
ESCUELA DE AVIACIÓN
26
ESCUELA DE AVIACIÓN - 1 - 1. Estadística Descriptiva En toda investigación científica y, en general, en la toma de decisiones de cualquier actividad humana, se requiere tener información. Por ejemplo, en demografía, interesa conocer la edad al momento de contraer matrimonio, el número de hijos, la longevidad, etc. Del mismo modo, en economía interesa conocer el ingreso de las personas, su situación ocupacional, su nivel socioeconómico; si se trata de empresas, interesan los capitales, ganancias, etc. En salud, es importante tener información sobre desnutrición infantil, incidencia de determinadas enfermedades, número de prestaciones hospitalarias, entre muchas otras variables. 1.1. Conceptos Básicos. En los ejemplos anteriores la información consiste en el conocimiento detallado de las características de ciertos elementos. Por ejemplo nos puede interesar saber: La edad de una persona al momento de contraer matrimonio. El número de hijos de una familia. El capital de una empresa. La presencia de defectos en un envase de vidrio. En el primer caso, los elementos son personas individuales; en el segundo, se trata de familias; y en los casos restantes, son empresas y envases de vidrio. Las características que nos interesan medir o determinar (en cada elemento), varían de uno a otro. Nos referiremos a ellas en lo sucesivo con el nombre de variables . De esta forma, edad, número de hijos, capital y presencia de defectos, son ejemplos de variables. Cuando queremos estudiar una variable, es importante tener claro cuáles son aquellos elementos de los que queremos saber su valor. Al conjunto de estos elementos los llamaremos población y al número de elementos de este conjunto lo llamaremos tamaño de la población, el cual suele denotarse por la letra N. El uso de la palabra población tiene aquí un significado técnico. En efecto, los elementos de la población no son necesariamente personas. Así en los ejemplos precedentes, aparecen poblaciones de personas, familias, empresas y envase de vidrio. No es difícil pensar en otras situaciones donde las poblaciones estén constituidas por huevos, automóviles o componentes electrónicos. Es conveniente clasificar las variables de acuerdo al conjunto de valores posibles que ellas puedan tener. Los valores de las variables edad, capital, número de hijos, se expresan en forma numérica. En cambio presencia de defectos, sabor, posición política muestran una cualidad del elemento y no pueden expresarse numéricamente, salvo de manera artificial. Entonces podemos distinguir dos tipos de variables: Variables cualitativas o no numéricas. Variables cuantitativas o numéricas. Las variables edad y número de hijos, son cuantitativas. Sin embargo, el número de hijos puede tomar los valores 0, 1,2,..., vale decir, un entero no negativo. No tiene sentido hablar de valores intermedios como 1.3 hijos. Por el contrario, si bien la edad se expresa en años cumplidos, esto lo podemos refinar usando meses, días, horas, minutos, segundos, etc. O sea, entre dos valores cualesquiera de la variable edad, por cercanos que sean, existe siempre un valor intermedio. Esto nos sugiere, que las variables cuantitativas pueden ser clasificadas según los valores que tomen. Por tanto si una variable cuantitativa toma valores en un conjunto finito o infinito numerable, careciendo de sentido valores intermedios, la
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of ESCUELA DE AVIACIÓN

ESCUELA DE AVIACIÓN
- 1 -
1. Estadística Descriptiva En toda investigación científica y, en general, en la toma de decisiones de cualquier actividad humana, se requiere tener información. Por ejemplo, en demografía, interesa conocer la edad al momento de contraer matrimonio, el número de hijos, la longevidad, etc. Del mismo modo, en economía interesa conocer el ingreso de las personas, su situación ocupacional, su nivel socioeconómico; si se trata de empresas, interesan los capitales, ganancias, etc. En salud, es importante tener información sobre desnutrición infantil, incidencia de determinadas enfermedades, número de prestaciones hospitalarias, entre muchas otras variables. 1.1. Conceptos Básicos. En los ejemplos anteriores la información consiste en el conocimiento detallado de las características de ciertos elementos. Por ejemplo nos puede interesar saber:
La edad de una persona al momento de contraer matrimonio. El número de hijos de una familia. El capital de una empresa. La presencia de defectos en un envase de vidrio.
En el primer caso, los elementos son personas individuales; en el segundo, se trata de familias; y en los casos restantes, son empresas y envases de vidrio. Las características que nos interesan medir o determinar (en cada elemento), varían de uno a otro. Nos referiremos a ellas en lo sucesivo con el nombre de variables. De esta forma, edad, número de hijos, capital y presencia de defectos, son ejemplos de variables. Cuando queremos estudiar una variable, es importante tener claro cuáles son aquellos elementos de los que queremos saber su valor. Al conjunto de estos elementos los llamaremos población y al número de elementos de este conjunto lo llamaremos tamaño de la población, el cual suele denotarse por la letra N. El uso de la palabra población tiene aquí un significado técnico. En efecto, los elementos de la población no son necesariamente personas. Así en los ejemplos precedentes, aparecen poblaciones de personas, familias, empresas y envase de vidrio. No es difícil pensar en otras situaciones donde las poblaciones estén constituidas por huevos, automóviles o componentes electrónicos. Es conveniente clasificar las variables de acuerdo al conjunto de valores posibles que ellas puedan tener. Los valores de las variables edad, capital, número de hijos, se expresan en forma numérica. En cambio presencia de defectos, sabor, posición política muestran una cualidad del elemento y no pueden expresarse numéricamente, salvo de manera artificial. Entonces podemos distinguir dos tipos de variables:
Variables cualitativas o no numéricas.
Variables cuantitativas o numéricas. Las variables edad y número de hijos, son cuantitativas. Sin embargo, el número de hijos puede tomar los valores 0, 1,2,..., vale decir, un entero no negativo. No tiene sentido hablar de valores intermedios como 1.3 hijos. Por el contrario, si bien la edad se expresa en años cumplidos, esto lo podemos refinar usando meses, días, horas, minutos, segundos, etc. O sea, entre dos valores cualesquiera de la variable edad, por cercanos que sean, existe siempre un valor intermedio. Esto nos sugiere, que las variables cuantitativas pueden ser clasificadas según los valores que tomen. Por tanto si una variable cuantitativa toma valores en un conjunto finito o infinito numerable, careciendo de sentido valores intermedios, la

ESCUELA DE AVIACIÓN
2
denominaremos variable discreta. Ahora si una variable cuantitativa toma valores en un rango o intervalo (es decir, si dados dos valores cualesquiera de la variable, siempre existe un valor intermedio) diremos que ella es una variable continua. Por otro lado, las variables sexo y grados en él ejercito son variables cualitativas. La variable sexo toma los valores masculino y femenino, en cambio la variable grados del ejercito puede tomar los valores soldado, suboficial, oficial. La diferencia entre ambas variables es que en grados del ejército existe un orden jerárquico, propio de la variable. De esta manera, si una variable cualitativa toma valores en un conjunto donde los valores son solo nombres, la llamaremos variable nominal, y si además estos nombres tienen un orden propio o jerarquía la llamaremos variable ordinal. Hay situaciones en que necesitamos información sobre los valores de ciertas variables de interés en cada uno de los elementos de la población. Por ejemplo, la estructura exacta de las edades en la población chilena, sólo puede conocerse determinando la edad de cada uno de los habitantes de Chile. La determinación de los valores de una o más variables de interés, en cada uno de los elementos de una población, es una actividad que llamaremos censo. La realización de un censo es una actividad compleja y costosa. Por ejemplo en el caso de los envases de vidrio, deberíamos examinar cada uno de ellos, ¡¡y estos podrían ser millones!! Aún cuando esto se pudiera realizar, el costo de una revisión exhaustiva sería tan alto que encarecería excesivamente el valor del envase. La palabra censo aparece vinculada normalmente con los “censos nacionales de población”. Estos se efectúan, por razones económicas, sólo cada diez años. En el ínter tanto es necesario contar con la información sobre la situación del momento. Las decisiones no pueden basarse sólo en el resultado del último censo, ni pueden esperar a que se realice el próximo. Además de las dificultades ya señaladas, los censos sólo miden variables de tipo general. Por ejemplo, poco aportan los resultados del último censo que se haya realizado, a la predicción del comportamiento de los votantes en una próxima elección. La discusión anterior indica, que muy raramente, es posible recolectar información completa. Tenemos que contentarnos, entonces, con información incompleta o parcial, lo que significa que los valores de las variables que nos interesan, se miden sólo en algunos elementos de la población. Se puede preguntar la edad sólo a algunas personas, determinar el capital de sólo algunas empresas, revisar sólo algunos envases, etc. Cuando compramos fruta es posible, con buena suerte, que podamos probar algunas de ellas. Es ilusorio pensar que podríamos probar toda la fruta antes de comprarla. Las personas a las cuales se les pregunta la edad, las empresas cuyo capital se determinan, los envases que se revisan, o las frutas que se prueban, constituyen ejemplos de lo que denominaremos muestra. La definición formal de este concepto es particularmente sencilla, ya que una muestra es un subconjunto de la población. El tamaño de la muestra es el número de elementos que ella contiene y se denota por n. Naturalmente, existe el riesgo de que los valores observados en la muestra difieran sustancialmente de los valores determinados en la población completa. Este riesgo se acentúa si los elementos de la muestra son seleccionados sin un método claro y utilizando juicios subjetivos, como por ejemplo:
Un 2° medio de cierto colegio de la capital, será medido, por el ministerio de educación, para poder determinar el nivel de conocimiento de los alumnos. Ante esta situación, la profesora jefe les indica a los alumnos de rendimiento deficiente que están autorizados para faltar a clases el día de la prueba, pero los alumnos de buen rendimiento están obligados a asistir a clases y rendir la prueba.

ESCUELA DE AVIACIÓN
3
Los resultados de la prueba ¿representan el rendimiento del curso? Como se puede ver, en realidad, los resultados obtenidos no representan el rendimiento del curso. Llamamos a este problema sesgo de selección. Para reducir o eliminar es sesgo de selección en la determinación de los elementos que compondrían la muestra, se utiliza, a propósito, el azar. De esta forma se elimina la subjetividad del proceso de selección de estos elementos. Existe un área de la estadística preocupada de esto, llamada teoría de muestreo. El método más sencillo para la selección de una muestra es el muestreo aleatorio simple, en el que todos los elementos de la población tienen la misma posibilidad de pertenecer a la muestra. Ahora, si la población se clasifica en un cierto número de grupos (llamados estratos) y luego, al interior de cada estrato, se obtiene una muestra por muestreo aleatorio simple, este método de selección de una muestra se denomina muestreo estratificado. En la práctica, los métodos de selección empleados suelen ser más complejos, pero la idea básica de uso del azar sigue siendo la misma. 1.2. Tablas de frecuencia. Como hemos mencionado anteriormente, la edad es una variable, en el sentido que cambia de una persona a otra. Sin embargo, una vez seleccionada la persona cuya edad queremos determinar, su edad es un número fijo. Para aclarar esta idea supongamos que Claudia Reyes pertenece a cierta población y tiene 17 años. Diremos entonces que el valor de la variable edad (expresada en años) para el elemento Claudia Reyes es 17. A este valor lo llamaremos el dato de Claudia Reyes. Suponga, que en un estudio realizado a un grupo de trabajadores, se les consultó por su nivel de instrucción educacional. Los datos recopilados a estos trabajadores se muestran en la siguiente tabla:
Trabajador Nivel de Instrucción
Trabajador Nivel de Instrucción
1 Básico 11 Superior 2 Medio 12 Medio 3 Superior 13 Básico 4 Superior 14 Básico 5 Básico 15 Medio 6 Básico 16 Medio 7 Medio 17 Básico 8 Medio 18 Medio 9 Medio 19 Superior 10 Superior 20 Básico
Al conjunto de datos, lo llamaremos la información. Se puede pensar que un dato es la información de un individuo en particular. Bueno, a cada dato lo consideraremos como la unidad básica de información. Generalmente, la información no presenta una imagen valiosa, debido a su extensión o al desorden que esta presenta. Por ejemplo, en la tabla anterior se observa lo segundo. Entonces, debemos organizar la información de una manera simple y que sea entendible. A esta organización la llamaremos tabla de frecuencias, que nos muestra el comportamiento de la variable en estudio. La construcción de esta tabla es bastante sencilla y se muestra en el siguiente diagrama:

ESCUELA DE AVIACIÓN
4
El número de veces que se repite cada valor de la variable, nos indica cuan frecuente es cada uno de estos valores. A esta cantidad la llamaremos frecuencia
absoluta ( in ). Notemos que si m es la cantidad de valores posibles de la
variable, entonces nnnn m 21 que es el total de datos. La proporción,
corresponde a lo que llamaremos frecuencia relativa ( if ) y es calculada como
n
nf i
i . La suma de las frecuencias relativas debe dar 1. El porcentaje no es
más que %100*if y la suma de estos debe dar 100%.
La tabla de frecuencias, para la variable nivel de instrucción de los trabajadores,
queda: En esta tabla de frecuencia se ha suprimido la columna de frecuencias relativas, por ser redundante, ya que está la columna de porcentajes. La tabla anterior se aplica a variables cualitativas, tanto nominales como ordinales, como a variables cuantitativas discretas. En cambio para variables cuantitativas continuas, la tabla se frecuencias se construye de manera diferente. Para aclarar ideas, consideremos el siguiente ejemplo: Se quiere estudiar el comportamiento de las notas obtenidas por 20 alumnos de la universidad en la primera cátedra. La información recopilada se muestra a continuación: Si se considera la variable nota como variable discreta, entonces la tabla de frecuencia tendría tantas filas como datos, a que nos referimos con estos, en este ejemplo tendríamos 17 filas. Imaginen si en vez de ser 20 alumnos fuesen 500, en este caso la tabla de frecuencia tendría a lo menos unas 300 filas. Esto nos conduce a desarrollar herramientas para este caso tan especial. Vale la pena recordar que una variable continua toma valores en un intervalo o rango de valores. En el ejemplo de las notas de los 20 alumnos, este intervalo es de 3,1 a 7,0. La idea natural es dividir este intervalo, en intervalos más pequeños. Para realizar esto, se deben contestar las siguientes preguntas: ¿En cuántos intervalos debemos dividir el intervalo? y ¿Cuál es la amplitud o largo de cada uno de estos intervalos? La respuesta a la primera pregunta debiese ser dada por el investigador. Si no es así se puede usar alguna de las siguientes aproximaciones: a) Algunos autores consideran que una buena aproximación para la cantidad de
intervalos es dada por nm .
Alumno Nota Alumno Nota Alumno Nota Alumno Nota
1 6,2 6 5,7 11 4,9 16 6,8 2 4,8 7 6,4 12 3,1 17 4,7 3 3,8 8 5,4 13 3,8 18 5,5 4 4,6 9 6,3 14 5,5 19 7,0 5 4,4 10 4,8 15 5,1 20 4,2
Nivel de Frecuencia Porcentaje
Instrucción Absoluta
Básico 7 35
Medio 8 40
Superior 5 25
Total 20 100

ESCUELA DE AVIACIÓN
5
b) Otros autores prefieren usar la fórmula de Sturger (1926) para obtener la
cantidad de intervalos, la que es )](log*3,3[1 10 nm
A pesar de existir diferencia entre ambas aproximaciones cuando la cantidad de información es pequeña, para grandes cantidades de datos los resultados de ambas expresiones son similares. Una vez determinada la cantidad de intervalos m , se debe contestar la segunda
pregunta. Se usará como norma que la amplitud de cada uno de estos intervalos es la misma, lo que conduce a la siguiente expresión matemática:
m
MínimoMáximoc
donde c es la amplitud de cada intervalo.
No siempre, la amplitud de los intervalos es constante. Hay muchas situaciones en las que la asignación de los largos de los intervalos es dada por el investigador. Así, la cantidad de intervalos en que debemos dividir el intervalo de 3,1 a 7,0 es
5)]20(log*3,3[1 10 m y la amplitud de cada uno de ellos es
78,05
1,30,7
c . Con esta información se construyen los intervalos:
3,88 4,66 5,44 6,22 7,00 | | | | | | 3,10 3,10+0,78 3,88+0,78 4,66+0,78 5,44+0,78 De esta manera, en la tabla de frecuencias, los valores que toma la variable son los intervalos que se han construido. Las frecuencias absolutas corresponden a la cantidad de datos que caen en cada intervalo. La columna de frecuencias relativas sigue igual que antes. Pero se incorporan dos nuevas columnas, correspondientes a las frecuencias acumuladas absolutas y relativas. La
frecuencia absoluta acumulada ( iN ) representa la cantidad de datos, que
están, acumulados hasta cada uno de los intervalos, es decir,
ii nnnN 21 . La frecuencia relativa acumulada ( iF ) corresponde a la
proporción de datos acumulados hasta cada uno de los intervalos y se calcula
como ii
i ffn
NF 1 .
Una vez construida la tabla de frecuencias, se pensará que la información original desaparece, como por arte de magia, entonces se produce ya un resumen de la información, porque a diferencia del caso de variables cualitativas o discreta, se puede reconstruir la información original. No así en el caso continuo. Por lo tanto es necesario obtener un representante de cada intervalo. Dicho representante se llamará marca de clase y corresponderá a la mitad de cada
intervalo, es decir, 2
ii
i
InfLimSupLimClaseMarca
, donde iInfLim y
iSupLim son el límite inferior y superior, respectivamente, de intervalo i -ésimo.
La tabla de frecuencias, para el estudio de las notas de los 20 alumnos queda:
Nota Marca de Frecuencia Frecuencia Frec. AbsolutaFrec. Relativa
Clase Absoluta Relativa Acumulada Acumulada
3,10-3,88 3,49 3 0,15 3 0,15
3,88-4,66 4,27 3 0,15 6 0,30
4,66-5,44 5,05 6 0,30 12 0,60
5,44-6,22 5,83 4 0,20 16 0,80
6,22-7,00 6,61 4 0,20 20 1,00
20 1,00

ESCUELA DE AVIACIÓN
6
1.3. Representación gráfica Al común de las personas, les es muy difícil la comprensión e interpretación de una tabla de frecuencias. Por esto se recurre a la representación gráfica. Los métodos gráficos poseen la ventaja de hacer más rápida la comprensión de la información y es sólo una forma distinta de mostrar lo que se desprende de la tabla de frecuencias. Es importante destacar que cuando se elabora una representación gráfica no existe solamente una respuesta correcta. El juicio del analista y las circunstancias que rodean el problema desempeñan un papel primordial en el desarrollo de esta. Una empresa tabacalera realiza un estudio de mercado, para determinar cuál es el tipo de cigarrillo que prefieren los consumidores (fumadores). Para este estudio se considera una muestra de 110 fumadores y se examina la marca del cigarrillo. La información es resumida en la siguiente tabla de frecuencias: La representación gráfica de la información en la tabla de frecuencias anterior, es
mostrada en las siguiente figura:
Este gráfico recibe el nombre de gráfico de barras separadas. Como se aprecia el eje horizontal es el eje de los valores de la variable, mientras que el eje vertical es el eje de la frecuencia absoluta ó frecuencia relativa ó el porcentaje. Es importante recalcar que los anchos de las barras debe ser el mismo, ya que puede distorsionar la información que se quiere mostrar. Otro gráfico útil para este tipo de dato, es el gráfico circular ó de torta:
La torta completa representa el 100% de la información y cada sector representa
Marca de Frecuencia Porcentaje
Cigarros Absoluta
Kent 22 20,00
Belmont 27 24,55
Derby 31 28,18
Viceroy 30 27,27
Total 110 100,00
Porcentaje de fumadores según marca de cigarro
KENT
20%
BELMONT
25%
DERBY
28%
VICEROY
27%

ESCUELA DE AVIACIÓN
7
el porcentaje que le corresponde a cada valor de la variable. Este gráfico, como el de barras separadas, indica que los cigarrillos preferidos por este grupo de fumadores son el Derby y el Viceroy (55,45%), mientras que el menos preferido es el Kent. Para el caso de una variable cuantitativa agrupada en intervalos, como el ejemplo de las notas de los 20 alumnos visto anteriormente, se realizan los siguientes gráficos:
A diferencia del gráfico de barras separadas visto anteriormente, este es un gráfico de barras juntas. Este gráfico recibe el nombre técnico de histograma, donde el eje horizontal del gráfico se colocan los intervalos y en el eje vertical la frecuencia absoluta ó la frecuencia relativa ó el porcentaje, siendo la altura de la barras la frecuencia correspondiente a cada intervalo. Nótese que los anchos de los intervalos son iguales, esto se debe a que por construcción la amplitud de los intervalos es la misma. Otro gráfico que presenta la misma información que el histograma, es la poligonal de frecuencia, la que es mostrada en la siguiente figura: La construcción de esta figura se basa en unir los puntos medios de la parte superior de cada una de las barras. Es importante dejar que baje a cero y esto se puede realizar de la siguiente manera, se construye un intervalo a la derecha del
máximo (de igual amplitud que el último intervalo) y se une el punto medio de la última barra con el punto medio de este intervalo. Análogamente, se construye un intervalo a la izquierda del mínimo (de igual amplitud que el primer intervalo) y se une el punto medio de la primera barra con el punto medio de este intervalo. Como se menciono en el párrafo anterior, esta figura contiene la misma información que el histograma y se debe a la forma en que se construye. 1.4. Medidas descriptivas. Llamaremos medidas descriptiva ó resúmenes, a aquellas cantidades que resumen la información y en algún sentido sean representativos del conjunto de

ESCUELA DE AVIACIÓN
8
datos. En el riguroso sentido, las medidas descriptivas reciben el nombre de estadígrafos, cuyos valores son obtenidos a través de los datos. Estas medidas descriptivas se dividen en tres categorías como se muestra en el siguiente esquema:
Medidas de tendencia central y posición
Medidas de dispersión Medidas de forma
Moda Promedio Mediana Percentiles
Rango Rango intercuartílico Varianza Desviación estándar Coeficiente de variación
Coeficiente de asimetría Coeficiente de Curtosis
En este escrito, se estudiaran las medidas de tendencia central y posición como las medidas de dispersión. Los otros tipos de medidas se dejan al lector. 1.4.1. Medidas de tendencia central y posición. Las medidas de tendencia central, como su nombre lo indica, nos describen el centro de la información. Dentro de estas medidas la más conocida es el promedio o media aritmética.
La moda Mo , es aquel valor de la variable en estudio, que más se repite o que
tiene mayor frecuencia. En el ejemplo de nivel de instrucción de los 20 trabajadores, se observa que lo más frecuente es el nivel de instrucción medio, por lo tanto la moda es nivel de instrucción medio. En el ejemplo de la marca de cigarrillo la moda es la marca Derby. Ahora, en el ejemplo de las 20 notas, lo que se obtiene es un intervalo modal, que en este caso es el tercer intervalo [4.66, 5.44). Entonces, en el caso de datos agrupados en intervalos la moda es una aproximación. La pregunta natural es cual aproximación se debe usar. En la mayoría de los libros de textos la moda es aproximada de la siguiente manera:
i
iiii
iii c
nnnn
nnInfLimMo
)()(
)(
11
1,
donde iInfLim es el límite o cota inferior de intervalo modal, in es la frecuencia
absoluta del intervalo modal, 1in es la frecuencia absoluta del intervalo anterior al
intervalo modal, 1in es la frecuencia absoluta del intervalo siguiente al intervalo
modal y ic es la amplitud del intervalo modal. Así, la moda en el problema de las
notas de los 20 alumnos es 128.578.0)46()36(
)36(66.4
Mo .
Una observación importante es que la moda puede no existir. Considere los siguientes datos recopilados a 8 estudiantes de la universidad sobre la cantidad de hijos en su grupo familiar: 1, 1, 2, 2, 3, 3, 4, 4. Como se aprecia, bajo la definición de moda, en este caso, no existe moda. Además puede ocurrir que exista más de una moda, y en estos casos se hablara de multimodalidad.
El promedio o media aritmética X , tal vez, es la medida de tendencia central
más conocida, la que es calculada sumando todos los valores de la variable en
estudio y dividiendo por el total de datos. Formalmente, si nxxx ,,, 21 son los
valores observados de una variable X , entonces el promedio se expresa
matemáticamente por n
x
X
n
i
i 1
. Considere la siguiente información obtenida al
consultar a 5 individuos: 6, 3, 8, 6 y 4. La media de estos 5 sujetos es

ESCUELA DE AVIACIÓN
9
4.55
86643
X . La interpretación del promedio se puede representar
de la siguiente manera: cada dato, en el ejemplo anterior, es representado por pequeño paralelepípedo y el eje real se considera como tabla, donde colocamos cada uno de los datos sobre ella. La siguiente figura muestra la situación anterior:
Como se aprecia, si se coloca el punto de apoyo a la izquierda del 3 la tabla se inclina hacia la derecha. Análogamente si se coloca el punto de apoyo a la derecha del 8 la tabla se inclina hacia la izquierda, por lo tanto la idea es buscar un punto de apoyo donde la tabla se mantenga en equilibrio, bueno el promedio es ese punto de apoyo. Por eso en muchos textos, el promedio es interpretado como un punto de equilibrio o un centro de gravedad. ¿Qué pasa si los datos están agrupados en intervalos, como el ejemplo de las notas de los 20 alumnos? Recordemos la información:
Lamentablemente, no disponemos de la información original. Pero se puede pensar por un momento, que la marca de clase de cada intervalo, es el dato observado. Entonces de esta manera se puede reconstruir la información de la siguiente manera:
6.61 6.61, 6.61, 6.61, 5.83, 5.83, 5.83, 5.83, 5.05, 5.05,
5.05 5.05, 5.05, 5.05, 4.27, 4.27, 4.27, ,49.3 ,49.3 ,49.3
así, .167.520
461.6483.5605.5327.4349.3
X Lógicamente, la
información anterior no es la real, pero ¿cuántas veces no se obtienen verdades de mentiras?, en todo caso el promedio calculado de esta manera es una aproximación al promedio real. La idea anterior permite dar la siguiente expresión para calcular el promedio en el caso de datos agrupados en intervalos:
n
nclasemarca
X
m
i
ii
1
donde m es la cantidad de intervalos.
La mediana Me , es aquel valor de la variable que ocupa la posición central
Nota Marca de Frecuencia Frecuencia Frec. AbsolutaFrec. Relativa
Clase Absoluta Relativa Acumulada Acumulada
3,10-3,88 3,49 3 0,15 3 0,15
3,88-4,66 4,27 3 0,15 6 0,30
4,66-5,44 5,05 6 0,30 12 0,60
5,44-6,22 5,83 4 0,20 16 0,80
6,22-7,00 6,61 4 0,20 20 1,00
20 1,00

ESCUELA DE AVIACIÓN
10
cuando los datos están ordenados de menor a mayor. En forma técnica se define como aquel valor de la característica en estudio que deja bajo sí al 50% de la información. La siguiente figura muestra la definición anterior:
Sean nxxx ,,, 21 los valores observados de una variable X . Generalmente los
datos vienen desordenados, así que lo primero que se debe realizar es ordenarlos
de menor a mayor digamos maxmin 21 nxxx . Entonces la
mediana se define como:
par es si ,2
impar es si ,
122
21
nxx
nx
Medianann
n
Imagine que la información observada es 6, 3, 8, 5 y 3. Ordenando la información de menor a mayor queda 3, 3, 5, 6 y 8. Como la cantidad de datos es impar
debemos encontrar aquel dato que ocupa la posición 32
15
2
1
n, que
corresponde al valor 5, por lo tanto la 5Mediana . Ahora considere la siguiente información: 9, 6, 7, 9, 10 y 8. Ordenando los datos de menor a mayor queda 6, 7, 8, 9, 9 y 10. Como la cantidad de datos es par debemos encontrar los datos que
ocupan las posiciones 32
6
2
n y 41
2
61
2
n, que corresponden a los datos
8 y 9, así la mediana es 5.82
98
Mediana . En el caso de datos agrupados
en intervalos, la mediana será calculada usando el siguiente algoritmo:
i. Determinar la posición que le corresponde a la mediana como
2100
50 nnPosición
ii. Determinar en qué intervalo cae la mediana, comparando la posición obtenida en i) y la columna de las frecuencias absolutas acumuladas.
iii. La mediana se calcula como: i
i
iin
cnNMe
1
2Inf lim , donde
iInf lim es el límite o cota inferior del intervalo en que esta la mediana
(obtenido en ii.); ic es la amplitud del intervalo en que esta la mediana;
in es la frecuencia absoluta del intervalo en que esta la mediana y 1iN
es la frecuencia absoluta acumulada del intervalo anterior al intervalo en que esta la mediana.
Para aprender a aplicar el algoritmo anterior, se verá con detalles en el ejemplo de las notas de los 20 alumnos. En el paso i. Se tiene que la posición que le corresponde a la mediana es 10. En el paso ii. recordemos la tabla de frecuencias.
Como se aprecia, la posición 10 cae en el tercer intervalo, por lo tanto la mediana
es 18.56
78.061066.4 Me
Los percentiles, son cantidades que tienen la característica de acumular
información hasta ellos. Para aclara ideas, imagine que la información la dividimos en 100 partes iguales donde cada una de las partes corresponde a un 1% de

ESCUELA DE AVIACIÓN
11
información, como muestra la siguiente figura:
Como se aprecia, 1P es aquel valor de la variable que tiene acumulado el 1% de la
información, 2P es aquel valor de la variable que tiene acumulado el 2% de la
información, , y 99P es aquel valor de la variable que tiene acumulado el 99%
de la información. Con esto, se define el percentil % P como aquel valor de
la variable en estudio que deja bajo sí al % de la información. Para calcular P
se debe realizar el siguiente procedimiento:
a) Ordenar los datos del más pequeño al más grande.
b) Calcular 100
n .
c) Si en el paso 2 se obtiene un entero, digamos, kn 100
. Entonces el
percentil % es el promedio de los datos que ocupan la posición k y la
posición 1k . Si en el paso 2 se obtiene un número con decimales, digamos
decimalkn .100
. Entonces el percentil %, es el dato que ocupa la
posición 1k . En un estudio realizado a 10 familias, se obtuvo el ingreso bruto mensual (expresado en salarios mínimos): 12, 16, 18, 20, 28, 30,40, 48, 50 y 54. Se quiere
encontrar el ingreso mínimo del 30% de los ingresos más altos. Para aclara ideas observe la siguiente figura: Por lo tanto, se debe calcular el percentil 70%. Como los datos ya están
ordenados se calcula 7100
7010
100
70n . Como nos da un valor entero,
debemos promediar los datos que ocupan las posiciones 7 y 8, es decir
442
484070
P . Por lo tanto, el ingreso mínimo del 30% de los ingresos más
altos es de 44 sueldos mínimos.
En el caso de datos agrupados en intervalos, el percentil % es calculado usando el siguiente algoritmo:
i. Determinar la posición que le corresponde al percentil %
100
nPosición

ESCUELA DE AVIACIÓN
12
ii. Determinar en qué intervalo cae el percentil %, comparando la posición obtenida en i) y la columna de las frecuencias absolutas acumuladas.
iii. El percentil % es calculado por: i
i
iin
cn NP
1
100Inf lim
,
donde iInf lim es el límite o cota inferior del intervalo en que esta el
percentil % (obtenido en ii.); ic es la amplitud del intervalo en que el
percentil %; in es la frecuencia absoluta del intervalo en que esta el
percentil % y 1iN es la frecuencia absoluta acumulada del intervalo
anterior al intervalo en que esta el percentil %. Para aprender a aplicar el algoritmo anterior, se verá con detalles en el ejemplo de las notas de los 20 alumnos. Imagine que se quiere calcular la nota mínima del 40% de las mejores notas. Así al aplicar el algoritmo anterior se tiene que en el
paso i. la posición que le corresponde al percentil 60% es 12. En el paso ii. recordemos la tabla de frecuencias.
Como se aprecia, la posición 12 cae en el tercer intervalo, por lo tanto el
percentil 60% es 44.56
78.061266.460 P . Por lo tanto, la nota mínima del
40% de las mejores notas es 5.44. Se deja al lector, investigar que son los cuartiles, deciles y quintiles. 1.4.2. Medidas de dispersión o de variabilidad Las medidas de dispersión o de variabilidad, como su nombre lo indica, son cantidades que describen cuan cercanos o alejados están los datos, es decir cuan homogéneos o heterogéneos son los datos. La siguiente figura muestra este problema.
Como se puede apreciar, para determinar cuan separado está el conjunto de datos, las medidas de dispersión, deben estar relacionadas con la idea de distancia. Porque, a menor distancia, los datos son homogéneos y a mayor distancia los datos son heterogéneos.

ESCUELA DE AVIACIÓN
13
La medida más simple para medir dispersión es el rango R , que ya se ha
estudiado. Una de las dificultades del rango es que depende de los valores extremos y por lo tanto no siempre refleja adecuadamente la dispersión existente en los datos ya que tiende a sobre estimarla. Para evitar de sobre estimar la
dispersión, se utiliza el rango intercuartílico RI que es el rango del 50% central
de los datos, es decir, es la distancia entre 75P y 25P , como se muestra en la
siguiente figura.
Por lo tanto, el rango intercuartílico es calculado por 2575 PPRI . Así, en el
ejemplo de las notas de los 20 alumnos, el rango es 9.3R y el rango
intercuartílico es 63.1RI .
Otra medida de dispersión es la varianza 2S , que mide la heterogeneidad de los
datos considerando un punto de referencia que es el promedio. Sean nxxx ,,, 21
los valores observados de una variable X . La varianza, se define como
n
i
i Xxn
S1
22
1
1. Esta cantidad se puede calcular como
2
1
2
2
1X
n
x
n
nS
n
i
i, donde
n
i
i
n
x
1
2
es el promedio de los cuadrados. Para
aclarar ideas considere los siguientes datos: 1, 3, 5, 6 y 10. El promedio de estos
datos es 55
106531
X y el promedio de los cuadrados es
2.345
106531
5
222225
1
2
i
ix. Por lo tanto la varianza es
5.1152.344
5 22 S . En el caso de datos agrupados en intervalos la varianza
es
m
i
iim
i
ii Xn
xn
n
n
n
XxnS
1
22
1
2
2
11
- , donde m es la cantidad de
intervalos y ix es la marca de clase del i-ésimo intervalo. En el ejemplo de las
notas de los 20 alumnos:
Nota Marca de Frecuencia Frecuencia Frec. AbsolutaFrec. Relativa
Clase Absoluta Relativa Acumulada Acumulada
3,10-3,88 3,49 3 0,15 3 0,15
3,88-4,66 4,27 3 0,15 6 0,30
4,66-5,44 5,05 6 0,30 12 0,60
5,44-6,22 5,83 4 0,20 16 0,80
6,22-7,00 6,61 4 0,20 20 1,00
20 1,00

ESCUELA DE AVIACIÓN
14
La nota promedio y el promedio de los cuadrados son: 167.5X y
7489.27
20
61.6483.5405.5627.4349.33
20
222225
1
2
i
ii xn
Entonces la varianza es 10633.1167.57489.2719
20 22 S .
Uno de los problemas de la varianza es que si la variable en estudio es la estatura y la unidad de medida es el metro, entonces, la unidad de medida de la varianza es (metro)2, si la variable en estudio es el peso y la unidad de medida es kilogramo, entonces, la unidad de medida de la varianza es (kilogramo)2. Para evitar esta dificultad se inventa la desviación estándar ó desviación típica, la
que se define como la raíz cuadrada de la varianza, es decir, 2SS . Como se
aprecia, la unidad de medida de la desviación estándar es la unidad de medida de la variable en estudio. En el ejemplo de las notas de los 20 alumnos, la desviación
estándar es 0518.110633.1 S .
Una de las grandes dificultades de las medidas de dispersión, que hasta el momento se han estudiado, es que dependen de la unidad de medida de la variable en estudio. Debido a esta dificultad, se inventa el coeficiente de
variación. El coeficiente de variación se define como X
SCV . Como se aprecia,
esta medida de dispersión es a dimensional y si multiplicamos 100 por el coeficiente de variación, tenemos el porcentaje de variabilidad, es decir,
%100CV . Algunos autores, proponen la siguiente clasificación para determinar
si los datos son homogéneos o heterogéneos:
os.heterogénemuy son datos Los %50%100 Si )
os.heterogéneson datos Los %50%10025% Si )
.homogéneosson datos Los %25%1005% Si )
.homogéneosmuy son datos Los %5%100 Si )
CVd
CVc
CVb
CVa
En el ejemplo de las notas de los 20 alumnos, el coeficiente de variación es
2036.0167.5
0518.1CV , el porcentaje de dispersión es de un 20.36%. Según la
clasificación anterior se concluye que las notas de los 20 alumnos son homogéneas. 1.5. Transformación Lineal. Existen situaciones donde las cantidades calculadas no son las que se utilizan. Considere la siguiente situación: “...Usted realiza un estudio sobre el calentamiento global, utilizando como unidad de medida grados Celsius. Ahora, un importante investigador lo invita con todos los gastos pagados a Estados Unidos, para que en un congreso internacional, que trata sobre el calentamiento global, usted exponga los resultados obtenidos en su trabajo. Lamentablemente, como se puede dar cuenta, en Estados Unidos se utilizan grados Fahrenheit, lo que implicaría rehacer todo el trabajo...”. A continuación se entregan resultados, cuando se realiza una transformación lineal a los datos.
Sean nxxx ......, 21 , las observaciones de una variable X , la pregunta es, ¿Qué
pasa con las cantidades calculadas, si a los datos, se les multiplica por una
constante y luego se les suma otra?, es decir, ix se transforma en bxa i (con
a 0) en todas las observaciones. Por ejemplo, se estudian las estaturas de 20

ESCUELA DE AVIACIÓN
15
alumnos de la universidad, los resultados son resumidos en la siguiente tabla de frecuencias:
Estatura (cm)
Marca de Clase
Frecuencias Absolutas
)166;161[ 163,5 2
)171;166[ 168,5 5
)176;171[ 173,5 6
)181;176[ 178,5 2
]186;181[ 183,5 5
Total 20
La media, mediana, varianza, desviación estándar y el coeficiente de variación son mostrados en la siguiente tabla:
Promedio 25,174X cm
Percentil 50 5,17350 P cm
Varianza 45,462 S cm2
Desviación Estándar 6,74S cm
Coeficiente de variación 25,174
74,6CV =0.0387
A estos alumnos se les dará un golpe vitamínico, que se sabe que aumenta en un 1% ( 01.1a ) sus estaturas, más 3 centímetros (b=3). La pregunta es, ¿Qué pasa con el promedio, mediana, varianza, desviación estándar y coeficiente de variación de las nuevas estaturas?. El siguiente cuadro, resume el cambio de los indicadores, si las observaciones sufren una transformación lineal.
Transformación Indicador Inicial Modificado
ix
se transforma en
bxa i *
Promedio X bXa
Moda Mo bMoa
Percentil % P bPa
Varianza 2S 22 Sa
Desviación Estándar
S Sa
Coeficiente de variación
X
SCV
|| bXa
SaCV
Al aplicar estos resultados al problema planteado anteriormente se tiene que: 3y01,1 ba
Datos agrupados en la tabla de frecuencias
Transformación Indicador Inicial Modificado
ix
se transforma en
3*01,1 ix
Promedio 25,174X 178,99
Percentil 50
5,17350 P 178,235
Desviación Estándar
6,74S 6,8074
Coeficiente de variación
25,174
74,6CV
=0.0387
CV0.0380

ESCUELA DE AVIACIÓN
16
Algunas transformaciones útiles ocurren cuando corresponde en aumentar o disminuir un ingreso en un porcentaje “p”, más un valor fijo b, lo que equivale a
transformar ix por bxp i )100/1( , por ejemplo al aumentar un ingreso en un
25% y sumarle 30.000 por concepto de locomoción mensualmente, lo que
equivale a transformar ix por 000.30)100/251( ix 000.3025,1 ix . Otro
ejemplo es cuando se disminuye un ingreso en un 10% por ajuste y quitarle 6.000
para fiestas de navidad mensualmente, lo que equivale a transformar ix por
000.6-)100/10-1( ix 000.6-9,0 ix .
1.6. Problemas Resueltos.
1. La siguiente información corresponde a los gastos mensuales en publicidad,
expresados en millones de pesos, de un grupo de empresas de una determinada industria:
Gastos
(en millones de pesos) Número de empresas
2 – 5 6
5 – 8 10
8 – 11 14
11 – 14 12
14 – 17 8
17 - 20 5
a) Determine y clasifique la variable de interés b) ¿Cuál es el gasto mensual en publicidad que se observa con mayor
frecuencia? c) ¿Cuál es el promedio de gastos mensual en publicidad de las empresas?
d) Calcule e interprete 84P
e) ¿Cuántas empresas tienen un gasto comprendido entre $6.2 millones y $12.7 millones?
f) Determine la desviación estándar y el coeficiente de variación de los gastos
Solución: Construyamos la tabla de frecuencias
Gastos (millones de
$)
Marca de
clase in
iN if iF if *100 iF *100
2 – 5 3.5 6 6 0,11 0,11 11 11
5 – 8 6.5 10 16 0,18 0,29 18 29
8 – 11 9.5 14 30 0,25 0,54 25 54
11 – 14 12.5 12 42 0,22 0,76 22 76
14 – 17 15.5 8 50 0,15 0,91 15 91
17 – 20 18.5 5 55 0,09 1.00 9 100
Total 55 1.00 100
a) La variable de interés es Gastos, y es una variable cuantitativa continua
b) Ubicación de la moda (intervalo con mayor frecuencia), es decir, i=5 ( in
=14), entonces la moda es Mo =
103
6
483
12-1410-14
10-148
,
Luego el gasto mensual que más se repite es de 10 millones de pesos.
c) 65.1055
5.18*55.15*85.12*125.9*145.6*105.3*6
X Luego el
gasto promedio mensual de las empresas es de 10.650.000
d)
575.158
3)42-
100
8455(1484 P , así el 84% de las empresas realizan un
gasto mensual en publicidad menor a $15.575.000 pesos

ESCUELA DE AVIACIÓN
17
e) Primero determinamos el porcentaje de empresas que tienen un gasto
menor a 6.2 millones, digamos x, luego determinaremos el porcentaje de empresas que tienen un gasto menor a 12,7 millones, digamos y, finalmente el porcentaje de empresa que gastan entre 6.2 y 12.7 millones será, y-x%. Para el Cálculo de x% =Px 6.2 (en el intervalo 2 de la variable) , así,
10
3)6-
100
*55(52.6
x , de lo que se desprende, que x=18.2%. De la misma
forma para y% , =PY 12.7 (en el intervalo 4 de la variable), entonces
12
3)30-
100
*55(117.12
y , de lo que se desprende, que y=66.9%. finalmente
el 66.9% - 18.2% = 47.7%, es decir, un 47,7% de las empresas gastan entre 6.2 y 12.7 millones, lo es equivalente decir que, 26 empresas (0.47*55) gastan entre 6.2 y 12.7 millones
f) La varianza muestral es 2.192 S , y por lo tanto, la desviación estándar
muestral es 4,42 SS millones de pesos y finalmente el coeficiente de
variación es C.V. = 65.10
4,4= 0,41 , es decir hay un 41% de dispersión, lo
que nos indica que los datos son heterogéneos.
2. Una línea Aérea transportaba, en término medio, en cada vuelo 72 pasajeros. Para aumentar la cantidad media de pasajeros, hace seis meses atrás , contrato a una Agencia de Publicidad para realizar un nuevo comercial para Diarios y Televisión. Para verificar la llegada del comercial, se recopiló la siguiente información:
Cantidad de Pasajeros
Número de Vuelos
50 – 60 3
60 – 70 7
70 – 80 18
80 – 90 12
90 – 100 8
100 – 120 2
a) En base a estos resultados ¿Usted diría que el comercial ha sido efectivo? b) Si la línea aérea quiere utilizar esta información para predecir los próximos
50 días y decide eliminar el 25% de los vuelos con menor número de pasajeros, ¿Cuál sería el mínimo número de pasajeros que la línea aérea permitiría por cada vuelo?
c) Determine la Mediana e interprete su valor d) Construya un gráfico adecuado para la distribución anterior.
Solución : Construyamos la tabla de frecuencias
Cantidad de Pasajeros
Marca de
clase in
iN if iF if *100 iF
*100
50 – 60 55 3 3 0,06 0,06 6 6
60 – 70 65 7 10 0,14 0,20 14 20
70 – 80 75 18 28 0,36 0,56 36 56
80 – 90 85 12 40 0,24 0,80 24 80
90 – 100 95 8 48 0,16 0,96 16 96
100 – 120 110 2 50 0,04 1.00 4 100
Total 50 1.00 100

ESCUELA DE AVIACIÓN
18
a) 4.7950
110*295*885*1275*1865*755*3
X
Suponiendo, que no existen otros factores que afecten la cantidad de pasajeros, podríamos decir, que el comercial ha tenido efecto, que se observa en el aumento promedio de 72 a 79,4.
b) La cantidad de pasajeros que acumula el 25% de los vuelos corresponde al
percentil 25 el que vale
4.7118
10)10-
100
2550(7025 P . La cantidad mínima de
pasajeros que permitiría cada vuelo será de 72 pasajeros (aproximadamente).
c) La mediana es 3.7818
10)10-
2
50(70 Me . En el 50% de los vuelos, se
transportan 78 o menos pasajeros.
d) Al graficar el histograma con las frecuencias relativas se obtiene la siguiente figura:
3. Se realizó un estudio en la 1ª plaza de peaje saliendo de Santiago hacia el
norte, en la fecha del 16 y 17 de Septiembre con respecto a las siguientes variables: X = “Número de personas que viajan dentro de cada vehículo que fue encuestado”. Y = “Monto en miles de pesos destinado a gastos”. Z = “Si el vehículo en que viajan es P=propio o A=arrendado”. Obteniendo los siguientes datos que se dan a continuación:
Gastos (miles de pesos)
0 – 100 100 –150 150 – 300 300 – 500
N° de personas
P A P A P A P A
1 2 3 4
2 3 3 1 3 2 2 3
3 4 2 5 3 5 2 4
2 4 7 6 8 7 6 5
3 0 5 0 4 0 7 2
a) Clasifique las variables en estudio. b) Determine una medida de tendencia central adecuada para resumir las
variables monto destinado a gastos y al número de personas que viajan en vehículos propios.
c) Grafique la distribución de frecuencias absolutas de la variable vehículo propio
d) Si para el próximo año se ha estimado que el monto destinado a gastos de fiestas patrias aumentará en un 10% más 30 mil pesos. Compare la homogeneidad del monto destinado a gastos actual con el estimado para el próximo año, solamente para los que en vehículos arrendados viajan con tres personas.
0.00.10.20.30.40.50.60.70.80.91.0
55 65 75 85 95
Fre
cu
en
cia
s r
ela
tivas
Marca de Clase (Cantidad de Pasajeros)
Histograma de frecuencias relativas

ESCUELA DE AVIACIÓN
19
e) Determine entre qué valores fluctúa el 50% de la variación central de las observaciones del monto dedicado a gasto para los que viajan en vehículo arrendado.
Solución :
a) Las variables en el estudio son : X = “Número de personas que viajan dentro de cada vehículo que fue
encuestado” que es Cuantitativa discreta Y = “Monto en miles de pesos destinado a gastos” que es Cuantitativa
continua Z = “Si el vehículo en que viajan es P=propio o A=arrendado” que es
Cualitativa
b) Consideramos los promedios de ambas variables:
Construyamos una tabla asociada al Monto en miles de pesos destinado a gastos
Esta tabla es llamada distribución marginal de Y= Monto destinado a Gastos.
Monto destinado a
gastos
*iy in iN
if iF if
*100
iF
*100
0 – 100 50 19 19 0,17 0,17 17 17
100 – 150 125 28 47 0,25 0,42 25 42
150 – 300 225 45 92 0,40 0,82 40 82
300 – 450 375 21 113 0,18 1 18 100
Total 113 1.00 100
25,197113
375*21225*45125*2850*19
Y
Luego, la cantidad promedio destinados a gastos es de 197.250 pesos.
Análogamente para Número de personas que viajan dentro de cada vehículo Esta tabla es llamada distribución marginal de X= Número de personas que viajan dentro de cada vehículo
Número de personas in
iN if iF if
*100
iF
*100
1 21 21 0,19 0,19 19 19
2 29 50 0,26 0,44 26 44
3 32 82 0,28 0,73 28 73
4 31 113 0,27 1,00 27 100
Total 113 1.00 100
65,2113
4*313*322*291*21
X
Luego, el número promedio de personas que viajan dentro de los vehículos es 2,65.
c) La tabla de frecuencias asociada a la variable Z, vehículo propio (variable cualitativa), llamada distribución marginal de Z= Tipo de vehículo es
Tipo de vehículo in if if *100
Propio 62 0.55 55
Arrendado 51 0.45 45
Total 113 1.00 100
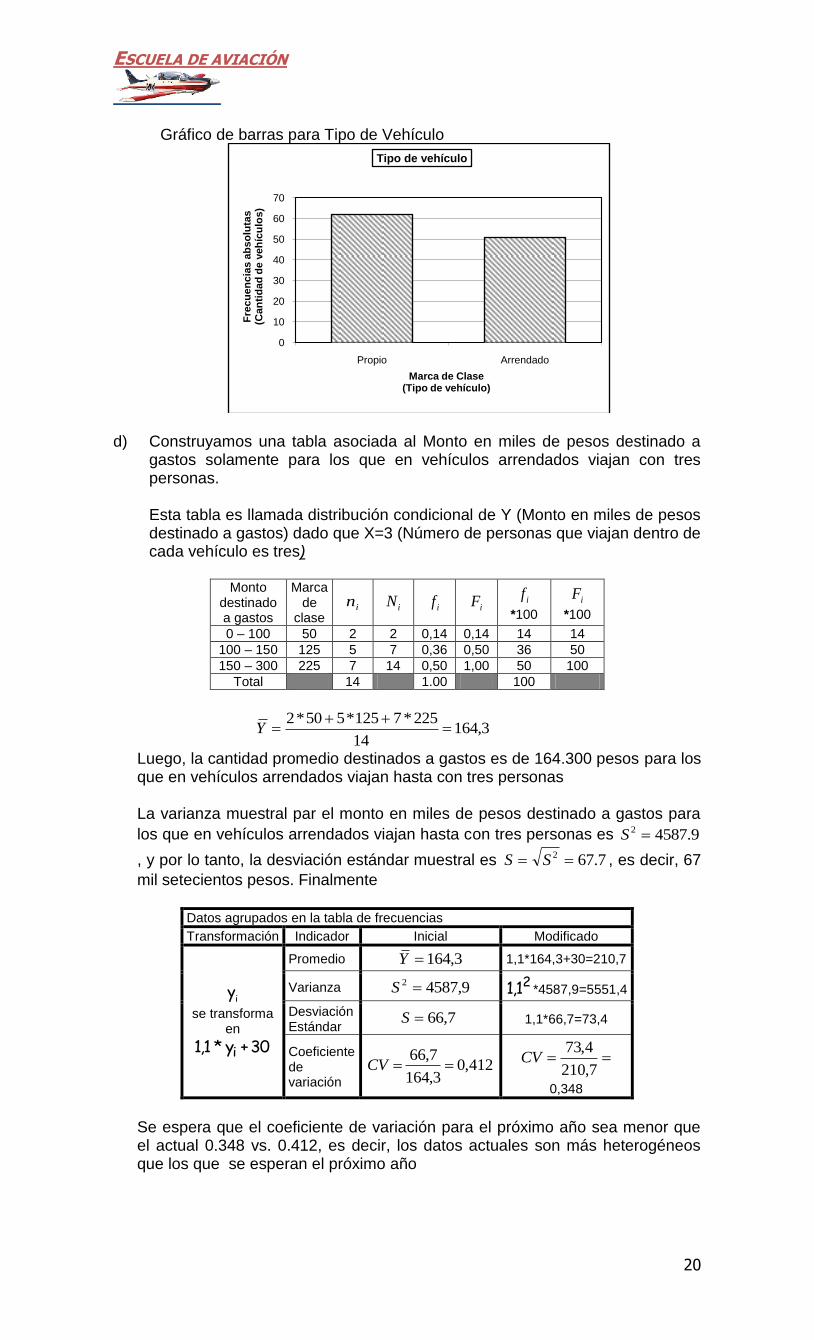
ESCUELA DE AVIACIÓN
20
Gráfico de barras para Tipo de Vehículo
d) Construyamos una tabla asociada al Monto en miles de pesos destinado a
gastos solamente para los que en vehículos arrendados viajan con tres personas. Esta tabla es llamada distribución condicional de Y (Monto en miles de pesos destinado a gastos) dado que X=3 (Número de personas que viajan dentro de cada vehículo es tres)
Monto
destinado a gastos
Marca de
clase in
iN if iF if
*100
iF
*100
0 – 100 50 2 2 0,14 0,14 14 14
100 – 150 125 5 7 0,36 0,50 36 50
150 – 300 225 7 14 0,50 1,00 50 100
Total 14 1.00 100
3,16414
225*7125*550*2
Y
Luego, la cantidad promedio destinados a gastos es de 164.300 pesos para los que en vehículos arrendados viajan hasta con tres personas
La varianza muestral par el monto en miles de pesos destinado a gastos para
los que en vehículos arrendados viajan hasta con tres personas es 9.45872 S
, y por lo tanto, la desviación estándar muestral es 7.672 SS , es decir, 67
mil setecientos pesos. Finalmente
Datos agrupados en la tabla de frecuencias
Transformación Indicador Inicial Modificado
iy
se transforma en
30+y*1,1 i
Promedio 3,164Y 1,1*164,3+30=210,7
Varianza 9,58742 S 21,1 *4587,9=5551,4
Desviación Estándar
66,7S 1,1*66,7=73,4
Coeficiente de variación
412,03,164
7,66CV
7,210
4,73CV
0,348
Se espera que el coeficiente de variación para el próximo año sea menor que el actual 0.348 vs. 0.412, es decir, los datos actuales son más heterogéneos que los que se esperan el próximo año
0
10
20
30
40
50
60
70
Propio Arrendado
Fre
cu
en
cia
s a
bso
luta
s(C
an
tid
ad
de v
eh
ícu
los)
Marca de Clase (Tipo de vehículo)
Tipo de vehículo

ESCUELA DE AVIACIÓN
21
e) Los valores donde fluctúa el 50% de la variación central de las observaciones del monto dedicado a gastos para los que viajan en vehículo arrendado, son entre el percentil 25 (cuartil 1) y el percentil 75 (Cuartil 3)
Construyamos una tabla asociada al Monto en miles de pesos destinado a gastos solamente para los que viajan en vehículos arrendados. Esta tabla es llamada distribución condicional de Y (Monto en miles de pesos destinado a gastos) dado que Z=A (Tipo de vehículo es arrendado)
Monto destinado a
gastos
Marca de
clase in
iN if iF if*100
iF*100
70 – 100 50 9 9 0,18 0,18 18 18
100 – 150 125 18 27 0,35 0,53 35 53
150 – 300 225 22 49 0,43 0,96 43 96
300 – 450 375 2 51 0,04 1,00 4 100
Total 51 1,00 100
El percentil 25 es 4,11018
50)9-
100
25*51(10025 P . El percentil 75 es
7,22622
150)27-
100
75*51(15075 P . Luego el 50% de los datos se encuentra
entre 110400 y 226700. 1.7. Problemas Propuestos. 1. Complete las siguientes aseveraciones
a) El proceso de, organizar y representar los datos demográficos se llama,.....................................................
b) El total de objetos bajo un estudio se llama, .....................................................
c) Una parte del Universo escogida para hacer el análisis estadístico, se llama, .....................................................
d) Un estudio que examina las características de la Población en su totalidad se conoce como .....................................................
2. Clasifique las variables de los siguientes problemas
a) El número de cuestionarios que una persona ha llenado el último año. b) La Edad en años cumplidos de una persona c) El Peso de una persona d) La profesión e) La Temperatura en la sala de Clases f) El grado de acuerdo o desacuerdo que se tiene por un político. g) Presencia o ausencia de una característica
3. El coordinador de Estadística quiere determinar, ¿cuál de dos libros deben utilizar los dos profesores del curso “Introducción a la Estadística” ?. Para llegar a una decisión, se seleccionan 20 alumnos en cada uno de las dos secciones (81 y 82) y cada sección entregar 10 de cada libro. La información que se recolectara de los estudiantes será: Sexo, Edad (en años), nota Final del semestre y libro utilizado. a) ¿Que dos variables son imprescindibles para el estudio? b) ¿Que variables son cuantitativas? c) ¿Que variables son cualitativas? d) ¿Qué variables son discretas? e) ¿Qué variables son continuas?

ESCUELA DE AVIACIÓN
22
4. La siguiente información fue obtenida al entrevistar a 300 alumnos de la Universidad que trabajan y estudian.
Sueldo anual en millones de
pesos
Frecuencia Relativa
1-2 0.35
2-3 0.30
3-4 0.10
4-5 0.25
Total 1.00
a) Identifique y clasifique la variable b) Complete la tabla de frecuencias c) ¿Cuántos estudiantes ganan entre 2 y 4 millones de pesos? d) ¿Que % de los estudiantes gana a lo más 3 millones?
5. El dueño de una empresa cree que el ausentismo diario en su oficina parece ir
en aumento. El año pasado un promedio de 47.8 empleados estuvo ausente algunos días, con una desviación estándar de 14.7. Se recolectó una muestra de 66 días para el año en curso y se ubicaron en la tabla que se muestra a continuación.
Empleados ausentes
Número de Días
20-30 5
30-40 9
40-50 8
50-60 10
60-70 12
70-80 11
80-90 8
90-100 3
a) Complete la tabla de frecuencias. b) Determine la Moda, la Media y la Mediana del número de empleados
ausentes. c) Muestre que la desviación estándar es de 19.7 empleados. d) En base a cuál de las medidas anteriores podría contestar al dueño de la
empresa ¿Cuál es su respuesta? 6. Los sindicalistas de la planta de la empresa ZZZZ en Valdivia, argumentan
que, en contra del contrato laboral, los trabajadores de la línea de producción tienen un promedio salarial por hora menor y con una mayor variabilidad que los trabajadores de oficina. Una muestra de 10n se toma de cada clase de trabajadores, entregando las siguientes observaciones.
Sujeto (N°)
Salario por hora Línea de producción
(miles de pesos)
Salario por hora oficina
(miles de pesos)
1 1.2 1.5
2 1.8 1.8
3 1.9 1.7
4 1.5 1.6
5 1.8 1.8
6 1.6 1.5
7 1.5 1.9
8 1.8 1.9
9 1.9 1.8
10 1.8 1.9

ESCUELA DE AVIACIÓN
23
a) Determine, la Media y la Moda en cada grupo b) Muestre que la desviación estándar de los trabajadores de producción es
0,23. c) Si la desviación estándar de los trabajadores de oficina es 0,16 y tomando
en cuenta los resultados obtenidos en a) y b) está de acuerdo con los dos argumentos de los sindicalistas
7. La siguiente tabla de frecuencias, entrega las ventas mensuales en miles de
pesos de equipos de paracaidismo en una tienda de la zona sur.
Ventas en miles de pesos
Número de meses
50-100 5
100-150 7
150-200 9
200-250 10
250-300 8
300-350 3
350-400 2
Total 44
a) Usted es el jefe de esa tienda, y su gerente le solicita una tabla de
distribución de frecuencias de las ventas. b) El gerente está interesado en el valor de la venta, para la cual se obtienen
el 60% más bajo de las observaciones, c) Además, usted siente que sería de utilidad determinar los valores de los
percentiles 10, 50 y 90. d) Si el gerente quiere que investigue las facturas de los meses, para los
cuales no superaron los 130.000 pesos de venta ¿Cuántos meses tendrá que investigar?
8. Los vendedores de una empresa comercial fueron clasificados de acuerdo al
volumen de dichas ventas en miles de $.
Volumen en miles de $
N° de Trabajadores
5 – 15 3 15 – 25 24 25 – 45 46 45 – 75 27
a) Clasifique e identifique la variable en estudio b) Determine el volumen promedio de ventas. c) Determine el 20% de los mayores volúmenes de ventas. d) Si para el próximo mes se determina un incremento en los volúmenes de
ventas dados por la siguiente expresión Y = 1.2X + 100. Determine el coeficiente de variabilidad del nuevo volumen de ventas.
9. Un fabricante desea comparar los tiempos de armado de cierto producto,
utilizando el proceso de armado estándar y un nuevo proceso. Para este propósito se seleccionaron 124 trabajadores con habilidades similares y se asignaron en forma aleatoria 62 trabajadores a cada proceso. Los resultados obtenidos se resumen en la tabla siguiente:

ESCUELA DE AVIACIÓN
24
Número de trabajadores
Tiempo de Armado (seg)
Estándar Nuevo
15 – 25 25 – 35 35 – 45 45 – 55 55 – 60
8 12 16 14 12
12 16 14 12 8
a) ¿Qué grupo es más homogéneo en el tiempo de armado? b) A nivel descriptivo, ¿Cuál método es mejor? Justifique. c) ¿Qué porcentaje de los trabajadores que utiliza el método estándar demora
más de medio minuto en armar el producto? d) ¿Cuántos trabajadores que utilizan el método nuevo superan el Percentil 25
de los que utilizan el estándar? e) Para un curso de capacitación se va a elegir al 40% de los trabajadores
más rápidos que utilizan el método nuevo. ¿Qué tiempo de armado deben obtener?
f) Si el tiempo de armado con el método estándar disminuye en un 10%, calcule el porcentaje de variabilidad.
10. En una empresa se han tabulado los sueldos diarios de 180 empleados:
Sueldos en miles de $
Frecuencia Acumulada
15 – 20 20 – 25 25 – 30 30 – 35 35 – 40
35 75
130 160 180
La empresa ofrece dos tipos de reajuste:
(A) Reajustar en un 15% más $2120 (B) Reajustar en un 11% más $3200
a) En total ¿Qué reajuste es más conveniente a la empresa? b) Calcule la desviación estándar de los sueldos
11. Las distribuciones de sueldos mensuales de 200 obreros de dos Empresas A
y B del mismo rubro son las siguientes (100 obreros en cada una):
Empresa A (miles de $)
Nº Trabajadores Empresa B (miles de $)
Nº Trabajadores
18 – 22 22 – 26 26 – 30 30 – 34 34 – 38 38 – 42 42 – 46
45 25 15 7 3 3 2
17 – 23 23 – 29 29 – 35 35 – 41 41 – 47 47 – 53 53 – 59
38 22 12 3
13 7 5
a) ¿En qué empresa es más uniforme la distribución de los sueldos de los
obreros? b) En la Empresa A, al 40% de los obreros con sueldos más bajos se les
otorgará una bonificación. ¿Cuál es el sueldo máximo que recibirá tal beneficio?
c) En la Empresa B, ¿Qué porcentaje de los obreros ganan más de $44500? d) Después de algún tiempo los obreros de la Empresa A recibirán un reajuste
de $3000 y los de la empresa B un reajuste del 30%. ¿Cómo se ven

ESCUELA DE AVIACIÓN
25
afectados los coeficientes de variación y los resultados de las partes (b) y (c)?.
12. Las primas directas en miles de pesos (X) en 100 contratos de seguros se
encuentran clasificadas en la siguiente tabla:
Primas (miles de $) Nº de contratos
0 – 50 50 – 100
100 – 150 150 – 200 200 – 250 250 – 300 300 – 350 350 – 400
7 28 20 18 12 8 5 2
a) Obtenga la prima directa mediana e interprete su valor. b) Determine el número de contratos que tienen prima directa entre 60 y 180
miles de pesos. c) Si se decide aumentar los riesgos de manera que todas las primas
aumenten en un 12%, determine la nueva prima media y compare el porcentaje de variabilidad antes y después de aplicada la medida
d) Si se clasifican las primas directas según los siguientes criterios:
Inferior a 150 : monto asegurado reducido
150 a 270 : monto asegurado de bajo riesgo
De 270 a 325 : valor monto asegurado alto
Sobre 325 : seguro de alto riesgo Construya un histograma de frecuencias relativas.
e) Suponga que se decide establecer a priori los porcentajes de cada categoría de la pregunta anterior (d), de la forma que al final se tenga un 24% de montos asegurados reducidos, un 50% de bajo riesgo, un 18% de valor monto asegurado alto y un 8% de seguros de alto riesgo. ¿Qué límites de primas deberíamos poner a estas categorías para conseguir estos porcentajes?
13. Los siguientes datos corresponden a los gastos fijos diarios asignados a
publicidad (X) y al monto de las ventas diarias (Y) de un grupo de 40 empresas dedicadas al rubro de seguro automotor.
a) Clasifique e identifique las variables en estudio b) Calcule medidas de tendencia central que resuman la información. c) ¿Qué porcentaje de las empresas gastan en publicidad entre 32 y 67 U.F.? d) Calcule la desviación estándar de las dos variables y compare los
coeficientes de variación. 14. Una empresa encargada de vender suministros computacionales, ha
realizado un estudio con respecto a la cantidad en miles de $ que vende, al tipo de empresa a las cuales atiende y al tipo de insumos, durante un mes, obteniendo la siguiente información (tipos de empresas: G = Grande, M = Medianas y pequeñas).
1. Monto de las Ventas (en U.F.)
Gastos fijos (en U.F.)
120 – 140 140 - 160 160 – 180 180 – 200
30 – 50 50 – 70 70 – 90
4 2 3
10 8 2
0 6 2
2 1 0

ESCUELA DE AVIACIÓN
26
Cantidad en miles de $ que venden
Tipos de Insumos
Tipo de Empresas
0 – 50 50 – 100
100 – 110
110 – 200
200 – 300
Papeles G 0 10 12 4 3
M 0 15 20 20 2
Otros G 6 3 10 10 8
M 0 8 10 10 8
a) Clasifique e identifique las variables en estudio b) Calcule medidas de tendencia central que resuman la información de la
variable “cantidad que vende” en miles de $, para las empresas Grande y para las empresas Medianas.
c) Esta empresa ha realizado un estudio para predecir las ventas del próximo mes, con un incremento del 12.5% más $105000. Se pide comparar la homogeneidad de la distribución de las ventas para ambos meses, sólo para las ventas de papeles.
d) Si se sabe que el promedio total de las ventas de este mes es de $160000, ¿Cuál debería ser el promedio de las ventas en dichas empresas que han comprado hasta $100000?
e) ¿Cuál es el porcentaje de las empresas que no compran papeles y compran otros insumos y que gastan entre $58000 y $210000 en este tipo de insumos?
15. Los pesos en Kg. de 58 cerdos fueros los siguientes :
36 69 71 97 36 63 128 63 45 78 58 41 83 53 48 80 51 107 69 75 57 36 50 86 148 65 129 112 56 57 76 72 125 99 55 51 66 39 48 39 105 63 112 70 59 72 136 65 72 89 80 149 60 92 114 93 51 32 a) Construya una tabla de frecuencias y construir el histograma de frecuencias
absolutas. Dibuje, sobre el histograma el polígono de frecuencias. b) Calcule Medidas de tendencia central y de dispersión a partir de los datos y
a partir de la tabla del punto a). c) Construya un polígono de frecuencias relativas acumuladas y úselo para
determinar el porcentaje de cerdos que satisface los siguientes enunciados.
Que un Cerdo tomado al azar pese 80 Kg. o más
Que un Cerdo tomado al azar pese entre 60 y 100 Kg.
Que un Cerdo tomado al azar pese hasta 70 Kg.




















