
From Flop to MegaFlops: Java for Technical Computing
29
From Flop to Megaflops: Java for Technical Computing JOS ´ E E. MOREIRA, SAMUELP. MIDKIFF, and MANISH GUPTA IBM Thomas J. Watson Research Center null Categories and Subject Descriptors: D.3,4 [Programming Languages]: Processor—compilers; run-time envi- ronments; D.1.3 [Programming Techniques]: Concurrent Programming—parallel programming 1. INTRODUCTION The scientific programming community has demonstrated a great deal of interest in the use of Java 1 for technical computing. There are many compelling reasons for such interest. First and foremost, Java enjoys growing popularity and an expanding programmer base. In addition, Java is object-oriented without excessive complications (in contrast to C++), and has support for networking and graphics. These features of Java are particularly important as technical computing continues to move toward a network-centric model of computa- tion. In this context, it is expected that Java will first be used where it is most natural: for visualization and networking components. Eventually, Java will spread into the core computational components of technical applications. Nevertheless, performance remains a major obstacle to the pervasive use of Java in tech- nical computing. Let us start by looking into the performance of a simple matrix-multiply routine in Java, as shown in Figure 1. This routine computes , where Java is a trademark of Sun Microsystems, Inc. Authors’ address: IBM Thomas J. Watson Research Center, PO Box 218, Yorktown Heights, NY 10598-0218; email: jmoreira;smidkiff;mgupta @us.ibm.com. Permission to make digital/hard copy of all or part of this material without fee is granted provided that the copies are not made or distributed for profit or commercial advantage, the ACM copyright/server notice, the title of the publication, and its date appear, and notice is given that copying is by permission of the Association for Computing Machinery, Inc. (ACM). To copy otherwise, to republish, to post on servers, or to redistribute to lists requires prior specific permission and/or a fee. c 1999 ACM 0164-0925/99/0100-0111 $00.75 ACM Transactions on Programming Languages and Systems Vol. X, No. y, Month 1999, Pages 1–29.
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of From Flop to MegaFlops: Java for Technical Computing

From Flop to Megaflops: Java for TechnicalComputing
JOSE E. MOREIRA, SAMUEL P. MIDKIFF, and MANISH GUPTAIBM Thomas J. Watson Research CenterAlthough there has been some experimentation with Java as a language for numerically intensivecomputing, there is a perception by many that the language is unsuited for such work because ofperformance de�ciencies. In this article we show how optimizing array bounds checks and nullpointer checks creates loop nests on which aggressive optimizations can be used. Applying theseoptimizations by hand to a simple matrix-multiply test case leads to Java-compliant programswhose performance is in excess of 500 M ops on a four-processor 332MHz RS/6000 model F50computer. We also report in this article the e�ect that various optimizations have on the per-formance of six oating-point-intensive benchmarks. Through these optimizations we have beenable to achieve with Java at least 80% of the peak Fortran performance on the same benchmarks.Since all of these optimizations can be automated, we conclude that Java will soon be a seriouscontender for numerically intensive computing.Categories and Subject Descriptors: D.3,4 [Programming Languages]: Processor—compilers; run-time envi-ronments; D.1.3 [Programming Techniques]: Concurrent Programming—parallel programmingGeneral Terms: Languages, PerformanceAdditional Key Words and Phrases: Arrays, Compilers, Java1. INTRODUCTION
The scientific programming community has demonstrated a great deal of interest in the useof Java1 for technical computing. There are many compelling reasonsfor such interest.First and foremost, Java enjoys growing popularity and an expanding programmer base. Inaddition, Java is object-oriented without excessive complications (in contrast to C++), andhas support for networking and graphics. These features of Java are particularly importantas technical computing continues to move toward a network-centric model of computa-tion. In this context, it is expected that Java will first be used where it is most natural:for visualization and networking components. Eventually,Java will spread into the corecomputational components of technical applications.
Nevertheless, performance remains a major obstacle to the pervasive use of Java in tech-nical computing. Let us start by looking into the performance of a simple matrix-multiplyroutine in Java, as shown in Figure 1. This routine computesC = C + A � B, where1Java is a trademark of Sun Microsystems, Inc.
Authors’ address: IBM Thomas J. Watson Research Center, PO Box 218, Yorktown Heights, NY 10598-0218;email:fjmoreira;smidkiff;[email protected] to make digital/hard copy of all or part of this material without fee is granted provided that the copiesare not made or distributed for profit or commercial advantage, the ACM copyright/server notice, the title ofthe publication, and its date appear, and notice is given that copying is by permission of the Association forComputing Machinery, Inc. (ACM). To copy otherwise, to republish, to post on servers, or to redistribute to listsrequires prior specific permission and/or a fee.c 1999 ACM 0164-0925/99/0100-0111 $00.75
ACM Transactions on Programming Languages and Systems Vol.X, No. y, Month 1999, Pages 1–29.

2 � Jose E. Moreira et al.
static void matmul(double[][] A, double[][] B, double[][] C,int m, int n, int p) {
int i, j, k;for (i=0; i<m; i++) {
for (j=0; j<p; j++) {for (k=0; k<n; k++) {
C[i][j] += A[i][k]*B[k][j];}
}}
}
Fig. 1. Simple matrix-multiply code in Java.C is anm � p matrix, A is anm � n matrix, andB is ann � p matrix. We use thisroutine to multiply two500 � 500 matrices (m = n = p = 500) on an RS/6000 modelF50 computer. This machine contains four 332MHz PowerPC 604e processors, each witha peak performance of 664 Mflops. We refer to this simple benchmark asMATMUL.
The Java code is compiled into a native executable by the IBM High Performance Com-piler for Java (HPCJ) [Seshadri 1997], and achieves a performance of 5 Mflops on theRS/6000 F50. For comparison, the equivalent Fortran code, compiled by the IBM XLFcompiler, achieves 265 Mflops, and the single-threaded version of ESSL (Engineering andScientific Subroutine Library [International Business Machines Corporation 1997]), care-fully hand-tuned to achieve optimum performance, executesthe matrix multiplication at355 Mflops. The multithreaded version of ESSL achieves 1278 Mflops. A greater than50-fold performance degradation makes it hard to justify using Java for a technical appli-cation.
Why is the performance of Java so bad when compared to Fortran? In the case ofmatrix-multiply, the IBM XLF Fortran compiler uses severalhigh-order transformationsto achieve the observed level of performance. These transformations include blocking(for better cache reuse), loop unrolling, and scalar replacement. Because of Java’s strictsequential semantics, combined with the generation of exceptions when an array index isout-of-bounds, these same transformations are normally inhibited in Java.
The goal of this article is to show that the performance gap between Java and Fortranor C++ can be closed. The key to achieving high performance inJava is to create regionsof an iteration space in which all array indices are guaranteed to be in-bounds. This hasboth direct and indirect benefits. First, the actual checks for array bounds can be removedin those regions. More important, though, because all iterations in thesesaferegions willexecute without exceptions, many of the high-order transformations applicable to Fortranand C++ (including parallelization) can be used. In the particular case ofMATMUL on aRS/6000 F50, we have achieved fully compliant Java performance in excess of 500 Mflops.
The rest of this article is organized as follows. Section 2 discusses two of our methodsto create safe regions, that is, regions without out-of-bounds array indices. Section 3 thendiscusses how to apply high-order transformations to theseregions and lists performanceimprovements obtained with Java for six benchmark programs. Section 4 shows how wecan parallelizeMATMUL and presents additional performance results. In Section 5 wediscuss some related work. Finally, in Section 6 we concludethis article and discuss somefuture work.
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

From Flop to Megaflops: Java for Technical Computing � 3
2. OPTIMIZATION OF ARRAY BOUNDS CHECKING
A major impediment to optimizing Java is the requirement that exceptions be thrown pre-cisely. An exception must be thrown for any attempt to dereference anull pointer orperform an out-of-bounds array access [Gosling et al. 1996]. (Note that Java floating-pointarithmetic does not generate exceptions.) Because most references in computationallyintense Java loops are to arrays or via pointers, most references have the potential to gen-erate an exception. Because of the precise exception requirement, it is impossible to docode motion across potential exceptions, and therefore it is impossible to perform manyoptimizations. We describe two different approaches to overcoming this difficulty createdby potential invalid accesses:regioningof the iteration space into safe and unsafe regions,andversioningof the code into safe and unsafe variants.
2.1 Regioning
Regioning works by transforming the program so that most computation in programs thatperform few or no invalid accesses is in loops that are provably free of invalid accesses.Intuitively, these loops are formed by partitioning the iteration space of the loop nest intoregions. A region is a set of adjacent iterations in the loop nest suchthat either (i) allaccesses in the region are provably safe and will not cause anexception to be thrown or(ii) one or more accesses may be invalid. An iterationi is placed into asaferegion if it canbe shown that no reference in iterationi causes an invalid access exception. Otherwise theiteration is placed into anunsaferegion.
To execute the two types of regions, two versions of the loop nest are formed. Oneversion, which executes the iterations in safe regions, hasno code to check for access vio-lations. The second version, which executes the iterationsin unsafe regions, performs allaccess violation checks explicitly mandated by the Java Virtual Machine (JVM) specifica-tion. By executing the regions and the iterations within theregions in the proper order, theiteration space of the loop is executed in the original execution order. However, checks areonly performed in unsafe regions.
The rest of this section will explain how iterations that perform safe accesses for a refer-ence are determined, how this information is used to partition the iteration space into safeand unsafe regions, and how code is generated to execute the iterations in the regions usingthe proper loop version. We discuss one particular method for forming regions in loopswhose references are either scalars or arrays with linear subscript expressions. In Guptaet al. [1998] and Midkiff et al. [1998] we discuss other methods for forming safe regions,and describe a variety of techniques to handle subscripted subscripts, constant subscripts,general affine subscripts, and subscripts involving modulooperators.
2.1.1 Determining Iterations with Safe Accesses.LetA[f(i)] be a reference for whichthe safe bounds are being found. Leti be the loop index variable of a normalized loopwith stride one. We refer to this loop as loopi. Let f(i) be a linear function of the formc � i + b, wherec andb are invariant within the loop, andc > 0. Again, see Gupta et al.[1998] and Midkiff et al. [1998] for details on how to handle more general subscripts. Witharrays of arrays, used in Java to simulate multidimensionalarrays, we treat the access toeach dimension of the array as a separate access.
Let lo(A) and up(A) be the lower and upper bounds of arrayA, respectively. Note, that,in Java programs, lo(A) is always zero, but we specify it symbolically for generality. Letli andui be the lower and upper bounds of the iteration space ofi, respectively. The safe
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

4 � Jose E. Moreira et al.
iterations ofi are defined as all iterationsi such thatf(i) � lo(A) andf(i) � up(A).Solving these two inequalities fori, and intersecting with the loop iteration space, givesthe range ofi that will not cause access violations in referenceA[c � i + b]:��
lo(A)� bc � � i � �up(A)� bc ��\ (li � i � ui) (1)
The intersection of all ranges defined by Eq. (1), for all references in loopi indexed byi,defines the lower and upper bounds of thesafe regionfor i. We denote these boundslsiandusi , respectively. The safe region for the loopi implicitly defines two other regions forloop i. One is the lower unsafe region,li � i < lsi , the other is the upper unsafe regionusi < i � ui. We note, that, in a nested(i; j) loop, the values oflsj andusj can, in general,be functions ofi.
Null pointer checks can be performed on array base pointers and other pointers whilecomputing the safe region. If anull pointer is found, the safe region is made empty, andall of the iterations are placed in either the lower or upper unsafe region. Details concerningnull pointer issues, handling the situation where the intersection of safe regions is empty,and other boundary cases are found in Midkiff et al. [1998].
2.1.2 Covering the Iteration Space with Regions.Consider a perfect loop nest definedby the loopsi1; i2; : : : ; id. We use the full (lik , uik) and safe (lsik , usik) bounds of theloops to partition the iteration space. An example of that isshown in Figure 2 for a two-dimensional iteration space. The outeri1 loop is divided into at most two unsafe regionsand one safe region. The inneri2 loop is, in the worst case, divided into three regions foreach iteration of the safe region of the outer loop. In the example, there are four iterationsin the outer loop safe region (i.e., those iterations between lsi1 andusi1).
Note that each region has its own characteristics as to whichreference tests need to beperformed. We are particularly interested in finding the safe regions (no tests). We treatany region needing at least one test as needing all tests. We do this for two reasons. First,this strategy simplifies code generation. Second, the primary benefit of having safe refer-ences is not in removing the overhead of doing the tests, but rather in enabling optimizingcompiler transformations. The more aggressive optimizingtransformations used by For-tran and C++ compilers typically change the order of loop iterations and array references.A single remaining unsafe reference in a loop body will prevent these transformations.This means that a relatively small gain in performance results from specializing the codefor the case where some, but not all, exceptions have been eliminated. Section 3 quantifiesthe gains resulting from enabling transformations and removing the overhead of boundschecks.
Procedureregions() in Figure 3 recursively computes the regions that tile the iterationspace of a perfect loop nest of depthd (see Figure 5(a)). See Gupta et al. [1998] andMidkiff et al. [1998] for a discussion on how to optimize nonperfect loop nests. Procedureregions() takes seven parameters. The first five are input parameters, and describe the loopnest being tiled. They are
(1) the indexj, which indicates that region extents along index variableij are being com-puted,
(2) the vector(�1; �2; : : : ; �j�1), where�k is the lower bound for loop indexik in theregions to be computed,
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

From Flop to Megaflops: Java for Technical Computing � 5
q q q q q q q qq q q q q q q qq q q q q q q qq q q q q q q qq q q q q q q qq q q q q q q qq q q q q q q qq q q q q q q qR[1] R[2] R[5] R[8] R[11]R[3] R[6] R[9] R[12]R[4] R[7] R[10]R[13] R[14]-i16i2 li2 lsi2 usi2 ui2li1# lsi1# usi1# ui1# � R[1]: tests ini1 andi2� R[2];R[5];R[8];R[11]: tests ini2� R[3];R[6];R[9];R[12]: no tests� R[4];R[7];R[10];R[13]: tests ini2� R[14]: tests ini1 andi2(a) Partitioning the iteration space into regions (b) Mandatory tests in each region
Fig. 2. Iteration space for a perfectly nested two-dimensional loop.
(3) the vector(!1; !2; : : : ; !j�1), where!k is the upper bound for loop indexik in theregions to be computed,
(4) the dimensionality (or depth)d of the loop nest, and(5) the vectorB[1 : d], whereB[k] = (lik ; uik ; lsik; usik) contains the full and safe bounds
(as computed in Section 2.1.1) for loopik.
The next two parameters are the output of the procedure. The first output parameter is thevector of regions,R, which has the following format:R[�] = (l(�); u(�); � (�)); (2)
l(�) = (li1(�); li2(�); : : : ; lid(�)); (3)
u(�) = (ui1(�); ui2(�); : : : ; uid(�)); (4)� (�) = ftest j notestg: (5)
Elementslij (�) anduij (�) denote the lower and upper bounds, respectively, of loopijin regionR[�]. The definition of a region also contains a flag,� (�), that has the valuetest if the region requires any array reference ornull pointer reference to be tested, andnotest otherwise. The second output parameter isu, the number of regions used to tile theiteration space.
Each invocation of procedureregions() for some value ofj partitions the iteration sub-space formed by loopsij ; ij+1; : : : ; id. Loop ij is partitioned into three parts: the lowernonsafe regionlij � ij < lsij , the safe regionlsij � ij � usij , and the upper nonsafe regionusij < ij � uij . The lower nonsafe region is formed in lines 2-5 of procedureregions(),and the upper nonsafe region is formed in lines 17-20. Note, that, once a region is nonsafein some loop of the loop nest, it is treated as nonsafe in all loops of the nest. Thus, the
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

6 � Jose E. Moreira et al.1 procedure regions(j;(�1; �2; : : : ; �j�1); (!1; !2; : : : ; !j�1); d;B;R; u) f2 if (lij < lsij ) f3 u = u + 14 R[u] = ((�1; : : : ; �j�1; lij ; lij+1 ; : : : ; lid); (!1; : : : ; !j�1; lsij � 1; uij+1 ; : : : ; uid ); test)5 g6 if (j == d) f7 u = u + 18 R[u] = ((�1; : : : ; �d�1; lsid); (!1; : : : ; !d�1; usid );notest)9 g else if (nochecks((lij+1 ; lij+2 ; : : : ; lid ); (lsij+1 ; lsij+2 ; : : : ; lsid);(uij+1 ; uij+2 ; : : : ; uid ); (usij+1 ; usij+2 ; : : : ; usid ))) f10 u = u + 111 R[u] = ((�1; : : : ; �j�1; lsij ; lij+1 ; : : : ; lid); (!1; : : : ; !j�1; usij ; uij+1 ; : : : ; uid );notest)12 g else f13 for (k = lsij ; k � usij ; k++) f14 regions(R; j + 1; (�1; �2; : : : ; �j�1; k); (!1; !2; : : : ; !j�1; k); d;B;R; u)15 g16 g17 if (uij > usij ) f18 u = u + 119 R[u] = ((�1; : : : ; �j�1; usij+1 ; lij+1 ; : : : ; lid); (!1; : : : ; !j�1 ; uij ; uij+1 ; : : : ; uid ); test)20 g21 g22 boolean function nochecks((li1; : : : ; lim ); (lsi1 ; : : : ; lsim); (ui1 ; : : : ; uim ); (usi1 ; : : : ; usim )) f23 if (((lij = lsij ) ^ (uij = usij ))8j = 1; : : : ;m)24 return true25 else26 return false27 gFig. 3. Procedure to compute the regions for a loop nest.
formation of the nonsafe regions does not require further recursive calls toregions(), butinstead uses the full iteration space of nested loops.
The saferegions are formed in lines 6-16. Lines 6-8 handle the case ofij being theinnermost loop by making the bounds of the safe region for loop ij be the safe boundscomputed in Section 2.1.1. Lines 9-16 handle the case whenij is not the innermost loop.There are two possibilities: (i) the safe region of all loopsnested withinij is identical to theiteration space of the loops; (ii) condition (i) does not hold. The call to functionnochecks()(line 9) tests if this condition holds. If it does, the safe region ofij and all its nested loopsform a single(d � j + 1)-dimensional safe region, which is computed in line11. Thisleads to the partitioning of the iteration space found in Figure 4 (ford = 2). If nochecks()returnsfalse the condition does not hold, and recursive calls are made then to regions() inlines 13-15 to fully partition the region based on the safe-region information for loopsij+1throughid. This leads to a tiling of the loop as shown in Figure 2 (ford = 2).
2.1.3 Code Generation.Consider a generald-dimensional rectangular loop nest, asshown in Figure 5(a). The body of the loop is denoted byB(i1; i2; : : : ; id). Figure 5(b)shows the code that is generated to form a loop nest transformed according to the regioningmethod. The version of the loop body denoted byBnotest(i1; i2; : : : ; id) requires no test,
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

From Flop to Megaflops: Java for Technical Computing � 7
q q q q q q q qq q q q q q q qq q q q q q q qq q q q q q q qq q q q q q q qq q q q q q q qq q q q q q q qq q q q q q q qR[1] R[2] R[3]-i16i2 lsi2 = li2 usi2 = ui2li1# lsi1# usi1# ui1# � R[1]: tests ini1 andi2� R[2]: no tests� R[3]: tests ini1 andi2
(a) Partitioning of the iteration space into regions (b) Mandatory tests in each region
Fig. 4. Iteration space for a perfectly nested two-dimensional loop.
for (i1 = li1 ; i1 � ui1 ; i1++)for (i2 = li2 ; i2 � ui2 ; i2++)
. . .for (id = lid ; id � uid ; id++)B(i1; i2; : : : ; id) regions(1; ( ); ( ); d; B; R; u = 0)
for (� = 1; � � u; �++) fif (�(�) == test) f
for (i1 = li1(�); i1 � ui1 (�); i1++)for (i2 = li2(�); i2 � ui2 (�); i2++)
. . .for (id = lid(�); id � uid (�); id++)Btest(i1; i2; : : : ; id)g else f
for (i1 = li1(�); i1 � ui1 (�); i1++)for (i2 = li2(�); i2 � ui2 (�); i2++)
. . .for (id = lid(�); id � uid (�); id++)Bnotest(i1; i2; : : : ; id)gg
(a) A d-dimensional loop nest (b) The loop nest transformed
Fig. 5. Bounds optimization code generation example.
and the version of the body that explicitly performs all tests specified by the Java VM isdenoted byBtest(i1; i2; : : : ; id).
In Figure 5(b), a call is first made toregionsto form the safe and unsafe regions. The�driver loop iterates over the regions. If a region is not safeand requires tests, the first loop,whose body contains all necessary tests, is executed. Otherwise, the second, check-freeloop nest is executed.
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

8 � Jose E. Moreira et al.
Because each instance of the loop invoked by the driver corresponds to exactly oneregion as illustrated in Figure 2 and Figure 4, the code generation strategy facilitates codetransformations. Within a region, and the corresponding loop nest, the iteration space is acontiguous subset of the original loop nest’s iteration space. Thus, if some iterationI 0 isadjacent to some iterationI in the loop nest instantiating a region, thenI 0 is also adjacentto iterationI in the original loop nest. Stated differently, and referring to Figure 2, theregionsR[1] throughR[14] are lexicographically ordered:R[1] < R[2] < R[3] < R[4] < : : : < R[14]: (6)
Because of this ordering, transformations within the loop nest corresponding to the saferegions are not constrained by exceptions thrown in the loopnest corresponding to anunsafe region. Furthermore, any orderings required to honor Java semantics in the presenceof exceptions (thrown in iterations corresponding to unsafe regions) are enforced by theorder in which regions are instantiated by the driver loop.
2.2 Versioning
Versioning is an alternative to the regioning method for creating safe regions. A normalexecution of a method such asmatmul in Figure 1 is expected to generate no exceptions.With current programming styles, an execution that causes an exception is most likely amisuse, and it is not really important to optimize. Optimization of the normal case (noexceptions) can be achieved by a simple set of range tests before the execution of a loopnest. Let a body of codeB have a reference of the formA[�] in its body. Letmin(�)andmax(�) be the smallest and largest values, respectively, that� evaluates to duringexecution of the loop nest. (Note that conservative estimates can be used instead of exactvalues ofmin(�) andmax(�).) A simple evaluation of(min(�) � lo(A)) ^ (max(�) �up(A)) can tell ifA[�] is guaranteed to always be safe or not.
If the body of codeB has� array references of the formA1[�1]; A2[�2]; : : : ; A�[��],then for each array referenceAi[�i] we can compute a simple test�i = (min(�i) �lo(Ai)) ^ (max(�i) � up(Ai)). The test� = �1 ^ �2 ^ : : :^ �� can be used to determineif any array reference has the potential to cause an exception. Two versions ofB can begenerated: one with tests for all array references and one without tests. The version ofBto execute can then be selected dynamically based on the outcome of test� .
Let us consider the particular case ofMATMUL. The subscriptsi, j, k take on theranges of values0 : m� 1, 0 : p� 1, and0 : n� 1, respectively. Since array lower boundsin Java are 0, the expressionsmin(�i) � lo(Ai) for MATMUL always evaluate totrue.Therefore, the triple-nested loop of Figure 1 can be transformed into the two-version codeof Figure 6. In that figure,rows(A) andcols(A) denote the number of rows and columnsof matrixA, respectively. We discuss how to computerows(A) andcols(A) for Java arraysin Section 2.3.
In loop nests where there are no exceptions (i.e., all iterations of a loop are in a singlesafe region) the two-version code is, for all practical purposes, equivalent to the region-ing method. In this situation we have verified that the performance of the two methods(measured usingMATMUL) differs by less than 1%. The numerical results we present inSection 3 were all obtained with the versioning method.
If there are bounds exceptions in the loop nest, the difference in performance between thetwo methods (regioning and versioning) can be dramatic. Forexample, if the two-versionmethod were used, a single exception in some iteration of theouter loop would force the
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

From Flop to Megaflops: Java for Technical Computing � 9
if ( (m � rows(C)) ^ (p � cols(C))^(m � rows(A)) ^ (n � cols(A))^(n � rows(B)) ^ (p � cols(B)) ) f// notest version of loop-nestfor (i = 0; i < m; i++)
for (j = 0; j < p; j++)for (k = 0;k < n; k++)C[notest(i)][notest(j)]+=A[notest(i)][notest(k)] �B[notest(k)][notest(j)];g else f
// test version of loop-nestfor (i = 0; i < m; i++)
for (j = 0; j < p; j++)for (k = 0;k < n; k++)C[test(i)][test(j)]+=A[test(i)][test(k)] �B[test(k)][test(j)];g
Fig. 6. Two-version code forMATMUL.
entire loop to run with checks and without optimizations. This is the case even if the excep-tion is expected and cleanly handled by a try-catch clause. Using the regioning method,the majority of the iteration space can still execute fully optimized. In Orchard [1998],a programming style that uses array bounds exceptions as loop termination conditions isadvanced. Regardless of how offensive this style may appearto a Fortran or C++ program-mer, the loop termination condition is apparently simpler.Therefore, it is likely that thisand related styles will enjoy some degree of popularity. With these styles of programming,the versioning method will provide no benefit. In contrast, the regioning method will allowcode with the best possible level of optimization to be selected dynamically (by the regionsdriver loop).
We note that it is not too difficult to extend versioning so that it is not an “all or nothing”method. We first stripmine the loop to be optimized, transforming it into an inner and anouter loop. Each iteration of the outer loop executes a chunkof iterations of the originalloop. We now apply versioning to the inner loop. Each chunk will be executed either by thesafe or the unsafe variant of the inner loop. The disadvantage is that the version test is per-formed once per chunk instead of once per entire iteration space. The overhead increasesas we improve execution flexibility by reducing the size of the chunk. For loop nests, thestripmining can be performed on the outermost loop. We have neither implemented normeasured the impact of this stripmining approach.
2.3 Thread safety
Threads are an integral part of the Java language specification. In general, it is not possibleto determine accurately if a method will be sharing data withother concurrent threads as itexecutes. Therefore, it is necessary that our optimizationbe thread safe. Thread safety ofthe bounds checking optimization can be ensured if the bounds of an array do not changeduring the execution of an optimized loop nest. In this section we first illustrate what thepotential problem with thread safety is. We then proceed to describe how to address theproblem.
Figure 7(a) shows the layout of an(m+1)�(n+1) two-dimensional Java array. VariableA points to a vector of pointers. Each element of this vector inturn points to a vector ofdata elements. In Java, not all data vectors must necessarily be of the same length, althoughthat is the case in our example. Each vector (either data vector or pointer vector) contains
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

10 � Jose E. Moreira et al.A[0 : m][0 : n]?AA[m]...
A[1]A[0] ---- A[m][0] A[m][1] � � � A[m][n]� � � � � � � � � � � �A[1][0] A[1][1] � � � A[1][n]A[0][0] A[0][1] � � � A[0][n] double[ ][ ]A0 = new double[A:length][ ]n =1for (i = 0; i < A:length; i++) fA0 [i] = A[i]n = min(n;A[i]:length)grows(A) = A:lengthcols(A) = n
(a) layout of2-dimensional array (b) making a private copy
Fig. 7. Thread safety issues are handled by privatizing data.
information about the extent of that vector. The bounds of the two-dimensional array canchange when an element of the pointer vector is assigned to point to another data vector,whose bounds are different than what originally existed. Issues of thread safety arise whenanother thread changes the bounds of an array that is accessed by a concurrently executingthread running code optimized by our transformations. The problem occurs with either theregioning or the versioning methods. We denote the thread changing the array bounds asTc, and the thread executing optimized code that accesses array elements asTo. We stress,that, while asynchronously changing array extents may be poor programming practice, itis legal Java.
Consider the following scenario. Code for matrix multiply was optimized using the ver-sioning method, as shown in Figure 6. ThreadTo performs the runtime test, which evalu-ates totrue, and starts executing thenotest version of the loop nest. Unknown to threadTo, a concurrently executing threadTc changes the structure of arrayA by performing anoperationA[i] = new double[n=2].The length of rowi of A is now much shorter thanTo was originally programmed toexpect. One of the iterations of the optimized loop nest willattempt to access beyond thebounds ofA[i]. SinceTo is executing thenotest version of the loop, this illegal accesswill go undetected. This is a clear violation of the Java semantics, which does not allowout-of-bounds array access to occur.
Fortunately, the Java memory model provides a solution to this problem. Java allowskeeping copies of shared (ormain memory) values in thread-private memory (orworkingmemory) between synchronization points. To guarantee thread safety, we keep the vectorsof pointers in private memory. Thus, in Figure 7(a), the values of theA[0 : m] vectorwill be kept in private memory during computation. These private values are then used forthe entire execution of the loop nest, including the runtimetest. Thus, the structure of thetwo-dimensional arrayA is maintained throughout execution of the optimized code.
We show how to explicitly implement the privatization by copying arrayA[0 : m] intoa private arrayA0[0 : m] in Figure 7(b). While copying we can find the minimum extentof a row ofA. In computing the safe bounds,A can be treated as rectangular, with this
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

From Flop to Megaflops: Java for Technical Computing � 11?AA[m]...
A[1]A[0] -- �?A[m][0] A[m][1] � � � A[m][n]A[0][0] A[0][1] � � � A[0][n] ?BB[m]...
B[1]B[0]?� �Fig. 8. Intra- and interarray aliasing with two-dimensional Java arrays.
minimum extent as its second-axis extent. In other words, this is the number of columns ofA, or cols(A) using the nomenclature of Section 2.2. The number of rows ofA, rows(A),is just the length of the vector of pointers (A:length). Matrix multiplication ofn � nmatrices is anO(n3) operation. The cost of privatizing and verifying the extents of one ofthe matrices is onlyO(n). This is certainly insignificant for large values ofn. We discusssome approaches to deal with very smalln or less intensive computations in Section 5.
2.4 Alias Disambiguation
So far we have stressed the importance of having a well-defined safe region of code whereno exception can be potentially generated. We discussed howaggressive compiler opti-mizations, such as those performed by state-of-the-art Fortran compilers, can be appliedto those safe regions. However, many compiler optimizations, particularly loop transfor-mations, require good aliasing information. For example, aggressive optimization of thenotest loop of Figure 6 can be performed only ifC is not aliased toA orB and if all rowsof C are distinct.
Alias analysis is particularly difficult in Java because of the general structure of multidi-mensional arrays, as shown in Figure 7(a). Organizing two-dimensional arrays as vectorsof pointers to single-dimensional arrays creates opportunities for both intra- and interarrayaliasing, as shown in Figure 8. Intraarray aliasing occurs when multiple array rows areactually the same vector of elements. This type of aliasing is illustrated by rows 1 andmof arrayA. Interarray aliasing occurs when two different arrays share one or more rows.This type of alias is illustrated by rows 0 of arraysA andB.
We can extend the versioning technique to work with runtime aliasing disambiguation.The selection test can be augmented with a check for intra- and interarray aliasing for allarrays present in the loop body. The safe region is only executed if all index operations arein bounds and if there is no aliasing. Therefore, the safe region is guaranteed to be bothexception-free and alias-free. We can finally apply all the aggressive transformations wewant to the safe region.
The real challenge with runtime alias disambiguation is computing the alias informa-tion efficiently. LetA andB be two-dimensional arrays withn rows each. Full aliasdisambiguation requires comparing all row pointers ofA andB. This comparison requiresO(n logn) steps (a sort of all pointers followed by a scan). AlthoughO(n logn) may
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

12 � Jose E. Moreira et al.A[0][0] � � � A[0][n] A[1][0] � � � A[1][n] � � � A[m][0] � � � A[m][n]dense = 1A[0] A[1] A[2] � � � A[m]? �? �?Fig. 9. A dense representation for Java arrays.
be an acceptable overhead for anO(n3) computation with largen (such asMATMUL), itsignificantly restricts the class of computations that can be effectively optimized.
We can facilitate alias disambiguation for the common case,at least in numerical ap-plications, where multidimensional arrays are rectangular and have independent rows. Weextend the internal representation of an array to include adenseflag. When a multidi-mensional arrayA is created with a singlenew statement (corresponding to the Java VMbytecodemultianewarray), such as
double[ ][ ]A = new double[m+ 1][n+ 1]we allocate all rows adjacent in memory and set the dense flag to 1, as shown in Figure 9.If a change to the structure ofA is performed through an operation such asA[i] = new double[2n] or A[i] = B[i]then the dense flag must be reset to 0. Interarray alias disambiguation between two densearraysA andB simply requires the checkA 6= B, because two dense arrays cannot bepartially overlapping. Note that there can be no intraarrayaliasing within a dense array.
An alternative approach is to create true multidimensionalarray classes which have theproperty that the array is always rectangular with independent rows. This is discussed inmore detail in Sections 3.6 and 5 and in Artigas et al. [1999] and Moreira et al. [2000].
3. OPTIMIZATIONS
In this section, we describe the impact of various program transformations on the perfor-mance of theMATMUL benchmark executing on a single processor. For completeness, weanalyze in detail another program,MICROSTRIP, which does not have such a favorableratio of computation to data movement asMATMUL does. We also present summarizedresults for four other floating-point-intensive benchmarks.
The experiments were performed using the IBM HPCJ compiler for the POWER familyof architectures [Seshadri 1997]. HPCJ is a static compiler that translates Java bytecodeinto native code of the target machine. C++ and Fortran versions of the benchmark wererespectively compiled with the IBM XLC and XLF production compilers. All of thesecompilers (HPCJ, XLC, and XLF) share the same code optimization and generation back-end, called TOBEY. However, the maximum level of optimization that can be used for eachlanguage is different. Because of its more strict semantics, Java is compatible only with the-O2 optimization level of TOBEY, while Fortran and C++ can becompiled with the moreaggressive -O3 optimization level. The IBM XLF compiler also performs high-order looptransformations (blocking, unrolling, etc). Finally, TOBEY is enabled to use the POWER
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

From Flop to Megaflops: Java for Technical Computing � 13
fma (fused multiply-add) instruction when compiling C++ or Fortran. This instructionhas to be disabled when compiling Java (see the discussion inSection 3.1), as its extendedfloating-point precision may cause slightly different results than a multiply followed by anadd.
In terms of hardware platforms, two different machines wereused for benchmarking.Experiments for PowerPC were performed on a four-processor 332MHz RS/6000 modelF50 computer. Each processor has a 664-Mflops peak performance, for an aggregate ma-chine peak performance of 2656 Mflops. Experiments for POWER2were performed ona uniprocessor 67MHz RS/6000 model 590 computer. The peak performance of this ma-chine is 266 Mflops. In each case, the appropriate-qarch and-qtune compiler optionswere set to turn on code tuning for the respective PowerPC and POWER2 architectures.
All benchmarks were coded so that all array references are valid. That is, nonull-pointer or bounds violation takes place in our benchmarks. Therefore, all computationhappens in safe regions, whether the regioning or the versioning method is used. ForMATMUL we explicitly verified that versioning and regioning produce almost the sameperformance result (within 1%). We expect the same behaviorfor all our other benchmarks,but we have not verified it experimentally. The results reported here are for the versioningmethod.
3.1 Program Transformations
The kernel of theMATMUL program is shown in Figure 1. The transformations that weapplied to this program are described below. The first program transformation reduces theoverhead of checking for out-of-bounds array access violations, as described in Section 2.We generate two versions of the loop nest, one in which bounds-checking computationsare performed for each array reference, and the other in which no such computations areneeded. This transformation not only reduces the overhead of array bounds checking, butalso creates program regions that are provably free from exceptions. Those regions cannow be transformed using standard loop transformation techniques [Banerjee 1990; Sarkar1997; Wolf and Lam 1991; Wolfe 1989] without violating Java semantics.
The next transformation on the program is to block the loop nest in the exception-freeregion, to improve the cache performance by promoting greater reuse of data [Sarkar 1997;Wolfe 1987]. Blocking requires both strip-mining, which does not change the order ofcomputation, and loop-interchange, which does change the order of computation. Loop-interchange (and blocking) can be legally performed only onthat part of a Java programin which no exception may be thrown. Based on the existing algorithm in the IBM XLFcompiler [Sarkar 1997] to select the loop-blocking parameters (which uses estimates ofthe number of distinct cache lines touched by the computation [Ferrante et al. 1991]), wechoose a strip size of 40 for each of thei; j, andk loops in the PowerPC 604e and a stripsize of 120 for the same loops in the POWER2.
Following loop blocking, we perform outer loop unrolling [Sarkar 1997] (also known asunroll-and-jam) to enhance temporal locality of data. Again, this transformation changesthe order of computation and can only be applied to safe regions in Java programs. Thistransformation also increases the size of the loop body and enables the back-end to generatea better schedule that exploits the instruction-level parallelism. Both thei and thej loopsare unrolled by a factor of four each.
The next program version uses scalar replacement [Callahanet al. 1990; Sarkar 1997],where references toC, the array being written, are replaced by references to scalar tempo-
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

14 � Jose E. Moreira et al.
rary variables in the innermost loop. Additional statements are used to load the temporariesfrom the array at the beginning of the loop iteration and to store them back at the end. It iswell known that scalar replacement enables the compiler back-end to improve register allo-cation and instruction scheduling for the code, as most back-ends are able to disambiguatescalar references more effectively.
Finally, to determine the performance benefits from thelooseNumerics extension toJava [Gosling 1997] (described in Section 5), which allows the use of extended precision(greater than 32- and 64-bit) arithmetic, we modified the compiler options that are passedon by the Java compiler to the back-end. We turned on the option that allows the back-end to use thefma (fused multiply-add) instruction. Thefma instruction in the POWERfamily of architectures,fma x; a; b; c, computesx = a � b+ c as a single operation.
3.2 Experimental Results
Figure 10 shows the performance of different versions of theMATMUL program on Pow-erPC 604e and POWER2 workstations, expressed as a fraction of the performance obtainedfor the best version written in C++. (Performance of a Fortranversion was similar.) Thenumbers at the top of the bars denote absolute Mflops achieved. On the PowerPC, thebase-line Java version achieves a performance of only 4.9 Mflops. After the transforma-tion to create a safe region with no array bounds checking, the performance improves to11.1 Mflops. The indirect impact of that transformation is even more significant. Theapplication of blocking, which is enabled by that transformation, followed by other looptransformations described above, steadily improves the performance of the program. Thefinal Java-compliant optimized program achieves a performance of 144.4 Mflops on thePowerPC, while the version which exploits the proposedlooseNumerics Java extension(by usingfma instructions) achieves 199.9 Mflops. This is 63.6% of the performance ofthe equivalent C++ version with identical loop transformations, and 56.2% of the hand-tuned ESSL version.
On the POWER2, the impact of these transformations is even more dramatic. The base-line Java program achieves 1.6 Mflops, whereas the optimizedversion withfma instruc-tions achieves a performance of 209.8 Mflops, for an improvement by a factor of 131. Thefully optimized Java program achieves 85.8% of the performance of the correspondingC++ version, and 84.5% of the ESSL performance.
For both machines, we also show the performance of the best Java version with blocking,unrolling, scalar replacement, andfma optimizations, but with the explicit bounds andnull-pointer checks left in. This version is identified by the “library” bar in Figure 10.It would not be legal for a compiler to derive such a version from the given base-lineprogram, as it has different semantics under Java when exceptions are possible. However,this measurement helps quantify the overhead of array bounds checking in an otherwisetuned (BLAS-3 style [Dongarra et al. 1991]) matrix-multiply routine. It can be seen thatthe performance of this version is quite poor on both the machines: 30.9 Mflops on aPowerPC and 4.8 Mflops on a POWER2.
In summary, the transformation to create exception-free regions in theMATMUL pro-gram has a large positive impact on the performance of the program, in two ways. First, iteliminates the actual overhead of bounds checking (which ismore significant on the higher-performance version of the program). Second, it enables other loop transformations, whichcan be performed automatically by a compiler.
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

From Flop to Megaflops: Java for Technical Computing � 15
plain nocheck blocking unrolling scalar fma C++ ESSL library
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
4.9 11.1
56.0
78.6
144.4
199.9
314.2
355.2
30.9
Optimization
Fra
ctio
n of
bes
t C+
+
Performance of MATMUL on 332MHz 604e (Mflops)
plain nocheck blocking unrolling scalar fma C++ ESSL library
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.6 5.5
30.4
51.6
100.9
209.8
244.6 248.3
4.8
Optimization
Fra
ctio
n of
bes
t C+
+
Performance of MATMUL on 67MHz POWER2 (Mflops)
Fig. 10. Summary of results forMATMUL.
3.3 An Explanation for the Differences between Java and C++/Fortran
Figure 10 shows, that, even when the same transformations are applied to Java and C++versions ofMATMUL, Java performance still lags behind what can be achieved with C++.(The same results hold when Java is compared to Fortran.) We observed, by inspectingthe generated object code forMATMUL, that the back-end (TOBEY) was able to softwarepipeline the inner loop when C++ was used but not when Java wasused. This happens de-spite the fact that the loop code is essentially identical inboth cases. This difference in thefinal object code seems to be caused by differences in the intermediate code produced bythe respective frontends, and is being investigated further. From a performance perspec-tive, software pipelining results in a better instruction scheduling, with longer distancesbetween dependent instructions. This better scheduling results in superior performance forMATMUL when coded in C++ (or Fortran).
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

16 � Jose E. Moreira et al.
for (int i=1; i<w; i++) {for (int j=1; j<h; j++) {
b[i][j] = 0.25*(a[i+1][j]+a[i-1][j]+a[i][j+1]+a[i][j-1]);}
}
(a) relaxation step
error = 0.0;for (int i=0; i<w+1; i++) {
for (int j=0; j<h+1; j++) {error += Math.abs(b[i][j] - a[i][j]);
}}error /= (w+1)*(h+1);
(b) error computation
Fig. 11. Main computations inMICROSTRIP.
3.4 Experiments with MICROSTRIP
We use another benchmark to demonstrate that the bounds-checking optimization and theenabled transformations can also improve the performance of a code that has a less favor-able ratio of computation to data movement thanMATMUL. TheMICROSTRIP bench-mark solves the Poisson equation for the potential field in a dielectric. It uses an iterativesolver. Each iteration involves two relaxation steps and the computation of an error value.Source code for these operations is shown in Figure 11. Theseare bothO(n2) computa-tions, in which the amount of computation is directly proportional to the size of the data.(In MATMUL, the amount of computation is a factor ofn larger that the data size.) In ourexperiments,w = h = 999.
The results forMICROSTRIP on both the PowerPC 604e and the POWER2 are shownin Figure 12. Note that there is no ESSL version for this benchmark. Also, it does notbenefit from thefma instruction (none can be generated by the compiler), and thereforethat bar is absent as well. The reference performance is thatobtained by the Fortran com-piler with the highest level of optimization. The benefit of optimizing the checks for Javais more evident on the POWER2, where the performance jumps from 4.0 to 34.0 Mflops.Further optimizing the code with loop unrolling (of both thei andj loops of Figure 11(a))and scalar replacement brings Java performance to 87% of peak Fortran performance onthe POWER2.
The performance ofO(n2) matrix computations is often constrained by memory band-width, rather than processor speed. Therefore, we do not seegreat improvements in thePowerPC 604e, which has lower memory bandwidth than the POWER2.Nevertheless, op-timizing the checks nearly doubles the performance of the Java version ofMICROSTRIP.Additional optimizations bring it to 90% of Fortran performance. Again, in both plots weindicate by “library” the performance of the best Java version with the checks forarraybounds andnull-pointer left in place.
3.5 Additional Examples
We continue the experimental evaluation of our techniques by applying the optimizations tofour additional benchmarks. All of the benchmarks are floating-point intensive. One of thebenchmarks,CHOLESKY, is a factorization kernel. Two,SHALLOW andTOMCATV,
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

From Flop to Megaflops: Java for Technical Computing � 17
plain nocheck unrolling scalar Fortran library
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
19.0
35.734.4
39.2
43.3
21.3
Optimization
Fra
ctio
n of
bes
t For
tran
Performance of MICROSTRIP on 332MHz 604e (Mflops)
plain nocheck unrolling scalar Fortran library
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
4.0
34.0
44.3
64.3
73.7
5.0
Optimization
Fra
ctio
n of
bes
t For
tran
Performance of MICROSTRIP on 67MHz POWER2 (Mflops)
Fig. 12. Summary of results forMICROSTRIP.
are representative of kernels of scientific applications. The last benchmark,BSOM, isrepresentative of data-mining kernels. A brief description of each benchmark follows.
CHOLESKY. TheCHOLESKY benchmark is a straightforward implementation of theCholesky decomposition algorithm, as described, for example, in Press et al. [1992]. Itcomputes the lower triangular factorL of a symmetric positive definite matrixA such thatA = LLT . The code is organized as a triple-nestedi,j,k-loop. Each iteration of the outeri loop computes rowi of the factorL through the following two expressions:Lij = 1Ljj Aij � j�1Xk=1LjkLik! ; j = 1; 2; : : : ; i� 1 (7)Lii = vuutAii � i�1Xj=1L2ij (8)
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

18 � Jose E. Moreira et al.
We implemented our code so that the factorization is performed in place, with the lowerhalf of matrixA being replaced by the factorL. For our experiments, we factor a matrixof size1000� 1000.
SHALLOW. TheSHALLOW benchmark is a computational kernel from a shallow watersimulation code from the National Center for Atmospheric Research (NCAR). It consistsof approximately 300 lines of code. The data structures inSHALLOW consist of 14 ma-trices (two-dimensional arrays) of sizen � m each. The computational part of the codeis organized as a time step loop, with several array operations executed in each time step(iteration):
for t = 1; : : : ; T f39 operations(A + A)8 operations(A � A)17 operations(s � A)1 operations(A = A)gIn the above code we indicate the number of occurrences for each kind of array operation.The notationsA+ A, A � A, andA=A denote addition, multiplication, and division of allcorresponding array elements. The notations �A denotes multiplication of a scalar valueby each of the elements of an array. For our measurements we fixthe number of time stepsT = 20 and usen = m = 256.
TOMCATV. The TOMCATV benchmark is part of the SPECfp95 suite (the reader isreferred towww.spec.org for additional information on SPEC). It is a vectorized meshgeneration with Thompson solver code, approximately 200 lines long. The benchmarkconsists of a main loop, which iterates until convergence oruntil a maximum number ofiterations is executed. At each iteration of the main loop, the major computation consist ofa series of stencil operations on two (coupled) grids,X andY , of sizen�n. In addition, aset of tridiagonal systems are solved through LU decomposition. For our experiments, weuse a problem sizen = 513.
BSOM. The BSOM (Batch Self-Organizing Map) benchmark is a data-mining kernelrepresentative of technologies incorporated into Version2 of the IBM Intelligent Miner. Itimplements a neural-network-based algorithm to determineclusters of input records thatexhibit similar attributes of behavior. The simplified kernel used for this study consistsof approximately 300 lines of code. We time the execution of the training phase of thisalgorithm, which actually builds the neural network. The training is performed in multiplepasses over the training data. Each pass is called anepoch. Let e be the number of epochs;letn be the number of neural nodes; letr be the number of records in the training data; andlet m be the number of fields in each input record. For each epoch andeach input record,the training algorithm performsnm connection updates in the neural network. Each updaterequires five floating-point operations. For our measurements, we usee = 25, n = 16, andr = m = 256. In all our other benchmarks, we report performance in Mflops. We reportthe performance ofBSOM in millions of connection updates per second, or MCUPs, as isusually done in the literature for neural-network training.
Results of our experiments with these four benchmarks, in addition to theMATMUL andMICROSTRIP benchmarks previously discussed, are summarized in Figure13. Each plotin that figure shows the results for one benchmark. For each benchmark, we present the
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

From Flop to Megaflops: Java for Technical Computing � 19
performance of five different versions of code when running on a POWER2 workstation(RS/6000 model 590). First, we present the performance of the standard Java implementa-tion in the “plain” bar. We then show the effects of optimizing away the bounds checks, inthe “nocheck” bar. The “optimized” bar represents the best performance obtained fromapplying various transformations to the code. With the exception ofMATMUL, where wealso used blocking, the optimizations consisted of (inner and outer) loop unrolling andscalar replacement. The “fma” bar represents the performance achieved when we madeuse of thefma instruction. Finally, the “Fortran” bar shows the performance achieved bythe Fortran compiler with the highest levels of optimization enabled.
We note that the “optimized” results represent the best fully Java-compliant results pos-sible today. The “fma” results represent the best possible results if the proposals for ex-tending Java floating-point semantics are approved [Gosling 1997; Java Grande Forum1998]. Within the “optimized” domain we achieve between 40% (forMATMUL) and 85%(for MICROSTRIP) of peak Fortran performance with Java. When thefma instructionis allowed, we always achieve at least 80% of peak Fortran performance. In one case,CHOLESKY, we achieve almost 100% Fortran performance with Java. It isalso impor-tant to note that the peak floating-point performance of our machine is 266 Mflops. We areachieving from 25% to 80% of that peak performance with Java.(For BSOM, 1 MCUPs= 5 Mflops.)
3.6 Results for Fully Automated Application of Versioning
We have developed a research prototype compiler that applies the versioning optimiza-tion, described in Section 2.2, in a fully automatic manner.Currently, the compiler onlyoptimizes Java code that uses the Array package. The Array package is a 100% Javaimplementation (i.e., no native code) of true rectangular multidimensional arrays. Java ap-plication code that uses the Array package has more constrained semantics than equivalentcode using primitive Java arrays. (As discussed in Section 2.3, Java arrays are not reallymultidimensional nor have to be necessarily rectangular.)The more constrained semanticsof the Array package facilitates the automation of our techniques. See Section 5, Artigaset al. [1999], and Moreira et al. [2000] for more details.
Table I summarizes the efficacy of our bounds-checking optimization. For each bench-mark, column “loops” lists the total number of loop constructs in the program. (TheMATMUL nest of Figure 1 counts as three loops.) Column “optimized” lists the num-ber of loop constructs that can be optimized with our compiler, i.e., the number of loopsfor which the compiler was able to compute enough information to generate the runtimetest that selects between the safe and unsafe versions. Column “coverage” is the ratio, ex-pressed as a percentage, of loops optimized to total loops. Finally, column “safe regions”lists the actual number of safe regions created for the benchmark. Since safe regions arecreated for loop nests and not loops, the number of safe regions can be much less thanthe number of optimized loops. For example, the safe region of Figure 6 contains andoptimizes three loops.
Figure 14 shows the best performance we achieve in Java usingour research prototypecompiler. The Java performance, for each benchmark, is shown as a fraction of the bestFortran performance for that benchmark. The Fortran performance is normalized to 1. Themeasurements were performed on an RS/6000 model 590 (67MHz POWER2) computer.
We note that the results from our research prototype compiler are in good agreementwith the hand-optimized results of Figure 13. We typically achieve with Java between 80
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

20 � Jose E. Moreira et al.
plain nocheck optimized fma Fortran
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.6 5.6
100.9
209.8
244.6
Code version
Fra
ctio
n of
bes
t For
tran
Performance of MATMUL on 67MHz POWER2 (Mflops)
plain nocheck optimized fma Fortran
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
4.0
34.0
64.3 64.3
73.7
Code version
Fra
ctio
n of
bes
t For
tran
Performance of MICROSTRIP on 67MHz POWER2 (Mflops)
plain nocheck optimized fma Fortran
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
3.8
42.1
83.4
129.9 132.0
Code version
Fra
ctio
n of
bes
t For
tran
Performance of CHOLESKY on 67MHz POWER2 (Mflops)
plain nocheck optimized fma Fortran
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0.8
10.2
18.9
24.125.6
Code version
Fra
ctio
n of
bes
t For
tran
Performance of BSOM on 67MHz POWER2 (MCUPs)
plain nocheck optimized fma Fortran
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
3.3
44.2
63.169.2
84.1
Code version
Fra
ctio
n of
bes
t For
tran
Performance of SHALLOW on 67MHz POWER2 (Mflops)
plain nocheck optimized fma Fortran
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
4.2
41.9
58.5
74.6
81.5
Code version
Fra
ctio
n of
bes
t For
tran
Performance of TOMCATV on 67MHz POWER2 (Mflops)
Fig. 13. Summary of experimental results.
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

From Flop to Megaflops: Java for Technical Computing � 21
Table I. Summary of Loops Optimized in Each Benchmarkbenchmark loops optimized coverage safe regionsMATMUL 17 14 82.4% 6MICROSTRIP 12 11 91.7% 5CHOLESKY 14 12 85.7% 6BSOM 25 21 84.0% 13SHALLOW 16 14 87.5% 9TOMCATV 20 20 100.0% 5
MATMUL MICRO CHOLESKY BSOM SHALLOW TOMCATV0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Benchmark
Per
form
ance
rel
ativ
e to
bes
t For
tran
Performance on RS/6000 590 with Array package
Java Fortran
Fig. 14. Summary of results with automatic versioning by compiler.
and 90% of the best Fortran performance. Only inTOMCATV do we not do so well, butwe still achieve 65% of the best Fortran performance. Even though it is clear that muchwork remains to be done on our compiler, we have shown a significant improvement inJava performance as compared to unoptimized code. More importantly, we have shownthat Java can achieve performance sufficient to allow it to beused as a platform for largenumerically intensive applications.
4. PARALLELIZATION
The final step in optimizing the performance ofMATMUL is parallelization. There isplenty of parallelism to exploit in that computation, and parallelizing the C++ version isstraightforward. However, it is not possible to directly parallelize the(i; j; k) loop nestof the Java version ofMATMUL. Java requires the execution of that loop nest to followstrictly sequential semantics. Because exceptions can be thrown in any iteration of the loopnest, we have to guarantee that the values ofC[i][j] are modified in the sequential order ofthe iterations.
Fortunately, the transformations of Section 2 create regions that are exception-free. Foreach of these regions, we know for sure that all the iterationpoints in the region willexecute. The same transformation that enabled blocking, outer loop unrolling, and theother optimizations of Section 3 also enables parallelization.
We parallelize the last version from Section 3, which includes blocking, unrolling, andscalar replacement. The loop nest in this version is six-dimensional. There are three loops
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

22 � Jose E. Moreira et al.
T0 T1 T2 T3 T0T3 T0 T1 T2 T3T2 T3 T0 T1 T2T1 T2 T3 T0 T1T0 T1 T2 T3 T0nI � 10 0 nJ � 1?I -Jfor (b = t; b < nInJ ; b+=nT ) fI = (b=nI)� bIJ = (b mod nI )� bJ
for (K = 0;K < n;K+=bK) ffor (i = I; i < min(m; I + bI); i++)
for (j = J; j < min(p; J + bJ ); j++)for (k = K; k < min(n;K + bK);k++)C[i][j]+=A[i][k] �B[k][j]gg
Fig. 15. Partitioning of a200� 200matrixC onto four threads.
over the blocks (I, J , andK), and three loops over the elements in those blocks (i, j, andk). As a good compromise between load balance and overhead, weparallelize the two outerblock loopsI andJ . This corresponds to parallelization by partitioning the computation ofthe blocks of theC matrix. The parallel execution is performed bynT threads, numberedfrom 0 to nT � 1. The computation of the blocks of matrixC are statically scheduledamongnT threads as follows: (i) the blocks are ordered in row-major order and (ii) areassigned cyclically to the threads. Figure 15 shows the partitioning of a200� 200 matrixC onto four threads, identified byT0, T1, T2, andT3. We use blocks of size40 � 40,and, therefore, there are 25 blocks in this example. The actual MATMUL benchmark uses500� 500 matrices, thus resulting in 169 blocks.
Also shown in Figure 15 is the pseudocode of the computation performed by each thread.The variablet in each thread contains the identifying number for that thread. The variableb works as a block counter. It starts fromt, the thread number, and it is incremented bynT , the number of threads, in each iteration. There are a total of nI � nJ blocks. Thecorresponding values forI andJ can be directly computed from the value ofb. The otherloops (K, i, j, andk) are exactly as in Section 3. For the sake of clarity, we do notshowhere the unrolling of thei andj loops or the scalar replacement.
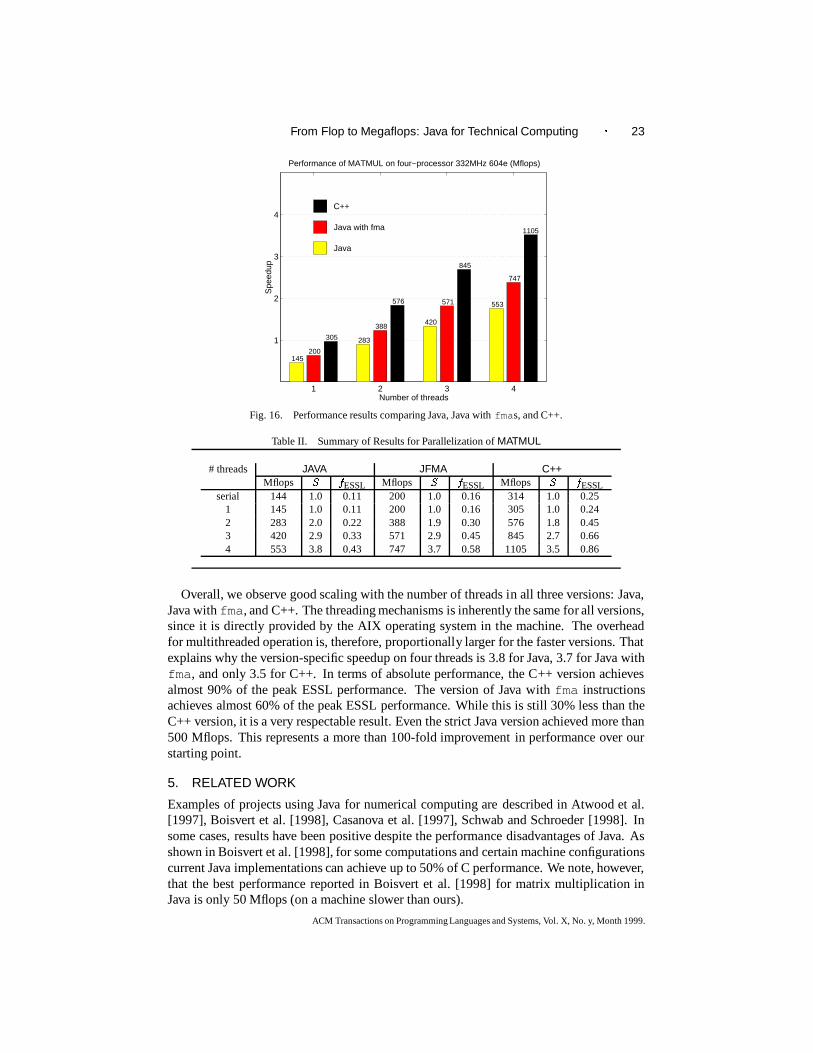
The results from our parallelization are summarized in Figure 16. Experiments wereperformed on a four-processor 332MHz RS/6000 model F50. We group the results by thenumber of threads (1, 2, 3, or 4), and within each group we showthe performance of threeversions ofMATMUL : (i) a version that conforms to current Java semantics, (ii)a versionwith Java using thefma instruction, and (iii) a C++ version. The numbers at the top ofthe bars are the absolute Mflops achieved by each version on that number of threads. Thespeedup in each case, indicated by the length of the bar alongthey-axis, is computed withrespect to the best overall serial version, 314 Mflops in C++.(The performance of a Fortranversion we tried was no better.)
We complete the reporting of our results with Table II. In that table we list the Mflopsachieved for each version with different numbers of threads. We also list the best se-rial performance achieved for each version. TheS column represents the version-specificspeedup, computed with respect to the best corresponding serial performance for each ver-sion (i.e., 144 Mflops for Java, 200 Mflops for Java withfma, and 314 Mflops for C++).Finally, thefESSL column list the fraction of the top ESSL performance (1278 Mflops)achieved in each case.
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.
From Flop to Megaflops: Java for Technical Computing � 23
1 2 3 4
1
2
3
4
145 200
305 283
388
576
420
571
845
553
747
1105
Number of threads
Spe
edup
Performance of MATMUL on four−processor 332MHz 604e (Mflops)
Java
Java with fma
C++
Fig. 16. Performance results comparing Java, Java withfmas, and C++.
Table II. Summary of Results for Parallelization ofMATMUL
# threads JAVA JFMA C++Mflops S fESSL Mflops S fESSL Mflops S fESSL
serial 144 1.0 0.11 200 1.0 0.16 314 1.0 0.251 145 1.0 0.11 200 1.0 0.16 305 1.0 0.242 283 2.0 0.22 388 1.9 0.30 576 1.8 0.453 420 2.9 0.33 571 2.9 0.45 845 2.7 0.664 553 3.8 0.43 747 3.7 0.58 1105 3.5 0.86
Overall, we observe good scaling with the number of threads in all three versions: Java,Java withfma, and C++. The threading mechanisms is inherently the same for all versions,since it is directly provided by the AIX operating system in the machine. The overheadfor multithreaded operation is, therefore, proportionally larger for the faster versions. Thatexplains why the version-specific speedup on four threads is3.8 for Java, 3.7 for Java withfma, and only 3.5 for C++. In terms of absolute performance, the C++ version achievesalmost 90% of the peak ESSL performance. The version of Java with fma instructionsachieves almost 60% of the peak ESSL performance. While thisis still 30% less than theC++ version, it is a very respectable result. Even the strictJava version achieved more than500 Mflops. This represents a more than 100-fold improvementin performance over ourstarting point.
5. RELATED WORK
Examples of projects using Java for numerical computing aredescribed in Atwood et al.[1997], Boisvert et al. [1998], Casanova et al. [1997], Schwab and Schroeder [1998]. Insome cases, results have been positive despite the performance disadvantages of Java. Asshown in Boisvert et al. [1998], for some computations and certain machine configurationscurrent Java implementations can achieve up to 50% of C performance. We note, however,that the best performance reported in Boisvert et al. [1998]for matrix multiplication inJava is only 50 Mflops (on a machine slower than ours).
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

24 � Jose E. Moreira et al.
for(i=0; i<n; i+=4) {s = s + a[i+3]*b[i+3];s = s + a[i+2]*b[i+2];s = s + a[i+1]*b[i+1];s = s + a[i ]*b[i ];
}
for(i=0; i<n; i+=4) {s = s + a[i ]*b[i ];s = s + a[i+1]*b[i+1];s = s + a[i+2]*b[i+2];s = s + a[i+3]*b[i+3];
}(a) (b)
Fig. 17. Elimination of redundant tests in Java: (a) only thefirst statement in the loop body needs an explicit test;(b) all statements need explicit tests.
There are four main approaches in the literature to optimizing array bounds checks:(i) the use of static data-flow analysis information to determine that a test is unnecessary[Cousot and Cousot 1977; Cousot and Halbwachs 1978a; 1978b;Harrison 1977; Schwarzet al. 1988], (ii) the use of data-flow information and symbolic analysis at compile timeto reduce the number of tests remaining in the program [Asuru1992; Gupta 1990; 1993;Kolte and Wolfe 1995; Markstein et al. 1982], (iii) the regions-based approach discussedin this article and more generally in Gupta et al. [1998] and Midkiff et al. [1998], and (iv)speculative methods discussed in Gupta et al. [1998].
Work in the first group uses data-flow information to prove at compile time that an arraybounds violation cannot occur at run-time and, therefore, that the test for the violation isunnecessary. Using the terms of our discussion, the goal of this work is to identify loopsthat are safe regions. In contrast, the goal of our work is to transform loops in order tocreatesafe regions.
Work in the second group attempts to reduce the dynamic and static number of boundstests. It also attempts to reduce the overhead induced by a test even if it cannot be elimi-nated. This is done (i) by hoisting tests out of loops when possible [Markstein et al. 1982]and (ii) by also determining that a test is covered by anothertest [Asuru 1992; Gupta 1990;1993; Kolte and Wolfe 1995] and can be eliminated.
Neither of these optimizations are usable with Java in general because the Java seman-tics requiring precise exceptions make the hoisting and reordering of tests illegal in manysituations. Also, when an access violation exception is caught by atry block in the loopbody, the loop should not be terminated (as would occur when hoisting tests). Coverageanalysis may be able to eliminate redundant tests in some situations. Consider, for exam-ple, the Java code in Figure 17(a). If statements = s + a[i+3]*b[i+3] executessuccessfully, so will the other three statements in the loopbody. (Sincei is nonnegative,we do not have to worry about lower bound violations.) If thatstatement fails, because ofan out-of-bounds ornull-pointer violation, the other three statements are not executed.Therefore, the tests in those three statements are totally redundant and can be eliminated.No such optimization can be performed in the Java code of Figure 17(b), since the Javacompiler cannot change the execution order of statements.
The work in the third and fourth groups differs from what is discussed here in the gener-ality of discussion, and in the experiments performed. Specifically, in Gupta et al. [1998]no benchmarking was performed. In Midkiff et al. [1998] measurements compared theperformance of Java programs with all checks, no checks, andour bounds check optimiza-tion transformations. The more important effects of the transformation in enabling otheroptimizations was neither discussed in any detail, nor measured.
We emphasize that creating safe regions has the important effect of enabling an entire set
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

From Flop to Megaflops: Java for Technical Computing � 25
of powerful optimization techniques. These techniques areconstrained in Java by the re-quirement of precise exceptions. An alternative approach that enables these optimizationseven in the presence of (potential) exceptions isspeculative execution[Gupta et al. 1998].A fully transformed and optimized version of a loop nest (or code fragment in general) canbe generated and executed speculatively. If an access violation is detected, then the compu-tation is rolled-back and restarted in strict order. This approach is analogous to speculativeexecution to explore parallelism in the presence of (potential) data dependences. Note thatsome mechanism to detect violations is necessary, so this approach does not get the benefitof eliminating the actual tests.
Versioning is a long-standing technique for optimizing compilers to deal with the lackof complete information at compile time. In particular, Byler et al. [1987] discusses ver-sioning in the context of vectorization and parallelization of loops. Runtime tests of loopincrements, data dependences, and loop bounds are used to select the best version (sequen-tial, vector, parallel, vector/parallel) of a loop nest forexecution. Our work applies theversioning transformation for a different purpose, to create safe regions where no arraybounds andnull-pointer violations may take place.
To evaluate the runtime condition that chooses between safeand unsafe execution, weneed to be able to compute the range of values assumed by all array-indexing expressionsin a loop. This evaluation of value ranges for variables and expressions was pioneered byHarrison [1997]. At compile time we compute symbolic expressions that define the lowerand upper bounds of the range of values for each array-indexing expression. These expres-sions are then used to construct the runtime condition that selects the proper version of aloop. When evaluating this expression, lower and upper bounds of an index are comparedagainst the lower and upper bounds of the corresponding array or array axis.
Several other projects have looked at aggressively optimizing Java. In Bik et al. [1997]and Bik and Gannon [1998], thejavar andjavab projects are described. These projectsare closely related, withjavar compiling Java source code andjavab compiling bytecode.Both produce Java bytecode as output. Thejavar program supports user-specified paral-lelism, andjavab performs automatic parallelization. In Budimlic and Kennedy [1997],a project begun at the JavaSoft division of Sun Microsystemsand its follow-on at RiceUniversity are outlined. The work was aimed at adynamic(or just-in-time) compilationsystem, and focused on local scalar optimizations. Hand compilations using a techniquecalledobject inliningachieved up to a 7-fold speedup on anOopackroutine (an object-oriented version of Linpack). The work of both of these projects are complementary to ourwork, and show the gains that can be made in Java performance.
Several groups have put forth proposals for altering the Java floating-point semanticsto allow greater freedom in scheduling floating-point operations and exploiting floating-point hardware. In Gosling [1997], James Gosling describesa looseNumerics andidealizedNumerics class and method modifiers. ThelooseNumerics modifier allows aclass or method to return floating-point results with more precision than allowed by theJava standard. This enables the use of thefma operation on the IBM POWER and Pow-erPC architectures. For Intelx86processors, it allows intermediate and local variables tobe kept in full 80-bit operand format. As seen in Section 3.2,enabling thefma operationcan have a dramatic effect on performance. Similar benefits should accrue to programscompiled for thex86processors. TheidealizedNumerics modifier would allow floating-point operations to be reordered as if they were associative, and would, for example, allowparallelization of the inner loop recurrence in the matrix multiply. The Java Grande Forum,
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

26 � Jose E. Moreira et al.
which is looking into the use of Java for high-performance computing, is also working onproposals (see Java Grande Forum [1998]) to relax Java floating-point semantics. Theirproposal would also allow the use of thefma operation.
Finally, various researchers have studied the benefit of adding rectangular, multidimen-sional arrays to Java. True multidimensional arrays have several advantages over Javaarrays-of-arrays. See Figure 18, where a Fortran-like(m + 1)� (n+ 1) two-dimensionalarray is represented byA(0 : m; 0 : n) and a corresponding Java-like array is representedbyA[0 : m][0 : n]):(1) The location of an elementA(i; j) can be computed using simple arithmetic. FindingA[i][j] involves, in general, pointer chasing.
(2) There is no guarantee thatA[0 : m][0 : n] is rectangular. Even if it was rectangularwhen created it may have been modified. This increases the overhead of array boundchecking (even with the optimizations described in this article), since the length ofrows may differ; therefore all rows must be checked.
(3) Aliasing disambiguation. Given two matrix objectsA andB it is sufficient to showthatA 6= B to prove there is no aliasing between them. In the case of two arrays ofarraysA[ ][ ] andB[ ][ ] one has to show thatA[i] 6= B[j] 8i; j to prove there is noaliasing.
(4) Regular array sections for the matrix objectA(1 : m; 1 : n) can be represented com-pactly using a Fortran 90-like triplet.
(5) Disambiguation between two array sectionsA(lA1 : uA1 : sA1 ; lA2 : uA2 : sA2 ) andB(lB1 : uB1 : sB1 ; lB2 : uB2 : sB2 ) reduces to proving that the source arrays are different(A 6= B) or that the sections do not intersect ((lA1 : uA1 : sA1 ) \ (lB1 : uB1 : sB1 ) = ; or(lA2 : uA2 : sA2 ) \ (lB2 : uB2 : sB2 ) = ;).
(6) Privatizing matrixA(1 : m; 1 : n), for thread safety, requires copying only one refer-ence. Privatizing arrayA[1 : m][1 : n] requires creating a new array withm elementsand copyingm references. This can become a performance problem for arrayopera-tions with complexityO(mn) or less.
One approach to having explicit rectangular arrays is to have the compiler identify Java ar-rays that have rectangular shape. Such an approach is described in Cierniak and Li [1997].For general applicability, it requires good interprocedural analysis in the presence of mul-tithreading. It also requires good alias analysis. This approach can be complemented withruntime techniques, as discussed in Section 2.4. Another approach, discussed in Gosling[1997], is to have standard Java classes for multidimensional arrays, and rely on com-piler technology to allow efficient invocations of methods to perform array operations. Astandard Java array package is also part of the Java Grande Forum proposal [Java GrandeForum 1998]. One implementation of such an Array package is described in Artigas etal. [1999] and Moreira et al. [2000], with the implementation available at Moreira et al.[1999]. The obvious solution of adding JVM bytecode operations to support multidimen-sional arrays is problematic because the number of remaining undefined bytecodes is small.
6. CONCLUSIONS
Eliminating and/or reducing the cost of verifying array references for validity is a keyfactor in achieving high performance with Java for technical computing. The methodswe presented in this article partition the iteration space of a loop-nest into regions with
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

From Flop to Megaflops: Java for Technical Computing � 27A(0 : m;0 : n)A(m; 0) A(m; 1) � � � A(m;n)� � � � � � � � � � � �A(1;0) A(1;1) � � � A(1; n)A(0;0) A(0;1) � � � A(0; n) A[0 :m][0 : n]A[m]...
A[1]A[0] ---- A[m][0] A[m][1] � � � A[m][n]� � � � � � � � � � � �A[1][0] A[1][1] � � � A[1][n]A[0][0] A[0][1] � � � A[0][n](a)m� n array (b)m array ofn-element arrays
Fig. 18. Differences between anm � n array and anm-element array ofn-element arrays.
different access violation characteristics. For technical computing, we expect most or allof the work to be performed in safe and exception-free regions. The benefit of creatingsafe regions is two-fold: (i) code to explicitly check for valid references is unnecessary inthose regions and (ii) operation-reordering optimizations are allowed.
By applying high-order loop transformations (available today in the IBM XLF compiler)we have achieved single-processor Java performance inMATMUL that is within 65–85%of the best library and Fortran/C++ versions. We want to stress the fact that there areno fundamental reasons for the Java code not to achieve the same performance of C++in the serial and parallel versions ofMATMUL. The current differences are due to par-ticularities in the compilers, which result in different instruction schedules. As part ofour future work, we want to investigate the causes of these differences and to provide thenecessary fixes. Furthermore, in theMICROSTRIP application, we achieved 87–90% ofthe performance of a Fortran version of the code. This shows that the performance gainsachieved withMATMUL are also attainable onO(n2) computations. Experiments withfour other floating-point-intensive benchmarks (CHOLESKY, SHALLOW, TOMCATV,andBSOM) also indicate that Java can be very competitive in performance with Fortranfor technical applications.
The safe regions also open up the possibility of automatic parallelization of Java codes.Automatic parallelization is being developed at IBM withinthe context of theTorontoPortable Optimizer(TPO) framework. This framework operates at an intermediatelan-guage level, and it is equally applicable to Fortran, C, C++,and Java. Parallelization ofMATMUL yielded almost linear speedup for Java, achieving over 550 Mflops on a four-processor 332MHz PowerPC 604e machine, with a strictly compliant execution. We alsoachieved 750 Mflops on the same platform when thefma instruction was used with Java.
ACKNOWLEDGMENTS
The authors wish to thank Rick Lawrence and Marc Snir for fruitful technical discussions,and for strongly supporting our research. We also wish to thank Ven Seshadri of IBMCanada for helping and supporting our experiments with HPCJ,Pedro Artigas for his work
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

28 � Jose E. Moreira et al.
in implementing the Array package and automatic versioningdiscussed in this article, andthe anonymous referees for their valuable comments and suggestions.
REFERENCES
ARTIGAS, P. V., GUPTA, M., M IDKIFF, S. P.,AND M OREIRA, J. E. 1999. High performance numerical com-puting in Java: Language and compiler issues. In J. FERRANTE ET AL. (Eds.),12th International Workshop onLanguages and Compilers for Parallel Computing. Springer Verlag. IBM Research Division report RC21482.
ASURU, J. 1992. Optimization of array subscript range checks.ACM Letters on Programming Languages andSystems 1,2 (June), 109–118.
ATWOOD, C. A., GARG, R. P.,AND DERYKE, D. 1997. A prototype computational fluid dynamics case studyin Java. Concurrency, Pract. Exp. (UK) 9,11 (November), 1311–18. Java for Computational Science andEngineering - Simulation and Modeling II Las Vegas, NV, USA 21 June 1997.
BANERJEE, U. 1990. Unimodular transformations of double loops. InProc. Third Workshop on ProgrammingLanguages and Compilers for Parallel Computing, Irvine, California.
BIK , A. AND GANNON, D. 1998. A prototype bytecode parallelization tool.Concurrency, Pract. Exp.(UK) 10,11-13 (September-November), 879–86. ACM 1998 Workshop on Java for High-Performance Net-work Computing. URL:http://www.cs.ucsb.edu/conferences/java98.
BIK , A., V ILLACIS , J.,AND GANNON, D. 1997.javar: A prototype Java restructuring compiler.Concurrency,Pract. Exp. (UK) 9,11 (November), 1181–91. Java for Computational Science andEngineering - Simulationand Modeling II Las Vegas, NV, USA 21 June 1997.
BOISVERT, R. F., DONGARRA, J. J., POZO, R., REMINGTON, K. A., AND STEWART, G. W. 1998. Developingnumerical libraries in Java.Concurrency, Pract. Exp. (UK) 10,11-13 (September-November), 1117–29. ACM1998 Workshop on Java for High-Performance Network Computing. URL:http://www.cs.ucsb.edu/conferences/java98.
BUDIMLIC , Z. AND KENNEDY, K. 1997. Optimizing Java: Theory and practice.Concurrency, Pract. Exp.(UK) 9,11 (November), 445–63. Java for Computational Science and Engineering - Simulation and ModelingII Las Vegas, NV, USA 21 June 1997.
BYLER, M., DAVIES, J. R. B., HUSON, C., LEASURE, B., AND WOLFE, M. 1987. Multiple version loops. InProceedings of the 1987 International Conference on Parallel Processing, pp. 312–318.
CALLAHAN , D., CARR, S.,AND KENNEDY, K. 1990. Improving register allocation for subscripted variables. InProc. ACM SIGPLAN ’90 Conference on Programming Language Design and Implementation, White Plains,NY, pp. 53–65.
CASANOVA , H., DONGARRA, J.,AND DOOLIN, D. M. 1997. Java access to numerical libraries.Concurrency,Pract. Exp. (UK) 9,11 (November), 1279–91. Java for Computational Science andEngineering - Simulationand Modeling II Las Vegas, NV, USA 21 June 1997.
CIERNIAK , M. AND L I , W. 1997. Just-in-time optimization for high-performanceJava programs.Concurrency,Pract. Exp. (UK) 9,11 (November), 1063–73. Java for Computational Science andEngineering - Simulationand Modeling II, Las Vegas, NV, June 21, 1997.
COUSOT, P. AND COUSOT, R. 1977. Abstract interpretation: A unified lattice model for static analysis of pro-grams by construction or approximation of fixpoints. InConference Record of the 4’th ACM Symposium onPrinciples of Programming Languages, pp. 238–252.
COUSOT, P. AND HALBWACHS, N. 1978a. Automatic discovery of linear restraints among variables of a pro-gram. InConference Record of the 5’th ACM Symposium on Principles ofProgrammingLanguages, pp. 84–96.
COUSOT, P. AND HALBWACHS, N. 1978b. Automatic proofs of the absence of common runtimeerrors. InConference Record of the 5’th ACM Symposium on Principles ofProgramming Languages, pp. 105–118.
DONGARRA, J. J., DUFF, I. S., SORENSEN, D. C.,AND VAN DER VORST, H. A. 1991.Solving Linear Systemson Vector and Shared Memory Computers. Society for Industrial and Applied Mathematics.
FERRANTE, J., SARKAR , V., AND THRASH, W. 1991. On estimating and enhancing cache effectiveness.InProc. Fourth Workshop on Programming Languages and Compilers for Parallel Computing.
GOSLING, J. 1997. The evolution of numerical computing in Java. URL:http://java.sun.com/people/jag/FP.html. Sun Microsystems.
GOSLING, J., JOY, B., AND STEELE, G. 1996.The Java(TM) Language Specification. Addison-Wesley.GUPTA, M., M IDKIFF, S. P.,AND M OREIRA, J. E. 1998. Method for optimizing array bounds checks in
programs. Patent pending, IBM Docket #YO-998-052, filed with U. S. Patent Office, April 24th, 1998.
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.

From Flop to Megaflops: Java for Technical Computing � 29
GUPTA, R. 1990. A fresh look at optimizing array bounds checking. In Proceedings of the ACM SIGPLAN ’90Conference on Programming Language Design and Implementation, pp. 272–282.
GUPTA, R. 1993. Optimizing array bound checks using flow analysis.ACM Letters on ProgrammingLanguagesand Systems 2,1-4 (March–December), 135–150.
HARRISON, W. H. 1977. Compiler analysis for the value ranges for variables. IEEE Transactions on SoftwareEngineering SE3,3 (May), 243–250.
INTERNATIONAL BUSINESSM ACHINES CORPORATION. 1997. IBM Engineering and Scientific SubroutineLibrary for AIX – Guide and Reference. INTERNATIONAL BUSINESSM ACHINESCORPORATION.
JAVA GRANDE FORUM. 1998. Java Grande Forum Report: Making Java Work for High-End Comput-ing. JAVA GRANDE FORUM. Java Grande Forum Panel, SC98, Orlando, FL. URL:http://www.javagrande.org/reports.htm.
KOLTE, P. AND WOLFE, M. 1995. Elimination of redundant array subscript range checks. InProceedings of theACM SIGPLAN ’95 Conference on Programming Language Design and Implementation, pp. 270–278.
M ARKSTEIN, V., COCKE, J.,AND M ARKSTEIN, P. 1982. Elimination of redundant array subscript range checks.In Proceedings of the ACM SIGPLAN ’82 Conference on Programming LanguageDesign and Implementation,pp. 114–119.
M IDKIFF, S. P., MOREIRA, J. E.,AND SNIR, M. 1998. Optimizing array reference checking in Java programs.IBM Systems Journal 37,3 (August), 409–453.
M OREIRA, J. E., MIDKIFF, S. P., GUPTA, M., AND ARTIGAS, P. V. 1999. Numerically Intensive Java. URL:http://www.alphaWorks.ibm.com/tech/ninja. A sequential version of the Array package isavailable for download.
M OREIRA, J. E., MIDKIFF, S. P., GUPTA, M., ARTIGAS, P. V., SNIR, M., AND LAWRENCE, R. D. 2000. Javaprogramming for high performance numerical computing.IBM Systems Journal 39,1. IBM Research Divisionreport RC21481.
ORCHARD, D. 1998. Better peformance with exceptions in Java.Byte 23,3 (March), 53–54. In theCoreProgrammingfeature.
PRESS, W. H., TEUKOLSKY, S. A., VETTERLING, W. T., AND FLANNERY, B. P. 1992.Numerical Recipes inFORTRAN: The Art of Scientific Computing. Cambridge University Press.
SARKAR , V. 1997. Automatic selection of high-order transformations in the IBM XL Fortran compilers.IBMJournal of Research and Development 41,3 (May), 233–264.
SCHWAB, M. AND SCHROEDER, J. 1998. Algebraic Java classes for numerical optimization. Concurrency,Pract. Exp. (UK) 10,11-13 (September-November), 1155–64. ACM 1998 Workshop onJava for High-Performance Network Computing. URL:http://www.cs.ucsb.edu/conferences/java98.
SCHWARZ, B., KIRCHGASSNER, W., AND LANDWEHR, R. 1988. An optimizer for Ada – design, experienceand results. InProceedings of the ACM SIGPLAN ’88 Conference on Programming Language Design andImplementation, pp. 175–185.
SESHADRI, V. 1997. IBM high performance compiler for Java. AIXpert Magazine. URL:http://www.developer.ibm.com/library/aixpert.
WOLF, M. E. AND LAM , M. S. 1991. A loop transformation theory and an algorithm tomaximize parallelism.IEEE Transactions on Parallel and Distributed Systems 2,4 (October), 452–471.
WOLFE, M. J. 1987. Iteration space tiling for memory hierarchies.In Proc. 3rd SIAM Conference on ParallelProcessing for Scientific Computing, Philadelphia, PA, pp. 357–361.
WOLFE, M. J. 1989.Optimizing Supercompilers for Supercomputers. The MIT Press.
Received September 1998; revised August 1999; accepted August 1999
ACM Transactions on Programming Languages and Systems, Vol. X, No. y, Month 1999.




















