
Cultural Evolution in Dutch Early Modern Songs - Utrecht ...
128
Cultural Evolution in Dutch Early Modern Songs Topical Fluctuations in the Dutch Song Database (1550-1750) Alie Lassche 3829065 Research Master’s thesis Dutch literature and culture Supervisor: prof. dr. Els Stronks Date: 4th July 2019
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of Cultural Evolution in Dutch Early Modern Songs - Utrecht ...

Cultural Evolution in Dutch EarlyModern Songs
Topical Fluctuations in the Dutch SongDatabase (1550-1750)
Alie Lassche3829065
Research Master’s thesis Dutch literature and culture
Supervisor: prof. dr. Els Stronks
Date: 4th July 2019

ii

Summary
In this thesis, I use computational methods to investigate what the mostpopular topics in Dutch early modern songs are and how topical fluctuationsin a diachronic corpus of Dutch songs relate to cultural-historical changes andcontemporary theses in qualitative research on the role of literature in earlymodern centuries. I use a sample from the Dutch Song Database (hosted atthe Meertens Institute), containing 43,772 songs from the period 1550-1750.To solve the problem of spelling variation in my corpus, I tested two tools tonormalize the spelling of the words in my corpus. The first method I usedwas a tool in which modernization was performed by querying all words inthe corpus using the INT Lexicon Service and replacing the words with thelemma resulting from the query. The other method I used was the semi-automatic VARiant Detector (VARD), which uses a normalized word listand a variant list to suggest or replace variant words with their normalizedcounterparts. The results of the VARD-tool turned out to be better than theresults obtained with the INL-tool. I therefore continued my analysis withthe VARD-normalized version of my corpus.
To perform topic modeling, I used the MALLET wrapper in the Pythonpackage gensim. I tested several settings and subsequently let the modelbuild fifty topics from my corpus. I assigned a subject to each topic, andby plotting them over time, I explored which topics were dominant at whattime. Furthermore, I distilled four claims about the roles of literature inearly modern centuries from qualitative research on early modern literature.With my results obtained with quantitative methods, I tested whether theseclaims were confirmed. The four theses on the roles of literature I tested,were the following:
1. Literature and ideology: I showed how literature is seen as a propagatorof an ideology and how this is the case for the literature of the FurtherReformation.
2. Literature and poetics: I used the topics on Petrarchism to show howthe Dutch literary tradition becomes more and more embedded in a
iii

iv
Renaissance and classical tradition.
3. Literature and politics: The topic nation and country made clear howliterature and politics are closely related in times of political crises.
4. Literature and diversity: I showed how my used methods fall shortin testing whether the groups of people involved in literature becomemore diverse over time. I did show how a growing variation appears inthe most popular topics over time.
I conclude this study with a reflection on the fields of cultural evolution,digital humanities and qualitative literary studies, stating that these threeshould function in addition to each other.

Contents
1 Introduction 1
I Theoretical framework 11
2 Digital humanities 132.1 Computation and culture . . . . . . . . . . . . . . . . . . . . . 132.2 Debate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.3 Extracting themes from a corpus . . . . . . . . . . . . . . . . 18
3 Cultural evolution 213.1 From biological to cultural evolution . . . . . . . . . . . . . . 213.2 Variation, competition and inheritance . . . . . . . . . . . . . 233.3 Transmission biases and turnover series . . . . . . . . . . . . . 25
II Methodology 29
4 Corpus 31
5 Spelling normalization 355.1 INL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 365.2 VARD2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
6 Topic models and turnovers 436.1 LDA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 436.2 Calculating turnover series . . . . . . . . . . . . . . . . . . . . 45
III Analysis and results 47
7 Dominant topics 49
v

vi CONTENTS
7.1 Preparation of data and choosing settings . . . . . . . . . . . 497.2 Building the final topic models . . . . . . . . . . . . . . . . . . 54
7.2.1 Original corpus . . . . . . . . . . . . . . . . . . . . . . 557.2.2 INL-normalized corpus . . . . . . . . . . . . . . . . . . 617.2.3 VARD2-normalized corpus . . . . . . . . . . . . . . . . 64
7.3 Evaluating models . . . . . . . . . . . . . . . . . . . . . . . . 69
8 Roles of literature 778.1 Literature and ideology . . . . . . . . . . . . . . . . . . . . . . 778.2 Literature and poetics . . . . . . . . . . . . . . . . . . . . . . 808.3 Literature and politics . . . . . . . . . . . . . . . . . . . . . . 838.4 Literature and diversity . . . . . . . . . . . . . . . . . . . . . 86
IV Conclusion 95
9 Conclusion and discussion 97
Bibliography 105
Stop list original corpus 111
Stop list INL-normalized corpus 113
Stop list VARD-normalized corpus 115
Topics original corpus 117
Topics INL-normalized corpus 119
Topics VARD2-normalized corpus 121

Chapter 1
Introduction
Ghy loopt by al die VrijstersEn maeckt veel waters vuyl:Met suycker soete woordenPayt ghy den gantschen hoop;Het schijnen mooye Boonen,Doch woorden zijn goet koop
— Anonymous (1645)
Waarom denk je dat je kansmaakt boy,Denk niet dat het zo is,Al je doekoe in een Louis store,je bankstatus is niks
— Famke Louise, Op MeMonnie (2017)
In a recent video on the Dutch YouTube channel VoxPop, Roel Maalderinkasks middle-aged people on the streets what they think of the genre of Dutchhip hop (‘Nederhop’). When they collectively express their disdain for thesesongs, Maalderink lets them read some lyrics of what he tells them are ‘eight-eenth century songs’, which are in fact just archaic translations of Dutch hiphop lyrics. Among these is this one, by the ‘eighteenth century poet AliBatavi’:
Want dit isdie leipe Batavenodeur
1

2 CHAPTER 1. INTRODUCTION
Geen probleem Philips IIbrengt de leipe Batavenodeur
Every not-so-middle-aged listener will immediately recognize the hip hopsong ‘Leipe Mocro Flavour’ (2004) by Ali B, Yes-R and Brace, but the middle-aged ladies and gentlemen in the video have no clue, and are impressed by thepoetical ingenuity of Ali Batavi and other songwriters, including ‘De jongeluivan heden ten dage’ and ‘Boef’. Although Maalderink does not realize thatPhilips the Second was a sixteenth-century king who had nothing to do withthe eighteenth century Batavian Republic, the outcome of the video is clear:as soon as contemporary hip hop lyrics are translated into historical Dutch,baby boomers see the beauty of it as well.
This provisional experiment raises a number of questions. To what extentis the idea true that topics and themes in song lyrics have changed overtime, if it takes just a quick translation to let people over fifty enjoy thesame lyrics the younger generation does? How do contemporary songs differfrom historical songs, except for their spelling and word choice? In terms oftheme, the quoted anonymous song from 1645 seems quite similar to FamkeLouise’s ‘Op Me Monnie’. What did people sing about during the earlymodern times? What changes can be observed over a long period of time?If there is one thing we know about the early modern Dutch song culture,it is the fact that it was an excelling field. According to Louis Peter Grijp,song culture is as typically Dutch as the culture of painting: ‘men is grootin het kleine’.1 Furthermore, Natascha Veldhorst argues that Dutch songculture ‘held the entire population in thrall, from young to old, from poorto rich’.2 For decades, literary scholars on the early modern period havepublished studies on historical songs and song culture, which contrasts withthe small number of studies on contemporary Dutch song culture. Onlysince a few years, this has become object of scrutiny for literary scholars,resulting in several studies, including ones on Dutch pop song lyrics, andrepresentation in Dutch hip hop.3 In sharp contrast to the large number of
1. Louis Peter Grijp, Het Nederlandse lied in de Gouden Eeuw: het mechanisme vande contrafactuur (Amsterdam: P.J. Meertens-Instituut voor Dialectologie, Volkskunde enNaamkunde, 1991), 29.
2. Natascha Veldhorst, ‘Pharmacy for the Body and Soul. Dutch Songbooks in theSeventeenth Century’, Early Music History 27 (October 2008): 217.
3. See for example Geert Buelens, ‘’Listen - I’m not dissin but there’s something thatyou’re missin’. Songteksten als literair genre en onderzoeksgebied voor culturele studies’, inMarges van de literatuur, by Arnout De Cleene, Dirk De Geest and Anneleen Masschelein(Gent: Academia Press, 2013), 115–132; Aafje de Roest, ‘Buurtvaders. Een kritische lezingvan de performance van represent door vier Nederlandse hiphopartiesten’ (Master’s thesis,Utrecht University, 2017).

3
case studies on historical Dutch song culture4 stands a very small numberof quantitative studies on Dutch early modern songs. In fact, Grijp is theonly one who undertook a successful attempt to mapping the Dutch earlymodern song culture, by writing his dissertation Het Nederlandse lied in deGouden Eeuw. Het mechanisme van de contrafactuur (1991). In this work,Grijp reconstructs the melodies of the songs, by finding their sources and indetermining their reception. One of the results of his extensive work is thebirth of the so-called ‘voetenbank’, a primitive electronic database containinginformation on melodies, verses and stanzas of (at that time) 5,700 Dutchhistorical songs.5
In her work on Dutch early modern songbooks, Veldhorst states that wedo not know enough about the early modern song production, to come upwith specific numbers. In the first place we do not have an overview ofall early modern songbooks that are kept in European libraries nowadays.Secondly, we need to keep in mind that songbooks were heavily modified, ex-panded, and revised in the course of time. Thirdly, the small survival chancesof the songbook further complicate any attempt at estimating.6 This sup-posed lack of data accounts for the relative scarcity of quantitative studieson early modern songs. If there is one thing you need in order to performquantitative research, it is numbers and data. However, almost thirty yearsafter the publication of Grijp’s dissertation, the ‘voetenbank’ has grown intothe extensive Dutch Song Database (DSD, Nederlandse Liederenbank, hos-ted at the KNAW Meertens Institute), containing metadata of more than175,000 Dutch songs. Moreover, in the last couple of decades the oppor-tunities to explore a corpus digitally have grown exponentially. While Grijphad to manually count and search for patterns, we have, thanks to the rap-idly growing field of the digital humanities, the computer to perform thesekind of tasks. Computational tools allow us to research a massive corpusand to count and investigate characteristics in ways not previously available.This thesis uses these new possibilities to quantitatively research Dutch earlymodern songs and explore how the outcome of quantitative research relatesto qualitative research done so far on early modern songs, and, in a broaderperspective, on early modern literature.
In doing so, I build on earlier research on the same corpus, in which we
4. See for example Els Stronks, ‘’Dees kennisse zuldy te kope vinnen’: Liedcultuur ende waarde van ‘know how’ in de vroegmoderne Republiek’, De zeventiende eeuw 30, no.2 (2014): 147–167; Els Stronks, Stichten of schitteren: de poezie van zeventiende-eeuwsegereformeerde predikanten (Houten: Den Hertog, 1996).
5. Grijp, Het Nederlandse lied in de Gouden Eeuw: het mechanisme van de contrafac-tuur, 13.
6. Veldhorst, ‘Pharmacy for the Body and Soul’, 225-227.

4 CHAPTER 1. INTRODUCTION
examined what kind of effect repetition in song lyrics has on the popular-ity of a song. Previous studies on repetition and popularity of pop songsshowed that repetitive lyrics have a positive effect on the popularity of asong.7 In our study, we confirmed that a similar pattern can be found re-garding early modern Dutch songs. After undertaking a series of ‘SurvivalAnalyses’, we analyzed the use of word repetition as a determinant for thesurvival patterns of religious and profane songs. Results showed a significanteffect of word entropy on the survival chances of a song, where songs withmore repeated words (i.e. lower entropy values) had longer lifespans andhigher reprint probability.8 As a sequel to this earlier study on a song’s form,I will examine the content of a song in this thesis. In order to establish whichtopics were dominant in the lyrics of early modern Dutch songs, I will per-form topic modelling on my corpus. I assume that if a topic becomes moreprevalent, the words describing it become more frequent as well.9 I will useMALLET’s adaptation of latent Dirichlet allocation (LDA) in the Pythonpackage gensim, in order to build topics from my corpus.
I will analyze which topics were more dominant than others, which dy-namics can be observed in the fluctuations of topics in my corpus over time,and how changes in these topic distributions can be related to cultural andhistorical real-world changes. For this last step I draw inspiration from thefield of cultural evolution. This research area provides a series of conceptsthat allow us to understand what drives cultural trends. Cultural evolutiondraws a parallel between genetic evolution and cultural change, arguing thatchanges in socially transmitted beliefs, knowledge, languages, and so on, canbe described in terms of just the three basic preconditions with which allbiological change is described by Charles Darwin in The Origin of Species(1859): variation, competition and inheritance.10 Moreover, following An-dres Karjus et al., I assume that ‘contexts, or topics, tend to change withthe times, along with the world that they describe’ and that ‘[t]hese changesare expected to be reflected in (...) diachronic corpora’.11 In analyzing fluc-
7. Joseph C. Nunes, Andrea Ordanini and Francesca Valsesia, ‘The Power of Repeti-tion: Repetitive Lyrics in a Song Increase Processing Fluency and Drive Market Success’,Journal of Consumer Psychology 25, no. 2 (2015): 187–199; Peter J. Alexander, ‘Entropyand Popular Culture: Product Diversity in the Popular Music Recording Industry’, Amer-ican Sociological Review 61, no. 1 (1996): 171–174.
8. Alie Lassche, Folgert Karsdorp and Els Stronks, ‘Repetition and Popularity in EarlyModern Songs’ (Utrecht, 2019).
9. Andres Karjus et al., ‘Quantifying the Dynamics of Topical Fluctuations in Lan-guage’, 2 June 2018, 6.
10. Alex Mesoudi, Cultural evolution: how Darwinian theory can explain human cultureand synthesize the social sciences (Chicago: University of Chicago Press, 2011), 26.
11. Karjus et al., ‘Quantifying the Dynamics of Topical Fluctuations in Language’, 1.

5
tuations in topic distributions, I will test how theses from contemporaryqualitative research about the role of literature in the early modern centur-ies, can be related to my quantitative results. Wrapping this all up in onesentence, the two research questions I aim to answer in this thesis are thefollowing:
What are the most popular topics in Dutch early modern songsand how do topical fluctuations in a diachronic corpus of Dutchsongs relate to cultural-historical changes and contemporary thesesin qualitative research on the role of literature in early moderncenturies?
Structure of this thesis
To answer my research question, I use the following structure. In the re-mainder of this first chapter I will give a brief introduction to the cultural-historical field of Dutch early modern song culture. Furthermore, I will dis-cuss in more detail some of the prevailing theses in contemporary qualitativeresearch on the role of literature in the early modern times. The rest of thisthesis I have divided in five parts. Part I, Theoretical framework, containstwo chapters in which the two fields in which this research is embedded arediscussed. Chapter 2 concerns the field of digital humanities. After a broadintroduction, I will zoom in on the debate on computational literary studies,and discuss existing methods to extract themes from a corpus. In Chapter3, I will examine the other theoretical pillar of my research: the field of cul-tural evolution. I will explore how the concepts of variation, competition andinheritance can be applied to culture. Subsequently I introduce the terms‘transmission bias’ and ‘turnover’. The next part, Methodology, consists ofthree chapters. In Chapter 4 I will introduce my corpus and discuss the maincorpus characteristics. The next chapter is about two methods I tested toperform spelling normalization on my corpus. Chapter 6 contains an in-depthdiscussion of Latent Dirichlet Allocation (LDA), the topic modeling method Iused. This chapter also includes a discussion of the methodology concerningthe calculation of turnover series. Chapters 7 and 8 belong to part III of thisthesis, the Analysis and results. In Chapter 7 I report the steps that I havetaken in building topic models from my corpus, which are critically evaluatedafterwards. In Chapter 8 I investigate how the observed topical fluctuationsrelate to four prevailing claims, drawn from qualitative research, on the roleof literature in early modern times. Part IV, Conclusion contains a chapterin which on the one hand the implications of these interpreted results, andon the other hand future work will be discussed. Part V, the final part ofthis thesis, contains all appendices.

6 CHAPTER 1. INTRODUCTION
Early modern literature and song culture
At the beginning of the seventeenth century, Dutch literature flourished likenever before. Karel Porteman and Mieke B. Smits-Veldt summarize it wellin the title of their contribution to the series ‘Geschiedenis van de Neder-landse literatuur’: Een nieuw vaderland voor de muzen, in other words, anew homeland for the muses. On the first pages of their extensive study,Porteman and Smits-Veldt explain how the words ‘homeland’ and ‘muses’indicate a new phase in the history of Dutch literature. The muses refer tothe ‘arts’, in particular to poetry, an art form that, after a long journey fromthe mountains Helicon and Parnassus, then successively via the Romans,Italy and France, finally had arrived in the Low Countries in the second halfof the sixteenth century. It was the birth of Dutch renaissance literature.12
The term ‘homeland’ refers to the idea that poets, in writing their poetry,contributed to the idea of a shared homeland with a shared language. Themuses therefore not only came to live in a new homeland, but also gave itshape.13
About the role of literature in the early modern times, a few claims areprevailing in current qualitative studies. I determine four different theses,which all have the idea in common that literature plays a major role in theconstruction of an identity. This did not only happen by poets contributingto the idea of a shared homeland and language during a long lasting war forpolitical and religious independence, but also by a growing focus on the con-tradiction between the local and the global. During the seventeenth century,Porteman and Smits-Veldt observe a regionalization of literature. AlthoughAmsterdam remained the cultural center of the Dutch Republic, new poetsfrom other places in the provinces Zeeland, Holland, and Friesland madethemselves heard.14
The first claim is that literature functioned as propagator of an ideology.This happened for example in the literature belonging to the pietistic tradi-tion which was rising in the second half of the seventeenth century. In theDutch historiography, this movement is sometimes referred to as the FurtherReformation. Pietism appealed to the pre-Reformational piety, in which theinner faith experience was centralized.15 A key concept of pietism was theidea of ‘bevindelijkheid’, meaning that protestant belief should not only be
12. K. Porteman and Mieke B. Smits-Veldt, Een nieuw vaderland voor de muzen:geschiedenis van de Nederlandse literatuur 1560 - 1700, Tweede druk (Amsterdam: Bak-ker, 2009), 17.
13. Ibid., 18.14. Ibid., 21.15. Joris van Eijnatten and F. A. van Lieburg, Nederlandse religiegeschiedenis (Hilver-
sum: Verloren, 2006).

7
manifested in all aspects of daily life, but especially in an inner experiencedreality. According to Porteman and Smits-Veldt, two trends can be determ-ined in the literature of the Further Reformation, which started around 1650.On the one hand, there were literary texts in which an external program wasrealized, focusing on a sanctification of society and all aspects of life: family,school, church, and public morals. On the other hand, texts appeared inwhich the personal lived experience with God was described and expressed.One of the literary text genres through which the dissemination of these ideastook place, were songs, since free songs (as in, songs that are not psalms) wereno longer seen as problematic in Calvinistic environments. Proponents of theFurther Reformation published their own catechisms, sermon bundles, andsongbooks, causing a quick rise of the number of reformed songbooks after1650.16 This is also what Els Stronks showed in her dissertation Stichtenof schitteren. De poezie van zeventiende-eeuwse gereformeerde predikanten.She explores how through the means of cheaply produced song collections andvery pious and instructive song texts, attempts were made to raise and purifythe lifestyle and behavior of the Calvinists.17 Besides, Stronks demonstratedhow some of these poets also hoped for a small literary career.
The relationship between literature and poetics is the second claim fromqualitative research I want to investigate. With ‘poetics’, I mean the ideathat poetry of early modern Dutch poets became more and more embeddedin a Renaissance and classical tradition. Genres and topics from these tra-ditions were appropriated by Dutch poets. One characteristic was the focuson and appreciation for the vernacular. Glorifying the native language wasaccompanied by the purification and expansion of language.18 How poetsfrom countries such as Italy and France adapted the Greek and Latin tra-dition, should also be able in the Dutch native language, was the thought.An important example of this embedding in the Renaissance tradition is thepractice of the Petrarchistic genre. Dutch poets wanted to demonstrate thatthey too belonged to the refined European culture which celebration of loveowed much to the Italian Renaissance poet Petrarch.19 Other examples arethe roles that were occupied by mythological figures in literature. With themove of the ‘muses’ to the Low Countries, all these aspects became moreprevalent in Dutch literature.
16. Porteman and Smits-Veldt, Een nieuw vaderland voor de muzen, 658-660.17. Stronks, Stichten of schitteren, 36-49.18. Porteman and Smits-Veldt, Een nieuw vaderland voor de muzen, 40.19. Arie-Jan Gelderblom, ‘Investing in your relationship’, in Learned Love. Proceedings of
the Emblem Project Utrecht Conference on Dutch Love Emblems and the Internet (Novem-ber 2006), ed. Els Stronks and Peter Boot (Den Haag: DANS Symposium Publications,2007), 131.

8 CHAPTER 1. INTRODUCTION
Another starting point that is often used in contemporary literary re-search, is the existence of a relation between literature and politics. Examplesof this relation are studies on Joost van den Vondel’s politically charged playPalamedes oft vermoorde onnoozelheit (1625), in which Vondel allegoricallyused the classical Greek hero Palamedes to convert the event of the execu-tion of Johan van Oldenbarnevelt in 1619 to a martyr’s story with classicalallure. In the article ‘Lezers in de marges van Vondels Palamedes ’ for ex-ample, we explored how the Palamedes was read in the seventeenth century.We found that, given the sales numbers of the play, and the nature of themarginalia in the survived copies, the play experienced renewed popularityduring the First Stadtholderless period (1650 - 1672), culminating in the year1672 (the ‘Rampjaar’) in which the murder of statesmen Johan and Cornelisde Witt took place.20 This suggests that, in times of political crises, literaturewith a political connotation becomes extra important: it is read more often.Moreover, literature with a political undertone is written more often dur-ing political crises, and can shape and intensify the debate. Roeland Harmsshows this in his dissertation on public opinion titled Pamfletten en publiekeopinie. Massamedia in de zeventiende eeuw. In this, he demonstrates howthe production of political pamphlets enabled the reader to be extensivelyinformed about the viewpoints of different political parties, which eventuallyled to the public at large participating in the political debate, and hence tothe invention of public opinion.21
Returning to the text genre that is key in this thesis – the song – themost striking and well-known example of the strong connection between lit-erature and politics is undoubtedly the song that became the Dutch nationalanthem in 1932: the Wilhelmus. This song, written in the late sixteenth cen-tury and containing no less than sixteen verses, voices William of Orange.The Wilhelmus functioned as a protest song, by which William of Orangegathered supporters to revolt against the Spanish rule, which resulted in theEighty Year’s War. It is not surprising that William of Orange choose asong to gather his crew: during the early modern period, the tradition ofthe monodic22 song in the vernacular was extremely popular in the DutchRepublic. Tens of thousands of Dutch songs were written, published, readand, obviously, sung. According to Veldhorst, everyone sang everywhere andeverytime: singing was a second nature of the Dutch.23 Proof of that can not
20. Alie Lassche and Arnoud Visser, ‘Lezers in de marges van Vondels Palamedes’, Neder-landse Letterkunde 24, no. 1 (1 March 2019): 36, 50.
21. Roeland Harms, Pamfletten en publieke opinie: massamedia in de zeventiende eeuw(Amsterdam University Press, 2011), 256.
22. Unisono.23. Natascha Veldhorst, Zingend Door Het Leven: Het Nederlandse Liedboek in de

9
only be found on contemporary paintings, but also in archives and libraries,where hundreds of early modern Dutch songbooks are still kept. The singingtradition was especially flowering in the seventeenth century: it rained song-books at that time, Gerrit Kalff once stated.24 The above made claim, howduring the early modern centuries larger and more varied groups of peoplegot involved in literature, is the fourth that is often used in contemporaryresearch and I want to test in this thesis. Not only the listeners and writersof songs became more diverse: the different number of occasions and sub-jects on which songs were made, expanded as well. Veldhorst determineslaments, wedding songs, prayers, lovers’ dialogues, shepherds’ plaints andpanegyrics.25
Most of the songs written in the early modern centuries were contrafacta,which means that a new text is written on an existing melody. One of thereasons for writing contrafacta rather than composing new songs (with botha new text and a new melody) was, according to Grijp, the combination ofa weak musical and a strong literary culture.26 Imagine you have to write asong for a wedding. It is much easier to write a text on an existing melody,than to compose a new melody and write a new text to it. And even if youmight be a musical genius and are able to write a song with both a new textand a new melody, hardly anyone would be able to sing along, since theydo not recognize the melody. The opportunity to sing along was thereforeanother importing consideration to choose in these kind of situations for acontrafacta.
The demarcation of the term ‘songbook’ is not as unambiguous as onemight expect. There is a wide variation between the different books withinthe genre, for example regarding the format, content and the presence orabsence of musical notation or melody name. I use Veldhorst’s definitionthat a songbook is a printed collection of songs in the vernacular, sometimesmingled with other poetry, and most often (but not always) with a melodyassigning above the song, instead of musical notation.27 The content of asongbook was not static: there was a lively exchange of songs between theproducers of songbooks. Publishers were accustomed to copying songs fromearlier songbooks or books printed elsewhere. Sometimes this even resultedin fifteen or more appearances of one popular song in different songbooks.28
Gouden Eeuw (Amsterdam: Amsterdam University Press, 2009), 12.24. Gerrit Kalff, Het Lied in de Middeleeuwen (Leiden: Brill, 1884), 666.25. Veldhorst, ‘Pharmacy for the Body and Soul’, 224.26. Grijp, Het Nederlandse lied in de Gouden Eeuw: het mechanisme van de contrafac-
tuur, 23, 24.27. Veldhorst, Zingend Door Het Leven, 15.28. Ibid., 73-74.

10 CHAPTER 1. INTRODUCTION
In this study I use a sample of the Dutch Song Database, which is inprinciple not designed to be a repository of songbooks, but a database ofindividual songs. However, this database also contains metadata about thesongbooks a song appeared in. I will focus on Dutch songs from 1550-1750.A motivation for this specific corpus definition, as well as a more in-depthexplanation of the characteristics of the corpus, will be given in Chapter 4,Corpus. With the methods used in this thesis, I will validate or evaluatethe above mentioned claims, drawn from qualitative research, on the role ofliterature in Chapter 8, Roles of literature.

Part I
Theoretical framework
11


Chapter 2
Digital humanities
This chapter focuses on one of the two main disciplines my thesis relates to:the digital humanities. I will start by giving an overview of the discipline,examining how the field has rapidly grown in the last decades. I will continueby discussing the critiques this relatively new field has had to endure, byfocusing in particular on the sub-field of computational literary studies. Iwill end this chapter with investigating the methods that can be used todraw topics from a corpus.
2.1 Computation and culture
As already mentioned in the Introduction of this thesis, numbers and dataare essential for a quantitative study. If we want to use numbers, thereis one crucial quality we need, and that is good counting. And if thereis anything that can perform calculations better than any human being,it is the computer. For decades, computation seemed to only belong tothe field of ‘hard sciences’, where physics, chemistry and biology were seenas scientific fields in which objectivity, methodological rigor and exactitudetake the lead: an environment in which the computer naturally resides. Thiscontrasted with the so-called ‘soft sciences’, to which fields as the socialsciences and the humanities belong and where methodological rigor is lacking.However, at some point it became ‘necessary, in the sense of unavoidable,to use computation to study culture’, Andrew Piper notices in his article‘There Will Be Numbers’.29 Several possible explanations Piper gives forthis development (a certain polemic, new kinds of data, the rise of analyticaltechniques, internet and social media, the critical mass), but I would say that
29. Andrew Piper, ‘There Will Be Numbers’, Journal of Cultural Analytics, 23 May 2016,1.
13

14 CHAPTER 2. DIGITAL HUMANITIES
first and foremost the ongoing large-scale process of text digitization gaverise to the introduction of computers in the humanities. The field of digitalhumanities was born, out of merging two very different fields: computationand culture.30 What the value of computation for the humanities is, is wellexplained by Piper:
Computation forces us to rethink our current disciplinary prac-tices in the humanities from the ground up. What counts asevidence? What is the relationship between theory and prac-tice? How do we account for the technological mediations of ourcritique? But culture too impinges upon computation. It chal-lenges the universalism and the neutrality implicit in many com-putational applications. It reminds us that knowledge is alwayssituated, somewhere, at some time, by someone. Putting cultureinto computation cautions us to remember where we are when wethink we know something.31
Regarding the field of literary studies, the introduction of digital methodscaused a ‘computational turn’, resulting in the birth of the subfield computa-tional literary studies. In that context, Italian literary scholar Franco Moretticoined the term ‘distant reading’ at the very beginning of the twenty-first cen-tury, which he accompanied with a moral claim to readers and scholars. Hisidea was that we only read and research 0.5 percent of all published novels,and by doing so, we send the other 99.5 percent to the so-called ‘slaughter-house of literature’.32 By ‘doing’ distant reading, we would be able to ‘lookbeyond the canon’33 and thus to research the other 99.5 percent. This con-trasts with the method of close reading, which depends in Moretti’s eyeson an extremely small canon (the 0.5 percent), and is therefore not able toinvestigate all literature of the world. Distant reading presents us with theopportunity ‘to focus on units that are much smaller or much larger than thetext’, Moretti explains.34 A unit can be a word, a theme, a genre, a style, etcetera. This new method of performing literary research was presented byMoretti as an offer one could not possibly refuse: ‘If you did not do distantreading, you were presumably ignoring the cries of thousands of volumesforgotten in “the slaughterhouse of literature”’, Ted Underwood ironically
30. Piper, ‘There Will Be Numbers’, 2.31. Ibid.32. Franco Moretti, ‘The Slaughterhouse of Literature’, MLQ: Modern Language
Quarterly 61, no. 1 (2000): 207–227.33. F. Moretti, ‘Conjectures on World Literature’, New Left Review, no. 1 (2000): 57.34. Ibid.

2.2. DEBATE 15
states in his latest work Distant Horizons.35
Although making this urgent call to his readers, Moretti himself includedseveral chapters in his book Distant Reading devoted to canonical worksthat have never even been close to the slaughterhouse of literature, such asShakespeare’s canonical work Hamlet.36 This one of the many critiques hereceived during the years. Others argued that, despite his approach to studyworld literature as a whole, Moretti is guilty of an ‘unavowed imperialismof English’37 and by focusing on the Anglophones, Moretti is reproducingthe same cultural hierarchy he is trying to describe.38 However, the point ofdistant reading is, in Underwood’s words, ‘not to recover a complete archiveof all published works but to understand the contrast between samples drawnfrom different periods or social contexts.’39 In the case of the present study,the goal is not to rescue a complete corpus of all published songs in the historyof Dutch song culture from the slaughterhouse. First of all, a large part of thelegacy of Dutch song culture is already ‘rescued’, and furthermore, the factthat there have been songs which we do not know (yet) and are therefore notincluded in our corpus, does not nullify the validation to research the corpusthat is at hand. As Underwood states, the availability of the corpus givesthe opportunity to research and understand how songs from different periodsrelate to each other.
The last has been done not only by Underwood, but also by Piper, Mat-thew Jockers and many more literary scholars. Crucial to this kind of researchis the digital availability of big corpora containing thousands of novels, newsarticles, songs, et cetera. The Dutch Song Database is just a tiny exampleof the process of digitization that has taken place since the last decades ofthe previous century.40
2.2 Debate
Two decades after postulating ‘distant reading’, the polemics that originallyaccompanied the term have been replaced by a broader debate on the im-
35. Ted Underwood, Distant Horizons: Digital Evidence and Literary Change (Chicago:The University of Chicago Press, 2019), xx.
36. Franco Moretti, Distant reading (London: Verso, 2013).37. Jonathan Arac, ‘Anglo-Globalism?’, New Left Review 16 (1 July 2002): 35–45.38. Rachel Serlen, ‘The Distant Future? Reading Franco Moretti’, Literature Compass
7, no. 3 (2010): 214–225.39. Underwood, Distant Horizons, xx.40. For example, Google Books contains over 25 million books nowadays. For compar-
ison: the Short Title Catalogue Netherlands (STCN) contains metadata of 210.000 Dutchtexts, published between 1540 and 1800.

16 CHAPTER 2. DIGITAL HUMANITIES
portance and relevance of the field of computational literary studies withinthe digital humanities. The most recent contribution to this discussion isthe essay ‘The Computational Case against Computational Literary Studies’by literary scholar Nan Z. Da. Her critique on the field of computationalliterary studies is divergent from other well-known comments, such as theclaim that computational literary studies try to eliminate all close readingfrom literary studies,41 that distant reading is neoliberalism pur sang,42 orthat numbers are reducing reading to visualization.43 Instead, Da states thatthere is a ‘fundamental mismatch between the statistical tools that are usedand the objects to which they are applied’.44 By rerunning several promin-ent studies, Da points at weaknesses in either their methodology, analysis orinterpretation of results.
According to Da, all things that appear in computational literary studies‘– network analysis, digital mapping, linear and nonlinear regressions, topicmodeling, topology, entropy – are just fancier ways of talking about wordfrequency changes’.45 She notes that computational literary criticism placesitself in a position of making claims based purely on word frequencies withoutregard to position, syntax, context, and semantics. In such way, it is prone tofallacious overclaims or misinterpretations of statistical results.46 This relatesto the important distinction between the processing and visualization of dataon the one hand and the interpretations and readings in their own right onthe other hand, a difference which is often not made. To believe that theseare the same thing is, according to Da,
to mistake basic data work that may or may not lead up to a goodinterpretation and the interpretive choices that must be made inany data work (or have no data work at all) for literary interpret-ation itself.47
In computational literary studies, word frequencies are asked to stand in for
41. Joseph North, Literary Criticism (Harvard University Press, 8 May 2017), 109.42. Daniel Allington, Sarah Brouillette and David Golumbia, ‘Neoliberal Tools (and
Archives): A Political History of Digital Humanities’, accessed 1 May 2019, https://lareviewofbooks.org/article/neoliberal-tools-archives-political-history-
digital-humanities/.43. Ted Underwood, ‘It Looks like You’re Writing an Argument against Data in Literary
Study . . . ’, 21 September 2017, accessed 1 May 2019, https://tedunderwood.com/2017/09/21/it-looks-like-youre-writing-an-argument-against-data-in-literary-
study/.44. Nan Z. Da, ‘The Computational Case against Computational Literary Studies’, Crit-
ical Inquiry 45, no. 3 (March 2019): 601.45. Ibid., 607.46. Ibid., 611.47. Ibid., 606.

2.2. DEBATE 17
vastly different things, Da states. To define changes in word frequency aschange itself is both tautological and risky.48 However, in his reaction onDa’s article (a post titled ‘Dear Humanists: Fear Not the Digital Revolution’in The Chronicle of Higher Education), Underwood shows that recent pub-lications go far beyond graphing the frequencies of words: ‘Sociologists havetheorized the function of ambiguity in literary criticism; cognitive scientistshave used information theory to describe historical change; the economistThomas Piketty [has been] reinterpreting the last two centuries of historywith illustrations drawn from Balzac.’49 The above mentioned publicationsare the result of interdisciplinary teams with an interest in the humanit-ies. Yet, the soothing title of Underwood’s piece suggests that humanistsshould not be afraid the questions that historians and literary critics usedto debate are completely scooped up by quantitative disciplines: there is anequal number of projects entirely led by humanists in the fields of digitalhumanities. And again, these projects are not merely about word frequen-cies. Underwood mentions a comparative study of Laura McGrath on titlesused in publishing, in which she suggests that non-white writers are system-atically pressured to compare themselves to white models. Another examplementioned is a study of Eve Kraicer and Andrew Piper, who studied millionsof interactions between characters to show that contemporary fiction is stillshaped by heteronormative patterns.50
Da’s argument that all computational literary studies do nothing morethan making claims based on word frequencies, therefore seems rather blunt.However, it would be unwise and incorrect to put away Da’s critiques asirrelevant nonsense. Computational methods in literary studies are in factlaborious. Many improvements have to be made. Researchers need to re-main or become critical on their methods. At the same time, humanitiesscholars should not be afraid to embrace quantitative methods in their re-search, because it will never replace the traditional methods, only add anew perspective. In that light I see this thesis: it introduces a very prom-ising discipline, but at the same time it shows how complex computationalmethods can be, especially when applied to a corpus of historical texts. Daconcludes with the bold statement that using computation in literary studies‘takes nearly as much, if not far more, time and arbitrariness (and with muchhigher chance of meaninglessness and error) than actually reading them’.51
I dare to state that reading 43,772 songs in historical Dutch will take much
48. Ibid., 614.49. Ted Underwood, ‘Dear Humanists: Fear Not the Digital Revolution’, The Chronicle
of Higher Education, 27 March 2019.50. Ibid.51. Da, ‘The Computational Case against Computational Literary Studies’, 638.

18 CHAPTER 2. DIGITAL HUMANITIES
more time and will provide fewer insights than taking a risk and actuallyfinding out which role computational methods can play in order to get a gripon Dutch historical song culture and the dynamics within it.
2.3 Extracting themes from a corpus
To get an impression of the themes that were dominant in early modernDutch songs, I could investigate which words are most frequently mentionedin the corpus. Imagine that, over all, the word ‘liefde’ [love] has the highestnumber of appearances in the corpus. It is hard to make sense of that result:are these songs on a ‘love’ towards another human being (a man, a woman,a mother, a son)? Or are they about ‘love’ in a religious context, the lovetowards God? Or should we read it in a more political way and does ‘love’refer to a country, maybe a political leader? Clearly, just the appearance ofa word is not enough to say something about topics of frequent occurrencein a corpus, since it does not take into account the multiple meanings a wordcan have. The meaning of a word can be found in the context, hence animprovement would be to look at the collocates: which words precede andfollow the word ‘love’? The problem with collocates is that their interpretat-ive value is limited: the meaning of a word might become clear when takingthe three preceding and three following words into account, but it does nothave to be that obvious. Moreover, themes are not based on the meaningof one frequently mentioned word and its collocates, but they are formed ofa collection of words. Therefore, word-to-word-collocations do not provideenough information to rise to the level of a theme.52
Topic modeling provides a solution to this. It is a way of extrapolatingbackward from a collection of documents to infer the discourses that couldhave generated them. Assumed is that each document in a collection of docu-ments is constructed from a mix of some set of possible topics. A topic can beunderstood as a collection of words that have different probabilities of appear-ance in passages discussing the topic. The model assigns high probabilitiesto words and sets of words that tend to co-occur in multiple contexts acrossthe corpus. Unlike collocates lists, that require careful human interrogationin order to parse out one word meaning from another, topic modeling is anunsupervised method. The model makes a wager that patterns in the dataare sufficiently strong that different latent classes of observations will makethemselves ‘visible’.53 In this context it means that the algorithm does not
52. Matthew L. Jockers, Macroanalysis: Digital Methods and Literary History (Bal-timore: University of Illinois Press, 2013), 122.
53. Folgert Karsdorp, Mike Kestemont and Allen Riddell, Humanities Data Analysis:

2.3. EXTRACTING THEMES FROM A CORPUS 19
know in advance what kind of texts are imported and what themes it has tolook for. The algorithm infers information about individual word meaningsbased on their repeated appearance in similar contextual situation. The onlyhuman intervention required in the process, is setting the number of topicsthe algorithm has to discover.54
One of Da’s other arguments against the computational literary studiesis that, when taking word frequency counting as method, position, syntaxand context of the words are not taken into account.55 This argument canbe countered as well, using topic modeling as example. In conventional topicmodels (such as LDA), statistical techniques are employed to identify theunderlying topic distribution, based on the high-order word co-occurencepatterns. In that sense, position and syntax are not taken into account.However, these conventional models experience a performance degradationover short texts because of limited word co-occurrence information in shorttexts. As a solution, topic models with word embeddings were introduced.With word embeddings, words are represented as fixed-length vectors or em-beddings. The goal of word embeddings is to capture semantic and syntacticregularities in language from large unsupervised sets of documents. Wordsthat occur in the same context are represented by vectors in close proximityto each other. One example is a study of Chenliang Li et al., who introducethe GPU-DMM model, based on the Dirichlet Multinomial Mixture (DMM)model. This is designed to leverage the general word semantic relatednessknowledge during the topic inference process, to tackle the data sparsity is-sue.56 Li et al. showed, using two real-word short text corpora, that theirGPU-DMM model outperforms existing state-of-the-art alternatives in termsof effectiveness and efficiency.57 Although in the context of their study themodel with auxiliary word embeddings gave better results, it is not proventhat topic models without word embeddings deliver poor and unreliable res-ults. This shows that Da’s statement about topic models not taking contextinto account, is an underestimation of the method.
Manually setting the number of topics the algorithm has to search for,is another majorly criticized part of the method. According to Da, topic
Case Studies with Python (2019), 267.54. Jockers, Macroanalysis: Digital Methods and Literary History, 123-124; Ted Under-
wood, ‘Topic Modeling Made Just Simple Enough.’, 7 April 2012, accessed 30 April 2019,https://tedunderwood.com/2012/04/07/topic- modeling- made- just- simple-
enough/.55. Da, ‘The Computational Case against Computational Literary Studies’, 611.56. Chenliang Li et al., ‘Topic Modeling for Short Texts with Auxiliary Word Embed-
dings’, in Proceedings of the 39th International ACM SIGIR Conference on Research andDevelopment in Information Retrieval - SIGIR ’16 (Pisa, Italy: ACM Press, 2016), 166.
57. Ibid., 173.

20 CHAPTER 2. DIGITAL HUMANITIES
modeling
is extremely sensitive to parametricization, prone to overfitting,and is fairly unstable as an “aboutness” finder for sophisticatedtexts because you need only tweak small details to discover com-pletely different topics.58
Not only non-users are skeptical about the method; professional users havecritically evaluated their methods as well. Jockers confirms that there is noconsensus nor conventional wisdom regarding a perfect number of topics toextract. The parameter determining the number of topics to be harvestedis largely dependent upon and determined by the scope and diversity of thecorpus. He explains that
[s]etting the number of topics too high may result in topics lackingenough contextual markers to provide a clear sense of how thetopic is being expressed in the text; setting the number too lowmay result in topics of such a general nature that they tend tooccur throughout the entire corpus.59
This shows that creating topic models is a precarious business. It needs tobe implemented in a methodology in which is room for critical evaluation.In Chapter 7, I will explain how I will apply the topic modeling method in afruitful way that allows me to critically evaluate it at the same time.
58. Da, ‘The Computational Case against Computational Literary Studies’, 625.59. Jockers, Macroanalysis: Digital Methods and Literary History, 128.

Chapter 3
Cultural evolution
To analyze the dynamical changes in the most dominant topics in early mod-ern songs, I draw inspiration from the field of cultural evolution. In thischapter I will first explain how this field originates from Darwin’s theory ofbiological evolution. I continue by investigating if and how the three pre-conditions of evolution can be applied to culture. This chapter closes witha section on biases and patterns that can be observed in human copyingbehavior.
3.1 From biological to cultural evolution
Before I will explain in more detail what cultural evolution comprises, weneed to go 160 years back in time, to the moment in 1859 in which TheOrigin of Species of Charles Darwin saw the light of day. For the first time,‘somebody had set out (...) a tenable scientific explanation for two phenom-ena that had predominantly been attributed to supernatural, mystical, orreligious forces’, as Alex Mesoudi puts it.60 The two phenomena he is refer-ring to, are (i) the diversity of biological organisms and (ii) the complexityof their adaptations. Darwin argued that these could be explained by threesimple principles: variation, competition and inheritance.61 The consequenceis natural selection, according to Darwin: the characteristics that increasethe chance of an individual to survive and reproduce, are more likely to beinherited by the next generation. In the end, such characteristics will in-crease in frequency within a population.62 Although Darwin himself alreadydrew parallels between biological evolution and cultural change, more spe-
60. Mesoudi, Cultural evolution, vii.61. Charles Darwin, The Origin of Species (New York: Gramercy Books, 1979).62. Mesoudi, Cultural evolution, viii.
21

22 CHAPTER 3. CULTURAL EVOLUTION
cific the change of language, it is only since a few decades that researchersin the social sciences and humanities have showed that the principles thatDarwin applied to biological change a century and a half ago, can also beapplied to culture. However, this does not mean that scholars such as histor-ians, literary researchers and linguists have not investigated and describedlarge-scale patterns of cultural change before. What is new though, is the useof rigorous, quantitative methods that are originally designed for explainingpatterns and trends in biological evolution.
To understand in more detail how cultural evolution works, let me firstdefine culture. I borrow Mesoudi’s definition, postulated in his book Cul-tural Evolution. How Darwinian Theory Can Explain Human Culture andSynthesize the Social Sciences :
[C]ulture is information that is acquired from other individualsvia social transmission mechanisms such as imitation, teaching,or language.63
This definition ties in with what Edward Burnett Tylor defined as culture in1871, namely ‘that complex whole which includes knowledge, belief, art, law,morals, custom, and any other capabilities and habits acquired by man as amember of society’,64 with the important difference that Mesoudi does notrestrict culture to the male half of species. His broad definition of culture alsoincludes literature, music, and art and therefore as well the subject of thisresearch: songs. In this definition, culture is defined as information ratherthan behavior, but that does not mean that ‘culturally acquired informationdoes not affect behavior.’65 This distinction is important to emphasize, be-cause if behavior is the thing we are trying to explain, then including it inthe definition of culture makes cultural explanations for behavior circular: athing cannot explain itself. Furthermore, there are other causes of behaviorbesides culture.66
Mesoudi signals problems with the way culture is studied in the last dec-ades. He quotes evolutionary psychologists John Tooby and Leda Cosmideswho have lamented that, during the second part of the twentieth century,every aspect of human behavior was explained in terms of some mysteriousforce called ‘culture’. Mesoudi considers this complaint a just one: in hisopinion, ‘social scientists studying cultural phenomena have been (...) un-able to specify in precise terms exactly how culture operates beyond some
63. Mesoudi, Cultural evolution, 2-3.64. Edward B. Tylor, Primitive culture (London: J. Murray, 1871).65. Mesoudi, Cultural evolution, 3.66. Ibid., 4.

3.2. VARIATION, COMPETITION AND INHERITANCE 23
vague and informal notion of “socialization” or “social influence”.’67 Thereis not only a lack of quantitative, formal methods and scientific hypothesistesting, but culture is also treated as static rather than dynamic, and thereis a general lack of communication of findings and methods across differentbranches of the social sciences. This is where the theory of cultural evolutioncomes in: it can provide solutions to the problems mentioned above. First,it fully recognizes the role of culture in explanations of human behavior.Furthermore, it provides formal, quantitative methods that can be used toexplain cultural phenomena in a way that explicitly incorporates change overtime.68
3.2 Variation, competition and inheritance
Although biologists have, since the publication of The Origin of Species, es-tablished that Darwin’s theory about biological change is correct, the historyof the concept of cultural evolution is still controversial. Darwin’s idea wasthat, if the three basic preconditions – variation, competition and inheritance– of natural selection can be demonstrated, evolution happens. At the sametime, if the three preconditions can not be demonstrated, evolution does nothappen. To verify if cultural evolution is a valid approach, the question istherefore if the three Darwinian preconditions can be applied to culture.
The first precondition Darwin distinguishes, is variation between indi-viduals of several species, in his case mostly pigeons. Applied to culture,one can say that people vary in their religious beliefs, political views, skills,hobby’s and so on. These variations in mental aspects of culture, results invariation in tools. The next step is to see if we can give documented examplesof this variation and verify if we can quantify it. Mesoudi illustrates this withthe example of historian Henry Petroski, who documented variation in forksfounded in the late 1800s. All sorts of forks he found varied in the numberof tines, the dimensions, the shape of the tines, the material used, and soon.69 Applied to the subject of this thesis, one can say that songs also showvariation. Genres as love songs and religious songs can be distinguished, andwithin a genre there is often a further variation: we can list love songs thatfocus on physical attraction, on love as a gift from God, on the impossiblelove, and so on. Since we have a database of these songs, this variation canbe quantified. It is therefore reasonable to conclude, following Mesoudi, thatvariation is present in human culture, and that this variation can be docu-
67. Ibid., 18.68. Ibid., 22-23.69. Ibid., 28.

24 CHAPTER 3. CULTURAL EVOLUTION
mented and quantified. We can state that the first of Darwin’s preconditionsis present in culture.70
Thinking of competition, the second precondition of Darwinian evolution,one might think of a situation in which two individuals are fighting andthe biggest or strongest or smartest individual wins. Competition can beindeed physical, but it does not have to be that direct. An example ofindirect competition can be two plants of which one is more able to dealwith dry conditions than the other, and therefore has a higher chance tosurvive in a dry season than the other.71 It is obvious that in culture somesort of competition is present as well. Darwin already gave an example ofcompetition in language himself:
A struggle for life is constantly going on amongst the words andgrammatical forms in each language. The better, the shorter, theeasier forms are constantly gaining the upper hand.72
Turning again to the subject of this research, this ‘struggle for life’ can alsobe adapted to songs. Taking two songs of which one turns out to be the hit ofa decade, while the other is forgotten after a couple of weeks, they function asexamples of competition as well. The former is replacing the latter, as a resultof competition between the two songs. My previous research,73 in which weconcluded that songs with more repeated words have a longer lifespan, canalso be seen in this light of Darwinian competition. We can conclude withMesoudi that cultural traits, like biological organisms, take part in an endlessstruggle for existence.74
The third and final precondition for evolution that Darwin distinguished,is inheritance. In a biological context, this means that individuals that aremore likely to survive and reproduce during the struggle for existence, willoften pass their traits or characteristics to their offspring. We can assumethat these traits are, at least partially, responsible for the parents’ increasedchances of survival and reproduction. The result is that there will be agradual increase in fitness and adaptation to the local environment. There-fore, without inheritance beneficial traits are not preserved, and evolutioncannot occur.75 The question is whether cultural information can be suc-cessfully reproduced, or transmitted, from one person to another as well.76
70. Mesoudi, Cultural evolution, 29.71. Ibid., 30.72. Charles Darwin, The Descent of Man (London: Gibson Square, 2003), 91.73. Lassche, Karsdorp and Stronks, ‘Repetition and Popularity in Early Modern Songs’.74. Mesoudi, Cultural evolution, 31.75. Ibid., 32.76. Ibid.

3.3. TRANSMISSION BIASES AND TURNOVER SERIES 25
Cross-cultural studies have shown that people acquire beliefs, attitudes, skillsand knowledge from other people via cultural transmission. On a smallerscale, cultural transmission can also take place from one person to another.The transmission from adult to child is the most common example. How-ever, there is more to say about inheritance. Darwin also was convincedthat ‘for biological evolution to work, minor modifications must not merelybe inherited from parent to offspring in a one-to-one fashion, inheritancemust be faithful enough such that potentially combined with other beneficialtraits.’77 Mesoudi explains that, in culture, we can see this gradual accu-mulation of modifications as well. He illustrates this with the example ofsuccessful innovations, such as the steam engine, which rarely, if ever, springout of nothing. Rather than suddenly emerging fully formed from a genius’mind, innovations are often a modified version of a preexisting artifact.78 Thesame can be said about a specific song, of which the words or melody can beslightly modified through time.
Now that we have seen that human culture also exhibits the last of Dar-win’s three preconditions for evolution, one can conclude that Darwinianevolution is a valid approach to investigate and understand culture. How-ever, cultural evolution does not take place in a purely random way, but thereare cognitive mechanisms that guide the evolution. In the next paragraphI will elaborate on the fact that humans use transmission biases to choosewhen, what or from whom, to copy.
3.3 Transmission biases and turnover series
Drawing the parallel between biological evolution and cultural evolution evenfurther, ‘natural selection’ becomes ‘cultural selection’. Mesoudi defines thisas the process that occurs when ‘one cultural trait is more likely to be ac-quired than an alternative trait.’79 Several kinds of learning biases that facil-itate this selection of useful traits can be distinguished. Different terms havebeen assigned to these biases, but in general two learning mechanisms are de-termined: content-based biases and context-based biases.80 The context-basedbiases can be further split up into model-based biases and frequency-dependent
77. Ibid., 33.78. Ibid.79. Ibid., 56.80. Mesoudi, Cultural evolution, 56; Joseph Henrich and Richard McElreath, ‘The Evolu-
tion of Cultural Evolution’, Evolutionary Anthropology: Issues, News, and Reviews 12, no.3 (2003): 129; Robert Boyd and Peter J. Richerson, Culture and the Evolutionary Process(Chicago: University of Chicago Press, 1985).

26 CHAPTER 3. CULTURAL EVOLUTION
biases, as Mesoudi calls them.81 Furthermore, according to Alberto Acerbiand Alexander R. Bentley, the frequency-dependent bias can either be a con-formity bias or an anti-conformity bias.82 Content-based biases affect thelikelihood of a particular cultural trait being transmitted because of the in-trinsic attractiveness of this trait. In other words: the inherent features of atrait determine the choice for it.83 For example, Acerbi and Bentley mentiona study of Olivier Morin who explained the success of direct-gaze portraitsover indirect-gaze ones with a content-based bias, namely that a direct eye-gaze is more cognitive appealing.84 The higher reprint probability of earlymodern Dutch songs with lower entropy values (i.e. more repetition in theirlyrics) can also be explained as a content-based bias.85
A context-based bias arises from the context of a cultural trait. Thechoice is not directly determined by the features of the traits, but by ex-ternal determinants. Context-based biases are often subdivided in model-based biases and frequency-dependent biases. A model-based bias occurswhen people preferentially adopt certain cultural traits on the basis of thecharacteristics of the model exhibiting them. Examples can be a prestige-based bias (when people prefer to copy prestigious models who have highsocial status) or a similarity-based bias (when people prefer to copy modelswho are similar to them in dress, beliefs, dialect).86 When engaging in thefrequency-dependent bias, people use the frequency of a treat in a populationas a guide as to whether adopt it, irrespective of its intrinsic characteristics.87
This results in two kinds of frequency-dependent biases. The first is the onewhere popular traits are preferred in respect to the unpopular ones: this isthe conformity bias. The opposite is also possible, where unpopular traitsare preferred in respect to the popular ones. Here transmission is negativelyfrequency-dependent: this is the non-conformity bias.88 A neutral model,
81. Mesoudi, Cultural evolution, 56.82. Alberto Acerbi and R. Alexander Bentley, ‘Biases in Cultural Transmission Shape
the Turnover of Popular Traits’, Evolution and Human Behavior 35, no. 3 (May 2014):229.
83. Mesoudi, Cultural evolution, 65; Henrich and McElreath, ‘The Evolution of CulturalEvolution’, 129.
84. Olivier Morin, ‘How Portraits Turned Their Eyes upon Us: Visual Preferences andDemographic Change in Cultural Evolution’, Evolution and Human Behavior 34, no. 3(1 May 2013): 222–229; as cited in Acerbi and Bentley, ‘Biases in Cultural TransmissionShape the Turnover of Popular Traits’, 228.
85. Lassche, Karsdorp and Stronks, ‘Repetition and Popularity in Early Modern Songs’.86. Mesoudi, Cultural evolution, 73; Henrich and McElreath, ‘The Evolution of Cultural
Evolution’, 129.87. Mesoudi, Cultural evolution, 71.88. Acerbi and Bentley, ‘Biases in Cultural Transmission Shape the Turnover of Popular
Traits’, 229.

3.3. TRANSMISSION BIASES AND TURNOVER SERIES 27
which assumes that copying is completely random and unbiased, would pro-duce characteristic right-bended distributions, where very few traits are verypopular, and the vast majority of traits remain rare. Adding a conform-ity bias to the neutral model results in a distribution which is even morebended than the one produced by a neutral model, since popular traits areproportionally more advantaged. The anti-conformity bias produces insteaddistributions where the majority of traits result at intermediate frequencies.89
Which biases are at stake in the cultural evolution of historical songs?To detect the transmission biases in the cultural evolution of early modernsong topics, I will study the ‘turnover series’ of these topics, in order toquantitatively map cultural changes in it. The turnover can be defined asthe number of new traits that enter a top-list of a certain size for a certaincultural domain. Popular examples of turnover calculations are the numberof new entries in hit charts, but it is possible to calculate turnovers for anycultural domain. Acerbi and Bentley showed that the turnover of recent babynames in the United States produces a ‘concave’ turnover profile (decreasingslope), signalling that people tend to prefer relatively uncommon names andthus that there is an anti-conformist bias. This contrasts with the case ofearly boys names, where a ‘convex’ turnover profile (increasing slope) canbe distinguished.90 Other examples are studies on the frequency of potterydesigns, word usage or bird song elements.91 In Chapter 6, I will furtherexplain how I am going to use and calculate turnover series in the context ofthis study.
89. Ibid.90. Ibid.91. R. Alexander Bentley, Matthew W. Hahn and Stephen J. Shennan, ‘Random Drift
and Culture Change’, Proceedings of the Royal Society of London. Series B: Biological Sci-ences 271, no. 1547 (22 July 2004): 1443–1450; R. Alexander Bentley, ‘Random Drift versusSelection in Academic Vocabulary: An Evolutionary Analysis of Published Keywords’,PLOS ONE 3, no. 8 (27-aug-2008): e3057; Bruce E. Byers, Kara L. Belinsky and R. Alex-ander Bentley, ‘Independent Cultural Evolution of Two Song Traditions in the Chestnut-Sided Warbler.’, The American Naturalist 176, no. 4 (1 October 2010): 476–489; as citedin Acerbi and Bentley, ‘Biases in Cultural Transmission Shape the Turnover of PopularTraits’, 229.

28 CHAPTER 3. CULTURAL EVOLUTION

Part II
Methodology
29


Chapter 4
Corpus
In this study, I use a sample of songs from the Dutch Song Database. TheDSD contains metadata of approximately 175,000 songs in the Dutch lan-guage, from the Middle Ages up to the twentieth century. It contains lovesongs, satirical songs, psalms and other religious songs, folksongs, children’ssongs, St Nicholas songs and Christmas songs, and so on and so forth. Forevery song the source where the text and/or the melody can be found is in-dicated. Other metadata that are available for the songs, are (if known) theauthor, first line, number of stanzas, genre, melody name, stanza form andnumber of verses. In 2014, the results of the project Dutch Songs On Line,which was a cooperation between the DSD and the Digital Library of DutchLiterature (DBNL), funded with a grant of NWO Medium Investments, be-came available. In this project, 53,351 full song texts were made accessibleonline. An additional result of this project are 29,590 songs (a sample ofthe 53,351 songs) whose lyrics and metadata have all been encoded withTEI compliant XML, which provides publication date, geographical loca-tion, melody, classification category and the actual lyrics of a song. Thissample is the object of scrutiny of my thesis. The oldest songs in this sampleare written in 1260, the most recent songs are from 1991, but the major partof the sample are songs from the seventeenth and the beginning of the eight-eenth century (see Figure 4.1). I have therefore decided to limit the sample tosongs that were published between 1550 and 1750, leaving me with a corpusof 22,297 songs.
Since the genre of the song was also tagged in the XML-file, I am able tosee how the songs are distributed over the various categories (see Table 4.1).A major part of the songs belong to the genre ‘religion’, followed at a distanceby ‘love and sex’, ‘seasons and annual events’, ‘formal genres’ and ‘amuse-ment’. One might ask why a study on topics in song lyrics is useful, sincewe already have these data on categories, but you can argue with that. This
31

32 CHAPTER 4. CORPUS
1300 1400 1500 1600 1700 1800 1900 2000
year
0
250
500
750
1000
1250
1500
1750
2000
Figure 4.1: Distribution of the songs by year (1260-1991) in the sample (n= 29,590)
categorical division not only seems a bit arbitrary (when does a song belongto ‘work’? What is a ‘formal genre’? What are the differences betweensongs on ‘seasons and annual events’ and songs on ‘occasions’?), there arealso more than 9000 songs that have not been assigned to a category. Thesedata thus does not give reliable information about the distribution of songsover different genres. Besides that, the wide-ranging categories don’t revealhow subdivisions within a category are distributed. Are all religious songs onthe same aspects of religion? Does ‘love and sex’ mean that some songs areon love, and others on sex? Which words are used to describe the one or theother? In summary, there is an important difference between a genre and atopic, since a genre can comprise many different topics. Topic modeling cangive answers to the above questions.
However, the corpus in its current state is not complete yet. It doesnot include the reprints and appearances of these songs in other songbooks.Since I want to examine which song topics were more prevalent than others,it is necessary to include these data as well. Although the number of lyricswill remain the same, the distribution of the songs can change. Imagine forexample that songs on politics and history, which are not very prominent in
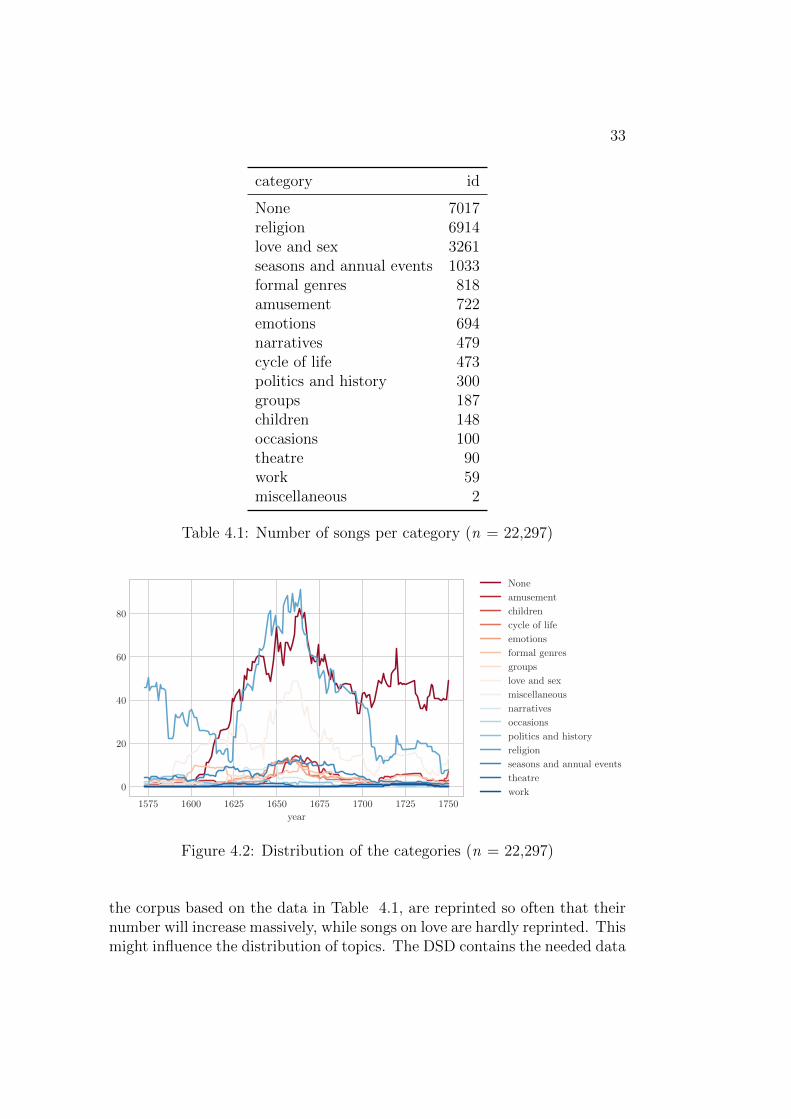
33
category id
None 7017religion 6914love and sex 3261seasons and annual events 1033formal genres 818amusement 722emotions 694narratives 479cycle of life 473politics and history 300groups 187children 148occasions 100theatre 90work 59miscellaneous 2
Table 4.1: Number of songs per category (n = 22,297)
1575 1600 1625 1650 1675 1700 1725 1750
year
0
20
40
60
80
None
amusement
children
cycle of life
emotions
formal genres
groups
love and sex
miscellaneous
narratives
occasions
politics and history
religion
seasons and annual events
theatre
work
Figure 4.2: Distribution of the categories (n = 22,297)
the corpus based on the data in Table 4.1, are reprinted so often that theirnumber will increase massively, while songs on love are hardly reprinted. Thismight influence the distribution of topics. The DSD contains the needed data

34 CHAPTER 4. CORPUS
for this extension of the corpus, but in order to extract them, it is importto understand the terminology that is used in the database. Each first printof a song has a recordid, which is the id that is mentioned in the XML-fileof a song. A reprint of a song does not contain a recordid, but a herdrukidinstead. Furthermore, each unique song has an incnormid. This means thata couple of songs with different recordid ’s and herdrukid ’s share the sameincnormid. I added songs to my corpus with the same incnormid and/orrecordid as the ones already in the corpus, resulting in a corpus of 43,772songs. Their distribution over time is visualized in Figure 4.3. The next stepis to make the lyrics of these songs ready for building topics from it.
1550 1575 1600 1625 1650 1675 1700 1725 1750
year
0
200
400
600
800
1000
1200
1400
Figure 4.3: Distribution of the songs by year (1550-1750) in the sample (n= 43,772)

Chapter 5
Spelling normalization
In the sixteenth and seventeenth century, Dutch authors and printers didn’thighly value the consistency of word spellings. This resulted in many differentspelling variants of the same word coexisting. Because a topic modelingmethod only looks at the position of words and how they are distributedthrough the corpus, it sees different spellings of the same word as differentwords. For instance, ‘Jezus’, ‘Jesu’ and ‘Iesus’ are regarded as differentwords, as well as ‘bloed’ and ‘bloet’. It is easy to understand that thisbiases the results of the topic modeling process. Therefore normalizationof spelling is a crucial step that needs to be taken. Regarding the Englishlanguage, quite some tools are available for converting historical texts to astandard spelling. For the Dutch language, options are limited, especiallymethods that are straightforward method and do not cost too much time.The tools that are available, come with both advantages and disadvantages.I have chosen to use two different methods to normalize the spelling of mycorpus. After normalization with these two methods, I will perform topicmodeling on the two different normalized versions of my corpus, as well onthe unnormalized version of my corpus, e.g. the original texts. Hopefully theresults of topic modeling will give more insight which version of the corpus isthe most productive to work with. Below I discuss the two tools that I willuse for spelling normalization. To illustrate the performance of both tools, Iwill show the normalized spelling versions of one particular song lyric92 lateron. Here I show the original version of this song:
Daar de gulde zon en maanEn de mindre hemelvieren,Die het stargewelf vercieren,Gods geboden gadeslaan:
92. id = 186989.
35

36 CHAPTER 5. SPELLING NORMALIZATION
Daar de felle noordewindenIn het bruissend elementOp die stem zig laten binden:Wie roept dat hy God niet kent?
’T aards gezinde en dwaze rotOp het vroom geslagt verbolgenEn geneigt zijn lust te volgen,Durft zig uiten, daar ’s geen God.Welkers oordeel sta te vreezenAls het lighaam zinkt in ’t graf.Want de ziel verliest haar wezen,Als wy leggen ’t leven af.
Aartsverraders schrikt, ziet toeGods gedult, en hand te tergen.Voor zijn oog is geen verbergen.Vreest, vreest ’s Hemels strenge roe!Eenmaal zal de dag genaken.(Is zijn wrake traag in ’t gaan)Die u zal te schande maken,En door blixemvuur verslaan.
5.1 INL
The first method I have used to modernize spelling is a tool built by MarijnSchraagen and Martijn van der Klis. The modernization is performed byquerying all words in the corpus using the INT Lexicon Service93 and re-placing the words with the lemma resulting from the query. An importantnote is that the tool cannot be trained: the first result of the query in theLexicon Service is always chosen as output, and this can not be manipu-lated. This means that it’s hard to correct the mistakes that are made bythe tool. In addition, all verbal words are normalized to the infinitive, whichmeans that the difference between past and present forms disappears. Afternormalization with INL, the song mentioned above looks like this:
Daar de gild zon en maanEn de minder hemelvieren
93. http://sk.taalbanknederlands.inl.nl/LexiconService/.

5.1. INL 37
Die het stergewelf versierenGods geboden gadeslaan :Daar de fel noordewindenIn het bruissend elementOp die stem zek laten binden :Wie roepen dat hei God niet ken ?
’T aards gezinde en dwaas rotOp het vroom geslacht verbolgenEn neigen zijn lust te volgenDurft zek uiten daar de geen GodWelkers oordeel staan te vreesAls het lichaam zinken in ’t grafWant de ziel verliezen haar wezenAls wi leggen ’t leven af
Aartsverraders schrikken zeer toeGods geduld en hand te tergenVoor zijn oog is geen verbergenVreest vrezen de Hemels streng roede !Eenmaal zullen de dag genaken( Is zijn wraak traag in ’t gaan )Die u zullen te schande makenEn door blixemvuur verslaan
Although this song’s lyrics were already quite easy to read, the tool haschanged some words to a modern form (‘vercieren’ becomes ‘versieren’, ‘geslagt’becomes ‘geslacht’). It also made several mistakes. In the first line, ‘gulde’is normalized to ‘gild’, but that should have been ‘gulden’ or ‘gouden’. Theword ‘zig’ is normalized to ‘zek’, which is not even a word. Other mistakesinclude the changing of ‘hy’ into ‘hei’, and ‘’s’ into ‘de’. Furthermore, thisexample shows that verbal forms are changed into the infinitive: ‘verliest’becomes ‘verliezen’, ‘zal’ becomes ‘zullen’. Strange is that ‘Vreest, vreest’is normalized to ‘Vreest vrezen’ instead of ‘vrezen vrezen’. That might becaused by the capital ‘V’. Figure 5.1 shows the reduction of unique wordsafter normalizing the original corpus with the INL tool – this number hasonly decreased with 1% (1,832 unique words).

38 CHAPTER 5. SPELLING NORMALIZATION
Original INL VARD2150000
155000
160000
165000
170000
175000
180000
Wor
dty
pes
Figure 5.1: Effect of normalization on number of word types
5.2 VARD2
A more reliable tool seems the semi-automatic tool VARiant Detector (VARD),in 2005 introduced by Alistair Baron and Paul Rayson. The tool uses twolists (a normalized word list and a variant list) to suggest or replace vari-ant words with their normalized counterparts. VARD (i) reads a given text,(ii) distinguishes variants within the text, (iii) chooses the most appropriatenormalized form for each variant found and (iv) matches the variant withthe normalized form.94 This first version of the tool used a manually createdlist of variants to modern equivalent mappings in order to search for andreplace any spelling variants found within a text. However, it was impossibleto include all possible spelling variants in a pre-defined list and therefore thetool was not of use when dealing with spelling variations in other languagesthan Early Modern English. Therefore, a more recent version of the tool,VARD2, was developed with a more flexible approach which allows the toolto deal with a much larger variety of spelling variants. The normalizationsuggestions are given, based on a combination of four different methods: (i)
94. Dawn Archer et al., ‘Guidelines for Normalising Early Modern English Corpora:Decisions and Justifications’ (2015).

5.2. VARD2 39
known variant replacements, (ii) character edit distance, (iii) letter rules and(iv) phonetic distance.95
In this thesis I use a setup of VARD2 that is trained to perform spellingnormalization on Dutch historical texts. It was built by Ivan Kisjes and TessaWijckmans, as a result of a collaboration between the CREATE-project ofthe University of Amsterdam and the Dutch digital research platform Neder-lab. Kisjes and Wijckmans presented the setup in a paper titled ‘Adaptinga Spelling Normalization Tool Designed for English to 17th Century Dutch’during the Digital Humanities Conference in Mexico City in 2018.96 Kisjesand Wijckmans created a Dutch configuration of VARD2, using the modi-fiable parts of VARD2: the letter rules, the variant list and the normalizedword list. As a training set they used the 1657 edition of the Dutch trans-lation of the Bible. There were two important reasons for this choice: first,there was a modern translation of the bible available that stuck rather closelyto the original word order, and second, since there was another edition ofthe bible printed in 1637 available, it would be possible to easily find morespelling variants for the words they had manually respelled or checked in the1637 edition.
In the VARD2 tool it is possible to manually process a single text aswell as to process a big corpus of texts. Words of texts are placed eithermanually or automatically into one of the following three categories: vari-ants, non variants and normalized words. VARD2 adds words to the variantcategory when they are not found in its real word list. Moreover, the user canadd words to this category manually as well. The variant category containsall words which the system considers necessary to normalize. The normal-ized category contains all words which have been normalized by the user orthrough automatic processing. The non variants category contains all wordswhich are in the modern lexicon. Besides the option to processing a singletext, VARD2 also offers the opportunity to process a batch of texts. In thatcase, the manual normalization option is not available, only the automaticnormalization option.
VARD2 will generally find numerous potential normalizations for a givenvariant. Each of these suggestions is given a confidence score. In the case ofautomatic processing, the suggested normalization with the highest confid-ence score is used to replace each variant. However, if the system’s normal-ization methods ‘struggle’ with a particular variant, the highest confidencescore may be relatively low – in these cases a threshold is required, which is
95. Alistair Baron and Paul Rayson, ‘VARD 2: A Tool for Dealing with Spelling Variationin Historical Corpora’.
96. Ivan Kisjes and Tessa Wijckmans, ‘Adapting a Spelling Normalization Tool Designedfor English to 17th Century Dutch’ (Mexico City, 2018).

40 CHAPTER 5. SPELLING NORMALIZATION
Threshold (%) Variants Variants (%) Normalized Normalized (%)
30 122 12.18 345 34.4340 122 12.18 345 34.4350 123 12.28 344 34.3360 144 14.37 323 32.2470 152 15.17 315 31.4480 219 21.86 248 24.7590 263 26.25 204 20.36
Table 5.1: VARD2-results at different thresholds (id = 11218, number oftokens = 467, number of non variants = 535)
the minimum confidence score needed for a normalization to take place. Ifthe threshold is not met by the top normalization suggestion, the word is leftas a variant. To get a feel for a suitable threshold for my corpus, I used asingle text of my corpus and checked which number of words were normalizedat different thresholds. A higher threshold will increase precision (less vari-ants will be normalized) but reduce recall. In Table 5.1 the results are shownfor different thresholds when processing one particular song (id = 11218).97
These results show that there is hardly any difference between a thresholdof 30% and 50%. The higher the threshold, the less variants are normalized.Since I observed that the tool didn’t perform any wrong normalizations, Idecided to set the threshold rather low, at 50%. The above mentioned songcontains the following lyrics after normalization with VARD2:
Daar de gulde zon en maanEn de mindre hemelvieren,Die het stargewelf versieren,Gods geboden gadeslaan:Daar de felle noordewindenIn het bruissend elementOp die stem zig laten binden:Wie roept dat hij God niet kent?
Het aards gezinde en dwaze rotOp het vroom geslagt verbolgenEn geneigd zijn lust te volgen,Durft zig uiten, daar des geen God.
97. I chose this song because it has a high number of word types.

5.2. VARD2 41
Welkers oordeel sta te vrezenAls het lighaam zinkt in het graf.Want de ziel verliest haar wezen,Als wij leggen het leven af.
Aartsverraders schrikt, ziet toeGods geduld, en hand te tergen.Voor zijn oog is geen verbergen.Vreest, vreest des Hemels strenge roe!Eenmaal zal de dag genaken.(Is zijn wrake traag in het gaan)Die u zal te schande maken,En door blixemvuur verslaan.
Most of the wrong normalizations that the INL tool performed, are not madeby the VARD2 tool: ‘gulde’ and ‘zig’ stay the same, as well as the verbalforms. The words ‘vercieren’ and ‘hy’ are correctly changed into ‘versieren’and ‘hij’. Besides that, the VARD2-tool replaces ‘’t’ with ‘het’. Althoughin this example less words are substituted with the VARD2- tool, Figure 5.1shows that, after normalization with VARD2, the number of unique wordsin the corpus was reduced with 17,692, which is 10% of the total numberof unique words. This suggests that the VARD2 tool obtains better resultsthan the INL tool, but the topic modeling results should give more insightin this case.

42 CHAPTER 5. SPELLING NORMALIZATION

Chapter 6
Topic models and turnovers
6.1 LDA
To perform topic modeling, I use the Python package gensim, which con-tains models.wrappers.ldamallet, a wrapper for Latent Dirichlet Alloca-tion (LDA) from MALLET, a Java topic modeling toolkit. The module usesan optimized version of collapsed Gibbs sampling from MALLET. MALLET(Machine Learning for Language Toolkit) is a package for several machinelearning applications to text, such as statistical natural language processing,document classification and clustering. LDA is the most commonly usedtopic modeling method. ‘Latent’ refers to the concept of latent distribu-tions in the model, and ‘Dirichlet’ is the name of the most common usedprior distribution, named after the German mathematician Johann Dirich-let (1805-1859). It consists of a nested multilevel structure, in which thefollowing three levels need to be distinguished:98
• A word is an item from a vocabulary indexed by {1, ..., V }. Words arerepresented using unit-basis vectors that have a single component equalto one and all other components equal to zero. Thus, using superscriptsto denote components, the vth word in the vocabulary is representedby a V -vector w such that wv = 1 and wu = 0 for u 6= v.
• A document is a sequence of N words denoted by d = (w1, w2, ..., wN),where wn is the nth word in the sequence.
• A corpus is a collection of M documents denoted byD = {d1, d2, ..., dM}.
98. David M Blei, ‘Latent Dirichlet Allocation’:995; David Blei, Lawrence Carin andDavid Dunson, ‘Probabilistic Topic Models’, IEEE Signal Processing Magazine 27, no. 6(1 November 2010): 55–65.
43

44 CHAPTER 6. TOPIC MODELS AND TURNOVERS
Furthermore, a topic φ is a distribution over a fixed vocabulary of V words.The words w of each document d will be associated with a mixture of Kdistributions. K stands for the number of topics you want the model tocreate, and is the only parameter that has to be fixed in advance.99 Theprobability of an individual word is the sum over all topics of the word’sprobability in a topic times the probability of a topic in the current document.The probability of a document is written as follows:100
p (~wd) =
nd∏i
p (wd,i) =
nd∏i
K∑k
θd,k Categorical(wd,i|~φk
)(6.1)
where Categorical(x|~φk
)=∏V
v φx(v)k,v . However, this is just the beginning.
The equation above is a model of the words associated with a single docu-ment, but I need to model all N words in the M documents in my corpusD. In this way I will be able to model the topological homogeneity whichexists across documents. Furthermore, I need to allow each document tohave distinct topic weights, since some documents will feature certain latentdistributions more prominently than others. The following steps need to betaken:
1. For each topic k, sample a probability distribution φk from Dirichlet(η).
2. For each document d :
(a) Sample a document-specific set of topic proportions, θd, from aDirichlet distribution with parameter α.
(b) For each word wd,i in document d :
i. Sample a word-specific latent mixture component, zd,i fromthe document-specific topic proportions θd.
ii. Sample a word from the latent distribution, wd,i ∼ Categorical(ηzd,i).
The probability of the entire corpus is then written as follows:
p (w1:D|θ1:D, φ1:K) =D∏
d=1
p (wd) =D∏
d=1
nd∏i
p (wd,i|θd, φ1:k)
=
nd∏i
K∑k
θd,k Categorical (wd|φk)
(6.2)
99. There are also topic models which infer K from data.100. Karsdorp, Kestemont and Riddell, Humanities Data Analysis: Case Studies withPython, 277.

6.2. CALCULATING TURNOVER SERIES 45
The earlier mentioned three levels in a LDA representation (word, document,corpus) have their own variables. The parameters α and φ are corpus-levelparameters, the variables θd are document-level variables and the variableszd,i and wd,i are word-level variables. The three-level-structure of LDA en-sures that one document can be associated with multiple topics, not withjust one.101 With LDA, a document collection is analyzed by examining theposterior distribution of the latent variables. Posterior inference means thatthe generative process is reversed several times. Conditioned on a corpus,the goal of posterior inference is to find the posterior distribution over al-ternative topical structures that generated its document.102 Posterior modesof the topics φ1:K identify corpus-wide patterns of words; posterior modesof the topic proportions θd identify how the dth document expresses thosepatterns; posterior modes of the topic assignments zd,i identify which topicsthe nth word of the dth document is associated with.103
6.2 Calculating turnover series
For the calculation of turnover profiles in the context of this study, I drawinspiration from a chapter on turnover in Humanities Data Analysis (to bepublished) from Folgert Karsdorp, Mike Kestemont and Alan Riddel. Theystate that turnover ‘can be defined as the number of new names that enter apopularity-ranked list at position n at a particular moment in time t.’104 Tocompute a turnover series, they distinguish the next three steps:
first, we can calculate an annual popularity index, which containsall unique names of a particular year ranked according to their fre-quency of use in descending order. Subsequently, the popularityindexes can be put in chronological order, allowing us to comparethe indexes for each year to the previous year. For each positionin the ranked lists, we count the number of ‘shifts’ in the rankingthat have taken place between two consecutive years. This ‘num-ber of shifts’ is called the turnover. Computing the turnover forall time steps in our collections yields a turnover series.105
This method can be applied to the subject of this research, although some
101. Blei, ‘Latent Dirichlet Allocation’, 997.102. Blei, Carin and Dunson, ‘Probabilistic Topic Models’.103. Ibid.104. Karsdorp, Kestemont and Riddell, Humanities Data Analysis: Case Studies withPython, 126.105. Ibid.

46 CHAPTER 6. TOPIC MODELS AND TURNOVERS
preliminary steps need to be taken. The following procedure needs to becarried out:
1. For each song in the corpus:
(a) Calculate the topic distribution using MALLET.
(b) Connect the year of print of the song to this topic distribution.
2. Calculate an annual popularity index, containing all song topics, rankedaccording to their frequency of appearance in descending order.
3. Put the annual popularity indexes in chronological order, in order tocompare the indexes for each year to the previous year.
4. For each position in the ranked lists, count the number of ‘shifts’ inthe ranking that have taken place between two consecutive years. This‘number of shifts’ is called the turnover.
5. Compute the turnover for all time steps, which yields a turnover series.
In Chapter 8, I will carry out this procedure and see if a certain transmissionbias can be derived from the shape of the turnover plot.

Part III
Analysis and results
47


Chapter 7
Dominant topics
With the three versions of my corpus (original, INL-normalized and VARD2-normalized), I continue my analysis. To build topic models with gensim, Ihave to take a few preliminary steps. In this chapter I will therefore firstexplain how a corpus needs to be prepared in order to perform topic modelingand how I have chosen the optimal settings. Afterwards, I will build the finaltopic models and discuss the results.
7.1 Preparation of data and choosing settings
At first, a corpus needs to be tokenized. This means that each text willbe converted to a list with separate words, and that punctuation will beremoved. Besides that, it is useful to filter ‘stop words’ from the corpus.Stop words are the very common words in a corpus, which are in this casemostly function words such as ik (personal pronoun), de (preposition) anden (conjunction). Content words, which have a more specific meaning, areoften less frequent than function words. I created a list with the 150 mostfrequent words, using the Python package nltk.FreqDist after tokenizationwith nltk.tokenize.word tokenize(language="dutch"). I did this oncefor each version of my corpus. I checked each list manually and removed thefunction words from it (see Table 7.1). The three stop lists can be found inthe appendix. I used the code below:106
import glob
import nltk
from utils import is_punct
106. In this paragraph I show the code and results from the preprocess of the VARD2-normalized corpus. For building topic models from the other corpora, I used the samesettings.
49

50 CHAPTER 7. DOMINANT TOPICS
TOKENIZER = nltk.tokenize.word_tokenize
CORPUS_PATH = "Corpus/VARDnormalized/varded50/*.txt"
STOP_WORDS_PATH = "stoplists/stoplist_VARD2.txt"
STOP_WORDS = [s.lower() for s in open(STOP_WORDS_PATH, "r",
encoding="utf-8").read().splitlines()]
remove_stopwords = lambda x: [word.lower() for word in x if
word.lower() not in STOP_WORDS and not is_punct(word) and
len(word) > 1]
texts = glob.glob(CORPUS_PATH, recursive=False)
tokenized_texts = [TOKENIZER(open(text, "r",
encoding="utf-8").read(), language="dutch") for text in
texts]
tokenized_texts = [remove_stopwords(text) for text in
tokenized_texts]
I added len(word) > 1 to the function remove stopwords to make sure thatno punctuation was left that for some reason was not included in the functionis punct. After tokenization and punctuation removal, the song that wasalso discussed in the previous chapter, looked like this:
["gulde", "zon", "maan", "mindre", "hemelvieren", "stargewelf",
"versieren", "gods", "geboden", "gadeslaan", "felle",
"noordewinden", "bruissend", "element", "stem", "zig", "laten",
"binden", "roept", "god", "kent", "aards", "gezinde", "dwaze",
"rot", "vroom", "geslagt", "verbolgen", "geneigd", "lust",
"volgen", "durft", "zig", "uiten", "god", "welkers", "oordeel",
"sta", "vrezen", "lighaam", "zinkt", "graf", "ziel",
"verliest", "leggen", "leven", "af", "aartsverraders",
"schrikt", "gods", "geduld", "hand", "tergen", "oog",
"verbergen", "vreest", "vreest", "hemels", "strenge", "roe",
"eenmaal", "genaken", "wrake", "traag", "schande",
"maken","blixemvuur", "verslaan"]
The two main inputs to a LDA topic model are dictionary and corpus.A dictionary is a commonly used python data type, containing key: valuepairs. Keys can be any immutable type, with the requirement that keysare unique within one dictionary. The keys of this dictionary are all uniquetokens that exist in tokenized texts. The corresponding values are thenumber of times the words appear in tokenized texts. gensim creates aunique id for each word in a text. With corpus, a corpus is produced from

7.1. PREPARATION OF DATA AND CHOOSING SETTINGS 51
Corpus removed words
Originalgodt, heer, god, hert, leven, liefde, ziel, gods, heere, lief,
min, heeren, godts, recht, mensch, menschen, lust
INLleven, heer, godt, hert, ziel, vreugde, hart, liefde, mens, tijd,gods, heere, kwaad, lief, zondaar, dag, dood, grond, eeuwig,
kracht, wereld, hand
VARD2god, gods, leven, hert, ziel, liefde, tijd, vreugd, here, geest,woord, lief, min, kwaad, zonden, heren, lof, hand, wereld,
mens, mensen, recht
Table 7.1: Removed words from stop lists
dictionary, resulting in a mapping of [word id, word frequency].
gensim gives the opportunity to remove terms from the dictionary thatappear too frequently or too infrequently in the corpus. This can be donewith the functions no below and no above. The input for no above needsto be a number between 0 and 1: if no above = 0.80, terms that appearin more than 80% of the documents are ignored. The input for no below
needs to be an absolute number, corresponding with an actual number ofdocuments: if no below = 20, terms that appear in less than 20 documentsare ignored. The no above function can be seen as a tool to remove ‘corpus-specific stop words’. Since I already created a list with corpus-specific words,using the no above function is unnecessary. I therefore use no above = 1,implying that only tokens are removed that appear in more than 100% of thedocuments, which, in fact, are zero tokens. Deciding what the right settingfor no below is, is a bit of trial and error. I built three dictionaries (withno below = 2, no below = 5 and no below = 10), using the following code:
import gensim
from gensim import corpora
from gensim.corpora import Dictionary
NO_BELOW = 2 #and 5 and 10. minimum document frequency (absolute)
NO_ABOVE = 1 #maximum document frequency (fraction)
dictionary = Dictionary(tokenized_texts)
dictionary.filter_extremes(no_below=NO_BELOW, no_above=NO_ABOVE)
corpus = [dictionary.doc2bow(text) for text in tokenized_texts]

52 CHAPTER 7. DOMINANT TOPICS
no below 10 5 2
Discarded tokens 174,247 160,705 117,045Kept tokens 19,912 33,454 77,114
Table 7.2: Dictionary sizes at different no below’s
Table 7.2 contains the dictionary sizes at different settings for no below. Itturns out that a rather big amount of tokens are discarded in all cases. Atno below = 2, all tokens are removed that appear in only one text. Thisnumber of tokens is already quite high: 117,045. The number of discardedtokens only grows extensively when increasing no below. At no below = 10,only 19,912 tokens remain. This seems a really small number, but when wekeep in mind that only those words are removed that appear in less thanten songs (out of a total number of 22,297 songs), this cut-off seems veryreasonable.
To make more sense of these numbers, I built a topic model for eachsetting of no below and compared the coherence score of each topic model.The topic coherence provides a measure to judge how good a given topicmodel is. The output is a number between 0 and 1. The higher this number,the better the topic model. For the time being, I let the model create 50topics. To build the topic model and to compute the coherence score, I usedthe following code:
from gensim.models import CoherenceModel
from gensim.models.wrappers import LdaMallet
N_TOPICS = 50
ITERATIONS = 2000
OPTIMIZE_INTERVAL = 20
EVAL_EVERY = 3 #for regular LDA
N_WORKERS = 3 #number of CPU’S for multiprocessing
lda =
LdaMallet("/Users/alielassche/applications/mallet/bin/mallet",
corpus=corpus, id2word=dictionary, num_topics=N_TOPICS,
iterations=ITERATIONS, workers=N_WORKERS,
optimize_interval=OPTIMIZE_INTERVAL)
# Compute Coherence score
coherence_model_ldamallet = CoherenceModel(model=lda,
texts=tokenized_texts, dictionary=dictionary, coherence="c_v")

7.1. PREPARATION OF DATA AND CHOOSING SETTINGS 53
no below Coherence score
2 0.505715 0.4957310 0.49014
Table 7.3: Coherence score at different no below’s
coherence_ldamallet = coherence_model_ldamallet.get_coherence()
The results are stored in Table 7.3. It turns out that the topic model madewith no below = 2 has the highest coherence score. Therefore I continuewith that parameter setting.
The next step is to choose the number of topics. Since this parameter canhighly influence the results, I use the coherence score here as well. With thecode below, I calculate the coherence score for 10 topic models with differentvalues for num topics, in the range 10:100.
def compute_coherence_values(dictionary, corpus, texts, limit,
start=2, step=3):
coherence_values = []
model_list = []
for num_topics in range(start, limit, step):
model = gensim.models.wrappers.LdaMallet
("/Users/alielassche/applications/mallet/bin/mallet",
corpus=corpus, num_topics=num_topics, id2word=dictionary,
iterations=ITERATIONS,
workers=N_WORKERS, optimize_interval=OPTIMIZE_INTERVAL)
model_list.append(model)
coherencemodel = CoherenceModel(model=model,
texts=tokenized_texts, dictionary=dictionary,
coherence="c_v")
coherence_values.append(coherencemodel.get_coherence())
return model_list, coherence_values
# model_list: List of LDA topic models
# coherence_values: Coherence values corresponding to the LDA
model with respective number of topics
model_list, coherence_values =
compute_coherence_values(dictionary=dictionary, corpus=corpus,
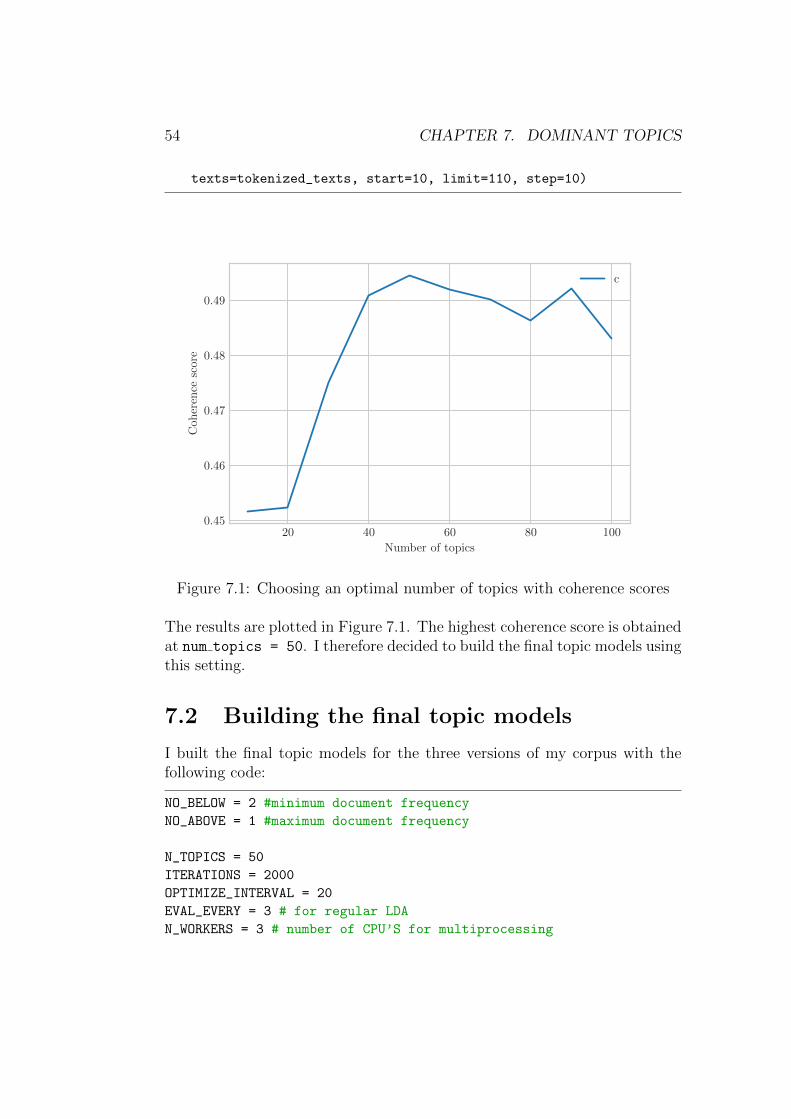
54 CHAPTER 7. DOMINANT TOPICS
texts=tokenized_texts, start=10, limit=110, step=10)
20 40 60 80 100
Number of topics
0.45
0.46
0.47
0.48
0.49
Coh
eren
cesc
ore
c
Figure 7.1: Choosing an optimal number of topics with coherence scores
The results are plotted in Figure 7.1. The highest coherence score is obtainedat num topics = 50. I therefore decided to build the final topic models usingthis setting.
7.2 Building the final topic models
I built the final topic models for the three versions of my corpus with thefollowing code:
NO_BELOW = 2 #minimum document frequency
NO_ABOVE = 1 #maximum document frequency
N_TOPICS = 50
ITERATIONS = 2000
OPTIMIZE_INTERVAL = 20
EVAL_EVERY = 3 # for regular LDA
N_WORKERS = 3 # number of CPU’S for multiprocessing

7.2. BUILDING THE FINAL TOPIC MODELS 55
lda =
LdaMallet("/Users/alielassche/applications/mallet/bin/mallet",
corpus=corpus, id2word=dictionary, num_topics=N_TOPICS,
iterations=ITERATIONS, workers=N_WORKERS,
optimize_interval=OPTIMIZE_INTERVAL)
The most basic and important output of the function LdaMallet is twodataframes: one with the keys of a topic model, the other one with thecomposition. The dataframe keys contains 50 rows, for each topic one, and2 columns: one for the topic number, the other one for the words that form aspecific topic. The dataframe composition contains as many rows as thereare texts in the corpus: in this case 22,297. The columns are numbered from0 to 49, corresponding with the numbers of the topics from keys. The cellsfrom each row contain the composition of the 50 topics in that text. Thehigher a value, the more dominant a topic is in a text. Other characteristicsof the model, the topics or the texts can be obtained, but I will discuss thatin more detail below, where I analyze the results of LdaMallet by the versionof the corpus.
7.2.1 Original corpus
The dictionary that was built from the original corpus, contained at first218,027 unique tokens, but after discarding 127,936 tokens (the number oftokens with a value of 1 in the dictionary, a result of the setting no below
= 2), 90,091 tokens remained. I let the tool build 50 topics from this corpusand dictionary. The coherence score of the model was 0.5097. All topicswith their corresponding words can be find in the appendix, but the mostself-explanatory topics I show in some word clouds in the Figures 7.2 to 7.9.I have to assign a word to each topic, with which the subject of the topiccan be described. I assigned the subject love and sadness to topic 3, whichis pictured in Figure 7.2, because of the presence of positive words such as‘lief’, ‘lieve’, ‘min’ and ‘schoone’ on the one hand and negative words as‘smert’, ‘tranen’, ‘verdriet’ and ‘pijn’ on the other hand. This topic differsfrom another love-topic, topic 49 (Figure 7.9), in such way that almost allwords in this topic are positive words: ‘hert’, ‘zoet’, ‘min’, ‘vreugd’ and ‘lief’.I assign the subject love & happiness to this topic.
Topic 7 (Figure 7.3) can easily be recognized as Christmas, due to wordsas ‘kindeken’, ‘stal’, ‘maria’, ‘bethlehem’, ‘geboren’ and ‘kindt’. To topic10 (Figure 7.4), I refer with nation & country : the words ‘prins’, ‘soldaten’,‘geusen’ and ‘oranje’ leave no doubt that these are words from political songs.In topic 12 (Figure 7.5), words from pastoral or bucolic poetry are clustered:

56 CHAPTER 7. DOMINANT TOPICS
Figure 7.2: love & sadness (3) Figure 7.3: Christmas (7)
Figure 7.4: nation & country (10) Figure 7.5: bucolic songs (12)
Figure 7.6: religion & happiness (42) Figure 7.7: drinking (43)
Figure 7.8: sea (46) Figure 7.9: love & happiness (49)

7.2. BUILDING THE FINAL TOPIC MODELS 57
many words refer to the shepherd life, such as ‘herder’, ‘vee’ and ‘schaepjes’.Less prominent, but still present in this topic, is the name ‘laura’ and thewords ‘lieve’ and ‘lief’, which suggests that not only the love for nature ischanted in these songs. I assign the subject bucolic songs to this topic. Topic42 (Figure 7.6) seems a very general religious topic with words as ‘gods’,‘godt’, ‘christus’ and ‘heeren’, all be it that almost only positive emotionsare mentioned: ‘reyn’, ‘fijn’, ‘liefde’, ‘vrienden’ and ‘vrede’. Therefore Iassign the subject religion & happiness to this topic. Topic 43 (Figure 7.7)can easily be recognized as drinking. All kinds of references to drinking areclustered in this topic, such as ‘drincken’, ‘wijn’, ‘bier’, ‘droncken’ and ‘glas’,accompanied by words as ‘bacchus’ (the Roman god of the wine) and ‘viva’.In topic 46 (Figure 7.8) words that refer to the life on sea are found: ‘zee’,‘schip’, ‘varen’, ‘winden’ and ‘baren’. I assign the word sea to this topic. Tothe groups of words that are not depicted here in word clouds, I assigned atopic as well. It turns out that a lot of topics have something to do withreligion. This is not surprising at all, since Table 4.1 already showed thatalmost 40% of the corpus are songs from the category ‘religion’. In somecases it is quite easy to determine a certain subcategory (such as religion& eternity, religion & happiness, religion & sin), but for a lot of religioustopics the difference is not easy to distinguish.
However, I do not know yet which topics are more dominant in the corpusthan the others. Each song receives a distribution over all the topics. Thismeans that, for each song, the sum of contributions of topics is always 1.Ideally, there is for each song one topic which is way more dominant thanthe 49 others. To see which topics are the most dominant in my corpus, Ichoose for each song the topic that has the highest contribution, using thefollowing code:
transformed_docs = lda.load_document_topics()
docs = [[texts[i]] + [r[0] for r in list(zip(max(row, key=lambda
x:x[1])))] for i, row in enumerate(transformed_docs)]
dominant_topics = pd.DataFrame(docs, columns=["document_id",
"dominant_topic", "perc_contribution"])
Subsequently, I group the dominant topics and count how many times theyappear in the dataframe dominant topics:
topic_counts = dominant_topics["dominant_topic"].value_counts()
topic_contribution = round(topic_counts/topic_counts.sum(), 4)
df_dominant_topics = pd.concat([topic_counts, topic_contribution],
axis=1)
df_dominant_topics.columns = ["Num_Documents", "Perc_Documents"]

58 CHAPTER 7. DOMINANT TOPICS
Topic Songs Subject
49 1377 love & happiness3 1078 love & sadness21 993 religion & eternity0 993 religion40 962 religion & emotions24 787 religion42 770 religion & happiness13 753 rejection30 704 religion18 703 ???26 698 virtuous life32 695 physical love25 646 religion4 643 religion & praise39 637 verbs29 579 love & consolation9 511 religion23 483 religion & sin15 429 religion & virtues28 413 religion27 403 death & passion7 389 Christmas12 381 bucolic songs44 365 religion22 351 religion...
......
Topic Songs Subject
......
...43 350 drinking19 338 religion1 337 religion & Mary41 328 love & happiness8 315 love48 305 profane love31 265 marriage14 262 verbs10 250 nation & country36 248 verbs38 246 nature35 244 religion11 241 religion20 238 German/French33 219 God & nation2 197 God & church47 178 old spelling6 163 ???46 144 sea16 133 pronouns37 125 Old Testament17 116 love & Jesus45 113 ???34 110 trash5 89 verbs
Table 7.4: Dominant topics in original corpus (n = 22,297)

7.2. BUILDING THE FINAL TOPIC MODELS 59
The results are stored in Table 7.4. It is important to realize that the sum ofsongs in this table is 22,297, which means that, for now, only the ‘original’songs are included, and not their reprints and appearances in other song-books. That is a step I will take in a later stadium, after I have evaluatedthe three different models.
A tool that can help to get more insight in the topics and how they arerelated to each other, is the Python package pyLDAvis, which is a library forinteractive topic model visualization. The package extracts information froma fitted LDA topic model to inform an interactive web-based visualization.In order to visualize my topic model, made with the MALLET wrapper ofgensim, I first have to convert it to a ‘normal’ LDA model in gensim. After-wards, I import the converted model into the pyLDAvis prepare-function:
model = gensim.models.wrappers.ldamallet.malletmodel2ldamodel(lda)
import pyLDAvis
import pyLDAvis.gensim
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim.prepare(model, corpus, dictionary,
sort_topics=False)
With sort topics=False, I make sure that the same topics are used as theones in the original model, made with gensim.models.wrappers.LdaMallet.The output is a so-called Intertopic Distance Map, with multidimensionalscaling. The screenshot in Figure 7.10 gives an impression how the interact-ive visualization looks like. Each bubble on the left-hand side plot representsa topic. The larger the bubble, the more prevalent the topic is. An import-ant note is that pyLDAvis starts counting at 1, while the topics made withgensim start at 0. Each number x in the pyLDAvis-plot therefore corres-ponds with topic x− 1. If you hover over the different topics at left, at rightthe most relevant terms for the topic in question are displayed.A good topic model should have bubbles scattered throughout the chart,instead of being clustered in one quadrant. A model with too many topics willtypically have many overlapping small sized bubbles clustered in one regionof the chart. Although the bubbles in Figure 7.10 are scattered throughoutthe chart, there are quite a few small sized bubbles, and many of them areoverlapping with others. When taking a closer look to the groups with topics,it turns out that the bubbles that cluster together, were also interpreted byme as comparable topics. All bubbles in the top left quadrant are religioustopics, as well as some topics in the top right quadrant. When hoveringover the most salient terms that are pictured in the right-hand side plot,

60 CHAPTER 7. DOMINANT TOPICS
Figure 7.10: Visualization of topics in the original corpus with pyLDAvis
the topics in which the word in question is represented, are shown. FigureFigure 7.11 confirms the notion that religious topics are clustered in thetop left quadrant. The bottom left and right quadrant are filled with themore ‘profane’ topics, with the two biggest topics on love (49 and 3 or, inFigure 7.10, 50 and 4) close to the x-axis, as a sort of divider between the twoareas. Figure 7.12 indeed shows that topics on love are scattered throughoutthe chart, but mainly represented along the x-axis.
Since these topics are made from a corpus with unnormalized spelling,there are also topics in which words from a certain time period are clustered,or topics with words that make no sense at all. I shall explain this witha few examples. Topic 47 contains words spelled in a way which was verycommon in the fifteenth and sixteenth century, such as ‘ghoed’, ‘dyn’, ‘dyne’,‘dyns’ and ‘dueghd’. To topic 34 I referred as trash in Table 7.4. The words‘dy’, ‘yn’, ‘soe’, ‘uwz’ and ‘jon’ seem to be the result of either a mistakein digitization or tokenization, or a wrong printed lyric. Topic 20 makesclear that there are some songs in the corpus that are written in Germanor French: there is no other explanation for words such as ‘ich’, ‘das’, ‘je’and ‘vous’ clustered together. Normalization of the spelling would not solvethe problem of foreign songs, but it can reduce the number of topics thatare built based on the time-specific spelling of the words that are in it. Inthe next paragraph I therefore built a topic model from the INL-normalizedcorpus, to see if this model outstands the one built and discussed in thecurrent paragraph.

7.2. BUILDING THE FINAL TOPIC MODELS 61
Figure 7.11: Visualization of topics with godt in the original corpus
Figure 7.12: Visualization of topics with liefde in the original corpus
7.2.2 INL-normalized corpus
The dictionary that was build from the INL-normalized corpus, containedat first 186,692 unique tokens. The setting no below = 2 resulted in theelimination of 114,100 tokens (the words with a value of 1 in the dictionary).The number of remaining tokens was 72,592. That is already 17,000 lesswords than in the dictionary of the original corpus. Again, I build a model

62 CHAPTER 7. DOMINANT TOPICS
Figure 7.13: ??? (38, INL) Figure 7.14: ??? (15, INL)
with 50 topics. The coherence score of this model is 0.4683, which is lowerthan the coherence score from the previous built model. Again, I tried toassign a subject to each topic. Besides that, I investigated also which topic isthe dominant for each song, and grouped the dominant topics to count howmany times they appear. The results of both actions are stored in Table 7.5.
While assigning subjects to the topics that were composed from the INL-normalized corpus, I noticed that this time, when compared to the topicscomposed from the original corpus, much more topics were inconclusive andtherefore hard to assign a subject to. Topic 38 and topic 15 for example arein the Top10 most dominant topics, but their subject is almost impossibleto distill (see Figures 7.13 and 7.14). The word ‘zek’, prominent in topic 15,I already discussed earlier, when pointing out to wrong spelling correctionsthat were performed by the INL-tool. In the example from Chapter 5, theword ‘zig’ was normalized to ‘zek’. It is possible though, that other words,resembling ‘zig’, were also normalized to ‘zek’. The same applies to the wordscene in topic 38. The suspicion prevails that this is also the result of a wrongnormalization, since there is no early modern Dutch resembling equivalentfor ‘scene’. The problem is, though, that there is no actual proof of that.The INL-tool does not give any statistical output containing data on whichnormalizations were performed on which words. This fact makes that I amgoing to question the results from the INL-normalized corpus more and more:how do I know that the words that are clustered in these topics still containthe same meaning as they supposed to contain?
A visualization with pyLDAvis actually confirms these doubts. Figure 7.15shows that, instead of an improved scatter plot compared to Figure 7.10, thetopics overlap just as much. It even seems that the bubbles, except thefour in the bottom right quadrant, are clustered closer to each other. Thisalso explains the difficulty to assign a specific subject to many topics. Ican therefore conclude that a normalization tool as raw and straightforward

7.2. BUILDING THE FINAL TOPIC MODELS 63
Topic Songs Subject
24 1337 sadness39 1113 heart & soul21 965 religion & Christ4 952 man & life25 910 live & love38 903 ???16 862 religion26 859 love33 807 religion15 759 ???30 671 religion & happiness42 663 religion & passion37 576 physical love20 550 bucolic songs22 510 religion & love2 496 family???11 492 persons34 462 religion6 459 drinking9 452 live & die3 430 religion8 425 religion41 407 Christmas43 394 marriage29 369 religion...
......
Topic Songs Subject
......
...10 354 beauty???28 351 old spelling40 332 religion & passion47 330 religion45 316 love5 267 truth & lie49 260 nature23 256 religion & positive emotions19 252 ???32 249 sea18 246 mother & father14 241 nation & country13 230 church17 224 religion48 218 enemy7 211 Old Testament27 176 happiness & singing46 156 sun0 147 eternal life31 144 French44 128 mythology1 121 possessives12 113 German36 94 trash35 58 solfege
Table 7.5: Dominant topics in INL-normalized corpus (n = 22,297)

64 CHAPTER 7. DOMINANT TOPICS
as the INL-tool does not improve further results of textual analysis. Thethird option is building topics from the corpus that is normalized with theVARD2-tool.
Figure 7.15: Visualization of topics in the INL-normalized corpus withpyLDAvis
7.2.3 VARD2-normalized corpus
At first there were 194,159 tokens in the dictionary that was built from theVARD2-normalized corpus. After eliminating 117,045 tokens with no below
= 2, 77,114 tokens remained. For the final time I let the tool compose 50topics. The coherence score of the built model was 0.4962, which is higherthan the score of the model built from the INL-normalized corpus. Thevisualization made with pyLDAvis immediately shows that this topic modelobtained better results than the one built in the previous paragraph. Thebubbles are more evenly scattered throughout the chart, and less bubblesoverlap with each other. This creates the expectation that the subjects ofthe topics made from this version of the corpus, are easier to assign. BelowI discuss some topics and how I assigned a subject to them. The results arestored in Table 7.6. Besides, I examined for each topic which song representedthis topic at best, in other words, which song had the highest contributionto that specific topic, using the following code:
song_topic_highest_contribution = pd.DataFrame()

7.2. BUILDING THE FINAL TOPIC MODELS 65
song_topics_outdf_grpd = dominant_topics.groupby("dominant_topic")
for i, grp in song_topics_outdf_grpd:
song_topic_highest_contribution =
pd.concat([song_topic_highest_contribution,
grp.sort_values(["perc_contribution"], ascending=[0]).head(1)],
axis=0)
song_topic_highest_contribution.reset_index(drop=True,
inplace=True)
song_topic_highest_contribution.columns = ["id", "topic",
"perc_contribution"]
To topic 28 (Figure 7.17), the most prevalent topic in this corpus, I as-signed the topic religion & intangibility, since the words in this topic weremainly about the intangible aspects of religion, such as ‘ziel’, ‘geest’ and‘eeuwig’. The song that represents this topic the most, is a sung version ofthe Lord’s prayer (id = 118423), of which I quote the first three stanzasbelow:
ONse Vader in Hemelrijck,Die ons heet kinders al gelijck,En wilt dat wy u roepen aen,Als wy met node zijn bevaen:Geeft dat niet bidt alleen den mondt,Maer dat het gae uyt ’s herten gront.
Geheyligt uwen name zy,U woordt ongevalscht blijv’ ons by:Dat wy oock leven heyliglijck,Na uwen name weerdiglijck,Behoet ons Heer, voor valsche leer,Dat ’t arm vervoerde volck bekeer.
U Koninghrijck koom’, Heere goet,Hier en hier na. Den trooster soetGeeft ons dien Chrisius ons toeseyMet zijn gaven menigerley:Breeckt Satans tooren ende macht;Voor zijn ergheyt u Kercke wacht.
It is understandable that this particular song represents this topic: the Lord’s

66 CHAPTER 7. DOMINANT TOPICS
Prayer commemorates specifically the intangible aspects of the christian be-lief. Topic 27 (Figure 7.18), to which I assigned world & money, is representedat best by this song, dated from 1645 (id = 3207):
ACh! snoode overdaedt,Vrouw-voedtster van de vuyle dartelheyt,Oorsaeck van alle quaedt,Of immers ’t geen den wegh daer toe bereyt:V weelde baert veel onghemack,En Wellust is een lastigh pack.
Die stil en wel te vre’enMet redelijck behoef is wel vernoegh,En gaet in vrede heen,En is gherust hoe ’t Godt de Heere voeght:Die isser vry veel beter an;Ghenoegh, dat maeckt een deftigh man.
Ghnoegh heeft overvloedt,Schoon dat sen kasjes ledigh zijn van geldt;Ghenoegh heeft schat en goedt,Ghenoegh is nimmermeer om Goudt ontsteldt:Hy leeft gherust die wynigh heeft,En by sijn weynigh eerlijck leeft.
Though the song contains various metaphorical phrases, such as ‘vrouw-voedster van de vuyle dartelheyt’, ‘oorsaeck van alle quadth’, ‘Wellust is eenlastigh pack’, the song is still recognized as a song on wealth and soberness.
Topic 24 (Figure 7.19) is a remarkable one: I assigned the word rejectionto it. Several words, including the ‘weg’, ‘waarom’ and especially the mostprevalent ‘neen’, suggest that songs with this topic are about an unansweredlove or the rejection of a lover. The song with this topic as its highestcontribution shows this perfectly. Here I quote the first two stanzas (id =10359):
Ick ongheluckigh Vrijer,Hoe ben ick in de ly?Ick kan gheen Vrijster winnen,Hoe dapper dat ick vry,Sy achten ’t maer voor grillen,’t En klemt niet wat ick doe:

7.2. BUILDING THE FINAL TOPIC MODELS 67
Topic Songs Subject
28 1151 intangible religion39 1094 love & sadness38 1092 love & happiness18 878 religion9 815 religion & old spelling0 756 religion & life24 618 rejection2 591 love & tragedy13 591 religion27 532 world & money6 521 possessives31 518 religion4 512 religion & happiness30 506 love7 499 God & enemy14 498 myth & beauty21 477 love & happiness47 477 bucolic songs44 465 religion & virtue40 464 religion & Jesus19 452 verbs36 436 religion49 432 God & country5 427 Christmas12 422 marriage...
......
Topic Songs Subject
......
...16 406 good & evil3 395 verbs1 390 religion & Mary35 388 religion46 386 earthly life10 383 suffer & sadness29 378 drinking48 377 love23 355 physical love34 351 seducing32 340 nation & country42 339 cross & passion37 280 nature8 268 godly life11 253 entertainment26 250 money & work15 248 Old Testament17 244 heaven22 227 church25 201 sea33 187 ???45 140 trash41 124 German43 97 French20 66 solfege
Table 7.6: Dominant topics in VARD2-normalized corpus (n = 22,297)
68 CHAPTER 7. DOMINANT TOPICS
Figure 7.16: Visualization of topics in the VARD2-normalized corpus withpyLDAvis
Sal dit noch langher duuren,Ick wordt mijn leven moe.
Ionghman waer toe dit klaghen,Ey! laet u grillen staen,’k En sagh van al mijn daghenNoyt sulcken vreemden Haen:Ghy reutelt en ghy rammelt,Als of ghy had’ een gons,Ghy Bongioert selfs in jou Bocxsen,En leght die schult op ons.
This song is a dialogue between Hylas and Phyllis. Hylas plays the role ofan unlucky youngster who laments about his futile attempts in conqueringa girl; Phyllis explains that girls do not like his rude approach. Anothertopic whose most representative song shows clearly the subjects of the songsbelonging to this topic, is topic 32 on nation & country (Figure 7.20). Thesong with the highest contribution is a so called Geuzen song (id = 27769)from Een Nieu Geuse Lieden boecxken (1578). Below the first three stanzasare quoted:
Wel op, wel op Spangiaerden,Die nu in Brabant zijn,

7.3. EVALUATING MODELS 69
Hoe smaken u die ghebradenDaer toe den coelen wijn,Ghy moet naer Spangien met ghewelt,Sonder Paspoort, sonder gelt,Jochey, nu slaet dien Spangiaerts vry.
In Brabant quamen sy dringhenDie Spaensche Jonckers wijs,Vlaendren wouden sy dwinghen,Die steden maecken prijsOf sy wolden hebben betaelt,Die leste penninck ongefaeltJochey nu slaet de Spangiaerts vry.
De Staten van den Lande,Die setten haer een dach,Wy sullen u wel betalenU Leeninghe corten afSoo moest ghy uyt den Lande gaenDie Spangiaerts riepen niet te verstaenJochey, nu slaet de Spangiaerts vry.
Geuzen songs were named after the Geuzen, the nickname for them whofought against the Spanish during the Dutch Revolt. In Geuzen songs, themotives for the battle against the Spanish were expressed, which is also thecase in the song quoted above.
7.3 Evaluating models
Now that I have built three models from the three versions of my corpus, it isessential to evaluate the models and decide which one is the most worthwhileto continue my analysis with. It will come as no surprise anymore that thecorpus normalized with the INL-tool is not worth the effort to investigateany further. Existing differences in words are smoothed out by wrong nor-malizations, resulting in inconclusive, resembling topics. The two remainingmodels are the one build from the original corpus, and the one build fromthe VARD2-normalized corpus. The biggest advantage of building topicsfrom the original corpus, is that there is no risk in words losing their originalmeaning. However, this enormous word variation is at the same time a ma-jor disadvantage. The dictionary built from the original corpus is much lar-

70 CHAPTER 7. DOMINANT TOPICS
Figure 7.17: religion & intangibility(28, VARD2)
Figure 7.18: world & money (27,VARD2)
Figure 7.19: rejection (24, VARD2)Figure 7.20: nation & country (32,VARD2)

7.3. EVALUATING MODELS 71
ger than the dictionary from the VARD2-normalized corpus: 218,027 tokensversus 194,159 tokens. After discarding tokens that appear only one time,the difference is still considerable: 90,091 versus 77,114 tokens. This meansthat, when building topics from the original corpus, 12,977 words were con-sidered as unique words, while, according to the VARD2-tool, these wordswere just variants of one of the other 77,114 words. From the original corpusare therefore topics composed that are based on the time-specific spellingof the words. A negative consequence of this is that diachronic patterns intopical fluctuations are harder, or in fact impossible, to determine.
The VARD2-tool functions as a solution to that problem. The biggestadvantage of this tool, compared to the INL-tool, is that I am able to verifywhich word was normalized to which word. VARD2 not only gives the nor-malized texts as .txt-output, but also every text as .xml-file, in which theperformed normalizations are tagged. Moreover, a statistical file with dataabout how many words are normalized in each text, is created as well. Con-sidering all this, I will continue my analysis with the version of the corpusthat is normalized with the VARD2-tool. Although there are still a numberof topics which can be considered as trash, the coherence of the words inthese topics is the best I got.
It is now necessary to extend the corpus with the other songs containingthe same incnormid, resulting in a corpus of 43,772 songs, in which to everysong the most dominant topic is assigned. I have used the following block ofcode for this:
nlb = pd.read_csv("data/nlb.csv", sep=",")
nlb_timeset = nlb[(nlb["jaar_begin"] >= 1550) & (nlb["jaar_begin"]
<= 1750)]
nlb_timeset = nlb_timeset[nlb_timeset["incnormid"] != 0]
topics = pd.read_csv("VARD2_dominant_topic_per_song.csv",
sep="\t", index_col=0)
msc = nlb_timeset.merge(topics, left_on="recordid", right_on="id")
nlb_timeset =
nlb_timeset.loc[nlb_timeset["incnormid"].isin(msc["incnormid"])]
incs = msc.groupby("incnormid").first()[["dominant_topic",
"perc_contribution"]]
topics =
nlb_timeset.set_index("incnormid").join(incs).sort_values("incnormid")

72 CHAPTER 7. DOMINANT TOPICS
topics = topics.reset_index()
The question is how the distribution of topics changes, now the size of thecorpus almost has doubled. In Table 7.7, the new numbers of songs arepresented. There are some changes in the ranking, but mostly because ofreligious topics that have taken over the Top10. A topic with a remarkablerise, is topic 32, on nation & country. Originally, there were 340 songs withthis topic as the most prevalent one, but that number has increased to 1221.Earlier I showed that the song that represented this topic at best, was aGeuzen song. The expansion of this topic can be explained by the fact thatsong books with the so called Geuzen songs were reprinted a lot during theDutch Revolt.
A methodical choice that needs some critical evaluation, is the fact thatI picked the most dominant topic for each song and discarded the rest. It ispossible, though, that a certain topic is very often the second-popular topicof a song. If that topic is rarely the most popular topic, it will end at thebottom of the ranking as stored in Tables 7.6 and 7.7, although it can be arather prevalent topic within the corpus. Another hypothesis, which can notbe tested with the current method and the results arising therefrom, is thatcertain topics often occur together in a Top3 of topic contributions of a song.To get more insight in these trends, I extracted the Top3 topics of each songwith the following code:
transformed_docs = lda.load_document_topics()
docs = [[texts[indx]] + [p[1] for p in doc] for indx, doc in
enumerate(transformed_docs)]
composition = pd.DataFrame(docs, columns=["document_id"] + ["topic
{}".format(x) for x in range(0, N_TOPICS)])
arr = np.argsort(-composition.values, axis=1)
df1 = pd.DataFrame(composition.columns[arr],
index=composition.index)
top3topics = df1[[0, 1, 2]].copy()
top3topics.columns = ["top1", "top2", "top3"]
songstop = nlb_timeset.merge(top3topics, left_on="recordid",
right_on="id")
nlb_timeset = nlb_timeset.loc[nlb_timeset["incnormid"].isin
(songstop["incnormid"])]
incstop = songstop.groupby("incnormid").first()[["top1", "top2",
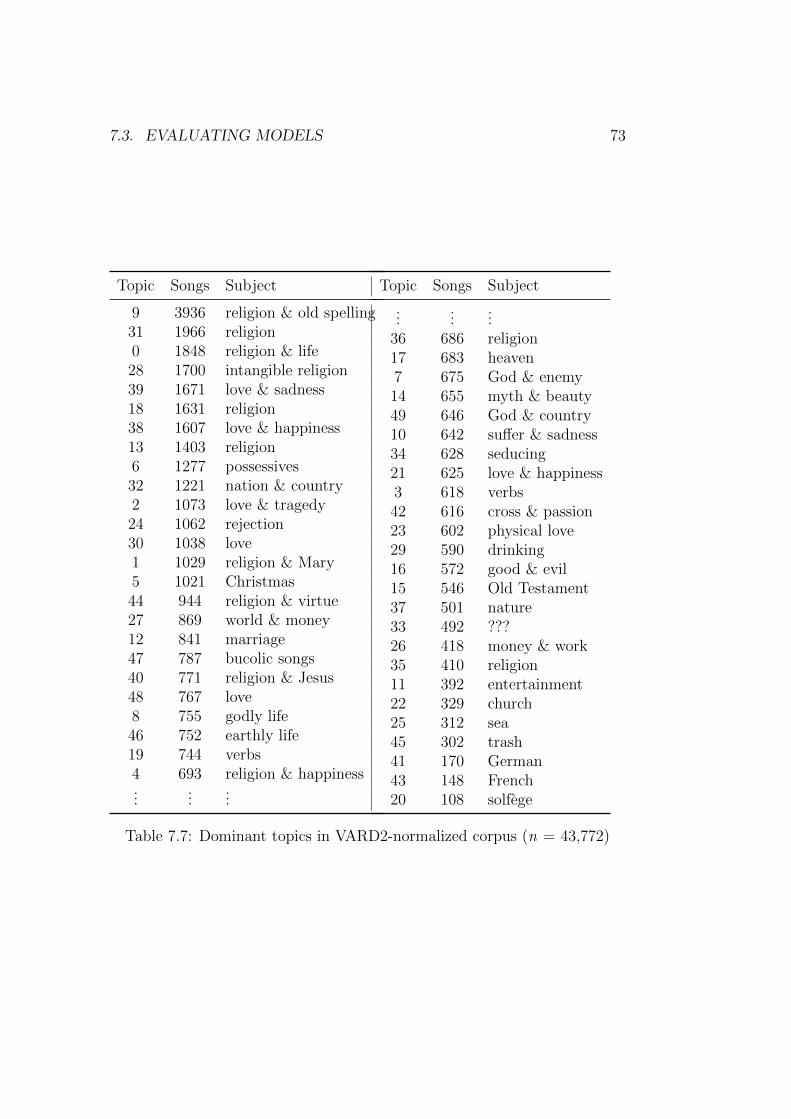
7.3. EVALUATING MODELS 73
Topic Songs Subject
9 3936 religion & old spelling31 1966 religion0 1848 religion & life28 1700 intangible religion39 1671 love & sadness18 1631 religion38 1607 love & happiness13 1403 religion6 1277 possessives32 1221 nation & country2 1073 love & tragedy24 1062 rejection30 1038 love1 1029 religion & Mary5 1021 Christmas44 944 religion & virtue27 869 world & money12 841 marriage47 787 bucolic songs40 771 religion & Jesus48 767 love8 755 godly life46 752 earthly life19 744 verbs4 693 religion & happiness...
......
Topic Songs Subject
......
...36 686 religion17 683 heaven7 675 God & enemy14 655 myth & beauty49 646 God & country10 642 suffer & sadness34 628 seducing21 625 love & happiness3 618 verbs42 616 cross & passion23 602 physical love29 590 drinking16 572 good & evil15 546 Old Testament37 501 nature33 492 ???26 418 money & work35 410 religion11 392 entertainment22 329 church25 312 sea45 302 trash41 170 German43 148 French20 108 solfege
Table 7.7: Dominant topics in VARD2-normalized corpus (n = 43,772)

74 CHAPTER 7. DOMINANT TOPICS
Topic 2 Songs Subject Topic 3 Songs Subject
19 3456 verbs 19 4513 verbs31 2295 religion 18 2244 religion9 2166 religion & old spelling 10 1988 suffer & sadness18 2109 religion 0 1928 religion & life0 1724 religion & life 3 1820 verbs10 1693 suffer & sadness 24 1790 rejection24 1659 rejection 7 1659 God & enemy3 1658 verbs 36 1433 religion36 1564 religion 15 1254 Old Testament7 1342 God & enemy 21 1235 love & happiness
Table 7.8: Top10 with second- and third-popular topics
"top3"]]
top3topicsong = nlb_timeset.set_index("incnormid").join(incstop).
sort_values("incnormid")
top3topicsong = top3topicsong.reset_index()
The result is a dataframe with 43,772 rows, where for each song (i.e. eachrow) the Top3 dominant topics are stored in columns. I grouped the topicsthat were in the second position of the Top3, and stored the most frequentten of them in Table 7.8. It turns out that from the Top10 second-populartopics, five topics were in the Top15 popular topics as well. They are allon religion.107 From the other five topic from the Top10 second-populartopics, two topics were composed of verbs.108 The three other topics in theTop10 second-popular topics were on suffer & sadness, religion and God &enemy. From the Top10 third-popular topics, eight topics were in the Top10second-popular topics as well. The two ‘new’ topics are topic 15 on theOld Testament and topic 21 on love & happiness. I conclude therefore that,except the topics on God & enemy and the Old Testament, the Top3 doesnot bring new topics to attention.
The answer to my question what the most dominant topics in my cor-pus are, is ‘religion and something’, for sure. That result is not surprisingat all: I already knew from the distribution of categories (Table 4.1) that Icould expect lots of topics concerning ‘religion’. However, since this category
107. Topics 31 (religion), 9 (religion & old spelling), 18 (religion), 0 (religion & life) and24 (rejection).108. Topics 19 and 3.

7.3. EVALUATING MODELS 75
assigning has been in some cases quite general and arbitrary, the topic mod-eling method could give more insight in topical subdivisions within a genre.For some reason, LDA was able to distinguish songs that were merely onreligion and happiness from songs that were merely on religion and virtue.The same applies to songs from the category ‘love and sex’. In the DutchSong Database, thousands of songs are placed in this category, leaving noroom for difference between songs on love and happiness, songs on love andsadness, or songs on rejection. Building a topic model has resulted in un-covering differences within the wide-ranging genres of songs. The next stepI want to take in this thesis is how these topics in song lyrics fluctuate overtime. Are songs on love and happiness and songs on love and sadness risingat the same time, or is the one a reaction to the other? When are songson God and country becoming prevalent? Are there certain religious topicsthat disappear over time, being replaced by others? Can I indicate certainhistorical or cultural events that drive these trends? And how do my obser-vations relate to prevailing theses in current research on the role of literaturein the early modern centuries? Can I confirm that literature functions as aconstructor of identity? Is the relation between politics and literature indeedreflected in my results? Does a certain ideology emerge from topics, and ifso, which one? Are song topics becoming more and more variate over time,as well as the audience of songs? In the next chapter I will try to find ananswer to these questions.

76 CHAPTER 7. DOMINANT TOPICS

Chapter 8
Roles of literature
In this chapter I examine how the composed topics and their dynamics overtime relate to prevailing theses drawn from contemporary qualitative researchon the role of early modern literature, which I already discussed in Chapter1, Introduction. I discuss each claim in more detail, after which I explorewhether the claim can be validated with the obtained results.
8.1 Literature and ideology
In the Introduction, I already discussed how literature is seen as a propagatorof an ideology and how this is the case for the literature of the pietistic tradi-tion. I also made clear in the previous chapter, that religion is by far the mostdominant topic in my corpus. From the fifty topics that were built, eight-een have, more or less, something to do with religion. Regarding the Top10most dominant topics, six of them are on religion. In Figure 8.1, I plottedthe evolution of these six topics over time. The y-axis shows the number ofsongs with a certain topic as their most dominant topic; the x-axis shows thedevelopment of a topic’s popularity through time. Table 7.7 already showedthat topic 9 was by far the most dominant topic in my corpus. Figure 8.1makes clear that this topic was mainly popular in the sixteenth century: iteven almost disappears after 1650. There is a clear explanation for that,to which I already referred in assigning the subject religion and old spellingto this topic. It contains words in a typical fifteenth and sixteenth-centuryspelling, ages in which no clear difference between the printed letters ‘v’, ‘w’and ‘u’ existed, resulting in words such as ‘wt’, ‘bouen’, ‘uan’, ‘verheuen’,and ‘blijuen’. These words were not normalized by the VARD2-tool. Anexplanation for this is that the tool was trained on more recent texts (datingfrom 1637 and 1657), in which words were spelled according to more modern
77
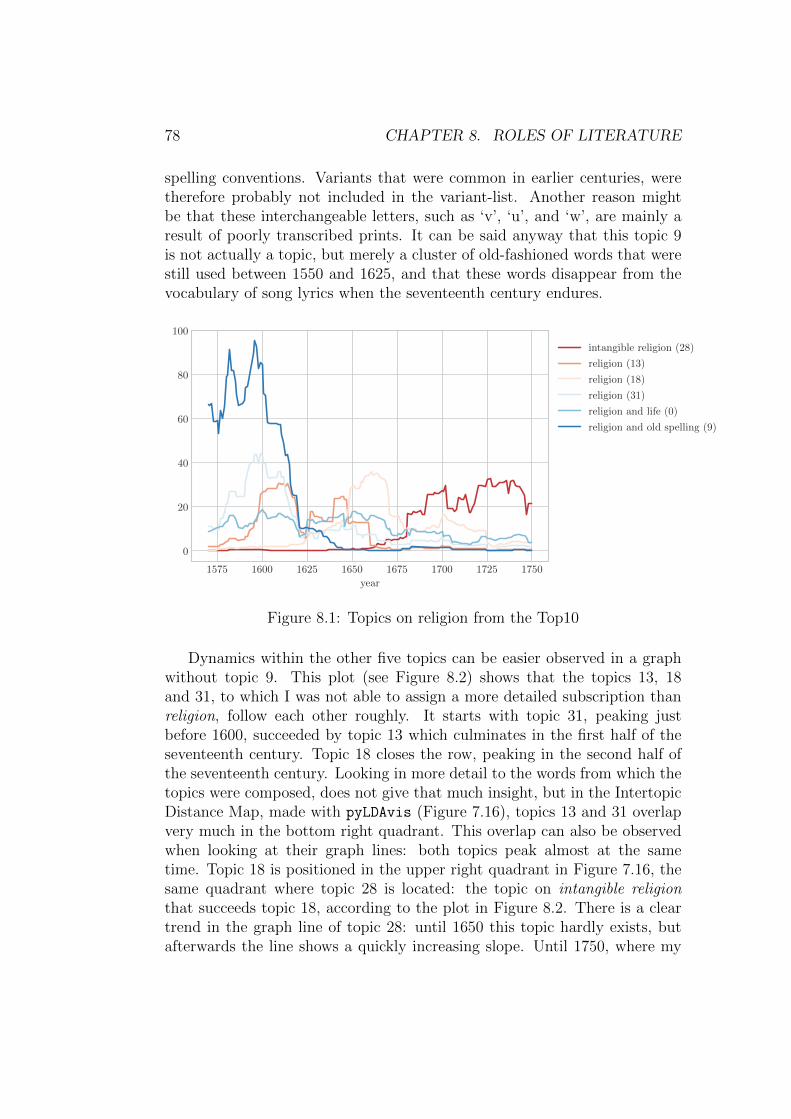
78 CHAPTER 8. ROLES OF LITERATURE
spelling conventions. Variants that were common in earlier centuries, weretherefore probably not included in the variant-list. Another reason mightbe that these interchangeable letters, such as ‘v’, ‘u’, and ‘w’, are mainly aresult of poorly transcribed prints. It can be said anyway that this topic 9is not actually a topic, but merely a cluster of old-fashioned words that werestill used between 1550 and 1625, and that these words disappear from thevocabulary of song lyrics when the seventeenth century endures.
1575 1600 1625 1650 1675 1700 1725 1750
year
0
20
40
60
80
100
intangible religion (28)
religion (13)
religion (18)
religion (31)
religion and life (0)
religion and old spelling (9)
Figure 8.1: Topics on religion from the Top10
Dynamics within the other five topics can be easier observed in a graphwithout topic 9. This plot (see Figure 8.2) shows that the topics 13, 18and 31, to which I was not able to assign a more detailed subscription thanreligion, follow each other roughly. It starts with topic 31, peaking justbefore 1600, succeeded by topic 13 which culminates in the first half of theseventeenth century. Topic 18 closes the row, peaking in the second half ofthe seventeenth century. Looking in more detail to the words from which thetopics were composed, does not give that much insight, but in the IntertopicDistance Map, made with pyLDAvis (Figure 7.16), topics 13 and 31 overlapvery much in the bottom right quadrant. This overlap can also be observedwhen looking at their graph lines: both topics peak almost at the sametime. Topic 18 is positioned in the upper right quadrant in Figure 7.16, thesame quadrant where topic 28 is located: the topic on intangible religionthat succeeds topic 18, according to the plot in Figure 8.2. There is a cleartrend in the graph line of topic 28: until 1650 this topic hardly exists, butafterwards the line shows a quickly increasing slope. Until 1750, where my
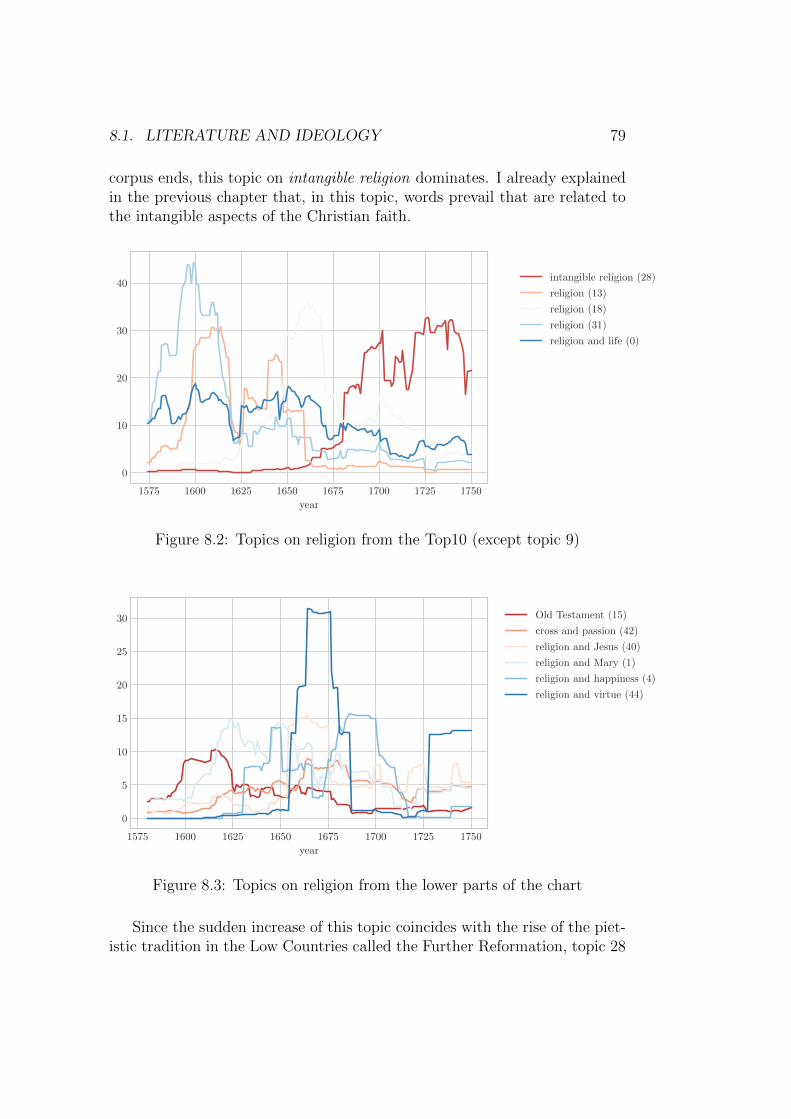
8.1. LITERATURE AND IDEOLOGY 79
corpus ends, this topic on intangible religion dominates. I already explainedin the previous chapter that, in this topic, words prevail that are related tothe intangible aspects of the Christian faith.
1575 1600 1625 1650 1675 1700 1725 1750
year
0
10
20
30
40intangible religion (28)
religion (13)
religion (18)
religion (31)
religion and life (0)
Figure 8.2: Topics on religion from the Top10 (except topic 9)
1575 1600 1625 1650 1675 1700 1725 1750
year
0
5
10
15
20
25
30 Old Testament (15)
cross and passion (42)
religion and Jesus (40)
religion and Mary (1)
religion and happiness (4)
religion and virtue (44)
Figure 8.3: Topics on religion from the lower parts of the chart
Since the sudden increase of this topic coincides with the rise of the piet-istic tradition in the Low Countries called the Further Reformation, topic 28

80 CHAPTER 8. ROLES OF LITERATURE
clearly represents one of the two trends Porteman and Smits-Veldt determ-ined in literary texts from this movement. On the one hand, literary textswith a focus on a sanctification on society and all aspects of life, prevailed.On the other hand, texts appeared in which the personal lived experiencewith God was described and expressed. These latter are brought togetherin topic 28. Figure 8.3 shows that the other religious topics, which werelocated lower in the chart, do not demonstrate a striking curve, except the‘Domtower-ish’ shape of topic 44, belonging to religion and virtue. Since thesudden rise of this topic is located in the second half of the seventeenth cen-tury as well, this seems to fit with the first trend of the literary texts from theFurther Reformation that Porteman and Smits-Veldt determined.109 Domin-ant words in this topic that confirm these thoughts, are ‘deughden’, ‘bidt’,‘leven’, and ‘vroom’. The twofold ideology the advocates of the Further Re-formation wanted to propagate according to contemporary research, is clearyrepresented in the obtained quantitative results.
8.2 Literature and poetics
I expect the relationship between literature and poetics to be most apparentin love topics that can be related to Petrarchism. Francesco Petrarca (1304 -1374), godfather of this movement, was an Italian poet from the fourteenthcentury, who became famous all over Europe during the early modern centur-ies. One of the reasons for this was because he started to write poetry in theItalian vernacular, and based on the classics. This was a great inspiration forDutch poets in the sixteenth and seventeenth century, who were searching fortheir own identity, during a war for political and religious independence.110
The other reason for Petrarca’s fame in the Netherlands was the popularityof his poetry on love. Distinctive of Petrarca’s love sonnets, was the worshipof a charming but unreachable woman. As a result of that, love always causesboth happiness and pain in his poems. The physical beauty of the beloved isoften described, using natural metaphors and mythological references. Thelover owns a split personality, and often struggles with suicidal tendencies.111
Regarding the results obtained in the previous chapter, the second-largestoverarching category of topics is love. The two most dominant topics in thiscategory, are two contradictory ones: topic 39 is on love and sadness, topic38 is on love and happiness. In Figure 8.4 I plotted the two topics through
109. Porteman and Smits-Veldt, Een nieuw vaderland voor de muzen, 658.110. Ibid., 17.111. G.J. van Bork et al., Algemeen Letterkundig Lexicon (Leiden: Stichting Digitale Bib-liotheek voor de Nederlandse Letteren (DBNL), cop. 2012.).

8.2. LITERATURE AND POETICS 81
time, which shows an interesting pattern. What immediately stands out, isthat the topics only start to occur around 1630. From that point in time,love and sadness is the most dominant topic, culminating around 1660, butdecreasing quickly afterwards. Around 1710, the line of topic 38 on love andhappiness suddenly rises, and rapidly becomes the dominant one of the twolove topics. This plot suggests that song with negative emotions are replacedby songs with a more light-footed view on love. The question is if that trendis confirmed by other topics on love. Therefore I included more love-topicsto the plot, resulting in the graph of Figure 8.5. Prior to topic 39, topic 2starts the list of topics on love. This topic, on love and tragedy, dominatesbetween 1575 and 1630. What follows, is a couple of overlapping peaks,all culminating around 1660, with the topic on love and sadness as mostdominant one. The smaller peaks belong to rejection, seducing and physicallove.
1640 1660 1680 1700 1720 1740
year
0
5
10
15
20
25
30
love and happiness (38)
love and sadness (39)
Figure 8.4: love and happiness versus love and sadness
All these topics, dominating the sixteenth and seventeenth century lovetopics, can be related to the heydays of the Petrarchism. The most famousimitators of Petrarca in the Netherlands were poets Jan van der Noot (1539- 1595) and Pieter Corneliszoon Hooft (1581 - 1647).112 In most of the poemsHooft wrote, he adhered to the international conventions of amorous lyric,in which Petrarca’s poetry strongly resonated. The case of Hooft demon-strates that not only poems, but songs as well, were written according toPetrarcian standards. Hooft’s songs ended up in song books, accompanied
112. Porteman and Smits-Veldt, Een nieuw vaderland voor de muzen, 46, 206.
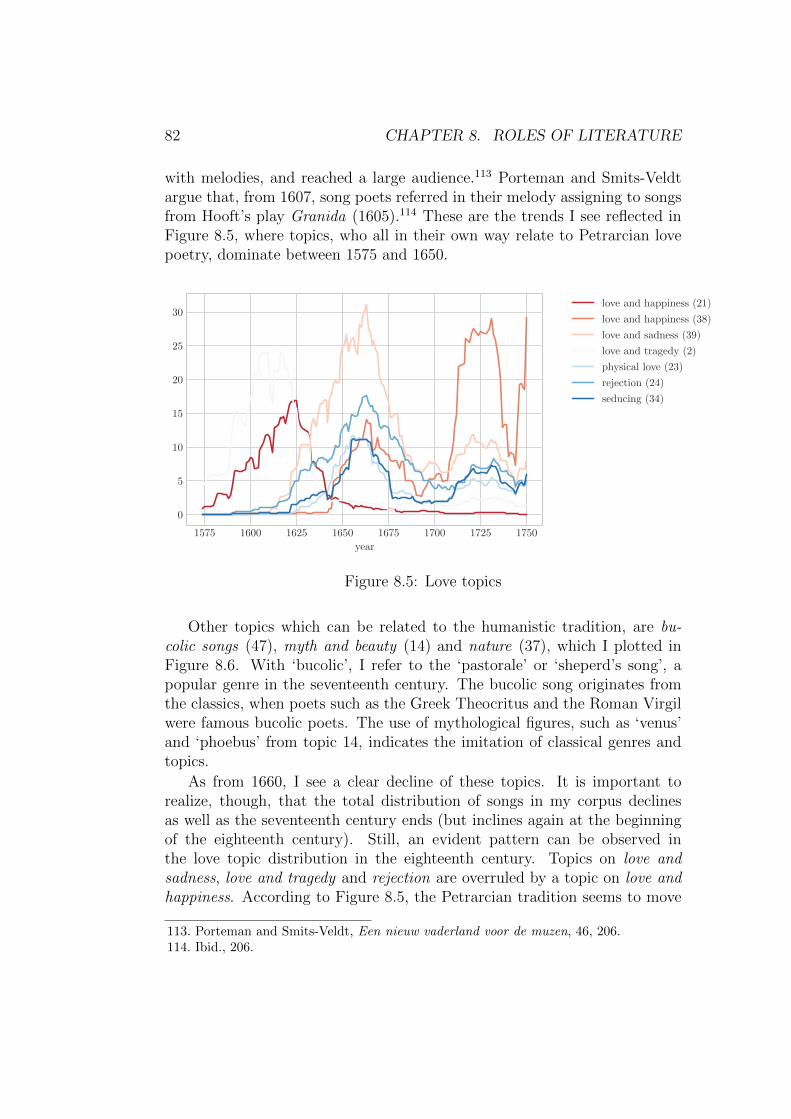
82 CHAPTER 8. ROLES OF LITERATURE
with melodies, and reached a large audience.113 Porteman and Smits-Veldtargue that, from 1607, song poets referred in their melody assigning to songsfrom Hooft’s play Granida (1605).114 These are the trends I see reflected inFigure 8.5, where topics, who all in their own way relate to Petrarcian lovepoetry, dominate between 1575 and 1650.
1575 1600 1625 1650 1675 1700 1725 1750
year
0
5
10
15
20
25
30love and happiness (21)
love and happiness (38)
love and sadness (39)
love and tragedy (2)
physical love (23)
rejection (24)
seducing (34)
Figure 8.5: Love topics
Other topics which can be related to the humanistic tradition, are bu-colic songs (47), myth and beauty (14) and nature (37), which I plotted inFigure 8.6. With ‘bucolic’, I refer to the ‘pastorale’ or ‘sheperd’s song’, apopular genre in the seventeenth century. The bucolic song originates fromthe classics, when poets such as the Greek Theocritus and the Roman Virgilwere famous bucolic poets. The use of mythological figures, such as ‘venus’and ‘phoebus’ from topic 14, indicates the imitation of classical genres andtopics.
As from 1660, I see a clear decline of these topics. It is important torealize, though, that the total distribution of songs in my corpus declinesas well as the seventeenth century ends (but inclines again at the beginningof the eighteenth century). Still, an evident pattern can be observed inthe love topic distribution in the eighteenth century. Topics on love andsadness, love and tragedy and rejection are overruled by a topic on love andhappiness. According to Figure 8.5, the Petrarcian tradition seems to move
113. Porteman and Smits-Veldt, Een nieuw vaderland voor de muzen, 46, 206.114. Ibid., 206.

8.3. LITERATURE AND POLITICS 83
1600 1620 1640 1660 1680 1700 1720 1740
year
0.0
2.5
5.0
7.5
10.0
12.5
15.0
17.5
bucolic songs (47)
myth and beauty (14)
nature (37)
Figure 8.6: Renaissance topics
to the background, making room for a less dramatic, and more light-footedinterpretation of love.
8.3 Literature and politics
Regarding the relation between literature and politics, I already mentionedthe claim from contemporary research that, during political crises, literaturewith such crises as subject is written and read more often. If that is correct,I should see an increase of topics related to country, war and enemy, duringtimes in which the Dutch Republic was in a precarious political situation.Although war was more of a rule than an exception in the history of theDutch Republic, there are for sure some moments to indicate in which thecrisis was peaking. First and foremost there is the Eighty Years’ War, lastingfrom 1568 until 1648, in which the Dutch struggled for independence fromthe Spanish king. Although the war was interrupted for the Twelve Year’sTruce, which was set from 1609 until 1621, this did not lead to a quiteand carefree period in the Dutch Republic: two factions emerged as resultof a theological disagreement between two professors in theology from theUniversity of Leiden about the predestination. The debate was not limitedto the religious discourse, but grew into a national conflict, concerning thequestion how and by whom the correct dogmas of the Reformed Church

84 CHAPTER 8. ROLES OF LITERATURE
(‘Gereformeerde Kerk’) should be decided.115 The conflict culminated in 1619in the death sentence of Johan van Oldebarnevelt, the land’s advocate of theRepublic, simultaneously with the Synod of Dort in which the controversyaround the remonstrants and counter-remonstrants was settled by sentencingcounter-remonstrantism to heresy. As a result, prince Maurits managed toend the intern agitation before the Truce itself ended.116 In the end, thedispute ensured an uninterrupted uproar in the Republic for eighty years,since the Revolt continued after the Twelve Year’s Truce ended in 1621.After an up and down wavy continuation of the battle, without a substantialdifference in power, the Peace of Munster was finally signed by the DutchRepublic and the Spanish Crown in the winter of 1648, indicating the end ofthe Revolt.117 Summarized, if there is one period in which songs with nationand war as topic should be excelling, it has to be during the Dutch Revolt.
The results from the last paragraph of Chapter 7 already showed that,after adding reprints to my corpus, the topic on nation and country is posi-tioned at the bottom of the Top10 dominant topics. Related topics seem tobe topic 7 on God and enemy and topic 49 on God and country, and thereforeI plotted these three topics together in Figure 8.7. It turns out that nationand country starts to appear as most dominant topic of a song around 1580.Striking is the fact that the line does not start close to zero, but close toten: the songs seem to appear almost out of nothing. In the next forty years,the number of songs per year with this topic as their dominant one, onlyrises. This sudden increase in popularity clearly indicates that songs withthis topic were written, read and sung much more often during that time.Dominant words show that this topic is indeed on the Revolt, which is mainlyillustrated by words as ‘prins’, ‘land’, ‘graaf’, ‘spaensche’ and ‘paus’. Thisconfirms the hypothesis that there should be an increase of topics relatedto country, war, and enemy, during the Eighty Years’ War. In the previouschapter I already suggested that the Geusen songbooks were probably largelyresponsible for the sudden popularity of this topic. The line of topic 32 inFigure 8.7 confirms that expectation: it appears around the same time asthe oldest known edition of Een nieu geuse lieden boexcken dates from, whichis the year 1577 or 1578.118 Around 1640, the graph line of topic 32 showsa drastic fall, which can be explained with the end of the Dutch Revolt in1648.
Remarkable is that, at the same time, two other relatable topics are rising,
115. Maarten Prak, Gouden Eeuw: het raadsel van de Republiek (Amsterdam: Boom,2012), 40.116. Ibid., 47.117. Ibid., 53.118. Porteman and Smits-Veldt, Een nieuw vaderland voor de muzen, 75.
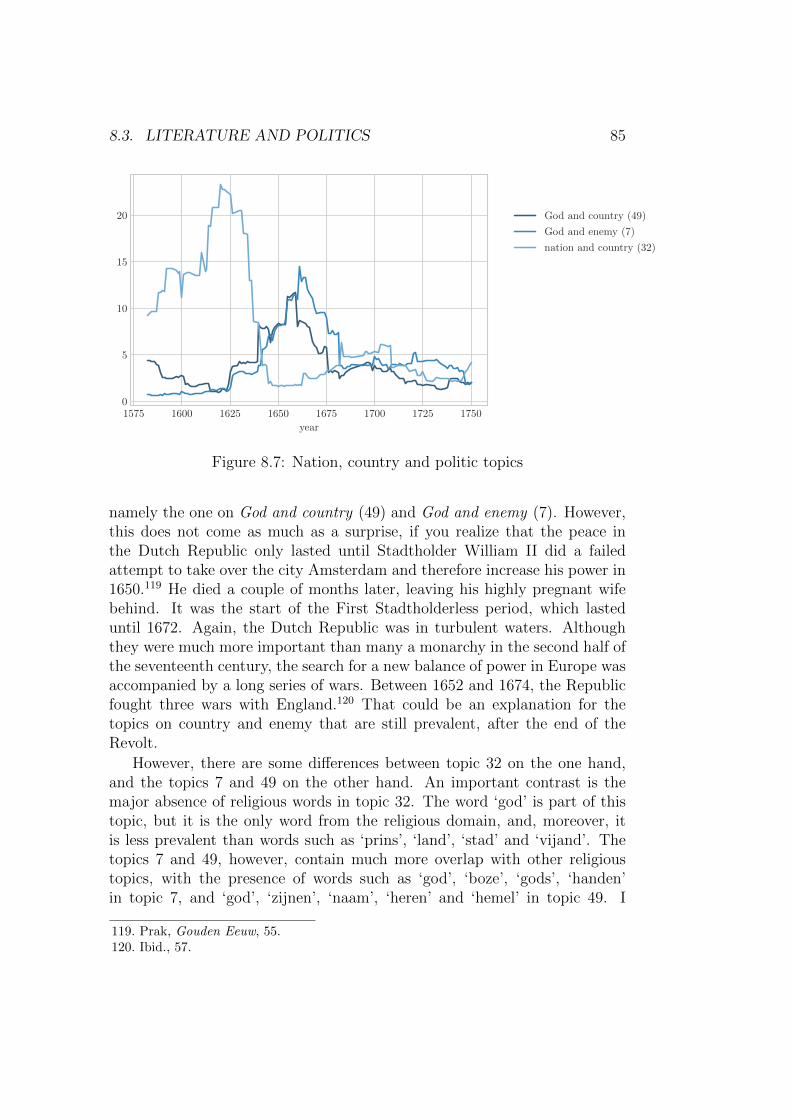
8.3. LITERATURE AND POLITICS 85
1575 1600 1625 1650 1675 1700 1725 1750
year
0
5
10
15
20 God and country (49)
God and enemy (7)
nation and country (32)
Figure 8.7: Nation, country and politic topics
namely the one on God and country (49) and God and enemy (7). However,this does not come as much as a surprise, if you realize that the peace inthe Dutch Republic only lasted until Stadtholder William II did a failedattempt to take over the city Amsterdam and therefore increase his power in1650.119 He died a couple of months later, leaving his highly pregnant wifebehind. It was the start of the First Stadtholderless period, which lasteduntil 1672. Again, the Dutch Republic was in turbulent waters. Althoughthey were much more important than many a monarchy in the second half ofthe seventeenth century, the search for a new balance of power in Europe wasaccompanied by a long series of wars. Between 1652 and 1674, the Republicfought three wars with England.120 That could be an explanation for thetopics on country and enemy that are still prevalent, after the end of theRevolt.
However, there are some differences between topic 32 on the one hand,and the topics 7 and 49 on the other hand. An important contrast is themajor absence of religious words in topic 32. The word ‘god’ is part of thistopic, but it is the only word from the religious domain, and, moreover, itis less prevalent than words such as ‘prins’, ‘land’, ‘stad’ and ‘vijand’. Thetopics 7 and 49, however, contain much more overlap with other religioustopics, with the presence of words such as ‘god’, ‘boze’, ‘gods’, ‘handen’in topic 7, and ‘god’, ‘zijnen’, ‘naam’, ‘heren’ and ‘hemel’ in topic 49. I
119. Prak, Gouden Eeuw, 55.120. Ibid., 57.

86 CHAPTER 8. ROLES OF LITERATURE
therefore suspect that these songs are religious songs with a strong focuson the aspect of war, peace, enemy, and the people. The song with thehighest contribution of topic 49, turns out to be a psalm in the translationof Petrus Datheen (id = 7998), the song with the highest contribution oftopic 7 is from the songbook Stichtelijcke Gesangen, behelsende: BybelscheIn-vallen. Geestelijcke Bedenckingen. Eerlijcke Vermaeckingen. from 1661(id = 155823). It is therefore also possible that the rise of these two topicshas something to do with the earlier mentioned rise of reformed songbooksafter 1650.
8.4 Literature and diversity
The last claim on the role of literature in early modern times I will test, isthe one on diversity of both the people that were involved with literature,as well as the topics in literature. I already cited Veldhorst, who made clearthat poor and rich, young and old were engaged with songs during the seven-teenth century.121 Furthermore, several studies have shown that songbooksprinted especially for young readers started to appear at the beginning ofthe seventeenth century.122 Their number only increased as the years passed.In the introduction of a twentieth century edition of G.A. Bredero’s Grootlied-boeck, F.H. Matter designates the publication of Den nieuwen Lust-hofin 1602 as the beginning of a new era, in which more and more songbooksappear that are especially intended for the youth, as appears from their titleor preliminary work.123 A major part of the songs were on love, but not allof them. Matter asks himself why poets and printers were keen to gain thefavor of the youth by producing songbooks especially for them. He does notbelieve that their one and only reason was the fact that youth is continuouslyin love and therefore yearns for love songs. Other possible explanations Mat-ter mentions, are that youth represents a potential market since they wererather prosperous, that they are not yet seized by household worries, andthat youth can be related to modern, anti-traditional and sensitive to newmovements in art and literature.124
121. Veldhorst, ‘Pharmacy for the Body and Soul’, 217.122. See for example Stronks, ‘’Dees kennisse zuldy te kope vinnen’: Liedcultuur en dewaarde van ‘know how’ in de vroegmoderne Republiek’; E.K. Grootes, ‘Het Jeugdig Pub-liek van de ”Nieuwe Liedboeken” in Het Eerste Kwart van de Zeventiende Eeuw’, in HetWoord Aan de Lezer. Zeven Literatuurhistorische Verkenningen, by W. van den Berg andJ. Schouten (Groningen: Wolters-Noordhoff, 1987), 72–88.123. G.A. Bredero, G. A. Bredero’s Boertigh, amoreus, en aendachtigh groot lied-boeck.,ed. F.H. Matter et al. (’s-Gravenhage: Tjeenk Willink-Noorduijn, 1975–1983), 18.124. Ibid., 19.

8.4. LITERATURE AND DIVERSITY 87
Another group that became more and more involved in literature, arewomen. Although male authors dominate the literary history, we know fromseveral studies that female authors and readers were not absent during theearly modern centuries. The extensive study Met en zonder lauwerkrans.Schrijvende vrouwen uit de vroegmoderne tijd 1550-1850: van Anna Bijnstot Elise van Calcar on writing women in the early modern time shows thatwomen were active in both the profane and religious domain, and in verydifferent genres.125 The sisters Anna and Tesselschade Roemers Visscher,Katharina Lescailje and Titia Brongersma are the most famous examplesof female poets, but Schenkeveld-van der Dussen et al. determine morethan seventy female writers from the seventeenth century alone. Womenwrote poetry on all sorts of worldly subjects, mostly published in anthologies.Porteman and Smits-Veldt notice that, in contrast to male poets who startedto publish collection bundles from the second half of the seventeenth century,this did not happen for the literary works by women.
Regarding female poets who wrote religious poetry, they put themselvescompletely at the service of the purpose of their texts: spiritual foundationand consolation.126 Many of them were pastor’s wives, and their work wasin line with the tradition of the Further Reformation. From about 1670,collection bundles from female poets began to be published as well. Thesebundles were for the most part filled with poetry on religious subjects, andsometimes alternated with poets on worldly subjects. Authors from suchmixed bundles saw their writership as subservient to the religious communitythey belonged to. If they discussed worldly subjects in their poetry, thishappened still in a religious perspective. In some cases, the intended public offemale writers were women as well. The addressates of sixteenth-century poetVrou Gerrits’ bundle are her sisters in Christ, and for Cornelia Teellinck’swork, a female readership is assumed as well.127 Geertruida Sluiter statesexplicitly that she is writing to clearly formulate her faith and help fellowfemales with that. However, we can not assume that women were only writingfor women, since there are as much examples that prove the opposite, forexample the works of the eighteenth-century poet Geertruyd Gordon.128
With the methods used in this thesis and the results obtained with it,it is hard to check whether the above claims are confirmed by quantitativeresearch. I can see that certain love topics become more and more prevalent
125. Riet Schenkeveld-van der Dussen et al., Met en zonder lauwerkrans: schrijvendevrouwen uit de vroegmoderne tijd 1550-1850: van Anna Bijns tot Elise van Calcar: tekstenmet inleiding en commentaar (Amsterdam: Amsterdam University Press, 1997).126. Porteman and Smits-Veldt, Een nieuw vaderland voor de muzen, 840.127. Schenkeveld-van der Dussen et al., Met en zonder lauwerkrans, 51.128. Porteman and Smits-Veldt, Een nieuw vaderland voor de muzen, 840.

88 CHAPTER 8. ROLES OF LITERATURE
indeed, but topics do not give me insight in the writer of a lyric or theintended public of a song. It is possible that there are changes in the genderof characters that are subject of a lyric, but the use of a stop list ensures thatpersonal pronouns which might suggest something on this, are excluded fromthe composed topics. To test the above claims, other quantitative methodsshould be used, for example an analysis of the preliminary works of songbooksto get insight in the intended public of a literary work.
My methods are more useful to say something about the growing diversityof topics in my corpus over time. The turnover, which I discussed previouslyin Chapter 3 and Chapter 6, can show me if the same topics stay the mostpopular over a longer period of time, or if the composition of the upper part ofthe ranking constantly, or during a certain time period, shifts. To computethe annual turnover of topics, I followed the steps I formulated earlier inChapter 6. From the DataFrame I created in Chapter 7, I extracted the mostdominant topic for each song. Afterwards I grouped these topics by year, andcounted the number of appearances for each topic in every year. In this way,I could create an annual popularity index, containing all song topics, rankedaccording to their frequency of appearance in descending order. I used thefollowing block of code:
import numpy as np
import pandas as pd
top3topicsong = pd.read_csv("top3topics_allsongs.csv", sep="\t",
index_col=0)
groups = top3topicsong.groupby("year")
year2index = {year: i for i, year in
enumerate(sorted(top3topicsong.year.unique()))}
X = np.zeros((top3topicsong.year.unique().size, 50))
counts = groups["top1"].value_counts()
for (year, topic), count in counts.iteritems():
topic = int(topic.replace("topic ", ""))
X[year2index[year], topic] += count
turnovertop1 = np.array([x[::-1] for x in X.argsort(1)])
The result is a numpy matrix in which each array corresponds with a year,and consists a list of topics, ranked from the most dominant to the leastdominant. Note that the length of the matrix is 196: the years are numberedfrom 0 to 195. This means that five years, from which no songs are presentin my corpus, are excluded from the matrix. It concerns the years 1555,

8.4. LITERATURE AND DIVERSITY 89
1606, 1691, 1726, and 1729. For each position in the ranked lists, I countthe number of ‘shifts’ in the ranking that have taken place between twoconsecutive years. This ‘number of shifts’ is called the turnover. Computingthe turnover for all time steps in our collections yields a turnover series.
However, calculating the turnover of this ranking would not make sense,since all fifty topics appear in each ranking every year. The number of shiftswould therefore always be zero, resulting in a flat graph line. Therefore I usea cutoff, to only include the upper part of the ranking in the calculation ofthe annual turnover. I use the following code for that (after I converted thenumpy matrix to a pandas DataFrame):
df_turnoverseries = pd.DataFrame(turnovertop1)
cutoff5 = df_turnoverseries[[0, 1, 2, 3, 4]].copy()
cutoff10 = df_turnoverseries[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]].copy()
My new DataFrame cutoff5 contains the Top5 topics for each year, whilecutoff10 contains the Top10 topics for each year. As said before, theturnover can be defined as the number of new topics that enter a popularity-ranked list at position n at a particular moment in time t. Therefore I needto compare two rankings of two consecutive years and return the size oftheir difference. Karsdorp, Kestemont and Riddell have defined the functionturnover as following:129
def turnover(df):
df = df.apply(set, axis=1)
turnovers = {}
for year in range(df.index.min() + 1, df.index.max() + 1):
name_set, prior_name_set = df.loc[year], df.loc[year - 1]
turnovers[year] = len(name_set.difference(prior_name_set))
return pd.Series(turnovers)
I invoke the function with the following lines of code:
turnover_topics_5 = turnover(cutoff5)
turnover_topics_10 = turnover(cutoff10)
The DataFrame turnover topics 5 now contains 196 rows, with each rowcontaining a number between 0 and 5, corresponding with the number ofshifts that have taken place between two consecutive years. The same ap-plies for the DataFrame turnover topics 10, except that each row in thisDataFrame contains a number between 0 and 10. In Figure 8.8, the abso-
129. Karsdorp, Kestemont and Riddell, Humanities Data Analysis: Case Studies withPython, 134.
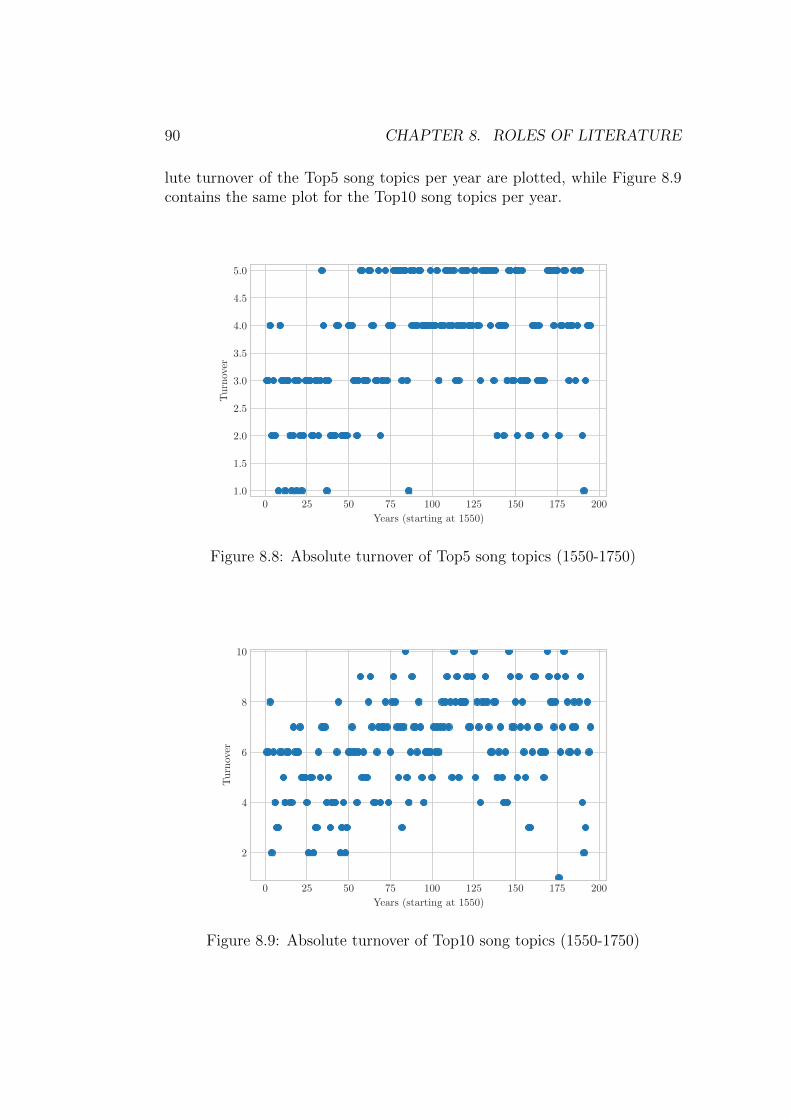
90 CHAPTER 8. ROLES OF LITERATURE
lute turnover of the Top5 song topics per year are plotted, while Figure 8.9contains the same plot for the Top10 song topics per year.
0 25 50 75 100 125 150 175 200
Years (starting at 1550)
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
Tu
rnov
er
Figure 8.8: Absolute turnover of Top5 song topics (1550-1750)
0 25 50 75 100 125 150 175 200
Years (starting at 1550)
2
4
6
8
10
Tu
rnov
er
Figure 8.9: Absolute turnover of Top10 song topics (1550-1750)

8.4. LITERATURE AND DIVERSITY 91
The reason why there are no numbers on the x-axis that can be recognizedas actual years, is that earlier on, I converted the years to an index, fromwhich five years were excluded of which I had no songs. The shortage ofthese years slightly distorts the image, but roughly the numbers on the x-axis can be converted to the actual years, by adding 1550 to it. According toFigure 8.9, a higher turnover seems to appear from 1600. From 1625 to 1700,a turnover value below 3 does not even appear, which means that during thisperiod, every year at least three new topics appear in the Top10. The sametrend can be observed in Figure 8.8. Between 1550 and 1600, the number ofnew topics in the Top5 is located between 1 and 4, but between 1625 and1700, this number is in general somewhere between 3 and 5. Still, the plotsin these figures are not very easy to interpret. Therefore it is helpful to use asmoothing function, which can make the visual intuitions I just made moreclear. I use the ‘moving average’ function, in pandas available through themethod rolling. This function takes a couple of datapoints and returns theaverage of these datapoints. With the argument window I specify the size ofthe window, i.e. how many previous data points the function should take tocalculate the average value. In the following code block I set the window sizeto 10 and create a plot afterwards:
turnover_rw_10 = turnover_topics_10.rolling(10).mean()
plt.rc("text", usetex=True)
plt.rc("font", family="serif")
turnover_rw_10.plot()
The same I did for the DataFrame turnover topics 5. Figures 8.10 and 8.11show the resulting plots. When looking at Figure 8.10 in more detail, Iobserve a clear increase in turnover regarding the years 1550-1675. Between1675 and 1720, the line drops, but starts to rise again after 1720. This riseonly endures until 1735: by then the line drops again. In Figure 8.11, moreor less the same pattern can be observed. This means that starting around1600, the number of topics that are in the upper part of the ranking in twoconsecutive years, quickly decreases. In other words: every year, more newtopics make their appearance in the Top5 or Top10 of most dominant topics.This confirms the claim that a growing variation in subjects appeared duringthe seventeenth century.
In Chapter 3, I already discussed the different biases that can be at stakein a process of cultural evolution. I mentioned the study of Acerbi andBentley, who showed a ‘concave’ turnover profile for the turnover of recentbaby names in the United States. The decreasing slope of the curve suggestsa preference for relatively uncommon names, which they assign as an anti-
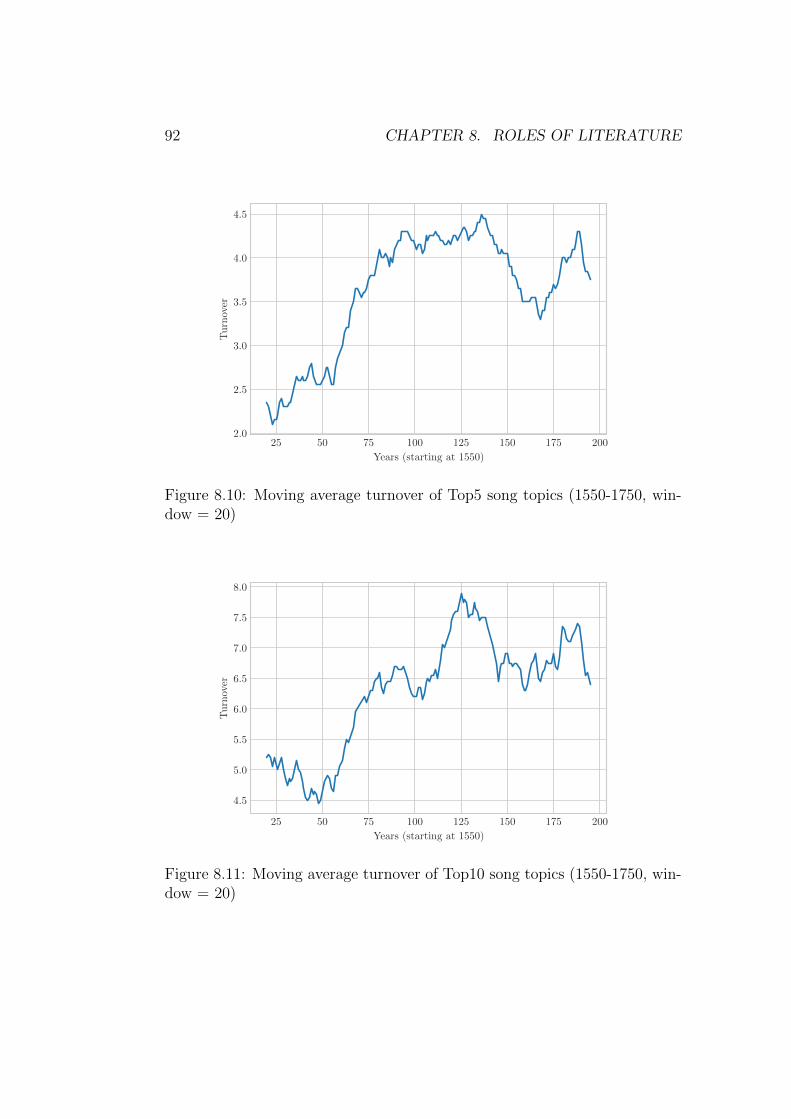
92 CHAPTER 8. ROLES OF LITERATURE
25 50 75 100 125 150 175 200
Years (starting at 1550)
2.0
2.5
3.0
3.5
4.0
4.5T
urn
over
Figure 8.10: Moving average turnover of Top5 song topics (1550-1750, win-dow = 20)
25 50 75 100 125 150 175 200
Years (starting at 1550)
4.5
5.0
5.5
6.0
6.5
7.0
7.5
8.0
Tu
rnov
er
Figure 8.11: Moving average turnover of Top10 song topics (1550-1750, win-dow = 20)

8.4. LITERATURE AND DIVERSITY 93
conformity bias. The opposite was the case for early boys names, where anincreasing slope suggested a preference for common names, in which Acerbiand Bentley recognized a conformity bias. In order to derive a certain biasfrom a turnover plot, Acerbi and Bentley use a variable top size to calculatethe average turnover for each value of the top size. Plotting these two againsteach other, reveals whether more shifts appear in the bottom of the chart, orin the upper part of the chart. More shifts in the bottom part of the chartresults in an increasing slope of the curve and therefore a conformity bias.More shifts in the upper part of the chart results in a decreasing slope of thecurve and therefore an anti-conformity bias. In the turnover series that isdepicted in Figure 8.10, a fixed top size is used, namely y = 5. To create acomparable plot as the ones Acerbi and Bentley plot, I need to calculate theaverage turnover for every length of the chart. I use the next block of codefor that:
def slicing(i):
cutoff = df_turnovertop1.iloc[:,0:i]
return cutoff
def turnover(i):
cutoff = slicing(i)
turnco = cutoff.apply(set, axis = 1)
turnovers = {}
for year in range(turnco.index.min() + 1, turnco.index.max() + 1):
name_set, prior_name_set = turnco.loc[year], turnco.loc[year - 1]
turnovers[year] = len(name_set.difference(prior_name_set))
return pd.Series(turnovers)
max_y = 51
scores = []
for i in range(1, max_y):
avg_turnover = np.mean(turnover(i))
scores.append(avg_turnover)
In Figure 8.12, the result of the code above is plotted, with max y = 51.This means that for every length of the rank (starting with 1), the averageturnover is calculated, ending at 50. Looking at the plot, it immediatelybecomes clear that this curve does not give any insight in possible biases.The reason for that is that in the ranking of song topics, a fixed numberof fifty topics fill the charts. The closer the top list size comes to 50, theless topics are excluded, eventually resulting in a turnover of 0: all topics

94 CHAPTER 8. ROLES OF LITERATURE
are included in the Top50, so no shifts have taken place. At first it soundsreasonable to create a plot with no negative slope, which means that thetop list size should not be larger than 20, but in the end, that would notgive extra insight. Since the shape of the curve in Figure 8.12 is parabolic,a cutoff would always show a curve with a decreasing slope. According toAcerbi and Bentley, a decreasing slope suggests an anti-conformity bias, butin this case, it is more of a ‘parabolic bias’, which has nothing to do withthe transmission of traits. Deriving a transmission bias from a turnover ploton early modern song topics will only make sense if the number of differenttopics is not equal to the maximum top list size.
0 10 20 30 40 50
Top list size
0
2
4
6
8
Tu
rnov
er
Figure 8.12: Average turnover per top list size

Part IV
Conclusion
95


Chapter 9
Conclusion and discussion
For years, literary researchers on the early modern period have publishedstudies on countless well-known and less well-known early modern texts andauthors, enough to fill complete libraries. These qualitative studies haveshaped our idea about the Dutch Republic, her inhabitants, leaders, en-emies, and in particular, her literature. To some extent, it is understandablethat these researchers are a bit wary of new, digital methods to investigatecultural products from a larger distance. Zooming out means that manydetails become invisible: details which, with close reading, would have givenus essential information about a text, its writer, publisher, reader, or thecontext in which it was created. However, in words of Underwood, ‘[a] singlepair of eyes at ground level can’t grasp the curve of the horizon’.130 If wetake our distance and get up in the sky, we will see things, patterns, wewere never able to see before. This does not mean that we should forget theobservations we did earlier, when we were still on our knees, studying a textthrough a magnifying glass. The golden mean shall always be a combinationof both: a confrontation of the one method with the other, to see how bothperspectives are related to each other and how they can complement eachother.
That is what I have tried to do in this thesis. In researching a corpus ofDutch early modern songs from a larger distance, I have not only added astudy to the very long list of studies on Dutch early modern song culture,but most of all, I have expanded the very short list of quantitative studieson the Dutch early modern song. The answers I have found on the twofoldquestion I asked in the first chapter of this thesis, are probably not the mostsurprising. However, the application of digital methods to a corpus of 43,772Dutch songs was a rather unexplored area. With the results obtained in this
130. Underwood, Distant Horizons, x.
97

98 CHAPTER 9. CONCLUSION AND DISCUSSION
research and the interpretation of these results, I have combined the twoperspectives mentioned above (close and distant reading), and evaluated ifand how the outcome of qualitative research on the one hand and quantitativeresearch on the other hand can be related to each other. I do believe thatthe combination of these two methods and the confrontation with each othercan help the early modern literary studies reach a new level.
The first of the two questions I asked was which topics the most dom-inant were in early modern Dutch songs. In answering this question, thepreliminary steps I had to take before I was actually able to let the computercompose topics, took the most time. In the previous months, during my in-ternship at the Meertens Institute, I had gained enough knowledge on skillssuch as parsing XML-files, that this was no longer a problem. However, theenormous variation in spelling of these songs turned out to be a big bump.Working with a corpus containing texts from a period of two hundred yearsin which no normalized spelling was set, was in this case a very complicatingfact. I use the words ‘in this case’, because I realize that there are also situ-ations in which this variation is no problem, or even desirable, for exampleto investigate how fast or slow the spelling of words change over time. Inthe context of this thesis, however, it was very important that all texts werenormalized to the same spelling. For topic modeling it is necessary that aword is spelled exactly the same way through time, otherwise the computerwill build different topics for situations in which one topic would be sufficient.
To normalize historical spelling, there are several methods available forthe English language, but regarding the Dutch language, options were lim-ited. The very straightforward INL-tool I used had been helpful in a sen-timent analysis of early modern songs, but in this study, the tool workedtoo sloppy and the results were therefore too unreliable. The VARD2-tool Itested had much more potential, especially because the tool gave an outputfile in which all made changes were reported. The fact that the training setof the tool was build from seventeenth century translations of the Bible, hadboth advantages and disadvantages. I already knew that a major part of mysong corpus consisted of religious songs, so there would be a lot of overlap-ping words between the Bible and my corpus. The dating of the trainingset in the seventeenth century, had the disadvantage that older words (fromthe fifteenth or sixteenth century) were not included in the set. ‘Old’ wordsin songs, such as ‘dijn’, were therefore not normalized by the tool. Still, Iconsidered the VARD-normalized version of the corpus as the best version,and therefore continued my analysis with that one.
Of all the digital methods to research literary texts computationally thathave arisen in the last decades, I have chosen a rather controversial one in thisthesis. Topic modeling is widely discussed, not only because it is based on

99
probabilities and the mathematical idea therefore seems a mystery to manyusers, but also because we know that the tool needs improvement and isnot already at its best at the moment. Changing some settings, for examplethe number of topics or the number of iterations, can highly influence theoutput. I therefore have had rerun the tool several times, searching for thebest settings. In this study, as well as for all studies in which computationalmethods are used, it is of great importance to critically evaluate the methodsused. Although I have done that to some extent, I realize that there are stillaspects that could have been evaluated more. Another point where humanintervention may have influenced the results negatively, is the assigning ofa certain subject to topics. I have done this assigning by looking at theword cloud of a topic, in which more dominant words were depicted largerthan less dominant words. I have tried to include this difference in worddominance in my consideration which subject would describe the topic atbest, but still it is possible that, if someone else would have done the topicassigning, different subjects would be given to the topics, simply because ahuman being can never be as objective as a computer – which, actually, iswhy a computer is never 100% objective as well, since I am (or somebodyelse is) the one building the tool.
This finally brings me to the answer on the first part of the twofoldresearch question, what the most dominant topics in my corpus were. As saidbefore, the answer did not come as a surprise. Based on the genre distributionin my corpus, I already expected the religious topics to be by far the mostdominant. However, what the genre distribution of the Dutch Song Databasedoes not show, are the subcategories within a genre. Furthermore, a genredoes not say anything about the topic of songs within that genre. Thoseinsights are obtained by building topics from the corpus. Apart from allcriticism, it is admirable that the topic modeling tool was able to distinguishbetween songs on, for example, love and tragedy, and songs on rejection.Another remarkable observation was the dominance of songs with nation andcountry as their most dominant topic, especially after adding the reprintsand songs from other songbooks to the corpus. It is necessary to discussthe method I used in choosing the most dominant topic for each song. Theoutput of a topic modeling tool is always a distribution over the number oftopics you let the tool made. In the context of this study, it meant thattheoretically, fifty topics were present in each song, and the sum of theircontributions was always one. However, for each song there was of course avast majority of topics that was not present, and their contribution was veryclose to (but never) zero. At the same time there was always one topic thatstood out as most dominant. In a lot of cases, the contribution of that topicwas quite high (0.6 or higher), but there were also songs in which the topic

100 CHAPTER 9. CONCLUSION AND DISCUSSION
with the highest contribution still had a very low contribution, in the worstcases even below 0.2. To be pragmatic I have limited my choice to the mostdominant topic for each song (regardless how small or large the contributionof that topic), but I realize that this undoubtedly has biased my results.
In answering the second part of the research question – investigating top-ical fluctuations in a diachronic corpus – the curve of the horizon Underwoodspoke about, came into view. I zoomed out in order to see which patterns be-came visible by observing topics over a longer period of time. What I learnedis that, speaking in general, every topic peaked at one particular moment.It means that most of the topics are not equally dominant at all times, butappear, peak and disappear at a certain moment. To what extent is this re-latable to spelling and word choice? Is it possible that songs from the sameperiod stick together anyway, because they look like each other regardingtheir words, and the way these words are spelled? This is exactly what Ihave tried to eliminate by using a spelling normalization tool, but since thistool has its limits as well, it is possible that I only partly succeeded in this.Still, intuitively I can not imagine that this is the only reason for the sharppeak in every topical plot. Above all, it suggests how certain topics appearand disappear over time, making room for other topics which are often verysimilar, but still at an important point different, otherwise these songs wouldhave had the same dominant topic.
In my thesis, I have related topical fluctuations to cultural-historicalchanges. It turned out that several topics can be related to certain events inthe Dutch Republic, for example the rise of Petrarchism, the Eighty Years’War and the heydays of the Further Reformation. A question that risesfrom these results is: are songs a predictor or follower of trends? Do songsarise as the result of a certain trend, or are they boosting a certain trend?From previous, qualitative studies, we know that both options were commonin the early modern times. The number of songs of the Further Reforma-tion, for example, grew because Calvinists published their own songbooks inhigh circulation. In these songs, subjects were described which were alreadydiscussed and preached about in churches. The Wilhelmus, however, is anexample of a song that functioned more as a booster of a trend, namely therevolt against the Spanish king. In the end, I think that the current resultsare too roughly meshed to say something wise about this matter. Othermethods will undoubtedly be more suitable to answer this question.
More than exploring the relationship between topical fluctuations in myresults on the one hand and cultural-historical changes in the Dutch Re-public on the other hand, I mainly explored how my results, obtained withquantitative research, can be related to the status quaestionis in qualitativeresearch on Dutch early modern literature. Which roles are assigned to lit-

101
erature, concerning the early modern centuries? I distinguished four of themand explored whether my obtained results could validate these four theses.Regarding the relationship between literature and ideology, I illustrated withsongs from the Further Reformation how a certain ideology is carried out insong lyrics. The relationship between literature and poetics of which weknow, thanks to numerous qualitative studies on humanism, the classicaltradition, the Renaissance tradition, and Petrarchism, was confirmed by thequantitative results regarding love topics in my corpus. Concerning the thirdthesis on early modern literature – literature and politics are closely relatedin times of political crises – this was confirmed mainly by the enormous num-ber of songs with nation and country as their most dominant topic, publishedduring the Revolt. The last claim on the role of literature in the early moderntimes – diversity in both involved people and topics – was more complicatedto test. With the used method, it is not possible to distill an intended publicfrom a text. I already stated that other methods would be more fruitful totest this thesis. The diversity in topics I have investigated in calculating theturnover.
In calculating the turnover of topics, I came close to the theoretical fieldI wanted to explore in this thesis: cultural evolution. Hearing and readingabout it in the months before I started to write my thesis, I had becomecurious about ‘how Darwinian theory can explain human culture and syn-thesize the social sciences’, to say it with Mesoudi.131 I wanted to investigateif and how cultural evolution could be applied to early modern songs. Butwhen does a study become a study on cultural evolution? It is more thanoffering a diachronic perspective. Cultural evolution links certain changes intexts, or any cultural product, to cultural and historical circumstances, andhuman behavior. I did the ‘Darwin check’ to see if the three preconditionsof biological evolution – variation, competition and inheritance – could beapplied to culture, and more specific, to a corpus of Dutch early modernsongs. The songs survived the test, and I explored how I would be able tosay something about the transmission bias that might have been at stake inhuman behavior when inheriting song topics. In the end, I did not gain theunambiguous result I was hoping for. I faced the limitations of either mycorpus, my skills and knowledge, or the available methods.
I am almost tempted to say that culture – and in this case, a complexcorpus of songs, uneven distributed over time, and with loads of spellingvariation – is too complex for simple evolutionary models. But then Mesoudirefutes:
It is not being argued that human culture really can be described
131. Mesoudi, Cultural evolution.

102 CHAPTER 9. CONCLUSION AND DISCUSSION
entirely in terms of just a handful of simple variables and pro-cesses. Rather, the reduction involved is methodological: facedwith an enormously complex phenomenon such as culture, themost productive approach to understanding that phenomenonis to divide it up in small pieces and try to explain them in apiecemeal style. (...) Only simple models can yield quantitative,testable predictions that can be shown to be either statisticallysupported or not; and if not, we simply build and test an altern-ative model.132
Against another objection, namely that cultural phenomena are too uniqueand particular to be compared with each other in the way cultural evolution-ists suggest, Mesoudi argues with stating that
the aim is not to replace the study of specific historical events orsocieties with general microevolutionary processes. On the con-trary, without details of specific societies or time periods, there isno data with which to test the validity of the general evolutionaryprocesses. Nor is it to deny that there are important differencesbetween societies and time periods. Of course there are. Butthere are also similarities, and identifying these similarities, andexplaining them with simple principles (...) surely adds to thestudy of specific cases rather than detracts from them.133
It is quite funny to recognize the same rhetoric as used by digital humanitiesscholars such as Underwood and Piper, in defending their computationalmethods, just as I did in the beginning of this chapter, as well as in Chapter2. I might not have understood yet the width and depth of cultural evolutionby writing this one thesis, what I do know is this: to investigate whether wecan indicate cultural evolution in a corpus of Dutch early modern songs,quantitative research of these songs is necessary. But, at the same time,in order to understand the observed patterns achieved with computationalmethods, we need the results obtained with qualitatively researching earlymodern literature as well.
Using computational methods on large digital corpora, is like zoomingout on Google Earth: you do not see the streets, the squares and the round-abouts anymore. Instead, you start to see cities, borders, huge woods, longrivers, mountains, deserts, oceans, and, eventually, the shape of the earth. Itchanges your whole perspective on the city you reside in, the country you are
132. Mesoudi, Cultural evolution, 131.133. Ibid., 132.

103
inhabitant of, and the continent on which you live. But to plan your routeto visit a concert of Famke Louise on a pop stage you have not been before,you still use Google Maps. And that is okay. Because the one does not haveto replace the other.

104 CHAPTER 9. CONCLUSION AND DISCUSSION

Bibliography
Acerbi, Alberto, and R. Alexander Bentley. ‘Biases in Cultural TransmissionShape the Turnover of Popular Traits’. Evolution and Human Behavior35, no. 3 (May 2014): 228–236.
Alexander, Peter J. ‘Entropy and Popular Culture: Product Diversity in thePopular Music Recording Industry’. American Sociological Review 61,no. 1 (1996): 171–174.
Allington, Daniel, Sarah Brouillette and David Golumbia. ‘Neoliberal Tools(and Archives): A Political History of Digital Humanities’. Accessed1 May 2019. https://lareviewofbooks.org/article/neoliberal-tools-archives-political-history-digital-humanities/.
Arac, Jonathan. ‘Anglo-Globalism?’ New Left Review 16 (1 July 2002): 35–45.
Archer, Dawn, Merja Kyto, Alistair Baron and Paul Rayson. ‘Guidelinesfor Normalising Early Modern English Corpora: Decisions and Justific-ations’. 2015.
Baron, Alistair, and Paul Rayson. ‘VARD 2: A Tool for Dealing with SpellingVariation in Historical Corpora’.
Bentley, R. Alexander. ‘Random Drift versus Selection in Academic Vocab-ulary: An Evolutionary Analysis of Published Keywords’. PLOS ONE3, no. 8 (27-aug-2008): e3057.
Bentley, R. Alexander, Matthew W. Hahn and Stephen J. Shennan. ‘RandomDrift and Culture Change’. Proceedings of the Royal Society of London.Series B: Biological Sciences 271, no. 1547 (22 July 2004): 1443–1450.
Blei, David M. ‘Latent Dirichlet Allocation’.
Blei, David, Lawrence Carin and David Dunson. ‘Probabilistic Topic Models’.IEEE Signal Processing Magazine 27, no. 6 (1 November 2010): 55–65.
105

106 BIBLIOGRAPHY
Bork, G.J. van, D. Delabastita, H. van Gorp, P.J. Verkruijsse and G.J. Vis.Algemeen Letterkundig Lexicon. Leiden: Stichting Digitale Bibliotheekvoor de Nederlandse Letteren (DBNL), cop. 2012.
Boyd, Robert, and Peter J. Richerson. Culture and the Evolutionary Process.Chicago: University of Chicago Press, 1985.
Bredero, G.A. G. A. Bredero’s Boertigh, amoreus, en aendachtigh groot lied-boeck. Edited by F.H. Matter, G. Stuiveling, A. Keersmaekers, C.F.P.Stutterheim, C.A. Zaalberg, F. Veenstra and P.J.J. van Thiel. ’s-Gravenhage:Tjeenk Willink-Noorduijn, 1975–1983.
Buelens, Geert. ‘’Listen - I’m not dissin but there’s something that you’remissin’. Songteksten als literair genre en onderzoeksgebied voor culturelestudies’. In Marges van de literatuur, by Arnout De Cleene, Dirk DeGeest and Anneleen Masschelein, 115–132. Gent: Academia Press, 2013.
Byers, Bruce E., Kara L. Belinsky and R. Alexander Bentley. ‘Independ-ent Cultural Evolution of Two Song Traditions in the Chestnut-SidedWarbler.’ The American Naturalist 176, no. 4 (1 October 2010): 476–489.
Da, Nan Z. ‘The Computational Case against Computational Literary Stud-ies’. Critical Inquiry 45, no. 3 (March 2019): 601–639.
Darwin, Charles. The Descent of Man. London: Gibson Square, 2003.
. The Origin of Species. New York: Gramercy Books, 1979.
Eijnatten, Joris van, and F. A. van Lieburg. Nederlandse religiegeschiedenis.Hilversum: Verloren, 2006.
Gelderblom, Arie-Jan. ‘Investing in your relationship’. In Learned Love. Pro-ceedings of the Emblem Project Utrecht Conference on Dutch Love Em-blems and the Internet (November 2006), edited by Els Stronks andPeter Boot, 131–142. Den Haag: DANS Symposium Publications, 2007.
Grijp, Louis Peter. Het Nederlandse lied in de Gouden Eeuw: het mechanismevan de contrafactuur. Amsterdam: P.J. Meertens-Instituut voor Dialect-ologie, Volkskunde en Naamkunde, 1991.
Grootes, E.K. ‘Het Jeugdig Publiek van de ”Nieuwe Liedboeken” in HetEerste Kwart van de Zeventiende Eeuw’. In Het Woord Aan de Lezer.Zeven Literatuurhistorische Verkenningen, by W. van den Berg and J.Schouten, 72–88. Groningen: Wolters-Noordhoff, 1987.

BIBLIOGRAPHY 107
Harms, Roeland. Pamfletten en publieke opinie: massamedia in de zeven-tiende eeuw. Amsterdam University Press, 2011.
Henrich, Joseph, and Richard McElreath. ‘The Evolution of Cultural Evol-ution’. Evolutionary Anthropology: Issues, News, and Reviews 12, no. 3(2003): 123–135.
Jockers, Matthew L. Macroanalysis: Digital Methods and Literary History.Baltimore: University of Illinois Press, 2013.
Kalff, Gerrit. Het Lied in de Middeleeuwen. Leiden: Brill, 1884.
Karjus, Andres, Richard A. Blythe, Simon Kirby and Kenny Smith. ‘Quanti-fying the Dynamics of Topical Fluctuations in Language’, 2 June 2018.
Karsdorp, Folgert, Mike Kestemont and Allen Riddell. Humanities Data Ana-lysis: Case Studies with Python. 2019.
Kisjes, Ivan, and Tessa Wijckmans. ‘Adapting a Spelling Normalization ToolDesigned for English to 17th Century Dutch’. Mexico City, 2018.
Lassche, Alie, Folgert Karsdorp and Els Stronks. ‘Repetition and Popularityin Early Modern Songs’. Utrecht, 2019.
Lassche, Alie, and Arnoud Visser. ‘Lezers in de marges van Vondels Palamedes ’.Nederlandse Letterkunde 24, no. 1 (1 March 2019): 35–63.
Li, Chenliang, Haoran Wang, Zhiqian Zhang, Aixin Sun and Zongyang Ma.‘Topic Modeling for Short Texts with Auxiliary Word Embeddings’. InProceedings of the 39th International ACM SIGIR Conference on Re-search and Development in Information Retrieval - SIGIR ’16, 165–174.Pisa, Italy: ACM Press, 2016.
Mesoudi, Alex. Cultural evolution: how Darwinian theory can explain humanculture and synthesize the social sciences. Chicago: University of ChicagoPress, 2011.
Moretti, F. ‘Conjectures on World Literature’. New Left Review, no. 1 (2000):54–68.
Moretti, Franco. Distant reading. London: Verso, 2013.
. ‘The Slaughterhouse of Literature’. MLQ: Modern Language Quarterly61, no. 1 (2000): 207–227.
Morin, Olivier. ‘How Portraits Turned Their Eyes upon Us: Visual Prefer-ences and Demographic Change in Cultural Evolution’. Evolution andHuman Behavior 34, no. 3 (1 May 2013): 222–229.

108 BIBLIOGRAPHY
North, Joseph. Literary Criticism. Harvard University Press, 8 May 2017.
Nunes, Joseph C., Andrea Ordanini and Francesca Valsesia. ‘The Power ofRepetition: Repetitive Lyrics in a Song Increase Processing Fluency andDrive Market Success’. Journal of Consumer Psychology 25, no. 2 (2015):187–199.
Piper, Andrew. ‘There Will Be Numbers’. Journal of Cultural Analytics,23 May 2016.
Porteman, K., and Mieke B. Smits-Veldt. Een nieuw vaderland voor de muzen:geschiedenis van de Nederlandse literatuur 1560 - 1700. Tweede druk.Amsterdam: Bakker, 2009.
Prak, Maarten. Gouden Eeuw: het raadsel van de Republiek. Amsterdam:Boom, 2012.
Roest, Aafje de. ‘Buurtvaders. Een kritische lezing van de performance vanrepresent door vier Nederlandse hiphopartiesten’. Master’s thesis, UtrechtUniversity, 2017.
Schenkeveld-van der Dussen, Riet, Karel Porteman, Pieter Couttenier andLia van Gemert. Met en zonder lauwerkrans: schrijvende vrouwen uit devroegmoderne tijd 1550-1850: van Anna Bijns tot Elise van Calcar: tek-sten met inleiding en commentaar. Amsterdam: Amsterdam UniversityPress, 1997.
Serlen, Rachel. ‘The Distant Future? Reading Franco Moretti’. LiteratureCompass 7, no. 3 (2010): 214–225.
Stronks, Els. ‘’Dees kennisse zuldy te kope vinnen’: Liedcultuur en de waardevan ‘know how’ in de vroegmoderne Republiek’. De zeventiende eeuw 30,no. 2 (2014): 147–167.
. Stichten of schitteren: de poezie van zeventiende-eeuwse gereformeerdepredikanten. Houten: Den Hertog, 1996.
Tylor, Edward B. Primitive culture. London: J. Murray, 1871.
Underwood, Ted. ‘Dear Humanists: Fear Not the Digital Revolution’. TheChronicle of Higher Education, 27 March 2019.
. Distant Horizons: Digital Evidence and Literary Change. Chicago:The University of Chicago Press, 2019.

BIBLIOGRAPHY 109
. ‘It Looks like You’re Writing an Argument against Data in LiteraryStudy . . . ’ 21 September 2017. Accessed 1 May 2019. https://tedunderwood.com/2017/09/21/it-looks-like-youre-writing-an-
argument-against-data-in-literary-study/.
. ‘Topic Modeling Made Just Simple Enough.’ 7 April 2012. Accessed30 April 2019. https://tedunderwood.com/2012/04/07/topic-
modeling-made-just-simple-enough/.
Veldhorst, Natascha. ‘Pharmacy for the Body and Soul. Dutch Songbooksin the Seventeenth Century’. Early Music History 27 (October 2008):217–285.
. Zingend Door Het Leven: Het Nederlandse Liedboek in de GoudenEeuw. Amsterdam: Amsterdam University Press, 2009.

110 BIBLIOGRAPHY

111

112 STOP LIST ORIGINAL CORPUS
Stop list original corpus
endieindevandatueenmet’tismijnnieticktedenhymyhetaloponsalsghy’zijntotdaerhaervooromsoosijnhem
doorsysalmaerikdanheefttgynuwatowelhierwantuwaenwywiltditnochbyhoeofgeendermynnawasmoetuytvmenoock
des‘laetseeralledoetwilveeldoenzysoendewaerdochkaneerendgrootsietmeerhaardaarschoonduskomthebtgaenzijtvoleenszynmaarwiesonder
’kgoet ten’sdtersoetdeesaanbengaetuwenwesennaersynhebzalnaeuwezoostaetgheeninttoevryhebbendienweerlustsultmachgeeftdese

113

114 STOP LIST INL-NORMALIZED CORPUS
Stop list INL-normalizedcorpus
enikdiedeinuvandatzijneenmetal’tistemijnnietdenonshetopalshaarhebben’heitotgijvoorcliticomzullenhem
doordezedaardoenzonadannutaanwatzijowelhierwantuwgaanuitgodofmaernochgeenhoegeiookderhyzeggenwiwasmoet
vmaardaerbijickstaanmendes‘eendwildsoozoeteergrootkomenwilveelkansierenWAARlaatghymogendochsyschoongeestwiemeerwaardmakendus
sullenhoogvoleensgoedwiltkwaadweeslieftendziedenwordensprekenminlanggevenbengyhebvrijlaetsijnzelfzooblijventoegheenrechtbrengenalleen

115

116 STOP LIST VARD-NORMALIZED CORPUS
Stop list VARD-normalizedcorpus
enhetindedievandatikumijnzijneenmetisgijtenietdenhijmijzoalopalsdaaronshaarzijtotzalvoormaar
omhemdooraandesodanheeft’nuwatwelnahierwantwijheerwiltditookuitnochbijderoflaathoegeenmenwasmoetv
uwzeerWAAR‘alledoetwilzietuweveeldoengoedkankomtendedochgaanzijteerendgrootdoodmeerzonderschoongaatwezenduszoethebtvolnaar
eenswiemag’kstaattengeeftterwerdgelijkbenuwensynhebmaaktwordtdezezoozultvrijweergheentoealtijdhebbennooitstaandagdiendezenzeonze

Topics original corpus
Topic Words
0 zo uit zich ook ziet waar laat naar zelf nooit1 lof maria hemels godt moeder godts boven reyn bruydegom schoone2 ook god heer kerk godes goods volk werd deur christus3 ach hert lief min ziel pijn leven och hart smert4 heer godt heere vader lof onse naem herten geest onsen5 hun godt leeven gaat vrolyk laat quaat waar geeven weesen6 ic lief es ooc moeder vader god ruyter man miin7 godt kindt stal kindeken nieuwe moeder kint iaer geboren mensch8 hart wiens gelijk sich ook er word waar n’t wijl9 god laat uit leeven heer naa goed gods waar hert10 prins jn jck graef paus soldaten schepen stadt onse spaensche11 heer godt se hen wt sullen doer ouer dies n’t12 herder vee groene harder coridon herders schaepjes herderin soete ey13 man neen weet mee ander sou staen gelt maeckt huys14 quam sprack sagh riep liet doe nam gaf gingh sey15 hemels heer god godes sint hart goods maeght lof groote16 hij sij mij ghij gij wij dij bij sall vive17 liefde liefd hert iesu ziel lief soete iesus min herte18 nog ook ’er jk zo sprak lief dog er ziet19 heer jesus ook iesus nogh seydt godt vader alleluja christus20 ich das mein vnnd mir je vous ein le la21 godt leven ziel godts heer goedt eeuwigh mensch vreught tijdt22 godt gods god mensch quaet wet hert wert recht menschen23 doodt godt sonden heer leven christus mensch bloedt lijden ziel24 leuen christus wt nv gods heere woort god doot godt25 heer dijn godt dy god heere hun wt du dies26 leven ghelijck oft gheven ooghen gheeft teghen gheest tijdt boven27 och doot lijden heere werelt godt noot comt verdriet herte28 god heer sich hand sijne hert lof goed vreughd dood
117

118 TOPICS ORIGINAL CORPUS
29 lief liefde hert adieu liefste troost reyn ic princesse mocht30 ziel hert heer god nog geest ook gods laat hemel31 la fa bruydt vrolijck bruydegom twee man bruyt paer vreught32 soete min venus minne ach hemel licht schoone wiens glans33 godt volck godts hulp landt macht hooft tegen vyanden strijden34 dy yn soe uwz mey jon fen god az heer35 godt hert sich godts quaedt loff wordt vw zich ziel36 sprack waren godt quam gods eenen quamen heeren wt hadden37 sprack godt man heere quam abraham vader israel water huys38 mey vruchten groen groene lof winter boomen vrucht onder schoone39 leven heer geven god sullen gelijck komen oogen heere dagen40 godt hert oft liefde leven vreught godts heer heel n’t41 vreucht comt liefd vvant deucht deur venus n’t vvilt reyn42 gods godt christus heeren woort sullen godts desen heer hoort43 wijn sa drincken wyn bier boer drinckt eenen bacchus nat44 heer hun uit ook godt god volk heeren naar heere45 ha n’t waar laat gaat ho gaan va dies staat46 zee schip baren varen mee ree winden schipper voort landt47 mit dyn god du dy ghoed zo dynen unde elck48 jou je jy nou kom ja meysje ey hey och49 min zo laat liefde hert nog zoet ach zoete ziel

Topics INL-normalized corpus
Topic Words
0 hun leven gods vreugde eeuwig godt heemels heemel vrome dood1 du end dijn heer deinen huur fijn myn dyne zek2 er nog jk zy dog zeer vader trouw kind adieu3 heer iesus jesus christus petrus godt vinden weer zegge twee4 mens leven lust rust zek hert ziel vreugde alles gemoed5 vals mens tong boos haat elk schijn snood lust waarheid6 wijn drinken sa bier glas boer lustig geld bacchus wy7 godt volk israel heere coninck man heeren ginck david abraham8 heer hun volk godt heeren heil woord na?m zek hen9 leven wereld godt mens tijd eeuwig sterven doden dood zonde10 schoonheid haer deugd lof scholen glans goud siet wit leven11 jij er kom nauw ja och mede meysje weer zien12 ich das mein vnnd mir ein mich jn nitt zei13 kerk geloof gods eerst nieuw christus godes zeer eigen heer14 stad waren moeten prins wy graef enten binnen menig laten15 zek zee hand heen water volk bloed hemel weer af16 gods enten zondaar leven heere elk heeren ghelijck fijn liefde17 godt hert zek godts woord af waer kracht ramp leven18 hij ende ic ghij vader wij alzo och willen moeder19 end heer godt hen zien volk n’t kracht myn dies20 groen herder vee harder ach waer coridon schaepjes herderin onder21 christus gods wart leven enten ende heere dood wereld mens22 hert hun n’t leven godt oft naer myn heel liefde23 godt ziel godts vreugde vinden heer haren boven leven troost24 ach hert leven smart hart pijn ziel droef sterven trouw25 nog myn leven zeer liefde zoete dog zy nooit er26 liefde enten hart deur troost vreugde ic reen hert zwaar27 vreugde zingen vrolijk blij zang spelen wy springen verheugd lof28 dijn end du heer godt dijnen dies dij alleluia godes
119

120 TOPICS INL-NORMALIZED CORPUS
29 godt maria godts lof moeder hemels boven vreugde klaar zondaar30 heer godt lof leven vader loven prijs hemel wy boven31 le vous la qui kwee mon les vive ma dobbe32 zee schip mede weer varen voort land prins wy landt33 godt godts leven gods heer heeren werk hart altijd deugd34 hemels godes heer sint haer leven deugd ziel goods maeght35 la fa hu bom lier ta mi tiere tieren sol36 du yn uwz dy fen gunnen mei az mof heer37 mond venus leven kusje ach ziel brand kussen lust hart38 sou ander tijd weet man neen denken waer weer haast39 ziel zich nog gods leven hert heer zeer eeuwig nooit40 bloed doden dood lijden kruis leven christus godt zonde vader41 kind godt nieuw mens stal geboren iaer klein kinnetje moeder42 heer ziel hert zonde leven mijne heere troost bidden och43 vreugde man trouw leven vrede twee vrouw wens liefde bruydt44 ha venus deur goden daphne cupido mars kleur ho diana45 liefde hert ziel lieven hart beminnen vreugde liefd leven zin46 licht nacht dag ogen son slaap zon gezicht duister stralen47 heer godt heere hun fijn noot hart vijand enten helpen48 vijand strijd tegen macht geweld strijden kracht sterk godt hulp49 groen mey vruchten tijd vrucht groeien bloeien kruid veld winter

Topics VARD2-normalizedcorpus
Topic Words
0 god vader geest lof leven herten onzen woord zonden naam1 maria moeder gods lof god hemels maagd vreugd klaar rein2 lief adieu liefste liefde hert troost mocht och herte minnen3 kwam zag sprak ging riep doe liet nam gaf stond4 god oft hert vreugd gods leven heel mijnen haren liefde5 kind geboren god stal kindeken moeder mens nieuwe bethlehem maria6 dijn dij god du hun wt mit fijn dijnen recht7 god volk bloed hand vijand tegen land geweld straf kwaad8 god hen zullen allen wt doer gants dies geprezen werden9 god wt leun gods nv woord christus genen si wereld10 och lijden ach hert pijn verdriet ziel druk tranen droefheid11 mee ’er twee ieder deur mof geld klok net je12 vreugd man bruid twee bruidegom geluk paar bruyt deugd trouw13 gods oft elk god woord heren geest enen rein leven14 venus licht schoonheid gezicht glans zon goden ogen schone stralen15 god sprak kwam zijnen enen gods volk waren ginck man16 kwaad elk zich recht licht waarheid mens eigen schijn haat17 vrolijk hemels hemel vreugd boven zon eeuwig ziel hert oog18 god gods mens leven woord geest godes hert recht heren19 leven zullen geven komen tijd maken dagen laten niemand moeten20 la ha fa hu bom alleluia liere vive tiere es21 liefde vreugd deur rein denkt tis liefd wt nieuwe tijd22 kerk gods geloof godes christus deur christen werk zou iae23 zoete mond lieve ei ach lipjes kusjes kussen lust vreugd24 neen weet lang weg ander sou ei tijd man kind25 zee schip land wind mee baren varen voort ree reis26 geld enen man hun boer oft vrouw huis sou boeren
121

122 TOPICS VARD2-NORMALIZED CORPUS
27 lust mens werelds rust ziel schat geld goud wereld zich28 god word geest nog ziel jezus gods leven hert naa29 wijn drinken sa vrolijk drinkt lustig bier vreugd bacchus zingen30 nog dog lief jk ’er ag zoete kind trouw zou31 gods christus god woord zullen hoort moeten heren och vrienden32 prins land stad vijand graaf god waren jn held kwamen33 zich god hert vw ren er zijns gods zelfs dies34 jou je jij meisje ja kom lieve och meid ien35 hun god zich hart hen leven gods volk zijne heil36 ziel mijne god mijnen woord hert ziele hand ogen recht37 mei vruchten groen groene vrucht schone bomen winter boom land38 min hart liefde nog hert ziel leven vreugd ach ogen39 ach min lief hert liefde ziel minne pijn hart leven40 sprak christus jesus jezus zeid kwam petrus zeide joden nog41 das mein vnnd mir ein mik jn nitt zei mit42 zonden kruis bloed jezus lijden jesu vader wonden god jesus43 le vous je la pour mon les qui ne boire44 god hemels godes sint hart gods maagd ziel lof deughden45 dij yn soe uwz jon fen mei god nat amor46 wereld god leven tijd eeuwig kwaad sterven werelds zonden mens47 vee herder groene zoete veld harder herders schaepjes coridon zon48 liefde hert liefd ziel herte ziele lief alleen zoete iesu49 god lof zijnen volk naam heren zijne hoog hemel looft




















