
LSDSem 2017 2nd Workshop on Linking Models of Lexical ...
105
LSDSem 2017 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics Proceedings of the Workshop April 3, 2017 Valencia, Spain
-
Upload
khangminh22 -
Category
Documents
-
view
3 -
download
0
Transcript of LSDSem 2017 2nd Workshop on Linking Models of Lexical ...

LSDSem 2017
2nd Workshop on Linking Models ofLexical, Sentential and Discourse-level Semantics
Proceedings of the Workshop
April 3, 2017Valencia, Spain

c©2017 The Association for Computational Linguistics
Order copies of this and other ACL proceedings from:
Association for Computational Linguistics (ACL)209 N. Eighth StreetStroudsburg, PA 18360USATel: +1-570-476-8006Fax: [email protected]
ISBN 978-1-945626-40-1
ii

Introduction
Welcome to the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics.
This workshop takes place for the second time, with the goal of gathering and showcasing theoreticaland computational approaches to joint models of semantics, and applications that incorporate multi-levelsemantics. Improved computational models of semantics hold great promise for applications in languagetechnology, be it semantics at the lexical level, sentence level or discourse level. This year we have anadditional focus on the comprehensive understanding of narrative structure in language. Recently a rangeof tasks have been proposed in the area of learning and applying commonsense/procedural knowledge.Such tasks include, for example, learning prototypical event sequences and event participants, modelingthe plot structure of novels, and resolving anaphora in Winograd schemas.
This year’s workshop further includes a shared task, the Story Cloze Test–a new evaluation for storyunderstanding and script learning. This test provides a system with a four-sentence story and twopossible endings, and the system must choose the correct ending to the story. Successful narrativeunderstanding (getting closer to human performance of 100%) requires systems to link various levelsof semantics to commonsense knowledge. A total of eight systems participated in the shared task,with a variety of approaches including end-to-end neural networks, feature-based regression models,and rule-based methods. The highest performing system achieves an accuracy of 75.2%, a substantialimprovement over the previous state-of-the-art of 58.5%.
We received 19 papers in total, out of which we accepted 13. These papers are presented as talks atthe workshop as well as in a poster session. In addition, the workshop program features talks fromtwo invited speakers who work on different aspects of semantics. The day will end with a discussionsession where invited speakers and workshop participants further discuss the insights gained during theworkshop.
Our program committee consisted of 23 researchers who provided constructive and thoughtful reviews.This workshop would not have been possible without their hard work. Many thanks to you all. Finally,a huge thank you to all the authors who submitted papers to this workshop and made it a big success.
Michael, Nasrin, Nate, and Annie
iii


Organizers:
Michael Roth, University of Illinois and Saarland UniversityNasrin Mostafazadeh, University of RochesterNate Chambers, United States Naval AcademyAnnie Louis, University of Essex
Program Committee:
Omri Abend, The Hebrew University of JerusalemTim Baldwin, University of MelbourneJohan Bos, University of GroningenIdo Dagan, Bar Ilan UniversityVera Demberg, Saarland UniversityKatrin Erk, University of Texas at AustinAnette Frank, Heidelberg UniversityAurelie Herbelot, University of TrentoGraeme Hirst, University of TorontoSebastian Martschat, Heidelberg UniversityPhilippe Muller, Toulouse UniversityBeata Beigman Klebanov, Educational Testing ServiceHwee Tou Ng, National University of SingaporeVincent Ng, University of Texas at DallasJan Snajder, University of ZagrebSwapna Somasundaran, Educational Testing ServiceCaroline Sporleder, Göttingen UniversityChristian Stab, Technische Universität DarmstadtManfred Stede, University of PotsdamJoel Tetreault, GrammarlyLucy Vanderwende, Microsoft ResearchLuke Zettlemoyer, University of WashingtonHeike Zinsmeister, Universität Hamburg
Invited Speakers:
Johan Bos, University of GroningenHannah Rohde, University of Edinburgh
v


Table of Contents
Inducing Script Structure from Crowdsourced Event Descriptions via Semi-Supervised ClusteringLilian Wanzare, Alessandra Zarcone, Stefan Thater and Manfred Pinkal . . . . . . . . . . . . . . . . . . . . . . . 1
A Consolidated Open Knowledge Representation for Multiple TextsRachel Wities, Vered Shwartz, Gabriel Stanovsky, Meni Adler, Ori Shapira, Shyam Upadhyay, Dan
Roth, Eugenio Martínez-Cámara, Iryna Gurevych and Ido Dagan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
Event-Related Features in Feedforward Neural Networks Contribute to Identifying Causal Relations inDiscourse
Edoardo Maria Ponti and Anna Korhonen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
Stance Detection in Facebook Posts of a German Right-wing PartyManfred Klenner, Don Tuggener and Simon Clematide . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
Behind the Scenes of an Evolving Event Cloze TestNathanael Chambers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
LSDSem 2017 Shared Task: The Story Cloze TestNasrin Mostafazadeh, Michael Roth, Annie Louis, Nathanael Chambers and James Allen . . . . . . 46
Story Cloze Task: UW NLP SystemRoy Schwartz, Maarten Sap, Ioannis Konstas, Leila Zilles, Yejin Choi and Noah A. Smith . . . . . 52
LSDSem 2017: Exploring Data Generation Methods for the Story Cloze TestMichael Bugert, Yevgeniy Puzikov, Andreas Rücklé, Judith Eckle-Kohler, Teresa Martin, Eugenio
Martínez-Cámara, Daniil Sorokin, Maxime Peyrard and Iryna Gurevych . . . . . . . . . . . . . . . . . . . . . . . . . . 56
Sentiment Analysis and Lexical Cohesion for the Story Cloze TaskMichael Flor and Swapna Somasundaran . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
Resource-Lean Modeling of Coherence in Commonsense StoriesNiko Schenk and Christian Chiarcos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
An RNN-based Binary Classifier for the Story Cloze TestMelissa Roemmele, Sosuke Kobayashi, Naoya Inoue and Andrew Gordon . . . . . . . . . . . . . . . . . . . . 74
IIT (BHU): System Description for LSDSem’17 Shared TaskPranav Goel and Anil Kumar Singh . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
Story Cloze Ending Selection Baselines and Data ExaminationTodor Mihaylov and Anette Frank . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
vii


Conference Program
Monday, April 3, 2017
09:30–11:00 Morning Session
9:30–9:40 IntroductionMichael Roth
9:40–10:40 Invited talk: Integrating Lexical and Discourse Semantics in the Parallel MeaningBankJohan Bos
10:40–11:00 Inducing Script Structure from Crowdsourced Event Descriptions via Semi-Supervised ClusteringLilian Wanzare, Alessandra Zarcone, Stefan Thater and Manfred Pinkal
11:00–11:30 Coffee break
11:30–12:40 Pre-lunch Session
11:30–11:50 A Consolidated Open Knowledge Representation for Multiple TextsRachel Wities, Vered Shwartz, Gabriel Stanovsky, Meni Adler, Ori Shapira, ShyamUpadhyay, Dan Roth, Eugenio Martínez-Cámara, Iryna Gurevych and Ido Dagan
11:50–12:05 Event-Related Features in Feedforward Neural Networks Contribute to IdentifyingCausal Relations in DiscourseEdoardo Maria Ponti and Anna Korhonen
12:05–12:25 Stance Detection in Facebook Posts of a German Right-wing PartyManfred Klenner, Don Tuggener and Simon Clematide
12:25–12:40 Behind the Scenes of an Evolving Event Cloze TestNathanael Chambers
12:40–14:30 Lunch Break
ix

Monday, April 3, 2017 (continued)
14:30–15:30 Post-lunch Session
14:30–14:45 LSDSem 2017 Shared Task: The Story Cloze TestNasrin Mostafazadeh, Michael Roth, Annie Louis, Nathanael Chambers and JamesAllen
14:45–15:00 Story Cloze Task: UW NLP SystemRoy Schwartz, Maarten Sap, Ioannis Konstas, Leila Zilles, Yejin Choi and Noah A.Smith
15:00–15:15 LSDSem 2017: Exploring Data Generation Methods for the Story Cloze TestMichael Bugert, Yevgeniy Puzikov, Andreas Rücklé, Judith Eckle-Kohler, TeresaMartin, Eugenio Martínez-Cámara, Daniil Sorokin, Maxime Peyrard and IrynaGurevych
15:15–15:30 Sentiment Analysis and Lexical Cohesion for the Story Cloze TaskMichael Flor and Swapna Somasundaran
15:30–16:30 Poster Session (all papers)
15:30–16:30 Resource-Lean Modeling of Coherence in Commonsense StoriesNiko Schenk and Christian Chiarcos
15:30–16:30 An RNN-based Binary Classifier for the Story Cloze TestMelissa Roemmele, Sosuke Kobayashi, Naoya Inoue and Andrew Gordon
15:30–16:30 IIT (BHU): System Description for LSDSem’17 Shared TaskPranav Goel and Anil Kumar Singh
15:30–16:30 Story Cloze Ending Selection Baselines and Data ExaminationTodor Mihaylov and Anette Frank
16:00–16:30 Coffee Break
x

Monday, April 3, 2017 (continued)
16:30–18:00 Afternoon Session
16:30–17:30 Invited talk: Using Story Continuations to Model Discourse ExpectationsHannah Rohde
17:30–18:00 Open Discussion
xi


Proceedings of the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics, pages 1–11,Valencia, Spain, April 3, 2017. c©2017 Association for Computational Linguistics
Inducing Script Structure from Crowdsourced Event Descriptionsvia Semi-Supervised Clustering
Lilian D. A. Wanzare Alessandra Zarcone Stefan Thater Manfred PinkalUniversitat des SaarlandesSaarland, 66123, Germany
{wanzare,zarcone,stth,pinkal}coli.uni-saarland.de
Abstract
We present a semi-supervised clusteringapproach to induce script structure fromcrowdsourced descriptions of event se-quences by grouping event descriptionsinto paraphrase sets (representing eventtypes) and inducing their temporal order.Our model exploits semantic and posi-tional similarity and allows for flexibleevent order, thus overcoming the rigidityof previous approaches. We incorporatecrowdsourced alignments as prior knowl-edge and show that exploiting a smallnumber of alignments results in a substan-tial improvement in cluster quality overstate-of-the-art models and provides an ap-propriate basis for the induction of tempo-ral order. We also show a coverage studyto demonstrate the scalability of our ap-proach.
1 Introduction
During their daily social interactions, people makeseamless use of knowledge about standardizedevent sequences (scripts) describing types of ev-eryday activities, or scenarios, such as GOING TO
THE RESTAURANT or BAKING A CAKE (Schankand Abelson, 1977; Barr and Feigenbaum, 1981).Script knowledge is often triggered by the broaderdiscourse context and guides expectations in textunderstanding and makes missing events and ref-erents in a discourse accessible. For example, ifwe hear someone say “I baked a cake on Sunday.I decorated it with buttercream icing!”, our scriptknowledge allows us to infer that the speaker musthave mixed the ingredients, turned on the oven,etc., even if these events are not explicitly men-tioned. Script knowledge is relevant for the com-putational modeling of various kinds of cogni-
tive abilities and has the potential to support NLPtasks such as anaphora resolution (Rahman andNg, 2011), discourse relation detection, semanticrole labeling, temporal order analysis, and appli-cations such as text understanding (Cullingford,1977; Mueller, 2004), information extraction (Rauet al., 1989), question answering (Hajishirzi andMueller, 2012).
Several methods for the automatic acquisitionof script knowledge have been proposed. Semi-nal work by Chambers and Jurafsky (2008; 2009)provided methods for the unsupervised wide-coverage extraction of script knowledge fromlarge text corpora. However, texts typicallyonly mention small parts of a script, banking onthe reader’s ability to infer missing script-relatedevents. The task is therefore challenging, and theresults are quite noisy.
The work presented in this paper follows the ap-proach proposed in Regneri et al. (2010) (hence-forth “RKP”) who crowdsourced scenario de-scriptions by asking people how they typicallycarry out a particular activity. The collectedevent sequence descriptions provide generic de-scriptions of a given scenario (e.g. BAKING A
CAKE) in concise telegram style (Fig. 1a). Basedon these crowdsourced event sequence descrip-tions or ESDs, RKP extracted high-quality scriptknowledge for a variety of different scenarios, inthe form of temporal script graphs (Fig. 1b). Tem-poral script graphs are partially ordered structureswhose nodes are sets of alternative descriptionsdenoting the same event type, and whose edges ex-press temporal precedence.
While RKP employ Multiple Sequence Align-ment (MSA) (Durbin et al., 1998), we use a semi-supervised clustering approach for script struc-ture induction. The choice of MSA was motivatedby the effect of positional information on the de-tection of scenario-specific paraphrases: event de-
1

Purchase cake mixPreheat ovenGrease panCarefully follow instructions step by stepOpen mix and add required ingredientsMix wellPour into prepared panSet timer on oven Bake cake for required timeRemove cake from oven and cool Turn cake out onto cake plateApply icing or glaze
Take out box of cake mix from shelfGather together cake ingredientsGet mixing bowl, or spoon or forkAdd ingredients to bowlStir together and mixUse fork to breakup clumpsPreheat ovenSpray pan with non stick or greasePour cake mix into panPut pan into ovenBake cakeRemove cake pan when timer goes offStick tooth pick into cake to see if done Let cake pan cool then remove cake
(a)
chooserecipe
buyingred.
addingred.
prepareingred.
put cakeinto oven
getingred.
– look up recipe– find cake recipe– get your recipe
– take out box of ingredients from shelf
– gather all cake ingredients
– get cake mix
– purchase ingredients– buy cake mix– buy proper
ingredients
– place cake into oven– put cake in oven
– stir to combine– mix well– mix ingredients
together in bowls– stir cake ingredients
– pour cake mix in bowl– add ingredients to bowl– add cake ingredients
(b)
Figure 1: Example ESDs (a) and induced scriptstructure (b) for the BAKING A CAKE scenariofrom Wanzare et al. (2016)
scriptions occurring in similar positions in ESDstend to denote the same event type. However,MSA makes far too strong an assumption aboutthe temporal ordering information in the ESDs. Itdoes not allow for crossing edges and thus mustassume a fixed and invariable order, while the or-dering of events in a script is to some degree flex-ible (e.g., one can preheat the oven before or aftermixing ingredients). We propose clustering as analternative method to overcome the rigidity of theMSA approach, and use a distance measure basedon both semantic similarity and positional similar-ity information, making our clustering algorithmsensitive to ordering information, while allowingfor order variation in the scripts.
Clustering accuracy depends on the reliabil-ity of similarity estimates, but scenario-specificparaphrase relations are often based on scenario-specific functional equivalence, which cannot beeasily determined using semantic similarity, evenif complemented with positional information. Forexample in the FLYING IN AN AIRPLANE sce-nario, it is challenging for any semantic simi-larity measure to predict that walk up the rampand board plane refer to the same event, as thebroader discourse context would suggest. To ad-dress this issue, we propose a semi-supervised ap-proach, capitalizing on previous work by Klein et
al. (2002). Semi-supervised approaches to cluster-ing have shown that performance can be enhancedby incorporating prior knowledge in the form ofa small number of instance-level constraints. Weautomatically identify event descriptions that arelikely to cause alignment problems (called out-liers), crowdsource alignments for these items andincorporate them as instance-level relational seedsinto the clustering process.
Lastly, a main concern with the approach inRKP is scalability: temporal script graphs are cre-ated scenario-wise in a bottom-up fashion. Theyrepresent only fragments of the rich amount ofscript knowledge people use in everyday commu-nication. In this paper we address this concernwith the first assessment of the coverage of exist-ing script resources, and an estimate of the con-crete costs for their extension.
2 Data
We will now introduce the resources used in ourstudy, namely the datasets of ESDs, the gold stan-dards and the crowdsourced alignments betweenevent descriptions.
Datasets and gold standards. Three largecrowdsourced collections of activity descriptionsin terms of ESDs are available: the OMICS cor-pus (Gupta and Kochenderfer, 2004), the SMILEcorpus (Regneri et al., 2010) and DeScript corpus(Wanzare et al., 2016). Sections 3-4 of this paperfocus on a subset of ESDs for 14 scenarios fromSMILE and OMICS, with on average 29.9 ESDsper scenario. In RKP, in the follow-up studies byFrermann et al. (2014) and Modi and Titov (2014)as well as in the present study, 4 of these scenarioswere used as development set and 10 as test set.
RKP provided two gold standard datasets forthis subset: the RKP paraphrase dataset containsjudgments for 60 event description pairs per sce-nario, the RKP temporal order dataset contains60 event description pairs that are separately an-notated in both directions, for a total of 120 dat-apoints per scenario. In order to directly evalu-ate our models for clustering quality, we also cre-ated a clustering gold standard for the RKP testset, adopting the experimental setup in Wanzareet al. (2016): we asked three trained students ofcomputational linguistics to annotate the scenarioswith gold standard alignments between event de-scriptions in different ESDs referring to the same
2

event1. Every ESD was fully aligned with ev-ery other ESD in the same scenario. Based onthe alignments, we derived gold clusters by group-ing the event descriptions into gold paraphrase sets(17 clusters per scenario on average, ranging from10 to 23).
In addition, we used a subset of 10 scenarioswith 25 ESDs each from DeScript, for which Wan-zare et al. (2016) provided gold clusters, to evalu-ate our models and to demonstrate that our methodis independent of the specific choice of scenarios.
Crowdsourced alignments. To provide seeddata for the semi-supervised clustering algorithm,we crowdsourced alignments between event de-scriptions, following the procedure in Wanzare etal. (2016). First, we identified challenging casesof event descriptions (called outliers), which weexpected to be particularly informative and helpimprove clustering accuracy. To this purpose, an(unsupervised) clustering system (Affinity Propa-gation, see below) was run with varying parametersettings. Those event descriptions whose nearestneighbors changed clusters across different runsof the system were then identified as outliers (seeWanzare et al. (2016) for more details). A comple-mentary type of seed data was obtained by select-ing event descriptions that did not change clustermembership at all (called stable cases).
In a second step, groups of selected descriptions(outliers and stable cases) in their original ESDwere presented to workers in a Mechanical Turkexperiment, paired with a target ESD. The work-ers were asked to select a description in the tar-get ESD denoting the same script event (e.g. forBAKING A CAKE: pour into prepared pan→ pourcake mix into pan). We aimed at collecting twosets of high-quality seeds based on outliers andstable cases, respectively, each summing up to 3%of the links required for a total alignment betweenall pairs of scenario-specific ESDs (6% links in to-tal). To guarantee high quality, we accepted onlyitems where three (out of up to four) annotatorsagree. We checked the annotators’ reliability bycomparing their aligments for stable cases againstthe gold standard and rejected the work on 3% ofthe annotators.
We collected alignments for 20 scenarios: forthe test scenarios of the SMILE+OMICS dataset,and for those in the clustering gold standard of De-
1This annotation was rather costly, so each scenario wasaligned by one annotator only.
Script. For the latter, a collection of alignmentdata was already available, but considerably dif-fered in size between scenarios and was in generalto small for our purposes.
3 Model
We first present a semi-supervised clusteringmethod to induce script events from ESDs usingcrowdsourced alignments as seeds (Section 3.1).In Section 3.2, we describe how we calculate theunderlying distance matrix based on semantic andpositional similarity information. In Section 3.3,we describe the induction of temporal order for thescript events, which turns the set of script eventsinto a temporal script graph (TSG).
3.1 Semi-supervised Clustering
We use the crowdsourced alignments betweenevent descriptions as instance-level relationalseeds for clustering, more specifically as must-linkconstraints, requiring that the linked items shouldgo into one cluster. We incorporate the constraintsinto the clustering process following the method inKlein et al. (2002): that is adapting the input dis-tance matrix in a pre-processing step, rather thandirectly integrating the constraints into the cluster-ing algorithm. This makes it possible to try dif-ferent adaptation strategies, independently of thespecific clustering algorithm, and the adapted ma-trices can be straightforwardly combined with theclustering algorithm of choice. Klein et al. (2002)handle must-link constraints by modifying the in-put matrix D in the following way: if two in-stances i and j are linked by a must-link con-straint, then the corresponding entry Di,j is setto zero, which forces i and j to be grouped intothe same cluster by the underlying clustering algo-rithm. In addition, distance scores for instances inthe neighborhood of i or j are affected: if the dis-tance is reduced for one pair of instances, triangle-inequality may be violated. An all-pairs-shortest-path algorithm propagates must-link constraints toother instances in D that restores triangle inequal-ity.
We use a modified version of this approach.First, as the crowdsourced information may notbe completely reliable, the clustering algorithmshould be able to override it. We thus do not setDi,j to zero but rather to a small constant valued, that is the smallest non-identity distance valueoccurring in the matrix. Second, we exploit the
3

inherent transitivity of paraphrase judgments toderive additional constraints: if (i, j) and (j, k)are must links, we assume the pair (i, k) to be amust link as well, and set the distance to d. Afterthe additional constraints are derived, the all-pairs-shortest-path algorithm is applied to the input ma-trix as in Klein et al. (2002).
We experimented with various state-of-art clus-tering algorithms including Spectral Clusteringand Affinity Propagation (AP). The results pre-sented in section 4 are based on AP, which provedto be most stable and provided the best results.
Determining the number of event-clusters.AP uses a parameter p, which influences the clus-ter granularity without determining the exact num-ber of clusters beforehand. There is considerablevariation between the optimal number of clustersbetween scenarios, depending on how many eventtypes are required to describe the respective activ-ity patterns (see Section 2). We use an unsuper-vised method for estimating scenario-specific set-tings of p, using the mean Silhouette Coefficient(Rousseeuw, 1987). This measure balances op-timal inter-cluster tightness and intra-cluster dis-tance, making sure that the elements of each clus-ter are as similar as possible to each other, and asdissimilar as possible to the elements of all otherclusters. We run the unsupervised AP algorithmfor each scenario with different settings of p andselect the number resulting in the highest total Sil-houette Coefficient as the optimal value for p.
3.2 Similarity Features
We now describe how we combine semantic andpositional similarity information to obtain the dis-tance measure that captures the similarities be-tween event descriptions.
3.2.1 Semantic SimilarityWe inspect different models for word-level sim-ilarity, as well as methods of deriving phrase-level semantic similarity from word-level similar-ity. We use pre-trained Word2Vec (w2v) wordvectors (Mikolov et al., 2013) and vector repre-sentations (rNN) by Tilk et al. (2016) to obtainword-level similarity information. The rNN vec-tors are obtained from a neural network trained onlarge amounts of automatically role-labeled textand capture different aspects of word-level simi-larity than the w2v representations. We also exper-imented with WordNet/Lin similarity (Lin, 1998),
but an ablation test (see below) showed that it wasnot useful.
To derive phrase-level similarity from word-level similarity, we employ the following three dif-ferent empirically informed methods:
Centroid-based similarity. This method de-rives a phrase-level vector for an event descriptionby taking the centroid over the word vectors of allcontent words in the event description. Similarityis computed using cosine.
Alignment-based similarity. Following RKP,we compute a similarity score for a pair of eventdescriptions by a linear combination of (a) thesimilarity of the head verbs of the two event de-scriptions and (b) the total score of the align-ments between all noun phrases in the two descrip-tions, as computed by the Hungarian algorithm(Papadimitriou and Steiglitz, 1982).
Vocabulary similarity. We use the approachin Fernando and Stevenson (2008) to detectparaphrases and calculate semantic similaritiesbetween two event descriptions p1 and p2 as:
simvocab(~p1, ~p2) =~p1W ~p2
T
|~p1| |~p2| (1)
where W is an n × n matrix that holds thesimilarities between all the words (vocabulary)in the two event descriptions being compared, nbeing the length of the vocabulary, and −→p1 and −→p2
are binary vectors representing the presence orabsence of the words in the vocabulary.
Combining these three methods with the threeword-level similarity measures we obtained a totalof 8 different features2.
3.2.2 Positional Similarity FeatureIn addition to the semantic similarity features de-scribed above, we also used information about theposition in which an event description occurs inan ESD. The basic idea here is that similar eventdescriptions tend to occur in similar (relative) po-sitions in the ESDs. We set:
simpos(n1, n2) = 1− abs
(n1
T1− n2
T2
)(2)
where n1and n2 are the positions of the two eventdescription and T1 and T2 represent the total num-ber of event descriptions in the respective ESDs.
2The centroid method can not be combined with Lin sim-ilarity.
4

3.2.3 Combination
We linearly combine our 9 similarity features intoa single similarity score, where the weights of theindividual features are determined using logisticregression trained (10-fold cross validation) on theparaphrases from the 4 scenarios in the RKP de-velopment set (see Section 2). We run an ablationtest by considering all possible subsets of featuresand using the 10 scenarios in the RKP test set, andfound that the combination of the following fivefeatures performed best:
• centroid-based, alignment-based and vocabu-lary similarity with w2v vectors
• centroid-based similarity with rNN vectors
• position similarity
3.3 Temporal Script Graphs
After clustering the event descriptions of agiven scenario into sets representing the scenario-specific event-types, we build a Temporal ScriptGraph (TSG) by determining the prototypical or-der between them. The nodes of the graph arethe event types (clusters); an edge from a clus-ter E to a cluster E′ indicates that E typicallyprecedes E′. We induce the edges as follows.We say that an ESD supports E → E′ if thereare event descriptions e ∈ E and e′ ∈ E′ suchthat e precedes e′ in the ESD. In a first step, weadd an edge E → E′ to the graph if there aremore ESDs that support E → E′ than E′ → E.In a second step, we compute transitive closure,i.e. we infer an edge E → E′ in cases wherethere are clusters E,E′, E′′ such that E → E′′
and E′′ → E′. Finally, we form “arbitrary or-der” equivalence classes from those pairs of eventclusters which have an equal number of supportingESDs in either direction and are not yet connectedby a directed temporal precedence edge.
This is an extension of the concept of a temporalscript graph used in RKP, in order to allow for theflexible event order assumed by our approach. Forexample, the event descrpitions preheat the ovenand mixing ingredients from the BAKING A CAKE
scenario are likely to occur in different clusters,which are members of the same equivalence class,expressing that the event descriptions are not para-phrases, but may occur in any order.
4 Evaluation
4.1 Experimental Setup
We applied different versions of our clustering al-gorithm to the SMILE+OMICS dataset. In partic-ular, we explored the influence of positional sim-ilarity, of the number of seeds (from 0 to 3%), aswell as the proportion of the two seed types (out-lier vs. stable). As a baseline, we ran the unsu-pervised clustering algorithm based on semanticsimilarity only. We evaluated the models on thetasks of event-type induction, paraphrase detec-tion, and temporal order prediction, using the re-spective gold standard datasets (see Section 2).
Cluster quality. First, we evaluated the qualityof the induced event types (i.e. sets of event de-scriptions) against the SMILE+OMICS gold clus-ters. We used the B-Cubed metric (Bagga andBaldwin, 1998), which is calculated by averagingper-element precision and recall scores. Amigoet al. (2009) showed B-Cubed to be the metricthat appropriately captures all aspects of measur-ing cluster quality.
Paraphrase detection. For direct comparisonwith previous work, we tested our model on RKP’sbinary paraphrase detection task. The model clas-sifies two event descriptions as paraphrases if theyend up in the same cluster. We computed standardprecision, recall and F-score by checking our clas-sification against the RKP paraphrase dataset.
Temporal order prediction. We tested the qual-ity of the temporal-order relation of the inducedTSG structures using the RKP temporal orderdataset as follows. For a pair of event descriptions(e, e′), we assume that (1) e precedes e′, but notthe other way round, if e ∈ E and e′ ∈ E′ for twodifferent clusters E and E′ such that E → E′. (2)e precedes e′ and vice versa (that is, both event or-derings are possible), if e ∈ E and e′ ∈ E′, and Eand E′ are different clusters, but part of the sameequivalence set. In all other cases (i.e. if e and e′
are members of the same cluster), we assume thatprecedence does not hold. We computed standardprecision, recall and F-score by checking our clas-sification against the RKP temporal order dataset.
4.2 Results
The main results of our evaluation are shown inTable 1. The last three rows show results for
5
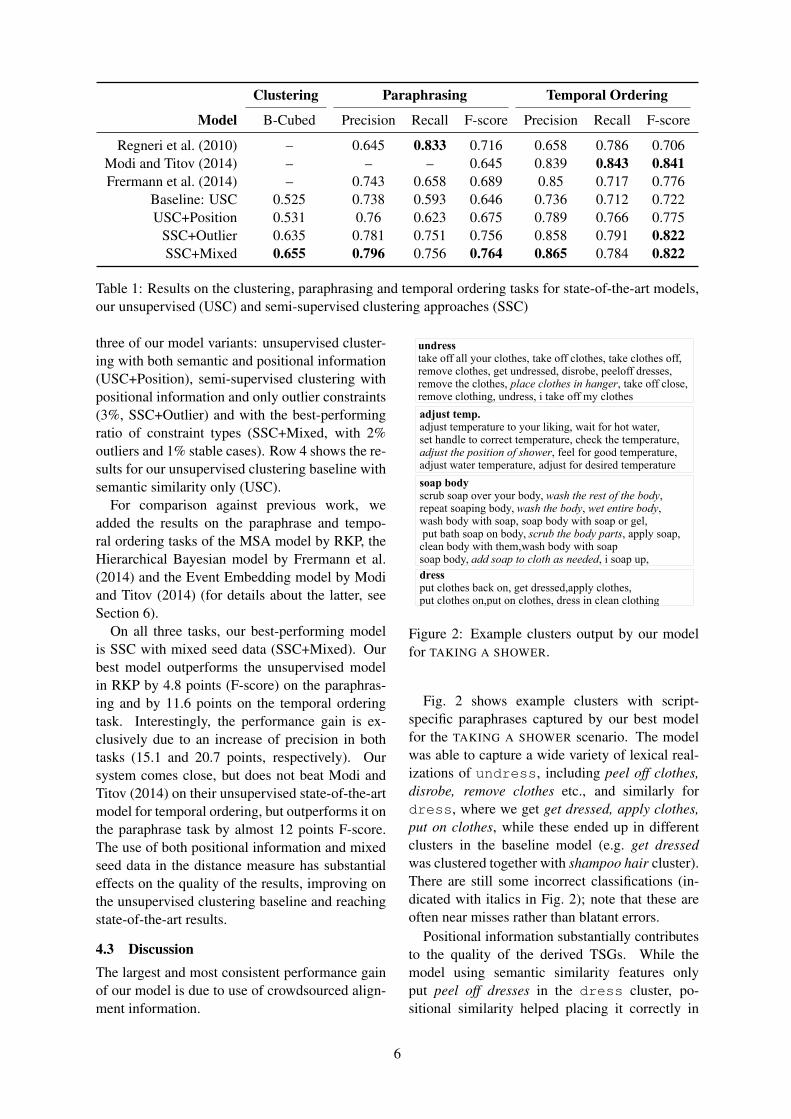
Clustering Paraphrasing Temporal Ordering
Model B-Cubed Precision Recall F-score Precision Recall F-score
Regneri et al. (2010) – 0.645 0.833 0.716 0.658 0.786 0.706Modi and Titov (2014) – – – 0.645 0.839 0.843 0.841Frermann et al. (2014) – 0.743 0.658 0.689 0.85 0.717 0.776
Baseline: USC 0.525 0.738 0.593 0.646 0.736 0.712 0.722USC+Position 0.531 0.76 0.623 0.675 0.789 0.766 0.775
SSC+Outlier 0.635 0.781 0.751 0.756 0.858 0.791 0.822SSC+Mixed 0.655 0.796 0.756 0.764 0.865 0.784 0.822
Table 1: Results on the clustering, paraphrasing and temporal ordering tasks for state-of-the-art models,our unsupervised (USC) and semi-supervised clustering approaches (SSC)
three of our model variants: unsupervised cluster-ing with both semantic and positional information(USC+Position), semi-supervised clustering withpositional information and only outlier constraints(3%, SSC+Outlier) and with the best-performingratio of constraint types (SSC+Mixed, with 2%outliers and 1% stable cases). Row 4 shows the re-sults for our unsupervised clustering baseline withsemantic similarity only (USC).
For comparison against previous work, weadded the results on the paraphrase and tempo-ral ordering tasks of the MSA model by RKP, theHierarchical Bayesian model by Frermann et al.(2014) and the Event Embedding model by Modiand Titov (2014) (for details about the latter, seeSection 6).
On all three tasks, our best-performing modelis SSC with mixed seed data (SSC+Mixed). Ourbest model outperforms the unsupervised modelin RKP by 4.8 points (F-score) on the paraphras-ing and by 11.6 points on the temporal orderingtask. Interestingly, the performance gain is ex-clusively due to an increase of precision in bothtasks (15.1 and 20.7 points, respectively). Oursystem comes close, but does not beat Modi andTitov (2014) on their unsupervised state-of-the-artmodel for temporal ordering, but outperforms it onthe paraphrase task by almost 12 points F-score.The use of both positional information and mixedseed data in the distance measure has substantialeffects on the quality of the results, improving onthe unsupervised clustering baseline and reachingstate-of-the-art results.
4.3 DiscussionThe largest and most consistent performance gainof our model is due to use of crowdsourced align-ment information.
undresstake off all your clothes, take off clothes, take clothes off, remove clothes, get undressed, disrobe, peeloff dresses, remove the clothes, place clothes in hanger, take off close, remove clothing, undress, i take off my clothes
soap bodyscrub soap over your body, wash the rest of the body, repeat soaping body, wash the body, wet entire body, wash body with soap, soap body with soap or gel, put bath soap on body, scrub the body parts, apply soap, clean body with them,wash body with soapsoap body, add soap to cloth as needed, i soap up,
adjust temp.adjust temperature to your liking, wait for hot water, set handle to correct temperature, check the temperature,adjust the position of shower, feel for good temperature, adjust water temperature, adjust for desired temperature
dressput clothes back on, get dressed,apply clothes, put clothes on,put on clothes, dress in clean clothing
Figure 2: Example clusters output by our modelfor TAKING A SHOWER.
Fig. 2 shows example clusters with script-specific paraphrases captured by our best modelfor the TAKING A SHOWER scenario. The modelwas able to capture a wide variety of lexical real-izations of undress, including peel off clothes,disrobe, remove clothes etc., and similarly fordress, where we get get dressed, apply clothes,put on clothes, while these ended up in differentclusters in the baseline model (e.g. get dressedwas clustered together with shampoo hair cluster).There are still some incorrect classifications (in-dicated with italics in Fig. 2); note that these areoften near misses rather than blatant errors.
Positional information substantially contributesto the quality of the derived TSGs. While themodel using semantic similarity features onlyput peel off dresses in the dress cluster, po-sitional similarity helped placing it correctly in
6

the undress cluster, as it appears in the ini-tial segment of its ESD. Positional informationsometimes also caused wrong clustering deci-sions: place cloth in hanger typically occurs di-rectly after undressing, and thus ended up inthe undress cluster.
As described above, we collected alignmentsfor outliers and for stable cases and tried sev-eral outlier-to-stable ratios. Outliers were muchmore effective than stable cases, as they improvedrecall by adjusting cluster boundaries to includescenario-specific functional paraphrases that weresemantically dissimilar. Interestingly, adding asmall number of stable cases leads to a slight im-provement, but adding more stable cases leads toa performance drop, and using only stable casesdoes not improve the unsupervised baseline at all.Fig. 3 shows how the model improves as moreconstraints are added.
We tried to reduce the amount of manual anno-tation in several ways. The decision to derive ad-ditional must-links using transitivity paid off: F-score consistently improves by about 1 point F-score. To further increase the set of seeds, we ex-perimented with propagating the links to nearestneighbors of aligned event descriptions, but didnot see an improvement. Also, we tried to usealignments obtained by majority vote, which how-ever led to a performance drop, showing that usinghigh quality seeds is crucial.
To make sure that our results are not dependenton the selection of a specific scenario set, we eval-uated our model also on the DeScript gold clusters.The results were comparable: B-Cubed improvedfrom 0.551 (RKP: 0.525) to 0.662 (RKP: 0.655).As the DeScript corpus provides 100 ESDs perscenario, we were also able to test whether an in-creased number of input ESDs also improves clus-tering performance. We observed no effect with50 ESDs compared to our model using 25 ESDs,and only a slight (less than 1 point) improvementwith the full 100 ESDs dataset.
A leading motivation to use clustering instead ofMSA was the opportunity to model flexible eventorder in script structures. Our expectations wereconfirmed by the evaluation results. A closer lookat the induces TSGs (as shown by the exampleTSG in Fig. 4), suggests that our system makesextensive use of the option of flexible event order-ing.
0.0 0.5 1.0 1.5 2.0 2.5 3.0
% constrained data
0.60
0.65
0.70
0.75
0.80
0.85
0.90
SSC_F-score
SSC_Precision
SSC_Recall
RKP_F-score
USCBaseline_F-score
Figure 3: Paraphrase detection results for RKP, forour Unsupervised baseline (USC) and for our bestSemi-supervised model (SSC+Mixed)
enter bathroom⇒(turn on shower↔ undress)⇒(adjust temp.↔ turn off water)⇒get in shower⇒(soap body↔ close curtains)⇒shampoo hair⇒(wash hair↔ wash body↔ shave)⇒rinse⇒exit shower⇒dry off⇒dress
Figure 4: Example TSG for TAKING A SHOWER.The arrows stand for default temporal precedence,the parentheses enclose equivalence classes ex-pressing arbitrary temporal order.
5 Costs and Coverage
We have demonstrated that semi-supervised clus-tering enables the extraction of script knowledgewith substantially higher quality than existingmethods. But how does the method scale? Can weexpect to obtain a script knowledge database withsufficiently wide coverage at reasonable costs?
The process of script extraction requires crowd-sourced data in terms of (1) ESDs and (2) seedalignments. To complete 3%+3% high-qualityalignments for the 10 DeScript scenarios via Me-chanical Turk (that is, 3% stable cases and 3% out-liers), workers spent a total of 37.5 hours, withan average of 3.75 hrs per scenario, ranging from2.5 (GOING GROCERY SHOPPING) to 7.52 hrs(BAKING A CAKE)3. It took on average 2.78 hrsto collect 25 scenario-specific ESDs, that is 6.53hrs of data acquisition time per scenario.
The costs per scenario are moderate. But howmany scenarios must be modeled to achieve suf-
3We used the DeScript scenarios as reference becausethey come with equal numbers of ESDs, while the ESD setsin the SMILE+OMICS corpus vary considerably in size.
7

Jessica needs milk. Jessica wakes up and wantsto eat breakfast. She grabs the cereal and pourssome into a bowl. She looks in the fridge formilk. There is no milk in the fridge so she can’teat her breakfast. She goes to the store to buysome milk comes home and eats breakfast.MAKE BREAKFAST: CGOING GROCERY SHOPPING: P
Figure 5: Example ROC-story with scenario an-notation.
ficient coverage for the analysis of script knowl-edge in natural-language texts? Answering thisquestion is not trivial, as scenarios vary consid-erably in granularity and it is not trivial that thetype of script knowledge we model can capture allkinds of event structures, even in narrative texts.In order to provide a rough estimate of coveragefor the currently existing script material, we car-ried out a simple annotation study on the recentlypublished ROC-stories database (Mostafazadeh etal., 2016a). The database consists of 50,000 shortnarrative texts, collected via Mechanical Turk.Workers were asked to write a 5-sentence lengthstory about an everyday commonsense event, andthey were encouraged to write about “anythingthey have in mind” to guarantee wide distributionacross topics.
For our annotation study, we merged the avail-able datasets containing crowdsourced ESD col-lections (i.e. OMICS, SMILE, and DeScript), ex-cluding two extremely general scenarios (GO OUT-SIDE, CHILDHOOD), which gives us a total of 226different scenarios.
We randomly selected 500 of the ROC-storiesand asked annotators to determine for each storywhich scenario (if any) was centrally addressedand which scenarios were just referred to or par-tially addressed with at least one event mention,and to label them with “C” and “P”, respectively.See an example story with its annotation in Fig. 5.
Each story was annotated by three students ofcomputational linguistics. To facilitate annotation,the stories were presented alongside ten scenar-ios whose ESDs showed strongest lexical overlapwith the story (calculated as tf-idf). However, an-notators were expected to consider the full sce-nario list4. The three annotations were merged us-
4We are aware that this setup may bias participants towardfinding a scenario from our collection, leading to an increase
ing majority vote. Cases without a clear majorityvote containing one single “C” assignment wereinspected and adjudicated by the authors of the pa-per.
26.4% of the stories were judged to centrally re-fer to one of the scenarios5. Although this per-centage cannot be directly translated to coveragevalues, it indicates that the extraction method pre-sented in this paper has the strong potential toprovide a script knowledge resource with reason-able costs, which can substantially contribute tothe task of text understanding.
6 Related Work
Following the seminal work of Chambers andJurafsky (2008) and (2009) on the induction ofscript-like narrative schemas from large, unla-beled corpora of news articles, a series of mod-els have been presented for improving the induc-tion method or explore alternative data sources forscript learning. Gordon (2010) mined common-sense knowledge from stories describing events inday-to-day life. Jans et al. (2012) studied differ-ent ways of selecting event chains and used skip-grams for computing event statistics. Pichotta andMooney (2014) employed richer event representa-tions, exploiting the interactions between multiplearguments to extract event sequences from a largecorpus. Rahimtoroghi et al. (2016) learned contin-gency relations between events from a corpus ofblog posts. All these approaches aim at high re-call, resulting in a large amount of wide-coverage,but noisy schemas.
Abend et al. (2015) proposed an edge-factoredmodel to determine the temporal order of events incooking recipes, but their model is limited to sce-narios with an underlying linear order of events.Bosselut et al. (2016) induce prototypical eventstructure in an unsupervised way from a large col-lection of photo albums with time-stamped imagesand captions. This method is however limited bythe availability of albums for “special” events suchas WEDDING or BARBECUE, in contrast to every-day, trivial activites such as MAKING COFFEE or
in recall. However, they had the option to label stories wherethey felt a scenario was only partially addressed in a differ-ent way, thus setting these cases apart from those where thescenario was centrally addressed.
5While we take the judgment about the “C” class to bequite reliable (24.8% qualified by majority vote, only 1.6 %were added via adjudication), there was considerable confu-sion about the “P” label. So we decided not to use the “P”label at all.
8

GOING TO THE DENTIST. Mostafazadeh et al.(2016b) presented the ROC-stories, a dataset ofc.a. 50.000 crowdsourced short commonsense ev-eryday story. They propose to use it for the evalu-ation of script knowledge models, and it may alsoturn out to be a valuable resource for script learn-ing, although to our knowledge this has not yetbeen attempted.
Closest to our approach is the work by RKPand subsequent work by Frermann et al. (2014)and Modi and Titov (2014). All these employthe same SMILE+OMICS dataset for evaluation,which we also used to allow for a direct compar-ison. Frermann et al. (2014) present a Bayesiangenerative model for joint learning of event typesand ordering constraints. Their model promis-ingly shows that flexible event order in scripts canbe suitably modelled. Modi and Titov (2014) fo-cussed mainly on event ordering between script-related predicates, using distributed representa-tions of predicates and arguments induced by a sta-tistical model. They obtained paraphrase sets as aby-product, namely by creating an event timelineand grouping together event mentions correspond-ing to the same interval.
7 Conclusions
This paper presents a clustering-based approach toinducing script structure from crowdsourced de-scriptions of scenarios. We use semi-supervisedclustering to group individual event descriptionsinto paraphrase sets representing event types, andinduce a temporal order among them. Crowd-sourced alignments between event descriptionsproved highly effective as seed data. On a para-phrase task, our approach outperforms all previousproposals, while still performing very well on thetask of temporal order prediction. A study on theROC-stories suggests that a model of script knowl-edge created with our method can cover a largefraction of event structures occurring in topicallyunrestricted narrative text, thus demonstrating thescalability of our approach.
Acknowledgments
This research was funded by the German ResearchFoundation (DFG) as part of SFB 1102 ‘Informa-tion Density and Linguistic Encoding’.
ReferencesOmri Abend, Shay B. Cohen, and Mark Steedman.
2015. Lexical event ordering with an edge-factoredmodel. In Proceedings of the 2015 Conferenceof the North American Chapter of the Associationfor Computational Linguistics: Human LanguageTechnologies, pages 1161–1171, Denver, Colorado,May–June. Association for Computational Linguis-tics.
Enrique Amigo, Julio Gonzalo, Javier Artiles, and Fe-lisa Verdejo. 2009. A comparison of extrinsicclustering evaluation metrics based on formal con-straints. Information retrieval, 12(4):461–486.
Amit Bagga and Breck Baldwin. 1998. Algorithmsfor scoring coreference chains. In The First Interna-tional Conference on Language Resources and Eval-uation Workshop on Linguistics Coreference, pages563–566.
Avron Barr and Edward A. Feigenbaum. 1981. Framesand scripts. In The Handbook of Artificial Intelli-gence, volume 3, pages 216–222. Addison-Wesley,California.
Antoine Bosselut, Jianfu Chen, David Warren, Han-naneh Hajishirzi, and Yejin Choi. 2016. Learningprototypical event structure from photo albums. InProceedings of the 54th Annual Meeting of the As-sociation for Computational Linguistics (Volume 1:Long Papers), pages 1769–1779, Berlin, Germany,August. Association for Computational Linguistics.
Nathanael Chambers and Dan Jurafsky. 2008. Unsu-pervised learning of narrative event chains. In Pro-ceedings of ACL-08: HLT, pages 789–797, Colum-bus, Ohio, June. Association for Computational Lin-guistics.
Nathanael Chambers and Dan Jurafsky. 2009. Unsu-pervised learning of narrative schemas and their par-ticipants. In Proceedings of the Joint Conference ofthe 47th Annual Meeting of the ACL and the 4th In-ternational Joint Conference on Natural LanguageProcessing of the AFNLP, pages 602–610, Suntec,Singapore, August. Association for ComputationalLinguistics.
Richard E. Cullingford. 1977. Script Applica-tion: Computer Understanding of Newspaper Sto-ries. Ph.D. thesis, Yale University.
Richard Durbin, Sean Eddy, Anders Krogh, andGraeme Mitchison. 1998. Biological sequenceanalysis: probabilistic models of proteins and nu-cleic acids. Cambridge University Press, Cam-bridge, UK.
Samuel Fernando and Mark Stevenson. 2008. A se-mantic similarity approach to paraphrase detection.In Proceedings of the 11th Annual Research Collo-quium of the UK Special Interest Group for Compu-tational Linguistics.
9

Lea Frermann, Ivan Titov, and Manfred Pinkal. 2014.A hierarchical bayesian model for unsupervised in-duction of script knowledge. In Proceedings of the14th Conference of the European Chapter of theAssociation for Computational Linguistics, pages49–57, Gothenburg, Sweden, April. Association forComputational Linguistics.
Andrew S. Gordon. 2010. Mining commonsenseknowledge from personal stories in internet we-blogs. In Proceedings of the First Workshop on Au-tomated Knowledge Base Construction, Grenoble,France.
Rakesh Gupta and Mykel J. Kochenderfer. 2004.Common sense data acquisition for indoor mobilerobots. In Proceedings of the 19th National Con-ference on Artificial intelligence, pages 605–610.AAAI Press.
Hannaneh Hajishirzi and Erik T. Mueller. 2012. Ques-tion answering in natural language narratives usingsymbolic probabilistic reasoning. In Proceedings ofthe Twenty-Fifth International Florida Artificial In-telligence Research Society Conference, pages 38–43.
Bram Jans, Steven Bethard, Ivan Vulic, and Marie-Francine Moens. 2012. Skip N-grams and rankingfunctions for predicting script events. In Proceed-ings of the 13th Conference of the European Chap-ter of the Association for Computational Linguistics,pages 336–344, Avignon, France, April. Associationfor Computational Linguistics.
Dan Klein, Sepandar D. Kamvar, and Christopher D.Manning. 2002. From instance-level constraints tospace-level constraints: Making the most of priorknowledge in data clustering. In Proceedings of theNineteenth International Conference on MachineLearning, pages 307–314.
Dekang Lin. 1998. An information-theoretic defini-tion of similarity. In In Proceedings of the 15th In-ternational Conference on Machine Learning, pages296–304.
Tomas Mikolov, Kai Chen, Greg S. Corrado, and Jef-frey Dean. 2013. Efficient estimation of word rep-resentations in vector space. In Proceedings of theInternational Conference on Learning Representa-tions.
Ashutosh Modi and Ivan Titov. 2014. Inducing neu-ral models of script knowledge. In Proceedings ofthe Eighteenth Conference on Computational Nat-ural Language Learning, pages 49–57, Ann Arbor,Michigan, June. Association for Computational Lin-guistics.
Nasrin Mostafazadeh, Nathanael Chambers, XiaodongHe, Devi Parikh, Dhruv Batra, Lucy Vanderwende,Pushmeet Kohli, and James Allen. 2016a. A cor-pus and cloze evaluation for deeper understandingof commonsense stories. In Proceedings of the
2016 Conference of the North American Chapter ofthe Association for Computational Linguistics: Hu-man Language Technologies, pages 839–849, SanDiego, California, June. Association for Computa-tional Linguistics.
Nasrin Mostafazadeh, Lucy Vanderwende, Wen-tauYih, Pushmeet Kohli, and James Allen. 2016b.Story cloze evaluator: Vector space representationevaluation by predicting what happens next. In Pro-ceedings of the 1st Workshop on Evaluating VectorSpace Representations for NLP, pages 24–29.
Erik T. Mueller. 2004. Understanding script-based sto-ries using commonsense reasoning. Cognitive Sys-tems Research, 5(4):307–340.
Christos H. Papadimitriou and Kenneth Steiglitz.1982. Combinatorial Optimization: Algorithm undComplexity. Dover Publications, Mineola, NY.
Karl Pichotta and Raymond Mooney. 2014. Statisti-cal script learning with multi-argument events. InProceedings of the 14th Conference of the Euro-pean Chapter of the Association for ComputationalLinguistics, pages 220–229, Gothenburg, Sweden,April. Association for Computational Linguistics.
Elahe Rahimtoroghi, Ernesto Hernandez, and MarilynWalker. 2016. Learning fine-grained knowledgeabout contingent relations between everyday events.In Proceedings of the 17th Annual Meeting of theSpecial Interest Group on Discourse and Dialogue,pages 350–359.
Altaf Rahman and Vincent Ng. 2011. Narrowing themodeling gap: a cluster-ranking approach to coref-erence resolution. Journal of Artificial IntelligenceResearch, 40:469–521.
Lisa F. Rau, Paul S. Jacobs, and Uri Zernik. 1989. In-formation extraction and text summarization usinglinguistic knowledge acquisition. Information Pro-cessing & Management, 25(4):419–428.
Michaela Regneri, Alexander Koller, and ManfredPinkal. 2010. Learning script knowledge with webexperiments. In Proceedings of the 48th AnnualMeeting of the Association for Computational Lin-guistics, pages 979–988, Uppsala, Sweden, July. As-sociation for Computational Linguistics.
Peter J. Rousseeuw. 1987. Silhouettes: A graphical aidto the interpretation and validation of cluster analy-sis. Journal of Computational and Applied Mathe-matics, 20:53 – 65.
Roger C. Schank and Robert P. Abelson. 1977. Scripts,Plans, Goals, and Understanding: An Inquiry intoHuman Knowledge Structures. Erlbaum, Hillsdale,NJ.
Ottokar Tilk, Vera Demberg, Asad Sayeed, DietrichKlakow, and Stefan Thater. 2016. Event partici-pant modelling with neural networks. In Proceed-ings of the 2016 Conference on Empirical Methods
10

in Natural Language Processing, pages 171–182,Austin, Texas, November. Association for Compu-tational Linguistics.
Lilian D. A. Wanzare, Alessandra Zarcone, StefanThater, and Manfred Pinkal. 2016. A crowd-sourced database of event sequence descriptions forthe acquisition of high-quality script knowledge.In N. Calzolari (Conference Chair), K. Choukri,T. Declerck, S. Goggi, M. Grobelnik, B. Maegaard,J. Mariani, H. Mazo, A. Moreno, J. Odijk, andS. Piperidis, editors, Proceedings of the Tenth In-ternational Conference on Language Resources andEvaluation (LREC 2016). European Language Re-sources Association (ELRA).
11

Proceedings of the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics, pages 12–24,Valencia, Spain, April 3, 2017. c©2017 Association for Computational Linguistics
A Consolidated Open Knowledge Representation for Multiple TextsRachel Wities∗ 1, Vered Shwartz1, Gabriel Stanovsky1, Meni Adler1, Ori Shapira1,Shyam Upadhyay2, Dan Roth2, Eugenio Martinez Camara3, Iryna Gurevych3,4 and
Ido Dagan1
1Bar-Ilan University, Ramat-Gan, Israel2University of Illinois at Urbana-Champaign, IL, USA
3Ubiquitous Knowledge Processing Lab (UKP), Technische Universitat Darmstadt4Ubiquitous Knowledge Processing Lab (UKP-DIPF),
German Institute for Educational Research{rachelvov,vered1986,gabriel.satanovsky,meni.adler,obspp18}@gmail.com
{upadhya3,danr}@illinois.edu, {camara,gurevych}@[email protected]
Abstract
We propose to move from Open Infor-mation Extraction (OIE) ahead to OpenKnowledge Representation (OKR), aim-ing to represent information conveyedjointly in a set of texts in an open text-based manner. We do so by consolidatingOIE extractions using entity and predicatecoreference, while modeling informationcontainment between coreferring elementsvia lexical entailment. We suggest thatgenerating OKR structures can be a usefulstep in the NLP pipeline, to give seman-tic applications an easy handle on consoli-dated information across multiple texts.
1 Introduction
Natural language understanding involves identify-ing, classifying, and integrating information aboutevents and other propositions mentioned in text.While much effort has been invested in genericmethods for analyzing single sentences and de-tecting the propositions they contain, little thoughtand effort has been put into the integration step:how to systematically consolidate and representinformation contributed by propositions originat-ing from multiple texts. Consolidating such in-formation, which is typically both complemen-tary and partly overlapping, is needed to con-struct multi-document summaries, to combine ev-idence when answering questions that cannot beanswered based on a single sentence, and to pop-ulate a knowledge base while relying on multiplepieces of evidence (see Figure 1 for a motivating
∗Corresponding author
example). Yet, the burden of integrating informa-tion across multiple texts is currently delegated todownstream applications, leading to various par-tial solutions in different application domains.
This paper suggests that a common consolida-tion step and a corresponding knowledge represen-tation should be part of the “standard” semanticprocessing pipeline, to be shared by downstreamapplications. Specifically, we pursue an OpenKnowledge Representation (OKR) framework thatcaptures the information expressed jointly in mul-tiple texts while relying solely on the termi-nology appearing in those texts, without requir-ing pre-defined external knowledge resources orschemata.
As we focus in this work on investigating anopen representation paradigm, our proposal fol-lows and extends the Open Information Extrac-tion (OIE) approach. We do that by first extract-ing textual predicate-argument tuples, each cor-responding to an individual proposition mention.We then merge these mentions by accounting forproposition coreference, an extended notion ofevent coreference. This process yields consoli-dated propositions, each corresponding to a singlefact, or assertion, in the described scenario. Simi-larly, entity coreference links are used to establishreference to real-world entities. Taken together,our proposed representation encodes informationabout events and entities in the real world, simi-larly to what is expected from structured knowl-edge representations. Yet, being an open text-based representation, we record the various lexicalterms used to describe the scenario. Further, wemodel information redundancy and containmentamong these terms through lexical entailment.
In this paper we specify our proposed represen-
12

1. Turkey forces down Syrian plane. 4. Turkish PM says plane was carrying ammunition for Syria government.2. Damascus sends note to Ankara over Syrian plane. 5. Last night Turkish F16s grounded a Syrian passenger jet.3. Turkey Escalates Confrontation with Syria. 6. Russia angry at Turkey about Russian passengers.
Figure 1: A sample of news headlines, illustrating the need for information consolidation. Two mentionsof the same proposition, for which event coreference holds, are highlighted, with the predicate in bold andthe arguments underlined. Some information is redundant, but may be described at different granularitylevels; for example, different mentions describe the interception target as a plane and as a jet, where jetentails plane and is accordingly more informative.
tation, while specifying the involved annotationsub-tasks from which our structures are composed.We then describe our annotated dataset, of newsheadline tweets about 27 news stories, which isthe first to be jointly annotated for all our requiredsub-tasks. We also provide initial predicted base-line results for each of the sub-tasks, pointing atthe limitations of current state of the art.1
Overall, our main contribution is in proposing tocreate a consolidated representation for the infor-mation contained in multiple texts, and in specify-ing how such representation can be created basedon entity and event coreference and lexical entail-ment. An accompanying contribution is our an-notated dataset, which can be used to analyze theinvolved phenomena and their interactions, and asa development and test set for automated gener-ation of OKR structures. We further note thatwhile this paper focuses on creating an open repre-sentation, by consolidating Open IE propositions,future work may investigate the consolidation ofother semantic sentence representations, for exam-ple AMR (Abstract Meaning Representation) (Ba-narescu et al., 2013), while exploiting similar prin-ciples to those proposed here.
2 Background: Relevant ComponentTasks
In this section we describe the prior annotationtasks on which we rely in our representation, asdescribed later in Section 3.
2.1 Open Information Extraction
Open IE (Open Information Extraction) (Etzioniet al., 2008) is the task of extracting coherentpropositions from a sentence, each comprising arelation phrase and two or more argument phrases.For example, (plane, landed in, Ankara).
Open IE has gained substantial and consistentattention, and many automatic extractors were cre-
1Our dataset, detailed annotation guidelines, the annota-tion tool and the baseline implementations are available athttps://github.com/vered1986/OKR.
ated (e.g., Fader et al. (2011); Del Corro andGemulla (2013)). Open IE’s extractions were alsoshown to be effective as intermediate sentence-level representation in various downstream appli-cations (Stanovsky et al., 2015; Angeli et al.,2015). Analogously, we conjecture a similar util-ity of our OKR structures at the multi-text level.
Open IE does not assign roles to the argumentsassociated with each predicate, as in other single-sentence representations like SRL (Semantic RoleLabeling) (Carreras and Marquez, 2005; Palmeret al., 2010). While the former is not consis-tent in assigning argument slots to the same ar-guments across different propositions, the latterrequires predefined thematic role ontologies. Amiddle ground was introduced by QA-SRL (Heet al., 2015), where predicate-argument structuresare represented using question-answer pairs, e.g.(what landed somewhere?, plane), (where didsomething land?, Ankara).
2.2 Coreference Resolution Tasks
In our representation, we use coreference resolu-tion to consolidate mentions of the same entity orthe same event across multiple texts.
Entity Coreference Entity coreference resolu-tion identifies mentions in a text that refer to thesame real-world entity (Soon et al., 2001; Ng andCardie, 2002; Bengtson and Roth, 2008; Clark andManning, 2015; Peng et al., 2015). In the cross-document variant, Cross Document CoreferenceResolution (CDCR), mentions of the same entitycan also appear in multiple documents in a cor-pus (Singh et al., 2011).
Event Coreference Event coreference deter-mines whether two event descriptions (mentions)refer to the same event (Humphreys et al., 1997).Cross document event coreference (CDEC) is avariant of the task in which mentions may occur indifferent documents (Bagga and Baldwin, 1999).
Compared to within document event corefer-ence (Chen et al., 2009; Araki et al., 2014; Liu et
13

al., 2014; Peng et al., 2016), the problem of crossdocument event coreference has been relativelyunder-explored (Bagga and Baldwin, 1999; Bejanand Harabagiu, 2014). Standard benchmarks forthis task are the Event Coreference Bank (ECB)(Bejan and Harabagiu, 2008) and its extensions,that also annotate entity coreference: EECB (Leeet al., 2012) and ECB+ (Cybulska and Vossen,2014). See (Upadhyay et al., 2016) for more de-tails on cross document event coreference.
Differently from our dataset described in Sec-tion 4, ECB and its extensions do not establishpredicate-argument annotations. A secondary lineof work deals with aligning predicates across doc-ument pairs, as done in Roth and Frank (2012).PARMA (Wolfe et al., 2013) treated the task asa token-alignment problem, aligning also argu-ments, while Wolfe et al. (2015) added joint con-straints to align predicates and their arguments.
Using Coreference for Consolidation Recog-nizing that two elements are corefering can helpin consolidating textual information. In discourserepresentation theory (DRT), a proposition ap-plies to all co-referring entities (Kamp et al.,2011). In recognizing textual entailment (Daganet al., 2013), lexical substitution of co-referring el-ements is useful (Stern and Dagan, 2012). For ex-ample, in Figure 1, sentence (1) together with thecoreference relation between plane and jet entailthat “Turkey forces down Syrian jet.”
2.3 Lexical Inference
Recognizing lexical inferences is an importantcomponent in semantic tasks, in order to bridgelexical variability in texts. For instance, in textsummarization, lexical inference can help identi-fying redundancy, when two candidate sentencesfor the summary differ only in terms that hold alexical inference relation (e.g. “the plane landed inAnkara” and “the plane landed in Turkey”). Rec-ognizing the inference direction, e.g. that Ankarais more specific than Turkey, can help in selectingthe desired granularity level of the description.
There has been consistent attention to recogniz-ing lexical inference between terms. Some meth-ods aim to recognize a general lexical inferencerelation (e.g. (Kotlerman et al., 2010; Turney andMohammad, 2015)), others focus on a specific se-mantic relation, mostly hypernymy (Hearst, 1992;Snow et al., 2005; Santus et al., 2014; Shwartz etal., 2016), while recent methods classify a pair of
terms to a specific semantic relation out of several(Baroni et al., 2012; Weeds et al., 2014; Pavlick etal., 2015; Shwartz and Dagan, 2016). It is worthnoting that most existing methods are indifferentto the context in which the target terms occur, withthe exception of few works, which were mostly fo-cused on a narrow aspect of lexical inference, e.g.lexical substitution (Melamud et al., 2015).
Determining entailment between predicates is adifferent sub-task, which has also been broadlyexplored (Lin and Pantel, 2001; Duclaye et al.,2002; Szpektor et al., 2004; Schoenmackers etal., 2010; Roth and Frank, 2012). Berant et al.(2010) achieved state-of-the-art results on the taskby constructing a predicate entailment graph opti-mizing a global objective function. However, per-formance should be further improved in order tobe used accurately within semantic applications.
3 Proposed Representation
Our Open Knowledge Representation (OKR) aimsto capture the consolidated information expressedjointly in a set of texts. In some analogy to struc-tured knowledge bases, we would like the ele-ments of our representation to correspond to en-tities in the described scenario and to statements(propositions) that relate them. Still, in the spiritof Open IE, we would like the representation to beopen, while relying only on the natural languageterminology in the given texts without referring topredefined external knowledge.
This section specifies our proposed structure,with a running example in Figure 2. The specifica-tion involves two aspects: the first is defining thecomponent annotation sub-tasks involved in cre-ating our representation, following those reviewedin Section 2; the second is specifying how we de-rive from these component annotations a consoli-dated representation. These two aspects are inter-leaved along the presentation, where for each stepwe first describe the relevant annotations and thenhow we use them to create the corresponding com-ponent of the representation.
3.1 Entities
To represent entities, we first annotate the text byentity mentions and coreference. Following thetypical notion for these tasks, an entity mentioncorresponds to a word or multi-word expressionthat refers to an object or concept in the describedscenario (in the broader sense of “entity”). Ac-
14

Original texts:(1) Turkey forces down Syrian plane.
(2) Syrian jet grounded by Turkey carried munitions from Moscow.
(3) Intercepted Syrian plane carried ammunition from Russia.
Entities:E1 = {Turkey}, E2 = {Syrian}, E3 = {plane, jet}E4 = {munitions, ammunition}, E5 = {Moscow}, E6 = {Russia}Proposition Mentions (+ coreference + argument alignment):P1: [a1] forces down [a2] (Turkey [E1], plane [E3])P2: [a1] [a2] (Syrian [E2], plane [E3]) (implicit)P2: [a1] [a2] (Syrian [E2], jet [E3]) (implicit)P1: [a2] grounded by [a1] (jet [E3], Turkey [E1])P3: [a1] carried [a2] from [a3]
(jet [E3], munitions [E4], Moscow [E5])P1: intercepted [a2] (jet [E3])P2: [a1] [a2] (Syrian [E2], plane [E3]) (implicit)P3: [a1] carried [a2] from [a3]
(plane [E3], ammunition [E6], Russia [E6])Consolidated Propositions:
P1 :
[a1] forces down [a2][a2] grounded by [a1]
intercepted [a2]
[a1: {E1}, a2: {E3}]
P2: { [a1] [a2] (implicit) } [a1: {E2}, a2: {E3}]
P3: { [a1] carried [a2] from [a3] }[ a1: {E3}, a2: {E4},
a3: {E5, E6}]
Entailment Graphs:
Propositions:
P1 :
[a1] forces down [a2] [a2] grounded by [a1]
intercepted [a2]
Entities:E3: planejet
E4: munitionsammunition
Arguments: P3.a3: RussiaMoscow
[a1] forcesdown [a2]
E1 P1
[a1] carried [a2]from [a3]
intercepted [a2]
[a2] grounded
by [a1]
E3{jet,plane}
E4{ammunition
,munitions}E6 {Russia}
E5 {Moscow}
IMPLICIT
E1{Turkey}
E3{jet,plane}
a2
a1
a2
a1
a3
E2{Syrian}
E3{jet,plane}
a2
a1
P2
P3
Turkey
E2 Syrian
E5 Moscow
E6 Russia
E4 munitions
ammunition
E3 plane
jet
(a) (b)
Figure 2: An illustration of our OKR formalism (a), with a corresponding graphical view of the consol-idated structure (b). In (b), dashed lines connect entities to their instantiation within arguments, whileallowing graph-traversal inferences such as: what is the relation between Turkey and Russia? Turkeyintercepted a plane that carried ammunition from Russia (the path from E1 to E6 via the darker dashedlines).
cordingly, we represent an entity in the describedscenario by the coreference cluster of all its men-tions. We represent the coreferring cluster of men-tions by the multiset of its terms, keeping pointersto each term’s mentions (see Entities in Figure 2;to avoid clutter, pointers are not presented in thefigure). We note that we take an inclusive viewwhich regards concepts as entities, for example theadjective Syrian is considered an entity mentionthat may corefer with Syria.
3.2 Proposition Mentions and ConsolidatedPropositions
To represent propositions, we first annotate OpenIE style extractions, which we term propositionmentions. Each mention consists of a predicateexpression, e.g. around verbs or nominalizations,
and a set of arguments (see Proposition Mentionsin Figure 2). We deviate slightly from standardOpen IE formats by representing the predicate ex-pression as a template, with place holders for thearguments (marked with brackets in the figure).This follows the common representation of predi-cates within predicate inference rules, as in DIRT(Lin and Pantel, 2001), and allows the span of en-tity arguments to correspond exactly to the entityterm. Further, as typical in Open IE, modalitiesand negations become part of the lexical elementsof the predicate. Notice that at this stage an ar-gument mention is already associated with its cor-responding entity. Further, we annotate implicitpredicates when a predication between two enti-ties is implied, without an explicit predicate ex-pression, as common for noun modifications (P2
15

in the figure). Nested propositions are representedby having one proposition mention as an argumentof the other (e.g. “the [plane] was forced to [landin Ankara]”).
To link different mentions of the same realworld fact, we annotate proposition coreference,which generalizes the notion of event corefer-ence to cover all types of predications (e.g., Johnis Mary’s brother would co-refer with Mary isJohn’s sister). This annotation specifies the coref-erence relation for a cluster of proposition men-tions (denoted by the same proposition index Pi inFigure 2), as well as an alignment of their argu-ments, (denoted by matching argument indexeswithin the same proposition cluster). We then con-sider a proposition to correspond to a coreferencecluster of proposition mentions, which jointly de-scribe the referred real-world fact.
Yet, a cluster of co-referring proposition men-tions does not provide a succinct representation forthe aggregated textual description of a proposition.To that end, we aggregate the information in thecluster into a Consolidated Proposition, composedof a consolidated predicate and consolidated ar-guments. Similar to entity representation, a con-solidated predicate is represented by the set of allpredicate expressions appearing in the cluster. Aconsolidated argument is specified by the set ofall entities (or propositions, in case of having oneproposition being an argument of another one) thatoccupy this argument’s slot in the different men-tions. As with entities, each element in this rep-resentation is accompanied by a set of pointers toall its original mentions (omitted from the figure).A graphical illustration of this structure is givenin Figure 2(b) (for now, ignore the arrows withinsome of the nodes).
A consolidated proposition encodes compactlyall possible textual descriptions for the referredproposition, which can be generated from its men-tions taken jointly. Each description can be gener-ated by picking one possible predicate expressionand then picking one possible lexical choice foreach argument. For example, P1 may be describedas Turkey intercepted a plane, Turkey forces downa jet etc. Some of these descriptions correspond tooriginal mentions in the text, while others can beinduced through coreference (as reviewed at theend of Section 2.2). The representation of a con-solidated proposition thus does not depend on theparticular way in which lexical choices were split
across the different proposition mentions.
3.3 Lexical Entailment Graphs
The set of descriptions encoded in a consolidatedproposition is highly redundant. To make it moreuseful, we would like to model the informationoverlap between different lexical choices. For ex-ample, we want to know that Turkey intercepted aplane is more general than, or equivalently, is en-tailed by, Turkey intercepted a jet. To that end, weannotate the lexical entailment relations betweenthe elements in each component of our represen-tation, that is, within each consolidated predicate,consolidated argument and entity. This yields alexical entailment graph within each component(see figure 2), which models the information con-tainment relationships between different descrip-tions.
Notice that in our setting the lexical entailmentrelation is considered within the given context (seeSection 2.3). For example, grounded and forceddown may not be generically synonymous, butthey do convey equivalent information in a givencontext of forcing a flying plane to land. Contra-dictions are modeled to a limited extent, by anno-tating contradiction relations (in context) betweenelements of our entailment graphs, for examplewhen different figures are reported for the numberof casualties in a disaster. This is a natural rep-resentation, since contradiction is often modeledwithin a three-way entailment classification task.Modeling of broader cases of contradiction is leftfor future work.
The entailment graphs yield better modelingof the supporting text mentions (and their totalcount) for each possible description. For exam-ple, knowing that Moscow entails Russia, we canassume in P3 two supporting mentions for know-ing that the ammunition was carried from Russia,while having only one supporting mention for themore detailed information regarding Moscow be-ing the origin. Such frequency support often cor-relates with confidence and prominence of infor-mation, which, together with generality modeling,may be very useful in applications such as multi-document summarization or question answering.Finally, the graphical view of our representationlends itself to graph-based inferences, such aslooking for all connections between two entities,similar to aggregated inferences over structuredknowledge graphs (see example in Figure 2(b)).
16

# Entities 1262# Entity mentions 5074# Entity singeltons 777# Propositions 1406# Proposition mentions 4311# Proposition Singletons 949Avg. mentions per entity chain 8.86Avg. distinct lemmas per entity chain 2.00Avg. mentions per proposition chain 7.35Avg. distinct lemmas per prop. chain 2.24Avg. number of elements per arg. chain 1.08
Table 2: Twitter dataset statistics. Distinct lemmaterms per proposition chain were calculated onlyon explicit propositions. Average number of el-ements per argument chain measures how manydistinct entities or propositions were part of thesame argument.
In summary, our open knowledge representa-tion consists of the following: entities, generatedby detecting entity mentions and coreference; con-solidated propositions, composed of consolidatedpredicates and arguments, which are generatedby detecting proposition mentions and coreferencerelations between them; lexical entailment graphsfor entities, consolidated predicates and consoli-dated arguments, which specify the inference rela-tions between the elements within each of thesecomponents. This yields a compact representa-tion of all possible descriptions of the statementsjointly asserted by the set of texts, as induced viacoreference-based inference, while tracking in-formation containment between different descrip-tions as well as tracking their (induced) supportingmentions.
4 News-Related Tweets Dataset
Following the formal definition of our OKR struc-tures, we compiled a corpus with gold annotationsof our 5 subtasks (listed in Table 1). As outlined inthe previous section, our structures follow deter-ministically from these annotations. Specifically,we make use of the news-related tweets collectedin the Twitter Event Detection Dataset (McMinnet al., 2013), which clusters tweets from majornews networks and other sources discussing thesame event (for example, the grounding of a Syr-ian plane by the Turkish government). We chose toannotate news related tweets in this first dataset forseveral reasons: (1) they represent self containedassertions, (2) they tend to be relatively factualand succinct, and (3) by looking at several newssources we can obtain a corpus with high redun-dancy, which our representation aims to address.
We note that while this dataset exhibits a limitedamount of linguistic complexity, making it suit-able for a first investigation, it still represents avery practical use case of consolidating informa-tion in a large stream of tweets about a news story.
This annotation serves two main purposes.First, it validates the feasibility of our annotationscheme in terms of annotator requirements, train-ing and agreement. Second, to the best of ourknowledge, this is the first time these core NLPannotations are annotated in parallel over the sametexts. Following, this annotation has the potentialof becoming a useful resource spurring future re-search into joint prediction of these annotations.For instance, predicate argument structures maybenefit from co-reference signals, and entity ex-traction systems may exploit signals from lexicalentailment.
Overall, we annotated 1257 tweets from 27clusters. We release the dataset both in full OKRformat, as well as ECB-like “light” format, con-taining only the annotated co-reference chains.Overall corpus statistics are depicted in Table 2.
4.1 Dataset CharacteristicsAn analysis of the annotations reveals interestingand unique characteristics of our annotated corpus.
First, the part of speech distribution of enti-ties and predicates (Table 3) shows that our cor-pus captures information beyond the current focuson verb-centric applications and corpora in NLP.Namely, our corpus contains a vast number of non-verbal predications (67%), and a relatively largenumber of adjectival entities, owing to the fact thatour structure annotates concepts such as “north-ern” or “Syrian” as entities in an implicit relation.
Second, the average number of unique lemmasper entity and proposition chains (2.00 and 2.24,respectively) shows that our corpus exhibits a fairamount of non-trivial lexical variability.
Finally, roughly 96% of our entailment graphs(entity and proposition) form a connected compo-nent. This data provides an interesting potentialfor investigating and modeling lexical inferencerelations within coreference chains.
4.2 Annotation Procedure and AgreementThe annotation was performed by two nativeEnglish speakers with linguistic academic back-ground, which had 10 hours of in house training.The entire annotation process took 200 person-hours using a graphical tool purposely-designed
17

TaskEntityMent.
Entity Co-referenceProp. Mentions Proposition Co-Reference Entailment
Pred. Arg. Predicate Argument Entity Propavg. acc MUC B3 CEAF CoNLL F1 avg. acc avg. acc MUC B3 CEAF CoNLL F1 MUC B3 CEAF CoNLL F1 F1 F1
IAA .85 .87 .92 .92 .90 .74 (.93, .72)† .85 .86 .88 .76 .83 .99 .99 .98 .99 .70 .82Pred .58 .84 .89 .81 .85 .41 (.73, .25)† .37 .47 .67 .56 .56 .93 .97 .94 .95 .44 .56
Table 1: Inter-Annotator Agreement (top) and off-the-shelf state-of-the-art predicted performance (bot-tom, see Section 5) for the OKR subtasks: (1) Entity mention extraction (for prediction we use F1 score)(2) Entity co-reference (3) Proposition Extraction (predicate identification and argument detection) (4)Proposition Co-reference (predicate coreference and argument alignment), and (5) Entailment graphs(entity and proposition entailment; argument entailment figures are not presented due to very low statis-tics). † Numbers in parenthesis denote verbal vs. non-verbal predicates, respectively.
to facilitate the incremental annotation for allsubtasks . We employ the QA-SRL annotationmethodology to help determining Open IE pred-icate and argument spans in the gold standard, forits intuitiveness for non-expert annotators (He etal., 2015). Five clusters were annotated indepen-dently by both annotators and were used to mea-sure their agreement on the task. The other clus-ters were annotated by one annotator and reviewedby an expert.
We measure agreement separately on each an-notation subtask. After each task in our pipelinewe keep only the consensual annotations. For ex-ample, we measure entity coreference agreementonly for entity mentions that were annotated byboth annotators. For entity, predicate and argu-ment mention agreement, we average the accuracyof the two annotators, each computed while takingthe other as a gold reference.
For entity, predicate, and argument co-referencewe calculated coreference resolution metrics: thelink-based MUC (Vilain et al., 1995), the mention-based B3 (Bagga and Baldwin, 1998), the entity-based CEAF, and the widely adopted CoNLL F1
measure which is an average of the three. For en-tity and proposition entailment we compute the F1
score over the annotated directed edges in eachentailment graph, as is common for entailmentagreement metrics (Berant et al., 2010).
We macro-averaged these scores to obtain anoverall agreement on the 5 events annotated byboth annotators. The agreement scores for the twoannotators are shown in Table 1, and overall showhigh levels of agreement. A qualitative analysis ofthe more common disagreements between annota-tors is shown in Table 4.
Overall, this shows that our parallel annotationis indeed feasible; agreement on each of the sub-tasks is relatively high and on par with reportedinter-annotator agreement on similar tasks.
POS Nouns Verbs Adj’s Impl. Others
Ent. Dist. .85 .01 .09 – .05Pred. Dist. .40 .33 .04 .18 .04
Table 3: Entity and Predicate distribution acrosspart of speech tags: nouns, verbs, adjectives, non-lexicalized (implicit) and all others.
Disagreement Type Examples
Phrasal verbs [placed to leave]pred. vs. [placed to]pred.[leave]pred.
[faces charges]pred. vs. [faces]pred. [charges]arg.
Nominalizations[suspect]ent. plane vs. [suspect]pred. plane[terror]ent. attack vs. [terror]pred. attackU.S. [elections]ent. vs. U.S. [elections]pred.
Entailment fuel→gas vs. gas→fuelscandal→case vs. case→scandal
Table 4: Typical cases of annotator disagreements.Annotated spans are denoted by square brackets,subscript denotes label for the mention (predicate,argument or entity).
5 Baselines
As we have shown in previous sections, our struc-ture is derived from known “core” NLP tasks, ex-tended where needed to fit our consolidated repre-sentation. Subsequently, a readily available meansof automatically recovering OKR is through apipeline which uses off-the-shelf models for eachof the subtasks.
To that end, we employ publicly available toolsand simple baselines which approximate the cur-rent state-of-the-art in each of these subtasks. Forbrevity sake, in the rest of the section we brieflydescribe each of these baselines. For a more de-tailed technical description see the OKR repos-itory (https://github.com/vered1986/OKR).
For Entity Mention extraction we use the spaCyNER model2 in addition to annotating all of thenouns and adjectives as entities. For PropositionMention detection we use Open IE propositionsextracted from PropS (Stanovsky et al., 2016),where non-restrictive arguments were reduced fol-lowing Stanovsky and Dagan (2016). For Proposi-
2https://spacy.io/
18

tion and Entity coreference, we clustered the entitymentions based on simple lexical similarity met-rics (e.g., lemma matching and Levenshtein dis-tance), shown to be effective on our news tweets.3
For Argument Mention detection we attach thecomponents (entities and propositions) as argu-ments of predicates when the components aresyntactically dependent on them. Argument Co-reference is simply predicted by marking co-reference if and only if the arguments are bothmentions of the same entity co-reference chain.For Entity Entailment purposes we used knowl-edge resources (Shwartz et al., 2015) and a pre-trained model for HypeNET (Shwartz et al., 2016)to obtain a score for all pairs of Wikipedia com-mon words (unigrams, bigrams, and trigrams). Athreshold for the binary entailment decision wasthen calibrated on a held out development set. Fi-nally, for Predicate Entailment we used the entail-ment rules extracted by Berant et al. (2012).
5.1 Results and Error Analysis
Using the same metrics used for measuring inter-annotator agreement, we evaluated how well thepresented models were able to recover the differ-ent facets of the OKR gold annotations. The per-formance on the different subtasks is presented inTable 1 (bottom).
We measure the performance of each compo-nent separately, while taking the annotations forall previous steps from the gold human annota-tions. This allows us to examine the performanceof the current component, alleviating any incurrederrors from previous steps. Thus, we can iden-tify technological “bottle-necks” – the steps whichmost significantly lower predicted OKR accuracyusing current off-the-shelf tools.
First, we noticed that non-verbal predicatespose a challenge for current verb-centric systems.This primarily manifests in low scores for iden-tifying entities, predicates and arguments. Manyentity mention errors are due to nominalizationsmistakenly annotated as entities. When excludinggold nominalizations, the entity mention baselineF1 score rises from 0.58 to 0.63. As mentioned
3We chose simple metrics over complex state-of-the-artentity coreference models since they target different scenariosfrom ours: first, they focus on named entities, and are likelyto overlook common nouns like plane and jet. Second, sincewe work in the context of the same news story, it is reasonableto assume that, for example, two mentions of a person withthe same last name belong to the same entity.
earlier (Section 4.2) nominalizations were also oneof the main challenges for the annotators. Further-more, recognizing nominalizations and other non-verbal predicates, which are very common in ourdataset (see Table 3), proves to be a difficult task.Indeed, we see a significant improvement in per-formance when comparing verbal predicate men-tion performance to non-verbal performance (ac-curacy of 0.73 vs. 0.25). Finally, argument iden-tification was hard mainly because of inconsisten-cies in verbal versus nominal predicate-argumentstructure in dependency trees.4
The low performance in predicate coreferencecompared to entity coreference can be explainedby the higher variability of predicate terms. Theargument co-reference task becomes easy givengold predicate-argument structures, as most argu-ments are singletons (i.e. composed of a singleelement).
Finally, while the performance of the predicateentailment component reflects the current state-of-the-art (Berant et al., 2012; Han and Sun,2016), the performance on entity entailment ismuch worse than the current state-of-the-art in thistask as measured on common lexical inference testsets. We conjecture that this stems from the natureof the entities in our dataset, consisting of bothnamed entities and common nouns, many of whichare multi-word expressions, whereas most work inentity entailment is focused on single word com-mon nouns. Furthermore, it is worth noting thatour annotations are of naturally occurring texts,and represent lexical entailment in real world co-reference chains, as opposed to synthetically com-piled test sets which are often used for this task.
While several tasks achieve reasonable perfor-mance on our datasets, most tasks leave room forimprovement. These bottle-necks are bound tohinder the performance of a pipeline end-to-endsystem. Future research into OKR should first tar-get these areas; either as a pipeline or in a jointlearning framework.
6 Applications and Related Work
The need to consolidate information originatingfrom multiple texts is common in applicationsthat summarize multiple text into some struc-ture, such as multi-document summarization andknowledge-base population. Currently, there is no
4E.g., “Facebook’s acquisition of Instagram” is repre-sented differently than “Facebook acquired Instagram”.
19

systematic solution, and the burden of integratinginformation across multiple texts is delegated todownstream applications, leading to partial solu-tions which are geared to specific applications.
Multi-Document Summarization (MDS)(Barzilay et al., 1999) is a task whose goal is toproduce a concise summary from a set of relatedtext documents, such that it includes the mostimportant information in a non-redundant manner.While extractive summarization selects salientsentences from the document collection, abstrac-tive summarization generates new sentences, andis considered a more promising yet more difficulttask.
A recent approach for abstractive summa-rization generates a graphical representation ofthe input documents by: (1) parsing each sen-tence/document into a meaning representationstructure; and (2) merging the structures into a sin-gle structure that represents the entire summary,e.g. by identifying coreferring items.
In that sense, this approach is similar to OKR.However, current methods applying this approachare still limited. Gerani et al. (2014) parse eachdocument to discourse tree representation (Joty etal., 2013), aggregating them based on entity coref-erence. Yet, they work with a limited set of (dis-course) relations, and rely on coreference only be-tween entities, which was detected manually.
Similarly, Liu et al. (2015) parse each input sen-tence into an individual AMR graph (Banarescuet al., 2013), and merge those into a single graphthrough identical concepts. This work extends theAMR formalism of canonicalized representationper entity or event to multiple sentences. How-ever, they only focus on certain types of namedentities, and collapse two entities based on theirnames rather than on coreference.
Event-Centric Knowledge Graphs (ECKG)(Vossen et al., 2016; Rospocher et al., 2016) isanother related work which represent news arti-cles as graphs. Event nodes are linked to DBPedia(Auer et al., 2007), with the goal of enriching en-tities and events with dynamic knowledge. For ex-ample, an event describing the interception of theSyrian plane by Turkey will be linked in DBPediato Syria and Turkey.
We propose that OKR can help the describedapplications by providing a general underlyingrepresentation for multiple texts, obviating the
need to develop specialized consolidation meth-ods for each application. We can expect the useof OKR structures in MDS to shift the research ef-forts in this task to other components, e.g. gener-ation, and eventually contribute to improving stateof the art on this task. Similarly, an algorithm cre-ating the ECKG structure can benefit from build-ing upon a consolidated structure such as OKR,rather than working directly on free text.
7 Conclusions
In this paper we advocate the development of rep-resentation frameworks for the consolidated infor-mation expressed in a set of texts. The key ingre-dients of our approach are the extraction of propo-sition structures which capture individual state-ments and their merging based on entity and eventcoreference. Coreference clusters are proposed asa handle on real world entities and facts, whilestill being self-contained within the textual realm.Lexical entailment is proposed to model infor-mation containment between different textual de-scriptions of the same real world components.
While we developed an “open” KR framework,future work may investigate the creation of similarmodels based on structures that do refer to exter-nal resources (such as PropBank, as in AbstractMeaning Representation – AMR). Gradually, finegrained semantic phenomena may be addressed,such as factuality, attribution and modeling sub-events and cross-event relationships. Finally, weplan to investigate performing the core annotationsub-tasks via crowdsourcing, for scalability.
Acknowledgments
This work was supported in part by grants fromthe MAGNET program of the Israeli Office of theChief Scientist (OCS) and the German ResearchFoundation through the German-Israeli ProjectCooperation (DIP, grant DA 1600/1-1), and byContract HR0011-15-2-0025 with the US DefenseAdvanced Research Projects Agency (DARPA).
ReferencesGabor Angeli, Melvin Jose Johnson Premkumar, and
Christopher D. Manning. 2015. Leveraging linguis-tic structure for open domain information extraction.In Proceedings of the 53rd Annual Meeting of theAssociation for Computational Linguistics and the7th International Joint Conference on Natural Lan-guage Processing (Volume 1: Long Papers), pages
20

344–354, Beijing, China, July. Association for Com-putational Linguistics.
Jun Araki, Zhengzhong Liu, Eduard Hovy, and TerukoMitamura. 2014. Detecting subevent structure forevent coreference resolution. In Proceedings of theNinth International Conference on Language Re-sources and Evaluation (LREC-2014), pages 4553–4558, Reykjavik, Iceland. European Language Re-sources Association (ELRA).
Soren Auer, Christian Bizer, Georgi Kobilarov, JensLehmann, Richard Cyganiak, and Zachary Ives.2007. The semantic web. In Lecture Notes in Com-puter Science, volume 4825, chapter Dbpedia: Anucleus for a web of open data, pages 722–735.Springer Berlin Heidelberg.
Amit Bagga and Breck Baldwin. 1998. Algorithmsfor scoring coreference chains. In Proceedings ofthe First International Conference on Language Re-sources and Evaluation (LREC’98), volume 1, pages563–566, Granada, Spain. European Language Re-sources Association (ELRA).
Amit Bagga and Breck Baldwin. 1999. Cross-document event coreference: Annotations, exper-iments, and observations. In Proceedings of theWorkshop on Coreference and its Applications,pages 1–8, College Park, Maryland,US. Associationfor Computational Linguistics.
Laura Banarescu, Claire Bonial, Shu Cai, MadalinaGeorgescu, Kira Griffitt, Ulf Hermjakob, KevinKnight, Philipp Koehn, Martha Palmer, and NathanSchneider. 2013. Abstract meaning representationfor sembanking. In Proceedings of the 7th Linguis-tic Annotation Workshop and Interoperability withDiscourse, pages 178–186, Sofia, Bulgaria, August.Association for Computational Linguistics.
Marco Baroni, Raffaella Bernardi, Ngoc-Quynh Do,and Chung-chieh Shan. 2012. Entailment above theword level in distributional semantics. In Proceed-ings of the 13th Conference of the European Chap-ter of the Association for Computational Linguistics,pages 23–32, Avignon, France, April. Associationfor Computational Linguistics.
Regina Barzilay, Kathleen R. McKeown, and MichaelElhadad. 1999. Information fusion in the contextof multi-document summarization. In Proceedingsof the 37th Annual Meeting of the Association forComputational Linguistics, pages 550–557, CollegePark, Maryland, USA, June. Association for Com-putational Linguistics.
Cosmin Bejan and Sanda Harabagiu. 2008. A lin-guistic resource for discovering event structures andresolving event coreference. In Proceedings of theSixth International Conference on Language Re-sources and Evaluation (LREC’08), pages 2881–2887, Marrakech, Morocco, May. European Lan-guage Resources Association (ELRA).
Cosmin A. Bejan and Sanda Harabagiu. 2014. Un-supervised event coreference resolution. Computa-tional Linguistics, 40(2):311–347.
Eric Bengtson and Dan Roth. 2008. Understanding thevalue of features for coreference resolution. In Pro-ceedings of the 2008 Conference on Empirical Meth-ods in Natural Language Processing, pages 294–303, Honolulu, Hawaii. Association for Computa-tional Linguistics.
Jonathan Berant, Ido Dagan, and Jacob Goldberger.2010. Global learning of focused entailment graphs.In Proceedings of the 48th Annual Meeting of theAssociation for Computational Linguistics, pages1220–1229, Uppsala, Sweden, July. Association forComputational Linguistics.
Jonathan Berant, Ido Dagan, and Jacob Goldberger.2012. Learning entailment relations by global graphstructure optimization. Computational Linguistics,38(1):73–111.
Xavier Carreras and Lluıs Marquez. 2005. Intro-duction to the CoNLL-2005 shared task: Semanticrole labeling. In Proceedings of the Ninth Confer-ence on Computational Natural Language Learning(CoNLL-2005), pages 152–164, Ann Arbor, Michi-gan, June. Association for Computational Linguis-tics.
Zheng Chen, Heng Ji, and Robert Haralick. 2009.A pairwise event coreference model, feature impactand evaluation for event coreference resolution. InProceedings of the Workshop on Events in Emerg-ing Text Types, pages 17–22, Borovets, Bulgaria,September. Association for Computational Linguis-tics.
Kevin Clark and Christopher D. Manning. 2015.Entity-centric coreference resolution with modelstacking. In Proceedings of the 53rd Annual Meet-ing of the Association for Computational Linguisticsand the 7th International Joint Conference on Natu-ral Language Processing (Volume 1: Long Papers),pages 1405–1415, Beijing, China, July. Associationfor Computational Linguistics.
Agata Cybulska and Piek Vossen. 2014. Using asledgehammer to crack a nut? lexical diversity andevent coreference resolution. In Proceedings of theNinth International Conference on Language Re-sources and Evaluation (LREC-2014), pages 4545–4552, Reykjavik, Iceland. European Language Re-sources Association (ELRA).
Ido Dagan, Dan Roth, and Mark Sammons. 2013. Rec-ognizing textual entailment. Morgan & ClaypoolPublishers, San Rafael, CA.
Luciano Del Corro and Rainer Gemulla. 2013.Clausie: Clause-based open information extraction.In Proceedings of the 22Nd International Confer-ence on World Wide Web, WWW ’13, pages 355–366, Rio de Janeiro, Brazil. Association for Com-puting Machinery.
21

Florence Duclaye, Francois Yvon, and Olivier Collin.2002. Using the web as a linguistic resource forlearning reformulations automatically. In Proceed-ings of the Third International Conference on Lan-guage Resources and Evaluation (LREC’02), vol-ume 2, pages 390–396, Las Palmas, Canary Islands- Spain. European Language Resources Association(ELRA).
Oren Etzioni, Michele Banko, Stephen Soderland, andDaniel S. Weld. 2008. Open information extrac-tion from the web. Communications of the ACM,51(12):68–74, December.
Anthony Fader, Stephen Soderland, and Oren Etzioni.2011. Identifying relations for open information ex-traction. In Proceedings of the 2011 Conference onEmpirical Methods in Natural Language Process-ing, pages 1535–1545, Edinburgh, Scotland, UK.,July. Association for Computational Linguistics.
Shima Gerani, Yashar Mehdad, Giuseppe Carenini,Raymond T. Ng, and Bita Nejat. 2014. Abstractivesummarization of product reviews using discoursestructure. In Proceedings of the 2014 Conference onEmpirical Methods in Natural Language Processing(EMNLP), pages 1602–1613, Doha, Qatar, October.Association for Computational Linguistics.
Xianpei Han and Le Sun. 2016. Context-sensitiveinference rule discovery: A graph-based method.In Proceedings of COLING 2016, the 26th Inter-national Conference on Computational Linguistics:Technical Papers, pages 2902–2911, Osaka, Japan,December. The COLING 2016 Organizing Commit-tee.
Luheng He, Mike Lewis, and Luke Zettlemoyer. 2015.Question-answer driven semantic role labeling: Us-ing natural language to annotate natural language.In Proceedings of the 2015 Conference on Empiri-cal Methods in Natural Language Processing, pages643–653, Lisbon, Portugal, September. Associationfor Computational Linguistics.
Marti A. Hearst. 1992. Automatic acquisition ofhyponyms from large text corpora. In COLING1992 Volume 2: Proceedings of the 15th Inter-national Conference on Computational Linguistics,volume 2, pages 539–545. Association for Compu-tational Linguistics.
Kevin Humphreys, Robert Gaizauskas, and Saliha Az-zam. 1997. Event coreference for information ex-traction. In Proceedings of a Workshop on Opera-tional Factors in Practical, Robust Anaphora Reso-lution for Unrestricted Texts, pages 75–81, Madrid,Spain, July. Association for Computational Linguis-tics.
Shafiq Joty, Giuseppe Carenini, Raymond Ng, andYashar Mehdad. 2013. Combining intra- and multi-sentential rhetorical parsing for document-level dis-course analysis. In Proceedings of the 51st AnnualMeeting of the Association for Computational Lin-guistics (Volume 1: Long Papers), pages 486–496,
Sofia, Bulgaria, August. Association for Computa-tional Linguistics.
Hans Kamp, Josef Van Genabith, and Uwe Reyle.2011. Discourse representation theory. In Hand-book of philosophical logic, volume 15, pages 125–394. Springer Netherlands.
Lili Kotlerman, Ido Dagan, Idan Szpektor, and MaayanZhitomirsky-Geffet. 2010. Directional distribu-tional similarity for lexical inference. Natural Lan-guage Engineering, 16(04):359–389.
Heeyoung Lee, Marta Recasens, Angel Chang, MihaiSurdeanu, and Dan Jurafsky. 2012. Joint entity andevent coreference resolution across documents. InProceedings of the 2012 Joint Conference on Empir-ical Methods in Natural Language Processing andComputational Natural Language Learning, pages489–500, Jeju Island, Korea, July. Association forComputational Linguistics.
Dekang Lin and Patrick Pantel. 2001. Dirt - discoveryof inference rules from text. In Proceedings of theSeventh ACM SIGKDD International Conference onKnowledge Discovery and Data Mining, KDD ’01,pages 323–328, San Francisco, California. Associa-tion for Computing Machinery.
Zhengzhong Liu, Jun Araki, Eduard Hovy, and TerukoMitamura. 2014. Supervised within-documentevent coreference using information propagation. InProceedings of the Ninth International Conferenceon Language Resources and Evaluation (LREC-2014), pages 4539–4544, Reykjavik, Iceland. Euro-pean Language Resources Association (ELRA).
Fei Liu, Jeffrey Flanigan, Sam Thomson, NormanSadeh, and Noah A. Smith. 2015. Toward abstrac-tive summarization using semantic representations.In Proceedings of the 2015 Conference of the NorthAmerican Chapter of the Association for Compu-tational Linguistics: Human Language Technolo-gies, pages 1077–1086, Denver, Colorado, May–June. Association for Computational Linguistics.
Andrew J. McMinn, Yashar Moshfeghi, and Joe-mon M. Jose. 2013. Building a large-scale cor-pus for evaluating event detection on twitter. InProceedings of the 22Nd ACM International Con-ference on Information & Knowledge Management,CIKM ’13, pages 409–418, San Francisco, Califor-nia, USA. Association for Computing Machinery.
Oren Melamud, Ido Dagan, and Jacob Goldberger.2015. Modeling word meaning in context with sub-stitute vectors. In Proceedings of the 2015 Confer-ence of the North American Chapter of the Associ-ation for Computational Linguistics: Human Lan-guage Technologies, pages 472–482, Denver, Col-orado, May–June. Association for ComputationalLinguistics.
Vincent Ng and Claire Cardie. 2002. Improving ma-chine learning approaches to coreference resolution.
22

In Proceedings of 40th Annual Meeting of the Asso-ciation for Computational Linguistics, pages 104–111, Philadelphia, Pennsylvania, USA, July. Asso-ciation for Computational Linguistics.
Martha Palmer, Daniel Gildea, and Nianwen Xue.2010. Semantic role labeling. Synthesis Lectureson Human Language Technologies, 3(1):1–103.
Ellie Pavlick, Johan Bos, Malvina Nissim, CharleyBeller, Benjamin Van Durme, and Chris Callison-Burch. 2015. Adding semantics to data-driven para-phrasing. In Proceedings of the 53rd Annual Meet-ing of the Association for Computational Linguisticsand the 7th International Joint Conference on Natu-ral Language Processing (Volume 1: Long Papers),pages 1512–1522, Beijing, China, July. Associationfor Computational Linguistics.
Haoruo Peng, Kai-Wei Chang, and Dan Roth. 2015. Ajoint framework for coreference resolution and men-tion head detection. In Proceedings of the Nine-teenth Conference on Computational Natural Lan-guage Learning, pages 12–21, Beijing, China, July.Association for Computational Linguistics.
Haoruo Peng, Yangqiu Song, and Dan Roth. 2016.Event detection and co-reference with minimal su-pervision. In Proceedings of the 2016 Conferenceon Empirical Methods in Natural Language Pro-cessing, pages 392–402, Austin, Texas, November.Association for Computational Linguistics.
Marco Rospocher, Marieke van Erp, Piek Vossen,Antske Fokkens, Itziar Aldabe, German Rigau,Aitor Soroa, Thomas Ploeger, and Tessel Bogaard.2016. Building event-centric knowledge graphsfrom news. Web Semantics: Science, Services andAgents on the World Wide Web, 37:132–151.
Michael Roth and Anette Frank. 2012. Aligning predi-cate argument structures in monolingual comparabletexts: A new corpus for a new task. In *SEM 2012:The First Joint Conference on Lexical and Compu-tational Semantics – Volume 1: Proceedings of themain conference and the shared task, and Volume 2:Proceedings of the Sixth International Workshop onSemantic Evaluation (SemEval 2012), pages 218–227, Montreal, Canada, 7-8 June. Association forComputational Linguistics.
Enrico Santus, Alessandro Lenci, Qin Lu, and SabineSchulte im Walde. 2014. Chasing hypernyms invector spaces with entropy. In Proceedings of the14th Conference of the European Chapter of the As-sociation for Computational Linguistics, volume 2:Short Papers, pages 38–42, Gothenburg, Sweden,April. Association for Computational Linguistics.
Stefan Schoenmackers, Jesse Davis, Oren Etzioni, andDaniel Weld. 2010. Learning first-order hornclauses from web text. In Proceedings of the 2010Conference on Empirical Methods in Natural Lan-guage Processing, pages 1088–1098, Cambridge,MA, October. Association for Computational Lin-guistics.
Vered Shwartz and Ido Dagan. 2016. Path-based vs.distributional information in recognizing lexical se-mantic relations. In Proceedings of the 5th Work-shop on Cognitive Aspects of the Lexicon (CogALex- V), pages 24–29, Osaka, Japan, December. TheCOLING 2016 Organizing Committee.
Vered Shwartz, Omer Levy, Ido Dagan, and JacobGoldberger. 2015. Learning to exploit structuredresources for lexical inference. In Proceedings ofthe Nineteenth Conference on Computational Nat-ural Language Learning, pages 175–184, Beijing,China, July. Association for Computational Linguis-tics.
Vered Shwartz, Yoav Goldberg, and Ido Dagan. 2016.Improving hypernymy detection with an integratedpath-based and distributional method. In Proceed-ings of the 54th Annual Meeting of the Associationfor Computational Linguistics (Volume 1: Long Pa-pers), pages 2389–2398, Berlin, Germany, August.Association for Computational Linguistics.
Sameer Singh, Amarnag Subramanya, FernandoPereira, and Andrew McCallum. 2011. Large-scalecross-document coreference using distributed infer-ence and hierarchical models. In Proceedings of the49th Annual Meeting of the Association for Com-putational Linguistics: Human Language Technolo-gies, pages 793–803, Portland, Oregon, USA, June.Association for Computational Linguistics.
Rion Snow, Daniel Jurafsky, and Andrew Y. Ng. 2005.Learning syntactic patterns for automatic hypernymdiscovery. In Advances in Neural Information Pro-cessing Systems, volume 17, pages 1297–1304. MITPress.
Wee M. Soon, Hwee T. Ng, and Daniel C. Y. Lim.2001. A machine learning approach to coreferenceresolution of noun phrases. Computational linguis-tics, 27(4):521–544.
Gabriel Stanovsky and Ido Dagan. 2016. Annotatingand predicting non-restrictive noun phrase modifi-cations. In Proceedings of the 54th Annual Meet-ing of the Association for Computational Linguis-tics (Volume 1: Long Papers), pages 1256–1265,Berlin, Germany, August. Association for Compu-tational Linguistics.
Gabriel Stanovsky, Ido Dagan, and Mausam. 2015.Open IE as an intermediate structure for semantictasks. In Proceedings of the 53rd Annual Meet-ing of the Association for Computational Linguisticsand the 7th International Joint Conference on Natu-ral Language Processing (Volume 2: Short Papers),pages 303–308, Beijing, China, July. Association forComputational Linguistics.
Gabriel Stanovsky, Jessica Ficler, Ido Dagan, and YoavGoldberg. 2016. Getting more out of syntax withprops. arXiv preprint.
23

Asher Stern and Ido Dagan. 2012. Biutee: A mod-ular open-source system for recognizing textual en-tailment. In Proceedings of the ACL 2012 SystemDemonstrations, pages 73–78, Jeju Island, Korea,July. Association for Computational Linguistics.
Idan Szpektor, Hristo Tanev, Ido Dagan, and Bonaven-tura Coppola. 2004. Scaling web-based acquisitionof entailment relations. In Dekang Lin and DekaiWu, editors, Proceedings of EMNLP 2004, pages41–48, Barcelona, Spain, July. Association for Com-putational Linguistics.
Peter D. Turney and Saif M. Mohammad. 2015. Ex-periments with three approaches to recognizing lex-ical entailment. Natural Language Engineering,21(03):437–476.
Shyam Upadhyay, Nitish Gupta, ChristosChristodoulopoulos, and Dan Roth. 2016. Re-visiting the evaluation for cross document eventcoreference. In Proceedings of COLING 2016, the26th International Conference on ComputationalLinguistics.
Marc Vilain, John Burger, John Aberdeen, Dennis Con-nolly, and Lynette Hirschman. 1995. A model-theoretic coreference scoring scheme. In Proceed-ings of the 6th conference on Message understand-ing, pages 45–52, Columbia, Maryland. Associationfor Computational Linguistics.
Piek Vossen, Rodrigo Agerri, Itziar Aldabe, Agata Cy-bulska, Marieke van Erp, Antske Fokkens, EgoitzLaparra, Anne-Lyse Minard, Alessio Palmero Apro-sio, German Rigau, et al. 2016. Newsreader: Us-ing knowledge resources in a cross-lingual readingmachine to generate more knowledge from mas-sive streams of news. Knowledge-Based Systems,110:60–85.
Julie Weeds, Daoud Clarke, Jeremy Reffin, David Weir,and Bill Keller. 2014. Learning to distinguish hy-pernyms and co-hyponyms. In Proceedings of COL-ING 2014, the 25th International Conference onComputational Linguistics: Technical Papers, pages2249–2259, Dublin, Ireland, August. Dublin CityUniversity and Association for Computational Lin-guistics.
Travis Wolfe, Benjamin Van Durme, Mark Dredze,Nicholas Andrews, Charley Beller, Chris Callison-Burch, Jay DeYoung, Justin Snyder, JonathanWeese, Tan Xu, and Xuchen Yao. 2013. Parma: Apredicate argument aligner. In Proceedings of the51st Annual Meeting of the Association for Com-putational Linguistics (Volume 2: Short Papers),pages 63–68, Sofia, Bulgaria, August. Associationfor Computational Linguistics.
Travis Wolfe, Mark Dredze, and Benjamin Van Durme.2015. Predicate argument alignment using a globalcoherence model. In Proceedings of the 2015 Con-ference of the North American Chapter of the As-sociation for Computational Linguistics: Human
Language Technologies, pages 11–20, Denver, Col-orado, May–June. Association for ComputationalLinguistics.
24

Proceedings of the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics, pages 25–30,Valencia, Spain, April 3, 2017. c©2017 Association for Computational Linguistics
Event-Related Features in Feedforward Neural Networks Contribute toIdentifying Causal Relations in Discourse
Edoardo Maria PontiLTL, University of Cambridge
Anna KorhonenLTL, University of Cambridge
Abstract
Causal relations play a key role in infor-mation extraction and reasoning. Most ofthe times, their expression is ambiguousor implicit, i.e. without signals in the text.This makes their identification challeng-ing. We aim to improve their identifica-tion by implementing a Feedforward Neu-ral Network with a novel set of features forthis task. In particular, these are based onthe position of event mentions and the se-mantics of events and participants. The re-sulting classifier outperforms strong base-lines on two datasets (the Penn DiscourseTreebank and the CSTNews corpus) anno-tated with different schemes and contain-ing examples in two languages, Englishand Portuguese. This result demonstratesthe importance of events for identifyingdiscourse relations.
1 Introduction
The identification of causal and temporal rela-tions is potentially useful to many NLP tasks(Mirza et al., 2014), such as information extractionfrom narrative texts (e.g., question answering, textsummarization, decision support) and reasoningthrough inference based on a knowledge source(Ovchinnikova et al., 2010).
A number of resources provide examples ofcausal relations annotated between event mentions(Mirza et al., 2014) or text spans (Bethard et al.,2008). Among the second group, there are corporacompliant with the assumptions of the Rhetori-cal Structure Theory (RST) in various languages(Carlson et al., 2002; Aleixo and Pardo, 2008),and the Penn Discourse Treebank (Prasad et al.,2007). The latter counts the largest amount of ex-
amples and is the only resource distinguishing be-tween explicit and implicit relations.
The discourse signal marking causal relations isoften ambiguous (i.e. shared with other kinds ofrelation), or lacking altogether. Identifying im-plicit causal relations is challenging for severalreasons. They often entail a temporal relation ofprecedence, but this condition is not mandatory(Bethard et al., 2008; Mirza et al., 2014). More-over, implicit causal relations are partly subjectiveand have low inter-annotator agreement (Grivaz,2012; Dunietz et al., 2015). Finally, they have tobe detected through linguistic context and worldknowledge: unfortunately, this information can-not be approximated by explicit relations deprivedof their signal (Sporleder and Lascarides, 2008).Notwithstanding the partial redundancy betweensignal and context, implicit examples and explicitexamples belonging to the same class appear to betoo dissimilar linguistically.
Although various techniques have been pro-posed for the task, ranging from distributionalmetrics (Riaz and Girju, 2013, inter alia) to tra-ditional machine learning algorithms (Lin et al.,2014, inter alia), few have been based on deeplearning. Those that have used deep learning havemostly relied on lexical features (Zhang et al.,2015; Zhang and Wang, 2015). The aim of ourwork is to enrich Artificial Neural Networks withfeatures that capture insights from linguistic the-ory (§ 2) as well as related works (§ 3). In particu-lar, they capture information about the content andposition of the events involved in the relation. Af-ter presenting the datasets (§ 4), the method (§ 6)and the experimental results (§ 7) we conclude (§8) by highlighting that the observed improvementsstem from the link between event semantics anddiscourse relations. Although our work focuses onimplicit causal relations, the proposed features areshown to be beneficial also for explicit instances.
25

2 Events in Linguistic Theory
Events are complex entities bridging between se-mantic meaning and the syntactic form (Croft,2002). The token expressing an event in a text iscalled a mention and usually consists in a verbalpredicate. An event denotes a situation and con-sists of various components, such as participantsand aspect. Participants are entities taking partin the situation, each playing a specific semanticrole (Fillmore, 1968; Dowty, 1991). Aspect is thestructure of the situation over time and is partlyinherent to verbs (Vendler, 1967).
Within discourse, events can establish betweenthemselves different kinds of relation, amongwhich a causal relation (Pustejovsky et al., 2003).This relation is asymmetrical, bridging between acause and an effect. Discourse-level causation isexpressed explicitly through verbs (e.g. to cause orto enable) (Wolff, 2007) or adverbial markers, ei-ther inter-clausal (e.g. because) or inter-sentential(e.g. indeed). These markers are often ambiguous.Moreover, causation is not necessarily explicit: itcan be entailed by the speakers and inferred by thelisteners only through world knowledge (Grivaz,2012).
Both explicit and implicit relations are regulatedby a long-standing cognitive principle, namely di-agrammatical iconicity. According to this princi-ple the tightness of the morphosyntactic packagingof two expressions is proportional to the degree ofsemantic integration of the concepts they denote(Haiman, 1985). The relevance of this principlefor causal relations has been validated empiricallyby comparing constructions used to describe cau-sation in visual stimuli (Kita et al., 2010): suchconstructions were affected by the mediation of ananimate participant and the absence of spatial con-tact or temporal contiguity.
This principle is useful to distinguish causalityfrom other relations. Among adverbial clauses,those expressing cause preserve more indepen-dence from the main (effect) clause than the otherscross-linguistically. Independence is measured bythe freedom in their relative order, the autonomousintonation contour, and non-reduced grammaticalcategories or valence of verbs (Lakoff, 1984; Dies-sel and Hetterle, 2011; Cristofaro, 2005). Theiconicity principle predicts that this morphosyn-tactic behaviour corresponds to situations not nec-essarily sharing time, place and participants froma semantic point of view.
3 Previous Work
Many previous works identified causal relationsusing metrics or traditional machine learning algo-rithms. Metrics of the ‘causal potential’ of eventpairs were estimated using distributional informa-tion (Beamer and Girju, 2009), verb pairs (Riazand Girju, 2013) or discourse relation markers (Doet al., 2011). Other techniques employed manu-ally defined rules, consisting in high-level patterns(Grivaz, 2012) or a set of axioms (Ovchinnikovaet al., 2010).
The machine learning approaches formulatedcausal relation identification as a binary classifica-tion problem. This problem sometimes involvedan intermediate step of discourse marker predic-tion (Zhou et al., 2010). Features based on fine-grained syntactic representations proved particu-larly helpful (Wang et al., 2010), and were some-times supplemented with information about wordpolarity, verb classes, and discourse context (Pitleret al., 2009; Lin et al., 2014).
Few approaches based on deep learning havebeen proposed for discourse relation classificationso far. Zhang et al. (2015) focused on implicit re-lations. They introduced a Shallow ConvolutionalNeural Network that learns exclusively from lexi-cal features. It adopts some strategies to amend thesparseness and imbalance of the dataset, such asa shallow architecture, naive convolutional opera-tions, random under-sampling, and normalization.This approach outperforms baselines based on aSupport Vector Machine, a Transductive SupportVector Machine, and a Recursive AutoEncoder.
Moreover, related work on nominal relationclassification (Zeng et al., 2014; Zhang and Wang,2015) showed improvements due to using ad-ditional features (neighbours and hypernyms ofnouns), as well as measuring the relative distanceof each token in a sentence from the target nouns.Although these features are possibly relevant forthe identification of causal relations, they have notbeen investigated for this task before.
4 Datasets
We ran our experiment on two datasets represent-ing different annotation schemes and different lan-guages: the Penn Discourse Treebank in English(Prasad et al., 2007) and the CSTNews corpus inBrazilian Portuguese (Aleixo and Pardo, 2008).The Penn Discourse Treebank was chosen becauseit distinguishes between explicit and implicit rela-
26

Figure 1: Layers of the Feedforward Neural Network with enriched features.
tions and offers the widest set of examples. Re-lations are classified into four categories at thecoarse-grained level: Contingency is considered asthe positive class, whereas the others as the nega-tive class.1 We divided the corpus into a trainingset (sections 2-20), a validation set (sections 0-1),and a test set (sections 21-22), following Pitler etal. (2009) and Zhang et al. (2015).
On the other hand, he CSTNews corpus con-tains documents in Brazilian Portuguese annotatedaccording to the Rhetorical Structure Theory. Wefiltered the texts to keep only relations amongleaves in the discourse tree (i.e. containing textspans). The examples labelled as volitional-cause,non-volitional-cause result, and purpose were as-signed to the positive class and the others to thenegative class. In this case, no distinction wasavailable between implicit and explicit relations.The data partitions in the datasets are detailed inTable 1.
Set PDTB CSTNewsTraining 3342/9290 190/1101Validation 295/888 19/143Test 279/767 19/142
Table 1: Number of examples: positive/negative
1Contingency overlaps with the fine-grained categoryCause for implicit relations: Condition instead can be hardlyconveyed without an explicit hypothetical marker (e.g. if ).
5 Features
The most basic kind of features we fed to our algo-rithm is lexical features, i.e. the vectors stemmingfrom the look-up of the words in every sentence.Vectors are obtained from a model trained withgensim (Rehurek and Sojka, 2010) on Wikipedia.Moreover, we included some additional features:event-related and positional features.
In order to obtain these, the PDTB and CST-News corpora were parsed using MATE tools(Bohnet, 2010). This parser was trained on theEnglish and Portuguese treebanks available in theUniversal Dependency collection (Nivre et al.,2016). In particular, for each of the two relatedsentences we employed the syntactic trees to dis-cover its root (considered as the event mention)and the nominal modifiers of the root (consideredas the participants).2 We extracted the vector rep-resentations of their lemmas, which we call event-related features. Moreover, we assigned to eachtoken two integers representing its absolute lin-ear distance from either event mention. These arecalled positional features.
The combination of lexical and additional fea-tures is called enriched feature set, as opposed toa basic feature set with just lexical features. Asan example, consider Figure 1. The lemmas of thetwo roots are emit and contaminate. Those of their
2The syntactic root is often, but not necessarily, a verb. Itsnominal modifiers are dependent nouns labelled as subject,direct object, or indirect object.
27

nominal dependents are plutonium+radiation andenvironment, respectively. Moreover, the token al-pha, for instance, is assigned the integers 1 (dis-tance from emits) and 5 (distance from contami-nated).
The rationale of the additional features is thatsimilar features were employed successfully fornominal relation classification (Zeng et al., 2014).Moreover, they are motivated linguistically. Po-sitional features encode the distance and hencethe iconic principle, whereas event-related fea-tures account for the semantics of the event andits participants (see § 2).
6 Method
We describe here the architecture of the Feedfor-ward Neural Network with an enriched featureset. The core components of the architecture area look-up step, a hidden layer and the final lo-gistic regression layer where a softmax estimatesthe probabilities of the two classes. These are areshown in Figure 1. Positional features are concate-nated to the input after the look-up step, and arerepresented as grey nodes. Event-related featuresinstead are concatenated to the output of the hid-den layer, and are represented as blue nodes. Thetraining set was under-sampled randomly: positiveexamples were pruned in order to obtain the sameamount of negative and positive examples.3 Af-terwards, all the sentences of the training set werepadded with zeroes to equalize them to a length n.Each word was transformed into its correspondingD-dimensional vector by looking up a word em-bedding matrix E. This matrix is a parameter ofthe model and is initialized with pre-trained vec-tors. Afterwards, each vector was concatenatedalong the D-dimensional axis with its two neigh-bouring vectors and its two positional features.
This input representation x was then fed to thehidden layer. It underwent a non-linear transfor-mation with a weight and a bias as parameters, andthe hyperbolic tangent tanh as activation function.The weight is a matrix W1 ∈ RD×h, where h isan hyper-parameter defining the size of the hid-den layer. The bias, on the other hand, is a vec-tor b1 ∈ Rh. Both were initialised by uniformlysampling values from the symmetric interval sug-gested by Glorot and Bengio (2010). The output
3Without random under-sampling, the algorithm wors-ened its performance, whereas no significant differences wereobserved with random over-sampling.
of this transformation was concatenated with fourword embeddings of the two events and the two(max-pooled) sets of their participants. The re-sulting matrix underwent a max pooling operationover the n axis, which yielded a vector.
Finally, the output of the hidden layer was fedinto a Logistic Regression layer. As above, it wasmultiplied to a weight W2 ∈ Rh×2 and added toa bias b2 ∈ R2. Note that the shape of these pa-rameters along a dimension has length 2 becausethis is the number of classes to output. Contrary tothe hidden layer, both parameters were initializedas zeros. The output of Logistic Regression wassquashed by a softmax function σ, which yieldedthe probability for each class given the example.
The set of parameters of the algorithm is θ ={E,W1, b1,W2, b2}. The loss function is basedon binary cross-entropy and is regularised by thesquared norm of the parameters scaled by a hy-perparameter `. Given an input array of indicesto the embedding matrix xi, the event-related fea-tures xe, the positional features xp, and a true classy, the objective function is as shown in Equation1:
J = −∑x,y
σ(W2||maxn
(tanh(W1·(xi·E⊕xe)+
+ b1)⊕ xp)||+ b2) logP (y) + `||θ||2. (1)
The optimization of the objective function wasperformed through mini-batch stochastic gradientdescent, running for 150 epochs. Early stoppingwas enforced to avoid over-fitting. The width ofthe batches was set to 20, whereas the learningrate λ to 10−1. The vector dimension D in theword embedding was 300, the regularization fac-tor ` 10−4, and the width of the hidden layer h3000.
7 Results
The performance of the classifier presented in §6 (named Enriched) was compared with a seriesof baselines. A naive baseline consists in alwaysguessing the positive class (Positive). A moresolid baseline is the state of the art for class-specific identification of implicit relations in thePDTB: the Shallow Convolutional Neural Net-work (SCNN) by Zhang et al. (2015). The config-uration of this algorithm, as mentioned in § 3, in-cludes max pooling, random under-sampling, andnormalization. Finally, the last baseline is our
28
Classifier Macro-F1 Precision Recall AccuracyPositive 42.11 26.67 100 26.67SCNN 52.04 39.80 75.29 63.00Basic 53.01 42.04 71.74 66.44Enriched 54.52 42.37 76.45 66.35
Classifier Macro-F1 Precision Recall AccuracyPositive 21.11 11.80 100 11.80Basic 48.36 35.51 76.48 82.82Enriched 55.62 40.66 88.24 85.00
Table 2: Different settings for the datasets PDTB (above) and CSTNews (below).
classifier deprived of the additional features (Ba-sic): in other words, it hinges only upon the lexicalfeatures.
The results for both the PDTB and CSTNewsdatasets are presented in Table 2.4 A McNamar’sChi-Squared test determined the statistical signif-icance of the difference between the classes pre-dicted by Enriched and Basic with p < 0.05. Theenriched features have a positive impact on preci-sion and recall. This effect is not always observedin accuracy: however, this metric is unreliable dueto the high number of negative examples. The im-provement on the PDTB is clearly related to im-plicit examples. From the results on the CSTNewscorpus, however, it is safe to gather only that iden-tification of causal relations in general is affected.
8 Conclusion
Drawing upon the semantic theory of events andinspired by work on related tasks, we enriched thefeature set previously used for the identification ofcausal relations. Eventually, this set included lex-ical, positional, and event-related features. Pro-viding this information to a Feedforward NeuralNetwork, we obtained a series of results. Firstly,our method outperformed earlier approaches andsolid baselines on two different datasets and in twodifferent languages, demonstrating the benefit ofenriched features. Secondly, our experiment con-firmed two theoretical assumptions, namely theiconic principle and the complexity of events. Ingeneral, exploiting the theory of event semanticscontributed significantly to discourse relation clas-sification, demonstrating that these domains areintertwined to a certain extent.
4The results for the CSTNews corpus equals to the aver-age of multiple initializations.
References
Priscila Aleixo and Thiago Alexandre Salgueiro Pardo.2008. CSTNews: um corpus de textos jor-nalısticos anotados segundo a teoria discursiva mul-tidocumento CST (cross-document structure theory.ICMC-USP.
Brandon Beamer and Roxana Girju. 2009. Using abigram event model to predict causal potential. InComputational Linguistics and Intelligent Text Pro-cessing, pages 430–441. Springer.
Steven Bethard, William J. Corvey, Sara Klingenstein,and James H. Martin. 2008. Building a corpusof temporal-causal structure. In Proceedings ofLREC’16, pages 908–915.
Bernd Bohnet. 2010. Very high accuracy and fast de-pendency parsing is not a contradiction. In Proceed-ings of the 23rd international conference on compu-tational linguistics, pages 89–97.
Lynn Carlson, Mary Ellen Okurowski, Daniel Marcu,Linguistic Data Consortium, et al. 2002. RST dis-course treebank. Linguistic Data Consortium, Uni-versity of Pennsylvania.
Sonia Cristofaro. 2005. Subordination. Oxford Uni-versity Press.
William Croft. 2002. Typology and universals. Cam-bridge University Press.
Holger Diessel and Katja Hetterle. 2011. Causalclauses: A cross-linguistic investigation of theirstructure, meaning, and use. Linguistic universalsand language variation, pages 21–52.
Quang Xuan Do, Yee Seng Chan, and Dan Roth.2011. Minimally supervised event causality identifi-cation. In Proceedings of the Conference on Empiri-cal Methods in Natural Language Processing, pages294–303.
David Dowty. 1991. Thematic proto-roles and argu-ment selection. Language, 67(3):547–619.
29

Jesse Dunietz, Lori Levin, and Jaime Carbonell. 2015.Annotating causal language using corpus lexicog-raphy of constructions. In The 9th Linguistic An-notation Workshop held in conjuncion with NAACL2015, pages 188–196.
Charles Fillmore. 1968. The case for case. In Em-mon Bach and Robert Harms, editors, Universals inlinguistic theory, pages 1–88. Holt, Rinehart & Win-ston.
Xavier Glorot and Yoshua Bengio. 2010. Understand-ing the difficulty of training deep feedforward neuralnetworks. In AISTATS, volume 9, pages 249–256.
Cecile Grivaz. 2012. Automatic extraction of causalknowledge from natural language texts. Ph.D. the-sis, University of Geneva.
John Haiman. 1985. Natural syntax. iconicity and ero-sion. Cambridge Studies in Linguistics, (44):1–285.
Sotaro Kita, N.J. Enfield, Jurgen Bohnemeyer, andJames Essegbey. 2010. The macro-event property:The segmentation of causal chains. In J. Bohne-meyer and E. Pederson, editors, Event representa-tion in language and cognition, pages 43–67. Cam-bridge University Press.
George Lakoff. 1984. Performative subordinateclauses. In Annual Meeting of the Berkeley Linguis-tics Society, volume 10, pages 472–480.
Ziheng Lin, Hwee Tou Ng, and Min-Yen Kan. 2014. APDTB-styled end-to-end discourse parser. NaturalLanguage Engineering, 20(02):151–184.
Paramita Mirza, Rachele Sprugnoli, Sara Tonelli, andManuela Speranza. 2014. Annotating causality inthe TempEval-3 corpus. In Proceedings of the EACL2014 Workshop on Computational Approaches toCausality in Language (CAtoCL), pages 10–19.
Joakim Nivre, Marie-Catherine de Marneffe, Filip Gin-ter, Yoav Goldberg, Jan Hajic, Christopher D Man-ning, Ryan McDonald, Slav Petrov, Sampo Pyysalo,Natalia Silveira, et al. 2016. Universal dependen-cies v1: A multilingual treebank collection. In Pro-ceedings of the 10th International Conference onLanguage Resources and Evaluation (LREC 2016),pages 1659–1666.
Ekaterina Ovchinnikova, Laure Vieu, AlessandroOltramari, Stefano Borgo, and Theodore Alexan-drov. 2010. Data-driven and ontological analysisof framenet for natural language reasoning. In Pro-ceedings of LREC’10, pages 3157–3162.
Emily Pitler, Annie Louis, and Ani Nenkova. 2009.Automatic sense prediction for implicit discourse re-lations in text. In Proceedings of the Joint Confer-ence of the 47th Annual Meeting of the ACL and the4th International Joint Conference on Natural Lan-guage Processing of the AFNLP: Volume 2, pages683–691.
Rashmi Prasad, Eleni Miltsakaki, Nikhil Dinesh, AlanLee, Aravind Joshi, Livio Robaldo, and Bonnie LWebber. 2007. The Penn Discourse Treebank 2.0annotation manual. Technical report.
James Pustejovsky, Jose M. Castano, Robert Ingria,Robert J. Gaizauskas, Andrea Setzer, Graham Katz,and Dragomir R. Radev. 2003. TimeML: Robustspecification of event and temporal expressions intext. Technical report, AAAI.
Radim Rehurek and Petr Sojka. 2010. SoftwareFramework for Topic Modelling with Large Cor-pora. In Proceedings of the LREC 2010 Workshopon New Challenges for NLP Frameworks, pages 45–50, Valletta, Malta, May. ELRA. http://is.muni.cz/publication/884893/en.
Mehwish Riaz and Roxana Girju. 2013. Towarda better understanding of causality between verbalevents: Extraction and analysis of the causal powerof verb-verb associations. In Proceedings of the an-nual SIGdial Meeting on Discourse and Dialogue(SIGDIAL), pages 21–30.
Caroline Sporleder and Alex Lascarides. 2008. Usingautomatically labelled examples to classify rhetori-cal relations: An assessment. Natural Language En-gineering, 14(03):369–416.
Zeno Vendler. 1967. Linguistics in philosophy. Cor-nell University Press.
WenTing Wang, Jian Su, and Chew Lim Tan. 2010.Kernel based discourse relation recognition withtemporal ordering information. In Proceedings ofthe 48th Annual Meeting of the Association for Com-putational Linguistics, pages 710–719.
Phillip Wolff. 2007. Representing causation. Journalof experimental psychology: General, 136(1):82.
Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou,Jun Zhao, et al. 2014. Relation classification viaconvolutional deep neural network. In Proccedingsof COLING’14, pages 2335–2344.
Dongxu Zhang and Dong Wang. 2015. Relation classi-fication via recurrent neural network. arXiv preprintarXiv:1508.01006.
Biao Zhang, Jinsong Su, Deyi Xiong, Yaojie Lu, HongDuan, and Junfeng Yao. 2015. Shallow convo-lutional neural network for implicit discourse rela-tion recognition. In Proceedings of the 2015 Con-ference on Empirical Methods in Natural LanguageProcessing, pages 2230–2235.
Zhi-Min Zhou, Yu Xu, Zheng-Yu Niu, Man Lan, JianSu, and Chew Lim Tan. 2010. Predicting discourseconnectives for implicit discourse relation recog-nition. In Proceedings of the 23rd InternationalConference on Computational Linguistics: Posters,pages 1507–1514.
30

Proceedings of the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics, pages 31–40,Valencia, Spain, April 3, 2017. c©2017 Association for Computational Linguistics
Stance Detection in Facebook Posts of a German Right-wing Party
Manfred Klenner and Don Tuggener and Simon ClematideComputational Linguistics
University of Zurich, Switzerland{klenner,tuggener,siclemat}@cl.uzh.ch
Abstract
We argue that in order to detect stance,not only the explicit attitudes of the stanceholder towards the targets are crucial. Itis the whole narrative the writer draftsthat counts, including the way he hyposta-sizes the discourse referents: as benefac-tors or villains, as victims or beneficia-ries. We exemplify the ability of oursystem to identify targets and detect thewriter’s stance towards them on the basisof about 100 000 Facebook posts of a Ger-man right-wing party. A reader and writermodel on top of our verb-based attitudeextraction directly reveal stance conflicts.
1 Introduction
Recently, verb-based sentiment relation extractionhas been used among others to derive positive andnegative attitudes of Democrats and Republicanstowards actors or topics. The system of Rashkinet al. (2016) accomplishes this task on the basis ofcrowd-sourced connotation frames of (transitive)verbs which indicate such relations. A connotationframe specifies, among others, the polar effects averb role bears, if the verb is used affirmatively.
We are also interested in stance detection, butstance, in our model, is not only the attempt toidentify the positive and negative attitudes of thewriter of the text (the main opinion holder) to-wards given actors (e.g. political parties) or (con-troversial) topics (henceforth targets) (see e.g. Mo-hammad et al. (2016)). We also strive to identifytargets in the first place. We claim that the waythe writer conceptualizes actors, namely as polar-ized actors - benefactors, villains, victims, benefi-ciaries (and so on) - reveals who/what the targetsare. This also unveils, as a by-product, the writer’sstance. A writer might not directly call someone
a villain, but if he puts forward that a person hastold a lie, then he obviously regards him as a vil-lain, which implies a negative attitude.
We propose the following model. The writerproduces - under the assumption of truth com-mitment - some text. The reader, on the basisof shared (lexical) semantic knowledge, is able toidentify what the text implies for the various tar-gets involved and described. The reader’s per-sonal preferences (his stance, his moral valuesetc.) might be affected by a given exposition. Hemight agree with the (implications of the) pro-claimed facts or not. From what is being said, thereader is thus able to derive at least two things:How does the writer conceptualize the world (i.e.what is his stance, what are the targets) and howdoes this relate to the reader’s stance. We focuson the interplay of these perspectives. Our modelconfronts the writer with the reader perspective.This way, conflicting conceptualizations of realityand incompatible stances become visible. This al-lows the reader to identify charged statements, i.e.main sources of disagreement.
We have implemented a system that predictsadvocate and adversary attitudes and that furtherassigns sources and targets their polarized roles(benefactor, victim etc.) on the basis of a con-notation verb lexicon comprising 1500 manuallyspecified connotation frames stemming from 1100different verbs, also including about hundred nom-inalisations. In order to do so, event factualityin the sense of Saurı and Pustejovsky (2009) alsoneeds to be coped with.
In this paper, we are interested in a qualita-tive validation of our approach. On the basis of100 000 Facebook posts of a right-wing Germanparty, the AfD (Alternative fur Deutschland), anda virtual (kind of prototypical) reader, we exem-plify how conflicting perspectives can be identi-fied and how stance is detected.
31

2 Stance Detection: Ways to Go
Presumably, one finds directly expressed attitudeslike I hate Burger King only in product reviews.In a political discourse, such aversions etc. are ex-pressed more subtly. We are unlikely to find asentence like We, the AfD, are against refugees inFacebook posts of AfD members. Then how canwe get to know that this is apparently the case?1
There are three ways how to identify the writer’sstance.
1. Inference patterns (cf. exemplification E1).There are sentences, where AfD and refugees co-occur, but where the relation between them isgiven only indirectly.
E1:If A0 is against an event that is good for A1,A0 is an adversary of A1
For example: The AfD criticizes that refugeesare tolerated by the German government. Ourmodel is able to derive an adversary relation be-tween AfD and refugee from such complex sen-tences. The underlying inference pattern is: Anegative attitude (criticize) of an opinion source(AfD) towards a situation (tolerate) that is positivefor a target (refugee) means that an adversary rela-tion holds between the two (AfD and refugee).
2. Inference chains (cf. E2).Assume that our system derived that refugee is
an adversary of Germany, and AfD is an advocateof Germany in the text. It then follows that refugeeis an adversary of AfD and vice versa.
E2:From: A01 is an adversary of A1and: A02 is an advocate of A1it follows that: A01 and A02 are adversaries
We also tried to find cliques of accomplices ofthe main opinion source, here the AfD. Shared ad-vocate or adversary relations help. For instance,from AfD is an adversary of refugees and Pegida2
is an adversary of refugees it follows that the AfDis an advocate of Pegida.
3. Assignment of polar roles (cf. E3).
E3:If a text has framed A0 as a villainthen the writer is an adversary of A0
The majority of sentences in our corpus thatcontain refugee do not even mention the AfD ex-plicitly. Nevertheless, some of them allow for the
1We, the authors, use our knowledge as informed citizensin order to make such characterizations.
2Another xenophobic German movement.
inference of an adversary relation. All those sen-tences that imply that refugees are villains giverise to such an inference. If the writer conceptu-alizes someone as a villain, then he is an adver-sary of him. Clearly, this is defeasible, e.g. Helied to me, but I still admire him. This, however,must be done explicitly, otherwise we are entitledto assume an adversary relation. It is a distinctivecomponent of our approach that we are able to de-termine such polar assignments. Their instantia-tion, however, must be licensed by the factualityor counterfactuality of events (cf. section 4).
Similarly, if someone conceptualizes someoneas a victim, then he is - to a certain degree andmaybe only situation-specific - an advocate ofhim, since normally victims do have our sympa-thy. Interestingly, the corresponding argumenta-tion while true for benefactor, is not true for ben-eficiary. Someone who benefits from somethingcould nevertheless be an adversary of us (we couldtake it as unjust that he benefits).
3 Attitudes and Polar Effects
According to Deng and Wiebe (2015) a verb mighthave a positive and a negative effect on the fillerof the direct object, which they map to the pa-tient or theme role. It is, however, not only thedirect object that bears a polar connotation, butalso the subject (e.g. to whitewash), the indirectobject (di-transitive to recommend), the PP object(to fight for), and the complement clause (to criti-cize that). For German, we (Klenner and Amsler,2016) have introduced a freely available verb lex-icon which we called sentiframes (about 300 verbframes). For each verb, it specifies the positiveand negative effects that the affirmative and fac-tual use of the verb has on the filler objects on thebasis of its grammatical functions. In case that averb subcategorizes for a complement clause, theverb’s implicature signature in the sense of Nairnet al. (2006) is specified as well. We have revisedthis resource3 and substantially augmented it byadding 800 additional verbs, their frames (1200)and their verb signatures. We have also started tomodel verb derived nominalisations (e.g. destruc-tion).
A sentiframe or connotation frame (we use thelater term, henceforth) of a verb in our new modelprovides a mapping from argument positions (A0etc.) to polar roles. We use two polar roles which
3https://pub.cl.uzh.ch/projects/opinion/lrec data.txt
32

we call source and target. Both roles are furtherqualified (verb specific) according to the polaritythey bear. This is summarized in principle P1.
P1:source and target are polar roles of verbs,they bear a positive or negative effect (ornone)
Take for example the verb whitewash:A0 (source) negative effectA1 (target) positive effect
It is negatively connotated to whitewash (A0),while being whitewashed - at least given a naivepoint of view - is positive (A1).
A positive effect on the target indicates that thesource either acts in a way that the target is posi-tively affected (cherish), or it expresses a positiverelationship directly (admire). Thus, principle P2holds:
P2:The type of attitude a verb expresses dependson the target role effect:advocate if positive, adversary if negative
The attitude relation is independent of the effecton the source (if any). We specify a function R(see Figure 1) that retrieves the attitude relation ofa verb v given its affirmative status, i.e. aff(v) = 1if v is affirmative and 0 if negated. The functionteff(v) retrieves the effect of verb v on its targetrole.
R(v) =adversary if teff(v)=negative ∧ aff(v) = 1adversary if teff(v)=positive ∧ aff(v) = 0advocate if teff(v)=positive ∧ aff(v) = 1advocate if teff(v)=negative ∧ aff(v) = 0
Figure 1: Attitude Determination for Verbs
Depending on the affirmative and factuality sta-tus of the verb (event), the polar roles (see P1) turninto what we call a polar assignment.
P3:benefactor, villain, beneficiary, victim,pos affected, neg affected, ... are polarassignments
For instance, given A01 regrets that A1 has beeninsulted, the negative target role of the verb insultgives rise to the polar assignment victim. The rea-son why we distinguish polar roles from polar as-signments is that negation might alter the realiza-tion of a polar role.
P4:The polar assignment (that a polar role givesrise to) depends on the affirmative status ofthe verb
For instance in A1 was not rewarded, the posi-tive target role of A1 (target of reward) is, givenverb negation, either neutralized or could even beinterpreted as negative (A1 receives a negative ef-fect). Note that an advocate relation between A0and A1 does not necessarily imply that any ofthem receive a polar assignment. Given A01 fearsthat A02 has insulted A1, we have an advocate re-lation between A01 and A1. But neither is A02 avillain nor A1 a victim. In the context of fears, thetruth value (factuality status) of the event denotedby insult is unknown.
P5:Polar assignments occur if factuality or coun-terfactuality is given, but are blocked givennon-factuality
In the case of a factual, but non-affirmative useof the verb, the situation is a bit more complicated,since negation might pragmatically be used in var-ious ways, e.g. as a reproach (We complain thatA0 has not helped A1) or as a plain denial (Weconfirm that A0 has not criticized A1). Only ina reproach the attitudes and the effects can safelybe (partially) inverted. Given A0 has not white-washed A1 (meant as a denial), we might infer thatthis is negative for A1. But we certainly would notsay that A0 has a negative attitude towards A1 northat A0 should receive a positive effect (invertingthe negative effect of the affirmative use).
The situation changes if we know that a state-ment is meant as a reproach, e.g. if it is embeddedinto a verb with a negative effect on its subclause,as in A01 criticizes that A02 has not whitewashedA1. We interpret this as a negative attitude of A01
towards A02 and a positive attitude of A01 towardsA1. Here is the (partial) frame for criticize (A3 de-notes a proposition):
A0 no effectA3 negative effect
Note that in this example we have to com-bine two attitudes stemming from different verbs,namely criticize and whitewash.
P6:An attitude towards an event might lead to apolar assignment for some roles of that event
An adversary relation on whitewash stem-ming from criticize combines with the adver-sary relation of not whitewash (=adversary) to
33

give an advocate relation between A01 andA1. Figure 2 shows the definition of thefunction C, which realizes relation composi-tion. In the current example, the call would be:C(R(criticize),R(whitewash)).
C(r, s) =adversary if r = advocate ∧ s = adversaryadvocate if r = adversary ∧ s = adversaryadversary if r = adversary ∧ s = advocateadvocate if r = advocate ∧ s = advocate
Figure 2: Attitude Composition
P7: Attitudes combine with attitudes to form aderived attitude
In P5, we saw that polar assignments dependon (counter-)factuality. We have not yet discussedhow to determine (counter-)factuality. In the con-text of verbs that have clausal complements, weneed a further notion, namely that of an implica-ture signature (Nairn et al., 2006). It relates to thetruth or falsehood commitment that a verb castson its clausal complement. The factuality of anevent denoted by a clausal complement can be de-termined from the implicature commitment of thematrix verb, the affirmative status of the matrixverb and the affirmative status of the clausal com-plement. We discuss this in the next section. Forthe moment we postulate P8.
P8:
The polar assignment (that a polar role givesrise to) not only depends on the affirmativestatus of the verb, but also on the affirma-tive status and the implicature signature ofthe matrix verb
4 Truth Commitment, Negation,Factuality Status
We distinguish factual (true), counterfactual (nottrue) and non-factual (truth value is unknown).We call this the factuality status of an event de-noted by a verb. In order to determine the fac-tuality status of a clausal complement of a verb,its implicature signature and the affirmative statusof the matrix and the subclause verb have to betaken into account. In order to specify the impli-cature signature, we use T, F, N for truth commit-ted, falsehood committed, and no commitment, re-spectively, which is along the lines of Nairn et al.(2006), though not totally identical (e.g. they usepolarity to denote what we call affirmative status).
For instance, to regret as a factive verb is truthcommitting (T), both in its affirmative and negatedusage. Thus, the clausal complement of an in-stance of to regret is factual if affirmative, andcounterfactual if negated. While to refuse is false-hood committing (F) if affirmatively used, there isno commitment (N) if negated. The clausal com-plement of negated to refuse thus is, in any case(i.e., affirmative or negated) non-factual.
In order to determine factuality, we first define afunction T (v) which assigns a signature to a verb(especially with clausal complements) given theaffirmative status of the verb. Figure 3 gives a(partial) definition of such a verb (class) specificmapping. Here, aff(v) = 0 (again) means that theverb v is negated, while aff(v) = 1 indicates anaffirmative use of the verb.
T (v) =T if v ∈ {force, . . .} ∧ aff(v) = 1N if v ∈ {force, . . .} ∧ aff(v) = 0F if v ∈ {forget, . . .} ∧ aff(v) = 0T if v ∈ {forget, . . .} ∧ aff(v) = 1
Figure 3: Implicature Signature
In order to determine the factuality of an eventdenoted by a subclause of a matrix verb, we ap-ply the function defined in Figure 4. We use’fact’, ’cfact’ and ’unk’ for factual, counterfactualand unknown. Note that we interpret factuality asevent factuality in the sense of Saurı and Puste-jovsky (2009). The function m applied to the verbv delivers the embedding matrix verb.
S(v) =
fact T (m(v)) = T ∧ aff(v) = 1cfact T (m(v)) = T ∧ aff(v) = 0fact T (m(v)) = F ∧ aff(v) = 1cfact T (m(v)) = F ∧ aff(v) = 0unk T (m(v)) = N
Figure 4: Factuality Determination
The main clause is non-factual if modals arepresent, otherwise it is factual or counterfactual.Negation turns the event denoted by the main verbinto counterfactuality. Under counterfactuality aswell as under factuality, polar assignments are li-censed. Only if a main clause is non-factual, polarassignments are blocked.
Another distinctive feature of our approach isthat not only clausal complements receive an im-plicature signature, but any verb role that could
34

take a nominalisation as a filler receives one.Moreover, nominalisations themselves have signa-tures. We are not aware of any model that alsoconsiders these cases. Take: He criticized the de-struction of the monuments of Palmyra throughIsis. Here destruction is the direct object and thereis a truth commitment stemming from criticize.The destruction, thus, is factual (affirmative use ofcriticize). Since destruction has ’T N’ (= ’affirma-tive negated’) as signature and since it is affirma-tive (T holds) Isis is recognized as a villain. If wetake to fear instead of to criticize, this no longerholds. Also, if we add supposed or postponed todestruction (supposed destruction) we have ’N’ ascommitment and polar assignments are blocked.
The factuality status is determined outside-in.Slightly simplifying, we can say that in order toinfer an attitude between actors, the verb (event)of A0 or the verb (event) of A1 must be factualor counterfactual. If both, A0 and A1 are argu-ments of the same verb, then it needs to be fac-tual (A0 cheats A1). Counterfactuality (e.g. A0 nolonger admires A1) might - depending on the verbor other indicators like no longer - also license anattitude derivation.
5 Reader Perspective
The reader perspective distinguishes opponentsfrom proponents. These classes need to be spec-ified in advance by the reader. For instance, hecould select particular political parties or politi-cians as proponents. In our experiments describedbelow, we created a virtual reader along the fol-lowing lines. Our reader is a proponent of Eu-rope, Merkel, Germany, refugees and so on andagainst the AfD. His values and aversions, hopesand fears are those of a typical member of theWestern society, which we fixed in a reader profilethat assigns polarities along the lines of the Ap-praisal theory (Martin and White, 2005), i.e. judg-ment, affect and appreciation. For instance, hon-esty is judgment positive and represents a moralvalue of the reader, while terrorist is a contemnerof the reader’s values. This lexicon4 serves twopurposes. It forms the basis of the reader’s abil-ity to understand what a text implies. But it alsorepresents (or better approximates) his moral val-ues, his aesthetic preferences, his emotional dis-positions. He is able to discern that in A0 ap-
4The lexicon is an adaptation of the lexicon described inClematide and Klenner (2010).
proves terrorism someone is an advocate of some-thing he finds immoral or inhuman. Altogether,we have six roles for the reader perspective: my-Values, myAversions, mvValueConfirmer, myVal-ueContemner, myProponent, myOpponent.
Note that the instantiation of these roles (exceptmyOpponent and myProponent) sometimes raisethe need for sentiment composition (not only lex-icon access). terrorist is a myValueContemnersince the word - according to the lexicon - de-notes a judgment negative animate entity. In orderto classify cheating colleague as a myValueCon-temner of the reader, composition is needed. Thejudgment negative adjective cheating combinedwith the neutral noun colleague, which denotes anactor, gives rise to a judgment negative phrase de-noting a myValueContemner of the reader. Thephrase sick minister, on the other hand, althoughminister is an actor and sick is a negative word (butappreciation negative, not judgment), does not de-note a myValueContemner, but a neutral entity.
6 Writer Perspective
The writer perspective tells the reader what thewriter wants him to believe (to be true) and ex-plicates what this implies for the status of the tar-gets involved, i.e. whether they are benefactorsetc. It is the way the writer conceptualizes theworld through his text.
The roles stemming from the polar assignment,e.g. victim, villain, benefactor and beneficiary areactor roles related to the moral dimension (verb-specific), while the additional roles pos actor,neg actor, pos affected, neg affected are used forthe remaining cases (roles of not morally loadedverbs).
Given a sentence, we combine the attitudes,the reader and the writer perspective into a singleview. Formally, we instantiate the relation 5-tuple〈Lr, Lw, rel, Lr, Lw〉 where LR, Lw is the readerand writer perspective, respectively and rel repre-sents the attitude of the source towards the target.The reader and writer view Lr and Lw are appliedtwice, to the source (left hand part of the 5-tuple)and the target (right hand part of the 5-tuple) con-nected by the (directed) attitude relation rel.
The writer perspective, Lw is determined bycalling the function A(a, v) (see. Figure 5) withthe verb v and the polar role a of the entity in ques-tion (target or source).
Given that terrorist is a value con-
35

A(a, v) =
benefactor if v ∈ {help..} ∧ a = source∧ S(v) = fact
beneficiary if v ∈ {help..} ∧ a = target∧ S(v) = fact
villain if v ∈ {cheat..} ∧ a = source∧ S(v) = fact
victim if v ∈ {cheat..} ∧ a = target∧ S(v) = fact
victim if v ∈ {help..} ∧ a = target∧ S(v) = cfact
. . .
Figure 5: Polar Assignment
temner of the reader then The politicianhelps the terrorist would lead to the tuple〈some,benefactor,advocate,myValueContemner,beneficiary〉which reads: some benefactor is an advocateof a value contemner as a beneficiary. Thisimmediately reveals the charge of the statement: avalue contemner as a beneficiary. We could thinkof even more charged cases, e.g. a proponent of usas a villain. Or a proponent of us as an advocateof an opponent. Our tuple notation makes thistransparent, it enables the search for such casesand we have defined secondary relations on top ofit. We have identified 16 pattern that instantiate4 new relations: new proponent, new opponent,no longer proponent and no longer opponent. Aproponent of the reader who is an advocate of anopponent might no longer be a proponent etc. Wegive a couple examples in section 9.
7 Attitude Prediction
Given a sentence, we consider all pairs 〈x, y〉 suchthat x and y denote a noun position that acts as apolar role of one or more verbs. Given a pair ofactors or entities, 〈x, y〉, both might occupy polarroles of the same or of different verbs. If x andy are arguments of the same verb, then, if factu-ality (or counterfactuality) holds, the attitude be-tween them comes from the underlying verb. Thatis R(v) is applied if S(v) = ’fact’ (or ’cfact’).
If x and y have different verbal heads, i.e. theverbal head of x either directly or recursively em-beds a verb with y as a polar role, then the rela-tions stemming from the intermediary vi are com-posed into a single relation rel (see Figure 2).If A01 approves that A02 criticizes A1, the rela-tion between A01 and A1 is that of an adversary.
This depends on the advocate relation of approveand the adversary relation of criticize. Techni-cally, we call C(R(v),R(v)), depending on S(v).In general, we use a recursive function where at-titude composition is performed outside-in alongthe lines just discussed. For instance, given A01
criticizes that A02 does not help A11 to free A12,we get: C(C(R(criticize),R(help)),R(free))which gives adversary (criticize) combined withadversary (negated help) which gives advocatewhich in turn is combined with advocate (free)which gives advocate: A01 advocate A12.
8 Sentiframes: Additional Details
The main components of a sentiframe or connota-tion frame are the effects that the source and tar-get roles receive. We have shown that the actualassignments and relations also depend on the af-firmative and factuality status. Of course, ambi-guity is a problem. We found that shallow selec-tional restrictions distinguishing roles that requiretheir filler to be an actor (persons, organizations,nations etc.) from roles where the filler must notbe an actor actually help to reduce verb ambigu-ity. Other restrictions that are very useful are con-straints that check the polarity of a filler objectbottom-up. There are a couple of verbs that only(should) trigger if a bottom restriction is met. Takeprevent: the one who prevents the solution of anurgent problem is a negative actor while if he pre-vents an assault, he is a hero. Other examples areverbs like to call, to take, e.g. to call it a good/badidea that produces a positive or negative effect onthe clausal complement. 95 connotation frames dohave such bottom-up restrictions. We have imple-mented a straight-forward phrase-level sentimentcomposition (Moilanen and Pulman, 2007) in or-der to check bottom-up restrictions.
9 Example
Take the sentence (relevant positions are in-dexed): The left-wing politician3 criticized4 thatMerkel6 helps7 the refugees9. We get three pairs:v4:〈x3, y6〉, v4:〈x3, y9〉 and v7:〈x6, y9〉. Let’s saythe reader has no prior attitudes towards left-wingpoliticians but that refugees has his sympathy (aremyProponents of his). We discuss the case ofv4:〈x3, y9〉, i.e. the directed relation of the left-wing politician towards the refugees. The sourceof criticize has a negative attitude towards the helpevent. Since affirmative help represents an advo-
36

# Relation Tuple Illustration1 〈myProp,entity,adversary,myProp,neg affected〉 US refuses Germany something2 〈some,entity,is,adversary,of,myAversions,neg affected〉 someone condemns terror3 〈some,entity,is,advocate,of,myAversions,pos affected〉 someone insists on vengeance4 〈myProp,benefactor,advocate,myValContemner,beneficiary〉 US supports dictator5 〈some,villain,adversary,myValues,neg affected 〉 someone ridicules human behavior
Table 1: Charged Relation Tuples
cate relation, we get adversary ∧ advocate = ad-versary (see Figure 2). The left-wing politicianis just an entity, but the reader is a proponent ofrefugees. Since help is factual, refugees are bene-ficiaries. This yields:〈 some,entity,adversary,myProponent,beneficiary〉.We could paraphrase this as some entity is an ad-versary of my proponent being a beneficiary. Notethat beneficiary as a role comes from factual help.This is the writer or text perspective. It tells usthat the refugees, the reader proponents, are ben-eficiaries of some event that happened in reality.The relation also tells us that some entity is an ad-versary of this. That is, he does not approve thestatus of the reader’s proponents, the refugees, asbeneficiaries. This immediately makes him a can-didate for the list of actors that are opponents ofthe reader.
Our tuple notation directly confronts the writerand the reader perspective and thus allows one tosearch for interesting cases. We have used a cor-pus comprising 3.5 million sentences taken fromGerman periodicals (ZEIT and Spiegel) to explorethis idea. Examples are given in table 1. The thirdcolumn illustrates the underlying cases; US andGermany are set to be proponents of the reader(for short: myProp). In 1, two proponents are(surprisingly) adversaries. In 2, someone disap-proves what the reader disapproves (a new propo-nent?). In 3, someone approves what the readerdisapproves (a new opponent?). In 4, a proponentacts in a way the reader finds morally question-able (no longer a proponent?), and in 5, someonemight turn out to be an opponent, since he violatesthe reader’s values.
10 Empirical Evaluation
We have evaluated our approach quantitatively onthe basis of 160 sentences. The data consistsof 80 (rather complex) made-up sentences (oneor more subclause embeddings) and 80 real sen-tences. Our goal was to verify the generative ca-
pacity of our model, thus the made-up sentences.It is much more convenient to invent complex sen-tences, where e.g. negation is permuted exhaus-tively over all subclauses, than to try to samplesuch rare constellations. Two annotators specifiedadvocate and adversary relations and harmonizedtheir annotations in order to get a gold standard.
Our goal was to see how our lexicon, includingthe principles of factuality determination, deter-mines the performance. The precision was 83.5%,recall was 75.2%, which gives an F measure of79.1%5. We then dropped the verb signatures fromthe lexicon, that is, we replaced the individual sig-natures by a default setting. There are three possi-ble settings. We set the signature for the affirma-tive use of the verbs to ’T’ (truth commitment), thesignature for negated cases was set to ’F’, ’N’ and’T’ in turn. We got a precision of 69.06%, 75.36%and 74.88% and a recall of 69.36%, 71.62% and75.2%. The F measure for the best default setting(’T T’) is 75.06% which is about 4% points worsethan the system’s result, 79.1%. We also see thatprecision droped by 8% points which is a substan-tial loss. This demonstrates that verb-specific in-formation is crucial.
Encouraged by these results, we decided tocarry out a qualitative study in stance detection.We took 360 000 sentences from 100 000 Face-book posts of AfD members. Our system pro-duced 44 000 polar facts from them: attitudes andpolar assignments. Since these posts are (mostly)from AfD members, they implicitly represent theirstance. The key messages, the self-conception ofthe party and the proclaimed friends and enemiesshould be accessible through these posts.
We aggregated polar facts by counting how of-ten an actor was conceptualized as a villain etc.,but also by counting the number of advocate andadversary relations between actors. We evaluatedthese aggregated polar facts through introspection.
5We use a dependency parser (Sennrich et al., 2009) anda rule-based predicate argument extractor, see Klenner andAmsler (2016) for the details
37

That is we relied on our knowledge about the AfD,its goals, methods, ideological stance etc. as por-trayed by the mainstream German media.
The most important (since most frequent) po-lar fact derived by our systems already wasin heart of the AfD’s stance, namely that An-gela Merkel, the German chancellor, is an ad-versary of Germany. That is exactly whatthe AfD claims. Actually, we get a verystrong statement, in our tuple notation (recallthat Merkel and Germany are reader proponents):〈myProponent,villain,adversary,myProponent,victim〉
That is: myProponent (Merkel) as villain is anadversary of myProponent (Germany) as a victim.Conversely, these texts imply that the AfD is anadvocate of Germany, that the refugees are adver-saries of Germany, while the German governmentis an advocate of the refugees. Curiously enough,for the relation of the AfD towards refugees, wegot inconsistent evidence (three times adversary,three times advocate). However, if we look at thepolar assignment of refugees, which is villain, thepicture is clear (see below). There are a couple ofpolar facts related to an event on New Year’s Evein 2015, where groups of men including migrantssexually assaulted women (that is the official state-ment). Our system came up with the polar fact thatrefugees are adversaries of (these) women.
Another question is, of course, who is to blamefor the situation (in Germany). The mere fact that,in the perception of the AfD, Merkel is an ad-versary of Germany does not tell us whether thisis positive or negative (in the eyes of the AfD).An adversary relation might be positive (e.g. A0adversary terrorism), or negative (e.g. A0 adver-sary truth), i.e. the holder of the adversary atti-tude might be someone who shares or contemnsour values, depending on the event underlying theadversary relation. If Merkel is said to cheat Ger-many, then the writer wants the reader to believethat Merkel is a villain and Germany her victim.Only then we know that the writer is (must be) anadversary of Merkel and an advocate of Germany.
In order to see who are villains and victims ac-cording to the AfD posts, we determined the mostfrequent actors that are classified as villains etc.To give a couple of examples: Among the vil-lains are the refugees (ranked highest), immedi-ately followed by Merkel and men (representingmale refugees), the German word for villain itself(Tater) and government. We believe that these are
perfect hits. Victims are Germany, women (NewYear’s eve event), the AfD (presumably since mis-understood), and the citizen of Germany (AfDseems to believe: the government cheats the cit-izen). Among the beneficiaries are men (malerefugees who are free to molest women withoutconsequences), but also refugees (there is a wel-come culture), Europe, criminals (since the gov-ernment is weak) and the government. From theselists we can also see that the AfD conceptualizesitself as a victim, a positive actor and even a bene-factor.
If someone is an adversary of the values of thereader, he might be a new opponent: we definedthis and similar relations (no-longer-opponent) ontop of our tuple notation. We found 80 dif-ferent new opponent candidates, including vari-ous politicians, countries (their governments), par-ties, institutions (e.g. Nato) and concepts likeFluchtlingswelle (flood of refugees) or politischeElite (political elite). The list of entities we shouldno longer consider a proponent of the readeris perfect, it comprises Asylbewerber (refugee),Bundesregierung (government), Bundestag (par-liament), EU, and Merkel. This exactly reflectsthe stance of the AfD.
11 Related Work
In this paper, stance detection is accomplished onthe basis of opinion inference. A basic form ofopinion inference is event evaluativity in the senseof Reschke and Anand (2011). They determine thepolarity of an event as a function of the polarityof the arguments of the verb denoting the event.Work in the spirit of Reschke and Anand (2011)for the German language is described in Ruppen-hofer and Brandes (2016a) and Ruppenhofer andBrandes (2016b). The goal of their approach is tocreate a verb-specific mapping from the prior at-titude a so-called external viewer of an event hastowards the verb arguments onto his overall eval-uation of the event. For instance, if an immoralperson lacks a good job, this is positive in the eyeof the external viewer. Their approach focuses ona lexical resource, not on a system carrying outopinion inference. Thus, the authors do not taketruth commitment, negation, and factuality deter-mination into account. Nevertheless, their findingsmight be useful for what we call the reader per-spective (where the prior polarity are needed).
A rule-based approach to sentiment implica-
38

tures (their term) is described in Deng and Wiebe(2015). This is the most recent and most elabo-rated version of a number of models of these au-thors. The goal is to detect entities that are ina positive or negative relation to each other. Po-sPair and NegPair are used as relation names, re-spectively. The model of Deng and Wiebe (2015)also copes with event-level sentiment inference,however factuality is not taken into account at all.Also, the reader is not modeled explicitly. More-over, only attitude relations are derived, no polarassignments (beneficiary etc.) are modeled.
Recently, Rashkin et al. (2016) have presentedan elaborate model that is meant to explicate therelations between all involved entities: the reader,the writer and the entities referred to by a sentence.Also, the internal states of the referents and theirvalues are part of the model. The underlying re-sources, called connotation frames, were createdin a crowd sourcing experiment, and the modelparameter (e.g. values for positive and negativescores) are average values. Our resource, in con-trast to such a layman’s guess, was specified by anexpert. The authors use belief propagation to in-duce the connotation frames of unseen verbs; theyalso use the connotation frames to predict entitypolarities. This was applied to analyze the pref-erences and dispreferences of Democrats and Re-publicans. Choi et al. (2016) presented another ap-plication of that resource. Rashkin et al. (2016)claim to have a reader and a writer model, how-ever, they do not seem to use it. This is in sharpcontrast to our approach. Like Deng and Wiebe(2015), Rashkin et al. (2016) do not incorporatepolar assignments (and factuality) in their model,which we deem crucial for stance detection.
Our previous model (Klenner, 2016; Klennerand Clematide, 2016) was realized with Descrip-tion Logic OWL and the rule language SWRL(Horrocks and Patel-Schneider, 2004). The goalwas to extract pro and contra relations from text.42 SWRL rules were needed in order to establishsuch a functionality. In this paper, we have intro-duced a new model based on functions carryingout (a lean) attitude composition. We have alsorevised our approach for factuality determination.We now have a tripartite distinction while previ-ously, our factuality labels were binary. The mostimportant new feature of our current approach isthe specification of our relation tuple which inte-grates the writer and the reader view.
A crucial difference of our model to existingapproaches from the field of stance detection isthat we do not only strive to classify the stance ofa writer towards known controversial topics (e.g.abortion, climate change) like in e.g. Somasun-daran and Wiebe (2010), Hasan and Ng (2014)or Anand et al. (2011). We also seek to identifythe targets of the writer’s stance in the first place.Among others, it is the way the writer frames theentities in his discourse (as villains etc.) that indi-cates his likes and dislikes.
12 Conclusions
We claim that the writer’s conceptualization of re-ality as a narrative reveals his stance. In our case,the members of a political party together writethat narrative which reflects how the AfD, a Ger-man right-wing party, divides the world into pro-ponents and opponents, benefactors and villainsand so. In contrast to previous approaches, westress the point that an attitude between an opin-ion source and an opinion holder alone does notnecessarily tell anything about how the writer per-ceives it. Only if we know the roles the source andthe target play (e.g. villain, victim) in the wholediscourse, we can identify the writer’s stance to-wards them.
On a more technical level, the contributions ofour approach are: 1200 new connotation framesfor German, and a framework that integrates in-ferences both in verbal and nominal contexts. Ourrelation tuples jointly encode the reader and thewriter perspective as well as the attitude amongthe source and target expressed by the underly-ing verb. Such a relation directly shows what thewriter wants the reader to believe and how thereader - given his personal stances - might per-ceive this. This enables the reader to search forinteresting constellations, where e.g. a proponentof his acts in an unexpected way.
Obvious future work stems from the need todefine a more elaborated evaluation scenario. Asmall quantitative and an introspective qualitativeevaluation was just a first (though successful) step.
Acknowledgments
We would like to thank Felix Michel and SimonWorpel (https://correctiv.org), who sampled thecorpus of Facebook posts.
39

ReferencesPranav Anand, Marilyn Walker, Rob Abbott, Jean E.
Fox Tree, Robeson Bowmani, and Michael Minor.2011. Cats rule and dogs drool!: Classifying stancein online debate. In Proceedings of the 2nd Work-shop on Computational Approaches to Subjectivityand Sentiment Analysis (WASSA), pages 1–9, Port-land, Oregon, USA.
Eunsol Choi, Hannah Rashkin, Luke Zettlemoyer, andYejin Choi. 2016. Document-level sentiment infer-ence with social, faction, and discourse context. InProceedings of the 54th Annual Meeting of the Asso-ciation for Computational Linguistics (ACL), pages333–343, Berlin, Germany, August.
Simon Clematide and Manfred Klenner. 2010. Eval-uation and extension of a polarity lexicon for Ger-man. In Proceedings of the First Workshop on Com-putational Approaches to Subjectivity and SentimentAnalysis (WASSA), pages 7–13, Lisbon, Portugal.
Lingjia Deng and Janyce Wiebe. 2015. Joint predic-tion for entity/event-level sentiment analysis usingprobabilistic soft logic models. In Proceedings ofthe 2015 Conference on Empirical Methods in Natu-ral Language Processing (EMNLP), pages 179–189,Lisbon, Portugal.
Kazi Saidul Hasan and Vincent Ng. 2014. Why areyou taking this stance? Identifying and classifyingreasons in ideological debates. In Proceedings ofthe 2014 Conference on Empirical Methods in Natu-ral Language Processing (EMNLP), pages 751–762,Doha, Qatar.
Ian Horrocks and Peter F. Patel-Schneider. 2004. Aproposal for an OWL rules language. In Proceed-ings of the Thirteenth International World Wide WebConference (WWW), pages 723–731, New York, NY,USA.
Manfred Klenner and Michael Amsler. 2016. Sen-tiframes: A resource for verb-centered Germansentiment inference. In Nicoletta Calzolari (Con-ference Chair), Khalid Choukri, Thierry Declerck,Sara Goggi, Marko Grobelnik, Bente Maegaard,Joseph Mariani, Helene Mazo, Asuncion Moreno,Jan Odijk, and Stelios Piperidis, editors, Proceed-ings of the Tenth International Conference on Lan-guage Resources and Evaluation (LREC), pages2888–2891, Portoro, Slovenia.
Manfred Klenner and Simon Clematide. 2016. Howfactuality determines sentiment inferences. InIvan Titov Claire Gardent, Raffaella Bernardi, edi-tor, Proceedings of *SEM 2016: The Fith Joint Con-ference on Lexical and Computational Semantics,pages 75–84, Berlin, Germany, August.
Manfred Klenner. 2016. A model for multi-perspective opinion inferences. In Carlo Strap-parava Larry Birnbaum, Octavian Popescu, editor,Proceedings of IJCAI Workshop Natural LanguageMeets Journalism, pages 6–11, New York, USA.
James R. Martin and Peter R. R. White. 2005. Ap-praisal in English. Palgrave Macmillan, London,England.
Saif Mohammad, Svetlana Kiritchenko, Parinaz Sob-hani, Xiao-Dan Zhu, and Colin Cherry. 2016. Se-mEval task 6: Detecting stance in tweets. In Pro-ceedings of the 10th International Workshop on Se-mantic Evaluation (SemEval), pages 31–41, SanDiego, CA, USA.
Karo Moilanen and Stephen Pulman. 2007. Senti-ment composition. In Recent Advances in Natu-ral Language Processing (RANLP), pages 378–382,Borovets, Bulgaria.
Rowan Nairn, Cleo Condoravdi, and Lauri Karttunen.2006. Computing relative polarity for textual infer-ence. In Proceedings of Inference in ComputationalSemantics (ICoS 5), pages 67–75, Buxton, England.
Hannah Rashkin, Sameer Singh, and Yejin Choi. 2016.Connotation frames: A data-driven investigation. InProceedings of the 54th Annual Meeting of the Asso-ciation for Computational Linguistics (ACL), pages311–321, Berlin, Germany, Angust.
Kevin Reschke and Pranav Anand. 2011. Extractingcontextual evaluativity. In Proceedings of the NinthInternational Conference on Computational Seman-tics (IWCS), pages 370–374, Oxford, England.
Josef Ruppenhofer and Jasper Brandes. 2016a. Ef-fect functors for opinion inference. In Nicoletta Cal-zolari (Conference Chair), Khalid Choukri, ThierryDeclerck, Sara Goggi, Marko Grobelnik, BenteMaegaard, Joseph Mariani, Helene Mazo, AsuncionMoreno, Jan Odijk, and Stelios Piperidis, editors,Proceedings of the Tenth International Conferenceon Language Resources and Evaluation (LREC),pages 2879–2887, Portoro, Slovenia, May.
Josef Ruppenhofer and Jasper Brandes. 2016b. Verify-ing the robustness of opinion inference. In StefanieDipper, Friedrich Neubarth, and Heike Zinsmeister,editors, Proceedings of the 13th Conference on Nat-ural Language Processing (KONVENS), pages 226–235. Bochum, Germany.
Roser Saurı and James Pustejovsky. 2009. FactBank:a corpus annotated with event factuality. LanguageResources and Evaluation, 43(3):227–268.
Rico Sennrich, Gerold Schneider, Martin Volk, andMartin Warin. 2009. A new hybrid dependencyparser for German. In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL), pages 115–124, Pots-dam, Germany.
Swapna Somasundaran and Janyce Wiebe. 2010. Rec-ognizing stances in ideological on-line debates. InProceedings of the NAACL HLT 2010 Workshop onComputational Approaches to Analysis and Gener-ation of Emotion in Text, pages 116–124, Los Ange-les, California, USA.
40

Proceedings of the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics, pages 41–45,Valencia, Spain, April 3, 2017. c©2017 Association for Computational Linguistics
Behind the Scenes of an Evolving Event Cloze Test
Nathanael ChambersDepartment of Computer Science
United States Naval [email protected]
Abstract
This paper analyzes the narrative eventcloze test and its recent evolution. Thetest removes one event from a docu-ment’s chain of events, and systems pre-dict the missing event. Originally pro-posed to evaluate learned knowledge ofevent scenarios (e.g., scripts and frames),most recent work now builds ngram-like language models (LM) to beat thetest. This paper argues that the test hasslowly/unknowingly been altered to ac-commodate LMs. Most notably, tests areauto-generated rather than by hand, andno effort is taken to include core scriptevents. Recent work is not clear on evalu-ation goals and contains contradictory re-sults. We implement several models, andshow that the test’s bias to high-frequencyevents explains the inconsistencies. Weconclude with recommendations on howto return to the test’s original intent, andoffer brief suggestions on a path forward.
1 Introduction
A small but growing body of work is looking atlearning real-world event knowledge. One partic-ular area is how to induce event structures calledschemas, scripts, or frames. This is a wide field,but variations on the narrative cloze test are of-ten used to evaluate learned models. However,their current form has evolved beyond the cloze’soriginal purpose. It has evolved into a languagemodeling (LM) task rather than an evaluation ofknowledge. One proposal suggested avoiding thecloze test absent other options (Rudinger et al.,2015), but we argue that it can be useful if care-
fully formulated. This is the first paper to evalu-ate why LMs can seemingly succeed on the eventcloze. This is also the first paper to reconcile con-tradictory results across recent papers. We repro-duce several models for cloze prediction, includea new instance-based learning model, and showhow high-frequency events pollute the test. Weconclude by discussing the future of the cloze inregards to new corpus developments.
2 Previous Work
2.1 The Original Narrative Event Cloze
The narrative event cloze task was first proposedin Chambers and Jurafsky (2008). These papersintroduced the first models that automatically in-duced event structures like Schankian scripts fromunlabeled text. They learned chains of events thatform common-sense structures. An event was de-fined as a verb/dependency tuple where the mainentity in a story (the protagonist) filled the typeddependency of the verb. The following is an ex-ample with its corresponding event chain:
TextThe police arrested Jon but he escaped.
Jon fled the country.Chain
(arrested, object), (escaped, subj), (fled, subj)
This is one instance of a chain. Research fo-cuses on generalizing this knowledge to a stereo-typical script of when a suspect escapes. In orderto evaluate this generalized knowledge, the narra-tive cloze was proposed as one possible test. Givena set of known events, the test removes one, and asystem must predict which was removed. Usingthe same short example:
(arrested, object), (escaped, subject), ( , )
41

A model of scripts can produce a ranked listof likely events to fill the hole. The test eval-uates where in the ranking the correct event isfound. Critically, these event tests were manuallyextracted from hand-selected documents.
2.2 Language Modeling Event Cloze
Jans et al. (2012) focused solely on the narrativecloze test as an end goal. They cited the clozeevaluation from Chambers and Jurafsky (2008),but made several cloze modifications that we ar-gue make it more amenable to language modeling.Since then, subsequent work has adopted the Jansevoluation of the cloze test. There are three mainchanges to the original Narrative cloze that turnedit into an LM cloze.
Automatic Tests: First, the LM cloze tests areautomatically generated with all the mistakes ofparsers and coreference. The original narrativecloze was manually created by human annotatorswho interpreted documents and extracted sets ofevents by hand. Accuracy was “true accuracy”,and it tested only one central chain in each docu-ment. It is not clear why everyone switched to LMcloze, but Jans et al. (2012) is revealing, “Ratherthan manually constructing a set of scripts onwhich to run the cloze test, we ... use the eventchains from that section as the scripts for whichthe system must predict events.” Their version isnot the narrative cloze from Chambers and Juraf-sky. This change created what is often desired: aquick automated test with instant results.
Text Order: The LM cloze is an evaluation whereevents are ordered to know the text position of themissing event. The original narrative cloze did notrequire ordering information because documentorder does not imply real-world order, and scriptsfocused on real-world structure. This change nat-urally benefits text language models.
All Chains: Instead of selecting the central entityin a document and testing that scenario’s chain,they included all entity chains. Different papersvary on this detail, but all appear to auto-extractmultiple chains per document. Some include min-imum chain length requirements.
All Events: Fourth, the LM cloze includes all re-peated events in a chain. If an event chain contains5 ’said’ events, 5 cloze tests with the same answer‘said’ are in the evaluation. Critically, variants of
‘said’ make up 20% of the data. The original clozeonly included unique events without repetition. Italso intentionally omitted all ‘be’ events, avoidinganother frequent/uninformative event in the tests(Chambers and Jurafsky, 2008). To clearly illus-trate the problem, below is one such LM cloze test:
X criticized, X said, X distributed, X asking, X said, X
said, X said, X said, X admitted, X asked
The narrative cloze would only test one X saidinstead of five. This seemingly small evaluationdetail drops a unigram model’s ‘said’ predictionfrom 50% (5 of 10) to 17% (1 of 6) accuracy.
Subsequent work adopted these changes. Pi-chotta and Mooney (2014) proposed a multi-argument language model. They showed that bi-grams which take into account all entity argumentscan outperform bigrams that only use a single ar-gument. Rudinger et al. (2015) showed that a log-bilinear language model outperforms bigram mod-els on the same LM cloze. Several have proposedneural network LMs (Pichotta and Mooney, 2016;Modi, 2016). Granroth-Wilding and Clark (2016)made the cloze a multiple choice prediction ratherthan a ranking. Curiously, they auto-generated onechain per document instead of all chains, and re-quired that chain to be at least 9 events in length.Ahrendt and Demberg (2016) build on the n-grammodels with argument typing and use the cloze teston a non-news corpus.
Notably with these variations, results across pa-pers contradict. A frequency baseline is the bestin some, but not in others. A PMI-based countingapproach is poor in some, but close to state-of-the-art in others. Rudinger et al.’s best LM leads themto conclude that either (1) script induction shoulduse LMs, or (2) the cloze should be abandoned.We argue instead for a third option: the LM clozeshould find its way back to the original intent.
3 Data Processing
To be consistent with recent work, we use the En-glish Gigaword Corpus for training and test. Weparse into typed dependencies with the CoreNLPtoolkit, run coreference, and extract event chainsconnected by a single entity’s mentions. Eachcoreference entity then extracts its event chain,made up of the predicates in which it is a subject,object, or preposition argument. An event is a tu-ple similar to Pichotta and Mooney (2014): (s, o,p, event) where s/o/p are the subject, object, andpreposition unique entity IDs. Entity singletons
42

are ignored, and all chains of length 2 or aboveare extracted as in these recent works.
4 Models
In order to ground our argument in the correctcontext, we implemented the main models fromChambers and Jurafsky (Chambers and Jurafsky,2008), Jans et al. (2012), and Pichotta and Mooney(2014). Others have been proposed, but thesecore models are sufficient to illustrate the idiosyn-crasies shared by LMs on event cloze prediction.
4.1 UnigramsThe unigram model is based on frequency countsfrom training. We define a similarity score for anevent e in a chain of events c at insertion index k:
simu(e, c, k) = C(e)/N (1)
where C(e) is the count of event e and N is thenumber of events seen in training.
4.2 BigramsThe bigram model is formulated as an ordered textequation as in Jans et al. (2012):
simb(e, c, k) =k∏
i=0
P (e|ci) ∗n∏
i=k+1
P (ci|e) (2)
where the conditional probability is defined:
P (x|y) =C(x, y) + λ
C(y) + |E| ∗ λ (3)
where C(x, y) is the text ordered bigram count, Eis the set of events, and λ a smoothing parameter.
4.3 PMIPointwise mutual information was the centralcomponent of Chambers and Jurafsky (2008).They learned a variety of script/event knowledgeincluding argument type information that is notnecessarily evaluated in the LM cloze. However,for consistency, previous work tends to duplicatetheir prediction model as follows:
simp(e, c, k) =n∑
i=0
logP (ci, e)P (ci)P (e)
(4)
where the joint probability is defined:
P (x, y) =C(x, y) + C(y, x)∑
i
∑j C(ei, ej)
(5)
Jans et al. (2012) propose an ordered PMI thatwe omit for simplicity. They found that orderingdoesn’t affect PMI (but is required for bigrams).
4.4 Multi-Argument N-Gram Models
The above models use a single entity in a chain (ar-rested X, X escaped, X fled). Pichotta and Mooney(2014) explored richer models that consider all ar-guments with the events. The single chain nowbecomes (Y arrested X, X escaped, X fled Z). Ifother entities are repeated across events, it uses thesame variable/ID so that coreference can be mod-eled beyond the main entity. The n-gram modelsare slightly more complicated now that argumentsneed to be normalized, particularly in how eventsare counted and how the conditional probability iscomputed. We refer the reader to their paper for acomplete formulation.
This richer formulation has not been adopted bylater work, possibly due to its complexity, but weduplicated their models for completeness.
4.5 Instance-Based N-Grams
We also propose a novel extension to previouswork in an attempt to not just duplicate perfor-mance, but maximize its results. Instead of train-ing on all documents, we train on-the-fly with aninstance-based learning approach. Given a chainof events, the algorithm retrieves documents in Gi-gaword that contain all the events, and computescounts C(x) and C(x, y) only from that subsetof documents. A parameter can be tuned to re-quire X% of the chain events to match in a docu-ment. We duplicated both unigrams and bigrams(as above) with this on-the-fly training method.
5 Experiment Setup
There are two ways to evaluate event predictionwith scripts. The first is to follow a single actorthrough a chain of events, and predict the miss-ing link in the chain. This prediction ignores otherevent arguments and only evaluates whether thesystem predicts the predicate and the correct syn-tactic position of the entity. This was part of theoriginal narrative cloze from Chambers and Juraf-sky (2008). The example in Section 2 illustratessuch a chain. Pichotta and Mooney (Pichotta andMooney, 2014) proposed a richer test that requiresall arguments of the missing event. A single ac-tor is still tracked through a chain of events, butcorrect prediction requires the complete event.
We trained on 12.5 million AP documents fromGigaword with duplicates removed. The test set is1000 random event chains not in training. Parame-ters were tuned on a smaller set of dev documents.
43
Single Argument ChainsModel Recall@50Unigrams 0.338Uni Exact 100% 0.347Uni Exact 50% 0.386Bigrams (k=2) 0.465Bi Exact 100% (k=2) 0.460PMI 0.038PMI w/cutoff 0.391
Table 1: Single entity event chain results.
Multiple Argument ChainsModel Recall@50Unigrams 0.322Uni Exact 100% 0.332Uni Exact 50% 0.368Bigrams (k=5) 0.408Bi Exact 100% (k=5) 0.396PMI 0.068PMI w/cutoff 0.364
Table 2: Multiple argument event chain results.
6 Results
Table 1 shows model performance. The best un-igram model used our new instance-based learn-ing, but bigrams gain by 8% absolute. Notably,PMI performs poorly as in Jans et al. (2012) andRudinger et al. (2015). However, by adding a fre-quency cutoff, the poor result is reversed. Figure1 shows the cutoff recall curve. Both papers con-cluded that PMI was the problem, but we found itis simply the over-evaluation of frequent events.
PMI is known to prefer infrequent events, andthis is evident by looking at the information con-tent (IC) of model predictions. The informationcontent of an event is its log probability in the Gi-gaword Corpus. What types of events do languagemodels predict? Table 3 shows that the averageLM prediction contains far less information. Per-haps more clear, Table 4 shows an actual list ofpredictions for one cloze test. The n-gram mod-els predict frequent events, but PMI predicts seem-ingly more meaningful events. We are not arguingin favor of PMI as a model, but simply illustratinghow frequency explains almost all of the contra-dictions in previous work.
Finally, Table 2 mirrors the relative results ofsingle arguments in the multi-argument setting.Once again, a simple cutoff parameter in the PMI
PMI Recall@50 with Frequency Cutoffs
Figure 1: Frequency cutoffs. Events seen less thanthe cutoff are not included in the PMI ranking.
Unigrams Bigrams PMI5.8 6.7 9.4
Table 3: Avg. information content of predictions.
setting drastically changes the results. It is difficultto always know what settings were used in each at-tempt at this task, but the normalized experimentsin this paper illustrate that the new cloze exper-iments have a heavy bias to the high-frequencyevents, regardless of how the events themselvesare formalized (e.g., single argument or multi ar-gument).
7 Conclusion and Recommendations
Automatically generating event chains for evalua-tion does not test relevant script knowledge. Theinformation content scores illustrate the huge ex-tent to which common events (said, tell, went)dominate. More concerning, we can simply adjustthe frequency cutoff in PMI learning, and it elim-inates “poor results” from multiple previous pa-pers. Language modeling approaches tend to cap-ture frequent event patterns, not script knowledge.
Cloze Test Unigram Bigram PMIX scored X said X made X scoredX set up X have X said X beatX headed X had X scored X playedX challenged told X X accused X missed
?? X told X had X hitX is told X X ledX was X told X joinedsaid X X is X wentX has X was X finishedkilled X said X X opened
Table 4: Example Cloze test and the top predic-tions from ngrams and PMI
44

This is revealed in our frequency-based results, aswell as in subjective error analysis like Table 4.
The core problem is that auto-generation doesnot evaluate script knowledge. We can’t includeall coreference chains from all documents andhope that this somehow measures script knowl-edge. The contradictory results from frequentevents is just a symptom of the larger problem.We believe a human annotator should be in theloop for a meaningful evaluation. The test shouldinclude meaningful core events, and avoid oth-ers that are not script-relevant, such as discourse-related events (e.g., reporting verbs). Further, thetest must not include events brought in throughparser and coreference errors. By evaluating onparser output as gold data, we evaluate how wellour models match our flawed text pre-processingtools. We acknowledge that human involvement isexpensive, but the current trend to automate eval-uations does not appear to be evaluating common-sense knowledge.
Finally, although this paper focuses on thenarrative event cloze, we recognize that differ-ent evaluations are also possible. However, thetraits of human-annotation and core-events seemto be required. One interesting task this year isMostafazadeh et al. (2016) and the Story Cloze(manually created). Different from event chains,it still meets the requirements and provides a verylarge common corpus with 100k short stories. An-other recent proposal is the InScript Corpus fromModi et al. (2016). They used Amazon Turk tocreate 1000 stories covering 10 predefined scenar-ios. While not as large and diverse as the StoryCloze, the entire corpus was annotated for goldevents, coreference, and entities. This is an in-teresting new resource that avoids many of theproblems discussed above, although issues of anevent’s coreness to a narrative may still need to beaddressed.
We ultimately hope this short paper helps clar-ify recent results, inspires future evaluation, andmost of all encourages discussion.
Acknowledgments
This work was supported by a grant from the Of-fice of Naval Research.
ReferencesSimon Ahrendt and Vera Demberg. 2016. Improving
event prediction by representing script participants.In Proceedings of North American Chapter of theAssociation for Computational Linguistics.
Nathanael Chambers and Dan Jurafsky. 2008. Unsu-pervised learning of narrative event chains. In Pro-ceedings of the Association for Computational Lin-guistics (ACL), Hawaii, USA.
Mark Granroth-Wilding and Stephen Clark. 2016.What happens next? event prediction using a com-positional neural network model. In Proceedings ofthe 13th AAAI Conference on Artificial Intelligence.
Bram Jans, Steven Bethard, Ivan Vulic, andMarie Francine Moens. 2012. Skip n-gramsand ranking functions for predicting script events.In Proceedings of the 13th Conference of theEuropean Chapter of the Association for Computa-tional Linguistics, pages 336–344. Association forComputational Linguistics.
Ashutosh Modi, Tatjana Anikina, Simon Ostermann,and Manfred Pinkal. 2016. Inscript: Narrative textsannotated with script information. In Proceedings ofthe 10th International Conference on Language Re-sources and Evaluation (LREC 16), Portoroz, Slove-nia, pages 3485–3493.
Ashutosh Modi. 2016. Event embeddings for semanticscript modeling. In Proceedings of the the SIGNLLConference on Computational Natural LanguageLearning (CoNLL).
Nasrin Mostafazadeh, Nathanael Chambers, XiaodongHe, Devi Parikh, Dhruv Batra, Lucy Vanderwende,Pushmeet Kohli, and James Allen. 2016. A cor-pus and cloze evaluation for deeper understandingof commonsense stories. In Proceedings of NorthAmerican Chapter of the Association for Computa-tional Linguistics.
Karl Pichotta and Raymond J. Mooney. 2014. Statis-tical script learning with multi-argument events. InProceedings of the 14th Conference of the EuropeanChapter of the Association for Computational Lin-guistics (EACL 2014), Gothenburg, Sweden, April.
Karl Pichotta and Raymond J. Mooney. 2016. Learn-ing statistical scripts with LSTM recurrent neuralnetworks. In Proceedings of the 30th AAAI Confer-ence on Artificial Intelligence (AAAI-16), Phoenix,Arizona.
Rachel Rudinger, Pushpendre Rastogi, Francis Ferraro,and Benjamin Van Durme. 2015. Script inductionas language modeling. In Proceedings of the 2015Conference on Empirical Methods in Natural Lan-guage Processing (EMNLP-15).
45

Proceedings of the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics, pages 46–51,Valencia, Spain, April 3, 2017. c©2017 Association for Computational Linguistics
LSDSem 2017 Shared Task: The Story Cloze Test
Nasrin Mostafazadeh1, Michael Roth2,3, Annie Louis4,Nathanael Chambers5, James F. Allen1,6
1 University of Rochester 2 University of Illinois at Urbana-Champaign 3 University of Edinburgh
4 University of Essex 5 United States Naval Academy 6 Florida Institute for Human & Machine Cognition
{nasrinm,james}@cs.rochester.edu [email protected]
[email protected] [email protected]
Abstract
The LSDSem’17 shared task is the StoryCloze Test, a new evaluation for story un-derstanding and script learning. This testprovides a system with a four-sentencestory and two possible endings, and thesystem must choose the correct ending tothe story. Successful narrative understand-ing (getting closer to human performanceof 100%) requires systems to link vari-ous levels of semantics to commonsenseknowledge. A total of eight systems par-ticipated in the shared task, with a varietyof approaches including end-to-end neuralnetworks, feature-based regression mod-els, and rule-based methods. The highestperforming system achieves an accuracyof 75.2%, a substantial improvement overthe previous state-of-the-art.
1 Introduction
Building systems that can understand stories orcan compose meaningful stories has been a long-standing ambition in natural language understand-ing (Charniak, 1972; Winograd, 1972; Turner,1994; Schubert and Hwang, 2000). Perhaps thebiggest challenge of story understanding is hav-ing commonsense knowledge for comprehendingthe underlying narrative structure. However, richsemantic modeling of the text’s content involvingwords, sentences, and even discourse is cruciallyimportant. The workshop on Linking Lexical,Sentential and Discourse-level Semantics (LSD-Sem)1 is committed to encouraging computationalmodels and techniques which involve multiple lev-els of semantics.
1http://www.coli.uni-saarland.de/˜mroth/LSDSem/
The LSDSem’17 shared task is the Story ClozeTest (SCT; Mostafazadeh et al., 2016). The SCTis one of the recent proposed frameworks onevaluating story comprehension and script learn-ing. In this test, the system reads a four-sentencestory along with two alternative endings. Itis then tasked with choosing the correct end-ing. Mostafazadeh et al. (2016) summarize theoutcome of experiments conducted using severalmodels including the state-of-the-art script learn-ing approaches. They suggest that current meth-ods are only slightly better than random perfor-mance and more powerful models will requirericher modeling of the semantic space of stories.
Given the wide gap between human (100%)and state-of-the-art system (58.5%) performance,the time was ripe to hold the first shared task onSCT. In this paper, we present a summary on thefirst organized shared task on SCT with eight par-ticipating systems. The submitted approaches tothis non-blind challenge ranged from simple rule-based methods, to linear classifiers and end-to-end neural models, to hybrid models that lever-age a variety of features on different levels of lin-guistic analysis. The highest performing systemachieves an accuracy of 75.2%, which substan-tially improves the previously established state-of-the-art. We hope that our findings and discussionscan help reshape upcoming evaluations and sharedtasks involving story understanding.
2 The Story Close Test (SCT)
In the SCT task, the system should choose theright ending to a given four-sentence story. Hence,this task can be seen as a reading comprehensiontest in which the binary choice question is always,‘Which of the two endings is the most plausiblecorrect ending to the story?’. Table 1 shows threeexample SCT cases.
46

Context Right Ending Wrong Ending
Sammy’s coffee grinder was broken. He needed somethingto crush up his coffee beans. He put his coffee beans in aplastic bag. He tried crushing them with a hammer.
It worked for Sammy. Sammy was not that much intocoffee.
Gina misplaced her phone at her grandparents. It wasntanywhere in the living room. She realized she was in thecar before. She grabbed her dads keys and ran outside.
She found her phone in the car. She didnt want her phone any-more.
Sarah had been dreaming of visiting Europe for years. Shehad finally saved enough for the trip. She landed in Spainand traveled east across the continent. She didn’t like howdifferent everything was.
Sarah decided that she preferredher home over Europe.
Sarah then decided to move toEurope.
Table 1: Example Story Cloze Test instances from the Spring 2016 release.
Story Title Story
The Hurricane Morgan and her family lived in Florida. They heard a hurricane was coming. They decided toevacuate to a relative’s house. They arrived and learned from the news that it was a terrible storm.They felt lucky they had evacuated when they did.
Marco VotesFor President
Marco was excited to be a registered voter. He thought long and hard about who to vote for.Finally he had decided on his favorite candidate. He placed his vote for that candidate. Marcowas proud that he had finally voted.
SpaghettiSauce
Tina made spaghetti for her boyfriend. It took a lot of work, but she was very proud. Herboyfriend ate the whole plate and said it was good. Tina tried it herself, and realized it wasdisgusting. She was touched that he pretended it was good to spare her feelings.
Table 2: Example ROCStories instances from the Winter 2017 release.
As described in Mostafazadeh et al. (2016), theSCT cases are collected through Amazon Mechan-ical Turk (Mturk) on the basis of the ROCStoriescorpus, a collection of five-sentence everyday lifestories which are full of stereotypical sequence ofevents. To construct SCT cases, they randomlysampled complete five-sentence stories from theROCStories corpus and presented only the firstfour sentences of each story to the Mturk work-ers. Then, for each story, a worker was asked towrite a ‘right ending’ and a ‘wrong ending’. Thisresulting set was further filtered by human verifi-cation: they compile each SCT case into two inde-pendent five-sentence stories, once with the ‘rightending’ and once with the ‘wrong ending’. Then,for each story they asked three crowd workers toverify if the given five-sentence story makes senseas a meaningful story, rating on the scale of {-1,0, 1}. Then they retain the cases in which the‘right ending’ had three 1 ratings and the ‘wrongending’ had three 0 ratings. This verification stepensures that there are no boundary cases of ‘rightending’ and ‘wrong ending’ for human. Finally,any stories used in creating this SCT set are re-moved from the original ROCStories corpus.
3 Shared Task Setup
For the shared task, we provided the same datasetas created by Mostafazadeh et al. (2016), whichconsists of a development and test set each con-taining 1,871 stories with two alternative end-ings. At this stage, we used this already exist-ing non-blind dataset with established baselinesto build up momentum for researching the task.This dataset can be accessed through http://cs.rochester.edu/nlp/rocstories/.
As the training data, we released an extended setof ROCStories2, called ROCStories Winter 2017.We followed the same crowdsourcing setup de-scribed in Mostafazadeh et al. Table 2 providesthree example stories in this dataset. As these ex-amples show, these are complete stories and do notcome with a wrong ending3. Although we pro-vided the additional ROCStories, the participantswere encouraged to use or construct any trainingdata of their choice. Overall, the participants wereprovided three datasets with the statistics listed inTable 3.
Following Mostafazadeh et al. (2016), we eval-
2The extended ROCStories dataset can be accessed viahttp://cs.rochester.edu/nlp/rocstories/.
3The ROCStories corpus can be used for a variety of ap-plications ranging from story generation to script learning.
47

ROCStories (training data) 98,159Story Cloze validation set, Spring 2016 1,871Story Cloze test set, Spring 2016 1,871
Table 3: The size of the provided shared taskdatasets.
uate the systems in terms of accuracy, which wemeasure as #correct
#test cases . Any other details re-garding our shared task can be accessed via ourshared task page http://cs.rochester.edu/nlp/rocstories/LSDSem17/.
4 Submissions
The Shared Task was conducted through CodaLabcompetitions4. We received a total of 18 registra-tions, out of which eight teams participated: fourteams from the US, three teams from Germany andone team from India.
In the following, we provide short paragraphssummarizing our baseline and approaches of thesubmissions. More details can be found in the re-spective system description papers.
msap (University of Washington). Linear clas-sifier based on language modeling probabilities ofthe entire story, and linguistic features of only theending sentences (Schwartz et al., 2017). Theseending “style” features include sentence length aswell as word and character n-gram in each candi-date ending (independent of story). These stylefeatures have been shown useful in other taskssuch as age, gender, or native language detection.
cogcomp (University of Illinois). Linear classi-fication system that measures a story’s coherencebased on the sequence of events, emotional trajec-tory, and plot consistency. This model takes intoaccount frame-based and sentiment-based lan-guage modeling probabilities as well as a topicalconsistency score.
acoli (Goethe University Frankfurt am Main)and tbmihaylov (Heidelberg University). Tworesource-lean approaches that only make use ofpretrained word representations and compositionsthereof (Schenk and Chiarcos, 2017; Mihaylovand Frank, 2017). Composition functions arelearned as part of a feed-forward and LSTM neuralnetworks, respectively.
4The Story Cloze CodaLab page can be accessedhere: https://competitions.codalab.org/competitions/15333
ukp (Technical University of Darmstadt).Combination of a neural network-based (Bi-LSTM) classifier and a traditional feature-rich ap-proach (Bugert et al., 2017). Linguistic featuresinclude aspects of sentiment, negation, pronomi-nalization and n-gram overlap between the storyand possible endings.
roemmele (University of Southern California).Binary classifier based on a recurrent neural net-work that operates over (sentence-level) Skip-thought embeddings (Roemmele et al., 2017). Fortraining, different data augmentation methods areexplored.
mflor (Educational Testing Service). Rule-based combination of two systems that score pos-sible endings in terms of how well they lexicallycohere with and fit the sentiment of the givenstory (Flor and Somasundaran, 2017). Sentimentis given priority, and the model backs off to lexicalcoherence based on pointwise mutual informationscores.
Pranav Goel (IIT Varanasi). Ensemble modelthat takes into account scores from two systemsthat measure overlap in sentiment and sentencesimilarity between the story and the two possibleendings (Goel and Singh, 2017).
ROCNLP (baseline) Two feed-forward neuralnetworks trained jointly on ROCStories to projectthe four-sentences context and the right fifth sen-tence into the same vector space. This model iscalled Deep Structured Semantic Model (DSSM)(Huang et al., 2013) and had outperformed allthe other baselines reported in Mostafazadeh et al.(2016).
5 Results
An overview of the models and the resourcesused in each participating system, along with theirquantative results, is given in Table 4. Giventhat the DSSM model was previously trained onabout 50K ROCStories, we retrained this modelon our full dataset of 98,159 stories. We includethe results of this model under ROCNLP in Ta-ble 4. With accuracy values in a range from 60%to 75.2%, we observe that all teams outperform thebaseline model. The best result in this shared taskhas been achieved by msap, the participating teamfrom the University of Washington.
48
Rank CodaLab Id Model ROCStories Pre-trainedEmbeddings
Other Resources Accuracy
1 msap Logisticregression
Spring 2016,Winter 2017
− NLTK Tokenizer, Spacy POStagger
0.752
2 cogcomp Logisticregression
Spring 2016,Winter 2017
Word2Vec UIUC NLP pipeline, FrameNet,two sentiment lexicons
0.744
3 tbmihaylov LSTM − Word2Vec − 0.728
4 ukp BiLSTM Spring 2016,Winter 2017
GloVe Stanford CoreNLP, DKPro TC 0.717
5 acoli SVM − GloVe,Word2Vec
− 0.700
6 roemmele RNN Spring 2016,Winter 2017
Skip-Thought − 0.672
7 mflor Rule-based − − VADER sentiment lexicon, Gi-gaword corpus PMI scores
0.621
8 Pranav Goel Logisticregression
Spring 2016,Winter 2017
Word2Vec VADER sentiment lexicon,SICK data set
0.604
9 ROCNLP(baseline)
DSSM Spring 2016,Winter 2017
− − 0.595
Table 4: Overview of models and resources used by the participating teams. For each team only theirbest performing system on the Spring 2016 Test Set is included, as submitted to CodaLab. Please referto the system description papers for a list of other models. Human is reported to perform at 100%.
6 Discussion
We briefly highlight some observations regardingmodeling choices and results.
Embeddings. All but two teams made use ofpretrained embeddings for words or sentences.tbmihaylov (Mihaylov and Frank, 2017) exper-imented with various pretrained embeddings intheir resource-lean model and found that thechoice of embeddings has a considerable impacton model accuracy. Interestingly, the best partici-pating team used no pretrained embeddings at all.
Neural networks. The six highest scoring mod-els all include neural network architectures in oneway or another. While the teams ranked 3–6 at-tempt to utilize hidden layers directly for predic-tion, the top two teams use the output of neurallanguage models to generate different combina-tions of features. Further, while the third placeteam’s best model was an LSTM, their logistic re-gression classifier with Word2Vec-based featuresachieved similar performance. The combinationof different neural features (including non-neuralones) appears to have made the difference in thetop system’s ablation tests.
Sentiment. Three teams report concurrently thata sentiment model alone can achieve 60–65%
accuracy but performance seems to vary depen-dent on implementation details. This is notablein that the sentiment baseline which chose theending with a matching sentiment to the context(presented in Mostafazadeh et al. (2016)) did notachieve accuracy above random chance. One dif-ference is that these more successful approachesused sentiment lexicons to score words and sen-tences, whereas Mostafazadeh et al. used the auto-matic sentiment classifier in Stanford’s CoreNLP.Finally, mflor (Flor and Somasundaran, 2017) an-alyzed the Story Cloze Test Validation (Spring2016) set and found that 78% of the stories havesentiment bearing words in the first sentences andin at least one possible ending. Evaluating onthat subset showed increased performance, furthersuggesting that sentiment is an important factor inalternate ending prediction.
Stylistic Features on Endings. One of the mod-els proposed by msap (Schwartz et al., 2017) ig-nored the entire story, building features only fromthe ending sentences. They trained a linear clas-sifier on the right and wrong ending sentencesadopting style features that have been shown use-ful in other tasks such as gender or native lan-guage detection. This model achieved remarkablygood performance at 72.4%, indicating that there
49

are characteristics inherent to right/wrong endingsindependent of story reasoning. It is not clearwhether these results generalize to novel storyending predictions, beyond the particular Spring2016 sets. Whether this model captures an artifactof the test set creation, or it indicates general fea-tures about how stories are ended must remain forfuture investigation.
Negative results. Some papers describe addi-tional experiments with features and methodsthat are not part of the submitted system, be-cause their inclusion resulted in sub-optimal per-formance. For example, Pranav Goel (Goeland Singh, 2017) discuss additional similaritymeasures based on doc2vec sentence representa-tions (Le and Mikolov, 2014); tbmihaylov (Mi-haylov and Frank, 2017) experiment with Con-ceptNet Numberbatch embeddings (Speer andChin, 2016); and mflor (Flor and Somasundaran,2017) showcase results with alternative sentimentdictionaries such as MPQA (Wilson et al., 2005).
7 Conclusions
All participants in the Story Cloze shared task ofLSDSem outperformed the previously publishedbest result of 58.5%, and the new state-of-the-art accuracy dramatically increased to 75.2% withthe help of a well-designed RNNLM and uniquestylistic features on the ending sentences.
One of the main takeaways from the 8 submis-sions is that the detection of correct ending sen-tences requires a variety of different reasoners. Itappears from both results and post-analysis thatsentiment is one factor in correct detection. How-ever, it is also clear that coherence is critical, asthe systems with language models all observedincreases in prediction accuracy. Beyond these,the best performing system showed that there arestylistic features isolated in the ending sentences,suggesting yet another area of further investigationfor the next phases of this task.
As the first shared task on SCT, we decided notto hold a blind challenge. For the future blindchallenges, the question is how robust are the pre-sented approaches to novel test cases and how wellcan they generalize out of the scope of the cur-rent evaluation sets. We speculate that the modelswhich use generic language understanding and se-mantic cohesion criteria rather than relying on cer-tain intricacies of the testing corpora can general-ize more successfully, which should be carefully
assessed in future.Although this shared task was successful at set-
ting a new state-of-the-art for SCT, clearly, thereis still a long way towards achieving human-levelperformance of 100% on even the current test set.We are encouraged by the high level of participa-tion in the LSDSem 2017 shared task, and hopethe new models and results encourage further re-search in story understanding. Our findings canhelp direct the creation of the next SCT datasetstowards enforcing deeper story understanding.
Acknowledgment
We would like to thank the wonderful crowd work-ers whose daily story writing made collecting theadditional dataset possible. We thank Alyson Gre-alish and Ahmed Hassan Awadallah for their helpin the quality control of ROCStories corpus. Thiswork was supported in part by grant W911NF-15-1-0542 with the US Defense Advanced Re-search Projects Agency (DARPA) as a part of theCommunicating with Computers (CwC) program,a grant from the Office of Naval Research, ArmyResearch Office (ARO), and a DFG Research Fel-lowship (RO 4848/1-1).
ReferencesMichael Bugert, Yevgeniy Puzikov, Andreas Rckl, Ju-
dith Eckle-Kohler, Teresa Martin, Eugenio Martnez-Cmara, Daniil Sorokin, Maxime Peyrard, and IrynaGurevych. 2017. LSDSem 2017: Exploring datageneration methods for the story cloze test. In Pro-ceedings of the 2nd Workshop on Linking Modelsof Lexical, Sentential and Discourse-level Semantics(LSDSem), Valencia, Spain. Association for Compu-tational Linguistics.
Eugene Charniak. 1972. Toward a Model of Children’sStory Comprehension. Ph.D. thesis, MIT.
Michael Flor and Swapna Somasundaran. 2017. Sen-timent analysis and lexical cohesion for the storycloze task. In Proceedings of the 2nd Work-shop on Linking Models of Lexical, Sententialand Discourse-level Semantics (LSDSem), Valencia,Spain. Association for Computational Linguistics.
Pranav Goel and Anil Kumar Singh. 2017. IIT (BHU):System description for LSDSem’17. In Proceed-ings of the 2nd Workshop on Linking Models of Lex-ical, Sentential and Discourse-level Semantics (LS-DSem), Valencia, Spain. Association for Computa-tional Linguistics.
Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng,Alex Acero, and Larry Heck. 2013. Learning deep
50

structured semantic models for web search usingclickthrough data. In Proceedings of the 22nd ACMInternational Conference on Information & Knowl-edge Management, (CIKM ’13), pages 2333–2338,New York, NY, USA. ACM.
Quoc V Le and Tomas Mikolov. 2014. Distributedrepresentations of sentences and documents. In Pro-ceedings of the 31st International Conference onMachine Learning, Beijing, China.
Todor Mihaylov and Anette Frank. 2017. Simple storyending selection baselines. In Proceedings of the2nd Workshop on Linking Models of Lexical, Senten-tial and Discourse-level Semantics (LSDSem), Va-lencia, Spain. Association for Computational Lin-guistics.
Nasrin Mostafazadeh, Nathanael Chambers, XiaodongHe, Devi Parikh, Dhruv Batra, Lucy Vanderwende,Pushmeet Kohli, and James Allen. 2016. A cor-pus and cloze evaluation for deeper understandingof commonsense stories. In Proceedings of the2016 Conference of the North American Chapter ofthe Association for Computational Linguistics: Hu-man Language Technologies, pages 839–849, SanDiego, California, June. Association for Computa-tional Linguistics.
Melissa Roemmele, Sosuke Kobayashi, Naoya Inoue,and Andrew Gordon. 2017. An RNN-based bi-nary classifier for the story cloze test. In Proceed-ings of the 2nd Workshop on Linking Models of Lex-ical, Sentential and Discourse-level Semantics (LS-DSem), Valencia, Spain. Association for Computa-tional Linguistics.
Niko Schenk and Christian Chiarcos. 2017. Resource-lean modeling of coherence in commonsense sto-ries. In Proceedings of the 2nd Workshop on LinkingModels of Lexical, Sentential and Discourse-levelSemantics (LSDSem), Valencia, Spain. Associationfor Computational Linguistics.
Lenhart K. Schubert and Chung Hee Hwang. 2000.Episodic logic meets little red riding hood: A com-prehensive, natural representation for language un-derstanding. In Natural Language Processing andKnowledge Representation: Language for Knowl-edge and Knowledge for Language. MIT/AAAIPress.
Roy Schwartz, Maarten Sap, Ioannis Konstas, LeilaZilles, Yejin Choi, and Noah A. Smith. 2017. Storycloze task: UW NLP system. In Proceedings of the2nd Workshop on Linking Models of Lexical, Senten-tial and Discourse-level Semantics (LSDSem), Va-lencia, Spain. Association for Computational Lin-guistics.
Robert Speer and Joshua Chin. 2016. An ensemblemethod to produce high-quality word embeddings.arXiv preprint arXiv:1604.01692.
Scott R. Turner. 1994. The creative process: A com-puter model of storytelling and creativity. Hillsdale:Lawrence Erlbaum.
Theresa Wilson, Janyce Wiebe, and Paul Hoffmann.2005. Recognizing contextual polarity in phrase-level sentiment analysis. In Proceedings of Hu-man Language Technology Conference and Confer-ence on Empirical Methods in Natural LanguageProcessing, pages 347–354, Vancouver, BritishColumbia, Canada, October.
Terry Winograd. 1972. Understanding Natural Lan-guage. Academic Press, Inc., Orlando, FL, USA.
51

Proceedings of the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics, pages 52–55,Valencia, Spain, April 3, 2017. c©2017 Association for Computational Linguistics
Story Cloze Task: UW NLP System
Roy Schwartz1,2, Maarten Sap1, Ioannis Konstas1,Leila Zilles1, Yejin Choi1 and Noah A. Smith1
1Computer Science & Engineering, University of Washington, Seattle, WA 98195, USA2Allen Institute for Artificial Intelligence, Seattle, WA 98103, USA
{roysch,msap,ikonstas,lzilles,yejin,nasmith}@cs.washington.edu
Abstract
This paper describes University ofWashington NLP’s submission for theLinking Models of Lexical, Sententialand Discourse-level Semantics (LSDSem2017) shared task—the Story Cloze Task.Our system is a linear classifier with avariety of features, including both thescores of a neural language model andstyle features. We report 75.2% accuracyon the task. A further discussion of ourresults can be found in Schwartz et al.(2017).
1 Introduction
As an effort to advance commonsense understand-ing, Mostafazadeh et al. (2016) developed thestory cloze task, which is the focus of the LSD-Sem 2017 shared task. In this task, systems aregiven two short, self-contained stories, which dif-fer only in their last sentence: one has a right (co-herent) ending, and the other has a wrong (incoher-ent) ending. The task is to tell which is the rightstory. In addition to the task, the authors also in-troduced the ROC story corpus—a training corpusof five-sentence (coherent) stories. Table 1 showsan example of a coherent story and an incoherentstory from the story cloze task.
In this paper, we describe University of Wash-ington NLP’s submission for the shared task. Oursystem explores several types of features for thetask. First, we train a neural language model(Mikolov et al., 2010) on the ROC story corpus.We use the probabilities assigned by the model toeach of the endings (right and wrong) as classifi-cation features.
Second, we attempt to distinguish between rightand wrong endings using style features, such assentence length, character n-grams and word n-
Story Prefix Ending
Kathy went shopping.She found a pair ofgreat shoes. Theshoes were $300. Shebought the shoes.
She felt buyer’s re-morse after the pur-chase.
Kathy hated buyingshoes.
Table 1: Examples of stories from the story clozetask (Mostafazadeh et al., 2016). The left columnshows that first four sentences of a story. Theright column shows two contrastive endings forthe story: a coherent ending (upper row) and a in-coherent one (bottom row).
grams. Our intuition is that the right endings usea different style compared to the wrong endings.The features we use were shown useful for styledetection in tasks such as age (Schler et al., 2006),gender (Argamon et al., 2003), and authorshipprofiling (Stamatatos, 2009).
We feed our features to a logistic regressionclassifier, and evaluate our system on the sharedtask. Our system obtains 75.2% accuracy on thetest set. Our findings hint that the different writingtasks used to create the story cloze task—writingright and wrong endings—impose different writ-ing styles on authors. This is further discussed inSchwartz et al. (2017).
2 System Description
We design a system that predicts, given a pair ofstory endings, which is the right one and which isthe wrong one. Our system applies a linear classi-fier guided by several types of features to solve thetask. We describe the system in detail below.
52

2.1 Model
We train a binary logistic regression classifier todistinguish between right and wrong stories. Weuse the set of right stories as positive samples andthe set of wrong stories as negative samples. Attest time, for a given pair, we consider the classi-fication results of both candidates. If our classifierassigns different labels to each candidate, we keepthem. If not, the label whose posterior probabilityis lower is reversed. We describe the classificationfeatures below.
2.2 Features
We use two types of features, designed to cap-ture different aspects of the problem. We use neu-ral language model features to leverage corpuslevel word distributions, specifically longer termsequence probabilities. We use stylistic featuresto capture differences in writing between coherentstory endings and incoherent ones.
Language model features. We experimentwith state-of-the-art text comprehension models,specifically an LSTM (Hochreiter and Schmid-huber, 1997) recurrent neural network languagemodel (RNNLM; Mikolov et al., 2010). OurRNNLM is used to generate two different prob-abilities: pθ(ending), which is the languagemodel probability of the fifth sentence aloneand pθ(ending | story), which is the RNNLMprobability of the fifth sentence given the first foursentences. We use both of these probabilities asclassification features.
In addition, we also apply a third feature:
pθ(ending | story)pθ(ending)
(1)
The intuition is that a correct ending should beunsurprising (to the model) given the four preced-ing sentences of the story (the numerator), control-ling for the inherent surprise of the words in thatending (the denominator).1
Stylistic features. We hypothesize that right andwrong endings might be distinguishable usingstyle features. We adopt style features that havebeen shown useful in the past in tasks such as de-tection of age (Schler et al., 2006; Rosenthal andMcKeown, 2011; Nguyen et al., 2011), gender
1Note that taking the logarithm of the expression in Equa-tion 1 gives the pointwise mutual information between thestory and the ending, under the language model.
(Argamon et al., 2003; Schler et al., 2006; Bam-man et al., 2014), and native language (Koppel etal., 2005; Tsur and Rappoport, 2007; Bergsma etal., 2012).
We add the following classification features tocapture style differences between the two endings.These features are computed on the story endingsalone (right or wrong), and do not consider, eitherat train or at test time, the first four (shared) sen-tences of each story.
• Length. The number of words in the sen-tence.
• Word n-grams. We use sequences of 1–5 words. Following Tsur et al. (2010) andSchwartz et al. (2013), we distinguish be-tween high frequency and low frequencywords. Specifically, we replace contentwords, which are often low frequency, withtheir part-of-speech tags (Nouns, Verbs, Ad-jectives, and Adverbs).
• Character n-grams. Character n-grams areuseful features in the detection of author style(Stamatatos, 2009) or language identification(Lui and Baldwin, 2011). We use character4-grams.
2.3 Experimental SetupThe story cloze task doesn’t have a training corpusfor the right and wrong endings. Therefore, we usethe development set as our training set, holding out10% for development (3,366 training endings, 374for development). We keep the story cloze test setas is (3,742 endings).
We use Python’s sklearn logistic regression im-plementation with L2 regularization, performinggrid search on the development set to tune a singlehyperparameter—the regularization parameter.
For computing the RNN features, we start bytokenizing the text using the nltk tokenizer.2 Wethen use TensorFlow3 to train the RNNLM using asingle-layer LSTM of hidden dimension 512. Weuse the ROC Stories for training, setting aside 10%for validation of the language model.4 We replaceall words occurring less than 3 times by a specialout-of-vocabulary character, yielding a vocabularysize of 21,582. Only during training, we apply a
2www.nltk.org/api/nltk.tokenize.html3www.tensorflow.org4We train on both the Spring 2016 and the Winter 2017
datasets, a total of roughly 100K stories.
53

Model Acc.DSSM (Mostafazadeh et al., 2016) 0.585LexVec (Salle et al., 2016) 0.599RNNLM features 0.677Stylistic features 0.724Combined (Style + RNNLM) 0.752Human judgment 1.000
Table 2: Results on the test set of the story clozetask. The first block are published results, thesecond block are our results. LexVec results aretaken from (Speer et al., 2017). Human judgementscores are taken from (Mostafazadeh et al., 2016).
dropout rate of 60% while running the LSTM overall 5 sentences of the stories. Using Adam opti-mizer (Kingma and Ba, 2015) and a learning rateof η = .001, we train to minimize cross-entropy.The resulting RNN features (see Section 2.2) aretaken in log space.
For the style features, we add a START symbol atthe beginning of each sentence.5 We keep n-gram(character or word) features that occur at least fivetimes in the training set. All stylistic feature valuesare normalized to the range [0, 1]. For the part-of-speech features, we tag all endings with the SpacyPOS tagger.6 The total number of features used byour system is 7,651.
3 Results
The performance of our system is described in Ta-ble 2. With 75.2% accuracy, our system achieves15.3% better than the published state of the art(Salle et al., 2016). The table also shows an anal-ysis of the different features types used by oursystem. While our RNNLM features alone reach67.7%, the style features perform better—72.4%.This suggests that while this task is about story un-derstanding, there is some information containedin stylistic features, which are slightly less sen-sitive to content. As expected, the RNNLM fea-tures complement the stylistic ones, boosting per-formance by 7.5% (over the RNNLM features)and 2.8% (over the style features).
In an attempt to provide explanation to thestrong performance of the stylistic feature, we hy-pothesize that the different writing tasks—writinga right and a wrong ending—impose a different
5Virtually all sentences end with a period or an exclama-tion mark, so we do not add a STOP symbol.
6spacy.io/
style on the authors, which is expressed in thedifferent style adopted in each of the cases. Thereader is referred to Schwartz et al. (2017) formore details and discussion.
4 Conclusion
This paper described University of WashingtonNLP’s submission to the LSDSem 2017 SharedTask. Our system leveraged both neural languagemodel features and stylistic features, achieving75.2% accuracy on the classification task.
Acknowledgments
The authors thank the shared task organizers andanonymous reviewers for feedback. This researchwas supported in part by DARPA under the Com-municating with Computers program.
ReferencesShlomo Argamon, Moshe Koppel, Jonathan Fine, and
Anat Rachel Shimoni. 2003. Gender, genre,and writing style in formal written texts. Text,23(3):321–346.
David Bamman, Jacob Eisenstein, and Tyler Schnoe-belen. 2014. Gender identity and lexical varia-tion in social media. Journal of Sociolinguistics,18(2):135–160.
Shane Bergsma, Matt Post, and David Yarowsky. 2012.Stylometric analysis of scientific articles. In Pro-ceedings of the 2012 Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics: Human Language Technologies, pages327–337, Montreal, Canada, June. Association forComputational Linguistics.
Sepp Hochreiter and Jurgen Schmidhuber. 1997.Long short-term memory. Neural Computation,9(8):1735–1780.
Diederik Kingma and Jimmy Ba. 2015. Adam: Amethod for stochastic optimization. In Proceedingsof the International Conference on Learning Repre-sentations, San Diego, California, USA.
Moshe Koppel, Jonathan Schler, and Kfir Zigdon.2005. Determining an author’s native language bymining a text for errors. In Proceedings of theEleventh ACM SIGKDD International Conferenceon Knowledge Discovery in Data Mining, pages624–628, Chicago, Illinois, USA. Association forComputing Machinery.
Marco Lui and Timothy Baldwin. 2011. Cross-domainfeature selection for language identification. In Pro-ceedings of 5th International Joint Conference on
54

Natural Language Processing, pages 553–561, Chi-ang Mai, Thailand, November. Asian Federation ofNatural Language Processing.
Tomas Mikolov, Martin Karafiat, Lukas Burget, JanCernocky, and Sanjeev Khudanpur. 2010. Recur-rent neural network based language model. In Pro-ceedings of the 11th Annual Conference of the Inter-national Speech Communication Association, pages1045–1048, Makuhari, Chiba, Japan. InternationalSpeech Communication Association.
Nasrin Mostafazadeh, Nathanael Chambers, XiaodongHe, Devi Parikh, Dhruv Batra, Lucy Vanderwende,Pushmeet Kohli, and James Allen. 2016. A cor-pus and cloze evaluation for deeper understanding ofcommonsense stories. In Proceedings of the 2016Conference of the North American Chapter of theAssociation for Computational Linguistics: HumanLanguage Technologies, pages 839–849, San Diego,California, USA, June. Association for Computa-tional Linguistics.
Dong Nguyen, Noah A. Smith, and Carolyn P. Rose.2011. Author age prediction from text using lin-ear regression. In Proceedings of the 5th ACL-HLT Workshop on Language Technology for Cul-tural Heritage, Social Sciences, and Humanities,pages 115–123, Portland, Oregon, USA, June. As-sociation for Computational Linguistics.
Sara Rosenthal and Kathleen McKeown. 2011. Ageprediction in blogs: A study of style, content, andonline behavior in pre- and post-social media gen-erations. In Proceedings of the 49th Annual Meet-ing of the Association for Computational Linguis-tics: Human Language Technologies, pages 763–772, Portland, Oregon, USA, June. Association forComputational Linguistics.
Alexandre Salle, Marco Idiart, and Aline Villavicen-cio. 2016. Enhancing the lexvec distributed wordrepresentation model using positional contexts andexternal memory. arXiv:1606.01283.
Jonathan Schler, Moshe Koppel, Shlomo Argamon,and James Pennebaker. 2006. Effects of age andgender on blogging. In AAAI Spring Symposium:Computational Approaches to Analyzing Weblogs,pages 199–205, Palo Alto, California, USA, March.AAAI Press.
Roy Schwartz, Oren Tsur, Ari Rappoport, and MosheKoppel. 2013. Authorship attribution of micro-messages. In Proceedings of the 2013 Confer-ence on Empirical Methods in Natural LanguageProcessing, pages 1880–1891, Seattle, Washington,USA, October. Association for Computational Lin-guistics.
Roy Schwartz, Maarten Sap, Ioannis Konstas, LeilaZilles, Yejin Choi, and Noah A. Smith. 2017.The effect of different writing tasks on linguisticstyle: A case study of the ROC story cloze task.arXiv:1702.01841.
Robert Speer, Joshua Chin, and Catherine Havasi.2017. Conceptnet 5.5: An open multilingual graphof general knowledge. In Proceedings of the 31stAAAI Conference on Artificial Intelligence, SanFrancisco, California, USA, February. AAAI Press.
Efstathios Stamatatos. 2009. A survey of modern au-thorship attribution methods. Journal of the Ameri-can Society for information Science and Technology,60(3):538–556.
Oren Tsur and Ari Rappoport. 2007. Using classifierfeatures for studying the effect of native languageon the choice of written second language words. InProceedings of the Workshop on Cognitive Aspectsof Computational Language Acquisition, pages 9–16, Prague, Czech Republic, June. Association forComputational Linguistics.
Oren Tsur, Dmitry Davidov, and Ari Rappoport. 2010.ICWSM—a great catchy name: Semi-supervisedrecognition of sarcastic sentences in online prod-uct reviews. In Proceedings of the Fourth Interna-tional AAAI Conference on Weblogs and Social Me-dia, pages 162–169, Washington, DC, USA, May.AAAI Press.
55

Proceedings of the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics, pages 56–61,Valencia, Spain, April 3, 2017. c©2017 Association for Computational Linguistics
LSDSem 2017: Exploring Data Generation Methods forthe Story Cloze Test
Michael Bugert∗, Yevgeniy Puzikov∗, Andreas Ruckle∗,Judith Eckle-Kohler∗, Teresa Martin†, Eugenio Martınez-Camara∗,
Daniil Sorokin∗, Maxime Peyrard† and Iryna Gurevych∗∗Ubiquitous Knowledge Processing Lab (UKP-TUDA)
Department of Computer Science, Technische Universitat Darmstadtwww.ukp.tu-darmstadt.de†Research Training Group AIPHES
Department of Computer Science, Technische Universitat Darmstadtwww.aiphes.tu-darmstadt.de
AbstractThe Story Cloze test (Mostafazadeh et al.,2016) is a recent effort in providing a com-mon test scenario for text understandingsystems. As part of the LSDSem 2017shared task, we present a system based ona deep learning architecture combined witha rich set of manually-crafted linguistic fea-tures. The system outperforms all knownbaselines for the task, suggesting that thechosen approach is promising. We addi-tionally present two methods for generat-ing further training data based on storiesfrom the ROCStories corpus. Our systemand generated data are publicly availableon GitHub1.
1 Introduction
The goal of the Story Cloze test is to provide a com-mon ground for the evaluation of systems on lan-guage understanding (Mostafazadeh et al., 2016).Given four sentences of a story on everyday lifeevents, a system has to identify the correct endingfrom a set of two predefined ending sentences. The“correct” ending in this case is the one which mosthumans would choose as the closing sentence forthe story context.
We first report the discoveries we made while ex-ploring the provided datasets (Section 2) followedby a description of our system (Section 3). Wepresent and discuss its results (Sections 4 and 5)and come to a close in the conclusion (Section 6).
2 Dataset Exploration
Mostafazadeh et al. (2016) provide a validation and1github.com/UKPLab/lsdsem2017-story-cloze
a test set for the Story Cloze test, both of whichcontain around 1800 stories2. Each of those storiesconsists of four context sentences and two end-ings to choose from. Additionally, two ROCStoriesdatasets were made available with close to 100 000stories in total. Stories from these datasets alsocover everyday life events but consist of a fixednumber of five sentences without ending candi-dates.
To gain an overview of the task, we categorizedtwo hundred stories from the validation set basedon how their correct ending can be identified.
We noticed that a large set of stories can indeedbe solved via text understanding and logical infer-ence. This includes stories where the correct end-ing is more likely according to script knowledge3
(Schank and Abelson, 1977), where the topic ofthe wrong ending doesn’t match the story context4
or where the wrong ending contradicts the storycontext5.
For some stories, the correct ending cannot beidentified rationally, but rather according to com-monly accepted moral values6 or based on thereader’s expectation of a positive mood in a story7.Regarding sentiments, we generally noticed a biastowards stories with “happy endings”, i. e. storieswhere the sentiment expressed in the correct endingis more positive than for the wrong ending.
We infer from these observations that an ap-proach focusing exclusively on text understanding
2As of Feb. 2017, see cs.rochester.edu/nlp/rocstories3See story 52dbbfda-5b42-4ace-8d59-55cee3eb30c0 in the
Story Cloze validation set.4See f8ff777f-de4d-4e3a-91bd-b197ed13f78e ibid.5See a11cf506-7d19-4ab9-b0ac-a0fd85a9bd38 ibid.6See 195a43c7-d43e-48e4-845b-fd6c75609df2 ibid.7See 80b6447f-4c37-4194-9862-3785e5075463 ibid.
56

should perform well. However, the dataset suggeststhat an approach which (additionally) exploits howhumans write and perceive stories could also leadto respectable results, albeit not in the way origi-nally intended for the Story Cloze test.
3 System Description
We interpret the Story Cloze test as a fully super-vised learning problem, meaning we train and testour approach on instances consisting of four con-text sentences and two ending candidates (i. e. theformat of the Story Cloze datasets). This stands incontrast to the systems reported by Mostafazadehet al. (2016) which were trained on five-sentencestories (the ROCStories dataset).
Our approach builds around recent advances ofdeep learning methods and conventional featureengineering techniques.
The core of the system is a Bidirectional Recur-rent Neural Network (BiRNN) (Schuster and Pali-wal, 1997) with Long Short-Term Memory (LSTM)units (Hochreiter and Schmidhuber, 1997), whichcomputes a feature representation of all given sen-tences. This representation is enriched by featurevectors computed over both ending candidates. Topredict the correct ending of a story, we executeour neural network twice to obtain a score for eachending. These scores are compared to make a finaldecision. The feature vectors ensure that informa-tion on the respective other ending is available tothe network during both executions.
Note that we could have instead learned endingembeddings jointly by feeding the network withboth endings at the same time. In order to train anetwork to distinguish between correct and wrongendings, we would have had to feed the same pairanother time, but with the endings swapped andthe label set to its binary counterpart. However, wewere concerned that such a system would eventu-ally learn the position of the correct ending insteadof its meaning. Hence, we decided against such ajoint learning approach.
The following sections cover the features andneural network architecture in greater detail.
3.1 Features
We defined a set of linguistic features in order toprofit from the discoveries of our dataset explo-ration (see Section 2). The features are:NGramOverlap: The number of overlapping n-
grams between an ending and a story context
s1 s2 s3 s4 e1 e2
Embed. Lookup
≡ ≡ ≡ ≡vc ≡ ve
BiLSTM
ic ie
Feat. Extr.
if
H
O
Figure 1: Neural network architecture. Depicted isthe execution for obtaining a score for ending e1.
for n = {1, 2, 3}. We filtered out bigrams andtrigrams using a linguistically motivated listof stopwords.
EndingLength: The token count of an ending.Negation: The presence of words indicating nega-
tion (none, never, etc.) in an ending.PronounContrast: The presence of pronoun mis-
matches between a story context and an end-ing. This helps to detect cases where thewrong ending is written in first person al-though the story context is written in thirdperson.
SentiContrast: Disagreement in the sentimentvalue between the third and fourth sentencesof a context and an ending. The sentimentvalue was computed based on a sentimentword list manually extracted from the ROC-Stories dataset.
For each of the features listed above, an addi-tional feature was added to model the feature valuedifference between the two endings of a story. Allfeatures were extracted using the DKPro TC Frame-work (Daxenberger et al., 2014).
3.2 Neural Network
The overall architecture of our neural networkmodel is shown in Figure 1.
First, the tokens of the context sentencess1, . . . , s4 and of ending e1 are looked up in theword embedding matrix to obtain vectorized rep-resentations. The embeddings of the context sen-tences are concatenated into the vector vc, whereas
57

those of the ending form vector ve. vc and ve arefed separately to a pair of RNN networks (forwardand backward) with LSTM units. This BiLSTMmodule encodes the meaning of context and endingin two separate vectors, ic and ie. Given the vectorof feature values if , extracted externally on the fourcontext sentences and both endings, we concate-nate ic, ie and if and feed them to the dense hiddenlayer H. The output of H is fed to the output layer,O. Afterwards, the softmax function is applied onthe output of O to obtain a score representing theprobability of ending e1 being correct.
The same procedure is applied for ending e2
in place of ending e1. Then, the highest-scoringending is chosen as the correct ending of the story.
Due to time constraints and system complexitywe decided against hyper-parameter optimizationand chose parameter values we deemed reasonable:We used pretrained 100-dimensional GloVe embed-dings (Pennington et al., 2014)8. Following previ-ous work on using BiLSTMs in NLP tasks (Tan etal., 2015; Tan et al., 2016; dos Santos et al., 2016),we chose a dimensionality of 141 for the LSTMoutput vectors and hidden layer H.
We employ zero padding for sentences longerthan 20 tokens. The network was trained inbatches (size 40) for 30 epochs with the Adamoptimizer (Kingma and Ba, 2014), starting with alearning rate of 10−4. We apply dropout (p = 0.3)after computing the BiLSTM output. Finally,ReLu (Glorot et al., 2011) is used as an activa-tion function in layer H. The system was imple-mented using the TensorFlow library (Abadi et al.,2016).
3.3 Intermediate Results
We performed an intermediate evaluation of thepreviously described system on the Story Cloze val-idation set. To this end, we partitioned the datasetinto a training and development split (85 % and15 %, respectively). We compared the followingsystems:BiLSTM-V: Our proposed system, trained on the
85 % training split without making use of thefeature set described in Section 3.1.
BiLSTM-VF: Same as BiLSTM-V, but includingthe feature set.
Happy: Motivated by our dataset exploration, thisbaseline always picks the happier ending (theending with the more positive sentiment). We
8nlp.stanford.edu/data/glove.6B.zip
employed the state-of-the-art sentiment anno-tator by Socher et al. (2013) for this purpose.This system does not take the story contextinto account.
The happy ending baseline reached an accuracyof 0.616 on the development split which is substan-tially higher than random guessing. BiLSTM-Vscored 0.708 whereas BiLSTM-VF reached aslightly higher accuracy of 0.712.
3.4 Dataset AugmentationBecause our presented approach conducts super-vised learning, it requires training data in the sameform as testing data. Up to this point, the onlydataset available in this form is the Story Clozevalidation set which consists of comparably fewinstances for training. We experimented with waysto automatically create larger training datasets.
3.4.1 Related Work in Data AugmentationMethods for automatic training data augmenta-tion using unlabeled data are investigated in semi-supervised learning and have been successfully ap-plied in many NLP tasks, for example in word sensedisambiguation (Pham et al., 2005), semantic rolelabeling (Furstenau and Lapata, 2012; Woodsendand Lapata, 2014) and textual entailment (Zanzottoand Pennacchiotti, 2010). Another example, whichis similar to the Story Cloze test, is the task ofselecting the correct answer to a question from apool of answer candidates. To train models for thistask, Feng et al. (2015) have extended a corpusof question-answer pairs by automatically addingnegative answers to each pair.
We draw our inspiration from the aforemen-tioned work and propose two methods for augment-ing the ROCStories dataset in order to use it forsupervised learning.
3.4.2 ShufflingGiven a ROCStory, shuffle the four context sen-tences, then randomly swap the fifth sentence withone of the first four. The resulting story is per-ceived as wrong by humans since the shufflingbreaks causal and temporal relationships betweenthe sentences. This method resembles the dataquality evaluation conducted by Mostafazadeh etal. (2016).
3.4.3 KDE SamplingIn order to obtain a dataset of the same structure asthe Story Cloze datasets, we heuristically comple-ment each ROCStory with a wrong ending taken
58

Story ID Story Context Correct Ending Gen. Wrong Ending
3447901e-6f57-4810-9d3c-92d72b6c0b42
A swan swam gracefully through the water. It wasbeautiful and white. It had a long orange beak. Thecrowd gathered and observed it.
It was a beautiful crea-ture.
A large blue whalebreached the water be-fore Kathy’s eyes.
0dd3e2c3-3ea4-450a-97c4-42a54c426018
Jane had recently gotten a new job. She was nervousabout her first day of work. On the first day of work,Jane overslept. Jane arrived at work an hour late.
Jane did not make agood impression at hernew job.
She told her husbandthat she was going allout this year.
Table 1: ROCStories with wrong endings as generated by the KDE sampling technique
from a pool of sentences. The pool can be chosenarbitrarily but for the sake of simplicity, we de-cided to use the existing set of ROCStory endingsthemselves.
Given four ROCStory context sentences, wemeasure the similarity between this context andeach sentence from the pool (excluding the originalending). To ensure that endings match the topic andnarrative of their context, our similarity measure isbased on word embeddings of content words and abag-of-words vector of occurring pronouns.
Instead of directly choosing whichever endingsentence scores the highest similarity, we attemptto replicate the characteristics of the Story Clozedatasets as close as possible. Therefore, we ob-serve the distribution of similarity values presentbetween each story context and its wrong ending inthe validation set. Using kernel density estimation,we obtain the probability density function (PDF)of these similarity values.
To choose an ending for a ROCStory context, wethen sample a similarity value from this PDF andidentify the sentence in the pool whose similarityis closest to the sampled value. In a final step,we replace proper nouns occurring in the endingsentence with random proper nouns from the storycontext, based on POS-tags.
Table 1 shows two exemplary story endings gen-erated using this method.
3.4.4 ComparisonWe constructed two training datasets, one for eachof the two augmentation methods. We then trainedour BiLSTM approach (without features) for eachdataset and compared their performance on the fullStory Cloze validation set. The BiLSTM usingthe shuffled ROCStories reached an accuracy of0.615, compared to the one using the KDE sam-pling method with 0.630.
From looking at the accuracies, the differencein quality between the two methods is slim. How-ever, the quality of the shuffled stories is inferior tothose of the KDE sampling method from a human
0 510 25 35 50 65 75 90 1000
20
40
60
80
70.8
66.2
65.5
59.8
59.8
59.8
61.6
61.2
62.6
63.3
% of all generated stories usedA
ccur
acy
(%)
Figure 2: Accuracies on the validation set devel-opment split for BiLSTM systems trained on thetraining split plus a varying amount of all 98 166generated stories.
point of view. For this reason, we conduct all sub-sequent data augmentation experiments using theKDE sampling method.
4 Results
Following our motivation for data augmentation,we trained several BiLSTM systems on the train-ing split of the Story Cloze validation set, aug-mented by a varying amount of stories generatedby KDE sampling. Figure 2 shows the accuracy ofthese systems evaluated on the 15 % developmentsplit of the validation set. As can be seen, in allour experiments with augmentation there occurs adecrease in performance compared to the resultsof BiLSTM-V/BiLSTM-VF on the same data (seeSection 3.3). We discuss possible reasons for thisresult in Section 5.
For the final evaluation, we compare the follow-ing approaches:DSSM: The best performing baseline reported by
Mostafazadeh et al. (2016).Happy, BiLSTM-V, BiLSTM-VF: The systems
previously explained in Section 3.3.BiLSTM-T: To assess the quality of the KDE sam-
pling method in isolation, we also include aBiLSTM system in the evaluation which istrained only on the ROCStories corpus with
59

Approach Validation Test
Dev Full
DSSM – 0.604 0.585Happy 0.616 0.590 0.602
BiLSTM-V 0.708 – 0.701*
BiLSTM-VF 0.712 – 0.717*
BiLSTM-T 0.637 – 0.560BiLSTM-TF 0.634 – 0.584
Table 2: System accuracies on the Story Clozedatasets. Results marked by * are statisticallysignificant according to McNemar’s test with ap-value ≤ 0.05.
generated wrong endings.BiLSTM-TF: Same as BiLSTM-T, but including
the feature set.Table 2 shows the performance of the systems on
the Story Cloze test set and (if applicable) on thefull validation set or its development split. It canbe seen that our happy ending baseline performscomparably to the more elaborate DSSM baseline.BiLSTM-V/VF outperform the two baselines sig-nificantly. BiLSTM-T/TF fall short in accuracycompared to the ones trained on the validation setalone. The addition of features leads to improve-ments except for BiLSTM-T/TF when evaluatedon the development split of the validation set.
5 Discussion
We manually examined several stories which weremisclassified by BiLSTM-VF to identify its weak-nesses. In the majority of cases, misclassified sto-ries were sparse in sentiment or relied heavily onlogical inference for identifying the correct end-ing. This appears plausible to us, since neitherthe BiLSTM nor the feature set were explicitly de-signed to perform advanced logical inference.
The proposed features increase the performanceof our BiLSTM system. The data properties theycapture are different from the distributional similar-ities of word embeddings and thus serve as an ad-ditional supervising signal for the neural network.
Given Figure 2 and the disparity between theresults of BiLSTM-T/TF and BiLSTM-V/VF, wehave to conclude that the training data augmenta-tion did not work as well as we expected.
While the KDE sampling method creates sto-ries resembling the ones found in the Story Cloze
validation and test datasets, it does not reproducethe characteristics of these original stories wellenough to produce truly valuable training data. Asan example, the method does not take sentimentinto account, although we demonstrated that theStory Cloze datasets are biased towards happy end-ings. Incorporating further characteristics into themethod would amount to redefining the utilizedsimilarity measure (no modifications would be nec-essary for the core idea of sampling a probabilitydistribution).
6 Conclusion
We showed that using a sentiment-based baseline,it is trivial to reach 60 % accuracy on the StoryCloze test set without relying on text understand-ing. However, more sophisticated techniques arerequired for reaching better results. Using a deeplearning architecture enriched with a set of linguis-tically motivated features, we surpass all previouslypublished baselines on the task and reach 71.7%accuracy on the test set.
We proposed two methods which generate ad-ditional training data for conducting supervisedlearning on the Story Cloze test. To our surprise,the systems trained on generated training data per-formed worse than those trained on conventionaltraining data. This could be due to our data genera-tion not reproducing the characteristics of the origi-nal Story Cloze datasets well enough. Nonetheless,we consider the presented methods to be a valuablecontribution related to the task.
Acknowledgments
We thank the anonymous reviewers for their valu-able comments and insights.
This work has been supported by the German Re-search Foundation as part of the Research TrainingGroup “Adaptive Preparation of Information fromHeterogeneous Sources” (AIPHES) under grantNo. GRK 1994/1, as part of the German-IsraeliProject Cooperation (DIP, grant No. DA 1600/1-1and grant No. GU 798/17-1), and as part of theQA-EduInf project (grant No. GU 798/18-1 andgrant No. RI 803/12-1).
ReferencesMartın Abadi, Paul Barham, Jianmin Chen, Zhifeng
Chen, Andy Davis, Jeffrey Dean, Matthieu Devin,Sanjay Ghemawat, Geoffrey Irving, Michael Isard,Manjunath Kudlur, Josh Levenberg, Rajat Monga,
60

Sherry Moore, Derek G. Murray, Benoit Steiner,Paul Tucker, Vijay Vasudevan, Pete Warden, MartinWicke, Yuan Yu, and Xiaoqiang Zheng. 2016. Ten-sorFlow: A System for Large-Scale Machine Learn-ing. In 12th USENIX Symposium on Operating Sys-tems Design and Implementation (OSDI 16), pages265–283, GA. USENIX Association.
Johannes Daxenberger, Oliver Ferschke, IrynaGurevych, and Torsten Zesch. 2014. DKPro TC:A Java-based Framework for Supervised LearningExperiments on Textual Data. In Proceedings of52nd Annual Meeting of the Association for Compu-tational Linguistics: System Demonstrations, pages61–66. Association for Computational Linguistics.
Cıcero Nogueira dos Santos, Ming Tan, Bing Xiang,and Bowen Zhou. 2016. Attentive Pooling Networks.CoRR, abs/1602.03609.
Minwei Feng, Bing Xiang, Michael R. Glass, LidanWang, and Bowen Zhou. 2015. Applying deep learn-ing to answer selection: A study and an open task. In2015 IEEE Workshop on Automatic Speech Recogni-tion and Understanding (ASRU), pages 813–820.
Hagen Furstenau and Mirella Lapata. 2012. Semi-Supervised Semantic Role Labeling via StructuralAlignment. Computational Linguistics, 38:135–171.
Xavier Glorot, Antoine Bordes, and Yoshua Bengio.2011. Deep sparse rectifier neural networks. InAISTATS, volume 15, page 275.
Sepp Hochreiter and Jurgen Schmidhuber. 1997. LongShort-Term Memory. Neural Computation, 9:1735–1780.
Diederik P. Kingma and Jimmy Ba. 2014. Adam:A Method for Stochastic Optimization. CoRR,abs/1412.6980.
Nasrin Mostafazadeh, Nathanael Chambers, XiaodongHe, Devi Parikh, Dhruv Batra, Lucy Vanderwende,Pushmeet Kohli, and James Allen. 2016. A Corpusand Cloze Evaluation for Deeper Understanding ofCommonsense Stories. In Proceedings of the 2016Conference of the North American Chapter of theAssociation for Computational Linguistics: HumanLanguage Technologies, pages 839–849, San Diego,California. Association for Computational Linguis-tics.
Jeffrey Pennington, Richard Socher, and ChristopherManning. 2014. GloVe: Global Vectors for WordRepresentation. In Proceedings of the 2014 Confer-ence on Empirical Methods in Natural Language Pro-cessing (EMNLP), pages 1532–1543, Doha, Qatar.Association for Computational Linguistics.
Thanh Phong Pham, Hwee Tou Ng, and Wee SunLee. 2005. Word Sense Disambiguation with Semi-supervised Learning. In Proceedings of the 20th Na-tional Conference on Artificial Intelligence - Volume3, AAAI’05, pages 1093–1098, Pittsburgh, Pennsyl-vania. AAAI Press.
Roger C. Schank and Robert P. Abelson. 1977. Scripts,Plans, Goals, and Understanding: An Inquiry IntoHuman Knowledge Structures. The Artificial Intelli-gence Series. Lawrence Erlbaum Associates.
Mike Schuster and Kuldip K. Paliwal. 1997. Bidirec-tional recurrent neural networks. IEEE Trans. SignalProcessing, 45:2673–2681.
Richard Socher, Alex Perelygin, Jean Wu, JasonChuang, Christopher D. Manning, Andrew Ng, andChristopher Potts. 2013. Recursive Deep Models forSemantic Compositionality Over a Sentiment Tree-bank. In Proceedings of the 2013 Conference onEmpirical Methods in Natural Language Processing,pages 1631–1642, Seattle, Washington, USA. Asso-ciation for Computational Linguistics.
Ming Tan, Bing Xiang, and Bowen Zhou. 2015. LSTM-based Deep Learning Models for non-factoid answerselection. CoRR, abs/1511.04108.
Ming Tan, Cicero dos Santos, Bing Xiang, and BowenZhou. 2016. Improved Representation Learning forQuestion Answer Matching. In Proceedings of the54th Annual Meeting of the Association for Compu-tational Linguistics (Volume 1: Long Papers), pages464–473, Berlin, Germany. Association for Compu-tational Linguistics.
Kristian Woodsend and Mirella Lapata. 2014. TextRewriting Improves Semantic Role Labeling. Jour-nal of Artificial Intelligence Research, 51:133–164.
Fabio Massimo Zanzotto and Marco Pennacchiotti.2010. Expanding textual entailment corpora fromWikipedia using co-training. In Proceedings of the2nd Workshop on The People’s Web Meets NLP: Col-laboratively Constructed Semantic Resources, pages28–36, Beijing, China. Coling 2010 Organizing Com-mittee.
61

Proceedings of the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics, pages 62–67,Valencia, Spain, April 3, 2017. c©2017 Association for Computational Linguistics
Sentiment Analysis and Lexical Cohesion for the Story Cloze Task
Michael FlorEducational Testing Service
660 Rosedale RoadPrinceton, NJ [email protected]
Swapna SomasundaranEducational Testing Service
660 Rosedale RoadPrinceton, NJ 08540
Abstract
We present two NLP components for theStory Cloze Task – dictionary-based senti-ment analysis and lexical cohesion. Whileprevious research found no contributionfrom sentiment analysis to the accuracyon this task, we demonstrate that senti-ment is an important aspect. We describea new approach, using a rule that estimatessentiment congruence in a story. Oursentiment-based system achieves strongresults on this task. Our lexical cohesionsystem achieves accuracy comparable topreviously published baseline results. Acombination of the two systems achievesbetter accuracy than published baselines.We argue that sentiment analysis shouldbe considered an integral part of narrativecomprehension.
1 Introduction
The Story Cloze Task (SCT) is a novel challengetask in which an automated NLP system has tochoose a correct ending for a short story, fromtwo predefined alternatives. This new challengestems from a long line of research on the typesof knowledge that are required for narrative com-prehension (Winograd, 1972; Schank and Abel-son, 1977). Specifically, it is related to a previoustype of challenge, the Narrative Cloze Task (NCT)(Chambers and Jurafsky, 2008).
The SCT departs from the narrow focus of theNCT. It is informed by the interest in the tempo-ral and causal relations that form the intricate fab-ric of narrative stories. Some previous researchon analyzing and learning commonsense informa-tion have focused on blogs (Gordon and Swanson,2009; Manshadi et al., 2008), which are challeng-ing and difficult texts. Other studies have focused
on analysis of short fables (Goyal et al., 2013; El-son and McKeown, 2010). Mostafazadeh et al.(2016) produced a large curated corpus of simplecommonsense stories, generated via crowdsourc-ing. Each story consists of exactly five short sen-tences, with a clear beginning, middle and end-ing, without embellishments, lengthy introduc-tions and digressions.
For the Story Cloze Task, human authors usedfour-sentence core stories form the corpus, andprovided two different ending sentences - a ‘right’one and a ‘wrong’ one. Some of the ‘wrong’ end-ings include logical contradictions, some includeevents that are impossible or highly unlikely givenour standard world knowledge. For example: 1.Yesterday Stacey was driving to work. 2. Unfor-tunately a large SUV slammed into her. 3. Luck-ily she was alright. 4. However her car was de-stroyed. Options: 5a. Stacey got back in her carand drove to work [wrong]. 5b. Stacey told thepolice what happened [right].
The current SCT has a validation set and a testset, with 1871 stories per set. Each story consistsof four sentences, and two competing sentences asstory endings. An NLP system is tasked to choosethe correct ending from the two alternatives. Sys-tems are evaluated on a simple accuracy measure(number of correct choices divided by number ofstories). In this setting, if ending-choices are maderandomly, the baseline success rate would be 50%.
In this paper we present our system for the SCTchallenge. Section 2 outlines the approach, section3 describes the algorithms and the results.
2 Approach
Our system is not designed for deep understand-ing of narrative or for semantic reasoning. Thegoal of our approach is to investigate the contribu-tion of sentiment and affect in the SCT task. We
62

build our system with components that performsentiment analysis and estimate discourse cohe-sion. Our system tries to pick the most coherentending based on the sentiment expectations thatthe story builds in the minds of the reader. Forsentiment we consider positive and negative emo-tions, feelings, evaluations of the characters, aswell as positive and negative situations and events(Wilson and Wiebe, 2005). In cases where senti-ment is absent, we rely on lexical cohesion. Ourapproach is to investigate, if and how, coherence,as modeled using simple methods, can perform inthe story completion task.
Consider this story with marked sentiment: 1.Ron started his new job as a landscaper today[neutral]. 2. He loves the outdoors and has alwaysenjoyed working in it [positive]. 3. His boss tellshim to re-sod the front yard of the mayor’s home[neutral]. 4. Ron is ecstatic, but does a thoroughjob and finishes super early [positive]. Choices forending (correct option is 5b): 5a. Ron is immedi-ately fired for insubordination [negative]. 5b. Hisboss commends him for a job well done [positive].
In this story, there is a positive sequence ofevents. Hence it would be rather incoherent tohave an ending that is starkly negative (incorrectoption 5a). If indeed a negative ending were to beapplied, it would be a twist in the story and wouldhave to be indicated with a discourse marker tomake the story coherent. In short stories, plottwists that relate to sentiment polarity are usu-ally expressed via adverbial phrases, such as ‘how-ever’, ‘unfortunately’ or ‘luckily’, and contrastiveconnectors, such as ‘but’ and ‘yet’. Notably, someadverbials only indicate contrast to previous con-text (such as ‘however’), while others induce aspecific sentiment polarity. For example, ‘luck-ily’ indicates positive sentiment, overriding othersentiment-bearing words in the sentence; ‘unfor-tunately’ indicates negative sentiment, again over-riding other indicators in the sentence. This is seenin the example below where a series of bad (nega-tive) situations suddenly change for the better. Thepositive twist in the story is indicated by ‘luckily’.
Example: 1. Addie was working at the mall atHollister when a strange man came in [negative].2. Before she knew it, Addie looked behind her andsaw stolen clothes [negative]. 3. Addie got scaredand tried to chase the man out [negative]. 4. Luck-ily guards came and arrested him [overall positive,with an indication for positive story twist]. Ending
options (correct is 5b): 5a. Addie was put in jailfor her crime [negative]. 5b. Addie was relievedand took deep breaths to calm herself [positive].
In the absence of sentiment in a story, discoursecoherence is, to some extent, captured by lexicalcohesion. Take for example the following: 1. Sambought a new television. 2. It would not turn on.3. He pressed the on button several times. 4. Fi-nally Jeb came over to check it out. Ending options(5b is correct): 5a. Jeb turned on the microwave.5b. Jeb plugged the television in and it turned on.Here, even though both sentences introduce a newterm (‘microwave’ and ‘plugged’), the latter is se-mantically closer to the main story.
3 System Description
We construct two systems, one based on sentimentand another based on cohesion. We use the pre-diction from the sentiment-based system when thestory has positive or negative sentiment elements,and back-off to a cohesion-based system when nosentiment is detected.
3.1 Sentiment-based system
Mostafazadeh et al. (2016) presented initial ef-forts to use sentiment analysis for the SCT. Theyused two approaches. Sentiment-Full: choose theending that matches the average sentiment of thecontext (sentences 1-4). Sentiment-Last: choosethe ending that matches the sentiment of the lastcontext sentence. In both cases, they used thesentiment analysis component from the StanfordCoreNLP toolkit (Manning et al., 2014). No de-tails were given on the algorithm they used for thestory completion task. These respective modelsachieved accuracy of 0.489 and 0.514 on the vali-dation set, and 0.492 and 0.522 on the test set.
For our analyses, we used an adapted versionof the VADER sentiment dictionary. The origi-nal VADER dictionary (Hutto and Gilbert, 2014)contains 7062 lexical entries, with valence (senti-ment) scores on the scale from -5 (very negative)to 5 (very positive). We expanded those lexicalentries, and added all their inflectional variants,using an in-house English morphological toolkit.Our modified sentiment dictionary has 8255 en-tries. New words inherited the valence scores oforigin words. For all entries, valence scores wererescaled into the range between -1 and 1.
For computing sentiment value for a sentencewe filter out stop words (using a list of 250 com-
63

mon English stopwords) and analyze only contentwords. For each word, we retrieve its valencefrom the sentiment dictionary (if present), and sumup the values for the whole sentence. We im-plement local negation handling - if a sentiment-bearing word is negated (by a preceding word),the sentiment value of the word flips (multiply by-1) (Taboada et al., 2011). In addition we handletwists by checking for adverbials. If a sentencestarts with a polarity-inducing adverbial, the sumof polarity values for the story is changed to thesign of the inducing adverbial (positive or nega-tive). For this purpose, we prepared our own dic-tionary of polarity-inducing adverbials.
The key component in using sentiment scoresfor SCT is the decision rule: choose the com-pletion sentence whose sentiment score is con-gruent with the rest of the story. The rule hastwo parts: a) Choose the completion sentence thathas the same sentiment polarity as the precedingstory. If the preceding story has positive (negative)sentiment, choose the positive (negative) comple-tion. b) If both completions have same polarity,sign-congruence will not work. In such cases, wechoose the completion whose value (magnitude) iscloser to the sentiment value of the preceding con-text.
While analyzing the stories from the validationset with the VADER dictionary, we noted that 78%of the stories have sentiment-bearing words, bothin the core sentences (sentences 1-4) and in at leastone of the alternative ending sentences. The testset has an even higher percentage of such stories:86%. The sentiment-based decision rule in theSCT cannot be applied in cases where the core-story or both completion sentences do not have asentiment value. Thus, in order to test the effec-tiveness of our sentiment-based approach, we firsttested its performance on sentiment-bearing sto-ries only. Results are presented in Table 1. Notethat the number of stories-with-sentiment dependson the lexicon. The results clearly indicate thatconsidering the sentiment of the whole precedingcontext has a strong contribution towards selectingthe correct ending (above 60% accuracy). Makinga choice while considering the sentiment of onlythe last context sentence is much less successful(performance is worse than random).
We conducted a similar analysis with anotherlexicon – MPQA (Wilson et al., 2005), which hasonly binary valence values. It provided similar (al-
Set Sentiment-Full Sentiment-LastValidation (1469) 0.679 0.436Test (1610) 0.607 0.358
Table 1: Sytem accuracy on stories where senti-ment is detected (in paretheses: number of storieswith sentiment).
beit lower) results: 66% of stories in the valida-tion set have sentiment, and accuracy on this setis 0.555. This indicates that even very simplifiedsentiment analysis has some utility for the SCT.
3.2 Lexical CohesionOur language model for lexical cohesion uses di-rect word-to-word associations (first-order wordco-occurrences). This type of model has beensuccessfully used for analyzing the contributionof lexical cohesion to readability and text diffi-culty of short reading materials (Flor and BeigmanKlebanov, 2014). The current model was trainedon the English Gigaword Fourth Edition corpus(Parker et al., 2009), approximately 2.5 billionword tokens. The model stores counts of wordco-occurrence collected within paragraphs (ratherthan windows of set length). We use Positive Nor-malized PMI as our association measure. Normal-ized PMI was introduced by (Bouma, 2009); pos-itive NPMI maps all negative values to zero. Tocalculate lexical cohesion between two sentences(or any other snippets of text), we use the fol-lowing procedure. First, for each sentence we re-move the stopwords. Then, we generate all pairsof words (so that one word comes from first sen-tence and the other word comes from the secondsentence), retrieve their association values fromthe model, and sum up the values. The sum ofpairwise associations can be used as a similarity(or relatedness) measure. We also experimentedwith average (dividing the sum by the numberof pairs), but the sum performed slightly betterin our experiments. For the SCT task, for eachstory, we computed lexical cohesion between sen-tences 1-4, taken together as a paragraph, and eachof the competing completion sentences (LexCohe-sion Full). The decision rule is to choose the com-pletion sentence that is more strongly associatedwith the preceding story. Accuracy is 0.534 onthe validation set and 0.527 on the test set (with1871 stories in each set). We also computed lexi-cal cohesion between the last sentence of contextand each of the competing endings (LexCohesion
64

Last). For this condition, accuracy is 0.556 on thevalidation set and 0.536 on the test set. Our resultsare comparable to those of (Mostafazadeh et al.,2016), who used vector-space embeddings and ob-tained 0.545 and 0.536 on the validation set, 0.539and 0.522 on the test set.
3.3 Combining the Models
To provide a full algorithm for the SCT task,we use our sentiment-based algorithm, and onlyback off to our lexical cohesion model when sen-timent is not detected in the story (sentences 1-4) or in neither of the ending sentences. Re-sults are presented in Table 2. Best accuracy isachieved by combining the Sentiment-Full modelwith LexCohesion-Last: 0.654 on the validationset and 0.620 on the test set. These results out-perform the previously published best baseline of0.604 and 0.585 (Mostafazadeh et al., 2016).
Set Sentiment-Full +LexCohesion-Full
Sentiment-Full +LexCohesion-Last
Validation 0.639 0.654Test 0.618 0.620
Table 2: System accuracy on all stories in each set.
4 Discussion
The role of affect and emotion has long been notedfor human story comprehension (Kneepkens andZwaan, 1994; Miall, 1989) and in AI research onnarratives (Lehnert and Vine, 1987; Dyer, 1983).Stories are typically about characters facing con-flict. Sometimes the plot complications (negativeevents or situations) have to be overcome. In manysuch cases, one expects to encounter sentiment ex-pressions in the story. Not surprisingly, we foundthat a large proportion of the stories, in both vali-dation and test sets, have sentiment-bearing words.Thus, it is only natural to expect that sentimentanalysis should be able to impact SCT. Our ap-proach is to look at the polarity of sentiments andfor sentiment congruence in a story. Using a senti-ment dictionary that assigns sentiment values on acontinuous scale, and looking only at lexically in-dicated sentiment, our algorithm chooses the cor-rect ending in more than 60% of stories (when sen-timent is detected).
We have demonstrated that even a rather sim-ple, lexically-based sentiment analysis, can pro-vide a considerable contribution to accuracy in theSCT. Our system only evaluates the congruence
of two competing solutions, without attempting todevelop a deep understanding of the story. For ex-ample, our system does not have the capability toreason that a car that has just been wrecked cannotbe used to drive away. However, we consider thatanalyzing the sentiment of a story is not a shal-low task (even if it is technically rather simple).We believe that human-level understanding of nar-rative involves many facets, including chains andschemas of events, plot units, character goals andstates, etc. Handling each of them presents uniquechallenges to an NLP system. We argue that thesentiment aspect of narratives is one of the key as-pects of stories. In fact, sentiment is a very deepaspect of narrative (Mar et al., 2011), one that wehave only begun to explore. As the SCT focuseson very short stories, it is interesting to note thatpatterning of sentiment and affect has also beenshown to exist on the scale of long novels (Reaganet al., 2016).
While our dictionary-based sentiment analysiswas quite successful, we note that it should beviewed only as a starting point for investigatingthe role of sentiment in narrative comprehension.In the SCT, there are cases were dictionary-basedsentiment detection fails to detect the sentiment ina story. For example: 1. Brad went to the beach.2. He made a sand castle. 3. He jumped into theocean waters. 4. He swam with the small fish. Op-tions: 5a: Brad’s day went very badly. 5b: Bradthen went home after a nice day.
The above story has quite positive connotations,but none of the lexical terms from sentences 1-4 carry sentiment values in the dictionary. Oursystem detects sentiment in each of the compet-ing ending sentences, but since no sentiment wasdetected in sentences 1-4, choice of the endingis relegated to lexical cohesion, rather than sen-timent. A human reader would choose the secondending, based on positive sentiment connoted bythe events.
5 Conclusion
In this paper we described a simple approach thatcombines sentiment- and cohesion-based systemsfor the Story Cloze Task. While previous researchfound sentiment analysis to be ineffective on thistask, we proposed a new approach, using a rulethat estimates sentiment congruence in a story.Our system achieves accuracy of 0.654 on the val-idation set and 0.620 on test set, mostly due to the
65

strong contribution from sentiment analysis. Ourresults provide support to the notion that sentimentis an important aspect of narrative comprehension,and that sentiment-analysis can be a strong con-tributing factor for NLP analysis of stories. Thereare a number of avenues for further exploration,such as using machine learning methods to com-bine different types of information that go intomaking a story, using vector spaces, automatedreasoning and extending the feature set to captureother aspects of language understanding.
ReferencesGerloff Bouma. 2009. Normalized (pointwise) mutual
information in collocation extraction. In From Formto Meaning: Processing Texts Automatically, Pro-ceedings of the Biennial GSCL Conference, pages31–40. Gunter Narr Verlag, Tubingen.
Nathanael Chambers and Daniel Jurafsky. 2008. Un-supervised learning of narrative event chains. InProceedings of the 46th Annual Meeting of the ACL,pages 789–797, Columbus, OH, USA, June. Associ-ation for Computational Linguistics, Association forComputational Linguistics.
Michael G. Dyer. 1983. The role of affect in narratives.Cognitive Science, 7:211–242.
David K. Elson and Kathleen R. McKeown. 2010.Building a bank of semantically encoded narratives.In Nicoletta Calzolari (Conference Chair), KhalidChoukri, Bente Maegaard, Joseph Mariani, JanOdijk, Stelios Piperidis, Mike Rosner, and DanielTapias, editors, Proceedings of the Seventh Interna-tional Conference on Language Resources and Eval-uation (LREC’10), Valletta, Malta. European Lan-guage Resources Association (ELRA).
Michael Flor and Beata Beigman Klebanov. 2014. As-sociative lexical cohesion as a factor in text com-plexity. International Journal of Applied Linguis-tics, 165(2):223–258.
Andrew S. Gordon and Reid Swanson. 2009. Identi-fying personal stories in millions of weblog entries.In Third International Conference on Weblogs andSocial Media, Data Challenge Workshop, San Jose,CA, USA.
Amit Goyal, Ellen Riloff, and Hal Daume III. 2013. Acomputational model for plot units. ComputationalIntelligence, 3(29):466–488.
C.J. Hutto and Eric Gilbert. 2014. Vader: A parsi-monious rule-based model for sentiment analysis ofsocial media text. In Proceedings of The 8th Inter-national AAAI Conference on Weblogs and SocialMedia (ICWSM14), Ann Arbor, MI, USA. Associa-tion for the Advancement of Artificial Intelligence.
E.W.E.M Kneepkens and Rolf A. Zwaan. 1994. Emo-tions and literary text comprehension. Poetics,23:125–138.
Wendy G. Lehnert and Elaine W. Vine. 1987. Therole of affect in narrative structure. Cognition andEmotion, 1(3):299–322.
Christopher Manning, Mihai Surdeanu, John Bauer,Jenny Finkel, Steven J. Bethard, and David Mc-Closky. 2014. The stanford corenlp natural lan-guage processing toolkit. In Proceedings of 52ndAnnual Meeting of the Association for Computa-tional Linguistics: System Demonstrations, pages55–60. Association for Computational Linguistics.
Mehdi Manshadi, Reid Swanson, and Andrew S. Gor-don. 2008. Learning a probabilistic model of eventsequences from internet weblog stories. In Proceed-ings of 21st Conference of the Florida AI Society,Applied Natural Language Processing Track, Co-conut Grove, FL, USA.
Raymond A. Mar, Keith Oatley, Maja Djikic, andJustin Mullin. 2011. Emotion and narrative fiction:Interactive influences before, during, and after read-ing. Cognition and Emotion, 25(2):818–833.
David S. Miall. 1989. Affective comprehension of lit-erary narratives. Cognition and Emotion, 3(1):55–78.
Nasrin Mostafazadeh, Nathanael Chambers, XiaodongHe, Devi Parikh, Dhruv Batra, Pushmeet KohliLucy Vanderwende, and James Allen. 2016. A cor-pus and cloze evaluation for deeper understanding ofcommonsense stories. In Proceedings of the 2016Conference of the North American Chapter of theAssociation for Computational Linguistics: HumanLanguage Technologies (NAACL HLT), pages 839–849, San Diego, California. Association for Compu-tational Linguistics.
Robert Parker, David Graff, JunboKong, Ke Chen, and Kazuaki Maeda.2009. English gigaword fourth edition.https://catalog.ldc.upenn.edu/LDC2009T13.
Andrew J. Reagan, Lewis Mitchell, Dilan Kiley,Christopher M Danforth, and Peter Sheridan Dodds.2016. The emotional arcs of stories are dominatedby six basic shapes. EPJ Data Science, 5(31).
Roger C. Schank and Robert P. Abelson. 1977. Scripts,Plans, Goals and Understanding. Lawrence Erl-baum, Hillsdale, NJ, USA.
Maite Taboada, Julian Brooke, Milan Tofiloski, Kim-berly Voll, and Manfred Stede. 2011. Lexicon-basedmethods for sentiment analysis. Computa-tional Linguistics, 2(37):267–307.
Theresa Wilson and Janyce Wiebe. 2005. Annotat-ing attributions and private states. In Proceedingsof ACL Workshop on Frontiers in Corpus Annota-tion II: Pie in the Sky, pages 53–60, Ann Arbor, MI,USA. Association for Computational Linguistics.
66

Theresa Wilson, Janyce Wiebe, and Paul Hoff-mann. 2005. Recognizing contextual polarityin phrase-level sentiment analysis. In Proceed-ings of the Human Language Technologies Confer-ence/Conference on Empirical Methods in NaturalLanguage Processing (HLT/EMNLP-2005), pages347–354, Vancouver. Association for ComputationalLinguistics.
Terry Winograd. 1972. Understanding Natural Lan-guage. Academic Press, Inc., Orlando, FL, USA.
67

Proceedings of the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics, pages 68–73,Valencia, Spain, April 3, 2017. c©2017 Association for Computational Linguistics
Resource-Lean Modeling of Coherence in Commonsense Stories
Niko Schenk and Christian ChiarcosApplied Computational Linguistics Lab
Goethe University Frankfurt am Main, Germany{n.schenk,chiarcos}@em.uni-frankfurt.de
Abstract
We present a resource-lean neural recog-nizer for modeling coherence in common-sense stories. Our lightweight system isinspired by successful attempts to mod-eling discourse relations and stands outdue to its simplicity and easy optimizationcompared to prior approaches to narrativescript learning. We evaluate our approachin the Story Cloze Test1 demonstrating anabsolute improvement in accuracy of 4.7%over state-of-the-art implementations.
1 Introduction
Semantic applications related to Natural LanguageUnderstanding have seen a recent surge of interestwithin the NLP community, and story understand-ing can be regarded as one of the supreme disci-plines in that field. Closely related to MachineReading (Hovy, 2006) and script learning (Schankand Abelson, 1977; Mooney and DeJong, 1985), itis a highly challenging task which is built on top ofa cascade of core NLP applications, including—among others—causal/temporal relation recogni-tion (Mirza and Tonelli, 2016), event extraction(UzZaman and Allen, 2010), (implicit) semanticrole labeling (Gerber and Chai, 2012; Schenk andChiarcos, 2016) or inter-sentential discourse pars-ing (Mihaylov and Frank, 2016).
Recent progress has been made in the field ofnarrative understanding: a variety of successfulapproaches have been introduced, ranging fromnarrative chains (Chambers and Jurafsky, 2008) toscript learning techniques (Regneri et al., 2010),or event schemas (Nguyen et al., 2015). What
1The shared task of the LSDSem 2017 workshop onLinking Models of Lexical, Sentential and Discourse-levelSemantics:http://www.coli.uni-saarland.de/˜mroth/LSDSem/,http://cs.rochester.edu/nlp/rocstories/LSDSem17/,https://competitions.codalab.org/competitions/15333
all these approaches have in common is that theyultimately seek to find a way to prototypicallymodel the causal and correlational relationshipsbetween events, and also to obtain a structured(ideally more compact and abstract) representationof the underlying commonsense knowledge whichis encoded in the respective story. The downsideof these approaches is that they are feature-rich(potentially hand-crafted) and therefore costly anddomain-specific to a large extent. On a relatednote, Mostafazadeh et al. (2016a) demonstrate thatthere is still room for improvement when test-ing the performances of these state-of-the-art tech-niques for learning procedural knowledge on anindependent evaluation set.
Our Contribution: In this paper, we propose alightweight, resource-lean framework for model-ing procedural knowledge in commonsense sto-ries whose only source of information are dis-tributed word representations. We cast the prob-lem of modeling text coherence as a special caseof discourse processing in which our model jointlylearns to distinguish correct from incorrect storyendings. Our approach is inspired by promis-ing related attempts using event embeddings andneural methods for script learning (Modi andTitov, 2014; Pichotta and Mooney, 2016). Oursystem is an end-to-end implementation of theideas sketched in Mostafazadeh et al. (2016b)of the joint paragraph and sentence level model(cf. Section 3 for details). We evaluate our ap-proach in the Story Cloze Test, a task for pre-dicting story continuations. Despite its simplic-ity, our system demonstrates superior performanceon the designated data over previous approachesto script learning and—due to its language andgenre-independence—it also represents a solid ba-sis for further optimization towards other textualdomains.
68

Four-Sentence Core Story Quiz 1 Quiz 2
I asked Sarah out on a date. She said yes.I was so excited for our date together. Wewent to dinner and then a movie.
I had a terrible time. I got to kiss Sarah goodnight.(wrong ending) (correct ending)
Table 1: An example of a ROCStory consisting of a core story and two alternative continuations.
2 The Story Cloze Test
2.1 Task Description
In the Story Cloze Test a participating system ispresented with a four-sentence core story alongwith two alternative single-sentence endings, i.e.a correct and a wrong one. The system is thensupposed to select the correct ending based on asemantic analysis of the individual story compo-nents. For this binary choice, outputs are evaluatedon accuracy level.
2.2 Data
The shared task organizers provide participantswith a large corpus of approx. 98k five-sentenceeveryday life stories (Mostafazadeh et al., 2016a,ROCStories2) for training their narrative story un-derstanding models. Also a validation and a testset are available (each containing 1,872 instances).The former serves for parameter optimization,whereas final performance is evaluated on the testset. The instances in all three sets are mutuallyexclusive. Note that in addition to the ROCSto-ries, both validation and test sets include an addi-tional wrong 5th-sentence story ending (either infirst or second position) plus hand-annotated de-cisions about which story ending is the right one.As an illustration, consider the example in Table 1consisting of a core story and two alternative con-tinuations (quizzes). The global semantics of thisROCStory is driven by two factors: i) a latent dis-coursive, temporal/causal relationship between theindividual events in each sentence and ii) a result-ing positive outcome of the story. Clearly, the rightending is the second quiz. Note that for all sto-ries in the data set, the task of choosing the correctending is human solvable with perfect agreement(Mostafazadeh et al., 2016a).
2http://cs.rochester.edu/nlp/rocstories/
3 Approach
Our proposed model architecture for finding theright story continuation is inspired by novel worksfrom (shallow) discourse parsing, most notably bythe recent success of neural network-based frame-works in that field (Xue et al., 2016; Schenk et al.,2016; Wang and Lan, 2016). Specifically for im-plicit discourse relations, i.e. for those sentencepairs which, for instance, can signal a temporal,contrast or contingency relation, but which sufferfrom the absence of an explicit discourse marker(such as but or because), it has been shown thatthe interaction of properly tuned distributed repre-sentations over adjacent text spans can be partic-ularly powerful in the relation classification task.We cast the Story Cloze test as a special case ofimplicit discourse relation recognition and attemptto model an underlying, latent connection betweena core story and its correct vs. incorrect contin-uation. For instance, the final example sentencein the core story in Table 1 and the two adjacentquizzes could be treated as argument pairs (Arg1and Arg2) in the classical view of the Penn Dis-course Treebank (Prasad et al., 2008), distinguish-ing different types of implicit discourse relationsthat hold between them.3
Arg1: We went to dinner and then a movie.
Arg2: I had a terrible time.
TEMP.SYNCHRONOUS
Arg1: We went to dinner and then a movie.
Arg2: I got to kiss Sarah goodnight.
TEMP.ASYNCHRONOUS.PRECEDENCE
Here, in the first example, the label SYN-CHRONOUS indicates that the two situationsin both arguments overlap temporally (whichcould be signaled explicitly by while, for in-stance), whereas in the second example ASYN-CHRONOUS.PRECEDENCE implies a temporal or-
3For details, see https://www.seas.upenn.edu/˜pdtb/PDTBAPI/pdtb-annotation-manual.pdf
69

Neural Hidden Layer
Softmax (Sigmoid) Output Layer
Composition Layer
Aggregation
Core Story / C Q1 Q2
t6t5t4t3t2 tnt1 t1 t2 tn t1 t2 tn
avg avg avg
Figure 1: The proposed architecture for the Story Cloze Test. Depicted is a training instance consistingof three distributed word representation matrices for core story (C), quiz 1 (Q1) and quiz 2 (Q2), eachcomponent of varying length n. Note that either Q1 or Q2 is a wrong story ending. Matrices are firstindividually aggregated by average computation. Resulting vectors are then concatenated to form a com-position unit which serves as input to the network with one hidden layer and binary output classification.
der of both events. The distinction between dif-ferent implicit discourse senses are subtle nuancesand are highly challenging to detect automati-cally; however, they are typical of the ROCSto-ries, as almost no explicit discourse markers arepresent between the individual story sentences. Fi-nally, note that our motivation for this approachis also related to the classical view of recogniz-ing textual entailment which would treat correctand wrong endings as the entailing and contradict-ing hypotheses, respectively (Giampiccolo et al.,2007; Mostafazadeh et al., 2016a).
3.1 Training InstancesFor the Story Cloze Test, we model a training in-stance as a triplet consisting of the four-sentencecore story (C), a first quiz sentence (Q1) and a sec-ond quiz sentence (Q2) from which either Q1 orQ2 is the correct continuation of the story. Notethat the original ROCStories contain only validfive-sentence sequences but the evaluation data re-quires a system to select from a pool of two alter-
natives. Therefore, for each single story in ROC-Stories, we randomly sample one negative (wrong)continuation Qwrong from all last sentences, andgenerate two training instances with the followingpatterns:[C, Q1, Q2wrong]:Label 1,[C, Q1wrong, Q2]:Label 2,where the label indicates the position of the cor-rect quiz. Our motivation is to jointly learn corestories together with their true ending while at thesame time discriminating them from semanticallyirrelevant continuations.
For each component in the triplet, we have ex-perimented with a variety of different calculationsin order to capture their idiosyncratic syntactic andsemantic properties. We found the vector averageover their respective words #�v avg = 1
N
∑Ni=1 E(ti)
to perform reasonably well, where N is the totalnumber of tokens filling either of C, Q1 or Q2,respectively, resulting in three individual vectorrepresentations. Here, we define E(·) as an em-bedding function which maps a token ti to its dis-
70

tributed representation, i.e., a precomputed vectorof d dimensions. As distributed word representa-tions, we chose out of the box vectors; GloVe vec-tors (Pennington et al., 2014), dependency-basedword embeddings (Levy and Goldberg, 2014) andthe pre-trained Google News vectors with d = 300from word2vec4 (Mikolov et al., 2013). Usingthe same tool, we also trained custom embeddings(bag-of-words and skip-gram) with 300 dimen-sions on the ROCStories corpus.5
3.2 Network ArchitectureThe feature construction process and the neuralnetwork architecture are depicted in Figure 1. Thebottom part illustrates how tokens are mappedthrough three stacked embedding matrices for C,Q1 and Q2, each of dimensionality Rd×n. A sec-ond step applies the average aggregation and con-catenates the so-obtained vectors #�c avg, #�q1
avg, #�q2avg
(each #�v avg ∈ Rd) into an overall composed storyrepresentation of dimensionality R3∗d which inturn serves as input to a feedforward neural net-work. The network is set up with one hidden layerand one sigmoid output layer for binary label clas-sification for the position of the correct ending, i.e.first or second.
3.3 Implementational DetailsThe network is trained only on the ROCStories(and the negative training items), totaling approx.200k training instances, over 30 iterations and 35epochs with pretraining and a mini batch size of120. All (hyper-)parameters are chosen and op-timized on the validation set. We conduct datanormalization, Xavier weight initialization (Glorotand Bengio, 2010) on the input layer, and employrectified linear unit activation functions to both thecomposition layer and hidden layer with 220-250nodes, and finally apply a sigmoid output layer forlabel classification. The learning rate is set to 0.04,l2 regularization = 0.0002 for penalizing networkweights using the cross entropy error loss func-tion. The network is trained using stochastic gradi-ent descent and backpropagation implemented inthe toolkit deeplearning4j.6
4https://code.google.com/p/word2vec/5We remove punctuation symbols in all settings.6https://deeplearning4j.org/
Performance
System Validation Test
DSSM 0.604 0.585Narrative-Chains 0.510 0.494Majority Class 0.514 0.513
Neural-ROCStoriesOnly 0.629 0.632SVM-ManualLabels – 0.700
Table 2: Performances (in % accuracy) on the val-idation and test sets of The Story Cloze Test.
4 Evaluation
We evaluate our model intrinsically on both val-idation and test set provided by the shared taskorganizers. As a reference, we also providethree baselines borrowed from Mostafazadeh etal. (2016a) at the time when the data set was re-leased, namely the best-performing algorithms in-spired by Huang et al. (2013, Deep Structured Se-mantic Model/DSSM) and Chambers and Jurafsky(2008, Narrative-Chains). Table 2 shows that cor-rect endings appear almost equally often in eitherfirst or second position in the annotated data sets.The majority class is only significantly beatenby the DSSM model. Our approach (denotedby Neural-ROCStoriesOnly), however, can furtherimprove upon the best system by an absolute in-crease in accuracy of 4.7%. Only the best config-uration is shown and has been achieved with the300-dimensional pre-trained Google News em-beddings. Interestingly, the performance of themodel on the test set is slightly better that on thevalidation set but also very similar which suggeststhat it is able to generalize well to unseen dataand is not prone to overfitting training or valida-tion data. A manual inspection of a subset of themisclassified items reveals that our neural recog-nizer is struggling to properly handle story contin-uations which change the underlying sentiment ofthe core story either towards negative or positive,e.g. fail test, study hard → pass test. In futurework we plan to address this issue in closer detail.
A Note on the Evaluation & Training Proce-dure: Although the task has been stated differ-ently, it stands to reason that one could exploitthe tiny amount of hand-annotated data in the val-idation set directly to train a classifier. We havedone so as a side experiment using as features the
71

same 900-dimensional composition layer embed-dings from Section 3.2 and optimized a minimalistSVM classifier by 10-fold cross-validation, withfeature and parameter selection on the validationset.7 The final model achieves a test set accu-racy of 70.02%, cf. SVM-ManualLabels in Table2. Besides the relatively good performance ob-tained here, however, we want to emphasize that—when no hand-annotated labels for the correct po-sition of the quizzes are available—the Neural-ROCStories approach introduced in Section 3 rep-resents a promising and more generic frameworkfor coherence learning, incorporating the plain textROCStories as only source of information.
5 Conclusion & Outlook
In this paper, we have introduced a highly genericand resource-lean neural recognizer for modelingtext coherence, which has been adapted to a des-ignated data set—the ROCStories for modelingstory continuations. Our approach is inspired bysuccessful models for (implicit) discourse relationclassification and only relies on the carefully tunedinteraction of distributed word representations be-tween story components.
An evaluation shows that state-of-the-art algo-rithms for script learning can be outperformed byour model. Future work should address the incor-poration of linguistic knowledge into the currentlyrather rigid representations of the story sentences,including sentiment polarities or weighted syn-tactic dependencies (Schenk et al., 2016). Eventhough it has been claimed that the simpler feed-forward neural networks do perform better in thediscourse modeling task (Rutherford and Xue,2016), it remains an open and challenging topic forfuture experiments on the ROCStories, whether re-current architectures (Pichotta and Mooney, 2016)can have additional value towards a deeper storyunderstanding.8
Acknowledgments
We want to thank Philip Schulz for constructivefeedback regarding the neural network setup andthe two anonymous reviewers for their very help-ful remarks and insightful comments.
7We used libsvm (https://www.csie.ntu.edu.tw/˜cjlin/libsvm/), RBF kernel, c = 1.85, g = 0.63.
8The code for this study is publicly available from thefollowing URL: http://www.acoli.informatik.uni-frankfurt.de/resources/.
ReferencesNathanael Chambers and Daniel Jurafsky. 2008. Un-
supervised Learning of Narrative Event Chains. InACL 2008, Proceedings of the 46th Annual Meet-ing of the Association for Computational Linguis-tics, June 15-20, 2008, Columbus, Ohio, USA, pages789–797.
Matthew Gerber and Joyce Chai. 2012. Semantic RoleLabeling of Implicit Arguments for Nominal Pred-icates. Comput. Linguist., 38(4):755–798, Decem-ber.
Danilo Giampiccolo, Bernardo Magnini, Ido Dagan,and Bill Dolan. 2007. The Third PASCAL Recog-nizing Textual Entailment Challenge. In Proceed-ings of the ACL-PASCAL Workshop on Textual En-tailment and Paraphrasing, RTE ’07, pages 1–9,Stroudsburg, PA, USA. Association for Computa-tional Linguistics.
Xavier Glorot and Yoshua Bengio. 2010. Understand-ing the difficulty of training deep feedforward neu-ral networks. In In Proceedings of the InternationalConference on Artificial Intelligence and Statistics(AISTATS10). Society for Artificial Intelligence andStatistics.
Eduard H. Hovy. 2006. Learning by Reading: AnExperiment in Text Analysis. In Petr Sojka, IvanKopecek, and Karel Pala, editors, TSD, volume 4188of Lecture Notes in Computer Science, pages 3–12.Springer.
Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng,Alex Acero, and Larry Heck. 2013. Learning DeepStructured Semantic Models for Web Search Us-ing Clickthrough Data. In Proceedings of the 22NdACM International Conference on Information &Knowledge Management, CIKM ’13, pages 2333–2338, New York, NY, USA. ACM.
Omer Levy and Yoav Goldberg. 2014. Dependency-Based Word Embeddings. In Proceedings of the52nd Annual Meeting of the Association for Com-putational Linguistics, ACL 2014, June 22-27, 2014,Baltimore, MD, USA, Volume 2: Short Papers, pages302–308.
Todor Mihaylov and Anette Frank. 2016. DiscourseRelation Sense Classification Using Cross-argumentSemantic Similarity Based on Word Embeddings.In Proceedings of the CoNLL-16 shared task, pages100–107. Association for Computational Linguis-tics.
Tomas Mikolov, Kai Chen, Greg Corrado, and JeffreyDean. 2013. Efficient Estimation of Word Repre-sentations in Vector Space. In Proceedings of Work-shop at International Conference on Learning Rep-resentations.
Paramita Mirza and Sara Tonelli. 2016. CATENA:causal and temporal relation extraction from natu-ral language texts. In COLING 2016, 26th Inter-national Conference on Computational Linguistics,
72

Proceedings of the Conference: Technical Papers,December 11-16, 2016, Osaka, Japan, pages 64–75.
Ashutosh Modi and Ivan Titov. 2014. Learning Se-mantic Script Knowledge with Event Embeddings.In Proceedings of the 2nd International Confer-ence on Learning Representations (Workshop track),Banff, Canada.
Raymond J. Mooney and Gerald DeJong. 1985.Learning Schemata for Natural Language Process-ing. In Proceedings of the 9th International JointConference on Artificial Intelligence. Los Angeles,CA, USA, August 1985, pages 681–687.
Nasrin Mostafazadeh, Nathanael Chambers, XiaodongHe, Devi Parikh, Dhruv Batra, Lucy Vanderwende,Pushmeet Kohli, and James Allen. 2016a. A Cor-pus and Cloze Evaluation for Deeper Understand-ing of Commonsense Stories. In Proceedings of the2016 Conference of the North American Chapter ofthe Association for Computational Linguistics: Hu-man Language Technologies, pages 839–849, SanDiego, California, June. Association for Computa-tional Linguistics.
Nasrin Mostafazadeh, Lucy Vanderwende, Wen-tauYih, Pushmeet Kohli, and James Allen. 2016b.Story Cloze Evaluator: Vector Space Representa-tion Evaluation by Predicting What Happens Next.In Proceedings of the 1st Workshop on EvaluatingVector-Space Representations for NLP, pages 24–29, Berlin, Germany, August. Association for Com-putational Linguistics.
Kiem-Hieu Nguyen, Xavier Tannier, Olivier Ferret,and Romaric Besancon. 2015. Generative EventSchema Induction with Entity Disambiguation. InProceedings of the 53rd Annual Meeting of theAssociation for Computational Linguistics and the7th International Joint Conference on Natural Lan-guage Processing of the Asian Federation of NaturalLanguage Processing, ACL 2015, July 26-31, 2015,Beijing, China, Volume 1: Long Papers, pages 188–197.
Jeffrey Pennington, Richard Socher, and Christo-pher D. Manning. 2014. Glove: Global vectors forword representation. In Empirical Methods in Nat-ural Language Processing (EMNLP), pages 1532–1543.
Karl Pichotta and Raymond J. Mooney. 2016. Usingsentence-level LSTM language models for script in-ference. In Proceedings of the 54th Annual Meet-ing of the Association for Computational Linguis-tics, ACL 2016, August 7-12, 2016, Berlin, Ger-many, Volume 1: Long Papers.
Rashmi Prasad, Nikhil Dinesh, Alan Lee, Eleni Milt-sakaki, Livio Robaldo, Aravind Joshi, and BonnieWebber. 2008. The Penn Discourse TreeBank 2.0.In Proceedings, 6th International Conference onLanguage Resources and Evaluation, pages 2961–2968, Marrakech, Morocco.
Michaela Regneri, Alexander Koller, and ManfredPinkal. 2010. Learning script knowledge from webexperiments. In Proceedings of the 48th AnnualMeeting of the Association for Computational Lin-guistics (ACL), Uppsala.
Attapol Rutherford and Nianwen Xue. 2016. Ro-bust Non-Explicit Neural Discourse Parser in En-glish and Chinese. In Proceedings of the CoNLL-16shared task, pages 55–59. Association for Computa-tional Linguistics.
Roger C. Schank and Robert P. Abelson. 1977. Scripts,Plans, Goals and Understanding: an Inquiry intoHuman Knowledge Structures. L. Erlbaum, Hills-dale, NJ.
Niko Schenk and Christian Chiarcos. 2016. Unsu-pervised learning of prototypical fillers for implicitsemantic role labeling. In NAACL HLT 2016, The2016 Conference of the North American Chapter ofthe Association for Computational Linguistics: Hu-man Language Technologies, San Diego California,USA, June 12-17, 2016, pages 1473–1479.
Niko Schenk, Christian Chiarcos, Kathrin Donandt,Samuel Ronnqvist, Evgeny Stepanov, and GiuseppeRiccardi. 2016. Do We Really Need All Those RichLinguistic Features? A Neural Network-Based Ap-proach to Implicit Sense Labeling. In Proceedingsof the CoNLL-16 shared task, pages 41–49. Associ-ation for Computational Linguistics.
Naushad UzZaman and James F Allen. 2010. Extract-ing Events and Temporal Expressions from Text. InSemantic Computing (ICSC), 2010 IEEE Fourth In-ternational Conference on, pages 1–8. IEEE.
Jianxiang Wang and Man Lan. 2016. Two End-to-end Shallow Discourse Parsers for English and Chi-nese in CoNLL-2016 Shared Task. In Proceedingsof the CoNLL-16 shared task, pages 33–40. Associ-ation for Computational Linguistics.
Nianwen Xue, Hwee Tou Ng, Sameer Pradhan, Bon-nie Webber, Attapol Rutherford, Chuan Wang, andHongmin Wang. 2016. The CoNLL-2016 SharedTask on Shallow Discourse Parsing. In Proceedingsof the Twentieth Conference on Computational Nat-ural Language Learning - Shared Task, Berlin, Ger-many, August. Association for Computational Lin-guistics.
73

Proceedings of the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics, pages 74–80,Valencia, Spain, April 3, 2017. c©2017 Association for Computational Linguistics
An RNN-based Binary Classifier for the Story Cloze TestMelissa Roemmele
Institute for Creative TechnologiesUniversity of Southern [email protected]
Sosuke Kobayashi∗Preferred Networks, [email protected]
Naoya InoueTohoku University
Andrew M. GordonInstitute for Creative TechnologiesUniversity of Southern California
Abstract
The Story Cloze Test consists of choos-ing a sentence that best completes a storygiven two choices. In this paper wepresent a system that performs this task us-ing a supervised binary classifier on topof a recurrent neural network to predictthe probability that a given story endingis correct. The classifier is trained todistinguish correct story endings given inthe training data from incorrect ones thatwe artificially generate. Our experimentsevaluate different methods for generatingthese negative examples, as well as dif-ferent embedding-based representations ofthe stories. Our best result obtains 67.2%accuracy on the test set, outperforming theexisting top baseline of 58.5%.
1 Introduction
Automatically predicting ”what happens next” in astory is an emerging AI task, situated at the pointwhere natural language processing meets com-monsense reasoning research. Story understand-ing began as classic AI planning research (Mee-han, 1977, e.g.), and has evolved with the shiftto data-driven AI approaches by which large setsof stories can be analyzed from text (Granroth-Wilding and Clark, 2016; Li et al., 2013; McIntyreand Lapata, 2009, e.g.). A barrier to this researchhas been the lack of standard evaluation schemesfor benchmarking progress. The new Story ClozeTest (Mostafazadeh et al., 2016) addresses thisneed through a binary-choice evaluation format:given the beginning sentences of a story, the taskis to choose which of two given sentences bestcompletes the story. The cloze framework also
∗This research was conducted at his previous affiliation,Tohoku University.
provides training stories (referred to here as theROC corpus) in the same domain as the evalua-tion items. Mostafazadeh et al. details the crowd-sourced authoring process for this dataset. Ulti-mately the training data consists of 97,027 five-sentence stories. The separate cloze test has 3742items (divided equally between validation and testsets) each containing the first four sentences of astory with a correct and incorrect ending to choosefrom.
In the current paper, we describe a set of ap-proaches for performing the Story Cloze Test. Ourbest result obtains 67.2% accuracy on the test set,outperforming Mostafazadeh et al.’s best baselineof 58.5%. We first report two additional unsuper-vised baselines used in other narrative predictiontasks. We then describe our supervised approach,which uses a recurrent neural network (RNN) witha binary classifier to distinguish correct story end-ings from artificially generated incorrect endings.We compare the performance of this model whenalternatively trained on different story encodingsand different strategies for generating incorrectendings.
2 Story Representations
We examined two ways of representing stories inour models, both of which encode stories as vec-tors of real numbers known as embeddings. Thiswas motivated by the top performing baseline inMostafazadeh et al. which used embeddings toselect the candidate story ending with the highercosine similarity to its context.
Word Embeddings: We first tried encod-ing stories with word-level embeddings using theword2vec model (Mikolov et al., 2013), whichlearns to represent words as n-dimensional vec-tor of real values based on neighboring words.We compared two different sets of vectors: 300-
74

dimension vectors trained on the 100-billion wordGoogle News dataset1 and 300-dimension vectorsthat we trained on ROC corpus itself. The latterwere trained using the gensim word2vec library2,with a window size of 10 words and negative sam-pling of 25 noise words. All other parameters wereset to the default values given by the library. Bycomparing these two sets of embeddings, we in-tended to determine the extent to which our mod-els can rely only on the limited training data pro-vided for this task. In our supervised experimentswe averaged the embeddings of the words in eachsentence, resulting in a single vector representa-tion of the entire sentence.
Sentence Embeddings: The second embed-ding strategy we used was the skip-thought model(Kiros et al., 2015), which produces vectors thatencode an entire sentence. Analogous to train-ing word vectors by predicting nearby words, theskip-thought vectors are trained to predict nearbysentences. We evaluated two sets of sentencevectors: 4800-dimension vectors trained on the11,000 books in the BookCorpus dataset3, and2400-dimension vectors we trained ourselves onthe ROC corpus4. The latter BookCorpus vectorswere also used in a baseline that measured vectorsimilarity between the story context and candidateendings in Mostafazadeh et al.
3 Unsupervised Approaches
Mostafazadeh et al. applied several unsupervisedbaselines to the Story Cloze Test. We evaluatedtwo additional approaches due to their success onother narrative prediction tasks.
Average Maximum Similarity (AveMax):The AveMax model is a slight variation onMostafazadeh et al.’s averaged word2vec baseline.It is currently implemented to predict story contin-uations from user input in the recently developedDINE application5. Instead of selecting the em-bedded candidate ending most similar to the con-text, this method iterates through each word in theending, finds the word in the context with mostsimilar embedding, and then takes the mean ofthese maximum similarity embeddings. We evalu-ated this method using both the word embeddings
1https://code.google.com/archive/p/word2vec/2https://radimrehurek.com/gensim/models/word2vec.html3https://github.com/ryankiros/skip-thoughts4We used the same code and default parameters available
at the above GitHub page.5http://dine.ict.usc.edu
from the Google News dataset and the ROC cor-pus.
Pointwise Mututal Information (PMI): ThePMI model was used successfully on the Choiceof Plausible Alternatives task (COPA) (Roemmeleet al., 2011; Gordon et al., 2011; Gordon et al.,2012; Luo et al., 2016) which similarly to theStory Cloze Test uses a binary-choice format toelicit inferences about a segment of narrative text.This model relies on lexical co-occurrence counts(of raw words rather than embeddings) to computea ‘causality score’ about how likely one sentenceis to follow another in a story. We applied the sameapproach to the Story Cloze Test to select the finalsentence with the higher causality score of the twocandidates. We evaluated word counts from twodifferent sources: a corpus of one million storiesextracted from personal weblogs (as was used inGordon et al.) and the ROC corpus.
4 Supervised Approaches
Given the moderate size of the ROC corpus atalmost 100,000 stories, and that the Story ClozeTest can be viewed as a classification task choos-ing from two possible outputs, we investigated asupervised approach. Unlike the training data fortraditional classification models, the ROC corpusdoes not involve a set of discrete categories bywhich stories are labeled. Moreover, while theStory Cloze Test provides a correct and incorrectoutcome to choose from, the training data onlycontains the correct ending for a given story. Soour strategy was to create a new training set withbinary labels of 1 for correct endings (positive ex-amples) and 0 for incorrect endings (negative ex-amples). Each story in the corpus was considereda positive example. Given a positive example, wegenerated a negative example by replacing its finalsentence with an incorrect ending. As describedbelow, we generated more than one negative end-ing per story, so that each positive example hadmultiple negative counterparts. Our methods forgenerating negative examples are described in thenext section. Our approach was to train a binaryclassifier to distinguish between these positive andnegative examples.
The binary classifier is integrated with an RNN.RNNs have been used successfully for other nar-rative modeling tasks (Iyyer et al., 2016; Pichottaand Mooney, 2016). Our model takes the contextsentences and ending for a particular story as in-
75
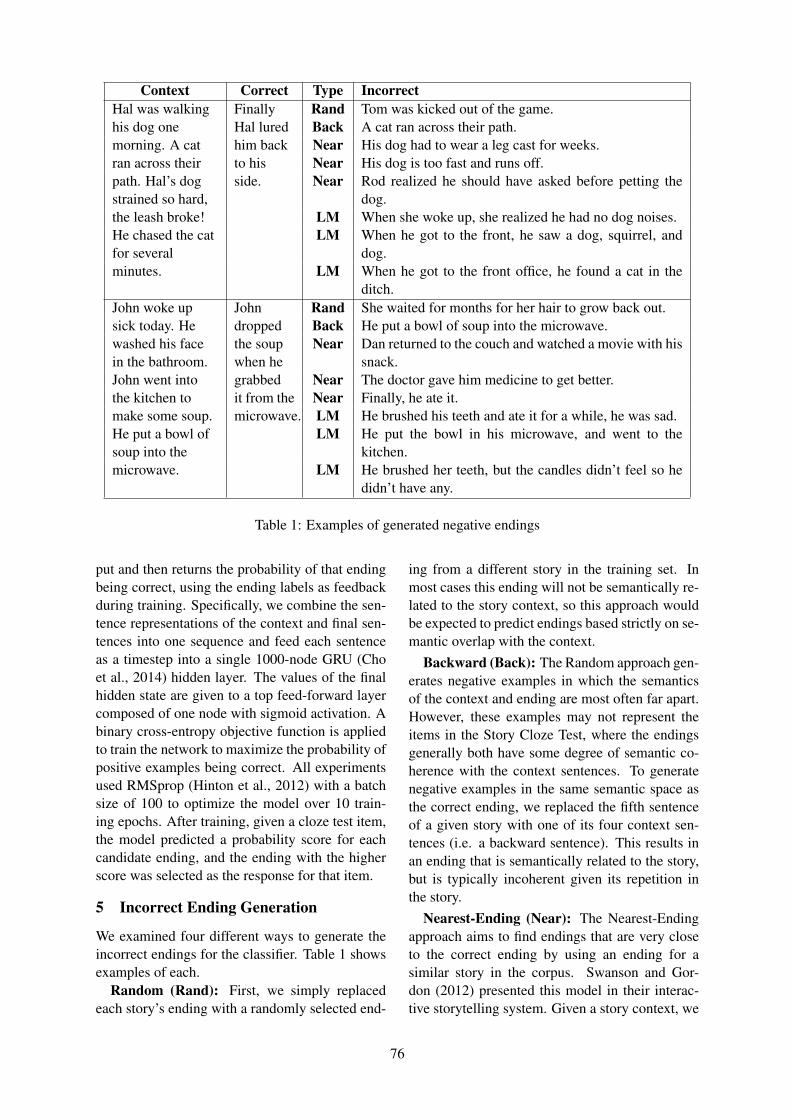
Context Correct Type IncorrectHal was walkinghis dog onemorning. A catran across theirpath. Hal’s dogstrained so hard,the leash broke!He chased the catfor severalminutes.
FinallyHal luredhim backto hisside.
Rand Tom was kicked out of the game.Back A cat ran across their path.Near His dog had to wear a leg cast for weeks.Near His dog is too fast and runs off.Near Rod realized he should have asked before petting the
dog.LM When she woke up, she realized he had no dog noises.LM When he got to the front, he saw a dog, squirrel, and
dog.LM When he got to the front office, he found a cat in the
ditch.John woke upsick today. Hewashed his facein the bathroom.John went intothe kitchen tomake some soup.He put a bowl ofsoup into themicrowave.
Johndroppedthe soupwhen hegrabbedit from themicrowave.
Rand She waited for months for her hair to grow back out.Back He put a bowl of soup into the microwave.Near Dan returned to the couch and watched a movie with his
snack.Near The doctor gave him medicine to get better.Near Finally, he ate it.LM He brushed his teeth and ate it for a while, he was sad.LM He put the bowl in his microwave, and went to the
kitchen.LM He brushed her teeth, but the candles didn’t feel so he
didn’t have any.
Table 1: Examples of generated negative endings
put and then returns the probability of that endingbeing correct, using the ending labels as feedbackduring training. Specifically, we combine the sen-tence representations of the context and final sen-tences into one sequence and feed each sentenceas a timestep into a single 1000-node GRU (Choet al., 2014) hidden layer. The values of the finalhidden state are given to a top feed-forward layercomposed of one node with sigmoid activation. Abinary cross-entropy objective function is appliedto train the network to maximize the probability ofpositive examples being correct. All experimentsused RMSprop (Hinton et al., 2012) with a batchsize of 100 to optimize the model over 10 train-ing epochs. After training, given a cloze test item,the model predicted a probability score for eachcandidate ending, and the ending with the higherscore was selected as the response for that item.
5 Incorrect Ending Generation
We examined four different ways to generate theincorrect endings for the classifier. Table 1 showsexamples of each.
Random (Rand): First, we simply replacedeach story’s ending with a randomly selected end-
ing from a different story in the training set. Inmost cases this ending will not be semantically re-lated to the story context, so this approach wouldbe expected to predict endings based strictly on se-mantic overlap with the context.
Backward (Back): The Random approach gen-erates negative examples in which the semanticsof the context and ending are most often far apart.However, these examples may not represent theitems in the Story Cloze Test, where the endingsgenerally both have some degree of semantic co-herence with the context sentences. To generatenegative examples in the same semantic space asthe correct ending, we replaced the fifth sentenceof a given story with one of its four context sen-tences (i.e. a backward sentence). This results inan ending that is semantically related to the story,but is typically incoherent given its repetition inthe story.
Nearest-Ending (Near): The Nearest-Endingapproach aims to find endings that are very closeto the correct ending by using an ending for asimilar story in the corpus. Swanson and Gor-don (2012) presented this model in their interac-tive storytelling system. Given a story context, we
76

retrieved the most similar story in the corpus (interms of cosine similarity), and then projected thefinal sentence of the similar story as the ending ofthe given story. Multiple endings were producedby finding the N most similar stories. The neg-ative examples generated by this scheme can beseen as ‘almost’ positive examples with likely co-herence errors, given the sparsity of the corpus.This is in line with the cloze task where both end-ings are plausible, but the correct answer is morelikely than the other.
Language Model (LM): Separate from the bi-nary classifier, we trained an RNN-based languagemodel (Mikolov et al., 2010) on the ROC cor-pus. The LM learns a conditional probability dis-tribution indicating the chance of each possibleword appearing in a sequence given the wordsthat precede it. During training, the LM iteratedthrough a story word by word, each time updat-ing its predicted probability of the next observedword. During generation, we gave the LM thecontext of each training story and had it producea final sentence by sampling words one by one ac-cording to the predicted distribution, as describedin Sutskever et al. (2011). Multiple sentences weregenerated for the same story by sampling the Nmost probable words at each timestep. The LMhad a 200-node embedding layer and two 500-node GRU layers, and was trained using the Adamoptimizer (Kingma and Ba, 2015) with a batch sizeof 50. This approach has an advantage over theNearest-Ending method in that it leverages all thestories in the training data for generation, ratherthan predicting an ending based on a single story.Thus, it can generate endings that are not directlyobserved in the training corpus. Like the nearest-ending approach, an ideal LM would be expectedto generate positive examples similar to the orig-inal stories it is trained on. However, we foundthat the LM-generated endings were relevant to thestory context but had less of a commonsense inter-pretation than the provided endings, again likelydue to training data sparsity.
6 Experiments
We trained a classifier for each type of nega-tive ending and additionally for each type of em-bedding, shown in Table 2. For each correctexample, we generated multiple incorrect exam-ples. We found that setting the number of neg-ative samples per positive example near 6 pro-
duced the best results on the validation set for allconfigurations, so we kept this number consistentacross experiments. The exception is the Back-ward method, which can only generate one of thefirst four sentences in each story. For each gen-eration method, the negative samples were keptthe same across runs of the model with differentembeddings, rather than re-sampling for each run.After discovering that our best validation resultscame from the random endings, we also evaluatedcombinations of these endings with the other typesto see if they could further boost the model’s per-formance. The samples used by these combined-method experiments were a subset of the negativesamples generated for the single-method results.
Table 2 shows the accuracy of all unsupervisedand supervised models on both the validation andtest sets, with the best test result within eachgroup in bold. Among the unsupervised models,the AveMax model with the GoogleNews embed-dings (55.2% test accuracy) performs compara-bly to Mostafazadeh et al.’s word2vec similaritymodel (53.9%). The PMI approach performs at thesame level as the current best baseline of 58.5%,and the counts from the ROC stories are just as ef-fective (59.9%) as those from the much larger blogcorpus (59.1%).
The best test result using the GoogleNews wordembeddings (61.5%) was slightly better than thatof the ROC word embeddings (58.8%). Amongthe single-method results, the word embeddingswere outperformed by the best result of the skip-thought embeddings (63.2%), suggesting that theskip-thought model may capture more informationabout a sentence than simply averaging its wordembeddings. For this reason we skipped evaluat-ing the word embeddings for the combined-endingexperiments. One caveat to this is the smallersize of the word embeddings relative to the skip-thought vectors. While it is unusual for word2vecembeddings to have more than a thousand dimen-sions, to be certain that the difference in perfor-mance was not due to the difference in dimen-sionality, we performed an ad-hoc evaluation ofword embeddings that were the same size as theROC sentence vectors (2400 nodes). We com-puted these vectors from the ROC corpus in thesame way described in Section 2, and applied themto our best-performing data configuration (Rand-3+ Back-1 + Near-1 + LM-1). The result (57.9%)was still lower than that produced by the cor-
77
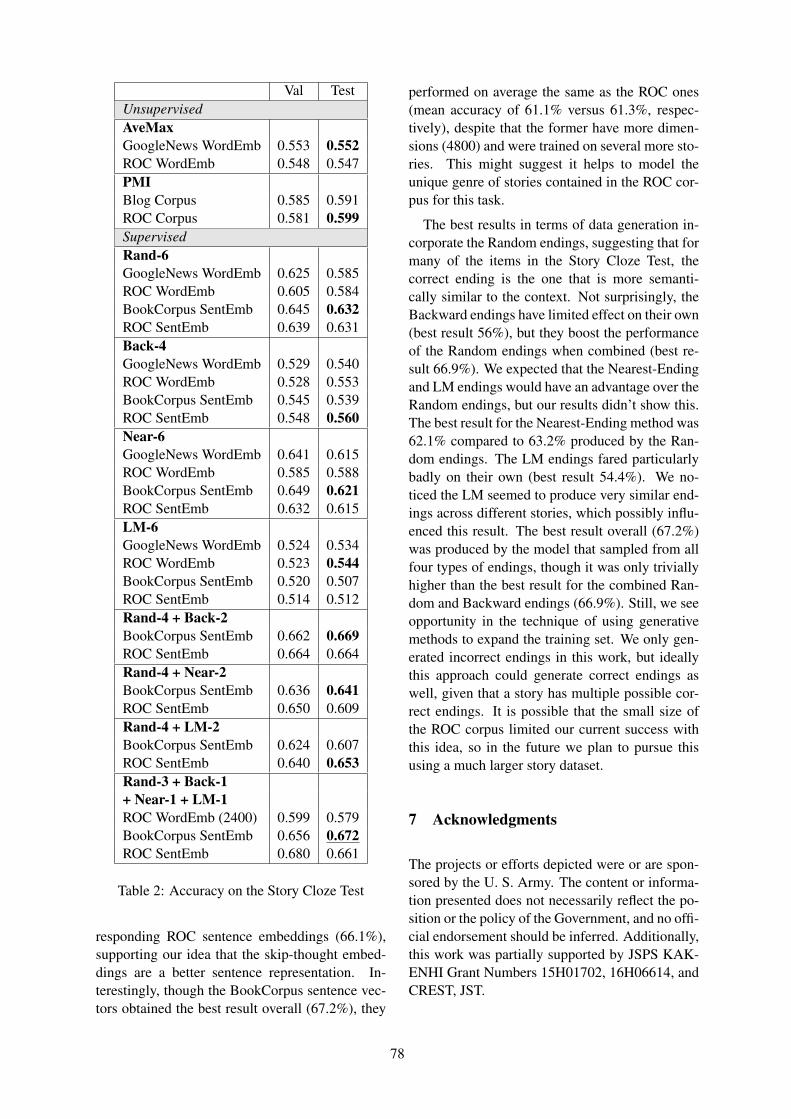
Val TestUnsupervisedAveMaxGoogleNews WordEmb 0.553 0.552ROC WordEmb 0.548 0.547PMIBlog Corpus 0.585 0.591ROC Corpus 0.581 0.599SupervisedRand-6GoogleNews WordEmb 0.625 0.585ROC WordEmb 0.605 0.584BookCorpus SentEmb 0.645 0.632ROC SentEmb 0.639 0.631Back-4GoogleNews WordEmb 0.529 0.540ROC WordEmb 0.528 0.553BookCorpus SentEmb 0.545 0.539ROC SentEmb 0.548 0.560Near-6GoogleNews WordEmb 0.641 0.615ROC WordEmb 0.585 0.588BookCorpus SentEmb 0.649 0.621ROC SentEmb 0.632 0.615LM-6GoogleNews WordEmb 0.524 0.534ROC WordEmb 0.523 0.544BookCorpus SentEmb 0.520 0.507ROC SentEmb 0.514 0.512Rand-4 + Back-2BookCorpus SentEmb 0.662 0.669ROC SentEmb 0.664 0.664Rand-4 + Near-2BookCorpus SentEmb 0.636 0.641ROC SentEmb 0.650 0.609Rand-4 + LM-2BookCorpus SentEmb 0.624 0.607ROC SentEmb 0.640 0.653Rand-3 + Back-1+ Near-1 + LM-1ROC WordEmb (2400) 0.599 0.579BookCorpus SentEmb 0.656 0.672ROC SentEmb 0.680 0.661
Table 2: Accuracy on the Story Cloze Test
responding ROC sentence embeddings (66.1%),supporting our idea that the skip-thought embed-dings are a better sentence representation. In-terestingly, though the BookCorpus sentence vec-tors obtained the best result overall (67.2%), they
performed on average the same as the ROC ones(mean accuracy of 61.1% versus 61.3%, respec-tively), despite that the former have more dimen-sions (4800) and were trained on several more sto-ries. This might suggest it helps to model theunique genre of stories contained in the ROC cor-pus for this task.
The best results in terms of data generation in-corporate the Random endings, suggesting that formany of the items in the Story Cloze Test, thecorrect ending is the one that is more semanti-cally similar to the context. Not surprisingly, theBackward endings have limited effect on their own(best result 56%), but they boost the performanceof the Random endings when combined (best re-sult 66.9%). We expected that the Nearest-Endingand LM endings would have an advantage over theRandom endings, but our results didn’t show this.The best result for the Nearest-Ending method was62.1% compared to 63.2% produced by the Ran-dom endings. The LM endings fared particularlybadly on their own (best result 54.4%). We no-ticed the LM seemed to produce very similar end-ings across different stories, which possibly influ-enced this result. The best result overall (67.2%)was produced by the model that sampled from allfour types of endings, though it was only triviallyhigher than the best result for the combined Ran-dom and Backward endings (66.9%). Still, we seeopportunity in the technique of using generativemethods to expand the training set. We only gen-erated incorrect endings in this work, but ideallythis approach could generate correct endings aswell, given that a story has multiple possible cor-rect endings. It is possible that the small size ofthe ROC corpus limited our current success withthis idea, so in the future we plan to pursue thisusing a much larger story dataset.
7 Acknowledgments
The projects or efforts depicted were or are spon-sored by the U. S. Army. The content or informa-tion presented does not necessarily reflect the po-sition or the policy of the Government, and no offi-cial endorsement should be inferred. Additionally,this work was partially supported by JSPS KAK-ENHI Grant Numbers 15H01702, 16H06614, andCREST, JST.
78

References
Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bah-danau, and Yoshua Bengio. 2014. On the propertiesof neural machine translation: Encoder-decoder ap-proaches. In Proceedings of SSST-8, Eighth Work-shop on Syntax, Semantics and Structure in Statisti-cal Translation, pages 103–111, Doha, Qatar, Octo-ber. Association for Computational Linguistics.
Andrew S. Gordon, Cosmin Adrian Bejan, and KenjiSagae. 2011. Commonsense causal reasoning usingmillions of personal stories. In Proceedings of theTwenty-Fifth AAAI Conference on Artificial Intelli-gence, AAAI’11, pages 1180–1185. AAAI Press.
Andrew S. Gordon, Zornitsa Kozareva, and MelissaRoemmele. 2012. Semeval-2012 task 7: Choiceof plausible alternatives: An evaluation of common-sense causal reasoning. In Proceedings of the FirstJoint Conference on Lexical and Computational Se-mantics - Volume 1: Proceedings of the Main Con-ference and the Shared Task, and Volume 2: Pro-ceedings of the Sixth International Workshop on Se-mantic Evaluation, SemEval ’12, pages 394–398,Stroudsburg, PA, USA. Association for Computa-tional Linguistics.
Mark Granroth-Wilding and Stephen Clark. 2016.What Happens Next? Event Prediction Using aCompositional Neural Network Model. In Proceed-ings of the Thirtieth AAAI Conference on ArtificialIntelligence, AAAI’16, pages 2727–2733. AAAIPress.
Geoffrey Hinton, Nitish Srivastava, and KevinSwersky. 2012. Overview of mini-batch gra-dient descent. http://www.cs.toronto.edu/˜tijmen/csc321/slides/lecture_slides_lec6.pdf.
Mohit Iyyer, Anupam Guha, Snigdha Chaturvedi, Jor-dan Boyd-Graber, and Hal Daume III. 2016. Feud-ing families and former friends: Unsupervised learn-ing for dynamic fictional relationships. In Proceed-ings of the 2016 Conference of the North Ameri-can Chapter of the Association for ComputationalLinguistics: Human Language Technologies, pages1534–1544, San Diego, California, June. Associa-tion for Computational Linguistics.
Diederik Kingma and Jimmy Ba. 2015. Adam: Amethod for stochastic optimization. In The Inter-national Conference on Learning Representations(ICLR), San Diego, May.
Ryan Kiros, Yukun Zhu, Ruslan R Salakhutdinov,Richard Zemel, Raquel Urtasun, Antonio Torralba,and Sanja Fidler. 2015. Skip-thought vectors. InC. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama,and R. Garnett, editors, Advances in Neural Infor-mation Processing Systems 28, pages 3294–3302.Curran Associates, Inc.
Boyang Li, Stephen Lee-Urban, George Johnston, andMark O. Riedl. 2013. Story generation with crowd-sourced plot graphs. In Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence,AAAI’13, pages 598–604. AAAI Press.
Zhiyi Luo, Yuchen Sha, Kenny Q. Zhu, Seung-wonHwang, and Zhongyuan Wang. 2016. Common-sense causal reasoning between short texts. In Pro-ceedings of the Fifteenth International Conferenceon Principles of Knowledge Representation andReasoning, KR’16, pages 421–430. AAAI Press.
Neil McIntyre and Mirella Lapata. 2009. Learningto tell tales: A data-driven approach to story gen-eration. In Proceedings of the Joint Conference ofthe 47th Annual Meeting of the ACL and the 4th In-ternational Joint Conference on Natural LanguageProcessing of the AFNLP, pages 217–225, Suntec,Singapore, August. Association for ComputationalLinguistics.
James R. Meehan. 1977. Tale-spin, an interactive pro-gram that writes stories. In Proceedings of the 5thInternational Joint Conference on Artificial Intelli-gence - Volume 1, IJCAI’77, pages 91–98, San Fran-cisco, CA, USA. Morgan Kaufmann Publishers Inc.
Tomas Mikolov, Martin Karafiat, Lukas Burget, JanCernocky, and Sanjeev Khudanpur. 2010. Recur-rent Neural Network based language model. In Pro-ceedings of the 11th Annual Conference of the In-ternational Speech Communication Association, IN-TERSPEECH 2010, pages 1045–1048.
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Cor-rado, and Jeffrey Dean. 2013. Distributed repre-sentations of words and phrases and their composi-tionality. In Proceedings of the 26th InternationalConference on Neural Information Processing Sys-tems, NIPS’13, pages 3111–3119, USA. Curran As-sociates Inc.
Nasrin Mostafazadeh, Nathanael Chambers, XiaodongHe, Devi Parikh, Dhruv Batra, Lucy Vanderwende,Pushmeet Kohli, and James Allen. 2016. A cor-pus and cloze evaluation for deeper understandingof commonsense stories. In Proceedings of the2016 Conference of the North American Chapter ofthe Association for Computational Linguistics: Hu-man Language Technologies, pages 839–849, SanDiego, California, June. Association for Computa-tional Linguistics.
Karl Pichotta and Raymond J. Mooney. 2016. Learn-ing statistical scripts with lstm recurrent neural net-works. In Proceedings of the Thirtieth AAAI Con-ference on Artificial Intelligence, AAAI’16, pages2800–2806. AAAI Press.
Melissa Roemmele, Cosmin Adrian Bejan, and An-drew S. Gordon. 2011. Choice of Plausible Alterna-tives : An Evaluation of Commonsense Causal Rea-soning. AAAI Spring Symposium: Logical Formal-izations of Commonsense Reasoning, pages 90–95,March.
79

Ilya Sutskever, James Martens, and Geoffrey Hinton.2011. Generating text with recurrent neural net-works. In Lise Getoor and Tobias Scheffer, editors,Proceedings of the 28th International Conferenceon Machine Learning (ICML-11), ICML ’11, pages1017–1024, New York, NY, USA, June. ACM.
Reid Swanson and Andrew S. Gordon. 2012. Say any-thing: Using textual case-based reasoning to enableopen-domain interactive storytelling. ACM Trans.Interact. Intell. Syst., 2(3):16:1–16:35, September.
80

Proceedings of the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics, pages 81–86,Valencia, Spain, April 3, 2017. c©2017 Association for Computational Linguistics
IIT (BHU): System Description for LSDSem’17 Shared Task
Pranav Goel and Anil Kumar SinghDepartment of Computer Science and Engineering
Indian Institute of Technology (BHU), Varanasi, India{pranav.goel.cse14, aksingh.cse}@iitbhu.ac.in
Abstract
This paper describes an ensemble systemsubmitted as part of the LSDSem SharedTask 2017 - the Story Cloze Test. Themain conclusion from our results is thatan approach based on semantic similarityalone may not be enough for this task. Wetest various approaches and compare themwith two ensemble systems. One is basedon voting and the other on logistic regres-sion based classifier. Our final system isable to outperform the previous state of theart for the Story Cloze test. Another veryinteresting observation is the performanceof sentiment based approach which worksalmost as well on its own as our final en-semble system.
1 Introduction
The Story Cloze Test (Mostafazadeh et al., 2016)is a recently introduced framework to evaluatestory understanding and script learning. Represen-tation of commonsense knowledge is major themein Natural Language Processing and is also impor-tant for this task. The organizers provide a train-ing corpus called the ROCStories dataset (we willrefer to it as the Story Cloze corpus or dataset). Itconsists of very simple 98161 everyday life stories(combining the spring and winter training sets).All stories consist of five sentences which capture‘causal and temporal common sense relations be-tween daily events’. The validation and test setscontain 1871 samples each, where each samplecontains the first four sentences (the context) ofthe story, and the system has to complete the storyby choosing the fifth sentence (the correct ending)out of the two alternatives provided.
Some of the approaches describedin (Mostafazadeh et al., 2016) are used as it
is in our system, while some approaches not triedbefore in the context of this task (to the best of ourknowledge) also form parts of our final ensemblemodels. Most approaches tried before and also inour experiments rely directly or indirectly on theidea of using semantic similarity of the contextand the ending to make the decision. The resultspoint to the conclusion that semantic similarity(at least on its own) may be inadequate as anapproach for the Story Cloze test.
Our final system is an ensemble combining thedifferent approaches we tried. It achieves an accu-racy of 60.45 on the test set.
The paper is structured as follows. The next sec-tion describes various experiments and approacheswe tried. Section 3 describes how the differentapproaches come together to form the system wesubmitted. Section 4 looks at the various resultsand draws inferences to make our point. Section5 presents a small error analysis. Finally, Section6 presents the conclusions and discusses possiblefuture work.
2 Approaches
We tried five different approaches, out of whichfour are directly or indirectly utilizing the idea ofsemantic similarity between the context and theending. Some past approaches are mentioned hereagain to enable readers to view them as seman-tic similarity based approaches, and to use theirperformance in our observations and conclusion.We give a brief description of our experiments be-low. The results (performance measured using ac-curacy which is simply the correct cases dividedby the total number of test cases) of all the sepa-rate approaches are presented in Table 1.
1. Gensim (Average Word2Vec): Choosesthe hypothesis with the closest averageword2vec (Mikolov et al., 2013) embedding
81

to the average word2vec embedding of thecontext. The concept of semantic similarityis at the very center of this approach. Wetried three different variations of this ap-proach:
a) Training on the Story Cloze trainingcorpus: This is the same as in (Mostafazadehet al., 2016) except that we train on the wintertraining set as well, which makes the corpussize about two times the one used previously.Removing the stop words, keeping a contextwindow of 10 words and vector dimensional-ity of 300 gave us the results reported in Table1.b) Training on Google news corpus:Google has released its pre-trained word vec-tors, trained on a news corpus with a vocab-ulary of about three million words, whichis much larger than the Story Cloze corpus(which contains about 35k unique words).Thus, we decided to explore if the larger setcould potentially result in better representa-tion and performance.c) Learning the representation of a poten-tial connective word between the contextand the ending: The idea is that a connec-tive with a particular ‘sense’ (probably tem-poral or causal in the Story Cloze training set)could perfectly link the context and the end-ing. We modified all the stories such that amanually introduced symbol (like ‘CCC’: notin the vocabulary) separates the first four sen-tences from the fifth sentence, and its repre-sentation is learned by training a word2vecmodel on the data. On the test and valida-tion set, the hypothesis whose representationis the closest to the sum of the vectors ofthe context and the connective symbol is cho-sen as the prediction. The intuition comesfrom the implicit connective sense classifica-tion task for the Shallow Discourse Parsingproblem (Xue et al., 2015). Context windowsize 100 and dimensionality 300 were foundto be the optimal hyperparameters in our ex-periments.
Combining the above three – calledword2vec (combined) approach – throughsimple voting produced slightly better resultsthan with any individual variation (as canbe seen in Table 1), and thus we used this
combined approach in our ensemble model.
2. Skip-thoughts Model: The skip-thoughtsmodel’s (Kiros et al., 2015) sentence embed-ding of the context and the alternatives isagain compared like the Gensim model, andthus this approach also revolves around se-mantic similarity.
3. Gensim Doc2Vec: Distributed representa-tion of documents and sentences extends theconcept of word vectors to larger textualunits (Le and Mikolov, 2014). A host of vari-ations were tried (as provided by Python’sGensim functionality (Rehurek and Sojka,2010)). The distributed bag of words model(dbow) along with a context window of threewords was found to give the best results forthis approach (Table 1). This approach isagain trying to model semantic similarity viasentence embedding.
4. Siamese LSTM: We also implement a deepneural network model for assessing the se-mantic similarity between a pair of sen-tences. It uses a Siamese adaptation ofthe Long Short-Term Memory (LSTM) net-work (Mueller and Thyagarajan, 2016). Themodel is implemented as in the paper - usingthe SICK training set and Google word2vec,with the weights optimized as per the Se-mEval 2014 task on semantic similarity ofsentences (Marelli et al., 2014). This is oneof the current state of the art models for cap-turing semantic similarity.
5. Sentiment: In this approach, we choosethe hypothesis that matches the average sen-timent of the context. We use NLTKVADER Sentiment Analyzer (Hutto andGilbert, 2014) instead of the Stanford CoreNLP tool for sentiment analysis by (Man-ning et al., 2014) as used in (Mostafazadehet al., 2016) due to notably better results (Ta-ble 1). In our experiments on the valida-tion set, matching sentiment of the full con-text instead of just the last one/two/three sen-tence(s) gives the best performance for thisapproach. This approach does not use seman-tic similarity.
3 The Ensemble Model
We tried various ways of combining the powerof the different approaches, comparing the perfor-
82
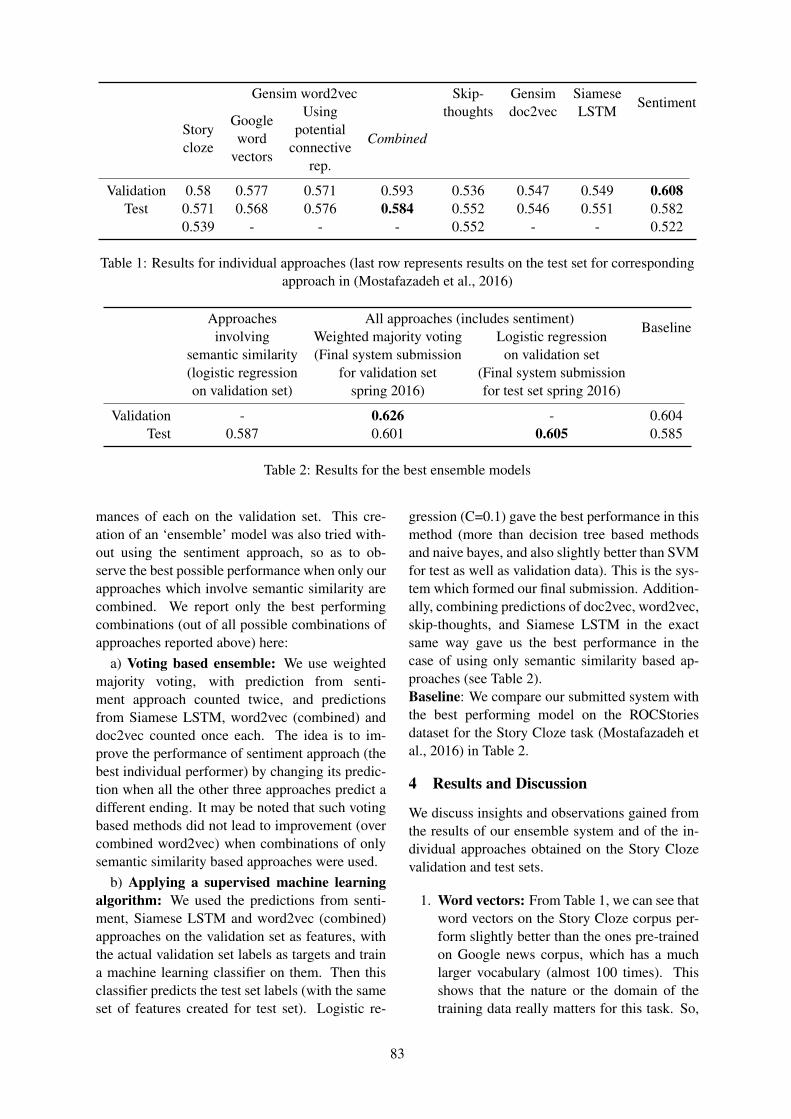
Gensim word2vec Skip-thoughts
Gensimdoc2vec
SiameseLSTM
Sentiment
Storycloze
Googleword
vectors
Usingpotential
connectiverep.
Combined
Validation 0.58 0.577 0.571 0.593 0.536 0.547 0.549 0.608Test 0.571 0.568 0.576 0.584 0.552 0.546 0.551 0.582
0.539 - - - 0.552 - - 0.522
Table 1: Results for individual approaches (last row represents results on the test set for correspondingapproach in (Mostafazadeh et al., 2016)
Approachesinvolving
semantic similarity(logistic regressionon validation set)
All approaches (includes sentiment)Baseline
Weighted majority voting(Final system submission
for validation setspring 2016)
Logistic regressionon validation set
(Final system submissionfor test set spring 2016)
Validation - 0.626 - 0.604Test 0.587 0.601 0.605 0.585
Table 2: Results for the best ensemble models
mances of each on the validation set. This cre-ation of an ‘ensemble’ model was also tried with-out using the sentiment approach, so as to ob-serve the best possible performance when only ourapproaches which involve semantic similarity arecombined. We report only the best performingcombinations (out of all possible combinations ofapproaches reported above) here:
a) Voting based ensemble: We use weightedmajority voting, with prediction from senti-ment approach counted twice, and predictionsfrom Siamese LSTM, word2vec (combined) anddoc2vec counted once each. The idea is to im-prove the performance of sentiment approach (thebest individual performer) by changing its predic-tion when all the other three approaches predict adifferent ending. It may be noted that such votingbased methods did not lead to improvement (overcombined word2vec) when combinations of onlysemantic similarity based approaches were used.
b) Applying a supervised machine learningalgorithm: We used the predictions from senti-ment, Siamese LSTM and word2vec (combined)approaches on the validation set as features, withthe actual validation set labels as targets and traina machine learning classifier on them. Then thisclassifier predicts the test set labels (with the sameset of features created for test set). Logistic re-
gression (C=0.1) gave the best performance in thismethod (more than decision tree based methodsand naive bayes, and also slightly better than SVMfor test as well as validation data). This is the sys-tem which formed our final submission. Addition-ally, combining predictions of doc2vec, word2vec,skip-thoughts, and Siamese LSTM in the exactsame way gave us the best performance in thecase of using only semantic similarity based ap-proaches (see Table 2).Baseline: We compare our submitted system withthe best performing model on the ROCStoriesdataset for the Story Cloze task (Mostafazadeh etal., 2016) in Table 2.
4 Results and Discussion
We discuss insights and observations gained fromthe results of our ensemble system and of the in-dividual approaches obtained on the Story Clozevalidation and test sets.
1. Word vectors: From Table 1, we can see thatword vectors on the Story Cloze corpus per-form slightly better than the ones pre-trainedon Google news corpus, which has a muchlarger vocabulary (almost 100 times). Thisshows that the nature or the domain of thetraining data really matters for this task. So,
83

further increase in the Story Cloze trainingdata itself may help by giving us better repre-sentations. However, comparing with resultsin (Mostafazadeh et al., 2016), doubling thesize of training set results in about 3-4% in-crease in performance (Table 1). For furtherincrease, trying different approaches mightbe better.
2. Improved performance of the sentimentapproach: For the sentiment approach, us-ing NLTK VADER sentiment analyzer toolfor getting polarity scores works notablybetter by outperforming the Stanford CoreNLP (Manning et al., 2014) tool used in(Mostafazadeh et al., 2016) by about 6-7%(the last column of Table 1). As discussedin (Hutto and Gilbert, 2014), the VADER toolis about as accurate in most domains and op-timal for the social media domain while beingquite simple and more efficient. It happens towork surprisingly well in the context of thistask though we do not conclude that it is abetter approach as compared to (Socher et al.,2013) approach to sentiment analysis as uti-lized in Stanford Core NLP tool in general.
3. General performance: Our best system (en-semble of sentiment and various semanticsimilarity based approaches) outperforms theprevious best system (using DSSM, as givenin (Mostafazadeh et al., 2016)) by about 2%(accuracy on both validation and test sets)(refer to Table 2). Most of the individ-ual approaches (Table 1) show performancethat hovers around 60% accuracy (or below).Since they are basically all based on seman-tic similarity (except the sentiment base ap-proach), the results indicate that we may needto approach the Story Cloze test from a verydifferent direction.
4. Semantic vs. sentiment similarity: We cansee from Table 1 that the simple sentimentbased approach basically outperforms all thesemantic similarity based approaches. Evencombining those approaches seems barelybetter than just the sentiment approach (Ta-ble 2). This could indicate either the lackof effectiveness of semantic similarity or thefact that sentiment based approach is quiteeffective. Since our sentiment based ap-proach does not rely on training corpus and
is unlikely to improve with more data (sinceno learning is involved), we are inclined to-wards the former inference: Semantic simi-larity alone may not be enough for the StoryCloze test.
5. Negative results of the Siamese LSTM:Siamese LSTM is a deep neural networktrained to capture semantic similarity andgave state of the art results on the data forSemEval 2014 shared task on semantic simi-larity. However, it does not perform well forthis task, supporting our conclusion.
6. Insignificant boost in performance by en-semble system: Our final ensemble model(Table 2, last column) offers hardly any im-provement over the individual sentiment ap-proach (Table 1, last column). This may indi-cate that the sentiment and semantic similar-ity based approaches are not complementary.
5 Error Analysis
Table 3 shows examples where our final ensem-ble system (the one we submitted for test set) andall the individual approaches (as per table 1) si-multaneously chose the wrong ending. We believethat a better understanding of commonsense and agood sense of which alternative is the logical con-clusion based not only on semantic similarity orsentiment, but the temporal aspect of the chain ofevents as well as plot consistency is missing. In thefirst example, the model needs to understand thatthe first three sentences constitute a ‘prejudice’,and how becoming friends with Sal, who is the tar-get of the prejudice, could lead to the protagonist(Franny) doubting her biased opinion. In the sec-ond example, once again, the model would needto understand that the context probably means anice and happy day for Feliciano, which requiressome world knowledge and the sense that spend-ing time like that with a loved one (the grand-mother) should lead to happiness. Both the incor-rectly chosen endings are inconsistent with the lastsentence of the context – Franny being deported –does not make semantic sense when she liked theimmigrant, and was not the immigrant herself (weknow that the immigrant would get deported andnot Franny by our commonsense), while it wouldnot make temporal sense for Feliciano to go pick-ing olives after already collecting them and com-ing back home to eat with his grandmother.
84

Context Incorrect Ending Correct Ending
Franny did not particularlylike all of the immigrationhappening. She thoughtimmigrants were comingto cause social problems.Franny was upset when animmigrant moved in nextdoor. The immigrant, Sal,was kind and becamefriends with Franny.
Franny ended upgetting deported
.Franny learned to examineher prejudices.
Feliciano went olive pickingwith his grandmother. Whilethey picked, she told himstories of his ancestors.Before he realized it, the sunwas going down. They tookthe olives home and ate themtogether.
The pair then went outto pick olives.
Feliciano was happy abouthis nice day.
Table 3: Examples of stories incorrectly predicted by our model as well as all individual approaches
It is interesting to note how the sentiment ap-proach fails in both the examples. NLTK Vaderrates ‘getting deported’ as neutral while giving ahighly negative rating for ‘prejudice’. The contextis only slightly negative, since the positivity in thelast sentence (which talks about Sal being ‘nice’and the act of ‘becoming friends’) offsets the neg-ativity of the previous sentences somewhat. Wecan see that perhaps the very use of sentiment isnot appropriate for example 1. In example 2, thecontext and the incorrect ending are both neutral,while the correct ending is very positive, hencesimilarity in sentiment gives an error, but realiz-ing that the context would give rise to a positiveending would have worked.
6 Conclusions and Future Work
We described our submitted system for the StoryCloze test, which combines simple sentimentbased approach with a variety of semantic simi-larity based methods. By highlighting individualand ensemble model results as well as the observa-tions arising from them, we have tried to establishthe apparent lack of effectiveness of solely seman-tic similarity based approaches for this task. Thisis validated by various experiments and especiallythe performance of the current state of the art ap-proach for semantic similarity (Siamese LSTM).
Also, an effective future approach should probablybe more sophisticated than our sentiment basedapproach, which does not learn from the trainingdata in any way.
We do not claim that semantic similarity or sen-timent based approaches are of no help as theymay certainly complement the performances of fu-ture approaches. However, they do not seem to beenough on their own, though it is certainly possi-ble that some other semantic similarity based mod-els designed for the Story Cloze training set per-form better than our approaches.
While word vectors, sentiment based approachand skip-thoughts sentence embeddings had al-ready been discussed as possible approaches be-fore, we also look at two approaches which havenot been tried before for this task, namely SiameseLSTM and Gensim Doc2Vec.
For our future work, we plan to build betterensemble methods. Another idea we are keen totry is logical entailment, since the context entailsthe ending, and a model which can detect this ef-fectively should be able to predict the right end-ing (our observations of the validation set make itclear that the context would certainly not be entail-ing a wrong hypothesis).
85

References
Clayton J. Hutto and Eric Gilbert. 2014. Vader: Aparsimonious rule-based model for sentiment anal-ysis of social media text. In Proceeding of EighthInternational AAAI Conference on Weblogs and So-cial Media.
Ryan Kiros, Yukun Zhu, Ruslan R. Salakhutdinov,Richard Zemel, Raquel Urtasun, Antonio Torralba,and Sanja Fidler. 2015. Skip-thought vectors. InProceedings of Advances in neural information pro-cessing systems, pages 3294–3302.
Quoc V. Le and Tomas Mikolov. 2014. Distributedrepresentations of sentences and documents. In Pro-ceeding of ICML, volume 14, pages 1188–1196.
Christopher D. Manning, Mihai Surdeanu, John Bauer,Jenny Rose Finkel, Steven Bethard, and David Mc-Closky. 2014. The stanford corenlp natural lan-guage processing toolkit. In Proceedings of the ACL(System Demonstrations), pages 55–60.
Marco Marelli, Luisa Bentivogli, Marco Baroni, Raf-faella Bernardi, Stefano Menini, and Roberto Zam-parelli. 2014. Semeval-2014 task 1: Evaluation ofcompositional distributional semantic models on fullsentences through semantic relatedness and textualentailment. In Proceedings of the 8th InternationalWorkshop on Semantic Evaluation (SemEval).
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S. Cor-rado, and Jeff Dean. 2013. Distributed representa-tions of words and phrases and their compositional-ity. In Proceeding of Advances in neural informa-tion processing systems, pages 3111–3119.
Nasrin Mostafazadeh, Nathanael Chambers, XiaodongHe, Devi Parikh, Dhruv Batra, Lucy Vanderwende,Pushmeet Kohli, and James Allen. 2016. A cor-pus and cloze evaluation for deeper understandingof commonsense stories. In Proceedings of NAACL-HLT, pages 839–849.
Jonas Mueller and Aditya Thyagarajan. 2016. Siameserecurrent architectures for learning sentence similar-ity. In Proceeding of AAAI, pages 2786–2792.
Radim Rehurek and Petr Sojka. 2010. SoftwareFramework for Topic Modelling with Large Cor-pora. In Proceedings of the LREC 2010 Workshopon New Challenges for NLP Frameworks, pages 45–50, Valletta, Malta, May. ELRA. http://is.muni.cz/publication/884893/en.
Richard Socher, Alex Perelygin, Jean Y. Wu, JasonChuang, Christopher D. Manning, Andrew Y. Ng,Christopher Potts, et al. 2013. Recursive deepmodels for semantic compositionality over a senti-ment treebank. In Proceedings of the conference onempirical methods in natural language processing(EMNLP), volume 1631, page 1642. Citeseer.
Nianwen Xue, Hwee Tou Ng, Sameer Pradhan, RashmiPrasad, Christopher Bryant, and Attapol Ruther-ford. 2015. The conll-2015 shared task on shal-low discourse parsing. In Proceedings of the CoNLLShared Task, pages 1–16.
86

Proceedings of the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics, pages 87–92,Valencia, Spain, April 3, 2017. c©2017 Association for Computational Linguistics
Story Cloze Ending Selection Baselines and Data Examination
Todor MihaylovResearch Training Group AIPHES
Institute for Computational LinguisticsHeidelberg University
Anette FrankResearch Training Group AIPHES
Institute for Computational LinguisticsHeidelberg University
Abstract
This paper describes two supervised base-line systems for the Story Cloze TestShared Task (Mostafazadeh et al., 2016a).We first build a classifier using featuresbased on word embeddings and semanticsimilarity computation. We further imple-ment a neural LSTM system with differ-ent encoding strategies that try to modelthe relation between the story and the pro-vided endings. Our experiments showthat a model using representation featuresbased on average word embedding vec-tors over the given story words and thecandidate ending sentences words, jointwith similarity features between the storyand candidate ending representations per-formed better than the neural models. Ourbest model achieves an accuracy of 72.42,ranking 3rd in the official evaluation.
1 Introduction
Understanding common sense stories is an easytask for humans but represents a challenge for ma-chines. A recent common sense story understan-ding task is the ’Story Cloze Test’ (Mostafazadehet al., 2016a), where a human or an AI systemhas to read a given four-sentence story and selectthe proper ending out of two proposed endings.While the majority class baseline performance onthe given test set yields an accuracy of 51.3%,human performance achieves 100%. This makesthe task a good challenge for an AI system. TheStory Cloze Test task is proposed as a Shared Taskfor LSDSem 20171. 17 teams registered for theShared Task and 10 teams submitted their results2.
1Workshop on Linking Models of Lexical, Sentential andDiscourse-level Semantics 2017
2https://competitions.codalab.org/competitions/15333 -Story Cloze Test at CodaLab
Our contribution is that we set a new baseline forthe task, showing that a simple linear model basedon distributed representations and semantic simi-larity features achieves state-of-the-art results. Wealso evaluate the ability of different embeddingmodels to represent common knowledge requiredfor this task. We present an LSTM-based classifierwith different representation encodings that triesto model the relation between the story and alter-native endings and argue about its inability to doso.
2 Task description and data construction
The Story Cloze Test is a natural language under-standing task that consists in selecting the rightending for a given short story. The evaluation dataconsists of a Dev set and a Test set, each containingsamples of four sentences of a story, followed bytwo alternative sentences, from which the systemhas to select the proper story ending. An exampleof such a story is presented in Table 1.
The instances in the Dev and Test gold datasets (1871 instances each) were crowd-sourcedtogether with the related ROC Stories corpus(Mostafazadeh et al., 2016a). The ROC storiesconsists of around 100,000 crowd-sourced shortfive sentence stories ranging over various topics.These stories do not feature a wrong ending, butwith appropriate extensions they can be deployedas training data for the Story Cloze task.
Task modeling. We approach the task as a su-pervised classification problem. For every clas-sification instance (Story, Ending1, Ending2) wepredict one of the labels in Label={Good,Bad}.
Obtaining a small training set from Dev set.We construct a (small) training data set from theDev set by splitting it randomly into a Dev-Trainand a Dev-Dev set containing 90% and 10% of the
87

Story context Good Ending Bad endingMary and Emma drove to the beach. They de-cided to swim in the ocean. Mary turned to talkto Emma. Emma said to watch out for the waves.
A big wave knockedMary down.
The ocean was a calmas a bathtub.
Table 1: Example of a given story with a bad and a good ending.
original Dev set. From each instance in Dev-Trainwe generate 2 instances by swapping Ending1 andEnding2 and inversing the class label.
Generating training data from ROC stories.We also make use of the ROC Stories corpus inorder to generate a large training data set. We ex-periment with three methods:
(i.) Random endings. For each story we em-ploy the first 4 sentences as the story context. Weuse the original ending as Good ending and definea Bad ending by randomly choosing some endingfrom an alternative story in the corpus. From eachstory with one Good ending we generate 10 Badexamples by selecting 10 random endings.
(ii.) Coherent stories and endings with com-mon participants and noun arguments. Giventhat some random story endings are too clearly un-connected to the story, here we aim to select Badcandidate endings that are coherent with the story,yet still distinct from a Good ending. To this end,for each story in the ROC Stories corpus, we ob-tain the lemmas of all pronouns (tokens with partof speech tag starting with ‘PR‘) and lemmas of allnouns (tokens with part of speech tag starting with‘NN‘) and select the top 10 endings from other sto-ries that share most of these features as Bad end-ings.
(iii.) Random coherent stories and endings.We also modify (ii.) so that we select the near-est 500 endings to the story context and select 10randomly.
3 A Baseline Method
For tackling the problem of right story ending se-lection we follow a feature-based classification ap-proach that was previously applied to bi-clausalclassification tasks in (Mihaylov and Frank, 2016;Mihaylov and Nakov, 2016). It uses features basedon word embeddings to represent the clauses andsemantic similarity measured between these rep-resentations for the clauses. Here, we adopt thisapproach to model parts of the story and the can-didate endings. For the given Story and the given
candidate Endings we extract features based onword embeddings. An advantage of this approachis that it is fast for training and that it only requirespre-trained word embeddings as an input.
3.1 Features
In our models we only deploy features basedon word embedding vectors. We are using twotypes of features: (i) representation features thatmodel the semantics of parts of the story us-ing word embedding vectors, and (ii) similarityscores that capture specific properties of the re-lation holding between the story and its candi-date endings. For computing similarity betweenthe embedding representations of the story com-ponents, we employ cosine similarity.
The different feature types are described below.
(i) Embedding representations for Story andEnding. For each Story (sentences 1 to 4) andstory endings Ending1 and Ending2 we constructa centroid vector from the embedding vectors ~wi
of all words wi in their respective surface yield.
(ii.) Story to Ending Semantic Vector Similari-ties. We calculate various similarity features onthe basis of the centroid word vectors for all orselected sentences in the given Story and the End-ing1 and Ending2 sentences, as well as on parts ofthe these sentences:
Story to Ending similarity. We assume that agiven Story and its Good Ending are connected bya specific semantic relation or some piece of com-mon sense knowledge. Their representation vec-tors should thus stand in a specific similarity rela-tion to each other. We use their cosine similarity asa feature. Similarity between the story sentencesand a candidate ending has already been proposedas a baseline by Mostafazadeh et al. (2016b) but itdoes not perform well as a single feature.
Maximized similarity. This measure rankseach word in the Story according to its similaritywith the centroid vector of Ending, and we com-pute the average similarity for the top-ranked N
88

words. We chose the similarity scores of the top1,2,3 and 5 words as features. Our assumption isthat the average similarity between the Story rep-resentation and the top N most similar words inthe Ending might characterize the proper endingas the Good ending. We also extract maximizedaligned similarity. For each word in Story, wechoose the most similar word from the yield ofEnding and take the average of all best word pairsimilarities, as suggested in Tran et al. (2015).
Part of speech (POS) based word vector simi-larities. For each sentence in the given four sen-tence story and the candidate endings we per-formed part of speech tagging using the Stan-ford CoreNLP (Manning et al., 2014) parser, andcomputed similarities between centroid vectors ofwords with a specific tag from Story and the cen-troid vector of Ending. Extracted features forPOS similarities include symmetric and asymmet-ric combinations: for example we calculate thesimilarity between Nouns from Story with Nounsfrom Ending and similarity between Nouns fromStory with Verbs from Ending and vice versa.
The assumption is that embeddings for someparts of speech between Story and Ending mightbe closer to those of other parts of speech for theGood ending of a given story.
3.2 Classifier settings
For our feature-based approach we concatenate theextracted representation and similarity features ina feature vector, scale their values to the 0 to 1range, and feed the vectors to a classifier. We trainand evaluate a L2-regularized Logistic Regressionclassifier with the LIBLINEAR (Fan et al., 2008)solver as implemented in scikit-learn (Pedregosaet al., 2011).
For each separate experiment we tune the regu-larization parameter C with 5 fold cross-validationon the Dev set and then train a new model on theentire Dev set in order to evaluate on the Test set.
4 Neural LSTM Baseline Method
We compare our feature-based linear classifierbaseline to a neural approach. Our goal is toexplore a simple neural method and to investi-gate how well it performs with the given smalldataset. We implement a Long Short-Term Mem-ory (LSTM) (Hochreiter and Schmidhuber, 1997)recurrent neural network model.
4.1 RepresentationsWe are using the raw LSTM output of the encoder.We also experiment with an encoder with attentionto model the relation between a story and a candi-date ending, following (Rocktaschel et al., 2015).
(i) Raw LSTM representations. For each giveninstance (Story, Ending1, Ending2) we first encodethe Story token word vector representations usinga recurrent neural network (RNN) with long short-term memory (LSTM) units. We use the last out-put hs
L and csL states of the Story to initialize the
first LSTM cells for the respective encodings e1
and e2 of Ending1 and Ending2, where L is thetoken length of the Story sequence.
We build the final representation ose1e2 by con-catenating the e1 and e2 representations. Finally,for classification we use a softmax layer over theoutput ose1e2 by mapping it into the target spaceof the two classes (Good, Bad) using a parametermatrix Mo and bias bo as given in (Eq.1). We trainusing the cross-entropy loss.
labelprob = softmax(W oose1e2 + bo) (1)
(ii) Attention-based representations We alsomodel the relation h∗ between the Story and eachof the Endings using the attention-weighted rep-resentation r between the last token output he
N ofthe Ending representation and each of the tokenrepresentations [hs
1..hsL] of the Story, strictly fol-
lowing the attention definition by Rocktaschel etal. (2015). The final representation for each end-ing is presented by Eq.2, where Wp and Wx aretrained projection matrices.
h∗ = tanh(W pr + W xheN ) (2)
We then present the output representation ose1e2
as a concatenation of the encoded Ending1 andEnding2 representations h∗
e1 and h∗e2 and use Eq.1
to obtain the output label likelihood.
(iii) Combined raw LSTM output and atten-tion representation We also perform experi-ments with combined LSTM outputs and repre-sentations. In this setting we present the outputose1e2 as presented in Eq.3:
ose1e2 = concat(e1, h∗e1, e2, h
∗e2) (3)
4.2 Model Parameters and TuningWe perform experiments with configurations ofthe model using grid search on the batch size (50,
89

System AccuracyHuman 100.00msap 75.20cogcomp 74.39Our features baseline 72.42Our neural system 72.10ukp 71.67DSSM 58.50Skip-thoughts sim 55.20Word2Vec sim 53.90Majority baseline 51.30
Table 2: Comparison of our models to sharedtask participants’ results and other baselines.Word2Vec sim, Skip-thoughts sim and DSSM aredescribed in (Mostafazadeh et al., 2016b).
100, 200, 300, 400, 500) and LSTM output size(128, 256, 384, 512), by training a simple modelwith raw LSTM encoding on Dev-Train and eval-uating on the Dev-Dev. For each configuration wetrain 5 models and take the parameters of the best.The best result on the Dev-Dev set is achieved forLSTM with output size 384 and batch Size 500after 7 epochs and achieves accuracy of 72.10 onthe official Test. For learning rate optimization weuse Adam optimizer (Kingma and Ba, 2015) withinitial learning rate 0.001.
Parameter initialization. We initialize theLSTM weights with Xavier initialization (Glo,2010) and bias with a constant zero vector.
5 Experiments and Results
Overall results. In Table 2 we compare our bestsystems to existing baselines, Shared Task par-ticipant systems3 and human performance. Ourfeatures baseline system is our best feature-basedsystem using embeddings and word2vec trained onDev and tuned with cross-validation. Our neu-ral system employs raw LSTM encodings as de-scribed in Section 4.1(i) and it is trained on theDev-Dev dataset which consists of 90% of the Devdataset selected randomly and tuned on the rest ofDev. The best result in the task is achieved bySchwartz et al. (2017) (msap) who employ stylis-tic features combined with RNN representations.We have no information about cogcomp and ukp.
3https://competitions.codalab.org/competitions/15333 -The Story Cloze Test Shared Task home page
Model variations and experiments. The StoryCloze Test is a story understanding problem.However, the given stories are very short and theyrequire background knowledge about relations be-tween the given entities, entity types and eventsdefining the story and their endings, as well as re-lations between these events. We first train ourfeature-based model with alternative embeddingrepresentations in order to select the best sourceof knowledge for further experiments.
We experiment with different word embeddingmodels pre-trained on a large number of tokens in-cluding word2vec4 (Mikolov et al., 2013), GloVe(Pennington et al., 2014) and ConceptNet Num-berbatch (Speer and Chin, 2016). Results on train-ing the feature-based model with different wordembeddings are shown in Table 3. The results in-dicate how well the vector representation modelsperform in terms of encoding common sense sto-ries. We present the performance of the embed-ding models depending on the defined features.We perform feature ablation experiments to de-termine the features which contribute most to theoverall score for the different models. Using Allfeatures defined in Section 3.1, the word2vec vec-tors, trained on Google News 100B corpus per-form best followed by ConcepNet enriched em-beddings and Glove trained on Common Crawl840B. The word2vec model suffers most whensimilarity features are excluded. We note that theConceptNet embeddings do not decrease perfor-mance when similarity features are excluded, un-like all other models. We also see that the POSsimilarities are more important than the MaxSimand the Sim (cosine betwen all words in Story andEnding) as they yield worse results, for almost allmodels, when excluded from All features.
In column WE E1, E2 we report results on fea-tures based only on Ending1 and Ending 2. Wenote that the overall results are still very good.From this we can derive that the difference ofGood vs. Bad endings is not only defined in thestory context but it is also characterized by the in-formation present in these sentences in isolation.This could be due to a reporting bias (Gordonand Van Durme, 2013) employed by the crowd-workers in the corpus construction process.
The last column Sims only shows results withfeatures based only on similarity features. It in-
4https://code.google.com/archive/p/word2vec/ - Pre-trained embeddings on Google News dataset (100B words).
90
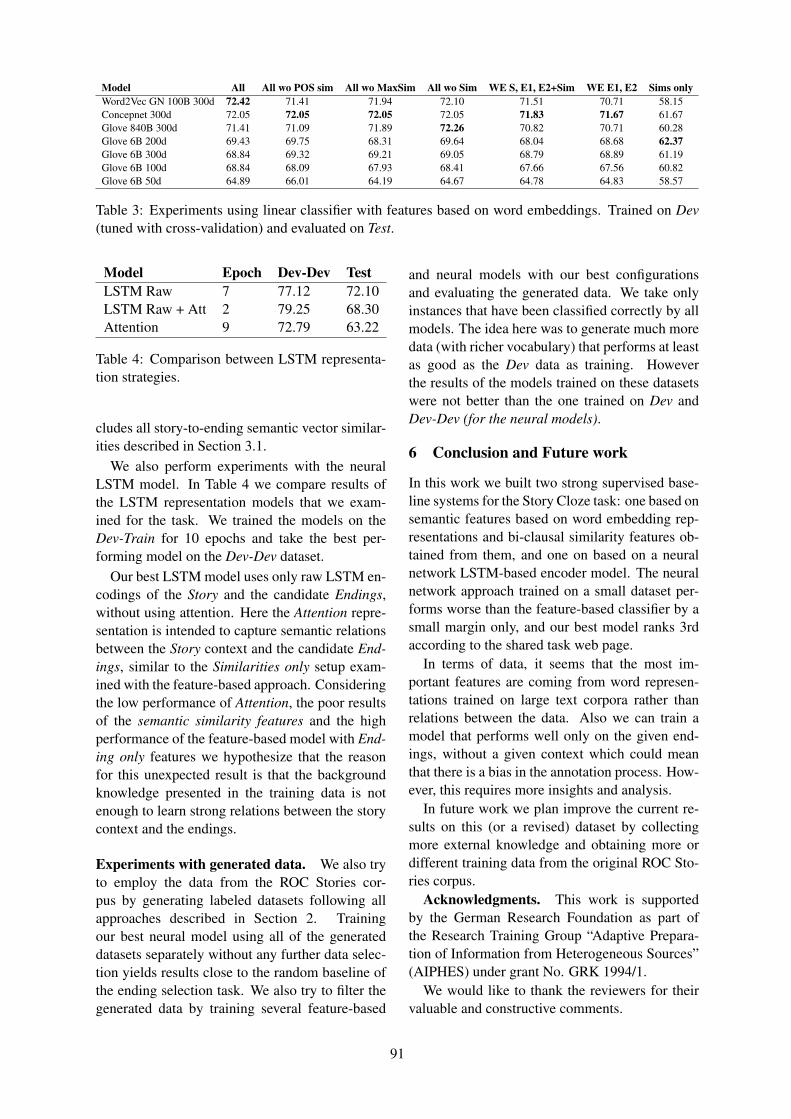
Model All All wo POS sim All wo MaxSim All wo Sim WE S, E1, E2+Sim WE E1, E2 Sims onlyWord2Vec GN 100B 300d 72.42 71.41 71.94 72.10 71.51 70.71 58.15Concepnet 300d 72.05 72.05 72.05 72.05 71.83 71.67 61.67Glove 840B 300d 71.41 71.09 71.89 72.26 70.82 70.71 60.28Glove 6B 200d 69.43 69.75 68.31 69.64 68.04 68.68 62.37Glove 6B 300d 68.84 69.32 69.21 69.05 68.79 68.89 61.19Glove 6B 100d 68.84 68.09 67.93 68.41 67.66 67.56 60.82Glove 6B 50d 64.89 66.01 64.19 64.67 64.78 64.83 58.57
Table 3: Experiments using linear classifier with features based on word embeddings. Trained on Dev(tuned with cross-validation) and evaluated on Test.
Model Epoch Dev-Dev TestLSTM Raw 7 77.12 72.10LSTM Raw + Att 2 79.25 68.30Attention 9 72.79 63.22
Table 4: Comparison between LSTM representa-tion strategies.
cludes all story-to-ending semantic vector similar-ities described in Section 3.1.
We also perform experiments with the neuralLSTM model. In Table 4 we compare results ofthe LSTM representation models that we exam-ined for the task. We trained the models on theDev-Train for 10 epochs and take the best per-forming model on the Dev-Dev dataset.
Our best LSTM model uses only raw LSTM en-codings of the Story and the candidate Endings,without using attention. Here the Attention repre-sentation is intended to capture semantic relationsbetween the Story context and the candidate End-ings, similar to the Similarities only setup exam-ined with the feature-based approach. Consideringthe low performance of Attention, the poor resultsof the semantic similarity features and the highperformance of the feature-based model with End-ing only features we hypothesize that the reasonfor this unexpected result is that the backgroundknowledge presented in the training data is notenough to learn strong relations between the storycontext and the endings.
Experiments with generated data. We also tryto employ the data from the ROC Stories cor-pus by generating labeled datasets following allapproaches described in Section 2. Trainingour best neural model using all of the generateddatasets separately without any further data selec-tion yields results close to the random baseline ofthe ending selection task. We also try to filter thegenerated data by training several feature-based
and neural models with our best configurationsand evaluating the generated data. We take onlyinstances that have been classified correctly by allmodels. The idea here was to generate much moredata (with richer vocabulary) that performs at leastas good as the Dev data as training. Howeverthe results of the models trained on these datasetswere not better than the one trained on Dev andDev-Dev (for the neural models).
6 Conclusion and Future work
In this work we built two strong supervised base-line systems for the Story Cloze task: one based onsemantic features based on word embedding rep-resentations and bi-clausal similarity features ob-tained from them, and one on based on a neuralnetwork LSTM-based encoder model. The neuralnetwork approach trained on a small dataset per-forms worse than the feature-based classifier by asmall margin only, and our best model ranks 3rdaccording to the shared task web page.
In terms of data, it seems that the most im-portant features are coming from word represen-tations trained on large text corpora rather thanrelations between the data. Also we can train amodel that performs well only on the given end-ings, without a given context which could meanthat there is a bias in the annotation process. How-ever, this requires more insights and analysis.
In future work we plan improve the current re-sults on this (or a revised) dataset by collectingmore external knowledge and obtaining more ordifferent training data from the original ROC Sto-ries corpus.
Acknowledgments. This work is supportedby the German Research Foundation as part ofthe Research Training Group “Adaptive Prepara-tion of Information from Heterogeneous Sources”(AIPHES) under grant No. GRK 1994/1.
We would like to thank the reviewers for theirvaluable and constructive comments.
91

ReferencesRong-En Fan, Kai-Wei Chang, Cho-Jui Hsieh, Xiang-
Rui Wang, and Chih-Jen Lin. 2008. Liblinear: A li-brary for large linear classification. J. Mach. Learn.Res., 9:1871–1874, June.
2010. Understanding the difficulty of training deepfeedforward neural networks. Proceedings of the13th International Conference on Artificial Intelli-gence and Statistics (AISTATS), 9:249–256.
Jonathan Gordon and Benjamin Van Durme. 2013.Reporting bias and knowledge acquisition. Proc.2013 Work. Autom. Knowl. base Constr. - AKBC ’13,(circa):25–30.
Sepp Hochreiter and Jurgen Schmidhuber. 1997. Longshort-term memory. Neural Comput., 9(8):1735–1780, November.
Diederik P. Kingma and Jimmy Lei Ba. 2015. Adam:a Method for Stochastic Optimization. Int. Conf.Learn. Represent. 2015, pages 1–15.
Christopher D Manning, John Bauer, Jenny Finkel,Steven J Bethard, Mihai Surdeanu, and David Mc-Closky. 2014. The Stanford CoreNLP Natural Lan-guage Processing Toolkit. Proceedings of 52nd An-nual Meeting of the Association for ComputationalLinguistics: System Demonstrations, pages 55–60.
Todor Mihaylov and Anette Frank. 2016. DiscourseRelation Sense Classification Using Cross-argumentSemantic Similarity Based on Word Embeddings. InProceedings of the Twentieth Conference on Compu-tational Natural Language Learning - Shared Task,pages 100–107, Berlin, Germany. Association forComputational Linguistics.
Todor Mihaylov and Preslav Nakov. 2016. SemanticZat SemEval-2016 Task 3: Ranking relevant answersin community question answering using semanticsimilarity based on fine-tuned word embeddings. InProceedings of the 10th International Workshop onSemantic Evaluation, SemEval ’16, San Diego, Cal-ifornia, USA.
Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig.2013. Linguistic regularities in continuous spaceword representations. In Proceedings of the 2013Conference of the North American Chapter of theAssociation for Computational Linguistics: HumanLanguage Technologies, NAACL-HLT ’13, pages746–751, Atlanta, Georgia, USA.
Nasrin Mostafazadeh, Nathanael Chambers, XiaodongHe, Devi Parikh, Dhruv Batra, Lucy Vanderwende,Pushmeet Kohli, and James Allen. 2016a. A Corpusand Evaluation Framework for Deeper Understand-ing of Commonsense Stories. Naacl.
Nasrin Mostafazadeh, Lucy Vanderwende, Wen-tauYih, Pushmeet Kohli, and James Allen. 2016b.Story cloze evaluator: Vector space representationevaluation by predicting what happens next. In
Proceedings of the 1st Workshop on EvaluatingVector-Space Representations for NLP, pages 24–29, Berlin, Germany, August. Association for Com-putational Linguistics.
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel,B. Thirion, O. Grisel, M. Blondel, P. Pretten-hofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Pas-sos, D. Cournapeau, M. Brucher, M. Perrot, andE. Duchesnay. 2011. Scikit-learn: Machine learn-ing in Python. Journal of Machine Learning Re-search, 12:2825–2830.
Jeffrey Pennington, Richard Socher, and Christopher DManning. 2014. GloVe: Global Vectors for WordRepresentation. Proceedings of the 2014 Confer-ence on Empirical Methods in Natural LanguageProcessing, pages 1532–1543.
Tim Rocktaschel, Edward Grefenstette, Karl MoritzHermann, Tomas Kocisky, and Phil Blunsom. 2015.Reasoning about Entailment with Neural Attention.Unpublished, (2015):1–9, sep.
Roy Schwartz, Maarten Sap, Ioannis Konstas, LeilaZilles, Yejin Choi, and Noah A Smith. 2017.The Effect of Different Writing Tasks on LinguisticStyle: A Case Study of the ROC Story Cloze Task.Proc. Link. Model. Lexical, Sentential Discourse-level Semant. Shar. Task, feb.
Robert Speer and Joshua Chin. 2016. An ensemblemethod to produce high-quality word embeddings.arXiv preprint arXiv:1604.01692.
Quan Hung Tran, Vu Tran, Tu Vu, Minh Nguyen, andSon Bao Pham. 2015. JAIST: Combining multiplefeatures for answer selection in community questionanswering. In Proceedings of the 9th InternationalWorkshop on Semantic Evaluation, SemEval ’15,pages 215–219, Denver, Colorado, USA.
92

Author Index
Adler, Meni, 12Allen, James, 46
Bugert, Michael, 56
Chambers, Nathanael, 41, 46Chiarcos, Christian, 68Choi, Yejin, 52Clematide, Simon, 31
Dagan, Ido, 12
Eckle-Kohler, Judith, 56
Flor, Michael, 62Frank, Anette, 87
Goel, Pranav, 81Gordon, Andrew, 74Gurevych, Iryna, 12, 56
Inoue, Naoya, 74
Klenner, Manfred, 31Kobayashi, Sosuke, 74Konstas, Ioannis, 52Korhonen, Anna, 25
Louis, Annie, 46
Martin, Teresa, 56Martínez-Cámara, Eugenio, 12, 56Mihaylov, Todor, 87Mostafazadeh, Nasrin, 46
Peyrard, Maxime, 56Pinkal, Manfred, 1Ponti, Edoardo Maria, 25Puzikov, Yevgeniy, 56
Roemmele, Melissa, 74Roth, Dan, 12Roth, Michael, 46Rücklé, Andreas, 56
Sap, Maarten, 52Schenk, Niko, 68
Schwartz, Roy, 52Shapira, Ori, 12Shwartz, Vered, 12Singh, Anil Kumar, 81Smith, Noah A., 52Somasundaran, Swapna, 62Sorokin, Daniil, 56Stanovsky, Gabriel, 12
Thater, Stefan, 1Tuggener, Don, 31
Upadhyay, Shyam, 12
Wanzare, Lilian, 1Wities, Rachel, 12
Zarcone, Alessandra, 1Zilles, Leila, 52
93




















