
Last in first out? : An investigation of the regression hypothesis in Dutch emigrants in Anglophone...
429
/DVW LQ ILUVW RXW" $Q LQYHVWLJDWLRQ RI WKH UHJUHVVLRQ K\SRWKHVLV LQ 'XWFK HPLJUDQWV LQ $QJORSKRQH &DQDGD
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Last in first out? : An investigation of the regression hypothesis in Dutch emigrants in Anglophone...























1

2

3

4

5

6

7

8

9

10
1 While these stages do tend to be universal across the board, in polysynthetic languages, which rely on morphologically-complex and long words, different tendencies can be identified. The latter group of languages includes many Native American varieties.

11

12

13

14

15
2 This order is not uncontroversial. For example, there are some syntactic features that will attrite before specific morphological phenomena. The hierarchy is only included to illustrate how hierarchies could also play a role in attrition research.

16

17

18

19

20

21

22

23

24

25

26

27

28

29

30
••••

31

32

33

34

35
3 This claim is not without its problems as the majority of the world’s population is in fact multilingual and what exactly is meant by ‘natural’ is not unequivocally clear either.

36

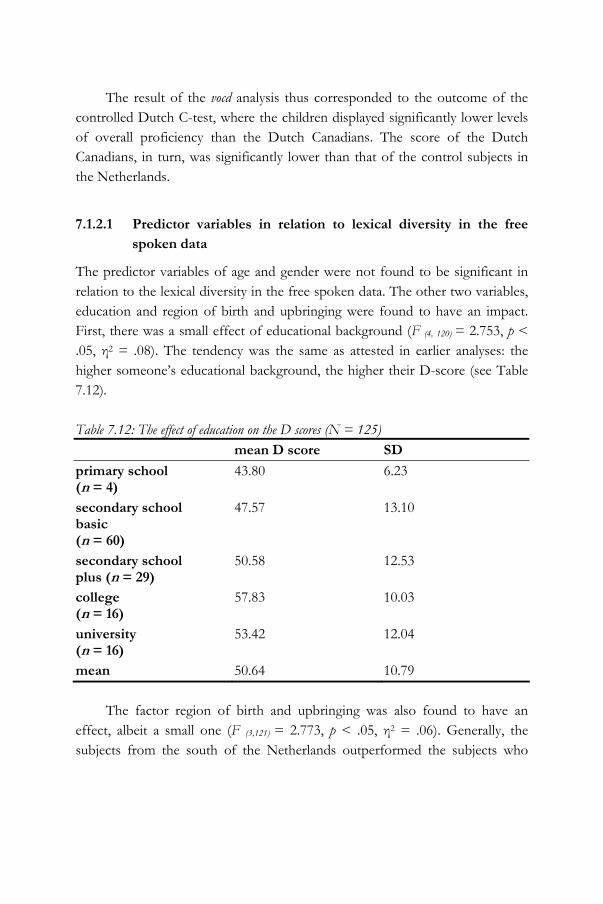
37

38

39

40

41

42

43

44

45
4 All implicational hierarchies that are presented in the following three chapters should be interpreted as relative rather than absolute for reasons outlined in 1.1.1.

46

47

48
–
( )
5 If Dutch nouns end in a vowel that is not realized as a schwa, the orthographic form of their plural contains an apostrophe –s. Other examples are oma – oma’s (‘grandmas’) or menu – menu’s (‘menus’).

49

50

51
6 It is interesting how, historically, English also made use of the plural marker –en that still exists in Dutch today. Remnants of this system can still be found in irregular forms like child-children, ox-oxen or the archaic brother – brethren (Quirk et al., 1985: 307). This similarity can be traced to the Germanic roots that Dutch and English share.

52
7 While the distinction between the singular and the plural is functional, the distinction between –s, -en and irregular plural markers is not. Using an incorrect plural marker does not result in a loss of information.

53

54

55

56
8 Even in these cases, there is a notable difference between Dutch and English. Whereas the Dutch feminine agentive suffix is attached to the verb stem, English adds the feminine marker directly to the masculine agent noun.

57

58

59

60
9 Although the distinction between definite and indefinite articles is functional, the distinction between de and het is not, given the fact that a replacement of one by the other does not result in a loss of information.

61

62

63

64

65

66

67

68

69

70

71

72

73
10 The use of diminutive markers itself is functional, but a wrong selection of diminutive suffix does not result in a loss of information. Consequently, the individual diminutive markers cannot be regarded as functional.

74

75

76

77
11 This is a case of vowel lengthening.

78
12
12 The personal pronouns are also indicated in these tables. The Dutch personal pronouns are ik (‘I’), jij (‘you’), hij/zij/het (‘he/she/it’), wij (‘we’), you (‘you-PL’), and zij (‘they’). 13 In spoken interaction, the final nasal sound is typically left unpronounced, and is reduced to an orthographic feature only. This phonological process is known as apocope of syllable-final –n (Smits, 1996: 97).

79

80
14 Before children can arrive at this stage, they must have a basic understanding of how word order works in Dutch (see also 5.3.1 and 5.3.2), because the acquisition of finiteness and word order are intrinsically linked.

81
15 The English verb stem is identical to its infinitive.

82
16 In yes-no interrogatives that include a tag element, this form appears as are: I am staying, aren’t I? 17 The distinction between the present and the past is functional, but the contrast between different present inflections is not, as an omission or substitution does not cause a loss of information.

83
18 The phonological process of apocope of syllable-final –n is at work here.

84

85

86

87
19 the past tense of zijn is the only one in the category of irregular verbs that exhibits a change in vowel quality between the singular and plural past tense forms: ik was (/was/) versus wij waren (/wa:r (n)/). 20 None of the modal auxiliaries have past participle forms in English. 21 Zullen does not have a past participle form for semantic reasons: something could not have taken place in the future.

88

89
22 The –ed past tense marker is typically devoiced in English: worked (/ωΕρκτ/).

90
23 It has been claimed that approximately 5% of all English verbs is strong, against 95% weak verbs (see Schmid, 2002: 133). The numbers for Dutch are less clear, but given that German has a division of 50% strong and 50% weak (Schmid, 2002: 133), it is likely that Dutch is somewhere in between English and German, as is frequently the case linguistically. 24 The use of the simple past versus other tenses, such as the simple present, is functionally motivated, but the distinction between the weak and strong declension groups within the simple past is not, as an error in their use does not lead to a miscommunication or loss of information.

91
25 -n is dropped because of syllable final –n apocope, see earlier footnote.

92
26 The mid-word consonant undergoes duplication here because it follows a short vowel.

93
27 While English has a clear aspectual difference between the simple past tense and periphrastic past constructions, this distinction is less clearly perceived in Dutch. The different between immediate and distant past, however, is clearly implied (see 4.2.2).

94

95

96
28 This effect is much less true for North American varieties of English than for British English. In North American English, the perfective/simple past distinction may not be so clearly felt. 29 As was noted for the simple past, the use of periphrastic constructions that include a past participle is functional, but the difference between strong and weak participle forms is not.

97
30 While English past participles also follow the weak/strong declension, the surface forms of the participles do differ from Dutch. 31 This preference for periphrastic constructions over the preterite also characterizes the initial stages of child Dutch (cf. 4.3.2).

98

99

100
32 While the use of auxiliaries in periphrastic constructions is functional, a non-standard selection of auxiliary does not result in a loss of information, making the distinction between hebben and zijn non-functional in nature.

101
33 In Iowa Dutch, the form het was often used as a replacement of heeft, presumably for simplification purposes (Smits, 1996: 181).

102

103
34 Native speakers of English also tend to accept structures like I see the boss tomorrow at 3:00, which contains a present tense to indicate futurity, but not as part of a dependent clause.

104

105

106

107

108

109

110

111

112
35 The phonological process of apocope of syllable-final –n is common in Dutch and is more elaborately discussed in the previous chapter (Chapter 4).

113
36 The da form here is an elliptical form of daar (‘there’).

114

115

116

117

118

119

120

121

122
37 German is typologically closely related to Dutch and shows similar patterns in verb placement (see Schmid, 2002).

123

124
38 Bare past participle forms, such as daan, reflect the relative difficulty children have with prefixes. The non-reduced form of daan is ge-daan (see 4.3.2).

125

126
39 Where no auxiliary is present to front in interrogatives, do support is needed (Mackenzie, 1997: 21-22).

127

128

129

130
40 Of in this context is analyzed as a subordinator that indicates that a state of affairs has not been realized (de Schutter & van Hauwermeiren, 1983: 53).

131
41 The Dutch pronoun hij (‘he’) tends to be reduced to ie (/i:/) in spoken interaction. As such, ie can be considered to be the weak counterpart of strong hij.

132
42 The replacement of the pronoun ik (‘I’) by ikke is frequently attested in child Dutch and can be analyzed as children’s attempts at regularization of the system. Personal pronouns typically have a strong and weak form, as in wij-we (‘we’) or jij –je (‘you-SG’). The first person singular pronoun ik does not have such a strong/weak distinction, but the form ikke is likely to be formed by analogy of the existing pronoun forms, like wij-we. 43 Even (‘just’) is often reduced to effe in colloquial Dutch.

133

134
44 It is important to note that, although English has equivalent subordinate constructions to Dutch, the use of subordination in English does not impact on word order as in Dutch.

135

136

137

138

139

140

141

142

143
45 Prior to the data collection, the test battery was pre-tested as part of a pilot study that involved 14 Dutch émigrés in the UK (in the London area) and 14 matched control subjects in the Netherlands. The results from this pretest were used to adapt the individual tests in the battery.

144

145

146

147
46 It is important to distinguish true attrition (within one individual) from language shift (across generations) (see also Köpke & Schmid, 2004). 47 Previous attrition studies have occasionally focused on language loss in subjects who moved away from their L1 environments at a very young age (Bolonyai, 1999; Schmitt, 2001). It is likely that these participants had not yet reached a level of complete mother tongue mastery upon

148
emigration. What is measured can therefore not be taken as evidence for attrition, but most likely indicates a gap in linguistic knowledge that was there before attrition set in.

149
48 No correlation was found between any of the predictor variables examined in this study.

150

151

152
49 Although the figures for both adult groups constitute the number of people who completed a particular form of education, the children had not yet left school. Instead, the figures represent the number of children currently enrolled in that form of education. All basic secondary school level students were in their second year, while the higher level students had already started their third year.

153
50 The number of subjects from these regions does not add up to 45. That is because 2 Dutch Canadian subjects were born in Indonesia, which at that time was a Dutch colony, but moved back to the Netherlands during early childhood. 51 Geographical data from two subjects in the control condition are missing.

154
52 Although the children attended three different schools in three different provinces, all the schools were located in the central provinces of the Netherlands.

155

156

157

158
53 Some researchers would argue that the term Likert scales can only be applied to scales that rank from ‘totally agree’ to ‘totally disagree’ and scales using any other formulations have to be referred to as ranking scales instead. Since the majority of researchers still use the term ‘Likert scale’ in a broader context, all scales employed in the present study are also denoted as Likert scales.

159

160

161

162
54 D is essentially a measure of vocabulary diversity or richness of language use. Overall measures of language proficiency, such as vocabulary diversity, are very common in applied linguistics, including child language development, language impairment, but also foreign and second language learning (Richards, 2000: 324). Past research assessing vocabulary diversity has typically relied on the ratio of different words (Types) to the total number of words (Tokens), also known as the Type-Token-Ratio (TTR). Type-Token measures have the disadvantage of resulting in lower TTR values in longer stretches of data and higher TTR values if the language sample contains fewer tokens (Richards, 2000: 324).

163

164

165

166

167

168

169

170

171

172

173

174

175

176

177

178

179

180

181

182

183
55 The results were obtained through statistical analyses. If such analyses are to be carried out, it is necessary for data to satisfy a number of assumptions (Field, 2005: 64). The criterion of normally distributed data was not always met in this study. In other words, the three groups differed significantly from each other with respect to their linguistic behavior. The best way to handle a violation of assumptions is to use non-parametric tests (Field, 2005: 521-570), but the nature of this study required multivariate testing for which there is no non-parametric, ready-to-use alternative. As a consequence, standard parametric tests were used, accompanied by non-parametric post-hoc tests (Games-Howell).

184
56 An effect size of .10 is generally believed to constitute a small effect, an effect size of .30 is a medium effect, and .50 or more a large effect (Cohen, 1988, 1992).

185
0102030405060708090
100
Attriters Controls Acquirers
57 There was an uneven distribution in relation to the number of subjects who completed each text of the C-test. The number that is given here indicates the mean number of participants across all five texts.

186
58 The test statistic of Wilks’ Lambda is often used in MANOVA analyses where group sizes are unequal, as in the present study (Field, 2000: 594). 59 For the age factor, the ages of the children were not taken into account. An inclusion of the youngest subjects would only result in another group comparison, but this time between children and adults in general, which was not the object of this study. In addition, the standard deviation of age in the learners was very small, as all children were between the ages of 13 and 16 (see 6.1.2.1). Instead, three age groups were created for the adult groups: 41-65; 66-70 and 71+. This division resulted in groups of roughly the same size and, in addition, could check whether the older subjects performed poorly in comparison to the other participants, because of their advanced age (see 6.1.2.1.)

187
60 An overview of the different educational types in the Netherlands can be found in 6.1.2.3.

188

189

190
0
10
20
30
40
50
60
70
80
Dutch C-test English C-test

191

192

193
0
10
20
30
40
50
60
70
Attriters Controls Acquirers
194

195

196

197

198
0
10
20
30
40
50
60
70
Attriters Controls Acquirers

199

200

201

202

203

204
61 Each subject in this study is referred to by a three-letter code to ensure the anonymity of the people who participated in this project. 62 It needs to be indicated how the lexical items on the wug test for which subjects had to select a definite article were all nonsense words. Although it might be challenging to provide a determiner in these cases, subjects could select the article on the basis of phonotactic cues and on the basis of analogies with existing items. This task did prove to discriminate between the three groups of subjects.

205

206

207

208

209

210

211

212
63 Although officially not a diminutive suffix, -ie is often attached to kop to form the diminutive form kop(p)ie. According to the phonological principles outlined in (3.5.1), however, kop-je is the expected form.

213
05
10152025303540455055
Attriters Controls Acquirers

214

215

216
64 Due to final devoicing in Dutch, the phonological forms mend and mendt are identical. The reason this was counted as a mistake is that the wug test was a written task and it is in the written domain that the difference between these two forms surfaces.

217

218

219

220

221

222
65 Since these pairs do not differ from each other in their phonemic realization, they may not be considered as deviations from the standard. However, the wug test was a written task where subjects were presented with the written form of the nonsense words and asked to inflect it. The endings of the words do matter in their written form and these instances were therefore treated as deviations.

223

224

225

226

227
66 The use of hun (‘them’) here is deviant as well, since this constitutes an object form, but is used as the subject of the clause. Because of this, the appropriate form to use would have been zij (‘they’).

228
67 As bappen is a nonsense verb it cannot be translated.

229

230
68 As with all the entries in this grid, the outcomes of free spoken data represent the deviations and not the number of occurrences. In other words, the attriters and acquirers produced significantly less agentive forms than the controls, but the three groups did not differ from each other with respect to number of deviations found in the narratives.

231

232
0
5
10
15
20
25
Attriters Controls Acquirers

233

234

235

236

237

238

239
69 The subject is omitted in this context, which is frequently done in everyday spoken interaction, but is inserted here for convenience sake.

240
70 As it is impossible to automatically count the number of V2, subordination and discontinuous word order occurrences in the free spoken data by means of CLAN (see 6.3.2.4), no such information is presented here.

241
71 And then is an example of code-switching, which was frequently attested in the speech of the Dutch Canadians (see 7.1.3). 72 When using a time adjunct in conjunction with a past tense reference, toen (‘then’) is preferred over dan (‘then’) in standard Dutch.

242

243

244
73 Wezen is an infinite form, which occasionally serves as a replacement for the more frequent zijn. For a more elaborate account of the constraints regarding the use of wezen, see Rooij (1986).

245

246

247

248

249

250
0
50
100
150
200
Dutch can-do scales English can-do scales

251

252
0
10
20
30
40
50
60
70
80
listening reading speaking writing
Dutch can-doscalesEnglish can-doscales

253
74 The test statistic that was used in these correlation analyses was that of Spearman’s correlation coefficient (rs). Because of its non-parametric nature, it can deal with data that violate the parametric assumptions, as was the case in this study (Field, 2005: 129). 75 As the control subjects did not complete either the English can-do scales or the English C-test, no score was obtained here.

254

255

256

257

258

259

260

261

262

263

264

265

266

267

268

269

270

271

272

273
76 Auxiliary selection is generally not mentioned in accounts of parameter (re)setting. Other binary choices, such as whether the subject of a clause is overtly expressed ([±pro-drop]) are. However, it is far from clear which binary choices do constitute parameters and which ones are clearly not parametric choices.

274

275

276

277
77 Perhaps the difficulty of leinde in comparison to degin is that in the former case a consonant has been added to the existing form einde (‘finish’). By contrast, degin was formed by replacing the initial [b] in begin (‘start’) by [d]. It may be that the word begin is more easily recognizable than einde.

278

279

280

281

282

283

284

285

286

287

288

289

290

291

292

293

294

295

296

297

298

299

300

301

302

303

304

305

306

307

308

309
78 Educational level codes: 1 = primary school 2 = secondary school basic 3 = secondary school plus 4 = college 5 = university For a definition of secondary school basic and plus, see 6.1.2.3.

310

311

312

313
79 None of the acquirers had completed their secondary education yet. The level of education that is given instead is the level in which the learners were enrolled at the time of testing.

314

315

316

317

318

319

320

321

322

323

324

325

326

327

328

329

330

331

332

333

334

335

336

337

338

339

340

341

342

343

344

345

346

347

348

349

350

351

352

353

354

355

356

357

358

359
80 The Dutch C-texts are not translated into English, as it is close to impossible to literally translate the texts while at the same time indicating which words have been gapped. For an example of the principle of the C-test, Appendix 4b contains the English C-test that was also included in the test battery for the attriters.

360

361

362

363

364

365
81 As the format of the sentences remains the same throughout the noun phrase part of the wug test, only the example sentences have been translated into English. 82 As English does not have a binary choice between two definite articles, it is hard to translate those sentences of the wug test that elicited article selection.

366

367

368

369

370

371
83 The English translations of the sentences that elicited verbal morphology are restricted to five sentences, one for each verb phrase morphological aspect under investigation (see Chapter 4), as the format of the sentences remains the same throughout the whole test. Only the (nonsense) verbs are different.

372

373

374

375
84 Because the three options to choose from remain the same throughout the grammaticality judgment task, they have only been translated into English for the first judgment.

376

377

378

379

380

381

382

383
85 The Dutch can-do scales are not translated into English, because an English equivalent of the questionnaire was also available for the attrition Group and is included in Appendix 7b.

384

385

386

387

388

389

390

391

392

393

394

395

396

397

398

399

400

401

402

403

404

405

406

407




















