
Flexible Designs for Phase II Comparative Clinical Trials Involving Two Response Variables
18
Research Article Received 10 September 2013, Accepted 15 September 2014 Published online 2 October 2014 in Wiley Online Library (wileyonlinelibrary.com) DOI: 10.1002/sim.6317 Flexible designs for phase II comparative clinical trials involving two response variables S. Bersimis, a * † A. Sachlas b and T. Papaioannou a,c The aim of phase II clinical trials is to determine whether an experimental treatment is sufficiently promising and safe to justify further testing. The need for reduced sample size arises naturally in phase II clinical trials owing to both technical and ethical reasons, motivating a significant part of research in the field during recent years, while another significant part of the research effort is aimed at more complex therapeutic schemes that demand the consideration of multiple endpoints to make decisions. In this paper, our attention is restricted to phase II clinical trials in which two treatments are compared with respect to two dependent dichotomous responses proposing some flexible designs. These designs permit the researcher to terminate the clinical trial when high rates of favorable or unfavorable outcomes are observed early enough requiring in this way a small number of patients. From the mathematical point of view, the proposed designs are defined on bivariate sequences of multi- state trials, and the corresponding stopping rules are based on various distributions related to the waiting time until a certain number of events appear in these sequences. The exact distributions of interest, under a unified framework, are studied using the Markov chain embedding technique, which appears to be very useful in clinical trials for the sample size determination. Tables of expected sample size and power are presented. The numerical illustration showed a very good performance for these new designs. Copyright © 2014 John Wiley & Sons, Ltd. Keywords: bivariate sequences of trials; clinical trials involving two binary endpoints; Markov chain embed- dable random variables; phase II clinical trials; decision rules; waiting time distribution 1. Introduction A clinical trial is an investigative study whose objective is to evaluate the effectiveness (efficacy) and safety of a treatment. Clinical trials are classified into four phases: phases I, II, III, and IV [1]. Phase II clinical trials are small screening procedures aimed at identifying treatments that are sufficiently promising to warrant further testing through larger-scale phase III trials [2]. The simplest form of phase II clinical trials are those involving a single-stage design (fixed sample size trial) where data are analyzed only once at the end of the study when all data have been collected [3–5]. Two-stage or multi-stage designs are considered whenever the primary endpoint can be evaluated in a sufficiently timely manner so that an interim analysis at the end of each stage can be used to decide on whether to continue or abandon the study [6–9]. Such designs are developed primarily for the purpose of reducing the sample by terminating clinical trials earlier than programmed. Stallard et al. in [10], in an excellent review paper, describe and compare different terminating rules. The necessity for small sample size arises naturally owing to both technical and ethical reasons, and this motivated much of the research in the field during the last 30 years. Ethical considerations may force a clinical trial to be terminated early if the cumulative results from patients entering the trial serially are too poor, leading in this way to a sequential design [11]. Although sequential procedures (e.g., the sequential probability ratio test) use fewer observations on the average than the corresponding fixed sample size a Department of Statistics & Insurance Science, University of Piraeus, Piraeus, Greece b Department of Nursing, University of Peloponnese, Sparta, Greece c Department of Mathematics, University of Ioannina, Ioannina, Greece * Correspondence to: S. Bersimis, Department of Statistics & Insurance Science, University of Piraeus, 80 Karaoli & Dimitriou str., 185 34, Piraeus, Greece. † E-mail: [email protected] Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214 197
Transcript of Flexible Designs for Phase II Comparative Clinical Trials Involving Two Response Variables

Research Article
Received 10 September 2013, Accepted 15 September 2014 Published online 2 October 2014 in Wiley Online Library
(wileyonlinelibrary.com) DOI: 10.1002/sim.6317
Flexible designs for phase II comparativeclinical trials involving tworesponse variablesS. Bersimis,a*† A. Sachlasb and T. Papaioannoua,c
The aim of phase II clinical trials is to determine whether an experimental treatment is sufficiently promising andsafe to justify further testing. The need for reduced sample size arises naturally in phase II clinical trials owingto both technical and ethical reasons, motivating a significant part of research in the field during recent years,while another significant part of the research effort is aimed at more complex therapeutic schemes that demandthe consideration of multiple endpoints to make decisions. In this paper, our attention is restricted to phaseII clinical trials in which two treatments are compared with respect to two dependent dichotomous responsesproposing some flexible designs. These designs permit the researcher to terminate the clinical trial when highrates of favorable or unfavorable outcomes are observed early enough requiring in this way a small number ofpatients. From the mathematical point of view, the proposed designs are defined on bivariate sequences of multi-state trials, and the corresponding stopping rules are based on various distributions related to the waiting timeuntil a certain number of events appear in these sequences. The exact distributions of interest, under a unifiedframework, are studied using the Markov chain embedding technique, which appears to be very useful in clinicaltrials for the sample size determination. Tables of expected sample size and power are presented. The numericalillustration showed a very good performance for these new designs. Copyright © 2014 John Wiley & Sons, Ltd.
Keywords: bivariate sequences of trials; clinical trials involving two binary endpoints; Markov chain embed-dable random variables; phase II clinical trials; decision rules; waiting time distribution
1. Introduction
A clinical trial is an investigative study whose objective is to evaluate the effectiveness (efficacy) andsafety of a treatment. Clinical trials are classified into four phases: phases I, II, III, and IV [1]. PhaseII clinical trials are small screening procedures aimed at identifying treatments that are sufficientlypromising to warrant further testing through larger-scale phase III trials [2].
The simplest form of phase II clinical trials are those involving a single-stage design (fixed samplesize trial) where data are analyzed only once at the end of the study when all data have been collected[3–5]. Two-stage or multi-stage designs are considered whenever the primary endpoint can be evaluatedin a sufficiently timely manner so that an interim analysis at the end of each stage can be used to decideon whether to continue or abandon the study [6–9]. Such designs are developed primarily for the purposeof reducing the sample by terminating clinical trials earlier than programmed. Stallard et al. in [10], inan excellent review paper, describe and compare different terminating rules.
The necessity for small sample size arises naturally owing to both technical and ethical reasons, andthis motivated much of the research in the field during the last 30 years. Ethical considerations may force aclinical trial to be terminated early if the cumulative results from patients entering the trial serially are toopoor, leading in this way to a sequential design [11]. Although sequential procedures (e.g., the sequentialprobability ratio test) use fewer observations on the average than the corresponding fixed sample size
aDepartment of Statistics & Insurance Science, University of Piraeus, Piraeus, GreecebDepartment of Nursing, University of Peloponnese, Sparta, GreececDepartment of Mathematics, University of Ioannina, Ioannina, Greece*Correspondence to: S. Bersimis, Department of Statistics & Insurance Science, University of Piraeus, 80 Karaoli & Dimitrioustr., 185 34, Piraeus, Greece.
†E-mail: [email protected]
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214
197

S. BERSIMIS, A. SACHLAS AND T. PAPAIOANNOU
designs, there are cases where sequential procedures require many more observations because there isno upper bound on the maximum number of observations [12]. Another option for reducing the requiredsample size is to use a curtailed sampling procedure (among others [12–15]) and to permit the terminationof the clinical trial as soon as a decision on accepting or rejecting the null hypothesis is reached [12].The structure and the design of a curtailed sampling procedure are very close to those of the familiarfixed sample size trial while using to advantage the sequential accumulation of information. Herrmannand Szatrowski in [12] use a curtailed sampling procedure in single-stage trial in order to take smallersample size in the case of comparative (two arms) clinical trials with paired data.
Phase II clinical trial designs (both single stage and multi-stage) are often developed on the basisthat only one endpoint is of interest, usually a proportion (e.g., response rate). However, nowa-days, as discussed in [16], there are situations where we need to consider two or more endpoints.The reason for this is that most medical treatments have multiple effects on patients [17], suchas more than one desirable anti-disease effect, which are called ‘responses’, as well as undesir-able effects that are usually called ‘adverse events’ (different treatments may vary in toxicity, cost,ease of administration, quality of life, etc.). Thus, many authors, during the last 20 years, developedsingle-stage or multiple-stage designs that consider the rates of such effects jointly [15–23]. In mostof these designs, the endpoints are binary random variables (see, e.g., [15, 16, 22–24]). Authors in[15, 22, 23] treated the case via curtailed sampling procedures.
Recently, many authors developed single-stage and two-stage designs with two dependent binary end-points and study the probability of type I and II errors and the required sample size. Many of them combinethese designs with sequential techniques (see [19], which proposes methods based on the enumeration ofthe exact distribution of the binary endpoints) or curtailed sampling procedures (see [22], which appliesthe curtailed sampling procedure to two-stage designs with two dependent binary endpoints) in order tofurther reduce sample sizes and speed up the development process for drugs. However, none of the afore-mentioned papers, which treat bivariate binary endpoints, do treat the case of comparative control trials,which is one of the most significant cases [24].
In this paper, we treat the case of clinical trials in which two treatments are compared (by taking pairs ofsubjects) with respect to two dependent dichotomous responses and propose some flexible designs undera unified framework using the Markov chain embedding technique. These designs permit the researcherto terminate the clinical trial when high rates of favorable or unfavorable outcomes are observed withrespect to a placebo or a competitive treatment, early enough demanding in this way a rather small num-ber of patients. Our approach is similar to response-adaptive designs because we stop the trial once wehave a high rate of favorable or unfavorable outcomes, and it does not have the weaknesses of the latterdesigns [25].
The paper is organized as follows: in Section 2, we present the setup of the problem under investigation.In Section 3, we derive the necessary mathematical framework for the problem under study, and we giveguidance for using the proposed designs as well as tables with numerical results. In Section 4, we presentfive extensions of the main design and some comparisons. Finally, in Section 5, we give some concludingremarks and discuss issues for further research.
2. A new design for phase II comparative clinical trials involving two dependentdichotomous responses
As already mentioned, in this paper, we treat the case of randomized phase II comparative clinical trialswhere pairs of patients enter the trial sequentially and are randomly assigned between the experimentaland reference treatments. The information from the clinical trial is accrued sequentially, and two depen-dent dichotomous responses are available relatively soon after treatment is started. According to Armitageet al. [11], it is essential for phase II trials to be completed relatively quickly. This means that efficacymust be assessed by a rapid response. Even in cancer therapy, where patient survival is at issue, severalother surrogate endpoints, such as the extent of tumor shrinkage or the remission of symptoms, may beused [11]. Thall et al. in [26] present the case of a therapy for a rapidly fatal disease, where early treatmentefficacy often is characterized by an event, called ‘response’, which is observed relatively quickly.
Today, such cases appear frequently because the necessity for new and more efficient medical methodsbecomes more and more intense. Using the methodology proposed in this paper, we can consider twocases of phase II comparative clinical trials with two binary endpoints. The first one is when we evaluatetwo efficacy endpoints. For example, two therapies for metastatic breast cancer can be compared throughcomplete (X1) and partial (X2) response [21]. The second case is the evaluation of one efficacy and one
198
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214

S. BERSIMIS, A. SACHLAS AND T. PAPAIOANNOU
safety endpoint. See, for example, the phase II study in [27], where the safety (X1) and efficacy (X2) oforal teriflunomide in multiple sclerosis with relapses were examined. The case of comparing two differentdoses with respect to efficacy and/or safety endpoints can also be treated.
2.1. The main design
Assume a randomized comparative, phase II clinical trial where patients are randomly assigned to twotreatments, the reference (R) one and the experimental (E) one. Pairs of two patients enter the clinicaltrial sequentially. The first patient is randomly assigned to either the experimental or reference treatment,while the second patient is assigned to the remaining treatment. As the patients are enrolled in the clinicaltrial sequentially, we assume that the information for the clinical trial is accrued also sequentially as usualand two dependent dichotomous responses are available relatively soon after treatment is started. Underthe case discussed in [26], it is possible to know the bivariate responses for each pair of patients evenbefore another pair of patients enter the trial.
Thus, sequentially, patients responses are accrued in terms of two characteristics, say Yg1 , Yg
2 , g = R,E,where each of them takes two values representing whether the treatment is successful (1) or not (0). Later,we shall treat the case where each Yg
1 , Yg2 , g = R,E, takes three values, taking into account the presence
of a severe adverse event (or even death).For exposition reasons, we present first the case that Yg
1 , Yg2 , g = R,E are independent. The dependent
case will be treated in Section 4.1. The probability that treatment g is successful with respect to Yi, i = 1, 2is denoted by 𝜋
g1,i = P
(Yg
i = 1), while the probability that treatment g is unsuccessful with respect to Yi
is denoted by 𝜋g0,i = P
(Yg
i = 0)= 1−𝜋
g1,i. For each pair of patients s, s = 1, 2,…, we have four outcomes
regarding the success or not of the two treatments on the two characteristics. Table I gives an example ofsuch a design for the first 12 pairs of patients.
As we may observe in Table I at the first pair, Treatment R is not successful with respect to bothcharacteristics, while Treatment E is successful with respect to both characteristics. Analogously, at theseventh pair, both treatments are successful with respect to the second characteristic. Thus, in Table I,we observe a four-dimensional sequence. The first two components of the sequence refer to TreatmentR, while the next two components refer to Treatment E. The results of each pair on all components areassumed to be time independent, because at each time point, data from a different pair of patients areaccrued from the clinical trial.
2.2. A decision rule for the new design
As already mentioned, our interest is in terminating the study as soon as we have sufficient evidencethat the experimental treatment is better than the reference one. It is evident that Treatment R may beconsidered better than Treatment E if a large number of 1s in at least one of the characteristics appear earlyenough in the sequence of YR
1 , YR2 . On the contrary, Treatment E can be considered better than Treatment
R if a large number of 1s in at least one of the characteristics appear early enough in the sequence YE1 ,
YE2 . Here, we have to note that the investigator has to give the appropriate label to each characteristic.Thus, a set of decision rules that may be used for the early termination of the clinical trial, using the
design described earlier, is as follows:
• (sr)1: The study is terminated in favor of Treatment E when a total of k cases showing improvementdue to Treatment E in at least one of the characteristics are observed early enough, say before thec-th pair of patients or
Table I. A realization of the clinical trial where the outcomes of the 12 first pairs ofpatients are presented.
Pair of patients (s)
1 2 3 4 5 6 7 8 9 10 11 12 …
Treatment R YR1 0 1 1 1 1 0 0 0 1 0 0 0 …
YR2 0 0 1 0 1 0 1 1 0 1 0 1 …
Treatment E YE1 1 1 0 1 1 0 0 1 0 1 1 1 …
YE2 1 1 1 0 1 1 1 0 0 1 0 0 …
Number of patients 2 4 6 8 10 12 14 16 18 20 22 24 …
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214
199

S. BERSIMIS, A. SACHLAS AND T. PAPAIOANNOU
• (sr)2: The study is terminated in favor of Treatment R when a total of k cases showing improvementdue to Treatment R in at least one of the characteristics are observed early enough, say before thec-th pair of patients or
• (sr)3: The study is terminated with a decision that the two drugs are equivalent when a total of k casesshowing improvement due to Treatment R or due to Treatment E are not observed until the c-th pairof patients
In order to determine values for the parameters c and k, involved in the decision rule, we define firsttwo random variables that count the cases showing improvement due to Treatment R and Treatment E,respectively. Thus, on the sequence of events
{YR
1 ,YR2 ,Y
E1 ,Y
E2
}, we define the two-dimensional random
variable(LR
s ,LEs
)as follows:
LRs = YR
1 + YR2 , LE
s = YE1 + YE
2 . (1)
Obviously, LRs is the sum of two independent Bernoulli variables with probabilities of success
(𝜋R
1,1, 𝜋R1,2
),
respectively, and similar for LEs with success probabilities
(𝜋E
1,1, 𝜋E1,2
), respectively.
(LR
s ,LEs
)takes values
on {0, 1, 2}× {0, 1, 2}. The number of successes for each treatment at each pair of the clinical trial givenin Table I is presented in Table II.
The probabilities associated with LRs , LE
s , that is, puv = P(LR
s = u,LEs = v
), u, v = 0, 1, 2, are
p00 = 𝜋R00 ⋅ 𝜋
E00, p10 = 𝜋R
10 ⋅ 𝜋E00 + 𝜋R
01 ⋅ 𝜋E00, p20 = 𝜋R
11 ⋅ 𝜋E00,
p01 = 𝜋R00 ⋅ 𝜋
E10 + 𝜋R
00 ⋅ 𝜋E01, p11 = 𝜋R
10 ⋅ 𝜋E01 + 𝜋R
01 ⋅ 𝜋E10 + 𝜋R
01 ⋅ 𝜋E01 + 𝜋R
10 ⋅ 𝜋E10, p21 = 𝜋R
11 ⋅ 𝜋E01 + 𝜋R
11 ⋅ 𝜋E10,
p02 = 𝜋R00 ⋅ 𝜋
E11, p12 = 𝜋R
10 ⋅ 𝜋E11 + 𝜋R
01 ⋅ 𝜋E11, p22 = 𝜋R
11 ⋅ 𝜋E11,
(2)with
𝜋Rij = P
(YR
1 = i,YR2 = j
), i, j = 0, 1 and 𝜋E
i′j′ = P(YE
1 = i′,YE2 = j′
), i′, j′ = 0, 1.
In case of independence it is evident that the following equalities are true:
𝜋Rij = 𝜋R
i,1 ⋅ 𝜋Rj,2 and 𝜋E
i′j′ = 𝜋Ei′,1 ⋅ 𝜋
Ej′,2.
Thus, having at hand the sequence of random variables LRs , LE
s , in order to determine the appropriatevalues for k and c needed for decision sub-rules (sr)1, (sr)2, and (sr)3, we have to define a random variableS that will count the number of pairs of patients until one of the rules is realized. It is evident that S equalsn if and only if upon the completion of the n-th comparison, we have
n∑s=1
LRs ⩾ k or
n∑s=1
LEs ⩾ k,
and none of the events stated earlier have occurred before the n-th pair. In other words, S counts the num-ber of pairs enrolled until the first appearance of either k cases showing improvement due to TreatmentR in at least one of the characteristics or k cases showing improvement due to Treatment E in at least oneof the two characteristics. It is a kind of a ‘waiting time’. It is obvious that S is a discrete variable takingvalues 1, 2,…. In Table II, we may observe how the two cumulative sums are evolving from one pair ofpatients to the next pair.
Table II. Number of successes and cumulative number of successes foreach treatment at each pair of patients of the clinical trial.
Pair of patients (s)
1 2 3 4 5 6 7 8 9 10 11 12 …
LRs 0 1 2 1 2 0 1 1 1 1 0 1 …
LEs 2 2 1 1 2 1 1 1 0 2 1 1 …∑n
s=1 LRs 0 1 3 4 6 6 7 8 9 10 10 11 …∑n
s=1 LEs 2 4 5 6 8 9 10 11 11 13 14 15 …
200
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214

S. BERSIMIS, A. SACHLAS AND T. PAPAIOANNOU
Terminating the clinical trial in favor of Treatment R or E must be associated with the success proba-bilities
(𝜋R
1,1, 𝜋R1,2, 𝜋
E1,1, 𝜋
E1,2
). It makes no sense to terminate the clinical trial if we do not know whether
the success probabilities 𝜋R1,1, 𝜋
R1,2 are equal to the 𝜋E
1,1, 𝜋E1,2 or not. The procedure for the early termination
of the clinical trial can be represented as a test of hypothesis based on the distribution of S that will bepresented later. The threshold value k and the probabilities 𝜋R
1,1, 𝜋R1,2, 𝜋E
1,1, 𝜋E1,2 are parameters of the dis-
tribution of S, while c is an appropriate percentile of the distribution of S, a critical value that denotes themaximum number of patients to be enrolled. It is obvious that the sums
∑ns=1 LR
s ,∑n
s=1 LEs , n = 1, 2,…
constitute a random walk on the discrete plane, which directly give us the maximum number of patientsthat will be needed in order to make a decision, and the distribution of the ‘waiting time’ S can be studiedusing the Markov chain embedding technique, where an absorbing barrier depending on k is introducedin the random walk (see, e.g., [28–30]).
3. Justification and implementation of the rule
3.1. The exact distribution of S
The Markov chain embedding technique is widely used today for finding the distribution of various typesof statistics defined on univariate or multivariate sequences of discrete random variables.
This technique permits us to capture the exact cumulative distribution of a discrete random variable,like S, defined on a sequence of multi-state trials using a Markov chain {Vs, s = 0, 1, 2,…} defined on astate space Ω, and the equation
P(S ⩽ n) = P(Vn = 𝛼d) = 𝝅′0𝚲
n0𝐞d,
where 𝛼d is an appropriate absorbing state, 𝝅′0 is the (row) vector of initial probabilities of the Markov
chain, 𝚲0 is the transition probability matrix, and finally, 𝐞′d is a 1 × d vector of the form (0, 0,… , 1).Then, the probability distribution of S may be calculated using the formula
P(S = n) = P(S ⩽ n) − P(S ⩽ n − 1) = 𝝅′0𝚲
n0𝐞d − 𝝅
′0𝚲
n−10 𝐞d
= 𝝅′0
(𝚲n
0 − 𝚲n−10
)𝐞d = 𝝅
′0𝚲
n−10 (𝚲0 − 𝐈)𝐞d = 𝝅
′1(𝚲1)n−1𝐡,
where 𝝅1 is a (d − 1) × 1 column vector that contains all the entries of the initial probability vector𝝅0 except the last one (which, for non-degenerate cases, vanishes) and 𝚲1 is matrix 𝚲0 without the lastcolumn and the last row. The vector 𝐡 appearing in the aforementioned equation can be easily calculatedby formula 𝐡 = 𝟏 − 𝚲1𝟏, where 𝟏 is a (d − 1) × 1 column vector of ones, using the fact that 𝚲0 is astochastic matrix. The vector 𝐡 contains the transition probabilities from the corresponding state to theabsorbing state (for more details, see [31] and references therein).
Thus, as it is clear from the previous discussion, in order to use the Markov chain embedding technique,an appropriate Markov chain {Vs, s = 0, 1, 2,…} has to be defined giving its state space and its transitionprobability matrix. Here, the appropriate state space is of the form Ω = {(j1, j2) ∶ j1, j2 = 0, 1, 2,… ,
k − 1} ∪ {𝛼d}, where 𝛼d is the absorbing state and the indices of the state space are as follows:
• j1 tracks the cumulative sum∑n
s=1 LRs on the bivariate sequence of
(LR
s ,LEs
), and
• j2 tracks the cumulative sum∑n
s=1 LEs on the bivariate sequence of
(LR
s , LEs
).
From the description of the state space Ω, it is clear that it consists of d = k2 + 1 elements. The{Vs, s = 0, 1, 2,…} is defined as follows:
Vn ={
(j1, j2), if∑n
s=1 LRs = j1,
∑ns=1 LE
s = j2𝛼d, if
∑ns=1 LR
s ⩾ k or∑n
s=1 LEs ⩾ k,
with V0 = (0, 0), by convention, n = 1, 2,…. It is evident that the 𝛼d state represents all the possibleabsorbing states of the Markov chain. Using the preceding definition, we may easily verify that the totalnumber of the ‘real’ absorbing states of the chain, accumulated into 𝛼d, equals to 4 × k observing that
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214
201

S. BERSIMIS, A. SACHLAS AND T. PAPAIOANNOU
the maximum step of the Markov chain for each dimension is 2. Thus, absorbing are all the states of theform (k, i), (k + 1, i), (i, k), and (i, k + 1), where i takes all the values from 0 to k − 1. The transitionprobability matrix is
𝚲0 =[P(Vs = 𝛼j|Vs−1 = 𝛼i)
](k2+1)×(k2+1) ,
where, here, 𝛼i, i = 1,… , d, 𝛼j, j = 1,… , d are the states of Ω. We order the elements of thestate space lexicographically (i.e., (0, 0), (0, 1),… , (0, k − 1), (1, 0), (1, 1),… , (1, k − 1),… , (k − 1, 0),(k − 1, 1),… , (k − 1, k − 1), 𝛼d). The transition probability matrix has the form
𝚲0 =[𝚲1 𝐡𝟎 1
](k2+1)×(k2+1)
, (3)
where 𝐡 is a vector with elements the quantities needed in order 𝚲0 to be a right stochastic matrix (i.e.,with each row summing to 1). It can be shown that the transition probability matrix𝚲1 is written as a blockdiagonal matrix. This fact helps us in interpreting and constructing the 𝚲1. The transition probabilitymatrix can be also written in the form
𝚲0 =
⎡⎢⎢⎢⎢⎢⎢⎢⎣
𝐀0 𝐁0 𝚪0𝐀1 𝐁1 𝚪1
⋱ ⋱ ⋱ 𝐡𝐀k−2 𝐁k−2 𝚪k−2
𝐀k−1 𝐁k−1𝐀k
0 0 0 0 0 0 1
⎤⎥⎥⎥⎥⎥⎥⎥⎦,
where 𝐀i = 𝐀, i = 0, 1,… , k, 𝐁i = 𝐁, i = 0, 1,… , k−1, and 𝚪i = 𝚪, i = 0, 1,… , k−2 are k×k matrices.The form 𝐀, 𝐁, and 𝚪 is given in Appendix A.1.
From the description of the states of the state space Ω is clear that the pair (0, 0) is the start-ing point of the Markov chain. Thus, the (row) vector of initial probabilities of the Markov chain is𝝅′0 = (1, 0, 0,… , 0)1×d.
3.2. Setting up a hypothesis test using the distribution of S
The null hypothesis of the test is
H0 ∶ 𝜋E1,1 = 𝜋R
1,1 and 𝜋E1,2 = 𝜋R
1,2,
that is, the probabilities of successes for both treatments are equal for both characteristics. The alternativehypotheses are
H11 ∶ 𝜋E
1,1 > 𝜋R1,1 and 𝜋E
1,2 > 𝜋R1,2 or 𝜋E
1,1 = 𝜋R1,1 and 𝜋E
1,2 > 𝜋R1,2 or 𝜋E
1,1 > 𝜋R1,1 and 𝜋E
1,2 = 𝜋R1,2,
or
H21 ∶ 𝜋E
1,1 < 𝜋R1,1 and 𝜋E
1,2 < 𝜋R1,2 or 𝜋E
1,1 = 𝜋R1,1 and 𝜋E
1,2 < 𝜋R1,2 or 𝜋E
1,1 < 𝜋R1,1 and 𝜋E
1,2 = 𝜋R1,2.
H11 is the hypothesis that Treatment E is better than Treatment R in both or in one of the characteristics,
while H21 is the opposite of H1
1 . (sr)1 corresponds to H11 , while (sr)2 corresponds to H2
1 . (sr)3 correspondsto H0. The parameters k and c may be chosen using the desired probability of type I error 𝛼 and power 𝛾 ,conditioning on the values of 𝜋R
1,1, 𝜋R1,2, 𝜋E
1,1, 𝜋E1,2.
The procedure for determining k and c and then applying the decision rule may now be described inthe form of an algorithm, as follows:
1. Define the success probabilities of the null hypothesis H0.2. Define the desired probability of type I error, 𝛼.3. Calculate several candidate values of c using equality P(S ⩽ c|k,H0) = 𝛼, for various values of k
and specific values of the 𝜋R1,j and 𝜋E
1,j, j = 1, 2 in H0.
202
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214

S. BERSIMIS, A. SACHLAS AND T. PAPAIOANNOU
4. Choose k such as to have a desired level of power 𝛾 , for the required alternative hypothesis. Thiswill fix c.
5. Run the clinical trial, tracking∑n
s=1 LRs ,
∑ns=1 LE
s . If for the first time at the n-th pair with n ⩽ c,∑ns=1 LR
s ⩾ k, then the study is interrupted in favor of Treatment R or if∑n
s=1 LEs ⩾ k then the
study is interrupted in favor of Treatment E. If n > c with both sums less than k, then the study isinterrupted with a decision that the two treatments are equivalent.
Note that the three sub-rules (sr)1, (sr)2, and (sr)3 are not applied independently of each other. At eachpair, all three are examined to see if they are satisfied or not. In this way, the proposed procedure satisfiesthe ethical requirement of terminating a study as soon as the outcome is known. A major advantage ofthe procedure is that it does not involve repeated significance testing on accumulating data, and thus, weare protected from an increased overall significance level. Furthermore, the exact power can be easilycalculated under different alternatives.
Figure 1(a–f) presents the probability mass function of S for some choices of k and success probabilities𝜋R
1,1, 𝜋R1,2, 𝜋E
1,1, and 𝜋E1,2. In each row, two graphs are presented. The left graph corresponds to the null
hypothesis, while the second one to a possible alternative hypothesis. From the figure, it is evident thatthe distribution of S has excellent discrimination properties.
Figure 1. The probability mass function of S for several choices of k and 𝜋R1,1, 𝜋R
1,2, 𝜋E1,1, and 𝜋E
1,2.
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214
203

S. BERSIMIS, A. SACHLAS AND T. PAPAIOANNOU
3.3. Using the rule
As a tool to the practitioner, we present Tables III and IV, which give the power, that is, P (S ⩽ c|k,𝜋R
1,1, 𝜋R1,2, 𝜋
E1,1, 𝜋
E1,2
)= 𝛾 , the expected number of pairs of patients (in brackets) and the values of c for k =
5 to 12 for several choices of success probabilities 𝜋R1,1, 𝜋R
1,2, 𝜋E1,1, 𝜋E
1,2. The expected number of pairs is themean value of S. For each choice of k, the value of c is determined for the following selected values of thenull hypothesis H0: (i) 𝜋R
1,1 = 𝜋E1,1 = 0.05, 𝜋R
1,2 = 𝜋E1,2 = 0.05; (ii) 𝜋R
1,1 = 𝜋E1,1 = 0.15, 𝜋R
1,2 = 𝜋E1,2 = 0.15;
(iii) 𝜋R1,1 = 𝜋E
1,1 = 0.25, 𝜋R1,2 = 𝜋E
1,2 = 0.15; and (iv) 𝜋R1,1 = 𝜋E
1,1 = 0.35, 𝜋R1,2 = 𝜋E
1,2 = 0.35.Tables III and IV can be used as follows: Assume that 𝜋R
1,1 = 0.05 and 𝜋R1,2 = 0.05 and
that we want to identify the case where Treatment E is better than Treatment R with probabilitiesof success 𝜋E
1,1 = 0.30 and 𝜋E1,2 = 0.20, 𝛼 ⩽ 0.05, 𝛾 ⩾ 0.95 and keeping the sample size as small
as possible. Here, H0 is 𝜋R1,1 = 𝜋E
1,1 = 0.05 and 𝜋R1,2 = 𝜋E
1,2 = 0.05, and the alternativeis 𝜋R
1,1 = 𝜋R1,2 = 0.05 and 𝜋E
1,1 = 0.30, 𝜋E1,2 = 0.20, which belongs to H1
1 . As we may seefrom Tables III and IV, the obvious choice for k is 6, as this is the smallest k, which gives 𝛾 ⩾0.95 (specifically 𝛾 = 0.98). The value of the critical point c (i.e., the maximum number ofpairs of patients required to be enrolled) equals to 22, which corresponds to an 𝛼 = 0.04. Theexpected number of pairs is 12.231 ≈ 13, so the expected number of patients that have to be recruitedis 26.
Considering the null hypothesis H0 ∶ 𝜋R1,1 = 𝜋E
1,1 = 0.15 and 𝜋R1,2 = 𝜋E
1,2 = 0.15 and the alternative𝜋R
1,1 = 𝜋R1,2 = 0.15 and 𝜋E
1,1 = 𝜋E1,2 = 0.40 (which again belongs to H1
1), the obvious choice for k is 12,which gives 𝛾 = 0.956. The maximum number of pairs of patients required to be enrolled is c = 21,which corresponds to an 𝛼 = 0.035. The expected number of pairs is 15.242 ≈ 16, so the expectednumber of patients that have to be recruited is 32.
Let us now see another characteristic of this design. Assume that, for the hypotheses H0 ∶ 𝜋R1,1 =
𝜋E1,1 = 0.05 and 𝜋R
1,2 = 𝜋E1,2 = 0.05 and H1 ∶ 𝜋R
1,1 = 𝜋R1,2 = 0.05 and 𝜋E
1,1 = 0.30, 𝜋E1,2 = 0.20,
we start the clinical trial using k = 5 and c = 16. In this case, we reject the null hypothesiswith power 0.933, if s < 16 (Table III). The notation s < 16 is used to denote that
∑ns=1 LR
s ⩾5 or
∑ns=1 LE
s ⩾ 5 before the 16th pair. The expected number of patients that have to beenrolled is 22. However, even if
∑ns=1 LR
s ⩾ 5 or∑n
s=1 LEs ⩾ 5 at some pair, before the 16th pair,
we can assign more patients (if this is possible) in the trial increasing in this way the power of thetest. For example, if we observe that at the sixth pair we have
∑ns=1 LE
s = 5, it is more than prob-able that by letting the clinical trial run for one more pair, we will take a value
∑ns=1 LE
s ⩾ 6.This will increase our power to 0.98 after seven pairs. This means that by adding only twomore patients in the trial, we can increase the power of the test. This of course will modify the probabilityof type I error.
Nevertheless, someone may be interested for other choices of 𝜋R1,1, 𝜋R
1,2, 𝜋E1,1, 𝜋E
1,2, not included inTables III and IV. The illustration of the necessary calculations for computing the distribution of Sis given in Appendix A.2. In order to provide an appropriate tool to practitioners, we have devel-oped a mathematica program for computing the distribution of S and the critical point based ondesired response rates.
4. Extensions of the main design
In this section, we present five useful extensions of the design presented. As we shall see, the method-ology already presented is used as the main framework for calculating the distribution of S. Only minormodifications are necessary for introducing the alternative designs.
4.1. The main design with dependent binary endpoints
Let us now assume that the pairs of random variables Yg1 , Yg
2 are dependent for g = R,E with jointprobabilities
P(Yg
1 = 0,Yg2 = 0
), P
(Yg
1 = 1,Yg2 = 0
), P
(Yg
1 = 0,Yg2 = 1
), P
(Yg
1 = 1,Yg2 = 1
).
204
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214

S. BERSIMIS, A. SACHLAS AND T. PAPAIOANNOU
Tabl
eII
I.Po
wer
,exp
ecte
dnu
mbe
rof
pair
s,an
dc
for
k=
5to
k=
8an
d𝛼⩽
0.05
.
𝜋E 1,
1
5%15%
25%
30%
35%
40%
50%
75%
85%
𝜋E 1,
2
𝜋R 1,
1𝜋
R 1,2
5%15%
15%
20%
35%
40%
75%
75%
85%
c
k=
55%
5%0.
040
0.54
50.
802
0.93
30.
996
0.99
90.
999
1.00
01.
000
16(3
8.25
7)(1
6.67
1)(1
2.67
5)(1
0.22
2)(7
.391
)(6
.499
)(5
.251
)(3
.603
)(3
.246
)15
%15
%0.
047
0.09
30.
176
0.43
10.
572
0.81
10.
997
0.99
96
(13.
137)
(11.
172)
(9.5
43)
(7.2
32)
(6.4
20)
(5.2
30)
(3.6
02)
(3.2
46)
25%
15%
0.01
90.
036
0.11
50.
182
0.37
00.
887
0.97
94
(10.
008)
(8.8
74)
(7.0
16)
(6.2
97)
(5.1
91)
(3.6
00)
(3.2
46)
35%
35%
0.04
40.
062
0.12
90.
544
0.78
23
(5.9
80)
(5.6
00)
(4.8
89)
(3.5
74)
(3.2
39)
k=
65%
5%0.
043
0.67
10.
902
0.98
00.
999
0.99
91.
000
1.00
01.
000
22(4
7.05
8)(2
0.07
4)(1
5.19
9)(1
2.23
1)(8
.821
)(7
.750
)(6
.250
)(4
.238
)(3
.739
)15
%15
%0.
047
0.10
20.
207
0.52
20.
679
0.89
70.
999
0.99
98
(16.
092)
(13.
638)
(11.
584)
(8.6
95)
(7.6
92)
(6.2
37)
(4.2
38)
(3.7
39)
25%
15%
0.03
70.
071
0.22
70.
347
0.62
00.
986
0.99
96
(12.
234)
(10.
821)
(8.4
79)
(7.5
78)
(6.2
06)
(4.2
37)
(3.7
38)
35%
35%
0.04
90.
074
0.16
60.
687
0.89
84
(7.2
66)
(6.7
94)
(5.8
96)
(4.2
18)
(3.7
34)
k=
75%
5%0.
049
0.79
20.
962
0.99
60.
999
0.99
91.
000
1.00
01.
000
29(5
5.95
9)(2
3.45
8)(1
7.71
4)(1
4.23
6)(1
0.25
0)(8
.999
)(7
.250
)(4
.924
)(4
.398
)15
%15
%0.
043
0.10
50.
230
0.59
30.
756
0.94
40.
999
1.00
010
(19.
078)
(16.
120)
(13.
628)
(10.
150)
(8.9
58)
(7.2
42)
(4.9
24)
(4.3
98)
25%
15%
0.02
20.
047
0.19
30.
315
0.60
90.
990
0.99
97
(14.
484)
(12.
782)
(9.9
40)
(8.8
56)
(7.2
18)
(4.9
23)
(4.3
97)
35%
35%
0.00
70.
012
0.03
90.
369
0.99
94
(8.5
64)
(7.9
97)
(6.9
09)
(4.9
08)
(4.3
95)
k=
85%
5%0.
046
0.84
70.
981
0.99
90.
999
1.00
01.
000
1.00
01.
000
35(6
4.93
8)(2
6.82
7)(2
0.22
2)(1
6.23
8)(1
1.67
9)(1
0.25
0)(8
.250
)(5
.579
)(4
.934
)15
%15
%0.
039
0.10
60.
248
0.65
00.
812
0.96
90.
999
1.00
012
(22.
090)
(18.
615)
(15.
672)
(11.
600)
(10.
220)
(8.2
45)
(5.5
79)
(4.9
34)
25%
15%
0.03
10.
075
0.28
30.
445
0.76
30.
999
0.99
99
(16.
751)
(14.
755)
(11.
400)
(10.
129)
(8.2
27)
(5.5
79)
(4.9
34)
35%
35%
0.01
00.
017
0.05
90.
528
0.82
15
(9.8
72)
(9.2
08)
(7.9
22)
(5.5
68)
(4.9
32)
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214
205

S. BERSIMIS, A. SACHLAS AND T. PAPAIOANNOU
Tabl
eIV
.Po
wer
,exp
ecte
dnu
mbe
rof
pair
s,an
dc
for
k=
9to
k=
12an
d𝛼⩽
0.05
.
𝜋E 1,
1
5%15%
25%
30%
35%
40%
50%
75%
85%
𝜋E 1,
2
𝜋R 1,
1𝜋
R 1,2
5%15%
15%
20%
35%
40%
75%
75%
85%
c
k=
95%
5%0.
048
0.90
20.
993
0.99
91.
000
1.00
01.
000
1.00
01.
000
42(7
3.98
1)(3
0.18
6)(2
2.72
7)(1
8.23
9)(1
3.10
7)(1
1.50
0)(9
.250
)(6
.253
)(5
.561
)15
%15
%0.
035
0.10
40.
262
0.70
00.
854
0.98
31.
000
1.00
06
(25.
121)
(21.
119)
(17.
714)
(13.
046)
(11.
478)
(9.2
47)
(6.2
53)
(5.5
61)
25%
15%
0.03
80.
091
0.36
60.
555
0.86
00.
999
1.00
011
(19.
033)
(16.
736)
(12.
857)
(11.
399)
(9.2
34)
(6.2
52)
(5.5
61)
35%
35%
0.04
80.
081
0.23
10.
891
0.98
97
(11.
187)
(10.
425)
(8.9
36)
(6.2
45)
(5.5
60)
k=
105%
5%0.
049
0.93
70.
997
0.99
91.
000
1.00
01.
000
1.00
01.
000
49(8
3.07
7)(3
3.53
8)(2
5.23
0)(2
0.24
0)(1
4.53
6)(1
2.75
0)(1
0.25
0)(6
.915
)(6
.120
)15
%15
%0.
047
0.14
50.
351
0.80
90.
929
0.99
61.
000
1.00
017
(28.
169)
(23.
629)
(19.
755)
(14.
488)
(12.
735)
(10.
248)
(6.9
15)
(6.1
20)
25%
15%
0.04
40.
110
0.44
00.
644
0.91
80.
999
1.00
013
(21.
327)
(18.
724)
(14.
312)
(12.
655)
(10.
238)
(6.9
15)
(6.1
20)
35%
35%
0.04
50.
080
0.24
50.
922
0.99
58
(12.
509)
(11.
647)
(9.9
51)
(6.9
09)
(6.1
20)
k=
115%
5%0.
049
0.96
00.
999
0.99
91.
000
1.00
01.
000
1.00
01.
000
56(9
2.21
8)(3
6.88
4)(2
7.73
2)(2
2.24
0)(1
5.96
4)(1
4.00
0)(1
1.25
0)(7
.584
)(6
.730
)15
%15
%0.
041
0.13
80.
357
0.83
30.
944
0.99
81.
000
1.00
019
(31.
232)
(26.
145)
(21.
793)
(15.
927)
(13.
989)
(11.
249)
(7.5
84)
(6.7
30)
25%
15%
0.04
90.
126
0.50
50.
716
0.95
20.
999
1.00
015
(23.
632)
(20.
718)
(15.
765)
(13.
930)
(11.
241)
(7.5
84)
(6.7
30)
35%
35%
0.04
20.
078
0.25
70.
944
0.99
79
(13.
836)
(12.
872)
(10.
965)
(7.5
80)
(6.7
30)
k=
125%
5%0.
048
0.97
40.
999
0.99
91.
000
1.00
01.
000
1.00
01.
000
63(1
01.3
98)
(40.
227)
(30.
233)
(24.
240)
(17.
393)
(15.
250)
(12.
250)
(8.2
50)
(7.3
02)
15%
15%
0.03
50.
132
0.36
20.
853
0.95
60.
999
1.00
01.
000
21(3
4.30
7)(2
8.66
4)(2
3.82
9)(1
7.36
3)(1
5.24
2)(1
2.24
9)(8
.250
)(7
.302
)25
%15
%0.
032
0.09
40.
457
0.68
20.
946
0.99
91.
000
16(2
5.94
5)(2
2.71
5)(1
7.21
4)(1
5.19
1)(1
2.24
4)(8
.249
)(7
.302
)35
%35
%0.
039
0.07
50.
266
0.96
00.
999
10(1
5.16
8)(1
4.10
1)(1
1.98
0)(8
.247
)(7
.302
)
206
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214

S. BERSIMIS, A. SACHLAS AND T. PAPAIOANNOU
We can work in exactly the same way, as in the independent case. The only difference is that, now, theassociated probabilities 𝜋R
ij ⋅ 𝜋Ei′j′ , i = 0, 1, j = 0, 1 cannot be expressed as the products of the marginal
probabilities. As in the design presented in [22], the odds ratio between the two endpoints should beconsidered known.
It is evident now that the procedure presented in the previous section, from this step and on, remainsthe same. The calculation of the transition probability matrix 𝚲0 is straightforward.
4.2. A design that takes into account only superiority of one treatment
Another modification of the proposed design is to take into account only the cases where one treatmentis superior from the other in at least one characteristic. In this way, we compare the two treatments ina straightforward way. If the new treatment is successful and the reference one is unsuccessful in termsof the same characteristic, then the new treatment scores against the reference. If the two treatments areboth successful in terms of the same characteristic, none of the treatments scores. This means that if a tieappears in one of the two variables, none of the treatments scores. Contrary to [32], where pairs (Failure,Failure) and (Success, Success) are assumed as equivalent ties, in this paper, we also consider that wehave a negative effect and a positive effect. This is an alternative way of handling ties, which is similarto the way Herrmann and Szatrowski [12] handle the ties. In fact, inference under this way of handlingties is based on the discordant pairs; that is, on the number of pairs where there is a preference for onetreatment over the other.
For example, consider the sequence that is provided in Table V. For the second pair, both treatmentsare successful on both characteristics (YR
1 = YE1 = 1 and YR
2 = YE2 = 1); thus, none of the two treatments
scores. Thus, the event (YR1 = YE
1 = 1 and YR2 = YE
2 = 1) is equivalent to the event (YR1 = YE
1 = 0and YR
2 = YE2 = 0) that appears at the first pair. Moreover, none of these events cause a transition of
the Markov chain(∑n
s=1 LRs = 0,
∑ns=1 LE
s = 0). Here, LR
s counts the number of times that Treatment R issuperior from Treatment E at stage s, which is similar for LE
s . Additionally, the Markov chain does nottransit in case of the event (YR
1 = YE1 = 1 and YR
2 = YE2 = 0), which appears at the third pair, and in the
case of the event (YR1 = YE
1 = 0 and YR2 = YE
2 = 1), which appears at the tenth pair. It is evident that theMarkov chain transits in cases where in the same characteristic the two treatments have different results(observe pairs 4, 5, 6, 7, 8, and 9). Table V presents which treatment is superior with respect to eachcharacteristic. Note that in this design, Lg
s is not the sum of Yg1 and Yg
2 , g = R,E as in Equation (1).In this case, the associated probabilities are
p00 = 𝜋R00 ⋅ 𝜋
E00 + 𝜋R
01 ⋅ 𝜋E01 + 𝜋R
10 ⋅ 𝜋E10 + 𝜋R
11 ⋅ 𝜋E11, p11 = 𝜋R
10 ⋅ 𝜋E01 + 𝜋R
01 ⋅ 𝜋E10, p22 = 0,
p01 = 𝜋R00 ⋅ 𝜋
E10 + 𝜋R
00 ⋅ 𝜋E01 + 𝜋R
10 ⋅ 𝜋E11 + 𝜋R
01 ⋅ 𝜋E11, p02 = 𝜋R
00 ⋅ 𝜋E11, p12 = 0,
p10 = 𝜋R10 ⋅ 𝜋
E00 + 𝜋R
00 ⋅ 𝜋E10 + 𝜋R
11 ⋅ 𝜋E01 + 𝜋R
11 ⋅ 𝜋E10, p20 = 𝜋R
11 ⋅ 𝜋E00, p21 = 0.
Probabilities p21 = p12 = p22 = 0 are kept in order to keep the general form of the transition probabilitymatrix given in Equation (3). Here, we have to note that if we set p11 = 0, p01 = 𝜋R
00 ⋅ 𝜋E10 + 𝜋R
00 ⋅ 𝜋E01,
p10 = 𝜋R10 ⋅ 𝜋
E00 + 𝜋R
00 ⋅ 𝜋E10, and plug the remaining quantities into p00, the design moves from superiority
to one or two variables to pure superiority of the treatment.
Table V. Number of successes and cumulative number of successes for eachtreatment at each pair of a realization of the Design 4.2.
Pair (s)
1 2 3 4 5 6 7 8 9 10 …
YR1 0 1 1 0 0 1 0 1 1 0 …
YR2 0 1 0 0 0 0 1 0 0 1 …
YE1 0 1 1 0 1 0 1 0 1 0 …
YE2 0 1 0 1 1 0 0 1 1 1 …
Superior treatment wrt Y1 — — — — E R E R — — …Superior treatment wrt Y2 — — — E E — R E E — …LR
s 0 0 0 0 0 1 1 1 0 0 …LE
s 0 0 0 1 2 0 1 1 1 0 …∑ns=1 LR
s 0 0 0 0 0 1 2 3 3 3 …∑ns=1 LE
s 0 0 0 1 3 3 4 5 6 6 …
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214
207
S. BERSIMIS, A. SACHLAS AND T. PAPAIOANNOU
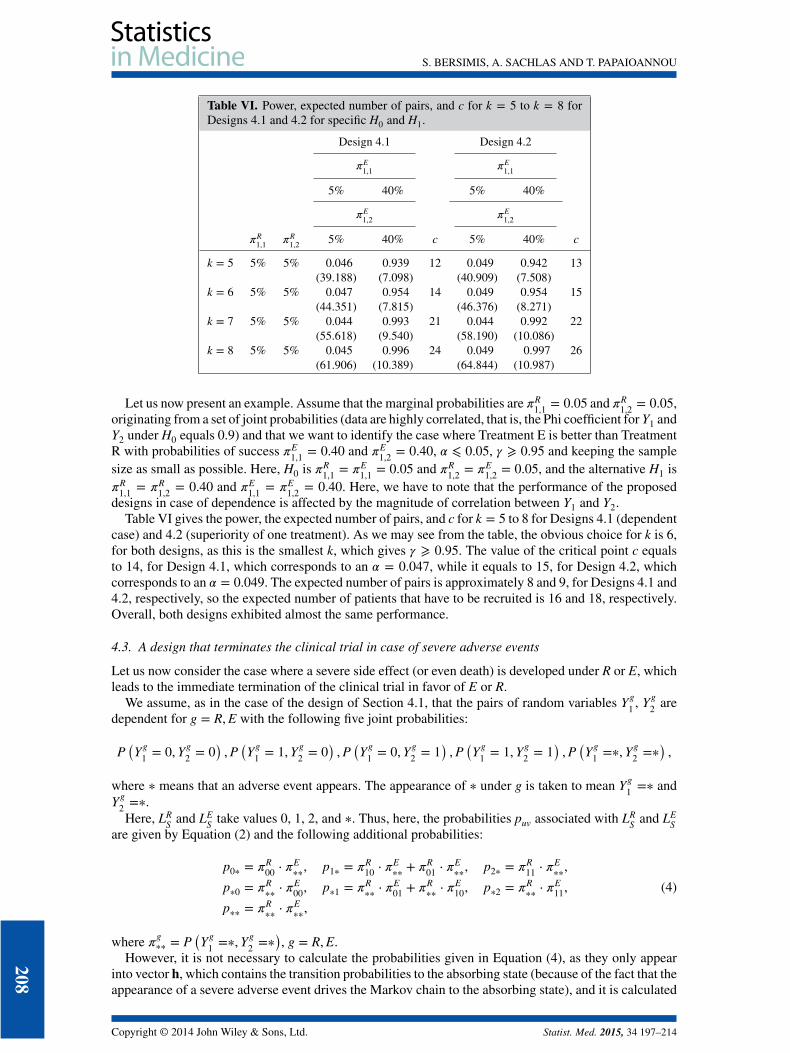
Table VI. Power, expected number of pairs, and c for k = 5 to k = 8 forDesigns 4.1 and 4.2 for specific H0 and H1.
Design 4.1 Design 4.2
𝜋E1,1 𝜋E
1,1
5% 40% 5% 40%
𝜋E1,2 𝜋E
1,2
𝜋R1,1 𝜋R
1,2 5% 40% c 5% 40% c
k = 5 5% 5% 0.046 0.939 12 0.049 0.942 13(39.188) (7.098) (40.909) (7.508)
k = 6 5% 5% 0.047 0.954 14 0.049 0.954 15(44.351) (7.815) (46.376) (8.271)
k = 7 5% 5% 0.044 0.993 21 0.044 0.992 22(55.618) (9.540) (58.190) (10.086)
k = 8 5% 5% 0.045 0.996 24 0.049 0.997 26(61.906) (10.389) (64.844) (10.987)
Let us now present an example. Assume that the marginal probabilities are 𝜋R1,1 = 0.05 and 𝜋R
1,2 = 0.05,originating from a set of joint probabilities (data are highly correlated, that is, the Phi coefficient for Y1 andY2 under H0 equals 0.9) and that we want to identify the case where Treatment E is better than TreatmentR with probabilities of success 𝜋E
1,1 = 0.40 and 𝜋E1,2 = 0.40, 𝛼 ⩽ 0.05, 𝛾 ⩾ 0.95 and keeping the sample
size as small as possible. Here, H0 is 𝜋R1,1 = 𝜋E
1,1 = 0.05 and 𝜋R1,2 = 𝜋E
1,2 = 0.05, and the alternative H1 is𝜋R
1,1 = 𝜋R1,2 = 0.40 and 𝜋E
1,1 = 𝜋E1,2 = 0.40. Here, we have to note that the performance of the proposed
designs in case of dependence is affected by the magnitude of correlation between Y1 and Y2.Table VI gives the power, the expected number of pairs, and c for k = 5 to 8 for Designs 4.1 (dependent
case) and 4.2 (superiority of one treatment). As we may see from the table, the obvious choice for k is 6,for both designs, as this is the smallest k, which gives 𝛾 ⩾ 0.95. The value of the critical point c equalsto 14, for Design 4.1, which corresponds to an 𝛼 = 0.047, while it equals to 15, for Design 4.2, whichcorresponds to an 𝛼 = 0.049. The expected number of pairs is approximately 8 and 9, for Designs 4.1 and4.2, respectively, so the expected number of patients that have to be recruited is 16 and 18, respectively.Overall, both designs exhibited almost the same performance.
4.3. A design that terminates the clinical trial in case of severe adverse events
Let us now consider the case where a severe side effect (or even death) is developed under R or E, whichleads to the immediate termination of the clinical trial in favor of E or R.
We assume, as in the case of the design of Section 4.1, that the pairs of random variables Yg1 , Yg
2 aredependent for g = R,E with the following five joint probabilities:
P(Yg
1 = 0,Yg2 = 0
),P
(Yg
1 = 1, Yg2 = 0
),P
(Yg
1 = 0,Yg2 = 1
),P
(Yg
1 = 1,Yg2 = 1
),P
(Yg
1 =∗,Yg2 =∗
),
where ∗ means that an adverse event appears. The appearance of ∗ under g is taken to mean Yg1 =∗ and
Yg2 =∗.Here, LR
S and LES take values 0, 1, 2, and ∗. Thus, here, the probabilities puv associated with LR
S and LES
are given by Equation (2) and the following additional probabilities:
p0∗ = 𝜋R00 ⋅ 𝜋
E∗∗, p1∗ = 𝜋R
10 ⋅ 𝜋E∗∗ + 𝜋R
01 ⋅ 𝜋E∗∗, p2∗ = 𝜋R
11 ⋅ 𝜋E∗∗,
p∗0 = 𝜋R∗∗ ⋅ 𝜋
E00, p∗1 = 𝜋R
∗∗ ⋅ 𝜋E01 + 𝜋R
∗∗ ⋅ 𝜋E10, p∗2 = 𝜋R
∗∗ ⋅ 𝜋E11,
p∗∗ = 𝜋R∗∗ ⋅ 𝜋
E∗∗,
(4)
where 𝜋g∗∗ = P
(Yg
1 =∗, Yg2 =∗
), g = R,E.
However, it is not necessary to calculate the probabilities given in Equation (4), as they only appearinto vector 𝐡, which contains the transition probabilities to the absorbing state (because of the fact that theappearance of a severe adverse event drives the Markov chain to the absorbing state), and it is calculated
208
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214

S. BERSIMIS, A. SACHLAS AND T. PAPAIOANNOU
Table VII. Power, expected number of pairsand c for k = 5 to 8 for Design 4.3 for aspecific H0 and H1.
𝜋E1,1
5% 45%
𝜋E1,2
𝜋R1,1 𝜋R
1,2 5% 45% c
k = 5 5% 5% 0.050 0.897 9(35.828) (6.014)
k = 6 5% 5% 0.049 0.912 10(41.243) (6.371)
k = 7 5% 5% 0.046 0.914 12(49.742) (7.904)
k = 8 5% 5% 0.047 0.922 13(55.688) (8.329)
using 𝐡 = 𝟏 − 𝚲1𝟏. For exposition reasons, the matrix 𝚲0 in case of k = 3 is given in Appendix A.3. Asit is clear, the general form of 𝐀, 𝐁, and 𝚪 remains the same.
Additionally to (sr)1 - (sr)3, we also now have the following:
• (sr)4: The study is terminated in favor of Treatment E when a severe event due to Treatment R isobserved or
• (sr)5: The study is terminated in favor of Treatment R when a severe event due to Treatment E isobserved.
Now, S equals n if and only if upon the completion of the n-th pair, we have
n∑s=1
LRs ⩾ k or
n∑s=1
LEs ⩾ k or LR
s =∗ or LEs =∗,
and none of the events stated earlier have occurred before the n-th pair.Let us now present an example. Assume that 𝜋R
1,1 = 0.05 and 𝜋R1,2 = 0.05 and that we want to identify
the case where Treatment E is better than Treatment R with probabilities of success 𝜋E1,1 = 0.45 and
𝜋E1,2 = 0.45, 𝛼 ⩽ 0.05, 𝛾 ⩾ 0.90 and keeping the sample size as small as possible. Table VII gives the
power, the expected number of pairs, and c for k = 5 to 8. The obvious choice is k = 6, as this is thesmallest k, which gives 𝛾 ⩾ 0.90. The value of the critical point c equals to 10, which corresponds to an𝛼 = 0.049. The expected number of pairs is approximately 7, so the expected number of enrolled patientsis 14. As our experimentation revealed, the performance of the decision rules is significantly affected bythe probability of the appearance of an adverse event.
This design can be generalized in order to accommodate more than one adverse event by modifyingappropriately the transition probability matrix of the Markov chain.
4.4. The case of more than two endpoints
The new design that we propose in Section 2, which is based on the Markov chain embedding technique,can efficiently handle more general cases, such as the case of more than two endpoints.
For example, let us assume that sequentially patient responses are accrued in terms of three character-istics, say Yg
1 , Yg2 , Yg
3 , g = R,E, where each of them takes two values representing whether the treatmentis successful (1) or not (0). The probability that treatment g is successful with respect to Yi, i = 1, 2, 3 isdenoted by 𝜋
g1,i = P
(Yg
i = 1), while the probability that treatment g is unsuccessful with respect to Yi is
denoted by 𝜋g0,i = P
(Yg
i = 0)= 1−𝜋g
1,i. For each pair of patients s, s = 1, 2,…, we will have six outcomesregarding the success or not of the two treatments on the three characteristics. Thus, in Table I, we willhave a six-dimensional sequence—the first three components of the sequence refer to Treatment R, whilethe next three components refer to Treatment E. Now, LR
s = YR1 +YR
2 +YR3 and LE
s = YE1 +YE
2 +YE2 , while
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214
209

S. BERSIMIS, A. SACHLAS AND T. PAPAIOANNOU
(LR
s ,LEs
)will take values on {0, 1, 2, 3}×{0, 1, 2, 3}. The computation of probabilities puv, u, v = 0, 1, 2, 3
is then straightforward. The transition probability matrix will have a similar form, but its dimension willbe higher.
In the way outlined earlier, we can work in order to extend the proposed design in higher dimen-sions, and the calculation of critical values of the distribution can be obtained using an appropriatecomputer program.
4.5. The case of single-arm clinical trials
The proposed methodology is not only appropriate for comparative clinical trials with two endpointsbut it can also be used in single-arm studies, too. This is performed by considering only sub-rules (sr)1and (sr)3. Specifically, in this case, the null hypothesis of the test is H0 ∶ 𝜋E
1,1 = q1 and 𝜋E1,2 = q2,
where q1 and q2 are known percentages from past studies. The methodology already described can bealso applied in this case. The appropriate transition probability matrix, which is much simpler than theprevious matrices, is given in Appendix A.4.
4.6. Comparisons and results
For reasons of comparison, we will first use a real data example presented in [16], which refers to a non-comparative phase II clinical trial with two efficacy endpoints. To the best of our knowledge, there are nopublished papers on comparative phase II clinical trials with two efficacy endpoints. More specifically,this was a two-stage phase II trial where a new oncology drug for a specific cancer type was evaluatedwith respect to its anti-tumor activity. As endpoint 1, they considered ‘objective response’ determinedby RECIST guidelines [33], while ‘clinical response’ was assessed as endpoint 2, which was defined bythe occurrence of objective response or a prolonged disease stabilization of ⩾ 24 weeks. The successprobabilities were specified as q1 = 0.05, q2 = 0.15 under the null hypothesis and q1 = 0.15, q2 = 0.30under the alternative hypothesis, respectively. The type I error rate was 𝛼 = 5% and the desired power𝛾 = 85%. Lin et al. in [16], through simulations, determined a sample size of n = 63 and a sample sizeof n1 = 38 for the first stage. The estimated type I error rate given in [16] was 0.0496 or 0.0488, and theestimated power amounts to 0.9226 or 0.8994, respectively. Kunz and Kieser in [23], for the same dataset, obtained exact values for significance level and power of 0.0424 or 0.0284 and 0.8979 or 0.8812,respectively. The expected sample size was 52.3. The optimal design [23] subject to the restrictions on 𝛼
and 𝛽 is given by n1 = 25, n = 58 with an expected sample size of 36.8. On the contrary, the minimaxdesign [23] has a maximum sample size of only n = 48 (n1 = 45) but an expected sample size of 45.6.Our design for the single-arm case, for k = 13, leads to an expected sample size of 29.2 patients with𝛼 = 0.048, 𝛾 = 0.910, and c = 39. By taking k = 15, we need to recruit 33.7 patients with 𝛼 = 0.049,𝛾 = 0.947, and c = 47. This means that in both cases, our design, applied to a non-comparative trial,requires less patients than those needed for the first stage of a two-stage design, apart from the optimaldesign. If we consider the aforementioned clinical trial as a comparative one, our method leads to 29.1pairs of patients (i.e., less than 30 patients per treatment) with 𝛼 = 0.044, 𝛾 = 0.816, k = 13, and c = 39.
Letierce et al. in [34] illustrated their method with data from a multi-center comparative phase IIIrandomized clinical trial involving patients with metastatic non-seminomatous germ cell tumors. Theyestimated the type I error rate for 50 patients and 100 patients in each group. We will use the same data inorder to apply our design in the framework of a phase II clinical trial. Here, we have to note that in orderto apply our method (i.e., in order H0 and H1 to be valid), we have to reverse the definition of toxicity.In others words, instead of toxicity, we evaluate non-toxicity. Our method, by taking k = 16, led to theenrollment of 22 patients (10.72 pairs) with 𝛼 ≈ 0.05, power 𝛾 = 0.9, and c = 11.
5. Discussion
In this paper, we propose a new flexible design for comparative phase II trials with two endpoints. Theproposed design is response adaptive in the sense that it terminates the clinical trial after a certain numberof favorable responses have occurred, under the conditions outlined before. Adaptive designs stop theclinical trial because of safety, futility, and/or efficacy (see, e.g., [25,35,36]). It is also flexible in the sensethat after the pre-specified power is achieved, we can take one or two more pairs (i.e., a few number)of patients to increase power. This is quite similar to the sample size re-estimation at interim looks forachieving the desired statistical power (see, e.g., [37]). The main advantage of the proposed method is thatit is an exact method (based on the exact distribution of S), and it does not have any of the shortcomings
210
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214

S. BERSIMIS, A. SACHLAS AND T. PAPAIOANNOU
of the adaptive methods [38, 39]. To the best of our knowledge, this is the first phase II design proposedfor comparing two treatments based on two binary endpoints. We assumed a randomized, comparative,phase II clinical trial where patients are randomly assigned between two treatments, an experimental oneand a reference one. Only two patients are involved at each pair. The first patient is randomly assignedto either the experimental or reference treatment, while the second patient is assigned to the remainingtreatment.
This new design is supplemented with appropriate and also flexible decision rules based on the dis-tribution of the number of pairs passed until a certain number of patients showing improvement on twohealth status related variables appear. The numerical illustration showed a very good performance of thenew design as well as of its modifications. The test terminates the clinical trial early enough (after a fewpairs and thus involving a small number of patients) with high power.
The main practical advantages of this new design and its modifications proposed in this paper are thefollowing:
• direct comparison of two treatments is permitted;• ties can be treated in various ways;• they can be applied in both cases when two efficacy endpoints are of interest and when one effi-
cacy and one safety endpoints are of interest, and thus, they can be applied in an extended class ofproblems;
• they use small number of patients;• they satisfy the ethical requirement of terminating a study as soon as possible;• retain the simplicity of a fixed sample design.
For the mathematical derivation of the new design, the Markov chain embedding technique was usedhere. The use of this technique for designing new decision rules, under a unified framework, was exhibitedin Section 4. The main advantages of the methodology proposed in this paper are the following:
• it offers a unified framework for handling an extensive family of cases because it is too flexible andadaptive;
• it is efficient and computationally feasible;• it permits the exact calculation of the probabilities of type I and II errors as well as the exact power
under different alternatives.
A mathematica program for computing the distribution of S and the critical point based on desiredresponse rates is available upon request.
As further research, we can also investigate the case where the clinical trial is terminated when atotal of k1 cases of subjects showing improvement in both characteristics arise or when a total of k2cases of subjects not showing improvement in both characteristics arise. We can also consider the casewhere the development of a side effect penalizes the corresponding treatment. This can be used as asolution to the problem of handling the case of different k’s for different endpoints (i.e., k1 for the efficacyendpoint and k2 for the adverse event or events). Another extension is to base the decision on waitingtimes related to various forms of scans [29, 30, 40]. Finally, because the method presented in this paperassumes equal weight for the two endpoints, a reasonable extension is to consider unequal weights foreach characteristic.
Appendix A
A.1 The components of the transition probability matrixThe matrices that compose the transition probability matrix 𝚲0 are
𝐀 =
⎡⎢⎢⎢⎢⎢⎢⎢⎢⎣
( ji, 0) ( ji, 1) ( ji, 2) … ( ji, k − 3) ( ji, k − 2) ( ji, k − 1)( ji, 0) p00 p01 p02( ji, 1) p00 p01 ⋱( ji, 2) p00 ⋱ ⋱⋮ ⋱ ⋱ ⋱
( ji, k − 3) p00 p01 p02( ji, k − 2) p00 p01( ji, k − 1) p00
⎤⎥⎥⎥⎥⎥⎥⎥⎥⎦,
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214
211

S. BERSIMIS, A. SACHLAS AND T. PAPAIOANNOU
𝐁 =
⎡⎢⎢⎢⎢⎢⎢⎢⎢⎣
( ji + 1, 0) ( ji + 1, 1) ( ji + 1, 2) … ( ji + 1, k − 3) ( ji + 1, k − 2) ( ji + 1, k − 1)( ji, 0) p10 p11 p12( ji, 1) p10 p11 ⋱( ji, 2) p10 ⋱ ⋱⋮ ⋱ ⋱ ⋱
( ji, k − 3) p10 p11 p12( ji, k − 2) p10 p11( ji, k − 1) p10
⎤⎥⎥⎥⎥⎥⎥⎥⎥⎦,
𝚪 =
⎡⎢⎢⎢⎢⎢⎢⎢⎢⎣
( ji + 2, 0) ( ji + 2, 1) ( ji + 2, 2) … ( ji + 2, k − 3) ( ji + 2, k − 2) ( ji + 2, k − 1)( ji, 0) p20 p21 p22( ji, 1) p20 p21 ⋱( ji, 2) p20 ⋱ ⋱⋮ ⋱ ⋱ ⋱
( ji, k − 3) p20 p21 p22( ji, k − 2) p20 p21( ji, k − 1) p20
⎤⎥⎥⎥⎥⎥⎥⎥⎥⎦,
ji = 0, 1,… , k − 1 for i = 1, 2.The matrix 𝐀 contains the probabilities associated with the transitions of the Markov chain from states
of the form (j1, j2) to states of the form (j1, j2+x), where x = 0, 1, 2. In other words, it describes transitionsof the Markov chain due to various numbers of successes of Treatment E, while Treatment R is totallyunsuccessful. The matrix 𝐁 contains the probabilities associated with the transitions of the Markov chainfrom states of the form (j1, j2) to states of the form (j1 + 1, j2 + x), where x = 0, 1, 2. In other words,it describes transitions of the Markov chain due to various numbers of successes of Treatment E, whileTreatment R is successful to one of the characteristics. The matrix 𝚪 contains the probabilities associatedwith the transitions of the Markov chain from states of the form (j1, j2) to states of the form (j1 +2, j2 +x),where x = 0, 1, 2. In other words, it describes transitions of the Markov chain due to various numbers ofsuccesses of Treatment E, while Treatment R is successful in both characteristics. The null cells of thepreceding matrices are equal to zero.
A.2 Calculating the distribution of S for other values of the parametersLet us assume that 𝜋R
1,1 = 0.05, 𝜋E1,1 = 0.30 and 𝜋R
1,2 = 0.05, 𝜋E1,2 = 0.20. In order to calculate
the distribution of S for some value of k, we have first of all to define the state space Ω and transitionprobability matrix 𝚲0 of the Markov chain {Vs, s = 0, 1, 2,…}. For k = 4, Ω = {(j1, j2) ∶ j1, j2 =0, 1, 2, 3}∪{𝛼d}. The matrices𝐀,𝐁, and𝚪, which are needed to construct the 17×17 transition probabilitymatrix 𝚲0, are
𝐀 =⎡⎢⎢⎢⎣
0.50540 0.34295 0.05415 00 0.50540 0.34295 0.054150 0 0.50540 0.342950 0 0 0.50540
⎤⎥⎥⎥⎦, 𝐁 =
⎡⎢⎢⎢⎣0.05320 0.03610 0.00570 0
0 0.05320 0.03610 0.005700 0 0.05320 0.036100 0 0 0.05320
⎤⎥⎥⎥⎦,
𝚪 =⎡⎢⎢⎢⎣
0.00140 0.00095 0.00015 00 0.00140 0.00095 0.000150 0 0.00140 0.000950 0 0 0.00140
⎤⎥⎥⎥⎦.
Let us now illustrate how these transition probabilities are computed. We shall compute, for example,the value 0.00570 that appears in cells (1,3) and (2,4) of 𝐁. This is the value of p12 = P
(LR
s = 1,LEs = 2
),
which by Equation (2) is computed as the sum of 𝜋R10 ⋅ 𝜋
E11 and 𝜋R
01 ⋅ 𝜋E11. Because 𝜋R
10 ⋅ 𝜋E11 = 0.00285
and 𝜋R01 ⋅ 𝜋
E11 = 0.00285, we have p12 = 𝜋R
10 ⋅ 𝜋E11 + 𝜋R
01 ⋅ 𝜋E11 = 0.00570. A mathematica program for
computing the distribution of S is available upon request.
212
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214

S. BERSIMIS, A. SACHLAS AND T. PAPAIOANNOU
A.3 The transition probability matrix of the Design 4.3The appropriate transition probability matrix 𝚲0 for the Design 4.3 in case of k = 3 is
𝚲0 =
⎡⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣
(0, 0) (0, 1) (0, 2) (1, 0) (1, 1) (1, 2) (2, 0) (2, 1) (2, 2) 𝛼d(0, 0) p00 p01 p02 p10 p11 p12 p20 p21 p22 p(0, 1) p00 p01 p10 p11 p20 p21 p + p22(0, 2) p00 p10 p20 p + p22 + p21(1, 0) p00 p01 p02 p10 p11 p12 p + p2(1, 1) p00 p01 p10 p11 p + p2 + p12(1, 2) p00 p10 p + p2 + p12 + p11(2, 0) p00 p01 p02 p + p1 + p2(2, 1) p00 p01 p + p1 + p2 + p02(2, 2) p00 p + p1 + p2 + p02 + p01𝛼d 1
⎤⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦
,
where
p = p∗∗ + p∗0 + p∗1 + p∗2 + p0∗ + p1∗ + p2∗, p1 = p10 + p11 + p12, and p2 = p20 + p21 + p22.
The null cells of the preceding matrix are equal to zero. As it is clear, the general form of 𝐀, 𝐁, and 𝚪remains the same.
A.4 The transition probability matrix for the case of a single-arm clinical trialThe appropriate transition probability matrix 𝚲0 for the case of a single-arm clinical trial is
𝚲0 =
⎡⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣
0 1 2 … k − 3 k − 2 k − 1 𝛼d0 𝜋00 𝜋01 + 𝜋10 𝜋111 𝜋00 𝜋01 + 𝜋10 ⋱2 𝜋00 ⋱ ⋱⋮ ⋱ ⋱ ⋱
k − 3 𝜋00 𝜋01 + 𝜋10 𝜋11k − 2 𝜋00 𝜋01 + 𝜋10 𝜋11k − 1 𝜋00 𝜋01 + 𝜋10 + 𝜋11𝛼d 1
⎤⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦
,
The null cells of the preceding matrix are equal to zero.
Acknowledgements
The authors would like to thank the Associate Editor and the two anonymous referees for their valuable commentsand suggestions that helped to improve the manuscript.
References1. Pocock SJ. Clinical Trials: A Practical Approach. John Wiley: Chichester, United Kingdom, 1983.2. Zohar S, Teramukai S, Zhou Y. Bayesian design and conduct of phase II single-arm clinical trials with binary outcomes: a
tutorial. Contemporary Clinical Trials 2008; 29(4):608–616.3. Ivanova A, Qaqish BF, Schell MJ. Continuous toxicity monitoring in phase II trials in oncology. Biometrics 2005;
61(2):540–545.4. Ding M, Rosner GL, Muller P. Bayesian optimal design for phase II screening trials. Biometrics 2008; 64(3):886–894.5. Wathen JK, Thall PF, Cook JD, Estey EH. Accounting for patient heterogeneity in phase II clinical trials. Statistics in
Medicine 2008; 27(15):2802–2815.6. Hanfelt JJ. Optimal multi-stage designs for a phase II trial that permits one dose escalation. Statistics in Medicine 1999;
18:1323–1339.7. Stallard N, Thall PF, Whitehead J. Decision theoretic designs for phase II clinical trials with multiple outcomes. Biometrics
1999; 55(3):971–977.8. Schlesselman JJ, Reis IM. Phase II clinical trials in oncology: strengths and limitations of two-stage designs. Cancer
Investigation 2006; 24:404–412.9. Huang WS, Liu JP, Hsiao CF. An alternative phase II/III design for continuous endpoints. Pharmaceutical Statistics 2011;
10:105–114.
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214
213

S. BERSIMIS, A. SACHLAS AND T. PAPAIOANNOU
10. Stallard N, Whitehead J, Todd, S, et al. Stopping rules for phase II studies. British Journal of Clinical Pharmacology 2001;51:523–529.
11. Armitage P, Berry G, Matthews JNS. Statistical Methods in Medical Research 4nd Edn. Blackwell Science Ltd: Oxford,2002.
12. Herrmann N, Szatrowski TH. Curtailed binomial sampling procedures for clinical trials with paired data. ControlledClinical Trials 1985; 6:25–37.
13. Herrmann N, Szatrowski TH. Small sample properties of asymptotic formulas for expected sample size savings in curtailedbinomial tests. Communication in Statistics 1982; C 1:221–245.
14. Chi YC, Chen CM. Curtailed two-stage designs in phase II clinical trials. Statistics in Medicine 2008; 27:6175–6189.15. Kunz CU, Kieser M. Curtailment in single-arm two-stage phase II oncology trials. Biometrical Journal 2012; 54(4):
445–456.16. Lin X, Allred R, Andrews G. A two-stage phase II trial design utilizing both primary and secondary endpoints.
Pharmaceutical Statistics 2008; 7:88–92.17. Thall PF. Some geometric methods for constructing decision criteria based on two-dimensional parameters. Journal of
Statistical Planning and Inference 2008; 138:516–527.18. Jennison C, Turnbull BW. Group sequential tests for bivariate response: interim analyses of clinical trials with both efficacy
and safety endpoints. Biometrics 1993; 49:741–752.19. Conaway MR, Petroni GR. Bivariate sequential designs for phase II trials. Biometrics 1995; 51:656–664.20. Thall PF, Cheng SC. Treatment comparisons based on two-dimensional safety and efficacy alternatives in oncology trials.
Biometrics 1999; 55:746–753.21. Lu Y, Jin H, Lamborn KR. A design of phase II cancer trials using total and complete response endpoints. Statistics in
Medicine 2005; 24:3155–3170.22. Chen CM, Chi Y. Curtailed two-stage designs with two dependent binary endpoints. Pharmaceutical Statistics 2012;
11:57–62.23. Kunz CU, Kieser M. Optimal two-stage designs for single-arm phase II oncology trials with two binary endpoints. Methods
of Information in Medicine 2011; 50:372–377.24. Hou W, Chang MN, Jung SH, Li Y. Designs for randomized phase II clinical trials with two treatment arms. Statistics in
Medicine 2013; 32:4367–4379.25. Chow SC, Chang M. Adaptive design methods in clinical trials - a review. Orphanet Journal of Rare Diseases 2008; 3:11.26. Thall PF, Wooten LH, Shpall EJ. A geometric approach to comparing treatments for rapidly fatal diseases. Biometrics
2006; 62:193–201.27. O’Connor PW, Li D, Freedman MS, Bar-Or A, Rice GPA, Confavreux C, Paty DW, Stewart JA, Scheyer R. A phase II
study of the safety and efficacy of teriflunomide in multiple sclerosis with relapses. Neurology 2006; 66:894–900.28. Lou WYW. On runs and longest run tests: a method of finite Markov chain imbedding. Journal of American Statistical
Association 1996; 91:1595–1601.29. Glaz J, Naus J, Wallenstein S. Scan Statistics. Springer: New York, 2001.30. Balakrishnan N, Koutras MV. Runs and Scans with Applications. John Wiley: New York, 2002.31. Balakrishnan N, Bersimis S, Koutras MV. Run and frequency quota rules in process monitoring and acceptance sampling.
Journal of Quality Technology 2009; 41(1):66–81.32. Elfring GL, Schultz JR. Group sequential designs for clinical trials. Biometrics 1973; 29:471–477.33. Therasse P, Arbuck SG, Eisenhauser EA, Wanders J, Kaplan RS, Rubinstein L, Verweij J, Van Glabbeke M, van Oosterom
AT, Christian MC, Gwyther SG. New guidelines to evaluate the response to treatment in solid tumours. Journal of theNational Cancer Institute 2000; 92:205–216.
34. Letierce A, Tubert-Bitter P, Kramar A, Maccario J. Two-treatment comparison based on joint toxicity and efficacy orderedalternatives in cancer trials. Statistics in Medicine 2003; 22:859–868.
35. Chow SC, Chang M, Pong A. Statistical consideration of adaptive methods in clinical development. Journal of Biophar-maceutical Statistics 2005; 15:575–591.
36. Posch M, Bauer P. Adaptive two-stage designs and the conditional error function. Biometrical Journal 1999; 41:689–696.37. Shih WJ. Group sequential, sample size re-estimation and two-stage adaptive designs in clinical trials: a comparison.
Statistics in Medicine 2006; 25:933–941.38. Karrison TG, Huo D, Chappell R. A group sequential, response-adaptive design for randomized clinical trials. Controlled
Clinical Trials 2003; 24(5):506–522.39. Chow SC, Chang M. Adaptive Design Methods in Clinical Trials. Chapman and Hall/CRC Press, Taylor and Francis: New
York, 2006.40. Bersimis S, Koutras MV, Papadopoulos G. Waiting time for an almost perfect run and applications in statistical process
control. Methodology and Computing in Applied Probability 2014; 16:207–222.
214
Copyright © 2014 John Wiley & Sons, Ltd. Statist. Med. 2015, 34 197–214




















