
KIỂM DUYỆT BÀI VIẾT VÀ BÌNH LUẬN TIẾNG VIỆT CÓ NỘI ...
89
ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ BÙI VĂN MINH KIỂM DUYỆT BÀI VIẾT VÀ BÌNH LUẬN TIẾNG VIỆT CÓ NỘI DUNG KHÔNG PHÙ HỢP TRÊN MẠNG XÃ HỘI FACEBOOK LUẬN VĂN THẠC SĨ AN TOÀN THÔNG TIN Hà Nội, tháng 12/2021
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of KIỂM DUYỆT BÀI VIẾT VÀ BÌNH LUẬN TIẾNG VIỆT CÓ NỘI ...

ĐẠI HỌC QUỐC GIA HÀ NỘI
TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
BÙI VĂN MINH
KIỂM DUYỆT BÀI VIẾT VÀ BÌNH LUẬN TIẾNG VIỆT
CÓ NỘI DUNG KHÔNG PHÙ HỢP TRÊN
MẠNG XÃ HỘI FACEBOOK
LUẬN VĂN THẠC SĨ AN TOÀN THÔNG TIN
Hà Nội, tháng 12/2021

2
ĐẠI HỌC QUỐC GIA HÀ NỘI
TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
BÙI VĂN MINH
KIỂM DUYỆT BÀI VIẾT VÀ BÌNH LUẬN TIẾNG VIỆT
CÓ NỘI DUNG KHÔNG PHÙ HỢP TRÊN
MẠNG XÃ HỘI FACEBOOK
Ngành: Công nghệ thông tin
Chuyên ngành: An toàn thông tin
Mã số: 8480202.01
LUẬN VĂN THẠC SĨ AN TOÀN THÔNG TIN
NGƯỜI HƯỚNG DẪN KHOA HỌC: TS. Lê Đình Thanh
Hà Nội, tháng 12/2021

3
LỜI CAM ĐOAN
Tôi cam đoan rằng, luận văn “Kiểm duyệt bài viết và bình luận tiếng Việt
có nội dung không phù hợp trên mạng xã hội Facebook” là công trình nghiên
cứu của riêng tôi. Những số liệu được sử dụng trong luận văn là trung thực được
chỉ rõ nguồn trích dẫn. Kết quả nghiên cứu này chưa được công bố trong bất kỳ
công trình nghiên cứu nào từ trước đến nay.
Tôi hoàn toàn chịu trách nhiệm với lời cam đoan của mình.
Hà Nội, ngày tháng 12 năm 2021
Người cam đoan
Bùi Văn Minh

4
LỜI CẢM ƠN
Để hoàn thành luận văn này, ngoài sự cố gắng của bản thân, tôi đã nhận
được sự giúp đỡ của nhiều tập thể, cá nhân trong và ngoài trường.
Tôi xin bày tỏ lòng biết ơn đến TS. Lê Đình Thanh đã luôn tận tình hướng
dẫn, động viên tôi thực hiện luận văn này.
Tôi xin bày tỏ lòng biết ơn tới các quý thầy cô Ngành An toàn thông tin,
Khoa Công nghệ Thông tin nói riêng và trong Trường Đại học Công nghệ -
ĐHQGHN nói chung đã tạo điều kiện tốt nhất cho tôi trong quá trình học tập,
nghiên cứu và hoàn thiện luận văn này.
Cuối cùng, tôi xin cảm ơn gia đình, đồng nghiệp, bạn bè, người thân đã
động viên, khích lệ tôi trong quá trình học tập và nghiên cứu.
Mặc dù bản thân đã có rất nhiều cố gắng nhưng luận văn không tránh khỏi
những khiếm khuyết, hạn chế. Vì vậy, tôi rất mong được sự góp ý chân thành
của quý thầy cô, đồng nghiệp và bạn đọc để luận văn được hoàn thiện hơn.
Xin trân trọng cảm ơn!
Hà Nội, tháng 12 năm 2021
Tác giả luận văn
Bùi Văn Minh

5
MỤC LỤC
LỜI CAM ĐOAN .................................................................................................. 3
LỜI CẢM ƠN ....................................................................................................... 4
MỤC LỤC ............................................................................................................. 5
DANH SÁCH CÁC HÌNH ................................................................................... 7
DANH SÁCH CÁC BẢNG ................................................................................ 10
DANH SÁCH CHỮ VIẾT TẮT ......................................................................... 11
LỜI MỞ ĐẦU ..................................................................................................... 12
CHƯƠNG 1: CƠ SỞ KHOA HỌC .................................................................... 14
1.1. Nội dung phản động trên Facebook ......................................................... 14
1.2. Tác hại của nội dung phản động trên Facebook ...................................... 17
1.3. Kiểm duyệt nội dung phản động trên Facebook ...................................... 19
1.4. Mục tiêu nghiên cứu của luận văn ........................................................... 20
1.5. Cấu trúc của luận văn ............................................................................... 21
CHƯƠNG 2: ĐỀ XUẤT PHƯƠNG PHÁP ....................................................... 23
2.1. Danh sách đen .......................................................................................... 23
2.1.1. User Facebook phản động ................................................................... 23
2.1.2. Fanpage Facebook phản động............................................................. 24
2.1.3. Group Facebook phản động ................................................................ 24
2.1.4. Website, blog phản động .................................................................... 24
2.2. Phương pháp học máy .............................................................................. 25
2.2.1. Trích chọn đặc trưng nội dung phản động .......................................... 25
2.2.2. Mô hình, thuật toán phân loại phổ biến .............................................. 39
2.3. Sử dụng Hệ số tương quan Matthews ...................................................... 44
CHƯƠNG 3: CÀI ĐẶT THỬ NGHIỆM ........................................................... 46
3.1. Mô hình kiểm duyệt nội dung phản động ................................................ 46
3.2. Xây dựng các blacklist phản động ........................................................... 47
3.3. Xây dựng tập dữ liệu mẫu ........................................................................ 51
3.3.1. Thu thập dữ liệu .................................................................................. 51
3.3.2. Gán nhãn dữ liệu ................................................................................. 54
3.4. Xây dựng bộ từ điển phản động ............................................................... 55
3.5. Xây dựng vector đặc trưng ....................................................................... 56

6
3.6. Các mô hình thử nghiệm .......................................................................... 58
3.6.1. SVM-3f ............................................................................................... 59
3.6.2. SVM-2f ............................................................................................... 60
3.6.3. MLP-2f ................................................................................................ 60
3.6.4. MLP-3f ................................................................................................ 61
3.6.5. SVM-BERT ........................................................................................ 61
3.6.6. MLP-BERT ......................................................................................... 62
CHƯƠNG 4: KẾT LUẬN VÀ HƯỚNG PHÁT TRIỂN ................................... 72
4.1. Kết luận .................................................................................................... 72
4.2. Hướng phát triển ...................................................................................... 72
TÀI LIỆU THAM KHẢO .................................................................................. 74
PHỤ LỤC............................................................................................................ 78
Mục 1: Trích xuất dữ liệu bình luận vào CSDL ............................................. 78
Mục 2: Xây dựng vector đặc trưng ................................................................. 78
Mục 3: Một số kết quả thực nghiệm ............................................................... 85
Mục 4: Kiểm duyệt nội dung phản động trên Facebook ................................. 88

7
DANH SÁCH CÁC HÌNH
Hình 2.1: Quy trình NLP ..................................................................................... 26
Hình 2.2. Kết quả thử nghiệm các mô hình phân loại văn bản tiếng Việt của
nhóm Underthesea ............................................................................................... 32
Hình 2.3. Kiến trúc mô hình BERT ..................................................................... 34
Hình 2.4. Mô hình chung của Word2Vec ............................................................ 38
Hình 2.5. Support Vectors trong SVM ................................................................ 41
Hình 2.6. Margin trong SVM .............................................................................. 41
Hình 2.7: Cấu tạo mạng MLP cơ bản ................................................................. 43
Hình 2.8: Sử dụng mô hình MLP cho bài toán phân loại văn bản ..................... 43
Hình 3.1: Mô hình kiểm duyệt 02 lớp đối với bài viết, bình luận phản động ..... 46
trên Facebook ...................................................................................................... 46
Hinh 3.2: Minh họa thu thập bài viết bằng Selenium ......................................... 52
Hinh 3.3: Minh họa thu thập bình luận bằng Selenium ...................................... 53
Hinh 3.4: Mẫu dữ liệu bài viết thu thập được ..................................................... 54
Hình 3.5: Mẫu dữ liệu bình luận thu thập được ................................................. 54
Hình 3.6: Mẫu dữ liệu bình luận sau khi được gán nhãn ................................... 55
Hình 3.7: Danh sách từ điển phản động đã xây dựng ........................................ 56
Hình 3.8: Tham số C tốt nhất .............................................................................. 59
Hình 3.9: Kết quả thử nghiệm bộ vector đặc trưng bao gồm Blacklist word phản
động, hình thái, n-gram với thuật toán SVM ...................................................... 60
Hình 3.10: Kết quả thử nghiệm bộ vector đặc trưng bao gồm Blacklist word
phản động, hình thái với thuật toán SVM ........................................................... 60
Hình 3.11: Kết quả huấn luyện bộ vector đặc trưng bao gồm Blacklist word
phản động và hình thái với mô hình MLP ........................................................... 60
Hình 3.12: Kết quả huấn luyện bộ vector đặc trưng bao gồm Blacklist word
phản động, hình thái và n-gram với mô hình MLP ............................................. 61
Hình 3.13: Kết quả huấn luyện mô hình sử dụng pretrained PhoBERT kết hợp
với thuật toán SVM .............................................................................................. 61
Hình 3.14: Kết quả huấn luyện mô hình sử dụng pretrained PhoBERT kết hợp
với mô hìnhMLP .................................................................................................. 62

8
Hình 3.15: Kết quả thực nghiệm các mô hình .................................................... 62
Hinh 3.16: Cấu trúc thư mục extension .............................................................. 64
Hinh 3.17: File manifest.json .............................................................................. 64
Hình 3.18: Giao diện extension Chrome ............................................................ 66
Hinh 3.19: Cài đặt extension thành công ........................................................... 66
Hinh 3.20: Trước khi sử dụng extension ............................................................. 67
Hình 3.21: Extension chặn các nhóm độc hại, chống phá .................................. 68
Hình 3.22: Extension chặn các người dùng có hành vi phản động .................... 68
Hình 3.23: Extension chặn các trang mạng có hành vi phản động .................... 69
Hinh 3.24: Kết quả hoạt động của extension trên bài viết ................................. 69
Hinh 3.25: Sau khi hiện ra bài viết bi ân (bài viết sẽ vẫn bi làm mờ). ............... 70
Hinh 3.26: Kết quả hoạt động của extension trên bình luận .............................. 71
Hinh 3.27: Sau khi hiện ra binh luận bi ân. ........................................................ 71
Hinh 3.28: Code tách comment json bằng Python.............................................. 78
Hình 3.29: Mã nguồn đọc bộ dữ liệu bao gồm 20.000 bài viết, bình luận trên
Facebook từ nhiều user, fanpage, group khác nhau. .......................................... 78
Hình 3.30: Mẫu dữ liệu sử dụng cho huấn luyện và kiểm tra mô hình .............. 79
Hình 3.31: Mã nguồn tính toán độ phản động của các bài viết, bình luận ........ 79
Hình 3.32: Hàm tính toán tỉ lệ ký tự viết hoa trong bình luận, bài viết ............. 80
Hinh 3.33: Hàm tính độ dài bài viết ................................................................... 80
Hình 3.34: Hàm tính tần suất sử dụng các ký tự không phải alphabet .............. 80
Hình 3.35: Hàm tính tần suất sử dụng các ký tự đặc biệt................................... 81
Hinh 3.36: Hàm tính độ dài trung bình các từ .................................................... 81
Hình 3.37: Hàm tính tần suất sử dụng các từ viết tắt ......................................... 82
Hình 3.38: Sử dụng bigram và trigram mức ký tự cho bài viết, bình luận. ........ 82
Hinh 3.39: Đặc trưng về độ phản động .............................................................. 83
Hinh 3.40: Đặc trưng về hình thái ...................................................................... 83
Hinh 3.41: Đặc trưng n-gram ............................................................................. 83
Hình 3.42: Phân chia dữ liệu và tính toán vector đặc trưng .............................. 83
Hình 3.43: Thuật toán GridSearchCV tìm tham số C tối ưu .............................. 84
Hình 3.44: Load pretrained PhoBERT model và tiền xử lý văn bản .................. 84
Hình 3.45: Tạo features từ PhoBert .................................................................... 85

9
Hình 3.46: Kết quả huấn luyện SVM-3f .............................................................. 86
Hình 3.47: Kết quả huấn luyện SVM-2f .............................................................. 86
Hình 3.48: Kết quả huấn luyện MLP-2f .............................................................. 86
Hình 3.49: Kết quả huấn luyện MLP-3f .............................................................. 87
Hình 3.50: Kết quả huấn luyện SVM-BERT ....................................................... 87
Hình 3.51: Kết quả huấn luyện MLP-BERT ....................................................... 87
Hình 3.52: Mã nguồn Server backend ................................................................ 88
Hình 3.53: Kiểm tra sự xuất hiện của các đường link URL đến website, blog
phản động trong nội dung bài viết, bình luận trên Facebook. ........................... 89
Hình 3.54: Một số thẻ div được sử dụng để lấy thông tin từ bài viết, bình luận 89

10
DANH SÁCH CÁC BẢNG
Bảng 3.1: Danh sách một số user Facebook phản động .................................... 47
Bảng 3.2: Danh sách một số fanpage Facebook phản động .............................. 48
Bảng 3.3: Danh sách một số group Facebook phản động .................................. 49
Bảng 3.4: Danh sách một số website, blog phản động ....................................... 50

11
DANH SÁCH CHỮ VIẾT TẮT
CH-CĐCT Cơ hội, chống đối chính trị
CNN Convolution Neural Network
DOM Document Object Model
Extension Thành phần mở rộng
Layer Tầng
MXH Mạng xã hội
MLP Multi-layer Perceptron
MCC Matthews Correlation Coefficient
NLP Natural Language Processing
URL Uniform Resource Locator
SVM Support Vetor Machines

12
LỜI MỞ ĐẦU
Facebook là một website mạng xã hội (MXH) truy cập miễn phí do Công ty
Facebook, Inc điều hành và sở hữu tư nhân. Người dùng có thể tham gia các
mạng lưới được tổ chức theo thành phố, nơi làm việc, trường học và khu vực để
liên kết và giao tiếp với người khác. Hiện nay, Facebook là MXH có số lượng
người sử dụng nhiều nhất, với khoảng 2,8 tỷ người dùng hàng tháng và 1,84 tỷ
người dùng hàng ngày (số liệu tháng 12/2020) [1]. Trong đó, Việt Nam xếp thứ
7 trong top 10 quốc gia sử dụng MXH Facebook đông nhất thế giới, với 69,28
triệu người dùng (số liệu tháng 6/2020) [2].
Về mặt tích cực, MXH Facebook đang là công cụ truyền thông phổ biến và
gần gũi với mọi người, đặc biệt là giới trẻ; cho phép kết nối người dùng trên
khắp thế giới tới gần nhau hơn; mang đến cho người dùng nhiều tính năng vượt
trội, hiện đại, đáp ứng nhu cầu giao tiếp trong xã hội như: Trò chuyện, xem
phim ảnh, nhật kí cá nhân, thành lập hội nhóm, tìm kiếm thông tin, kinh doanh
trực tuyến…
Qua quá trình nghiên cứu, tìm hiểu về MXH Facebook, tôi nhận thấy rằng,
bên cạnh những nội dung tích cực, cũng có rất nhiều những nội dung tiêu cực,
không phù hợp trên Facebook, như: Các nội dung về bạo hành/đe dọa trực tuyến
(cyberbullying), nội dung về lời nói căm thù (hate speech), nội dung ngôn ngữ
xúc phạm (offensive language), nội dung tin giả, tin đầu độc, nội dung phản
động… thuộc các thể loại, lĩnh vực khác nhau, như: Chính trị, sắc tộc, tôn giáo,
giới tính, khủng bố,… Để kiểm duyệt tất cả các thể loại nội dung không phù hợp
thuộc các lĩnh vực khác nhau trên MXH Facebook là điều rất khó. Trong giới
hạn phạm vi nghiên cứu của luận văn, tôi chọn một chủ đề nghiên cứu nhỏ
hơn là về nội dung phản động trong lĩnh vực chính trị, nhằm làm nổi bật về
phương pháp, cách thức trong kiểm duyệt các nội dung không phù hợp trên
MXH Facebook, từ đó có thể làm nền tảng để áp dụng trên các MXH khác.
Việc nghiên cứu các nội dung liên quan đến vấn đề chính trị mặc dù rất
nhạy cảm, ít người làm, nhưng tôi vẫn lựa chọn là bởi vì: Thực trạng hiện nay,
nhiều đối tượng xấu đã và đang lợi dụng MXH Facebook để tuyên truyền, kích
động bạo lực, chiến tranh, gây thù hằn dân tộc, đòi lật đổ chế độ; xúc phạm nhân
phẩm, bôi nhọ danh dự cá nhân, tổ chức; chia rẽ dân tộc tôn giáo;… Tại Việt
Nam, nhiều đối tượng cơ hội, chống đối chính trị (CH-CĐCT) ở trong và ngoài
nước đã và đang sử dụng Facebook để tạo lập, kêu gọi nhiều đối tượng khác

13
tham gia các trang cộng đồng (fanpage), hội/nhóm (group) chống đối chính trị,
như: Việt Tân, Nhật ký yêu nước, VOA Tiếng Việt, Đài Á Châu Tự Do, BBC
News Tiếng Việt, Quân Đội Việt Nam Cộng Hòa,… Bên cạnh đó, nhiều đối
tượng tinh vi hơn còn lập ra rất nhiều fanpage núp dưới những tên gọi nghiêm
túc, chính thống, như: “Đảng Cộng sản Việt Nam Vinh quang”, hay trang “Nhật
ký tin tức thể hiện lòng yêu nước”… để đăng tải những thông tin xuyên tạc, bịa
đặt về tình hình chính trị ở Việt Nam, xen vào những nội dung phản động, chống
phá Đảng, Nhà nước rất quyết liệt [3]. Với nhiều thủ đoạn khác nhau, các đối
tượng này tập trung tuyên truyền, xuyên tạc chủ trương, đường lối của Đảng,
chính sách và pháp luật của Nhà nước; chống phá, đòi lật đổ chế độ XHCN; mạo
danh, nói xấu các lãnh đạo cấp cao của Đảng, Nhà nước…
Việc đăng tải, tán phát các bài viết, bình luận có nội dung phản động,
chống phá trên MXH Facebook đã trở thành vấn đề nhức nhối nhiều năm qua.
Các cơ quan chức năng của Nhà nước Việt Nam cũng đã đề ra những quy định
nghiêm ngặt nhằm hạn chế việc sử dụng các nền tảng MXH trực tuyến để tuyên
truyền chống phá Đảng, Nhà nước, chế độ. Tuy nhiên, việc theo dõi, giám sát,
phát hiện và xử lý các đối tượng lợi dụng MXH Facebook để tuyên truyền,
chống phá Đảng, Nhà nước vẫn còn nhiều hạn chế nhất định cả về con người,
phương tiện, cũng như cơ chế hợp tác của nhà phát triển Facebook với Chính
phủ Việt Nam.Vì vậy, rất cần có một giải pháp công nghệ để hỗ trợ để phát hiện
và kịp thời ngăn chặn các thông tin phản động đến với người dùng Facebook.
Luận văn được thực hiện với mục tiêu nghiên cứu giải pháp phát hiện, loại
bỏ bài viết và bình luận tiếng Việt có nội dung phản động trước khi tiếp cận đến
các người dùng Facebook. Trong toàn bộ nội dung của luận văn, tôi sẽ tập trung
làm rõ thế nào là các nội dung phản động và phương pháp để phát hiện, kiểm
duyệt các nội dung phản động trước khi tiếp cận người dùng.
Luận văn của tôi tập trung nghiên cứu cơ sở lý thuyết về xử lý ngôn ngữ tự
nhiên (NLP-Natural Language Processing); các thuật toán học máy, mô hình
mạng nơ-ron nhân tạo áp dụng cho phát hiện nội dung phản động như SVM
(Support Vector Machine), MLP (Multi-layer Perceptron) và các phương pháp
trích trọn đặc trưng của bài viết và bình luận tiếng Việt có nội dung phản động
trên Facebook. Luận văn đã phát triển một mô-đun dịch vụ phát hiện nội dung
phản động trong bài viết và bình luận tiếng Việt trên MXH Facebook. Với mô-
đun này, các bài viết, bình luận tiếng Việt có nội dung phản động sẽ được kiểm
duyệt và ẩn khỏi trang Facebook của người dùng.

14
CHƯƠNG 1: CƠ SỞ KHOA HỌC
1.1. Nội dung phản động trên Facebook
Trong những năm gần đây, sự ra đời, phát triển của internet và MXH đã
thay đổi một cách đáng kể cách sống, suy nghĩ và hành động của người dân trên
toàn thế giới, đặc biệt là giới trẻ. Ở Việt Nam, Facebook là MXH được sử dụng
nhiều nhất và đã trở thành một phần không thể thiếu trong cuộc sống hiện đại.
Nhờ có MXH nói chung và Facebook nói riêng, không thể phủ nhận rằng, nếu
sử dụng một cách hợp lý và đúng đắn nó mang lại những lợi ích to lớn. Đầu tiên
phải kể đến giúp con người dễ dàng chia sẻ, trao đổi thông tin với nhau thông
qua việc nhắn tin, trò chuyện trực tuyến, chia sẻ âm thanh, hình ảnh, bày tỏ cảm
xúc, bình luận..., mà không bị giới hạn về không gian và địa lý. Đặc biệt, tất cả
đều miễn phí, do vậy, giúp tiết kiệm tài chính và tạo điều kiện lí tưởng để kết nối
mọi người lại gần nhau hơn.
Các thông tin trên Facebook được cập nhật nhanh chóng theo thời gian
thực, từ những chia sẻ của cá nhân, gia đình, bạn bè, nhà trường cho đến những
sự kiện chính trị trong nước và trên thế giới. Qua đó, giúp người dùng nắm bắt
nhanh thông tin và xu thế phát triển của xã hội. Những nội dung thông tin được
đăng tải trên Facebook không chỉ đa dạng mà còn là kho kiến thức khổng lồ, góp
phần làm phong phú đời sống tinh thần, nâng cao nhu cầu hưởng thụ, trao đổi
thông tin trong xã hội. Thông qua những thông tin được đăng tải, chia sẻ dưới
dạng bài viết, hình ảnh, video cũng là cách mà mọi người thể hiện nhận thức và
hành động. Khi mà thông tin ngày càng trở thành nhân tố quan trọng trong việc
nắm bắt thời cơ, cơ hội để hợp tác và phát triển, thì những tiện ích mà Facebook
mang lại còn giúp cho kinh tế, xã hội ngày càng phát triển hơn thông qua các
hoạt động trao đổi, kinh doanh, buôn bán… góp phần làm phong phú hơn đời
sống vật chất và tinh thần của người dân.
Bên cạnh những mặt tích cực, MXH Facebook cũng tồn tại thực trạng xuất
hiện nhiều thông tin giả, thông tin xấu độc, đặc biệt là những thông tin phản
động, chống phá Đảng, Nhà nước ảnh hưởng tiêu cực đến tình hình kinh tế,
chính trị, văn hóa - xã hội, an ninh quốc phòng… của đất nước; đặt ra nguy cơ
mất an ninh chính trị, trật tự và an toàn xã hội.
Với đặc tính lan truyền nhanh, có khả năng mở rộng phạm vi tác động,
vượt qua rào cản ngôn ngữ, khoảng cách địa lý, gây tác hại trên diện rộng hơn
bất cứ hình thức chống phá nào khác của các thế lực thù địch, việc lợi dụng
MXH Facebook để tuyên truyền, xuyên tạc, chống phá Đảng, Nhà nước được

15
coi là thủ đoạn có tổ chức phổ biến hiện nay, có tính chất phức tạp và ngày càng
tinh vi.
Tại Việt Nam, để thực hiện âm mưu chống phá Đảng, Nhà nước, các tổ
chức phản động lưu vong cùng nhiều đối tượng CH-CĐCT trong và ngoài nước
đã lợi dụng chính sách quản lý còn lỏng lẻo của Facebook để tạo lập, kêu gọi
nhiều đối tượng tham gia các fanpage, group chống đối chính trị (cả group công
khai và group kín) để cùng trao đổi, bàn bạc các thủ đoạn tuyên truyền, chống
phá chính quyền, như: Việt Tân, Nhật ký yêu nước, Khối 8406, VOA Tiếng
Việt, Đài Á Châu Tự Do, BBC News Tiếng Việt, Quân Lực Việt Nam Cộng
Hòa… Thủ đoạn của các thế lực thù địch là lợi dụng các sự kiện chính trị nóng
của đất nước để tuyên truyền xuyên tạc chủ trương, đường lối của Đảng, chính
sách và luật pháp của Nhà nước. Bản chất của những thông tin có nội dung phản
động trên MXH Facebook là những thông tin bịa đặt, bóp méo sự thật, xuyên tạc
vấn đề, “đổi trắng, thay đen”, cố tình đưa tin với dụng ý xấu, phân tích và định
hướng dư luận bằng luận điệu thù địch. Các thông tin bị xuyên tạc thuộc đa dạng
các thể loại, chủ đề, lĩnh vực khác nhau, từ kinh tế, chính trị, văn hóa, ngoại
giao, an ninh - quốc phòng cho tới việc nói xấu tổ chức, lãnh đạo cấp cao của
Đảng, Nhà nước… Tất cả đều nhằm định hướng dư luận để chống phá Đảng,
Nhà nước, hòng lật đổ chế độ XHCN tại Việt Nam… Đáng chú ý, việc chống
phá sự lãnh đạo của Đảng Cộng sản Việt Nam là một trong những mục tiêu hàng
đầu thường được các thế lực thù địch nhắc tới mối khi tuyên truyền chống phá.
Hoạt động của các thế lực thù địch thường diễn ra dưới nhiều thủ đoạn tinh vi,
như: Lợi dụng sai sót nhỏ của chính quyền để thổi phồng vụ việc, vu cáo, đổ lỗi
cho sự lãnh đạo của Đảng, nhằm bôi nhọ, hạ thấp uy tín của Đảng; lợi dụng các
thành phần có dân trí thấp, dễ bị tác động, để kích động biểu tình, bạo loạn, làm
mất trật tự an ninh, an toàn xã hội… Điển hình như thời gian gần đây, trên MXH
xuất hiện rất nhiều thông tin sai lệch về công tác phòng, chống dịch Covid-19 tại
Việt Nam, như: “Từ 0h ngày 15/7, TP.HCM sẽ giới nghiêm người dân, ngưng
tất cả các ngành nghề, cấm người dân di chuyển ra ngoài”, “lãnh đạo TP.HCM
đã nhiễm Covid-19”, hay bức ảnh nhiều thi thể nạn nhân trong bệnh viện, được
chụp ở Indonesia thì lại bị các đối tượng gán là “chụp ở bệnh viện Chợ Rẫy,
TP.HCM” [4]; lợi dụng vụ việc liên quan đến sự kiện quân nhân Trần Đức Đô tử
vong tại Trường Quân sự thuộc Quân khu 1, các phần tử CH-CĐCT đã đăng tải
các bài viết, hình ảnh về khám nghiệm tử thi, cảnh tang thương của gia đình
quân nhân, kèm những bình luận phê phán nhằm bóp méo sự thật, kích động hận
thù, gây chia rẽ mối quan hệ Quân - Dân, xuyên tạc bản chất, truyền thống Quân
đội và phẩm chất “Bộ đội Cụ Hồ”. Bên cạnh đó, gần đây vào ngày 08/09/2021,

16
Trương Châu Hữu Danh và nhóm “Báo Sạch” đã bị Viện Kiểm sát nhân dân
huyện Thới Lai, TP. Cần Thơ truy tố về các hành vi đăng tải, chia sẻ bài viết,
hướng cộng đồng mạng tham gia bình luận tiêu cực, cố ý xâm phạm đến lợi ích
của Nhà nước, cơ quan tổ chức tại tỉnh Cần Thơ [5]…
Ngoài những thông tin đăng tải trên bài viết (post), nhiều user, fanpage,
group Facebook tận dụng triệt để tính năng chia sẻ bài viết từ các website, blog
khác để thu hút bình luận (comment) của người dùng, tạo dư luận trái chiều, qua
đó thu thập thông tin, tiếp tục tuyên truyền, kích động chống phá… Điển hình là
các blog “Dân Làm Báo”, “Báo Tiếng Dân”, “Anh Ba Sàm”, “Việt Nam Thời
Báo”, “VOA Tiếng Việt”,... Các website, blog này thường được các đối tượng
xấu, đối tượng chống phá tạo lập ẩn danh hoặc sử dụng những dịch vụ tạo blog
miễn phí của Google, WordPress…, đăng ký tên miền và đặt máy chủ lưu trữ dữ
liệu tại Mỹ để tránh bị lực lượng chức năng của Việt Nam bóc gỡ. Những thông
tin từ các website, blog phản động này đang ngày càng đa dạng, phong phú, tổ
chức dưới nhiều hình thức, có lực lượng đăng tải thông tin hàng ngày lên các
MXH (nhất là Faccebook) để thu hút người đọc, gây hoang mang dư luận, ảnh
hưởng xấu đến tư tưởng chính trị của người dân trong xã hội.
Các bài viết, bình luận tiếng Việt có nội dung phản động được đăng tải trên
MXH Facebook dưới nhiều thể loại, hình thức khác nhau, từ văn bản, âm thanh,
hình ảnh đến các video-clip (bao gồm cả trực tuyến-livestream). Do giới hạn về
khả năng, công nghệ, cũng như lực lượng thực hiện, phạm vi của luận văn này
chỉ tập trung nghiên cứu phát hiện các nội dung phản động dưới dạng văn bản,
chưa xét đến các nội dung hình ảnh, âm thanh, video-clip trên MXH Facebook.
Để xác định các nội dung phản động trên Facebook, bản thân tôi đã tự tìm
hiểu, nghiên cứu các điều khoản của Luật An ninh mạng 2018 và Nghị định
174/2013/NĐ-CP của Chính phủ Việt Nam công khai trên không gian mạng
[7,8,9,10], từ đó rút ra 11 nội dung sau đây được coi là nội dung phản động,
bao gồm:
(1) Tổ chức, hoạt động, câu kết, xúi giục, mua chuộc, lừa gạt, lôi kéo, đào
tạo, huấn luyện người chống Nhà nước Cộng hòa xã hội chủ nghĩa Việt Nam;
(2) Xuyên tạc lịch sử, phủ nhận thành tựu cách mạng, phá hoại khối đại
đoàn kết toàn dân tộc, xúc phạm tôn giáo, phân biệt đối xử về giới, phân biệt
chủng tộc;
(3) Thông tin sai sự thật gây hoang mang trong Nhân dân, gây thiệt hại cho
hoạt động kinh tế - xã hội, gây khó khăn cho hoạt động của cơ quan nhà nước

17
hoặc người thi hành công vụ, xâm phạm quyền và lợi ích hợp pháp của cơ quan,
tổ chức, cá nhân khác;
(4) Tuyên truyền xuyên tạc, phỉ báng chính quyền nhân dân;
(5) Chiến tranh tâm lý, kích động chiến tranh xâm lược, chia rẽ, gây thù
hận giữa các dân tộc, tôn giáo và nhân dân các nước;
(6) Xúc phạm dân tộc, quốc kỳ, quốc huy, quốc ca, vĩ nhân, lãnh tụ, danh
nhân, anh hùng dân tộc;
(7) Kêu gọi, vận động, xúi giục, đe dọa, gây chia rẽ, tiến hành hoạt động vũ
trang hoặc dùng bạo lực nhằm chống chính quyền nhân dân;
(8) Kêu gọi, vận động, xúi giục, đe dọa, lôi kéo tụ tập đông người gây rối,
chống người thi hành công vụ, cản trở hoạt động của cơ quan, tổ chức gây mất
ổn định về an ninh, trật tự;
(9) Tuyên truyền chống Nhà nước Cộng hòa xã hội chủ nghĩa Việt Nam;
phá hoại khối đại đoàn kết toàn dân tộc mà chưa đến mức truy cứu trách nhiệm
hình sự;
(10) Tuyên truyền kích động chiến tranh xâm lược, gây hận thù giữa các
dân tộc và nhân dân các nước; kích động bạo lực; truyền bá tư tưởng phản động
mà chưa đến mức truy cứu trách nhiệm hình sự;
(11) Xuyên tạc sự thật lịch sử, phủ nhận thành tựu cách mạng; xúc phạm
dân tộc, danh nhân, anh hùng dân tộc mà chưa đến mức truy cứu trách nhiệm
hình sự.
Ngoài 11 nội dung tổng hợp nêu trên, có thể còn nhiều nội dung khác chưa
được liệt kê hết. Tuy nhiên, trong phạm vi luận văn, tôi sử dụng 11 nội dung này
làm căn cứ để đánh giá, huấn luyện mô hình học máy phục vụ cho thử nghiệm
hoạt động của dịch vụ kiểm duyệt bài viết và bình luận tiếng Việt có nội dung
phản động trên MXH Facebook.
1.2. Tác hại của nội dung phản động trên Facebook
Những nội dung mang tính chất phản động, chống phá Đảng, Nhà nước,
chống phá chế độ… trên MXH Facebook đã và đang gây ảnh hưởng tiêu cực
mạnh mẽ đến nhận thức, suy nghĩ và hành động của nhiều người, thuộc mọi
thành phần, lứa tuổi. Hiện nay, những thông tin phản động được lan truyền, tán
phát với tần suất lớn, tức thời, kèm theo là tính chất phản động rất tinh vi khiến
người dùng MXH Facebook khó nhận ra được đâu là thông tin chính
thống/không chính thống, đâu là thông tin thật/giả. Thông tin phản động sẽ dần
làm ảnh hưởng lớn tới nhận thức của người dùng; càng tiếp cận nhiều thông tin

18
phản động thì càng làm cho người dùng có cách nhìn nhận lệch chuẩn. Từ đó, có
những hành vi đi ngược lại với các chuẩn mực thông thường. Việc cân bằng
giữa quyền tự do ngôn luận và sự tôn trọng cá nhân là điều vô cùng khó kiểm
soát đối với những thông tin được đưa ra trên MXH Facebook. Đối với người trẻ
nói chung, trong đó có thiếu niên và trẻ em, là một trong những đối tượng chính
sử dụng Facebook với tần suất lớn. Lợi dụng điều này, những đối tượng xấu sẽ
tiêm nhiễm dần các thông tin xấu độc, nhằm lan truyền tư tưởng chống phá từ
khi còn trẻ. Ở một bộ phận người trung niên, cao tuổi tại Việt Nam, trong những
năm gần đây đang có xu hướng sử dụng Facebook làm phương tiện liên lạc, chia
sẻ thông tin song hành cùng các phương tiện thông tin đại chúng khác. Với đặc
điểm, dễ bị lôi kéo và không thông thạo cách sử dụng Facebook, không am hiểu
về tình hình chính trị của Việt Nam, có thể chính là nguyên nhân gián tiếp tiếp
tay cho những hành động tán phát thông tin phản động. Đặc biệt, có nhiều đối
tượng vì thiếu bản lĩnh, thiếu niềm tin vào Đảng, Nhà nước, vì lợi ích bản thân,
suy thoái về tư tưởng, chính trị, đạo đức, lối sống, dễ bị các đối tượng xấu trên
MXH Facebook mua chuộc, tác động, dẫn đến “tự diễn biến”, “tự chuyển hóa”,
quay lại đối đầu với Đảng, Nhà nước.
Hiện nay, ngoài các trang diễn đàn cũng như các MXH khác, tại Việt Nam,
các thế lực thù địch, lực lượng phản động, CH-CĐCT trong và ngoài nước đã và
đang triệt để lợi dụng MXH Facebook làm công cụ để tuyên truyền, tán phát các
nội dung phản động, chống phá Đảng, Nhà nước, chống phá chế độ... Có thể
nhận thấy rằng, việc tạo lập một tài khoản cũng như một trang cộng đồng trên
Facebook rất dễ dàng và đơn giản. Các trang cộng đồng thường giả danh các cơ
quan, tổ chức của Đảng, Nhà nước nhưng lại đăng các thông tin đi ngược với
các chủ trương, đường lối của Đảng, chính sách và pháp luật của Nhà nước. Đặc
biệt, trước những sự kiện nóng diễn ra trong nước, các trang cộng đồng này
thường thu hút được số lượng lớn thành viên, từ đó lôi kéo người dùng
Facebook tham gia các hoạt động chống phá. Do vậy, cần thiết phải có giải pháp
để hạn chế nguồn thông tin có tác động xấu đối với người dùng Facebook.
Trước thực trạng đó, các cơ quan chức năng của Việt Nam cũng đã đề ra những
quy định nghiêm ngặt về việc sử dụng các nền tảng MXH, tiêu biểu như: Luật
An toàn thông tin mạng năm 2015; Luật An ninh mạng Việt Nam năm 2018, có
hiệu lực từ 01/01/2019 hay quy định của Bộ Thông tin và Truyền thông về việc
yêu cầu các MXH phải thực hiện các yêu cầu của cơ quan quản lý để ngăn chặn,
gỡ các tài khoản giả mạo, bài viết xuyên tạc, đưa thông tin sai lệch [6]. Tuy
nhiên, việc giám sát, theo dõi, phát hiện và xử lý các đối tượng lợi dụng MXH
Facebook để chống phá Đảng, Nhà nước vẫn còn nhiều hạn chế nhất định cả về

19
nhân lực, phương tiện thực hiện, cũng như sự hợp tác của nhà phát triển
Facebook với Chính phủ Việt Nam. Bên cạnh đó, MXH Facebook hiện nay
không có tính năng cho phép người dùng báo cáo (report) đối với các bài viết,
bình luận có nội dung phản động (các nước phương Tây chỉ coi đây là quan
điểm chính tri binh thường của người dùng), mà chỉ tập trung vào các vấn đề
như bạo hành, bạo lực, khủng bố, phân biệt giới tính, sắc tộc, tôn giáo… Từ đó,
những nội dung phản động thường không nằm trong các thể loại mà Facebook
cho phép người dùng report, cho nên việc report các bài viết, bình luận phản
động (nhất là các nội dung phản động bằng tiếng Việt) thường không hiệu quả.
Với những đặc điểm, tình hình và hệ lụy nêu trên, việc nghiên cứu giải
pháp kiểm duyệt nội dung bài viết, bình luận tiếng Việt có nội dung phản động
trên MXH Facebook hiện nay là hết sức cần thiết.
1.3. Kiểm duyệt nội dung phản động trên Facebook
Qua tìm hiểu, tôi nhận thấy, hiện có nhiều nghiên cứu về phát hiện nội
dung bạo hành/đe dọa trực tuyến (cyberbullyingdetection), lời nói căm thù (hate
speechdetection), ngôn ngữ xúc phạm (offensive languagedetection) trên các nền
tảng MXH như Facebook, YouTube, Twitter, Instagram... với ngôn ngữ phổ
biến là tiếng Anh. Ngoài ra còn một số nghiên cứu khác trên các ngôn ngữ
không phổ biến như tiếng Ý, tiếng Hà Lan… Với tiếng Việt, nhiều tác giả người
Việt cũng đã có những nghiên cứu liên quan đến các vấn đề nêu trên. Tuy nhiên,
chưa có nghiên cứu cụ thể nào về việc phát hiện bài viết, bình luận tiếng Việt có
nội dung phản động trên các MXH, nhất là MXH Facebook.
Để thực hiện luận văn về nghiên cứu phát hiện nội dung phản động trên
MXH Facebook, bản thân tôi đã tự tìm hiểu về nội dung, quy trình các bước và
kết quả của các nghiên cứu trước đây về phát hiện bạo hành, xúc phạm, căm thù
trên các nền tảng MXH. Các vấn đề mà tôi đã tìm hiểu, như: Vấn đề NLP tiếng
Việt; tiền xử lý dữ liệu; trích chọn đặc trưng; xây dựng danh sách đen (blacklist
word); áp dụng các phương pháp, thuật toán học máy, để huấn luyện mô hình…
Một số bài báo mà tôi đã nghiên cứu, tìm hiểu, bao gồm:
Nghiên cứu của Ying Chen [15] đã ứng dụng kiến trúc đặc trưng cú pháp từ
vựng (LSF-Lexical Syntactic Feature) để phát hiện nội dung xúc phạm, đồng
thời xác định người dùng có khả năng đưa ra nội dung xúc phạm trên MXH. Kết
quả là, khung kiến trúc LSF hoạt động tốt hơn những phương pháp hiện tại trong
việc phát hiện nội dung xúc phạm. Đạt độ chính xác (precision) 98,24% và độ
hồi tưởng (recall) 94,34% khi phát hiện nội dung xúc phạm; đạt độ chính xác

20
77,9% và recall 77,8% đối với xác định người dùng có khả năng đưa ra nội dung
xúc phạm trên MXH.
Nghiên cứu của Chikashi Nobata [16] đã đề cập đến khả năng phát hiện
ngôn ngữ lạm dụng (abusive language) trong nội dung của người dùng trực
tuyến bằng cách sử dụng đặc trưng n-gram, các đặc trưng ngôn ngữ (chiều dài
câu, chiều dài trung binh của từ, số lượng dấu chấm câu, dấu chấm hỏi, ngoặc
kép…), đặc trưng về cú pháp, đặc trưng về ngữ nghĩa; tiến hành huấn luyện đối
với từng loại đặc trưng riêng rẽ và gộp tất cả các đặc trưng để so sánh kết quả.
Nghiên cứu đạt được độ chính xác 79,5% đối với tập dữ liệu về tài chính và
81,7% đối với tập dữ liệu về tin tức.
Nghiên cứu của Anna Schmidt [17] về một khảo sát việc phát hiện lời nói
căm thù bằng NLP. Tác giả đã sử dụng các đặc trưng bề mặt đơn giản như đặc
trưng túi từ BoW (bag of words - một túi các từ không phân biệt thứ tự), đặc
trưng n-gam (cấp độ từ và cấp độ ký tự); tổng quát hóa từ (word generalization)
bổ sung cho BoW; đề cập đến phân tích sắc thái câu (sentiment analysis), tài
nguyên từ vựng (lexical resources), các đặc trưng ngôn ngữ, đặc trưng về siêu
dữ liệu (meta-data) khác…
Nghiên cứu của Theodora Chu [18] sử dụng các mô hình thuật toán học sâu
như LSTM (mạng nơ-ron hồi quy RNN với ô nhớ ngắn hạn và dài hạn) và CNN
(mạng nơ-ron tích chập kết hợp với word embedding và character embedding).
Kết quả, đối với CNN kết hợp character embedding cho F1 score là 0,73 với
50.000 bước; còn CNN kết hợp word embedding cho F1 score là 0,70 với chỉ
5.000 bước. LSTM thực hiện gần giống với CNN kết hợp word embedding, cho
F1 score là 0,69 với 5.000 bước để huấn luyện.
1.4. Mục tiêu nghiên cứu của luận văn
Nhằm xây dựng giải pháp tự động phát hiện, loại bỏ các bài viết và bình
luận tiếng Việt có nội dung phản động trước khi đến với người dùng Facebook;
thử nghiệm xây dựng công cụ/dịch vụ (extension) triển khai trên máy tính người
dùng nhằm ngăn chặn các bài viết, bình luận có nội dung phản độngtiếp cận
người dùng Facebook. Tuy nhiên, hai mục tiêu này cũng không hề đơn giản,
nhất là việc chưa có một bộ từ điển phản động nào được xây dựng trước đây
dùng để phát hiện các nội dung phản động. Đây cũng chính là mục tiêu thứ ba
của luận văn, nhằm xây dựng một bộ từ điển các từ ngữ phản động. Bộ từ điển
này sẽ thường xuyên được cập nhật, thay đổi cùng thời gian theo sự phát triển
của xã hội, cách mà các đối tượng đăng tải bài viết, bình luận có nội dung phản
động. Bên cạnh đó, luận văn còn đề cập đến danh sách các user, fanpage, group

21
trên Facebook, các website, blog phản động, những đối tượng này (là nguồn gốc
xuất phát các nội dung phản động) được tập hợp thành một blacklist để ngăn
chặn ngay từ đầu, không để tán phát thông tin xấu độc đến người dùng.
1.5. Cấu trúc của luận văn
Nội dung của luận văn được chia thành 04 chương, tập trung nghiên cứu cơ
sở lý thuyết về NLP; các phương pháp trích trọn đặc trưng; các thuật toán học
máy, mô hình mạng nơ-ron tiêu biểu áp dụng cho phát hiện nội dung phản động
như: SVM, mô hình mạng nơ-ron đa tầng truyền thẳng MLP. Luận văn cũng đã
phát triển một dịch vụ tự động phát hiện nội dung phản động trong bài viết và
bình luận tiếng Việt trên MXH Facebook. Dịch vụ này kiểm duyệt nội dung
phản động theo mô hình 02 tầng (Layer). Layer 1, kiểm duyệt dựa vào tập danh
sách các user, fanpage, group đã nằm trong blacklist phản động. Khi gặp các đối
tượng trong danh sách này, dịch vụ sẽ ngăn chặn ngay các nội dung, không để
tiếp cận đến người dùng; Layer 2, kiểm duyệt dựa vào nội dung của bài viết,
bình luận thu thập được từ Facebook. Tại đây, dịch vụ sẽ thực hiện kiểm tra nội
dung đầu vào, nếu phát hiện nội dung phản động thì sẽ ẩn nội dung đó đi. Với
dịch vụ này, các bài viết, bình luận tiếng Việt có nội dung phản động sẽ bị ẩn
khỏi Facebook trước khi đến với người dùng.
Bố cục của luận văn cụ thể như sau:
Chương 1. Cơ sở khoa học
Giới thiệu về thực trạng báo động về các bài viết và bình luận tiếng Việt có
nội dung phản động trên MXH Facebook; nhu cầu cần thiết trong việc kiểm
duyệt nội dung của các bài viết và bình luận tiếng Việt có nội dung phản động
trên MXH Facebook; tìm hiểu các nghiên cứu trước đây về phát hiện nội dung
phản động trên các nền tảng MXH. Cuối cùng là mục tiêu và nội dung chính của
luận văn.
Chương 2. Đề xuất phương pháp
Phần thứ nhất của chương này nhằm tìm hiểu và làm rõ các nội dung, như:
Blacklist là gì; cách sử dụng blacklist trong kiểm duyệt bài viết, bình luận có nội
dung phản động trên Facebook; giới thiệu chi tiết các loại blacklist user,
fanpage, group, website và blog phản động.
Phần thứ hai của chương này trình bày các phương pháp tiếp cận để trích
chọn đặc trưng nội dung phản động của văn bản đầu vào, tập trung chính là các
văn bản trên MXH Facebook. Trước khi xác định các đặc trưng cụ thể, tôi đi vào
tìm hiểu trích chọn đặc trưng trong công nghệ NLP; tìm hiểu các đặc trưng ngôn
ngữ tiếng Việt. Tiếp đến, tôi tìm hiểu các đặc trưng ngôn ngữ trong kiểm duyệt

22
bài viết, bình luận phản động; tìm hiểu về các phương pháp biểu diễn từ trong
trích chọn đặc trưng; phương pháp trích chọn đặc trưng (n-gram;
BERT/PhoBERT); tìm hiểu các mô hình, thuật toán phân loại văn bản phổ biến.
Cuối cùng, tôi giới thiệu một số thuật toán về phân lớp nhị phân; trình bày đại
diện các thuật toán được sử dụng để phát hiện bài viết, bình luận tiếng Việt có
nội dung phản động, gồm: Thuật toán học máy SVM và mô hình mạng nơ-ron
đa tầng truyền thẳng MLP. Đây đều là các thuật toán cơ bản và phổ biến ứng
dụng trong phân lớp dữ liệu văn bản.
Chương 3. Cài đặt thử nghiệm
Trong chương này, đầu tiên, tôi trình bày về cách thức xây dựng blacklist
user, fanpage, group, website, blog phản động; cách thức thu thập dữ liệu mẫu
(dataset); xây dựng từ điển phản động; xây dựng vector đặc trưng cho dữ liệu;
cài đặt các thuật toán đã nghiên cứu trong Chương 3. Cuối cùng là thử nghiệm
phát triển một dịch vụ trên trình duyệt Google Chrome nhằm tự động kiểm
duyệt các bài viết, bình luận tiếng Việt có nội dung phản động trên MXH
Facebook. Dịch vụ này bao gồm một Backend có chức năng phát hiện bài viết,
bình luận tiếng Việt có nội dung phản động, nó cung cấp một API cho phép các
ứng dụng gửi nội dung đến để thẩm định; một Frontend dưới dạng extension cho
trình duyệt Chrome, có thể đọc các bài viết, bình luận trên Facebook, thực hiện
kiểm duyệt thông qua mô hình 02 tầng.
Chương 4. Kết luận và hướng phát triển
Chương này nhằm tóm tắt lại các công việc chính đã thực hiện và kết quả
đạt được của luận văn; đề xuất các hướng nghiên cứu, phát triển trong tương lai.

23
CHƯƠNG 2: ĐỀ XUẤT PHƯƠNG PHÁP
2.1. Danh sách đen
Danh sách đen (blacklist) là một tập hợp danh sách các đối tượng, gồm:
User, fanpage, group phản động trên Facebook; các website, blog phản động.
Các blacklist này được dùng để đối chiếu với dữ liệu đầu vào của Facebook.
Nếu dữ liệu đầu vào của Facebook đến từ các blacklist user, fanpage, group
phản động hoặc chứa blacklist website, blog phản động thì sẽ bị chặn lại ngay từ
đầu, không cho dữ liệu tiếp cận đến người dùng Facebook. Thông tin cụ thể về
các đối tượng blacklist được nêu dưới đây:
2.1.1. User Facebook phản động
Thông tin về user Facebook là một yếu tố góp phần xác định được chính
xác các nội dung mà user đăng tải có là phản động hay không. Thông thường,
các user thường xuyên đăng tải bài viết, bình luận có nội dung phản động (nằm
trong 11 nội dung đã xác đinh trong Mục 1.1) thì đều được xác định là các tài
khoản phản động, được đưa vào blacklist. Như vậy, việc lập blacklist chứa tên
và địa chỉ URL của các user Facebook phản động sẽ giúp nhanh chóng xác định
được các nội dung phản động trên Facebook (kể cả đối tượng có đăng tải hoặc
không đăng tải nội dung phản động), kịp thời ngăn chặn các nội dung mà user
Facebook phản động này đăng tải đến với người dùng.
Đối với những user Facebook thông thường, không thuộc blacklist. Việc
xác định nội dung mà người dùng đăng tải có phản động hay không sẽ dựa vào
blacklist word (từ điển phản động có đánh trọng số) và các đặc trưng ngôn
ngữ khác.
Ngoài ra, đối với những user Facebook mà trong danh sách bạn bè của user
này có những user thuộc blacklist phản động thì cũng có thể coi là user phản
động. Bởi vì, một khi user có bạn bè là phản động thì các thông tin do user phản
động đăng tải sẽ tự động hiển thị trên tường (feed) của user này. Khi đó, nội
dung phản động sẽ tiếp cận được đến các user khác. Tuy nhiên, trong phạm vi
của luận văn này, tôi chỉ đề cập đến các user Facebook thường xuyên đăng tải,
tán phát các nội dung hoặc có nhiều bình luận phản động.
Blacklist user phản động nằm trong Layer 1 của dịch vụ kiểm duyệt. Dịch
vụ kiểm duyệt sẽ thực hiện kiểm tra, đối chiếu dữ liệu Facebook thu được với
URL của blacklist user. Nếu trùng khớp, dịch vụ sẽ ẩn tất cả nội dung của user
phản động trước khi tiếp cận các user Facebook khác.

24
2.1.2. Fanpage Facebook phản động
Thông tin về fanpage là một trong những nhân tố góp phần xác định đâu là
nội dung phản động trên Facebook. Đối với bất kỳ fanpage nào, nếu thường
xuyên đăng tải các nội dung phản động (nằm trong 11 nội dung đã xác đinh
trong Mục 1.1.) thì đều được xác định là fanpage phản động và được đưa vào
blacklist. Một khi fanpage năm trong blacklist thì mặc định bất kỳ nội dung nào
đăng tải trên đó đều được coi là phản động và cần hạn chế tiếp cận đến những
người dùng Facebook khác.
Blacklist fanpage phản động nằm trong Layer 1 của dịch vụ kiểm duyệt.
Dịch vụ kiểm duyệt sẽ thực hiện kiểm tra, đối chiếu dữ liệu Facebook thu được
với URL của blacklist fanpage. Nếu trùng khớp, dịch vụ sẽ ẩn tất cả nội dung
của fanpage phản động trước khi tiếp cận các user khác.
2.1.3. Group Facebook phản động
Thông tin về các hội/nhóm là một nhân tố góp phần xác định nội dung phản
động trên Facebook. Đối với các group thường xuyên xuất hiện các bài viết,
bình luận phản động thì được coi là group phản động, được đưa vào blacklist.
Một khi đã nằm trong blacklist, thì bất kỳ nội dung nào mà thành viên trong
group này đăng lên đều được coi là phản động và cần hạn chế tiếp cận đến các
tài khoản người dùng Facebook khác.
Đối với những group bình thường nhưng trong danh sách thành viên
(members) lại có tài khoản thuộc blacklist user Facebook phản động, thì những
thông tin bình luận mà user phản động đăng tải trên fanpage sẽ phải đi qua bước
kiểm tra user phản động được nêu tại Mục 2.1.
Blacklist group phản động nằm trong Layer 1 của dịch vụ kiểm duyệt. Dịch
vụ kiểm duyệt sẽ thực hiện kiểm tra, đối chiếu dữ liệu Facebook thu được với
URL của blacklist group. Nếu trùng khớp, dịch vụ sẽ ẩn tất cả nội dung của
group phản động trước khi tiếp cận các user khác.
2.1.4. Website, blog phản động
Thông tin về các website, blog (tên, đia chỉ URL) là một nhân tố góp phần
xác định nội dung bài viết, bình luận có là phản động hay không. Thông thường,
các tài khoản Facebook chính thống không đăng tải đường dẫn URL của các
website, blog phản động; coi đó như một hình thức tiếp tay, tán phát cho các đối
tượng phản động. Do đó, mặc định, cứ có bài viết, bình luận nào chứa URL của
website, blog phản động thì được coi là nội dung phản động.
Blacklist website, blog phản động nằm trong Layer 2 của dịch vụ kiểm
duyệt. Dịch vụ kiểm duyệt sẽ thực hiện kiểm tra, đối chiếu dữ liệu Facebook thu

25
được với URL của blacklist website, blog phản động. Nếu các bài viết, bình luận
chứa URL của website, blog phản động thì mặc định dịch vụ sẽ ẩn nội dung đó
trước khi tiếp cận người dùng Facebook.
2.2. Phương pháp học máy
2.2.1. Trích chọn đặc trưng nội dung phản động
Với bài toán phát hiện bài viết, bình luận có nội dung phản động trên MXH
Facebook, nhiệm vụ quan trọng hàng đầu đặt ra là trích chọn được các đặc trưng
tiêu biểu của dữ liệu đầu vào. Trong mục này, tôi sẽ trình bày các phương pháp
tiếp cận để trích chọn đặc trưng nội dung phản động của văn bản đầu vào, tập
trung chính là các văn bản trên MXH Facebook. Ngoài những đặc trưng của văn
bản nói chung, văn bản trên Facebook cũng như các phương tiện truyền thông
xã hội khác có những đặc trưng khác biệt so với văn bản chính quy như: Phi
hình thức, sử dụng nhiều từ lóng, từ viết tắt, từ cách điệu không có trong từ điển,
câu không hoàn chỉnh hoặc không đúng ngữ pháp… Tất cả những đặc trưng này
cần được khai thác nhằm đem lại hiệu quả tốt trong phát hiện nội dung phản
động. Trước khi xác định các đặc trưng cụ thể, tôi đi vào tìm hiểu trích chọn đặc
trưng trong công nghệ NLP; tìm hiểu các đặc trưng ngôn ngữ tiếng Việt. Tiếp
đến, tôi tìm hiểu các đặc trưng ngôn ngữ trong kiểm duyệt bài viết, bình luận
phản động (gồm: blacklist word, các đặc trưng hinh thái). Tiếp theo tôi tìm hiểu
về các phương pháp biểu diễn từ trong trích chọn đặc trưng; phương pháp trích
chọn đặc trưng (n-gram; BERT/PhoBERT). Cuối cùng, tôi tìm hiểu các mô hình,
thuật toán phân loại văn bản phổ biến. Dưới đây là chi tiết các tìm hiểu của tôi:
2.2.1.1. Ứng dụng công nghệ xử lý ngôn ngữ tự nhiên
Ứng dụng công nghệ NLP là một nhánh của Trí tuệ nhân tạo, được xem là
một quy trình phức tạp với các công nghệ, quy trình giúp máy tính hiểu, giải
thích và mô phỏng ngôn ngữ con người bằng cách học hỏi từ cả ngôn ngữ học
máy tính và ngôn ngữ học tính toán. Ngày nay, nhu cầu ứng dụng công nghệ
NLP ngày một tăng cao, phát triển với nhiều ứng dụng thực tiễn trong đời sống
như robot, chat-bot, call-bot, sửa lỗi chính tả, sửa lỗi cú pháp, dịch tự động,
phân loại văn bản, phân tích sắc thái văn bản, suy luận ngôn ngữ tự nhiên, tóm
tắt trích rút văn bản.
Quy trình xử lý ứng dụng ngôn ngữ tự nhiên có thể được khái quát như sau:
Thu thập, gán nhãn dữ liệu; xử lý tiền huấn luyện; sử dụng các kiến trúc, mô
hình, thuật toán học máy/học sâu; ứng dụng vào bài toán/nhu cầu thực tế.

26
Hình 2.1: Quy trình NLP
Trong các phương pháp học máy, thông thường số lượng đặc trưng
(features) càng nhiều thì độ chính xác càng cao. Tuy nhiên, khi số lượng đặc
trưng quá nhiều sẽ khiến cho quá trình huấn luyện, quá trình phân loại mất nhiều
thời gian hơn. Ngoài ra, điều này còn dẫn đến tình trạng chương trình chiếm
nhiều dung lượng bộ nhớ lưu trữ và bộ nhớ tạm thời. Do đó, đối với phương
pháp học máy, rất cần thiết phải lựa chọn từ tập các đặc trưng ra một tập con
nhỏ hơn mà vẫn đảm bảo độ chính xác của quá trình phân loại. Việc lựa chọn
đó, gọi là trích chọn đặc trưng (Feature Selection, hay còn các tên khác như
Variable Selection, Feature Reduction, Attribute Selection hoặc Variable Subset
Selection). Từng phương pháp học máy sẽ có hiệu quả riêng, từng bài toán cụ
thể cũng sẽ có những phương pháp trích chọn đặc trưng mang lại hiệu quả
riêng biệt.
Trích chọn đặc trưng là một phần quan trọng trong quá trình xử lý dữ liệu
tiền huấn luyện, thường được đi kèm với một số kỹ thuật mô hình hóa, biểu diễn
các từ tiếng Việt lên không gian vector. Dữ liệu văn bản có thể đến từ nhiều
nguồn và có nhiều định dạng khác nhau (kí tự thường, kí tự hoa, kí tự đặc
biệt…). Do đó sẽ có nhiều phương pháp xử lý dữ liệu phù hợp với từng bài toán
cụ thể. Tuy nhiên, phương pháp phổ biến nhất là sử dụng kỹ thuật tokenization
sẽ giúp ta thực hiện điều này. Mã hóa đơn giản là việc chúng ta chia đoạn văn
thành các câu văn, các câu văn thành các từ. Trong mã hóa thì từ là đơn vị cơ sở.
Chúng ta cần một bộ tokenizer có kích thước bằng toàn bộ các từ xuất hiện trong
văn bản hoặc bằng toàn bộ các từ có trong từ điển. Một câu văn sẽ được biểu
diễn bằng một sparse vector (vector có nhiều phần tử bằng 0) mà mỗi một phần
tử đại diện cho một từ, giá trị của nó bằng 0 hoặc 1 tương ứng với từ không xuất

27
hiện hoặc có xuất hiện. Các bộ tokernizer sẽ khác nhau cho mỗi một ngôn ngữ
khác nhau.
2.2.1.2. Đặc trưng ngôn ngữ tiếng Việt
2.2.1.2.1. Đặc trưng hinh thái
Tiếng Việt không sử dụng các hình thái (morpheme) để tạo ra các ý nghĩa
của từ và tạo ra các sắc thái ý nghĩa khác nhau, tiếng Việt phụ thuộc vào trật tự
của từ chứ không thay đổi hình thái của từ (như trong tiếng Anh, class → classes
thi ‘es’ là hinh thái số nhiều).
Ví dụ: với năm âm tiết (năm từ đơn): “sao, nó, bảo, không, đến” khi sắp
xếp theo các trật tự khác nhau sẽ cho ra các nghĩa khác nhau: Nó bảo sao không
đến? Nó bảo không đến sao? Nó đến, sao không bảo? Nó đến, không bảo sao?
Nó đến, sao bảo không? Nó đến bảo không sao! Nó đến, bảo sao không?…
Mặt khác, dấu cách (space) trong tiếng Việt không có tác dụng phân tách
các từ như tiếng Anh mà chỉ có tác dụng phân tách các tiếng (âm tiết) mà thôi.
Vì thế việc phân tách từ trong tiếng Việt là một việc không thể thiếu.
2.2.1.2.2. Đặc trưng cấu tạo từ tiếng Việt
Theo thống kê từ Vietnam Lexicography Center (Vietlex) [11], tiếng Việt
sử dụng nhiều và rộng rãi dựa trên 40.181 từ, với 7.729 âm tiết, trong đó 81,55%
các âm tiết đồng thời là từ đơn, 70,72% các từ ghép có 2 âm tiết, 13,59% các từ
ghép có 3, 4 âm tiết, và 1,04% các từ ghép có từ 5 âm tiết trở lên.
Các phương thức cấu tạo từ tiếng Việt:
- Từ đơn: Từ có ý nghĩa từ vựng; từ có ý nghĩa ngữ pháp (từ công cụ); từ
tượng thanh; từ cảm thán.
- Từ phức: Từ ghép; từ ghép đẳng lập (tổng hợp); từ ghép chính phụ; từ
ghép phụ gia (yếu tố ghép trước hay ghép sau để tạo từ hàng loạt); từ láy;
dạng lặp.
- Ngữ cố định: Thành ngữ, tục ngữ; quán ngữ (nói tóm lại, đáng chú ý là,
mặt khác thi…).
- Ngoài ra, trong văn bản còn có các thành phần sau: Tên riêng (tên người,
đia danh, tổ chức); các dạng ngày - tháng - năm; các dạng số - chữ số - kí hiệu;
dấu câu, dấu ngoặc; từ tiếng nước ngoài; chữ viết tắt.
2.2.1.3. Đặc trưng nội dung phản động
2.2.1.3.1. Blacklist word
Trong nhiều nghiên cứu về phát hiện ngôn ngữ bạo hành trực tuyến, lời nói
căm thù…, các tác giả thường sử dụng một danh sách đen (blacklist) các từ/cụm
từ có đánh trọng số về nội dung nghiên cứu. Các blacklist này được sử dụng một

28
cách rộng rãi và gần như trở thành một danh sách quy chuẩn, từ đó chỉ việc áp
dụng các phương pháp học máy vào để nhận dạng nội dung bạo hành trực tuyến.
Tương tự, trong luận văn này, tôi sử dụng một blacklist các từ/cụm từ phản động
có đánh trọng số để xác định nội dung phản động. Tuy nhiên, blacklist word
phản động hiện tại trong luận văn được xác định và đánh trọng số bằng phương
pháp thủ công. Việc làm thủ công như hiện tại mặc dù sẽ thiếu sự chính xác
hoàn toàn và còn phụ thuộc vào ý kiến chủ quan của tác giả. Tuy nhiên, trong
giới hạn luận văn này, tôi chỉ trình bày về phương pháp để phát hiện nội dung
phản động, không đi sâu phân tích phương pháp trích chọn và đánh trọng số cho
các blacklist word phản động. Một số quy định chính trong việc xác định các
blacklist word phản động như sau:
- Blacklist word là một danh sách các từ tiếng Việt (từ đơn hoặc từ ghép)
liên quan đến nội dung phản động được gán trọng số trong khoảng (0, 1]. Ví dụ:
“Tổng Trọng”, “Trọng Lú”, “Thủ tướng Fuck”, “Fuck Niễng”, “Phúc Niễng
Nổ”, “độc đảng”, “ngày quốc hận”, “độc tài cộng sản”…
- Blacklist word có thể chứa tên (đã bi các đối tượng xấu biến tướng) của
những lãnh đạo cấp cao của Đảng, Nhà nước.
- Blacklist word có thể chứa tên của các đối tượng phản động trong và
ngoài nước, các đối tượng CH-CĐCT, “tù nhân lương tâm”, như: Thanh Hiếu
Bùi; Lê Nguyễn Hương Trà; Cấn Thị Thêu; Trịnh Bá Tư; Nguyễn Văn Đài;
Huỳnh Ngọc Chênh, Nguyễn Thúy Hạnh...
2.2.1.3.2. Đặc trưng hinh thái
Đối với các đặc trưng hình thái trong kiểm duyệt bài viết, bình luận có nội
dung phản động, ta xét các đặc trưng cụ thể sau:
- Độ dài của bài viết.
- Số ký tự viết hoa/tổng số ký tự của câu hoặc bài viết.
- Số các ký tự không phải alphabet xuất hiện trong câu hoặc bài viết.
- Số các dấu câu xuất hiện trong câu hoặc bài viết.
- Số từ không có trong từ điển tiếng Việt xuất hiện trong bài viết (từ lóng,
từ viết tắt).
- Độ dài trung bình của các từ.
- Độ dài trung bình của các câu.
2.2.1.4. Các phương pháp biểu diễn từ
Thực tế khi NLP phát sinh nhu cầu không chỉ biểu diễn cho dữ liệu ở cấp
độ từ mà còn ở mức độ câu văn, đoạn văn. Ví dụ, đối với bài toán kiểm duyệt

29
bài viết, bình luận có nội dung phản động được đề cập đến trong nghiên cứu
này, nếu chỉ dựa trên một số từ ngữ hay một số câu văn riêng lẻ, không có trong
ngữ cảnh nhất định, sẽ không thể đưa ra nhận định, đánh giá chính xác nội dung
của toàn bộ bài viết.
Một số phương pháp biểu diễn từ tiêu biểu, gồm:
2.2.1.4.1. Word embedding
Word embedding là một nhóm các kỹ thuật đặc biệt trong NLP, có nhiệm
vụ ánh xạ một từ hoặc một cụm từ trong bộ từ vựng tới một vector số thực. Từ
không gian một chiều cho mỗi từ tới không gian các vector liên tục. Các vector
từ được biểu diễn theo phương pháp word embedding thể hiện được ngữ nghĩa
của các từ, từ đó ta có thể nhận ra được mối quan hệ giữa các từ với nhau (tương
đồng, trái nghich,...).
Các phương pháp thường được sử dụng trong word embedding bao gồm:
Giảm kích thước của ma trận đồng xuất hiện; mạng nơ-ron (Word2vec, Glove
[19],...); sử dụng các mô hình xác suất,…
2.2.1.4.2. Tf-idf
Những từ hiếm khi được tìm thấy trong tập văn bản (corpus) nhưng có mặt
trong một văn bản cụ thể có thể quan trọng hơn. Do đó, cần tăng trọng số của
các nhóm từ ngữ để tách chúng ra khỏi các từ phổ biến. Cách tiếp cận này được
gọi là Tf-idf (Term Frequency - Inverse Document Frequency), thường được sử
dụng như một trọng số trong việc khai phá dữ liệu văn bản. Tf-idf chuyển đổi
dạng biểu diễn văn bản thành dạng không gian vector (VSM), hoặc thành những
vector thưa thớt.
TF (Term Frequency): Là tần suất xuất hiện của một từ trong một đoạn văn
bản. Với những đoạn văn bản có độ dài khác nhau, sẽ có những từ xuất hiện
nhiều ở những đoạn văn bản dài thay vì những đoạn văn bản ngắn. Vì thế, tần
suất này thường được chia cho độ dài của đoạn văn bản như một phương thức
chuẩn hóa (normalization). TF được tính bởi công thức:
(1)
(với t là một từ trong đoạn văn bản; f(t,d) là tần suất xuất hiện của t trong
đoạn văn bản d; T là tổng số từ trong đoạn văn bản).
IDF (Inverse Document Frequency): Tính toán độ quan trọng của một từ.
Khi tính toán TF, mỗi từ đều quan trọng như nhau, nhưng có một số từ trong
tiếng Việt như “và”, “thì”, “là”, “mà”... xuất hiện khá nhiều nhưng lại rất ít quan
trọng. Vì vậy, chúng ta cần một phương thức bù trừ những từ xuất hiện nhiều lần

30
và tăng độ quan trọng của những từ ít xuất hiện những có ý nghĩa đặc biệt cho
một số đoạn văn bản hơn bằng cách tính IDF:
(2)
(trong đó, N là tổng số đoạn văn bản; tập |{ }| là số văn bản
chứa từ t).
Một từ càng phổ biến khi IDF càng nhỏ và Tf-idf càng lớn. Đặc biệt, Tf-idf
được sử dụng rộng rãi trong hệ thống tìm kiếm. Hệ thống sẽ xác định được từ
nào mà người dùng quan tâm nhất, từ đó sẽ trả ra kết quả đáp ứng mong muốn
của người dùng. Ví dụ khi tiến hành tìm kiếm: “làm thế nào để học AI” thì AI có
Tf-idf cao nhất. Hệ thống sẽ xác định và trả ra một loạt các kết quả có AI trước
rồi sau đó mới đối chiếu với văn bản cần tìm kiếm.
2.2.1.4.3. Mô hinh ngôn ngữ n-gram
Mô hình ngôn ngữ là một phân bố xác suất trên các tập văn bản. Nói đơn
giản, mô hình ngôn ngữ có thể cho biết xác suất một câu (hoặc cụm từ) thuộc
một ngôn ngữ là bao nhiêu.
Ví dụ: khi áp dụng mô hình ngôn ngữ cho tiếng Việt:
P[“hôm nay là thứ hai”] = 0,001
P[“hai thứ hôm là nay”] = 0
Mô hình ngôn ngữ được áp dụng trong rất nhiều lĩnh vực của NLP, như:
Kiểm lỗi chính tả, dịch máy hay phân đoạn từ... Chính vì vậy, nghiên cứu mô
hình ngôn ngữ chính là tiền đề để nghiên cứu các lĩnh vực tiếp theo. Mô hình
ngôn ngữ có nhiều hướng tiếp cận, nhưng chủ yếu được xây dựng theo mô hình
n-gram. Nhiệm vụ của mô hình ngôn ngữ là cho biết xác suất của một câu w1w2
...wm là bao nhiêu. Theo công thức Bayes: P(AB) = P(B|A) * P(A),thì:
P(w1w2…wm) = P(w1) * P(w2|w1) * P(w3|w1w2) *…* P(wm|w1w2…wm-1) (3)
Theo công thức này, mô hình ngôn ngữ cần phải có một lượng bộ nhớ vô
cùng lớn để có thể lưu hết xác suất của tất cả các chuỗi độ dài nhỏ hơn m. Rõ
ràng, điều này là không thể khi m là độ dài của các văn bản ngôn ngữ tự nhiên
(m có thể tiến tới vô cùng). Để có thể tính được xác suất của văn bản với lượng
bộ nhớ chấp nhận được, ta sử dụng xấp xỉ Markov bậc n:
P(wm|w1,w2,…, w ) = P(wm|wm-n,wn-m+1, …,wm-1) (4)
Nếu áp dụng xấp xỉ Markov, xác suất xuất hiện của một từ (wm) được coi
như chỉ phụ thuộc vào n từ đứng liền trước nó (wm-nwm-n+1…wm-1) chứ không

31
phải phụ thuộc vào toàn bộ dãy từ đứng trước (w1w2…wm-1). Như vậy, công
thức tính xác suất văn bản được tính lại theo công thức:
P(w1w2…wm) = P(w1) * P(w2|w1) * P(w3|w1w2) *…* P(wm-1|wm-n-1wm-n
…wm-2)* P(wm|wm-nwm-n+1…wm-1) (5)
Với công thức này, ta có thể xây dựng mô hình ngôn ngữ dựa trên việc
thống kê các cụm có ít hơn n+1 từ. Mô hình ngôn ngữ này gọi là mô hình ngôn
ngữ n-gram.
2.2.1.5. Phương pháp trích chọn đặc trưng
2.2.1.5.1. Mô hình n-gram
N-gram là tần suất xuất hiện của n kí tự (hoặc từ) liên tiếp nhau có trong dữ
liệu của nghiên cứu. N-gram được sử dụng dưới 2 dạng là word n-gram (n-gram
cấp độ từ) và character n-gram (n-gram cấp độ ký tự) với các kiểu phổ biến là:
- Unigram với n = 1 và tính trên kí tự, ta có thông tin về tần suất xuất hiện
nhiều nhất của các chữ cái. Ví dụ ‘b’, ‘t’, ‘m’.
- Bigram với n = 2. Ví dụ với các chữ cái tiếng Việt, bigram ta có ‘th’, ‘iê’,
‘ch’, ‘au’, ‘mi’.
Bigram được sử dụng nhiều trong việc phân tích hình thái (từ, cụm từ, từ
loại) cho các ngôn ngữ khó phân tích như tiếng Việt [20], tiếng Nhật [21,22],
tiếng Trung [23,24],… Dựa vào tần suất xuất hiện cạnh nhau của các từ, người
ta sẽ tính cách chia một câu thành các từ sao cho tổng bigram là cao nhất có thể.
Với thuật giải phân tích hình thái dựa vào trọng số nhỏ nhất, người ta sử dụng
n = 1 để xác định tần suất xuất hiện của các từ và tính trọng số.
- Trigram với n = 3. Ví dụ ‘đản’, ‘cộn’, ‘sản’.
Để xây dựng một mô hình n-gram, ban đầu người ta dựa trên một tập dữ
liệu huấn luyện (training set). Sau khi mô hình được xây dựng sẽ tiến hành kiểm
tra mô hình dựa trên một tập dữ liệu test. Việc kiểm tra tốt nhất là sử dụng một
tập dữ liệu không có trong tập huấn luyện. Dựa vào việc kiểm tra này mà ta có
thể biết được mô hình có tốt hay không.
Theo kết quả nghiên cứu được công bố của nhóm Underthesea [12] đối với
bài toán phân loại văn bản tiếng Việt cho thấy, kết quả sử dụng mô hình Tf-idf
với unigram, bigram cho kết quả tốt hơn mô hình CountVectorizer với unigram,
bigram và trigram.

32
Hình 2.2. Kết quả thử nghiệm các mô hình phân loại văn bản tiếng Việt của
nhóm Underthesea
Vì n càng lớn thì số trường hợp càng lớn nên thường người ta chỉ sử dụng
n-gram với n = 1, 2 hoặc đôi lúc là 3. Đặc biệt, với đặc điểm về sắp xếp tiếng
Việt và thành phần ký tự, âm tiết (a à ả ã á ạ ă ằ ẳ ẵ ắ ặ â ầ â ẫ ấ ậ b c d đ e è ẻ
ẽ é ẹ ê ề ể ễ ế ệ g h i ì ỉ ĩ í i j k l m n o ò ỏ õ ó ọ ô ồ ổ ỗ ố ộ ơ ờ ở ỡ ớ ợ p q r s t u
ù ủ ũ ú ụ ư ừ ử ữ ứ ự v x y ỳ ỷ ỹ ý ỵ), n-gram ở cấp độ ký tự đối với tiếng Việt là
lớn hơn nhiều so với xử lý ngôn ngữ tiếng Anh (90 ký tự so với 26 ký tự). Ví dụ,
khi sử dụng bigram, việc vector hóa sẽ tiến hành với vector gồm 902 = 8.100
chiều; số chiều sẽ tăng lên tới 903 = 729.000 chiều đối với trigram.
Trong nghiên cứu này, n-gram được sử dụng là n-gram cấp độ ký tự với hai
kiểu là bigram và trigram.
Nhược điểm của mô hình ngôn ngữ n-gram:
- Phân bố không đều: Khi sử dụng mô hình n-gram theo công thức “xác
suất thô”, sự phân bố không đều trong tập văn bản huấn luyện có thể dẫn đến
các ước lượng không chính xác. Khi các n-gram phân bố thưa, nhiều cụm n-
gram không xuất hiện hoặc chỉ có số lần xuất hiện nhỏ, việc ước lượng các câu
có chứa các cụm n-gram này sẽ có kết quả tồi. Với V là kích thước bộ từ vựng,
ta sẽ có V*n cụm n-gram có thể sinh từ bộ từ vựng. Tuy nhiên, thực tế thì số
cụm n-gram có nghĩa và thường gặp chỉ chiếm rất ít.
Ví dụ: Tiếng Việt có khoảng hơn 5.000 âm tiết khác nhau, ta có tổng số
cụm 3-gram có thể có là: 5.0003 = 125.000.000.000. Tuy nhiên, số cụm trigram
thống kê được chỉ xấp xỉ 1.500.000. Như vậy sẽ có rất nhiều cụm trigram không
xuất hiện hoặc chỉ xuất hiện rất ít.
Khi tính toán xác suất của một câu, có rất nhiều trường hợp sẽ gặp cụm
n-gram chưa xuất hiện trong dữ liệu huấn luyện bao giờ. Điều này làm xác suất
của cả câu bằng 0, trong khi câu đó có thể là một câu hoàn toàn đúng về mặt ngữ

33
pháp và ngữ nghĩa. Để khắc phục tình trạng này, người ta phải sử dụng một số
phương pháp “làm mịn”.
- Kích thước bộ nhớ của mô hình ngôn ngữ: Khi kích thước tập văn bản
huấn luyện lớn, số lượng các cụm n-gram và kích thước của mô hình ngôn ngữ
cũng rất lớn. Nó không những gây khó khăn trong việc lưu trữ mà còn làm tốc
độ xử lý của mô hình ngôn ngữ giảm xuống do bộ nhớ của máy tính là hạn chế.
Để xây dựng mô hình ngôn ngữ hiệu quả, chúng ta phải giảm kích thước của mô
hình ngôn ngữ mà vẫn đảm bảo độ chính xác.
Một số phương pháp làm mịn dữ liệu khắc phục điểm yếu của mô hình
ngôn ngữ n-gram:
Để khắc phục tình trạng các cụm n-gram phân bố thưa như đã đề cập,
người ta đã đưa ra các phương pháp “làm mịn” kết quả thống kê nhằm đánh giá
chính xác hơn (min hơn) xác suất của các cụm n-gram. Các phương pháp “làm
mịn” đánh giá lại xác suất của các cụm n-gram bằng cách:
- Gán cho các cụm n-gram có xác suất 0 (không xuất hiện) một giá trị
khác 0.
- Thay đổi lại giá trị xác suất của các cụm n-gram có xác suất khác 0 (có
xuất hiện khi thống kê) thành một giá trị phù hợp (tổng xác suất không đổi).
Các phương pháp làm mịn có thể được chia ra thành loại như sau:
- Chiết khấu (Discounting): Giảm (lượng nhỏ) xác suất của các cụm n-gram
có xác suất lớn hơn 0 để bù cho các cụm n-gram không xuất hiện trong tập
huấn luyện.
- Truy hồi (Back-off): Tính toán xác suất các cụm n-gram không xuất hiện
trong tập huấn luyện dựa vào các cụm n-gram ngắn hơn có xác suất lớn hơn 0.
- Nội suy (Interpolation): Tính toán xác suất của tất cả các cụm n-gram dựa
vào xác suất của các cụm n-gram ngắn hơn.
2.2.1.5.2. Biểu diễn BERT/PhoBERT
Mô hình mã hóa hai chiều dữ liệu từ các khối Transformer (Bidirectional
Encoder Representations from Transformers - BERT) [25], là một phương pháp
kỹ thuật được xây dựng dựa trên mô hình mạng mô phỏng theo hệ thống nơ-ron
thần kinh của con người, dùng để đào tạo trước (pre-train) quá trình NLP. Nói
một cách đơn giản, thì nó có thể được sử dụng để giúp Google phân biệt rõ hơn
ngữ cảnh của các từ xuất hiện trong truy vấn tìm kiếm.
Ví dụ, trong các cụm từ “nine to five” (từ 9 giờ sáng đến 5 giờ chiều) và “a
quarter to five” (5 giờ kém 15 phút) thì từ “to” có hai ý nghĩa khác nhau, sự
34
khác biệt này có thể rõ ràng đối với con người chúng ta nhưng không phải đối
với các máy tìm kiếm. BERT được thiết kế để phân biệt những sắc thái ngữ
nghĩa như thế, từ đó giúp đưa ra những kết quả phù hợp và có liên quan hơn.
Điểm đột phá của BERT nằm ở khả năng huấn luyện các mô hình ngôn ngữ
dựa trên toàn bộ tổ hợp các từ trong một câu hoặc truy vấn (huấn luyện hai
chiều), thay vì cách thức huấn luyện truyền thống dựa trên thứ tự xuất hiện của
các từ (từ trái qua phải hoặc kết hợp giữa trái qua phải và phải qua trái). BERT
cho phép mô hình ngôn ngữ học về ngữ cảnh của từ vựng dựa trên các từ xung
quanh nó, thay vì chỉ dựa vào từ ngữ đứng trước hoặc ngay sau nó.
Google gọi BERT là công nghệ “có tính hai chiều rất sâu” [26] bởi vì sự
diễn giải ngữ cảnh của các từ bắt đầu từ “tầng đáy thấp nhất trong một mạng
lưới nơ-ron gồm rất nhiều tầng”.
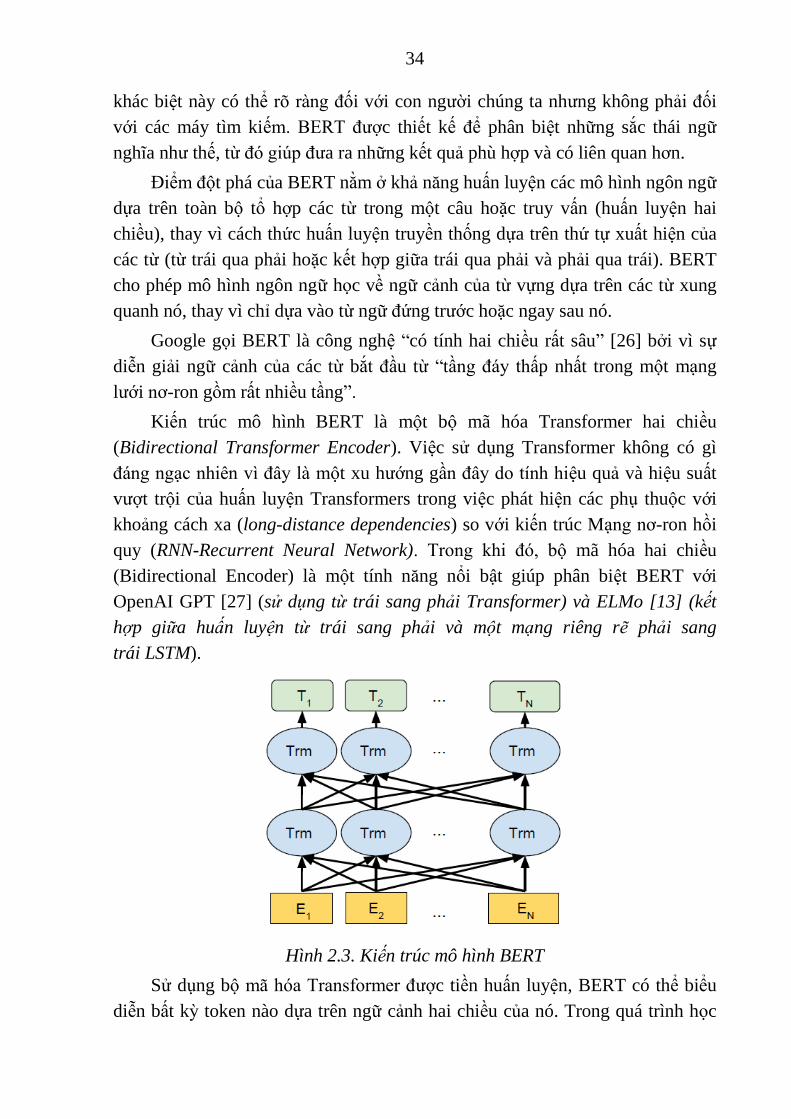
Kiến trúc mô hình BERT là một bộ mã hóa Transformer hai chiều
(Bidirectional Transformer Encoder). Việc sử dụng Transformer không có gì
đáng ngạc nhiên vì đây là một xu hướng gần đây do tính hiệu quả và hiệu suất
vượt trội của huấn luyện Transformers trong việc phát hiện các phụ thuộc với
khoảng cách xa (long-distance dependencies) so với kiến trúc Mạng nơ-ron hồi
quy (RNN-Recurrent Neural Network). Trong khi đó, bộ mã hóa hai chiều
(Bidirectional Encoder) là một tính năng nổi bật giúp phân biệt BERT với
OpenAI GPT [27] (sử dụng từ trái sang phải Transformer) và ELMo [13] (kết
hợp giữa huấn luyện từ trái sang phải và một mạng riêng rẽ phải sang
trái LSTM).
Hình 2.3. Kiến trúc mô hình BERT
Sử dụng bộ mã hóa Transformer được tiền huấn luyện, BERT có thể biểu
diễn bất kỳ token nào dựa trên ngữ cảnh hai chiều của nó. Trong quá trình học

35
có giám sát trên các tác vụ xuôi dòng, BERT tương tự như GPT ở hai khía cạnh.
Đầu tiên, các biểu diễn BERT sẽ được truyền vào một tầng đầu ra được bổ sung,
với những thay đổi tối thiểu tới kiến trúc mô hình tùy thuộc vào bản chất của tác
vụ, chẳng hạn như dự đoán cho mỗi token hay dự đoán cho toàn bộ chuỗi. Thứ
hai, tất cả các tham số của bộ mã hóa Transformer đã tiền huấn luyện đều được
tinh chỉnh, trong khi tầng đầu ra bổ sung sẽ được huấn luyện từ đầu.
Hiện tại, có nhiều phiên bản khác nhau của mô hình BERT. Các phiên bản
đều dựa trên việc thay đổi kiến trúc của Transformer tập trung ở 3 tham số: Số
lượng các block sub-layers trong Transformer; kích thước của embedding vector
(hay còn gọi là hidden size); số lượng head trong multi-head layer, mỗi một
head sẽ thực hiện một self-attention. Tên gọi của 2 kiến trúc bao gồm:
- BERT base: Tổng tham số 110 triệu.
- BERT Large: Tổng tham số 340 triệu.
Như vậy, ở kiến trúc BERT Large chúng ta tăng gấp đôi số layer, tăng kích
thước hidden size của embedding vector gấp 1,33 lần và tăng số lượng head
trong multi-head layer gấp 1,33 lần.
Mô hình BERT multilingual:
BERT multilingual là một mô hình của google BERT đa ngôn ngữ. Mô
hình được đào tạo trước trên 104 ngôn ngữ hàng đầu có Wikipedia lớn nhất bằng
cách sử dụng mục tiêu tạo mô hình ngôn ngữ bị che (MLM-masked language
modeling). Mô hình này phân biệt chữ hoa và chữ thường.
Các kỹ thuật quen thuộc phổ biến như Word2vec, Fasttext hay Glove cũng
tìm ra đại diện của từ thông qua ngữ cảnh chung của chúng. Tuy nhiên, những
ngữ cảnh của các kỹ thuật này là đa dạng trong dữ liệu tự nhiên. Ví dụ các từ
như “con chuột” có ngữ nghĩa khác nhau ở các ngữ cảnh khác nhau như “Con
chuột máy tính này thật đep!” và “con chuột này to thật”. Trong khi các mô hình
như Word2vec, FastText tìm ra 01 vector đại diện cho mỗi từ dựa trên 01 tập
ngữ liệu lớn nên không thể hiện được sự đa dạng của ngữ cảnh. Việc biểu diễn
mỗi từ dựa trên các từ khác trong câu thành một đại diện sẽ mang lại kết quả ý
nghĩa rất nhiều. Như trong ví dụ trên, ý nghĩa của từ “con chuột” sẽ được biểu
diễn cụ thể dựa vào các từ phía trước hoặc sau nó trong câu. Nếu đại diện của từ
“con chuột” được xây dựng dựa trên những ngữ cảnh cụ thể này thì sẽ có được
biểu diễn tốt hơn.
Mô hình BERT đã tạo các biểu diễn theo ngữ cảnh dựa trên các từ trước và
sau đó để dẫn đến một mô hình ngôn ngữ với ngữ nghĩa phong phú hơn. Điều
này cho thấy, mô hình BERT mở rộng khả năng của các phương pháp trước đây.

36
PhoBERT là mô hình huấn luyện trước dành riêng cho tiếng Việt.
PhoBERT huấn luyện dựa trên kiến trúc và cách tiếp cận giống RoBERTa [28]
của Facebook, được Facebook giới thiệu giữa năm 2019. Tương tự như BERT,
PhoBERT cũng có hai phiên bản là PhoBERT base với 12 transformers block và
PhoBERT Large với 24 transformers block.
Hiện nay BERT đã được ứng dụng rất rộng rãi trong các bài toán NLP như
tóm tắt văn bản [29], phân tích sắc thái [30,31], phân biệt đối thoại [32],….
Ngoài PhoBERT đã được huấn luyện cho tiếng Việt, BERT cũng đã được fine-
tuning trên nhiều ngôn ngữ khác nhau như tiếng Đức [33], Ả rập [34], Pháp
[35], Tây Ban Nha [36]….
2.2.1.6. Một số phương pháp trích chọn đặc trưng khác
Bên cạnh những đặc trưng đã nêu ở trên, còn nhiều các đặc trưng khác và
phương pháp biểu diễn từ khác bổ trợ cho việc xác định nội dung bài viết, bình
luận mang tính chất phản động hay không. Tuy nhiên do sự phức tạp trong tính
toán cũng như khó khăn trong việc phân tích, đánh giá, kết hợp vào mô hình, tôi
không sử dụng những đặc trưng này như một phần trong xây dựng vector đặc
trưng của bài viết, bình luận. Một số đặc trưng có thể kể đến như:
2.2.1.6.1. Một số đặc trưng khác
(1) Đặc trưng về ngữ cảnh:
Việc sử dụng đặc trưng về ngữ cảnh đã được áp dụng để giải quyết nhiều
bài toán liên quan đến ngôn ngữ tự nhiên [37-38]. Một văn bản là phản động hay
bình thường có thể phụ thuộc nhiều vào yếu tố thế giới xung quanh văn bản. Do
đó việc phát hiện nội dung phản động có thể dựa vào việc phân tích các thông
tin không liên quan trực tiếp đếnngôn ngữ.
Khi có các thông tin về ngữ cảnh, có thể phán đoán, suy luận về tính chất
của văn bản.Các yếu tố ngữ cảnh được xét đến có thể bao gồm:
- Văn bản thuộc lĩnh vực gì? Có sự kiện gì xoay quanh?
- Thời điểm xuất bản.
- Ngôn ngữ (ở đây là tiếng việt).
- Vị trí địa lý (thông thường những đối tượng viết nội dung phản động đều
có đia chỉ đăng ký tại Mỹ, Pháp, Đức và nhiều nước châu Âu khác). Số còn lại
vẫn có thể ở trong nước nhưng thường tạo nick ảo, không có thông tin thật.
(2) Đặc trưng về sắp xếp tiếng Việt:

37
Các mục từ (đơn vi từ vựng) trong từ điển tiếng Việt được xếp theo thứ tự
các chữ cái: a ă â b c d đ e ê g h i j k l m n o ô ơ p q r s t u ư v x y,và theo các
dấu giọng: không dấu, huyền, hỏi, ngã, sắc, nặng. Có thể cụ thể hoá hai quy tắc
trên bằng trật tự như sau: a à ả ã á ạ ă ằ ẳ ẵ ắ ặ â ầ â ẫ ấ ậ b c d đ e è ẻ ẽ é ẹ ê ề
ể ễ ế ệ g h i ì ỉ ĩ í i j k l m n o ò ỏ õ ó ọ ô ồ ổ ỗ ố ộ ơ ờ ở ỡ ớ ợ p q r s t u ù ủ ũ ú ụ
ư ừ ử ữ ứ ự v x y ỳ ỷỹ ý ỵ.
Đơn vị căn cứ để sắp xếp là từng khối viết liền (tổ hợp các con chữ), đơn
tiết hoặc đa tiết, tính từ trái sang phải, khối chữ viết thường xếp trước khối chữ
viết hoa, khối chữ nào có ít con chữ hơn (thường là âm tiết) luôn xếp trước khối
chữ (có phần trùng với khối chữ có ít con chữ) có nhiều chữ hơn. Ví dụ a (đơn vi
đo diện tích) xếp trước A (kí hiệu viết tắt của Ampere); cha xếp trước
chan. Ngoài ra, tiếng Việt ưu tiên trật tự chữ cái trước, sau mới đến thanh điệu
trong khi sắp xếp.
2.2.1.6.2. Một số phương pháp biểu diễn từ khác
(1) One-hot vector:
Trong các ứng dụng về NLP, học máy,... các thuật toán không thể nhận
được đầu vào là chữ với dạng biểu diễn thông thường. Để máy tính có thể hiểu
được, ta cần chuyển các từ trong ngôn ngữ tự nhiên về dạng mà các thuật toán
có thể hiểu được (dạng số). Một kỹ thuật đơn giản nhất được sử dụng là One-hot
vector (1-of-N) [14]. Để chuyển đổi ngôn ngữ tự nhiên về dạng 1-of-N, cần tiến
hành xây dựng một bộ từ vựng. Mỗi vector đại diện cho một từ có số chiều bằng
số từ trong bộ từ vựng. Trong đó, mỗi vector chỉ có một phần tử duy nhất khác 0
(bằng 1) tại vị trí tương ứng với vị trí từ đó trong bộ từ vựng. Tuy nhiên, phương
pháp này lại để lộ ra những điểm hạn chế vô cùng lớn: Thứ nhất, độ dài của
vector là quá lớn (Ví dụ: Corpus Size(74M), Vocabulary size(10K) - theo
Vietwiki); Thứ hai, phương pháp này không xác định được sự tương quan ý
nghĩa giữa các từ do tích vô hướng của 2 từ bất kì đều bằng 0 dẫn đến độ tương
đồng cosin giữa 2 từ bất kì luôn bằng 0.
(2) Word2vec:
Năm 2013, Tomas Mikolov- một kỹ sư đang làm tại Google, đã giới thiệu
một mô hình mới có thể giải quyết tốt các vấn đề trên, mô hình được sử dụng tốt
cho đến ngày nay và được gọi là mô hình Word2vec [40]. Thay vì đếm và xây
dựng ma trận đồng xuất hiện, Word2vec học trực tiếp word vector có số chiều
thấp trong quá trình dự đoán các từ xung quanh mỗi từ. Đặc điểm của phương
pháp này là nhanh hơn và có thể dễ dàng kết hợp một câu văn bản mới hoặc
thêm vào từ vựng.

38
Word2vec là một mạng nơ-ron 2 lớp với duy nhất 1 tầng ẩn, lấy đầu vào là
một corpus lớn và sinh ra không gian vector (với số chiều khoảng vài trăm), với
mỗi từ duy nhất trong corpus được gắn với một vector tương ứng trong không
gian. Các word vector được xác định trong không gian vector sao cho những từ
có chung ngữ cảnh trong corpus được đặt gần nhau trong không gian. Dự đoán
chính xác cao về ý nghĩa của một từ dựa trên những lần xuất hiện trước đây.
Có 2 phương pháp chính được sử dụng trong quá trình xây dựng Word2vec:
- Sử dụng ngữ cảnh để dự đoán mục tiêu (Continuous Bag of Word -
CBOW).
- Sử dụng một từ để dự đoán ngữ cảnh mục tiêu (skip-gram) (cho kết quả
tốt hơn với dữ liệu lớn).
Mô hình chung của Word2vec (cả CBOW và Skip-gram) đều dựa trên 1
mạng nơ-ron khá đơn giản. Gọi V là tập tất cả các từ hay vocabulary với n từ
khác nhau. Layer input biểu diễn dưới dạng one-hot encoding với n node đại
diện cho n từ trong vocabulary. Activation function (hàm kích hoạt) chỉ có tại
layer cuối là softmax function, loss function là cross entropy loss, tương tự như
cách biểu diễn mô hình của các bài toán phân lớp thông thường vậy. Ở giữa 2
layer input và output là 1 layer trung gian với size = k, chính là vector sẽ được
sử dụng để biểu diễn các từ sau khi huấn luyện mô hình. Ta sẽ sử dụng từ ở giữa
(target word hoặc center word) cùng với các từ xung quanh nó (context words)
để mô hình thông qua đó sẽ tiến hành huấn luyện, cùng với đó, quy định 1 tham
số c hay window là việc sử dụng bao nhiêu từ xung quanh, gồm 2 bên trái, phải
của target word.
Hình 2.4. Mô hình chung của Word2Vec

39
Ý tưởng chính của CBOW là dựa vào các context word (hay các từ xung
quanh) để dự đoán center word (từ ở giữa). CBOW có điểm thuận lợi là training
mô hình nhanh hơn so với mô hình skip-gram, thường cho kết quả tốt hơn với
frequence words (các từ thường xuất hiện trong văn cảnh).
Skip-gram thì ngược lại với CBOW, dùng target word để dự đoán các từ
xung quanh. Skip-gram huấn luyện chậm hơn. Thường làm việc khá tốt với các
tập data nhỏ, đặc biệt do đặc trưng của mô hình nên khả năng vector hóa cho các
từ ít xuất hiện tốt hơn CBOW.
(3) Wordnet:
Wordnet [41] là một cơ sở dữ liệu về từ, trong đó các từ được nhóm lại
thành các loạt từ đồng nghĩa, các loạt từ đồng nghĩa này được gắn kết với nhau
nhờ các quan hệ ngữ nghĩa. Tuy nhiên, wordnet có một số hạn chế như:
- Thiếu sắc thái, ví dụ như các từ đồng nghĩa: Cố, cố gắng, gắng, nỗ lực
được xem là có mức độ như nhau.
- Thiếu từ mới hoặc ý nghĩa mới (không thể cập nhật): Sống thử, lầy, thả
thính, trẻ trâu, gấu…
- Chủ quan, phụ thuộc vào người tạo.
- Yêu cầu nhiều công sức tạo ra và cập nhật để thích ứng.
- Khó đo chính xác khoảng cách về nghĩa giữa các từ.
- Các hạn chế khác về chất lượng và cấu trúc lưu trữ.
(4) Fasttext:
Một nhược điểm lớn của Word2vec là nó chỉ sử dụng được những từ có
trong dataset, để khắc phục được điều này, chúng ta có Fasttext [42] là mở rộng
của Word2vec, được xây dựng bởi Facebook năm 2016. Thay vì training cho
đơn vị word, Fasttext chia văn bản ra làm nhiều đoạn nhỏ được gọi là n-gram
với cấp độ ký tự, ví dụ apple sẽ thành app, ppl và ple, vector của từ apple sẽ
bằng tổng của tất cả cái các thành phần này. Do vậy, nó xử lý rất tốt cho những
trường hợp từ hiếm gặp.
2.2.2. Mô hình, thuật toán phân loại phổ biến
Trong phần trước, luận văn đã đưa ra các phương pháp trích chọn đặc trưng
của ngôn từ phản động; cách thức vector hóa các đặc trưng của văn bản. Mỗi bài
viết, bình luận sau khi được trích chọn đặc trưng, đều sẽ được biểu diễn bằng
một vector đặc trưng như đã được trình bày. Nội dung của Mục này sẽ trình bày
một số mô hình, thuật toán phân lớp phổ biến được sử dụng để phát hiện nội
dung phản động.

40
Trong NLP, các kiến trúc, mô hình huấn luyện được áp dụng chủ yếu là
thuật toán học máy (Machine Learning) và thuật toán học sâu (Deep Learning).
Các thuật toán học máy được chia làm 3 loại chính: Học có giám sát (Supervised
Learning), học không giám sát (Unsupervised Learning), học tăng cường
(Reinforcement Learning). Học có giám sát thường được dùng trong các trường
hợp một thuộc tính/nhãn có sẵn cho một tập dữ liệu nhất định (tập huấn luyện),
nhưng không được đầy đủ và được dự đoán cho nhiều trường hợp khác. Học
không giám sát thường được sử dụng trong các trường hợp cần khám phá các
mối quan hệ tiềm ẩn nằm trong dữ liệu không có nhãn. Học tăng cường là
phương pháp nằm giữa hai loại thuật toán trên.
Zaghloul và cộng sự [54] đã so sánh độ hiệu suất trong việc phân lớp nhị
phân khi sử dụng SVM và mạng nơ-ron nhân tạo. Nghiên cứu chỉ ra rằng, SVM
là bộ phân loại tốt nhất, và mạng nơ-ron nhân tạo có thể sử dụng làm bộ phân
loại văn bản nếu hiệu suất của chúng tương đương với SVM. Các tác giả đã phát
hiện ra rằng, mạng nơ-ron nhân tạo là công cụ phân lớp văn bản rất khả thi với
hiệu suất tương đương với SVM, hơn thế, nó còn làm giảm kích thước dữ liệu đi
nhiều lần. Việc sử dụng các mạng nơ-ron để phân lớp văn bản sẽ là một lợi thế
lớn như một công cụ phân loại so với các công cụ khác vì nó có thể mang lại sự
tiết kiệm đáng kể về thời gian và chi phí tính toán.
Trong phạm vi bài toán xây dựng giải pháp kiểm duyệt bài viết, bình luận
tiếng Việt có nội dung phản động, tôi thử nghiệm một thuật toán học có giám sát
là thuật toán máy vector hỗ trợ SVM và một mô hình mạng nơ-ron đa tầng
truyền thẳng MLP.
2.2.2.1. Thuật toán SVM
Thuật toán SVM được Vapnik giới thiệu vào năm 1995. SVM được dùng
cho bài toán phân lớp nhị phân, tức là số lớp hạn chế là hai lớp. Giả sử đầu bài
cho tập hợp các điểm thuộc 2 loại trong môi trường N chiều, SVM là phương
pháp để tìm ra N-1 mặt phẳng để ngăn các điểm thành 2 nhóm. Một ví dụ cụ thể
đó là cho một tập hợp các điểm thuộc 2 loại như hình mô tả phía dưới, SVM có
nhiệm vụ tìm ra một đường thẳng để phân tách những điểm đó thành 2 loại sao
cho độ dài khoảng cách giữa đường thẳng và những điểm là xa nhất có thể.
SVM rất hiệu quả để giải quyết các bài toán với dữ liệu có số chiều lớn như các
vector biểu diễn văn bản. Hiện nay, SVM được đánh giá là bộ phân lớp chính
xác nhất cho bài toán phân lớp văn bản, bởi đặc tính phân lớp với tốc độ rất
nhanh và hiệu quả đối với bài toán phân lớp văn bản. Đối với bài toán phân lớp
văn bản sử dụng phương pháp SVM thì việc lựa chọn thuộc tính cho từng phân

41
lớp lại là vấn đề cực kỳ quan trọng, nó quyết định đến hiệu quả của phân lớp.
Phương pháp này thực hiện phân lớp dựa trên nguyên lý Cực tiểu hóa rủi ro
có cấu trúc SRM (Structural Risk Minimization) [43], được xem là một trong các
phương pháp phân lớp giám sát không tham số tinh vi. Các hàm công cụ của
SVM cho phép tạo không gian chuyển đổi để xây dựng mặt phẳng phân lớp để
phân chia các lớp ra thành các phần riêng biệt.
Hình 2.5. Support Vectors trong SVM
Các đường phân chia lớp được gọi là siêu phẳng (hyper-plane). Support
Vectors là các đối tượng trên đồ thị tọa độ quan sát, SVM là một biên giới để
chia hai lớp tốt nhất.
Hình 2.6. Margin trong SVM
Margin là khoảng cách giữa siêu phẳng đến 2 điểm dữ liệu gần nhất tương
ứng với các phân lớp. Trong ví dụ ở hình trên, margin chính là khoảng cách giữa
siêu phẳng và hai hình vuông, tròn gần nó nhất. Điều quan trọng ở đây đó là
phương pháp SVM luôn cố gắng cực đại hóa margin này, từ đó thu được một

42
siêu phẳng tạo khoảng cách xa nhất so với các hình vuông và tròn.
Ưu điểm của SVM:
Là một kĩ thuật phân lớp khá phổ biến, SVM thể hiện được nhiều ưu điểm
trong số đó có việc tính toán hiệu quả trên các tập dữ liệu lớn. Có thể kể thêm
một số ưu điểm của phương pháp này như:
- Xử lý trên không gian số chiều cao: SVM là một công cụ tính toán hiệu
quả trong không gian có số chiều cao, trong đó đặc biệt áp dụng cho các bài toán
phân loại văn bản và phân tích quan điểm nơi chiều có thể cực kỳ lớn.
- Tiết kiệm bộ nhớ: Do chỉ có một tập hợp con của các điểm được sử dụng
trong quá trình huấn luyện và ra quyết định thực tế cho các điểm dữ liệu mới
nên chỉ có những điểm cần thiết mới được lưu trữ trong bộ nhớ khi ra
quyết định.
- Tính linh hoạt - phân lớp thường là phi tuyến tính. Khả năng áp dụng
Kernel mới cho phép linh động giữa các phương pháp tuyến tính và phi tuyến
tính từ đó khiến cho hiệu suất phân loại lớn hơn.
Nhược điểm của SVM:
- Bài toán số chiều cao: Trong trường hợp số lượng thuộc tính (p) của tập
dữ liệu lớn hơn rất nhiều so với số lượng dữ liệu (n) thì SVM cho kết quả
khá tồi.
- Chưa thể hiện rõ tính xác suất: Việc phân lớp của SVM chỉ là việc cố
gắng tách các đối tượng vào hai lớp được phân tách bởi siêu phẳng SVM. Điều
này chưa giải thích được xác suất xuất hiện của một thành viên trong một nhóm
là như thế nào. Tuy nhiên, hiệu quả của việc phân lớp có thể được xác định dựa
vào khái niệm margin từ điểm dữ liệu mới đến siêu phẳng phân lớp đã nêu trên.
2.2.2.2. Mô hình MLP
MLP là mạng nơ-ron đơn giản được tạo ra từ các liên kết giữa các
perceptron (nơ-ron đơn lẻ) và là nền tảng để hiểu các mạng khác phức tạp hơn
trong học sâu. Một mạng MLP tổng quát là mạng có n (n≥2) tầng (thông thường
tầng đầu vào không được tính đến): Trong đó, gồm một tầng đầu ra (tầng thứ n)
và (n-1) tầng ẩn.

43
Hình 2.7: Cấu tạo mạng MLP cơ bản
Kiến trúc của một mạng MLP tổng quát có thể mô tả như sau:
Đầu vào là các vector (x1, x2, …, xp) trong không gian p chiều, đầu ra là
các vector (y1, y2, …, yq) trong không gian q chiều. Đối với các bài toán phân
loại, p chính là kích thước của mẫu đầu vào, q chính là số lớp cần phân loại.
Mỗi nơ-ron thuộc tầng sau liên kết với tất cả các nơ-ron thuộc tầng liền
trước nó. Đầu ra của nơ-ron tầng trước là đầu vào của nơ-ron thuộc tầng liền
sau nó.
Hoạt động của mạng MLP như sau:
Hình 2.8: Sử dụng mô hình MLP cho bài toán phân loại văn bản

44
Tại tầng đầu vào các nơ-ron nhận tín hiệu vào xử lý (tính tổng trọng số, gửi
tới hàm truyền) rồi cho ra kết quả (là kết quả của hàm truyền); kết quả này sẽ
được truyền tới các nơ-ron thuộc tầng ẩn thứ nhất; các nơ-ron tại đây tiếp nhận
như là tín hiệu đầu vào, xử lý và gửi kết quả đến tầng ẩn thứ 2. Quá trình tiếp tục
cho đến khi các nơ-ron thuộc tầng ra cho kết quả. Mạng MLP có thể được huấn
luyện bởi cả ba phương pháp học phổ biến là học có giám sát, học không giám
sát và học tăng cường.
Ứng dụng MLP cho bài toán phân loại văn bản: Để có thể sử dụng MLP
cho bài toán phân loại văn bản, cần nhúng từ (word embedding) để chuyển đổi
dữ liệu văn bản sang mô hình vector. Sau khi qua các lớp ẩn, đầu ra của mạng
MLP là số lượng lớp văn bản cần phần loại. Chúng ta có thể dễ dàng thiết kế
mạng MLP với số lượng lớp ẩn, số lượng nút tùy biến phù hợp với yêu cầu bài
toán. Các hàm kích hoạt thường được sử dụng bao gồm hàm ReLU, hàm
sigmoid và hàm tanh.
2.3. Sử dụng Hệ số tương quan Matthews
Độ chính xác của mô hình thử nghiệm trong luận văn được đánh giá dựa
trên Hệ số tương quan Matthews (MCC) [51].
MCC là một phương pháp riêng của giới Machine Learning, dùng để đánh
giá phẩm chất của mô hình phân loại nhị phân. Mục tiêu của MCC là khắc phục
vấn đề dữ liệu bị mất cân bằng. MCC có bản chất là một hệ số tương quan giữa
giá trị thực tế và kết quả dự báo của mô hình, nó được xác định như sau:
(6)
Trong đó: TP - True Positive (dự đoán đúng là Positive), TN - True
Negative (dự đoán đúng là Negative), FP - False Positive (dự đoán sai là
Positive), FN - False Negative (dự đoán sai là Negative).
Giá trị của MCC dao động trong khoảng từ -1 đến +1, MCC = +1 biểu thị
cho “kết quả phân loại hoàn hảo”, MCC = 0 cho thấy mô hình vô dụng (không
hơn gi sự phán đoán ngẫu nhiên), còn MCC = -1 cho thấy mô hình không những
vô dụng hoàn toàn mà còn tuyệt đối sai, vì kết quả phân loại hoàn toàn trái
nghịch với quan sát thực tế.
Như giải thích của Davide Chicco và Giuseppe Jurman [51] trong bài báo
“Ưu điểm của hệ số tương quan Matthews (MCC) so với điểm F1 và độ chính
xác trong hệ nhị phân đánh giá phân loại” (2020), hệ số tương quan MCC có
nhiều thông tin trong việc đánh giá các vấn đề phân loại nhị phân, vì nó tính đến
tỷ lệ cân bằng của bốn loại ma trận nhầm lẫn (TP, TN, FP, FN), trong khi nhiều
độ đo khác bỏ qua số lượng phủ định thực (TN).

45
Ví dụ: Ma trận nhầm lẫn với các mục: TP = 90, FP = 4; TN = 1, FN = 5.
Điểm F1 = 0,9524, khiến chúng ta hiểu nhầm rằng, bộ phân loại là cực kỳ tốt.
Ngược lại, bằng cách cắm những con số đó vào công thức của MCC, chúng ta
nhận được MCC = 0,14. MCC nằm trong khoảng từ -1 đến 1 (dù sao nó cũng là
hệ số tương quan) và 0,14 có nghĩa là bộ phân loại rất gần với bộ phân loại đoán
ngẫu nhiên. Từ ví dụ này, chúng ta có thể nói rằng, MCC giúp người ta xác định
sự kém hiệu quả của bộ phân loại trong việc phân loại, đặc biệt là các mẫu lớp
phủ định.
Hãy xem xét một ví dụ khác bằng cách đảo ngược nhãn âm và dương: Ma
trận nhầm lẫn với các mục: TP = 1, FP = 5; TN = 90, FN = 4. Điểm F1 là 0,18
và MCC là 0,103. Cả hai chỉ số đều gửi tín hiệu cho rằng, trình phân loại hoạt
động không tốt.
Kết luận: Để đánh giá phân loại nhị phân, các nhà nghiên cứu có thể sử
dụng một tỉ lệ thống kê phù hợp với mục tiêu bài toán mà họ đặt ra. Mặc dù đây
là một vấn đề quan trọng trong học máy, tuy nhiên hiện nay vẫn chưa đạt được
sự đồng thuận rộng rãi về lựa chọn chỉ số nào là tốt nhất. Độ chính xác
(Acccuracy) và F1 score tính toán trên ma trận nhầm lẫn (confusion matrix) đã
(và vẫn là) những chỉ số được sử dụng phổ biến nhất trong các nhiệm vụ phân
loại nhị phân. Tuy nhiên, các biện pháp thống kê nhiều khi sử dụng các chỉ số
này để thổi phồng quá mức các kết quả thí nghiệm đạt được, đặc biệt là trên các
bộ dữ liệu không cân bằng (imbalanced dataset). Trong khi F1 score bỏ qua số
lượng phủ định thực (TN), MCC mở rộng công thức của mình áp dụng cho cả 4
chỉ số của ma trận nhầm lẫn (TP, FP, TN, FN). Chỉ số MCC chỉ cao khi mô hình
“hoạt động tốt trên cả hai yếu tố tích cực và tiêu cực”. Đối với bài toán phân loại
bài viết, bình luận phản động, tôi nhận thấy sự mất cân bằng giữa hai loại nội
dung phản động và không phản động. Do đó, trong luận văn này, tôi thử nghiệm
dùng hệ số tương quan Matthews (MCC) để tính toán độ chính xác của các
bộ phân lớp.

46
CHƯƠNG 3: CÀI ĐẶT THỬ NGHIỆM
Trong chương này, tôi trình bày mô hình dịch vụ phát hiện bài viết, bình
luận mang nội dung phản động trên MXH Facebook. Từ mô hình này, tôi tập
trung tìm hiểu và khai thác các đặc trưng bổ trợ là blacklist về user, fanpage,
group trên Facebook và các website, blog phản động. Sau đó, tôi xây dựng mô
hình huấn luyện sử dụng học máy để tự động phát hiện nội dung phản động
trong các bài viết, bình luận. Để xây dựng mô hình, tôi bắt đầu từ việc thu thập
dữ liệu mẫu, gán nhãn dữ liệu, xây dựng bộ từ điển phản động (do nhiều hạn
chế, thuật toán được cài đặt mới chỉ dừng lại ở khai thác đặc trưng blacklist
word là chủ yếu, chưa xét đến phụ thuộc cú pháp hay từ loại trong tính độ phản
động của bài viết, binh luận). Tôi cũng trình bày quy trình triển khai, cài đặt một
extension cho trình duyệt Chrome với chức năng phát hiện nội dung phản động
trong bài viết, bình luận trên Facebook. Với extension này, các nội dung phản
động trên Facebook sẽ hạn chế hiển thị trên dòng thời gian của người dùng vì
phải chạy qua các bộ lọc của extension kiểm duyệt. Nếu phát hiện nội dung phản
động, extension sẽ ẩn nội dung đó trước khi đến với người dùng.
3.1. Mô hình kiểm duyệt nội dung phản động
Nhận thấy, thực trạng các bài viết, bình luận mang nội dung phản động,
chống phá Đảng, Nhà nước đang tràn lan trên MXH Facebook, tôi nhận thấy,
cần phải phát triển một dịch vụ kiểm duyệt nội dung bài viết, bình luận phản
động ngay trên trình duyệt của người dùng.
Hình 3.1: Mô hình kiểm duyệt 02 lớp đối với bài viết, bình luận phản động
trên Facebook

47
Cụ thể: Tôi xây dựng một extension trên trình duyệt Google Chrome bao
gồm 02 thành hần là Backend và Frontend. Phần Backend có chức năng đánh
giá nội dung của bài viết, bình luận có phản động hay không. Phần Frontend có
chức năng lọc các user, fanpage, group độc hại và gửi request kiểm duyệt nội
dung tới Backend. Backend sẽ cung cấp một API cho Frontend bất kỳ (trình
duyệt, app di động,…) có thể gửi bài viết, bình luận đến để thẩm định nội dung.
Extension hoạt động dựa trên mô hình gồm 02 lớp (Layer): Layer 1 có chức
năng thẩm định user, fanpage, group Facebook và Layer 2 có chức năng thẩm
định nội dung bài viết, bình luận.
3.2. Xây dựng các blacklist phản động
Căn cứ vào cách thức xây dựng blacklist nêu tại Chương 2. Tôi đã tập hợp
được danh sách những user, fanpage, group, website và blog phản động tiêu biểu
để đưa vào backlist. Các blacklist tập hợp được đến thời điểm hiện tại nhỏ hơn
so với thực tế rất nhiều. Tuy nhiên, những blacklist này sẽ tiếp tục được bổ sung
trong quá trình vận hành, sử dụng dịch vụ kiểm duyệt bài viết, bình luận phản
động. Những user, fanpage, group đều có lịch sử đăng tải rất nhiều bài đăng,
bình luận mang tính chất phản động, xúc phạm lãnh đạo Đảng và Nhà nước, do
vậy việc xây dựng danh sách này là vô cùng cần thiết. Người dùng sẽ được hạn
chế tối đa việc tiếp cận nội dung trên tường của các user, fanpage, group này.
Đối với blacklist các website, blog phản động, thông thường những website này
đều có lịch sử lâu dài đăng tải những bài viết xuyên tạc, bôi nhọ chủ trương,
đường lối của Đảng, chính sách và luật pháp của Nhà nước. Thuật toán tôi sẽ tự
động xác định xem bài viết, bình luận trên Facebook có chứa đường link URL
của các website, blog trong blacklist hay không, nếu có dịch vụ của tôi sẽ tự
động khóa bài đăng, bình luận đó.
Chi tiết các blacklist như sau:
Bảng 3.1: Danh sách một số user Facebook phản động
TT Tên người dùng Địa chỉ URL
01 Thanh Hieu Bui
(Người Buôn Gió) https://www.facebook.com/nguoibuon.gio.9
02
Lê Nguyễn Hương
Trà (Cô Gái Đồ
Long)
https://www.facebook.com/lenguyenhuongtra.de
03 Nguyễn Đình Ngọc https://www.facebook.com/profile.php?id=1000

48
TT Tên người dùng Địa chỉ URL
26376973361
04 Le Trung Khoa https://www.facebook.com/le.t.khoa.1
05 Nguyễn Văn Đài https://www.facebook.com/nguyenvandai0906
06 Dũng Trương https://www.facebook.com/truong.v.dung.73
07 Thao Teresa https://www.facebook.com/thao.teresa.3
08 Võ Hồng Ly https://www.facebook.com/hongly.vo.5059
09 Huynh Ngoc Chenh https://www.facebook.com/ho.lytien.1
10 ThanhTam Nguyen https://www.facebook.com/thanhtam.nguyen.52
643
11 Dominic Pham https://www.facebook.com/dominic.pham.12
12 Phạm Thanh Nghiên https://www.facebook.com/thanh.nghien.1
13 Nguyễn Thúy Hạnh
(Liberty) https://www.facebook.com/Melinh.liberty
14 Võ Hồng Ly https://www.facebook.com/hongly.vo.35
15 Pham Doan Trang https://www.facebook.com/pham.doan.trang
Bảng 3.2: Danh sách một số fanpage Facebook phản động
TT Tên fanpage Địa chỉ URL
01 Việt Tân https://www.facebook.com/Vi%E1%BB%87t
t%C3%A2n-206659726627079/
02 Bùi Thanh Hiếu https://www.facebook.com/nguoibuongio197
2hanoi/
03 Trương Châu Hữu
Danh https://www.facebook.com/hdanh81/
04 Nhật ký yêu nước https://www.facebook.com/nhatkyyeunuoc1/
05 VOA Tiếng Việt https://www.facebook.com/VOATiengViet/
06 Đài Á Châu Tự Do https://www.facebook.com/RFAVietnam/
07 Chân Trời Mới Media https://www.facebook.com/chantroimoimedia
08 ThuVien VietNam
ToanCau https://www.facebook.com/thuvientoancau/

49
TT Tên fanpage Địa chỉ URL
09 Dong Mau Lac Hong https://www.facebook.com/dongmau.lachong
10 Khối 8406 https://www.facebook.com/tudodanchudangu
yen
11
Hội Anh Em Dân Chủ -
Brotherhood For
Democracy
https://www.facebook.com/hoianhemdanchu/
12 Luật Sư Nguyễn Văn
Đài https://www.facebook.com/nvdai0906/
13 BBC News Tiếng Việt https://www.facebook.com/BBCVietnamese/
14 RFI Tiếng Việt https://www.facebook.com/RFIvi/
15 Đáp Lời Sông Núi https://www.facebook.com/radiodlsnvn/
Bảng 3.3: Danh sách một số group Facebook phản động
TT Tên nhóm Địa chỉ URL
01 VIỆT NAM CỘNG
HÒA
https://www.facebook.com/groups/Republico
fVN/
02 Quân Đội Việt Nam
Cộng Hòa
https://www.facebook.com/groups/80206172
3169611/
03 Quân lực - Việt Nam -
Cộng hòa
https://www.facebook.com/groups/RepublicO
fvietnamArmedForces/
04
TỔ QUỐC VN ĐANG
LÂM NGUY PHẢI
DIỆT CỘNG, THOÁT
TÀU
https://www.facebook.com/groups/17648929
2534071/
05 Lật đổ đảng Cộng Sản
VN Bán Nước, Hại Dân
https://www.facebook.com/groups/65267145
4882680/
06 Chế Độ Cộng Sản Thối
Nát
https://www.facebook.com/groups/29605356
4311454/
07 Hội anh em Dân Chủ
VNCH
https://www.facebook.com/groups/50133652
3359919/
08 HẬU DUỆ QUÂN
LỰC VNCH
https://www.facebook.com/groups/10370343
76349291/

50
TT Tên nhóm Địa chỉ URL
09
GÌN GIỮ VĂN HÓA
VÀ TRUYỀN THỐNG
CỜ VÀNG VNCH
https://www.facebook.com/groups/55146917
1673500/
10 Chiến Sĩ Việt Nam
Cộng Hòa
https://www.facebook.com/groups/chiensivod
anh/
11
Bộ Môi Trường Chính
Phủ Việt Nam Cộng
Hoà Lưu Vong.
https://www.facebook.com/groups/32381913
1434115/
12
Diễn Đàn Chính Phủ
Việt Nam Cộng Hoà
Lưu Vong
https://www.facebook.com/groups/RepublicO
fVietnamGovernmentInExile.Group/
13 Thân Hữu Chính Phủ
Việt Nam Cộng Hoà
https://www.facebook.com/groups/NguoiViet
QuocGiaChongTauCongVaVietCong/
14
Hội Đồng Chính Quyền
Địa Phương Việt Nam
Cộng Hoà
https://www.facebook.com/groups/HoiDong.
ChinhQuyen.DiaPhuong.VNCH.Group/
Bảng 3.4: Danh sách một số website, blog phản động
TT Tên website, blog Đường dẫn URL
01 Anh Ba Sàm https://basamnguyenhuuvinh.wordpress.com
02 Thông tin để tiến bộ http://dinhdan.blogspot.com
03 Bốn phương http://bon-phuong.blogspot.com/
04
TNT MEDIA SAN
DIEGO – Tiếng Nước
Tôi San Diego
http://tntmediasandiego.com
05 BÁO TIẾNG DÂN https://baotiengdan.com
06 THÁNH GIÓNG VIỆT
NAM
https://www.youtube.com/channel/UCnyZ9f0
InySiC7Ya5hzth5w
07 Viet vision https://www.youtube.com/user/vietvisionchan
nel
08 TIN MỚI HOA KỲ https://www.youtube.com/channel/UCrSaD9
wnMjaHB85GQJ-bxvA

51
TT Tên website, blog Đường dẫn URL
09 RFA Tiếng Việt https://www.youtube.com/user/RFAVietname
se
10 Hội nhà báo độc lập VN http://www.vietnamthoibao.org
11 CSVN-NHAN-QUYEN http://csvn-nhan-quyen.blogspot.com
12 CSVN lũ hèn https://fucksho.blogspot.com
13 Đài Đáp Lời Sông Núi http://www.radiodlsn.com
14 BBC News Tiếng Việt https://www.youtube.com/user/BBCVietnam
ese
15 RFA https://www.rfa.org/vietnamese
3.3. Xây dựng tập dữ liệu mẫu
3.3.1. Thu thập dữ liệu
Qua khảo sát, tôi đã tìm hiểu các công cụ thu thập dữ liệu Facebook được
sử dụng nhiều như Proxy Crawl [44], Octoparse [45], GNU Wget Software [46]
và Facepager [47]. Các công cụ có thể thu thập được dữ liệu Facebook với rất
nhiều tham số khác nhau page, post, comment, photo, video,... Tuy nhiên, điểm
yếu của các bộ công cụ là sử dụng Graph API [48], được Facebook thường
xuyên cập nhật phiên bản mới mà đa số các công cụ đều sử dụng phiên bản cũ.
Do đó, một số tính năng đôi khi sẽ bị lỗi khi sử dụng.
Trong nghiên cứu này, tôi đã tìm hiểu và sử dụng một Headless Browser
(chương trinh giả lập một trinh duyệt nhưng không có giao diện người dùng) là
Selenium [49] kết hợp trong ngôn ngữ Python để giả lập hành vi người dùng
trên trình duyệt web. Việc sử dụng Headless Browser sẽ làm cho các giới hạn
khi sử dụng Graph API được giải quyết, thu thập được nhiều dữ liệu hơn từ
Facebok. Các bước thực hiện để thu thập dữ liệu Facebook như sau:
Bước 1: Truy cập trang https://m.facebook.com và đăng nhập bằng tài
khoản, mật khẩu có sẵn.
Bước 2: Tìm ID của một user/fanpage bằng công cụ findmyfbid.in
Bước 3: Truy cập vào user/fanpage để thu thập các PostID (đặt giới hạn
mỗi page khoảng 2.500 post)
Bước 4: Từ danh sách PostID, thực hiện truy cập chi tiết bài viết, thu thập
dữ liệu bài viết và các bình luận.
Bước 5: Trích xuất dữ liệu bài viết và bình luận từ trang chi tiết bài viết.

52
Hinh 3.2: Minh họa thu thập bài viết bằng Selenium
Ứng với mỗi bài viết cụ thể, thuật toán tiếp tục thực hiện các bước trích
xuất nội dung bài viết và bình luận của bài viết như sau:

53
Hinh 3.3: Minh họa thu thập bình luận bằng Selenium
Thực hiện thuật toán trên tương ứng với các bài đăng trên trang cá nhân và
group ta thu được dữ liệu bài đăng của các đối tượng trên Facebook.
Dữ liệu được lưu trữ vào Hệ quản trị cơ sở dữ liệu MongoDB [50] để dễ
dàng trích xuất sang định dạng khác sau này. Trong đó, các thông tin bài viết
được lưu vào bảng post, gồm các trường cơ bản như: post_id, text, photo, video,
shared_text,... Tương tự, các bình luận trong các bài viết được lưu vào bảng
comment, gồm các trường cơ bản như: comment_id, text, photo, reaction,... Tôi

54
đã viết một đoạn script chạy bằng Python để trích xuất dữ liệu ra dạng CSV
(hình 3.28 phần Phụ lục).
Sau khi truy vấn dữ liệu từ MongoDB, thực hiện lưu dữ liệu dưới định
dạng CSV bằng thư viện Pandas trong Python.
Hinh 3.4: Mẫu dữ liệu bài viết thu thập được
Hình 3.5: Mẫu dữ liệu bình luận thu thập được
Kết thúc quá trình thu thập dữ liệu, tôi thu được dataset với gần hơn 20.000
bài viết và bình luận trên Facebook.
3.3.2. Gán nhãn dữ liệu
Sau khi thu thập dữ liệu, để phục vụ cho việc cài đặt các thuật toán đã tìm
hiểu, tôi tiến hành gán nhãn cho dữ liệu. Việc gán nhãn dữ liệu được thực hiện
hoàn toàn thủ công.

55
Mỗi bài viết hoặc bình luận sẽ được gán nhãn tương ứng. Cụ thể như sau:
- Nhãn là 1 nếu bài viết hoặc bình luận là phản động.
- Nhãn là -1 nếu bài viết hoặc bình luận không phải là phản động.
Một bài viết hoặc bình luận được coi là phản động khi thuộc một trong 11
nội dung mà tôi đã chỉ ra ở Mục 1.1.
Để có thể gán nhãn chính xác cho toàn bộ dataset đã thu thập ở trên, tôi đã
kêu gọi sự giúp đỡ từ đồng nghiệp với hai lượt gán nhãn và kiểm tra.
Tập dữ liệu được chia thành 20 file dữ liệu, mỗi file dữ liệu được một
người phụ trách gán nhãn. Sau khi quá trình gán nhãn hoàn tất, mỗi file dữ liệu
đã gán nhãn được kiểm tra lại bởi một người khác để đảm bảo nhãn của dữ liệu
là chính xác nhất có thể. Nếu có sự bất đồng quan điểm giữa người gán nhãn và
người kiểm tra, sẽ tiến hành mời một người thứ ba tham gia biểu quyết số đông
để xác định nhãn cho dữ liệu.
Hình 3.6: Mẫu dữ liệu bình luận sau khi được gán nhãn
3.4. Xây dựng bộ từ điển phản động
Do chưa có blacklist word các từ phản động cho tiếng Việt, cho nên luận
văn của tôi là công trình đầu tiên xây dựng từ điển phản động trong tiếng Việt.
Mỗi từ trong từ điển phản động được đánh trọng số tương ứng. Trọng số của các
từ trong blacklist word thể hiện mức độ phản động của từ và nằm trong khoảng
từ (0; 1]. Từ có trọng số càng lớn thì mức độ phản động càng cao. Để xây dựng
từ điển phản động cho tiếng Việt, tôi và đồng nghiệp hỗ trợ gán nhãn đã thực
hiện như sau: (1) Trong quá trình gán nhãn, nếu gặp từ nào là phản động sẽ thêm
từ đó vào từ điển (căn cứ vào 11 nội dung phản động đã xác đinh ở Mục 1.1);
(2) Tập hợp và theo dõi các user, fanpage, group, website, blog phản động để

56
nhận biết được các từ, cụm từ thường dùng trong các bài viết, bình luận
phản động.
Việc đánh trọng số cho các từ phản động cũng được tiến hành dựa trên việc
khảo sát từ các đồng nghiệp có cùng chuyên môn. Danh sách các từ phản động
sau khi được tập hợp sẽ được gửi cho nhóm từ 3-5 chuyên gia thẩm định, đánh
trọng số. Trọng số cuối cùng sẽ bằng trung bình chung trọng số của các thành
viên. Trọng số của từ phản động được đánh giá trên thang điểm từ 0-1, lẻ 2 số
thập phân.
Hình 3.7: Danh sách từ điển phản động đã xây dựng
3.5. Xây dựng vector đặc trưng
Sau khi hoàn tất khâu chuẩn bị dữ liệu và xây dựng các blacklist word phản
động, tôi đã tiến hành biểu diễn các đặc trưng cho dữ liệu như đã được trình bày
ở Chương 3 để tiến hành tổng hợp thành vector đặc trưng cho bài viết, bình luận.
Vector đặc trưng của bài viết, bình luận bao gồm:

57
- Các đặc trưng ngôn ngữ được xây dựng từ blacklist word phản động.
- Một số đặc trưng hình thái liên quan đến nội dung và ngữ pháp:
+ Độ dài của bình luận hoặc bài viết.
+ Số ký tự viết hoa/ tổng số ký tự của bình luận hoặc bài viết.
+ Số các ký tự không phải alphabet xuất hiện trong bình luận hoặc bài viết.
+ Số các dấu câu xuất hiện trong bình luận hoặc bài viết.
+ Số từ không có trong từ điển tiếng Việt xuất hiện trong bình luận hoặc
bài viết.
+ Tần xuất các từ viết tắt trong bài viết.
+ Độ dài trung bình của các từ.
+ Độ dài trung bình của các câu.
- Đặc trưng hình thái n-gram.
Một số đặc trưng hỗ trợ khác như ngữ cảnh, đặc trưng liên quan đến người
dùng và thông tin đa phương tiện, do khó khăn về kĩ thuật nên chưa áp dụng cho
việc xây dựng vector đặc trưng trong luận văn này. Cụ thể các bước được thực
hiện theo quy trình như sau:
(1) Bước 1: Đọc dữ liệu.
(2) Bước 2: Tách từ và gán trọng số phản động cho các từ trong câu.
Những từ nào có trong bộ từ điển phản động sẽ được gắn trọng số khác 0; những
từ còn lại có trọng số bằng 0. Để tính trọng số phản động cho toàn bộ nội dung
của bài viết hoặc bình luận, trước hết tôi tách dữ liệu văn bản thành các câu. Sau
đó, sử dụng thư viện VnCoreNLP để tách từ. Sau khi tách từ, đối chiếu với bộ từ
điển phản động để gắn trọng số cho các từ trong từng câu. Độ phản động của bài
viết, bình luận là tổng hợp toàn bộ độ phản động của các câu trong nó.
(3) Bước 3: Đặc trưng hình thái liên quan đến nội dung và ngữ pháp. Tính
toán các chỉ số liên quan đến các đặc trưng hình thái đã được mô tả ở Chương 3
để tạo thành thành phần vector đặc trưng của bài viết, bình luận.
- Tính số ký tự viết hoa/tổng số ký tự của bài viết hoặc bình luận. Sau đó
chuẩn hóa dữ liệu thành dưới dạng số trong khoảng [0;1].
- Tính độ dài bài viết, bình luận sau đó chuẩn hóa độ dài đó dưới dạng số
trong khoảng [0-1].
- Tính số ký tự không phải chữ cái xuất hiện trong bài viết, bình luận sau
đó chuẩn hóa thành số nằm trong khoảng [0-1].
- Tính tần suất sử dụng các ký tự đặc biệt trong bài viết, bình luận, sau đó
chuẩn hóa thành số nằm trong [0-1].

58
- Tính độ dài trung bình các từ sau đó chuẩn hóa thành số nằm trong [0-1].
- Tính tần suất xuất hiện từ viết tắt trong bài viết hoặc bình luận, sau đó
chuẩn hóa dữ liệu thu được thành dạng số nằm trong [0-1].
(Mã nguồn đọc dữ liệu, tính toán đặc trưng hinh thái liên quan đến nội
dung và ngữ pháp của bài viết, bình luận được tôi trình bày ở hình 3.29 đến
hình 3.37 mục 2 phần Phụ lục).
(4) Bước 4: Đặc trưng hình thái n-gram. Áp dụng bigram và trigram mức
ký tự cho bài viết và bình luận để trở thành một phần vector đặc trưng. Sử dụng
thư viện sklearn thông qua CountVectorizer. Do giới hạn về trang thiết bị dùng
để huấn luyện, tôi chỉ sử dụng mô hình bigram và trigram ở mức kí tự mà không
sử dụng mức từ. Tương lai nếu tiếp tục theo đuổi đề tài này, tôi sẽ thử áp dụng
nhiều phương pháp hơn, trong đó có sử dụng n-gram cấp độ từ.
(5) Bước 5: Tổng hợp vector đặc trưng. Gom các đặc trưng đã tạo ta có
vector đặc trưng hoàn chỉnh cho bài viết, bình luận.Vector đặc trưng là tổng hợp
từ 3 loại đặc trưng như đã nêu ở Bước 2, 3, 4.
Dữ liệu được scale lại bằng StandardScaler để mỗi đặc trưng thu được có
độ lệch chuẩn và trung bình tương tự phân phối chuẩn, thuận lợi cho việc huấn
luyện.Dữ liệu được phân chia thành tập huấn luyện và tập kiểm thử, trong đó tập
kiểm thử chiếm 30% toàn bộ lượng dữ liệu như đoạn code mô hình thể hiện
(14.000 mẫu ở tập huấn luyện, 6.000 mẫu ở tập kiểm tra).
Như vậy, bộ dữ liệu huấn luyện bao gồm 14.000 mẫu, mỗi mẫu đặc trưng
bởi 1 vector 42.229 chiều bao gồm các đặc trưng về hình thái, độ phản động dựa
trên bộ từ điển và đặc trưng n-gram. Cụ thể:
Đặc trưng về độ phản động: 1 chiều
Đặc trưng về hình thái: 6 chiều
Đặc trưng n-gram: 42.222 chiều
(Chi tiết tính toán các đặc trưng và tổng hợp vector đặc trưng được mô tả
ở hình 3.38-3.42 mục 2 phần Phụ lục).
3.6. Các mô hình thử nghiệm
Sau khi xử lý và chuẩn hóa dữ liệu, vector đặc trưng đã có được từ Mục 3.5
sẽ được sử dụng để huấn luyện mô hình.
* Độ quan trọng của mô hình n-gram trong xây dựng vector đặc trưng:
Để kiểm tra độ quan trọng của mô hình n-gram trong xây dựng vector đặc trưng
của bài viết, bình luận tiếng Việt, tôi tiến hành thử nghiệm theo phương pháp đó
là: Sử dụng thuật toán SVM và mô hình MLP để lần lượt huấn luyện với đầu
vào là 02 loại vector đặc trưng. Vector đặc trưng thứ nhất, bao gồm độ phản

59
động, hình thái và n-gram; vector đặc trưng thứ hai, chỉ có độ phản động và hình
thái mà không có n-gram.
* Thử nghiệm: Tôi lần lượt thực hiện 06 thử nghiệm, bao gồm:
SVM-3f: Bộ vector đặc trưng bao gồm: Blacklist word phản động, hình
thái và n-gram kết hợp với thuật toán SVM.
SVM-2f: Bộ vector đặc trưng bao gồm: Blacklist word phản động và hình
thái kết hợp với thuật toán SVM.
MLP-2f: Bộ vector đặc trưng bao gồm: Blacklist word phản động và hình
thái kết hợp mô hình MLP.
MLP-3f: Bộ vector đặc trưng bao gồm: Blacklist word phản động, hình
thái và n-gram kết hợp mô hình MLP.
SVM-BERT: Sử dụng pretrained PhoBert kết hợp với thuật toán SVM.
MLP-BERT: Sử dụng pretrained PhoBert kết hợp với mô hình MLP.
3.6.1. SVM-3f
Tôi sử dụng thư viện scikit-learn [52] cùng thuật toán LinearSVM để huấn
luyện mô hình. Cùng lúc, tôi sử dụng GridSearchCV để lựa chọn tham số C cho
thuật toán. C là tham số phạt trong bài toán soft-margin, được điều chỉnh để giúp
đưa các điểm dữ liệu nằm trong khoảng hai siêu mặt phẳng được vẽ bởi thuật
toán SVM về đúng phân lớp của chúng. Tôi cho chạy thuật toán GridSearchCV
với các tham số C lần lượt là [0.001, 0.01, 0.1, 1, 10, 100, 1.000, 10.000] (hình
3.43 phần Phụ lục).
Với mỗi tham số C, tôi sử dụng phương pháp cross-validation trên tập huấn
luyện với số lượng là 5.
Hình 3.8: Tham số C tốt nhất
Như vậy với tham số C ở giá trị 0,001, mô hình đạt kết quả khả quan nhất.
Đối với các bài viết, bình luận không phản động: Mô hình nhận diện sai
602/4.030 mẫu.
Đối với bài viết, bình luận có tính chất phản động: Mô hình nhận diện sai
539/1.970mẫu.
Kết quả tính toán hệ số MCC của mô hình là 0,572:

60
Hình 3.9: Kết quả thử nghiệm bộ vector đặc trưng bao gồm Blacklist word phản
động, hình thái, n-gram với thuật toán SVM
3.6.2. SVM-2f
Kết quả thử nghiệm bộ vector đặc trưng bao gồm Blacklist word phản
động, hình thái với thuật toán SVM đạt được như sau:
Hình 3.10: Kết quả thử nghiệm bộ vector đặc trưng bao gồm Blacklist word
phản động, hình thái với thuật toán SVM
Đối với các bài viết, bình luận không phản động: Mô hình nhận diện sai
1.889/4.279 mẫu.
Đối với bài viết, bình luận có tính chất phản động: Mô hình nhận diện sai
310/1.721 mẫu.
Kết quả tính toán hệ số MCC của mô hình là 0,344. Mô hình đem lại kết
quả phân loại khá tốt. Tuy nhiên, trong khi đạt kết quả khả quan trong việc nhận
diện các nội dung phản động, mô hình lại tỏ ra kém hiểu quả trong việc nhận
diện nội dung không phản động. Việc áp dụng mô hình này vào trong sản phẩm
thực tế sẽ gây khó dễ cho người dùng, khi gần như mô hình đánh giá quá nhiều
nội dung bài viết, bình luận là phản động.
3.6.3. MLP-2f
Kết quả mô hình đạt được như sau:
Hình 3.11: Kết quả huấn luyện bộ vector đặc trưng bao gồm Blacklist word
phản động và hình thái với mô hình MLP
Đối với các bài viết, bình luận không phản động: Mô hình nhận diện sai
398/4.279 mẫu.
Đối với bài viết, bình luận có tính chất phản động: Mô hình nhận diện sai
1.255/1.721 mẫu.

61
Kết quả tính toán hệ số MCC của mô hình là 0,228, phân loại khá tốt trong
việc xác định các bài viết, bình luận không phản động, tuy nhiên độ chính xác
khá thấp trong việc xác định các bài viết, bình luận phản động.
3.6.4. MLP-3f
Kết quả mô hình đạt được như sau:
Hình 3.12: Kết quả huấn luyện bộ vector đặc trưng bao gồm Blacklist word
phản động, hình thái và n-gram với mô hình MLP
Đối với các bài viết, bình luận không phản động: Mô hình nhận diện sai
897/4.279 mẫu.
Đối với bài viết, bình luận có tính chất phản động: Mô hình nhận diện sai
580/1.721 mẫu.
Kết quả tính toán hệ số MCC của mô hình là 0,432. Mô hình đạt chỉ số
tương đối khả quan trong việc nhận diện các bình luận không phản động lẫn
phản động. Tuy nhiên các chỉ số đạt được đều thấp hơn SVM-3f.
3.6.5. SVM-BERT
Với lần thử nghiệm này, tôi tiếp tục sử dụng Google Colab [53] để huấn
luyện và kiểm thử mô hình. Bộ dữ liệu huấn luyện vẫn bao gồm 20.000 dữ liệu,
chia ra thành 02 phần:
Bước 1: Load pretrained PhoBERT model và tiền xử lý văn bản.
Bước 2: Tạo features từ PhoBert. Bao gồm các công đoạn như:
- Tách từ trước khi đưa văn bản vào PhoBert.
- Tokenize văn bản bằng bộ Tokenizer của PhoBert (thêm 2 Token đặc biệt
là CLS và SEP vào đầu và cuối câu).
- Đưa văn bản đã được tokenize vào model kèm theo Attension Mask.
- Lấy output đầu ra làm đặc trưng cho đoạn văn bản sử dụng cho bước
tiếp theo.
Bước 3: Huấn luyện mô hình với SVM.
Hình 3.13: Kết quả huấn luyện mô hình sử dụng pretrained PhoBERT kết hợp
với thuật toán SVM

62
Đối với các bài viết, bình luận không phản động: Mô hình nhận diện sai
567/4.313 mẫu.
Đối với bài viết, bình luận có tính chất phản động: Mô hình nhận diện sai
857/1.687 mẫu.
Kết quả tính toán hệ số MCC của mô hình là 0,383. Mô hình có kết quả
phân loại tương tự MLP-3f, khá tốt với cả các bài viết, bình luận phản động và
không phản động. Tuy nhiên, mô hình này có độ chính xác trong nhận diện bài
viết, bình luận phản động thấp hơn MLP-3f.
3.6.6. MLP-BERT
Kết quả mô hình đạt được như sau:
Hình 3.14: Kết quả huấn luyện mô hình sử dụng pretrained PhoBERT kết hợp
với mô hìnhMLP
Đối với bài viết, bình luận không phản động: Mô hình nhận diện sai
1.618/4.274.
Đối với bài viết, bình luận phản động: Mô hình nhận diện sai
630/1.726 mẫu.
Kết quả tính toán hệ số MCC của mô hình là 0,233, tương đối thấp khi so
sánh với các mô hình đã được huấn luyện trước đó.
So sánh kết quả của 06 lần thử nghiệm:
Hình 3.15: Kết quả thực nghiệm các mô hình

63
Như vậy, dễ dàng nhận thấy hệ số MCC của việc sử dụng các bộ vector đặc
trưng gồm độ phản động, hình thái và n-gram kết hợp với thuật toán SVM
(SVM-3f) đạt kết quả cao nhất (0,572) khi so sánh tương quan với các mô
hình khác.
SVM-3f và MLP-3f có hệ số MCC cao hơn hẳn so với SVM-2f và MLP-2f
cho thấy đặc trưng n-gram vẫn đóng vài trò rất quan trọng trong việc đánh giá
nội dung bài viết, bình luận. Điều đó dẫn tới việc hi sinh các đặc trưng n-gram
khỏi tính toán bộ vector đặc trưng để tăng tốc độ đánh giá nội dung bình luận,
bài viết sẽ đem tới những kết quả không mong đợi.
Mặc dù không có mô hình nào đạt kết quả cao nhất, nhưng có thể nhận thấy
PhoBert hoạt động khá tốt, có tiềm năng cao trong việc ứng dụng xử lý ngôn
ngữ tiếng Việt. Đối với bài toán kiểm duyệt bài viết, bình luận phản động, có thể
do hạn chế về mặt kĩ thuật tôi fine-tune (tinh chỉnh) PhoBert theo ý của mình.
Do đó, tôi quyết định sẽ sử dụng mô hình SVM-3f để phát triển dịch vụ kiểm
duyệt bài viết, bình luận phản động trên Facebook.
(Một số kết quả chi tiết hơn của các mô hinh được tôi trình bày ở Mục 3
phần Phụ lục).
Cách thức làm việc: Dữ liệu bài viết, bình luận Facebook (kèm theo đinh
danh của user, fanpage, group) khi đi qua extension, Layer 1 sẽ kiểm tra, đối
chiếu, ngăn chặn các dữ liệu chứa user, fanpage, group nằm trong blacklist như
đã đề cập ở nội dung Chương 2. Dữ liệu Facebook nào vượt qua Layer 1, tiếp
tục được Layer 2 kiểm tra, Layer 2 có chức năng kiểm duyệt nội dung dựa trên
mô hình tôi đã thử nghiệm và phát triển tại Chương 3. Hệ thống sẽ trả lại giá trị
1 (dương tính) nếu bài viết mang tính chất phản động, và -1 (âm tính) đối với bài
viết không mang tính chất phản động.
Backend RESTful API được xây dựng trên framework Flask của Python dễ
dàng tích hợp với checkpoint của model. Backend gửi trả lại kết quả phân loại
nội dung bài viết, bình luận cho Frontend (mã nguồn của Backend được thể hiện
ở hình 3.52 trong phần Phụ lục).
Trước khi đánh giá nội dung phản động, các bài viết, bình luận sẽ được
kiểm tra liệu có chứa các đường link URL của các website, blog phản động hay
không. Nếu có, extension sẽ lập tức ẩn đi các nội dung đường link URL đó (hình
3.53 phần Phụ lục). Nội dung các bài viết, bình luận sẽ được tính toán, xây dựng
thành bộ vector đặc trưng như trong bước huấn luyện model. Bộ vector đặc
trưng này sẽ được Backend sử dụng và gán nhãn cho bài viết, bình luận phản
động hay không phản động, tương ứng kết quả trả về cho Frontend là 1 hoặc -1.

64
Bên cạnh Backend, tôi đã phát triển một Frontend khai thác dịch vụ do
Backend cung cấp để kiểm duyệt các bài viết, bình luận có nội dung phản động
trên Facebook. Frontend được cài đặt dưới dạng extension cho trình duyệt
Chrome, có chức năng đọc các bài viết, bình luận trên Facebook, gửi bài viết,
bình luận đến Backend để thẩm định và ẩn đi bài viết, bình luận nếu nó chứa nội
dung phản động.
Extension của Chome có cây thư mục bao gồm các file dưới đây:
Hinh 3.16: Cấu trúc thư mục extension
Hinh 3.17: File manifest.json
- Manifest.json: Là một file JSON bắt buộc phải có của extension trên trình
duyệt Google Chrome. File này khai báo các quyền cần cung cấp để hoạt động,
các thư viện dùng bên thứ ba, khai báo icon, các URL mà extension này hoạt
động, giới thiệu về extension.
Trong file này có khai báo name là tên extension, description là giới thiệu
về extension, version cho biết phiên bản của extension, conten_scripts cho biết
nhưng đoạn script sẽ được sử dụng trong extension. Trong extension này chỉ sử
dụng một file là content.js nhằm tương tác với trình duyệt, matches cho biết
những url sẽ thực thi extension (ở đây là facebook -
https://www.facebook.com/*). Đặc biệt là khai báo permissions bắt buộc phải có
url của server để khai báo xin phép Chrome là URL này được phép hoạt động.
Trong thử nghiệm này, tôi thử nghiệm server trên chính máy tính nội bộ, chạy
dịch vụ ở cổng 5.000 trong localhost, nên ta sẽ khai báo http://localhost:5000.
- Content.js: Là file javascript quan trọng nhất trong tiện ích mở rộng này,
có chức năng thực hiện nhiệm vụ đọc bài viết trên Facebook. Sau khi đọc được

65
bài viết, bình luận trên Facebook, extension sẽ gửi nội dung bài viết, bình luận
lên Backend để nhờ kiểm tra nội dung. Việc này được thực hiện thông qua hàm
startApp và kỹ thuật short polling (frontend sẽ gửi request đến server nhiều lần,
nếu có kết quả thi sẽ cập nhật). Như đã biết, Facebook dùng cơ chế loadmore để
để hiển thị thêm bài viết trên newsfeeds hoặc hiển thị thông tin bài viết trên
fanpage, group. Mỗi khi loadmore dữ liệu được load về và được đưa vào cây
DOM và render lại. Tương tự với bình luận, mỗi khi chọn xem thêm bình luận,
thì các bình luận mới được thêm vào cây DOM. Như vậy, cứ mỗi 03 giây, ta sẽ
lại xử lý những bài viết, bình luận mới được thêm vào trên cây DOM.
Nhận thấy, các bài viết và bình luận trong Facebook được gán vào những
thẻ div với những class tương ứng. Như vậy, sau khi tìm được những class mà
Facebook dùng để gán cho bình luận và bài viết, ta có thể lọc ra được nội dung
chứa trong thẻ div đó. Trước đây, để thực hiện được việc tìm HTMLElement
theo class đòi hỏi phải sử dụng thêm những thư viện ngoài như JQuery. Tuy
nhiên, từ năm 2015, với sự ra đời của tiêu chuẩn ES6, Javascript giờ đã hỗ trợ
lệnh querySelector, cho phép ta có thể tra các HTMLElement theo tên thẻ, tên
class, tên id.
Sau khi sử dụng querySelector để tìm được những HTMLElement cần, ta
có thể dễ dàng lọc ra nội dung của nó thông qua attribute (thuộc tính) innerText,
từ đó lấy được nội dung bên trong là bài viết, bình luận. Đồng thời, ta có thể
thay đổi và quản lý nó, thông qua việc update DOM (hình 3.54 phần Phụ lục).
Cơ chế hoạt động của hàm startApp: Để lấy được nội dung bài viết và
bình luận, ta sử dụng selector để lấy. Trước hết, ta cần phải tìm được các class,
id chứa nội dung cần tìm. Để làm được điều này ta có thể dùng công cụ inspect
elements trên Google chrome. Sau khi tìm được selector, ta sử dụng hàm
document.querySelector và document.querySelectorAll trong Javascript. Để hạn
chế việc gửi lên các nội dung cũ đã từng được check thì qua mỗi vòng lặp ta
thêm class “checked” để nếu có class này thì extension bỏ qua, việc này hạn chế
việc submit những nội dung đã check lên server, thông qua đó giảm tải cho
server, đồng thời tăng hiệu năng cho extension. Sau khi đã lấy được nội dung thì
ta gửi request tới server kiểm tra. Nếu response trả về là -1 nghĩa là không chứa
nội dung phản động. Ngược lại, nếu response trả về là 1 thì có chứa nội dung
phản động và ta tiến hành ẩn bài viết, bình luận.
Cài đặt Extension:
Để cài đặt extension cho trình duyệt Chrome, ta thực hiện các bước sau:
66
Bước 1: Vào trình duyệt Chrome > Customize and Control Google Chrome
> More Tools > Extensions
Bước 2: Nhấn vào Load unpacked.
Bước 3: Trỏ đến folder chứa extension và nhấn OK.
Hình 3.18: Giao diện extension Chrome
Hinh 3.19: Cài đặt extension thành công
Thực hiện cài đặt extension “Bộ lọc bình luận 1.0” thành công.

67
Hình 3.20: Trước khi sử dụng extension
Trước khi sử dụng extension, các bài viết, bình luận trên Facebook hiển thị
bình thường. Sau khi cài đặt extension thành công, extension sẽ đọc và phân tích
nội dung các bài viết, bình luận trên Facebook và sẽ có hành động tương ứng.
Khi người dùng truy cập vào trang cá nhân, fanpage hay hội nhóm bị cấm,
extension sẽ chặn người dùng tiếp cận đến những thông tin độc hại mà những
trang đó cung cấp.

68
Hình 3.21: Extension chặn các nhóm độc hại, chống phá
Hình 3.22: Extension chặn các người dùng có hành vi phản động
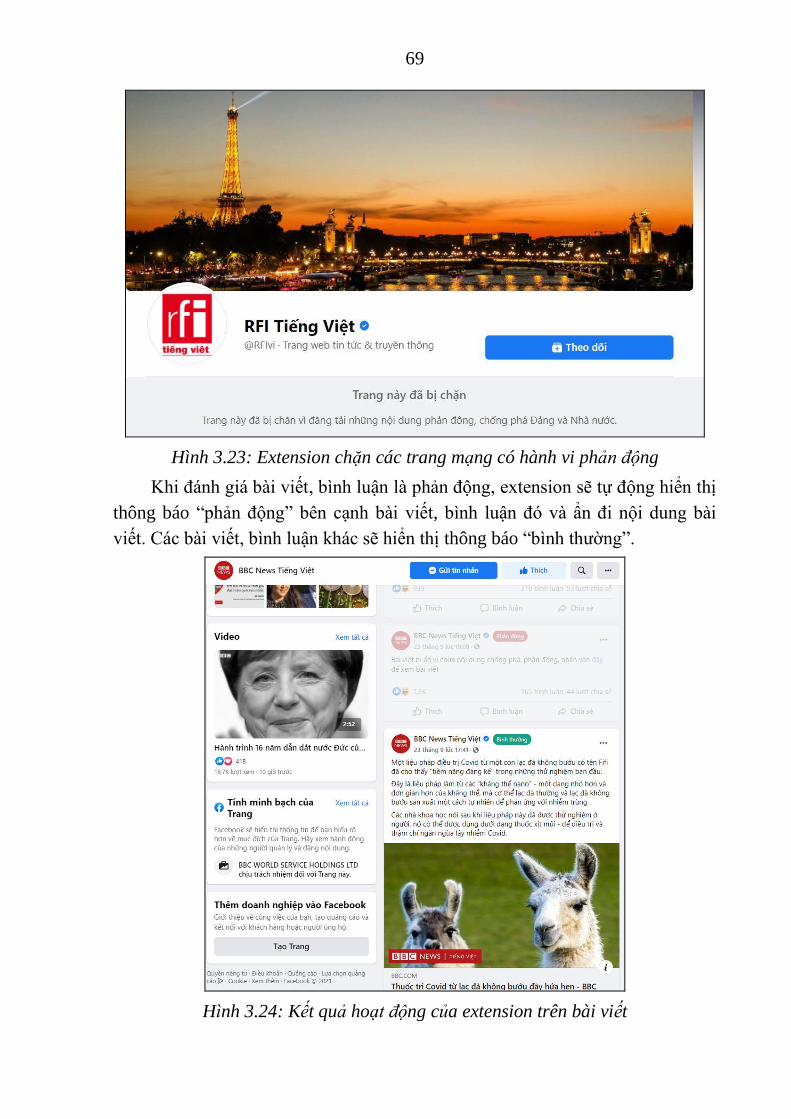
69
Hình 3.23: Extension chặn các trang mạng có hành vi phản động
Khi đánh giá bài viết, bình luận là phản động, extension sẽ tự động hiển thị
thông báo “phản động” bên cạnh bài viết, bình luận đó và ẩn đi nội dung bài
viết. Các bài viết, bình luận khác sẽ hiển thị thông báo “bình thường”.
Hinh 3.24: Kết quả hoạt động của extension trên bài viết

70
Có thể thấy rõ 02 bài viết trên fanpage BBC News Tiếng Việt, một bài viết
đã bị ẩn đi, một bài viết vẫn hiển thị bình thường. Khi nhấn vào xem nội dung
bài viết phản động, bài viết vẫn sẽ được hiển thị bình thường, nhưng được làm
mờ đi.
Hinh 3.25: Sau khi hiện ra bài viết bi ân (bài viết sẽ vẫn bi làm mờ).
Đối với các bình luận, cách thức hoạt động tương tự đối với các bài đăng.
Các bình luận có nội dung phản động sẽ được ẩn đi nội dung như hình dưới.

71
Hinh 3.26: Kết quả hoạt động của extension trên bình luận
Người dùng có thể nhấn vào chữ “đây” để hiển thị bình luận bị ẩn. Các
bình luận bị ẩn khi người dùng muốn hiển thị trợ lại sẽ được làm mờ.
Hinh 3.27: Sau khi hiện ra binh luận bi ân.
Sau khi đã hiện bình luận bị ẩn, để ẩn lại, chúng ta click vào icon “Phản
động” của bình luận đó.

72
CHƯƠNG 4: KẾT LUẬN VÀ HƯỚNG PHÁT TRIỂN
4.1. Kết luận
Luận văn nghiên cứu về kiểm duyệt bài viết và bình luận tiếng Việt có nội
dung phản động trên MXH Facebook nhằm hạn chế các thông tin tiêu cực, có
ảnh hưởng, tác động xấu đến tư tưởng chính trị của người dùng. Đây là một
nghiên cứu ban đầu, làm nền tảng cơ sở xây dựng các bộ công cụ hạn chế âm
mưu của các thế lực thù địch, lực lượng phản động, CH-CĐCT sử dụng MXH
Facebook nhằm lôi kéo, kích động người dân chống đối chính quyền, chống phá
Đảng, Nhà nước Việt Nam. Luận văn đã thực hiện những công việc chính sau:
(1) Ứng dụng 02 tầng (Layer) để kiểm duyệt nội dung phản động, gồm:
Layer 1 kiểm duyệt các blacklist đã xây dựng sẵn; Layer 2 kiểm duyệt nội dung
bằng các phương pháp học máy.
(2) Layer 2 ứng dụng các phương pháp học máy tiêu biểu (SVM, MLP)
trong phân lớp văn bản nhị phân kết hợp với các phương pháp trích chọn đặc
trưng phổ biến là n-gram để huấn luyện các mô hình kiểm duyệt.
(3) Xây dựng bộ từ điển phản động (blacklist word) có đánh trọng số làm
tiêu chí đánh giá bài viết, bình luận có nội dung phản động.
(4) So sánh độ hiệu quả của việc sử dụng và không sử dụng mô hình n-
gram trong việc trích trọn đặc trưng phản động.
(5) So sánh độ hiệu quả của phương pháp xây dựng vector đặc trưng mới là
PhoBERT với các phương pháp xây dựng vector đặc trưng truyền thống.
(6) Sử dụng Hệ số tương quan Matthews (MCC) thay cho F1 score để đánh
giá phẩm chất của mô hình phân loại nhị phân; đã khắc phục được vấn đề dữ
liệu mất cân bằng.
(7) Sử dụng Headless Browser kết hợp với ngôn ngữ lập trình Python để
thu thập dữ liệu huấn luyện; giải quyết được những hạn chế trước đây khi sử
dụng Graph API của Facebook.
4.2. Hướng phát triển
Trong phạm vi luận văn này, dịch vụ kiểm duyệt nội dung phản động mới
chỉ đơn giản là tổng hợp một số đặc trưng để tính mức độ phản động của bài
viết, bình luận; kết hợp với việc sử dụng các blacklist user, fanpage, group,
website, blog phản động. Để nâng cao hiệu quả kiểm duyệt và đạt độ chính xác
cao hơn, cần xác định thêm các đặc trưng phản động khác; thử nghiệm trên các
mô hình, thuật toán khác nhau để tìm ra được mô hình, thuật toán hiệu quả nhất.

73
Từ đó ứng dụng để phát triển các công cụ, phần mềm hỗ trợ hiệu quả cho việc
ngăn chặn, kiểm duyệt các nội dung phản động trên các nền tảng MXH nói
chung và trên Facebook nói riêng. Tiến tới nghiên cứu, cài đặt thuật toán trên
Forward Proxy Server để áp dụng tại các cơ quan, tổ chức, trường học... nhằm
hạn chế người dùng tiếp cận các nội dung không phù hợp (phản động) trên
MXH Facebook./.

74
TÀI LIỆU THAM KHẢO
Tiếng Việt
1. Hơn 35 thống kê và sự kiện của Facebook cho năm 2021 (2021).
https://www.websitehostingrating.com/vi/research/facebook-statistics/
2. Số liệu thống kê: Việt Nam có 69.280.000 người sử dụng Facebook
(2020). https://vietnamnet.vn/vn/goc-nhin/so-lieu-thong-ke-viet-nam-co-
69-280-000-nguoi-su-dung-facebook-700013.html
3. Kiên quyết đấu tranh với thủ đoạn lợi dụng internet và mạng xã hội để
thúc đây “tự diễn biến”, “tự chuyển hóa”.
http://tinhuyhoabinh.vn/chuyenmuc/chitietchuyenmuc/tabid/236/title/759
1/ctitle/234/Default.aspx?TopMenuId=6&cMenu1=234
4. Các thế lực thù đich đang lợi dụng dich Covid-19 để chống phá Đảng,
Nhà nước (2021). https://vov.vn/phap-luat/cac-the-luc-thu-dich-dang-loi-
dung-dich-covid-19-de-chong-pha-dang-nha-nuoc-875534.vov
5. Cần xử lý nghiêm hành vi của Trương Châu Hữu Danh và các thành viên
nhóm “Báo Sạch” (2021). https://cand.com.vn/Lan-theo-dau-vet-toi-
pham/can-xu-ly-nghiem-hanh-vi-cua-truong-chau-huu-danh-va-cac-
thanh-vien-nhom-bao-sach-i628982/
6. Facebook sẽ chặn quảng cáo chính tri từ các tài khoản phản động (2020).
https://congan.com.vn/tin-chinh/facebook-se-chan-quang-cao-chinh-tri-tu-
cac-tai-khoan-phan-dong_100905.html
7. Khoản 1, Điều 8 của Luật An ninh mạng 2018 quy định “Các hành vi bị
nghiêm cấm về an ninh mạng”
8. Khoản 1, Điều 16 của Luật An ninh mạng 2018 quy định “Thông tin trên
không gian mạng có nội dung tuyên truyền chống Nhà nước Cộng hòa xã
hội chủ nghĩa Việt Nam”
9. Khoản 2, Điều 16 của Luật An ninh mạng 2018 quy định “Thông tin trên
không gian mạng có nội dung kích động gây bạo loạn, phá rối an ninh,
gây rối trật tự công cộng”
10. Khoản 4, Điều 64, Nghị định 174/2013/NĐ-CP ngày 13/11/2013 của
Chính phủ quy định về “xử phạt vi phạm hành chính trong lĩnh vực bưu
chính, viễn thông, công nghệ thông tin và tần số vô tuyến điện”
11. Vietlex. http://www.vietlex.com/
12. Phân loại văn bản tiếng Việt (2019).
https://github.com/undertheseanlp/classification
13. Biểu diễn Mã hóa hai chiều từ Transformer (BERT).
https://d2l.aivivn.com/chapter_natural-language-processing-

75
pretraining/bert_vn.html
14. Mã hóa one-hot.
https://machinelearningcoban.com/tabml_book/ch_data_processing/oneho
t.html
Tiếng Anh
15. Ying Chen, Sencun Zhu, Yilu Zhou, Heng Xu (2012), Detecting Offensive
Language in Social Media to Protect Adolescent Online Safety,
International Conference on Privacy, Security, Risk and Trust and 2012
International Confernece on Social Computing, Amsterdam, Netherlands.
16. Chikashi Nobata, Joel Tetreault, Achint Thomas, Yashar Mehdad, Yi
Chang (2016), Abusive Language Detection in Online User Content,
WWW '16: Proceedings of the 25th International Conference on World
Wide Web, pp 145-153, Montréal Québec, Canada.
17. Anna Schmidt, Michael Wiegand (2017), A Survey on Hate Speech
Detection using Natural Language Processing, Saarbrucken, Germany
18. Chu, Theodora, Kylie Jue and Max Wang. “Comment Abuse
Classification with Deep Learning.” (2017).
19. Jeffrey Pennington, Richard Socher, Christopher D Manning 2014 Glove:
Global vectors for word representation , Proceedings of the 2014
conference on empirical methods in natural language processing
(EMNLP)
20. Cao Van Viet, Do Ngoc Quynh, Le Anh Cuong Building and Evaluating
Vietnamese Language Models VNU Jounal of science, Mathermatics -
Physics 27 (2011) 134-146
21. Chung, Sungyup et al. “N-gram language modeling of Japanese using
bunsetsu boundaries.” INTERSPEECH (2004).
22. Ito, Akinori & Kohda, M. (1996). Language modeling by string pattern N-
gram for Japanese speech recognition. 1. 490 - 493 vol.1.
10.1109/ICSLP.1996.607161.
23. S. Yang, H. Zhu, A. Apostoli and P. Cao, “N-gram Statistics in English
and Chinese: Similarities and Differences”, International Conference on
Semantic Computing (ICSC 2007), 2007, pp. 454-460, doi:
10.1109/ICSC.2007.46.
24. Ha, Le Quan et al. “Extension of Zipf's Law to Word and Character N-
grams for English and Chinese.” Int. J. Comput. Linguistics Chin. Lang.
Process. 8 (2003): n. pag.
25. Nguyen, Dat Quoc and Anh Gia-Tuan Nguyen. “PhoBERT: Pre-trained
language models for Vietnamese.” ArXiv abs/2003.00744 (2020): n. pag.
26. Devlin, Jacob et al. “BERT: Pre-training of Deep Bidirectional

76
Transformers for Language Understanding.” NAACL (2019).
27. Radford, Alec and Karthik Narasimhan. “Improving Language
Understanding by Generative Pre-Training.” (2018).
28. Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi
Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov
RoBERTa: A Robustly Optimized BERT Pretraining
ApproacharXiv:1907.11692
29. Yang Liu Fine-tune BERT for Extractive Summarization
arXiv:1903.10318
30. Sun, Chi et al. “Utilizing BERT for Aspect-Based Sentiment Analysis via
Constructing Auxiliary Sentence.” NAACL (2019).
31. Xu, Hu et al. “BERT Post-Training for Review Reading Comprehension
and Aspect-based Sentiment Analysis.” NAACL (2019).
32. Tianda Li , Jia-Chen Gu , Xiaodan Zhu , Quan Liu , Zhen-Hua Ling ,
Zhiming Su , Si Wei DialBERT: A Hierarchical Pre-Trained Model for
Conversation Disentanglement arXiv:2004.03760
33. Raphael Scheible, Fabian Thomczyk, Patric Tippmann, Victor Jaravine,
Martin Boeker GottBERT: a pure German Language Model
arXiv:2012.02110
34. Abdelali, Ahmed et al. “Pre-Training BERT on Arabic Tweets: Practical
Considerations.” ArXiv abs/2102.10684 (2021): n. pag.
35. Le, Hang & Vial, Loïc & Frej, Jibril & Segonne, Vincent & Coavoux,
Maximin & Lecouteux, Benjamin & Allauzen, Alexandre & Crabbé,
Benoît & Besacier, Laurent & Schwab, Didier. (2019). FlauBERT:
Unsupervised Language Model Pre-training for French.
36. Jose Canete, Gabriel Chaperon, Rodrigo Fuentes, Jou-Hui Ho, Hojin
Kang, Jorge Perez, SPANISH PRE-TRAINED BERT MODEL AND
EVALUATION DATA, PML4DC, ICLR 2020
37. Zheng, Xiaoqing et al. “Learning Context-Specific Word/Character
Embeddings.” AAAI (2017).
38. Feng, Jiangtao and Xiaoqing Zheng. “Geometric Relationship between
Word and Context Representations.” AAAI (2018).
39. Huang, Eric Hsin-Chun et al. “Improving Word Representations via
Global Context and Multiple Word Prototypes.” ACL (2012).
40. T Mikolov, K Chen, G Corrado, J Dean - Efficient Estimation of Word
Representations in Vector Space arXiv preprint arXiv:1301.3781, 2013
41. George A. Miller, Richard Beckwith, Christiane Fellbaum, Derek Gross,
and Katherine Miller - Introduction to WordNet: An On-line Lexical
Database 1995

77
42. Bojanowski, Piotr & Grave, Edouard & Joulin, Armand & Mikolov,
Tomas. (2016). Enriching Word Vectors with Subword Information.
Transactions of the Association for Computational Linguistics. 5.
10.1162/tacl_a_00051.
43. Vapnik, Vladimir N. The Nature of Statistical Learning Theory. New
York: Springer, 1995
44. Proxy. Crawl. Scale. https://proxycrawl.com/
45. Facebook Scraping Case Study | Scraping Facebook Groups (2017).
https://www.octoparse.com/tutorial/facebook-scraping-case-study-
scraping-facebook-groups/?qu
46. GNU Wget. https://www.gnu.org/software/wget/
47. Facepager. https://github.com/strohne/Facepager/releases
48. Graph API. https://developers.facebook.com/docs/graph-api/
49. Selenium with Python. https://selenium-python.readthedocs.io/
50. MongoDB. https://www.mongodb.com/
51. Davide Chicco, Giuseppe Jurman (2020), The advantages of the
Matthews correlation coefficient (MCC) over F1 score and accuracy in
binary classification evaluation, https://doi.org/10.1186/s12864-019-
6413-7
52. Scikit-learn. Machine Learning in Python. https://scikit-learn.org/stable/
53. Google Colab. https://colab.research.google.com
54. Zaghloul, W., Lee, S.M. and Trimi, S. (2009), "Text classification: neural
networks vs support vector machines", Industrial Management & Data
Systems, Vol. 109 No. 5, pp. 708-717.
https://doi.org/10.1108/02635570910957669

78
PHỤ LỤC
Mã nguồn dịch vụ kiểm duyệt bài viết, bình luận phản động trên Facebook
Mục 1: Trích xuất dữ liệu bình luận vào CSDL
Hinh 3.28: Code tách comment json bằng Python
Mục 2: Xây dựng vector đặc trưng
Hình 3.29: Mã nguồn đọc bộ dữ liệu bao gồm 20.000 bài viết, bình luận trên
Facebook từ nhiều user, fanpage, group khác nhau.

79
Hình 3.30: Mẫu dữ liệu sử dụng cho huấn luyện và kiểm tra mô hình
Hình 3.31: Mã nguồn tính toán độ phản động của các bài viết, bình luận

80
Hình 3.32: Hàm tính toán tỉ lệ ký tự viết hoa trong bình luận, bài viết
Hình 3.33: Hàm tính độ dài bài viết
Hình 3.34: Hàm tính tần suất sử dụng các ký tự không phải alphabet

81
Hình 3.35: Hàm tính tần suất sử dụng các ký tự đặc biệt
Hình 3.36: Hàm tính độ dài trung bình các từ

82
Hình 3.37: Hàm tính tần suất sử dụng các từ viết tắt
Hình 3.38: Sử dụng bigram và trigram mức ký tự cho bài viết, bình luận.

83
Hình 3.39: Đặc trưng về độ phản động
Hình 3.40: Đặc trưng về hình thái
Hình 3.41: Đặc trưng n-gram
Hình 3.42: Phân chia dữ liệu và tính toán vector đặc trưng

84
Hình 3.43: Thuật toán GridSearchCV tìm tham số C tối ưu
Hình 3.44: Load pretrained PhoBERT model và tiền xử lý văn bản

85
Hình 3.45: Tạo features từ PhoBert
Mục 3: Một số kết quả thực nghiệm

86
Hình 3.46: Kết quả huấn luyện SVM-3f
Hình 3.47: Kết quả huấn luyện SVM-2f
Hình 3.48: Kết quả huấn luyện MLP-2f

87
Hình 3.49: Kết quả huấn luyện MLP-3f
Hình 3.50: Kết quả huấn luyện SVM-BERT
Hình 3.51: Kết quả huấn luyện MLP-BERT

88
Mục 4: Kiểm duyệt nội dung phản động trên Facebook
Hình 3.52: Mã nguồn Server backend

89
Hình 3.53: Kiểm tra sự xuất hiện của các đường link URL đến website, blog
phản động trong nội dung bài viết, bình luận trên Facebook.
Hình 3.54: Một số thẻ div được sử dụng để lấy thông tin từ bài viết, bình luận




















