
Deployment and management of large planar reflectarray antennas simulation on grid
10
Deployment and Management of Large Planar Reflectarray Antennas Simulation on Grid R´ emi Sharrock *‡ , Fadi Khalil *‡ , Thierry Monteil *‡ , Herv´ e Aubert *‡ , Fabio Coccetti *‡ , Patricia Stolf †‡ , Laurent Broto †‡ and Robert Plana *‡ * LAAS – CNRS ; Universit´ e de Toulouse, 7, avenue du Colonel Roche, F-31077 Toulouse, France † IRIT ; Universit´ e de Toulouse, 118 Route de Narbonne, F-31062 Toulouse cedex 9, France ‡ Universit´ e de Toulouse ; UPS, INSA, INP, ISAE Abstract—Nowadays, scientists are interested in using com- puter grids to run their specific domain applications. Nevertheless the difficulty for non expert in computer science to run those applications on a high number of nodes discourages them. This paper deals with the deployment and the management of an electromagnetic simulator on a computer grid, by using the TUNe autonomic middleware. First, we describe the simulator and how to make it work with TUNe. Then, we measure TUNe’s performance during specific phases: deployment, starting and undeployment. Moreover, some capabilities like automatic repair of applications in case of failure are shown. I. I NTRODUCTION Computational Electromagnetics (CEM) is the science of numerically solving a complex set of Maxwell’s equations using computer resources. These solutions describe the physi- cal interactions and phenomena between charged particles and materials. A fundamental understanding of these phenomena is critical in the design of many devices such as antenna, radars, satellites, computer chips, optical fiber systems, mobile phone systems, medical imaging, among other applications. CEM has evolved rapidly during the past decade to a point where extremely accurate predictions can be made for very general scattering and antenna structures. Many criteria may be used to classify the techniques involved in CEM, like the domain in which they are operating (time/frequency), the type of equations on which they are based (integral/differential) and the dimensionality of the problem (two-dimensional/three- dimensional). Today there are many important problems in areas such as electromagnetic compatibility (EMC) and elec- tromagnetic interference (EMI), wireless communications, and coupling between radiators and biological organisms that cannot be addressed with the existing electromagnetic analysis tools simply because the analysis is too time consuming and costly to carry out. Even with the advances made in parallel computing on user’s computer, the resource requirements of popular electromagnetic analysis techniques exceed the supply of necessary resources. A technology that has come forward as an efficient way for addressing the overwhelming demands of scientific applications is grid computing. Grid platforms offers to the end user the opportunity to access a large amount of computing resources [1]. For non expert users in grid environments, it can be challenging to carry their existing applications to a large scale parallel environment. Not only they have to parallelize these applications but in addition, they have to face running problems. They also have to create a set of scripts to deploy, stop and get the results over the grid. Most of the time, those scripts have to be modified to fit the heterogeneity of platforms. Even if those conditions are verified, when the user tries to execute his application, there is a high probability that a failure will occur. Most of the time, at least, one of the nodes is down and the user’s scripts do not take into account the dynamicity of the grid. One of the promising solutions is to use an autonomic computing environment. This paper will show the use of a full wave electromagnetic simulator over a french national research grid called Grid5000 [2] and its autonomic management with the TUNe project (Toulouse University Network) [3]. II. RELATED WORK Cardiff University and the University of Wales, Swansea, have teamed with Hewlett-Packard, BAE SYSTEMS and the Institute of High Performance Computing in Singapore, to use grid computing for the exploration of advanced, collab- orative simulation and visualization in aerospace and defense design [4]. One year after, Lumerical launches parallel FDTD solutions on the supercomputing infrastructure of WestGrid in Canada [5], even though their field of interest is more in optical and quantum devices rather than in RF applications. Another very recent example of distributed computing using a code based on the TLM (Transmission Line Matrix, defined below) method has been demonstrated in Germany [6]. Later, a Web-based, grid-enabled environment for wideband code- division multiple-access (WCDMA) system simulations, based on Monte Carlo methods, has been implemented and evaluated on the production grid infrastructure deployed by the Enabling Grids for E-sciencE (EGEE) project [7]. The autonomic computing concept [8],[9] has been intro- duced about six years ago and has been recognized as one of the biggest challenges on which the future of information depends [10]. It provides a vision on how to solve a wide variety of management problems: for example reserving the resources, deploying the software, ensuring that the simulation starts well, restarting parts of the simulation that failed with a minimum of human intervention. Architectural frameworks based on self-managed systems have been recently proposed [11],[12]. An interesting compar- ison between academic and industrial projects in autonomic
-
Upload
telecom-paristech -
Category
Documents
-
view
6 -
download
0
Transcript of Deployment and management of large planar reflectarray antennas simulation on grid

Deployment and Management of Large PlanarReflectarray Antennas Simulation on GridRemi Sharrock!‡, Fadi Khalil!‡, Thierry Monteil!‡, Herve Aubert!‡, Fabio Coccetti!‡,
Patricia Stolf†‡, Laurent Broto†‡ and Robert Plana!‡! LAAS – CNRS ; Universite de Toulouse, 7, avenue du Colonel Roche, F-31077 Toulouse, France
† IRIT ; Universite de Toulouse, 118 Route de Narbonne, F-31062 Toulouse cedex 9, France‡ Universite de Toulouse ; UPS, INSA, INP, ISAE
Abstract—Nowadays, scientists are interested in using com-puter grids to run their specific domain applications. Neverthelessthe difficulty for non expert in computer science to run thoseapplications on a high number of nodes discourages them. Thispaper deals with the deployment and the management of anelectromagnetic simulator on a computer grid, by using theTUNe autonomic middleware. First, we describe the simulatorand how to make it work with TUNe. Then, we measure TUNe’sperformance during specific phases: deployment, starting andundeployment. Moreover, some capabilities like automatic repairof applications in case of failure are shown.
I. INTRODUCTIONComputational Electromagnetics (CEM) is the science of
numerically solving a complex set of Maxwell’s equationsusing computer resources. These solutions describe the physi-cal interactions and phenomena between charged particles andmaterials. A fundamental understanding of these phenomena iscritical in the design of many devices such as antenna, radars,satellites, computer chips, optical fiber systems, mobile phonesystems, medical imaging, among other applications.CEM has evolved rapidly during the past decade to a point
where extremely accurate predictions can be made for verygeneral scattering and antenna structures. Many criteria maybe used to classify the techniques involved in CEM, like thedomain in which they are operating (time/frequency), the typeof equations on which they are based (integral/differential)and the dimensionality of the problem (two-dimensional/three-dimensional). Today there are many important problems inareas such as electromagnetic compatibility (EMC) and elec-tromagnetic interference (EMI), wireless communications, andcoupling between radiators and biological organisms thatcannot be addressed with the existing electromagnetic analysistools simply because the analysis is too time consuming andcostly to carry out. Even with the advances made in parallelcomputing on user’s computer, the resource requirements ofpopular electromagnetic analysis techniques exceed the supplyof necessary resources. A technology that has come forwardas an efficient way for addressing the overwhelming demandsof scientific applications is grid computing. Grid platformsoffers to the end user the opportunity to access a large amountof computing resources [1]. For non expert users in gridenvironments, it can be challenging to carry their existingapplications to a large scale parallel environment. Not onlythey have to parallelize these applications but in addition, they
have to face running problems. They also have to create a setof scripts to deploy, stop and get the results over the grid.Most of the time, those scripts have to be modified to fitthe heterogeneity of platforms. Even if those conditions areverified, when the user tries to execute his application, thereis a high probability that a failure will occur. Most of thetime, at least, one of the nodes is down and the user’s scriptsdo not take into account the dynamicity of the grid. One ofthe promising solutions is to use an autonomic computingenvironment. This paper will show the use of a full waveelectromagnetic simulator over a french national research gridcalled Grid5000 [2] and its autonomic management with theTUNe project (Toulouse University Network) [3].
II. RELATED WORKCardiff University and the University of Wales, Swansea,
have teamed with Hewlett-Packard, BAE SYSTEMS and theInstitute of High Performance Computing in Singapore, touse grid computing for the exploration of advanced, collab-orative simulation and visualization in aerospace and defensedesign [4]. One year after, Lumerical launches parallel FDTDsolutions on the supercomputing infrastructure of WestGridin Canada [5], even though their field of interest is more inoptical and quantum devices rather than in RF applications.Another very recent example of distributed computing usinga code based on the TLM (Transmission Line Matrix, definedbelow) method has been demonstrated in Germany [6]. Later,a Web-based, grid-enabled environment for wideband code-division multiple-access (WCDMA) system simulations, basedon Monte Carlo methods, has been implemented and evaluatedon the production grid infrastructure deployed by the EnablingGrids for E-sciencE (EGEE) project [7].The autonomic computing concept [8],[9] has been intro-
duced about six years ago and has been recognized as oneof the biggest challenges on which the future of informationdepends [10]. It provides a vision on how to solve a widevariety of management problems: for example reserving theresources, deploying the software, ensuring that the simulationstarts well, restarting parts of the simulation that failed with aminimum of human intervention.Architectural frameworks based on self-managed systems
have been recently proposed [11],[12]. An interesting compar-ison between academic and industrial projects in autonomic

computing is provided by [13]. They often rely on self-regulating components that make decisions on their ownusing high-level policies. For instance, the Automat project[14] provides an interactive environment to deploy and testautonomic platforms. Users can get resources on demand,choose between predefined software components or user-specific components (legacy software), load generators, faultgenerators and controllers. Once the system is deployed, theycan experiment sense and respond by monitoring, or dynamicadaptation under closed-loop control (they call it the MAPEloop : Monitoring ! Analyzing ! Plan ! Execute).All these solutions help the grid user to face the scal-
ability problem more easily, and ensure a fast reaction incase of a reconfiguration of the system during execution.Our solution provides a support for legacy systems that isautomatically wrapped in a generic component model. Thisensures a uniform management interface that is compatiblewith virtually any distributed application. Other approachesoften use a proprietary application programming model andthe user has to modify the source code of its application.This is not the case with our approach, even a user with aclosed binary file is able to deploy and autonomously manageit without changing any line of code.
III. PLANAR ARRAYS SIMULATIONThe design of reflectarrays is a complex and time-
consuming process that very often relies on a trial-and-errorapproach. In this part, a simplified optimization analysis basedon a non-commercial simulator, valid for both passive andactive antennas, is presented. This simulator is being used byour experiments on the grid.
A. Planar Array AntennasThe studied reflectarray consists of printed radiating ele-
ments on a thin-grounded dielectric substrate. In recent years,the planar reflectarray antenna has evolved into an attractivecandidate for applications requiring high-gain, low-profile re-flectors [15]. In passive reflectarrays, phasing of the scatteredfield to form the desired radiation pattern is achieved bymodifying the printed characteristics of the individual radiatingelements composing the array. Beams are formed by shiftingthe phase of the signal emitted from each radiating element, toprovide constructive/destructive interference so as to steer thebeams in the desired direction. The analysis and optimizationof such a structure requires a rigorous electromagnetic model-ing. TLM [16] has been used as it can deal with complexthree dimensional structures and provides wide bandwidthcharacterization in a single simulation. The radiation patterndata, half-power beamwidths, and directivities and frequencybandwidth must be calculated for the design array (the inputdata files).
B. Yet Another Tlm simulation PACkageFor TLM-based software, YATPAC [17] is the most pow-
erful one available. It is an open source full-wave electro-magnetic simulation package. Its core engine is written in
FORTRAN. Various complex structures could be characterizedwith its efficient tools in time-domain.1) TLM modeling method: The Transmission Line Matrix
(TLM) modeling method is known as a general purposetime-domain technique suitable for the simulation of wavepropagation phenomena in guided wave structures and dis-continuities of arbitrary shape [16]. In the three-dimensionalTLM method, the space is discretized by a three-dimensionaltransmission line network in which impulses are scatteredamong the junctions of the transmission lines (nodes) and theboundaries at a fixed time step. Thus the problem is discretizedin both time and space and the impulse distribution withinthe network describes the evolution of the electromagneticfield. An advantage of the TLM method resides in the largeamount of information in one single computation. Not onlyis the impulse response of a structure obtained, yielding, inturn, its response to any excitation, but also the characteristicsof the dominant and higher order modes are accessible inthe frequency domain through the Fourier transforms. Thecalculations required are intensive but very simple, and theTLM procedure is especially suited for implementation witha relatively simple algorithm and this efficient technique canbe implemented not only on single CPU computers but alsoon parallel computers.2) Simulation flow: The structure design files, containing
information of the engineered structure (<filename>.gds)and describing the dicretization of the simulation ob-ject (<filename>.laydef), are prepared. The prepro-cessor yatpre generates from these two files an output file(I3D.<filename>), which is used as input to the simula-tion engine called yatsim. In order to reduce the optimizationtime, and consequently the time-to-market, the proposed ap-proach consists in evaluating a wide range of design param-eters in a single analysis run without the need of traditionaliterative process. Due to the fact that the optimization run con-sists of a large number of identical and completely independentsimulations, it can be decomposed into a number of processesthat do not need to communicate with each other (except forthe postprocess phase). This makes this kind of simulationsuitable for efficient large-scale distributed execution on a gridinfrastructure. TUNe is used to add flexibility to launch suchparametric studies on Grid computing platforms.
IV. TUNEA. PrincipleTUNe is a project that aims to give a solution to the
increasing complexity in the domain of distributed softwareexecution management. It is based on the concept of au-tonomous computing [8]. TUNe can be used in differentdomains: web architecture, middleware architecture [3], gridcomputing. Users give an abstraction of the platform execution(hardware) and application (software). A subset of UMLgraphical language is used to describe the global view in a highlevel of abstraction. The main idea is then to automaticallycreate a representation based on fractal components [18] ofthe real system, with:

• Application components, also called legacy componentsbecause they can wrap legacy software pieces.
• Running platform components, each one representing anode on which the legacy software piece can run.
The application components are connected to the real sys-tem with a wrapping language based on XML, describingmethods that are reflected on the real system by makingaction commands. The global dynamic behavior of the systemis expressed with UML state charts or activity diagrams,some steps of these diagrams referring to the methods in thewrapping XML files.
B. Platform description
The platform (hardware) is described with a UML classdiagram (see figure 1). Each class represents a family of nodes(called host-family). The difference between the families isup to the user level, so different users could have differentfamilies. For example, a user can specify with one class onepowerful local machine in its network that is not managed(directly accessible without asking a resource scheduler), orone local cluster (a set of directly accessible machines) in thesame way. One class can also specify grid platforms (managedresources, thus they are not directly accessible) which use aresource scheduler to access the machines. Each family hasdifferent parameters which specify its particularities on howto get resources, or how to access them. For grid utilization,the following parameters are useful:
• type: this parameter is used in grid environments. It makesthe relation with the batch scheduler. For example withGrid’5000, the oargrid tool is used for multi-clusterson multi-sites reservations, but the oar tool could alsobe used for multi-clusters on one geographical site. Onthe diagram 1, the allsites class represents a grid-levelreservation using the oargrid tool, and the toulouse classrepresents a site-level reservation of the nodes for the cityof Toulouse using the OAR tool.
• sites: is a specific parameter for the batch scheduler,representing the sites (city names) and the number ofnodes to reserve for each site. We are working on anautomatic way to calculate the best number of nodes foreach site based on profiling applications and analyzingtheir logs.
• walltime: is the duration of the nodes reservation, here 2hours.
• user: allows to have different login on different families.• keypath: facilitates the remote login with ssh keys on thegrid to avoid password typing.
• javahome: is the directory where java is located for thisfamily. This is the only necessary software to make TUNework.
• dirlocal: is the working directory for the application(where it will be installed and started).
• protocole: allows to have different remote protocol con-nections (local commands, ssh, via oarsh specific toGrid5000).
Fig. 1. Platform description
With the actual version of TUNe, the javahome propertyhas to be defined on each class of the grid diagram. Javais indeed needed on each node for the RMI process (java’sremote procedure calls) to send events to the TUNe managereventually from every computing node. If java is not presenton the node, TUNe will consider this node in a special deployerror state and will not try to redeploy it. We have an ongoingwork on this issue and will use the following steps:
• 1: use of the javahome property defined in the class ofthe grid diagram to find the java binary
• 2: if the java binary is not present, TUNe will use theJAVA HOME environment variable of the node
• 3: if this variable is not set, TUNe will use the first javabinary found in the PATH environment variable of thenode
• 4: if the java binary cannot be found in any of these steps,TUNe will engage a java runtime environment copy. Thedifficult part is to define where and how TUNe will getthe good java version for the good architecture.
Anyway, any java runtime version with support of RMI isacceptable for TUNe (for instance any java version superiorto 1.4.2).Altought we do not present this concept here, the user
would be capable of describing if he is a member of a VirtualOrganization. A Virtual Organization (VO) is a set of usersworking on similar topics and whose resources requirementsare quite comparable. The users usually share their resourcesbetween them (data, software, CPU, storage space). A userneeds to be a member of a VO before he is allowed to submitjobs to the grid. Moreover, a VO is usually defined by aname, and a scope which represents a geographical locationconstraint. Within the platform description diagram, a VOcould be represented by a class. Indeed, the name of theVO would be the name of the class, and the geographicalconstraints would be represented as for the sites locations forGrid5000. Furthermore, this diagram could also be extendedto take into account specific VO policies constraints. Eachconstraint would be expressed with a property of the class.These properties could then be used to dynamically generate

commands to communicate with particular schedulers to getthe resources. This set of specific commands would finallydescribe a specialized protocol to get the resources, connectto them, as for the specific OAR tools on grid5000.Finally, if the user wanted to target production grids like
EGEE, he would have to define a specialized protocol byextending the generic protocol java class within TUNe andwrite the different commands to get and to connect to theresources (like the specialized protocols for OAR tools ongrid5000). TUNe is also able to read a set of nodes from whatwe call a nodefile. In this case, the user has to construct this fileby hand by manually getting the resources from the specificscheduler. Another option is again to describe the reservationmechanism specifying which commands have to be launchedand where to get the resources, by extending the generic nodejava class within TUNe.For now, the platform description diagram is used to con-
struct the reservation commands; therefore it includes an ex-haustive description of the resources allocated by the resourcemanager. This allows the user to fix a maximum limit forthe reservation process and if the application needs moreresources, it forces TUNe to aggregate some of the processeson same nodes. We are actually working on an evolution ofthese diagrams: an improved application description diagramwill be used with more specific QoS constraints and theplatform diagram will permit a more precise description of thehardware architecture. We are working on the way to calculatethe best fit between the application demands and the actualavailabilities of the resources.
C. Application description
Fig. 2. Application description
The goal of this diagram is to describe what should be therunning distributed application at its best (with no failures).As for the platform description, it is also based on a UMLclass diagram. The user has to create the different families ofits program. Two kinds of programs can be distinguished:
• the architecture and information specific to its application.This part requires an abstraction work for the user.
• the probing system which senses the state of the applica-tion and therefore can asks TUNe to change the behavior
of the application during its execution by sending events.TUNe provides a set of different probes (to check if aPID is alive, a node is alive) but the users can create theirown programs (that will also be automatically deployedby TUNe) to observe specific values of their applicationsand send events to the TUNe manager in a very simpleway: they only have to write into a pipe.
In diagram 2, three families of program are described: yatsim,yatpre and a probe that can observe these two programs.Each class contains TUNe specific parameters or legacy spe-cific parameters. A minimum of parameters for the yatpacsimulation are:
• legacyFile: is an archive of all necessary files to executethis program.
• initial: is an integer which represents the desired numberof running processes of this program.
• host-family or host: represents how TUNe maps thesoftware component with the platform component. It canbe a family in the Platform description (see figure 1) or aspecific host in the family. Those values can be estimatedby using the batch scheduler or by taking the host nameof another running process. For instance, here we wantedto precise that the yatpre program should be on the samenode than the yatsim program that it is linked to. Theyatsim node is therefore chosen by the scheduler and thelinked instance of yatpre will also take the same node toexecute itself.
• wrapper is the name of the wrapping XML file whichcontains all the methods that can be called for the legacy,and will be explain further.
The user should also create relations between program partsby creating links between them. Those links can also benamed, and are useful for two main reasons. First, it allowsa component to get some information (value of parameters,value of TUNe variables) about the components it is connectedto. Secondly, it also creates a cardinality between the differentprograms. In figure 2, it is expressed that when TUNe createsa yatsim program, a yatpre program should also be createdand reciprocally (cardinality 1-1). For the probe, it limits forone instance of the probe program the number of observedcomponents. Here there is a maximum limit of 60 yatpre and60 yatsim for one probe.D. Behavior descriptionTwo types of diagram are used to express the behavior of
the application: state chart diagrams and activity diagrams.Activity diagrams are still under development and allowsto create more sophisticated reactions. Here we present theminimum state chart diagrams needed to start and stop theapplication:
• The startchart: describes what should be done to start thedistributed application, shown by figure 3.
• The stopchart: gives the different actions to stop thedistributed application.
The user can also create some other state chart diagramswhich are run when the TUNe manager receives an event from

Fig. 3. Start behavior description
the probe for example. In this case, the name of the diagramis the name of the received event. That is the case in figure 4for the state chart ”repair”, which makes TUNe sensible to theevent ”repair”. This diagram is started when a probe detects ayatpre or a yatsim failed execution.A state chart begins at the initial node and finishes whenit arrives at an ending node. Some of the actions can beexecuted in parallel with the use of fork junctions. The joinjunctions wait for the different forked paths to arrive beforethe execution of the diagram can be continued.State charts use a language to manipulate the components andto call the methods in the wrapping XML file. The first part ofa command represents one component or a set of components.For instance, it can be a family name (in figure 3 ”yatpre”),a variable defined by TUNe (in figure 4 ”arg” which is anargument passed to the state chart) or by the user (in figure4 ”new” represents the last component created by the user).The second part of a command is the action to be executed onthese components. It can be a TUNe operator (like ”""” infigure 4) or a call to a method defined in the wrapping XMLfile (in figure 3 ”sendresults”). A more detailed execution ispresented in the Experiments section.
E. Wrapping filesOne of the most promising approaches with TUNe is
the encapsulation mechanism of legacy software into genericwrappers. This permits any legacy software to be wrappedwithout modifying any line of its code. The user simply hasto describe the wrapper using a simple XML syntax. Howeverthis limits the controls on the component: basic controls arestarting the component, stopping it and dynamically generateconfiguration files. Other available controls of the legacy canbe described, but TUNe does not offer a controller API tointegrate to the codes of the legacies. First, the wrapper isassociated to a class with the ”wrapper” parameter of the appli-cation diagram. All the methods are listed and the commandsto run effectively on the nodes, including their parameters,are described. The character $ allows to get the different
Fig. 4. Example of dynamic behavior description
values from component instances of the class diagram, or frominternal variables of TUNe.example of wrapping file:
<wrapper name=’yatsim’>.....<method name="sendresults"key="extension.GenericCommands"method="start" >
<param value="./sendresults.sh"/><param value="$dirLocal"/><param value="$node.user"/><param value="$node.keypath"/><param value="$nodeName"/>
</method>
<method name="start"key="extension.GenericCommands"method="start" ><param value="./yatsim Temp"/><param value="$dirLocal"/><param value="$node.user"/><param value="$node.keypath"/><param value="$nodeName"/><param value="LD_LIBRARY_PATH
=$dirLocal"/></method>
......</wrapper>
V. EXPERIMENTS
A. Experiment conditions
In this section, we try to review all the steps that the enduser has to achieve in order to launch effectively a yatpacsimulation with TUNe. These steps include:

• Preparing locally the simulation: First of all, the user hasto create compressed archives (tgz) containing the legacybinary files and all the libraries they use. We provide arecursive ldd script that copies all the libraries used by abinary, including libraries used by libraries, and createsthe archive. We chose to use the generic probe.tgz todetect the presence of the pid process in the followingsimulations. The user also has to prepare all the necessaryinput files for its simulation and number them.
• Describing the application for TUNe: the user creates thethree types of diagrams for TUNe: platform description(figure 1), application description (figure 2), and behaviordescription (figures 3 and 4) using a graphical UMLeditor like Eclipse or Topcased. He then writes thewrapping files to describe what commands should belaunched by the behavior description diagrams.
• Launching TUNe: The user has to send all the files (ap-plication files, TUNe software and the uml file containingthe diagrams) to the grid, for instance the frontnode of itssite on Grid5000. TUNe can then be launched manuallyand it prompts the user for the commands interactively, orit can be launched in remote control mode. In this case,it can be controlled using telnet or writing into a pipe. Todeploy and start the application, one simple command isgiven to TUNe: deploy <path to applicationfiles> <uml file>.
We made two experiments with different numbers of sitesand nodes as shown by table I. The first experiment is asmall scale deployment, concerning 8 sites and 20 nodes oneach site. The second experiment is a large scale deployment,concerning 6 sites and between 30 to 110 nodes on each site.For these experiments, we want to show how fast TUNe candeploy and start the simulation on all nodes, and also howfast it can undeploy everything. To do this, we gradually addthe sites one by one, relaunching TUNe everytime we add anew site in order to always mesure the global times. Thus,the first step will concern only one site, the second step twosites etc. On the following figures 5, 6 and 7, the first pointof an experiment represents the first step (deployment on onesite) and the last point represents the last step (deploymenton all sites). To choose which sites are concerned, we onlyhave to modify for each step the platform description diagram,adding one site to the list of sites (figure 1), and changing theinitial parameter values of the application diagram to the totalnumber of nodes. This is a very simple way to add or removeone site without touching any other file or configuration.
Experiment Rennes Nancy Nice Toulouse Lyon Lilleexperiment 1 20 20 20 20 20 20experiment 2 100 110 90 63 30 70
TABLE INODES AND LOCATION
Note that the sites of Paris and Bordeaux are also used with20 nodes in the experiment 1.
B. Deployment
0 50 100 150 200 250 300 350 400 450 5000
200
400
600
800
1000
1200
1400
1600
1800
Experiment 2Experiment 1
Number of nodes
Tim
e (m
s)
Fig. 5. Creation of system representation
The deployment consists of three phases:• The creation of the internal system represention of TUNe:illustrated by figure 5.
• The deployment of the application on the nodes: shownin figure 6.
• The initialisation of the software components: shown infigure 7.
1) Initialisation of the deployment: When TUNe receivesthe ”deploy” command, it parses the uml file and eventuallysends a request to the resource scheduler of the grid ifthe resources are not directly listed in a nodefile. For thisexperiment, we actually used the grid5000 OAR resourcescheduler, that’s why on figure 1 the type is equal to oargrid.This means that TUNe will get the resources needed usingthe oargrid tool. It is very important to note that we did notmeasured the time spent by the oargrid tool to achieve TUNe’srequest. Indeed, depending on the tool used to schedule thegrid resources and depending on TUNe’s demand, the time canvary a lot and we only wanted to show TUNe performances.We then started to mesure the times as soon as we get all theresources needed.Moreover, the TLM simulations deployed include time
range and time step parameters that can vary from onesimulation to the other. For instance, the user can specify aless time precision for some area of the electronic circuit. Hecan therefore focus on some interesting parts of the electroniccircuit and ask for a very precise time step and time range ona specific area. Depending on these parameters, the runningtime for one simulation can vary from 5 minutes to a fewhours.2) Creation of the internal system represention of TUNe:
Figure 5 shows how much time TUNe spends in creating itsinternal representation of the global system to be deployed.This represents the time needed by TUNe to create an in-stanciation of the application description diagram(figure 2)mapped to the platform description diagram(figure 1). For eachinstance of the classes in the application desciption diagram,
0 50 100 150 200 250 300 350 400 450 5000
50000
100000
150000
200000
250000
Experiment 2Experiment 1
Number of nodes
Tim
e (m
s)
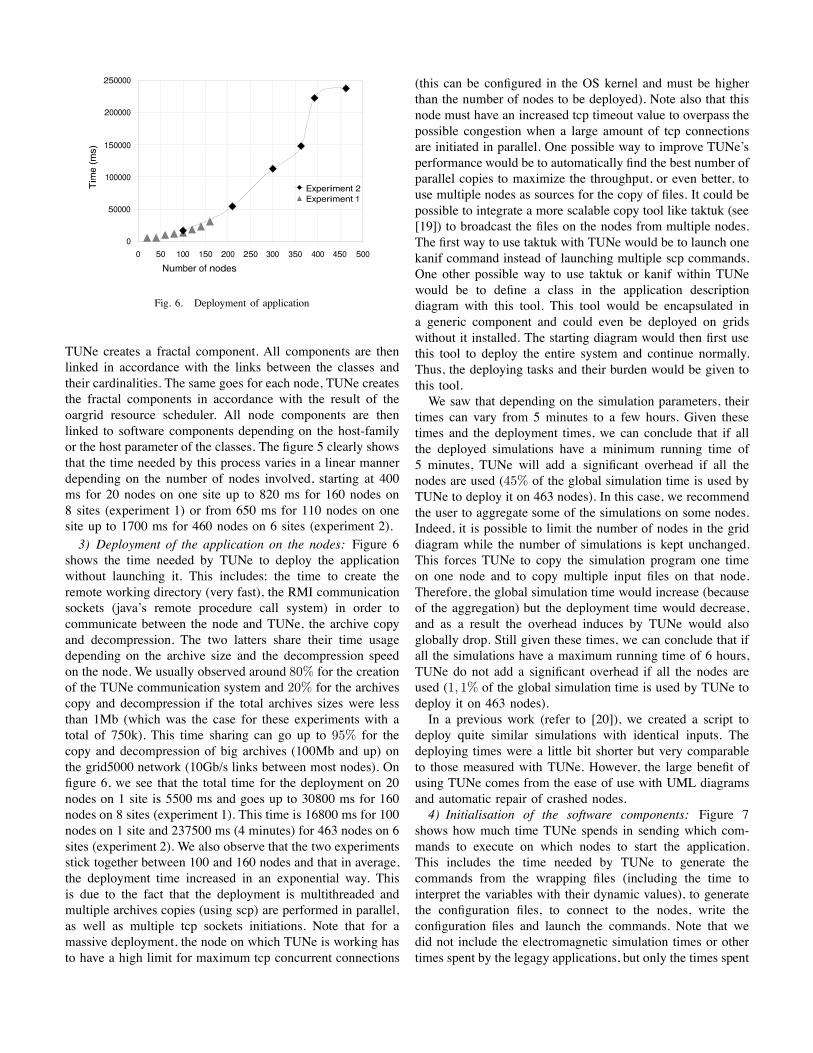
Fig. 6. Deployment of application
TUNe creates a fractal component. All components are thenlinked in accordance with the links between the classes andtheir cardinalities. The same goes for each node, TUNe createsthe fractal components in accordance with the result of theoargrid resource scheduler. All node components are thenlinked to software components depending on the host-familyor the host parameter of the classes. The figure 5 clearly showsthat the time needed by this process varies in a linear mannerdepending on the number of nodes involved, starting at 400ms for 20 nodes on one site up to 820 ms for 160 nodes on8 sites (experiment 1) or from 650 ms for 110 nodes on onesite up to 1700 ms for 460 nodes on 6 sites (experiment 2).3) Deployment of the application on the nodes: Figure 6
shows the time needed by TUNe to deploy the applicationwithout launching it. This includes: the time to create theremote working directory (very fast), the RMI communicationsockets (java’s remote procedure call system) in order tocommunicate between the node and TUNe, the archive copyand decompression. The two latters share their time usagedepending on the archive size and the decompression speedon the node. We usually observed around 80% for the creationof the TUNe communication system and 20% for the archivescopy and decompression if the total archives sizes were lessthan 1Mb (which was the case for these experiments with atotal of 750k). This time sharing can go up to 95% for thecopy and decompression of big archives (100Mb and up) onthe grid5000 network (10Gb/s links between most nodes). Onfigure 6, we see that the total time for the deployment on 20nodes on 1 site is 5500 ms and goes up to 30800 ms for 160nodes on 8 sites (experiment 1). This time is 16800 ms for 100nodes on 1 site and 237500 ms (4 minutes) for 463 nodes on 6sites (experiment 2). We also observe that the two experimentsstick together between 100 and 160 nodes and that in average,the deployment time increased in an exponential way. Thisis due to the fact that the deployment is multithreaded andmultiple archives copies (using scp) are performed in parallel,as well as multiple tcp sockets initiations. Note that for amassive deployment, the node on which TUNe is working hasto have a high limit for maximum tcp concurrent connections
(this can be configured in the OS kernel and must be higherthan the number of nodes to be deployed). Note also that thisnode must have an increased tcp timeout value to overpass thepossible congestion when a large amount of tcp connectionsare initiated in parallel. One possible way to improve TUNe’sperformance would be to automatically find the best number ofparallel copies to maximize the throughput, or even better, touse multiple nodes as sources for the copy of files. It could bepossible to integrate a more scalable copy tool like taktuk (see[19]) to broadcast the files on the nodes from multiple nodes.The first way to use taktuk with TUNe would be to launch onekanif command instead of launching multiple scp commands.One other possible way to use taktuk or kanif within TUNewould be to define a class in the application descriptiondiagram with this tool. This tool would be encapsulated ina generic component and could even be deployed on gridswithout it installed. The starting diagram would then first usethis tool to deploy the entire system and continue normally.Thus, the deploying tasks and their burden would be given tothis tool.We saw that depending on the simulation parameters, their
times can vary from 5 minutes to a few hours. Given thesetimes and the deployment times, we can conclude that if allthe deployed simulations have a minimum running time of5 minutes, TUNe will add a significant overhead if all thenodes are used (45% of the global simulation time is used byTUNe to deploy it on 463 nodes). In this case, we recommendthe user to aggregate some of the simulations on some nodes.Indeed, it is possible to limit the number of nodes in the griddiagram while the number of simulations is kept unchanged.This forces TUNe to copy the simulation program one timeon one node and to copy multiple input files on that node.Therefore, the global simulation time would increase (becauseof the aggregation) but the deployment time would decrease,and as a result the overhead induces by TUNe would alsoglobally drop. Still given these times, we can conclude that ifall the simulations have a maximum running time of 6 hours,TUNe do not add a significant overhead if all the nodes areused (1, 1% of the global simulation time is used by TUNe todeploy it on 463 nodes).In a previous work (refer to [20]), we created a script to
deploy quite similar simulations with identical inputs. Thedeploying times were a little bit shorter but very comparableto those measured with TUNe. However, the large benefit ofusing TUNe comes from the ease of use with UML diagramsand automatic repair of crashed nodes.4) Initialisation of the software components: Figure 7
shows how much time TUNe spends in sending which com-mands to execute on which nodes to start the application.This includes the time needed by TUNe to generate thecommands from the wrapping files (including the time tointerpret the variables with their dynamic values), to generatethe configuration files, to connect to the nodes, write theconfiguration files and launch the commands. Note that wedid not include the electromagnetic simulation times or othertimes spent by the legagy applications, but only the times spent

0 50 100 150 200 250 300 350 400 450 5000
1000
2000
3000
4000
5000
6000
7000
Experiment 2Experiment 1
Number of nodes
Tim
e (m
s)
Fig. 7. Starting application
by the TUNe processes to launch the commands. This timegoes from 1500 ms for 20 nodes on 1 site to an average of5000 ms if the number of nodes is greater than 60 on anynumber of sites. This means that this time does not increasedramatically with the number of nodes involved, unlike thetime of deployment. We can however observe that for the samenumber of nodes the starting time is lower when the nodes areconcentrated on a lower number of sites. For example, with100 nodes on 1 site (first point of experiment 2), the startingtime is 3760 ms whereas with 100 nodes on 5 sites (fifth pointof experiment 1) the starting time is 5440 ms.5) Undeploying times: Figure 8 shows the time needed by
TUNe to undeploy completely the application. This includesthe time to clean working directories and cleanly stop all thenetwork connections. This figure shows that this time increaseswith the number of nodes involved, starting from 349 ms with20 nodes on 1 site to 7845 ms with 160 nodes on 8 sites forthe experiment 1, and from 2863 ms with 100 nodes on 1 siteto 32568 ms with 463 nodes on 6 sites for experiment 2. Asfor the deployment, an important number of tcp connectionsare initiated during this phase.Note again that we do not take into account the time to
retreive the simulation results as it can vary a lot dependingon the output files size created by the application deployed.With TUNe, it is possible to use pulling or pushing for theresult retrieval. In the pushing case, and using the applicationdescription diagram, it is possible for the user to define adifferent target for a set of nodes. For example, the 50 firstsimulations can push the results on a certain node, the 50next on another node etc. It is also possible to define a singletarget for each site, and the nodes from that site would pushthe results to that particular node. We could again use a morescalable copy tool like taktuk.
C. Repair
We saw that TUNe is a software that can be used to deployand configure applications in a distributed environment. It canalso monitor the environment and react to events such asfailures or overloads and reconfigure applications accordingly
0 50 100 150 200 250 300 350 400 450 5000
5000
10000
15000
20000
25000
30000
35000
Experiment 2Experiment 1
Number of nodes
Tim
e (m
s)
Fig. 8. Undeployment of application
and autonomously. Management solutions for legacy systemsare usually proposed as ad-hoc solutions that are tied toparticular legacy system implementations. This unfortunatelyreduces reusability and requires autonomic management pro-cedures to be re-implemented each time a legacy systemis taken into account in a particular context. Moreover, thearchitecture of managed systems is often very complex (e.g.multi-tier architectures), which requires advanced support forits management. Still to propose a high level interface we use aUML profile for specifying reconfiguration policies. The mainbenefit of this approach is to provide a higher level interfaceto the software environment administrator to autonomouslymanage its distributed applications.Indeed, when deploying on a large amount of nodes a
yatpac simulation that can run for hours, it often happens thatsome of the nodes crash or some of the processes hang. Inthe experiments presented above, it is possible to restart onesimulation with the same input files in case of failure becausethe simulation tasks do not communicate between them andall the input files are not collerated. In certain conditions,TUNe is able to restart communicative tasks (for web servicesarchitectures for example). In order to detect these failures, weused the monitoring system consisting of a number of genericprobes given by default by TUNe. These probes regularlyconnect to the nodes they are in charge and scan for the pidof the processes to see if they are alive and not in a blockedstate. When a simulation finishies successfully and the resultshave been sent back, we stop the monitoring by unregisteringits pid. When such failures occurs, a repair event is sent toTUNe with the name of the component involved in the failure,and the corresponding state chart being executed. For instanceif a yatsim process is dead, the probe sends the repair event toTUNe with the instance name of the yatsim process involved,and the state chart shown in figure 4 is executed. Followingthis chart, we see that TUNe tries to stop the failed process($arg.stop) and tries to stop the process connected by the simlink on the class diagram ($arg.sim.stop, the sim link is shownon figure 2). Indeed, if a yatpre failure occurs, then the yatsimwill fail anyway so it’s better not to start the yatsim process

in this case. Then TUNe tries to undeploy the yatpre andyatsim files ($arg"" and $arg.sim""), as well as cleaningcompletely the node. Anyway if it was a node failure, allof that would have no consequence and the statechart wouldcontinue normally. After the join junction, the next action isyatpre++, that creates and deploys a new yatpre componentand also creates and deploys a new yatsim component becausethey are connected with a 1-1 cardinality. New.getfiles gets theinput files for the newly created simulation and new.start isthe equivalent for yatpre.start in the startchart diagram (figure7). The same goes for new.sim.start that is the equivalent ofyatsim.start and new.sim.sendresults that is the equivalent ofyatsim.sendresults.We present different time measurements for a repair process
in real conditions in table II. To get these values, we modifieda probe to communicate with it during the execution processand simulated a node failure by forcing the event node failureby hand. However, we regularly had a difference between thenumber of nodes asked to the scheduler and the number ofnodes actually ready to receive the simulation binaries andinput files. For instance, during the experiments, when TUNeasked for 105 nodes, it received 100 ready nodes. The samewent when TUNe asked for 480 nodes and received 463ready nodes. In that case, TUNe continued the deploymentnormally but the probes would eventually detect those failuresand TUNe would redeploy the failed parts on new nodes. Onthe other hand, process hangs were very rare cases (1 of 463nodes on long simulations running times) and often related tohardware overloads. We also consider here the oargrid requesttime in order to get an idea of the global repair time in realconditions. The average total time we measured for one repairprocess is around 12 seconds.
action time (ms)undeploying 683
component removals 126oargrid request 4904
component creation 167deployment 4525
start 1855
TABLE IITIME MEASUREMENT FOR REPAIRING THE APPLICATION
VI. CONCLUSIONGrid computing offers a great opportunity for scientists to
access a large amount of shared resources, but at the sametime distributed softwares on a large scale environment areincreasingly complex and difficult to manage. To address thisissue, a promising approach based on autonomic computinghas been used. An electromagnetic simulator called yatpacwas easily managed with TUNe. This middleware has sim-plified the deployment and undeployment of yatpac for theelectronic engineers. It has also increased the robustness ofthe application execution by automatically restarting partsof the simulation that failed and redeploying them on newnodes. The deployment and starting phase times we measured
can be negligible compared to such simulations that usuallytake hours of running time. Furthermore, this fact makes thereparation procedure even more remarkable. Indeed, the globalsystem is less affected by failures because only the concernedsimulation tasks are restarted.We are currently working on various enhancements. In the
future, TUNe will allow more functionality like detectingbottleneck simulations, interrupting and migrating them tofaster computing nodes. Another interesting feature would bea cooperation between TUNe and the simulator to restart asimulation with new input parameters dynamically generatedto find the optimized solutions. Finally, it would be very usefulif TUNe could automatically detect the availability of newnodes during execution in order to deploy more simulationsand decrease the standby grid nodes time.
ACKNOWLEDGMENT
Experiments presented in this paper were carried out usingthe Grid’5000 experimental testbed, being developed underthe INRIA ALADDIN development action with support fromCNRS, RENATER and several Universities as well as otherfunding bodies (see https://www.grid5000.fr).The authors wish to acknowledge the National ResearchAgency (ANR) for support of MEG Project and the frenchMidiPyrenees region.
REFERENCES
[1] I. Foster and C. Kesselman. The Grid 2: Blueprint for a New ComputingInfrastructure. Morgan Kaufmann, 2004.
[2] Cappello Franck, Caron Eddy, Dayde Michel, Desprez Frederic, Jean-not Emmanuel, Jegou, Yvon, Lanteri Stephane, Leduc Julien, MelabNouredine, Mornet Guillaume, Namyst Raymond, Primet Pascale andRichard Olivier, Grid’5000: a large scale, reconfigurable, controlableand monitorable Grid platform, Grid’2005 Workshop, Seattle, USA,November 13-14, 2005.
[3] L. Broto, D. Hagimont, P. Stolf, N. Depalma, S. Temate, Autonomicmanagement policy specification in Tune, 23rd Annual ACM Symposiumon Applied Computing, Fortaleza, Brazil, March 2008.
[4] GECEM - Electromagnetic Compatibility in Aerospace Designhttp://www.wesc.ac.uk/projectsite/gecem/
[5] The Lumerical/WestGrid partnership http://www.westgrid.ca/files/webfm/-about docs/Lumerical7.pdf
[6] Lorenz, P., Vagner Vital, J., Biscontini, B., Russer, P. TLM-G – A Grid-Enabled Time-Domain Transmission-Line-Matrix System for the Analysisof Complex Electromagnetic Structures. IEEE Transactions on MicrowaveTheory and Techniques, vol. 53, no. 11, 3631–3637 (2005)
[7] T. E. Athanaileas , P. K. Gkonis, G. E. Athanasiadou, F G. V. Tsoulosand D. L. Kaklamani, Implementation and Evaluation of a Web-BasedGrid-Enabled Environment for WCDMA Multibeam System Simulations,IEEE Antennas and Propagation Magazine, Vol. 50, No. 3, June 2008
[8] J. Kephart and D. Chess, The Vision of Autonomic Computing, IEEE Com-puter, Vol. 36, No. 1 (2003), pp. 41-50, http://www.research.ibm.com/autonomic/research/papers/AC Vision Computer Jan 2003.pdf.
[9] P. Horn, Autonomic Computing: IBM’s Perspectiveon the State of Information Technology, IBM Corp.(October 2001), http://www.research.ibm.com/ auto-nomic/manifesto/autonomic computing.pdf.
[10] S. White, J. Hanon, I. Whalley, D. Chess, and J. Kephart. An Archi-tectural Approach to Autonomic Computing. In Proceedings ICAC 04,2004.
[11] S. Hariri, L. Xue, H. Chen, M. Zhang, S. Pavuluri, an S. Rao.Autonomia: an autonomic computing environment In IEEE InternationalConference on Performance, Computing, and Communications, Apr.2003.

[12] R. Renesse, K. Birman, and W. Vogels. Astrolabe: A robust and scalabletechnology for distributed systems monitoring, management, and datamining. ACM Transaction on Computer Systems, 21(2), 2003.
[13] M Salehie, L Tahvildari, Autonomic computing: emerging trends andopen problems - ACM SIGSOFT Software Engineering Notes, 2005. Vol.30, No. 4. (July 2005), pp. 1-7
[14] A. Yumerefendi, P. Shivam, D. Irwin, P. Gunda, L. Grit, A. Demberel,J. Chase, and S. Babu. Towards an autonomic computing testbed InProceedings of the Workshop on Hot Topics in Autonomic Computing,June 2007.
[15] C. Balanis, Antenna Theory: Analysis and Design. John Wiley and sons,2005.
[16] C. Christopoulos, The Transmission-Line Modeling Method. Wiley-IEEEPress, 1996.
[17] Yatpac homepage. [Online]. Available: http://www.yatpac.org/index.php[18] Bruneton, E., Coupaye, T., Leclercq, M., Quema, V., Stefani, J.B.: An
open component model and its support in Java. In: Proceedings of the7th International Symposium on Component-Based Software Engineering(CBSE-7). Volume 3054 of Lecture Notes in Computer Science., Springer(2004) 722
[19] Guillaume Huard and Cyrille Martin. TakTuk.http://taktuk.gforge.inria.fr/, 2005.
[20] F Khalil, B Miegemolle, T Monteil, H Aubert Simulation of MicroElectro-Mechanical Systems (MEMS) on Grid 8th International Meetingon High Performance Computing for Computational Science, June 2008




















