
ECONET: Effective Continual Pretraining of Language Models ...
14
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5367–5380 November 7–11, 2021. c 2021 Association for Computational Linguistics 5367 ECONET: Effective Continual Pretraining of Language Models for Event Temporal Reasoning Rujun Han 1 Xiang Ren 1 Nanyun Peng 1,2 1 University of Southern California 2 University of California, Los Angeles {rujunhan,xiangren}@usc.edu;[email protected] Abstract While pre-trained language models (PTLMs) have achieved noticeable success on many NLP tasks, they still struggle for tasks that re- quire event temporal reasoning, which is essen- tial for event-centric applications. We present a continual pre-training approach that equips PTLMs with targeted knowledge about event temporal relations. We design self-supervised learning objectives to recover masked-out event and temporal indicators and to discrim- inate sentences from their corrupted counter- parts (where event or temporal indicators got replaced). By further pre-training a PTLM with these objectives jointly, we reinforce its attention to event and temporal information, yielding enhanced capability on event tem- poral reasoning. This Effective CONtinual pre-training framework for Event Temporal reasoning (ECONET ) improves the PTLMs’ fine-tuning performances across five relation extraction and question answering tasks and achieves new or on-par state-of-the-art perfor- mances in most of our downstream tasks. 1 1 Introduction Reasoning event temporal relations is crucial for natural language understanding, and facilitates many real-world applications, such as tracking biomedical histories (Sun et al., 2013; Bethard et al., 2015, 2016, 2017), generating stories (Yao et al., 2019; Goldfarb-Tarrant et al., 2020), and forecasting social events (Li et al., 2020; Jin et al., 2020). In this work, we study two prominent event temporal reasoning tasks as shown in Figure 1: event relation extraction (ERE) (Chambers et al., 2014; Ning et al., 2018; O’Gorman et al., 2016; Mostafazadeh et al., 2016) that predicts temporal relations between a pair of events, and machine reading comprehension (MRC) (Ning et al., 2020; Zhou et al., 2019) where a passage and a question 1 Reproduction code, training data and models are available here: https://github.com/PlusLabNLP/ECONET. Figure 1: Top: an example illustrating the difference between ERE and QA / MRC samples of event tempo- ral reasoning. Bottom: our targeted masking strategy for ECONET v.s. random masking in PTLMs. about event temporal relations is presented, and models need to provide correct answers using the information in a given passage. Recent approaches leveraging large pre-trained language models (PTLMs) achieved state-of-the- art results on a range of event temporal reasoning tasks (Ning et al., 2020; Pereira et al., 2020; Wang et al., 2020; Zhou et al., 2020c; Han et al., 2019b). Despite the progress, vanilla PTLMs do not focus on capturing event temporal knowledge that can be used to infer event relations. For example, in Figure 1, an annotator of the QA sample can easily infer from the temporal indicator “following” that “transfer” happens BEFORE “preparing the paper- work”, but a fine-tuned RoBERTa model predicts that “transfer” has no such relation with the event “preparing the paperwork.” Plenty of such cases ex- ist in our error analysis on PTLMs for event tempo- ral relation-related tasks. We hypothesize that such deficiency is caused by original PTLMs’ random masks in the pre-training where temporal indicators and event triggers are under-weighted and hence not attended well enough for our downstream tasks.
-
Upload
khangminh22 -
Category
Documents
-
view
4 -
download
0
Transcript of ECONET: Effective Continual Pretraining of Language Models ...

Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5367–5380November 7–11, 2021. c©2021 Association for Computational Linguistics
5367
ECONET: Effective Continual Pretraining of Language Models for EventTemporal Reasoning
Rujun Han1 Xiang Ren1 Nanyun Peng1,2
1University of Southern California 2University of California, Los Angeles{rujunhan,xiangren}@usc.edu;[email protected]
Abstract
While pre-trained language models (PTLMs)have achieved noticeable success on manyNLP tasks, they still struggle for tasks that re-quire event temporal reasoning, which is essen-tial for event-centric applications. We presenta continual pre-training approach that equipsPTLMs with targeted knowledge about eventtemporal relations. We design self-supervisedlearning objectives to recover masked-outevent and temporal indicators and to discrim-inate sentences from their corrupted counter-parts (where event or temporal indicators gotreplaced). By further pre-training a PTLMwith these objectives jointly, we reinforce itsattention to event and temporal information,yielding enhanced capability on event tem-poral reasoning. This Effective CONtinualpre-training framework for Event Temporalreasoning (ECONET) improves the PTLMs’fine-tuning performances across five relationextraction and question answering tasks andachieves new or on-par state-of-the-art perfor-mances in most of our downstream tasks.1
1 IntroductionReasoning event temporal relations is crucial fornatural language understanding, and facilitatesmany real-world applications, such as trackingbiomedical histories (Sun et al., 2013; Bethardet al., 2015, 2016, 2017), generating stories (Yaoet al., 2019; Goldfarb-Tarrant et al., 2020), andforecasting social events (Li et al., 2020; Jin et al.,2020). In this work, we study two prominent eventtemporal reasoning tasks as shown in Figure 1:event relation extraction (ERE) (Chambers et al.,2014; Ning et al., 2018; O’Gorman et al., 2016;Mostafazadeh et al., 2016) that predicts temporalrelations between a pair of events, and machinereading comprehension (MRC) (Ning et al., 2020;Zhou et al., 2019) where a passage and a question
1Reproduction code, training data and models are availablehere: https://github.com/PlusLabNLP/ECONET.
Figure 1: Top: an example illustrating the differencebetween ERE and QA / MRC samples of event tempo-ral reasoning. Bottom: our targeted masking strategyfor ECONET v.s. random masking in PTLMs.about event temporal relations is presented, andmodels need to provide correct answers using theinformation in a given passage.
Recent approaches leveraging large pre-trainedlanguage models (PTLMs) achieved state-of-the-art results on a range of event temporal reasoningtasks (Ning et al., 2020; Pereira et al., 2020; Wanget al., 2020; Zhou et al., 2020c; Han et al., 2019b).Despite the progress, vanilla PTLMs do not focuson capturing event temporal knowledge that canbe used to infer event relations. For example, inFigure 1, an annotator of the QA sample can easilyinfer from the temporal indicator “following” that“transfer” happens BEFORE “preparing the paper-work”, but a fine-tuned RoBERTa model predictsthat “transfer” has no such relation with the event“preparing the paperwork.” Plenty of such cases ex-ist in our error analysis on PTLMs for event tempo-ral relation-related tasks. We hypothesize that suchdeficiency is caused by original PTLMs’ randommasks in the pre-training where temporal indicatorsand event triggers are under-weighted and hencenot attended well enough for our downstream tasks.

5368
Category Words
before, until, previous to, prior to,[before]preceding, followed by
[after] after, following, since, now thatsoon after, once∗∗
during, while, when, at the time,[during]at the same time, meanwhile
[past] earlier, previously, formerly,yesterday, in the past, last timeconsequently, subsequently, in turn,[future]henceforth, later, then
[beginning] initially, originally, at the beginningto begin, starting with, to start with
[ending] finally, in the end, at last, lastly
Table 1: The full list of the temporal lexicon. Cat-egories are created based on authors’ domain knowl-edge and best judgment. ∗∗ ‘once’ can be also placedinto [past] category due to its second meaning of ‘pre-viously’, which we exclude to keep words unique.
TacoLM (Zhou et al., 2020a) explored the idea oftargeted masking and predicting textual cues ofevent frequency, duration and typical time, whichshowed improvements over vanilla PTLMs on re-lated tasks. However, event frequency, duration andtime do not directly help machines understand pair-wise event temporal relations. Moreover, the maskprediction loss of TacoLM leverages a soft cross-entropy objective, which is manually calibratedwith external knowledge and could inadvertentlyintroduce noise in the continual pre-training.
We propose ECONET , a continual pre-trainingframework combining mask prediction and con-trastive loss using our masked samples. Our tar-geted masking strategy focuses only on event trig-gers and temporal indicators as shown in Figure 1.This design assists models to concentrate on eventsand temporal cues, and potentially strengthen mod-els’ ability to understand event temporal relationsbetter in the downstream tasks. We further pre-trainPTLMs with the following objectives jointly: themask prediction objective trains a generator thatrecovers the masked temporal indicators or events,and the contrastive loss trains a discriminator thatshares the representations with the generator anddetermines whether a predicted masked token iscorrupted or original (Clark et al., 2020). Our ex-periments demonstrate that ECONET is effectiveat improving the original PTLMs’ performances onevent temporal reasoning.
We briefly summarize our contributions. 1) Wepropose ECONET , a novel continual pre-trainingframework that integrates targeted masking andcontrastive loss for event temporal reasoning. 2)
Our training objectives effectively learn from thetargeted masked samples and inject richer eventtemporal knowledge in PTLMs, which leads tostronger fine-tuning performances over five widelyused event temporal commonsense tasks. In mosttarget tasks, ECONET achieves SOTA results incomparison with existing methods. 3) Comparedwith full-scale pre-training, ECONET requires amuch smaller amount of training data and can copewith various PTLMs such as BERT and RoBERTa.4) In-depth analysis shows that ECONET success-fully transfers knowledge in terms of textual cuesof event triggers and relations into the target tasks,particularly under low-resource settings.
2 MethodOur proposed method aims at addressing the issuein vanilla PTLMs that event triggers and tempo-ral indicators are not adequately attended for ourdownstream event reasoning tasks. To achieve thisgoal, we propose to replace the random masking inPTLMs with a targeted masking strategy designedspecifically for event triggers and temporal indi-cators. We also propose a continual pre-trainingmethod with mask prediction and contrastive lossthat allows models to effectively learn from thetargeted masked samples. The benefits of ourmethod are manifested by stronger fine-tuning per-formances over downstream ERE and MRC tasks.
Our overall approach ECONET consists of threecomponents. 1) Creating targeted self-supervisedtraining data by masking out temporal indicatorsand event triggers in the input texts; 2) leveragingmask prediction and contrastive loss to continuallytrain PTLMs, which produces an event temporalknowledge aware language model; 3) fine-tuningthe enhanced language model on downstream EREand MRC datasets. We will discuss each of thesecomponents in the following subsections.
2.1 Pre-trained Masked Language Models
The current PTLMs such as BERT (Devlin et al.,2018) and RoBERTa (Liu et al., 2019) follow arandom masking strategy. Figure 1 shows suchan example where random tokens / words aremasked from the input sentences. More formally,let x = [x1, ..., xn] be a sequence of input tokensand xmt ∈ xm represents random masked tokens.The per-sample pre-training objective is to predictthe identity (xt) of xmt with a cross-entropy loss,
LMLM = −∑
xmt ∈xm
I[xmt = xt] log(p(xmt |x)) (1)

5369
Figure 2: The proposed generator-discriminator (ECONET) architecture for event temporal reasoning. The upperblock is the mask prediction task for temporal indicators and the bottom block is the mask prediction task forevents. Both generators and the discriminator share the same representations.
Next, we will discuss the design and creation oftargeted masks, training objectives and fine-tuningapproaches for different tasks.
2.2 Targeted Masks Creation
Temporal Masks. We first compile a lexicon of40 common temporal indicators listed in the Ta-ble 1 based on previous error analysis and expertknowledge in the target tasks. Those indicators inthe [before], [after] and [during] categories canbe used to represent the most common temporalrelations between events. The associated wordsin each of these categories are synonyms of eachother. Temporal indicators in the [past], [future],[beginning] and [ending] categories probably donot represent pairwise event relations directly, butpredicting these masked tokens may still be helpfulfor models to understand time anchors and hencefacilitates temporal reasoning.
With the temporal lexicon, we conduct stringmatches over the 20-year’s New York Times newsarticles 2 and obtain over 10 million 1-2 sentencepassages that contain at least 1 temporal indicators.Finally, we replace each of the matched temporalindicators with a 〈mask〉 token. The upper blockin Figure 2 shows two examples where “following”and “after” are masked from the original texts.Event Masks. We build highly accurate eventdetection models (Han et al., 2019c; Zhang et al.,2021) to automatically label event trigger wordsin the 10 million passages mentioned above. Simi-larly, we replace these events with 〈mask〉 tokens.The bottom block in Figure 2 shows two exampleswhere events “transfer” and “resumed” are maskedfrom the original texts.
2NYT news articles are public from 1987-2007.
2.3 Generator for Mask PredictionsTo learn effectively from the targeted samples, wetrain two generators with shared representations torecover temporal and event masks.Temporal Generator. The per-sample temporalmask prediction objective is computed using cross-entropy loss,
LT = −∑
xTt ∈xT
I[xTt = xt] log(p(xTt |x)) (2)
where p(xTt |x) = Softmax (fT (hG(x)t)) andxTt ∈ xT is a masked temporal indicator. hG(x) isx’s encoded representation using a transformer andfT is a linear layer module that maps the maskedtoken representation into label space T consistingof the 40 temporal indicators.Event Generator. The per-sample event maskprediction objective is also computed using cross-entropy loss,
LE = −∑
xEt ∈xE
I[xEt = xt] log(p(xEt |x)) (3)
where p(xEt |x) = Softmax (fE(hG(x)t)) andxEt ∈ xE are masked events. hG(x) is the sharedtransformer encoder as in the temporal generatorand fE is a linear layer module that maps themasked token representation into label space Ewhich is a set of all event triggers in the data.
2.4 Discriminator for Contrastive LearningWe incorporate a discriminator that provides addi-tional feedback on mask predictions, which helpscorrect errors made by the generators.Contrastive Loss. For a masked token xt, wedesign a discriminator to predict whether the re-covered token by the mask prediction is original

5370
or corrupted. As shown in Figure 2, “following”and “resumed” are predicted correctly, so they arelabeled as original whereas “during” and “run” areincorrectly predicted and labeled as corrupted. Wetrain the discriminator with a contrastive loss,LD = −
∑xt∈M
y log(D(xt|x)) + (1− y) log(1−D(xt|x))
where M = xE ∪ xT and D(xt|x) =Sigmoid (fD(hD(x)t)) and y is a binary indicatorof whether a mask prediction is correct or not. hDshares the same transformer encoder with hG.Perturbed Samples. Our mask predictions fo-cus on temporal and event tokens, which are easiertasks than the original mask predictions in PTLMs.This could make the contrastive loss not so pow-erful as training a good discriminator requires rel-atively balanced original and corrupted samples.To deal with this issue, for r% of the generator’soutput, instead of using the recovered tokens, wereplace them with a token randomly sampled fromeither the temporal lexicon or the event vocabu-lary. We fix r = 50 to make original and corruptedsamples nearly balanced.
2.5 Joint TrainingTo optimize the combining impact of all compo-nents in our model, the final training loss calcu-lates the weighted sum of each individual loss,L = LT + αLE + βLD, where α and β are hyper-parameters that balance different training objec-tives. The temporal and event masked samples areassigned a unique identifier (1 for temporal, 0 forevent) so that the model knows which linear layersto feed the output of transformer into. Our over-all generator-discriminator architecture resemblesELECTRA (Clark et al., 2020). However, our pro-posed method differs from this work in 1) we usetargeted masking strategy as opposed to randommasks; 2) both temporal and event generators andthe discriminator, i.e. hG and hD share the hiddenrepresentations, but we allow task-specific final lin-ear layers fT , fE and fD; 3) we do not train fromscratch and instead continuing to train transformerparameters provided by PTLMs.
2.6 Fine-tuning on Target TasksAfter training with ECONET , we fine-tune the up-dated MLM on the downstream tasks. ERE sam-ples can be denoted as [P, ei, ej , ri,j ], where P isthe passage and (ei, ej) is a pair of event triggertokens in P. As Figure 3a shows, we feed (P, ei, ej)
(a) ERE
(b) QA: TORQUE
(c) QA: MCTACO
Figure 3: Target ERE and QA task illustrations.into an MLM (trained with ECONET). Followingthe setup of Han et al. (2019a) and Zhang et al.(2021), we concatenate the final event representa-tions vi, vj associated with (ei, ej) to predict tem-poral relation ri,j . The relation classifier is imple-mented by a multi-layer perceptron (MLP).
MRC/QA samples can be denoted as [P,Q,A],where Q represents a question and A denotes an-swers. Figure 3b illustrates an extractive QA taskwhere we feed the concatenated [P,Q] into anMLM. Each token xi ∈ P has a label with 1 in-dicating xi ∈ A and 0 otherwise. The token clas-sifier implemented by MLP predicts labels for allxi. Figure 3c illustrates another QA task where Ais a candidate answer for the question. We feedthe concatenated [P,Q,A] into an MLM and thebinary classifier predicts a 0/1 label of whether Ais a true statement for a given question.
3 Experimental Setup
In this section, we describe details of implement-ing ECONET , datasets and evaluation metrics, anddiscuss compared methods reported in Section 4.
3.1 Implementation DetailsEvent Detection Model. As mentioned brieflyin Section 2, we train a highly accurate event pre-diction model to mask event (triggers). We experi-mented with two models using event annotationsin TORQUE (Ning et al., 2020) and TB-Dense(Chambers et al., 2014). These two event annota-tions both follow previous event-centric reasoning

5371
research by using a trigger word (often a verb oran noun that most clearly describes the event’s oc-currence) to represent an event (UzZaman et al.,2013; Glavaš et al., 2014; O’Gorman et al., 2016).In both cases, we fine-tune RoBERTaLARGE onthe train set and select models based on the perfor-mance on the dev set. The primary results shownin Table 2 uses TORQUE’s annotations, but weconduct additional analysis in Section 4 to showboth models produce comparable results.
Continual Pretraining. We randomly selectedonly 200K out of 10 million samples to speed upour experiments and found the results can be asgood as using a lot more data. We used half ofthese 200K samples for temporal masked samplesand the other half for the event masked samples.We ensure none of these sample passages overlapwith the target test data. To keep the mask tokensbalanced in the two training samples, we maskedonly 1 temporal indicator or 1 event (closest to thetemporal indicator). We continued to train BERTand RoBERTa up to 250K steps with a batch size of8. The training process takes 25 hours on a singleGeForce RTX 2080 GPU with 11G memory. Notethat our method requires much fewer samples andis more computation efficient than the full-scalepre-training of language models, which typicallyrequires multiple days of training on multiple largeGPUs / TPUs.
For the generator only models reported in Ta-ble 2, we excluded the contrastive loss, trainedmodels with a batch size of 16 to fully utilize GPUmemories. We leveraged the dev set of TORQUEto find the best hyper-parameters.Fine-tuning. Dev set performances were usedfor early-stop and average dev performances overthree randoms seeds were used to pick the besthyper-parameters. Note that test set for the targettasks were never observed in any of the trainingprocess and their performances are reported in Ta-ble 2. All hyper-parameter search ranges can befound in Appendix C.
3.2 DatasetsWe evaluate our approach on five datasets concern-ing temporal ERE and MRC/QA. We briefly de-scribe these data below and list detailed statisticsin Appendix A.
ERE Datasets. TB-Dense (Chambers et al.,2014), MATRES (Ning et al., 2018) and RED(O’Gorman et al., 2016) are all ERE datasets. Their
samples follow the input format described in Sec-tion 2.6 where a pair of event (triggers) togetherwith their context are provided. The task is topredict pairwise event temporal relations. The dif-ferences are how temporal relation labels are de-fined. Both TB-Dense and MATRES leverage aVAGUE label to capture relations that are hard todetermine even by humans, which results in denserannotations than RED. RED contains the mostfine-grained temporal relations and thus the lowestsample/relation ratio. MATRES only considers starttime of events to determine their temporal order,whereas TB-Dense and RED consider start and endtime, resulting in lower inter-annotator agreement.
TORQUE (Ning et al., 2020) is an MRC/QAdataset where annotators first identify event trig-gers in given passages and then ask questions re-garding event temporal relations (ordering). Cor-rect answers are event trigger words in passages.TORQUE can be considered as reformulating tem-poral ERE tasks as an MRC/QA task. Therefore,both ERE datasets and TORQUE are highly cor-related with our continual pre-training objectiveswhere targeted masks of both events and temporalrelation indicators are incorporated.
MCTACO (Zhou et al., 2019) is another MR-C/QA dataset, but it differs from TORQUE in1) events are not explicitly identified; 2) answersare statements with true or false labels; 3) ques-tions contain broader temporal commonsense re-garding not only temporal ordering, but also eventfrequency, during and typical time that may not bedirectly helpful for reasoning temporal relations.For example, knowing how often a pair of eventshappen doesn’t help us figure out which event hap-pens earlier. Since our continual pre-training fo-cuses on temporal relations, MCTACO could theleast compatible dataset in our experiments.
3.3 Evaluation Metrics
Three metrics are used to evaluate the fine-tuningperformances.
F1: for TORQUE and MCTACO, we followthe data papers (Ning et al., 2020) and (Zhou et al.,2019) to report macro average of each question’sF1 score. For TB-Dense, MATRES and RED, wereport standard micro-average F1 scores to be con-sistent with the baselines.Exact-match (EM): for both MRC datasets, EM= 1 if answer predictions match perfectly with goldannotations; otherwise, EM = 0.

5372
TORQUE MCTACO TB-Dense MATRES RED
Methods F1 EM C F1 EM F1 F1 F1
TacoLM 65.4(±0.8) 37.1(±1.0) 21.0(±0.8) 69.3(±0.6) 40.5(±0.5) 64.8(±0.7) 70.9(±0.3) 40.3(±1.7)
BERTLARGE 70.6(±1.2) 43.7(±1.6) 27.5(±1.2) 70.3(±0.9) 43.2(±0.6) 62.8(±1.4) 70.5(±0.9) 39.4(±0.6)+ ECONET 71.4(±0.7) 44.8(±0.4) 28.5(±0.5) 69.2(±0.9) 42.3(±0.5) 63.0(±0.6) 70.4(±0.9) 40.2(±0.8)
RoBERTaLARGE 75.1(±0.4) 49.6(±0.5) 35.3(±0.8) 75.5(±1.0) 50.4(±0.9) 62.8(±0.3) 78.3(±0.5) 39.4(±0.4)+ Generator 75.8(±0.4) 51.2(±1.1) 35.8(±0.9) 75.1(±1.4) 50.2(±1.2) 65.2(±0.6) 77.0(±0.9) 41.0(±0.6)+ ECONET 76.1(±0.2) 51.6(±0.4) 36.8(±0.2) 76.3(±0.3) 52.8(±1.9) 64.8(±1.4) 78.8(±0.6) 42.8(±0.7)
ECONET (best) 76.3 52.0 37.0 76.8 54.7 66.8 79.3 43.8Current SOTA 75.2∗ 51.1 34.5 79.5† 56.5 66.7†† 80.3‡ 34.0‡‡
Table 2: Overall experimental results. Refer to Section 3.4 for naming conventions. The SOTA performances forTORQUE∗ are provided by Ning et al. (2020) and the numbers are average over 3 random seeds. The SOTAperformances for MCTACO† are provided by Pereira et al. (2020); TB-Dense†† and MATRES‡ by Zhang et al.(2021) and RED‡‡ by Han et al. (2019b). †, ††, ‡ and ‡‡ only report the best single model results, and to make faircomparisons with these baselines, we report both average and best single model performances. TacoLM baselineuses the provided and recommended checkpoint for extrinsic evaluations.
EM-consistency (C): in TORQUE, some ques-tions can be clustered into the same group due tothe data collection process. This metric reportsthe average EM score for a group as opposed to aquestion in the original EM metrics.
3.4 Compared Methods
We compare several pre-training methods withECONET: 1) RoBERTaLARGE is the origi-nal PTLM and we fine-tune it directly on tar-get tasks; 2) RoBERTaLARGE + ECONET isour proposed continual pre-training method; 3)RoBERTaLARGE + Generator only uses the gen-erator component in continual pre-training; 4)RoBERTaLARGE + random mask keeps the orig-inal PTLMs’ objectives and replaces the targetedmasks in ECONET with randomly masked to-kens. The methods’ names for continual pre-training BERTLARGE can be derived by replacingRoBERTaLARGE with BERTLARGE .
We also fine-tune pre-trained TacoLM on targetdatasets. The current SOTA systems we comparewith are provided by Ning et al. (2020), Pereiraet al. (2020), Zhang et al. (2021) and Han et al.(2019b). More details are presented in Section 4.1.
4 Results and AnalysisAs shown in Table 2, we report two baselines.The first one, TacoLM is a related work that fo-cuses on event duration, frequency and typical time.The second one is the current SOTA results re-ported to the best of the authors’ knowledge. Wealso report our own implementations of fine-tuningBERTLARGE and RoBERTaLARGE to comparefairly with ECONET. Unless pointing out specifi-cally, all gains mentioned in the following sectionsare in the unit of absolute percentage.
4.1 Comparisons with Existing Systems
TORQUE. The current SOTA system reportedin Ning et al. (2020) fine-tunes RoBERTaLARGE
and our own fine-tuned RoBERTaLARGE achieveson-par F1, EM and C scores. The gains ofRoBERTaLARGE + ECONET against the currentSOTA performances are 0.9%, 0.5% and 2.3% perF1, EM and C metrics.MCTACO. The current SOTA system ALICE(Pereira et al., 2020) also uses RoBERTaLARGE
as the text encoder, but leverages adversarial at-tacks on input samples. ALICE achieves 79.5%and 56.5% per F1 and EM metrics on the test set forthe best single model, and the best performancesfor RoBERTaLARGE + ECONET are 76.8% and54.7% per F1 and EM scores, which do not outper-form ALICE. This gap can be caused by the factthat the majority of samples in MCTACO reasonabout event frequency, duration and time, whichare not directly related to event temporal relations.TB-Dense + MATRES. The most recent SOTAsystem reported in Zhang et al. (2021) uses bothBERTLARGE and RoBERTaLARGE as text en-coders, but leverages syntactic parsers to build largegraphical attention networks on top of PTLMs.RoBERTaLARGE + ECONET’s fine-tuning perfor-mances are essentially on-par with this work with-out additional parameters. For TB-Dense, our bestmodel outperforms Zhang et al. (2021) by 0.1%while for MATRES, our best model underperformsby 1.0% per F1 scores.RED. The current SOTA system reported in Hanet al. (2019b) uses BERTBASE as word represen-tations (no finetuning) and BiLSTM as feature ex-tractor. The single best model achieves 34.0% F1
score and RoBERTaLARGE + ECONET is 9.8%higher than the baseline.

5373
4.2 The Impact of ECONETOverall Impact. ECONET in general works bet-ter than the original RoBERTaLARGE across 5 dif-ferent datasets, and the improvements are moresalient in TORQUE with 1.0%, 2.0% and 1.5%gains per F1, EM and C scores, in MCTACO with2.4% lift over the EM score, and in TB-Dense andRED with 2.0% and 3.4% improvements respec-tively over F1 scores. We observe that the improve-ments of ECONET over BERTLARGE is smallerand sometimes hurts the fine-tuning performances.We speculate this could be related to the propertythat BERT is less capable of handling temporalreasoning tasks, but we leave more rigorous inves-tigations to future research.Impact of Contrastive Loss. Comparing the av-erage performances of continual pre-training withgenerator only and with ECONET (generator + dis-criminator), we observe that generator alone canimprove performances of RoBERTaLARGE in 3out of 5 datasets. However, except for TB-Dense,ECONET is able to improve fine-tuning perfor-mances further, which shows the effectiveness ofusing the contrastive loss.Significance Tests. As current SOTA modelsare either not publicly available or under-performRoBERTaLARGE , we resort to testing the statisti-cal significance of the best single model betweenECONET and RoBERTaLARGE . Table 8 in theappendix lists all improvements’ p-values per Mc-Nemar’s test (McNemar, 1947). MATRES appearsto be the only one that is not statistically significant.
4.3 Impact of Event ModelsEvent trigger definitions have been consistent inprevious event temporal datasets (O’Gorman et al.,2016; Chambers et al., 2014; Ning et al., 2020).Trigger detection models built on TORQUE andTB-Dense both achieve > 92% F1 scores and >95% precision scores. For the 100K pre-trainingdata selected for event masks, we found an 84.5%overlap of triggers identified by both models. Wefurther apply ECONET trained on both event maskdata to the target tasks and achieve comparableperformances shown in Table 10 of the appendix.These results suggest that the impact of differentevent annotations is minimal and triggers detectedin either model can generalize to different tasks.
4.4 Additional Ablation StudiesTo better understand our proposed model, we exper-iment with additional continual training methodsand compare their fine-tuning performances.
TORQUE TB-D RED
Methods F1 EM C F1 F1
RoBERTaLARGE 75.1 49.6 35.3 62.8 39.4+ random mask 74.9 49.5 35.1 58.7 38.3+ ECONET 76.1 51.6 36.8 64.8 42.8
Table 3: Fine-tuning performances with different pre-training methods. All numbers are average over 3 ran-dom seeds. Std. Dev. ≥ 1% is underlined.
Random Masks. As most target datasets we useare in the news domain, to study the impact ofpotential domain-adaption, we continue to trainPTLMs with the original objective on the samedata using random masks. To compare fairly withthe generator and ECONET , we only mask 1 tokenper training sample. The search range of hyper-parameters is the same as in Section 3. As Table 3and 11 (appendix) show, continual pre-trainingwith random masks, in general, does not improveand sometimes hurt fine-tuning performances com-pared with fine-tuning with original PTLMs. Wehypothesize that this is caused by masking a smallerfraction (1 out of≈50 average) tokens than the orig-inal 15%. RoBERTaLARGE + ECONET achievesthe best fine-tuning results across the board.
Full Train Data 10% Train Data
RoBERTa ∆ ∆% RoBERTa ∆ ∆%
TORQUE 75.1 +1.0 +1.3% 59.7 +7.2 +12.1%MCTACO 75.5 +0.8 +1.1% 44.0 +5.6 +12.7%TB-Dense 62.8 +2.0 +3.2% 48.8 +2.8 +5.7%MATRES 78.3 +0.5 +1.3% 71.0 +2.4 +3.4%RED 39.4 +2.4 +6.0% 27.2 +1.8 +6.6%
Table 4: RoBERTaLARGE + ECONET’s improvementsover RoBERTaLARGE using full train data v.s. 10% oftrain data. ∆ indicates absolute points improvementswhile ∆% indicates relative gains per F1 scores.
4.5 Fine-tuning under Low-resource SettingsIn Table 4, we compare the improvements offine-tuning RoBERTaLARGE + ECONET overRoBERTaLARGE using full and 10% of the trainingdata. Measured by both absolute and relative per-centage gains, the majority of the improvements aremuch more significant under low-resource settings.This suggests that the transfer of event temporalknowledge is more salient when data is scarce. Wefurther show fine-tuning performance comparisonsusing different ratios of the training data in Fig-ure 6a-6b in the appendix. The results demonstratethat ECONET can outperform RoBERTaLARGE
consistently when fine-tuning TORQUE and RED.
4.6 Attention Scores on Temporal IndicatorsIn this section, we attempt to show explicitly howECONET enhances MLMs’ attentions on temporalindicators for downstream tasks. As mentioned in
5374
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24Layers
0
5
10
15
20
25
30
Aver
age
Atte
ntio
n Sc
ores
ECONET [before]RoBERTa [before]ECONET [after]RoBERTa [after]ECONET [during]RoBERTa [during]
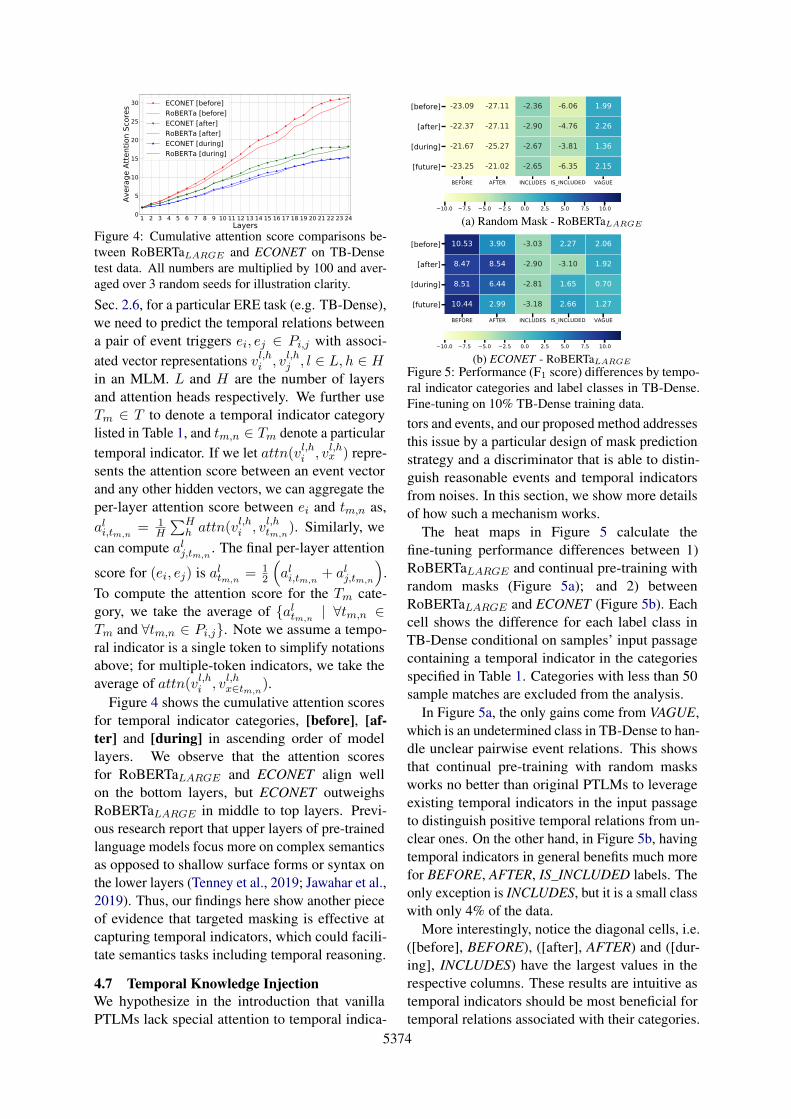
Figure 4: Cumulative attention score comparisons be-tween RoBERTaLARGE and ECONET on TB-Densetest data. All numbers are multiplied by 100 and aver-aged over 3 random seeds for illustration clarity.
Sec. 2.6, for a particular ERE task (e.g. TB-Dense),we need to predict the temporal relations betweena pair of event triggers ei, ej ∈ Pi,j with associ-ated vector representations vl,hi , vl,hj , l ∈ L, h ∈ Hin an MLM. L and H are the number of layersand attention heads respectively. We further useTm ∈ T to denote a temporal indicator categorylisted in Table 1, and tm,n ∈ Tm denote a particulartemporal indicator. If we let attn(vl,hi , vl,hx ) repre-sents the attention score between an event vectorand any other hidden vectors, we can aggregate theper-layer attention score between ei and tm,n as,ali,tm,n
= 1H
∑Hh attn(vl,hi , vl,htm,n
). Similarly, wecan compute alj,tm,n
. The final per-layer attention
score for (ei, ej) is altm,n= 1
2
(ali,tm,n
+ alj,tm,n
).
To compute the attention score for the Tm cate-gory, we take the average of {altm,n
| ∀tm,n ∈Tm and ∀tm,n ∈ Pi,j}. Note we assume a tempo-ral indicator is a single token to simplify notationsabove; for multiple-token indicators, we take theaverage of attn(vl,hi , vl,hx∈tm,n
).Figure 4 shows the cumulative attention scores
for temporal indicator categories, [before], [af-ter] and [during] in ascending order of modellayers. We observe that the attention scoresfor RoBERTaLARGE and ECONET align wellon the bottom layers, but ECONET outweighsRoBERTaLARGE in middle to top layers. Previ-ous research report that upper layers of pre-trainedlanguage models focus more on complex semanticsas opposed to shallow surface forms or syntax onthe lower layers (Tenney et al., 2019; Jawahar et al.,2019). Thus, our findings here show another pieceof evidence that targeted masking is effective atcapturing temporal indicators, which could facili-tate semantics tasks including temporal reasoning.
4.7 Temporal Knowledge InjectionWe hypothesize in the introduction that vanillaPTLMs lack special attention to temporal indica-
BEFORE AFTER INCLUDES IS_INCLUDED VAGUE
[before]
[after]
[during]
[future]
-23.09 -27.11 -2.36 -6.06 1.99
-22.37 -27.11 -2.90 -4.76 2.26
-21.67 -25.27 -2.67 -3.81 1.36
-23.25 -21.02 -2.65 -6.35 2.15
10.0 7.5 5.0 2.5 0.0 2.5 5.0 7.5 10.0
(a) Random Mask - RoBERTaLARGE
BEFORE AFTER INCLUDES IS_INCLUDED VAGUE
[before]
[after]
[during]
[future]
10.53 3.90 -3.03 2.27 2.06
8.47 8.54 -2.90 -3.10 1.92
8.51 6.44 -2.81 1.65 0.70
10.44 2.99 -3.18 2.66 1.27
10.0 7.5 5.0 2.5 0.0 2.5 5.0 7.5 10.0
(b) ECONET - RoBERTaLARGE
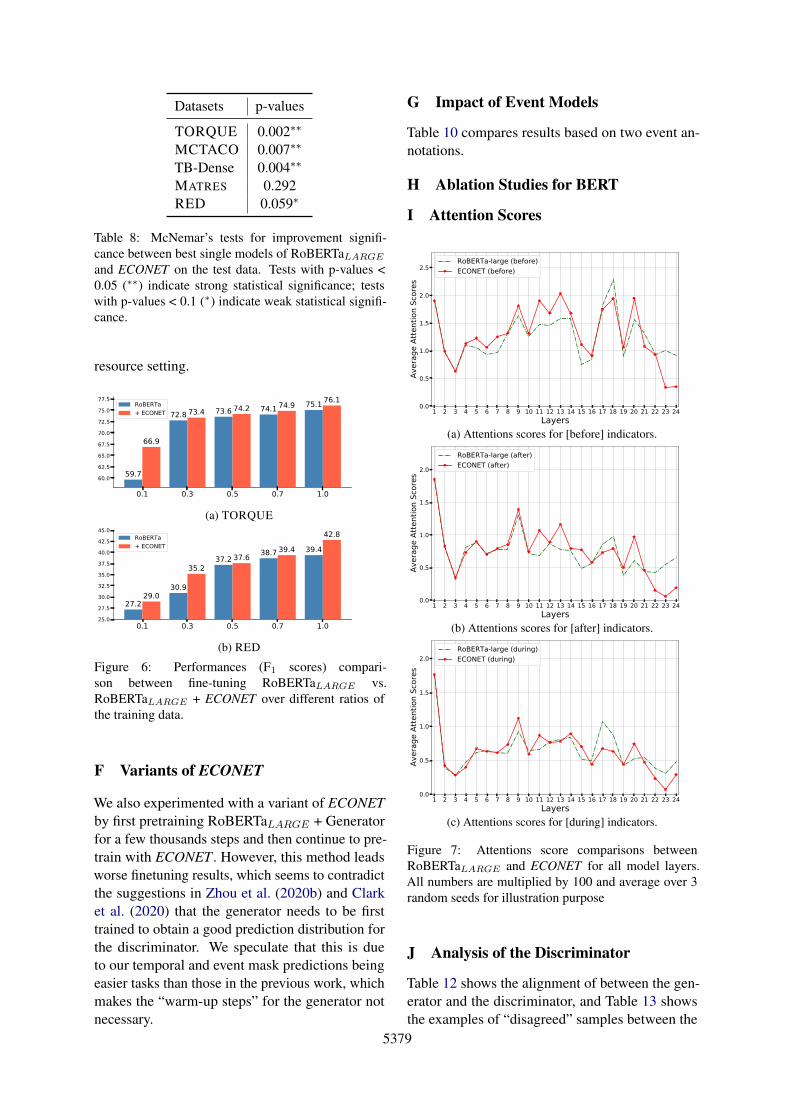
Figure 5: Performance (F1 score) differences by tempo-ral indicator categories and label classes in TB-Dense.Fine-tuning on 10% TB-Dense training data.
tors and events, and our proposed method addressesthis issue by a particular design of mask predictionstrategy and a discriminator that is able to distin-guish reasonable events and temporal indicatorsfrom noises. In this section, we show more detailsof how such a mechanism works.
The heat maps in Figure 5 calculate thefine-tuning performance differences between 1)RoBERTaLARGE and continual pre-training withrandom masks (Figure 5a); and 2) betweenRoBERTaLARGE and ECONET (Figure 5b). Eachcell shows the difference for each label class inTB-Dense conditional on samples’ input passagecontaining a temporal indicator in the categoriesspecified in Table 1. Categories with less than 50sample matches are excluded from the analysis.
In Figure 5a, the only gains come from VAGUE,which is an undetermined class in TB-Dense to han-dle unclear pairwise event relations. This showsthat continual pre-training with random masksworks no better than original PTLMs to leverageexisting temporal indicators in the input passageto distinguish positive temporal relations from un-clear ones. On the other hand, in Figure 5b, havingtemporal indicators in general benefits much morefor BEFORE, AFTER, IS_INCLUDED labels. Theonly exception is INCLUDES, but it is a small classwith only 4% of the data.
More interestingly, notice the diagonal cells, i.e.([before], BEFORE), ([after], AFTER) and ([dur-ing], INCLUDES) have the largest values in therespective columns. These results are intuitive astemporal indicators should be most beneficial fortemporal relations associated with their categories.

5375
Combining these two sets of results, we provideadditional evidence that ECONET helps PTLMsbetter capture temporal indicators and thus resultsin stronger fine-tuning performances.
Our final analysis attempts to show why discrim-inator helps. We feed 1K unused masked samplesinto the generator of the best ECONET in Table 2to predict either the masked temporal indicatorsor masked events. We then examine the accuracyof the discriminator for correctly and incorrectlypredicted masked tokens. As shown in Table 12of the appendix, the discriminator aligns well withthe event generator’s predictions. For the temporalgenerator, the discriminator disagrees substantially(82.2%) with the “incorrect” predictions, i.e. thegenerator predicts a supposedly wrong indicator,but the discriminator thinks it looks original.
To understand why, we randomly selected 50 dis-agreed samples and found that 12 of these “incor-rect” predictions fall into the same temporal indica-tor group of the original ones and 8 of them belongto the related groups in Table 1. More details andexamples can be found in Table 13 in the appendix.This suggests that despite being nearly perfect re-placements of the original masked indicators, these40% samples are penalized as wrong predictionswhen training the generator. The discriminator, bydisagreeing with the generator, provides opposingfeedback that trains the overall model to better cap-ture indicators with similar temporal signals.
5 Related WorkLanguage Model Pretraining. Since the break-through of BERT (Devlin et al., 2018), PTLMshave become SOTA models for a variety ofNLP applications. There have also been sev-eral modifications/improvements built on the orig-inal BERT model. RoBERTa (Liu et al., 2019)removes the next sentence prediction in BERTand trains with longer text inputs and moresteps. ELECTRA (Clark et al., 2020) proposes agenerator-discriminator architecture, and addressesthe sample-inefficiency issue in previous PTLMs.
Recent research explored methods to continueto train PTLMs so that they can adapt better todownstream tasks. For example, TANDA (Garget al., 2019) adopts an intermediate training onmodified Natural Questions dataset (Kwiatkowskiet al., 2019) so that it performs better for the An-swer Sentence Selection task. Zhou et al. (2020b)proposed continual training objectives that requirea model to distinguish natural sentences from those
with concepts randomly shuffled or generated bymodels, which enables language models to capturelarge-scale commonsense knowledge.Event Temporal Reasoning. There has been asurge of attention to event temporal reasoning re-search recently. Some noticeable datasets includeERE samples: TB-Dense (Chambers et al., 2014),MATRES (Ning et al., 2018) and RED (O’Gormanet al., 2016). Previous SOTA systems on these dataleveraged PTLMs and structured learning (Hanet al., 2019c; Wang et al., 2020; Zhou et al., 2020c;Han et al., 2020) and have substantially improvedmodel performances, though none of them tack-led the issue of lacking event temporal knowledgein PTLMs. TORQUE (Ning et al., 2020) andMCTACO (Zhou et al., 2019) are recent MRCdatasets that attempt to reason about event tem-poral relations using natural language rather thanERE formalism.
Zhou et al. (2020a) and Zhao et al. (2020) aretwo recent works that attempt to incorporate eventtemporal knowledge in PTLMs. The formal onefocuses on injecting temporal commonsense withtargeted event time, frequency and duration maskswhile the latter one leverages distantly labeled pair-wise event temporal relations, masks before/afterindicators, and focuses on ERE application only.Our work differs from them by designing a tar-geted masking strategy for event triggers and com-prehensive temporal indicators, proposing a con-tinual training method with mask prediction andcontrastive loss, and applying our framework on abroader range of event temporal reasoning tasks.
6 Conclusion and Future WorkIn summary, we propose a continual training frame-work with targeted mask prediction and contrastiveloss to enable PTLMs to capture event temporalknowledge. Extensive experimental results showthat both the generator and discriminator compo-nents can be helpful to improve fine-tuning perfor-mances over 5 commonly used data in event tempo-ral reasoning. The improvements of our methodsare much more pronounced in low-resource set-tings, which points out a promising direction forfew-shot learning in this research area.
Acknowledgments
This work is supported by the Intelligence Ad-vanced Research Projects Activity (IARPA), viaContract No. 2019-19051600007 and DARPA un-der agreement number FA8750-19-2-0500.

5376
ReferencesSteven Bethard, Leon Derczynski, Guergana Savova,
James Pustejovsky, and Marc Verhagen. 2015.SemEval-2015 task 6: Clinical TempEval. In Pro-ceedings of the 9th International Workshop on Se-mantic Evaluation (SemEval 2015), pages 806–814,Denver, Colorado. Association for ComputationalLinguistics.
Steven Bethard, Guergana Savova, Wei-Te Chen, LeonDerczynski, James Pustejovsky, and Marc Verhagen.2016. SemEval-2016 task 12: Clinical TempEval.In Proceedings of the 10th International Workshopon Semantic Evaluation (SemEval-2016), pages1052–1062, San Diego, California. Association forComputational Linguistics.
Steven Bethard, Guergana Savova, Martha Palmer,and James Pustejovsky. 2017. SemEval-2017 task12: Clinical TempEval. In Proceedings of the11th International Workshop on Semantic Evalua-tion (SemEval-2017), pages 565–572, Vancouver,Canada. Association for Computational Linguistics.
Nathanael Chambers, Taylor Cassidy, Bill McDowell,and Steven Bethard. 2014. Dense event orderingwith a multi-pass architecture. In ACL.
Kevin Clark, Minh-Thang Luong, Quoc V. Le, andChristopher D. Manning. 2020. Electra: Pre-training text encoders as discriminators rather thangenerators. In International Conference on Learn-ing Representations.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, andKristina Toutanova. 2018. Bert: Pre-training of deepbidirectional transformers for language understand-ing. In NAACL-HLT.
Siddhant Garg, Thuy Vu, and Alessandro Moschitti.2019. Tanda: Transfer and adapt pre-trained trans-former models for answer sentence selection.
Goran Glavaš, Jan Šnajder, Marie-Francine Moens, andParisa Kordjamshidi. 2014. HiEve: A corpus forextracting event hierarchies from news stories. InProceedings of the Ninth International Conferenceon Language Resources and Evaluation (LREC’14),pages 3678–3683, Reykjavik, Iceland. EuropeanLanguage Resources Association (ELRA).
Seraphina Goldfarb-Tarrant, Tuhin Chakrabarty, RalphWeischedel, and Nanyun Peng. 2020. Content plan-ning for neural story generation with aristotelianrescoring. In the 2020 Conference on EmpiricalMethods in Natural Language Processing (EMNLP),pages 4319–4338.
Rujun Han, I-Hung Hsu, Mu Yang, Aram Galstyan,Ralph Weischedel, and Nanyun Peng. 2019a. Deepstructured neural network for event temporal rela-tion extraction. In Proceedings of the 23rd Confer-ence on Computational Natural Language Learning(CoNLL), pages 666–106, Hong Kong, China. Asso-ciation for Computational Linguistics.
Rujun Han, Mengyue Liang, Bashar Alhafni, andNanyun Peng. 2019b. Contextualized word embed-dings enhanced event temporal relation extractionfor story understanding. In 2019 Annual Conferenceof the North American Chapter of the Associationfor Computational Linguistics (NAACL-HLT 2019),Workshop on Narrative Understanding.
Rujun Han, Qiang Ning, and Nanyun Peng. 2019c.Joint event and temporal relation extraction withshared representations and structured prediction. InProceedings of the 2019 Conference on EmpiricalMethods in Natural Language Processing and the9th International Joint Conference on Natural Lan-guage Processing (EMNLP-IJCNLP), pages 434–444, Hong Kong, China. Association for Computa-tional Linguistics.
Rujun Han, Yichao Zhou, and Nanyun Peng. 2020. Do-main knowledge empowered structured neural netfor end-to-end event temporal relation extraction. InProceedings of the 2020 Conference on EmpiricalMethods in Natural Language Processing (EMNLP),pages 5717–5729, Online. Association for Computa-tional Linguistics.
Ganesh Jawahar, Benoît Sagot, and Djamé Seddah.2019. What does BERT learn about the structureof language? In Proceedings of the 57th AnnualMeeting of the Association for Computational Lin-guistics, pages 3651–3657, Florence, Italy. Associa-tion for Computational Linguistics.
Woojeong Jin, Suji Kim, and Xiang Ren. 2020. Fore-castqa: A question answering challenge for eventforecasting. arXiv preprint arXiv:2005.00792.
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Red-field, Michael Collins, Ankur Parikh, Chris Alberti,Danielle Epstein, Illia Polosukhin, Matthew Kelcey,Jacob Devlin, Kenton Lee, Kristina N. Toutanova,Llion Jones, Ming-Wei Chang, Andrew Dai, JakobUszkoreit, Quoc Le, and Slav Petrov. 2019. Natu-ral questions: a benchmark for question answeringresearch. Transactions of the Association of Compu-tational Linguistics.
Manling Li, Qi Zeng, Ying Lin, Kyunghyun Cho, HengJi, Jonathan May, Nathanael Chambers, and ClareVoss. 2020. Connecting the dots: Event graphschema induction with path language modeling. InProceedings of the 2020 Conference on EmpiricalMethods in Natural Language Processing (EMNLP),pages 684–695, Online. Association for Computa-tional Linguistics.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Man-dar Joshi, Danqi Chen, Omer Levy, Mike Lewis,Luke Zettlemoyer, and Veselin Stoyanov. 2019.Roberta: A robustly optimized bert pretraining ap-proach. arXiv preprint, arXiv:1907.11692.
Quinn McNemar. 1947. Note on the sampling errorof the difference between correlated proportions orpercentages. Psychometrika, 12(2):153–157.

5377
Nasrin Mostafazadeh, Alyson Grealish, NathanaelChambers, James Allen, and Lucy Vanderwende.2016. Caters: Causal and temporal relation schemefor semantic annotation of event structures. InNAACL, San Diego, USA.
Qiang Ning, Hao Wu, Rujun Han, Nanyun Peng, MattGardner, and Dan Roth. 2020. TORQUE: A readingcomprehension dataset of temporal ordering ques-tions. In Proceedings of the 2020 Conference onEmpirical Methods in Natural Language Process-ing (EMNLP), pages 1158–1172, Online. Associa-tion for Computational Linguistics.
Qiang Ning, Hao Wu, and Dan Roth. 2018. A multi-axis annotation scheme for event temporal relations.In ACL. Association for Computational Linguistics.
Tim O’Gorman, Kristin Wright-Bettner, and MarthaPalmer. 2016. Richer event description: Integratingevent coreference with temporal, causal and bridg-ing annotation. In Proceedings of the 2nd Work-shop on Computing News Storylines (CNS 2016),pages 47–56, Austin, Texas. Association for Com-putational Linguistics.
Lis Pereira, Xiaodong Liu, Fei Cheng, Masayuki Asa-hara, and Ichiro Kobayashi. 2020. Adversarial train-ing for commonsense inference. In Proceedings ofthe 5th Workshop on Representation Learning forNLP, pages 55–60, Online. Association for Compu-tational Linguistics.
Weiyi Sun, Anna Rumshisky, and Ozlem Uzuner. 2013.Evaluating temporal relations in clinical text: 2012i2b2 challenge.
Ian Tenney, Dipanjan Das, and Ellie Pavlick. 2019.BERT rediscovers the classical NLP pipeline. InProceedings of the 57th Annual Meeting of the Asso-ciation for Computational Linguistics, pages 4593–4601, Florence, Italy. Association for ComputationalLinguistics.
Naushad UzZaman, Hector Llorens, Leon Derczyn-ski, James Allen, Marc Verhagen, and James Puste-jovsky. 2013. SemEval-2013 task 1: TempEval-3:Evaluating time expressions, events, and temporalrelations. In Second Joint Conference on Lexicaland Computational Semantics (*SEM), Volume 2:Proceedings of the Seventh International Workshopon Semantic Evaluation (SemEval 2013), pages 1–9, Atlanta, Georgia, USA. Association for Computa-tional Linguistics.
Haoyu Wang, Muhao Chen, Hongming Zhang, andDan Roth. 2020. Joint constrained learning forevent-event relation extraction. In Proceedings ofthe 2020 Conference on Empirical Methods in Natu-ral Language Processing (EMNLP), pages 696–706,Online. Association for Computational Linguistics.
Lili Yao, Nanyun Peng, Weischedel Ralph, KevinKnight, Dongyan Zhao, and Rui Yan. 2019. Plan-and-write: Towards better automatic storytelling. In
The Thirty-Third AAAI Conference on Artificial In-telligence (AAAI-19).
Shuaicheng Zhang, Lifu Huang, and Qiang Ning. 2021.Extracting temporal event relation with syntactic-guided temporal graph transformer. arXiv preprintarXiv:arXiv:2104.09570.
Xinyu Zhao, Shih-ting Lin, and Greg Durrett. 2020. Ef-fective distant supervision for temporal relation ex-traction. arXiv preprint arXiv:2010.12755.
Ben Zhou, Daniel Khashabi, Qiang Ning, and DanRoth. 2019. “going on a vacation” takes longerthan “going for a walk”: A study of temporal com-monsense understanding. In Proceedings of the2019 Conference on Empirical Methods in Natu-ral Language Processing and the 9th InternationalJoint Conference on Natural Language Processing(EMNLP-IJCNLP), pages 3363–3369, Hong Kong,China. Association for Computational Linguistics.
Ben Zhou, Qiang Ning, Daniel Khashabi, and DanRoth. 2020a. Temporal Common Sense Acquisitionwith Minimal Supervision. In Proc. of the AnnualMeeting of the Association for Computational Lin-guistics (ACL).
Wangchunshu Zhou, Dong-Ho Lee, Ravi Kiran Sel-vam, Seyeon Lee, Bill Yuchen Lin, and Xiang Ren.2020b. Pre-training text-to-text transformers forconcept-centric common sense.
Yichao Zhou, Yu Yan, Rujun Han, J. Harry Caufield,Kai-Wei Chang, Yizhou Sun, Peipei Ping, and WeiWang. 2020c. Clinical temporal relation extrac-tion with probabilistic soft logic regularization andglobal inference. arXiv preprint, arXiv:2012.08790.

5378
A Data Summary
Table 5 describes basic statistics for target datasetsused in this work. The numbers of train/dev/testsamples for TORQUE and MCTACO are ques-tion based. There is no training set provided inMCTACO. So we train on the dev set and re-port the evaluation results on the test set followingPereira et al. (2020). The numbers of train/dev/testsamples for TB-Dense, MATRES and RED refer to(event, event, relation) triplets. The standard devset is not provide by MATRES and RED, so wefollow the split used in Zhang et al. (2021) and Hanet al. (2019b).
Data #Train #Dev #Test #Label
TORQUE 24,523 1,483 4,668 2MCTACO - 3,783 9,442 2TB-Dense 4,032 629 1,427 6MATRES 5,412 920 827 4RED 3,336 400 473 11
Table 5: The numbers of samples for TORQUE refersto number of questions; the numbers for MCTACOare valid question and answer pairs; and the numbersof samples for TB-Dense, MATRES and RED are all(event, event, relation) triplets.
Downloading link for the (processed) continualpretraining data is provided in the README fileof the code package.
B Event Detection Model
As mentioned briefly in Secion 2, we train anevent prediction model using event annotations inTORQUE. We finetune RoBERTaLARGE on thetraining set and select models based on the perfor-mance on the dev set. The best model achieves> 92% event prediction F1 score with > 95% pre-cision score after just 1 epoch of training, whichindicates that this is a highly accurate model.
C Reproduction Checklist
Number of parameters. We continue to trainBERTLARGE and RoBERTaLARGE and so thenumber of parameters are the same as the origi-nal PTLMs, which is 336M.
Hyper-parameter Search Due to computationconstraints, we had to limit the search range ofhyper-parameters for ECONET . For learning rates,we tried (1e−6, 2e−6); for weights on the con-trastive loss (β), we tried (1.0, 2.0).
Best Hyper-parameters. In Table 6 and Table 7,we provide hyper-parameters for our best per-forming language model using RoBERTaLARGE +ECONET and BERTLARGE + ECONET and besthyper-parameters for fine-tuning them on down-stream tasks. For fine-tuning on the target datasets.We conducted grid search for learning rates in therange of (5e−6, 1e−5) and for batch size in therange of (2, 4, 6, 12). We fine-tuned all models for10 epochs with three random seeds (5, 7, 23).
Method learning rate batch size β
ECONET 1e−6 8 1.0TORQUE 1e−5 12 -MCTACO 5e−6 4 -TB-Dense 5e−6 4 -MATRES 5e−6 2 -RED 5e−6 2 -
Table 6: Hyper-parameters of our best performing LMwith RoBERTaLARGE + ECONET as well as besthyper-parameters for fine-tuning on downstream tasks.
Method learning rate batch size β
ECONET 2e−6 8 1.0TORQUE 1e−5 12 -MCTACO 1e−5 2 -TB-Dense 1e−5 2 -MATRES 5e−6 4 -RED 1e−5 6 -
Table 7: Hyper-parameters of our best performing LMwith BERTLARGE + ECONET as well as best hyper-parameters for fine-tuning on downstream tasks.
Dev Set Performances We show average dev setperformances in Table 9 corresponding to our mainresults in Table 2.
D Significance Tests.
We leverage McNemar’s tests (McNemar, 1947)to show ECONET’s improvements againstRoBERTaLARGE . McNemar’s tests computestatistics by aggregating all samples’ predictioncorrectness. For ERE tasks, this value is simplyclassification correctness; for QA tasks (TORQUEand MCTACO), we use EM per question-answerpairs.
E Fine-tuning under Low-resourceSettings
Table 4 shows improvements of ECONET overRoBERTaLARGE are much more salient under low-
5379
Datasets p-values
TORQUE 0.002∗∗
MCTACO 0.007∗∗
TB-Dense 0.004∗∗
MATRES 0.292RED 0.059∗
Table 8: McNemar’s tests for improvement signifi-cance between best single models of RoBERTaLARGE
and ECONET on the test data. Tests with p-values <0.05 (∗∗) indicate strong statistical significance; testswith p-values < 0.1 (∗) indicate weak statistical signifi-cance.
resource setting.
0.1 0.3 0.5 0.7 1.0
60.0
62.5
65.0
67.5
70.0
72.5
75.0
77.5
59.7
72.8 73.6 74.1 75.1
66.9
73.4 74.2 74.9 76.1RoBERTa+ ECONET
(a) TORQUE
0.1 0.3 0.5 0.7 1.025.027.530.032.535.037.540.042.545.0
27.2
30.9
37.238.7 39.4
29.0
35.237.6
39.442.8RoBERTa
+ ECONET
(b) RED
Figure 6: Performances (F1 scores) compari-son between fine-tuning RoBERTaLARGE vs.RoBERTaLARGE + ECONET over different ratios ofthe training data.
F Variants of ECONET
We also experimented with a variant of ECONETby first pretraining RoBERTaLARGE + Generatorfor a few thousands steps and then continue to pre-train with ECONET . However, this method leadsworse finetuning results, which seems to contradictthe suggestions in Zhou et al. (2020b) and Clarket al. (2020) that the generator needs to be firsttrained to obtain a good prediction distribution forthe discriminator. We speculate that this is dueto our temporal and event mask predictions beingeasier tasks than those in the previous work, whichmakes the “warm-up steps” for the generator notnecessary.
G Impact of Event Models
Table 10 compares results based on two event an-notations.
H Ablation Studies for BERT
I Attention Scores
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24Layers
0.0
0.5
1.0
1.5
2.0
2.5
Aver
age
Atte
ntio
n Sc
ores
RoBERTa-large (before)ECONET (before)
(a) Attentions scores for [before] indicators.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24Layers
0.0
0.5
1.0
1.5
2.0
Aver
age
Atte
ntio
n Sc
ores
RoBERTa-large (after)ECONET (after)
(b) Attentions scores for [after] indicators.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24Layers
0.0
0.5
1.0
1.5
2.0
Aver
age
Atte
ntio
n Sc
ores
RoBERTa-large (during)ECONET (during)
(c) Attentions scores for [during] indicators.
Figure 7: Attentions score comparisons betweenRoBERTaLARGE and ECONET for all model layers.All numbers are multiplied by 100 and average over 3random seeds for illustration purpose
J Analysis of the Discriminator
Table 12 shows the alignment of between the gen-erator and the discriminator, and Table 13 showsthe examples of “disagreed” samples between the

5380
TORQUE TB-Dense MATRES RED
Methods F1 EM C F1 F1 F1
TacoLM 65.5(±0.8) 36.2(±1.6) 22.7(±1.4) 56.9(±0.7) 75.1(±0.8) 40.7(±0.3)
BERTLARGE 70.9(±1.0) 42.8(±1.7) 29.0(±0.9) 56.7(±0.2) 73.9(±1.0) 40.6(±0.0)+ ECONET 71.8(±0.3) 44.8(±0.4) 31.1(±1.6) 56.1(±0.8) 74.4(±0.4) 41.7(±1.5)
RoBERTaLARGE 76.7(±0.2) 50.5(±0.5) 36.2(±1.1) 59.8(±0.3) 79.9(±1.0) 43.7(±1.0)+ Generator 76.6(±0.1) 51.0(±1.0) 36.3(±0.8) 61.5(±0.9) 79.8(±0.9) 43.2(±1.2)+ ECONET 76.9(±0.4) 52.2(±0.9) 37.7(±0.4) 60.8(±0.6) 79.5(±0.1) 44.1(±1.7)
Table 9: Average Dev Performances Corresponding to Table 2. Note that for MCTACO, we train on dev set andevaluate on the test set as mentioned in Section 3, so we do not report test performance again here.
TORQUE TB-D RED
Event Annotations F1 EM C F1 F1
TORQUE 76.1 51.6 36.8 64.8 42.8TB-Dense 76.1 51.3 36.4 65.1 42.6
Table 10: Fine-tuning performance comparisons usingevent detection models trained on TORQUE v.s. TB-Dense event annotations. All numbers are average over3 random seeds. Std. Dev. ≥ 1% is underlined.
TORQUE TB-D RED
Methods F1 EM C F1 F1
BERTLARGE 70.6 43.7 27.5 62.8 39.4+ random mask 70.6 44.1 27.2 63.4 35.3+ ECONET 71.4 44.8 28.5 63.0 40.2
Table 11: Fine-tuning performances. All numbers areaverage over 3 random seeds. Std. Dev. ≥ 1% is un-derlined.
generator and the discriminator. Detailed analysiscan be found in Section 4 in the main text.
Temporal Generator Event Generator
Corr. Incorr. Corr. Incorr.
Total # 837 163 26 974
Discr. Corr. # 816 29 25 964
Accuracy 97.5% 17.8% 96.2% 99.0%
Table 12: Discriminator’s alignment with generator’smask predictions in ECONET . Second column showsthat discriminator strongly disagree with the “errors”made by the temporal generator.
Type I. Same Group: 12/50 (24%)
〉 〉Ex 1. original: when; predicted: while
Text: A letter also went home a week ago in Pelham, inWestchester County, New York, 〈mask〉 a threat madeby a student in a neighboring town circulated inseveral communities within hours...
〉 〉Ex 2. original: prior to; predicted: before
Text: ... An investigation revealed that rock gauges werepicking up swifter rates of salt movement in the ceilingof the room, but at Wipp no one had read the computerprintouts for at least one month 〈mask〉 the collapse.
Type II. Related Group: 8/50 (16%)
〉 〉Ex 3. original: in the past; predicted: before
text: Mr. Douglen confessed that Lautenberg, whichhad won 〈mask〉, was “a seasoned roach and wasready for this race...
〉 〉Ex 4. original: previously; predicted: once
text: Under the new legislation enacted by Parliament,divers who 〈mask〉 had access to only 620 miles of the10,000 miles of Greek coast line will be able to exploreships and “archaeological parks” freely...
Table 13: Categories and examples of highly related“incorrect” temporal indicator predictions by the gener-ator, but labeled as “correct” by the discriminator.




















