Kleynhans Oddur Kjartansson Martin Janscheand Linne Ha 2017 Rapid development of TTS cor-pora for four South African languages In Proc In-terspeech 2017 pages 2178ndash2182 Stockholm Swe-den
Ashish Vaswani Noam Shazeer Niki Parmar JakobUszkoreit Llion Jones Aidan N Gomez LukaszKaiser and Illia Polosukhin 2017 Attention is allyou need CoRR abs170603762
Sarah Wild 2021 African languages to get more be-spoke scientific terms Nature 596(7873)469ndash470
Ronald J Williams and David Zipser 1989 A learn-ing algorithm for continually running fully recurrentneural networks Neural Computation 1(2)270ndash280
Linting Xue Noah Constant Adam Roberts Mi-hir Kale Rami Al-Rfou Aditya Siddhant AdityaBarua and Colin Raffel 2021 mT5 A massivelymultilingual pre-trained text-to-text transformer InProceedings of the 2021 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 483ndash498 Online Association for Computa-tional Linguistics
Biao Zhang Philip Williams Ivan Titov and RicoSennrich 2020 Improving massively multilingualneural machine translation and zero-shot translationCoRR abs200411867
411
Jiajun Zhang and Chengqing Zong 2016 Exploit-ing source-side monolingual data in neural machinetranslation In Proceedings of the 2016 Conferenceon Empirical Methods in Natural Language Process-ing pages 1535ndash1545 Austin Texas Associationfor Computational Linguistics
Barret Zoph Deniz Yuret Jonathan May and KevinKnight 2016 Transfer learning for low-resourceneural machine translation In Proceedings of the2016 Conference on Empirical Methods in Natu-ral Language Processing pages 1568ndash1575 AustinTexas Association for Computational Linguistics

405
and BTampREC BTampREC contributed very littlewhen compared with BT and sometimes even per-formed poorly (in engminusrarrfon) We attribute thispoor performance from the reconstruction objec-tive to the fact that the mt5-base model wasnot originally pretrained on Fon Therefore withonly 3 epochs of finetuning (and 1 epoch beforeintroducing the reconstruction and backtranslationobjectives) the model was not able to meaningfullyutilize both objectives
Conversely when the target language is iboBTampREC gives best results ndash even in scenarios
where BT underperforms BASE (as is the caseof framinusrarribo and engminusrarribo) We believe that thedecoder of the model being originally pretrainedon corpora containing Igbo was able to better useour reconstruction to improve translation quaity in minusrarribo direction
Drawing insights from fonlarrrarribo we offer thefollowing propositions concerning ALlarrrarrALmultilingual translation
bull our backtranslation (section 42) from mono-lingual data improves the cross-lingual map-ping of the model for low-resource Africanlanguages While it is computationally expen-sive our parallelization and decay of numberof backtranslated sentences are some potentialsolutions towards effectively adopting back-translation using monolingual data
bull Denoising objectives typically have beenknown to improve machine translation qual-ity (Zhang and Zong 2016 Cheng et al 2016Gu et al 2019 Zhang et al 2020 Xue et al2021) because they imbue the model withmore generalizable knowledge (about that lan-guage) which is used by the decoder to pre-dict better token likelihoods for that languageduring translation This is a reasonable ex-planation for the improved quality with theBTampREC over BT in the minusrarribo As we
learned from minusrarrfon using reconstructioncould perform unsatisfactorily if not handledwell Some methods we propose are
1 For African languages that were includedin the original model pretraining (aswas the case of Igbo Swahili Xhosaand Yorugravebaacute in the mT5 model) usingthe BTampREC setting for finetuning pro-duces best results While we did not per-form ablation studies on the data size
ratio for backtranslation and reconstruc-tion we believe that our ratio of 2 1(in our final experiments) gives the bestcompromise on both computation timeand translation quality
2 For African languages that were not orig-inally included in the original model pre-training (as was the case of Kinyarwandaand Fon in the mT5 model) reconstruc-tion together with backtranslation (espe-cially at an early stage) only introducesmore noise which could harm the cross-lingual learning For these languages wepropose(a) first finetuning the model on only
our reconstruction (described in sec-tion 42) for fairly long training stepsbefore using BTampREC This waythe initial reconstruction will help themodel learn that language represen-tation space and increase its the like-lihood of tokens
52 MMTAfrica Results and InsightsIn Table 4 we compared MMTAfrica with theM2M MMT(Fan et al 2020) benchmark resultsof Goyal et al (2021) using the same test set theyused ndash FLORES Test Set On all languagepairs except swararreng (which has a comparableminus276 spBLEU difference) we report an improve-ment from MMTAfrica (spBLEU gains rangingfrom +058 in swaminusrarrfra to +1946 in framinusrarrxho)The lower score of swararreng presents an intriguinganomaly especially given the large availability ofparallel corpora in our training set for this pair Weplan to investigate this in further work
In Table 5 we introduce benchmark results ofMMTAfrica on MMTAfrica Test Set Wealso put the test size of each language pair
Interesting analysis about Fon (fon) andYorugravebaacute (yor) For each language the lowest sp-BLEU scores in both tables come from the minusrarryordirection except fonlarrrarryor (from Table 5) whichinterestingly has the highest spBLEU score com-pared to the other fonminusrarr ~ directions We donot know the reason for the very low performancein the ~ minusrarryor direction but we offer below aplausible explanation about fonlarrrarryor
The oral linguistic history of Fon ties it to theancient Yorugravebaacute kingdom (Barnes 1997) Further-more in present day Benin where Fon is largely
406
spoken as a native language Yoruba is one of the in-digenuous languages commonly spoken 11 There-fore Fon and Yorugravebaacute share some linguistic charac-teristics and we believe this is one logic behind thefonlarrrarryor surpassing other fonminusrarr ~ directions
This explanation could inspire transfer learningfrom Yorugravebaacute which has received comparably moreresearch and has more resources for machine trans-lation to Fon We leave this for future work
Source Target spBLEU (FLORES)uarr spBLEU (Ours)uarr spCHRFuarr spTERdarr
ibo swa 438 2184 3738 7148
ibo xho 244 1397 3195 8137
ibo yor 154 1072 2655 7572
ibo eng 737 1362 3890 7623
ibo fra 602 1646 3510 7548
swa ibo 197 1980 3395 6822
swa xho 271 2171 3986 7316
swa yor 129 1168 2744 7523
swa eng 3043 2767 5612 5591
swa fra 2669 2727 4620 6347
xho ibo 380 1702 3130 7066
xho swa 614 2947 4468 6321
xho yor 192 1042 2677 7625
xho eng 1086 2077 4869 6409
xho fra 828 2148 4065 6931
yor ibo 185 1145 2526 7499
yor swa 193 1499 3049 7990
yor xho 194 931 2634 8608
yor eng 418 815 3065 8694
yor fra 357 1059 2760 8132
eng ibo 353 2149 3724 6568
eng swa 2695 4011 5313 5280
eng xho 447 2715 4493 6777
eng yor 217 1209 2834 7474
fra ibo 169 1948 3447 6850
fra swa 1717 3421 4895 5811
fra xho 227 2173 4006 7372
fra yor 116 1142 2767 7533
Table 4 Evaluation Scores of the Flores M2M MMTmodel and MMTAfrica on FLORES Test Set
6 Conclusion and Future Work
In this paper we introduced MMTAfrica a mul-tilingual machine translation model on 6 AfricanLanguages which outperformed the M2M MMTmodel Fan et al (2020) Our results and analy-ses including a new reconstruction objective giveinsights on MMT for African languages for fu-ture research Moreover we plan to launch themodel on Masakhane MT and FFRTranslate in or-der to get human evaluation feedback from theactual speakers of the languages in the Masakhanecommunity (Orife et al 2020) and beyond
In order to fully test the advantage ofMMTAfrica we plan to finish comparing it on
11httpsenwikipediaorgwikiBenin(Last Accessed 30082021)
direct and pivot translations with the Masakhanebenchmark models (forall et al 2020) We alsoplan to perform human evaluation All test setsresults code and checkpoints will be releasedat httpsgithubcomedaiofficialmmtafrica
7 Acknowledgments
The computational resources for running all ex-periments were provided by the FLORES com-pute grants12 as well as additonal computationalresources provided by Paco Guzman (FacebookAI) and Mila Quebec AI Institute We expressour profound gratitude to all who contributed inone way or the other towards the development ofMMTAfrica including (in no order)
Mathias Muumlller (University of Zurich) for giv-ing immense technical assistance in finetuning themodel and advising us on best hyperparameter tun-ing practises
Graham Neubig (Carnegie Mellon University)for explaining and setting up comparemt for usto better understand and evaluate the performanceof our baseline models
Angela Fan (FacebookAI) for guiding us duringthe shared task and taking the time to answer allour questions
Julia Kreutzer (GoogleAI) for advising us on use-ful model comparison and evaluation techniques
Colin Leong (University of Dayton) for painstak-ingly proof-reading the paper and helping us makeit more reader-friendly
Daria Yasafova (Technical University of Mu-nich) and Yeno Gbenou (Drexel University) foradditionally proof-reading the paper
Finally the entire Masakhane community13 foramong many other things 1) guiding us to exist-ing parallel and monolingual data set for the focusAfrican languages 2) explaining their (the focusAfrican languages) important linguistic charteris-tics which helped us work better with them (likein preprocessing) and 3) performing (in the future)human evaluation on MMTAfrica
Indeed it took a village to raise MMTAfrica1412httpwwwstatmtorgwmt21
flores-compute-grantshtml13httpswwwmasakhaneio14lsquoIt takes a village to raise a childrsquo is an African proverb
that means that an entire community of people with differentexpertise must provide for and interact positively with the childfor the child to actually develop and reach the best possiblepotential
407
Source Target Test size spBLEUuarr spCHRFuarr spTERdarr
ibo swa 60 3489 4738 6828
ibo xho 30 3669 5066 5965
ibo yor 30 1177 2954 12984
ibo kin 30 3392 4653 6773
ibo fon 30 3596 4314 6321
ibo eng 90 3728 6042 6205
ibo fra 60 3086 4409 6953
swa ibo 60 3371 4302 6001
swa xho 30 3728 5253 5586
swa yor 30 1409 2750 11363
swa kin 30 2386 4259 9467
swa fon 30 2329 3352 6511
swa eng 60 3555 6047 4732
swa fra 60 3011 4833 6338
xho ibo 30 3325 4536 6283
xho swa 30 3926 5375 5372
xho yor 30 2200 3806 7045
xho kin 30 3066 4619 7470
xho fon 30 2580 3487 6596
xho eng 90 3025 5512 6211
xho fra 30 2945 4572 6103
yor ibo 30 2511 3419 7480
yor swa 30 1762 3471 8518
yor xho 30 2931 4313 6682
yor kin 30 2516 3802 7267
yor fon 30 3181 3745 6339
yor eng 90 1781 4173 9300
yor fra 30 1544 3097 9057
kin ibo 30 3125 4236 6673
kin swa 30 3365 4634 7270
kin xho 30 2040 3971 8997
kin yor 30 1834 3353 7043
kin fon 30 2243 3249 6726
kin eng 60 1582 4310 9655
kin fra 30 1623 3351 9182
fon ibo 30 3236 4644 6182
fon swa 30 2984 4296 7228
fon xho 30 2882 4374 6698
fon yor 30 3045 4263 6072
fon kin 30 2388 3959 7806
fon eng 30 1663 4163 6903
fon fra 60 2479 4339 8215
eng ibo 90 4424 5489 6392
eng swa 60 4994 6145 4783
eng xho 120 3197 4974 7289
eng yor 90 2393 3619 8405
eng kin 90 4098 5600 7637
eng fon 30 2719 3686 6254
fra ibo 60 3647 4693 5991
fra swa 60 3653 5142 5594
fra xho 30 3435 4939 6030
fra yor 30 726 2554 12453
fra kin 30 3107 4226 8106
fra fon 60 3107 3872 7574
Table 5 Benchmark Evaluation Scores onMMTAfrica Test Set
ReferencesSolomon Teferra Abate Michael Melese Martha Yi-
firu Tachbelie Million Meshesha Solomon AtinafuWondwossen Mulugeta Yaregal Assabie HafteAbera Binyam Ephrem Tewodros Abebe Wondim-agegnhue Tsegaye Amanuel Lemma Tsegaye An-dargie and Seifedin Shifaw 2018 Parallel corporafor bi-lingual English-Ethiopian languages statisti-cal machine translation In Proceedings of the 27thInternational Conference on Computational Linguis-tics pages 3102ndash3111 Santa Fe New Mexico USAAssociation for Computational Linguistics
Jade Abbott and Laura Martinus 2019 Benchmarkingneural machine translation for Southern African lan-guages In Proceedings of the 2019 Workshop onWidening NLP pages 98ndash101 Florence Italy Asso-ciation for Computational Linguistics
Jade Z Abbott and Laura Martinus 2018 Towardsneural machine translation for african languages
David I Adelani Dana Ruiter Jesujoba O Al-abi Damilola Adebonojo Adesina Ayeni MofeAdeyemi Ayodele Awokoya and Cristina Espantildea-Bonet 2021a The effect of domain and diacritics inyorugravebaacute-english neural machine translation
David Ifeoluwa Adelani Jade Z Abbott GrahamNeubig Daniel Drsquosouza Julia Kreutzer Constan-tine Lignos Chester Palen-Michel Happy Buza-aba Shruti Rijhwani Sebastian Ruder StephenMayhew Israel Abebe Azime Shamsuddeen Has-san Muhammad Chris Chinenye Emezue JoyceNakatumba-Nabende Perez Ogayo Aremu An-uoluwapo Catherine Gitau Derguene Mbaye Je-sujoba O Alabi Seid Muhie Yimam Tajud-deen Gwadabe Ignatius Ezeani Rubungo An-dre Niyongabo Jonathan Mukiibi Verrah OtiendeIroro Orife Davis David Samba Ngom Tosin PAdewumi Paul Rayson Mofetoluwa Adeyemi Ger-ald Muriuki Emmanuel Anebi Chiamaka Chuk-wuneke Nkiruka Odu Eric Peter Wairagala SamuelOyerinde Clemencia Siro Tobius Saul BateesaTemilola Oloyede Yvonne Wambui Victor Akin-ode Deborah Nabagereka Maurice Katusiime Ayo-dele Awokoya Mouhamadane Mboup Dibora Ge-breyohannes Henok Tilaye Kelechi Nwaike De-gaga Wolde Abdoulaye Faye Blessing SibandaOrevaoghene Ahia Bonaventure F P DossouKelechi Ogueji Thierno Ibrahima Diop AbdoulayeDiallo Adewale Akinfaderin Tendai Marengerekeand Salomey Osei 2021b Masakhaner Namedentity recognition for african languages CoRRabs210311811
Željko Agic and Ivan Vulic 2019 JW300 A wide-coverage parallel corpus for low-resource languagesIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages3204ndash3210 Florence Italy Association for Compu-tational Linguistics
Roee Aharoni Melvin Johnson and Orhan Firat 2019Massively multilingual neural machine translation
408
In Proceedings of the 2019 Conference of the NorthAmerican Chapter of the Association for Compu-tational Linguistics Human Language Technolo-gies Volume 1 (Long and Short Papers) pages3874ndash3884 Minneapolis Minnesota Associationfor Computational Linguistics
Jesujoba Alabi Kwabena Amponsah-Kaakyire DavidAdelani and Cristina Espantildea-Bonet 2020 Mas-sive vs curated embeddings for low-resourced lan-guages the case of Yorugravebaacute and Twi In Proceed-ings of the 12th Language Resources and EvaluationConference pages 2754ndash2762 Marseille FranceEuropean Language Resources Association
Naveen Arivazhagan Ankur Bapna Orhan Firat RoeeAharoni Melvin Johnson and Wolfgang Macherey2019a The missing ingredient in zero-shot neuralmachine translation CoRR abs190307091
Naveen Arivazhagan Ankur Bapna Orhan FiratDmitry Lepikhin Melvin Johnson Maxim KrikunMia Xu Chen Yuan Cao George F Foster ColinCherry Wolfgang Macherey Zhifeng Chen andYonghui Wu 2019b Massively multilingual neuralmachine translation in the wild Findings and chal-lenges CoRR abs190705019
Mikko Aulamo Umut Sulubacak Sami Virpioja andJoumlrg Tiedemann 2020 OpusTools and parallel cor-pus diagnostics In Proceedings of The 12th Lan-guage Resources and Evaluation Conference pages3782ndash3789 European Language Resources Associ-ation
Dzmitry Bahdanau Kyunghyun Cho and Yoshua Ben-gio 2015 Neural machine translation by jointlylearning to align and translate In 3rd Inter-national Conference on Learning RepresentationsICLR 2015 San Diego CA USA May 7-9 2015Conference Track Proceedings
ST Barnes 1997 Africarsquos Ogun Old World andNew African systems of thought Indiana Univer-sity Press
Loiumlc Barrault Magdalena Biesialska Ondrej BojarMarta R Costa-jussagrave Christian Federmann YvetteGraham Roman Grundkiewicz Barry HaddowMatthias Huck Eric Joanis Tom Kocmi PhilippKoehn Chi-kiu Lo Nikola Ljubešic ChristofMonz Makoto Morishita Masaaki Nagata Toshi-aki Nakazawa Santanu Pal Matt Post and MarcosZampieri 2020 Findings of the 2020 conference onmachine translation (WMT20) In Proceedings ofthe Fifth Conference on Machine Translation pages1ndash55 Online Association for Computational Lin-guistics
Loiumlc Barrault Ondrej Bojar Marta R Costa-jussagraveChristian Federmann Mark Fishel Yvette Gra-ham Barry Haddow Matthias Huck Philipp KoehnShervin Malmasi Christof Monz Mathias MuumlllerSantanu Pal Matt Post and Marcos Zampieri 2019
Findings of the 2019 conference on machine transla-tion (WMT19) In Proceedings of the Fourth Con-ference on Machine Translation (Volume 2 SharedTask Papers Day 1) pages 1ndash61 Florence Italy As-sociation for Computational Linguistics
Lukas Biewald 2020 Experiment tracking withweights and biases Software available fromwandbcom
Yong Cheng Wei Xu Zhongjun He Wei He HuaWu Maosong Sun and Yang Liu 2016 Semi-supervised learning for neural machine translationIn Proceedings of the 54th Annual Meeting of the As-sociation for Computational Linguistics (Volume 1Long Papers) pages 1965ndash1974 Berlin GermanyAssociation for Computational Linguistics
Kyunghyun Cho Bart van Merrienboer CcedilaglarGuumllccedilehre Dzmitry Bahdanau Fethi Bougares Hol-ger Schwenk and Yoshua Bengio 2014 Learningphrase representations using RNN encoder-decoderfor statistical machine translation In Proceedings ofthe 2014 Conference on Empirical Methods in Nat-ural Language Processing EMNLP 2014 October25-29 2014 Doha Qatar A meeting of SIGDAT aSpecial Interest Group of the ACL pages 1724ndash1734ACL
Alexis Conneau Kartikay Khandelwal Naman GoyalVishrav Chaudhary Guillaume Wenzek FranciscoGuzmaacuten Edouard Grave Myle Ott Luke Zettle-moyer and Veselin Stoyanov 2019 Unsupervisedcross-lingual representation learning at scale
Jacob Devlin Ming-Wei Chang Kenton Lee andKristina Toutanova 2018 BERT pre-training ofdeep bidirectional transformers for language under-standing CoRR abs181004805
Daxiang Dong Hua Wu Wei He Dianhai Yu andHaifeng Wang 2015 Multi-task learning for mul-tiple language translation In Proceedings of the53rd Annual Meeting of the Association for Compu-tational Linguistics and the 7th International JointConference on Natural Language Processing (Vol-ume 1 Long Papers) pages 1723ndash1732 BeijingChina Association for Computational Linguistics
Bonaventure F P Dossou and Chris C Emezue 2020FFR V10 fon-french neural machine translationCoRR abs200312111
Bonaventure F P Dossou and Chris C Emezue 2021aCrowdsourced phrase-based tokenization for low-resourced neural machine translation The case offon language CoRR abs210308052
Bonaventure F P Dossou and Chris C Emezue 2021bOkwugbeacute End-to-end speech recognition for fonand igbo CoRR abs210307762
David M Eberhard Gary F Simons and CharlesD Fennig (eds) 2020 Ethnologue Languages ofthe world twenty-third edition
409
Sergey Edunov Myle Ott Michael Auli and DavidGrangier 2018 Understanding back-translation atscale CoRR abs180809381
Ignatius Ezeani Paul Rayson Ikechukwu E OnyenweChinedu Uchechukwu and Mark Hepple 2020Igbo-english machine translation An evaluationbenchmark CoRR abs200400648
Angela Fan Shruti Bhosale Holger Schwenk ZhiyiMa Ahmed El-Kishky Siddharth Goyal Man-deep Baines Onur Celebi Guillaume WenzekVishrav Chaudhary Naman Goyal Tom Birch Vi-taliy Liptchinsky Sergey Edunov Edouard GraveMichael Auli and Armand Joulin 2020 Be-yond english-centric multilingual machine transla-tion CoRR abs201011125
Thibault Feacutevry and Jason Phang 2018 Unsuper-vised sentence compression using denoising auto-encoders CoRR abs180902669
Orhan Firat Kyunghyun Cho and Yoshua Bengio2016a Multi-way multilingual neural machinetranslation with a shared attention mechanism InProceedings of the 2016 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 866ndash875 San Diego California Associationfor Computational Linguistics
Orhan Firat Baskaran Sankaran Yaser Al-onaizanFatos T Yarman Vural and Kyunghyun Cho 2016bZero-resource translation with multi-lingual neuralmachine translation In Proceedings of the 2016Conference on Empirical Methods in Natural Lan-guage Processing pages 268ndash277 Austin TexasAssociation for Computational Linguistics
forall Wilhelmina Nekoto Vukosi Marivate TshinondiwaMatsila Timi Fasubaa Tajudeen Kolawole TaiwoFagbohungbe Solomon Oluwole Akinola Sham-suddee Hassan Muhammad Salomon Kabongo Sa-lomey Osei et al 2020 Participatory research forlow-resourced machine translation A case study inafrican languages Findings of EMNLP
Naman Goyal Cynthia Gao Vishrav Chaudhary Peng-Jen Chen Guillaume Wenzek Da Ju Sanjana Kr-ishnan MarcrsquoAurelio Ranzato Francisco Guzmanand Angela Fan 2021 The flores-101 evaluationbenchmark for low-resource and multilingual ma-chine translation
Jiatao Gu Yong Wang Kyunghyun Cho and Vic-tor OK Li 2019 Improved zero-shot neural ma-chine translation via ignoring spurious correlationsIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages1258ndash1268 Florence Italy Association for Compu-tational Linguistics
Thanh-Le Ha Jan Niehues and Alexander H Waibel2016 Toward multilingual neural machine trans-lation with universal encoder and decoder CoRRabs161104798
Vu Cong Duy Hoang Philipp Koehn GholamrezaHaffari and Trevor Cohn 2018 Iterative back-translation for neural machine translation In Pro-ceedings of the 2nd Workshop on Neural MachineTranslation and Generation pages 18ndash24 Mel-bourne Australia Association for ComputationalLinguistics
Melvin Johnson Mike Schuster Quoc V Le MaximKrikun Yonghui Wu Zhifeng Chen Nikhil ThoratFernanda Vieacutegas Martin Wattenberg Greg CorradoMacduff Hughes and Jeffrey Dean 2017 Googlersquosmultilingual neural machine translation system En-abling zero-shot translation Transactions of the As-sociation for Computational Linguistics 5339ndash351
Pratik Joshi Sebastin Santy Amar Budhiraja KalikaBali and Monojit Choudhury 2020 The state andfate of linguistic diversity and inclusion in the NLPworld In Proceedings of the 58th Annual Meet-ing of the Association for Computational Linguisticspages 6282ndash6293 Online Association for Computa-tional Linguistics
Taku Kudo and John Richardson 2018 SentencePieceA simple and language independent subword tok-enizer and detokenizer for neural text processing InProceedings of the 2018 Conference on EmpiricalMethods in Natural Language Processing SystemDemonstrations pages 66ndash71 Brussels BelgiumAssociation for Computational Linguistics
Surafel Melaku Lakew Mauro Cettolo and MarcelloFederico 2018 A comparison of transformer andrecurrent neural networks on multilingual neural ma-chine translation In Proceedings of the 27th Inter-national Conference on Computational Linguisticspages 641ndash652 Santa Fe New Mexico USA Asso-ciation for Computational Linguistics
Guillaume Lample Ludovic Denoyer andMarcrsquoAurelio Ranzato 2017 Unsupervisedmachine translation using monolingual corporaonly CoRR abs171100043
Jason Lee Kyunghyun Cho and Thomas Hofmann2017 Fully Character-Level Neural Machine Trans-lation without Explicit Segmentation Transactionsof the Association for Computational Linguistics5365ndash378
Ilya Loshchilov and Frank Hutter 2017 Fixingweight decay regularization in adam CoRRabs171105101
Yichao Lu Phillip Keung Faisal Ladhak Vikas Bhard-waj Shaonan Zhang and Jason Sun 2018 A neu-ral interlingua for multilingual machine translationIn Proceedings of the Third Conference on MachineTranslation Research Papers pages 84ndash92 Brus-sels Belgium Association for Computational Lin-guistics
Laura Martinus and Jade Z Abbott 2019 A focuson neural machine translation for african languagesCoRR abs190605685
410
Graham Neubig Zi-Yi Dou Junjie Hu Paul MichelDanish Pruthi Xinyi Wang and John Wieting 2019compare-mt A tool for holistic comparison of lan-guage generation systems CoRR abs190307926
Graham Neubig and Junjie Hu 2018 Rapid adapta-tion of neural machine translation to new languagesIn Proceedings of the 2018 Conference on Empiri-cal Methods in Natural Language Processing pages875ndash880 Brussels Belgium Association for Com-putational Linguistics
Rubungo Andre Niyongabo Qu Hong Julia Kreutzerand Li Huang 2020 KINNEWS and KIRNEWSBenchmarking cross-lingual text classification forKinyarwanda and Kirundi In Proceedings ofthe 28th International Conference on Computa-tional Linguistics pages 5507ndash5521 BarcelonaSpain (Online) International Committee on Compu-tational Linguistics
Linda Nordling 2018 How decolonizationcould reshape south african science Nature554(7691)159ndash162
Evander Nyoni and Bruce A Bassett 2021 Low-resource neural machine translation for southernafrican languages CoRR abs210400366
Iroro Orife Julia Kreutzer Blessing Sibanda DanielWhitenack Kathleen Siminyu Laura MartinusJamiil Toure Ali Jade Z Abbott Vukosi Mari-vate Salomon Kabongo Musie Meressa Es-poir Murhabazi Orevaoghene Ahia Elan VanBiljon Arshath Ramkilowan Adewale AkinfaderinAlp Oumlktem Wole Akin Ghollah Kioko KevinDegila Herman Kamper Bonaventure DossouChris Emezue Kelechi Ogueji and Abdallah Bashir2020 Masakhane - machine translation for africaCoRR abs200311529
Maja Popovic 2015 chrF character n-gram F-scorefor automatic MT evaluation In Proceedings of theTenth Workshop on Statistical Machine Translationpages 392ndash395 Lisbon Portugal Association forComputational Linguistics
Matt Post 2018 A call for clarity in reporting BLEUscores In Proceedings of the Third Conference onMachine Translation Research Papers pages 186ndash191 Brussels Belgium Association for Computa-tional Linguistics
Colin Raffel Noam Shazeer Adam Roberts KatherineLee Sharan Narang Michael Matena Yanqi ZhouWei Li and Peter J Liu 2019 Exploring the limitsof transfer learning with a unified text-to-text trans-former CoRR abs191010683
Machel Reid Junjie Hu Graham Neubig and YutakaMatsuo 2021 Afromt Pretraining strategies andreproducible benchmarks for translation of 8 africanlanguages
Rico Sennrich Barry Haddow and Alexandra Birch2015 Improving neural machine translation modelswith monolingual data CoRR abs151106709
Shivachi Casper Shikali and Mokhosi Refuoe 2019Language modeling data for swahili
Aditya Siddhant Ankur Bapna Yuan Cao Orhan Fi-rat Mia Xu Chen Sneha Reddy Kudugunta NaveenArivazhagan and Yonghui Wu 2020 Lever-aging monolingual data with self-supervision formultilingual neural machine translation CoRRabs200504816
Ilya Sutskever Oriol Vinyals and Quoc V Le 2014Sequence to sequence learning with neural networksIn Proceedings of the 27th International Conferenceon Neural Information Processing Systems - Vol-ume 2 NIPSrsquo14 page 3104ndash3112 Cambridge MAUSA MIT Press
Xu Tan Jiale Chen Di He Yingce Xia Tao Qin andTie-Yan Liu 2019 Multilingual neural machinetranslation with language clustering In Proceedingsof the 2019 Conference on Empirical Methods inNatural Language Processing and the 9th Interna-tional Joint Conference on Natural Language Pro-cessing (EMNLP-IJCNLP) pages 963ndash973 HongKong China Association for Computational Lin-guistics
Joumlrg Tiedemann 2012 Parallel data tools and inter-faces in opus In Proceedings of the Eight Interna-tional Conference on Language Resources and Eval-uation (LRECrsquo12) Istanbul Turkey European Lan-guage Resources Association (ELRA)
Daniel van Niekerk Charl van Heerden Marelie DavelNeil Kleynhans Oddur Kjartansson Martin Janscheand Linne Ha 2017 Rapid development of TTS cor-pora for four South African languages In Proc In-terspeech 2017 pages 2178ndash2182 Stockholm Swe-den
Ashish Vaswani Noam Shazeer Niki Parmar JakobUszkoreit Llion Jones Aidan N Gomez LukaszKaiser and Illia Polosukhin 2017 Attention is allyou need CoRR abs170603762
Sarah Wild 2021 African languages to get more be-spoke scientific terms Nature 596(7873)469ndash470
Ronald J Williams and David Zipser 1989 A learn-ing algorithm for continually running fully recurrentneural networks Neural Computation 1(2)270ndash280
Linting Xue Noah Constant Adam Roberts Mi-hir Kale Rami Al-Rfou Aditya Siddhant AdityaBarua and Colin Raffel 2021 mT5 A massivelymultilingual pre-trained text-to-text transformer InProceedings of the 2021 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 483ndash498 Online Association for Computa-tional Linguistics
Biao Zhang Philip Williams Ivan Titov and RicoSennrich 2020 Improving massively multilingualneural machine translation and zero-shot translationCoRR abs200411867
411
Jiajun Zhang and Chengqing Zong 2016 Exploit-ing source-side monolingual data in neural machinetranslation In Proceedings of the 2016 Conferenceon Empirical Methods in Natural Language Process-ing pages 1535ndash1545 Austin Texas Associationfor Computational Linguistics
Barret Zoph Deniz Yuret Jonathan May and KevinKnight 2016 Transfer learning for low-resourceneural machine translation In Proceedings of the2016 Conference on Empirical Methods in Natu-ral Language Processing pages 1568ndash1575 AustinTexas Association for Computational Linguistics

406
spoken as a native language Yoruba is one of the in-digenuous languages commonly spoken 11 There-fore Fon and Yorugravebaacute share some linguistic charac-teristics and we believe this is one logic behind thefonlarrrarryor surpassing other fonminusrarr ~ directions
This explanation could inspire transfer learningfrom Yorugravebaacute which has received comparably moreresearch and has more resources for machine trans-lation to Fon We leave this for future work
Source Target spBLEU (FLORES)uarr spBLEU (Ours)uarr spCHRFuarr spTERdarr
ibo swa 438 2184 3738 7148
ibo xho 244 1397 3195 8137
ibo yor 154 1072 2655 7572
ibo eng 737 1362 3890 7623
ibo fra 602 1646 3510 7548
swa ibo 197 1980 3395 6822
swa xho 271 2171 3986 7316
swa yor 129 1168 2744 7523
swa eng 3043 2767 5612 5591
swa fra 2669 2727 4620 6347
xho ibo 380 1702 3130 7066
xho swa 614 2947 4468 6321
xho yor 192 1042 2677 7625
xho eng 1086 2077 4869 6409
xho fra 828 2148 4065 6931
yor ibo 185 1145 2526 7499
yor swa 193 1499 3049 7990
yor xho 194 931 2634 8608
yor eng 418 815 3065 8694
yor fra 357 1059 2760 8132
eng ibo 353 2149 3724 6568
eng swa 2695 4011 5313 5280
eng xho 447 2715 4493 6777
eng yor 217 1209 2834 7474
fra ibo 169 1948 3447 6850
fra swa 1717 3421 4895 5811
fra xho 227 2173 4006 7372
fra yor 116 1142 2767 7533
Table 4 Evaluation Scores of the Flores M2M MMTmodel and MMTAfrica on FLORES Test Set
6 Conclusion and Future Work
In this paper we introduced MMTAfrica a mul-tilingual machine translation model on 6 AfricanLanguages which outperformed the M2M MMTmodel Fan et al (2020) Our results and analy-ses including a new reconstruction objective giveinsights on MMT for African languages for fu-ture research Moreover we plan to launch themodel on Masakhane MT and FFRTranslate in or-der to get human evaluation feedback from theactual speakers of the languages in the Masakhanecommunity (Orife et al 2020) and beyond
In order to fully test the advantage ofMMTAfrica we plan to finish comparing it on
11httpsenwikipediaorgwikiBenin(Last Accessed 30082021)
direct and pivot translations with the Masakhanebenchmark models (forall et al 2020) We alsoplan to perform human evaluation All test setsresults code and checkpoints will be releasedat httpsgithubcomedaiofficialmmtafrica
7 Acknowledgments
The computational resources for running all ex-periments were provided by the FLORES com-pute grants12 as well as additonal computationalresources provided by Paco Guzman (FacebookAI) and Mila Quebec AI Institute We expressour profound gratitude to all who contributed inone way or the other towards the development ofMMTAfrica including (in no order)
Mathias Muumlller (University of Zurich) for giv-ing immense technical assistance in finetuning themodel and advising us on best hyperparameter tun-ing practises
Graham Neubig (Carnegie Mellon University)for explaining and setting up comparemt for usto better understand and evaluate the performanceof our baseline models
Angela Fan (FacebookAI) for guiding us duringthe shared task and taking the time to answer allour questions
Julia Kreutzer (GoogleAI) for advising us on use-ful model comparison and evaluation techniques
Colin Leong (University of Dayton) for painstak-ingly proof-reading the paper and helping us makeit more reader-friendly
Daria Yasafova (Technical University of Mu-nich) and Yeno Gbenou (Drexel University) foradditionally proof-reading the paper
Finally the entire Masakhane community13 foramong many other things 1) guiding us to exist-ing parallel and monolingual data set for the focusAfrican languages 2) explaining their (the focusAfrican languages) important linguistic charteris-tics which helped us work better with them (likein preprocessing) and 3) performing (in the future)human evaluation on MMTAfrica
Indeed it took a village to raise MMTAfrica1412httpwwwstatmtorgwmt21
flores-compute-grantshtml13httpswwwmasakhaneio14lsquoIt takes a village to raise a childrsquo is an African proverb
that means that an entire community of people with differentexpertise must provide for and interact positively with the childfor the child to actually develop and reach the best possiblepotential
407
Source Target Test size spBLEUuarr spCHRFuarr spTERdarr
ibo swa 60 3489 4738 6828
ibo xho 30 3669 5066 5965
ibo yor 30 1177 2954 12984
ibo kin 30 3392 4653 6773
ibo fon 30 3596 4314 6321
ibo eng 90 3728 6042 6205
ibo fra 60 3086 4409 6953
swa ibo 60 3371 4302 6001
swa xho 30 3728 5253 5586
swa yor 30 1409 2750 11363
swa kin 30 2386 4259 9467
swa fon 30 2329 3352 6511
swa eng 60 3555 6047 4732
swa fra 60 3011 4833 6338
xho ibo 30 3325 4536 6283
xho swa 30 3926 5375 5372
xho yor 30 2200 3806 7045
xho kin 30 3066 4619 7470
xho fon 30 2580 3487 6596
xho eng 90 3025 5512 6211
xho fra 30 2945 4572 6103
yor ibo 30 2511 3419 7480
yor swa 30 1762 3471 8518
yor xho 30 2931 4313 6682
yor kin 30 2516 3802 7267
yor fon 30 3181 3745 6339
yor eng 90 1781 4173 9300
yor fra 30 1544 3097 9057
kin ibo 30 3125 4236 6673
kin swa 30 3365 4634 7270
kin xho 30 2040 3971 8997
kin yor 30 1834 3353 7043
kin fon 30 2243 3249 6726
kin eng 60 1582 4310 9655
kin fra 30 1623 3351 9182
fon ibo 30 3236 4644 6182
fon swa 30 2984 4296 7228
fon xho 30 2882 4374 6698
fon yor 30 3045 4263 6072
fon kin 30 2388 3959 7806
fon eng 30 1663 4163 6903
fon fra 60 2479 4339 8215
eng ibo 90 4424 5489 6392
eng swa 60 4994 6145 4783
eng xho 120 3197 4974 7289
eng yor 90 2393 3619 8405
eng kin 90 4098 5600 7637
eng fon 30 2719 3686 6254
fra ibo 60 3647 4693 5991
fra swa 60 3653 5142 5594
fra xho 30 3435 4939 6030
fra yor 30 726 2554 12453
fra kin 30 3107 4226 8106
fra fon 60 3107 3872 7574
Table 5 Benchmark Evaluation Scores onMMTAfrica Test Set
ReferencesSolomon Teferra Abate Michael Melese Martha Yi-
firu Tachbelie Million Meshesha Solomon AtinafuWondwossen Mulugeta Yaregal Assabie HafteAbera Binyam Ephrem Tewodros Abebe Wondim-agegnhue Tsegaye Amanuel Lemma Tsegaye An-dargie and Seifedin Shifaw 2018 Parallel corporafor bi-lingual English-Ethiopian languages statisti-cal machine translation In Proceedings of the 27thInternational Conference on Computational Linguis-tics pages 3102ndash3111 Santa Fe New Mexico USAAssociation for Computational Linguistics
Jade Abbott and Laura Martinus 2019 Benchmarkingneural machine translation for Southern African lan-guages In Proceedings of the 2019 Workshop onWidening NLP pages 98ndash101 Florence Italy Asso-ciation for Computational Linguistics
Jade Z Abbott and Laura Martinus 2018 Towardsneural machine translation for african languages
David I Adelani Dana Ruiter Jesujoba O Al-abi Damilola Adebonojo Adesina Ayeni MofeAdeyemi Ayodele Awokoya and Cristina Espantildea-Bonet 2021a The effect of domain and diacritics inyorugravebaacute-english neural machine translation
David Ifeoluwa Adelani Jade Z Abbott GrahamNeubig Daniel Drsquosouza Julia Kreutzer Constan-tine Lignos Chester Palen-Michel Happy Buza-aba Shruti Rijhwani Sebastian Ruder StephenMayhew Israel Abebe Azime Shamsuddeen Has-san Muhammad Chris Chinenye Emezue JoyceNakatumba-Nabende Perez Ogayo Aremu An-uoluwapo Catherine Gitau Derguene Mbaye Je-sujoba O Alabi Seid Muhie Yimam Tajud-deen Gwadabe Ignatius Ezeani Rubungo An-dre Niyongabo Jonathan Mukiibi Verrah OtiendeIroro Orife Davis David Samba Ngom Tosin PAdewumi Paul Rayson Mofetoluwa Adeyemi Ger-ald Muriuki Emmanuel Anebi Chiamaka Chuk-wuneke Nkiruka Odu Eric Peter Wairagala SamuelOyerinde Clemencia Siro Tobius Saul BateesaTemilola Oloyede Yvonne Wambui Victor Akin-ode Deborah Nabagereka Maurice Katusiime Ayo-dele Awokoya Mouhamadane Mboup Dibora Ge-breyohannes Henok Tilaye Kelechi Nwaike De-gaga Wolde Abdoulaye Faye Blessing SibandaOrevaoghene Ahia Bonaventure F P DossouKelechi Ogueji Thierno Ibrahima Diop AbdoulayeDiallo Adewale Akinfaderin Tendai Marengerekeand Salomey Osei 2021b Masakhaner Namedentity recognition for african languages CoRRabs210311811
Željko Agic and Ivan Vulic 2019 JW300 A wide-coverage parallel corpus for low-resource languagesIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages3204ndash3210 Florence Italy Association for Compu-tational Linguistics
Roee Aharoni Melvin Johnson and Orhan Firat 2019Massively multilingual neural machine translation
408
In Proceedings of the 2019 Conference of the NorthAmerican Chapter of the Association for Compu-tational Linguistics Human Language Technolo-gies Volume 1 (Long and Short Papers) pages3874ndash3884 Minneapolis Minnesota Associationfor Computational Linguistics
Jesujoba Alabi Kwabena Amponsah-Kaakyire DavidAdelani and Cristina Espantildea-Bonet 2020 Mas-sive vs curated embeddings for low-resourced lan-guages the case of Yorugravebaacute and Twi In Proceed-ings of the 12th Language Resources and EvaluationConference pages 2754ndash2762 Marseille FranceEuropean Language Resources Association
Naveen Arivazhagan Ankur Bapna Orhan Firat RoeeAharoni Melvin Johnson and Wolfgang Macherey2019a The missing ingredient in zero-shot neuralmachine translation CoRR abs190307091
Naveen Arivazhagan Ankur Bapna Orhan FiratDmitry Lepikhin Melvin Johnson Maxim KrikunMia Xu Chen Yuan Cao George F Foster ColinCherry Wolfgang Macherey Zhifeng Chen andYonghui Wu 2019b Massively multilingual neuralmachine translation in the wild Findings and chal-lenges CoRR abs190705019
Mikko Aulamo Umut Sulubacak Sami Virpioja andJoumlrg Tiedemann 2020 OpusTools and parallel cor-pus diagnostics In Proceedings of The 12th Lan-guage Resources and Evaluation Conference pages3782ndash3789 European Language Resources Associ-ation
Dzmitry Bahdanau Kyunghyun Cho and Yoshua Ben-gio 2015 Neural machine translation by jointlylearning to align and translate In 3rd Inter-national Conference on Learning RepresentationsICLR 2015 San Diego CA USA May 7-9 2015Conference Track Proceedings
ST Barnes 1997 Africarsquos Ogun Old World andNew African systems of thought Indiana Univer-sity Press
Loiumlc Barrault Magdalena Biesialska Ondrej BojarMarta R Costa-jussagrave Christian Federmann YvetteGraham Roman Grundkiewicz Barry HaddowMatthias Huck Eric Joanis Tom Kocmi PhilippKoehn Chi-kiu Lo Nikola Ljubešic ChristofMonz Makoto Morishita Masaaki Nagata Toshi-aki Nakazawa Santanu Pal Matt Post and MarcosZampieri 2020 Findings of the 2020 conference onmachine translation (WMT20) In Proceedings ofthe Fifth Conference on Machine Translation pages1ndash55 Online Association for Computational Lin-guistics
Loiumlc Barrault Ondrej Bojar Marta R Costa-jussagraveChristian Federmann Mark Fishel Yvette Gra-ham Barry Haddow Matthias Huck Philipp KoehnShervin Malmasi Christof Monz Mathias MuumlllerSantanu Pal Matt Post and Marcos Zampieri 2019
Findings of the 2019 conference on machine transla-tion (WMT19) In Proceedings of the Fourth Con-ference on Machine Translation (Volume 2 SharedTask Papers Day 1) pages 1ndash61 Florence Italy As-sociation for Computational Linguistics
Lukas Biewald 2020 Experiment tracking withweights and biases Software available fromwandbcom
Yong Cheng Wei Xu Zhongjun He Wei He HuaWu Maosong Sun and Yang Liu 2016 Semi-supervised learning for neural machine translationIn Proceedings of the 54th Annual Meeting of the As-sociation for Computational Linguistics (Volume 1Long Papers) pages 1965ndash1974 Berlin GermanyAssociation for Computational Linguistics
Kyunghyun Cho Bart van Merrienboer CcedilaglarGuumllccedilehre Dzmitry Bahdanau Fethi Bougares Hol-ger Schwenk and Yoshua Bengio 2014 Learningphrase representations using RNN encoder-decoderfor statistical machine translation In Proceedings ofthe 2014 Conference on Empirical Methods in Nat-ural Language Processing EMNLP 2014 October25-29 2014 Doha Qatar A meeting of SIGDAT aSpecial Interest Group of the ACL pages 1724ndash1734ACL
Alexis Conneau Kartikay Khandelwal Naman GoyalVishrav Chaudhary Guillaume Wenzek FranciscoGuzmaacuten Edouard Grave Myle Ott Luke Zettle-moyer and Veselin Stoyanov 2019 Unsupervisedcross-lingual representation learning at scale
Jacob Devlin Ming-Wei Chang Kenton Lee andKristina Toutanova 2018 BERT pre-training ofdeep bidirectional transformers for language under-standing CoRR abs181004805
Daxiang Dong Hua Wu Wei He Dianhai Yu andHaifeng Wang 2015 Multi-task learning for mul-tiple language translation In Proceedings of the53rd Annual Meeting of the Association for Compu-tational Linguistics and the 7th International JointConference on Natural Language Processing (Vol-ume 1 Long Papers) pages 1723ndash1732 BeijingChina Association for Computational Linguistics
Bonaventure F P Dossou and Chris C Emezue 2020FFR V10 fon-french neural machine translationCoRR abs200312111
Bonaventure F P Dossou and Chris C Emezue 2021aCrowdsourced phrase-based tokenization for low-resourced neural machine translation The case offon language CoRR abs210308052
Bonaventure F P Dossou and Chris C Emezue 2021bOkwugbeacute End-to-end speech recognition for fonand igbo CoRR abs210307762
David M Eberhard Gary F Simons and CharlesD Fennig (eds) 2020 Ethnologue Languages ofthe world twenty-third edition
409
Sergey Edunov Myle Ott Michael Auli and DavidGrangier 2018 Understanding back-translation atscale CoRR abs180809381
Ignatius Ezeani Paul Rayson Ikechukwu E OnyenweChinedu Uchechukwu and Mark Hepple 2020Igbo-english machine translation An evaluationbenchmark CoRR abs200400648
Angela Fan Shruti Bhosale Holger Schwenk ZhiyiMa Ahmed El-Kishky Siddharth Goyal Man-deep Baines Onur Celebi Guillaume WenzekVishrav Chaudhary Naman Goyal Tom Birch Vi-taliy Liptchinsky Sergey Edunov Edouard GraveMichael Auli and Armand Joulin 2020 Be-yond english-centric multilingual machine transla-tion CoRR abs201011125
Thibault Feacutevry and Jason Phang 2018 Unsuper-vised sentence compression using denoising auto-encoders CoRR abs180902669
Orhan Firat Kyunghyun Cho and Yoshua Bengio2016a Multi-way multilingual neural machinetranslation with a shared attention mechanism InProceedings of the 2016 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 866ndash875 San Diego California Associationfor Computational Linguistics
Orhan Firat Baskaran Sankaran Yaser Al-onaizanFatos T Yarman Vural and Kyunghyun Cho 2016bZero-resource translation with multi-lingual neuralmachine translation In Proceedings of the 2016Conference on Empirical Methods in Natural Lan-guage Processing pages 268ndash277 Austin TexasAssociation for Computational Linguistics
forall Wilhelmina Nekoto Vukosi Marivate TshinondiwaMatsila Timi Fasubaa Tajudeen Kolawole TaiwoFagbohungbe Solomon Oluwole Akinola Sham-suddee Hassan Muhammad Salomon Kabongo Sa-lomey Osei et al 2020 Participatory research forlow-resourced machine translation A case study inafrican languages Findings of EMNLP
Naman Goyal Cynthia Gao Vishrav Chaudhary Peng-Jen Chen Guillaume Wenzek Da Ju Sanjana Kr-ishnan MarcrsquoAurelio Ranzato Francisco Guzmanand Angela Fan 2021 The flores-101 evaluationbenchmark for low-resource and multilingual ma-chine translation
Jiatao Gu Yong Wang Kyunghyun Cho and Vic-tor OK Li 2019 Improved zero-shot neural ma-chine translation via ignoring spurious correlationsIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages1258ndash1268 Florence Italy Association for Compu-tational Linguistics
Thanh-Le Ha Jan Niehues and Alexander H Waibel2016 Toward multilingual neural machine trans-lation with universal encoder and decoder CoRRabs161104798
Vu Cong Duy Hoang Philipp Koehn GholamrezaHaffari and Trevor Cohn 2018 Iterative back-translation for neural machine translation In Pro-ceedings of the 2nd Workshop on Neural MachineTranslation and Generation pages 18ndash24 Mel-bourne Australia Association for ComputationalLinguistics
Melvin Johnson Mike Schuster Quoc V Le MaximKrikun Yonghui Wu Zhifeng Chen Nikhil ThoratFernanda Vieacutegas Martin Wattenberg Greg CorradoMacduff Hughes and Jeffrey Dean 2017 Googlersquosmultilingual neural machine translation system En-abling zero-shot translation Transactions of the As-sociation for Computational Linguistics 5339ndash351
Pratik Joshi Sebastin Santy Amar Budhiraja KalikaBali and Monojit Choudhury 2020 The state andfate of linguistic diversity and inclusion in the NLPworld In Proceedings of the 58th Annual Meet-ing of the Association for Computational Linguisticspages 6282ndash6293 Online Association for Computa-tional Linguistics
Taku Kudo and John Richardson 2018 SentencePieceA simple and language independent subword tok-enizer and detokenizer for neural text processing InProceedings of the 2018 Conference on EmpiricalMethods in Natural Language Processing SystemDemonstrations pages 66ndash71 Brussels BelgiumAssociation for Computational Linguistics
Surafel Melaku Lakew Mauro Cettolo and MarcelloFederico 2018 A comparison of transformer andrecurrent neural networks on multilingual neural ma-chine translation In Proceedings of the 27th Inter-national Conference on Computational Linguisticspages 641ndash652 Santa Fe New Mexico USA Asso-ciation for Computational Linguistics
Guillaume Lample Ludovic Denoyer andMarcrsquoAurelio Ranzato 2017 Unsupervisedmachine translation using monolingual corporaonly CoRR abs171100043
Jason Lee Kyunghyun Cho and Thomas Hofmann2017 Fully Character-Level Neural Machine Trans-lation without Explicit Segmentation Transactionsof the Association for Computational Linguistics5365ndash378
Ilya Loshchilov and Frank Hutter 2017 Fixingweight decay regularization in adam CoRRabs171105101
Yichao Lu Phillip Keung Faisal Ladhak Vikas Bhard-waj Shaonan Zhang and Jason Sun 2018 A neu-ral interlingua for multilingual machine translationIn Proceedings of the Third Conference on MachineTranslation Research Papers pages 84ndash92 Brus-sels Belgium Association for Computational Lin-guistics
Laura Martinus and Jade Z Abbott 2019 A focuson neural machine translation for african languagesCoRR abs190605685
410
Graham Neubig Zi-Yi Dou Junjie Hu Paul MichelDanish Pruthi Xinyi Wang and John Wieting 2019compare-mt A tool for holistic comparison of lan-guage generation systems CoRR abs190307926
Graham Neubig and Junjie Hu 2018 Rapid adapta-tion of neural machine translation to new languagesIn Proceedings of the 2018 Conference on Empiri-cal Methods in Natural Language Processing pages875ndash880 Brussels Belgium Association for Com-putational Linguistics
Rubungo Andre Niyongabo Qu Hong Julia Kreutzerand Li Huang 2020 KINNEWS and KIRNEWSBenchmarking cross-lingual text classification forKinyarwanda and Kirundi In Proceedings ofthe 28th International Conference on Computa-tional Linguistics pages 5507ndash5521 BarcelonaSpain (Online) International Committee on Compu-tational Linguistics
Linda Nordling 2018 How decolonizationcould reshape south african science Nature554(7691)159ndash162
Evander Nyoni and Bruce A Bassett 2021 Low-resource neural machine translation for southernafrican languages CoRR abs210400366
Iroro Orife Julia Kreutzer Blessing Sibanda DanielWhitenack Kathleen Siminyu Laura MartinusJamiil Toure Ali Jade Z Abbott Vukosi Mari-vate Salomon Kabongo Musie Meressa Es-poir Murhabazi Orevaoghene Ahia Elan VanBiljon Arshath Ramkilowan Adewale AkinfaderinAlp Oumlktem Wole Akin Ghollah Kioko KevinDegila Herman Kamper Bonaventure DossouChris Emezue Kelechi Ogueji and Abdallah Bashir2020 Masakhane - machine translation for africaCoRR abs200311529
Maja Popovic 2015 chrF character n-gram F-scorefor automatic MT evaluation In Proceedings of theTenth Workshop on Statistical Machine Translationpages 392ndash395 Lisbon Portugal Association forComputational Linguistics
Matt Post 2018 A call for clarity in reporting BLEUscores In Proceedings of the Third Conference onMachine Translation Research Papers pages 186ndash191 Brussels Belgium Association for Computa-tional Linguistics
Colin Raffel Noam Shazeer Adam Roberts KatherineLee Sharan Narang Michael Matena Yanqi ZhouWei Li and Peter J Liu 2019 Exploring the limitsof transfer learning with a unified text-to-text trans-former CoRR abs191010683
Machel Reid Junjie Hu Graham Neubig and YutakaMatsuo 2021 Afromt Pretraining strategies andreproducible benchmarks for translation of 8 africanlanguages
Rico Sennrich Barry Haddow and Alexandra Birch2015 Improving neural machine translation modelswith monolingual data CoRR abs151106709
Shivachi Casper Shikali and Mokhosi Refuoe 2019Language modeling data for swahili
Aditya Siddhant Ankur Bapna Yuan Cao Orhan Fi-rat Mia Xu Chen Sneha Reddy Kudugunta NaveenArivazhagan and Yonghui Wu 2020 Lever-aging monolingual data with self-supervision formultilingual neural machine translation CoRRabs200504816
Ilya Sutskever Oriol Vinyals and Quoc V Le 2014Sequence to sequence learning with neural networksIn Proceedings of the 27th International Conferenceon Neural Information Processing Systems - Vol-ume 2 NIPSrsquo14 page 3104ndash3112 Cambridge MAUSA MIT Press
Xu Tan Jiale Chen Di He Yingce Xia Tao Qin andTie-Yan Liu 2019 Multilingual neural machinetranslation with language clustering In Proceedingsof the 2019 Conference on Empirical Methods inNatural Language Processing and the 9th Interna-tional Joint Conference on Natural Language Pro-cessing (EMNLP-IJCNLP) pages 963ndash973 HongKong China Association for Computational Lin-guistics
Joumlrg Tiedemann 2012 Parallel data tools and inter-faces in opus In Proceedings of the Eight Interna-tional Conference on Language Resources and Eval-uation (LRECrsquo12) Istanbul Turkey European Lan-guage Resources Association (ELRA)
Daniel van Niekerk Charl van Heerden Marelie DavelNeil Kleynhans Oddur Kjartansson Martin Janscheand Linne Ha 2017 Rapid development of TTS cor-pora for four South African languages In Proc In-terspeech 2017 pages 2178ndash2182 Stockholm Swe-den
Ashish Vaswani Noam Shazeer Niki Parmar JakobUszkoreit Llion Jones Aidan N Gomez LukaszKaiser and Illia Polosukhin 2017 Attention is allyou need CoRR abs170603762
Sarah Wild 2021 African languages to get more be-spoke scientific terms Nature 596(7873)469ndash470
Ronald J Williams and David Zipser 1989 A learn-ing algorithm for continually running fully recurrentneural networks Neural Computation 1(2)270ndash280
Linting Xue Noah Constant Adam Roberts Mi-hir Kale Rami Al-Rfou Aditya Siddhant AdityaBarua and Colin Raffel 2021 mT5 A massivelymultilingual pre-trained text-to-text transformer InProceedings of the 2021 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 483ndash498 Online Association for Computa-tional Linguistics
Biao Zhang Philip Williams Ivan Titov and RicoSennrich 2020 Improving massively multilingualneural machine translation and zero-shot translationCoRR abs200411867
411
Jiajun Zhang and Chengqing Zong 2016 Exploit-ing source-side monolingual data in neural machinetranslation In Proceedings of the 2016 Conferenceon Empirical Methods in Natural Language Process-ing pages 1535ndash1545 Austin Texas Associationfor Computational Linguistics
Barret Zoph Deniz Yuret Jonathan May and KevinKnight 2016 Transfer learning for low-resourceneural machine translation In Proceedings of the2016 Conference on Empirical Methods in Natu-ral Language Processing pages 1568ndash1575 AustinTexas Association for Computational Linguistics

407
Source Target Test size spBLEUuarr spCHRFuarr spTERdarr
ibo swa 60 3489 4738 6828
ibo xho 30 3669 5066 5965
ibo yor 30 1177 2954 12984
ibo kin 30 3392 4653 6773
ibo fon 30 3596 4314 6321
ibo eng 90 3728 6042 6205
ibo fra 60 3086 4409 6953
swa ibo 60 3371 4302 6001
swa xho 30 3728 5253 5586
swa yor 30 1409 2750 11363
swa kin 30 2386 4259 9467
swa fon 30 2329 3352 6511
swa eng 60 3555 6047 4732
swa fra 60 3011 4833 6338
xho ibo 30 3325 4536 6283
xho swa 30 3926 5375 5372
xho yor 30 2200 3806 7045
xho kin 30 3066 4619 7470
xho fon 30 2580 3487 6596
xho eng 90 3025 5512 6211
xho fra 30 2945 4572 6103
yor ibo 30 2511 3419 7480
yor swa 30 1762 3471 8518
yor xho 30 2931 4313 6682
yor kin 30 2516 3802 7267
yor fon 30 3181 3745 6339
yor eng 90 1781 4173 9300
yor fra 30 1544 3097 9057
kin ibo 30 3125 4236 6673
kin swa 30 3365 4634 7270
kin xho 30 2040 3971 8997
kin yor 30 1834 3353 7043
kin fon 30 2243 3249 6726
kin eng 60 1582 4310 9655
kin fra 30 1623 3351 9182
fon ibo 30 3236 4644 6182
fon swa 30 2984 4296 7228
fon xho 30 2882 4374 6698
fon yor 30 3045 4263 6072
fon kin 30 2388 3959 7806
fon eng 30 1663 4163 6903
fon fra 60 2479 4339 8215
eng ibo 90 4424 5489 6392
eng swa 60 4994 6145 4783
eng xho 120 3197 4974 7289
eng yor 90 2393 3619 8405
eng kin 90 4098 5600 7637
eng fon 30 2719 3686 6254
fra ibo 60 3647 4693 5991
fra swa 60 3653 5142 5594
fra xho 30 3435 4939 6030
fra yor 30 726 2554 12453
fra kin 30 3107 4226 8106
fra fon 60 3107 3872 7574
Table 5 Benchmark Evaluation Scores onMMTAfrica Test Set
ReferencesSolomon Teferra Abate Michael Melese Martha Yi-
firu Tachbelie Million Meshesha Solomon AtinafuWondwossen Mulugeta Yaregal Assabie HafteAbera Binyam Ephrem Tewodros Abebe Wondim-agegnhue Tsegaye Amanuel Lemma Tsegaye An-dargie and Seifedin Shifaw 2018 Parallel corporafor bi-lingual English-Ethiopian languages statisti-cal machine translation In Proceedings of the 27thInternational Conference on Computational Linguis-tics pages 3102ndash3111 Santa Fe New Mexico USAAssociation for Computational Linguistics
Jade Abbott and Laura Martinus 2019 Benchmarkingneural machine translation for Southern African lan-guages In Proceedings of the 2019 Workshop onWidening NLP pages 98ndash101 Florence Italy Asso-ciation for Computational Linguistics
Jade Z Abbott and Laura Martinus 2018 Towardsneural machine translation for african languages
David I Adelani Dana Ruiter Jesujoba O Al-abi Damilola Adebonojo Adesina Ayeni MofeAdeyemi Ayodele Awokoya and Cristina Espantildea-Bonet 2021a The effect of domain and diacritics inyorugravebaacute-english neural machine translation
David Ifeoluwa Adelani Jade Z Abbott GrahamNeubig Daniel Drsquosouza Julia Kreutzer Constan-tine Lignos Chester Palen-Michel Happy Buza-aba Shruti Rijhwani Sebastian Ruder StephenMayhew Israel Abebe Azime Shamsuddeen Has-san Muhammad Chris Chinenye Emezue JoyceNakatumba-Nabende Perez Ogayo Aremu An-uoluwapo Catherine Gitau Derguene Mbaye Je-sujoba O Alabi Seid Muhie Yimam Tajud-deen Gwadabe Ignatius Ezeani Rubungo An-dre Niyongabo Jonathan Mukiibi Verrah OtiendeIroro Orife Davis David Samba Ngom Tosin PAdewumi Paul Rayson Mofetoluwa Adeyemi Ger-ald Muriuki Emmanuel Anebi Chiamaka Chuk-wuneke Nkiruka Odu Eric Peter Wairagala SamuelOyerinde Clemencia Siro Tobius Saul BateesaTemilola Oloyede Yvonne Wambui Victor Akin-ode Deborah Nabagereka Maurice Katusiime Ayo-dele Awokoya Mouhamadane Mboup Dibora Ge-breyohannes Henok Tilaye Kelechi Nwaike De-gaga Wolde Abdoulaye Faye Blessing SibandaOrevaoghene Ahia Bonaventure F P DossouKelechi Ogueji Thierno Ibrahima Diop AbdoulayeDiallo Adewale Akinfaderin Tendai Marengerekeand Salomey Osei 2021b Masakhaner Namedentity recognition for african languages CoRRabs210311811
Željko Agic and Ivan Vulic 2019 JW300 A wide-coverage parallel corpus for low-resource languagesIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages3204ndash3210 Florence Italy Association for Compu-tational Linguistics
Roee Aharoni Melvin Johnson and Orhan Firat 2019Massively multilingual neural machine translation
408
In Proceedings of the 2019 Conference of the NorthAmerican Chapter of the Association for Compu-tational Linguistics Human Language Technolo-gies Volume 1 (Long and Short Papers) pages3874ndash3884 Minneapolis Minnesota Associationfor Computational Linguistics
Jesujoba Alabi Kwabena Amponsah-Kaakyire DavidAdelani and Cristina Espantildea-Bonet 2020 Mas-sive vs curated embeddings for low-resourced lan-guages the case of Yorugravebaacute and Twi In Proceed-ings of the 12th Language Resources and EvaluationConference pages 2754ndash2762 Marseille FranceEuropean Language Resources Association
Naveen Arivazhagan Ankur Bapna Orhan Firat RoeeAharoni Melvin Johnson and Wolfgang Macherey2019a The missing ingredient in zero-shot neuralmachine translation CoRR abs190307091
Naveen Arivazhagan Ankur Bapna Orhan FiratDmitry Lepikhin Melvin Johnson Maxim KrikunMia Xu Chen Yuan Cao George F Foster ColinCherry Wolfgang Macherey Zhifeng Chen andYonghui Wu 2019b Massively multilingual neuralmachine translation in the wild Findings and chal-lenges CoRR abs190705019
Mikko Aulamo Umut Sulubacak Sami Virpioja andJoumlrg Tiedemann 2020 OpusTools and parallel cor-pus diagnostics In Proceedings of The 12th Lan-guage Resources and Evaluation Conference pages3782ndash3789 European Language Resources Associ-ation
Dzmitry Bahdanau Kyunghyun Cho and Yoshua Ben-gio 2015 Neural machine translation by jointlylearning to align and translate In 3rd Inter-national Conference on Learning RepresentationsICLR 2015 San Diego CA USA May 7-9 2015Conference Track Proceedings
ST Barnes 1997 Africarsquos Ogun Old World andNew African systems of thought Indiana Univer-sity Press
Loiumlc Barrault Magdalena Biesialska Ondrej BojarMarta R Costa-jussagrave Christian Federmann YvetteGraham Roman Grundkiewicz Barry HaddowMatthias Huck Eric Joanis Tom Kocmi PhilippKoehn Chi-kiu Lo Nikola Ljubešic ChristofMonz Makoto Morishita Masaaki Nagata Toshi-aki Nakazawa Santanu Pal Matt Post and MarcosZampieri 2020 Findings of the 2020 conference onmachine translation (WMT20) In Proceedings ofthe Fifth Conference on Machine Translation pages1ndash55 Online Association for Computational Lin-guistics
Loiumlc Barrault Ondrej Bojar Marta R Costa-jussagraveChristian Federmann Mark Fishel Yvette Gra-ham Barry Haddow Matthias Huck Philipp KoehnShervin Malmasi Christof Monz Mathias MuumlllerSantanu Pal Matt Post and Marcos Zampieri 2019
Findings of the 2019 conference on machine transla-tion (WMT19) In Proceedings of the Fourth Con-ference on Machine Translation (Volume 2 SharedTask Papers Day 1) pages 1ndash61 Florence Italy As-sociation for Computational Linguistics
Lukas Biewald 2020 Experiment tracking withweights and biases Software available fromwandbcom
Yong Cheng Wei Xu Zhongjun He Wei He HuaWu Maosong Sun and Yang Liu 2016 Semi-supervised learning for neural machine translationIn Proceedings of the 54th Annual Meeting of the As-sociation for Computational Linguistics (Volume 1Long Papers) pages 1965ndash1974 Berlin GermanyAssociation for Computational Linguistics
Kyunghyun Cho Bart van Merrienboer CcedilaglarGuumllccedilehre Dzmitry Bahdanau Fethi Bougares Hol-ger Schwenk and Yoshua Bengio 2014 Learningphrase representations using RNN encoder-decoderfor statistical machine translation In Proceedings ofthe 2014 Conference on Empirical Methods in Nat-ural Language Processing EMNLP 2014 October25-29 2014 Doha Qatar A meeting of SIGDAT aSpecial Interest Group of the ACL pages 1724ndash1734ACL
Alexis Conneau Kartikay Khandelwal Naman GoyalVishrav Chaudhary Guillaume Wenzek FranciscoGuzmaacuten Edouard Grave Myle Ott Luke Zettle-moyer and Veselin Stoyanov 2019 Unsupervisedcross-lingual representation learning at scale
Jacob Devlin Ming-Wei Chang Kenton Lee andKristina Toutanova 2018 BERT pre-training ofdeep bidirectional transformers for language under-standing CoRR abs181004805
Daxiang Dong Hua Wu Wei He Dianhai Yu andHaifeng Wang 2015 Multi-task learning for mul-tiple language translation In Proceedings of the53rd Annual Meeting of the Association for Compu-tational Linguistics and the 7th International JointConference on Natural Language Processing (Vol-ume 1 Long Papers) pages 1723ndash1732 BeijingChina Association for Computational Linguistics
Bonaventure F P Dossou and Chris C Emezue 2020FFR V10 fon-french neural machine translationCoRR abs200312111
Bonaventure F P Dossou and Chris C Emezue 2021aCrowdsourced phrase-based tokenization for low-resourced neural machine translation The case offon language CoRR abs210308052
Bonaventure F P Dossou and Chris C Emezue 2021bOkwugbeacute End-to-end speech recognition for fonand igbo CoRR abs210307762
David M Eberhard Gary F Simons and CharlesD Fennig (eds) 2020 Ethnologue Languages ofthe world twenty-third edition
409
Sergey Edunov Myle Ott Michael Auli and DavidGrangier 2018 Understanding back-translation atscale CoRR abs180809381
Ignatius Ezeani Paul Rayson Ikechukwu E OnyenweChinedu Uchechukwu and Mark Hepple 2020Igbo-english machine translation An evaluationbenchmark CoRR abs200400648
Angela Fan Shruti Bhosale Holger Schwenk ZhiyiMa Ahmed El-Kishky Siddharth Goyal Man-deep Baines Onur Celebi Guillaume WenzekVishrav Chaudhary Naman Goyal Tom Birch Vi-taliy Liptchinsky Sergey Edunov Edouard GraveMichael Auli and Armand Joulin 2020 Be-yond english-centric multilingual machine transla-tion CoRR abs201011125
Thibault Feacutevry and Jason Phang 2018 Unsuper-vised sentence compression using denoising auto-encoders CoRR abs180902669
Orhan Firat Kyunghyun Cho and Yoshua Bengio2016a Multi-way multilingual neural machinetranslation with a shared attention mechanism InProceedings of the 2016 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 866ndash875 San Diego California Associationfor Computational Linguistics
Orhan Firat Baskaran Sankaran Yaser Al-onaizanFatos T Yarman Vural and Kyunghyun Cho 2016bZero-resource translation with multi-lingual neuralmachine translation In Proceedings of the 2016Conference on Empirical Methods in Natural Lan-guage Processing pages 268ndash277 Austin TexasAssociation for Computational Linguistics
forall Wilhelmina Nekoto Vukosi Marivate TshinondiwaMatsila Timi Fasubaa Tajudeen Kolawole TaiwoFagbohungbe Solomon Oluwole Akinola Sham-suddee Hassan Muhammad Salomon Kabongo Sa-lomey Osei et al 2020 Participatory research forlow-resourced machine translation A case study inafrican languages Findings of EMNLP
Naman Goyal Cynthia Gao Vishrav Chaudhary Peng-Jen Chen Guillaume Wenzek Da Ju Sanjana Kr-ishnan MarcrsquoAurelio Ranzato Francisco Guzmanand Angela Fan 2021 The flores-101 evaluationbenchmark for low-resource and multilingual ma-chine translation
Jiatao Gu Yong Wang Kyunghyun Cho and Vic-tor OK Li 2019 Improved zero-shot neural ma-chine translation via ignoring spurious correlationsIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages1258ndash1268 Florence Italy Association for Compu-tational Linguistics
Thanh-Le Ha Jan Niehues and Alexander H Waibel2016 Toward multilingual neural machine trans-lation with universal encoder and decoder CoRRabs161104798
Vu Cong Duy Hoang Philipp Koehn GholamrezaHaffari and Trevor Cohn 2018 Iterative back-translation for neural machine translation In Pro-ceedings of the 2nd Workshop on Neural MachineTranslation and Generation pages 18ndash24 Mel-bourne Australia Association for ComputationalLinguistics
Melvin Johnson Mike Schuster Quoc V Le MaximKrikun Yonghui Wu Zhifeng Chen Nikhil ThoratFernanda Vieacutegas Martin Wattenberg Greg CorradoMacduff Hughes and Jeffrey Dean 2017 Googlersquosmultilingual neural machine translation system En-abling zero-shot translation Transactions of the As-sociation for Computational Linguistics 5339ndash351
Pratik Joshi Sebastin Santy Amar Budhiraja KalikaBali and Monojit Choudhury 2020 The state andfate of linguistic diversity and inclusion in the NLPworld In Proceedings of the 58th Annual Meet-ing of the Association for Computational Linguisticspages 6282ndash6293 Online Association for Computa-tional Linguistics
Taku Kudo and John Richardson 2018 SentencePieceA simple and language independent subword tok-enizer and detokenizer for neural text processing InProceedings of the 2018 Conference on EmpiricalMethods in Natural Language Processing SystemDemonstrations pages 66ndash71 Brussels BelgiumAssociation for Computational Linguistics
Surafel Melaku Lakew Mauro Cettolo and MarcelloFederico 2018 A comparison of transformer andrecurrent neural networks on multilingual neural ma-chine translation In Proceedings of the 27th Inter-national Conference on Computational Linguisticspages 641ndash652 Santa Fe New Mexico USA Asso-ciation for Computational Linguistics
Guillaume Lample Ludovic Denoyer andMarcrsquoAurelio Ranzato 2017 Unsupervisedmachine translation using monolingual corporaonly CoRR abs171100043
Jason Lee Kyunghyun Cho and Thomas Hofmann2017 Fully Character-Level Neural Machine Trans-lation without Explicit Segmentation Transactionsof the Association for Computational Linguistics5365ndash378
Ilya Loshchilov and Frank Hutter 2017 Fixingweight decay regularization in adam CoRRabs171105101
Yichao Lu Phillip Keung Faisal Ladhak Vikas Bhard-waj Shaonan Zhang and Jason Sun 2018 A neu-ral interlingua for multilingual machine translationIn Proceedings of the Third Conference on MachineTranslation Research Papers pages 84ndash92 Brus-sels Belgium Association for Computational Lin-guistics
Laura Martinus and Jade Z Abbott 2019 A focuson neural machine translation for african languagesCoRR abs190605685
410
Graham Neubig Zi-Yi Dou Junjie Hu Paul MichelDanish Pruthi Xinyi Wang and John Wieting 2019compare-mt A tool for holistic comparison of lan-guage generation systems CoRR abs190307926
Graham Neubig and Junjie Hu 2018 Rapid adapta-tion of neural machine translation to new languagesIn Proceedings of the 2018 Conference on Empiri-cal Methods in Natural Language Processing pages875ndash880 Brussels Belgium Association for Com-putational Linguistics
Rubungo Andre Niyongabo Qu Hong Julia Kreutzerand Li Huang 2020 KINNEWS and KIRNEWSBenchmarking cross-lingual text classification forKinyarwanda and Kirundi In Proceedings ofthe 28th International Conference on Computa-tional Linguistics pages 5507ndash5521 BarcelonaSpain (Online) International Committee on Compu-tational Linguistics
Linda Nordling 2018 How decolonizationcould reshape south african science Nature554(7691)159ndash162
Evander Nyoni and Bruce A Bassett 2021 Low-resource neural machine translation for southernafrican languages CoRR abs210400366
Iroro Orife Julia Kreutzer Blessing Sibanda DanielWhitenack Kathleen Siminyu Laura MartinusJamiil Toure Ali Jade Z Abbott Vukosi Mari-vate Salomon Kabongo Musie Meressa Es-poir Murhabazi Orevaoghene Ahia Elan VanBiljon Arshath Ramkilowan Adewale AkinfaderinAlp Oumlktem Wole Akin Ghollah Kioko KevinDegila Herman Kamper Bonaventure DossouChris Emezue Kelechi Ogueji and Abdallah Bashir2020 Masakhane - machine translation for africaCoRR abs200311529
Maja Popovic 2015 chrF character n-gram F-scorefor automatic MT evaluation In Proceedings of theTenth Workshop on Statistical Machine Translationpages 392ndash395 Lisbon Portugal Association forComputational Linguistics
Matt Post 2018 A call for clarity in reporting BLEUscores In Proceedings of the Third Conference onMachine Translation Research Papers pages 186ndash191 Brussels Belgium Association for Computa-tional Linguistics
Colin Raffel Noam Shazeer Adam Roberts KatherineLee Sharan Narang Michael Matena Yanqi ZhouWei Li and Peter J Liu 2019 Exploring the limitsof transfer learning with a unified text-to-text trans-former CoRR abs191010683
Machel Reid Junjie Hu Graham Neubig and YutakaMatsuo 2021 Afromt Pretraining strategies andreproducible benchmarks for translation of 8 africanlanguages
Rico Sennrich Barry Haddow and Alexandra Birch2015 Improving neural machine translation modelswith monolingual data CoRR abs151106709
Shivachi Casper Shikali and Mokhosi Refuoe 2019Language modeling data for swahili
Aditya Siddhant Ankur Bapna Yuan Cao Orhan Fi-rat Mia Xu Chen Sneha Reddy Kudugunta NaveenArivazhagan and Yonghui Wu 2020 Lever-aging monolingual data with self-supervision formultilingual neural machine translation CoRRabs200504816
Ilya Sutskever Oriol Vinyals and Quoc V Le 2014Sequence to sequence learning with neural networksIn Proceedings of the 27th International Conferenceon Neural Information Processing Systems - Vol-ume 2 NIPSrsquo14 page 3104ndash3112 Cambridge MAUSA MIT Press
Xu Tan Jiale Chen Di He Yingce Xia Tao Qin andTie-Yan Liu 2019 Multilingual neural machinetranslation with language clustering In Proceedingsof the 2019 Conference on Empirical Methods inNatural Language Processing and the 9th Interna-tional Joint Conference on Natural Language Pro-cessing (EMNLP-IJCNLP) pages 963ndash973 HongKong China Association for Computational Lin-guistics
Joumlrg Tiedemann 2012 Parallel data tools and inter-faces in opus In Proceedings of the Eight Interna-tional Conference on Language Resources and Eval-uation (LRECrsquo12) Istanbul Turkey European Lan-guage Resources Association (ELRA)
Daniel van Niekerk Charl van Heerden Marelie DavelNeil Kleynhans Oddur Kjartansson Martin Janscheand Linne Ha 2017 Rapid development of TTS cor-pora for four South African languages In Proc In-terspeech 2017 pages 2178ndash2182 Stockholm Swe-den
Ashish Vaswani Noam Shazeer Niki Parmar JakobUszkoreit Llion Jones Aidan N Gomez LukaszKaiser and Illia Polosukhin 2017 Attention is allyou need CoRR abs170603762
Sarah Wild 2021 African languages to get more be-spoke scientific terms Nature 596(7873)469ndash470
Ronald J Williams and David Zipser 1989 A learn-ing algorithm for continually running fully recurrentneural networks Neural Computation 1(2)270ndash280
Linting Xue Noah Constant Adam Roberts Mi-hir Kale Rami Al-Rfou Aditya Siddhant AdityaBarua and Colin Raffel 2021 mT5 A massivelymultilingual pre-trained text-to-text transformer InProceedings of the 2021 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 483ndash498 Online Association for Computa-tional Linguistics
Biao Zhang Philip Williams Ivan Titov and RicoSennrich 2020 Improving massively multilingualneural machine translation and zero-shot translationCoRR abs200411867
411
Jiajun Zhang and Chengqing Zong 2016 Exploit-ing source-side monolingual data in neural machinetranslation In Proceedings of the 2016 Conferenceon Empirical Methods in Natural Language Process-ing pages 1535ndash1545 Austin Texas Associationfor Computational Linguistics
Barret Zoph Deniz Yuret Jonathan May and KevinKnight 2016 Transfer learning for low-resourceneural machine translation In Proceedings of the2016 Conference on Empirical Methods in Natu-ral Language Processing pages 1568ndash1575 AustinTexas Association for Computational Linguistics

408
In Proceedings of the 2019 Conference of the NorthAmerican Chapter of the Association for Compu-tational Linguistics Human Language Technolo-gies Volume 1 (Long and Short Papers) pages3874ndash3884 Minneapolis Minnesota Associationfor Computational Linguistics
Jesujoba Alabi Kwabena Amponsah-Kaakyire DavidAdelani and Cristina Espantildea-Bonet 2020 Mas-sive vs curated embeddings for low-resourced lan-guages the case of Yorugravebaacute and Twi In Proceed-ings of the 12th Language Resources and EvaluationConference pages 2754ndash2762 Marseille FranceEuropean Language Resources Association
Naveen Arivazhagan Ankur Bapna Orhan Firat RoeeAharoni Melvin Johnson and Wolfgang Macherey2019a The missing ingredient in zero-shot neuralmachine translation CoRR abs190307091
Naveen Arivazhagan Ankur Bapna Orhan FiratDmitry Lepikhin Melvin Johnson Maxim KrikunMia Xu Chen Yuan Cao George F Foster ColinCherry Wolfgang Macherey Zhifeng Chen andYonghui Wu 2019b Massively multilingual neuralmachine translation in the wild Findings and chal-lenges CoRR abs190705019
Mikko Aulamo Umut Sulubacak Sami Virpioja andJoumlrg Tiedemann 2020 OpusTools and parallel cor-pus diagnostics In Proceedings of The 12th Lan-guage Resources and Evaluation Conference pages3782ndash3789 European Language Resources Associ-ation
Dzmitry Bahdanau Kyunghyun Cho and Yoshua Ben-gio 2015 Neural machine translation by jointlylearning to align and translate In 3rd Inter-national Conference on Learning RepresentationsICLR 2015 San Diego CA USA May 7-9 2015Conference Track Proceedings
ST Barnes 1997 Africarsquos Ogun Old World andNew African systems of thought Indiana Univer-sity Press
Loiumlc Barrault Magdalena Biesialska Ondrej BojarMarta R Costa-jussagrave Christian Federmann YvetteGraham Roman Grundkiewicz Barry HaddowMatthias Huck Eric Joanis Tom Kocmi PhilippKoehn Chi-kiu Lo Nikola Ljubešic ChristofMonz Makoto Morishita Masaaki Nagata Toshi-aki Nakazawa Santanu Pal Matt Post and MarcosZampieri 2020 Findings of the 2020 conference onmachine translation (WMT20) In Proceedings ofthe Fifth Conference on Machine Translation pages1ndash55 Online Association for Computational Lin-guistics
Loiumlc Barrault Ondrej Bojar Marta R Costa-jussagraveChristian Federmann Mark Fishel Yvette Gra-ham Barry Haddow Matthias Huck Philipp KoehnShervin Malmasi Christof Monz Mathias MuumlllerSantanu Pal Matt Post and Marcos Zampieri 2019
Findings of the 2019 conference on machine transla-tion (WMT19) In Proceedings of the Fourth Con-ference on Machine Translation (Volume 2 SharedTask Papers Day 1) pages 1ndash61 Florence Italy As-sociation for Computational Linguistics
Lukas Biewald 2020 Experiment tracking withweights and biases Software available fromwandbcom
Yong Cheng Wei Xu Zhongjun He Wei He HuaWu Maosong Sun and Yang Liu 2016 Semi-supervised learning for neural machine translationIn Proceedings of the 54th Annual Meeting of the As-sociation for Computational Linguistics (Volume 1Long Papers) pages 1965ndash1974 Berlin GermanyAssociation for Computational Linguistics
Kyunghyun Cho Bart van Merrienboer CcedilaglarGuumllccedilehre Dzmitry Bahdanau Fethi Bougares Hol-ger Schwenk and Yoshua Bengio 2014 Learningphrase representations using RNN encoder-decoderfor statistical machine translation In Proceedings ofthe 2014 Conference on Empirical Methods in Nat-ural Language Processing EMNLP 2014 October25-29 2014 Doha Qatar A meeting of SIGDAT aSpecial Interest Group of the ACL pages 1724ndash1734ACL
Alexis Conneau Kartikay Khandelwal Naman GoyalVishrav Chaudhary Guillaume Wenzek FranciscoGuzmaacuten Edouard Grave Myle Ott Luke Zettle-moyer and Veselin Stoyanov 2019 Unsupervisedcross-lingual representation learning at scale
Jacob Devlin Ming-Wei Chang Kenton Lee andKristina Toutanova 2018 BERT pre-training ofdeep bidirectional transformers for language under-standing CoRR abs181004805
Daxiang Dong Hua Wu Wei He Dianhai Yu andHaifeng Wang 2015 Multi-task learning for mul-tiple language translation In Proceedings of the53rd Annual Meeting of the Association for Compu-tational Linguistics and the 7th International JointConference on Natural Language Processing (Vol-ume 1 Long Papers) pages 1723ndash1732 BeijingChina Association for Computational Linguistics
Bonaventure F P Dossou and Chris C Emezue 2020FFR V10 fon-french neural machine translationCoRR abs200312111
Bonaventure F P Dossou and Chris C Emezue 2021aCrowdsourced phrase-based tokenization for low-resourced neural machine translation The case offon language CoRR abs210308052
Bonaventure F P Dossou and Chris C Emezue 2021bOkwugbeacute End-to-end speech recognition for fonand igbo CoRR abs210307762
David M Eberhard Gary F Simons and CharlesD Fennig (eds) 2020 Ethnologue Languages ofthe world twenty-third edition
409
Sergey Edunov Myle Ott Michael Auli and DavidGrangier 2018 Understanding back-translation atscale CoRR abs180809381
Ignatius Ezeani Paul Rayson Ikechukwu E OnyenweChinedu Uchechukwu and Mark Hepple 2020Igbo-english machine translation An evaluationbenchmark CoRR abs200400648
Angela Fan Shruti Bhosale Holger Schwenk ZhiyiMa Ahmed El-Kishky Siddharth Goyal Man-deep Baines Onur Celebi Guillaume WenzekVishrav Chaudhary Naman Goyal Tom Birch Vi-taliy Liptchinsky Sergey Edunov Edouard GraveMichael Auli and Armand Joulin 2020 Be-yond english-centric multilingual machine transla-tion CoRR abs201011125
Thibault Feacutevry and Jason Phang 2018 Unsuper-vised sentence compression using denoising auto-encoders CoRR abs180902669
Orhan Firat Kyunghyun Cho and Yoshua Bengio2016a Multi-way multilingual neural machinetranslation with a shared attention mechanism InProceedings of the 2016 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 866ndash875 San Diego California Associationfor Computational Linguistics
Orhan Firat Baskaran Sankaran Yaser Al-onaizanFatos T Yarman Vural and Kyunghyun Cho 2016bZero-resource translation with multi-lingual neuralmachine translation In Proceedings of the 2016Conference on Empirical Methods in Natural Lan-guage Processing pages 268ndash277 Austin TexasAssociation for Computational Linguistics
forall Wilhelmina Nekoto Vukosi Marivate TshinondiwaMatsila Timi Fasubaa Tajudeen Kolawole TaiwoFagbohungbe Solomon Oluwole Akinola Sham-suddee Hassan Muhammad Salomon Kabongo Sa-lomey Osei et al 2020 Participatory research forlow-resourced machine translation A case study inafrican languages Findings of EMNLP
Naman Goyal Cynthia Gao Vishrav Chaudhary Peng-Jen Chen Guillaume Wenzek Da Ju Sanjana Kr-ishnan MarcrsquoAurelio Ranzato Francisco Guzmanand Angela Fan 2021 The flores-101 evaluationbenchmark for low-resource and multilingual ma-chine translation
Jiatao Gu Yong Wang Kyunghyun Cho and Vic-tor OK Li 2019 Improved zero-shot neural ma-chine translation via ignoring spurious correlationsIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages1258ndash1268 Florence Italy Association for Compu-tational Linguistics
Thanh-Le Ha Jan Niehues and Alexander H Waibel2016 Toward multilingual neural machine trans-lation with universal encoder and decoder CoRRabs161104798
Vu Cong Duy Hoang Philipp Koehn GholamrezaHaffari and Trevor Cohn 2018 Iterative back-translation for neural machine translation In Pro-ceedings of the 2nd Workshop on Neural MachineTranslation and Generation pages 18ndash24 Mel-bourne Australia Association for ComputationalLinguistics
Melvin Johnson Mike Schuster Quoc V Le MaximKrikun Yonghui Wu Zhifeng Chen Nikhil ThoratFernanda Vieacutegas Martin Wattenberg Greg CorradoMacduff Hughes and Jeffrey Dean 2017 Googlersquosmultilingual neural machine translation system En-abling zero-shot translation Transactions of the As-sociation for Computational Linguistics 5339ndash351
Pratik Joshi Sebastin Santy Amar Budhiraja KalikaBali and Monojit Choudhury 2020 The state andfate of linguistic diversity and inclusion in the NLPworld In Proceedings of the 58th Annual Meet-ing of the Association for Computational Linguisticspages 6282ndash6293 Online Association for Computa-tional Linguistics
Taku Kudo and John Richardson 2018 SentencePieceA simple and language independent subword tok-enizer and detokenizer for neural text processing InProceedings of the 2018 Conference on EmpiricalMethods in Natural Language Processing SystemDemonstrations pages 66ndash71 Brussels BelgiumAssociation for Computational Linguistics
Surafel Melaku Lakew Mauro Cettolo and MarcelloFederico 2018 A comparison of transformer andrecurrent neural networks on multilingual neural ma-chine translation In Proceedings of the 27th Inter-national Conference on Computational Linguisticspages 641ndash652 Santa Fe New Mexico USA Asso-ciation for Computational Linguistics
Guillaume Lample Ludovic Denoyer andMarcrsquoAurelio Ranzato 2017 Unsupervisedmachine translation using monolingual corporaonly CoRR abs171100043
Jason Lee Kyunghyun Cho and Thomas Hofmann2017 Fully Character-Level Neural Machine Trans-lation without Explicit Segmentation Transactionsof the Association for Computational Linguistics5365ndash378
Ilya Loshchilov and Frank Hutter 2017 Fixingweight decay regularization in adam CoRRabs171105101
Yichao Lu Phillip Keung Faisal Ladhak Vikas Bhard-waj Shaonan Zhang and Jason Sun 2018 A neu-ral interlingua for multilingual machine translationIn Proceedings of the Third Conference on MachineTranslation Research Papers pages 84ndash92 Brus-sels Belgium Association for Computational Lin-guistics
Laura Martinus and Jade Z Abbott 2019 A focuson neural machine translation for african languagesCoRR abs190605685
410
Graham Neubig Zi-Yi Dou Junjie Hu Paul MichelDanish Pruthi Xinyi Wang and John Wieting 2019compare-mt A tool for holistic comparison of lan-guage generation systems CoRR abs190307926
Graham Neubig and Junjie Hu 2018 Rapid adapta-tion of neural machine translation to new languagesIn Proceedings of the 2018 Conference on Empiri-cal Methods in Natural Language Processing pages875ndash880 Brussels Belgium Association for Com-putational Linguistics
Rubungo Andre Niyongabo Qu Hong Julia Kreutzerand Li Huang 2020 KINNEWS and KIRNEWSBenchmarking cross-lingual text classification forKinyarwanda and Kirundi In Proceedings ofthe 28th International Conference on Computa-tional Linguistics pages 5507ndash5521 BarcelonaSpain (Online) International Committee on Compu-tational Linguistics
Linda Nordling 2018 How decolonizationcould reshape south african science Nature554(7691)159ndash162
Evander Nyoni and Bruce A Bassett 2021 Low-resource neural machine translation for southernafrican languages CoRR abs210400366
Iroro Orife Julia Kreutzer Blessing Sibanda DanielWhitenack Kathleen Siminyu Laura MartinusJamiil Toure Ali Jade Z Abbott Vukosi Mari-vate Salomon Kabongo Musie Meressa Es-poir Murhabazi Orevaoghene Ahia Elan VanBiljon Arshath Ramkilowan Adewale AkinfaderinAlp Oumlktem Wole Akin Ghollah Kioko KevinDegila Herman Kamper Bonaventure DossouChris Emezue Kelechi Ogueji and Abdallah Bashir2020 Masakhane - machine translation for africaCoRR abs200311529
Maja Popovic 2015 chrF character n-gram F-scorefor automatic MT evaluation In Proceedings of theTenth Workshop on Statistical Machine Translationpages 392ndash395 Lisbon Portugal Association forComputational Linguistics
Matt Post 2018 A call for clarity in reporting BLEUscores In Proceedings of the Third Conference onMachine Translation Research Papers pages 186ndash191 Brussels Belgium Association for Computa-tional Linguistics
Colin Raffel Noam Shazeer Adam Roberts KatherineLee Sharan Narang Michael Matena Yanqi ZhouWei Li and Peter J Liu 2019 Exploring the limitsof transfer learning with a unified text-to-text trans-former CoRR abs191010683
Machel Reid Junjie Hu Graham Neubig and YutakaMatsuo 2021 Afromt Pretraining strategies andreproducible benchmarks for translation of 8 africanlanguages
Rico Sennrich Barry Haddow and Alexandra Birch2015 Improving neural machine translation modelswith monolingual data CoRR abs151106709
Shivachi Casper Shikali and Mokhosi Refuoe 2019Language modeling data for swahili
Aditya Siddhant Ankur Bapna Yuan Cao Orhan Fi-rat Mia Xu Chen Sneha Reddy Kudugunta NaveenArivazhagan and Yonghui Wu 2020 Lever-aging monolingual data with self-supervision formultilingual neural machine translation CoRRabs200504816
Ilya Sutskever Oriol Vinyals and Quoc V Le 2014Sequence to sequence learning with neural networksIn Proceedings of the 27th International Conferenceon Neural Information Processing Systems - Vol-ume 2 NIPSrsquo14 page 3104ndash3112 Cambridge MAUSA MIT Press
Xu Tan Jiale Chen Di He Yingce Xia Tao Qin andTie-Yan Liu 2019 Multilingual neural machinetranslation with language clustering In Proceedingsof the 2019 Conference on Empirical Methods inNatural Language Processing and the 9th Interna-tional Joint Conference on Natural Language Pro-cessing (EMNLP-IJCNLP) pages 963ndash973 HongKong China Association for Computational Lin-guistics
Joumlrg Tiedemann 2012 Parallel data tools and inter-faces in opus In Proceedings of the Eight Interna-tional Conference on Language Resources and Eval-uation (LRECrsquo12) Istanbul Turkey European Lan-guage Resources Association (ELRA)
Daniel van Niekerk Charl van Heerden Marelie DavelNeil Kleynhans Oddur Kjartansson Martin Janscheand Linne Ha 2017 Rapid development of TTS cor-pora for four South African languages In Proc In-terspeech 2017 pages 2178ndash2182 Stockholm Swe-den
Ashish Vaswani Noam Shazeer Niki Parmar JakobUszkoreit Llion Jones Aidan N Gomez LukaszKaiser and Illia Polosukhin 2017 Attention is allyou need CoRR abs170603762
Sarah Wild 2021 African languages to get more be-spoke scientific terms Nature 596(7873)469ndash470
Ronald J Williams and David Zipser 1989 A learn-ing algorithm for continually running fully recurrentneural networks Neural Computation 1(2)270ndash280
Linting Xue Noah Constant Adam Roberts Mi-hir Kale Rami Al-Rfou Aditya Siddhant AdityaBarua and Colin Raffel 2021 mT5 A massivelymultilingual pre-trained text-to-text transformer InProceedings of the 2021 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 483ndash498 Online Association for Computa-tional Linguistics
Biao Zhang Philip Williams Ivan Titov and RicoSennrich 2020 Improving massively multilingualneural machine translation and zero-shot translationCoRR abs200411867
411
Jiajun Zhang and Chengqing Zong 2016 Exploit-ing source-side monolingual data in neural machinetranslation In Proceedings of the 2016 Conferenceon Empirical Methods in Natural Language Process-ing pages 1535ndash1545 Austin Texas Associationfor Computational Linguistics
Barret Zoph Deniz Yuret Jonathan May and KevinKnight 2016 Transfer learning for low-resourceneural machine translation In Proceedings of the2016 Conference on Empirical Methods in Natu-ral Language Processing pages 1568ndash1575 AustinTexas Association for Computational Linguistics

409
Sergey Edunov Myle Ott Michael Auli and DavidGrangier 2018 Understanding back-translation atscale CoRR abs180809381
Ignatius Ezeani Paul Rayson Ikechukwu E OnyenweChinedu Uchechukwu and Mark Hepple 2020Igbo-english machine translation An evaluationbenchmark CoRR abs200400648
Angela Fan Shruti Bhosale Holger Schwenk ZhiyiMa Ahmed El-Kishky Siddharth Goyal Man-deep Baines Onur Celebi Guillaume WenzekVishrav Chaudhary Naman Goyal Tom Birch Vi-taliy Liptchinsky Sergey Edunov Edouard GraveMichael Auli and Armand Joulin 2020 Be-yond english-centric multilingual machine transla-tion CoRR abs201011125
Thibault Feacutevry and Jason Phang 2018 Unsuper-vised sentence compression using denoising auto-encoders CoRR abs180902669
Orhan Firat Kyunghyun Cho and Yoshua Bengio2016a Multi-way multilingual neural machinetranslation with a shared attention mechanism InProceedings of the 2016 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 866ndash875 San Diego California Associationfor Computational Linguistics
Orhan Firat Baskaran Sankaran Yaser Al-onaizanFatos T Yarman Vural and Kyunghyun Cho 2016bZero-resource translation with multi-lingual neuralmachine translation In Proceedings of the 2016Conference on Empirical Methods in Natural Lan-guage Processing pages 268ndash277 Austin TexasAssociation for Computational Linguistics
forall Wilhelmina Nekoto Vukosi Marivate TshinondiwaMatsila Timi Fasubaa Tajudeen Kolawole TaiwoFagbohungbe Solomon Oluwole Akinola Sham-suddee Hassan Muhammad Salomon Kabongo Sa-lomey Osei et al 2020 Participatory research forlow-resourced machine translation A case study inafrican languages Findings of EMNLP
Naman Goyal Cynthia Gao Vishrav Chaudhary Peng-Jen Chen Guillaume Wenzek Da Ju Sanjana Kr-ishnan MarcrsquoAurelio Ranzato Francisco Guzmanand Angela Fan 2021 The flores-101 evaluationbenchmark for low-resource and multilingual ma-chine translation
Jiatao Gu Yong Wang Kyunghyun Cho and Vic-tor OK Li 2019 Improved zero-shot neural ma-chine translation via ignoring spurious correlationsIn Proceedings of the 57th Annual Meeting of theAssociation for Computational Linguistics pages1258ndash1268 Florence Italy Association for Compu-tational Linguistics
Thanh-Le Ha Jan Niehues and Alexander H Waibel2016 Toward multilingual neural machine trans-lation with universal encoder and decoder CoRRabs161104798
Vu Cong Duy Hoang Philipp Koehn GholamrezaHaffari and Trevor Cohn 2018 Iterative back-translation for neural machine translation In Pro-ceedings of the 2nd Workshop on Neural MachineTranslation and Generation pages 18ndash24 Mel-bourne Australia Association for ComputationalLinguistics
Melvin Johnson Mike Schuster Quoc V Le MaximKrikun Yonghui Wu Zhifeng Chen Nikhil ThoratFernanda Vieacutegas Martin Wattenberg Greg CorradoMacduff Hughes and Jeffrey Dean 2017 Googlersquosmultilingual neural machine translation system En-abling zero-shot translation Transactions of the As-sociation for Computational Linguistics 5339ndash351
Pratik Joshi Sebastin Santy Amar Budhiraja KalikaBali and Monojit Choudhury 2020 The state andfate of linguistic diversity and inclusion in the NLPworld In Proceedings of the 58th Annual Meet-ing of the Association for Computational Linguisticspages 6282ndash6293 Online Association for Computa-tional Linguistics
Taku Kudo and John Richardson 2018 SentencePieceA simple and language independent subword tok-enizer and detokenizer for neural text processing InProceedings of the 2018 Conference on EmpiricalMethods in Natural Language Processing SystemDemonstrations pages 66ndash71 Brussels BelgiumAssociation for Computational Linguistics
Surafel Melaku Lakew Mauro Cettolo and MarcelloFederico 2018 A comparison of transformer andrecurrent neural networks on multilingual neural ma-chine translation In Proceedings of the 27th Inter-national Conference on Computational Linguisticspages 641ndash652 Santa Fe New Mexico USA Asso-ciation for Computational Linguistics
Guillaume Lample Ludovic Denoyer andMarcrsquoAurelio Ranzato 2017 Unsupervisedmachine translation using monolingual corporaonly CoRR abs171100043
Jason Lee Kyunghyun Cho and Thomas Hofmann2017 Fully Character-Level Neural Machine Trans-lation without Explicit Segmentation Transactionsof the Association for Computational Linguistics5365ndash378
Ilya Loshchilov and Frank Hutter 2017 Fixingweight decay regularization in adam CoRRabs171105101
Yichao Lu Phillip Keung Faisal Ladhak Vikas Bhard-waj Shaonan Zhang and Jason Sun 2018 A neu-ral interlingua for multilingual machine translationIn Proceedings of the Third Conference on MachineTranslation Research Papers pages 84ndash92 Brus-sels Belgium Association for Computational Lin-guistics
Laura Martinus and Jade Z Abbott 2019 A focuson neural machine translation for african languagesCoRR abs190605685
410
Graham Neubig Zi-Yi Dou Junjie Hu Paul MichelDanish Pruthi Xinyi Wang and John Wieting 2019compare-mt A tool for holistic comparison of lan-guage generation systems CoRR abs190307926
Graham Neubig and Junjie Hu 2018 Rapid adapta-tion of neural machine translation to new languagesIn Proceedings of the 2018 Conference on Empiri-cal Methods in Natural Language Processing pages875ndash880 Brussels Belgium Association for Com-putational Linguistics
Rubungo Andre Niyongabo Qu Hong Julia Kreutzerand Li Huang 2020 KINNEWS and KIRNEWSBenchmarking cross-lingual text classification forKinyarwanda and Kirundi In Proceedings ofthe 28th International Conference on Computa-tional Linguistics pages 5507ndash5521 BarcelonaSpain (Online) International Committee on Compu-tational Linguistics
Linda Nordling 2018 How decolonizationcould reshape south african science Nature554(7691)159ndash162
Evander Nyoni and Bruce A Bassett 2021 Low-resource neural machine translation for southernafrican languages CoRR abs210400366
Iroro Orife Julia Kreutzer Blessing Sibanda DanielWhitenack Kathleen Siminyu Laura MartinusJamiil Toure Ali Jade Z Abbott Vukosi Mari-vate Salomon Kabongo Musie Meressa Es-poir Murhabazi Orevaoghene Ahia Elan VanBiljon Arshath Ramkilowan Adewale AkinfaderinAlp Oumlktem Wole Akin Ghollah Kioko KevinDegila Herman Kamper Bonaventure DossouChris Emezue Kelechi Ogueji and Abdallah Bashir2020 Masakhane - machine translation for africaCoRR abs200311529
Maja Popovic 2015 chrF character n-gram F-scorefor automatic MT evaluation In Proceedings of theTenth Workshop on Statistical Machine Translationpages 392ndash395 Lisbon Portugal Association forComputational Linguistics
Matt Post 2018 A call for clarity in reporting BLEUscores In Proceedings of the Third Conference onMachine Translation Research Papers pages 186ndash191 Brussels Belgium Association for Computa-tional Linguistics
Colin Raffel Noam Shazeer Adam Roberts KatherineLee Sharan Narang Michael Matena Yanqi ZhouWei Li and Peter J Liu 2019 Exploring the limitsof transfer learning with a unified text-to-text trans-former CoRR abs191010683
Machel Reid Junjie Hu Graham Neubig and YutakaMatsuo 2021 Afromt Pretraining strategies andreproducible benchmarks for translation of 8 africanlanguages
Rico Sennrich Barry Haddow and Alexandra Birch2015 Improving neural machine translation modelswith monolingual data CoRR abs151106709
Shivachi Casper Shikali and Mokhosi Refuoe 2019Language modeling data for swahili
Aditya Siddhant Ankur Bapna Yuan Cao Orhan Fi-rat Mia Xu Chen Sneha Reddy Kudugunta NaveenArivazhagan and Yonghui Wu 2020 Lever-aging monolingual data with self-supervision formultilingual neural machine translation CoRRabs200504816
Ilya Sutskever Oriol Vinyals and Quoc V Le 2014Sequence to sequence learning with neural networksIn Proceedings of the 27th International Conferenceon Neural Information Processing Systems - Vol-ume 2 NIPSrsquo14 page 3104ndash3112 Cambridge MAUSA MIT Press
Xu Tan Jiale Chen Di He Yingce Xia Tao Qin andTie-Yan Liu 2019 Multilingual neural machinetranslation with language clustering In Proceedingsof the 2019 Conference on Empirical Methods inNatural Language Processing and the 9th Interna-tional Joint Conference on Natural Language Pro-cessing (EMNLP-IJCNLP) pages 963ndash973 HongKong China Association for Computational Lin-guistics
Joumlrg Tiedemann 2012 Parallel data tools and inter-faces in opus In Proceedings of the Eight Interna-tional Conference on Language Resources and Eval-uation (LRECrsquo12) Istanbul Turkey European Lan-guage Resources Association (ELRA)
Daniel van Niekerk Charl van Heerden Marelie DavelNeil Kleynhans Oddur Kjartansson Martin Janscheand Linne Ha 2017 Rapid development of TTS cor-pora for four South African languages In Proc In-terspeech 2017 pages 2178ndash2182 Stockholm Swe-den
Ashish Vaswani Noam Shazeer Niki Parmar JakobUszkoreit Llion Jones Aidan N Gomez LukaszKaiser and Illia Polosukhin 2017 Attention is allyou need CoRR abs170603762
Sarah Wild 2021 African languages to get more be-spoke scientific terms Nature 596(7873)469ndash470
Ronald J Williams and David Zipser 1989 A learn-ing algorithm for continually running fully recurrentneural networks Neural Computation 1(2)270ndash280
Linting Xue Noah Constant Adam Roberts Mi-hir Kale Rami Al-Rfou Aditya Siddhant AdityaBarua and Colin Raffel 2021 mT5 A massivelymultilingual pre-trained text-to-text transformer InProceedings of the 2021 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 483ndash498 Online Association for Computa-tional Linguistics
Biao Zhang Philip Williams Ivan Titov and RicoSennrich 2020 Improving massively multilingualneural machine translation and zero-shot translationCoRR abs200411867
411
Jiajun Zhang and Chengqing Zong 2016 Exploit-ing source-side monolingual data in neural machinetranslation In Proceedings of the 2016 Conferenceon Empirical Methods in Natural Language Process-ing pages 1535ndash1545 Austin Texas Associationfor Computational Linguistics
Barret Zoph Deniz Yuret Jonathan May and KevinKnight 2016 Transfer learning for low-resourceneural machine translation In Proceedings of the2016 Conference on Empirical Methods in Natu-ral Language Processing pages 1568ndash1575 AustinTexas Association for Computational Linguistics

410
Graham Neubig Zi-Yi Dou Junjie Hu Paul MichelDanish Pruthi Xinyi Wang and John Wieting 2019compare-mt A tool for holistic comparison of lan-guage generation systems CoRR abs190307926
Graham Neubig and Junjie Hu 2018 Rapid adapta-tion of neural machine translation to new languagesIn Proceedings of the 2018 Conference on Empiri-cal Methods in Natural Language Processing pages875ndash880 Brussels Belgium Association for Com-putational Linguistics
Rubungo Andre Niyongabo Qu Hong Julia Kreutzerand Li Huang 2020 KINNEWS and KIRNEWSBenchmarking cross-lingual text classification forKinyarwanda and Kirundi In Proceedings ofthe 28th International Conference on Computa-tional Linguistics pages 5507ndash5521 BarcelonaSpain (Online) International Committee on Compu-tational Linguistics
Linda Nordling 2018 How decolonizationcould reshape south african science Nature554(7691)159ndash162
Evander Nyoni and Bruce A Bassett 2021 Low-resource neural machine translation for southernafrican languages CoRR abs210400366
Iroro Orife Julia Kreutzer Blessing Sibanda DanielWhitenack Kathleen Siminyu Laura MartinusJamiil Toure Ali Jade Z Abbott Vukosi Mari-vate Salomon Kabongo Musie Meressa Es-poir Murhabazi Orevaoghene Ahia Elan VanBiljon Arshath Ramkilowan Adewale AkinfaderinAlp Oumlktem Wole Akin Ghollah Kioko KevinDegila Herman Kamper Bonaventure DossouChris Emezue Kelechi Ogueji and Abdallah Bashir2020 Masakhane - machine translation for africaCoRR abs200311529
Maja Popovic 2015 chrF character n-gram F-scorefor automatic MT evaluation In Proceedings of theTenth Workshop on Statistical Machine Translationpages 392ndash395 Lisbon Portugal Association forComputational Linguistics
Matt Post 2018 A call for clarity in reporting BLEUscores In Proceedings of the Third Conference onMachine Translation Research Papers pages 186ndash191 Brussels Belgium Association for Computa-tional Linguistics
Colin Raffel Noam Shazeer Adam Roberts KatherineLee Sharan Narang Michael Matena Yanqi ZhouWei Li and Peter J Liu 2019 Exploring the limitsof transfer learning with a unified text-to-text trans-former CoRR abs191010683
Machel Reid Junjie Hu Graham Neubig and YutakaMatsuo 2021 Afromt Pretraining strategies andreproducible benchmarks for translation of 8 africanlanguages
Rico Sennrich Barry Haddow and Alexandra Birch2015 Improving neural machine translation modelswith monolingual data CoRR abs151106709
Shivachi Casper Shikali and Mokhosi Refuoe 2019Language modeling data for swahili
Aditya Siddhant Ankur Bapna Yuan Cao Orhan Fi-rat Mia Xu Chen Sneha Reddy Kudugunta NaveenArivazhagan and Yonghui Wu 2020 Lever-aging monolingual data with self-supervision formultilingual neural machine translation CoRRabs200504816
Ilya Sutskever Oriol Vinyals and Quoc V Le 2014Sequence to sequence learning with neural networksIn Proceedings of the 27th International Conferenceon Neural Information Processing Systems - Vol-ume 2 NIPSrsquo14 page 3104ndash3112 Cambridge MAUSA MIT Press
Xu Tan Jiale Chen Di He Yingce Xia Tao Qin andTie-Yan Liu 2019 Multilingual neural machinetranslation with language clustering In Proceedingsof the 2019 Conference on Empirical Methods inNatural Language Processing and the 9th Interna-tional Joint Conference on Natural Language Pro-cessing (EMNLP-IJCNLP) pages 963ndash973 HongKong China Association for Computational Lin-guistics
Joumlrg Tiedemann 2012 Parallel data tools and inter-faces in opus In Proceedings of the Eight Interna-tional Conference on Language Resources and Eval-uation (LRECrsquo12) Istanbul Turkey European Lan-guage Resources Association (ELRA)
Daniel van Niekerk Charl van Heerden Marelie DavelNeil Kleynhans Oddur Kjartansson Martin Janscheand Linne Ha 2017 Rapid development of TTS cor-pora for four South African languages In Proc In-terspeech 2017 pages 2178ndash2182 Stockholm Swe-den
Ashish Vaswani Noam Shazeer Niki Parmar JakobUszkoreit Llion Jones Aidan N Gomez LukaszKaiser and Illia Polosukhin 2017 Attention is allyou need CoRR abs170603762
Sarah Wild 2021 African languages to get more be-spoke scientific terms Nature 596(7873)469ndash470
Ronald J Williams and David Zipser 1989 A learn-ing algorithm for continually running fully recurrentneural networks Neural Computation 1(2)270ndash280
Linting Xue Noah Constant Adam Roberts Mi-hir Kale Rami Al-Rfou Aditya Siddhant AdityaBarua and Colin Raffel 2021 mT5 A massivelymultilingual pre-trained text-to-text transformer InProceedings of the 2021 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics Human Language Technologiespages 483ndash498 Online Association for Computa-tional Linguistics
Biao Zhang Philip Williams Ivan Titov and RicoSennrich 2020 Improving massively multilingualneural machine translation and zero-shot translationCoRR abs200411867
411
Jiajun Zhang and Chengqing Zong 2016 Exploit-ing source-side monolingual data in neural machinetranslation In Proceedings of the 2016 Conferenceon Empirical Methods in Natural Language Process-ing pages 1535ndash1545 Austin Texas Associationfor Computational Linguistics
Barret Zoph Deniz Yuret Jonathan May and KevinKnight 2016 Transfer learning for low-resourceneural machine translation In Proceedings of the2016 Conference on Empirical Methods in Natu-ral Language Processing pages 1568ndash1575 AustinTexas Association for Computational Linguistics

411
Jiajun Zhang and Chengqing Zong 2016 Exploit-ing source-side monolingual data in neural machinetranslation In Proceedings of the 2016 Conferenceon Empirical Methods in Natural Language Process-ing pages 1535ndash1545 Austin Texas Associationfor Computational Linguistics
Barret Zoph Deniz Yuret Jonathan May and KevinKnight 2016 Transfer learning for low-resourceneural machine translation In Proceedings of the2016 Conference on Empirical Methods in Natu-ral Language Processing pages 1568ndash1575 AustinTexas Association for Computational Linguistics
Copyright © 2022 FDOKUMEN




















