
French Language DRS Parsing
183
THÈSE DE DOCTORAT DE L’ÉCOLE NATIONALE SUPÉRIEURE MINES-TELECOM ATLANTIQUE BRETAGNE PAYS DE LA LOIRE - IMT ATLANTIQUE Ecole Doctorale N°601 Mathèmatique et Sciences et Technologies de l’Information et de la Communication Spécialité : Informatique Par Ngoc Luyen LE French Language DRS Parsing Thèse présentée et soutenue à PLOUZANÉ, le 15 septembre 2020 Unité de recherche : Lab-STICC UMR 6285 - CNRS Thèse N° : 2020IMTA0202 Rapporteurs avant soutenance : Panayota Tita Kyriacopoulou Professeure des universités, Université Gustave Eiffel Benoît Crabbé Professeur, Université Paris Diderot & Institut Universitaire de France Composition du jury : Président : Ismaïl Biskri Professeur, Université du Québec à Trois-Rivières Examinateur : Panayota Tita Kyriacopoulou Professeure des universités, Université Gustave Eiffel Benoît Crabbé Professeur, Université Paris Diderot & Institut Universitaire de France Annie Forêt Maître de Conféfrences HDR, IRISA-ISTIC Dir. de thèse : Philippe Lenca Professeur, IMT Atlantique Co-dir. de thèse : Yannis Haralambous Directeur d’études, IMT Atlantique
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of French Language DRS Parsing

THÈSE DE DOCTORAT DE
L’ÉCOLE NATIONALE SUPÉRIEURE MINES-TELECOM ATLANTIQUEBRETAGNE PAYS DE LA LOIRE - IMT ATLANTIQUE
Ecole Doctorale N°601Mathèmatique et Sciences et Technologies de l’Information et de la CommunicationSpécialité : Informatique
Par
Ngoc Luyen LEFrench Language DRS Parsing
Thèse présentée et soutenue à PLOUZANÉ, le 15 septembre 2020Unité de recherche : Lab-STICC UMR 6285 - CNRSThèse N° : 2020IMTA0202
Rapporteurs avant soutenance :
Panayota Tita Kyriacopoulou Professeure des universités, Université Gustave EiffelBenoît Crabbé Professeur, Université Paris Diderot & Institut Universitaire de France
Composition du jury :
Président : Ismaïl Biskri Professeur, Université du Québec à Trois-Rivières
Examinateur : Panayota Tita Kyriacopoulou Professeure des universités, Université Gustave EiffelBenoît Crabbé Professeur, Université Paris Diderot & Institut Universitaire de FranceAnnie Forêt Maître de Conféfrences HDR, IRISA-ISTIC
Dir. de thèse : Philippe Lenca Professeur, IMT Atlantique
Co-dir. de thèse : Yannis Haralambous Directeur d’études, IMT Atlantique


IMT ATLANTIQUE
DOCTORAL THESIS
French Language DRS Parsing
Author:Ngoc Luyen L
Supervisors:Yannis HARALAMBOUS
Philippe LENCA
A thesis submitted in fulfillment of the requirementsfor the degree of Doctor of Philosophy
Thesis prepared at
Department of Computer ScienceDECIDE - Lab-STICC - CNRS, UMR 6285
IMT Atlantique
This research was sponsored by Crédit Mutuel Arkéa Bank
Plouzané, Autumn 2020


iii
AcknowledgementsFirst and foremost I express my deep sense of gratitude and profound respect to my thesisadvisors, professor Yannis Haralambous and professor Philippe Lenca who have helped andencouraged me at all stages of my thesis work with great patience and immense care. I am spe-cially indebted to Yannis Haralambous who gave me the golden opportunity to do this wonderfulthesis and gave me the opportunity to acquire a great amount of knowledge and experience inthe fields of natural language processing as well as deep learning, and devoted his time to helpme both in resolving scientific matters as well as correcting the manuscripts that I wrote duringthese years.
I gratefully acknowledge the members of my Individual Thesis Monitoring Committee fortheir serving time and valuable feedback on my report in the academic years. I would par-ticularly like to acknowledge Dr. Éric Saux and Professor Serge Garlatti, who gave me theirextremely useful help, advice and encouragements.
I also would like to thank all my colleagues from the Computer Science department of IMTAtlantique and the CNRS Lab-STICC DECIDE research team for making these past years beunforgettable memories. Among others, a very special thank you to Lina Fahed and KafcahEmani Cheikh for their invaluable advice on my research and for always being supportive of mywork. I am also very grateful to Armelle Lannuzel who all helped me in numerous ways duringvarious stages of my PhD.
I took part in many other activities with countless people teaching and helping me everystep. Thank you to my friends from Plouzané, Brest and other cities, especially tonton Riquet,Francette, Denise, Daniel, Nanette, Landy, Fabrice, Gildas and Polla. I am really thankfulto Dr. Pierre Larmande who have gave a chance to study in France and guided me during mymaster internship. I would like to thank to my teachers and colleagues at information technologyfaculty of Da Lat University.
As always it is impossible to mention everybody who had an impact to this work howeverthere are those whose spiritual support is even more important. I feel a deep sense of gratitudefor my grand parents, father, mother, my brothers, who formed part of my vision and taught memyriad good things that really matter in life. I owe my deepest gratitude towards my belovedand supportive wife, Hoai Phuong who is always by my side when times I needed her most andhelped a lot in making this study, and my lovable son An Lap, who served as my inspiration topursue this undertaking. Their infallible love and support has always been my strength. Theirpatience and sacrifice will remain my inspiration throughout my life.
This research is financed in a collaboration between Crédit Mutuel Arkéa Bank and IMTAtlantique. I would especially like to thank to Dr. Riwal Lefort, Maxime Havez and BertrandMignon from the Innovation IA Department of Arkéa who gave me permission to work in theirindustrial laboratory. I also appreciate very much the discussions that we had.
Last, I dedicate this thesis to the memory of my grandfather and my grandmother, whoserole in my life was, and remains, immense.


v
AbstractIMT Atlantique
Department of Computer Science
French Language DRS Parsingby Ngoc Luyen L
The rise of the internet, of personal computers and of mobile devices has been changing variouscommunication forms from one-way communication, such as the press or television, to two-way flows of information or interactive communications. In particular, the advent of socialnetworking platforms makes this communication trend ever more prevalent. User-generatedcontents from the social networking services become a giant source of information which can beuseful for organizations or businesses in the sense that users are regarded as clients or potentialclients for businesses or members of organizations. The exploitation of user-generated textscan help to identify their sentiments or intentions, or reduce the effort of agents in businesses ororganizations who are responsible for gathering or receiving information on social networkingservices. In this thesis, we realized a study about semantic analysis and representation for naturallanguage texts in various formats such discourses, utterances, and conversations from interactivecommunication on the social networking platforms.
With the purpose of finding an effective way to analyze and represent semantics of natu-ral language utterances, we examine and discuss various approaches ranging from the usingrule-based methods to current deep neural network approaches. Deep learning approachesrequire massive amounts of data, in our case: natural language utterance and their meaningrepresentations—to leverage this requirement we employ an empirical approach and propose ageneral architecture for a meaning representation framework for the French language.
First of all, for each sequence of input texts, we analyze each word morphologically andsyntactically using the formalism of dependency syntax, and this constitutes the first module ofour architecture. During this step, we explore lemmas, part-of-speech tags and dependenciesas features of words.
Then, a bridge between syntax and semantic is built based on the formalism of Combi-natory Categorial Grammars (CCG), which provides a transparent syntax-semantic interface.This constitutes the second module of our architecture. The morphological and syntactic dataobtained from the previous module are employed as input in the process of extraction of a CCGderivation tree. More precisely, this process consists of two stages: the first one is the task of theassignment of lexical categories to each word depending on its position and its relationship withother words in the sentence; the second one focuses on the binarization of dependency trees.The parsing of CCG derivation trees is realized on binary trees by applying the combinatoryrules defined in CCG theory.
Finally, we construct a meaning representation for utterances based on the Discourse Rep-resentation Theory (DRT) which is built from Discourse Representation Structure (DRS) andthe Boxer tool by Johan Bos. This constitutes the last module of our architecture. Data suchas CCG derivation trees obtained by the previous module are used as input for this module,together with additional information such as chunks and entities. The transformation of in-put CCG derivation trees into the DRS format is able to process linguistic phenomena such asanaphoras, coreferences and others. As output, we obtain data either in FOL or in the DRSboxing format.
By implementing our architecture we have built a French CCG corpus based on the FrenchTree Bank corpus (FTB). Furthermore, we have proven efficiency of the use of embedding

vi
features from lemmas, POS tags and dependency relations in order to improve the accuracy ofthe CCG supertagging task using deep neural networks.

vii
RésuméIMT Atlantique
Département Informatique
Analyse de la structure de représentation du discours pour le françaispar Ngoc Luyen LE
L’essor d’Internet, des ordinateurs personnels, des appareils numériques et mobiles changentdiverses formes de communication, passant à sens unique comme les articles, les livres, lestélévisions au flux de deux sens d’informations ou aux communications interactives. Plus par-ticulièrement, l’avènement des plateformes de réseaux sociaux rend cette communication ten-dance de plus en plus populaire. Les contenus générés par les utilisateurs à partir des servicesde réseaux sociaux deviennent une source géante d’informations qui peuvent être utile aux or-ganisations ou aux entreprises sur l’aspect où les utilisateurs sont considérés comme des clientsou des clients potentiels pour les entreprises ou les membres d’organisations. L’exploitation destextes générés par les utilisateurs peut aider à identifier leurs sentiments ou leurs intentions, ouréduire l’effort des agents dans les entreprises ou les organisations qui sont responsables de re-cueillir ou de recevoir des informations sur les services de réseaux sociaux. Dans la cadre decette thèse, nous réalisons une étude sur l’analyse sémantique et la représentation de textes enlangage naturel qui ont été créés sous différents formats tels que discours, énoncés, conversa-tions issues de la communication interactive sur les plateformes de réseaux sociaux.
Dans le but de trouver un moyen efficace d’analyser et de représenter la sémantique pour desénoncés de langage naturel donnés, nous examinons et discutons des divers travaux importants,allant de l’utilisation de méthodes basées sur des règles aux approches actuelles des réseaux deneurones profonds. Avec la limitation d’une quantité massive de données sur les paires d’énoncésdu langage naturel et sa représentation de sens qui sont devenues une exigence obligatoire pourles approches d’apprentissage en profondeur, nous utilisons l’approche empirique et avons pro-posé une architecture générale pour un cadre de représentation de sens utilisant pour le françaissaisie en langage naturel.
Tout d’abord, avec chaque séquence de texte donnée, nous réalisons un processus d’analysedes informations morphologiques de chaque mot dans le premier module de l’architecture. Àpartir de là, nous explorons la lemma, l’étiquette et les caractéristiques du mot dans le texte.Ces informations cruciales sont utilisées comme entrée pour extraire la relation entre les motset les constituants en utilisant la grammaire des dépendances. En conséquence, nous obtenonsles informations syntaxiques et de dépendance de chaque mot des textes d’entrée.
Ensuite, le pont entre la syntaxe et la sémantique est construit sur la base du formalismegrammatical avec la grammaire catégorielle combinatoire (CCG) qui nous aide à posséder uneinterface transparente syntaxique-sémantique dans le deuxième module. Le résultat d’analyseobtenue du module précédent est utilisé comme entrée du processus d’extraction d’un arbre dedérivation CCG. Plus particulièrement, ce processus comprend deux étapes dont la premièreconsiste à attribuer des catégories lexicales à chaque mot en fonction de sa position et de sarelation avec les autres mots de la phrase. Le second se concentre sur la binarisation de l’arbrede dépendance en un arbre binaire. L’analyse de l’arbre de dérivation CCG est réalisée surl’arbre binaire en appliquant les règles combinatoires définies dans la théorie CCG.
Enfin, nous construisons une représentation de sens pour un énoncé donné basée sur lathéorie de la représentation du discours (DRT) qui est construite à partir de la structure dereprésentation du discours (DRS) et du travail Boxer de Johan Bos dans le dernier module. Parconséquent, le résultat de l’analyse de l’arbre de dérivation CCG dumodule précédent est consid-éré comme l’entrée pour ce module, à côté des informations supplémentaires sur les morceaux

viii
et les entités dans la phrase. La transformation de l’arbre de dérivation CCG d’entrée en unformat DRS accompagne la résolution des phénomènes linguistiques telles que l’anaphorique,la co-référence, etc. En conséquence, nous obtenons la forme logique ou les formats de boxede DRS pour les énoncés d’entrée.
La mise en œuvre de l’architecture proposée permet d’obtenir des résultats importants telsque la proposition d’une méthode pour obtenir un arbre de dérivation CCG à partir de la struc-ture de dépendance d’une phrase donnée. À partir de cela, nous construisons un corpus françaisde CCG basé sur un corpus de français. En outre, nous prouvons l’efficacité des intégrations del’utilisation du lemme, de l’étiquette pos et des informations de dépendance afin d’améliorer laprécision de la tâche de super-étiquetage CCG avec un modèle de réseau de neurones profond.Dans l’ensemble, nous créons un prototype pour transformer des énoncés de langage natureldonnés en DRS ou en représentation de forme logique.

Contents
Acknowledgements iii
Abstract v
Résumé vii
Résumé étendu xix1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xix2 État de l’art de la représentation sémantique du discours . . . . . . . . . . . . xx3 Interface entre syntaxe et sémantique . . . . . . . . . . . . . . . . . . . . . . xxi
3.1 Grammaires combinatoires catégorielles . . . . . . . . . . . . . . . . xxi3.2 Extraction d’une dérivation GCC à partir des dépendances syntaxiques xxiii
Affectation de catégories lexicales aux nœuds de l’arbre de dépendances xxiiiBinarisation des arbres de dépendance . . . . . . . . . . . . . . . . . xxivConstruction d’une dérivation GCC complète et validation . . . . . . . xxv
3.3 Expérimentation et évaluation sur le corpus French TreeBank . . . . . xxvi4 Architecture proposée d’analyseur de structure de représentation du discours
pour le français . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xxvii4.1 Introduction de la structure de représentation du discours . . . . . . . xxvii4.2 Relation entre la GCC et la SRD . . . . . . . . . . . . . . . . . . . . xxx4.3 Construction d’un analyseur SRD pour le français . . . . . . . . . . . xxx
Analyses syntaxique et grammaticale . . . . . . . . . . . . . . . . . . xxxiExtraction de l’arbre de dérivations GCC . . . . . . . . . . . . . . . . xxxiReprésentation sémantique à travers Boxer . . . . . . . . . . . . . . . xxxii
5 Expérimentation et évaluation . . . . . . . . . . . . . . . . . . . . . . . . . . xxxiv6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xxxv
1 Introduction 11.1 The context . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2 Challenges . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
I Discourse AnalysisandSocial Networking Platforms 7
2 Discourse on Social Networks: Challenges and Opportunities 92.1 Social Networks Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1.1 Social Networks Definitions . . . . . . . . . . . . . . . . . . . . . . . 92.1.2 A Brief History of Social Networks . . . . . . . . . . . . . . . . . . . 112.1.3 User Characteristics and Motivations . . . . . . . . . . . . . . . . . . 12
2.2 Opportunities and Challenges . . . . . . . . . . . . . . . . . . . . . . . . . . 15

x
2.2.1 Opportunities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.2.2 Challenges . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3 Discourse on Social Networks . . . . . . . . . . . . . . . . . . . . . . . . . . 162.3.1 Basic Definitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.3.2 Discourse Forms . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3 Discourse Analysis and Applications 193.1 Intrasentential Linguistic Analysis . . . . . . . . . . . . . . . . . . . . . . . . 193.2 Discourse Analysis Overview . . . . . . . . . . . . . . . . . . . . . . . . . . 203.3 Coherence and Cohesion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203.4 Discourse Parsing Task . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
4 A Proposed Architecture for a French DMR Framework 234.1 State-of-the-Art in Discourse Meaning Representation . . . . . . . . . . . . . 23
4.1.1 Rule-Based Approaches . . . . . . . . . . . . . . . . . . . . . . . . . 234.1.2 Empirical Approaches . . . . . . . . . . . . . . . . . . . . . . . . . 244.1.3 Semantic Annotation Corpora . . . . . . . . . . . . . . . . . . . . . 264.1.4 Corpus-driven approaches . . . . . . . . . . . . . . . . . . . . . . . 28
Supervised Learning Approaches . . . . . . . . . . . . . . . . . . . . 28Unsupervised Learning Approaches . . . . . . . . . . . . . . . . . . 29Sequence-to-Sequence learning approaches . . . . . . . . . . . . . . . 29
4.2 Meaning Representation Parsing Through Deep Neural Network Models . . . . 314.3 An Architecture for a French Semantic Parsing Framework . . . . . . . . . . 33
4.3.1 Text Input Preprocessing . . . . . . . . . . . . . . . . . . . . . . . . 344.3.2 Syntax and Dependency Analysis . . . . . . . . . . . . . . . . . . . . 35
Parts of speech tags . . . . . . . . . . . . . . . . . . . . . . . . . . . 36Chunk analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43Constituency Structure and Parsing . . . . . . . . . . . . . . . . . . . 45Dependency structure and parsing . . . . . . . . . . . . . . . . . . . 48
4.3.3 A bridge between syntax and semantics . . . . . . . . . . . . . . . . . 61
II Building French DiscourseMeaning Representation Parsing Framework 64
5 CCG Derivations out of Dependency Syntax Trees 655.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 655.2 Combinatory Categorial Grammars . . . . . . . . . . . . . . . . . . . . . . . 66
5.2.1 Categories and Combinatory Rules . . . . . . . . . . . . . . . . . . . 665.2.2 Some Principles Applied to CCG . . . . . . . . . . . . . . . . . . . . 695.2.3 Spurious ambiguity . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
5.3 The State-of-the-art of French CCG Corpora . . . . . . . . . . . . . . . . . . 715.4 French Dependency Tree Bank . . . . . . . . . . . . . . . . . . . . . . . . . 725.5 CCG Derivation Tree Construction . . . . . . . . . . . . . . . . . . . . . . . 73
5.5.1 Assigning Lexical Categories to Dependency Tree Nodes . . . . . . . 735.5.2 Binarization of Dependency Trees . . . . . . . . . . . . . . . . . . . 765.5.3 CCG Derivation Tree Building and Validation . . . . . . . . . . . . . 77
Some type-changing rules . . . . . . . . . . . . . . . . . . . . . . . . 78Coordination construction . . . . . . . . . . . . . . . . . . . . . . . . 79Subordination construction . . . . . . . . . . . . . . . . . . . . . . . 80Wh-questions construction . . . . . . . . . . . . . . . . . . . . . . . 81Topicalization construction . . . . . . . . . . . . . . . . . . . . . . . 81

xi
Negation structure construction . . . . . . . . . . . . . . . . . . . . . 815.6 Experiments and Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . 825.7 Error analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 825.8 Conclusion of the Chapter . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
6 CCG Supertagging Using Morphological and Dependency Syntax Information 856.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 856.2 State-of-the-art of the CCG Supertagging Task . . . . . . . . . . . . . . . . . 866.3 Neural Network Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
6.3.1 Input Features . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 876.3.2 Basic Bi-Directional LSTM and CRF Models . . . . . . . . . . . . . 87
Unidirectional LSTM Model . . . . . . . . . . . . . . . . . . . . . . 87Bidirectional LSTM Model . . . . . . . . . . . . . . . . . . . . . . . 88CRF Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
6.3.3 Our Model for Feature Set Enrichment and CCG Supertagging . . . . 906.4 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
6.4.1 Data Set and Preprocessing . . . . . . . . . . . . . . . . . . . . . . . 906.4.2 Training procedure . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
Pre-trained Word Embeddings . . . . . . . . . . . . . . . . . . . . . 92Parameters and Hyperparameters . . . . . . . . . . . . . . . . . . . . 92Optimization algorithm . . . . . . . . . . . . . . . . . . . . . . . . . 92
6.4.3 Experimental Results . . . . . . . . . . . . . . . . . . . . . . . . . . 936.5 Related CCG Parsing Works . . . . . . . . . . . . . . . . . . . . . . . . . . 94
6.5.1 Chart parsing algorithms . . . . . . . . . . . . . . . . . . . . . . . . 956.5.2 CCG parsing via planning . . . . . . . . . . . . . . . . . . . . . . . . 966.5.3 Shift-reduce parsing algorithms . . . . . . . . . . . . . . . . . . . . . 976.5.4 A* parsing algorithms . . . . . . . . . . . . . . . . . . . . . . . . . . 100
6.6 Conclusion of the Chapter . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
7 Towards a DRS Parsing Framework for French 1037.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1037.2 Discourse Representation Theory . . . . . . . . . . . . . . . . . . . . . . . . 104
7.2.1 Type Lambda Expression . . . . . . . . . . . . . . . . . . . . . . . . 1047.2.2 Discourse Representation Structure . . . . . . . . . . . . . . . . . . . 1057.2.3 The CCG and DRS Interface . . . . . . . . . . . . . . . . . . . . . . 109
7.3 DRS Parsing Based on Boxer . . . . . . . . . . . . . . . . . . . . . . . . . . 1097.3.1 Syntactic and grammar analysis . . . . . . . . . . . . . . . . . . . . . 1097.3.2 Extraction of CCG derivation tree . . . . . . . . . . . . . . . . . . . 1117.3.3 Boxer Semantic Parsing . . . . . . . . . . . . . . . . . . . . . . . . . 112
7.4 Experiment and Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . 1137.4.1 Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1137.4.2 Error Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
7.5 Conclusion of the Chapter . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
8 Conclusion and Perspectives 1178.1 Limitations and Perspectives . . . . . . . . . . . . . . . . . . . . . . . . . . 118
8.1.1 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1188.1.2 Perspectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118

xii
A Supporting Information 120A.1 The λ-calculus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121A.2 Combinatory Logic and The λ-calculus . . . . . . . . . . . . . . . . . . . . . 123
Bibliography 127

List of Figures
1 Une dérivation GCC de la phrase: «Henri regarde la télévision» . . . . . . . . xxiii2 Exemples d’arbres de dépendances avec étiquettes de parties du discours . . . . xxiv3 Les groupes de mots (en pointillés) et l’arbre binaire de la phrase . . . . . . . . xxvi4 Les règles d’inférence des catégories lexicales . . . . . . . . . . . . . . . . . . xxvi5 Croissance des types de catégories lexicales (échelle logarithmique pour les
deux axes) dans le corpus FTB . . . . . . . . . . . . . . . . . . . . . . . . . xxvii6 Distribution des catégories lexicales GCC dans le corpus FTB . . . . . . . . . xxvii7 Correspondance entre des différentes expressions pour la phrase “Mon enfant
mange des raisins» . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xxxi8 Architecture proposée pour l’analyse sémantique française . . . . . . . . . . . xxxii9 L’arbre de dérivation CCG de la phrase «Tous les soirs, mon voisin met sa
voiture au garage». . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xxxiii10 Un extrait de la ressource lexicale Verbnet pour le français . . . . . . . . . . . xxxiv11 La sortie en logique du premier ordre de l’exemple . . . . . . . . . . . . . . . xxxiv12 La sortie en SRD de l’exemple . . . . . . . . . . . . . . . . . . . . . . . . . xxxv
2.1 A statistic about amount of active users on the 18 biggest social networks(Source: wearesocial.com October 2019) . . . . . . . . . . . . . . . . . . . . 14
2.2 A statistic about daily time spent on social networks (Source: statista.com) . . . 15
4.1 Proposed Architecture for French Semantic Parsing . . . . . . . . . . . . . . 344.2 A conversation on a message platform . . . . . . . . . . . . . . . . . . . . . . 354.3 Tokenization and lemmatization of the sentence “je n’arriverai pas à l’heure” (I
won’t arrive on time) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354.4 A visual example of the chunking task result for the sentence “Pension reform
will be completed” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 444.5 A visual tree of constituent analysis for the sentence “Pension reform will be
completed.” by using Berkeley Neural Parser . . . . . . . . . . . . . . . . . . 454.6 A formal parse tree by using CFG . . . . . . . . . . . . . . . . . . . . . . . . 464.7 A visual tree of dependency parse tree of the sentence “Pension reform will be
completed.” by using BONSAI Malt Parser . . . . . . . . . . . . . . . . . . . 494.8 A visual dependency tree of the sentence “My child hears the birds of our neigh-
bor.” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 544.9 A visualization on a simple example with the Chu-Liu-Edmonds algorithms for
a graph-based parsing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
5.1 Chomsky’s hierarchy of formal languages . . . . . . . . . . . . . . . . . . . . 665.2 The 1st CCG derivation of the sentence: “Henri watches TV” . . . . . . . . . 695.3 A 2nd CCG derivation for the sentence: “Henri watches TV” . . . . . . . . . . 715.4 Distribution of French words by POS tags in the French Tree Bank corpus . . . 735.5 Distribution of dependency relations in the French Tree Bank corpus . . . . . 745.6 Dependency tree of the French sentence “My son buys a gift”. . . . . . . . . . 755.7 Dependency tree of the French sentence “He will give it to his mother”. . . . . 75

xiv
5.8 Dependency tree of the sentence “I would like to make an appointment fortomorrow” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
5.9 Chunks (in dotted lines) and binarized tree of sentence “He will give it to hismother” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
5.10 Inference rules for lexical categories . . . . . . . . . . . . . . . . . . . . . . . 785.11 CCG derivation tree of the sentence “He will give it to his mother.” . . . . . . 795.12 Coordination rules for lexical categories . . . . . . . . . . . . . . . . . . . . . 805.13 Subordination rules for lexical categories . . . . . . . . . . . . . . . . . . . . 805.14 Wh-question rules for lexical categories . . . . . . . . . . . . . . . . . . . . . 815.15 The growth of lexical category types . . . . . . . . . . . . . . . . . . . . . . 825.16 Distribution of CCG lexical categories . . . . . . . . . . . . . . . . . . . . . 83
6.1 A sentence with POS tags, dependencies and CCG lexical categories. . . . . . 866.2 A simple RNN model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 886.3 A bidirectional LSTM model . . . . . . . . . . . . . . . . . . . . . . . . . . 896.4 A CRF model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 896.5 Architecture of the BiLSTM network with a CRF layer on the output . . . . . 906.6 Histogram of sentence lengths in the corpora . . . . . . . . . . . . . . . . . . 916.7 CKY table parsing for the sentence “Henri borrows books from the Capuchins” 95
7.1 A type-based expression for the sentence “My child eats grapes” . . . . . . . . 1057.2 An excerpt of the Verbnet lexical resource for French . . . . . . . . . . . . . 1127.3 An ontology resource example . . . . . . . . . . . . . . . . . . . . . . . . . 1137.4 CCG derivation tree for the sentence “Tous les soirs, mon voisin met sa voiture
au garage”. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1147.5 DRS output of the utterance . . . . . . . . . . . . . . . . . . . . . . . . . . . 1157.6 FOL output of the utterance . . . . . . . . . . . . . . . . . . . . . . . . . . . 115

List of Tables
2.1 Mapping active user behavior and functionalities . . . . . . . . . . . . . . . . 132.2 The different forms of discourse on SNS . . . . . . . . . . . . . . . . . . . . 17
4.1 Volumetry of the OntoNotes corpus . . . . . . . . . . . . . . . . . . . . . . . 274.2 An example of various cases of natural language input and logical form output . 304.3 POS tagging of the example sentence “Pension reform will be completed.” by
using Stanford Tagger . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 364.4 Contraction of prepositions and articles . . . . . . . . . . . . . . . . . . . . . 374.5 The POS tag list used in the French Tree Bank Corpus . . . . . . . . . . . . . 384.6 A List of POS Tagging Systems for English and French . . . . . . . . . . . . 404.7 The tagset used in the French Tree Bank corpus for the shallow parsing task . . 444.8 Grammar rule set in CFG and its examples . . . . . . . . . . . . . . . . . . . 464.9 List of dependency relations extracted from the FTB corpus . . . . . . . . . . 524.10 A transition sequence example for the sentence in the figure 4.8 . . . . . . . . 54
5.1 Examples of lexical categories assigned to words . . . . . . . . . . . . . . . . 765.2 Words with the highest number of lexical categories and their frequencies . . . 84
6.1 Statistics on the corpus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 916.2 1-best tagging accuracy comparison results on the test set in the French FTB
Corpus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 936.3 1-best tagging accuracy comparison results on the test set in English GMBCorpus 94
7.1 Some translations between types, λ-expressions and lexical categories . . . . . 1107.2 The original representation in CONLL format of dependency analysis for the
sentence “You can test the compatibility of your computer with our website”by using MElt and Maltparser . . . . . . . . . . . . . . . . . . . . . . . . . 111
A.1 A comparison of rules between λ-calculus and combinatory logic . . . . . . . 126


List of Abbreviations
SNS Social Networking Sites
SN Social Network
NLP Natural Language Processing
POS Part-Of-Speech
CCG Combinatory Categorial Gammar
DRS Discourse Representation Structure
DRT Discourse Representation Theory
FTB French Corpus Treebank
DMR DiscourseMeaning Representation
GMB GroningenMeaning Bank
PMB ParallelMeaning Bank
AMR AbstractMeaning Representation
UCCA Universal Conceptual Cognitive Annotation
UDS Universal Decompositional Semantics
PDTB Penn Discourse TreeBank
SPARQL SPARQL Protocol and RDF Query Language
RNN Recurrent Neural Network
LSTM Long Short TermMemory
CNN Convolutional Neural Networks
RNN Recurrent Neural Network
TLG Type-Logic Grammar
FOL First-Order Logic
RDF Resource Description Framework
OWL Web Ontology Language
MRL Meaning Representation Language
PCCG Probabilistic Combinatory Categorial Grammars
TAG Tree-Adjointing Grammar
LTAG Lexicalized Tree-Adjointing Grammar

xviii
LFG Lexical Functional Grammar
HPSG Head-driven Phrase Structure Grammar
CFG Context-Free Grammar
PCFG Probabilitic Context-Free Grammar
CPU Central Processing Unit
GPU Graphics Processing Unit
TPU Tensor Processing Unit
SGD Stochastic Gradient Descent
GOFAI Good Old Fashioned Artificial Intelligence
CRF Conditional Random Fields
CMM ConditionalMarkovModel
HMM HiddenMarkovModel
WSJ Wall Street Journal
ME Maximum Entropy
CKY Cocke Kasami Younger
MST Maximum Spanning Tree

Résumé étenduAnalyse de la structure de représentation du discours pour le français
par Ngoc Luyen L
1 IntroductionL’essor d’Internet, des ordinateurs personnels, des appareils numériques et des mobiles a eucomme effet une mutation des diverses formes de communication, qui étaient auparavant à sensunique, comme les articles de presse, les livres, la télévision, et qui sont aujourd’hui des fluxd’informations allant dans les deux sens. Plus particulièrement, l’avènement des plate-formesde réseaux sociaux a rendu ce type de communication de plus en plus populaire. Les contenusgénérés par les utilisateurs à partir des services de réseaux sociaux deviennent une source mas-sive d’informations qui peuvent être utiles aux organisations ou aux entreprises dans la mesureoù elles considèrent les utilisateurs comme des clients ou des clients potentiels. À travers lesproductions textuelles des utilisateurs il est possible d’identifier leurs sentiments ou leurs inten-tions. L’automatisation de cette tâche permet de réduire celle des agents dans les entreprisesou organisations qui sont responsables de recueillir des informations sur les services de réseauxsociaux.
Le but général est le développement d’un cadre qui permet d’analyser des énoncés de languefrançaise dans le contexte du discours, afin d’en obtenir une représentation du sens. Au coursdes dernières décennies, de nombreuses théories fondamentales du langage ont été introduiteset appliquées aux analyses syntaxique et sémantique, cependant il reste encore de nombreusesquestions ouvertes comme, par exemple, le choix du cadre de représentation sémantique quiconvienne à la représentation du discours ou la résolution d’ambiguïtés sémantiques, d’anaphoreoù de coréférence.
Voici les contributions que nous décrirons dans cet article :
• Une nouvelle méthode algorithmique qui permet l’analyse de la structure de dépendanced’une phrase et sa transformation en un arbre de dérivation de grammaire catégoriellecombinatoire (GCC).
• Une nouvelle ressource de corpus GCC pour la langue française, basée sur le corpusFrench Tree Bank 1
• Une architecture pour la représentation sémantique de textes en langue française.
Après un aperçu de l’état de l’art, nous présentons l’interface syntaxe/sémantique basée surles GCC. Ensuite, nous décrivons notre architecture proposée, nos expérimentations et leurévaluation, à travers un exemple. Enfin, nous terminons l’article avec une conclusion.
1https://github.com/lengocluyen/FrenchCCGBank

xx
2 État de l’art de la représentation sémantique du discoursNous appellerons «discours» des unités de texte utilisées pour l’analyse des phénomènes lin-guistiques qui s’étendent sur plus d’une phrase, et générées dans le cadre d’une communicationorale ou écrite naturelle entre personnes, sur un sujet particulier. Un discours peut être perçude diverses manières, en fonction de facteurs tels que le contexte, l’ambiguïté langagière, lesémotions ou les sentiments. De nombreuses approches ont été mises en œuvre afin de proposerun cadre de représentation du discours. Elles appartiennent généralement à trois approchesprincipales : les approches basées sur des règles, l’approche empirique et les approche axées surles corpus.
En guise d’exemple d’approches basées sur des règles, mentionnons des systèmes interpré-tant le langage naturel en langage de requête de base de données basés sur des règles spécifiquesau domaine, comme le système SAVVY (1984) qui répond aux questions des humains, en util-isant des techniques basées sur les règles (Johnson, 1984) ; le système LUNAR (1973) qui per-met aux gens de poser des questions en langage naturel et de demander au système d’effectuerdes calculs dans le domaine de la géologie en utilisant les techniques basées sur des règles et lasyntaxe (Woods, 1973) ; le système NLIDB (1983) qui génère des arbre syntaxiques en consul-tant un ensemble de règles de syntaxe (Templeton and Burger, 1983; Androutsopoulos, Ritchie,and Thanisch, 1995).
Nous qualifions d’«empiriques» les approches utilisant des techniques basées sur des règles,une analyse statistique basée sur des données ou une association de ces deux méthodes (Geand Mooney, 2005; Raymond and Mooney, 2006; Wong and Mooney, 2006; Chiang, 2005).L’utilisation de formalismes grammaticaux tels que les grammaires d’arbres adjoints, les gram-maires lexicales de fonctions, les grammaire catégorielles combinatoires ou les grammaire syn-tagmatique guidée par les têtes sont assez populaires dans le but de construire un cadre immédiatpour dériver des structures sémantiques à partir de structures syntaxiques (Forbes et al., 2003;Reddy et al., 2016). Dans le même contexte, l’application Boxer se sert d’un formalisme gram-matical GCC lexicalisé, dans lequel les mots de la phrase sont affectés à des catégories lexicalespour produire la structure de représentation du discours dans un formalisme ad hoc (Curran,Clark, and Bos, 2007; Bos, 2008; Bos, 2015).
Enfin, dans la dernière décennie on a constaté l’émergence de plus en plus de méthodesbasées sur des corpus tels que FrameNet (Baker, Fillmore, and Lowe, 1998), Propbank (Palmer,Gildea, and Kingsbury, 2005), PDTB (Prasad et al., 2005; Prasad et al., 2008), OntoNotes(Hovy et al., 2006), GMB (Basile et al., 2012), SemBanking (Banarescu et al., 2013), UDS(White et al., 2016), etc., qu’elles soient supervisées ou non-supervisées (Kate and Mooney,2006; Allen et al., 2007; Litman et al., 2009; Young et al., 2010). Par exemple, à l’aide d’unapprentissage supervisé de correspondance de séquence à séquence, l’entrée en langage naturelq = x1x2 . . . xn est associée à une représentation sous forme logique a = y1y2 . . . ym obtenuecomme le argmax d’une probabilité conditionnelle
p(a | q) =n∏
t=1
p(yt | y<t, q) (1)
Dans cette méthode le «codage» est la tâche qui consisté à convertir l’entrée en langage naturelq en une représentation vectorielle a, tandis que le «décodage» consiste à générer les formulesy1y2 . . . ym correspondant au vecteur de codage (Dong and Lapata, 2016; Liu, Cohen, andLapata, 2018).
Dans le but d’analyser et de représenter la sémantique pour des énoncés de langage natureldonnés, nous avons parcouru diverses méthodes, allant de l’utilisation de règles aux approchesactuelles basées sur des réseaux de neurones profonds. Néanmoins, comme ces dernières de-mandent au préalable une quantité massive de données d’apprentissage, exigence obligatoire

xxi
pour les approches d’apprentissage en profondeur, nous allons plutôt utiliser l’approche em-pirique et notre proposition d’architecture générale pour la représentation du discours en françaisva dans ce sens.
3 Interface entre syntaxe et sémantiqueL’utilisation d’un formalisme grammatical pour effectuer l’analyse de phrases est cruciale pourpasser de la syntaxe à la sémantique. Parmi les informations les plus utiles que nous allonsutiliser, il y a les fonctions grammaticales. En général, cinq éléments jouent le rôle de fonc-tions grammaticales principales pour la construction d’une phrase, à savoir le sujet, le verbe, lesobjets direct et indirect, le complément et l’adverbe. La position de ces fonctions grammati-cales est différente selon la langue. Par exemple, en français, une phrase utilise principalementl’ordre sujet-verbe-objet. Cependant, des phrases avec des ordres différents peuvent apparaître,comme par exemple dans le cas de l’interrogation directe. En utilisant la morphologie, les infor-mations syntaxiques et les fonctions grammaticales, nous nous proposons de faire des déductionssur la sémantique. Différents formalismes grammaticaux ont été introduits dans ce but, nousavons choisi les grammaires combinatoires catégorielles en raison de leur capacité à gérer desphénomènes à longue distance et de l’utilisation des λ-expressions (Le and Haralambous, 2019).
3.1 Grammaires combinatoires catégoriellesLe concept de grammaire combinatoire catégorielle (GCC) a été introduit par Mark Steedmandans les années 2000 (Steedman, 1999; Steedman, 2000a; Steedman, 2000b). Les GCC ontété introduites comme extension des grammaires catégorielles (Ajdukiewicz, 1935; Bar-Hillel,1953) avec l’ajout de règles d’inférence de catégorie afin d’obtenir une large couverture deslangages naturels. Une GCC est essentiellement un formalisme grammatical lexicalisé danslequel les mots sont associés à des catégories syntaxiques et lexicales spécifiques à une languedonnée.
De façon plus formelle, une GCC est un quintuplet G = <Σ,∆, f, ς,<> où:
• Σ est un ensemble fini de symboles appelés terminaux, ils correspondent aux mots de laphrase étudiée.
• ∆ est un ensemble fini de symboles appelés catégories d’axiomes. Celles-ci sont formésà partir de symboles de base, par exemple S, NP, N, PP, etc., et leurs combinaisons àtravers les opérateurs \ et /. Ainsi, si X,Y ∈∆, alors X/Y et X\Y ∈∆.
• f est la fonction de catégorie lexicale qui gère la correspondance entre terminaux et caté-gories.
• ς est le symbole d’axiome de départ de la grammaire, ς ∈∆.
• < est un ensemble fini de règles de production de grammaire formelle qui, dans le contextedes GCC sont appelées règles combinatoires et que nous décrivons ci-dessous.
Nous désignons par X, Y, Z des méta-catégories (elles représentent n’importe quelle caté-gorie de la grammaire).
En premier lieu, l’ensemble < comprend deux règles de base héritées des grammaires caté-gorielles AB:
Règle d’application avant: X/Y:f Y :a ⇒ X:f(a)
Règle d’application arrière: Y:a X\Y:f ⇒ X:f(a)(2)

xxii
Ces règles permettent de considérer aussi bien la catégorie du mot/syntagme qui suit (opérateur«/») un mot/syntagme donné que celle qui le précède (opérateur «\»).
Une contribution importante des GCC vis-à-vis des grammaires catégorielles AB est l’ajoutd’un ensemble de règles inspirées des combinateurs de la logique combinatoire (Curry et al.,1958). Ces règles permettent le traitement des dépendances à longue distance et des construc-tions d’extraction/coordination. Ils peuvent être représentés à l’aide du λ-calcul, utilisé commenotation pour la représentation sémantique, comme suit:
Règle demontée de type avant:
X:x ⇒T T/(T\X):λf.f(x)
Règle de montée de type ar-rière :
X:x ⇒T T\(T/X):λf.f(x)(3)
Règle de compositionavant :
X/Y Y/Z⇒B
X/Z
λy.f(y) λz.g(z) λz.f(g(z))
Règle de compositioncroisée avant :
X/Y Y\Z⇒B
X\Z
λy.f(y) λz.g(z) λz.f(g(z))
Règle de compositionarrière :
Y\Z X\Y⇒B
X\Z
λz.g(z) λy.f(y) λz.f(g(z))
Règle de compositioncroisée arrière :
Y/Z X\Y⇒B
X/Z
λz.g(z) λy.f(y) λz.f(g(z))
(4)
Règle desubstitution avant :
(X/Y)/Z Y/Z⇒S
X/Z
λzy.f(z, y) λz.g(z) λz.f(z, g(z))
Règle desubstitution croiséeavant :
(X/Y)\Z Y\Z⇒S
X\Z
λzy.f(z, y) λz.g(z) λz.f(z, g(z))
Règle desubstitution arrière :
Y\Z (X\Y)\Z⇒S
X\Z
λz.g(z) λzy.f(z, y) λz.f(z, g(z))
Règle desubstitution croiséearrière :
Y/Z (X\Y)/Z⇒S
X/Z
λz.g(z) λzy.f(z, y) λz.f(z, g(z))
(5)
Dans le cas des constructions de coordination, la catégorie lexicale (X/X)\X est utiliséepour valider la combinaison de composants similaires dans les règles de formule (6.2). La règlecorrespondante se présente comme suit :
Coordination : X : g X : f ⇒Φn X:λx.f(x) ∧ g(x) (6)
Donnons un exemple simple de GCC: G =< Σ,∆, f, ς,< >, où:
• Σ := {Henri, regarde, la, télévision}.
• ∆ := {S, NP}
• C(∆) := {S, NP, S\NP}

xxiii
• Function f : f (Henri) := {NP,NP/NP}, f (regarde) := {S\NP, (S\NP)/NP}, f (la_télévision):= {NP}
• ς := S (la phrase)
• < comportant les règles décrites dans (6.1), (6.2), (6.5), (6.6), (6.7).
Afin d’obtenir une dérivation GCC, les catégories lexicales appropriées doivent d’abord êtreaffectés à chaque mot de la phrase. Cette affectation est loin d’être unique, en effet un mot peutavoir différentes catégories lexicales selon sa position ou sa fonction dans la phrase. Voici celleque nous avons choisi pour notre exemple :
(1)
Henri ← NP : henri′
regarde ← (S\NP)/NP : λx.λy.regarde′xy
la ← NP : la′
la ← NP/NP : λx.la′(x)
bien ← (S\NP)/(S\NP) : λf.λx.bien′(fx)
dors ← (S\NP) : λx.dors′x
Dans les règles combinatoires ci-dessus, chaque catégorie est accompagnée d’uneλ-expressionreprésentant sa sémantique. Dans la fig. 5.2 nous illustrons l’arbre de dérivation CCG obtenuen appliquant les règles combinatoires et aboutissant à la sémantique de la phrase.
Henri regarde la television
NP (S\NP )/NP NP/NP NP>
NP:x :λxλy.regarde′xy : y
>
S\NP :λx.regarde′la television′x<
S : regarde′la television′henri′
F 1: Une dérivation GCC de la phrase: «Henri regarde la télévision»
3.2 Extraction d’une dérivation GCC à partir des dépendances syntaxiquesDans cette section, nous décrivons un processus en trois étapes permettant d’obtenir des arbresde dérivation GCC. Dans la première étape, nous avons choisi parmi les nombreuses catégorieslexicales qui ont été utilisées dans le corpus pour chaque mot, celles qui «s’emboîtent» dans laphrase donnée et les attachent en tant qu’étiquettes à l’arbre de dépendances. Dans la deuxièmeétape, nous extrayons des blocs de l’arbre des dépendances et ajoutons de nouveaux nœuds etarêtes afin de binariser l’arbre. Dans la dernière étape, nous déduisons des catégories lexicalespour les nouveaux nœuds et vérifions que nous pouvons monter à partir des feuilles jusqu’à laracine de l’arbre en appliquant des règles combinatoires – la racine de l’arbre doit alors néces-sairement être munie de la catégorie lexicale S.
Affectation de catégories lexicales aux nœuds de l’arbre de dépendances
Les arbres de dépendances sont obtenus par analyse des dépendances (cf. figure 5.7). Pource faire, il existe différentes méthodes, certaines basées sur des algorithmes d’apprentissageautomatique entraînés sur de grands ensembles de phrases annotées syntaxiquement, d’autres

xxiv
Mon fils achete un cadeau .DET NC V DET NC PONCT(son) (fils) (acheter) (un) (cadeau) (.)
root
det suj det
obj
ponct
Il le donnera a sa mere .CLS CLO V P DET NC PONCT(cln) (cla) (donner) (a) (son) (mere) (.)
root
suj objmod
det
a obj
ponct
F 2: Exemples d’arbres de dépendances avec étiquettes de parties du dis-cours
basées sur des approches empiriques utilisant des grammaires formelles. Dans notre cas, nousavons utilisé la version française de MaltParser (Candito et al., 2010).
La théorie de GCC assigne deux types de catégories lexicales aux mots: les catégories debase (par exemple, S, NP, PP), et les catégories complexes obtenues par combinaison de caté-gories de base en utilisant les fonctions d’application \ et /. Par exemple, S\NP est une catégoriecomplexe. Elle peut être attribuée à un mot/syntagme susceptible de se trouver adjacent à unmot/snytagme de catégorie lexicale NP à sa gauche, afin de produire un S; S/NP signifie quele mot/syntagme NP est attendu à droite. Afin d’affecter des catégories lexicales aux nœudsde l’arbre de dépendances, nous traitons d’abord les mots qui dont les catégories lexicales ob-servées dans le corpus sont uniques. Ainsi, par exemple, les noms ont une catégorie lexicaleNP, les adjectifs ont une catégorie lexicale NP/NP ou NP\NP selon qu’ils sont placés à gaucheou à droite du nom, etc. Une fois que nous avons affecté les catégories lexicales uniques (oudépendantes de la position, comme dans les adjectifs), nous passons aux verbes.
Le verbe principal de la phrase, qui est normalement la racine de l’arbre de dépendances,peut avoir des dépendances d’argument, étiquetées suj, obj, a_obj, de_obj, p_obj, c’est-à-dire lescorrespondances avec le sujet, l’objet direct et indirect, et / ou des dépendances complémentaires,étiquetées mod, ats, etc., représentant des informations complémentaires telles que le nombre,l’heure, le lieu, etc. On affecte la catégorie lexicale S\NP à un verbe principal ayant un sujetà sa gauche, puis on ajoute /NP (ou \NP, selon sa position par rapport au verbe) pour chaqueobjet direct ou indirect (dans l’ordre des mots dans la phrase).
Les verbes auxiliaires suivis d’autres verbes reçoivent la catégorie lexicale (S\NP)/(S\NP).Par exemple dans la phrase «Je voudrais demander un rendez-vous pour demain», le verbeprincipal est «demander». Il a un sujet, donc sa catégorie lexicale doit contenir S\NP. Deplus, il a une dépendance d’objet directe pointant vers «rendez-vous». Par conséquent, nous luiattribuons également une catégorie lexicale (S\NP)/NP. Le verbe «voudrais» étant auxiliaire,il obtient la catégorie lexicale (S\NP)/(S\NP).
Binarisation des arbres de dépendance
La binarisation de l’arbre de dépendance est effectuée sur la base d’informations sur la structurede phrase dominante pour la langue spécifique. En français, la plupart des phrases sont detype SVO, comme dans «Mon fils (S) achète (V) un cadeau (O)» ou SOV comme dans «Il (S)le (O) donne (V) à sa mère (indirect O)» (figure 5.7). En utilisant cette propriété générale,spécifique à la langue française (et aux langues romanes, en général), nous pouvons extraire etclasser les composants de la phrase en sujets, objets directs, objets indirects, verbes et phrasescomplémentaires.
L’algorithme proposé pour transformer un arbre de dépendances en arbre binaire se com-pose de deux étapes. Tout d’abord, nous extrayons des groupes de mots dans l’arbre de dépen-dance qui est basé sur des informations syntaxiques et des étiquettes de dépendance entre les

xxv
Algorithm 1: Binarisation de l’arbre de dépendancesBinarisation_arbre_dépendant (groupe_de_mots)Input: La liste des groupes de mots de la phraseOutput: L’arbre binaire)arbre_binaire← vide; sous_arbres_binaires← vide;i← longueur de group_de_mots;while i ≥ 0 do
if group_de_mots[i] est une liste de groupes de mots thensous_arbres_binaires←construction_arbre_binaire_avec_mots(groupe_de_mots);
elsesous_arbres_binaires← récursion sur binarisation_arbre_dpendantavec groupe_de_mots[i];
if arbre_binaire est vide thenarbre_binaire← sous_arbres_binaires;
elsecréer un arbre temporaire arbre_binaire_temporaire;racine est le nœud racine de arbre_binaire_temporaire;mettre arbre_binaire à la droite de arbre_binaire_temporaire;mettre sous_arbres_binaires à la gauche de arbre_binaire_temporaire;arbre_binaire← arbre_binaire_temporaire;sous_arbres_binaires← vide;
i← i− 1;return arbre_binaire
mots. Par exemple, le groupe de mot de sujet est obtenu en trouvant un mot qui a une dépen-dance étiquetée suj, le groupe de mot des verbes correspond à la racine de la structure de dépen-dance, les groupes d’objet directs ou indirects sont obtenus sous forme de mots avec des liensdirigés vers la racine (le verbe) et ayant des étiquettes obj ou p_obj, etc. Ensuite, nous con-struisons un arbre binaire pour chaque groupe de mots, comme décrit dans l’algorithme 6, puiscombinons les arbres binaires dans l’ordre inverse de la structure de la phrase dominante. Parexemple si SVO est la structure dominante, nous commençons par construire l’arbre binaire dugroupe de mots d’objet, puis le combinons avec l’arbre binaire du groupe verb, et finalement nousobtenons l’arbre binaire du groupe sujet. Sur la figure 5.9, le lecteur peut voir quatre groupes deblocs dans l’arborescence de dépendances, affichés sous forme de régions de l’arbre binarisée.
Construction d’une dérivation GCC complète et validation
La dernière étape est la vérification de l’affectation des catégories lexicales aux mots par la con-struction d’un arbre GCC complet. Cette dernière opération est effectuée de manière itérativeen appliquant des règles combinatoires. Nous partons des feuilles de l’arbre binarisé (cf. fig-ure 5.9) – pour lequel nous avons déjà des catégories lexicales de l’étape 1 – et remontons enappliquant des règles combinatoires.
Les règles combinatoires nécessitent généralement deux paramètres d’entrée pour formerune nouvelle catégorie lexicale, à l’exception de la règle de montée de type qui nécessite un seulparamètre d’entrée. Dans l’arbre binaire, chaque fois que deux nœuds ont des informations decatégorie lexicale qui leur sont affectées, nous pouvons inférer la catégorie lexicale du troisièmenœud, comme dans la figure 5.10.

xxvi
mere “NP”sa “NP\NP”
“NP”a “NP/NP”
“NP”donnera
“((S\NP)\NP)/NP”
“(S\NP)\NP”le “NP”
“S\NP”Il “NP”
“S”
det a obj
mod
root
obj
suj
Application avant
Application avant
Application avant
Application arriere
Application arriere
Groupe demots de l’objet
Groupe demots des verbes
Groupe demots de l’objet
Groupe demots du sujet
F 3: Les groupes de mots (en pointillés) et l’arbre binaire de la phrase
X/Y Y
[X]
X/Y [Y]
X
[X/Y] Y
X
F 4: Les règles d’inférence des catégories lexicales
3.3 Expérimentation et évaluation sur le corpus French TreeBank
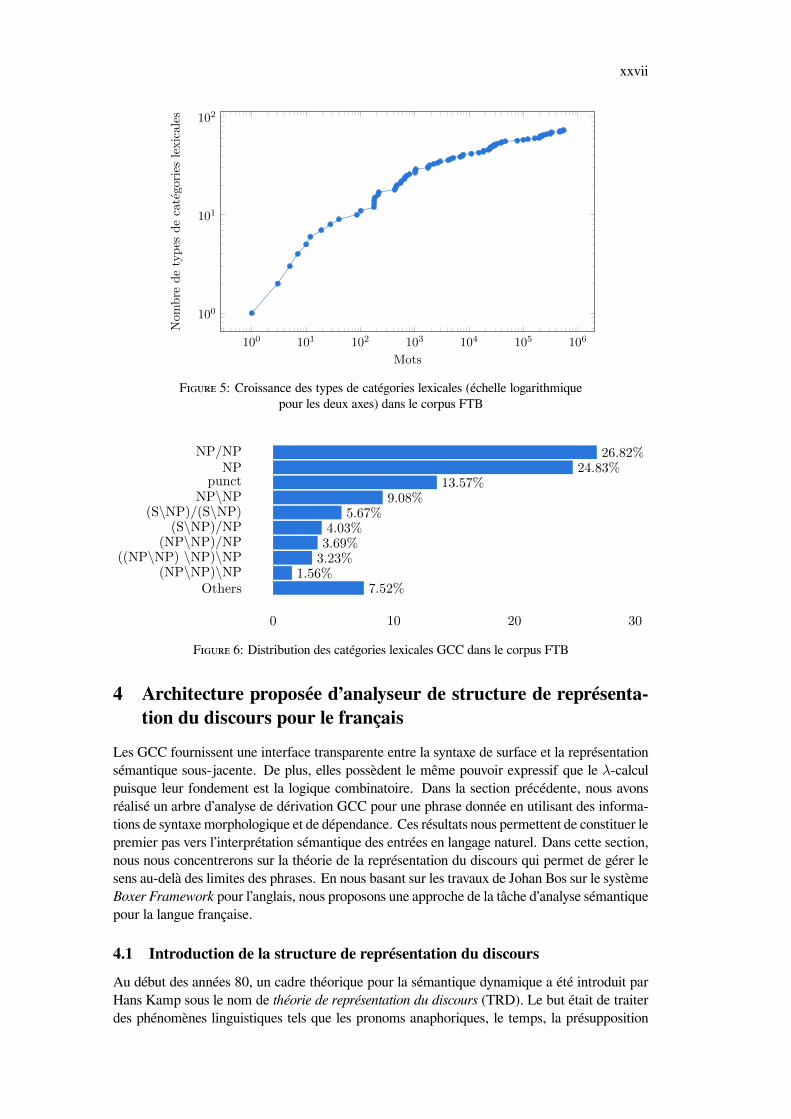
Nous avons utilisé le corpus French TreeBank (FTB – ) qui contient environ un million de motsextraits d’articles du quotidien Le Monde pour la période 1991–1993. Nous avons utilisé laversion basée sur les dépendances, décrite dans (Candito, Crabbé, and Denis, 2010; Candito etal., 2009). En appliquant notre méthode à l’ensemble complet de 21 550 arbres de dépendancesdu corpus, nous avons obtenu des arbres de dérivation GCC pour 94,02% des phrases.
Au total, nous obtenons un ensemble de 73 catégories lexicales distinctes pour le corpusfrançais complet. Plus précisément, on voit que le nombre de catégories lexicales augmenterapidement au cours des 10 000 premières phrases (figure 5.15) et de moins en moins par lasuite. De plus, les catégories lexicales NP/NP et NP, qui correspondent aux articles, adjectifset noms, sont attribuées à plus de la moitié des mots (figure 5.16).
Le taux d’échec de notre approche est élevé par rapport aux résultats dans d’autres langues(99,44% de phrases analysées avec succès en anglais (Hockenmaier and Steedman, 2007) ou96% en hindi (Ambati, Deoskar, and Steedman, 2018)). Parmi les causes d’erreur, les trois sontprincipales sont : erreurs d’étiquetage de partie du discours, erreurs dans les dépendances ouleur étiquetage et, enfin, erreurs résultant de problèmes linguistiques complexes tels que lacuneslexicales, des lacunes parasitaires, etc.
xxvii
100 101 102 103 104 105 106
100
101
102
Mots
Nom
bre
de
typ
esd
eca
tego
ries
lexic
ale
s
F 5: Croissance des types de catégories lexicales (échelle logarithmiquepour les deux axes) dans le corpus FTB
0 10 20 30
Others(NP\NP)\NP
((NP\NP) \NP)\NP(NP\NP)/NP(S\NP)/NP
(S\NP)/(S\NP)NP\NPpunct
NPNP/NP
7.52%1.56%
3.23%3.69%4.03%
5.67%9.08%
13.57%24.83%
26.82%
F 6: Distribution des catégories lexicales GCC dans le corpus FTB
4 Architecture proposée d’analyseur de structure de représenta-tion du discours pour le français
Les GCC fournissent une interface transparente entre la syntaxe de surface et la représentationsémantique sous-jacente. De plus, elles possèdent le même pouvoir expressif que le λ-calculpuisque leur fondement est la logique combinatoire. Dans la section précédente, nous avonsréalisé un arbre d’analyse de dérivation GCC pour une phrase donnée en utilisant des informa-tions de syntaxe morphologique et de dépendance. Ces résultats nous permettent de constituer lepremier pas vers l’interprétation sémantique des entrées en langage naturel. Dans cette section,nous nous concentrerons sur la théorie de la représentation du discours qui permet de gérer lesens au-delà des limites des phrases. En nous basant sur les travaux de Johan Bos sur le systèmeBoxer Framework pour l’anglais, nous proposons une approche de la tâche d’analyse sémantiquepour la langue française.
4.1 Introduction de la structure de représentation du discoursAu début des années 80, un cadre théorique pour la sémantique dynamique a été introduit parHans Kamp sous le nom de théorie de représentation du discours (TRD). Le but était de traiterdes phénomènes linguistiques tels que les pronoms anaphoriques, le temps, la présupposition

xxviii
et les attitudes propositionnelles (citekamp1981theory,kamp2013discourse). L’émergence dela TRD a rendu possible une approche dynamique de la sémantique du langage naturel. Danscette approche, le sens d’une phrase donnée est identifié dans une relation avec son contexte.En particulier, l’interaction entre une phrase et son contexte est réciproque. Ainsi l’analysed’un énoncé dépendra de son contexte et le contexte peut être mis à jour pour donner lieu à unnouveau contexte lorsqu’on ajoute les informations de l’énoncé à celui-ci.
Le noyau de la TRD est la SRD, qui est le composant principal pour la construction dereprésentations sémantiques pour les textes. L’objectif de la SRD n’est pas seulement de réaliserdes interprétations de phrases uniques, mais aussi de représenter des unités linguistiques, desparagraphes, des discours ou des textes plus larges. En général, la représentation du sens àtravers la SRD se déroule phrase par phrase. Chaque phrase traitée fournit ses informations àla SRD qui contient les informations des phrases précédentes.
La représentation des SRD utilisée dans cette section repose sur des expressions de basede la théorie des types compatibles avec les représentations sémantiques formelles (Bos et al.,2017). Dans ce formalisme, le type 〈e〉 est utilisé pour les expressions de référents de discoursou de variables, tandis que le type 〈t〉 est utilisé pour les expressions SRD de base, comme suit:
〈expe〉 ::= 〈ref〉|〈vare〉
〈expt〉 ::= 〈srd〉(7)
Une expression de SRD de base 〈srd〉 est une paire d’ensembles : un ensemble de référents dudiscours 〈ref〉 qui représente les objets en discussion, et un ensemble de conditions 〈condition〉qui sont des propriétés des référents du discours et des relations entre eux. Nous utilisons la no-tation suivante:
〈srd〉 ::=〈ref〉∗
〈condition〉∗(8)
En général, les conditions de SRD sont de trois types: 〈élémentaire〉, 〈lien〉, et 〈complexe〉:
〈condition〉 ::= 〈élémentaire〉 | 〈lien〉 | 〈complexe〉 (9)Les conditions de base sont des propriétés des référents de discours ou des relations entre eux:
〈élémentaire〉 ::= 〈sym1〉(〈expe〉) | 〈sym2〉(〈expe〉, 〈expe〉)
| temps(〈expe〉, 〈sym0〉)
| nommé(〈expe〉, 〈sym0〉, classe),
(10)
où 〈expe〉 désigne des expressions de type, 〈symn〉 désigne des prédicats n-aires, 〈nombre〉désigne des nombres cardinaux, temps exprime des informations temporelles et classe désignedes classes d’entités nommées.
Les conditions de lien sont des marqueurs ou constantes référents de discours qui sont util-isés pour des références ou des inégalités entre les marqueurs ou les constantes du discours:
〈lien〉 ::= 〈expe〉 = 〈expe〉 | 〈expe〉 = 〈nombre〉
| 〈expe〉 6= 〈expe〉 | 〈expe〉 6= 〈nombre〉.(11)
Les conditions complexes représentent les SRD embarqués: implication (→), négation (¬),disjonction (∨), ainsi que des opérateurs modaux exprimant la nécessité (□) et la possibilité

xxix
(♢). Les types de conditions complexes sont unaires et binaires:
〈complexe〉 ::= 〈unaire〉 | 〈binaire〉
〈unaire〉 ::= ¬〈expt〉 | □〈expt〉 | ♢〈expt〉 | 〈ref〉 : 〈expt〉
〈binaire〉 ::= 〈expt〉 → 〈expt〉 | 〈expt〉 ∨ 〈expt〉 | 〈expt〉?〈expt〉,
(12)
où la condition 〈ref〉 : 〈expt〉 désigne des verbes à contenu propositionnel.Illustrons la SRD à travers l’exemple de la phrase suivante :
(2) a. La femme achète des poissons.
b. Elle les donne à son mari.
La phrase 13.a peut être analysée et réécrite dans le formalisme de la SRD comme suit:
[x, y : femme(x), poisson(y), acheter(x, y)].
Plus spécifiquement, l’expression SRD contient deux référents de discours 〈ref〉 = {x, y},alors que l’ensemble de conditions inclut 〈condition〉 = {femme(x), poisson(y), acheter(x, y)}.Supposonsmaintenant que la phrase de l’exemple 13.b soit suivie de la phrase 13.a. L’expressionSRD pour la deuxième phrase inclut les référents de discours 〈ref〉 = {u, v, w}, alors quel’ensemble de conditions est 〈condition〉 = {donner(u, v, w),mari(w), personne1(v), chose1(w)}.Ainsi, la SRD de la deuxième phrase sera réécrite comme suit: [u, v, w : donner(u, v, w),mari(w), personne1(v),chose1(w)]. Enfin, nous obtenons l’expression SRD finale après avoirintégré la SRD de la deuxième phrase dans la SRD de la première phrase, en résolvant l’anaphorecomme suit :
[x, y, u, v, w : femme(x), poisson(y), acheter(x, y),donner(u, v, w), mari(u), v = x, w = y].
Afin d’illustrer les différentes expressions de SRD, nous disposons de trois formalismes quenous illustrons à l’aide des phrases ci-dessus:
1. La notation SRD «officielle»:
<{∅}, <{x, y, u}>, {femme(x), poisson(y), acheter(x, y),mari(u)}>⇒ <{∅}, {donne(u, y, x)}>.
2. La notation linéaire:
[∅ : [x, y, u: femme(x), poisson(y), acheter(x, y),mari(u)]⇒ [∅ : donne(u, y, x)]].
3. La notation en boîtes imbriquées :

xxx
x, y, u
femme(x)
poisson(y)
acheter(x, y)
mari(u)
⇒donne(u, y, x)
4.2 Relation entre la GCC et la SRDEn général, nous pouvons transformer un arbre d’analyse de dérivation GCC en expression SRDen définissant une correspondance entre les catégories lexicales et les types sémantiques. Parexemple, si les catégories lexicales primitives employées dans le corpus français GCC sont NP(groupe nominal), S (La phrase), la catégorie S est associée à une expression SRD de type 〈t〉,alors que les catégories NP correspondent à une expression de type 〈e, t〉. Avec des catégoriescomplexes où la direction de la barre oblique indique si l’argument est placé à la gauche si unebarre oblique est utilisée, ou à la droite en cas de barre oblique, la catégorie (S\NP)/NP, quicorrespond à un groupe verbale transitif, nécessite un NP comme argument à sa gauche etse traduit par une expression SRD de type 〈〈e〉,〈e, t〉〉. La catégorie lexicale NP/NP quiindique un article ou un adjectif, nécessite une catégorie NP comme argument à sa droite, etpossède le type sémantique 〈〈e, t〉, 〈e〉〉. La figure 7.1 montre quelques exemples de tellescorrespondances.
Les expressions λ-typées peuvent également être considérées comme une interface entreles catégories lexicales et les expressions SRD. Si λx.φ est une expression λ, alors x est unevariable de type 〈e〉 et φ est une formule de type 〈t〉.
4.3 Construction d’un analyseur SRD pour le françaisNotre objectif dans ce travail a été le développement d’un framework qui permette de réaliserdes analyses sémantiques pour la langue française. Le manque de disponibilité de donnéesd’entraînement massives nous a empêché d’utiliser des modèles de réseaux de neurones pro-fonds. En outre, l’utilisation de l’approche traditionnelle a fait ses preuves dans de nombreusesapplications. Ainsi, Boxer (programmé en Prolog) est un outil efficace pour obtenir une représen-tation sémantique de phrases en langue anglaise et il est devenu le composant le plus impor-tant dans la génération des corpus de représentation sémantique GMB et PMP (abzianidz;Bos, 2008). En suivant l’approche empirique, nous pouvons éviter la contrainte sur les donnéesdisponibles et nous servir de la propriété de compositionnalité dans l’analyse de la constructionde phrases.
Nous présenterons une architecture complète pour obtenir une représentation du sens àpartir d’un énoncé français fourni en entrée (figure 4.1). Cette architecture comprend dif-férentes étapes de traitement que nous pouvons regrouper dans trois tâches principales: (a)pré-traitement et analyse de la syntaxe et des dépendances de l’énoncé, (b) utilisation du for-malisme grammatical des GCC, (c) analyse de la représentation sémantique de discours.

xxxi
Smange(mon′enfant′, des′raisins′)
〈t 〉
NPλy.mon′enfant(y)
〈e 〉
NP/NPλQ.mon′(Q)〈〈e,t〉,〈e〉〉
Mon
NPλy.enfant′(y)
〈e,t 〉
enfant
S\NPλy.mange′(y, des′raisin)
〈e,t 〉
(S\NP)/NPλx.λy.mange′(y, x)
〈〈e〉,〈e,t〉〉
mange
NPλx.des′(raisins′(x))
〈e 〉
NP/NPλP.des′(P )〈〈e,t〉,〈e〉〉
des
NPλx.raisins′(x)
〈e,t 〉
raisins
F 7: Correspondance entre des différentes expressions pour la phrase“Mon enfant mange des raisins»
Analyses syntaxique et grammaticale
Nous utilisons des grammaires de dépendances pour analyser la structure syntaxique de phrasesdonnées. La plupart du temps, la racine de l’arbre de dépendances correspond au verbe prin-cipal et tous les autres mots sont directement ou indirectement reliés à ce verbe par des arêtesdirigées. Chaque arête a une étiquette qui décrit la nature de la relation entre les deux mots.Ces étiquettes appartiennent à un ensemble de fonctions syntaxiques, par exemple, sujet, objet,oblique, déterminant, attribut, etc. Les fonctions syntaxiques sont des relations grammaticalesjouant un rôle important dans la reconnaissance des composants de la phrase.
Pour le discours fourni en entrée, les informations syntaxiques sur les mots et leurs interre-lations peuvent être obtenues via un analyseur de dépendances. Il existe de nos jours plusieursanalyseurs de dépendances pour le français tels que MaltParser Candito, Crabbé, and Denis,2010, Stanford Parser (Green et al., 2011), MSTParser (McDonald, Lerman, and Pereira,2006), SpaCy (Honnibal, Goldberg, and Johnson, 2013; Honnibal and Johnson, 2015), GrewParser (Guillaume and Perrier, 2015). Nous avons choisi d’utiliser MaltParser afin d’obtenirdes informations morphosyntaxiques sur les mots dans les phrases. Nous conservons les infor-mations suivantes pour chaque mot: lemme, étiquettes POS et relations de dépendance.
Nous avons utilisé MElt (Denis and Sagot, 2009; Denis and Sagot, 2012; Sagot, 2016) poureffectuer la tokenisation et l’analyse morphologique (radical, préfixe, suffixe, etc.) de chaquemot des phrases d’entrée. La sortie de cette étape est utilisée comme entrée pour MaltParserafin d’analyser les structures de dépendance de la phrase donnée.
Extraction de l’arbre de dérivations GCC
Afin d’obtenir un arbre de dérivations CCG pour chaque phrase française d’entrée, nous avonsutilisé l’approche empirique introduite à la section précédente 3. En utilisant les informations desyntaxe et de dépendance obtenues à l’étape précédente, nous traitons d’abord les mots qui ontdes catégories lexicales uniques. Ainsi, par exemple, les noms ont une catégorie lexicale NP, les

xxxii
Discours français
Analyse syntaxiques et dépendantes
Analyse GCC
VerbNet Ontologies
Analyse sémantique avec Boxer
Sortie
Logique depremier ordre
Format enboîte SRD
F 8: Architecture proposée pour l’analyse sémantique française
adjectifs ont une catégorie lexicale NP/NP ou NP\NP selon qu’ils placés à gauche ou à droitedu nom, etc. Une fois ces catégories lexicales uniques (mais dépendantes de la position, puisque,par exemple, les adjectifs en français peuvent être situés des deux côtés du nom) attribuées, nouspassons aux verbes. La catégorie lexicale S\ NP est affectée à un verbe principal ayant un sujetà sa gauche, puis on ajoute un /NP (ou un \NP, selon sa position par rapport au verbe) pourchaque objet direct ou indirect (dans l’ordre des mots dans la phrase).
L’étape suivante consiste à binariser l’arbre de dépendances sur la base d’informations surla structure de la phrase dominante: en français, la plupart des phrases sont de types SVOou SOV. En utilisant cette propriété linguistique générale, nous utilisons un algorithme pourextraire et classer les composants de la phrase en sujet, objet direct, objet indirect, verbes etphrases complémentaires. Cet algorithme vise à transformer un arbre de dépendances en un ar-bre binaire. En appliquant les règles combinatoires, nous obtenons l’arbre binaire correspondantà une dérivation GCC donnée pour la phrase d’entrée.
Pour chaque phrase d’entrée, nous obtenons un seul arbre de dérivation GCC, correspondantà son entrée d’arbre de dépendances. L’arbre de dérivation CCG de sortie est re-écrit de manièreà être compatible avec le format d’entrée de Boxer. En même temps, la phrase est analyséeafin d’extraire des composants d’entités nommées (par exemple, lieu, personne, date, heure,organisation, etc.) en utilisant l’application SpaCy.
Représentation sémantique à travers Boxer
Implémentée dans le langage Prolog avec un code source accessible au public, l’applicationBoxer est conçue pour fournir une analyse sémantique de discours pour l’anglais avec des arbresde dérivation GCC en entrée et une représentation du sens sous la forme de SRD en sortie. Pourfaire de même en français, nous avons dû adapter le code source aux spécificités de la languefrançaise.
Les verbes sont la composante centrale de la plupart des phrases. Une fois qu’un verbe estdonné, nous sommes en mesure de connaître les composants qui peuvent lui être attachés. Parexemple, le verbe «acheter» doit être suivi d’un objet direct, et le verbe «dormir» n’en disposepas de par son intransitivité. Les relations entre un verbe et ses arguments nominaux sont illus-trées par des rôles thématiques (par exemple, agent, expérience, thème, objectif, source, etc.).

xxxiii
ccg(1,)
ba(np,
fa(np,
t(np/np,‘tous’,‘tout’,‘ADJ’,‘O’,‘O’),
fa(np,
t(np/np,‘les’,‘le’,‘DET’,‘O’,‘O’),
t(np,‘soirs’,‘soir’,‘NC’,‘O’,‘O’))),
lp(np\np,t(ponct,‘,’,‘,’,‘PONCT’,‘O’,‘O’),
lx(np\np,s:dcl,ba(s:dcl,
fa(np,
t(np/np,‘mon’,‘ma’,‘DET’,‘B-NP’,‘O’ ),
t(np,‘voisin’,‘voisin’,‘NC’,‘I-NP’,‘O’)),
fa(s:dcl\np,t((s:dcl\np)/np,‘met’,‘mettre’,‘V’,‘O’,‘O’ ),
rp(np,
fa(np,
t(np/np,‘sa’,‘son’,‘DET’,‘B-NP’,‘O’ ),
ba(np,
t(np,‘voiture’,‘voiture’,‘NC’,‘I-NP’,‘O’),
fa(np\np,t((np\np)/np,‘au’,‘a le’,‘P+D’,‘O’,‘O’),
t(np,‘garage’,‘garage’,‘NC’,‘O’,‘O’)))),
t(ponct,‘.’,‘.’,‘PONCT’,‘O’,‘O’)))))))).
F 9: L’arbre de dérivation CCG de la phrase «Tous les soirs, mon voisinmet sa voiture au garage».
Dans Boxer, les verbes et leurs rôles thématiques sont extraits du corpus de ressources lexi-cales VerbNet (Schuler, 2005). Pour le français, nous avons utilisé le corpus VerbNet français(Pradet, Danlos, and De Chalendar, 2014) (voir un exemple sur la figure 10), tandis que unensemble d’ontologies nous a fourni des relations hiérarchiques ou d’équivalence entre entités,concepts.
Les problèmes concernant l’anaphore et les déclencheurs de présupposition introduits pardes phrases nominales, des pronoms personnels, des pronoms possessifs, des pronoms réflexifs,des pronoms démonstratifs, etc., sont traités au cas par cas, sur la base de l’algorithme de réso-lution proposé dans (Bos, 2003). Enfin, la représentation sémantique de l’analyse du discoursest produite sous deux formalismes différents: la logique de premier ordre et le format de boîtesimbriquées de la SRD.

xxxiv
% Primary: ‘NP V NP’ (‘allow-64’)
% Syntaxe: [np:‘Agent’,v,np:‘Thème’]
% GCC: (s:dcl\np)/np
% Rôles: [‘Thème’,‘Agent’]
% Exemple: ‘Luc approuve l’attitude de Léa’
VerbNet:
(approuver, (s:dcl\np)/np, [‘Thème’,‘Agent’]).
(autoriser, (s:dcl\np)/np, [‘Thème’,‘Agent’]).
(supporter, (s:dcl\np)/np, [‘Thème’,‘Agent’]).
(tolérer, (s:dcl\np)/np, [‘Thème’,‘Agent’]).
F 10: Un extrait de la ressource lexicale Verbnet pour le français
5 Expérimentation et évaluationNous illustrons les capacités de l’analyse du discours français via notre architecture par l’exemplesuivant: «Tous les soirs, mon voisin met sa voiture au garage. Il arrose ses rosiers avec sonfils.». Nous avons deux phrases dans ce texte, contenant des pronoms possessifs, des pronomspersonnels et des groupes nominaux.
∃ z3 z7 z8 z9 z10 z11 z12 z13 z14 z5 z6.(np_fils(z6) ∧ de(z6, z5) ∧ np_male(z5)∧ np_rosier(z14) ∧ de(z14, z13) ∧ np_male(z13) ∧ np_male(z12) ∧ au(z10, z11) ∧np_garage(z11) ∧ np_voiture(z10) ∧ de(z10, z9) ∧ np_male(z9) ∧ np_voisin(z8)∧ de(z8, z7) ∧ np_male(z7) ∧ ∀ z4.(np_soir(z4) → ∃ z1.(a_topic(z4) ∧ ∃z2.(Recipient(z2, z10) ∧ Theme(z2, z8) ∧ a_mettre(z2)) ∧ alors(z4, z1))) ∧Theme(z3, z14) ∧ Actor(z3, z12) ∧ a_arroser(z3) ∧ avec(z14, z6))
F 11: La sortie en logique du premier ordre de l’exemple
Nous appliquons d’abord un analyseur pour obtenir des relations de dépendances. Nousobtenons alors un arbre de dérivation GCC en sortie de l’étape d’extraction de dérivation GCC.Les résultats sont représentés (figure 9) dans un format compatible avec le format d’entrée deBoxer. Chaque mot est traité comme un terme (t) avec les informations suivantes: catégorielexicale GCC, mot original, lemme, étiquette POS, chunks et informations d’entité nommée.
Le lecteur peut voir la sortie de l’exemple dans deux formats: logique de premier ordre (lafigure 11) et format en boîte de SRD (la figure 12). Dans le cas de la langue française, Boxerarrive à analyser correctement les phénomènes linguistiques tels que les pronoms possessifs (ses,mon, sa, son), les quantificateurs propositionnels (tout) et les groupes nominaux (sa voiture augarage). Cependant, il y a encore place à l’amélioration, par exemple, on n’obtient pas l’ordrechronologique des actions dans l’exemple.
D’autre part, nous avons expérimenté notre système avec 4 525 phrases du corpus françaisFTB () afin d’avoir une vue d’ensemble sur un corpus à large couverture. La longueur des phrases

xxxv
__________________________________________________ | s2 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 ||--------------------------------------------------|| np_fils(x11) || de(x11,x10) || np_male(x10) || np_rosier(x9) || de(x9,x8) || np_male(x8) || np_male(x7) || au(x5,x6) || np_garage(x6) || np_voiture(x5) || de(x5,x4) || np_male(x4) || np_voisin(x3) || de(x3,x2) || np_male(x2) || _____________ _________________________ || | x1 | | p1 | || (|-------------| -> |-------------------------|) || | np_soir(x1) | | a_topic(x1) | || |_____________| | __________________ | || | p1:| s1 | | || | |------------------| | || | | Recipient(s1,x5) | | || | | Theme(s1,x3) | | || | | a_mettre(s1) | | || | |__________________| | || | alors(x1,p1) | || |_________________________| || Theme(s2,x9) || Actor(s2,x7) || a_arroser(s2) || avec(x9,x11) ||__________________________________________________|
F 12: La sortie en SRD de l’exemple
dans notre expérimentation est limitée à 20 mots car le corpus FTB a été extrait de journauxfrançais, les phrases sont donc assez longues et complexes. Nous avons obtenu que 61,94% desphrases peuvent être analysées avec succès par notre système. En analysant les erreurs survenuesdans nos résultats, nous identifions deux causes principales : la première découle d’erreurs dansl’analyse des dépendances ou dans l’étape d’analyse GCC ; la seconde provient de manques dansla définition de la représentation sémantique des catégories lexicales GCC pour le français.
L’analyse sémantique est une tâche difficile dans le domaine du traitement du langage na-turel. Nous obtenons une analyse du discours français étape par étape, et pour obtenir unereprésentation sémantique fidèle, nous devons nous assurer de l’exactitude des étapes d’analyseprécédentes. S’il y a une erreur dans celles-ci, elle entraînera fatalement des erreurs dans lesrésultats. Par exemple, les erreurs des étiquettes de partie de discours sont la principale cause derésultats erronés. Ce type d’erreur va des erreurs de bas niveau des analyseurs de dépendancesaux phrases qui sont intrinsèquement ambiguës et peuvent avoir plusieurs arbres de syntaxe,tels que la belle porte le voile où belle/porte/voile peuvent être aussi bien nom/verbe/nom queadjectif/nom/verbe.
Enfin, des problèmes linguistiques complexes surviennent lors du traitement d’énoncés danslesquele-s l’omission d’un mot ou d’un groupe de mots – qui autrement sont nécessaires àl’exhaustivité grammaticale d’une phrase – est tolérée. Ces problèmes entraînent souvent uneidentification incorrecte des arguments verbaux. Par exemple, dans Henri veut aller au parc etsa mère à la bibliothèque, l’absence d’un verbe entre les mots mère et à la bibliothèque aboutit àl’obtention de catégories lexicales incorrectes pour les mots restants.
6 ConclusionNous avons proposé une approche empirique pour construire une application de représentationsémantique pour la langue française, basée sur le cadre GCC (pour analyser dans le cadre de

xxxvi
la phrase) et sur SRD (pour traiter les relations sémantiques entre les phrases d’un discours).Les informations syntaxiques et les relations de dépendances entre les mots sont analysées etextraites à l’aide d’un analyseur de dépendances. Après cela, les informations sont utiliséespour construire un arbre de dérivation GCC pour chaque phrase. Enfin, les phrases sous formed’arbre de dérivation GCC sont traitées par Boxer, que nous avons adapté à la langue françaisepar intervention directe sur le code source, et nous obtenons une représentation sémantiquedu discours en logique du premier ordre ou en format en boîtes imbriquées SRD. Dans lesrecherches futures, nous prévoyons de construire un corpus avec des discours et leur représen-tation de signification sous forme de SRD, en utilisant cette application. Nous prévoyons égale-ment d’utiliser des modèles de réseaux de neurones profonds pour améliorer la robustesse desrésultats obtenus.

Chapter 1
Introduction
The emergence and popularization of social networks in this century have opened up new com-munication channels between individuals as well as between organizations and individuals, byreplacing traditional interaction channels such as post, telephone and email. Along with the ex-plosion of the number of users of social networks, organizations have realized the importance ofbeing adequately represented on social networks, in order to increase their presence and estab-lish a communication channel with their customers. Therefore, information flows received andprocessed by the appropriate agents in organizations have encountered an increasing growth.Much of the information is created in the form of texts such as ordered lists of comments ormessages around a given theme. The automatic or semi-automatic processing of these texts isan essential requirement for any organization. However, the analysis and understanding of textsby the machine is still confronted with many challenges. On social networks, conversationsbetween two or more people involve the exchange of news, ideas, evaluations, requirements,questions or complaints, in the form of a sequence of messages or comments. In general, thesetexts are written in natural language and cannot be directly understood by machines. Thanks tothe advancements in the domain of natural language processing, machines can assist people inperforming various tasks involving reading and understanding language, from simple tasks suchas spelling correction or spam detection to complex tasks such as question answering, text sum-marizing, and machine translation. More specifically, the classification of conversations can berealized by the use of supervised learning algorithms, and this can be realized with a high levelof precision. However, in order to understand a conversation, the analysis of discourse mustgo through different complex and interactive levels of text study such as morphology, syntax,semantics and pragmatics. In other words, the meaning of a sentence or a discourse in contextneeds to be captured and synthesized through a general language representation that can beinterpreted both by the machine and by humans.
It is the role of a semantic representation framework to introduce a formalism through whichmachines become capable of capturing the meaning of expressions in natural language. In fact,semantic representations define lexical categories and rules that map meaning to syntax. Thus,texts in natural language are transformed into a new representation form where semantic rela-tionships are linked to each other and implicit information can be explored by reasoning rules.Ontologies are of the most popular semantic representation frameworks used for knowledgedescription. More specifically, ontologies are appropriate for the construction of knowledgebases in particular domains. We can build information warehouses and access their knowledgewith requests through a special query language. In particular, by organizing knowledge throughontologies, we can provide feedback for information requests or questions in conversations.
A conversation in the frame of communication between an individual and an organizationon social networks will normally involve a set of topics of interest for the individual or for theorganization. Such a conversation can be considered as a dialog, where texts are exchangedbetween the agents. The analysis of these texts must be placed in the context of the givenconversation, and information can be spread out in different sentences—we call a sequenceof sentences, a discourse. Synthesizing and representing information contained in a discourse

2 Chapter 1. Introduction
allows fast capture of the individuals’ intentions, and this gives us a means to classify moreprecisely the type of discourse.
In the context of this thesis, we concentrate on studying discourses between individualsand organizations on social networks. We look for approaches to analyze these discourses atthe semantic level for French language. More specifically, our research involves analysis ofdiscourses and their representation in a given semantic representation form. Besides that, wecreate knowledge bases through ontologies in order to semantically annotate the discourse andto obtain relationships between concepts that occur in it.
1.1 The contextIn the last decade, social networks have become an important communication channel for com-panies and organizations with customers. Through this channel, customers can easily commu-nicate with a counselor or a consultant at any time of the day. However, the number of usersattempting to communicate through social media channels is increasing. Therefore, companiesare required to build chatbot systems to help them receive and process messages from customersover social network applications. Nevertheless, the application scope of these chatbots is quitelimited with simple functions based on defined templates or existing training datasets. Cur-rently, most chatbots do not access the content of texts in a robust manner and therefore areunable to take decisions in a conversation with users. Essentially, all processes and decisions arestill made by company agents. Therefore, understanding the content of user messages can helpimprove the chatbot system in classifying messages, in responding or in providing requestedinformation, as well as in reducing the workload of agents.
In general, data involved in daily exchanges between customers and supporters, not only onsocial networks but also via emails, messenger, and forums are mainly in textual form. Thesecommunications begin with the enumeration of customer issues. Thereafter, exchanges pursuein order to clarify and resolve these issues. Instead of processing message threads and redirectthem to counselors, having the machine analyze messages and capture meaning can assist com-panies in providing a better solution for understanding user intentions and for providing answersto customers.
Messages in a conversation are created in chronological order, and information can bespread in more than one sentences, produced at different times. Therefore, messages shouldbe placed into the context of the conversation to be understood. This is also necessary, in par-ticular, to detect the intentions of users. We normally begin with syntactic analysis in order toanalyze and determinate the structure of a text considered as a sequence of tokens with respectto a given formal grammar. After terminological analysis we provide the meaning of terms,their roles, and the relationship between individual terms that we use in order to detect lexicalhierarchies, such as hyponyms, synonyms, antonyms. At a higher level, and thanks to the prin-ciple of compositionality, semantic analysis allows us to access meaning of syntactic structuressuch as phrases, clauses, sentences or paragraphs. In order to accomplish this, we constructa semantic parser mapping natural language utterances into a semantic representation. Theserepresentations are regularly based on grammars or other underlying formalisms, used to derivevalid logical forms.
With nearly 4,000 languages having an elaborate writing system among the 7,000 livinglanguages on the world1, every language cab be described through graphemes, morphemes, andgrammatical rules allowing to create complete sentences. Therefore, syntactic analysis in eachlanguage is very different in terms of graphemes, and morphemes, as well as the relationshipbetween elements in the sentence. We need to adopt a linguistic theory in order to analyze the
1Metrics from https://www.ethnologue.com/enterprise-faq/how-many-languages-world-are-unwritten-0

1.2. Challenges 3
fundamental grammar structure of a language, for example, Phrase Structure Grammar (Chom-sky, 1959) where the constituency relation concept involves subject-predicate division and relieson phrasal nodes such as noun phrases for subjects and verb phrases for predicates, or Depen-dency Grammar (Tesnière, 1934, Hays, 1960; Hays, 1964a; Hays, 1967, Osborne, 2019) inwhich there is a root for every sentence and other words are directly or indirectly connected toit, Montague Grammar (Montague, 1970a; Montague, 1970b; Montague, 1970c) where gram-matical relationships are expressed through FOL and lambda calculus, or Categorial grammar(Bar-Hillel, 1953; Bar-Hillel et al., 1960; Lambek, 1988) that is a development branch of phrasestructure grammar, in which syntactic constituents are combined as functions or according to afunction-argument relationship.
Besides obtaining shallow structures such as grammatical constituents and syntactic rela-tions, and identifying the parts of speech, our grammar theory explores the meaning of sen-tences or phrases through deep structure analysis. In this case the meaning of utterances andphrases is determined by combining the meaning of their subphrases using rules that are drivenby the syntactic structure. Thanks to compositional semantics we obtain the complete mean-ing of a given utterance. Furthermore, meaning representation of an utterance is crucial intasks such as linking linguistic elements to non-linguistic elements, representing unambiguouscanonical forms at the syntax level, reasoning on what is true in the world as well as inferringnew knowledge from semantic representations. We have different approaches at our disposalfor representing meaning: first-order logic, frames, rule-based architectures, and conceptualgraphs, to name a few.
Discourse processing in the context of this thesis focuses on conversations or communi-cations in which coherent sequences of sentences/phrases are created by using social networkapplications. We analyze and investigate features that are part of communicative acts such ascontext of utterance, relationship, and mode of discourse. As one of the goals of this analysis,we identify the topic of a conversation or the intention of the individual leading it. Therefore,the determination of formal semantic framework helps in constructing mathematical modelsthat are used to define the relations between expressions in discourse.
The purpose of this thesis is to propose an approach for analyzing and capturing themeaningof an utterance in the context of discourse in social networks, as well as the development of aframework that allows parsing utterances in order to obtain meaning representation with inpututterances in French language. In previous decades many fundamental language theories havebeen introduced and applied to syntactic and semantic analysis; however there are still manyproblems to solve, corresponding to the following questions:
1. What is a discourse in social networks and how can we extract discourses from socialnetworks?
2. How do we analyze texts from a discourse at the syntactic and semantic level?
3. What semantic representation framework is suitable for analyzing and representing dis-courses?
4. How do we extract meaning from a sentence or from a discourse ?
1.2 ChallengesIn natural language, words, phrases or sentences can sometimes have more than one meaning.The ambiguity of language is always a complex problem that NLP algorithms have to solve bytaking disambiguation decisions. In fact, there are different kinds of ambiguity: ambiguity ofword sense, of word category, of syntactic structure, of semantic scope. Each kind of ambiguityrequires a specific approach. For example, a knowledge-based approach will map meanings to

4 Chapter 1. Introduction
words in context by using theWordNet corpus (Chaplot and Salakhutdinov, 2018); a supervisedapproach to the same problem will require a large training data (Huang et al., 2019). Neverthe-less, despite the variety of approaches, the results we obtain are still limited and depend on theparticular knowledge domain.
Interpretation of an entity, occurrence or concept in a given utterance may depend on en-tities, occurrences or concepts located in other utterances. This linguistic phenomenon, calledanaphora, raises the problem of how to identify relations between entities, occurrences or con-cepts and their referents in one or many utterances. There are generally many types of anaphorasuch as pronominal anaphora, propositional anaphora, adjectival anaphora, modal anaphora,etc. Since more than one sentences are potentially involved, the anaphora resolution problemshould also be coined in the context of discourse.
Discourse on social network has its own characteristics, that singularizes it from other typesof discourse. First, utterances in social networks inherit both from the spoken and from themodality. Secondly, emoticons can be used to accompany words to express sentiments in theutterance. In general, emoticons are considered to be handy and reliable indicators of sentimentsand are used as expressive, non-verbal components in utterances playing a role similar to theone of facial expression in speech (Novak et al., 2015). The use of emoticons may or may notobey to grammatical rules of a given natural language. Thus, using emoticons for extractingmeaning from utterance remains a challenge.
Converting a natural language utterance to a machine-understandable representation can beoperated using semantic parsing. There are numerous fundamental formal semantics theoriesfor representing meaning such as Abstract Meaning Representation (Banarescu et al., 2013),Discourse Representation Theory (Kamp and Reyle, 1993), or Conceptual Meaning Represen-tations (Abelson and Schank, 1977; Jackendoff, 1992). Each framework has its own advantagesand disadvantages and therefore the choice of a framework for analyzing discourse on socialnetworks can play an important role with respect to the quality of obtained results.
Moving from natural language processing to natural language understanding remains a bigchallenge for researchers in computational linguistics. With fundamental theories about syntac-tic, semantic, or discourse analysis, we can construct parsing systems in order to capture andrepresent utterance meanings. However, there are still many drawbacks because of the diversityand complexity of natural language used to represent the real world. It is no exaggeration to saythat solving this problem will open a new era for human-machine interaction.
1.3 ContributionsHeading towards the ultimate goals of achieving semantic representation of French discourseson social networks, here are the contributions we will describe in the frame of this thesis:
• Based-on the fundamental theory of Combinatory Categorial Grammar and DependencyGrammar, a novel algorithmic method that allows analysis of the dependency structureof a sentence and its transformation into a CCG derivation tree (Le and Haralambous,2019). This is an important step to obtain information on syntax and semantics of thesentence.
• Applying the above method to the French Tree bank corpus, we created a new corpusresource for the French language. In general, a CCG corpus (such as CCGBank2 forEnglish), can be used as training data for machine learning or deep learning algorithmsin order to create a CCG parser for a given language (Le and Haralambous, 2019).
2http://groups.inf.ed.ac.uk/ccg/ccgbank.html

1.3. Contributions 5
• In order to obtain a CCG parser for French sentences, we proposed a supervised archi-tecture model for the CCG Suppertagging task based-on using the morphological anddependency information in the sentence (Le and Haralambous, 2019). The experimen-tation and evaluation have been realized on two corpora: French Tree Bank3 for Frenchand GroningenM∃∀NİNG Bank4 for English.
• Finally, by combining the above French language CCG analysis results with DiscourseRepresentation Theory, we propose an architecture for achieving a semantic represen-tation from French discourse input. The output is obtained in two formats: First-OrderLogic and Discourse Representation Structure (Le, Haralambous, and Lenca, 2019).
3http://ftb.linguist.univ-paris-diderot.fr4https://gmb.let.rug.nl


7
Part I
Discourse Analysisand
Social Networking Platforms


Chapter 2
Discourse on Social Networks:Challenges and Opportunities
The emergence of social networking platforms provides a new communication channel of ourtimes, in which people can create and publish their thoughts, information, statements aboutany topic, freely and without limitation. In general, each platform has its own special featuresand characteristics as well as its own target audience. User-generated contents therefore willbe different in terms of format, content and purpose. In this chapter, we will introduce anoverview about social networking services, their features and their user objects in order to un-ravel differences between these platforms and user-generated contents which we aim to captureand explore. Furthermore, we also synthesize challenges and opportunities on these platforms,which will be geared towards serving businesses or organizations with their clients or potentialclients.
2.1 Social Networks Overview2.1.1 Social Networks DefinitionsThe emergence of the Internet in the 60s of the last century has established a new era for theworld of computers and communications. The Internet provides a new communication channelfor the transmission of information, a new mechanism for information dissemination, and a newmedium for collaboration and interaction between individuals and computers without dependingon geographic location (Leiner et al., 2009). A notorious application of the Internet is theWorld-WideWeb1 which is an information system where resources such as Web pages and multimediacontents are identified by unique links and are accessible over the Internet. There are currentlyover 1.7 billion Web sites on the World-Wide Web and this number steadily increases. A Website can be have many functions and can be used in various fashions depending on its purpose,such as personal Web sites, corporate Web sites for organizations, governments, or companies,searching portals, commercial Web sites, or social networking Web sites.
Another invention in the domain of communications, namely smartphones, has broughtimportant changes in the way people interact on Internet-based applications as well as on Web-based services. According to statistics of the gsma.comWeb site based on real-time intelligencedata, there are currently over 5.13 billion mobile device users in the world. Mobile devicesare currently used not only for making and receiving calls or messages over a radio frequencybut also for a wide variety of tasks ranging from playing games, sharing files such as picturesand videos, accessing the Internet through the use of integrated Web browsers. Using social
1Introduced by Tim Berners-Lee, a British computer scientist, in 1989. The first Web site—info.cern.ch—hasbeen developed on August 1991 while he was working at CERN, in Geneva, Switzerland. He is also the author of theSemantic Web the central idea of which is the availability of a common framework for data sharing and re-usabilityacross application, enterprise, and community boundaries (Berners-Lee, Hendler, Lassila, et al., 2001).

10 Chapter 2. Discourse on Social Networks: Challenges and Opportunities
networks through dedicated applications on mobile device has become an inevitable trend ofmodern times. Thereby, people can access their social network at any time, and at any place.
Social Networking Sites or Social Networking Platforms are currently popular social mediaterms, representing a multitude of different online platforms allowing people to build socialrelationships with other people, to communicate with each other, to discuss opinions about news,events or favorite topics, to share knowledge about similar interests, to rate and review productsor company services. More specifically, these platforms are built upon Web-based services orInternet-based applications that are designed to enable users to construct public or semi-publicprofiles within a bounded scope of the platform, to search and establish a connection to otherindividuals or groups in order to or articulate or view their sharing contents, or to interact withthem throughmessages (Boyd and Ellison, 2007; Obar andWildman, 2015; Quan,Wu, and Shi,2011). Social Networks provide a medium for creating and publishing contents for all users.User-generated contents can be read by other community members, and can be continuouslymodified by authors.
The above description of social networks is based on their most common characteristics.Besides, each social network platform can have its own specificity depending on its purposes andaudiences. Along with allowing the participation of individuals to social networks, connectivityfeatures enable them not only to make their presence visible but also to meet with each other toform virtual communities. Users can create content by interaction features such as comments ormessages. In general, user profiles, connectivity and interaction will be required on most currentsocial network platforms. In addition, each platform has specific features depending on itspurpose. For example, linkedin.com is aimed for professionals, companies and businesses, andits users can create profiles for spreading their professional achievements and career. Anotherexample, instagram, is a platformmostly accessed via mobile devices and designed for the youngusers—it allows sharing of visual creative content.
Every social network is distinct in its own way, reaches out to different audiences and servesfor a different purpose. Classification of social networking sites can be based on criteria such asuser interests or shifting technology features. Thereby, social networking sites can be classifiedinto three general categories: the generic social networking, the professional and the teenagersocial networking sites (Wink, 2010). There have been other classifications, such as (White,2016) using seven categories such as social connections, multimedia sharing, professional, in-formational, educational, hobbies and academic networking sites or (Aichner and Jacob, 2015)using thirteen categories such as blogs, business networks, collaborative projects, enterprise so-cial networks, forums, microblogs, photo sharing, products/service reviews, social bookmarking,social gaming, social networks, video sharing and virtual worlds. Based on user expectation(Foreman, 2018), we propose the division of social networks into the following categories:
• Social Connecting Networks. They currently have the largest number of users in theworld. These social networking sites were constructed for Internet users wanting to keepin touch with friends or family members and they are used for sharing information as wellas keeping up-to-date activities of other people whether across town or around the world.Typical representatives for this category are Facebook.com, Twitter.com, Tumblr.com.
• Multimedia Sharing Networks. They have been designed for users wishing to postand share music, videos, photos or other kinds of media. The main representative ofthis category is Youtube.com, the largest user-driven content provider in the world. Itssuccess comes from the user-to-user social experience through multimedia content (Wat-tenhofer, Wattenhofer, and Zhu, 2012). Besides, we have many other platforms such as:Instagram.com, Vimeo.com, Flickr.com, TikTok.com.
• Social Messaging Networks. They are accessed through applications on mobile de-vices or platforms that allow users to send messages to, or receive messages from, other

2.1. Social Networks Overview 11
users. Social networking services have created messaging services as a basic compo-nent of their overall platform. The most widely used mobile applications of this kind areWhatsapp.com, Messenger.com, WeChat.com, SnapChat.com, Viber.com.
• Professional Networks. They target professional users to share their professional expe-rience, abilities or qualifications, to build relationships with new contacts, to stay in touchwith business partners and to create business opportunities. The pioneer of this categoryis Linkedin.com for business professionals, ResearchGate.com and Academia.edu in theAcademic domain. Beside these we also have ViaDeo.com, Xing.com, MeetUp.com.
• Publishing and Discussion Networks. They connect users through content, news, in-formation or opinions. Online tools are provided to find, discuss or publish content. Inthis category, we have the emergence of social networks sites such as Quora.com, Red-dit.com, or Medium.com.
• Consumer & Business Review Networks. They give users a place to find, review orshare information about products, services, brands, travel destinations or anything else.These platforms are also a place to learn from the experiences of others at any time with-out depending on one-way information from businesses. We have some names that leadthe way on this competition such as Google My Business, Yelp.com, TripAdvisor.com,FourSquare.com.
• Social Commerce2 Networks. They are designed to integrate social experience withonline transaction experience. Buying or selling is done by users for who online toolsare provided to find items, to follow brands, to share their experiences and to make theirtransactions. Users can be individuals or organizations. Common networks in this groupare GroupOn.com, AirBnb.com, Fancy.com, OpenSky.com.
• Interest-BasedNetworks. They are constructed to connect audiences based on commoninterests, hobbies, ideas or passions as reading, music, home design, online game, etc., byremoving barriers of geography, time zones, cultural habits or societal restraints. Popularplatforms are GoodRead.com, Friendster.com, Last.fm, Houzz.com, MegPlay.com.
• Anonymous social networks. They create a space where real-life information on usersis not required to fill-in profiles and where users can post and share content anonymously.These social networking sites types are often considered as ‘dark sides’ of social media,thus they may not be suitable for some audiences. Among platforms of this class we haveAferSchool.com, Whisper.com, Ask.fm.
2.1.2 A Brief History of Social NetworksIn the early days of theWeb, when the concept of social networks was still vague, a large numberof Web sites have been built for various purposes. Some of them appeared in the form ofgeneralized virtual communities with some characteristics of social networks such as Geocities(1994), TheGlobe.com, Tripod.com Classmates.com (1995) and PlanetAll.com (1996). Theseplatforms have been designed to bring users together in order to interact with each other throughchat rooms. Online publishing tools were built for users to create and share their personalinformation or ideas with others. Nevertheless, the first real social network site is consideredto be SixDegrees.com, developed by Andrew Weinreich in 1997. This first platform allowed
2There are different definitions around the “Social Commerce” term. In our context, we used the definition: “So-cial Commerce is a subset of electronic commerce that involves using social media, online media that supports socialinteraction and user contributions, to assist in the online buying and selling of products and services.” (Marsden,2011).

12 Chapter 2. Discourse on Social Networks: Challenges and Opportunities
users to create their profiles, connect with others and display the list of their friends. Makingfriends, expanding virtual groups, sending and receiving messages are important features of thissite which is generally considered as being the first social network in history.
In the period between 1997 and 2001, many other social networks have were launchedto bring some improvements in functionality. The amelioration of the profile function allowedusers to customize their information into personal, professional, and dating profiles. Users couldalso receive updates from others by marking them as friends and manage relationships on theirpersonal profiles. Typical examples are AsianAvenue.com (1997), OpenDiary.com(1998),Makeoutclub.com, CyWorld.com(1999), LunarStorm.se, BlackPlanet.com (2001). In 2001,Ryze.com was released as a novel type of social network for professional and business commu-nities.
The next wave of social networks began when Frienster.com was launched in 2002 withimprovements such as connectivity functions, share of content such as videos, photos, mes-sages and comments with other members via profiles and networks. Users could contact othermembers and expand their networks through friend-of-friend relationships. Thereby, this plat-form gained over 300,000 users before May 2002 (Boyd and Ellison, 2007). The success ofFrienster.com ushered in a new period of explosion of SNS. The big names of current SNSwere born in the period between 2003 and 2008 such as LinkedIn.com (2003), FaceBook.com3
(2004), Youtube.com, Reddit.com (2005), Twiter.com, QQ.com, VK.com (2006), and Tum-blr.com (2007). Besides, we are also familiar with other cases likes MySpace.com, Flickr.com,Hi5.com (2003), Yahoo!360 (2005). Based on the web technology development and the largeamount of users around the world, a multitude of different SNS were released with the basicarchitecture of a SNS to which special functions were added, aiming to connect different audi-ences from personal users to professional users, and creating and sharing multimedia content,blogs, microblogs, discussions and reviews.
In the period between 2009 and 2019, the concurrence between SNS became more intensethan ever by witnessing the collapse or transformation of SNS of previous stages in other forms.MySpace.com, Frienster.com, Yahoo!360 and many others were the typical losers of this com-petition. Many causes lead to the failure of these platforms such as the lack of loyalty to itsusers, or the lack of technological innovation and of enhancement of the user experience. Be-sides, a major branch of social messaging platforms emerged during this period: WhatsApp(2009), Viber(2010), Messenger, WeChat, Line (2011), SnapChat, Telegram, Google Hangout(2013). Messaging or chat platforms became widely popular communication channel acrossthe globe. These communication channels, some of which originated via SNS, have developedinto independent platforms such as Google Hangout derived from Google+ and Messenger.comseparated from Facebook.com.
2.1.3 User Characteristics and MotivationsTable 2.1 represents the mapping between active behaviors by SNS users and available func-tionalities provided by SNS platforms. In general, user behavior on SNs can be classified infour categories, namely: content creation, content transmission, relationship building and rela-tionship maintenance (Chen et al., 2014). Content creation is focused on creating or generatingcontent by microblogs, blogs, photos or videos in the social network site. These user-generatedcontents can possibly contain valuable information that may influence the behavior of others,for example, user-generated reviews can change consumers’ purchase intention (Park, Lee,and Han, 2007). Content transmission behavior is identified by sharing information on SNSamong friends, colleagues or family members. With this behavior, information and knowledge
3Facebook was launched on February 4, 2004 with a registration limitation to students in the US and Canada. Itopened to the general public in 2006.
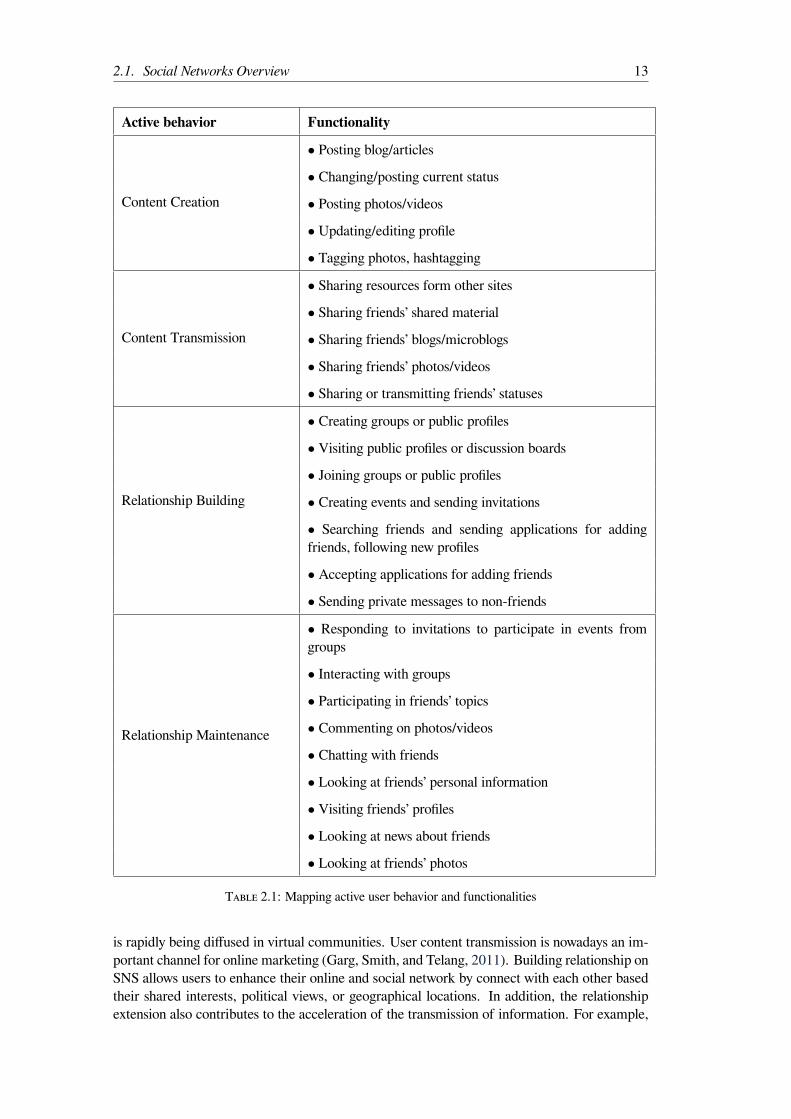
2.1. Social Networks Overview 13
Active behavior Functionality
Content Creation
• Posting blog/articles
• Changing/posting current status
• Posting photos/videos
• Updating/editing profile
• Tagging photos, hashtagging
Content Transmission
• Sharing resources form other sites
• Sharing friends’ shared material
• Sharing friends’ blogs/microblogs
• Sharing friends’ photos/videos
• Sharing or transmitting friends’ statuses
Relationship Building
• Creating groups or public profiles
• Visiting public profiles or discussion boards
• Joining groups or public profiles
• Creating events and sending invitations
• Searching friends and sending applications for addingfriends, following new profiles
• Accepting applications for adding friends
• Sending private messages to non-friends
Relationship Maintenance
• Responding to invitations to participate in events fromgroups
• Interacting with groups
• Participating in friends’ topics
• Commenting on photos/videos
• Chatting with friends
• Looking at friends’ personal information
• Visiting friends’ profiles
• Looking at news about friends
• Looking at friends’ photos
T 2.1: Mapping active user behavior and functionalities
is rapidly being diffused in virtual communities. User content transmission is nowadays an im-portant channel for online marketing (Garg, Smith, and Telang, 2011). Building relationship onSNS allows users to enhance their online and social network by connect with each other basedtheir shared interests, political views, or geographical locations. In addition, the relationshipextension also contributes to the acceleration of the transmission of information. For example,
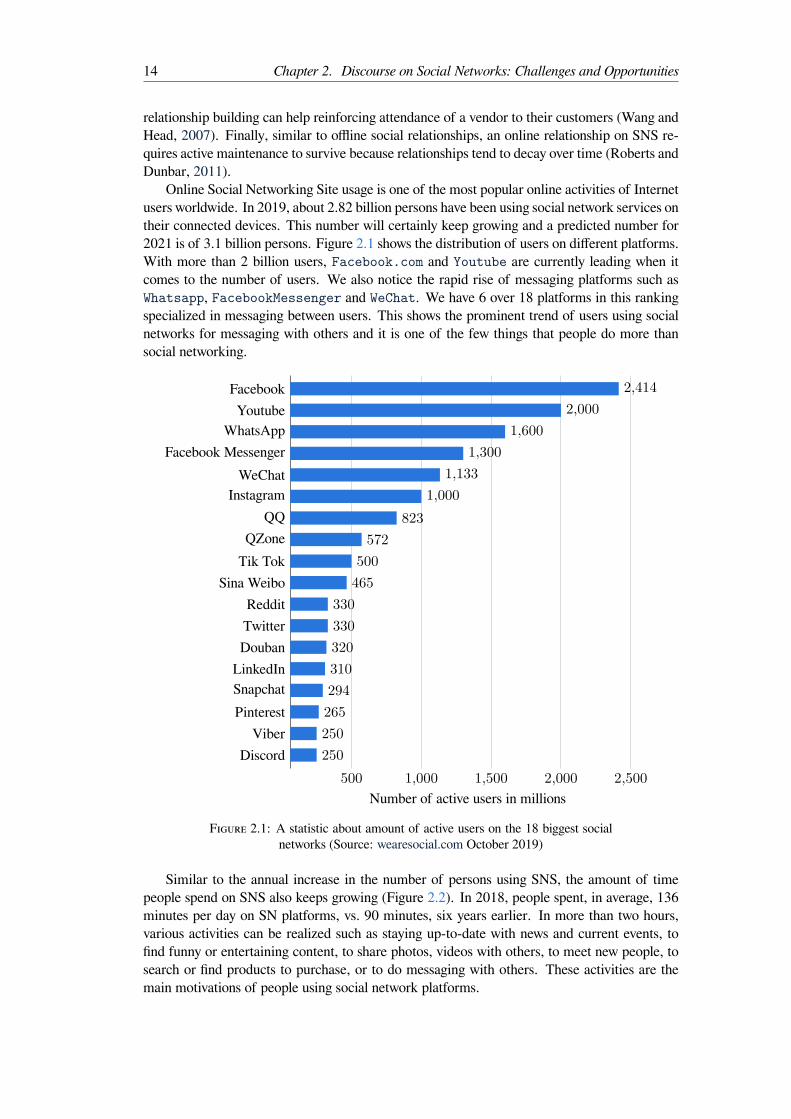
14 Chapter 2. Discourse on Social Networks: Challenges and Opportunities
relationship building can help reinforcing attendance of a vendor to their customers (Wang andHead, 2007). Finally, similar to offline social relationships, an online relationship on SNS re-quires active maintenance to survive because relationships tend to decay over time (Roberts andDunbar, 2011).
Online Social Networking Site usage is one of the most popular online activities of Internetusers worldwide. In 2019, about 2.82 billion persons have been using social network services ontheir connected devices. This number will certainly keep growing and a predicted number for2021 is of 3.1 billion persons. Figure 2.1 shows the distribution of users on different platforms.With more than 2 billion users, Facebook.com and Youtube are currently leading when itcomes to the number of users. We also notice the rapid rise of messaging platforms such asWhatsapp, FacebookMessenger and WeChat. We have 6 over 18 platforms in this rankingspecialized in messaging between users. This shows the prominent trend of users using socialnetworks for messaging with others and it is one of the few things that people do more thansocial networking.
500 1,000 1,500 2,000 2,500
DiscordViber
PinterestSnapchatLinkedInDoubanTwitterReddit
Sina WeiboTik TokQZone
QQInstagramWeChat
Facebook MessengerWhatsAppYoutubeFacebook
250
250
265
294
310
320
330
330
465
500
572
823
1,000
1,133
1,300
1,600
2,000
2,414
Number of active users in millions
F 2.1: A statistic about amount of active users on the 18 biggest socialnetworks (Source: wearesocial.com October 2019)
Similar to the annual increase in the number of persons using SNS, the amount of timepeople spend on SNS also keeps growing (Figure 2.2). In 2018, people spent, in average, 136minutes per day on SN platforms, vs. 90 minutes, six years earlier. In more than two hours,various activities can be realized such as staying up-to-date with news and current events, tofind funny or entertaining content, to share photos, videos with others, to meet new people, tosearch or find products to purchase, or to do messaging with others. These activities are themain motivations of people using social network platforms.

2.2. Opportunities and Challenges 15
2012 2013 2014 2015 2016 2017 2018
90
100
110
120
130
140
90
95
101
109
126
135 136
Numberperday
F 2.2: A statistic about daily time spent on social networks (Source:statista.com)
2.2 Opportunities and Challenges2.2.1 OpportunitiesSN services have become popular channels of information, media and communication for com-panies and their customers. Through this medium, customers have a platform to share reviewsabout specific services or products, to contact companies directly and to communicate with eachother. The participation of a company in SN platforms gives it a change to maintain and makestronger relationships with its customers through its presence; it also allows it to improve itscustomer service, by receiving and handling reports on customer problems.
Traditionally a brand or company was widely known through word-of-mouth communi-cation between individuals. Nowadays, SN services are offering enormous opportunities asa new communication channel for companies and their potential customers. A SN platformwith millions of users interacting with each other is a great place for companies to ultimatelyreach their customers. By the use of search tools, companies can achieve benefits by explor-ing user-generated contents and user interactions, and by opening close relationships with theircustomers.
Instead of using traditional marketing channels such as radio, television, newspapers, SNplatforms have become a modern approach to introduce or promote new services and productsto potential customers. Customers can use these SN platforms to communicate with each otheror to share their thoughts, ideas, comments, experiments, and evaluations about a company’sservices or products. In addition, SN platforms provide features allowing customers to followinformation about products or services by other customers.
The message management feature, that exists on most SN platforms, allows users to con-verse with other users. Therefore, companies can receive various messages from their customersrequesting information about services or products, or complaining about shortcomings. Con-versation management helps companies to quickly provide required information or to resolveproblems of their customers. Furthermore, using SN services for collecting feedback can berealized more quickly and more cost-efficiently than using traditional ways such as email, orphone surveys (Rana, Kumar, et al., 2016).
The use of SNS platforms as a media channel to provide company-specific content, servicesor products information is currently quite popular. Information is directly received by customersand, as a result, conversations about a particular topic are generated in real time in the network.

16 Chapter 2. Discourse on Social Networks: Challenges and Opportunities
Discourses generated in this way contain useful information about opinions of customers withbehalf to the company.
SNS platforms are commonly accessed by connected devices such as laptops, tablets, smart-phones, and smart television. People can easily access SN platforms from anywhere and at anytime. Therefore, they changed the way a company communicates with its customers. Peo-ple can contact and converse with company representatives at any moment about products andservices, be it for resolving problems or for obtaining information.
Marketing campaigns allow reaching customers in a low-cost, impact-full and effective way.SN platforms have become a crucial marketing channel for businesses. Indeed, a companycan identify its target customers for new promotions, products or services based on customerattention on the company content or interaction activities on SNS.
2.2.2 ChallengesWhile there are numerous opportunities that SN platforms bring up for companies today, thereare also key challenges that companies need to overcome to benefit from these opportunities.One of the challenges is diversity and abundance of SN platforms of different kinds such associal networking sites, online forums, instant messaging services. This requires companies ororganizations to build common integrated social media strategies (Paliwal, 2015). Based on thecharacteristics of SN platforms, companies need a standard framework to determine on whatthey want to focus on and how to establish their target audience.
The spread of online fake news and misinformation can cause public panic and changethe perception users have for a given brand. In particular, false contents can be received byany audience and can be shared with anyone on SN platforms. Therefore, misinformation canspread very fast in a cascaded manner and one of its negative effects is that it can be difficult tocontrol (Tong, Du, and Wu, 2018). Misinformation detection has thus become a challenge anda hot research topic in recent years.
SNS platforms allow users to own personal virtual spaces. They can post any content in theirspace, and this content will be read by others. If some of the content is posted with negativesentiments about a given brand, it will directly affect the reputation of the concerned companies.There is little or no control on the type of content that gets shared on SN platforms. Accordingly,it becomes difficult for companies to protect themselves from destructive comments or rumors.
Information propagates through SN platforms via cascades. In a competitive context, if anew service or product is introduced to a target audience, it can grasp an advantage in terms ofrevenue and profits. Therefore, competing with other companies on SN platforms is a challengethat companies need to plan and execute in the frame of business strategies in order to grow.
Privacy, security, and safety issues in SN platforms play an important role in motivatingpeople engaged in online social networking activities. Indeed, the availability of a large amountof personal information on SN services has attracted the attention of criminals and hackerswho can engage in undesired or fraudulent activities such as identity theft, phishing, spamming,clickjacking or cross-site scripting (Deliri and Albanese, 2015). Malicious users can start at-tacks against SN providers in order to appropriate personal information and access informationshared by users. Therefore, SN service users can be at risk.
2.3 Discourse on Social Networks2.3.1 Basic DefinitionsDefinition 2.3.1. Discourse is a unit of text used by linguists for the analysis of linguistic phe-nomena that ranges over more than one sentences. Discourse is created based on a naturalspoken or written communication between people on a particular subject.

2.3. Discourse on Social Networks 17
The term ‘conversation’ denotes talk, especially of the informal type, between two or morepeople, in which news or ideas are exchanged. In ordinary usage, conversation usually implies aspoken expression rather than written language. However, interactions of people via SNS occursregularly in written language. Therefore, we can use various terms—discourse, conversation,speech, talk—for what might appear to be very much the same thing.
Definition 2.3.2. Discourse Theory expresses broadly the study of aspects of language andcommunication distinct from linguistic structure. In computational linguistics, discourse theoryattempts to provide a new theoretical apparatus and frameworks to deal with language phenom-ena.
Discourse theory intersects with various disciplines such as linguistics, communication stud-ies, anthropology, literary studies, political science, social psychology, translation studies, to so-ciology or cultural studies (Karlberg, 2011). In our scope, discourse theory will be associatedwith language structure and phenomena, and with meaning representations through texts.
Definition 2.3.3. Discourse Analysis is a natural language processing task that focuses on ex-tracting linguistic structures and phenomena using with different units and ranging from sen-tence and paragraph to conversation at different levels of syntax, semantics, or pragmatics. Inaddition, it also concerns studies of contextual meaning representation of texts.
In order to understand thoroughly a text or a conversation, we need to put it into context.Therefore, instead of focusing on smaller units of texts, such as words or phrases, discourseanalysis tends to study larger units of language such as paragraphs, entire conversations or texts.Discourse analysis also provides an analytical framework and tool for the study of texts (Moser,Groenewegen, and Huysman, 2013).
2.3.2 Discourse FormsAlong with the explosion of mobile and new digital technologies (smartphones, tablets, Internet-connected devices), both the number of users and the amount of information sharing on SNplatforms have increased. Users can easily converse with others. Therefore, the number ofdiscourses keeps growing on all platforms. Discourses are regularly produced during writtencommunication on a user-generated content, during user-sharing content, or during messagingbetween people about a particular topic.
Text Speech
Monologue� Articles � Broadcast-shared
� Reviews � Radio-shared
Conversation� Text messaging � Phone conversation
� Blogs, Microblogs � Video conversation
� Discussions � Live stream shows
� Emails
T 2.2: The different forms of discourse on SNS
Adiscourse can be amonologue or a conversation, depending on the number of participants.Various forms of discourses on SNS are enumerated in Table 2.2. Conversational discourseson social networking platforms encapsulate three main components: the topic (as textual or

18 Chapter 2. Discourse on Social Networks: Challenges and Opportunities
visual content), the process involved in producing the texts, and the participants. When a user-originated topic appears on a SN it is read and attracts attention by other persons among theirrelationships. A discourse is then formed when the topic results in interactions between usersof the SNS.

Chapter 3
Discourse Analysisand Applications
This chapter provides an overview of discourse processing and analysis based on extractionof meaning from language units such as words, terms, sentences, discourse. The relationshipbetween language structures involves identifying the topic structure, the coherence structure,the coreference structure and the conversation structure for conversational discourse.
3.1 Intrasentential Linguistic AnalysisAt the level beneath the sentence, three kinds of tokens are considered by linguistics (mor-phemes, words, terms) as well as their combinations in order to build sentences (syntax).
In oral language, units of sound used for communication between humans are called phones.Classes of phones that are discriminating in a given language are called phonemes. In a similarway, units of written communication between humans are called graphs and their discriminatingclasses in a given language are called graphemes. Phonemes and graphemes are concatenated(the former in a linear way, because of the characteristics of the human speech organ, the latterin a way that is not always linear but has a main direction and develops in a 2-dimensional space).
By a phenomenon called “first articulation,” when emes (phonemes of graphemes) are con-catenated, at some point meaning emerges, for example: in English, if we take the graphemes<c>, <a>, <t>, the grapheme <c> per se carries no meaning (other than the fact of being thethird member of a system called the alphabet), the concatenation <ca> of <c> and <a> carriesno meaning, but the concatenation <cat> carries a meaning.
Minimal units of meaning emerging from the concatenation of emes are called morphemes(and the discipline studying them, is called “morphology”). There are two kinds of morphemes:lexical morphemes (such as “cat”) and grammatical morphemes (such as suffixes, prefixes, etc.),there are thousands of the former (and newmorphemes appear frequently) and only a very smalllist of the latter (which are considered the “stable” part of a language).
“Words” are concatenations of morphemes (the discipline studying them is “lexicography,”from theGreek “lexis” meaning word). They exist only in writing systems using intermorphemicspaces, such as alphabetic of abjad languages. Writing systems such as Thai, Chinese, Koreanor Japanese use no intermorphemic spaces and hence the notion of “word” cannot be triviallydefined. Nevertheless the term “word” is very widespread outside linguistics and therefore wecannot avoid it. Also word boundaries are often useful for disambiguation: for example in En-glish, the graphemic string <the rapist> represents clearly three morphemes (the article <the>,the lexical morpheme <rap>, the suffix <ist>) while <therapist> represents two morphemes (thelexical morpheme <therap> and the suffix <ist>).
The third level of elementary tokens is the one of “term” (and the corresponding discipline,“terminology”). A term is a single word or a syntagm (a sequence of words according to awell-defined pattern) carrying a specific meaning in a given knowledge domain. Single-word

20 Chapter 3. Discourse Analysis and Applications
terms (also called “simple terms”) have a monosemy constraint in a given knowledge domain.Multi-word terms (called “complex terms”), besides the monosemy constraint, must follow aspecific pattern of part-of-speech properties and often carry more information than each one oftheir components. For example, “mobile phone” is a term in the domain of telecommunications,since it describes a very popular category of communication devices, and English speakers ofour time period recognize the specific device, rather than just a phone which happens to bemobile. On the other hand, “pink phone” is just a phone which happens to be pink and does notcorrespond to a term in the domain of telecommunications.
In our study we took these three token levels into account. A morphological analysis ofwords provided the meaning of individual words, and terminological analysis allowed us tocombine specific words that were components of complex terms. Once combined, we processedthese complex terms as individual entities belonging to a given part-of-speech (the part-of-speech of the kernel of the complex term: for example, if “mobile” is an adjective and “phone”a noun, we attached the POS “noun” to the complex term “mobile_phone”).
The discipline studying the catenation of morphemes (or words or terms) in order to buildsentences, is syntax. We used parsers to obtain descriptions of syntactic structures of sentencesin various formalisms (constituency syntax, dependency syntax, combinatory categorical gram-mars, etc.).
By a phenomenon called “second articulation,” out of the catenation of morphemes (andhence of words and terms) emerges meaning. According to the principle of compositionality,the semantics of a sentence can be obtained out of the semantics of its parts (morphemes, words,terms) and the way they are combined (syntax). We have used the combinatory categoricalgrammar formalism to calculate sentence meaning out of the meaning of morphemes (words,terms), their category and their position in the sentence.
3.2 Discourse Analysis OverviewDiscourse analysis has been a fundamental problem in language analysis beyond the sentenceboundary where information in a sentence will be analyzed and extracted (e.g., identifying refer-ents for a pronoun from context) in association with information of other sentences in a context(e.g., inferring a coherence relationship concerned with more two sentences). In other words,we focus on building frameworks or tools to automatically model language phenomena that arebeing implicit beyond the language units.
3.3 Coherence and CohesionAccording to stede2011 we can define coherence as follows:
Definition 3.3.1. A coherent text is designed around a common topic. In the reading process,individual units of information enter meaningful relationships to one another. The text coheresand is not just a sequence of sentences to be interpreted in isolation.
In other words, coherence refers to linking adjacent material on the level of semantic/prag-matic interpretation. The way of doing this is not specified and one can equally well expectcoherence to emerge through the use of connectives (“My son does not go to school yet, be-cause he is only two years old”) or implicitly through pragmatic means (“My son does not go toschool yet. He is only two years old”). Coherence is what is expected from text, and surrealistgames (such as the “cadavre exquis”) or Zen meditation techniques invite the reader/meditatingindividual to build coherence ab nihilo.
On the other hand, cohesion can be defined as follows:

3.4. Discourse Parsing Task 21
Definition 3.3.2. Sentences are connected to one another not only underneath the surface (thusrequiring understanding and interpretation) but also by more-readily identifiable linguistic sig-nals.
These signals can be lexical, such as pronouns or connectives, or syntactic, such as the useof comparatives (“Paris is a nice city. Brest is even better”), or parallel sentence structures (“Ilove my son. He loves me”).
3.4 Discourse Parsing TaskThe discourse parsing task will first apply intrasentential linguistic analysis to obtain morphol-ogy, syntax and semantics of each individual sentence, and then will build a network of ref-erences between sentences in order to build a semantic representation of the entire discourse.The formalism for representing a discourse is based on First-Order Logic and uses boxes torepresent the scope of definitions and relations.


Chapter 4
A Proposed Architecture for a FrenchDiscourse Meaning RepresentationFramework
An important area in research fields such as information retrieval, human computer interaction,or computational linguistics, is natural language understanding, in which meaning represen-tation is considered as a crucial objective. Meaning representation is generated as a bridgebetween roles and objects present in texts and common-sense non-linguistic knowledge presentin the context. This chapter introduces the state-of-the-art on speculations for extracting mean-ing out of discourses and building meaning representations, both in English and in French. Wewill present various approaches based on logical reasoning or on machine learning, by usingavailable corpora. Finally, we present our proposed architecture to obtain a semantic represen-tation framework for French discourse based on an approach by John Bos (Curran, Clark, andBos, 2007; Bos, 2008; Bos, 2015).
4.1 State-of-the-Art in Discourse Meaning RepresentationDiscourse meaning representation plays an a crucial role for building natural language automaticanalysis systems using machine-interpretable meaning representations. However, this task stillfaces difficult obstacles because of the diversity of discourse forms and the complexity of humanlanguage expressions. A discourse can be perceived in various ways, depending on factorssuch as context, ambiguity of language, emotions or sentiments. Many approaches have beenimplemented in order to propose a discourse representation framework. In the following section,we will present typical works tackling directly this task.
4.1.1 Rule-Based ApproachesIn the early temps of semantic representation research, interpretative systems from natural lan-guage to some query language for database management systems have been built on the basis ofdomain-specific rule-based theories. Building a natural language interface can improve com-munication between humans and computers. One of the pioneers in the field is SAVVY, whichbuilds replies to questions by humans, using pattern match techniques (Johnson, 1984). Thesystem requires a lexicon of the vocabulary of the domain as well as syntactic and semanticinformation about each word. The main advantage of the pattern matching technique is its sim-plicity. Nevertheless, this methodology is quite brittle because of pattern limitation and shallowsemantic representation.
Other methodologies are based on syntax-rule-based techniques. For instance, the LU-NAR system has proposed a prototype for building a natural English understanding systemwhich allows people to ask questions and request computations out their natural utterances in

24 Chapter 4. A Proposed Architecture for a French DMR Framework
the domain of geology (Woods, 1973). In general, the LUNAR system processes input phrasesin three stages. First of all, the syntactic analysis of the phrase is realized by using heuristicinformation. The semantic analysis is then performed in order to obtain a formal semantic in-terpretation of the query to the system. In the final stage, the formal expression is obtained bythe retrieval component in order to generate the answer for the request. By providing answersfor most of the expected questions intended to query data from the database, this system hasdemonstrated a serious advance in natural language understanding.
Using natural language for querying data rather than formal query languages is easier fornewbies who are not required to learn a new artificial language. Based on both syntax-rule-basedand semantic-grammar-rule-based techniques, the NLIDB system first processes syntacticallythe utterance input through a parser which generates a parse tree by consulting a set of syntaxrules. The semantic analysis then transforms the parse tree into an intermediate logic query(Androutsopoulos, Ritchie, and Thanisch, 1995). With this approach, NLIDB can be used forwide knowledge domains by updating semantic grammar definitions. Indeed, new semanticgrammars need to be rewritten or declared in order to adapt the system to new knowledgedomains. Stricter grammar rules that allow linking of semantic categories instead of syntaxrules have been used in semantic-grammar-rule-based systems such as Thompson et al., 1969;Hendrix et al., 1978; Templeton and Burger, 1983.
4.1.2 Empirical ApproachesIn the rule-base approach, semantic meaning representation has been applied mainly to simplenatural utterances in a specific domain. Natural language utterances are very diversified and canbe expressed under numerous forms. In fact, semantic analysis is a complex problem and hasdiverse applications such as machine translation, question answering systems, automated rea-soning, knowledge representation, and code generation. “Empirical approaches” is the generalterm for approaches using rule-based techniques, data-driven statistical analysis, or a combina-tion of these methods.
Ge and Mooney, 2005; Raymond and Mooney, 2006 have constructed a statistical parserthat aims to produce a semantically augmented parse tree (SAPT). Each internal node of theSAPT includes both a syntactic and a semantic annotation that are captured by semantic inter-pretation of individual words and basic predicate-argument structure of the sentence input. Arecursive procedure is then used to form a meaning representation for each node, in order toannotate the node and obtain meaning representation of the node’s children. In the final steps,SAPT is translated into a formal meaning representation.
Word Alignment-based Semantic Parsing (WASP1) (Wong and Mooney, 2006) has inher-ited the motivation found in statistical machine translation techniques to build a semantic parser.With no prior knowledge of the natural language syntax, WASP proposes an algorithm thattrains a semantic parser out of a set of natural language sentences annotated with their stan-dard meaning representations. More specifically, the authors of the system have analyzed thesyntactic structure of sentences using a semantic grammar (Allen, 1995). Sentence meaninghas been subsequently obtained by compositionality out of subparts extracted from the seman-tic parse. This work can be considered as a syntax-based translation model (Chiang, 2005).Thereby, translation is an important part of semantic parser. It includes a set of natural lan-guage sentence-meaning representation pairs. Another approach, called Synchronous Context-Free Grammar (SCFG) has been used for generating the pairs in the translation. SCFG definespair rules: X → <α, β> whereX → α denotes a production of the natural language semanticgrammar and X → β is a production of the meaning representation grammar. For each inpututterance e the task of semantic parsing provides derivations <e, f>, where f is a translation
1http://www.cs.utexas.edu/~ml/wasp/

4.1. State-of-the-Art in Discourse Meaning Representation 25
of e. Therefore, the semantic parsing model consists of an SCFG G and a probabilistic modelwith parameterized λ that has a possible derivation d, and returns its likelihood of being correctgiven an input e. The translation f is defined as:
f = m(arg maxd∈D(G|e)
Prλ(d | e)) (4.1)
wherem(d) is the meaning representation expression, D(G | e) denotes the set of all possiblederivations of G that yield e. In general, employing statistical machine translation techniquescan be viewed as a syntax-based translation approach (Wong and Mooney, 2006). We canachieve good performance and results comparable to the state-of-the-art on GeoQuery with(Andreas, Vlachos, and Clark, 2013).
The typed versions of grammar formalisms such as TAG, CCG, LFG or HPSG can be usedto build an immediate framework for deriving syntactic structure into a semantic representa-tion. Dependency structure analysis provides full annotation of words and their relations witheach other in the sentence. By using dependency trees, we can obtain a logical form through asequence of three steps: binarization, substitution, and composition (Reddy et al., 2016). First,a binarization is realized by mapping a dependency tree into an s-expression. For example, thesentence “Microsoft defeated Amazon” has the s-expression
(nsubj(dobj defeated Amazon)Microsoft).
As a second step comes the process of substitution by assigning a word or label in the s-expression to a λ-expression. For example,
defeated 7→λx.defeated(xe),
Microsoft 7→λy.Microsoft(ya),
Amazon 7→λz.Amazon(za),
nsubj 7→λfgz.∃x.f(z) ∧ g(x) ∧ arg1(ze, xa),
dobj 7→λfgz.∃x.f(z) ∧ g(x) ∧ arg2(ze, xa).
The composition step starts with a β-reduction used to compose the λ-expression terms inorder to obtain the final semantics of the input utterance. Here is an example after composition:“λz.∃x.defeated(ze) ∧ Microsoft(xa) ∧ arg2(ze, xa)”. In addition, the authors provide someremarks and post-processing operations related to the handling of prepositions, coordination andcontrol. For the learning task, they consider semantic parsing as a graph matching operationand use a linear model.
The D-LTAG System introduced an approach for discourse parsing based on the use ofthe lexicalized Tree-Adjoining Grammar (Forbes et al., 2003). Considering the compositionalaspects of semantics at discourse level is similar to the sentence level by factoring away infer-ential semantics and coreference features of the discourse markers. In their system, sentencesare disconnected and parsed independently from the discourse input. Then, the discourse con-stituent units and discourse connectives are extracted from the LTAG output derivations of thesentences. Finally, fully lexicalized trees of the discourse input are parsed anew using the sameprocess. One of the main contributions of this work is a corpus of discourse connectives thataims to determine the semantic meanings and the elementary tree of types that are lexicalizedin the scope of discourse grammar.
The approach based on the empirical modeling of language, along with the developmentof grammatical reasoning theory have led to improve robustness and efficiency of NLP appli-cations (Kaplan et al., 2004). The Boxer application has demonstrated the efficiency of usingthe empirical approach for achieving a semantic meaning representation from natural language

26 Chapter 4. A Proposed Architecture for a French DMR Framework
utterances in English (Curran, Clark, and Bos, 2007; Bos, 2008; Bos, 2015). Designed for awide-coverage domain of natural language, Boxer generates semantic meaning representationsfrom discourse input under the CCG lexicalized grammar formalism where words in the sen-tence are assigned to lexical categories. In the output, one obtains meaning representation eitherin DRS formalism or represented as First-Order Logic expressions.
Based on the result of Boxer framework, the FRED system allows the generation of RD-F/OWL ontologies—a popular formal knowledge representation form on the web—and pro-vides linked data out of natural language utterances (Gangemi et al., 2017; Draicchio et al.,2013). Indeed, natural language input is analyzed and transformed into DRSs by using Boxer.In parallel to this process, information on semantic role labeling and named entities is added tothe DRSs output. The final stage focused on transforming DRSs into a RDF/OWL representa-tion by the use of patterns.
Concerning French language, the Grail tool allows parsing of French discourses in orderto obtain meaning representations in DRS (Moot, 1998; Moot, 1999; Moot, 2010; Lefeuvre,Moot, and Retoré, 2012). Unlike Boxer, the input of Grail requires syntactically analyzed databased on the TLG (Type-Logical categorial Grammars) formalism (Moortgat, 1997; Morrill,2012). TLG has been mostly applied in theoretical issues and relations to logic and theoremproving, while CCGs have been rather concerned with keeping expressive power and automata-theoretic complexity to a minimum. Therefore, CCGs are more relevant to the issues of lin-guistic explanation and practical computational linguistics (Steedman and Baldridge, 2011).
4.1.3 Semantic Annotation CorporaFrameNet (Baker, Fillmore, and Lowe, 1998) is one of the first corpora that were created for thepurpose of semantic annotations. FrameNet has been developed on the base of ameaning theorycalled Frame Semantics (Fillmore et al., 1976). A frame semantic is a schematic representationof a situation using different participants, propositions, and conceptual roles. In other words, themeaning of a syntax can be interpreted as a semantic frame description containing informationrelated on a type of event, relation, entity, and participants.
The Propbank corpus (Palmer, Gildea, and Kingsbury, 2005) adds a layer to the syntac-tic structures of the Penn Treebank (Marcus et al., 1994). This layer contains information onpredicate-argument, or semantic role labels. This is a shallow semantic annotation resourcebecause it does not annotate co-reference, quantification, or some higher-order language phe-nomena. Propbank prioritizes annotation of verbs rather than the one of other word types.
The PDTB corpus(Prasad et al., 2005; Prasad et al., 2008) is a large-scale semantic an-notation corpus with the rationale that discourse relations can be identified by a set of explicitwords or syntagms (discourse connectives). PDTB aims to annotate the million words of thePenn TreeBank by adding a layer of information related to discourse structure and discoursesemantics. More specifically, there is a large number of annotation types in this layer, such asexplicit or implicit discourse connectives and their arguments, semantic sense of each discourseconnective, semantic classification of each argument, and attribution of discourse connectivesand their arguments.
The OntoNotes corpus (Hovy et al., 2006) has been created on the base of a methodol-ogy that can produce a corpus with 90% inter-annotator agreement. This corpus focuses on awide-coverage domain of meaning representation which encompasses word sense, predicate-argument structure, ontology linking, and co-reference. This corpus covers three languages—English, Arabic and Chinese—and numerous text genres such as articles, blogs, newswires,broadcast news, etc., in order to obtain a independent domain resource (Table 4.1).
The GMB corpus (Basile et al., 2012) is a large semantically-annotated English text cor-pus with deep semantics represented in the DRS formalism. It is an optimal semantic resourcesince it annotates various language phenomena, such as rhetorical relations, presuppositions,

4.1. State-of-the-Art in Discourse Meaning Representation 27
T 4.1: Volumetry of the OntoNotes corpus
English Chinese Arabic
Newswire 625,000 250,000 300,000
Broadcast News 200,000 250,000 N/A
Broadcast Conversation 200,000 150,000 N/A
Web Data 300,000 150,000 N/A
Telephone Conversation 120,000 100,000 N/A
Pivot Text N/A 300 N/A
predicate-argument structure, thematic roles, etc., which can be reused or be enhanced by con-tributions from other researchers. The authors have first created a gold-standard semantic rep-resentation corpus by manual annotation. Then, PMB, a parallel corpus over four languages(English, German, Italian and Dutch) has been developed in recent times with the same objec-tive as GMB (Abzianidze et al., 2017).
The Sembanking corpus (Banarescu et al., 2013) is a semantic annotation corpus of En-glish texts with annotated named entities, co-reference, semantic relations, temporal entitiesand discourse connectives using the AMR representation format. Based on assigning similarAMR representations to sentences having the same basic meaning, this corpus aims to abstractaway from syntactic characteristics. Nevertheless, a limitation of this corpus is the fact that itdoes not annotate inflectional morphology for tense and number, or universal quantifiers. Thiscorpus has been created by manual annotation as well.
The UCCA corpus (Abend and Rappoport, 2013) has been created by analyzing and anno-tating English texts using purely semantic categories and structures. The semantic annotationsare based on argument-structure and linkage language phenomena. A Basic Linguistic The-ory (Dixon, 2010b; Dixon, 2010a; Dixon, 2012) is used for grammatical description based onthe computation of semantic similarity as its main criterion for structuring and categorizingconstructions. More specifically, this corpus is based on a semantic schema that generalizesspecific syntactic structures and is not relative to a specific domain or language. There arecurrently 160,000 tokens from English Wikipedia, as well as 30,000 parallel English-Frenchannotations.
The UDS corpus (White et al., 2016) is built with the purpose of strengthening universaldependencies for current data sets with the addition of robust, scalable semantic annotations.This corpus aims to provide two important contributions. The first one is standardization ofsyntactic dependency annotations, so that they can be reused across different languages. Theother contribution is to provide semantic annotations that include numerous types of semanticinformation for different languages. In its latest version (White et al., 2019), the UDS cor-pus provides a semantic graph specification with graph structures defined by using predicativepatterns. As a result, we can query UDS graphs using SPARQL.
The emergence and rapid development of corpora that annotate syntactic and semantic in-formation brought a novel approach for building language analysis tools. For example, syntacticanalysis with POS tagging can be achieved with high accuracy by using probability estimatesfrom the Penn Treebank training corpus: 97.96% in (Bohnet et al., 2018), 97.85% in (Akbik,Blythe, and Vollgraf, 2018), and 97.78% in (Ling et al., 2015). For the constituency pars-ing task, extracting a constituency-based parse tree that represents the syntactic structure of asentence according to a phrase structure grammar, can be achieved with 96.34% accuracy viaa supervised learning approach using the Penn Treebank corpus (Mrini et al., 2019). Recent

28 Chapter 4. A Proposed Architecture for a French DMR Framework
work in the NLP community shows that empirical or corpus-based methods are currently themost promising approach to improve accuracy and efficiency in many tasks (Devlin et al., 2018;Yang et al., 2019; Liu et al., 2019).
4.1.4 Corpus-driven approachesSupervised Learning Approaches
A consistent current tendency is the increasing use of supervised learning techniques that con-sider learning models on feeding examples of available input output pairs. Along with therise of numerous semantic annotation corpora, the supervised learning approach is consideredas a modern approach to developing robust, efficient NLP applications (Church and Mercer,1993). Several works attempt to tackle semantic parsing using semantic annotation corpus withsentence-meaning representation form pairs (Zelle andMooney, 1996; Zettlemoyer and Collins,2012; Kwiatkowski et al., 2010).
In machine learning, SVMs are considered as an important maximum-margin separatorlearning method to prevent over-fitting for high dimensional data such as texts (Joachims, 1998).Along with this supervised learning approach, Kernel-based Robust Interpretation for SemanticParsing (KRISP2) (Kate andMooney, 2006) provides an approach for mapping natural languageutterances to formal meaning representations, this method uses SVMs with string kernel-basedclassifiers (Lodhi et al., 2002). KRISP defines a semantic derivation D of an natural languageutterence s as parse tree of a meaning representation. Each node of the parse tree containsa substring of the sentence and a production, denoted as a tuple (π[i . . . j], ), where π is theproductions and [i . . . j] the substring s[i . . . j] of s. A semantic derivation of an natural lan-guage is assigned to a meaning representation. If a semantic derivation is corresponding withthe correct meaning representation of the natural sentence, it is called a correct semantic deriva-tion otherwise it is an incorrect semantic derivation. The probability model using string-kernelbased SVM classifiers Pπ(u) is defined as production π of the MRL grammar G that coversthe natural lanuage substring u:
P (D) =∏
π,[i...j]∈D
Pπ(s[i . . . j]). (4.2)
In a nutshell, once the training corpus of natural language utterances are paired with their mean-ing representation (si,mi)|i = 1 . . . N , KRISP first parses the meaning representations usingmeaning representation language grammar G. KRISP then learns a semantic parser iterativelyfor every production π ofG, and for each iteration, position and negative examples sets are col-lected. In the first iteration, the set of positive examples for production π contains all sentencesthe meaning representation parse tree of which use the production π. The negative example setincludes other training utterances. By this, an SVM classifier is trained for each production πwith a normalized string kernel. Besides, we have others approaches using SVM for classifier inorder to learn semantic parsing (Nguyen, Shimazu, and Phan, 2006; Merlo and Musillo, 2008;Lim, Lee, and Ra, 2013).
Conversation text is a rich source for analyzing the meaning of an utterance in a interactivecommunication context. Many dialog systems has been developed with parsing semantic fromuser utterances (Allen et al., 2007; Litman et al., 2009; Young et al., 2010). For example, in atrain booking system, the sentence “I want to travel to Paris on Saturday” can be transformedto lambda-calculus expression “λ.to(x, Paris) ∧ date(x, Saturday)”. This expression is arepresentation form of the semantic meaning extracted from the sentence. In this scope, Artziand Zettlemoyer, 2011 has presented an approach for learning the meaning representation of
2http://www.cs.utexas.edu/~ml/krisp/

4.1. State-of-the-Art in Discourse Meaning Representation 29
a user’s utterance. The authors define a conversation C = (U,O) as a sequence of utterancesU = [u0, . . . , um] and a set of conversational objects O. Training data is a set of n examples:(ji, Ci) : i = 1, . . . , n. For each example, the goal is to learn to parse the user utterance atposition ji in Ci. The label meaning representation data paired with x are defined as latentvariables (Singh-Miller and Collins, 2007). Learning for semantic parsing is defined by PCCGs,which contain a lexicon and a weighted linear model for parse selection.
Unsupervised Learning Approaches
Unlike supervised machine learning, unsupervised learning infers unknown patterns from adata without reference to labeled outcomes. It is regularly used to discover potential underlyingstructures implied in the data. The authors of Poon and Domingos, 2009 were pioneers in at-tempting to build Unsupervised Semantic Parsing (USP) based on Markov logic. Their parsingmodel consists of three key ideas. First, the target predicate and object constants can be con-sidered as clusters of syntactic variations of the same meaning and can be directly learned fromdata. Secondly, the identification and clustering of candidate semantic representation forms areintegrated with learning for meaning composition. Thirdly, this approach starts from syntac-tic analyses and focuses on their translation into semantic representations. The input data ofthe training process consists of dependency structures of utterances that contain more seman-tic information than constituent structure. The output is a probability distribution over logicalform clusters and their compositions. It is worth mentioning that a knowledge base extractedfrom the GENIA biomedical data set (Kim et al., 2003) has been used for the experiment andevaluation based on the performance in answering a set of questions.
A problem with the generation of self-induced clusters for the target logical forms is ab-sence of information matching with an existent knowledge base, ontology, or database. TheUSP approach we describe above is consequently unable to directly answer complex questionsagainst an existing database without an knowledge base matching step. Grounded UnsupervisedSemantic Parsing (GUSP) (Poon, 2013) alternately employs the database as a form for indirectsupervision. GUSP proposed an approach that combines unsupervised semantic parsing withgrounded learning from a database, which does not require ambiguous annotations or oracleanswers. With a set of natural language questions and a database, GUSP learns a probabilisticsemantic distribution by using the Expectation-Maximization algorithm (Dempster, Laird, andRubin, 1977). Dealing with the lack of direct supervision, GUSP constrains the search spacethrough the database schema, and through bootstrap learning. The evaluation is based on theATIS travel planning domain by experimenting directly the task of translating questions intodatabase queries and by measuring question-answering accuracy.
Sequence-to-Sequence learning approaches
Along with the emergence of annotated corpora for semantic meaning representation, machinelearning—especially through neural network models and their proven efficiency in a varietyof NLP tasks—has motivated the investigation of the method of handling semantic meaningrepresentation as a sequence transduction problem, where discourse is mapped into a meaningrepresentation format. In what follows, we will examine some works based on this researchorientation.
Transforming directly natural language into a logical formalism, a machine intepretablemeaning representation, can be implemented through neural network models. Indeed, Dongand Lapata, 2016 introduces a method based on an attention-enhanced encoder-decoder model.This method transforms input sentences into vector representations, and then generates theirlogical forms by adjusting the sequence output on the encoding vectors. More specifically, itbuilds a learning model where natural language input q = x1x2 . . . xn is mapped to a logical

30 Chapter 4. A Proposed Architecture for a French DMR Framework
form representation a = y1y2 . . . ym. A conditional probability if calculated for each elementin a versus q.
p(a | q) =n∏
t=1
p(yt | y<t, q) (4.3)
where y<t = y1y2 . . . yt−1. Here, encoding is the task of converting natural language input qinto the vector representation a, while decoding is the task of learning to generate y1y2 . . . ymmatched with the encoding vector.
Xiao, Dymetman, and Gardent, 2016 introduce an approach mapping natural language (re-stricted to questions) into logical form representations by using a RNN model associated withLSTM units (Hochreiter and Schmidhuber, 1997). Based on the use of a simple grammar tomap logical forms paired with canonical utterances (Wang, Berant, and Liang, 2015), the au-thors have realized three different sequentialization approaches for a logical form: a normallinearization of the logical form, a canonical form, and a derivation sequence related to the un-derlying grammar (Table 4.2). Therefore, they have a large amount of choices for building avector representation input using their encoder-decoder neural network model.
T 4.2: An example of various cases of natural language input and logicalform output
Natural language article published in 1950
Logical Form get[[lambda,s,[filter,s,pubDate,=,1950]],article]
Canonical Form article whose publication date is 1950
Derivation Sequence s0 np0 np1 typenp0 cp0 relnp0 entitynp0
The amount of annotated data needed for training is a recurrent problem in NLP task us-ing the supervised approach, since acquiring data is expensive and sometimes even infeasible.To overcome this drawback, transfer learning can be used: a model trained on one task is re-purposed for another, related task (Torrey and Shavlik, 2010). Fan et al., 2017 has proposedan approach to use multiple representations in a multi-task framework by modifying the pa-rameters of the learning process. The repesentations have common structures that are implicitacross different formalisms (SPARQL for WikiData (Vrandečić and Krötzsch, 2014), MQlfor Freebase (Flanagan, 2008)) and tasks. They use encoder-decoder architectures for trans-fer learning in semantic parsing under the hypothesis that the sequence-to-sequence paradigmlearns a canonicalized representation across all tasks. Based on a single task encoder-decoderbaseline, the authors update the process to achieve an improvement in accuracy.
One of the latest work involving the generation of discourse meaning representation (Liu,Cohen, and Lapata, 2018) uses the GMB corpus. The authors propose an approach that be-gins with the conversion of DRSs data to tree forms and then builds a structure-aware modelin which they divide the decoder task into three small decoding processes: basic DRS structureprediction, condition prediction, and referent prediction. Based on an encoder-decoder neuralnetwork model, natural language input X is encoded into vector representations and a Bidi-rectional RNN with LSTM units is used to obtain hidden state representation of the encoderlayer. The decoder is initialized through the hidden state of the encoder layer, and then data arepassed to a forward LSTM:
hdj = LSTM(eyj−1) (4.4)where hdj is the hidden state representation of the j-th token in the decoder, and eyj is a vectorword embedding of output yj . Besides, the decoder layer adds context information from theencoder layer by creating a embedding of the (i−1)-th predicted token to the output of the i-th

4.2. Meaning Representation Parsing Through Deep Neural Network Models 31
token. As a result, with experimental outcomes on the GMB corpus, this approach can recoverDRS with an accuracy of 77.54%. On the other side, using the same GMB corpus, Noord et al.,2018; Noord, 2019 have demonstrated that using sequence-to-sequence neural network modelsallows obtaining well-formed DRSs with high accuracy.
4.2 Meaning Representation Parsing Through Deep Neural Net-work Models
Currently deep neural network models such as Convolutional Neural Networks(CNN), Recur-rent Neural Network (RNN), Recursive Neural Networks, Attention Mechanisms, ParallelizedAttention (Transformer), etc., are frequently applied to NLP tasks (Young et al., 2018). Whencompared to traditional machine learning algorithms, these models achieve impressive results.On the whole, it is not exaggerated to say that using deep neural network models is one the theleading research trends in the next decade for improving the outcome of NLP tasks such as ma-chine translation, language modeling, question answering, natural language inference (Edunovet al., 2018; Melis, Kočiskỳ, and Blunsom, 2019; Šuster and Daelemans, 2018; Liu et al., 2019).Meaning Representation parsing may also fall inside the scope of this trend, more precisely thetask of mapping natural language into an interpreted form that can be understood by the ma-chine. As mentioned previously, we have recently observed the emergence of the use of thesequence-to-sequence model that is built upon RNNs or Attention Mechanisms. This provesthat the use of deep neural network may only be in the early stages of its development and stillhas many prospects in the future.
Traditional machine learning algorithms can achieve a good outcome when data are of suf-ficient size. However, when data size is increased, the outcome is very difficult to improve.In other words, we observe a saturation on the result even in hte presence of a large data size.Therefore, the dramatic development of deep neural network models is based, among other fac-tors, on their ability to outperform other machine learning methods in the presence of massivedata amounts. Besides, deep neural network models carry other benefits, such as:
• The same neural network model can be applied to numerous applications and differentdata types. For example, the CNN model is frequently used in image and video recogni-tion applications (Lawrence et al., 1997). It can also be used for recommendation systemor NLP applications (Ying et al., 2018; Kim, 2014). The data input for deep learningmethods can be in text, image, video, sound, or time series format.
• An important step in machine learning algorithms is feature engineering, where featuresare extracted from raw data in order to achieve a better data representation for the givenproblem. This work can improve the model’s accuracy. Deep learning techniques candirectly start with raw data. Features will be automatically searched and created by theneural network in learning process. Therefore, we can save time spent on searching fea-ture representation of data.
• Neural network algorithms can uncover new, more complex features than those that hu-mans can imagine. In other words, deep learning techniques are able to achieve an optimalrepresentation of data by automatic learning.
• Hardware computation power advances are one of the foundation for deep learning in-novations (Moshovos et al., 2018). Changing computation from using CPUs to paral-lel computation by GPUs improves performance and reduces time-consumption for thetraining phase. Besides, neural network model can be scaled for massive volumes of data.

32 Chapter 4. A Proposed Architecture for a French DMR Framework
• Deep neural network architecture is usually flexible enough to be reused for problemsthat can be encountered in other fields or in new problems in the future.
Although the importance of deep neural network models is increasing and several advancesin its research are reaching great heights, deep learning still has a few drawbacks and challengesthat we need to tackle in order to obtain the desired outcomes. One of the limitations of deeplearning is the requirement of the amount of data using for training models. In general, deepneural network models has downsides as follows:
• Massive amount of available data collected over the recent years has contributed to theincrease of the use of deep learning methods. Nevertheless, the deep neural networksmodel requires a large amount of data in order to obtain better performance versus tradi-tional machine learning. Although there are approaches where neural networks manageto operate with small amounts of data, in most cases they require overwhelming amountsof data.
• Deep neural network architectures have a more complex structure than traditional ma-chine learning algorithms. Therefore, they are expensive with respect to the time requiredto train models for computing complex data models. State-of-the-art neural networkmodels can take several days to complete the training phase of a model. For example,BERT-large model (Devlin et al., 2018), which consists of 24 different layers and 1024elements for each hidden state size, has in total 340 millions parameters. This model hastaken 4 days to train completely from scratch.
• Deep learning approaches require a large number of computationally heavy operationsto handle high-dimensional matrices that can be executed parallely on GPUs or TPUs.Therefore, it requires significant hardwareGPU or TPU power. For example, by adjustingthe batch size and adding more TPU power, time consumption for training of the BERTmodel was reduced from 4 days to 76 minutes (You et al., 2019). As a result, using moreGPU or TPU power leads to an increase in the cost of implementing projects for users.
• The development of deep learning is based on applied research with important contri-butions coming form both the academic and the industrial side. The fundamental theoryof deep learning is currently inherited from machine learning with concepts such as bias,variance, and overfitting that are also used in disciplines such as statistical learning andgeneralization bounds. In deep learning, concepts such as SGD, Batch Normalization,which are used for estimating the gradient descent with mini batches, have become morepopular and are used as powerful regularizers. Indeed, their mathematical structure hasnot yet been clearly defined. We currently do not still have a standard theory for deeplearning. As a result, it is difficult to select a right deep learning model or cost functionfor people with deep learning practical skills because this work requires knowledge oftopology, training methods and other notions.
• Most of deep learning models behave as black boxes and are unable to provide explana-tions on their outcomes. In high-risk domains (e.g., health care, finance and banking),this issue influences the decision to use deep learning models because the trust in a modeland the ability to to understand its behavior play the most crucial role.
When it comes to the representation parsing task, mapping natural language data sets to a mean-ing representation form plays an extremely important role in successfully using deep learningnetworks. It also becomes a crucial criterion for selecting the approach to be used. The gen-eration of an open domain data set for this task requires a lot of time and effort because ofthe richness and diversity in structure of natural language. There exist some data sets for the

4.3. An Architecture for a French Semantic Parsing Framework 33
English language, in FOL, AMR, or DRS formalisms as listed in the previous section. For otherlanguages such data sets are often lacking. In the case of French language, it is difficult to finda data set to be used for a semantic parsing task. This problem can be solved in some cases suchas language translation or cross-language, using transfer learning. Nevertheless, the achievedresults are rather limited (Mikolov, Le, and Sutskever, 2013; Singla, Bertino, and Verma, 2019).
Deep neural network models have limitations when it comes to compositionality, an impor-tant principle in linguistics in general and for the semantic parsing task in particular. Com-positionality expresses the fact that the meaning of an expression can be determined from themeaning of its constituent expressions and the combination rules used to build them. For ex-ample, if a person knows meaning of a verb “to run” and an adverb “slowly”, e can immediatelyunderstand the meaning of “to run slowly” even though e has never seen or heard this expres-sion before (because of its semantic contradiction). This principle explains a part of reason howhuman can quickly create a large number of expressions from a limited vocabulary set (Loula,Baroni, and Lake, 2018). In general, deep neural network are not able to discover and storelanguage skills like humans in order to reuse or recombine them in a hierarchical structure inorder to face new problems or challenges. Many approaches have been proposed to tackle thisproblem such as using composition of primitives, which is based on the classic idea that newrepresentations can be built by the combination of primitive elements (Lake et al., 2017), orby using the GOFAI infrastructure, which provides a valid and useful set of primitives (Gar-nelo and Shanahan, 2019). Besides, there is the Recursive Model Network architecture, oneof the first models used to learn distributed representations of linguistic structures (Goller andKuchler, 1996). This architecture has been proposed as an approach of compositional learningsequence out of natural language input (Socher et al., 2011; Lewis, 2019). Finally, the inabilityof deep neural network models to effect a computation on compositional learning is one of themain reasons for deep learning most critical limitations, besides of the requirement of feedingmodels with massive amount of data.
4.3 An Architecture for a French Semantic Parsing FrameworkIn the previous section we gave an overview on the state-of-the-art of research in semanticparsing, with approaches based on reasoning in syntax-based, grammar-based or rules-based,statistical models and deep neural model networks. The popularity of the sequence-to-sequencemodel in the recent period reveals the advantages of deep learning networks versus other tradi-tional machine learning models. However semantic parsing is a challenging and important taskin NLP domain that aims to transform natural language utterance into a meaning representationform.
Our objective in this work is the proposal and development of a framework in order toperform semantic parsing for French language. The lack of available data sets and the limita-tion in computation with compositional learning—i.e., learning concepts and combining themtogether in different ways—are major obstacles when engaging in deep neural network models.Furthermore, using the traditional approach has proven its success in numerous applications.For example, Boxer is an efficient tool for obtaining a semantic representation of English sen-tences and it became the most important factor in generating the GMB and PMP meaning rep-resentation corpora (Bos, 2008; Abzianidze et al., 2017). Following the empirical approach, wecan overcome the constraint on available data and keep compositionality in analyzing linguisticsthrough natural manner in building sentences.
In this section, we will introduce a complete architecture for achieving meaning repre-sentation from the French utterance input (Figure 4.1). This architecture includes differentprocessing steps which we can encapsulate in four main tasks:
1. preprocessing with French discourse input,
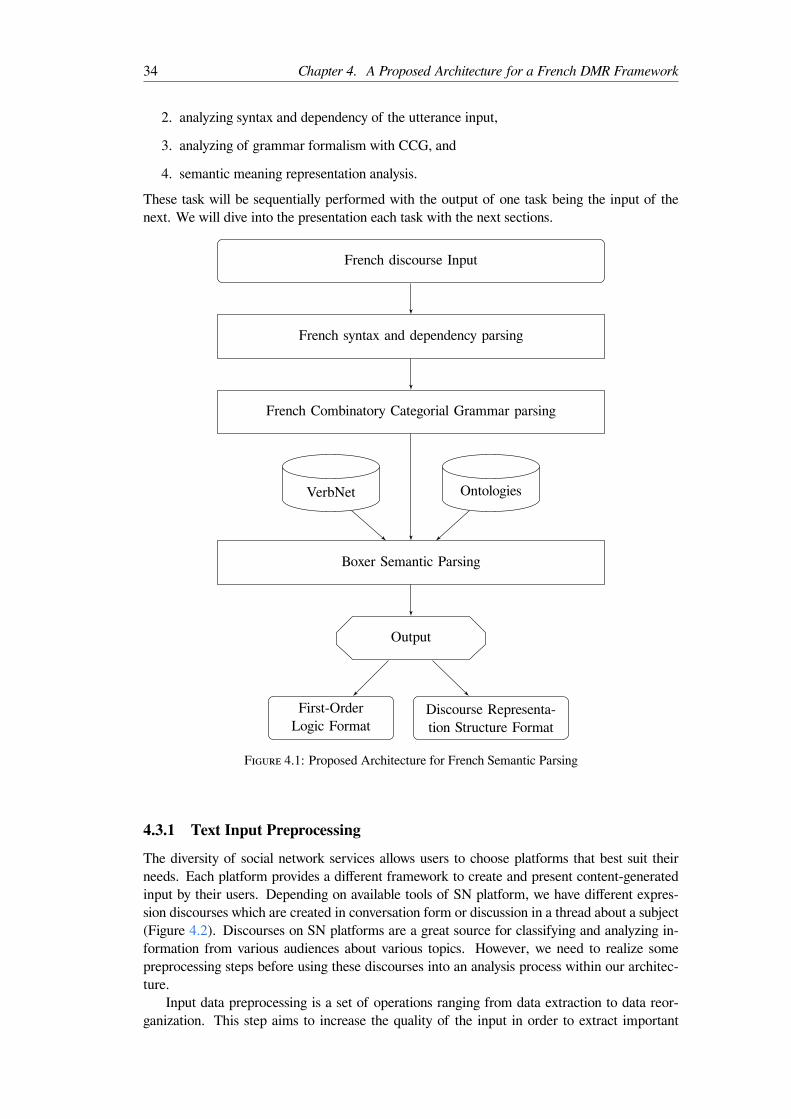
34 Chapter 4. A Proposed Architecture for a French DMR Framework
2. analyzing syntax and dependency of the utterance input,
3. analyzing of grammar formalism with CCG, and
4. semantic meaning representation analysis.These task will be sequentially performed with the output of one task being the input of thenext. We will dive into the presentation each task with the next sections.
French discourse Input
French syntax and dependency parsing
French Combinatory Categorial Grammar parsing
VerbNet Ontologies
Boxer Semantic Parsing
Output
First-OrderLogic Format
Discourse Representa-tion Structure Format
F 4.1: Proposed Architecture for French Semantic Parsing
4.3.1 Text Input PreprocessingThe diversity of social network services allows users to choose platforms that best suit theirneeds. Each platform provides a different framework to create and present content-generatedinput by their users. Depending on available tools of SN platform, we have different expres-sion discourses which are created in conversation form or discussion in a thread about a subject(Figure 4.2). Discourses on SN platforms are a great source for classifying and analyzing in-formation from various audiences about various topics. However, we need to realize somepreprocessing steps before using these discourses into an analysis process within our architec-ture.
Input data preprocessing is a set of operations ranging from data extraction to data reor-ganization. This step aims to increase the quality of the input in order to extract important

4.3. An Architecture for a French Semantic Parsing Framework 35
information. There are many steps such as elimination of unnecessary characters, analysis ofemoticons, or spell checking. In general, this task is divided into two small tasks: data collectionand data preparation. Data collection focuses on extracting texts concerning communicationsor discussions about a interested topic on SN platforms. Data preparation is the process ofcleaning up the raw data.
: Bonjour, J’aimerais avoir des informations concernant vos services.Pourriez-vous m’aider? (Hello, I would like to have information about your ser-vices. Could you help me?)
24: Bonjour, Très bien je peux vous assister dans vos recherches. Quel serviceattire votre attention? (Hello, Very well I can assist you in your research. Whichservice attracts your attention?)
: J’ai consulté la fiche de compte d’épargne de Livret A sur votre site. Aussi jesouhaiterais connaître le taux maintenu de ce service? (I have consulted the LivretA savings account sheet on your site. Also I would like to know the maintained rateof this service?)
24: …
F 4.2: A conversation on a message platform
The analysis of a sentence begins from lexical units or groups of lexical units. At the lowestlevel, text input is a character sequence and lexical units or tokens need to be identified andextracted from it. This process is called tokenization. In most cases, the extraction of tokensconsists simply in splitting by the space character. However, a space-separated token may becreated from different words as in contractions of particles in front of verbs or nouns startingwith a vowel. Tokenization is best done in parallel with lemmatization, an important operationfor French, in which many words may change form depending on some factor such as the genderor number for nouns and adjectives, tense or mode for verbs, etc. (for example, see Figure 4.3).
<sentence><word><token> je </token> <lemma> je </lemma></word><word><token> ne </token> <lemma> ne </lemma></word><word><token> arriverai </token> <lemma> arriver </lemma></word><word><token> pas </token> <lemma> pas </lemma></word><word><token> à </token> <lemma> à </lemma></word><word><token> la </token> <lemma> le </lemma></word><word><token> heure </token> <lemma> heure </lemma></word></sentene>
F 4.3: Tokenization and lemmatization of the sentence “je n’arriverai pasà l’heure” (I won’t arrive on time)
4.3.2 Syntax and Dependency AnalysisSyntax is an essential component of every language, it is a set of specific rules, constraints,conventions, and principles defined in order to govern the way words are combined into phrases,phrases are linked into clauses, and clauses form sentences. Like in the case of English language,words in French language are combine in order to form constituent units. In general, theseconstituent components include words, phrases, clauses and sentences. A sentence is regularlybuilt up following a hierarchical structure of the components: sentence← clauses← phrases

36 Chapter 4. A Proposed Architecture for a French DMR Framework
← words. The sense of an utterance can be investigated on the basis of these constituentcomponents.
Analysis of the language’s syntax brings helpful information into many NLP tasks such astext processing, text classification, spell checking, annotation or other parsing tasks. Whilesyntax analysis is the process of analyzing the input utterances with words conforming to thegrammar rules of the language, we call structural analysis the task of extracting dependencyrelations in a sentence, represent its grammatical structure and the relationships between thewords or constituent components. We currently have several typical parsing techniques forsyntax and structure analysis as follows:
• POS Tagging
• Syntax Chunking
• Constituency Parsing
• Dependency Parsing
Parts of speech tags
La réforme des retraites sera menée à son terme .
DET NC P NC V VPP P DET N PUNC
T 4.3: POS tagging of the example sentence “Pension reform will be com-pleted.” by using Stanford Tagger
Definition 4.3.1. Parts of speech tagging is the process of classifying words in a sentence to acorresponding part-of-speech label, depending on its context and role.
Parts-of-speech tags are among the lower analysis levels, together with morphological andlexical analysis. Their analysis provides information related to each word in the sentence (Table4.3). In French language, words can belong to the following categories:
• Noun: the words in this category has the largest quantity in most languages, includingFrench. This word type refers to a thing, a person, an animal, a place, an event, a sub-stance, a quality, an ideal or an action. We have two small groups of this category: com-mon nouns and proper nouns. In French, a noun may take several forms depending ongender (masculine or feminine) or number (singular or plural). For example, the word“chat” (cat) in French can take four forms depending on the context: un chat (M/S), unechatte (F/S), des chats (M/P or M+F/P), des chattes (F/P). In our POS tag list, N is usedfor labeling nouns.
• Determiner: a class of words used in front of a noun or of a noun phrase. Determinerscan be definite articles (le, la, les: the), indefinite articles (e.g. une, un, des: a, an),demonstratives (e.g., ce, cette, ces: this, that, these, those), possessive pronouns (e.g.,ma, mon, mes: my; ta, ton, tes, votre, vos: your; sa, son, ses - its, her, his ; notre, nos- our ; leur, leurs - their). Besides, there are other determiner types such as quantity,relative or interrogative determiners. The DET label is used for this type of POS tag.
• Verb: a group of words used to describe an action, state, experience or occurrence. Verbsplay an important role in order to constitute a predicate in a clause. Besides that, verbs

4.3. An Architecture for a French Semantic Parsing Framework 37
are governed by grammatical categories such as tense (i.e., past, present, or future), mood(i.e., indicative, imperative, subjunctive or conditional), voice (i.e., active, passive or re-flexive), and aspect (i.e., perfective or imperfective). In general, verbs are mostly themain sentence part along with nouns. Verbs can be divided into auxiliary verbs whichare used to indicate the tense or mood of other verbs (e.g., être, avoir: to be, to have), andmain verbs (the major part). Modal verb can be auxiliary verbs or main verbs dependingon their role in the sentence. V and AUX labels are used to present for main verbs andauxiliary verbs in POS tag list.
• Adjective: a class of words used to modify or describe nouns or pronouns. The role ofadjectives in a sentence is to provide more detail information about the word to whichit refers. In English an adjective is usually placed in front of the noun it modifies, whilein French the majority of adjectives occurs after the nouns it’s describing in French, theexception being some adjectives with basic meanings (e.g., bon, beau, bref, grand, joli,petit: fine, good, brief, large, pretty, small etc.), functional adjectives (e.g., autre, même,nombreux, divers: other, same, numerous, various, etc.), emphatic adjectives (e.g., vaste,horrible, excellent: huge, terrible, exellent, etc.), adjectives with different meaning de-pending on their position (e.g. ,“cher” adjective is used before the noun with meaning“dear” and after the noun with meaning “expensive”). The ADJ label is assigned to ad-jectives in the POS tag set.
• Adverb: a class of words or phrases that changes, modifies or qualifies several types ofwords including verbs, adjectives, clauses, other adverbs. Adverbs can be categorizedinto some typical categories depending on activities denoted by verbs in sentences: ad-verbs of manner, place, time, quantity, affirmation, and negation. First of all, adverbsof manner denote how an action can be carried out (e.g., rapidement, malheureusement,facilement: rapidly, sadly, easily). Secondly, adverbs of place focus on explaining wherean action occurs in order to provide information of direction, distance or position (e.g.,ici, dehors, autour: here, outside, around). Thirdly, adverbs of time express when orhow often something occurs (e.g., toujours, aujourd’hui, hier: always, today, yesterday).Fourthly, adverbs of quantity are used to indicate the quantity of an action (e.g., moins,très, environ: less, very, about). Finally, adverbs of affirmation and negation are used todeclare that some statement is true or false (e.g., certes, oui, vraiment, nullement, pas:certainly, yes, really, not, not). The ADV label is used for this class of words in the POStag set.
• Preposition: a small set of words placed in front of nouns, pronouns, or phrases to expressa relationship between words within a sentence. Like adverbs, prepositions do not changeform. In French, a preposition can be combined with an article to create a single word(see Table 4.4). The PRP label is used for prepositions in the POS tag set.
T 4.4: Contraction of prepositions and articles
Preposition Article Combined Word Meaning
àle au
at, in ,toles aux
dele du
from, of, byles des
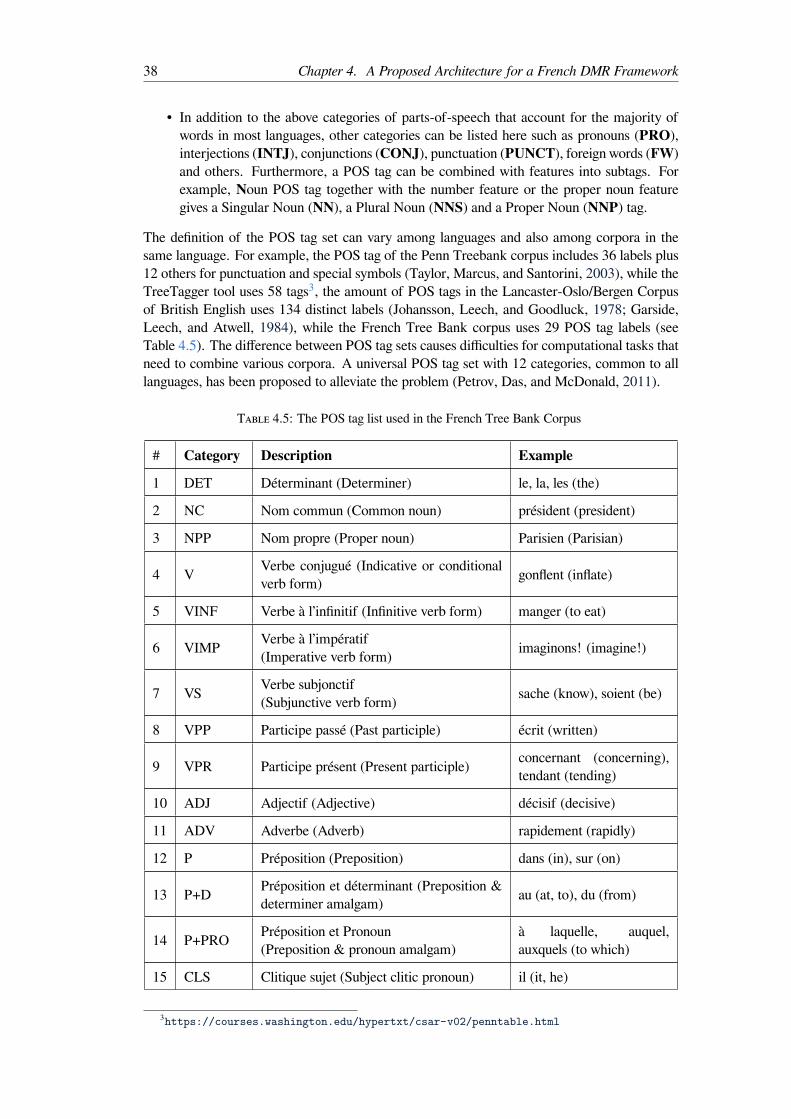
38 Chapter 4. A Proposed Architecture for a French DMR Framework
• In addition to the above categories of parts-of-speech that account for the majority ofwords in most languages, other categories can be listed here such as pronouns (PRO),interjections (INTJ), conjunctions (CONJ), punctuation (PUNCT), foreign words (FW)and others. Furthermore, a POS tag can be combined with features into subtags. Forexample, Noun POS tag together with the number feature or the proper noun featuregives a Singular Noun (NN), a Plural Noun (NNS) and a Proper Noun (NNP) tag.
The definition of the POS tag set can vary among languages and also among corpora in thesame language. For example, the POS tag of the Penn Treebank corpus includes 36 labels plus12 others for punctuation and special symbols (Taylor, Marcus, and Santorini, 2003), while theTreeTagger tool uses 58 tags3, the amount of POS tags in the Lancaster-Oslo/Bergen Corpusof British English uses 134 distinct labels (Johansson, Leech, and Goodluck, 1978; Garside,Leech, and Atwell, 1984), while the French Tree Bank corpus uses 29 POS tag labels (seeTable 4.5). The difference between POS tag sets causes difficulties for computational tasks thatneed to combine various corpora. A universal POS tag set with 12 categories, common to alllanguages, has been proposed to alleviate the problem (Petrov, Das, and McDonald, 2011).
T 4.5: The POS tag list used in the French Tree Bank Corpus
# Category Description Example
1 DET Déterminant (Determiner) le, la, les (the)
2 NC Nom commun (Common noun) président (president)
3 NPP Nom propre (Proper noun) Parisien (Parisian)
4 V Verbe conjugué (Indicative or conditionalverb form) gonflent (inflate)
5 VINF Verbe à l’infinitif (Infinitive verb form) manger (to eat)
6 VIMP Verbe à l’impératif(Imperative verb form) imaginons! (imagine!)
7 VS Verbe subjonctif(Subjunctive verb form) sache (know), soient (be)
8 VPP Participe passé (Past participle) écrit (written)
9 VPR Participe présent (Present participle) concernant (concerning),tendant (tending)
10 ADJ Adjectif (Adjective) décisif (decisive)
11 ADV Adverbe (Adverb) rapidement (rapidly)
12 P Préposition (Preposition) dans (in), sur (on)
13 P+D Préposition et déterminant (Preposition &determiner amalgam) au (at, to), du (from)
14 P+PRO Préposition et Pronoun(Preposition & pronoun amalgam)
à laquelle, auquel,auxquels (to which)
15 CLS Clitique sujet (Subject clitic pronoun) il (it, he)
3https://courses.washington.edu/hypertxt/csar-v02/penntable.html
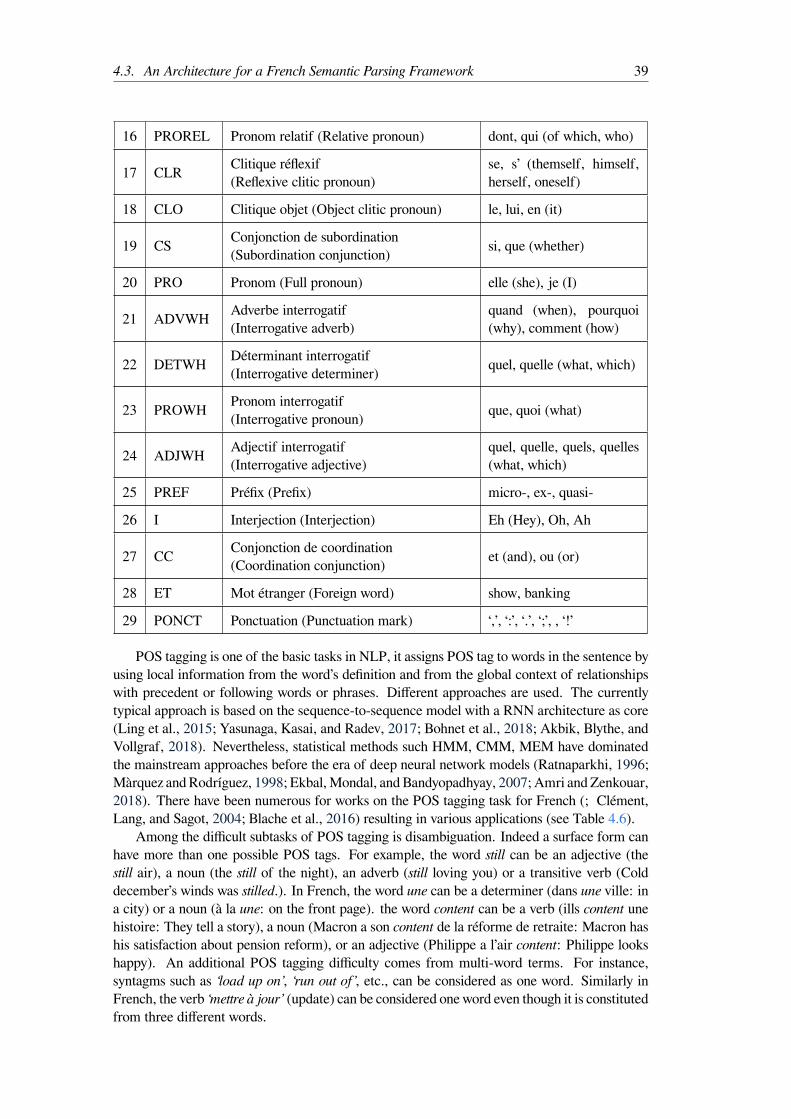
4.3. An Architecture for a French Semantic Parsing Framework 39
16 PROREL Pronom relatif (Relative pronoun) dont, qui (of which, who)
17 CLR Clitique réflexif(Reflexive clitic pronoun)
se, s’ (themself, himself,herself, oneself)
18 CLO Clitique objet (Object clitic pronoun) le, lui, en (it)
19 CS Conjonction de subordination(Subordination conjunction) si, que (whether)
20 PRO Pronom (Full pronoun) elle (she), je (I)
21 ADVWH Adverbe interrogatif(Interrogative adverb)
quand (when), pourquoi(why), comment (how)
22 DETWH Déterminant interrogatif(Interrogative determiner) quel, quelle (what, which)
23 PROWH Pronom interrogatif(Interrogative pronoun) que, quoi (what)
24 ADJWH Adjectif interrogatif(Interrogative adjective)
quel, quelle, quels, quelles(what, which)
25 PREF Préfix (Prefix) micro-, ex-, quasi-
26 I Interjection (Interjection) Eh (Hey), Oh, Ah
27 CC Conjonction de coordination(Coordination conjunction) et (and), ou (or)
28 ET Mot étranger (Foreign word) show, banking
29 PONCT Ponctuation (Punctuation mark) ‘,’, ‘:’, ‘.’, ‘;’, , ‘!’
POS tagging is one of the basic tasks in NLP, it assigns POS tag to words in the sentence byusing local information from the word’s definition and from the global context of relationshipswith precedent or following words or phrases. Different approaches are used. The currentlytypical approach is based on the sequence-to-sequence model with a RNN architecture as core(Ling et al., 2015; Yasunaga, Kasai, and Radev, 2017; Bohnet et al., 2018; Akbik, Blythe, andVollgraf, 2018). Nevertheless, statistical methods such HMM, CMM, MEM have dominatedthe mainstream approaches before the era of deep neural network models (Ratnaparkhi, 1996;Màrquez andRodríguez, 1998; Ekbal, Mondal, and Bandyopadhyay, 2007; Amri and Zenkouar,2018). There have been numerous for works on the POS tagging task for French (; Clément,Lang, and Sagot, 2004; Blache et al., 2016) resulting in various applications (see Table 4.6).
Among the difficult subtasks of POS tagging is disambiguation. Indeed a surface form canhave more than one possible POS tags. For example, the word still can be an adjective (thestill air), a noun (the still of the night), an adverb (still loving you) or a transitive verb (Colddecember’s winds was stilled.). In French, the word une can be a determiner (dans une ville: ina city) or a noun (à la une: on the front page). the word content can be a verb (ills content unehistoire: They tell a story), a noun (Macron a son content de la réforme de retraite: Macron hashis satisfaction about pension reform), or an adjective (Philippe a l’air content: Philippe lookshappy). An additional POS tagging difficulty comes from multi-word terms. For instance,syntagms such as ‘load up on’, ‘run out of’, etc., can be considered as one word. Similarly inFrench, the verb ‘mettre à jour’ (update) can be considered one word even though it is constitutedfrom three different words.

40 Chapter 4. A Proposed Architecture for a French DMR Framework
T 4.6: A List of POS Tagging Systems for English and French
POS TagSystem Description Supported
LanguagesMainPublications
Morfette
Lemmatization and POS tagging are indepen-dently handled with logistic regression mod-els. Learning models are dynamically orga-nized to produce a globally plausible sequenceof morphological tag-lemmas pairs for a sen-tence. Their outcomes achieved 97.68% ofaccuracy on FTP corpus.
Romanian,Spanish,Polish,French
Chrupała,Dinu, andVan Genabith,2008; Seddahet al., 2010
MElt(Maximum-EntropyLexicon-enrichedTagger)
A Pos Tagger based on the maximum en-tropy conditional sequence model in associa-tion with external linguistic resources: an an-notated corpus and morphosyntactic lexicons.This system obtained a 97.7% accuracy on theFTB corpus.
French,English,Spanish
Denis andSagot, 2009;Denis andSagot, 2010;Denis andSagot, 2012;Sagot, 2016
StanfordPOSTagger
Based on the use of context information ofboth preceding and following tags, based ona dependency network representation, the au-thors have built a tagger system with bidirec-tional dependency learning with a conditionalMarkov model. Experiments have been re-alized on Penn TreeBank with 97.32% accu-racy.
English,French,Chinese,German,Arabic,Spanish
Toutanovaand Man-ning, 2000;Toutanovaet al., 2003
TnT(Trigrams’n’Tags)
The system was implemented based on aViterbi algorithm which is guaranteed to findhighest probability on sequence states, and aHMM. Furthermore the author proposed atechnique to deal with unknown words by suf-fix trie and successive abstraction. Experi-ments on both German NEGRA corpus andEnglish Penn Treenbank have been evaluatedwith 96.7% accuracy on both corpora.
German,English Brants, 2000
TreeTagger
Implemented in C language, this taggerachieves a high performance and can tag8,000 tokens per second. Based on theMarkov Model, TreeTagger uses a decisiontree to get more reliable estimates for con-textual parameters. This approach achieved97.5% accuracy on a German newspaper cor-pus.
German,English,French,Italian,Danish,and 21others4
Schmid, 1994;Schmid, 1999
4Include: Danish, Swedish, Norwegian, Dutch, Spanish, Bulgarian, Russian, Portuguese, Galician, Greek, Chi-nese, Swahili, Slovak, Slovenian, Latin, Estonian, Polish, Romanian, Czech, Coptic and old French.
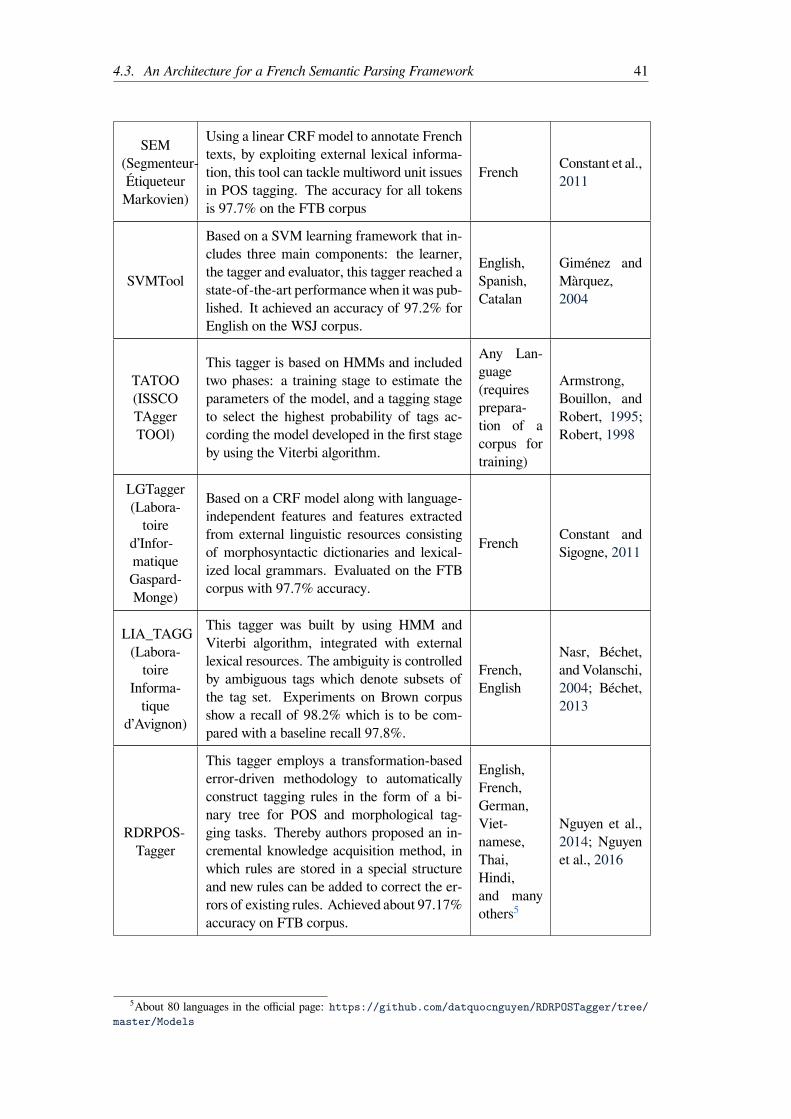
4.3. An Architecture for a French Semantic Parsing Framework 41
SEM(Segmenteur-ÉtiqueteurMarkovien)
Using a linear CRF model to annotate Frenchtexts, by exploiting external lexical informa-tion, this tool can tackle multiword unit issuesin POS tagging. The accuracy for all tokensis 97.7% on the FTB corpus
French Constant et al.,2011
SVMTool
Based on a SVM learning framework that in-cludes three main components: the learner,the tagger and evaluator, this tagger reached astate-of-the-art performance when it was pub-lished. It achieved an accuracy of 97.2% forEnglish on the WSJ corpus.
English,Spanish,Catalan
Giménez andMàrquez,2004
TATOO(ISSCOTAggerTOOl)
This tagger is based on HMMs and includedtwo phases: a training stage to estimate theparameters of the model, and a tagging stageto select the highest probability of tags ac-cording the model developed in the first stageby using the Viterbi algorithm.
Any Lan-guage(requiresprepara-tion of acorpus fortraining)
Armstrong,Bouillon, andRobert, 1995;Robert, 1998
LGTagger(Labora-toire
d’Infor-matiqueGaspard-Monge)
Based on a CRF model along with language-independent features and features extractedfrom external linguistic resources consistingof morphosyntactic dictionaries and lexical-ized local grammars. Evaluated on the FTBcorpus with 97.7% accuracy.
French Constant andSigogne, 2011
LIA_TAGG(Labora-toire
Informa-tique
d’Avignon)
This tagger was built by using HMM andViterbi algorithm, integrated with externallexical resources. The ambiguity is controlledby ambiguous tags which denote subsets ofthe tag set. Experiments on Brown corpusshow a recall of 98.2% which is to be com-pared with a baseline recall 97.8%.
French,English
Nasr, Béchet,and Volanschi,2004; Béchet,2013
RDRPOS-Tagger
This tagger employs a transformation-basederror-driven methodology to automaticallyconstruct tagging rules in the form of a bi-nary tree for POS and morphological tag-ging tasks. Thereby authors proposed an in-cremental knowledge acquisition method, inwhich rules are stored in a special structureand new rules can be added to correct the er-rors of existing rules. Achieved about 97.17%accuracy on FTB corpus.
English,French,German,Viet-namese,Thai,Hindi,and manyothers5
Nguyen et al.,2014; Nguyenet al., 2016
5About 80 languages in the official page: https://github.com/datquocnguyen/RDRPOSTagger/tree/master/Models
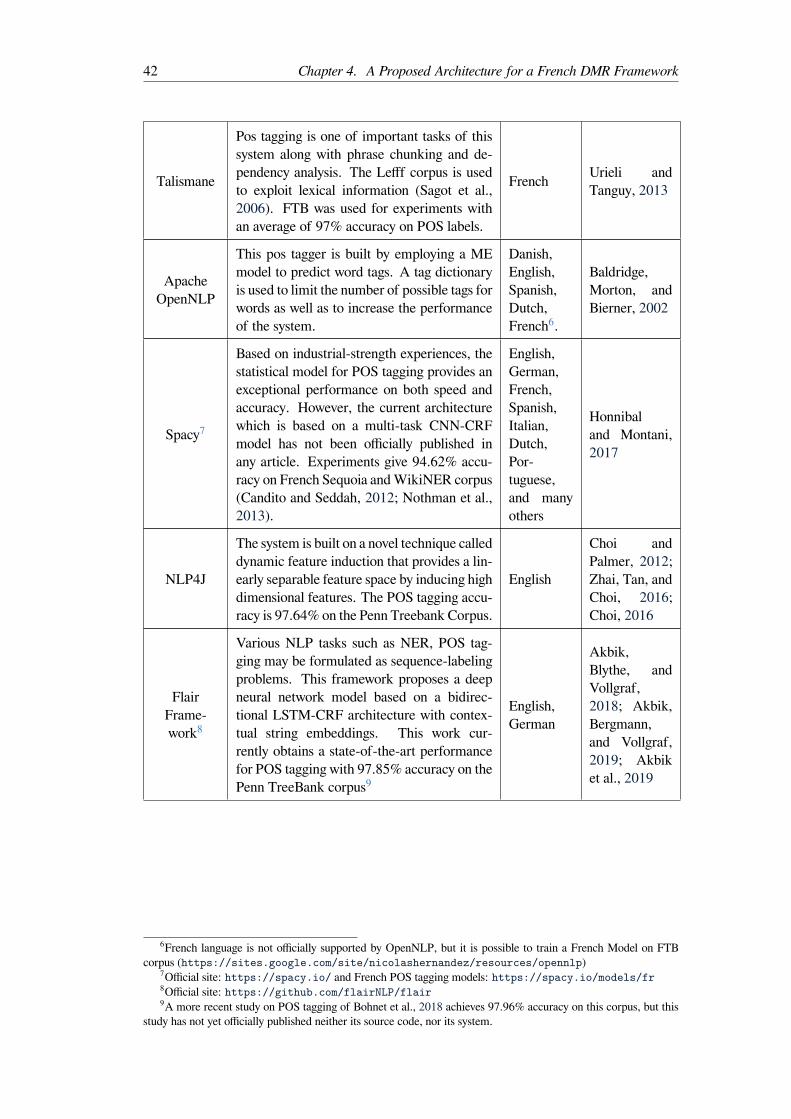
42 Chapter 4. A Proposed Architecture for a French DMR Framework
Talismane
Pos tagging is one of important tasks of thissystem along with phrase chunking and de-pendency analysis. The Lefff corpus is usedto exploit lexical information (Sagot et al.,2006). FTB was used for experiments withan average of 97% accuracy on POS labels.
French Urieli andTanguy, 2013
ApacheOpenNLP
This pos tagger is built by employing a MEmodel to predict word tags. A tag dictionaryis used to limit the number of possible tags forwords as well as to increase the performanceof the system.
Danish,English,Spanish,Dutch,French6.
Baldridge,Morton, andBierner, 2002
Spacy7
Based on industrial-strength experiences, thestatistical model for POS tagging provides anexceptional performance on both speed andaccuracy. However, the current architecturewhich is based on a multi-task CNN-CRFmodel has not been officially published inany article. Experiments give 94.62% accu-racy on French Sequoia andWikiNER corpus(Candito and Seddah, 2012; Nothman et al.,2013).
English,German,French,Spanish,Italian,Dutch,Por-tuguese,and manyothers
Honnibaland Montani,2017
NLP4J
The system is built on a novel technique calleddynamic feature induction that provides a lin-early separable feature space by inducing highdimensional features. The POS tagging accu-racy is 97.64% on the Penn Treebank Corpus.
English
Choi andPalmer, 2012;Zhai, Tan, andChoi, 2016;Choi, 2016
FlairFrame-work8
Various NLP tasks such as NER, POS tag-ging may be formulated as sequence-labelingproblems. This framework proposes a deepneural network model based on a bidirec-tional LSTM-CRF architecture with contex-tual string embeddings. This work cur-rently obtains a state-of-the-art performancefor POS tagging with 97.85% accuracy on thePenn TreeBank corpus9
English,German
Akbik,Blythe, andVollgraf,2018; Akbik,Bergmann,and Vollgraf,2019; Akbiket al., 2019
6French language is not officially supported by OpenNLP, but it is possible to train a French Model on FTBcorpus (https://sites.google.com/site/nicolashernandez/resources/opennlp)
7Official site: https://spacy.io/ and French POS tagging models: https://spacy.io/models/fr8Official site: https://github.com/flairNLP/flair9A more recent study on POS tagging of Bohnet et al., 2018 achieves 97.96% accuracy on this corpus, but this
study has not yet officially published neither its source code, nor its system.

4.3. An Architecture for a French Semantic Parsing Framework 43
Stanza10
The latest python NLP library has been devel-oping for various NLP tasks from tokeniza-tion, lemmatization to the constituency anddependency parser. With the POS taggingtask, the authors use the robustness of the neu-ral network architecture based on the BIL-STM with fully-connected layer, and apply-ing a biaffine score mechanism to predict-ing the output labels Qi et al., 2019. Theyachieve a state-of-the-art performance on theUniversal Dependencies v2.5 datasets withmore than 100 treebanks about different hu-man languages in the world.
English,French and64 otherlanguages
Qi et al., 2020
Chunk analysis
Chunking, also referred to by the terms shallow or light parsing is realized after POS tagging inorder to extract and attach more structure information to sentences using POS tagging results(Abney, 1991). For example, the sentence “La réforme de retraites sera menée à son terme”(Pension reform will be completed) can be broken down into three flat chunks correspondingto two noun phrase chunks and one verb phrase chunk (see Figure 4.4)).
Definition 4.3.2. Chunking is the process of analyzing and classifying the flat/non-overlappingstructure of a sentence to identify the basic non-recursive constituent parts and to group theminto higher-level components that underlie a grammatical meaning form.
A chunk is a group of words built around a head lexical item and considered as a phrase.There is no rule about the size of a chunk, however it must have at least one word. A sentenceis basically composed of combinations of different phrases (or different chunks in other words).The function of a phrase is presented by the function of the headword contained in it (Tallerman,2013). In general, we classify types of phrases into five major categories as follows:
• Noun Phrase (NP): a group of words playing the role of a noun. In a NP, the head wordcan be a noun or pronoun. In a sentence, an NP can function as a subject, as an object,or as a complement component.
• Verb Phrase (VP): a sequence of lexical units that contain at least one verb playing therole of head word. Verb phrases indicate what happened in the clause, or sentence.
• Adverbial Phrase (ADVP): a group of words with an adverb playing the role of headword.Adverbial phrases are employed to give more information about other components.
• Adjectival Phrase (ADJP): the head of such a phrase is an adjective, used to describe orqualify other components in the sentence, such as nouns or pronouns. They are usuallyplaced after the noun in French, and before the noun in English.
• Prepositional Phrase (PP): a preposition will be the head word of this type of phrase.Other dependent words can be of any word type such as noun, adjective, verb, etc. Thefunction of this category is to provide modifiers for other components.
10Official site: https://stanfordnlp.github.io/stanza/

44 Chapter 4. A Proposed Architecture for a French DMR Framework
The definition of chunk categories varies among languages and depends on their structuralgrammars. Syntactic annotations for French corpora employ six categories for syntactic chunks:Noun Group (GN), Prepositional group (GP), Adjectival group (GA), Adverbial group (GR),Verb group with a preposition (PV), and Other verb groups (NV) (Gendner et al., 2004). In theFrench Tree Bank corpus (), chunk categories are separated in 10 groups illustrated in Table4.7.
T 4.7: The tagset used in the French Tree Bank corpus for the shallowparsing task
# Tag Meaning # Tag Meaning
1 AP Adjectival phrases 6 AdP Adverbial phrase
2 COORD Coordinated phrases 7 NP Noun phrases
3 PP Prepositional phrases 8 VN Verbal nucleus
4 VPinf Infinitive clauses 9 VPpart Nonfinite clauses
5 SENT Sentences 10 Sint, Srel, Ssub Finite clauses
In order to identify chunks in a sentence, a classical approach is to use curated regular ex-pression rules based on POS tag information to extract chunk boundaries (Grover and Tobin,2006; Mohammed and Omar, 2011). Another popular approach is based on machine learningmethods that require available corpora to learning patterns such as transformation-based learn-ing (Ramshaw and Marcus, 1999; Avinesh and Karthik, 2007), decision forest model (Pammiand Prahallad, 2007), HMM and CRF (Awasthi, Rao, and Ravindran, 2006; Sha and Pereira,2003), MEM (Sun et al., 2005), or SVM (Kudo and Matsumoto, 2001). In recent trends,chunking is considered as a sequence labeling problem where each word in a sentence is as-signed a label (a prefix is one of the following three characters: I for Inside, O for outside, Bfor beginning of each chunk type). This type of label indicates full information about a chunkand its boundaries in the sentence (Akhundov, Trautmann, and Groh, 2018). As a result, usingdeep neural network models with this approach achieves start-of-the-art performance on theCoNLL chunking dataset (Sang and Buchholz, 2000; Zhai et al., 2017). The chunking task forFrench Language has also been realized by using rule-based approaches such as a cascade offinite state transducers to produce tree-like representations (Antoine, Mokrane, and Friburger,2008), logical grammar (Blanc et al., 2010), or by applying machine learning methods such asan CRF model (Tellier et al., 2012).
S
NP
DET
La
NC
réforme
P
des
NC
retraites
VP
V
sera
VPP
menée
P
à
NP
DET
son
N
terme
F 4.4: A visual example of the chunking task result for the sentence “Pen-sion reform will be completed”

4.3. An Architecture for a French Semantic Parsing Framework 45
Constituency Structure and Parsing
A higher level of sentence analysis is the constituent-based grammar analysis in which the con-stituents and relations between them is identified in a sentence. Conventionally, a constituentis a lexical item or a group of lexical items organized in a hierarchical structure, and plays therole of a single unit in the sentence. A constituent can be a word, phrase, clause in the sentence.Constituency grammar is a theoretical foundation in order to analyze constituent structure. Infact, there are different terms used to denote this type of grammar like context-free grammar orphrase structure grammar, which was originally introduced by Noam Chomsky 11 in the 1950s(Chomsky, 1956; Chomsky, 1957; Chomsky, 1975). An example of constituent analysis ofthe sentence “La réforme des retraites sera menée à son terme” is given in Figure 4.5. The ex-ample shows that hierarchical constituents structures are usually nested. Constituency analysisprovides deeper information about sentence structure than the shallow parser approach.
SENT
NP-SUJ
DET
La
NC
réforme
PP
P+D
des
NP
NC
retraites
VN
V
sera
VPP
menée
ADV+
P
à
DET
son
NC
terme
PONCT
.
F 4.5: A visual tree of constituent analysis for the sentence “Pensionreform will be completed.” by using Berkeley Neural Parser12
Definition 4.3.3. AContext-FreeGrammarG is conventionally defined as a quadruple (N,T, P, S),consisting of:
• N , a finite set of non-terminal symbols that corresponds to abstraction names or variablesover terminals in T . For example, we useNP , V P , PP denoted for Noun Phrase, VerbPhrase, and Prepositional Phrase.
• T , a finite set of terminal symbols that correspond to lexical items in the natural languageand build up the content of the sentence. This set is disjoints with the set of non-terminals.
• R, a finite set of rewriting rules or productions. Each element exists in the form ofA → β, where A is an element of N , β is a sequence of symbols constructed from(N ∪ T ). For example in Table 4.8, some examples of grammar rules given.
• S, a designated start symbol used to represent the whole sentence, which is often notedS. It must be a member of N .
A derivation of the string of words is a sequence that generated by applying rules or pro-ductions. In other words, a derivation is the result of the process of inference based on the rulesdefined in R. Therefore, it can be organized as a parse tree with non-terminal symbols at the
11https://en.wikipedia.org/wiki/Noam_Chomsky12https://github.com/nikitakit/self-attentive-parser

46 Chapter 4. A Proposed Architecture for a French DMR Framework
internal nodes and terminal at the leaves. For example, a parse tree or derivation in the figure4.6 is the result of using grammar rules in the table 4.8
Grammar rules Examples
S → NP VP [Il] [vend sa voiture àmon voisin]
[He] [sells his car to myneighbor]
NP → Determiner Noun [sa] [voiture], [mon][voisin]
[his] [car], [my] [neigh-bor]
NP → Pronoun il he
NP → Noun voiture, voisin car, neighbor
VP → VP NP PP [vend] [sa voiture] [àmon voisin]
[sells] [his car] [to myneighbor]
VP → VP NP [vend] [sa voiture] [sells] [his car]
VP → Verb vend sells
PP → PP NP [à] [mon voisin] [to] [my neighbor]
PP → Preposition à to
T 4.8: Grammar rule set in CFG and its examples
S
NP
Pronoun
Il
VP
VP
Verb
vend
NP
Determiner
sa
Noun
voiture
PP
Preposition
à
NP
Determiner
mon
Noun
voisin
F 4.6: A formal parse tree by using CFG for the sentence “Il vend savoiture à mon voisin” (He sells his car to my neighbor)
Definition 4.3.4. Consitutency Parsing is a process of analyzing and determining the constituentstructures and their linking in order to extract a constituency-based parse tree from a sentencethat must accord to the syntax and rules of the phrase structure grammar.
In order to build a constituency parser, we need to resolve some problems concerned tostructural ambiguity. Two popular kinds of structural ambiguity are attachment ambiguity andcoordination ambiguity.
As it happens often both in English and in French language, a particular constituent in asentence can be attached at more than one places to the constituent parse tree. We have a

4.3. An Architecture for a French Semantic Parsing Framework 47
common pattern of this kind ambiguity: “verb 1st_noun_phrase preposition 2nd_noun_phrase”where the preposition and 2nd_noun_phrase are the prepositional phrases that can be attachedto the 1st_noun_phrase or directly to the verb. Furthermore, the ambiguity still occurs evenwhen the preposition and 2nd_noun_phrase are replaced by a relative or subordinate clauses.The sentence of the example (1) gives an illustration of this kind of ambiguity.
(3) Ma voisine [a acheté]VP [un nouveau vélo]1st NP [pour]PP [son garçon]2nd NP.My neighbor [bought]VP [a new bike]1st NP [for]PP [her boy]2nd NP.
The second common kind of ambiguity occurs with conjunction words like and, or, but (inEnglish), et, ou (in French), or similar words. Indeed, words, phrases, clauses and sentencescan be coordinated with a modifier that can be placed either before or after the coordination(Okumura and Muraki, 1994). The examples (2) (3), below illustrate ambiguous cases relyingon the usage of coordinated words.
(4) a. [La maître observe la photo] et [la classe][The teacher observes the photo] and [the class]
b. La maître observe [la photo] et [la classe]The teacher observes [the photo] and [the class]
(5) a. [Exigences de communication] et [performance][Communication] and [performance requirements]
b. Exigences de [communication] et [performance][Communication] and [performance] requirements
Many approaches deal with ambiguous issues and achieve a full constituency parse tree.A dynamic programming approach developed by Richard Bellman 13 has become a powerfulframework for tackling this task with popular algorithms such as Viterbi (Forney, 1973), orforward algorithm (Federgruen and Tzur, 1991). Based on the idea of solving a problem bybreaking it into smaller problems (sub-problems), the optimal solution can recursively be foundfrom results of the sub-problems (Bellman, 1966). Using this approach in constituency parsingtask, we have three popular parsing algorithms: Cocke-Kasami-Younger (CKY) parsing algo-rithm (Kasami, 1966; Younger, 1967; Cocke, 1970), Early algorithm (Earley, 1970) and Chartparsing (Kaplan, 1973; Kay, 1980). These parsing algorithms still play a crucial role in cur-rent outstanding parsers. For instance, the state-of-the-art performance and accuracy on PennTree bank corpus used CKY-style algorithm to find the optimal constituency tree along withthe modern approach based on sequence-to-sequence learning models (Kitaev and Klein, 2018;Zhou and Zhao, 2019; Mrini et al., 2019). A transition-based (shift-reduce) approach can alsobe also used to obtain a constituency parser that employs sequences of local transition actionsto build up parsed tree-over-input sentences (Zhu et al., 2013; Mi and Huang, 2015; Liu andZhang, 2017b; Liu and Zhang, 2017a).
Besides that, probability theory can be applied to solve the problem of disambiguation basedon computing the probability of each derived interpretation. Probabilistic context-free gram-mars (PCFG) (Booth, 1969) use the probabilistic constituency grammar formalism. Based onthis approach, a probabilistic CYK algorithm is proposed for building a constituency parser(Ney, 1991).
In order to achieve a constituency parse tree for French, we can used various applicationssuch as Berkeley Neural Parser (Kitaev and Klein, 2018) or Stanford Parser (Zhu et al., 2013).
13https://en.wikipedia.org/wiki/Richard_E._Bellman

48 Chapter 4. A Proposed Architecture for a French DMR Framework
Furthermore, different constituency-parsed tree corpora for French are built by applying trans-formation algorithms to obtain a complete corpus. For example, the Sequoia Treebank contains2,099 French sentences from different sources. It has been annotated with constituency trees(Candito and Seddah, 2012). Another example is the Modified French Treebank (MFT), ex-tracted from the FTB corpus with added Lexical Functional Grammar annotations (Schluterand Van Genabith, 2008).
Dependency structure and parsing
The dependency grammar formalism focuses on the exploitation of dependency relations at theword-based level and explains more specifically the role of these relationships in the context ofthe sentence. Thereby lexical items are analyzed and connected to others by directed links rep-resenting binary asymmetric relations called dependencies that include the information aboutfunctional categories of the relation. In general, dependency grammar is a generic name fora class of contemporary grammatical theories based on the foundation of dependency rela-tions analysis. Basic concepts and descriptions of this grammar theory has been introduced bythe French linguist Lucien Tesnière14 in his book “Élements de syntaxe structurale” (Elementof Structural Syntax) published posthumously in 1959. Nowadays, he is honored as the pio-neer in the field of dependency grammar theory by his crucial contributions (Tesnière, 1959).Various theoretical frameworks have been built up based on the grammatical theories of depen-dency structures such as Functional Generative Desscription (Sgall et al., 1986), Word Gram-mar (Hudson, 1991; Hudson and Hudson, 2007), Dependency Unification Grammar (Hellwig,1986), Meaning-Text Theory (Mel′cuk et al., 1988), Functional Dependency Grammar (Järvi-nen and Tapanainen, 1997), Link Grammar (Sleator and Temperley, 1995), Operator Grammar(Harris, 1982), Extensible Dependency Grammar (Debusmann, 2006), Categorial DependencyGrammar (Dekhtyar, Dikovsky, and Karlov, 2015) or Universal Dependency Grammar (Mc-Donald et al., 2013).
We will use notation S = w0, w1, . . . , wn to denote a sentence, while S denotes a set ofsentences. A dependency structure is expressed by G, while G indicates a set of dependencystructures, that can be used in expressions of the next part.
Definition 4.3.5. Adependency structure can be defined as a directed graph. That is, a structureG = (V,A) consisting of a set of vertices V and a set of directed edges A.
In general, a total order < can be used on V to present the word order. The set of nodes,A, corresponds completely to the set of words and punctuation marks used to form a sen-tence. Furthermore, this set can occasionally contain subword morphemes such as stems oraffixes used in the analysis of some languages. Dependency relation types are defined as a setL = {l1, . . . , ln}. Each dependency arc in A is a triple (wi, lk, wj), representing a depen-dency relation type from the word wi to the word wj with label lk. We have some notationsrepresenting relationships in A:
• wi → wj if and only if (wi, lk, wj) ∈ A for lk ∈ L, used to indicate the dependencyrelation in a graph G = (V,A).
• wi →∗ wj if and only if i = j or (wi →∗ wi′ and wi′ → wj) for wi′ ∈ V , expressed thereflexive transitive closure of the dependency relation in a graph G = (V,A).
• wi↔wj if and only if eitherwi→wj orwj→wi, denoted the undirected depdendencyrelation in G = (V,A).
14https://en.wikipedia.org/wiki/Lucien_Tesnière

4.3. An Architecture for a French Semantic Parsing Framework 49
• wi ↔∗ wj if and only if i = j or (wi →∗ w′i and wi′ ↔ wj) for wi′ ∈ V , indicated thereflexive transitive closure of the undirected dependency relations in G.
Besides, the dependency structure G need to obey some constraints or conditions as follows:
• Dependency structure is connected. G is connected, if wi, wj ∈ V , wi ↔∗ wj . Theconnectedness of a dependency structure can be obtained by inserting a special root nodewhich is directly linked with a head word in the sentence.
• Dependency structure is hierarchical. G is acyclic, if wi → wj , then not wi →∗ wj . Thedependency structure is essentially a dependency tree.
• Every word has at most one syntactic head with the exception of the root node. G satisfiesthe single-head constraint, if wi → wj , then not w′i → wj , for any w′i 6= wi.
• The tree structure does not contain crossing dependency edges or projection lines. Gis projective, if wi → wj , then wi →∗ w′i, for any w′i such that wi < w′i < wj orwj < w′i < wi.
To illustrate the definition, we consider the dependency tree of Figure 4.7, which is representedby:
1. G = (V,A)
2. V = {root, La, réforme, des, retraites, sera, menée, à, son, terme, .}
3. A = {(root, pred, sera), (La, dep, réforme), (des, dep, réforme), (retraites, obj, des),(réforme, suj, sera), (menée, ats, sera), (à, mod, menée), (son, det, terme), (terme, obj,à), (., ponct, sera)}
La réforme des retraites sera menée à son terme .+
(le) (réforme) (de) (retraite) (être) (mener) (à) (son) (terme) (.)
det
suj
dep obj
root
ats mod detobj
ponct
F 4.7: A visual tree of dependency parse tree of the sentence “Pensionreform will be completed.” by using BONSAI Malt Parser
Diving profound into projective and non-projective dependency tree situations, a depen-dency arc (wi, l, wj) is said to be projective if there is a directed path from wi to all words.We can draw a dependency arc between wi and wj without any other dependency arc crossingit (Covington, 2001). Accordingly, a dependency graph G = (V,A) is viewed as a projectivedependency tree if it is a dependency tree and if all dependency arcs are projective. By contrast.a dependency graphG = (V,A) is considered as a non-projective dependency tree if it is a de-pendency tree and contains an non-projective arc. Most dependency structures in English andFrench are projective dependency trees. However, non-projective constructions of sentencesstill exist in some kind of expressions in these two languages even though they are infrequent.Some examples of French non-projective trees are given below: (6) using the clitic en, (7) usingthe comparative mode, (8) using relative pronouns.
(6) Ma femme en achète deux. (My wife buys two of them)

50 Chapter 4. A Proposed Architecture for a French DMR Framework
Ma femme en achète deux .
(son) (femme) (en) (acheter) (deux) (.)
root
detsuj
obj
det ponct
(7) Cette femme est aussi belle qu’intelligente.(This woman is as smart as she is beautiful.)
Cette femme est aussi belle qu’ intelligente .
(ce) (femme) (être) (aussi) (beau) (que) (intelligent) (.)
root
det suj mod
ats
modarg
ats
ponct
(8) C’est dans cette maison que je crois que les trésors ont été trouvés .(It is in this house that I believe that the treasures have been found.)
C’ est dans cette maison que je crois que les trésors ont été trouvés
(cln) (être) (dans) (ce) (maison) (que) (cln) (croire) (que) (le) (trésor) (être) (trouver)
suj
root
mod det
obj objsuj
mod_rel
obj det suj
obj
ats
depobj
Definition 4.3.6. Dependency parsing is the process of determining a dependency structure fora sentence based on exploration of the grammatical relations of words with each other.
Consider a given sentence S =w0, w1, . . . , wn with a hypothesisw0 =root, the dependencyparsing task is defined as the searching of dependency trees G = (V,A) for the input sentenceS where V = 0, 1, . . . , n denotes the vertex set, and A is the dependency arc set of tuples(wi, l, wj)which represents a dependency relation fromwi towj with label l ∈ L that is a set ofdependency relation type. The set of dependency is defined based on the particular characteristicof the language used. For example, Figure 4.9 provides an overview about dependency relationsused in the FTB corpus (Candito, Crabbé, and Falco, 2009).
Broadly speaking, there are currently different approaches for dependency parsing and itcan be divided into two main types: grammar-based ones and data-driven ones. IN grammar-based approaches, dependency structures are mapped to phrase structures in order to benefitfrom parsing algorithms originally developed for constituency parsing. The earliest work ofthis approach is based on a modification of constituent-based grammar theory with building
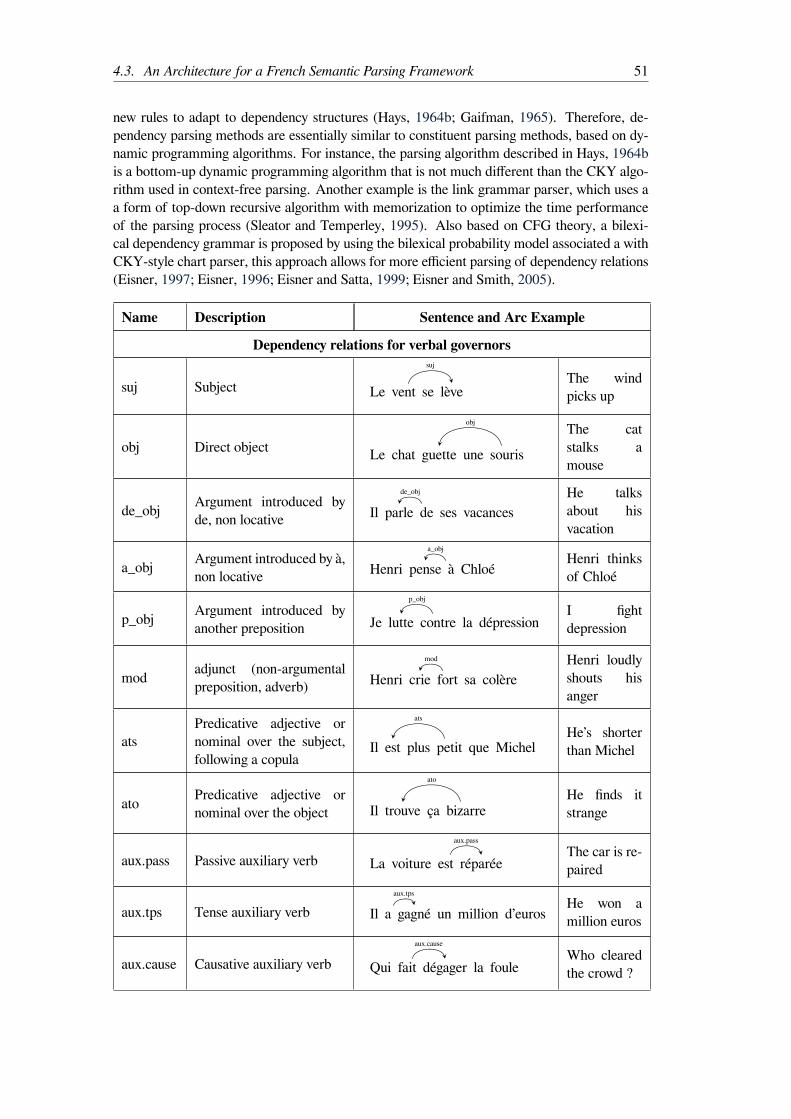
4.3. An Architecture for a French Semantic Parsing Framework 51
new rules to adapt to dependency structures (Hays, 1964b; Gaifman, 1965). Therefore, de-pendency parsing methods are essentially similar to constituent parsing methods, based on dy-namic programming algorithms. For instance, the parsing algorithm described in Hays, 1964bis a bottom-up dynamic programming algorithm that is not much different than the CKY algo-rithm used in context-free parsing. Another example is the link grammar parser, which uses aa form of top-down recursive algorithm with memorization to optimize the time performanceof the parsing process (Sleator and Temperley, 1995). Also based on CFG theory, a bilexi-cal dependency grammar is proposed by using the bilexical probability model associated a withCKY-style chart parser, this approach allows for more efficient parsing of dependency relations(Eisner, 1997; Eisner, 1996; Eisner and Satta, 1999; Eisner and Smith, 2005).
Name Description Sentence and Arc Example
Dependency relations for verbal governors
suj Subject Le vent se lève
suj
The windpicks up
obj Direct object Le chat guette une souris
obj The catstalks amouse
de_obj Argument introduced byde, non locative Il parle de ses vacances
de_obj He talksabout hisvacation
a_obj Argument introduced by à,non locative Henri pense à Chloé
a_objHenri thinksof Chloé
p_obj Argument introduced byanother preposition Je lutte contre la dépression
p_objI fightdepression
mod adjunct (non-argumentalpreposition, adverb) Henri crie fort sa colère
mod Henri loudlyshouts hisanger
atsPredicative adjective ornominal over the subject,following a copula
Il est plus petit que Michel
ats
He’s shorterthan Michel
ato Predicative adjective ornominal over the object Il trouve ça bizarre
ato
He finds itstrange
aux.pass Passive auxiliary verb La voiture est réparéeaux.pass
The car is re-paired
aux.tps Tense auxiliary verb Il a gagné un million d’eurosaux.tps
He won amillion euros
aux.cause Causative auxiliary verb Qui fait dégager la fouleaux.cause
Who clearedthe crowd ?

52 Chapter 4. A Proposed Architecture for a French DMR Framework
aff Clitics in fixed expressions(including reflexive verbs) Il s’ en souvient
affHe remem-bers it
Dependency relations for non-verbal governors
det Determiners Le contrat est terminédet
The work isfinished
arg Used to linked preposi-tions De Brest à Paris
arg
from Brest toParis
mod.relUsed to relative pronoun’santecedent to the verb gov-erning the relative phrase La série dont Henri parle
mod.rel
The seriesthat Henritalks about
coord Links coordinators to thepreceding conjunct
Un professeur et un étudiantcoord dep.coord
A teacherand a student
dep.coordLinks a conjunct (exceptfor the first) to the previouscoordinator
depSub-speficied relation forprepositional dependentsof non verbal governors
L’utilisation des services
dep
The use ofservices
ponctPunctuations, except forcommas playing the role ofcoordinators Henri mange du riz ?
ponct
Does Henrieat rice ?
T 4.9: List of dependency relations extracted from the FTB corpus
Extensions to PCFGs have also been used for the dependency parsing task. Indeed, a PCFGcan be lexicalized by assigning words and POS tag information to non-terminal nodes of theparse tree. Thus, we can apply the PCFG model to the lexicalized rules and trees. As a result,generative statistical parsers have been built with chart parsing algorithms for probabilistic orweighted grammars using the Penn Treebank corpus (Charniak, 2000; Collins, 2003). Further-more, the combination of grammar-based models with each other has been studied in variousworks. For example, the PCFG structure model is combined with a dependency structure modelto create a lexicalized phrase structure model. The factored model based on this novel structureuses the A* parsing algorithm allowing fast exact inference on probable parses (“Fast ExactInference with a Factored Model for Natural Language Parsing”; Klein and Manning, 2003b).
Another working direction of the grammar-based approach is to view a dependency pars-ing task as a constraint satisfaction problem. Thereby, a grammar rule set is considered asa constraint set attached on dependency structures. The parsing task becomes a problem ofsearching a adapted dependency graph for a sentence that obeys all constraints defined. Basedon this idea, Constraint Dependency Grammar (CDG) is created by mapping each grammat-ical rule to a constraint (e.g., word(pos(x)) = D ⇒ (label(x) =DET, word(mod(x)) = N ,pos(x) < mod(x)), that mean, a determiner D modifies a noun N on the right with the label

4.3. An Architecture for a French Semantic Parsing Framework 53
DET) (Maruyama, 1990). Constraint propagation is one in many solutions for dependency pars-ing with CDG (Montanari, 1974; Waltz, 1975). About applications, PARSEC is a constraint-based dependency parser implemented based on constraint propagation, which is used for inte-gration into a spoken recognition system (Harper and Helzerman, 1995; Harper et al., 1995).Furthermore, constraint propagation contributes to construct Topological Dependency Gram-mar (TDG) (Duchier, 1999; Duchier and Debusmann, 2001), where the grammatical constraintset consists of immediate dominance and linear precedence constrains.
The majority of dependency parsing systems is based on data-driven approaches. As itsname indicates, data about sentences and theirs dependency structure annotations plays an im-portant role when it comes to decide on using this approach. Nevertheless, the success of data-driven approaches remains dependent on the learning methods used. At the moment, supervisedlearning methods dominate in most approaches. A supervised dependency parsing method canbe divided into two stages: learning the model and parsing. Learning the model is the task ofbuilding a model to learn from input sentence samples and their dependency structures in orderto obtain the most optimal model. Parsing is the task of applying the model provided by thefirst task in order to obtain a dependency structure for a new sentence. In general, most data-driven dependency parsing approaches can be grouped in two main classes: transition-basedapproaches and graph-based approaches.
The idea of transition-based method has been proposed by Joakim Nivre (Nivre, 2004;Nivre, 2008). It employs a transition system and a supervised learning method to obtain depen-dency structures from sentence input. The learning model thus is constructed by predicting thenext state transition and provides the history parse. The parsing problem focuses on predictingnew parse tree using a greedy or a deterministic parsing algorithm and on inducing an optimaltransition sequence model. A transition system is essentially an abstract machine that includesa set of states and a set of transitions between states. In the case of dependency parsing, the setof states is matched to a set C of configurations of internal dependency structures that includesinitial and terminal configurations for the sentence. The set of transitions is correlated to a setT of steps in the derivation of a parse tree (Kübler, McDonald, and Nivre, 2009).
Definition 4.3.7. A configuration is defined as a triple c = (α, β,A), where:
• α is a stack of ordered words wi ∈ V that’s is been processed,
• β is a buffer of ordered words wi ∈ V that’s waiting to be processed,
• A is a set of dependency arcs (wi, l, wj) with l ∈ L, wi and wj ∈ V
Adependency parse tree needs to be derived through a transition sequence Cn0 = (c0, c1, . . . , cn−1, cn),that begins in the initial configuration c0 = ([w0]α, [w1, . . . , wn]β, ∅) for a input sentence andkeeps on with a series of valid transitions of configurations ci = t(ci−1) with i ∈ [1, n− 1]and τ ∈ T , in order to reach a terminal configuration cn = (α, [∅]β, A) for any α and A.
Definition 4.3.8. A transition is an action that adds a new dependency arc to A or modifies thestack α or the buffer β.
With the hypothesis that wi denotes the word on the top of stack α, and wj is the word atthe bottom of the buffer β, a transition of an arc-standard parser will be chosen through threebasic actions:
• LEFT-ARC (LA): add a new dependency arc (wi, l, wj) to the arc set A and removethe word at the top of the stack α, with preconditions α, β 6= ∅ and, wi 6= root node.
• RIGHT-ARC (RA): add a new dependency arc (wj , l, wi) to the arc set A, removethe word at the top of the stack α and replace wj by wi at the top of buffer β, withprecondition α, β 6= ∅.

54 Chapter 4. A Proposed Architecture for a French DMR Framework
• SHIFT (SH): remove the first word in the buffer α and push it onto the stack β, withprecondition β 6= ∅.
Mon enfant entend les oiseaux de notre voisin .
ROOT
det suj det detobj
depobj
ponct
F 4.8: A visual dependency tree of the sentence “My child hears the birdsof our neighbor.”
T 4.10: A transition sequence example for the sentence in the figure 4.8
C Transition sequence τ
c0 ([root]α, [Mon, enfant, …]β , A = {∅}) SH
c1 ([root, Mon]α, [enfant, …]β , A = A ∪ {(mon, ldet, enfant)} LA
c3 ([root]α, [enfant, entend, …]β , A = A ∪ ∅) SH
c4 ([root, enfant]α, [entend, …]β , A = A ∪ {(enfant, lsuj, entend)}) LA
c5 ([root]α, [entend, les, …]β , A = A ∪ {∅} SH
c6 ([root, entend]α, [les, …]β , A = A ∪ {∅} SH
c7 ([root, …, les]α, [oiseaux, …]β , A = A ∪ {(les, ldet, oiseaux)} LA
c8 ([root, entend]α, [oiseaux, …]β , A = A ∪ {∅} SH
c9 ([root, …, oiseaux]α, [de, …]β , A = A ∪ {∅} SH
c10 ([root, …, de]α, [notre, …]β , A = A ∪ {∅} SH
c11 ([root, …, notre ]α, [ voisin, …]β , A = A ∪ {(notre, ldet, voisin)} LA
c12 ([root, …, de]α, [ voisin, …]β , A = A ∪ {(voisin, lobj, de)} RA
c13 ([root, …, oiseaux]α, [ de, …]β , A = A ∪ {(de, ldep, oiseaux)} RA
c14 ([root, entend]α, [ oiseaux, …]β , A = A ∪ {(oiseaux, lobj, entend)} RA
c15 ([root]α, [entend, …]β , A = A ∪ {∅} SH
c16 ([root, entend]α, […]β , A = A ∪ {(., lponct, entend)} RA
c17 ([root]α, [entend]β , A = A ∪ {(., lponct, entend)} RA
c18 ([root]α, [entend]β , A = A ∪ {(root, lroot, entend)}) LA
c19 ([∅]α, [root]β , A = A ∪ {(root, _, entend)}) LA
c20 ([root]α, [∅]β , A = A ∪ {∅})

4.3. An Architecture for a French Semantic Parsing Framework 55
A dependency tree can be achieved from a transition sequence of a transition system. How-ever, a transition sequence does not always produce a valid dependency tree because a depen-dency structure requires always conditions and constraints on connectedness, root node, and sin-gle head properties. In addition, all dependency trees generated by transition-based approachessatisfy the projective structure constraint.
The example in Table 4.10 shows a transition sequence by displaying steps from a con-figuration to another by using one of three standard transitions. We can see that the LA andRA transitions are used to reduce or replace words in the stack α and the buffer β. While theSH transition aims to shift a word into processing. The transition sequence in our example isnot unique. In fact, different transition sequences can be created from an initial configuration.There are usually many choices for each state step corresponding to the change from a valid con-figuration to another valid configuration. Therefore, it is possible to obtain the same dependencyparse tree from more than one transition sequences. Furthermore, different dependency parsetrees can be derived from different transition sequences due to natural language ambiguity.
A problem of the transition-based approach is the occurrence of nondeterministic situationswhen changing states in non-terminal configurations. Accordingly, a deterministic first-bestsearch or beam search can be applied to build up an oracle function o(c) to find an optimaltransition τ = o(c) that is used into a configuration chain to reach the next configuration τ(c)(Goldberg and Nivre, 2013). The use of machine learning techniques becomes more efficientby simply replacing the oracle function as a model parameter that must be learned from data.More generally, the learning model is based on predicting the correct transition o(c) for anyconfiguration c from corpus input, which need to be organized under the feature representationfunction f(c) : C → T , where C is the set of possible configurations and T is the set of possibletransitions. More specifically, sentences and their dependency parsing trees in the corpus willbe used for extracting and validating the set of possible configurations C and the set of possibletransitions T by using the transition system. Using the terminology of supervised learning, thetraining data is formed as (f(c), τ) or f(c) → τ , with τ = o(c). Various machine learningmethods can be used such as memory-based learning (Nivre, Hall, and Nilsson, 2004), SVMs(Nivre et al., 2006), or the sequence-to-sequence deep neural network model, which is the mostpopular at the moment (Ballesteros et al., 2016; Ballesteros et al., 2017; Lhoneux, Ballesteros,and Nivre, 2019).
The most popular version of transition system is the arc-eager model which is developed by(Nivre, 2003) and used in dependency parsers for various languages such as Swedish and English(Nivre, Hall, and Nilsson, 2004; Nivre and Scholz, 2004). Instead of using three basic transitionactions as in the arc-standard model, the arc-eager approach adds a REDUCE transition intothe set of transitions. As a result, a dependency parse tree can be achieved in linear time byusing a deterministic algorithm, and it is faster than results achieved by arc-standard approach.
There are two directions in order to improve performance on proposed algorithms in thetransition-based approach. The first one focuses on the transition system in which we canimprove the system by defining novel transition actions or configurations, or by using otherstrategies of efficient searching for optimal transitions. For example, the author of (Gómez-Rodríguez and Nivre, 2013) has defined a new transition system with composition and restric-tion of the five transition actions SHIFT, UNSHIFT, REDUCE, LEFT-ARC, RIGHT-ARC.Similarly, the authors of (Zhang et al., 2016) have focused on building up a novel transitionsystem that can generate arbitrary directed graphs in an incremental manner. The beam searchusing heuristic was modified to obtain higher efficiency (Johansson and Nugues, 2006; Zhangand Nivre, 2012). The latter dives into improvements on extracting new feature representa-tion on the available corpus and using novel learning model (Zhang and Nivre, 2011; Chen andManning, 2014; Weiss et al., 2015; Andor et al., 2016; Kiperwasser and Goldberg, 2016).
Transition-based approaches also have limitations, such as being unable to produce non-projective dependency trees and to handle long-distance dependency problems. Therefore,

56 Chapter 4. A Proposed Architecture for a French DMR Framework
graph-based dependency parsing approaches are proposed to tackle directly with these prob-lems. Graph-based methods can produce both projective and non-projective dependency trees,which occur in many languages. Also, graph-based models obtain better accuracy than thetransition-based models when predicting long-distance arcs by scoring entire trees using globalinference (McDonald and Nivre, 2011).
Based on graph theory, a discipline that has been studied for centuries, with numerousefficient algorithms available for processing directed and undirected graphs, the graph-basedapproach considers parsing as a search-based structure prediction problem in the space of allpossible dependency trees for a given sentence (McDonald et al., 2005). More specifically, thenotion of score is used on each dependency tree G = (V,A) of a given input sentence. Theoverall score of each dependency tree achieved is computed on the scores of all edges in thetree G, i.e., score(G) = score(V,A). Thus, the best dependency tree GS in the space of allpossible dependency trees GS for the sentence S is defined as:
GS = argmaxG=(V,A) ∈ GS
score(G). (4.5)
w0
w1
w2 w3
52 1
8 114
3
7
4
( ) The graph G = (V,A) and its scores
w0
w1
w2 w3
8 117
4
( ) The graph G′ is not a MST
w0
w1
w2 w3
Cycle C
8 117
( ) A cycle found on G′
w0
w1
w2 w3
Cycle C162
8 1115
10
7
( ) The graph after contraction
w0
w1
w2 w3
16
8 11
4
( ) The dependency tree obtained at the finalstep from graph G
F 4.9: A visualization on a simple example with the Chu-Liu-Edmondsalgorithms for a graph-based parsing
In order to explore this approach, let us consider the arc-factored parsing model, which is

4.3. An Architecture for a French Semantic Parsing Framework 57
one of the common graph-based parsing approaches (McDonald, 2006). For a given sentence,a standard directed graph GS = (VS , AS) is constructed, that is:
• A set of vertices VS = w0, w1, . . . , wn, which are the ordered words of the sentence.
• A set of directed edges AS = {(wi, l, wj) | for wi, wj ∈ VS , l ∈ L with j 6= 0}denotes all possible head-dependent relations.
• Weights on edges γS = {γ(i, j) ∈ R | for each (i, j) ∈ (wi, l, wj) and (wi, l, wj) ∈ A}denote the score value of all possible edges in A.
The graphG is a directed multi-graph, that is: there exist possibly multiple arcs between a pairof verticeswi andwj . If nodew0 is eliminated, graph VS ,GS becomes a complete graph. Thisis due to the fact that w0 is a regular root node with outgoing edges from w0 to all other words.
Definition 4.3.9. Amaximum spanning tree (MST) of a directed graphG is the highest scoringof all edges of the directed graph G′ that satisfies the spanning tree conditions V ′ = V .
Based on the graph-theoretic concept of spanning tree, arc-factored methods treat depen-dency parsing as searching the maximum spanning tree G′S on the set of spanning trees of thedirected graphGS . To find theMSTG′S of a directed graphGS , we can use Chu-Liu-Edmondsalgorithm, that was independently developed by two different researchers: Chu, 1965 and Ed-monds, 1967. This algorithm consists of a greedy edge-selection step, followed by a edge-weightupdating step, and then possibly by a call of a recursive procedure on a new graph, derived fromthe original graph GS . In general, the algorithm begins with each vertex in the graph, greedilyfinds the incoming edge with the highest score. If the result obtained is a tree, it is the MSTtree. If not, there exists a cycle between at least one pair vertex in the graph. In the case ofexistence of a cycle, a procedure is used to identify the cycle and contract it into a single vertexand recalculate weights by adding the highest score into the outgoing and incoming edges of thecycle. Now, we have a new graph GC with the new weights. A recursive procedure applies thealgorithm to the new graph. This gives us either the resulting MST tree or a graph with a cycle.The call of the recursive procedure can continue as long as cycles occur. Parameters of verticesand edges are restored from the cycle when the recursion completes. The pseudo-code of thealgorithm is Algorithm 2. As as result, the resulting spanning tree is the best non-projectivedependency tree GS for the input sentence.
An simple example of the use of the Chu-Liu-Edmonds algorithm is displayed in the Fig-ure 4.9. We use the sentence S = {w0, w1, w2, w3, w4} where w0 is a root vertex and theother vertices correspond to words, for example, “Elle est courageuse” (She is courageous) , w1
is ‘elle’ (she), w2 is ‘est’ (is) and w3 is ‘courageuse’ (couragous). The initial weights of edges arerandom numbers.
Conventionally, the score of an edge is the dot product between a high dimensional featurerepresentation f and a weight vector w:
γ(i, j) = w.f(i, j). (4.6)
The score of a dependency treeGS = (VS , AS) for the input sentence S is subsequently definedas:
score(GS) =∑
(i,j)∈γS
γ(i, j) =∑
(i,j)∈γS
w.f(i, j). (4.7)
In general, we consider training data as D = {(Sd, Gd)}|D|d=1, that is, pairs of input sen-
tences St and their corresponding valid dependency treesGd. By contrast with transition-basedapproach, we do not require a transformation on the training data, this is due to the fact that

58 Chapter 4. A Proposed Architecture for a French DMR Framework
Algorithm 2: Chu-Liu-Edmonds AlgorithmData: A directed graph G = (V,A) and scores γResult: A dependency tree out of MST Gbegin
A′←− {(wi, wj)|wj ∈ V,wi = argmaxwiγ(i, j)};
G′ ←− (V,A′);if G′ has no cycles then
return G′, it is a MST;else
C ←− a cycle in G′, the result of a search procedure;GC ←− contract(G, C, γ), defined in algorithm 3;G←− a recursion on Chu-Liu-Edmonds algorithm’s procedure with GC andγ as input data;
wj ←− find a vertex in C, such that, (wi, wj) ∈ A and (wk, wj) ∈ C;A←− A ∪ C \ {(wk, wj)};return G
Algorithm 3: Contracted Graph AlgorithmData: A directed graph G = (V,A), a cycle C and scores γResult: A contracted graph GC
beginGC ←− G excluding nodes in C;Add a node wc into GC representing cycle C;for wj ∈ V \C : ∃wi∈C(wi, wj) ∈ A do
Add edge (wi, wj) to GC with γ(wi, wj) = argmaxwi∈C γ(wi, wj);for wi ∈ V \C : ∃wj∈C(wi, wj) ∈ A do
Add edge (wi, wc) to GC with γ(wi, wc) =argmaxwj∈C [γ(wi, wj)− γ(a(wj), wj) + γ(C)], where a(v) is thepredecessor of v in C and γ(C) =
∑v∈C γ(a(v), v);
return GC
models are directly parsing over trees. Thus the training model focuses on assigning higherscores to valid trees rather than to invalid ones, instead of the classifying item into categories.
The extraction of features and the calculation of weights used for the score are the mainproblems that need to be solved, they correspond to variables w and f in formula (4.7). First,similar to the transition-based approach, extracting features to train edge-factored models is animportant step that directly influences the accuracy of the result achieved when building thelearning model. In general, we can used different features such as word embedding, originalword form, lemma, POS tag of the head word and its dependent, dependency relation withitself, or distance from head to the dependent, etc. Secondly, we need to build a model to learna set of weights corresponding to each feature. A popular learning framework for the problemis inference-based learning, also known as Perceptron Learning Algorithm (Rosenblatt, 1958;Collins, 2002). More specifically, an initial random set is assigned to initial weights. Eachsentence in the training corpus D is parsed along with its initial weights. If the obtained parsetree matches the valid dependency tree in D, we keep the weights unchanged. If not, we filterthe features corresponding to the invalid parse and subtract a small number from their weights.Pseudo-code for the algorithm is illustrated in Algorithm 4.

4.3. An Architecture for a French Semantic Parsing Framework 59
Algorithm 4: Perceptron Learning AlgorithmData: D = {(Sd, Gd)}
|D|d=1
Result: w: the weight vectorbegin
Initializaze w randomly;for n←− 1 to N do
for d←− 1 to |D| doG′←− argmaxG′ ∈ G′Sd
∑(i,j)∈γ′ w.f(i, j);
if G′ 6= Gd thenw←− w +
∑(i,j)∈γd w.f(i, j) -
∑(i,j)∈γ′ w.f(i, j);
return w;
Graph-based methods are frequently employed for building dependency parsing systems.The major part of ameliorations of novel approaches focuses on applying deep neural net-work models to achieve a new feature representation and weight vector. More specially, thescore(GS) in the equation (4.7) is calculated as the output layer of a multi-layer perceptron(Pei, Ge, and Chang, 2015). More specifically, the hidden layer h is calculated as:
h = g(W eh .a+ beh), (4.8)
where g is an activation function, a is a vector that is concatenated out of word embeddings,and e ∈ 0, 1 indicates the direction between head and dependent. Then,
score(GS) = W eo .h+ beo, (4.9)
where Wh, Wo, bh, bo are the weights and bias of the hidden layer and of the output layer.Indeed, several neural network models are employed to graph-based systems, achieving signifi-cant results. For instance, experiments on the Penn Tree Bank corpus have proven the efficiencyof the approach, obtaining the currently highest accuracy15 for dependency parsing (Mrini et al.,2019; Zhou and Zhao, 2019).
Corpus data play an extremely important role for training and evaluating dependency parsingsystems. In particuler, the Penn Tree Bank corpus has become quite popular in studies ondependency as well as constituency parsing. Similarly, the FTB corpus in French is the mainresource contributing for builders of French dependency parsers. Each language has its ownset of dependency relations. Therefore, a study on dependency can only apply to one languageor to a group of closely related languages. Nevertheless, in recent time, work is in progress todefine a general dependency set: universal dependencies are proposed as a consistent frameworkfor building dependency tree bank annotations across languages (McDonald et al., 2013; Nivreet al., 2016). There are over 30 languages that have been annotated using universal dependencyrelations.
Dependency parsing for French language has been extensively studied on the basis of meth-ods such as the above and accompanied by the development of French dependency corpora,such as the dependency structures on the French Tree Bank corpus that have been convertedfrom the original format, namely constituency structures (Candito et al., 2009), or the develop-ment of the deep dependency structure on the Sequoia corpus (“Deep syntax annotation of theSequoia French treebank”). Many dependency parsers have been completely implemented and
15Table http://nlpprogress.com/english/dependency_parsing.html synthesizes latest results withtheir accuracy.

60 Chapter 4. A Proposed Architecture for a French DMR Framework
deployed for different applications. In a nutshell, we describe below six powerful parsers forFrench, currently in use:
• The Berkeley parser (Petrov et al., 2006; Petrov and Klein, 2007) employs a statisticalgrammar-based approach with a latent-variable PCFG model. The core of its learningmodel is the Expectation-Maximization algorithm that is used to estimate probabilities ofsymbols by using latent annotations. Essentially, symbols are split according to phrasal orlexical properties. The original version of the Berkeley parser did not work for French.However, the development of a French version has been realized, with adaptations togrammar, and to unknown words suffixes.
• MaltParser (Nivre, Hall, and Nilsson, 2006) is built upon the transition-based approach.The arc-eager algorithm has been employed to build transitions between configurationsin the transition system. Concerning to the feature representation of the learning model,the authors have used word forms, POS tags, dependency types of words. The originalclassifier of the parser is the first version of the library LIBSVM as of 2001 (Chang andLin, 2011). However, the MaltParser implementation of the French version uses a linearclassifier from the library LIBLINEAR (Fan et al., 2008). In fact, the French version hasbeen customized and retrained using dependency structures from the French Tree Bankcorpus.
• MSTParser (McDonald, Lerman, and Pereira, 2006) has been developed on the basis ofthe graph-based approach. Based on the computation of the score between pair words ofthe training corpus, this model processes candidate word pairs and gives as output either”no link” or a link with a specified direction and type, by using the Greedy PrependAlgorithm (Yuret and Türe, 2006), which has been employed to obtain a decision list ondependency relation information. An adaptation of theMSTParser for French 16 has beencustomized by using the MElt tagger for extracting POS tag information of sentences.
• Grew Parser (Guillaume and Perrier, 2015) is based on a symbolic method defined in agraph rewriting framework for French language only. The parsing process is consideredas a sequence of atomic transformations which begin from a list of lexical items and endup with the dependency tree. A set of rules is defined depending on linguistic contextswhere a dependency relation can appear. Each atomic transformation is described by oneof these rules. In the final step, a CKY-style algorithm is used in order to obtain validdependency trees. Experiments obtain an 89.21% accuracy on the Sequoia corpus.
• Stanford Parser (Chen and Manning, 2014) is a large NLP framework that can do var-ious tasks, such as POS tagging, constituency parsing, named entity recognition, or de-pendency parsing, for many languages. This framework has evolved significantly. Inthe latest version, a dependency parser has being developed, based on a transition-basedapproach, using an arc-standard system for treating transitions. A neural network modelwith a hidden layer is included, embeddings of features are added to the input layer, infact the input layer is mapped to the hidden layer through a cube action function. Thetransition with the highest score is picked up and used for the next configuration. As asresult, experiments have achieved an accuracy that is higher than the ones of MSTParseror MaltParser.
• SpaCy Parser (Honnibal, Goldberg, and Johnson, 2013; Honnibal and Johnson, 2015)also uses a transition-based approach. Based on the arc-eager system, a new non-monotonictransition “UNSHIFT” is added that aims to repair configurations in which the buffer
16Downloads of French versions for Berkeley Parser, MaltParser and MSTParser are available at: http://alpage.inria.fr/statgram/frdep/fr_stat_dep_parsing.html.

4.3. An Architecture for a French Semantic Parsing Framework 61
is exhausted and the stack contains multi-words having no incoming arc. The trainingprocedure employs the dynamic oracle-based search-and-learn training strategy whichallows one or more transition sequences for a given tree and gives optimal predictions forall configurations (Goldberg and Nivre, 2012). An amelioration using a multi-task CNNtraining model for classification in the training procedure provides an 84.48% accuracyfor labeled dependencies on the French Sequoia corpus (with universal dependency an-notations) and the WikiNER corpus17.
• Stanza Parser (Qi et al., 2019; Qi et al., 2020) uses a graph-based approach with anarchitecture described in (Dozat, Qi, and Manning, 2017). A neural network architec-ture with a multilayer BiLSTM network is used to obtain vector representations frominput features. These vector representations are then used to calculate scores betweeninput words and potential arcs. In the last step, inference on dependency trees uses amaximum spanning tree search based on the Chu-Liu-Edmonds algorithm. The systemachieved a state-of-the-art performance on different languages by using Universal De-pendency TreeBanks18.
In addition, several recent studies focus on improving the performance of learning models inboth transition-based and graph-based approaches by using complex deep neural network mod-els. These studies achieve good accuracy results on various corpora created according to theuniversal dependencies (Nguyen, Dras, and Johnson, 2017; Fernández-González and Gómez-Rodríguez, 2019). Thanks to the availability of trained models and code sources, they open theroad to the development of new dependency parsers for French.
4.3.3 A bridge between syntax and semanticsWe already described the basic concepts and techniques needed to analyze a given sentence.On the lowest level, a sentence is considered as a sequence of characters. The tokenizationstep allows splitting the sentence into lexical items. Lemmatization refers to the analysis ofradical tokens based on vocabulary resources nad morphological analysis, in order to removeinflectional endings and give the basic form of a word. Each word in the ordered word list of thesentence is classified into word-categories, and this task is called POS tagging task. At a higherlevel of syntactic analysis, words and their relationships are considered in a chunking task, inwhich groups of words in the sentence are identified based on the analysis of the head wordand its adjacent words. We call such a group of words a chunk and its function depends on thefunction of its head word.
Any sentence in a language can be analyzed with respect to a set of grammar rules in whichreside characteristics of the language, along with a subset of the vocabulary. Shallow parsingpartitions a sentence into chunks of words but it does not essentially comply with any specificgrammar rule of the language. We have introduced two typical approaches for the sentenceanalysis task. First, constituency parsing, which uses context-free grammar as a theoreticalfoundation for forming a sentence structure; constituency parsing can be viewed as an evolutionof shallow parsing by using recursive structures for constituents. The resulting constituencytrees show how lexical items are grouped together in order to provide richer information aboutphrases in the sentence. Secondly, we have introduced dependency parsing which is based ondependency grammars and analyzes sentences using of dependency relations between the words.Dependency trees are used to illustrate how words are related to each other via dependencyrelations of specific types.
17Downloads of the model are available at: https://github.com/explosion/spacy-models/releases//tag/fr_core_news_sm-2.2.5.
18Official site: https://universaldependencies.org/.

62 Chapter 4. A Proposed Architecture for a French DMR Framework
Dependency-based or constituency-based analysis propose different approaches of sentenceanalysis. Each approach has its advantages and disadvantages. For example, constituency pars-ing provides the entire structure of a sentence with all substructures, while dependency parsingachieves better performance with non-projective and fragmented sentences and seems to havea closer connection to meaning representation. However, it is very difficult to assert that oneapproach is better than the other and vice versa due to the fact that each one is constructed ondifferent grammatical theories.
The usage of a grammar formalism to perform sentence analysis is crucial to move fromsyntactic analysis to meaning analysis. Syntax and grammatical functions provide useful infor-mation for accessing the meaning of a given sentence. In general, five elements play the roleof main grammatical functions for building a sentence, namely subject, verb, direct and indi-rect object, complement and adverb. The position of these grammatical functions is differentdepending on the language. For example, in French a sentence mostly uses the order subject-verb-object. However, sentence with different orders may occur, such as subject-object-verb.Using morphology, syntax information and grammatical functions, we can infer a higher levelof linguistic representation, namely, semantics.
One of the main purposes of syntactic representation analysis is to constitute a bridgeheadto semantic interpretation. On the syntactic side, we can take a dependency tree and represent itin predicate-like form, which includes a grammatical relation, a source, and a target term (e.g.,sub(sleeps, Henri) is a semantic representation of the sentence “Henri sleeps”). Moving tothe semantic side, we can use a formalism for semantic representation, called semantic frames,which define events and semantic roles declared by the participants. For example, a framedescribing an eating event can include semantic roles like food, time, location, etc.
In general, grammar formalisms have been invented to describe constraints about syntaxwith grammatical rules. Otherwise, these formalisms also play an role in creating a mapping ofsyntax into semantic representation. Using a grammar formalism to create an interface betweensyntax and semantics has become a prevalent trend, fueled by the emergence of several differentgrammars. Beside of the head phrase structure and dependency grammars above, many othergrammar formalisms have emerged, such as:
• Tree Adjoining Grammar (TAG, Joshi, Levy, and Takahashi, 1975), a tree-rewritingsystem where a grammar consists of a set of elementary trees divided in initial and aux-iliary trees which are combined of two tree rewriting operations called adjunction andsubstitution. The set of grammar rules is somewhat similar to CFG, but TAG consti-tutes a tree-generating rather than a string-generating system such as CFG. Using theseoperations, elementary structures over local dependencies can be specified such as agree-ment, subcategorization or filler-graph relations. Lexicalized Tree-Adjoining Grammars(LTAG) are a variant of TAG that has been created using lexicons associating sets ofelementary trees with lexical items.
• Lexical Functional Grammar (LFG, Bresnan, 1982; Kaplan and Bresnan, 1982), builtupon the idea of using parallel formal representations corresponding to types of linguisticinformation. Accordingly, LFG analyzes sentences by two main kinds of syntactic struc-tures. First, c-structures deal with the surface of syntactic information such as linear orhierarchical organization of words into constituencies. Secondly, f-structures (functionalstructure) are finite sets of attribute-value pairs where an attribute denotes a symbol andits value can be a symbol, a semantic form, a set, or another f-structure. At the f-structurerepresentation, we can capture abstract syntactic relations such as agreement, control andraising, binding, or unbounded dependencies.
• Head-driven Phrase Structure Grammar (HPSG, Pollard and Sag, 1994), a constraint-based approach for representing rich contextual syntax and meaning representation for

4.3. An Architecture for a French Semantic Parsing Framework 63
natural language. Indeed, this grammar framework was heavily influenced by General-ized Phrase Structure Grammar (GPSG, Gazdar et al., 1985) that has been derived fromPhrase Structure Grammar (PSG). In general, HPSG consists of two essential compo-nents: typed feature structures and descriptive constraints that play a role similar to gram-matical rules. A typed feature structure is created from signs and grammatical rules, inwhich signs are basic types of HPSGs. Words and phrases are two different sign subtypes.A sign’s feature structure contains its morphological, syntactic or semantic properties. Afeature structure in HPSG can be represented by Attribute-Value Matrices (AVM).
• Categorial Grammar (CG) (Ajdukiewicz, 1935), a general term used for a number ofrelated formalisms that create intermediate interfaces between syntax and semantics fornatural languages. CG is classified in the same group with the three above grammarformalisms based on lexicalized theory for grammar. In its purest form, CG consists oftwo essential components: a lexicon and a set of category inference rules. The lexiconplays the role of a function assigning a set of categories to each basic symbol, while thecategory rules will determine how categories can be matched and what new categories canbe reached by inference. Many variants of CG have been created, such as Type-LogicalGrammar (TLG, Morrill, 1994; Moortgat, 1997) and Combinatory Categorial Grammar(CCG, Steedman and Baldridge, 2011)
In the remained of this thesis we will focus on the CCG theory and its applications. Essen-tially, we will introduce a method to apply CCGs to French sentences. The choice of CCG isbased on the following rationale:
• CCGs provide a transparent interface between syntax and underlying semantic represen-tation. They allows access to a deep semantic structure of the phrase using λ-expressionsand facilitate recovering of non-local dependencies involved in the construction such ascoordination, extraction, control, and raising.
• We map CCG derivation trees to λ-calculus expressions. The latter is a formal systemin mathematical logic. Every CCG inference rule is mapped to an equivalent λ-calculusexpression.
• CCG inference rules are based on the foundational theory of combinatory logic which hashad many applications in natural language processing (Schönfinkel, 1924; Curry et al.,1958; Haralambous, 2019). Therefore, CCG is based on a strong mathematical theoryas has a high potential for wide coverage applications in natural languages.
In the next chapters, we will dive into the description of a syntax-semantic interface withCCG. More specifically, we will study CCG and apply them to syntax analysis of natural lan-guage. The process of mapping syntax to semantic representations will be presented. We willalso introduce our main contributions in obtaining a French CCG corpus based on using depen-dency structure of sentences.

64
Part II
Building French Discourse MeaningRepresentation Parsing Framework

Chapter 5
CCG Derivations out of DependencySyntax Trees
Grammar formalisms act like a bridge linking syntax and semantics of natural languages. In theprevious chapter we gave an overview on syntactic processing and on the importance of grammarformalisms for obtaining semantic representations. Among different grammar formalisms, wechose CCG for an interface between the syntax and semantics because of its ability to handlelong-range phenomena and its mapping with λ-expressions. In this chapter, we first focus onthe definition of CCG and problems arising. The lack of a CCG corpus for French has beenone the motivations for obtaining a method to transform the French tree Bank corpus in orderto achieve a CCG Corpus (Le and Haralambous, 2019). These issues will be addressed in nextsections of the chapter, followed by an evaluation of the obtained CCG corpus.
5.1 IntroductionThe concept of CCG has first been introduced by Mark Steedman1 in the 2000s (Steedman,1999; Steedman, 2000a; Steedman, 2000b). They were introduced as an extension of CGs(Ajdukiewicz, 1935; Bar-Hillel, 1953) with the addition of category inference rules in order toobtain a wide coverage of natural languages. CCG is essentially a lexicalized grammar formal-ism in which words are mapped to syntactic categories that capture language-specific informa-tion about basic words and their lexical categories. Moreover, the CCG formalism is regardedas a mildly context-sensitive grammar in Chomsky’s hierarchy and thereby an efficient way todescribe a natural language’s syntax (Figure 5.1).
Similar to some grammar formalisms such as TAL or LFG, CCG is able to capture thenon-local dependencies2 related to a substantial number of linguistic phenomena such as co-ordination, raising and control construction, relativization or topicalisation. Accordingly, theprocessing of non-local dependencies has a important influence to the accurate and complete de-termination of semantic compositions that can be represented in the form of predicate-argumentstructures.
The analysis of sentences in natural languages in the CCG formalism provides a transpar-ent interface between the syntactic representation and composition of the underlying meaningrepresentation. In other words, rules of semantic composition are mapped one-to-one directlyto rules of syntactic composition. Thus, the predicate-argument structure or λ-expressions canbe use to rewrite any CCG derivation tree.
CCG is based on a strong foundation of combinatory logic, which bears a close connection toformal semantics (e.g., Montague Gammar, Partee, 1975 and Haralambous, 2019). In addition,CCGs can gain expressive power from λ-calculus which is broadly used in combinatory logic.
1Currently a professor of Cognitive Science at the university of Edinburgh. His personal page is available at theaddress: https://homepages.inf.ed.ac.uk/steedman/
2This term is a synonym of long-distance dependency, long-range dependency and unbounded dependency.

66 Chapter 5. CCG Derivations out of Dependency Syntax Trees
Regular languages
Context free languages
Mildly contextsensitive languages
Context sensitive languages
Recursively enumerable languages
F 5.1: Chomsky’s hierarchy of formal languages
With advantages on wide-coverage of natural languages, CCGs have been successfully ap-plied to a broad range of different practical applications such as data-driven parsing (Vaswaniet al., 2016; Lewis, Lee, and Zettlemoyer, 2016), wide-coverage semantic parsing (Bos, 2008),question answering (Clark, Steedman, and Curran, 2004; Ahn et al., 2005), and machine trans-lation (Birch, Osborne, and Koehn, 2007; Nadejde et al., 2017).
5.2 Combinatory Categorial Grammars5.2.1 Categories and Combinatory RulesCCG is essentially a non-transformational grammatical theory relying on combinatory logic.Beyond that, CCG is also a lexicalized grammar formalism. Therefore, syntactic types or cat-egories play an crucial role in the construction of a grammar. Categories are regularly usedto identify constituents which are called as either axiom categories (primitive categories) or ascomplex categories. While axiom categories are used as exponents of basic units of sentencessuch as number, common noun, case, inflection and so on, complex categories are created fromthe association of different axiom categories or other complex categories. For example a com-plex category for verbs (e.g., X\Y) bears categories identifying the type of the results (X) andarguments/complements (Y). The order of arguments is fixed and cannot be changed in thesecategories.
Definition 5.2.1. Let∆ be a finite set of given axiom categories. A lexical category C(∆) over∆ is the smallest set such that:
• ∆ ⊆ C(∆);
• if X, Y ∈ C(∆), then X/Y ∈ C(∆);
• if X, Y ∈ C(∆), then X\Y ∈ C(∆).
Definition 5.2.2. Let Σ be a set of terminals and C(∆) a finite set of lexical categories. Alexicon is a finite set of binary relations (σ, c) where σ ∈ Σ and c ∈ C(∆).
Definition 5.2.3. A CCG is defined as a set G = <Σ, C(∆), f, ς,<> where:
• Σ defines the finite set of terminals.
• C(∆) is defined as the definition 5.2.1
• f is the lexical category function mapping terminals into categories, which is also calleda lexicon.
• ς is a unique starting symbol, ς ∈∆.
• < is a finite set of combinatory rules which we describe below.

5.2. Combinatory Categorial Grammars 67
By X, Y, Z we denote meta-categories (they stand for any category of the grammar). Theset < includes two basic rules inherited from AB categorial grammars:
Forward Application:
X/Y:f Y :a ⇒ X:f(a),
Backward Application:
Y:a X\Y:f ⇒ X:f(a).
(5.1)
The first version of the rule set< from pure CG (Ajdukiewicz, 1935; Bar-Hillel, 1953) con-tains only the application function with functors to the left \ or to the right /, called Backward orForward application. The restriction on the rule set aims to limit expressiveness to the level ofCFGs. An important contribution of CCG theory is the extension of AB categorial grammarsby a set of rules based on composition (B), substitution (S), and type-raising (T) combinatorsof combinatory logic (Curry et al., 1958). These rules allow processing of long-range depen-dencies, and extraction/coordination constructions. They can be represented via λ-calculus, asfollows:
Forward Composition:
X/Y Y/Z⇒B
X/Z
λy.f(y) λz.g(z) λz.f(g(z)),
Forward Crossing Composition:
X/Y Y\Z⇒B
X\Z
λy.f(y) λz.g(z) λz.f(g(z)),
Backward Composition:
Y\Z X\Y⇒B
X\Z
λz.g(z) λy.f(y) λz.f(g(z)),
Backward Crossing Composition:
Y/Z X\Y⇒B
X/Z
λz.g(z) λy.f(y) λz.f(g(z)),
(5.2)

68 Chapter 5. CCG Derivations out of Dependency Syntax Trees
Forward Substitution:
(X/Y)/Z Y/Z⇒S
X/Z
λzy.f(z, y) λz.g(z) λz.f(z, g(z)),
Forward Crossing Substitution:
(X/Y)\Z Y\Z⇒S
X\Z
λzy.f(z, y) λz.g(z) λz.f(z, g(z)),
Backward Substitution:
Y\Z (X\Y)\Z⇒S
X\Z
λz.g(z) λzy.f(z, y) λz.f(z, g(z)),
Backward Crossing Substitution:
Y/Z (X\Y)/Z⇒S
X/Z
λz.g(z) λzy.f(z, y) λz.f(z, g(z)).
(5.3)
There are also type-raising rules in CCG:
Forward type-raising:
X:x ⇒T T/(T\X):λf.f(x),
Backward type-raising:
X:x ⇒T T\(T/X):λf.f(x).
(5.4)
In the case of coordination constructions, the lexical category (X/X)\X is used to validatethe combination of similar components in the rules of formula (5.2) and (5.3). It is formalizedas follows:
Coordination:
X : g X : f ⇒Φn X:λx.f(x) ∧ g(x)(5.5)
Let us give a simple example of CCG: G =< Σ,∆, f, ς,< >, where:
• Σ := {Henri, regarde, la, télévision }.
• ∆ := {S, NP }
• C(∆) := {S, NP, S\NP }
• Function f : f (Henri) := {NP,NP/NP}, f (regarde) := {S\NP, (S\NP)/NP}, f (la_télévision):= {NP}
• ς := S (sentence)
• < as defined in formulas (5.1), (5.2), (5.3), (5.4), (5.5).
In order to achieve CCG derivation, each word in a sentence first needs to be assigned tothe appropriate lexical categories. A word can have different lexical categories depending on itsposition or function in the sentence (e.g., word ‘la’ in the example 9). For instance, we have thefollowing lexical categories:

5.2. Combinatory Categorial Grammars 69
(9)
Henri ← NP
regarde ← (S\NP)/NP
la ← NP
la ← NP/NP
bien ← (S\NP)/(S\NP)
dort ← (S\NP)
We see that transitive verbs (e.g., regarder (to watch)) are assigned to lexical categories that aredifferent than those of intransitive verbs (e.g., dort (to sleep)); the latter take a single argument,which is of category NP. Modifier words (e.g., bien (well)) can be associated with a verb tobecome constituents taking the same argument from the verb accompanied with.
In the combinatory rules above, each category is accompanied by a correspondingλ-expression.Example 10 illustrates the process of obtaining a semantic interpretation out of a syntactic cat-egory. The transparency between syntactic interpretation and semantic representation is illus-trated through each transformation from applying the combinatory rules in Figure 5.2.
(10)
Henri ← NP : henri′′
regarde ← (S\NP)/NP : λx.λy.regarde′xy
la ← NP : la′
la ← NP/NP : λx.la′(x)
bien ← (S\NP)/(S\NP) : λf.λx.bien′(fx)
dors ← (S\NP) : λx.dors′x
Syntax ↔ CCG ↔ Semantics
By using the definition of CCG and the rule set <, we find a CCG derivation for the exampleillustrated in Figure 5.2.
Henri regarde la télévisionNP (S\NP)/NP NP/NP NP
>
NP: x : λxλy.regarde′xy : y
>
S\NP : λx.regarde′la_télévision′x<
S : regarde′la_télévision′henri′
F 5.2: The 1st CCG derivation of the sentence: “Henri watches TV”
5.2.2 Some Principles Applied to CCGMapping between syntactic and semantic components must comply to the following three prin-ciples (Steedman, 2000b, p32) as follows:
• The Principle of Lexical Head Government: Both bounded and unbounded syntacticdependencies are specified by the lexical syntactic type of their head.
• The Principle of Head Categorial Uniqueness: A single nondisjunctive lexical cateogoryfor the head of a given construction specifies both the bounded dependencies that arise

70 Chapter 5. CCG Derivations out of Dependency Syntax Trees
when its complements are in canonical position and the unbounded dependencies thatarise when those complements are displaced under relativization, coordination, and thelike.
• The Principle of Categorial Type Transparency: For a given language, the semantic typeof the interpretation together with a number of language-specific directional parametersettings uniquely determines the syntactic category of a word.
From the head government and head categorial uniqueness principles we can see that composi-tion generalization may be required for sentences. In particular, generalization allows compo-sition into functions with more than one argument. Generalized composition can be defined asfollows:
Generailized Forward Composition:
X/Y (Y/Z)/$1 ⇒Bn
(X/Z)/$1f . . . λz.g(z) . . . . . . λz.f(g(z . . .)),
Generalized Forward Crossing Composition:
X/Y (Y\Z)$1 ⇒Bn
(X/Z)$1f . . . λz.g(z) . . . . . . λz.f(g(z . . .)),
Generalized Backward Composition:
(Y\Z)\$1 X\Y⇒Bn
(X\Z)\$1. . . λz.g(z) . . . f . . . λz.f(g(z . . .)),
Generalized Backward Crossing Composition:
(Y/Z)/$1 X\Y⇒Bn
(X\Z)$1. . . λz.g(z) . . . f . . . λz.f(g(z . . .)),
(5.6)
here the “$ convention” is defined recursively: For a category α, notation α$ (respectively α/$,α\$) denotes the set containing α and all functions (respectively leftward functions, rightwardfunctions) mapping it to a category in α$ (respectively α/$, α\$) (Steedman, 2000b, p. 42).
We can characterize all combinatory rules that conform to the directionality of their inputsby the three following principles (Steedman, 2000b, p. 54):
• The Principle of Adjacency: Combinatory rules may only apply to finitely many phono-logically realized and string-adjacent entities.
• The Principle of Inheritance: All syntactic combinatory rules must be consistent with thedirectionality of the principal function. By applying this principle, we can exclude rulessimilar to the following instance of composition:
X/Y Y/Z 6=⇒ X\Z (5.7)
• The Principle of Consistency: If the category that results from the application of a com-binatory rule is a function category, then the slash functor defines the directionality ofthe corresponding arguments in the input function. With this principle, we can eliminatethe following kind of rule:
X\Y Y 6=⇒ X (5.8)

5.3. The State-of-the-art of French CCG Corpora 71
5.2.3 Spurious ambiguityThere is a second CCG derivation for the sentence “Henri regarde la télévision” (Henri watchesTV) ans we illustrate it in Figure 5.3. Indeed, a sentence can be parsed into many different CCGstructures. In other words, we encounter here a situation where a grammatical sentence mayhave many valid and equivalent semantic parses. This phenomenon is called spurious ambiguityand is the cause of a combinatory explosion in the search space when we parse. Nevertheless,this problem is not considered as a drawback of CCGs, on the contrary: its existence addsflexibility to CCGs when analyzing coordination and extraction constructions.
Henri regarde la télévisionNP (S\NP)/NP NP/NP NP
>
NP: x : λxλy.regarde′xy : y
>T <TS/(S\NP) S\(S/NP): λp.p henri′ : λp.p la_télévision′
>BS/NP : λx.regarde′xhenri′
<
S : regarde′la_télévision′henri′
F 5.3: A 2nd CCG derivation for the sentence: “Henri watches TV”
5.3 The State-of-the-art of French CCG CorporaDifferent approaches based on sentence structure can be used to build a CCG derivation tree.The two main ones are based more specifically on constituents and on dependencies. Each onehas its own drawbacks and advantages—however, both require a pre-analysis step to obtain thenecessary meta-information from the corpus.
Constituency trees have allowed the construction of a CCG Bank corpus for English (Hock-enmaier and Steedman, 2007) out of the Penn Wall Street Journal Phrase Structure Treebank(Marcus, Marcinkiewicz, and Santorini, 1993), where a CCG derivation tree was created outof each sentence of the corpus. First, the authors used results from (Magerman, 1994) fordetermining the constituent type of each node, which was assigned to a head complement orto an adjust. Then, they transformed the constituency trees of the corpus into binarized trees.Finally, they assigned CCG categories based on the nodes of the binarized trees.
Similarly to (Hockenmaier and Steedman, 2007) and (Tse and Curran, 2010), (Xue et al.,2005) constructed a Chinese CCG Bank using the Penn Chinese Treebank. A CCG Bank forGerman has also been created, out of the Tiger Tree Bank (Hockenmaier, 2006). The authorsused an algorithm based on the binarization of constituency trees. In particular, they builtsentence digraphs, the nodes of which are labeled with syntactic categories and POS tags, andthe edges of which are labeled with syntactic functions. These graphs are pre-processed andtransformed into planar trees. Then a binarization step is applied to the planar trees in order toallow CCG derivation extraction. There exists also an Arabic CCG Bank built out of the PennArabic Tree Bank (El-Taher et al., 2014), using similar methods.
Concerning the approach based on dependency trees, (Bos, Bosco, and Mazzei, 2009) cre-ated an Italian CCG Bank out of the Turin University Tree Bank. The authors first converteddependency trees into phrase structure trees and then used an algorithm similar to the one that(Hockenmaier and Steedman, 2007). (Çakıcı, 2005) and (Ambati, Deoskar, and Steedman,2018) used to extract CCGs for Turkish and Hindi. They parsed dependency trees and assigned

72 Chapter 5. CCG Derivations out of Dependency Syntax Trees
CCG lexical categories to nodes based on complement or adjunct labels. In the case of Hindi,a further parsing step was added, using the CKY algorithm.
As for French, Richard Moot created a corpus called TLGBank based not on CCGs, buton Type-Logical Grammars (TLG, Moot, 2015). TLGs and CCGs are derived from the samenotion of Categorial Grammar, but TLGs have been usedmainly for theoretical issues in relationto logic and theorem-proving, while CCGs are more relevant to computational linguistics sincethey keep expressive power and automata-theoretic complexity to a minimum (Steedman andBaldridge, 2011).
There also exists an extension of CCGs to French, introduced in (Biskri, Desclés, and Jouis,1997) under the name Application and Combinatory Categorial Grammar (ACCG). This theoryinherits the combinatory rules of CCGs and adds meta-rules to control type-raising.
In this chapter, we use the dependency-based approach because we consider that it has sev-eral advantages over constituency based structures (see Kahane, 2012 for an interesting discus-sion of this issue, as well as Osborne, 2019). First, dependency-based structures provide betterconnections between words and their neighbors in the sentence. Secondly, dependency-basedstructures give a closer look to the syntax-semantics interface. And finally, the dependency-basestructures are more adapted to lexical function processing.
5.4 French Dependency Tree BankA tree bank is a linguistically annotated corpus made of large collections of manually anno-tated and verified syntactic analyses of sentences. Annotations are applied to words, compo-nents, phrases in the sentence, such as tokenization, part-of-speech tagging, constituency tree,dependency tree and semantic role labeling, named entity recognition, etc.
The French Tree Bank (FTB, ) contains approx. a million words, mapped into 21,550sentences taken from annotated news articles of the newspaper Le Monde in the period 1991–1993. Initially, the corpus was constituency-based. Then, a dependency-based version has beenautomatically created, as described in Candito, Crabbé, and Denis, 2010 and Candito et al.,2009. More specifically, each word is annotated with information on part-of-speech tagging,sub-categorization, inflection, lemma, and parts for compounds. Each sentence is annotatedinto two structures: dependency structure and constituency structure.

5.5. CCG Derivation Tree Construction 73
0 0.3 0.9 1.7·105
ADVP+D,PDETADJ
NC,NPPPROREL
V,INF,VPP,VPR,VS,VIMPPRO,P+PRO,CLR,CLO,CLS,CS
(DET,ADV,ADJ,PRO)WHCC
PREFETI
PONCT
27409106368
9267945242
1641606512
7069927285
47513915
465221566
67202
Number french words on tagset in FTB
F 5.4: Distribution of French words by POS tags in the French Tree Bankcorpus
Figures 5.4 and 5.5 display statistics about the distribution of POS tags and dependencyrelation types in the French Tree Bank corpus. Accordingly, we can see that words of nountype and their satellites, such as determinants, prepositions or adjectives, account for the largestnumber of types in the corpus. In a similar way, the mod, obj.p and det dependency relationtypes occupy the highest position in the distribution chart. These types are used for relationsinvolving noun words.
5.5 CCG Derivation Tree ConstructionIn this section we describe our three-step process for obtaining CCG derivation trees. In thefirst step we chose among the many lexical categories that have been used in the corpus foreach word those that fit together in the given sentence; we then attach them as labels to thedependency tree. In the second step we extract chunks from the dependency tree and add newnodes and edges in order to binarize the tree. In the final step we infer lexical categories for thenew nodes and check whether we can move from the leaves to the root of the tree by applyingcombinatory rules—the root of the tree must necessarily have the lexical category S.
5.5.1 Assigning Lexical Categories to Dependency Tree NodesAs already mentioned in § 5, dependency trees connect linguistic units (e.g., words) by directededges representing syntactic dependencies. They are rooted digraphs, the root being the head ofthe sentence (most often the verb). Edges are labeled with labels belonging to a set of syntacticfunctions, e.g., subject, object, oblique, determiner, attribute, etc. Dependency trees are ob-tained by dependency parsing. There are different methods for building high precision parsers,some based on machine learning algorithms trained on large sets of syntactically annotated sen-tences, others based on an empirical approaches using formal grammars. For this task, we haveused the French version of MaltParser (Candito et al., 2010).
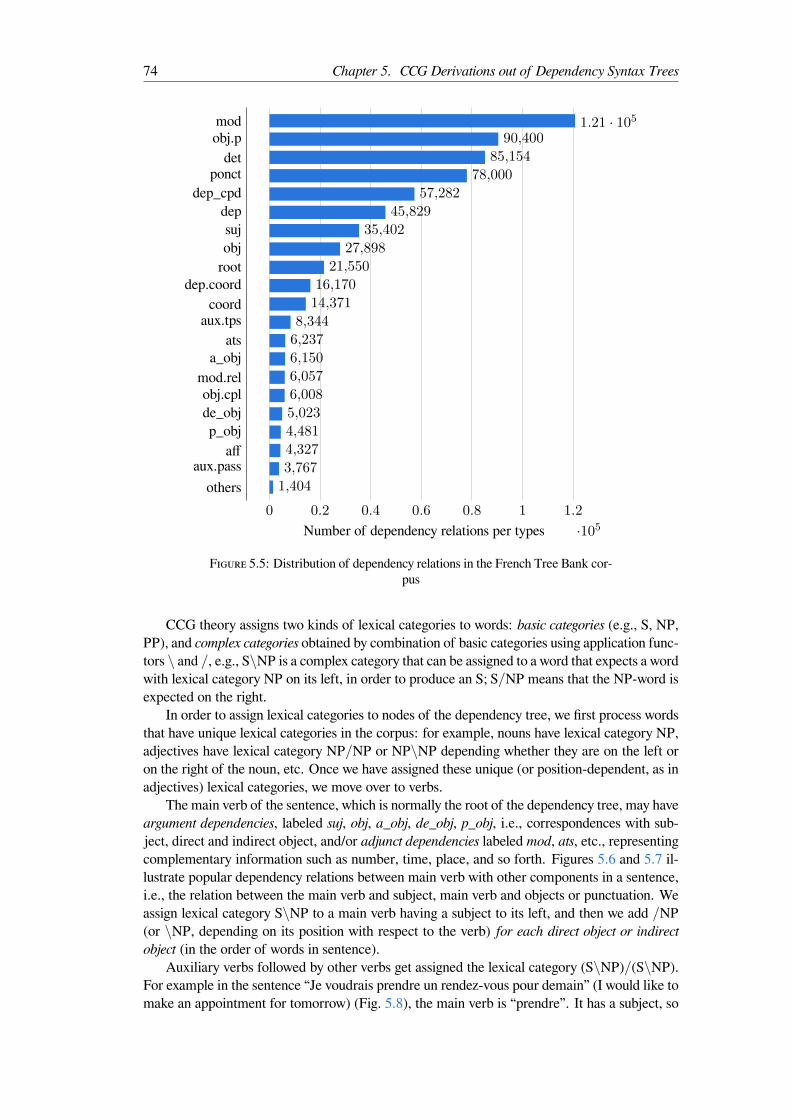
74 Chapter 5. CCG Derivations out of Dependency Syntax Trees
0 0.2 0.4 0.6 0.8 1 1.2
·105
othersaux.pass
affp_objde_objobj.cplmod.rela_objats
aux.tpscoord
dep.coordrootobjsujdep
dep_cpdponctdet
obj.pmod
1,404
3,767
4,327
4,481
5,023
6,008
6,057
6,150
6,237
8,344
14,371
16,170
21,550
27,898
35,402
45,829
57,282
78,000
85,154
90,4001.21 · 105
Number of dependency relations per types
F 5.5: Distribution of dependency relations in the French Tree Bank cor-pus
CCG theory assigns two kinds of lexical categories to words: basic categories (e.g., S, NP,PP), and complex categories obtained by combination of basic categories using application func-tors \ and /, e.g., S\NP is a complex category that can be assigned to a word that expects a wordwith lexical category NP on its left, in order to produce an S; S/NP means that the NP-word isexpected on the right.
In order to assign lexical categories to nodes of the dependency tree, we first process wordsthat have unique lexical categories in the corpus: for example, nouns have lexical category NP,adjectives have lexical category NP/NP or NP\NP depending whether they are on the left oron the right of the noun, etc. Once we have assigned these unique (or position-dependent, as inadjectives) lexical categories, we move over to verbs.
The main verb of the sentence, which is normally the root of the dependency tree, may haveargument dependencies, labeled suj, obj, a_obj, de_obj, p_obj, i.e., correspondences with sub-ject, direct and indirect object, and/or adjunct dependencies labeled mod, ats, etc., representingcomplementary information such as number, time, place, and so forth. Figures 5.6 and 5.7 il-lustrate popular dependency relations between main verb with other components in a sentence,i.e., the relation between the main verb and subject, main verb and objects or punctuation. Weassign lexical category S\NP to a main verb having a subject to its left, and then we add /NP(or \NP, depending on its position with respect to the verb) for each direct object or indirectobject (in the order of words in sentence).
Auxiliary verbs followed by other verbs get assigned the lexical category (S\NP)/(S\NP).For example in the sentence “Je voudrais prendre un rendez-vous pour demain” (I would like tomake an appointment for tomorrow) (Fig. 5.8), the main verb is “prendre”. It has a subject, so

5.5. CCG Derivation Tree Construction 75
Mon fils achète un cadeau .DET NC V DET NC PONCT(son) (fils) (acheter) (un) (cadeau) (.)
root
det suj det
obj
ponct
F 5.6: Dependency tree of the French sentence “My son buys a gift”.
Il le donnera à sa mère .CLS CLO V P DET NC PONCT(cln) (cla) (donner) (à) (son) (mère) (.)
root
suj objmod
det
a_obj
ponct
F 5.7: Dependency tree of the French sentence “He will give it to hismother”.
its lexical category must contain S\NP. Furthermore, it has a direct object dependency pointingto “rendez-vous”. Therefore, we assign lexical category (S\NP)/NP to it. The verb “voudrais,”being auxiliary, gets the lexical category (S\NP)/(S\NP).
POS tag Example Lexical categories
DET un(e) (a,an), le la, l’, les (the) NP/NP
ADJ petit (small), pareil (similar),même (same) NP/NP, NP\NP
NC, NPP soirée (evening) NP
ADV vraiment (really), longuement(long)
(S\NP)/(S\NP),(S\NP)\(S\NP)
CL(R,O,S) ce (this), se (-self), o n(they) NP, NP/NP, (S\NP)/(S\NP)
PRO il (he), nous (we) NP
CS que (what), comme (as) NP, NP/NP, (S\NP)/(S\NP)
P+D,P, P+PRO au (to), du (of), des (of), à (at),sur (on)
NP/NP, NP\NP, (NP\NP)/NP,(NP/NP)/NP, (S/S)/NP
PROREL qui (who), que (what), où (where) (NP\NP)/(S\NP),(NP\NP)/NP, (NP\NP)/S
(DET, ADV, ADJ,PRO)WH
quel (which), comment (how),quand (when) (S/(S\NP), (S\NP)/(S\NP)
PREF mi- (half), vice- NP/NP, (NP/NP)(NP/NP)
I oui (yes), non (no), bravo NP

76 Chapter 5. CCG Derivations out of Dependency Syntax Trees
T 5.1: Examples of lexical categories assigned to words
Lexical categories are iteratively assigned to the other words based on syntax functions anddependencies. For example, the noun words always get lexical category NP assigned to them,articles get (NP\NP). Categories (NP\NP) or (NP/NP) are assigned to adjectives depending ontheir position relatively to nouns. In Table 5.1, we list lexical category examples by word classesbased on syntactic analysis and dependency structure. It should be noted that lexical categoriesassigned to words during this step can be replaced by others at later steps of the process ofbuilding the CCG derivation tree.
5.5.2 Binarization of Dependency Trees
Algorithm 5: Chunk extractionChunkExtraction (chunk, sentence)Input: Chunk as part of dependency tree (full sentence at begin), dependency treeOutput: List of chunks in global variable chunkedListchunkedList← empty array;mainV erb← main verb of chunk;headConnectedWords← words connected tomainV erb;for element ∈ headConnectedWords do
elementList, newChunk ← empty array;add element into elementList and newChunk;while elementList is not empty do
firstElement← the first item in elementList;for word ∈ dependency tree do
if word has dependency with firstElement thenadd word to elementList and newChunk;
remove firstElement from elementList;add to chunkedList the result of applying recursively ChunkExtraction functionto newChunk;
return chunkedList
Binarization of the dependency tree is performed on the basis of information about thedominant sentence structure for the specific language. In French, most sentences are SVO, asin “Mon fils (S) achète (V) un cadeau (O)” (My son buys a gift, cf. Fig. 5.6), or SOV as in “Il(S) le (O) donnera (V) à sa mère (indirect O)” (He will give it to his mother, cf. Fig. 5.7). Usingthis general linguistic property, we can extract and classify the components of the sentence intosubjects, direct objects, indirect objects, verbs, and complement phrases.
The proposed algorithm for transforming a dependency tree into a binary tree consists of twosteps. First, we extract chunks from the dependency tree by using Algorithm 5 which is basedon syntactic information and dependency labels between words. For example, the subject chunkis obtained by finding a word that has a dependency labeled suj, the verb chunk corresponds tothe root of the dependency structure, direct or indirect object chunks are obtained as words withlinks directed to the root verb and having labels obj or p_obj, etc. Next, we build a binary treefor each chunk, as described in Algorithm 6, and then combine the binary trees in the inverseorder of the dominant sentence structure. For example if SVO is the dominant structure, westart by building the binary tree of the object chunk, then combine it with the binary tree of the
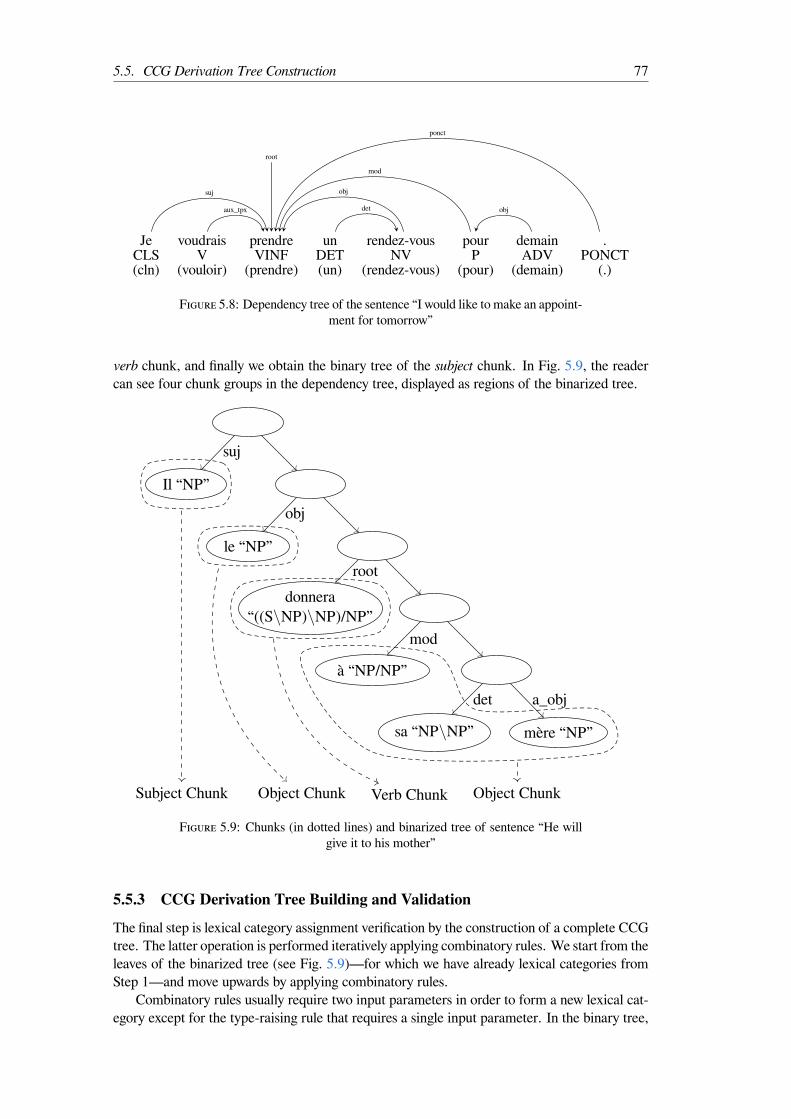
5.5. CCG Derivation Tree Construction 77
Je voudrais prendre un rendez-vous pour demain .CLS V VINF DET NV P ADV PONCT(cln) (vouloir) (prendre) (un) (rendez-vous) (pour) (demain) (.)
root
suj
aux_tpx det obj
obj
mod
ponct
F 5.8: Dependency tree of the sentence “I would like to make an appoint-ment for tomorrow”
verb chunk, and finally we obtain the binary tree of the subject chunk. In Fig. 5.9, the readercan see four chunk groups in the dependency tree, displayed as regions of the binarized tree.
mère “NP”sa “NP\NP”
à “NP/NP”
donnera“((S\NP)\NP)/NP”
le “NP”
Il “NP”
det a_obj
mod
root
obj
suj
Object ChunkVerb ChunkObject ChunkSubject Chunk
F 5.9: Chunks (in dotted lines) and binarized tree of sentence “He willgive it to his mother”
5.5.3 CCG Derivation Tree Building and ValidationThe final step is lexical category assignment verification by the construction of a complete CCGtree. The latter operation is performed iteratively applying combinatory rules. We start from theleaves of the binarized tree (see Fig. 5.9)—for which we have already lexical categories fromStep 1—and move upwards by applying combinatory rules.
Combinatory rules usually require two input parameters in order to form a new lexical cat-egory except for the type-raising rule that requires a single input parameter. In the binary tree,

78 Chapter 5. CCG Derivations out of Dependency Syntax Trees
Algorithm 6: Tree binarizationBinarizationTree (chunk)Input: Chunk list of sentenceOutput: Binary treebTree← empty; bChildTree← empty;i← get length of chunk;while i ≥ 0 do
if chunk[i] is a list of words thenbChildTree← buildTreeWithWords(chunk);
elsebChildTree← perform a recursion on BinarizationTree with chunk[i];
if bTree is empty thenbTree← bChildTree;
elseCreate a new temporary tree bTempTree;rootNode is root node of bTempTree;Put bTree to the right of bTempTree;Put bChildTree to the left of bTempTree;bTree← bTempTree;bChildTree← empty;
i← i− 1;return bTree
X/Y Y
[X]
X/Y [Y]
X
[X/Y] Y
X
F 5.10: Inference rules for lexical categories
whenever two nodes have lexical category information assigned to them, we can infer the lexicalcategory of the third node, as in Fig. 5.10. Using this method we move upwards, and if, afterhaving applied all necessary combinatory rules, we obtain S as the root of the tree, then wevalidate the CCG derivation tree thus obtained. The result of obtaining this method for the treeof Fig. 5.9 can be seen in Fig. 5.11 (next to each node we have displayed the combinatory ruleused to obtain its lexical category).
Some type-changing rules
In order to reduce the number of possible lexical category types, in cases such as bare nounphrases, type raising, clausal adjuncts, and sentence modifiers, we can use some unary type-changing rules:
N ⇒ NP
S[dcl]/NP ⇒ NP\NP
S[others]\NP ⇒ NP\NP
S\NP ⇒ S/S
(5.9)

5.5. CCG Derivation Tree Construction 79
mère “NP”sa “NP\NP”
“NP”à “NP/NP”
“NP”donnera“((S\NP)\NP)/NP”
“(S\NP)\NP”le “NP”
“S\NP”Il “NP”
“S”
det a_obj
mod
root
obj
suj
Forward Application
Forward Application
Forward Application
Backward Application
Backward Application
Object ChunkVerb ChunkObject ChunkSubject Chunk
F 5.11: CCG derivation tree of the sentence “He will give it to hismother.”
We can also use binary type-change rules in the case of words and punctuation:
NP , ⇒ S/S
, NP ⇒ S\S
, NP ⇒ (S\NP )\(S\NP )
X . ⇒ X
(5.10)
In the following we will consider some special cases arising while building CCG derivation trees,such as coordination, subordination, wh-questions, topicalization, and negation.
Coordination construction
In coordination we connect similar components (e.g., nouns, verbs, adjective-nouns, or phrases).Here are some examples whereWe use label CC in the dependency structure for words et (and),ou (or), mais (but), and so forth:
• Between components, in an elliptical construction: La France a battu [l’Argentine] (NP)et (CC) [la Belgique] (NP) (France has beaten [Argentina] and [Belgium]).
• Between components of the same type: [Le président adore] (S/NP) et (CC) [sa femmedéteste] (S/NP) le foot ([The president loves] and [his wife hates] football).
• Between components with different structures: Henri [cuisine] (S\NP) et (CC) [écoute dela musique] (S\NP) (Henri [cooks] and [listens music]).
• Between components without distribution: [Henri] (NP) et (CC) [sa femme] (NP) gagnentexactement 2000 dollars ensemble (Henri and his wife earn exactly 2000 dollars together).

80 Chapter 5. CCG Derivations out of Dependency Syntax Trees
Punctuation (e.g., comma or semicolon) can also be used in a way similar to coordinationin listing similar components.
Following Hockenmaier and Steedman, 2007, we consider conjuncts as nodes in the binarytree and obtain new lexical categories by inference on adjacent nodes, as in the rules given inFig. 5.12.
CC - ‘,’, ‘;’ X
[X\X]
X CC - ‘,’, ‘;’
[X/X]
F 5.12: Coordination rules for lexical categories
Subordination construction
In French, there are three types of clauses: independent, subordinate, and main. Independentclauses stand alone. They are either complete sentences or are attached to other independentclauses through coordinating conjunctions, for example, “[Henri est prêt] donc [on peut com-mencer]” (Henri is ready so we can start). A main clause is the principal component of asentence with subject and verb.
Let us examine the issue of subordination construction. A subordinate (or dependent) clauseis used to provide supplementary information about the sentence and is introduced by a subor-dinating conjunction or a relative pronoun. In addition, it does not express a complete idea andcannot stand alone. For example, “Henri aime le gâteau [que sa mère a acheté]” (Henri likesthe cake that his mother has bought). We divide subordinating clauses into two groups. Thefirst one uses subordinating conjunctions (comme (as, since), lorsque (when), puisque (since,as), quand (when), que (that), si (if)), annotated with label CS. The second group uses relativepronouns (qui (who, what, whom), que (whom, what, which, that), lequel (what, which, that),dont (of which, from what, whose), où (when, where)), annotated with label PRO. Lexical cat-egories are assigned according to context, for example (NP\NP)/(S\NP), (NP\NP)/(S/NP) isassigned to relative pronouns as in the case of English (cf. Steedman, 1996).
NPS\NP
NP, SNP/NP,(NP/NP)/S
NP, S/SS\NP
S
Chunk of SVO or VO typesSubordinating Conjunction
Main clause
F 5.13: Subordination rules for lexical categories

5.5. CCG Derivation Tree Construction 81
Wh-questions construction
French questions starting with interrogative words can take a wide variety of forms. In general,we consider four basic patterns (Boucher, 2010):
• Wh-word in situ and verb in situ: Vous allez où? (You go where?)
• Wh-word raised, verb in situ: Où vous allez? (Where do you go?)
• Wh-word raised, verb raised: Où allez-vous? (Where go you?)
• Wh-word raised + est-ce que, verb in situ: Où est-ce que vous allez? (Where is it that yougo?)
In our approach, interrogative words are separated from the sentence as in Fig. 5.14. Dependingon their position in the sentence (head or last), lexical categories assigned to them are S[wh]/S,S[wh]/(S\NP), S\S[wh], or (S\NP)\S[wh]. We treat the rest of the sentence in the standard way.
NPS/NP,(S\NP)/NPNPS/NP,
(S\NP)/NP
S\S[wh],(S\NP)\S[wh]
S,S\NP
S,S\NP
S[wh]/S,S[wh]/(S\NP)
S[wh]S[wh]
Chunk of SVO or VO types
Interrogative Words
F 5.14: Wh-question rules for lexical categories
Topicalization construction
Like in English, topicalization concerns expressions where a clause topic appears at the front ofa sentence or clause, for example, “Ce livre, je l’aime vraiment” (This book, I really like it). Thecomponent before the verb and subject is labeled MOD and can be considered as a sentence ornoun phrase. Therefore, we use unary ad hoc type-changing rules such as N⇒ NP, S/NP⇒NP\NP, S\NP⇒ NP\NP and S\NP⇒ S/S, or binary ad hoc type-changing rules involvingpunctuation, such as NP ‘,’ ⇒ S/S, ‘,’ NP ⇒ S\S, ‘,’ NP ⇒ (S\NP)\(S\NP), X ‘.’ ⇒ X, totransform the CCG derivation tree.
Negation structure construction
Negative sentences are formed by using two negative particles. The first one is ne or n’ (no) andthe second one can be pas (not) or some other particle such as plus (anymore), rien (nothing),jamais (never) or personne (nobody). Usually two negative words surround the conjugated verb,as in Henri ne mange jamais de viande (Henri never eats meat). In our process, negative wordsare filtered and placed in a verb chunk with the lexical categories that have been assigned usingthe adverb tag set.

82 Chapter 5. CCG Derivations out of Dependency Syntax Trees
100 101 102 103 104 105 106
100
101
102
Words
Numberoflexicalcate
gorytypes
F 5.15: The growth of lexical category types
5.6 Experiments and EvaluationIn our experiment we used the French TreeBank corpus (FTB) () that contains a million wordstaken from annotatedLeMonde news articles from the period 1991–1993. We used the dependency-based version, as in (Candito, Crabbé, and Denis, 2010; Candito et al., 2009). By applying ourmethod to the complete set of 21,550 dependency trees of the corpus, we obtain CCG derivationtrees for 94,02% of the sentences.
All in all, we obtain a set of 73 distinct lexical categories for the complete French corpus.More specifically, we see that the number of lexical categories increases rapidly during the10.000 first sentences (Fig. 5.15) and that, as expected, there are less newly generated lexicalcategories towards the last sentences in the corpus. In addition, lexical categories NP/NP andNP, which correspond to articles, adjectives and nouns, are assigned to more than half of thewords (Fig. 5.16). In Table 5.2, the reader can see the list of French words with the highestnumber of distinct lexical categories—notice that the four verbs of the table (être, avoir, faire,voir are used both as main and as auxiliary verbs).
Another experiment has been done on a small data set of sentences and the dependencystructure obtained through the MaltParser tool. Out of 360 sentences, we obtained only 83% ofcompleted sentences with lexical categories. This result shows that the accuracy of our approachstrongly depends on dependency parsing.
5.7 Error analysisThe failure rate of our approach is high when compared to results in other languages, such as99.44% of successfully parsed sentences in English or 96% in Hindi. There are three maincauses of error: incorrect POS tags, incorrect dependencies or dependency labels, and finallyerrors resulting from complex linguistic issues like sentential gapping, parasitic gaps, etc.
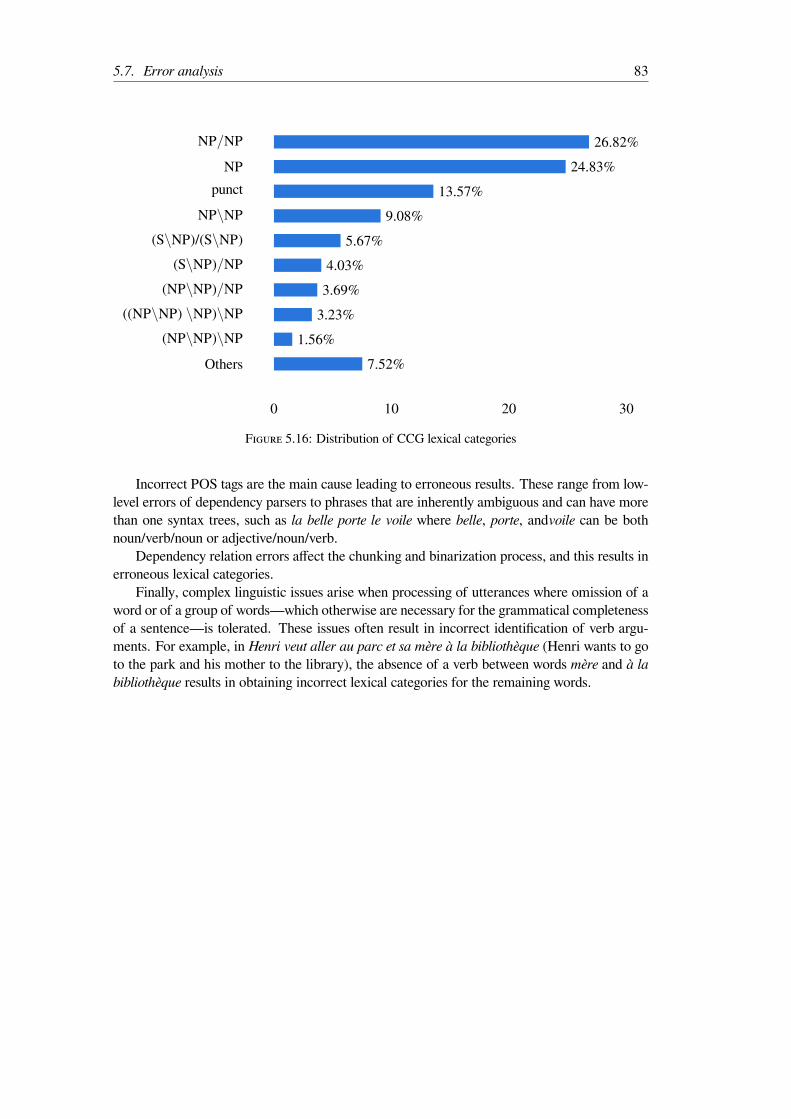
5.7. Error analysis 83
0 10 20 30
Others(NP\NP)\NP
((NP\NP) \NP)\NP(NP\NP)/NP(S\NP)/NP
(S\NP)/(S\NP)NP\NPpunctNP
NP/NP
7.52%1.56%
3.23%3.69%4.03%
5.67%9.08%
13.57%24.83%
26.82%
F 5.16: Distribution of CCG lexical categories
Incorrect POS tags are the main cause leading to erroneous results. These range from low-level errors of dependency parsers to phrases that are inherently ambiguous and can have morethan one syntax trees, such as la belle porte le voile where belle, porte, andvoile can be bothnoun/verb/noun or adjective/noun/verb.
Dependency relation errors affect the chunking and binarization process, and this results inerroneous lexical categories.
Finally, complex linguistic issues arise when processing of utterances where omission of aword or of a group of words—which otherwise are necessary for the grammatical completenessof a sentence—is tolerated. These issues often result in incorrect identification of verb argu-ments. For example, in Henri veut aller au parc et sa mère à la bibliothèque (Henri wants to goto the park and his mother to the library), the absence of a verb between words mère and à labibliothèque results in obtaining incorrect lexical categories for the remaining words.
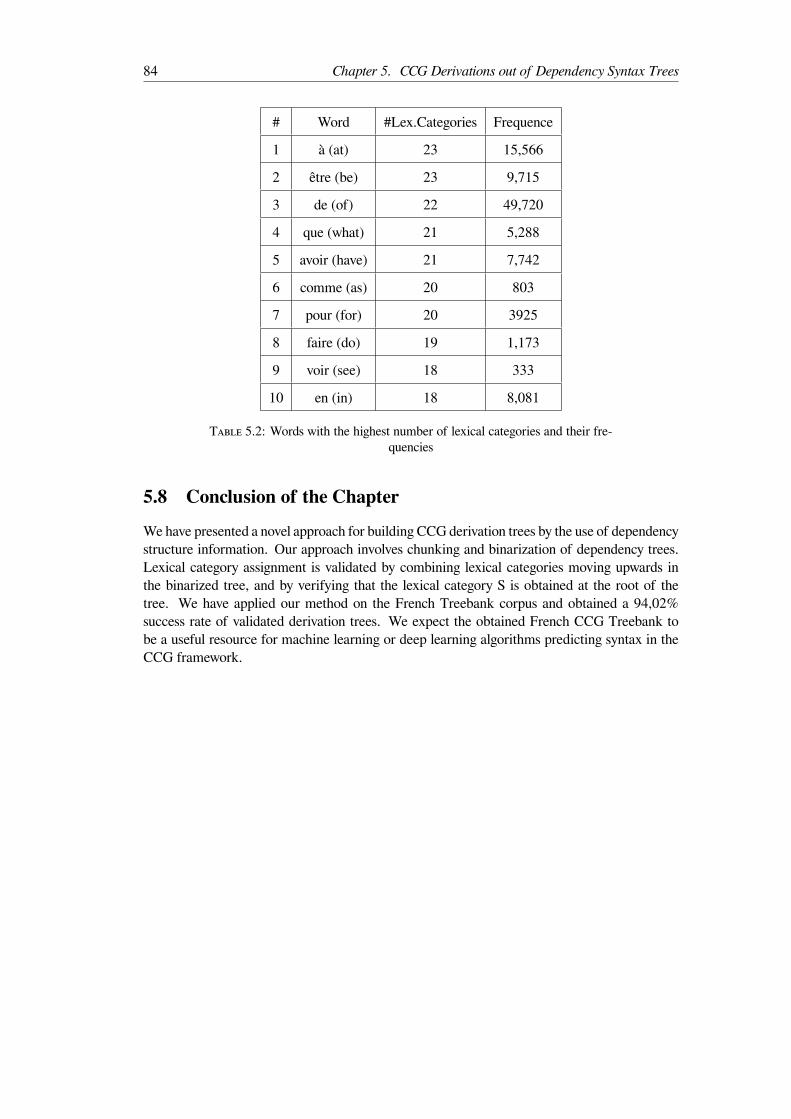
84 Chapter 5. CCG Derivations out of Dependency Syntax Trees
# Word #Lex.Categories Frequence
1 à (at) 23 15,566
2 être (be) 23 9,715
3 de (of) 22 49,720
4 que (what) 21 5,288
5 avoir (have) 21 7,742
6 comme (as) 20 803
7 pour (for) 20 3925
8 faire (do) 19 1,173
9 voir (see) 18 333
10 en (in) 18 8,081
T 5.2: Words with the highest number of lexical categories and their fre-quencies
5.8 Conclusion of the ChapterWe have presented a novel approach for building CCG derivation trees by the use of dependencystructure information. Our approach involves chunking and binarization of dependency trees.Lexical category assignment is validated by combining lexical categories moving upwards inthe binarized tree, and by verifying that the lexical category S is obtained at the root of thetree. We have applied our method on the French Treebank corpus and obtained a 94,02%success rate of validated derivation trees. We expect the obtained French CCG Treebank tobe a useful resource for machine learning or deep learning algorithms predicting syntax in theCCG framework.

Chapter 6
CCG Supertagging UsingMorphological and DependencySyntax Information
In the previous chapter we described the creation of the French CCG Tree Bank corpus (20,261sentences) out of the French Tree Bank corpus by . In order to improve the assignment oflexical categories to words, we have developed a new CCG supertagging algorithm based onmorphological and dependency syntax information. We then used the French CCG Tree BankCorpus, as well as the Groningen Tree Bank corpus for the English language, to train a newBiLSTM+CRF neural architecture that uses (a) morphosyntactic input features and (b) fea-ture correlations as input features. We show experimentally that for an inflected language likeFrench, dependency syntax information allows significant improvement of the accuracy of theCCG supertagging task when using deep learning techniques (Le and Haralambous, 2019).
6.1 IntroductionCCG supertagging plays an important role in parsing systems, as a preliminary step to the buildof complete CCG derivation trees. In general, this task can be considered as a sequence label-ing problem with input sentence sinput = (w1, w2, . . . , wn) and the CCG supertags soutput =(t1, t2, . . . , tn) as output. Input features can be words or features extracted from words, suchas suffix, capitalization property or a selection of characters (Lewis, Lee, and Zettlemoyer,2016; Wu, Zhang, and Zong, 2017; Xu, 2016; Ambati, Deoskar, and Steedman, 2016; Kadariet al., 2018b). We will use morphosyntactic annotations such as lemma, suffix, POS tags anddependency relations (Honnibal, Kummerfeld, and Curran, 2010) to build feature sets. Theseannotations are extremely useful in order to add additional information about words as wellas long-range dependencies in the sentence (Figure 6.1). These novel features allow us to im-prove accuracy of a supertagging neural network. We also consider adding correlations betweenfeatures as additional input features of the network and examine the results.
In the past few years, Recurrent Neural Networks (RNN) (Goller and Kuchler, 1996) alongwith their variants such as Long-Short Term Memory (LSTM) (Hochreiter and Schmidhuber,1997; Gers, Schmidhuber, and Cummins, 1999) and GRU (Cho et al., 2014) have been provento be effective for many NLP tasks, and especially for sequence labeling such as POS tagging,Named Entity Recognition, etc. In the CCG supertagging task, different RNN-based modelshave been proposed and have obtained high accuracy results. Following this trend, we baseour model on the Bi-Directional LSTM (BiLSTM) architecture associated with ConditionalRandom Fields (CRF) as output layer. Thus, we take advantage of the ability to remember theinformation of previous and next words in the sentence with the BiLSTM network and increasethe ability to learn from the relationship of output labels with CRF.

86 Chapter 6. CCG Supertagging Using Morphological and Dependency Syntax Information
Intelligent robots will replace human jobs by 2025 .(intelligent) (robot) (will) (replace) (human) (jobs) (by) (2025) (.)
NP/NP NP (S\NP)/(S\NP) (S\NP)/NP NP/NP NP (NP\NP)/NP NP
amod
nsubj
aux
ROOT
amod
dobj
prep
pobj
punct
F 6.1: A sentence with POS tags, dependencies and CCG lexical cate-gories.
6.2 State-of-the-art of the CCG Supertagging TaskOne of the first applications of machine learning to CCG supertagging is the development ofa statistical parser by Clark and Curran, 2007. They proceed in two main steps: supertaggingand combination of lexical categories. Their supertagging approach is based on the log-linearmodel by using the lexical category set in a local five-word context to obtain a distribution.The model’s features are POS tags of words included in the five-word window, plus the twopreviously assigned lexical categories (to the left). They applied their method on the CCG Bankcorpus (Hockenmaier and Steedman, 2007) with 92.6% of accuracy for words and (only) 36.8%of accuracy for complete sentences (that is the percentage of sentences of which all words aretagged correctly).
Likemany others supervisedmethods, CCG supertagging requires a sufficiently large amountof labeled training data to achieve good results. Lewis and Steedman, 2014b have introduced asemi-supervised approach to improve a CCG parser with unlabeled data. They have constructeda model for the prediction of CCG lexical categories, based on vector-space embeddings. Fea-tures are words and some other information (e.g., POS tagging, chunking, named-entity recog-nition, etc.) in the context window. Their experiments use the neural network model of (Col-lobert, 2011) in association with conditional random fields (CRF) (Turian, Ratinov, and Bengio,2010).
Using RNN for CCG supertaging has been proven to provide better results with a similarset of features and window size in the work of Xu, Auli, and Clark, 2015. However, the con-ventional RNN is often difficult to train and there still exist problems such as gradient vanishingand exploding, in the layers over long sequences (Bengio, Frasconi, and Simard, 1993; Pascanu,Mikolov, and Bengio, 2013). Therefore, LSTM networks—a special variant of RNNs capableof learning long-term dependencies—were proposed to overcome these RNN limitations. Inparticular, Bi-directional LSTM network models have been created with the ability to storetwo-way information, and the majority of literature in the area (Lewis, Lee, and Zettlemoyer,2016; Wu, Zhang, and Zong, 2017; Xu, 2016; Ambati, Deoskar, and Steedman, 2016; Kadariet al., 2018b) use this model with different training procedures and achieve high accuracy.
The performance of BiLSTMnetworkmodels has been improved by combining themwith aCRF model for the sequence labeling task (Huang, Xu, and Yu, 2015; Steedman and Baldridge,2011; Ma and Hovy, 2016). Using a BiLSTM-CRF model similar to the one in (Huang, Xu,and Yu, 2015), Kadari et al., 2018a have shown the efficiency of CRF by achieving a higheraccuracy in CCG supertagging and multi-tagging tasks.
In most of the above works, similarly to many sequence labeling tasks, the model inputsare words and their features are extracted directly from words. However, we claim that lexicalcategories assignment to words can use morphological and dependency syntax to enrich the

6.3. Neural Network Model 87
feature set. In the following section, we present a neural network model based on BiLSTM-CRF architecture with moprhosyntactic features.
6.3 Neural Network Model6.3.1 Input FeaturesWe will use the following input features for words in sentences:
• the word per se (word);
• the word lemma (lemma);
• the POS tag of the word (postag);
• the dependency relation (deprel) of the word with its parent in the dependency tree (andthe tag “root” for the head of the dependency tree, which has no parent).
Each one of these features provides predictive information about the CCG supertag label.Therefore, our input sentence will be s = {x1, x2, . . . , xn} where each xi is a vector of thefeatures xi = [wordi, lemmai, postagi, depreli].
Before describing our model, let us briefly review pre-existing models.
6.3.2 Basic Bi-Directional LSTM and CRF ModelsUnidirectional LSTMModel
Asmentioned earlier, the shortcomings of standard RNNs in practice involve gradient vanishingand an explosion problem when dealing with long term dependencies. LSTMs are designed tocope with these gradient problems. Basically, a conventional RNN is defined as follows: theinput x = (x1, x2, . . . , xT ) feeds the network, and the network computes the hidden vectorsequence h = (h1, h2, . . . , hT ), and the output sequence, y = (y1, y2, . . . , yT ), from t =1, . . . , T where T is the number of time steps as in the following formulas:
ht = f(Uxt +Wht−1 + bh) (6.1)yt = g(V ht + by), (6.2)
where U , W , V denote weight matrices that are computed in training time, b denotes biasvectors and f(z), g(z) are activation functions as follows.
f(z) =1
1 + e−z(6.3)
g(z) =ez∑k e
zk. (6.4)
Based on basic RNN architecture, an LSTM layer is formed from a set of memory blocks(Hochreiter and Schmidhuber, 1997; Graves and Schmidhuber, 2005). Each block containsone or more recurrently connected memory cells and three gate units: input, output and “forget”gate. More specifically, activation computation in a memory cell at time step t is defined by the

88 Chapter 6. CCG Supertagging Using Morphological and Dependency Syntax Information
Henri
x
eats two apples
h
NPy
(S\NP)/NP NP/NP NP
F 6.2: A simple RNN model
following formulas:
it = σ(Wxixt +Whiht−1 +Wcict−1 + bi) (6.5)ft = σ(Wxfxt +Whfht−1 +Wcfct−1 + bf ) (6.6)ot = σ(Wxoxt +Whoht−1 +Wcoct−1 + bo) (6.7)ct = ft � ct−1 + it � tanh(Wxcxt +Whcht−1 + bc) (6.8)ht = ot � tanh(ct), (6.9)
where it, ft, ot, ct correspond to input gate, forget gate, output gate and cell vectors, σ isthe logistic sigmoid function, tanh is the hyperbolic tangent function, W terms denote weightmatrices, and b terms denote bias vectors.
Figure 6.2 illustrates the simple RNN model that includes an input layer x, a hidden layerh and an output layer y. For the CCG supertagging task, the input feature x consists of wordembedding vectors, the output layers provides CCG lexical categories.
Bidirectional LSTMModel
In order to assign a supertag to a word, we need to use the word’s information and its relationsto the previous and next word in the sentence. Two-way information access from past to futureand vice-versa gives global information in a sequence. However, the LSTM cell only retrievesinformation from the past using input and output of the previous LSTM cell. In other words,an LSTM cell does not receive any information from the LSTM cell following it. Therefore,a Bi-Directional LSTM (BiLSTM) model has been proposed in (Schuster and Paliwal, 1997;Baldi et al., 2000) to overcome this problem, as follows:
Bi-LSTMsequence(x1:n) := LSTMbackward(xn:1) ◦ LSTMforward(x1:n). (6.10)
In general architectures, one may have one forward LSTM layer and one backward LSTMlayer for the complete sequence and run them in reverse time. The features of the two layersare concatenated at the level of the output layers. Thus, information from both the past and thefuture is transmitted to each memory LSTM cell. The hidden state is computed as follows:
ht := f(W←−h
←−ht +W−→
h
−→ht), (6.11)
where←−ht is the backward hidden sequence and−→ht is the forward hidden sequence. As in the
illustration in Figure 6.3, we can access both past and future input features for a given word inthe BiLSTM model.

6.3. Neural Network Model 89
Henri eats two apples
Forward
Backward
NP (S\NP)/NP NP/NP NP
F 6.3: A bidirectional LSTM model
CRF Model
BiLSTM networks are used to build efficient predictive models of the output sequence basedon the features of the input sequence. However, they cannot consider the correlation betweenoutput labels and their neighborhoods. In our case, CCG supertags, by nature, always havecorrelations with the previous or next labels, for example, an output CCG supertag of a wordis NP/NP (usually an article), which allows us to predict the fact that the next CCG supertagis NP. Figure 6.4 shows a simple CRFmodel—note that the feature input and output are directlyconnected, as opposed to LSTM or BiLSTMmodel network where memory cells are employed.
Henri eats two apples
NP (S\NP)/NP NP/NP NP
F 6.4: A CRF model
In order to enhance the ability of predicting the next label from the current label in an outputsequence, two approaches can be used:
1. building a tag distribution for each training step and using an heuristic search algorithmto find optimal tag sequences (Vaswani et al., 2016), or
2. focusing on the context using sentence-level information instead of only word-level infor-mation. The leading work of this approach is the CRF model of (Lafferty, McCallum,and Pereira, 2001).
We use the second approach in the output layer of our model. The combination of BiLSTMnetwork and CRF network can improve the efficiency of the model by strengthening the rela-tionship between the output labels through the CRF layer, based on the input features throughthe BiLSTM layer.

90 Chapter 6. CCG Supertagging Using Morphological and Dependency Syntax Information
BILSTM
CRF
Output Layer
CRFLayer
2nd Output BiLSTM Layer
2nd BiLSTMLayer
2nd Concatenation
Layer
1st Output BiLSTM
Layer
1st BiLSTM
Layer
1st Concatenation
Layer
Embedding Layer
BILSTM BILSTM BILSTM BILSTM BILSTM
BILSTM
Henri eats two apples
NNS VBS CD NNSHenri eat two apple
nsuj root nummod dobj
Henri eats two apples
Input Layer
NP (S\NP)/NP NP/NP NP
WordLemma Pos-tag
Deprel
F 6.5: Architecture of the BiLSTM network with a CRF layer on theoutput
6.3.3 Our Model for Feature Set Enrichment and CCG SupertaggingIn our model (see Fig. 6.5), each input is a set of features: word, lemma, POS tag and depen-dency relation. These features are vectorized with a fixed size by using the embedding matrixin the embedding layer. In the next layer, the correlation between pairs of features is calculatedby combining them. Then, we use a BiLSTM network to memorize and learn the relations withother words in the context of the sentence for these pairs of features. After that, all features areconcatenated to become the input of the second BiLSTM network layer. Finally, CCG supertaglabels are obtained in the output of the CRF network layer, the input of which is the output ofthe 2nd output BiLSTM layer.
6.4 Evaluation6.4.1 Data Set and PreprocessingWe use two different corpora to experiment our model, one in English and one in French. Thefirst corpus is the Groningen Meaning Bank (GMB) corpus Bos et al., 2017 which has beenbuilt for deeper semantic analysis on a discourse scope. The second one is our CCG Corpus forFrench which we extracted from the French Tree Bank (FTP) corpus () by using the dependencyanalysis of the sentence (see Chapter 5).
In order to obtain a standard data set for the training process, we extract all sentences withannotations for each word such as lemma, POS tag, dependency relation and CCG label, for
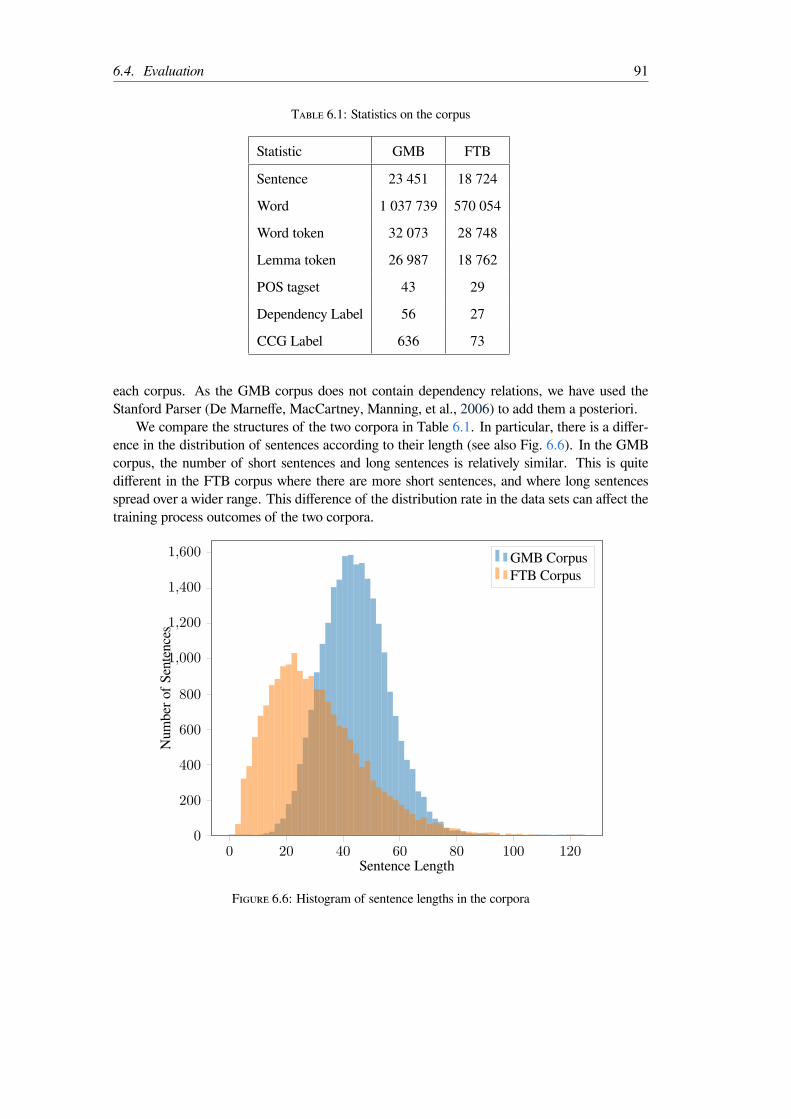
6.4. Evaluation 91
T 6.1: Statistics on the corpus
Statistic GMB FTB
Sentence 23 451 18 724
Word 1 037 739 570 054
Word token 32 073 28 748
Lemma token 26 987 18 762
POS tagset 43 29
Dependency Label 56 27
CCG Label 636 73
each corpus. As the GMB corpus does not contain dependency relations, we have used theStanford Parser (De Marneffe, MacCartney, Manning, et al., 2006) to add them a posteriori.
We compare the structures of the two corpora in Table 6.1. In particular, there is a differ-ence in the distribution of sentences according to their length (see also Fig. 6.6). In the GMBcorpus, the number of short sentences and long sentences is relatively similar. This is quitedifferent in the FTB corpus where there are more short sentences, and where long sentencesspread over a wider range. This difference of the distribution rate in the data sets can affect thetraining process outcomes of the two corpora.
0 20 40 60 80 100 1200
200
400
600
800
1,000
1,200
1,400
1,600
Sentence Length
NumberofS
enten
ces
GMB CorpusFTB Corpus
F 6.6: Histogram of sentence lengths in the corpora

92 Chapter 6. CCG Supertagging Using Morphological and Dependency Syntax Information
6.4.2 Training procedureWe implement our neural network by using the Keras deep learning library (Chollet, 2018). Thedata sets are divided into three sets: training set, validation set and test set with the proportion
0.8 ∗ (0.8 ∗ (training_set) + 0.2 ∗ (validation_set)) + 0.2 ∗ (test_set).
The validation set is used to measure performance at each epoch. Final evaluation on the testset is based on the best accuracy results on the validation set.
Pre-trained Word Embeddings
In order to work with numeric data in the neural network, we use pre-trained word embed-dings to transform words or lemmas of the corpora into numeric vectors. More specifically, weuse Glove (Pennington, Socher, and Manning, 2014) (a 200-dimensional embedding trained on6 billion words collected fromWikipedia) for the GMB corpus, and Word2vec (Mikolov et al.,2013) (the French version by Fauconnier (Fauconnier, 2015), also with 200 dimensions, andtrained on 1.6 billion words collected from the web) for the FTB corpus. For out-of-vocabularywords, we assign embeddings by random samples. Based on the distribution by length of sen-tences (Fig. 6.6), we assign a fixed length of 120 words to all sentences, so that the input di-mension is [120, 200] for each sentence input. Finally, the other features are transformed tonumeric vectors by using a one-hot encoding matrix with size depending on their number in thedictionary.
Parameters and Hyperparameters
We fix the number of training examples (batch size) as 32 for each forward or backward prop-agation. Each training process runs 20 times to evaluate and compare outcomes (epoch). Inaddition, we have experimented with the number of different hidden states, such as 64, 128,256, 512 to find a configuration that is optimally consistent with the model. We decided to carryon the experiment with 128 hidden states because this choice optimally balances accuracy andperformance.
Optimization algorithm
Choosing an optimizer is a crucial part of the model building process. Our model uses theRoot Mean Square Prop (RMSprop) optimizer (Tieleman and Hinton, 2012) which proceedsby keeping an exponentially weighted average of the squares from past gradients. To increaseconvergence, the learning rate is divided by this average:
vdw := βvdw + (1− β) · dw2, (6.12)vdb := βvdb + (1− β) · db2, (6.13)W := W − α dw√
vdw+ϵ , (6.14)b := b− α db√
vdw+ϵ , (6.15)
where vdw vdb are the exponentially weighted averages from past squares of gradients, dw2 anddb2 are cost gradient related to the current layer weight, W and b denote weight and bias, α isthe learning rate from 0.9 to 0.0001 (α = 0.01 is the default setting), β is an hyperparameterto be tuned and ϵ is very small to avoid dividing by zero.

6.4. Evaluation 93
6.4.3 Experimental ResultsIn order to evaluate the proposed input features and the model, we conduct two sorts of com-parisons:
1. we compare the outcomes of different feature sets such as [word], [word, suffix], [word,suffix, cap(italization)], [word, lemma, suffix, cap], [word, lemma, postag, suffix, cap],[word, lemma, postag, deprel, suffix, cap], [lemma, postag, deprel], [lemma, postag],[lemma];
2. we compare the outcomes of different neural network architectures such as BiLSTM(Lewis, Lee, and Zettlemoyer, 2016), standard BiLSTM CRF (Huang, Xu, and Yu,2015), Double-BiLSTM CRF (Kadari et al., 2018a), and ours.
Evaluation on our test set is shown on Table 6.2 for the French FTB corpus and on Table 6.3for the English GMB corpus.
Because of the architecture chosen and since we use correlations of features as additionalfeatures, our model requires at least two features in the input data. Therefore, we can notproduce results on input data with a single feature like [word] or [lemma]. Nevertheless wecompare the outcome of other models on our input features, including single input features.
T 6.2: 1-best tagging accuracy comparison results on the test set in theFrench FTB Corpus
Feature set BiLSTM BiLSTMCRF
DoubleBiLSTMCRF
Ourmodel
word 78.60 78.76 77.14 -word, suffix 78.97 78.80 76.58 78.90word, suffix, cap 78.56 78.97 75.96 84.43word, lemma, suffix, cap 79.16 79.67 78.78 78.49word, lemma, postag, suffix, cap 81.28 81.84 81.24 81.50word, lemma, postag, deprel, suffix, cap 83.23 83.95 83.56 84.06word, lemma, postag, deprel 83.43 83.98 83.70 85.05lemma,postag,deprel 83.00 83.05 83.15 82.40lemma,postag 80.20 80.37 81.40 80.05lemma 77.61 77.83 76.66 -
Let us first start with the French corpus. In Table 6.2 we have displayed methods from theliterature in italics: word, suffix and cap(italization) as input features, BiLSTM, BiLSTM+CRFand Double BiLSTM+CRF as architectures. As the reader can see, by applying pre-existingmethods we obtain a maximum accuracy of 75.96%. By using our input features with pre-existing architectures we obtain a maximum accuracy of 83.98%. By using our architecturewith input features used by others we get an accuracy of 84.43%. Both of these results aresignificantly better than those in previous works. Finally, by combining our input features withour model we manage to gain another 1% and achieve a topmost accuracy of 85.05%.
It is interesting to notice that, even though the lemma feature carries less information thanthe word feature (as expected), the combination of lemma and POS tag features provides betterresults than the word feature, and that these results are systematically increased by 2% whendependency relations are added as well.
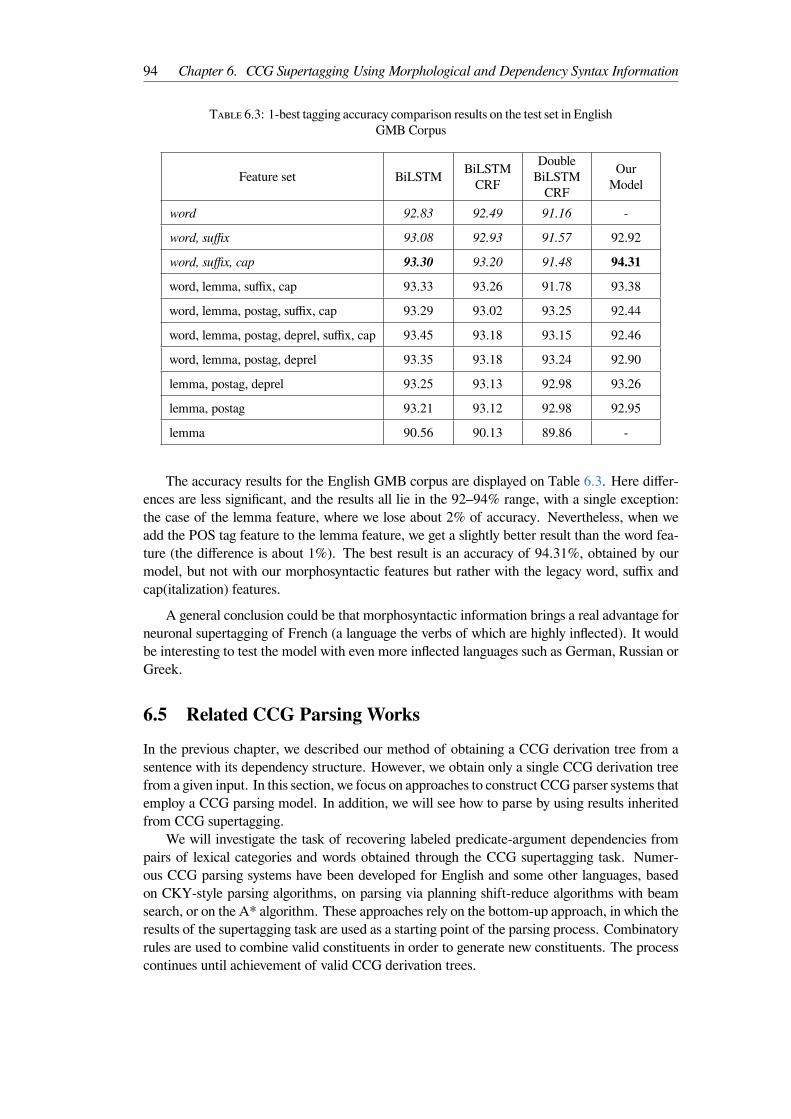
94 Chapter 6. CCG Supertagging Using Morphological and Dependency Syntax Information
T 6.3: 1-best tagging accuracy comparison results on the test set in EnglishGMB Corpus
Feature set BiLSTM BiLSTMCRF
DoubleBiLSTMCRF
OurModel
word 92.83 92.49 91.16 -word, suffix 93.08 92.93 91.57 92.92word, suffix, cap 93.30 93.20 91.48 94.31word, lemma, suffix, cap 93.33 93.26 91.78 93.38word, lemma, postag, suffix, cap 93.29 93.02 93.25 92.44word, lemma, postag, deprel, suffix, cap 93.45 93.18 93.15 92.46word, lemma, postag, deprel 93.35 93.18 93.24 92.90lemma, postag, deprel 93.25 93.13 92.98 93.26lemma, postag 93.21 93.12 92.98 92.95lemma 90.56 90.13 89.86 -
The accuracy results for the English GMB corpus are displayed on Table 6.3. Here differ-ences are less significant, and the results all lie in the 92–94% range, with a single exception:the case of the lemma feature, where we lose about 2% of accuracy. Nevertheless, when weadd the POS tag feature to the lemma feature, we get a slightly better result than the word fea-ture (the difference is about 1%). The best result is an accuracy of 94.31%, obtained by ourmodel, but not with our morphosyntactic features but rather with the legacy word, suffix andcap(italization) features.
A general conclusion could be that morphosyntactic information brings a real advantage forneuronal supertagging of French (a language the verbs of which are highly inflected). It wouldbe interesting to test the model with even more inflected languages such as German, Russian orGreek.
6.5 Related CCG Parsing WorksIn the previous chapter, we described our method of obtaining a CCG derivation tree from asentence with its dependency structure. However, we obtain only a single CCG derivation treefrom a given input. In this section, we focus on approaches to construct CCG parser systems thatemploy a CCG parsing model. In addition, we will see how to parse by using results inheritedfrom CCG supertagging.
We will investigate the task of recovering labeled predicate-argument dependencies frompairs of lexical categories and words obtained through the CCG supertagging task. Numer-ous CCG parsing systems have been developed for English and some other languages, basedon CKY-style parsing algorithms, on parsing via planning shift-reduce algorithms with beamsearch, or on the A* algorithm. These approaches rely on the bottom-up approach, in which theresults of the supertagging task are used as a starting point of the parsing process. Combinatoryrules are used to combine valid constituents in order to generate new constituents. The processcontinues until achievement of valid CCG derivation trees.

6.5. Related CCG Parsing Works 95
6.5.1 Chart parsing algorithmsThe CKY algorithm is a popular choice for constituency parsing. Similarly, various CCG pars-ing system have employed this algorithm to obtain CCG derivation parse tree with an O(n3)worst case time complexity. The CKY algorithm is essentially a bottom-up algorithm and be-gins by combining adjacent words to obtain a span of size two. It then carries on in combiningadjacent spans of size three in a higher row. The algorithm terminates when spans covering thewhole sentence are reached.
More specifically, given a sentencewithnwords correspondingwith pos∈ {0, 1, . . . , n− 1}.A span is a unit of length of words, e.g., in the sentence “Henri emprunte des livres aux Ca-pucins” (Henri borrows books from the Capucins), the span of the phrase “aux Capucins” is 2,while its position pos is 4 (see Figure 6.7). A set of derivations is defined as the result achievedby parsing each valid (pos, span) pair. The derivations for (pos,span) is then combined with thederivations in (pos, i) and (pos+ i, span− i) for all i ∈ {1, . . . , span−1}. By this way, we canparse a sentence by finding the derivations that span the whole sentence (0, n) recursively byfinding derivations in (0, i) and (i, n−i) for all i ∈ {1, . . . , n−1}. In order to stay in the limitsof polynomial time for the parsing process, we use a dynamic programming approach with achart data structure to store the derivations for each (pos, span) which is evaluated and can bereused. The chart data structure includes two dimensional array indexed by pos and span, thevalid pairs corresponding to pos+ span ≤ n.
S
S\NP
NP
NP NP\NP
NP (S\NP)/NP NP/NP NP (NP\NP)/NP NP
Henri emprunte les livres aux Capucins0
1
2
3
4
5
span
0 1 2 3 4 5
pos
F 6.7: CKY table parsing for the sentence“Henri borrows books from the Capuchins”
The C&C parser (Clark and Curran, 2003; Clark and Curran, 2004; Djordjevic and Curran,2006; Djordjevic, Curran, and Clark, 2007) is one of the complete implementations based onCKY-style parsing algorithms to obtain CCG derivation trees from given sentences. This systememploys a chart-parsing algorithm along with repair on the chart that reduces the search spacebased on reusing the partial CKY chart from the previous parsing step. Besides, the use of con-straints also improves parsing efficiency by avoiding the construction of useless sub-derivations.For example, the punctuation constraints that apply on semicolons, colons or hyphens reducethe sentence into a set of smaller units that significantly improves the time using for parsing, aswell as the accuracy of the parsing result.

96 Chapter 6. CCG Supertagging Using Morphological and Dependency Syntax Information
The NLTK CCG Parser is another complete CCG parser for English, first developed by(Gange, 2008). The current version of the NLTK parser, implemented by (Nakorn, 2009),has expansions to support feature unification, semantic derivation or probabilistic parsing. Theparsing algorithm is build on the packed-chart approach (Clark and Curran, 2004), which is animprovement of the chart parsing. The basic ideas behind the packed chart approach is basedon grouping edges. In particular, edges having the same category in the same cell are groupedtogether. Thus, the parsing algorithm processes the packed edge instead of all edges that havesimilar structure and category. This helps to improve parsing efficiency up to 10 times (Haolianget al., 2007).
The OpenCCG Parser1 (White and Baldridge, 2003) is developed as a component of theOpenNLP toolkit, which is an open source NLP library implemented in Java language. Thisparser used Multi-Modal CCG, an extension of the CCG version by Mark Steedman usingmodalities and hierarchies of lexical categories (Baldridge and Kruijff, 2003). Essentially, theparsing algorithm is constructed on a bottom-up chart and an agenda that ranks partial parsesolutions based on an n-gram measure (Varges and Mellish, 2001). The first partial parse itemin the agenda is fed to the chart in the parsing process.
The StatCCG Parser (Hockenmaier, 2003) uses a standard chart parsing algorithm for prob-abilistic grammars, in which conditional probability is used to measure derivation parse trees.In particular, the probability of partial derivation parse trees is computed as the product of therelevant probabilities such as expansion, head, non-head and lexical probability. The final prob-ability of a complete derivation tree is the product of the probabilities of each partial derivationparse tree in this tree. Moreover, beam search and dynamic programming are used to iden-tify the constituents within a cell of the chart that have the highest probability parse. Thesestrategies guarantee an efficient parsing process with wide-coverage grammar.
6.5.2 CCG parsing via planningAnswer Set Programming (ASP))—a declarative programming paradigm—may be used to ob-tain all CCG derivation parse trees for a given sentence, based on a prominent knowledge-representation formalism. The basic idea of ASP is to represent a computational problem by aprogram whose answer set contains solutions, and then employs an answer-set solver to gener-ate answer-sets for the program (Lierler and Schüller, 2012). The search of all CCG derivationparse trees for a given sentence is regarded as a planning problem. Thus, we can consider thistask as answer-set programming.
In order to realize a CCG parsing-via-planning problem, we need to declare states andactions of the program. States are defined as Abstract Sentence Representations (ASR) of sen-tences, whereas actions are annotated combinators. More specifically, by going through thesupertagging task, we obtain a full lexicon, i.e., a mapping function of lexical categories towords. We define an ASR as a sequence of lexical categories annotated by a unique identifier.The words in the sentence are replaced by corresponding lexical categories in the lexicon. Ex-ample 11 shows an ASP of the sentence “Henri watches TV” and the sample lexicon {Henri `NP, regarde ` (S\NP)/NP, la ` NP/NP, télévision ` NP}.
(11) a. Henri1 regarde2 la3 télévision4b. [NP1, (S\NP)/NP2, NP/NP3, NP4]
An equivalent representation via combinatory rules can be given using an instance of a CCGcombinator ζ that has a general form like:
X1, . . . , Xn
Yζ,
1Official site: http://openccg.sourceforge.net/.

6.5. Related CCG Parsing Works 97
where X1, . . . , Xn are functions and arguments of the left clause of a combinatory rule that iscalled a precondition sequence of ζ, whereas Y is the result of a combinatory rules or the effectof applying the combinator ζ.
The annotation of combinators is realized by assigning distinct identifiers. Thus, an anno-tated combinator includes the assignment of a distinct identifier for each element of its precon-dition sequence, and the identifier of the left most annotated lexical category in the preconditionsequence to its effect. For example, the annotated combinator ζ1 for the phrase “la télévision”(the television) which has a ASR [NP/NP3, NP4] is illustrated in Example 12.a.
(12) a. NP/NP 3 NP 4
NP 3 >
b. (S\NP )NP 2 NP 3
S\NP 2 >
c. NP 1 S\NP 2
S1 <
Similar to that, we can find annotated combinators for other parts of the sentence in Ex-ample 11.a. These annotated combinators correspond to Examples 12.a, 12.b, 12.c that aredenoted ζ1, ζ2, ζ3, respectively.
Given an ASR in the example 11.b, a sequence of actions ζ1, ζ2, ζ3 forms a plan:
Time 0: [NP1, (S\NP)/NP2, NP/NP3, NP4]
action: ζ1Time 1: [NP1, (S\NP)/NP2, NP3]
action: ζ2Time 2: [NP1, S\NP2]
action: ζ3Time 3: [S1].
This plan provides a derivation tree for the sentence (11.a). With this approach, the declarationof states and actions that correspond to ASP encoding and the application of combinatory rulesbecome most important because performance time and results achieved depend on them.
The ASPCCGTK toolkit2 (Lierler and Schüller, 2011; Lierler and Schüller, 2012) is a com-plete implementation of this approach. Using the output of the C&C supertagger that provideslexical categories for words of a given sentence, this tool creates a set of ASP facts that is usedto find CCG derivation parse trees.
6.5.3 Shift-reduce parsing algorithmsShift-reduce or transition-based parsers have become increasingly popular for dependency pars-ing. In general, the advantages of these approaches are based on their scoring model, which isdefined over transition actions. Efficient parsing is obtained by using a beam search that al-lows to find the highest scoring action. Using a shift-reduce approach for the CCG parsing taskimproves operations such as easy treatment of sentences for which finding a spanning analysisis difficult, production of fragmentary analyses for sentences (Zhang, Kordoni, and Fitzgerald,2007), or creation of local structures.
Similar to the transition-based parsing approach, shift-reduce CCG parsing consists of astackα of partial derivations, a buffer β for incoming words and a transition system that includes
2The official site: http://www.kr.tuwien.ac.at/staff/former_staff/ps/aspccgtk/.

98 Chapter 6. CCG Supertagging Using Morphological and Dependency Syntax Information
a series of actions T and a set of configurations. In particular, the set of action types is definedas follows:
• SHIFT-X: remove the first word wi in the buffer α, assign the lexical category X to it(X(wi)), and then push it onto the stack β.
• COMBINE-X: pop the top two nodes Xk(wi), Xl(wj) out of the stack α, combineXk(wi), Xl(wj) into a new node Xh(wi), and then push Xh(wi) back on the stack α.We can see that this action corresponds to using a CCG combinatory rule.
• UNARY-X: pop the top node Xk(wi) out of the stack α, transform Xk(wi) into a newnode with categoryXl, and then push the new nodeXl(wi) onto the stack α. This actionscorresponds to using a type-raising rule in CCG.
• FINISH: the buffer β is empty, that is, all words in β have been shifted onto the stack α.The parsing process is finished.
For decoding in CCG shift-reduce parsing, we can use a greedy local search (Yamada andMatsumoto, 2003; Nivre and Scholz, 2004) or a beam-search (Johansson and Nugues, 2007;Huang, Jiang, and Liu, 2009; Zhang and Clark, 2009; Zhang and Clark, 2011; Vaswani et al.,2016). The authors of (Zhang and Clark, 2011) formulate their decoding algorithm as follows:
• The initial item is defined as the unfinished item, in which the stack α is empty, the bufferβ contains all ordered words from a given sentence.
• A candidate item is a tuple (α, β, γ), where α and β represent stack and buffer as above,γ is a boolean value representing the status of the candidate item. A candidate item isthereby marked as finished if and only if the FINISH action is used. In that case no moreactions can be applied to it.
• A derivation is the result of a process started with the initial item and consisting of asequence of actions until the candidate item acquires finished status.
The beam-search algorithm includes an agenda variable that contains the initial item at thebeginning step and is used to hold the N-best partial candidate items for each parsing step. Acandidate output variable is used to store the current best finished item, which is set empty at thebeginning step. At each step of the algorithm, each candidate item from the agenda is exploitedand extended by using actions. After this step a number of new candidate items can be created.If a new candidate item has a finished status, a comparison of the score between the currentcandidate output and the new candidate item is realized. If the current candidate output is noneor the score of the new candidate item is higher, the candidate output is replaced by the newcandidate item; otherwise, we continue with the candidate output. Otherwise, if the new itemhas unfinished status, the new candidate is appended to a list that contains new partial candidateitems. After every candidate item in agenda has been processed, we will clear all items in theagenda and add the N-best items from the list into the agenda. The process continues with newN-best candidate item in the agenda. The algorithm terminates when the agenda is empty, i.e.,when no new candidate times are generated. We obtain a derivation from the final candidateoutput. The pseudo code of the algorithm is illustrated in Algorithm 7.
The Z&C Parser3 (Zhang and Clark, 2011) is the first CCG parser based on the transition-based approach. The authors have used a global linear model to score candidate items, fea-tures are extracted from each action. The training model is based on the perceptron algorithm(Collins, 2002). The CCG parser of (Xu, Clark, and Zhang, 2014; Ambati et al., 2015) fo-cuses on improving the result of the Z&C Parser with dependency models (Clark and Curran,
3Available source code: https://sourceforge.net/projects/zpar/.

6.5. Related CCG Parsing Works 99
Algorithm 7: Agenda-based Searching AlgorithmData: x1, . . . , xn are input words, grammar, N is size of agendaResult: An agenda Abegin
A←− ∅ ; // Agenda A is emptiedfor initial_item ∈ TAG(x1 . . . xn) do
PUSH(A,initial_item) ;candidate_ouput←− ∅;while A 6= ∅ do
list←− ∅;for item ∈ A do
for action ∈ grammar.get_actions(item) docandidate_item←− item.apply(action);if candidate_item.finished is True then
if candidate_output is ∅ or candidate_item.score ≥candidate_output.score then
candidate_output←− candidate_item;else
list.append(candidate_item);
A←− ∅;A←− list.best(N);
2007). Using dependencies provides an elegant solution to handle the spurious ambiguity issue.Moreover, a training data for dependencies can be achieved easier than others, such as syntacticderivation data. The authors have used the dependency oracle (Goldberg and Nivre, 2012) tocreate dependencies and score the CCG derivations trees through a unification mechanism.
Several shift-reduce CCGparsers such as LSTM-CCG (Xu, 2016) and TranCCG4 (Ambati,Deoskar, and Steedman, 2016) have used deep learning models and have achieved significantimprovements when compared with previous works. In particular, (Xu, 2016) factors a modelinto five components: U , V ,X , Y denote four LSTMs and W denotes a BiLSTM. In the initialstep, W obtains sentences converted into embedding vectors as input. We redefine a candidateitem as a tuple (j, α, β, δ), where j is the index of the first item of the buffer β and δ denotesthe set of CCG dependencies (Clark and Curran, 2007). The stack α for a candidate item atstep t (t ≥ 1) is:
αt = [hUt ;hVt ;h
Xt ;hYt ]. (6.16)
The pair [αt, wj ] represents a candidate item. [α0, w0] represents the initial item, where α0 =[hU⊥;h
V⊥;h
X⊥ ;h
Y⊥], h⊥ is the initial state of the hidden layer of the component. Before obtaining
the probability of the i-th action, we need to calculate two affine transformation layers as follows:
bt = f(A[αt;wj ] + r),
at = f(Bbt + s),(6.17)
4Available source code: https://github.com/bharatambati/tranccg

100 Chapter 6. CCG Supertagging Using Morphological and Dependency Syntax Information
where B, A are weight matrices, r, s are bias vectors, and f is an activation function. Theprediction of the next action is based on the probability of the previous action:
p(τ it | bt) =ea
it∑
τkt ∈T (αt,βt)ea
kt
, (6.18)
where T (αt, βt) denotes the set of possible actions for the current candidate item, and τ it ∈T (αt, βt).
We continue the training of the neural architecture by a shift-reduce CCG parsing basedon a greedy model. Let θ = {U, V,X, Y,W,B,A} represent the weights of the greedy model,the value of the tuple θ will be optimized in different training epochs. At each training epoch,we first get a sentence sn from the training set, then use beam search to decode sn to obtain an-best list of candidate output with the current θ and denote the result as P(sn). In the secondstep, for each derivation yi in P(sn), we compute the F1 score at the sentence level by usingthe CCG dependency set δ. Then, we compute the log-linear score of the action sequence asfollows:
ρ(yi) :=
|yi|∑j=1
log f(yji ), (6.19)
where |yi| is the number of actions derived in yi, and f(yji ) denotes the softmax action scoreof the j-th action. In the final step, we minimize the negative F1 score objective for Sn. Werepeat these steps for other sentences and other epochs. The objective function is defined as:
J(θ) := −∑
yi∈P(sn)
p(yi | θ) F1(δyi , δsn), (6.20)
where F1(δyi , δsn) is the F1 score at the sentence level for derivation yi compared with thestandard dependency structure δsn of sn, and p(yi | θ) denotes the probability score of theaction sequence yi:
p(yi|θ) :=eρ(yi)∑
y∈P(sn) eρ(y)
. (6.21)
6.5.4 A* parsing algorithms(Klein andManning, 2003a) introduce an extension of the classic A* search algorithm to tabularPCFG parsing, which is called A* parsing algorithm. A* search essentially is an agenda-basedbest-first graph search approach that finds the lowest cost parse with a heuristic estimation func-tion without traversing the entire search space. Using the A* parsing approach to build a CCGparser has been realized in works such as (Auli and Lopez, 2011; Lewis and Steedman, 2014a;Lewis, Lee, and Zettlemoyer, 2016). More generally, the A* parser is based on a chart/tableand an agenda. The agenda can be a buffer or queue of items with a priority order. Each itemin the agenda marks its priority by a cost or score that consists of the items’ inside probabilityand an estimated heuristic upper bound on the outside probability that is computed with respectto the context. These aim to give a the probability of the complete parse. Then, the chart issynthesized in best-first order, until a complete derivation parse for the sentence is achieved.
Compared with chart parsing or shift-reduce parsing, A* parsing does not require pruningof the search space of the lexical categories of each word (supertagging task). For example, theC&C parser takes an average of 3.57 lexical categories par word into account when calculatingCCG derivation parse trees, whereas A* parsing can consider the complete set of 425 lexicalcategories per word (Lewis and Steedman, 2014a). That is because the A* parsing algorithmfocuses on best-first search for sentence derivation, rather than constructing a complete chart

6.5. Related CCG Parsing Works 101
containing all lexical categories of all words. Moreover, the performance of A* parsing is fasterthan CKY by up to 5 times, while keeping accuracy (Lewis, He, and Zettlemoyer, 2015).
Each item on the agenda is ranged by cost and computed as the product5 of the inside prob-ability and an upper bound on the outside probability. More specifically, for a span wi, . . . , wj
corresponding to lexical categories ci, . . . , cj of a sentenceS = w0, . . . , wn, the cost of the par-tial parse item yi,j corresponding to spanwi, . . . , wj is computed as f(yi,j) := g(yi,j)×h(yi,j),where g(yi,j) represents the inside probability, computed as:
g(yi,j) :=
j∏k=i
p(ck|S), (6.22)
Whereas g(yi,j) denotes the upper bound of the outside (or “context”) probability, computedas:
h(yi,j) :=k<i∏k=1
maxck
p(ck | S) ×k≤n∏
k=j+1
maxck
p(ck | S). (6.23)
If there are two items in the agenda with the same cost, then the number of dependency relationsis used to select among them.
In order to formulate the A* parsing model, let the CCG derivation parse y of sentence Sbe a list of lexical categories c1, . . . , cn. The optimal derivation parse y is computed as follows:
y := argmaxy
n∏i=1
p(ci | S). (6.24)
A sentence can have many CCG derivation parse trees for the same initial sequence of lexi-cal categories. Thus, the model needs to be extended by a deterministic heuristic for rankingderivation parses having the same initial lexical categories. In particular, in case two derivationparses have the same probability, one uses the sum of lengths of edges to select among them.
The A* search-based parser begins by finding a derivation tree of the given sentence basedon 1-best categories for each word. The objective is to build a complete chart as soon as possible.If this search fails, the process continues by adding one more lexical categories (having thehighest probability in the agenda) into the chart and attempting again. This process allows toexclude a number of lexical categories for each word until achievement of a derivation parsetree for the input sentence.
The EasyCCG parser6 (Lewis and Steedman, 2014a; Lewis, He, and Zettlemoyer, 2015;Lewis, Lee, and Zettlemoyer, 2016) is a complete CCG parsing application based on a supertag-factored A* parsing approach, in which the search of the highest scoring supertag sequence hasbeen combined to build up a complete derivation parse tree. This parser achieves a higherefficiency than the C&C parser, which uses the CKY parsing approach, both in accuracy andtime.
The NeuralCCG parser (Lee, Lewis, and Zettlemoyer, 2016) improves A* by combiningoptimal decoding and global representation via Tree-LSTM (Tai, Socher, and Manning, 2015).This tool currently achieves a state-of-the-art accuracy for CCG parsing task when using a CCGbank as training corpus. In this case, parsing is considered as graph search problem. The parsingmodel is reformulated as a search for the highest scoring path for the graph. Let a node y in thegraph represent a labeled spanwi, . . . , wj , and let an edge e in the graph represent a combinatoryrule production in partial parse. The head node HEAD(e) of the edge e is defined as the parentof the combinatory rule production, its children nodes are the children of the combinatory ruleproduction. A start node ∅ denotes an empty parse with outgoing edges. A path is a set of edges
5We can in fact replace product by sum (Lewis, Lee, and Zettlemoyer, 2016).6Online demo at the address: http://4.easy-ccg.appspot.com.

102 Chapter 6. CCG Supertagging Using Morphological and Dependency Syntax Information
E that begins at ∅ and ends at a destination node. A derivation parse is defined as a path in thegraph. Each edge e has a score (weight) s(e). The score of the derivation parse from path E iscomputed as:
f(E) :=∑e∈E
s(e). (6.25)
As a result, the search of the complete parse is equivalent to the search of the highest scoringpath.
The score of each edge e is a sum of the local score slocal(e) which corresponds to theinside probability in §6.22 and of the global score sglobal(e) which corresponds to the upperbound of the context probability in equation 6.23. The global score is computed by using ahidden representation representing the derivation parse of y = HEAD(e). In the Tree-LSTMneural network (Tai, Socher, and Manning, 2015), we can have a hidden representation of bothconstituents and a complete sentence from a given sentence w1, w2, . . . , wn for the derivationparse y in forward and backward directions, as follows:
iy = σ(WRi [cl, hl, cr, hr, xy] + bRi ),
fy = σ(WRf [cl, hl, cr, hr, xy] + bRf ),
oy = σ(WRo [cy, hl, hr, xy] + bRo ),
crl = fy ◦ cl + (1− fy) ◦ cr,
cy = tanh(WRc [hl, hr, xy] + bRc ),
cy = iy ◦ c ◦ clr,
hy = oy ◦ tanh(cy),
(6.26)
where hl, cl, hr, cr denote hidden and cell states of left and right childs respectively, xy repre-sents a learned embedding vector for the lexical category at the root of y, σ is a cost function,W, b denote weights and biases parametrized by the combinatory rule R. The global score isformulated as follows:
sglobal(e) := log(σ(W.hy)). (6.27)
6.6 Conclusion of the ChapterWe have presented a new CCG supertagging task based on morphological and dependencysyntax information, which has allowed us to create a CCG version of the French Tree Bankcorpus FTB. We used this corpus to train a new BiLSTM+CRF neural architecture that usesnew, morphosyntactic, input features and feature correlations as separate input features. Wehave experimentally shown that, at least for an inflected language as French, dependency syntaxinformation is useful for improving the accuracy of the CCG supertagging task when using deeplearning techniques.

Chapter 7
Towards a DRS Parsing Frameworkfor French
Combinatory Categorial Grammars provide a transparent interface between surface syntax andunderlying semantic representation. Moreover, CCGs gain the same expressive power as thelambda calculus because their foundation is combinatory logic. In previous chapters we haveachieved a CCG derivation parse tree for a given sentence, by using morphological and depen-dency syntax information. These results help us to constitute the first bridgehead on the waytowards semantic interpretation for natural language inputs. In this chapter, we will focus onDiscourse Representation Theory that allows the handling of meaning across sentence bound-aries. Based on the foundations of these two theories, along with the work of Johan Bos onthe Boxer Framework for English language, we propose an approach to the task of semanticparsing with Discourse Representation Structure for the French language. In addition, we willsynthesize experiments, evaluations, and error analysis about our approach (Le, Haralambous,and Lenca, 2019).
7.1 IntroductionResearchers in the domain of computational linguistics have studied for a long time variousforms of logic aiming to capture semantic information from natural language data. Amongthese, Discourse Representation Theory (DRT) is one of the first frameworks for exploringmeaning across sentences, with a formal semantics approach Kamp and Reyle, 1993. DRT hasbeen used for various applications such as the implementation of a semantic parsing system ornatural language understanding systems. This chapter addresses the build of a semantic parsingapplication based on CCG andDiscourse Representation Structure (DRS) which is an importantelement of DRT.
CCGs essentially illustrate an explicit relation between syntax and semantic representationSteedman, 1996. They allow access to a deep semantic structure of the phrase and facilitaterecovering of non-local dependencies involved in the construction, such as coordination, ex-traction, control, and raising. In addition, CCGs are compatible with first order logic (FOL)and lambda-expressions. Their use allows analysis of syntax and semantic relationship betweenwords or phrases in the scope of the sentence. Nevertheless, the analysis of CCG is limited inscope of a single sentence. We thus need a higher language formalism analysis level which caneffect an analysis on utterances with several sentences.
DRT is one of the theoretical frameworks used for discourse interpretation in which theprimary concern is to account for the context dependence of meaning. Indeed, a discoursemay be interpretable only when the framework takes account of the contexts of the discourse.Furthermore, DRT can be used to deal with a variety of linguistic phenomena such as anaphoricpronouns or temporal expressions, within or across different sentences. DRS expressions have

104 Chapter 7. Towards a DRS Parsing Framework for French
two advantages: (1) they provide meaning representation for several sentences in discourseinstead of a single sentence only, and (2) they can be translated into First-Order Logic.
In the next sections, after an introduction to semantic parsing, we provide an overview ofDRT and its core DRS. In the next section, we present the architecture of Boxer semanticparsing, which is a fundamental in order to construct DRS parsing for French language. Thenwe describe our approach, experimentation, and evaluation through an example. Finally, wefinish the chapter with a summary about our work.
7.2 Discourse Representation TheoryIn the early 1980s, a theoretical framework for dynamic semantics has been introduced byHans Kamp under the name Discourse Representation Theory (DRT). The goal was to deal withlinguistic phenomena such as anaphoric pronouns, time, tense, presupposition, and propositionalattitudes (Kamp, 1981; Kamp and Reyle, 1993). The emergence of DRT made a dynamicapproach on natural language semantics possible. In this approach, the meaning of a givensentence is identified in a relationship with its context. In particular, the interaction between asentence and its context is reciprocal. The analysis of an utterance will depend on its context.Otherwise the context can be transformed into a new context if information from the utteranceis used and added to the context.
Unlike other theoretical frameworks using First-Order Logic syntax for semantic represen-tations, DRT uses a semantic representation called “Discourse Representation Structure” (DRS)in order to describe objects mentioned in an utterance and their properties. On the one hand,DRS plays the role of semantic content in which it provides the precise expressive meaning fora natural language inputs. On the other hand, DRS keeps the role of discourse context where itaggregates the interpretation of subsequent expressions occurring in the utterance.
The dynamicity of DRT is represented through three major components. The first andcrucial component includes recursive definitions of the set of all well-formed DRSs used inthe meaning representation of natural language. The second component is a model-theoreticalsemantic interpretation used to link the members in the set of DRSs. The third componentconstitutes an algorithm that integrates natural language input into DRSs.
7.2.1 Type Lambda ExpressionThe type in the formal language Lλ which we introduce more detail in Appendix A.1 can beused to express both constants and variables in syntactic categories, and it also allows quantifi-cation over variables of any category. Syntactic categories can be matched with semantic typesspecifying object type in categories. More generally, there are two basic semantic types, whichwe denote by 〈e〉 and 〈t〉. Type 〈e〉 denotes for entities or individuals (i.e., any discrete object),whereas type 〈t〉 denotes truth values (i.e., propositions, sentence).
Definition 7.2.1 (Recursive definition of types). 1. 〈e〉 and 〈t〉 are types.
2. If 〈a〉 and 〈b〉 are types, then 〈a,b〉 is a type.
3. Nothing else is a type.
All pairs 〈a,b〉 made out of basic or complex types 〈a〉, 〈b〉 are types. 〈a,b〉 can be re-garded as the type of functions that map arguments of type 〈a〉 to values of type 〈b〉. Somepopular examples of complex types are: 〈e,t〉 (unary predicate), 〈e,〈e,t〉〉 (binary predicate),〈t,t〉 (unary function), 〈〈e,t〉,〈e,t〉〉 (unary predicate transformer), 〈〈e,t〉,t〉 (second-order predicate) and so on. The figure 7.1 illustrates an usage of the type-base theory for theanalysis of a sentence.

7.2. Discourse Representation Theory 105
S
mange(mon′enfant′, des′raisins′)
〈t〉
NP
λy.mon′enfant(y)
〈e〉
NP/NP
λQ.mon′(Q)
〈〈e,t〉,〈e〉〉
Mon
NP
λy.enfant′(y)
〈e,t〉
enfant
S\NP
λy.mange′(y, des′raisin)
〈e,t〉
(S\NP)/NP
λx.λy.mange′(y, x)
〈〈e〉,〈e,t〉〉
mange
NP
λx.des′(raisins′(x))
〈e〉
NP/NP
λP.des′(P )
〈〈e,t〉,〈e〉〉
des
NP
λx.raisins′(x)
〈e,t〉
raisins
F 7.1: A type-based expression for the sentence “My child eats grapes”
7.2.2 Discourse Representation StructureThe core of DRT is DRS, which is main component for the construction of semantic represen-tations for natural language texts. The objective of DRS is not only to achieve interpretationsof single sentences, but also to represent larger linguistic units, paragraphs, discourses or texts.In general, the meaning representation for large unit sentences through DRS proceeds unit byunit. Each sentence that gets processed contributes its information to the DRS that containsinformation from preceding sentences.
The representation of DRSs used from this section relies on basic type-theoretic expressionsthat are compatible with formal semantic representations (Bos et al., 2017). Therefore, the type〈e〉 is used for expressions of discourse referents or variables, whereas type 〈t〉 is used for basicDRS expressions.
〈expe〉 ::= 〈ref〉|〈vare〉
〈expt〉 ::= 〈drs〉(7.1)
Definition 7.2.2. A basic DRS expression 〈drs〉 is a set-theoretic object built from two princi-pal components: a set of discourse referents 〈ref〉 that represents the objects under discussion,

106 Chapter 7. Towards a DRS Parsing Framework for French
and a set of conditions 〈condition〉 that are properties of discourse referents, and express re-lations between them. We use the following notation:
〈drs〉 ::=〈ref〉∗
〈condition〉∗(7.2)
In general, DRS conditions are of three types: 〈basic〉, 〈link〉, and 〈complex〉:
〈condition〉 ::= 〈basic〉 | 〈link〉 | 〈complex〉 (7.3)
The basic conditions are properties of discourse referents or relations between them:
〈basic〉 ::= 〈sym1〉(〈expe〉) | 〈sym2〉(〈expe〉, 〈expe〉)
| timex(〈expe〉, 〈sym0〉)
| named(〈expe〉, 〈sym0〉, class),
(7.4)
where 〈expe〉 denotes expressions of type, 〈symn〉 denotes n-ary predicates, 〈num〉 denotes car-dinal numbers, timex expresses temporal information and class denotes named entity classes.
The link conditions are discourse referentmarkers or constants which are used for referencesor separations between these discourse makers or constants:
〈link〉 ::= 〈expe〉 = 〈expe〉 | 〈expe〉 = 〈num〉
| 〈expe〉 6= 〈expe〉 | 〈expe〉 6= 〈num〉.(7.5)
The complex conditions represent embedded DRSs: implication (→), negation (¬), dis-junction (∨), modal operators expressing necessity (□) and possibility(♢). The types of com-plex conditions are unary and binary:
〈complex〉 ::= 〈unary〉 | 〈binary〉
〈unary〉 ::= ¬〈expt〉 | □〈expt〉 | ♢〈expt〉 | 〈ref〉 : 〈expt〉
〈binary〉 ::= 〈expt〉 → 〈expt〉 | 〈expt〉 ∨ 〈expt〉 | 〈expt〉?〈expt〉
(7.6)
where the condition 〈ref〉 : 〈expt〉 denotes verbs with propositional content.
Definition 7.2.3. The construction of DRSs from basic DRSs is defined according to the fol-lowing clauses:
1. If 〈expx〉 is a discourse referent marker, [〈expx〉: ∅] is a DRS.
2. If [∅: 〈conditionk〉] is a DRS.
3. If 〈symk〉 is a n-ary predicate and τ1, . . . , τn are terms, then [∅:〈symk〉(τ1, . . . , τn)] is aDRS.
4. If v = 〈expx〉 is a discourse referent marker and τ is a term, then [∅:v = τ ] is a DRS.
5. If v = 〈expx〉 is a discourse referent marker and τ is a term, then [∅:v 6= τ ] is a DRS.
6. If 〈drs〉 ::= [〈ref〉:〈condition〉] is a DRS, then [∅: ¬〈drs〉] is a DRS.

7.2. Discourse Representation Theory 107
7. If 〈drs〉 ::= [〈ref〉:〈condition〉] and 〈drs'〉 ::= [〈ref'〉:〈condition'〉] are DRSs,then 〈drs〉 ⊕ 〈drs'〉 ::= [〈ref〉 ∪ 〈ref'〉:〈condition〉 ∪ 〈condition'〉] is a DRS.
8. Nothing else is a DRS.
Let us illustrate DRS through the example of sentence 13.a. This sentence can be analyzedand rewritten under DRS form as follows:
[x, y : femme(x), poisson(y), acheter(x, y)].
More specifically, theDRS expression contains two discourse referents 〈ref〉 = {x, y}, whereasthe set of conditions includes 〈condition〉 = {femme(x), poisson(y), acheter(x, y)}. Sup-pose now that the sentence in the example 13.b is followed by sentence 13.a. The DRS expres-sion for the second sentence includes discourse referents 〈ref〉 = {u, v, w}, whereas the set ofconditions is 〈condition〉 = {donner(u, v, w),mari(w), person1(v), thing1(w)}. Thus, TheDRS of the second sentence will be rewritten as follows: [u, v, w : donner(u, v, w), mari(w),person1(v), thing1(w)]. Finally, we obtain the final DRS expression after integrating the DRSof the second sentence into the DRS of the first sentence, as well as resolving anaphoric problemas follows:
[x, y, u, v, w : femme(x), poisson(y), acheter(x, y),donner(u, v, w), mari(u), v = x, w = y].
(13) a. La femme achète des poissons.(The woman buys fishes.)
b. Elle les donne à son mari.(She gives them to her husband.)
In order to illustrate the different DRS expressions, we have three formalisms ofr repre-senting the above sentences:
1. The “official” DRS notation:
<{∅}, <{x, y, u}>, {femme(x), poisson(y), acheter(x, y),mari(u)}>⇒ <{∅}, {donne(u, y, x)}>.
2. The linear notation:
[∅ : [x, y, u: femme(x), poisson(y), acheter(x, y),mari(u)]⇒ [∅ : donne(u, y, x)]].
3. The boxed notation:

108 Chapter 7. Towards a DRS Parsing Framework for French
x, y, u
femme(x)
poisson(y)
acheter(x, y)
mari(u)
⇒donne(u, y, x)
We can generalize DRSs through a model-theoretic interpretation. Conventionally, an ap-propriate modelM for the DRS 〈drs〉 is an ordinary first-order modelM = 〈D,F〉, whereD denotes the set of individuals occurring in the conditions of 〈drs〉, and F is an interpreta-tion function that maps the n-ary predicate in the basic condition of 〈drs〉 to n-ary relationsof D. An embedding function is defined as a partial mapping from discourse referents 〈ref〉to elements of D. Thus, the function f verifies inM if f maps an discourse referents ontoan individual in D. For instance, we have the embedding functions in the example 13.a suchfemme(x), poisson(y) and so on.
Let f , g, and 〈drs〉 ::= [〈ref〉 : 〈condition〉] be two embedding functions and a DRS,f〈drs〉g denotes the extension g on f with respect of 〈drs〉, if domain(g) = domain(f) ∪〈condition〉 and for all v in domain(f): f(v) = g(v). The verification of the function f usedto verify the DRS 〈drs〉 in modelM is as follows:
• The function f verifies the DRS 〈drs〉 if f verifies all conditions in 〈condition〉.
• The function f verifies an n-ary predicateP(v1, . . . , vn) if 〈f(v1), . . . , f(vn)〉 ∈ F(P).
• The function f verifies v = u if f(v) = f(u).
• The function f ¬〈drs〉 if there is no g such that f〈drs〉g and g verifies 〈drs〉.
• The function f verifies 〈drs〉 ∨ 〈drs'〉 if f there is a g such that f〈drs〉g and g verifies〈drs〉 or 〈drs'〉.
• The function f verifies 〈drs〉 ⇒ 〈drs'〉 if for all f〈drs〉g such that g verifies 〈drs〉,there is an h such that g〈drs〉h and h verifies 〈drs'〉.
• The function f verifies 〈drs〉(∀v)〈drs'〉 if for all individuals d ∈ D for which there isa g such that g(v) = d and g verifies 〈drs〉, every h such that g〈drs'〉h verifies 〈drs'〉.
The truth-conditional semantics of the DRS 〈drs〉 is true in the modelM if there exists anembedding function f such that domain(f) = 〈condition〉 and the function f is satisfiedinM.
Definition 7.2.4. The translation from DRS to FOL is defined as follows:
• For DRSs, if 〈drs〉 ::= [〈ref〉 ⇔ {v1, . . . , vn}:〈condition〉 ⇔ {C1, . . . , Cm}] then,〈drs〉⟨fol⟩ ::= ∃v1, . . . , ∃vn(C⟨fol⟩
1 ∧ · · · ∧ C⟨fol⟩m ).
• For basic or link conditions C⟨fol⟩ ::= C.
• For negations: (¬〈drs〉)⟨fol⟩ := ¬〈drs〉⟨fol⟩

7.3. DRS Parsing Based on Boxer 109
• For implications: (〈drs〉 ⇒ 〈drs'〉)⟨fol⟩ ::= ∀v1, . . .∀vn((C⟨fol⟩1 ∧ · · · ∧ C⟨fol⟩
m ) →〈drs'〉⟨fol⟩)
DRS expressions are compatible with first-order logic (FOL) through specific steps of trans-lation like in Definition 7.2.4 (Van Eijck and Kamp, 1997; Blackburn et al., 1999; Bos, 2004).First, we consider each discourse referent as a first-order quantifier. Then, DRS conditions areinterpreted into a conjunctive formula of FOL. Finally, the embedded DRSs such as implica-tion, negation, disjunction are translated to corresponding formulas (Bos, 2008). For instance,the FOL which is equivalent with the DRS for utterances in the example 13 is transformed asfollows:
(14) ∀x∀y∀u((femme(x) ∧ poisson(y) ∧ acheter(x, y) ∧mari(u))→ (donner(u, y, x))).
7.2.3 The CCG and DRS InterfaceCategorial type transparency is one of the important principles applied to CCG (see chapter 5).It states that there is an equivalence of representations between lexical categories and logicalforms. Each syntactic category will be mapped to an unique semantic type in order to ensure atransparency between a CCG derivation and an expression under using semantic types.
In general, we can transform a CCG derivation parse tree to DRS expressions by defining anequivalent mapping between lexical categories and semantic types. For instance, if the primitivelexical categories employed in French CCG corpus are NP(Noun Phrase), S (Sentence), the Scategory is associatedwithDRS expression of type 〈t〉, whereas theNP categories correspond toDRS expression of type 〈e,t〉. With complex categories where the direction of slash will pointout whether the argument come from its left if backward slash is used , or its right if forwardslash is presented, the category S\NP/NP which correspond to a transitive verb phrase, requiresa NP as argument on its left and has a DRS expression of type 〈〈e〉,〈e,t〉〉. Or the lexicalcategory NP/NP which indicates an article or an adjective, requires a category NP as argumenton its right, and owns the semantic type 〈〈e,t〉,〈e〉〉. Figure 7.1 shows some examples of suchmappings.
Typed λ-expressions can also become a bridge for connecting between lexical categoriesand DRS expressions. If λx.φ is a λ-expression, then we have that x is a variable of type 〈e〉and φ is a formula of type 〈t〉. Table 7.1 shows some examples of equivalences between types,lexical categories and λ-expressions.
7.3 DRS Parsing Based on BoxerIn Chapter 4 we proposed an architecture for building a French semantic parsing framework.We have gone through the steps required to obtain syntactic or grammar analysis for a givenutterance. Before going into semantic parsing based on Boxer andDRS, let us recall the previoustasks in this framework.
7.3.1 Syntactic and grammar analysisWe employ dependency grammars to analyze the structure of given sentences. In particular, adependency structure of sentences is a result of the analysis and description of the dependencyof the linguistic units, e.g., words, which are connected to each other by dependency paths.Most of the time, the root of the dependency tree corresponds to the main verb and all otherwords are either directly or indirectly connected to this verb by directed edges. Each edgehas a label for describing the relation between the two words. These labels belong to a set ofsyntactic functions, e.g., subject, object, oblique, determiner, attribute, etc. Syntactic functionsare grammatical relations playing an important role in recognizing components of the sentence.
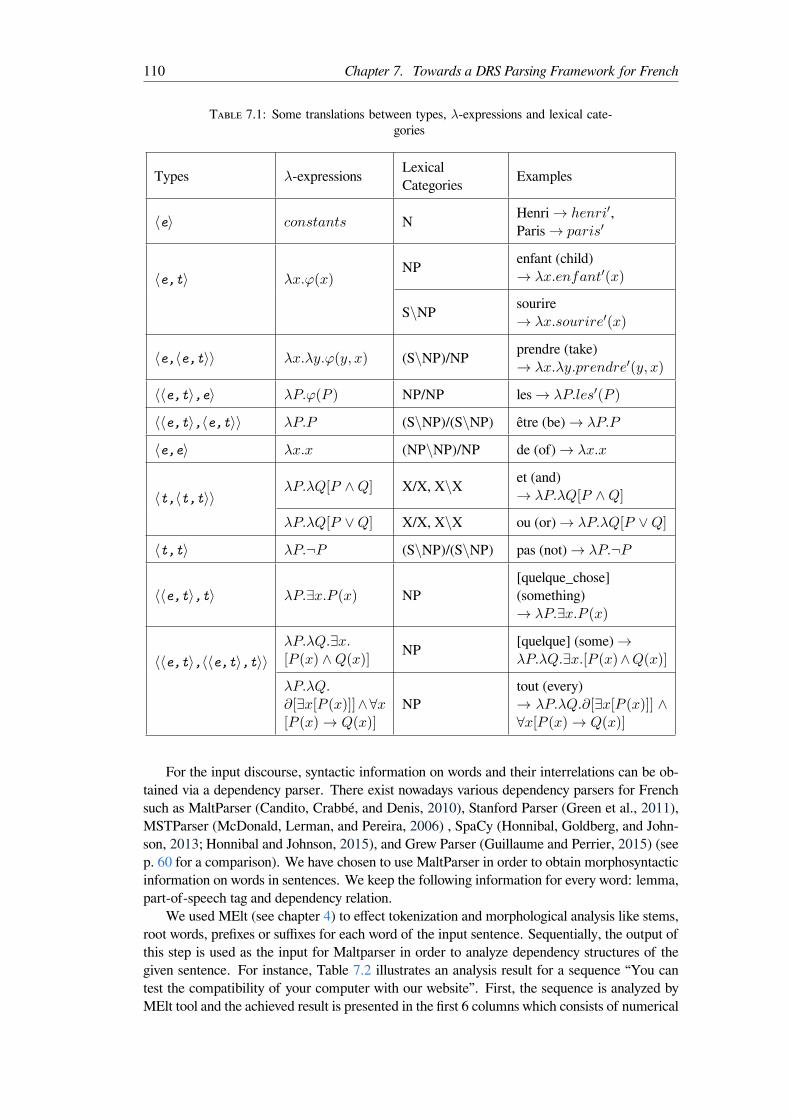
110 Chapter 7. Towards a DRS Parsing Framework for French
T 7.1: Some translations between types, λ-expressions and lexical cate-gories
Types λ-expressions LexicalCategories Examples
〈e〉 constants N Henri→ henri′,Paris→ paris′
〈e,t〉 λx.φ(x)NP enfant (child)
→ λx.enfant′(x)
S\NP sourire→ λx.sourire′(x)
〈e,〈e,t〉〉 λx.λy.φ(y, x) (S\NP)/NP prendre (take)→ λx.λy.prendre′(y, x)
〈〈e,t〉,e〉 λP.φ(P ) NP/NP les→ λP.les′(P )
〈〈e,t〉,〈e,t〉〉 λP.P (S\NP)/(S\NP) être (be)→ λP.P
〈e,e〉 λx.x (NP\NP)/NP de (of)→ λx.x
〈t,〈t,t〉〉λP.λQ[P ∧Q] X/X, X\X et (and)
→ λP.λQ[P ∧Q]
λP.λQ[P ∨Q] X/X, X\X ou (or)→ λP.λQ[P ∨Q]
〈t,t〉 λP.¬P (S\NP)/(S\NP) pas (not)→ λP.¬P
〈〈e,t〉,t〉 λP.∃x.P (x) NP[quelque_chose](something)→ λP.∃x.P (x)
〈〈e,t〉,〈〈e,t〉,t〉〉λP.λQ.∃x.[P (x) ∧Q(x)]
NP [quelque] (some)→λP.λQ.∃x.[P (x)∧Q(x)]
λP.λQ.∂[∃x[P (x)]]∧∀x[P (x)→ Q(x)]
NPtout (every)→ λP.λQ.∂[∃x[P (x)]] ∧∀x[P (x)→ Q(x)]
For the input discourse, syntactic information on words and their interrelations can be ob-tained via a dependency parser. There exist nowadays various dependency parsers for Frenchsuch as MaltParser (Candito, Crabbé, and Denis, 2010), Stanford Parser (Green et al., 2011),MSTParser (McDonald, Lerman, and Pereira, 2006) , SpaCy (Honnibal, Goldberg, and John-son, 2013; Honnibal and Johnson, 2015), and Grew Parser (Guillaume and Perrier, 2015) (seep. 60 for a comparison). We have chosen to use MaltParser in order to obtain morphosyntacticinformation on words in sentences. We keep the following information for every word: lemma,part-of-speech tag and dependency relation.
We used MElt (see chapter 4) to effect tokenization and morphological analysis like stems,root words, prefixes or suffixes for each word of the input sentence. Sequentially, the output ofthis step is used as the input for Maltparser in order to analyze dependency structures of thegiven sentence. For instance, Table 7.2 illustrates an analysis result for a sequence “You cantest the compatibility of your computer with our website”. First, the sequence is analyzed byMElt tool and the achieved result is presented in the first 6 columns which consists of numerical
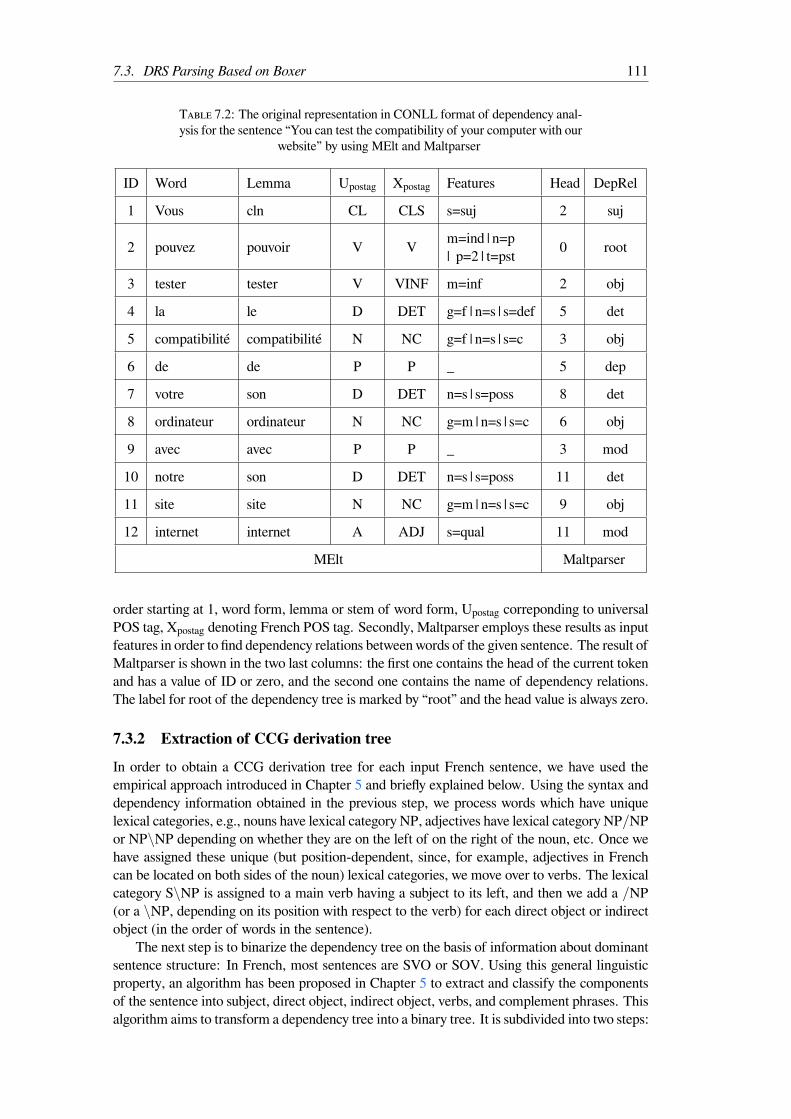
7.3. DRS Parsing Based on Boxer 111
T 7.2: The original representation in CONLL format of dependency anal-ysis for the sentence “You can test the compatibility of your computer with our
website” by using MElt and Maltparser
ID Word Lemma Upostag Xpostag Features Head DepRel
1 Vous cln CL CLS s=suj 2 suj
2 pouvez pouvoir V V m=ind | n=p| p=2 | t=pst 0 root
3 tester tester V VINF m=inf 2 obj
4 la le D DET g=f | n=s | s=def 5 det
5 compatibilité compatibilité N NC g=f | n=s | s=c 3 obj
6 de de P P _ 5 dep
7 votre son D DET n=s | s=poss 8 det
8 ordinateur ordinateur N NC g=m | n=s | s=c 6 obj
9 avec avec P P _ 3 mod
10 notre son D DET n=s | s=poss 11 det
11 site site N NC g=m | n=s | s=c 9 obj
12 internet internet A ADJ s=qual 11 mod
MElt Maltparser
order starting at 1, word form, lemma or stem of word form, Upostag correponding to universalPOS tag, Xpostag denoting French POS tag. Secondly, Maltparser employs these results as inputfeatures in order to find dependency relations between words of the given sentence. The result ofMaltparser is shown in the two last columns: the first one contains the head of the current tokenand has a value of ID or zero, and the second one contains the name of dependency relations.The label for root of the dependency tree is marked by “root” and the head value is always zero.
7.3.2 Extraction of CCG derivation treeIn order to obtain a CCG derivation tree for each input French sentence, we have used theempirical approach introduced in Chapter 5 and briefly explained below. Using the syntax anddependency information obtained in the previous step, we process words which have uniquelexical categories, e.g., nouns have lexical category NP, adjectives have lexical category NP/NPor NP\NP depending on whether they are on the left of on the right of the noun, etc. Once wehave assigned these unique (but position-dependent, since, for example, adjectives in Frenchcan be located on both sides of the noun) lexical categories, we move over to verbs. The lexicalcategory S\NP is assigned to a main verb having a subject to its left, and then we add a /NP(or a \NP, depending on its position with respect to the verb) for each direct object or indirectobject (in the order of words in the sentence).
The next step is to binarize the dependency tree on the basis of information about dominantsentence structure: In French, most sentences are SVO or SOV. Using this general linguisticproperty, an algorithm has been proposed in Chapter 5 to extract and classify the componentsof the sentence into subject, direct object, indirect object, verbs, and complement phrases. Thisalgorithm aims to transform a dependency tree into a binary tree. It is subdivided into two steps:

112 Chapter 7. Towards a DRS Parsing Framework for French
1. Chunks are extracted from the dependency tree based on syntactic information and de-pendency labels between words. For example, the subject chunk is obtained by findinga word that has a dependency labeled suj; the verb chunk corresponds to the root of thedependency structure; direct or indirect object chunks are obtained as words with linksdirected to the root verb and having labels obj or p_obj, etc.
2. A binary tree is built for each chunk, then binary trees are combined in inverse order ofthe dominant sentence structure. For example if SVO is the dominant structure, we startby building the binary tree of the object chunk, then combine it with the binary tree ofthe verb chunk, and finally we obtain the binary tree of the subject chunk.
For each input sentence we obtain a single CCG derivation tree, corresponding to its de-pendency tree input. The output CCG derivation tree is modified to be compatible with Boxer’sinput format. At the same time, the sentence is analyzed in order to extract named entity com-ponents (e.g., Location, Person, Date, Time, Organization, etc.) and chunk phrases by using theFrench models of SpaCy application.
7.3.3 Boxer Semantic ParsingImplemented in the Prolog language with publicly available source code, the Boxer applicationis designed to provide semantic analysis of discourses for English with CCG derivation trees asinput and meaning representation under the form of DRS as output. In order to do the same inFrench, we had to adapt the source code to the specific characteristics of the French language.
% Primaire: ‘NP V NP’ (‘allow-64’)
% Syntax: [np:‘Agent’,v,np:‘Theme’]
% CCG: (s:dcl\np)/np
% Roles: [‘Theme’,‘Agent’]
% Example: ‘Luc approuve l’attitude de Léa’
VerbNet:
(approuver, (s:dcl\np)/np, [‘Theme’,‘Agent’]).
(autoriser, (s:dcl\np)/np, [‘Theme’,‘Agent’]).
(supporter, (s:dcl\np)/np, [‘Theme’,‘Agent’]).
(tolérer, (s:dcl\np)/np, [‘Theme’,‘Agent’]).
F 7.2: An excerpt of the Verbnet lexical resource for French
Verbs are the central component of most sentences. Once a verb is given, we are able toknow the components that can be attached to it. For example, the verb “to buy”must be followedby a direct object, and the verb “to sleep” cannot since it is intrasitive. Relationships betweena verb and its noun phrase arguments are illustrated by thematic roles (e.g., Agent, Experi-ence, Theme, Goal, Source, etc.). In Boxer, verbs and their thematic roles are extracted fromthe VerbNet lexical resources corpus (Schuler, 2005). For French, we have used the French

7.4. Experiment and Evaluation 113
Entity
Object
is a
Organism
is a
Animal
is a
Person
is a
Mangender
Woman
gender
F 7.3: An ontology resource example
VerbNet corpus (Pradet, Danlos, and De Chalendar, 2014) (see an example in Fig. 7.2), whileontologies have provided hierarchical or equivalent relationships between entities, concepts,etc. (Fig. 7.3).
Issues concerning anaphora and presupposition triggers introduced by noun phrases, per-sonal pronouns, possessive pronouns, reflexive pronouns, demonstrative pronouns, etc., are pro-cessed on a case-by-case basis, based on the resolution algorithm proposed in (Bos, 2003). Fi-nally, the meaning representation of the discourse analysis is exported in two different formats:FOL and DRS.
7.4 Experiment and Evaluation7.4.1 ExperimentsWe illustrate the capabilities of French discourse analysis via our architecture by the followingexample: “Tous les soirs, mon voisin met sa voiture au garage. Il arrose ses rosiers avec son fils.”(Every evening, my neighbor puts his car in the garage. He waters his rose bushes with hisson). We have two sentences in this text, containing possessive pronouns, personal pronouns,and noun phrases.
We first apply a parser to obtain dependency relations. We then obtain a CCGderivation treeas output of the CCG parsing stage. The results are represented (cf. Fig. 7.4) in a format whichis compatible with the input format of Boxer. Each word is handled as a term (t) together withthe following information: CCG lexical category, original word, lemma, POS tag label, chunksand named entity information.
The reader can see the output of the example in two formats: FOL (Figure 7.6) and DRS(Figure 7.5). Boxer for French can analyze correctly linguistic phenomena such as possessivepronouns (ses, mon, sa, son), propositional quantifiers (tout) and noun phrases (sa voiture augarage). However, there is still room for improvement, for example, we do not obtain thechronological order of actions in the example.
On the other hand, we experimented our system with 4,525 sentences from the FrenchTreeBank corpus in order to have an overview on a wide-coverage corpus. The length of thesentences in our experimentation is limited to 20 words because the FTB corpus was extractedfrom French newspapers, the sentences are thus regularly long and complex compared to thesimple and short sentences of a discourse. Finally, we have obtained 61,94% of sentences whichcan be analyzed successfully by our system. By analyzing errors that occurred in our outcomes,we figure out two main causes. The first one derives from errors in dependency analysis or CCGanalysis step. The second one originates from the lack of semantic representation definition onthe CCG lexical in Boxer for French.

114 Chapter 7. Towards a DRS Parsing Framework for French
ccg(1,)ba(np,
fa(np,t(np/np,`tous',`tout',`ADJ',`O',`O'),fa(np,
t(np/np,`les',`le',`DET',`O',`O'),t(np,`soirs',`soir',`NC',`O',`O'))),
lp(np\np,t(ponct,`,',`,',`PONCT',`O',`O'),
lx(np\np,s:dcl,ba(s:dcl,
fa(np,t(np/np,`mon',`ma',`DET',`B-NP',`O' ),t(np,`voisin',`voisin',`NC',`I-NP',`O')),
fa(s:dcl\np,t((s:dcl\np)/np,`met',`mettre',`V',`O',`O' ),rp(np,
fa(np,t(np/np,`sa',`son',`DET',`B-NP',`O' ),ba(np,
t(np,`voiture',`voiture',`NC',`I-NP',`O'),
fa(np\np,t((np\np)/np,`au',`à le',`P+D',`O',`O'),t(np,`garage',`garage',`NC',`O',`O')))),
t(ponct,`.',`.',`PONCT',`O',`O')))))))).
F 7.4: CCG derivation tree for the sentence “Tous les soirs, mon voisinmet sa voiture au garage”.

7.4. Experiment and Evaluation 115
__________________________________________________ | s2 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 ||--------------------------------------------------|| np_fils(x11) || de(x11,x10) || np_male(x10) || np_rosier(x9) || de(x9,x8) || np_male(x8) || np_male(x7) || au(x5,x6) || np_garage(x6) || np_voiture(x5) || de(x5,x4) || np_male(x4) || np_voisin(x3) || de(x3,x2) || np_male(x2) || _____________ _________________________ || | x1 | | p1 | || (|-------------| -> |-------------------------|) || | np_soir(x1) | | a_topic(x1) | || |_____________| | __________________ | || | p1:| s1 | | || | |------------------| | || | | Recipient(s1,x5) | | || | | Theme(s1,x3) | | || | | a_mettre(s1) | | || | |__________________| | || | alors(x1,p1) | || |_________________________| || Theme(s2,x9) || Actor(s2,x7) || a_arroser(s2) || avec(x9,x11) ||__________________________________________________|
F 7.5: DRS output of the utterance
∃ z3 z7 z8 z9 z10 z11 z12 z13 z14 z5 z6.(np_fils(z6) ∧ de(z6, z5) ∧ np_male(z5)∧ np_rosier(z14) ∧ de(z14, z13) ∧ np_male(z13) ∧ np_male(z12) ∧ au(z10, z11) ∧np_garage(z11) ∧ np_voiture(z10) ∧ de(z10, z9) ∧ np_male(z9) ∧ np_voisin(z8)∧ de(z8, z7) ∧ np_male(z7) ∧ ∀ z4.(np_soir(z4) → ∃ z1.(a_topic(z4) ∧ ∃z2.(Recipient(z2, z10) ∧ Theme(z2, z8) ∧ a_mettre(z2)) ∧ alors(z4, z1))) ∧Theme(z3, z14) ∧ Actor(z3, z12) ∧ a_arroser(z3) ∧ avec(z14, z6))
F 7.6: FOL output of the utterance
7.4.2 Error AnalysisSemantic parsing is a difficult task in the natural language processing field. We obtain a parseof French discourse step by step, and in order to obtain the semantic representation accurately,we have to ensure accuracy of previous analysis stages. If there is an error in them, this willfatally lead to errors in the results. For example, incorrect POS tags are one of the leadingcauses of erroneous results. Also phrases can be inherently ambiguous and therefore can havemore than one syntax trees, such as la belle porte le voile where belle, porte, voile can be bothnoun/verb/noun or adjective/noun/verb. In addition, complex linguistic issues arise in the pro-cessing of utterances, where omission of a word or of a group of words—which otherwise arenecessary for the grammatical completeness of a sentence—is tolerated. These issues oftenresult in incorrect identification of verb arguments. For example, in Henri veut aller au parcet sa mère à la bibliothèque (Henri wants to go to the park and his mother to the library), theabsence of a verb between words mère and à la bibliothèque may result in obtaining incorrectlexical categories for the remaining words.

116 Chapter 7. Towards a DRS Parsing Framework for French
7.5 Conclusion of the ChapterWe have proposed an empirical approach towards building a semantic representation appli-cation for the French language, based on the CCG framework (for analyzing in the scope ofthe sentence) and on DRS (for dealing with semantic relations between the sentences of a dis-course). Syntactic information and dependency relations between words are analyzed and ex-tracted using a dependency parser. After that, the information is used to build a CCG derivationtree for each sentence. Finally, sentences in the form of CCG derivation trees are treated byBoxer, which we have adapted to French language by direct intervention on the source code,and we obtain a semantic representation of the discourse in FOL or in boxed format. In futureresearch, we plan to build a corpus with discourses and their meaning representation in DRSform, using this application. We also plan to use deep neural network models to improve therobustness of the results obtained.

Chapter 8
Conclusion and Perspectives
In this thesis, we concentrated on study different aspects for building a meaning representationframework from natural language texts which are increasingly generated by conversations anddiscussions on the social networking platforms. In a general context, the rise of many socialnetworking web-based services along with internet-based applications across multiple mobileplatforms allow user to create and publish theirs content freely and without limitations. User-generated contents are created in the form of short text, articles, images, videos or mixed ofother formats, depending on what kind of data the social networking platform supports. In ourresearch, we dealt with user-generated texts that can be easily created by the vast majority ofusers and can be used to explore the users’ sentiments or intentions. This helps to reduce theeffort of agents in an organization or company that are responsible for gathering or receivinginformation, and for interacting with their customers on social networking platforms.
Capturing and representing semantics of natural language texts has been realized by manydifferent research teams working with diverse methods, paradigms and ideologies for many dif-ferent purposes, such as machine translation, question answering, automated reasoning or codegeneration. In particular, meaning representation of a given sentence requires not only the iden-tification of roles and objects in the sentence but also the use of automated reasoning. Meaningrepresentation also enables exploring and analyzing data by parsing natural language utterancecorresponding to databases, or parsing questions, commands from conversational agents or chat-bots such as Alexa, Siri, Cotana. More generally, the most basic idea of meaning representationis how to achieve a machine-understandable representation of given natural language utterances.
With the purpose of finding an effective way of analysis and representation of semanticsfor given natural language utterances, we have examined and discussed the various prominentworks ranging from using rule-based methods to current deep neural network approaches. Withthe limitation of a massive amount of data about pairs of natural language utterances and theirmeaning representations that have been becoming a mandatory requirement for the deep learn-ing approaches, we have decided to use the empirical approach and proposed a general architec-ture for a meaning representation framework using French natural language input. In the firstmodule of the architecture, we start by analyzing morphological information for each word.From that, we achieve lemma, POS tag and features of the word in text. These crucial data areused as input for extracting relationships between words and constituents by using dependencygrammar. As the result of this step, we obtain the syntactic and dependency information ofevery word of the input utterance.
In the second module in the architecture, the bridge between syntax and semantic is con-structed based on CCGs, and this helps us in obtaining a syntax-semantic transparent interface.The result of the previous module is employed as input of the process of extraction of a CCGderivation tree. More particularly, this process consists of two stages: the first one is the task ofassignment of lexical categories to each word depending on its position and its relationship withother words in the sentence; the second one focuses on the binarization of the dependency treeinto a binary tree. Parsing of the CCG derivation tree is realized on the binary tree by applyingcombinatory rules defined in CCG theory.

118 Chapter 8. Conclusion and Perspectives
Analysis of CCGs is encapsulated within the scope of a single sentence. Nevertheless, anatural language utterance can regularly be created with more than two sentences. The analysisof an utterance will need to be considered in its context. Therefore, in the general meaning con-text of the utterance, each sentence will contribute information to the common context—andsometimes may change its meaning. Otherwise, the context also gives information to explainthe meaning of the sentence. In the last module of our proposed architecture, we construct ameaning representation for a given utterance based on DRT theory, DRS format and the Boxertool by Johan Bos and is team. Accordingly, the analysis result of CCG derivation tree of theprevious module is regarded as the input for this module, besides of the additional informa-tion about chunks and named entities in the sentence. The transformation of the input CCGderivation tree into a DRS format allows us to process linguistic phenomena such as anaphora,coreference and so on. As a result, we obtain ether a logical form or data in DRS boxing format.
8.1 Limitations and Perspectives8.1.1 LimitationsWe attempted to explore, propose and build the most appropriate solution for a general modelaiming to capture meaning representation from natural language input. However, there are stillmany limitations that need to be tackled:
• The building of CCG derivation trees for each given sentence must employ syntax anddependency information obtained by other tools. Therefore, we are dependent on theaccuracy of results provided by these tools. In other words, our approach can collapsecompletely when syntax and dependency information for the input is not correct as ex-pected.
• In the CCG grammar formalism, a sentence can own more than one CCG derivationtrees, depending on the relationships between constituents of the sentence. However ourapproach provides always only a single CCG derivation tree for each sentence becausethe CCG derivation tree is a directly obtained from the structure of the dependency tree.
• The diversity and complexity of French syntax structures has caused many difficulties inthe analysis process. Thus, the results achieved for the semantic representation frameworkare still weak and an extra effort is needed to improve them by adding special semanticpatterns for French language, as well as handling mutli-word problems.
8.1.2 PerspectivesIn theNLP field, meaning representation or semantic interpretation plays nowadays a crucial rolein the building of machine-understandable representation systems for natural languages such asconversational agents, robotic navigation, language translation, automated reasoning and so on.From the result of our work, we propose a summary of some promising research directions:
• The construction of French CCG parser becomes an indispensable requirement becauseits application potential is quite large, and this for various NLP tasks. With results ob-tained in this thesis such as the French CCG corpus, the CCG supertagging model anda state-of-the-art in the development of a CCG parser, we believe that the complete im-plementation of such a tool is perfectly feasible.
• In the CCG supertagging model, we have proven that the usage of embedding featuresfrom lemma, postag and dependency information helps to improvd the accuracy of ourmodel in comparison with other models. The transformation of characters, words, or

8.1. Limitations and Perspectives 119
sentences into a numerical vector representation is a mandatory requirement when usingdeep learning techniques. Based on these transformations, we have operations such ascharacter embedding, word embedding and sentence embedding, respectively. Similarly,we can propose a novel feature embedding, calledmeaning embedding or meaning vectorrepresentation. Using our work, we can obtain a DRS or logical form representation foreach natural language utterance.


Appendix A
Supporting Information
A.1 The λ-calculusIn order to obtain meaning representation, we need to fulfill different steps and a number oftasks as in the architecture we propose. In this process, First-Order Logic augmented withλ-calculus is employed as an inference-allowing formalism between human language and in-terpreted machine language. We can capture and represent the semantic representations forlexical items and then use compositionality to obtain semantic representation of constituents,in First-Order Logic and λ-calculus.
Lambda calculus was first introduced by Alonzo Church in the 1930s, in his research on thefoundations of mathematics (Church, 1936). λ-calculus is essentially a branch in mathematicallogic used for expressing computations based on abstraction functions and applications that isrely on variable binding and substitution. Nowadays, λ-calculus has becomes quite popularwith applications in different areas of mathematics, linguistics and computer science. Morespecifically, λ-calculus is a foundational theory for the development of functional programminglanguages. λ-calculus also plays a crucial role in the semantic representation of natural languagein computational linguistics.
In general, We distinguish between typed λ-calculus and untyped λ-calculus. Typed λ-calculus includes constraints about types of variables and functions, in which the type of avariable, which plays the role of argument of a function, must be compatible with the type ofthis function. By contrast, there is no restriction involving type in untyped λ-calculus. In formallinguistics, we are mostly interested with typed λ-calculus.
λ-calculus is regarded as a formal language Lλ. The expressions of λ-calculus are calledλ-expressions or λ-terms. Essentially, a λ-calculus expression consists of symbols for variablesand functions, the symbol λ and parentheses. If E is the set of all λ-expressions, and x, y, z, . . .are variables, then we have the following properties:
• if x is a variable, then x belong to E ;
• if x is a variable and P ∈ E , then λx.P (we call it an abstraction) belongs to E ;
• if Q ∈ E and S ∈ E , then the application of Q to S, denoted QS, belongs to E .For instance, here are some λ-expressions and the corresponding explanations:
• Px – a function P applied to an argument x;
• (Px)y – a function P that applied to two arguments x, y (in fact, a function P applied tox, and the result applied to y), this is equivalent to the mathematical expression P (x, y);
• P (Qx) – a functionP applied to the result of applying a functionQ to x, this is equivalentto the mathematical expression P ◦Q(x);
• λx.x – the identify function (notice that this is a function, it can be applied to any otherfunction: (λx.x)(P ) = P ;

122 Appendix A. Supporting Information
• λx.(λy.x z) v – an abstraction and application.
A variable is a symbol used to represent an unspecified term or basic object. We have boundvariables that are used in the scope of an abstraction, and free variables. For instance, given aλ-expression as in example 16, we have two kinds of variables: v and z are free variable becausethere is no abstraction operator λ bounding them, whereas x and y, are bound variables. Hereis an example of various bound variables with different scopes:
(15)
λx . (λy . (λx . λz . z x) y) x y
free variable
Bound variables can be renamed to increase readability of the λ-expression by a human:
(16)
λx . (λu . (λv . λz . z v) u) x y
free variable
λ-expressions that contain no free variable are called closed and they are equivalent to termsin combinatory logic.
We have some writing conventions to reduce the number of parentheses:
• function applications is left-associative: (P1P2P3 . . . Pn) := (((P1P2)P3) . . . Pn);
• variables are listed after λ: λxyz.P := λx.λy.λz.P ;
• the body of abstractions extends to the right: λx.Q S := λx.(Q S).
Let us give a First-Order Logic+λ-expression example:
(17) a. λx.λy.watch(y, x)
b. (λx.λy.watch(y, x))(television, henri)
c. λy.watch(y, henri)(television)⇒ watch(television, henri).
We have two variables x, y corresponding to prefixes λx, λy that bind the occurrencesof x, y in the expression (17).a. The aim of abstracting over two variables is to mark theslots in which we want the substitution to be made, as in expression (17).b. With argument(television, henri) and functor λx.λy.watch(y, x), the operation of (17).b is also calledfunctional application. Finally in (17).c give we reduce the functional application by replac-ing λ-bound variables by arguments.
The process of simplification and evaluation clarifies the meaning of a given λ-expression.Simplifying and evaluating λ-expressions is reducing the expression until there is no more re-duction. More generally, we have four kinds of transformation and reduction operations definedon λ-expressions, namely α-conversion, substitution, β-reduction and η-reduction:

A.2. Combinatory Logic and The λ-calculus 123
• α-conversion is the process of changing names of bound variables used in λ-expressions.For instance, from the λ-expression λx.λy.own(y, x), we can obtain a new λ-expressionλz.λy.own(y, z). New λ-expressions that differ only by α-conversion are called α-equivalent. We regularly apply α-conversion before carrying out substitution becausethe variables must be distinguished. The aim is to prevent errors in the binding process.
• Substitution is considered as the process of replacing all occurrences of a variable by aλ-expression. Thus, the substitution, written as [expression to be substituted/variable tosubstitue] is defined as:
– If x is a variable and P is a λ-expression, then x[P/x] ≡ P
– If x, y are variables and P is a λ-expression, then y[P/x] ≡ y, ∀x 6= y
– If x is a variable and P, Q, S are λ-expressions, then(P Q)[S/x] ≡ (P [Q/x])(Q[S/x])
– If x is a variable and P,Q areλ-expressions, then λx.P [Q/x] ≡ λx.P
– Ifx, y are variables andP,Q areλ-expressions, then (λy.P )[Q/x] ≡ λy.(P [Q/x]),∀x 6= y and y must be bound variable in P
– If x, y, z are variables and P, Q are λ-expressions, then(λy.P )[Q/x] ≡ λz.(P [z/y][Q/x]), ∀x 6= y and y must be bound variable in P
• β-reduction is regarded as a basic computational step of the λ-calculus that allows usto simplify λ-expressions. Conventionally, given a variable x and λ-expressions P, Q,β-reduction is defined by the following “β-rules”:
(λx.P )Q becomes P [Q/x]by β-reduction
P −→β Q =⇒ (P S) −→β (Q S)
P −→β Q =⇒ (S P ) −→β (S Q)
P −→β Q =⇒ λx.P −→β λx.Q
(A.1)
β-reduction have the same idea with functional applications.
• η-reduction is based on principle of extensionality, in which in the same context, twofunctions are identical if they return the same result for given arguments. Conventionally,if x is a bound variable in the λ-expression P , η-reduction is defined by the followingrule:
λx.(Px) becomes P by η-reduction. (A.2)With η-reduction, we can switch from λx.(Px) to P and vice-versa, depending on eachparticular context. For instance, we can rewrite the λ-expression like λx.eats(x) simplyas eats by applying η-reduction.
The purpose of applying transformations and β-reduction is to compute a value which isequivalent to a function in λ-calculus. We say that a λ-expression achieves a normal form, if itcan not be reduce any more with the rules in β-reduction or η-reduction.
A.2 Combinatory Logic and The λ-calculusThe initial ideas of combinatory logic were introduced in a talk by Moses Schönfinkel in the1920s, and a paper of his (Schönfinkel, 1924). Seven years later, Haskell Curry independently

124 Appendix A. Supporting Information
rediscovered combinators and gave important contributions to foundations of logic and math-ematics, as well as computational aspects (Curry, 1930). See (Seldin, 2006) for more detailsabout the history of the development of this field.
In general, combinatory logic is an applicative language that becomes a foundational theoryto construct functional programming languages such as Haskell, Brook and Curry language.Similar to λ-expressions in the λ-calculus, combinatory logic is constructed around the notionof combinatory term (combinatory expression). Conventionally, a combinatory term is madeup of variables, atomic constants including basic combinators and applications. The set ofcombinatory terms Ecl is defined inductively as follows:
• Variable: if x is a variable, then x is a combinatory term.
• Primitive Function: if P is a basic combinator, then P is a combinatory term.
• Application: IfM and N are combinatory terms, then (M N ) is a combinatory term.
Instead of abstraction and application like in the λ-calculus, combinatory calculus has onlyone operation—application—to manufacture functions. In addition, combinatory logic buildsa limited set of primitive functions, based on basic combinators, besides other functions thatcan be constructed. Primitive functions essentially are combinators or functions that contain nobound variable. Therefore, the combinatory terms do not use the λ operator symbol.
Combinators play an crucial role in combinatory logic, in which they are considered asan abstract operator. Using combinators, we can obtain new “complex” operators from givenoperators. Based on original works of Haskell Curry and his colleagues (Curry et al., 1958), wehave the following basic set of combinators (see also (Haralambous, 2019), an introduction to(Smullyan, 1985), which describes combinators as talking birds in a “certain enchanted forest”):
• I: This combinator expresses a variable as function of itself, it is called elementary iden-tificator. The combinator I is defined as:
Ix ≡ x
I ≡ λx.x(A.3)
• C: give a function f of two arguments, we have combinator Cf , which is the converse.This combinator is called elementary permutator.
Cfxy ≡ fyx
C ≡ λfxy.fyx(A.4)
• W: given a function f of two arguments, we have combinator Wf , which has one ar-gument getting duplicated into two arguments. This combinator is called elementaryduplicator.
Wfx ≡ fxx
W ≡ λfxy.fxx(A.5)
• K: given a constant c, this constant can be expressed as a function with combinator K,which is called elementary cancellator.
Kcx ≡ c
K ≡ λfx.f ≡ λxy.x(A.6)

A.2. Combinatory Logic and The λ-calculus 125
• B: given two functions f and g, combinator B expresses their composition. This combi-nator is called elementary compositor.
Bfgx ≡ f(gx)
B ≡ λfgx.f(gx) ≡ λfxy.f(xy)(A.7)
• S: given two terms f , g, the combinator S intertwines them as functions of x:
Sfgx ≡ fx(gx)
S ≡ λfgx.fx(gx) ≡ λxyz.xz(yz)(A.8)
• Φ: similarly to S, this combinator intertwines the two first arguments of a function f :
Φfabx ≡ f(ax)(bx)
Φ ≡ λfghx.f(gx)(hx) ≡ λfxyz.f(xz)(yz)(A.9)
• Ψ: a variation ofΦwhere a function is distributed into the arguments of another function:
Ψfgxy ≡ f(gx)(gy)
Ψ ≡ λfgxy.f(gx)(gy) ≡ λfxyz.f(xy)(xz)(A.10)
The commonly used reducibility relation in combinatory calculus is called weak reducibility(→w) . Aweak reduction of a relationM −→w N is defined inductively as the following clauses:
1. M −→w M .
2. Sfgx −→w fx(gx), Kcx −→w c, Ix −→w x.
3. IfM −→w N and N −→w O, thenM −→w O.
4. IfM −→w N , then OM −→w ON .
5. IfM −→w N , thenMO −→w NO.
All combinators can be generated or derived from basic combinators. We can see that anycombinator can be rewritten by an equivalent λ-expression. In standard combinatory calculus,the basic combinators has only combinators I, K and S because we can redefine other combi-nators by using them1. For instance, the combinator B can be redefined as:
Bfgx ≡ S(KS)Kfgx
−→w KSf(Kf)gx by constracting S(KS)Kf to KSf(Kf)
−→w S(Kf)fg by constracting KSf to S
−→w Kfx(gx) by constracting S(Kf)gx
−→w f(gx) by constracting Kfx.
(A.11)
1In fact, as can be seen in (Haralambous, 2019), {S,K} is already a basis of the set of combinators, and thisbasis can be reduced to a single element ι defined as ιx := xSK.

126 Appendix A. Supporting Information
T A.1: A comparison of rules between λ-calculus and combinatory logic
Combinatory logic λ-calculusAxiom-schemes
(I) Ix = X(α) λx.P = λy.[y/x]Q if y is not a free
variable in Q(K) Kcx = c(S) Sfgx = fx(gx) (β) (λx.P )Q = [Q/x]P
(ρ) M = M (ρ) P = P
Rules of inferences(µ) M = N =⇒ OM = ON (µ) P = Q =⇒ SP = SQ
(υ) M = N =⇒MO = NO (υ) P = Q =⇒ PS = QS
(τ ) M = N andN = O =⇒M = O (υ) P = Q andQ = S =⇒ P = S
(σ) M = N =⇒ N = M (υ) P = Q =⇒ Q = P
(ξ) M = N =⇒ [x].M = [x].N (ξ) P = Q =⇒ λx.P = λx.Q
A combinatory termM is in weak normal form if and only ifM does not contain any termamong Ix, Kfx, Sfgx (weak redex). Furthermore, we have also a strong normal form, whichis based on strong reduction. We say that the combinatory term N is a strong reduction of thetermM , which expresses asM >−N , if and only ifM >−N is provable by using axioms andrules of combinatory logic.
In general, combinatory logic and λ-calculus are two systems of logic that share lot of com-mon features. For instance, in Table A.1, we can see that there is an equivalence between thetwo formal systems through inference rules such as reflexiveness, transitivity, symmetry, rightand left monotony. We can have an equivalence transformation from combinatory terms toλ-expressions (a “λ-mapping”), as follows:
• xλ ≡ x.
• Iλ ≡ λx.x, Kλ ≡ λxy.x, Sλ ≡ λxyz.xz(yz).
• (M N)λ ≡Mλ Nλ.
By contrast, we can also make an equivalent transformation from λ-expression to combina-tory terms which is called “Hη-mapping” and is defined inductively as follows:
• xHη ≡ x.
• (P Q)Hη ≡ PHη QHη .
• (λx.P )Hη ≡ [x]η.(PHη)

Bibliography
Abelson, Robert and Roger C. Schank (1977). Scripts, plans, goals and understanding. An in-quiry into human knowledge structures. New Jersey: Psychology Press.
Abend, Omri and Ari Rappoport (2013). “Universal conceptual cognitive annotation (UCCA)”.In: Proceedings of ACL 2013, Sofia, Bulgaria, pp. 228–238.
Abney, Steven P. (1991). “Parsing by chunks”. In: Principle-based parsing. Springer, pp. 257–278.
Abzianidze, Lasha et al. (2017). “The Parallel Meaning Bank: Towards a Multilingual Corpusof Translations Annotated with Compositional Meaning Representations”. In: Proceedingsof EACL 2017, Valencia, Spain.
Ahn, Kisuh et al. (2005). “Question Answering with QED at TREC 2005”. In: Proceedings ofTREC 2005, Gaithersburg, Maryland.
Aichner, Thomas and Frank Jacob (2015). “Measuring the degree of corporate social mediause”. In: International Journal of Market Research 57.2, pp. 257–276.
Ajdukiewicz, Kazimierz (1935). “Die syntaktischeKonnexität”. In: Studia philosophica 1, pp. 1–27.
Akbik, Alan, Tanja Bergmann, and Roland Vollgraf (2019). “Pooled Contextualized Embed-dings for Named Entity Recognition”. In: Proceedings of NAACL 2019, Minneapolis, MN,pp. 724–728.
Akbik, Alan, Duncan Blythe, and Roland Vollgraf (2018). “Contextual string embeddings forsequence labeling”. In: Proceedings of the 27th International Conference on ComputationalLinguistics, Melbourne, Australia, pp. 1638–1649.
Akbik, Alan et al. (June 2019). “FLAIR: An Easy-to-Use Framework for State-of-the-ArtNLP”. In: Proceedings of NAACL 2019, Minneapolis, MN. Minneapolis, Minnesota, pp. 54–59.
Akhundov, Adnan, Dietrich Trautmann, and Georg Groh (2018). “Sequence labeling: A prac-tical approach”. arXiv:1808.03926.
Allen, James (1995). Natural language understanding. Pearson.Allen, James et al. (2007). “Deep linguistic processing for spoken dialogue systems”. In: Pro-
ceedings of the Workshop on Deep Linguistic Processing, Prague, Czech Republic, pp. 49–56.
Ambati, Bharat Ram, Tejaswini Deoskar, andMark Steedman (2016). “Shift-reduce CCG pars-ing using neural network models”. In: Proceedings of NAACL 2016, San Diego, California,pp. 447–453.
— (2018). “Hindi CCGbank: A CCG treebank from the Hindi dependency treebank”. In: Lan-guage Resources and Evaluation 52.1, pp. 67–100.
Ambati, Bharat Ram et al. (2015). “An incremental algorithm for transition-based CCG pars-ing”. In: Proceedings of NAACL 2016, San Diego, CA, pp. 53–63.
Amri, Samir and Lahbib Zenkouar (2018). “Amazigh POS Tagging Using TreeTagger: A Lan-guage Independent Model”. In: International Conference on Advanced Intelligent Systemsfor Sustainable Development, Tangier, Morocco. Springer, pp. 622–632.
Andor, Daniel et al. (2016). “Globally normalized transition-based neural networks”. arXiv:1603.06042.Andreas, Jacob, Andreas Vlachos, and Stephen Clark (2013). “Semantic parsing as machine
translation”. In: Proceedings of ACL 2013, Sofia, Bulgaria, pp. 47–52.

128 Bibliography
Androutsopoulos, Ion, Graeme D. Ritchie, and Peter Thanisch (1995). “Natural language in-terfaces to databases–an introduction”. In: Natural language engineering 1.1, pp. 29–81.
Antoine, Jean-Yves, Abdenour Mokrane, and Nathalie Friburger (2008). “Automatic Rich An-notation of Large Corpus of Conversational transcribed speech: the Chunking Task of theEPAC Project”. In: Proceedings of LREC 2008, Marrakech, Morocco. Citeseer.
Armstrong, Susan, Pierrette Bouillon, and Gilbert Robert (1995). Tagger overview (TechnicalReport). https://www.issco.unige.ch/en/staff/robert/tatoo/tagger.html.[Online; accessed 1-January-2020].
Artzi, Yoav and Luke Zettlemoyer (2011). “Bootstrapping semantic parsers from conversa-tions”. In: Proceedings of EMNLP 2011, Edinburgh, Scotland, pp. 421–432.
Auli, Michael and Adam Lopez (2011). “Efficient CCG parsing: A* versus adaptive supertag-ging”. In: Proceedings of ACL 2011, Portland OR, pp. 1577–1585.
Avinesh, PVS and G. Karthik (2007). “Part-of-speech tagging and chunking using conditionalrandom fields and transformation based learning”. In: Proceedings of Shallow Parsing forSouth Asian Languages, Hyderabad, India 21.
Awasthi, Pranjal, Delip Rao, and Balaraman Ravindran (2006). “Part of speech tagging andchunking with HMM and CRF”. In: Proceedings of NLP Association of India (NLPAI) Ma-chine Learning Contest 2006.
Baker, Collin F., Charles J. Fillmore, and John B. Lowe (1998). “The Berkeley FrameNetproject”. In: Proceedings of the 17th international conference on Computational linguistics,Montréal, Québec, pp. 86–90.
Baldi, Pierre et al. (2000). “Bidirectional dynamics for protein secondary structure prediction”.In: Sequence Learning. Vol. 1828. Springer Lecture Notes in Computer Science. Springer,pp. 80–104.
Baldridge, Jason and Geert-Jan M. Kruijff (2003). “Multi-modal combinatory categorial gram-mar”. In: Proceedings of EACL 2003, Stroudsburg, PA, pp. 211–218.
Baldridge, Jason, Thomas Morton, and Gann Bierner (2002). The OpenNLP Maximum EntropyPackage. Tech. rep. : https://sourceforge.net/projects/maxent/.
Ballesteros, Miguel et al. (2016). “Training with exploration improves a greedy stack-LSTMparser”. arXiv:1603.03793.
Ballesteros,Miguel et al. (2017). “Greedy transition-based dependency parsingwith stack LSTMs”.In: Computational Linguistics 43.2, pp. 311–347.
Banarescu, Laura et al. (2013). “Abstract meaning representation for sembanking”. In: Proceed-ings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse, Sofia,Bulgaria, pp. 178–186.
Bar-Hillel, Yehoshua (1953). “A Quasi-Arithmetical Notation for Syntactic Description”. In:Language 29, pp. 47–58.
Bar-Hillel, Yehoshua et al. (1960). On categorial and phrase-structure grammars. WeizmannScience Press.
Basile, Valerio et al. (2012). “Developing a large semantically annotated corpus”. In:Proceedingsof LREC 2012, İstanbul, Turkey, pp. 3196–3200.
Béchet, Frédéric (2013). LIA_TAGG: A Statistical POS Tagger and Syntactic Bracketer. https://gitlia.univ-avignon.fr/jean-francois.rey/otmedia/tree/630a18786e1f92f097d4df348f91193435ef6b16/tools/lia_ltbox/lia_tagg. [Online; accessed 1-January-2020].
Bellman, Richard (1966). “Dynamic programming”. In: Science 153.3731, pp. 34–37.Bengio, Yoshua, Paolo Frasconi, and Patrice Simard (1993). “The problem of learning long-
term dependencies in recurrent networks”. In: IEEE International Conference on NeuralNetworks 1993. IEEE, pp. 1183–1188.
Berners-Lee, Tim, James Hendler, Ora Lassila, et al. (2001). “The semantic web”. In: Scientificamerican 284.5, pp. 28–37.

Bibliography 129
Birch, Alexandra, Miles Osborne, and Philipp Koehn (2007). “CCG supertags in factored sta-tistical machine translation”. In: Proceedings of the second Workshop on Statistical MachineTranslation, Prague, Czech Republic, pp. 9–16.
Biskri, Ismaïl, Jean Pierre Desclés, and Christophe Jouis (1997). “La Grammaire CatégorielleCombinatoire Applicative appliquée au français”. In: Actes de LTT 1997, Tunis, pp. 25–27.
Blache, Philippe et al. (2016). “4Couv: A New Treebank for French”. In: Proceedings of LREC2016, Portorož, Slovenia, pp. 1546–1551.
Blackburn, Patrick et al. (1999). “Inference and computational semantics”. In: Third Interna-tional Workshop on Computational Semantics (IWCS-3), Tilburg, The Netherlands.
Blanc, Olivier et al. (2010). “Partial Parsing of Spontaneous Spoken French”. In: Proceedingsof LREC 2010, Valletta, Malta. Citeseer.
Bohnet, Bernd et al. (2018). “Morphosyntactic tagging with a meta-biLSTMmodel over contextsensitive token encodings”. arXiv:1805.08237.
Booth, Taylor L. (1969). “Probabilistic representation of formal languages”. In: 10th annualsymposium on Switching and Automata Theory (SWAT 1969), Waterloo, Ontario. IEEE,pp. 74–81.
Bos, Johan (2003). “Implementing the binding and accommodation theory for anaphora reso-lution and presupposition projection”. In: Computational Linguistics 29.2, pp. 179–210.
— (2004). “Computational semantics in discourse: Underspecification, resolution, and infer-ence”. In: Journal of Logic, Language and Information 13.2, pp. 139–157.
— (2008). “Wide-coverage semantic analysis with boxer”. In: Proceedings of the 2008 Con-ference on Semantics in Text Processing, Stroudsburg, PA, pp. 277–286.
— (2015). “Open-domain semantic parsing with boxer”. In: Proceedings of the 20th nordicconference of computational linguistics (NODALIDA 2015), Vilnius, Lithuania, pp. 301–304.
Bos, Johan, Cristina Bosco, and AlessandroMazzei (2009). “Converting a dependency treebankto a categorial grammar treebank for Italian”. In: Eighth international workshop on treebanksand linguistic theories (TLT8), Milan, Italy. Educatt, pp. 27–38.
Bos, Johan et al. (2017). “The Groningen Meaning Bank”. In: Handbook of Linguistic Annota-tion. Ed. by Nancy Ide and James Pustejovsky. Vol. 2. Springer, pp. 463–496.
Boucher, Paul (2010). “L’interrogation partielle en français: l’interface syntaxe/sémantique”. In:Syntaxe et sémantique 1, pp. 55–82.
Boyd, Danah M. and Nicole B. Ellison (2007). “Social network sites: Definition, history, andscholarship”. In: Journal of computer-mediated Communication 13.1, pp. 210–230.
Brants, Thorsten (2000). “TnT: a statistical part-of-speech tagger”. In: Proceedings of the sixthconference on Applied natural language processing, Seattle, WA, pp. 224–231.
Bresnan, Joan (1982). The mental representation of grammatical relations. MIT Press.Candito, Marie, Benoît Crabbé, and Pascal Denis (2010). “Statistical French dependency pars-
ing: treebank conversion and first results”. In: Proceedings of LREC 2010, Valletta, Malta,pp. 1840–1847.
Candito, Marie, Benoît Crabbé, and Mathieu Falco (2009). “Dépendances syntaxiques de sur-face pour le français”. In: Rapport technique, Université Paris 7.
Candito, Marie and Djamé Seddah (2012). “Le corpus Sequoia: annotation syntaxique et ex-ploitation pour l’adaptation d’analyseur par pont lexical (The Sequoia Corpus: SyntacticAnnotation and Use for a Parser Lexical Domain Adaptation Method)[in French]”. In: Pro-ceedings of the Joint Conference JEP-TALN-RECITAL 2012, volume 2: TALN, pp. 321–334.
Candito, Marie et al. “Deep syntax annotation of the Sequoia French treebank”. In: Proceedingsof LREC 2014, Reykjavik, Iceland.
Candito, Marie et al. (2009). “Analyse syntaxique du français: des constituants aux dépen-dances”. In: Actes de TALN 2009, Senlis, France.

130 Bibliography
Candito, Marie et al. (2010). “Benchmarking of statistical dependency parsers for French”. In:Proceedings of COLING 2010, Beijing, China, pp. 108–116.
Çakıcı, Ruken (2005). “Automatic induction of a CCG grammar for Turkish”. In: Proceedingsof the ACL student research workshop, Ann Arbor, MI, pp. 73–78.
Chang, Chih-Chung and Chih-Jen Lin (2011). “LIBSVM: A library for support vector ma-chines”. In: ACM transactions on intelligent systems and technology (TIST) 2.3, p. 27.
Chaplot, Devendra Singh and Ruslan Salakhutdinov (2018). “Knowledge-based word sense dis-ambiguation using topic models”. In: Proceedings of AAAI-18, New Orleans, LA.
Charniak, Eugene (2000). “A maximum-entropy-inspired parser”. In: Proceedings of NAACL2000, Seattle, WA, pp. 132–139.
Chen, Aihui et al. (2014). “Classifying, measuring, and predicting users’ overall active behavioron social networking sites”. In: Journal of Management Information Systems 31.3, pp. 213–253.
Chen, Danqi and Christopher Manning (2014). “A fast and accurate dependency parser usingneural networks”. In: Proceedings of EMNLP 2014, Doha, Qatar, pp. 740–750.
Chiang, David (2005). “A hierarchical phrase-based model for statistical machine translation”.In: Proceedings of ACL 2005, Ann Arbor, MI, pp. 263–270.
Cho, Kyunghyun et al. (2014). “On the properties of neural machine translation: Encoder-decoder approaches”. arXiv:1409.1259.
Choi, Jinho D. (2016). “Dynamic feature induction: The last gist to the state-of-the-art”. In:Proceedings of NAACL 2016, San Diego, CA, pp. 271–281.
Choi, Jinho D. and Martha Palmer (2012). “Fast and robust part-of-speech tagging using dy-namic model selection”. In: Proceedings of ACL 2012, Jeju Island, Korea, pp. 363–367.
Chollet, François (2018). Deep Learning with Python. Manning Publications.Chomsky, Noam (1956). “Three models for the description of language”. In: IRE Transactions
on information theory 2.3, pp. 113–124.— (1957). “Syntactic Structures (The Hague: Mouton, 1957)”. In: Review of Verbal Behavior
by BF Skinner, Language 35, pp. 26–58.— (1959). “On certain formal properties of grammars”. In: Information and control 2.2, pp. 137–
167.— (1975). The logical structure of linguistic theory. Kluwer Academic Publishers.Chrupała, Grzegorz, Georgiana Dinu, and Josef Van Genabith (2008). “Learning morphology
with morfette”. In: Proceedings of LREC 2008, Marrakech, Morocco, pp. 2362–2367.Chu, Yoeng-Jin (1965). “On the shortest arborescence of a directed graph”. In: Scientia Sinica
14, pp. 1396–1400.Church, Alonzo (1936). “An unsolvable problem of elementary number theory”. In: American
journal of mathematics 58.2, pp. 345–363.Church, Kenneth W. and Robert L. Mercer (1993). “Introduction to the special issue on com-
putational linguistics using large corpora”. In: Computational linguistics 19.1, pp. 1–24.Clark, Stephen and James R. Curran (2003). “Log-linear models for wide-coverage CCG pars-
ing”. In: Proceedings of the 2003 conference on Empirical methods in natural language pro-cessing, pp. 97–104.
— (2004). “Parsing the WSJ using CCG and log-linear models”. In: Proceedings of ACL 2004,Barcelona, Spain, p. 103.
— (2007). “Wide-coverage efficient statistical parsing with CCG and log-linear models”. In:Computational Linguistics 33.4, pp. 493–552.
Clark, Stephen, Mark Steedman, and James R. Curran (2004). “Object-extraction and question-parsing using CCG”. In: Proceedings of EMNLP 2004, Barcelona, Spain.
Clément, Lionel, Bernard Lang, and Benoît Sagot (2004). “Morphology based automatic acqui-sition of large-coverage lexica”. In: Proceedings of LREC 2004, Lisbon, Portugal, pp. 1841–1844.

Bibliography 131
Cocke, John (1970). Programming languages and their compilers: Preliminary notes. CourantInstitute of Mathematical Sciences.
Collins, Michael (2002). “Discriminative training methods for hidden markov models: Theoryand experiments with perceptron algorithms”. In: Proceedings of EMNLP 2002, Philadel-phia, PA, pp. 1–8.
— (2003). “Head-driven statistical models for natural language parsing”. In: Computationallinguistics 29.4, pp. 589–637.
Collobert, Ronan (2011). “Deep learning for efficient discriminative parsing”. In: Proceedingsof the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Laud-ersdale, FL, pp. 224–232.
Constant, Mathieu et al. (2011). “Intégrer des connaissances linguistiques dans un CRF: appli-cation à l’apprentissage d’un segmenteur-étiqueteur du français”. In: Actes de TALN 2011,Montpellier, France. Vol. 1, p. 321.
Constant, Matthieu and Anthony Sigogne (2011). “MWU-aware part-of-speech tagging with aCRF model and lexical resources”. In: Proceedings of the workshop on multiword expres-sions: from parsing and generation to the real world, pp. 49–56.
Covington, Michael A. (2001). “A fundamental algorithm for dependency parsing”. In: Pro-ceedings of the 39th Annual ACM Southeast Conference, Athens, GA. Citeseer, pp. 95–102.
Curran, James R., Stephen Clark, and Johan Bos (2007). “Linguistically motivated large-scaleNLP with C&C and Boxer”. In: Proceedings of the 45th Annual Meeting of the ACL, Prague,Czech Republic, pp. 33–36.
Curry, Haskell Brooks (1930). “Grundlagen der kombinatorischen Logik”. In:American journalof mathematics 52.4, pp. 789–834.
Curry, Haskell Brooks et al. (1958). Combinatory logic. Vol. 1. North-Holland Amsterdam.DeMarneffe, Marie-Catherine, Bill MacCartney, Christopher D. Manning, et al. (2006). “Gen-
erating typed dependency parses from phrase structure parses”. In: Proceedings of LREC2006, Genoa, Italy. Vol. 6. 2006, pp. 449–454.
Debusmann, Ralph (2006). “Extensible Dependency Grammar: a modular grammar formalismbased on multigraph description”. PhD thesis. Universität Saarland, Saarbrücken.
Dekhtyar, Michael I., Alexandre Ja. Dikovsky, and Boris Karlov (2015). “Categorial depen-dency grammars”. In: Theor. Comput. Sci. 579, pp. 33–63.
Deliri, Sepideh and Massimiliano Albanese (2015). “Security and privacy issues in social net-works”. In: Data Management in Pervasive Systems. Springer, pp. 195–209.
Dempster, Arthur P., Nan M. Laird, and Donald B. Rubin (1977). “Maximum likelihood fromincomplete data via the EM algorithm”. In: Journal of the Royal Statistical Society: Series B(Methodological) 39.1, pp. 1–22.
Denis, Pascal and Benoît Sagot (2009). “Coupling an annotated corpus and a morphosyntacticlexicon for state-of-the-art POS tagging with less human effort”. In: Proceedings of the 23rdPacific Asia Conference on Language, Information and Computation, Volume 1.
— (2010). “Exploitation d’une ressource lexicale pour la construction d’un étiqueteur mor-phosyntaxique état-de-l’art du français”. In: Actes de TALN 2010, Montréal, Québec.
— (2012). “Coupling an annotated corpus and a lexicon for state-of-the-art POS tagging”. In:Language resources and evaluation 46.4, pp. 721–736.
Devlin, Jacob et al. (2018). “Bert: Pre-training of deep bidirectional transformers for languageunderstanding”. arXiv:1810.04805.
Dixon, Robert M.W. (2010a). Basic Linguistic Theory. Grammatical Topics. Oxford UniversityPress.
— (2010b). Basic linguistic theory volume 1: Methodology. Vol. 1. Oxford University Press.— (2012). Basic Linguistic Theory: Further Grammatical Topics. Oxford University Press.

132 Bibliography
Djordjevic, Bojan and James R. Curran (2006). “Efficient combinatory categorial grammarparsing”. In: Proceedings of the Australasian Language Technology Workshop 2006, Syd-ney, Australia, pp. 3–10.
Djordjevic, Bojan, James R. Curran, and Stephen Clark (2007). “Improving the efficiency ofa wide-coverage CCG parser”. In: Proceedings of the Tenth International Conference onParsing Technologies, Prague, Czech Republic, pp. 39–47.
Dong, Li andMirella Lapata (2016). “Language to logical formwith neural attention”. arXiv:1601.01280.Dozat, Timothy, Peng Qi, and Christopher D. Manning (2017). “Stanford’s graph-based neural
dependency parser at the conll 2017 shared task”. In: Proceedings of CoNLL 2017, Vancou-ver, Canada, pp. 20–30.
Draicchio, Francesco et al. (2013). “Fred: From natural language text to RDF and OWL in oneclick”. In: Extended Semantic Web Conference, Montpellier, France. Springer, pp. 263–267.
Duchier, Denys (1999). “Axiomatizing dependency parsing using set constraints”. In: SixthMeeting on Mathematics of Language, Orlando, FL. : https : / / www . ps . uni -saarland.de/Publications/documents/duchier-mol6.pdf.
Duchier, Denys and Ralph Debusmann (2001). “Topological dependency trees: A constraint-based account of linear precedence”. In: Proceedings of the ACL 2001, Toulouse, France,pp. 180–187.
Earley, Jay (1970). “An efficient context-free parsing algorithm”. In: Communications of theACM 13.2, pp. 94–102.
Edmonds, Jack (1967). “Optimum branchings”. In: Journal of Research of the national Bureauof Standards B. 71.4, pp. 233–240.
Edunov, Sergey et al. (2018). “Understanding back-translation at scale”. arXiv:1808.09381.Eisner, Jason (1997). “An empirical comparison of probability models for dependency gram-
mar”. arXiv:cmp-lg/9706004.Eisner, Jason and Giorgio Satta (1999). “Efficient parsing for bilexical context-free grammars
and head automaton grammars”. In: Proceedings of ACL 1999, College Park, Maryland,pp. 457–464.
Eisner, Jason and Noah A. Smith (2005). “Parsing with soft and hard constraints on depen-dency length”. In: Proceedings of the Ninth International Workshop on Parsing Technology,Vancouver, British Columbia, pp. 30–41.
Eisner, Jason M. (1996). “Three new probabilistic models for dependency parsing: An explo-ration”. In: Proceedings of COLING 1996, Copenhagen, Danemark, pp. 340–345.
Ekbal, Asif, S. Mondal, and Sivaji Bandyopadhyay (2007). “POS Tagging using HMM andRule-based Chunking”. In:The Proceedings of SPSAL, IJCAI, Hyderabad, India 8.1, pp. 25–28.
El-Taher, Ahmed I. et al. (2014). “An Arabic CCG approach for determining constituent typesfrom Arabic Treebank”. In: Journal of King Saud University-Computer and InformationSciences 26.4, pp. 441–449.
Fan, Rong-En et al. (2008). “LIBLINEAR: A library for large linear classification”. In: Journalof machine learning research 9.Aug, pp. 1871–1874.
Fan, Xing et al. (2017). “Transfer learning for neural semantic parsing”. arXiv:1706.04326.Fauconnier, Jean-Philippe (2015). “FrenchWord Embeddings”. http://fauconnier.github.
io.Federgruen, Awi and Michal Tzur (1991). “A simple forward algorithm to solve general dy-
namic lot sizing models with n periods in 0 (n log n) or 0 (n) time”. In:Management Science37.8, pp. 909–925.
Fernández-González, Daniel and Carlos Gómez-Rodríguez (2019). “Left-to-Right DependencyParsing with Pointer Networks”. arXiv:1903.08445.

Bibliography 133
Fillmore, Charles J. et al. (1976). “Frame semantics and the nature of language”. In: Annals ofthe New York Academy of Sciences: Conference on the origin and development of languageand speech. Vol. 280. 1, pp. 20–32.
Flanagan, David (2008). MQL Reference Guide. Freebase.Forbes, Katherine et al. (2003). “D-LTAG system: Discourse parsing with a lexicalized tree-
adjoining grammar”. In: Journal of Logic, Language and Information 12.3, pp. 261–279.Foreman, Curtis (2018). “Types of social media and how each can benefit your business”. :
https://blog.hootsuite.com/types-of-social-media/.Forney, G. David (1973). “The Viterbi algorithm”. In: Proceedings of the IEEE 61.3, pp. 268–
278.Gaifman, Haim (1965). “Dependency systems and phrase-structure systems”. In: Information
and control 8.3, pp. 304–337.Gange, Graeme (2008). “433-460 Project: Chart Parsing for Combinatory Categorial Gram-
mars”. https://www.researchgate.net/publication/265141403_433-460_Project_Chart_Parsing_for_Combinatory_Categorial_Grammars.
Gangemi, Aldo et al. (2017). “Semantic web machine reading with FRED”. In: Semantic Web8.6, pp. 873–893.
Garg, Rajiv, Michael D. Smith, and Rahul Telang (2011). “Measuring information diffusion inan online community”. In: Journal of Management Information Systems 28.2, pp. 11–38.
Garnelo, Marta and Murray Shanahan (2019). “Reconciling deep learning with symbolic ar-tificial intelligence: representing objects and relations”. In: Current Opinion in BehavioralSciences 29, pp. 17–23.
Garside, RG, Geoffrey Leech, and Eric Atwell (1984). “The Grammatical Tagging of Unre-stricted English Text”. In: International Conference on the Methodology and Techniques ofMachine Translation, Cranfield, UK.
Gazdar, Gerald et al. (1985). Generalized phrase structure grammar. Harvard University Press.Ge, Ruifang and Raymond J. Mooney (2005). “A statistical semantic parser that integrates
syntax and semantics”. In: Proceedings of the ninth conference on computational naturallanguage learning, pp. 9–16.
Gendner, Véronique et al. (2004). “Les annotations syntaxiques de référence PEAS”. :http://atoll.inria.fr/passage/PEAS_reference_annotations_v2.html.
Gers, Felix A., Jürgen Schmidhuber, and Fred Cummins (1999). “Learning to forget: Continualprediction with LSTM”. In: Proceedings of ICANN 99, Edinburgh, UK. IET.
Giménez, Jesús and Lluís Màrquez (2004). “SVMTool: A general POS tagger generator basedon Support Vector Machines”. In: Proceedings of LREC 2004, Lisbon, Portugal.
Goldberg, Yoav and Joakim Nivre (2012). “A dynamic oracle for arc-eager dependency pars-ing”. In: Proceedings of COLING 2012, Mumbai, India, pp. 959–976.
— (2013). “Training deterministic parsers with non-deterministic oracles”. In: Transactions ofthe association for Computational Linguistics 1, pp. 403–414.
Goller, Christoph and Andreas Kuchler (1996). “Learning task-dependent distributed represen-tations by backpropagation through structure”. In: Proceedings of International Conferenceon Neural Networks (ICNN’96). Vol. 1. IEEE, pp. 347–352.
Gómez-Rodríguez, Carlos and Joakim Nivre (2013). “Divisible transition systems and multi-planar dependency parsing”. In: Computational Linguistics 39.4, pp. 799–845.
Graves, Alex and Jürgen Schmidhuber (2005). “Framewise phoneme classification with bidirec-tional LSTM and other neural network architectures”. In:Neural Networks 18.5-6, pp. 602–610.
Green, Spence et al. (2011). “Multiword expression identification with tree substitution gram-mars: A parsing tour de force with French”. In: Proceedings of EMNLP 2011, Edinburgh,UK, pp. 725–735.

134 Bibliography
Grover, Claire and Richard Tobin (2006). “Rule-Based Chunking and Reusability.” In: Pro-ceedings of LREC 2006, Genoa, Italy, pp. 873–878.
Guillaume, Bruno and Guy Perrier (2015). “Dependency Parsing with Graph Rewriting”. In:Proceedings of the 14th International Conference on Parsing Technologies, pp. 30–39.
Haoliang, Qi et al. (2007). “Packed Forest Chart Parser”. In: Journal of Computer Science 3.1,pp. 9–13.
Haralambous, Yannis (2019). “Ne vous moquez pas de l’oiseau moqueur : un aperçu de lalogique combinatoire, avec des applications en linguistique mathématique”. In: Quadrature113, pp. 22–34.
Harper, Mary P. and Randall A. Helzerman (1995). “Extensions to constraint dependency pars-ing for spoken language processing”. In: Computer Speech and Language 9.3, pp. 187–234.
Harper, Mary P. et al. (1995). “Implementation issues in the development of the PARSECparser”. In: Software: Practice and Experience 25.8, pp. 831–862.
Harris, Zellig Sabbettai (1982). A grammar of English on mathematical principles. John Wiley& Sons Incorporated.
Hays, David (1960). “Grouping and dependency theories”. In: Proceedings of the National Sym-posium on Machine Translation. UCLA, pp. 257–266.
— (1964a). “Dependency theory: A formalism and some observations”. In:Language 40, pp. 159–525.
— (1967). Introduction to computational linguistics. London: Macdonald & Co.Hays, David G. (1964b). “Dependency theory: A formalism and some observations”. In: Lan-
guage 40.4, pp. 511–525.Hellwig, Peter (1986). “Dependency unification grammar”. In: Proceedings of COLING 1986,
Bonn, Germany.Hendrix, Gary G. et al. (1978). “Developing a natural language interface to complex data”. In:
ACM Transactions on Database Systems (TODS) 3.2, pp. 105–147.Hochreiter, Sepp and Jürgen Schmidhuber (1997). “Long short-termmemory”. In: Neural com-
putation 9.8, pp. 1735–1780.Hockenmaier, Julia (2003). “Data and models for statistical parsing with Combinatory Catego-
rial Grammar”. PhD thesis. University of Edinburgh.— (2006). “Creating a CCGbank and a wide-coverage CCG lexicon for German”. In: Proceed-
ings of COLING/ACL 2006, Sydney, Australia, pp. 505–512.Hockenmaier, Julia and Mark Steedman (2007). “CCGbank: a corpus of CCG derivations and
dependency structures extracted from the Penn Treebank”. In: Computational Linguistics33.3, pp. 355–396.
Honnibal, Matthew, Yoav Goldberg, and Mark Johnson (2013). “A non-monotonic arc-eagertransition system for dependency parsing”. In: Proceedings of the Seventeenth Conference onComputational Natural Language Learning, Sofia, Bulgaria, pp. 163–172.
Honnibal, Matthew and Mark Johnson (2015). “An improved non-monotonic transition systemfor dependency parsing”. In:Proceedings of EMNLP 2015, Lisbon, Portugal, pp. 1373–1378.
Honnibal, Matthew, Jonathan K. Kummerfeld, and James R. Curran (2010). “Morphologicalanalysis can improve a CCG parser for English”. In: Proceedings of COLING 2010, Beijing,China, pp. 445–453.
Honnibal, Matthew and Ines Montani (2017). “Industrial-strength Natural Language Process-ing”. https://spacy.io.
Hovy, Eduard et al. (2006). “OntoNotes: the 90% solution”. In: Proceedings of NAACL 2006,Minneapolis, MN, pp. 57–60.
Huang, Liang,Wenbin Jiang, andQun Liu (2009). “Bilingually-constrained (monolingual) shift-reduce parsing”. In: Proceedings of EMNLP 2009, Singapore, pp. 1222–1231.
Huang, Luyao et al. (2019). “GlossBERT: BERT for Word Sense Disambiguation with GlossKnowledge”. arXiv:1908.07245.

Bibliography 135
Huang, Zhiheng, Wei Xu, and Kai Yu (2015). “Bidirectional LSTM-CRF models for sequencetagging”. arXiv:1508.01991.
Hudson, Richard and Richard A. Hudson (2007). Language networks: The new word grammar.Oxford University Press.
Hudson, Richard A. (1991). English word grammar. B. Blackwell.Jackendoff, Ray (1992). Semantic structures. MIT press.Järvinen, Timo and Pasi Tapanainen (1997). A dependency parser for English. Tech. rep. Uni-
versity of Helsinki, Department of General Linguistics.Joachims, Thorsten (1998). “Text categorization with support vector machines: Learning with
many relevant features”. In: European conference on machine learning, Chemnitz, Germany.Springer, pp. 137–142.
Johansson, Richard and Pierre Nugues (2006). “Investigating multilingual dependency parsing”.In: Proceedings of CoNLL 2006, New York, NY, pp. 206–210.
— (2007). “Incremental dependency parsing using online learning”. In:Proceedings of EMNLP/-CoNLL 2007, Prague, Czech Republic, pp. 1134–1138.
Johansson, Stig, Geoffrey N. Leech, and Helen Goodluck (1978).Manual of information to ac-company the Lancaster-Oslo/Bergen Corpus of British English, for use with digital computer.Tech. rep. Department of English, University of Oslo.
Johnson, Tim (1984). “Natural language computing: the commercial applications”. In: TheKnowledge Engineering Review 1.3, pp. 11–23.
Joshi, Aravind K., Leon S. Levy, and Masako Takahashi (1975). “Tree adjunct grammars”. In:Journal of computer and system sciences 10.1, pp. 136–163.
Kadari, Rekia et al. (2018a). “CCG supertagging via Bidirectional LSTM-CRF neural archi-tecture”. In: Neurocomputing 283, pp. 31–37.
— (2018b). “CCG supertagging with bidirectional long short-termmemory networks”. In:Nat-ural Language Engineering 24.1, pp. 77–90.
Kahane, Sylvain (2012). “Why to choose dependency rather than constituency for syntax: a for-mal point of view”. In:Meanings, Texts, and other exciting things: A Festschrift to Commem-orate the 80th Anniversary of Professor Igor A. Mel′cuk. Ed. by J. Apresjan et al. Moscow:Languages of Slavic Culture, pp. 257–272.
Kamp, Hans (1981). “A theory of truth and discourse representation”. In: Formal methods inthe study of language. Ed. by J. Groenendijk, T.M.V. Janssen, andM. Stockhof. 135. Math-ematical Centre.
Kamp, Hans and Uwe Reyle (1993). From Discourse to Logic. Introduction to Modeltheoretic Se-mantics of Natural Language, Formal Logic and Discourse Representation Theory. Springer.
Kaplan, Ronald M. (1973). “A general syntactic processor”. In: Natural language processing 8,pp. 194–241.
Kaplan, Ronald M. and Joan Bresnan (1982). “Lexical-Functional Grammar: A Formal Systemfor Grammatical Representation”. In:TheMental Representations of Grammatical Relations.Ed. by Joan Bresnan. The MIT Press, pp. 173–281.
Kaplan, Ronald M. et al. (2004). Speed and accuracy in shallow and deep stochastic parsing.Tech. rep. Palo Alto Research Center CA.
Karlberg, Michael (2011). “Discourse theory and peace”. In: The encyclopedia of peace psy-chology.
Kasami, Tadao (1966). An efficient recognition and syntax-analysis algorithm for context-freelanguages. Tech. rep. Coordinated Science Laboratory Report no. R-257.
Kate, Rohit J. and Raymond J. Mooney (2006). “Using string-kernels for learning semanticparsers”. In: Proceedings of COLING/ACL 2006, Sydney, Australia, pp. 913–920.
Kay, M. (1980). Algorithm Schemata and Data Structures in Syntactic Processing. Tech. rep.Xerox Palo Alto Research Center CSL-80-12.

136 Bibliography
Kim, J-D et al. (2003). “GENIA corpus—a semantically annotated corpus for bio-textmining”.In: Bioinformatics 19.suppl_1, pp. i180–i182.
Kim,Yoon (2014). “Convolutional neural networks for sentence classification”. arXiv:1408.5882.Kiperwasser, Eliyahu and Yoav Goldberg (2016). “Simple and accurate dependency parsing
using bidirectional LSTM feature representations”. In: Transactions of the Association forComputational Linguistics 4, pp. 313–327.
Kitaev, Nikita and Dan Klein (2018). “Constituency parsing with a self-attentive encoder”.arXiv:1805.01052.
Klein, Dan and Christopher D. Manning. “Fast Exact Inference with a Factored Model forNatural Language Parsing”. In: Advances in Neural Information Processing Systems.
— (2003a). “A parsing: fast exact Viterbi parse selection”. In: Proceedings of NAACL 2003,Edmonton, Canada, pp. 40–47.
— (2003b). “Accurate unlexicalized parsing”. In: Proceedings of ACL 2003, Sapporo, Japan,pp. 423–430.
Kübler, Sandra, Ryan McDonald, and Joakim Nivre (2009). “Dependency parsing”. In: Synthe-sis Lectures on Human Language Technologies 1.1, pp. 1–127.
Kudo, Taku and Yuji Matsumoto (2001). “Chunking with support vector machines”. In: Pro-ceedings of NAACL 2001, Pittsburgh, PA, pp. 1–8.
Kwiatkowski, Tom et al. (2010). “Inducing probabilistic CCG grammars from logical formwith higher-order unification”. In: Proceedings of EMNLP 2010, Cambridge, MA, pp. 1223–1233.
Lafferty, John, Andrew McCallum, and Fernando CN Pereira (2001). “Conditional randomfields: Probabilistic models for segmenting and labeling sequence data”. In: Proceedings ofICML 2001, Williamstown, MA, pp. 282–289.
Lake, BrendenM. et al. (2017). “Building machines that learn and think like people”. In: Behav-ioral and brain sciences 40. : Buildingmachinesthatlearnandthinklikepeople.
Lambek, Joachim (1988). “Categorial and categorical grammars”. In: Categorial grammars andnatural language structures. Springer, pp. 297–317.
Lawrence, Steve et al. (1997). “Face recognition: A convolutional neural-network approach”.In: IEEE transactions on neural networks 8.1, pp. 98–113.
Le, Ngoc Luyen and Yannis Haralambous (2019). “CCG Supertagging Using Morphologicaland Dependency Syntax Information”. In: Proceedings of the 20th International Conferenceon Computational Linguistics and Intelligent Text Processing (CICLING).
Le, Ngoc luyen, Yannis Haralambous, and Philippe Lenca (2019). “Towards a DRS ParsingFramework for French”. In: 2019 Sixth International Conference on Social Networks Anal-ysis, Management and Security (SNAMS), pp. 357–363.
Lee, Kenton, Mike Lewis, and Luke Zettlemoyer (2016). “Global neural CCG parsing withoptimality guarantees”. arXiv:1607.01432.
Lefeuvre, Anaïs, Richard Moot, and Christian Retoré (2012). “Traitement automatique d’uncorpus de récits de voyages pyrénéens: analyse syntaxique, sémantique et pragmatique dansle cadre de la théorie des types”. In: SHS Web of Conferences. Vol. 1. EDP Sciences,pp. 2485–2495.
Leiner, Barry M. et al. (2009). “A brief history of the Internet”. In: ACM SIGCOMM ComputerCommunication Review 39.5, pp. 22–31.
Lewis, Martha (2019). “Compositionality for Recursive Neural Networks”. arXiv:1901.10723.Lewis, Mike, Luheng He, and Luke Zettlemoyer (2015). “Joint A* CCG parsing and semantic
role labelling”. In: Proceedings of EMNLP 2015, Lisbon, Portugal, pp. 1444–1454.Lewis,Mike, Kenton Lee, and Luke Zettlemoyer (2016). “LSTMCCGparsing”. In:Proceedings
of NAACL 2016, San Diego, California, pp. 221–231.Lewis, Mike and Mark Steedman (2014a). “A* CCG parsing with a supertag-factored model”.
In: Proceedings of EMNLP 2014, Doha, Qatar, pp. 990–1000.

Bibliography 137
— (2014b). “Improved CCG parsing with semi-supervised supertagging”. In: Transactions ofthe ACL 2, pp. 327–338.
Lhoneux, Miryam de, Miguel Ballesteros, and Joakim Nivre (2019). “Recursive Subtree Com-position in LSTM-Based Dependency Parsing”. arXiv:1902.09781.
Lierler, Yuliya and Peter Schüller (2011). “Parsing combinatory categorial grammar with an-swer set programming: Preliminary report”. arXiv:1108.5567.
— (2012). “Parsing combinatory categorial grammar via planning in answer set programming”.In: Correct Reasoning. Springer, pp. 436–453.
Lim, Soojong, Changki Lee, and Dongyul Ra (2013). “Dependency-based semantic role label-ing using sequence labeling with a structural SVM”. In: Pattern Recognition Letters 34.6,pp. 696–702.
Ling, Wang et al. (2015). “Finding function in form: Compositional character models for openvocabulary word representation”. arXiv:1508.02096.
Litman, Diane et al. (2009). “Using natural language processing to analyze tutorial dialoguecorpora across domains and modalities”. In: Artificial Intelligence in Education. IOS Press,pp. 149–156.
Liu, Jiangming, Shay B. Cohen, and Mirella Lapata (2018). “Discourse representation structureparsing”. In: Proceedings of ACL 2018, Melbourne, Australia, pp. 429–439.
Liu, Jiangming and Yue Zhang (2017a). “In-order transition-based constituent parsing”. In:Transactions of the Association for Computational Linguistics 5, pp. 413–424.
— (2017b). “Shift-reduce constituent parsing with neural lookahead features”. In: Transactionsof the Association for Computational Linguistics 5, pp. 45–58.
Liu, Yinhan et al. (2019). “Roberta: A robustly optimized bert pretraining approach”. arXiv:1907.11692.Lodhi, Huma et al. (2002). “Text classification using string kernels”. In: Journal of Machine
Learning Research 2.Feb, pp. 419–444.Loula, Joao, Marco Baroni, and Brenden M. Lake (2018). “Rearranging the familiar: Testing
compositional generalization in recurrent networks”. arXiv:1807.07545.Ma, Xuezhe and Eduard Hovy (2016). “End-to-end sequence labeling via bi-directional LSTM-
CNNs-CRF”. arXiv:1603.01354.Magerman, David M. (1994). “Natural language parsing as statistical pattern recognition”.
arXiv:cmp-lg/9405009.Marcus, Mitchell et al. (1994). “The Penn Treebank: annotating predicate argument structure”.
In: Proceedings of the Workshop on Human Language Technology, Plainsboro, NJ, pp. 114–119.
Marcus, Mitchell P., Mary Ann Marcinkiewicz, and Beatrice Santorini (1993). “Building alarge annotated corpus of English: The Penn Treebank”. In: Computational linguistics 19.2,pp. 313–330.
Màrquez, Lluís and Horacio Rodríguez (1998). “Part-of-speech tagging using decision trees”.In: Proceedings of the European Conference on Machine Learning, Chemnitz, Germany.Springer, pp. 25–36.
Marsden, P. (2011). “Simple Definition of Social Commerce (with Word Cloud & DefinitiveDefinition List)”. In: Social Commerce Today. : https://socialcommercetoday.com/social- commerce- definition- word- cloud-definitive- definition-list/.
Maruyama, Hiroshi (1990). “Structural disambiguation with constraint propagation”. In: Pro-ceedings of ACL 1990, Pittsburgh, PA, pp. 31–38.
McDonald, Ryan (2006). “Discriminative training and spanning tree algorithms for dependencyparsing”. PhD thesis. University of Pennsylvania.
McDonald, Ryan, Kevin Lerman, and Fernando Pereira (2006). “Multilingual dependency anal-ysis with a two-stage discriminative parser”. In: Proceedings of the Tenth Conference onComputational Natural Language Learning, pp. 216–220.

138 Bibliography
McDonald, Ryan and Joakim Nivre (2011). “Analyzing and integrating dependency parsers”.In: Computational Linguistics 37.1, pp. 197–230.
McDonald, Ryan et al. (2005). “Non-projective dependency parsing using spanning tree algo-rithms”. In: Proceedings of the conference on Human Language Technology and EmpiricalMethods in Natural Language Processing, pp. 523–530.
McDonald, Ryan et al. (2013). “Universal dependency annotation for multilingual parsing”. In:Proceedings ACL 2013, Sofia, Bulgaria, pp. 92–97.
Mel′cuk, Igor Aleksandrovic et al. (1988).Dependency syntax: theory and practice. SUNYpress.Melis, Gábor, TomášKočiskỳ, and Phil Blunsom (2019). “Mogrifier LSTM”. arXiv:1909.01792.Merlo, Paola and Gabriele Musillo (2008). “Semantic parsing for high-precision semantic role
labelling”. In: Proceedings of CoNLL 2008, Manchester, UK, pp. 1–8.Mi, Haitao and Liang Huang (2015). “Shift-Reduce Constituency Parsing with Dynamic Pro-
gramming and POS Tag Lattice”. In: Proceedings of NAACL 2015, Denver, CO, pp. 1030–1035.
Mikolov, Tomas, Quoc V. Le, and Ilya Sutskever (2013). “Exploiting similarities among lan-guages for machine translation”. arXiv:1309.4168.
Mikolov, Tomas et al. (2013). “Distributed representations of words and phrases and their com-positionality”. In: Proceedings of NeurIPS 2013, Lake Tahoe, NV, pp. 3111–3119.
Mohammed, Mona Ali and Nazlia Omar (2011). “Rule based shallow parser for Arabic lan-guage”. In: Journal of Computer Science 7.10, pp. 1505–1514.
Montague, Richard (1970a). “English as a formal language”. In: : https://philpapers.org/rec/MONEAA-2.
— (1970b). “Pragmatics and intensional logic”. In: Synthese 22.1-2, pp. 68–94.— (1970c). “Universal grammar”. In: Theoria 36.3, pp. 373–398.Montanari, Ugo (1974). “Networks of constraints: Fundamental properties and applications to
picture processing”. In: Information sciences 7, pp. 95–132.Moortgat, Michael (1997). “Categorial type logics”. In: Handbook of logic and language. Else-
vier, pp. 93–177.Moot, Richard (1998). “Grail: An automated proof assistant for categorial grammar logics”. In:— (1999). “Grail: an interactive parser for categorial grammars”. In: Proceedings of VEXTAL.
Vol. 1999, pp. 255–261.— (2010). “Wide-coverage French syntax and semantics using Grail”. In:Actes de TALN 2010,
Montréal, Québec.— (2015). “A type-logical Treebank for French”. In: Journal of Language Modelling 3.1,
pp. 229–264.Morrill, Glyn V. (1994). Categorial Logic of Signs.— (2012).Type logical grammar: Categorial logic of signs. Springer Science&BusinessMedia.Moser, Christine, Peter Groenewegen, and Marleen Huysman (2013). “Extending social net-
work analysis with discourse analysis: Combining relational with interpretive data”. In: Theinfluence of technology on social network analysis and mining. Springer, pp. 547–561.
Moshovos, Andreas et al. (2018). “Exploiting Typical Values to Accelerate Deep Learning”. In:Computer 51.5, pp. 18–30.
Mrini, Khalil et al. (2019). “Rethinking Self-Attention: An Interpretable Self-Attentive Encoder-Decoder Parser”. In: arXiv:1911.03875.
Nadejde, Maria et al. (2017). “Predicting target language CCG supertags improves neural ma-chine translation”. arXiv:1702.01147.
Nakorn, TaninNa (2009).Combinatory Categorial Grammar Parser in Natural Language Toolkit.Nasr, Alexis, Frédéric Béchet, and Alexandra Volanschi (2004). “Tagging with hidden Markov
models using ambiguous tags”. In: Proceedings of COLING 2004, Geneva, Switzerland,p. 569.

Bibliography 139
Ney, Hermann (1991). “Dynamic programming parsing for context-free grammars in continu-ous speech recognition”. In: IEEE Transactions on Signal Processing 39.2, pp. 336–340.
Nguyen, Dat Quoc, Mark Dras, and Mark Johnson (2017). “A novel neural network model forjoint POS tagging and graph-based dependency parsing”. arXiv:1705.05952.
Nguyen, Dat Quoc et al. (2014). “RDRPOSTagger: A Ripple Down Rules-based Part-Of-Speech Tagger”. In: Proceedings of EACL 2014, Gothenburg, Sweden, pp. 17–20.
— (2016). “A robust transformation-based learning approach using ripple down rules for part-of-speech tagging”. In: AI Communications 29.3, pp. 409–422.
Nguyen, Le-Minh, Akira Shimazu, and Xuan-Hieu Phan (2006). “Semantic parsing with struc-tured SVM ensemble classification models”. In: Proceedings of COLING/ACL 2006, Sydney,Australia, pp. 619–626.
Nivre, Joakim (2003). “An efficient algorithm for projective dependency parsing”. In: Pro-ceedings of the Eighth International Conference on Parsing Technologies, Nancy, France,pp. 149–160.
— (2004). “Incrementality in deterministic dependency parsing”. In: Proceedings of the Work-shop on Incremental Parsing: Bringing Engineering and Cognition Together, Barcelona, Spain,pp. 50–57.
— (2008). “Algorithms for deterministic incremental dependency parsing”. In: ComputationalLinguistics 34.4, pp. 513–553.
Nivre, Joakim, Johan Hall, and Jens Nilsson (2004). “Memory-based dependency parsing”. In:Proceedings of HLT-NAACL 2004, Boston, MA, pp. 49–56.
— (2006). “Maltparser: A data-driven parser-generator for dependency parsing.” In: Proceed-ings of LREC 2006, Genoa, Italy. Vol. 6, pp. 2216–2219.
Nivre, Joakim and Mario Scholz (2004). “Deterministic dependency parsing of English text”.In: Proceedings of COLING 2004, Geneva, Switzerland, p. 64.
Nivre, Joakim et al. (2006). “Labeled pseudo-projective dependency parsing with support vectormachines”. In: Proceedings of CoNLL 2006, New York, NY, pp. 221–225.
Nivre, Joakim et al. (2016). “Universal dependencies v1: A multilingual treebank collection”.In: Proceedings of LREC 2016, Portorož, Slovenia, pp. 1659–1666.
Noord, Rik van (2019). “Neural Boxer at the IWCS shared task on DRS parsing”. In: Proceed-ings of the IWCS Shared Task on Semantic Parsing, Gothenburg, Sweden.
Noord, Rik van et al. (2018). “Exploring neural methods for parsing discourse representationstructures”. In: Transactions of the Association for Computational Linguistics 6, pp. 619–633.
Nothman, Joel et al. (2013). “Learning multilingual named entity recognition fromWikipedia”.In: Artificial Intelligence 194, pp. 151–175.
Novak, Petra Kralj et al. (2015). “Sentiment of emojis”. In: PloS one 10.12, e0144296.Obar, Jonathan A. and Steven S. Wildman (2015). “Social media definition and the governance
challenge-an introduction to the special issue”. In: Obar, JA and Wildman, S.(2015). Socialmedia definition and the governance challenge: An introduction to the special issue. Telecom-munications policy 39.9, pp. 745–750.
Okumura, Akitoshi and Kazunori Muraki (1994). “Symmetric pattern matching analysis forEnglish coordinate structures”. In: Proceedings of the fourth conference on Applied naturallanguage processing, pp. 41–46.
Osborne, Timothy (2019). A Dependency Grammar of English. John Benjamins.Paliwal, Gunjan (2015). “Social media marketing: opportunities and challenges”. PhD thesis.
Massachusetts Institute of Technology. : http://hdl.handle.net/1721.1/98997.Palmer, Martha, Daniel Gildea, and Paul Kingsbury (2005). “The proposition bank: An anno-
tated corpus of semantic roles”. In: Computational linguistics 31.1, pp. 71–106.

140 Bibliography
Pammi, Sathish Chandra and Kishore Prahallad (2007). “POS tagging and chunking using de-cision forests”. In: IJCAI Workshop on Shallow Parsing for South Asian Languages, Hyder-abad, India, pp. 33–36.
Park, Do-Hyung, Jumin Lee, and Ingoo Han (2007). “The effect of on-line consumer reviewson consumer purchasing intention: The moderating role of involvement”. In: Internationaljournal of electronic commerce 11.4, pp. 125–148.
Partee, Barbara (1975). “Montague grammar and transformational grammar”. In: Linguisticinquiry 6.2, pp. 203–300.
Pascanu, Razvan, Tomas Mikolov, and Yoshua Bengio (2013). “On the difficulty of trainingrecurrent neural networks”. In: International Conference on Machine Learning, Atlanta, GA,pp. 1310–1318.
Pei,Wenzhe, Tao Ge, and Baobao Chang (2015). “An effective neural networkmodel for graph-based dependency parsing”. In: Proceedings of ACL 2015, Denver, CO, pp. 313–322.
Pennington, Jeffrey, Richard Socher, and Christopher D.Manning (2014). “GloVe: Global Vec-tors for Word Representation”. In: Proceedings of EMNLP 2014, Doha, Qatar, pp. 1532–1543.
Petrov, Slav, Dipanjan Das, and Ryan McDonald (2011). “A universal part-of-speech tagset”.arXiv:1104.2086.
Petrov, Slav and Dan Klein (2007). “Improved inference for unlexicalized parsing”. In: Pro-ceedings of NAACL 2007, Rochester, NY, pp. 404–411.
Petrov, Slav et al. (2006). “Learning accurate, compact, and interpretable tree annotation”. In:Proceedings of COLING/ACL 2006, Sydney, Australia, pp. 433–440.
Pollard, Carl and Ivan A. Sag (1994). Head-driven phrase structure grammar. University ofChicago Press.
Poon, Hoifung (2013). “Grounded unsupervised semantic parsing”. In: Proceedings of ACL2013, Sofia, Bulgaria, pp. 933–943.
Poon, Hoifung and Pedro Domingos (2009). “Unsupervised semantic parsing”. In: Proceedingsof ACL 2009, Singapore, pp. 1–10.
Pradet, Quentin, LaurenceDanlos, andGaël DeChalendar (2014). “AdaptingVerbNet to Frenchusing existing resources”. In: Proceedings of LREC 2014, Reykjavik, Iceland.
Prasad, Rashmi et al. (2005). “The Penn Discourse TreeBank as a resource for natural languagegeneration”. In: Proceedings of the Corpus Linguistics Workshop on Using Corpora for NLG.
Prasad, Rashmi et al. (2008). “The Penn Discourse TreeBank 2.0.” In: Proceedings of LREC2008, Marrakech, Morocco.
Qi, Peng et al. (2019). “Universal dependency parsing from scratch”. arXiv:1901.10457.Qi, Peng et al. (2020). “Stanza: A Python Natural Language Processing Toolkit for Many Hu-
man Languages”. arXiv:2003.07082.Quan, Huangmao, JieWu, and J. Shi (2011). “Online social networks & social network services:
A technical survey”. In: Pervasive Communication Handbook. Ed. by Syed Ijlal Ali Shah,Mohammad Ilyas, and Hussein T. Mouftah. CRC Press. : 10.1201/b11271-22.
Ramshaw, LanceA. andMitchell P.Marcus (1999). “Text chunking using transformation-basedlearning”. In: Natural language processing using very large corpora. Springer, pp. 157–176.
Rana, Kulwant Singh, Anil Kumar, et al. (2016). “Social media marketing: Opportunities andchallenges”. In: Journal of Commerce and Trade 11.1, pp. 45–49.
Ratnaparkhi, Adwait (1996). “A maximum entropy model for part-of-speech tagging”. In: Pro-ceedings of EMNLP 1996, Philadelphia, PA, pp. 133–142.
Raymond, Ruifang Ge and J. Mooney (2006). “Discriminative reranking for semantic parsing”.In: Proceedings of COLING/ACL 2006, Sydney, Australia, pp. 263–270.
Reddy, Siva et al. (2016). “Transforming dependency structures to logical forms for semanticparsing”. In: Transactions of the Association for Computational Linguistics 4, pp. 127–140.

Bibliography 141
Robert, Gilbert (1998). TATOO: ISSO TAgger TOOl. https://www.issco.unige.ch/en/staff/robert/tatoo/tatoo.html. [Online; accessed 1-January-2020].
Roberts, SamGB and Robin IMDunbar (2011). “Communication in social networks: Effects ofkinship, network size, and emotional closeness”. In: Personal Relationships 18.3, pp. 439–452.
Rosenblatt, Frank (1958). “The perceptron: a probabilistic model for information storage andorganization in the brain.” In: Psychological review 65.6, p. 386.
Sagot, Benoît (2016). “External Lexical Information for Multilingual Part-of-Speech Tagging”.arXiv:1606.03676.
Sagot, Benoît et al. (2006). “The Lefff 2 syntactic lexicon for French: architecture, acquisition,use”. In: Proceedings of LREC 2006, Genoa, Italy, pp. 1–4.
Sang, Erik F. and Sabine Buchholz (2000). “Introduction to the CoNLL-2000 shared task:Chunking”. arXiv:cs/0009008.
Schluter, Natalie and Josef Van Genabith (2008). “Treebank-based acquisition of LFG parsingresources for French”. In: pp. 2909–2916.
Schmid, Helmut (1994). “Probabilistic Part-of-Speech Tagging Using Decision Trees”. In: Pro-ceedings of International Conference on New Methods in Language Processing, Manchester,UK.
— (1999). “Improvements in part-of-speech tagging with an application to German”. In: Nat-ural language processing using very large corpora. Springer, pp. 13–25.
Schönfinkel,Moses (1924). “Über die Bausteine dermathematischen Logik”. In:Mathematischeannalen 92.3-4, pp. 305–316.
Schuler, Karin Kipper (2005). “VerbNet: A broad-coverage, comprehensive verb lexicon”. PhDthesis. University of Pennsylvania.
Schuster, Mike and Kuldip K. Paliwal (1997). “Bidirectional recurrent neural networks”. In:IEEE Transactions on Signal Processing 45.11, pp. 2673–2681.
Seddah, Djamé et al. (2010). “Lemmatization and lexicalized statistical parsing of morpholog-ically rich languages: the case of French”. In: Proceedings of NAACL 2010, Minneapolis,MN, First Workshop on Statistical Parsing of Morphologically-Rich Languages, pp. 85–93.
Seldin, Jonathan P. (2006). “The logic of Curry and Church”. In: Handbook of the History ofLogic 5, pp. 819–873.
Sgall, Petr et al. (1986). The meaning of the sentence in its semantic and pragmatic aspects.Springer Science.
Sha, Fei and Fernando Pereira (2003). “Shallow parsing with conditional random fields”. In:Proceedings of NAACL 2003, Edmonton, Canada, pp. 134–141.
Singh-Miller, Natasha and Michael Collins (2007). “Trigger-based language modeling using aloss-sensitive perceptron algorithm”. In: 2007 IEEE International Conference on Acoustics,Speech and Signal Processing, Honolulu, HI. Vol. 4. IEEE, pp. IV–25.
Singla, Ankush, Elisa Bertino, and Dinesh Verma (2019). “Overcoming the Lack of LabeledData: Training Intrusion Detection Models Using Transfer Learning”. In: 2019 IEEE Inter-national Conference on Smart Computing, Bologna, Italy. IEEE, pp. 69–74.
Sleator, Daniel DK andDavy Temperley (1995). “Parsing Englishwith a link grammar”. arXiv:cmp-lg/9508004.
Smullyan, Raymond (1985). To Mock a Mockingbird, and Other Logic Puzzles including anAmazing Adventure in Combinatory Logic. Alfred A. Knopf.
Socher, Richard et al. (2011). “Parsing natural scenes and natural language with recursive neu-ral networks”. In: Proceedings of the 28th international conference on machine learning,Bellevue, WA, pp. 129–136.
Steedman, Mark (1996). Surface structure and interpretation. MIT Press.— (1999). “Quantifier scope alternation in CCG”. In: Proceedings of ACL 1999, College Park,
MD, pp. 301–308.

142 Bibliography
Steedman, Mark (2000a). “Information structure and the syntax-phonology interface”. In: Lin-guistic inquiry 31.4, pp. 649–689.
— (2000b). The syntactic process. Vol. 24. MIT press Cambridge, MA.Steedman, Mark and Jason Baldridge (2011). “Combinatory categorial grammar”. In: Non-
Transformational Syntax: Formal and explicit models of grammar, pp. 181–224.Sun, Guang-Lu et al. (2005). “A maximum entropy markov model for chunking”. In: 2005
International Conference on Machine Learning and Cybernetics, Guangzhou, China. Vol. 6.IEEE, pp. 3761–3765.
Šuster, Simon and Walter Daelemans (2018). “Clicr: A dataset of clinical case reports for ma-chine reading comprehension”. arXiv:1803.09720.
Tai, Kai Sheng, Richard Socher, and Christopher D. Manning (2015). “Improved semantic rep-resentations from tree-structured long short-term memory networks”. arXiv:1503.00075.
Tallerman, Maggie (2013). Understanding syntax. Routledge.Taylor, Ann,MitchellMarcus, and Beatrice Santorini (2003). “The Penn treebank: an overview”.
In: Treebanks. Springer, pp. 5–22.Tellier, Isabelle et al. (2012). “Apprentissage automatique d’un chunker pour le français”. In:
Actes de JEP-TALN-RECITAL 2012, Grenoble, France, pp. 431–438.Templeton,Marjorie and JohnBurger (1983). “Problems in natural-language interface toDBMS
with examples from EUFID”. In: Proceedings of the first conference on Applied natural lan-guage processing, Santa Monica, CA, pp. 3–16.
Tesnière, Lucien (1934). “Comment construire une syntaxe”. In:Bulletin de la Faculté des Lettresde Strasbourg 7, pp. 219–229.
— (1959). Eléments de syntaxe structurale. Klincksieck.Thompson, Frederick B. et al. (1969). “REL: A rapidly extensible language system”. In: Pro-
ceedings of COLING 1969, Stockholm, Sweden. ACM, pp. 399–417.Tieleman, Tijmen and Geoffrey Hinton (2012). “Lecture 6.5-rmsprop: Divide the gradient by
a running average of its recent magnitude”. In: COURSERA: Neural networks for machinelearning 4.2, pp. 26–31.
Tong, Amo, Ding-Zhu Du, and Weili Wu (2018). “On misinformation containment in onlinesocial networks”. In: Advances in Neural Information Processing Systems, pp. 341–351.
Torrey, Lisa and Jude Shavlik (2010). “Transfer learning”. In:Handbook of research onmachinelearning applications and trends: algorithms, methods, and techniques. IGI Global, pp. 242–264.
Toutanova, Kristina and Christopher D. Manning (2000). “Enriching the knowledge sourcesused in a maximum entropy part-of-speech tagger”. In: Proceedings of EMNLP 2000, HongKong, pp. 63–70.
Toutanova, Kristina et al. (2003). “Feature-rich part-of-speech tagging with a cyclic dependencynetwork”. In: Proceedings of NAACL 2003, Edmonton, Canada, pp. 173–180.
Tse, Daniel and James R. Curran (2010). “Chinese CCGbank: extracting CCG derivations fromthe Penn Chinese treebank”. In: Proceedings of COLING 2010, Beijing, China, pp. 1083–1091.
Turian, Joseph, Lev Ratinov, and Yoshua Bengio (2010). “Word representations: a simple andgeneral method for semi-supervised learning”. In: Proceedings of ACL 2010, Uppsala, Swe-den, pp. 384–394.
Urieli, Assaf and Ludovic Tanguy (2013). “L’apport du faisceau dans l’analyse syntaxique endépendances par transitions: études de cas avec l’analyseur Talismane”. In: Actes de TALN2013, Les Sables d’Olonne, France, publication–en.
Van Eijck, Jan and Hans Kamp (1997). “Representing discourse in context”. In: Handbook oflogic and language. Elsevier, pp. 179–237.
Varges, Sebastian and Chris Mellish (2001). “Instance-based natural language generation”. In:Proceedings of NAACL 2001, Pittsburgh, PA, pp. 1–8.

Bibliography 143
Vaswani, Ashish et al. (2016). “Supertagging with LSTMs”. In: Proceedings of NAACL 2016,San Diego, California, pp. 232–237.
Vrandečić, Denny and Markus Krötzsch (2014). “Wikidata: a free collaborative knowledgebase”. In:
Waltz, David (1975). Understanding line drawings of scenes with shadows. McGraw-Hill.Wang, Fang and Milena Head (2007). “How can the web help build customer relationships?: an
empirical study on e-tailing”. In: Information & Management 44.2, pp. 115–129.Wang, Yushi, Jonathan Berant, and Percy Liang (2015). “Building a semantic parser overnight”.
In: Proceedings of ACL/IJCNLP 2015, Beijing, China, pp. 1332–1342.Wattenhofer, Mirjam, Roger Wattenhofer, and Zack Zhu (2012). “The YouTube social net-
work”. In: Sixth International AAAI Conference on Weblogs and Social Media, Dublin, Ire-land.
Weiss, David et al. (2015). “Structured training for neural network transition-based parsing”.arXiv:1506.06158.
White, Aaron Steven et al. (2016). “Universal decompositional semantics on universal depen-dencies”. In: Proceedings of EMNLP 2016, Austin, TX, pp. 1713–1723.
White, Aaron Steven et al. (2019). “The Universal Decompositional Semantics Dataset andDecomp Toolkit”. arXiv:1909.13851.
White, Mary (2016). “What types of social networks exist”. In: Love to know. : https://socialnetworking.lovetoknow.com/What_Types_of_Social_Networks_Exist.
White, Michael and Jason Baldridge (2003). “Adapting Chart Realization to CCG”. In: Pro-ceedings of EACL 2003, Stroudsburg, PA.
Wink, Diane M. (2010). “Social networking sites”. In: Nurse educator 35.2, pp. 49–51.Wong, Yuk Wah and Raymond J. Mooney (2006). “Learning for semantic parsing with statis-
tical machine translation”. In: Proceedings of NAACL 2006, New York, NY, pp. 439–446.Woods, William A. (1973). “Progress in natural language understanding: an application to lu-
nar geology”. In: Proceedings of the June 4-8, 1973, National Computer Conference andExposition, New York, NY. ACM, pp. 441–450.
Wu, Huijia, Jiajun Zhang, and Chengqing Zong (2017). “A Dynamic Window Neural Networkfor CCG Supertagging”. In: Proceedings of AAAI-17, San Francisco, CA, pp. 3337–3343.
Xiao, Chunyang, Marc Dymetman, and Claire Gardent (2016). “Sequence-based structuredprediction for semantic parsing”. In: Proceedings of the ACL 2016, Berlin, Germany. Vol. 1,pp. 1341–1350.
Xu, Wenduan (2016). “LSTM shift-reduce CCG parsing”. In: Proceedings of EMNLP 2016,pp. 1754–1764.
Xu, Wenduan, Michael Auli, and Stephen Clark (2015). “CCG supertagging with a recurrentneural network”. In: Proceedings of ACL/IJCNLP 2015, Beijing, China. Vol. 2, pp. 250–255.
Xu, Wenduan, Stephen Clark, and Yue Zhang (2014). “Shift-reduce CCG parsing with a de-pendency model”. In: Proceedings of ACL 2014, Baltimore, MA, pp. 218–227.
Xue, Naiwen et al. (2005). “The Penn Chinese TreeBank: Phrase structure annotation of a largecorpus”. In: Natural language engineering 11.2, pp. 207–238.
Yamada, Hiroyasu and Yuji Matsumoto (2003). “Statistical dependency analysis with supportvector machines”. In: Proceedings of the Eighth International Conference on Parsing Tech-nologies, Nancy, France, pp. 195–206.
Yang, Zhilin et al. (2019). “XLNet: Generalized Autoregressive Pretraining for Language Un-derstanding”. arXiv:1906.08237.
Yasunaga, Michihiro, Jungo Kasai, and Dragomir Radev (2017). “Robust multilingual part-of-speech tagging via adversarial training”. arXiv:1711.04903.

144 Bibliography
Ying, Rex et al. (2018). “Graph convolutional neural networks for web-scale recommendersystems”. In: Proceedings of the 24th ACM SIGKDD International Conference on KnowledgeDiscovery & Data Mining, London, UK. ACM, pp. 974–983.
You, Yang et al. (2019). “Large batch optimization for deep learning: Training bert in 76 min-utes”. arXiv:1904.00962.
Young, Steve et al. (2010). “The hidden information state model: A practical framework forPOMDP-based spoken dialogue management”. In: Computer Speech & Language 24.2,pp. 150–174.
Young, Tom et al. (2018). “Recent trends in deep learning based natural language processing”.In: ieee Computational intelligence magazine 13.3, pp. 55–75.
Younger, Daniel H. (1967). “Recognition and parsing of context-free languages in time n3”. In:Information and control 10.2, pp. 189–208.
Yuret, Deniz and Ferhan Türe (2006). “Learning morphological disambiguation rules for Turk-ish”. In: Proceedings of HLT/NAACL 2006, New York, NY, pp. 328–334.
Zelle, John M. and Raymond J. Mooney (1996). “Learning to parse database queries usinginductive logic programming”. In: Proceedings of AAAI-96, Portland, Oregon, pp. 1050–1055.
Zettlemoyer, Luke S. and Michael Collins (2012). “Learning to map sentences to logical form:Structured classification with probabilistic categorial grammars”. arXiv:1207.1420.
Zhai, Feifei et al. (2017). “Neural models for sequence chunking”. In: Proceedings of AAAI-17,San Francisco, CA.
Zhai, Michael, Johnny Tan, and Jinho D. Choi (2016). “Intrinsic and extrinsic evaluations ofword embeddings”. In: Proceedings of AAAI-16, Phoenix, AZ.
Zhang, Xun et al. (2016). “Transition-based parsing for deep dependency structures”. In: Com-putational Linguistics 42.3, pp. 353–389.
Zhang, Yi, Valia Kordoni, and Erin Fitzgerald (2007). “Partial parse selection for robust deepprocessing”. In: ACL 2007 Workshop on Deep Linguistic Processing, pp. 128–135.
Zhang, Yue and Stephen Clark (2009). “Transition-based parsing of the Chinese treebank us-ing a global discriminative model”. In: Proceedings of the 11th International Conference onParsing Technologies, pp. 162–171.
— (2011). “Shift-reduce CCG parsing”. In: Proceedings of ACL/HLT 2011, Portland, OR,pp. 683–692.
Zhang, Yue and Joakim Nivre (2011). “Transition-based dependency parsing with rich non-local features”. In: Proceedings of ACL/HLT 2011, Portland, OR, pp. 188–193.
— (2012). “Analyzing the effect of global learning and beam-search on transition-based de-pendency parsing”. In: Proceedings of COLING 2012, Mumbai, India, pp. 1391–1400.
Zhou, Junru and Hai Zhao (2019). “Head-driven phrase structure grammar parsing on PennTreebank”. arXiv:1907.02684.
Zhu, Muhua et al. (2013). “Fast and accurate shift-reduce constituent parsing”. In: Proceedingsof ACL 2013, Sofia, Bulgaria, pp. 434–443.

Titre : Analyse de la structure de représentation du dis-
cours pour le français
Mot clés : Grammaire Catégorielle Combinatoire, Structure de Représentation duDiscours, Structure de Dépendance, Contenu Généré par l’Utilisateur
Resumé : Nous nous intéressons auxcontenus textuels tels que des discours,énoncés, ou conversations issus de lacommunication interactive sur les plate-formes de réseaux sociaux en nous ba-sant sur le formalisme des grammairescatégorielles combinatoires (GCC) et sur
la théorie de représentation du discours.Nous proposons une méthode pour l’ex-traction d’un arbre de GCC à partir del’arbre de dépendances de la phrase,ainsi qu’une architecture générale pourconstruire une interface entre la syntaxeet la sémantique de phrases françaises.
Title : French Language DRS Parsing
Keywords : Combinatory Categorial Grammar, Discourse Representation Structure,Dependency Structure, User-Generated Content
Abstract : In the rise of the internet, user-generated content from social networkingservices is becoming a giant source of in-formation that can be useful to businesseson the aspect where users are viewedas customers or potential customers forcompanies. We are interested in textualcontent such as speeches, statements,or conversations resulting from interac-
tive communication on social network plat-forms based on the formalism of Combina-tory Categorical Grammars (GCC) and onthe theory of representation of discourse.We propose a method for extracting aGCC tree from the sentence dependencytree, as well as a general architecture tobuild an interface between the syntax andthe semantics of French sentences.




















