
Karuza, E., Farmer, T., Fine, A. B., Smith, F. X., and Jaeger, T. F. UNDER REVIEW. Evidence for the...
68
Running head: PREDICTION DURING LEARNING Evidence for the fine-tuning of expectations in self-paced non- adjacent dependency learning Elisabeth A. Karuza *1 , Thomas A. Farmer 2 , Alex B. Fine 3 , Francis X. Smith 2 , & T. Florian Jaeger 1,4,5 1 Department of Brain and Cognitive Sciences, University of Rochester, Rochester, NY 14627 2 Department of Psychology, University of Iowa, Iowa City, IA 52242 3 Department of Psychology, The Hebrew University of Jerusalem, Israel 4 Department of Linguistics, University of Rochester, Rochester, NY 14627 5 Department of Computer Science, University of Rochester, Rochester, NY 14627 1
Transcript of Karuza, E., Farmer, T., Fine, A. B., Smith, F. X., and Jaeger, T. F. UNDER REVIEW. Evidence for the...

Running head: PREDICTION DURING LEARNING
Evidence for the fine-tuning of expectations in self-paced non-
adjacent dependency learning
Elisabeth A. Karuza*1, Thomas A. Farmer2, Alex B. Fine3, Francis
X. Smith2, & T. Florian Jaeger1,4,5
1Department of Brain and Cognitive Sciences, University ofRochester, Rochester, NY 14627
2Department of Psychology, University of Iowa, Iowa City, IA52242
3Department of Psychology, The Hebrew University of Jerusalem,Israel
4Department of Linguistics, University of Rochester, Rochester,NY 14627
5Department of Computer Science, University of Rochester,Rochester, NY 14627
1

Running head: PREDICTION DURING LEARNING
Corresponding Author*:Elisabeth A. Karuza
Center for Cognitive NeuroscienceGoddard Laboratories Room 322University of Pennsylvania
Philadelphia PA 19104Email: [email protected]
*Author’s current affiliation differs from the bylineaffiliation
WORD COUNT: 7165
Abstract
As lifelong statistical learners, humans are remarkably sensitive
to the unfolding of elements and events in their surroundings. In
the present work, we examine the bi-directional influence of
prediction-based processing and learning as adult participants
were exposed to a visual artificial grammar containing a non-
adjacent dependency. Using a self-paced moving window display, we
recorded response times as learners progressed through a series
of structured glyph sequences. After accounting for general task
adaptation effects, we quantified the growing influence of
element predictability on those response times. We find that, as
a function of exposure, participants generally processed the
2

Running head: PREDICTION DURING LEARNING
grammar increasingly faster; however, the facilitatory benefit
was significantly greater for the perfectly predictable items of
the grammar. In turn, this progressive processing benefit on
predictable elements was uniquely correlated with off-line
performance on a post-test. Our results indicate that
participants who develop implicit predictions as they learn, and
have their expectations met, achieve higher learning outcomes.
Links between these findings, obtained with novel stimuli in an
experimental context, and the role of prediction in natural
language comprehension are considered.
Introduction
3

Running head: PREDICTION DURING LEARNING
Underlying our ability to interact effectively with the
environment is neural machinery equipped to acquire novel
representations and take advantage of expectations about familiar
ones. In the case of language, this means that the human brain
contends both with learning and efficiently understanding it.
Though acquisition and comprehension differ in a number of
respects, they are related in that they both hinge on an
exquisite sensitivity to the statistical patterns inherent to
linguistic input (Seidenberg & MacDonald, 1999). A substantial
literature on “statistical learning” has demonstrated that
infants and adults can detect regularities embedded in artificial
languages in order to form representations of previously unknown
structures (see Romberg & Saffran, 2010 for a review). Likewise,
studies of natural language processing offer evidence that stored
knowledge of probabilistic grammatical patterns plays a central
role in on-line comprehension (e.g., Arai & Keller, 2013;
Garnsey, Pearlmutter, Myers, & Lotocky, 1997; Jurafsky, 1996;
Levy, 2008; MacDonald, Pearlmutter, & Seidenberg, 1994;
Trueswell, Tanenhaus, & Garnsey, 1994; for a review, see
MacDonald, 2013). Recurrent in this work is the observation
4

Running head: PREDICTION DURING LEARNING
that, as syntactic structures unfold, downstream elements that
are statistically predictable require fewer processing resources.
Furthermore, once we have developed relatively stable knowledge
of predictive relationships, we can rapidly adapt our
expectations about upcoming input based on context-specific
statistics (e.g., Farmer, Fine, Yan, Cheimariou, & Jaeger, 2014;
Fine, Jaeger, Farmer, & Qian, 2013; Kamide, 2012). Adult
listeners will, for example, show a reduction in ERP surprisal
effects as they are repeatedly exposed to syntactic violations in
their native language (Hanulíková, Van Alphen, Van Goch, & Weber,
2012; see also Hahne & Friederici, 1999).
Thus, expectation-based processing has been implicated as a
key mechanism in language comprehension. While knowledge of
predictive relationships are known to arise early in first
language acquisition (e.g., Bannard & Matthews, 2008; Lew-
Williams & Fernald, 2007), less attention has been paid to how
this knowledge, as it is being acquired, affects processing
efficiency in adults. In the present set of experiments, we offer
new insight into the intersection between the language
comprehension and acquisition literatures. We investigate how
5

Running head: PREDICTION DURING LEARNING
statistical learning mechanisms shape the development of accurate
expectancies made during exposure to unfamiliar input. Modifying
the canonical statistical learning paradigm to allow for the
collection of an on-line index of processing difficulty, we
examine the time-course over which learners develop knowledge of
dependent relationships. These relationships are presented in the
context of an artificial grammar so that participants are without
strong prior knowledge about its structure. We explore properties
of the learning curve that underlies this process and trace, at
an individual differences level, the link between the implicit
generation of expectations during exposure to a novel language
and ultimate learning outcomes. We begin by discussing previous
work that has played a central role in informing the design of
the current study before outlining the details of the experiment.
Learners become attuned to various kinds of statistical
regularities as they extract structure from their surroundings.
Studies of statistical learning commonly involve manipulation of
a specific type of regularity: the transitional probabilities
between adjacent elements. For example, in a word segmentation
task, a high transitional probability between neighboring
6

Running head: PREDICTION DURING LEARNING
syllables might suggest that those syllables form a coherent
chunk (i.e., a word; Saffran, Aslin, & Newport, 1996). However,
contingencies exist not only between adjacent items, but also
between items that are not in direct proximity to one another
(Newport & Aslin, 2004). To offer an example from natural
language: the present progressive in English can be formed by
combining the auxiliary verb is and a main verb marked with the
inflectional suffix -ing. Thus, is and -ing have a high
transitional probability, whereas the intervening main verbs vary
widely (e.g., is eating, is sleeping, is walking, etc.). Along
these lines, Gómez (2002) created an artificial grammar of the
form A-X-B in which pseudowords in the final position of a string
(B) were perfectly predictable given pseudowords in the initial
position (A). In contrast, X items were drawn from a
systematically varied set of possible elements. Gómez
demonstrated that both infant and adults acquired the non-
adjacent dependencies between A and B after a period of passive
auditory exposure.
Here, we capitalize on a well-established behavioral metric
of implicit learning—motor response time—to monitor progressive
7

Running head: PREDICTION DURING LEARNING
changes in the allocation of processing resources during the
acquisition of non-adjacent dependencies. Importantly, canonical
studies of statistical learning tend to assess acquisition of a
statistical regularity by embedding it in an artificial language,
exposing participants to the artificial language, and
administering one off-line post-exposure grammaticality judgment
test to assess whether or not knowledge of the regularity was
acquired (but see, e.g., Hunt & Aslin, 2001; Karuza et al., 2013;
Misyak, Christiansen, & Tomblin, 2010a). As a result, we have
only a surface understanding of the time course of the
acquisition of statistical relationships among units of an
artificial language. To address this limitation, we adopt a self-
paced moving window display used frequently to study word-by-word
reading in the sentence processing literature (Just, Carpenter, &
Woolley, 1982). This paradigm has been used to examine changes in
expectations in natural language processing (e.g. Fine et al.,
2013), and trades on the firmly established inverse relation
between reading times and readers’ expectations (i.e., that a
reader will spend a greater amount of time processing
unpredictable words or syntactic structures, e.g., Frank & Bod,
8

Running head: PREDICTION DURING LEARNING
2011; Garnsey et al., 1997; Levy, 2008; McDonald & Shillcock,
2003; McRae, Spivey-Knowlton, & Tanenhaus, 1998; Smith & Levy,
2013). The moving window display enables us to collect reaction
time (RT) data as participants progress, at their own pace,
through each element in an artificial grammar. On a trial-by-
trial level, we are thus able to measure the incremental cumulative
effect of exposure on the processing difficulty from the earliest
stages of non-adjacent dependency learning onward.
Specifically, we translate the Gómez grammar into the visual
modality using a set of glyphs unfamiliar to subjects, and
instruct participants to advance through each A-X-B triplet by
pressing the space bar. We then measure, on a glyph-by-glyph
basis, how the processing difficulty associated with each element
in the grammar changes over the course of repeated instances of
the non-adjacent dependency. In parallel with successful
learning, participants should develop increasingly accurate
expectations about the nature of upcoming stimuli, which should
manifest as a processing benefit on predictable elements in the
input sequence (i.e., faster motor response time). Thus, we
expect to observe a facilitatory effect—a growing decrease in
9

Running head: PREDICTION DURING LEARNING
processing time, on predictable elements (B in the A-X-B sequence)
relative to predictive elements (A) as a function of exposure to
the artificial grammar.
To test these hypotheses, we measured glyph-by-glyph RTs as
participants read sequences of glyphs sampled from one of two
grammars: an A-X-B grammar in which A perfectly predicts B (the
structured condition), or a control condition in which glyph
frequency was matched, but non-adjacent elements were
comparatively uninformative (Unstructured condition). We find
that in the statistically Structured condition, in which A is
perfectly predictive of B, relative to the Unstructured
condition, which lacks a robust non-adjacent dependency,
processing of B elements was facilitated relative to the
predictive A elements as exposure increased. This effect held
even after completely removing the effect of “task adaptation” (a
general speedup in RTs as subjects become increasingly familiar
with the self-paced moving window paradigm). Finally, we probe
the relationship between on-line facilitatory learning effects
and post-exposure learning performance by asking whether
participants who develop more precise predictions during exposure
10

Running head: PREDICTION DURING LEARNING
(those individuals with the greatest processing benefits on
predictable elements) also exhibit more accurate knowledge of the
language’s grammar on an off-line post-test. Thus, we
demonstrate that statistical learning of non-adjacent
dependencies can be characterized not as a singular passive
process by which the learner merely stores statistical
information, but instead as a bi-directional process in which the
progressive accrual of knowledge about a predictive relationship
leads to the generation of more accurate predictions that
facilitate processing over the time-course of learning.
Additionally, we demonstrate a previously unspecified link
between variability in the on-line development and fine-tuning of
predictions and individual differences in the extent of
acquisition as gauged by post-test familiarity judgments.
Materials and Methods
Participants
68 participants recruited from the University of Rochester
and University of Iowa communities completed the study. All were
11

Running head: PREDICTION DURING LEARNING
native English speakers between the ages of 18 and 30. They
provided informed consent and were compensated financially
(Rochester) or for course credit (Iowa). The experiment lasted
approximately one hour, depending on the pace of the participant.
No participant reported familiarity with the glyph-based writing
system used to generate the stimuli (as indicated by a language
history questionnaire).
Stimuli
All images used in this study were glyphs borrowed from the
Ge’ez script, a syllabic alphabet used for several, mostly
Semitic, languages spoken primarily in Ethiopia and Eritrea,
including Amharic and Tigre (Appendix A; font downloaded from
http://www.senamirmir.org). These stimuli were selected because
we required a large set of visually distinct items that would be
unfamiliar to participants in our experiment.
~~~~~~~~~Figure 1~~~~~~~~~~
12

Running head: PREDICTION DURING LEARNING
Structured condition. Participants in this condition were
exposed to a series of 3-element strings of the form A-X-B. A and
B elements were drawn from a set of 6—3 always occurring as A and
3 always occurring as B—and were paired such that each A-element
always co-occurred with the same B element (i.e., A1-X-B1, A2-X-
B2, A3-X-B3). In contrast, X elements were drawn from a pool of
24 items. Thus, calculated over the entire exposure phase, the
transitional probability between non-adjacent items within a string
(i.e., B|A) was 1.0, but the transitional probability between
adjacent items within a string (i.e., X|A or B|X) was
comparatively low, either 0.04 or 0.33, respectively (Figure 1).
The 3 pairs of A and B elements were combined exhaustively with
the full set of 24 X elements, rendering 72 unique sequences. As
in the original Gómez study, these strings were repeated 6 times
and then randomized to create a list of 432 triplets.
Of the triplets tested post-exposure, half matched the A-X-B
form found in the exposure phase (e.g., A1-X4-B1) and half
violated that form because they contained unmatched A and B items
(e.g., A1-X4-B3). By design, the matched strings had occurred 6
13

Running head: PREDICTION DURING LEARNING
times during exposure, while the unmatched strings had not
occurred during exposure.
Unstructured control. In the previous condition, unique A
and B glyphs (of which there were only 6, each appearing 144
times) were far more frequent than unique X glyphs (of which
there were 24, each appearing a total of 18 times). We were not
interested in the effect of such differences in overall symbol
frequency, but rather in differences related to non-adjacent
element predictability. Thus, to examine non-adjacent dependency
learning separately from RT effects potentially attributable to
highly unbalanced glyph frequency, we created an “Unstructured”
control condition also consisting of 72 triplet strings also
repeated 6 times each. Individual A, B, and X items were exactly
matched in frequency to the Structured condition, but the sharp
contrast between adjacent and non-adjacent transitional
probabilities were no longer a stable cue to grammatical
structure, which was purposefully lacking in this condition.
Stimuli were engineered such that the transitional probability
between any two adjacent or non-adjacent items was matched.
Furthermore, triplet region was comparatively uninformative in
14

Running head: PREDICTION DURING LEARNING
the Unstructured condition; that is, all A, X, and B glyphs
occurred in each of the 3 presentation slots. In contrast,
recall that in the Structured condition, item B was perfectly
predictable given A (p(B|A)=1.0) and always occurred in the first
and third regions of the triplets, respectively (Figure 1).
Exactly as in the Structured condition, 6 of the test trials
were seen previously in the exposure, and, 6 contained a single-
glyph violation on a previously viewed triplet. The 6 test
triplets were drawn at random from the exposure list and the
violations occurred with equal frequency in each triplet region.
Thus, the Unstructured and Structured conditions were as closely
matched as possible, but differed along a critical dimension: the
absence of a strong non-adjacent dependency. For both conditions,
exposure and test lists were presented in one of two randomized
orders.
Random control. To account for general task adaptation in
the absence of any robust statistical regularities, we also
created a completely random (with replacement) condition in which
the frequency and position of glyphs in each triplet string
varied freely throughout the exposure phase. A unique series of
15

Running head: PREDICTION DURING LEARNING
432 triplets was generated for each subject by sampling, at each
triplet region, from a uniform distribution of all 30 possible
elements. Post-test triplets were drawn at random from the
exposure phase, and foils were triplets that never appeared in
the exposure phase.
Procedure
The experiment consisted of 4 phases: familiarization with
the individual glyphs, exposure to the glyph sequences, an off-
line post-test establishing the extent of learning, and a
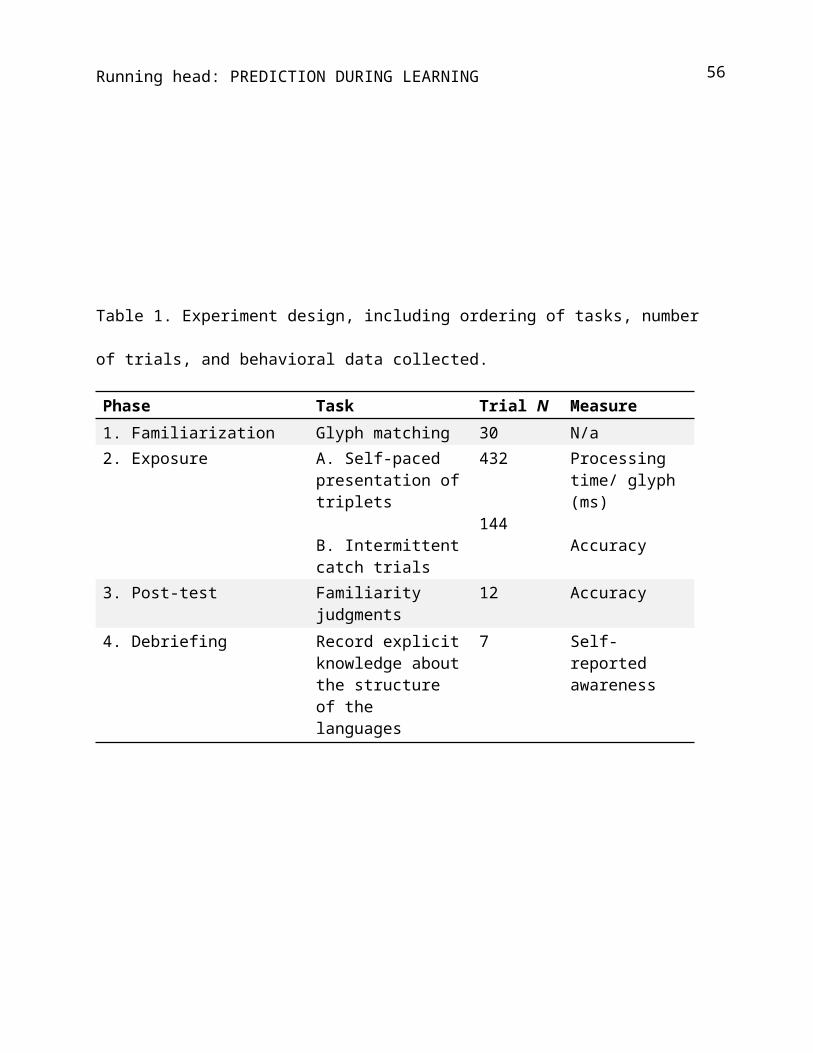
debriefing phase (Table 1). Procedures were matched across
conditions.
~~~~~~~~~Table 1~~~~~~~~~~
Familiarization. Participants first completed a brief (~5
min) matching task. This task ensured that RT effects would be
largely reflective of learning, not of surprisal at the
occurrence of a novel glyph (though with such a brief
familiarization phase, it is likely that participants were still
16

Running head: PREDICTION DURING LEARNING
acquiring the inventory of glyphs during the early stages of the
exposure phase). During the matching task, each glyph was flashed
on the computer screen for 2 s. Next, the participant was
presented with three options and asked to select which option
corresponded to the glyph they had just observed. Participants
advanced to the next trial only after a correct response.
Exposure. The exposure phase consisted of 432 triplets and
144 intermittent catch trials (72 response “yes”, 72 response
“no”). Since we were interested in changes in processing time, we
included these catch trials to ensure that participants were
attending to the stimuli during the exposure phase. They required
participants to indicate whether or not they had seen a specific
item in the previous triplet sequence, ensuring that participants
actually “read” the elements. In both the Structured and
Unstructured conditions, 96 catch trials tested on X glyphs and
48 tested on the highly frequent A and B glyphs1. This
1 There was a slight difference in the format of the catch trialsbetween the Structured and Unstructured conditions related to thefact that the triplet region (position 1, 2 or 3 in the string) and glyph identity (A, X, or B) were perfectly correlated in the Structured condition. Of the 72 “yes” trials in the Structured condition, 48 probed region 2 and a total of 24 probed regions 1 and 3. In the Unstructured condition, each region was probed
17

Running head: PREDICTION DURING LEARNING
distribution was purposefully selected so as not to bring undue
attention to the regularity present in the highly repetitive A
and B elements. In the Random condition, in which triplets were
generated by sampling from a uniform distribution of all
elements, participants were tested on each glyph an equal number
of times. Participants were instructed to pay attention to the
screen and make their best effort. Regardless of condition, they
were informed that stimuli might become familiar over time.
Participants performed three initial practice trials consisting
of number and letter—instead of glyph—sequences.
The pace of the exposure trials was controlled entirely by
the participant, as shown in Figure 2. RTs were recorded for each
element in the sequence, thus providing a by-element index of
processing difficulty associated with each element as training
progressed. At the start of each triplet trial, the participant
saw 5 horizontal dashes centered on the computer screen. They
initiated a sequence by pressing the space bar, at which point
the first dash became a small, opaque circle. At the next press
of the space bar, the circle became a dash and the second dash
equally: 24 times.
18

Running head: PREDICTION DURING LEARNING
was replaced by the first glyph (A). With another press of the
space bar, the first glyph became a dash again and the next dash
became the second glyph (X). This process continued until the
trial was completed. The circles in the initial and final
positions were included to reduce any effects on RTs associated
with initiating or ending a trial. Participants were offered a
built-in break option every 96 trials.
~~~~~~~~~Figure 2~~~~~~~~~~
Post-test. The final phase contained 12 test items. Triplets
were presented in their entirety (i.e., all glyphs appeared
simultaneously in a row). For each trial, participants indicated
whether or not that 3-part sequence had been observed during the
exposure phase by pressing “yes” or “no”. Instructions were
phrased as follows: “Now we'd like you to indicate whether or not
some test sequences seem familiar, like you saw them in the
previous exposure phase. We want you to tell us whether or not
you have already seen each entire sequence.” Post-exposure
learning was estimated as the proportion of correctly accepted
19

Running head: PREDICTION DURING LEARNING
matched strings and correctly rejected unmatched string out of
all 12 strings.
Debriefing. At the end of the experiment, participants
filled out a debriefing form intended to examine the extent of
their explicit knowledge about the structure of the language
presented to them. In the control conditions, this debriefing
form was essentially meaningless, as there was no strong
dependency to learn. However, in the structured condition
questions such as, Did you notice any patterns? and How did you make your
familiarity judgments during the test phase? These questions enabled us to
determine whether participants had explicit knowledge of the
strong non-adjacent association between the A and B items in the
exposure strings.
Results
Exclusions
Of the original 68 participants, 11 were excluded because
their performance on the catch trial task fell below a pre-
determined threshold of 70% accuracy (thus we could not be sure
whether or not those participants were completing the task as
20

Running head: PREDICTION DURING LEARNING
directed). Therefore, 57 participants are included in the present
analyses: n=19 in the Structured condition, n=18 in the
Unstructured and n=20 in the Random condition2. We excluded
trials with response times exceeding 6 s (data loss 0.3%) or RTs
deviating more than 3 SDs of the mean processing time per glyph
(data loss 2.1%). These criteria parallel standard exclusions
from self-paced reading experiments. All results reported below
hold also without these exclusions.
Overview of Analyses
Our objective was to evaluate changes throughout the
exposure phase in RTs for each element in the triplet sequences.
We expected that as participants learned the structure of the A-
X-B grammar, we would observe an increasing facilitatory effect
on the predictable B items of the Structured condition (relative
to the predictive A items). In addressing this question, however,
it is important to keep in mind that RTs also are known to
reflect effects unrelated to the learning of statistical
2 Approximately similar sample sizes used in prior studies of statistical learning in adults (e.g., Karuza et al., 2013; Newport & Aslin, 2004; Saffran, Newport & Aslin, 1996).
21

Running head: PREDICTION DURING LEARNING
dependencies. In particular, RTs often differ depending on the
position of words in a sentence (Kuperman, Dambacher, Nuthan, &
Kleigl, 2010). Second, it is well known that RTs in self-paced
reading experiments are subject to considerable task adaptation
effects (i.e., participants show an overall decrease in motor
response time as the experiment progresses, Fine, Qian, Jaeger, &
Jacobs, 2010; Fine et al., 2013). Since we are interested in
differences in the changes in RTs between triplet regions over
the course of the experiment, these two confounds are potentially
critical. Ruling out task adaptation as an explanation for the
learning effects we predicted in the structured condition
motivated the Random control condition, which allowed us to
remove such task-general effects from our contrast of primary
interest: RTs in the Structured relative to the Unstructured
condition.
In Step 1 of our analyses, we estimate region-specific and
practice effects against data from only the Random condition,
which does not contain non-adjacent dependencies. These estimates
are used to calculate corrected RTs for the Structured and
Unstructured conditions (in much the same way that length-
22

Running head: PREDICTION DURING LEARNING
corrected RTs are used in self-paced reading studies). These
corrected RTs remove the effects of symbol position and task
practice from the raw recorded RTs.
In Step 2 we analyze corrected RTs by comparing how
differences between these corrected RTs in Regions 1 and 3 change
over the course of the experiment in both conditions. We thus
establish an index of each participant’s ability to pick up on
the predictive relationships during learning.
Finally, Step 3 tests whether this measure of individual
variation in participants’ sensitivity to predictability during
processing predicts their performance on offline grammaticality
judgments during the post-exposure test.
Step 1: General task effects. We begin by visualizing the
effects of task practice and triplet region observed in the
Random conditions compared to the Structured and Unstructured
conditions. Figure 3 shows a non-linear generalized additive
model in which Trial (1-432), Region 1, 2, 3) and their
interaction were regressed onto log-transformed RTs for each of
the three experimental conditions. Generalized additive models
are a powerful tool to fit data with unknown degrees of non-
23

Running head: PREDICTION DURING LEARNING
linearity, accommodating highly non-linear relations between a
set of predictors. We note that logarithm-transformed RTs were
used because a) this is a common transform in RT analyses in
order to correct for violations of normality due to the (lower)
boundedness of RT data (for a discussion see Whelan, 2008) and b)
log-transforming the RTs indeed led to normally distributed
residuals. When reporting the analyses below, we specify
instances when lack of a log-transform alters the significance of
our results.
~~~~~~~~~Figure 3~~~~~~~~~~
As evident in Figure 3, RTs are overall faster in Region 3
than in Regions 1 and 2, even in the Random condition, which
lacked robust statistical regularity. Additionally, we observe
an overall decrease in RTs over the course of the experiment,
regardless of triplet region. The impression that RTs are subject
to task-general effects was confirmed by a linear mixed effects
regression against RTs from the Random condition. Using the lmer()
function (library lme4, v. 1.1-7; Bates, Maechler, Bolker, &
24

Running head: PREDICTION DURING LEARNING
Walker, 2014) in R (v. 3.1.1; R Development Core Team, 2014), we
regressed log RTs from the Random condition onto all main effects
and interactions of Trial (1-432) and Region (1, 2 and 3). We
included by-participant random effects with the maximal random
effects structure that still allowed the model to converge. All
predictors were centered to reduce collinearity between main
effects and their interactions (fixed effect correlation rs<
0.6).
In addition to a significant main effect of Trial (β =
−0.001, t = −41.52, p<0.001), we find that Region 3 was
processed more quickly than the average of Regions 1 and 2 (β =
−0.06, t = −7.09, p<0.001). Moreover, a significant interaction
between Trial and Region indicates that this facilitatory effect
on Region 3 grew more pronounced over the course of exposure,
even when there was no underlying triplet structure (β = −0.0001,
t = −7.30, p<0.001)3. In sum, we observe in the Random condition
that participants processed all glyphs increasingly faster over
the course of exposure and that participants showed the greatest
3 All p-values for these and future results were calculated usingthe Sattherwaite approximation method implemented in the lmerTest package (v. 2.0-25; Kuznetsova, Brockhoff, & Christiansen, 2014).
25

Running head: PREDICTION DURING LEARNING
facilitatory effect for Region 3. Most strikingly, we observed
that RTs for the last elements in each triplet progressively
diverged over the course of the experiment, even in the absence of non-
adjacent dependency learning. Note that this pattern of diverging RTs
is precisely our prediction for the Structured condition, in
which we anticipate that processing times on B elements should
continue to decrease relative to A elements as learning unfolds.
Therefore, to avoid anti-conservativity and to ensure that
we were not misinterpreting task-general RT effects as a
signature of learning, we removed these overall task effects from
the RTs before comparing the Structured and Unstructured
conditions. We accomplished this by fitting a generalized
additive model (as in Figure 3) to data from the Random condition
and using that function to derive predicted RTs for the Structured
and Unstructured groups.4 The model was fit with the gam()
4 An alternative approach would be to use a linear mixed effect regression with non-linear terms for the Trial effect. Using model comparison over linear mixed effect regressions found that the best fit is obtained for a model with square-root transformedTrial effects. Since the effects reported in Step 2 were robust to the choice of residualization technique, we report the generalized additive model residualization since it is arguably the most conservative approach for our purpose.
26

Running head: PREDICTION DURING LEARNING
function from the mgcv library (v. 1.8-0; Wood, 2011). The
difference between the actual and predicted log RTs (i.e., the
residual log RTs) were used as the dependent variable in the next
step of our analysis, where we compare RT effects in the
Structured and Unstructured conditions. We note that the
significant effects of predictability reported below hold even
without residualization; our approach removes effects that would
otherwise bias in favor of our hypothesis. The use of
residualized RTs is standard in, for example, self-paced reading
experiments (e.g., to remove word-length effects, Ferreira &
Clifton, 1986; and practice effects, Fine et al., 2013). To
demonstrate that this procedure successfully removes region and
practice effects, Figure 4 plots these residual log RTs for the
Random condition over time.
~~~~~~~~~Figure 4~~~~~~~~~~
Step 2: Sensitivity to predictability in non-adjacent
dependency learning. Focusing on contrasts between predictive
and predictable elements in the Structured and Unstructured
27

Running head: PREDICTION DURING LEARNING
group, we then analyzed the corrected RTs for Regions 1 and 3,
respectively. Recall that in the Structured condition, Region 1
corresponded to the predictive A glyphs and Region 3 corresponded
to the predictable B glyphs. Figure 5 illustrates the change of
corrected RTs over the course of the experiment for both the
Structured and Unstructured group (cf. Figure 4 for the Random
group). The effect of element predictability in the Structured
condition is clearly visible: as participants in the Structured
group incrementally learn to predict B glyphs from A glyphs, they
increasingly ‘read’ B glyphs faster (Figure 5, left panel). No
such divergence between Region 1 and 3 is expected –and none is
observed—in the Unstructured condition.
~~~~~~~~~Figure 5~~~~~~~~~~
This result was confirmed through linear mixed effects
regression that included an additional predictor intended to
capture the cumulative probabilities of position-specific glyphs.
This predictor, which we label Predictability, was calculated at
each trial as a moving proportion of instances a given glyph
28

Running head: PREDICTION DURING LEARNING
appeared in a specific triplet region, capturing both time (i.e.,
number of trials as they unfolded) and element probability within
a given region. It was thus reflective of the statistical
regularity to which an ideal learner would likely be sensitive in
extracting the underlying structure of the A-X-B grammar. To be
clear, we do not claim here that participants would exploit this
specific statistic at the exclusion of all others. Rather, we
simply sought a reasonable model of the probabilistic beliefs
that a learner might develop in the process of acquiring the non-
local grammatical dependency. In the Structured condition,
position-specific glyph probabilities were highly informative;
the small set of A and B glyphs were unique to the first and
third regions of the triplet, and they shared a strong, though
non-adjacent link (p(B | A) = 1.0). In contrast, individual
glyphs in the Unstructured condition occurred with equivalent
probability in all locations within a triplet, and the
transitional probability between the first and final positions
was far less robust (Figure 1). As a result, an ideal learner in
the latter condition would presumably be less likely to learn position-
29

Running head: PREDICTION DURING LEARNING
specific probabilistic regularities in generating predictions
about the nature of upcoming stimuli.
To test whether participants exhibited differing levels of
sensitivity to position-specific regularities in the Structured
relative to the Unstructured condition, corrected RTs were
regressed onto all main effects and interactions of log-
transformed Predictability, Region (1 or 3) and Condition
(Structured v. Unstructured). The Predictability measure was
derived by computing, at each trial, the cumulative frequency of
each glyph in a given position, then normalizing by the previous
number of trials. We used simple add-1 smoothing, which assumes
that, due to the matching task prior to exposure, each glyph had
been observed once prior to beginning the experiment. The model
included the maximal random effects structure (random by-
participant intercepts and slopes for all within-participant
manipulations, i.e., for the main effects and interaction of
Predictability and Region). Because position-specific glyph
probabilities were largely uninformative in the case of the
Unstructured condition, we anticipated that RTs in the Structured
30

Running head: PREDICTION DURING LEARNING
condition would show a stronger facilitatory effect contingent on
Predictability.
Results are summarized in Table 2. We obtained a significant
main effect of Predictability (β = −0.10, t = −5.10, p<0.001) as
well as a significant two-way interaction between Predictability
and Condition (β = −0.06, t = −3.13, p<0.01). These results
indicate that participants differed in their sensitivity to
Predictability between conditions, and that the magnitude of the
facilitatory RT effect was greater in the highly predictable
Structured condition. A subsequent simple effects analysis
revealed that the effect of position-specific Predictability was
significant in the Structured Condition (β= −0.16, t =
−5.69, p<0.001), but not the Unstructured condition ((β= −0.04, t
= −1.43 p=0.17). This result was expected, as an ideal learner
would likely exploit the highly regular position-specific
statistics in the Structured condition, but less so in the
Unstructured condition. Crucially, the significant three-way
interaction between Predictability, Region, and Condition (β=
−0.04, t = −3.03, p<0.01) demonstrates that participants’
sensitivity to element predictability was not only greater in the
31

Running head: PREDICTION DURING LEARNING
Structured relative to the Unstructured condition, but also that
it was highly dependent on a given glyph’s position in the
triplet. Namely, as exposure progressed (and position-specific
glyph probabilities increased), processing time associated with
the last element in each triplet decreased more quickly than
processing time on the first element in each triplet, and this
difference was greater when the first and last regions contained
a robust non-adjacent dependency (i.e., in the Structured
condition, where the glyphs in Region 3 were perfectly
predictable given the glyphs in Region 1)5.
~~~~~~~~~Table 2~~~~~~~~~~
5 Without log-transforming our RTs, we maintain a significant effect of Predictability. However, the two-way interaction between Predictability and Condition and the three-way interaction between Predictability, Region, and Condition are only marginally significant (β= −32.68, t = −1.97, p=0.06 and β=−19.00, t = −1.63, p=0.12, respectively). As noted above, however, log-transformation of RTs was justified both on prior theoretical grounds and by the distribution of residuals. We further note that the use of corrected RTs is highly conservative, as it effectively attributes all variance that is ambiguous between task adaptation and non-adjacent dependency learning to the former.
32

Running head: PREDICTION DURING LEARNING
Step 3: The relationship between prediction and learning
outcomes. To evaluate the relationship between the development
of predictions during online sequence processing and the
performance on post-exposure offline grammaticality judgments, we
assessed the correlation between participants’ sensitivity to our
Predictability measure during processing and off-line accuracy
scores in the post-exposure familiarity test. For each
participant, sensitivity to predictability score was calculated by summing
the simple fixed effect coefficients for the Predictability
effect and the by-participant random effects from the linear
mixed effect regression (i.e., the Best Linear Unbiased
Predictors; Baayen et al., 2008). We evaluated these scores
separately for Regions 1 and 3. Figure 6B reveals that
sensitivity to glyph predictability is only significantly
correlated with ultimate learning performance on the B elements
in the Structured condition (r = -0.51, p=0.03). That is, the
faster an individual’s RTs decrease on the predictable (B) items
in triplet sequence, the greater their ultimate performance at
post-test grammaticality judgments. In the Structured condition,
this effect only holds true for the B elements, which are
33

Running head: PREDICTION DURING LEARNING
perfectly predictable given the A glyphs in Region 1. In line
with our expectations, we do not find a significant correlation
between sensitivity to predictability on Region 1 and post-test
performance (r = -0.30, p=0.21), indicating that, although
participants were indeed sensitive to region-specific statistics
associated with the A items, that sensitivity did not predict
their learning outcomes. Finally, as anticipated, we do not
observe a correlation between post-test performance and
sensitivity to glyph probability for either Region 1 (r = 0.20,
p=0.44) or Region 3 (r = 0.26, p=0.30) in the Unstructured
condition.
~~~~~~~~~Figure 6~~~~~~~~~~
Discussion
While statistical learning has been richly supported as a
domain-general mechanism of acquisition, its real-time processing
dynamics have been largely obscured by the overwhelming use of
off-line post-tests (but see, e.g., Misyak et al., 2010a). That
children and adults tap into regularities in their environment
34

Running head: PREDICTION DURING LEARNING
has been demonstrated thoroughly, yet far less attention has been
paid to how that sensitivity impacts the manner in which we
process and interact with novel surroundings. By visualizing
trial-by-trial motor response to patterned input, we have framed
prediction, not as a by-product of learning, but as a concurrent,
interlinked process related to post-exposure learning outcomes.
At their core, the present results suggest that the acquisition
of knowledge about statistical dependencies can be indexed by
participants’ success in generating increasingly precise
expectations about that regularity. These findings enable us to
make contact with prior proposals that error-driven learning plays a
central role in both processing and acquisition; language
processing is assumed to involve prediction and prediction errors
are assumed to lead to learning (e.g., Chang, Dell, Bock, &
Griffin, 2000; Chang, Dell, & Bock, 2006; Fine & Jaeger, 2013;
Jaeger & Snider, 2013; for recent reviews, see also Dell & Chang,
2013; Kleinschmidt & Jaeger, 2015; MacDonald, 2013). Here, we
provide evidence that individuals with the strongest sensitivity
to element predictability, those whose on-line predictions
increasingly aligned with the statistics of the input, ultimately
35

Running head: PREDICTION DURING LEARNING
performed better on an off-line measure of learning. Finally,
these results contribute to a small but growing literature on
non-adjacent pattern learning that is not auditory-linguistic in
nature (e.g., involving perceptually similar tones, Creel,
Newport, & Aslin, 2004; certain types of alternating visual
sequences, Howard & Howard, 1997; or learning in dual-task
conditions, Conway & Christiansen, 2006); we demonstrate that the
processing of non-local dependencies shares a link to learning
that is neither domain nor modality specific.
Prior Work on Prediction and Artificial Grammar Learning
Prior work on artificial grammar processing has capitalized
on similar motor response measures to investigate facilitatory
processing in non-adjacent dependency learning (Amato &
MacDonald, 2010; Misyak et al., 2010a). However, key elements of
the present experimental design and analysis enabled us to expand
on these earlier studies. Misyak et al. (2010a) found strong
evidence of predictive processes in artificial language learning
by employing a mouse-clicking task. In their set-up, participants
were required to match auditorily and visually presented
36

Running head: PREDICTION DURING LEARNING
pseudowords from the Gómez grammar. An increasingly facilitatory
effect on response time was observed for the dependent items in
the grammar, a result we replicate here. However, the present
study also includes control conditions that enable us to account
for potential effects of element frequency or general task
adaptation. Moreover, our self-paced paradigm addresses a
limitation of Misyak et al.—in that experiment, participants were
required to select between successive pairs of visually presented
pseudowords, narrowing the set of items that could occur in a
given position and potentially altering the nature of learning.
In addition, we have tested directly the relationship between on-
line prediction measures and ultimate learning outcomes; Misyak
et al. (2010a) concentrated on the link between prediction during
artificial grammar learning and sentence processing in natural
language (see also Misyak, Christiansen, & Tomblin, 2010b). We
have demonstrated that participants who develop more precise
predictions as they learn, and thus experience the on-line
facilitatory effects associated with having their expectations
met, also achieve higher off-line learning outcomes.
37

Running head: PREDICTION DURING LEARNING
In a related study, Amato & MacDonald (2010) used self-paced
reading as a metric of artificial language learning, focusing
analyses on mean reading times after a period of extensive
training on a complex grammar. Here, we investigate the
cumulative effect of stimulus exposure (i.e., the role of
prediction-based processes throughout learning, as opposed to
resulting from it). Interestingly, the authors found that,
despite facilitatory RT effects on predictable pseudowords,
participants were unsuccessful in performing a sentence
completion task. In contrast, participants in Misyak et al.’s
mouse-clicking study achieved above-chance scores on a similar
completion task with a different underlying grammar. While our
post-test was comparatively more implicit, our debriefing
questionnaire allowed us to determine participants’ level of
awareness of the non-adjacent dependency. In the next section, we
perform a follow-up analysis that probes whether individual
differences in explicit awareness might explain some of the
observed RT effects.
38

Running head: PREDICTION DURING LEARNING
Follow-up Analyses
The role of explicit awareness. In both Amato & MacDonald
(2010) and Misyak et al. (2010a), participants made relatively
explicit off-line judgments about the grammatical structure of
the input. Participants were not asked whether a grammatical or
ungrammatical string “looked familiar” (as they were in the
current experiment), but rather selected an appropriate
pseudoword to fill in a missing spot in a sequence. To reveal any
potential effects of differences in the post-test structure
(i.e., the extent to which learners were tested on explicit
knowledge), we used data from our debriefing questionnaire to
examine the influence of explicit, verbalizable awareness on the
learning process. Participants from the Structured condition were
categorized as “aware” (n=7) if they indicated that the first and
the third elements in each triplet shared a dependent
relationship and “unaware” (n=12) if they did not explicitly
describe this pattern. Participants from the Unstructured
condition, in which there was no non-adjacent dependency to
verbalize, are not included in these analyses. In the Structured
39

Running head: PREDICTION DURING LEARNING
group, we find that participants with explicit knowledge of the
A-B dependency significantly outperformed participants without
this explicit knowledge (mean proportion correct for aware=0.83;
unaware=0.60; t(17)=3.1, p<0.01). This correlation needs to be
interpreted with caution; it is possible that better performance
on the post-test or factors that lead to higher performance on
the post-test make it more likely that participants become
explicitly aware of the structure of the language. In this
context, it is also interesting that lack of explicit knowledge
did not preclude above chance performance on post-test. Post-test
scores in the “unaware” group still, on average, differed
significantly from chance t(11)=2.4, p=0.04).
We then evaluated the effect of awareness on RTs during
exposure by repeating the logistic analysis from Step 2 with an
additional predictor signifying participants’ explicit awareness
of the non-adjacent dependency 6. Corrected RTs from the
Structured condition were regressed onto all main effects and
interactions of Predictability, Region, and Awareness (“aware” or
6 To be clear, this analysis has limitations in that we cannot determine the precise point at which each participant became aware.
40

Running head: PREDICTION DURING LEARNING
“unaware”). All predictors were centered to reduce collinearity
(all rs<0.6). Results indicate that participants with explicit
awareness of the regularity tended to have slower overall RTs,
though this effect was not significant (β = 0.09, t=1.60,
p=0.13). Thus, it is potentially the case that participants who
engaged in more deliberative processing had explicit awareness of
the underlying A-B regularity, but our results are not conclusive
in this respect. We find no significant interaction between
awareness and any of the other predictors (Table 3), and our
original effects of Predictability (β = −0.17, t = −4.25,
p<0.001) and Region (β = −0.06, t = −2.5, p=0.02) are maintained.
Their interaction is marginally significant (β = −0.06, t =
−1.97, p=0.07). Note that the absence of a significant three-way
interaction between Predictability, Region, and Awareness
indicates that the on-line generation of predictions throughout
dependency learning is not necessarily an implicit process. The
previously discussed correlation between post-test performance
and glyph probability further shows that learners who were better
predictors were ultimately better performers, regardless of
explicit knowledge of the dependency.
41

Running head: PREDICTION DURING LEARNING
~~~~~~~~~Table 3~~~~~~~~~~
Conclusions and Outstanding Questions
In sum, we have provided evidence of predictive processing
in the context of exposure to a visual artificial grammar.
Reaction times revealed a progressive facilitatory effect for
predictable items, suggesting that predictions, when they are
favorably resolved with subsequent input, speed up processing of
temporally ordered elements. Furthermore, we observed that those
participants who developed the most accurate predictions, and
thus increasingly experienced their expectations being met,
performed better on a post-test requiring familiarity judgment.
We have therefore demonstrated a link between on-line and off-
line measures of learning. While this correlation does not allow
us to make specific claims about the directionality of that
relationship, it strongly indicates a tight coupling between the
generation of implicit expectations, in this case the speed up on
statistically dependent elements, and a commonly used metric of
learning outcome, familiarity judgments following exposure.
42

Running head: PREDICTION DURING LEARNING
By developing and validating a learning task that enables us
to trace, at an individual differences level, learners’ ability
to generate accurate predictions within a novel environment, we
have opened up exciting possibilities for future research. For
example, one might ask which factors might either speed up or
perturb the process of successfully generating predictions within
various learning contexts (e.g., the complexity or stationarity
of the input). Alternatively, this fine-grained metric of on-line
processing might also be used to predict acquisition in much
larger-scale learning tasks (e.g., second language learning). Are
faster, more accurate predictors better natural language
learners? This question would build on previous observations that
performance on a simple statistical learning task correlates with
second language literacy outcomes (Frost, Siegelman, Narkiss, &
Afek, 2013).
Of final note, our paradigm has provided evidence for the
formation of prediction when learners lack strong prior
expectation about underlying structure (because we used a set of
unfamiliar glyphs). Self-paced processing paradigms have also
been used to examine how expectations based on prior natural
43

Running head: PREDICTION DURING LEARNING
language experience (e.g., from one’s native language) can be
adapted to unexpected distributions during comprehension. Fine et
al. (2013), for example, found that a priori infrequent syntactic
structures, which typically incur a processing cost, are read
increasingly faster in a context in which they are more probable
(i.e., the structures become expected). It remains an important
outstanding question whether statistical learning, as examined in
artificial worlds with novel stimuli, and adaptation or priming
effects in native language comprehension rely on a common
learning mechanism.
Acknowledgments
This research was supported by NSF Career Grant IIS-1150028 to
TFJ, and NSF GRFs to EAK and ABF.
References
Altmann, G.T.M., & Mirkovic, J. (2009). Incrementality and
prediction in human sentence
processing. Cognitive Science, 33, 1–27.
Amato, M.S., & MacDonald, M.C. (2010). Sentence Processing in an
Artificial Language:
44

Running head: PREDICTION DURING LEARNING
Learning and Using Combinatorial Constraints. Cognition, 116,
143–148.
Arai, M., & Keller, F. (2013). The use of verb-specific
information for prediction in sentence
processing. Language and Cognitive Processes, 28, 525–560.
Baayen, R.H., Davidson, D.J., & Bates, D.M. (2008). Mixed effects
modeling with crossed
random effects for subjects and items. Journal of Memory and
Language, 59, 390–412.
Bannard, C., & Matthews, D. (2008). Stored word sequences in
language learning. Psychological
Science, 19, 241–248.
Bates, D., Maechler, M., Bolker, B. & Walker, S. (2014). lme4:
Linear mixed-effects models
using Eigen and S4_. R package version 1.1-7, <URL:
http://CRAN.R-project.org/package=lme4>.
Chang, F., Dell, G. S., Bock, K., & Griffin, Z. M. (2000).
Structural priming as implicit learning:
A comparison of models of sentence production. Journal of
Psycholinguistic Research, 29, 217–229.
45

Running head: PREDICTION DURING LEARNING
Chang, F., Dell, G. S., & Bock, K. (2006). Becoming syntactic.
Psychological Review, 113, 2,
234–272.
Conway, C.M., & Christiansen, M.H. (2006). Statistical learning
within and between modalities: Pitting abstract against
stimulus-specific representations. Psychological Science, 17, 905–
912.
Creel, S. C., Newport, E. L., & Aslin, R. N. (2004). Distant
melodies: Statistical learning of non-
adjacent dependencies in tone sequences. Journal of Experimental
Psychology: Learning, Memory, and Cognition, 30, 1119–1130.
Dell, G.S., & Chang, F. (2014). The P-Chain: Relating sentence
production and its disorders to
comprehension and acquisition. Philosophical Transactions of the
Royal Society B, 369, 1471–2970.
Farmer, T. A., Fine, A. B., Yan, S., Cheimariou, S., & Jaeger, T.
F. (2014). Syntactic expectation
adaptation in the eye-movement record. In P. Bello, M.
Guarini, M. McShane, & B. Scassellati (Eds.), Proceedings of the
46

Running head: PREDICTION DURING LEARNING
36th Annual Meeting of the Cognitive Science Society (pp. 2181–
2186). Austin, TX: Cognitive Science Society.
Ferreira, F., & Clifton, C. E. (1986). The independence of
syntactic processing. Journal of
Memory and Language, 25, 348–368.
Fine, A.B., & Jaeger, T.F. (2013). Evidence for implicit learning
in syntactic
comprehension. Cognitive Science, 37, 578–591.
Fine, A. B., Jaeger, T. F., Farmer, T. A., & Qian, T. (2013).
Rapid expectation adaptation during
syntactic comprehension. PLoS ONE, 8, e77661.
Fine, A.B., Qian, T., Jaeger, T.F., & Jacobs, R.A. (2010).
Syntactic Adaptation in Language
Comprehension. In Proceedings of the 2010 Workshop on Cognitive
Modeling and Computational Linguistics (pp. 18–26). Uppsala, Sweden:
Association for Computational Linguistics.
Frost, R., Siegelman, N., Narkiss, A., & Afek, L. (2013). What
predicts successful literacy
acquisition in a second language? Psychological Science, 24, 1243–
1252.
47

Running head: PREDICTION DURING LEARNING
Garnsey, S. M., Pearlmutter, N. J., Myers, E., & Lotocky, M.
A. (1997). The contributions of
verb bias and plausibility to the comprehension of
temporarily ambiguous sentences. Journal of Memory and
Language, 37, 58–93.
Gómez, R. L. (2002). Variability and detection of invariant
structure. Psychological Science,
13, 431–436.
Hahne, A., & Friederici, A. D. (1999). Electrophysiological
evidence for two steps in syntactic
analysis: Early automatic and late controlled processes.
Journal of Cognitive Neuroscience, 11, 194–205.
Hanulíková A., van Alphen P. M., van Goch M. M., & Weber A.
(2012). When one person’s
mistake is another’s standard usage: the effect of foreign
accent on syntactic processing. Journal of Cognitive Neuroscience, 24,
878–887.
Howard, J.H., & Howard, D.V. (1997). Age differences in implicit
learning of higher order
48

Running head: PREDICTION DURING LEARNING
dependencies in serial patterns. Psychology and Aging, 12, 634–
656.
Hunt, R.H., & Aslin, R.N. (2001). Statistical learning in a
serial reaction time task: Simultaneous
extraction of multiple statistics. Journal of Experimental
Psychology: General, 130, 658–680.
Jaeger, T. F., & Snider, N. (2013). Alignment as a consequence of
expectation adaptation:
Syntactic priming is affected by the prime’s prediction
error given both prior and recent experience. Cognition, 127,
57–83.
Jurafsky, D. (1996). A Probabilistic model of lexical and
syntactic access and
disambiguation. Cognitive Science, 20, 137–194.
Just M.A., Carpenter P.A., & Woolley J.D. (1982). Paradigms and
processes in reading
comprehension. Journal of Experimental Psychology: General, 111, 228–
238.
Kamide, Y. (2012). Learning individual talkers' structural
preferences. Cognition, 124, 66-71.
49

Running head: PREDICTION DURING LEARNING
Karuza, E.A., Newport, E.L., Aslin, R.N., Starling, S.J.,
Tivarus, M.E., & Bavelier, D. (2013).
Neural correlates of statistical learning in a word
segmentation task: An fMRI study. Brain and Language, 127, 46–
54.
Kleinschmidt, D.F., & Jaeger, T.F. (2015). Robust speech
perception: Recognize the familiar,
generalize to the similar, and adapt to the
novel. Psychological Review, 122, 148–203.
Kuperman, V., Dambacher, M., Nuthmann, A., & Kliegl, R. (2010).
The effect of word position
on eye-movements in sentence reading: A cross-corpora
analysis. Quarterly Journal of Experimental Psychology, 63, 1838–1857.
Kuznetsova, A., Brockhoff, P.B., & Christensen, R.H.B. (2015).
lmerTest: Tests in Linear
Mixed Effects Models. R package version 2.0-25. <URL:
http://CRAN.R-project.org/package=lmerTest>.
Levy, R. (2008). Expectation-based syntactic comprehension.
Cognition, 106, 1126–1177.
50

Running head: PREDICTION DURING LEARNING
Lew-Williams, C. & Fernald, A. (2007). Young children learning
Spanish make rapid use of
grammatical gender in spoken word recognition. Psychological
Science. 18, 193–198.
MacDonald, M. C., Pearlmutter, N. J., & Seidenberg, M. S. (1994).
The lexical nature of
syntactic ambiguity resolution. Psychological Review, 101, 676–
703.
MacDonald, M. C. (2013). How language production shapes language
form and
comprehension. Frontiers in Psychology, 4, 1–16.
McDonald, S. A., & Shillcock, R. C. (2003). Low-level predictive
inference in reading: The
influence of transitional probabilities on eye
movements. Vision Research, 43,1735–1751.
McRae, K., Spivey-Knowlton, M. J., & Tanenhaus, M. K. (1998).
Modeling the influence of
thematic fit (and other constraints) in on-line sentence
comprehension. Journal of Memory and Language, 38, 283–312.
51

Running head: PREDICTION DURING LEARNING
Misyak, J.B., Christiansen, M.H., & Tomblin, J.B. (2010a).
Sequential expectations: The role of
prediction-based learning in language. Topics in Cognitive Science,
2, 138–153.
Misyak, J. B., Christiansen, M. H., & Tomblin, J. B. (2010b). On-
line individual differences in
statistical learning predict language processing. Frontiers in
Psychology, 1, 1–9.
Newport, E. L., & Aslin, R. N. (2004). Learning at a distance I.
Statistical learning of non-
adjacent dependencies. Cognitive Psychology, 48, 127–162.
Nissen, M. J., & Bullemer, P. (1987). Attentional requirements of
learning: evidence from
performance measures. Cognitive Psychology, 19, 1–32.
R Core Team (2014). R: A language and environment for statistical
computing. R Foundation for
Statistical Computing, Vienna, Austria. URL http://www.R-
project.org/.
Romberg, A.R. & Saffran, J.R. (2010). Statistical learning and
language acquisition. Wiley
52

Running head: PREDICTION DURING LEARNING
Interdisciplinary Reviews: Cognitive Science, 1, 906–814
Saffran, J., Aslin, R., & Newport, E. (1996). Statistical
learning by 8-month-old infants. Science,
274, 1926–1928.
Saffran, J.R., Newport, E.L., & Aslin, R.N. (1996). Word
segmentation: The role of
distributional cues. Journal of Memory and Language, 35, 606–621.
Seidenberg, M. S., & MacDonald, M. C. (1999). A probabilistic
constraints approach to
language acquisition and processing. Cognitive Science, 23, 569–
588.
Smith, N.J., & Levy, R. (2013). The effect of word predictability
on reading time is logarithmic.
Cognition, 128, 302–319.
Trueswell, J. C., Tanenhaus, M. K., & Garnsey, S. (1994).
Semantic influences on parsing: Use
of thematic role information in syntactic ambiguity
resolution. Journal of Memory and Language, 33, 285–318.
Whelan, R. (2008). Effective analysis of reaction time data. The
Psychological Record, 58, 475–
53

Running head: PREDICTION DURING LEARNING
482.
Wood, S.N. (2011) Fast stable restricted maximum likelihood and
marginal likelihood
estimation of semiparametric generalized linear models.
Journal of the Royal Statistical Society (B), 73, 3–36.
54

Running head: PREDICTION DURING LEARNING
Figure 1. Directed graph displaying the underlying triplet
structure of each of the three language conditions: Structured,
Unstructured, and Random. Edges represent the mean transitional
probabilities between pairs of items in each triplet region.
Nodes represent the glyphs that appear in each region. Note how
region and glyph type (A, X, or B) are perfectly correlated only
in the highly regular Structured condition; in the other two
conditions, glyphs appear in the each of the three presentation
slots and transitional probabilities do not vary across edges.
55
Running head: PREDICTION DURING LEARNING
Table 1. Experiment design, including ordering of tasks, number
of trials, and behavioral data collected.
Phase Task Trial N Measure1. Familiarization Glyph matching 30 N/a2. Exposure A. Self-paced
presentation oftriplets
B. Intermittentcatch trials
432
144
Processing time/ glyph (ms)
Accuracy
3. Post-test Familiarity judgments
12 Accuracy
4. Debriefing Record explicitknowledge aboutthe structure of the languages
7 Self-reported awareness
56

Running head: PREDICTION DURING LEARNING
Figure 2. Example of a single triplet trial. Each trial began
with a row of dashes. Participants advanced each item in the
sequence by pressing the space bar. Response times between the
initiation of successive elements were recorded, revealing the
duration each glyph was present on the screen.
57

Running head: PREDICTION DURING LEARNING 58

Running head: PREDICTION DURING LEARNING 59

Running head: PREDICTION DURING LEARNING
Figure 3. Change in log-transformed RTs for each Region, smoothed
with a generalized additive function in light of high degrees of
non-linearity present in the data. In each of the three
conditions, Random (top plot), Structured (middle plot), and
Unstructured (lower plot), we observe a pronounced facilitatory
effect for Region 3 (blue), motivating the residualization
approach we employed. Note, however, the robust learning
signature unique to the Structured condition: higher overall RTs
for the unpredictable Region 2 glyphs (purple) coupled with a
growing difference in processing time for Region 1 and Region 3,
shown in orange and blue respectively). Shading represents 95%
confidence intervals.
60

Running head: PREDICTION DURING LEARNING
Figure 4. Corrected (residual log-transformed) RTs for the Random
condition plotted across experimental trials. Values centered on
0 indicate that general task and region-specific effects were
successfully removed. Error bars represent 95% confidence
intervals.
61

Running head: PREDICTION DURING LEARNING
Figure 5. Corrected (residual log-transformed) RTs plotted across
trials for the Structured (left panel) and Unstructured (right panel)
conditions. The facilitatory effect on Region 3 is strikingly
clear for the Structured condition. That is, as participants
learn the non-adjacent dependency of the A-X-B grammar, they
“read” B items increasingly faster over time (blue). In contrast,
there is no evidence of a prediction-based learning in the
62

Running head: PREDICTION DURING LEARNING
Unstructured condition (Regions 1 and 3 do not dissociate over
time). Error bars represent 95% confidence intervals.
Table 2. Coefficients
(and corresponding t-
values) for each
predictor in the model
presented in Step 2 of
our analyses comparing
the Structured and
Unstructured conditions. Significant values (determined using the
Sattherwaite approximation and corresponding to p<0.05) are
bolded.
63
Predictor Estimate
T-value
Predictability −0.10 −5.10Region 0.005 0.23Condition 0.03 0.67Predictability*Region −0.02 −1.85Predictability*Condition
−0.06 −3.13
Region*Condition −0.02 −1.00Predictability*Region*Condition
−0.04 −3.03

Running head: PREDICTION DURING LEARNING
A
B
64

Running head: PREDICTION DURING LEARNING
Figure 6. Relationship between RT sensitivity to increasing
element probability and off-line grammaticality judgments. We
find no significant correlation between the effect of Region 1
Predictability and ultimate off-line learning performance in
either condition (top plot, A). However, the bottom plot (B)
demonstrates a significant correlation between sensitivity to
Predictability for Region 3 and post-test performance that is
specific to the Structured condition (red). That is, the faster
an individual’s RTs on the perfectly predictable (B) items, the
greater their ultimate performance at post-test grammaticality
judgments. Shaded areas represent 95% confidence intervals.
65

Running head: PREDICTION DURING LEARNING
Table 3. Coefficients (and corresponding t-values) for each
predictor in a model examining the effect of explicit awareness
of grammatical structure on residual-log RTs. Significant values
66

Running head: PREDICTION DURING LEARNING
(determined using the Sattherwaite approximation and
corresponding to p<0.05) are bolded.
67
Predictor Coefficient
T-value
Predictability −0.17 −4.25Region −0.06 −2.50Awareness 0.09 1.60Predictability*Region −0.06 −1.97Predictability*Awareness
−0.04 −1.00
Region*Awareness −0.0006 −0.02Predictability*Region*Awareness
−0.003 −0.08

Running head: PREDICTION DURING LEARNING
Appendix A
68







![gjnk/f;L lhNnfsf] :jLs[t lhNnf b/ /]^](https://static.fdokumen.com/doc/165x107/6332b2ac4d54c8e1f90787d5/gjnkfl-lhnnfsf-jlst-lhnnf-b-.jpg)












