
Generic Visual Categorization Using Weak Geometry
15
∗ • *
-
Upload
independent -
Category
Documents
-
view
5 -
download
0
Transcript of Generic Visual Categorization Using Weak Geometry

Generi Visual Categorization Using Weak Geometry∗Gabriela Csurka, Christopher R. Dan e, Florent Perronnin, and Jutta WillamowskiXerox Resear h Centre Europe, 6 hemin de Maupertuis38240, Meylan Fran eFirstname.Lastname�xr e.xerox. omFebruary 19, 2014Abstra tIn the �rst part of this hapter we make a general presentation of the bag-of-keypat hes approa hto generi visual ategorization (GVC). Our approa h is inspired by the bag-of-words approa h totext ategorization. This method is able to identify the obje t ontent of natural images whilegeneralizing a ross variations inherent to the obje t lass. To obtain a visual vo abulary insensi-tive to viewpoint and illumination, rotation or a�ne invariant orientation histogram des riptors ofimage pat hes are ve tor quantized. Ea h image is then represented by one visual word o urren ehistogram. To lassify the images we use one-against-all SVM lassi�ers and hoose the best ranked ategory. The main advantages of the method are that it is simple, omputationally e� ient andintrinsi ally invariant. We obtained ex ellent results as well for multi- lass ategorization as forobje t dete tion.In the se ond part we improve the ategorizer by in orporating geometri information. Based ons ale, orientation or loseness of the keypat hes we an onsider a large number of simple geometri alrelationships, ea h of whi h an be onsidered as a simplisti lassi�er. We sele t from this multitudeof lassi�ers (several millions in our ase) and ombine them e�e tively with the original lassi�er.Results are shown on a new hallenging 10 lass dataset.1 Introdu tionThe proliferation of digital imaging sensors in mobile phones and onsumer-level ameras is produ ing agrowing number of large digital image olle tions and in reasing the pervasiveness of images on the weband in other do uments. To sear h and manage su h olle tions it is useful to have a ess to high-levelinformation about obje ts ontained in the images. We are therefore interested in re ognizing severalobje ts or image ategories within a multi- lass ategorization system, but not in the lo alization ofthe obje ts whi h is unne essary for most appli ations involving tagging and sear h. In this hapterwe des ribe a generi visual ategorization (GVC) system whi h is su� iently generi to ope withmany obje t types simultaneously and whi h an readily be extended to new ategories. It an handlevariations in view, ba kground lutter, lighting and o lusion as well as intra- lass variations.Before des ribing the approa h we underline the distin tion of visual ategorization from three relatedproblems:• Re ognition: This on erns the identi� ation of parti ular obje t instan es. For instan e, re og-nition would distinguish between images of two stru turally distin t ups, while ategorizationwould pla e them in the same lass.
∗Published in Le ture Notes in Computer S ien e Volume 4170, 2006, pp 207-224, Springer BerlinHeidelberg, DOI 10.1007/11957959_11 1

• Content Based Image Retrieval: This refers to the pro ess of retrieving images on the basis of low-level image features, given a query image or manually onstru ted des ription of these low-levelfeatures. Su h des riptions frequently have little relation to the semanti ontent of the image.• Dete tion: This refers to de iding whether or not a member of one visual ategory is present in agiven image. While it would be possible to perform generi ategorization by applying a dete torfor ea h lass of interest to a given image, this approa h be omes ine� ient given a large numberof lasses. In ontrast to the te hnique proposed in this paper, most existing dete tion te hniquesrequire pre ise manual alignment of the training images and the segregation of these images intodi�erent views, neither of whi h is ne essary in our ase.Our generi visual ategorization system is a bag-of-keypat hes approa h whi h was motivated by ananalogy to learning methods using the bag-of-words representation for text ategorization [9, 23, 13℄. Inthe bag-of-words representation, a text do ument is en oded as a histogram of the number of o urren esof ea h word. Similarly, one an hara terize an image by a histogram of visual word ounts. The visualvo abulary provides a "mid-level" representation whi h helps to bridge the semanti gap between thelow-level features extra ted from an image and the high-level on epts to be ategorized [1℄. However,the main di�eren e from text ategorization is that there is no given vo abulary for images. Instead wegenerate a visual vo abulary automati ally from a training set.The idea of adapting text ategorization approa hes to visual ategorization is not new. Zhu et al[26℄ investigated the ve tor quantization of small square image windows, whi h they alled keyblo ks.They showed that these features produ ed more "semanti s-oriented" results than olor and texturebased approa hes, when ombined with analogues of the well-known ve tor-, histogram-, and n-gram-models of text retrieval. In ontrast to our approa h, their keyblo ks do not possess any invarian eproperties. Our visual vo abulary [4℄ is obtained by lustering rotation or a�ne invariant orientationhistogram des riptors using the K-means algorithm. In a similar way Sivi and Zisserman [22℄ usedve tor quantized SIFT des riptors of shape adapted regions and maximally stable regions to lo alize allthe o urren es of a given obje t in a video sequen e.In these ases ea h entroid orresponds to a visual word and, to build a histogram, ea h featureve tor is assigned to its losest entroid. In [8℄, Hsu and Chang argue that the lusters obtained withK-means have a high orrelation with the low-level features but a weak orrelation with the on epts.They devised a visual ue luster onstru tion based on the information bottlene k prin iple. Morere ently soft lustering using Gaussian Mixture Model (GMM) was proposed as an alternative to K-means [5, 19℄. In this ase, a low-level feature is not assigned to one visual word but to all wordsprobabilisti ally, resulting in a ontinuous histogram representation.Others have explored the post-pro essing of K-means lustering. For instan e Sivi et al [21℄ useProbabilisti Latent Semanti Analysis (PLSA) to dis over topi s in a orpus of unlabelled images. Testimages were then ategorized based on the most relevant topi .In order to improve the a ura y of our system we further exploit a boosting approa h based onkeypat hes and simple geometri al relationships (similar s ales, similar orientation, loseness) betweenthem. We hose to adopt the boosting approa h be ause there are many possible geometri relationshipsand boosting o�ers an e�e tive way to sele t from this multitude of possible features. Boosting wasused with su ess in [16℄ to dete t the presen e of bikes, persons, ars or airplanes against ba kground.However their approa h di�ers from ours as they do not in lude any geometry and onsider everyappearan e des riptor without onsidering a vo abulary.The main advantage of our approa h is that geometri onstraints are introdu ed as weak onditionsin ontrast to others su h as [6, 11℄, where due to the use of relatively strong geometri models, su hprevious methods requires the alignment and segregation of di�erent views of obje ts in the dataset.Several other ategorization approa hes have re ently been developed that are based on image seg-mentation [2, 12, 17, 3℄, rather than the interest point des riptors. In [2℄ geometry has been in ludedthrough generative MRF models of neighboring relations between segmented regions. In ontrast weprefer to take a dis riminative lassi�er approa h in order to optimize overall a ura y.The remainder of this paper is organized as follows: se tion 2 des ribes the original bag of keypat hesapproa h; in se tion 3 we introdu e an alternative based on the boosting framework; in se tion 4 we

Figure 1: The main steps of the bag-of-keypat hes approa h.then des ribe how to in orporate weak geometry in the boosting approa h; we present experimentalresults in se tion 5 and on lude in se tion 6.2 The Bag-of-Keypat h Approa hThe main steps of the bag-of-keypat hes approa h introdu ed in [4℄ are as follows (see also Figure 1):• Dete t image pat hes and assign ea h of them to one of a set of predetermined lusters (a visualvo abulary) on the basis of their appearan e des riptors.• Constru t a bag-of-keypat hes by ounting the number of pat hes assigned to ea h luster.• Apply a multi- lass lassi�er, treating the bag-of-keypat hes as the feature ve tor, and thus deter-mine whi h ategories to assign to the image. The multi- lass lassi�er is built from a ombinationof one-against-all lassi�ers.The extra ted des riptors of image pat hes should be invariant to the variations that are irrelevant tothe ategorization task (viewpoint hange, lighting variations and o lusions) but ri h enough to arryall ne essary information to be dis riminative at the ategory level. We used Lowe's SIFT approa h [14℄to dete t and des ribe image pat hes. This produ es s ale-invariant ir ular pat hes that are asso iatedwith 128-dimensional feature ve tors of Gaussian derivatives. While in [4℄ we used a�ne invariantellipti al pat hes [15℄, similar performan e was obtained with ir ular pat hes. Moreover, the use of ir ular pat hes makes it simpler to deal with geometri issues.The visual vo abulary was onstru ted using the K-means algorithm applied to a set of over 10000pat hes obtained from a set of images that was ompletely independent from the images used to train ortest the lassi�er. We are not interested in a orre t lustering in the sense of feature distributions, butrather in an a urate ategorization. Therefore, to over ome the initialization dependen e of K-means,we run it several times with di�erent initial luster enters and sele t the �nal lustering giving thehighest ategorization a ura y using an SVM lassi�er (without any geometri properties) on a subsetof the dataset.For ategorization we use the SVM whi h �nds the hyperplane that separates two- lass data withmaximal margin [25℄. The margin is de�ned as the distan e of the losest training point to the separatinghyperplane. The SVM de ision fun tion an be expressed as:
f(x) = sign(∑i
yiαiK(x,xi) + b)where xi are the training features from data spa e and yi ∈ {−1, 1} is the label of xi. The parametersαi are zero for most i, so the sum is taken only over a sele ted set of xi known as support ve tors. It anbe shown that the support ve tors are those feature ve tors lying nearest to the separating hyperplane.In this hapter, the input features xi are the binned histograms formed by the number of o urren esof keypat hes in the input image. K is a kernel fun tion orresponding to an inner produ t between twotransformed feature ve tors, usually in a high and possibly in�nite dimensional spa e. In the experimentsdes ribed here we used a linear kernel, whi h is the dot produ t of x and xi.

In order to apply the SVM to multi- lass problems we took the one-against-all approa h. Given anm- lass problem, we trained m SVM's, ea h of whi h distinguishes images from some ategory i fromimages from all the other m − 1 ategories j not equal to i. Given a query image, we assigned it to the lass with the largest SVM output.3 The Boosting Approa hAn alternative to the SVM lassi�er is the boosting approa h. Here we exploit the generalized versionof the AdaBoost algorithm des ribed in [20℄. Boosting is a method of �nding an a urate lassi�er Hby ombining M simpler lassi�ers hm:
H(x) =(
M∑
m=1
αmhm(x))
/(
M∑
m=1
αm
)
. (1)Ea h simpler lassi�er hm(x) ∈ [−1, 1] needs only to be moderately a urate and is therefore known asa weak lassi�er. They are hosen from a lassi�er spa e to maximize orrelation1 of the predi tionsand labels:rm =
∑
i
Dm(i)hm(xi)yi,where Dm(i) is a set of weights (distribution) over the training set. At ea h step the weights are updatedby in reasing the weights of the in orre tly predi ted training examples:Dm+1(i) = Dm(i) exp{−αmyihm(xi)}/Zm (2)where
αm =1
2log
1 + rm
1 − rm
(3)and Zm is a normalization onstant, su h that ∑
i Dm+1(i) = 1.To de�ne the weak lassi�ers we onsider the same inputs as for the SVM, i.e. the binned histogramsxi. The simplest keypat h-based weak lassi�er hk,T ounts the number of pat hes whose SIFT featuresbelong to luster k, whi h is equivalent to omparing x
ki to some threshold T . If this number is at least
T , then the lassi�er output is 1, otherwise -1:hk,T (xi) =
{
1 if xki ≥ T
−1 otherwise.We may build similar weak lassi�ers hkl,T from a pair of keypat h types k, l. If at least T keypat hesof both types are observed, then the lassi�er output is 1:
hkl,T (xi) =
{
1 if xki ≥ T and x
li ≥ T
−1 otherwise.In pra ti e we sele t weak lassi�ers by sear hing over a prede�ned set of thresholds su h as {1, 5, 10}.The opposite weak lassi�er hk,T̄ an also be de�ned by inverting the inequality (xk < T ). Four su hde�nitions are possible for pairs of keypat hes hkl,T , hkl,T̄ , hkl,T T̄ and hkl,T̄T , e.g:
hkl,T T̄ (xi) =
{
1 if xki ≥ T and x
li < T
−1 otherwise.In pra ti e, we sear h over the full set of di�erent possibilities when working with weak lassi�ers andrefer to them olle tively as hk and hkl. Obviously, it would be possible to further extend the de�nitionfor pairs to applying a di�erent threshold to ea h keypat h type (Tk and Tl). In pra ti e, we avoid thisas it results in a prohibitively large number of possible weak lassi�ers.1This is equivalent to minimizing the weighted training error whi h is equal to (1 − rm)/2.

4 In orporating Geometri InformationIn this se tion we des ribe some ways to onstru t geometri weak lassi�ers. As input, we assume ea hpat h i in a query image has been labeled a ording to its appearan e via the index of the luster entreki to whi h it is assigned. Ea h pat h is asso iated with its orientation θi and a ball ( ir ular pat h) Biwhi h has enter position pi and s ale σi.A simple way to in orporate geometri al information in weak lassi�ers depending on one keypat his to threshold the number of interest points belonging to a luster k and having a parti ular orientation:
hk,Tθ (I) =
{
1 if ∃ θ su h that ∣
∣{i ∈ PI : ki = k, θi = θ}∣
∣ ≥ T−1 otherwisewhere ∣
∣A∣
∣ denotes the ardinality of the set A and PI denotes the set of pat hes in image I.Note that a large number of di�erent orientations are produ ed by the interest point dete tors.Therefore we exploit a oarse quantization of the orientations into eight bins. Two keypat hes are onsidered to have the same orientation if they fall into the same bin2. This does not onstitute exa torientation invarian e, as a small rotation ould ause two keypat hes in one bin to move to di�erentbins. However, this approa h is more e� ient than dire tly measuring and thresholding the di�eren ein orientations ‖θi − θj‖ between pairs of keypat hes.Likewise, we de�ne sets of weak lassi�ers that ount the number of keypat hes with the same s aleor a set that ount pat hes with both the same s ale and orientation. The s ale bins are sele ted withlogarithmi spa ing, in order to approximate s ale invarian e. Colle tively3 these lassi�ers are denotedby hkθ , hk
σ, hkσ,θ.Another way to in orporate geometry is to ount the number of interest points in the ball arounda keypat h of a given type. This ount is made irrespe tive of the type of keypat hes in the ball. Aswith the other weak lassi�ers, this property is invariant to shift, s aling and rotation. In a given image,there may be multiple keypat hes of a given type ontaining di�erent numbers of points. We de�ne hk
Bin terms of the keypat h of type k with the maximum number of points in its ball:hk,T
B (I) =
{
1 if ∃ i su h that ki = k and ∣
∣{j ∈ PI : pj ∈ Bi}∣
∣ ≥ T−1 otherwisewhere pj ∈ Bi means that the enter of the pat h j is inside of the ball Bi de�ned by the pat h i.Taking two types of keypat hes k and l into onsideration, there are more ways to introdu e geometry.Classi�ers based on ommon s ale or orientation an be extended in two obvious ways. Firstly we an require that the pat hes of type k and those of type l have identi al s ale and/or orientation,giving hkl
σ=, hklθ=
, hklσθ=
. Alternatively we an allow ea h type to have their own independent s alesor orientations, giving hklσ , hkl
θ , hklσθ. The latter orresponds to a Boolean ombination of single point lassi�ers, e.g. hk
σ and hlσ.A weak lassi�er hkl
B an be onstru ted similarly to hkB that he ks for the existen e of a pair ofinterest points labeled k, l su h that both of them have at least T interest points inside their balls.We additionally onsider �ve other ways of exploiting the position information asso iated withpat hes:
• hk∈l tests if there are at least T keypat hes labeled l whi h ontain an interest point labeled kwithin their ball.• hk⊂l tests if there are at least T keypat hes labeled l whose balls ontain the whole ball of aninterest point labeled k.• hk∩l tests if there are at least T keypat hes labeled l whose balls interse t with the ball of at leastone interest point labeled k.• hk∝l tests if there are at least T keypat hes labeled l su h that their losest neighboring interestpoints in the image are labeled k.2The equality in the notation θi = θ should be interpreted in this way.3Considering similar threshold reversals as for hk and hkl, e.g. hk,T̄
θand hkl,T̄T
σ,θ.

hy,5σ , hy,4
σθ , hry,2σ , hry,5
θ , hry,2σθ , h1
y∩r and h1y∈r = 1
hr,6, hy,6θ , hry,6, hry,1
σ= , hry,1θ=
, h1σθ=
and h1r⊂r = −1Figure 2: Examples of weak lassi�ers on a typi al image for keypat hes of type r, y (red or yellow).For larity, only the pat hes of type r and y are shown. In these examples, the threshold T on whi hthe weak lassi�ers depend has been hosen as large as possible for output 1 (�rst row) and as small aspossible for output -1 (se ond row).
• hk∈ℵNltests if there are at least T keypat h labeled l su h that there exist a keypat h labeled kamong its N losest neighbors.The set of weak lassi�ers we onsidered is summarized in Table 1 and Figure 2 illustrates some ofthem. Of ourse there are a lot of other possibilities that ould be experimented with.5 ResultsThis se tion presents some results from our experiments. First we ompare our bag-of-keypat h approa hwith the method des ribed in [6℄. Therefore we used the obje t lasses from their FPZ dataset that arefreely available, i.e. �ve obje t lasses - 1074 airplane side images, 651 ar rear images, 720 ar sideimages, 450 frontal fa e images, and 826 motorbike side images - and a set of 451 ba kground images.The se ond set of experiments were done on a more hallenging in-house dataset. This test was madeto test larger number of lasses, more variable poses and intra- lass variations and signi� ant amountsof ba kground lutter. The images have resolutions between 0.3 and 2 mega-pixels and were a quiredwith a diverse set of ameras. The images are olor but only the luminan e omponent is used in ourmethod. They were gathered by XRCE and Graz University. This dataset4 ontains 3084 images from10 ategories. The number of images per lass are: bikes (237), boats (434), books (270), ars (307), hairs (346), �owers (242), phones (250), road signs (211), shoes (525) and soft toys (262). Figure 3shows some images from this database.We used the onfusion matrix (4) to evaluate the multi- lass lassi�ers and the overall orre t rate4The dataset is publi ly available on ftp://ftp.xr e.xerox. om/pub/ftp-ip

Table 1: Complete list of weak lassi�ers investigated. p ∝ q indi ates that p is the losest point to qand ℵNpj
is the set of the N losest neighbors of pj .h h =
{
1 if this quantity ≥ T−1 otherwise h h =
{
1 if this quantity ≥ T−1 otherwise
hk,Tσ max
σ
∣
∣{i : ki = k, σi = σ}∣
∣ hk,Tσθ max
σ,θ
∣
∣{i : ki = k, σi = σ, θi = θ}∣
∣
hkl,Tσ min
u∈{k,l}max
σ
∣
∣{i : ki = u, σi = σ}∣
∣ hkl,Tσθ min
u∈{k,l}maxσ,θ
∣
∣{i : ki = u, σi = σ, θi = θ}∣
∣
hk,Tθ max
θ
∣
∣{i : ki = k, θi = θ}∣
∣ hkl,Tσθ=
maxσ,θ
minu∈{k,l}
∣
∣{i : ki = u, σi = σ, θi = θ}∣
∣
hkl,Tθ min
u∈{k,l}max
θ
∣
∣{i : ki = u, θi = θ}∣
∣ hTk∈l
∣
∣{j : kj = l,∃ki = k, pi ∈ Bj}∣
∣
hkl,Tσ= max
σmin
u∈{k,l}
∣
∣{i : ki = u, σi = σ}∣
∣ hTk⊂l
∣
∣{j : kj = l,∃ki = k,Bi ⊂ Bj}∣
∣
hkl,Tθ=
maxθ
minu∈{k,l}
∣
∣{i : ki = u, θi = θ}∣
∣ hTk∩l
∣
∣{j : ki = l,∃ki = k,Bi ∩ Bj 6= ∅}∣
∣
hk,TB max
i
∣
∣{j : ki = k, pj ∈ Bi}∣
∣ hTk∝l
∣
∣{j : kj = l,∃ki = k, pi ∝ pj}∣
∣
hkl,TB max
imin
u∈{k,l}
∣
∣{j : ki = u, pj ∈ Bi}∣
∣ hTk∈ℵN
l
∣
∣{j : kj = l,∃ki = k, pi ∈ ℵNpj}∣
∣
(5) for the obje t dete tion:Mij =
∣
∣{I ∈ Cj : Hi(I) ≥ Hm(I),∀m}∣
∣
∣
∣Cj
∣
∣
, (4)andR = 1 −
∑Nc
j=1
∣
∣Cj
∣
∣Mjj
∑Nc
j=1
∣
∣Cj
∣
∣
(5)where Nc is the number of onsidered lasses, i, j ∈ {1, · · · , Nc}, Cj is the set of test images from ategory j and Hm(I) is the real output of the lassi�er Hm whi h was trained to distinguish lass mfrom the rest of the lasses.5.0.1 Vo abulary size.There exist methods allowing to automati ally sele t the number of lusters for K-means. For example,Pelleg et al [18℄ use luster splitting, where the splitting de ision depend on the Bayesian InformationCriterion. However, in the present ase we do not really know anything about the density or the ompa tness of our lusters. Moreover, we are not even interested in a " orre t lustering" in the senseof feature distributions, but rather in a urate ategorization. We therefore simply ompare error ratesfor di�erent values of K.Figure 4 presents the overall error rates using the bag-of-keypat hes approa h on our in-house datasetas a fun tion of the number of lusters K. Ea h point in Figure 4 is the �best�5 of 10 random trials of5Best in the sense of lowest empiri al risk in ategorization [25℄.

Figure 3: Examples from our 10 lass dataset.Table 2: Corre t rates for all lasses obtained in 2-fold ross-validation at the equal error rate point byFergus et al (FPZ) with our bag-of-keypat hes method (SV Mi) and a PLSA based approa h (PLSA)des ribed in [21℄. The best results for ea h lass are shown in bold fa e.method Airplanes Cars(rear) Cars(side) Fa es MotorbikesFPZ 90.2 N/A 88.5 96.4 92.5SV M1 97.1 98.6 87.3 99.3 98SV M2 96.4 97.9 86.1 98.9 97.3PLSA 96.6 88.1 N/A 94.7 84.6K-means. We an noti e that the error rate only improves slightly as we move from k = 1000 to k =2500. We therefore assert that k = 1000 presents a good trade-o� between a ura y and speed and inall of our experiments we worked with the �best� vo abulary of size 1000.5.0.2 Obje t Dete tion.Table 2 ompares our results with the ones obtained by Fergus et al as far as they are available from theirpaper [6℄ on the FPZ dataset. They were obtained using 2-fold ross-validation and the orre t ratesreported orrespond to the equal error operating point. As they did, we train our lassi�ers to re ognizeforeground images, i.e. images belonging to the onsidered lass, and reje t ba kground images. Thedi�eren e between SV M1 and SV M2 is that to build the visual vo abulary (K-means) in the former ase we used a subset of images from the FPZ database and in the latter ase a ompletely independentimage set. We an observe only a slight di�eren e between the performan es of SV M1 and SV M2,showing a low in�uen e of the initial sample feature set on the lassi� ation results.Ex ept for ars (side) all the lassi�ers trained with our method perform mu h better, no matter

0 500 1000 1500 2000 250024
26
28
30
32
34
36
38Error rate for different choice of k
erro
r ra
teKFigure 4: The lowest overall error rate (per entage) found for di�erent hoi es of k.whi h set of keypat hes we use. The small di�eren e on the ars (side) dataset is probably not signi� ant.One possible reason why we do not perform so well on this ategory is that the ars (side) images aresmall and ontain few keypat hes (only about 50 keypat hes ompared with 500-1000 for the other lasses).Figure 5.0.2 shows the ROC urves for the lassi�ers obtained for SV M1 with the di�erent lassesusing 2-fold ross-validation. It shows that even for lassi�ers with a very small false positive rate there all is very high.5.0.3 Multi- lass Classi�er.Tables 3 and 4 report the results we obtain using our method for training a multi- lass lassi�er on theabove mentioned �ve- lass dataset. Table 3 shows the results with 2-fold ross-validation. This allowsto ompare the results with those from the obje t dete tion ase (Table 2). It shows that in all asesex ept ars (side) the orre t rates observed in the multi- lass ase are inferior to those obtained inthe obje t dete tion ase. Again this might be linked to the small number of keypat hes present in theimages belonging to this ategory.Table 3: Overall orre t rates for all lasses obtained with 2-fold ross-validation with the di�erentkeypat h sets. method Airplanes Cars(rear) Cars(side) Fa es Motorbikes
SV M1 96.4 97.1 97.1 92.4 92.4SV M2 94.4 94.6 97.3 89.8 90.5SREZF1 95.2 98.1 N/A 94 83.6SREZF2 97.5 99.3 N/A 99.5 96.5In two last rows of Table 3 (SREZF1 and SREZF2) we show the re ent results obtained by Sivi et al [21℄ on this dataset using PLSA. They do not used ars (side) images. The in lusion of ars (side)is belived to onfuse the lassi�er and signi� antly in rease error rates.They �rst used the training images (one fold) plus about 200 ba kground images without their labeland sear hed for 7 topi s. In this way the PLSA dis overed 3 topi s related to ba kground ontentand 4 topi s orresponding to the 4 ategories. In SREZF1 the test images were assigned to the mostprobable of the 7 topi s. In SREZF2 test images were assigned only to the most probable of the 4topi s orresponding to ategories (ex luding the ba kground topi from the ranking).The results shows that using PLSA for automati topi dete tion is promising and has the advantagethat it do not need individual labeling of images. However it is di� ult to judge how it s ales with
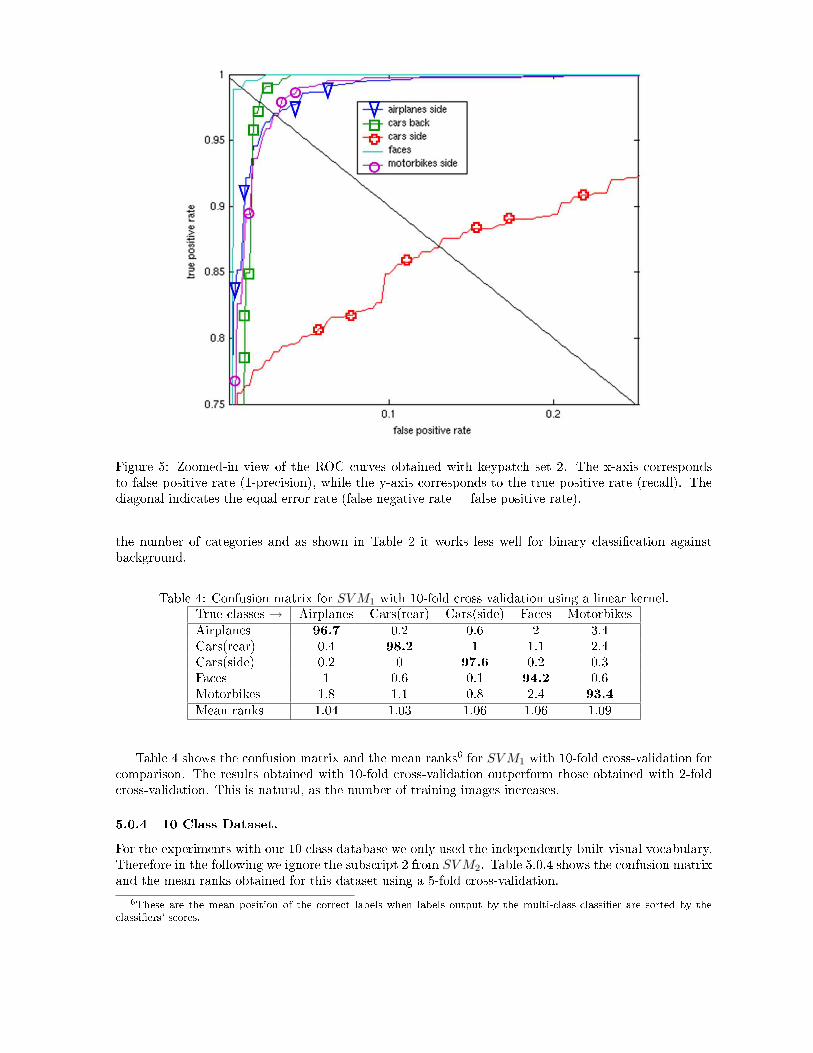
Figure 5: Zoomed-in view of the ROC urves obtained with keypat h set 2. The x-axis orrespondsto false positive rate (1-pre ision), while the y-axis orresponds to the true positive rate (re all). Thediagonal indi ates the equal error rate (false negative rate = false positive rate).the number of ategories and as shown in Table 2 it works less well for binary lassi� ation againstba kground.Table 4: Confusion matrix for SV M1 with 10-fold ross validation using a linear kernel.True lasses → Airplanes Cars(rear) Cars(side) Fa es MotorbikesAirplanes 96.7 0.2 0.6 2 3.4Cars(rear) 0.4 98.2 1 1.1 2.4Cars(side) 0.2 0 97.6 0.2 0.3Fa es 1 0.6 0.1 94.2 0.6Motorbikes 1.8 1.1 0.8 2.4 93.4Mean ranks 1.04 1.03 1.06 1.06 1.09Table 4 shows the onfusion matrix and the mean ranks6 for SV M1 with 10-fold ross-validation for omparison. The results obtained with 10-fold ross-validation outperform those obtained with 2-fold ross-validation. This is natural, as the number of training images in reases.5.0.4 10 Class Dataset.For the experiments with our 10 lass database we only used the independently built visual vo abulary.Therefore in the following we ignore the subs ript 2 from SV M2. Table 5.0.4 shows the onfusion matrixand the mean ranks obtained for this dataset using a 5-fold ross-validation.6These are the mean position of the orre t labels when labels output by the multi- lass lassi�er are sorted by the lassi�ers' s ores.

Table 5: Confusion matrix and mean ranks for SV M . lasses bikes boats books ars hairs �owers phones r. signs shoes s. toysbikes 69.2 1.7 1.9 1 5.3 1.2 0.4 3.2 1.2 1.3boats 3.7 79.3 5.2 4.6 7.7 1.7 1.2 1.3 1.8 1.7books 1.3 2.2 70.3 2.4 2.7 0.6 4.6 4.5 0.6 1.7 ars 4.2 3.7 2.4 72.1 8.3 0.3 3.1 3.1 1.5 0.8 hairs 10.8 3.9 5.3 5.4 58.8 2.2 2.7 5.8 1.3 1.1�owers 1.2 1.2 1.3 1.6 1.2 86.7 1.6 1.6 0.7 0.8phones 1.9 0.7 4.1 3.7 2.8 1.4 70.4 1.7 1.3 1.4road signs 1.7 1.9 2.4 1.9 4.9 1.1 2.7 69 1.4 1.2shoes 3.6 5.2 4.5 6.4 6.7 1.6 11.6 8.3 86.3 10.8soft toys 2.4 0.2 2.6 0.9 1.6 3.2 1.7 1.5 3.9 79.2mean ranks 1.5 1.3 1.5 1.3 1.9 1.3 1.9 1.7 1.3 1.25.0.5 In orporating Geometry Information.Table 6 shows the orre t lassi� ation rates (Mii) for ea h lass obtained with the boosting approa hwithout adding geometri information. The �rst row orresponds to the approa h hk where only singlekeypat h based weak lassi�ers were sele ted, and the se ond row shows results of the hk,l approa h orresponding to weak lassi�ers based on pair of keypat hes. In the third row we show the results ofthe SV M (the diagonal of the onfusion matrix shown in Table 5.0.4) for omparison. All results wereobtained by 5-fold ross-validation.Table 6: Corre t lassi� ation rates for: boosting without geometry (hk, hk,l); SVM with a linear kernel;boosting all types of weak lassi�ers hall and boosting SVM with all types of weak lassi�ers (SV Mall).The standard error on the orre t rate for ea h ategory is about 0.4%. lasses bikes boats books ars hairs �owers phones r. signs shoes s. toys meanhk 61.7 74.5 67.0 55.6 50.7 82.5 67.6 61.4 73.9 68.9 66.4hk,l 64.6 76.1 68.5 61.0 50.7 84.6 69.6 64.8 76.6 69.2 68.6SV M 69.2 79.3 70.3 72.1 58.8 86.7 70.4 69.0 86.3 79.2 74.1hall 70.0 73.8 68.2 64.1 57.4 82.9 68.0 61.9 75.2 76.2 69.8SV Mall 74.6 81.8 78.2 77.5 65.2 89.6 76.0 76.2 83.8 83.8 78.7We an see that hk,l outperforms hk, but both boosting approa hes have mu h lower performan ethan the linear SV M . We also tested the quadrati kernel for SV M as it impli itly onsiders keypat hpairs but the results were very similar to those of the linear kernel.Furthermore, we investigated how well ea h weak lassi�er type performed when it was used ex lu-sively for boosting. Results are given in Table 7 and sele ted weak lassi�er examples are shown inFigure 6.We then ombined the 17 types of geometri weak lassi�ers with hypotheses hk and hk,l. This (seefourth row of Table 6) slightly improved on the boosting results without geometry (�rst two rows) butgave still lower performan e than the SVM.Finally, we ombined the SVM outputs with the weak lassi�ers using generalized AdaBoost. Firstthe SVM outputs were normalized to [−1, 1] using a sigmoid �t7 [?℄. This lassi�er was onsidered as�rst �weak� lassi�er h1 of the boosting approa h (see Eqn (1)) and the orresponding α1 and D2(i)were a ordingly omputed (see Eqn's (3) and (2)). Other weak lassi�ers were sele ted from the fullset of 19's h's. The se ond row of Table 7 shows how often ea h lassi�er type was used. Clearly hkl
Band hklσ are importnat omplements to the SVM.7This transformation of SVM outputs to on�den e was also applied when we ranked the outputs from di�erent lasses.
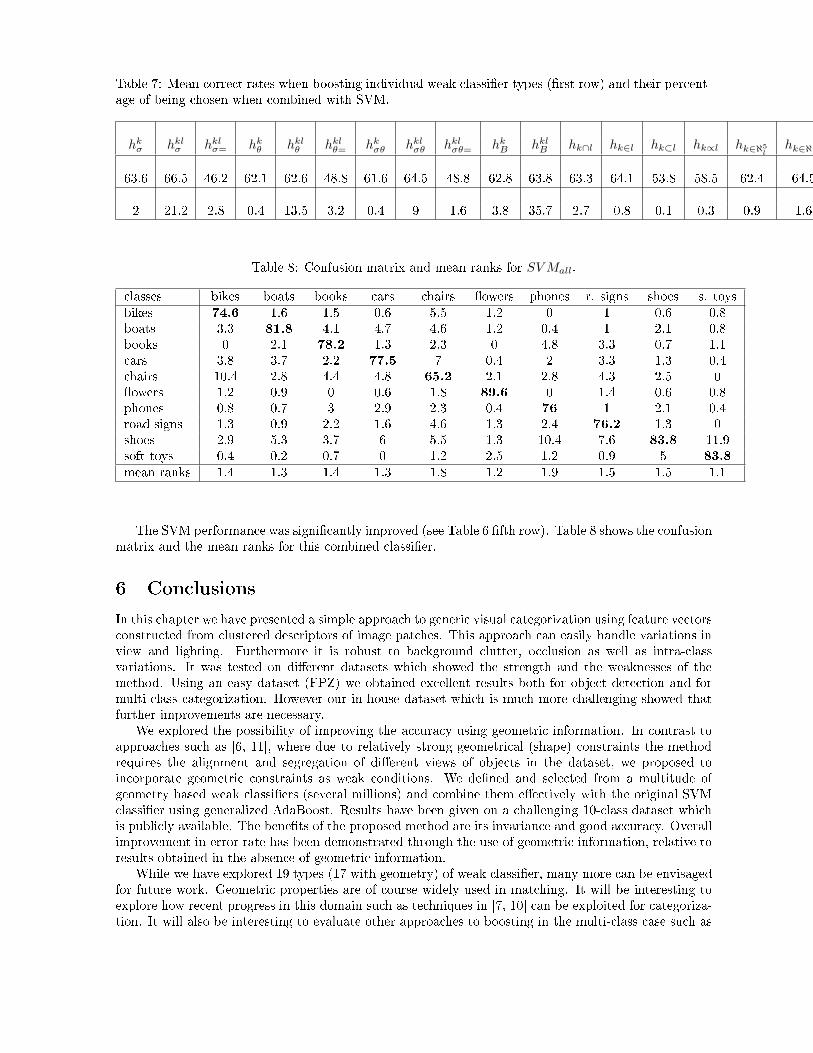
Table 7: Mean orre t rates when boosting individual weak lassi�er types (�rst row) and their per ent-age of being hosen when ombined with SVM.hk
σ hklσ hkl
σ= hkθ hkl
θ hklθ=
hkσθ hkl
σθ hklσθ=
hkB hkl
B hk∩l hk∈l hk⊂l hk∝l hk∈ℵ5
lhk∈ℵ10
l63.6 66.5 46.2 62.1 62.6 48.8 61.6 64.5 48.8 62.8 63.8 63.3 64.1 53.8 58.5 62.4 64.52 21.2 2.8 0.4 13.5 3.2 0.4 9 1.6 3.8 35.7 2.7 0.8 0.1 0.3 0.9 1.6Table 8: Confusion matrix and mean ranks for SV Mall. lasses bikes boats books ars hairs �owers phones r. signs shoes s. toysbikes 74.6 1.6 1.5 0.6 5.5 1.2 0 1 0.6 0.8boats 3.3 81.8 4.1 4.7 4.6 1.2 0.4 1 2.1 0.8books 0 2.1 78.2 1.3 2.3 0 4.8 3.3 0.7 1.1 ars 3.8 3.7 2.2 77.5 7 0.4 2 3.3 1.3 0.4 hairs 10.4 2.8 4.4 4.8 65.2 2.1 2.8 4.3 2.5 0�owers 1.2 0.9 0 0.6 1.8 89.6 0 1.4 0.6 0.8phones 0.8 0.7 3 2.9 2.3 0.4 76 1 2.1 0.4road signs 1.3 0.9 2.2 1.6 4.6 1.3 2.4 76.2 1.3 0shoes 2.9 5.3 3.7 6 5.5 1.3 10.4 7.6 83.8 11.9soft toys 0.4 0.2 0.7 0 1.2 2.5 1.2 0.9 5 83.8mean ranks 1.4 1.3 1.4 1.3 1.8 1.2 1.9 1.5 1.5 1.1The SVM performan e was signi� antly improved (see Table 6 �fth row). Table 8 shows the onfusionmatrix and the mean ranks for this ombined lassi�er.6 Con lusionsIn this hapter we have presented a simple approa h to generi visual ategorization using feature ve tors onstru ted from lustered des riptors of image pat hes. This approa h an easily handle variations inview and lighting. Furthermore it is robust to ba kground lutter, o lusion as well as intra- lassvariations. It was tested on di�erent datasets whi h showed the strength and the weaknesses of themethod. Using an easy dataset (FPZ) we obtained ex ellent results both for obje t dete tion and formulti- lass ategorization. However our in-house dataset whi h is mu h more hallenging showed thatfurther improvements are ne essary.We explored the possibility of improving the a ura y using geometri information. In ontrast toapproa hes su h as [6, 11℄, where due to relatively strong geometri al (shape) onstraints the methodrequires the alignment and segregation of di�erent views of obje ts in the dataset, we proposed toin orporate geometri onstraints as weak onditions. We de�ned and sele ted from a multitude ofgeometry based weak lassi�ers (several millions) and ombine them e�e tively with the original SVM lassi�er using generalized AdaBoost. Results have been given on a hallenging 10- lass dataset whi his publi ly available. The bene�ts of the proposed method are its invarian e and good a ura y. Overallimprovement in error rate has been demonstrated through the use of geometri information, relative toresults obtained in the absen e of geometri information.While we have explored 19 types (17 with geometry) of weak lassi�er, many more an be envisagedfor future work. Geometri properties are of ourse widely used in mat hing. It will be interesting toexplore how re ent progress in this domain su h as te hniques in [7, 10℄ an be exploited for ategoriza-tion. It will also be interesting to evaluate other approa hes to boosting in the multi- lass ase su h as

(a) (b)
( ) (d)Figure 6: The three most relevant single keypat hes hk for the � hair� lassi�er are shown in (a). Thefollowing images show the single most relevant weak lassi�er based on pairs of pat hes for types (b)hkl
σ , ( ) hk⊂l and (d) hk∩l respe tively in the ase of �road sign�, ��owers� and �boat� lassi�ers. Inea h ase we show all pat hes of type k (in blue) and all pat hes of type l (in green). Not all of thesepat hes verify the respe tive geometri ondition. For (d) hk∩l it happends that the most relevant weak lassi�er hk⊂l for the �boat� lassi�er was obtained for k = l hen e only blue ir les are shown.

the joint-boosting proposed in [24℄, whi h promises improved generalization performan e and the needfor fewer weak lassi�ers.However, one of the main in onvenien es of the proposed approa h is the ost of the training whi hdoes not s ale well with the number of images and number of lasses (all weak lassi�ers must be testedon the whole training set at ea h step of the boosting). One way to redu e the sear h is to build avo abulary of doublets (pair of keypat hes) using only the most relevant visual words as in [21℄.More re ently, in [19℄ we have shown that approa hes based on soft lustering using GMM ratherthan K-means an enable substantial improvements in a ura y. It was also shown that when ombinedwith adaptation te hniques drawn from spee h re ognition, su h approa hes an s ale well with thenumber of lasses. It will be an interesting hallenge to in orporate geometri information with su hsoft lustering approa hes.7 A knowledgmentsThis work was supported by the European Proje t IST-2001-34405 LAVA (Learning for AdaptableVisual Assistants, http://www.l-a-v-a.org). We are grateful to DARTY for their permission to a quireimages in their shops, to INRIA for the use of their multi-s ale interest point dete tor and to TU Grazfor the bikes image database.Referen es[1℄ A. Amir, J. Argillander, M. Berg, S.-F. Chang, M. Franz, W. Hsu, G. Iyengar, J. Kender, L. Kennedy,C.-Y. Lin, M. Naphade, A. Natsev, J. Smith, J. Tesi , G. Wu, R. Yang, and D. Zhang. IBM resear hTRECVID-2004 video retrieval system. In Pro . of TREC Video Retrieval Evaluation, 2004.[2℄ P. Carbonetto, N. de Freitas, and K. Barnard. A statisti al model for general ontextual obje t re ognition.In Pro . ECCV, volume 1, pages 350�362, 2004.[3℄ Y. Chen and J. Z. Wang. Image ategorization by learning and reasoning with regions. JMLR, 5:913�939,2004.[4℄ G. Csurka, C. Dan e, L. Fan, J. Willamowski, and C. Bray. Visual ategorization with bags of keypoints.In Pro . ECCV International Workshop on Statisti al Learning in Computer Vision, 2004.[5℄ J. Farquhar, S. Szedmak, H. Meng, and J. Shawe-Taylor. Improving �bag-of-keypoints� image ategorisation.Te hni al report, University of Southampton, 2005.[6℄ R. Fergus, P. Perona, and A. Zisserman. Obje t lass re ognition by unsupervised s ale-invariant learning.In Pro . CVPR, volume 2, pages 264�271, 2003.[7℄ V. Ferrari, T. Tuytelaars, and L. Van Gool. Simultaneous obje t re ognition and segmentation by imageexploration. In Pro . ECCV, volume 1, pages 40�54, 2004.[8℄ W. H. Hsu and S.-F. Chang. Visual ue luster onstru tion via information bottlene k prin iple and kerneldensity estimation. In Pro . CIVR, 2005.[9℄ T. Joa hims. Text ategorization with support ve tor ma hines: learning with many relevant features. InPro . ECML, volume 1398, pages 137�142, 1998.[10℄ S. Lazebnik, C. S hmid, and J. Pon e. Semi-lo al a�ne parts for obje t re ognition. In Pro . BMVC,volume 2, pages 959�968, 2004.[11℄ B. Leibe, A. Leonardis, and B. S hiele. Combined obje t ategorization and segmentation with an impli itshape model. In Pro . ECCV Workshop on Statisti al Learning in Computer Vision, pages 17�32, 2004.[12℄ Y. Li, J. A. Bilmes, and L. G. Shapiro. Obje t lass re ognition using images of abstra t regions. In Pro .ICPR, volume 1, pages 40�44, 2004.[13℄ H. Lodhi, J. Shawe-Taylor, N. Christianini, and C. Watkins. Text lassi� ation using string kernels. InAdvan es in Neural Information Pro essing Systems, volume 13, 2001.[14℄ D.G. Lowe. Obje t re ognition from lo al s ale-invariant features. In Pro . ICCV, pages 1150�1157, 1999.[15℄ K. Mikolaj zyk and C. S hmid. An a�ne invariant interest point dete tor. In Pro . ECCV, volume 1, pages128�142, 2002.

[16℄ A. Opelt, M. Fussenegger, A. Pinz, and P. Auer. Weak hypotheses and boosting for generi obje t dete tionand re ognition. In Pro . ECCV, volume 2, pages 71�84, 2004.[17℄ J.-Y. Pan, H.-J. Yang, C. Faloutsos, and P. Duygulu. GCap: Graph-based automati image aptioning. InPro . CVPR Workshop on Multimedia Data and Do ument Engineering, 2004.[18℄ D. Pelleg and A. Moore. X-means: Extending k-means with e� ient estimation of the number of lusters.In Pro . ICML, 2000.[19℄ F. Perronnin, C. Dan e, G. Csurka, and M. Bressan. Adapted vo abularies for generi visual ategorization.Submitted to ECCV 2006.[20℄ R.E. S hapire and Y. Singer. Improved boosting algorithms using on�den e-rated predi tions. Ma hineLearning, 37(3):297�336, 1999.[21℄ J. S. Sivi , B. C. Russell, A. A. Efros, A. Zisserman, and W. F. Feeman. Dis overing obje ts and theirlo alization in images. In Pro . ICCV, pages 370�377, 2005.[22℄ J. S. Sivi and A. Zisserman. Video google: A text retrieval approa h to obje t mat hing in videos. InPro . ICCV, volume 2, pages 1470�1477, 2003.[23℄ S. Tong and D. Koller. Support ve tor ma hine a tive learning with appli ations to text lassi� ation. InPro . ICML, 2000.[24℄ A. Torralba, K. P. Murphy, and W. T. Freeman. Sharing features: E� ient boosting pro edures formulti lass obje t dete tion. In Pro . CVPR, volume 2, pages 762�769, 2004.[25℄ V. Vapnik. Statisti al Learning Theory. Wiley, 1998.[26℄ L. Zhu, A. Rao, and A. Zhang. Theory of keyblo k-based image retrieval. ACM Transa tions on InformationSystems, 20(2):224�257, 2002.




















