
Document image retrieval through word shape coding
16
1 Document Image Retrieval through Word Shape Coding Shijian Lu, Member, IEEE, Li Linlin, Chew Lim Tan, Senior Member, IEEE April 10, 2008 DRAFT
-
Upload
independent -
Category
Documents
-
view
4 -
download
0
Transcript of Document image retrieval through word shape coding

1
Document Image Retrieval through Word
Shape Coding
Shijian Lu, Member, IEEE, Li Linlin, Chew Lim Tan, Senior Member, IEEE
April 10, 2008 DRAFT

2
Abstract
This paper presents a document retrieval technique that is capable of searching document images
without OCR (optical character recognition). The proposed technique retrieves document images by a
new word shape coding scheme, which captures the document content through annotating each word
image by a word shape code. In particular, we annotate word images by using a set of topological shape
features including character ascenders/descenders, character holes, and character water reservoirs. With
the annotated word shape codes, document images can be retrieved by either query keywords or a query
document image. Experimental results show that the proposed document image retrieval technique is
fast, efficient, and tolerant to various types of document degradation.
Index Terms
Document image retrieval, document image analysis, word shape coding.
I. INTRODUCTION
With the proliferation of digital libraries and the promise of paper-less office, an increasing
number of document images of different qualities are being scanned and archived. Under the
traditional retrieval scenario, scanned document images need to be first converted to ASCII text
through OCR (optical character recognition) [12]. However, for a huge amount of document
images archived in digital libraries, the OCR of all of them for the retrieval purpose is wasteful
and has been proven prohibitively expensive, particularly considering the arduous post-OCR
correction process. In addition, compared with structured representation of documents via OCR,
image-based representation of documents is often more intuitive and more flexible because it
preserves the physical document layout and non-text components (such as embedded graphics)
much better [20]. Under such circumstances, a fast and efficient document image retrieval
technique will facilitate the location of the imaged text information, or at least significantly
narrow the archived document images down to those interested ones.
There is therefore a recent trend towards content-based document image retrieval techniques
without going through the OCR process. A large number of content-based image retrieval
techniques [16] has been reported. For the retrieval of document images, the earlier works were
often based on the character shape coding that annotates character images by a set of pre-defined
codes. For example, Nakayama annotates character images by seven codes and then uses them
April 10, 2008 DRAFT

3
Fig. 1. The three topological character shape features in use: (a) the sample word image “shape”; (b) character ascenders and
descenders; (c) character holes; (d) character water reservoirs.
for content word detection [7] and document image categorization [6]. Similarly, Spitz et al.
take a character shape coding approach for language identification [3], word spotting [8], and
document image retrieval [9]. In [11], Tan et al. also propose a character shape coding scheme
that annotates character images based on the vertical component cut. In addition, a number of
image matching techniques [19], [18] have also been reported for the word image spotting. The
major limitation of the above character shape coding techniques lies with their sensitivity to the
character segmentation error. For document images of low quality, the accuracy of the resultant
character shape codes is often severely degraded by the character segmentation error resulting
from various types of document degradation.
To overcome the limitation of the character shape coding, we have proposed a number of
word shape coding schemes, which treat each word image as a single component and so are
much more tolerant to the character segmentation error. In our earlier work [21], the vertical
bar pattern is used for the word shape coding and document image retrieval. In [4], we code
word images by using character extremum points and the resultant word shape codes are then
used for the language identification. Later, the number of horizontal word cuts is incorporated
in [5] and then used for the multilingual document image retrieval. Besides, we also reported a
keyword spotting technique in [10] where each word image is annotated by a primitive string.
This paper presents a new word image annotation technique and its applications to the docu-
ment image retrieval by either query keywords or a query document image. We annotate word
images by a set of topological character shape features including character ascenders/descenders,
April 10, 2008 DRAFT

4
Fig. 2. The detection of word and text line images through the analysis of the horizontal and vertical projection profiles and
the illustration of the x line and base line of text.
character holes, and character water reservoirs illustrated in Figs. 1(b-d). Compared with the
coding schemes reported in our earlier works [4], [5], [21], the word annotation technique
presented in this paper has the following advantages. First, it is much faster because it does not
require the time-consuming connected component labeling. Second, the character shape features
in use are more tolerant to the document skew and the variations in text fonts and text styles.
Third and most importantly, its collision rate is much lower because of the distinguishability of
the three character shape features in use.
The rest of this paper is organized as follows. Section 2 describes the proposed word image
annotation scheme. The proposed document image retrieval techniques are then presented in
Section 3. Section 4 then presents and discusses experimental results. Finally, some concluding
remarks are drawn in Section 5.
II. WORD IMAGE ANNOTATION
This section presents the proposed word image annotation technique. In particular, we’ll divide
this section into three subsections, which deal with the document image preprocessing, the word
shape feature extraction, and the word image representation, respectively.
A. Document Image Preprocessing
Archived document images often suffer from various types of document degradation such as
impulse noise and low contrast. Therefore, document images need to be preprocessed so as to
extract the character shape features in use properly. In the proposed technique, document images
are first smoothed to suppress noise by a simple mean filter within a 3 × 3 window.
April 10, 2008 DRAFT

5
The filtered document images are then binarized. A large number of document binarization
techniques [2] have been reported and we directly make use of Otsu’s global method [1]. After
that, words and text lines are located through the analysis of the horizontal and vertical docu-
ment projection profiles illustrated in Fig. 2. For Latin based document images, the horizontal
projection profile normally shows two peaks at the x line and base line of the text. Besides, due
to the blanks between adjacent words within the same text line, some zero-height segments of
significant length can also be detected from the vertical projection profile. Word and text line
images can thus be located based on the peaks and the zero-height segments of the horizontal
and vertical projection profiles, respectively.
B. Word Shape Feature Extraction
This section presents the extraction of the three character shape features in use, namely,
character ascenders/descenders, character holes, and character reservoirs. Among them, character
ascenders and descenders can be simply located based on the observation that they lie above the
x line and below the base line of the text, respectively. Character holes and character reservoirs
can then be detected through the analysis of character white runs described below.
Scanning vertically (or horizontally) from top to bottom (or from left to right), a character
white run can be located by a beginning pixel BP and an ending pixel EP corresponding to “01”
and “10” illustrated in Fig. 3 (“1” and “0” denote white background pixels and gray foreground
pixels in Fig. 3). As we only need leftward and rightward reservoirs (to be discussed in the next
subsection), we scan word images vertically column by column. Clearly, two vertical white runs
from the two adjacent scanning columns are connected if they satisfy the following constraint:
BPc < EPa & EPc > BPa (1)
where [BPc EPc] and [BPa EPa] refer to the BP and EP of the white runs detected in the
current and adjacent scanning columns. Consequently, a set of connected vertical white runs
form a white run component whose centroid can be estimated as follows:
Cx =∑Nr
i=1(EPi,y−BPi,y)BPi,x
∑Nr
i=1(EPi,y−BPi,y
)
Cy =∑Nr
i=1(EPi,y−BPi,y)(EPi,y+BPi,y+1)/2
∑Nr
i=1(EPi,y−BPi,y)
(2)
April 10, 2008 DRAFT

6
Fig. 3. The illustration of the beginning pixel and ending pixel of a horizontal and a vertical white runs.
where the denominator gives the number of pixels (component size) within the white run
component under study. The numerator instead gives the sums of the x and y coordinates of
pixels within the white run component. Parameter Nr refers to the number of white runs within
the white run component under study.
Character holes and character reservoirs can be detected based on the openness and closeness
of the detected white run components shown in Figs. 1c and 1d. Generally, a white run component
is closed if all neighboring pixels on the left of the first and on the right of the last constituent
white run are text pixels. On the contrary, a white run component is open if some neighboring
pixels on the left of the first or on the right of the last constituent white run are background
pixels. Therefore, a leftward and rightward closed white run component results in a character
hole (such as the hole of character “o”). At the same time, a leftward (or rightward) open and
rightward (or leftward) closed white run component results in a leftward (or rightward) character
reservoir (such as the leftward reservoir of character “a”).
It should be noted that due to the document degradation, there normally exist a large number
of tiny concavities along the character stroke boundary. As a result, a large number of character
reservoirs of a small depth will be detected by the above vertical scanning process. However,
these small reservoirs are not desired, which can be identified based on their depth (Nr in
April 10, 2008 DRAFT

7
Equation (2) above) relative to the x height (the distance between x line and base line of the
text shown in Fig. 2). Generally, the relative depth of these undesired reservoirs is much smaller
than that of these desired ones. Our experiments show that a relative depth threshold at 0.2 is
capable of identifying character reservoirs of a small depth adequately.
C. Word Image Representation
Each word image can thus be annotated by a sequence of character codes for the three types
of character shape features. However, not every character (i.e. “mnruvw” in Table I) has a code
and some characters (such as “hlIJL” in Table I) may share a code with another, while other
characters (such as p, b, x in Table I) may be represented by more than one code. The idea here
is to represent a word as a linear sequence of codes rather than representing each and every
character in a word. To deal with character segmentation error, we particularly annotate word
images by using five shape features including character ascenders/descenders, character holes,
and leftward and rightward character reservoirs. We do not use upward and downward reservoirs
based on two observations. First, most character segmentation error is due to the touching of
two or more adjacent characters at either x line or base line position but seldom at both x line
and base line positions. Second, a typical touching at the x line or base line position introduces
an upward or downward reservoir, which seldom affects leftward or rightward reservoirs.
The five shape features in use are annotated by two types of codes according to their vertical
alignment. Particularly, the first type is used when the five shape features have no vertically
aligned shape features (such as the hole of “o” and the rightward reservoir of “c”). In this
case, the five shape features (i.e. character ascenders/descenders, character holes, and leftward
and rightward character reservoirs from left to right) are annotated by “l”, “n”, “o”, “u”, and
“c”, respectively. The second type is used when the five shape features have vertically aligned
features (such as “e” whose hole lies right above its rightward reservoir). In this case, the shape
feature together with its vertical alignments usually determines a Roman letter uniquely. Under
such circumstance, we annotate the shape feature together with its vertical alignments by the
uniquely determined Roman letter. It should be noted that we annotate character descenders and
leftward reservoirs by “n” and “u” for the first type of codes because both “n” and “u” have no
desired shape features and so will not contribute any shape codes.
Table I shows the proposed coding scheme where 52 Roman letters and numbers 0–9 are
April 10, 2008 DRAFT

8
TABLE I
CODES OF 52 ROMAN LETTERS AND NUMBERS 0-9 BY USING THE THREE PROPOSED SHAPE FEATURES.
Characters Shape codes Characters Shape codes Characters Shape codes Characters Shape codes
a a b lo c c d ol
e e f f g g hlIJLT17 l
i i j j ktK lc o o
p no q on s s xX uc
y y z z A A B8 B
CG C DO04 O E E F F
HMNUVWY ll P P Q Q R R
S S Z Z 2 2 3 3
5 5 6 6 9 9 mnruvw no codes
annotated by 35 codes. For example, character “b” is annotated by “lo” (the first type of code),
indicating a character hole (o) directly on the right of a character ascender (l). Character “a” is
coded by itself (the second type of code) because a leftward reservoir right above a character
hole uniquely indicates an entity of character “a”. Based on the coding scheme in Table I, the
word image “shape” in Fig. 1a, can be represented by a code sequence “slanoe” where “s”,
“l”, “a”, “no”, and “e” are converted from the five spelling characters, respectively. It should be
noted that character “g” in Table I may have two holes with one lying below the base line (for
serif “g”) or a single hole lying above a leftward reservoir (for sans serif “g”). However, both
the two feature patterns uniquely indicate the entity of the character “g”.
The proposed word shape coding scheme is tolerant to character segmentation error. For
example, though characters “ab” are frequently touched at the base line position, they can still
be properly annotated by “alo”. Another example, characters “rt” touched at the x line position
can be properly annotated as “lc” as well. In addition, though some text font such as serif may
produce a number of leftward and rightward reservoirs, the depth of the reservoir from serif is
normally much smaller than that of those real reservoirs (such as the rightward reservoir of “c”).
Therefore, the reservoirs from serif can be simply detected based on their depth relative to the
x height as described in the last subsection.
April 10, 2008 DRAFT

9
III. DOCUMENT IMAGE RETRIEVAL
Based on the word shape coding scheme described above, the content of document images can
be captured by the converted word shape codes. Similar to most content-based image retrieval,
document images can then be retrieved by either query keywords or a query document image
based on their content similarity.
A. Retrieval by Query Keywords
Similar to a Google search, which retrieves web pages containing the query keywords, our
document image retrieval works by matching the codes transliterated from the query keywords
and those converted from words within the archived documents. Practically, such type of retrieval
can be simply accomplished by matching the codes transliterated from the query keywords and
those converted from words within archived document images. In particular, we define it as a
retrieval success if a document image containing any of the query keywords is retrieved. In
addition, we define it as a retrieval failure if a document image containing query keywords
is not retrieved or a document image containing no query keywords is retrieved. Acting as a
pre-screening procedure, such retrieval by query keywords significantly narrows the archived
document images down to those containing the query keywords, though it may not locate the
relevant document images accurately.
For text images, such retrieval by query keywords can be simply adapted for the keyword
spotting. For the keyword spotting purpose, the word position needs to be determined. In addition,
the page number needs to be determined as well because query keywords may appear multiple
times at different pages. To locate the query keywords properly, we format each word image W
with an unique spelling as a word record as follows:
WR =[
WSC 〈p1 blx1 bly1 w1 h1〉 · · · 〈pi blxi blyi wi hi〉 · · ·]
(3)
where WSC denotes the indexing word shape code converted from the W . Terms pi, blxi, blyi,
wi, and hi i = 1 · · ·n specify the page number, the position (blxi and blyi give the x and y
coordinates of the word left bottom corner), and the size (wi, and hi refer to the word width and
height) of the ith occurrence of the W , respectively. In our implemented system, all word records
are stored within a table where each record is indexed by the corresponding word shape code.
April 10, 2008 DRAFT

10
Word images can thus be located if their indexing word shape codes match those transliterated
from the query keywords.
B. Retrieval by A Query Document Image
Similar to content-based retrieval of images from image database, archived document images
can also be retrieved by a query document image according to the content similarity based on our
proposed word shape coding. To evaluate the document similarity, we first convert a document
image into a document vector. Particularly, each document vector element is composed of two
components including a word shape component and a word frequency component:
D = [(WSC1 : WON1), · · · , (WSCN : WONN)] (4)
where N is the number of unique words within the document image under study. WSCi and
WONi denote the word shape and word frequency components, respectively.
The document vector construction process can be summarized as follows. Given a word
shape code converted from a word within the document image under study, the corresponding
document vector is searched for the element with the same word shape code component. If such
element exists, the word frequency component of that document vector element is increased
by one. Otherwise, a new document vector element is created and the corresponding word
shape and word frequency components are initialized with the converted word shape code and
one, respectively. The conversion process terminates when all words within the document image
under study have been converted and examined as described above. Finally, to compensate for the
variable document length, the frequency component of the converted document vector elements
is normalized by dividing by the number of words within the document image under study.
The similarity between two document images can thus be evaluated based on the frequency
component of their document vectors. In particular, the similarity between the two document
vectors DV1 and DV2 can be evaluated by using the cosine measure as follows:
sim(DV1, DV2) =
∑Vi=1 DV F1,i · DV F2,i
√
∑Vi=1(DV F1,i)2 ·
∑Vi=1(DV F2,i)2
(5)
where V defines the vocabulary size, which is equal to the number of unique word shape
codes within the DV1 and DV2. DV F1,i and DV F2,i specify the word frequency information. In
particular, if the word shape code under study finds a match within DV1 and DV2, DV F1,i and
April 10, 2008 DRAFT
11
TABLE II
COLLISION RATES OF THE FOUR CODING SCHEMES THAT ARE EVALUATED BASED ON 57000 ENGLISH WORDS (WCR:
WORD COLLISION RATE).
Collision word WCR of the coding
scheme in [3]
WCR of the coding
scheme in [21]
WCR of the coding
scheme in [5]
WCR of the present
coding scheme
0 0.2769 0.2317 0.3769 0.7221
1 0.0602 0.0991 0.1368 0.1381
2 0.0478 0.0587 0.0714 0.0479
3 0.0335 0.0472 0.0518 0.0266
4 0.0265 0.0335 0.0406 0.0171
5 0.0255 0.0295 0.0305 0.0102
6 0.0195 0.0262 0.0278 0.0077
7 0.0154 0.0241 0.0224 0.0061
≥ 8 0.3985 0.4495 0.2414 0.0230
DV F2,i are determined as the corresponding word frequency components (WON component).
Otherwise, both are simply set at zero.
It should be noted that documents normally contain a large number of stop words, which
greatly affect the document similarity because they frequently dominate the direction of the con-
verted document vectors. Therefore, stop words must be removed from the converted document
vectors before the document similarity evaluation. In our proposed technique, we simply utilize
the stop words provided by the Cross-Language Evaluation Forum (CLEF) [13]. In particular,
all listed stop words are first transliterated into a stop word template according to the coding
scheme in Table I. The converted document vectors are then updated by removing elements that
share the word shape component with the constructed stop word template.
IV. EXPERIMENTAL RESULTS
This section evaluates the performance of the proposed word image annotation and document
image retrieval techniques. Throughout the experiments, we use 252 text documents selected
from the Reuters-21578 [15] where every 63 deal with one specific topic.
April 10, 2008 DRAFT

12
A. Coding Performance
The proposed document retrieval techniques depend heavily on the performance of the pro-
posed word shape coding scheme. To retrieve document image properly, the collision rate
(frequency of words that have different spelling but share the same word shape code) of the
word shape coding scheme should be as low as possible. In addition, the coding scheme should
be tolerant to various types of document degradation. In our experiments, we particularly compare
our word shape coding scheme with Spitz’s [3] and our earlier coding schemes that use character
extremum points [5] and vertical bar pattern [21], respectively.
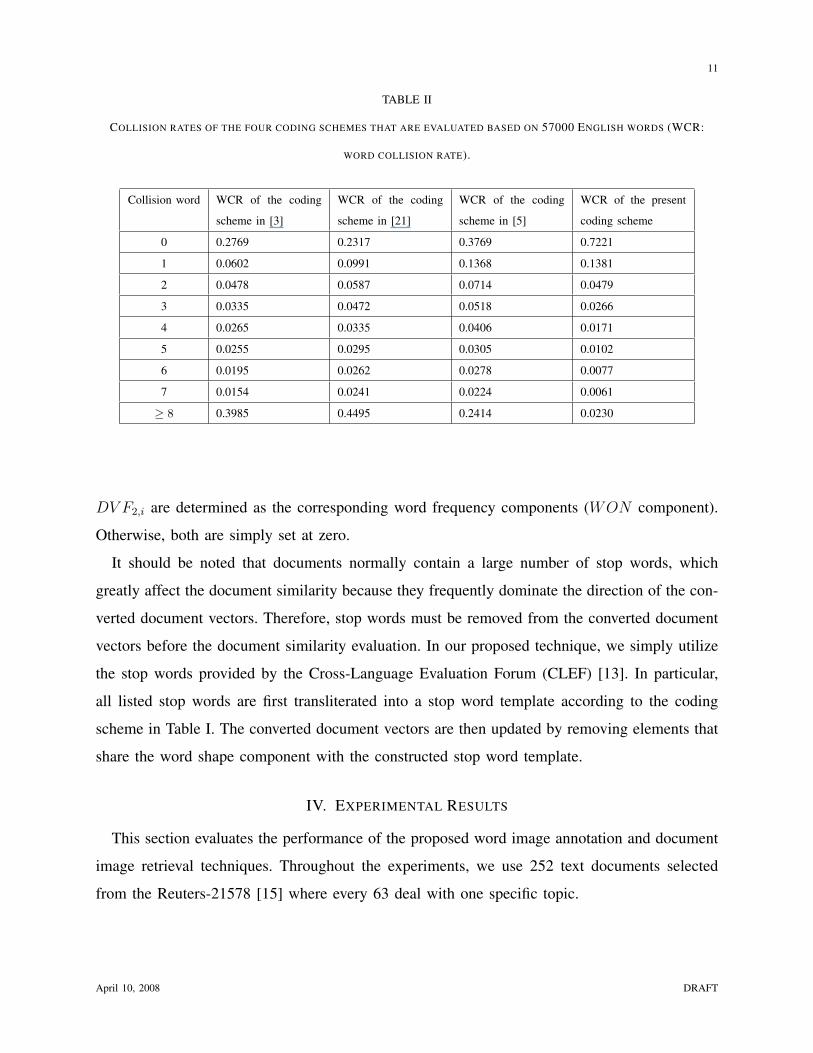
We test the coding collision rate by using a dictionary that is composed of 57000 English
words. First, the 57000 English words are transliterated into word shape codes according to our
proposed word shape coding scheme and the other three. The coding collision rates are then
calculated and the results are shown in Table II. As Table II shows, our proposed word shape
coding scheme significantly outperforms the other three in term of the coding collision rate.
Such experimental results can be explained by the fact that our coding scheme annotates 26
lowercase Roman letters by 18 codes, while the other three comparison schemes annotate 26
lowercase Roman letters by 6 [3], 9 [21], and 13 [5] codes, respectively.
The coding robustness is then tested by the 252 text documents described above. For each text
document, five test document images are first created including: 1) a synthetic image created by
Photoshop, 2-3) two noisy images by adding impulse noise (noise level = 0.05) and Gaussian
noise (σ = 0.08) to the synthetic image, and 4-5) two real images scanned at 600 dpi (dots per
inch) and 300 dpi, respectively. Therefore, five sets of test document images are created where
each set is composed of 252 document images. After that, words within the five sets of document
images are converted into word shape codes by using the four word image shape coding schemes.
Table III shows the coding accuracy under various types of document degradation.
As Table III shows, Spitz’s character shape coding scheme is the most accurate when the
document image is synthetic. However, for document images scanned at a low resolution, the
accuracy of Spitz’s coding scheme drops severely because of the dramatic increase of character
segmentation error. In addition, compared with our earlier word shape coding schemes [5], [4],
[21], the word shape coding scheme presented in this paper is more tolerant to noise. Furthermore,
the proposed coding scheme is fast. It is 5-8 times faster than our earlier coding schemes [5],
April 10, 2008 DRAFT

13
TABLE III
ACCURACY OF THE SPITZ’S CHARACTER SHAPE CODING SCHEME [3], OUR EARLIER TWO WORD SHAPE CODING SCHEMES
[5], [21], AND THE WORD SHAPE CODING SCHEME PRESENTED IN THIS PAPER.
Coding schemes Synthetic Impaired by impulse Impaired by Gaussian Scanned at 600dpi Scanned at 300dpi
Method in [3] 0.9617 0.9379 0.9348 0.8372 0.5163
Method in [21] 0.9421 0.7218 0.7195 0.8586 0.8419
Method in [5] 0.9434 0.6583 0.6277 0.8526 0.8418
Present method 0.9524 0.9396 0.9288 0.9316 0.8692
[21] and up to 15 times faster than OCR (evaluated by Omnipage [14]). The speed advantage
can be explained by the fact that our word shape coding scheme needs neither time-consuming
connected component labeling nor complicated post-processing.
B. Retrieval by Query Keywords
The performance of the retrieval by query keywords is then evaluated. First, 137 frequent words
are selected from the 252 text documents as query keywords. The retrieval is then conducted
over the five sets of test document images described above. In our experiments, the retrieval
performance is evaluated by precision (P), recall (R), and the F1 rating [17] defined as follows:
P =No of correctly searched words
No of all searched words, R =
No of correctly searched words
No of all correct words, F1 =
2RP
R + P(6)
where the retrieval precision (P ) and recall (R) are averaging over all occurrence of the 137
selected keywords, respectively.
Table IV shows the experimental results where the retrieval precisions and recalls are evaluated
based on the number of word images searched by using the 137 query keywords. As Table IV
shows, our proposed word shape coding scheme consistently outperforms the other three in term
of the retrieval precision, recall, and F1. In fact, such experimental results coincide with the
coding performance described in the last subsection.
C. Retrieval by A Query Document Image
The retrieval by a query document image is also evaluated based on the five sets of document
images described in Section IV. Instead of designing retrieval experiments, we just evaluate the
April 10, 2008 DRAFT

14
TABLE IV
PERFORMANCE OF THE RETRIEVAL BY QUERY KEYWORDS EVALUATED BY PRECISION, RECALL, AND F1 PARAMETER.
Retrieval by the method
in [3]
Retrieval by the method
in [21]
Retrieval by the method
in [5]
Retrieval by the present
method
Precision 0.6537 0.7848 0.8411 0.9488
Recall 0.9369 0.8261 0.8136 0.9026
F1 0.7750 0.8099 0.8182 0.9251
similarity between document images of the same and different topics. This is based on the belief
that document images can be ranked properly if their topic similarity can be gauged properly.
In addition, the similarity between the 252 ASCII text documents is also evaluated to verify the
performance of the proposed document image retrieval technique.
In our experiments, the five sets of test images are first converted into document vectors.
The similarity among them is then evaluated as described in Section III. B. In particular, the
similarity between documents of the same topic (315 images created from the 63 text documents
of one specific topic described in Section IV. A) is evaluated as follows:
Sim =M · (M − 1)
2
M∑
i=1
M∑
j=1
sim(DVi, DVj) ∀i, j : j > i (7)
where M is the number of the document images of the same topic. DVi and DVj denote the
document vectors (stop words removed) of two document images of the same topic under study.
The function sim() refers to the cosine similarity defined in Equation (5). The similarity between
document images of two different topics (630 document images with each 315 created from 63
text documents that deal with one specific topic) is evaluated as follows:
Sim =1
M2
M∑
i=1
M∑
j=1
sim(DVi, DVj) (8)
where DVi and DVj denote the document vectors of two different topics instead.
The upper part of Table V shows the similarity between document images of the same and
different topics. Clearly, the topic similarity between documents of the same topic is much larger
than those between documents of different topics. Archived document images can therefore be
ranked based on the similarity between their document vectors and the query document vector.
In addition, the similarity among the 252 text documents is also evaluated where document
April 10, 2008 DRAFT

15
TABLE V
SIMILARITIES BETWEEN DOCUMENTS OF THE SAME AND DIFFERENT TOPICS.
text image class I text image class II text image class III text image class IV
text image class I 0.3251 0.2391 0.0644 0.1088
text image class II 0.2391 0.5896 0.0969 0.1436
text image class III 0.0644 0.0969 0.2812 0.0326
text image class IV 0.1088 0.1436 0.0326 0.2659
ASCII text class I ASCII text class II ASCII text class III ASCII text class IV
ASCII text class I 0.3624 0.2734 0.1238 0.1533
ASCII text class II 0.2734 0.6474 0.0873 0.1612
ASCII text class III 0.1238 0.0873 0.3916 0.1195
ASCII text class IV 0.1533 0.1612 0.1195 0.3026
vectors are constructed by using the ASCII text [12]. The lower part of Table V shows the
evaluated document similarity. As Table V shows, the topic similarities evaluated by the proposed
technique are close to those evaluated over the ASCII text, indicating that the proposed technique
captures the document topics properly. In addition, it also indicates that the proposed document
retrieval technique is comparable to the OCR+Search whose performance should be more or less
(depending on OCR error) lower than that directly evaluated over ASCII text.
V. CONCLUSION
This paper reports a document image retrieval technique that searches document images by
either query keywords or a query document image. A novel word image annotation technique
is presented, which captures the document content by converting each word image into a word
shape code. In particular, we convert word images by using a set of topological character shape
features including character ascenders/descenders, character holes, and character water reservoirs.
Experimental results show that the proposed word image annotation technique is fast, robust,
and capable of retrieving imaged document effectively.
VI. ACKNOWLEDGMENTS
This research is supported by Agency for Science, Technology and Research (A*STAR),
Singapore, under grant no. 0421010085.
April 10, 2008 DRAFT

16
REFERENCES
[1] N. Otsu, “A threshold selection method from graylevel histogram,” IEEE Transactions on System, Man, Cybernetics, vol.
19, no. 1, pp. 62–66, 1979.
[2] O. D. Trier and T. Taxt, “Evaluation of Binarization Methods for Document Images,” IEEE Transaction on Pattern Analysis
and Machine Intelligence, vol. 17, no. 3, pp. 312–315, 1995.
[3] A. L. Spitz, “Determination of Script and Language Content of Document Images,” IEEE Transaction on Pattern Analysis
and Machine Intelligence, vol. 19, no. 3, pp. 235–245, 1997.
[4] S. Lu and C. L. Tan, “Script and Language Identification in Noisy and Degraded Document Images,” IEEE Transaction on
Pattern Analysis and Machine Intelligence, vol. 30, no. 1, pp. 14–24, 2008.
[5] S. Lu and C. L. Tan, “Retrieval of Machine-printed Latin Documents through Word Shape Coding,” Pattern Recognition,
vol. 41, no. 5, pp. 1816–1826, 2008.
[6] T. Nakayama, “Content-oriented categorization of document images”, International Conference On Computational Linguis-
tics, pp. 818–823, 1996.
[7] T. Nakayama, “Modeling Content Identification from Document Images, Fourth conference on Applied natural language
processing, pp. 22–27, 1994.
[8] A. L. Spitz, “Using Character Shape Codes for Word Spotting in Document Images,” Shape, Structure and Pattern
Recognition, World Scientific, pp. 382–389, 1995.
[9] A. F. Smeaton and A. L. Spitz, “Using character shape coding for information retrieval,” 4th International Conference on
Document Analysis and Recognition, pp. 974–978, 1997.
[10] Y. Lu and C. L. Tan, “Information retrieval in document image databases,” IEEE Transactions on Knowledge and Data
Engineering, vol. 16, no. 11, pp. 1398–1410, 2004.
[11] C. L. Tan and W. Huang and Z. Yu and Y. Xu, “Image document text retrieval without OCR,” IEEE Transaction on Pattern
Analysis and Machine Intelligence, vol. 24, no. 6, pp. 838–844, 2002.
[12] , Gerard Salton, “Introduction to Modern Information Retrieval,” McGraw-Hill, 1983.
[13] http://www.unine.ch/info/clef/.
[14] http://www.nuance.com/omnipage/.
[15] http://kdd.ics.uci.edu/databases/reuters21578.
[16] M. Lew, N. Sebe, C. Djeraba, and R. Jain, “Content-based Multimedia Information Retrieval: State-of-the-art and
Challenges,” ACM Transactions on Multimedia Computing, Communication, and Applications, vol. 2, no. 1, pp. 1–19,
2006.
[17] Y. Yang and X. Liu, “A Re-Examination of Text Categorization Methods,” The 22nd annual international ACM SIGIR
conference on Research and development in information retrieval, vol. 42–49, 1999.
[18] S. Khoubyari and J. J.Hull, “Keyword location in noisy document image,” Second Annual Symposium on Document Analysis
and Information Retrieval, pp. 217–231, 1993.
[19] F. R. Chen and D. S. Bloomberg and L. D. Wilcox, “Spotting Phrases in Lines of Imaged Text,” SPIE conf. on Document
Recognition II, pp. 256–269, 1995.
[20] T. M. Breuel, “The Future of Document Imaging in the Era of Electronic Documents, Proceedings of International Workshop
on Document Analysis, pp. 275–296, 2005.
[21] C. L. Tan and W. Huang and Z. Yu and Y. Xu, “Text retreival from document images based on word shape analysis,”
Applied Intelligence, vol. 18, no. 3, pp. 257–270, 2003.
April 10, 2008 DRAFT




















