
ELABORAÇÃO DE ESCOPO DE LABORATÓRIOS DE ENSAIOS E DE PROVEDORES DE ENSAIOS DE PROFICIÊNCIA
Upload
independentCategory
view
5download
0
Exploration of Motion Estimation Algorithms in Graphic Processing Environments
Exploração de Algoritmos de Estimativa de Movimento emAmbiente de Processamento Gráfico
Ronaldo HusemannDELET – UFRGS
Av. Osvaldo Aranha, 103Porto Alegre – RS – [email protected]
Augusto L. Lenz, Marco GobbiUNIVATES
Av. Alberto Tallini, 171Lajeado – RS – Brasil
[email protected]@universo.univates.br
Valter Roesler, José Valdeni LimaII – UFRGS
Av. ~Bento Gonçalves, 9500 B. IVPorto Alegre – RS – Brasil
[email protected]@inf.ufrgs.br
ABSTRACTCurrently, even considering the recent advances in themicroprocessor power computing, high definition multimediaapplications still require very complex demands to allow real-timevideo encoding. Particularly, modern video encoders (MPEG/ITUH.26x series) depend of complex and computationally exhaustivemotion estimation algorithms to identify and remove temporalredundancy among consecutive (or not) frames inside a videosequence, as strategy to reduce the final compressed bit rate. Infact, the mechanism of block matching can be considered the mostcritical encoder algorithm, in terms of computational demands,like it is responsible for searching, in distinct reference frames, forsimilar pixel blocks related with each one of the input imageblocks. The number of required block comparisons for highdefinition videos represents a clear and important restriction forreal-time implementations. This paper introduces an improvedstrategy of block matching method, which was optimized formultiprocessing execution, mainly focusing in implementationover general purpose graphical processing unit technologies, asthe NVidia CUDA® GPUs. The improved motion estimationsolution was implemented in the JSVM reference code (scalableversion of H.264 video encoder), when it was registered a speedup gain of more than 350% in average for 4CIF videos.
Categories and Subject DescriptorsD.1.3 [Concurrent Programming]: Parallel programming
General TermsAlgorithms, Performance, Design.
KeywordsSAD method, H.264 encoding, CUDA.
1. INTRODUÇÃOImpulsionado pela indústria do entretenimento, a demanda
pelo emprego de complexos codificadores de vídeo tem crescidomuito nos últimos anos. Estes codificadores, que são responsáveis
por comprimir as informações de vídeo, reduzindo suas demandaspor espaço, requerem entretanto computação intensa, tornandonecessárias técnicas computacionais sofisticadas, muitas vezesimplementadas em hardware (usando, por exemplo, componentesdo tipo ASIC - Application Specific Integrated Circuit), paratornar possível sua execução com características de tempo real [1]
A implementação de modernos padrões de codificação, paraprocessar vídeos de alta definição, através de soluções somentepor software é ainda um grande desafio. Para se ter uma idéiadesta complexidade, pode-se considerar os resultados de [2] queapontam que um codificador de vídeo H.264, padrão ITU-T de2002, para operar sobre vídeos de alta definição, chega a exigirdemandas de até 3,6 TIPS (Tera Instructions Per Second).
Basicamente, dentro de um codificador de vídeo, se destacampor sua complexidade os algoritmos de estimativa de movimento.Estes algoritmos realizam processos extensivos de pesquisa ecomparação, sobre sequências de imagens, responsáveis poranalisar para cada bloco de pixels da imagem de entrada pelaposição mais provável para onde este possa ter se movido dentrouma determinada janela de busca. Quando esta movimentação édetectada o codificador pode apenas guardar esta informação,dispensando a necessidade de retransmitir dados já recebidos pelodecodificador.
Uma estratégia possível para atender a altas demandascomputacionais como dos algoritmos de estimativa demovimento, se baseia no uso de processadores gráficos de altodesempenho como motores de co-processamento, auxiliando ocomputador na realização de algoritmos de alta complexidadecomputacional. Os modernos processadores gráficos (GraphicalProcessing Units – GPUs) possuem uma arquitetura altamenteparalela, compostas por centenas de núcleos operacionais, quepermitem executar em um mesmo ciclo de instrução um grandenúmero de procedimentos simultâneos. Esta forma de organizaçãoé particularmente apropriada para processamento de gráficos emduas ou três dimensões (3D), mas também pode ser empregada naimplementação de uma grande diversidade de algoritmos emdiversos outros campos [3]. Este conceito é genericamentechamado de General Purpose Graphics Processing Unit(GPGPU), uma vez que visa explorar o poder de processamentodas placas aceleradoras de vídeo em aplicações nãonecessariamente gráficas [4].
Considerando este cenário, o presente artigo apresenta umaanálise investigativa do uso da tecnologia de GPGPU NVIDIACUDA® como plataforma de desenvolvimento para aumento develocidade de um algoritmo de estimativa de movimento, voltado
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copies arenot made or distributed for profit or commercial advantage and thatcopies bear this notice and the full citation on the first page. To copyotherwise, or republish, to post on servers or to redistribute to lists,requires prior specific permission and/or a fee.Webmedia12, Outubro 15-18, 2012, São Paulo, Brazil.Copyright 2012 ACM 1-58113-000-0/00/0010 …$15.00.

Exploration of Motion Estimation Algorithms in Graphic Processing Environments
para uma solução aplicável para qualquer codificador de vídeoH.264 compatível.
Dentro deste enfoque, foi produzida uma versão de estimadorotimizada para suportar elevado grau de paralelismo, tornando-seassim mais adequada para implementação em arquiteturas deprocessamento paralelo, como é o caso destas modernas GPUs.
Como estratégia de validação da solução proposta, esta foiimplementada sobre o software de referência JSVM, que édisponibilizado pela entidade JVT (Joint Vídeo Team), paradesenvolvedores de soluções de codificação baseadas no H.264SVC (Scalable Vídeo Coding), versão mais recente do codificadorITU-T H.264 [4].
Os resultados obtidos comparando-se a nova arquitetura deestimativa de movimento em ambiente de computaçãoconvencional (monoprocessador) com uma solução em placa deprocessamento gráfico apontam para ganhos de desempenhobastante relevantes.
O artigo é organizado da seguinte maneira: a seção 2 trazuma visão geral de mecanismos de estimativa de movimento, aseção 3 apresenta a arquitetura GPGPU NVIDIA CUDA; a seção4 apresenta alguns trabalhos relacionados; a seção 5 descreve aarquitetura da solução de estimativa de movimento proposta; aseção 6 mostra os dados reais obtidos comparando o métodoproposto com uma arquitetura tradicional e finalmente a seção 7apresenta as considerações finais do artigo.
2. ESTIMATIVA DE MOVIMENTOO módulo de estimativa de movimento procura explorar a
redundância temporal existente entre imagens de um mesmovídeo. A pesquisa por movimentação ocorre no nível de blocos depixels e é feita normalmente em uma janela de busca de tamanhofixo em imagens de referência (já previamente recebidas),utilizando-se um determinado critério de similaridade. Dentre osdiferentes mecanismos de cálculo de similaridade, o mais comumé o SAD (Sum of Absolute Differences), que apresenta o erroresidual entre dois blocos pelo cálculo das diferenças absolutasentre pixels. Este algoritmo é bastante utilizado, pois utilizaapenas operações triviais como somas e subtrações, enquanto queoutros cálculos alternativos de similaridade como o MSE (MeanSquare Error) ou SSE (Sum of Square Errors), demandam poroperações de multiplicação ou outras funções ainda maiscomplexas [1].
Abaixo se apresenta a expressão usada para o cálculo deSAD entre dois blocos de pixels.
SAD = ∑ ∑ abs (PSij – PRij)Onde:
PSij = Valor do pixel do bloco de origem localizado naposição (i,j);
PRij = Valor do pixel do bloco de referência localizadona posição (i,j).
Durante um processo de estimativa de movimento, o blocode pixels da imagem de referência que apresentar o menor valorde SAD terá o menor erro residual e por este motivo deverá serselecionado como a melhor estimativa de movimento encontrada.Sua distância em relação ao bloco atual é chamada de vetor demovimento e salvo como resultado do algoritmo de busca.
O algoritmo de estimativa de movimento que gera o vetor demovimento mais preciso é conhecido como algoritmo de pesquisacompleta (full search), uma vez que pesquisa na totalidade dajanela de busca da(s) imagem(s) de referência pelo bloco de pixelsmais próximo possível do bloco da imagem atual.
Este procedimento é efetuado para todos os possíveis blocosimagem, buscando verificar se o bloco alvo foi movimentado paraqualquer outro ponto da imagem, não importando o quão longeesteja do ponto original dentro da janela de busca. Pelo fato doalgoritmo de busca completa analisar todas as opções possíveis dedeslocamento, ele consegue determinar com precisão o melhorvetor de movimento para aquela região pesquisada.
Apesar, entretanto, de obter o melhor resultado, na práticaeste procedimento de busca completa não costuma ser muitoutilizado, devido ao fato de demandar um custo computacionalmuito elevado. Além disso, dificilmente num vídeo ocorremgrandes movimentações de uma imagem em relação à anterior, oque indica que a maior parte dos procedimentos de buscacompleta seria desnecessária.
Visando otimizar o método full-search, surgiram osalgoritmos de busca esparsa. A principal característica destesalgoritmos é de que eles não analisam todos os blocos da janela debusca, mas sim buscam por um padrão que infere o melhorcaminho para encontrar o bloco mais parecido.
Alguns dos algoritmos mais conhecidos são o Three-StepSearch (TSS), um dos primeiros desta linha [5], e também suasevoluções, o New Three-Step Search (NTSS) [6] e o Four StepSearch (4SS) [7].
Um mecanismo alternativo de busca esparsa foi proposto porChung [8], trabalhando com cálculos estatísticos visando otimizara área de busca.
Outra proposta menos intensiva computacionalmente e queleva a menores erros foi apresentada por Shan Zhu, e ficouconhecida como Diamond Search (DS), empregando dois padrõesde busca: diamante grande e diamante pequeno [9].
Na implementação do presente trabalho, utilizou-se apenas atopologia de diamante pequeno para estimativa de movimento,pois este padrão além de mais simples, se ajusta bem a aplicaçõesque apresentam nível pequeno e médio de movimentação [10].
Uma ilustração do padrão de busca em diamante pequenoestá representada na Figura 1. Neste padrão, sempre que umabusca for iniciada, deve-se conferir o bloco inicial em relação aobloco na posição imediatamente superior, imediatamente inferiore aos seus vizinhos laterais (direita e esquerda).
Na Figura 1, a posição inicial é identificada pelo no círculoclaro, no centro do diamante, enquanto que os blocos vizinhos sãocírculos escuros.

Exploration of Motion Estimation Algorithms in Graphic Processing Environments
Figura 1. Visão geral da topologia de diamante pequeno.No primeiro estágio da busca, o bloco original é comparado
com todos os quatro blocos vizinhos utilizando a métrica SAD,partindo-se do bloco superior e seguindo-se o sentido horário paracomparar os demais. O bloco que obtiver o menor resultado deerro absoluto indica o caminho para o próximo estágio. Se doisvalores de SAD forem iguais deve-se escolher o primeiro bloco nasequencia definida (partindo-se do bloco superior no sentidohorário). O algoritmo encerra a busca quando encontra o menorerro no centro do diamante.
3. TECNOLOGIA GPU NVIDIANos últimos anos, as demandas crescentes por processamento
tridimensional de placas aceleradoras gráficas, impulsionaramavanços das arquiteturas de processadores gráficos dedicados.Apesar do crescimento deste mercado, porém, as ferramentas elinguagens disponíveis para desenvolvimento de aplicações deprocessamento gráfico (ex. OpenGL) não se mostravamadequadas para outros propósitos mais gerais tais como aplicaçõescientíficas. Este cenário se modificou com a decisão das empresasfabricantes de processadores gráficos em disseminar o uso destasplataformas para fins não gráficos. Um fato marcante foi olançamento, em 2006, da plataforma de software e hardwareCUDA, que visava estimular exatamente este mercado.
CUDA é uma arquitetura de computação paralela depropósito geral que faz uso da capacidade de processamentopresente nas GPUs da empresa NVIDIA. A arquitetura CUDAdefiniu duas alterações principais na organização das GPUs: aunificação dos shaders (vertex e pixel shaders) e a criação de umamemória compartilhada de alto desempenho. O componenteresultante da união dos shaders é chamado Stream Processor(SP). Essas alterações transformaram as GPUs em dispositivosmais adequados ao processamento de propósito geral [11].
Grupos de threads (tarefas independentes previstas peloalgoritmo) podem ser escalonados para execução em um dosnúcleos, sequencialmente ou simultaneamente, sem que sejanecessário explicitar em qual núcleo o bloco será alocado,tornando assim a solução mais flexível.
As placas de vídeo compatíveis com a tecnologia CUDApossuem um conjunto escalável de multiprocessadores, que sãochamados Streaming Multiprocessors (SMs). Os SMs sãocompostos por uma série de processadores escalares (scalarprocessors – SP), uma unidade de instrução multi thread ememória compartilhada. Os blocos de threads criados peloalgoritmo são escalonados automaticamente para execução emSMs com capacidade ociosa. As threads dentro de um mesmobloco são executadas concorrentemente, pois cada thread émapeada em um SP, com seus próprios registradores (Figura 2)[12].
O escalonador de threads separa-as em grupos, chamadoswarps. A cada ciclo de operação um warp é selecionado paraexecução, então a mesma instrução pode ser executada em todasas threads ativas neste warp [11].
Apesar de todas threads começarem a execução no mesmoponto do código, há a possibilidade de que haja ramificação naexecução (ex. conflito no acesso a memórias). Neste caso, nemtodas as threads estarão ativas no mesmo momento, resultando naserialização da execução. Portanto, para que seja alcançadaeficiência máxima na execução paralela das threads é necessárioque não hajam ramificações no fluxo de execução dentro de ummesmo warp [13].
A organização das threads se dá na forma de blocos comuma, duas ou três dimensões. Esse arranjo particular torna simplesa execução de cálculos em elementos de vetores, matrizes ouvolumes. A identificação da thread que está sendo executada éimplementada através de índices que identificam a posição dathread dentro do bloco (Figura 2). Os índices são disponibilizadosao programador através da variável tridimensional threadIdx quecontém três campos de inteiros sem sinal: x, y, z. As threads queresidem no mesmo bloco são executadas no mesmo SM podendocooperar entre si através do compartilhamento de dados (pelamemória compartilhada) e da sincronização da execução comfunções intrínsecas que servem como barreiras na execução, deforma que a execução prossiga apenas quando todas as threadstiverem finalizado a execução de uma determinada sequência deinstruções.
Figura 2 Organização das threads em uma arquitetura CUDA
Além do alinhamento de threads internas é interessanteobservar as características dos diferentes tipos de memóriapresentes nesta arquitetura, uma vez que sua adequada utilizaçãopode influenciar diretamente o desempenho do algoritmodesenvolvido. Na prática são cinco tipos de memórias previstos:
• Memória local e registradores;
• Memória compartilhada;
• Memória global;
• Memória de textura;
• Memória de constantes;

Exploration of Motion Estimation Algorithms in Graphic Processing Environments
Os registradores são utilizados para armazenar as variáveisautomáticas (variáveis locais). Se não houver espaço suficiente, ocompilador alocará as variáveis na memória local. Como amemória local está localizada fora do chip esta apresenta tempoacesso elevado [14]. A memória local é apenas uma abstraçãosobre a memória global, com escopo limitado a cada thread [15].
A memória compartilhada está localizada dentro de cadamultiprocessador, por isso, possui latência cerca de cem vezesmenor do que a memória global ou local, porém o tamanho totaldesta memória é reduzido [14]. A memória compartilhada podeser utilizada como uma memória cache explicitamente gerenciada.A memória compartilhada é organizada em bancos, ou seja,módulos que podem ser acessados simultaneamente, a fim deobter uma alta largura de banda. Essa arquitetura permite quediversas requisições simultâneas, que acessem endereçoslocalizados em diferentes bancos, possam ser atendidas ao mesmotempo. Por outro lado, se uma requisição de acesso à memóriacontiver acessos em endereços localizados no mesmo bancopoderá haver um conflito de acesso. A ocorrência de conflitos sedá quando mais de uma thread pertencente ao mesmo half-warp1
solicitam acesso a posições de memória que localizam-se em ummesmo banco. Há uma exceção no caso de todas threads de umhalf-warp executarem leituras no mesmo endereço. Neste caso oconteúdo lido é disponibilizado para todas as threads através deuma operação de transferência global (broadcast).
A memória global está localizada na placa de vídeo, noentanto, não sendo integrada ao chip da GPU, possui alta latênciano acesso. Esta memória pode ser acessada através de transaçõesalinhadas de 32, 64 ou 128 bytes. Na prática, o endereço doprimeiro elemento manipulado precisa ser um múltiplo dotamanho do segmento. As requisições de acesso à memória globalefetuadas por um half-warp ou por um warp são combinadasresultando na menor quantidade de transações possível, queobedeça as regras de alinhamento impostas pela arquitetura dehardware. A Figura 3 ilustra padrões de acesso que permitem oacesso coalescido, ou seja, o acesso a várias posições de memóriaem apenas uma transação. Desta forma, os efeitos da latência deacesso são diluídos. A figura (a) exemplifica o acesso coalescido avariáveis float de quatro bytes. A figura (b) ilustra o acessocoalescido por um warp divergente, quando nem todas as threadsacessam as respectivas variáveis.
Figura 3 Padrões de acesso coalescido
1 Half-warp é um grupo de threads, com metade do tamanho deum warp.
A memória de textura ou superfície está localizada namemória da placa de vídeo e possui cache otimizado para acesso adados que apresentem localidade espacial em duas dimensões, ouseja, dados localizados em posições próximas. Além disso, esseespaço de memória é projetado de forma a obter fluxos de leituracom latência constante. Dessa forma, uma leitura do cache reduz alargura de banda demandada, mas a latência se mantém constante.Quando um warp necessita de um dado que está presente nocache há um ganho significativo no tempo de leitura. Caso o dadonão esteja disponível no cache o tempo de acesso será o mesmo deuma leitura na memória global convencional. A memória detextura pode ser escrita a partir do computador externo, mas doponto de vista da GPU é uma memória somente de leitura.
Por fim, a memória de constantes está localizada nodispositivo e possui também memória cache. Possui acessosomente de leitura pela GPU. Esta memória pode ser utilizadapelo compilador através de instruções específicas [14].
4. TRABALHOS RELACIONADOSPor se tratar de uma área bastante relevante, diversos autores
da comunidade acadêmica têm buscado a utilização destatecnologia como forma de aprimoramento do desempenho decodificadores de vídeo [15-18].
O trabalho [15], por exemplo, propõe um algoritmo rápidopara cálculo de estimativa de movimento visando aplicação diretasobre um codificador H.264/AVC a partir da exploração daplataforma CUDA. Foi escolhido, para este trabalho, o algoritmode estimativa por busca completa (full search) para estafinalidade. Na solução desenvolvida, inicialmente, pixels do blocoatual e do quadro de referência são transferidos do domínio daCPU para a memória da GPU. As threads implementadas na GPUprocessam e acumulam seus resultados na memória compartilhadada placa. A operação de comparação de resultados (SADs dosdiferentes blocos) assim como o algoritmo de soma de diferenças(SAD) em si basicamente exploram o mesmo algoritmodestacando-se apenas, que para o caso das comparações sãoutilizadas operações acumuladas de subtração e não de soma.Resultados de simulação mostram que o apoio da GPU chega agerar uma implementação cerca de 40 a 60% mais rápida quandocomparada com uma solução baseada unicamente em uma CPU.
Por sua vez, o trabalho [16], em comparação, implementauma solução de estimativa de movimento baseado em umalgoritmo esparso rápido de diamante pequeno (small diamond).Este algoritmo foi especialmente adaptado para explorar ascaracterísticas de processamento paralelo de modernas GPUs(assim como as larguras das diferentes memórias envolvidas).Como forma de validação os resultados obtidos com a soluçãootimizada para GPU foram comparados com o algoritmoUMHexagonS implementado para uma solução tradicional deCPU.
Os testes práticos foram feitos sobre o software de referênciaJM9.0 (modelo de código aberto do codificador H.264), o qual foiestendido, na solução proposta, através do uso da API DirectX 9como forma prática de acessar a GPU. Os resultados de melhoriade desempenho obtidos por esta solução otimizada apontarampara ganhos entre 1,5 e 3 vezes em relação a uma solução baseadaem CPU somente.

Exploration of Motion Estimation Algorithms in Graphic Processing Environments
5. ALGORITMO PROPOSTOVisando-se contribuir com uma solução que pudesse
aumentar o desempenho de algoritmos de estimativa demovimento compatíveis com o padrão H.264, foi desenvolvidauma proposta que alinha a localidade de dados deste tipo dealgoritmo com a estrutura interna de processadores gráficoscompatível com a arquitetura CUDA.
Conforme comentado, o algoritmo escolhido se baseia natopologia de busca por diamante pequeno. A ideia proposta estácentrada na paralelização do mecanismo de cálculos desimilaridade por SAD, que trabalha a cada vez com dois blocos depixels.
O projeto, desenvolvido sob a forma de aplicativo CUDA,executa os cálculos de similaridade SAD, valendo-se do conceitode que cada diferença absoluta de pixel de uma dada posição podeocorrer de forma independente e totalmente paralela em relaçãoaos demais pixels vizinhos. Esta condição permite adequar oalgoritmo para explorar um elevado nível de paralelismo.
Conforme visto na seção anterior, para a tecnologia CUDA,este paralelismo deve ser traduzido em threads, que, em últimainstância, podem ser interpretadas como unidades de execuçãosimultâneas.
Particularmente, na implementação proposta, cada módulode cálculo de cálculo de SAD foi estruturado para uma grade comtamanho básico de 16x8 threads. O tamanho desta grade dethreads é calculado dinamicamente de forma a acomodar osquadros em diferentes resoluções.
De forma geral, o tamanho de bloco de 16x8 elementospermite uma arquitetura de 128 threads para esta implementação.Na prática, o algoritmo de cálculo de SAD utiliza estas 128threads durante os cálculos de diferença absoluta entre pixels dosdois blocos analisados, enquanto que as tomadas de decisão doalgoritmo de busca são realizadas apenas pela thread (0,0).
Uma ilustração deste procedimento, conforme proposto, éapresentada na Figura 4, onde se observa à esquerda a imagem dereferência e à direita a imagem corrente em processo decodificação.
Figura 4 Alinhamento dos dados com o processador gráfico,conforme proposto.
Na prática, o cálculo completo de um SAD consiste em duasoperações sequenciais:
(i) obtenção da diferença absoluta para cada pixel dosblocos analisados (bloco de pixels do quadro dereferência em relação ao bloco atual da imagem que estásendo codificada);
(ii) somatório dos resultados anteriormente calculados.
A implementação dessas operações foi feita utilizando ainstrução de baixo nível usad que recebe três argumentos ecalcula a soma da diferença absoluta dos dois primeirosargumentos com o terceiro. Essa instrução de baixo nível executaas duas operações (diferença absoluta e soma) com maiorvelocidade quando comparada com a implementação dessasoperações em código de mais alto nível (linguagem C), que seriatraduzido em um maior número de instruções pelo compilador.Além disso, a capacidade da instrução de realizar as duasoperações conjuntamente permite acelerar a primeira etapa doalgoritmo de redução através da junção do cálculo da diferençaabsoluta e a primeira etapa do somatório de resultados [19].
Para entender melhor este procedimento, pode-se consideraro caso de blocos de 16x16 (macrobloco padrão H.264). Nestecaso, inicialmente calcula-se a diferença absoluta dos 128 últimospixels (parte inferior do macrobloco). A seguir, obtém-se adiferença absoluta dos 128 primeiros pixels (parte superior) e, namesma instrução, soma-se esse resultado com as diferençasobtidas na etapa anterior.
A partir deste resultado (vetor de 128 elementos), dá-seinício ao procedimento de redução (em verdade o primeiro estágiode redução já foi implementado no sequenciamento das duasinstruções usad a partir da soma dos dois vetores de 128elementos em um apenas). A seguir, o número de threads ativasutilizadas é reduzido para 64 (cada qual somando dois elementosvizinhos) e, posteriormente, para 32. Após isso, as threadscontidas no último warp (cada warp comporta 32 threads)realizam os estágios restantes do algoritmo de redução. Ao fim doprocesso, o vetor tem apenas um valor que é o somatório dasdiferenças absolutas.
A Figura 4 ilustra o procedimento da redução implementado[19]. Na figura se demonstra como um vetor de 16 elementos seriatratado para permitir o somatório de todos seus elementos emapenas cinco ciclos de operação.
É interessante observar também como, a cada etapa, onúmero de threads ativas reduz à metade, sempre lendo eescrevendo na mesma memória, chegando, no último estágio,apenas uma thread ativa para determinar o valor final desejado.
Após o cálculo do SAD para as cinco posições da busca emdiamante (centro, cima, baixo, direita e esquerda), são realizadosos testes para determinar qual a posição possui o menor SAD(maior similaridade) e, portanto, se a busca deve ser executadamais uma vez ou se a obtenção do vetor de movimento chegou aofim.

Exploration of Motion Estimation Algorithms in Graphic Processing Environments
Figura 5. Procedimento de redução utilizado para o cálculo dovalor de SAD.
Além do alinhamento entre threads e posições dos elementosinternos a serem manipulados no cálculo de SAD, também foibuscado o melhor uso das memórias da plataforma. Isso é muitoimportante, pois as memórias disponíveis possuem diferentesvelocidades de acesso, produzindo efeito direto sobre odesempenho global da solução proposta.
O quadro de referência a ser utilizado pelo algoritmo, porexemplo, foi armazenado na memória de texturas, a qual possuiestrutura de cache otimizada para dados com localidade 2D [20].
Essa característica é particularmente apropriada devido ànatureza do acesso aos pixels do quadro de referência, ondethreads vizinhas acessam posições adjacentes da memória e, acada iteração do algoritmo de busca, a posição acessada serádeslocada em uma posição.
Já as variáveis de controle, índices e resultadosintermediários foram armazenados na memória compartilhada, afim de que possam ser acessados por diferentes threads residentesem um mesmo bloco.
Esta decisão permitiu uma significativa redução na latênciado algoritmo de controle em si.
Por fim, o quadro a ser codificado e os resultados a seremlidos pelo aplicativo no microprocessador da placa mãe residemna memória global.
Isso, pois a cada vez que uma transferência de dados érealizada, estes devem ser armazenados na memória global. Esta éuma memória mais lenta, motivando que o algoritmo propostobuscasse reduzir o número de acessos à memória global, a qual foiassim usada apenas como interfaces de entrada e saída de dadosda placa.
As transferências de dados entre o computador e a placaocorrem com pacotes que comportam a cada transferênciamúltiplos macroblocos H.264 (16x16 pixels), o que permitiureduzir também as latências de comunicação entre o aplicativoprincipal e o algoritmo em GPU (latências estas fortementedependentes do sistema operacional) [7]
6. RESULTADOS EXPERIMENTAISA experimentação prática da solução proposta fez uso do
software de referência JSVM (Joint Scalable Video Model) queimplementa o codificador H.264/SVC [21]. O padrão SVC(Scalable Video Coding) é um anexo à norma H.264, que trata dacodificação de vídeo escalável. No entanto, nestes experimentos,não foi prevista a exploração dos conceitos de escalabilidade dacodificação, trabalhando o aplicativo apenas como um codificadorH.264 compatível.
O software JSVM precisou ser adaptado para tornar possívelexpor à GPU um conjunto de dados suficientemente grande paraque se pudesse fazer uso eficiente da arquitetura paralela emquestão.
Na implementação original do software de referência, omódulo de estimativa de movimento recebe um macrobloco,processa-o e devolve os resultados. A alteração realizada fez comque o módulo em questão tenha acesso ao quadro inteiro, deforma a entregar à placa de vídeo, de uma só vez, um conjunto dediversos macroblocos a serem processados.
Nos experimentos realizados foram avaliadas duas situações:variabilidade de movimentação (diferentes sequências de vídeo) ediferença na resolução dos vídeos avaliados.
O ambiente utilizado no desenvolvimento e experimentaçãoé composto por um computador com processador Intel Core 2Quad de 2,66GHz com 2 GB de memória RAM e utilizando-seuma placa de vídeo NVIDIA GTX 560 Ti. Nos experimentos, foiutilizado sistema operacional GNU/Linux (distribuição Ubuntu,versão 11) e o toolkit CUDA versão 4.2, que contém ocompilador e demais ferramentas necessárias ao desenvolvimentode programas que utilizem a GPU.
As tabelas a seguir resumem os resultados de ganho develocidade registrados comparando-se a implementação doalgoritmo proposto na placa gráfica em relação ao mesmoalgoritmo sendo executado no processador principal docomputador (atrasos de comunicação entre computadores placagráfica estão inclusos nestas medições).
A tabela 1 traz os resultados obtidos para a avaliação devídeos em resolução QCIF (144x176 pixels).
Tabela 1. Ganho de desempenho para vídeos QCIF
Vídeo médio máximo
City 1,03 1,43
Crew 1,04 1,61
Harbour 0,79 1,06
A análise dos resultados da Tabela 1 aponta para pequenosganhos de desempenho nesta condição (inclusive para o vídeoHarbour a solução em GPU foi, em média, mais lenta que asolução em CPU). O fato que explica este baixo desempenho é arelação entre o tamanho dos pacotes transferidos comparado como tempo total de execução.
Exploration of Motion Estimation Algorithms in Graphic Processing Environments
Para volumes pequenos de dados o tempo de transferência dedados entre computador e placa gráfica se torna significativo, oque limita bastante o desempenho da solução.
Já a tabela 2 apresenta traz os resultados obtidos para aavaliação do mesmo algoritmo, porém, neste caso avaliandovídeos em resolução CIF (288x356 pixels).
Tabela 2. Ganho de desempenho para vídeos CIF
Vídeo médio máximo
City 1,85 2,37
Crew 2,22 3,73
Harbour 1,47 2,01
Conforme comentado o tamanho dos pacotes transferidosafeta o desempenho global do sistema. Para vídeos maiores, com éo caso da resolução CIF, o ganho se apresentou com maiorevidência chegando a ser em média cerca de duas vezes maisrápido na solução em GPU.
O menor ganho de desempenho para o vídeo Harbour emrelação aos demais (City e Crew) se justifica, pois este é um vídeocom movimentação horizontal muito uniforme, o que faz com quetanto as versões em CPU quanto GPU sejam muito rápidas nadeterminação do vetor mais adequado [22].
A tabela 3, por fim, traz os resultados obtidos da soluçãoproposta, durante a avaliação de vídeos em resolução 4CIF(576x704 pixels).
Tabela 3. Ganho de desempenho para vídeos 4CIF
Vídeo médio máximo
City 3,53 4,09
Crew 4,16 5,54
Harbour 2,9 3,77
Observa-se que para vídeos maiores, o ganho registrado semostra ainda mais significativo, chegando-se a atingir mais de350% na média dos três vídeos e mais de 550% no melhor caso(vídeo Crew).
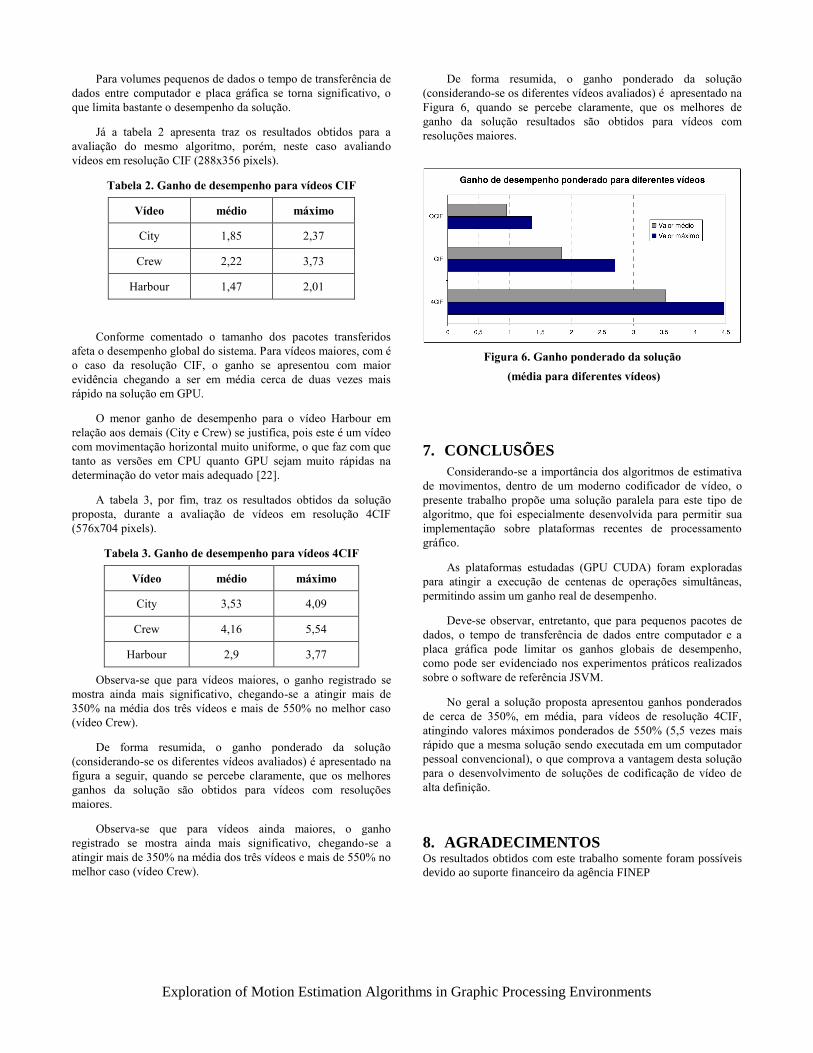
De forma resumida, o ganho ponderado da solução(considerando-se os diferentes vídeos avaliados) é apresentado nafigura a seguir, quando se percebe claramente, que os melhoresganhos da solução são obtidos para vídeos com resoluçõesmaiores.
Observa-se que para vídeos ainda maiores, o ganhoregistrado se mostra ainda mais significativo, chegando-se aatingir mais de 350% na média dos três vídeos e mais de 550% nomelhor caso (vídeo Crew).
De forma resumida, o ganho ponderado da solução(considerando-se os diferentes vídeos avaliados) é apresentado naFigura 6, quando se percebe claramente, que os melhores deganho da solução resultados são obtidos para vídeos comresoluções maiores.
Figura 6. Ganho ponderado da solução (média para diferentes vídeos)
7. CONCLUSÕESConsiderando-se a importância dos algoritmos de estimativa
de movimentos, dentro de um moderno codificador de vídeo, opresente trabalho propõe uma solução paralela para este tipo dealgoritmo, que foi especialmente desenvolvida para permitir suaimplementação sobre plataformas recentes de processamentográfico.
As plataformas estudadas (GPU CUDA) foram exploradaspara atingir a execução de centenas de operações simultâneas,permitindo assim um ganho real de desempenho.
Deve-se observar, entretanto, que para pequenos pacotes dedados, o tempo de transferência de dados entre computador e aplaca gráfica pode limitar os ganhos globais de desempenho,como pode ser evidenciado nos experimentos práticos realizadossobre o software de referência JSVM.
No geral a solução proposta apresentou ganhos ponderadosde cerca de 350%, em média, para vídeos de resolução 4CIF,atingindo valores máximos ponderados de 550% (5,5 vezes maisrápido que a mesma solução sendo executada em um computadorpessoal convencional), o que comprova a vantagem desta soluçãopara o desenvolvimento de soluções de codificação de vídeo dealta definição.
8. AGRADECIMENTOSOs resultados obtidos com este trabalho somente foram possíveisdevido ao suporte financeiro da agência FINEP

Exploration of Motion Estimation Algorithms in Graphic Processing Environments
9. REFERÊNCIAS
[1] Richardson I. E. G., H.264 and MPEG-4 VideoCompression. England, Ed Wiley . Sons, v2 2003, 281p.
[2] Chen, and H.-Y Chen, "Physical Design for System-On-aChip" in Essential Issues in SOC Design (Y.-L Lin, Editor),Springer, 2009.
[3] Do D. M. T., GPUs - Graphics Processing Units Institute ofComputer Science, University of Innsbruck July 7, 2008.
[4] ITU, .H.264/AVC Reference Software Decoder (version13.0). 2008 <http://iphome.hhi.de/suehring/tml/doc/
ldec/html.
[5] Koga T. et al. Motion-compensated interframe coding forvideo conferencing. In: proceedings Nat. Telecom. Conf. dez81.
[6] Li r., Zeng B., Liou M., “A new three-step search algorithmfor block motion estimation,” IEEE Transaction on CircuitSystems and Video Technology, vol. 4, pp. 438–442, Aug.1994.
[7] Po L. M. and Ma W. C., “A novel four-step search algorithmfor fast block motion estimation,” IEEE Transaction onCircuit Video Technology, vol. 6, pp. 313–317, June 1996.
[8] Chung K.L., Chang L.-C., A new predictive search areaapproach for fast block motion estimation. IEEETransactions on Image Processing. V. 12 N. 6, pp 648-652.2003.
[9] Zhu S. and Ma K.-K., A New Diamond Search Algorithm forFast Block-Matching Motion Estimation. IEEE Transactionson Image Processing. V. 9, n. 2, Feb. 2000.
[10] Tourapis A. M., Au 0. C. and Liou M. L. “PredictiveMotionVector Field Adaptive Search Technique (PMVFAST) -Enhancing Block Based Motion Estimation,” in Proc. ofVisual Communications and Image Processing, pp.883-892,Jan. 2001.
[11] Huang Y.-L., Shen Y.-C., Wu J.-L., Scalable computation forspatially scalable video coding using NVIDIA CUDA andmulti-core CPU MM.09, October, 2009, China pp.361-370.
[12] W -N Chen, H -M Hang, .H.264/AVC motion estimationimplementation on Compute Unified Device Architecture(CUDA), IEEE International Conference on Multimedia andExpo 2008, pp 697-700, 2008.
[13] Han T. D. and Abdelrahman T. S., Reducing BranchDivergence in GPU programs. Proceedings of the FourthWorkshop on General Purpose Processing on GraphicsProcessing Units [S.l.]: 2011.
[14] NVIDIA. NVIDIA’s Next Generation CUDA ComputeArchitecture: Fermi . 2009. 22 p.
[15] Song, T. et al. Parallel Implementation Algorithm of MotionEstimation for GPU Applications 6 p.
[16] Schwalb, M. Ewerth, R. and Freisleben, B. Fast motionestimation on graphics hardware for H.264 video encodingIEEE Transactions on Multimedia Volume 11 Issue 1,January 2009 pp. 1-10.
[17] Cheng, R. Yang, E. and Liu, T. Speeding up motionestimation algorithms on CUDA technology Asia PacificConference in Multimedia and Electronics 2010. pp. 93-96.
[18] Massanes F., Cadennes M. and Brankov J. G., CUDAimplementation of a block-matching algorithm for MultipleGPU cards Journal of Electron Imaging. 2011 20(3) pp.1-21.
[19] Crow T. S. Evolution of the Graphical Processing Unit.2004. 59 p.
[20] Harris M. Optimizing Parallel Reduction in CUDA 2010,38p.
[21] ITU – International Telecommunication Unit, H.264/SVCReference Software for H.264 advanced video coding (JSVMversion 9.19.9), 2010.
[22] Chung K.-L. and Chang L.-C., A new predictive search areaapproach for fast block motion estimation. IEEETransactions on Image Processing. V. 12 N. 6, pp 648-652.2003.
Copyright © 2022 FDOKUMEN




















