
Knowledge-based extraction of intellectual capital-related information from unstructured data
11
Knowledge-based extraction of intellectual capital-related information from unstructured data Eric Tsui ⇑ , W.M. Wang, Linlin Cai, C.F. Cheung, W.B. Lee Knowledge Management and Innovation Research Centre, Department of Industrial and Systems Engineering, The Hong Kong Polytechnic University, Hung Hom, Kowloon, Hong Kong article info Keywords: Intellectual capital management Unstructured information management Information extraction Knowledge-based systems Case-based reasoning abstract Nowadays, there is an increasing demand for the identification of an organization’s intellectual capital (IC) for decision support and providing important managerial insights in knowledge-intensive industries. In traditional approaches, identification of an organization’s IC is usually done manually through inter- views, surveys, workshops, etc. These methods are labor and time intensive and the quality of the results is highly dependent on, among other things, the experience of the investigators. This paper presents a Knowledge-based Intellectual Capital Extraction (KBICE) algorithm which incorporates the technologies of computational linguistics and artificial intelligence (AI) for automatic processing of unstructured data and extraction of important IC-related information. The performance of KBICE was assessed through a series of experiments conducted by using publicly available financial reports from the banking industry as the testing batch and encouraging results have been obtained. The results showed that, through the use of hybrid intelligent matching strategies, it is possible to extract commonly referred IC-related infor- mation from unstructured data automatically. IC information analyst can rely on this method as an addi- tional mean to identify and extract the commonly sought IC information from financial reports in a fast, systematic and reliable manner. Ó 2013 Elsevier Ltd. All rights reserved. 1. Introduction Intellectual capital (IC) as a whole refers to the total resources and potential that determines the value and competitiveness of an enterprise (Magrassi, 2002). The concept of IC has been associ- ated with organizational knowledge and intangible resources. Edv- insson and Malone (1997) refer IC as the cumulative value of an organization’s intangible assets. The intangible assets are impor- tant today as knowledge and innovation are the key drivers to long-term business competitiveness. Current research has found that there are significant relationships between the IC and value- added productivity, measuring IC can therefore strengthen ongoing productivity measurement efforts on a firm’s intangible assets (Phusavat, Comepa, & Sitko-Lutek, 2013). It has also been shown that IC is significantly positively associated with firm operating efficiency hence companies should invest and fully utilize IC to gain competitive advantage (Lua, Wang, & Kweh, 2014). According to the knowledge-based view of the firm (Grant, 1996; Spender, 1996), all intangible assets can be categorized into different types of knowledge. Similarly, Brooking (1996) conceptualizes IC as com- bined intangible assets of market, intellectual property, human capital, and firm’s infrastructure that all together enable a com- pany to function. Prior research suggests that the development of IC resources creates value for organizations, especially since the majority of an organization’s assets are intangibles that are not shown on the balance sheet (Stewart, 1997). IC is rapidly becoming a new instrument for gauging organizational hidden values; mea- suring the real value and the total performance of IC are essential to any corporate heads who know how high the stakes have be- come for corporate survival in the knowledge and information age (Khavandkar & Khavandkar, 2009). As a result, the identifica- tion of an organization’s IC is important as this provides insights on management action. Such actions often relates to the goal of enhancing the transparency of the concerned organization and benefits both internal stakeholders and external investors and beneficiaries. However, the identification of an organization’s IC is intrinsically difficult and is often subjective and inaccurate. Such inaccuracies not only mislead the market’s observation over a corporation’s con- sistency in performance but may also cause legal issues. This in turn leads to low business transparency in a knowledge-economy with a huge service-sector from which the most valuable assets are in fact intangibles. The fundamental challenge for these quality variations is the knowledge related to intangible assets which is mostly repre- sented in unstructured or semi-structured formats. Due to the inherent nature of information, intangible assets account for a big proportion of a firm’s capital that are neither has properly refined 0957-4174/$ - see front matter Ó 2013 Elsevier Ltd. All rights reserved. http://dx.doi.org/10.1016/j.eswa.2013.08.029 ⇑ Corresponding author. Tel.: +852 2766 6609. E-mail address: [email protected] (E. Tsui). Expert Systems with Applications 41 (2014) 1315–1325 Contents lists available at ScienceDirect Expert Systems with Applications journal homepage: www.elsevier.com/locate/eswa
-
Upload
independent -
Category
Documents
-
view
2 -
download
0
Transcript of Knowledge-based extraction of intellectual capital-related information from unstructured data

Expert Systems with Applications 41 (2014) 1315–1325
Contents lists available at ScienceDirect
Expert Systems with Applications
journal homepage: www.elsevier .com/locate /eswa
Knowledge-based extraction of intellectual capital-related informationfrom unstructured data
0957-4174/$ - see front matter � 2013 Elsevier Ltd. All rights reserved.http://dx.doi.org/10.1016/j.eswa.2013.08.029
⇑ Corresponding author. Tel.: +852 2766 6609.E-mail address: [email protected] (E. Tsui).
Eric Tsui ⇑, W.M. Wang, Linlin Cai, C.F. Cheung, W.B. LeeKnowledge Management and Innovation Research Centre, Department of Industrial and Systems Engineering, The Hong Kong Polytechnic University, Hung Hom, Kowloon, Hong Kong
a r t i c l e i n f o a b s t r a c t
Keywords:Intellectual capital managementUnstructured information managementInformation extractionKnowledge-based systemsCase-based reasoning
Nowadays, there is an increasing demand for the identification of an organization’s intellectual capital(IC) for decision support and providing important managerial insights in knowledge-intensive industries.In traditional approaches, identification of an organization’s IC is usually done manually through inter-views, surveys, workshops, etc. These methods are labor and time intensive and the quality of the resultsis highly dependent on, among other things, the experience of the investigators. This paper presents aKnowledge-based Intellectual Capital Extraction (KBICE) algorithm which incorporates the technologiesof computational linguistics and artificial intelligence (AI) for automatic processing of unstructured dataand extraction of important IC-related information. The performance of KBICE was assessed through aseries of experiments conducted by using publicly available financial reports from the banking industryas the testing batch and encouraging results have been obtained. The results showed that, through theuse of hybrid intelligent matching strategies, it is possible to extract commonly referred IC-related infor-mation from unstructured data automatically. IC information analyst can rely on this method as an addi-tional mean to identify and extract the commonly sought IC information from financial reports in a fast,systematic and reliable manner.
� 2013 Elsevier Ltd. All rights reserved.
1. Introduction
Intellectual capital (IC) as a whole refers to the total resourcesand potential that determines the value and competitiveness ofan enterprise (Magrassi, 2002). The concept of IC has been associ-ated with organizational knowledge and intangible resources. Edv-insson and Malone (1997) refer IC as the cumulative value of anorganization’s intangible assets. The intangible assets are impor-tant today as knowledge and innovation are the key drivers tolong-term business competitiveness. Current research has foundthat there are significant relationships between the IC and value-added productivity, measuring IC can therefore strengthen ongoingproductivity measurement efforts on a firm’s intangible assets(Phusavat, Comepa, & Sitko-Lutek, 2013). It has also been shownthat IC is significantly positively associated with firm operatingefficiency hence companies should invest and fully utilize IC togain competitive advantage (Lua, Wang, & Kweh, 2014). Accordingto the knowledge-based view of the firm (Grant, 1996; Spender,1996), all intangible assets can be categorized into different typesof knowledge. Similarly, Brooking (1996) conceptualizes IC as com-bined intangible assets of market, intellectual property, humancapital, and firm’s infrastructure that all together enable a com-
pany to function. Prior research suggests that the development ofIC resources creates value for organizations, especially since themajority of an organization’s assets are intangibles that are notshown on the balance sheet (Stewart, 1997). IC is rapidly becominga new instrument for gauging organizational hidden values; mea-suring the real value and the total performance of IC are essentialto any corporate heads who know how high the stakes have be-come for corporate survival in the knowledge and informationage (Khavandkar & Khavandkar, 2009). As a result, the identifica-tion of an organization’s IC is important as this provides insightson management action. Such actions often relates to the goal ofenhancing the transparency of the concerned organization andbenefits both internal stakeholders and external investors andbeneficiaries.
However, the identification of an organization’s IC is intrinsicallydifficult and is often subjective and inaccurate. Such inaccuraciesnot only mislead the market’s observation over a corporation’s con-sistency in performance but may also cause legal issues. This in turnleads to low business transparency in a knowledge-economy with ahuge service-sector from which the most valuable assets are in factintangibles. The fundamental challenge for these quality variationsis the knowledge related to intangible assets which is mostly repre-sented in unstructured or semi-structured formats. Due to theinherent nature of information, intangible assets account for a bigproportion of a firm’s capital that are neither has properly refined

1316 E. Tsui et al. / Expert Systems with Applications 41 (2014) 1315–1325
nor structured. In traditional approaches, the identification of anorganization’s IC is done manually through interviews, surveys,workshops, etc. (Yin, 2003). These methods are not only labor andtime intensive but the quality of the results is highly dependenton the experience of the investigators. Up to now, there is still nouniform architecture available for intangible knowledge acquisitionand elicitation. As a result, there exist significant variations in thequality of reported intangibles by organizations.
On the other hand, the established eXtensible Business Report-ing Language (XBRL) attempts to standardize financial reportingwith a machine-interpretable format that makes corporate reportseasier to consume (interpret) and integrate data (O’Riaina, Currya,& Harth, 2012). Since its inception, XBRL has become an importantelement of the financial reporting landscape (Vasarhelyi, Chan, &Krahel, 2012). However, there are also problems with the use ofXBRL. As XBRL has a highly structured format for exchanging busi-ness information, tedious initial manual efforts are required infiling XBRL-compliant documents. Furthermore, prior researchhas revealed that XBRL documents often contain multiple errorsin signage, amounts, labeling, and classification (Bartley, Chen, &Taylor, 2010). These are serious errors, since XBRL data is com-puter-readable and users are generally unable to visually recognizeand correct these errors.
Although the value of manual approaches (e.g. surveys andinterviews) in identifying and collecting IC information is not tobe under-estimated, there is also a considerable number of existingand alternative sources whereby an organization can tap into in or-der to retrieve IC-related information. Some of these sources in-deed are explicit knowledge assets which are routinely producedby an organization (e.g. annual report) as part of its normal opera-tion. It is not uncommon that a lot of efforts has been expended onthe compilation of such explicit assets though such efforts are gen-erally not IC-directed.
In order to provide a fast, systematic, consistent and reliableway to identify IC, this paper illustrates how to extract the relatedinformation of organization’s IC from unstructured documents ofan organization using an automatic and knowledge-based informa-tion extraction approach.
The amount of available electronic data of all kinds is increasingdramatically (Abiteboul, 1997). It was found that most of the infor-mation or knowledge in an organization is unstructured or semi-structured (Waters, 2005) such as e-mails, office documents, PDFdocuments and many other text-based documents, which containmuch human knowledge and details of customer relationships re-lated to daily operations. Many companies realize the value of theknowledge inherent in unstructured information which constitutesup to 80–98% of all the data, information and knowledge in anorganization (Cheung, Lee, & Wang, 2005). In this paper, to addressthe challenge, a study has been conducted for efficient knowledgediscovery and the extraction of intangibles by revealing IC-relatedinformation that are embedded mostly in unstructured data andpartly in semi-structured data. A Knowledge-based IntellectualCapital Extraction (KBICR) algorithm is presented; this algorithmincorporates a 2-tier filtration by applying Rule-Base Reasoning(RBR) and Case-Based Reasoning (CBR). The KBICE algorithm hasbeen evaluated by applying it to several publicly available financialreports from the banking industry.
2. Related work
Maeques, Simon, and Caranana (2006) divide IC into threedimensions including human capital, structural capital, and rela-tional capital, based on the knowledge source and structure. Subr-amaniam and Youndt (2005) believe that IC consists of three highlyinterdependent facets of human capital, organizational capital, andsocial capital. Human capital comprises of all individual
knowledge, both tacit knowledge (knowing how) and explicitknowledge (knowing what). Recently, Joshi, Cahill, Sidhu, and Kan-sal (2013) discovered that the value creation capability is highlyinfluenced by human capital. The paper addressed those factorsaffecting IC performance in to the process of maximizing valuecreation. Structural capital composes of organization’s routines,procedures, strategies, and policies that are in charge of organiza-tion’s daily operations whereas organizational capital is the collec-tive and institutionalized knowledge and experience residingwithin and utilizing through databases, patents, manuals, struc-tures, systems, and processes of an organization. In Pandey andDutta (2013), they found that there is relevance between knowl-edge infrastructure capability and KM excellence. They highlightedthat the important role of a knowledge-sharing culture throughoutmanagement systems and routines. Their findings also suggestedthat organizational structure (a principal part of an organization’sstructural capital) plays both facilitating and steering roles indeveloping the culture of knowledge. Relational capital refers toall knowledge acquired by organizations because of their interac-tion with the external environment such as competitors, partners,customers, regulators, etc. Social capital, on the other hand, isdefined as knowledge embedded within, available through and uti-lized by interactions among individuals and their social networks.In particular, empirical results have revealed that the social capitalhas significant effects, directly or indirectly, on supply chain inte-gration and performance (Yim & Leem, 2013); it is suggested thatsupply chain integration among partners in the value chain canbe improved by building up social capital.
Content analysis is the most popular method adopted to identifyintellectual capital-related information (Guthrie, Petty, Yongva-nich, & Ricceri, 2004). It is a manual method that involves in codify-ing qualitative and quantified IC-related information into thepre-defined IC indicator categories. A list of IC indicators is prere-quisite, which was first compiled by Guthrie, Petty, and Wells(1999) based on the literatures on government policy and profes-sional policy pronouncements. According to the context, cultureas well as the environment changing, the list are modified byvarious scholars based on the various materials, such as the projectresults of US Financial Accounting Standards Board (FASB) (Bozzo-lan, Favotto, & Ricceri, 2003), the extant IC academic articles(Abdolmohammadi, 2005), stakeholder consultation principles(Schneider & Samkin, 2008), etc. Then these indicators are put intodifferent categories for coding IC-related information. One of themost commonly used frameworks is derived from the Sveiby(1997) IC framework: internal structures, external structures; andemployee competence. Coders record the IC data in the materialssuch as annual reports (Bontis, 2003; Guthrie & Petty, 2000; Guthrieet al., 1999), IPO prospectuses (Bukh, Nielsen, Gormsen, & Mourit-sen, 2005), sustainability reports (Cinquini, Passetti, Tenucci, &Frey, 2012), etc. Finally, other coders put the IC data that was re-corded into the designated classification. However, a completelymanual method greatly limits the volume of process-able textsdue to the labor-intensive data collection process (Beattie & Thom-son, 2007; Oliverira, Gowthorpe, Kasperskaya, & Perramon, 2008).Even though at least two researchers participate in the assessingprocess, the subjectivity is inevitably involved, thus the reliabilityof the extracted data is also affected by personal bias (Abeysekera,2006; Beattie & Thomson, 2007; Guthrie et al., 2004; Lee & Guthrie,2010). Furthermore, multiple coders increase the risk of inconsis-tency due to the different coding rules (Abeysekera, 2006; Beattie& Thomson, 2007; Lee & Guthrie, 2010) being applied/interpreted.
Considering these disadvantages, some researchers turn tocomputers to solve the problem. Bontis (2003) applied the elec-tronic search to identify the IC-related information in the elec-tronic database which contains approximately 11,000 CanadianCorporations annual reports. Then a list of IC terminology was used

Fig. 1. A schematic diagram of Knowledge-based Intellectual Capital Extraction.
E. Tsui et al. / Expert Systems with Applications 41 (2014) 1315–1325 1317
as the IC disclosure reference. Every term was searched individu-ally in the database. This computer-aided method makes it possi-ble to identify IC items in huge volume of data. However, the lowlevel of IC disclosure demonstrates that this kind of electronicsearch was not an effective way to identify IC-related information.Firstly, it failed to recognize the synonyms and words with multi-ple meanings that related to IC (Beattie & Thomson, 2007).Secondly, the context of the keywords cannot be understood bythe computer, and therefore has greatly reduced the amount ofthe related information that can be matched.
Since the disappointing result reported by Bontis (2003), re-search on using the computer-aided methods to identify IC has sub-sided for quite a long period. Oliverira et al. (2008) used thesoftware program ‘‘Concordance’’ to investigate the level of the ICdisclosure in Spain. ‘‘Concordance’’ is a kind of software that canhelp to study the text and analyze language in depth. Even thoughthe software program can increase the reliability, replicability andobjectivity of the extracted data to some degree, the first experi-mental result by using the same framework as Guthrie and Petty(2000) is far from promising, the number of identified instances iseven less than it was done manually. Subsequently, the range ofsub-terms was expanded based on the Guthrie and Petty (2000)in an attempt to net a wider net of IC information. Moreover, withthe function of the identifying the word frequencies within thecontext of sentences, ‘‘Concordance’’ has helped to successfullyanalysis 3 years’ of annual reports by leading Spanish firms.
Another method tried is to map IC-related information tooff-the-shelf taxonomies/classifications. Lee and Guthrie (2010)utilized Factiva to identify IC-related information in the businessand analyst reports. Factiva is an intelligent taxonomy tool that as-sists in classifying IC-related information automatically by usingthe fixed terms in their database. Firstly, electronic search was con-ducted to extract the IC-related data. Then, human reviews andcorrects the gross errors. Finally, a manual mapping was done be-tween accepted IC terms and the Factiva intelligent taxonomyterms. The mapping results of this project obviously show thatthe domain of Factiva taxonomy terms is larger than the termsused in the framework developed by Guthrie and Petty (2000),which greatly helps to identify the potential IC terms that do notemerge in the literatures. However, the result of this project is verydifficult to be replicated. The Factiva intelligent taxonomy termsare commercial and proprietary products which cannot be usedin the public domain. Therefore researchers have few opportunitiesto study the design of the original taxonomy which greatly affectsthe accuracy and performance of the mapping. Even though thepersonal biased in coding is eliminated by using Factiva, constanthuman interaction are still needed in other steps, thus introducingother types of subjectivities. This approach has also demonstratedthat it is impossible to cope with a huge volume data.
In this study, a Knowledge-based Intellectual Capital Extraction(KBICR) algorithm is presented; this algorithm incorporates a 2-tierfiltration by applying Rule-Base Reasoning (RBR) and Case-BasedReasoning (CBR). Case-based reasoning (CBR) is a technique toincrease the learning capability of the algorithm. CBR is a prob-lem-solving approach that relies on past and similar cases to findsolutions to new problems (Kolodner, 1993). It simulates humandecision making processes and enables the accumulation of previ-ous experience. A knowledge cycle consists of knowledge processessuch as acquisition transfer, and retention of knowledge. This isstrongly correlated with the CBR cycle which includes retrieve, re-use, revise, and retain knowledge (Aamodt & Plaza, 1994). A case isoften specified by a set of attributes. This set of attributes is struc-tured by the domain. Each case has a unique key and the casedescription. A new problem is solved by retrieving similar casesabout similar situations from the knowledge repository (KR), reus-ing or revising the case in the context of the new situation, and
retaining the new case in the KR (Aamodt & Plaza, 1994). Oneimportant advantage of CBR is its learning capability (Weber &Aha, 2003). Its problem-solving ability enhances with the increas-ing amount of accumulated cases. By adopting a CBR system, orga-nizations are able to gradually deal with new problems by referringto their past knowledge more effectively (Weber & Aha, 2003).
As a result, CBR is some kind of experience mining (Richter,2009). The approach has been extended to more general situationswhere experience is retained. Major examples are the ‘‘experiencefactory’’ (Althoff, Birk, von Wangenheim, & Tautz, 1998) and thetechnique of ‘‘lessons learnt’’ (Weber, Aha, & Becerra-Fernandez,2001). CBR has also been widely used in various studies and issues,including medical and the clinic industry (Chang, 2005), mentalhealth (Wang, Cheung, Lee, & Kwok, 2007), logistics (Cheung, Chan,Kwok, Lee, & Wang, 2006), education (Chu, Chen, Lin, Liao, & Chen,2009), physical asset management (Wang, 2005) and customer ser-vice management (Cheung, Lee, Wang, Chu, & To, 2003). Moreexamples can be found in the paper authored by Schmidt, Montani,Bellazzi, Portinale, and Gierl (2001). They concluded that CBR is asuitable technology for retaining knowledge learned from experi-ence for future reuse.
3. Methodology for Knowledge-based Intellectual CapitalExtraction (KBICE)
The proposed KBICE algorithm consists of a process of construc-tion of knowledge repository and a process of IC informationextraction. The proposed method adapts the Case-based reasoning(CBR) approach with Rule-based reasoning (RBR) for enhancing thelearning capability of the automatic extraction of IC related infor-mation. As shown in Fig. 1, pattern-based rules with the IC relatedkey phrases are stored in the knowledge repository based on man-ually extraction for the initial setting, and review and revise of newIC information extracted by the system for continuous replenish-ment of the knowledge repository.
The initial set of rules are extracted by an IC information analystby reviewing a set of documents which is used as the initial set oftraining data for the construction of a knowledge repository. Aschematic diagram of the process is shown in Fig. 2. Firstly, theIC analyst identified IC elements by reviewing the seminal IC liter-ature (Bontis, 2003; Bose, 2004; Guthrie & Petty, 2000; Whiting &

Fig. 2. A schematic diagram of the construction of knowledge repository.
Table 1A list of IC elements.
HC elements SC elements RC elements
Employee profile Infrastructure and capability Customers, image and stakeholdersEmployee diversity Customer support function Company image and reputationEmployee productivity Business procedure Public relationEmployee development Quality management and improvements Public awarenessManagement development Corporate culture PublicationsEmployee flexibility Management processes Customer relationshipsEmployee capability Information systems (Technical Infrastructure) Relationship with suppliersStaff turnover Networking systems Relationship with stakeholdersEducation Process (quality and efficiency) BrandsCommitment and Motivation Organizational structure Quality and customer satisfactionTraining/competence development Technology Customer communicationValue creation De-layering and transparency Investor relationsPrevention of occupational hazards Flexibility Social action, social relationshipSkills/Know-how/Expertise/Knowledge/Experience Management structure and strategic management Support for education, culture and innovationKnowledge acquisition Quality of pension summaries Corporation and networks
1318 E. Tsui et al. / Expert Systems with Applications 41 (2014) 1315–1325
Miller, 2008). An IC checklist is then compiled according to the ICtriple model (HC, SC and RC) as shown in Table 1. Based on the sig-nificant IC elements, the analyst used sentence as the basic unit ofanalysis to identify the practical IC information from annual re-ports and IC reports. This is a reasonable assumption as all such re-ports are mostly texts supplemented by tables and figures. Afterthe IC sentences are identified, patterns and key phrases are ex-tracted from the sentences from both the semantic and syntax per-spectives. Considering IC key phrases and sentence patterns can bereused for identifying IC information, they are stored into theknowledge repository are further analysis.
In the process of IC information extraction, as shown in Fig. 1,new document is firstly preprocessed by an ad hoc sentenceboundary detection algorithm based on regular expressions (suchas the new line character, full stop, and question mark) so as todetermine the paragraphs and sentences. The sentence is furtherdivided into tokens by regular expressions such as space, comma,parentheses, etc. The tokens are then tagged with its parts-of-speech (POS) using a POS tagger developed by Schmid (1994). Atthe same time, using heuristics rules, certain specific data typesare assigned to the tokens (e.g. date, year, and numbers. The flowof the parsing process is shown in Fig. 3.
The parsed text is then passed to the IC information extraction.The pattern-based rules with IC-related key phrases in the knowl-edge repository are applied to the parsed texts. A rule consists oftwo major parts – patterns, and key phrases. The IC informationextraction algorithm is shown in Figs. 4 and 5. Two examples ofthe rules are given as follow:
1. Rule No: 1Pattern: a total of [NUMBER]Key Phrase: Business management centre
2. Rule No: 2Pattern: with an average of [NUMBER]Key Phrases: workforce, graduates
As shown in Figs. 4 and 5, the results can be divided into 3groups which are Group A, Group B and Group C. For Group A, sen-tences are extracted if the sentences are exactly matched with oneor more than one existing rules. Weights are assigned to the sen-tences based on the number of rules being matched by the sen-tences as shown in Eqs. (1) and (2). The sentences are then sortedby weights in a descending order. The sentences of Group A havethe highest priority for suggesting the IC related information

Fig. 3. A process flow of the parsing process.
E. Tsui et al. / Expert Systems with Applications 41 (2014) 1315–1325 1319
WeightAi ¼
Xn
j
ScoreðSentencei;RulejÞ ð1Þ
ScoreðSentencei;RulejÞ
¼1 if Sentencei is exactly matched with Rulej
0 if Sentencei is not exactly matched with Rulej
� ð2Þ
where n is the total number of rules.For Group B and Group C, sentences are extracted if the sen-
tences are partially matched with one or more of the existing rules.For Group B, sentences are extracted if the sentences are matchedwith at least one of the existing rules’ key phrases. For Group C,sentences are extracted if the sentences are matched with at leastone of the existing rules’ patterns. A weight of each of the extractedsentences is determined by number of rules being matched and thesimilarity among the extracted sentences. It is argued that the sen-tence that matched with more rules is more likely containing IC re-lated information. The calculation of weight of the ith paragraph isshown in Eqs. (3)–(5)
WeightCi ¼
Xn
j
ScoreðSentencei;RulejÞ ð3Þ
ScoreðSentencei;RulejÞ ¼Xm
k
SimilarityðSentencei; Sentencek;RulejÞ
ð4Þ
SimilarityðSentencei; Sentencek;RulejÞ
¼jv i\vk jjv i[vk j
if Sentencei is partially matched with Rulej
0 if Sentencei or Sentencej is not matched with Rulej
(
ð5Þ
where n is total number of rules, m is the total number of sen-tences, mi ¼ ðmi1; mi2; . . .Þ are the set of frequencies of words of theith sentence, jmi \ mkj is the size of the intersection between the setsmi and mk, and jmi [ mkj is the size of the union between the sets mi
and mk.Hence, the sentences of Group B and Group C are also sorted in
descending order by the weights of the extracted sentences as sug-gestions for users to review. After review, new patterns and keyphrases are stored into the knowledge repository for future reuse.Following are two examples for suggesting new patterns and keyphrases:
1. Original Content: ‘‘As a public sector contractor, the OeNB is sub-ject to the Federal Procurement Act, which prescribes a call for ten-ders for procurements exceeding a certain threshold. In 2004, atotal of 26 calls for tender were carried out, guaranteeing efficient,free and fair competition in the procurement process. The OeNBsucceeded in reducing costs massively in 2004 by continuouslyoptimizing efficiency. All corporate expenditure-related activity fol-lows economic and ecological principles’’.Matched Pattern: a total of [NUMBER]Extracted Sentences: ‘‘In 2004, a total of 26 calls for tender werecarried out, guaranteeing efficient, free and fair competition in theprocurement process’’.Potential Key Phrase: calls for tender
2. Original Content: ‘‘In order to get to know the perception of thesuppliers and to identify the areas of improvement in their rela-tionship with BBVA, two surveys were carried out on satisfaction,achieving a high response index and an overall satisfaction scoreof 3.7 out of 5’’.Matched Key Phrase: overall satisfaction scoreExtracted Sentences: ‘‘In order to get to know the perception ofthe suppliers and to identify the areas of improvement in their rela-tionship with BBVA, two surveys were carried out on satisfaction,achieving a high response index and an overall satisfaction scoreof 3.7 out of 5’’.Potential Pattern: [NUMBER] out of [NUMBER]
4. Experimental evaluation
4.1. Evaluation methodology
The KBICE approach has been evaluated by using the financialreports of the banking industry that were found in the public do-main. 22 English documents have been selected from 4 differentbanking companies for the experiment (which are obtained fromthe website of the companies: http://www.atp.dk, http://www.bbva.com, http://www.oenb.at, https://webcorporati-va.bankinter.com). The Banking industry is well known for havingestablished structures for reporting tangible assets through dec-ades of data refinements. It is also partially capable of derivingsemi-structured data of intangibles from banks’ financial reports.Moreover, the selected companies are considered to be pioneersof creating IC reports in the industry. Hence, the financial reportsof the banking industry are considered to be a principal source ofsignificant and reliable benchmarking data for evaluation. Basedon the document, a set of rules is extracted by an IC informationanalyst through reviewing the documents for the construction ofthe knowledge repository. Some rules consist of both pattern andkey phrase; some have key phrase only. A list of rules is shownin Appendix A. Among the documents, there are 110 pages thatcontain IC related information. Among the 110 pages, 130 para-graphs contain IC related information, and 807 paragraphs do notcontain IC-related information. In other words, there are 937 para-graphs with 41,706 words which together constitute the base ofthe evaluation data. The right answer set and the training set of
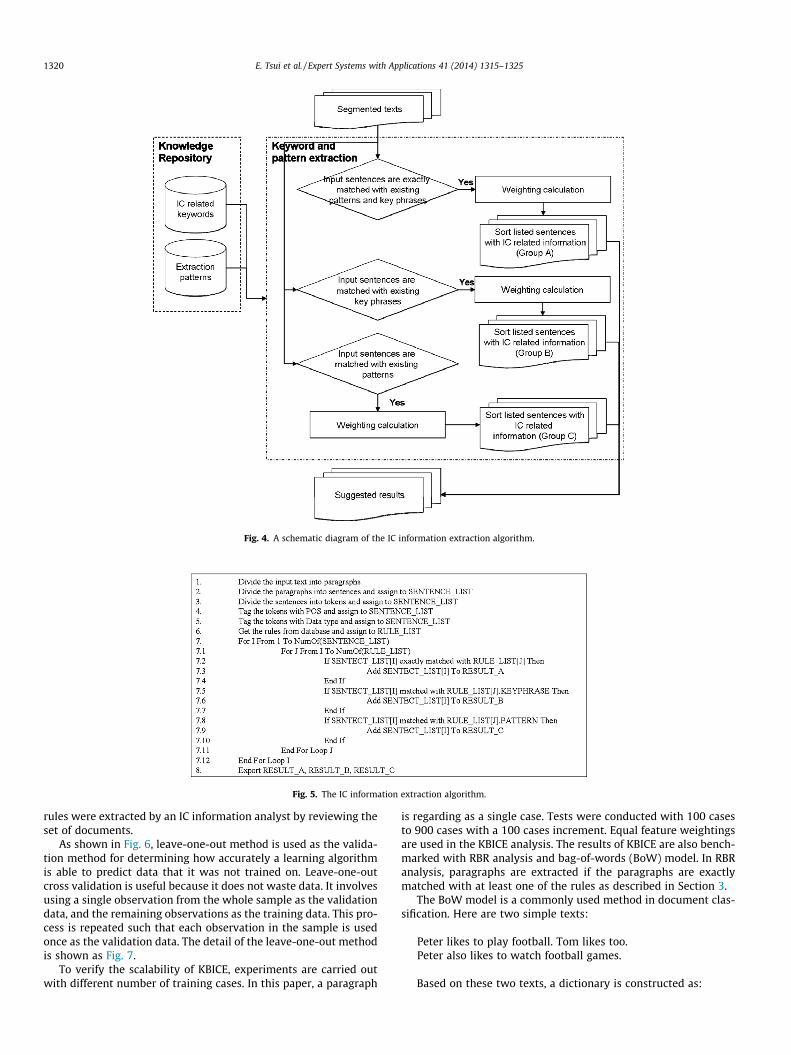
Fig. 4. A schematic diagram of the IC information extraction algorithm.
Fig. 5. The IC information extraction algorithm.
1320 E. Tsui et al. / Expert Systems with Applications 41 (2014) 1315–1325
rules were extracted by an IC information analyst by reviewing theset of documents.
As shown in Fig. 6, leave-one-out method is used as the valida-tion method for determining how accurately a learning algorithmis able to predict data that it was not trained on. Leave-one-outcross validation is useful because it does not waste data. It involvesusing a single observation from the whole sample as the validationdata, and the remaining observations as the training data. This pro-cess is repeated such that each observation in the sample is usedonce as the validation data. The detail of the leave-one-out methodis shown as Fig. 7.
To verify the scalability of KBICE, experiments are carried outwith different number of training cases. In this paper, a paragraph
is regarding as a single case. Tests were conducted with 100 casesto 900 cases with a 100 cases increment. Equal feature weightingsare used in the KBICE analysis. The results of KBICE are also bench-marked with RBR analysis and bag-of-words (BoW) model. In RBRanalysis, paragraphs are extracted if the paragraphs are exactlymatched with at least one of the rules as described in Section 3.
The BoW model is a commonly used method in document clas-sification. Here are two simple texts:
Peter likes to play football. Tom likes too.Peter also likes to watch football games.
Based on these two texts, a dictionary is constructed as:
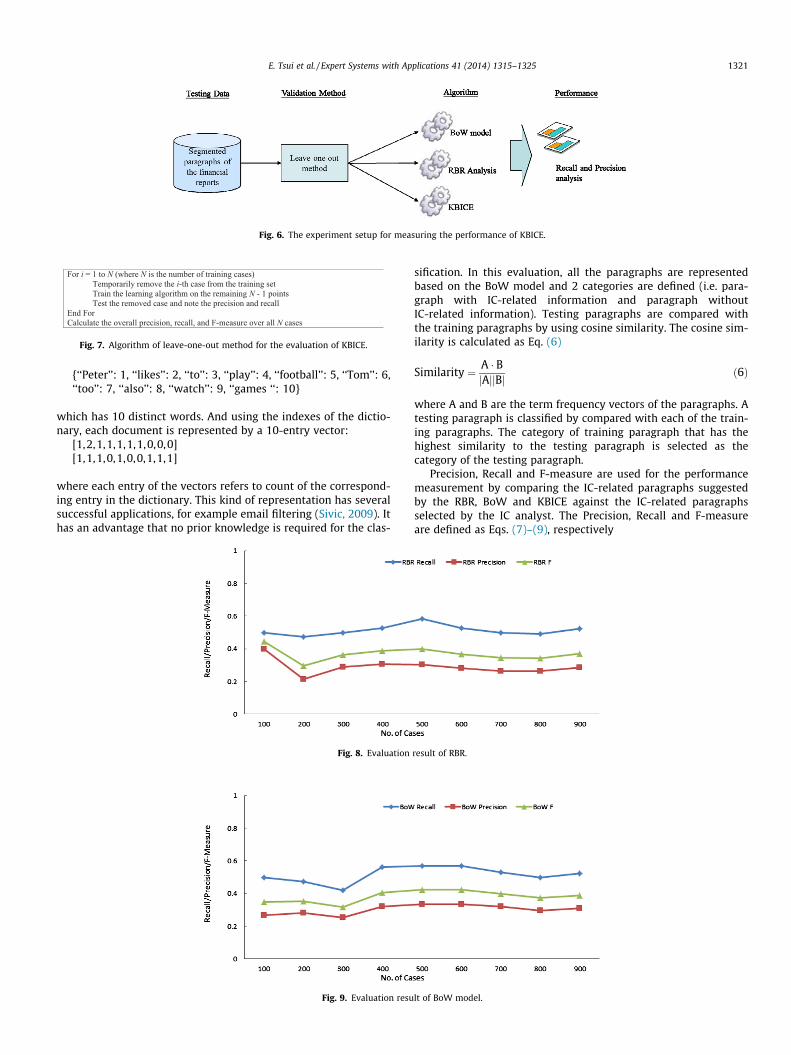
Fig. 6. The experiment setup for measuring the performance of KBICE.
For i = 1 to N (where N is the number of training cases)Temporarily remove the i-th case from the training setTrain the learning algorithm on the remaining N - 1 pointsTest the removed case and note the precision and recall
End ForCalculate the overall precision, recall, and F-measure over all N cases
Fig. 7. Algorithm of leave-one-out method for the evaluation of KBICE.
E. Tsui et al. / Expert Systems with Applications 41 (2014) 1315–1325 1321
{‘‘Peter’’: 1, ‘‘likes’’: 2, ‘‘to’’: 3, ‘‘play’’: 4, ‘‘football’’: 5, ‘‘Tom’’: 6,‘‘too’’: 7, ‘‘also’’: 8, ‘‘watch’’: 9, ‘‘games ‘‘: 10}
which has 10 distinct words. And using the indexes of the dictio-nary, each document is represented by a 10-entry vector:
[1,2,1,1,1,1,1,0,0,0][1,1,1,0,1,0,0,1,1,1]
where each entry of the vectors refers to count of the correspond-ing entry in the dictionary. This kind of representation has severalsuccessful applications, for example email filtering (Sivic, 2009). Ithas an advantage that no prior knowledge is required for the clas-
Fig. 8. Evaluation
Fig. 9. Evaluation resu
sification. In this evaluation, all the paragraphs are representedbased on the BoW model and 2 categories are defined (i.e. para-graph with IC-related information and paragraph withoutIC-related information). Testing paragraphs are compared withthe training paragraphs by using cosine similarity. The cosine sim-ilarity is calculated as Eq. (6)
Similarity ¼ A � BjAjjBj ð6Þ
where A and B are the term frequency vectors of the paragraphs. Atesting paragraph is classified by compared with each of the train-ing paragraphs. The category of training paragraph that has thehighest similarity to the testing paragraph is selected as thecategory of the testing paragraph.
Precision, Recall and F-measure are used for the performancemeasurement by comparing the IC-related paragraphs suggestedby the RBR, BoW and KBICE against the IC-related paragraphsselected by the IC analyst. The Precision, Recall and F-measureare defined as Eqs. (7)–(9), respectively
result of RBR.
lt of BoW model.

Fig. 10. Evaluation result of KBICE.
Table 2Evaluation result.
No. of cases
100 200 300 400 500 600 700 800 900
RBR Recall 0.500 0.474 0.500 0.527 0.583 0.529 0.500 0.491 0.524RBR Precision 0.400 0.214 0.288 0.309 0.304 0.280 0.266 0.263 0.286RBR F 0.444 0.295 0.365 0.389 0.400 0.367 0.347 0.343 0.370BoW Recall 0.500 0.474 0.421 0.564 0.569 0.569 0.529 0.500 0.524BoW Precision 0.267 0.281 0.254 0.320 0.336 0.336 0.320 0.298 0.310BoW F 0.348 0.353 0.317 0.408 0.423 0.423 0.399 0.373 0.389KBICE Recall 0.625 0.684 0.763 0.800 0.792 0.816 0.804 0.804 0.810KBICE Precision 0.455 0.236 0.330 0.308 0.318 0.335 0.327 0.327 0.330KBICE F 0.526 0.351 0.460 0.444 0.454 0.475 0.465 0.465 0.469
Table 3Evaluation results of all approaches with 937 cases.
Approaches Recall Precision F-measure
RBR 0.531 0.289 0.374BoW 0.515 0.306 0.384KBICE 0.815 0.330 0.470
Table 4Statistical analysis among different approaches.
Measuretype
Analysis RBR BoW KBICE
Recall Mean 0.514211873 0.516720376 0.766349317Variance 0.001004415 0.002441958 0.004455682StandardDeviation
0.031692507 0.04941617 0.066750898
Standard Error 0.010564169 0.016472057 0.022250299p (t-test) 7.60379E�07 1.10145E�06
Precision Mean 0.290000884 0.30231798 0.329505701Variance 0.002476143 0.000875173 0.003118895StandardDeviation
0.049760859 0.029583322 0.055847067
Standard Error 0.016586953 0.009861107 0.018615689p (t-test) 0.000401184 0.135743416
F-measure Mean 0.368896938 0.381343595 0.456688859Variance 0.001715798 0.001329782 0.002091208
1322 E. Tsui et al. / Expert Systems with Applications 41 (2014) 1315–1325
Precision ¼ jfrelevant paragraphsg \ fretrieved paragraphsgjjfretrieved paragraphsgj ð7Þ
Recall ¼ jfrelevant paragraphsg \ fretrieved paragraphsgjjfall retrieved paragraphsgj ð8Þ
F ¼ 2 � Precision � RecallPrecisionþ Recall
ð9Þ
StandardDeviation0.041422187 0.03646618 0.045729732
Standard Error 0.013807396 0.012155393 0.015243244p (t-test) 5.39629E�06 0.001972817
4.2. Result and discussions
The results of the evaluations of different case numbers areshown in Figs. 8–10 and Table 2. From the results, the proposedmethod KBICE has outperformed RBR and BoW in all the threemeasures (recall, precision, and F-measure), while the results ofRBR is similar to that of BoW model. The result showed that KBICEmaintain a high recall rate with different number of training cases,and similar precision rate against RBR and BoW.
A summary of evaluation results of all approaches with 937cases is provided in Table 3. From the results, we can see thatthe proposed method KBICE has outperformed the other threemethodologies in all the three measures. High recall rate alwayssacrifices with low precision rate. It is interesting to note thatKBICE has a higher recall rate (around 0.8) against RBR and BoW(around 0.5), but KBICE continues to maintain a higher precision
rate (around 0.33) against RBR (around 0.29) and BoW (around0.3).
Different statistical analysis and a series of student’s t-testswere conducted to compare the recall, precision and F-measureof different case numbers (i.e. 100, 200, 300, 400, 500, 600, 700,800 and 900) in RBR and BoW with those in the proposed method,respectively. The results are shown in Table 4. Based on the results,one can see that nearly all the measures of the proposed approachwere significantly better than those of the other approaches(p < 0.05). The exception is the comparison of precision in BoWwith the proposed approach. The result shows that the precisionof proposed approach is not significantly better than that of BoW

E. Tsui et al. / Expert Systems with Applications 41 (2014) 1315–1325 1323
(p = 0.136). However, the mean of precision of the proposed ap-proach is better than that of BoW.
To summarize, the proposed method enables the extraction ofIC-related information and improves the performance of the exist-ing algorithms. Traditional methods extract the information bysearching for lexico-syntactic patterns among the given docu-ments. The proposed approach applies further inferencing amongthe extracted patterns so as to deduce some hidden IC-relatedinformation. The proposed approach can also be used as an auto-matic tool for suggesting new patterns thereby further improvingthe extraction process.
On the other hand, several limitations need to be overcome andcautions are needed in future work. Similar to other research intext analysis, KBICE also requires tedious pre-processing workand data cleansing. Furthermore, in this research there was anassumption of similar writing style being adopted from year toyear in reports from the same industry. Although the learningmechanism of KBICE can improve the performance of the extrac-tion process, it still requires human intervention to review the sug-gestion of the system and provide feedback to the system. In futurework, the method should be also extended to different domainsand data sets in order to find out more about the scope, limitations,and/or optimal point of the method. The knowledge repositoryshould maintain plenty of representative and rare case types. Bydoing so, the system can help to record and retrieve cases whichrequire different extraction strategies.
Another limitation of the paper is that the experiment was justdone with annual reports. Many other reports can also be explored.For example, IPO prospectus, sustainability report, announcementand company website etc. The rich IC information in these reportshas greater impact on the capital market. Besides reports, nowa-days, internal and external social media are also commonly usedas an important management tool (for marketing, communications,brand building purposes). Such data may well contain IC-relatedinformation or even information that can predict changes in IC.
5. Conclusions
The identification of an organization’s IC is important to provideinsights on management action. This often relates to the goal ofenhancing the transparency of the concerned organization andbenefits both internal stakeholders and external investors and ben-eficiaries. Traditional approaches based on manually methodsthrough interviews, surveys, workshops. These methods rely heav-ily on manpower, which are time consuming and costly. This paperpresents a Knowledge-based Intellectual Capital Extraction (KBICE)algorithm which allows for automatic extraction of important ICrelated information from massive amount of unstructured data.
In the present study, the capability and advantages of the KBICEare demonstrated through a successful pilot test conducted in
Appendix A
Examples of rule set.
ICcategory
IC element Key phrases
HC Employee diversity Women %RC Customer communication (eg.
Telephone Platform, Internet)Member receiving a pens
RC Customer relationships Number of attendees in m
banking industry. Public financial reports were analyzed to extractthe IC related information. According to the results, it is shown thatit is possible for extracting IC related information from unstruc-tured data automatically and a high recall rate is achieved. Withthe use of this method, the time, the cost and the workload onidentification of an organization’s IC could be significantly reduced.The present study contributes to the advancement of methods andtools for managing IC related information. With appropriate cus-tomization of KBICE, it can be further applied in other industryfor IC analysis.
6. Managerial implication
With the growing awareness about the importance of IC, orga-nizations are starting to define, track, measure and report on thegrowth of IC. While no doubt many of the IC elements may be un-ique to organizations and as such, they need to be defined and spe-cifically sourced, organizations nevertheless do not need to startfrom scratch. Assuming an organization is routinely reporting onits performance hence generating various types of company re-ports, the automated technique outlined in this paper can beadapted and used to identify and extract information related tothose commonly defined IC elements. The derivation of the IC ele-ments by the IC analyst in this research is based on seminal IC pub-lications as well as a highly representative set of IC reportspublished by banks in the last decade. IC management and report-ing is still at an infancy stage in the business world but it is ex-pected that organizations can rely on IC to
1. Align corporate objective with business strategy and in par-ticular identifying the growth in IC and progress towardsaccomplishment of defined goals with regard to corporateinvestments
2. Track, grow and make refinements to any value creationprocess
3. Communicate the ‘‘hidden potential’’ of an organization tovarious stakeholders, internal and external; and
4. Analyze and predict the fluctuations in various elements ofIC based on past data, events and activities. Doing so canhelp an organization to avert a crisis or reduce the impactof an undesired incident
Some organizations indeed are already leveraging IC for one ormore of the above strategies (Gu, 2012).
Acknowledgment
The work described in this paper was fully supported by a grantfrom the Research Grants Council of the Hong Kong Special Admin-istrative Region, China (Project No. 529210). Many thanks are also
Patterns
Employee, womenion Receive a pension
embership meeting Held open meeting, meeting, number ofparticipant
(continued on next page)

(continued)
ICcategory
IC element Key phrases Patterns
RC Customer relationships ATP-Pensioners receiving current pension Pensioners, received current pensionRC Customer communication (eg.
Telephone Platform, Internet)Number of attendees in membership meeting Member, participated, membership
meetingRC Customers, image and
stakeholdersATP-Pensioners receiving current pension Member paid contributions
RC Customer communication (eg.Telephone Platform, Internet)
Number of attendees in membership meeting Members attended, information meeting
RC Quality and customersatisfaction
Proportion of satisfied/very satisfiedattendees in membership meeting
Attendees, satisfied
SC Quality of pension summaries Customers find the summary to be written inan easy-to-understand language
Members find the pension summaries,written in an easy-to-understandlanguage
HC Staff turnover Departed employees (staff turnover) Staff reductionHC Employee flexibility Number of employees people, workingHC Employee flexibility Number of employees Originators of ideasHC Employee flexibility Number of employees Total, staffRC Corporation and networks Number of SME Management Centres SME segment, number of these branchesRC Corporation and networks Number of SME Management Centres New centre specialising in SMEs, total,
such centreHC Training (Competence
development)Total number of courses taught Workforce, receive training, total, courses
HC Training (Competencedevelopment)
Average number of training hours peremployee trained
Training hours, per employee trained
RC Corporation and networks Number of SME Management Centres Total number of SME branchesRC RC upgrouped Transactions through channels other than
branch network as % of total banktransactions
%, transaction, remote channel
SC Quality management andimprovements
Number of quality projects and initiativescarried out
Quality, improvement project, started
1324 E. Tsui et al. / Expert Systems with Applications 41 (2014) 1315–1325
due to Miss Carrie M.Y. Cheung and Mr. Matthew K.K. Cheung fortheir technical support in the research work.
References
Aamodt, A., & Plaza, E. (1994). Case-based reasoning: Foundational issues.Methodological Variations, and System Approaches Artificial IntelligenceCommunications, 7(1), 39–52.
Abdolmohammadi, M. J. (2005). Intellectual capital disclosure and marketcapitalization. Journal of Intellectual Capital of Intellectual Capital, 6(3), 397–416.
Abeysekera, I. (2006). The project of intellectual capital disclosure: Researching theresearch. Journal of Intellectual capital, 7(1), 61–77.
Abiteboul, S. (1997). Querying semi-structured data. In Proceedings of sixthinternational conference of database theory (pp. 1–18).
Althoff, K.-D., Birk, A., von Wangenheim, C. G., & Tautz, C. (1998). CBR forexperimental software engineering. Case-Based Reasoning Technology, 1998,235–254.
Bartley, J. W., Chen, Y. A., & Taylor, E. Z. (2010). A comparison of XBRL filings tocorporate 10-Ks – evidence from the voluntary filing program. Available atSSRN: <http://ssrn.com/abstract=1397658> or <http://dx.doi.org/10.2139/ssrn.1397658>.
Beattie, V., & Thomson, S. J. (2007). Lifting the lid on the use of content analysis toinvestigate intellectual capital disclosures. Accounting Forum, 31(2), 129–163.
Bontis, N. (2003). Intellectual capital disclosure in Canadian Corporations. Journal ofHuman Resource Costing and Accounting, 7(1), 9–20.
Bose, R. (2004). Knowledge management metrics. Industrial Management and DataSystems, 104(6), 457–468.
Bozzolan, S., Favotto, F., & Ricceri, F. (2003). Italian annual intellectual capitaldisclosure: An empirical analysis. Journal of Intellectual Capital, 4(4), 543–558.
Brooking, A. (1996). Intellectual capital: Core assets for the third millennium enterprise.London: Thomson Business Press, London.
Bukh, P. N., Nielsen, C., Gormsen, P., & Mouritsen, J. (2005). Disclosure ofinformation on intellectual capital in Danish IPO prospectuses. AccountingAuditing and Accountability Journal, 18(6), s713–s732.
Chang, C. L. (2005). Using case-based reasoning to diagnostic screening of childrenwith developmental delay. Expert Systems with Applications, 28(2005), 237–247.
Cheung, C. F., Chan, Y. L., Kwok, S. K., Lee, W. B., & Wang, W. M. (2006). A knowledge-based service automation system for service logistics. Journal of ManufacturingTechnology Management, 17(6), 750–771.
Cheung, C. F., Lee, W. B., & Wang, Y. (2005). A multi-facet taxonomy system withapplications in unstructured knowledge management. Journal of KnowledgeManagement, 9(6), 76–91.
Cheung, C. F., Lee, W. B., Wang, W. M., Chu, K. F., & To, S. (2003). A multi-perspectiveknowledge-based system for customer service management. Expert Systemswith Applications, 24(4), 457–470.
Chu, H. C., Chen, T. Y., Lin, C. J., Liao, M. J., & Chen, Y. M. (2009). Development of anadaptive learning case recommendation approach for problem-based e-learningon mathematics teaching for students with mild disabilities. Expert Systems withApplications, 36(3), 5456–5468.
Cinquini, L., Passetti, E., Tenucci, A., & Frey, M. (2012). Analyzing intellectual capitalinformation in sustainability reports: some empirical evidence. Journal ofIntellectual Capital, 13(4), 531–561.
Edvinsson, L., & Malone, M. S. (1997). Intellectual capital: Realizing your company’strue value by finding its hidden brainpower. New York: Harper Business.
Grant, R. (1996). Toward a knowledge-based theory of the firm. StrategicManagement Journal, 17, 109–122. Winter Special Issue.
Gu, J. (2012). Development of an intellectual capital driven knowledge auditmethodology for managing unstructured information. Hong Kong: The HongKong Polytechnic University.
Guthrie, J., Petty, R., & Wells, R. (1999). There is no accounting for intellectual capitalin Australia: A review of annual reporting practices and internal measurementof intangibles. In OECD symposium on measuring and reporting of intellectualcapital, Amsterdam.
Guthrie, J., & Petty, R. (2000). Intellectual capital: Australian annual reportingpractices. Journal of Intellectual Capital, 1(3), 241–251.
Guthrie, J., Petty, R., Yongvanich, K., & Ricceri, F. (2004). Using content analysis as aresearch method to inquire into intellectual capital reporting. Journal ofIntellectual Capital, 5(2), 282–293.
Joshi, M., Cahill, D., Sidhu, J., & Kansal, M. (2013). Intellectual capital and financialperformance: An evaluation of the Australian financial sector. Journal ofIntellectual Capital, 14(2), 264–285.
Khavandkar, J., & Khavandkar, E. (2009). Intellectual capital: Managing, developmentand measurement models. Iran Ministry of Science: Research and TechnologyPress.

E. Tsui et al. / Expert Systems with Applications 41 (2014) 1315–1325 1325
Kolodner, J. (1993). Case-based reasoning. San Mateo, CA: Morgan KaufmannPublishers.
Lee, L. L., & Guthrie, J. (2010). Visualizing and measuring the intellectual capital incapital markets: Research method. Journal of Intellectual Capital, 11(1), 4–22.
Lua, W.-M., Wang, W.-K., & Kweh, Q. L. (2014). Intellectual capital and performancein the Chinese life insurance industry. Omega, 42(1), 65–74.
Maeques, D. P., Simon, F. J., & Caranana, C. D. (2006). The effect of innovation onintellectual capital: An empirical evaluation in the biotechnology andtelecommunication industries. International Journal of Innovation Management,10(1), 89–112.
Magrassi, P. (2002). A taxonomy of intellectual capital, Research Note COM-17-1985, Gartner.
Oliverira, E., Gowthorpe, C., Kasperskaya, Y., & Perramon, J. (2008). Reportingintellectual capital in Spain. Corporate Communications: An International Journal,13(2), 168–181.
O’Riaina, S., Currya, E., & Harth, A. (2012). XBRL and open data for global financialecosystems: A linked data approach. International Journal of AccountingInformation Systems, 13(2), 141–162.
Pandey, S. C., & Dutta, A. (2013). Role of knowledge infrastructure capabilitiesin knowledge management. Journal of Knowledge Management, 17(3),435–453.
Phusavat, K., Comepa, N., & Sitko-Lutek, A. (2013). Productivity management:Integrating the intellectual capital. Industrial Management and Data Systems,113(6), 840–855.
Richter, M. M. (2009). The search for knowledge, contexts, and case-basedreasoning. Engineering Applications of Artificial Intelligence, 22(1), 3–9.
Schmid, H. (1994). Probabilistic part-of-speech tagging using decision trees. InProceedings of the international conference on new methods in language processing(pp. 44–49). Manchester, UK.
Schmidt, R., Montani, S., Bellazzi, R., Portinale, L., & Gierl, L. (2001). Cased-basedreasoning for medical knowledge-based systems. International Journal ofMedical Informatics, 64(2001), 355–367.
Schneider, A., & Samkin, G. (2008). Intellectual capital reporting by the New Zealandlocal government sector. Journal of Intellectual Capital, 9(3), 456–486.
Sivic, J. (2009). Efficient visual search of videos cast as text retrieval. IEEETransactions on Pattern Analysis and Machine Intelligence, 31(4), 591–605.
Spender, J.-C. (1996). Making knowledge the basis of a dynamic theory of the firm.Strategic Management Journal, 17(S2), 45–62.
Stewart, T.A. (1997). Intellectual capital. The New Wealth of Organisations,Doubleday – Currency, London.
Subramaniam, M., & Youndt, M. A. (2005). The influence of intellectual capital onthe types of innovative capabilities. Academy of Management Journal, 48(3),450–463.
Sveiby, K. E. (1997). The intangible asset monitor. Journal of Human Resource Castingand Accounting, 2(1), 71–97.
Vasarhelyi, M. A., Chan, D. Y., & Krahel, J. P. (2012). Consequences of XBRLstandardization on financial statement data. Journal of Information Systems:Spring 2012, 26(1), 155–167.
Wang, W. K. (2005). A knowledge-based decision support system for measuring theperformance of government real estate investment. Expert Systems withApplications, 29(4), 901–912.
Wang, W. M., Cheung, C. F., Lee, W. B., & Kwok, S. K. (2007). Knowledge-basedtreatment planning for adolescent early intervention of mental healthcare: Ahybrid case-based reasoning approach. Expert Systems, 24(4), 232–251.
Waters, J.K. (2005). Managing unstructured information, application developmenttrends articles. Available at: <http://www.adtmag.com/article.aspx?id=10542&page=>. (Accessed June 2nd, 2005).
Weber, R., & Aha, D. W. (2003). Intelligent delivery of military lessons learned.Decision Support Systems, 34(3), 287–304.
Weber, R., Aha, D. W., & Becerra-Fernandez, I. (2001). Intelligent lessons learnedsystems. Expert Systems with Applications, 20(1), 17–34.
Whiting, R. H., & Miller, J. C. (2008). Voluntary disclosure of intellectual capital inNew Zealand annual reports and the ‘‘hidden value’’. Journal of Human ResourceCosting and Accounting, 12(1), 26–50. http://dx.doi.org/10.1108/14013380810872725.
Yim, B., & Leem, B. (2013). The effect of the supply chain social capital. IndustrialManagement and Data Systems, 113(3), 324–349.
Yin, R. K. (2003). Case study research: Design and methods. Thousand Oaks, CA: Sage.Website: ATP, <http://www.atp.dk>.Website: BBVA, <http://www.bbva.com>.Website: Oesterreichische NationalBank, <http://www.oenb.at>.Website: Bankinter, <https://webcorporativa.bankinter.com>.




















