Contents - CiteSeerX - Penn State University
254
Contents Overview . . . . . . . . . . . . . . . . . . . . . 3 Programme . . . . . . . . . . . . . . . . . . . . 11 Abstracts . . . . . . . . . . . . . . . . . . . . . 57 Directory . . . . . . . . . . . . . . . . . . . . 207 General Information . . . . . . . . . . . . . . . 247
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of Contents - CiteSeerX - Penn State University

ContentsOverview . . . . . . . . . . . . . . . . . . . . . 3
Programme . . . . . . . . . . . . . . . . . . . . 11
Abstracts . . . . . . . . . . . . . . . . . . . . . 57
Directory . . . . . . . . . . . . . . . . . . . . 207
General Information . . . . . . . . . . . . . . . 247


Overview

Mon
day,
July
26Tu
esda
y,Ju
ly27
Wed
nesd
ay,J
uly
28T
hurs
day,
July
29F
riday
,Jul
y30
Sat
urda
y,Ju
ly31
9:00
–10:
009:
00–1
0:00
9:00
–10:
009:
00–1
0:00
9:00
–10:
009:
20–1
0:20
Ope
ning
Cer
emon
yLe
vyLe
ctur
eW
ald
Lect
ure
IW
ald
Lect
ure
IIW
ald
Lect
ure
IIILa
plac
eLe
ctur
e
9:00
–10:
209:
00–1
0:20
9:00
–10:
209:
00–1
0:20
Con
trib
.S
ess.
C5,
C62
,M9
Con
trib
.S
ess.
C34
,C53
,M6
Con
trib
.S
ess.
C6,
C38
,C63
Con
trib
.S
ess.
C59
,C61
,C65
10:2
0–10
:45
Cof
fee
Bre
ak
10:4
5–11
:45
10:4
5–12
:30
10:4
5–12
:30
10:4
5–12
:30
10:4
5–12
:30
10:4
5–11
:45
Kol
mog
orov
Lect
ure
Invi
ted
Ses
s.1,
3,12
,13
Invi
ted
Ses
s.5,
20,2
9,35
Invi
ted
Ses
s.10
,22,
31,3
3In
vite
dS
ess.
17,1
9,23
,26
Rie
tzLe
ctur
e
11:4
5–12
:45
Con
trib
.S
ess.
C9,
C52
,C55
Con
trib
.S
ess.
C19
,C31
,M8
Con
trib
.S
ess.
C22
,C48
,M2
Con
trib
.S
ess.
C3,
C21
,C32
11:4
5
Ber
noul
liLe
ctur
eC
losi
ngC
erem
ony
12:3
0–15
:00
Lunc
hB
reak
12:4
5–14
:15
12:3
0–14
:00
12:3
0–14
:00
12:3
0–13
:45
12:3
0–14
:00
ER
CIM
S3a
-3b
CB
SIM
S5
GA
BS
12:3
0–18
:30
12:3
0–18
:30
12:3
0–18
:30
Pos
ter
Ses
sion
P1
Pos
ter
Ses
sion
P2
Pos
ter
Ses
sion
P3
15:0
0–16
:00
15:0
0–16
:00
15:0
0–16
:00
15:0
0–16
:00
15:0
0–16
:00
Med
aillo
nLe
ctur
eM
edai
llon
Lect
ure
Med
aillo
nLe
ctur
eM
edai
llon
Lect
ure
Med
aillo
nLe
ctur
e
15:0
0–16
:45
15:0
0–16
:45
15:0
0–16
:45
15:0
0–16
:45
15:0
0–16
:45
Invi
ted
Ses
s.2,
8,16
,25
Invi
ted
Ses
s.4,
6,9,
18In
vite
dse
ss.
7,14
,21,
32In
vite
dS
ess.
11,2
7,28
,30,
34In
vite
dS
ess.
15,2
4
Con
trib
.S
ess.
C45
Con
trib
.S
ess.
C2,
C37
Con
trib
.S
ess.
C39
,C57
,M3
Con
trib
.S
ess.
C10
Con
trib
.S
ess.
C16
,C29
,C44
16:4
5–17
:05
Cof
fee
Bre
ak
16:4
5–20
:45
16:4
5–19
:45
IMS
2IM
S6
17:0
5–18
:50
17:0
5–18
:50
17:0
5–18
:50
17:0
5–18
:50
17:0
5–18
:50
Con
trib
.S
ess.
C1,
C11
,C
ontr
ib.
Ses
s.C
12,C
28,
Con
trib
.S
ess.
C8,
C20
,C24
,C
ontr
ib.
Ses
s.C
7,C
13,
Con
trib
.S
ess.
C4,
C15
,
C14
,C23
,C47
,C36
,M1
C35
,C43
,C49
,C51
,M5
C25
,C27
,C40
,M4
C33
,C41
,C46
,C54
,C56
C17
,C18
,C30
,C58
19:1
5–20
:45
1900
–21:
0019
:15–
20:4
5
BS
ICIM
S4
EU
19:3
019
:45
21:0
019
:45
Wel
com
eR
ecep
tion
Din
ner
Soc
ialE
vent

Overview 5
Special Lectures ∗1
Session Speaker Day Hour Room PageKolmogorov Lecture David ALDOUS Monday 10:45 Paranimf 13Bernoulli Lecture Jun LIU Monday 11:45 Paranimf 13Medaillon Lecture Dominique PICARD Monday 15:00 Aula Magna 13Levy Lecture Wendelyn WERNER Tuesday 9:15 Paranimf 18Medaillon Lecture Cun-Hui ZHANG Tuesday 15:00 Aula Magna 22Wald Lecture I Iain JOHNSTONE Wednesday 9:15 Paranimf 28Medaillon Lecture Alison ETHERIDGE Wednesday 15:00 Aula Magna 32Wald Lecture II Iain JOHNSTONE Thursday 9:00 Paranimf 38Medaillon Lecture Vladimir KOLTCHINSKII Thursday 15:00 Aula Magna 42Wald Lecture III Iain JOHNSTONE Friday 9:00 Paranimf 48Medaillon Lecture Evarist GINÉ Friday 15:00 Aula Magna 51Laplace Lecture Steffen LAURITZEN Saturday 9:20 Paranimf 56Rietz Lecture Peter BICKEL Saturday 10:45 Paranimf 56
Invited Sessions ∗2 in chronological order
Session Title Day Hour Room Page2 Inference for Dynamical Spatial/Temporal Models Monday 15:00 1.1 138 Statistics in Finance and Econometrics Monday 15:00 BB6 13
16 Metastability Monday 15:00 2.1 1425 Causality and Multi-Stage Decision Problems Monday 15:00 0.1 14
1 Biological Networks - Modelling and Inference Tuesday 10:45 AM5 193 Mathematical Finance Tuesday 10:45 BB6 19
12 Concentration Inequalities Tuesday 10:45 0.1 1913 Conformal Invariance and Stochastic Loewner Evolutions Tuesday 10:45 1.1 20
4 Modeling and Temporal Dependence for Extremes Tuesday 15:00 2.1 236 Statistics in Molecular Biology Tuesday 15:00 0.1 239 The Interface of Insurance and Finance Tuesday 15:00 BB6 23
18 Percolation, Statistical Mechanics, Interacting Particle Syst. Tuesday 15:00 1.1 235 Statistical Genetics Wednesday 10:45 0.1 29
20 Random Matrices and Related Processes I Wednesday 10:45 2.1 2929 Machine Learning in Complex Structures Wednesday 10:45 1.1 2935 Graphical Models in Statistics Wednesday 10:45 AM5 30
7 Statistical Methods in Brain Mapping Wednesday 15:00 2.1 3214 Large Deviations Wednesday 15:00 1.1 3321 Random Matrices and Related Processes II Wednesday 15:00 2.2 3332 Statistical Inference for Stochastic Differential Equations Wednesday 15:00 0.1 3310 Brownian Motion Thursday 10:45 1.1 3922 Random Walks in Random Environ. and Random Media Thursday 10:45 2.1 3931 Statistical Analysis of Point Processes Thursday 10:45 0.1 3933 Function Space Valued Modeling Thursday 10:45 AM5 4011 Coalescents, Coagulation and Fragmentation Thursday 15:00 4.1 4227 False Discovery Rates Thursday 15:00 3.1 4328 Model Choice and Goodness of Fit in Nonparametrics Thursday 15:00 2.1 4330 Nonparametric Analysis for Time Series Thursday 15:00 2.2 4334 Biostatistics Thursday 15:00 0.1 4317 Mixing of Finite Markov Chains Friday 10:45 2.2 4919 Probability on Graphs Friday 10:45 2.1 4923 Function Estimation Friday 10:45 0.1 4926 Dimension Reduction for High Dimensional Data Friday 10:45 AM5 4915 Measure-Valued Processes and SPDE Friday 15:00 0.1 5124 Applications of Particle Filtering in Statistics Friday 15:00 2.1 51
∗See Notes on page 10

6 6th BS/ IMSC
Invited Sessions ∗2 ordered by session number
Session Title Day Hour Room Page1 Biological Networks - Modelling and Inference Tuesday 10:45 AM5 192 Inference for Dynamical Spatial/Temporal Models Monday 15:00 1.1 133 Mathematical Finance Tuesday 10:45 BB6 194 Modeling and Temporal Dependence for Extremes Tuesday 15:00 2.1 235 Statistical Genetics Wednesday 10:45 0.1 296 Statistics in Molecular Biology Tuesday 15:00 0.1 237 Statistical Methods in Brain Mapping Wednesday 15:00 2.1 328 Statistics in Finance and Econometrics Monday 15:00 BB6 139 The Interface of Insurance and Finance Tuesday 15:00 BB6 23
10 Brownian Motion Thursday 10:45 1.1 3911 Coalescents, Coagulation and Fragmentation Thursday 15:00 4.1 4212 Concentration Inequalities Tuesday 10:45 0.1 1913 Conformal Invariance and Stochastic Loewner Evolutions Tuesday 10:45 1.1 2014 Large Deviations Wednesday 15:00 1.1 3315 Measure-Valued Processes and SPDE Friday 15:00 0.1 5116 Metastability Monday 15:00 2.1 1417 Mixing of Finite Markov Chains Friday 10:45 2.2 4918 Percolation, Statistical Mechanics, Interacting Particle Syst. Tuesday 15:00 1.1 2319 Probability on Graphs Friday 10:45 2.1 4920 Random Matrices and Related Processes I Wednesday 10:45 2.1 2921 Random Matrices and Related Processes II Wednesday 15:00 2.2 3322 Random Walks in Random Environ. and Random Media Thursday 10:45 2.1 3923 Function Estimation Friday 10:45 0.1 4924 Applications of Particle Filtering in Statistics Friday 15:00 2.1 5125 Causality and Multi-Stage Decision Problems Monday 15:00 0.1 1426 Dimension Reduction for High Dimensional Data Friday 10:45 AM5 4927 False Discovery Rates Thursday 15:00 3.1 4328 Model Choice and Goodness of Fit in Nonparametrics Thursday 15:00 2.1 4329 Machine Learning in Complex Structures Wednesday 10:45 1.1 2930 Nonparametric Analysis for Time Series Thursday 15:00 2.2 4331 Statistical Analysis of Point Processes Thursday 10:45 0.1 3932 Statistical Inference for Stochastic Differential Equations Wednesday 15:00 0.1 3333 Function Space Valued Modeling Thursday 10:45 AM5 4034 Biostatistics Thursday 15:00 0.1 4335 Graphical Models in Statistics Wednesday 10:45 AM5 30
Contributed Sessions ∗3 in chronological order
Session Title Day Hour Room PageC45 Bootstrap and Simulation Monday 15:00 2.2 14
C1 Population Models Monday 17:05 AM5 15C11 Stochastic Analysis I Monday 17:05 0.1 15C14 Empirical Processes Monday 17:05 2.2 15C23 Applied Probability Monday 17:05 3.1 16C36 Optimal Stopping and Control Monday 17:05 2.1 16C47 Bootstrap Monday 17:05 1.1 17M1 Stochastic Volatility Models Monday 17:05 BB6 17
(Continued on next page)
∗See Notes on page 10
Overview 7
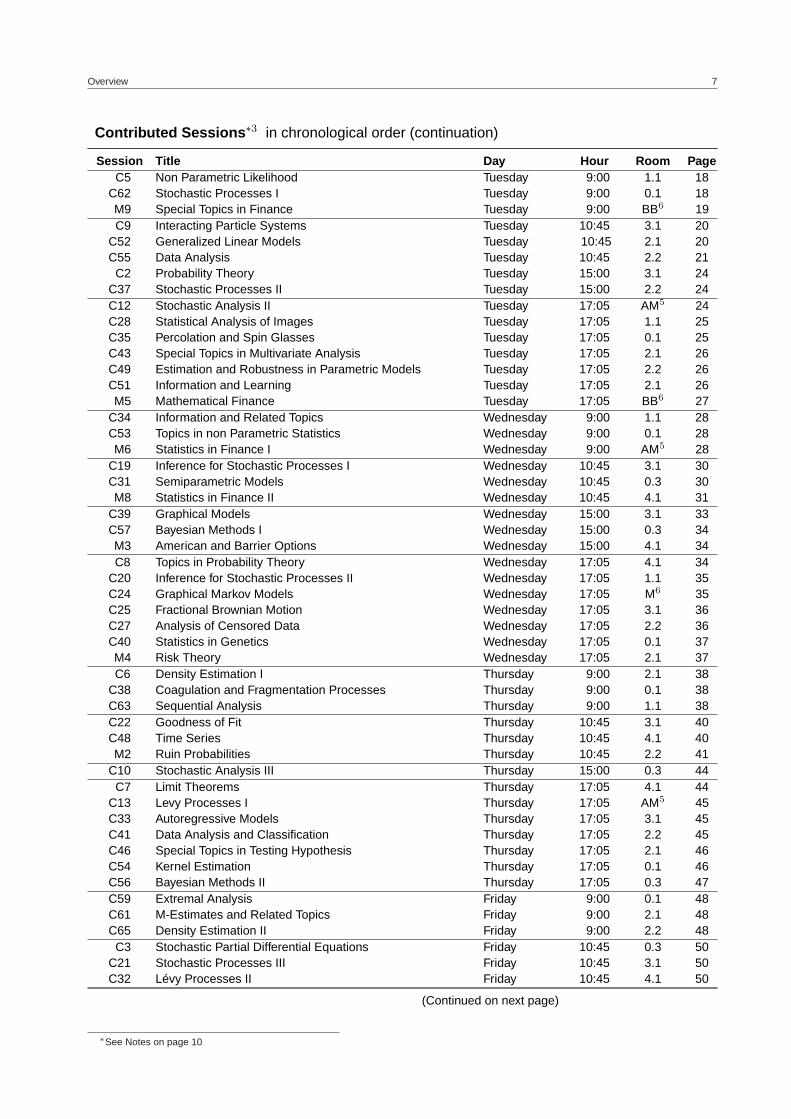
Contributed Sessions ∗3 in chronological order (continuation)
Session Title Day Hour Room PageC5 Non Parametric Likelihood Tuesday 9:00 1.1 18
C62 Stochastic Processes I Tuesday 9:00 0.1 18M9 Special Topics in Finance Tuesday 9:00 BB6 19C9 Interacting Particle Systems Tuesday 10:45 3.1 20
C52 Generalized Linear Models Tuesday 10:45 2.1 20C55 Data Analysis Tuesday 10:45 2.2 21
C2 Probability Theory Tuesday 15:00 3.1 24C37 Stochastic Processes II Tuesday 15:00 2.2 24C12 Stochastic Analysis II Tuesday 17:05 AM5 24C28 Statistical Analysis of Images Tuesday 17:05 1.1 25C35 Percolation and Spin Glasses Tuesday 17:05 0.1 25C43 Special Topics in Multivariate Analysis Tuesday 17:05 2.1 26C49 Estimation and Robustness in Parametric Models Tuesday 17:05 2.2 26C51 Information and Learning Tuesday 17:05 2.1 26M5 Mathematical Finance Tuesday 17:05 BB6 27
C34 Information and Related Topics Wednesday 9:00 1.1 28C53 Topics in non Parametric Statistics Wednesday 9:00 0.1 28M6 Statistics in Finance I Wednesday 9:00 AM5 28
C19 Inference for Stochastic Processes I Wednesday 10:45 3.1 30C31 Semiparametric Models Wednesday 10:45 0.3 30M8 Statistics in Finance II Wednesday 10:45 4.1 31
C39 Graphical Models Wednesday 15:00 3.1 33C57 Bayesian Methods I Wednesday 15:00 0.3 34M3 American and Barrier Options Wednesday 15:00 4.1 34C8 Topics in Probability Theory Wednesday 17:05 4.1 34
C20 Inference for Stochastic Processes II Wednesday 17:05 1.1 35C24 Graphical Markov Models Wednesday 17:05 M6 35C25 Fractional Brownian Motion Wednesday 17:05 3.1 36C27 Analysis of Censored Data Wednesday 17:05 2.2 36C40 Statistics in Genetics Wednesday 17:05 0.1 37M4 Risk Theory Wednesday 17:05 2.1 37C6 Density Estimation I Thursday 9:00 2.1 38
C38 Coagulation and Fragmentation Processes Thursday 9:00 0.1 38C63 Sequential Analysis Thursday 9:00 1.1 38C22 Goodness of Fit Thursday 10:45 3.1 40C48 Time Series Thursday 10:45 4.1 40M2 Ruin Probabilities Thursday 10:45 2.2 41
C10 Stochastic Analysis III Thursday 15:00 0.3 44C7 Limit Theorems Thursday 17:05 4.1 44
C13 Levy Processes I Thursday 17:05 AM5 45C33 Autoregressive Models Thursday 17:05 3.1 45C41 Data Analysis and Classification Thursday 17:05 2.2 45C46 Special Topics in Testing Hypothesis Thursday 17:05 2.1 46C54 Kernel Estimation Thursday 17:05 0.1 46C56 Bayesian Methods II Thursday 17:05 0.3 47C59 Extremal Analysis Friday 9:00 0.1 48C61 M-Estimates and Related Topics Friday 9:00 2.1 48C65 Density Estimation II Friday 9:00 2.2 48
C3 Stochastic Partial Differential Equations Friday 10:45 0.3 50C21 Stochastic Processes III Friday 10:45 3.1 50C32 Lévy Processes II Friday 10:45 4.1 50
(Continued on next page)
∗See Notes on page 10

8 6th BS/ IMSC
Contributed Sessions ∗3 in chronological order (continuation)
Session Title Day Hour Room PageC16 Random Graphs Friday 15:00 2.2 52C29 Dimension Reduction Friday 15:00 3.1 52C44 Testing in Mixture Models Friday 15:00 4.1 52
C4 Stochastic Equations Friday 17:05 3.1 53C15 Random Walks Friday 17:05 0.1 53C17 Stochastic Geometry Friday 17:05 2.1 53C18 Markov Chains Friday 17:05 2.2 54C30 Long Memory Processes Friday 17:05 4.1 54C58 Non-Parametric Regression Friday 17:05 AM5 55
Contributed Sessions ∗3 ordered by session number
Session Title Day Hour Room PageC1 Population Models Monday 17:05 AM5 15C2 Probability Theory Tuesday 15:00 3.1 24C3 Stochastic Partial Differential Equations Friday 10:45 0.3 50C4 Stochastic Equations Friday 17:05 3.1 53C5 Non Parametric Likelihood Tuesday 9:00 1.1 18C6 Density Estimation I Thursday 9:00 2.1 38C7 Limit Theorems Thursday 17:05 4.1 44C8 Topics in Probability Theory Wednesday 17:05 4.1 34C9 Interacting Particle Systems Tuesday 10:45 3.1 20
C10 Stochastic Analysis III Thursday 15:00 0.3 44C11 Stochastic Analysis I Monday 17:05 0.1 15C12 Stochastic Analysis II Tuesday 17:05 AM5 24C13 Levy Processes I Thursday 17:05 AM5 45C14 Empirical Processes Monday 17:05 2.2 15C15 Random Walks Friday 17:05 0.1 53C16 Random Graphs Friday 15:00 2.2 52C17 Stochastic Geometry Friday 17:05 2.1 53C18 Markov Chains Friday 17:05 2.2 54C19 Inference for Stochastic Processes I Wednesday 10:45 3.1 30C20 Inference for Stochastic Processes II Wednesday 17:05 1.1 35C21 Stochastic Processes III Friday 10:45 3.1 50C22 Goodness of Fit Thursday 10:45 3.1 40C23 Applied Probability Monday 17:05 3.1 16C24 Graphical Markov Models Wednesday 17:05 AM5 35C25 Fractional Brownian Motion Wednesday 17:05 3.1 36C27 Analysis of Censored Data Wednesday 17:05 2.2 36C28 Statistical Analysis of Images Tuesday 17:05 1.1 25C29 Dimension Reduction Friday 15:00 3.1 52C30 Long Memory Processes Friday 17:05 4.1 54C31 Semiparametric Models Wednesday 10:45 0.3 30C32 Lévy Processes II Friday 10:45 4.1 50C33 Autoregressive Models Thursday 17:05 3.1 45C34 Information and Related Topics Wednesday 9:00 1.1 28C35 Percolation and Spin Glasses Tuesday 17:05 0.1 25C36 Optimal Stopping and Control Monday 17:05 2.1 16
(Continued on next page)
∗See Notes on page 10

Overview 9
Contributed Sessions ∗3 ordered by session number (continuation)
Session Title Day Hour Room PageC37 Stochastic Processes II Tuesday 15:00 2.2 24C38 Coagulation and Fragmentation Processes Thursday 9:00 0.1 38C39 Graphical Models Wednesday 15:00 3.1 33C40 Statistics in Genetics Wednesday 17:05 0.1 37C41 Data Analysis and Classification Thursday 17:05 2.2 45C43 Special Topics in Multivariate Analysis Tuesday 17:05 2.1 26C44 Testing in Mixture Models Friday 15:00 4.1 52C45 Bootstrap and Simulation Monday 15:00 2.2 14C46 Special Topics in Testing Hypothesis Thursday 17:05 2.1 46C47 Bootstrap Monday 17:05 1.1 17C48 Time Series Thursday 10:45 4.1 40C49 Estimation and Robustness in Parametric Models Tuesday 17:05 2.2 26C51 Information and Learning Tuesday 17:05 2.1 27C52 Generalized Linear Models Tuesday 10:45 2.1 20C53 Topics in non Parametric Statistics Wednesday 9:00 0.1 28C54 Kernel Estimation Thursday 17:05 0.1 46C55 Data Analysis Tuesday 10:45 2.2 21C56 Bayesian Methods II Thursday 17:05 0.3 47C57 Bayesian Methods I Wednesday 15:00 0.3 34C58 Non-Parametric Regression Friday 17:05 AM5 55C59 Extremal Analysis Friday 9:00 0.1 48C61 M-Estimates and Related Topics Friday 9:00 2.1 48C62 Stochastic Processes I Tuesday 9:00 0.1 18C63 Sequential Analysis Thursday 9:00 1.1 38C65 Density Estimation II Friday 9:00 2.2 48M1 Stochastic Volatility Models Monday 17:05 BB6 17M2 Ruin Probabilities Thursday 10:45 2.2 41M3 American and Barrier Options Wednesday 15:00 4.1 34M4 Risk Theory Wednesday 17:05 2.1 37M5 Mathematical Finance Tuesday 17:05 BB6 27M6 Statistics in Finance I Wednesday 9:00 AM5 28M8 Statistics in Finance II Wednesday 10:45 4.1 31M9 Special Topics in Finance Tuesday 9:00 BB6 19
Poster Sessions ∗4
Session Title Day Hour Room PageP1 General Topics in Statistics I Tuesday 12:30–18:30 Hall 21P2 General Topics in Probability Wednesday 12:30–18:30 Hall 31P3 General Topics in Statistics II Thursday 12:30–18:30 Hall 41
∗See Notes on page 10
10 6th BS/ IMSC
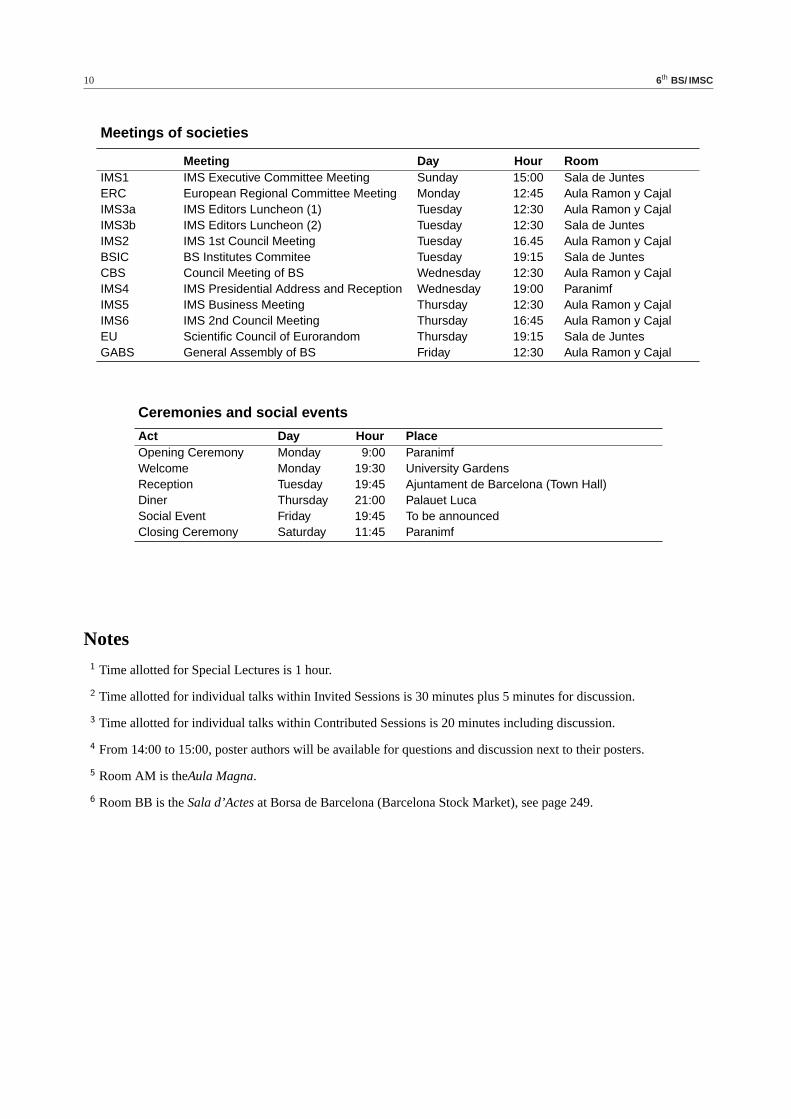
Meetings of societies
Meeting Day Hour RoomIMS1 IMS Executive Committee Meeting Sunday 15:00 Sala de JuntesERC European Regional Committee Meeting Monday 12:45 Aula Ramon y CajalIMS3a IMS Editors Luncheon (1) Tuesday 12:30 Aula Ramon y CajalIMS3b IMS Editors Luncheon (2) Tuesday 12:30 Sala de JuntesIMS2 IMS 1st Council Meeting Tuesday 16.45 Aula Ramon y CajalBSIC BS Institutes Commitee Tuesday 19:15 Sala de JuntesCBS Council Meeting of BS Wednesday 12:30 Aula Ramon y CajalIMS4 IMS Presidential Address and Reception Wednesday 19:00 ParanimfIMS5 IMS Business Meeting Thursday 12:30 Aula Ramon y CajalIMS6 IMS 2nd Council Meeting Thursday 16:45 Aula Ramon y CajalEU Scientific Council of Eurorandom Thursday 19:15 Sala de JuntesGABS General Assembly of BS Friday 12:30 Aula Ramon y Cajal
Ceremonies and social events
Act Day Hour PlaceOpening Ceremony Monday 9:00 ParanimfWelcome Monday 19:30 University GardensReception Tuesday 19:45 Ajuntament de Barcelona (Town Hall)Diner Thursday 21:00 Palauet LucaSocial Event Friday 19:45 To be announcedClosing Ceremony Saturday 11:45 Paranimf
Notes1 Time allotted for Special Lectures is 1 hour.
2 Time allotted for individual talks within Invited Sessions is 30 minutes plus 5 minutes for discussion.
3 Time allotted for individual talks within Contributed Sessions is 20 minutes including discussion.
4 From 14:00 to 15:00, poster authors will be available for questions and discussion next to their posters.
5 Room AM is theAula Magna.
6 Room BB is theSala d’Actesat Borsa de Barcelona (Barcelona Stock Market), see page 249.

Programme


Monday, July 269:00 Opening Ceremony Paranimf
10:15 –10:45 Coffee Break
Kolmogorov Lecture ParanimfChair: Don DAWSON,Carleton University, Canada
10:45 Scaling exponents in random combinatorial optimization[Abstract 7]David ALDOUS, University of California, Berkeley, USA
Bernoulli Lecture ParanimfChair: Susan MURPHY,University of Michigan, USA
11:45 Finding short repetitive patterns in genomic sequences[Abstract 252]Jun LIU , Harvard University, USA
12:30 –15:00 Lunch Break
Medaillon Lecture Aula MagnaChair: Peter HALL,Australian National University, Australia
15:00 What do we learn from maxisets?[Abstract 327]Dominique PICARD, CNRS-Université Paris VII, France
Invited Session 2 Room 1.1Inference for dynamical spatial/temporal modelsOrganizer and Chair: Valerie ISHAM,UCL, UK
15:00 Space-time model for regional seismicity and detection of crustal stress changes[Abstract 306]Yosihiko OGATA , Institute of Statistical Mathematics, Tokyo, Japan
15:35 Generalized linear models for large space-time datasets[Abstract 69]Richard E. CHANDLER , University College London, UK
16:10 Spatio-temporal point processes in ecological models and their approximation by means of mo-ment closures[Abstract 101]Ulf DIECKMANN , International Institute for Applied Systems Analysis, Laxenburg, Austria
Invited Session 8 Borsa de BarcelonaStatistics in finance and econometricsOrganizer and Chair: Yacine AÏT-SAHALIA,Princeton University, USA
15:00 Dynamic integration of time- and state-domian methods for volatility estimation[Abstract 125]Jianqing FAN and Jiancheng JIANG,Princeton University, USA

Mon
day
14 6th BS/ IMSC
15:35 Parametric inference for discretely observed non-ergodic diffusions[Abstract 189]Jean JACOD, Université P. et M. Curie, France
16:10 A table of two time scales: determining integrated volatility with noisy high frequency data[Abstract 296]Per MYKLAND , The University of Chicago, USA
Invited Session 16 Room 2.1MetastabilityOrganizer and Chair: Frank den HOLLANDER, Eurorandom, Eindhoven, The Netherlands
15:00 A potential theoretic approach to metastability[Abstract 50]Anton BOVIER , University Berlin, Germany
15:55 Metastability in conservative dynamics[Abstract 379]Elisabetta SCOPPOLA, Dipartimento di Matematica, Università di Roma Tre,Italy
Invited Session 25 Room 0.1Causality and multi-stage decision problemsOrganizer and Chair: James ROBINS,Harvard School of Public Health, USA
15:00 Using Q-Learning to estimate an optimal dynamic treatment regime[Abstract 295]S.A. MURPHY, University of Michigan, USA
15:35 A linear programming approach to approximate dynamic programming[Abstract 446]Benjamin VAN ROY , Stanford University, USA
Contributed Session C45 Room 2.2Bootstrap and SimulationChair: Juan Alberto CUESTA-ALBERTOS,Universidad de Cantabría, Spain
15:00 Bootstrap of empirical Wasserstein metrics with applications[Abstract 26]Eustasio del BARRIOand Carlos MATRÁN,Universidad de Valladolid, Spain
15:20 Resampling methods to estimate the distribution and the variance of functions of sample meansbased on nonstationary spatial data[Abstract 113]Magnus EKSTRÖM, Swedish University of Agricultural Sciences, SwedenSara SJÖSTEDT-DE LUNA,Umeå University, Sweden
15:40 Broadening the scope of bootstrap in complex problems[Abstract 4]Víctor AGUIRRE TORRES and Manuel DOMÍNGUEZ TORIBIO,Instituto TecnológicoAutónomo de Mexico (ITAM), Mexico
16:00 Iterating them out ofn bootstrap for smooth function models with null derivatives[Abstract 235]K.Y. CHEUNG,Stephen M.S. LEE, The University of Hong Kong, HKSAR, ChinaG. Alastair YOUNG,University of Cambridge, U.K.
16:20 Fast Simulation Of New Coins From Old[Abstract 298]Serban NACUand Yuval PERES ,Univeristy of California at Berkeley, USA
16:45 –17:05 Coffee Break

July, 26 15
Mon
dayContributed Session C1 Aula Magna
Population ModelsChair: Thomas KURTZ,University of Wisconsin-Madison, USA
17:05 Population growth in near-critical random environments[Abstract 191]Peter JAGERS, Chalmers University, SwedenFima C. KLEBANER,Monash University, Australia
17:25 On the partition structure of subdivided populations[Abstract 399]R.C. GRIFFITHS andDario SPANÒ, University of Oxford, UK
17:45 Coexistence in locally regulated competing populations[Abstract 43]J. BLATH , A.M. ETHERIDGE and M.E. MEREDITH,University of Oxford, UK
18:05 Ewens’ sampling formula; a combinatorial derivation[Abstract 161]Robert C. GRIFFITHS , University of Oxford, UKSabin LESSARD,University of Montreal, Canada
18:25 Coherent modeling of macroevolution[Abstract 337]David ALDOUS,University of California Berkeley, USALea POPOVIC, IMA, University of Minnesota, USA
18:45 Partition distributions for symmetric overdominance selection[Abstract 167]Kenji HANDA Saga University, Japan
Contributed Session C11 Room 0.1Stochastic Analysis IChair: Mirieille CHALEYAT-MAUREL, Université René DESCARTES, Paris, France
17:05 On weak Dirichlet processes[Abstract 83]François COQUET, LMAH, Université du Havre, FranceAdam JAKUBOWSKI,Copernicus University, Torun, PolandJean MÉMIN,IRMAR, Université de Rennes 1, FranceLeszek SLOMINSKI, Copernicus University, Torun, Poland
17:25 Towards a general Doob-Meyer decomposition theorem[Abstract 193]Adam JAKUBOWSKI , Nicolaus Copernicus University, Torun, Poland
17:45 Central Limit Theorems for functionals of isonormal Gaussian processes[Abstract 317]Giovanni PECCATI , Université Paris VI, France
18:05 Approximation of stochastic integrals, fractional Sobolev spaces, and interpolation[Abstract 146]Stefan GEISS, University of Jyväskylä, Finland
18:25 Generating functions for stochastic integrals[Abstract 232]Claudio ALBANESE,Imperial College, University of London, UKStephan LAWI , University of Toronto, Canada
18:45 L2-construction of stochastic integrals of nonrandom kernels for nonorthogonal stochastic mea-sures [Abstract 47]I.S. BORISOV and A.A. BYSTROV,Sobolev Institute of Mathematics, Russia
Contributed Session C14 Room 2.2Empirical ProcessesChair: Juan ROMO,Universidad Carlos III De Madrid, Spain
17:05 Functional Chung laws for small increments of the empirical process and a remark on the stronginvariance principle[Abstract 38]Philippe BERTHET , University Rennes 1, France

Mon
day
16 6th BS/ IMSC
17:25 Asymptotics of K-means clustering[Abstract 345]Peter RADCHENKO , Yale University, USA
17:45 Strong uniform representation of the local polynomial estimator. Application to inference withbiased data[Abstract 307]José Tomás ALCALÁ, José Antonio CRISTÓBAL andJorge Luis OJEDA, Universidad deZaragoza, Spain
18:05 Large deviations for random upper semicontinuous functions[Abstract 421]Pedro TERÁN, Universidad de Zaragoza, Spain
18:25 Empirical process based on the recursive residuals in functional measurement error models[Ab-stract 346]A.R. RASEKH , Shahid Chamran University, Ahwaz, Iran
Contributed Session C23 Room 3.1Applied ProbabilityChair: Jeffrey COLLAMORE,University of Copenhagen, Denmark
17:05 Relative risk forests for exercise heart rate recovery as a predictor of mortality[Abstract 188]Hemant ISHWARAN , Cleveland Clinic Foundation, U.S.A.
17:25 High resolution asymptotics for the angular bispectrum of spherical random fields[Abstract 269]Domenico MARINUCCI , University of Rome “Tor Vergata", Italy
17:45 On the equivalence of two expected average cost criteria for semi-Markov control processes[Ab-stract 195]Anna JASKIEWICZ , Politechnika Wrocławska, Poland
18:05 Archimedean Ice[Abstract 114]Kari ELORANTA , University of Technology, Helsinki, Finland
18:25 Stochastic models for the expected time to recruitment in an organisation with two grades[Ab-stract 221]G. GOPAL,R. SURESH KUMAR, University of Madras, Chennai, IndiaR. SATHIYAMOORTHI, Annamalai University, Annamalai nagar, India
Contributed Session C36 Room 2.1Optimal Stopping and ControlChair: Huyen PHAM,University Paris 7, France
17:05 Convergence of values in optimal stopping and convergence of optimal stopping times[Abstract426]Sandrine TOLDO, Université Rennes 1, France
17:25 Maturity randomization for stochastic control problems[Abstract 49]B. BOUCHARD, University Paris VI, FranceN. El Karoui,Ecole Polytechnique, FranceN. TOUZI, University Paris IX, France
17:45 Moderate deviations for particle filtering[Abstract 300]Randal DOUC,Ecole Polytechnique, FranceArnaud GUILLIN, Université Paris-Dauphine, FranceJamal NAJIM , CNRS, France
18:05 Adaptive particle filters[Abstract 311]Anastasia PAPAVASILIOU , Columbia University, USA

July, 26 17
Mon
dayContributed Session C47 Room 1.1
BootstrapChair: Enno MAMMEN,University of Mannheim, Germany
17:05 Application of the bootstrap tok-sample problems in shape analysis[Abstract 465]Andy WOOD , University of Nottingham, UK
17:25 Regenerative bootstrap for Markov chains[Abstract 37]Patrice BERTAIL , CREST, FranceStéphan CLÉMENÇON,MODALX, Université Paris X, France
17:45 Bootstrap algorithms for testing and determining the cointegration rank in VAR models[Abstract409]Anders Rygh SWENSEN, University of Oslo, Norway
18:05 Computationally intensive spectrum estimation methods and non-stationarity[Abstract 366]Juana SANCHEZ, UCLA, USA
Contributed Session M1 Borsa de BarcelonaStochastic Volatility ModelsChair: Ole BARNDORFF-NIELSEN,University of Aarhus, Denmark
17:05 Stochastic volatility models for ordinal valued time series[Abstract 294]Claudia CZADO andGernot MÜLLER , Munich University of Technology, Germany
17:25 Diffusion-type stochastic volatility models[Abstract 39]Bo Martin BIBBY , The Royal Veterinary and Agricultural University, DenmarkMichael SØRENSEN,University of Copenhagen, Denmark
17:45 Volatility and variance swaps for assets with stochastic volatility[Abstract 410]Anatoliy SWISHCHUK , York University, Canada
18:05 Pricing process with stochastic volatility controlled by a semi-Markov process in option pricing[Abstract 404]Dmitrii SILVESTROV andFredrik STENBERG , Malardalen University, Sweden

Tuesday, July 27
Lévy Lecture ParanimfChair: Michel LEDOUX,University of Toulouse, France
9:00 Brownian loop-soups, SLE and Conformal Field Theory[Abstract 461]Wendelin WERNER, Université Paris-Sud, France
Contributed Session C5 Room 1.1Non Parametric LikelihoodChair: Per MYKLAND,The University of Chicago, USA
9:00 Empirical likelihood based goodness-of-fit test for parametric regression[Abstract 444]Wenceslao GONZÁLEZ MANTEIGA and César SÁNCHEZ SELLERO,Universidad de San-tiago de Compostela, SpainIngrid VAN KEILEGOM , Université Catholique de Louvain, Belgium
9:20 Empirical likelihood in nonparametric regression for length biased samples[Abstract 12]J.T. ALCALÁ andE. ANDRÉS, Univ. of Zaragoza, Spain
9:40 Nonparametric maximum likelihood estimator for inverse problems[Abstract 258]Djelil CHAFAI, INRA and Ecole Vétérinaire de Toulouse, FranceJean-Michel LOUBES, CNRS and University of Paris Sud, France
10:00 Empirical energy minimizers[Abstract 168]Patrice BERTAIL,Crest, Laboratoire de Statistique, FranceHugo HARARI , INRA-Corela et Crest, LS, FranceDenis RAVAILLE, ENS, Cachan, France
Contributed Session C62 Room 0.1Stochastic processes IChair: Victor PÉREZ ABREU,Centro de Investigación en Matemáticas, Guanajuato, Mexico
9:00 Power spectra of spatial Hawkes processes[Abstract 51]Pierre BRÉMAUD , EPFL, Lausanne, SwitzerlandLaurent MASSOULIÉ,MicrosoftAndrea RIDOLFI,EPFL, Lausanne, Switzerland
9:20 Gaussian limits for random geometric structures[Abstract 471]Y. BARYSHNIKOV, Bell-Labs, USAM. PENROSE,Univ. of Bath, EnglandJ.E. YUKICH , Lehigh University, USA
9:40 Tree and grid factors in point processes[Abstract 424]Ádám TIMÁR , Indiana University, USA
10:00 Power processes: definition and some properties[Abstract 256]Eva LÓPEZ SANJUÁN and Inmaculada TORRES CASTRO,Universidad de Extremadura,Spain

July, 27 19
Tues
day
Contributed Session M9 Borsa de BarcelonaSpecial topics in FinanceChair: Paul EMBRECHTS,ETH-ZÜRICH, Switzerland
9:00 Fractional Brownian motion as a weak limit of Poisson shot noise processes – with applications tofinance [Abstract 215]Claudia KLÜPPELBERG , Munich University of Technology, GermanyChristoph KÜHN,Goethe-University Frankfurt, Germany
9:20 A continuous time GARCH(1,1) model[Abstract 251]Claudia KLÜPPELBERG,Alexander LINDNER , Munich Technical University, GermanyRoss MALLER,Australian National University, Canberra, Australia
9:40 Bankruptcy prediction with long-term survivors and industry effects[Abstract 402]Sudheer CHAVA,University of Houston, USACatalina STEFANESCU, London Business School, UKYildiray YILDIRIM, Syracuse University, USA
10:15 –10:45 Coffee Break
Invited Session 1 Aula MagnaBiological networks - modelling and inferenceOrganizer and Chair: Marianne HUEBNER,Michigan State University, USA
10:45 Small world networks[Abstract 348]Gesine REINERT, University of Oxford, UK
11:20 Qualitative simulation of genetic regulatory networks: theory and application[Abstract 91]Hidde de JONG, INRIA Rhone-Alpes, France
11:55 Ecological networks[Abstract 184]Marianne HUEBNER , Michigan State University, USA
Invited Session 3 Borsa de BarcelonaMathematical financeOrganizer and Chair: Nizar TOUZI,University Paris IX, France
10:45 Optimal partially reversible investment with entry decision and general production function[Ab-stract 326]Xin GUO, Cornell University, USAHuyên PHAM , University Paris 7, France
11:20 Hedging under gamma constraintsNizar TOUZI , University Paris IX, France
11:55 Constrained investment problems[Abstract 21]Peter BANK, Humbolt University, Berlin, Germany
Invited Session 12 Room 0.1Concentration inequalitiesOrganizer and Chair: Sergey BOBKOV,University of Minnesota, USA
10:45 A finite dimensional logarithmic Sobolev inequality[Abstract 234]D. BAKRY andM. LEDOUX , University of Toulouse, France

Tues
day
20 6th BS/ IMSC
11:20 Moment and tail estimates for Random chaoses andU -statistics [Abstract 228]Rafał LATAŁA , Institute of Mathematics, Warsaw University, Poland
11:55 On the concentration phenomena for infinitely divisible laws[Abstract 182]Christian HOUDRE , Georgia Institute of Technology, USA and University Paris XII, France
Invited Session 13 Room 1.1Conformal invariance and stochastic Loewner evolutionsOrganizer and Chair: Wendelin WERNER,Université Paris-Sud, France
10:45 Excursion decompositions for SLE and Watts’ formula[Abstract 109]Julien DUBÉDAT , Université Paris-Sud, France
11:20 Contour lines and altimeter-compass rays of the Gaussian free field[Abstract 388]Oded SCHRAMM,Microsoft Research, USAScott SHEFFIELD, U.C. Berkeley, USA
11:55 SLE-type processes on Riemann surfaces[Abstract 265]Nikolai MAKAROV and Dapeng ZHAN,California Institute of Technology, USA
Contributed Session C9 Room 3.1Interacting Particle SystemsChair: Claudio LANDIM,IMPA, Brasil and CNRS Université de Rouen, France
10:45 Invariant measure for a Fleming-Viot type Brownian particle system[Abstract 255]Joerg-Uwe LOEBUS, University of Delaware, USA
11:05 On energy and clusters in stochastic systems of sticky gravitating particles[Abstract 457]Vladislav VYSOTSKY , Saint-Petersburg State University, Russia
11:25 Occupation time large deviations of two dimensional symmetric simple exclusion process[Ab-stract 70]Chih-Chung CHANG , National Taiwan University, R.O.C.Claudio LANDIM, IMPA, Brasil and CNRS Université de Rouen, FranceTzong-Yow LEE,University of Maryland, USA
11:45 Perturbations of the symmetric exclusion process[Abstract 204]Paul JUNG, Cornell Math Dept, Ithaca, NY, USA
12:05 Hitting times for asymmetric independent random walks onZd [Abstract 16]Amine ASSELAH, Université de Provence, FrancePablo A. FERRARI,Universidade de São Paulo, Brazil
12:25 Ordering of interacting particle systems with simultaneous changes[Abstract 257]R. DELGADO,University Autònoma of Barcelona, SpainF. J. LÓPEZ and G. SANZ ,University of Zaragoza, Spain
Contributed Session C52 Room 2.1Generalized Linear ModelsChair: Joan del CASTILLO,Universitat Autònoma de Barcelona, Spain
10:45 Variable selection in generalized linear models[Abstract 241]Frédérique LEBLANC,LMC/SMS-UJF-Grenoble 1, FranceFrédérique LETUÉ , LabSAD-UPMF-Grenoble 2 and LMC/SMS-UJF-Grenoble 1, France
11:05 Bandwidth selection for kernel binomial regression[Abstract 308]Kanta NAITO,Shimane University, JapanHidenori OKUMURA , Chugoku Jounior College, Japan

July, 27 21
Tues
day
11:25 Confidence intervals for sum of variance components under unbalanced designs[Abstract 246]Guoying LI and Xinmin LI,Chinese Academy of Sciences, Beijing, P.R.C
Contributed Session C55 Room 2.2Data AnalysisChair: Carles CUADRAS,Universitat de Barelona, Spain
10:45 Mining massive text data and developing tracking statistics[Abstract 253]Daniel JESKE,UC Riverside, USARegina Y. LIU, Rutgers University, USA
11:05 Data depth for nonparametric tests of multivariate location and scale[Abstract 249]Jun LI and Regina LIU,Rutgers University, USA
11:25 Functional observations and depth[Abstract 357]Sara LÓPEZ-PINTADO andJuan ROMO, Universidad Carlos III de Madrid, Spain
11:45 Mining association rules using lattice theory[Abstract 102]Florent DOMENACH , Tsukuba University, Japan
12:05 Data mining by skewering a data cloud[Abstract 380]David W. SCOTT, Rice University, USA
12:30 –15:00 Lunch Break
Poster Session P1 Hall
12:30–18:30
• Residual analysis of multidimensional point process models for earthquake occurrences and goodness-of-fit assessment using a weighted analog of Ripley’s K-function[Abstract 447]Alejandro VEEN , University of California, Los Angeles, USA
• An EM estimation of distribution functions with accelerated life test data[Abstract 247]Linxiong LI , University of New Orleans, USA
• Signal polynomial estimation based on covariances[Abstract 54]R. CABALLERO-ÁGUILA , Universidad de Jaén, SpainA. HERMOSO-CARAZO, J. LINARES-PÉREZ,Universidad de Granada, SpainS. NAKAMORI, Kagoshima University, Japan
• Modeling hot extreme temperature events using a non homogeneous Poisson model[Abstract 64]Jesús ABAURREA andAna C. CEBRIÁN , Universidad de Zaragoza, Spain
• Application of optimization techniques to Bayesian networks design[Abstract 271]Ana M. MARTÍNEZ-RODRÍGUEZ , Luis PARRAS,University of Jaén, SpainLuis G. VARGAS,University of Pittsburgh, U.S.A
• Goodness-of-fit measures for statistical daily rainfall models[Abstract 15]J. ABAURREA andJ. ASÍN, Zaragoza University, Spain
• Hierarchical Bayesian analysis of the partial adjustment of financial ratios using mixture models[Ab-stract 142]José Luis GALLIZO,University of Lleida, SpainPILAR GARGALLO and Manuel SALVADORUniversity of Zaragoza, Spain

Tues
day
22 6th BS/ IMSC
• Continuous-time signal filtering fram uncertain observations with white plus coloured noise[Abstract198]A. HERMOSO-CARAZO, J. LINARES-PÉREZ,Universidad de GranadaJ.D. JIMÉNEZ-LÓPEZ , Universidad de Jaén, SpainS. NAKAMORI, Kagoshima University, Japan
• Reduced bootstrap for bagging prediction models[Abstract 331]María Dolores JIMÉNEZ GAMERO, Juan M. MUÑOZ PICHARDO, Ana MUÑOZ REYES andRafael PINO MEJÍAS , Universidad de Sevilla, Spain
• Fixed-interval smoother under non-independent uncertainty with white plus coloured noises[Abstract368]A. HERMOSO-CARAZO, J. LINARES-PÉREZ,SÁNCHEZ-RODRIGUEZ, M. I. , Universidad deGranada, SpainS. NAKAMORI, Kagoshima University, Japan
• Homogeneity testing of the trajectories of a stochastic process[Abstract 173]J. ARTILES, C.N. HERNÁNDEZ, I.LUENGO , P. SAAVEDRA and A. SANTANA,University ofLas Palmas de Gran Canaria, Spain
• Variable selection in PLS regression with factorial designs[Abstract 474]Alberto FERRER andManuel ZARZO , Polytechnic University of Valencia, Spain
• Principal component determination and random vector estimate with method of partitioned data or-thogonalisation[Abstract 428]P. HOWLETT, S. LUCAS andA. TOROKHTI , University of South Australia, Australia
• Optimal nonlinear transform formed by reduced-rank operators[Abstract 430]P. HOWLET andA. TOROKHTI , University of South Australia, Australia
• Comparison of time series using subsampling[Abstract 10]Andrés M. ALONSO, Universidad Autónoma de Madrid, SpainElizabeth A. MAHARAJ,Monash University, Australia
• On the estimation of parameters in finite mixture models of Generalized Gamma distributions[Ab-stract 17]N. ATIENZA , A. ENGUIX GONZÁLEZ, J. GARCÍA HERAS and J. MUÑOZ-PICHARDO,Univer-sity of Seville, Spain
• Tests of fit for parametric families of Copulas application to financial data[Abstract 375]J. DOBRIC andF. SCHMID , Universitaet zu Koeln, Germany
• Estimation of a pattern from a Set of Signals[Abstract 261]J. ARTILES, C.N. HERNÁNDEZ,I. LUENGO and P. SAAVEDRA,Universidad de Las Palmas GC,Spain
• Estimating flood risk; a long-memory model with time varying variance for daily river discharge[Ab-stract 270]Péter ELEK andLászló MÁRKUS, Eötvös Loránd University, Budapest, Hungary
• Gaussian hypergeometric distributions in modelling a WWW browsing session[Abstract 355]Antonio CONDE SÁNCHEZ, María José OLMO JIMÉNEZ,José RODRÍGUEZ AVI and AntonioJosé SÁEZ CASTILLO,Universidad de Jaén, España
Medaillon Lecture Aula MagnaChair: Lawrence BROWN,University of Pennsylvania, Philadelphia, USA
15:00 Recent results in nonparametric regression and empirical Bayes[Abstract 476]Cun-Hui ZHANG , Rutgers University, USA

July, 27 23
Tues
day
Invited Session 4 Room 2.1Modeling spatial and temporal dependence for extremesOrganizer: Richard A. DAVIS,Colorado State University, USAChair: Claudia KLÜPPELBERG,Munich University of Technology, Germany
15:00 Kriging extreme climate events[Abstract 302]Philippe NAVEAU , University of Colorado at Boulder, USA
15:35 Spatial extremes: models for the stationary case[Abstract 90]Laurens DE HAAN , Erasmus university Rotterdam, The NetherlandsTeresa THEMIDO PEREIRA,University of Lisbon, Portugal
16:10 Extremal behavoir for regularity varying stochastic processes[Abstract 185]Henrik HULT , University of Copenhagen, DenmarkFilip LINDSKOG, ETH Zürich, Switzerland
Invited Session 6 Room 0.1Statistics in molecular biologyOrganizer and Chair: Terry SPEED,University of California at Berkeley, USA
15:00 Probabilistic patterns in gene prediction[Abstract 162]Robert CASTELO andRoderic GUIGÓ, Institut Municipal d’Investigació Mèdica, Barcelona,Catalonia, Spain
15:35 RP scores: a comparative genomics tool for identifying regulation sequences[Abstract 76]F. CHIAROMONTE , L. ELNITSKI, R. HARDISON, J. KASTURI, D. KING, W. MILER andJ. TAYLOR,Penn State University, USA
16:10 Modeling the dependence between sequence motifs[Abstract 374]Gaelle GUSTO andSophie SCHBATH, Institut National de la Recherche Agronomique, France
Invited Session 9 Borsa de BarcelonaThe interface of insurance and financeOrganizer and Chair: Ragnar NORBERG,London School Of Economics, UK
15:00 Optimal risk transfer and diversification in financial markets[Abstract 25]Pauline BARRIEU, London School of Economics, United KingdomNicole EL KAROUI, Ecole Polytechnique, CMAP, France
15:35 Stochastic methods for quantitative risk management[Abstract 115]Paul EMBRECHTS, ETH-ZÜRICH, Switzerland
16:10 Optimization in life insurance[Abstract 403]Mogens STEFFENSEN, University of Copenhagen, Denmark
Invited Session 18 Room 1.1Percolation, statistical mechanics, interacting particle systemsOrganizer: Agoston PISZTORA,Carnegie Mellon University, USAChair: Vincent BEFFARA,ENS Lyon, France
15:00 Random walks on percolation clusters[Abstract 23]Martin T. BARLOW , University of British Columbia, CanadaTakashi KUMAGAI,RIMS, Kyoto, Japan
15:30 Random evolution of surfaces[Abstract 131]Pablo A. FERRARI and Leandro P. R. PIMENTEL,Universidade de São Paulo, Brazil

Tues
day
24 6th BS/ IMSC
16:05 A stable marriage of Poisson and Lebesgue[Abstract 178]Christopher HOFFMAN,Alexander E. HOLROYD and Yuval PERES,University of BritishColumbia, Canada
Contributed Session C2 Room 3.1Probability TheoryChair: Vladimir ZAIATS,Universitat de Vic and Universitat Autònoma de Barcelona, Spain
15:00 The moment problem for random sums[Abstract 165]Allan GUT , Uppsala University, Sweden
15:20 Stochastic order relations and lattices of probability measures[Abstract 293]Alfred MÜLLER , Universität Karlsruhe, GermanyMarco SCARSINI,Universita di Torino, Italy
15:40 Zonoid based trimmed regions[Abstract 62]Ignacio CASCOS FERNÁNDEZ, Public University of Navarra, SpainMiguel LÓPEZ-DÍAZ,University of Oviedo, Spain
16:00 Two integral stochastic orders and their maximal generators[Abstract 61]Jesús de la CAL andJavier CÁRCAMO , Universidad del País Vasco, Bilbao, Spain
Contributed Session C37 Room 2.2Stochastic Processes IIChair: Christian HOUDRÉ,Georgia Institute of Technology, Atlanta, USA and University Paris XII, France
15:00 Locating lines among scattered points[Abstract 166]Peter HALL , Australian National University, AustraliaP.E. MALIN, Duke University, USANader TAJVIDI,Lund Institute of Technology, Sweden
15:20 Law of Large Numbers versus local extinction for superdiffusions[Abstract 117]János ENGLÄNDER, University of California, USAAndreas E. KYPRIANOU,Utrecht University, The NetherlandsAnita WINTER,University of Erlangen, Germany
15:40 Multiscale analysis of Poisson arrival times with time varying intensities[Abstract 194]Maarten JANSEN, TU Eindhoven, The Netherlands
16:00 Upper bounds for exponential momentsof hitting times for semi-Markov processes[Abstract 390]Dmitrii SILVESTROV , Mälardalen University, Sweden
16:20 Asymptotic behaviour of a reaction-difussion equation[Abstract 175]Adrian HINOJOSA , Universidade Federal de Minas Gerais, Brasil
16:45 –17:05 Coffee Break
Contributed Session C12 Aula MagnaStochastic Analysis IIChair: Giovanni PECCATI,Université Paris VI, France
17:05 Stable stationary processes related to cyclic flows[Abstract 416]Vladas PIPIRAS,University of North Carolina, Chapel Hill, USAMurad S. TAQQU , Boston University, USA

July, 27 25
Tues
day
17:25 The Wiener disorder problem with finite horizon[Abstract 139]Pavel V. GAPEEV, Russian Academy of Sciences, RussiaGoran PESKIR,University of Aarhus, Denmark
17:45 Explicit Skorokhod Embedding for functionals of excursions[Abstract 305]Jan OBŁÓJ, Université Paris 6, France and Warsaw University, PolandMarc YOR,Université Paris 6, France
18:05 Large Deviation and central limit theorem of diffusion processes with discontinuous drift[Abstract75]Tzuu-Shuh CHIANG and Shenn-Jyi SHEU,Institute of Mathematics, Academia Sinica, Taipei,Taiwan
18:25 Hölder-Sobolev properties of the solution of the stochastic wave equation in spatial dimensionthree [Abstract 370]R.C. DALANG, EPFL, SwitzerlandM. SANZ-SOLÉ , Universitat de Barcelona, Spain
18:45 Exponential stability of stationary solutions for functional stochastic evolution equations[Abstract143]T. CARABALLO, M.J. GARRIDO-ATIENZA Universidad de Sevilla, SpainB. SCHMALFUSS,University of Technology and Applied Sciences, Merseburg, Germany
Contributed Session C28 Room 1.1Statistical Analysis of ImagesChair: Peter GREEN,University of Bristol, UK
17:05 Structural adaptation by adaptive weights[Abstract 335]Jörg POLZEHL and Vladimir SPOKOINY,Weierstrass Institute for Applied Analysis andStochastics, Germany
17:25 Fitting smoothing splines to data in shape spaces of planar configurations[Abstract 222]I.L. DRYDEN, A. KUME , H. LE and A.T.A. WOOD,University of Nottingham, U.K.
17:45 Multiscale/multigranular image segmentation[Abstract 221]Sucharita GOPAL, Junchang JU andEric D. KOLACZYK Boston University, USA
18:05 Finding optimal distance functions for statistical image segmentation[Abstract 218]András HAJDU,János KORMOSand Zoltán ZÖRGO,University of Debrecen, Hungary
18:25 Modeling images as a superposition of random objects with scaling properties[Abstract 360]Yann GOUSSEAU andFrançois ROUEFF, Telecom Paris, France
Contributed Session C35 Room 0.1Percolation and Spin GlassesChair: TBA
17:05 Measurability of the frozen percolation process on an infinite regular tree[Abstract 20]David J. ALDOUS,University of California, Berkeley, USAAntar BANDYOPADHYAY , Institute for Mathematics and Its Applications, USA
17:25 Corner percolation onZ2 is critical [Abstract 323]Gábor PETE, University of California, Berkeley, USA
17:45 Computation of percolation threshold bounds using non-crossing partitions[Abstract 463]John C. WIERMAN The Johns Hopkins University, Baltimore, USA

Tues
day
26 6th BS/ IMSC
18:05 Nucleation pattern at low temperature for local Kawasaki dynamics in two dimensions[Abstract145]A. GAUDILLIÈRE , Paris Sud and Roma Tor Vergata Universities, France/Italy
18:25 Asymptotic behavior of the magnetization for the perceptron model[Abstract 425]David MÁRQUEZ-CARRERAS, Carles ROVIRA,Universitat de Barcelona, SpainSamy TINDEL , Université Henri Poincaré (Nancy), Vandoeuvre-lès-Nancy, France
18:45 Moderate deviations of the overlap parameter in the Hopfield model[Abstract 112]Peter EICHELSBACHER , Ruhr-University of Bochum, GermanyMatthias LÖWE,University of Münster, Germany
Contributed Session C43 Room 2.1Special Topics in Multivariate AnalysisChair: Holger DETTE,Ruhr-Universität Bochum, Germany
17:05 Applications of the tube formula and the Euler characteristic methods to multivariate distributionalproblems [Abstract 412]Satoshi KURIKI,The Institute of Statistical Mathematics, Minato-ku, Tokyo, JapanAkimichi TAKEMURA , University of Tokyo, Bunkyo-ku, Tokyo, Japan
17:25 A new look at iterative proportional fitting, alternating scaling, cyclic projections, and bipropor-tional apportionment[Abstract 342]Friedrich PUKELSHEIM , Universität Augsburg, Germany
17:45 Fully nonparametric ANCOVA with fixed window sizes[Abstract 14]Michael G. AKRITAS andEfi ANTONIOU The Pennsylvania State University, USA
18:05 Universal optimality of block designs for competition effects[Abstract 192]V.K. GUPTA, Seema JAGGIand Cini VARGHESE,Indian Agricultural Statistics Research In-stitute, New Delhi
18:25 Admissible matrix linear estimators in multivariate linear models[Abstract 466]Kasuo NODA,Meisei University, JapanQiguang WU, Chinese Academy of Sciences, P.R.C
Contributed Session C49 Room 2.2Estimation and Robustness in Parametric ModelsChair: Marie HUSKOVA,Charles University, Czech Republic
17:05 Count distributions with mixed Poisson random effects[Abstract 341]Pedro PUIG, Universitat Autónoma de Barcelona, SpainJordi VALERO,Escola Superior d’Agricultura de Barcelona UPC, Spain
17:25 A new look at an old problem: the double truncated normal distribution[Abstract 87]Gabriela DAMILANO , Universidad de Rio Cuarto, ArgentinaPedro PUIG, Universitat Autònoma de Barcelona, Spain
17:45 Robust estimates, admissibility and shrinkage[Abstract 205]Jana JURECKOVÁ Charles University in Prague, Czech Republic
18:05 Some real time sampling methods[Abstract 278]Kadri MEISTER , Umeå University, Sweden
18:25 Robust estimation and forecasting for beta-mixed hierarchical models of grouped binary data[Ab-stract 210]Yurij KHARIN and Maxim PASHKEVICH,Belarusian State University, Belarus

July, 27 27
Tues
day
Contributed Session C51 Room 2.1Information and LearningChair: TBA
17:05 Complexity regularization via localized random penalties[Abstract 460]Gabor LUGOSI,Pompeu Fabra University, SpainMarten WEGKAMP , The Florida State University, USA
17:25 Generalizing the functional ANOVA: diagnostics in machine learning[Abstract 179]Giles HOOKER, Stanford University, USA
17:45 Controlled variable selection and consistent function estimates with the Lasso for high-dimensional regression and classification[Abstract 277]Peter BÜHLMANN andNicolai MEINSHAUSEN , ETH Zurich, Switzerland
18:05 Adaptive regression estimation with multilayer feedforward neural networks[Abstract 220]Michael KOHLER , Universität Stuttgart, GermanyAdam KRZYZAK, Concordia University, Montreal, Quebec, Canada
18:25 Nonparametric independent component analysis[Abstract 364]Alexander SAMAROV , UMass-Lowell and MIT, USAAlexander TSYBAKOV,Université Paris VI, France
18:45 Bagging Nearest-Neighbour Classifiers[Abstract 365]Richard SAMWORTH University of Cambridge, UKPeter HALL,Australian National University, Australia
Contributed Session M5 Borsa de BarcelonaMathematical FinanceChair: Peter BANK,Humbolt university, Berlin, Germany
17:05 On general futures prices in supermartingale term structure models[Abstract 29]Dirk BECHERER , Imperial College London, UK
17:25 Term structure of interest rates and Generalized Mehler semigroups[Abstract 268]Carlo MARINELLI , Universität Bonn, Germany
17:45 Optimal portfolio choice in bond markets[Abstract 420]Michael TEHRANCHI , University of Texas, USA
18:05 Stopping the maximum of a correlated random walk, with application to Russian options[Abstract8]Pieter C. ALLAART , University of North Texas, USA
18:25 Environment & financial markets[Abstract 411]Monique JEANBLANC,Université d’Evry Val d’Essone, FranceWojciech SZATZSCHNEIDER , Escuela de Actuaria Universidad Anahuac, Mexico
18:45 Stochastic modeling of insurance business with dynamical control of investments[Abstract 391]Anatoliy MALYARENKO, Dmitrii SILVESTROV and Evelina SILVESTROVA,MälardalenUniversity, Sweden

Wednesday, July 28Wald Lecture I ParanimfChair: Bernard SILVERMAN,Oxford University, UK
9:15 Growing Gaussian Models (1)[Abstract 199]Iain JOHNSTONE , Stanford University, USA
Contributed Session C34 Room 1.1Information and Related TopicsChair: Peter SPREIJ,Universiteit van Amsterdam, The Netherlands
9:00 Optimal error exponent in model selection[Abstract 144]E. GASSIAT, Orsay University, France
9:20 On the measure of the information in a statistic[Abstract 150]Josep GINEBRA, Universitat Politècnica de Catalunya, SpainPrem K. GOEL,Ohio State University, USALourdes RODERO,Universitat Politècnica de Catalunya, Spain
9:40 Characterization results via link between the Hellinger distance, mutual information and entropy[Abstract 287]G.R. MOHTASHAMI BORZADARAN , University of Birjand, Birjand, Iran
10:00 Multiobjective optimal MCM placement based on fuzzy approach[Abstract 183]Meihui GUO,National Sun Yat-sen Univ., Kaohsiung, Taiwan, ROCYu-Jung HUANG I-Shou University, Kaohsiung, Taiwan, ROC
Contributed Session C53 Room 0.1Topics in non Parametric StatisticsChair: Miguel DELGADO,Universidad Carlos III, Madrid, Spain
9:00 Sharp adaptive estimation in severely ill-posed inverse problems[Abstract 63]Laurent CAVALIER ,Yuri K. GOLUBEV, Oleg V. LEPSKI,Université Aix-Marseille 1, FranceAlexander B. TSYBAKOV,Université Paris 6, France
9:20 AdaptiveLp estimation under a general class of error densities[Abstract 224]P.Y. LAI and Stephen M.S. LEE,The University of Hong Kong, China
9:40 Model checks using residual marked empirical processes[Abstract 122]J. Carlos ESCANCIANO, Universidad Carlos III de Madrid, Spain
Contributed Session M6 Aula MagnaStatistics in Finance IChair: Albert SATORRA,Universitat Pompeu Fabra, Spain
9:00 Testing the Markov property with ultra-high frequency financial data[Abstract 128]João AMARO DE MATOS,Universidade Nova de Lisboa, PortugalMarcelo FERNANDES, Getulio Vargas Foundation, Brazil
9:20 On covariance estimation for high-frequency financial data[Abstract 170]Takaki HAYASHI , Columbia University, USA, and The University of Tokyo, JAPANNakahiro YOSHIDA,The University of Tokyo, JAPAN

July, 28 29
Wed
nesd
ay
9:40 Estimation and filtering by simulation in a model for ultra-high-frequency financial data[Abstract65]Silvia CENTANNI and Marco MINOZZO,University of Perugia, Italy
10:15 –10:45 Coffee Break
Invited Session 5 Room 0.1Statistical geneticsOrganizer: David CLAYTON,Cambridge University, UKChair: Roderic GUIGÓ,Institut Municipal d’Investigació Mèdica, Barcelona, Catalonia, Spain
10:45 Statistical inference for SFP data[Abstract 418]Justin BOREVITZ,University of Chicago, USARong JIANG, Paul MARJORAM andSimon TAVARÉ , University of Southern California, USA
11:20 Population substructure in population–based association studies[Abstract 80]David CLAYTON , Cambridge University, UK
11:55 Jointly characterizing allelic associations and estimating haplotype frequencies from diploid databy graphical modeling[Abstract 423]Alun THOMAS , University of Utah, USA
Invited Session 20 Room 2.1Random Matrices and Related Processes IOrganizer and Chair: Alexander SOSHNIKOV,University of California at Davis, USA
10:45 Differential equations for Dyson processes[Abstract 432]Craig A. TRACY , UC Davis, USAHarold WIDOM,UC Santa Cruz, USA
11:20 Continuous time Markov chains related to Plancherel measure[Abstract 48]Alexei BORODIN, California Institute of Technology, USA
11:55 MOPs – a Maple library for multivariate orthogonal polynomials (symbolically)[Abstract 110]Ioana DUMITRIU , University of California at Berkeley, USA
Invited Session 29 Room 1.1Machine learning in complex structuresOrganizer and Chair: Peter BARTLETT,University of California at Berkeley, USA
10:45 Variational inference algorithms for large-scale probabilistic models: An alternative to MCMC[Abstract 201]Michael I. JORDAN , University of California at Berkeley, USA
11:20 Graphical processesJohn LAFFERTY , Carnegie Mellon University, USA
11:55 On the rate of convergence of regularized boosting classifiers[Abstract 262]Gilles BLANCHARD, Université Paris-Sud, FranceGábor LUGOSI , Pompeu Fabra University, Barcelona, SpainNicolas VAYATIS, Université Paris 6-Pierre et Marie Curie, France

Wed
nesd
ay30 6th BS/ IMSC
Invited Session 35 Aula MagnaGraphical models in statisticsOrganizer and Chair: Thomas RICHARDSON,Harvard School of Public Health, USA
10:45 Testing and discovery of non-independence restrictions in observed marginals of dags with hiddenvariables: implications for causal inference[Abstract 353]Thomas RICHARDSON andJames ROBINS, Harvard School of Public Health, USA
11:20 Maximum likelihood estimation in ancestral graph Markov models[Abstract 107]Mathias DRTON, University of Washington, USA
11:55 A unified approach to the characterisation of equivalence classes of DAGs, chain graphs with noflags and chain graphs[Abstract 408]Alberto ROVERATO , Universitá di Modena e Reggio Emilia, Italy
Contributed Session C19 Room 3.1Inference for Stochastic Processes IChair: Michael SORENSEN,University of Copenhagen, Denmark
10:45 Estimation of integrated volatility in continuous time financial models with applications togoodness-of-fit testing[Abstract 99]Holger DETTE , Mark PODOLSKIJ and Mathias VETTER,Ruhr-Universität Bochum, Bochum,Germany
11:05 Identification of stochastic differential equation from panel data[Abstract 133]A. David McDONALD, CSIRO Marine Research, AustraliaDaria. V. FILATOVA , University of Kielce, PolandMarek GRZYWACZEWSKI, University of Radom, PolandLeif K. SANDAL, Norwegian School of Economics and Business Administration, Norway
11:25 Statistical modeling of digraph panel data with random coefficients for the vertices[Abstract 378]M. SCHWEINBERGER and Tom A.B. SNIJDERS,University of Groningen, the Netherlands
11:45 Estimation of intrinsic processes affected by additive factial noise[Abstract 129]José M. ANGULO,University of GranadaRosaura FERNÁNDEZ-PASCUAL, University of Jaén, SpainMaría D. RUIZ-MEDINA,University of Granada
Contributed Session C31 Room 0.3Semiparametric ModelsChair: Yuedong WANG,University of California - Santa Barbara, USA
10:45 Algorithms for rank regression[Abstract 135]Ian ABRAMSON, Michael DONOHUE andAnthony GAMST , University of California, SanDiego, USA
11:05 Estimation and tests for semiparametric density ratio models viaφ−divergences[Abstract 238]Amor KEZIOU,Universitè Paris VI et Institut Galilèe Universitè Paris, FranceSamuela LEONI , Università di Padova, Padova, Italy
11:25 Minimax estimation of the noise level and of the signal density in a semiparametric convolutionmodel [Abstract 274]Cristina BUTUCEA,Université Paris VI, FranceCatherine MATIAS , CNRS, France
11:45 Efficient semi-parametric estimation of an error-in-covariates with validation sample arising inreliability [Abstract 172]Nick HENGARTNER and Alyson WILSON,Los Alamos National Laboratory, USA

July, 28 31
Wed
nesd
ay
Contributed Session M8 Room 4.1Statistics in Finance IIChair: Bo Martin BIBBY,The Royal Veterinary and Agricultural University, Denmark
10:45 Two-level analysis of structural equation models for longitudinal data[Abstract 372]Juan Carlos BOU,Universitat Jaume I, SpainAlbert SATORRA , Universitat Pompeu Fabra, Spain
11:05 Nonparametric kernel-based sequential investment strategies[Abstract 439]László GYÖRFI,Technical University of Budapest, HungaryGábor LUGOSI andFrederic UDINA , Universitat Pompeu Fabra, Spain
11:25 A functional auto-regression as a model of interest rate dynamics[Abstract 309]Vladislav KARGIN,Cornerstone Research, USAAlexei ONATSKI , Columbia University, USA
11:45 A new nonparametric ANCOVA model, used in the financial problem of stock returns anomalies[Abstract 435]Haritini TSANGARI , Intercollege, Cyprus
12:30 –15:00 Lunch Break
Poster Session P2 Hall
12:30–18:30
• Multiple Stratonovich fractional integral with Hurst parameter lesser thanfrac12 [Abstract 22]Xavier BARDINA and Maria JOLIS,Universitat Autónoma de Barcelona, Catalonia, Spain
• A Poisson approximation for colored graphs under exchangeability[Abstract 66]Annalisa CERQUETTI and Sandra FORTINI,Bocconi University, Milan, Italy
• Controlled multitype branching processes with random control: extinction probability[Abstract 155]M. GONZÁLEZ , R. MARTÍNEZ and M. MOTA,University of Extremadura
• Asymptotic results for perturbed risk processes with delayed claims[Abstract 263]Claudio MACCI , Università di Roma "Tor Vergata", ItalyGiovanni Luca TORRISI,Istituto per le Applicazioni del Calcolo "Mauro Picone", Italy
• A Lévy generalization of compound poisson processes in finance: theory and applications[Abstract180]Enrique TER HORST , Credit Suisse First Boston, England
• A note on multimodal first entrance time distributions for a class of jump-diffusion processes[Abstract151]María Teresa GIRAUDO and Laura SACERDOTE,University of Torino, Italy
• Retrieving exponential Lévy models from option prices using relative entropy[Abstract 415]Rama, CONT andPeter TANKOV , Ecole Polytechnique, France
• Optimal contributions and portfolio selection in a pension funding with stochastic salaries[Abstract203]Ricardo JOSA-FOMBELLIDA and Juan Pablo RINCON ZAPATERO,Universidad de Valladolid,Spain
• An extension of Hull and White formula and application to option pricing approximation[Abstract11]Elisa ALÒS , Universitat Pompeu Fabra, Barcelona, Spain
• Cross-estimate and tightness for non-symmetric Markov processes[Abstract 418]Yiwen JIANG and Guangshan LI,Wuhan Military Economics Academy, China

Wed
nesd
ay32 6th BS/ IMSC
• A metapopulation model with environmental stochasticity[Abstract 359]Joshua V. ROSS, The University of Queensland, Australia
• Inference and filtering for partially observed diffusion processes via sequential Monte Carlo[Abstract187]Edward IONIDES , University of Michigan, Ann Arbor, USA
• Invariance principles for long memory random fields[Abstract 231]Frédéric LAVANCIER , Université des Sciences et Technologies de Lille, France and Centre deRecherche en Economie et Statistique, Paris, France
• Extremal behaviour of subexponential continuous-time MA processes[Abstract 127]Vicky FASEN, Munich University of Technology, Germany
• Properties of European and American barrier options[Abstract 121]Jonatan ERIKSSON, Uppsala University, Sweden
• On the sum of autocorrelations of a process with absolutely summable partial autocorrelations[Ab-stract 93]Łukasz DEBOWSKI , Polish Academy of Sciences, Warszawa, Poland
• Adaptive stochastic linear automata in random media[Abstract 392]Evelina SILVESTROVA , Mälardalen University, Sweden
• Monte Carlo Markov Chain analysis of time-changed Levy processes of stock return dynamics[Ab-stract 470]Long YU, Cornell University, USA
• Estimation of value-at-risk using copula and extreme value theory[Abstract 181]Luiz K. HOTTA , Edimilson LUCAS and Helder P. PALARO,State University of Campinas, Brazil
• Anisotropy effects in nucleation for conservative dynamics[Abstract 301]F. R. NARDI , University of Roma La Sapienza, ItalyE. OLIVIERI, University of Roma Tor Vergata, ItalyE. SCOPPOLA,University of Roma Tre, Italy
Medaillon Lecture Aula MagnaChair: Marta SANZ-SOLÈ,Universitat de Barcelona, Spain
15:00 Some mathematical problems from population genetics[Abstract 124]Alison ETHERIDGE , University of Oxford, UK
Invited Session 7 Room 2.1Statistical methods in brain mappingOrganizer and Chair: Keith WORSLEY,McGill University, Montreal, Quebec, Canada
15:00 Extrema of random fields[Abstract 3]Robert J. ADLER , Technion. Israel
15:35 Connections between stagewise algorithms and the LASSO: with applications to neuroanatomicalstudies [Abstract 419]Jonathan TAYLOR , Stanford, USA
16:10 Connectivity analysis via Bayesian EEG-fMRI fusion[Abstract 442]Pedro VALDES, Cuban Neuroscience Center, La Habana, Cuba

July, 28 33
Wed
nesd
ay
Invited Session 14 Room 1.1Large deviationsOrganizer and Chair: Erwin BOLTHAUSEN,Universität Zürich, Switzerland
15:00 Large deviations and some generalizations of GREM[Abstract 45]Erwin BOLTHAUSEN and Nicola KISTLER,Universität Zürich, Switzerland
15:35 Localization phenomena for hetero-polymers[Abstract 148]Giambattista GIACOMIN , Universite Paris VII, Paris
16:10 Hydrodynamic limit of asymmetric exclusion processes under diffusive scaling ind ≥ 3 [Abstract226]Claudio LANDIM , IMPA, Brazil and CNRS UMR, France
Invited Session 21 Room 2.2Random Matrices and Related Processes IIOrganizer and Chair: Alan EDELMAN,Massachusetts Institute of Technology, USA
15:00 Advances in random matrix theory[Abstract 111]Alan EDELMAN, Massachusetts Institute of Technology, USA
15:35 Random matrices and communication networks[Abstract 242]Olivier LEVEQUE , EPFL , Lausanne, SwitzerlandEmre TELATAR, Bell Laboratories, NJ, USADavid TSE, UCLA, USA
16:10 The Shannon transform in random matrix theory[Abstract 450]Antonia M. TULINO , Universitá degli Studi di Napoli “Federico II", ItalySergio VERDÚ,Princeton University, New Jersey, USA
Invited Session 32 Room 0.1Statistical inference for stochastic differential equationsOrganizer and Chair: Mathieu KESSLER,Technical University of Cartagena, Spain
15:00 Stochastic differential equations: recent statistical developments[Abstract 398]Michael SØRENSEN, University of Copenhagen, Denmark
15:35 Stochastic volatility: what do we learn from historical data?[Abstract 176]Marc HOFFMANN , CNRS-UMR, France
16:10 Exact simulation for diffusions and applications[Abstract 349]Alexandros BESKOS, Omiros PAPASPILIOPOULOS andGareth ROBERTS, Lancaster Uni-versity, UK
Contributed Session C39 Room 3.1Graphical ModelsChair: Michael D. PERLMAN,University of Washington, USA
15:00 Hyper Dirichlet processes[Abstract 328]Claudio ASCI, Giovanna NAPPO andMauro PICCIONI , Università di Roma La Sapienza, Italy
15:20 Collapsibility for Conditional Gaussian Chain Graph Models[Abstract 100]Vanessa DIDELEZ, University College London, UK
15:40 Covariate selection for estimating treatment effects[Abstract 92]Xavier DE LUNA and Ingeborg WAERNBAUM,Umeå University, Sweden

Wed
nesd
ay34 6th BS/ IMSC
16:00 Gaussian conditional independence structures[Abstract 393]Radim LNENICKA andPetr ŠIMECEK , Institute of Information Theory and Automation, CzechRepublic
Contributed Session C57 Room 0.3Bayesian Methods IChair: Lasse HOLMSTRÖM,University of Oulu, Finland
15:00 Tests of function fit, motivated via Bayesian methods, and their frequentist properties[Abstract79]Gerda CLAESKENS, Université Catholique de Louvain, Belgium
15:20 Hierarchical mixture modelling with normalized inverse Gaussian priors[Abstract 340]Antonio LIJOI,Università degli Studi di Pavia, ItalyRamses MENA,UNAM, MéxicoIgor PRÜNSTER Università degli Studi di Pavia, Italy
15:40 Bayesian Gaussian mixture autoregressive model[Abstract 229]John W. LAU and Mike K.P. SO,Hong Kong University of Science and Technology, Hong Kong
16:00 Bayesian analysis of nonlinear and non-Gaussian state space models via multiple-try samplingmethods[Abstract 396]Mike K.P. SO, Hong Kong University of Science and Technology, Hong Kong
Contributed Session M3 Room 4.1American and Barrier OptionsChair: Bruno BOUCHARD,University Paris VI, France
15:00 Small time behavior of the critical stock price for the american put on alternative stochastic pro-cesses[Abstract 373]John CHADAM andDavid SAUNDERS, University of Pittsburgh, USA
15:20 Optimal stopping strategies for American type options[Abstract 200]Henrik JÖNSSON, Mälardalen University, SwedenAlexander KUKUSH,Kiev University, UkraineDmitrii SILVESTROV, Mälardalen University, Sweden
15:40 Dry markets and superreplication bounds of american derivatives[Abstract 223]João AMARO DE MATOS andAna LACERDA , Universidade Nova Lisboa, Portugal
16:00 Analytical pricing of double-barrier options under a double-exponential jump diffusion process[Abstract 385]Artur SEPP , University of Tartu, Estonia
16:45 –17:05 Coffee Break
Contributed Session C8 Room 4.1Topics in Probability TheoryChair: Maria JOLIS,Universitat Autònoma de Barcelona, Spain
17:05 The polynomial method for random matrices[Abstract 299]Alan Edelman andRaj Rao NADAKUDITI , Massachusetts Institute of Technology, USA

July, 28 35
Wed
nesd
ay
17:25 Generic epigraphical laws of large numbers[Abstract 77]Christine CHOIRAT , Università degli Studi dell’Insubria, ItalyChristian HESS,Université Paris 9 Dauphine, FranceRaffaello SERI,Università degli Studi dell’Insubria, Italy
17:45 A local limit theorem and logical limit laws for expansive multisets[Abstract 401]Boris GRANOVSKY,Tel Aviv University, IsraelDudley STARK, Queen Mary, University of London, United Kingdom
18:05 Convergence rates in the law of large numbers for Riemann random sums[Abstract 440]Víctor HERNÁNDEZ,National Distance University of SpainHenar URMENETA , Public University of Navarra, Spain
18:25 Polynomials orthogonal with respect to the negative binomial distribution[Abstract 211]V.I. KHOKHLOV , Steklov Mathematical Institute, Russian Federation
18:45 On effective replacement strategies taking into account the wear and tear of equipment[Abstract338]Mikhail POSTAN and Lydmila SHIRYAEVA,Odessa National Maritime University, Ukraine
Contributed Session C20 Room 1.1Inference for Stochastic Processes IIChair: Marc HOFFMANN,CNRS-UMR, France
17:05 Ignorable observation patterns of stochastic processes[Abstract 82]Daniel COMMENGES and Anne GEGOUT-PETIT,INSERM EMI, France
17:25 A martingale estimating approach for two parameters diffusion processes[Abstract 284]Rosa Maria MININNI and Silvia ROMANELLI,University of Bari, Italy
17:45 Parameter estimation in a stochastic predator-prey system[Abstract 314]Carla CALVI PARISETTI,Università di Parma, ItalySara PASQUALI, CNR-IMATI, Italy
18:05 Lan in partially observed small noise diffusions[Abstract 57]Fabien CAMPILLO and François LE GLAND,IRISA / INRIA Rennes, France
18:25 Estimation of the impulse response function in linear and nonlinear systems[Abstract 472]Vladimir ZAIATS , Universitat de Vic and Universitat Autònoma de Barcelona, Spain
Contributed Session C24 Aula MagnaGraphical Markov ModelsChair: Steffen LAURITZEN,University of Oxford, UK
17:05 A characterization of Markov equivalence classes for AMP chain graph models[Abstract 322]Steen A. ANDERSON,Indiana University, USAMichael D. PERLMAN , University of Washington, USA
17:25 Maturity randomization for stochastic control problems[Abstract 408]Alberto ROVERATO,University of Modena and Reggio Emilia, ItalyMilan STUDENÝ , Institute of Information Theory and Automation (Prague), Czech Republic
17:45 Wishart distributions on matrices with prescribed zeros[Abstract 240]Gérard LETAC , Université Paul Sabatier, Toulouse, FranceHélène MASSAM,York University, Canada
18:05 The Wishart distribution and the Matsumoto-Yor property[Abstract 273]Hélène MASSAM, York University, CanadaJasek WESOŁOWSKI,Politechnika Warszawska, Poland

Wed
nesd
ay36 6th BS/ IMSC
18:25 On qualitative comparisons of dependence between d-connected vertices of a singly connectedGaussian DAG[Abstract 71]Sanjay CHAUDHURI and Thomas RICHARDSON,University of Washington, Seattle, USA
18:45 Dynamic graphical models: structural learning with time-varying components[Abstract 413]Nicolas HENGARTNER,Los Alamos National Laboratory, USAMakram TALIH , City University of New York, Hunter College, USA
Contributed Session C25 Room 3.1Fractional Brownian MotionChair: Murad TAQQU,Boston University, USA
17:05 Fluctuation limits of occupation processes of particle systems. Sub-fractional vs fractional Brow-nian motions[Abstract 44]Tomasz BOJDECKI, University of Warsaw, PolandLuis G. GOROSTIZA,Centro de Investigación y de Estudios Avanzados, MexicoAnna TALARCZYK, Institute of Mathematics, University of Warsaw, Poland
17:25 Limits for weightedp−variations and likewise functionals of fractional diffusions with drift[Ab-stract 260]José R. LEÓN,UCV, VenezuelaCarenne LUDEÑA, IVIC, Venezuela
17:45 Functional limit theorems for multiparameter fractional Brownian motion[Abstract 266]Anatoliy MALYARENKO , Mälardalen University, Sweden
18:05 Heavy traffic limits of a data traffic model[Abstract 56]Mine ÇAGLAR , Koç University, Turkey
Contributed Session C27 Room 2.2Analysis of Censored DataChair: Ian McKEAGUE,Florida State University, USA
17:05 Censored regression using preliminary kernel smoothing[Abstract 174]Cédric HEUCHENNE and Ingrid VAN KEILEGOM, Université Catholique de Louvain, Bel-gium
17:25 Estimation of the conditional survival function under dependent censoring[Abstract 449]Noël VERAVERBEKE , Limburgs Universitair Centrum, Belgium
17:45 A product-limit estimator of the survival function with left and right censored data from cross-sectional studies[Abstract 315]Valentin PATILEA , CREST-ENSAI, FranceJean-Marie ROLIN,Institute of Statistics, Louvain-la-Neuve, Belgium
18:05 Smooth estimation of mean residual life under random censoring[Abstract 384]Yogendra P. CHAUBEY,Arusharka SEN, Concordia University, CanadaPranab K. SEN,University of North Carolina at Chapel Hill, USA
18:25 Estimating the cumulative incidence functions under length bias[Abstract 89]J.-Y. DAUXOIS and A. GUILLOUX,CREST-ENSAI, Campus de Ker-Lann, France
18:45 Estimation in a competing risks proportional hazards model under length-biased sampling withcensoring[Abstract 163]Jean-Yves DAUXOIS,Agathe GUILLOUX CREST-ENSAI, FranceSyed N.U.A KIRMANI, University of Northern Iowa, USA

July, 28 37
Wed
nesd
ay
Contributed Session C40 Room 0.1Statistics in GeneticsChair: Francesca CHIAROMONTE,Penn State University, USA
17:05 Clustering gene expression data based on p-values[Abstract 202]Rebecka JÖRNSTEN, Jun LI and Regina LIU,Rutgers University, USA
17:25 Robust estimation of cDNA microarray intensities with replicates[Abstract 158]Roger BUMGARNER,Raphael GOTTARDO, Adrian E. RAFTERY and Ka Yee YEUNG,Uni-versity of Washington, USA
17:45 Weak signal detection and applications to microarrays (Bayesian approach)[Abstract 13]Vladimir ANISIMOV , GlaxoSmithKline, UKValerii FEDOROV,GlaxoSmithKline, US
18:05 A look at the gene identification problem from a hypothesis test perspective[Abstract 367]Àlex SÁNCHEZ and Mireia VILARDELL, Universitat de Barcelona, Spain
18:25 On the power of profiles for transcription factor binding site detection[Abstract 344]Sven RAHMANN, Max Planck Institute for Molecular GeneticsandFreie Universität Berlin,Germany, Present addressUniversität Bielefeld, GermanyTobias MÜLLER,Universität Würzburg, GermanyMartin VINGRON,Max Planck Institute for Molecular Genetics, Germany
Contributed Session M4 Room 2.1Risk TheoryChair: Pauline BARRIEU,London School of Economics, UK
17:05 Stop-loss premiums for dependent risks[Abstract 6]W. ALBERS , University of Twente, The Netherlands
17:25 Bounds for dynamicV aR and mean loss associated to diffusion processes[Abstract 276]Laurent DENIS,Université du Maine, FranceBegoña FERNÁNDEZ andAna MEDA , Universidad Nacional Autónoma de México, Mexico
17:45 Distribution-invariant dynamic risk measures[Abstract 459]Stefan WEBER, Humboldt-Universität zu Berlin, Germany
18:05 Adaptive filtering in insurance with jump noise[Abstract 438]Krystyna TWARDOWSKA and Tomasz MICHALSKI,Warsaw University of Technology,Poland
18:25 A functional approach for the individual risk model[Abstract 333]Susan PITTS, University of Cambridge, UK
18:45 A simple model of liquidity risk [Abstract 67]Umut ÇETIN , Vienna University of Technology, AustriaChris ROGERS,Cambridge University, UK

Thursday, July 29
Wald Lecture II ParanimfChair: Bernard SILVERMAN,Oxford University, UK
9:15 Growing Gaussian Models (2)[Abstract 199]Iain JOHNSTONE , Stanford University, USA
Contributed Session C6 Room 2.1Density Estimation IChair: Oleg LEPSKI,Université Aix-Marseille 1, France
9:00 Locally superoptimal projection density estimators: the case of the trigonometric system[Abstract18]Jean-Baptiste AUBIN, Université Paris 6, France
9:20 Confidence bands for multivariate densities[Abstract 318]Abdelkader MOKKADEM andMariane PELLETIER , Université de Versailles–Saint-Quentin,France
9:40 A statistical quality control procedure based on tolerance regions[Abstract 19]Amparo BAÍLLO , Universidad Carlos III de Madrid, SpainAntonio CUEVAS,Universidad Autónoma de Madrid, Spain
Contributed Session C38 Room 0.1Coagulation and Fragmentation ProcessesChair: Gregory MIERMONT,École Normale Supérieure, and LPMA, France
9:00 Exchangeable Fragmentation-Coalescence processes and their equilibrium measures[Abstract 35]Julien BERESTYCKI , Universités Paris VI & Paris X, France
9:20 Dual coagulation and fragmentation and the genealogy of Yule processes[Abstract 154]Jean BERTOIN andChristina GOLDSCHMIDT , Université Pierre et Marie Curie (Paris 6),France
9:40 Reversible coagulation-fragmentation processes: Three different pictures of asymptotic clusteringat the equilibrium[Abstract 160]Boris L. GRANOVSKY , Technion, Israel
10:00 Ising models and multiresolution quad-trees[Abstract 209]Wilfrid KENDALL and Roland WILSON,University of Warwick, UK
Contributed Session C63 Room 1.1Sequential AnalysisChair: Akimichi TAKEMURA, University of Tokyo, Tokyo, Japan
9:00 Multi-arm clinical trials with finite response and a sequence of urn functions[Abstract 288]José A. MOLER, Universidad Pública de Navarra, SpainFernando PLO and Miguel SAN MIGUEL,Universidad de Zaragoza, Spain
9:20 Optimal two-stage hypotheses testing[Abstract 303]Andrey NOVIKOV , Universidad Autonoma Metropolitana - Unidad Iztapalapa, Mexico

July, 29 39
Thu
rsda
y
9:40 Optimal multistage procedures for testing simple hypotheses[Abstract 27]Jay BARTROFF, Caltech, USA
11:05 Asymptotic Bayesian change-point detection theory for general continuous time stochastic pro-cesses[Abstract 417]Michael BARON,University of Texas at Dallas, USAAlexander G. TARTAKOVSKY , University of Southern California, USA
10:15 –10:45 Coffee Break
Invited Session 10 Room 1.1Brownian motionOrganizer: Yuval PERES,University of California at Berkeley, USAChair: Bálint VIRÁG,University of Toronto, Canada
10:45 The multifractal spectrum of Brownian intersection local times[Abstract 290]Achim KLENKE, Johannes Gutenberg Universität Mainz, GermanyPeter MÖRTERS, University of Bath, England
11:20 An almost sure invariance principle for the range of planar random walks[Abstract 358]Richard F. BASS,University of Conneticut, USAJay ROSEN, C.U.N.Y., USA
11:55 Some subsets of the Brownian curve[Abstract 30]Vincent BEFFARA , ENS Lyon, France
Invited Session 22 Room 2.1Random walks in random environments and random mediaOrganizer and Chair: Nina GANTERT,University Karlsruhe, Germany
10:45 Favourite sites and occupation times of random walk in random environment[Abstract 389]Zhan SHI and Olivier ZINDY,Université Paris VI, France
11:20 Recent results on edge-reinforced random walks[Abstract 280]Franz MERKL , Leiden University, The NetherlandsSilke ROLLES,University of California at Los Angeles, USA
11:55 Biased random walk on percolation clusters[Abstract 36]Noam BERGER, Caltech, USANina GANTERT,University Karlsruhe, GermanyYuval PERES,University of California at Berkeley, USA
Invited Session 31 Room 0.1Statistical analysis of point processesOrganizer and Chair: Rick SHOENBERG,UCLA, USA
10:45 Summary statistics for marked point patterns[Abstract 445]Marie-Collette VAN LIESHOUT , CWI, Amsterdam, The Netherlands
11:20 On ratio estimators of summary statistics for stationary point processes[Abstract 407]Dietrich STOYAN , TU Bergakademie, Freiburg
11:55 Perfect and Approximate Simulation of Hawkes Processes[Abstract 289]Jesper MØLLER , Aalborg University, Denmark

Thu
rsda
y40 6th BS/ IMSC
Invited Session 33 Aula MagnaFunction space valued modelingOrganizer and Chair: Anestis ANTONIADIS,University Joseph Fourier, France
10:45 A statistical model for signaturesIan McKEAGUE , Florida State University, USA
11:20 Monotone empirical bayes and its applications to functionBernard SILVERMAN , Oxford University, UK
11:55 Functional aggregation[Abstract 436]Alexandre B. TSYBAKOV , Université Paris 6, France
Contributed Session C22 Room 3.1Goodness of FitChair: Ingrid Van KEILEGOM,Université Catholique de Louvain, Belgium
10:45 Comparison of regression curves based on the errors distribution[Abstract 312]Wenceslao GONZÁLEZ-MANTEIGA,Universidade de Santiago de Compostela, SpainJuan Carlos PARDO-FERNÁNDEZ, Universidade de Vigo, SpainIngrid VAN KEILEGOM, Université Catholique de Louvain, Belgium
11:05 Goodness of fit test for linear regression models with missing response data[Abstract 156]W. GONZÁLEZ MANTEIGA , University of Santiago de Compostela, SpainA. PÉREZ GONZÁLEZ,University of Vigo, Spain
11:25 Testing normality with transformed empirical processes[Abstract 55]Alejandra CABAÑA , IVIC, Venezuela and Universidad de Valladolid, SpainEnrique M. CABAÑA,Universidad de la República, Uruguay
11:45 Goodness-of-fits tests, adapted to extreme-value models[Abstract 475]A. ZEMPLÉNI , Eötvös Loránd University, Budapest, Hungary
12:05 A “missing-plot" technique for goodness-of-fit tests with censored data[Abstract 383]Arusharka SEN, Concordia University, Canada
Contributed Session C48 Room 4.1Time SeriesChair: Daniel PEÑA,Universidad Carlos III de Madrid, Spain
10:45 Time series clustering based on forecast densities[Abstract 9]Andrés M. ALONSO, José R. BERRENDERO,Universidad Autónoma de Madrid, SpainAdolfo HERNÁNDEZ,University of Exeter, United KingdomAna JUSTEL,Universidad Autónoma de Madrid, Spain
11:05 Using least squares to generate forecasts in regression models with autocorrelated disturbances[Abstract 213]Yue FANG andSergio KOREISHA, University of Oregon, USA
11:25 Semi-parametric estimation of the periods in a superposition of periodic functions with unknownshape[Abstract 244]Céline LÉVY-LEDUC , Université Paris-Sud and Thalès Optronique, France
11:45 Aggregation of replicated signals[Abstract 53]Florentina BUNEA , Florida State University, USA

July, 29 41
Thu
rsda
y
Contributed Session M2 Room 2.2Ruin ProbabilitiesChair: Mogens STEFFENSEN,University of Copenhagen, Denmark
10:45 Small-time ruin estimates for a financial process modulated by a Harris recurrent Markov chain[Abstract 81]Jeffrey F. COLLAMORE , University of Copenhagen, DenmarkAndrea HÖING,ETH Zürich, Switzerland
11:05 New stability estimates in the classical risk model[Abstract 157]E. GORDIENKO , Universidad Autónoma Metropolitana - Iztapalapa, México
11:25 On necessary and sufficient conditionsfor approximations of ruin probabilities[Abstract 106]Myroslav DROZDENKO and Dmitrii SILVESTROV,Mälardalen University, Sweden
11:45 Error bounds for ruin probabilities via Steklov operators[Abstract 369]José A. ADELL andC. SANGÜESA, Universidad de Zaragoza, Spain
12:05 Simulating the ruin probability of risk processes with delay in claim settlement[Abstract 431]Giovanni Luca TORRISI , CNR-Istituto per le Applicazioni del Calcolo, Italy
12:30 –15:00 Lunch Break
Poster Session P3 Hall
12:30–18:30
• A new approach to detect strictly algebraic distributions[Abstract 130]José María FERNANDEZ-PONCE, Teresa GOMEZ-GOMEZ,José Luis PINO-MEJIAS andRosario RODRIGUEZ-GRIÑOLO,Universidad de Sevilla, Spain
• Reduced bootstrap for sample quantiles[Abstract 197]M. Dolores CUBILES DE LA VEGA,M. Dolores JIMÉNEZ GAMERO , Joaquín MUÑOZ GAR-CÍA and Rafael PINO MEJÍAS,Universidad de Sevilla, Spain
• Influence measures on profile analysis with elliptical data through Frèchets’s metric[Abstract 118]A. ENGUIX-GONZÁLEZ, J.L. MORENO-REBOLLO, J.M. MUÑOZ-PICHARDO and A.PASCUAL-ACOSTA,Universidad de Sevilla, Spain
• Conditional Bias of eigenvalues as an influence measure un principal components analysis[Abstract119]N. ATIENZA-MARTÍNEZ, I. BARRANCO-CHAMORRO, A. ENGUIX-GONÁLEZ and J.M.MUÑOZ-PICHARDO,Universidad de Sevilla, Spain
• A Nonparametric test of the conditional distribution function[Abstract 132]Gilles R. DUCHARME andSandie FERRIGNO, Laboratoire de Probabilités et Statistique, Mont-pellier, France
• Estimation in the two-parameter exponential distribution and related distributions[Abstract 24]I. BARRANCO-CHAMORRO , M.D. CUBILES DE LA VEGA and J.M. MUÑOZ-PICHARDO,Universidad de Sevilla, Spain
• An additive-multiplicative hazard model in analysis of survival[Abstract 343]Julia GARCIA-LEAL, Ana M. LARA-PORRAS, Esteban NAVARRETE-ALVAREZ andJoseManuel QUESADA-RUBIO , Universidad de Granada, Spain
• Setting Bartlett adjusted likelihood intervals[Abstract 304]Tommi NURMINEN and Esa UUSIPAIKKA,University of Turku, Finland

Thu
rsda
y42 6th BS/ IMSC
• Local influence in survey sampling[Abstract 120]I. BARRANCO-CHAMORRO,A. ENGUIX-GONZALEZ , J.L. MORENO-REBOLLO and M.M.MUÑOZ-CONDE,Universidad de Sevilla, Spain
• Properties of minimum and maximum from bivariate exponential distributions[Abstract 455]Manuel FRANCO NICOLAS andJuana Maria VIVO MOLINA , University of Murcia, Spain
• Some comments on the existence of projections in statistics[Abstract 140]Gloria GARCÍA , Autonoma University of Barcelona, SpainJosep M. OLLERUniversity of Barcelona, Spain
• Quadratic regression estimation[Abstract 363]Mariano RUIZ-ESPEJO , UNED, Madrid, SpainHousila P. SINGH,Vikram University, India
• Bartlett correction for the LR test in cointegrating models: a bootstrap approach[Abstract 58]A. CANEPA, University of York, UK
• Smoothing spline regression estimates for randomly right censored data[Abstract 464]Stefan WINTER, University of Stuttgart, Germany
• On the distribution of predictors and residuals[Abstract 137]Anthony GAMST , University of California, San Diego, USA
• Minimum Hellinger distance estimators for some multivariate distributions[Abstract 427]Aida TOMA , Academy of Economic Studies, Romania
• Estimation in discrete parameter models[Abstract 386]Christine CHOIRAT andRaffaello SERI, Università degli Studi dell’Insubria, Italy
• Linear estimators of a continuous signal correlated with the observation noise[Abstract 123]Maria D. ESTUDILLO MARTÍNEZ , Rosa M. FERNÁNDEZ-ALCALÁ, Jesús NAVARRO-MORENO, and Juan C. RUIZ-MOLINA,University of Jaén, Spain
• Model selection and likelihood ratios[Abstract 387]Christine CHOIRAT andRaffaello SERI , Università degli Studi dell’Insubria, Italy
• Statistical properties of quadratic discrepancies[Abstract 78]Christine CHOIRAT and Raffaello SERI ,Università degli Studi dell’Insubria, Italy
Medaillon Lecture Aula MagnaChair: Gabor LUGOSI,Universitat Pompeu Fabra, Spain
15:00 Data Dependent Complexities and Oracle Inequalities in StatisticalLearningTheory [Abstract 217]
Vladimir KOLTCHINSKII , University of New Mexico, USA
Invited Session 11 Room 4.1Coalescents, coagulation and fragmentationOrganizer and Chair: Jean BERTOIN,Université Pierre et Marie Curie (Paris 6), France
15:00 The genealogy of self-similar fragmentations as a continuum random tree[Abstract 283]Bénédicte HAAS,LPMA, Université Paris VI, FranceGrégory MIERMONT , École Normale Supérieure, and LPMA, France
15:35 On moment bounds and self-similarity of the coagulation equation[Abstract 285]Miguel ESCOBEDO,Universidad del Pais Vasco, SpainStéphane MISCHLER, Univérsité de Paris-Dauphine, FranceMariano RODRIGUEZ RICARD,Universidad de La Habana, Cuba

July, 29 43
Thu
rsda
y
16:10 Applications of coalescents with multiple collisions[Abstract 377]Jason SCHWEINSBERG, University of California at San Diego, USA
Invited Session 27 Room 3.1False discovery ratesOrganizer: Felix ABRAMOVICH,Tel Aviv University, IsraelChair: Yoav BENJAMINI,Tel Aviv University, Israel
15:00 FDR based confidence intervals following selection[Abstract 32]Yoav BENJAMINI and Daniel YEKUTIELI,Tel Aviv University, Israel
15:35 Pre-ordered hypotheses and false discovery rate[Abstract 134]Helmut FINNER , Leibniz-Institut an der Heinrich-Heine-Universität Düsseldorf, GermanySanat K. SARKAR,Temple University, Philadelphia, USA
16:10 Confidence envelopes and false discovery controlCristopher GENOVESE, Carnigie Melton University, USA
Invited Session 28 Room 2.1Model choice and goodness of fit in nonparametricsOrganizer and Chair: Winfried STUTE,University of Giessen, Germany
15:00 Goodness-of-fit testing of conditional models[Abstract 257]Miguel A. DELGADO , Universidad Carlos III, Madrid, Spain
15:35 Testing for homoscedasticity in nonparametric regresion[Abstract 59]Ricardo CAO, Universidade da Coruña, SpainIrene GIJBELS,Université catholique de Louvain, Louvain-la-Neuve, Belgium
16:10 Fitting an error d.f. in some nonlinear time series model[Abstract 214]Hira L. KOUL , Michigan State University, USA
Invited Session 30 Room 2.2Nonparametric analysis for time seriesOrganizer and Chair: Qiwei YAO,London School of Economics, UK
15:00 Inference of semi-parametric time series models with constraints[Abstract 468]Yingcun XIA , National University of Singapore, Singapore
15:35 Inference for volatility functions: Goodness of fit, stochastic ordering, and inverse regression[Abstract 334]Wolfgang POLONIK , University of California, Davis
16:10 Specification testing for nonstationary diffusions against nonparametric alternatives[Abstract 5]Yacine AÏT-SAHALIA , Princeton University, USA
Invited Session 34 Room 0.1BiostatisticsOrganizer and Chair: Niels KEIDING,University of Copenhagen, Denmark
15:00 Statistical challenges in space-time surveillance of infectious diseases[Abstract 171]Leonhard HELD , Michael HÖHLE, Mathias HOFMANN, Günter RASSER and VolkerSCHMID, University of Munich, Germany

Thu
rsda
y44 6th BS/ IMSC
15:35 Estimation of contact parameters for nonstationary infections[Abstract 126]Paddy FARRINGTON and Heather WHITAKER,Open University, UK
16:10 Flexible regression models for survival data: theory and practise[Abstract 272]Torben MARTINUSSEN , Royal Veterinary and Agricultural University, Denmark
Contributed Session C10 Room 0.3Stochastic Analysis IIIChair: Josep VIVES,Universitat Autònoma de Barcelona, Spain
15:00 Domain sensitivity for diffusion processes constrained a time dependent domain[Abstract 153]Cristina COSTANTINI,Universita’ di Chieti-Pescara, Pescara, ItalyNicole EL KAROUI andEmmanuel GOBET, École Polytechnique, Palaiseau, France
15:20 Discrete approximations of killed Itô processes[Abstract 279]Emmanuel GOBET,Ecole Polytechnique, FranceStéphane MENOZZI, Université Paris VI, France
15:40 A regression-based Monte-Carlo method for the resolution of backward stochastic differentialequations[Abstract 237]Emmanuel GOBET andJean-Philippe LEMOR, Ecole Polytechnique, Palaiseau France
16:00 Skorokhod embeddings, minimality and non-centred target distributions[Abstract 84]Alexander COX and David HOBSON,University of Bath, UK
16:20 Monte Carlo method using Malliavin calculus on the Poisson space for the computation of Greeks[Abstract 282]Marouen MESSAOUD and Marie-Pierre BAVOUZET-MOREL,NRIA, France
16:45 –17:05 Coffee Break
Contributed Session C7 Room 4.1Limit TheoremsChair: Allan GUT,Uppsala University, Sweden
17:05 Central limit theorems for the number of records in discrete models[Abstract 159]R. GOUET, University of Chile, ChileF. J. LÓPEZ and G. SANZ,University of Zaragoza, Spain
17:25 A differential calculus for linear operators and its application to the central limit theorem[Abstract2]José A. ADELL, Universidad de Zaragoza, Spain
17:45 A new concept of integrability and the weak law of large numbers for weighted sums of randomvariables [Abstract 310]Manuel ORDOÑEZ CABRERA , University of Sevilla, SpainAndrei VOLODIN, University of Regina, Saskatchewan, Canada
18:05 Convergence rate of the dependent bootstrapped means[Abstract 456]Alia GATAULLINA, Kazan State University, RussiaManuel ORDÓÑEZ CABRERAUniversity of Seville, SpainAndrei VOLODIN , University of Regina, Canada
18:25 Iterated medians[Abstract 281]Milan MERKLE , Faculty of Electrical Engineering, Belgrade, Yugoslavia
18:45 On the central limit theorem for non-archimedean Diophantine approximations[Abstract 98]Eveyth DELIGERO and Hitoshi NAKADA,Keio University, Japan

July, 29 45
Thu
rsda
y
Contributed Session C13 Aula MagnaLevy Processes IChair: Jean JACOD,Université P. et M. Curie, France
17:05 Some classes of multivariate infinitely divisible distributions related to the mapping of Barndorff-Nielsen and Thorbjørnsen[Abstract 371]Ole E. BARNDORFF-NIELSEN,University of Aarhus, DenmarkMakoto MAEJIMA, Keio University, JapanKen-iti SATO , Nagoya, Japan
17:25 Some nested subclasses of infinitely divisible distributions[Abstract 264]Ole E. BARNDORFF-NIELSEN,University of Aarhus, DenmarkMakoto MAEJIMA, Keio University, JapanKen-iti SATO,Nagoya, Japan
17:45 Some remarks on matrix subordinators[Abstract 320]Ole E. BARNDORFF-NIELSEN,MaPhySto, DenmarkVictor PEREZ-ABREU , CIMAT, Mexico
18:05 Dependence structure of spectrally positive multidimensional Lévy processes[Abstract 414]Peter TANKOV , Ecole Polytechnique, France
18:25 Some fluctuation identities for Lévy processes[Abstract 478]Xiaowen ZHOU, Concordia University, Canada
Contributed Session C33 Room 3.1Autoregressive ModelsChair: Paul FEIGIN,Technion, Israel
17:05 Practical small-sample inference for order one subset autoregressive models via saddlepoint ap-proximations [Abstract 434]Robert L. PAIGE,Texas Tech University, U.S.A.A. Alexandre TRINDADE , University of Florida, U.S.A.
17:25 Application of quasi-least squares to analyze replicated autoregressive time series model[Abstract68]N. Rao CHAGANTY and Genming SHI,Old Dominion University, Norfolk, USA
17:45 Testing parameters in a heteroskedastic random coefficient autoregressive model[Abstract 339]Zuzana PRÁŠKOVÁ Charles University in Prague, Czech Republic
18:05 Efficiency of some estimators for a generalized Poisson autoregressive process of order 1[Abstract103]Louis DORAY , Université de Montréal, CanadaAndrew LUONG,Université Laval, CanadaEl-Halla NAJEM,Université de Montréal, Canada
Contributed Session C41 Room 2.2Data Analysis and ClassificationChair: Elizaveta LEVINA,University of Michigan, USA
17:05 Nonparametric independent component analysis[Abstract 364]Alexander SAMAROV , UMass-Lowell and MIT, USAAlexander TSYBAKOV,Université Paris VI, France
17:25 On the asymptotic properties of reduced rank linear discriminant analysis[Abstract 448]Adolfo HERNÁNDEZ,University of Exeter, United KingdomSantiago VELILLA , Universidad Carlos III, Spain

Thu
rsda
y46 6th BS/ IMSC
17:45 Parametric correspondence analysis[Abstract 86]Carles M. CUADRAS, University of Barcelona, Barcelona, Spain
18:05 Method of best hybrid approximations for constructing fixed rank optimal estimators[Abstract429]P. HOWLET,University of South Australia, AustraliaC. PEARCE,University of Adelaide, AustraliaA. TOROKHTI , University of South Australia, Australia
18:25 Monotone missing data and elliptical distributions[Abstract 28]A. BATSIDIS and K. ZOGRAFOS,University of Ioannina, Greece
18:45 Classification rules for elliptical distributions with monotone missing data[Abstract 479]A. BATSIDIS andK. ZOGRAFOS , University of Ioannina, Greece
Contributed Session C46 Room 2.1Special Topics in Testing HypothesisChair: Peter BICKEL,University of California, Berkeley, USA
17:05 A conditionally distribution-free multivariate sign test for one-sided alternatives[Abstract 227]Melanie LABARRE,Industrielle Alliance, CanadaDenis LAROCQUE, HEC Montreal, Canada
17:25 Coping with multiplicity by exploiting the empirical distribution ofP -values [Abstract 41]Mikelis BICKIS University of Saskatchewan, Canada
17:45 Testing for circular reflective symmetry about a known median axis[Abstract 325]Arthur PEWSEY , Universidad de Extremadura, Cáceres, Spain
18:05 On the Chernoff bound for efficiency of quantum hypothesis testing[Abstract 206]Vladislav KARGIN , Cornerstone Research, USA
Contributed Session C54 Room 0.1Kernel EstimationChair: Ricardo CAO,University of A Coruña, Spain
17:05 Bandwidth selection for a presmoothed density estimator with censored data[Abstract 190]Ricardo CAO ABAD,University of A Coruña, SpainM. Amalia JACOME PUMAR , University of Vigo, Spain
17:25 Nonparametric deconvolution and wild-aging[Abstract 95]Aurore DELAIGLE , University of California, Davis, USA
17:45 Combining kernel estimators in the uniform deconvolution model[Abstract 443]Bert VAN ES Universiteit van Amsterdam, The Netherlands
18:05 On multi-bandwidth smoothing based on M-estimatorsand on efficient quantile estimation[Abstract 219]Andrzej S. KOZEK , Macquarie University, Australia
18:25 On theu-th geometric conditional quantile[Abstract 74]Yebin CHENG and Jan G. DE GOOIJER,University of Amsterdam, The Netherlands

July, 29 47
Thu
rsda
y
Contributed Session C56 Room 0.3Bayesian Methods IIChair: Gerda CLAESKENS,Université Catholique de Louvain, Belgium
17:05 Bayesian analysis for finite mixtures of exponential distributions[Abstract 362]J. MARTÍN, C.J. PÉREZ andM. J. RUFO, University of Extremadura, Spain
17:25 Our walk through Particle Filtering: Simultaneous estimation of state and parameters[Abstract 1]Lesly María ACOSTA ARGUETA , Manuel MARTÍ-RECOBER and Pilar MUÑOZ GRACIA.Universitat Politècnica de Catalunya, Spain
17:45 BSiZer for making Bayesian inferences about features in scatter plots[Abstract 177]Panu ERÄSTÖ,University of Helsinki, FinlandLasse HOLMSTRÖM, University of Oulu, Finland
18:05 Bayesian shape matching and protein structure alignment[Abstract 376]Scott C. SCHMIDLER , Duke University, USA

Friday, July 30Wald Lecture III ParanimfChair: Bernard SILVERMAN,Oxford University, UK
9:15 Growing Gaussian Models (3)[Abstract 199]Iain JOHNSTONE , Stanford University, USA
Contributed Session C59 Room 0.1Extremal AnalysisChair: Laurens DE HAAN,Erasmus university Rotterdam, The Netherlands
9:00 Non-parametric estimation of rare threshold probability[Abstract 395]Ashoke Kumar SINHA , Tilburg University, The Netherlands
9:20 Weighted approximations to multivariate tail dependence processes with application to testing theextreme value condition[Abstract 245]John H.J. EINMAHL,Tilburg University, the NetherlandsLaurens de HAAN andDeyuan LI, Erasmus University Rotterdam, the Netherlands
9:40 Extremes of deterministic sub-sampled processes[Abstract 381]Manuel G. SCOTTO, University of Aveiro, Portugal
Contributed Session C61 Room 2.1M-Estimates and Related TopicsChair: C. MATRÁN,Universidad de Valladolid, Spain
9:00 Asymptotics for M-estimators based on sample cells and restrictions[Abstract 275]J.A. CUESTA-ALBERTOS,Universidad de Cantabria, SpainC. MATRÁN andA. MAYO , Universidad de Valladolid, Spain
9:20 Saddlepoint approximations for multivariate M-estimates[Abstract 354]Chris FIELD,Dalhousie University, CanadaJohn ROBINSON, University of Sydney, AustraliaElvezio RONCHETTI,University of Geneva, Switzerland
9:40 Least weighted squares for panel data[Abstract 453]Jan Ámos VÍŠEK, Charles University, the Czech Republic
10:00 Fitting sets to distributions in metric spaces[Abstract 313]Meelis KÄÄRIK andKalev PÄRNA, University of Tartu, Estonia
Contributed Session C65 Room 2.2Density Estimation IIChair: Michael KOHLER,University of Stuttgart, Germany
9:00 Estimates of the rate of approximation in the CLT forL1-norm of density estimators[Abstract473]A. Yu. ZAITSEV , St. Petersburg Department of the Steklov Mathematical Institute, Russia
9:20 Remarks on local likelihood density estimation[Abstract 97]Pedro DELICADO , Universitat Politècnica de Catalunya, Spain

July, 30 49
Frid
ay
9:40 Rootn estimates of integrated squared density partial derivatives[Abstract 467]Huang-Yu CHEN andTiee-Jian WU, National Cheng-Kung University, Taiwan
10:15 –10:45 Coffee Break
Invited Session 17 Room 2.2Mixing of finite Markov chainsOrganizer and Chair: Dana RANDALL,Georgian Institute of Technology, USA
10:45 Boundary conditions, mixing times, and the ising model on trees[Abstract 394]Fabio MARTINELLI, Università Roma Tre, ItalyAlistair SINCLAIR and Dror WEITZ,UC Berkeley, USA
11:20 Gibbs measures and stochastic networks[Abstract 422]Prasad TETALI , Georgian Institute of Technology, USA
11:55 Coupling with the stationary distribution[Abstract 451]Eric VIGODA , University of Chicago and Georgian Institute of Technology, USA
Invited Session 19 Room 2.1Probability on graphsOrganizer and Chair: Jeff STEIF,Chalmers University of Technology, Gothenburg, Sweden
10:45 Random walks on the infinite cluster of Bernoulli percolations[Abstract 73]Dayue CHEN, Peking University, China
11:20 Attracting edge property for reinforced random walks[Abstract 250]Vlada LIMIC , University of British Columbia, Canada
11:55 Random walks and amenability of fractal groups[Abstract 452]Bálint VIRÁG , University of Toronto, CanadaLaurent BARTHOLDI,UC Berkeley, USA
Invited Session 23 Room 0.1Function estimationOrganizer and Chair: Alexander TSYBAKOV,Université Paris VI, France
10:45 Model selection for Gaussian vectors[Abstract 42]Lucien BIRGÉ , Université Paris VI, France
11:20 Infinitely divisible AR and MA models[Abstract 52]Lawrence D. BROWN, University of Pennsylvania, Philadelphia, USA
11:55 Local oracle inequalities and global estimation[Abstract 239]O. LEPSKI , Université de Provence, France
Invited Session 26 Aula MagnaDimension reduction for high dimensional dataOrganizer and Chair: Ker-Chau LI,UCLA, USA
10:45 Data dimension reduction using multivariate adaptive splines[Abstract 477]Heping ZHANG , Yale University School of Medicine
11:20 The SAR procedure: a diagnostic analysis of heterogeneous data[Abstract 319]Daniel PEÑA , Universidad Carlos III de Madrid, Spain

Frid
ay50 6th BS/ IMSC
11:55 Dimension reduction in gene expression data analysis[Abstract 248]Ker-Chau LI , UCLA, USA
Contributed Session C3 Room 0.3Stochastic Partial Differential EquationsChair: Samy TINDEL,Université Henri Poincaré (Nancy), Vandoeuvre-lès-Nancy, France
10:45 McKean-Vlasov representations for linear SPDEs[Abstract 85]Dan CRISAN, Imperial College London, UK
11:05 Numerical approximation for a white noise driven spde with bounded drift[Abstract 324]Roger PETTERSSON, Växjö University, SwedenMikael SIGNAHL, Linköping University, Sweden
11:25 SPDEs driven by Poisson random measure[Abstract 169]Erika HAUSENBLAS , Department of Mathematics, Salzburg, Austria
11:45 Path integrals for stochastic Schrödinger equations driven by Brownian motion[Abstract 350]Luis RINCON , UNAM, Mexico
Contributed Session C21 Room 3.1Stochastic processes IIIChair: Frederic UTZET,Universitat Autònoma de Barcelona, Spain
10:45 Reduction of gibbs phenomenom in wavelet thresholding[Abstract 105]T.R. DOWNIE , Univesity College London, U.K.
11:05 Asymptotic properties of uniform quantizer for Gaussian processes[Abstract 382]Oleg SELEZNJEV and Mykola SHYKULA,Umeå University, Sweden
11:25 A weak consistent wavelet estimator of cointegration coefficient and its application in finance[Abstract 469]Xiamin LI, Beijing Polytechnic University, ChinaHongmin TANG andZhongjie XIE , Peking University, China
11:45 p-variation of strong Markov processes[Abstract 267]Martynas MANSTAVI CIUS, University of Connecticut, USA
12:05 Convergence of markov processes near saddle fixed points[Abstract 437]A.G.TURNER , Cambridge University, United Kingdom
Contributed Session C32 Room 4.1Lévy Processes IIChair: Gérard LETAC,Université Paul Sabatier, Toulouse, France
10:45 Conditional moments andq-Meixner processes[Abstract 462]Włodzimierz BRYC,University of Cincinnati, USAJacek WESOŁOWSKI, Warsaw University of Technology, Poland
11:05 Overshoots of Levy processes and weak convergence of positive self similar Markov processes[Abstract 72]María Emilia CABALLERO,Université de Paris X et Instituto de Matemáticas, Universidad Na-cional Autónoma de MéxicoLoic CHAUMONT , Université Paris VI, France

July, 30 51
Frid
ay
11:25 On exit and ergodicity of reflected Lévy processes[Abstract 332]Martijn PISTORIUS , King’s College London, UK
11:45 On recurrent extensions of self–similar Markov processes and Cramer’s condition[Abstract 352]Víctor RIVERO , Université Paris VI et Université Paris X, France
12:05 Generalized chaos expansion for Lévy functionals: applications to hedging[Abstract 454]M’hamed EDDAHBI,Université Cadi Ayyad, MarocJosep L. SOLÉ andJosep VIVES, Universitat Autònoma de Barcelona, Spain
12:30 –15:00 Lunch Break
Medaillon Lecture Aula MagnaChair: Wenceslao GONZALEZ MANTEIGA,University of Santiago de Compostela, Spain
15:00 Recent results on asymptotics of kernel density estimators[Abstract 149]Evarist Giné, University of Connecticut, USA
Invited Session 15 Room 0.1Measure-valued processes and SPDEOrganizer and Chair: Jean Francois LE GALL,Ecole Normale Superieure, Paris, France
15:00 On pathwise uniqueness for stochastic heat equations with non-Lipschitz coefficients[Abstract297]Leonid MYTNIK , Technion-Israel Institute of Technology, IsraelEdwin PERKINS and Anja STURM,The University of British Columbia Canada
15:35 Lotka-Volterra models and super-Brownian motion[Abstract 321]Ed PERKINS, University of British Columbia, Canada
16:10 Phase diagram for a stochastic reaction diffusion system[Abstract 433]Carl MUELLER,Rochester, USARoger TRIBE, Warwick, UK
Invited Session 24 Room 2.1Applications of particle filtering in statisticsOrganizer and Chair: Cristophe ANDRIEU,University of Bristol, UK
15:00 A new class of genealogical and interacting Metropolis particle models[Abstract 94]P. DEL MORAL , LSP-CNRS, FranceA. DOUCET,Cambridge University, England
15:35 Smooth interacting particle approximation of Feynman–Kac flows depending on a parameter[Ab-stract 236]Natacha CAYLUS,IRISA/Université de Rennes 1, FranceArnaud GUYADER,Université de Haute Bretagne, FranceFrançois LE GLAND , IRISA/INRIA Rennes, FranceNadia OUDJANE,EDF R&D Clamart, France
16:10 TBAMichael K. PITT , Warwick University, UK

Frid
ay52 6th BS/ IMSC
Contributed Session C16 Room 2.2Random GraphsChair: Eric VIGODA,University of Chicago and Georgia Tech, USA
15:00 Cores of general random hypergraphs[Abstract 88]R.W.R. DARLING , Department of Defense, USAJ. R. NORRIS,Cambridge University, UK
15:20 Connectivity and diameter of small-world random graphs[Abstract 138]Ayalvadi GANESH, Microsoft Research, Cambridge, UKFeng XUE,University of Illinois, Urbana-Champaign, USA
15:40 A (Gittins) index theorem for randomly evolving graphs[Abstract 397]Ernst PRESMAN,CEMI RAS, RussiaIsaac SONIN, UNC Charlotte, USA
16:00 Random minimal directed spanning trees and Dickman-type distributions[Abstract 471]Mathew D. PENROSE,University of Bath, UKAndrew WADE , University of Durham, UK
Contributed Session C29 Room 3.1Dimension ReductionChair: Heping ZHANG,Yale University, USA
15:00 Nonparametric estimation of principal components through coordinate selection[Abstract 316]Debashis PAUL, Stanford University, USA
15:20 The topography of multivariate normal mixtures[Abstract 347]Bruce G. LINDSAY,Pennsylvania State University, USASurajit RAY , University of North Carolina, Chapel Hill, USA
15:40 On the estimation of asynergistic functions[Abstract 135]Ian ABRAMSON, Michael DONOHUE andAnthony GAMST , University of California, SanDiego, USA
16:00 Estimating intrinsic dimension from the joint distribution of nearest neighbor distances[Abstract243]Peter J. BICKEL,University of California, Berkeley, USAElizaveta LEVINA , University of Michigan, USA
16:20 Adaptive multivariate orthonormal series regression estimates[Abstract 212]Michael KOHLER , University of Stuttgart, Germany
Contributed Session C44 Room 4.1Testing in Mixture ModelsChair: Pedro DELICADO,Universitat Politècnica de Catalunya, Spain
15:00 Power for tests of no mixture[Abstract 406]John ROBINSON andMichael STEWART , University of Sydney, Australia
15:20 Asymptotic theory of the likelihood ratio test for the identification of a mixture[Abstract 141]Bernard GAREL , University of Toulouse 3 and INPT-N7 , France
15:40 Likelihood ratio tests for covariance structures in the presence of non-identifiability[Abstract 351]Christian RITZ , The Royal Veterinary and Agricultural University, Denmark
16:00 The volume-of-tube formula and perturbation tests I: complete specification of the null model[Abstract 329]Catherine LOADER andRamani S. PILLA , Case Western Reserve University, U.S.A.

July, 30 53
Frid
ay
16:20 The volume-of-tube formula and perturbation tests II: nuisance parameters under the null model[Abstract 254]Catherine LOADER and Ramani S. PILLA,Case Western Reserve University, U.S.A.
16:45 –17:05 Coffee Break
Contributed Session C4 Room 3.1Stochastic EquationsChair: Carles ROVIRA,Universitat de Barcelona, Spain
17:05 On weak solutions of backward stochastic differential equations[Abstract 116]Rainer BUCKDAHN,Université de Bretagne Occidentale, Brest, FranceHans-Jürgen ENGELBERT, Friedrich Schiller-Universität, Jena, GermanyAurel RASCANU, Universitatea Alexandru Ioan Cuza, Iasi, Romania
17:45 Approximations of the value function of stochastic knapsack problem[Abstract 259]Yingdong LU, IBM T.J. Watson Research Center, USA
18:05 Solutions of nonlinear SPDE via random Colombeau distributions[Abstract 60]Ulug ÇAPAR, E.M.U. North Cyprus
Contributed Session C15 Room 0.1Random WalksChair: Martin BARLOW,University of British Columbia, Canada
17:05 A phase transition in the random transposition randon walk[Abstract 34]Nathanaël BERESTYCKI and Rick DURRETT,Cornell University, U.S.A. and Ecole NormaleSupérieure, France
17:25 Moderate deviations and limit law for transition probabilities for Sinai’s random walk in randomenvironment[Abstract 336]Francis COMETS,Paris-7, FranceSerguei POPOV, University of São Paulo, Brazil
17:45 Counting planar random walk holes[Abstract 31]Christian BENEŠ, Duke University, USA
18:05 Local theorem for the first passage time of fix level for recurrent random walk[Abstract 286]Anatolii A. MOGULSKII and BORIS A. ROGOZIN,Sobolev Institute of Mathematics, Novosi-birsk, Russia
18:25 Repulsion of an evolving surface on random walls[Abstract 441]Luiz Renato G. FONTES,University of São Paulo, BrazilMarina VACHKOVSKAIA , University of Campinas, BrazilAnatoli YAMBARTSEV, University of São Paulo, Brazil
Contributed Session C17 Room 2.1Stochastic GeometryChair: Dietrich STOYAN,TU Bergakademie, Freiburg, Germany
17:05 The MDS model for shape: an alternative approach[Abstract 233]I.L. DRYDEN, A. KUME, H. LE and A.T.A. WOOD,University of Nottingham, UK
17:25 Statistical analysis on high-dimensional spheres and shape spaces[Abstract 108]Ian DRYDEN , University of Nottingham, UK

Frid
ay54 6th BS/ IMSC
17:45 Random alpha hulls[Abstract 356]Alberto RODRÍGUEZ-CASAL , Universidade de Vigo, Spain
18:05 V-variable random fractals[Abstract 405]Michael F. BARNSLEY,John E. HUTCHINSON,Australian National University, AustraliaÖrjan STENFLO , Stockholm University, Sweden
Contributed Session C18 Room 2.2Markov ChainsChair: Dudley STARK,University of London, UK
17:05 Realization of hidden Markov chains[Abstract 400]Lorenzo FINESSO,CNR, ItalyPeter SPREIJ, Universiteit van Amsterdam, The Netherlands
17:25 On the spectrum of the covariance operator for a nilpotent Markov Chain[Abstract 208]Janusz KAWCZAK and Stanislav MOLCHANOV,University of North Carolina at Charlotte,USA
17:45 Computable bounds for subgeometric Markov chains[Abstract 104]Randal DOUC, Ecole Polytechnique, FranceEric MOULINES,Ecole Nationale Supérieure des Télécommunication, FrancePhilippe SOULIER,Université de Paris X-Nanterre, France
18:05 Limit theorems and deviation inequalities for subgeometric Markov chains[Abstract 292]Randal DOUC,École Polytechnique, Palaiseau, FranceArnaud GUILLIN, CEREMADE, Université Paris IX Dauphine, Paris, FranceEric MOULINES , École Nationale Supérieure des Télécommunications (ENST), Paris, France
18:25 Inequalities of the uniform ergodicity and strong stability for homogeneous Markov chains andapplication [Abstract 291]Djamil AISSANI andZahir MOUHOUBI , University of Béjaia, Algeria
Contributed Session C30 Room 4.1Long Memory ProcessesChair: Makoto MAEJIMA,Keio University, Japan
17:05 Nonparametric estimation, long memory and heteroskedasticity[Abstract 33]Jan BERAN and Yuanhua FENG,University of Konstanz, Germany
17:25 Asymptotics for linear predictors of long-memory processes[Abstract 46]Pascal BONDON, CNRS UMR 8506, Gif-sur-Yvette, FranceWilfredo PALMA, P. Universidad Católica de Chile
17:45 Statistical control charts of long memory processes[Abstract 164]Meihui GUO and Chi-Ling WANG,National Sun Yat-sen University, Kaohsiung, Taiwan, ROC
18:05 Moment generating function estimation for linear processes[Abstract 147]Sucharita GHOSH, Swiss Federal Research Institute WSL, Switzerland
18:25 Periodic long memory models[Abstract 207]Mohamed BENTARZI,University of Algiers (U.S.T.H.B), AlgeriaBelaide KARIMA , University of Bejaia, Algeria

July, 30 55
Frid
ay
Contributed Session C58 Aula MagnaNon-Parametric RegressionChair: Lucien BIRGÉ,Université Paris VI, France
17:05 Remarks on tests of continuity of regression functions[Abstract 186]Marie HUŠKOVÁ , Charles University, Czech Republic
17:25 A simple nonparametric estimator of a monotone regression function[Abstract 330]Kay F. PILZ , Ruhr-Universität Bochum, Germany
17:45 Jump-preserving regression and smoothing using local linear fitting: a compromise[Abstract 225]I. GIJBELS andA. LAMBERT , Université catholique de Louvain, BelgiumP. QIU,University of Minnesota, USA
18:05 Nonlinear nonparametric regression models[Abstract 458]Chunlei KE,St. Jude Medical, USAYuedong WANG, University of California - Santa Barbara, USA
18:25 Nonnegative monotone convex-concave multivariate extrapolation models with application tocomputer cache rates[Abstract 152]Ilya GLUHOVSKY and David VENGEROV,Sun Microsystems Laboratories, USA

Saturday, July 31
Laplace Lecture ParanimfChair: David NUALART,Universitat de Barcelona, Spain
9:30 Estimation of structure in graphical models[Abstract 230]Steffen LAURITZEN , University of Oxford, UK
10:30 –11:00 Coffee Break
Rietz Lecture ParanimfChair: Louis CHEN,Institute For Mathematical Sciences, Singapore
10:45 The frontiers of statistics and computer science[Abstract 40]Peter BICKEL , University of California, Berkeley, USA
11:45Closure Ceremony Paranimf

AbstractsBy alphabetical order
of speaker


Abstracts 59
1 Our walk through Particle Filtering: Si-multaneous estimation of state and parame-ters [Contributed Session C56 (page 47)]
Lesly María ACOSTA ARGUETA , Manuel MARTÍ-RECOBER and Pilar MUÑOZ GRACIA.Universitat Politèc-nica de Catalunya, Spain
This work deals with the application of the Particle Filter (PF)methodology to estimate the parameters for both the linear andnormal contaminated AR(1) model, and the basic nonlinearstochastic volatility model (Taylor 1994 [1]). These modelsare cast in an augmented state space representation and it isassumed a prior distribution not only for the state but also forthe unknown parameters (Acosta 2003 [2], Muñoz 1988b [3]).A Particle Filter is a simulation based method of sequentialBayesian analysis of dynamic models. Moreover, a PF uses asequential importance sampling (SIS) Bayesian technique anda resampling step, to produce samples from a specific posteriordistribution; see Doucet, de Freitas and Gordon (2001) [4].Our walk begins with Kitagawa’s 1996 [5] article and the ideasof Gordon, Salmond, and Smith (1993) [6], who were the firstones to point out the need for a resampling step. Since then, sev-eral authors have fruitfully applied and improved the so-calledgeneric PF, for example by applying a sampling importance re-sampling (SIR) scheme; see Kitagawa (1998) [7]. Other authorswent further trying to make the PF more efficient. For instance,Pitt and Shephard (1999) [8], constructed an auxiliary samplingimportance resampling (ASIR) particle filter. They basicallyintroduced an auxiliary variable into the model which allowedthem to obtain very good results. Liu and West [9], also, use anASIR strategy to get a combined estimation of state and param-eters.We apply the PF, with strategies SIS, SIR and ASIR, to estimatesimultaneously the state and fixed parameters of simulated andreal time series data. We focus on the advantages and drawbacksof each one of the implemented filters, considering both statis-tical and computational efficiency. Further, based on simulationresults, we propose a modified PF combining the ideas of Kita-gawa and Liu and West.References[1] Taylor, S.J. (1994) Modelling Stochastic Volatility: A Rewiew andcomparative study.Mathematical Finance4, 183–204.[2] Acosta, L., Martí-Recober, M., and Muñoz M.P. (2003) Autoregres-sive parameter estimation via Particle filtering.Actas del 27 Congresode Estadística e Investigación Operativa, Lleida, 1947–1953.[3] Muñoz, M.P., Egozcue, J.J., and Martí Recober, M. (1988b) Esti-mació del Pol y de la Variancia del Soroll d’un Model AR(1) mitjançantFiltratge No-Lineal.Questió 12, 21–42.[4] Doucet A., De Freitas, N., and Gordon, N. (2001)Sequential MonteCarlo Methods in Practice, Springer Verlag.[5] Kitagawa, G. (1996) Monte Carlo Filter and Smoother for Non-Gaussian nonlinear State Space models.Journal of Computational andGraphical Statistics5, 1–25.[6] Gordon, N.J., Salmond, D.J., and Smith, A.F.M. (1993) Novelapproach to nonlinear/nongaussian Bayesian state estimation.IEE.Proceedings-F140, 107–110.[7] Kitagawa, G. (1998) Self Organizing State-Space Model.Journal ofthe American Statistical Association93, 1203–1215.[8] Pitt, M.K. and Shephard, N. (1999) Filtering via simulation: auxil-iary particle filters.Journal of the American Statistical Asociation94,590–599.[9] Liu, J. and West, M. (2001)Combined parameter and state estima-tion in simulation-based filering, in Doucet, De Freitas, and Gordon:Sequential Monte Carlo Methods in Practice, 197–222.
2 A differential calculus for linear opera-
tors and its application to the central limittheorem [Contributed Session C7 (page 44)]
José A. ADELL, Universidad de Zaragoza, Spain
We propose a differential calculus for linear operators repre-sented by a family of finite signed measures, based on the no-tions of g-derived operators and processes andg-integratingmeasures,g being a right-continuous nondecreasing function. Astriking feature is that, for suitable choices ofg, this differentialcalculus works for non-smooth functions and under weak inte-grability conditions. A computational characterization criterionof g-differentiability in terms of the characteristic functions ofthe random variables involved is provided.As an application, we estimateEφ(X(t)) − Eφ(Z), where(X(t), t ≥ 0) is a standardized subordinator andZ is a standardnormal random variable. Apart from the consideration of a con-tinuous parametert, the main achievements of the method in thecase at hand are the following: (a) sufficient conditions onφ toensure monotonic convergence, (b) simple proofs of the Edge-worth expansions whenφ is smooth, (c) closed form expressionsin terms ofφ for the remainders, whenφ is moderately smooth,and (d) sharp lower and upper bounds for the Kolmogorov dis-tance betweenX(t) andZ in terms of the jumps of the distribu-tion functionFt of X(t), wheneverFt is a lattice distribution.
3 Extrema of random fields [Invited Session 7(page 32)]
Robert J. ADLER , Technion. Israel
I shall start by briefly discussing some statistical problems re-lated to controlling false discovery rates in detecting activ-ity in the brain, both the cerebrum (a 3-dimensional manifoldwith boundary) and the cerebral cortex, or ‘brain surface’ (a 2-dimensional manifold in 3-dimensional space, also with bound-ary). We shall also see how, in real life settings, one actuallyencounters far higher dimensional manifolds with singularities.This problem has motivated recent deep results describing thegeometry of random fieldsf on abstract manifoldsM, which Ishall describe and relate back to the original problem.The new results centre on the expected Euler-Poincaré charac-teristic of the random ‘excursion sets’t ∈M : f (t)≥ u, u∈ℜ,for which there are now very elegant and explicit formulae forboth Gaussian and non-Gaussian random fields over Whitneystratified manifolds.Furthermore, it has recently been shown, at least in the settingof smooth, centered, unit variance Gaussian processes, that theseexplicit formula provide an excellent (asymptotic inu) approx-imation to the extremal probabilitiesPsupt∈M f (t) ≥ u. Theerror in this approximation has also been shown to be super-exponentially small with an identifiable rate.The talk will be based on the joint papers [1] and [2], and a fulltreatment of the subject is currently being put together in [3].References[1] Taylor, J.E. and Adler, R.J. (2002) Euler characteristics for Gaussianfields on manifolds.Annals of Probability30, 533–563.[2] Taylor, J.E., Takemura, A., and Adler, R.J. (2004) Validity of theexpected Euler characteristic heuristic.Annals of Probability, to appear.[3] Adler, R.J. and Taylor, J.E. (2005)Random Fields andGeometry, Birkhaüser, Boston. Some Chapters available atie.technion.ac.il/Adler.phtml.
4 Broadening the scope of bootstrap incomplex problems [Contributed Session C45 (page 14)]
Víctor AGUIRRE TORRES and Manuel DOMÍNGUEZTORIBIO, Instituto Tecnológico Autónomo de Mexico (ITAM),

60 6th BS/ IMSC
Mexico
The availability of computers has allowed the increase of com-plexity of models in Statistics reach levels never seen before.Computer intensive methods [1] and estimation methods basedon simulations to estimate the coefficients of stochastic differ-ential equations [2] are two examples just to name a few. Boot-strap methods are becoming increasingly familiar in Statistics.Since these methods are applied by means of Monte-Carlo ex-periments, the computational cost involved in its applicationto methods like the ones mentioned before could become pro-hibitive. Therefore, results for reducing this computational costshould be welcome. In this paper we propose an approach tothe bootstrap that allows us to apply accurate inferential proce-dures with very small Monte-Carlo experiments. Also, the useof this approach permits the determination of the smallest num-ber of bootstrap replications needed to achieve a desired accu-racy level. The approach is very general and it applies to the iidor dependent situation as well. This approach could be used todetermine the minimum sizeB required to achieve a preestab-lished accuracy level with less demanding assumptions like in[3]. The assumptions required are those that insure convergencein distribution of bootstrap, there is no need of extra assump-tions to insure convergence of moments. Hence the procedurereduces the computational demands of bootstrap as long as thelarge sample distribution of the statistic is standard, typicallyasymptotically normal, this is in contrast to [4] where it is re-quired that the statistic is the result of a Newton’s type algorithm.The procedure could also be used in the usual applications ofbootstrap, with the corresponding savings in computation, butalso an increase in relative accuracy of the asymptotic approxi-mation.References[1] Hjorth, J.S. (1994)Computer Intensive Statistical Methods: Valida-tion Model Selection and Bootstrap, Chapman & Hall/CRC.[2] Gallant, A.R. and Long, J.R. (1997) Estimating stochastic differen-tial equations efficiently by minimum chi-squared,Biometrika84, 125–141.[3] Andrews, D. and Buchinsky, M. (2000) A three-step method forchoosing the number of bootstrap repetitions ,Econometrica68, 23–51.[4] Andrews, D. (2002) Higher-order improvements of a computation-ally attractivek-step bootstrap for extremum estimators, Econometrica70, 119–162.
5 Specification testing for nonstationarydiffusions against nonparametric alterna-tives [Invited Session 30 (page 43)]
Yacine AÏT-SAHALIA , Princeton University, USA
We study the properties of specification tests for discretely-observed diffusions when the process is either nonstationary orclose to being nonstationary. Near unit-root behavior is an im-portant stylized fact of interest rate time series. The class oftests we study are based on comparing the implied density froman assumed parametric model against a nonparametric alterna-tive. We calculate the asymptotic distribution of the test statisticas the process crosses the unit root barrier and find that the be-havior of the test statistic is affected by nonstationarity, and thatthe distribution of the statistic under nonstationarity is a betterapproximation to the small sample distribution when the processis calibrated to the empirical properties of interest rates. We thenpropose test statistics that are robust to nonstationarity of the un-derlying diffusion process.
6 Stop-loss premiums for dependent risks
[Contributed Session M4 (page 37)]
W. ALBERS , University of Twente, The Netherlands
In an insurance portfolio one of the main quantities of interestis the sumS of the claims of the individual risks during a ref-erence period (usually one year). By specifying a distributiontype both for the number (e.g. Poisson) and for the amount (e.g.Gamma) of claims, a model is given and the distribution ofScan (in principle) be determined explicitly. This is e.g. use-ful for reinsurance purposes as it allows to obtain the so-calledstop-loss premiumEmax(0,(S−a)), wherea is the retentionor threshold involved (e.g.a = 1.5ES).In doing so, typically it is tacitly assumed that the individualrisks are independent. Of course it is recognized that in practicedependencies do occur. Man and wife can be both insured, car-poolers can be collectively insured through their mutual com-pany, catastrophes can hit many insured simultaneously, etc.,but at first sight these effects may seem negligible. However,the combination of such dependence with extremal events asoccurring in stop-loss is in fact bound to cause trouble. Thestraightforward belief that small dependence effects will onlycause small changes in the outcomes of the model, might besound for quantities mainly based on the central parts of the dis-tributions involved. But this type of robustness will no longerexist in the tail. Extremely rare events require a substantial num-ber of the summands inS to be exceptionally large, which is in-deed very unlikely to happen under independence. However, itdoes seem likely that only a small bit of dependence needs to bethrown in to make such events still rare, but very much less sothan under independence. Hence the venom might very well bein the tail.To study the problem first suitable approximations for the dis-tribution of S are obtained. These are easier to work with andmore transparent. In this way it can be analysed how changesin the underlying parameters affect the result. The idea is to usesuch approximations as well once dependence has been added tothe basic model. The focus will then lie on the sensitivity of thebehavior ofS to changes in the dependence parameters. As de-pendence models, some simple proposals are studied which areessentially mixtures of individual risk parts and group risk parts.Such models are shown to nicely approximate many commonlyused models with competing risks.The results obtained confirm the suspicions ventilated above: al-locating as little as 1-5% of the expected claim amountESto thegrouped part can raise the required stop-loss premiums in per-fectly well-behaved situations already by factors (not percent-ages!) like 5-7.References[1] Albers, W. (1999) Stop-loss premiums under dependence, Insurance:Math. Econ.24, 173–185.[2] Reijnen, R., Albers, W., and Kallenberg, W.C.M. (2003)Approxima-tions for stop-loss reinsurance premiums,Tech. Rep. 1695, Appl. Math.Dept, Univ. Twente.
7 Scaling exponents in random combinato-rial optimization [Kolmogorov Lecture (page 13)]
David ALDOUS, U.C. Berkeley, USA
45 years ago, Beardwood-Halton-Hammersley [1] showed thatthe lengthLn of the TSP path (traveling salesman problem, theshortest tour through a set of points) onn random points of den-sity 1 per unit area satisfiesELn ∼ cn for some constantc. ThisBHH theorem provides a starting point for explorations in manydirections [2]. We can view it as one of a family of24 = 16

Abstracts 61
questions obtained by varying 4 aspects of problem description:(i) pathor tree?(ii) spanning (visit every point)or percolative (visit a small frac-tion of points)?(iii) two-dimensional geometryor mean-field geometry?(iv) mean valuesor scaling exponent?In (iv), scaling exponentrefers to near-critical behavior of ananalog of the percolation function (in the percolative setting),or to comparison between optimal and near-optimal solutions(in the spanning context). Our current level of understandingof solutions varies from rigorous proofs to dubious simulationheuristics. We focus on the mean-field setting, where we outlinerecent methodology (see [3] for a worked example). In somesense , this methodology formalizes thecavity methodof sta-tistical physics [4], relying on local weak convergence [5] andrecursive distributional equations [6].References[1] Beardwood, J., Halton, H.J., and Hammersley, J.M. (1959) Theshortest path through many pointsProc. Cambridge Phil. Soc.55,299–327.[2] Steele, J.M. (1997)Probability Theory and Combinatorial Optimiza-tion, Number 69 in CBMS-NSF Regional Conference Series in AppliedMath. SIAM, 1997.[3] Aldous, David and Percus, Allon G. (2003) Scaling and universalityin continuous length combinatorial optimization,Proc. Natl. Acad. Sci.USA 100, 11211–11215.[4] Mézard, M. and Parisi, G. (2003) The cavity method at zero temper-ature,J. Statist. Phys.111, 1–34.[5] Aldous, D.J. and Steele, J.M. (2003)The objective method: Prob-abilistic combinatorial optimization and local weak convergence, InH. Kesten, editor,Probability on Discrete Structures, volume 110 ofEn-cyclopaedia of Mathematical Sciences, 1–72. Springer-Verlag.[6] Aldous, D.J. and Bandyopadhyay, A. (2004)A survey of max-typerecursive distributional equations, arXiv:math.PR/0401388.
8 Stopping the maximum of a correlatedrandom walk, with application to Russian op-tions [Contributed Session M5 (page 27)]
Pieter C. ALLAART , University of North Texas, USA
A correlated random walk is a processSn = S0 + ∑nj=1Xj ,
whereX1,X2, . . . are−1,1-valued random variables such thatP(Xn+1 = 1|Xn = 1) = p andP(Xn+1 = −1|Xn = −1) = q, for0 < p,q < 1. Correlated random walks have been used fre-quently to model directionally reinforced physical and biolog-ical processes. Recently, Allaart and Monticino [1] suggestedusing a correlated random walk to model price processes ex-hibiting momentum, and derived optimal buy/sell strategies forsuch processes. In this paper, we obtain optimal stopping rulesfor the processMn−nc, whereM0 ≥ S0 is an arbitrary integer,Mn = maxM0,S1, . . . ,Sn for n≥ 1, andc> 0 is a constant costfor observation. Assuming thatc exceeds the driftδ of the walk,the optimal rule is shown to be of threshold type: stop the firsttimen at whichMn−Sn≥ K, for some positive constantK. Ex-plicit expressions are given both for the thresholdK and the op-timal stopping value. This work generalizes results obtained byFerguson and MacQueen [2] for the uncorrelated random walk.We will show how the optimal stopping rule can be interpretedas the optimal exercise time for the Russian option [3] when theunderlying price process exhibits momentum.References[1] Allaart, P.C. and Monticino, M.G. (2001) Optimal stopping rules fordirectionally reinforced processes,Adv. in Appl. Probab.33, 483–504.[2] Ferguson, T.S. and MacQueen, J.B. (1992) Some time-invariant stop-ping rule problems,Optimization23, 155–169.[3] Shepp, L. and Shiryaev, A.N. (1993) The Russian option: Reduced
regret,Ann. Appl. Probab.3, 631–640.
9 Time series clustering based on forecastdensities [Contributed Session C48 (page 40)]
Andrés M. ALONSO , José R. BERRENDERO and Ana JUS-TEL Universidad Autónoma de Madrid, Spain
1. Introduction
Suppose we have observed a sample of independent time se-ries, and we want to classify them into different clusters.In manypractical situations, we may not be interested in clustering onthe basis of the models that generated the observations, but inrespect of similarities of the forecasts at a specific future time.Therefore, it may be appropriate to employ a cluster method re-lying directly on the properties of the predicted values instead ofother aspects of the time series analysis, such as model structureor parameter estimates.In this paper, we propose an approach for time series cluster-ing based on the full probabilitiy density of the forecasts corre-sponding to each of the series in the sample. We use the fore-cast densities and not just the point forecasts. The advantage ofthis method is that it potentially allows us to classify in differentclusters time series generated by models which are similar (e.g.differ only in the variability of the observations, or in the innova-tions distribution) but which produce different forecast densities.A resampling method combined with a nonparametric kernel es-timator allows us to approximate the forecast distributions. Thecomparison of the nonparametricly estimated prediction densi-ties yields a measure of discrepancy among the time series whichcan be used as the basis for a cluster analysis. A survey of clus-tering and other relevant multivariate techniques for time series,including further references, can be found in Galeano and Peña(2000).
2. Description of the method
For i = 1, . . . ,n, let X i = (X1,i , . . . ,XT,i) be the correspondingtime series in the sample. We assume that the model generatingeach of the series can be approximated by an autoregressiveprocess. The proposed method applies the following steps toeach of theX i for i = 1, . . . ,n:
1. Identification of the orderp of the AR model using anyof the standard criteria (AIC, BIC) and estimation of theautoregressive parameters.
2. Using the estimated model found in 1), a bootstrap re-sampling scheme due to Alonso, Peña and Romo (2002)allows us to obtainB copies of thek-step-ahead predictedvaluesX∗T+k,i(b), b = 1, . . . ,B, where the horizonk is se-lected by the user.
3. Computation of a kernel estimatef ∗i ofthe probabilitydensity function ofXT+h,i using the bootstrap forecasts.
4. The pairwise discrepancies between the estimated fore-cast densities are evaluated through theL1 distancesDi j =
∫ | f ∗i − f ∗j |. The dissimilarity matrix obtained isthen used to carry out the cluster analysis.
References[1] Alonso, A.M., Peña, D., and Romo, J. (2002) Forecasting time serieswith sieve bootstrap,Journal of Statistical Planning and Inference, 100,1–11.[2] Galeano, P. and Peña, D. (2000) Multivariate analysis in vector timeseries,Resenhas4, 383–403.
10 Comparison of time series using sub-sampling [Poster Session P1 (page 22)]
Andrés M. ALONSO , Universidad Autónoma de Madrid,

62 6th BS/ IMSC
Spain
Elizabeth A. MAHARAJ,Monash University, Australia
The comparison of two or more time series is a problem ofgreat interest in many practical situations: (i) in geology, forexample, it is interesting to detect the differences between thewaves produced by earthquakes and by mining explosions; (ii )in medicine, the comparison of different sections of a biomedi-cal signal is used as a diagnostic procedure; (iii ) in economics,it is interesting to compare the interest rates or the inflation ratesin different regions or countries.In this paper, we propose a procedure based on subsampling(see, e.g. Politis and Romano (1994)) for testing the equalityof the generating processes of two stationary time series that arenot necessarily independent. The proposed procedure is differ-ent from the methods of Basawa et al. (1984), Maharaj (1996),Guo (1999) and Maharaj (2000) since it does require the selec-tion and the estimation of models. Also, it is different from themethods of Coates and Diggle (1986), Swanepoel and Van Wyk(1986), Diggle and Fisher (1991) and Timmer et al. (1999) sinceit does require spectral estimation. With the exception of Ma-haraj (2000), the above–mentioned methods are only applicableto independent series. The procedure based on subsampling isvalid both independent and dependent series and it is free ofmodel or spectral estimation.The paper is organized as follows. Section 2 presents the generalapproach for hypothesis testing using subsampling. In Section3 we develop the procedure of testing the equality of generat-ing processes. Particularly, we study a test based on the Eu-clidean distance between the autocorrelation functions of twoseries. Section 4 includes the results of a Monte Carlo study ofthe properties of the test where we consider the dependence ofthe proposed method on the subsample lengths and a calibrationprocedure is implemented. We have confirmed the competitivebehavior of the subsampling test procedure with regard to theprocedures proposed by Diggle and Fisher (1991) and Maharaj(2000). Finally, in Section 5, we illustrate the performance of theproposed method with a real data example where the assumptionof independent series is not appropriated.References[1] Basawa, I., Billard, L., and Srinivasan, R. (1984) Large-sample testsof homogeneity for time series models,Biometrika71, 203–206.[2] Coates, D.S. and Diggle, P.J. (1986) Tests for comparing two esti-mated spectral densities,J. Time Ser. Anal.7, 7–20.[3] Diggle, P.J. and Fisher, N.I. (1991) Nonparametric comparison ofcumulative periodograms,J. Rov. Statist. Soc. Ser. C40, 423–434.[4] Guo, J.H. (1999) A nonparametric test for the parallelism of twofirst–order autoregressive processes,Aust. N. Z. J. Statist.41, 59–65.[5] Maharaj, E.A. (1996) A significance test for classifying ARMA mod-els,J. Statist. Comput. Simulation54, 305–331.[6] Maharaj, E.A. (2000) Clusters of time series,J. Classification17,297–314.[7] Politis, D.N. and Romano, J.P. (1994) Large sample confidence re-gions based on subsamples under minimal assumptions,Ann. Statist.22, 2031–2050.[8] Swanepoel, J.W.H. and Van Wyk, J.W.J. (1986) The comparison oftwo spectral density functions using the bootstrap,J. Statist. Comput.Simulation24, 271–282.[9] Timmer, J., Lauk, M., Vach, W. and Lucking, C.H. (1999) A test fora difference between spectral peak frequencies,Comput. Statist. DataAnal. 30, 45–50.
11 An extension of Hull and White formulaand application to option pricing approxima-tion [Poster Session P2 (page 31)]
Elisa ALÓS , Universitat Pompeu Fabra, Barcelona, Spain
The work of Black and Scholes (1973) and Merton (1973) as-sumes that the stock pricesSt satisfy a stochastic differentialequation of the form
dSt = µStdt+σStdWt ,
whereµ andσ are constants andW is a standard Brownian mo-tion. The parameterσ is called thevolatility of the model.Iit is widely recognized that the simplicity of this popular modelis not longer sufficient to capture modern market phenomena. Inparticular, the constant volatility assumption is clearly not truefrom empirical studies. One of the natural extensions of theBlack-Scholes model is to modify the specification of volatil-ity to make it a stochastic process. Some examples of mod-elling are: Hull and White (1987), Stein and Stein (1991), Balland Roma (1994) and Heston (1993). However, new difficultiesarise from this approach. In particular, these models are morecomplex, and then it is more difficult to obtain analytic formu-las for option prices. Even when closed-form pricing solutionscan be derived, the analytical computations are usually hard. Bythis reason, as an alternative to this closed-form solutions, ap-proximate option prices have been constructed (see for exampleFouque, Papanicolau and Sircar (2000)).In the paper [2] we construct an option pricing approximationformula by means of a decomposition result. Using MalliavinCalculus we decompose the option priceVt as
Vt = E∗ (CBS(t,Xt ;vt)|Ft)
+12
E∗(∫ T
te−r(s−t)
(∂ 3
∂x3 −∂ 2
∂x2
)CBS(s,Xs,vs)
×(∫ T
sDW
s σ2r dr
)σsds
∣∣∣∣Ft
)
where(Ft) denotes theσ−algebra generated by the volatility,E∗ is the expectation with respect to the risk-neutral probability,vt := 1
T−t
∫ Tt σ2
s ds, CBS(t,x,σ) is the classical Black-Scholesformula for call option prices with initial log stock pricex, strikepriceK and time to maturityT− t andDW
s σ2r denotes the Malli-
avin derivative of the volatility process with respect to the Brow-nian motionW. Notice that the processvt is notFt−adapted, sothe Malliavin anticipative Calculus is a very natural tool for ourproblem.This decomposition allows us to consider the following approx-imation formula:
Vt = CBS
(t,Xt ;
√E∗
(v2t
∣∣Ft))
+12
(∂ 3
∂x3 −∂ 2
∂x2
)CBS
(t,Xt ;
√E∗
(v2t
∣∣Ft))
×E∗(∫ T
t
(∫ T
sDW
s σ2r dr
)σsds
∣∣∣∣Ft
)
This formula is easy to apply and quite good under some generalhypotheses, as we show in some numerical applications.References
[1] Alòs, E. (2003) A general decomposition formula for derivativeprices in stochastic volatility models, Working Paper 665, UniversitatPompeu Fabra.[2] Alòs, E. (2004) An extension of Hull and White formula and applica-tions to option pricing approximations, Working Paper 740, UniversitatPompeu Fabra.[3] Fouque, J-P., Papanicolau, G., and Sircar, K.R. (2000):Derivativesin Finantial markets with Stochastic Volatility,Cambridge.[4] Nualart, D. (1995)The Malliavin Calculus and Related Topics,Springer.

Abstracts 63
12 Empirical likelihood in nonparametricregression for length biased samples [Con-tributed Session C5 (page 18)]
J.T. ALCALÁ andE. ANDRÉS, Univ. of Zaragoza, Spain
In this work, empirical likelihood and kernel smoothing tech-niques are combined in order to study punctual estimation andthe coverage error of confidence intervals for a nonparametricregression function when data are biased in the response vari-able, specifically by length-bias. Length-biased sampling situ-ations may occur in clinical trials, reliability, queueing models,survival analysis and population studies where a proper sam-pling frame is absent. In such situations, items are sampled ata rate proportional to their length, so that larger values of thequantity being measured are sampled with higher probabilities.Let (Y1,X1), · · · ,(Yn,Xn) be an i.i.d. sample of(Y,X) with con-ditional density function given by:
fw(y|x) =y f(y|x)m(x)
,
where0< m(x) = E(Y∗|X = x) < ∞ is the regression function inthe original population, which we want to estimate, andf (y|x) isthe conditional density of the original random variableY∗ givenX. In Cristóbal and Alcalá (2000), several local polynomial esti-mators for the regression function in this situation are proposed.In the particular case of local linear estimators, we have
mh(x) =∑n
i=1Wi,h(x)
∑ni=1Wi,h(x)Y−1
i
,
wherewi,h(x) denote the usual local linear smoothing weights.The profile empirical likelihood ratio function for this kernel re-gression estimator is:
Rx(µ) = max n
∏i=1
npi |n
∑i=1
piZin(x,µ) = 0, pi ≥ 0,
n
∑i=1
pi = 1
,
where
Zin(x,µ) = Wi,h(x)(
Yi −µYi
),
due to the length-bias sampling.Following the work of Chen and Qin (2000, 2001), in this paperwe compare confidence intervals obtained from the asymptoticnormal distribution of the kernel estimator with the confidenceintervals obtained from the empirical likelihood ratio. The com-parison is carried out at interior and boundaryx points.References[1] Chen, S.X. and Qin, Y.S. (2000) Empirical likelihood confidenceintervals for local linear smoothers ,Biometrika87(4), 946–953.[2] Chen, S.X. and Qin, Y.S. (2001)Confidence intervals based on locallinear smoother, Scandinavian Journal of Statistics29(2), 89–99.[3] Cristóbal, J.A. and Alcalá, J.T. (2000)Nonparametric regression es-timators for length biased data, J. Stat. Plan. Infer.89(1-2), 145–168.[4] Owen, A.B. (2001)Empirical Likelihood, Chapman and Hall, BocaRaton.
13 Weak signal detection and applicationsto microarrays (Bayesian approach) [Con-tributed Session C40 (page 37)]
Vladimir ANISIMOV , GlaxoSmithKline, UK
Valerii FEDOROV,GlaxoSmithKline, US
We discuss the problem of detecting a signal in the presence of
noise with similar intensity, i.e. estimating a useful signalX1from observations of the sumX = X1 + X2, whereX2 is noise.The research was motivated by the needs of microarray analysiswhere one of the main problems in the pre-processing stage isto estimate the useful signal (observed intensity of some gene orspot) in the presence of noise or background.Various types of processing software estimate a useful signal byaveraging the observations in regions with small intensities andsubtracting the sample mean from the intensities in other regionsthat are viewed as a sum of useful signal and noise. The majorproblem here is that many of the differences that are used asestimators of the signal can be negative because of random fluc-tuations. Thus, corresponding observations are often reported asmissing.Different approaches [1-4] exist to resolve this problem, and sev-eral models for the distribution of signal–noise are considered inthe literature.Many papers deal with normal or log-normal distributions (see,for instance, [2]). binomial-beta and Poisson-gamma distribu-tions to model within- and between-sample replications are con-sidered in [1], but the problem of signal detection was not con-sidered there.We use the Bayesian approach and analyze the following mod-els: Poisson signal and noise with gamma prior rates, gammasignal and noise with gamma prior rates, and log-normal signaland noise with normal prior means. Closed-form expressions forposterior distributions, their means (which can be viewed as theBayesian estimators) and their variances are obtained. We con-sider also the empirical Bayesian setting and derive estimatorsfor the corresponding parameters of the prior distribution. Thelatter approach is closely related to the random effects setting.A simulation study shows that the approach gives very good re-sults for a wide range of parameters and high intensities of noise,as well. The algorithm of the normalization of the microarraydata using the proposed estimators is suggested and was run ona few data sets.One of the major advantages of the proposed technique is that itdoes not lead to “negative" values of the estimates of the signal,a common problem in the processing of microarray observations[2-4].References[1] Baggerly K.A., Coombes K.R., Hess K.R., Stivers D.N., AbruzzoL.V., and Zhang, W. (2001) Identifying differently expressed genes incDNA microarray experiments ,J. of Computational Biology8, No. 6,639–659.[2] Baldi, P. and Hatfield, G.W. (2002)DNA Microarrays and Gene Ex-pression, Cambridge Univ. Press.[3] Efron, B., Tibshirani, R., Storey, J.D., and Tusher, V. (2001) Empir-ical Bayes analysis of a microarray experiment,JASA 96 (456), 1151–1160.[4] Speed, T. (2003)Statistical analysis of gene expression microarraydata, Chapman & Hall/CRC Press, USA.
14 Fully nonparametric ANCOVA withfixed window sizes [Contributed Session C43 (page 26)]
Michael G. AKRITAS andEfi ANTONIOU , The PennsylvaniaState University, USA
We consider testing for covariate-adjusted main effects and in-teractions in the context of the fully nonparametric ANCOVAmodel. The test procedures of Akritas, Arnold and Du (2000) arebased on consistent estimation of the conditional distributionsand as such they involve the cumbersome task of bandwidth de-termination. The proposed methodology does not require suchconsistent estimation. Asymptotic theory and numerical results,

64 6th BS/ IMSC
indicate that nearest neighbor windows of fixed (small) size per-form well. This makes the applicability of the fully nonparamet-ric methodology in real-life situations easily feasible.References[1] Akritas, M.G., Arnold, S.F., and Du, Y. (2000) Nonparametric mod-els and methods for nonlinear analysis of covariance.Biometrika. 87,507–526.[2] Akritas, M.G, Arnold, S.F., and Brunner, E. (1997) NonparametricHypotheses and Rank Statistics for Unbalanced Factorial Designs.J.American Statistical Association92, 258–265.[3] Akritas, M.G. and Wang, L. (2002) Lack-of-fit test in nonparametricrandom design regressionsubmitted.[4] Bhattacharya, P.K. (1974) Convergence of sample paths of normal-ized sums of induced order statistics.Ann. Statist.12, 1034–1039.[5] Lehmann, E.L. (1998)Elements of Large Sample Theory. New York,Springer-Verlag.[6] Pyke, R. (1965) Spacings (with discussions).Journal of the RoyalStatistical Society. Series B.27, 395–449.[7] Sacks, J. and Ylvisaker, D. (1970) Designs for regression problemswith correlated errors III.Ann. Math. Statist.41, 2057–2074.[8] Tsangari, H. and Akritas, M.G. (2004) Nonparametric ANCOVAwith two and three covariates.Journal of Multivariate Analysis. 88,298–319.[9] Wang, L. and Akritas, M.G. (2002). Two-way heteroscedasticANOVA when the number of levels is large(submitted).
15 Goodness-of-fit measures for statisticaldaily rainfall models [Poster Session P1 (page 21)]
J. ABAURREA andJ. ASÍN, Zaragoza University, Spain
In recent years, many daily rainfall statistical models have beendeveloped and fitted to answer important questions related to cli-mate change scenarios. Before accepting forecasts from a modelit is necessary to evaluate model ability in reproducing precipi-tation characteristics. Usually, the properties related to seasonalpattern or to aggregated precipitation in wide periods are consid-ered, see for example, Wilby et al. (1998), Legates and McCabe(1999). If the model is going to be used in the daily scale, agood description of rainfall aggregated characteristics is a nec-essary requirement but not sufficient; daily rainfall models mustbe validated using measures related to daily rainfall behaviour.For checking a daily rainfall occurrence model, Klein Tank andBuishand (1995) classified each day as wet-predicted or dry-predicted according to its fitted value and calculated the per-centage of success obtained as a goodness-of-fit measure. Wepropose to obtain these percentages taking into account also thestate of the process in the previous day; this procedure allows usto analyze if wet and dry state persistence and transition betweenstates are well reproduced by the model. For the amount model,we classify the quantities observed in wet days into classes de-fined by quantiles of fitted distribution; the percentage distribu-tion obtained is useful for identifying model inadequacies. Fi-nally, we verify if the model is able to generate simulated se-ries which are indistinguishable from those observed, applyingstatistical tests to compare dry and wet run length and wet-dayamount distributions. In order to avoid false conclusions we ap-ply these tests to rainfall series corresponding to homogeneousperiods.To analyze the behaviour of these goodness-of-fit measures wefit daily rainfall models consisting of a logistic regression for fit-ting the occurrence series and a generalized linear model withGamma distribution for the rainfall amount in wet days, seeStern and Coe (1984), Beckmann and Buishand (2002). Severalmodels using very different atmospheric information are fitted.Besides the GLM tools for model checking and the comparisonof aggregated rainfall properties, the models are evaluated using
the daily scale goodness-of-fit measures proposed.References[1] Beckmann, B.R. and Buishand, T.A. (2002) Downscaling relation-ships for precipitation for the Netherlands and North Germany,Interna-tional Journal of Climatology22, 15–32.[2] Klein Tank, A.M.G. and Buishand, T.A. (1995) Transformation ofprecipitation time series for climate change impact studies, KNMI, DeBilt.[3] Legates, D. R. and McCabe, G.J. (1999) Evaluating the use ofgoodness-of-fit measures in hydrologic and hydroclimatic model vali-dation,Water Resour. Res.35, 233–241.[4] McCullagh, P. and Nelder, J.A. (1989)Generalized Linear Models,Chapman & Hall.[5] Stern, R.D. and Coe, R. (1984) A Model Fitting Analysis of DailyRainfall Data,J. R. Statist. Soc. A147, 1–34.[6] Wilby, R.L., Wigley, T.M.L., Conway, D., Jones, P.D., Hewitson,B.C., Main, J., and Wilks, D.S. (1998) Statistical downscaling of gen-eral circulation model output: A comparison of methods,Water Resour.Res.34, 2995–3008.
16 Hitting times for asymmetric indepen-dent random walks onZd [Contributed Session C9(page 20)]
Amine ASSELAH, Université de Provence, France
Pablo A. FERRARI,Universidade de São Paulo, Brazil
We consider a system of independent random walks onZd, de-noted byηt , t ∈ R, stationary under the product Poisson mea-sureνρ of marginal densityρ > 0. We fix a patternA, an increas-ing local event, and denote byτ the hitting time ofA. By using aLoss Network representation of our system, at small density andwhend≥ 3, we obtain bounds on the rate of convergence of thelaw of ηt conditioned onτ > t towards its limiting probabilitymeasure ast tends to infinity.
17 On the estimation of parameters in fi-nite mixture models of Generalized Gammadistributions [Poster Session P1 (page 22)]
N. ATIENZA , A. ENGUIX GONZÁLEZ, J. GARCÍA HERASand J. MUÑOZ-PICHARDO,University of Seville, Spain
In order to describe complex statistical problems, mixture mod-els are often used in the literature. Normal, Binomial, Gamma,Log-normal, Exponential or Weibull distributions, among oth-ers, are widely used as components of finite mixture models.Stacy[1] introduced the three-parameter generalized gamma dis-tribution (GGD) as follows
f (x,a,b,c) =1
bacΓ(a)cxac−1e−
xb
c
This model includes the Exponential, Weibull and Gamma dis-tributions among others as special cases, what makes it interest-ing in applications. Its ability to behave like other more com-monly used life distributions is sometimes used to determinewhich of those life distributions should be used to model a par-ticular set of data. Thus, the modelization with finite mixturesfrom GGD includes finite mixture models whose componentsbelong to any of these three families, increasing considerablythe flexibility of the model.In order to estimate the parameters in finite mixture models, twoproblems are essential to be solved. First, a requirement for theestimation procedures to be well defined is the identifiability ofthe problem, concerning with the question about whether it ispossible to estimate the parameters of a model in a unique way.On the other hand, the existence and good properties of the es-timators are desirable. In that work, we analyze problems for

Abstracts 65
GGD finite mixtures.In particular, we prove the identifiability of finite mixtures ofGamma Generalized distributions. Using new techniques wegive results which assure the existence, consistency and asymp-totic normality behavior of estimators of maximum likelihood.
References
[1] Stacy, E.W. (1962) A generalization of the gamma distribution,Ann.Math. Statist.33, 1187–1192.
18 Locally superoptimal projection densityestimators: the case of the trigonometric sys-tem [Contributed Session C6 (page 38)]
Jean-Baptiste AUBIN, Université Paris 6, France
D.Bosq [1] has introduced and studied a locally superoptimalversion of the projection estimator of an unknown densityfbased on independent observations. More precisely, letX1,X2,. . . , Xn be independent random variables whose distributionis given by a probability densityf with respect toµ , anotherprobability density. Furthermore, lete0 = 1,e1,e2,. . . be thetrigonometric basis ofL2(µ).The following projection estimator of the densityf = ∑∞
j=0a jejwas introduced by Cencov [3]:
fn =kn
∑j=0
a jnej
wherea jn = 1n ∑n
i=1ej (Xi) andkn, the truncation index, is chosenby the statistician.Bosq generalized the projection estimator changing the trunca-tion index:
fn =kn
∑j=0
a jnej
wherekn = max j : 0≤ j ≤ kn, |a jn|> γn. As in [1], we choose
γn = c√
lognn , c > 0 andkn such thatkn → ∞, and kn
n → 0 whenn→ ∞.Bosq has shown that by selecting the dimension of the projec-tion space this way, one could obtain estimators which convergeto f with superoptimal rate for the mean integrated square er-ror in the subspace ofL2(µ) composed of the functions whichadmit a finite development with respect to the basisF0. OnF1 := L2(µ)\F0, the rate of convergence is quasioptimal.The aim of the study is first to precise the influence of the con-stantc on the truncation index when other parameters are fixed.Then, two others projection estimators respectively defined in[2] and [3] are compared to the one introduced in [1]. Criterionof comparison are uniform error,L1 error, and mean integratedsquare error. Moreover, some functions to estimate are taken inF0, others inF1, andn, the number of realisations observed inthe sample, is chosen successively equal to100, 500and1000.References[1] Bosq, D. (2002) Estimation localement suroptimale et adaptative dela densité,C.R. Acad. Sci. Paris, Ser.I, 334, 591–595.[2] Bosq, D. and Lecoutre, J.P. (1987)Théorie de l’Estimation Fonc-tionelle, Editions Economica.[3] Cencov, N.N. (1962)Soviet Math. Dokl.3, 1559–1562.
19 A statistical quality control procedurebased on tolerance regions[Contributed Session C6(page 38)]
Amparo BAÍLLO , Universidad Carlos III de Madrid, Spain
Antonio CUEVAS,Universidad Autónoma de Madrid, Spain
A major problem in statistical quality control is to detect achange in the underlying distribution of independent sequentialobservationsX1,X2, . . . of ad-dimensional random vectorX. Forexample,X might be certain quality characteristics of a manu-factured item. Assume that the manufacturing process is beingmonitored for potential change in the distribution ofX, by se-quentially analyzing the dataXi . Initially, when the process is incontrol, the observations follow a distributionF given by den-sity f . At some stage, the process may run out of control andthe distribution of theXi ’s changes. Our aim is to detect a realchange in the distribution of the process as quickly as possible,subject to a boundα ∈ (0,1) on the probability of false alarm.The case where the pre-change distribution is Gaussian has beenextensively analyzed (see, e.g., Fuchs and Kenett 1998). We areconcerned here with the less usual non-normal multivariate case.The classical concept of tolerance region of a distributionF as aset with a prespecified probability content1−α has given rise todetection procedures in several fields of statistics (see Aitchisonand Dunsmore 1975 and Bucchianico, Einmahl and Mushkudi-ani 2001). The idea is that any observation coming from that dis-tribution should “most likely” be within the tolerance limits ofthis region. When dealing with populations such as mixtures ofnormal distributions it is very reasonable to use tolerance regionsof the type f ≥ c, wherec is such that
∫ f≥c f = 1−α. We
suggest using a detection procedure that raises the alarm (thatis, decides that observationXn+1 does not follow the densityf )wheneverXn+1 /∈ f ≥ c.One of the advantages of this procedure is that the required levelsets f > c can be estimated in a plug-in way by fn > cn,wherefn is an estimator of the densityf (see also Baíllo, Cuesta-Albertos and Cuevas 2001). We will study the asymptotic be-haviour of tolerance regions of the type fn ≥ cn when fn is akernel estimator off and only some analytical assumptions areplaced onf . Later we will consider the asymptotic performanceof fn≥ cn, when fn is a parametric estimator off and f = fθbelongs to a parametric family.>From a more practical point of view, we will also check andcompare the detection performance provided by tolerance re-gions fn ≥ cn, when the original densityf belongs to theparametric family of mixtures of normals andfn is either an es-timator from that family or a kernel one. The approach is donethrough some simulation results and the analysis of a real dataset.References[1] Aitchison, J. and Dunsmore, I.R. (1975),Statistical Prediction Anal-ysis, Cambridge University Press.[2] Baíllo, A., Cuesta-Albertos, J.A., and Cuevas, A. (2001) Conver-gence rates in nonparametric estimation of level sets.Statist. Prob. Let-ters53, 27–35.[3] Di Bucchianico, A., Einmahl, J.H.J., and Mushkudiani, N. (2001)Smallest nonparametric tolerance regions,Ann. Statist.29, 1320–1343.[4] Fuchs, C. and Kenett, R.S. (1998)Multivariate Quality Control, The-ory and Applications, Marcel Dekker, New York.
20 Measurability of the frozen percolationprocess on an infinite regular tree [ContributedSession C35 (page 25)]
David J. ALDOUS,University of California, Berkeley, USA
Antar BANDYOPADHYAY , Institute for Mathematics and ItsApplications, USA
Let T = (V ,E ) be an infinite regular tree with independentUniform[0,1] edge weights given by(Ue)e∈E . Consider the fol-lowing modification of the usual percolation process where we

66 6th BS/ IMSC
openan edgee∈ E only at the time instancet = Ue providedeach end-vertex ofe is in a finite cluster. In other words weforbid the infinite clusters to grow any further. This process iscalled frozen percolationprocess and was first studied by Al-dous in [1], where he constructed an automorphism invariantversion of the process onT . The construction used someex-ternally defined random variables whose distribution satisfy aparticular “max-type"recursive distributional equation (RDE).In this work we prove that the process so constructed is actu-ally measurable with respect to the edge weights(Ue)e∈E andhence exclude the possibility of presence of any external ran-domness. The method uses the general framework developed byAldous and Bandyopadhyay [2]. We show using some analytictechniques that the associatedrecursive tree process (RTP)hasbivariate uniquenessand hence isendogenous, which impliesthat the frozen percolation process onT is measurable. Thisgives yet another interesting example where a “max-type" RDEplays a very crucial role.References[1] Aldous, David J. (2000) : The percolation process on a tree whereinfinite clusters are frozen.Proc. Cambridge Philos. Soc., 128, 465–477.[2] Aldous, David J. and Bandyopadhyay, Antar, (2004) A Survey ofMax-Type Recursive Distributional Equations,(submitted), available at<http://www.arXiv.org/pdf/math.PR/0401388>.
21 Constrained investment problems [In-vited Session 3 (page 19)]
Peter BANK, Humbolt university, Berlin, Germany
We study the investment problem of an investor who can use adynamically increasing, but limited amount of resources (’finitefuel’) in an irreversible manner to maximize his utility. The firstorder conditions of this optimization problem are stated in termsof the Snell envelope of the optimal utility gradient. The solutionto these conditions can be specified in terms of a representationproblem as studied in Bank and El Karoui (Ann. Prob., Vol 1,2004). In the second part of the talk, we describe how this ap-proach can be extended to situations where investment and dis-investment are possible at certain costs. This offers a new viewon Dynkin games and their connection with two-sided singularcontrols.
22 Multiple Stratonovich fractional inte-gral with Hurst parameter lesser than f rac12
[Poster Session P2 (page 31)]
Xavier BARDINA and Maria JOLIS,Universitat Autónoma deBarcelona, Catalonia, Spain
In this work we study the multiple integrals with respect to thefractional Brownian motion with Hurst parameterH < 1/2, inthe itì-Wiener and Sttratonovich sense. First, we find a sim-ple characterization of the domain of the Wiener integral in thesimple and the multiple case and then, we raise the problem ofdefining the multiple Stratonovich-type integral. A Hu-Meyerformula relating both types of integrals is also obtained.
23 Random walks on percolation clusters[Invited Session 18 (page 23)]
Martin T. BARLOW , University of British Columbia, Canada
Takashi KUMAGAI,RIMS, Kyoto, Japan
This talk will survey recent progress in understanding the be-haviour of (unbiased) simple random walks on percolation clus-ters in two situations.The first is supercritical percolation inZd. Let C∞(ω) be the
unique infinite cluster,Yt , t ≥ 0 be the continuous time SRWonC∞, andpω
t (x,y) be the transition density ofY. Then one hasGaussian upper and lower bounds on the transition probabilities:
Theorem 1. (See [1]). Let p > pc. There existsΩ1 ⊆ Ω withPp(Ω1) = 1, and r.v. Sx,x ∈ Zd, such thatSx(ω) < ∞ for eachω ∈Ω1, x∈C∞(ω). There exist constantsci = ci(d, p) such thatfor x,y∈ C∞(ω), t ≥max(1,Sx(ω), |x−y|),
c1t−d/2e−c2|x−y|2/t ≤ pωt (x,y)≤ c3t−d/2e−c4|x−y|2/t . (1)
Further one has
Pp(x∈ C∞,Sx ≥ n)≤ cexp(−c′nδd). (2)
The proof uses a mixture of percolation and ‘heat kernel’ tech-niques. On the percolation side one needs to control the size andthe spectral gap of the largest cluster in a cube. On the heat ker-nel side, it is necessary to use methods which are ‘local’ ratherthan ‘global’.These bounds have been used in [4] to prove a quenched invari-ance principle whend≥ 4.
The second area is the study the random walkZt , and its transi-tion densitiesqω
t (x,y), on the incipient infinite clusterC , on thebinary treeB. Some annealed estimates for this process wereobtained by Kesten in [3].
Theorem 2. (See [2]). Let Px(·) = P(·|x∈ C ). (a) There existc1,c2,γ1,γ2 > 0 such that for eachx, Px- a.s., for all sufficientlylarget,
c1t−2/3(logt)−γ1 ≤ qωt (x,x)≤ c2t−2/3(logt)γ2. (3)
(b) For eachx∈ B andt ≥ 1
c4t−2/3 ≤ Ex[qωt (x,x)]≤ c5t−2/3. (4)
The logarithmic oscillations in (3) are really there, and arecaused by scale invariant irregularities in the clusterC . Thepowert−2/3 was conjectured by Alexander and Orbach to holdfor the incipient infinite cluster in all dimensions.References[1] Barlow., M.T. Random walks on supercritical percolation clusters,To appearAnn. Probab.[2] Barlow, M.T. and T. Kumagai, T.Random walks on the incipientinfinite cluster on trees,In preparation.[3] Kesten, H. (1986) Subdiffusive behavior of random walk on a ran-dom cluster,Ann. Inst. Henri Poincaré22, 425–487.[4] Sidoravicius, V. and Sznitman, A.-S. (2003)Quenched invarianceprinciples for walks on clusters of percolation or among random con-ductances,Preprint.
24 Estimation in the two-parameter expo-nential distribution and related distributions
[Poster Session P3 (page 41)]
I. BARRANCO-CHAMORRO , M.D. CUBILES DE LAVEGA and J.M. MUÑOZ-PICHARDO,Universidad de Sevilla,Spain
In this paper, we obtain the limiting distribution of the maxi-mum likelihood estimator (MLE) of a given parametric functionwhen sampling from a two-parameter exponential distribution.Approximations to the moments of this estimator are proposed.We apply these results to the estimation of several parametric

Abstracts 67
functions of interest. We propose approximate confidence inter-vals. Finally, we consider extensions of these results to otherdistributions with unknown location and scale parameters.References[1] Barranco-Chamorro, I. (1996)Estimación paramétrica en distribu-ciones no regulares, Unpublished Ph.D. Thesis, Universidad de Sevilla.[2] Johnson, N.L., Kotz, S., and Balakrishnan, N. (1994)Continuos Uni-variate Distributions, Vol. 1, Second Edition, Wiley.[3] Lehmann, E.L. (1999)Elements of Large-Sample Theory, Springer-Verlag.
25 Optimal risk transfer and diversifica-tion in financial markets [Invited Session 9 (page23)]
Pauline BARRIEU, London School of Economics, UnitedKingdom
Nicole EL KAROUI, Ecole Polytechnique, CMAP, France
Financial markets have witnessed for several years the arrivalof a new breed of instruments, depending on non-financial risksand usually considered as falling within the competence of theinsurance sector. One may think, for instance, of weather orcatastrophic contracts, the flows of which are contingent to theoccurrence of certain weather or catastrophic events. Howeverthis global phenomenon of convergence and interplay betweeninsurance and finance raises several questions about the classi-fication of these new products but also about their pricing andmanagement. The characterization of their price is very inter-esting as it questions the logic of these contracts itself. Indeed,standard techniques for derivatives pricing, using, for instance,replication, are not valid any more because of the specific na-ture of the underlying risk. Moreover, the determination of thecontract structure is a problem in itself: on the one hand, theunderlying market related to these risks is extremely illiquid,but on the other hand, the logic of these products itself is closerto that of an insurance policy. Consequently the question of theproduct design, unusual in finance, is raised.
In this paper, we develop a methodology to optimally design afinancial issue to hedge non-tradable risk on financial markets.The modelling involves a minimization of the risk borne by is-suer given the constraint imposed by a buyer who enters thetransaction if and only if her risk level remains below a giventhreshold. Both agents have also the opportunity to invest alltheir residual wealth on financial markets but they do not havethe same access to financial investments. The problem may bereduced to a unique inf-convolution problem involving sometransformation of the initial risk measures. Some argumentsfrom BSDEs are then adopted to characterize completely the op-timal solution and lead to a definition of dynamic risk measures.References[1] Artzner, P., Delbaen, F., Eber, J.M., and Heath, D. (1999) CoherentMeasures of Risk,Mathematical Finance9, 203–228.[2] Becherer, (2004) Rational Hedging and Valuation of Integrated Risksunder Constant Absolute Risk Aversion, To appear in Insurance: Math-ematics and Economics.[3] Borch, K. (1962) Equilibrium in a Reinsurance Market,Economet-rica30, 424–444.[4] Davis, M. (1997)Option Pricing in Incomplete Markets; In: Demp-ster, M.A.H. et al. (eds.): Mathematics of Derivative Securities,Cam-bridge University Press, 227–254.[5] El Karoui, N. and Quenez, M.C. (1996)Non-linear Pricing Theoryand Backward Stochastic Differential Equations, Financial Mathematics(ed: W.J. Runggaldier), Lecture Notes in Mathematics 1656, SpringerVerlag, 191–246.[6] El Karoui, N. and Rouge, R. (2000) Pricing via Utility Maximization
and Entropy,Mathematical Finance10, 259–276.[7] Föllmer, H. and Schied, (2002) Convex Measures of Risk and Trad-ing Constraints,Finance and Stochastics6, 429–447.[8] Musiela, M. and Zariphopoulou, T. (2001)Pricing and Risk Man-agement of Derivatives Written on Non-Traded Assets,Working Paper.[9] Raviv, A. (1979) The Design of an Optimal Insurance Policy,Amer-ican Economic Review69, 84–96.[10] Rockafellar, R.T. (1970)Convex Analysis, Princeton Landmarks inMathematics.
26 Bootstrap of empirical Wasserstein met-rics with applications [Contributed Session C45 (page14)]
Eustasio del BARRIO and Carlos MATRÁN,Universidad deValladolid, Spain
Let Xn∞n=1 be a sequence of i.i.d. random variables with con
distribution functionF in the domain of attraction of theα-stable lawcτ Poisµ(c1,c2;α), where1< α < 2 and letan∞
n=1be a sequence of norming constants such that
X1 + · · ·+Xn−nEX1,τan
w→ cτ Poisµ(c1,c2;α). (1)
If d1 denotes theL1-Wasserstein distance between probabilitylaws on the real line then it is shown [1] that
nan
d1(Fn,F) w→ 1α
(c1
c1 +c2
)1/a∫ ∞
0|N1(s)−s|s−1−1/α ds
+1α
(c2
c1 +c2
)1/a∫ ∞
0|N2(s)−s|s−1−1/α ds, (2)
whereN1 andN2 are independent Poisson processes.The limiting law in (??) does not depend onF but only onc1,c2andα , that is, on the particular domain of attraction to whichFbelongs. Unfortunately we cannot directly make use of this in-variance result for testing whether the underlying unknown d.f.,F , of a sample belongs to a particular domain of attraction sincewe would need to knowF in order to computed1(Fn,F). Inthis talk we will show how to use a bootstrap version of (??)as a basis for inference on the domain of attraction to whichFbelongs.
References
[1] del Barrio, E., Giné, E., and Matrán, C. (1999) Central Limit The-orems for the Wasserstein distance between the empirical and the truedistributions,Ann. Probab.27, 1009–1071.
27 Optimal multistage procedures for test-ing simple hypotheses[Contributed Session C63 (page39)]
Jay BARTROFF, Caltech, USA
A method for constructing multistage hypothesis tests with vari-able stage sizes, based on the multistage sampling proceduresof Bartroff (2003), are described for testing simple hypothesesconcerning the mean drift of Brownian Motion. The optimaltest is defined to be that which minimizes the integrated risk,using a loss function that is a linear combination of the sam-pling costs and a penalty for a wrong decision. Our procedureis shown to minimize this integrated risk to second order as thecosts per stage and per unit time approach zero. A numericalsimulation compares our procedure to competing procedures, in-cluding group sequential sampling. Extensions to i.i.d. data andcomposite hypotheses are discussed.
References

68 6th BS/ IMSC
[1] Bartroff, J. (2003) A Multistage Boundary-Crossing Prob-lem for Brownian Motion, submitted, Preprint available atwww.its.caltech.edu/∼bartroff/papers/boundary_crossing.pdf
28 Monotone missing data and ellipticaldistributions [Contributed Session C41 (page 46)]
A. BATSIDIS and K. ZOGRAFOS,University of Ioannina,Greece
Incomplete data are a common theme in multivariate analysis.In the last decades, statistical analysis of missing data receivedthe attention of researchers in several disciplines and contexts(cf. Schafer (1997), Little and Rubin (2002)). Monotone miss-ing data is an attractive type of missing data, because they arecommon in practice and usually non monotone data sets can bemade monotone, or nearly so, by reordering the variables ac-cording to their missingness rates. On the other hand ellipticallycontoured models (cf. Fang and Zhang (1990)) is an importantfamily of multivariate distributions which share common prop-erties with the multivariate normal model. Moreover, ellipticdistributions can be used in order to study random phenomena,which the multivariate normal model fails to significantly de-scribe and formulate.There is an extensive bibliography concerned with statistical in-ference for the parameters of the multivariate normal distribu-tion in the case of monotone missing data (cf. Andrson (1957),Hao and Krishnamoorthy (2001), Srivastava (2002)). This talkis concentrated to estimation and testing problems on the pa-rameters of the elliptic family of distributions when the avail-able data is of a monotone missing pattern. Explicit expressionsfor the maximum likelihood estimators of the parameters will bederived and several statistical tests will be presented for testinghypotheses about the parameters of the elliptic distributions.References[1] Anderson, T.W. (1957) Maximum likelihood estimates for a mul-tivariate normal distribution when some observations are missing,J.Amer. Statist. Assoc.52, 200–203.[2] Fang, K.T. and Zhang, Y.T. (1990)Generalized multivariate analysis,Springer-Verlag, Berlin, Science Press, Beijing.[3] Hao, J. and Krishnamoorthy, K. (2001) Inferences on a normal co-variance matrix and generalized variance with monotone missing data,J. Multivariate Anal.78, 62–82.[4] Little, R.J.A. and Rubin, D.B. (2002)Statistical Analysis with Miss-ing data, Second edition, Wiley, New York.[5] Schafer, J.L. (1997)Analysis of incomplete multivariate data, Mono-graphs on Statistics and Applied Probability, Chapman and Hall, Lon-don.[6] Srivastava, M.S. (2002)Methods of multivariate statistics, Wiley Se-ries in Probability and Statistics, Wiley, New York.
29 On general futures prices in super-martingale term structure models [ContributedSession M5 (page 27)]
Dirk BECHERER , Imperial College London, UK
Futures are among the practically most important and liquidlytraded instruments. There is a vast literature on them with manyarticles, and also excellent treatment in textbooks on mathemat-ical finance by Björk, Duffie, and Hunt & Kennedy, among oth-ers. Nevertheless, the literature about theoretical models on fu-tures appears technically rather less developed and mathemati-cally elaborated than other areas of mathematical finance, likeequities, credit risk, or interest rate theory.This talk is concerned with general futures prices in frameworkof semimartingale pricing kernel models with positive interest,
i.e. supermartingale pricing models. We show how recent re-sults on supermartingale term structure models in connectionwith stochastic backward integration allow for a general and uni-fying view on discretely and continuously resettled contingentclaims, and also reveal the natural martingale structure behindthe appropriate numeraires for obtaining the futures price pro-cess. The analysis does not need to assume a Brownian filtrationor continuous martingales. And for key results, one does notneed to assume the existence of a classical savings account ei-ther.
References
[1] Becherer, Dirk (2004)On general futures prices, discrete and contin-uous resettlement, and the role of numeraires, Working paper, ImperialCollege London.
30 Some subsets of the Brownian curve[In-vited Session 10 (page 39)]
Vincent BEFFARA , ENS Lyon, France
We present a general way to compute the Hausdorff dimensionof a random set and apply it to show the existence of certain ex-ceptional points on a planar Brownian path, for instance “pivotpoints” (i.e. cut-points around which one half of the path can ro-tate of a positive angle without intersecting the other half). Thesame setup, combined with estimates forSLE6, can be used todetermine the dimension of the Brownian frontier.
31 Counting planar random walk holes[Contributed Session C15 (page 53)]
Christian BENEŠ, Duke University, USA
In [2], Mandelbrot pointed out that computer simulations sug-gest the following: IfC is the complex plane andN(A) is thenumber of connected components ofC\ S[0,n] of area greaterthanAn, whereS is a planar simple random walk cluster (i.e.a planar simple random walk starting and ending at the samepoint), then for large holes,N³ A−1, whereas for smaller holesan exponent of5/6 is observed. We base our work on relatedresults by Mountford ([3]) and Le Gall ([1]) for asymptoticallysmall connected components ofC \B[0,1], whereB is planarstandard Brownian motion, and show that for a certain range oflarge holes, the exponent for planar simple random walk is in-deed 1. We use a coupling between random walk and Brownianmotion to extend a large-scale version of the results in [1] and[3] to random walk. Some of the techniques used are Beurl-ing estimates and ideas related disconnection exponents and theBrownian frontier. Our result is the following:
Theorem. There exists anε0 > 0 such that for all0 < ε ≤ ε0, ifSis planar simple random walk and
Nε = #connected components ofC\S[0,2n] of area≥ n1−ε,then
log2(nε )nε Nε
P→ 2π, as n→ ∞.
References[1] Le Gall, J.-F. (1991) On the connected components of the comple-ment of a two-dimensional Brownian path.[2] Mandelbrot, B.B. (2002) Gaussian Self-affinity and Fractals.[3] Mountford, T. (1989) On the asymptotic number of small compo-nents created by planar Brownian motion.
32 FDR based confidence intervals follow-ing selection [Invited Session 27 (page 43)]
Yoav BENJAMINI and Daniel YEKUTIELI,Tel Aviv Univer-sity

Abstracts 69
Often, in applied research, confidence intervals are constructed,reported, or highlighted only for parameters selected after view-ing the data. We discuss two such studies, the results of whichmade headlines. By generalizing the False Discovery Rate(FDR) approach from multiple testing to selected multiple con-fidence intervals, we suggest the False Coverage-statement Rate(FCR) as a measure of interval coverage following selection.A general procedure is then introduced, offering FCR controlat level q under any selection rule for independent test statis-tics. If we further utilize the FDR controlling testing procedurein Benjamini and Hochberg (1995) for selecting the parameters,the newly suggested procedure offers confidence intervals whichare dual to the testing procedure, and are shown to be optimal inthe independent case. Results for positive dependency and gen-eral dependency are also given.
33 Nonparametric estimation, long mem-ory and heteroskedasticity [Contributed SessionC30 (page 54)]
Jan BERAN and Yuanhua FENG,University of Konstanz, Ger-many
We consider nonparametric trend estimation for long-memoryprocesses with heteroskedastic volatilities. Trends can occurin the mean or in the volatility. In the case of a trend in themean, suitable moment conditions are required in order that ker-nel and local polynomial estimation can be applied (see e.g. Be-ran and Feng 2001). In this talk, some limit theorems for tri-angular arrays and related results needed in this context willbe discussed. The key result can be stated as follows: LetXi = ∑ai− j ε j be a linear process with∑a2
j < ∞ and weights
wi such thatσ2n = var(∑wiXi) > 0 for all n,
max|wi |/σn → 0,
and
supk|
n
∑i=1
wiak−i |/σn → 0.
Then under suitable conditions onεi , ∑wi,nXi/σn converges indistribution to a standard normal random variable. This resultcan be applied to prove asymptotic consistence and normality oflocal polynomial estimates of the trend function and its deriva-tives. Bandwidth choice, including an appropriate treatment ofboundary problems can be solved along the line of Beran andFeng (2002). Similar questions are considered for nonparamet-ric trend estimation in volatility.References[1] Beran, J. and Feng, Y. (2001) Local polynomial estimation with aFARIMA-GARCH error process,Bernoulli7, No. 5, 733–750.[2] Beran, J. and Feng, Y. (2002) Local polynomial fitting with long-memory, short-memory and antipersistent errors,Annals of the Instituteof Statistical Mathematics54No. 2, 291–311.
34 A phase transition in the random trans-position randon walk [Contributed Session C15 (page53)]
Nathanaël BERESTYCKI and Rick DURRETT,Cornell Uni-versity, U.S.A. and Ecole Normale Supérieure, France
Traditionally, biologists have studied rates of evolution inducedby certain types of mutations with parsimony methods. Han-nehalli and Pevzner (1995) developed a polynomial algorithm todeal with this problem in the case of random reversals. Our workis motivated by Bourque and Pevzner’s simulation study of the
effectiveness of this parsimony method in studying genome rear-rangement. With the help of numerical simulations Bourque andPevzner (2002) concluded that the parsimony distance was anaccurate estimate only as long as the distance was at most0.4n,wheren is the size of the analyzed sample. To have a cleanermathematical problem, we consider the analogous problem ofrandom transpositions, and obtain a surprising result about therandom transposition random walk(σt , t ≥ 0) on the symmetricgroup of ordern.Let Dt be the minimum number of transpositions needed to goback to the identity from the location at timet. We show thatDt undergoes a phase transition around the critical timen/2.Theorem
1n
Dcn/2 → u(c) = 1−∞
∑k=1
1c
kk−2
k!(ce−c)k
in probability. Moreoveru satisfies the following properties:u(c) = c/2 for c≤ 1, u(c) < c/2 for c > 1 and it is not analyticat c = 1. In other words, the distance to the identity is roughlylinear during the subcritical phase, and after critical timen/2 itbecomes sublinear.We use this result to return to the original problem of randomreversals, therefore providing a theoretical explanation for theobservation of Bourque and Pevzner (2002).In addition, in the random transposition case, we describe thefluctuations ofDcn/2 about its mean in each of the three regimes(subcritical, critical and supercritical). The techniques usedinvolve viewing the cycles in the random permutation as acoagulation-fragmentation process and relating the behavior tothe Erdos-Renyi random graph model.We finally discuss some interesting related open questions, par-ticularly concerning theemergence of a giant cycleat timen/2.We present both numerical and theoretical evidence that for anyc > 1 there should be some cycle whose size is of ordern, afact that is of course well known in the case of random graphs.In fact, the simulations support an even stronger conjecture ofD. Aldous (private communication) that states that the relativepieces of the giant component in the random graph should beasymptotically distributed according to thePD(0,1) Poisson-Dirichlet distribution at any given supercritical time.References[1] Bourque, G. and Pevzner, P.A. (2002) Genome-scale evolution: re-constructing gene orders in the ancestral species.Genome Research12,26–36.[2] Hannehalli, S. and Pevzner, P.A. (1995) Transforming cabbage intoturnip (polynomial algorithm for sorting signed permutations by rever-sals).Proceedings of the27th Annual Symposium on the Theory of Com-
puting, 178–189. Full version in theJournal of the ACM46, 1–27.
35 Exchangeable Fragmentation-Coalescenceprocesses and their equilibrium measures
[Contributed Session C38 (page 38)]
Julien BERESTYCKI , Universités Paris VI & Paris X, France
We define and study a family of Markov processes with statespace the compact set of all partitions ofN (the set of positiveintegers) that we call exchangeable fragmentation-coalescenceprocesses. They can be viewed as a combination of exchange-able fragmentation as defined by Bertoin [1,2] and of homoge-nous coalescence as defined by Pitman [4] and Schweinsberg[5] or Möhle and Sagitov [3]. We show that they admit a uniqueinvariant probability measure and we study some properties oftheir paths and of their equilibrium measure.References

70 6th BS/ IMSC
[1] Bertoin, J. (2001) Homogeneous fragmentation processes,Probab.Theory Related Fields121, 3, 301–318.[2] Bertoin, J. (2003) The asymptotic behaviour of fragmentation pro-cesses,J. Euro. Math. Soc.5, 395–416.[3] Möhle, M. and Sagitov, S. (2001) A classification of coalescent pro-cesses for haploid exchangeable population models,Ann. Probab.294, 1547–1562.[4] Pitman J. (1999)Coalescents with multiple collisions,Ann. Probab.,274, 1870–1902.[5] Schweinsberg J. (2000)Coalescents with simultaneous multiple col-lisions, Electron. J. Probab.,5 Paper no. 12, 50 pp. (electronic).
36 Biased random walk on percolationclusters [Invited Session 22 (page 39)]
Noam BERGER, Caltech, USA
Nina GANTERT,U. Karlsruhe, Germany
Yuval PERES,U.C. Berkeley, USA
We study the behavior of biased random walk on the infinitecluster of super-critical percolation in two dimension. We showthat if the bias is large then the walker has zero speed, while ifthe bias is small then the walker has a positive speed.
37 Regenerative bootstrap for Markovchains [Contributed Session C47 (page 17)]
Patrice BERTAIL , CREST, France
Stéphan CLÉMENÇON,MODALX, Université Paris X, France
Renewal theory plays a key role in the analysis of the asymptoticstructure of many kinds of stochastic processes, and especially inthe development of asymptotic properties of general irreducibleMarkov chains (Meyn & Tweedie,1996). The underlying groundconsists in the fact that limit theorems proved for sums of inde-pendent random vectors may be easily extended to regenerativerandom processes, that is to say random processes that may bedecomposed at random times, called regeneration times, into asequence of mutually independent segments, namely regenera-tion cycles. The method based on this principle is traditionallycalled the regenerative method. Harris chains that possess anatom, i.e. a Harris set on which the transition probability kernelis constant, are special cases of regenerative processes. The the-ory developed in Nummelin (1978) showed that general Markovchains could all be considered as regenerative in a broader sense(i.e. in the sense of the existence of a regenerative extension forthe chain), as soon as the Harris recurrence property is satisfied.The aim of this paper is to reexamine and develop further theapplication of the regenerative method to construct an accuratedata-resampling procedure for Markov chains.The regenerative bootstrap developed in Datta and McCormick(1993) does not seem to be widely known in the Bootstrap lit-erature, nor used in practice. The main idea underlying ofthis method consists in resampling a deterministic number ofdata blocks corresponding to regeneration cycles. However thismethod fails to be second order correct in the stationary as wellas in the nonstationary case, as a careful examination of the sec-ond order properties of the sample mean statistic shows (see Ma-linovskii (1987), Bertail & Clémençon (2003)). Our proposalconsists in imitating the renewal structure of the chain by sam-pling complete regeneration data blocks, until the length of thereconstructed Bootstrap series is larger than the length n of theoriginal data series, so as to approximate the distribution of the(random) number of regeneration blocks in a series of length nand remove bias terms. In this paper we study in particular thehigher order properties of this resampling method, which we callthe regenerative block-bootstrap (RBB) and show how it may be
extended to the much broader class of Harris Markov chains.We first consider the particular case of Markov chains withan atom (also called Markov models with regeneration times),which find many applications in the field of operational researchfor modeling queuing/storage systems. We demonstrate herethe power of this method for suitably studentized statistics: theRBB has in particular an uniform rate of convergence of orderOP(n−1), that is the optimal rate in the i.i.d case. Moreover, it isnoteworthy that, unlike the moving block bootstrap (see Götze &Künsch, 1996), there is no need in the RBB procedure to choosethe size of the blocks, which are entirely determined by the data.Besides, theOP(n−1) accuracy of the RBB holds under weakmixing conditions (polynomial rate for the decay of the strongmixing coefficients).Then, we extend this methodology to general positive recurrentchains. Our proposal is based on a practical use of the split-ting technique introduced in Nummelin (1978) and an empiri-cal method to build approximatively a realization drawn froman extension of the chain with a regeneration set. We establishthe asymptotic validity of this procedure, even in a nonstation-ary framework. We also show how to obtain the second ordervalidity and discuss the practical choice of the regeneration set.These results are illustrated by some examples.References[1] Bertail, P. and Clémençon, S. (2003) Edgeworth expansions for suit-ably normalized sample mean statistics of atomic Markov chains, Doc-ument de travail CREST, 2003-24,http://www.crest.fr/pageperso/ls/bertail/download.htm.[2] Datta, S. and McCormick W.P. (1993) Regeneration-based bootstrapfor Markov chains,Canadian J. Statist.21, No.2, 181–193.[3] Götze, F. and Künsch, H.R. (1996) Second order correctness of theblockwise bootstrap for stationary observations,Ann. Statist., 24, 1914–1933.[4] Malinovskii, V.K. (1987) Limit theorems for Harris Markov chainsI, Theory Prob. Appl.31, 269–285.[5] Meyn, S.P. and Tweedie, R.L. (1996)Markov chains and stochasticstability,Springer.[6] Nummelin, E. (1978) A splitting technique for Harris recurrentchains,Z. Wahrsch. Verw. Gebiete,43, 309–318.
38 Functional Chung laws for small incre-ments of the empirical process and a remarkon the strong invariance principle [ContributedSession C14 (page 15)]
Philippe BERTHET , University Rennes 1, France
Let I denote the identity function on[0,1] andFn be the empiri-cal d.f. based on i.i.d. uniform r.v.’sU1, ...,Un with common d.f.I . Consider the setΘn = αn(t +anI)−αn(t) : t ∈ [0,1−an]of the an−sized increment processes of the uniform empiri-cal processαn =
√n(Fn− I). Assume thatan ↓ 0, nan ↑ ∞,
dn = nan(logn)−1 → ∞ andnan(logn)−7/3 = O(1). In [1] thefourth assumption was shown to be critical with respect to thepointwise rates of convergence in the functional law of [3] whichattests thatΘn almost surely completely covers the Strassen setS under the sup norm metric‖·‖. When n−1 logn ¿ an ¿n−1(logn)7/3 strong approximation methods using [4] becomeineffective and moreover overlapping increments are not easy tocontrol at too small scale.We are now able to compute the exact rate of clustering ofΘn
to any f ∈ S having Lebesgue derivative of bounded variation.This provides an a.s. deterministic equivalent for‖ f ,Θn‖. Thetechnique developed allows to work at a high precision in a non–Gaussian framework and relies on the sharp small deviation es-timate for a Poisson process of high intensity obtained in [5].

Abstracts 71
Note that boundary functions are included. This is useful forstatistical applications since typically suchf lead the largest de-viation of the statistic of interest, as in density estimation.
Surprisingly the best ratesO(d1/4n (logn)−1) are obtained for
mostly increasing limit functionsf and are faster than in the
Brownian case. Conversely the slowest ratesO(d−1/2n ) are
achieved for mostly decreasing functions and are of the sameorder as those obtained in [1] by means of Gaussian small ballprobabilities. For instance we get
‖−I ,Θn‖ ∼ 1
6√
2
1√dn¿‖I ,Θn‖ ∼ π
√3
29/4
d1/4n
logna.s.
These differences at small scale between the empirical andBrownian paths provide a quantitative link between strong in-variance and non–invariance principles through the second or-der behaviour. In particular this implies a lower bound in thestrong invariance principle and gives a new insight into the fa-mous Hungarian construction of [4]. Namely, for any sequenceof Brownian bridgesBn defined on the same probability spaceasαn we have
liminfn→∞
√n
logn‖αn−Bn‖ ≥ 1
6a.s.
Similar results hold for the oscillations of a centered Poissonprocess at small scale.References [1] Berthet, P. (2003) Inner rates of coverage of Strassentype sets by increments of the uniform empirical and quantile processes,Stochastic Process. Appl.in press.[2] Berthet, P. (2003)Functional Chung laws for small increments ofthe empirical process and a remark on the strong invariance principle,Prepubl. IRMAR 03–43.[3] Deheuvels, P. and Mason, D.M. (1992) Functional laws of the iter-ated logarithm for the increments of empirical and quantile processes,Ann. Probab.20, 1248–1287.[4] Komlós, J., Major, P., and Tusnády, G. (1975)An approximation ofpartial sums of independent r.v.’s, and the sample d.f. I. Z. Wahrsch.Verw. Gebiete 32, 111–131.[5] Shmileva, E. (2003)Small ball probability for centered Poisson pro-cess of high intensity. Zap. Nauchn. Sem. S.–Peterburg. Otdel. Mat.Inst. Steklov. (POMI), 298, to appear, in Russian.
39 Diffusion-type stochastic volatility mod-els [Contributed Session M1 (page 17)]
Bo Martin BIBBY , The Royal Veterinary and Agricultural Uni-versity, Denmark
Michael SØRENSEN,University of Copenhagen, Denmark
We introduce a class of stochastic volatility models where thevolatility process has a given marginal distribution and autocor-relation function. In the case of an infinitely divisible marginaldistribution and a completely monotone autocorrelation functionthe volatility process is defined as a sum of diffusion processeseach with linear drift and diffusion coefficient derived from themarginal distribution.In the talk we will discuss how to construct the volatility process,[1], and the implied features of the stochastic volatility model.We will also address the problem of pricing derivatives based onthe model.Inference is made difficult by the fact that the volatility processis not necessarily a Markov process. We propose a method forparameter estimation using prediction based estimating func-tions, introduced in [2]. Stock prices and associated optionprices will be considered in order to assess the ability of themodel to describe real data.References
[1] Bibby, B.M., Skovgaard, I.M., and Sørensen, M. (2003) Diffusion-type Models with given Marginal Distribution and AutocorrelationFunction.[2] Sørensen, M. (2000) Prediction-based Estimating Functions,Econom. J.3, 123–147.
40 The frontiers of statistics and computerscience [Bernoulli Lecture (page 56)]
Peter BICKEL , University of California, Berkeley, USA
Prediction in Machine Learning and prediction in statistics areessentially equivalent fields, but with different emphasis. I willtry to illustrate the relation between theory and practice in thislarge area by a few examples and results. In particular I willtry to address an apparent puzzle: Worst case analyses, usingempirical process theory, seem to suggest that even for moder-ate data dimension and reasonable sample sizes good prediction(supervised learning) should be very difficult. On the other hand,practice seems to indicate that even when the number of dimen-sions is very much higher than the number of observations, wecan often do very well. The efficacy of cross validation will alsobe discussed and some research directions pointed out.
41 Coping with multiplicity by exploitingthe empirical distribution of P-values [Con-tributed Session C46 (page 46)]
Mikelis BICKIS University of Saskatchewan, Canada
In the analysis of large data sets, such as those arising in bioin-formatics, many significance tests may be performed. Tradi-tional ideas of size and power lose their usefulness in such a con-text. Instead, thefalse discovery rate, developed by Benjaminiand Hochberg [1] has become a popular concept for handling themultiplicity of tests. The false discovery rate, however, does notaddress the question of false negatives. Estimates of false neg-ative rates based on the empirical distribution ofP-values wereconsidered by Bickis et al. [2] and Crump & Krewski [3].In this paper, the set ofP-values is modelled as a sample froma mixed population composed of a uniform distribution for thenull cases and an unknown distribution for the alternatives.Rather than casting the situation as a multiple decision problem,one views it as an estimation of the null and alternative com-ponents of the distribution. Such an approach will allow one toset a threshold of significance that is sensitive to the actual mix-ture of nulls and positives in the data, rather than being limitedby an arbitrarily chosen false discovery rate. In this way, equalattention is paid to both false positives and false negatives andone can in fact measure the separation between the two and thusquantify the ambiguity of the inference.Several approaches to filtering out the null distribution are ex-amined, including smoothing algorithms and Bayesian methods.The techniques are illustrated using both real and simulated data.References[1] Benjamini, Y. and Hochberg, Y. (1995) Controlling the false discov-ery rate: A practical and powerful approach to multiple testing,JRSS B57, 289–300.[2] Bickis, M., Bleuer, S., and Krewski, D. (1996) On the estimationof the proportion of positives in a sequence of screening experiments,Can. J. of Statistics24, 1–15.[3] Crump, K.S. and Krewski, D. (1998) Estimation of the numberof studies with positive trends when studies with negative trends arepresent,Can. J. of Statistics26, 643–655.
42 Model selection for Gaussian vectors[In-vited Session 23 (page 49)]

72 6th BS/ IMSC
Lucien BIRGÉ , Université Paris VI, France
We discuss here a general model selection procedure for the es-timation of the mean vector and diagonal covariance matrix ofa Gaussian vector in high-dimensional Euclidean spaceRn. Ourmethod focuses on situations for which the problem does not re-duce to model selection for the mean (which happens when thecovariance can be estimated independently of the mean, as isthe case when there exists a largest model of dimension smallerthann) and the vector is homoscedastic. As a consequence, theproblem to be solved is quite different from model selection forGaussian sequences with known variance as considered in [1].Our study includes heteroscedastic vectors and nonlinear mod-els, provided that their dimension (in a suitable sense) is not toolarge. We do not assume that any of the models is correct, butmerely ask that one of them provides a reasonable approxima-tion to the true distribution.We provide a purely theoretical construction according to thegeneral scheme described in [2]. It is based on purely metricarguments, which allows us to use nonlinear models, togetherwith suitable families of tests. This requires to build special ro-bust tests between Gaussian vectors with possibly different co-variances.If the number of models of a given dimension is not too large,the risk of the resulting estimator is comparable to the risk ofthe best model. If there are many models, one has to pay anextra price for the high complexity as is typically the case insuch problems. The results apply in particular to variable selec-tion with many more variables than observations or estimatinga regression function with an unknown amount of (possibly het-eroscedastic) noise.References[1] Birgé, L. and Massart, P. (2001) Gaussian model selection,J. Eur. Math. Soc.3, 203–268.[2] Birgé, L. (2003)Model selection via testing : an alternative to (penal-ized) maximum likelihood estimators, Technical Report No 862, Labo-ratoire de Probabilités, Université Paris VI.http://www.proba.jussieu.fr/mathdoc/preprints/index.html#2003
43 Coexistence in locally regulated compet-ing populations [Contributed Session C1 (page 15)]
J. BLATH , A.M. ETHERIDGE and M.E. MEREDITH,Univer-sity of Oxford, UK
We propose two models of the evolution of a pair of competingpopulations. Both are lattice based. The first is a compromisebetween fully spatial models, which do not appear amenable toanalytic results, and interacting particle system models, whichdon’t, at present, incorporate all the competitive strategies thata population might adopt. The second is a simplification of thefirst in which competition is only supposed to act within lat-tice sites and the total population size within each lattice pointis a constant. In a special case, this second model is dual to abranching-annihilating random walk.For each model, using a comparison withN-dependent orientedpercolation, we show that for certain parameter values both pop-ulations will persist for all time with positive probability.We also present a number of conjectures relating to the rôle ofspace in the survival probabilities for the two populations.
References
[1] Blath, J., Etheridge, A.M., and Meredith, M.E. (2003)Coexistencein locally regulated competing populations, submitted.
44 Fluctuation limits of occupation pro-cesses of particle systems. Sub-fractional vs
fractional Brownian motions [Contributed SessionC25 (page 36)]
Tomasz BOJDECKI, University of Warsaw, Poland
Luis G. GOROSTIZA,Centro de Investigación y de EstudiosAvanzados, Mexico
Anna TALARCZYK, Institute of Mathematics, University ofWarsaw, Poland
Consider a system of particles inRd starting off from a stan-dard Poisson random field (i.e., with intensityλ= the Lebesguemeasure), and independently moving according to a symmetricα-stable Lévy process and undergoing critical binary branchingat rateV.N is the empirical process, i.e.,Nt(B) denotes the number ofparticles in the setB at timet. L(t) =
∫ t0 Nsds is the occupation
process. We accelerate the time, i.e., we defineLT(t) = L(tT)and letT → ∞. We consider the fluctuation process
XT(t) =1
FT(LT(t)−ELT(t)),
whereFT is a norming. We prove that ifα < d < 2α i FT =T3/2−d/(2α) then for eachτ > 0
XT =⇒Cλβ asT → ∞, in C([0,τ],S ′(Rd),
(=⇒ denotes convergence in law), whereβ is a sub-fractionalBrownian motion (sub-fBm) with parameterh= 3−d/α, i.e., acentered continuous Gaussian process inR with covariance
Cov(βs,βt) = th +sh−1/2[(t +s)h + |t−s|h].
In the no branching case (V = 0), for d < α, FT = T1−d/(2α) weobtain convergence toCλξ , whereξ is a fractional Brownianmotion (fBm) with Hurst parameterH = h/2, h = 2−d/α.Sub-fBm has many properties of fBm but its increments aremore weakly correlated and the long-range dependence decaysfaster.References[1] Bojdecki, T., Gorostiza, L.G., and Talarczyk, A. (2004) Sub-fractional Brownian motion and its relation to occupation times.Stat.Prob. Lett.To appear.[2] Bojdecki, T., Gorostiza, L.G., and Talarczyk, A. (2004) Functionallimit theorems for occupation time fluctuations of branching systems inthe case of long-range dependence. Submitted.
45 Large deviations and some generaliza-tions of GREM [Invited Session 14 (page 33)]
Erwin BOLTHAUSEN and Nicola KISTLER, UniversitätZürich, Switzerland
The generalized random energy model (GREM) had been intro-duced by Derrida a simple model for spin glass behavior. De-spite of its simplicity, it plays a crucial role in spin glass the-ory, and in particular for the Parisi approach to mean-field spinglasses. It has however the drawback that it has an inbuilt hier-archical structure, and so it sheds no light on one of the crucialissues in spin glass theory, namely ultrametricity. We proposesome natural non-hierarchical generalizations which in the limitbecome ultrametric. The analysis of these models is largly basedon large deviation theory.
46 Asymptotics for linear predictors oflong-memory processes [Contributed Session C30(page 54)]
Pascal BONDON, CNRS UMR 8506, Gif-sur-Yvette, France

Abstracts 73
Wilfredo PALMA, P. Universidad Católica de Chile
Let (Xt)t∈Z be a real, zero-mean, purely nondeterministicweakly stationary process with spectral densityf and covari-ance functionγ . The best linear mean square predictor ofXt
based on the entire infinite pastXs;s< t is denoted byXt andits prediction error variance isσ2 > 0. We assume thatXt hasthe mean square convergent autoregressive (AR) representation
Xt = ∑∞k=1akXt−k (1)
where(ak) are the AR parameters of(Xt). In practice, only anapproximation ofXt can be calculated since just a finite seg-ment of the process, sayXs; t − n≤ s < t, can be observed.Rest on these data, the best linear mean square predictorXt,n
and its prediction error varianceσ2n can be computed using the
Yule-Walker equations. Alternatively, thenth partial sum of theinfinite series (1) provides a finite predictorSt,n which is subop-timal compared toXt,n but easier to calculate. It is of theoreticalinterest to know the rates of convergence to zero asn→ ∞ ofδn = σ2
n −σ2, var(Xt − Xt,n) andrn = var(Xt −St,n). As shownin [6], var(Xt − Xt,n) = δn andδn ≤ rn. Moreover, if f satisfiesthe boundedness condition
0 < c≤ f ≤ d < ∞, (2)
we havern ≤ δnd/c. The problem of estimatingδn for differentclasses of spectral densities has been addressed by many authors.Typically if f satisfies (2) and some additional smoothness con-ditions,δn (and hencern) converges exponentially or hyperboli-cally to zero, see [1] and [2]. On the other hand, iff has zeros oris unbounded, then in general we cannot expectδn to convergeto zero faster than1/n, see [3]. For example, for an autoregres-sive moving average (ARMA) process with a positive spectraldensity,δn andrn converge exponentially to zero. Under somenon-negativity and monotonicity conditions on the MA and theAR parameters of(Xt) (which are not satisfied for an autoregres-sive fractionally integrated moving average (ARFIMA) model),[4] has shown that the relationγn ∼ n2d−1l(n) asn→ ∞, where0 < d < 1/2 and l is a slowly varying function at infinity, im-plies thatδn ∼ σ2d2/n asn→ ∞. This asymptotic formula wasextended to a long-memory ARFIMA process in [5].The spectral density of a long-memory ARFIMA process has apole at the origin and therefore fails to satisfy (2). In this case,the asymptotic behavior ofrn cannot be derived from the one ofδn. In this paper, we investigate the rate of convergence ofrn asn→∞ for a class of long-memory processes including ARFIMAmodels. More precisely, we show thatrn ∼ d tan(πd)/πn asn→ ∞, whered is the long-memory parameter.
References
[1] Grenander, U. and Rosenblatt, M. (1954) An extension of atheorem of G. Szegö and its application to the study of stochasticprocesses.Trans. Amer. Math. Soc.76, 112–126.[2] Ibragimov, I. A. (1964) On the asymptotic behavior of theprediction error.Theory Probab. Appl.9, 627–633.[3] Ibragimov, I. A. and Solev, V. N. (1968) The asymptotic be-havior of the prediction error of a stationary sequence with aspectral density of special type.Theory Probab. Appl.13, 703–707.[4] Inoue, A. (2000) Asymptotics for the partial autocorrelationfunction of a stationary process.J. Anal. Math.81, 65–109.[5] Inoue, A. (2002) Asymptotic behavior for partial autocor-relation functions of fractional ARIMA processes.Ann. Appl.Probab.12, 1471–1491.
[6] Pourahmadi, M. (2001)Foundations of Time Series Analysisand Prediction Theory. Wiley, New York.
47 L2-construction of stochastic integralsof nonrandom kernels for nonorthogonalstochastic measures [Contributed Session C11 (page15)]
I.S. BORISOV and A.A. BYSTROV,Sobolev Institute of Math-ematics, Russia
Let X be an arbitrary set andM be a semi-ring of it’s sub-sets with identity. Letµ(A); A ∈ M be a centered Hilbertrandom process indexed byM and defined on a probabilityspaceΩ,Θ,P. The processµ(A) is calledelementary stochas-tic measureif
µ(A1∪A2) = µ(A1)+ µ(A2) P-a.s.
for all subsets satisfying the conditionsA1∩A2 = /0 andA1∪A2 ∈M . We studyL2-construction of stochastic integrals of theform ∫
X
f (t)µ(dt),
where f (t) is a non-randomσ(M )-measurable kernel function,whereσ(M ) is the minimalσ -field containingM .The goal of the talk is to discuss a generalL2-constructionof the stochastic integral for elementary stochastic measuresµwithout the classical orthogonality conditionEµ(A1)µ(A2) =m(A1∩A2) , wherem(A) is a measure onσ(M ). As examples,we consider a few classes of random processes with nonorthog-onal increments on the real line generating the corresponding el-ementary stochastic measures, for which the stochastic integralexists under minimal restrictions on the kernel functions.Moreover, as an application of the above-mentioned generalscheme, we also study multiple stochastic integrals of the form
∫
Xn
f (t1, . . . , tn)µ(dt1) . . .µ(dtn)
and discuss some statistical applications of this construction.
48 Continuous time Markov chains relatedto Plancherel measure [Invited Session 20 (page 29)]
Alexei BORODIN, California Institute of Technology, USA
Consider the standard Poisson process in the first quadrant of theEuclidean plane, and for any point (u,v) of this quadrant take theYoung diagram obtained by applying the Robinson-Schenstedcorrespondence to the intersection of the Poisson point configu-ration with the rectangle with vertices (0,0), (u,0), (u,v), (0,v). Itis known that the distribution of the random Young diagram thusobtained is the poissonized Plancherel measure with parameteruv.We show that for (u,v) moving along any southeast-directedcurve in the quadrant, these Young diagrams form a Markovchain with continuous time. We also describe these chains interms of jump rates. Our main result is the computation of thedynamical correlation functions of such Markov chains and theirbulk and edge scaling limits.This is a joint work with Grigori Olshanski.
49 Maturity randomization for stochasticcontrol problems [Contributed Session C36 (page 16)]
B. BOUCHARD , University Paris VI, France
N. El Karoui,Ecole Polytechnique, France
N. TOUZI, University Paris IX, France

74 6th BS/ IMSC
We study the maturity randomization approach proposed by P.Carr (1998) for the computation of American option prices. Itconsists in approximating the fixed maturityT by a sequenceof random variablesSn defined as a mean ofn exponentiallydistributed independent random variables(ξ k
n)k≤n with ξ kn ∼
E (T). When the underlying processX is Markov and time ho-mogeneous, and theIF generated byX, writing (formally) thedynamic programming principle, between the random times de-fined by the partial sumsn−1 ∑k
j=1 ξ jn andn−1 ∑k+1
j=1 ξ jn , allows
to reduce the problem to the resolution of a sequence ofn opti-mal stopping problems in infinite horizon. In some cases, theseproblems can be solved explicitly, thus providing a fast and ac-curate numerical procedure.The first objective of this paper was to provide a rigorous proofof consistency for the scheme proposed by P. Carr. This openedthe door for a much larger generality of this technique.1. Al-
though, the dynamic programming principle does not apply inthis context, as theξ k
n ’s are independent of the filtrationIF , weshow that the recursive scheme suggested by P. Carr is consis-tent.
2. The above result is established for general optimal stoppingproblems, thus dropping the Markov and the homegeneity as-sumptions on the reward process. The random variablesξ k
n arealso allowed to have different distributions. This can be ex-ploited as an error reduction factor.
3. We also show that the maturity randomization technique ap-plies to general stochastic control problems, and mixed stop-ping/control problems.
4. We conclude the paper by providing another interesting ex-ample where the maturity randomization technique leads to anexplicit recursive relation. The example consists in the problemof hedging a European contingent claim in the context of theuncertain volatility model, i.e. the diffusion coefficient is onlyknown to lie in between two bounds.
References
[1] Carr, P. (1998) Randomization and the American Put,The Reviewof Financial Studies11, 597–626.
50 A potential theoretic approach tometastability [Invited Session 16 (page 14)]
Anton BOVIER , University Berlin, Germany
A stochastic dynamical system is said to exhibit metastability, ifits phase space can be decomposed into quasi-invariant subsetswith the property that transitions between these subsets occuronly on time-scales that are much greater that then the typicalequilibration times of the process conditioned to stay in such aset.In this talk I will discuss a somewhat new approach to the prob-lem of metastability in the context of reversible Markov pro-cesses that has been developed over the last years in collabo-ration with M. Eckhoff, V. Gayrard and M. Klein [1,2]. Thisapproach is based on the observation that the main character-istics of the long-term motion of such systems, such as meanexit times from quasi-invariant sets and the low-lying eigenval-ues of the generator, can be expressed with very good precisionin terms of certaincapacities, which in turn can be estimatedvery precisely in many examples. A non-trivial example is theconservative dynamics of an Ising lattice gas (Kawasaki dynam-ics) in a large finite box coupled to a reservoir of particles, atlow temperatures. In collaboration with F. den Hollander and F.Nardi [3] we have shown that in this case, a combination with
a detailed analysis of the relevant parts of the energy landscapeof this model with this general approach allows to get upper andlower bounds on the mean nucleation times that differ by mul-tiplicative factors that tend to one, as the temperature tends tozero, only. Moreover, one obtains precise estimate on the con-vergence of the probability distribution of the nucleation timetowards an exponential distribution.References[1] Bovier, A., Eckhoff, M., Gayrard, V., and Klein, M. (2002) Metasta-bility and low-lying spectra in reversible Markov chains,Comm. Math.Phys.228, 219–255.[2] Bovier, A. (2004)Metastability and ageing in stochastic dynamics”,in: A. Maas, S. Martínez, J. San Martin (Eds.), Dynamics and random-ness II, Santiago de Chile, Dec. 9-13, 2002. Kluwer Acad. Publishers(2004).[3] Bovier, A. and den Hollander, Th.W.F. (2004)Sharp asymptoticsfor Kawasaki dynamics on a finte box with open boundary conditions,preprint, submitted to Probab. Theor. Rel. Fields.
51 Power spectra of spatial Hawkes pro-cesses[Contributed Session C62 (page 18)]
Pierre BRÉMAUD , EPFL, Lausanne, Switzerland
Laurent MASSOULIÉ,Microsoft
Andrea RIDOLFI,EPFL, Lausanne, Switzerland
Spatial Hawkes processes are branching point processes onRn.They are described as follows. One starts with a second-order (inparticular, locally finite) stationary point process of “ancestors”N0 with a given Bartlett spectral measureµ0. We then constructthe successive generations of point processesNn, n≥ 1. Thepoint processNn+1 consists of all the children of the points inNn. The pointx∈ Nn creates its children as a doubly stochasticpoint process with intensityh(y−x,Zn(x))≥ 0, where the fam-ily of random elementsZn(x)n≥0,x∈Rn is iid and independentof N0. Call Z the typicalZn(x). It is assumed that
which guarantees that the processN = ∑n ∈ N is locally finite.Under additional conditions on the “impulse response”h, N isa second order point process of which we compute the Bartlettspectral measure. Then on this process we build a “shot noise”
Z(y) = ∑n≥0
∑x∈Nn
ϕ(y−x,Zn(x))
of which we compute (under adequate conditions onϕ) theCramer spectral measure. This includes as a particular case thelinear birth and death process on the line (birth rateλn = α +nβand death ratenγ , for which the spectral measure was so far un-known.References[1] Brémaud, P. and Massoulié, L. (2001) Hawkes branching processeswithout ancestors.J. Appl. Probab.38, 122–135.[2] Brémaud, P., Massoulié, L., and Ridolfi, A. Power spectra of randomspike fields and related processes, submitted.
52 Infinitely divisible AR and MA models[Invited Session 23 (page 49)]
Lawrence D. BROWN, University of Pennsylvania, Philadel-phia
We construct and study a class of stationary stochastic processeshaving general infinitely divisible finite-dimensional marginals,and auto-regressive and/or moving average type of dependencestructure. These models were motivated by an application totelephone call-center modeling that will be briefly described,

Abstracts 75
but should also have broad applicability in many other contexts.The processes we construct have an additional property we call"decomposability". This property allows for convenient para-metric representation of these processes while still providingreasonable flexibility in the construction. It should also admitreasonably convenient computation of maximum likelihood orBayesian estimators in data contexts. In the Poisson case the de-composable processes are the only stationary ones satisfying theconstraint on the marginals; otherwise more general processesexist but will not be considered here.This is a joint work with Xuefeng Li and Robert Wolpert
53 Aggregation of replicated signals [Con-tributed Session C48 (page 40)]
Florentina BUNEA , Florida State University, USA
We study the problem of estimating the population log spectrumwhen the data consists in a collection of curves assumed to fol-low a stationary time series. We show that this can be re-castedas an aggregation problem in nonparametric regression modelsand we suggest a penalized least squares approach to the prob-lem. The resulting estimator achieves optimal rates of aggre-gation, in the minimax sense. We then suggest a data adaptivemethod for constructing confidence bands for the population logspectrum and illustrate our method on a medical data set con-sisting in EEG signals (brain curves) obtained from patients suf-fering from depression.References[1] Juditsky, A. and Nemirovski, A. (2002) Functional aggregation fornonparametric regression,Annals of Statistics28, 681–712.[2] Tsybakov, A.B. (2003)Optimal rates of aggregation, Proceedings of16th Annual Conference on Learning Theory (COLT) and 7th AnnualWorkshop on Kernel Machines, Springer-Verlag, Heidelberg.[3] Bunea, F. (2004)Consistent covariate selection and post model se-lection inference in semiparametric regression, Annals of Statistics, 32.[4] Bunea, F., Tsybakov, A.B., and Wegkamp, M.H. (2004)Oracle in-equalities for regression aggregates,Technical Report 68, Florida StateUniversity, Department of Statistics.[5] Bunea, F., Ombao, H., and Auguste, A. (2004)Spectral estimationfor replicated signals,Technical Report 69, Florida State University, De-partment of Statistics.
54 Signal polynomial estimation based oncovariances [Poster Session P1 (page 21)]
R. CABALLERO-ÁGUILA , Universidad de Jaén, Spain
A. HERMOSO-CARAZO, J. LINARES-PÉREZ,Universidadde Granada, Spain
S. NAKAMORI, Kagoshima University, Japan
The estimation problem in discrete-time linear stochastic sys-tems has been widely studied, usually under the hypothesis thatthe involved processes are gaussian. As it is known, in thatcase, the least-squares (LS) estimator of the signal is a linearfunction of the observations and, consequently, it can be eas-ily obtained as the LS linear estimator. However, there exista considerable number of situations where this gaussianity as-sumption must be removed in order to obtain a more realisticstatistical description of the problem at hand and the LS estima-tor is not easily obtainable, in general. This difficulty has moti-vated the necessity of looking for suboptimal estimators whichimprove the extensively used linear ones. In this context, someauthors have focused the study of the estimation problem in non-gaussian systems on the search of polynomial estimators. Undera state-space approach, a recursive algorithm for the LS poly-nomial filter in non-gaussian systems is derived in Carraveta etal. [1] and generalized in Caballero et al. [2] to the case of
systems with uncertain observations; this estimation theory hasallowed to address different signal processing problems (see, forexample, Dalla-Mora et al. [3]) and this fact justify the study ofpolynomial estimators.The aforementioned papers use the full knowledge of the state-space model of the signal to be estimated, but usually this modelis unavailable and only covariance information about the pro-cesses involved is often accessible. Using this kind information,the LS estimation problem for gaussian systems has been con-sidered, for example, in Nakamori [4]; the algorithm proposedby Nakamori provides only the LS linear estimator of the signalif the gaussianity assumption is removed.In this paper the results in [4] are generalized; specifically, weconsider the LSν th-order polynomial filtering and fixed-pointsmoothing problems of discrete-time signals, when only someinformation about the moments of the processes involved isavailable. For this purpose, a suitable augmented observationequation is defined by aggregating the original signal and obser-vation vectors with their Kronecker powers; the optimal polyno-mial estimators of the original signal are obtained from the opti-mal linear estimators of the augmented signal based on the aug-mented observations and recursive algorithms for these linearestimators are deduced by using an innovation approach. Themain advantage of this study in comparison with [1] is that theproposed estimators do not require the knowledge of the state-space model of the signal, but only the moments up to the2ν thone of the signal and observation noise (in a specific form whichis satisfied by a general kind of processes).References[1] Carravetta, F., Germani, A., and Raimondi, M. (1996) Polynomialfiltering for linear discrete time non-gaussian systems,SIAM Journal onControl and Optimization34, 1666–1690.[2] Caballero, R., Hermoso, A., and Linares, J. (2003) Polynomial fil-tering with uncertain observations in stochastic linear systems,Interna-tional Journal of Modelling and Simulation23, 22–28.[3] Dalla Mora, M., Germani, A., and Nardecchia, A. (2001) Restorationof images corrupted by additive non-gaussian noise,IEEE Transactionson Circuits and Systems I: Fundamental Theory and Applications48,859–875.[4] Nakamori, S. (1992) Design of recursive fixed-point smoother us-ing covariance information in linear discrete-time systems,InternationalJournal of Systems Science23(12) 2323–2334.
55 Testing normality with transformed em-pirical processes [Contributed Session C22 (page 40)]
Alejandra CABAÑA , IVIC, Venezuela and Universidad de Val-ladolid, Spain
Enrique M. CABAÑA,Universidad de la República, Uruguay
Transformed Empirical Processes (TEPs) are a tool introducedlong ago (see [1], [2]) for designing goodness-of-fit tests whichare both consistent against any alternative and focused in oderto detect special departures from the null distribution selectedby the user.Among the most interesting of these type of procedures is thetesting for normality or, in general, testing goodness-of-fit toany location-scale familyF of probability distributions.We will describe several families of univariate (introduced in[4]) and multivariate tests of nomality, focused to detect depar-tures from normality due to changes in skewness or kurtosis.The tests will be based on a collection of basic functional statis-tics, each denoted generically bywi
n. The starting point for theconstruction of these statistics is the selection of a basic p.d.f.F0, and an orthonormal basis(hi)i=0,1,2,... (h0 = 1) in the L2-space of functions on the domain ofF0, square integrable with

76 6th BS/ IMSC
respect toF0. For instance, in testing for univariate normality,F0 will be the standard Gaussian distribution function, andhithe normalized Hermite polynomials.Eachwi
n is focused onhi , that is, is specially sensitive to local
alternativesF << F0 such that the departure√
dFdF0
−1 is in the
direction ofhi (i ≥ 1).The wi
n can be written as series of functions with random coef-ficients constructed from the sample. When the sample consistsof i.i.d. variables, with a p.d.f. inF , these series behave asymp-totically, for largen, as centred Gaussian processes with inde-pendent increments, with limit0 at−∞ and increasing variancethat reaches the limit value1 at+∞. For samples of distributionsnot belonging toF , the series are stochastically unbounded forlargen. This is the clue for the consistency of the tests based onthese processes.Functionals of eachwi
n such asMi = maxx |win(x)| or a suitable
quadratic formQi ([3]) will be used in order to detect as well aspossible alternatives in the direction ofhi . The asymptotic lawsof eachwi
n, Mi andQi can be written explicitely by means ofrapidly convergent series, and are independent of the focusi.Linear combinations or maxima of some of these statistics willbe used to focuse the tests oncompositealternatives, for in-stance, skewness and/or changes in kurtosis when assessing nor-mality for multidimensional samples. Their laws will be dis-cussed.In general, all procedures based on TEPs are easily computedform data, and compare very favourably to other widely usedtesting procedures in terms of power. Several power compar-isons are presented.References[1] Cabaña, A. (1996) Transformations of the empirical measure andKolmogorov-Smirnov tests,The Annals of Statistics24, 2020–2035.[2] Cabaña, A. and Cabaña, E.M. (1997) Transformed Empirical Pro-cesses and Modified Kolmogorov-Smirnov Tests for multivariate distri-butions,The Annals of Statistics25, 2388–2409.[3] Cabaña, A. and Cabaña, E.M. (2001)Modified Anderson - Darlingtests with selective power inprovement, Publicaciones Matemáticas delUruguay,9, 1–13.[4] Cabaña, A. and Cabaña, E.M. (2003) Tests of normality based onTransformed Empirical Processes,Methodology and Computing in Ap-plied Probabilitym Kluwer5, 309–335.
56 Heavy traffic limits of a data trafficmodel [Contributed Session C25 (page 36)]
Mine ÇAGLAR , Koç University, Turkey
We consider a stochastic process introduced in [1] to representdata traffic. The model is a tailored version of the general work-load models studied in [2] for telecommunications. It capturesthe dynamics of packet generation in data traffic as well as ac-counting for long-range dependence and self-similarity exhib-ited by real traces.The traffic workload has stationary increments as observed inhigh-speed data networks for constrained time periods. It isfound by aggregating the number of packets, or their sizes, gen-erated by the arriving sessions. The arrival time, the durationand the packet generation process of a session are all governedby a Poisson random measure. We study various heavy trafficlimits and characterize the limiting processes.The workload process converges in distribution to a fractionalBrownian motion (FBM) as the number of session arrivals andthe number of packet generations increase while the packet sizesand the lowest possible holding times decrease [1]. For mosttime scales the correlation structure of the input process is as in
FBM even before taking the limit. In this study, we show thatthe limit is a stable Levy motion rather than a FBM if the sessionarrival rate increases more slowly. In the limit, the workload hasindependent increments and self-similarity exists without long-range dependence. These two different scalings leading to twodifferent limits can essentially be considered as fast and slowgrowth of the session arrival rate, respectively. Under a third,intermediate scaling regime, another limit process is character-ized in [3] for a workload model based on a renewal countingprocess with heavy-tailed inter-renewal times. We explore thevalidity of a similar result for our model.References[1] Çaglar, M. (2004) A Long-Range Dependent Workload Model forPacket Data Traffic,Mathematics of Operations Research2992–105.[2] Kurtz, T. (1996) Limit Theorems for Workload Input Models. F.P.Kelly, S. Zachary, I. Ziedins, eds.,Stochastic Networks: Theory andApplications, Clarendon Press, Oxford.[3] Gaigalas, R. and Kaj, I. (2003) Convergence of Scaled Renewal Pro-cesses and a Packet Arrival Model,Bernoulli9 671–703.
57 Lan in partially observed small noisediffusions [Contributed Session C20 (page 35)]
Fabien CAMPILLO and François LE GLAND,IRISA / INRIARennes, France
We consider the following statistical model
dXt = b(θ ,Xt)dt+ ε σ(θ ,Xt)dWt , X0 ∼ µε0 (dx) ,
dYt = h(θ ,Xt)dt+ ε dVt , Y0 = 0 ,
where only the processY = Yt , 0≤ t ≤ T is observed, andwhere both the parameterθ and the initial conditionX0 (a nui-sance parameter) are unknown. We use the small noise asymp-totics [3], a powerful approach already used in [1], [4], whereit is easy to obtain interesting explicit results asε ↓ 0, in termsclose to the language of nonlinear deterministic control theory.Using techniques from large deviations and from contaminatedmodels [2], we study several questions, such as local asymptoticnormality of the probability distributions of the processY, con-sistency and asymptotic normality of the maximum likelihoodestimator (MLE) and the Bayesian estimator of the parameterθ ,in the following three different cases• known initial condition,• asymptotically known random initial condition,• unknown deterministic initial condition,
of increasing level of difficulty. This extends preliminary resultsobtained in [4].References[1] Campillo, F., Kutoyants, Y.A., and Le Gland F. (2000) Small noiseasymptotics of the GLR test for off–line change detection in misspeci-fied diffusion processes.,Stochastics and Stochastics Reports70, (1–2)109–129.[2] Kleptsina, M.L., Liptser, R.S., and Serebrovski., A.P. (1997) Non-linear filtering problem with contamination.The Annals of AppliedProbability7(4) 917–934.[3] Kutoyants, Y.A. (1994)Identification of Dynamical Systems withSmall Noise, volume 300 ofMathematics and its ApplicationsKluwerAcademic Publisher, Dordrecht.[4] Le Gland, F. and Wang, B. (2002) Asymptotic normality in partiallyobserved diffusions with small noise : application to FDI.In B. Pasik-Duncan, editor, (2002)Workshop on Stochastic Theory andControl, University of Kansas 2001. In honor of Tyrone E. Duncan on
the occasion of his 60th birthday, number 280 in Lecture Notes in Con-trol and Information Sciences, pages 267–282. Springer–Verlag, Berlin.
58 Bartlett correction for the LR test incointegrating models: a bootstrap approach

Abstracts 77
[Poster Session P3 (page 42)]
A. CANEPA, University of York, UK
Likelihood ratio test for linear restrictions on cointegrating spaceis asymptoticallyχ2 distributed. However, it is well known thatJohansen tests are quite heavily affected by the sample size. Asimple technique to obtain accurate small-sample correctionswas introduced by Bartlett (1937). The basic idea behind theBartlett correction is scaling with the ratio of the asymptoticexpectation and the finite sample expectation of the test statis-tics. In i.i.d. situation the Bartlett correction has been usefulfor solving size distortion problem. In this paper we considerJohansen’s likelihood ratio tests for linear restriction on cointe-grating space and we propose that the Bartlett adjustment fac-tor be computed using the bootstrap. The Monte Carlo resultsshow that asymptoticχ2 based inference can be quite inaccuratein small sample applications. By contrast, the bootstrap and theBartlett correctedLR tests deliver remarkably accurate inferencefor the restrictions considered. Furthermore, the comparison ofthe power among different procedure reveals that the power ofthe bootstrap, and bootstrap Bartlett corrected likelihood is al-most as good as the asymptotic power, although in some sit-uations the bootstrap Bartlett correctedLR test seems to havehigher power than the bootstrap test.In addition to estimating the Bartlett correction using the boot-strap, we consider correcting theLR test with the Bartlett cor-rection factor calculated analytically and then bootstrapping thesize-corrected test. This approach may yield further asymptoticrefinements. An intuitive explanation for that is the following.The Bartlett correction forLR test yields a test which is asymp-totically consistent with an error in the rejection probability oforder O(T−3/2). Bootstrapping the Bartlett correctedLR testamount to a one term Edgeworth expansion of the distributionfunction of the Bartlett corrected likelihood ratio test. This pro-cedure may yield a level of the error in rejection probability oforder O(T−2), so considerably smaller than the conventionalfirst order approximation (see Beran (1988)). The simulationresults reveal that this procedure works remarkably well. How-ever, the response surface analysis reveals that the size distortionof the test heavily depends on the parameter values. There areregions of the parameter space were the usual asymptoticχ2
approximation works reasonably well, whereas there are param-eters points close to the boundary where the distribution of theLR test is very sensitive to the parameter values. In this case thefirst order approximation is quite inaccurate, as is the BartlettcorrectedLR test.References[1] Bartlett, M.S. (1937) “Properties of sufficiency and statistical tests”.Proceedings of the Royal Society160, 263–268.[2] Beran, R. (1988) “Prepivoting test statistic: A bootstrap view ofasymptotic refinements”,Journal of the American Statistical Associa-tion 83403, 687–697.
59 Testing for homoscedasticity in non-parametric regresion [Invited Session 28 (page 43)]
Ricardo CAO, Universidade da Coruña, Spain
Irene GIJBELS,Université catholique de Louvain, Louvain-la-Neuve, Belgium
Let us consider a simple random sample(X1,Y1) ,(X2,Y2) , . . . ,(Xn,Yn), coming from a bivariate population with marginaldistribution F (x) = P(X ≤ x), regression functionm(x) =E (Y|X=x) and conditional varianceσ2 (x) = Var(Y|X=x). Theproblem of interest is to testH0 : σ2 (x) = σ2
0 , for some unknown
σ20 > 0 versusH1 : σ2 (x) is not a constant function, when no
parametric model is assumed form. Some related literature onchecks for homoscedasticity via nonparametric function estima-tion includes [1] and [2], while [3] deales with empirical processtheory when a parametric model for the regression function isspecified in advance.We follow [4] and define the integrated conditional variancefunction
J(x) =∫ x
−∞σ2 (y) dF (y)
= E(
σ2 (X)1X≤x)
= E((Y−m(X))21X≤x
).
UnderH1, J(x) can be estimated by
Jn (x) =1
2n(n−1) ∑i 6= j
(Yi −Yj
)2Kh
(Fn (Xi)−Fn
(Xj
))
1Xi≤x1Xj≤x,
whereKh (u) = 1hK
( uh
)andK is a kernel with support in[−1,1].
EquationJ(x) = σ20 F (x) could be used, underH0, to estimate
J(x), however some (more tractable) modification uses that, un-derH0,
E(
Jn (x)|X1,X2,...,Xn
)' σ2
0
n(n−1)
×∑i 6= j
Kh(Fn (Xi)−Fn
(Xj
))1Xi≤x1Xj≤x.
Consequently, we define
Jn,0 (x) =σ2
0
n(n−1)
×∑i 6= j
Kh(Fn (Xi)−Fn
(Xj
))1Xi≤x1Xj≤x,
where
σ20 =
12n(n−1) ∑
i 6= j
(Yi −Yj
)2Kh(Fn (Xi)−Fn
(Xj
)).
Finally the integrated conditional variance empirical process is
Un (x) =√
n(Jn (x)−Jn,0 (x)
)
=1√
n(n−1) ∑i 6= j
[(Yi −Yj
)2
2− σ2
0
]
×Kh(Fn (Xi)−Fn
(Xj
))1Xi≤x1Xj≤x,
which can be proven to converge to a Gaussian limit process.Based on this, homoscedasticity tests are constructed.References[1] Dette, H. (2002) A consistent test for heteroscedasticity in nonpara-metric regression based on the kernel method,J. Statist. Plann. Infer.103, 311–329.[2] Liero, H. (2003) Testing homoscedasticity in nonparametric regres-sion,J. Nonparam. Statist.15, 31–51.[3] Ngatchou-Wandji, J. (2002) Weak convergence of some marked em-pirical process: application to testing heteroscedasticity,J. Nonparam.Statist.14, 325–339.[4] Stute, W. (1997)Nonparametric model checks for regression, Ann.Statist.25, 613–641.
60 Solutions of nonlinear SPDE via ran-dom Colombeau distributions [Contributed Ses-sion C4 (page 53)]

78 6th BS/ IMSC
Ulug ÇAPAR, E.M.U. North Cyprus
The solutions of nonlinear SPDE are usually involved with thesingular objects like the products of the Dirac delta, Heavi-side functions and the nonlinear white-noise functionals whichare difficult to handle within the classical theory. In this workthe framework is the white-noise space(Ω,Σ,ν), where Ωis the space of tempered distributions,Σ is an appropriateσ -algebra andν is the Bochner-Minlos measure. Following [1]and[2] a generalized s.p. is defined as a measurable mappingΩ → GΩ(Rn+1), whereGΩ is the space of Colombeau distri-butions. In this set-up the solutions to the SPDE are soughtin the representative platform using the representatives in theColombeau factor space, of the random excitations. When themoderateness of the representative solutions are demonstrated,their equivalence classes constitute the Colombeau solutions. Ashock-wave equation of the formUt +UxU ≈ .
W and a prey-predator system with white-noise excitation are handled in thisspirit. (≈ denotes the association relation in the Colombeautheory).References[1] Çapar, U. and Aktuglu, H. (2001) A new construction of randomColombeau distributions,Stat. and Prob. Letters54, 291–299 .[2] Oberguggenberger, M. and Russo, F. (1998)Nonlinear SPDE’s:Colombeau solutions and pathwise limits, Workshop on StochasticAnalysis and Related Topics VI, 325-339, Birkhauser.
61 Two integral stochastic orders and theirmaximal generators [Contributed Session C2 (page24)]
Jesús de la CAL andJavier CÁRCAMO , Universidad del PaísVasco, Bilbao, Spain
An integral stochastic order(see [1] and [2], and the refer-ences therein) is a stochastic order defined by a class of func-tionsF . That is, given a class of measurable functionsF , wecan define a stochastic order in the following way:X ≤F Y ifE f(X) ≤ E f(Y), for all f ∈ F such that the previous expec-tations exist. The functions of the classF are known as thegeneratorsof the order≤F . In this situation, it is interesting todetermine themaximal generatorof the order, i.e., the set of allmeasurable functionsf with the property thatX ≤F Y impliesE f(X)≤ E f(Y) whenever the expectations are well defined.Many important stochastic orders are actually integral orders.For instance, ifI is the class of nondecreasing functions, then≤I =≤st is the usual stochastic order; ifC is the class of convexfunctions, then≤C =≤cx is the convex order; ifI C := I ∩C ,then≤I C =≤icx is the increasing convex order.In the present work, we study two stochastic orders. The firstone includes the well-knownless dangerous order, often used inmathematical economy, and the second one is a stronger order.We characterize these relations as integral orders and give someinequalities for integrable random variables ordered accordingthese relations. Some of them can be viewed as generalizationsof the classic Jensen inequality. Maximal generators of the or-ders are also found.References[1] Muller, A. (1997) Stochastic orders generated by integrals: a unifiedstudy.Adv. Appl. Probab.29, 414–428.[2] Muller, A. and Stoyan, D. (2002)Comparison methods for stochasticmodels and risks, John Wiley & Sons.
62 Zonoid based trimmed regions [Con-tributed Session C2 (page 24)]
Ignacio CASCOS FERNÁNDEZ, Public University of
Navarra, Spain
Miguel LÓPEZ-DÍAZ,University of Oviedo, Spain
Let ξ be a random vector inRd with finite first moment. Itszonoidis the convex bodyZ(Fξ )⊂ Rd defined as
Z(Fξ ) :=∫
g(x)xdFξ (x) : g :Rd −→ [0,1]
measurable
,
and itslift zonoid, denoted byZ(Fξ ), is the zonoid of the randomvector(1,ξ ) i.e. Z(Fξ ) := Z(F(1,ξ )).The lift zonoid of a random vector characterizes its distributionand determines the linear convex order by inclusion relation, see[5]. Further, a family of central regions, thezonoid trimmed re-gions, see [4], is given in terms of it as
ZDα (Fξ ) := α−1projα (Z(Fξ )) with α ∈ (0,1], (1)
where for anyC ⊂ Rd+1, projα (C) is the projection on thelast d coordinates of the intersection ofC with the hyperplanex∈ Rd+1 : x1 = α.We define thezonoid hullof the random vectorξ as the convexbodyW(Fξ )⊂ Rd+1 given by
W(Fξ ) := co(Z(Fξ )∪1×Z(Fξ )
),
whereco stands for the convex hull. The zonoid hull character-izes the distribution of a random vector (with finite first moment)and determines the symmetric stochastic order by inclusion re-lation, see [3]. We define a family of central regions inspired bythe symmetric order following the same construction as the oneused in (1),
WDα (Fξ ) := α−1projα (W(Fξ )) with α ∈ (0,1],
see [1] and [2] for generalizations of this family of central re-gions. The depth of a pointx∈ Rd with respect to a probabilitydistribution is given as usual byWD(x;Fξ ) := supα ∈ (0,1] :x∈ WDα (Fξ ). The central region of a given depthα ∈ (0,1]can be obtained as a union of zonoids as the following relationshows
WDα (Fξ ) =⋃
g∈Gα (Fξ )
Z(Fg(ξ )ξ ) with Gα (Fξ )
:=
g : Rd −→ [0,α−1] measurable and∫
g(x)dFξ (x) = 1
.
(2)
The most central points with respect to a random vector andthe new family of central regions constitute the zonoid ofthe random vector,WD1(Fξ ) = Z(Fξ ). Observe that simi-larly to (2), ZDα (Fξ ) = ∪g∈Gα Eg(ξ )ξ holds. The con-tour plots of the central regions based on the symmetric or-der can be easily obtained for an empirical distribution apply-ing the following relation. Letx1,x2, . . . ,xn ⊂ Rd such thatFξ (x) = 1/n∑n
i=11(−∞,xi ](x), if α ∈ (k/n,(k + 1)/n] for anyk∈ 0,1, . . . ,n−1, then
WDα (Fξ ) = co
(αn)−1k
∑j=1
xi j +(1−k/(αn)
)xik+1
: i1, . . . , ik+1 ⊂ N∗
,
(3)
whereN∗ = −n, . . . ,−1,1, . . . ,n and x−i = 0 for every i ∈1, . . . ,n.

Abstracts 79
If α ∈ (0,1/n], the relation (3) implies WDα (Fξ ) =co0,x1, . . . ,xn.References[1] Cascos, I. and López-Díaz, M. (2004) Integral trimmed regions,Sub-mitted.[2] Cascos, I. and López-Díaz, M. (2004) A new family of central re-gions, location trimmed regions,Submitted.[3] Cascos, I. and Molchanov, I. (2003). A stochastic order for ran-dom vectors and random sets based on the Aumann expectation.Statist.Probab. Lett.63295–305.[4] Koshevoy, G. and Mosler, K. (1997) Zonoid trimming for multivari-ate distributions,Ann. Statist.251998–2017.[5] Koshevoy, G. and Mosler, K. (1998) Lift zonoids, random convexhulls and the variability of random vectors,Bernoulli4 377–399.
63 Sharp adaptive estimation in severelyill-posed inverse problems [Contributed Session C53(page 28)]
Laurent CAVALIER ,Yuri K. GOLUBEV, Oleg V. LEPSKI,Université Aix-Marseille 1, France
We consider the problem of solving linear operator equationsfrom noisy data under the assumption that the singular valuesof the operator decrease exponentially fast and that the underly-ing solution is also exponentially smooth in the Fourier domain.This kind of model naturally appear in the framework of inverseproblems linked to partial differential equations. We suggest anestimator of the solution based on a running version of blockthresholding in the space of Fourier coefficients. This estimatoris shown to be sharp adaptive to the unknown smoothness of thesolution.
64 Modeling hot extreme temperatureevents using a non homogeneous Poissonmodel [Poster Session P1 (page 21)]
Jesús ABAURREA andAna C. CEBRIÁN , Universidad deZaragoza, Spain
The aim of this work is to develop a stochastic model to ana-lyze the occurrence and intensity of extremely hot temperatureevents (heat waves) in the second half of the twentieth century.First of all, an exploratory analysis to describe the evolution andcharacteristics of maximum and minimum daily temperature se-ries is performed. Taking into account its results, extreme eventsare defined using an excess over threshold approach based onthe comparison of temperature series,s(t), and a threshold,u(t),which represents a critical level for the process. As consecutiveexceedances overu(t) are not independent, we define criteria forestablish clusters of observations which form the heat waves. Tocomplete the process characterization, several variables describ-ing the seriousness of the heat wave (such as duration, excess ormaximum intensity) are defined.Once these complex extreme events are defined, we modeltheir occurrence and characteristics using a non homogeneousmarked cluster Poisson model; a non homogeneous processseems to be necessary since most of recent work on climateevolution (see for example the contributions to the Third As-sessment report of the IPCCClimate change 2001. The scien-tific basis) show a clear evidence of change in temperature seriesduring the last century. The process considered fits a time vary-ing Poisson intensity parameter; moreover, to describe the markprocess of the model, formed by the variables representing theheat wave magnitude, time dependent distributions are consid-ered. Thus, the non homogeneous model proposed becomes auseful tool to statistically establish the existence of time trendsin the extreme behaviour of temperature process.
The validity of the model is checked using adequate control pro-cedures on several daily temperature series of about 40 yearslong (from 1960 to 2000 approximately) located in the Ebrovalley (Spain). Band confidence for model parameters are es-timated using asymptotical properties of maximum likelihoodestimators and bootstrap methods.References[1] Abaurrea, J. and Cebrián, A.C. (2004) Drought analysis based ona marked cluster Poisson model, Submitted toInternational Journal ofClimatology.[2] Coles, S. (2001)An introduction to Statistical modeling of extremevalues, Springer.[3] Domonkos P., Kysely J., Piotrowicz K., Petrovic P., and Likso T.(2003) Variability of extreme temperature events in south-central Europeduring the 20th century and its relationship with large scale circulation,Int. J. Climatol.23, 987–1010.[4] Kysely, J. (2002) Probability estimates of extreme temperatureevents: stochastic modelling approach vs, extreme value distributions,Studia geoph. et geod.46, 93–112.
65 Estimation and filtering by simulationin a model for ultra-high-frequency financialdata [Contributed Session M6 (page 29)]
Silvia CENTANNI and Marco MINOZZO,University of Peru-gia, Italy
Until recently almost all financial asset models have regardeddiffusion processes driven by Wiener processes as an appropri-ate description of asset prices evolution in continuous time. Al-ternatively time series models for regularly time-spaced data (forinstance, GARCH models) have also widely been used. With theadvent of ultra-high-frequency (UHF) databases and with the in-creasing amount of studies on markets microstructures, the ca-pability of these models to provide an appropriate descriptionof the intraday characteristics of financial markets has been putmore and more under question. UHF data, nowadays availablefor most exchange markets of financial assets, provide a muchfiner information than standard data sets, recording, togetherwith the corresponding characteristics (volumes, etc.), the timeat which all market events, such as trades or quote updates by amarket maker, take place. Whereas the use of models with con-tinuous trajectories is clearly inappropriate for such data sets, theuse of models designed for regularly time-spaced data implies asignificant loss of information since data have to be transformed(or sampled) to a given frequency.A more satisfactorily approach is to build a model for what isactually observed. Mathematically, the UHF price relative to agiven stock can be viewed as a trajectory of a marked point pro-cess (MPP), that is a sequence of random times (point process),complemented by a sequence of random variables, one for eachrandom time, containing the values taken by some variable ofinterest, called the marks. In particular, here we will pursue anew class of models, tailored to the irregular time-spacing ofUHF data, belonging to the class of the doubly stochastic Pois-son processes (DSPP) with marks [1]. These processes are char-acterized by having the number of events, in any fixed time inter-val, as being conditionally independent and Poisson distributed,given an underlying, usually unobserved, nonnegative stochasticprocess, called intensity. In our modeling framework the volatil-ity clustering of the price will result from the clustering of thelevel of activity in the market, measured by the tick frequency,which, in turn, will be directly influenced by the information re-lease. To this end, the underlying intensity is modeled as a jumpprocess with drift, given by an exponential decay, having a finitenumber of positive jumps in bounded intervals. Interestingly, fil-

80 6th BS/ IMSC
tering of this intensity can be accomplished by simulation meth-ods through reversible jump Markov chain Monte Carlo (RJM-CMC) algorithms [2]. Moreover, although the (marginal) like-lihood function based (solely) on the observed prices were notavailable in closed form, and although the integration requiredin the E step of the EM algorithm were not analytically feasible,likelihood based estimation can be carried out by resorting to thestochastic version of the EM algorithm [3]. In this algorithm, theanalytic integration required in the EM is replaced by a MonteCarlo simulation, which can be performed with the RJMCMC.The modeling framework proposed is shown in the study ofsome classical financial problems such as price forecasting andderivative pricing, for which close formulas are not availoableand in which the required predictions are carried out by MonteCarlo simulation.References[1] Rydberg, T.H. and Shephard, N. (2000)A modelling framework forthe prices and times of trades made on the New York stock exchange, inNonlinear and Nonstationary Signal Processing, W. J. Fitzgerald, R. L.Smith, A. T. Walden and P. C. Young (eds.), 217–246.[2] Green P.J. (1995) Reversible jump Markov chain Monte Carlo com-putation and Bayesian model determination,Biometrika82, 711–732.[3] Celeux, G., Chauveau, D., and Diebolt, J. (1995)On stochastic ver-sions of the EM algorithm, N. 2514, Institut National de Recherche enInformatique et en Automatique, Rhône-Alpes, Faculté de Médicine deGrenoble, Dept. de Statistique, 38700 Latronche, France.
66 A Poisson approximation for coloredgraphs under exchangeability [Poster Session P2(page 31)]
Annalisa CERQUETTI and Sandra FORTINI,Bocconi Uni-versity, Milan, Italy
A large class of results in graphs theory concerns the problemof counting the number of times a certain substructure appearsin a random graph; seee.g [2]. Let G(n, p) be the Erdos basicrandom graph model, defined by taking a finite set of vertices,1, . . . ,n and then randomly selecting each of the
(n2
)possible
edges with probabilityp independently of all other edges. Fora fixed graphH, consider the number of copies ofH in G(n, p),Wn = ∑H ′ 1H ′ ⊂ Gn,p, where the sum ranges over all sub-graphs that are isomorphic toH. It is known that ifp is such thatthe expected number ofWn converges to some finite value, thenWn has asymptotically a Poisson distribution; see [1,2]. Resultsof this kind rely upon one of the most elegant developments inmodern probability theory, theChen-Stein method[3], which isa general method to establish Poisson approximations for sumsof weakly dependent indicator random variables, with small oc-currence probabilities.As pointed out in [6], Erdos standard model generally failsto describe many real-world networks for its intrinsic lack ofedge correlation. In fact, in many different fields, like molec-ular biology, ecology or information-technology, observed net-work structures frequently showclustering i.e.vertices are morelikely to be connected when they have a common neighbour.One of the most appealing generalizations of the Erdos basicmodel, allowing correlation among edges, is obtained by ran-domly coloring vertices and realizing edges independently withcolor dependent probabilities [7]. Subgraphs enumeration inrandomly colored random graphs was originally introduced in[5] as an alternative formulation of the famousbirthday prob-lem [8]. If vertex color Xi denotes birthday of personi, and1α = 1Xi = Xj, then the number of pairs of people sharing thesame birthday,W = ∑α 1α , is the number of subgraphs consist-
ing of one edge connecting two vertices. In this framework anupper bound to the total variation distance between the law ofW and a Poisson distribution is obtained. In [4] some results forthe birthday problem are obtained under the hypothesis that thebirthdays are exchangeable, without resorting to graphs theory.Here we introduce exchangeability in random colored graphs:we assume that the random graph is obtained by coloring ver-tices according to anexchangeablelaw and then deleting edgesconnecting vertices with different colors. We consider occur-rences of a generalconnectedsubgraphH of v≥ 2 vertices. Inthis framework we give necessary and sufficient conditions forthe number of subgraphs isomorphic to a given graph to con-verge, under a negligibility assumption on the frequencies ofcolors. Moreover we prove that the limiting law, when it exists,is a mixture of Poisson distributions.References
[1] Barbour, A.D., Holst, L., and Janson, S. (1992)Poisson Approxima-tion, Oxford University Press.[2] Bollobás, B. (1985)Random graphs, Academic Press, London.[3] Chen, L.H.Y. (1975) Poisson approximations for dependent trials,Annals of Probability3, 534–45.[4] Diaconis, P. and Holmes, S. (2002) A Bayesian peek into Feller Vol-ume I,Sankhya, Series A64, 820–841.[5] Janson, S. (1986) Birthday problems, randomly coloured graphs andPoisson limits of sums of dissociated variables,Uppsala University De-partment of Mathematics Report No. 1986:16.[6] Newman, M.E.J. (2003) Random graphs as models of networks, InHandbook of Graphs and Networks, S. Bornholdt and H. G. Schuster(eds.), Wiley-VCH, Berlin.[7] Penman, D.B. (1998) Random graphs with correlation structure,Ph.D Thesis, University of Sheffield.[8] Von Mises, R. (1939) Über aufteilungs und besetzungswahrsceinlichkeiten,Rev. Fac. Sci. Istambul4, 145–163.
67 A simple model of liquidity risk [Con-tributed Session M4 (page 37)]
Umut ÇETIN , Vienna University of Technology, Austria
Chris ROGERS,Cambridge University, UK
We study a financial market in discrete time with general proba-bility space where liquidity costs are present. Similar to the con-tinuous time model of Çetin, Jarrow and Protter [1], we supposethe trader incurs a liquidity cost at each trade depending on thetrade size in a convex fashion. Having defined the self-financingcondition under this new setting, we then proceed to study op-timal liquidation strategies in this model. It is shown that themarginal utility of the terminal wealth of the optimal liquidationstrategy makes the marginal cost process of the optimal strat-egy (i.e. stock price + marginal liquidity cost of following theoptimal strategy) a martingale. A characteristic of this liquiditymodel is that the optimal solution can be found even under thepresence of arbitrage opportunities since infinite arbitrage prof-its are in general not possible due to large liquidity costs of bigorders.We also study necessary and sufficient conditions for no arbi-trage under the proposed liquidity structure. It is shown thatno arbitrage condition is equivalent to the existence of a fam-ily of pairs (QX ,MX) indexed by self-financing trading strate-gies (s.f.t.s.) whereQX is a probability measure equivalent tothe original measure andMX follows a martingale underQX .Roughly speaking,MX is a process that always lies between thebid and ask prices for the order sizes defined byX. In a per-fectly liquid setting,MX coincides with the stock price for allXandQX is an equivalent probability measure independent of thetrading strategy.

Abstracts 81
Another point of interest is the nature of the continuous timelimit of the model. If one also introduces the depth of the mar-ket (i.e. there is a limit on the number of shares that can besold or purchased at each trading date), the only feasible trad-ing strategies in the continuous time are adapted processes of fi-nite variation with bounded left-derivatives where the bound is apredictable process determined by the depth of the market. Thisspecific case is closely related to Longstaff’s liquidity model [2].Finally, we illustrate our results in a simple binomial model.References[1] Çetin, U., Jarrow, R., and Protter, P. (2004) Liquidity Risk and Arbi-trage Pricing Theory, to appear inFinance and Stochastics.[2] Longstaff, F. (2001) Optimal portfolio choice and the valuation ofilliquid securities.Review of Financial Studies14, 407–431.
68 Application of quasi-least squares to an-alyze replicated autoregressive time seriesmodel [Contributed Session C33 (page 45)]
N. Rao CHAGANTY and Genming SHI,Old Dominion Uni-versity, Norfolk, USA
Time series regression model was widely studied in the literatureby several authors. However, statistical analysis of replicatedtime series regression model has received little attention. In thispaper, we study the application of quasi-least squares methodto estimate the parameters in replicated time series model witherrors that follow an autoregressive process of orderp (AR(p)).We also discuss two other established methods for estimatingthe parameters: the maximum likelihood assuming normalityand the Yule-Walker method. When the number of repeatedmeasurements is bounded and the number of replications goesto infinity, the regression and the autocorrelation parameters areconsistent and asymptotically normal for all the three methods ofestimation. Basically, the three methods estimate the regressionparameter efficiently and differ in how they estimate the autocor-relation. We use simulations to show that the quasi-least squaresestimate of the autocorrelation is undoubtedly better than theYule-Walker estimate. It is highly efficient for normal data andmore robust than the maximum likelihood estimate when thereis a departure from normality.
69 Generalized linear models for largespace-time datasets[Invited Session 2 (page 13)]
Richard E. CHANDLER , University College London, UK
This talk will consider the analysis of large space-time datasets,which arise frequently in applications such as climatology. Of-ten, the goal in analysing such a dataset is to investigate the re-lationship between one or more response variables and a (some-times large) number of covariates. It is natural to study suchrelationships using regression-based methods. We explore theuse of Generalized Linear Models (GLMs) in this context and,in particular, focus on the problem of computationally efficientmodel selection when faced with a space-time dataset of hun-dreds of thousands, or millions, of observations. The main ideais to adjust the independence likelihood ratio test for inter-sitedependence. The proposed adjustment is easy to calculate anddiffers from others in the literature; simulation results suggestthat it performs at least as well as other selection techniquesbased on independence estimating equations. The work is moti-vated by, and illustrated using, a case study involving Europeanwindspeed.
70 Occupation time large deviations of twodimensional symmetric simple exclusion pro-
cess [Contributed Session C9 (page 20)]
Chih-Chung CHANG , National Taiwan University, R.O.C.
Claudio LANDIM, IMPA, Brasil and CNRS Université deRouen, France.
Tzong-Yow LEE,University of Maryland, USA.
A large deviations principle for the occupation time in the sym-metric simple exclusion process in dimensiond 6= 2 has been es-tablished by Landim [l]. In dimension2 he proved thatt/ logt isthe right decay rate by obtaining lower and upper bounds. Herewe complete the cased = 2. Namely, we prove a large devia-tions principle for the occupation time of a site in the two dimen-sional symmetric simple exclusion process. The decay proba-bility rate is of ordert/ logt and the rate function is given byϒα (β ) = (π/2)sin−1(2β − 1)− sin−1(2α − 1)2. The proofrelies on a large deviations principle for the polar empiricalmeasure which contains an interestinglog scale spatial average.A contraction principle permits to deduce the occupation timelarge deviations from the large deviations for the polar empiricalmeasure.
References
[1] Landim, C. (1992) Occupation time large deviations for the symmet-ric simple exclusion process,Ann. Probab.20, 206–231.
71 On qualitative comparisons of depen-dence between d-connected vertices of asingly connected Gaussian DAG [ContributedSession C24 (page 36)]
Sanjay CHAUDHURI and Thomas RICHARDSON,Univer-sity of Washington, Seattle, USA
Pearl’s d-connection criterion identifies the independence re-lations implied by the global Markov property for a directedacyclic graph (DAG). It allows one to read off the conditionalindependencies directly from the DAG, by checking for the ex-istence of a certain kind of path. However, the d-connectioncriterion does not indicate the degree of conditional dependencebetween a pair of d-connected vertices given a subset disjoint tothem.Conditional dependence between the vertices in a DAG can bechanged in two ways. The subset to be conditioned on may befixed and the dependence of different pairs of vertices, condi-tional on that fixed set may be compared. On the other hand,one may be interested in fixing two vertices and comparing theirconditional dependence by conditioning on different subsets.The talk will address both of these issues for singly connectedGaussian DAGs. In particular by conditioning upon a fixed sub-set we will show that for certain d-connecting paths the squaredconditional correlation decreases with an increase in the lengthof the path. We will also show that the squared conditional corre-lations between two given vertices, conditioned on different sub-sets may be partially ordered by examining the relationship be-tween the d-connecting path and the set of vertices conditionedupon.Some negative results on multiply connected and discrete DAGswill also be mentioned.
72 Overshoots of Levy processes and weakconvergence of positive self similar Markovprocesses[Contributed Session C32 (page 50)]
María Emilia CABALLERO,Université de Paris X et Institutode Matemáticas, Universidad Nacional Autónoma de México
Loic CHAUMONT , Université Paris VI, France

82 6th BS/ IMSC
We give conditions for the law of a positive self-similar pro-cess to converge weakly in the space of Skorohod as the initialstate tends to 0 and we describe the limit law. These condi-tions are given in terms of the behaviour of the overshoots ofthe Levy process asociated to the self-similar process via Lam-perti’s transformation. We give some examples that illustrate thedifferent situations. (joint work with Loic Chaumont).
73 Random walks on the infinite cluster ofBernoulli percolations [Invited Session 19 (page 49)]
Dayue CHEN, Peking University, China
Benjamini, Lyons and Schramm (1999) considered propertiesof an infinite graphG, and the simple random walk on it, thatare preserved by random perturbations. We study the simplerandom walk on infinite percolation clusters, and solve severalproblems raised by those authors. For the Cayley graph of cer-tain amenable group known as “lamplighter groups", zero speedfor random walk on a lamplighter groups implies zero speedfor random walk on an infinite cluster, for any supercritical per-colation parameterp. For p large enough, we also establishedthe converse. For the Scherk’s graph, the critical probability ofBernoulli bond percolation is less than 1/2. The infinite clusteris transient forp > 1/2 and is recurrent forp < 1/2.References[1] Benjamini, I., Lyons, R., and Schramm, O. (1999)Percolation per-turbation in potential theory and random walks, In Random Walks andDiscrete Potential Theory, Cambridge University Press, 56–84.
74 On the u-th geometric conditional quan-tile [Contributed Session C54 (page 46)]
Yebin CHENG and Jan G. DE GOOIJER,University of Ams-terdam, The Netherlands
Motivated by Chaudhuri’s work (1996) on unconditional geo-metric quantiles, we explore the asymptotic properties of samplegeometric conditional quantiles, defined through kernel func-tions, in high dimensional spaces. First, we establish a Bahadurtype linear representation for the conditional quantile estimator.Also we obtain the convergence rate of the remainder term inthis representation. Using these results, we prove that the esti-mated conditional geometric quantile is asymptotically normallydistributed. Based on these results we propose confidence ellip-soids for multivariate conditional quantiles. These ellipsoids areshown to have asymptotically good coverage properties and tobehave well in finite-sample situations. The methodology is il-lustrated via data analysis and a Monte Carlo study.References[1] Abdous, B. and Theodorescu, R. (1992) Note on the spatial quantileof a random vector,Statist. Probab. Lett.13, 333–336.[2] Bosq, D. and Lecoutre, J.P. (1987)Théorie de l’estimation fonction-nelle,Economica.[3] Cadre, B. and Gannoun, A. (2000) Asymptotic normality of consis-tent estimate of the conditionalL1-median,Ann. I.S.U.P.44, 13–35.[4] Chaudhuri, P. (1992) Multivariate location estimation using exten-sion of R-estimates through U-statistics type approach,Ann. Statist.20,897–916.[5] Chaudhuri, P. (1996), On a geometric notation of quantiles for mul-tivariate data,J. Amer. Statist. Assoc.91, 862–872.[6] De Gooijer, J.G., Gannoun, A., and Zerom, D. (2002)A multivariatequantile predictor, Submitted for publication.[7] Devroye, L. (1981) On the almost everywhere convergence of non-parametric regression function estimates,Ann. Statist.9, 1310–1319.[8] Eubank, R.L. and Speckman, P.L. (1993) Confidence bands in non-parametric regression,J. Amer. Statist. Assoc.88, 1287–1301.[9] Falk, M. (1993) Asymptotically optimal estimators of general regres-sion functions,J. Multivariate Anal.47, 59–81.
[10] Ferguson, T.S. (1967)Mathematical Statistics: A Decision Theo-retic Approach, Academic Press, New York.[11] Kemperman, J.H.B. (1987) The median of a finite measure on aBanach space, inStatistical Data Analysis Based on the L1 Norm andRelated Methods, ed. Y. Dodge, Amsterdam: North-Holland, 217–230.[12] Serfling, R.J. (1980)Approximation Theorems of MathematicalStatistics,Wiley Series in Probability and Mathematical Statistics.[13] Serfling, R.J. (2002) Quantile functions for multivariate analysis:approaches and applications,Statist. Neerlandica56, 214–232.[14] Willems, J.P., Saunders, T.J., Hunt, D.E., and Schorling, J.B. (1997)Prevalence of coronary heart disease risk factors among rural blacks: acommunity-based study,Southern Medical Journal90, 814–820.[15] Yu, K. and Jones, M.C. (1998) Local linear quantile regression,J.Amer. Statist. Assoc.93, 228–237.
75 Large Deviation and central limit theo-rem of diffusion processes with discontinuousdrift [Contributed Session C12 (page 25)]
Tzuu-Shuh CHIANG and Shenn-Jyi SHEU,Institute of Math-ematics, Academia Sinica, Taipei, Taiwan
For the stochastic differential equation
dXεt = b(Xε
t )dt+ εdWt (1)
Xε0 = x0 ∈ Rd (2)
whereb(·) is a smooth vector field inRd except possibly on thehyperplaneH+ = x = (x1, ...,xd) ∈ Rd,x1 = 0, i.e., there aretwo smooth vector fieldsb+(·) andb−(·) such thatb(x) = b+(x)whenx1 ≥ 0 andb(x) = b−(x) whenx1 ≤ 0, the large devia-tion principle was proved to hold in [1]. When the system isstable atx1 = 0, i.e., b+(x) ≤ 0 when x1 ≥ 0 and b−(x) ≥ 0when x1 ≤ 0, then there is a uniqueφ in C[0,1]d such thatlimε→0P(‖Xε − φ‖ ≤ δ ) = 0 for any δ ≥ 0. In this talk, weshow that a central limit theorem hold for the stable system inthe sense that ifξ ε (t) = 1
ε (Xε (t)−φ(t)), thenξ ε (t) convergesto a Gaussian processξ 0(t) in distribution. We also show thatξ 0(t) satisfies a linear stochastic differential equation.References[1] Chiang, Tzuu-Shuh and Sheu, Shenn-Jyi, (2002) Small Perturbationof diffusion s in inhomogeneous Media,Ann. Inst. H. Poncairé Probab.Statist. PR38, 285–318.[2] Chiang, Tzuu-Shuh and Sheu, Shenn-Jyi, Central Limit Theorem ofDiffusion Processes with Small Perturbation in Discontinuous Media,preprint.
76 RP scores: a comparative genomics toolfor identifying regulation sequences [InvitedSession 6 (page 23)]
F. CHIAROMONTE , L. ELNITSKI, R. HARDISON, J. KAS-TURI, D. KING, W. MILER and J. TAYLOR,Penn State Uni-versity, USA
In recent work ([1], [2]) we used data from whole-genomemammalian alignments (human and mouse, and human, mouseand rat) to compute scores capable of discriminating regula-tory sequences from neutrally evolving DNA. Regulatory Po-tential (RP) scores exploit a mix of conservation, compositionand short alignment pattern information, by fitting two Markovmodels on training sets of known regulatory elements and ances-tral repeats. Selection of model state space and order determinesthe mix of information employed in the scores, and is realizedthrough exploratory (e.g. dimension reduction, hierarchical ag-glomerations) and cross-validation analyses. Our results sug-gest that considering multiple species alignments and introduc-ing constraints on the state space selection procedure (symme-try) improve the performance of RP scores in identifying reg-

Abstracts 83
ulatory sequences. We are currently conducting a study on thehemoglobin beta gene cluster to compare RP scores with conser-vation scores, and a series of experiments to validate RP scorespredictions, with encouraging results. Finally, we are devisingstrategies to combine expression information from microarrays,RP scores and motif searches to investigate gene co-regulationin erythroid differentiation.References[1] Elnitski, L., Hardison, R., Li, J., Yang, S., Kolbe, D., Eswara, P.,O’Connor, M., Schwartz, S., Miller, W., and Chiaromonte, F. (2003)Distinguishing regulatory DNA from neutral sites ,Genome Research13, 64–72.[2] Kolbe, D., Taylor, J., Elnitski, L., Eswara, P., Li, J., Miller, W., Hardi-son, R.C., and Chiaromonte, F. (2004) Regulatory potential scores fromgenome-wide 3-way alignments of human, mouse and rat ,Genome Re-search14, 700–707.
77 Generic epigraphical laws of large num-bers [Contributed Session C8 (page 35)]
Christine CHOIRAT , Università degli Studi dell’Insubria,Italy
Christian HESS,Université Paris 9 Dauphine, France
Raffaello SERI,Università degli Studi dell’Insubria, Italy
Starting from the sixties, uniform laws of large numbers(ULLN’s for short) are considered as a cornerstone of the mod-ern theory of statistical inference. Indeed, consider a probabilityspace(Ω,A ,P), a compact metric space(Θ,d) and a sequenceof random functions(hn (ω,θ))n∈N. Then, if forP−almost allω ∈ Ω, hn (ω ,θ) converges to a continuous functionh(θ) uni-formly in θ ∈ Θ and if h(θ) is uniquely minimized atθ0, thenone has:
argminθ∈Θ
hn (ω,θ)→ θ0
asn tends to infinity (see Newey and McFadden, 1994). A gen-eralization of the proof has been obtained through the introduc-tion of generic uniform laws of large numbers(GULLN): con-sider a sequence of random elements(Yi (ω))i∈N and of func-tions(gi (y,θ))i∈N and define:
hn (ω ,θ) =1n
n
∑i=1
gi (Yi (ω) ,θ) .
Suppose that theYi ’s andgi ’s are such that a law of large num-bers holds, either a pointwise one, that ishn (ω,θ) → h(θ)P−as for anyθ ∈Θ, or a local one, that is
lim supθ∈Θi
hn (ω,θ) = supθ∈Θi
h(θ) P−as,
lim infθ∈Θi
hn (ω,θ) = infθ∈Θi
h(θ) P−as,
for a class of setsΘi ⊂ Θ, i ∈ N. The basic idea of aGULLNis to prove uniform convergence ofhn to h starting from somehypotheses on the general behavior of thegi ’s and from a lo-cal or pointwise law of large numbers, thus avoiding any directassumption on the process(Yi)i∈N. This can be very useful inmany cases to allow for dependent and heterogeneous data andeven for nonergodic processes.However, in the last years, an approach based on a differentkind of convergence, namely epigraphical convergence or epi-convergence, has seen the light. Some theorems based on epi-convergence with statistical applications are in Dupacová andWets (1988), Hess (1996) and Choiratet al. (2003). Until now,the approach had never been applied in the form of ageneric epi-graphical laws of large numbers(GELLN). We provide such a
result and we show how it can be used to prove consistency. Ourfunctional limit theorem allows for objective functions given bythe Cesaro mean of a sequence of different discontinuous ex-tended real-valued functions, whose domains can depend on theparameters; moreover, the parameters can vary in infinite dimen-sional spaces. The theorem can be used to derive consistencyof statisticalM−estimators and convergence of minimizers inempirical approximations of stochastic programming problems.Applications range from extreme value theory to robust statis-tics, to functional versions of the Shannon-McMillan-BreimanTheorem of Information Theory.References[1] Choirat, C., Hess, C., and Seri, R. (2003) A functional version ofthe Birkhoff Ergodic Theorem for a normal integrand: A variational ap-proach,Ann. Probability31, 63–92.[2] Dupacová, J. and Wets, R.J-B. (1988) Asymptotic behavior of sta-tistical estimators and of optimal solutions of stochastic optimizationproblems,Ann. Statist.16, 1517–1549.[3] Hess, C. (1996) Epi-convergence of sequences of normal integrandsand strong consistency of the maximum likelihood estimator,Ann.Statist.24, 1298–1315.
78 Statistical properties of quadratic dis-crepancies [Poster Session P3 (page 42)]
Christine CHOIRAT and Raffaello SERI,Università degliStudi dell’Insubria, Italy
The main objective of this paper is to show that many wellknown figures of merit can be written in a common form and thattheir statistical properties can be studied jointly. Therefore, weintroduce thequadratic discrepancies, defined as a class of dis-crepancies arising in numerical integration by Monte Carlo andquasi-Monte Carlo methods, in design of experiments, in unifor-mity and randomness testing and goodness of fit assessment. Weshow that the Cramér-von Mises and Anderson-Darling statis-tics, the generalizedL 2−discrepancies of Hickernell (1996,1998a, 1998b, 1999) and Lianget al. (2000), the classical andthe dyadic diaphony, the weighted spectral test of Hellekalek andNiederreiter (1998), the discrepancies of Hoogland and Kleiss(1996a, 1996b, 1997), Hooglandet al. (1998) and van Hamerenet al. (1997), and the class ofχ2−tests, such as the serial test orthe overlapping serial test, can be written in this form.Then, we derive the asymptotic distribution forn going to infin-ity under the null hypothesis of uniformity (a second order Gaus-sian chaos, that is a weighted infinite sum ofχ2 random vari-ables), under the alternative (a Gaussian random variable), undera Pitman drift (a noncentered second order Gaussian chaos) andunder the null when bothn andd increase without limit (a Gaus-sian random variable). The rate of convergence to these asymp-totic distributions is investigated through Berry-Esséen bounds.A simulation study shows the interest of the previously derivedresults on generalizedL 2−discrepancies.Even if some of the results are partly known, the unified theorydeveloped in the paper appears to be new not only in NumericalAnalysis but also in Statistics.References[1] Hellekalek, P. and Niederreiter, H. (1998) The weighted spectral test:Diaphony,ACM Transactions on Modeling and Computer Simulation8,43–60.[2] Hickernell, F.J. (1996) Quadrature error bounds and applications tolattice rules,SIAM J. Numer. Anal.33, 1995–2016.[3] Hickernell, F.J. (1998a) A generalized discrepancy and quadratureerror bound,Math. Comp.67, 299–322.[4] Hickernell, F.J. (1998b)Lattice rules: How well do they measureup?, in Random and Quasi-Random Point Sets, 109-166, P. Hellekalek

84 6th BS/ IMSC
and G. Larcher eds., Springer Verlag, New York.[5] Hickernell, F.J. (1999) Goodness-of-fit statistics, discrepancies androbust designs,Statist. Probab. Lett.44, 73–78.[6] Hoogland, J., James, F., and Kleiss, R. (1998)Quasi-Monte Carlo,discrepancies and error estimates, Monte Carlo and quasi-Monte Carlomethods 1996., 266–276, H. Niederreiteret al. eds., Springer Verlag,New York.[7] Hoogland, J. and Kleiss, R. (1996a) Discrepancy-based error esti-mates for quasi-Monte Carlo. I: General formalism,Comput. Phys.Comm.98, 111–127.[8] Hoogland, J. and Kleiss, R. (1996b) Discrepancy-based error esti-mates for quasi-Monte Carlo. II: Results in one dimension,Comput.Phys. Comm.98, 128–136.[9] Hoogland, J. and Kleiss, R. (1997) Discrepancy-based error esti-mates for quasi-Monte Carlo. III: Error distribution and central limits,Comput. Phys. Comm.101, 21–30.[10] Liang, J.-J., Fang, K.-T., Hickernell, F.J., and Li, R. (2000) Testingmultivariate uniformity and its applications,Math. Comp.70, 337–355.[11] van Hameren, A., Kleiss, R., and Hoogland, J. (1997) Gaussianlimits for discrepancies,Comput. Phys. Comm.107, 1–20.
79 Tests of function fit, motivated viaBayesian methods, and their frequentistproperties [Contributed Session C57 (page 34)]
Gerda CLAESKENS, Université Catholique de Louvain, Bel-gium
We propose and analyze nonparametric tests of the null hypoth-esis that a regression function belongs to a specified paramet-ric family. The testsπBIC are based on approximations via theBayesian Information Criterion (BIC) to the posterior probabil-ity of the null model, and may be carried out in either Bayesianor frequentist fashion. Perhaps the most interesting aspect ofthe approximation, especially for a frequentist, is that it is com-pletely free of prior probabilities and thus is immediately usableas a test of the null hypothesis versus general alternatives. For aBayesian,πBIC can serve as a rough and ready approximation tothe posterior probability of the null model when the sample sizeis large.We obtain results on the asymptotic distribution ofπBIC underboth the null hypothesis and local alternatives. One version ofπBIC, call it π∗BIC, uses a class of models that are orthogonal toeach other and growing in number without bound as sample size,n, tends to infinity. We show that
√n(1−π∗BIC) converges in dis-
tribution to a stable law under the null hypothesis. We also showthat π∗BIC can detect local alternatives converging to the null atthe rate
√logn/n. A particularly interesting finding is that the
power of theπ∗BIC-based test is asymptotically equal to that of atest based on the maximum of alternative log-likelihoods.Simulation results and an example involving variable star dataillustrate desirable features of the proposed tests.This is joint work with Marc Aerts and Jeffrey Hart.
80 Population substructure in population–based association studies[Invited Session 5 (page29)]
David CLAYTON , Cambridge University, UK
Until recently, the main approach to mapping disease genes wasa combination of linkage studies to identify a large region con-taining a causal variant, followed by direct association studiesfor fine mapping. However, as the focus of main concern hasshifted from studies of single gene disorders to diseases whoseaetiology involves complex interplay of many genes, togetherwith environmental factors. It has become clear that linkagestudies are of much less use in this context and association stud-ies must be much larger than hitherto contemplated in order to
detect the relatively small effects now thought to be observableat any single locus. While the shift towards association studieshas been made possible by the availability of hundred of thou-sands of single nucleotide polymorphisms now available, the re-sultant multiple testing issues have necessitaed yet bigger sam-ples.In the context of the very large scale population–based studiesnow widely accepted as being necessary, there are renewed con-cerns about two issues:• "cryptic relatedness" between study subjects, and
• confounding by unobserved population stratification andadmixture,
so that study subjects may not be regarded as independentlysampled from a single hyperpopulation. The effects of this isboth to increase the type 1 error rate of tests, together with someloss of power.These problems have been discussed in the literature [1,2]. Theywere widely regarded as ignorable [3], until recent work sug-gested that they may become important in the current context oflarge studies of small effects. Several statistical solutions havebeen proposed:
1. stratification for surrogate measures of population struc-ture, particularly geographical region,
2. “genomic control”, using the behaviour of large numbersof unselected markers to estimate empirical correctionsfor naive tests, and
3. full probability modelling using MCMC methods tomodel latent admixture.
These approaches will be reviewed and related them to discus-sion of confounding and causality in the wider statistical liter-ature. The prospects for resolutiuon of these difficulies will bediscussed.References[1] Devlin and Roeder (1999)Biometrics55, 997–1004.[2] Pritchard, Stephens, Rosenberg and Donnelly (2000)American Jour-nal of Human Genetics155, 945–959.[3] Wacholder, Rothman and Caporaso (2002)Cancer Epidemiology,Biomarkers and Prevention11, 513–520.[4] Freedman, Reich, Penney, et al. (2004)Nature Genetics36, 388–393.[5] Marchini, Cardon, Phillips and Donnelly (2004)Nature Genetics36,512–517.
81 Small-time ruin estimates for a finan-cial process modulated by a Harris recurrentMarkov chain [Contributed Session M2 (page 41)]
Jeffrey F. COLLAMORE , University of Copenhagen, Den-mark
Andrea HÖING,ETH Zürich, Switzerland
We consider the large deviation behavior of the sums,
Sn = F(X1)+ · · ·+F(Xn),
whereXi is a general Harris recurrent Markov chain,F a ran-dom function, and the tail decay ofF(Xi) is subexponential (andthus does not have exponential moments).Our interest in such processes arose from a problem in opera-tional risk management, whereXi determines the rate of Poissonarrivals in periodi, andXi is an underlying financial process,such as an AR(1) process, which is Markov-dependent. An-other possible application is to the case whereXi is governed bya stochastic recurrence equation (relevant e.g. for the study ofGARCH financial processes), andSn just denotes the sums oftheX′i s.

Abstracts 85
Under the assumptions thatSn has positive drift and the con-stantδ is appropriately small, we show that
PSn ≥ u, somen≤ δu ∼CuH ((1− γ)u) . (1)
Here,H(u) is roughly the tail distribution function, under sta-tionarity, of F(Xi), andC andγ are constants. The method ofproof draws upon regenerative techniques from the theory ofHarris recurrent Markov chains, as well as methods from insur-ance mathematics.>From a structural point of view, the two examples mentionedabove turn out to be rather different. In the example from oper-ational risk, the heavy-tailed decay in (1) arises from the heavy-tailed behavior of the increments,Sn−Sn−1. In the example ofstochastic recurrence equations, the heavy-tailed behavior arisesinstead from large exceedences during times of regeneration,which can be explicitly characterized.
82 Ignorable observation patterns ofstochastic processes[Contributed Session C20 (page35)]
Daniel COMMENGES and Anne GEGOUT-PETIT,INSERM,France
We precisely define likelihoods for stochastic processes, usingRadon-Nykodym derivatives as in [1]; however, we add a conti-nuity property. Thanks to this continuity property we can definethe likelihood everywhere rather than almost everywhere, whichallows to give a meaning to the equality of two likelihoods ona set of null probability. We also define in this general contextconditional and marginal likelihoods. This allows us to studyignorability in a scheme of observation described by a responseprocess indicator which tells for each time whether the processof interest was observed or not: this allows to include right-, left-and interval-censoring, as well as non-standard schemes. We de-fine ignorability as the proportionality, on the observed event,of the true likelihood and the likelihood considering the mecha-nism leading to incomplete data as fixed. Then we give generalconditions of ignorability which generalize the conditions givenby Rubin [2]; the framework is also more general than previousextensions due to Heitjan and Rubin [3] and coined coarsen-ing. In particular, this approach allows to unify the problems ofmissing data and of censoring, and should also allow to tackleless conventional problems.References[1] Barndorff-Nielsen, O.E. and Sorensen, M. (1994) A review of someaspects of asymptotic likelihood theory for stochastic processes,Int.Statist. Rev.62, 133–165.[2] Rubin, D.B. (1976) Inference and missing data,Biometrika, 63, 581–592.[3] Heitjan, D.F. and Rubin, D.B. (1991) Ignorability and coarse data,Annals of Statistics, 19, 2244–2253.
83 On weak Dirichlet processes [ContributedSession C11 (page 15)]
François COQUET LMAH, Université du Havre, France
Adam JAKUBOWSKI,Copernicus University, Torun, Poland
Jean MÉMIN,IRMAR, Université de Rennes 1, FranceLeszek SLOMINSKI, Copernicus University, Torun, Poland
A weak Dirichlet processes is the sum of a local martingaleand a predictable process orthogonal to every continuous mar-tingale. The class of weak Dirichlet processes, recently intro-duced in [1] in a slightly different manner than ours by Erramiand Russo is strictly wider than the class of ordinary Dirichlet
processes, however it shares some well-known properties of thislatter class. In particular, it is stable underC 1 transformations.In this talk, as a start we precise the links between such notionsas quadratic variation, energy, Dirichlet processes, weak Dirich-let processes and Doob-Meyer type decompositions.Then we state, along with theC 1−stability of weak Dirichletprocesses, an explicit Ito-type formula forC 2 transformations ofa weak Dirichlet process (it is only partly explicit forC 1 trans-formations which are notC 2).At last, we give assumptions under which processes of the form
Xt =∫ t
0G(t,s)dLs (1)
for a quasi left-continuous martingaleL and a deterministicfunctionG are weak Dirichlet processes, with examples.
References
[1] Errami M.,Russo F. (2003)n-covariation, generalized Dirichlet pro-cesses and calculus with respect to finite cubic variation processes,Stochastic process. appl., 104, 259-299.
84 Skorokhod embeddings, minimality andnon-centred target distributions [ContributedSession C10 (page 44)]
Alexander COX and David HOBSON,University of Bath, UK
The Skorokhod embedding problem was first proposed, and thensolved, by Skorokhod in [6] and may be described thus:
Given a Brownian motion(Bt)t≥0 and a centred tar-get lawµ can we find a stopping timeT such thatBT has distributionµ?
An obvious extension of the problem is to consider more gen-eral classes of processes. Here the question of the existence ofan embedding becomes more interesting. In the case of diffu-sions onR simple necessary and sufficient conditions are givenin [5] and [2], along with some constructions which solve theproblem.The work we present here is motivated by the following ques-tion:
Given a diffusion(Xt)t≥0 and a target distributionµX for which an embedding exists, which embed-ding maximises the law ofsups≤T Xs (respectivelysups≤T |Xs|)?
For Brownian motion, the question is solved in [1] (respectively[3]) under the condition thatBt∧T is a UI-martingale.There are several considerations that need to be made whenmoving from the Brownian case to the diffusion case. Firstly,the mean-zero assumption is no longer natural since we are nolonger necessarily dealing with a martingale. The second as-pect that needs to be considered is with what restriction shouldwe replace the UI condition? That such a condition is desir-able may be seen by considering a recurrent diffusion. Here themaximisation problem without restriction can easily seen to bedegenerate.In this work we propose using the class of minimal stoppingtimes introduced in [4] to provide us with a natural restrictionon the set of admissible embeddings.A stopping timeT for the processX is minimal if wheneverS≤ T is a stopping time such thatXS andXT have the same dis-tribution thenS= T a.s.. Further considerations show this to bea sensible class of stopping times.One of the main results is to recharacterise the minimality con-dition on T in terms of a condition onE(BT |FS) for stoppingtimesS≤ T.

86 6th BS/ IMSC
Further, given a non-minimal embeddingT, we show how toconstruct a new (minimal) stopping timeT ′ ≤ T which embedsµ.Having established the concept of minimality, we are able tosolve the problems posed above subject to the restriction that thestopping times are minimal. For the problem of maximising themaximum, in the case where the target distribution is centred,the solution is that of [1], and if the mean is positive the solutionagrees with that of [5]. The general solution is an extension ofthe idea of [1]. The problem of maximising the modulus is alsosolved, and we are able for example to specify the stopping timewhich maximises the distribution ofsupt≤T f (Xt) for a general(time-homogeneous) diffusion and any (measurable) functionf .References[1] Azéma, J. and Yor, M. (1979)Une Solution Simple au Problème deSkorokhod.[2] Cox, A.M.G. and Hobson, D.G. (2002)An Optimal Embedding forDiffusions.[3] Jacka, S.D. (1988)Doob’s Inequalities Revisited: A MaximalH1-Embedding.[4] Monroe, I. (1972)On Embedding Right Continuous Martingales inBrownian Motion.[5] Pedersen, J.L. and Peskir, G. (2001)The Azéma-Yor Embedding inNon-singular Diffusions.[6] Skorokhod, A.V. (1965)Studies in the Theory of Random Processes.
85 McKean-Vlasov representations for lin-ear SPDEs [Contributed Session C3 (page 50)]
Dan CRISAN, Imperial College London, UK
I report on recent results on representation of solutions of cer-tain linear SPDEs as time marginals of nonlinear processes (asdefined in Sznitman [1]). This leads to a corresponding approxi-mation using systems of interacting particles of McKean-Vlasovtype. As an application I deduce an unweighted particle repre-sentation for the solution of the Zakai equation and the Kushner-Stratonovitch equation.Existing particle approximations to the Zakai equation and theKushner-Stratonovitch equation require extra corrections proce-dures either by means of particle weighting as is the case of thestandard Monte Carlo approximation (see Kurtz and Xiong [2]and [3]) or by means of particle branching/resampling (see, forexample, [4], [5] and [6]). By contrast, the above approximationrequires no such procedure. The particle interaction occurs atthe level of particle motion. As a result we expect faster conver-gence rates than those of other particle methods.References[1] Sznitman, A. (1991)Topics in Propagation of ChaosEcole d’Eté deProbabilités de Saint-Flour XIX - 1989, Lecture Notes in Mathematics,1464, Springer-Verlag, 1991.[2] Kurtz, T.G. and Xiong, J. (1999) Particle Representation for a Classof Nonlinear SPDE’s,Stochastic Process. Appl.83, no. 1, pp 103–126.[3] Kurtz, T.G. and Xiong, J. (2001)Numerical Solutions for a Classof SPDEs with Application to FilteringStochastics in finite and infinitedimensions, 233–258, Trends Math., Birkhäuser, Boston.[4] Crisan, D., Gaines, J., and Lyons, T. (1998) Convergence of aBranching Particle Method to the Solution of the Zakai Equation,SIAMJournal of Applied Probability58No. 5 1568–1591, 1998.[5] D. Crisan, T. Lyons (1999)A Particle Approximation of the Solutionof the Kushner-Stratonovitch Equation, Probability Theory and RelatedFields, Vol 115 no 4, pp 549-578.[6] Crisan, D., Del Moral, P., T. Lyons, T. (1999)Interacting ParticleSystems Approximations of the Kushner Stratonovitch Equation, Ad-vances in Applied Probability31, no 3.
86 Parametric correspondence analysis[Contributed Session C41 (page 46)]
Carles M. CUADRAS, University of Barcelona, Barcelona,Spain
Correspondence Analysis (CA, Greenacre, 1984; Cuadras etal., 2000; Cuadras, 2002) and the alternative approach us-ing Hellinger distance (HD, Rao, 1995), for representingcategorical data in a contingency table, are compared. Asboth methods may be appropriate (Cuadras and Greenacre,2003), we introduce a parameterα and define a General-ized version of Correspondence Analysis (GCA) via the SVD
D−1/2r (Dα
r P(1−α)Dαc − rc′)D−1/2
c = Uα DλV ′α , 0≤ α ≤ 1/2,whereP is the correspondence matrix,r,c are the row and col-umn marginal vectors,Dr ,Dc are diagonal matrices andP(1−α)
stands for the matrix with entriesp1−αi j . This approach reduces
to CA and HD for particular values ofα. Comparison withalternative approaches (weighted multidimensional scaling andcompositional data analysis) are performed. We propose thecoefficientθα = 1′(P−Dα
r P(1−α)Dαc )1, which lies between 0
and 1 and globally measures the similarity between CA andGCA. This coefficient can be decomposed into several compo-nents, one component for every principal dimension, indicatingthe contribution of the dimensions on the difference betweenboth representations. Criteria for choosing the best value of theparameter to fit GCA to the data are discussed on the basis of anillustrative example.References[1] Cuadras, C.M. (2002) Correspondence analysis and diagonal expan-sions in terms of distribution functions.J. of Stat. Plan. and Infer.103,137–150.[2] Cuadras, C.M., Fortiana, J., and Greenacre, M.J. (2000) Continu-ous extensions of matrix formulations in correspondence analysis, withapplications to the FGM family of distributions. In: R.D.H. Heijmans,D.S.G. Pollock and A. Satorra, (Eds.),Innovations in Multivariate Sta-tistical Analysis, Kluwer Ac. Publ., Dordrecht, 101–116.[3] Cuadras, C.M. and Greenacre, M.J. (2003) Comparing three meth-ods for representing categorical data. IMUB, Barcelona,MathematicsPreprint Series341.[4] Greenacre, M.J. (1984)Theory and Applications of CorrespondenceAnalysis.Academic Press, London.[5] Rao, C.R. (1995) A review of canonical coordinates and an alterna-tive to correspondence analysis using Hellinger distance.Qüestiió 19,23-63.
87 A new look at an old problem: the dou-ble truncated normal distribution [ContributedSession C49 (page 26)]
Gabriela DAMILANO , Universidad de Rio Cuarto, Argentina
Pedro PUIG,Universitat Autònoma de Barcelona, Spain
Almost 200 years ago Laplace studied how to estimate themeanµ of symmetric distributions. Because the sample meanx and the sample medianx are both unbiased estimators ofµ ,and this is also true for every linear combination of the formwx+(1−w)x, wherew is a constant, Laplace proposed to usethese kind of estimators choosingw in such a way that theasymptotic variance was minimized. A nonparametrical ap-proach to this old problem can be found in Chan and He (1994).The following result characterizes all the symmetric locationmodels (under mild conditions) for which a linear combinationof the median and the sample mean is asymptotically “the best"estimator ofµ :
Theorem. (Damilano and Puig, 2004) The symmetric locationmodels which have an asymptotically efficient estimator of thelocation parameterµ of the formµ = wx+(1−w)x have a den-

Abstracts 87
sity function of the form:
fθ (x; µ ,σ)
=φ(θ)
2(1−Φ(θ))σexp(−θ
|x−µ|σ
− (x−µ)2
2σ2 ) ,(1)
whereφ(.) andΦ(.) denote the standard normal density and cu-mulative distribution functions,µ andσ are location and scaleparameters, andθ is a fixed value. Moreover,w = w(θ) =(1−Φ(θ))/(1−Φ(θ)+θφ(θ)).The resulting models can be regarded as a three parameter fam-ily of distributions that can be understood as a symmetrized ordoubled truncated normal distribution. Whenθ = 0 it is the nor-mal distribution. Whenθ andσ tend to∞ in such a way thatθ/σ tends to a constant, then the limiting density is that of theLaplace distribution. This distribution can be used to analyzedata sets which present a slight departure from the normal dis-tribution reflected by an increment of their kurtosis coefficient.In this talk, a simple method to estimate the three parameters isalso presented. This method, based on pseudo-likelihood (Gongand Samaniego, 1981), can be implemented using standard soft-ware working with the singly truncated normal distribution, likeStata, Eviews, etc.An application to time series of currency exchange rates hasbeen analyzed. The fit obtained by using this new three param-eter distribution is much better than the one obtained using thenormal distribution (Black-Scholes model).References[1] Chan, Y.M. and He, X. (1994) A Simple and Competitive Estimatorof Location,Statist. Probab. Lett.19, 137–142.[2] Damilano, G. and Puig, P. (2004) Efficiency of a linear combina-tion of the median and the sample mean: the double truncated normaldistribution,Scandinavian J. Statist.(to appear).[3] Gong, G. and Samaniego, F.J. (1981) Pseudo Maximum LikelihoodEstimation: Theory and Applications,Ann. Statist. 9, 861–869.
88 Cores of general random hypergraphs[Contributed Session C16 (page 52)]
R.W.R. DARLING , Department of Defense, USA
J. R. NORRIS,Cambridge University, UK
A hypergraph is a list(E1, . . . ,En) of subsets of a “vertex set" V;in the familiar case of a graph, every “hyperedge"Ei has exactlytwo elements, but in a hypergraph variable sizes are allowed.The number of hyperedges in which a vertexv appears is calledits degree. Given integersd1,d2, . . . and w1,w2, . . ., such that∑ idi = m= ∑ jw j let H be a hypergraph selected uniformly atrandom from those hypergraphs withdi vertices of degreei, andw j edges of sizej, for everyi and j. Observe the symmetricalrole of vertices and hyperedges in this construction, unlike themodel we used in [1].The coreC of H consists of the maximal subset (possibly empty)of the hyperedges such no vertex has degree 1. ConstructC byrepeating the following step: pick uniformly at random a vertexof degree 1, and remove the unique hyperedge containing it.For a large random hypergraphH with given hyperedge size andvertex degree distributions (taking a limit asm→∞), the coreChas a concise statistical characterization in terms of the param-eters ofH, derived by taking a fluid limit of a Markov process.The size ofC may depend discontinuously on these parameters.
References
[1] Darling, R.W.R. and Norris, J.R. (2001)Structure of large randomhypergraphs, arXiv:math.PR/0109020, to appear in Annals of AppliedProbability.
89 Estimating the cumulative incidencefunctions under length bias [Contributed SessionC27 (page 36)]
J.-Y. DAUXOIS and A. GUILLOUX, CREST-ENSAI, Campusde Ker-Lann, France
In a competing risks setup, an individual is liable to die fromany of theK ≥ 2 causesD1, . . . ,DK . The causes are not neces-sarily independent but each death is due to a single cause. Whena member of this population dies, the age at deathT and the un-derlying cause of death are recorded. If we letXi , i = 1, . . . ,K,denote the age at death in the hypothetical situation in whichDiis the only possible cause of death then
T = min1≤i≤K
Xi .
The random variablesX1, . . . ,XK are unobservable. The randomvariableδ is the index such thatδ = i if and only if the underly-ing cause of death isDi , in which caseT = Xi . The distributionof the random pair(T,δ ) is specified by the cumulative inci-dence function (CIF)
Fi(t) = P(T ≤ t,δ = i), i = 1, . . . ,K;0 < t < +∞.
Moreover, we suppose that the observation we are doing on thispair (T,δ ) is subject tolength bias. In this case, the individualsin the sample are recruited from those who are alive at a fixedtime t0, i.e. those who have begun their life beforet0 and are notdead at this time.Finally, we also suppose that arandom right censoring mech-anism can also occur, as for example an “end of study” or “lostto follow up” type of censoring.Our work is to derive estimators of the CIFFi , for i = 1, . . . ,K,based on this length biased and censored observation of the life-times with competing risks. We also prove weak convergenceresults for the processes associated to these estimators.References[1] Asgharian M., M’Lan C.E., and Wolfson D.B. (2002) Length-biasedsampling with right censoring : an unconditional approach,J. Amer.Statist. Assoc.97, 201–209.[2] Huang, Y. and Wang, M.-C. (1995) Estimating the occurence ratefor prevalent survival data in competing risks models,J. Amer. Statist.Assoc.90, 1406–1415.[3] Lund, J. (2000) Sampling bias in population studies - How to usethe Lexis diagram,Scand. J. Statist.27, 589–604.[4] de Uña-Àlvarez, J. (2002)Product-limit estimation for length-biasedcensored data, Test,11, 109–125.[5] Van Es B., Klaassen, C.A.J. and Oudshoorn, K. (2000) Survival anal-ysis under cross-sectional sampling : length bias and multiplicative cen-soring,J. Statist. Plann. Inference91, 295–312.
90 Spatial extremes: models for the sta-tionary case [Invited Session 4 (page 23)]
Laurens DE HAAN , Erasmus university Rotterdam, TheNetherlands
Teresa THEMIDO PEREIRA,University of Lisbon, Portugal
The aim of the paper is to provide models for spatial extremes inthe case of stationarity. The spatial dependence at extreme lev-els of a stationary process is modelled using an extension of thetheory of max-stable processes of de Haan and Pickands (1986).We propose three one-dimensional and three two-dimensionalmodels. These models depend on just one parameter or a fewparameters that measure the strength of tail dependence as afunction of the distance between locations. We also propose two

88 6th BS/ IMSC
estimators for this parameter and prove consistency and asymp-totic normality under appropriate extra conditions.
91 Qualitative simulation of genetic regula-tory networks: theory and application [InvitedSession 1 (page 19)]
Hidde DE JONG, Institut National de Recherche en Informa-tique et en Automatique (INRIA), 38334 Saint Ismier Cedex,France,
In order to cope with the large amounts of data that have be-come available in genomics, mathematical tools for the anal-ysis of networks of interactions between genes, proteins, andother molecules are indispensable [1]. I will present a methodfor the qualitative simulation of genetic regulatory networks,based on a class of piecewise-linear (PL) differential equationsthat has been well-studied in mathematical biology [2]. Thesimulation method is well-adapted to state-of-the-art measure-ment techniques in genomics, which often provide qualitativeand coarse-grained descriptions of genetic regulatory networks.Given a qualitative model of a genetic regulatory network, con-sisting of a system of PL differential equations and inequal-ity constraints on the parameter values, the method producesa graph of qualitative states and transitions between qualitativestates, summarizing the qualitative dynamics of the system. Thequalitative simulation method has been implemented in Java inthe computer tool GNA (Genetic Network Analyzer, availableat http://www-helix.inrialpes.fr/gna) [3]. I will dis-cuss the application of the computer tool to the modeling andsimulation of several bacterial regulatory systems, in particularthe networks controlling the initiation of sporulation inBacillussubtilis and the nutritional stress response inEscherichia coli[4].
References
[1] de Jong, H. (2002) Modeling and simulation of genetic regulatorysystems: A literature review,Journal of Computational Biology9(1)69–105. [2] de Jong, H., Gouzè, J.-L., Hernandez, C., Page, M., Sari,T., and Geiselmann, J. (2004) Qualitative simulation of genetic regula-tory networks using piecewise-linear models,Bulletin of MathematicalBiology 66(2) 301–340. [3] de Jong, H., Geiselmann, J., Hernandez,C., and Page, M. (2003) Genetic Network Analyzer: Qualitative simula-tion of genetic regulatory networks,Bioinformatics19(3) 336–344. [4]de Jong, H., Geiselmann, J., Batt, G., Hernandez, C., Page, M. (2004)Qualitative simulation of the initiation of sporulation in Bacillus subtilis,Bulletin of Mathematical Biology66(2) 261–300.
92 Covariate selection for estimating treat-ment effects [Contributed Session C39 (page 33)]
Xavier DE LUNA and Ingeborg WAERNBAUM,Umeå Uni-versity, Sweden
The potential outcome framework (also called Rubin model)was introduced by Rubin (1974) to estimate the effect of a bi-nary treatment on an outcome of interest based on observationaldata (i.e. where treatment assignment to individuals has not beenrandomized). In this framework the key assumption is that thetreatment can be considered as randomized when conditioningwith respect to a set of pre-treatment variables. In particular, thetreatment effect can be estimated while avoiding the bias due todifferences in covariates between treated and untreated individu-als, by using matching estimators; see, for instance, Rosenbaumand Rubin (1983) and Rosenbaum (2002). This corresponds tothe idea of “controlling” or “adjusting” for covariates in anal-ysis of covariance (ANCOVA) models. When using ANCOVA
models the selection of covariates to be included in the model isa classical covariate selection problem. In particular, some co-variates may be introduced either because they are needed forcontrolling or because they reduce the variance of the error termand thereby the variance of the estimation of the treatment ef-fect.The situation is different with the more general matching esti-mators associated to the Rubin model, which allows us to es-timate treatment effects without making strong parametric as-sumptions. In a typical observational study a large amountof covariates describing the individuals entering the study areavailable. In order to fulfill the condition of randomized-liketreatment assignment mentioned above, it is tempting to con-trol for as many covariates as possible. However, adjusting forcovariates that are not necessary will typically bias the estima-tion (Rosenbaum 2002, p. 76). This means that with the Rubinmodel only true control variables should be used in contrast withthe fully parametric ANCOVA setting.In this paper we show that for the general Rubin model a two-step procedure is needed in order to identify an optimal amountof covariates in the sense that they guarantee the randomized-like treatment assignment while making sure that no unneces-sary covariates are controlled for. In a first step the variablespredicting the treatment are identified, followed by a step whereamong the variables identified in the first step we look for thevariables predicting the outcome under a given treatment assign-ment. Alternatively these two steps may be taken in the reverseorder with some slight modifications.The theory on graphical models (see, e.g., Lauritzen, 1996) al-lows us to demonstrate that these two steps procedures identifyan optimal set of covariates. Moreover, several practical issuesare illustrated with the Lalonde (1986) data set.References[1] Lalonde, R.J. (1986) Evaluating the econometric evaluations oftraining programs with experimental data,American Economic Review76, 604–620.[2] Lauritzen, S. (1996)Graphical Models, Oxford: Oxford UniversityPress.[3] Rosenbaum, P.R. (2002)Observational Studies, Berlin: Springer.[4] Rosenbaum, P.R. and Rubin, D.B. (1983) The central role of thepropensity score,Biometrika70, 41–55.[5] Rubin, D.B. (1974) Estimatin causal effects of treatments in ran-domized and nonrandomized studies,Journal of educational psychology66, 688–701.
93 On the sum of autocorrelations of a pro-cess with absolutely summable partial auto-correlations [Poster Session P2 (page 32)]
Łukasz DEBOWSKI , Polish Academy of Sciences, Warszawa,Poland
Let φnk be the coefficients of the best linear predictors ofXn+1based onX1, ...,Xn for a weakly stationary processXZ. Defineφn0 := −1 and φnk := 0 for k > n and letα(n) be the partialautocorrelation of the process.The following statement follows from Durbin-Levinson recur-sion [1] and [2] theorem:
Theorem 1 Let φn(z) := ∑nk=0 φnkz
k. For |z| ≤ 1 we have
|φn(z)| ∈[
n
∏k=1
(1−|α(k)|) ,n
∏k=1
(1+ |α(k)|)]
. (1)
Furthermore,∑nj=0 |φn j| ≤ ∏n
k=1 (1+ |α(k)|) and ∑nj=0 |φn j −
φm j| ≤∏nk=1 (1+ |α(k)|)−∏m
k=1 (1+ |α(k)|) for n > m. If ad-

Abstracts 89
ditionally α(k) ∈ R for all k≤ n then
φn(±1) =n
∏k=1
(1− (±1)kα(k)
). (2)
Definition 1 ProcessXZ is called quasifinitary if∑∞k=1 |α(k)|<
∞ and|α(k)|< 1 for all k.
In view of Theorem 1, for any quasifinitary process and|z| ≤ 1,φn(z) is uniformly convergent to its limitφ(z).We consider standard white noise processesZp
p+1,p+2,...,
where Zpp+n :=
[−∑n−1
k=0 φn−1,kXp+n−k
]/√
γ(0)vn−1 and vn = ∏nk=1
(1−|α(k)|2). For any fi-
nite p we have Xp+n = ∑n−1k=0 ψn−1,kZp
p+n−k and Zpp+n =
∑n−1k=0 πn−1,kXp+n−k, where πnk and ψnk can be computed
from φnk. For every nondeterministic process, equalitieslimp→∞ Z−p
n = Z−∞n hold in L 2, whereZ−∞
Z is the standardwhite noise given uniquely by Wold decomposition. Pointwiseconvergenceψk := limn→∞ ψnk andπk := limn→∞ πnk holds aswell.For every quasifinitary process and|z| ≤ 1, πn(z) := ∑n
k=0 πnkzk
is also uniformly convergent toπ(z) = φ(z)/σ , whereσ > 0
is the innovation variance. Since|π(z)| ≥∏∞k=1
√1−|α(k)|1+|α(k)| > 0,
we can prove thatπk andψk define sound invertible and causalforms, Z−∞
n = ∑∞k=0 πkXn−k and Xn = ∑∞
k=0 ψkZ−∞n−k. More-
over, processXZ is causal and invertible, i.e.∑∞k=0 |ψk| < ∞,
∑∞k=0 |πk|< ∞.
Let ρ(n) be the autocorrelation function ofXZ. The precedingconsiderations imply the main theorem:
Theorem 2 Any quasifinitary process is short-range dependent,i.e. ∑∞
k=−∞ |ρ(k)|< ∞, and
∞
∑k=−∞
ρ(k)zk ∈[
∞
∏k=1
1−|α(k)|1+ |α(k)| ,
∞
∏k=1
1+ |α(k)|1−|α(k)|
](3)
for |z| ≤ 1. Furthermore,α(k) ∈ R for all k implies
∞
∑k=−∞
(±1)kρ(k) =∞
∏k=1
1+(±1)kα(k)1− (±1)kα(k)
. (4)
References[1] Brockwell, P.J. and Davis, R.A. (1987)Time Series: Theory andMethods, Springer.[2] Grenander, U. and Szegö, G. (1984)Toeplitz Forms and Their Ap-plications, Chelsea.
94 A new class of genealogical and interact-ing Metropolis particle models [Invited Session 24(page 51)]
P. DEL MORAL , LSP-CNRS, France
A. DOUCET,Cambridge University, England
One central question in Monte-Carlo Markov chain literature isthe construction of Markov models with nice stability proper-ties and having a prescribed invariant measure. The traditionalMetropolis-Hasting algorithm is one of these universal and sin-gle particle search model. In this talk we present a novel ap-proach based on Feynman-Kac semi-groups, branching and in-teracting particle models. We introduce a natural and powerfulinteracting Metropolis algorithm whose decays to equilibriumdo not depend on the nature of the limiting target distribution.
More interestingly this particle methodology induces a new ge-nealogical tree simulation technique for drawing Markov-pathsamples restricted to their terminal values. For a more thoroughand detailed discussion, we refer the reader to the article [1], andthe research monograph [2].References[1] Del Moral, A. and Doucet, A. (2003)On a class of genealogicaland interacting Metropolis Models., Séminaire de Probab. 37, LectureNotes in Math.1832, Eds. J. Azéma, M. Emery, M. Ledoux, M. Yor,Springer-Verlag, 415–446.[2] Del Moral, P. (2004)Feynman-Kac formulae. Genealogical and in-teracting particle approximations, Springer New York, Series: Proba-bility and Applications.
95 Nonparametric deconvolution and wild-aging [Contributed Session C54 (page 46)]
Aurore DELAIGLE , University of California, Davis, USA
We consider estimation of a density from a sample that containsmeasurement errors. This problem, known as a deconvolutionproblem, has applications in many different fields such as as-tronomy, chemistry or public health, since in real data applica-tions, it happens quite often that the observations are made witherror. The contaminating density, or error density, is often as-sumed to be known. In this context, a so-called deconvolutionkernel density estimator has been proposed in the literature (seefor example Carroll and Hall (1988) or Stefanski and Carroll(1990)).The behavior of the deconvolution kernel density estimator de-pends strongly on a smoothing parameter called the bandwidth.We discuss several possible ways of choosing an appropriatebandwidth in practice, and illustrate the methods via a simu-lation study. See Delaigle and Gijbels (2002,2004a,2004b).The methodology can be used to estimate the survival time offlies in the wild given two samples of flies with partially orcompletely recorded survival time. In this context, the densi-ties involved have a finite left boundary point. It is well knownthat in that case, the kernel density estimator is not consistent atthe boundary point, and has to be modified in order to take theboundary point into account. Using these techniques, we pro-pose a method to estimate the survival time of flies in the wild.This is joint work with Irène Gijbels, Hans-Georg Müller, Jane-Ling Wang and James Carey.References[1] Carroll, R.J. and Hall, P. (1988) Optimal rates of convergence fordeconvolving a density,Journal of the American Statistical Association83, 1184–1186.[2] Delaigle, A. and Gijbels, I. (2002) Estimation of integrated squareddensity derivatives from a contaminated sample,Journal of the RoyalStatistical Socitey B64, 869–886.[3] Delaigle, A. and Gijbels, I. (2003)Boundary estimation and estima-tion of discontinuity points in deconvolution problems, Discussion paper#0320, Institut de Statistique, Université catholique de Louvain.[4] Delaigle, A. and Gijbels, I. (2004a) Comparison of data-driven band-width selection procedures in deconvolution kernel density estimation,Computational Statistics and Data Analysis42, 249–267.[5] Delaigle, A. and Gijbels, I. (2004b)Bootstrap bandwidth selectionin kernel density estimation from a contaminated sample, Annals of theInstitute of Statistical Mathematics, to appear.[6] Delaigle, A. (with Carey, J., Müller, H-G., Wang, J-L.).Deconvolu-tion in wild-aging,Work in progress
[7] Stefanski, L. and Carroll, R.J. (1990) Deconvoluting kernel densityestimators,Statistics2, 169–184.
96 Goodness-of-fit testing of conditionalmodels [Invited Session 28 (page 43)]

90 6th BS/ IMSC
Miguel A. DELGADO , Universidad Carlos III, Madrid, Spain
We propose asymptotically pivotal goodness-of-fit tests for thecomposite hypothesis of a parametrically specified conditionaldistribution function. Tests are based on a martingale innovationof the biparameter empirical process after applying Rosenblatt(1952) transformation, but substituting the unknown marginaldistribution by its empirical analogue, and the unknown param-eters of the conditional distribution by some suitable estimators.Rosenblatt’s transformation results in a parametric empirical se-quential process of concomitants unsuitable for testing purposes,since its limiting distribution depends on the unknown parame-ters and on the unknown marginal distribution. The innovationpart of the empirical sequential process converges in distributionto the standard biparameter Brownian motion, and is obtained inthe lines suggested by Khmaladze (1981) for the single param-eter empirical process with estimated parameters. Tests of verydifferent nature can be constructed using, as tests statistics, al-ternative functionals of the innovation process. Despite omnibustests, we apply results in Grenander (1950) to construct optimaltests in the direction of contiguous alternatives, as well as toconstruct Neyman-type smooth tests, a compromise between di-rectional and omnibus tests. We illustrate our results in the con-text of testing conditional normality with constant conditionalvariances, considering optimal tests in the direction of contigu-ous heteroskedastic alternatives. We also discuss the case whereseveral explanatory variables enters in the conditional distribu-tion through a linear projection. The small sample performanceof the proposed test is studied by means of some Monte Carlosexperiments.References[2] Khmaladze, E.V. (1981) Martingale approach to the goodness of fittests,Theory Probab. Appl.26, 246–265.[3] Rosenblatt, M. (1952) Remarks on a multivariate transformation,Ann. Math. Statist.23, 470.
97 Remarks on local likelihood density es-timation [Contributed Session C65 (page 48)]
Pedro DELICADO , Universitat Politècnica de Catalunya,Spain
Local likelihood is recognized as a very successful and intu-itively appealing method for nonparametric regression. The den-sity estimation version of local likelihood has theoretical proper-ties comparable to those in regression. Nevertheless, it is rarelyused in practice. It is our belief that the main reason for that isthe lack of straightforward motivation for the formulas recentlyput forward by the literature in the topic of local likelihood den-sity estimation.The local likelihood problem formulation proposed by Copas(1995) is
maxθ
n
∑i=1
w(xi − t) log f (xi ;θ)+( n
∑i=1
(1− w(xi − t)))
log
(1−
∫
Rw(u− t) f (u;θ)du
),
(1)
where w(u) = vw(u), w is a kernel function, andw(0) = 1.Loader (1996) and Hjort and Jones (1996) propose
maxθ
n
∑i=1
w(xi − t) log f (xi ;θ)−n∫
Rw(u− t) f (u;θ)du. (2)
An alternative approach is considered in this paper. It is based onvery intuitive truncation arguments. Moreover, it is established
that the three apparently different approaches to local likelihooddensity estimation coincide when the parametric model they arebased on is closed for product by constants. We consider theoptimization problem
maxθ
n
∑i=1
w(xi − t) logf (xi ;θ)
v∫R w(u− t) f (u;θ)du
, (3)
Let θST(t) be the maximum. The proposed estimator off (t) is
f ST(t) =f (t; θST(t))∫
R w(u− t) f (u; θST(t))dufw(t),
where fw(t) = ∑ni=1w(xi − t)/n is the kernel estimation off (t).
(ST comes fromSmooth Truncation).Let us consider (1), and (2) when the parametric family isF = c f(θ) : c> 0,θ ∈Θ, and the maximization is done over(c,θ). Let (cC(t), θC(t)) and (cL(t), θL(t)) be their solutions.The derived estimations off (t) are
fC(t) = f1(t; cC(t), θC(t)) and
f L(t) = f1(t; cL(t), θL(t)).
At (3) it is enough to considerF0 = f (θ) : θ ∈Θ as the para-metric model. The derived estimator off (t) is
f ST(t) =f0(t; θST(t))∫
R w(u− t) f0(u; θST(t))dufw(t).
Theorem 1. In the previous context,θC(t) = θL(t) = θST(t)and fC(t) = f L(t) = f ST(t). Moreover
cC(t) = cL(t) =fw(t)∫
R w(u− t) f0(u; θST(t))du.
References[1] Copas, J.B. (1995) Local likelihood based on kernel censoring,J.Roy. Statist. Soc. Ser. B, 57, 221–235.[2] Hjort, N.L. and M.C. Jones (1996) Locally parametric nonparametricdensity estimation,Ann. Statist.24, 1619–1647.[3] Loader, C.R. (1996) Local likelihood density estimation,Ann.Statist.24, 1602–1618.
98 On the central limit theorem for non-archimedean Diophantine approximations
[Contributed Session C7 (page 44)]
Eveyth DELIGERO and Hitoshi NAKADA, Keio University,Japan
Consider a finite fieldFq of q elements. We putFq[X] the ring ofFq-coefficients polynomials,Fq(X) the quotient field ofFq[X],andFq((X−1)) the field of formal Laurent power series, that is,
Fq((X−1)) = f = anXn +an−1Xn−1
+ · · · : ai ∈ Fq for i ≤ n, n∈ Z.
For f ∈ Fq((X−1)), we define| f | = qdegf
In the field of formal Laurent power seriesFq((X−1)), which isalso non-archimedean, we are interested in the metrical proper-ties of following Diophantine inequality:
∣∣∣∣ f − PQ
∣∣∣∣ <Ψ(degQ)|Q| , P, Q∈ Fq[X], (P,Q) = 1, (1)
whereΨ is a non-negative real valued function defined on theset of positive integers and(P,Q) = 1. Similar to the classical

Abstracts 91
case, we want to know the conditions for this inequality to haveinfinitely many solutions a.e. and if the solutions are infinitewe want to know if the limit theorems hold for the number ofsolutions. In 1970, deMathan proved the Khinchine type theo-rem: suppose that∑∞
n=1qnΨ(n) = ∞ andqnΨ(n) is monotonenon-increasing asn→∞, then the inequality has infinitely manysolutions for a.e. f . With these two conditions of deMathanand adding few more conditions, Fuchs (2000) proved the cen-tral limit theorem for the number of solutions using the conceptof continued fraction theory. However, recently, Inoue- Nakada(2003) showed that for (1) to have infinitely many solutionsP
Qfor m-a.e. f , the monotonicity condition onqnΨ(n) is not nec-essary, that is, (1) has infinitely many solutions form-a.e. f ifand only if∑qnΨ(n) = ∞.In this paper, we consider the central limit theorem for the num-ber of solutionsP
Q after works by Fuchs and Inoue-Nakada with-out using the concept of continued fraction theory. We discussthe number of solutions of (1) without using the continued frac-tions and show that the central limit theorem holds whenqnΨ(n)is monotone non-increasing and∑qnΨ(n) = ∞.References[1] Berthé, V. and Nakada, H. (2000) On continued fraction expansionsin positive characteristic: equevalence relations and some metric prop-erties,Expo. Math.18, 257–284.[2] Billingsley, P. (1995)Probability and Measure,3rd edition, John Wi-ley & Sons,New York.[3] Fuchs, M. (2002) On Metric Diophantine Approximations in the fieldof formal Laurent series,Finite Fields Appl.8, 343–368.[4] Hoeffding, W. and Robbins, H. (1948) The central limit theorem fordependent random variables,Duke Math. J.15, 773–780.[5] Inoue, K. and Nakada, H. (2003) On metric diophantine approxima-tion in positive characteristic,Acta Arith. 110, 205–218.[6] Philipp, W. (1967) Some metrical theorems in number theory,PacificJ. Math.20, 109–127.
99 Estimation of integrated volatility incontinuous time financial models with appli-cations to goodness-of-fit testing [ContributedSession C19 (page 30)]
Holger DETTE , Mark PODOLSKIJ and Mathias VETTER,Ruhr-Universität Bochum, Germany
A new specification test for the parametric form of the variancefunction in diffusion processes of the form
dXt = b(t,Xt)dt+σ (t,Xt)dWt ,
is proposed, which does not require specific knowledge of thefunctional form of the model. The corresponding test statisticis based on an estimate of the integrated volatility and has anasymptotic normal distribution under the null hypothesis and di-verges at an appropriate rate under the alternative. In contrast torecent work the approach of the present paper does not requirethe specification of particular time points at which the hypothe-sis of a parametric form is checked. As a by-product we obtaina very simple test for homoscedasticity in diffusion processes.Moreover, the new test does not use nonparametric estimationtechniques for estimating the variance function and is thereforeindependent of the specification of a particular smoothing pa-rameter. The results are illustrated by a small simulation studyand a data example is analyzed.References[1] Dette, H. von Lieres and Wilkau, C. (2003) A test for a parametricform of the volatility in continuous time financial models.Finance &Stochastics7, 363–384.
[2] Corradi, V. and White, H. (1999) Specification tests for the varianceof a diffusion.J. Time Series20, 253–270.
100 Collapsibility for Conditional Gaus-sian Chain Graph Models [Contributed SessionC39 (page 33)]
Vanessa DIDELEZ, University College London, UK
A chain graph can be regarded as the visual representation of theconditional independence structure in a sequence of multivariateregressions. The classical chain graphs, as introduced by Wer-muth & Lauritzen [5], are based on so–called conditional Gaus-sian (CG)–regressions, specific multivariate regressions that al-low for responses of different measurement scale, continuousand categorical. This class of regression models results fromconditioning in the class of multivariate conditional Gaussiandistributions. The suitability of CG–regressions for chain graphmodels is due to the fact that the independence structure inducedby a marked chain graph leads to specific, relatively simple pa-rameter restrictions in this class.However, when the multivariate responses are indeed of mixedscale, CG–regressions are difficult to fit. Heuristic data drivenstrategies have been proposed and applied [1] that are based onbreaking down the multivariate regression into univariate regres-sions in an ad–hoc way. The recent development of the TM algo-rithm [3] has simplified the practical fitting of actualmultivari-ate CG–regressions considerably. This algorithm can be mademore efficient by exploiting collapsibility of CG–regressions al-lowing the decomposition of the multivariate model into lowerdimensional or even univariate regressions that are still CG andare consistent with the corresponding subgraphs [2].In this talk, I will review the conditions for collapsibility, showhow they can easily be checked on the graph and indicate com-putational advantages. In addition, a simple graphical conditionis given for checking whether a complete decomposition intounivariateregressions is possible. The results will be illustratedwith some graphical and numerical examples. Their implica-tions for the model selection and fitting of chain graphs as wellas for latent variable models [4] will be discussed.References[1] Cox, D.R. and Wermuth, N. (1996)Multivariate Dependencies,Analysis and Interpretation,Chapman and Hall, London.[2] Didelez, V. and Edwards, D. (2004)Collapsibility in graphical CG–regression models, to appear in Scand. J. of Stat.[3] Edwards, D. and Lauritzen, S.L. (2001) The TM algorithm for max-imising a conditional likelihood function,Biometrika88, 961–72.[4] Richardson, T. and Spirtes, P. (2002) Ancestral graph Markov mod-els,Ann. Statist.30, 962–1030.[5] Wermuth, N. and Lauritzen, S. (1990) On substantive research hy-potheses, conditional independence graphs and graphical chain models(with discussion).J. Roy. Statist. Soc. Ser. B52, 21–72.
101 Spatio-temporal point processes inecological models and their approximationby means of moment closures [Invited Session 2(page 13)]
Ulf DIECKMANN , International Institute for Applied SystemsAnalysis, Laxenburg, Austria
The field of spatial ecology has expanded dramatically over thepast few years. Individual-based models now play an indispens-able role in bridging between the local scale of individual inter-actions and the larger spatial scales at which correlation patternsdevelop and populations are observed and managed. While tra-ditional ecological theory sadly fails to account for the rich suitof phenomena arising in spatial ecology, complex simulation

92 6th BS/ IMSC
studies also offer only limited insights into the inner workingsof spatially structured ecological interactions. A middle groundbetween spatially ignorant and spatially explicit approaches isprovided by dynamical models based on the hierarchy of spa-tial moments. Such models arguably offer the most promisingstrategy for simplifying spatial complexity in ecological models.To this end, suitable moment closures have to be identified bywhich moment hierarchies can be accurately truncated. In mytalk I will review recent progress in applying spatio-temporalpoint processes in continuous two-dimensional space to ecolog-ical problems and present results that highlight the differentialperformance of alternative moment closures.References[1] Dieckmann, U. (2000) Simplifying spatial complexity. Interna-tional Institute for Applied Systems Analysis,Options Spring:17 (seewww.iiasa.ac.at/Research/ADN/ADNopt-spr00.pdf#Simplifying)[2] Dieckmann, U., Law, R. and Metz, J.A.J. eds. (2000)The Geometryof Ecological Interactions: Simplifying Spatial Complexity.CambridgeUniversity Press(see www.iiasa.ac.at/Research/ADN/Books.html)[3] Dieckmann, U. and Law, R. (2000) Relaxation projections and themethod of moments. In:The Geometry of Ecological Interactions: Sim-plifying Spatial Complexity, eds. Dieckmann, U., Law, R., and Metz,J.A.J., 412–455. Cambridge University Press.[4] Law, R. and Dieckmann, U. (2000) Moment approximations ofindividual-based models. In:The Geometry of Ecological Interac-tions: Simplifying Spatial Complexity, eds. Dieckmann, U., Law,R., and Metz, J.A.J., 252–270. Cambridge University Press.[5] Law, R. and Dieckmann, U. (2000) A dynamical system for neigh-borhoods in plant communities.Ecology81, 2137–2148.[6] Law, R., Purves, D.W., Murrell, D.J. and Dieckmann, U. (2001)Causes and effects of small-scale spatial structure in plant populations.In: Integrating Ecology and Evolution in a Spatial Context, BritishEcological Society Symposium Volume Series14, eds. Silvertown,J. and Antonovics, J., 21–44. Blackwell Science.[7] Law, R., Murrell, D.J. and Dieckmann, U. (2003) Population growthin space and time: Spatial logistic equations.Ecology84, 252–262.[8] Doebeli, M. and Dieckmann, U. (2003) Speciation along environ-mental gradients.Nature421, 259–264.[9] Murrell, D.J., Dieckmann, U., and Law, R. (2004) On moment clo-sures for population dynamics in continuous space.Journal of Theoreti-cal Biology, in press.
102 Mining association rules using latticetheory [Contributed Session C55 (page 21)]
Florent DOMENACH , Tsukuba University, Japan
Discovering nontrivial association rules from large databaseshas recently become critical, especially in data mining areawhere there is a substantial need to develop efficient miningalgorithms for complex data. In this talk, we consider the sit-uation where we have some a priori knowledge on the itemsor on the attributes, i.e., some taxonomies (or hierarchies) areknown. We first show how taxonomies can be generalized usinglattices, which are ordered structures, to represent such knowl-edge. Then, we propose a new approach to find association rules,based on the notion of biclosures introduced by the author.References[1] Agrawal, R., Imielinski, T., and Swami, A. (1993) Mining Associa-tions between Sets of Items in Massive Databases, Proc. of the ACM-SIGMOD 1993 Int’l Conference on Management of Data, WashingtonD.C., 207–216.[2] Birkhoff, G. (1967)Lattice Theory, Amer. Math. Soc., Providence,R.I., third edition.[3] Davey, B.A. and Priestley, H.A. (1990)Introduction to lattices andorder, Cambridge University Press, Cambridge (U.K.).[4] Domenach, F. and Leclerc, B. (2001), Biclosed binary relations andGalois connections,Order18, 89–104.
[5] Guigues, J.L. and Duquenne, V. (1986) Familles minimalesd’implications informatives resultant d’un tableau de donnees binaires,Math. Sci. Hum.95, 5–18.[6] Srikant, R., Vu, Q., and Agrawal, R. (1997) Mining AssociationRules with Item Constraints, Proc. of the 3rd Int’l Conference onKnowledge Discovery in Databases and Data Mining, Newport Beach,California.
103 Efficiency of some estimators for ageneralized Poisson autoregressive process oforder 1 [Contributed Session C33 (page 45)]
Louis DORAY , Université de Montréal, Canada
Andrew LUONG,Université Laval, Canada
El-Halla NAJEM,Université de Montréal, Canada
Various models have been proposed to study non-negativeinteger-valued time series. In this paper, we study estimatorsfor the generalized Poisson autoregressive process of order 1, amodel developed by Alzaid and Al-Osh [1]. We compare threeestimation methods, the methods of moments, quasi-likelihoodand conditional maximum likelihood and study their asymptoticproperties. To compare the bias of the estimators in small sam-ples, we perform a simulation study for various parameter val-ues. Using the theory of estimating equations, we obtain expres-sions for the variance-covariance matrix of those three estima-tors, and we compare their asymptotic efficiency. Finally, weapply the methods derived in the paper to a real time series.
References
[1] Alzaid, A.A. and Al-Osh, M.A. (1993) Some Autoregressive Mov-ing Average Processes with Generalized Poisson Marginal Distributions,Annals of the Institute of Mathematical Statistics45, 223–232.
104 Computable bounds for subgeometricMarkov chains [Contributed Session C18 (page 54)]
Randal DOUC, Ecole Polytechnique, France
Eric MOULINES,Ecole Nationale Supérieure des Télécommu-nication, France
Philippe SOULIER,Université de Paris X-Nanterre, France
In this work [2], quantitative bounds for general Markov chainsunder conditions implying sub-geometric ergodicity are derived.These bounds are obtained from pathwise coupling techniquecombined with a drift condition recently introduced in [1] al-lowing to control modulated moment of the return time to thecoupling set. This condition, extending a condition proposedby [3] for polynomial convergence rates, turns out to be veryconvenient to prove subgeometric rates of convergence. The re-sults are illustrated in several models from queueing theory andMarkov Chain Monte Carlo.References[1] Douc, R., Fort, G., Moulines, E., and Soulier, P. (2003) Practicaldrift conditions for subgeometric rates of convergence, To appear in theAnnals of Applied Probability.[2] Douc, R., Moulines, E., and P. Soulier, P. (2003)Computable boundsfor subgeometric ergodicity, Submitted.[3] Jarner, S. and Roberts, G. (2002) Polynomial convergence rates ofMarkov Chains,Annals of Applied Probability12, 224–247.
105 Reduction of gibbs phenomenom inwavelet thresholding [Contributed Session C21 (page50)]
T.R. DOWNIE , Univesity College London, U.K.
Wavelet thresholding is an effective method of noise reductionfor a wide class of naturally occurring signals. However, in

Abstracts 93
the vicinity of a discontinuity there is usually considerable biasand oscillation in the thresholded estimated signal (Gibbs phe-nomenon).The Haar wavelet basis is good at approximating discontinuities,but is bad at approximating other signal artefacts. A methodof detecting jumps in a signal will be presented that comparesthe non-decimated Haar wavelet coefficients, with higher orderwavelet coefficients, in order to detect the presence of jumps.The method has been designed to be used in conjunction withany existing wavelet thresholding method.Using a simulation study, the method is demonstrated. In mostcases, a substantial reduction in bias can be obtained, in the lo-cation of a discontinuity, leading to a corresponding reductionin mean square error. In situations where no discontinuities arepresent, the method gives results that are no worse than whenthe jump detection method is not used.
106 On necessary and sufficient conditionsfor approximations of ruin probabilities [Con-tributed Session M2 (page 41)]
Myroslav DROZDENKO, Mälardalen University, Sweden
Dmitrii SILVESTROV, Mälardalen University, Sweden
We consider standard risk processesXε (t), t ≥ 0 with character-istics depending on small perturbation parameterε ≥ 0. It isassumed that claims have finite expectation and that safety load-ing coefficientsαε < 1,αε → 1 asε → 0.We give a variety of necessary and sufficient conditions for weakconvergence of scaled non-ruin distribution functionsφε (u) =1−Puuε + inft≥0Xε (t) < 0, where0 < uε → ∞ asε → 0 is ascale parameter which determines the rate of growth for the ini-tial capital. A special attention is payed to the cases of diffusionand stable type approximations.
107 Maximum likelihood estimation in an-cestral graph Markov models [Invited Session 35(page 30)]
Mathias DRTON, University of Washington, USA
Ancestral graph Markov models, introduced by Richardson andSpirtes [1], are a new class of graphical models that general-ize both Markov random fields (underlying undirected graph)and Bayesian networks (underlying DAG = directed acyclicgraph). A key feature of ancestral graph models is that the globalMarkov property is closed under conditioning and marginal-ization. Thus, ancestral graphs can encode all conditionalindependence structures, which may arise from a Bayesiannetwork/DAG model with selection and unobserved variables.Since DAGs can be interpreted causally (e.g. Lauritzen [2]),ancestral graph models provide promising new methodologyfor exploring causally interpretable association structures if thepresence of selection effects and unobserved variables cannot beexcluded (Richardson and Spirtes [3]).
Here we present a new algorithm for maximum likelihood esti-mation in ancestral graph models. We call this new algorithmiterative conditional fitting (ICF) since in each step of the pro-cedure, a conditional distribution is estimated, subject to con-straints, while a marginal distribution is held fixed. The ICFalgorithm is in duality to the well-known iterative proportionalfitting algorithm, in which a marginal distribution is fitted for afixed conditional distribution.
The ICF approach is applicable for continuous as well as dis-crete variables. In the continuous case, in which a multivariatenormal distribution is assumed, ICF may be implemented by re-
gressions on “pseudo-variables” (Drton and Richardson [4,5]).In the discrete case with multinomial sampling, initial work sug-gests that ICF allows one to decompose the complicated over-all problem of maximizing the likelihood function under non-linear constraints into several simpler optimization problems,namely maximizations of concave functions under linear con-straints. However, these simpler optimization problems must besolved repeatedly until convergence.References[1] Richardson, T.S. and Spirtes, P. (2002) Ancestral graph Markov mod-els,Annals of Statistics 30, 962–1030.[2] Lauritzen, S.L. (2001)Causal inference from graphical models, In:Complex Stochastic Systems (Eds. Barndorff-Nielsen O. E., Cox D. R.,Klüppelberg C.), Chapman and Hall, London, 63–107.[3] Richardson, T.S. and Spirtes, P. (2003)Causal inference via ances-tral graph models, In: Highly Structured Stochastic Systems (Eds. GreenP. J., Hjort N. L., Richardson S.), Oxford University Press, Oxford, 83–105.[4] Drton, M. and Richardson, T.S. (2003)A New Algorithm for Maxi-mum Likelihood Estimation in Gaussian Graphical Models for MarginalIndependence, Proceedings of the Nineteenth Conference on Uncer-tainty in Artificial Intelligence (Eds. Kjærulff U., Meek C.), MorganKaufmann, San Francisco, 184–191.[5] Drton, M. and Richardson, T.S. (2003)Iterative Conditional Fittingfor Gaussian Ancestral Graph Models, Department of Statistics, Univer-sity of Washington, Tech. Report 437.
108 Statistical analysis on high-dimensional spheres and shape spaces[Con-tributed Session C17 (page 53)]
Ian DRYDEN , University of Nottingham, UK
The statistical analysis of functional data arises in a wide varietyof situations. We consider probability distributions and statis-tical inference when the functions are represented by points onhigh-dimensional spheres or shape spaces.Initially we review the Wiener measure and its connection withthe infinite dimensional sphere. We also discuss work on densi-ties of Gaussian measures with respect to Wiener measure. Wethen define a non-uniform measure on the infinite dimensionalsphere. We show that particular high dimensional Bingham andhigh dimensional zero mean multivariate normal distributionshave this distribution in the limit as the dimensionp→ ∞.Maximum likelihood based inference is described, and in par-ticular we discuss practical implementations. We also discussasymptotic distributions in the cases where dimension and sam-ple size are large. We make connections with existing resultsfor the high dimensional uniform, von Mises-Fisher and Watsondistributions. We also discuss the complex Bingham and com-plex Watson distributions, which have important applications inshape analysis. Finally we discuss applications in brain shapeand spinal shape modelling which motivated the work.
109 Excursion decompositions for SLEand Watts’ formula [Invited Session 13 (page 20)]
Julien DUBÉDAT , Université Paris-Sud, France
Schramm-Loewner Evolutions constitute a one-parameter fam-ily of planar growth processes, ie probability laws on increas-ing families of compact subsets of a given plane simply con-nected domain. These processes have built-in conformal invari-ance properties that make them natural candidates to describethe scaling limit of various critical plane models. Convergencein law to SLE has been established for several discrete models,including the Loop Erased Random Walk, the Uniform Span-ning Tree, and critical percolation.

94 6th BS/ IMSC
Qualitative features of these processes depend crucially on thevalue of the (positive)κ parameter. The SLE law is supportedon simple paths iffκ ≤ 4; for κ > 4, SLE is generated by a non-simple, non self-traversing curve (the trace), and forκ ≥ 8, thetrace is space-filling.We will be interested in two exceptional subsets of the SLEtrace: frontier points and cutpoints. Frontier points are an ex-ceptional subset whenκ > 4 (when the trace is non-simple), andcutpoints are known to exist if4 < κ < 8. These two subsetshave an intrinsic geometrical definition, so that it is quite naturalto study the decomposition of SLE with respect to these excep-tional sets.In the case of the Brownian excursion (a conformally invariantobject that is closely connected to SLE6), Virág has shown theexistence of a “bead decomposition” w.r.t cutpoints that can becast in terms similar to Itô’s formulation of excursion theory.We prove that such excursion-like decompositions can be ob-tained for appropriate conditional versions of SLE, with respectto frontier points if4 < κ and w.r.t cutpoints if4 < κ < 8. Forκ = 6, one can connect with Viràg’s results.Finally, we apply this construction to a percolation problem:Watts’ formula. Smirnov has proved that the scaling limit ofcritical percolation interfaces is SLE6; this result is based onthe proof of Cardy’s formula, that stipulates the probability thatthere exists a left-right crossing in a rectangle. Similarly, Watts’formula, that was derived from (non-rigorous) Conformal FieldTheory considerations, describes the probability that there existssimultaneously a left-right and a top-bottom crossing in a rect-angle. This event can be described in terms of the SLE trace,and its probability can be computed rigorously using some keyfeatures of the previous excursion-theory construction.References[1] Cardy, J. (1992) Critical percolation in finite geometries,J. Phys. A25(4), L201–L206.[2] Dubédat, J. (2004)Excursion Decompositions for SLE and Watts’formula, arXiv:math.PR/0405074[3] Rohde, S. and Schramm, O. (2001) Basic properties of SLE,Ann.Math.[4] Schramm, O. (2000) Scaling limits of loop-erased random walksand uniform spanning trees,Israel J. Math.118221–288.[5] Smirnov, S. (2001)Critical percolation in the plane, I, ConformalInvariance and Cardy’s formula II, Continuum scaling limit,[6] Virág, B. (2003)Brownian Beads, Probab. Theory Related Fields127(3), 367–387.[7] Watts, G.M.T. (1996) A crossing probability for critical percolationin two dimensions,J. Phys. A29(14), L363–L368.
110 MOPs – a Maple library for mul-tivariate orthogonal polynomials (symboli-cally) [Invited Session 20 (page 29)]
Ioana DUMITRIU ,
Many problems in statistics, physics, and engineering make useof random matrix theory, and require computations of eigen-value statistics (moments of the determinant, powers of the trace,extremal eigenvalue distributions) for theβ -Hermite, Laguerreand Jacobi ensembles (which include the GOE, GUE, GSE,Wishart real and complex, etc). Such computations often in-volve either evaluatingβ -dependent (and messy) integrals oversubsets ofRn.Using multivariate orthogonal polynomial theory, we have writ-ten and implemented in Maple a set of codes which provide aunified (valid for allβ ) way of dealing with many such compu-tations, for these three classical types of random matrix ensem-bles. These codes are fast (in a relative sense, as the complexity
of the problem is super-polynomial) and have the advantage ofworking both symbolically and numerically.We will present the ideas behind the codes and the computationsthey involve, and exemplify the performance of MOPs in a fewcases.This is joint work with Gene Shuman and Alan Edelman (MIT).
111 Advances in random matrix theory [In-vited Session 21 (page 33)]
Alan EDELMAN , Massachusetts Institute of Technology, USA
In addition to the steady mathematical advances in random ma-trix theory, our ability to compute distributions and apply theresults continues to grow. In this talk, we will survey some im-portant developments in this direction.Some examples include the polynomial method, new results onthe tails of condition numbers of random matrices, the abilityto numerically compute the distributions of the smallest andlargest eigenvalues, and very importantly the ability to numer-ically compute zonal and Jack polynomials, and hypergeometricfunctions of matrix argument.
112 Moderate deviations of the overlap pa-rameter in the Hopfield model [Contributed Ses-sion C35 (page 26)]
Peter EICHELSBACHER , Ruhr-University of Bochum, Ger-many
Matthias LÖWE,University of Münster, Germany
We derive moderate deviation principles for the overlap pa-rameter in the Hopfield model of spin glasses and neural net-works. If the inverse temperatureβ is different from the crit-ical inverse temperatureβc = 1 and the number of patternsM(N) satisfiesM(N)/N → 0, the overlap parameter multipliedby Nγ , 1/2 < γ < 1, obeys a moderate deviation principle withspeedN1−2γ and a quadratic rate function (i.e. the Gaussianlimit for γ = 1/2 remains visible on the moderate deviationscale). At the critical temperature we need to multiply theoverlap parameter byNγ , 1/4 < γ < 1. If then M(N) satis-fies(M(N)6 logN∧M(N)2N4γ logN)/N→ 0, the rescaled over-lap parameter obeys a moderate deviation principle with speedN1−4γ and a rate function that is basically a fourth power. Therandom term occurring in the Central Limit theorem for theoverlap atβc = 1 is no longer present on a moderate deviationscale. If the scaling is even closer toN1/4, e.g. if we multiply theoverlap parameter byN1/4 log logN the moderate deviation prin-ciple breaks down. The case of variable temperature convergingto one is also considered. IfβN converges toβc fast enough,i.e. faster thanO(N−2γ ), the non-Gaussian rate function per-sists, whereas forβN converging to one slower thanO(N−2γ ),the moderate deviations principle is given by the Gaussian rate.At the borderline the moderate deviation rate function is the oneat criticality plus an additional Gaussian term.References[1] Eichelsbacher, P. and Löwe, M. (2004) Moderate deviations for aclass of mean-field models, to appear in MPRF.[2] Eichelsbacher, P. and Löwe, M. (2004) Moderate deviations of theoverlap parameter in the Hopfield model, to appear in PTRF.
113 Resampling methods to estimate thedistribution and the variance of functions ofsample means based on nonstationary spatialdata [Contributed Session C45 (page 14)]
Magnus EKSTRÖM, Swedish University of Agricultural Sci-ences, Sweden

Abstracts 95
Sara SJÖSTEDT-DE LUNA,Umeå University, Sweden
Subsampling and block resampling methods have been sug-gested in the literature to nonparametrically estimate the distri-bution and the variance of statistics computed from spatial data.Usually stationary data are required. However, in empirical ap-plications (e.g., in forestry and agricultural experiments), the hy-pothesis of stationarity often must be rejected. In this talk theconsidered statistics are (functions of) sample means, and non-parametric resampling methods are proposed that consistentlyestimate the distribution and the variance of (functions of) sam-ple means based on nonstationary spatial data with smoothlyvarying expected values. For related results, see [1].We assume that we have spatially indexed dataXi : i ∈ A,whereA is a finite subset of the integer latticeZ2. Remote sens-ing data from satellites are, for example, of this form. Spatialdata of this type may be used for different purposes, with appli-cations to forestry, agriculture, environmental monitoring, land-scape ecology, etc. Due to the variation on the ground it is rea-sonable to believe that features measured at different locationsare differently distributed although nearby observations tend tobe more alike than observations far apart. Motivated by this,we consider differently distributed and locally dependent latticedata, with smoothly varying expected values. The setA may beirregularly shaped, and no distributional assumptions on the dataare required.Usually, the sample meanXA over A is observed only once,and therefore we would like to construct pseudoreplicates ofXA from the data available inA. Standard subsampling [2] usesthe sample mean computed on (overlapping) subshapes ofA as“replicates". However, standard subsampling cannot handle datahaving smoothly varying expected values [1]. Therefore, ratherthan using the subshape means as “replicates", we create groupsof 2× 2 adjacent subshapes, and in each group we compute a“crosswise difference" by adding the sample means from thesubshapes at the upper right and the lower left and subtractingthe sample means from the remaining two subshapes. By us-ing these crosswise differences we reduce the variation comingfrom the smoothly varying expected values, and by resampling(standardized) crosswise differences we obtain consistent esti-mators of the distribution and the variance ofXA. In order toobtain valid estimators of distribution and variance for smoothfunctions of sample mean vectors, a slight modification of theabove procedure is needed.Our work is partly motivated by the following example.Example: An underlying assumption of many environmental de-cisions is that some patterns or combinations of land cover areoptimal or more desirable than others. Management plans fre-quently seek to change the structure of a landscape to realizeparticular management goals, because it is recognized that thespatial arrangement of elements in a land cover mosaic controlthe ecological processes which operate within it [3]. Up-to-dateland cover information can be obtained by combining existingfield inventory information with satellite data. Tools are neededto understand and describe the spatial structures of landscapes,and one idea is to use a set of indices that captures importantaspects of landscape structure in a few numbers. Since the late1980s many landscape indices have been proposed [3]. Some ofthem, like Shannon’s and Simpson’s diversity indices, and thecontagion index, are functions of sample mean vectors of landcover information. Therefore, by using our methods, valid sta-tistical inference can be made about these indices. For example,our methods make it possible to test whether certain aspects of
the landscape structure has changed or not.References[1] Ekström, M. and Sjöstedt - de Luna, S. (2003) Subsampling meth-ods to estimate the variance of sample means based on nonstationaryspatial data with varying expected values. To appear in theJournal ofthe American Statistical Association.[2] Politis, D.N., Romano, J.P., and Wolf, M. (1999)Subsampling.Springer, New York.[3] Haines-Young, R. and Chopping, M. (1996) Quantifying landscapestructure: a review of landscape indices and their application to forestedlandscapes.Progress in Physical Geography20, 418–445.
114 Archimedean Ice [Contributed Session C23(page 16)]
Kari ELORANTA , University of Technology, Helsinki, Finland
The striking boundary dependency (the Arctic Circle phe-nomenon) exhibited in the Statistical Mechanics Ice model onthe square lattice extends to some other planar set-ups. We firstpresent this result for the triangular and the Kagomé latticesunder appropriate boundary conditions on a hexagon. Certaingraph connectivity/irreducibility results as well as height func-tions feature critically in the analysis. Secondly we show that forthe remaining one of the four Archemedean lattices, for whichthe Ice model can be defined, the 3.4.6.4. lattice, the long rangebehavior is completely different. This is characterized by resultson the uniformity of the equilibrium distribution.
References
[1] Eloranta, K. (1999) Diamond Ice,J. Stat. Phys.96, 5/6, 1091–1109.
115 Stochastic methods for quantitativerisk management [Invited Session 9 (page 23)]
Paul EMBRECHTS, ETH-ZÜRICH, Switzerland
I will discuss how recent applied work in the realm of RiskManagement for Insurance (Solvency 2) and Finance (BaselII) leads to interesting research problems in stochastics. Ex-amples from practice include such topics as risk aggregation([1]) and risk allocation ([2]), stress testing of credit portfo-lios ([3]) and the quantitative modelling of operational risk([4]). From a mathematical point of view, methodology usedrelates to Fréchet problems, dependence modelling beyondcorrelation (copulae)([5],[6]) and ruin estimation for generalrisk processes ([7]). More information is to be found underwww.math.ethz.ch/finance.References[1] Embrechts, P., Hoeing, A., and Juri, A. (2003) Using Copulae tobound the Value-at-Risk for functions of dependent risks,Finance &Stochastics7(2), 145–167.[2] Denault, M. (2001) Coherent Allocation of Risk Capital,Journal ofRisk4(1), 1–34.[3] Frey, R. and McNeil, A.J. (2003) Dependent Defaults in Models ofPortfolio Credit Risk, To appear in theJournal of Risk.[4] Embrechts, P., Kaufmann, R., and Samorodnit-sky, G. (2002) Ruin theory revisited: stochastic modelsfor operational risk, Preprint ETH-Zürich, Available fromhttp://www.math.ethz.ch/baltes/ftp/papers.html.[5] Breymann, W., Dias, A., and Embrechts, P. (2003) Dependencestructures for multivariate high-frequency data in finance,QuantitativeFinance3(1) 1–16.[6] Dias, A. and Embrechts, P. (2003) Dynamic copula models for mul-tivariate high-frequency data in finance, Available fromhttp://www.math.ethz.ch/baltes/ftp/papers.html.[7] Embrechts, P. and Samorodnitsky, G. (2003) Ruin problem and howfast stochastic processes mix,The Annals of Applied Probability13, 1–36.

96 6th BS/ IMSC
116 On weak solutions of backwardstochastic differential equations [ContributedSession C4 (page 53)]
Rainer BUCKDAHN, Université de Bretagne Occidentale,Brest, France
Hans-Jürgen ENGELBERT, Friedrich Schiller-Universität,Jena, Germany
Aurel RASCANU, Universitatea Alexandru Ioan Cuza, Iasi,Romania
The main objective of this paper consists in discussing the con-cept of weak solutions of a certain type of backward stochasticdifferential equations. Using weak convergence in the Meyer–Zheng topology, we shall give a general existence result. Theterminal conditionH depends in functional form on a drivingcàdlàg processX, and the coefficientf depends on timet andin functional form onX and the solution processY. The func-tional f (t,x,y),(t,x,y) ∈ [0,T]×D
([0,T];Rd+m
), is assumed
to be bounded and continuous in(x,y) on the Skorohod spaceD
([0,T];Rd+m
)in the Meyer–Zheng topology. By several ex-
amples of Tsirelson type, we will show that there are, indeed,weak solutions which are not strong, i.e., are not solutionsin the usual sense. We will also discuss pathwise uniquenessand uniqueness in law of the solution and conclude, similar tothe Yamada–Watanabe theorem, that pathwise uniqueness andweak existence ensure the existence of a (uniquely determined)strong solution. Applying these concepts, we are able to statethe existence of a (unique) strong solution if, additionally to theassumptions described above,f satisfies a certain generalizedLipschitz type condition.
117 Law of Large Numbers versus local ex-tinction for superdiffusions [Contributed SessionC37 (page 24)]
János ENGLÄNDER, University of California, USA
Andreas E. KYPRIANOU,Utrecht University, The Netherlands
Anita WINTER,University of Erlangen, Germany
Let D ⊆ Rd, let X be an(L,β ,α;D)-superdiffusion, and let0 6≡ f ∈C+
c . If 〈Xt , f 〉 is normalized by its mean, then one canwonder if the ratio tends (in probability) to some non-degeneratelimit as t → ∞. If so, the LLN holds. Pinsky observed that if thegeneralized principal eigenvalue of the expectation operator isnegative or zero, then the superprocess exhibits local extinction,thus ruling out LLN. If however, the generalized principal eigen-value is positive and equalsl > 0, then, as the first two authorsproved, there is local exponential growth with ratel . The talkwill address this topic and further conditions obtained by the lasttwo authors that guarantee that beyond exponential growth theprocess actually obeys the LLN. This last result improves signif-icantly a recent result of the speaker with Turaev that involveddynamical system arguments and only proved convergence inlaw.The main tools are now probabilistically conceptual and in-volve a version of the ‘spine’ decomposition as well asweighted superdiffusions with time-inhomogeneous weights(H-transformed superdiffusion).
118 Influence measures on profile analysiswith elliptical data through Frèchets’s metric
[Poster Session P3 (page 41)]
A. ENGUIX-GONZÁLEZ, J.L. MORENO-REBOLLO, J.M.MUÑOZ-PICHARDO and A. PASCUAL-ACOSTA,Universi-dad de Sevilla, Spain
The profile analysis (PA) is a statistic technique often used inareas such as Medicine, Psychology, Biology, etc. Generally, itis applied assuming that the data are distributed according to anormal distribution, but it is interesting its generalization to el-liptical distributions because it allows to widen its applicationrange in order to raise experiences where the resultant data areadjusted to a symmetric distribution, no necessarily a multivari-ate normal distribution. It frequently happens in biomedical, en-vironmental and biological studies.In any statistical technique, it is of great interest to analyze theinfluence of the observations, since they can highly affect the in-ferential process. However, the papers specifically dedicated tothe study of influence in PA are limited.In this paper, we propose some influence diagnostics in PA withelliptical data, by modelling the PA as a particular case of Mul-tivariate General Linear Model and constructing influence mea-sures from Frèchet’s metric. We focus on the influence on theBLUEs of the three most interesting parametric linear functionsin PA, those that model the profiles, the parallelism of the pro-files and the mean profile.The application of Frèchet’s metric in the influence analysis canbe considered as a particular case of the general approach sug-gested by Jiménez-Gameroet al. (2002), that propose to con-struct influence measures from the distances between the distri-butions of the statistic of interest under the postulated model andthe perturbed one. This approach has been satisfyingly used byMuñoz-Pichardoet al. (2003).As influence diagnostic of thei-th observation on each BLUEof the considered parametric functions, we propose Frèchet’s
distance, (δi(θ)), betweenF(·, θ
)and F(i)
(·, θ(i)
), where
F(·, θ
)andF(i)
(·, θ(i)
)represent the cumulative distribution
functions ofθ andθ(i), respectively, the BLUEs obtained fromthe complete sample and under the deletion of thei-th obser-vation. As a consequence of the expression of Frèchet’s dis-tance in the case of elliptical distributions, two components areidentified in the obtained diagnostics, one location component(LCi(θ)) and one dispersion component (DCi(θ)), such thatδ 2
i (θ) = LC2i (θ)+DC2
i (θ). This decomposition allows to iden-tify wether the influence affect on the location of the distributionor on the covariances structure of it. We present two examplesto illustrate the proposed diagnostics.References[1] Jiménez-Gamero, M.D., Muñoz-Pichardo, J.M., Muñoz-García, J.,and Pascual-Acosta, A. (2002) Rao distance as a measure on influencein multivariate linear model,Journal of Applied Statistics29(6), 841-854.[2] Muñoz-Pichardo, J.M., Enguix-González, A., Muñoz-García, J., andPascual-Acosta, A. (2003) The Frèchet’s metric as a measure of influ-ence in multivariate linear models with random errors elliptically dis-tributed,Computational Statistics ans Data Analysis, (In press).
119 Condition Bias of eigenvalues as aninfluence measure un principal componentsanalysis [Poster Session P3 (page 41)]
N. ATIENZA-MARTÍNEZ, I. BARRANCO-CHAMORRO, A.ENGUIX-GONÁLEZ and J.M. MUÑOZ-PICHARDO,Uni-versidad de Sevilla, Spain
In every statistical analysis, in order to guarantee the reliabilityof the conclusions, it is advisable to carry out a previous studyabout the repercussion that the data could exert on the obtainedresults. In general, it is the aim of the Influence Analysis.One of the fields where those methods have been applied is

Abstracts 97
the Principal Components Analysis (PCA), where the sensibil-ity due to the presence of certain extreme observations has beenshown in different papers. The most of these works have beendone from the individual point of view by using technics basedon influence functions. However, an alternative approach wasproposed by Muñoz-Pichardoet al. [5] through the concept ofconditional bias.The parameters of interest traditionally analyzed in PCA havebeen the simple eigenvalues and the associated eigenvectors ofthe matrix that the calculation of the principal components restson. In this paper, we study the influence exerted on a simpleeigenvalues of the sample covariance matrix through the condi-tional bias and we give several joint influence diagnostics basedon it. With this aim, several points have been to be considered:
1. The conditional bias is based on the expectation of thestatistic of interest, so it is necessary to suppose a previ-ous distributional hypothesis. This paper is based on themultivariate normal distribution, a very frequent conditionin real life. The eigenvalues will be simple and non-null,as in the most of the papers based on influence functions.
2. An approximation of the conditional bias of the simplenon-null eigenvalues is necessary to be calculated. So weuse a series expansion of the corresponding estimator as afunction of populational parameters and the componentsof the sample covariances matrix (Lawley [4]).
3. Since conditional bias is a populational characteristic, es-timators of it must be used to assess the influence exerted.The proposed estimator is based on the direct comparisonof the eigenvalues calculated with the full sample and un-der the deletion of observations. It is well-known the prob-lem related to this comparison (see Critchley [1], Enguix-González [2], Enguix-González et al. [3]), so it is of con-venience to resort to approximations.
References[1] Critchley, F. (1985) Influence in Principal Component Analysis,Biometrika72, 627–636.[2] Enguix-González, A. (2001) PhD Thesis, Universidad de Sevilla.[3] Enguix-González, A., Muñoz-Pichardo, J.M., Moreno Rebollo,J.L., and Pino-Mejías, R. Influence Analysis in Principal Componentsthrough power series expansions, To be published.[4] Lawley, D.N. (1956) Test of Significance for the Latent Roots ofCovariance and Correlation Matrices,Biometrika43, 128–36.[5] Muñoz-Pichardo, J.M., Muñoz-García, J., Moreno Rebollo, J.L., andPino-Mejías, R. (1995) A New Approach to Influence Analysis in Lin-ear Models,Sankhya : The Indian Journal of Statistics Series A57,393–409.
120 Local influence in survey sampling[Poster Session P3 (page 42)]
I. BARRANCO-CHAMORRO, A. ENGUIX-GONZALEZ ,J.L. MORENO-REBOLLO and M.M. MUÑOZ-CONDE,Uni-versidad de Sevilla, Spain
In any statistical study it is important to assess the effect of mi-nor perturbations, in model assumptions or data, on key resultsof the analysis such as parameter estimates.Cook (1986) introduced the notion of local influence as a wayof describing the effect of a small perturbation and proposedvarious influence diagnostics based on the curvature of the in-fluence graph(ω,LD(ω))t , with LD(ω) the likelihood displace-ment. Cook applied the method to linear regression analysis,but the method is general and can be applied to a wide variety ofproblems. Other authors have used different measures replacingthe likelihood by a parameter estimate. In the literature can be
found papers studying the local influence on discriminant anal-ysis, factor analysis, canonical correlation analysis, the generallinear model, non-linear regression, structural equations models,partial least squared regression, incomplete data models,... Thisfact highlights the interest of the local influence.Smith (1987) emphasized that in survey sampling it is as im-portant to detect and treat influential observations if the infer-ence is based on the randomisation provided by the sample de-sign (design-based inference) as if the observations are consid-ered realisations of random variables (model-based inference).However, the influence analysis is a topic scarcely treated in thisframework. Until our knowledge, there is no paper focused onlocal influence in survey sampling.The aim of this paper is to assess the local influence on twoestimators of the population totalT(y): the ratio estimator andthe Horvitz-Thompson (HT) estimator, under a model-based andunder a design-based approach to inference, respectively. Wecarry out a similar study for these estimators since both can beexpressed byβ T(x), with T(x) the population total of the aux-
iliary variable(x) andβ = argminβ∫ (y−β x)2
x dF, for an appro-priate sampling distribution functionF .We consider different schemes of perturbation: in model as-sumptions for the ratio estimator and in the response(y) andauxiliary (x) variables for ratio and HT estimators.Following Loynes (2001), we obtain the curvature in the di-rection of each case: if all these are of similar size, the corre-sponding perturbation cannot be relatively influential. The re-sults obtained allow us to characterize influential observationsand to make comparisons in two ways: to compare different per-turbation schemes for an estimator and compare a perturbationscheme on both estimators.References[1] Cook, R.D. (1986) Assessment of Local Influence,Journal of the
Royal Statistical Society Serie B48, n.2, 133–169.[2] Loynes, R.M. (2001) A new measure in local influence,Journal ofStatistical Planning and Inference92, 47–53.[3] Smith, T.M.F. (1987) Influential observations in survey sampling,Journal of Applied Statistics14, 143–152.
121 Properties of European and Americanbarrier options [Poster Session P2 (page 32)]
Jonatan ERIKSSON, Uppsala University, Sweden
We investigate monotonicity in volatility and convexity in theinitial stock price for barrier option prices when the underlyingprocess follows a one-dimensional Itô-diffusion with time- andlevel dependent volatility. For European contingent claims it isshown in Hobson [1] and more recently in Janson & Tysk [2]that convexity of the pay-off function is a sufficient conditionfor monotonicity in volatility and convexity of the option pricein initial stock price to hold. It is clear that this is in general nolonger true when it comes to barrier options. We show that whenthe interest rater = 0, a sufficient condition for the above mono-tonicity and convexity to hold is that the pay-off is convex andzero at the barrier. Whenr > 0 it is shown that the monotonicityand convexity need no longer hold within this class of pay-offfunctions. In this case additional conditions are needed and weshow that sufficent conditions for monotonictiy and convexity tohold are:
1. that the pay-off is convex,
2. that the barrier hasconstant value, i.e. has a time-dependence of the formbe−r(T−t) whereb > 0 is a realconstant andT− t is the time to maturity,

98 6th BS/ IMSC
3. and that the pay-off is zero atb.
These results are then generalized to barrier options of Ameri-can type by arguing with Bermudan options and dynamical pro-gramming. The method used in [2] to obtain monotonicity inthe volatility is to write the stock price as a time changed Brow-nian motion. In this setting the stochastic process is naturallyabsorbed at zero and so is the corresponding Brownian motion.We show that by a simple shifting argument the same methodscan be applied to barrier options when the process is absorbed atsome point different from zero.References[1] Hobson, D.G. (1998) Volatility Misspecification, Option pricing andSuper-replication via Coupling,The Annals of Applied Probability8,No.1, 193–205.[2] Janson, S. Tysk, J. (2003) Volatility Time and Properties of OptionPrices,The Annals of Applied Probability13, No.3, 890–913.[3] Ekström, E.Properties of American Option Prices,to appear inStochastic Process. Appl.
122 Model checks using residual markedempirical processes [Contributed Session C53 (page28)]
J. Carlos ESCANCIANO, Universidad Carlos III de Madrid,Spain
This paper proposes omnibus and directional tests for testing thegoodness-of-fit of the conditional mean of linear and nonlineartime series models. The purposes of the paper are twofold; onthe one hand, we present a general theory for a large class ofResidual Marked Empirical Processes (RMEP) based tests in-cluding those of Bierens (1984) and Koul and Stute (1999) asparticular cases. On the other hand, we propose new test statis-tics within this general class which are based on a RMEP usingprojections.There is a huge literature on testing the correct specification ofa time series model, see Chen, Härdle and Li (2003) for a re-cent reference. The tests proposed can be divided in two classesof tests. First, because the correct specification of the condi-tional mean is equivalent to the fact that the errors are condi-tional mean independent (CMI) of the conditioning set, one canuse nonparametric smoothing estimations of the regression func-tion of the errors and checks for a unique orthogonality condi-tion, see e.g. Li (1999). We call this approach the “local ap-proach”, because of the use of local measures of dependence.The second class reduces the CMI to an infinite number of un-conditional orthogonality conditions over a parametric family offunctionsw(It−1,x), whereIt−1 is the conditioning set andx isan auxiliary parameter. In the specification literature, most fre-quently used weighted functions have been the exponential func-tions, e.g.w(It−1,x) = exp(ix′It−1) in Bierens (1984), and theindicators functionsw(It−1,x) = 1(It−1 ≤ x), see, for instance,Koul and Stute (1999). Different functionsw deliver differentpower properties of the test statistics and usually demand differ-ent technical approaches, due essentially to the continuity withrespect tox. We call this second approach the “integrated ap-proach”, because it uses cumulative measures of dependence.In the general theory part of this paper, our aim is to study insome detail the integrated approach in a unified way. To thisend, we establish a new weak convergence theorem under mildassumptions, to the best of our knowledge the mildest in the lit-erature, which allows us to study in a unified way the asymptoticdistribution of the integrated based test statistics under the null,fixed and local alternatives. We study in detail the asymptoticlocal power of the Cramér-von Mises (CvM) tests. In particu-
lar, we find the directions of maximum asymptotic local power,we define the asymptotic relative efficiencies of using differentweighting familiesw and the most local powerful test for a fixeddirection and we show the asymptotic admissibility of the CvMtests. It turns out that the asymptotic null distributions dependon the data generating process, so a new bootstrap procedure isconsidered and theoretically justified.As the second main purpose of the paper, we proposed new teststatistics within the integrated approach based class, which arefunctionals of a RMEP based on projections, so by construc-tion they overcome the problem of the curse of dimensionality,which affects most tests when the dimension ofIt−1 is large oreven moderate, and at the same time, avoids the choice of a nui-sance auxiliary parameter space. We apply some of our generaltheory to several test statistics based on particular projectionswith nuisance parameter-free asymptotic null distributions andsome considerations about the choice of the projection directionare discussed. Finally, a Monte Carlo study shows that the boot-strap and the asymptotic results provide good approximationsfor small sample sizes and an empirical application to the Cana-dian lynx data set is considered.
References[1] Bierens, H.J. (1984) Model specification testing of time series re-gressions,J. Econometrics26,323–353.[3] Chen, S.X., Härdle, W., and Li, M. (2003) An empirical likeli-hood goodness-of-fit test for time series,J. R. Stat. Soc. Ser. B Stat.Methodol.65, 663–678.
[4] Koul, H.L. and Stute, W. (1999) Nonparametric model checks fortime series,Ann. Statist.27, 204–236.
[5] Li, Q. (1999) Consistent model specification test for time serieseconometric models,J. Econometrics92, 101–147.
123 Linear estimators of a continuous sig-nal correlated with the observation noise
[Poster Session P3 (page 42)]
Maria D. ESTUDILLO MARTÍNEZ , Rosa M.FERNÁNDEZ-ALCALÁ, Jesús NAVARRO-MORENO, andJuan C. RUIZ-MOLINA,University of Jaén, Spain
This paper is concerned with the problem of estimating a sig-nal vector in additive white gaussian noise correlated with thesignal. This estimation problem is useful in applications tofeedback control and feedback communications.From the knowledge of the correlation functions involved, animbedding method is applied in order to derived efficient algo-rithms for the recursive computation of the linear least-squaresestimators corresponding to all types of estimation problems (fil-ter; fixed-point, fixed-interval, and fixed-lead prediction; fixed-point, fixed-interval, and fixed-lag smoothing) and their associ-ated error covariances.The proposed solutions can be computed without the assump-tion that the signal verified a state-space model and it is valid forstationary as well as non-stationary processes.References[1] Fernández-Alcalá, R.M., Navarro-Moreno, J., and Ruiz-Molina, J.C.(2002)A Solution to the Linear Estimation problem with Correlated Sig-nal and Noise, Signal Processing. On second revision.[2] Fernández-Alcalá, R.M., Navarro-Moreno, J., and Ruiz-Molina, J.C.(2004)Linear Least-Square Estimation Algorithms Involving CorrelatedSignal and Noise, IEEE Transactions on Signal Processing. Submittedfor publication.[3] Ruiz-Molina, J.C., Navarro-Moreno, J., and Estudillo, M.D. (2004)On the problem of Estimating a Signal Correlated with the observationnoise, IEEE Signal Processing Letters. To be published in March.[4] Sugisaka, M. (1983) The Design of On-line Linear Least-Squares

Abstracts 99
Estimations Given Covariance Specifications via an Imbedding Method,Applied Mathematics and Computation13:, 55-85.
124 Some mathematical problems frompopulation genetics [Medaillon Lecture (page 32)]
Alison ETHERIDGE , University of Oxford, UK
Kingman’s coalescent provides an elegant description of thegenealogy of a neutral panmictic population of constant size.There is now a huge literature that modifies and extends the co-alescent to encapsulate more realistic biological situations in-cluding variable population size, selection, recombination andstructure (spatial or genetic).The standard approach to structure, the so-called structured coa-lescent, assumes that the population is subdivided into demes ofconstant size. In the context of a very simple problem, that of aneutral locus embedded in a fluctuating genetic background byvirtue of being linked to a selected site, [1] examines the accu-racy of this approximation in the case of balancing selection andreveals that fluctuations can considerably suppress the effects ofthe selection. This also then calls into question the accuracy ofthe standard structured coalescent for populations with spatialstructure where, as discussed for example in [2], even the fluc-tuations in local population size are hard to model.We discuss these and related mathematical problems arising inpopulation genetics. In particular, if time permits, we will de-scribe work in pogress, the ultimate aim of which is to developnew tests for the detection of genetic loci subject to natural se-lection.References[1] Barton, N.H., Sturm, A.K., and Etheridge, A.M. (2004)Coalescencein a random background,Ann Appl Probab (to appear),[2] Etheridge, A.M. (2004) Survival and extinction in a locally regulatedpopulation,Ann. Appl. Probab.14, no. 1.
125 Dynamic integration of time- andstate-domian methods for volatility estima-tion [Invited Session 8 (page 13)]
Jianqing FAN and Jiancheng JIANG,Princeton University,USA
Time- and state-domain methods are two commonly approachesfor prediction. The former predominantly uses the data in therecent history while the latter mainly rely on historical informa-tion. The question of combining these two pieces of valuableinformation is an interesting challenge in statistics. We first ap-proach the problem by proposing two Bayesian methods. Mo-tivated by a study of the Bayesian estimation of volatility, wepropose to estimate the volatility via dynamically integrating in-formation from both the time and the state domains. The es-timators from both domains are optimally combined based ona data driven weighting strategy, which provides several moreefficient estimators of volatility. The proposed dynamic integra-tion approach is also applicable to other estimation problems intime series. Extensive simulations are conducted to demonstratethat the newly proposed procedure outperforms some popularones such as the RiskMetrics and the historical simulation ap-proaches, among others. Empirical studies endorse convincinglyour integration method.
126 Estimation of contact parameters fornonstationary infections [Invited Session 34 (page44)]
Paddy FARRINGTON and Heather WHITAKER,Open Uni-versity, UK
Standard methods for estimating contact rates and epidemiolog-ical parameters such as the basic reproduction number and crit-ical vaccine coverage for infectious diseases from data on pop-ulation immunity require strong assumptions. One assumptionis that the infection is stationary. Others govern the form of thecontact structure, which is usually unidentifiable.In this talk the stationarity assumption is relaxed, to allow forslowly varying contact rates. The equilibrium equation that ap-plies under stationarity is replaced by an approximate local equi-librium equation. Estimation of the contact structure involvessolving this integral equation. A benefit of time-varying contactrates is that the contact structure becomes identifiable, given lon-gitudinal data on age-specific infection rates.The methods are applied to data on Varicella-Zoster infection inthe UK. It is found that non-stationarity of contact rates amongyoung children has little impact on the basic reproduction num-ber.
127 Extremal behaviour of subexponentialcontinuous-time MA processes[Poster Session P2(page 32)]
Vicky FASEN, Munich University of Technology, Germany
We consider a stationary continuous-time moving average (MA)process
Y(t) =∫ t
−∞f (t−s)dL(s) for t ≥ 0,
where f is a deterministic kernel function andL is a Lévy pro-cess whose increments, represented byL(1), are subexponen-tial and in the domain of attraction of the Gumbel distribution.Examples are Weibull-like distributions withα ∈ (0,1). Theextremal behaviour of subexponential MA processes in the do-main of attraction of the Fréchet distribution are well studied byRootzén (1978) and Rosinski and Samorodnitsky (1993).Extremes ofY(t)t≥0 are caused by big jumps of the drivingLévy process in combination with large values of the kernelfunction f . This means that discrete time pointstnn∈N cho-sen properly to incorporate the times where big jumps of theLévy process and the extremes of the kernel function occur char-acterise the extremal behaviour of the continuous time process.We restrict ourselves to kernel functions with a finite numberof local extremes. Examples forY include a Weibull-Ornstein-Uhlenbeck process, certain shot noise processes and CARMAprocesses (Brockwell (2001)).The extremal behaviour of the discrete-time processY(tn)n∈Nis described by the weak limit of a sequence of marked pointprocesses, i.e.
– by the point processes of exceedances over high thresh-olds, and
– by marks, which are stochastic processes themselves, andcharacterize the behaviour ofY(t)t≥0, if Y(tn) exceedsa high threshold.
The limiting distribution of such a sequence of marked pointprocesses is a Poisson process with deterministic marks repre-sented by a scaled version of the kernel function. Further wecan compute the normalising constants of the maxima to con-verge weakly to the Gumbel distribution. The results are similarto the extremal behaviour of discrete MA processes (Davis andResnick (1988), Rootzén (1986)).References[1] Brockwell, P.J. (2001) Lévy-driven CARMA processes,Ann. Inst.Statist. Math.53(1): 113–123.

100 6th BS/ IMSC
[2] Davis, R. and Resnick, S. (1988) Extremes of moving averages ofrandom variables from the domain of attraction of the double exponen-tial distribution,Stochastic Process. Appl.3041–68.[3] Rootzén, H. (1978) Extremes of moving averages of stable processes,Ann. Probab.6 847–869.[4] Rootzén, H. (1986) Extreme value theory for moving average pro-cesses,Ann. Probab.14, 612–652.[5] Rosinski, J. and Samorodnitsky, G. (1993) Distributions of subad-ditive functionals of sample paths of infinitely divisible processes,Ann.Probab.21996–1014.
128 Testing the Markov property withultra-high frequency financial data [ContributedSession M6 (page 28)]
João AMARO DE MATOS,Universidade Nova de Lisboa, Por-tugal
Marcelo FERNANDES, Getulio Vargas Foundation, Brazil
This paper develops a framework to nonparametrically testwhether discrete-valued irregularly-spaced financial transac-tions data follow a Markov process. For that purpose, webuild on the theory of Markov processes with stochastic timechanges. In particular, we consider a specific optional samplingin which the underlying continuous-time Markov process is ob-served only when it crosses some discrete level. This frameworkis convenient for it accommodates not only the irregular spac-ing of transactions data, but also price discreteness. Under suchan observation rule, the current price duration is independent ofprevious price durations given the current price realization. Asimple nonparametric test then follows by examining whetherthis conditional independence property holds.We derive the limiting distribution of the test statistic usingFan and Ullah’s (1997) central limit theorem for degenerate U-statistics. However, as the asymptotic behavior of kernel-basedtests is sometimes of little value in finite samples (see Fan andLinton, 1993), we also consider bootstrap-based tests by relyingon Markov resampling schemes (Horowitz, 2003). As suggestedby Bickel, Götze and van Zwet (1997), we resample onlym outof n observations so as to cope with the fact that the U-statisticimplied by the test statistic is degenerate.A relevant application of our testing procedure is to checkwhether bid-ask spreads follow Markov processes. Asymmet-ric information models of market microstructure predict that thebid-ask spread depends on the whole trading history, and hencethe Markov property does not hold (e.g., Easley and O’Hara,1992). Our nonparametric approach to test the Markov propertyis consistent with Hasbrouck’s (1991) goal to uncover the extentof adverse selection costs in a framework that is robust to de-viations from the assumptions of the formal models of marketmicrostructure. Bearing that in mind, we examine transactionsdata from five stocks actively traded on the New York Stock Ex-change: Boeing, Coca-Cola, Disney, Exxon, and IBM.The results reveal that the Markov assumption is consistent withthe Disney and Exxon bid-ask spreads, whereas the converseis true for Boeing, Coca-Cola and IBM. This indicates that thelatter stocks presumably have higher rates of return for, in equi-librium, uninformed traders require compensation to hold stockswith greater private information (Easley, Hvidkjaer and O’Hara,2002). The usual objection that the actions of arbitrageurs re-move any chance of higher returns does not apply because ad-verse selection risk is systematic. An uninformed investor in-deed is always at a disadvantage relative to traders with better in-formation. Our results thus imply that the standard asset-pricingframework is not suitable to examine the Boeing, Coca-Cola and
IBM returns, though it may work for Disney and Exxon.References[1] Bickel, P.J., Götze, F., and van Zwet, W.R. (1997) Resampling fewerthan n observations: Gains, losses, and remedies for losses,Statist.Sinica 7, 1–31.[2] Easley, D., Hvidkjaer, S., and O’Hara, M. (2002) Is information riska determinant of asset returns?,J. Finance57, 2185–2221.[3] Easley, D. and O’Hara, M. (1992) Time and the process of securityprice adjustment,J. Finance47, 577–605.[4] Fan, Y. and Linton, O. (2003) Some higher-order theory for a consis-tent non-parametric model specification test,J. Statisti. Plann. Inference109, 125–154.[5] Fan, Y. and Ullah, A. (1999) On goodness-of-fit tests for weakly de-pendent processes using kernel method,J. Nonparametric Statistics11,337–360.[6] Hasbrouck, J. (1991) Measuring the information content of stocktrades,J. Finance46, 179–207.[7] Horowitz, J.L. (2003) Bootstrap methods for Markov processes,Econometrica71, 1049–1082.
129 Estimation of intrinsic processes af-fected by additive factial noise [Contributed Ses-sion C19 (page 30)]
José M. ANGULO,University of Granada
Rosaura FERNÁNDEZ-PASCUAL, University of Jaén, Spain
María D. RUIZ-MEDINA, University of Granada
Fractal Gaussian models have been widely used to represent thesingular behaviour of phenomena arising in different appliedfields; for example, fractional Brownian motion and fractionalGaussian noise are considered as monofractal models in subsur-face hydrology and geophysical studies (Mandlebrot, 1982). Inthis paper, we address the problem of least-squares linear esti-mation of an intrinsic fractal input random field from the obser-vation of an output random field affected by fractal noise (seeAngulo, Ruiz-Medina and Anh, 2000, and Ruiz-Medina, An-gulo and Anh, 2003a, 2003b). Conditions on the fratality orderof the additive noise are studied to obtain a bounded inversion ofthe associated Wiener-Hopf equation. A stable solution is thenobtained in terms of orthogonal bases of the reproducing ker-nel Hilbert spaces associated with the random fields involved.Such bases are constructed from orthonormal wavelet bases (seeAngulo and Ruiz-Medina, 1999, and Fernández-Pascual, Ruiz-Medina and Angulo, 2004). A simulation study is carried outto illustrate the influence of the difference between the fractalityorders of the intrinsic input random field and the fractal additivenoise on the stability of the solution derived.References[1] Angulo, J.M. and Ruiz-Medina, M.D. (1999) Multiresolution ap-proximation to the stochastic inverse problem,Adv. Appl. Prob. 31,1039–1057.[2] Angulo, J.M., Ruiz-Medina, M.D., and Anh, V.V. (2000) Estimationand filtering of fractional generalised random fields,J. Austral. Math.Soc. A 69, 1–26.[3] Fernández-Pascual, R., Ruiz-Medina, M.D., and Angulo, J.M.(2004) Wavelet-based functional reconstruction and extrapolation offractional random fields, Test (in press).[4] Mandelbrot, B.B. (1982)The Fractal Geometry of Nature, W.H.Freeman, New York.[5] Ruiz-Medina, M.D., Angulo, J.M., and Anh, V.V. (2003a)Fractional-order regularization and wavelet approximation to the inverseestimation problem for random fields, J. Multiv. Anal. 85, 192–216.[6] Ruiz-Medina, M.D., Angulo, J.M., and Anh, V.V. (2003b)Fractionalgeneralised random fields on bounded domains Stoch. Anal. Appl.21,465–492.
130 A new approach to detect strictly alge-braic distributions [Poster Session P3 (page 41)]

Abstracts 101
José María FERNÁNDEZ-PONCE, Teresa GÓMEZ-GÓMEZ, José Luis PINO-MEJÍAS and Rosario RODRIGUEZ-GRIÑOLO,Universidad de Sevilla, Spain
One interesting problem studied in Environmental Statistics is toestimate the tail index of a distribution function using the plot ofthe corresponding relative mean excess function (see Chaoucheet al., 2002). But this approach has one disadvantage when thedata proceed from an exponential distribution. That is, whenthe threshold tends to infinity, it can not be appreciated graph-ically if the limit of the relative excess mean function is zero.Furthermore, the threshold must not be too high because of thedivergence of the bias. Also, we need a high sample size to sta-ble the tail index estimator for a strictly algebraic distribution.These problems can be solved using the right spread function(see Fernández-Ponceet al., 1998). This function possesses abounded domain and characterizes graphically the exponentialdistribution versus any continuous distribution function.Our data analysis is twofold:
1. Testing exponentiality which is characterized by the ex-cess wealth function.
2. Inference: estimate the algebraic tail indexq in the alge-braic case.
References[1] Bahadur, R.R. (1966) A note on quantiles in large samples,Ann.Math. Stat.37, 577–580.[2] Basu, D. (1975) Statistical Information and likehood,Sankhya, A37, 1–71.[3] Borokov, A.A. (1988)Estadística Matemática,Mir Moscú.[4] Chaouche, K; Hubert, P., and Lang, G. (2002) Graphical character-isation of probability distribution tails,Stochastic Environmental Re-search and Risk Assessment16, 342–357.[5] Fernández-Ponce, J.M., Kochar, S.C., and Muñoz-Perez, J. (1998)Partial orderings of distributions based on right spread function,J. Appl.Prob.35, 221–228.[6] Karr, A.F. (1993)Probability, Springer-Verlag, New York, Inc.[7] Shaked, M. and Shanthikuman, J.G. (1998) Two variability orders,Prob. Eng. Infor. Sci.12, 1–23.
131 Random evolution of surfaces [InvitedSession 18 (page 23)]
Pablo A. FERRARI and Leandro P. R. PIMENTEL,Universi-dade de São Paulo, Brazil
The one-dimensional nearest neighbor totally asymmetric sim-ple exclusion process can be constructed in the same space asa last-passage percolation problem in the positive integer quad-rant. We show that the trajectory of a second class particle in theexclusion process can be mapped to the interface of a compet-ing spatial growth process in the percolation model. As a conse-quence we get a strong law of large numbers for the second classparticle in the rarefaction fan for the exclusion process and de-scribe the distribution of the asymptotic angle of the competingspatial growth interface.The convergence in law of the second class particle to a uni-form random variable was proven by Ferrari and Kipnis (1995).Recently Guiol and Mountford (2004) proved the almost sureconvergence using Seppalainen variational representation. Ourapproach uses Licea and Newman (1996) study of geodesics.References[1] Ferrari, P.A. and Kipnis, C. (1995) Second class particles in the rar-efaction fan,Ann. Inst. H. Poincaré Probab. Statist.31, no. 1, 143–154.[2] Licea, Cristina and Newman, Charles M. (1996) Geodesics in two-dimensional first-passage percolation,Ann. Probab.241, 399–410.[3] Guiol, Hervé and Mountford, T. (2004) The motion of a second class
particle in the rarefaction fan, Preprint.
132 A Nonparametric test of the condi-tional distribution function [Poster Session P3(page 41)]
Gilles R. DUCHARME andSandie FERRIGNO, Laboratoirede Probabilités et Statistique, Montpellier, France
Let (X,Y), be a random vector ofIR2. The relation betweenXandY is entierely captured by the conditional distribution func-tion
F(y|x) = P(Y ≤ y|X = x),
and virtually, all the statistical quantities used in practice tounderstand this relationship are functional of this distributionfunction; notably, the regression function, corresponding to theconditional expectation and very used in pratical applicationsbut also the conditional variance and the conditional quantiles,among others. In many applications, such as in classical regres-sion, hypotheses are made about this conditional distribution andit seems important to to be able to check them.In this work, we propose a global approach that test simultane-ously all hypotheses made about the model. In general, thesehypotheses involve unknown parameters. We regroup them in avectorθ that belongs to the parametric spaceΘ. Let F(y|x;θ),denote the enternained model. We are interested in testing thefollowing composite null hypothesis :
H0 : F(y|x) ∈ F(y|x;θ),θ ∈Θ. (1)
The idea of the test is to compareFn(y|x), a nonparametric esti-mator ofF(y|x) with F(y|x; θ), a parametric one underH0 andto reject the null hypothesis if the “distance” between these twoquantities exceeds a critical value. As a “distance”, we use aL2-norm such as that in Härdle and Mammen (1993) and Alcaláand al (1999); in particular, we suggest to use a generalizedCramer-von Mises type test statistic.There are many possibilities to getFn(y|x), from (Xi ,Yi), i =1, . . . ,n, n independent and identically distributed copies from(X,Y). We use local polynomial estimation, studied by Fanet Gijbels (1996). The idea of this method is to locally fit theconditional distribution function by a fixed-order polynomial atall point x.
The asymptotic distribution of the test is derived underH0 andwe study its local asymptotic power by checking its asymptoticdistribution under contiguous alternatives. We also give a theor-ical choice of the bandwith parameter used in the local polyno-mial estimation ofF(y|x).References[1] Alcalá, J.T., Cristóbal, J.A., and González-Manteiga, W. (1999)Goodness-of-fit tests for linear models based on local polynomials,Statistics& Probability Letters42, 39–46.[2] Fan, J. and Gijbels, I. (1996)Local polynomial modelling and itsapplications,Chapman and Hall.[3] Härdle, W. and Mammen, E. (1993) Comparing nonparametric ver-sus parametric regression fits,The Annals of Statistics21, 1926–1947.
133 Identification of stochastic differentialequation from panel data [Contributed Session C19(page 30)]
A. David McDONALD, CSIRO Marine Research, Australia
Daria. V. FILATOVA , University of Kielce, Poland
Marek GRZYWACZEWSKI, University of Radom, PolandLeif K. SANDAL, Norwegian School of Economics and Busi-ness Administration, Norway

102 6th BS/ IMSC
We propose a method for the parametric identification ofstochasticdifferential equation coefficients from panel data. Themain focus is on the numerical optimisation algorithm of Soboland Statnikov (1980) which is implemented by matching thedistribution of field data with a panel of simulated data. Thefit between the two distributions is evaluated by means ofthe Kolmogorov-Smirnov goodness-of-fit statistic which deter-mines the goal function. Monte Carlo esperiments verify theeffectiveness of the method for estimating SDE parameters.References[1] Basawa, I.V. and Prakasa Rao B.L.S. (1980)Statistical inference forstochastic process, Academic Press, London.[2] Dacunha-Castelle D., Florens-Zmiorou D. (1986).Estimators of thecoefficients of a diffusion from discrete observations. Stochastics 19,263 – 284.[3] Elliot, R.J. and Kopp, P.E. (2001)Mathematics of Financial Markets,Springer-Verlag, New York.[4] Hurn, A.S. and Lindsay, K.A. (1997) Estimating the parameters ofstochastic differential equations by Monte Carlo methods,Mathematicsand Computers in Simulation43, 495–501.[5] Gallant, A.R. and Long, J.R. (1997) Estimating stochastic differen-tial equations efficiently by minimum chi-squared,Biometrika84 (1),125–141.[6] Kloeden, P.E. and Platen, E. (1999)Numerical Solution of StochasticDifferential Equations, Springer-Verlag, Berlin.[7] Prakasa Rao B.L.S. (2003) Parametric estimation for linear stochas-tic differential equations driven by fractional Brownian motion,RandomOper. and Stoch. Equ.11, 229–242.[8] Pugachov, V.S. and Sinitsyn, I.N. (2000)Theory of stochastic pro-cesses, Logos Press, Moscow (in Russian).[9] Shao, J. (1999)Mathematical Statistics, Springer-Verlag, New York.[10] Sobol, I.M. and Statnikov, R.B. (1980)Optimal Parameters Selec-tion in the Multicriteria Tasks, Nauke Press, Moscow (in Russian).
134 Pre-ordered hypotheses and false dis-covery rate [Invited Session 27 (page 43)]
Helmut FINNER , Leibniz-Institut an der Heinrich-Heine-Universität Düsseldorf, Germany
Sanat K. SARKAR,Temple University, Philadelphia, USA
In this talk we present a stepwise multiple test procedure fornpre-ordered hypotheses which controls the false discovery rate(FDR) at some pre-specified levelα when independent p-valuesare at hand. A simple formula for the actual FDR allows thedetermination of least favorable distributions and a set of exactcritical values for a stepwise test procedure. The critical valuesturn out to be non-decreasing starting withα and approach 1when the number of hypotheses increases. Moreover, we com-pute the expected number of type I errors (ENE) and its limitfor n tending to infinity. Surprisingly, for large values ofα, theENE tends to infinity. Finally, a possible application in qualitycontrol is illustrated.References[1] Benjamini, Y. and Hochberg, Y. (1995) Controlling the false discov-ery rate:A practical and powerful approach to multiple testing, Journalof the Royal Statististical Society, B57, 289–300.[2] Benjamini, Y. and Yekutieli, D. (2001) The control of the false dis-covery rate in multiple testing under dependency,Annals of Statistics29, 1165–1188.[3] Eklund, G. and Seeger, P. (1965) Massignifikansanalys,StatistiskTidskrift Stockholm, third series4, 355–365.[4] Finner, H. and Roters, M. (2002) Multiple hypotheses testing andexpected number of type I errors,Annals of Statistics30, 220–238.[5] Finner, H. and Roters, M. (2001) On the false discovery rate andexpected type I errors,Biometrical Journal43, 985–1005.[6] Finner, H. and Sarkar, S.K. (2004)Pre-ordered hypotheses and falsediscovery rate,In preparation.[7] Sarkar, S.K. (2002) Some results on false discovery rate in stepwise
multiple testing procedures,Annals of Statistics30, 239–257.[8] Seeger, P. (1968) A note on a method for the analysis of significanceen masse,Technometrics10, 586–593.
135 Algorithms for rank regression [Con-tributed Session C31 (page 30)]
Ian ABRAMSON, Michael DONOHUE and AnthonyGAMST , University of California, San Diego, USA
Let (Xi ,Yi) be generated by a semi-parametric monotone singleindex model, where
h(Yi) = g(X′i β ,εi), (1)
with h strictly increasing,g increasing in both arguments, andtheεi iid F , independent ofXi ∈ Rd.If only the (Xi ,Ri) are observed, whereRi = rank(Yi), thenβ isunidentifiable; even wheng is known. However, using only the(Xi ,Ri), it is possible to estimateγ = β/||β ||.We discuss several algorithms for estimatingγ from the(Xi ,Ri),including spearmax estimation [1] and sliced inverse regression[3]. We focus on consistency and asymptotic distribution theoryfor the resulting parameter estimates.References[1] Cavanagh, C. and Sherman, R.P. (1998) Rank Estimators for Mono-tonic Index Models,J. Econometrics84, 351–381.[2] Doksum, K.A. (1987) An Extension of Partial Likelihood Methods,Annals of Statistics15, 325–345.[3] Li, K.C. (1991) Sliced Inverse Regression,JASA86 (414) 316–327.
136 On the estimation of asynergistic func-tions [Contributed Session C29 (page 52)]
Ian ABRAMSON, Michael DONOHUE and AnthonyGAMST , University of California, San Diego, USA
Let ϕ(p,q) map R+ × R+ to R, with α(x) = ϕ(x,0) andβ (y) = ϕ(0,y) and assume thatα andβ are both (strictly) mono-tone. For a given responseθ = ϕ(p,q), definex(p,q) = α−1(θ)andy(p,q) = β−1(θ), and callϕ asynergistic whenever
py(p,q)+qx(p,q) = x(p,q)y(p,q) (1)
holds for allp,q≥ 0.Asynergistic functions are important in dose-response modelingand the definition (above) can be extended in an obvious way todimensionsd > 2.We discuss algorithms for estimating asynergistic functions on(R+)d nonparametrically. Both least-squares and local likeli-hood estimates are discussed and we prove a conjecture of Kellyand Rice [1] that asynergistic functions achieve a reduction indimensionality comparable to (but different from) that offeredby additivity [2].References[1] Kelly, C. and Rice, J. (1990) Monotone Smoothing with Applicationto Dose-Response.Biometrics46, 1071–1085.[2] Buja, A., Hastie, T., and Tibshirani, R. (1989) Linear Smoothers andAdditive Models.Ann. Stat.17, 453–555.[3] van de Geer, S. (2000)Empirical Processes inM-Estimation. Cam-bridge University Press.
137 On the distribution of predictors andresiduals [Poster Session P3 (page 42)]
Anthony GAMST , University of California, San Diego, USA
Several nonparametric goodness-of-fit tests for (semi-parametric, generalized) linear regression models are computedas functions of residuals over subsets of the fitted predictors.Using techniques similar to those employed by Durbin [1] and

Abstracts 103
Stute [2], we study weak convergence of the bivariate empiricalprocess
νn(s, t) = n−1/2n
∑j=1
X′j β ≤ s, ε j ≤ t
(1)
whereA is the indicator function of the eventA. The limitingGaussian process is shown to depend in an integral way on boththe design and error densities.References[1] Durbin, J. (1973) Weak Convergence of the Sample DistributionFunction when Parameters are Estimated.Ann. Stat.1, 279–290.[2] Stute, W. (1997) Nonparametric Model Checks for Regression.Ann.Stat.25, 613–641.
138 Connectivity and diameter of small-world random graphs [Contributed Session C16 (page52)]
Ayalvadi GANESH, Microsoft Research, Cambridge, UK
Feng XUE,University of Illinois, Urbana-Champaign, USA
Erdos and Rényi [1] introduced the following model of a ran-dom graph: there aren nodes, and an edge is present betweeneach pair of nodes with some fixed probabilitypn, independentof all other edges. They showed for this model that there isa sharp threshold for connectivity atpn = (logn)/n: for anyε > 0, the probability that the graph is connected goes to 1 ifpn > (1+ε)(logn)/n, and goes to 0 ifpn < (1−ε)(logn)/n. Asimilar result holds for nearest neighbour graphs. Here,n pointsare placed uniformly at random on the unit square, and eachpoint is connected to itsmn nearest neighbours. Xue and Kumar[2] showed that there are constantsc1, c2 such that the probabil-ity of the graph being connected goes to 0 ifmn < c1 logn, andto 1 if mn > c2 logn.In this paper, we consider a hybrid of these models wherein eachnode is connected tomn nearest neighbours in addition to havingrandom “shortcuts", independently with probabilitypn to everyother node. Similar models have been used to study the so-calledsmall-world phenomenon. We derive sufficient conditions onmn
andpn for the graph to be connected with high probability, andobtain an upper bound on the diameter.References[1] Erdos,P. and Rényi, A. (1960) On the evolution of random graphs,Mat Kutato Int. Közl5(17) 17–60.[2] Feng, Xue and Kumar, P.R. (2004)The number of neighbors neededfor connectivity of wireless networks,Wireless Networks, to appear.
139 The Wiener disorder problem with fi-nite horizon [Contributed Session C12 (page 25)]
Pavel V. GAPEEV, Russian Academy of Sciences, Russia
Goran PESKIR,University of Aarhus, Denmark
The Wiener disorder problem seeks to determine a stopping timewhich is as close as possible to the (unknown) time of “dis-order" when the drift of an observed Wiener process changesfrom one value to another. In this paper we present a solutionof the Wiener disorder problem when the horizon is finite. Themethod of proof is based on reducing the initial problem to aparabolic free-boundary problem where the continuation regionis determined by a continuous curved boundary. By means of thechange-of-variable formula containing the local time of a diffu-sion process on curves we show that the optimal boundary canbe characterized as a unique solution of the nonlinear integralequation.References
[1] Carlstein, E., Müller, H.-G., and Siegmund, D. (eds) (1994) Change-point problems,IMS Lecture Notes Monogr. Ser.23.[2] Davis, M.H.A. (1976) A note on the Poisson disorder problem,Ba-nach Center Publ.1, 65–72.[3] Dufresne, D. (2001) The integral of geometric Brownian motion,Adv. Appl. Probab.33, 223–241.[4] Dynkin, E. B. (1963) The optimum choice of the instant for stoppinga Markov process,Soviet Math. Dokl.4, 627–629.[5] Gal’chuk, L.I. and Rozovskii, B.L. (1972) The ’disorder’ problemfor a Poisson process,Theory Probab. Appl.16, 712–716.[6] Grigelionis, B.I. and Shiryaev, A.N. (1966) On Stefan’s problem andoptimal stopping rules for Markov processes,Theory Probab. Appl.11,541–558.[7] Jacka, S.D. (1991) Optimal stopping and the American put,Math.Finance1, 1–14.[8] Komogorov, A.N., Prokhorov, Yu.V., and Shiryaev, A.N. (1990)Probabilistic-statistical methods of detecting spontaneously occuring ef-fects, Proc. Steklov Inst. Math.182, (1) 1–21.[9] Liptser, R.S. and Shiryaev, A.N. (1977)Statistics of Random Pro-cesses I,Springer, Berlin.[10] McKean, H.P Jr. (1965) Appendix: A free boundary problem forthe heat equation arising form a problem of mathematical economics,Ind. Management Rev.6, 32–39.[11] Myneni, R. (1992) The pricing of the American option,Ann. Appl.Probab.2, 1–23.[12] Pedersen, J.L. and Peskir, G. (2002) On nonlinear integral equa-tions arising in problems of optimal stopping,Proc. Functional Anal.VII (Dubrovnik 2001),Various Publ. Ser.46, 159–175.[13] Peskir, G. (2002)A change-of-variable formula with local time oncurves, Research ReportNo. 428, Dept. Theoret. Statist. Aarhus 17.[14] Peskir, G. (2002)On the American option problem, Research Re-portNo. 431, Dept. Theoret. Statist. Aarhus 13.[15] Peskir, G. (2003)The Russian option: Finite horizon, Research Re-port No. 433, Dept. Theoret. Statist. Aarhus 16, To appear inFinanceStoch.[16] Peskir, G. and Shiryaev, A.N. (2002)Solving the Poisson disorderproblem. Advances in Finance and Stochastics.Essays in Honour ofDieter Sondermann. Sandmann, K. and Schönbucher, P. eds. Springer295–312.[17] Revuz, D. and Yor, M. (1999)Continuous Martingales and Brown-ian Motion,Springer, Berlin.[18] Schröder, M. (2003) On the integral of geometric Brownian mo-tion, Adv. Appl. Probab.35, 159–183.[19] Shewhart, W.A. (1931)The Economic Control of the Quality of aManufactured Product, Van Nostrand.[20] Shiryaev, A.N. (1967) Two problems of sequential analysis,Cy-bernetics3, 63–69.[21] Shiryaev, A.N. (1978)Optimal Stopping Rules,Springer, Berlin.[22] Shiryaev, A.N. (2002)Quickest detection problems in the technicalanalysis of the financial data. Math. Finance Bachelier Congress, Paris2000, Springer, 487–521.[23] van Moerbeke, P. (1976) On optimal stopping and free-boundaryproblems,Arch. Rational Mech. Anal.60, 101–148.[24] Yor, M. (1992) On some exponential functionals of Brownian mo-tion, Adv. Appl. Probab.24, 509–531.
140 Some comments on the existence ofprojections in statistics [Poster Session P3 (page 42)]
Gloria GARCÍA , Autonoma University of Barcelona, Spain
Josep M. OLLERUniversity of Barcelona, Spain
The role and importance of minimizing elements in statistics iswell-known. Here we examine the existence of the projection ofa probability measure in a parametric statistical model. Once,in a general framework, the existence of the projection is esta-blished, we consider the problem from a statistical point of view,modelling a parametric statistical model as a convenient mani-fold. Several statisticians have worked with projections but asignificant contribution was made by Amari [2]. He treats in de-tail the problem of approximate a probability measure in a para-metric statistical model by the closest element in a given sub-

104 6th BS/ IMSC
model according to anα–divergence. Other authors have alsoworked in this direction, including Kass and Vos [5] and Murrayand Rice [4]. Murray and Rice, following Amari, characterizethe minimizing element. Kass and Vos deal with minimum di-vergence estimators, establishing the equivalence between max-imum quasi–likelihood estimators and minimum divergence es-timators.The framework of this work is the information geometry, wherethe parametric statistical models are represented via Rieman-nian manifolds, most of which are finite dimensional. On theother hand, if dominated by aσ–finite measure these models areprecisely Hilbertian (see Dawid [1] and Burbea [3] for furtherdetails). We start setting down the conventions on a paramet-ric statistical model that cover both scenarios and establishingwhat will be understood by anenlargementof a parametric sta-tistical model. Next we proof the existence of the projectionin submanifold according to a measure of non-proximity calleddiscrepancy; starting from a regular enough point, to be calledregular projectable, we ensure the existence and uniqueness ofa smooth local projection map.Taking into account that a parametric statistical model, with suit-able regularity conditions, has a natural Riemannian structuregiven by the information metric, the latter allows us to projectin the sub-model if necessary where, it must be pointed out, thatno need of convexity or completeness of the set where project-ing is needed. The Hilbertian case is also analyzed taking asa discrepancy anyf -divergence twice differentiable on the firstargument by establishing the existence of the local projectionmap with respect to it. Finally, several concrete examples on thematter based on well-known parametric statistical models arepresented.References[1] Dawid, A.P. (1977) Further comments on some comments on a paperby Efron,The Annals of Statistics5, 1249.[2] Amari, S.-I. (1985)Differential Geometry Methods in Statistics, vol-ume 28 of Lecture Notes in Statistics, Springer-Verlag, New York.[3] Burbea, J. (1986) Informative geometry of probability spaces,Expo-sitiones Mathematicae4, 347–378.[4] Murray, M.K. and Rice, J.W. (1993)Differential geometry and statis-tics, volume 48 of Monographs on Statistics and Applied Probability,Chapman & Hall, London.[5] Kass, R.E. and Vos, P.W. (1997)Geometrical foundations of asymp-totic inference, Wiley Series in Probability and Statistics, John Wiley &Sons, New York.
141 Asymptotic theory of the likelihood ra-tio test for the identification of a mixture [Con-tributed Session C44 (page 52)]
Bernard GAREL , University of Toulouse 3 and INPT-N7 ,France
The problems that arise when using the likelihood ratio test forthe identification of a mixture distribution are well known: non-identifiability of the parameters and null hypothesis correspond-ing to a boundary point of the parameter space. In their approachto the problem of testing homogeneity against a mixture withtwo components, Ghosh and Sen took into account these specificproblems. Under general assumptions they obtained the asymp-totic distribution of the likelihood ratio test statistic. However,their result requires a separation condition which is not com-pletely satisfactory. We show that it is possible to remove thiscondition with assumptions which involve the second derivativesof the density only.References[1] Ghosh, J.K. and Sen, P.K. (1985)On the asymptotic performance
of the log-likelihood ratio statistic for the mixture model and related re-sults,Proc. Berkeley Conf. in Honor of Jerzy Neyman and Jack Kiefer(Vol.II), L.M. Le Cam and R.A. Olshen (eds), Wadsworth, Monterey,789–806.[2] Liu, X. and Shao, Y. (2003) Asymptotics for likelihood ratio testsunder loss of identifiability,Ann. Statist.31, 807–832.
142 Hierarchical Bayesian analysis of thepartial adjustment of financial ratios usingmixture models [Poster Session P1 (page 21)]
José Luis GALLIZO,University of Lleida, Spain
PILAR GARGALLO and Manuel SALVADOR,University ofZaragoza, Spain
This paper presents a hierarchical Bayesian analysis of the par-tial adjustment model of financial ratios using mixture modelswith un unknown number of components. This approach allowsus to estimate the distribution of the adjustment coefficients andto analyse the existence of homogeneus groups of firms withrespect to their speed of reaction in the presence of shocks af-fecting the objectives fixed for the financial ratios of these firms.The proposed methodology is illustrated by analysing a set ofratios of a sample of firms operating in the US manufacturingsector.References[1] Davis, H. and Peles, Y. (1993) Measuring equilibrating forces of fi-nancial ratios.The Accounting Review68, 725–747.[2] Gallizo, J.L. and Salvador, M. (2003) Understanding the behaviourof financial ratios: the adjustment process.Journal of Economics andBusiness55, 267–283.[3] Stephens, M. (2000) Bayesian Analysis of Mixture Models with anunknown number of components-an alternative to reversible jump meth-ods.The Annals of Statistics28, 40–74.
143 Exponential stability of stationary so-lutions for functional stochastic evolutionequations [Contributed Session C12 (page 25)]
T. CARABALLO, M.J. GARRIDO-ATIENZA Universidad deSevilla, Spain
The asymptotic behaviour of stochastic partial differential equa-tions is an important task which has been receiving much atten-tion during the last decades. In particular, stochastic evolutionequations containing some sort of delay or retarded argumenthave also been extensively studied due to their importance inapplications. However, even in the non-delay framework, mostresults in the literature are concerned with the exponential sta-bility of constant stationary solutions, mainly the trivial one.Recently, Caraballo, Kloeden and Schmalfuss have analysed theasymptotic behaviour of semilinear stochastic partial differen-tial equations, focusing on the exponential stability of their non-constant stationary solutions.Our aim in this work is to develop a similar analysis in the casein which the non-linear term contains some hereditary features.Several and important differences appear due to the different na-ture of the problem. It is remarkable that, for instance, the usualHilbert spaces considered as phase spaces in the non-delay con-text, becomes now a Banach space of continuous trajectories,what requires a different treatment.To reach our objective we will study the existence of randomfixed points of random dynamical systems by means of trans-forming the semilinear stochastic evolution equation with delays(considered in the sense of Stratonovich) into a random partialdifferential equation, that is, that containsω as a parameter.
144 Optimal error exponent in model se-

Abstracts 105
lection [Contributed Session C34 (page 28)]
E. GASSIAT, Orsay University, France
For any integerr, let M r be a set of probability distributionson R∞, such that(M r )r is a sequence of embbeded mod-els: M r ⊆ M r+1. Define the orderr∗ of some distributionP∗ ∈ ∪rM r as the smallest integerr such thatP∗ ∈ M r . Weconsider the problem of estimatingr∗ on the basis of observa-tions Y1, . . . ,Yn, to provide almost surely consistent estimatorsand to analyze the behaviour of the probability of underestima-tion and of overestimation.Applications include independent observations, Markov orderestimation, HMM order estimation.Let r be an estimator of the order,αn the probability of under-estimation,βn the probability of overestimation. We providegeneral lower bounds onαn andβn. We prove that, in varioussituations, the lower bound forαn may be attained by penalizedmaximum likelihood estimators, and we evaluate the rate of ex-ponential decay ofβn depending on the penalization term. Theresults rely on functional large and moderate deviations for thelikelihood process.Lower bounds on penalties are also given to achieve almost sureconsistency. They are related to coding probabilities and Infor-mation Theory tools. z
145 Nucleation pattern at low temperaturefor local Kawasaki dynamics in two dimen-sions [Contributed Session C35 (page 26)]
A. GAUDILLIÈRE , Paris Sud and Roma Tor Vergata Univer-sities, France/Italy
We study the metastable behaviour of a two-dimensional opensystem evolving at low temperature under the local versionof Kawasaki conservative dynamics introduced in [2]. Theparticles of a lattice gas evolve with attractive interaction in-side a finite square box and we describe the first successfulattempt of the system to reach its ground state starting fromthe configuration corresponding to an empty box. In partic-ular we control geometrically the configurations on paths fol-lowed, in a typical way, along this nucleation process. We thenshow that the whole evolution goes with a very large proba-bility from ‘quasi squares’ to bigger “quasi squares". More-over we show that along these paths, between two successive“quasi squares", the fluctuations in the dimensions of clus-ters are bounded: if anl × L rectangle, withl ≤ L, circum-scribes one of these clusters thenL− l ≤ 1+ 2
√L. Finally we
show that fluctuations of this order cannot be neglected: suchfluctuations occur with a probability “non exponentially smallin β ". This nucleation process is thus substantially differentfrom the one which takes place under the Glauber dynamics–described in [1]– chiefly in its supercritical part, but in its sub-critical one too.References[1] Schonmann, R. (1992) The pattern of escape from metastability of astochastic Ising model.Comm. Math. Phys.147, 231–240.[2] den Hollander, F., Olivieri, E., and Scoppola, B. (2000) Metastabil-ity and nucleation for conservative dynamicsJ. Math. Phys.41, 1424–1498.
146 Approximation of stochastic integrals,fractional Sobolev spaces, and interpolation
[Contributed Session C11 (page 15)]
Stefan GEISS, University of Jyväskylä, Finland
For certain diffusionsX = (Xt)t∈[0,T] with finite time horizon
T > 0 and Borel functionsf : R→ R we consider the approxi-mation problem
f (XT)∼ [E f(XT)]+n
∑i=1
vi−1(Xti −Xti−1),
whereτ = (ti)ni=0 is a time-net andv = (vi)n−1
i=0 is a predictablesequence of random variables. Theerror-process, associated tothis problem, is defined as
Ct(v,τ) := E( f (XT)|Ft)− [E f(XT)]
−n
∑i=1
vi−1(Xti∧t −Xti−1∧t).
The approximation problem is of interest for example inStochastic Finance, where continuously adjusted portfolios arereplaced by discretely adjusted ones (cf. [7]). From an analyti-cal point of view we want to relate properties off to propertiesof the error process as closely as possible. Here we want to givean overview over some results in this direction. For simplicity,we assume thatX is the geometric Brownian motion and thatT = 1.
(a) Letting γ be the standard Gaussian measure on thereal line, the function f (ex−1/2) belongs to the frac-tional Sobolev space(D1,2(γ),L2(γ))θ ,2, obtained bythe real interpolation method (cf. [8]), if and only ifinfv‖CT(v,τθ
n )‖L2 ≤ cn−1/2, where τθn are explicitely
given deterministic time-nets of cardinalityn which takeinto the account the smoothness off via the parameterθ .Hence: knowing the smoothness off , we know the opti-mal time nets (the raten−1/2 is optimal). Conversely, weget the smoothness off from the asymptotic behavior of‖CT(v,τ)‖L2. See [4], [6].
(b) Looking for stronger criteria thanL2 to measure the size ofthe error process, one can use as borderline case weightedBMO (bounded mean oscillation) spaces. This gives: thefunction f is Lipschitz if and only if the approximationrate with respect toBMOX
2 is n−1/2 where equidistant timenets of cardinalityn are used. The Lipschitz condition canbe can considered as a borderline case for our fractionalsmoothness off . See [2], [3].
(c) We give an application for approximations where one op-timizes the quadratic error overrandomtime nets havinga certain cardinality. See [5].
References[1] Geiss, S. (2002) Quantitative approximation of certain stochastic in-tegrals,Stochastics and Stochastics Reports(73), 241–270.[2] Geiss, S. (2002)On the approximation of stochastic integrals andweighted BMO, Stochastic Processes and Related Topics. Eds. R. Buck-dahn, H.J. Engelbert, M. Yor. Stochastics Monographs. Taylor & Fran-cis Books.[3] Geiss, S. (2003)Weighted BMO and discrete time hedging withinthe Black-Scholes model, submitted.[4] Geiss, C. and Geiss, S. (2003)On approximation of a class ofstochastic integrals and interpolation, submitted.[5] Geiss, C. and Geiss, S. (2003)On an approximation problem forstochastic integrals where random time nets do not help, Preprint 283,Department of Mathematics and Statistics, University of Jyväskylä.[6] Geiss, S. and Hujo, M. (2004)Interpolation and approximation inL2(γ), Preprint 290, Department of Mathematics and Statistics, Univer-sity of Jyväskylä.[7] Gobet, E. and Temam, E. (2001) Discrete time hedging errors foroptions with irregular payoffs,Finance and Stochastics(5), 357–367.[8] Hirsch, F. (1999) Lipschitz functions and fractional Sobolev spaces,Potential Analysis(11), 415-429.

106 6th BS/ IMSC
147 Moment generating function estima-tion for linear processes [Contributed Session C30(page 54)]
Sucharita GHOSH, Swiss Federal Research Institute WSL,Switzerland
The empirical moment generating function (emgf) has oftenbeen proposed as an alternative means to test the underlying dis-tribution function for a set of observations. Given the observa-tionsX1,X2, ...,Xn, the empirical moment generating function isdefined as the quantity
mn(t) =n
∑j=1
exp(tXj ),
t ∈ (−T,T) where0 < T < ∞ is a finite constant. The emgfmn(t) is an unbiased estimate of the population moment gener-ating function (mgf)µX(t). Its consistency properties have alsobeen established in the literature (see for instance Csörgo 1982,Ghosh & Beran 2000 and references therein).In case of a linear process, that is a convolution of a sequence ofindependently and identically distributed innovations, the mo-ment generating function becomes a natural choice.Thus suppose that
Xi =∞
∑j=0
a j εi− j
is a linear process where∑a2j < ∞, the innovationsεi are iid
with distributionFε , E(εi) = 0 andσ2ε = var(εi) < ∞. In partic-
ular we assume that the mgf of theεi exists and it is denoted byµε (t).In this case, in addition to the classical emgf, the linear represen-tation can be used to define a second estimator (Ghosh & Beran2004). In this paper, we take a closer look at these two estima-tors under short and long-memory correlations in the data andderive some asymptotic results. The work of Giraitis and Sur-gailis (1999) is relevant here, who study the properties of the em-pirical cumulative distribution function of a linear process underlong-memory serial correlations.References[1] Csörgo, S. (1982) The empirical moment generating function, Non-parametric Statistical Inference, 139-150.[2] Ghosh, S. and Beran, J. (2000) Two-SampleT3 Plot: A GraphicalComparison of Two Distributions,Journal of Computational and Graph-ical Statistics9, 167–179.[3] Ghosh, S. and Beran, J. (2004)On estimating the cumulant generat-ing of a linear process, submitted.[4] Giraitis, L. and Surgailis, D. (1999) Central limit theorem for theempirical process of a linear sequence with long memory,Journal ofStatistical Planning and Inference80, 81–93.
148 Localization phenomena for hetero-polymers [Invited Session 14 (page 33)]
Giambattista GIACOMIN , Universite Paris VII, Paris
I present and discuss some recent results on a (1+1)-dimensiondirected random walk model of a polymer dipped in a mediumconstituted by two immiscible solvents separated by a flat in-terface. The polymer chain is heterogeneous in the sense thata single monomer may energetically favor one or the other sol-vent. We focus on the case in which the polymer types are ran-domly distributed along the chain. The phenomenon that onewants to understand is thelocalization at the interface: energet-ically favored configurations placemost ofthe monomers in thepreferred solvent and this can happen only if the polymer sticks
close to the interface. The results include some new free energybounds. Moreover a particular attention will be paid to the sub-tle interplay between probability estimates and path propertiesin this class of polymer models.
149 Recent results on asymptotics of kerneldensity estimators [Medaillon Lecture (page 51)]
Evarist GINÉ , University of Connecticut, USA
Under minimal regularity, all the possible limits of the weighteduniform discrepancy between a kernel density estimator and itsmean, or even the true density, as well as new limit theorems fortheLp norm of this discrepancy,p = 1,2, are obtained. One ofthe main tools is the landmark Talagrand’s 1996 concentrationinequality. This is joint work with several authors: A. Guillou,V.I. Koltchinskii, D.M. Mason, L. Sakhanenko, A. Zaitsev andJ. Zinn.
150 On the measure of the information in astatistic [Contributed Session C34 (page 28)]
Josep GINEBRA, Universitat Politècnica de Catalunya, Spain
Prem K. GOEL,Ohio State University, USA
Lourdes RODERO,Universitat Politècnica de Catalunya, Spain
An experimenter trying to choose between the experimentE thatobserves from a random variableX with distributionPθ , and theexperimentF that observes from a random variableY with dis-tribution Qθ , in order to learn about the unknown parameterθ ,must use an optimality criterion that best captures the featuresessential to him/her. The criterion amounts to maximizing somemeasure of the information aboutθ in the experiment. Ginebraand Goel (2003), building on the literature on the sufficiency or-dering of experiments stemming from Blackwell (1951, 53) andreviewed in Goel and Ginebra (2003), states a minimal set ofrequirements that must be satisfied by all such measures of in-formation. Under this framework, one can express all measuresof the information in an experiment in terms of the variability ofits likelihood ratio statistics; That includes all best known infor-mation measures, like the expected value of sample information,the mutual information betweenX andθ , and the negative of thelogarithm of the Hellinger transform, as well as measures thathave never been proposed in the literature.In this presentation, we consider the special case where one in-tends to compare the amount of information aboutθ in experi-mentE = (X;Pθ ), with the amount of information aboutθ in asubexperimentET , that observes a statisticT(X). By adaptingthe concept of information advocated for in Ginebra and Goel(2003) to this situation, we present a unified framework for themeasure of the information in a statistic, and thus for the com-parison of the statistical efficiency ofT(X) relative to the wholesampleX, as well as relative to any other statisticS(X) basedon X. We illustrate our point through the comparison of theinformation in an experiment observing a sample ofi.i.d. obser-vations, and the information in an experiments observing from aspecific order statistic of that sample.References[1] Ginebra, J. and Goel, P.K. (2003)Unified Framework for the Mea-sure of the Information in a Statistical Experiment, Technical Report#2003/20, Depart. of Statistics, U. Politècnica de Catalunya. Subm. forpublication.[2] Blackwell, D. (1951) Comparison of experiments, InProc. 2ndBerkeley Symp. Math. Statist. Prob.93–102. Univ. of Calif. Press,Berkeley.[3] Blackwell, D. (1953) Equivalent comparison of experiments,Ann.Math. Statist.24, 265–272.

Abstracts 107
[4] Goel, P.K. and Ginebra, J. (2003) When is one experiment alwaysbetter than another?,Journal of the Royal Statistical Society, Ser. D52,515–537.
151 A note on multimodal first entrancetime distributions for a class of jump-diffusion processes [Poster Session P2 (page 31)]
María Teresa GIRAUDO and Laura SACERDOTE,Universityof Torino, Italy
The problem of the first entrance time in a given region of thestate space for jump-diffusion processes is a challenging onewhose interest is grounded both in the theoretical field and inthe field of applications ranging from biology to engineering,physics or computer science. Indeed jump-diffusion processesare often invoked for the description of stochastic neuronal ac-tivity or of other biological systems (cf. for example [1]), ofrandom assets in mathematical finance or of complex queueingsystems (cf. as an example [2]). Unluckily few analytical resultsexist for this kind of processes and those available are mainlyfocused on bounds or on equations for the moments of the firstentrance time (cf. [4], [6]). Simulation techniques have oftenappeared to be the most efficient methods to resort to for obtain-ing reliable estimates of the distributions involved. Even in thesimplest case where upward and downward jumps of constantamplitudea andi respectively, occurring in accordance with in-dependent Poisson processesNu andNd, are superimposed on aone dimensional Wiener process with driftµ and varianceσ2,i.e. when the resulting processY is solution to the stochasticdifferential equation:
dYt = µdt+σdWt +adNu
t + idNdt
Y0 = 0,
no closed form is known for the probability density function ofthe first entrance time into the region of the state space delimitedby a constant boundary.By proving that the first entrance time density function in thiscase is solution to a suitable integral equation we present herean approximate formula for the evaluation of such distributionin some particular instances and we obtain an estimate of theerror connected with its use resorting to a fixed point theorem.Furthermore we show that this approximate formula allows toidentify multimodal shapes of the probability density functionand to find out relationships between the diffusion and the jumpparameters that cause this behavior. These results can be appliedin neuronal modeling context where it has been recently shownby means of simulation (cf. [3]) that a multimodal behavior forthe first passage time distribution arises also for certain classesof jump-diffusion processes and not only as an effect of addinga time periodic term to the diffusion drift coefficient (cf. forexample [5]).References[1] Giraudo, M.T. and Sacerdote, L. (1997) Jump-diffusion processes asmodels for neuronal activity,BioSystems40, 75–82.[2] Perry, D. and Stadje, W. (2001) The busy cycle of the reflected super-position of Brownian motion and a compound Poisson process,J. Appl.Prob.38, 255–261.[3] Sacerdote, L. and Sirovich, R. (2003) Multimodality of the inter-spike interval distribution in a simple jump-diffusion model,ScientiaeMathematicae Japonicae582, 307–321.[4] Schäl, M. (1993) On hitting times for jump-diffusion processes withpast dependent local characteristics,Stoch. Proc. Appl.47, 131–142.[5] Shimokawa, T., Pakdaman, K., and Sato, S. (1999) Time-scalematching in the response of a leaky integrate-and-fire neuron model toperiodic stimulus with additive noise,Phys. Rev. E59, 3427–3443.
[6] Tuckwell, H.C. (1976) On the first-exit time problem for temporallyhomogeneous Markov processes,J. Appl. Prob.13, 39–48.
152 Nonnegative monotone convex-concave multivariate extrapolation modelswith application to computer cache rates
[Contributed Session C58 (page 55)]
Ilya GLUHOVSKY and David VENGEROV,Sun Microsys-tems Laboratories, USA
In this work we propose an approach to building multivariateregression models for prediction beyond the range of the data.The extrapolation model attempts to accurately estimate the highlevel trend of the data, which can be extended in a natural way.Shape constraints such as monotonicity and convexity/concavityplay an important role of controlling the behavior and variabil-ity of the extrapolation fit, which would otherwise remain ratherarbitrary. The shape constraints must be rigid enough, so thatif two functions that satisfy the constraints behave differentlyover the extrapolation region, they should be far enough overthe data region for the data to be able to discriminate betweenthem. The monotonicity and convexity/concavity constraints weconsider do not allow a pair of functions to follow each other(and the data) closely and then diverge in different directions inthe extrapolation region. Although this will typically mean thatfor the purposes of extrapolation we can only model high leveltrends of the data, this does not preclude us from uncoveringlocal features in the data using more flexible (less constrained)modeling. That is, we allow for consideration of functions thatare (locally) different over the data but give similar extrapolationfits.Our novel extrapolation model incorporates the monotonicityand convexity/concavity constraints in multiple dimensions. Wefurther constrain the problem by describing the trend as a non-negative linear combination of twice-integrated multivariate B-splines and their variations. The specific basis functions in ourapproach are chosen so that any such combination is a plausi-ble a priori model. As a result, one can optimize basis functioncoefficients to fit the data best without losing control over thehigh-level trend of the extrapolation model. Our approach alsoallows one to use standard model selection techniques. We il-lustrate this by applying cross-validation to roughness penaltyparameter selection.We demonstrate the validity of our approach by successfully ap-plying it to modeling computer cache miss rates, a key problemin computer system performance analysis. We show stability ofthe extrapolation fit by applying residual bootstrap. In particular,using a roughness penalty is shown to improve stability.References[1] Currie, I., Durban, M., and Eilers, P. (2003) “Using P-Splines to Ex-trapolate Two-Dimensional Poisson Data,” InProceedings of the 18thInternational Workshop on Statistical Modeling, G. Verbeke, G. Molen-berghs, A. Aerts, and S. Fieuws (Eds.). Leuven: Katholieke UniversiteitLeuven, 97–102.[2] Gluhovsky, I. (2003) “Isotonic Additive Interaction Models”,RecentAdvances and Trends in Nonparametric Statistics, eds. M. Akritas andD. Politis, North Holland: Elsevier.[3] Hall, P. and Huang, L.-S. (2001) “Nonparametric Kernel RegressionSubject to Monotonicity Constraints,”Annals of Statistics29, 624–647.[4] Mukarjee, H. and Stern, S. (1994) “Feasible Nonparametric Esti-mation of Multiargument Monotone Functions”,Journal of AmericanStatistical Association89, no. 425, 77–80.[5] Ramsay, J.O. (1988) “Monotone Regression Splines in Action,”Sta-tistical Science3, no. 4, 425–461.[6] Schwetlick, H. and Kunert, V. (1993) “Spline Smoothing under Con-straints on Derivatives”,BIT, 33, 512–528.

108 6th BS/ IMSC
[7] Turlach, B.A. (1997) “Constrained Smoothing Splines Revisited”,Technical Report SSR97-008, Australian National University, Centre forMathematics and its Applications.
153 Domain sensitivity for diffusion pro-cesses constrained a time dependent domain
[Contributed Session C10 (page 44)]
Cristina COSTANTINI,Universita’ di Chieti-Pescara, Pescara,Italy
Nicole EL KAROUI andEmmanuel GOBET, École Polytech-nique, Palaiseau, France
Both time inhomogeneous diffusion processes stopped at theexit from a time dependent domain[1] and time inhomogeneousdiffusion processes with normal reflection on the boundary of atime dependent domain are considered. The sensitivity of theexpectation of a general Feynman Kac type functional of thediffusion process with respect to a perturbation of the domainis studied. It is proved that such an expectation is differentiablewith respect to the perturbation and the derivative is computed.The derivative has the form of the expectation of another func-tional of the process. Previous analytical results obtained in thearea of shape optimization for Brownian motion[2] are thus ex-tended and represented in a probabilistically meaningful way.The results of this work have applications to pricing of Amer-ican options, regularity of the densities of a stopped diffusionprocess, simulation of reflecting diffusions, etc. . .References[1] Costantini, C., El Karoui, N., and Gobet, E. (2003) Représentationde Feynman-Kac dans des domaines temps-espace et sensibilité par rap-port au domaine: Feynman-Kac’s representation in time-space domainsand sensitivity with respect to the domain.C. R. Acad. Sci Paris, Ser. I,337, 337–342.[2] Sokolowski, J. and Zolesio, J.P. (1992)Introduction to shape opti-mization,Springer, Berlin.
154 Dual coagulation and fragmentationand the genealogy of Yule processes[ContributedSession C38 (page 38)]
Jean BERTOIN andChristina GOLDSCHMIDT , UniversitéPierre et Marie Curie (Paris 6), France
We describe a nice example of duality between coagulation andfragmentation which arises naturally in the context of Yule pro-cesses.For n ≥ 1, let ∆n =
x = (x1,x2, . . . ,xn+1) : xi ≥ 0 for every
1 ≤ i ≤ n + 1 and ∑n+1i=1 xi = 1
. We will think of the co-
ordinates of elements of∆n as masses. We define two randomtransformations,Coagk andFragk, on these spaces. The coag-ulation operatorCoagk : ∆n+k → ∆n takes an elementx∈ ∆n+kand picks an indexI ∈ 1,2, . . . ,n+ 1 uniformly at random.It coalescesxI ,xI+1, . . . ,xI+k into a single mass∑I+k
i=I xi andleaves the other masses unchanged. The fragmentation operatorFragk : ∆n→ ∆n+k picks a co-ordinate ofx∈ ∆n in a size-biasedmanner and splits it using an independentDirichletk(1/k) ran-dom variable (the subscriptk indicates that the Dirichlet variabletakes its values in∆k and the single argument indicates that allk+ 1 parameters are equal to1/k). These transformations aredual in the sense that if we takeξ ∼ Dirichletn(1/k) and setξ ′ =Fragk(ξ ) then, equivalently, we haveξ ′ ∼ Dirichletn+k(1/k)and ξ = Coagk(ξ ′). Similar relationships hold on the infinite(ranked) simplex of countable non-negative sequences whosesum is 1, which are reminiscent of the duality relations in Pit-man [4].Suppose that for somek≥ 1 we have a Yule process withk+1
offspring (that is, a continuous-time Markov branching processin which the single individual alive at time 0 waits an exponen-tial amount of time with unit parameter and then splits intok+1individuals, each of which behaves independently in the same
way as its parent). LetY(k)t be the number of individuals alive
at timet. Then it is a classical result that(
e−ktY(k)t : t ≥ 0
)is
a uniformly integrable martingale. The almost sure limit,W, ofthis martingale has aGamma(1/k,1/k) distribution. ViewingWas the size of the final population descended from the initial in-dividual, we define a genealogy for this process by tracking thesizes of the sub-populations descended from each of the parti-cles alive att. Conditional onW and subject to a deterministictime-change, this process of sub-population sizes is, in the ter-minology of [1], a self-similar fragmentation of index 1 withno erosion and dislocations according toDirichletk(1/k). (Thisgeneralises a result of Kendall [2].) Thus, the controlling mech-anism isFragk. When time reversed (and with another deter-ministic time-change), we obtain a coagulation process which isa relation of Kingman’s coalescent [3], with coagulation mech-anismCoagk. In the case of the coagulation and fragmentationoperators on the infinite simplex, we obtain results for the ge-nealogy of a continuous-state version of the Yule process.References[1] Bertoin, J. (2002) Self-similar fragmentations,Ann. Inst. HenriPoincaré38, 319–340.[2] Kendall, D.G. (1966) Branching processes since 1873,J. LondonMath. Soc.41, 385–406.[3] Kingman, J.F.C. (1982) The coalescent,Stochastic Process Appl.13,235–248.[4] Pitman, J. (1999) Coalescents with multiple collisions,Ann. Probab.27, 1870–1902.
155 Controlled multitype branching pro-cesses with random control: extinction prob-ability [Poster Session P2 (page 31)]
M. GONZÁLEZ , R. MARTÍNEZ and M. MOTA,University ofExtremadura
Controlled Branching Processes with random control have beenwidely studied for the univariate case (e.g. see Yanev (1975)or González et al. (2002, 2003)), but the multidimensional ver-sion of these processes has not been studied yet. In our paper, weconsider a Multitype Controlled Branching Process with randomcontrol,Z(n)n≥0, where:
Z(0) = z∈ Nm0 , Z(n+1)
= (Z1(n+1), . . . ,Zm(n+1)) =m
∑i=1
φni (Z(n))
∑j=1
Xi,n, j
(∑01 = 0, N0 = N∪ 0), being m∈ N the number of differ-
ent types andXi,n, j : i = 1, . . . ,m; n = 0,1, . . . ; j = 1,2, . . .,φn(z) : n = 0,1, . . . ; z∈ Nm
0 two independent sequences ofm-dimensional, non negative, integer valued random vectors de-fined on the same probability triple,(Ω,A ,P), such that:
(i) The random vectorsXi,n, j : i = 1, . . . ,m; n =0,1, . . . ; j = 1,2, . . . are independent and, for eachi =1, . . . ,m, the vectorsXi,n, j : n = 0,1, . . . ; j = 1,2, . . .are identically distributed.
(ii) For eachz∈ Nm0 , the random vectorsφn(z)n≥0 are in-
dependent and identically distributed.
(iii) If n, n∈ N0 are such thatn 6= n, then the random vectorsφn(z) andφ n(z) are independent, for everyz, z∈ Nm
0 .

Abstracts 109
This work deals with the problem of the extinction for thismodel. In order to establish adequately the framework we as-sume that the dualityP(Z(n)→ 0)+P(‖Z(n)‖→∞) = 1 holds.We provide some conditions which guarantee this property. Wealso suppose that for each pairi, j = 1. . . ,m there exists the limit
mi j = E[Xi,0,1j ] lim
‖z‖→∞ : zi 6=0
E[φ0i (z)]zi
and that the matrixM = (mi j )1≤i, j≤m is irreducible with Perron-Frobenius eigenvalueρ.
The setZ(n) → 0 is calledextinction eventbecause it indi-cates there are no individuals of any type from some generationon. Thus, under the assumptions above, we provide sufficientconditions for the almost sure extinction of the process, that isP(Z(n)→ 0) = 1, as well as for its non-extinction with a posi-tive probability, that isP(Z(n)→ 0) < 1. All the conditions aregiven in terms of the eigenvalueρ and the control vectorsφn(z),z∈ Nm
0 , n = 0,1, . . .
References[1] González, M., Molina, M., and Del Puerto, I. (2002) On the class ofcontrolled branching process with random control functions,Journal ofApplied Probability39(4), 804–815.[2] González, M., Molina, M., and Del Puerto, I. (2003) On the geo-metric growth in controlled branching processes with random controlfunction, Journal of Applied Probability40(4), 995–1006.[3] Yanev, N.M. (1975) Conditions for degeneracy ofϕ-branching pro-cesses with randomϕ, Theory of Probability and its Applications20,421–428.
156 Goodness of fit test for linear regres-sion models with missing response data[Con-tributed Session C22 (page 40)]
W. GONZÁLEZ MANTEIGA , University of Santiago deCompostela, Spain
A. PÉREZ GONZÁLEZ,University of Vigo, Spain
In this work, we propose tests to check the hypothesis of a lin-ear regression model when we have missing data in the responsevariable. The test statistics are based on theL2 distance betweennonparametric regression estimators and rootn-consistent esti-mators of the regression function under the parametric model.Two possible nonparametric estimators are considered, basedon the Multivariate Local Linear Smoother (Ruppert and Wand(1994)): theSimplified Multivariate Local Linear Smootherandthe Imputed Multivariate Local Linear Smoother. Both esti-mators have been recently studied by González Manteiga, W.and Pérez González, A. (2004a, 2004b). The two test statis-tics considered in this paper are based on these two estimators.We obtain the limit distribution of each statistic. For the im-puted estimator, we have to distinguish three cases according tothe asymptotic behavior of smoothing parameters. The asymp-totic results extend results for complete data such as those per-formed by Härdle and Mammen (1993) or by Alcalá, Cristóbaland González-Manteiga (1999).Also, a Bootstrap procedure is proposed for the approximationof the critical values of the tests. We have designed a resam-pling Bootstrap mechanism adapted to the lack of data in theresponse variable, and we have shown the asymptotic validityof the Bootstrap versions of the proposed contrast statistics. Ina simulation study, we compare the level and the power for thetests with incomplete samples with the resultant of having thecomplete samples.Finally, we compare the two test statistics with regard to theirAsymptotic Relative Pitman Efficiency (Pitman, 1949). Asymp-
totic developments and results from a simulation study are pre-sented and they show that the test for the Imputed estimatorbehaves better than that of the Simplified one.
References[1] Pitman, E.J.G. (1949) Lecture notes on nonparametric statistical in-ference, Columbia University.[2] Härdle, W. and Mammen, E. (1993) Comparing nonparametric ver-sus parametric regression fits,Ann. Statist.21, 1926–1947.[3] Ruppert, D. and Wand, M.P. (1994) Multivariate locally weightedleast squares regression,Ann. Statist.22, 1346–1370.[4] Alcalá, J.T., Cristóbal, J.A., and González-Manteiga, W. (1999)Goodness-of-fit test for linear models based on local polynomials,Statist. Probab.42, 39–46.[5] González Manteiga W. and Pérez González, A. (2004a) Nonpara-metric mean estimation with missing data, to appearCommunicationsin Statistics.[6] González Manteiga W., Martínez Miranda M.D., and PérezGonzález, A. (2004b) The choice of smoothing parameter in Nonpara-metric regression through Wild Bootstrap, to appear inComputationalStatistics and Data Analysis.
157 New stability estimates in the classicalrisk model [Contributed Session M2 (page 41)]
E. GORDIENKO , Universidad Autónoma Metropolitana - Iz-tapalapa, México
Let us consider a risk process:Z(t) = x+ γt−∑N(t)k=1 Zk and its
approximationZ(t) = x+ γt −∑N(t)k=1 Zk. Herex > 0 is an ini-
tial capital,γ > 0 is a gross premium rate,N(t) is the Poissonprocess modelling the number of claims occurred within[0, t]and the sequences of nonnegative independent, identically dis-tributed random variables(Zk, k≥ 1), (Zk, k≥ 1) (independentof N(t)) represent the costs of successive claims.Primarily we are concerned with an upper bound for the follow-ing uniform distance
ρ(Ψ,Ψ) := supx≥0
|Ψ(x)− Ψ(x)|
between the ruin probabilities
Ψ(x) := P(inft≥0
Z(t)<0),Ψ(x) := P(inft≥0
Z(t)<0).
Under the moment conditions:EZ1 = EZ1; Var(Z1) = Var(Z1);E|Z1|3, E|Z1|3 < ∞ we obtain the following inequality:
ρ(Ψ,Ψ) ≤ c max
supx>0
∣∣∫ x
0
[FZ1(u)−FZ1
(u)]du big|,
12
∫ ∞
0u2|FZ1(u)−FZ1
(u)|du
,
where the constantc is explicitly calculated by means ofγ ,E[N(1)] and first tree power moments ofZ1 andZ1.Also, assuming a certain smoothness of the distribution ofZ1andZ1 we get the stability estimate forZ(t):
ρ(FZ(t),FZ(t))≤c√t
max
ρ(FZ1,FZ1),
12∫ ∞
0u2
∣∣∣FZ1(u)−FZ1(u)
∣∣∣du
.
158 Robust estimation of cDNA microar-ray intensities with replicates [Contributed SessionC40 (page 37)]

110 6th BS/ IMSC
Roger BUMGARNER, Raphael GOTTARDO, Adrian E.RAFTERY and Ka Yee YEUNG,University of Washington,USA
We consider robust estimation of gene intensities from cDNAmicroarray data with replicates. Several statistical methods forestimating gene intensities from microarrays have been pro-posed [2,3,4], but there has been little work on robust estimationof the intensities. This is particularly relevant for experimentswith replicates, because even one outlying replicate can havea disastrous effect on the estimated intensity for the gene con-cerned. Because of the many steps involved in the experimentalprocess from hybridization to image analysis, cDNA microarraydata often contain outliers. For example, an outlying data valuecould occur because of scratches or dust on the surface, imper-fections in the glass, or imperfections in the array production.We develop a Bayesian hierarchical model for robust estimationof cDNA microarray intensities. Outliers are modeled explicitlyusing at-distribution [1], and our model also addresses classicalissues such as design effects, normalization, transformation, andnonconstant variance [2,3,4,5]. Parameter estimation is carriedout using Markov Chain Monte Carlo.The method is illustrated using two publicly available gene ex-pression data sets [6]. The between-replicate variability of theintensity estimates is reduced by 64% in one case and by 83% inthe other compared to raw log ratios. The method is also com-pared to the ANOVA normalized log ratio, the removal of out-liers based on Dixon’s test, and the lowess normalized log ratio,and the between-replicate variation is reduced by more than 55%relative to the best of these methods for both data sets.We also address the issue of whether the image backgroundshould be removed when estimating intensities. It has been ar-gued that one should not do so because it increases variability,while the arguments for doing so are that there is a physical basisfor the image background, and that not doing so will bias the es-timated log-ratios of differentially expressed genes downwards.We show that the arguments on both sides of this debate are cor-rect for our data, but that by using our model one can have thebest of both worlds: one can subtract the background withoutgreatly increasing variability.References[1] Besag, J. E. and D. M. Higdon (1999).Bayesian analysis of agricul-tural field experiments (with discussion).Journal of the Royal StatisticalSociety, Series B 61, 691–746.,[2] Dudoit, S., Y. H. Yang, M. J. Callow, and T. P. Speed (2002).Statis-tical methods for identifying differentially expressed genes in replicatedcDNA microarray experiments.Statistica Sinica 12, 111–139.[3] Ideker, T., V. Thorsson, A. F. Siegel, and L. E. Hood (2000).Test-ing for differentially expressed genes by maximum-likelihood analysisof microarray data.Journal of Computational Biology 7, 805–817.[4] Kerr, M. K., M. Martin, and G. Churchill (2000).Analysis of vari-ance for gene expression microarray data.Journal of ComputationalBiology 7, 819–837.[5] Lewin, A., S. Richardson, C. Marshall, A. Glazier, and T. Aitman(2003). Bayesian modeling of differential gene expression. Technicalreport, Imperial College, London.[6] van’t Wout, A. B., G. K. Lehrma, S. A. Mikheeva, G. C. O’Keeffe,M. G. Katze, R. E. Bumgarner, G. K. Geiss, and J. I. Mullins (2003).Cellular gene expression upon human immunodeficiency virus type 1 in-fection ofCD4+−T−Cell lines. Journal of Virology 77, 1392–1402.
159 Central limit theorems for the numberof records in discrete models [Contributed SessionC7 (page 44)]
R. GOUET, University of Chile, Chile
F.J. LÓPEZ and G. SANZ,University of Zaragoza, Spain
Consider a sequence(Xn) of independent and identically dis-tributed random variables, taking nonnegative integer values andcall Xn a record if Xn > maxX1, . . . ,Xn−1. In Gouet et al(2001), a martingale approach combined with asymptotic resultsfor sums of partial minima was used to derive strong conver-gence results for the number of records among the firstn obser-vations. In this work we exploit the connection between recordsand martingales to establish a central limit theorem for the num-ber or records in a wide range of discrete distributions, identify-ing the centering and scaling sequences.
References
[1] Gouet, R. López, F.J., and San Miguel, M. (2001) A martingaleapproach to strong convergence of the number of records,Adv. Appl.Probab.33, 864–873.
160 Reversible coagulation-fragmentationprocesses: Three different pictures of asymp-totic clustering at the equilibrium [ContributedSession C38 (page 38)]
Boris L. GRANOVSKY , Technion, Israel
We study the asymtotic behaviour of the reversible measure thatdescibes the steady state of a class of coagulation-fragmentationprocesses given by a regular varying parameter functiona(k)∼kp−1L(k), p∈ R, L is a slowly varying function. We prove thatin the study of the asymptotic clustering of groups, the followingthree cases should be distinguished:p < 0- the convergent case;p = 0− the logarithmic case andp > 0- the expansive case.
I will report on results recently obtained in [1]-[4].References[1] Barbour, A. and Granovsky, B. (2003) Random combinato-rial structures: The convergent case, Preprint, math.Pr/0305031,[email protected], .[2] Freiman, G. and Granovsky, B. (2002) Asymptotic formula for a par-tition function of reversible coagulation-fragmentation processes,IsraelJ. Math.130, 259–279.[3] Freiman, G. and Granovsky, B. (2002) Clustering in coagulation-fragmentation processes, random combinatorial structures and addi-tive number systems: Asymptotic formulae and limiting lawas, Tobe published in Transactions of AMS. Preprint, math. Pr/0207265,[email protected], .[4] Erlihson, M. and Granovsky, B. (2003) Reversible coagulation-fragmentation processes and random combinatorial structures: asymp-totics for the number of groups, To be published in Rand. Str. Alg.,Preprint, math.Pr/0212170, [email protected], .
161 Ewens’ sampling formula; a combina-torial derivation [Contributed Session C1 (page 15)]
Robert C. GRIFFITHS , University of Oxford, UK
Sabin LESSARD,University of Montreal, Canada
Ewens’ sampling formula is the probability distribution of thenumber of different types of genes and their frequencies at a se-lectively neutral locus under the infinitely-many-alleles modelof mutation. The coalescent process of Kingman describing thegenealogy of a sample underlies the sampling distribution. Thesampling formula is related to partition structures, with the sam-ple of genes being partitioned by gene types. The limit distribu-tion as the sample size tends to infinity is the Poisson Dirichletprocess, a point process of gene frequenciesx(1) > x(2) > · · · ,with ∑∞
j=1x( j) = 1. The population frequencies can also be or-dered according to the age when they arose by mutation, whichis equivalent to a size-biassed ordering of the gene frequencies.

Abstracts 111
This talk presents an elementary combinatorial proof of theEwens’ sampling formula. The combinatorial approach is usedto extend the sampling formula and the Poisson Dirichlet distri-bution to a model with variable population size. The approachis based on age-ordered gene frequencies, while in the PoissonDirichlet process gene frequencies are labelled in size order.The age distribution of a gene type of current frequencyx is thedistribution of the time back to when the type arose by mutation.The problem is a classical one studied by many authors begin-ning with Kimura and Ohta. The combinatorial approach is anatural way to study genealogy and the age of a mutant gene.
References
Warren J. Ewens (2004)Mathematical Population Genetics, I., The-oretical Introduction, Second Edition, Mathematical Biology series,Springer-Verlag, New York.
162 Probabilistic patterns in gen predic-tion [Invited Session 6 (page 23)]
Robert CASTELO andRoderic GUIGÓ, Institut Municipald’Investigació Mèdica, Barcelona, Catalonia, Spain
Sequencing of genomes is important because the biology of anorganism is determined by the sequence of its genome. The de-tails of this determination are mostly unknown, but in generalthey involve complex (bio)chemical processes that are initiatedby protein synthesis. Many thousand protein species are typi-cally found in an eukaryotic organism. The amino acid sequencecharacteristic of each of them is dictated by the nucleotide se-quence of a unique region within the genome–the so-called gene.Identification of protein coding genes is thus a fundamental stepin the analysis of newly sequenced genomes. Without gene iden-tification there is no link between an organism genome sequenceand its biology.In eukaryotic genomes, genes are not continuos; they occur sep-arated from each other by large non-coding intergenic regions;within a gene, moreover, the sequence actually coding for theprotein is splitted in smaller fragments—the so-called exons—separated by larger non-coding regions. It is currently thoughthat less than 2% of the sequence of the human genome codesfor protein–the remaining mostly of unknown function. Char-acteristic conserved sequences are found that delimit the geneand exon boundaries. Exons in particular are defined by theso-called 3’ and 5’ splice sites. The sequences at these sites,however, are too short and degenerate to allow their unequivo-cal identification, a problem which arises with virtually all typesof DNA functional sites. A way to handle this lack of certaintyis by using a probabilistic model of the functional site that con-sists of a family of probability distributions, from one of whichwe assume the functional sites are drawn from, and therefore, itassigns high probabilities to sequences that resemble the func-tional sites. This probability distribution associated to the func-tional site is more popularly known as a probabilistic sequencepattern.By assuming that the functional sites we observe are samples ofa probability distribution we can use the available probabilisticmethods to try to infer that distribution that should allow us toidentify functional sites along the genome.Given a genomic sequences that forms a candidate functionalsite, one of the most popular, and simple, probabilistic methodsto decide whethers belongs to a setS of real sites, or belongsto a setN of false sites, is the ratio of the likelihood thats∈S ,over the likelihood thats∈N . This ratio is implemented by as-suming that the statistical properties of the functional sites inS
andN can be summarized through two sets of parametersθS
andθN , and hence we write the likelihood ratio as:
λ =LS (s|θS )LN (s|θN )
. (1)
The valueλ is regarded as the likelihood-ratio statistic and,when we considerλ sufficiently small, we discards as a realfunctional site (thus,s ∈ N ). However, in practice the setsof parametersθS and θN are unknown, and can only be es-timated through some training data of confirmed real, and false,functional sites. This implies that we should selectθS andθN
as those that maximize the likelihood functionsLS (s|θS ) andLN (s|θN ).Since the parameters inθS andθN correspond to probabilitiesof observing a particular genomic sequence forming the (real orfalse) functional site, the number of them for which we need toobtain the maximum likelihood estimators (MLE), grows expo-nentially in the number of nucleotides ofs. This makes infea-sible to simply count occurrences of each different site in thetraining data in order to obtain a MLE. A standard approach,commonly known asposition weight matrix(PWM), has been toassume that given a functional site of lengthn, the nucleotidesoccur independently within the site, and thus only3×n param-eters are required.For splice sites, however, the information content of such pat-terns is usually small and the probability of finding them bychance alone is large. During the past years a number of meth-ods have been developed that by taking into account dependen-cies between positions, increase the information content of thepattern, and decrease consequently the probability of findingthem by chance alone. During my talk I will discuss some ofthese methods, and its impact in eukaryotic gene identification.
163 Estimation in a competing risks pro-portional hazards model under length-biasedsampling with censoring [Contributed Session C27(page 36)]
Jean-Yves DAUXOIS,Agathe GUILLOUX CREST-ENSAI,France
The central problem in the analysis of duration data is the ef-ficient estimation of the distribution of the timeZ between twospecified events under different sampling scenarios. The twoevents whose gap time is of interest will be called the initiatingand terminating events. Frequently, the distribution ofZ mustbe estimated from a cross-sectional sample at timet0 consist-ing of subjects who experienced the initiating event, but not theterminating event, prior tot0. As it is well-known, such data suf-fer from length-bias in the sense thatZb, the time gap betweeninitiating and terminating events for a cross-sectionally selectedsubject, is stochastically larger thanZ with dP(Zb < t) propor-tional to tdP(Z < t). This phenomenon, to be referred to aslength-biased sampling (LBS), was noted, for instance, by Cox(1969) and Feinlieb& Zelen (1996).The motivation for the present paper comes from the conjunc-tion of LBS and competing risks (CR). Suppose that the termi-nating event can occur in either of two competing waysA andB e.g.A may be death due to a specific disease, say cancer, andB death from a natural cause. Then the time gap between ini-tiating and terminating events is of lengthZ = X ∧Y whereX(Y) is the latent (potential) survival time associated with riskA(B). However, under LBS,Z is not observable. To be precise,we shall consider the following situation. The observed sampleconsists ofn independent individuals, cross-sectionally selected

112 6th BS/ IMSC
at t0, who were exposed to riskA at known time pointsσi ≤ t0,i = 1, ...,n. These individuals are followed up to a certain timeτand each has the following four possibilities : (i) dies of causeA,(ii) dies of causeB (a natural cause or all causes other thanA),(iii) withdraws from the study, and (iv) is alive and still understudy at timeτ. The possibilities (iii) and (iv) will be referredto as censoring andCi will denote the potential censoring timefor the ith member of the length-biased sample. Similarly,Xb
i(Yb
i ) will denote the potential survival time of the ith subjectwhen facing riskA (B). The sample data thus consists ofn in-dependent pairs(Ti ,δi) whereTi = Zb
i ∧Ci , andδi indicates themode of termination (death due toA, death due toB, censoring).In the general LBS-CR setup, Huang& Wang (1995) consid-ered non-parametric estimation without allowing the possibilityof censoring.Assume, in addition, that the two independent risksA andB haveproportional hazards, i.e. that there existsβ > 0 such that, forall t ≥ 0,
GY(t) = P(Y > t) =(GX(t)
)β
whereGX(t) = P(X > t). The main objective of the present pa-per is the estimation of the survivor functionGX in the LBS-CRsetup described above under this proportional hazards assump-tion. An estimatorˆGX is then developed on the basis of the data(Ti ,δi), for i = 1, . . . ,n. The main result of this paper is the weak
convergence of the process√
n( ˆGx−GX) in the Skohorod spaceD[0,∞]. It is mainly based on technics developed by Dauxois&Guilloux (2004) in the general LBS-CR setup.References[1] Cox, D.R. (1969)New development in survey sampling. Eds. John-son and Smith, Wiley.[2] Dauxois, J.Y. and Guilloux, A. (2004) Estimating the cumulativeincidence functions under length-biased sampling. Submitted andRap-ports techniques du CREST1.[3] Dauxois, J.Y., Guilloux, A., and Kirmani, S.N.U.A. (2004) Submit-ted andRapports techniques du CREST2.[4] Huang, Y. and Wang, M.-C. (1995) Estimating the occurence ratefor prevalent survival data in competing risks models.J. Amer. Statist.Assoc.90, 1406–1415.
164 Statistical control charts of long mem-ory processes [Contributed Session C30 (page 54)]
Meihui GUO and Chi-Ling WANG,National Sun Yat-sen Uni-versity, Kaohsiung, Taiwan, ROC
Long range dependent process occur in many different fields, itis important to establish monitoring system of these process todetect mean or variance shifts. In this paper, we establish statis-tical control charts of ARFIMA(p,d,q) processes. Control limitsof EWMA and EWRMS control charts are derived. The averagerun lengths of these control charts are obtained by simulations.Finally, we establish control charts for several empirical exam-ples, which includes the Nile River’s annual lowest water levels,air pollution index in Hong Kong and the ozon levels in Wash-ington.References[1] Macgregor, J.F. and Harris, T.J. (1993) The exponentially weightedmoving variance,J. Quality Technology25, 106–117.[2] Lu, C.W. and Reynolds, M.R., JR. (1993) Control charts for mon-itoring the mean and variance of autocorrelated processes,J. QualityTechnology31, 259–274.[3]Lu, C.W. and Reynolds, M.R., JR. (1993) EWMA control charts formonitoring the mean of autocorrelated processes,J. Quality Technology31, 166–188.
165 The moment problem for randomsums [Contributed Session C2 (page 24)]
Allan GUT , Uppsala University, Sweden
The moment problem concerns the question whether or not aprobability distribution or random variable is uniquely deter-mined by the sequence of moments, all of which are supposedto exist, finite. A trivial sufficient condition is the existence ofthe moment generating function. A more sophisticated one isthe Carleman condition. A necessary condition in the absolutelycontinuous case is the divergence of the so called Krein integral.One problem is whether or not powers of random variables thatare uniquely determined by their moment sequence remains so.Another one, introduced in a recent paper by Lin and Stoyanov[1] is to consider sums of a random number of independent,identically distributed random variables. In this talk we providepositive answers to three conjectures made in [1] concerning theimpact of (in)determinacy of the summands and the random in-dex on the random sum.References[1] Lin, G.D. and Stoyanov, J.M. (2002) On the moment determinacyof the distributions of compound geometric sums,J. Appl. Prob. 39,545–554.[2] Gut, A. (2003) On the moment problem for random sums,J. Appl.Prob.40, 797–802.
166 Locating lines among scattered points[Contributed Session C37 (page 24)]
Peter HALL , Australian National University, Australia
P.E. MALIN, Duke University, USA
Nader TAJVIDI,Lund Institute of Technology, Sweden
Consider a process of events on a line L, where, for the mostpart, the events occur randomly in both time and location. Ascatterplot of the pair that represents position on the line, andoccurrence time, will resemble a bivariate stochastic point pro-cess in a plane, P say. If, however, some of the points on Larise through a more regular phenomenon which travels alongthe line at an approximately constant speed, creating new pointsas it goes, then the corresponding points in P will occur roughlyin a straight line. It is of interest to locate such lines, and therebyidentify, as nearly as possible, the points on L which are asso-ciated with the (approximately) constant-velocity process. Sucha problem arises in connection with the study of seismic data,where L represents a fault line and the constant-velocity processresults from the steady diffusion of stress. We suggest method-ology for solving this needle-in-a-haystack problem, and discussreal-data applications.
167 Partition distributions for symmetricoverdominance selection [Contributed Session C1(page 15)]
Kenji HANDA Saga University, Japan
We discuss partition distributions in a population genetics modelinvolving natural selection called symmetric overdominance se-lection. They can be regarded as extension of Ewens distribu-tions in the infinitely-many-neutral-alleles model. Approximaterepresentations of this extended family were given in [1]. Ourattempt will be made to obtain certain implicit formula for itby means of the gamma process (e.g. [3]) and Poisson processcalculus [2].References[1] Grote, Mark N. and Speed, Terence P. (2002) Approximate Ewensformulae for symmetric overdominance selection,Ann. Appl. Probab.

Abstracts 113
12637–663.[2] James, Lancelot F. (2002)Poisson process partition calculus withapplications to exchangeable models and Bayesian nonparametrics,arXiv:mathPR/0205093[3] Tsilevich, N., Vershik, A., and Yor, M. (2001) An infinite-dimensional analogue of the Lebesgue measure and distinguished prop-erties of the gamma process,Journ. Funct. Anal.185274–296.
168 Empirical energy minimizers [Con-tributed Session C5 (page 18)]
Patrice BERTAIL,Crest, Laboratoire de Statistique, France
Hugo HARARI , INRA-Corela et Crest, LS, France
Denis RAVAILLE, ENS, Cachan, France
Empirical likelihood has been mainly introduced by Owen(1988). Owen and many other authors (see Owen 2001 for refer-ences) have shown that using this method a non-parametric ver-sion of Wilks’ theorem can be established for many statisticalmodels : the normalized empirical likelihood ratio converges toa χ2 distribution. Tests and non-parametric confidence regionscan thereby be constructed for the parameters of the model. Inparticular, these results have been generalized to many econo-metric models, as soon as the parameters of interest are de-fined by moment constraints (Qin and Lawless 1994, Neweyand Smith 2003), and is actually asymptotically valid for ev-ery multidimensional Hadamard diffentiable parameter (Bertail2003). The empirical likelihood method is now an alternativeto Generalized Moments Method (GMM), see Qin and Lawless(1994) or Newey and Smith (2003). It can also be seen as aempirical inverse problem method in that it minimizes the Kull-back distance between the empirical probability on the dataPn
and a measure (or probability)Q dominated byPn satisfying themodel’s constraints. The use of metrics different from the Kull-back (relative entropy, Cressie-Read discrepancies), leading towhat we call empirical energy minimizers, has been suggestedby Owen (1988)(2001) and many other authors. In this paper wewill focus on three questions:1) Which metrics still keep similar properties to those of Owen’soriginal method (1988)?2) Are there some preferable metrics, from a theoretical or algo-rithmic point of view?3) What are the finite-sample properties of this method?We show with very simple convex-duality arguments( see Bor-wein and Lewis, 1991) that Kullback distance can be replacedby a γ∗-divergence, for every convex functionγ∗ that satisfya few regularity properties. These results apply to more gen-eral discrepancies than the Cressie-Read family. In particularwe study two interesting families of gamma divergence : thePolygamma divergence and the chi2-reguralized Kullback diver-gence. We quickly look to the second question from the point ofview of asymptotic theory, following mainly the work of Bag-gerly (1998) and Corcoran (1998). One outstanding property ofempirical likelihood is that it is Bartlett adjustable, like thelog-likelihood parametric ratio. This means that an explicit normal-ization of thelog of the likelihood ratio by its expectation yieldsthird order properties of the confidence regions. This property isagain a consequence of convex duality properties (see Bertail,2003). The empirical likelihood is the only Cressie-Read tobe Bartlett adjustable, but not the onlyγ−discrepancy with thisproperty as will be seen.We bring a few theoretical arguments using a particular familyof gammma divergence to answer the third question. We illus-trate these results with some simulations for confidence regions
for multidimensional data (p = 2) using different discrepancies.References[1] Baggerly, K.A. (1998) Empirical likelihood as a good-ness of fit measure,Biometrika 85, 535–547, Complète version(1995), available on-line http://www.stat.rice.edu/~kabagg/Research/interpub.html.[2] Bertail, P. (2003) Empirical likelihood in non paramet-ric and semi-parametric models: a survey, to appear in“Semi-parametrics models and applications”, Ed. M. Nikulin.http://www.crest.fr/pageperso/ls/bertail/download.htm[3] Borwein, J.M. and Lewis, A.S. (1991) Duality relationships for en-tropy like minimization problem,SIAM J. Optim.29, 325–338.[4] Corcoran, S.A. (1998) Bartlett adjustment of empirical discrepancystatistics,Biometrika85, 4, 967–972.[5] Newey, W.K. et Smith, R.J. (2003). Higher order properties of GMMand generalized empirical likelihood estimators, to appear.[6] Owen, A.B.(1988). Empirical Likelihood Ratio Confidence intervalsfor a Single Functional.Biometrika, 75, 2, 237-249. Owen, A.B. (2001).Empirical Likelihood, Chapman and hall/CRC.[7] Qin, J. et Lawless, J. (1994). Empirical Likelihood and General Es-timating Equations,Ann. Statist., 22, 300-325.
169 SPDEs driven by Poisson randommeasure [Contributed Session C3 (page 50)]
Erika HAUSENBLAS , Department of Mathematics, Salzburg,Austria
The topic of the talk will be Stochastic Partial Differential Equa-tions (SPDEs) driven by a Lévy process or a Poisson randommeasure, in certain Banach spaces i.e. uniformlyp–smoothableBanach spaces. This are Banach spaces in which most of theprobabilistic theorems necessary for defining a stochastic inte-gral, are valid. For example a Hilbert space is a uniformly2–smoothable Banach spaces.First, a short survey about Lévy processes and Poisson randommeasures in Banach spaces will be given. Then, I will outlineM-type p Banach spaces, stochastic integration in this spaces,and the relation to certain geometric properties of this spaces.Uniformly p–smoothable Banach spaces provides the geometricstructure to carry over the Itô integral and its extension proce-dure and many connections exist between validity of probabilis-tic theorems of Banach space valued processes with indepen-dent increments and the geometric structure of this space. Next,SPDEs driven by Poisson random measure will be introducedand questions about existence and uniqueness of the solutionwill be tackled. Finally, regularity problems of the solution willbe discussed.The talk will based on the works Hausenblas (2003) and Hausen-blas, Seidler (2004).References[1] Hausenblas, E. (2003) Existence, Uniqueness and Regularity ofParabolic SPDEs driven by Poisson Random Measure, submitted.[2] Hausenblas, E. and Seidler, J. (2004) Maximal Inequality forStochastic Convolutions driven by Martingals and Random measures,manuscript.
170 On covariance estimation for high-frequency financial data [Contributed Session M6(page 28)]
Takaki HAYASHI , Columbia University, USA, and The Uni-versity of Tokyo, JAPAN
Nakahiro YOSHIDA,The University of Tokyo, JAPAN
Modeling and analyzing high-frequency data has become impor-tant in finance (Dacorogna,et al.(01)). We consider the problemof estimating the covariance (or correlation) of two diffusionprices when they are observed only atdiscretetimes in anon-

114 6th BS/ IMSC
synchronousmanner.In the literature, it has gained an increasing popularity to usecumulativevariance/covariance estimators (or “realized volatili-ties"), which are the sums of squares/cross-products of intradaylog-price changes measured onregularly-spacedintervals overa day (e.g., Andersen,et al. (01)). In the first half of the talk,we show in a simple setup that the nature of nonsynchronoussampling of prices may potentially cause serious biases for therealized covariance estimators when the length of regular mea-surement intervals decreases. This appears to explain partially aphenomenon reported in the empirical studies, often referred toas theEpps effect(Epps (79)).In the second half, we propose a new estimator which is freeof such biases, by avoiding any “synchronization” processing oforiginal data. In particular, the estimator is shown to be con-sistent as the observation frequency (or the market liquidity) in-creases up to infinity, which is not possessed by the realized co-variance estimators.References[1] Epps, T.W. (1979) Comovements in stock prices in the very shortrun,JASA74, 29–298.[2] Dacorogna, M.M., Gençay, R., Müller U., Olsen, R.B., and Pictet,O.V. (2001)An Intro. to High-Frequency Finance, Academic Press.[3] Andersen, T.G., Bollerslev, T., Diebold, F.X., and Labys, P. (2001)The distribution of exchange rate volatility,JASA96, 42–55.
171 Statistical challenges in space-timesurveillance of infectious diseases[Invited Ses-sion 34 (page 43)]
Leonhard HELD , Michael HÖHLE, Mathias HOFMANN,Günter RASSER and Volker SCHMID,University of Munich,Germany
Routine collection of data on the incidence of infectious diseasesis compulsary in most countries for a large number of diseases,for example influnza, campylobacter or meningitis. Typicallythe counts of cases are reported in areal units and on each dayor week. The data therefore form a multivariate time series withadditional spatial information through the locations and adjacen-cies of the areal units.In this talk I will briefly review concepts currently used in can-cer registries for the detection of outbreaks in infectious diseasesurveillance data. For a recent review see Farrington and An-drews (2003). However, all of these methods do not incorporatea spatial dimension in the data, and I will first discuss generalissues and challanges in spatial outbreak detection (Diggle etal,2003).I will then describe two specific approaches developed in ourresearch group. One method is based on a multivariate spa-tial branching process model with immigration and Poisson off-spring. This model framework has been chosen as an attemptto describe at least qualitatively the outbreak behaviour of in-fectious diseases. Additionally it allows for overdispersion aswell as for seasonal and temporal trends and regional differencesin incidence and population. Statistical inference is done usingMarkov chain Monte Carlo methods.An alternative approach is to predict expected counts (under theassumption of no outbreak) based on historical records and aPoisson generalized linear model with spatial and seasonal com-ponents. The expected counts are then compared with the actu-ally observed data for the time point in question, using meth-ods developed in the area of disease mapping (Besag, York andMollié, 1991, Knorr-Held and Rasser, 2000). Here spatial cor-relation is taken into account in order to increase the statistical
power in outbreak detection. This method is particularly use-ful to detect small increases in incidence in larger subareas, forexample caused by food contamination.The performance of the different methods is illustrated on realdata, obtained from the Robert-Koch-Institut, Berlin, Germany.Support from the German Science Foundation (DFG), SFB 386,Teilprojekt B9, is gratefully acknowledged.References[1] Besag, J.E., York, J.C., and Mollié, A. (1991) Bayesian imagerestoration with two applications in spatial statistics (with discussion),Ann. Inst. Statist. Math.43, 1–59.[2] Diggle, P.J., Knorr-Held, L., Rowlingson, B., Su, T.-L., Hawtin,P., and Bryant, T. (2003) Towords on-line spatial surveillance., In: R.Brookmeyer and D.F. Stroup (eds.),Monitoring the Health of Popula-tions, Oxford: Oxford University Press.[3] Farrington, P. and Andrews, N. (2003) Outbreak detection: Appli-cation to infectious disease surveillance, In: R. Brookmeyer and D.F.Stroup (eds.),Monitoring the Health of Populations, Oxford: OxfordUniversity Press.[4] Knorr-Held, L. and Rasser, G. (2000) Bayesian detection of clustersand discontinuities in disease maps,Biometrics56, 13–21.
172 Efficient semi-parametric estimationof an error-in-covariates with validation sam-ple arising in reliability [Contributed Session C31(page 30)]
Nick HENGARTNER and Alyson WILSON,Los Alamos Na-tional Laboratory, USA
This talk arises from a class of reliability problems encoun-tered at the Los Alamos National Laboratory. Consider that foreach unit, we can either observe the pairs(Z,W), whereZ is apass/fail indicator andW covariates (such as age, manufactur-ing lot, and storage conditions), or the pairs(X,W), whereXis a measurement of some property (“performance”) of the unit.Both type of measurements are destructive, and hence for no unitdo we observe bothX andZ. The goals (1) to understand the re-lationship betweenZ and X and use the latter to evaluate thereliability as a function of the covariates, using both data sets.The central problem reduces to estimatingP[Z = 1|X] from twoindependent samples
D1 = (Wi ,Zi); i = 1, . . . ,nand
D2 = (Wj ,Xj ); j = 1, . . . ,m,for which we are willing to make the surrogacy assumptionP[Z = z|X,W] = P[Z|X].For known conditional distributionF(x|w) of X given W, themaximum likelihood estimatorθ solves the estimating equationWhen the conditional distribution ofX givenW is not known,Reilly and Pepe (1995) propose to use the validation sampleD2to estimate parametrically the score function. We extend theirideas to estimate the score function via nonparametric regres-sion techniques. Armed with such estimates, we then can esti-mate the parameter.The main contribution is that, under suitable regularity condi-tions, this estimatorθ is asymptotically Gaussian with variancethe inverse of the Fisher information forθ with knownF(x|w),which enables us to conclude that this estimator is fully efficient.
References
[1] Reilly and Pepe (1995) A mean score method for missing auxiliarycovariate data in regression models.,Biometrika 82, 299–314.
173 Homogeneity testing of the trajectoriesof a stochastic process[Poster Session P1 (page 22)]

Abstracts 115
J. ARTILES, C.N. HERNÁNDEZ ,I. LUENGO, P. SAAVE-DRA and A. SANTANA,University of Las Palmas de Gran Ca-naria, Spain
A regression model with random effects and fixed designYi j =µ
(t j
)+ ai
(t j
)+ ei j i = 1, · · · , r ; j = 1, · · · ,n is considered,
whereµ (t) is a fixed function,ai (t) are independent realizationsof a stochastic process such thatE [a(t)] = 0 for all t andei j areindependent noise variables at i, but not necessary independentat j. These models emerge when repeated measures are observedon objectsω1, · · · ,ωr randomly chosen from a certain popula-tion at the same time points. The objects are homogeneous withrespect to the measuresYi1, · · · ,Yin whenvar(a(t)) = 0, for all t.Thus, the main purpose of this paper is to testH0 : var(a(t)) = 0.This test is carried out using a statistic test based on the distance1r
r∑
i=1
π∫0
ai (t)2dτ (t), for the same measure t defined on the do-
main of the process. Since the trajectories are not directly ob-
served, we consider the statistics1r
r∑
i=1
π∫0
ai (t)2dτ (t), beingai (t)
a estimate ofai (t). We discuss this problem in the nonparamet-ric context and denote byQi (t) = µ (t) + ai (t) the trajectory
corresponding to objectωi . Let Qi (t) = 1nλ ∑ j K
((t−t j )
λ
)·Yi j
(1) be the kernel estimate, where K is the kernel function andl, the bandwidth. In the same way, we estimate the population
parameterµ (t) by µ (t) = 1nhr ∑i ∑ j K
((t−t j )
h
)·Yi j (2), being
now h the bandwidth. Finally, the trajectoryai (t) is estimatedby ai (t) = Qi (t)− µ (t). Two questions emerge in this analysis,namely: first, the evaluation of the power of the test as a functionof the smoothing parameters l and h, and secondly, the approachof the probability distribution of statistic test under the null hy-pothesis. We analyse these problems considering that I=[0,1], t j = j
n , j = 1, · · · ,n and taking as measureτ (t) the uniformone on the set of design points. Therefore, we defineδ 2
r,n =1nr ∑i ∑ j
Qi
(t j
)− µ(t j
)2. It is easy to prove thatE
[δ 2
r,N
]6
3n
n∑j=0
var
(Qi
(t j
))+mse
(µ
(t j
))+E
[mse
(Qi
(t j
))]. From
this result emerge the fact that the optimum power test is ob-tained when the mean square errors are minimized by meansof optimum bandwidths. Finally, we consider the statistics testD2
r,n = rnδ 2r,n, and approach its probability distribution under the
null hypothesis by the bootstrap.References[1] Härdle, W. and Bowman, A. (1988)Bootstraping i NonparametricRegression: Local Adaptive Smoothing and Confidence Bands.[2] Hart, J.D. and Wehrly, T.E. (1986) Kerne Regression estimation Us-ing Repeated Measurement Data,Journal of the American Statistic As-sociation81, 1080–1088.
174 Censored regression using preliminarykernel smoothing [Contributed Session C27 (page 36)]
Cédric HEUCHENNE and Ingrid VAN KEILEGOM,Univer-sité Catholique de Louvain, Belgium
Consider the heteroscedastic modelY = m(X)+ σ(X)ε, whereε andX are independent,Y is subject to right censoring,m(·)is an unknown but smooth location functional (like e.g. condi-tional mean, median, trimmed mean...) andσ(·) an unknownbut smooth scale functional. It is well known that the com-pletely nonparametric estimator of the conditional distributionof Y given X suffers from inconsistency problems in the righttail (Beran,1981), which might lead to the inconsistency of thecorresponding location estimator. In this paper, we propose a
new way to estimate these location functionals under the abovemodel and we obtain the asymptotic properties of the estimator.Simulations show that the proposed estimator outerperforms theclassical estimator in many cases. Finally, the method is appliedto a study of quasars in astronomy and a practical way to choosethe smoothing parameter (bootstrap procedure) is proposed.References[1] Beran, R. (1981)Nonparametric regression with randomly censoredsurvival data, Technical Report, Univ. California, Berkeley.
175 Asymptotic behaviour of a reaction-difussion equation [Contributed Session C37 (page 24)]
Adrian HINOJOSA , Universidade Federal de Minas Gerais,Brasil
We consider the Glauber + Kawasaki Process, whose macro-scopic limit is a Reaction Difussion equation, with double wellpotential. Recently was proven that there exists an ergodic mea-sure for this process. We prove that the exit time from a localminimizer of the potential follows an exponential law. Also weprove some asymptotics of the ergodic measure.References[1] Brassesco, S., Presutti, E., Sidoravicius, V., and Vares, M.E. (2001)Ergodicity and exponential convergence of a Glauber Kawasaki process.Amer. Math. Soc. Transl. Ser. 2198, 37–49.[2] Brassesco, S., Presutti, E., Sidoravicius, V., and Vares, M.E.(2000) Ergodicity of a Glauber Kawasaki process with metastable states.Markov Process. Related Fields6, 181–203.[3] De Massi, A., Ferrari, P., and Lebowitz, J.L. (1988) Reaction Di-fussion equationsfor interacting particle systems.J. Statist. Phys.44,589–644.
176 Stochastic volatility: what do we learnfrom historical data? [Invited Session 32 (page 33)]
Marc HOFFMANN , CNRS-UMR, France
We consider different issues arising in diffusion stochasticvolatility models, whhen the statistician relies on historical (highfrequency) data solely. Parameter estimation, nonparametric es-timation and the forecasting of some nonparametric functionals(like the pricing of simple European options) is embodied into asingle framework. Instead of advokating in favor of one methodor another, we aim at proving estimation bounds that somehowassess the limitation of inference, based on historical data only.This approach may prove helpful in order to give benchmarks(in a sense to be precised) for other pricing methods, like e.g.calibration.
177 BSiZer for making Bayesian infer-ences about features in scatter plots [Con-tributed Session C56 (page 47)]
Panu ERÄSTÖ,University of Helsinki, Finland
Lasse HOLMSTRÖM, University of Oulu, Finland
A rather common problem of data analysis is to find interestingfeatures, such as local minima, maxima and trends in a scatterplot. Variance in the data can then be a problem and inferencesabout features must be made at some selected level of signifi-cance. The SiZer [1] technique uses a family of nonparamet-ric smooths of the data to uncover features in a whole range ofscales. A color map visualizes the inferences made about thesignificance of the features. This paper presents Bayesian ver-sions of SiZer. The prior distributions of the smooths are basedon a roughness penalty. Simulation based algorithms are pro-posed for making simultaneous inferences about the features inthe data. We call the proposed method BSiZer for “Bayesian

116 6th BS/ IMSC
SiZer”.There are two underlying ideas that distinguish SiZer from othersmoothing based inference tools. First, instead of consideringjust one, in some sense “optimal” bandwidth, a wide range ofsmoothing parameter values are used. Second, instead of con-sidering the “true” underlying curve itself, the inference in factfocuses on its smooths where a “smooth” is defined as the expec-tation of the curve estimator used. The importance of focusingon the smooths instead of the of the underlying curve itself lies inthe fact that it provides a clever way to side-step the ever-presentbias problem in nonparametric curve estimation by defining theobject of interest in such a way that the confidence intervals areprecisely centered on it (cf. Section 2 of [1]).In some applications, making inferences about the smooths ofthe underlying curve is useful also for other reasons. For ex-ample, in reconstructing the past temperature fluctuation overthousands of years [2], different smooths capture variation in theunderlying curve (the true temperature) in different time scalesand inference about the features in the smooths provides evi-dence of climate change in time scales that vary from centuriesto millennia.We formulate our basic method in terms of a discrete regressionmodelyi = µi +εi , i = 1, . . . ,n, where the object of inference arethe valuesµ = [µ1, . . . ,µn]T of some quantity of interest at fixedvalues of an explanatory variable,y = [y1, . . . ,yn]T are their ob-served values, and theεi ’s are errors. In the simplest case theerrors are normally distributed and i.i.d. but generalizations tomore general error structures are also possible. Another exten-sion discussed is allowing errors in the values of the explana-tory variable. In our discrete setting we use the signs of differ-ence quotients instead of derivatives in the search for interestingfeatures in the data. An analogous approach based on smooth-ing splines can readily be developed for a continuous regressionmodel.To describe the basic idea of Bayesian SiZer, consider a smooth-ing parameterλ , a smoothing operatorSλ and a smoothµλ =Sλ µ of µ . Given the datay, Bayesian inference aboutµλ isbased on its posterior densityp(µλ |y). This posterior densitycan be obtained by applying the transformation defined bySλ tothe densityp(µ |y). Posterior density of the difference quotientsof µ can be obtained by yet another transformation. Comparedto the original SiZer our Bayesian approach is mathematicallysimple and it avoids the various approximations used in the con-struction of frequentist confidence bands. Our examples showthat there are also potential data-analytic advantages that make itpossible to find features in situations where the original methodfails.References[1] Chaudhuri, P. and Marron, J.S. (1999) Sizer for Exploration of Struc-tures in Curves,J. Amer. Statist. Assoc.94, 807–823.[2] Holmström, L. and Erästö, P. (2002) Making inferences about pastenvironmental change using smoothing in multiple time scales,Comput.Statist. Data Anal.41, 289–309.
178 A stable marriage of Poisson andLebesgue [Invited Session 18 (page 24)]
Christopher HOFFMAN,Alexander E. HOLROYD and YuvalPERES,University of British Columbia, Canada
Given a point process of unit intensity in the plane, the well-known Voronoi tesselation assigns polygons of different areasto the points by allocating each site in the plane to the closestpoint of the process. The geometry of “fair" allocations (assign-ing unit area to each point of the process) is richer and more
mysterious.There is a unique fair allocation that is a “stablemarriage" in the sense of Gale and Shapley. See“http://www.math.ubc.ca/ holroyd/stable" for a picture. Everypoint of the process is assigned a bounded region with finitelymany components, but it is an open problem to find ANY tailestimate for the diameter of the regions!One application concerns shift-coupling. Consider the randompoint to which the region containing the origin is assigned.Viewed from this location, the point process has the Palm distri-bution.
179 Generalizing the functional ANOVA:diagnostics in machine learning [Contributed Ses-sion C51 (page 27)]
Giles HOOKER, Stanford University, USA
The Functional ANOVA decomposition has become an impor-tant tool for diagnostic interpretation for machine learning. Inthis setting, very flexible models are used to fit functions in highdimensional spaces. These models tend not to be easily inter-pretable as formulas, and therefore some graphical representa-tion of functional behavior is needed.Typically, plots of low-order effects are used to provide an in-terpretable representation of the behavior of a learned function.The variance decomposition also allows us to define measuresfor variable and interaction importance. Diagnostic tools, suchas the partial dependence plots found in [1] can be viewed asperturbations of this decomposition.The Functional ANOVA is usually defined for functions on theunit hypercube and effects are given as partial integrals withrespect to uniform measure. It is easily generalizable to anyproduct measure; assuming independence in the predictors. Inreality, however, machine learning is done using a base set ofpredictors that exhibit complex dependence structures and leavelarge regions of space empty. In these regions of extrapolation,rather than being influenced by data, functional behavior is dic-tated by properties of the modeling procedure and is often highlyvariable. By evaluating such a function on a product distribu-tion, the Functional ANOVA, can place large probability massin these empty regions, distorting the true effect that we wish tocapture.We demonstrate the dangers of using the standard FunctionalANOVA for machine learning diagnostics. We then produce ajoint optimality criterion for all the Functional ANOVA effectsand generalize this to take on an arbitrary weight function thatindicates the degree of confidence we have in the function val-ues. Specifically, this can take the form of a non-product proba-bility distribution.The solution to this generalized criteria maintains some of thedesirable properties of the Functional ANOVA. In particular, itexactly recovers the components of an additive function. Wepresent feasible methods for computing effects and interactionimportance scores in low dimensions along with confidencebounds and show that these produce a representation of func-tional behavior that is robust with respect to extrapolation.
References
[1] Friedman, Jerome H. (2001) Greedy Function Approximation: AGradient Boosting Machine ,Annals of Statistics29(5) 1189–1232.
180 A Lévy generalization of compoundpoisson processes in finance: theory and ap-plications [Poster Session P2 (page 31)]
Enrique ter HORST , Credit Suisse First Boston, England

Abstracts 117
Since Black& Scholes (1973) Mathematical Finance has grownas a branch of mathematicsin its own right. The rejection of the normality of asset returndistributions by Mandelbrot (1963) led toconsideration of Lévy-stable stochastic processes as an interest-ing alternative.Modelling asset returns through a stochasic volatility model,composed of a diffusion and a general Lévy purejump process, is described in Chapter 2. The pricing of Euro-pean options is also considered in Chapter 2, leading toa derivation of conditions that allow us to use the approach ofDuffie et al. (2000), to transform a measure to a risk neutral one.The equivalence between risk-neutrality and no-arbitrage is thenguaranteed by Delbaen and Schachermayer (1994).We perform a Bayesian analysis of a stochastic volatility modelof Barndorff-Nielsen and Shephard (2001), where we treat Lévyjump times and sizes as uncertain and are interested in theirposterior distributions. We also find the posterior distributionof the parameters governing the law of the Lévy subordinator.The computations are done through the Reversible Jump MonteCarlo approach of Green (1995), since we deal with a Lévy purejumps process that has an uncertain number of large jumps.
181 Estimation of value-at-risk using cop-ula and extreme value theory [Poster Session P2(page 32)]
Luiz K. HOTTA , Edimilson LUCAS and Helder P. PALARO,State University of Campinas, Brazil
Value-at-Risk (VaR) is one of the most popular risk measureand play a central role in risk management. Although VaR isa simple measure, it is not easily estimated. There are sev-eral approaches for the estimation of VaR, such as the variance-covariance, the historical simulation and the Monte Carlo ap-proaches. The variance-covariance approach, mainly based onthe Riskmetrics methodology is probably the most widely usedone and adopts the assumption of multivariate normality of thejoint distribution of the assets returns. In this case, the covari-ance matrix is a natural measure of dependence among the assetsand the portfolio variance is a good measure of risk. In financethis rarely is an adequate assumption. The deviation from nor-mality could lead to an inadequate VaR estimate and the portfo-lio could be either riskier than what is desired or unnecessarilyconservative.The theory of copulas is a very powerful tool for modellingjoint distributions because it does not require the assumptionof joint normality. This theory allow us to decompose any n-dimensional joint distribution into its n marginal distributionsand a copula function. Conversely, copulas produce multivari-ate joint distribution combining marginal distributions and thedependence among the variables. Copula has been broadly usedin the statistical literature (see, for instance, [5]) and has beenlargely applied to finance (see, for instance, [1], [2] and [3]).Fortin and Kuzmics [4] used convex linear combinations of cop-ulas in estimating the VaR of a portfolio composed by the FSTEand DAX stock indexes. Recently, Patton [6] extended the un-conditional copula theory to the conditional case and used it tomodel time-varying conditional dependence and the joint distri-bution of returns. Time variations in the first and second condi-tional moments are also widely discussed in the statistical liter-ature, so allowing for temporal variation in the conditional de-pendence in time series seems to be natural.We discuss the application of conditional copula to the estima-tion of VaR in a portfolio with two assets. The marginal dis-
tributions are modelled by AR-GARCH models, the marginaldistributions of the innovations are modelled by empirical dis-tributions and a by a mixture of empirical and GPD distribution,and the joint distribution of the innovations by copula models.We also present some techniques for selecting the appropriatecopula and some diagnostics statistics. The method is appliedto a portfolio composed by Brazilian (IBOVESPA) and Argen-tinean (MERVAL) stock market indices. We estimate the com-plete model by the IFM method. During the copula estimationwe put more emphasis on the extreme observations using a cen-sured type procedure.Finally, we use simulation to test the accuracy of each model inthe VaR estimation. The results are compared with traditionalmethods like univariate GARCH and bivariate GARCH BEKKmodels and univariate and bivariate exponential weighted mov-ing average models. In general, the copula approach gave thebest performance for large confidence VaR estimation.References[1] Bouyé, E., Durrleman, V., Nikeghbali, A., Riboulet, G., and Ron-calli, T. (2003)Copulas for finance, a reading guide and some applica-tions, Working paper, Cass Business School, City University, London.[2] Embrechts, P., Hoing, A., and Juri, A. (2003) Using copulae to boundthe value-at-risk for functions of dependent risks,Finance and Stochas-tics7, 145–167.[3] Embrechts, P., Lindskog, F., and McNeil, A. Modelling dependencewith copulas and applications to risk management, InHandbook ofHeavy Tailed Distributions in Finance, S. Rachev (ed), Elsevier, V8,329–384.[4] Fortin, I. and Kuzmics, C. (2002) Tail-dependence in stock returnspairs, International Journal of Intelligent Systems in Accounting, Fi-nance and Management11, 89–107.[5] Nelsen, R.B. (1998)Introduction to Copulas, New York: SpringerVerlag.[6] Patton A. (2003)Modelling asymmetric exchange rate dependence,Working Paper, University of California, San Diego.
182 On the concentration phenomena forinfinitely divisible laws [Invited Session 12 (page 20)]
Christian HOUDRÉ , Georgia Institute of Technology, Atlanta,USA and University Paris XII, France
I will survey some recent results giving a rather complete un-derstanding of the concentration phenomenon for infinitely di-visible vectors. In the independent case, a dichotomy occurs:Under finite exponential moment conditions dimension free es-timates hold true while it is not the case in general. For norms,complementary lower bounds will also be shown.
183 Multiobjective optimal MCM place-ment based on fuzzy approach [Contributed Ses-sion C34 (page 28)]
Meihui GUO,National Sun Yat-sen Univ., Kaohsiung, Taiwan,ROC
Yu-Jung HUANG I-Shou University Kaohsiung, Taiwan, 84008ROC
A fuzzy analytical model for the optimal component place-ment on the multichip module (MCM) substrate is presented.Our methodology considers multiobjective component place-ment based on thermal reliability as well as routing length cri-teria for multichip module. In this paper, the main design is-sue addressed is on the coupled placement for reliability androutability. The purpose of the coupled placement is to enhancethe system performance and reliability by obtaining an optimalcost during multichip module placement. For reliability consid-erations, the design methodology addressed is on the placement

118 6th BS/ IMSC
of the power dissipating chips to achieve uniform thermal distri-bution. For routability consideration, the total wirelength mini-mization is estimated by the half perimeter method. Case studiesof the coupled placement are presented. In addition, the thermaldistribution of the coupled placement results is simulated withthe finite element method.References[1] Huang, Yu-Jun, Guo, Meihui, and Fu, Shen-Li, (2001) Reliabilityand routability consideration for MCM placement,Microelectronics Re-liability 42, 83–91.[2] Huang, Yu-Jung, Fu, Shen-Li, Jen, Sun-Lon, and Guo, Meihui,(2001) Fuzzy thermal modeling for MCM placementMicroelectronicsJournal32, 863–868.[3] Chu, C.C.N. and Wong, D.F. (1998) A Matrix Synthesis Approachto Thermal Placement,IEEE Trans. Computer-Aided Design17 1166–1174.[4] Queipo, N.V., Humphrey, A.C., and Ortega, A. (1998) MultiobjectiveOptimal Placement of Convectively Cooled Electronic Components onPrinted Wiring BoardsIEEE Transactions on Components, Packagingand Manufacturing Technology -Part (A)21, 142–153.
184 Ecological networks [Invited Session 1 (page19)]
Marianne HUEBNER , Michigan State University, USA
Ecological processes involve many levels, from environmentalinputs, to interacting populations, to genetic determinants. Com-putational models can help interpret the observed dynamics andguide the collection of data. Simulation studies can provideinsights into the relative importance or interplay between fac-tors. This talk addresses design priniciples, dynamic propertiesand challenges encountered in the example of an aquatic host-parasite system.Ecological processes involve many levels, fromenvironmental inputs, to interacting populations, to genetic de-terminants. Computational models can help interpret the ob-served dynamics and guide the collection of data. Simulationstudies can provide insights into the relative importance or in-terplay between factors. This talk addresses design priniciples,dynamic properties and challenges encountered in the exampleof an aquatic host-parasite system.References[1] Hastings, A. and Palmer, M.A. (2003) A bright future for biologists
and mathematicians ,Science299, 2003–2004.[2] Huebner, M., Kroos, L., Chan, C., Sun, F., and Chen, T. (2004) Bi-ological Networks: design and dynamics at different levels,J. Comput.Biol. Submitted.
185 Extremal behavoir for regularity vary-ing stochastic processes[Invited Session 4 (page 23)]
Henrik HULT , University of Copenhagen, Denmark
Filip LINDSKOG, ETH Zürich, Switzerland
We study a formulation of regular variation for multivariatestochastic processes in the spaceD([0,1];Rd). In this frame-work the extremal behavior of a stochastic process is charac-terised in terms of a limit measure. For a wide class of Markovprocesses satisfying a condition of weak dependence in the tails(including regularly varying Lévy processes) the limit measureconcentrates on step functions with one step. From this resultwe may conclude that the extremal behavior of such processesis due to one big jump.In our framework a version of the Continuous Mapping Theo-rem can be proved, which enables the derivation of the tail be-havior of rather general mappings of regularly varying stochasticprocesses. We will give explicit examples including the compo-
nentwise suprema and the mean of multivariate Lévy processes.Using The Continuous Mapping Theorem we can also derive thetail behavior of filtered regularly varying Lévy processes.References[1] de Haan, L. and Lin, T. (2002) On convergence toward an extremevalue limit inC[0,1], Ann. Probab.29, 467–483.[2] Hult, H. (2003)Topics on fractional Brownian motion and regularvariation for stochastic processes, PhD thesis, Royal Institute of Tech-nology, Stockholm, Department of Mathematics.[3] Lindskog, F. (2004)Multivariate extremes and regular variation forstochastic processes, PhD thesis, ETH, Zürich, Department of Mathe-matics.[4] Rosinski, J. and Samorodnitsky, G. (1993) Distributions of subad-ditive functionals of sample paths of infinitely divisible processes,Ann.Probab.21, 996–1014.
186 Remarks on tests of continuity of re-gression functions [Contributed Session C58 (page 55)]
Marie HUŠKOVÁ , Charles University, Czech Republic
The problem to test whether the regression function is smoothversus it has at least one jump in the model of nonparametric re-gression with independent not necessarily identically distributederrors. The proposed test procedures are based on functionals(e.g. supremum) of the difference of the one sided local lin-ear smoothers or of the one sidedM-smoothers. It is shownthat bootstrap provides reasonable approximations for the criti-cal values. The proposed procedure also suggest estimators oflocation of jumps. The choice of the kernel and the bandwidthare discussed.Theoretical properties of the tests are accompanied a simulationstudy and an application to a real data set.References[1] Capek, V. (2004)Tests based onM-smoothers, submitted.[2] Antoch, J., Gregoire, G., and Hušková, M. (2004)Tests for continu-ity of regression functions, in preparation.
187 Inference and filtering for partiallyobserved diffusion processes via sequentialMonte Carlo [Poster Session P2 (page 32)]
Edward IONIDES , University of Michigan, Ann Arbor, USA
Stochastic models involving discrete time sampling of an un-derlying continuous time process, possibly with observation er-ror, arise in many fields. Examples include cell biology, eco-nomics, finance, meteorology, neuroscience and signal process-ing. When the underlying process is Markov and has continu-ous sample paths, the model is called a partially observed dif-fusion process. Questions of interest include reconstruction ofthe unobserved process and estimation of unknown model pa-rameters. Work on these problems goes back at least as far asKalman (1960), in the linear Gaussian case. The widespread useof partially observed diffusion processes, and the desire to an-alyze ever more complex and general models, means that newmethods for inference have potentially many important applica-tions.Partially observed diffusion processes can be viewed as a spe-cial case of state space models (i.e., partially observed Markovprocesses). Sequential Monte Carlo, also known as the ParticleFilter, is a Monte Carlo technique which has been widely ap-plied to state space models (Doucet et al., 2001, and referencestheirin). This work investigates a new class of Sequential MonteCarlo algorithms which takes advantage of special properties ofdiffusion processes. Transition densities of nonlinear diffusionsand conditional nonlinear diffusions are hard to calculate, how-

Abstracts 119
ever diffusion processes are easy to simulate from. Likelihoodratios are also easy to calculate. In addition, nonlinear diffusionsare similar to linear, Gaussian processes locally in space andtime. Questions are raised (and partially answered) concerningthe mixing properties of the “particles,” for which the new al-gorithms differ from standard Sequential Monte Carlo, and thesomewhat surprising ability of the new algorithms to functionwhen the observation error is low or singular. Empirical resultsalso help to explain why and when the proposed algorithms canbe more effective than previous methods.References[1] Doucet, A., de Freitas, N., and Gordon, N., eds. (2001)SequentialMonte Carlo Methods in Practice,Springer-Verlag New York.[2] Kalman, R.E. (1960)A new approach to linear filtering and predic-tion problems, Journal of Basic Engineering82, 35–45.
188 Relative Risk Forests for ExerciseHeart Rate Recovery as a Predictor of Mor-tality [Contributed Session C23 (page 16)]
Hemant ISHWARAN , Cleveland Clinic Foundation, U.S.A.
Recent studies have confirmed heart rate fall after treadmill ex-ercise testing, orheart rate recovery, as a powerful predictor ofmortality from heart disease. Heart rate recovery depends oncentral reactivation of vagal tone and decreased vagal activity isa risk factor for death. If heart rate recovery is defined as thefall in heart rate after one minute following peak exercise, then aheart rate recovery value of 12 beats per minute (bpm) or lowerhas been shown to be a good prognostic threshold for identify-ing patients at high risk. Although this finding establishes a sim-ple, useful relationship between heart recovery and mortality, aworking understanding of how heart rate recovery interacts withother characteristics of a patient in determining risk of death isstill largely unexplored. In addressing this question we analyzea large database of over 23,000 patients who underwent exer-cise testing. A rich assortment of data was collected on thesepatients, including clinical and physiological information, heartrate recovery, and other exercise test performance measures. Ourapproach was to growrelative risk forests, a novel method thatcombines random forest methodology with survival trees grownusing Poisson likelihoods. Our analysis reveals a complex rela-tionship between peak heart rate, age, level of fitness, heart raterecovery, and risk of death.
189 Parametric inference for discretely ob-served non-ergodic diffusions [Invited Session 8(page 14)]
Jean JACOD, Université P. et M. Curie, France
We consider a multidimensional diffusion processX whose driftand diffusion coefficients depend respectively on a parameterλandθ . This process is observed atn+ 1 equally–spaced times0,∆n,2∆n, . . . ,n∆n, andTn = n∆n denotes the length of the “ob-servation window”. We are interested in estimatingλ and/orθ .Under suitable smoothness and identifiability conditions, we ex-hibit estimatorsλn andθn, such that the variables
√n (θn−θ)
and√
Tn (λn− λ ) are tight, as soon as∆n → 0 and Tn → ∞.Whenλ is known, we can even drop the assumptionTn → ∞.WhenTn does not go to+∞ the estimation ofθ at a rate
√n is
a rather old result: see e.g. Donhal [2] or Genon-Catalot andJacod [3]. WhenTn → ∞ and the diffusion is ergodic this isalso a known result: see for example Yoshida [8], Kessler [4],Kessler and Sørensen [5], Aït–Sahalia [1], and also the books ofPrakasa Rao [7] and Kutoyants [6], and indeed in this case one
does not need∆n to go to0. In the non–ergodic situations andwhenTn → ∞, there are so far very few results and most are invery specific cases: see [7] for a review of known results.So the novelty in this paper consists in providing estimatorswhich work, with the above–prescribed rate, without ergodic-ity assumption. The estimators are explicit, although they arebased upon moments of the diffusion which are usually not “ex-plicitely” known as functions of the parameters. Some morecomments are in order:1) In the ergodic case, the variables
√n (θn−θ) and
√Tn (λn−
λ ) indeed converge to some centered Gaussian vectors, and therates are “efficient”. In the non–ergodic case, the rate forλ is ob-viously not efficient: one can consider to this effect an Ornstein-Uhlenbeck process, for which the efficient rate for estimatingthe drift is n in the null–recurrent case and exponential inn inthe transient case.2) However, it is quite likely that the rate
√n for θ is efficient,
and even that√
n (θn− θ) converges in law to some Gaussianvector, in the non–ergodic case as well. This is what happens forexample for the diffusion coefficient of an Ornstein-Uhlenbeckprocess, regardless of the ergodicity or non–ergodicity.3) Apart from the smoothness assumptions, we need some iden-tifiability assumptions for the parameters. These identifiabil-ity assumptions seem quite reasonable when the coefficients arebounded. They are unfortunately much less so when the coeffi-cients have linear growth.References[1] Aït Sahalia, Y. (2002) Maximum-likelihood estimation of discretely-sampled diffusions: a closed-form approximation approach,Economet-rica, 70, 223–262.[2] Dohna,l G. (1987) On estimating the diffusion coefficient,J. AppliedProbab.24, 105–114.[3] Genon-Catalot, V. and Jacod, J. (1993) On the estimation of the dif-fusion coefficient for multi-dimensional diffusion processes,Ann. Inst.H. Poincaré, Probab.29, 119–151.[4] Kessler, M. (1997) Estimation of an ergodic diffusion from discreteobservations,Scand. J. Statistics24, 211–229.[5] Kessler, M. and Sørensen M. (1999) Estimating equations based oneigenfunctions for a discretely observed diffusion process,Bernoulli 5,299–314.[6] Kutoyants, Yu.A. (2003)Statistical Inference for Ergodic DiffusionProcesses, To appear.[7] Prakasa Rao, B.L.S. (1999)Statistical inference for diffusion typeprocesses, Arnold: London.[8] Yoshida, N. (1992) Estimation for diffusion processes from discreteobservations,J. Multivariate Anal.41, 220–242.
190 Bandwidth selection for a pres-moothed density estimator with censoreddata [Contributed Session C54 (page 46)]
Ricardo CAO ABAD,University of A Coruña, Spain
M. Amalia JACOME PUMAR , University of Vigo, Spain
One of the most usual features in survival analysis is the pres-ence of right random censorship: letY be a positive randomvariable with unknown density functionf . In this model, thesurvival timeY is censored to the right by a positive variableC, with unknown density functiong, so we can only observeZi ,δin
i=1 with Zi = min(Yi ,Ci) having density functionh, andδi = 1Yi≤Ci. We consider an estimator for the density whichmakes use of presmoothing ideas, replacing the indicators of nocensoringδ by some preliminary nonparametric estimator ofthe conditional probability of uncensoringp(t) = E(δ/Z = t):
f Pn (t) =
∫Ks(t−v)dFP
n (v) =(
Ks∗FPn
)(t)

120 6th BS/ IMSC
where
1−FPn (t) = ∏
Z(i)≤t
1−
pn
(Z(i)
)
n− i +1
is the presmoothed Kaplan-Meier estimator of the survival func-tion 1−F (·) proposed in Cao, López de Ullibarri, Janssen andVeraverbeke (2004),pn (·) is the Nadaraya-Watson estimatorfor the regression functionp(·) with presmoothing parameterb = bn, andKs(·) = s−1K (·/s) is the rescaled kernel functionK (·) according to the smoothing parameters= sn. Some i.i.d.representation, limit distribution and the asymptotic mean inte-grated squared error for this estimatorf P
n (·) were obtained byCao and Jácome (2004).The almost sure representation of this presmoothed kernel den-sity estimator is presented in this context:
f Pn (t) = f (t)+βn (t)+σn (t)+en (t)
that gives a decomposition off Pn (·) in terms of the true density
function f (·), the bias partβn (·), its variance partσn (·) anden (·) representing the approximation error.Global plug-in bandwidth selectors fors andb are introduced,based on theMISE function, and the consistency of these band-width selectors is shown under certain conditions on the pilotbandwidths, the kernelK (·), the densitiesf (·) andh(·), and onthe functionp(·). Finally, a simulation study was carried out toasses its behavior.References[1] Cao, R. and Jácome, M.A. (2004) Presmoothed kernel density esti-mator for censored data.Journal of Nonparametric Statistics. 16, 289–309.[2] Cao, R., López de Ullibarri, I., Janssen, P., and Veraverbeke,N. (2004) Presmoothed estimators for censored data.Unpublishedmanuscript.[3] Kaplan, E.L. and Meier, P. (1958) Nonparametric estimation for in-complete observations.J. Amer. Statist. Assoc.53, 457–481.
191 Population growth in near-critical ran-dom environments [Contributed Session C1 (page 15)]
Peter JAGERS, Chalmers University, Sweden
Fima C. KLEBANER,Monash University, Australia
Branching processes are studied in random environments thatare influenced by the population size and approach criticality asthe population gets large. Results are applied to the polymerasechain reaction (PCR), which is empirically known to exhibit firstexponential and then linear growth of molecule numbers.Some remarks are made upon the historical role of exponentialgrowth as the canonical growth pattern of populations.
192 Universal optimality of block designsfor competition effects [Contributed Session C43(page 26)]
V.K. GUPTA, Seema JAGGI and Cini VARGHESE,IndianAgricultural Statistics Research Institute, New Delhi
In agricultural field experiments, there may be situations wherein order to control heterogeneity and conserve resources, thetreatments are assessed using small, adjacent units. As a re-sult, the estimates of treatment differences may deviate from thedifferences shown in larger units because of competition fromneighbouring units. For example, inter-varietal competition mayoccur in long narrow plots without guards where the yield of avariety may be depressed by more aggressive neighbouring va-rieties. Competition thus occurs as the responses to treatments
from experimental units are affected by the treatments in neigh-boring units. The competition effects can contribute to variabil-ity in experimental results and lead to substantial losses in effi-ciency. These effects can be estimated and also minimised byproperly organizing the experimental material. Block designsbalanced for neighbour effects have been found quite useful byexperimenters because they lead to simplified ! analysis. Butthese cannot be justified on statistical grounds unless they pos-sess some optimal statistical properties as well. Azais et al.(1993) have obtained a series of neighbour balanced block de-signs in t-1 blocks of size t and t blocks of size t-1, where t isthe number of treatments and their optimality has been studiedby Druilhet (1999). Gill (1993) has studied the optimality of de-signs for estimating local and remote effects in complete blocksetting.This paper deals with optimality aspects of designs for studyingthe competition among treatments applied to neighbouring ex-perimental units in incomplete block setting. Conditions havebeen obtained for the block design to be universally optimal forestimating direct and neighbour effects. Class of block designshave been identified to be universally optimal for the estimationof direct, left and right neighbour effects and It is seen that theuniversally optimal block designs with competition effects in theclasses considered are necessarily balanced. A catalogue of uni-versally optimal designs for v<20 has also been prepared.References[1] Azais, J.M., Bailey, R.A., and Monod, H. (1993) A catalogue of ef-ficient neighbour - design with border plots,Biometrics49, 1252–1261.[2] Druilhet, P. (1999) Optimality of neighbour balanced designs,J. Sta-tistical Plann. Inf.81, 141–152.[3] Gill, P.S. (1993) Design and analysis of field experiments incorpo-rating local and remote effects of treatments,Biom. J.3, 343–354.
193 Towards a general Doob-Meyer de-composition theorem [Contributed Session C11 (page15)]
Adam JAKUBOWSKI , Nicolaus Copernicus University,Torun, Poland
In his seminal papers [5] and [6], P.A. Meyer proved that anysubmartingale belonging to so called class (D) admits a uniquedecomposition into a sum of a uniformly integrable martingaleand a “natural" (nowadays: “predictable") integrable increasingprocess. More than twenty years later, Graversen and Rao [2]obtained a Doob-Meyer type decomposition for processes “withfinite energy", in general without uniqueness. Despite lack ofuniqueness, the latter result is a useful tool in analysis of Markovprocesses [2] and weak Dirichlet processes [1].In the present paper we provide a unifying theorem on exis-tence of a generalized Doob-Meyer decomposition. In partic-ular, we show that the space of processes admitting the gener-alized Doob-Meyer decomposition is larger than the subspacegenerated by the two types of processes mentioned above.The method of proof is similar to that of [3] and is quite differentfrom the classical one. The key step consists in providing an a.s.approximation of the predictable process based on the Komlósresult [4].References[1] Coquet, F., Jakubowski, A., Mémin, J., and Słominski, L. (2004)Natural decomposition of processes and weak Dirichlet processes, sub-mitted.[2] Graversen, S.E. and Rao, M. (1985) Quadratic variation and energy,Nagoya Math. J.100, 163–180.[3] Jakubowski, A. (2003) An almost sure approximation for the pre-dictable process in the Doob-Meyer decomposition theorem, to appear

Abstracts 121
in: Séminaire de Probabilités XXXVIII, Lecture Notes in Mathematics.[4] Komlós, J. (1967) A generalization of a problem of Steinhaus,ActaMath. Acad. Sci. Hungar.18, 217–229.[5] Meyer, P.A. (1962) A decomposition theorem for supermartingales,Illinois J. Math.6, 193–205.[6] Meyer, P.A. (1963) Decomposition of supermartingales: The unique-ness theorem,Illinois J. Math.7, 1–17.
194 Multiscale analysis of Poisson arrivaltimes with time varying intensities [ContributedSession C37 (page 24)]
Maarten JANSEN, TU Eindhoven, The Netherlands
We present a multiscale analysis of arrival times of a Poissonprocess with time varying intensities. The objective is to iden-tify the exact change points in the intensity curve. To this end,we first bin together the observed arrivals into Poisson countswith time dependent intensities. This binning process, when per-formed in an iterative way, can be regarded as a Haar (wavelet)transform, up to an intermediate scale. From this intermediatescale, the analysis proceeds in two directions. First, a globalintensity curve is fitted through the given binned counts, usinga further wavelet decomposition and a Poisson adapted non-linear normalisation, called Conditional Variance Stabilisation[2]. This method is fast and generalises and combines ear-lier methods [1,3]. We also explore a Bayesian approach withDirichlet priors for the normalised wavelet coefficients. Second,details on the exact change point location are further filled inby going the other direction, i.e., back to the finer scales. Inboth directions (scale up and down), we investigate a tree struc-tured coefficient selection. The implementation details of thistree structured algorithm are however slightly different in bothdirections, in order to conciliate a smooth reconstruction witha sharp singularity localisation. A parameter to assess in thisprocedure is also the choice of the intermediate resolution level.This choice is directed by the application: if the data have finescale features to be detected, one needs a full wavelet thresholdprocedures up to fine scales. Otherwise, one can concentrate onrefining details on features detected at coarse scales.References[1] Fryzlewicz, P. and Nason, G. (2004) A wavelet-Fisz algorithm forPoisson intensity estimation,J. Comp. Graphical Statistics,to appear.[2] Jansen, M. (2003)Multiscale Poisson data smoothing, Technical Re-port SPOR 2003-29, TU Eindhoven, Submitted.[3] Kolaczyk, E.D. and Nowak, R.D. (2004) Multiscale likelihood anal-ysis and complexity penalized estimation,Ann. Statist.to appear.
195 On the equivalence of two expected av-erage cost criteria for semi-Markov controlprocesses[Contributed Session C23 (page 16)]
Anna JASKIEWICZ , Politechnika Wrocławska, Poland
In this paper we study two basic optimality criteria used in thetheory of semi-Markov control processes. According to the firstone, the average cost is thelimsup of the expected total costsover a finite number of jumps divided by the expected cumu-lative time of these jumps. According to the second definition,the average cost is thelimsup of the expected total costs overthe finite deterministic horizon divided by the length of the hori-zon. We call them theratio-average costandtime-average cost,respectively. It is known that in general these two criteria mayhave nothing to do with each other. In other words, they maylead to different costs and optimal policies. The ratio-averagecost is somewhat easier to study and has been used by manyauthors in zero-sum semi-Markov games and in dynamic pro-gramming.
Recently, some results concerning the optimality equation forsemi-Markov decision processes with Borel state space and theratio-average criterion were given. However, an equivalence re-sult has been reported so far for the Borel (uncountable) statespace models.The aim of this paper is to show the equivalence between two ex-pected average costs under some geometric ergodic conditions.At the same time, we prove that the optimality equations for themodels with these criteria are the same.Our proof is based on [1] employs basic facts from renewal the-ory. Certain consequences ofV-geometric ergodicity enable usto apply the optional sampling theorem of Doob, which is thecore of the proof.
References
[1] Jaskiewicz, A. (2004)On the equivalence of two expected averagecost criteria for semi-Markov control processes,Mathematics of Opera-tions Research.
196 Cross-estimate and tightness for non-symmetric Markov processes [Poster Session P2(page 31)]
Yiwen JIANG and Guangshan LI,Wuhan Military EconomicsAcademy, China
We extend the cross-estimate of Lyons-Zheng Markov pro-cesses from the symmetric case to the general stationary situ-ation. Let (Xt)t∈[0,T] and (XT−t)t∈[0,T] are continuous strongMarkov processes, we have the following crossing estimateIEN([0,T],X·,F,G)≤ 9TeF→G, whereeF→G is the energy fromF to G. As corollaries we obtain a tightness result for laws ofMarkov processes. The main tool is the forward-backward mar-tingale decomposition. Finally we give an example to show howto obtain the crucial cross-estimate.
197 Reduced bootstrap for sample quan-tiles [Poster Session P3 (page 41)]
M. Dolores CUBILES DE LA VEGA,M. Dolores JIMÉNEZGAMERO , Joaquín MUÑOZ GARCÍA and Rafael PINOMEJÍAS,Universidad de Sevilla, Spain
Let X1,X2, . . . ,Xn be a random sample from a univariate pop-ulation with distribution functionF . Let 0 < ξ < 1 and letθ = inft/F(t) ≥ ξ be the populationξ th quantile. IfF hasa positive derivativef atθ and f (θ) > 0, thenZn =
√n(θn−θ)
converges weakly toN(0,σ2), whereθn is the sampleξ th quan-tile, θn = inft/Fn(t)≥ ξ, Fn is the empirical distribution func-tion of the sample andσ2 = ξ (1− ξ )/ f 2(θ). If f (θ) wereknown, one could approximate the distribution ofZn by its weaklimit and estimate its variance by its asymptotic varianceσ2.However, f is rarely known.Another way to approximate the distribution and the varianceof Zn is by the bootstrap. Bickel and Freedman [2] have shownthat, under the above stated condition, the bootstrap estimatesconsistently the distribution ofZn. Nevertheless, Ghosh, Parr,Singh and Babu [3] have proved that the bootstrap variance ofZn may not be a consistent estimator ofvar(Zn). This is causedby the fact thatZ∗n, the bootstrap version ofZn, may take someexceptionally large values. To solve this inconsistency one canassume additional conditions onF (Babu [1], Ghosh, Parr, Singhand Babu [3]), modify the original sample (Ghosh, Parr, Singhand Babu [3]), modify the usual bootstrap variance estimator(Shao [6], Shao [7]) or modify the resampling scheme generat-ing the bootstrap samples (Jiménez-Gamero, Muñoz-García andMuñoz-Reyes [4], Jiménez-Gamero, Muñoz-García and Pino-Mejías [5]).

122 6th BS/ IMSC
In this paper we consider the method in [5], the reduced boot-strap, in short RB, which consists of only considering thosebootstrap samples verifyingk1 ≤ νn ≤ k2, for some1≤ k1 ≤k2 ≤ n. The main advantage of RB over usual bootstrap is that,for adequate choices ofk1 andk2, the breakdown point of the RBversion ofZn is greater than the one of usual bootstrap, whichis 1/n regardless of the breakdown point of the estimator. Thisway, the RB bootstrap variance estimator is not affected by theexceptionally large values thatZ∗n may take.Jiménez-Gamero, Muñoz-García and Pino-Mejías [5] haveshown that, forξ = 1/2 and certain choices ofk1 andk2, theRB estimator of the distribution ofZn has the same asymptoticaccuracy as the usual bootstrap estimator and that, in contrast tousual bootstrap, the RB estimator of the variance ofZn is con-sistent without imposing more conditions onF . The aim of thispaper is to generalize these results for arbitraryξ .References[1] Babu, G.J. (1986) A note on bootstrapping the variance of samplequantiles,Ann. Inst. Statist. Math.38, 439–443.[2] Bickel, P.J. and Freedman, D.A. (1981) Some asymptotic theory forthe bootstrap,Ann. Statist.9, 1196–1217.[3] Ghosh, M., Parr, W.C., Singh, K., and Babu, G.J. (1984) A note onbootstrapping the sample median,Ann. Statist.12, 1130–1135.[4] Jiménez-Gamero, M.D., Muñoz-García, J., and Muñoz-Reyes, A.(1998) Bootstrapping the sample median,Commun. Statist.-TheoryMeth. 27, 1979–1990.[5] Jiménez-Gamero, M.D., Muñoz-García, J., and Pino-Mejías, R.(2004)Reduced bootstrap for the median,To appear in Statistica Sinica.[6] Shao, J. (1990) Bootstrap estimation of the asymptotic variance ofstatistical functionals,Ann. Inst. Statist. Math.42, 737–752.[7] Shao, J. (1992)Bootstrap variance estimators with truncation, Statist.Prob. Letter15, 95–101.
198 Continuous-time signal filtering framuncertain observations with white pluscoloured noise [Poster Session P1 (page 22)]
A. HERMOSO-CARAZO and J. LINARES-PÉREZ,Universi-dad de Granada
J.D. JIMÉNEZ-LÓPEZ , Universidad de Jaén, Spain
S. NAKAMORI, Kagoshima University, Japan
The least mean-squared error (LMSE) linear estimation prob-lem of signals in stochastic systems has been usually solved bymeans of algorithms based on Riccati-type equations. Nev-ertheless, the interest in finding fast estimation algorithmshas led many authors to replace those equations by a set ofChandrasekhar-type ones. In this sense, for continuous-timeinvariant systems, Kailath [1] proposed a Chandrasekhar-typealgorithm which improves computationally the Kalman filtersince it reduces the number of differential equations includedin it. From this work, there have been many authors who haveproposed Chandrasekhar-type algorithms to solve different es-timation problems. For example, Nakamori [2] has recentlyproposed a Chandrasekhar-type algorithm to estimate a wide-sense stationary signal from observations perturbed by whiteand coloured additive noises but assuming, in contrast to [1],that the state-space model is not completely known and usingconvariance information about the processes involved.
On the other hand, in the last decades, the estimation problemin systems with uncertain observations has been widely studiedsince there are many practical situations which can be modelledby this kind of systems. The main characteristic of these onesis that the observations may contain signal plus noise or onlynoise in a random manner. This fact is reflected in the obser-vation equation by including a multiplicative noise, described
by Bernoulli random variables. For these systems, differentestimation algorithms have been developed; for example, inthe discrete-time case, NaNacara and Yaz [3] have proposed aRiccati-type algorithm assuming that the state-space model iscompletely known and, more recently, Nakamori et al. [4] haveobtained a Chandrasekhar-type filtering algorithm for wide-sense stationary signals from uncertain observations withoutusing the state-state model but covariance information.
In this paper we generalize the results in [2] to the case of sys-tems with uncertain observations; assuming that the Bernoullirandom variables are independent and that the state-space modelof the signal is not available, we derive a Chandrasekhar and aRiccati-type algorithm using only the knowledge of the systemmatrices for the state and the coloured noise, the crosscovari-ance function of the state and the signal, the autocovariancefunction of the coloured noise and the probability that the signalexists in the observations. By comparing both algorithms it isdeduced that the Chandrasekhar-type one is computationallymore advantageous.References[1] Kailath, T. (1973) Some new algorithms for recursive estimation inconstant linear systems,IEEE Transactions on Information Theory, IT-19, 750–760.[2] Nakamori, S. (2000) Chandrasekhar-type filter using covariance in-formation for white Gaussian plus colored observation noise,Signal Pro-cessing80, 1959–1970.[3] NaNacara, W. and Yaz, E.E. (1997) Recursive estimator for linearand nonlinear systems with uncertain observations,Signal Processing62, 215–228.[4] Nakamori, S., Hermoso, A., Jiménez, J., and Linares, J. (2004)Chandrasekhar-type filter for a wide-sense stationary signal from uncer-tain observations using covariance information,Applied Mathematicsand Computation151(2), 315–325.
199 Growing Gaussian models[Wald LecturesI, II and III (pages 28, 38 and 48)]
Iain JOHNSTONE , Stanford University, USA
A common thread in these lectures will be finite dimensionalGaussian distributions whose dimensionp grows with samplesizen. The first two concern estimation of means and the thirdinference about covariance structure.
I. Function Estimation and Good Old Normal Theory
The Gaussian location model has, through asymptotic approx-imation, long provided a foundation for parametric estimationand inference. Multiresolution systems like wavelets make itpossible to study non-parametric function estimation by assem-bling results from growingfinite dimensionalGaussian locationmodels. This introductory talk will illustrate the approach by ex-amples such as: James-Stein and kernel methods; thresholdingand sparsity; Bernstein-von Mises and posterior distributions.
II. The Threshold Selection Problem
As reviewed in the previous talk, estimation of a function canbe improved by taking advantage of a sparse or parsimoniousrepresentation by using, say, thresholding. Roughly, sparse sig-nals call for high thresholds and “dense” signals for no or lowones. A basic problem, then, is to determine threshold sizes em-pirically from data when the degree of sparsity is unknownapriori . The status of several attempts (e.g. false discovery rates,unbiased risk, empirical Bayes) will be reviewed.
III. Large Covariance Matrices
This talk, although continuing the growing Gaussian theme, isindependent of the first two. We first review the role of sample

Abstracts 123
eigenvalues in some classical methods of multivariate statistics,such as principal components and canonical correlation analy-sis. Results from random matrix theory can provide practicallyuseful approximations when the ratio of the number of variables(p and q) to sample sizen is not necessarily small. For con-creteness, we focus on the limiting distribution for the largestprincipal component variance and the largest canonical correla-tion in “null hypothesis” settings when the data matrices haveindependent standard Gaussian entries.
The talks are based on collaborations with F. Abramowich, Y.Benjamini, D. Donoho, P. Forrester, G. Kerkyacharian, D. Paul,D. Picard and B. Silverman.
200 Optimal stopping strategies for Amer-ican type options [Contributed Session M3 (page 34)]
Henrik JÖNSSON, Mälardalen University, Sweden
Alexander KUKUSH,Kiev University, Ukraine
Dmitrii SILVESTROV, Mälardalen University, Sweden
The structure of optimal stopping strategies is described forAmerican type put and call options with convex pay-off func-tions. The model of pricing process under consideration is a dy-namical Markov processSn = An(Sn−1,ξn), n = 1,2, . . ., whereξn,n = 1,2, . . . is a sequence of independent random variables.Pay-off functions under consideration are: (a) an inhomoge-neous in time analogues of a standard pay-off functions thatis gn(x) = an[x−Kn]+, (b) inhomogeneous in time piecewiselinear convex functions, and finally (c) general convex func-tions. As is known, the optimal stopping time should be of theform τ∗ = min(n : Sn ∈ Dn). We show that under some natu-ral monotonicity and convexity conditions imposed on the tran-sition dynamical functions, the optimal stopping domains haveone-threshold structure, i.e.Dn = [dn,∞), in case (a). How-ever, optimal stopping domains may be of a multi-thresholdstructure, i.e. be unions of disjoint intervals, in case (b). Fi-nally, ε-optimal strategies are described via approximation ofthe corresponding pay-off functions by piecewise linear func-tions in case (c). Similar results are presented for continuoustime models and skeleton type approximations connecting con-tinuous and discrete time models. Sufficient conditions, whichprovide one-threshold structure for optimal stopping strategies,are given. It is proved that the optimal stopping domains havea one-threshold structure if the derivative of the expected fu-ture profit exists a.e. with respect to the asset price and thisderivative is less than the derivative of the payoff function, i.e.g′n−1(x)≥ e−Rn d
dx(Egn(An(x,ξn))) a.e. with respect tox. Theseand related results let us, for example, answer the question aboutthe critical values of the slopes of piecewise linear pay-off func-tions. At these values the structure of optimal stopping domainsswitches from one-threshold to multi-threshold type. These re-sults are illustrated by experimental computer studies. Partly,results can be found in [1]-[2].References[1] Kukush, A.G. and Silvestrov, D.S. (2004) Optimal pricing for Amer-ican type options with discrete time,Theory Stoch. Proces.10(25),No.1-2 (to appear).[2] Jönsson, H., Kukush, A.G., and Silvestrov, D.S. (2002) Thresholdstructure of optimal stopping domains for American type options, InProceedings of the Conference Dedicated to 90th Anniversary of B.V.Gnedenko, Kyiv, 2002 / Eds. V. Korolyuk, Yu. Prokhorov, V. Khoklov.Theory Stoch. Proces,8(24), 1-2, 170–177.
201 Variational inference algorithms forlarge-scale probabilistic models: An alterna-
tive to MCMC [Invited Session 29 (page 29)]
Michael I. JORDAN , University of California, Berkeley, USA
Martin WAINWRIGHT, University of California, Berkeley, USA
Markov chain Monte Carlo (MCMC) has played an importantrole in statistics in recent years. MCMC is not a panacea, how-ever, and it is important to explore other methods for proba-bilistic inference, particularly in the setting of models aimedat large-scale data analysis problems. One general approach,like MCMC having its origins in statistical physics, is providedby variational methodology. Variational methods express com-putations as the solutions to optimization problems, and deriveapproximations by “relaxations” of this optimization problem.These methods are particularly powerful in the context of ex-ponential family distributions, where tools from convex analy-sis and convex optimization come into play. They also are alsonatural in the setting of graphical models, where the graphicalstructure of the model can aid in developing relaxations. I thustell a story with three interrelated themes: exponential families,graphical models and variational inference. I will illustrate theseideas with examples taken from bioinformatics and informationretrieval.
202 Clustering gene expression data basedon p-values [Contributed Session C40 (page 37)]
Rebecka JÖRNSTEN, Jun LI and Regina LIU,Rutgers Uni-versity, USA
Clustering is an important task in the analysis of microarray geneexpression data. Finding groups of co-regulated genes assists inassigning functions to genes, and can increase the understand-ing of the distinction between experimental conditions. In manymicroarray experiments, gene expression data consists of n re-peated measures in C multiple conditions. However, when genesare clustered this experimental setup is largely ignored. One ap-proach is to cluster genes based on their average-across-replicateprofiles, i.e. cluster in C dimensions. Another is to ignore thatreplication is present and cluster in nC dimensions. The first ap-proach can be preferred due to the high noise level in the data,but the drawback is that experimental variability is disregarded.The second approach has other limitations. This approach toclustering can be driven by spurious patterns, and outliers. In or-der to reflect the exact experimental setup and take the variabilityof the data into account, we propose a new clustering method-ology, which groups genes by testing the equality of the meanand/or variance vectors across experimental conditions. We usethe P-value from this test as a measure of dissimilarity betweentwo (or two groups of) genes, in which a small P-value indicatesthat the mean and/or variance vectors differ significantly.Based on the P-values obtained from pairwise tests of all genes,we develop a new clustering algorithm, starting with the pairwhose pairwise P-value is the smallest. To determine the crite-rion for grouping the genes, which is essentially equivalent todetermining how homogeneous the genes are within the clus-ter, Fisher’s method for combining P-values is used. Only if thecombined pairwise P-value associated with the genes in the clus-ter is greater than some preset value, are those genes groupedtogether. By this cluster-building procedure, the final combinedP-values for the candidate clusters can also be used for valida-tion.Our clustering method based on P-values of tests provides aproper statistical framework for the problem of clustering geneexpression data with repeated measurements. The P-value-basedmeasure of dissimilarity provides a standardized way to assess

124 6th BS/ IMSC
the strength of association between genes. It is less arbitrarythan the existing choices such as Euclidean, correlation etc, andcan be calibrated for different separating criteria. Our clusteringalgorithm using P-values is also supported by statistical justifi-cation. This is an advantage over most existing clustering al-gorithm which are generally exploratory in nature. Our methoduses the combined P-values for cluster validation, and hence hasthe built-in ability to carry out automatic model selection. Wehave applied our clustering methodology to simulated and pub-licly available gene expression data sets, as well as data from acomparative drug study conducted at the Keck center for Col-laborative Neuroscience at Rutgers. The preliminary findingsappear to be quite supportive of the proposed methodology.References[1] Kaufman, L. and Rousseuw, P.J. (1990)Finding groups in data: andintroduction to cluster analysis,Wiley, NY.[2] Pan, J., Jornsten, R., and Hart, R. (2004)Screening anti-inflammatory compounds in injured spinal cord, Revised for Physio-logical Genomics[3] Tibshirani, R., Walther, G., and Hastie, T. (2000)Estimating thenumber of clusters in a data set via the gap statisticTechnical report,Stanford University.
203 Optimal contributions and portfolioselection in a pension funding with stochas-tic salaries [Poster Session P2 (page 31)]
Ricardo JOSA-FOMBELLIDA and Juan Pablo RINCON ZA-PATERO,Universidad de Valladolid, Spain
The dynamically optimal management of pension plans has con-siderable economic interest, due to the great importance thatthe world of pensions provision has acquired in financial mar-kets. This subject is discussed in the literature; see, for example,Deelstra, Graselli and Hoehl (2000, 2003), Haberman and Sung(1994), Josa–Fombellida and Rincón–Zapatero (2001) and Tay-lor (2002).In this paper we consider the optimal management in an agre-gated dynamic pension fund of an employment system. ThereareN workers whose salaries are described by a system of SDE(stochastic differential equations). A portion of salary is con-tributed to the pension fund. The plan sponsor invests the fundin a portfolio withn risky assets and a risky–free security. Themain objective is to minimize the cost of contributions in a fi-nite horizonT and to maximize the expected utility functionof the terminal wealth. We assume a separable instantaneousutility function. The optimal contributions policy and the opti-mal investment strategies are obtained explicitly when the salaryprocesses are geometric Brownian motions and the final utilitybelong to the CRRA (constant relative risk aversion) family.References
[1] Deelstra, G., Grasselli, M., and Koehl, P.F. (2000) Optimal invest-ment strategies in a CIR model,Journal of Applied Probability37, 936–946.[2] Deelstra, G., Grasselli, M., and Koehl, P.F. (2003) Optimal invest-ment strategies in the presence of a minimum guarantee,Insurance:Mathematics and Economics33, 189–207.[3] Haberman, S. and Sung, J.H. (1994) Dynamics approaches to pen-sion funding.Insurance: Mathematics and Economics15, 151–162.[4] Josa–Fombellida, R. and Rincón–Zapatero, J.P. (2001) Minimizationof risks in pension funding by means of contribution and portfolio selec-tion, Insurance: Mathematics and Economics29, 35–45.[5] Taylor, G. (2002) Stochastic control of funding systems,Insurance:Mathematics and Economics30, 323–350.
204 Perturbations of the symmetric exclu-
sion process [Contributed Session C9 (page 20)]
Paul JUNG, Cornell Math Dept, Ithaca, NY, USA
This paper gives results concerning the asymptotics of the invari-ant measures,I , for exclusion processes wherep(x,y) = p(y,x)except for finitely manyx,y ∈ S and p(x,y) corresponds toa transient Markov chain onS . As a consequence, a com-plete characterization ofI is given for the case wherep(x,y) =p(y,x) for all but a single ordered pair(u,v). Also, this paperaddresses the question: When do local changes to a symmet-ric kernel p(x,y) = p(y,x) affect the evolution of the exclusionprocess globally?
References
[1] Jung, P. Perturbations of the Symmetric Exclusion Processwww.math.cornell.edu/˜ pjung/perturbations.pdf
205 Robust estimates, admissibility andshrinkage [Contributed Session C49 (page 26)]
Jana JURECKOVÁ Charles University in Prague, Czech Re-public
The robust estimates are usually considered with respect to theirbreakdown point, global sensitivity, maxbias and asymptoticvariance, and their performance is compared with that of clas-sical estimates under the normal model. We shall discuss therobust estimates from more viewpoints of the estimation theory.Many robust estimates of location and regression are inadmissi-ble for any probability distribution with respect to standard lossfunctions and they even cannot be Bayesian (Jurecková and Kle-banov (1997, 1998)). Then they are obviously not admissible inthe multivariate models and their asymptotic quadratic risk canbe often shrunken, at least in a
√n-neighborhood of the true pa-
rameter value (Jurecková and Milhaud (1993)) and Jureckováand Sen (1996)). Because even the Pitman estimator is not ad-missible in the multivariate normal model, we should discuss theinteresting question with which class of estimates should be therobust estimates compared.References[1] Jurecková, J. and Klebanov, L.B. (1997) Inadmissibility of robust es-timators with respect toL1-norm,L1- Statistical Procedures and RelatedTopics (Y. Dodge, ed.).IMS Lecture Notes - Monogr. Ser. 31, 71–78.[2] Jurecková, J. and Klebanov, L.B. (1999) Trimmed, Bayesian and ad-missible estimators,Statist. Probab. Lett.42, 47–51.[3] Jurecková, J. and Milhaud, X. (1993).Shrinkage of maximum like-lihood estimators of multivariate location.Asymptotic Statistics, Proc.5th Prague Symp. (P. Mandl and M. Hušková, eds.), 303–318.[4] Jurecková, J. and Sen, P. K. (1996).Robust Statistical Procedures:Asymptotic and Inter-Relations,J. Wiley, New York.
206 On the Chernoff bound for efficiencyof quantum hypothesis testing [Contributed Ses-sion C46 (page 46)]
Vladislav KARGIN , Cornerstone Research, USA
The quantum statistic is a rapidly growing area of modern statis-tics (see [1] and [2]). The paper contributes by estimating theChernoff-Hoeffding rate for the efficiency of testing hypothesesabout quantum states.On of the open problem of quantum statistics is to find outwhether the joint measurements on a sample of quantum statescan outperform separate measurements of each state in the sam-ple. This paper derives exact expressions and bounds on theChernoff-Hoeffding rates of testing efficiency for both joint andseparate measurements. The exact espressions are derived if atleast one of the states is pure and the approximate bounds are

Abstracts 125
given if both states are mixed. The rates and bounds are givenin terms of the geometrical properties of quantum states. Thederived expressions are then used to compare efficiency of jointand separate measurements.In detail, for the case of joint measurements and pure states, theasymptotic rate is,
1N
logR∼ 2log|〈ψ0| ψ1〉|asN→ ∞. (1)
If only one of the states is pure then
1N
logR∼ log〈ψ0|ρ1 |ψ0〉 ,asN→ ∞. (2)
If both states are mixed then the following inequality holds
2logF (ρ0,ρ1) . 1N
logR. logF (ρ0,ρ1) ,
asN→ ∞,(3)
where
F(ρ0,ρ1) = tr√√
ρ0ρ1√
ρ0 (4)
is fidelity between two states.For separate measurements there is a measurement with a sim-ple structure and the optimal asymptitotic rate. In caseof purequantum states the asymptotic rate is the same as for joint mea-surements. For the mixed states it is proved that
1N
logR. logF(ρ0,ρ1). (5)
The results are illustrated by a test of quantum entanglement.References[1] Barndorff-Nielsen, O.E., Gill, R.D., and Jupp, P.E. (2003) On Quan-tum Statistical Inference,J. R. Statist. Soc. Ser. B Stat. Methodol.65,775–805.[2] Gill, R.D. (2001)Asymptotics in Quantum Statistics, in State of theArt in Probability and Statistics, Volume 36 in IMS Lecture Notes -Monograph Series, 255–285.
207 Periodic long memory models [Con-tributed Session C30 (page 54)]
Mohamed BENTARZI,University of Algiers (U.S.T.H.B), Alge-ria
Belaide KARIMA , University of Bejaia, Algeria
The independance of the observed random variables is the firsthypothesis taken in account by the statisticiens. In general, thishypothesis is only an approximation of the reality. Effectively, ifwe assume the independence of the random variables which arein fact correlated, then the errors produced may have a non ne-glected effects. Hence, it is necessary to construct models whichtakes in account this weak correlations. For this, we introducethe class of models of short memories.However, this class is insufficient in the modelization field. Ef-fectively, if we are interesting for modelization by the corre-lated random variables which presented the decreasing corre-lation ρ (k) ∼ |k|α , with α ∈ [0,1], then the correlation are nonsommable. This phenomena is called long memory and have thenegative effects in the case when we assume the independenceof the random variables. Therefore, the idea to consider the pro-cess with long memory is naturel.GRANGER and JOYEUX (1980), HOSKING (1981) have in-troduced the ARIMA model with fractionnel differentiation(AFRIMA) in order to describe the long memory behavior ofsome time series which met in economy, hydrology,... as like as
the price conception may present a strong dependence. A Pro-cess is called with long memory if the autocorrelation functionis such thatρ (k)∼ ck2d−1, for k tends to infinity andc > 0 andd < 1/2.Recently, much attention have been considered for the time se-ries models with periodic coefficient. These models, are veryimportant in particular in economy (LUTKEPOHL 1991 a andb, GHYSELS and HALL 1992 a, and FRANSES 1993), hydrol-ogy or in spatial study.In this paper, we are interesting about the fractionary autoregres-sive long memory model with order 1 (FAR(1)). We establishthe relation sheep between the periodic fractionary autoregres-sive processes with order 1 and the multivariatestationary processes with constant coefficients.After this, We will give a sufficient condition (not necessary) ofcausality and inversibility. The propriety LAN (Normal LocalAsymptotic), using the lemma of SWENSEN (1985). Moreover,we obtain the quadratic decomposition (LAQ) of the logarithmconditionnelle Rosemblat function when the density of errors isunknown, and the asymptotic law of the central sequence givenby (LAC).The second part of our paper concerns the construction adaptatifestimator of the memory parameterdt . Starting with the estima-
tor d(n)t of dt , we construct an adaptatif estimatord(n)
t . We sup-pose that the densityf is unknown, and we proceed with the ana-log proof as KREISS (1987 b) and A. SERROUKI (1996). Wefirst propose a class of estimators for the score functionΦ f (.)and the de Fisher informationI( f ) which give an adaptative es-timator of dt .References[1] Bentarzi, M. (1998) Etude des modèles des séries chronologiques àcoefficients périodiques.[2] Serroukh, A. (1996) Inférence asymptotique paramétrique et nonparamétrique pour les modèles ARMA fractionnaires.[3] Taylan, A. Ula And Abdullah, A. Smadi (1997) Periodic stationar-ity conditions for periodic autoregressive moving average processes aseigenvalue problems.
208 On the spectrum of the covariance op-erator for a nilpotent Markov Chain [Con-tributed Session C18 (page 54)]
Janusz KAWCZAK and Stanislav MOLCHANOV,Universityof North Carolina at Charlotte, USA
We study the spectrum of the covariance operator of the nilpo-tent Markov Chain. This is a special case of the general MarkovChain with the Doeblin condition and under the assumption thatthere exist a finitek such that for alll ≥ k (P−Π)l = 0, whereΠ is an invariant distribution andP is the transition operatorassociated with the chain. The chains with this property arisenaturally in testing Random Number Generators (RNG) when itis understood that a finite sequence of digits is produced to forma word. We specialize our approach to the study of weak con-vergence with the improved estimation of the remainder term forthe Marsaglia [1] permutation type test statistics.A complete analysis of the spectrum of the covariance opera-tor is presented for theL2(X,µ) space. We give an explicit de-composition ofL2(X,µ) into the direct sum of the eigenspacesassociated to the eigenvalues of the covariance operator. Thisdecomposition allows for the development of efficient compu-tational algorithms when establishing the limiting distributionof the functional Central Limit Theorem generated by a generalMarkov Chain.

126 6th BS/ IMSC
We also present some results of Berry-Esseen type for generalMarkov chains with and without nilpotent property [2], [3].References[1] Marsaglia G. (1985)A Current View of Random Number Genera-tors, Computer Science and Statistics, Elsevier Science Publisher B.V.North-Holland.[2] Prokhorov, Yu.V. and Statulevicius, V. (2000)Limit Theorem ofProbability Theory, Springer-Verlag.[3] Woodroofe, M.A. (1992) A central limit theorem for functions of aMarkov chain with applications to shifts,Stochastic Process. Appl.41,33–44.
209 Ising models and multiresolutionquad-trees [Contributed Session C38 (page 38)]
Wilfrid KENDALL and Roland WILSON,University of War-wick, UK
We study percolation and Ising models defined on general-izations of quad-trees used in multiresolution image analysis.These can be viewed as trees for which each mother vertex has2d daughter vertices, and for which daughter vertices are linkedtogether ind-dimensional Euclidean configurations. Retentionprobabilities / interaction strengths differ according to whetherthe relevant bond is between mother and daughter, or betweenneighbours. Bounds are established which locate phase tran-sitions and show the existence of a coexistence phase for thepercolation model. Results are extended to the correspondingIsing model using the Fortuin-Kasteleyn random-cluster repre-sentation. The results resemble those reported in [1,3], but newmethods have to be developed to take account of the lack ofsymmetry in quad-tree structures.vspace*.1cmReferences[1] Grimmett, G.R. and Newman, C.M. (1990)Percolation in∞ + 1dimensions, In Disorder in physical systems, pages 167–190. TheClarendon Press Oxford University Press, New York.(WWW: http://www.statslab.cam.ac.uk/ grg/books/hammfest/10-grg.ps)[2] Kendall, W.S. and Wilson, R.G. (2003) Ising models and multireso-lution quad-trees,Advances in Applied Probability351, 96–122.(EUCLID: http://projecteuclid.org/getRecord?id=euclid.aap/1046366101)[3] Newman, C.M. and Wu, C.C. (1990) Markov fields on branchingplanes,Probability Theory and Related Fields85 (4), 539–552.
210 Robust estimation and forecasting forbeta-mixed hierarchical models of groupedbinary data [Contributed Session C49 (page 26)]
Yurij KHARIN and Maxim PASHKEVICH,Belarusian StateUniversity, Belarus
The paper is devoted to the problem of increasing the modellingadequacy and the forecasting efficiency for the beta-binomialand beta-logistic models of grouped binary data in the case ofstochastic additive distortions of binary observations [2].Let us considerk objects with propertiesZi ∈ Rm, i = 1,2, . . . ,k,and a random eventA, and letBi = (Bi1,Bi2, . . . ,Bini ) ∈ 0,1ni
be results ofni Bernoulli experiments with the eventA over theobjecti. The beta-mixed hierarchical models assume that for theobject i, the probability of successpi is a random variable thathas the beta distribution with true unknown parametersα0
i =fα (Zi), β 0
i = fβ (Zi), and the random variablesp1, p2, . . . , pkare independent in total. This kind of model often arises in bio-metrics, sociology and economics [1]. We consider a distortedmodel: the observations are contaminated with stochastic addi-tive binary distortions:Bi j = Bi j ⊕ηi j , Pηi j = 1|Bi j = 0= ε0,
Pηi j = 1|Bi j = 1= ε1, whereε0,ε1 < 1 are the distortion lev-els.In this paper, we focus on two beta-mixed models that are fre-quently used in practical applications: the beta-binomial model(Zi = const,ni = n, fα (Zi) = α0, fβ (Zi) = β 0) and the beta-
logistic model (fα (Zi) = eZTi a0
, fβ (Zi) = eZTi b0
) [3]. It is provedthat under distortions, the classical estimators become inconsis-tent and the classical forecasting technique looses its optimality.New robust estimators and a robust predictor under distortionsare proposed and analyzed. The performance of the developedprocedures is demonstrated via computer simulations and testson real data sets.References[1] Diggle, P., Heagerty, P., Liang, K., and Zeger, S. (2002)Analysis ofLongitudinal Data, Oxford : University Press.[2] Kharin, Yu. (1996)Robustness in Statistical Pattern Recognition,Kluwer Academic Publishers, Dordrecht.[3] Kharin, Yu. and Pashkevich, M. (2003) Statistical Estimation of theParameters for the Beta-Binomial Distribution under Distortions of Bi-nary Observations //Journal of the National Academy of Sciences ofBelarus (Series in Physics and Mathematics)1, 11–17.
211 Polynomials orthogonal with respectto the negative binomial distribution [Con-tributed Session C8 (page 35)]
V.I. KHOKHLOV , Steklov Mathematical Institute, RussianFederation
It is established that the factorial-power polynomials (for thedefinition and notation see [1, section 1])
Hα (x) =pα
[r]α√
qα
([x]− q
p[α +(r−1)]
)α,
whereα = 0,1, . . . , r = 1,2, . . . , and[r]α = r(r +1) · · ·(r +α−1),α = 1,2, . . . , [r]0 = 1, constitute an orthonormal system ofpolynomials orthogonal with respect to the negative binomial(Pascal) distribution
PXr,p = ν=(
r +ν−1ν
)prqν ,
ν = 0,1, . . . , p+q = 1, p,q > 0,
i. e. a system with the propertyEHα (Xr,p)Hβ (Xr,p) =δαβ ,α,β = 0,1, . . . , whereδαβ is the Kronecker delta.This result extends to the case of the negative binomial distribu-tion the result established earlier in [2] for the case of the geo-metric distribution.References[1] Khokhlov, V.I. (2001) Polynomials orthogonal with respect to themultinomial distribution and the factorial-power formalism.TheoryProbab. Appl.46, 529–536.[2] Khokhlov, V.I. (2003)Polynomials orthogonal with respect to thegeometric distribution.OP&PM Surveys Appl. Industr. Math.10, No2, pp. 520. (In Russian.)x
212 Adaptive multivariate orthonormal se-ries regression estimates [Contributed Session C29(page 52)]
Michael KOHLER , University of Stuttgart, Germany
Estimation of multivariate regression functions from i.i.d. datais considered. Estimates are defined by using ideas derived inthe context of wavelet estimates (i.e., hard thresholding of es-timates of coefficients of a series expansion of the regressionfunction) together with interaction models. Multivariate func-tions constructed analogously to the classical Haar wavelets are

Abstracts 127
used for the series expansion. These functions are orthogonalin L2(µn), whereµn denotes the empirical design measure, andcan be considered as design adapted Haar wavelets.Bounds on the expectedL2 error of the estimates are presented,which imply that the estimates are able to adapt to local changesin the smoothness of the regression function and to the distribu-tion of the design.A practical algorithm, derived by heuristic simplifications of theoptimization problem underlying the theoretical definition of theestimates, is computable in timeO(n · log(n)) for a sample ofsizen, and is therefore applicable to huge data sets.
213 Using least squares to generate fore-casts in regression models with autocorre-lated disturbances [Contributed Session C48 (page 40)]
Yue FANG andSergio KOREISHA, University of Oregon, USA
The topic of serial correlation in regression models has attracteda great deal of research in the last fifty years. Most of thesestudies have assumed that the structure of the error covariancematrixΩ was known or could be consistently estimated from thedata.In this article we developed a new procedure for generating fore-casts for regression models with serial correlation based on ordi-nary least squares and on a misspecified, albeit adequate, repre-sentation of the form of the autocorrelations. A large simulationstudy is used to compare the finite sample predictive efficienciesof this new estimator vis-a-vis estimators based on ordinary leastsquares and generalized least squares with estimated, but knownΩ, as well as with misspecifiedΩ. We also use real economicdata to contrast the forecast performance of the proposed newmethod with other approaches.
214 Fitting an error d.f. in some nonlineartime series model [Invited Session 28 (page 43)]
Hira L. KOUL , Michigan State University, USA
This talk will discuss tests for fitting an error distribution insome stationary and ergodic nonlinear time series models likeGARCH and ARMA-GARCH models. The proposed tests arebased on a certain weighted residual empirical process. Typi-cally the asymptotic null distribution of these tests depends onthe fitted null error distribution. The talk will describe a martin-gale type transformation of this process whose asymptotic nulldistribution is known, regardless of which error d.f. is beingfitted among a large class of error d.f.’s.
215 Fractional Brownian motion as a weaklimit of Poisson shot noise processes – withapplications to finance [Contributed Session M9 (page19)]
Claudia KLÜPPELBERG , Munich University of Technology,Germany
Christoph KÜHN,Goethe-University Frankfurt, Germany
We consider Poisson shot noise processes that are appropriateto model stock prices and provide an economic reason for long-range dependence in asset returns. Under a regular variationcondition we show that our model converges weakly to a frac-tional Brownian motion. Whereas fractional Brownian motionallows for arbitrage, the shot noise process itself can be chosenarbitrage-free. Using the marked point process skeleton of theshot noise process we construct a corresponding equivalent mar-tingale measure explicitly.
References
[1] Klüppelberg, C. and Kühn, C. (2002)Fractional Brownian motionas a weak limit of Poisson shot noise processes - with applications tofinance.Submitted for publication.
216 Multiscale/multigranular image seg-mentation [Contributed Session C28 (page 25)]
Sucharita GOPAL, Junchang JU andEric D. KOLACZYKBoston University, USA
We consider the problem of segmenting an image, as a classifi-cation task, based on multivariate, pixel-wise measurements, inwhich the goal is to assign one of a set of pre-determined la-bels to each pixel. Motivated by current challenges in the fieldof remote sensing land cover characterization, we introduce aframework that allows for adaptive choice of both spatial res-olution and categorical granularity in the construction of a seg-mentation. Our framework is based upon a blending of recursivedyadic partitions and finite mixture models, yielding a class ofwhat we callmixletmodels. The first component of these mod-els allows for the sparse representation of smooth boundaries atmultiple spatial resolutions. The second component provides anatural mechanism for capturing the varying degrees of mixingof pure categories that accompany the different resolutions, andenables them to be related to a hierarchy of labels of multiplegranularities in a straightforward manner.A segmentation is produced in our framework by selecting anoptimal mixlet model, through complexity-penalized maximumlikelihood, and summarizing or interpreting the information inthat model with respect to a categorical hierarchy. We presenta risk analysis showing that our model selection procedure has,in the context of a certain ‘horizon’ or ‘boundary fragments’model, the type of asymptotically near-optimal rates of conver-gence as that in the standard ‘signal plus noise’ setting. Ad-ditionally, to evaluate the overall segmentation procedure in amore realistic context, we apply our methodology to a well-known dataset for the Sierra Nevada region of the United States,with measurements derived from Landsat multi-spectral remotesensing instruments. Comparison of our results to that of an ex-pert evaluation, using a fuzzy rating system, confirms the poten-tial of our approach for producing improved characterizations ofland cover.
217 Data dependent complexities and Or-acle inequalities in statistical learning theory
[Medaillon Lecture (page 42)]
I. KOLTCHINSKII , University of New Mexico, USA
Let F be a class of measurable functions on a probability space(S,A ,P) and letPn denote the empirical measure based on asample(X1, . . . ,Xn) of i.i.d. random variables taking values inSwith common distributionP. Consider an empirical risk mini-mization problem
Pn f =∫
Sf dPn −→min, f ∈F .
Given a solutionfn of this problem, the goal is to obtain verygeneral upper bounds on its excess risk
EP( fn) := Pfn− inff∈F
P f,
expressed in terms of relevant geometric parameters of the classF . There has been a considerable work on this problem by anumber of authors for the last years. Using Talagrand’s concen-tration inequalities and other empirical processes tools, it be-came possible to obtain both distribution dependent and data

128 6th BS/ IMSC
dependent upper bounds on the excess risk that are of asymp-totically correct order in many examples. The bounds involvecomplexity measures of function classes based on certain param-eters describing the geometry of the class (the simplest examplewould be theL2(P)-diameter ofF ) and on localized sup-normsof empirical and Rademacher processes indexed by functionsfrom the class that provide a measure of accuracy of approxi-mation of P by Pn. These complexities can be also expressedin terms of various metric entropies and dimensions of func-tion classes, and they can be further developed and specializedfor specific classes that often occur in statistical learning theory(such as convex hulls needed for ensemble methods and balls inreproducing kernel Hilbert spaces used in the theory of kernelmachines), becoming in such cases complexity measures of in-dividual functions from the class. They provide tools needed todesign model selection techniques in general risk minimizationproblems and to apply them to more specialized frameworks ofregression and classification. In particular, this approach allowsone to obtain a number of results on fast convergence rates inclassification and to develop adaptive classification proceduresfor which these rates are attained. More generally, it allows oneto handle a number of problems related to minimizing risk withrespect to a convex loss.
218 Finding optimal distance functions forstatistical image segmentation [Contributed Ses-sion C28 (page 25)]
András HAJDU, János KORMOS and ZoltánZÖRGO,University of Debrecen, Hungary
Distance functions play important role at those areas which usesome distance measurement. In such applications the final re-sults highly depend on the chosen distance functions, but theliterature contains very few guidelines [3] for choosing them.The obvious reason of this poor support is that it is very sophis-ticated to handle these problems theoretically, and e.g. performan optimisation for some parameters to determine “optimal"distance functions. If the given task is well-defined it is still noteasy to find appropriate distance functions and probably otherparameters used by the given technique. Our aim is to showhow one can take advantage of using distance functions havingspecial behaviour, and also provide such tools that may helpwith finding the suitable distance measurement. As a specialapplication area we focus on multidimesonal (e.g. colour) im-age segmentation which is a key problem in many digital imageprocessing applications [11]. As these problems are usuallybased on integer domains, the consideration of digital distancefunctions is also a natural point. Hence beside investigatingwell-known metrics (e.g.Lp ones) we also consider the largefamily of distance functions generated by neighbourhood se-quences (see [2,4] for details). These distance functions canbe used in arbitrary dimensions and also on other grids (e.g.triangular ones [10]), thus the proposed 3D methods for colourimage segmentation can be easily extended.Lp metrics alsocan be approximated by such distance functions [6,9]. Neigh-bourhood sequences do not generate metrics in general [2,4],and using this irregular behaviour we can realize such ideas thatcannot be reached by metrics. In our investigations we focuson colour range definition, region growing and clustering algo-rithms as frequently applied procedures in image segmentation[5]. On the one hand we illustrate how the results of these pro-cedures change according to the given distance function, and onthe other hand we perform statistical analysis on how the choiceof the optimal distance measurement can be made as automatic
as possible. Our statistical approach is based on histogramanalysis, where the histograms are composed from the distancevalues between the elements of the observed domain (e.g. theRed-Green-Blue cube). We perform modality analysis and con-sider histogram distances [1] to compare the performance ofdifferent distance functions. We use density estimation [12] tohelp with finding local minima/maxima in the histograms thatserve as threshold values in the segmentation tasks. Moreover,we consider hierarchical clustering algorithm [7] (as an objec-tive tool) to compare the performance of distance functions, butalso investigate other ones (e.g.K-means [7]) that provide betterresults for images (e.g. with respect to some quatitative measure[8]). As segmentation methods usually require some parameters(e.g. seed values, distance thresholds) we explain how thesehistograms help with optimizing the choice of such additionaldata.References[1] Cha, S.H. and Srihari, S.N. (2002) On measuring the distance be-tween histograms,Pattern Recognition35, 1355-1370.[2] Das, P.P., Chakrabarti, P.P., and Chatterji, B.N. (1987) Distancefunctions in digital geometry,Inform. Sci.42, 113–136.[3] Everitt, B. (1973)Cluster analysis, Heinemann Educational BooksLtd, London.[4] Fazekas, A., Hajdu, A., and Hajdu, L. (2002) Lattice of generalizedneighbourhood sequences innD and ∞D, Publ. Math. Debrecen60,405–427.[5] Gonzalez, R.C. and Woods, R.E. (1992)Digital image processing,Addison-Wesley, Reading, MA.[6] Hajdu, A. and Hajdu, L. (2004)Approximating the Euclidean dis-tance by digital metrics, Discrete Math., to appear.[7] Johnson, R.A. and Wichern, D.W. (1992)Applied Multivariate Sta-tistical Analysis, Prentice Hall, New York, NY.[8] Levine, M.D. andNazif, A.M. (1985) Dynamic measurement of com-puter generated image segmentations,IEEE Trans. PAMI7, 155–164.[9] Mukherjee, J., Das, P.P., Kumar, M.A., and Chatterji, B.N. (2000)On approximating Euclidean metrics by digital distances in 2D and 3D,Pattern Recognition Lett.21, 573–582.[10] Nagy, B. (2002)Metrics based on neighbourhood sequences in tri-angular grids, PU.M.A. 13, 259-274.[11] Pal, N.R. and Pal, S.K. (1993) A review on image segmentationtechniques,Pattern Recognition26, 1277–1294.[12] Silverman, B.W. (1986)Density estimation for statistics and dataanalysis,Champman and Hall, London.
219 On multi-bandwidth smoothing basedon M-estimators and on efficient quantile es-timation [Contributed Session C54 (page 46)]
Andrzej S. KOZEK , Macquarie University, Australia
In (Kozek 2003) it has been shown that proper linear combina-tions of some M-estimators provide efficient and robust estima-tors of quantiles of near normal probability distributions. In thepresent paper we show that this approach can be extended in anatural way to a general case, not restricted to a vicinity of aspecified probability distribution. The new class of nonparamet-ric quantile estimators obtained this way can also be viewed as aspecial class of linear combinations of kernel-smoothed quantileestimators with different window width. The new estimators areconsistent and can be made more efficient than popular quantileestimators based on kernel smoothing with a single bandwidthchoice considered in (Nadaraya 1964), (Azzalini 1981), (Falk1984) and (Cheng & Parzen 1997).Our approach can be further extended to estimation of regressionquantiles introduced by (Koenker & Bassett 1978) and quantilesof time series with application in CAViaR, conditional autore-gressive value at risk by regression quantiles, (Engle & Man-ganelli 1999).

Abstracts 129
The present approach also yields simple and efficient nonpara-metric estimators of a score functionf ′(x)/ f (x).References[1] Azzalini, A. (1981) A note on the estimation of a distribution func-tion and quantiles by a kernel method,Biometrika68(1), 326–328.[2] Cheng, C. and Parzen, E. (1997) Unified estimators of smoothquantile and quantile density functions,J. Statist. Plann. Inference59(2), 291–307.[3] Engle, R.F. and Manganelli, S. (1999)Caviar: Conditional autore-gressive value at risk by regression quantiles, University of California,San Diego, Department of Economics, Discussion Paper 99-20. 1–51.[4] Falk, M. (1984) Relative deficiency of kernel type estimators ofquantiles,Ann. Statist.12(1), 261–268.[5] Koenker, R.W. and Bassett, G. (1978)Regression quantiles, Econo-metrica46(1), 33–50.[6] Kozek, A.S. (2003) OnM-estimators and normal quantiles ,Ann.Statist.31(4), 1170–1185.[7] Nadaraya, È. (1964) Some new estimates for distribution function,Theory Probab. Appl.9, 497–500.
220 Adaptive regression estimation withmultilayer feedforward neural networks
[Contributed Session C51 (page 27)]
Michael KOHLER,Universität Stuttgart, Germany
Adam KRZYZAK , Concordia University, Montreal, Quebec,Canada
Motivated by approximation results derived in Mhaskar (1993),we estimate in this paper regression functions by neural net-works with two hidden layers. We use complexity regularizationto choose data-dependent way.We prove general bounds on the expectedL2 error of adaptiveleast squares estimates defined via complexity regularization.The constants, which occur in these bounds, are much smallerthan in previously known results like Theorem 12.1 in Györfi etal. (2002) (compare also the remark there on page 231). Theproof relies on an extension of a proof technique introduced inHamers and Kohler (2003) to complexity regularization.We apply the resulting bounds to our neural network estimates.We show that in case of Hölder continuous regression functions,i.e., in case ofm satisfying
|m(x)−m(z)| ≤C · ‖x−z‖p (x,z∈Rd) (1)
for someC > 0 and0 < p≤ 1, and bounded data, the expectedL2 error of our estimate is bounded by some constant times
C2d/(2p+d)(
log2(n)n
)2p/(2p+d)
.
In addition we show, that if the regression function is equal toa sum of functions where each of these functions depends on atmostd∗ < d components ofX and satisfies (1), then the expectedL2 error of our estimate is bounded by some constant times
C2d∗/(2p+d∗)(
log2(n)n
)2p/(2p+d∗)
.
Hence our estimate is able to circumvent the so-called curse ofdimensionality in this case.References[1] Györfi, L., Kohler, M., Krzyzak, A., and Walk, H., (2002)ADistribution-free Theory of Nonparametric Regression,Springer Seriesin Statistics, Springer, New York.[2] Hamers, M. and Kohler, M. (2002)Nonasymptotic bounds on theL2error of neural network regression estimates, Submitted for publication.
[3] Mhaskar, H.N. (1993) Approximation properties of multilayer feed-forward artificial neural network,Advances in Computational Mathe-matics1, 61–80.
221 Stochastic models for the expectedtime to recruitment in an organisation withtwo grades [Contributed Session C23 (page 16)]
G. GOPAL, R. SURESH KUMAR , University of Madras,Chennai, India
An organisation is considered wherein the exit of manpower oc-curs at the time of policy announcements regarding wage revi-sion, perquisites, targets etc. As the recruitment involves sev-eral costs, it is usual that the organisation has the natural re-luctance to go in for frequent recruitments. Even though themanpower loss occurs to the organisation at a decision epoch,the organisation sustains itself with the existing manpower avail-able and several policy announcements at different epochs leadto the cumulative loss of manpower. As and when the cumula-tive loss crosses the threshold level, the organisation reaches abreakdown point and hence immediate recruitment is suggested.In this paper, an organisation with two grades is considered inwhich both the grades undergo cumulative loss of manpower.Two models have been suggested here. In the first model, boththe grades have the loss of manpower at the time of a decisionepoch and to keep the grade which has greater loss intact, thetransfer of persons is made to the that grade so that the man-power system will be kept going on with its usual performance.It is taken that the threshold levels of the two grades are com-bined together and as and when the total cumulative loss in bothgrades due to several epochs crosses the threshold level, the sys-tem breaks down. In the second model, both the grades expe-rience cumulative loss and the transfer of persons between thegrades is not permitted. Also it is assumed that each grade hasits own renewal process of policy announcements and if any onegrade has the cumulative loss which crosses its threshold level,the system breaks down. For both the models, the expectedtimes for recruitment and their variance are obtained by usingthe shock model approach.
222 Fitting smoothing splines to data inshape spaces of planar configurations [Con-tributed Session C28 (page 25)]
I.L. DRYDEN, A. KUME , H. LE and A.T.A. WOOD,Univer-sity of Nottingham, U.K.
Suppose that inΣk2, the space of shapes of planar configurations
with k labelled vertexes, we are given data consisting ofn shapesobserved at successive times. In practice, we are often inter-ested in fitting a smooth curve to these shapes (cf. [7], [4] &[6]). SinceΣk
2 is not a flat Euclidean space, we cannot usuallyapply the classical methods of linear regression and spline fit-ting directly on the shape data (cf. [1] & [3]). If the sample isconcentrated, the problem can be transfered to the tangent spaceto Σk
2 at the Procrustes mean of these shapes and the fitting pro-cedure is performed in the tangent space which is a Euclideanspace (cf. [6]). The fitting method to be proposed in this talkcan be applied to dispersed data points inΣk
2 where the tangentspace approximation is no longer appropriate.SinceΣ3
2 is isometric with the 2-dimensional sphere of radius1/2, the corresponding problem for data inΣ3
2 can be solved bya method proposed by Jupp and Kent in [2], where they intro-duce an algorithm for fittingspherical splinesto spherical databased on the techniques ofunrolling and unwrappingonto an ap-propriate tangent space. Using the results on unrolling in shape

130 6th BS/ IMSC
spaces obtained in [5], we generalise the fitting method of [2] todata inΣk
2 by giving an alternative description for the unrollingand unwrapping along a piecewise geodesic inΣk
2 and also amethod for fitting splines to data in tangent spaces toΣk
2. Thepaths that we fit are continuous curves on the shape space suchthat their unrolled versions at the tangent spaces of the startingpoint are splines.The choice of splines such as cubic splines and piece-wise lin-ear splines provides the option of determining the level of thesmoothness of the path (cf. [8]). In particular, as the smooth-ing parameter tends to infinity the corresponding fitted path isa geodesic which is analogous to the linear regression in realspaces. In this talk we describe the unrolling and unwrappingteqnichues inΣk
2 followed by our spline fitting method in shapespaces. In particular, we consider a practical example, whichconsists of the human movement of the right arm towards dif-ferent target points. Our fitting method confirms that these pathsfollow aproximate geodesics in the shape spaceΣ4
2 and the sta-tistical inference carried out confirms that such geodesics differby the direction of the target point.References[1] Dryden, I.L. and Mardia, K.V. (1998)Statistical Shape Analysis.John Wiley, Chichester.[2] Jupp, P.E. and Kent, J.T. (1987) Fitting smooth paths to sphericaldata.Appl. Statist.36, 34–46.[3] Kendall, D.G., Barden, D., Carne, T.K., and Le, H. (1999)Shape andShape Theory. John Wiley and Sons.[4] Le, H. and Kume A. (2000) Detection of shape changes in biologicalfeatures.Journal of Microscopy200, 140–147.[5] Le, H. (2003) Unrolling shape curves.J. London Math. Soc.68,511–526.[6] Morris, R.J., Kent, J.T., Mardia, K.V., Fidrich, M., Aykroyd, R.G.,and Linney, A. (1999) Analysing growth in faces. InProc. Conf. Imag-ing Science, Systems and Technology. Las Vegas, 404–410.[7] Goodall, C.R. and Lange, N. (1989) Growth curve models for corre-lated triangular shapes. InProceedings of the 21st INTERFACE Sym-posium. Interface Foundation, Fairfax Station, 445–454.[8] Silverman, B.W. (1985) Some aspects ofthe spline smoothing ap-proach to non-parametric regreesion curve fitting (with discussion).J.R. Statist. Soc.(B), 47, 1–52.
223 Dry markets and superreplicationbounds of american derivatives [Contributed Ses-sion M3 (page 34)]
João AMARO DE MATOS andAna LACERDA , UniversidadeNova Lisboa, Portugal
In this paper we study the impact of market restrictions on thepricing of American derivatives using a discrete time frame-work. In particular, we study the case where the market for theunderlying and the derivative is dry. The market restrictions re-lated to dry markets concern the possibility of transactions atsome points in time. We consider two different types of drymarkets. First we take the case of deterministic dryness where,ex-ante, it is exactly known at which points in time the mar-ket exists or not. Second is termed probabilistic dryness since,at some given points in time, a probability of the existence ofthe market is assigned. Markets’ dryness implies that marketsmay become incomplete in the sense that perfect hedging of thederivative in all states of the nature is no longer possible. Us-ing superreplicating strategies, we derive the expectation repre-sentations for the bounds of the arbitrage-free range of varia-tion for a American derivative’s value. When dryness is deter-ministic, the bounds are the supremum of the implied Europeanderivatives, this supremum being taken over deterministic stop-ping times. When dryness is probabilistic there is an additional
source of uncertainty, namely the existence or not of the marketat given points in time. Interpreting the existence of the marketas the realization of an additional random variable, we consideran enlarged filtration resulting from the price process and themarket existence process. With respect to that enlarged filtra-tion, we show that only ordinary stopping times are required todescribe the upper and lower bounds, as opposed to the resultof Jha and Chalasani (2001) where the resulting stopping timescould be randomized. An interpretation and a comparison withthe aforementioned case will also be presented. Additionally,several comparisons are performed between the bounds obtainedwith complete markets and the ones obtained with dry markets.Namely, it is shown that the arbitrage-free range of variation ofthe American derivative in the probabilistic case is wider thanthe one that would be obtained in the deterministic case. If Eu-ropean derivatives were considered this last particular conclu-sion would be the inverse. Finally, we will show that arbitragearguments are not enough to define the optimal exercise policy.
References
[1] Chalasani, P. and Jha, S. (2001) Randomized Stopping Times andAmerican Option Pricing with Transaction Costs,Mathematical Finance11-1, 33–77.
224 Adaptive Lp estimation under a gen-eral class of error densities [Contributed SessionC53 (page 28)]
P.Y. LAI and Stephen M.S. LEE,The University of Hong Kong,China
We consider the problem ofLp estimation of regression coef-ficients under a general class of error densities. It is knownthat both the convergence rate of theLp estimator and the ac-tual mode ofLp estimation depend crucially on the choice ofpand the shape of the error density near the origin. We developa procedure for choosingp adaptively to yield highly accurateLp estimators. It makes use of a special algorithm to automati-cally select the right mode ofLp estimation and them out of nbootstrap to consistently estimate the log mean squared error ofthe Lp estimator. Our proposed adaptiveLp estimator is com-pared with other adaptive and non-adaptiveLp estimators in asimulation study, which confirms superiority of our procedure.
225 Jump-preserving regression andsmoothing using local linear fitting: a com-promise [Contributed Session C58 (page 55)]
I. GIJBELS,A. LAMBERT , Université catholique de Louvain,Belgium
This paper deals with nonparametric estimation of a regressioncurve, where the estimation method should preserve possiblejumps in the curve. In the literature, one can find two possibleapproaches to handle this problem. The first one, calledindi-rect approach, consists of two steps. The first step estimatesthe number of the jump points and their locations, the secondstep reconstructs the curve between estimates jump points usingclassical nonparametric tools. This step can also estimates thejump magnitude. Of course the accuracy of this last step de-pends crucially on the first one. This approach is usually usedwhen the objectives are to estimate the jump positions and thejump magnitudes. The curve estimation in itself is often sec-ondary. The second approach, calleddirect approach estimatesdirectly the regression curve without preliminary estimation ofthe jump point locations. Methods developped in this directionshoud have at least two good properties : smoothing and jump

Abstracts 131
preserving. By this approach one starts with the idea that eachpoint in the design interval is a potential discontinuity point andthus the curve estimation method should adapt at each point to apossible discontinuity. Therefore it is convenient to use and alsopreserves potential jumps well. A consequence of this built-inflexibility is that the resulting estimates often show a quite ‘un-smooth’ behaviour in regions where the underlying regressionfunction is actually continuous.This paper proposes a new direct approach based on local lin-ear kernel estimation. At each pointx at which one wants toestimate the regression function, the proposed method choosesin an adaptive way among three estimates: a local linear esti-mate using only datapoints to the left ofx, a local linear esti-mate based on only datapoints to the right ofx, and finally alocal linear estimate using data in a two-sided neighbourhoodaroundx. The choice among these three estimates is made bylooking at differences of the weighted residual mean squares ofthe three fits. The resulting estimate preserves the jumps welland in addition gives smooth estimates of the continuity parts ofthe curve. This property of compromise between local smooth-ing and jump-preserving is what,among others, distinguishes theproposed method from other methods, that mainly focus on localsmoothing and consequently blur possible jumps, or mainly fo-cus on jump-preserving and hence led to rather noisy estimatesin continuity regions of the underlying regression curve. Strongconsistency of the estimator is established and its performanceis tested via a simulation study. The method is illustrated in an-alyzing a real dataset. The methodology can also be extendedto the bivariate case. It can be used in the image analysis areawhere one needs good procedures for denoising digital imagesand for preserving the edges of any object in the images.
226 Hydrodynamic limit of asymmetric ex-clusion processes under diffusive scaling ind≥ 3 [Invited Session 14 (page 33)]
Claudio LANDIM , IMPA, Brazil and CNRS UMR 6085, France
We consider the asymmetric exclusion process. We start from aprofile which is constant along the drift direction and prove thatthe density profile, under a diffusive rescaling of time, convergesto the solution of a parabolic equation.
227 A conditionally distribution-free mul-tivariate sign test for one-sided alternatives
[Contributed Session C46 (page 46)]
Melanie LABARRE,Industrielle Alliance, Canada
Denis LAROCQUE, HEC Montreal, Canada
We consider the problem of testing the hypothesis that a multi-variate location vector is in the positive orthant. A conditionallydistribution-free sign test is proposed for this problem. This testis related to Hodges test and can be motivated by the union-intersection principle. Moreover, it is valid under very mildassumptions. A characterization of the conditional null distri-bution of the test statistic is given. We provide a step by stepprocedure that can be used to perform the test in practice. In thebivariate case, an explicit formula for the exact null conditionaldistribution of the test statistic is derived. This conditional dis-tribution can be used to compute exact conditionalP-values. Asimulation study compares the new test to some competitors in-cluding the likelihood ratio test. The results show that the newtest is very competitive for a wide variety of distributional mod-els. A real data example illustrating the use of the test is alsopresented.References
[1] Follmann, D. (1996) A Simple Multivariate Test for One-Sided Al-ternatives,J. Amer. Statist. Assoc.91, 854–861.[2] Perlman, M.D. and Wu, L. (1999) The Emperor’s New Tests,Statist.Sci. 14, 355–381.[3] Perlman, M.D. and Wu, L. (2002) A Class of Conditional Tests fora Multivariate One-sided Alternative,J. Statist. Plann. Inference107,155–171.[4] Schucany, W.R., Frawley, W.H., Gray, H.L., and Wang, S. (1999)Bootstrap Testing for Ordered Multivariate Means, Unpublished South-ern Methodist University Technical Report.[5] Sen, P.K. and Silvapulle, M.-J. (2002) An Appraisal of Some Aspectsof Statistical Inference Under Inequality Constraints.J. Statist. Plann.Inference107, 3–43.[6] Sen, P.K. and Tsai, M.-T. (1999) Two-Stage Likelihood Ratio andUnion-Intersection Tests for One-Sided Alternatives Multivariate Meanwith Nuisance Dispersion Matrix,J. Multivariate Anal.68, 264–282.[7] Tang, D.-I. (1994) Uniformly More Powerful Tests in a One-SidedMultivariate Problem,J. Amer. Statist. Assoc.89, 1006–1011.[8] Wang, Y. and McDermott, M.P. (1998) Conditional Likelihood RatioTest for a Nonnegative Normal Mean Vector,J. Amer. Statist. Assoc.93, 380–386.
228 Moment and tail estimates for Ran-dom chaoses andU-statistics [Invited Session 12(page 20)]
Rafał LATAŁA , Institute of Mathematics, Warsaw University,Poland
We will review several inequalities concerning moments andtails of real and vector valued random multilinear forms andU-statistics. We will also discuss applications to limit theoremsand random graphs and present some related open questions andconjectures.
229 Bayesian Gaussian mixture autore-gressive model [Contributed Session C57 (page 34)]
John W. LAU and Mike K.P. SO,Hong Kong University of Sci-ence and Technology, Hong Kong
A Gaussian mixture autoregressive model for modelling nonlin-ear time series is considered from a Bayesian viewpoint. Thetransition distribution of the next observation given the past isassumed to be a scale, autoregressive parameters and autore-gressive order mixture of Gaussian densities. The unknown pa-rameter of this model is the mixing distribution. Note that themodel considered is notably different from some recently pro-posed nonlinear time series models by Le, Martin and Raftery(1996) and Wong and Li (2000). A Dirichlet process prior isassumed on the mixing distribution. The posterior distributionof the autoregressive parameters, the scale, and the order of theAR process are expressed as finite sums over partitions of thetime series data. A weighted Chinese restaurant process whichclusters the data, and an imputation based on the sequential im-putations are developed to evaluate posterior distributions. Nu-merical results from simulated and real data are presented to il-lustrate the methodology.References[1] Le, N.D., Martin, R.D., and Raftery, A.E. (1996) Modeling FlatStretches, Bursts, and Outliers in Time Series Using Mixture TransitionDistribution Models,Journal of the American Statistical Association91,1504–1514.[2] Wong, C.S. and Li, W.K. (2000) On a mixture autoregressive model,Journal of the Royal Statistical Society, Series B, 62, 95–115.
230 Estimation of structure in graphicalmodels [Laplace Lecture (page 56)]
Steffen L. LAURITZEN University of Oxford, United King-

132 6th BS/ IMSC
dom
Graphical models have become increasingly used to describecomplex relationships between several random variables. Suchmodels are generally built up by a structural component, repre-sented by a finite graph, which might contain directed and undi-rected links, and a specification of a joint probability distributionwhich satisfies conditional independence restrictions associatedwith the graph.
Methods for identification of the structural component fromavailable data have been developed, mainly within the computerscience community. This lecture describes and discusses someof these methods, also from a general theoretical perspective.
231 Invariance principles for long memoryrandom fields [Poster Session P2 (page 32)]
Frédéric LAVANCIER , Université des Sciences et Technolo-gies de Lille, France and Centre de Recherche en Economie etStatistique, Paris, France
Generalising a recent paper by Lang and Soulier (2000), wepresent a spectral convergence theorem and we apply it to in-variance principles. More precisely, we consider a random fieldhaving a bounded spectral density and whose partial sums con-verge. We show that its properly dilated spectral field admitsa limit in law. This result applies to linear random fields con-structed by filtering a white noise and provides a limit theoremfor their partial sums. Among these random fields, some areweakly dependent while others present standard as well as nonstandard long memory.References[1] Lang, G. and Soulier, P. (2000) Convergence de mesures spectralesaléatoires et applications à des principes d’invariance,Stat. InferenceStoch. Process3, 41–51.[2] Lavancier, F. (2003)Invariance principles for non standard longmemory random fields,submitted.
232 Generating functions for stochastic in-tegrals [Contributed Session C11 (page 15)]
Claudio ALBANESE,Imperial College, University of London,UK
Stephan LAWI , University of Toronto, Canada
Generating functions for stochastic integrals have been knownin analytically closed form for just a handful of stochastic pro-cesses: namely, the Ornstein-Uhlenbeck [1], the Cox-Ingerssol-Ross (CIR) process [2] and the exponential of Brownian motion[3-5]. In virtue of their analytical tractability, these processes areextensively used in modeling applications. In this paper, we con-struct broad extensions of these process classes. We show howthe known models fit into a classification scheme for diffusionprocesses for which generating functions for stochastic integralsand transition probability densities can be evaluated as integralsof hypergeometric functions against the spectral measure forcertain self-adjoint operators. We also extend this scheme to aclass of finite-state Markov processes related to hypergeometricpolynomials in the discrete series of the Askey-Wilson classifi-cation tree.References[1] Vasicek, O. (1977) An equilibrium characterization of the term struc-ture,Journal of Financial Economics5, 177–188.[2] Cox, J.C., Ingersoll, J.E., and Ross, S.A. (1985) A theory of the termstructure of interest rates,Econometrica53, 385–407.[3] Geman, H. and Yor, M. (1993) Bessel Processes, Asian Options andPerpetuities,Mathematical Finance3, 349–75.
[4] Donati-Martin, C., Ghomrasni, R., and Yor, M. (2001) On certainMarkov processes attached to exponential functionals of Brownian mo-tion; applications to Asian options,Rev. Mat. Iberoamericana17, 179–193.[5] Yor, M. (2001) Exponential Functionals of Brownian Motion andRelated Processes, Springer, Berlin.
233 The MDS model for shape: an alterna-tive approach [Contributed Session C17 (page 53)]
I.L. DRYDEN, A. KUME, H. LE and A.T.A. WOOD,Univer-sity of Nottingham, UK
We propose an alternative to Kendall’s shape space for (reflec-tion) shapes of configurations inRm with k labelled vertices.The proposed approach embeds the space of such shapes intothe spaceP(k−1) of (k−1)× (k−1) real symmetric positivesemi-definite matrices and defines mean shapes as the naturalprojections of Euclidean means inP(k−1) onto the embeddedcopy of the shape space. This approach has strong connectionswith multi-dimensional scaling and mean shapes so defined givegood approximations to other commonly used mean shapes. Wealso use a result of Watson to obtain a central limit theoremwhich then enables the application of standard statistical tech-niques to shape analysis inm≥ 2 dimensions.References[1] Dryden, I.L. and Mardia, K.V. (1998)Statistical Shape Analysis,John Wiley, Chichester.[2] Hendriks, H. and Landsman, Z. (1998) Mean location and samplemean location on manifolds: asymptotics, tests, confidence regions,J.Multivariate Analysis67, 227–243.[3] Kendall, D.G., Barden, D., Carne, T.K., and Le, H. (1999)Shape andShape Theory, John Wiley, Chichester.[4] Kendall, W.S. (1990)The diffusion of Euclidean shape, In Disorderin Physical Systems, ed. by Grimmett, G.R. and Welch, D.J.A., 203–217, Oxford University Press, Oxford.[5] Kent, J.T. (1992)New directions in shape analysis, In The Art of Sta-tistical Science, ed. by Mardia, K.V., 115–127, John Wiley, Chichester.[6] Watson, G.S. (1983)Statistics on Spheres, University of ArkansasLecture Notes in the Mathematical Sciences,6, John Wiley, New York.
234 A finite dimensional logarithmicSobolev inequality [Invited Session 12 (page 19)]
D. BAKRY andM. LEDOUX , University of Toulouse, France
We present a finite dimensional version of the logarithmicSobolev inequality for heat kernel measures of non-negativelycurved diffusion operators. This new inequality is of interestalready in Euclidean space for the standard Gaussian measure.It contains and improves upon the Li-Yau parabolic inequality.While the classical logarithmic Sobolev inequality is related,through the Herbst argument, to measure concentration, ex-ponential Laplace differential inequalities yield here diameterbounds and dimensional estimates on the heat kernel volume ofballs.
235 Iterating the m out of n bootstrap forsmooth function models with null derivatives
[Contributed Session C45 (page 14)]
K.Y. CHEUNG, Stephen M.S. LEE, The University of HongKong, HKSAR, China
The bootstrap provides an attractive approach to nonparametricinference on a scalar parameterθ of interest. In certain situa-tions validity of the conventionaln out of n bootstrap may de-pend on the true value of the parameter. Themout ofn bootstrapis well known to produce consistent estimators of sampling dis-tributions in nonregular problems, where the conventional boot-strap breaks down, but is often accompanied by a loss in effi-

Abstracts 133
ciency as compared to regular applications of the conventionalbootstrap. Of theoretical and practical importance is the ques-tion of whether iteration can improve them out of n bootstrapby reducing its asymptotic error.The problem of constructing a confidence interval for a functionθ of a population mean under regularity conditions, but with thefunction having a null derivative at the true population mean,provides an important testing ground for analysis of iterationof the m out of n bootstrap. In this setting substitution estima-tors aren-consistent with limiting chi-squared type distributions,and then out of n bootstrap is inconsistent for their samplingdistributions. Them out of n bootstrap percentile method inter-val is, by contrast, found to be consistent, incurring a one-sidedcoverage error of orderO(n−1/2) if m is chosen optimally. Wepropose a new scheme for iterating them out of n bootstrap toreduce the coverage error further to orderO(n−2/3), providedthat the first-level and second-level bootstrap resample sizes areappropriately chosen. Our new scheme is computationally di-rectly comparable to the conventional bootstrap iterative schemeas would have been used in regular settings.Several numerical examples, including a natural application ofbootstrap confidence intervals in a hypothesis testing problem,are presented to motivate our development and illustrate the the-oretical findings.
236 Smooth interacting particle approxi-mation of Feynman–Kac flows depending ona parameter [Invited Session 24 (page 51)]
Natacha CAYLUS,IRISA/Université de Rennes 1, France
Arnaud GUYADER,Université de Haute Bretagne, France
François LE GLAND , IRISA/INRIA Rennes, FranceNadia OUDJANE,EDF R&D Clamart, France
In general statistical models where the hidden states and theobservations form jointly a Markov chain, with characteristicsdepending on an unknown parameter to be estimated from theobservations only, the likelihood function can be expressed interms of the optimal filter, i.e. in terms of a Feynman–Kac flow,depending on a parameter. Two different approaches are pre-sented to derive interacting particle approximation of the scorefunction, i.e. of the derivative of the likelihood function w.r.t.the parameter.• The first approach is based on an interacting particle im-
plementation of the MCML algorithm [?, ?], and providesa smooth particle approximation of the optimal filter, inwhich a single particle system is used, corresponding to agiven value of the parameter, and secondary weights arecomputed for each possible value of the parameter. Theresulting approximation, in terms of the empirical distri-bution of a weighted particle system, can be differentiatedw.r.t. the parameter, under mild regularity assumptions onthe characteristics of the Markov chain.
• The second alternative approach takes the derivative w.r.t.the parameter of the Feynman–Kac flow satisfied by theoptimal filter, i.e. obtains the linear tangent Feynman–Kac flow satisfied by the derivative of the optimal filterw.r.t. the parameter. Sufficient conditions are given underwhich this derivative is a finite signed measure, absolutelycontinuous w.r.t. the optimal filter, and a joint particleapproximation is proposed for the optimal filter and thelinear tangent filter, using the same unique system of par-ticles.
The two approaches have been introduced in [4] and [1] respec-tively, and it is shown that they actually coincide, i.e. they give
rise to the same numerical algorithms exactly. Several exam-ples of applications to statistical inference of HMM will also bepresented.References[1] Caylus, N., Guyader, A., Le Gland, F., and Oudjane, N. (2004) Ap-plication du filtrage particulaire à l’inférence statistique des HMM. InActes des 36èmes Journées de Statistique, Montpellier. SFdS.[2] Geyer, Ch.J. (1994) On the convergence of Monte Carlo maximumlikelihood calculations.Journal of the Royal Statistical Society, Series B56, 261–274.[3] Geyer, Ch.J. (1996) Estimation and optimization of functions. InWalter R. Gilks, Sylvia Richardson, and David J. Spiegelhalter, editors,Markov Chain Monte Carlo in Practice, chapter 14, 241–258. Chapman& Hall, London.[4] Guyader, A., Le Gland, F., and Oudjane, N. (2003) A particle im-plementation of the recursive MLE for partially observed diffusions. InProceedings of the 13th Symposium on System Identification (SYSID),Rotterdam, 1305–1310. IFAC/IFORS.
237 A regression-based Monte-Carlomethod for the resolution of backwardstochastic differential equations [ContributedSession C10 (page 44)]
Emmanuel GOBET andJean-Philippe LEMOR, Ecole Poly-technique, Palaiseau France
Let (Ω,F ,P,Ft) be a filtered probability space where(Ft)t isthe completed filtration of ad-dimensional brownian motion.We consider thed-dimensional diffusionX which satisfies:
dXt = b(t,Xt)dt+σ(t,Xt)dWt , X0 = x0 (1)
with appropriate conditions onb and σ . We aim at approxi-mating the solution(Y,Z) of the following backward stochasticdifferential equation:
YT = H(XT)+∫ T
tf (s,Xs,Ys,Zs)ds−
∫ T
tZsdWs (2)
with suitable assumptions onf andH. This kind of equation ap-pears in financial mathematics where one wants to replicate thepayoff H(XT) of an european option under possible market im-perfections. This equation is also linked to quasilinear parabolicpartial differential equations (see [2] and [3] for details) and soour method provides a way to approximate the solution of suchequations.The method that we analyze consists, given a partition of[0,T]in N intervals[tk, tk+1], in approximating at each timetk the so-lution (Ytk ,Ztk) by a regression on a finite number of functions,based onM Euler simulations ofX.We establish a central limit theorem for the approximation of(Y,Z) and analyze the error with respect toN and to the num-ber of functions used. Explicit choices of functions are given toachieve a given global rate of convergence.Different numerical methods have been proposed and analyzedin [1] and [4]. Our work is different from [4] because we explainhow to approximate all the conditional expectations involved inthe algorithm and different from [1] because we need onlyMMonte-Carlo paths (instead ofMN paths) and we provide notonly the approximation error onY but also onZ.Finally, we extend our method to other path-dependent terminalconditionsYT and numerical experiments illustrate the efficiencyof the method.References[1] Bouchard, B. and Touzi, N. (2004)Discrete time approximation andMonte-Carlo simulation of backward stochastic differential equations,Stochastic processes and their applications, in press.

134 6th BS/ IMSC
[2] El Karoui, N., Peng, S., and Quenez, M.C. (1997) Backwardstochastic differential equations in finance,Mathematical Finance7(1),1–71.[3] Pardoux, E. and S. Peng, S. (1992)Backward stochastic differentialequations and quasilinear parabolic partial differential equations, Lec-ture Notes in CIS, Vol. 176, Springer-Verlag, 200–217.[4] Zhang, J. (2004)A numerical scheme for bsdes, The Annals of Ap-plied Probability14, 459–488.
238 Estimation and tests for semiparamet-ric density ratio models via φ−divergences
[Contributed Session C31 (page 30)]
Amor KEZIOU,Universitè Paris VI et Institut Galilèe Univer-sitè Paris, France
Samuela LEONI , Università di Padova, Padova, Italy
In this paper, we aim to introduce a new method in order to givenew answers for the following problems : tests of comparison oftwo populations and estimation of the parameters for semipara-metric density ratio models.We dispose of two samples,X1, . . . ,Xn0 andY1, . . . ,Yn1 from twounknown distributions, notedGandH, respectively. A semipara-metric density ratio model is of the form
dHdG
(x) = m(θ0,x) (1)
whereθ0 is the unknown parameter of interest which we sup-pose to be unique and which belongs to some open setΘ⊆ Rd.The functionm(·, ·) is known and nonnegative.Comparison of two populations, the logistic and themultiplicative-intercept risk models are statistical examples andmotivations for the model (1) (c.f. [5], [2] and [4]).In this paper, we present a new approach for estimation of theparameterθ0 and tests of the hypothesisH0 : H = G intwo-sample semiparametric models of the form (1) with inde-pendent or paired samplesX1, . . . ,Xn0 andY1, . . . ,Yn1 (c.f. [4]).Our method is based onφ -divergences between probability mea-sures, using the so-called dual representation ofφ -divergences(c.f. [1] and [3]). In the particular case of multiplicative-intercept risk model, our method includes the semiparametricmaximum empirical likelihood one. Large and small sample sizebehaviors of some proposed estimates and the semiparametricmaximum empirical likelihood estimate are illustrated and theirsensibilities in the case of contaminated data are compared. Wealso present a power comparison of our tests with thet and theWilcoxon rank sum test, obtained by means of simulations.References[1] Broniatowski, M. and Keziou, A. (2003)Parametric estimation andtests through divergences, Submitted to Annals of Statistics. Prépubli-cation 2004-1, LSTA-Universitè Paris 6.[2] Fokianos, K., Kedem, B., Qin, J., and Short, D.A. (2001)A semi-parametric approach to the one-way layout, Technometrics43(1), 56–65.[3] Keziou, A. (2003) Dual representation ofφ−divergences and appli-cations,C. R. Acad. Sci. Paris, Ser. I336, 857–862.[4] Keziou, A. and Leoni, S. (2004)Estimation and Tests by Divergencesfor Case-Control and Semiparametric Two-Sample Density Ratio Mod-els. Submitted to Biometrika. Prépublication 2003-5, LSTA-UniversitèParis 6.[5] Qin, J. (1998)Inferences for case-control and semiparametric two-sample density ratio models, Biometrika85(3), 619–630.
239 Local oracle inequalities and global es-timation [Invited Session 23 (page 49)]
O. LEPSKI , Université de Provence, France
In the frameworks of an abstract statistical model we first dis-
cuss the problem of the estimation of function at a given point.Let us imagine that we dispose a family of linear estimators (es-timator is called linear if its mathematical expectation is a linearfunctional of the function to be estimated). We are mainly inter-ested in the problem of aggregation of such type of estimators,in other words, starting with given family we try to construct asingle estimator which ’works as good as ’ any estimator fromthis collection. The uniform bound of the risk of this estimatorestablished foranyunderlying function is called the local ’ora-cle’ and corresponding inequality for its risk is called the localoracle inequality.We propose the explicit construction of the aggregated estimatorand present the explicit expression for upper bound of its localrisk (local oracle inequality ).Next, we discuss how to apply such type of the results to globalestimation (estimation of whole function). We show how to de-duce the minimax or adaptive minimax results from our localoracle inequality. In particular, we apply our approach to con-structing an estimator which is adaptive to the rotation of thecoordinate system.The similar ideas were used in [1] to obtain the minimax re-sults (to find the minimax rate of convergence) on anisotropicBesov spaces and in [2] to construct an adaptive estimator forthe classes of multivariate infinitely differentiable functions.References[1] Kerkyacharian, G., Lepski, O., and Picard, D. (2001) Non linearestimation in anisotropic multi-index denoising,PTRF121, 137–170.[2] Lepski, O. and Levit, B. (1999) Adaptive non-parametric estimationof smooth multivariate functions,Math. Meth. of Statist.8(3), 344–370.
240 Wishart distributions on matrices withprescribed zeros [Contributed Session C24 (page 35)]
Gérard LETAC , Université Paul Sabatier, Toulouse, France
Hélène MASSAM,York University, Canada
In covariance selection models, that is, graphical Gaussian mod-els Markov with respect to a decomposable graphG, the prob-lems of maximum likelihood estimation and of choice of priordistribution for the covariance matrix have led to the definitionof generalized Wishart distributions such as, respectively, thehyper Wishart distribution on the coneQG of incompleteG pos-itive definite matrices (see Dawid and Lauritzen, 1993) and theG Wishart distribution on the conePG of positive definite matri-ces with prescribed zeros in the entries corresponding to missingedges ofG (see Roverato, 2000).We define, here, a new extended class of Wishart distributionsdefined onQG and PG which includes the distributions men-tioned above and also those defined by Andersson and Wojnar(2003) which correspond to homogeneous graphs as defined byCastelo and Siebes (2003). This new class of Wishart distribu-tion gives more freedom and flexibility for the choice of priordistribution on the covariance matrix corresponding to a decom-posable graphG.References[1] Castelo, R. and Siebes, A. (2003) A characterization of moral transi-tive acyclic transitive graphs Markov models as labeled trees,J. Statist.Plann. Inference115, 235–259.[2] Dempster, A.P. (1972) Covariance selection,Biometrics28, 157–175.[3] Dawid, A.P. and Lauritzen S.L. (1993) Hyper Markov laws in the sta-tistical analysis of graphical Gaussian models,Ann. Statist.21, 1272–1317.[4] Roverato, A. (2000) Cholesky decomposition of a hyper inverseWishart matrix,Biometrika, 87, 99–112.

Abstracts 135
241 Variable selection in Generalized Lin-ear Models [Contributed Session C52 (page 20)]
Frédérique LEBLANC,LMC/SMS-UJF-Grenoble 1, France
Frédérique LETUÉ , LabSAD-UPMF-Grenoble 2 andLMC/SMS-UJF-Grenoble 1, France
Herein, we deal with the problem of variable selection in theGeneralized Linear Models regression framework. For suchmodels, the distribution of the variable of interest given theregressors belongs to an exponential family. This implies inparticular that the variance of the innovation depends on theunknown regression function. These models include classicalregression models such as Gaussian, binary or Poisson.In this context, we propose some estimator for the linear pre-dictor, related to the regression function via the canonical link,which selects adaptively to the data, the most relevant regres-sors, which are assumed to be deterministic. To this end, weconsider a collection of linear spaces called models, spanned bythe regressors. We construct the maximum likelihood estimatoron each of the models. Next, we select the best of these estima-tors by a data-driven penalized contrast criterion.We provide a non-asymptotic Kullback-Leibler risk bound forour estimator. Our technics are based on the model selectiontheory developped by Barron, Birgé and Massart (1999) and onthe work of Baraud (2000) for the case of standard homoscedas-tic regression.References[1] Baraud Y. (2000) Model selection for regression on a fixed design,Probab. Theory Relat. Fields117, 467–493.[2] Barron, A.R. and Birgé, L., and Massart, P. (1999) Risk bounds formodel selection via penalization,Probab. Theory Related Fields113,301–413.
242 Random matrices and communicationnetworks [Invited Session 21 (page 33)]
Olivier LEVEQUE , EPFL , Lausanne, Switzerland
Emre TELATAR, Bell Laboratories, NJ, USA
David TSE, UCLA, USA
We intend to present a new result concerning the capacity of ad-hoc wireless networks, that is, decentralized communication net-works with no fixed infrastructure that helps relaying communi-cations. It has been shown recently (Gupta-Kumar 2000) thatthe capacity of such networks does not scale with the number ofusers in the network. However, the assumptions made in order toestablish this result are not of information-theoretic nature, sinceit is assumed that interference in the network is treated as noise.Our aim is to recover the result of Gupta and Kumar without anyassumptions on the way communications take place.The approach we take leads us to the study of eigenvalues oflarge random matrices. In various situations, we are able to re-cover Gupta and Kumar’s result, but the most general case is stillopen.
243 Estimating intrinsic dimension fromthe joint distribution of nearest neighbor dis-tances [Contributed Session C29 (page 52)]
Peter J. BICKEL,University of California, Berkeley, USA
Elizaveta LEVINA , University of Michigan, USA
Recently developed nonlinear manifold projection methods suchas Locally Linear Embedding [3] and Isomap [4] have becomepopular dimensionality reduction tools. Using these methodssuccessfully for applications such as classification requires esti-mating intrinsic data dimensionality from a sample of sizen em-
bedded inRm, with unknown “true” intrinsic dimensiond ≤m.Here we propose new methods for estimating intrinsic dimen-sionality, derived through a rigorous analysis of the joint distri-butions of nearest neighbor distances, accounting for their de-pendencies.The existing methods for intrinsic dimension estimation aremostly heuristic and are based on either principal componentanalysis or geometric properties of the data, such as fractal di-mensions. Very little is known about how they scale with thenumber of observations and the true dimension. A geometricmethod [2] perhaps most closely related to ours proposed es-timating the dimension from nearest neighbor distances by re-gressinglogRk on logk, whereRk is the average distance to thek-th nearest neighbor in the sample. It is easy to see that in thisregression the errors are correlated and their variance depends onk. Considering the joint distribution ofRk over k instead leadsus to a better regression estimate based on approximately inde-pendent increments
Uk = k logRk− (k−1) logRk−1.
The corresponding regression is
Uk = a+(1/d)b(k)+ εk
whereεk are approximately i.i.d., and therefored can be esti-mated by the inverse of the slope of this regression.Taking the analysis of the joint distribution ofRk one step fur-ther, we propose a maximum likelihood estimator ofd, based ontreating observations in a small sphere around a fixed pointx asa homogeneous Poisson process. The MLE has a very simpleclosed form,
1d(x)
=−1k
k
∑j=1
logRj (x)Rk(x)
,
wherek is a small number of near neighbors. The estimators canthen be averaged overx andk.We also calculate the bias and variance of the ML dimensionestimator, and study its behavior with growing dimension andsample size. We apply the methods to some of the popular man-ifold datasets and compare them with the other major class ofdimension estimation methods based on fractal dimensions [1].The ML method produces good results for a number of differentcases.References[1] Kegl, B. (2002) Intrinsic dimension estimation using packing num-bers. InAdvances in NIPS14, MIT Press, Cambridge, MA.[2] Pettis, K., Bailey, T., Jain, A., and Dubes, R. (1979) An intrinsicdimensionality estimator from near-neighbor information.IEEE Trans.on Pattern Analysis and Machine Intelligence1, 25–37.[3] Roweis, S.T. and Saul, L.K. (2000) Nonlinear dimensionality reduc-tion by locally linear embedding.Science290, 2323–2326.[4] Tenenbaum, J.B., de Silva, V., and Landford, J.C. (2000) A globalgeometric framework for nonlinear dimensionality reduction.Science290, 2319–2323.
244 Semi-parametric estimation of the pe-riods in a superposition of periodic functionswith unknown shape [Contributed Session C48 (page40)]
Céline LÉVY-LEDUC , Université Paris-Sud and Thalès Op-tronique, France
Let us assume that we haven observations of a sampled signalcorrupted by white noise:
Xj = s0( jtn)+ ε j ; 1≤ j ≤ n, (1)

136 6th BS/ IMSC
wheres0 is a real unknown function (the signal), and theε jare independent centered gaussian random variables of unknownvarianceσ2
0 .In the case wheres0 is an unknown single periodic signal,we propose a consistent and asymptotically efficient semi-parametric estimator of the period. This problem has alreadybeen addressed by Golubev (1988) in [1] but in the white noisemodel (that is the continuous version of the model (1)).We use methods proposed by Mac Neney and Wellner (2000) in[2] to prove that the asymptotic variance of the estimation of theperiod is four times as big as it would be if the function was ofknown shape.We then study the case of a sum of two periodic signals of un-known shape with different periods. For a large class of signals,we propose semi-parametric estimators of the two periods thatare consistent and asymptotically gaussian. When the ratio ofthe periods is not rational, the estimators are asymptotically in-dependent and efficient.We finally propose a way to implement our estimation methodin the two previous cases and apply it to laser vibrometry andreal musical data.References[1] Golubev, G.K. (1988) Estimation of the period of a signal with anunknown form against a white noise background,Problemy PederachyInformatsii24, 38–52.[2] McNeney, B. and Wellner, J.A. (2000) Application of convolutiontheorems in semiparametric models with non-i.i.d. data,J. Statist. Plann.Inferencebf 9, 441–480.[3] Gassiat, E. and Lévy-Leduc, C. (2003) Efficient semi-parametric es-timation of the periods in a superposition of periodic functions with un-known shape,Technical report Orsay, 2003-51.[4] Lavielle, M. and Lévy-Leduc, M. (2004) Semi-parametric estimationof the frequency of unknown periodic functions,submitted.
245 Weighted approximations to multi-variate tail dependence processes with appli-cation to testing the extreme value condition
[Contributed Session C59 (page 48)]
John H.J. EINMAHL,Tilburg University, the Netherlands
Laurens de HAAN andDeyuan LI, Erasmus University Rotter-dam, the Netherlands
Consider a two-dimensional distribution with uniform marginaldistributions, i.e. a copula. Under sharpening of extreme valuecondition, we devise a weighted approximation for the tail em-pirical process (near the origin). This approximation is then usedto devise a test to check whether extreme value conditions holdby comparing two estimators of the limiting extreme value dis-tribution, one obtained from the tail empirical process and theother obtained by first estimating the spectral measure which isthen used as a building block for limiting extreme value distri-bution.References[1] Billingsley, P. (1968)Convergence of probability measures,John Wi-ley and Sons, New York.[2] Orey, S. and Pruitt, W. (1973)Sample functions of the N-paraneterWiner process, Ann. Probability1, 138–163.[3] Einmahl, J. (1992) Limit theorems for tail processes with applica-tion to intermediate quantile estimation,Journal of Statistcal Planningand Inference32, 137–145.[4] Einmahl, J., de Haan, L., and Piterbarg, V. (2001) Nonparametricestimation of the special measure of an extreme value distribution,Ann.Statistics 29No. 5, 1410–1423.[5] Huang, X. (1992)Statistics of bivariate extremes,Thesis, ErasmusUniversity Rotterdam, Tinbergen Insitute Series no. 22.[6] Neuhaus, G. (1971) lOn weak convergence of stochastic processes
with multidimensional times parameter,Ann. Math. Statistics42, No.4, 1285–1295.[7] Shorack, J. and Wellner, J. (1986)Empirical process with applica-tions to statistics, John Wiley, New York.[8] van der Vaart, A. and Wellner, J. (1996)Weak convergence and em-pirical processes with applications to statistics,Springer, New York.
246 Confidence intervals for sum of vari-ance components under unbalanced designs
[Contributed Session C52 (page 21)]
Guoying LI and Xinmin LI,Chinese Academy of Sciences, Bei-jing, P.R.C
Variance component models are applied in many fields, espe-cially in biological sciences, where interval estimation of theresponse variance, i.e. the sum of variance components, is of-ten desired. For the case with balanced designs several methodshave been proposed, including the generalized confidence inter-vals [2]. However, for the unbalanced cases, only an approxi-mate approach, the modified large-sample (MLS) method [1] isavailable. This paper constructs generalized confidence intervals(GCI) for the response variances. It is shown that the generalizedpivotal quantity in the method can be derived by fiducial argu-ment directly and easily. To compare the proposed GCI methodwith the MLS method, a simulation study is conducted. The re-sults indicate that the GCI method performs better than the MLSmethod, especially for the very unbalanced designs.References[1] Burdick, R.K. and Grabill, F.A. (1984) Confidence intervals on lin-ear combinations of variance components in the unbalanced one-wayclassification,Technometrics26, 131–136.[2] Weerahandi, S. (1993) Generalized confidence intervals,J. Amer.Statist. Assoc.88, 899–905.
247 An EM estimation of distributionfunctions with accelerated life test data
[Poster Session P1 (page 21)]
Linxiong LI , University of New Orleans, USA
Suppose that when a unit operates in a certain condition, its life-time has distributionG, and when the unit operates in anothercondition, its lifetime has a different distribution, sayF . More-over, suppose the unit is operated for a certain period of timein the first condition and is then transferred to the second con-dition. Thus we observe a censored lifetime in the first con-dition and a failure time of a “used” unit in the second condi-tion. This produces accelerated lifetime data. We propose anEM algorithm approach for obtaining a self-consistent estimatorof F using observations from both conditions. Both parametricand nonparametric approaches each with complete and censoreddata are considered. We also establish the maximum likelihoodestimator ofF when the unit is repairable.Application and simulation studies are presented to illustrate themethods derived.References[1] Dempster, A.P., Laird, N.M., and Rubin, D.B. (1977) Maximum like-lihood from incomplete data via the EM algorithm ,J. R. Statist. Soc. B39, 1–38.[2] Kaplan, E.L. and Meier, P. (1967) Nonparametric Estimation fromIncomplete Observations,J. Am. Stati. Assoc.53, 457–481.[3] McLachlan, G.J. and Krishnan, T. (1997)The EM algorithm andextensions, Wiley, New York.[4] Meeker, W.Q. and Escobar, L.A. (1998)Statistical Methods for reli-ability data, Wiley, New York.[5] Tsai, W. and Crowley. J. (1985) A large sample study of the gen-eralized maximum likelihood estimators from incomplete data via self-consistency ,Ann. Stat.13, 1317–1334.

Abstracts 137
[6] Yu, Q. and Li, L. (1994) On the Strong Consistency of the ProductLimit Estimator,Sankhya A 56, 416–430.
248 Dimension reduction in gene expres-sion data analysis [Invited Session 26 (page 50)]
Ker-Chau LI , UCLA, USA
Gene expression data can be thought of as a matrix with N rowsand M columns. Each row represents the expression profile ofa gene under M conditions. N is the total number of genes,which is about 6000 for yeast, and can be over 30,000 for hu-man. For the microarray experiments that we are interested in,M is typically greater than 50. One central question in bioinfor-matics is how to help biologists deduce interesting informationfrom such a matrix. Motivated by the rationale that genes withsimilar profiles are likely to be functionally associated, methodssuch as hierarchical clustering, principal component analysis,self-organization map and other variants have been widely used.They offer biologists some valuable genome-wide portraits ofhow clusters of genes may be coregulated. But such approacheshave a limitation because it turns out that the majority of genesdo not fall into the detected clusters. If one has a gene of pri-mary interest in mind and cannot find any nearby clusters, whatadditional analysis can be pursued ? In this talk, we will showhow to address this issue using the newly developed statisticalnotion of liquid association.References[1] Li (2002) Proceedings of National Academy of Sciences99, 16875–16880.[2] Li and Yuan (2004)The Pharmacogenomics Journal4, 127–135.
249 Data depth for nonparametric tests ofmultivariate location and scale [Contributed Ses-sion C55 (page 21)]
Jun LI and Regina LIU,Rutgers University, USA
Multivariate statistics plays a role of ever increasing importancein this modern era of information technology. Much multivari-ate analysis still relies on the assumption of normality or near-normality which is often difficult to justify in practice. Usingthe center-outward ranking induced by the notion of data depth,we construct several nonparametric tests of location and scaledifferences for multivariate distributions. The tests of locationdifference are derived from applying the ideas of permutationand resampling to the so-called DD-plots (depth vs depth plots).The tests of scale difference are natural multivariate rank testsderived from the center-outward depth ranking, and they can beviewed as multivariate generalizations of the Siegel-Tukey andAnsari-Bradley rank tests for testing the equality of variance inthe univariate setting. We present these nonparametric tests, anddiscuss their properties. We also provide some simulation re-sults and a comparison study under normality. Finally, we showseveral applications of the proposed tests to the comparison ofairlines in terms of their safety performances.References[1] Liu, R., Parelius, J., and Singh, K. (1999) Multivariate analysis bydata depth: descriptive statistics, graphics and inference (with discus-sions),Annals of Statistics27, 783–858.[2] Liu, R. and Singh, K. (2003) Rank Tests for Comparing MultivariateScale Using Data Depth: Testing for Expansion or Contraction,Techni-cal report, Rutgers University.
250 Attracting edge property for rein-forced random walks [Invited Session 19 (page 49)]
Vlada LIMIC , University of British Columbia, Canada
Reinforcement is observed frequently in nature and society,where beneficial interactions tend to be repeated. Edge rein-forced random walker on a graph remembers the number oftimes each edge was traversed in the past, and decides to makethe next random step with probabilities favoring places visitedbefore. Using martingale techniques and comparison with thegeneralized Urn scheme, it is shown in [1] that the edge rein-forced random walker on a graph of bounded degree, with thereinforcement weight functionW(k) = kρ , ρ > 1, traverses a ran-domattractingedge at all large times, with probability1. A re-markably short argument of Sellke [2] shows that attracting edgeexists if and only if
∑k
1W(k)
< ∞, (2)
whenever underlying graph has no even cycle. The conjecturethat condition (2) implies existence of attracting edge when theunderlying graph is atriangle is still open.Progress has been made recently [3] toward better understandingof attracting edge property for convex and increasing weightsWwith property (2).References
[1] V. Limic (2003) Attracting edge property for a class of reinforcedrandom walks.Ann. Probab.,31: 1615–1654.[2] T. Sellke (1994)Reinforced random walks on thed−dimensionalinteger lattice.Preprint.[3] V. Limic and P. Tarrés, in progress.
251 A continuous time GARCH(1,1) model[Contributed Session M9 (page 19)]
Claudia KLÜPPELBERG,Alexander LINDNER , MunichTechnical University, Germany
Discrete time GARCH(1,1) models are commonly used tomodel financial time series like asset prices and exchange rates.They capture many of the so-called stylized features such asheavy tails and uncorrelatedness without being independent.The latter is e.g. manifested in the nonzero autocorrelation ofthe squared sequence. Various attempts have been made to cap-ture these features in acontinuous timemodel such as diffusionapproximations [3], [5] and other stochastic volatility models, ase.g. in [1] or [2]. These models have in common that they aredriven by two random processes. Here, we propose a continu-ous time GARCH(1,1) model with only one source of random-ness, capturing the stylized features by the dependence structurealone. The talk is based on [4].References[1] Ahn, V.V., Heyde, C.C., and Leonenko, N.N. (2002) Dynamic mod-els of long-memory processes driven by Lévy noise,J. Appl. Probab.39, 730–747.[2] Barndorff-Nielsen, O.E. and Shephard, N. (2001) Non-GaussionOrnstein-Uhlenbeck based models and some of their uses in financialeconomics (with discussion),J. R. Stat. Soc. Ser. B Stat. Methodol.63,167–241.[3] Duan, J.C. (1996)A unified theory of option pricing under stochasticvolatility – from GARCH to diffusion, Working paper, available athttp://www.rotman.utoronto.ca/∼jcduan/.[4] Klüppelberg, C., Lindner, A., and Maller, R. (2004) A continuoustime GARCH process driven by a Lévy process: stationarity and secondorder behaviour,J. Appl. Probab.41, (to appear).[5] Nelsen, D.B. (1990) ARCH models as diffusion approximations,J.Econometrics45, 7–38.
252 Finding short repetitive patterns in ge-nomic sequences[Bernoulli Lecture (page 13)]
Mayetri GUPTA,University of North Carolina, USA

138 6th BS/ IMSC
Charles E. LAWRENCE,Brown University, USA
Jun S. LIU , Harvard University, USA
Cells regulate their activity by varying the amounts of differ-ent proteins that are present within the cell. The first step inthis regulation process is at the level of transcription. Intran-scriptional regulation, sequence signals upstream of each geneprovide a target (called the promoter region) for an enzyme com-plex, RNA polymerase, to bind and initiate the transcription ofthe gene intomessengerRNA. Simultaneously, certain proteinscalled transcription factors(TFs) can bind to the promoter re-gions, either interfering with the action of RNA polymerase andinhibiting gene expression, or enhancing gene expression. TFsrecognize sequence sites (of about 7-30 nucleotides long) thatgive a favorable binding energy, which often translates into asequence-specific pattern; binding sites thus tend to be relativelywell-conserved in composition. These conserved repetitive pat-terns are often called sequencemotifs.
Although for some important genes, their tanscription factorbinding sites (TFBSs) have been located experimentally, theseexperiments are usually very labor-intensive and expensive.Thus, in most cases the locations of TFBSs as well as the mo-tif pattern of the TF are unknown. Computational prediction ofthese sites thus has attracted much attention. Motifs in the vicin-ity of genes in DNA sequences often correspond to TF bindingsites. The challenge of the problem is to simultaneously esti-mate the parameters of a model describing the position-specificnucleotide type preference for the TF (or TFs) and identify thelocations of these binding sites, based only on a set of DNA se-quences expected to contain multiple motif sites.
In the past decade, statistical models and sophisticated compu-tational algorithms have been developed to discover such se-quence motifs. We will discuss some recent progresses in suchmodeling and computation efforts. In particular, we will re-view the original missing-data formulation of this “motif find-ing” problem and its connection with a “stochastic dictionary”model. Such a model assumes that each motif is like a key word(with perhaps unknown width) that repeatedly appearing in atext, except that each letter of the word has a certain chance tobe mis-typed. Thus, different occurrences of the same “word” inthe genomic sequence may look slightly differently due to such“typos.” The goal is to both infer the pattern of the word andpredict its occurrences in the genomic sequences. The modelcan then be generalized to account for correlated “typos.”
The regulation of high eukaryotes such as human and mouseis often accomplished by combinatorial interactions among sev-eral TFs. The binding sites for these factors are often clusteredin close proximity to each other as a “module.” We will discussa hidden Markov model and Gibbs sampling algorithms for lo-cating regulatory modules. The algorithm finds approximately69% of the possible experimentally reported TF binding sitesand 85% of the possible modules in a test data set. We also showthat the same algorithm can be used to mine genomic sequencesto find similar regulatory modules.References[1] Gupta, M. and Liu, J.S. (2003) Discovery of conserved sequencepatterns using a stochastic dictionary model,J. Am. Statist. Assoc.98,55–66.[2] Thompson, W., Palumbo, M.J., Wasserman, W.W., Liu, J.S., andLawrence, C.E. (2004)Decoding Human Regulatory Circuits, submit-ted.
253 Mining massive text data and develop-ing tracking statistics [Contributed Session C55 (page
21)]
Daniel JESKE,UC Riverside, USA
Regina Y. LIU , Rutgers University, USA
We present a systematic data mining procedure for exploringmassive free-style text databases to discover useful features anddevelop tracking statistics, generally referred to as performancemeasures or risk indicators. The procedure includes text mining,risk analysis, classification for error measurements and nonpara-metric multivariate analysis. Two aviation safety report reposi-toriesPTRSfrom theFederal Aviation AdministrationandAASfrom theNational Transportation Safety Boardwill be used to il-lustrate applications of our research to aviation risk managementand general decision-support systems. Some specific text anal-ysis methods will be discussed. Several tracking statistics andtheir related inference procedures will be proposed. Approachesto incorporating misclassified data or error measurements intotracking statistics will be discussed as well.References[1] Jeske, D. and Liu, R. (2003)Measuring risk or performance from asea of text data, Technical report, Dept of Statistics, Rutgers University.[2] Hastie, T., Tibshirani, R., and Friedman, J. (2001)The Elements ofStatistical Learning, Data Mining, Inference, and Prediction, Springer,Berlin Heidelberg New York.[3] Lewis, D. (1998)Naive (Bayes) at forty: the independence assump-tion in information retrieval, In ECML ’98: Tenth European Conferenceon Machine Learning, 4–15.[4] Liu, R., Madigan, D., and Eheramendy, S. (2002)Text classifica-tion for mining massive aviation inspection report Data, In Dodge, Y.(ed)Statistical Data Analysis Based onL1 Norm and Related Methods,Birkhäuser, 379–392.[5] Liu, R., Parelius, M., and Singh, K. (1999) Multivariate analysis bydata depth: descriptive statistics, graphics and inference (with discus-sions),Annals of Statistics27, 783–858.[6] Spiegelhalter, D. and Knill-Jones, R. (1984) Statistical and knowl-edge based approaches to clinical decision support systems, with an ap-plication in gastroenterology (with discussion),Journal of the Royal Sta-tistical Society Ser. A, 147, 35–77.
254 The volume-of-tube formula and per-turbation tests II: nuisance parameters un-der the null model [Contributed Session C44 (page 53)]
Catherine LOADER and Ramani S. PILLA,Case Western Re-serve University, U.S.A.
In this talk, we develop theory and inferential methods for fit-ting theperturbation modelsfor the general case when the nullmodel contains a set ofnuisance parameters(nuisance underthe null hypothesis of testing for the presence of a perturbation).In the context of mixture models, the null density arises froma parametric family with a vector of nuisance parameters; thenull density may represent anm-component mixture with thenuisance parameter vector being a vector of support points andmixing weights of them-component mixture. Thescore processis then searching for an(m+ 1)-component. The test statisticwill be the supremum (over the nuisance parameter vector) ofthe normalized score process; however, estimating the nuisanceparameter vector means that the covariance function is no longerappropriate. First, we derive a series of results that provide alinearization of the normalized score process, to identify the cor-rect covariance under the nuisance parameter setting. Such lin-earization enables us to properly normalize the score process andin turn apply the Hotelling-Weylvolume-of-tube formulato ap-proximate the distribution of the test statistic, based on the nor-malized score process. Second, the resulting theory is applied tothe problem of testing for the order of a mixture model; in par-

Abstracts 139
ticular, the asymptotic null distribution is derived for a generalfamily of mixture models. Third, we relate our results to otherexisting results for mixture case and obtain explicit and easilycomputable expressions for the geometric constants appearing inthe asymptotic distribution. Fourth, we provide a careful studyof “singularities” of the score process that occur in the contextof mixture models.
255 Invariant measure for a Fleming-Viottype Brownian particle system [Contributed Ses-sion C9 (page 20)]
Joerg-Uwe LOEBUS, University of Delaware, USA
We consider a systemX = X1, . . . ,XN of N particles in ad-dimensional domainD. During periodes none of the particlesX1, . . . ,XN hits the boundary∂D, the system behaves likeN in-dependentd-dimensional Brownian motions. When one of theparticles hits the boundary∂D, then it instantaneously jumpsto the site of one of the remainingN− 1 particles with prob-ability (N− 1)−1. For the systemX, the existence of an in-variant measure was demonstrated in [1]. We provide a struc-tural formula for this invariant measure involving the invariantmeasure of the Markov chain which returns the sites the processX := (X1, . . . ,XN) jumps to after hitting the boundary∂DN. Fur-thermore, duality between these two measures will be discussed.
References
[1] Burdzy, R. and Hołyst, P. (2000) A Fleming-Viot particle represen-tation of the Dirichlet Laplacian,Comm. Math. Phys.214, No. 3,679–703.
256 Power processes: definition and someproperties [Contributed Session C62 (page 18)]
Eva LÓPEZ SANJUÁN and Inmaculada TORRES CASTRO,Universidad de Extremadura, Spain
The study of stochastic processes suitable to model operatingand repair times of a repairable system is a common topic in re-liability. Geometric processes introduced by Lam [1] have con-vergence properties that make them very well suited to modeldeteriorative systems, in which operating times decrease and re-pair times increase. However, when operating times are modeledas general discrete integer-valued random variables (see Alfa [2]and Alfa & Castro[3]), the state space is different for each vari-able of the geometric process. To solve this problem, in Castro& Sanjuán [4], we introduce “power process" : a stochastic pro-cess in which all the variables take values in the same set, alsouseful to model deteriorative systems.A sequence of non-negative independent random variablesXn,n ≥ 0 is called a power process associated with the se-quenceγn,n = 0,1, . . ., whereγn ∈ (0,∞) andγ0 = 1, if thesurvival function ofXn is F(x)γn, n = 0,1,2, ..., whereF is thesurvival function onX0.We can remark that the renewal process is a particular case ofpower process. Whenγn ∈ N, n≥ 1, Xn is the minimum ofγn
i.i.d. random variables with survival functionF(x). Besides,if a random variable of the power process is exponentially dis-tributed, then all of them are. This property also holds for geo-metric, Bernouilli and Weibull distributions.A power process is increasing (decreasing) ifγn is decreasing(increasing). By increasing (decreasing) we mean stochasticallyincreasing (decreasing), but also hazard-rate, mean-residual-lifeand likelihood-ratio increasing (decreasing).Convergence properties of the process are:If γn is increasing,γn ↑ ∞, then Xn converges, almostsurely (and in probability) to a random variable degenerate at
m= infX0. If M = supX0< ∞, thenXn converges tom inLp.If γn is decreasing,γn ↓ 0, andM < ∞, thenXn convergesto the random variable degenerate atM almost surely, in prob-ability and in Lp. If M = ∞, Xn converges to infinity withprobability 1.Another point of study are IFR (DFR), NBU (NWU) and IFRA(DFRA) properties.If we denotern(·) the failure rate function ofXn, power processverifies:If X0 is continuous, thenrn(t) = γnr0(t), ∀t ≥ 0, ∀n≥ 0If X0 is discrete, thenrn(k) = 1 − (1 − r0(k))γn, ∀k =0,10, . . . ,∀n≥ 0.>From this results, in a power process, the following propertieshold:If Xj is IFR (DFR) for somej, thenXn is IFR (DFR),∀n≥ 0.If Xj is NBU (NWU) for some j, then Xn is NBU (NWU),∀n≥ 0.If Xj is IFRA (DFRA) for somej, thenXn is IFRA (DFRA),∀n≥ 0.Finally, we study some numerical examples of repairable sys-tems where the successive operating and repair times are mod-eled as discrete integer-valued random variables, using potentialprocesses.References[1] Lam, Y. (1992) Geometric processes and replacement problem,Actamath. Appl. Sinica4, 366–377.[2] Alfa, A.S. (2004)Markov chain representation of discrete distribu-tions applied to queueing models. Comput. oper. Res., to appear.[3] Alfa, A.S. and Castro, I.T. (2002)Discrete time analysis of a re-pairable machine, J. Appl. Probab. 39 (2), 503-516.
[4] I.T. Castro, E. L. Sanjuán.Power processes and their application toreliability, Operations Research Letters. In press.
257 Ordering of interacting particle sys-tems with simultaneous changes [ContributedSession C9 (page 20)]
R. DELGADO,University Autònoma of Barcelona, Spain
F. J. LÓPEZ and G. SANZ ,University of Zaragoza, Spain
In this work we study the stochastic comparison of interactingparticle systems where more than one particle can change ineach transition. The set of particles,S, will be countable andthe state space of each particle,W, is a finite set endowed withan arbitrary partial order. All our results apply for a countableset of particlesS and their main novelty appears in the case ofinfinite S, since the state space is not countable. WhenS is finite,the processes are finite state Markov chains and the conditionsfor comparability are well known (Brand and Last, 1994).We obtain local conditions on the rates of change of the parti-cles which assure the comparison of the processes. Our resultsare based in the existence of an order preserving coupling whoseexplicit form is given. The existence of an order preserving cou-pling for continuous Markov chains has been shown in López etal. (2000) and for spin-like interacting particle systems in Lópezand Sanz (1998). The main difficulty now comes from the factthat the set of change of particles overlap. The conditions for thestochastic comparison and the rates of the coupling must takethis into account. We apply our results to obtain both neces-sary and sufficient conditions for the stochastic comparison ofinfinite-servers Jackson networks.References[1] Brand, A. and Last, G. (1994)On the pathwise comparison of jump

140 6th BS/ IMSC
processes driven by stochastic intensities.Math. Nachr.167, 21-42.[2] López, F.J. and Sanz, G. (1998)Stochastic comparisons and cou-plings for interacting particle systems.Stat. Probab. Lett.40, 93-102.[3] López, F.J.; Martínez, S. and Sanz, G. (2000)Stochastic dominationand Markovian couplings.Adv. Appl. Prob.32, 1064-1076.
258 Nonparametric maximum likelihoodestimator for inverse problems [Contributed Ses-sion C5 (page 18)]
Djelil CHAFAI, INRA and Ecole Vétérinaire de Toulouse,France
Jean-Michel LOUBES, CNRS and University of Paris Sud,France
This work concerns some class of nonlinear stochastic inverseproblems for repeated measurement data. Our objective istwofold. First we prove consistency of a non parametric maxi-mum likelihood estimator by embedding the framework into thegeneral settings of an early result of Pfanzagl related to mixtures(1988). Second, we propose a finite dimensional approximationof the maximum likelihood estimator by mean of a stochasticapproximation version of the EM algorithm, SAEM, developedrecently by Moulines, Lavielle and Delyon, (1999).Let (Si ,Ti)i∈N∗ be a sequence of i.i.d. random variables with val-ues inRp×Rn
+, with law µS⊗µT . Let (εi)i∈N∗ be a sequence ofi.i.d. standard normal random variables onRn, independent ofthe preceding sequence. We consider in the sequel the inverseproblem which consists in estimating the lawµS given the finitesequence(Yi ,Ti)1≤i≤N whenN goes to+∞ where
Yi := f (Si ,Ti)+σ εi ,
and wheref : Rp×Rn→Rn is a known smooth function, whichcan be in particular nonlinear in the first variable.σ > 0 is someknown nonnegative variance parameter. In this paper, we as-sume in addition for simplicity that the lawµT is known. Thelaw L (Xi) = L (Yi ,Ti) is nothing else but
∫
s∈Rpγσ ,n(y− f (s, t))dµT(t)dµS(s)dy,
where ”(y, t) = x” and γσ ,n is the Gaussian density function.Such a model is often used in economy or biology in pharma-cocinetics.We consider the nonparametric case, whereµS has a densityhwith respect to Lebesgue measure, and assume thath lies in afunctional setFS, with some regularity assumptions. To esti-mateh, we will construct a maximum loglikelihood estimator.For this we will proceed in two steps:
• Construct a family of nested sieves with a mulireso-lution analysis with mother wavelet functionψ, andwrite FS = ∪m∈ΛFS,m where FS,m = f ∈ FS, f =∑l∈Λm
βλ ψλ , |Λm| = m. Hence the loglikelihood esti-mator is constructed over an approximation spaceFm.
• Replace the traditionnal loglikelihood estimator with itsapproximation, obtained by an SAEM type algorithm.
We show that, under the assumption thatL (S) ∈ SS is iden-
tifiable, the estimator we obtainh(k)m,N is convergent, in a sense
that depends on topological properties of the setFS. k standsfor the number of iteration in the modified EM algorithm,m ischosen such that the maximum of the contrast function is nottoo far from the maximum over the whole set. Moreover, thisprocedure gives us a fully tractable estimate which can be usedfor mixture effect models and their applications.References
[1] Delyon, B., Lavielle, M., and Moulines, E. (1999) Convergence of astochastic approximation of the EM algorithm,Ann. Statist.27, 94–128.[2] Eggermont, P. and LaRiccia, V. (2001)Maximum penalized likelihooestimation,Springer Series in Statistics, Springer-Verlag, New York.[3] Pfanzag, J. (1988) Consistency of maximum likelihood estimatorsfor certain nonparametrics families, in particular: mixturesAnn. Statist.
259 Approximations of the value functionof stochastic knapsack problem [Contributed Ses-sion C4 (page 53)]
Yingdong LU, IBM T.J. Watson Research Center, USA
Stochastic knapsack problem, also known as dynamic knapsackproblem, deals with problem of optimally allocate resources se-quentially to meet random requirement. It has many applicationsin the fields of telecommunications and dynamic pricing. Theproblem can be formulated as a dynamic programming prob-lem, and solved numerically. In this paper, we study asymptoticbehavior of the value function. First, we show that under properscaling, the value function can be approximated by a solution ofthe following first order partial differential equation,
∂u(x,y)∂x + ∂u(x,y)
∂y g( ∂u(x,y)∂y ) = 0,
u(X,y) = h(y),u(x,0) = 0,
(x,y) ∈ [0,X]× [0,Y]
For properly defined functiong(·) andh(·) It then can be shownthat the solution can be obtained explicitly through solving a ho-mogeneous Monge-Ampére equation. Then, under the diffusionscaling, we show that the limiting process satisfies a stochas-tic partial differential equation, solution of the Monge-Ampéreequation helps us to derive an alternative representation of thesolution.
260 Limits for weighted p−variations andlikewise functionals of fractional diffusionswith drift [Contributed Session C25 (page 36)]
José R. LEÓN,UCV, Venezuela
Carenne LUDEÑA, IVIC, Venezuela
Let Xt be the pathwise solution of a diffusion driven by a frac-tional Brownian motionBH
t with Hurst constantH > 1/2 anddiffusion coefficientσ(t,x). Consider the successive incre-ments of this solution,∆Xi = Xi/n−X((i−1)/n. Based on ap-proximation results developed in [1] for the solutionXt , weshow that if 1/2 < H < 3/4 then, if Z is a standard nor-mal random variable which is independent ofBH , the process
1/√
n∑[nt]i=1 f (Xi/n)[|∆XinH |p−σ p(i/n,Xi/n)E(|Z|p)] converges
weakly toW(Cp∫ t0 f (Xs)σ p(s,Xs)ds) as n→ ∞ whereW is a
Wiener process, independent ofBH andCp =CHVar(|Z|p), withCH a constant which depends onH. We then generalize theabove results for functionsG satisfying an almost multiplicativecondition in the place ofp-variations. Our work extends previ-ous results [2] obtained for solutions of diffusions with vanish-ing drift.References[1] Nualart, D. and Rascanu, A (2001) Differential equations driven byfractional brownian motion,Collect. Math.53, 55–81.[2] León, J.R. and Ludeña, C. (2004) Stable convergence of certain func-tionals of diffusions driven by fBm, To appearStochast. Anal. Applic.
261 Estimation of a pattern from a Set ofSignals [Poster Session P1 (page 22)]

Abstracts 141
J. ARTILES, C.N. HERNÁNDEZ,I. LUENGO , P. SAAVE-DRA andUniversidad de Las Palmas GC, Spain
For each object belonging to a certain population, a signal can beobserved. We suppose that those signals come from an additiverandom effect model involving a population pattern, individualeffect and intra-individual noise. The main purpose of our workis to estimate the underlying pattern from a set of signals ob-served on a random sample of objects of the population at thesame time points. If the number of observations per object isa dyadic number, several estimations of the population patternare proposed using the wavelet transforms. A simulation studyis carried out using the four test functions given by Donoho andJohnstone (1994) as patterns, considering two types of individ-ual components and white and correlated noise. The goodnessof fit in terms of mean square error and smoothness is analysedfor the aforementioned four signal types. A threshold obtainedby successive iterations, proposed by Baxter and Upton (2002),is also analysed with special emphasis in the choice of the con-stant.References[1] Abramovich, F., Sapatinas, T., and Silverman, B.W. (1998) Waveletthresholding via a Bayesian approach,J. R. Statist. Soc. B60, 725–749.[2] Baxter P.D. and Upton, J.K. (2002) Denoising radiocommunicationssignals by using iterative wavelet shrinkage,Appl. Statist. 51, Part 4,393 – 403.[3] Daubechies, I. (1988) Orthonormal basis of compactly supportedwavelets,Communs. Pure Appl. Math.41, 909 – 996.[4] Diggle, P.J. and Al-Wasel, I. On Periodogram-Based Spectral Esti-mation for Replicated Time Series, in: Subba Rao (Ed), Developmentsin Time Series Analysis, Chapman and Hall, Great Britain, 341 – 354.[5] Donoho D. and Johnstone I.M. (1994) Ideal spatial adaptation bywavelet shrinkage,Biometric 81, 3, 425 – 455.[6] Horgan, G.W. (1999) Using wavelets for data smoothing: a simula-tion study,J. Appl. Statist.26, 923 – 932.[7] Johnstone, I.M. and Silverman, B.W. (1997) Wavelet threshold esti-mators for data with correlated noise,J. R. Statist. Soc. B59, 319 – 351.[8] Nason, G.P. and Silverman, B.W. (1994) The discrete wavelet trans-form in R,J. Comput. Graph. Statist.3, 163 – 191.[9] Nason, G.P., von Sachs, R., and Kroisandt, G. (2000) Wavelet pro-cesses and adaptative estimation of the evolutionary wavelet spectrum,J. R. Statist. Soc. B62, 271 – 292.[10] Saavedra, P., Hernandez, C.N., and Artiles, J. (2000) Spectral Anal-ysis with Replicated Time Series,Communications in Statistics Theoryand Methods, 29, 2343 – 2362.
262 On the rate of convergence of regular-ized boosting classifiers[Invited Session 29 (page 29)]
Gilles BLANCHARD, Université Paris-Sud, France
Gábor LUGOSI , Pompeu Fabra University, Barcelona, Spain
Nicolas VAYATIS, Université Paris 6-Pierre et Marie Curie,France
We introduce a regularized boosting method for which regular-ization is obtained through a penalization function. It is shownthrough oracle inequalities that this method is model adaptive.The rate of convergence of the probability of misclassification isinvestigated. It is shown that for a quite large class of distribu-tions, the probability of error converges to the Bayes risk at a ratefaster thann−(V+2)/(4(V+1)) whereV is theVC dimension of the“base” class whose elements are combined by boosting methodsto obtain an aggregated classifier. The dimension-independentnature of the rates may partially explain the good behavior ofthese methods in practical problems. Under Tsybakov’s noisecondition the rate of convergence is even faster. We investigatethe conditions necessary to obtain such rates for different baseclasses. The special case of boosting using decision stumps is
studied in detail. We characterize the class of classifiers real-izable by aggregating decision stumps. It is shown that someversions of boosting work especially well in high-dimensionallogistic additive models. It appears that adding a limited la-belling noise to the training data may in certain cases improvethe convergence, as has been also suggested by other authors.
263 Asymptotic results for perturbed riskprocesses with delayed claims [Poster Session P2(page 31)]
Claudio MACCI , Università di Roma “Tor Vergata", Italy
Giovanni Luca TORRISI,Istituto per le Applicazioni del Cal-colo “Mauro Picone", Italy
The object of this paper is the study of some asymptotic prop-erties of the perturbed risk process with delayed claims(Xt),which is the sum of a Brownian motion with drift and a shot-noise whose underlying point process is a doubly stochasticPoisson process. More in particular, under suitable hypotheses,we show that(Xt) satisfies a large deviation principle, and wegive asymptotic estimates of the corresponding ruin probabili-
ties. Moreover we introduce two suitable processes(L(X)t ) and
(R(X)t ), which can be seen as simplified versions of(Xt), and
we show some inequalities between the rate function and theLundberg parameter concerning(Xt), and the rate functions and
the Lundberg parameters concerning(L(X)t ) and(R(X)
t ), respec-tively.References[1] Arjas, E. (1989) The claims reserving problem in non-life insurance:some structural ideas,Astin Bull. 19, 139–152.[2] Asmussen, S. and O’Cinneide, C. (2002) On the tail of the waitingtime in a Markov-modulatedM/G/1 queue,Oper. Res.50, 559–565.[3] Baldi, P. and Piccioni, M. (1999) A representation formula for thelarge deviation rate function for the empirical law of a continuous timeMarkov chain,Statist. Probab. Lett.41, 107–115.[4] Brémaud, P. (1981)Point Processes and Queues. Martingale Dy-namics, Springer-Verlag, New York.[5] Brémaud, P. (1999) Unpublished manuscript.[6] Brémaud, P. (2000) An insensitivity property of Lundberg’s estimatefor delayed claims,J. Appl. Probab.37, 914–917.[7] Dembo, A. and Zeitouni, O. (1993)Large Deviations Techniques andApplications, Jones and Bartlett, Boston.[8] Duffield, N.G. and O’Connell, N. (1995) Large deviations and over-flow probabilities for a general single server queue, with applications,Math. Proc. Camb. Phil. Soc.118, 363–374.[9] Dufresne, F. and Gerber, H.U. (1991) Risk theory for the compoundPoisson process that is perturbed by diffusion,Insurance Math. Econom.10, 51–59.[10] Klüppelberg, C. and Mikosch, T. (1995) Explosive Poisson shotnoise processes with applications to risk reserves,Bernoulli1, 125–147.[11] Macci, C. (2001)Continuous-time Markov additive processes:composition of large deviations principles and comparison between ex-ponential rates of convergences, J. Appl. Probab.38, 917–931.[12] Neuhaus, W. (1992) IBNR models with random delay distributions,Scand. Actuar. J.1992, 97–107.[13] Norberg, R. (1993) Prediction of outstanding liabilities in non-lifeinsurance,Astin Bull. 23, 95–115.[14] Rolski, T., Schmidli, H., Schmidt, V., and Teugels, J. (1999)Stochastic Processes for Insurance and Finance, Wiley and Sons, NewYork.[15] Schmidli, H. (1995) Cramér-Lundberg approximations for ruinprobabilities of risk processes perturbed by diffusion,Insurance Math.Econom.16, 135–149.[16] Waters, H.R. and Papatriandafylou, A. (1985) Ruin probabilitiesallowing for delay in claims settlement,Insurance Math. Econom.4,113–122.
264 Some nested subclasses of infinitely di-

142 6th BS/ IMSC
visible distributions [Contributed Session C13 (page45)]
Ole E. BARNDORFF-NIELSEN,University of Aarhus, Den-mark
Makoto MAEJIMA, Keio University, Japan
Ken-iti SATO,Nagoya, Japan
Let ID be the class of all infinitely divisible distributions onRd.In the cased = 1, Barndorff-Nielsen and Thorbjørnsen(2002)introduced a transformationϒ from ID into ID, in terms of gen-erating triplets and showed that
ϒ(µ) = L
(∫ 1
0log
1t
dX(µ)t
), (1)
whereX(µ)t is the Lévy process onR with L (X(µ)
1 ) = µ andL stands for distribution. The Lévy measuresνµ of µ andνϒ(µ)of ϒ(µ) satisfy
νϒ(µ)(B) =∫ ∞
0νµ (s−1B)e−sds, B∈B(R).
We extend this transformation by (1) to a general dimensiond,
by lettingX(µ)t be a Lévy process onRd.
We say thatµ ∈ ID belongs toL0, the class of all selfdecom-posable distributions onRd, if for any b∈ (0,1), there exists adistributionρb such that
µ(z) = µ(bz)ρb(z). (2)
We note that the Lévy measure ofµ ∈ L0 is represented as
νµ (B) =∫
Sλ (dξ )
∫ ∞
01B(rξ )
kξ (r)r
dr,
whereλ is a measure onS= ξ ∈ Rd : |ξ | = 1,kξ (r) is mea-surable inξ for each r, and kξ is nonincreasing and right-continuous inr for λ -a.e.ξ ∈ S. Let hξ (u) = kξ (e−u).We say thatµ ∈ L0 belongs to the classT0, if hξ (− logr) = kξ (r)is completely monotone inr for λ -a.e.ξ . This classT0 was firstintroduced by Thorin(1977) for distributions on positive realline, as the smallest class that contains allΓ-distributions andthat is closed under convergence and convolution. The transfor-mationϒ links L0 to T0 as follows.Theorem 1.ϒ(L0) = T0.For eachm= 1,2, .., we say thatµ ∈ L0 belongs to the classLm,if (2) holds for someρb ∈ Lm−1, and thatµ ∈ T0 belongs to the
classTm, if h( j)ξ (− logr) is completely monotone inr for λ -a.e.
ξ and for1≤ j ≤m. Let L∞ = ∩mLm andT∞ = ∩mTm.>From their definitions,Lm andTm are nested subclasses ofL0 andT0, respectively. The transformationϒ also linksLm toTm as follows.Theorem 2.ϒ(Lm) = Tm, for m= 1,2, ....Theorem 3.ϒ(L∞) = T∞ = L∞.
265 SLE-type processes on Riemann sur-faces [Invited Session 13 (page 20)]
Nikolai MAKAROV and Dapeng ZHAN,California Instituteof Technology, USA
Let M∗ be a non-compact, finite type Riemann surfaceM withseveral interior and/or boundary marked points. We study ran-dom Loewner chainsMt in M generated by SLE(κ)-typecurvesγ(t) such that the conditional law of the evolution givenγ [0, t] depends only on the conformal type of the marked Rie-mann surface[M∗
t ,γ(t)]. Any such process corresponds to some
choice of a cross-section in a certain line bundle over the mod-uli space of marked Riemann surfaces of given topologicaltype. We explicitly compute these cross-sections for the scal-ing limits of (various versions of) the lattice models for whichthe corresponding theory exists in the simply connected case(κ = 2,4,6,8). By uniformizing the Loewner chains by meansof canonical conformal maps, we represent the processes as fi-nite dimensional diffusions such that the coefficients are alge-braic functions. Finally, we discuss some aspects of the theoryof restriction measures in the Riemann surface setting.
266 Functional limit theorems for multi-parameter fractional Brownian motion [Con-tributed Session C25 (page 36)]
Anatoliy MALYARENKO , Mälardalen University, Sweden
Let ξ (x), x∈RN be the multiparameter fractional Brownian mo-tion om the probability space(Ω,F ,P), i.e., the centred Gaus-sian random field with the autocorrelation function
Eξ (x)ξ (y) =12(‖x‖2H +‖y‖2H −‖x−y‖2H),
where‖ · ‖ denotes the usual Euclidean norm on the spaceRN.The parameterH ∈ (0,1) is called theHurst parameter.Let t0 be a real number. Let for everyt ≥ t0 there exists a non-empty set of indicesJ (t). Let every elementj ∈J (t) definesthe vectory j ∈ RN and the positive real numberu j . Let
B = x ∈ RN : ‖x‖ ≤ 1be the closed unit ball of the spaceRN. Finally, we define
P(t) = (y j ,u j ) : j ∈J (t)and thecloud of normed increments
S (t) =
η(x) =ξ (y+ux)−ξ (y)√
2h(t)uH: (y,u) ∈P(t)
⊂C(B)
in the spaceC(B) of all continuous functions onB.Under some conditions concerning the functionh(t), we prove afunctional limit theorem. It states that, in the uniform topology,the set ofP-a. s. limit points of the cloud of normed incrementsS (t) ast → ∞ is the closed unit ballK in the reproducing ker-nel Hilbert spaceHξ of the multiparameter fractional Brownianmotionξ (x), x ∈ B. The description of the functionsf ∈K interms of their expansions in eigenfunctions of some self-adjointoperators is included.Our result generalises the result of [1]. The functional law of theiterated logarithm, functional Lévy’s modulus of continuity andmany other results are particular cases of this general theorem.
References
[1] Mueller C. (1981) A unification of Strassen’s law and Lévy’s modu-lus of continuity,Z. Wahrsch. Verw. Gebiete, 56, 163–179.
267 p-variation of strong Markov pro-cesses[Contributed Session C21 (page 50)]
Martynas MANSTAVI CIUS, University of Connecticut, USA
Let ξt , t ∈ [0,T], be a strong Markov process with values ina complete separable metric space(X,ρ) and with transitionprobability functionPs,t(x,dy), 0≤ s≤ t ≤ T, x ∈ X. For anyh∈ [0,T] anda > 0 consider the function
α(h,a) =supPs,t(x,y : ρ(x,y)≥ a): x∈ X,0≤ s≤ t ≤ (s+h)∧T.

Abstracts 143
This talk will focus on a nice connection between the argumentsof α(h,a) and variational properties of paths ofξt , in particular,p-variation which in many instances is very useful as discussedin Dudley (1992), Dudley and Norvaiša (1999), Mikosch andNorvaiša (2000), Lyons (1998), etc.References[1] Dudley, R.M. (1992) Fréchet differentiability,p-variation and uni-form Donsker classes.Ann. Probab.20, 1968–1982.[2] Dudley, R.M. and Norvaiša, R. (1999)Differentiability of Six Opera-tors on Nonsmooth Functions andp-Variation, Springer, Lecture Notesin Math. 1703.[3] Mikosch, T. and Norvaiša, R. (1999) Stochastic integral equationswithout probability.Bernoulli 6, 401–434.[4] Lyons, T.J. (1999) Differential equations driven by rough signals.Rev. Mat. Iberoamericana14, 215–310.
268 Term structure of interest rates andGeneralized Mehler semigroups [ContributedSession M5 (page 27)]
Carlo MARINELLI , Universität Bonn, Germany
We consider the Musiela stochastic partial differential equation(SPDE) for the evolution of forward rates
d f(t,ξ ) =[ ∂
∂ξf (t,ξ )+
∞
∑k=1
σk(t,ξ )∫ ξ
0σk(t,y)dy
]dt
+∞
∑k=1
σk(t,ξ )dYk(t),
and study some of its properties in the setting of Ornstein-Uhlenbeck-type equations in infinite dimensional spaces and as-sociated generalized Mehler semigroups. In particular we shallconcentrate on the case of Lévy driving noisesYk, showing thatforward rates are the unique solution of the Musiela SPDE ina suitable sense, and characterizing long forward rates as theinvariant measures of the SPDE, generalizing recent results ofT. Vargiolu. Some related open problems will be briefly dis-cussed.
269 High resolution asymptotics for the an-gular bispectrum of spherical random fields
[Contributed Session C23 (page 16)]
Domenico MARINUCCI , University of Rome “Tor Vergata",Italy
A fundamental probe for the physics of primordial epochs is theanalysis of Cosmic Microwave Background radiation (CMB),which can be viewed (loosely speaking) as a snapshot of theUniverse approximately 300000 years after the Big Bang (i.e.,at about 0.002 per cent of its current age). Several ongoing andforthcoming satellite and balloon-borne missions from ESA andNASA are providing a flood of data on the order of several bil-lion observations on CMB fluctuations. Many, if not most, ofthe greatest challenges of current cosmological research relateto the analysis of the distributional properties of these data.>From the mathematical point of view, CMB fluctuations canbe viewed as an homogenous and isotropic random fields de-fined on the surface of a unit sphere. The dependence structureof a spherical random field is uniquely determined by the angu-lar correlation function or its harmonic transform, the angularpower spectrum, if the field is Gaussian. Thus, among the manystatistical issues arising in the context of CMB research, one ofthe most important is testing the assumption of Gaussianity. Notonly this is necessary to validate statistical inference on the an-gular power spectrum; much more importantly, the determina-tion of the distribution function of CMB fluctuations is by itself
the main tool to discriminate among competing scenarios for theBig Bang dynamics. A huge amount of Gaussianity tests havehence been considered in the physical literature, some authorsconsidering topological properties of Gaussian fields, some oth-ers harmonic-space statistics, others still wavelets. Very little isknown on the theoretical properties of the various approaches.In this paper, we advocate a new proposal, based on a func-tional of the squared bispectrum; we establish convergence tostandard Brownian motion under Gaussianity, whereas we alsodiscuss consistency under a wide class of non-Gaussian alterna-tives. The main instrument for these results is a diagram-typeformula for the higher order moments of the sample bispectrum,which may have some independent interest in the statistical anal-ysis of spherical random fields.References[1] Adler, R.J. (1981)The Geometry of Random Fields, Wiley.[2] Dore’, O. et al. (2003) Probing non-Gaussianity using local curva-ture,Monthly Notices of the Royal Astronomical Society344, 905–916.[3] Komatsu, E. at al. (2003) First WMAP observations: tests of Gaus-sianity,The Astrophysical Journal148119–134.[4] Hansen, F., Marinucci, D., and Vittorio, N. (2003)The extended em-pirical process test for non-Gaussianity in CMB, Physical Review D,67,id.3004.[5] Marinucci, D. (2004) Testing for non-Gaussianity on CMB: a Re-view, Statist. Sci.in press.[6] Marinucci, D. and Piccioni, M. (2004) The empirical process onGaussian spherical harmonics,Ann. Statist. 32, in press.[7] Wasserman, L. et al. (2003) Nonparametric inference in astro-physics, preprint.[8] Martinez-Gonzalez, E. et al. (2002) The performance of sphericalwavelets to detect non-Gaussianity in the CMB, preprint.
270 Estimating flood risk; a long-memorymodel with time varying variance for dailyriver discharge [Poster Session P1 (page 22)]
Péter ELEK andLászló MÁRKUS, Eötvös Loránd University,Budapest, Hungary
The results of our modelling efforts aimed at the estimation ofinundation risks of Tisza River in Hungary on the basis of dailyriver discharge data registered in the last 100 years will be pre-sented in the conference. The deseasonalised series has skewedand leptokurtic distribution and various methods suggest thatit possesses substantial long memory. This motivates the firststep: to fit a fractional ARIMA model with non-Gaussian inno-vations. Synthetic streamflow series can then be generated byappropriate resampling from the innovations. This approach hasrecently been used by Montanari et al. [1]. However, simulat-ing flows for the Tisza River this way, there remains a signif-icant difference between the empirical and the synthetic den-sity functions as well as the quantiles. It brings attention tothe fact that the innovations are not independent. Evidencesshow that both their squares and absolute values are autocor-related. Furthermore, the innovations display non-seasonal pe-riods of high and low variances. This behaviour is very charac-teristic in generalised autoregressive conditional heteroscedastic(GARCH) models. However, simulations clearly show the over-estimation of the quantiles and the extremes when innovationsare generated as GARCH processes. Therefore we suggest to fita smooth transition GARCH process to the innovations, cf. [2].In a standard GARCH-model the dependence of the varianceon the lagged innovation is quadratic whereas in the proposedmodel, it is a bounded function.While preserving long memory and eliminating the correlationfrom both the generating noise and its square, the new model

144 6th BS/ IMSC
is superior to the previously mentioned ones in approximatingthe probability density, the high quantiles and the extremal be-haviour of the empirical river flows. Hence the model can be andin fact is used for flood risk estimation and planning preventionmeasures in the Great Hungarian Plain.References[1] Montanari, A., Rosso, R., and Taqqu, M.S. (1997) Fractionally dif-ferenced ARIMA models applied to hydrologic time series: Identifica-tion, estimation and simulation.Water Resources Research33, 1035–1044.[2] Elek, P. and Márkus, L. (2004) A long range dependent model withnonlinear innovations for simulating river floods.Natural hazards andearth system sciences, to appear.
271 Application of optimization techniquesto Bayesian networks design [Poster Session P1(page 21)]
Ana M. MARTÍNEZ-RODRÍGUEZ and Luis PARRAS,Uni-versity of Jaén, Spain
During last years we have access to large databases of a lot ofvariables in which a great amount of information is stored. Thisinformation has to be processed so investigators can understandit. A graphical model of the probabilistic relationships betweenthe domain variables are Bayesian networks. A characteristic ofa Bayesian network is that the arcs can have a causal interpre-tation; the final node of the arc is direct cause of the node thatis beginning of it. In this case, Bayesian networks are known ascausal networks [4]. A Bayesian network constitutes an efficientdevice to perform probabilistic inference.When ones wants to establish a Bayesian network that models asituation, the design of the network can be done in two ways: (a)with the aid of an expert who knows in depth the problem, so heis able to synthesize the relations between the different variables,or (b) by a learning method to extract the Bayesian network di-rectly from a data set. The construction of Bayesian networksfrom the information that provides an expert is time consumingand is subject to mistakes. This is the cause why the investi-gators have tried during last years to recover, from databases,the graphical structure of the Bayesian network that better rep-resents the underlying distribution.A wide set of algorithms has been proposed to learn Bayesiannetworks structures. Different approaches to Bayesian networkmodel induction can be classified according to the nature of themodeling: (1) Score+Search methods. For this kind of methods,a metric that measures the goodness of every candidate Bayesiannetwork with respect to a dataset of cases is needed. In addition,a search procedure, to move through the space of possible net-work structures is also necessary. According to the score metricswe have: (a) Bayesian Scores. Given a database over a set ofnvariables, the model whose posterior probability is maximum isselected [2]. (b) Scores inspired in the Information theory. Inthis case scores that involve the entropy of the network are used[1]. (2) Constraint-based learning. In this case the algorithmstry to recover the structure of the Bayesian network by detectingthe conditional (in)dependencies among the variables from thedata [5].In this work we apply a new methodology for the design ofthe structure of a Bayesian network proposed by [3] to modela study of Sewell and Shad about the variables that influencedthe decision of high school students concerning attending col-lege. We define coefficients of dependence between variablesthat allow us to establish a measure of the global dependencein the network, then we maximize this measure in the space of
structures of Bayesian networks. In fact we formulae the prob-lem as one of mathematical programming with binary variables.The feasible set is the set of Bayesian networks structures withadjacency matrixX =
(xi j
)that verify some constraints: they
are directed acyclic graphs, the dependent variables are known,and no isolated variables are allowed.References[1] Chow, C. and Liu, C. (1968) Approximating discrete probabilitydistributions with dependency trees,IEEE Transactions on InformationTheory14462–467.[2] Heckerman, D. Geiger, D., and Chickering, D. (1995)LearningBayesian networks: The combination of knowledge and statistical data,Machine Learning20149–163.[3] Heckerman, D. Meek, C., and Cooper, G. (1999)A Bayesian ap-proach to causal discovery, Computation, Causation, and Discovery,AAAI Press, 1999[4] Pearl J. (2001)Causality, Models, reasoning and inference, Cam-bridge University Press.[5] Spirtes, P., Glymour, C., and Sheines, R. (2000)Causation, Predic-tion and Search. MIT Press
272 Flexible regression models for survivaldata: theory and practise [Invited Session 34 (page44)]
Torben MARTINUSSEN , Royal Veterinary and AgriculturalUniversity, Denmark
The Cox regression model is the standard tool for analysingright-censored survival data. It is easily fitted using for instanceSAS or R. Often, however, the proportional hazards assumptionof this model is violated in practise and there is definitely a needfor more flexible models. A typical violation of the Cox modelis when there is a time-dependent treatment effect. This talkwill show several models that all can deal with time-dependenteffects. Estimators will be derived and and their large sampleproperties will be described. I will also give several practicalexamples and demonstrate a newly developed R-package, whichcan be used for analysis with these new flexible models.References[1] Aalen, O.O. (1989)A linear regression model for the analysis of lifetimes.[2] Martinussen, T. and Scheike, T.H. (2002)A flexible additive multi-plicative hazard model.[3] Martinussen, T., Scheike, T.H., and Skovgaard, I.M. (2002)Efficientestimation of fixed and time-varying covariate effects in multiplicativeintensity models.[4] McKeague, I.W. and Sasieni, P.D. (1994)A partly parametric addi-tive risk model.
273 The Wishart distribution and theMatsumoto-Yor property [Contributed Session C24(page 35)]
Hélène MASSAM, York University, Canada
Jasek WESOŁOWSKI,Politechnika Warszawska, Poland
In this talk, we explore the relationship between a general-ized matrix Matsumoto-Yor (MY) property (see Matsumoto-Yor2001) and the Wishart distribution. This relationship was firstconsidered in Letac and Massam (2001), for the case of2× 2matrices. A MY property, univariate or multivariate, typicallyinvolves two pairs of independent variables(X,Y) and (U,V)linked by a relationship of the type
U = (X +Y)−1, V = X−1− (X +Y)−1.
For a random matrixK, with the block partitioning(K1,K12,K2)we identifyK−1
1 with X andK2·1 with Y, while conditioning onK12.

Abstracts 145
We will derive from this relationship a characterization of theWishart distribution similar to that obtained by Geiger andHeckerman (2002) but which involves independences for onlythree block partitionings of the matrix variateK .To do so, we first extend the Matsumoto-Yor independence prop-erty to generalized inverse Gaussian and Wishart random matri-ces of different dimensions. We then give a characterization ofthe matrix generalized inverse Gaussian and Wishart distribu-tions seen as a couple of distributions. This is an extension tothe case of matrices of different dimensions, of results previ-ously given by Letac and Wesolowski (2000).Using the two previous results, we obtain the new characteriza-tion of the Wishart distribution.References[1] Geiger, D. and Heckerman, D. (2002) Parameter priors for directedacyclic graphical models and the characterization of several probabilitydistributions,Ann. Statist.30, 1412–1440.[2] Letac, G. and Massam, H. (2001) The normal quasi-Wishart distribu-tion, in: Algebraic Methods in Statistics and Probability, (M.A.G. Viana,D.St.P. Richards, eds), AMS Contemporary Mathematics287, 231–239.[3] Letac, G. and Wesołowski, J. (2000) An independence property forthe product of GIG and gamma laws,Ann. Probab.28, 1371–1383.[4] Matsumoto, H. and Yor, M. (1998) An analogue of Pitman’s2M−X
theorem for exponential Wiener functionals, Part II: The role of the gen-eralized inverse Gaussian laws,Nagoya Math. J.162, 65–86.
274 Minimax estimation of the noise leveland of the signal density in a semiparametricconvolution model [Contributed Session C31 (page 30)]
Cristina BUTUCEA,Université Paris VI, France
Catherine MATIAS , CNRS, France
We consider a semiparametric convolution model of an un-known signal with supersmooth noise having unknown scale pa-rameter. The observations consist in a sample of the densityfY
of the form fY = σ−1 f ε (·/σ) ∗ f , where∗ stands for the con-volution product, the noise densityf ε is fixed and known to besupersmooth and both the signal densityf and the scale param-eterσ are to be estimated. For identifiability reasons, the noisehas to be smoother than the signal in this problem and we distin-guish two classes of signals according to different smoothnessproperties.We first construct a consistent estimation procedure for the noiselevel σ and prove that its rate is optimal in the minimax sense.Two convergence rates are distinguished according to the twodifferent smoothness assumptions on the signal. These rates ob-tained for the finite-dimensional part of the parameter are non-parametric and exhibit the semiparametric nature of the prob-lem. In one case the rate is sharp optimal, i.e. the asymptoticvalue of the risk is evaluated up to a constant.In a second part, we construct a consistent estimator of the sig-nal, by using a plug-in method in the classical kernel estimationprocedure. This yields to the study of a kernel estimator withrandom bandwidth. We establish that the estimation of the sig-nal is deteriorated comparatively to the case of entirely knownnoise distribution, emphasising the idea thatσ plays the role ofa nuisance parameter. In fact, the rates of convergence for signaldensity estimation are governed by the rates of convergence fornoise level estimation. We also prove that the rates for the esti-mation of the signal density are optimal in the minimax sense.
275 Asymptotics for M-estimators basedon sample cells and restrictions [Contributed Ses-sion C61 (page 48)]
J.A. CUESTA-ALBERTOS,Universidad de Cantabria, Spain
C. MATRÁN andA. MAYO , Universidad de Valladolid, Spain
The cell device was introduced by the authors in the frameworkof estimation of the parameters in a multivariate mixture of dis-tributions. By using a genetic simile, we can describe the deviceas the ability of a cell to regenerate a body under smoothnesshypotheses. After an appropriate choice for the cell (or cells),that will be based on the sample data, the statistical analysis ishandled through the maximum likelihood via EM algorithm. Toovercome the inherent problem of singularities we proposed theuse of restrictions also based on the sample data. In this workwe will study the asymptotic behaviour of the estimators by re-sorting to a wider scheme (which we call MER-estimators) thatis studied through the general empirical processes theory. Asa remarkable result we obtain that the asymptotic distributionof the estimators based on cells does not depend on the rate ofconvergence of the chosen cell.
References
[1] Cuesta-Albertos, J.A., Matrán, C., and Mayo, A. (2003)Stem-cellbased estimators in the mixture model.
276 Bounds for dynamic VaR and meanloss associated to diffusion processes[Con-tributed Session M4 (page 37)]
Laurent DENIS,Université du Maine, France
Begoña FERNÁNDEZ andAna MEDA , Universidad NacionalAutónoma de México, Mexico
Let Xt be a stochastic process driven by a differential equa-tion of the formdXt = σ(Xt)dWt + b(Xt)dt, t > 0. Let X?
s,t =sups≤u≤t Xu, be the maximum of the diffusion. We define sev-eral dynamicVaRtype quantiles for this process and give upperbounds for both, theVaRquantile and the conditioned mean lossassociated to it.One way to deal with the estimation of high quantiles (Value atRisk, VaR) and mean loss given that an extreme event has oc-curred is to use Extreme Value Theory, by fitting Fréchet, Gum-bel or Weibul distributions to approximateVaRand the Gener-alized Pareto distribution to fit the conditional loss distribution(See [6]). An enormous amount of work in this direction hasbeen done also for time series (See [7], for example).The behavior of extremes for diffusion processes has been stud-ied by Davis ([5], 1982) who found a distributionFt which isthe asymptotic limit for the distribution of the maxima of theprocess ast tends to∞. On the other hand, Borkovec and Klüp-pelberg (1998, [4]) described the tail behavior of the limitFt
-using again Extreme Value Theory- in terms of the coefficientsof the equation and proved that the number ofε−up crossingsof certain level converges to a homogeneous Poisson Process ast tends to∞.Another point of view is that of Talay and Zheng ([8], 2003),who combined Monte-Carlo Methods with the Euler discretiza-tion to calculateVaRfor diffusion processes that have densities(uniformly elliptic, or a more general setting as in Bally andTalay, [1] and [2]). They applied their results to findVaR forportfolios.Our approach is completely different to that of the authors men-tioned above and is based on the reflection principle and martin-gale inequalities (as those in [3]). We obtain results that can beapplied to a general class of diffusions and work with typical ex-amples in Finance as the Vasicek and the the Cox-Ingersoll-Rossmodels, and the Geometric Brownian Motion.References[1] Bally, V. and Talay, D. (1996) The law of the Euler scheme for

146 6th BS/ IMSC
stochastic differential equations, I, Convergence rate of the distributionfunction,Probab. Theory Related Fields104, no. 1, 43–60.[2] Bally, V. and Talay, D. (1996) The law of the Euler scheme forstochastic differential equations, II, Convergence rate of the density,Monte Carlo Methods Appl.2, no. 2, 93–128.[3] Berman, S.M. (1991)Sojourns and extremes of stochastic processes,Wadsworth & Brooks.[4] Borkovec, M. and Klüppelberg, C. (1998) Extremal Behavior ofDiffusion Models in Finance , sl Extremes1, no. 1, 47–80.[5] Davis, R. (1982) Maximum and minimum of one-dimensional dif-fusions ,Stoch. Proc. Appl.13, 1–9.[6] Embrechts, P., Klüppelberg, C., and Mikosch, T. (1999)ModellingExtremal Events for Insurance and Finance, Springer Verlag, Berlin-Heidelberg-New York.[7] McNeil, A. (2000) Extreme Value Theory for Risk Managers.InExtremes and Integrated Risk Management, P. Embrechts (Ed.) RiskBooks, Risk Waters Group, London, 3–18.[8] Talay, D. and Zheng, Z (2003) Quantiles of the Euler Scheme forDiffusion Processes and Financial Applications, Confe-rence on Applications of Malliavin Calculus in Finance (Rocquencourt,2001),Math. Finance13, no. 1 187–199.
277 Controlled variable selection and con-sistent function estimates with the Lasso forhigh-dimensional regression and classifica-tion [Contributed Session C51 (page 27)]
Peter BÜHLMANN and Nicolai MEINSHAUSEN , ETHZurich, Switzerland
Proposed by Tibshirani [1] in 1996, the Lasso has proven to bea useful regularisation technique in regression and, to a lesserextent, in classification.We examine the properties of the Lasso for high-dimensionalpredictor selection for least squares and logistic regressionwhere the numberp of predictor variables is growing fast withthe numbern of observations, possibly almost exponentiallysuch thatlogp = o(n). Related settings have been examined byJuditsky and Nemirovski [2] for fixedl1-balls and by Lee et al.[3] in the case of neural network learning. Greenshtein and Ri-tov [4] obtain similar results but focus more on possible growthrates of the norm of the best predictor forp→ ∞, whereas wefocus more on the possibility of controlled variable selection andtreat additionally the case of logistic regression.We illustrate several desirable properties of the Lasso-estimatefor a specificl1-penalty parameterλ = λ (α) with control pa-rameterα > 0.Consider a set of “noise” variables(Xm)m∈I , I ⊆ 1, . . . , p,which are defined to be independently distributed fromY and(Xm)m/∈I . The probability of erroneously including one or moreof these noise variables into the model is smaller thanα.For a sequenceα = αn→ 0 for n→∞ we show risk-consistencyof the estimated predictor under both the squared error and lo-gistic loss function. Finally, we show for logistic regression thatthe log-oddslogitP(Y = 1|X) can be estimated consistently.
References
[1] Tibshirani, R. (1996) Regression Shrinkage and Selection via theLasso ,Journal of the Royal Statistical Society B58, 267–288.[2] Judistky, A. and Nemirovski, A. (2000) Functional aggregation fornonparametric regression ,Annals of Statistics28, 681–712.[3] Lee, W.S., Bartlett, P.L., and R Williamson, R.C. (1996) Efficientagnostics learning of neural networks with bounded fan in,IEEE Trans-actions on Information Theory42, 2118–2132.[4] Greenshtein, E. and Ritov, Y. (2004)Persistency in High dimensionallinear predictor-selection and the virtue of over parameterization, to ap-pear in Bernoulli.
278 Some real time sampling methods[Con-tributed Session C49 (page 26)]
Kadri MEISTER , Umeå University, Sweden
We look at a finite population and a sampling situation whereunits come, one by one, in real time to a sampler. For every unitthe sampler should decide immediately whether or not to sam-ple it by using some sequential selection method. Alternatively,the sampler visits the units in some order chosen by the sam-pler. There is no list of the population and the population sizeis most often unknown for the sampler in advance. This kind ofsampling is here referred to asreal time sampling.Let I1, I2, . . . be indicator variables telling whether or not a unitin the population should be sampled. We consider the case whenIi is a real stationary Bernoulli process in discrete time. Weare then sampling with equal inclusion probabilities. It is of-ten of interest not to sample units close to each other too oftenand therefore sampling with negative correlations has advan-tages. We consider sequencesIi with sampling correlationsRk = Corr(Ii , Ii+k) such thatRk < 0 for k = 1, . . . ,m, and 0 fork > m, wherem is some fixed constant. Hence we sample unitswith lag up tom apart dependently, and those more than lagmapart independently.Some suitable sampling designs for real time situations areBernoulli sampling, sampling according to the stationary pro-cess, and renewal sampling, where the latter can be describedas a sampling with independent random step–lengths. TheBernoulli design is a sampling design, where the sampling cor-relations are equal to zero. Hence we sample units indepen-dently. For the other sampling designs, the sampling dependson what has happened in the past. We can sample with nega-tive correlations and get estimates with better properties. Us-ing some function of independent uniform random variables fordefining the value ofIi can be considered as a generalization ofthe Bernoulli sampling for sampling units dependently. We alsoapply stratified simple random sampling in real time samplingsituation. Some modifications are needed to obtain stationaryIi. All sampling designs are briefly described, advantages anddisadvantages are discussed.Some asymptotic results are presented. The asymptotic model-based expectation of the mean square error (MSE) of the samplemean is studied. It depends on both model correlations and sam-pling correlations. Under certain conditions optimal samplingcorrelations have a simple form. For a stationary populationmodel with decreasing correlations, we conclude that samplingwith negative correlations give smaller asymptotic model–basedexpectation of the MSE of the sample mean than Bernoulli sam-pling. Numerical calculations are presented for some stationaryautocorrelated population models.References[1] Meister, K. (2002) Asymptotic Considerations Concerning RealTime Sampling MethodsStatistics in Transition5, 1037–1050.[2] Meister, K. and Bondesson, B. (2001)Some Real Time SamplingMethods, Research Report No. 2, Department of Mathematical Statis-tics, Umeå University, Sweden.
279 Discrete approximations of killed Itôprocesses[Contributed Session C10 (page 44)]
Emmanuel Gobet,, Ecole Polytechnique, France
Stéphane MENOZZI, Université Paris VI, Paris
Let (Xt)t≥0 be a multidimensional Itô process. For a smoothdomainD we introduce the exit timeτ := infs≥ 0 : Xs 6∈ D.For a fixed final timeT and a given functiong, we are interested

Abstracts 147
in the impact of a discretization of the exit time in the quantityIE[g(T ∧ τ,XT∧τ )].Wheng is smooth or satisfies a support condition w.r.t.D andthe exit time is discretized along a regular mesh with time steph,we prove under a non characteristic boundary condition, that thediscretization error is aO(
√h). We thus extend a previous result
of [1] obtained in the Markovian case under uniform ellipticityassumptions withg(T ∧ τ,XT∧τ ) = f (XT)1τ>T .Under additional assumptions the result remains valid for anintersection of smooth domains.
References
[1] Gobet, E. (2000) Euler schemes for the weak approximation of killeddiffusion,Stoch. Proc. Appl.87, 167–197.
280 Recent results on edge-reinforced ran-dom walks [Invited Session 22 (page 39)]
Franz MERKL , Leiden University, The Netherlands
Silke ROLLES,University of California at Los Angeles, USA
Edge reinforced random walks were introduced in the eightiesby Persi Diaconis. In the talk, I will describe recent results aboutlinearly edge reinforced random walks on infinite ladders: Con-vergence to a stationary distribution, and exponential bounds forthe distribution of the location of the the random walker. Theproofs are based on an representation of the reinforced randomwalk on an infinite ladder as a random walk in random environ-ment. The random environment has a complicated dependencestructure; it is given by a marginal of an infinite-volume Gibbsmeasure. This Gibbs measure is analyzed using entropy esti-mates and deformation arguments from equilibrium statisticalmechanics.
281 Iterated medians [Contributed Session C7(page 44)]
Milan MERKLE , Faculty of Electrical Engineering, Belgrade,Yugoslavia
Let X be a random variable, with a medianMedX = m. We de-fine a sequence of random variables byX1 = X,m1 = m,Xn+1 =|Xn−mn|,mn+1 = Med (Xn). The resulting sequence of me-diansmn we call iterated medians. The second term of thissequence,m2 = Med |X−m| is a measure of deviation aroundm, known in the literature as the median absolute deviation. Itseems that terms with the index higher than two have not beenstudied.In this work we investigate some properties of iterated mediansand associated sequence of random variables and their distribu-tions. Although it might seem intuitive thatmn→ 0 asn→+∞,the proof is non-trivial, and we give it under the assumption thatX has a finite expectation and that its distribution function is in-creasing and continuous on the range ofX. We also prove thatXn converges in distribution, and we find the form of the lim-iting distribution function. We prove several theorems regardingthe shape of the limiting distribution. One of main results is thefollowing.
Theorem. If the distribution ofX is continuous andmn con-verges to zero, then the series∑mn is divergent, or there exitsn0 such thatmn≤∑+∞
k=n+1mk, for n≥ n0. If the series is conver-
gent, then
limn→+∞
Xn = t > 0 if and only if
Xn =+∞
∑k=n
mk + t, for eachn≥ n0.
Moreover, the limiting distribution functionG is determined by
G(t) = P(
Xn ≤+∞
∑k=n
mk + t), t ≥ 0,
wheren≥ n0.For some common distribution functions, we found first severaliterated medians, computationally.
282 Monte Carlo method using Malliavincalculus on the Poisson space for the compu-tation of Greeks [Contributed Session C10 (page 44)]
Marouen MESSAOUD and Marie-Pierre BAVOUZET-MOREL, NRIA, France
We use the Malliavin calculus for Poisson processes in order tocompute the sensitivity of European options with an underlyingfollowing a jump type diffusion.The key point of the calculus is to state an integration by partsformula for general random variables: we have to define the dif-ferential operators which are involved in the weight followingfrom this formula. Then, we compute them to perform MonteCarlo simulations of this weight. We use the diffusion
St = λ +∫ t
0
∫
Rc(u,a,Su−) N(du,da)+
∫ t
0b(u,Su)du,
whereN is the compensator of a compound Poisson processN.We introduce an abstract Malliavin calculus as in [1]. LetH = (H1, . . . ,Hm) be a random variable with a positive densitypH . We define first Malliavin derivative of a random variabledependent onH. We define also the Skorohod and the OrnsteinUhlenbeck operators. We state the integration by parts formulaby introducing functions "πi" in the derivative to remove the bor-der terms that appear at the singular points of the densitypH . Tocompute the Greeks with a poisson diffusion we chooseH to bethe amplitude or the time of the jump. Finally we perform MonteCarlo simulation of the delta with some European options andsome jump diffusion processes. We compare the Malliavin, thefinite difference and the localized Malliavin methods.References[1] Bally, V. (2003)An Elementary Introduction to Malliavin Calculus,INRIA Research Report.[2] Fournié, E., Lasry, J.M., Lebouchoux, J., Lions, P.L., and Touzi, N.(1999)Applications of Malliavin Calculus to Monte Carlo Methods inFinance, Finance Stoch..[3] Ikeda, N. and Watanabe, S. (1989)Stochastic Differential Equationsand Diffusion Processes,Amsterdam: North-Holland.[4] Nualart, D. (1995)Malliavin Calculus and Related Topics,Springer.[5] Bichteler, K., Gravereaux, J.B., and Jacod, J. (1987)Malliavin cal-culus for processes with jumps,Gordon and Breach.[6] El Khatib, Y. and Privault, N.Computation of Greeks in a marketwith jumps via the Malliavin calculus.
283 The genealogy of self-similar fragmen-tations as a continuum random tree [Invited Ses-sion 11 (page 42)]
Bénédicte HAAS,LPMA, Université Paris VI, France
Grégory MIERMONT , DMA, École Normale Supérieure, andLPMA, France

148 6th BS/ IMSC
We encode a certain class of stochastic fragmentation processes,namely self-similar fragmentation processes with a negative in-dex of self-similarity, into a metric family tree which belongsto the family of Continuum Random Trees of Aldous. When thesplitting times of the fragmentation are dense near 0, the tree canin turn be encoded into a continuous height function, just as theBrownian Continuum Random Tree is encoded in a normalizedBrownian excursion. Under mild hypotheses, we then computethe Hausdorff dimensions of these trees, and the maximal Hölderexponents of the height functions.
284 A martingale estimating approach fortwo parameters diffusion processes[ContributedSession C20 (page 35)]
Rosa Maria MININNI and Silvia ROMANELLI,University ofBari, Italy
In many applications to Financial Mathematics and Life Sci-ences the class of degenerate elliptic operators plays a funda-mental role. The investigation of this topics involves differentaspects which range from Operator Theory and Partial Differen-tial Equations to Stochastic Differential Equations and Statisti-cal Inference. Here we focus the diffusion processes governedby degenerate elliptic operators of the type
Aθ1,θ2 u(x) := θ2x2u′′(x)+θ1xu′(x), x≥ 0, (1)
whereθ1 ∈ R, θ2 > 0, are unknown parameters. Our aim istwofold: to present a case of degenerate elliptic operators withboundary conditions not considered in [2] for which recent func-tional analytic results hold and to face the statistical problem ofconstructing optimal (in the asymptotic sense) estimators of theparametersθ1 andθ2. We present an outline of this work. Ourresults are obtained in the setting of the spaceC[0,+∞] := u∈C[0,+∞) : limx→+∞ u(x) ∈ R, equipped with the sup-norm.HereC[0,+∞) denotes the space of all real-valued continuousfunctions defined in the closed interval[0,+∞).According to the Feller theory, the domain ofAθ1,θ2 includes theso-called Wentzell boundary conditions which read as
limx→0,x→+∞
Aθ1,θ2 u(x) = 0,
From the probabilistic point of view, these boundary conditionsrepresent a diffusion phenomenon such that a Markovian parti-cle moves continuously in the state space sticking to the bound-ary. Therefore, we take into account the results by Stroock andVaradhan [1], in order to find existence and uniqueness for thesolution of a suitable martingale problem. In our previous pa-per [6] we constructed an optimal estimator of the parameterθ1 in (1), assumingθ2 = 1, by applying two recent estimationmethods proposed by Bibby and Sørensen in [3] and Kesslerand Sørensen in [4], based on determining martingale estimat-ing functions for discretely observed diffusion processes. Ourmain goal here is to extend the results obtained in [6] when theparameterθ2 in (1) is unknown too. To this end we construct es-timators from suitable multivariate martingale estimating func-tions presented in [5].By taking into account that we are dealing with a non-ergodicMarkovian diffusion-type model, we prove the consistency andthe asymptotic normality of the estimators ofθ1 andθ2 by ap-plying martingale convergence theorems.References[1] Stroock, D.W. and Varadhan, S.R.S. (1979)Multidimensional Diffu-sion Processes, Springer-Verlag, New York.
[2] Karlin, S. and Taylor, H.M.,(1981)A Second Course in StochasticProcesses, Academic Press, New York.[3] Bibby, B.M. and Sørensen, M. (1995) Martingale estimation func-tions for discretely observed diffusion processes,Bernoulli1, 17–39.[4] Kessler, M. and Sørensen, M, (1999) Estimating equations based oneigenfunctions for a discretely observed diffusion process,Bernoulli 5,299–314.[5] Bibby, B.M., Jacobsen, M. and Sørensen, M. (2003)Estimatingfunctions for discretely sampled diffusion-type models, in Handbookof Financial Econometrics (Aït-Sahalia Y. Hansen L.P., Eds.), North-Holland, Amsterdam.[6] Mininni, R.M. and Romanelli, S. (2003) Martingale estimating func-tions for diffusion processes generated by degenerate elliptic operators,J. Concrete Appl. Mathematics1 No. 3, 191–216.
285 On moment bounds and self-similarityof the coagulation equation [Invited Session 11(page 42)]
Miguel ESCOBEDO,Universidad del Pais Vasco, Spain
Stéphane MISCHLER, Univérsité de Paris-Dauphine, France
Mariano RODRIGUEZ RICARD,Universidad de La Habana,Cuba
We establish several a priori moment bounds for solutions tothe coagulation equation and to the coagulation equation in self-similar variables. Two applications are then presented. A firstapplication is the proof of occurence of gelation for multiplica-tive kernels of homogeneityλ > 1. Informations about profile atgelling time are also obtained. A second application is the proofof existence of a self similar solution of any given mass to thecoagulation equation for multiplicative kernels of homogeneityλ ∈ (0,1).
286 Local theorem for the first passagetime of fix level for recurrent random walk
[Contributed Session C15 (page 53)]
Anatolii A. MOGULSKII and BORIS A. ROGOZIN,SobolevInstitute of Mathematics, Novosibirsk, Russia
Let X,X(1),X(2), ... be i.i.d. random variables,EX = 0, EX2 ∈(0,∞) and
S(n) = X(1)+ ...+X(n).
For a fix numbery≥ 0 define the first passage time
η+(y) = infn≥ 1 : S(n) > y, η+ = η+(0).
The problem of the asymptotic behavior of the distribution ofthe first passage timesη+(y) was studied by many authors. Thereader is referred to [1] for a survey of results in this field.Theorem 1. ([3]) 1. For someλ > 0 andc > 0 the convergence
n3/2E(e−λS(η+), η+ = n)→ c, n→ ∞,
is true if and only if the distribution ofX is either arithmetic ornonlattice. In this case for allx∈ (0,∞)
n3/2P(S(η+) < x, η+ = n)→C+Q(x), n→ ∞, (1)
where the distribution functionQ(x) and the constantC+ areknown in explicit form.2. If E|X|3 < ∞ and the distribution ofX is either arithmetic ornonlattice then in (1) the convergence is true for allx∈ (0,∞].Theorem 2. ([3])If the distribution ofX is either arithmetic ornonlattice and in the statement (1) the convergence is true forall x∈ (0,∞] then for any fixy≥ 0 we have
P(η+(y) = n)∼ +n3/2
H([0,y]), n→ ∞,

Abstracts 149
where the measureH(V) is defined by Laplace transform∫ ∞0 e−λxH(dx) = (1−Ee−λS(η+))−1, λ > 0.
In Theorem 2 we reinforce the results of the paper [2], where thelocal theorem forη+(y) was obtained under stronger momentand structural conditions. Theorem 2 agrees with the results of[1] and [4], where the integral theorem forη+(y) was obtained.References[1] Borovkov, A.A. (2004) On the asymptotic behavior of the first pas-sage times, I,IIMath. Notes(to appear).[2] Mogulskii, A.A. and Rogozin, A.A. (2001) Random walks in posi-tive quadrant, III,Siberian Adv. Math.11, 35–59.[3] Mogulskii, A.A. and Rogozin, A.A. (2004) Local theorem for thefirst passage time of a fix level for recurrent random walk,Siberian Adv.Math. (to appear).[4] Doney, R.A. (1989) On the asymptotic behavior of the first pas-sage times for transient random walk,Probab. Theory Related Fields81, 239–246.
287 Characterization results via link be-tween the Hellinger distance, mutual infor-mation and entropy [Contributed Session C34 (page28)]
G.R. MOHTASHAMI BORZADARAN , University of Bir-jand, Birjand, Iran
One of the important issues in many applications of the prob-ability is finding an appropriate measure of distance betweentwo probability distributions. Among them, we will concen-trate on Kullback-Leibler information, Hellinger distance,χ2
distance and Renyiα−information measures[2]. Characteriza-tion results via the above information measures and their linkswith the Fisher information and entropy are derived here.The mutual information between two variables can be measuredeither by Renyi’s divergence or Kullback-Leibler divergence be-tween their joint pdf and factorized marginal pdfs. Character-ization in view of the Vajda’s results[1] are obtained for somemultivariate families. Also, link between mutual informationand other measures are discussed in this paper.References[1] Darbellay, G. A. and Vajda, I. (2000) Entropy expressions for multi-variate continuous distributions.IEEE Inf. Theory46, 709–712.[2] Dembo, A. and Cover, M. (1991) Information theoretic inequalities.IEEE Inf. Theory37, 1501–1518.
288 Multi-arm clinical trials with finite re-sponse and a sequence of urn functions[Con-tributed Session C63 (page 38)]
José A. MOLER, Universidad Pública de Navarra, Spain
Fernando PLO,Universidad de Zaragoza, Spain
Miguel SAN MIGUEL, Universidad de Zaragoza, Spain
A sequential design is called adaptive when, at each stage, theallocation is made depending on the past outcomes. In the con-text of clinical trials, the use of accruing information can reducethe number of patients exposed to treatments with poorer perfor-mance. Randomised urn models are the techniques commonlyused to perform adaptive designs (see, for example, [3] and thereferences therein).The Play-The-Winner rule introduced in [4] is a well-knownadaptive design used in clinical trials which has been modifiedin order to perform designs in more general settings, as in [2].In this work we describe an adaptive design for a clinical trialwith prognostic factors and more than two treatments. Patientsarrive sequentially and treatments are applied according to afunction of the urn composition. This function may change at
each stage. Patient’s response is immediate and discrete, witha finite number of possible values. The evolution of the urncomposition is expressed by a recurrence equation that fits theRobbins-Monro scheme of stochastic approximation. In this set-ting, we obtain asymptotic properties for the performance ofeach treatment by using results obtained in [1] and martingaletechniques. Finally, we illustrate the application of the rule withan example.References[1] Higueras, I., Moler, J., Plo, F., and San Miguel, M. (2003) Urn mod-els and differential algebraic equations.J. Appl. Probab.40, 401–412.[2] Moler, J.A., Plo, F., and San Miguel, M. (2004) Adaptive desgins andRobbins-Monro algorithm. (To appear in Journal of Statiscal Planningand Inference).[3] Rosenberger, W.F. (2002) Randomized Urn Models and SequentialDesign.Seq. Anal.21, 1–28.[4] Wei, L.J. and Durham, S. (1978) The randomized Play-The-Winnerrule in medical trials.J. Amer. Statist. Soc.73, 364, 840-843.
289 Perfect and Approximate Simulationof Hawkes Processes[Invited Session 31 (page 39)]
Jesper MØLLER , Aalborg University, Denmark
Hawkes processes play a fundamental role for point process the-ory and its applications. This talk concerns simulation algo-rithms for unmarked and marked Hawkes processes: the usualstraightforward algorithm, which suffers from edge effects, anda perfect simulation algorithm, which does not. By viewingHawkes processes as Poisson cluster processes and using theirbranching and conditional independence structure, useful ap-proximations of the distribution function for the length of a clus-ter are derived. This is first used to derive various useful mea-sures for the error committed when using the usual algorithm,and next to construct upper and lower processes for the perfectsimulation algorithm. Examples of applications and empiricalresults are presented.
290 The multifractal spectrum of Brown-ian intersection local times [Invited Session 10 (page39)]
Achim KLENKE, Johannes Gutenberg Universität Mainz, Ger-many
Peter MÖRTERS, University of Bath, England
Suppose is the (projected) intersection local time of two inde-pendent planar Brownian paths started at the origin and runningfor finite time. We determine the tail at zero of the random vari-able`(U), whereU is the unit ball. This result is used to findthe multifractal spectrum of the intersection local time, namelyfor all 2≤ a≤ 2ξ/(ξ −2), almost surely,
dim
x∈ IR2 : limsupr↓0
log`(B(x, r))logr
= a
=2ξa
+2−ξ ,
whereξ = ξ (2,2) = 35/12 is the Brownian intersection expo-nent recently evaluated by Lawler, Schramm and Werner [2, 3].This talk is based on joint work with Achim Klenke [1].References[1] Klenke, A. and Mörters, P. (2004)The multifractal spectrum ofBrownian intersection local times, University of Bath MathematicsPreprint 04/01.[2] Lawler, G.F., Schramm, O., and Werner, W. (2001) Values of Brow-nian intersection exponents I: Half-plane exponents,Acta Math. 187,237–273.[3] Lawler, G.F., Schramm, O., and Werner, W. (2001) Values of Brow-nian intersection exponents II: Plane exponents,Acta Math. 187, 275–308.

150 6th BS/ IMSC
291 Inequalities of the uniform ergodic-ity and strong stability for homogeneousMarkov chains and application [Contributed Ses-sion C18 (page 54)]
Djamil AISSANI and Zahir MOUHOUBI , University of Bé-jaia, Algeria
In this paper, we present some results which generalize, pre-cise and complete those exposed by D. Aissani and N.V. Kar-tashov [1], N.V. Kartashov [3] and Z. Mouhoubi [4,5]. In more-over of continuity qualitative affirmation, we obtain quantita-tive uniform ergodicity and strong stability estimates for generalMarkov chains.We must be precise that in the difference of the method pro-posed by Kalashnikov (1978) and Zolotarev (1975), we supposethat the perturbation of the corresponding transition kernel of theMarkov chain is small with respect to some operators norm. Thiscondition, more stringent than other usual conditions, enable usto obtain more better approximation for the perturbed stationarydistributions. Furthermore, the strong stability method give usan exactly calculus of constants which we allowed us to test thepower of the results.We should finally indicate that in practice, in the analysis of thecomplex systems, we never know exactly the distributions of thearrivals (we only estimate the degree of proximity relatively tothe one given [2]. That is why obtaining inequalities of this typewill allow us to estimate numerically the uncertainty shown inthis analysis.An application for the waiting process is considered and gener-alize the results obtained in [4] ford≥ 1.References[1] Aissani, D. and Kartashov, N.V., (1983) Ergodicity and stability ofMarkov chains with respect to operator topology in the space of transi-tion kernels,Dokl. Acad. Nauk, Ukr. SSR, Ser. A11, 3–5.[2] Aissani, D. and Kartashov, N.V. (1984) Strong Stability of imbebedMarkovchains in anM/G/1 system,Theor. Prob. and Math. Stat.29, 1–5.[3] Kartashov, N.V. (1996) Strong stable Markov chains. VSP (Eds),UltrechtTBMIMC scientific Publishers, Kiev.[4] Mouhoubi, Z. and Aissani, D. (2002) On the Quantitatives Estimatesof the Uniform Ergodicity for Markov chains. Proceeding of the 8-th In-ternational Vilnius Conference on Probability Theory and MathematicalStatistics. Vilinius, Lithuania, 7–8.[5] Mouhoubi, Z. and Aissani, D. (2002) On the Quantitatives estimatesof the Strong Stability for Markov chains, Proceeding of the XXII-th In-ternational Seminar on Stability Problems for Stochastic Models and theSeminar on Statistical Data Analysis. Varna, Bulgaria, 67–68.[6] Mouhoubi, Z. and Aissani, D. (2003) On the Uniform Ergodicity andStrong Stability Estimates of Waiting Process. Bulletin of the Interna-tional Statistical Institute, Volume LX, Book 2, Berlin 2003, 97–98.
292 Limit theorems and deviation inequal-ities for subgeometric Markov chains [Con-tributed Session C18 (page 54)]
Randal DOUC,École Polytechnique, Palaiseau, France
Arnaud GUILLIN,CEREMADE, Université Paris IX Dauphine,Paris, France
Eric MOULINES , École Nationale Supérieure des Télécom-munications (ENST), Paris, France
In recent years, there has been a renewal of interest for the studyof Markov chain under conditions which imply sub-geometricergodicity. Examples of such chains are numerous in renewaltheory, queuing theory, econometry and Markov chain Monte-Carlo. The study of such chain has been considerably simplified
by the recent discovery of a drift criterion (playing the samerole than the Foster-Lyapunov drift condition for geometricallyergodic Markov chain) which has been first derived in [1] forriemanian (or polynomial) ergodicity and then extended in [2]to general subgeometric sequence.The central result of the paper is an explicit bound for the (pos-sibly weighted) additive functional of the split Markov chainsfrom quantities appearing in the subgeometric drift equation andon the minorizing constant. The underlying technique use theembedding of the Markov chain in a wide-sense regenerativeprocess with the help of the splitting construction [3]. Fromthese explicit bounds, we are able to derive, using standard ar-guments, moderate deviation principles for (unbounded) addi-tive functional, extending the results obtained in [4] for chainshaving an atom as well as deviation inequalities “à la Chernoff".References[1] Jarner, S. and Roberts, G. (2001) Polynomial convergence rates ofMarkov chains,,Annals of Applied Probability.[2] Douc, R., Fort, G., Moulines, E., and Soulier, P. (2004)Practicaldrift conditions for subgeometric rates of convergence, Annals of Ap-plied Probability.[3] Nummelin, E. (1984)General Irreducible Markov Chains and Non-negative Operators. Cambridge University Press, Cambridge, England.[4] Djellout, H. and Guillin, A. (2001) Moderate deviations for Markovchains with atom,Stochastic Processes and Appl., 95, 203–217.
293 Stochastic order relations and latticesof probability measures [Contributed Session C2(page 24)]
Alfred MÜLLER , Universität Karlsruhe, Germany
Marco SCARSINI,Universita di Torino, Italy
A great deal of literature has appeared in the recent decadesabout ordered sets of probability measures (see for instanceShaked and Shanthikumar (1994) and Müller and Stoyan (2002)for the state of the art), but surprisingly little attention has beengiven to the lattice structure of these sets.In this paper we will try to study this issue in a more systematicway. It will turn out that the space of probability measures onR(or some suitable subsets of it) is a lattice when endowed withmost of the well known stochastic orders like usual stochasticorder, convex order, hazard rate order etc., whereas it it turnsout that the space of probability measures onRd is in not a lat-tice, if endowed with usual stochastic order, convex order, linearconvex order or supermodular order. In order to obtain a latticestructure for sets of probability measures onRd we need to putsevere restrictions on their dependence structure.Moreover, we give an application to a stochastic optimizationproblem from mathematical finance, where in case of a latticethe computationally difficult problem of multiple restrictionscan be reduced to a much more simple problem with only onerestriction.References[1] Müller, A. and Stoyan, D. (2002)Comparison methods for stochasticmodels and risks, Wiley, Chichester.[2] Shaked, M., and Shanthikumar, J.G. (1994)Stochastic orders andtheir applications, Academic Press, Boston.
294 Stochastic volatility models for ordinalvalued time series [Contributed Session M1 (page 17)]
Claudia CZADO andGernot MÜLLER , Munich University ofTechnology, Germany
Our aim is to model the intraday development of stock prices,in particular the development of the price change process. The

Abstracts 151
price changes have some specific features which we want to becovered by our model. One important feature is that they onlyoccur in integer multiples of a certain amount, the so-called ticksize. In modelling the price changes we therefore have to takeinto account that we observe a time series with discrete response.Also other important features of such time series as non-constantvolatility or the dependence on covariates are covered by the fol-lowing model:
yobst = k ⇐⇒ yt ∈ [ck−1,ck) k∈ 1, . . . ,K (1)
yt = x′tβ +exp(ht/2)εt t ∈ 1, . . . ,T (2)
ht = µ +z′tα +φ(ht−1−µ−z′t−1α)+σηt (3)
A modified version of the underlying stochastic volatility model(2) and (3) for continuous responses was considered in [1]. Weobserve only the variablesyobs
t , which are discretized versionsof the latent continuous variablesyt . xt andzt are vectors of co-variates,εt andηt are assumed to be i.i.d.N(0,1). We fix c1 andµ for reasons of identifiability.For the estimation of the parameters in this model we de-velop an MCMC algorithm, which is based on the algorithmpresented in [1] for the underying continuous model. How-ever, standard MCMC steps for the additional discretizationin Equation (1) lead to a very bad convergence of the result-ing MCMC method. Therefore we develop additional groupedmove (GM) steps to speed up the convergence especially of thechains for the cutpointsck. The idea of GM steps is basedon a theorem in [2] which states: IfΓ is a locally compactgroup of transformations defined on the sample spaceS, Lits left-Haar measure,w ∈ S follows a distribution with den-sity π, and γ ∈ Γ is drawn fromπ(γ(w))|Jγ (w)|L(dγ), withJγ (w) = det(∂γ(w)/∂w), ∂γ(w)/∂w the Jacobian matrix, thenw∗ = γ(w) has densityπ, too.Commonlyπ is considered to be the interesting posterior dis-tribution. The difficulty in the choice of a suitable transfor-mation group is to find one where on the one hand the prob-lematic parameters are transformed and on the other hand thedistributionπ(γ(w))|Jγ (w)|L(dγ) allows to draw samples veryfast. We apply this theorem only to the conditional distribu-tion of w :=
(y1,. . .,yT ,c3,. . .,cK−1,β0, . . . ,βp
)given all the
observations and all the remaining parameters. In order toget an easy sampling distribution we use the scale group,Γ =γ > 0 : γ(w) = (γw1, . . . ,γwd), with γ−1dγ as left-Haar mea-sure. This finally leads to a Gamma distribution forγ2. There-fore, in each iteration of our MCMC sampler we insert the cor-responding GM-step, which consists of drawing aγ2 from theresulting Gamma distribution and the updatew→ γ ·w. We il-lustrate that this significantly speeds up the convergence of thealgorithm.Finally we fit the model to IBM intraday data collected in Jan-uary 2001. We show that a positive price jump increases theprobability that the next price jump will be negative and viceversa. Furthermore, the time between transactions has an im-pact on the log-volatility in Equation (3): The more time elapsesbetween two subsequent transactions, the higher is the probabil-ity for a big price jump, upwards or downwards.References[1] Chib, S., Nardari, F., and Shephard, N. (2002) Markov chain MonteCarlo methods for stochastic volatility models,Journal of Econometrics108, 281–316.[2] Liu, J.S. and Sabatti, C. (2000) Generalized Gibbs sampler and multi-grid Monte Carlo for Bayesian computation,Biometrika87, 353–369.
295 Using Q-Learning to estimate an opti-mal dynamic treatment regime [Invited Session25 (page 14)]
S.A. MURPHY, University of Michigan, USA
Q-Learning is a common method used in the field of machinelearning for estimating the optimal policy in a multistage deci-sion process. This method can also be used to estimate the deci-sion rules which make up an optimal dynamic treatment regime.We derive finite sample error bounds for Q-Learning with func-tion approximation and discuss how there is a mismatch betweenthe method and the goal of producing the best decision ruleswithin a function approximation class.
296 A table of two time scales: determin-ing integrated volatility with noisy high fre-quency data [Invited Session 8 (page 14)]
Per MYKLAND , The University of Chicago, USA
In the analysis of high frequency financial data, a major prob-lem concerns the nonparametric determination of the volatilityof an asset return process. A common practice is to estimatevolatility from the sum of the frequently-sampled squared re-turns. Though this approach is justified under the assumptionof a continuous stochastic model, it runs into the challenge ofmarket microstructure in real applications. We argue that thiscustomary way of estimating volatility is flawed in that it over-looks what is, in fact, observation error. The usual mechanismfor dealing with the problem is to throw away part of the data, bysampling less frequently. We propose here a statistically sounderdevice. Our device is model-free, it takes advantage of the richsources in tick-by-tick data, and to a great extent it corrects theeffect of the microstructure noise on volatility estimation. Wealso develop a limit theory for the corrected estimator.
297 On pathwise uniqueness for stochas-tic heat equations with non-Lipschitz coeffi-cients [Invited Session 15 (page 51)]
Leonid MYTNIK , Technion-Israel Institute of Technology, Is-rael
Edwin PERKINS and Anja STURM,The University of BritishColumbia Canada
We consider the pathwise uniqueness for the stochastic partialdifferential equation
∂∂ t
u(t,x) =12
∆u(t,x)dt+σ(u(t,x))W(x, t),
t ≥ 0, x∈ Rd.
driven by Gaussian noiseW on Rd ×R+. W is white in timeand "colored" in space. We focus on the case of non-Lipschitzcoefficientsσ and singular spatial noise correlations.
298 Fast Simulation Of New Coins FromOld [Contributed Session C45 (page 14)]
Serban NACU and Yuval PERES ,Univeristy of California atBerkeley, USA
You are given a coin with probability of headsp, where p isunknown. Can you use it to simulate a coin with probability ofheads2p? This question was raised by Asmussen in 1991, mo-tivated by an application in the simulation of renewal processes.More generally, if f is a known function, can you use a coinwith probability of headsp (p unknown) to simulate a coin withprobability of headsf (p)? In 1994, Keane and O’Brien obtained

152 6th BS/ IMSC
necessary and sufficient conditions for a functionf to have sucha simulation.We are looking at the problem of efficient simulation. LetNbe the number ofp-coin tosses required to simulate af (p)-cointoss. TypicallyN will be random; we say the simulation is fastif N has exponential tails. We prove that a functionf has a fastsimulation if and only if it is real analytic. The proof is construc-tive, and leads to algorithms that can be implemented. We usetools from the theory of large deviations, approximation theory,and complex analysis.
299 The polynomial method for randommatrices [Contributed Session C8 (page 34)]
Alan Edelman andRaj Rao NADAKUDITI , Massachusetts In-stitute of Technology
The empirical distribution function (e.d.f.) of random matriceswith real eigenvalues is of particular interest to many researchcommunities. For infinitely large random matrices, in many in-teresting cases, the e.d.f. can be obtained from the solution ofa bivariate polynomial equation in the probability space vari-ablezand the asssociated Stieltjes transform variablem(z), suchthat L(z,m(z)) = 0. The Marcenko-Pastur [1] theorem and theR and S transforms in free probability [2], for example, allowus to obtain such bivariate polynomials. We show that this bi-variate polynomial is the most natural representation for randommatrices in many instances. Our evidence for this hypothesisis our observation that if we perform simple transformations onthe random matrix, then the transformations inL(z,m(z)) canbe represented very simply. We present these transformationsas a mathematical tool [3] as well as a computational realizationthat simplifies and extends researchers abilities to get answers tocomplicated random matrix questions.References[1] Marcenko, V. and Pastur, L. (1967) The eigenvalue distribution forsome sets of random matrices,Math USSR - Sbornik4, 457–483.[2] Voiculescu, D.V., Dykema, K.J., and Nica, A. (1992)Free randomvariables, Providence, R.I., Amer. Math. Soc.[3] Rao, R. Nadakuditi and Alan Edelman,The polynomial method forrandom matrices, In preparation.
300 Moderate deviations for particle filter-ing [Contributed Session C36 (page 16)]
Randal DOUC,Ecole Polytechnique, France
Arnaud GUILLIN, Université Paris-Dauphine, France
Jamal NAJIM , CNRS, France
Consider the state space model(Xt ,Yt) where(Xt) is a Markovchain and(Yt) are the observations. In order to solve the so-called filtering problem, one has to compute
L (Xt |Y1, . . . ,Yt) ,
the law of Xt given the observations(Y1, . . . ,Yt). The par-ticle filtering method gives an approximation of the lawL (Xt |Y1, . . . ,Yt) by an empirical measure1n ∑n
1 δxi,t . In this pa-per, we establish the Moderate Deviation Principle for the em-pirical mean1
n ∑n1 ψ(xi,t) (centered and properly rescaled) when
the number of particles grows to infinity, enhancing the CentralLimit theorem. Several extensions and examples are also stud-ied.
Manuscript of the corresponding article available athttp://www.tsi.enst.fr/najim/ .References[1] Del Moral, P. (1996) Nonlinear filtering: interacting particle solution.Markov Process,Related Fields 24, 555–579.
[2] Del Moral, P. and Guionnet, A. (1999) Central limit theorem for non-linear filtering and interacting particle systems,Ann. Appl. Probab. 9,no. 2, 275–297.[3] Del Moral, P. and Miclo, L. (2000) Branching and interacting particlesystems approximations of Feynman-Kac formulae with applications tonon-linear filtering. Séminaire de Probabilités, XXXIV, 1–145, LNM,Springer, Berlin.[4] Dembo, A. and Zeitouni, O. (1998) Large deviations techniques andapplications. Second edition. Springer-Verlag, New York.[5] Doucet, A., de Freitas, N., and Gordon, N. (Editors) An introductionto sequential Monte Carlo methods. Sequential Monte Carlo methods inpractice, Springer, New York, 2001.
301 Anisotropy effects in nucleation forconservative dynamics [Poster Session P2 (page 32)]
F. R. NARDI , University of Roma La Sapienza, Italy
E. OLIVIERI University of Roma Tor Vergata, Italy
E. SCOPPOLAUniversity of Roma Tre, Italy
We analyze metastability and nucleation in the context of a lo-cal version of the Kawasaki dynamics for the two-dimensionalanisotropicIsing lattice gas at very low temperature.Let L ⊂ Z2 be a sufficiently large finite box. Particles performsimple exclusion onL, but when they occupy neighboring sitesthey feel a binding energy−U1 < 0 in the horizontal directionand−U2 < 0 in the vertical direction. Along each bond touch-ing the boundary ofL from the outside, particles are created withrateρ = e−Db and are annihilated with rate 1, whereb is the in-verse temperature andD > 0 is an activity parameter. Thus, theboundary ofL plays the role of an infinite gas reservoir withdensityρ.We takeD ∈ (U1,U1 +U2) where the totally empty (full) con-figuration can be naturally associated to metastability (stability).We investigate how the transition from empty to full takes placeunder the dynamics. In particular, we identify the size and somecharacteristics of the shape of thecritical droplet and the timeof its creation in the limit asb→ ∞.We observe very different behavior in the weakly or stronglyanisotropic case. In any case we find that Wulff shape is notrelevant for the nucleation pattern.
References
[1] G. Ben Arous and R. Cerf, (1996)Metastability of the three-dimensional Ising model on a torus at very low temperature. Electron. J.Probab. 1 Research Paper 10.[2] D. Capocaccia, M. Cassandro and E. Olivieri, (1974)A study ofmetastability in the Ising model, Commun. Math. Phys. 39 185–205.[3] M. Cassandro A. Galves, E. Olivieri and M. E. Vares,(1984)Metastable behaviour of stochastic dynamics: A pathwise approach. J.Statis. Phys.35 )
302 Kriging extreme climate events [InvitedSession 4 (page 23)]
Philippe NAVEAU , University of Colorado at Boulder, USA
Modeling spatially and temporally extreme climate events (rain-falls, winds, etc) still remains a mathematical challenge. In thistalk, we focus on developing a statistical scheme for interpolat-ing extreme events. The motivation for solving such a krigingproblem is the geographical support difference between climatedata sets. For example, the meteorologist would like to com-pare and integrate her/his extreme observations (e.g annual max-imum precipitation at different weather stations) with the ex-treme events from numerical outputs of climate models availableon a regular grid. In geostatistics, the original variables are clas-sically transformed into a Gaussian vector and then variograms

Abstracts 153
are used to represent the spatial structure. Besides the prob-lem of choosing the adequate transform, there are a few difficul-ties associated with this method, for example dealing with heavytail distributions (the variogram being a second-order statistic).Other approaches are based on max-stable processes or latentspatial processes for which the Generalized extreme value distri-bution parameters vary with location. As an alternative to thesemethods, we propose to model the spatiotemporal dependencebased on the madogram (a variogram of first order) whose prop-erties are closely linked to probability weighted moments. Thisnew strategy has many advantages. Classical tools for geostatis-tics can be used without transforming the data and the specificityof the extreme value theory can be implemented in our model.We apply this framework in the context of statistical extremevalue analysis of observed hourly precipitation records in theU.S. One of the more general goals is to compare the represen-tation of precipitation extremes in climate models to regionalprecipitation data.
303 Optimal two-stage hypotheses testing[Contributed Session C63 (page 38)]
Andrey NOVIKOV , Universidad Autonoma Metropolitana -Unidad Iztapalapa, Mexico
This work deals with optimal two-stage tests for two simple hy-potheses. The structure of both the optimal decision rule andthe optimal continuation rule is given. The results are appliedto the optimal two-stage tests for a Wiener process with a lin-ear drift, and to obtain an asymptotically optimal test for twoclose hypotheses in the case of locally asymptotically normalstatistical experiment (see, e.g. [2]). The numerical results ofcomparison between the optimal Neyman-Pearson test, Wald’ssequential probability ratio test and the proposed optimal two-stage test are given (cf. [1] and [4]). Based on recent results bythe author [3], applications to testing hypothesis for a Markovergodic discrete-time stochastic processes will be discussed.References[1] Aivazjan, S.A. (1959) A comparison of the optimal properties of theNeyman-Pearson and the Wald sequential probability ratio test.TheoryProb. Appl.4, 86–93.[2] Le Cam, L. (1986)Asymptotic methods in statistical decision theory,Springer Series in Statistics. Springer-Verlag, New York-Berlin.[3] Novikov, A. (2001) Uniform asymptotic expansion of likelihood ra-tio for Markov dependent observations.Ann. Inst. Statist. Math.53,799–809.[4] Novikov, A. (2002) Efficiency of sequential hypotheses testing.Aportaciones matemáticas. Serie Comunicaciones30, 71–79.
304 Setting Bartlett adjusted likelihood in-tervals [Poster Session P3 (page 41)]
Tommi NURMINEN and Esa UUSIPAIKKA,University ofTurku, Finland
Setting likelihood based confidence intervals relies on the re-sult that under certain mild conditions, the distribution of like-lihood ratio statistic is chi-square distribution with one degreeof freedom. If the sampling distribution is not close to normaland sample size is small the approximation may turn out to beimplausible, and thus confidence intervals based on chi-squareapproximation become either too narrow (liberal) or too wide(conservative).The approximation can often be improved by using Bartlett ad-justed likelihood ratio statistic. Confidence intervals calculatedfrom Bartlett adjusted statistic usually have coverage closer todesired level but they usually have the unfortunate feature of notbeing likelihood intervals, because likelihood ratio statistic has
been modified by Bartlett adjustment.In this poster we present a way to calculate Bartlett adjusted con-fidence intervals which are likelihood intervals and have cover-age improved by Bartlett adjustment. In this method Bartlettadjustment is used for modifying confidence limits so that theirlikelihoods remain the same. We restrict our examinations tomodels with only one unknown parameter.
305 Scaling [Contributed Session C12 (page 25)]
Jan OBŁÓJ, Université Paris 6, France and Warsaw Univer-sity, Poland
Marc YOR,Université Paris 6, France
Exactly 40 years ago Skorokhod posed a problem of findinga stopping time, which embeds a given measure in Brownianmotion. This problem has been since generalized and solveda number of times (see a survey on this subject [3]). It founda numerous applications. Still, an explicit solution for discon-tinuous processes has not been found, and some of them as theAzéma martingale, or more generally, functionals of Brownianexcursions, are of great interest.One of the most celebrated solutions of the classical Skorokhodembedding problem is the Azéma and Yor’s solution [1]. In arecent paper [2], together with Marc Yor, we solved the embed-ding problem for positive functionals of Brownian excursions,such as the age process, obtaining explicit formulae. In this talk,we propose to explain this results, but in the context of new,more general ones. We will treat the case of signed functionalsof Markov Processes. Having such a general approach, will al-low not only to obtain very widely applicable formulae, but alsoto understand better, the expressions obtained in the above men-tioned paper. The approach will follow the general methodologysuggested in the paper [2].More specifically, if(Xt) is a Markov process with a well de-fined excursion process(el ) and the local time at zero(Lt), welook at a process(Ft), whereF is functional, which associatesa monotone, real valued function to an excursion. The mostimportant examples are the age process, the maximum processor the principal value process (for Brownian motion). Givena probability measureµ on R we want to specify a stoppingtime T such thatFT ∼ µ . We look forT of the following formT = inft > 0 : Ft > ϕ(Lt) and are able to specify the func-tion ϕ which realizes the embedding. Moreover, this functiondepends onF only through the image of the excursion measureit induces, thus giving a solution for family of functionals at thesame time.We will conclude with some examples and applications of theabove solution to the Skorokhod embedding problem. This willin particular involve an explicit, non-randomized solution for theAzéma martingale.References[1] Azéma, J. and Yor, M. (1979)Une solution simple au problème deSkorokhod, Séminaire de Probabilités XIII, Lectures notes in Math721,90–115.[2] Obłój, J. and Yor, M. (2004) An explicit Skorokhod embedding forthe age of Brownian excursions and Azéma martingale,Stochastic Pro-cess. Appl.110, no. 1, 83–110.[3] Obłój, J. (2004)The Skorokhod problem and its offspring, MathArXiv:math.PR/0401114.[4] Skorokhod, A.V. (1965)Studies in the theory of random processesTranslated from the Russian by Scripta Technica. Inc. Addison-WesleyPublishing Co., Inc., Reading, Mass.
306 Space-time model for regional seismic-ity and detection of crustal stress changes[In-

154 6th BS/ IMSC
vited Session 2 (page 13)]
Yosihiko OGATA , Institute of Statistical Mathematics, Tokyo,Japan
This paper is concerned with a space-time point-process modelfor the analysis of earthquake data of occurrence times, loca-tions, and magnitudes. The parameters of the space-time point-process model also vary spatially (i.e., a hierarchical Bayesianmodel). For example, the inverse-power coefficient (p-value)of the aftershock decay rate in the model is represented as aspline function of location, being constructed based on Delau-nay tessellation. Likewise, the other parameters of the modelare represented by such functions of location in order to visual-ize regional features of the seismic activity. The validity of themodel is demonstrated by comparison between the traditionallyobtainedp-value estimates from respective individual sequencesof aftershocks and our spatial estimate ofp-values obtained byapplying the Bayesian model to the space-time data of events ofmagnitude (M ≥ 5) in and around Japan during the period 1926-1995. Also, among the other parameter functions, the aftershockproductivity (K-value), relative to the size of the main shock, isfound to take high values in regions around the so-called ’as-perities’ of large earthquakes on the active upper boundary ofsubducting Pacific plate, while the asperities were identified bythe inversion of historical strong motion seismograms.Furthermore, I propose a ’Bayesian diagnostic analysis’ of thespace-time model, which reveals the seismically anomalous pe-riods and regions in which the actual occurrence rates deviatesignificantly from the modeled (or predicted) ones. Such ananomaly (activation and quiescence) relative to the model couldsensitively reveal the change (increase or decrease) of shearstresses working across potential seismic faults in a region. Iattempt to relate this activation and lowering of the seismicityto the changed pattern of Coulomb failure stress caused by arupture or silent slip elsewhere that are computed based on thetheory of stress transfer in an elastic media [4]. For example,such anomalies seen in the seismic activity in the central Japan(M≥ 2.5) during 1995-1999 and during 2001 are likely to be theconsequence of the Coulomb stress changes respectively due tothe 1995 Kobe rupture of M7.2 and the inter-plate aseismic slipduring 2001 beneath the western Tokai region that was identifiedand inverted by geodetic anomalies observed by GPS network.References[1] Ogata, Y., Katsura, K., and Tanemura, M. (2003) Modelling hetero-geneous space-time occurrences of earthquake and its residual analysis,Applied Statistics (JRSSC), 52, 499–509.[2] Ogata, Y. (2003) Sesimicity changes in western Japan (1995-2001)detected by a statistical space-time model (in Japanese),Report of theCoordinating Committee for Earthquake Prediction, 58, GeographicalSurvey Institute, Ministry of Construction, Japan, pp. 5-6 and pp. 361-364.[3] Ogata, Y. (2004) Space-time model for regional seismicity and detec-tion of crustal stress changes,Journal of Geophysical Researchin press,American Geophysical Union, Washington DC.[4] Okada, Y. (1992) Internal deformation due to shear and tensile faultsin a half-space,Bull. Seism. Soc. Am., 82, 1018–1040.
307 Strong uniform representation of thelocal polynomial estimator. application to in-ference with biased data [Contributed Session C14(page 16)]
José Tomás ALCALÁ, José Antonio CRISTÓBAL andJorgeLuis OJEDA , Universidad de Zaragoza, Spain
In this work we present a strong uniform representation of the
local polynomial estimator for the regression functionm(x) =E[Y|X = x] for a bivariate population(X,Y) such thatX ∈ [0,1]andY is bounded. Ifmn(x) denotes the local polynomial estima-tor of orderp we find that
mn(x) = m(x)+√
Cn(x)Z∗n(x)+o( 1√
nhn
)
uniformly in [0,1] and almost surely, whereCn(x) is the the vari-ance ofmn(x) andZ∗n(x) is a second order Gaussian process witha null mean and whose covariance is known. Furthermore, theanalysis of the covariance function shows that this process doesnot only comprises the main features of the stochastic comport-ment ofmn, but is also particularly useful in order to study thedistributional behavior of this estimator.In order to obtain the result, we have used the expression forthe local polynomial estimator given in [4] in terms of matrices.Accordingly, we first study the strong uniform consistency of itscomponents by means of the Theory of Empirical Processes in-dexed by VC-classes of functions. Then, and taking advantageof the strong approximation results for empirical processes in-dexed by sets given in [7] we obtain the above–mentioned Gaus-sian process. The result is proved for a kernel with a compactsupport and, for suitable bandwidth sequence, convergence ratesare also provided.As examples of the utility of these developments, we presenttwo goodness of fit tests for the functional form of the regres-sion function. Both tests are based on the comparison of theparametric and noparametric residuals; while the first uses thesupreme distance, see [6], the second uses an appropriate inte-grated squared deviation, see [5]. These tests are presented fordata in the usual context, as well as in the case of length biasedobservations when the estimators are based on the idea ofcom-pensationas presented in [1].References[1] Cristóbal, J.A. and Alcalá, J.T. (2000) Nonparametric regression es-timators for length biased data,J. Statist. Plann. Inference89, 145–168.[2] Cristóbal, J.A., Ojeda, J.L., and Alcalá, J.T. Confidence Bands inNonparametric Regression with Length Biased Data,Ann. Inst. Statist.Math. to appear.[3] de la Peña, V.H. and Giné, E. (1999)Decoupling. From depen-dence to independence, Randomly stopped processes.U-statistics andprocesses, Martingales and beyond, Springer-Verlag, New York.[4] Fan, J. and Gijbels, I. (1996)Local polynomial modeling and itsapplications, Chapman & Hall, London.[5] Härdle, W. and Mammen, E. (1993) Comparing nonparametric ver-sus parametric regression fits,Ann. Statist.21(4), 1926–1947.[6] Kozek, A.S. (1990) A nonparametric test of fit of a linear model,Comm. Statist. Theory Methods19(1), 169–179.[7] Massart, P. (1989) Strong approximation for multivariate empiricaland related processes, via KMT constructions,Ann. Probab. 17(1),266–29.[8] van der Vaart, A.W. and Wellner, J.A. (1996)Weak convergence andempirical processes, With applications to statistics. Springer-Verlag,New York.
308 Bandwidth selection for kernel bino-mial regression [Contributed Session C52 (page 20)]
Kanta NAITO,Shimane University, Japan
Hidenori OKUMURA , Chugoku Jounior College, Japan
In nonparametric binomial regression, the weighted kernel esti-mator of the regression function and its efficient bias-adjustedversion have been proposed in Okumura and Naito [1] with con-sideration to differences of variances of observed response pro-portions at each covariates. The aim of this talk is to proposean effective data-based method for bandwidth selection of the

Abstracts 155
bias-adjusted estimator. The proposed method is developed us-ing the plug-in method by Ruppertet al. [2] with some suitablearrangements. Theoretical considerations on the performance ofthe selected bandwidth are given under the situation where thenumbers of covariates and responses observed at each covari-ates increase. The effectivities for the proposed method are alsoillustrated by some simulation studies.References[1] Okumura, H. and Naito, K. (2003) The weighted kernel estimatorsin nonparametric binomial regression,J. Nonpar. Statist.16, 39–62.[2] Ruppert, D., Sheather, S.J., and Wand, D.W. (1995) An effectivebandwidth selector for local least squares regression,J. Am. Statist.Ass.90, 1257–1270.
309 A functional auto-regression as amodel of interest rate dynamics [Contributed Ses-sion M8 (page 31)]
Vladislav KARGIN,Cornerstone Research, USA
Alexei ONATSKI , Columbia University, USA
The forward rate is the equilibrium interest rate, at which bor-rowing at a future date can be arranged today. It can be eitherinferred from the current prices of different maturity bonds, orobserved directly in prices of forward interest rate contracts. Forone thing the study of forward rates is important since the mar-ket of interest rate futures contracts is large and growing. Thenumber of futures contracts on interest rates traded on U.S. Ex-changes grew more than 20 times during the last two decades:from 12.5 millions in 1980 to 248.7 millions in 2000. For an-other, the study of forward rate curve dynamics is important forpricing other interest rate securities and for managing risk offixed-income portfolios. Finally, models of term structure shedlight on how investors form their expectations about future in-terest rates. In this paper we construct a model of forward ratesdynamics based on functional autoregression:
ft(T)− f (T) = ρ[
ft−δ (T)− f (T)]+ εt(T), (1)
wheret is the calendar time, measured in discrete incrementsδ , forward rateft(T) is a Hilbert-space valued random variable,andρ is a linear operator on this Hilbert space. We show how toestimate this model and why it is useful for both pricing interestrate products and forecasting the forward rate curve.The models of forward curve dynamics come in 3 varieties.Equilibrium models (like [2]) start with assumption that thereare several factors, typically short and long interest rates, thatdetermine the prices of all other bonds. The process of the fac-tors is specified in a parametric form and estimated. The bondsin these models may be mispriced. Arbitrage-free models startfrom the assumption that all bonds are priced correctly and focuson how to price interest rate derivatives. The most well-knownof those models, Heath-Jarrow-Morton (HJM) model [4], addthe insight that modeling forward rate curve evolution instead ofbond yields makes pricing derivatives easier. The focus in thesepapers is, however, on novel methods of pricing, not on estima-tion. The random string models ([5]) relax the assumption thatevolution of term structure should be driven by a finite numberof factors. In their current form, however, they are ill-suitablefor estimation purposes.We model interest rate dynamics by representing it as a particu-lar case of a functional auto-regression. The theory of functionalauto-regressions has made a significant progress in last years(see monograph [1] and [3]) and we capitalize on it. We developa strategy of estimation of the forward rate auto-regression andprove its consistency.
Next we show how the model can be applied in prediction offuture forward rates, evaluation of portfolio risk, and pricing ofinterest rate securities. With respect to the question whether ourmodel can be made arbitrage-free, we provide a result on theexistence of the martingale measure in our model.In an empirical section our method is illustrated by an appli-cation to the data on Eurodollar future rates. We estimate thefunctional auto-regression and extract the factors. We find thatthe factor dynamic cannot be separated in 3 components inde-pendent from each other.References
[1] Bosq, D. (2000)Linear Processes in Function Spaces: Theory andApplications, Springer-Verlag.[2] Cox, J.C., Ingersoll, J.E., and Ross, S.A. (1985) A theory of the termstructure of interest rates,Econometrica53, 385–408.[3] Da Prato, G. and Zabczyk, J. (1992)Stochastic equations in infinitedimensions, Cambridge University Press.[4] Heath, D., Jarrow, R., and Morton, A. (1992) Bond Pricing and theTerm Structure of Interest Rates: A New Methodology for ContingentClaims Valuation,Econometrica60, 77–105.[5] Kennedy, D.P. (1997) Characterizing Gaussian Models of the TermStructure of Interest Rates,Math. Finance7, 107–116.
310 A new concept of integrability and theweak law of large numbers for weighted sumsof random variables [Contributed Session C7 (page44)]
Manuel ORDOÑEZ CABRERA , University of Sevilla, Spain
Andrei VOLODIN, University of Regina, Saskatchewan,Canada
From the classical notion of uniform integrability of a sequenceof random variables, a new concept of integrability (calledα-integrability) is introduced for an array of random variables,concerning an array of constants. We prove that this conceptis weaker than another previous related notions of integrability,such as Cesàro uniform integrability ([1]), uniform integrabilityconcerning the weights ([2]) and Cesàroα-integrability ([3]).Under this condition of integrability and appropriate conditionson the array of weights, WLLN for weighted sums of an arrayof random variables is obtained when the random variables aresubject to some special kinds of dependence: a) rowwise pair-wise negative dependence, or b) rowwise pairwise negative cor-relation, or c) when the sequence of random variables in everyrow is a martingale difference sequence with respect to a non-decreasing sequence ofσ -algebras.References[1] Chandra, T.K. (1989) Uniform integrability in the Cesàro sense andthe weak law of large numbers,Sankhya Ser. A51, 309–317.[2] Ordóñez Cabrera, M. (1994) Convergence of weighted sums of ran-dom variables and uniform integrability concerning the weights,Collect.Math. 45, 121–132.[3] Chandra, T.K. and Goswami, A. (2003) Cesàroα-integrability andlaws of large numbers I,J. Theoret. Probab.16, 655–669.
311 Adaptive particle filters [Contributed Ses-sion C36 (page 16)]
Anastasia PAPAVASILIOU , Columbia University, USA
We study the problem of adaptive estimation of a partially ob-served Markov chain, whose transition kernelKθ depends onan unknown parameterθ . Following a standard bayesian tech-nique, we include the parameters in the Markov chain, so that thetransition kernel is now completely known. Then, the bayesianestimator of the parameter becomes a marginal of the optimal

156 6th BS/ IMSC
filter of the new Markov chain. The problem of adaptive esti-mation is now equivalent to the problem of asymptotic stabilityof the optimal filter with respect to the initial conditions. Thisproblem has been discussed in [3], where sufficient conditionsfor the asymptotic stability have been given. We will be review-ing some of these results. However, we are mainly concernedhere with the computation of the optimal filter: we present twoparticle filters that, under the asymptotic stability assumption,will eventually converge to the optimal filter corresponding tothe true value of the parameter. The main difficulty in this caseis that the transition kernel of the augmented system will obvi-ously not be ergodic, which is an essential condition for mostconvergence results for particle filters.Our main assumption, which is also used in [3] to show theasymptotic stability of the optimal filter, is that for each fixedparameter valueθ , the kernelKθ is mixing. The main idea is tocompute the optimal filter corresponding to a fixed parameterθby a uniformly convergent particle filter (see, for example, [2])and then approximate the optimal filter of the augmented systemby a weighted average of the optimal filters depending onθ .One obvious choice for the weights is the likelihood of the pa-rameters. However, the computation of the likelihood also in-volves the optimal filters. We use a second particle filter to com-pute them. We choose a variation of the Monte-Carlo particlefilter presented in [1]. This does not require any ergodicity con-dition for the transition kernel. Instead, it requires the asymp-totic stability of the optimal filter, which has been assumed. Themain idea of the Monte-Carlo particle filter is to keep track ofthe path for each particle and then compute their weighted av-erage, the weights being the likelihood of the path. In general,this is quite inefficient, since it requires a dense sampling of thepath space. However, in this case the particles correspond to theparameters that have no dynamics, thus the path space becomestrivial.The previous particle filter is still quite involved computation-ally: we have to have a good approximation of the optimal fil-ter for each parameter value irrespectively of their likelihood,since the optimal filter is actually used for the computation of thelikelihood. Thus, we would like the weights on the parametersnot to depend on the corresponding optimal filter. To achievethis, we make use of another assumption made in [3], which isthat the observations corresponding to different parameter val-ues have to belong to different ergodic classes. Thus, for eachparameter value, we only need one corresponding path of theMarkov chain. Then, the weight can be computed by comparingthe paths of the simulated observations and the actual ones. Thisparticle filter will not converge uniformly to the optimal filter ofthe augmented system as the previous one, but it will eventuallyconverge to the optimal filter corresponding to the true parame-ter value.References[1] Del Moral, P. (1998) A Uniform Convergence Theorem for Numeri-cal Solving of the Nonlinear Filtering Problem,Journal of Applied Prob-ability 35(4) 873–884.[2] Le Gland. F. and Oudjane. N. (2004) Stability and Uniform Approx-imation of Nonlinear Filters using the Hilbert Metric, and Applicationto Particle Filters,Annals of Applied Probability14(1) 144–187.[3] Papavasiliou, A. (2004) Parameter Estimation and Asymptotic Sta-bility in Stochastic Filtering,Submitted. Preprint:http://www.columbia.edu/pp2102/stability.pdf
312 Comparison of regression curvesbased on the errors distribution [ContributedSession C22 (page 40)]
Wenceslao GONZÁLEZ-MANTEIGA,Universidade de Santi-ago de Compostela, Spain
Juan Carlos PARDO-FERNÁNDEZ, Universidade de Vigo,Spain
Ingrid VAN KEILEGOM, Université Catholique de Louvain,Belgium
Let (X1,Y1) and (X2,Y2) be two independent random vectors,and assume that they satisfy two non-parametric regressionmodelsYj = mj (Xj ) + σ j (Xj )ε j , for j = 1,2, where the errorvariableε j is independent ofXj , mj (x) = E(Yj |Xj = x) is anunknown regression function andσ2
j (x) = Var(Yj |Xj = x) isthe conditional variance function. Suppose thatε1 andε2 havecommon distribution with mean0 and variance1.In this paper we introduce a procedure to test the hypothesisH0 : m1(x) = m2(x) of equality of the regression functions. Thetest is based on the comparison of the empirical distribution ofthe errors in each model (see Akritas and Van Keilegom, 2001).A Kolmogorov-Smirnov type statistic and a Cramér-von Misestype statistic are considered.Some asymptotic results are proved: weak convergence of theprocess of interest, convergence of the test statistics. We de-scribe a bootstrap procedure in order to get the critical valuesof the test. Finally, some simulations are presented to checkthe behaviour of this testing procedure with small and moderatesample sizes.
References
[1] Akritas, M.G. and Van Keilegom, I. (2001) Nonparametric estima-tion of the residual distribution,Scand. J. Statist.28, 549-568.
313 Fitting sets to distributions in metricspaces [Contributed Session C61 (page 48)]
Meelis KÄÄRIK andKalev PÄRNA, University of Tartu, Esto-nia
Let us consider a problem, where a given probability distribu-tion is to be approximated by a subset of given type or shape(e.g. spheres, lines, parametric curves etc.). More closely, weexamine the following optimization task. LetP be a probabil-ity on a given metric space(S,d), and letA = A(θ) : θ ∈ Tbe a parametric class of subsets ofS– the class of all potentialapproximative sets. We are looking for a value of the parameterθ∗ ∈ T such that corresponding setA(θ∗)⊂ S is ’closest’ to thedistributionP, i.e. A(θ∗) minimizes the mean discrepancy of arandom pointX ∼ P from the sets of typeA(θ):
W(θ ,P) =∫
Sφ(x,A(θ))P(dx)→min
θ∈T.
For each optimalθ∗, corresponding subsetA(θ∗) ⊂ S is calledbest approximative set forP.We refer to Pollard (1981) and Cuesta, Matran (1988) for thecase when the class of approximative setsA(θ) : θ ∈ T is acollection of all finite subsets ofSconsisting of at mostk points.The well-known terms ’k-centre’ and ’k-means’ denote optimalapproximative sets for this particular case.In this paper we try to answer questions like 1) when does anoptimal approximating set exist, and 2) does the sequence of op-timal approximations converge. The latter question arises whenbest approximating sets have been founded for a sequence ofmeasuresPn which converges weakly to the measureP. Ob-viously, the sequence of empirical measuresPn corresponding toP is a very motivating example here. The convergence of empir-ically optimal (or Pn-optimal) approximative sets would meanthat they act as consistent estimators ofP-optimal sets.

Abstracts 157
We introduce some properties of the parameterization transformA : θ → A(θ) to define ’normal’ parameterization, which allowus to obtain several results on the existence and convergence ofbest approximative sets in some functional spaces.As an example, the following general result (see [3]) has beenproved for allε-optimal approximations (the caseε = 0 corre-sponds the best approximation itself):For anyε ≥ 0, if the parameterization is normal, then the dis-tance between the sequence ofPn-ε-optimal parametersθ ε
nand the set ofP-ε-optimal parameters (denoted asU ε (P)) con-verges to zero, i.e. the convergenceρ(θ ε
n ,U ε (P)) → 0 takesplace.We also cover the case where the distributionP is being approx-imated by multiple sets (k lines,k circles, etc).References[1] Cuesta, J.A. and Matran, C. (1988) The Strong Law of Large Num-bers fork-means and best possible nets of Banach valued random vari-ables,Probability Theory and Related Fields78, 523–534.[2] Pollard, D. (1981) Strong consistency of k-means clustering,TheAnnals of Statistics9, 135–140.[3] Käärik, M. and Pärna, K. (2003) Approximation of distributions byparametric sets,Acta Applicandae Mathematicae78, 175–183.
314 Parameter estimation in a stochasticpredator-prey system [Contributed Session C20 (page35)]
Carla CALVI PARISETTI,Università di Parma, Italy
Sara PASQUALI, CNR-IMATI, Italy
In this work the problem of parameter estimation for a stochasticpredator-prey system is studied starting from a discrete numberof observations. The dynamics of the system is described by atwo-dimensional SDE with drift and diffusion coefficients linearin the parameterq0.Parametric inference for discretely observed diffusion processeshas been widely studied in literature. There are mainly two dif-ferent approaches: one based on the likelihood function and thesecond based on the least square method. An extensive reviewof all these methods can be found in Prakasa-Rao (1999).A common hypothesis requested to prove consistency andasymptotic normality of the estimator is the ergodicity of thediffusion process. In this case it is not clear if the process isergodic or not for each value of the parameterq0, so it is notpossible to follow the methods presented in Prakasa-Rao.Nevertheless, a method based on likelihood function which al-lows to obtain the estimator in a closed form, is applied. Themaximum likelihood estimator converges in mean square to thetrue value of the parameter when the final time is sufficientlyhigh and the interval between two consecutive observations issufficiently small. Numerical results confirm this convergenceand show also a relation between the estimate ofq0 and the sta-bility properties of the stationary solutions of the predator-preysystem.References[1] Buffoni, G., Cola, G. Di, and Baumgartener, J. (1995)A mathemat-ical model of trophic interactions in an acarine predator-prey system,Journal of Biological System3(2), 303–312.[2] Calvi Parisetti, C. and Pasquali, S. (2000), l Stability of a stochasticpredator-prey system ,Rivista di Matematica dell’Università di Parma,3(6), 245–258.[3] Kessler, M. and Parades, S. (2002), Computational aspects relatedto martingale estimating functions for a discretely observed diffusion ,Scand. J. Statist.29, 425–440.[4] Prakasa-Rao, B.L.S. (1999)Statistical inference for diffusion typeprocesses, Arnold, London.
[5] Sørensen, M. (1999) On asymptotics of estimating functions, Braz.J. Probab. Statist.13, 111–136.
315 A product-limit estimator of the sur-vival function with left and right censoreddata from cross-sectional studies [ContributedSession C27 (page 36)]
Valentin PATILEA , CREST-ENSAI, France
Jean-Marie ROLIN,Institute of Statistics, Louvain-la-Neuve,Belgium
The goal of this paper is to propose and analyze a simple modelfor data that can be left or right censored. In many cross-sectional studies whereT the age at onset for a disease is an-alyzed, the examined individuals belong to one of the followingcategories: (i) evidence of the disease is present and the ageat onset is known (from medical records, interviews, ...); (ii) thedisease is diagnosed but the age at onset is unknown or the accu-racy of the information on it is questionable; and (iii) the diseaseis not diagnosed at the examination time. LetC denote the ageof the individual at the examination time. In the first case the ex-act ‘failure’ timeT is observed. In case (ii) the ‘failure’ timeTis left-censored byC. Finally, the onset timeT is right-censoredbyC for the individuals who have not yet developed the disease.The California high school students data analyzed by Turnbulland Weiss (1978) is an example of such left and right censoredobservations.The model we propose is the following. The survival time of in-terest isT. LetC be a censoring time and∆ a Bernoulli randomvariable. Assume thatT, C and∆ are independent. The observa-tions are independent copies of the variables(Y,A), with Y ≥ 0andA∈ 0,1,2, where
Y = min(T,C)+(1−∆)max(C−T,0)
= C+∆min(T−C,0)
andA = 2(1−∆)1T≤C+ 1C<T (here1A denote the indica-tor function of the setA). With this censoring mechanism, thelifetime T is observed, right censored or left censored. If∆ isconstant and equal to one (resp. zero), we obtain the classicalright censored (resp. current status) data model. Huang (1999)considered a closely related model for left and right censored ob-servations and proposed a NPMLE which does not have a closedform.Let FT andFC denote the distributions ofT andC, respectively,and letp = P(∆ = 1). Define the observed subdistributions ofY as Hk (B) = P(Y ∈ B, A = k), with k = 0,1,2, and B Borelsubset of[0,∞]. As usually in survival analysis, the censoringmechanism defines a map between the distributions of the ‘la-tent’ variablesT, C and∆ and the observed subdistributionsHk.We show that for the model considered this map is invertible andthe inverse is explicit. By the plug-in (or substitution) principleapplied to the empirical distribution, the nonparametric estima-tion of FT becomes straight. We obtain a product-limit estimatorof FT for which we deduce the asymptotic properties under weakconditions. The strong uniform convergence is obtained throughthe techniques of Rolin (2001). For the asymptotic normality weuse the delta-method.References[1] Huang, J. (1999) Asymptotic Properties of Nonparametric Estima-tion Based on Partly Interval-Censored Data,Statistica Sinica9, 501–519.[2] Rolin, J.-M. (2001) Nonparametric Competing Risks Models: Iden-tification and Strong Consistency, DP 0115, Institut de Statistique,Louvain-la-Neuve, http://www.stat.ucl.ac.be.

158 6th BS/ IMSC
[3] Turnbull, B.W. and Weiss, L. (1978) A Likelihood Ratio Statisticsfor Testing Goodness of Fit with Randomly Censored Data,Biometrics
34, 367–375.
316 Nonparametric estimation of princi-pal components through coordinate selection
[Contributed Session C29 (page 52)]
Debashis PAUL, Stanford University, USA
We consider the problem of estimation of the principal com-ponents in a multivariate estimation problem where the dimen-sion of the data vectors approaches infinity as sample size in-creases, even though the intrinsic dimensionality remains finite.Specifically, we assume that we have i.i.d. observations froma N-variate normal distribution with zero mean and covariancematrix Σ of the form Σ = I + Σ0 whereΣ0 is of fixed, finiterank. It is shown that ifN → ∞ as n → ∞ such that someregularity conditions on the eigenvalues and eigenvectors ofΣare satisfied, then the problem of estimation of the eigenvectorsshow some interesting nonparametric characteristics. Under cer-tain circumstances the ordinary principal component analysis ofsample covariance matrix fails to provide a consistent estimateof the true eigenvalues and eigenvectors. Following Johnstoneand Lu (2004), we propose an estimator which uses a threshold-ing approach to first select a set of significant coordinates andthen performs a PCA on the submatrix of the sample covariancematrix corresponding to the selected coordinates. We show thatunder some sparsity restrictions on the population eigenvectors,the proposed estimator has nearly optimal rate of convergencein the mean-squared loss.References[1] Debashis, Paul and Johnstone, Iain M. (2004)Estimation of principalcomponents through coordinate selection (Working paper), . . .[2] Johnstone, Iain M. and Yu Lu, Arthur (2004)Sparse principal com-ponent analysis (Submitted to JASA), . . .
317 Central Limit Theorems for function-als of isonormal Gaussian processes[Con-tributed Session C11 (page 15)]
Giovanni PECCATI , Université Paris VI, France
Let H be a separable Hilbert space, and letX = X (h) : h∈ Hbe an isonormal Gaussian process overh. In [1] and [2], sev-eral conditions are discussed to have that a sequence ofRd –valued, square integrable functionals ofX, sayFn (X) : n≥ 1,converges in law towards a Gaussian distribution. In particular,necessary and sufficient conditions for CLTs are stated, whenFn
is a vector of multiple Wiener-Itô integrals. The aim of this talkis to use such results to give a unified discussion of: (i) the clas-sic CLTs for functionals of Gaussian sequences, such as the onesobtained e.g. [5], for which new and simplified proofs can beprovided, as well as some generalization; (ii) the family of limittheorems for Gaussian processes proved in [3] and [4]. Someexample of non-central limit theorems will be also provided.References[1] Nualart, D. and Peccati, G. (2004)Central Limit Theorems for se-quences of multiple stochastic integrals, to appear in The Annals ofProbability.[2] Peccati, G. and Tudor, C. (2003)Gaussian limits for vector-valuedmultiple stochastic integrals, submitted.[3] Deheuvels, P., Peccati, G., and Yor, M. (2004)On quadratic func-tionals of the Brownian sheet and related processes, preprint of the Uni-versity of Paris VI.[4] Peccati, G. and Yor, M. (2004)Four limit theorems for quadraticfunctionals of Brownian motion and Brownian bridge, to appear.[5] Giriaitis, L. and Surgailis, D. (1985) CLT and other limit theorems
for for functionals of Gaussian sequences,Z. W. verw. Geb.70, 191–212.
318 Confidence bands for multivariatedensities [Contributed Session C6 (page 38)]
Abdelkader MOKKADEM and Mariane PEL-LETIER Université de Versailles–Saint-Quentin, France
Let X1, . . . ,Xn be independent and identically distributedRd-valued random variables with probability density functionf .The problem of computing confidence bands forf is of centralinterest in nonparametric statistics. LetC⊂Rd be a compact seton which f is bounded away from zero, and letfn be the kernelestimator off . The main known approach to the construction ofconfidence bands forf onC is due to Bickel and Rosenblatt [1]in the cased = 1 and to Rosenblatt [2] in the cased ≥ 2; it isbased on their result, which gives the limiting distribution of thenormalized uniform error of the kernel density estimate.Let Bn,α be a confidence band with asymptotic levelα ∈]0,1[,provided by Bickel and Rosenblatt’s result;Bn,α can be viewedas the union of confidence intervalsIn(x), x ∈ C. Now, let hn
(hn → 0) denote the bandwidth used for the computation of thekernel density estimatorfn. Since the weak convergence rate ofsupx∈C | fn(x)− f (x)| is
√log(1/hn)/
√nhn, whereas, for each
x∈C, the weak convergence rate of| fn(x)− f (x)| is 1/√
nhn, itturns out that that the asymptotic level of each confidence inter-vals In(x) (x∈C) whose union givesBn,α , is zero.We first note that an adequate translation ofBn,α gives a newconfidence bandB∗n = ∪x∈CI∗n(x), which satisfies the followingproperties:
• B∗n has, at each pointx∈C, the same width asBn,α .
• The asymptotic level ofB∗n is zero instead ofα ∈]0,1[.
• The logarithmic asymptotic level ofB∗n (that is, the con-vergence rate toward zero of the level ofB∗n) equals thelogarithmic asymptotic level ofI∗n(x) ∀x∈C.
Taking this observation as a starting point, we propose a newapproach for the construction of confidence bands for densities,based on the use of Moderate Deviations Principles. Our ap-proach has two main advantages.
• In order to deal with the multivariate framework, Rosen-blatt [2] has to require the use of higher order kernels and,consequently, to impose rather stringent conditions onf ;in contrast, in our approach, all the dimensions are dealtwith in the same way, and thus without any additional as-sumption neither on the density, nor on the kernel, in thecased≥ 2.
• Whatever the dimensiond is, Bickel and Rosenblatt re-quire the condition “f is bounded away from zero onC”.On the contrary, our approach enables us to sort out theproblem of providing confidence bands forf on compactsets on whichf vanishes. As a matter of fact, we intro-duce a truncation operation, which modifies the width ofour confidence bands at some pointsx∈C, but which doesnot affect the logarithmic asymptotic level of our confi-dence bands. This truncation operation also enables us toprovide confidence bands forf on allRd.
References[1] Bickel, P.J. and Rosenblatt, M. (1973) On some global measures ofthe deviations of density function estimates ,Ann. Statist.1, 1071–1095.[2] Rosenblatt, M. (1976) On the maximal deviation of ak-dimensionaldensity estimates,Ann. Probab.4, 1009-1015.

Abstracts 159
319 The SAR procedure: a diagnosticanalysis of heterogeneous data[Invited Session 26(page 49)]
Daniel PEÑA , Universidad Carlos III de Madrid, Spain
This paper presents a procedure for detecting heterogeneity ina sample with respect to a given class of models. It can be ap-plied to determine if a sample of univariate or multivariate datahas been generated by different distributions, or if a regressionequation is really a mixture of different regression lines. The ba-sic idea of the procedure is first to split (S) the sample into smallhomogeneous subgroups and (A) then recombine (R) the obser-vations in the subgroups to form homogeneous clusters. Thesample is split by using a new measure of association amongthe points in the sample given the model and is continued un-til groups of minimal size that cannot be split further are found.The recombining is made by checked iteratively one by one theobservations with respect to a given group.The performance ofthe procedure is illustrated in univariate, multivariate and linearregression problems.
320 Some remarks on matrix subordina-tors [Contributed Session C13 (page 45)]
Ole E. BARNDORFF-NIELSEN,MaPhySto, Denmark
Victor PEREZ-ABREU , CIMAT, Mexico
After a brief overview of what is known about infinitely divisiblepositive (semi-) definite matrices, the talk will focus on the prop-erties of a regularising mapping of the Levy measures of suchmatrices. (The mapping is a matrix version of a mapping for realand vector infinitely divisible random variates recently studiedby Barndorff-Nielsen, Thorbjørnsen, Maejima and Sato.) Rela-tions to distributions of matG type will also be mentioned.
321 Lotka-Volterra models and super-Brownian motion [Invited Session 15 (page 51)]
Ed PERKINS, University of British Columbia, Canada
We show that ford ≥ 3 a space-time rescaling of a Lotka-Volterra model introduced by Neuhauser and Pacala convergesweakly to super-Brownian motion with drift. The Neuhauser-Pacala modelLV(α0,α1) is a two-parameter model which mod-els the spatial distribution of two types, say0’s and1’s. Hereα0 measures the competitive effect of nearby1’s on a0 andα1measures the competitive effect of nearby0’s on a1. The self-competition parameters are both set to1. LV(1,1) is then thevoter model. Ifαi → 1 at an appropriate rate we get conver-gence of the rescaled LV to super-Brownian motion with drift.The theorem is then used to get information on the critical sur-vival curve, a phase transition in the asymptotic survival prob-abilities, and the coexistence region near(1,1). It is a specialcase of a more general convergence result for perturbations ofthe voter model to super-Brownian motion with drift. In addi-tion long range limit theorems are established forα0 ∈ [0,1] andα1 approaching1. These lead to natural conjectures and resultson the precise rate of convergence of the critical survival curveto that of the mean-field case.
322 A characterization of Markov equiv-alence classes for AMP chain graph models
[Contributed Session C24 (page 35)]
Steen A. ANDERSON,Indiana University, U.S.A.
Michael D. PERLMAN , University of Washington, U.S.A.
Chain graphs (= adicyclic graphs) have both undirected andirected edges and can be used to represent simultaneously both
structural and associative dependences. Like acyclic directedgraphs (ADGs≡DAGs), the chain graph associated with a givenstatistical model may not be unique, so chain graphs fall intoMarkov equivalence classes, which may be superexponentiallylarge, leading to possible ambiguity and computational ineffi-ciency in model search and selection. It is shown here that un-der the Andersson-Madigan-Perlman (AMP) Markov interpre-tation of a chain graph, each Markov-equivalence class can beuniquely represented by a single chain graph, the AMP essen-tial graph, that is itself simultaneously Markov equivalent to allchain graphs in the AMP Markov equivalence class. A com-plete characterization of AMP essential graphs is obtained. Likethe essential graph previously introduced for ADGs (cf. [1], theAMP essential graph will play a fundamental role for inferenceand model search and selection for AMP CGs.
References
[1] Andersson, S.A., Madigan, D., and Perlman, M.D. (1997) A char-acterization of Markov equivalence classes for acyclic digraphs,Ann.Statist.25, 505–541.
323 Corner percolation on Z2 is critical[Contributed Session C35 (page 25)]
Gábor PETE, University of California, Berkeley, USA
We consider a dependent bond percolation model onZ2, intro-duced by Bálint Tóth, which might be considered as “criticaledge percolation conditioned on each vertex having exactly twoincident edges, perpendicular to each other”. In this work weshow that this “conditioning” does not ruin the criticality of thepercolation.More precisely, to each vertical linen×Z and horizontal lineZ×m we assign independently a fair random+/− signξ (n)or η(m). If the sign of a line is ‘+’, then we keep all the evenedges,. . . , [−2,−1], [0,1], [2,3], . . . , along that line, and deleteall odd edges.If the sign is ‘−’, delete the even and keep theodd edges. Thus we get a random 2-regular subgraphGξ ,η of
Z2. Each connected component ofGξ ,η is clearly a cycle or aninfinite path.
Theorem. Gξ ,η has no infinite components a.s. Moreover, eachvertex is surrounded by infinitely many cycles. The expected di-ameter of the cycle containing a fixed vertex is infinite. A typicalcycle of diametern has length of the order ofn3/2. The scal-ing limit of the natural height function determined by the cy-cle structure is the sum of two independent Brownian motions,H (t,s) = 1/2(Wt +W′
s).The exponent for the length being 3/2 is obviously related to thefact [5] that the level sets of the functionH (t,s) have Haus-dorff dimension 3/2. However, our result concerns a single levelcurve, not the whole level set, while the topology of theH -levelsets is not known at this time.The details of the critical behaviour of independent percolation[6] are certainly not preserved. For example, our computer sim-ulations suggest thatPr(the cycle of the origin reaches fartherthanR)≈R−0.23 approximately, while this exponent for criticalindependent percolation is5/48. (The mathematical derivationof our exponent is work in progress.) Also, critical percolationis conformally invariant (proven at least on the triangular lat-tice), while the additive Brownian motion appearing in our scal-ing limit is not.Another conformally invariant process is the double dimermodel, which might be considered as “critical edge percolationconditioned on 2-regularity”. Also in this model it is true [4],that each vertex ofZ2 is surrounded by infinitely many closed

160 6th BS/ IMSC
cycles a.s. In [3], R. Kenyon proved that the correspondingheight function has the Gaussian Free Field as its scaling limit,which is the conformally invariant two-time-dimensional ver-sion of Brownian motion. In this much more complex model,the exponent3/2 for the cycle length holds only conjecturally.In the corner percolation model, one can also view the compo-nent of a fixed vertex as the path of a random walk onZ2 withlong-term memory. A little bit surprisingly, while simple ran-dom walk and our walk are both “recurrent”, if we “interpolate”between them by doing SRW in one coordinate, and the walkwith memory in the second, then the resulting walk has beenshown to be transient [2].Our model is also related to P. Winkler’s non-oriented depen-dent percolation [7, 1]. Our methods imply the known resultthat there is no percolation in that model with 3 characters, whilethere is percolation with 4 characters.References[1] Balister, P., Bollobás, B., and Stacey, A. (2000) Dependent percola-tion in two dimensions.Probab. Theory Related Fields117, 495–513.[2] Campanino, M. and Petritis, D. (2003) Random walks on randomlyoriented lattices.Markov Proc. Related Fields9, 391–412.[3] Kenyon, R. (2001) Dominos and the Gaussian free field.Ann. Probab.29, 1128–1137.[4] Kenyon, R., Okounkov, A., and Sheffield, S. (2003) Dimers andamoebae,http://www.arxiv.org/abs/math-ph/0311005[5] Khoshnevisan, D. and Xiao, Y. (2002) Level sets of additive Lévyprocesses.Ann. Probab.30, 62–100.[6] Smirnov, S. and Werner, W. (2001) Critical exponents for two-dimensional percolation.Math. Res. Lett.8, 729–744.[7] Winkler, P. (2000) Dependent percolation and colliding randomwalks,Random Struct. Algorithms16, 58–84.
324 Numerical approximation for a whitenoise driven spde with bounded drift [Con-tributed Session C3 (page 50)]
Roger PETTERSSON, Växjö University, Sweden
Mikael SIGNAHL, Linköping University, Sweden
A numerical scheme for a stochastic partial differential equationof heat equation type is considered where the drift is measurableand bounded and the dispersion may be state dependent. Uni-form convergence in probability is obtained.In [1] convergence for time-space discretization was obtainedwith measurable and bounded drift and constant drift. In [2]convergence for time discretization was obtained with measur-able and bounded drift and state-dependent drift. Here conver-gence for space-time dicretization is obtained with measurableand bounded drift and state-dependent drift. Ideas from [1] and[2] are used. Fine properties of the kernel related to the numeri-cal approximation is needed.References[1] Gyöngy, I. and Nualart, D. (1997) Implicit scheme for stochasticparabolic partial differential equations driven by space-time white noise,Potential Anal.7, 725–757.[2] Gyöngy I. (1999) Lattice approximations for stochastic quasi-linearparabolic partial differential equations driven by space-time white noiseII, Potential Anal.11, 1–37.
325 Testing for circular reflective symme-try about a known median axis [Contributed Ses-sion C46 (page 46)]
Arthur PEWSEY , Universidad de Extremadura, Cáceres,Spain
In the modelling of circular data, interest will often focus onwhether the underlying distribution from which the data arise is
symmetric about a specific axis associated with the experimen-tal set-up under consideration. For instance, in many animalorientation experiments the variable of interest is a circular one,namely the direction in which an animal moves in response to astimulus, such as a source of light, heat or sound. A basic ques-tion of scientific interest in such contexts is whether the animalsmove in directions described by a circular distribution which issymmetric about a particular axis associated with the orientationof the stimulus or whether the distribution about the same axisis skew. In this paper, the situation in which the axis of inter-est is known to be a median axis is considered and a simple,asymptotically distribution-free test for circular reflective sym-metry against skew alternatives is developed. Simulation is thenused to derive a hybrid testing strategy incorporating the newtest and the circular analogue of a test originally proposed foruse with linear data. The application of the testing strategy is il-lustrated using circular data arising from two animal orientationexperiments.
326 Optimal partially reversible invest-ment with entry decision and general produc-tion function [Invited Session 3 (page 19)]
Xin GUO, Cornell University, USA
Huyên PHAM , University Paris 7, France
This paper studies the problem of a company that adjusts itsstochastic production capacity in reversible investments withcontrols of expansion and contraction. The company may alsodecide on the activation time of its production. The profit pro-duction function is of a very general form satisfying minimalstandard assumptions. The objective of the company is to findan optimal entry and production decision to maximize its ex-pected total net profit over an infinite time horizon. The result-ing dynamic programming principle is a two-step formulationof a singular stochastic control problem and an optimal stoppingproblem. The analysis of value functions relies on viscosity so-lutions of the associated Bellman variational inequations. Wefirst state several general properties and in particular smooth-ness results on the value functions. We then provide a completesolution with explicit expressions of the value functions and theoptimal controls: the company activates its production once afixed entry-threshold of the capacity is reached, and invests incapital so as to maintain its capacity in a closed bounded inter-val. The boundaries of these regions can be computed explicitlyand their behavior are studied in terms of the parameters of themodel.References[1] Dixit, A.K. and Pindyck, R. (1994)Investment under uncertainty,Princeton University Press.[2] Fleming, W. and Soner, M. (1993)Controlled Markov processes andviscosity solutions, Springer Verlag, New York.[3] Kobila, T.O. (1993) A class of solvable investment problems involv-ing singular controls.Stoch. and Stoch. Reports43, 20–63.
327 What do we learn from maxisets?[Medaillon Lecture (page 13)]
Dominique PICARD, CNRS-Universite Paris VII, France
In the last decade a lot of new methods in nonparametric statis-tics have been devoped mostly oriented towards adaptation, in-homogenous smoothness, sparse representation pursuit. Theperformances of these methods have been in general comparedeither in a practical way on test-signals, or theoretically usingminimax type results. We will here focus on a new way of eval-uating the performances of a procedure. Themaxisetpoint of

Abstracts 161
view consists in investigating the maximal set where a givenprocedure has a given rate of convergence. Although the set-ting is not extremely different from the minimax context, it is ina sense less pessimistic and provides a functional set which isauthentically connected to the procedure and the model. We arestill looking for the ’bad functions’ to estimate, but in a more’pragmatic’ way. Moreover, this gives as a by-product a very ef-ficient way of producing the rates of convergence over specifiedspaces.We shall adopt this point of view to compare standard waveletalgorithms, and it appears that the mathematical results are sur-prisingly close to some particularly accurate practical observa-tions.For instance we find that linear methods have generally smallermaxisets and less acurate practical performances as well. Wefind that the maxisets associated to thresholding algorithms cor-respond to the set of functions having in a rough sense a smallnumber of high wavelet coefficients, which was also observed inpractice.But there also other facts that can be learned from maxisetswhich are less intuitive.Let us mention, as an example the fact that Bayesian methodshave maxisets which are equivalent to thresholding algorithmsif the priors are chosen among heavy tails probability distribu-tion, but they can also have equivalent maxisets when the priorsare gaussian if the variance is properly chosen. This proves in-cidentally that the heavy tail distributions are not necessary forthis problem.It can also be proven that adaptation methods using Lepski cri-teria yield to better maxisets than thresholding.Moreover, maxisets, not only allows a comparison between esti-mation methods, it also produces a paradigm where new sort ofobjects can play the role of wavelet bases such as, for instancewarped wavelet bases.References[1] Cohen, A., DeVore, R., Kerkyacharian, G., and Picard, D. (2001)Maximal spaces with given rate of convergence for thresholding algo-rithms,Appl. Comput. Harmon. Anal.11, no. 2, 167–191.[2] Kerkyacharian, G. and Picard, D. (2002) Minimax or maxisets?Bernoulli8, no. 2, 219–253.[3] Autin, F., Kerkyacharian, G., Picard, D., and Rivoirard, V. (2004)What do we learn from maxiset comparisons of procedures ?
328 Hyper Dirichlet processes [ContributedSession C39 (page 33)]
Claudio ASCI, Giovanna NAPPO andMauro PICCIONI , Uni-versità di Roma La Sapienza, Italy
Dirichlet processes are still the most known prior laws for theBayesian analysis of nonparametric inference problems. In thistalk we consider how to use these processes in nonparametricgraphical models, where conditional independence constraintsare assumed a priori on the sampling variables. A graph repre-sents all these conditional independence statements whose ver-tices correspond to sampling variables and separation of two setsby a third one implies conditional independence of the corrre-sponding two block of variables given the third. A distribu-tion belongs to the graphical model whenever all these condi-tional independence properties are met, in which case we saythat the distribution is Markov (w.r.t. the given graph). The sim-plest class of graphical models is that of decomposable mod-els, corresponding to decomposable (or triangulated, or chordal)graphs: it can be proved that in some sense they are the mostnatural extension of Markov chains. In particular a Markov dis-
tribution w.r.t. to a decomposable graph can be uniquely speci-fied by giving the consistent family of marginals on the cliquesof the graph: the unique Markov distribution with these fixedmarginals is called the Markovian combination of the family.
Random distributions whose realizations belong to a decompos-able graphical model can be pathwise generated by making theMarkovian combination of realizations of the marginals on eachclique. In order to draw these consistently we have to assignhyperconsistent laws for these marginals, in the sense that theyshould agree on variables belonging to more than one clique.Moreover, there is still a freedom in prescribing their joint law.Dawid and Lauritzen ([1]) suggested to do this by "lifting" theMarkov property at the level of laws for these marginal randomdistributions, obtaining what they call the hyper Markov prop-erty (w.r.t. the given decomposable graph). They proved thatthere is only one law with the hyper Markov property which in-duces the prescribed laws on the marginals of the cliques, andcalled it their hyper Markov combination. Between the exam-ples they presented there is the hyper Dirichlet law, i.e. the hy-per Markov combination of hyperconsistent Dirichlet laws forcontingency tables.
In this talk we consider hyper Dirichlet processes, i.e. hyperMarkov combinations of hyper consistent Dirichlet processes.By using the Sethuraman representation of Dirichlet processes([2]) we prove that, under suitable "diffusivity" assumptions,which are satisfied when the parameter measures of the Dirich-let process are absolutely continuous w.r.t. to the Lebesgue mea-sure, these are again Dirichlet process. The situation is quitedifferent for hyper Dirichlet laws, which are never Dirichlet, ex-cept in trivial cases. We then prove a weak convergence resultof a sequence hyper Dirichlet laws, obtained from "discretiza-tions" of a family of consistent marginal parameter measures, toa hyper Dirichlet process. Finally we remove the "diffusivity"assumption to discuss the conjugacy property of hyper Dirichletprocesses w.r.t. to simple random sampling. The talk is mostlybased on ([3]).References[1] Dawid, A.P. and Lauritzen, S.L. (1993) Hyper Markov laws in thestatistical analysis of decomposable graphical models,Ann. Statist.24,1272–1317.[2] Sethuraman, J. (1994) A constructive definition of Dirichlet priors,Statistica Sinica4, 639–650.[3] Asci, C., Nappo, G., and Piccioni, M. (2004)The hyper Dirichletprocess and its discrete approximations: the single conditional indepen-dence model, preprint available ashttp://www.mat.uniroma1.it/people/nappo/papers. pdf/HYP.pdf(or http://www.mat.uniroma1.it/people/nappo/ papers.pdf/HYP.dvi)
329 The volume-of-tube formula and per-turbation tests I: complete specification of thenull model [Contributed Session C44 (page 52)]
Catherine LOADER andRamani S. PILLA , Case Western Re-serve University, U.S.A.
In this talk, we introduce a general class ofperturbation modelswhich are described by an underlyingnull modelthat accountsfor most of the structure in data while a perturbation accountsfor possible small localized departures. We develop theory andinferential methods for fitting the perturbation models for thecase when the null model is completely specified. In particular,we (1) derive a test statistic based on thenormalized score pro-cessfor detecting the presence of perturbation which is shownto be equivalent to the likelihood ratio test in the limit, (2) de-

162 6th BS/ IMSC
velop a general theory to derive the asymptotic null distribu-tion of the test statistic for a class of non-regular problems viathe Hotelling-Weylvolume-of-tube formula, (3) show that theasymptotic null distribution of the test statistic is equivalent tothe supremum of a Gaussian process over a high-dimensionalmanifold with boundaries and singularities and (4) illustrate aprocedure to approximate the quantiles of the test statistic viathe boundary crossing probabilities. The proposed general the-ory is applicable to testing for an arbitrary number of compo-nents from smooth families of distributions, including multivari-ate mixtures. Applications of the perturbation models includefinite mixture models and spatial scan process. In the finite mix-ture context, the null density represents anm-component mix-ture model and the perturbation density represents additionalcomponents. In the spatial scan process context, the null den-sity accounts for the background or noise whereas the perturba-tion searches for an unusual region such as a tumorous tissuein mammography or a target in an automatic target recognitionproblem.
330 A simple nonparametric estimator ofa monotone regression function [Contributed Ses-sion C58 (page 55)]
Kay F. PILZ , Ruhr-Universität Bochum, Bochum, Germany
In this paper a new method for monotone estimation of a regres-sion function is proposed. The estimator is obtained by the com-bination of a density and a regression estimate and is appealingto users of conventional smoothing methods as kernel estima-tors, local polynomials, series estimators or smoothing splines.The main idea of the new approach is to construct a density es-timate from the estimated valuesm(i/N) (i = 1, . . . ,N) of theregression function to use these “data” for the calculation of anestimate of the inverse of the regression function. The final es-timate is then obtained by a numerical inversion. Compared tothe conventially used techniques for monotone estimation thenew method is computationally more efficient, because it doesnot require constrained optimization techniques for the calcu-lation of the estimate. We prove asymptotic normality of thenew estimate and compare the asymptotic properties with theunconstrained estimate. In particular it is shown that for kernelestimates or local polynomials the monotone estimate is first or-der asymptotically equivalent to the unconstrained estimate. Wealso illustrate the performance of the new procedure by meansof a simulation study.References[1] Dette, H., Neumeyer, N., and Pilz, K.F. (2003) A simple nonpara-metric estimator of a monotone regression function.Technical ReportRuhr-Universität Bochum;http://www.ruhr-uni-bochum.de/mathematik3/[2] Dette, H., Neumeyer, N., and Pilz, K.F. (2003) A note on nonpara-metric estimation of the effective dose in quantal bioassay.TechnicalReport Ruhr-Universität Bochum;http://www.ruhr-uni-bochum.de/mathematik3/
331 Reduced bootstrap for bagging predic-tion models [Poster Session P1 (page 22)]
María Dolores JIMÉNEZ GAMERO, Juan M. MUÑOZPICHARDO, Ana MUÑOZ REYES andRafael PINOMEJÍAS , Universidad de Sevilla, Spain
Bagging is an ensemble method proposed to improve the predic-tive performance of learning algorithms, being specially effec-tive when applied to unstable predictors. It is based on the aggre-gation of a certain number of prediction models, each one gener-
ated from a bootstrap sample of the available training set. How-ever, if we consider other classes of neighborhoods of the empir-ical distribution of the original sample, or if we vary the methodto carry out the aggregating process, a more general bagging isdefined. The use of robust location measures, as the median, isan example of the second approach. For the first approach, wecould draw samples with or without replacement, and samplesizes not necessarily equal to the training set size would also beconsidered, as is the case for Subbagging in [2]. In [3] we de-fined a variation of the bootstrap method II of Efron based onthe outlier bootstrap sample concept, namely OBS, that is basedon only considering those bootstrap samples having a numberνn
of distinct original observations greater or equal to some valuecomputed from the distribution of such random variable. Severalempirical studies carried out in [3] showed closer estimations ofthe parameters under study and a reduction of the standard de-viations of such estimations. These results were theoreticallyconfirmed in [4]. In this paper we consider a generalization ofthe OBS method, that consists of drawing bootstrap samples ver-ifying k1≤ νn≤ k2, for some1≤ k1≤ k2≤ n. We will name RB(Reduced Bootstrap) to this method. This way, onlyαnn boot-strap samples are sampled, whereα = P(k1≤ νn≤ k2). We alsopropose an efficient algorithm to get a reduced bootstrap. Theuse of RB inside a bagging procedure lets us to define Baggingwith Reduced Bootstrap. We will name Rbagging the result-ing procedure. In [5], six choices fork1 andk2 are proposedin a study about the consistent estimation of the variance of thesample median, including the usual bagging as a particular case.Because of its good performance, we have used these selectionsto empirically study the performance of Rbagging over severalreal and simulated data sets appropriated for building predictionmodels. Two unstable prediction models, regression trees andneural networks, are used as the base algorithm. R system is theselected computational tool for our study, whereas the tree andnnet libraries have provided us with the implementation of re-gression trees and multilayer perceptrons, respectively. Tree li-brary is based on the CART methodology proposed by Breiman.Nnet library fits single-hidden-layer neural networks by a quasi-Newton method. We have used the logistic activation functionin the hidden layer and the identity function as the activationfunction for the output layer, selecting the hidden layer size bycross validation. The alternative bagging methodology based onreduced bootstrap sampling shows good and hopeful results, anda lower mean and variance of the test mean squared error is gen-erally achieved by this Rbagging procedure.References[1] Breiman, L. (1996) Bagging Predictors MachineLearning24, 123–140.[2] Buhlman, P. and Yu, B. (2002) Analyzing Bagging,The Annals ofStatistics30(4), 927–961.[3] Muñoz-García, J., Pino-Mejías, R., Muñoz-Pichardo, J.M., andCubiles-de-la-Vega, M.D. (1997) Identification of outlier bootstrapsamples,Journal of Applied Statistics24(3), 333–342.[4] Jiménez-Gamero, M.D., Muñoz-García, J., Muñoz-Reyes, A., andPino-Mejías, R. (1998)On Efrons method II with identification of out-lier bootstrap samples. Computational Statistics 13, 301-318[5] Jiménez-Gamero, M.D., Muñoz-García, J., and Pino-Mejías, R.(2004)Reduced bootstrap for the median, Statistica Sinica (accepted)
Research partially supported by Ministerio de Ciencia y Tecnología,SPAIN, Project BMF 2001-3844.
332 On exit and ergodicity of reflectedLévy processes[Contributed Session C32 (page 51)]
Martijn PISTORIUS , King’s College London, UK

Abstracts 163
Consider a spectrally one-sided Lévy processX and reflect itat its past infimumI . Call this processY. In applied probabil-ity, this reflected process frequently turns up, for example in themodeling of the water level in a dam, the work load in a queue orthe stock level (See e.g. the books by Asmussen [1] and Prabhu[5] and references therein.) For spectrally positiveX, Avramet al. [2] found an explicit expression for the law of the firsttime thatY = X− I crosses a finite positive levela in terms ofthe scale functionsW(q) and Z(q) of X. Here we find a sim-ilar expression for the Laplace transform of this crossing timefor Y if X is spectrally negative. Combining then theR-theorydeveloped by Tuominen and Tweedie for a general irreducibleMarkov process with special properties of fluctuation theory ofcompletely asymmetric Lévy processes and elementary proper-ties of analytic functions, we determine the exponential decayparameter for the transition probabilities of the processY killedupon leaving[0,a] and find its quasi-stationary distribution. Fi-nally, we condition then the processY to stay in[0,a] and provesome properties of this conditioned process.References[1] Asmussen, S. (1989)Applied Probability and Queues, Wiley seriesin probability.[2] Avram, F., Kyprianou, A.E., and Pistorius, M.R. (2004) Exitproblems for spectrally negative Lévy processes and applications to(Canadized) Russian options,Ann. Appl. Probab.14, 215–238.[3] Bertoin, J. (1997) Exponential decay and ergodicity of completelyasymmetric Lévy processes in a finite interval,Ann. Appl. Probab.7,156–169.[4] Lambert, A. (2000) Completely asymmetric Lévy processes confinedin a finite interval,Ann. Inst. H. Poincaré Probab. Statist.36, 251–274.[5] Pistorius, M.R. On exit and ergodicity of the completely asymmet-ric Lévy process reflected at its infimum,J. Theoretical Probability, toappear.[6] Pistorius, M.R. A potential theoretical review of some exit problemsof spectrally negative Lévy processes,submitted.[7] Prabhu, N.U. (1997)Insurance, queues, dams, Springer Verlag.[8] Tuominen, P. and Tweedie, R. (1979) Exponential decay and ergodicproperties of general Markov processes,Adv. Appl. Prob.11, 784–803.
333 A functional approach for the individ-ual risk model [Contributed Session M4 (page 37)]
Susan PITTS, University of Cambridge, UK
A functional approach is taken for the total claim amount distri-bution for the individual risk model. Various commonly usedapproximations for this distribution are considered, includingthe compound Poisson approximation, the compound binomialapproximation, the compound negative binomial approximationand the normal approximation. New approximation formu-lae are obtained as refinements to the existing approximations.Other applications of the functional approach to quantities of in-terest in risk theory are also considered.
334 Inference for volatility functions:Goodness of fit, stochastic ordering, and in-verse regression [Invited Session 30 (page 43)]
Wolfgang POLONIK , University of California, Davis
We investigate multivariate volatility functions nonparametri-cally based on an idea of feature extraction. Features of volatil-ity functions are extracted by comparing their concentration.The approach may be viewed as a comparison of a specificintegral stochastic ordering of two different distributions. Weillustrate the general methodology via testing the hypothesis of aconstant volatility function, and of a version of "smile effect". Atest based on an inverse regression will also be presented, whichis less computationally demanding. All our testing procedures
are aided by diagnostic plots. Some further extensions of theproposed procedures will be outlined if time permits.
335 Structural adaptation by adaptiveweights [Contributed Session C28 (page 25)]
Jörg POLZEHL and Vladimir SPOKOINY,Weierstrass Insti-tute for Applied Analysis and Stochastics, Germany
Adaptive weights smoothing (AWS), first proposed in [1] asa method for image denoising, provides a new class of adap-tive smoothing methods. The general concept behind adaptiveweights smoothing is structural adaptation. The procedure at-tempts to recover the unknown local structure from the data in aniterative way while utilizing the obtained structural informationto improve the quality of estimation. This approach possesses anumber of remarkable properties like preservation of edges andcontrasts and nearly optimal noise reduction inside large homo-geneous regions. It is almost dimension free and applies in ahigh dimensional situations.The original procedure from [1], emphasizing on a local con-stant model, has been improved and generalized to cover piece-wise smooth functions, using local polynomial approximations,in [4] and likelihood based models in [3]. The latter allows e.g.for estimation of intensities of spatial Poisson processes, prob-abilities in binary models and time varying volatilities. It alsooffers a new approach to tail index estimation, density estima-tion and classification. A vectorized version of the procedurehas been successfully applied for image signal detection in func-tional MR data and tissue classification in dynamic MR, see [2].Currently generalizations covering non stationary time series,especially time varying (E)GARCH models, are under develop-ment [5]. Further extensions include nonparametric generalizedmodels [6].The algorithms from [3] and [4] are implemented as an con-tributed library for the R statistical system and available fromthe R website.In the talk we will explain the main principle of AWS and illus-trate the properties of the procedure in various settings, includ-ing volatility estimation for financial time series.References
[1] Polzehl, and V. Spokoiny, J. (2000) Adaptive Weights Smoothingwith applications to image restoration,Journal of the Royal StatisticalSoc. Ser. B62, 335–354.[2] Polzehl, J. and Spokoiny, V. (2001) Functional and dynamic Mag-netic Resonance Imaging using vector adaptive weights smoothing,Journal of the Royal Statistical Society Ser. C50, 485–501.[3] Polzehl, J. and Spokoiny, V. (2002)Local likelihood modeling byadaptive weights smoothing, WIAS-Preprint No. 787.[4] Polzehl, J. and Spokoiny, V. (2003)Varying coefficient regressionmodeling by adaptive weights smoothing, WIAS-Preprint No. 818.[5] Polzehl, J. and Spokoiny, J. (2004)Adaptive estimation for a varyingcoefficient (E)GARCH model, Manuscript in preparation.[6] Grama, I., Polzehl, J., and V. Spokoiny (2004)Adaptive estimationfor varying coefficient generalized linear models, Manuscript in prepa-ration.
336 Moderate deviations and limit law fortransition probabilities for Sinai’s randomwalk in random environment [Contributed SessionC15 (page 53)]
Francis COMETS,Paris-7, France
Serguei POPOV, University of São Paulo, Brazil
We consider a one-dimensional random walk in random envi-ronment in the Sinai’s regime. We show that the probability for

164 6th BS/ IMSC
the particle to be, at timet and in a typical environment, at adistance larger thanta (0 < a < 1) from its initial position, isexp−Const· ta/[(1− a) ln t](1+ o(1)). Also, we show thatlogarithms of the transition probabilities, after a suitable rescal-ing, converge in distribution as time tends to infinity, to somefunctional of the Brownian motion. We compute the law of thisfunctional when the initial and final points agree.References[1] Comets, F. and Popov, S.Yu. (2003) Limit law for transition prob-abilities and moderate deviations for Sinai’s random walk in randomenvironment,Probab. Theory Related Fields126, 571–609.[2] Comets, F. and Popov, S.Yu. (2004) A note on quenched moderatedeviations for Sinai’s random walk in random environment, to appear in:ESAIM-PS.
337 Coherent modeling of macroevolution[Contributed Session C1 (page 15)]
David ALDOUS,University of California Berkeley, USA
Lea POPOVIC, IMA, University of Minnesota, USA
Stochastic models of evolution have been extensively used fordata analysis as well as for making speculative calculations ondifferent levels of taxonomy (species, genera, families) sepa-rately. However, it is certainly desirable to ensure hierarchicalconsistency between different taxonomic levels, so that a phylo-genetic tree on a higher order taxon is consistent with a phylo-genetic tree on the lower order taxa that it encompasses.Our purpose is to present what is arguably the mathematicallyfundamental stochastic model that allows for such a hierarchi-cal structure. We start off with the most basic branching modelfor evolution of the lowest order taxa, and extend it to createa branching model of the higher taxonomic levels. Within ourbranching model we allow a choice of different schemes forgrouping lower levels into higher taxonomic levels: one formingpurely monophyletic groups, one forming paraphyletic groups,and a combination of the two.A wide range of stochastic calculations are possible within sucha hierarchical model. We illustrate a few, regarding the shape ofphylogenetic trees at different hierarchical levels, and regardingthe fluctuations of population sizes at different levels. We em-phasize that this is a basic “purely random” model, useful forinference about evolutionary processes in terms of determiningthe amount of evidence that should be attributed real biologicalsignificance, as opposed to features that would be observed bypure chance or are artifacts of one’s choice of hierarchical clas-sification. At the same time, this model is also a logical startingplatform for building more realistic models, provided modifica-tions to accommodate more realistic biological assumptions aremade.
References
[1] Aldous, D. and Popovic, L. (2003)Coherent Stochastic Models forMacroevolution, preprint.
338 On effective replacement strategiestaking into account the wear and tear ofequipment [Contributed Session C8 (page 35)]
Mikhail POSTAN and Lydmila SHIRYAEVA,Odessa NationalMaritime University, Ukraine
The equipment subjected to sudden failures taking into accountits wear and tear is under consideration. The extended com-pound renewal process(N(t),σ(t)), where
σ(t) =N(t)
∑i=1
σi +vt
is analysed. HereN(t) is the number of failures in interval(0, t);σi is positive random variable describing wear and tear causedby a failure (e.g. cost of repair);v is operational expenses pertime unit. It is assumed that sudden failures occur indepen-dently from each other and equipment’s life-time betweenr-thand(r +1)-st failures is random variable with d.f.Ar (t), whichhas the density. It is natural to suppose thatλ0(t)≤ λ1(t)≤ . . .,whereλr (t) = A′r (r)/(1−Ar (t)).Immediately afterr-th failure, equipment has been repaired (weignore the repair-time). The valuesσ1,σ2, . . . are independentrandom variables with d.fD1(x),D2(x), . . . respectively. At mo-ment of processσ(t) crossing the levelC, equipment is writtenoff and replaced by a new one with the same statistical charac-teristics and so on. By application of Markov processes theory[1], the joint distribution
Fr (x, t) = PrN(t) = r,σ(t) < x,r = 0,1,2, . . . ; 0 < x < C
has been found. D.f. of useful life of equipmentG(τ) =Prinf(t : σ(t) ≤C) < τ has been determined as well and itis given by
G(τ) = ∑r≥1
min(τ,C/v)∫
0
[D1 ∗ . . .∗Dr−1(C−vy)
−D1 ∗ . . .∗Dr (C−vy)]dA0 ∗ . . .∗Ar−1(y),
where∗ is the symbol of d.f. convolution. The following re-placement strategy is also analysed: planned renewals are usediff the age of equipment under operation reaches the given valuetp, thoughσ(tp) < C.The results obtained are related to further development of wear-depending renewal processes theory [2].
References
[1] Feller, W. (1971)An Introduction to Probability Theoryand Its ApplicationsII . J. Wiley, New York-London-Sydney-Toronto.[2] Cox, D.R. (1962)Renewal Theory. Methuen, London, J.Wiley, New York.
339 Testing parameters in a heteroskedas-tic random coefficient autoregressive model
[Contributed Session C33 (page 45)]
Zuzana PRÁŠKOVÁ Charles University in Prague, Czech Re-public
In the contribution, random coefficient autoregressive process
Xt = btXt−1 + εt
will be studied, where variances of errorsεt are changing intime.In literature there were developed various statistics for testingconstancy of random parameterbt under assumptions of station-arity (see e.g. Nicholls and Quinn (1982), Lee (1998) or Ha andLee (2002)). Here we establish the asymptotic distribution ofsuch statistics under more general assumptions.Connection to a general test of heteroskedasticity (see e.g.White (1980)) will be also mentioned and the influence of vari-ous sources of heteroskedasticity will be discussed.References[1] Ha, J. and Lee, S. (2002) Coefficient constancy test in AR-ARCHmodels,Statist. Probab. Lett.57, 65–77.

Abstracts 165
[2] Lee, S. (1998) Coefficient constancy test in a random coefficient au-toregressive model,J. Statist. Plann. Inference74, 98–101.[3] Nicholls, D.F. and Quinn, B.G. (1982)Random Coefficient Autore-gressive Models: An Introduction,Lecture Notes in Statistics, Springer-Verlag, New York.[4] White, H. (1980) A heteroskedasticity consistent covariance matrixestimator and a direct test for heteroskedasticity,Econometrica48, 817–838.
340 Hierarchical mixture modelling withnormalized inverse Gaussian priors [Con-tributed Session C57 (page 34)]
Antonio LIJOI,Università degli Studi di Pavia, Italy
Ramses MENA,UNAM, México
Igor PRÜNSTER Università degli Studi di Pavia, Italy
In recent years the Dirichlet process prior has experienced agreat success in the context of Bayesian mixture modelling. Themixture of Dirichlet process, which overcomes discreteness ofthe realizations of the Dirichlet process by exploiting it in hier-archical models, was introduced by Lo (1984) and popularizedby Escobar and West (1995) by means of the development ofsuitable sampling techniques. In this paper we aim at propos-ing the normalized inverse Gaussian process as an alternativeto the Dirichlet process to be used in Bayesian hierarchicalmodels. The normalized inverse Gaussian prior is constructedvia its finite-dimensional distributions mimicking the procedureadopted by Ferguson (1973) for defining the Dirichlet process.Such a prior belongs to the class of normalized random measureswith independent increments introduced by Regazzini, Lijoi andPrünster (2003). See also James (2002) and Pitman (2003). In-deed, the normalized inverse Gaussian prior, though sharing thediscreteness property of the Dirichlet prior, turns out to have acrucial advantage: it is characterized by a more elaborate andsensible clustering which makes use of all the information con-tained in the data. While in the Dirichlet case the mass assignedto each observation depends solely on the number of times itoccurred, in our case the weight of a single observation heavilydepends on the whole number of ties present in the sample. Ex-pressions corresponding to relevant statistical quantities of thenormalized inverse Gaussian process, such as a priori moments,predictive distributions and both prior and posterior distributionsof its means are deduced. The tractability of the inverse Gaus-sian process makes it suitable for Bayesian hierarchical mod-elling and implies that well-established sampling schemes, suchas the ones set forth by Ishwaran and James (2001), can be eas-ily extended to cover a mixture of normalized inverse Gaussianprocess. The distribution of the number of components, givena sample of sizen, is obtained: it is shown to be less infor-mative than the one corresponding to a Dirichlet mixture, thusbeing less sensitive with respect to the choice of the parame-ters. Thanks to the sensible updating mechanism, the mixtureof normalized inverse Gaussian process is expected to producea better fit than the corresponding mixture of Dirichlet process.This is illustrated by means of two examples involving mixturesof normals.References[1] Escobar, M.D. and West, M. (1995) Bayesian density estimation andinference using mixtures,J. Amer. Statist. Assoc.90, 577–588.[2] Ferguson, T.S. (1973) A Bayesian analysis of some nonparametricproblems,Ann. Statist.1, 209–230.[3] Ishwaran, H. and James, L.F. (2001) Gibbs sampling methods forstick-breaking priors,J. Amer. Stat. Assoc.96, 161–173.[4] James, L.F. (2002)Poisson Process Partition Calculus with applica-tions to exchangeable models and Bayesian Nonparametrics, Mathemat-ics ArXiv math.PR/0205093.
[5] Lo, A.Y. (1984) On a class of Bayesian nonparametric estimates: I,Density estimatesAnn. Statist.12, 351–357.[6] Pitman, J. (2003)Poisson-Kingman partitions, in Science and Statis-tics: A Festschrift for Terry Speed(Ed. Goldstein, D.R.), Lecture Notes,Monograph Series40, 1–35, Institute of Mathematical Statistics, Hay-ward.[7] Regazzini, E., Lijoi, A. and Prünster, I. (2003) Distributional re-sults for means of random measures with independent increments,Ann.Statist.31, 560–585.
341 Count distributions with mixed Pois-son random effects [Contributed Session C49 (page 26)]
Pedro PUIG, Universitat Autónoma de Barcelona, Spain
Jordi VALERO, Escola Superior d’Agricultura de BarcelonaUPC, Spain
In parametric statistics it is important that the used distribu-tions describe well the behaviour of the modelled empirical data.In experiments where the data are counts, the phenomenon ofoverdispersion is very frequent and, in this case, Poisson distri-bution is not adequate. A real source of overdispersion in themodel is the presence of random effects. A very general form todeal with random effects is by means of the mixed Poisson dis-tributions, that is, by considering a Poisson distribution P(µε)where the parameterµ is perturbed by a positive random vari-ableε with expectation equal to1.Sometimes it is reasonable to work with statistical models thatare closed under addition, as it happens for the Poisson and Her-mite distribution (Puig, 2003). However, this condition is oftenvery strong and it is more natural to consider the property of be-ing "partially closed under addition":Given a parametric modelwe shall say that it is "partially closed under addition" if foreach random variableX belonging to this model the sum of anynumber of independent copies ofX also belongs to this para-metric model(Puig and Valero, 2004). For instance, if we joincount unities it is natural to hope that these groups follow thesame distribution than each unity.In this talk we characterize all the modelsY such that theyare mixed Poisson P(µε) with ε independent ofµ , with vari-anceσ2
ε and E[(ε−1)3
]< ∞, that are partially closed under
addition and the maximum likelihood estimator of the expec-tation is the sample mean. The result is thatY belongs tothe three parameter family of distributionsP(t; µ,d,k) (Puigand Valero, 2004) where the domain ofk is k ≥ 1 and k =0, 1/2, 2/3, ...,(n−2)/(n−1), ..., wheren is a natural number.The probability generating function (pgf) of this family is:
g(t; µ ,d,k) = eµ (1+(d−1)(1−k)(t−1))2−k1−k −1
(d−1)(2−k) .
Calculating the limit whenk tends to1 and2, we get the pgf ofthe Neyman A and the Negative Binomial distribution respec-tively. The parametersd andk come from the random variableε , d = 1+ µσ2
ε andk = E[(ε −1)3]/σ4ε and the model is NB2
(Cameron and Trivedi, 1998) becauseV(Y) = µ + µ2σ2ε .
These results can be applied to estimate the models by maximumlikelihood in several practical situations, with Poisson count datawith classical random effects: paired data, repeated or longitu-dinal measures, random blocks, etc.References[1] Cameron, A.C. and Trivedi, P.K. (1998)Regression Analysis ofCount Data, Cambridge University Press, Cambridge.[2] Puig, Pedro (2003) Characterizing additively closed discrete modelsby a property of their MLEs, with an application to generalized Hermitedistributions,J. Amer. Statist. Assoc.98, 687–692.

166 6th BS/ IMSC
[3] Puig, P. and Valero, J. (2004) Some characterizations of count datadistributions with applications, submitted toJ. Amer. Statist. Assoc.
342 A new look at iterative proportionalfitting, alternating scaling, cyclic projections,and biproportional apportionment [ContributedSession C43 (page 26)]
Friedrich PUKELSHEIM , Universität Augsburg, Germany
A problem occurring in various sciences in various disguisesis to fit a nonnegative matrix to a given weight matrix, sub-ject to satisfying prescribed row sums and prescribed columnsums. The problem is solved by what is called theiterativeproportional fitting procedurein statistics, theRAS algorithmin econometrics, orbiproportional apportionmentin electoralsystems’ theory. We discuss the discrete version of the prob-lem in which the fitted matrix must consist of integers only,or of reals with a fixed number of decimal places, and wherethe side conditions on row and column sums are met with-out any rounding error. The main result states that the dis-crete version of the above algorithms converges in finitely manysteps. Our approach rests on a careful anaysis of theflaw count,an L1-error function. The algorithm is available on the Inter-net atwww.uni-augsburg.de/bazi. This is joint work withStéphanie Gier.References[1] Bacharach, M. (1970)Biproportional Matrices and Input-OutputChange, Cambridge UK.[2] Balinski, M.L. and Demange, G. (1989) An axiomatic approach toproportionality between matrices,Math. Oper. Res.14, 700–719.[3] Balinski, M.L. and Demange, G. (1989) Algorithms for proportionalmatrices in reals and integers,Math. Programming Ser. B45, 193–210.[4] Balinski, M.L. and Rachev, S.T. (1997) Rounding proportins: meth-ods of rounding,Math. Sci.22, 1–26.[5] Deming, W.E. and Stephan, F.F. (1940) On a least squares adjust-ment of a sampled frequency table when the expected marginal totalsare known,Ann. Math. Statistics11, 427–444.[6] Fienberg, S.E. (1970) An iterative procedure for estimation in con-tingency tables,Ann. Math. Statistics41, 907–917.[7] Gaffke, N. and Mathar, R. (1989) A cyclic projection algorithm viaduality,Metrika36, 29–54.[8] Rüschendorf, L. (1995) Convergence of the iterative proportional fit-ting procedure,Ann. Statist.23, 1160–1174.
343 An additive-multiplicative hazardmodel in analysis of survival [Poster Session P3(page 41)]
Julia GARCIA-LEAL, Ana M. LARA-PORRAS, EstebanNAVARRETE-ALVAREZ and Jose Manuel QUESADA-RUBIO , Universidad de Granada, Spain
In this work, we consided the study of an additive-multiplicativehazard model in analysis of survival outlined in the context ofthe counting processes. They are obtained the vector of derivatesand the information matrix for the parameters of the model. Aparticular case is analyzed.References[1] Aalen, O.O. (1978) Nonparametric inference for a family of countingprocesses,Annals of Statistics6, No.4, 701–726.[2] Andersen, P.K., Borgan, Ø., Gill, R.D., and Keiding, N. (1993)Statistical Models Based on Counting Processes, Springer-Verlag NewYork.[3] Andersen, P.K. and Gill, R.D. (1982) Cox’s regression model forcounting processes: A large sample study,Annals of Statistics10, 1100–1120.[4] Borgan, Ø. (1984) Maximum Likelihood Estimation in ParametricCounting Process Models, with Applications to Censored Failure TimeData,Scand. J. Statist.11, 1–16.
[5] Cox, D.R. (1972) Regression models and life-tables (with dicussion)J. Roy. Statist. Soc. B34, 187–220.[6] Cox, D.R. and Oakes, D. (1984)Analysis of Survival Data,Chapmanand Hall, London.[7] Fleming, T.R. and Harrington, D.P. (1991)Counting Processes andSurvival Analysis,Wiley & Sons, New York.[8] Lin, D.Y. & Ying, Z. (1994) Semiparametric analysis of the additiverisk model,Biometrika81, 61–71.[9] Lin, D.Y. and Ying, Z. (1995) Semiparametric analysis of generaladditive-multiplicative hazard models for counting processes,Annals ofStatistics23, 1712–1734.[10] Prentice, R.L. and Self, S.G. (1983) Asymptotic distribution theoryfor Cox-type regressions models with general relative risk form,Ann.Statist.11, 804–813.[11] Self, S.G. and Prentice, R.L. (1982) Commentary on Andersen andGill’s Cox’s regression model for counting processes: A large samplestudy,Ann. Statist.10, 1121–1124.
344 On the power of profiles for transcrip-tion factor binding site detection [ContributedSession C40 (page 37)]
Sven RAHMANN, Max Planck Institute for Molecular Genet-icsandFreie Universität Berlin, Germany, Present addressUni-versität Bielefeld, Germany
Tobias MÜLLER,Universität Würzburg, Germany
Martin VINGRON, Max Planck Institute for Molecular Genet-ics, Germany
Transcription factor binding site (TFBS) detection plays an im-portant role in computational biology, with applications in genefinding and gene regulation. The sites are often modeled bygapless profiles, also known as position-weight matrices. Pastresearch has focused on the significance of profile scores (theability to avoid false positives), but this alone is not enough:The profile must also possess the power to detect the true pos-itive signals. Several completed genomes are now available,and the search for TFBSs is moving to a large scale; so dis-criminating signal from noise becomes even more challenging.We develop measures that help in judging profile quality, basedon both sensitivity and selectivity of a profile. It is shown thatthese quality measures can be efficiently computed, and we pro-pose statistically well-founded methods to choose score thresh-olds. Our findings are applied to the TRANSFAC database [3]of transcription factor binding sites. The results are disturbing:If we insist on a significance level of5% in sequences of length500, only19%of the profiles detect a true signal instance with95% success probability under varying background sequencecompositions. Aprofile is a probabilistic description of a se-quence. It specifies a probability distribution over the alphabet’sletters for each position. More formally, a profileP of lengthLover Σ is anL×|Σ| matrix (Pi j ) (i = 1, . . . ,L; j ∈ Σ), such thatPi j ≥ 0 for all i, j and ∑ j∈Σ Pi j = 1 for all i. We write PLΣfor the set of all length-L profiles overΣ. For a sequence win-dow (“word”) W of lengthL, we want to decide whether it isan occurrence of the signal described by profileP ∈ PLΣ, orwhether it is “background” sequence, meaning everything ex-cept the signal. To make a meaningful decision, we need a prob-abilistic model for the background. It should capture composi-tional properties of the sequences under consideration withoutmodeling any signal-like properties. For homogeneity reasons,the background is usually a simple i.i.d. model, that is, a profilematrix Π ∈ PLΣ, where each row consists of the same prob-ability vector π. The decision is based on thelog-odds scoreScore(W) := log(¶P(W)/¶Π(W)) = ∑L
i=1 log(Pi,Wi /πWi ). Forcomputational purposes, we round all scores to a certain granu-

Abstracts 167
larity ε ¿ 1 (for exampleε = 0.01). Whenε is small enough,this leaves the scores unchanged for all practical purposes. Sofar consideration has been restricted to the significance level ofa given score threshold ([2] and others). When a score of atleastt frequently occurs in a sequence generated according tothe background model, it is insignificant. In practice a scoreof t is called significant for a sequence when the probability thatsuch a score is reached at least once in a background sequence ofthe same length is at most0.05 or 0.01. Choosingt in this waylimits false positive classifications. Significance provides onlyhalf of the picture, however. We also need to know the probabil-ity to successfully identify a true signal when it is present in thesequence, i.e., thepowerof the thresholdt. When a highly sig-nificant threshold is enforced, it easily happens thatt becomesso large that even true signal scores can rarely reacht. We showthat both significance level and power of any thresholdt can bedetermined accurately. Although it seems strange that the powerof profiles has not yet been systematically analyzed, we foundno such considerations in the literature. Our full paper is acces-sible as [1].References
[1] S. Rahmann, T. Müller, and M. Vingron. On the powerof profiles for transcription factor binding site detection. Statis-tical Applications in Genetics and Molecular Biology, 2(1), 2003.www.bepress.com/sagmb/vol2/iss1/art7.[2] R. Staden. Methods for calculating the probabilities of finding pat-terns in sequences.CABIOS, 5:89–96, 1989. E. Wingender, X. Chen,R. Hehl, H. Karas, I. Liebich, V. Matys, T. Meinhardt, M. Prüss,I. Reuter, and F. Schacherer. TRANSFAC: an integrated system forgene expression regulation.Nucleic Acids Research, 28:316–319, 2000.
345 Asymptotics of K-means clustering[Contributed Session C14 (page 16)]
Peter RADCHENKO , Yale University, USA
When standard regularity conditions break down, asymptotic be-havior of estimators becomes unusual. The talk addresses thisproblem by considering a number of examples in k-means clus-tering. These examples demonstrate how singularities in thesecond derivative matrix of the population criterion function af-fect the asymptotics. Typically the asymptotics for problems ofthis sort are controlled by Taylor expansions to quadratic termsaround a unique population solution. My examples treat caseswhen either the population solution is not unique or when higherorder terms in the Taylor expansion become important. In eachcase I apply empirical process techniques and find explicit lim-iting distributions. The motivation for this research came froma question in [1] about the rate of convergence of the populationcriterion function evaluated at the empirical optimum. The ex-amples show that the rate suggested by central limit theorem in[2] no longer holds when regularity conditions are violated.References[1] Bartlett, P., Linder, T., Lugosi, G. (1998) The minimax distortion re-dundancy in empirical quantizer design,IEEE Trans. Inform. Theory44, 1802–1813.[2] Pollard, D. (1982) A central limit theorem for k-means clustering,Ann. Probability4, 919–926.
346 Empirical process based on the recur-sive residuals in functional measurement er-ror models [Contributed Session C14 (page 16)]
A.R. RASEKH , Shahid Chamran University, Ahwaz, Iran
Recursive residuals have frequently been suggested for testingmodel fit and model assumptions in linear regression (Kianifard
Swallow, 1996). Unlike ordinary residuals they are indepen-dently and identically distributed and do not have the problemof deficiencies in one part of the data being smeared over all theresiduals. In this paper, we generalize the theory of the empiricalprocess based on the residuals in the measurement error mod-els (Miller, 1989) to the recursive residuals in the measurementerror models. We show that the weak convergence propertiesof the standardized residuals hold for the studentised recursiveresiduals in this case. Furthermore, we look at the some tests forgoodness of fit based on the weak convergence of the empiricaldistribution of the recursive residuals.References[1] Kianifard, F. and Swallow, W.H. (1996) A review of the develop-ment and application of recursive residuals in linear models.Journal ofAmerican Statistical Association433, 391–400.[2] Miller, S. M. (1989) Empirical processes based upon residuals fromerrors in variables regressions.Annals of Statistics17, 282–292.
347 The topography of multivariate nor-mal mixtures [Contributed Session C29 (page 52)]
Bruce G. LINDSAY,Pennsylvania State University, USA
Surajit RAY , University of North Carolina, Chapel Hill, USA
Fitting a mixture model offers a primary data reduction throughthe number, location, and shape of its components. However, inmore complex settings we would like to know more about howthe components interact to describe an overall pattern of den-sity. What, for example, is the modal structure, or in a richersense, the configuration of major features? This paper presentsmajor new insights into the topography of multivariate normalmixture densities, providing tools that are useful even in highdimensional data. The literature on determination of the num-ber of modes has focused primarily on univariate mixtures. [4]determined necessary and sufficient conditions for bimodality inthe mixture of univariate normals with equal variances and mix-ing proportions. Later, conditions for bimodality in the mixtureof univariate normal distribution with unequal variance and un-equal mixing proportions was studied by [3],[1] and [6]. Recentpapers in the machine learning literature have also tackled theproblem of modes in mixture of normals(see [2]). Our investi-gation into the topography of mixture ofD-variate normal withK = 2 components yielded several interesting results. First, atremendous dimension reduction is possible, fromD down toONE dimension (see Chapter 8,[5]). More generally, finding themodes forK components is aK−1 dimensional problem. Forthis reason we will assume thatK − 1 ≤ D, as otherwise ourmethods offer no dimension reduction. Also, for a mixture ofmultivariate normals the generalization of the univariate result“a mixture of two normals cannot have more than two modes”no longer holds; that is the multivariate normal case has a verydifferent, and more complex, modal structure than the univari-ate. Given, the parameters of aK-component,D-dimensionalnormal mixture we find theK − 1 dimensional surface whichtravels through all the modes of the mixture. This dimension re-duction tool opens up further graphical and analytic doors. Wehave constructed a functionΠ(.) whose plot can be used to de-termine the number and location of modes as they depend onthe mixing proportionπ. Going beyond this, it can be shownanalytically that there exists a fundamental curvature functionK(.), whose zeroes determine the modality potential of a pair ofcomponent densities. To our knowledge, this paper provides themost general theory on determination of the number and locationof modes in a multivariate mixture for arbitrary dimension andvariance. Most previous results on the topography of mixture of

168 6th BS/ IMSC
normal distributions can be obtained as special cases of the gen-eralized result we present in this paper. Applications of thesemethods to real and simulated dataset will also be discussed.References[1] Behboodian, J. (1970) On the modes of a mixture of two normaldistributions,Technometrics12, 131–139.[2] Carreira-Perpiñán, M.A. and Williams, C.K.L. (2003) On the num-ber of modes of a gaussian mixture, InScale-Space Methods in Com-puter Vision, Lecture Notes in Computer Science, volume 2695, pages625–640, Springer-Verlag.[3] Eisenberger, I. (1964) Genesis of bimodal distributions,Technomet-rics6, 357–363.[4] Helguero, F.D. (1904) Sui massimi delle curve dimorfiche,Biometrika3, 85–98.[5] Ray, S. (2003)Distance-based Model-Selection with application tothe Analysis of Gene Expression Data, PhD thesis, Pennsylvania StateUniversity.[6] Robertson, C.A. and Fryer, J.G. (1969) Some descriptive propertiesof normal mixtures,Skandinavisk Aktuarietidskrift69, 137–146.
348 Small world networks [Invited Session 1(page 19)]
Gesine REINERT, University of Oxford, UK
Small world models are networks consisting of many local linksand fewer long range ’shortcuts’. We consider some particu-lar instances, and rigorously investigate the distribution of theirinter-point network disatances as well as soime measures for lo-cal clustering. The motivating applications are metabolic net-works.References[1] Barbour, A.D. and Reinert, G. (2001)Small worlds, Random Struc-tures and Algorithms19, 54–74.[2] Watts, D.J. and Strogatz, S.H. (1998) Collective dynamics of “small-world" networks,Nature 393, 440–442.
349 Exact simulation for diffusions and ap-plications [Invited Session 32 (page 33)]
Alexandros BESKOS, Omiros PAPASPILIOPOULOS andGareth ROBERTS, University of Lancaster, UK
This talk will review recent work on the exact simulation of dif-fusion processes using a retrospective simulation methodology,and introduced in [1] and [2]. The algorithms output skeletonsof sample paths which can be “filled-in" by using appropriateBrownian bridge dynamics. The techniques derived are numer-ically efficient. Applications of the methodology will be de-scribed, including a Monte Carlo ML technique, and exact simu-lation from boundary hitting time distributions. The technique isalso of theoretical interest as it can be seen as a way of factoris-ing the law of a diffusion into those of a point process (whosedistribution depends on the diffusion under consideration) and acollection of independent Brownian bridges.References[1] Beskos, A. and Roberts G.O. (2003) Exact Simulation of Diffusions,submitted.[2] Beskos, A., Papaspiliopoulos, O., and Roberts, G.O. (2004) Retro-spective rejection sampling of diffusion sample paths with applications,submitted.
350 Path integrals for stochasticSchrödinger equations driven by Brownianmotion [Contributed Session C3 (page 50)]
Luis RINCON , UNAM, Mexico
This is a short talk where we study the solutions of some stochas-tic Schrödinger equations. We are interested in the classical
Schrödinger equation plus a linear transform of the wave func-tion times white noise [4]. We show that these sort of equationsadmit a path integral representation and explicitly solve a coupleof particular examples for quadratic potentials [3]. These for-mulae generalise the classical Mehler kernel formula not onlywhen the drift is Brownian motion but also for any continuoussemimartingale [1],[2].References[1] Rincon, L. (2003) Phase space path integral representation for thesolution of a stochastic Schrödinger equation in Stochastic Models,Con-temporary Mathematics Series, AMS336, 237–252.[2] Rincon, L. (2003)Path integral representation for the solution of astochastic Schrödinger equation driven by a semimartingale, manuscriptsubmitted to the Journal of Interdisciplinary Mathematics.[3] Truman, A. and Zastawniak, T. (2001) Stochastic Mehler kernelsVia oscillatory Path Integrals,J. Korean Math. Soc.38, No. 2, 469–483.[4] Zastawniak, T.J. (1997) Frenel type path integral for the stochasticSchrödinger equation,Lett. Math. Phys.41, 93–99.
351 Likelihood ratio tests for covari-ance structures in the presence of non-identifiability [Contributed Session C44 (page 52)]
Christian RITZ , The Royal Veterinary and Agricultural Uni-versity, Denmark
Likelihood ratio (LR) tests of null hypotheses versus one-sidedalternatives in cases where the null hypothesis renders a one-dimensional parameter non-identifiable have been considered inseveral settings. The example motivating the present develop-ment arises frequently in analysis of data with repeated mea-surements; each vector of observationsy, say, has covariancegiven by cov(y j ,yk) = σ2
e δ jk +σ2u +φ exp(−ρ(t j − tk)2), where
δ jk = 1 if j = k and δ jk = 0 if j 6= k, and t j , tk are times atwhich the two observationsy j ,yk are taken. Consider testingthe hypothesisφ = 0 at which the parameterρ becomes non-identifiable. Frequently it is assumed in applications that theasymptotic distribution of the LR statistic is aχ2-distributionwith one or two degrees of freedom or a mixture of these twodistributions, but this assumption lacks theoretical foundation.In the present paper we derive the asymptotic distribution in theform of the distribution of the supremum of a squared, truncatedGaussian process with specified covariance.Lemdani and Pons (1995) derive the asymptotic distribution ofthe LR test for testing binomial mixtures against a single bino-mial. Test of the order of ARMA processes and tests in mixturemodels are considered in Dacunha-Castelle and Gassiat (1999).Lindsay (1995) discusses LR tests for general mixture models,and he distinguishes between three types of LR tests. Using histerminology the LR tests in presence of a non-identifiable pa-rameter fall into the category "type III LR tests", which do nothaveχ2-distributions or mixtures ofχ2-distributions as asymp-totic distributions. One way to think of these LR tests is in termsof score statistics: for each value of the parameter which is non-identifiable we have a score test. If one were to combine all thesescore tests into a simultaneous test the naive approach would beto take the supremum over all score tests as the relevant teststatistic.Thus there are two main steps in the derivation of the asymptoticdistribution. First, to ensure that the score test is asymptoticallyequivalent to the LR test, and, second, to establish weak con-vergence of the score test. The above-mentioned papers all usespecific properties of the models investigated and their methodsare not easily transferable to the case of repeated measurements.Our method uses the fact that the model is a sub-model of anexponential family. Since other models and other covariance

Abstracts 169
structures are covered by the method, we formulate the result ina general setting and then use it for the repeated measurementsproblem.The main result that we establish is an explicit asymptotic rep-resentation of the LR test, based on exponential family theory.This representation has the form of a supremum of a squaredtruncated Gaussian process. An explicit covariance matrix of theGaussian process is obtained by exploiting the covariance struc-ture in repeated measurements models. From the proof it alsoemerges that the LR statistic and the score statistic are asymp-totically equivalent.Results from a small simulation study show reasonable perfor-mance of the asymptotic distribution for various small samplesizes in the repeated measurements model mentioned above.References[1] Dacunha-Castelle, D. and Gassiat, E. (1999) Testing the order ofa model using locally conic parametrization: population mixtures andstationary ARMA processes,Ann. Statist.27, 1178–1209.[2] Lemdani, M. and Pons, O. (1995) Tests for Genetic Linkage andHomogeneity ,Biometrics51, 1033–1041.[3] Lindsa,y B. G. (1995)Mixture Models: Theory, Geometry and Ap-plications, Institute of Mathematical Statistics, Hayward, CA.
352 On recurrent extensions of self–similarMarkov processes and Cramer’s condition
[Contributed Session C32 (page 51)]
Víctor RIVERO , Université Paris VI et Université Paris X,France
Let P be the law of a non–arithmetic real valued Lévy processξ , that has been killed at an independent exponential time of pa-rameterk≥ 0, andζ its lifetime. We assume thatξ satisfies thehypotheses: (a) there exists aθ > 0 such thatE(eθξ1) = 1 and(b) E(ξ +
1 eθξ1) < ∞. The condition (a) is called Cramer’s condi-tion. Let (X,(Px,x≥ 0)) be the 1–self–similar Markov processassociated toξ via Lamperti’s [1] transformation. More pre-cisely, letAt =
∫ t0 eξsds, t ≥ 0 andτ its inverse. For anyx > 0,
let Px be the law of the processX defined byXt = xexpξτ(t/x)if 0≤ t < Aζ and0 otherwise. The processX is a strong Markovprocess that fulfills the scaling property: for anyc> 0 the law of(cXt/c, t ≥ 0) underPx is Pcx. Moreover,X hits0 in a finite timea.s. and has0 as cemetery point. We deduce from conditions (a)and (b) that if0 < θ < 1 the law of the processX satisfies theassumptions of Vuolle–Apiala [2] and as a consequence thereexists a unique excursion measuren compatible with the semi-group ofX such thatn(X0+ > 0) = 0. In this work we give aprecise description ofn. To that end, we construct a self–similarMarkov processX\, which can be viewed asX conditioned neverto hit 0. Then we constructn, using the law ofX\, in a mannerthat is reminiscent of the construction of the Itô excursion mea-sure of a Brownian motion using the law of a Bessel(3) process.We characterize the unique self–similar Markov processX thatbehaves likeX before its first hitting time of0 and such that0 isa recurrent regular state and whose excursion measure isn. Analternative description ofn is given by specifying the law of theexcursion process conditioned to have a given length. Further-more, if θ ≥ 1 we prove that there does not exist an excursionmeasuren such thatn(X0+ > 0) = 0.
References[1] Lamperti, J. (1972)Semi-stable Markov processes. I, Z. Wahrschein-lichkeitstheorie und Verw,Gebiete22, 205–225.[2] Vuolle-Apiala, J. (1994) Itô excursion theory for self-similar Markovprocesses,Ann. Probab.22(2) 546–565.
353 Testing and discovery of non-
independence restrictions in observedmarginals of dags with hidden variables: im-plications for causal inference [Invited Session 35(page 30)]
Thomas RICHARDSON andJames ROBINS, Harvard Schoolof Public Health, US
Under the causal Markov assumption missing arrows on a causal(i.e generating) DAG represent the abscence of causal effects.When some of the variables on a causal DAG are unobserved(hidden), it is still sometimes possible to determine from thethe observed data whether certain arrows are missing, oftenby testing for a conditional independence. However in certaininteresting cases the absence of an arrow may not entail anyconditional independence restrictions on the joint distributionof the observed variables, yet still entail (often complex) non-independence restrictions and thereby be identifiable. In thistalk we describe how to recognize such cases and how to ef-fectively test for the prescence of these complex restrictions.Finally, when the underlying generating DAG is unknown, wedescribe how, under an extended faithfulness assumption, ourprocedures can be used to enhance the power of search algo-rithms (currently based on conditional independence testing)that attempt to identify the arrows that are either missing orpresent in all DAGs that may have generated the data.
354 Saddlepoint approximations for multi-variate M-estimates [Contributed Session C61 (page48)]
Chris FIELD,Dalhousie University, Canada
John ROBINSON, University of Sydney, Australia
Elvezio RONCHETTI,University of Geneva, Switzerland
We obtain marginal tail area approximations for a one-dimensional test statistic based on the appropriate component ofan M-estimate for both standardized and Studentized versions.The result is proved under conditions which allow the appli-cation to the bootstrap and involves discretization with saddle-points being used for each neighbourhood. This uses results in[1] to extend [2] to the case where densities do not exist. Theseresults can be used to obtain second order relative error resultson the accuracy of the Studentized bootstrap and the tilted boot-strap.References[1] Robinson, J., Höglund, T., Holst, L., and Quine, M.P. (1990) Onapproximating probabilities for large and small deviations inRd, Ann.Probab.18, 727–753.[2] Almudevar, A., Field, C.A., and Robinson, J. (2000) The density ofmultivariate M-estimates,Ann. Statist.28, 275–297.x
355 Gaussian hypergeometric distribu-tions in modelling a WWW browsing session
[Poster Session P1 (page 22)]
Antonio CONDE SÁNCHEZ, María José OLMO JIMÉNEZ,José RODRÍGUEZ AVI and Antonio José SÁEZ CASTILLO,Universidad de Jaén, España
Family of Gaussian Hypergeometric Distributions includesprobability distributions that have been used as probabilisticmodels of discrete random variables from different scientificand technological fields (Rodríguezet al 2003a, 2003b, 2003c,2004).Distributions in this family may be strongly skewed, with heavy-tail and infinite variance effect. They also may possess two

170 6th BS/ IMSC
modal values, apart from the usual unimodal or J-transpose pro-files.These and other properties providea priori an adequate contextfor fitting data from WWW-traffic. Traces in this context are,in general, highly overdispersed and very large and may be uni-modal or no.In this poster we show advantages and disadvantages of the useof Gaussian Hypergeometric Distributions for fitting parametersthat describe a WWW browsing session. The goodness of thesefits will provide conditions for construct a hierarchical model tosimulate real traffic.References[1] Rodríguez-Avi, J., Conde-Sánchez, A., and Sáez-Castillo, A.J.(2003a) A new class of discrete distributions with complex parametersStatistical Papers44, 1, 67–88.[2] Rodríguez-Avi, J., Conde-Sánchez, A., Sáez-Castillo, A.J., andOlmo-Jiménez, M.J. (2003b) Estimation of parameters in gaussian hy-pergeometric distributionsCommunications in Statistics, Theory andMethods32, 7, 1101–1118.[3] Rodríguez-Avi, J., Conde-Sánchez, A., Sáez-Castillo, A.J., andOlmo-Jiménez, M.J. (2003c) On Discrete Multivariate DistributionsSymmetric in Frequencies,Test12, 2, 459–480.[4] Rodríguez-Avi, J., Conde-Sánchez, A., Sáez-Castillo, A.J., andOlmo-Jiménez, M.J. (2004) A triparametric discrete distribution withcomplex parameters,Statistical Papers45, 1, 81–96.
356 Random alpha hulls [Contributed SessionC17 (page 54)]
Alberto RODRÍGUEZ-CASAL , Universidade de Vigo, Spain
The concept of alpha hulls formalizes the intuitive notion of“shape” for a point set data,S. Alpha hulls are generalizationsof the convex hull. Think of Euclidean space filled with Styro-foam and the points ofS made of solid rock. Now imagine aneraser in the form of a ball with radius alpha. It is omnipresent inthe sense that it carves out Styrofoam at all positions where theStyrofoam particle does not contain any of the sprinkled rocks,that is, points ofS. The resulting object is called the alpha hull.For alpha near zero, this leaves the point set, and for alpha nearinfinity, we obtain the convex hull. In between these two limits,we have objects that are possibly disconnected and non-convex.Here we analyze the effect of this parameter alpha in the shapeof the alpha hull when the data are a random sample. In partic-ular we give asymptotic bounds (when the sample size goes toinfinity) for the expected number of extreme points of the alphashape.References[1] Edelsbrunner, H. and Mucke, E.P. (1994) Three-dimensional alphashapes,ACM Trans Graphics13, 43–72.[2] Rodríguez-Casal, A. (2003)Estimación de conjuntos y sus fronteras.Un enfoque geométrico. PhD thesis, Universidade de Santiago de Com-postela.[3] Walther, G. (1997) Granulometric smoothing,Ann. Statist25,2273–2299.
357 Functional observations and depth[Contributed Session C55 (page 21)]
Sara LÓPEZ-PINTADO andJuan ROMO, Universidad CarlosIII de Madrid, Spain
The use of statistical depth is growing in nonparametric multi-variate analysis. Since there is no natural order for observationsin more than one dimension, the extension of the ideas of orderstatistics, ranks and medians to higher dimensions is not trivial.The concept of depth allows to measure the ‘centrality’ or ‘out-lyingness’ of an observation within a given data set or within
the underlying distribution and it provides a centre-outward or-der for multivariate observations. Liu (1990) and Zuo and Ser-fling (2000) established four key properties a depth should ver-ify: invariance, maximality at center, monotonicity with respectto the deepest point and vanishing at infinity. They also studiedsome general structures for depth functions and compared themwith respect to these four properties. Liu, Parelius and Singh(1999) analyzed applications of the concept of depth. They de-fined trimmed regions, contours and intoduced one dimensioanlcurves for visualizing ‘scale’ and ‘kurtosis’ of a multivariate dis-tribution. Zuo and Serfling (2000) presented in a very generalframework the properties of depth-based trimmed region andcontours. These concepts of depth are computationally very in-tensive. Another problem is that they are not adequate for high-dimensional data. A recent area of research in statistics is thestudy of functional observations. The goal of this paper is tointroduce and explore depth for functional data. A previous pro-posal is Fraiman and Muniz (2001). We give graph based defini-tions of depth for curves. One of the interesting features of thesedefinitions is that they can be easily adapted to high-dimensionaldata and they are not computationaly intensive. Given a collec-tion of curves, the depth allows to measure the centrality of afunction and it gives a criterion to order a sample of functionsfrom centre-outward. We present some of their properties, in-cluding asymptotics results. We extend the ideas of ranks, medi-ans, order statistics and trimmed regions to a functional contextand high-dimensional context. We illustrate the performance ofthe functional depth with some real data examples. As an ap-plication we generalize the depth-based Wilcoxon rank sum testintroduced in Liu and Singh (1993) to check if two groups ofcurves come from the same population.References[1] Fraiman, R. and Muniz, G. (2001)Trimmed mean forfunctional data, Test 10, 419–440.[2] Liu, R. (1990) On a notion of data depth based on random simplices,Ann. Statist.18, 405–414.[3] Liu, R., Parelius, J.M., and Singh, K. (1999) Multivariate analysis bydata depth: Descriptive statistics, graphics and inference,Ann. Statist.27, 783–858.[4] Liu, R. and Singh, K. (1993) A quality index based on data depthand multivariate rank test,J. Amer. Statist. Assoc.88, 257–260.[5] Zuo, Y. and Serfling, R. (2000a)General notions of statistical depthfunction, Ann. Statist.28, 461–482.[6] Zuo, Y. and Serfling, R. (2000b)Structural properties and conver-gence results for contours of sample statistical depth functions, Ann.Statist.28, 483–499.
358 An almost sure invariance principlefor the range of planar random walks [InvitedSession 10 (page 39)]
Richard F. Bass,University of Conneticut, USA
Jay ROSEN, C.U.N.Y., USA
For a symmetric random walk inZ2 with 2+ δ moments, werepresent|R(n)|, the cardinality of the range, in terms of an ex-pansion involving the renormalized intersection local times of aBrownian motion. We show that for eachk≥ 1
(logn)k[1
n|R(n)|+
k
∑j=1
(−1) j ( 12π logn+cX)− j γ j,n
]→ 0,a.s.
whereWt is a Brownian motion,W(n)t = Wnt/
√n, γ j,n is the
renormalized intersection local time at time 1 forW(n), andcXis a constant depending on the distribution of the random walk.
359 A metapopulation model with environ-mental stochasticity [Poster Session P2 (page 32)]

Abstracts 171
Joshua V. ROSS, The University of Queensland, Australia
A stochastic metapopulation model incorporating environmentalstochasticity is presented. This is the stochastic logistic modelwith the novel aspect that it incorporates varying carrying capac-ity. A suitably scaled version of the model is shown to convergeuniformly in probability, over finite time intervals, to a deter-ministic model studied previously by Mark Johnson. We alsoestablish a Gaussian approximation for the state-probabilitiescorresponding to the number of suitable and occupied patchesin the metapopulation network. This approximation is valid atall times during the evolution of the process. We also considerthe effects of environmental stochasticity on metapopulation dy-namics through a comparison with the stochastic logistic model.
360 Modeling images as a superposition ofrandom objects with scaling properties [Con-tributed Session C28 (page 25)]
Yann GOUSSEAU andFrançois ROUEFF, Telecom Paris,France
Most statistics of natural images exhibit non-gaussianity, as wellas scaling properties. These two phenomena may for instancebe easily observed on the distribution of the gradient of im-ages gray levels [8]. Other quantity bearing these propertiesinclude the power spectrum [2], wavelet coefficients [9], [5],morphological quantities [1] or the distribution of local patches[3]. Non-gaussiannity is strongly related to the occlusion phe-nomenon. Indeed, in the process of image formation, objectshide themselves depending on where they lie with respect to thecamera, which differs totally from an additive generation. Thisphenomenon leads to peculiar two-dimensional structures suchas homogeneous regions, borders and T-junctions. Besides, thescaling properties of an image may also be seen as a result ofscaling properties present in nature, that is in the object sizesdistribution.Several studies [7], [1], [6] show (either theoretically or exper-imentally) that most of natural images statistics may be repro-duced though the use of a simple model of images, consist-ing in the sequential superposition of random objects, the deadleaves model of Mathematical Morphology. The mere nature ofthe model enables the reproduction of characteristic structuresof natural images (discontinuities, homogeneous zones). More-over, the use of a power law distribution for the sizes of objectsenables to reproduce scaling phenomena. But the presence ofsmall and large scale "cut-off" sizes, which keep objects sizesaway from zero and infinity, must be assumed in this context.In this contibution (see details in [4]), we present a new modelfor natural images, that is obtained from a dead leaves modelwith scaling properties when letting the small scale "cut-off"frequency tend to zero. By doing so, we model the small scalesproperties in a non-trivial way, and we are then in a position tostudy the regularity of images from a functional analysis pointof view. We introduce the specific dead leaves model with scal-ing properties, and derive some of its property in the case whereobjects are bounded. Then we look at the convergence of thismodel when objects sizes tends to zero. We show that the finitedimensional distributions of the colored model exhibit interest-ing behavior. Eventually, having in mind the standard a priori as-sumptions of classical non-parametric estimation problems suchas denoising, we study the regularity of this limit process usingBesov spaces.References[1] Alvarez,L., Gousseau, Y., and Morel, J.M. (1999) The size of ob-jects in natural and artificial images,Advances in Imaging and Electron
Physics, Academic Press111, 167–242.[2] Field, D.J., (1987) Relations between the statistics of natural imagesand the response properties of cortical cells,Jour. Opt. Soc. Amer. A42379–2394.[3] Geman, D. and Koloydenko, A. (1999)Invariant statistics and codingof natural microimages, in IEEE Workshop on Statistical and Computa-tional Theory of Vision, Fort Collins, Co. .[4] Gousseau, Y. and Roueff, F. (2003)The dead leaves model : generalresults and limits at small scales, Tech. Rep. 2003D009, GET/TelecomParis, http://arxiv.org/abs/math.PR/0312035.[5] Huang, J. and Mumford, D. (1999)Statistics of natural images andmodels, Proc IEEE Conf. Computer Vision and Pattern Recognition,541–547.[6] Lee, A., Mumford, D., and Huang, J. (2001) Occlusion models fornatural images: A statistical study of a scale invariant dead leaves model,Int’l J. of Computer Vision41, 35–59.[7] Ruderman, D.L. (1997)Origins of scaling in natural images, VisionResearch37, 3385–3398.[8] Ruderman, D.L. and W. Bialek, W. (1994)Statistics of natural im-ages: Scaling in the woods, Physical Review Letters 814–817.[9] Simoncelli, E.P. (1997)Statistical model for images: Compression,restoration and synthesis, in 31st Asilomar Conference on Signal, Sys-tems and Computers.
361 A unified approach to the characteri-sation of equivalence classes of DAGs, chaingraphs with no flags and chain graphs [Con-tributed Session C24 (page 35)]
Alberto ROVERATO , Universitá di Modena e Reggio Emilia,Italy
A Markov property associates a set of conditional independen-cies to a graph. Two alternative Markov properties are availablefor chain graphs, the LWF and the AMP Markov property, whichare different in general but coincide for the subclass of chaingraphs with no flags. Markov equivalence induces a partitionof the class of chain graphs into equivalence classes and everyequivalence class contains a, possibly empty, subclass of chaingraphs with no flags itself containing a, possibly empty, subclassof directed acyclic graphs (DAGs). LWF-Markov equivalenceclasses of chain graphs can be naturally characterised by meansof the so-called largest chain graphs whereas a graphical char-acterisation of equivalence classes of DAGs is provided by theessential graphs. We show the existence of largest chain graphswith no flags that provide a natural characterisation of equiva-lence classes of chain graphs of this kind, with respect to boththe LWF and the AMP Markov properties. We propose a proce-dure for the construction of the largest chain graphs, the largestchain graphs with no flags and the essential graphs, thereby pro-viding a unified approach to the problem. As by-products we ob-tain a characterisation of graphs which are largest chain graphswith no flags and an alternative characterisation of graphs whichare largest chain graphs. Furthermore, a known characterisationof the essential graphs is shown to be a special case of our moregeneral framework. The three graphical characterisations havea common structure: they use two versions of a locally verifi-able graphical rule. Moreover, in case of DAGs, an immediatecomparison of three characterising graphs is possible.
362 Bayesian analysis for finite mixtures ofexponential distributions [Contributed Session C56(page 47)]
J. MARTÍN, C.J. PÉREZ andM. J. RUFO, University of Ex-tremadura, Spain
In the last few years, the analysis of finite mixture models hasreceived an increasing consideration (see e.g. Richardson and

172 6th BS/ IMSC
Green [5], Roeder and Wasserman [6] and, Stephens [7]). Mix-ture models are required in many applications arising in differentfields of knowledge. We focus on Bayesian analysis of mixtureswith a known number of components. In this case, the maindifficulties are the prior distribution choice and the parameteridentifiability problem.In this work, we propose an extension of the normal mixturemodels by considering a mixture of distributions belonging toa natural exponential family with a quadratic variance function(NEF-QVF). Some interesting papers about natural exponen-tial families are provided by Diaconis and Ylvisaker [1], Morris[2,3] and, Gutiérrez-Peña and Mendoza [4].Reference priors can not be used in this context because im-proper posterior distributions are obtained. In order to solve thisproblem in some particular cases, Richardson and Green [5] andStephens [7] considered the prior distributions defined in a hier-archical model, while Roeder and Wasserman [6] used partiallyproper prior distributions. We propose to use conjugate priordistributions for the mixture parameters in the NEF-QVF case.In normal mixture models, the identifiability problem is solvedby imposing identifiability constrictions to the parameters(Richardson and Green [5] and Roeder and Wasserman [6]) orby considering labeled sample points from the posterior distri-bution (Stephens [7]). We extend the results in Stephens [7] tobe valid for the NEF-QVF case.In order to make inferences, approximation techniques must beused. Markov Chain Monte Carlo methods are used by intro-ducing allocation latent variables. Concretely, Gibbs sampling-based algorithms are used.We conclude the work by considering an illustrative examplethat is solved by using the proposed technique.References[1] Diaconis, P. and Ylvisaker, D. (1979) Conjugate Priors for Exponen-tial Families,The Annals of Statistics7, 269–281.[2] Morris, C.N. (1982) Natural Exponential Families with QuadraticVariance Functions,The Annals of Statistics10, 65–80.[3] Morris, C.N. (1983) Natural Exponential Families with QuadraticVariance Functions: Statistical Theory,The Annals of Statistics11,515–529.[4] Gutiérrez-Peña E. and Mendoza, M. (1999) A Note on Bayes Esti-mates for Exponential Families,Revista de la Real Academia de Cien-cias Exactas, Físicas y Naturales de España, 93, 351–356.[5] Richardson, S. and Green, P.J. (1997) On Bayesian Analysis of Mix-tures with an Unknown Number of Components,Journal of the RoyalStatistical Society59, 731–792.[6] Roeder, K. and Wasserman, L. (1997) Practical Bayesian DensityEstimation Using Mixtures of Normals,Journal of the Royal StatisticalSociety92, 894–902.[7] Stephens, M. (1997) Bayesian Methods for Mixtures of Normal Dis-tributions, Ph.D. Thesis, University of Oxford.
363 Quadratic regression estimation [PosterSession P3 (page 42)]
Mariano RUIZ-ESPEJO , UNED, Madrid, Spain
Housila P. SINGH,Vikram University, India
We introduce the quadratic regression estimator for finite pop-ulation meanY = ∑N
k=1Yk/N, when simple random samplingwith replacement (of a fixed sample sizen) is used as samplingdesign. This estimator is
Y = a01+m11
m20(A10−a10)
+ c
[A20−a20+(A10−a10)
a20a10−a30
m20
],
where
ai j =1n
n
∑k=1
xiky j
k and mi j
=1n
n
∑k=1
(xk−a10)i (yk−a01)
j
are sample moments,
Ai j =1N
N
∑k=1
XikY
jk (andthen,Y = A01)
are finite population moments, and
c =m20(a21−a01a02)−m11(a30−a20a10)
m20(a40−a2
20
)− (a30−a20a10)2 .
The estimatorY generalizes the usual linear regression estima-tor (whenc = 0), and it is based on a best fitted polynomial ofdegree two, which possesses less residual variance than that ofbest fitted polynomial of degree one, for same data.References[1] Cassel, C.M., Särndal, C.E., and Wretman, J.H. (1977)Foundationsof Inference in Survey Sampling,Wiley, New York.[2] Cochran, W.G. (1977)Sampling Techniques, third edition, Wiley,New York.
364 Nonparametric independent compo-nent analysis [Contributed Session C41 (page 45)]
Alexander SAMAROV , UMass-Lowell and MIT, USA
Alexander TSYBAKOV,Université Paris VI, France
We propose a new method of simultaneous estimation of thecomponent directions in the independent component analysis(see, e.g., Hyvarinen, Karhunen, and Oja (2001) or Roberts andEverson (2001)), which does not rely on parametric distribu-tional assumptions on the component distribution. Our methodis based on nonparametric estimation of the average outer prod-uct of the density gradient and on simultaneous diagonalizationof this estimated matrix and the sample covariance matrix of thedata. We show that our estimates converge to the true directionswith the parametricn−1/2 rate. We then use the estimated com-ponent directions to estimate the component densities and showthat they can be estimated at the usual one-dimensional non-parametric rate and that the resulting product estimator of thejoint density has the one-dimensional (optimal) nonparametricrate corresponding to the independent component density withthe worst smoothness.References[1] Hyvarinen, A., Karhunen, J., and Oja, E. (2001)Independent Com-ponent Analysis,J. Wiley and Sons, N.Y.[2] Roberts, S. and Everson, R. (2001)Independent Component Analy-sis: Principles and Practice,Cambridge Univ. Press.
365 Bagging Nearest-Neighbour Classi-fiers [Contributed Session C51 (page 27)]
Richard SAMWORTH University of Cambridge, UK
Peter HALL,Australian National University, Australia
Suppose we have a random sample from anX-population, arandom sample from aY-population, and wish to classify a newdata value,z, as coming from one or other of the populations.The nearest-neighbour classifier assignsz to theX-population ifand only if the nearest sample value tozcomes from theX-data.Breiman (1996) proposed bagging, or bootstrap aggregation, asa means of improving the performance of a classifier. For the

Abstracts 173
bagged nearest-neighbour classifier, the data values are resam-pled, andz is assigned to theX-population if and only if thenearest-neighbour classifier assigns it to theX-population for themajority of resamples.We find that bagging can result in a considerable improvement inperformance, provided the resample size is small in comparisonwith the training samples. Specifically, if the resample size di-verges but is asymptotically negligible compared to the trainingsample sizes, we show that the bagged nearest-neighbour clas-sifier converges to the ideal Bayes classifier. For large samplingfractions there is no asymptotic improvement.References
[1] Hall, P. and Samworth, R. (2004)Properties of bagged nearest-neighbour classifiers, submitted to J. Roy. Statist. Soc., Ser. B.
366 Computationally intensive spectrumestimation methods and non-stationarity
[Contributed Session C47 (page 17)]
Juana SANCHEZ, UCLA, USA
Considerable progress has been made in estimating the spectraldistribution of a stationary time series. New computationally in-tensive methods such as log-spline, ensemble and bootstrap arenow easy to implement. When a time series is non-stationary,however, the user is at the mercy of the controversy on the appro-priate way to make the data stationary so that the spectrum canbe estimated accurately. If, in addition to non-stationarity, thedata present seasonal frequencies that are so dominant that it isvery hard to discern the presence of other frequencies, one has toworry about what to do with those. The nonexistence of a unifiedway to approach the problem of making a non-stationary data setstationary and the problem of dominant frequencies without los-ing information about the data, makes it hard to avoid that con-troversy. In this paper, I build on the latest computationally in-tensive spectrum estimation methodology to explore ways to in-tegrate the spectrum estimation and handling of non-stationarityin a unified framework that retains all the information about thedata while at the same time providing information about otherthan the low non-stationarity frequencies and the seasonal fre-quencies. Several data sets from agriculture, computer science,astronomy and physics are used to illustrate the methods.
367 A look at the gene identification prob-lem from a hypothesis test perspective [Con-tributed Session C40 (page 37)]
Àlex SÁNCHEZ and Mireia VILARDELL, Universitat deBarcelona, Spain
Many gene identification methods assign scores to gene ele-ments –exons in eukaryotes– as a previous step to their assemblyin predicted genes. The scoring system is often based on log–likelihood ratios (LLRs) whose meaning is somehow differentfrom the usual likelihood ratio tests that appear in many statis-tical problems.GeneId(Parra et al. 2000) is an example of aprogram which relies on this approach, although other similarexist.In this work we have tried to give an interpretation of the statis-tical meaning of LLRs–based scoring systems and we have de-veloped several tests of significance for the scores: the "Sum-of-Scores test" (SSt), based on the straightforward score obtainedby the programs, the "Intersection-Union test" (IUt) based ona multiple hypothesis testing interpretation of an exon’s scoreand several meta–analytical approaches which combine p-valuescorresponding to the exon’s parts. We have performed simula-
tion studies to analyze the performance of these tests. WhereasSSt and IUt tests are appealing from the statistical point of viewthe meta–analytic approach has proved to have a much bettersensitivity and specificity which suggests they may be incor-porated in actual gene prediction methods as a complimentary"probabilistic" score.References[1] Guigó, R. (1997) Computational Gene Identification,J. Mol. Med.75, 389–397.[2] Parra G., Blanco E., and Guigó, R. (2000)GeneID in Drosophila,Genome Research, 511-515.
368 Fixed-interval smoother under non-independent uncertainty with white pluscoloured noises [Poster Session P1 (page 22)]
A. HERMOSO-CARAZO, J. LINARES-PÉREZ,SÁNCHEZ-RODRIGUEZ, M. I. , Universidad de Granada, Spain
S. NAKAMORI, Kagoshima University, Japan
There are many practical situations in which the measurementsof a signal are available in every instant of a time fixed-intervaland the aim is to estimate the signal at times inside this intervalusing all the available observations, that is, to obtain the fixed-interval smoothers. Fixed-interval smoothing techniques havebeen widely applied in the resolution of many practical prob-lems when the state-space model of the signal is known (see [1]and [5]). However, in many situations, the state-space modelof the signal is not available and estimation algorithms usinganother type of information, as covariance one, must be used.Some of these studies consider that the signal is always presentin the observations used for its estimation, but there is a largeclass of real situations where the signal appears in the observa-tion in a random manner, such as problems of target tracking,inaccessibility of the data during certain times or fading phe-nomena in propagation channels. In these cases, the optimalapproach to least-squares estimation problems is not practicalfrom a computational viewpoint, because it requires to save aquantity of information that increases exponentially, and subop-timal estimators have been obtained for systems with uncertainobservations by some authors when the state-space of the signalis known, such as in NaNacara and Yaz [4]. On the other hand,the linear fixed-interval smoothing problem has been studied,using covariance information, when the uncertainty is modelledby a sequence of independent Bernoulli random variables andthe observations are perturbed by white plus coloured noises [2]and in the case of non-independent uncertainty, only for the caseof white noise [3].This paper generalizes the previous works by presenting theleast-squares linear filtering and fixed-interval smoothing prob-lems of discrete-time signals from uncertain observations whenthe random interruptions in the observation process are modelledby a sequence of not necessarily independent Bernoulli ran-dom variables and the observation are perturbed by white pluscoloured noises. The proposed filter and fixed-interval smootherdo not require the knowledge of the state-space model generat-ing the signal, but just the second-order moments of the signaland the noises, assuming a semi-degenerate kernel form for theautocovariance functions of the signal and the coloured noise,the probability that the signal exists in the observed values andthe(2,2)-element of the conditional probability matrices of thesequence describing the uncertainty in the observations.References[1] Helmick, R.E., Blair, W.D. and Hoffman, S.A. (1995) Fixed-intervalsmoothing for Markovian switching systems,IEEE Transactions on In-

174 6th BS/ IMSC
formation Theory, vol. 41(6), pp. 1845-1855.[2] Nakamori, S., Caballero, R., Hermoso A. and Linares, J. (1999)Fixed-interval smoothing from uncertain observations with white pluscoloured noises using covariance information,IEICE Trans. Fundamen-tals, in press.[3] Nakamori, S., Caballero, R., Hermoso A. and Linares, J. (2002)Lin-ear recursive estimators using covariance information in discrete-timesystems with independent uncertain observations, Proceedings of Inter-national Symposium on Advanced Control of Industrial Processes, 333-337.[4] Nakamori, S., Caballero, R., Hermoso A., Linares, J. and SánchezM. I. (2003) Fixed-interval smoother with non-independent uncertaintyusing covariance information,Proceedings of the Twelfth IASTED In-ternational Conference on Applied Simulation and Modelling, pp. 399-404.[5] NaNacara, W. and Yaz, E. E. (1997) Recursive estimator for linearand nonlinear systems with uncertain observations,Signal Processing,vol. 62, pp. 215-228.[6] Weinert, H. L. (2001)Fixed-interval smoothing for state-space mod-els, Kluwer Academic Publishers, Boston.
369 Error bounds for ruin probabilities viaSteklov operators [Contributed Session M2 (page 41)]
José A. ADELL and C. SANGÜESA, Universidad deZaragoza, Spain
In this work, we obtain an expression for the probability of non-ruin in the classical risk model with discrete independent claimamounts. This expression is given in terms of Steklov opera-tors, which are well-known in approximation theory and, from aprobabilistic point of view, are defined in terms of convolutionsof uniform random variables. Their approximation propertiesallow us to give sharp error bounds between the ruin probabil-ity and a suitable approximation of this one by means of a dis-cretization of the record lows. These error bounds are given interms of appropriate moduli of smoothness applied to the distri-bution functions of the aggregate claim amounts.
370 Hölder-Sobolev properties of the solu-tion of the stochastic wave equation in spatialdimension three [Contributed Session C12 (page 25)]
R.C. DALANG, EPFL, Switzerland
M. SANZ-SOLÉ , Universitat de Barcelona, Spain
We shall report on recent results on path properties of the solu-tion of the stochastic partial differential equation
( ∂ 2
∂ t2 −∆3
)u(t,x) = σ
(u(t,x)
)F(t,x)+b
(u(t,x)
), (1)
with initial conditionsu(0,x) = v0(x), ∂u∂ t (0,x) = v0(x), where
(t,x) ∈ [0,T]×R3; ∆3 denotes the Laplacian operator onR3 andF is a Gaussian noise white in time and correlated in space withspectral correlation given byµ(dξ ) = ϕ(ξ )|ξ |3−β , β ∈ (0,2),whereϕ(ξ ) is a regular function.We prove that, uniformly with respect tot ∈ [0,T],the solution of(1) is a random vector taking values in some fractional Sobolevspace of arbitrary integration order and, uniformly with respectto x on bounded sets, the solution isγ-Hölder continuous int.By virtue of Sobolev imbeddings this yields joint(α,γ)-Höldercontinuity in (x, t)). In the case wherev0 and v0 are smooth,
α ∈ (0, 2−β2 ) andγ ∈ (0, inf( 1
2 , 2−β2 )).
Applying of specific techniques of Gaussian processes, our re-sults are proved to be optimal.We give a rigourous formulation of equation (1) be means of astochastic integral for non stationary stochastic processes whichallows distribution-valued integrands, as has been developed in
[1].References[1] Dalang, R.C. and Mueller, C. (2003)Some non-linear SPDE’s thatare second order in time, Electron. J. Probab.8, 21.[2] Dalang, R.C. and Sanz-Solé, M. (2004) Hölder-Sobolev regularity ofthe solutions of a stochastic wave equation in spatial dimension three, Inpreparation.
371 Some classes of multivariate infinitelydivisible distributions related to the mappingof Barndorff-Nielsen and Thorbjørnsen [Con-tributed Session C13 (page 45)]
Ole E. BARNDORFF-NIELSEN,University of Aarhus, Den-mark
Makoto MAEJIMA, Keio University, Japan
Ken-iti SATO , Nagoya, Japan
Barndorff-Nielsen and Thorbjørnsen [1], [2] introduced a map-ping ϒ from ID(R), the class of infinitely divisible distributionson R, into ID(R) in relation to the Bercovici–Pata bijection be-tween the free infinite divisibility and the classical infinite divis-ibility. They show that
ϒ(µ) = L
(∫ 1
0log
1t
dX(µ)t
), (1)
whereX(µ)t is the Lévy process withL (X(µ)
1 ) = µ andL
stands for “distribution of". Now, lettingµ ∈ ID(Rd), we defineϒ(µ) ∈ ID(Rd) by the same formula (1). We study the total im-ageϒ(ID(Rd)) and the imageϒ(L(Rd)) of the classL(Rd) ofselfdecomposable distributions onRd.Thorin [4] introduced the class of generalizedΓ-convolutions on[0,∞) and [5] extended it to a class of distributions onR. Bon-desson [3] studied the class of generalized convolutions of mix-tures of exponential distributions. We define multidimensionalanalogues of these classes in terms of Lévy measures. Letν(µ)
be the Lévy measure ofµ ∈ ID(Rd). Decomposeν(µ) as
ν(µ)(B) =∫
Sλ (dξ )
∫ ∞
01B(rξ )νξ (dr),
whereλ is a measure on the unit sphereS in Rd and νξ aremeasures on(0,∞) measurable with respect toξ ∈ S.
Definition. Let T(Rd) be the class ofµ ∈ ID(Rd) such thatνξ (dr) = r−1kξ (r)dr with kξ (r) completely monotone. Let
B(Rd) be the class ofµ ∈ ID(Rd) such thatνξ (dr) = lξ (r)drwith lξ (r) completely monotone. (Arbitrary Gaussian part andlocation are admitted.)
Theorem 1.ϒ(ID(Rd)) = B(Rd) andϒ(L(Rd)) = T(Rd).
Another characterization of these classes is as follows.
Definition. Call Ux an elementaryΓ-variable in Rd (resp.el-ementary mixture of exponential variables inRd) if x is a non-random nonzero vector inRd andU is a realΓ-distributed ran-dom variable (resp. a real random variable whose distribution isa mixture of a finite number of exponential distributions).
Theorem 2. The classT(Rd) (resp.B(Rd)) is the smallestclass of distributions onRd closed under convolution and con-vergence and containing the distributions of all elementaryΓ-variables (resp. all elementary mixtures of exponential variables)in Rd.
Let Φ(µ) = L(∫ ∞
0 e−tdX(µ)t
)for µ ∈ ID(Rd) with∫
|x|>1 log|x|µ(dx) < ∞. It is known that the image of this map-

Abstracts 175
ping Φ coincides withL(Rd). We show thatϒ andΦ commuteand expressϒΦ by a stochastic integral.References[1] Barndorff-Nielsen, O.E. and Thorbjørnsen, S. (2002)Proc. Nat.Acad. Sci. USA99, 16568–16575.[2] Barndorff-Nielsen, O.E. and Thorbjørnsen, S. (2002)Proc. Nat.Acad. Sci. USA99, 16576–16580.[3] Bondesson, L. (1981)Zeit. Wahrsch. Verw. Gebiete57, 39–71.[4] Thorin, O. (1977)Scand. Actuarial J.31–40.[5] Thorin O. (1978)Scand. Actuarial J.141–149.
372 Two-level analysis of structural equa-tion models for longitudinal data [ContributedSession M8 (page 31)]
Juan Carlos BOU,Universitat Jaume I, Spain
Albert SATORRA , Universitat Pompeu Fabra, Spain
Anderson and Hsiao’s State-Dependence model (1982) for paneldata is extended to the context of two-level data, where we haverandom effects with a dynamic structure both for the first andtwo-level units. ML estimation and inferences for this gen-eral model is considered, as well as its practical implementa-tion using current software for covariance structure analysis.The comparison of the ML approach with alternatives basedon weighted-least square estimation of two-level moment struc-tures, and statistics for goodness-of-fit testing, receives specialattention. An illustration using data of returns of assets (ROA)of firms, classified in industries (second level units), is provided.
References
[1]Anderson, T. and Hsiao, C. (1982) Estimation of dynamic modelsusing panel data,Journal of Econometrics18, 47–82.
373 Small time behavior of the criticalstock price for the american put on alterna-tive stochastic processes[Contributed Session M3(page 34)]
John CHADAM andDavid SAUNDERS, University of Pitts-burgh, USA
We present a mathematical analysis of the critical stock price ofthe American put option on a stochastic process other than ge-ometric Brownian motion. Examples include the constant elas-ticity of variance (CEV) model, and a class of jump diffusions.Consider a stock whose value follows the stochastic processSt
(which could be a diffusion process or a jump diffusion). AnAmerican put option pays its holder(K−Sτ )+ if it is exercisedat a timeτ ∈ [0,T], to be chosen at the discretion of the optionholder. A fair price for the option at timet is given by:
p(t,S) = supτ∈T[t,T]EQ[e−r(τ−t)(K−Sτ ) | St = S] (1)
wherer is the risk-free interest rate,T[t,T] is the set of all stop-ping times with values in[t,T], andQ is a probability measuremakinge−rt St a martingale. There is a continuous increasingfunction b(t) such that it is optimal for an investor holding theput option to exercise at timet if St ≤ b(t) and to continue hold-ing the option otherwise, see Jacka (1991) and Pham (1997).Understanding the behavior ofb(t), particularly for t close toT, is an important problem in financial mathematics. Barles etal. (1995) showed that ifSt is geometric Brownian motion, fortnearT it holds that:
K−b(t)K
∼ σ√−(T− t) log(T− t) (2)
Chen and Chadam (2000,2003) (independently using techniquessimilar to those in Goodman and Ostrov (2002)) derived ac-
curate higher order approximationsb(t) = K · exp(−2√
T− t ·√α(T− t)) with
α(T− t) =−ξ2− 1
ξ+
12ξ 2 +
173ξ 3 −
514x4 −·· · (3)
where ξ = log(4πγ2(T − t)) and γ = 2rσ2 . Chen and
Chadam (2000) also provide an efficient method of calculatingb(t) at all times by solving an integro-differential equation. Forjump diffusions it is only known that (2) holds, see Pham (1998).Little is known about the behavior of the boundary for diffusionsother than geometric Brownian motion.We extend the results of Chen and Chadam (2000,2003) in orderto derive accurate higher order expansions for the critical stockpriceb(t) near expiry in the case whereSt is a diffusion processwith nonlinear diffusion coefficient, or a jump diffusion. Meth-ods for computing the boundary at all times are also discussed.References[1] Barles, G., Burdeau, J., Romano, M., and Samsœn, N. (1995) CriticalStock Price Near Expiration.Mathematical Finance5, 77–95.[2] Chen, X. and Chadam, J. (2000) A Mathematical Analysis for theOptimal Exercise Boundary of the American Put Option, submitted toSIAM Journal of Mathematical Analysis.[3] Chen, X. and Chadam, J.(2003) Analytical and Numerical Approx-imations for the Early Exercise Boundary for American Put Options.Dynamics of Continuous, Discrete and Impulsive Systems10, 649–660.[4] Goodman, J. and Ostrov, D. (2002) On the Early Exercise Boundaryof the American Put Option.SIAM Journal of Applied Mathematics62,1823–1835.[5] Jacka, S. (1991) Optimal Stopping and the American Put,Mathemat-ical Finance1, 1–14.[6] Pham, H. (1997) Optimal Stopping, Free Boundary and AmericanOption in a Jump-Diffusion Model.Applied Mathematics & Optimiza-tion 35, 145–164.
374 Modeling the dependence between se-quence motifs [Invited Session 6 (page 23)]
Gaelle GUSTO andSophie SCHBATH, Institut National de laRecherche Agronomique, France
The study of word occurrences along DNA sequences is a clas-sical problem in statistical analysis of genomes. It concerns, forexample, the frequence of a word or the distance between wordoccurrences (see [3] for an overview). Our objective is to modelthe dependence between one or two word occurrences along asequence in order to detect possible correlations. These corre-lations can reveal a common biological process in which bothwords are involved and a possible protein interaction. Proteininteraction can indeed impose some constraints on the space be-tween particular words.Our statistical method consists in estimating the intensity ofthe point process(Ui)i=1,...,I composed of the ordered positionsof the I occurrences of a wordu along a sequence. We usethe Hawkes model (mixed doubly stochastic Poisson and self-exciting process): the intensity depends linearly on the distancesto the previous occurrences ofu and another wordv. This modelis classically used to model earthquake events [2]. Our aim isto estimate the two functions that specify the favored or avoideddistances between word occurrences. We assume these func-tions to be linear combinations ofB-splines and we estimate theparameters by maximizing the likelihood under the constraintthat the intensity is positive. When considering the knots equallydistributed for theB-splines, we use the AIC criterion in orderto choose the number of knots. We are studying other meth-ods to penalize the likelihood function depending on the modeldimension [1].

176 6th BS/ IMSC
We will present simulation results and real biological examples.
References[1] Birgé, L. and Massart, P. (1997) From model selection to adaptativeestimation,Festschrift for Lucien Le Cam, 55–87, Springer, New York.[2] Ogata, Y. and Akaike, H. (1982) On linear intensity models for mixeddoubly stochastic Poisson and self-exciting processes,J. R. Statist. Soc.B 44, 102–107.[3] Reinert, G., Schbath, S., and Waterman, M. (2000) Probabilistic andstatistical properties of words: an overview.J. Comp. Biol.7, 1–46.
375 Tests of fit for parametric families ofCopulas application to financial data [PosterSession P1 (page 22)]
J. DOBRIC andF. SCHMID , Universitaet zu Koeln, Germany
We suggest a Chi-Square test of fit for parametric families obivariate Copulas. Marginal distributions are assumed to beunknown and treated as nuisance parameters. Using the em-pirical distribution functions for the margins instead of the un-known true distribution functions results in an unknown asymp-totic distribution of the test statistic which differs from thestandard case. Simulations show that aχ2-distribution withd f = (r − 1)(s− 1)− 1 = rs− r − s degrees of freedom is areasonable approximation, wherers is the number of rectanglesinto which [0,1]2 is partitioned. It is further shown that the testhas power against alternative families of Copulas. An empiri-cal application to 8 German asset returns shows, that a gaussianCopula is totally unsatisfactory. At-Copula with 3 or 4 degreesof freedom performs better, but not satisfactorily.References[1] Breymann, W., Dias, A., and Embrechts, P. (2003)DependenceStructures for Multivariate High-Frequency Data in Finance. Quanti-tative Finance 3 No.1[2] Greenwood, P.E. and Nikulin, M.S. (1996)A Guide to Chi-SquaredTesting,Wiley, New York.[3] Joe, H. (1997). Multivariate Models and Dependence Concepts,Chapman & Hall, London.[4] Junker, M. and May, A. (2002). Measurement of Aggregate Risk withCopulas,Caesar Preprint, Bonn.[5] Malevergne, Y. and Sornette, D. (2001)Testing the Gaussian Cop-ula Hypothesis for Financial Asset Dependences,Economics WorkingPaper Archive at WUSTL.[6] Mari, D.D. and Kotz, S. (2001)Correlation and Dependence Con-cepts,Imperial college Press, London.[7] Nelsen, R.B. (1999)An Introduction to Copulas, Lecture Notes inStatistics 139, Springer-Verlag, New York.
376 Bayesian shape matching and proteinstructure alignment [Contributed Session C56 (page47)]
Scott C. SCHMIDLER , Duke University, USA
A key challenge in bioinformatics and computational biologyis to understand the function and mechanism of proteins at thelevel of 3D atomic structure. One problem which arises often isthe need toalign two or more protein structures, in order to studyconservation and variability in protein families, define evolu-tionary distances between homologous structures, search struc-tural databases for similar folds, analyze simulations, or performclustering or classification of structures.We introduce a statistical framework for modeling and align-ment of protein structures based on techniques adapted from sta-tistical shape analysis. We develop novel Bayesian approachesto several problems in statistical shape analysis including land-mark matching, registration, and estimation of mean shape.Bayesian pairwise alignment:Let X denote ann×3 matrix of
landmark coordinatesxi ∈ R3 identified on the source object(protein structure, image, shape, etc.), and similarly letY be a setof m landmarks identified on the target object. Typical choicesfor landmarks in aligning protein structures are the 3D coordi-nates of theCα backbone atoms.We define an alignment as a pair(A,θ), whereA = (ai j ) is ann×malignment matrix withai j = 1 if Xi is matched withYj andai j = 0 otherwise. andθ are parameters of a registration trans-formationT(X;θ). For rigid-body transformationsθ = (µ ,R)whereµ ∈ R3 is a translation andR∈ SO(3) is an orthogonalrotation. Bayesian inference of alignments proceeds by obtain-ing the posterior distribution over all possible alignments via:
P(A,θ | X1,X2) =P(X1,X2 | A,θ)P(A,θ)
P(X1,X2)(1)
where
P(X1,X2) = ∑A
∫
θP(X1,X2 | A,θ)P(A,θ)
Several classes of prior distributions over alignment matricesP(A) are discussed, includinggap penalty-based methods, pri-ors on bipartite matchings, and more expressive priors. Foreach, algorithms for findingmaximum a posteriorialignmentsand for sampling from the posterior (1) are provided, using dy-namic programming, combinatorial matching, and reversible-jump Markov chain Monte Carlo (MCMC) methods.Bayesian multiple alignment:The multiple structure alignmentproblem involves the simultaneous alignment of a set ofk pro-tein structuresX1,X2, . . . ,Xk. We extend our previous work onmultiple alignment by estimation of mean shape [1]:
X = argminm
∑j=1
∥∥∥(X jRj + µ j )− X∥∥∥
2(2)
to include Bayesian approaches to landmark matching via (1)and Bayesian estimation of mean shape.Bayesian flexible alignment:We extend the Bayesian pairwiseand multiple alignment approaches to handle the difficult prob-lem offlexiblestructure alignment [2], using flexible transforma-tions estimated by Bayesian changepoint analysis. We demon-strate these methods on several examples of real protein familiesand database matches.References[1] Wu, T.D., Schmidler, S.C., Hastie, T., and Brutlag, D.L. (1998) Re-gression analysis of multiple protein structures.J. Comp. Biol.5, 597–607.[2] Schmidler, S.C. (2004)A Bayesian approach to flexible proteinstructure alignment, (submitted).
377 Applications of coalescents with multi-ple collisions [Invited Session 11 (page 43)]
Jason SCHWEINSBERG, University of California at SanDiego, USA
Coalescents with multiple collisions are coalescent processeswith the property that many clusters can merge at once into asingle cluster. We will explain how these coalescent process canbe used to describe the genealogy of populations in which therecan be very large families, such as when the offspring distribu-tion has infinite variance. We will also discuss how coalescentswith multiple collisions can be used to represent the genealogyof continuous-state branching processes.

Abstracts 177
378 Statistical modeling of digraph paneldata with random coefficients for the vertices
[Contributed Session C19 (page 30)]
M. SCHWEINBERGER and Tom A.B. SNIJDERS,Univer-sity of Groningen, the Netherlands
A popular approach to model digraph panel data is to embedthe discrete observations of the digraph into an unobserved con-tinuous time Markov process. An appealing and large familyof Markovian probability distributions was considered by [1].The infinitesimal generator of the Markov process is parameter-ized by multinomial logit modeling as advocated by [2]. The di-graph evolution is modeled as vertex-driven, by vertices makingchoices regarding arcs to other vertices, and the choice proba-bilities depend on an objective function. The objective functionis modeled as linear in an unknown parameterθ , andθ capturesrelational tendencies (patterns) such as reciprocity or transitiv-ity. Convenient distributional assumptions lead to a multinomiallogit form of the choice probabilities.The present paper builds upon, and extends, the mentioned fam-ily of probability distributions. The objective function lying atthe heart of the multinomial logit formulation is modeled as lin-ear function where some parameter coordinatesθk are treatedas random coefficients that can be predicted by covariates. Thevalue of the approach lies in the fact that vertex heterogeneitycan be modeled parsimoniously, that is, the number of parame-ter coordinates needs not to increase with the number of vertices.This implies that (1) the dangers of vertex-dependent parame-ter spaces (bad estimators and numerical problems) are reduced,and (2) covariates can be used to explain vertex-dependentpredilections regarding, for instance, reciprocity or transitivity.The maximum likelihood method is proposed to estimate theunknown parameterη ("fixed coefficient") and the unknown co-variance matrix of the random coefficients from digraph paneldata. As the continuous time Markov process is unobserved, thelikelihood function cannot be written in closed form, but max-imum likelihood estimates can be obtained by augmenting theobserved data with latent data using MCMC methods.References[1] Snijders, T.A.B. (2001) The Statistical Evaluation of Social NetworkDynamics,Sociological Methodology31, 361–395.[2] McFadden, D. (1974)Conditional Logit Analysis of QualitativeChoice Behavior, In: Zarembka, P.Frontiers in Econometrics, NewYork: Academic Press, 105–142.
379 Metastability in conservative dynam-ics [Poster Session P2 (page 32)]
Elisabetta SCOPPOLA, Dipartimento di Matematica, Univer-sità di Roma Tre,Italy
We review results on metastability following the pathwise ap-proach. This is actually the most natural probabilistic approachto describe the physical metastability problem expecially as faras the nucleation pattern is concerned.We first discuss the simplest case of a reversible Markov chainwith finite state spaceX . More precisely we consider the longtime behavior of a Markov chain with transition probabilities:
P(η ,η ′) = q(η ,η ′)e−β [H(η ′)−H(η)]+
for given energy functionH and symmetric Markov kernelq.We will denote byση0
t the Markov chain at timet ∈ N startingfrom η0 at t = 0.In this context, the problem of metastability is the study of thefirst arrival of the processση0
t to the stable stateηs, correspond-
ing to the absolute minimum ofH, (or to the setX s of absoluteminima ofH) when starting from an initial local minimumη0.Local minima can be ordered in terms of their increasingstabil-ity leveli.e., the height of the barrier separating them from lowerenergy states. A particularly relevant case is whenη0 turns outto be in the setX m of local minima of maximal stability inX \X s, also called set of “metastable states". This is the mosttypical metastability problem. The first hitting time toX s ofthe processση0
t starting fromη0 is calledtunnelling time.There are, mainly, two different aspects in the problem of thedecay fromη0 to X s:
1. The asymptotic behavior for largeβ of the tunnellingtime;
2. The tube of typical paths realizing the tunnelling i.e., theminimal tube of paths going for the first time fromη0 toX s, still having a probability exponentially close to one.
An easier version of this second problem on the typical paths isthe study of thegate, that is of the saddle configurations (con-figurations of maximal energy) that are visited by the paths real-izing the tunneling with probability exponentially close to one.We will give a short survey of general, i.e., model independentresults on these problems starting from the Freidlin Wentzelltheory (see [1]).We will apply the general theory to cases of conservative dy-namics for lattice gas systems (see for example [2]). Indeed inthe conservative case there is an high degeneracy of the energylandscape so that the general theory is not applicable directly,since the needed detailed control on the specific Markov chainis too difficult to obtain.Finally we will discuss the more difficult problem of metastabil-ity in volumes exponentially large inβ (see [3] for a simplifiedmodel).The talk is based on collaborations with:F. den Hollander, A.Gaudilliére, F.Manzo, F.Nardi, E.Olivieri,...References[1] Manzo, F., Nardi, F., Olivieri, E., and Scoppola, E. (2004) On theEssential Features of Metastability: Tunnelling Time and Critical Con-figurations ,J. Stat. Phys.115, 591–642.[2] den Hollander, F., Nardi, F., Olivieri, E., and Scoppola, E. (2003)Droplet growth for three-dimensional Kawasaki dynamics ,PTRF125,153–194.[3] den Hollander, F., Olivieri, E., and Scoppola, E. (2000) Metastabilityand nucleation for conservative dynamics ,J. Math. Phys.41, 1424–1498
380 Data mining by skewering a data cloud[Contributed Session C55 (page 21)]
David W. SCOTT, Rice University, USA
Clusteringp-dimensional data by fitting a mixture ofK normalshas enjoyed renewed interest (see, for example, the Splus func-tion mclust [1]). However, the number of parameters for themodel grows rapidly with dimensionp. Even if all the covari-ance matrices are assumed to be equal, the number of parame-ters is(K− 1) + K p+ p(p+ 1)/2 for the weights, means andcovariance matrix. Scott [2] introduced the partial mixture com-ponent algorithm which fits a single component of the mixturemodel at a time. This algorithm requires only1+ p+ p(p+1)/2parameters for the weight, mean vector, and covariance matrix.In this talk, we introduce a new algorithm which attempts tofind the “best line” through an individual cluster. This modelrequires only2p parameters. In particular, the new algorithm islinear rather than quadratic inp. By repeatedly re-initializing the

178 6th BS/ IMSC
search algorithm, many clusters may be identified. Intuitively,the line found is approximately the eigenvector correspondingto the largest eigenvalue of the local covariance matrix. TheGGobi visualization program will be used to illustratethe success of this algorithm on real and simulated data.References[1] Banfield, J.D. and Raftery, A.E. (1993) “Model-Based Gaussian andNon-Gaussian Clustering,”Biometrics49, 803–822.[2] Scott, D.W. (2001) “Parametric Statistical Modeling by MinimumIntegrated Square Error,”Technometrics43, 274–285.z
381 Extremes of deterministic sub-sampled processes [Contributed Session C59 (page48)]
Manuel G. SCOTTO, University of Aveiro, Portugal
The analysis of the impact of sampling frequency on the extremevalues of a process is a rapidly developing subject and it has beena topic if active research over the last years. This is importantsince although time series observations are made available atsome given equal time interval, the process could be observedat one sampling frequency but interest is in its behavior at adifferent frequency. Motivation comes, mainly, for the desireof comparison of schemes for monitoring a variety of financeand environmental data sets. The consequences of systematicsub-sampling, i.e., sub-sequences obtained from the originaltime series by sub-sampling every fixedM time intervals, on theextremal properties of time series were first studied by Robin-son and Tawn [2]. Scotto et al. [5] have report some alternativelimit results for linear time series models driven by heavy-tailedinnovations. Scotto and Turkman [3] derived more general re-sults for systematic sub-sampled time series represented viastochastic difference equations. More recently, Hall and Scotto[1] have analyzed the impact of systematic sub-sampling on theextremal properties of integer-valued sequences, namely non-negative integer-valued moving averages with regularly varyingtails. Often, however, there are many situations which can not behandled through a systematic sub-sampled approach. Examplesare encountered in the analysis of foreign exchange marketssince volatility patterns are likely to occur at the overlappingbusiness hours of the main market centers in the world beingthe most active period on the afternoon when the European andAmerican markets are open simultaneously. What the above ex-ample show is that when the relationship between the extremesof the original process and those of the sub-sampled sequenceis of interest, it seems reasonable to sub-sample the process byblocks, instead of considering systematic sub-sampling. Thisissue was treated in detail by Scotto and Ferreira [4].Formally, the problem considered in this work is as follows: letXkk≥1 be a stationary process of the form
Xk =∞
∑j=1
(j−1
∏s=1
Ak−s
)Bk− j , (1)
where Ak,Bk are i.i.d R2+-valued random pairs with some
given joint distribution andX0 is independent of these, withsome given starting distribution. For a class of strictly in-creasing deterministic sampling functionsg : N → N, such asg(k+ I) = g(k)+M, k≥ I , 1≤ I ≤M, where[·] represents theinteger part, defineYk = Xg(k), k ≥ k0, for a fixed k0 ≥ 1, asthe deterministic sub-sampled time series. The question we putforward is: how the extremes of the deterministic sub-sampledprocessYk should behave when theXk is represented through
equation (1).References[1] Hall, A. and Scotto, M.G. (2003) Extremes of sub-sampled integer-valued moving average models with heavy-tailed innovations,Statist.Probab. Lett.63, 97–105.[2] Robinson, M.E. and Tawn, J.A. (2000) Extremal analysis of pro-cesses sampled at different frequencies,J. Roy. Statist. Soc. B62,117–135.[3] Scotto, M.G. and Turkman, K.F. (2002) On the extremal behaviorof sub-sampled solutions of stochastic difference equations,Portugal.Math. 59, 267–282.[4] Scotto, M.G. and Ferreira, H. (2003) Extreme of deterministic sub-sampled moving averages with heavy-tailed innovations,Appl. Stochas-tic Models Bus. Ind.19, 303–313.[5] Scotto, M.G., Turkman, K.F., and Anderson, C.W. (2003) Extremesof some sub-sampled time series,J. Time Ser. Anal.24, 579–590.
382 Asymptotic properties of uniformquantizer for Gaussian processes [ContributedSession C21 (page 50)]
Oleg SELEZNJEV and Mykola SHYKULA,Umeå University,Sweden
Quantization of a continuous signal into discrete form (or dis-cretization of amplitude) is a standard task in all analog/digitaldevices. The oldest example of quantization is rounding off.Quantization is generally less well understood than time sam-pling (or linear approximation). One of the reasons is that itis a nonlinear operation. Ignoring the quantization problem wemay use various linear approximation methods to restore an ini-tial signal with a given accuracy, for example, splines [1],[2].Various quantization problems are considered in the number ofsignal processing papers, [3]. We consider quantization of acontinuous random signal in a probabilistic framework. In orderto demonstrate the general approach, the uniform quantizationof a Gaussian process is studied in more detail. We investigateasymptotic properties of some accuracy characteristics, such asrate and distortion, in terms of correlation structure of the signalwhen quantization cellwidth tends to zero. Some examples andnumerical experiments are discussed.Let X(t), t ∈ [0,T], be a signal observed on[0,T]. For deter-ministic signals the evaluation of necessary capacity of mem-ory for a quantized signal is a complicated task in general. Wedevelop an average case analysis of this problem assuming aprobabilistic model for a signalX. Henceforth, letX(t), t ∈[0,T], be a Gaussian zero mean process with covariance func-tion K(t,s), t,s∈ [0,T], and continuously differentiable samplepaths. For a positiveε, consider the uniform quantization ofthe processX(t), t ∈ [0,T], with an infinite levels’ gridu(ε) =uk,k∈Z := kε,k∈Z and with (uniform) quantizerqε (X) =qε (X(t)) := ε[X(t)/ε]. Denote byrε (X) := rε (X, [0,T]) the to-tal number of quantization points in[0,T] (or random quantiza-tion rate), that is the cumulative number of all crossings of theε-quantization grid. The goal is to investigate the asymptoticbehavior of ratesrε (X) asε → 0 in various convergence modes,specifically, a.s.-convergence and convergence of the first andthe second moments. Let the derivatives of random processes bein mean square. Denote by
r0(X) :=∫ T
0
∣∣X(1)(t)∣∣dt
the variation ofX(t), t ∈ [0,T].
Theorem 1.Let X(t), t ∈ [0,T], be a zero mean Gaussian process with sec-ond continuous derivative. Then

Abstracts 179
(i) εrε (X)→r0(X)(a.s.) asε → 0;(ii) εrε (X)→r0(X)(in mean) asε → 0.(iii) If X has third continuous derivative, thenεrε (X)→r0(X)(in mean square) asε → 0.In particular,
εErε (X)→ E∫ T
0
∣∣X(1)(t)∣∣dt
=√
2/π∫ T
0
√K11(t, t)dt asε → 0,
whereK11(t,s) = ∂ 2K(t,s)/∂ t∂s.References[1] Seleznjev, O. (2000) Spline approximation of random processes anddesign problems.Jour. Stat. Plan. Infer.84, 249–262.[2] Hüsler, J., Piterbarg, V., and Seleznjev, O. (2003) On convergenceof the uniform norms for Gaussian processes and linear approximationproblems,Ann. Appl. Probab.13, 1615–1653.[3] Gray, R.M. and Neuhoff, D.L. (1993) Quantization,IEEE Trans.Inform. Theor.44, 2325–2383.
383 A “missing-plot" technique forgoodness-of-fit tests with censored data[Con-tributed Session C22 (page 40)]
Arusharka SEN, Concordia University, Canada
Let X1, . . . ,Xn be i.i.d. observations with distribution func-tion (d.f.) F, and suppose the observations are at risk ofsome kind of censoring. We want to test the hypothesisH0 : F = F0, where F0 is a specified d.f.. From a non-parametric point of view, the most crucial problem caused bycensoring is that we can no longer determine the empirical d.f.Fn(·) = n−1 ∑n
i=11Xi ≤ ·. In this talk, we propose a generalscheme of ‘reconstructing’ the empirical d.f., under various cen-soring mechanisms, by imputing values, of the censored obser-vations, that minimize the Kolmogorov-Smirnov (K-S) distance||Fn−F0||= supx |Fn(x)−F0(x)|. The reconstructed K-S statis-tic may then be used to testH0. We illustrate our method for afew well-known censoring mechanisms, e.g., Type-I, Type-II,Random Censoring, Interval Censoring (Case-1) etc. We thendiscuss the problem of obtaining the null distribution of the test-statistic in some of these models. Problems for further research,including extension to the two-sample problem, will also beindicated.
384 Smooth estimation of mean residuallife under random censoring [Contributed SessionC27 (page 36)]
Yogendra P. CHAUBEY,Arusharka SEN, Concordia Univer-sity, Canada
The methodology developed in Chaubey et al (2003), general-izing the idea of Chaubey and Sen (1996), is adapted here forsmooth estimation of mean residual life under random censor-ing. A modified weighting scheme is proposed, as in Chaubeyand Sen (1999), which is different from the one based on Hille’stheorem in Chaubey and Sen (1996). Asymptotic properties ofthe resulting estimator are investigated.References[1] Chaubey, Y.P., Sen, P.K. (1996) On smooth estimation of survivaland density functions.Statist. Decisions14, 1–22.[2] Chaubey, Y.P., Sen, P.K. (1999) On smooth estimation of mean resid-ual life. J. Statist. Plann. Inference75, 223–236.[3] Chaubey, Y.P., Sen, A., and Sen, P.K. (2003) A new smooth densityestimator for non-negative random variables, submitted.
385 Analytical pricing of double-barrieroptions under a double-exponential jump dif-fusion process [Contributed Session M3 (page 34)]
Artur SEPP , University of Tartu, Estonia
We derive explicit formulas for pricing double (single) barrierand touch options with time-dependent rebates assuming that theasset price follows a double-exponential jump diffusion process.The problem of pricing exotic options consistent with the volatil-ity smile has been attracting much attention in financial studies.Various models have been proposed to explain the smile. Kou(2002) proposed a double exponential jump diffusion. It turnsout that this jump diffusion has a few appealing features whichallow analytical pricing of barrier options. Significant papers inthis direction include those of Kou&Wang (2001, 2004), whoworked out formulas for the distribution of the first exit timeand single barrier options using memoryless property of the ex-ponential distribution, and Lipton (2002), who derived pricingformulas for single barrier options relying on fluctuation identi-ties. Sepp (2004) develops an alternative approach to the pricingproblem of barrier options and derives explicit pricing formulasfor double-barrier and double-touch options with rebates undera double-exponential jump diffusion process.Assuming risk-neutrality, the value of a barrier option satis-fies the generalized Black-Scholes equation with the appropri-ate boundary conditions. We take the Laplace transform of thisequation in time and solve it explicitly. Option price and riskparameters are computed via the numerical inversion of the cor-responding solution. Numerical examples reveal that the pricingformulas are easy to implement and they result in accurate pricesand risk parameters. Proposed formulas allow fast computing ofsmile-consistent prices of barrier and touch options.References[1] Kou, S. (2002) A jump diffusion model for option pricing,Manage-ment Science48, 1086–1101.[2] Kou, S. and Wang, H. (2003) First passage times of a jump diffusionprocess,Adv. Appl. Probab.35, 504–531.[3] Kou, S. and Wang, H. (2004)Option Pricing under a Jump DiffusionModel, Management Sciences, forthcoming.[4] Lipton, A. (2002)Assets with Jumps, Risk, September, 149–153.[5] Sepp, A. (2004)Analytical Pricing of Double-Barrier Options undera Double-Exponential Jump Diffusion Process: Applications of LaplaceTransform, International Journal of Theoretical and Applied Finance,forthcoming, 23.
386 Estimation in discrete parameter mod-els [Poster Session P3 (page 42)]
Christine CHOIRAT andRaffaello SERI, Università degli Studidell’Insubria, Italy
In some estimation problems, especially in applications dealingwith information theory, signal processing and biology, theoryprovides us with additional information allowing us to restrictthe parameter space to a finite number of points. In this case, wespeak of discrete parameter models.Discrete parameter models arise in approximate inference in Au-tomatic Control (Baram and Sandell, 1978a, b), stochastic ap-proximations of Integer Programming and Discrete Optimiza-tion problems (van der Vlerk, 2001), detection and multihypoth-esis testing in Statistical Processing (Hero, 1997) and some Ge-netics problems (Hammersley, 1950, p. 236), but the interest inthis class of models is above all theoretic. Even though the prob-lem is quite old and has interesting connections with testing andmodel selection, asymptotic theory for these models has hardlyever been studied after the seminal paper of Hammersley (1950).

180 6th BS/ IMSC
Therefore, we discuss consistency, asymptotic distribution the-ory, information inequalities and their relations with efficiencyand superefficiency for a general class ofm−estimators. In par-ticular, we derive some approximations to the asymptotic distri-bution of the estimators using exact asymptotics for large devi-ations (Ney, 1983, 1984, Iltis, 1995) and saddlepoint approxi-mations. After deriving a classical and a minimax informationinequality, we tackle the problems of efficiency and supereffi-ciency. Indeed, an interesting feature of these models is thatseveral definitions of efficiency and superefficiency arise quitenaturally and this makes the analysis much more complex thanin standard models; this sheds some light on the same topics inthe classical case.Then, we extend some of the previous results to other classes ofestimators.References[1] Baram, Y. and Sandell, N.R. Jr. (1978a) An information theoretic ap-proach to dynamical systems modeling and identification,IEEE Trans-actions on Automatic Control23, 61–66.[2] Baram, Y. and Sandell, N.R. Jr. (1978b) Consistent estimation onfinite parameter sets with application to linear systems identification,IEEE Transactions on Automatic Control23, 451–454.[3] Hammersley, J.M. (1950) On estimating restricted parameters,Jour-nal of the Royal Statistical Society, Series B12, 192–240.[4] Hero, A. (1971) Signal detection and classification, inDigital Sig-nal Processing (DSP) Handbook, edited by V.K. Madisetti and D.B.Williams, CRC Press/IEEE Press.[5] Iltis, M. (1995) Sharp asymptotics of large deviations inRd, Journalof Theoretical Probability8, 501–522.[6] Ney, P.E. (1983) Dominating points and asymptotics of large devia-tions for random walk onRd, Annals of Probability11, 158–167.[7] Ney, P.E. (1984) Convexity and large deviations,Annals of Probabil-ity 12, 903–906.[8] van der Vlerk, M.H. (2001)Stochastic Integer Programming Bibli-ography, World Wide Web,http://mally.eco.rug.nl/biblio/stoprog.html.
387 Model selection and likelihood ratios[Poster Session P3 (page 42)]
Christine CHOIRAT andRaffaello SERI , Università degliStudi dell’Insubria, Italy
The aim of this paper is to give a theoretical foundation to somewidely used model selection procedures.The first step is to define a lexicographic weak preference rela-tion on the class of statistical models under scrutiny: modelAis weakly preferred to modelB if its limit loglikelihood (whenn = ∞) is greater than the one of modelB or if it is equal but themodel is more parsimonious in terms of parameters. We definethe true modelas the majorant of this relation out of the collec-tion of models under scrutiny.Unfortunately, onlyn observations are available and thereforethis preference relation can only be approximated by amodelselection procedure(MSP). We say that a MSP isconsistentif itchooses the true model out of a collection with probability oneandconservativeif it chooses with probability one a model withhigher limit loglikelihood than the true one.At present, nothing guarantees that model selection can be re-duced to pairwise comparison of statistical models, that is thatthe MSP is arelation. Then, under an hypothesis ensuring ratio-nality of the MSP (equivalent to absence of rank reversal as de-fined in Mathematical Psychology), we are able to reduce modelselection to pairwise choice of models. This result is the ra-tionale for considering MSPs based on penalized loglikelihood(Schwarz, 1984) or on likelihood ratio tests (Vuong, 1989).We can therefore reduce any complex model selection problem
to a series of comparisons beween couples of models. Turning tothe case of MSPs based on penalization, we give necessary andsufficient conditions on the penalization term for an MSP to beconservative or consistent as long as the number of observationsgoes to∞. The results are based on asymptotic expansions andstrong limit theorems for empirical sums andV−statistics, andshow once more that AIC is only conservative, while BIC andHQIC are indeed consistent. It turns out that these conditionsare linked to the asymptotic distribution of the likelihood ratiotests of Vuong (1989), since they exploit the Laws of the IteratedLogarithm associated with these weak limit theorems.References[1] Schwarz, G. (1978) Estimating the dimension of a model,Annals ofStatistics6, 461–464.[2] Vuong, Q.H. (1989) Likelihood ratio tests for model selection andnon-nested hypotheses,Econometrica57, 307–333.
388 Contour lines and altimeter-compassrays of the Gaussian free field [Invited Session 13(page 20)]
Oded SCHRAMM,Microsoft Research, USA
Scott SHEFFIELD, U.C. Berkeley, USA
A hiker holding an analog altimeter (with a needle indicating al-titude modulo a constantχ) in one hand and a compass in theother traces analtimeter-compass ray (ACR) by walking insuch a way that the altimeter and compass needles are alwaysaligned (and thus direction is a linear function of altitude). For-mally, if the terrain is described by a smooth real-valued func-tion h on a planar domain, an ACR is a flow line of one of thecomplex vector fieldse2π i(α+h/χ) (whereα ∈ [0,1) depends onhow the hiker holds the altimeter).Whenh is constant, the ACRs are the rays of Euclidean geom-etry. We show how to constructcontour lines and ACRs whenh is an instance of the (Euclidean, massless, bosonic)Gaus-sian free field. Becauseh is almost surely discontinuous (andnot even defined as a function in the usual sense), parallel raysmay converge, non-parallel rays may “bounce off” one anotherat multiple places (though they still “cross” only once), and(when χ is small enough) rays may circle their starting pointsand bounce off themselves.Individual rays look locally like SLE(κ) whereκ ≤ 4 dependson χ. They also form the boundaries of curves that look likeSLE(κ ′) with κ ′ = 16/κ and can be used to construct confor-mally invariant ensembles of loops calledGaussian loop en-sembles.References[1] Schramm, O. and Sheffield, S. (2003) The harmonic explorer and itsconvergence to SLE(4), math.PR/0310210.[2] Schramm, O. and Sheffield, S. [in preparation] Contour lines of the2D Gaussian free field .[3] Sheffield, S. [in preparation] Altimeter-compass walks on the Gaus-sian free field.[4] Scott Sheffield (2003) Gaussian free fields for mathematicians,arXiv.org:math.PR/0312099.
389 Favourite sites and occupation times ofrandom walk in random environment [InvitedSession 22 (page 39)]
Zhan SHI and Olivier ZINDY,Université Paris VI, France
Motivated by an open problem of Erdos and Révész originallyformulated for the usual random walk, discussions will be madeupon the relation between favourite sites and occupation timesof one-dimensional random walk in random environment.

Abstracts 181
390 Upper bounds for exponential mo-mentsof hitting times for semi-Markov processes
[Contributed Session C37 (page 24)]
Dmitrii SILVESTROV, Mälardalen University, Sweden
Hitting times are an important class of functionals for Markov-type stochastic processes. They are often interpreted as transi-tion times for different stochastic systems such as occupationtimes or waiting times in queuing systems, lifetimes in relia-bility models, extinction times in population dynamic models,etc. The problem of estimating the tails of the correspondingdistributions leads one to the use of exponential moments forhitting times. Moments of this type play also an important rolein limit, large deviation and ergodic theorems for Markov typeprocesses. In particular, they are appear in estimates for ratesof convergence and in asymptotical expansions as well as in ap-plications of coupling method to ergodic theorems by providingeffective estimates for moments of coupling times.Necessary and sufficient conditions for the existence of expo-nential moments for hitting times of semi-Markov processes aregiven. These conditions and the corresponding upper boundsfor exponential moments are given in terms of test-functions.Applications to hitting times for semi-Markov random walksand queuing systems illustrate the results as well as applica-tions to explicit estimates for rates of convergence in ergodictheorems for regenerative processes and processes with semi-Markov swsitchings.The present results extend the results obtained in [1], wherethe operator techniques of test-functions was applied to studiesof power type moments of generalised hitting times for semi-Markov processes. Partly the results will be presented in [2].References[1] Silvestrov, D.S. (1996) Recurrence relations for generalized hittingtimes for semi-Markov processes,Ann. Appl. Probab.6, 617–649.[2] Silvestrov, D.S. (2004) Upper bounds for exponential moments ofhitting times for semi-Markov processes,Comm. Statist. Theory andMethods, 33(3)(to appear).
391 Stochastic modeling of insurance busi-ness with dynamical control of investments
[Contributed Session M5 (page 27)]
Anatoliy MALYARENKO, Dmitrii SILVESTROV and EvelinaSILVESTROVA,Mälardalen University, Sweden
The model for stochastic modelling of insurance business withdynamical control of investments is described. It is based on therepresentation of business of an insurance company as a multi-component dynamical systems. The components of the modelare the capital process representing stochastic dynamics of thecapital of the insurance company and other stochastic dynamicprocesses such as the rates of return for different types of assets,the rate of inflation and the inflation index, the aggregated claimamount, the premium income, the expected number of claims,the index of risk propensity, the expected value and the variationof aggregated claim amount. The stochastic dynamics of com-ponents is described by appropriate linear or non-linear equa-tions of autoregressive type.The main new element is that modeling of insurance businessis performed for the model, which incorporates non-stationaryand non-linear dynamic threshold strategies for re-distributionof capital between various types of assets and non-stationaryand non-linear dynamic threshold insurance strategies. It meansthat the quotas of the current capital corresponding to differenttypes of investment and safety loading coefficients in the next
time period are switching in correspondence with the value ofcompany’s capital at the end of the present time period. Theswitching levels, or thresholds, are functions of time. Thus theprocess under consideration is essentially non-linear. Analyticalmethods do not work here, but the methods of intensive com-puter simulation can be successfully applied.A pilot program systemSMIB for stochastic modeling ofinsurancebusiness based on the model have been elaboratedand used in research studies of functioning of insurance com-panies directed to finding of optimal dynamic investment andinsurance strategies. Experimental studies realised so far showvery interesting and non-trivial results concerning shapes of dis-tribution of capital of insurance company at given time horizonsin the case of non-linear investment strategies. In particular,computer experiments show that non-linear character of non-stationary threshold investment strategies sharply impacts theresulting distribution of capital. It can be highly non-symmetric,multi-modal and display non-trivial tail effects. Also interestingresults are obtained in studies of ruin mechanisms, in particularin studies of influence of maximal capital jumps, proportion ofcatastrophic and accumulation ruin cases as well as in estimationof extra-small ruin probabilities. Partly, results are presented in[1].
References
[1] Silvestrov, D., Malyarenko, A., and Silvestrova, E. (2004) Stochasticmodelling of insurance business with dynamical control of investments,Theory Stoch. Proces.10(25), (to appear).
392 Adaptive stochastic linear automata inrandom media [Poster Session P2 (page 32)]
Evelina SILVESTROVA , Mälardalen University, Sweden
Adaptive stochastic linear automata functioning in stationaryrandom media are considered. Upper bounds, which link thesize of memory of a stochastic linear automaton with the indexof optimality, are given.In particular the linear automataLr with the size of memoryrare constructed such that
supθ∈Θ
|M(θ ,Lr )−R(θ)| ≤ Kr
,
where (a)M(θ ,Lr ) is an index of optimality for automatonLr
that is the upper limit of the expected stationary penalty pertime unit for this automaton, (b)R(θ) is minimum of expectedpenalty per time unit in a random mediumθ , (c) K is a constantgiven in an explicit form, and (d) supremum is taken over spaceΘ of all stationary random media.Classification of various types of linear types automata basedon the corresponding stochastic domination inequalities is alsogiven.
393 Gaussian conditional independencestructures [Contributed Session C39 (page 34)]
Radim LNENICKA andPetr ŠIMECEK , Institute of Informa-tion Theory and Automation, Czech Republic
Let ξ = (ξi)i∈N be a random vector indexed by a non–emptyfinite setN, which has joint Gaussian distribution. By a condi-tional independence structure induced byξ will be understoodthe collection of all tuples〈A,B|C〉, such thatA,B,C ⊂ N arepairwise disjoint subsets ofN and (ξi)i∈A is conditional inde-pendent of(ξi)i∈B given(ξi)i∈C.A natural question is what are Gaussian conditional indepen-dence structures given an index setN. This question can be

182 6th BS/ IMSC
raised either in the framework of regular Gaussian distributions(whose variance matrix is positive definite) or in the frameworkof general Gaussian distributions (whose variance matrix is pos-itive semi–definite). Radim Lnenicka [1] has solved this prob-lem in the framework of regular Gaussian distributions in thecase|N| = 4. The topic of this contribution is what are gen-eral Gaussian conditional independence structures in the case of|N| = 4; respectively|N| = 5. We have succeeded to character-ize all Gaussian conditional independence structures induced byfour random variables.This helped to solve an open problem from [2] whether thereexists a Gaussian conditional independence structure which isnot induced by any discrete random vector(νi)i∈N. We found asimple example of it in the case|N|= 4.Finally we will present partial results concerning the case|N|=5 and the framework of regular Gaussian distributions.References[1] Lnenicka, R. (2004), personal communication.[2] Studený, M. (to be appeared — 2004)On mathematical descriptionof probabilistic conditional independence structures (preprint), mono-graph, Springer–Verlag.
394 Boundary conditions, mixing times,and the ising model on trees [Invited Session 17(page 49)]
Fabio MARTINELLI, Università Roma Tre. Italy
Alistair SINCLAIR and Dror WEITZ,UC Berkeley, USA
A long-standing conjecture asserts that, in the presence of a +boundary, the mixing time of the Glauber dynamics for the clas-sical Ising model in two dimensions is bounded by a fixed poly-nomial in the volume at all temperatures. By contrast, with a freeboundary the mixing time is known to grow exponentially withthe (square root of the) volume below the critical temperature.In this talk we prove the analogous conjecture for the Isingmodel on trees: namely, that the mixing time with a + boundaryis O(n log n) at all temperatures. The main technical innovationis a framework that relates spatial mixing and temporal mixingin the context of a fixed boundary. Previous such relationships(of which there are many) have applied to all boundaries simul-taneously. The techniques are actually quite general and extendto most other models on trees.No knowledge of statistical physics will be assumed.
395 Non-parametric estimation of rarethreshold probability [Contributed Session C59 (page48)]
Ashoke Kumar SINHA , Tilburg University, The Netherlands
A vast land-space in the Netherlands is below the average sea-level. So to protect the country from flood dikes are built alongthe sea coast. Water levels during high tide have been monitoredwithout any interruption and in a reliable way at five stationsalong the Dutch sea coast. Now we consider two cities on theDutch sea coast,viz.,Hoek van Holland and Delfzijl, which areprotected by the dikes. There has been no flood in these twocities since the beginning of the monitoring of high tide water-levels. We want to estimate the probability of the occurrenceof flood in future in any of the two cities on the basis of theobserved data. The common practice of estimating by the em-pirical distribution function will not help in this case. So weare trying to estimate the probability of a calamity which hasnot occurred yet from the given data. We formulate the problem
mathematically in the following way.Let (X,Y),(X1,Y1), . . . ,(Xn,Yn) be a random sample from a bi-variate distribution functionF . Given a threshold(w,z), we in-tend to construct a non-parametric estimate of the probability
p := Pr(X > w, or Y > z) = 1−F(w,z).
However, in our case the thresholdsw andz are so large (andhencep so small) that none of the observations exceeds thethresholds, which discards the possibility of using empirical dis-tribution for estimation. It can be interpreted in the way thatthe exceedance probabilityp¿ 1
n . For that purpose one has toextrapolate outside the range of the sample. In a finite-samplecontext this problem cannot be solved without assuming a cer-tain parametric model. But a fixed model which may fit verywell to the sample may not reflect the behaviour of the variablesbeyond the range of the observation. So it may turn out to beunsuitable for extrapolation.Hence we do not consider a finite-sample framework and ratherset up an asymptotic framework where the sample-size goes toinfinity. For the purpose of extrapolation, we need to assumecertain smoothness conditions ofF near the endpoints of bothvariables. Thus we estimatep in the setup of bivariate extremevalue distribution function, assuming thatF is in the domain ofattraction of a bivariate extreme value distributionG, i.e., thereexist a sequencesa1(n),a2(n) > 0, andb1(n),b2(n) ∈R so that,
limn→∞
Fn (a1(n)x+b1(n),a2(n)y+b2(n)) = G(x,y)
for all continuity points ofG. Under suitable second orderconditions we can prove asymptotic normality of the estimatorwhich can be used to compute confidence intervals.The same problem has also been discussed in de Haan (1994).However we use here the homogeneity property of stable tail de-pendence function (cf. Huang (1992)) for the necessary extrap-olation. The one-dimensional version of the similar problem hasbeen discussed in Dijk and de Haan (1992).References[1] Dijk, V. and de Haan, L. (1992)On the estimation of the exceedanceprobability of a high level. Order Statistics and Nonparametrics: Theoryand Applications. P.K. Sen and I.A. Salama (Editors). Elsevier, Amster-dam.[2] Huang, Xin (1992) Some Results on the Estimation of the Stable TailDependence Function. Statistics of Bivariate Extreme Values: Ph.D. the-sis.Tinbergen Institute Research Series - Subseries A. No. 22.[3] de Haan, L. (1994) Estimating Exceedance Probabilities in Higher-Dimensional Space.Communications in Statistics - Stochastic Models10, 765–780.
396 Bayesian analysis of nonlinear andnon-Gaussian state space models viamultiple-try sampling methods [Contributed Ses-sion C57 (page 34)]
Mike K.P. SO, Hong Kong University of Science and Technol-ogy, Hong Kong
We develop in this paper three multiple-try blocking schemesfor Bayesian analysis of nonlinear and non-Gaussian state spacemodels. To reduce the correlations between successive iteratesand to avoid getting trapped in a local maximum, we con-struct Markov chains by drawing state variables in blocks withmultiple trial points. The first and second methods adopt au-toregressive and independent kernels to produce the trial points,while in the third method, we sample along suitable directions.Using the time series structure of the state space models, thethree sampling schemes can be implemented efficiently. In two

Abstracts 183
multimodal examples, the three multiple-try samplers are ableto generate desired posterior sample, whereas existing methodsfail to do so.
397 A (Gittins) index theorem for ran-domly evolving graphs [Contributed Session C16(page 52)]
Ernst PRESMAN,CEMI RAS, Russia
Isaac SONIN, UNC Charlotte, USA
We consider the problem which informally can be formulatedas follows. Initially a finite set of independent trials is avail-able. If a Decision Maker (DM) chooses to test a specific trialshe receives a reward depending on the trial tested. As a result oftesting, two outcomes can happen. With some probability, whichdepends on the trial, the process of testing isterminatedand withcomplementary probability the tested trial becomes unavailablebut some random finite set (possibly empty) of new independenttrials is added to the set of available trials. This process can berepeated, but the total number of potential trials is finite. A DMknows the rewards and transition probabilities of all trials. Ateach step she can eitherquit or continue. Her goal is to select anorder to test trials and a quitting time to maximize the expectedtotal reward.On one side this problem is a generalization of a “least cost test-ing sequencing” problem solved independently by a few authorsin 1960 (see [1]), and on the other side is a generalization of theso called Multi-armed Bandit problem with independent arms(see, for example, [2]). It is also a generalization of [3] wherethe set of new trials was deterministic.Formally the model can be formulated as a Markov DecisionProcess (MDP) modelM = (B,A(x), p(x′|x,e)) defined on agraph which is a directed forestF0 with a finite number of edges,where each edge represents a possible trial. A statex ∈ B iseither an absorbing statex∗, or consists of a subset (possiblyempty) of edges ofF0, available for testing at that moment.For each edgee of the forest, denote byT(e) the directed treewhich consists of all edges which followe, and denote byN(e),the set of all edges which followe immediately. The follow-ing parameters are defined for every edgee : 1) a partition
N(e) =∪ j(e)i=1Ni(e), j(e)≥ 1 if N(e) is nonempty; 2) a probability
distributionq(e), pi(e), i = 0,1, · · · , j(e), q(e)+∑ j(e)i=0 pi(e) = 1.
The action setA(x) = x∪ e∗, i.e. a DM can test any avail-able edge or select a quit actione∗. The transitional probabili-ties are defined as follows: if at statex an edgee,e∈ x is se-lected then edgee is not available anymore and with probabil-ity q(e) system transits to an absorbing state and the process isterminated; otherwise with probabilitypi(e), i = 0, · · · , j(e) alledges from the setNi(e) are added to the set of edges avail-able for testing, whereN0(e) is the empty set. An arbitrary re-ward functionr(e) is given such thatr(e∗) = 0. Given an initialstatex and strategyπ, the goal is to maximize the expected totalreward,Rπ
x = Eπx ∑∞
i=0 r(Ai), whereAi is the edge tested at mo-menti.
Main Problem: Given an initial statex, maximizeRπx over all
strategies.
Let γ(e) be a function on a forestF0. We call a strategyπ a(γ ,c)-priority rule or simply apriority rule (PR) if π tests each timethe edge with the highest value ofγ among all available edgeswith values greater thanc, and quits otherwise. For any ad-missible trajectoryh = (x0,e0,x1,e1, . . .) define a random timeτ = τ(h) = infi : Ai = e∗ or Xi = x∗; in other wordsτ is theminimum of the quitting moment and the termination moment.
Let Sπe = PπXτ = x∗, i.e. probability of termination under PR
π with an initial statex = e.
Auxiliary problem: For any edgee, maximizeRπe/Sπ
e over allpriority rules defined onT(e).
Let α(e) denote the result of maximization in the Auxiliaryproblem.
Theorem. a) A (unique) optimal strategy in the Main Problemis a (α,0)-priority rule,
(b) a (unique) optimal strategy in the Auxiliary Problem is a(α,α(e))-priority rule defined onT(e).
Remark 1. Under some assumptions the theorem can be gener-alized to the case of an infinite forest.
* The work of the first author was partly supported by RBRFgrant 03-01-00479.References[1] Mitten, L.G. (1960) An Analytic Solution to the Least Cost TestingSequence Problem,J. Industr. Eng.11, 17.[2] Berry, D.A. and Fristedt, B. (1985)Bandit Problems, Sequential Al-location of Experiments,Monographs on Statistics and Applied Proba-bility, Chapman & Hall, London.[3] Denardo, E.V., Rothblum, U.G., and Van der Heyden, L. (2003)In-dex Policies for Stochastic Search in a Forest with Application to R &D Project Management,manuscript.
398 Stochastic differential equations: re-cent statistical developments [Invited Session 32(page 33)]
Michael SØRENSEN, University of Copenhagen, Denmark
Stochastic differential equation models pose interesting statis-tical problems that have recently attracted increasing attention.The data can be of several types, for instance direct observa-tions, observations with measurement errors, averages over in-tervals, sampling at random time-points, partial observation ofa multi-dimensional system, and combinations of these types.To study the distribution of estimators and other statistics, theclassical large-sample asymptotics can be supplemented by highfrequency asymptotics, small diffusion asymptotics, and combi-nations of the three.A review will be given of some recent developments in the areaof likelihood related parametric statistical inference for stochas-tic differential equations with emphasis on the aspects men-tioned above. Several types of stochastic differential equationmodels will be considered. Examples will be presented of appli-cations of stochastic differential equations and related statisticalmethods to climatological data from ice cores, to a physiologicalproblem, and to interest rate data.
399 On the partition structure of subdi-vided populations [Contributed Session C1 (page 15)]
R.C. GRIFFITHS andDario SPANÒ, University of Oxford, UK
The theory of Exchangeable Random Partitions (ERP) is usedin Population Genetics to represent the distribution of theun-ordered(or size-ordered) allele frequencies, when the number ofpossible alleles is assumed to be infinite (Kingman (1984)). Thetheory of Size-Biased Permutations (SBP), on the other side, isused to interpret the relationship between unordered andage or-deredallele frequencies (Donnelly-Tavarè (1986)).We propose a simple extension of both notions of ERPs andSBPs, useful to give a representation of both unordered and age-ordered frequencies, for bivariate populations, i.e. where each

184 6th BS/ IMSC
individual has two labels, each taking values in an infinite space.Such is the case, for instance, of the distribution within one demein the so-called “infinitely-many-demes” model for structuredIn Wakeley’s model, a population is subdivided in a large num-ber of islands or demes of equal size; migration between demesoccurs, from generation to generation, at a constant, symmetricrate. At each generation, every individual has two labels: hisallelic type and his island of origin, i.e. the deme-location ofhis ancestry timet ≥ 0 ago, for fixedt. Whent is small, andthe number of demes tends to infinity, it is sufficient to under-stand how both variables are distributed within one deme, sincesamples between demes are exchangeably distributed.The results given in literature mostly relate to theunordered,marginal frequencies only, with genes labeled either by alleleor by deme type. An extension of ERP and SBPs leads to a bet-ter insight on theirjoint frequencies, bothunorderedandage-ordered.Bivariate ERP and SBPs can also be used in a more generalsetting, to characterize, via a system of prediction rules (urnschemes), the partition structure of bivariate random discretedistributions. This is done by following the same approach asthat developed in Pitman (1995) and Pitman (1996) for uni-variate populations. It is shown that, even in bivariate models,ranked atoms and size-biased atoms of such random distribu-tions are coupled and the usual weak convergence results holdtrue, once the meaning of “ranked” and “size-biased” is rede-fined.References[1] Donnelly, P. and Tavarè, S. (1986) The ages of alleles and a coales-cent,Adv. in Appl. Probab.18, no. 1, 1–19.[2] Kingman, J.F.C. (1982)Exchangeability and the evolution of largepopulations, In “Exchangeability in probability and statistics (Rome,1981)”, pp. 97–112, North-Holland, Amsterdam-New York[3] Pitman, J. (1995) Exchangeable and Partially Exchangeable Ran-dom Partitions,Probab. Theory Related Fields102, no. 2, 145–158.[4] Pitman, J. (1996)Some Developments of the Blackwell-MacQueenUrn Scheme,In “Statistics, Probability and Game Theory”, 245–267,IMS Lecture Notes Monogr. Ser., 30, Inst. Math. Statist., Hayward, CA[5] Wakeley, J. (1999) Nonequilibrium Migration in Human History,Genetics153, 1863–1871.
400 Realization of hidden Markov chains[Contributed Session C18 (page 54)]
Lorenzo FINESSO,CNR, Italy
Peter SPREIJ, Universiteit van Amsterdam, The Netherlands
Hidden Markov models have become increasingly popular inmany applied research areas like in biology and in speech recog-nition. Theoretical results have become available on the statisti-cal analysis of these models.The matter is different however from a realization point of view.That is, given the distribution of the process, to find the prob-abilistic structure of the underlying Markov process. For theseproblems one often studies a subclass in which the observationprocess is finite valued as well as the underlying Markov chain.In this case one tries to find the transition matrix of the chainand the read-out map. Problems of this kind have a long history.A major technical problem one is faced with is the factorizationof a given nonnegative matrix into two others of lower order.There is still no definite solution to this problem. As an alter-native one might look at approximate factorizations (that maybe used for approximate realization), which has recently beenpaid attention to, although in a completely different context. Ap-proximations are obtained by minimization of the divergence be-tween a given a matrix and an approximating one. This diver-
gence is a generalization of the divergence between two (finitelysupported) probability measures. Properties of this divergenceare well-known and in many areas of probability theory resultsare formulated in terms of this divergence, which indicates thatit should also be a natural criterion to use to approximate a givenrandom process by a hidden Markov one.An alternating minimization algorithm (similar to the EM algo-rithm) to obtain an approximating sequence will be presentedand motivated and its convergence properties will be discussed.
401 A local limit theorem and logical limitlaws for expansive multisets [Contributed SessionC8 (page 35)]
Boris GRANOVSKY,Tel Aviv University, Israel
Dudley STARK, University of London, United Kingdom
A multiset is an unordered sample from a set of object typesin which the number of items is variable, but the total weightof the objects equals a parametern. The number of types ofobjects of weightj is a j . Suppose that multisets of weightnare chosen from uniformly at random and letCi(n) be the num-ber of objects of weighti. Arratia and Tavaré [1] showed that
(C1(n),C2(n), . . . ,Cn(n)) d= (Z1,Z2, . . . ,Zn|Tn = n) where theZiare independent but not identically distributed negative binomialrandom variables with appropriate parameters andTn = ∑n
i=1 iZi .The distribution of theZi depends on a parameterσ which doesnot affect the distribution of the conditioned process. Letcn
be the number of multiset representatives of total weightn. Byexamination of the normalization constants they showed thatcn = enσ ∏n
j=1
(1−e−σ j
)−a j P(Tn = n). This representation canalso be shown using the method of Freiman and Granovsky [4]starting from the generating function relation1+ ∑∞
n=0cnzn =∏∞
j=1(1−zj )−a j . Whena j ³ j r−1y j for somer > 0, y≥ 1, thenwe say that the multiset isexpansive. For expansive multisetswe prove a local limit lemma forTn under the condition thatσis chosen so thatE(Tn) = n. The method used is similar to theone in [4].Moreover, we prove thatcn/cn+1 → 1 and thatcn/cn+1 < 1 forlarge enoughn. This allows us to apply a Theorem of Comp-ton and prove Monadic Second Order Limit Laws for expansivemultisets, thereby extending a result of Bell and Burris [2]. Ifthe conditiona j = A jr−1y j + O(yν j ) is imposed, whereA > 0,r > 0, y≥ 1, ν ∈ (0,1), then we are able to find asymptoticsfor cn, thus generalizing a result on “factorisatio numerorum”obtained by Knopfmacher, Knopfmacher and Warlimont [3] forthe caser = 1 to expansive multisets withr > 0.References[1] Arratia, R.A. and Tavaré, S. (1994) Independent process approxima-tions for random combinatorial structures,Adv. Math. 104, 90–154.[2] Bell, J.P. and Burris, S. N. (2003) Asymptotics for logical limit laws:when the growth of the components is in an RT class,Trans. Amer.Math. Soc.355, 3777–3794.[3] Knopfmacher, A., Knopfmacher, J., and Warlimont, R. (1992)“Fac-torisatio numerorum” in arithmetical semigroups, Acta Arith. 61, 327–336.[4] G. A. Freiman and B. L. Granovsky (2002) Asymptotic formula fora partition function of reversible coagulation-fragmentation processes,Israel J. Math.130, 259–279.
402 Bankruptcy prediction with long-termsurvivors and industry effects [Contributed Ses-sion M9 (page 19)]
Sudheer CHAVA,University of Houston, USA
Catalina STEFANESCU, London Business School, UK

Abstracts 185
Yildiray YILDIRIM, Syracuse University, USA
This paper proposes a mixture model with random–effects andlong–term survivors, for the analysis of clustered failure timedata when some individuals may never experience the event un-der study. The motivation behind this research is given by theneed for more accurate bankruptcy prediction techniques (Chavaand Jarrow (2002), Shumway (2001)). Typically, there are twomethodological challenges in bankruptcy forecasting with haz-ard rate models. Firstly, many firms usually do not fail by theend of the study and therefore there is a high proportion of cen-sored observations in the sample. Techniques which account forheavy censoring in the data include the cure–rate models investi-gated among others by Kuk and Chen (1992) and Sy and Taylor(2000). Secondly, firms in the same industry tend to exhibit cor-relation both in event incidence and in event timing. Clusteringis typically modelled with frailty variables, where the lifetimesare assumed independent conditionally on some common latentfactor which acts multiplicatively on the hazard rates.We investigate a discrete–time hazard rate model which can ac-commodate both clustering and heavy censoring. The modelassumes that there are two frailty variables which induce clus-tering — one variable affects the proportion of firms that arelong–term survivors in each cluster, the other affects the fail-ure risk of firms subject to failure through their hazard function.Both firm–level and cluster–level covariates can be accountedfor through a logistic specification. We assume that the frailtieshave a multivariate normal distribution, which leads to a flexiblerange of correlation values. This specification can model bothnegative and positive intracluster correlation, corresponding toa competition versus cooperation effect. We develop maximumlikelihood techniques for joint estimation of the long–term sur-vival probability and the hazard rate parameters using an EM al-gorithm. The methodology discussed here is exemplified with anapplication to a large bankruptcy data set containing U.S. com-panies over the time period 1962–1999.References[1] Chava, S. and Jarrow, R. (2002)Bankruptcy prediction with industryeffects, working paper, Cornell University.[2] Kuk, A.Y.C. and Chen, C.H. (1992) A mixture model combininglogistic regression with proportional hazards regression ,Biometrika79,531–541.[3] Shumway, T. (2001)Forecasting bankruptcy more accurately: A sim-ple hazard model Journal of Business74, 101–124.[4] Sy, J.P. and Taylor, J.M.G. (2000) Estimation in a Cox proportionalhazards cure model ,Biometrics56, 227–236.
403 Optimization in life insurance [InvitedSession 9 (page 23)]
Mogens STEFFENSEN, University of Copenhagen, Denmark
A life insurance policy may contain several decision problemson part of the insurance company as well as the policy holder.The design of guaranteed payments, the design of additionalperformance-dependent payments, and the investment drivingthe performance may all play roles as decision variables. Whothe decision maker is, for each decision variable, depends on thetype of life insurance contract. We approach some of these deci-sion problems by utility maximization and recognize, on the onehand, similarities to classical financial consumption-investmentproblems but unveil, on the other hand, also special delicate fea-tures of the problems and their solutions. References on the sub-ject are Richard (1975) and Steffensen (2003,2004).References[1] Richard, S.F. (1975). Optimal consumption, portoflio and life in-
surance rules for an uncertain lived individual in a continuous model,Journal of Financial Economics2 187–203.[2] Steffensen, M. (2003) Quadratic Optimization of Life Insurance Pay-ment Streams, Working paper No. 190, Laboratory of Actuarial Math-amtics, UIniversity of Copenhagen, Submitted toASTIN Bulletin.[3] Steffensen, M. (2004) On Merton’s Problem for Life Insurers,ASTIN Bulletin 34(1).
404 Pricing process with stochastic volatil-ity controlled by a semi-Markov process inoption pricing [Contributed Session M1 (page 17)]
Dmitrii SILVESTROV andFredrik STENBERG , MalardalenUniversity, Sweden
We derive methods to price European-type options for the modelin which the pricing process is a geometrical Brownian motioncontrolled by a semi-Markov process. The controlling Markovtype process, usually of a lower dimension, can be constructedby quantization of voting indexes, general pricing indexes, pa-rameters trade volume parameters or other parameters charac-terizing state of the market. In some cases, for example such asenergy pricing processes, parameters characterizing weather canbe involved to construct the corresponding controlling Markovtype process. Note also that one should consider such processesas observable since they are constructed from observable mar-ket data. A discrete version, the binomial model controlled by asemi-Markov chain, is examined and limit theorems describingthe transition from discrete to continuous time model are given.We present several alternative theoretical results, amonge these asystem of partial differential equations for the distribution func-tion for average volatility, that can be used to build up differentMonte Carlo algorithms for estimation of the risk neutral pricefor European-type options.
References
[1] Silvestrov, D.S. and Stenberg, F. (2004)A Pricing Process withStochastic Volatility Controlled by a Semi-Markov Process,To appearin: Communications in Statistics Theory and Methods33(3).
405 V-variable random fractals [ContributedSession C17 (page 54)]
Michael F. BARNSLEY, John E. HUTCHINSON,AustralianNational University, Australia
Örjan STENFLO , Stockholm University, Sweden
The use of random fractals in applications, is often restricted bythe computational complexity of these objects. In this talk wepresent a formalism for random probability measures on fractalsand discuss a new class of random fractals that possess compu-tational advantages.References[1] Barnsley, M., Hutchinson, J.E., and Stenflo, Ö. (2003) A frac-tal valued random iteration algorithm and fractal hierarchy, Preprint(arXiv:math.PR/0312187).[2] Barnsley, M., Hutchinson, J.E., and Stenflo, Ö. (2003)V-Variablefractals and superfractals, Preprint (arXiv:math.PR/0312314).
406 Power for tests of no mixture [ContributedSession C44 (page 52)]
John ROBINSON andMichael STEWART , University of Syd-ney, Australia
We discuss power for tests of no mixture against a two-component mixture based on a random sample of sizen, underlocal alternatives, when the components of the mixture are froma one-parameter exponential family. We focus on non-regularcases where likelihood-based statistics tend to infinity in prob-

186 6th BS/ IMSC
ability at a slowly varying rate under the null hypothesis of nomixture. We show in such cases that the only alternatives withnon-trivial power are a (Hellinger) distance of ordern−1/2 awayfrom a precise frontier which is a distancen−1/2L(n) away fromthe null hypothesis, whereL(n) → ∞ is slowly varying. Theprecise form ofL(n) depends on the exponential family. Thiswork builds on results of Hartigan (1985), Bickel and Chernoff(1993), Liu, Pasarica and Shao (2003), Liu and Shao (2004),Stewart and Robinson (2004) and Hall and Stewart (2004).References[1] Bickel, P. and Chernoff, H. (1993) Asymptotic distribution of thelikelihood ratio statistic in a prototypical non regular problem.Statis-tics and Probability: A Raghu Raj Bahadur Festschrift, Wiley Eastern,83–96.[2] Hall, P. and Stewart, M. (2004) Theoretical analysis of power in atwo-component normal mixture model.Journal of Statistical Planningand Inference, to appear.[3] Hartigan, J.A. (1985) A failure of likelihood ratio asymptotics fornormal mixtures, inProceedings of the Berkeley Conference in Honorof Jerzy Neyman and Jack Kiefer2, Wadsworth, 807–810.[4] Liu, X., Pasarica, C., and Shao, Y. (2003) Testing homogeneity ingamma mixture models.Scaninavian Journal of Statistics30, 227–240.[5] Liu, X. and Shao, Y. (2004) Asymptotics for the likelihood ratio testin a two-component normal mixture model.Journal of Statistical Plan-ning and Inference, in press.[6] Stewart, M. and Robinson, J. (2004)Extremes of certain non-Donsker empirical processes, submitted for publication.
407 On ratio estimators of summary statis-tics for stationary point processes [Invited Ses-sion 31 (page 39)]
Dietrich STOYAN , TU Bergakademie, Freiburg, Germany
The nearest-neighbour distance distribution, Ripley’s K-function, the L-function and the pair correlation function arefundamental summary statistics for stationary point processes.These functions are usually estimated by ratio estimators, wherethe numerators are Horvitz-Thompson estimators and the de-nominators estimators of intensity or squared intensity. Surpris-ingly, the intensity estimators play a crucial role in the whole es-timation procedure. It is essential to adapt the intensity estimatorto the numerator estimator, and for the different summary statis-tics different intensity estimators are useful. By clever choicesof intensity estimators the estimation variances of the summarystatistics estimators can be considerably reduced in comparisonto the classical estimators in the literature. If by some externalinformation the true intensity should be known, it should notbe used, but instead the adapted estimate from the data. Unfor-tunately, in the literature there is confusion in regard to whichestimator to use, and the role of intensity estimators seems to benot well understood. This talk tries to make order in this field.References[1] Stoyan, D. and Stoyan, H. (2000) Improving ratio estimators of sec-ond order point process characteristics,Scand. J. Statistics27, 641–656.[2] Stoyan, D., Stoyan, H., Tscheschel, A., and Mattfeldt, T. (2001) Onthe estimation of distance distribution functions for point processes andrandom sets,Image Anal. Stereol.20, 65–69.
408 Maturity randomization for stochasticcontrol problems [Contributed Session C24 (page 35)]
Alberto ROVERATO,University of Modena and Reggio Emilia,Italy
Milan STUDENÝ , Institute of Information Theory and Automa-tion (Prague), Czech Republic
Chain graph models are statistical models of conditional inde-
pendence structure described by chain graphs, that is, graphswhich have both undirected and directed edges and are acyclic.At least two different statistical interpretations of chain graphshave appeared in the literature: the classic LWF interpretation[1,2] and an alternative AMP interpretation introduced in [3].This contribution concerns AMP chain graph models.One statistical model can be described by different chain graphs.Thus, chain graphs over a fixed set of variables (= nodes) fallinto Markov equivalence classes. To avoid ambiguity and con-sequent computational inefficiency in model learning every par-ticular Markov equivalence class must be represented by a suit-able standard representative. Andersson, Madigan and Perlman[3] proposed to use a so-called AMP essential graph for this pur-pose. In this contribution we propose another representative ofan AMP Markov equivalence class.First, we analyze the internal structure of an AMP equivalenceclass. A basic observation is that it decomposes into smallerequivalence classes, calledstrong equivalence classes. Thereexists a natural ordering between strong equivalence classeswithin an AMP equivalence class, and this allows one to choosea distinguished strong equivalence class. Moreover, each ofstrong equivalence classes has the largest chain graph, that is, auniquely determined graph with the largest amount of undirectededges. We propose to represent every AMP equivalence class bythe largest chain graph of the distinguished strong equivalenceclass, called thelargest deflagged graph. The advantage of thismethod for representing AMP equivalence classes is that thereare effective procedures to get the largest deflagged graph; theywill be described in details in [4]. Note that in case of acyclic di-rected graph models the essential graph and the largest deflaggedgraph of the respective AMP equivalence class coincide.References[1] Lauritzen, S.L. and Wermuth, W. (1989) Graphical models for as-sociations between variables some of which are qualitative and some ofwhich are quantitative,Annals of Statistics1731–57.[2] Frydenberg, M. (1990) The chain graph Markov property,Scandi-navian Journal of Statistics17333–353.[3] Andersson, S.A., Madigan D., and Perlman M.D. (2001) AlternativeMarkov properties for chain graphs,Scandinavian Journal of Statistics2833–85.[4] Roverato, A. and Studený, M. (2004)A graphical representation ofequivalence classes of AMP chain graphs, in preparation.
409 Bootstrap algorithms for testing anddetermining the cointegration rank in VARmodels [Contributed Session C47 (page 17)]
Anders Rygh SWENSEN, University of Oslo, Norway
Vector autoregressive (VAR) models are one of the workhorsesin econometric modeling of macroeconomic time series. Oftenthese series have characteristics which are not captured by sta-tionary or stationary plus a time trend VAR models. Therefore, amethod which is extensively used is to force one or several rootsof the determinant of the characteristic polynomial to be equalto 1. The vector time series is then no longer stationary. Whenthe series are integrated of order one I(1), that is all componentsbecome stationary after differencing, a much used model is ofthe form
∆Xt = ΠXt−1 +Γ1∆Xt−1 + · · ·+Γk−1∆Xt−(k−1) + εt
whereΠ has reduced rank r, and can be writtenΠ = αβ ′ whereα andβ arep× r matrices of full rank. Nowβ ′Xt are stationaryseries, so-calledcointegratedand the columns ofβ describe thespace spanned by thecointegration vectors.

Abstracts 187
A common extension of the model above is to include a trendand a constant term. Reduced rank VAR models of this formare treated in Johansen[1] with Gaussian errors, where he alsofinds the likelihood ratio test for the hypothesesH0 : rank(Π) = rversusH0 : rank(Π) = p and develops a sequential method fordetermining the rank.In this paper a bootstrap algorithm for a reduced rank VAR-model with a restricted linear trend is analyzed where the pseudoobservations are computed recursively from the autoregressivescheme with errors sampled from the residuals of the fittedmodel. A bootstrap algorithm for testing the cointegration rankis proposed, and it is shown that the asymptotic distribution un-der the hypothesis is the same as for the usual likelihood ra-tio test. It is furthermore shown that a bootstrap procedure forsequentially determining the rank is asymptotically consistent.This involves problems which are nonstandard in a bootstrapcontext, since simulation has to be carried out for several mod-els where the imposed rank differs. An empirical illustration isgiven.
References
[1] Johansen, S. (1995)Likelihood-based inference in cointegrated vec-tor autoregressive models(Oxford University Press, Oxford).
410 Volatility and variance swaps for as-sets with stochastic volatility [Contributed SessionM1 (page 17)]
Anatoliy SWISHCHUK , York University, Canada
We propose one probabilistic approach to the study of stochasticvolatility model, introduced by Heston (1993) [2].The Heston asset process has a varianceσ2
t that follows a Cox,Ingersoll & Ross (1985) process [3].We find some analytical close forms for expectation and vari-ance of the realised both continuously and discrete sampled vari-anceV, which need for study of variance and volatility swaps[4], and price of some statistics associated with variance andvolatility.The same expressions forE[V] and forVar[V] were obtained byBrockhaus & Long (2000) [1] by another approach.Our approach may be also applied to the study of statistics asso-ciated with covariance and correlation swaps [1].References[1] Brockhaus, O. and Long, D. (2000)"Volatility swaps made simple", RISK, January, 92-96.[2] Heston, S. (1993) "A closed-form solution for options with stochas-tic volatility with applications to bond and currency options,Review ofFinancial Studies6, 327–343.[3] Cox, J., Ingersoll, J., and Ross, S. (1985) "A theory of the termstructure of interest rates" ,Econometrica53, 385–407.[4] Demeterfi, K., Derman, E., M. Kamal, M., and Zou, J. (1999)"AGuide to Volatility and Variance Swaps",The Journal of Derivatives,Summer, 9-32.
411 Environment & financial markets [Con-tributed Session M5 (page 27)]
Monique JEANBLANC, Université d’Evry Val d’Essone,France
Wojciech SZATZSCHNEIDER , Escuela de Actuaria Univer-sidad Anahuac, Mexico
We argue that practical solutions for the environmental degra-dation are in a short supply. Most of the increasingly complexmodels set off different opinions about their applicability. Mod-els should be well specified. It means that inputs should be ob-served or estimated. This requirement is hard to meet in en-
vironmental studies. Thus, the efficient global environmentaldecision–making becomes very difficult. Moreover politiciansoften tend to justify their decisions by inappropriate theories.This situation leads to proliferation of ineffective studies andwaste of resources.We shall propose to apply the market approach in the solutionsof several environmental problems. It could result in more trans-parent transfer of funds and the involvement of everybody con-cerned. Also we can expect that the transparency could stem inan increment of these funds.We shall focus on the issue of deforestation due to its importancefor the global well–being, and the possibility to assess the num-ber of trees. Our approach is based on a positive involvement ofholders of "good" options bought or, in the first stage, obtainedfor free. In the case of the forest "good" means a kind of Asiancall option. We will show that, in a natural way, three kinds ofoptimization problems crop up:1)Individual agent problem. 2)Local optimization prob-lem. 3)Global optimization problem.The first one is how the holder of a good option could eventu-ally contribute to reforestation. The second one is how to chooseprices of options, to maximize the space mean of the temporalmean of the "asset" in given place. The last one is how to dis-tribute funds into particular projects.In the final part we analyze the dynamical control for boundedprocesses and awards partially based on the mean of the under-lying value.
References
[1] Jeanblanc, M. and W. Szatzschneider (2002) Environment and fi-nance: why we should make the environment a part of the financial mar-kets,Revista Mexicana de Economia y Finanzas1, 131–142.
412 Applications of the tube formula andthe Euler characteristic methods to multi-variate distributional problems [Contributed Ses-sion C43 (page 26)]
Satoshi KURIKI, The Institute of Statistical Mathematics,Minato-ku, Tokyo, Japan
Akimichi TAKEMURA , University of Tokyo, Bunkyo-ku,Tokyo, Japan
We will discuss number of multivariate distributional problems,where the tail probability of the null distribution of a maximumtype statistic can be evaluated by the tube formula or the Eulercharacteristic methods. The equivalence of these two methodshave been recently established. The problems we consider in-clude• maximum of multilinear forms,• maximum covariance test for equality of two covariance
matrices,• Anderson-Stephens statistic for testing uniformity on the
sphere,• Order restricted inference in two-way contingency tables.
References[1] Kuriki, S. and Takemura, A. (2001) Tail probabilities of the maximaof multilinear forms and their applications,Ann. Statist.29, 328–371.[2] Kuriki, S. and Takemura, A. (2002) Application of tube formula todistributional problems in multiway layouts,Applied Stochastic Modelsin Business and Industry, 18, 245–257.[3] Kuriki, S. and Takemura, A. (2004) Tail probabilities of the limit-ing null distributions of the Anderson-Stephens statistics, To appear inJ. Multivariate Anal.[4] Takemura, A. and Kuriki, S. (2001) Maximum covariance differencetest for equality of two covariance matrices, inAlgebraic Methods in

188 6th BS/ IMSC
Statistics and Probability,pp.283–301, M. Viana and D. Richards eds.,Contemporary Mathematics Vol. 287, American Mathematical Society.[5] Takemura, A. and Kuriki, S. (2002) On the equivalence of the tubeand Euler characteristic methods for the distribution of the maximumof Gaussian fields over piecewise smooth domains,Ann. Appl. Probab.,12, 768–796.[6] Takemura, A. and Kuriki, S. (2003) Tail probability via the tube for-mula when the critical radius is zero,Bernoulli, 9, No. 3, 535–558.
413 Dynamic graphical models: structurallearning with time-varying components [Con-tributed Session C24 (page 36)]
Nicolas HENGARTNER,Los Alamos National Laboratory,USA
Makram TALIH , City University of New York, Hunter College,USA
When modelling multivariate financial data, the problem ofstructural learning is compounded by the fact that the covariancestructure changes with time. Previous work has focused on mod-elling those changes using the so-called multivariate stochasticvolatility models of Jacquier et al. (1994). We present an alter-native to these models that focuses instead on the latent graph-ical structure related to the precision matrix. The latter is theinverse of the variance-covariance matrix, a natural parameter inthe multivariate Normal model, intimately related to the coeffi-cients in the simultaneous regression of each variable on all theremaining ones.We develop a graphical model for sequences of Gaussian ran-dom vectors when changes in the underlying graph –which isspecified by zeroes in the precision matrix– occur at randomtimes, and a new block of data is created with the addition ordeletion of an edge. We show how a Bayesian hierarchicalmodel incorporates both the uncertainty about that graph, andthe time-variation thereof. Further, we show how to extend ourmodel to deal with a varying number of vertices in the graph,such as arises, in finance, from mergers or splits. Our main ob-jective is to learn the graph underlying the most current block ofdata. In fact, our framework allows us to make inference aboutthe whole history up to and including the last block.Dahlhaus and Eichler (2002) have developed a related class ofmodels, termed time-series graphs. For stationary time series,conditional independence is characterised in the frequency do-main by zeroes in the inverse spectral matrix. Using Gibbs po-tentials, Guyon and Hardouin (2002) develop another class ofdynamic spatiotemporal models, which they call Markov chainMarkov fields. Finally, in the context of communication net-works, Cortes et al. (2003) address some of the challenges posedby structural learning when vertices and edges appear and dis-appear through time.References[1] Cortes, C., Pregibon, D., and Volinsky, C. (2003) ComputationalMethods for Dynamic Graphs.Journal of Computational and GraphicalStatistics12, 950–970.[2] Dahlhaus, R., and Eichler, M. (2002)Causality and graphical modelsin time series analysis.In P. Green, N. Hjort, and S. Richardson (Eds.),Highly Structured Stochastic Systems. Oxford, UK: Oxford UniversityPress.[3] Guyon, X. and Hardouin, C. (2002) Markov chain Markov field dy-namics: Models and statistics.Statistics13, 339–363.[4] Jacquier, E., Polson, N.G., and Rossi, P.E. (1994) Bayesian analysisof stochastic volatility models (with discussion).Journal of Business &Economic Statistics12, 371–417.
414 Dependence structure of spectrallypositive multidimensional Lévy processes
[Contributed Session C13 (page 45)]
Peter TANKOV , Ecole Polytechnique, France
We give a general characterization of the dependence amongcomponents of multidimensional Lévy processes admitting onlypositive jumps in every component, by introducing Lévy copu-las. Lévy copulas are functions with the same properties as or-dinary copulas but defined on a different domain.F : [0,∞]n →[0,∞] is aLévy copulaif
1. F is grounded, that is,F is zero if at least one of its argu-ments is equal to zero
2. F is n-increasing, that is,F has finite variation on com-pacts anddF is a positive measure
3. F has uniform margins: F(x,∞, . . . ,∞) = . . . =F(∞, . . . ,∞,x) = x ∀x
The Lévy measure of a spectrally positive Lévy process can berepresented via its tail integral as follows. Letν be a Lévymeasure on[0,∞)n. The tail integral of ν is U(x1 . . .xn) =ν([x1,∞)× . . .× [xn,∞)). The knowledge ofU determines theLévy measure completely. The margins ofν are 1-dimensionalLévy measures of components of the Lévy process with Lévymeasureν , for exampleν1(A) = ν(A× [0,∞)× . . .× [0,∞)).Marginal tail integrals ofν are tail integrals ofν1, . . . ,νn.The main theorem of the present paper shows that Lévy copulascharacterize all types of dependence of spectrally positive Lévyprocesses. From a modelling perspective, a multidimensionalLévy process can be specified by taking any marginal Lévy mea-sures and any Lévy copula (e.g. from a parametric family).Theorem
1. For every spectrally positive Lévy process with Lévy mea-sureν on [0,∞)n, there exists a Lévy copulaF that de-scribes its dependence structure:
U(x1, . . . ,xn) = F(U1(x), . . . ,Un(xn)), (1)
whereU is the tail integral ofν andU1 . . .Un are marginaltail integrals.
2. For every Lévy copulaF , Equation (1) defines a tailintegral of a Lévy process with marginal tail integralsU1, . . . ,Un.
Using Equation (1), we compute Lévy copulas correspondingto various dependence patterns of multidimensional Lévy pro-cesses (complete dependence, independence, dependence of sta-ble processes) and give methods to construct parametric familiesof Lévy copulas.
• Independence: F⊥(x1, . . . ,xn) = x11x2...xn=∞ + . . . +xn1x1...xn−1=∞
• Complete dependence:F‖(x1, . . . ,xn) = min(x1, . . . ,xn)
• Example of a parametric family:Fθ (x1, . . . ,xn) = (x−θ1 +
. . .+x−θn )−1/θ . This family includes independence (θ →
0) and complete dependence (θ → ∞)
The notion of Lévy copula allows us to develop a new methodfor simulating multidimensional Lévy processes with positivejumps in every component. A recent book [2, Chapter 5] dis-cusses possible applications of Lévy copulas in finance and in-surance and compares this approach to other ways of construct-ing multidimensional models with jumps.References[1] Tankov, P. (2003) Dependence structure of spectrally

Abstracts 189
positive multidimensional Lévy processes /, Download atwww.cmap.polytechnique.fr/~tankov[2] Cont, R. and Tankov, P. (2004)Financial Modelling with Jump Pro-cesses /, Chapman & Hall / CRC Press.
415 Retrieving exponential Lévy modelsfrom option prices using relative entropy
[Poster Session P2 (page 31)]
Rama, CONT andPeter TANKOV , Ecole Polytechnique,France
We consider a problem of calibrating an exponential Lévy modelto a set of market option prices. In this model, stock price is rep-resented asSt = S0ert+Xt , where(Xt) is a Lévy process on prob-ability space(Ω,F ,Q) such thateXt is aQ-martingale. Call op-tion prices can be evaluated as discounted expectations of termi-nal payoffs:CQ(T,K) = e−rT EQ[(S0erT+XT −K)+]. The prob-ability measureQ is parametrized by the characteristic triplet(σ ,ν ,γ) of (Xt), whereσ is the volatility of the continuousGaussian component,ν is the Lévy measure andγ denotes thedrift coefficient. The martingale condition allows to computeγfrom σ andν .The calibration problem consists in finding the lawQ(σ ,ν)such that the model option pricesCQ(σ ,ν)(Ti ,Ki) coincide withthe market pricesC∗(Ti ,Ki) for a set of strikes and maturities(Ti ,Ki)i∈I . The problem of reproducing the observed optionprices exactly is ill-posed: it does not always admit a solutionand when it does, the solution is not stable with respect to per-turbations in the data. We therefore formulate a regularized ver-sion of the calibration problem: find a risk-neutral Lévy processQ(σ ,ν), minimizing the followingcalibration functional:
J(Q) = E (Q)+ I(Q|P),
over the set of all risk-neutral Lévy processes, where
E (Q) :=∫
[T1,T2]×[0,∞)(CQ(T,K)−C∗(T,K))2w(dT×dK)
is the pricing error (w is used to assign weights to the obser-vations) andI(Q|P) := EP[ dQ
dP log dQdP ] is the relative entropy
(Kullback-Leibler distance) ofQ(σ ,ν) with respect to a refer-ence Lévy processP(σP,νP). This reference process (prior)allows to introduce additional information into the calibrationproblem, in order to gain stability. It can be estimated from his-torical data or, more generally, chosen based on our views aboutthe model underlying the market option prices.For the relative entropyI(Q|P) to be finite, necessarilyσ = σP
and ν ¿ νP. Therefore, the calibration problem can be ex-pressed as that of finding the Lévy measureν ¿ νP, minimizing
J(ν) = E (ν)+ I(ν). (2)
After deriving the explicit expression of the relative entropy interms ofν , νP andσP, we show that
• The regularized calibration problem always admits a solu-tion (though the solution need not be unique).
• The solutions are continuous with respect to input data andthe prior Lévy measure.
Moreover, when the noise level in the data tends to zero, we givethe conditions under which the solutions of the regularized prob-lem converge to the solutions of the initial calibration problem.In order to solve the regularized calibration problem numeri-cally, we discretize the prior measure on a finite grid of points:νP = ∑N
i=1aiδxi . The set of measuresν such thatν ¿ νP is
then finite-dimensional, and the calibration functional (2) canbe minimized using a gradient descent method. The discretizedcalibration problem and its numerical solution are discussed inour recent paper [1]. Finally, we show that the solutions of thecalibration problem are weakly continuous with respect to theprior Lévy measure. This allows to conclude that ifνP
n is asequence of discrete priors, converging weakly to a continuousmeasureνP, the sequence of solutions will also converge weaklyto the solution of the calibration problem with prior measureνP.
References
[1] Cont, R. and Tankov, P. (2004) Non-parametric calibration of jump-diffusion option pricing models,Journal of Computational Finance7(3),1–49.
416 Stable stationary processes related tocyclic flows [Contributed Session C12 (page 24)]
Vladas PIPIRAS,University of North Carolina, Chapel Hill,USA
Murad S. TAQQU , Boston University, USA
Rosinski (1995) showed that one can decompose a stationarystable process into three independent components:
(1) a mixed moving-average process
(2) a harmonizable process
(3’) a component which is none of the above.
We show that one can identify a "cyclic" component in category(3’). One can therefore decompose a stationary stable processinto independent four components. The components (1) and (2)listed above,and
(3) a cyclic (non-harmonizable) process
(4) a process which is none of the above.
Category (4) contains for example the stationary sub-Gaussianprocesses. The cyclic processes (3) are related to cyclic flows.These processes are not ergodic. We characterize them, provideexamples and show how to identify them among general station-ary stable processes.References[1] Pipiras, V. and Taqqu, M.S. (2003) Stable stationary processes re-lated to cyclic flows, to appear inAnn. Probab..[2] Rosinski, J. (1995) On the structure of stationary stable processesAnn. Probab.23, 1163-1187.
417 Asymptotic Bayesian change-point de-tection theory for general continuous timestochastic processes[Contributed Session C63 (page39)]
Michael BARON,University of Texas at Dallas, USA
Alexander G. TARTAKOVSKY , University of Southern Cali-fornia, USA
The problem of detecting abrupt changes in stochastic modelsarises across various branches of science and engineering in-cluding such important applications as biomedical signal andimage processing; quality control engineering; financial mar-kets; link failure detection in communication; intrusion detec-tion in computer networks and security systems; chemical orbiological warfare agent detection systems to protect against ter-rorist attacks; detection of the onset of an epidemic; failure de-tection in manufacturing systems and large machines; and tar-get detection in surveillance systems. In the beginning of the1960s, Shiryaev obtained the structure of the Bayes rule for de-tecting abrupt changes in independent and identically distributed

190 6th BS/ IMSC
(i.i.d.) sequences as well as in the constant drift of a Brownianmotion (see [1] and references therein). However, the analysisof the performance of this procedure in terms of average de-tection delay versus false alarm probability, as well as in termsof average risk versus cost of detection delay has been an openproblem. Recently, Tartakovsky and Veeravalli [2] investigatedasymptotic performance of the Shiryaev change detection pro-cedure when the false alarm probability goes to zero for gen-eral discrete-time models. In this paper, we investigate asymp-totic performance of this procedure for general continuous-timestochastic models under small false alarm probability and smallcost of detection delay. We show that it has asymptotic opti-mality properties under mild conditions. We also analyze theasymptotic performance of another well-known change detec-tion procedure, the Shiryaev-Roberts-Pollak procedure, in theBayesian framework for general statistical models. The con-clusion is that it loses the asymptotic optimality property underthe Bayesian criterion for prior distributions with exponentialright tails but remains asymptotically optimal for prior distribu-tions with tails heavier than exponential. The presented asymp-totic Bayesian detection theory substantially generalizes previ-ous work in the field of change-point detection for continuous-time processes. This asymptotic theory relies on the strong lawof large numbers for the log-likelihood ratio process and therates of convergence in the strong law. A similar approach hasbeen previously used by Lai [4], Tartakovsky [5], and Dragalin,Tartakovsky and Veeravalli [6] to establish asymptotic optimal-ity of sequential hypothesis tests.References[1] Shiryaev, A.N. (1978)Optimal Stopping Rules, Springer-Verlag:New York.[2] Tartakovsky, A.G. and Veeravalli, V.V. (2003)General asymptoticBayesian theory of quickest change detection, Submitted to the Theoryof Probability and Its Applications.[3] Lai, T.L. (1998) Information bounds and quick detection of param-eter changes in stochastic systems,IEEE Transactions on InformationTheory, IT-44, 2917–2929.[4] Lai, T.L. (1981) Asymptotic optimality of invariant sequential prob-ability ratio tests,Ann. Statist.9, 318–333.[5] Tartakovsky, A.G. (1998) Asymptotic optimality of certain mul-tihypothesis sequential tests: non-i.i.d. case,Statistical Inference forStochastic Processes,1, no. 3, 265–295.[6] Dragalin, V.P., Tartakovsky, A.G., and Veeravalli, V.V. (1999) Multi-hypothesis sequential probability ratio tests, part I: asymptotic optimal-ity, IEEE Transactions on Information Theory,IT-45, 2448–2461.
418 Statistical inference for SFP data [In-vited Session 5 (page 29)]
Justin BOREVITZ,University of Chicago, USA
Rong JIANG, Paul MARJORAM andSimon TAVARÉ , Univer-sity of Southern California, USA
High-throughout oligonucleotide microarray technology can beused to produce a new type of polymorphism data, the Single-Feature Polymorphism (SFP) [1]. The DNA from each samplefrom a population is hybridized to an array. A particular probeis called an SFP when significant differences between the hy-bridization intensities of the sample DNA to that probe are iden-tified. SFPs provide a high-throughput but somewhat indirectassessment of the genomic variation in a sample. Our interestis in developing methods of statistical inference for such data.In this talk we describe a coalescent-based approach that usesideas from approximate Bayesian computation [2,3] to estimaterecombination rates across the genome ofArabidopsis thaliana.References
[1] Borevitz, J.O., Liang, D., Plouffe, D., et al. (2003) Large-scaleidentification of single-feature polymorphisms in complex genomes,Genome Research13, 513–523.[2] Beaumont, M.A., Zhang, W. and Balding, D.J. (2002) ApproximateBayesian computation in population genetics,Genetics162, 2025–2035.[3] Marjoram, P., Molitor, J., Plagnol, V., and Tavaré, S. (2003) Markovchain Monte Carlo without likelihoods,Proc. Natl. Acad. Sci. USA100, 15324–15328.
419 Connections between stagewise algo-rithms and the LASSO: with applications toneuroanatomical studies [Invited Session 7 (page32)]
Jonathan TAYLOR , Stanford, USA
The Lasso (Tibshirani 1996) is a method for regularizing leastsquares regression via L1 constraints. The LAR (Least angleregression) algorithm of (Efron et al 2003) provides an efficientmethod for computing the entire sequence of Lasso solutions. Inthe process, the LAR algorithm also provides a conceptual linkbetween the Lasso and Forward Stagewise regression. The latterstrategy is an important component in adaptive regression pro-cedures like boosting, and hence this link helps us understandhow boosting works.In this work, we (partially) characterize problems for which thecoefficient curves for Lasso are monotone as a function of theL1 norm; this is the situation where all three procedures (LAR,Lasso, and Forward Stagewise) coincide. Surprisingly, the con-ditions under which all three algorithms agree involve Gaussianprocesses associated to transient Markov processes.Inspired by this relation, we compare the results stagewise re-gression (or the LASSO, by equivalence) to the results of stan-dard voxel-based morphometry.
420 Optimal portfolio choice in bond mar-kets [Contributed Session M5 (page 27)]
Michael TEHRANCHI , University of Texas, USA
We consider the Merton problem of optimal portfolio choicewhen the traded instruments are the set of zero-coupon bonds.Working within an infinite-factor Markovian Heath-Jarrow-Morton model of the interest rate term structure, we find condi-tions for the existence and uniqueness of optimal trading strate-gies. When there is uniqueness, we provide a characterizationof the optimal porfolio.In particular, letPt(T) denote the price at timet of a zero-couponbond which is worth one unit of money at the maturityT. Thedynamics of the bond price curve(Pt(·))t≥0 is modeled by astochastic evolution equation in a separable Hilbert spaceH,where the driving noise is given by a cylindrical Wiener process.In this setting, the trading strategies are processesφ = (φt)t≥0taking values in the dual spaceH∗ and satisfying a self-financingcondition.We fix a utility functionu and a terminal dateT, and considerthe functionalJ(φ) = E u(Xφ
T ) whereXφT is the accumulated
wealth at timeT generated by the trading strategyφ . We ex-tend the work of Ekeland and Taflin [4] by solving this Mertonproblem when bond prices are Markovian but not necessarilylog-normal. We find a representation of the optimal strategyφby appealing to the infinite dimensional version of the Clark-Ocone-Haussmann formula.References[1] Björk, T., Masi, G. Di, Kabanov, Y., and Runggaldier, W. (1997) To-wards a general theory of bond markets,Finance Stochast.1 141–174.[2] Carmona, R. and Tehranchi, M. (2004)A characterization of hedg-

Abstracts 191
ing portfolios for interest rate contingent claims,to appear in Ann. Appl.Prob.[3] De Donno, M., and Pratelli, M. (2004) On the use of measured-valued strategies in bond markets,Finance Stochast.8 87–109.[4] Ekeland, I. and Taflin, E. (2002)A theory of bond portfolios,preprint, CEREMADE and EISTI.
421 Large deviations for random uppersemicontinuous functions [Contributed Session C14(page 16)]
Pedro TERÁN, Universidad de Zaragoza, Spain
The general empirical process provides a convenient frameworkfor proving limit theorems of many kinds. In particular, it hasbeen applied to obtaining the Strong Law of Large Numbers [4,6] and the Central Limit Theorem [3, 5] within the theory of ran-dom upper semicontinuous functions initiated by M. L. Puri andD. A. Ralescu [8, 9].Notice that random upper semicontinuous functions (otherwiseknown as fuzzy random variables, random fuzzy sets and gener-alized random sets) can be viewed as random elements of a non-separable metric cone of functions endowed with non-pointwiseaddition and product by non-negative scalars. The naturalσ -algebra in that theory is larger than the Borelσ -algebra. Thatleads, in the end, to the unavailability of devices in the spiritof Pettis’ measurability theorem in order to reduce the non-separable case to the better behaved separable case. Here iswhere the machinery of the general empirical process, whichuses the non-separable spaces`∞(T), becomes very valuable.Recent developments suggest strong links between large devia-tions convergence and weak convergence. A. Puhalskii [7] hasrecast l. d. convergence as a form of generalized weak conver-gence where limits are maxitive set functions termed deviabil-ities. As a matter of fact, deviabilities are in one-to-one corre-spondence with a subfamily of upper semicontinuous functions.In his turn, M. A. Arcones [2] has convincingly shown that, toa great extent, the familiar finite-dimensional approach to weakconvergence can be replicated in the large deviations setting.It is only natural in this situation to wonder whether Arcones’results [1] can be useful in deriving the Large Deviations Princi-ple for random upper semicontinuous functions, and that is theproblem which we will address. In our knowledge, no resulton large deviations for random upper semicontinuous functionsexists in the literature.The obtention of the Large Deviations Principle is divided intotwo parts. First, prove it under the assumption of quasiconcav-ity by using the results on the empirical process. Second, dropthat assumption by adapting a device which is classical in limittheorems for random upper semicontinuous functions.References[1] Arcones, M.A. (2003)Large deviations of empirical processes,In:“High Dimensional Probability III" (J. Hoffmann-Jørgensen, M. B. Mar-cus, J. A. Wellner, eds.), 205–223. Birkhäuser, Boston.[2] Arcones, M.A. The large deviation principle for stochastic pro-cesses, Parts I and II,Theory Probab. Appl.to appear.[3] Li, S., Ogura, Y., and Kreinovich, V. (2002)Limit theorems andapplications of set-valued and fuzzy-valued random variables,Kluwer,Dordrecht.[4] Proske, F.N. and Puri, M.L. (2002) Strong law of large numbers forBanach space valued fuzzy random variables.J. Theoret. Probab.15,543–551.[5] Proske, F.N. and Puri, M.L. (2002) Central limit theorem for Ba-nach space valued fuzzy random variables,Proc. Amer. Math. Soc.130,1493–1501.[6] Proske, F.N. and Puri, M.L. (2003) A strong law of large numbersfor generalized random sets from the viewpoint of empirical processes,
Proc. Amer. Math. Soc.131, 2937–2944.[7] Puhalskii, A. (2001)Large deviations and idempotent probability,Chapman & Hall, Boca Raton.[8] Puri, M.L. and Ralescu, D.A. (1985) The concept of normality forfuzzy random variables,Ann. Probab.13, 1373–1379.[9] Puri, M.L. and Ralescu, D.A. (1986) Fuzzy random variables.J. Math. Anal. Appl.114, 409–422.
422 Gibbs measures and stochastic net-works [Invited Session 17 (page 49)]
Prasad TETALI , Georgia Tech
We consider questions of phase coexistence and uniqueness ofGibbs measures arising in loss network models of telecommu-nication systems that support multicast and unicast connections.Multicast connections are assumed to arrive to each node of thenetwork at a Poisson arrival rateλ > 0 and require unit capacityon each edge emanating from the node, while unicast connec-tions arrive at each edge at a Poisson arrival rate nu and requireunit capacity on that edge. Connections are accepted only if therequired capacity is available – otherwise they are lost. Whenthere are only multicast connections (i.e.,ν = 0) and each link oredge in the network has capacity C = 1, this model correspondsto the hard-core lattice gas model arising in statistical physics.We present some results for the general model as studied on theinfinite d-ary tree and onZd.
423 Jointly characterizing allelic associa-tions and estimating haplotype frequenciesfrom diploid data by graphical modeling [In-vited Session 5 (page 29)]
Alun THOMAS , University of Utah, USA
Two extentions are made to the method of using a graphicalmodel to describe allelic associations between genetic loci inlinkage disequilibrium developed by Thomas and Camp [1]. Thefirst extention builds an additional layer to the graphical modelto represent the relationships between the unobservable phaseknow allelic states and the observed genotypes. This also en-ables haplotype frequency estimation and estimation of phasefor sampled individuals. The second development is to restrictthe set of possible graphical models to those whose Markovgraph is an interval graph. This greatly improves the tractabilityof the method, but does not significantly affect the accuracy ofthe results. This approach is compared with the PHASE program[2] and the results from each method are shown to be broadlysimiliar. Graphical modeling is shown to have some advan-tages over coalescent methods in terms of tractability and canbe used to select informative subsets of loci and to map loci in-fluencing phenotypes. A program calledHapGraphimlementsthe method and is available from the author’s internet web sitehttp://bioinformatics.med.utah.edu/∼alun.References[1] Thomas, A. and Camp, N.J. (2004)Graphical modeling of the jointdistribution of alleles at associated loci, American Journal of HumanGenetics 74.[2] Stephens, M., Smith, N.J., and Donnelly, P. (2001) A new statisticalmethod for haplotype reconstruction from population data,AmericanJounal of Human Genetics68, 978–989.
424 Tree and grid factors in point pro-cesses[Contributed Session C62 (page 18)]
Ádám TIMÁR , Indiana University, USA
We study isomorphism invariant point processes ofRd whosegroups of symmetries are almost surely trivial. We define a 1-

192 6th BS/ IMSC
ended, locally finite tree factor on the points of the process, thatis, a mapping of the point configuration to a graph on it that ismeasurable and equivariant with the point process. This answersa question of Holroyd and Peres. The tree will be used to con-struct a factor isomorphic toZn. This perhaps surprising result(that anyd andn works) solves a problem by Steve Evans. Theconstruction, based on a connected clumping with2i vertices ineach clump of thei’th partition, can be used to define variousother factors.References[1] Holroyd, A.E. and Peres, Y. (2003) Trees and matchings from pointprocesses.Elect. Comm. in Probab.[2] Ádám Timár (2003) Tree and Grid Factors of General Point Pro-cesses, accepted byElect. Comm. in Probab.
425 Asymptotic behavior of the magneti-zation for the perceptron model [ContributedSession C35 (page 26)]
David MÁRQUEZ-CARRERAS, Carles ROVIRA,Universitatde Barcelona, Spain
Samy TINDEL , Université Henri Poincaré (Nancy),Vandoeuvre-lès-Nancy, France
The perceptron model is a model of spins glasses, that has beenintroduced in order to get some information about the capacityof neural networks. One of the basic information of interest forphysicists (see [1]) is the asymptotic behavior of the magnetiza-tion, namely of a random variable of the form〈σk〉, whereσk isthe value of a single spin. In this communication, we will showthat those random variables converge inL2 when the size of thesystem tends to infinity, in case of a perceptron model for whichthe number of outputs is a small proportion of the size of thesystem.References[1] Hertz, J., Krogh, A., and Palmer, R. (1991)Introduction to the The-ory of Neural Computation. Addison-Wesley Publishing Company.[2] Márquez-Carreras, D., Rovira, C., and Tindel, S. (2003) Asymptoticbehavior of the magnetization for the perceptron model, submitted.[3] Talagrand, M. (2003)Spin Glasses: a Challenge for Mathematicians.Springer. Berlin.
426 Convergence of values in optimal stop-ping and convergence of optimal stoppingtimes [Contributed Session C36 (page 16)]
Sandrine TOLDO, Université Rennes 1, France
Let us consider a càdlàg processX indexed by[0,T] and takingvalues inR. Let us denote byF = (Ft)t≤T the right-continuousassociated filtration.Let γ : [0,+∞[×R→ R a bounded continuous function. We de-fine the value in optimal stopping of horizonT of the processXby :
Γ(T) = supE[γ(τ,Xτ )],where the supremum is taken over allF-stopping timesτbounded byT.Let us consider a sequence(Xn)n of processes which convergesin probability toX. For everyn, we denote byFn = (Fn
t )t≤T thenatural filtration ofXn. Then, we define the values in optimalstoppingΓn(T) by
Γn(T) = supE[γ(τ,Xnτ )],
where the supremum is taken over allFn-stopping timesτbounded byT.We prove that it happens under the hypothesis of inclusion offiltrations Fn ⊂ F , or under convergence of filtrations that is if
processes(E[1B|Fnt ])t≤T converge to the process(E[1B|Ft ])t≤T
for all B∈ FT .
Then, when we have the convergence of the optimal values(Γn(T))n to Γ(T), we are interested in the possible convergenceof a sequence of associated optimal stopping times. The problemhere is that, in general, the limit of a sequence of stopping timesis not a stopping time. However, we give an example of situationwhere the limitτ is a stopping time for whichγ(τ,Xτ ) = Γ(T).
427 Minimum Hellinger distance estima-tors for some multivariate distributions
[Poster Session P3 (page 42)]
Aida TOMA , Academy of Economic Studies, Romania
In this paper we consider the multivariate Johnson translationsystem distributions, more precisely the multivariate lognormal,normal-lognormal and sinh−1-normal distributions. These dis-tributions have been shown to have many practical applications.We define minimum Hellinger distance estimators (MHDE) forthe parameters of these distributions and show the relationshipwith MHDE of the multivariate normal distribution. We ex-plore some properties of these estimators such as consistencyand asymptotic normality. Finally we consider a special measureof discrepancy between parameter values and the correspond-ing breakdown point. Then for each MHDE we find an inferiorbound of the breakdown point and this show the advantage ofusing these estimators from the robustness point of view.References[1] Tamura, R.N., Boos, D.D. (1986) Minimum Hellinger distance esti-mation for multivariate location and covariance,JASA81, 223–229.[2] Toma, A. (2003) Robust estimations for multivariate normal-lognormal distributions,Bulletin of ISI 60, 79–89.
428 Principal component determinationand random vector estimate with method ofpartitioned data orthogonalisation [Poster Ses-sion P1 (page 22)]
P. HOWLETT, S. LUCAS andA. TOROKHTI , University ofSouth Australia, Australia
In this paper, we propose and justify an estimator which allowsus to estimate a random vector and its principal componentsfrom observed data with a higher associated accuracy and a bet-ter compression ratio than those by principal component analy-sis (PCA), for the same or smaller computational work as thatby PCA.Such advantages are achieved under a certain condition whichfollows from a comparison of the error estimate associated withthe presented method and that of PCA. The proposed estimatoris implemented through a sequence of procedures which involvea partition of the observed data, a special orthogonalisation ofthe partitoned data, and the rank-constrained minimization ofthe associated error.An extension of this technique to the case of the unconstrainederror minimization is also studied.We give rigorous proofs of the statements associated with theproposed technique. The theory of the method is illustrated withresults of numerical experiments using real data.A device for the proposed method is as follows.The observed datay∈ L2(Ω,Rn) are partitioned in ‘shorter’ vec-tors z1, . . . ,zs such thatzi ∈ L2(Ω,Rni ) for i = 1, . . . ,s wheren1 + · · ·+ns = n. Thenz1, . . . ,zs are transformed to orthogonalvectorsv1, . . . ,vs.

Abstracts 193
A desired estimator follows from the solution of the con-strainedminimization problem which is posed in terms of vec-torsv1, . . . ,vs.The idea of random vector orthogonalisation is not, of course,new. Goldstein, Reed and Scharf(1998), and Mathews andSicuranza(2001) have considered the orthogonalisation proce-dures, but for different problems. The novelty of our procedureis a generalisation of the Gram-Schmidt technique to the case ofoperators, not matrices as in the known references, and when theoperators are not invertible.Unlike the known problems, which are formulated for one con-straint only, the problem under considereation is subject toscon-straints withs= 1,2, . . . .. As a result, our estimatorP is deter-mined bysmatrices of small sizesm×ni andni×ni while PCA-like techniques imply computation of largerm×n andn×n ma-trices.Such a special form of the estimatorP implies advantages re-lated to the associated accuracy, compression ratio and compu-tational work.In particular, evaluations involvingm×ni andni ×ni matricesrequire less computational work than that for largerm× n andn×n matrices.There are specific differences from the known techniques devel-oped, in particular, by Yamada, Sekiguchi and Sakaniwa(2000),Hua, Nikpour and Stoica(2001) and Torokhti and Howlett(2001,2002,2003).The methods by Yamada, Sekiguchi and Sakaniwa(2000), andTorokhti and Howlett(2001, 2002) are based on polynomial op-erators. The proposed estimator is not polynomial.Hua, Nikpour and Stoica(2001) considered an advanced powermethod for computing the matrix which implements PCA. Al-though the proposed method is not PCA, the technique by Hua,Nikpour and Stoica(2001) can be applied here as well.The methods by Torokhti and Howlett(2003) are based on spe-cific iterative procedures. Unlike the techniques (Torokhti andHowlett2003), the proposed estimator relates to so called directestimators, which are not iterative.We would also like to mention that techniques of establish-ing our main results are different from the techniques used byTorokhti and Howlett(2001,2002,2003).We show that, similar to PCA, our estimator can be representedas a composition of two transforms. The first of them is to de-termine the principal components, and the second transform isto restore the reference vector.The proposed approach can be extended to the estimators ofhigher degrees (Yamada, Sekiguchi, Sakaniwa 2000), locallyreduced-rank estimators (Yamada, Elbadraoui 2003) and the it-erative estimators (Torokhti, Howlett 2003).References[1] Yamada, I., Sekiguchi, T., and Sakaniwa, K. (2000)Proc. 2nd Int.Workshop Multidim. Syst., Poland.[2] Ocaña, F.A., Aguilera, A.M., and Valderrama, M.J. (1999) Func-tional principal components analysis by choice of norm,J. MultivariateAnal. 71, 262–276.[3] Stock, J.H. and Watson, M.W. (2002) Forecasting using principalcomponents from a large number of predictors,J. Amer. Statist. Assoc.97, 1167–1179.[4] Torokhti, A. and Howlett, P. (2003) Constructing fixed rank optimalestimators with method of best recurrent approximations,J. MultivariateAnal. 86, 293–309.
429 Method of best hybrid approximationsfor constructing fixed rank optimal estima-tors [Contributed Session C41 (page 46)]
P. HOWLET,University of South Australia, Australia
C. PEARCE,University of Adelaide, Australia
A. TOROKHTI , University of South Australia, Australia
We propose a new approach which generalizes and improvesprincipal component analysis (PCA) and its recent advances.The approach is based on the following underlying ideas. PCAcan be reformulated as a technique which provides the best lin-ear estimator of the fixed rank for random vectors. By the pro-posed method, the vector estimate is presented as a special poly-nomial operator of degreer aimed to improve the error of esti-mation compared with customary linear estimates. The vector isfirst pre-estimated from the special iterative procedure such thateach iterative loop consists of a solution of the unconstrainednonlinear best approximation problem. Then, the final vectorestimate is obtained from a solution of the constrained best ap-proximation problem with the polynomial approximant.We show that this hybrid technique produces a computationallyefficient and flexible estimator. The method has two degreesof freedom, the degreer of the approximating operator and thenumber of iterations, to decrease the associated error.As a result, the proposed approach allows us to provide a newnonlinear estimator with a significantly better performance com-pared with that of PCA and its known modifications.The basic device is based on a development and combination oftechniques presented by Tipping and Bishop (1999), Kneip andUtikal (2001), Honig and Xiao (2001), and Torokhti, Howlettand Ejov (submitted).Let F be a nonlinear transform such thats= F (x). Lety be thenoise-corrupted version ofx. It is supposed that the image of thetransformPk, which approximatesF , isy and that informationon F is given in terms of the statistical characteristics ofs andy such as the mean, covariance matrices etc.To find an optimal transformPk, the idea of a concatenationof approximating subtransforms can be exploited in the follow-ing way. LetB0 approximateF in a certain sense. We callB0 a subtransform. The image ofB0 is used as the preimageof the subsequent approximating subtransformB1 that has tobe determined, and then the procedure is repeated. As a result,the link betweeny and s is modelled from the concatenationPk = Bk Bk−1 . . . B0 with k = 0,1, . . .. For the appro-priate choice ofB0, . . ., Bk, the operatorPk is treated as anapproximation toF .This device initiates the problem as follows. Find a constructiveapproximationPk for F such that eachBk approximatesFwith a minimal possible error for everyk = 0,1, . . . , and further,the error is decreased whenk is increased.Pk is determined byBk,Bk−1, . . . ,B0, We note that while the transform concatena-tion is a natural idea, the methodology of an optimal determi-nation of the parameters of each subtransform is not obvious.In particular, the nonlinearity of each approximating subtrans-form Bi is essential. No improvement in the accuracy can beachieved by the following subtransformBi+1 if Bi+1 is linear.This observation is described in more detail.We prove that the error is decreased when either the degreer ofoperatorBi or the number of iterationsk is increased.Results of numerical simulations are givenThe proposed approach has direct applications to feature selec-tion, clustering, filtering and data compression.References[1] Tipping M.E. and Bishop, C.M. (1999) Probabilistic principal com-ponent analysis,J. R. Stat. Soc. Ser. B Stat. Methodol.61, 611–622.[2] Kneip A. and Utikal, K.J. (2001) Inference for density families usingfunctional principal component analysis,J. Amer. Statist. Assoc.96,

194 6th BS/ IMSC
519–542.[3] Honig, M.L. and Xiao, W. (2001) Performance of reduced-rank lin-ear interference suppresion,IEEE Trans. Inform. Theory47, 1928–1946.[4] Torokhti, A., Howlett, P. and Ejov, V. (submitted)Comput. Stat. &Data Analysis.
430 Optimal nonlinear transform formedby reduced-rank operators [Poster Session P1(page 22)]
P. HOWLET andA. TOROKHTI , University of South Aus-tralia, Australia
The linear reduced-rank transforms have successfully been ap-plied to the solution of many problems related to data compres-sion, filtering, clustering, feature selection, forecasting, etc. Aperformance of the reduced-rank transform is characterised bythe three associated parameters: accuracy, compression ratio andcomputational work.The principal component analysis (PCA) is optimal in the classof linear reduced-rank tramsforms. Nevertheless, it may hap-pen that the accuracy and compression ratio, associated with thePCA, are still not satisfactory. In such a case, an improvementin the accuracy and compression ratio can be reached by a trans-form with a more general structure than that of the PCA.We propose and rigorously justify a new approach to construct-ing nonlinearoptimal transforms which possess properties re-lated to reduced-ranklinear transforms. The approach is basedon a reduction of the associated constrained minimization prob-lem to the problem of finding a special operator extension ofa truncated Fourier series in a separable Hilbert spaceH. Weshow that the accuracy and compression ratio associated withthe proposed transform are better than those of the PCA.An important particular case follows from the proposed trans-form when no constraint is imposed. Such an unconstrainedtransform is treated as an optimal nonlinear filter which repre-sents a broad generalisation of the Wiener filter.The novelty of the approach consists of(i) a new methodology for constructing optimal transformswhich implies advantages over the known transforms, and(ii) new techniques for analysis of properties associated withsuch a methodology.The basic idea is to represent a nonlinear transform as a com-bination of p reduced-rank linear operatorsF 1, . . . ,F p. Un-like the Volterra polynomials which suffer a severe computa-tional burden associated with the large number of termsN, itis proposed to use a transform structure based on exploiting the“intermediate” operatorsϕ1, . . . ,ϕ p andQ1, . . . ,Qp. These op-erators aim both to reduce the number of terms fromN to pwith p << N and improve the transform characteristics com-pared with those of the known transforms. In the paper, twomethods for choosing these operators are considered.The proposed transform T p is represented by
T p(y) =p
∑k=1
F k(vk) with vk = Qkϕk(y). It is interesting to
observe thatT p can be interpreted as an operator generali-sation of the truncated Fourier series inH if F 1, . . . ,F p aredefined from an associated minimization problem. We note thatunlilke the definition of customary Fourier series,F 1, . . . ,F p
are operators, not scalars.The associated minimization problem is formulated subject topconstraints on ranks ofF 1, . . . ,F p . The solution to the prob-lem is given. Some paricular cases of the solution are consideredas well. In particular, we give the solution to the unconstarained
problem. We show that the determination ofF 1, . . . ,F p fromthe unconstrained problem leads, indeed, to a special generalisa-tion of the truncated Fourier series inH. Such an unconstrainedtransform represents a broad generalisation of the Wiener filterand, therefore, is important in its own.A rigorous analysis of errors associated with the proposed trans-forms is provided. A discussion of distinctive features of theproposed techniques is also presented. Numerical realisation ofthe proposed transform is given. Theoretical results are associ-ated with those by Ledoit and Wolf (2004), Tipping and Bishop(1999), Kubokawa and Srivastava (2003), and Torokhti, Howlettand Lucas (submitted). Numerical simulations with real data arediscussed.References[1] Ledoit, O. and Wolf, M. (2004) A well-conditioned estimator forlarge-dimensional covariance matrices,J. Multivariate Anal. 88, 365–411.[2] Tipping, M.E. and Bishop, C.M. (1999)Neural Computation,11,443–482.[3] Kubokawa, T. and Srivastava, M.S. (2003) Estimating the covariancematrix: a new approach,J. Multivariate Anal.86, 28–47.[4] Torokhti, A., Howlett, P., and Lucas, S. (submitted)J. Amer. Stat.Assoc.
431 Simulating the ruin probability of riskprocesses with delay in claim settlement[Con-tributed Session M2 (page 41)]
Giovanni Luca TORRISI , CNR-Istituto per le Applicazioni delCalcolo, Italy
A risk process with delay in claim settlement is usually de-scribed in terms of a Poisson shot-noise process; see Klüppel-berg and Mikosch (1995), and Brémaud (2000). In particular,Brémaud (2000) has proved that under suitable light tail condi-tions the corresponding ruin probability goes to zero not slowerthan an exponential rate. This yields problems if we want to es-timate the ruin probability by a Monte Carlo simulation. In thispaper we overcome these difficulties deriving the asymptoticallyefficient simulation law.References[1] Brémaud, P. (2000) An insensitivity property of Lundberg’s estimatefor delayed claims,J. Appl. Prob.37, 914–917 ,[2] Klüppelberg, C. and Mikosch, T. (1995) Explosive Poisson shotnoise processes with applications to risk reserves.Bernoulli 1, 125–147.
432 Differential equations for Dyson pro-cesses[Invited Session 20 (page 29)]
Craig A. TRACY , UC Davis, USA
Harold WIDOM,UC Santa Cruz, USA
We call Dyson process any process on ensembles of matrices inwhich the entries undergo diffusion. The original Dyson processis what we call the Hermite process. Scaling the Hermite pro-cess at the edge leads to the Airy process [3] and in the bulk tothe sine process. Similarly we define a Bessel process by scal-ing the Laguerre process at the hard edge. For a given Dysonprocess one is interested in the induced process on the eigenval-ues,λ j (τ); and in particular, the process defined by the largesteigenvalueλmax(τ). It is known (see, e.g. [2,3]) that the finitedimensional distributionsP(λmax(τ1)≤ ξ1, . . . ,λmax(τm)≤ ξm)are expressible in terms of a Fredholm determinat of an operatorwith m×m matrix kernel. Form= 1 earlier results of the au-thors show that these Fredholm determinants can be expressed interms of solutions to certain Painlevé equations. We show thatfor generalm the finite dimensional distributions are express-

Abstracts 195
ible in terms of solutions to a system of total partial differentialequations with theξ j the independent variables [4]. Form= 2a different set of PDEs were found for the Hermite and Airyprocess by Adler and van Moerbeke [1].In this lecture we give an overview of these results as well asdiscussing the significance for growth processes.References[1] Adler, M. and van Moerbeke, P. A PDE for the joint distributions ofthe Airy process, preprint (arXiv:math.PR/0302329).[2] Johansson, K. Discrete polynuclear growth processes and determi-nantal processes, preprint (arXiv:math.PR/0206208).[3] Prähofer, M. and Spohn, H. (2002) Scale invariance of the PNGdroplet and the Airy process.J. Stat. Phys.108, 1071–1106.[4] Tracy, C.A. and Widom, H. (2003) A system of differential equationsfor the Airy process.Elect. Comm. in Probab.8, 93–98; Differentialequations for Dyson processes, preprint (arXiv:math.PR/0309082).
433 Phase diagram for a stochastic reac-tion diffusion system [Invited Session 15 (page 51)]
Carl MUELLER,Rochester, USA
Roger TRIBE, Warwick, UK
A two dimensional reaction diffusion system
∂tu = ∆u+βuv− γu+
√udW,
∂tv =−uv.
describes the spread of a populationu and the decay of a non-renewable resourcev. The deterministic system, where the noiseterm is omitted, exhibits travelling pulses (or solitary waves).The spatial noise can destroy this behaviour, preventing the pop-ulation spreading.The aim of this work is to investigate a phase diagram, in theparameters(β ,γ), describing when the population can persist.This exploits the comparison methods developed by Durrett andothers, and used by the authors previously for a one dimensionalmodel controlled by a single parameter [1]. The key new toolis the use of exit measures, which describe the flux of the pop-ulations across regions. These allow one to prove monotonicityresults in the initial conditions and parameter values.
References
[1] Mueller, C. and Tribe, R. (1994) A phase transition for a stochasticPDE associated to the contact process.PTRF100, 131–156.
434 Practical small-sample inference fororder one subset autoregressive models viasaddlepoint approximations [Contributed SessionC33 (page 45)]
Robert L. PAIGE,Texas Tech University, U.S.A.
A. Alexandre TRINDALE , University of Florida, U.S.A.
We propose some approaches for saddlepoint approximatingdistributions of estimators in single lag subset autoregressivemodels of order one. Theroots of estimating equationsmethodis the most promising, not requiring that an explicit expres-sion for the estimator be available. We find the distributionsof the Burg estimators to be almost coincidental with those ofmaximum likelihood. By inverting a hypothesis test, we showhow confidence intervals for the autoregressive coefficient canbe constructed from saddlepoint approximations. A simulationstudy reveals the resulting coverage probabilities to be very closeto nominal levels, and to generally outperform asymptotics-based confidence intervals. The reason is shown to be linkedto near parameter orthogonality between the autoregressive co-efficient and the white noise variance. Our findings are substan-
tiated by percent relative error calculations that show the saddle-point approximations to be very accurate.
435 A new nonparametric ANCOVAmodel, used in the financial problem of stockreturns anomalies [Contributed Session M8 (page 31)]
Haritini TSANGARI , Intercollege, Cyprus
A new nonparametric ANCOVA model has been developed.In this model the response distributions need not be continu-ous or to comply to any parametric or semiparametric model.The model allows for possibly nonlinear covariate effect whichcan have different shape in different factor level combinations.Nonparametric hypotheses of no main factor effects, no in-teraction and no simple effect, which adjust for the covariatevalues, are considered. The test statistics are based on averagesover the covariate values of certain Nadaraya-Watson regressionquantities. Under their respective null hypotheses they have acentral chi-squared distribution. Small sample corrections to theasymptotic distribution, which use the F-distribution, are alsoprovided. The model was first developed for independent data([1]). We hereby consider the extension of the model to thecase of longitudinal data, with a column factor that has manylevels and a different way to select the bandwidth. The model isapplied in the area of Finance, in the popular problem of identi-fying anomalies in stock returns. Financial literature has shownthat fundamental variables such as firm size, Earnings Yield,Book-to-Market ratio, or the month of January, have an effecton stock returns. If anomalies do exist, then investors can setup strategies that would give them abnormal profits and therewill be serious questions about the central prediction of modernfinance, which asserts that systematic risks are the fundamentaldeterminant of asset returns. However, empirical proceduresfor identifying if these so called “anomalies" exist were basedon traditional statistical techniques, such as regressions, usingformed portfolios. An alternative approach for identifying ef-fects on returns is thus presented, using the new nonparametricANCOVA model. ANCOVA, on one hand, tests for main factoreffects and interactions simultaneously, while adjusting for thecovariate effects; the new nonparametric model, on the otherhand, avoids conflicting results caused by the violation of basicmodeling assumptions. The advantages of the new approach aremade clear throughout the presentation.
References
[1] Tsangari, Haritini and Akritas, Michael G. (2004) NonparametricANCOVA with two and three covariates,J. Multivariate Anal.88, 298–319.
436 Functional aggregation [Contributed Ses-sion C41 (page 45)]
Alexandre B. TSYBAKOV , Université Paris 6, France
We study the problem of aggregation ofM arbitrary estimatorsof a regression function with respect to the mean squared risk.Three main types of aggregation are considered: model selec-tion, convex and linear aggregation. We define the notion of op-timal rate of aggregation in an abstract context and prove lowerbounds valid for any method of aggregation. We then constructprocedures that attain these bounds, thus establishing optimalrates of linear, convex and model selection type aggregation.
References
[1] Tsybakov, A. (2003) Optimal rates of aggregation,ComputationalLearning Theory and Kernel Machines,B.Schölkopf and M.Warmuth,eds. Lecture Notes in Artificial Intelligence, v.2777. Springer, Heidel-

196 6th BS/ IMSC
berg, 303–313.
437 Convergence of markov processes nearsaddle fixed points [Contributed Session C21 (page 50)]
A.G.TURNER , Cambridge University, United Kingdom
We consider sequences(XNt )t≥0 of Markov processes in two di-
mensions whose fluid limit is a stable solution of an ordinary dif-ferential equation of the formxt = b(xt), whereb(x) = Bx+τ(x)for some matrixB with eigenvaluesλ ,−µ whereλ ,µ > 0 andτ(x) = O(|x|2). The simplest example arises from the OK Cor-ral gunfight model which was formulated by Williams and McIl-roy (1998) and studied by Kingman (1999) and subsequently byKingman and Volkov (2001). These processes exhibit their mostinteresting behaviour at timesΘ(logN) so it is necessary to es-tablish a fluid limit that is valid for large times. We find that thislimit is inherently random and obtain its distribution. Using this,it is possible to derive scaling limits for the points where theseprocesses hit straight lines through the origin, and the minimaldistance from the origin that they can attain. The power ofNthat gives the appropriate scaling is surprising. For example ifT is the time thatXN
t first hits one of the linesy = x or y = −x,then
Nµ
2(λ+µ) |XNT | ⇒ |Z|
µλ+µ ,
for some zero mean Gaussian random variableZ.
References
[1] Turner, A.G. (2004)Convergence of Markov Processes Near SaddleFixed Points, In Preparation.
438 Adaptive filtering in insurance withjump noise [Contributed Session M4 (page 37)]
Krystyna TWARDOWSKA , Warsaw University of Technol-ogy, Poland
Tomasz MichalskiWarsaw School of Economics, Poland
We apply the so-called Kalman filter technique to predict thenumber of claims and the total claim payments for the futureyears in the collective risk model in insurance. We use theheavy-tailed probability distributions so the large claims are notneglected. The filtering method proposed here allows us to pre-dict not only the claim amounts and numbers of claims but alsothe loss ratios, the burning costs, the level of the reserve for un-paid compensations, the level of the catastrophic reserves, theportfolio structure, etc. We have used the similar method in[1], namely we have used the averaging adaptive Kalman fil-ter combined with IBNR (Incurred But Not Reported) techniquefor the loss reserving in automobile liability insurance. The dataset was given from the non-cumulative run-off triangle. We getsome satisfactory results. We generalize here the equations ofthe filtering method from [1]. Namely, some risk sensitive ma-trices can be derived from the knowledge about the insuranceprocesses and we also use some properties of the jump processesoccuring as the noises in our equations.
References
[1] Michalski, T., Twardowska, K., and Tylutki, B. (2004) Adaptive fil-tering in the presence of heavy-tailed distributions in insurance, submit-ted to International Advances in Economic Research,First paper.
439 Nonparametric kernel-based sequen-tial investment strategies [Contributed Session M8(page 31)]
László GYÖRFI,Technical University of Budapest, Hungary
Gábor LUGOSI andFrederic UDINA , Universitat Pompeu
Fabra, Spain
The purpose of this paper is to introduce sequential investmentstrategies that guarantee an optimal rate of growth of the capi-tal under minimal assumptions on the behaviour of the market.The new strategies are analyzed both theoretically and empiri-cally. The theoretical results show that the asymptotic rate ofgrowth matches the optimal one that one could achieve with afull knowledge of the statistical properties of the underlying pro-cess generating the market, under the only assumption that themarket is stationary and ergodic.More precisely, we consider anRd-vector-valued stationary andergodic processXn∞−∞ and we model the market as a sequenceX1,X2, . . . drawn from it. Componenti of X j is the ratio of theclosing and opening prices of asseti in period j. An investmentstrategyB is a functionb(Xn−1
1 ) from then−1 first periods (de-noted byXn−1
1 ) gives a portfolio distribution over thed assets,that is an element of the simplex∆d ⊂Rd.Given an initial wealthS0, aftern trading periods, the investmentstrategyB achieves the wealth
Sn = S0
n
∏i=1
⟨b(X i−1
1 ) , X i
⟩, with
Wn(B) =1n
n
∑i=1
log⟨
b(X i−11 ) , X i
⟩.
being theaverage growth rate. Our goal is to maximizeSn =Sn(B) or equivalently, to maximizeWn(B).It is well known (see references below) then the so-calledlog-optimum portfolioB∗ = b∗(·) is the best possible choice. Thisis defined as follows: on trading periodn let b∗(·) to be such that
E
log⟨
b∗(Xn−11 ) , Xn
⟩∣∣∣Xn−11
= E
maxb(·)
log⟨
b(Xn−11 ) , Xn
⟩∣∣∣∣Xn−11
.
(1)
This portfolio, that can only be computed with full knowledgeof the process, achieves (almost surely) the maximal possiblegrowth rate of any investment strategy, namely
W∗ = E
maxb(·)
E
log⟨
b(X−1−∞) , X0
⟩∣∣∣X−1−∞
Thekernel strategywe define is auniversal strategyin the sensethat it achieves the maximum average growth rate for a generalclass of processes, and of course this is done without foresight.The kernel strategy, in brief, consists in estimating the condi-tional distribution needed in (1) using the data in the past thataresimilar to recently observed past. To judge similarity, wediscuss several possibilities, the use of a kernel weighting func-tion being one of the more successful.The empirical results show that the performance of the proposedinvestment strategies measured on pastNYSE and currency ex-change data is solid, and sometimes even spectacular.References[1] Algoet, P. (1994) The strong law of large numbers for sequential de-cisions under uncertainty,IEEE Transac. Inform. Theory40, 609–634.[2] Algoet, P. and Cover, T.M. (1988) Asymptotic optimality asymptoticequipartition properties of log-optimum investments,Ann. Probab.16,876–898.[3] Breiman, L. (1960) The individual ergodic theorem of informationtheory,Ann. Math. Statist.31, 809–810.
440 Convergence rates in the law of largenumbers for Riemann random sums [Con-tributed Session C8 (page 35)]

Abstracts 197
Víctor HERNÁNDEZ,National Distance University of Spain
Henar URMENETA , Public University of Navarra, Spain
Let Xnknk=1, n = 1, 2, . . . be an array rowwise indepen-
dent, but not necessarily identically distributed random vari-ables and letSn = ∑n
k=1Xnk. We give necessary and sufficientconditions for the convergence of∑∞
n=1npP(|Sn−an|> εbn) or∑∞
n=1npP(supk≥n |Sk−ak|> εbk) for all ε > 0. We characterizethe convergence of the above series in the case wherean = ESn,provided the expectation exists andbn = n1/α , α < 2. Theseresults have been obtained for Baum and Katz in [1] for sums ofindependent and identically distributed random variables gener-alizing Hsu-Robbins-Erdös’s law of large numbers.Our results generalize Pruss’s [2] on complete convergence forrowwise independent arrays and the basic method is to useMontgomery-Smith and Pruss’s inequality [3].References[1] Baum, L.E. and Katz, M. (1965) Convergence rates in the law oflarge numbers,Trans. Amer. Soc.120, 108–123.[2] Pruss, A.R. (1996) Randomly sampled Riemann sums and completeconvergence in the Law of Large Numbers for a case without identicaldistribution,Proc. Amer. Math.124, 919–929.[3] Montgomery-Smith, S.J. and Pruss, A.R. (2001)A comparison in-equality for sums of independent random variables, J. Math. Anal. Appl.254, 35–42.
441 Repulsion of an evolving surface onrandom walls [Contributed Session C15 (page 53)]
Luiz Renato G. FONTES,University of São Paulo, Brazil
Marina VACHKOVSKAIA , University of Campinas, Brazil
Anatoli YAMBARTSEV, University of São Paulo, Brazil
We consider the motion of a discrete random surface interact-ing by exclusion with a random wall. Two kinds of randomnessare considered: rarefied wall and wall of random height. Thedynamics is given by the serial harness process. In the case ofrarefied wall, we prove that the process delocalizes iff the meannumber of visits to the set of sites where the wall is present bya random walk is infinite. When the surface delocalizes, boundson its average speed are obtained. In the case of wall of randomheight, we study the effect of the distribution of the wall heightson the repulsion speed.References[1] Ferrari, P.A., Fontes, L.R.G., Niederhauser, B., and Vachkovskaia,M. (2004) The serial harness interacting with a wall, To appear in:Stochastic Process. Appl.[2] Fontes, L.R.G., Vachkovskaia, M., and Yambartsev, A. (2003) En-tropic repulsion on a rarefied wall,Discrete Math. Theor. Comput. Sci.AC, 105–112.[3] Fontes, L.R.G., Vachkovskaia, M., and Yambartsev, A. (2004)Re-pulsion of an evolving surface on random walls,Work in progress.
442 Connectivity analysis via BayesianEEG-fMRI fusion [Invited Session 7 (page 32)]
Pedro VALDES, Cuban Neuroscience Center
EEG/fMRI neuroimage fusion promises simultaneous high spa-tial and temporal resolution, benefits that carry over to connec-tivity analysis. A principled fusion effort may be carried out viasymmetrical hierarchical Bayesian modeling in which both EEGand fMRI are given equal status as data produced by unobservedstate variables. We continue to develop tools for this task by ex-panding the Bayesian Multivariate Autoregressive Model usingspatial priors that allow the analysis of massive datasets. In thispresentation we show that the lasso sparse regression techniquemay be used to analyze jointly connectivity patterns efficiently.
443 Combining kernel estimators in theuniform deconvolution model [Contributed Ses-sion C54 (page 46)]
Bert VAN ES Universiteit van Amsterdam, The Netherlands
In the uniform deconvolution model we observe X’s which areequal to the sum of independent and unknown Y’s and Z’s, soX=Y+Z. We assume that Z has a Uniform(0,1) distribution.Our aim is to estimate the unknown density, or distribution func-tion, of Y, from the observed X’s. We construct a density esti-mator and an estimator of the distribution function in this model.The estimators are based on inversion formulas and kernel es-timators of the density of the observations and its derivative.Some asymptotic properties will be derived.
References
[1] van Es, B. (2002)Combining kernel estimators in the uniform de-convolution model, ArXiv:math.PR/0211079.
444 Empirical likelihood based goodness-of-fit test for parametric regression [ContributedSession C5 (page 18)]
Wenceslao GONZÁLEZ MANTEIGA and César SÁNCHEZSELLERO,Universidad de Santiago de Compostela, Spain
Consider a random vector(X,Y) and letm(x) = E(Y|X = x) bethe regression function. We are interested in testingH0 : m∈MΘ = mθ : θ ∈ Θ for some parameter spaceΘ ⊂ Rp. Thepurpose of this paper is to study a new testing procedure forH0. The idea of this procedure is to make use of the so-calledmarked empirical process introduced by Stute (1997), in com-bination with the theory of empirical likelihood ratio in order toobtain a powerful testing procedure. The asymptotic distributionof the proposed test statistic is established, and its finite sampleperformance is compared with other existing tests by means ofa simulation study.
References
[1] Stute, W. (1997) Nonparametric model checks for regression,Ann.Statist.25, 613–641.
445 Summary statistics for marked pointpatterns [Invited Session 31 (page 39)]
Marie-Collette VAN LIESHOUT , CWI, Amsterdam, TheNetherlands
We propose a new summary statistic for exploring the interac-tion structure in marked point patterns which generalises a J-function for multivariate point processes introduced in collabo-ration with Baddeley (1996, 1999). The statistic captures simul-taneously the range and strength of interaction. We discuss therelation to the mark correlation function (e.g. Stoyan (1984)),derive an expression in terms of the Papangelou conditional in-tensity and a mixture formula, then turn to estimation and testingfor independent random mark allocation, and finally illustratethe approach by means of a forestry data set.References[1] Chen, J. (2003) Summary statistics in point patterns and their appli-cations, PhD thesis, Curtin University of Technology.[2] Lieshout, M.N.M. van and Baddeley, A.J. (1996) A nonparametricmeasure of spatial interaction in point patterns,Statist. Neerl.50, 344–361.[3] Lieshout, M.N.M. van and Baddeley, A.J. (1999) Indices of depen-dence between types in multivariate point patterns,Scand. J. Stats.26,511–532.
446 A linear programming approach to ap-

198 6th BS/ IMSC
proximate dynamic programming [Invited Ses-sion 25 (page 14)]
Benjamin VAN ROY , Stanford University, USA
I will discuss approaches based on linear programming that ap-proximate a dynamic programming value function via a linearcombination of basis functions. The goal is to generate an ef-fective control policy for a Markov decision process. The talkwill focus on algorithmic developments and theoretical resultsthat bound the performance loss relative to an optimal controlpolicy in terms of the proximity of the dynamic programmingvalue function to the span of the basis functions.References[1] Pucci de Farias, D. and Van Roy, B. (2003) The Linear Program-ming Approach to Approximate Dynamic Programming.OperationsResearch51, 850–865.[2] Pucci de Farias, D. and Van Roy, B. On Constraint Sampling in theLinear Programming Approach to Approximate Dynamic Programming,to appear inMathematics of Operations Research.[3] Pucci de Farias, D. and Van Roy, B. (2004) A Cost-Shaping LinearProgram for Bellman Error Minimization with Performance Guarantees,submitted to the Neural Information Processing Systems Conference.
447 Residual analysis of multidimensionalpoint process models for earthquake occur-rences and goodness-of-fit assessment using aweighted analog of Ripley’s K-function [PosterSession P1 (page 21)]
Alejandro VEEN , University of California, Los Angeles, USA
This work presents alternative approaches for assessinggoodness-of-fit for multidimensional point process models. Onenew technique, based on an idea of P. Brémaud, involves aug-menting the data set with an additional dimension to create aresidual point process. The procedure is applied to commonlyused models for California earthquake occurrence data and theresults are compared to other residual analysis methods such asrescaling and thinning. Furthermore, a statistic which involves aweighted analog of Ripley’s K-function is proposed for evaluat-ing goodness-of-fit.References[1] Schoenberg, F. (1999) Transforming spatial point processes intoPoisson processes,Stochastic Processes and their Applications81(2),155–164.[2] Schoenberg, F.P. (2003) Multidimensional residual analysis of pointprocess models for earthquake occurrences,Journal of the Americal Sta-tistical Association98, 789–795.
448 On the asymptotic properties of re-duced rank linear discriminant analysis [Con-tributed Session C41 (page 45)]
Adolfo HERNÁNDEZ,University of Exeter, United Kingdom
Santiago VELILLA , Universidad Carlos III, Spain
The asymptotic behavior of the conditional probability of errorof reduced rank linear discriminant analysis(RLDA) is studied,as a function of the number of canonical coordinates considered,under wide assumptions on the class conditional distributions.The techniques of analysis used are related to the consistencyproperties of a properly definedpseudoplug-in representationof RLDA. Results obtained may offer, as an alternative to com-plex tests of dimension, some useful guidelines for choosing inpractice the number of canonical coordinates.
449 Estimation of the conditional survivalfunction under dependent censoring [Con-
tributed Session C27 (page 36)]
Noël VERAVERBEKE , Limburgs Universitair Centrum, Bel-gium
In nonparametric estimation with randomly right censored data,it is well known that the distribution function of the failure timeis not identifiable if the censoring time is dependent of the fail-ure time. To make the problem identifiable, we model the de-pendence structure by specifying a copula function for the un-derlying joint distribution of failure time and censoring time.In this talk we consider this problem in the case where fixed de-sign covariates are present. Assuming a known Archimedeancopula (depending on the covariate variable), we propose an es-timator for the conditional distribution function of the failuretime. It generalizes the product-limit estimator of Beran to thecase of dependent censoring and it reduces to Beran’s estimatorif we take the copula of independent censoring. We obtain analmost sure asymptotic representation and prove weak conver-gence of the estimator.This is joint work with Roel Braekers.References[1] Rivest, L. and Wells, M.T. (2001) A martingale approach to thecopula-graphic estimator for the survival function under dependent cen-soring,J. Multivariate Anal.79, 138–155.[2] M. Zheng, M. and Klein, J.P. (1995) Estimates of marginal survivalfor dependent competing risks based on an assumed copula,Biometrika82, 127–138.
450 The Shannon transform in randommatrix theory [Invited Session 21 (page 33)]
Antonia M. TULINO, Universitá degli Studi di Napoli “Fed-erico II", Italy
Sergio VERDÚ, Princeton University, New Jersey, USA
The landmark contributions to the theory of random matricesof Wishart (1928), Wigner (1955), and Marcenko and Pastur(1967), were motivated to a large extent by their applications.In this paper we report on a new transform motivated by theapplication of random matrices to various problems in the infor-mation theory of noisy communication channels.The Shannon transform of a nonnegative random variableX isdefined as
VX(γ) = E[log(1+ γX)]. (1)
whereγ is a nonnegative real number. Originally introduced in[1-2], its applications to random matrix theory and engineeringapplications have been developed in [3]. In this paper we givea summary of its main properties and applications in randommatrix theory. As is well known since the work of Marcenkoand Pastur [4], it is rare the case that the limiting empiricaldistribution of the squared singular values of random matrices(whose aspect ratio converges to a constant) admit closed-formexpressions. However, [4] showed a very general result wherethe characterization of the solution is accomplished through afixed-point equation involving the Stieltjes transform. Also mo-tivated by applications, [2] introduced theη-transform which isvery related to both the Stieltjes and Shannon transforms andleads to compact definitions of other transforms used in randommatrix theory such as the S-transform [5].In applications in information theory, the Shannon transform isdirectly of interest as it gives the capacity of various noisy coher-ent communication channels. In the paper we give several exam-ples of closed-form expressions for the Shannon transform, in-cluding the Marcenko-Pastur law, and instances where the Shan-

Abstracts 199
non andη transforms lead to particularly simple solutions forthe limiting empirical distribution of the squared singular valuesof random matrices with dependent entries.References[1] Verdú, S. (1999) Random matrices in wireless communication, pro-posal to the National Science Foundation.[2] Verdú, S. (2002) Large random matrices and wireless communica-tions.2002 MSRI Information Theory Workshop.[3] Tulino, A.M. and Verdú, S. (2004) Random Matrix Theory and Wire-less Communications.Foundations and Trends in Communications andInformation Theory1.[4] Marcenko, V.A. and Pastur, L.A. (1967) Distributions of eigenvaluesfor some sets of random matrices.Math USSR-Sbornik1, 457–483.[5] Voiculescu, D. (1987) Multiplication of certain non-commuting ran-dom variables.J. Operator Theory18, 223–235.
451 Coupling with the stationary distribu-tion [Invited Session 17 (page 49)]
Eric VIGODA , U. of Chicago and Georgia Tech
We present a refinement of the standard coupling techniquewhich can take advantage of typical properties of the station-ary distribution. We’ll present an application of our techniqueto a simple Markov chain for generating a random coloring of agraph.
452 Random walks and amenability offractal groups [Invited Session 19 (page 49)]
Bálint VIRÁG , University of Toronto, Canada
Laurent BARTHOLDI,UC Berkeley, USA
Cayley graphs of some fractal groups admit random walks thatare self-similar in a novel way. We discuss explicit examples, in-cluding Grigorchuk’s group. This phenomenon, along with theresults of [4], can be used to answer a generalization of a ques-tion of Day (1957) [2,3], and show that not all amenable groupsare built of groups of subexponential growth.References[1] Bartholdi, L. and Virag, B. (2003) Amenability via random walks.Preprint, math.GR/0305262.[2] Day, M.M. (1957) Amenable semigroups,Illinois J. Math. 1, 509–544.[3] Grigorchuk, R.I. (1998) An example of a finitely presented amenablegroup that does not belong to the class EG,Mat. Sb.189(1), 79–100.[4] Grigorchuk, R.I. andZuk, A. (2002) On a torsion-free weakly branchgroup defined by a three state automaton,Internat. J. Algebra Comput.12 (1-2), 223–246, International Conference on Geometric and Combi-natorial Methods in Group Theory and Semigroup Theory (Lincoln, NE,2000).
453 Least weighted squares for panel data[Contributed Session C61 (page 48)]
Jan Ámos VÍŠEK, Charles University, the Czech Republic
Employing, under the suspicion of contamination of panel data,the linear regression modelYt = XT
t β0+ et , t = 1,2, ...,T wecannot (of course) utilize any robust method which deletes someobservations (as theLeast Trimmed Squaresor theLeast Medianof Squaresdo). Clearly, we would like to preserve affine- andscale-equivariance of the LTS and LMS, see [2] (M-estimatorslack these properties, see [1]) but rid off the extreme sensitivityof both these estimators with respect to shifting a bit even oneobservation, see [7,9,11]. The possibility to adapt the level ofrobustness (just assigning the appropriate breakdown point withrespect to the level of contamination) would be nice. The esti-mator should obey Hampel program (see [2]) and be equippedby a reliable algorithm with the user-friendly implementation
(see [7,9]. The last but not least, it should posses an accept-able heuristics. Finally, a grant-project for supplementing theestimator by diagnostic tools (as modification of Durbin-Watsonstatistics, White test of homoscedasticity, etc.) and modified ver-sions of the estimator in question for the case when “classical”assumptions do not hold (as a modification of White estimatorof covariance matrix of coordinate of the estimator under het-eroscedasticity, Hausman test of specificity, a robust version ofinstrumental variables, etc.) would be plausible. Putting for anyβ ∈ Rp, r i(β ) = Yi −XT
i β , define theLeast Weighted Squaresestimator as
β (LWS,n,w) = arg minβ∈Rp
n
∑i=1
w
(i−1
n
)r2(i)(β ) with
r2(1)(β )≤ r2(2)(β )≤ ... ≤ r2(n)(β )
(1)
where the weight functionw : [0,1] → [0,1] is absolutely con-tinuous and nonincreasing, with the derivativew′(α) boundedfrom below byL, w(0) = 1, see [7]. Both, in the frameworkwith random explanatory variables as well as deterministic ones,we have asymptotic normality (and hence
√n-consistency) and
asymptotic representation of Bahadur type, see [5,6]. Influencefunction andB-robustness was also derived, see [4,5]. Moreover,the modification of Durbin-Watson statistic (see [3]) and Whitetest of homoscedasticity (see [10]) are available as well as themodification of instrumental variables, see [12]. The reliablealgorithm is implemented in MATLAB as well as in MATHE-MATICA, see [5,6]. Moreover, very recent numerical resultsindicate that the estimator can cope directly with heteroscedas-ticity, weighting down residuals of observations which seem tohave larger variance of error term, see [6].References[1] Jurecková, J. and Sen, P.K. (1984) On adaptive scale-equivariantM-estimators in linear models,Statistics and Decisions,2 (1984), Suppl.Issue No. 1.[2] Hampel, F.R., Ronchetti, E.M., Rousseeuw, P.J., and Stahel, W.A.(1986)Robust Statistics – The Approach Based on Influence Functions,New York: J.Wiley and Sons.[3] Kalina, J. (2003)Autocorrelated disturbances of robust regression,European Young Statistician Meeting 2003.[4] Mašícek, L. (2003)Optimality of the least weighted squares estima-tor, Proc. of ICORS’2003, Antwerp.[5] Mašícek, L. (2004)Diagnostics and sensitivity of robust estimators,Dissertation, Charles University, Prague.[6] Plát, P. (2003)The Least Weighted Squares,Dissertation, the CzechTechnical University, Prague.[7] Víšek, J.Á. (1996) On high breakdown point estimation,Computa-tional Statistics11, 137–146, Berlin.[8] Víšek, J.Á. (2000)Regression with high breakdown point,ROBUST2000, 324–356, ISBN 80-7015-792-5.[9] Víšek, J.Á. (2000) On the diversity of estimates,Comput. Statist.and Data Analysis34, 67–89.[10] Víšek, J.Á. (2002)White test for the least weigthed squares,COMPSTAT 2002, (CD), ISBN 3-00-009819-4.[11] Víšek, J.Á. ( 2002) Sensitivity analysis ofM-estimates of nonlinearregression model: Influence of data subsets,Annals of the Institute ofStatistical Mathematics54, No.2, 261–290.[12] Víšek, J.Á. ( 2004)Robustifying instrumental variables.COMP-STAT 2004.
454 Generalized chaos expansion for Lévyfunctionals: applications to hedging [Con-tributed Session C32 (page 51)]
M’hamed EDDAHBI,Université Cadi Ayyad, Maroc
Josep L. SOLÉ andJosep VIVES, Universitat Autònoma deBarcelona, Spain

200 6th BS/ IMSC
In the paper [1] we find a Stroock type formula in the set-ting of generalized chaos expansion introduced by Nualart andSchoutens in [4] for a certain class of Lévy processes. This for-mula uses the Malliavin type derivative, based on the chaoticapproach, introduced in [3] and allows to compute explicitly thekernels of the chaotic expansion. As an application, we get thechaotic expansion of the price of a financial asset driven by sucha Lévy process, the price of an European call option written onthis asset, and discuss the interest of these expansions in deltahedging following some ideas introduced by V. Lacoste in [2].References[1] Eddahbi, M., Solé J.L., and Vives, J. (2004)A Stroock formula for acertain class of Levy processes and applications to Finance, Preprint.[2] Lacoste, V. (1996) Wiener chaos: a new approach to option hedging, Mathematical Finance6 (2), 197–213.[3] León, J.A., Solé, J.L., Utzet, F., and Vives, J. (2002) On Lévy pro-cesses, Malliavin calculus and market models with jumps ,Finance andStochastics6 (2), 197–225.[4] Nualart, D. and Schoutens, W. (2000) Chaotic and predictable rep-resentation for Lévy processes ,Stochastic Processes and Applications90 (1) 109–122.
455 Properties of minimum and maxi-mum from bivariate exponential distribu-tions [Poster Session P3 (page 42)]
Manuel FRANCO NICOLAS andJuana Maria VIVOMOLINA , University of Murica, Spain
The minimum or maximum order statistics from some commonbivariate exponential distributions, are a generalized mixture oftwo or three exponential distributions. In this work we study thelog-concavity and log-convexity of the density function of thegeneralized mixtures of two or three exponential distributions,and we apply these results to classify the minimum and max-imum from some common bivariate exponential distributions,which marginal variables can be dependent and not necessarilyidentically distributed.References[1] Baggs, G.E. and Nagaraja, H.N. (1996) Reliability properties of or-der statistics from bivariate exponential distributions,Commun. Statist.Stochastic Models12, 611–631.[2] Barlow, R.E. and Proschan, F. (1975)Statistical theory of reliabilityand life testing: Probability models, Holt, Rinehart and Winston (eds),New York.[3] Franco, M. and Vivo, J.M. (2002) Reliability properties of series andparallel systems from bivariate exponential models,Commun. Statist.Theory and Methods31, 2349–2360.[4] Freund, J.E. (1961) A bivariate extension of the exponential distri-bution,J. Amer. Stat. Assoc.56, 971–977.[5] Friday, D.S. and Patil, G.P. (1977)A bivariate exponential modelwith applications to reliability and computer generation of random vari-ables, In Tsokos, C.P. and Shimi, I. (eds), Theory and Applications ofReliability, Academic Press, New York, 1, 527-549.[6] Gumbel, E.J. (1960) Bivariate exponential distributions,J. Amer.Stat. Assoc.55, 698–707.[7] Hutchinson, T.P. and Lai, C.D. (1990)Continuous Bivariate Distri-butions, Emphasizing Applications, Rumsby Scientific Publishing, Aus-tralia.[8] Marshall, A.W. and Olkin, I. (1967) A multivariate exponential dis-tribution,J. Amer. Stat. Assoc.62, 30-40.[9] Nagaraja, H.N. and Baggs, G.E. (1996)Order statistics of bivariateexponential random variables, In Nagaraja, H.N.; Sen P.K. and Mor-rison D.F. (eds), Statistical Theory and Applications, Springer-Verlag,New York, 129–141.[10] Raftery, A.E. (1984) A continuous multivariate exponential distri-bution,Commun. Statist. Theory and Methods13, 947–965.[11] Stetuel, F.W. (1967) Note on the infinite divisibility of exponentialmixtures,Ann. Math. Statist.38, 1303–1305.
[12] Shaked, M. and Shanthikumar, G. (1994)Stochastic Orders andTheir Applications, Wiley, New York.
456 Convergence rate of the dependentbootstrapped means [Contributed Session C7 (page44)]
Alia GATAULLINA, Kazan State University, Russia
Manuel ORDÓÑEZ CABRERAUniversity of Seville, Spain
Andrei VOLODIN , University of Regina, Canada
Let Xn,n≥ 1 be a sequence of random variables defined on aprobability space(Ω,F ,P). Let m(n),n≥ 1 andk(n),n≥1 be two sequences of positive integers such that for alln≥ 1 :m(n) ≤ nk(n). For ω ∈ Ω andn≥ 1, the dependent bootstrap
is defined as the sample of sizem(n), denotedX(ω)n, j ,1≤ j ≤
m(n), drawn without replacement from the collection ofnk(n)items made up ofk(n) copies each of the sample observationsX1(ω), · · · ,Xn(ω). Let Xn(ω) = 1
n ∑nj=1Xj (ω) denote the sam-
ple mean ofXj (ω),1≤ j ≤ n,n≥ 1.This dependent bootstrap procedure is proposed as a procedureto reduce variation of estimators and to obtain better confidenceintervals, cf. [2].The next theorem is an analog of the Theorem 2.1 [1] for thecase of the dependent bootstrap procedure.Theorem. Let Xn,n ≥ 1 be a sequence of (not necessaryindependent or identically distributed) random variables andan,n≥ 1 be a sequence of positive real numbers. If
lognm(n)an
max1≤i≤n
|Xi | → 0 andlogn
nm(n)a2n
n
∑i=1
X2i → 0
a.s.,
then for any real numberr, everyε > 0, and almost everyω ∈Ω:
∞
∑n=1
nrP
∣∣∣∣∣∣∑m(n)
j=1 X(ω)n, j
m(n)−Xn(ω)
∣∣∣∣∣∣≥ εan
< ∞.
Corollary. Let Xn,n ≥ 1 be a sequence of identically dis-tributed (which are not necessarily independent) random vari-ables and0 < α < 2. If E|X1|α |log|X1||α < ∞, then for everyreal numberr, everyε > 0 and almost everyω ∈Ω:
∞
∑n=1
nrP
∣∣∣∣∣1
n1/α
n
∑j=1
(X(ω)n, j −Xn(ω))
∣∣∣∣∣≥ ε
< ∞.
References[1] Li, D., Rosalsky, A., and Ahmed, S.E. (1999) Complete convergenceof bootstrapped means and moments of the supremum of normed boot-strapped sums,Stochastic Anal. Appl.17, 799–814.[2] Smith, W. and Taylor, R.L. (2001) Consistency of dependent boot-strap estimators,Amer. J. Math. Management Sci.21, 359–382.
457 On energy and clusters in stochasticsystems of sticky gravitating particles [Con-tributed Session C9 (page 20)]
Vladislav VYSOTSKY , Saint-Petersburg State University,Russia
We considerone-dimensional modelof gravitational gas. At thetime zero the gas consists ofn particles. A particle is character-ized by it’s massn−1, initial position and initial speed. Particlesbegin to move under the influence of forces of mutual attrac-tion (gravitational forceequals to the product of masses, so itis

Abstracts 201
independent of the distance). While colliding, particlesstick to-gether forming a new particle("cluster") which characteristicsare defined by the laws of mass and momentum conservation.Between collisions particles move according to the laws of clas-sical mechanics.Our goal is to study gas’ properties on the condition that initialpositions and initial speeds of particles arerandomvariables andn→ ∞. The results are formulated in terms of convergence byprobability. Various limit properties of the gas are analyzed in[1]-[4].We investigate the behavior of previously unstudied variableKn(t) which denotes thenumber of clustersin the system. Inthe case of zero initial speeds ("cold gas") we obtained that foranyt ≥ 0
Kn(t)n
P−→ f (t), n→ ∞,
where f (t) is a deterministic function.We also explore kineticenergyof the gasEn(t). In the case ofnon-zero initial speeds ("warm gas") it’s proved that the gas in-stantly "cools". Precisely,
En(0) P−→ σ2
2, n→ ∞,
butEn(t)
P−→ 0, (t,n)→ (+0,∞).
Moreover, in the both cases of cold and warm gas at any instantt ∈ (0,1)
En(t)P−→ t2
6, n→ ∞.
References[1] Martin, Ph.A. and Piasecki, J. (1996) Aggregation dynamics in aself-gravitating one-dimensional gas,J. Statist. Phys.84, 837–857.[2] Giraud, C. (2001) Clustering in a self-gravitating one-dimensionalgas at zero temperature,J. Statist. Phys.105, 585–604.[3] Lifshits, M. and Shi, Z. (2003) Aggregation rates in one-dimensional stochastic systems with adhesion and gravitation, Preprint(www.arxiv.org, Physics, Condensed Matter, paper 0311025).[4] Bonvin, J.C., Martin, Ph.A., Piasecki, J., and Zotos, X. (1998) Statis-tics of mass aggregation in a self-gravitating one-dimensional gas,J.Statist. Phys.91, 177–197.
458 Nonlinear nonparametric regressionmodels [Contributed Session C58 (page 55)]
Chunlei KE,St. Jude Medical, USA
Yuedong WANG, University of California - Santa Barbara,USA
Almost all of the current nonparametric regression methods suchas smoothing splines, generalized additive models and varyingcoefficients models assume a linear relationship when nonpara-metric functions are regarded as parameters. In this article,we propose a general class of nonlinear nonparametric mod-els that allow nonparametric functions to act nonlinearly. Theyarise in many fields as either theoretical or empirical models.Our new estimation methods are based on an extension of theGauss-Newton method to infinite dimensional spaces and thebackfitting procedure. We extend the generalized cross valida-tion and the generalized maximum likelihood methods to esti-mate smoothing parameters. We establish connections betweensome nonlinear nonparametric models and nonlinear mixed ef-fects models. Approximate Bayesian confidence intervals arederived for inference. We also develop a user friendly S func-tion for fitting these models. We illustrate the methods with an
application to ozone data and evaluate their finite-sample perfor-mance through simulations.References[1] O’Sullivan, F. (1990). Convergence Characteristics of Methodsof Regularization Estimators for Nonlinear Operator Equations,SIAMJournal on Numerical Analysis27, 1635–1649.[2] O’Sullivan, F. and Wahba, G. (1985) A Cross Validated BayesianRetrieval Algorithm for Nonlinear Remote Sensing Experiments,Jour-nal of Computational Physics59, 441–455.[3] Wahba, G. (1990)Spline Models for Observational Data, SIAM,CBMS-NSF Regional Conference Series in Applied Mathematics, V59,Philadelphia.[4] Wang, Y. and Ke, C. (2002) ASSIST: A suite ofS Functions Implementing Spline Smoothing Techniques,Manual for the ASSIST package, Available athttp://www.pstat.ucsb.edu/faculty/yuedong/research,
459 Distribution-invariant dynamic riskmeasures [Contributed Session M4 (page 37)]
Stefan WEBER, Humboldt-Universität zu Berlin, Germany
The paper provides an axiomatic characterization of dynamicrisk measures for multi-period financial positions. For the spe-cial case of a terminal cash flow, we require that risk dependson its conditional distribution only. We prove a representationtheorem for dynamic risk measures and investigate their relationto static risk measures. Two notions of dynamic consistencyare proposed. A key insight of the paper is that dynamic con-sistency and the notion of “measure convex sets of probabilitymeasures” are intimately related. Measure convexity can be in-terpreted using the concept of compound lotteries. We charac-terize the class of static risk measures that represent consistentdynamic risk measures.It turns out that these are closely connected to shortfall risk. Un-der weak additional assumptions, static convex risk measurescoincide with shortfall risk, if compound lotteries of acceptablerespectively rejected positions are again acceptable respectivelyrejected. This result implies a characterization of dynamicallyconsistent convex risk measures.
References
[1] Weber, S. (2003)Distribution-Invariant Dynamic Risk Measures,Working Paper, Humboldt-Universität zu Berlin. Download atwww.math.hu-berlin.de/∼finance/papers/weber.pdf
460 Complexity regularization via local-ized random penalties [Contributed Session C51(page 27)]
Gabor LUGOSI,Pompeu Fabra University, Spain
Marten WEGKAMP , The Florida State University, USA
Model selection via penalized empirical loss minimization innonparametric classification problems is studied.Data-dependent penalties are constructed, which are based onestimates of the complexity of a small subclass of each modelclass, containing only those functions which have small empiri-cal loss. The penalties are novel since the penalties consideredin the literature are typically based on the entire model class.Oracle inequalities using these penalties are established, and theadvantage of the new penalties over the penalties based on thecomplexity of the whole model class is demonstrated.
References
[1] Gabor, Lugosi and Marten, Wegkamp (in press), Complexity Regu-larization via Localized Random Penalties,Ann. Statist.
461 Brownian loop-soups, SLE and confor-

202 6th BS/ IMSC
mal field theory [Levy Lecture (page 18)]
Wendelin WERNER, Université Paris-Sud, France
It has been observed long ago that physical systems at their crit-ical temperature (typically, at the temperature where a phasetransition occurs) can behave randomly. In three dimensions,one can not describe mathematically such phenomena, but intwo dimensions, it turns out to be possible. This is related tocomplex analysis (conformal invariance of these random sys-tems plays a key-role), representation theory of some infinite-dimensional Lie algebras, and of course, to probability theory.In the 70’s and 80’s, the theoretical physicists’ approach wasmostly based on conformal field theory, which conjecturally de-scribes the scaling limit of these two-dimensional systems, andit enabled them (via the classification of certain representations)to predict a number of features of these critical phenomena, thathave been confirmed by simulations and experiments.More recently, mathematicians, combining ideas from complexanalysis and probability theory, have defined and studied theunderlying mathematical object (the Schramm-Loewner Evolu-tions, SLE in short), that enabled to reach a better understandingof these random systems, as well as some of their relations torepresentation theory, and to confirm mathematically some ofthe physicists’ predictions.In recent joint work with Greg Lawler and Oded Schramm, weclassified the random sets that are in some sense invariant un-der perturbation of the domains that they are defined in, andit turns out that they are all closely related to planar Brown-ian motion. Pushing this approach further leads to the Brown-ian loop-soups, which are Poissonian cloud of Brownian loopsin the plane, that we defined with Greg Lawler. Their comple-ments are natural conformally invariant Sierpinski gasket typerandom fractals that turn out to be very closely related to SLE,to conformal field theory and representation theory.After a general introduction to the subject, we will (try to) givea non-technical review of some of these recent developments.
462 Conditional moments and q-Meixnerprocesses[Contributed Session C32 (page 50)]
Włodzimierz BRYC,University of Cincinnati, USA
Jacek WESOŁOWSKI, Warsaw University of Technology,Poland
Let (Xt)t≥0 be a separable square-integrable stochastic process,normalized so thatE(Xt) = 0, E(XtXs) = mint,s. We are in-terested in the processes with linear conditional expectations
E(Xt |F≤s∨F≥u) = aXs+bXu, (1)
and quadratic conditional variances
E(X2t |F≤s∨F≥u) =
AX2s +BXsXu +CX2
u +D+αXs+βXu.
Here0≤ s< t < u, andF≤s∨F≥u denotes theσ -field gener-ated byXt : t ∈ [0,s]∪ [u,∞). We assume that the coefficientsa = a(s, t,u),b = b(s, t,u), A = A(s, t,u),B = B(s, t,u),C =C(s, t,u),D = (s, t,u),α = α(s, t,u),β = β (s, t,u) are some un-specified non-random functions ofs, t,u. For technical reasons,we also assume that Var(Xt |Fs) is non-random, that the distri-bution of Xt is supported on at least three points, and that thecoefficientD(s, t,u) 6= 0 for all 0≤ s< t < u.Processes which satisfy condition (1) are sometimes called har-nesses [5]; we consider processes where bothXt and X2
t sat-isfy harness-like assumptions. We show that these processes are
Markov, and that their transition probabilities are related to aq-generalization of the Meixner orthogonal polynomials.Theorem. There are constants−1 < q ≤ 1, −∞ < θ < ∞,andτ ≥ 0 such that(Xt) is a Markov process, with the transi-tion probabilitiesPs,t(x,dy) determined as the unique probabil-ity measure orthogonalizing the polynomialsQn in variableywhich are given by the three-step recurrence
yQn(y|x) = Qn+1(y|x)+(θ [n]q +xqn)Qn(y|x)+(t−sqn−1 + τ[n−1]q)[n]qQn−1(y|x).
Whenq = 1, theq-Meixner processes have independent incre-ments and we recover the five Lévy processes from [7, Theorem2], and [6, Ch.4 ]. Whenq = 0 theq-Meixner processes are re-lated to the class of free Lévy processes considered in [2]. Forother values of parameterq, some of these processes have Fockspace representations and are related to non-commutative gener-alizations of the Lévy processes. Theq-Meixner process is theclassical version of theq-Brownian motion [3] whenτ = θ = 0;it is the classical version of theq-Poisson process, [1, Def. 6.16]whenτ = 0, θ 6= 0.References[1] Anshelevich, M. (2001) Partition-dependent stochastic measures andq-deformed cumulants,Doc. Math.6, 343–384.[2] Anshelevich, M. (2003) Free martingale polynomials,J. Func. Anal.201, 228–261.[3] Bozejko, M., Kümmerer, B., and Speicher, R. (1997)q-Gaussianprocesses: non-commutative and classical aspects,Comm. Math. Phys.185, 129–154.[4] Bryc, M. (2001) Stationary fields with linear regressions,Ann.Probab.29, 504–519.[5] Hammersley, J.M. (1967)Harnesses, Proc. Fifth Berkeley Sympos.Mathematical Statistics and Probability (Berkeley, Calif., 1965/66), III,89–117.[6] Schoutens, W. (2000)Stochastic processes and orthogonal polyno-mials, Lecture Notes in Statistics, 146, Springer-Verlag, New York.[7] Wesolowski, J. (1993) Stochastic processes with linear conditionalexpectation and quadratic conditional variance,Probab. Math. Statist.14, 33–44.
463 Computation of percolation thresholdbounds using non-crossing partitions [Con-tributed Session C35 (page 25)]
John C. WIERMAN The Johns Hopkins University, Baltimore,USA
Percolation thresholds are exactly known for very few lattices.Very accurate bounds for the percolation threshold have re-cently been calculated for some lattices using the substitutionmethod, which is based on the equivalence of stochastic order-ing and coupling. The improved bounds are possible becauseof dramatic reductions in the computational complexity, involv-ing graph-welding, symmetry reduction, network flow methods,and, most recently, the use of non-crossing partitions from par-tially ordered set theory.
464 Smoothing spline regression estimatesfor randomly right censored data [Poster Ses-sion P3 (page 42)]
Stefan WINTER, University of Stuttgart, Germany
We consider the problem of constructing multivariate smoothingspline estimates in censored regression. Let thereforeX ∈ IRd
be a bounded random vector,Y a non-negative and boundedrandom variable, andC a right censoring random variable op-erating onY and independent of(X,Y). Given a sample of

Abstracts 203
(X,minY,C, I[Y<C]), our goal is to construct estimates of theregression functionm(x) = EY|X = x.In order to reduce censored regression to ordinary regression,we transform the data above as described in [1]. For the result-ing uncensored data, multivariate smoothing spline estimates arenow defined as usual.Under the above assumptions, we will proof similar to the re-sults in [2] that these estimates are consistent with respect to theL2 error. By using techniques developed in [3], it is shown thatfor smooth regression functions the estimates achieve the opti-mal rate of convergence up to a logarithmic factor. Furthermore,this rate of convergence still holds for data-dependent choicesof the parameters of the estimates, i.e., for estimates which areindependent of the smoothness ofm. Finally, the estimates areillustrated by applying them to simulated data.References[1] Fan, J. and Gijbels, I. (1996)Local Polynomial Modelling and ItsApplications, Chapman & Hall, London.[2] Györfi, L., Kohler, M., Krzyzak, A., and Walk, H. (2002)ADistribution-Free Theory of Nonparametric Regression, Springer Seriesin Statistics, Springer.[3] Kohler, M., Krzyzak, A., and Schäfer, D. (2000) Application of struc-tural risk minimization to multivariate smoothing spline regression esti-mates,Bernoulli8 1–15.
465 Application of the bootstrap to k-sample problems in shape analysis[ContributedSession C47 (page 17)]
Andy WOOD , University of Nottingham, UK
A bootstrap approach for testing a null hypothesis of equality ofmean shapes acrossk populations of shapes will be described.It is assumed that a sample of shapes is drawn from each ofthe k populations. The approach is based on a statistic whichcan be expressed as the smallest eigenvalue,λmin say, of a cer-tain positive definite matrix determined by thek samples. Thisstatistic, which is related to the one-sample pivotal statistics pro-posed by Fisher et al (1996), has a limitingχ2 distribution underthe null hypothesis, and is therefore pivotal under the null hy-pothesis. There are different versions of the statistic, dependingon whether or not we wish to assume (a) isotropy within pop-ulations or (b) constant dispersion structure across populations.The question of how to resample under the null hypothesis isdiscussed. Practical results will be presented. This work is jointwith Getulio Amaral and Ian Dryden; further details are given inAmaral et al (2003).References[1] Amaral, G.J.A., Dryden, I.L., and Wood, A.T.A. (2003) Pivotal boot-strap methods fork-sample problems in directional statistics and shapeanalysis, Research Report, Division of Statistics, University of Notting-ham.[2] Fisher, N.I., Hall, P., Jing, B.-Y. and Wood, A.T.A. (1996) Improvedpivotal methods for constructing confidence regions with directionaldata,Journal of the American Statistical Association, 91, 1062–1070.
466 Admissible matrix linear estimators inmultivariate linear models [Contributed SessionC43 (page 26)]
Kasuo NODA,Meisei University, Japan
Qiguang WU, Chinese Academy of Sciences, P.R.C
This paper studies admissibility of matrix linear estimators forestimable matrix linear functions of the matrix regression co-efficient in multivariate linear models. Assume that the rows ofthe error matrix are uncorrelated random vectors with mean vec-
tor zero and unknown common covariance matrix. Under eachof the three different kinds of quadratic matrix loss functions, anecessary and sufficient condition for a matrix linear estimatorbeing admissible in the class of all matrix linear estimators, anda sufficient condition, with assumption of normality, for a ma-trix linear estimators being admissible in the class of all matrixestimators are derived respectively.
467 Root n estimates of integrated squareddensity partial derivatives [Contributed Session C65(page 49)]
Huang-Yu CHEN andTiee-Jian WU, National Cheng-KungUniversity, Taiwan
Based on a random sample of sizen from an unknownd-dimensional densityf , the problem of the nonparametric esti-mation of
∫f (m) will be investigated, wheref (m) denotes the
partial derivative off of orderm = (m1, · · · ,md). These func-tionals are important in a number of contexts. The proposedestimates will be constructed in the frequency domain by usingthe sample characteristic function. We shall prove that for ev-ery d, m and sufficiently smoothf , the proposed estimates isasymptotically normal with the optimalOp(n−1/2) relative con-vergence rate and attain the information bound. This generalizesthe work of Wu (1995) (who dealt with the cased = 1). Further-more, we do extensive simulation to compare our estimates withthe estimate of Wand and Jones (1994) at practical sample sizes,and the superior performance of our estimates is clearly demon-strated.References[1] Wand, M.P. and Jones, M.C. (1994)Multivariate plug-in Bandwidthselection, Comput. Statist.,9, 97–116.[2] Wu, T.-J. (1995)Adaptive root n estimates of integrated squared den-sity derivatives, Ann. Statist.,23, 1474–1495.
468 Inference of semi-parametric time se-ries models with constraints [Invited Session 30(page 43)]
Yingcun XIA , National University of Singapore, Singapore
There are growing demands for us to use prior and sample in-formation for semi-parametric models. The information can beimposed on unknown nonparametric functions or on parametersor on both. In this paper, we propose a method to incorporatethe information into the models by “globalising” the local kernelsmoothing. Implementation of the method is a simple quadraticprogramming. An ad hoc approach to check the constraints isproposed. As applications of the approach, we focus on the an-imal population dynamics and shows that the approach is verypowerful in modelling the dynamics and capture the oscillation.
469 A weak consistent wavelet estimator ofcointegration coefficient and its applicationin finance [Contributed Session C21 (page 50)]
Xiamin LI, Beijing Polytechnic University, China
Hongmin TANG andZhongjie XIE , Peking University, China
In this paper, an estimator of the cointegration coefficient bywavelet sequence is introduced and some basic statistical prop-erties of such estimator is also discussed.It is well known that the estimations of cointegration coefficientsmay be found in the literature published last century, such as Jo-hanson’s MLE, Engle and Granger’s method, etc. However, ingeneral case, those methods require some comparatively severeconditions so that they could not be used for several kinds of

204 6th BS/ IMSC
stochastic processes, e.g. fractionally differenced process.It may be proved that under some mild mathmatical conditions,wavelet estimator of the cointegration coefficient introduced inthis paper is a consistent estimate, and is particularly appropriatefor long memory cointegration residue.Finally, the authors show some pratical applications of theirmethod to the cointegration analysis of exchange rates and stockprice indexes.References[1] Engle, R.F. and Granger, C.W.J. (1987) Co-integration and ErrorCorrection: Representation, Estimation, and Testing,Econometrica105,225–247.[2] Marinucci, D. and Robinson, P.M. (2001) Semiparametric FractionalCointegration Analysis,J. Econometrics105, 225–247.[3] Wojtaszczyk, P. (1997)A Mathenatical Introduction to wavelets,Cambridge University Press, London.
470 Monte Carlo Markov Chain analysisof time-changed Levy processes of stock re-turn dynamics [Poster Session P2 (page 32)]
Long YU, Cornell University, USA
We develop Monte Carlo Markov Chain techniques for estimat-ing time-changed Levy processes of stock return dynamics. Themodels exhibit stochastic volatility and jumps. Unlike Poissonjumps considered in most existing studies, jumps in our modelsfollow Levy-type of distributions, such as Variance Gamma andLog Stable distribution. While Poisson jumps are typically largeand happen rarely, Levy jumps can be both large and small andcan happen all the time. Special techniques are needed for esti-mating Levy processes because for certain models the probabil-ity density does not have analytic form and certain moments donot exist. The MCMC methods developed in our paper have ex-cellent performance in estimating Levy processes. Empiricallywe show that forS&P 500 andNasdaq100 indices, stochasticvolatility models with jumps follow Variance Gamma and LogStable distribution perform much better than stochastic volatilitymodels with Poisson jumps. Bayes factor analysis shows that theimprovements are much more significant than that of the modelin Eraker, Johannes and Polson (2003), which also allows Pois-son jumps in stochastic volatility. In fact, once Levy jumps areincluded, jumps in stochastic volatility play a much less signifi-cant role.
471 Gaussian limits for random geometricstructures [Contributed Session C62 (page 18)]
Y. BARYSHNIKOV, Bell-Labs, USA
M. PENROSE,Univ. of Bath, England
J.E. YUKICH , Lehigh, USA
We describe general methods showing that re-normalizedweighted random point measures on Poisson and binomial spa-tial point sets converge to a Gaussian limit with a covariancefunctional which depends on the underlying density of points.The methods apply to point measures whose weights satisfy aweak spatial dependence condition known as stabilization. Thegeneral results are applied to deduce Gaussian central limit the-orems for measures and functionals arising in random sequen-tial packing and ballistic deposition models, random Euclideangraphs, interacting particle systems in the continuum, and theprocess of maximal points. In each case the large scale limit be-havior of the point measures is linked to the local behavior ofthe underlying density of points.
472 Estimation of the impulse responsefunction in linear and nonlinear systems [Con-
tributed Session C20 (page 35)]
Vladimir ZAIATS , Universitat de Vic and UniversitatAutònoma de Barcelona, Spain
The problem of estimation of a functional characteristic (cor-relation function, spectral function, spectral density, probabilitydensity, etc.) of a stochastic process is a classical problem instatistics. There are different settings of the problem, and theliterature is quite extensive both on theory and applications. Weare interested in the framework where the underlying process isobserved at discrete times which may be random. If the processis sampled at equally spaced times, then the so-called “alias-ing” appears making impossible that a consistent estimate of thecorrelation function could exist unless the underlying process isband limited. This fact motivated the need in considering ir-regularly spaced sampling schemes. There are two notions ofalias-free sampling. We follow the one developed in detail byMasry [5] for nonparametric estimates of the correlation func-tion [6] and further extended by him and his collaborators to theestimation of the spectral density and the probability density [7].We would like to make use of these ideas and apply them tothe framework of estimation of the impulse response functionin a time-invariant continuous linear system. Linear and nonlin-ear impulse response analysis play an important role in differ-ent applications: aerodynamics [9], genetic programming [4],macroeconomic research [2, 3, 8, 10], etc. We use discrete-timecross-correlograms in our approach [1]. An input-output cross-correlogram is well-known to be a good estimate of the impulseresponse function in a linear system. Therefore any estimate ofthe impulse response function seems to inherit all properties ofthat of the cross-correlation function. This analogy, however,does not work at full strength since there is an important differ-ence between these functions: a correlation function is alwayssymmetric, while an impulse response function need not be so.Moreover, the impulse response function can never be symmet-ric in a causal system. We will try to reveal what implicationsare driven by this intrinsic difference in the nature of these func-tions.This research has partly been carried out in collaboration withE. Saavedra (Universidad de Santiago de Chile).References[1] Buldygin, Valery, Utzet, Frederic, and Zaiats, Vladimir (2004)Asymptotic normality of cross-correlogram estimates of the responsefunction,Statist. Inference Stoch. Processes, to appear.[2] Chang, Pao-Li and Sakata, Shinichi (2003)A misspecification-robust impulse response estimator, submitted to J. Amer. Statist.Assoc., available at http://ww.econ.ubc.ca/ssakata/public_html/cv/cv.html#papers[3] Hafner, Christian M. and Herwartz, Helmut (1998)Volatility impulse response functions for multivariateGARCH models, Core Discussion Paper 9847, available athttp://www.core.ucl.ac.be/services/psfiles/dp98/dp9847.pdf[4] Keane, Martin A., Koza, John R., and Rice, James P. (1993) Find-ing an impulse response function using genetic programming, In Proc.1993 American Control Conf. Evanston, IL: American AutomaticControl Counsil, vol. III, 2345–2350, available at http://www.genetic-programming.com/jkpubs72to93.html#anchor282331[5] Masry, Elias (1978) Alias-free sampling: an alternative conceptual-ization and its applications,IEEE Trans. Inform. Theory 24, 317–324.[6] Masry, Elias (1983) Non-parametric covariance estimation from ir-regularly spaced data,Adv. Appl. Probab.15, 113–132.[7] Masry, Elias (1984)Spectral and probability density estimation fromirregularly observed data,In: Time series analysis of irregularly ob-served data, E. Parsen (ed.), Lect. Notes Statist., vol. 25, Springer-Verlag, 224–250.

Abstracts 205
[8] Potter, Simon M. (2000) Nonlinear impulse response functions.J.Econ. Dynamic Control24, 1425–1446.[9] Silva, Walter A. (1997) Identification of linear and non-linear aerodynamic impulse responses using digital filter tech-niques, NASA Technical Memorandum 112872, availableat http://techreports.larc.nasa.gov/ltrs/PDF/1997/tm/ NASA-97-tm112872.pdf[10] Tschernig, Rolf and Yang, Lijian (2000)Nonparametric esti-mation of generalized impulse response functions, SFB 373 Discus-sion Paper 89, available at http://www.personeel.unimaas.nl/r.tschernig/papers/gir.ps
473 Estimates of the rate of approximationin the CLT for L1-norm of density estimators
[Contributed Session C65 (page 48)]
A. Yu. ZAITSEV , St. Petersburg Department of the SteklovMathematical Institute, Russia
Let X1, X2, . . . be a sequence of i.i.d. random variables inR withdensity f . Let hnn≥1 be a sequence of positive constants suchthathn → 0 asn→ ∞. The classical kernel density estimator isdefined as
fn(x)def=
1nhn
n
∑i=1
K
(x−Xi
hn
), for x∈ R,
where K is a kernel satisfyingK(u) = 0, for |u| > 1/2,supu∈R |K(u)| < ∞ and
∫R K(u)du = 1. Let || · || denote the
L1(R)-norm. For anyt ∈ R, set
ρ(t) = ρ(t,K) def= ||K2||−1∫
RK(u)K(u+ t)du.
Let Z, Z1 andZ2 be independent standard normal random vari-ables and set
σ2 = σ2(K) def= ||K2||∫ 1
−1cov
(∣∣∣√
1−ρ2(t)Z1
+ρ(t)Z2
∣∣∣, |Z2|)
dt.
Defineξndef= ‖ fn−E fn‖ andσ2
ndef= Var(ξn). Mason has shown
that (ξn−Eξn)/σn →d Z andlimn→∞ nσ2n = σ2 under no as-
sumptions at all on the densityf . Giné, Mason and Zaitsev [1]extended the CLT result to processes indexed by kernelsK. Themain results of this talk (published in [2]) provide estimates ofthe rate of strong approximation and bounds for probabilities ofmoderate deviations in the CLT forarbitrary densitiesf .References[1] Giné E., Mason, D.M., and Zaitsev, A.Yu. (2003) TheL1-norm den-sity estimator process,Ann. Probab.31, 719–768.[2] Zaitsev, A.Yu. (2003) Estimates of the rate of approximation in theCLT for L1-norm of kernel density estimators,Progr. Probab.55, 255–292.
474 Variable selection in PLS regressionwith factorial designs [Poster Session P1 (page 22)]
Alberto FERRER andManuel ZARZO , Polytechnic Universityof Valencia, Spain
Partial Least Squares regression (PLS) is useful to obtain predic-tive models with much more variables than observations [1]. hisoccurs in batch chemical processes, where the trajectory (evolu-tion versus time) of process variables like pressures or tempera-tures are often recorded from every batch [2].The trajectories of 50 process variables from 31 batches of achemical process have been analysed. After synchronising thesetrajectories, a matrix with 8500 variables is obtained. Many of
them are highly correlated. At the end of the process, one qualityparameter is determined in laboratory, that presents an excessivevariability from batch to batch. To help in the diagnosis of theroot causes, a PLS regression has been carried out with this ma-trix, resulting that the first component is statistically significantaccording to cross-validation criterion. Although this model canbe used for prediction, it is advisable to identify the trajectoriesthat have a significant effect in the capability of the model topredict the quality parameter in new batches. For that purpose,the approach presented is a method to select blocks of variables(trajectories) based on a design of experiments [3].First, as the process consists of 4 stages, a full factorial designhas been carried out with 4 factors (one per stage) at two lev-els: one level considers that the block of variables from the cor-responding stage is included in the model, and the other oneconsiders that the variables are excluded. For every one of the16 combinations, the goodness of prediction has been obtainedwith cross-validation. Analysing the results, stage 4 is the onlyone with a statistically significant effect. Taking into accountthat this stage contains 7 trajectories, a fractional factorial de-sign27−3
IV has been conducted in a similar way. A normal proba-bility plot of the effects highlights that one of the trajectories hasa very significant effect in the goodness of prediction. Accord-ing to technical knowledge, this effect seems to be related witha problem in the enthalpy of the steam used in the last stage.Thus, these results focus on a specific part of the process as alikely critical point that requires a more exhaustive control. Fur-thermore, a PLS regression fitted with this trajectory (comprisedby 535 variables) can be used for monitoring purposes, since thismodel presents the same goodness of prediction as the initial onewith 8500 variables.References[1] Geladi, P. and Kowalski, B.R. (1986) Partial Least-Squares Regres-sion: a tutorial,Anal. Chim. Acta185, 1-17.[2] Nomikos, P. and MacGregor, J.F. (1995) Multivariate SPC charts formonitoring batch processes,Technometrics37, 41–59.[3] Baroni, M., Clementi, S., Cruciani, G., Constantino, G., and Rig-anelli, D. (1992) Predictive ability of regression models, part 2: selectionof the best predictive PLS model,J. Chemometrics6, 347–356.
475 Goodness-of-fits tests, adapted toextreme-value models [Contributed Session C22(page 40)]
A. ZEMPLÉNI , Eötvös Loránd University, Budapest, Hungary
Extreme value theory has been one of the most quickly devel-oping area of mathematical statistics in the last decades. Themethods, based on the Fisher-Tippett theorem about the possi-ble limits of normalized maxima of iid random variables is nowroutinely applied in very different branches of areas from finan-cial mathematics to environmetrics, from reliability to internettraffic.However, there are no routinely applicable goodness-of-fit testavailable, which are tailored to the specific problems of the in-ference for extremes. In this paper we present specific tests,developed exactly for this problem including a computationallyeasier version of the test, originally presented in Zempléni, [2],see also Kotz and Nadarajah, [1]. Another method is based on aversion of the Anderson-Darling test, adapted to the problems,where the emphasis is on the fit for the upper tail of the distribu-tion as follows:
B2 = n∫ ∞
−∞
(Fn(x)−F(x))2
1−F(x)dF(x)

206 6th BS/ IMSC
We give small-sample and asymptotic critical values for the newtests by simulation and compare their performances to the clas-sical Anderson-Darling, Kolmogorov-Smirnov and Cramér-vonMises tests for simulated and for real hydrological data sets.We also consider the case of the generalized Pareto distribution,which is the candidate for modelling the values higher than agiven threshold.References[1] Kotz, S. and Nadarajah, S. (2000)Extreme Value Distributions,Im-perial College Press London.[2] Zempléni, A. (1996) Inference for generalized extreme value distri-butions,J. Appl. Statis. Sci.4, 107–122.
476 Recent results in nonparametric re-gression and empirical Bayes [Medaillon Lecture(page 22)]
Cun-Hui ZHANG , Rutgers University, USA
We consider three nonparametric estimation problems: nonpara-metric regression, estimation of sums of random variables, andtwo-way semi-linear regression. In nonparametric regression,we show that general empirical Bayes wavelet methods pro-vide simultaneously sharp asymptotically minimax estimationin large collections of classes of regression functions. In thesecond problem, we provide information bounds for the esti-mation of sums of utility functions of both observable variablesand unobservable variables. The two-way semi-linear regres-sion model extends and combines the standard semi-linear re-gression model and two-way ANOVA. We outline our theoreti-cal results and discuss applications in signal processing, speciesand data confidentiality problems, and normalization and analy-sis of cDNA microarray data.
477 Data dimension reduction using multi-variate adaptive splines [Invited Session 26 (page 49)]
Heping ZHANG , Yale University School of Medicine
Data reduction and regression involving high dimensional dataare challenging statistical issues. As the technology advances,our ability of collecting massive information and high dimen-sional data is rapidly progressing. Thus, it is more importantthan ever to study ways to handle high dimensional data. In thispresentation, I will first introduce multivariate adaptive splinesand then some of the latest developments in the research area ofdimension reduction. Combining these two types of methods, Iwill demonstrate the benefits of their combination in regressionanalysis involving a large number of predictors.
478 Some fluctuation identities for Lévyprocesses[Contributed Session C13 (page 45)]
Xiaowen ZHOU, Concordia University, Canada
A Lévy process with only negative jumps is considered. Theone–sided (respectively, two–sided) exit problem concerns whenand where the process first exits a semi–infinite (respectively, fi-nite) interval. Two–dimensional Laplace transforms on the exittime and the exit value in such problems can be found in [1] and[2].In this work the Laplace transform is obtained for the time whenthe Lévy process exits a finite interval from above. It is ex-pressed in terms of the Laplace transform for the one–sided exit
problem. This allows us to derive another expression of theLaplace transform for the two-sided exit problem. It also allowsus to obtain the joint distribution of the minimum and maximumof the Lévy process up to an independent exponential time.References[1] Bingham, N.H. (1975) Fluctuation theory in continuous time,Adv.in Appl. Probab.7, 705–766.[2] Emery, D.J. (1973) Exit probability for a spectrally positive process,Adv. in Appl. Probab.5, 498–520.
479 Classification rules for elliptical dis-tributions with monotone missing data [Con-tributed Session C41 (page 46)]
A. BATSIDIS and K. ZOGRAFOS , University of Ioannina,Greece
Classification of a new observation into one of two or more wellspecified populations is a classic problem of multivariate anal-ysis. In order to solve this problem, classification rules havebeen developed under the assumptions that the underlying pop-ulations are multivariate normal and that the available trainingsamples from the said populations are complete. Two types ofextensions of the above classic problem have been presentedin the literature. The first type introduces and studies classi-fication rules for the allocation of new observations into oneof two or more non-normal populations. In this context, thecase of elliptic populations drew attention of the researchers (cf.for instance, Koutras (1987), Sutradhar (1990), Cacoullos andKoutras (1997)). The second type extends the classic classifica-tion procedures to the case of incomplete training samples fromthe said populations (cf. among others, Twedt and Gill (1992)).The procedures developed in this case were mainly based on dif-ferent methods of handling missing data, like imputation tech-niques.This talk is dealt with classification rules that help to allocatea new observation into one of two elliptic populations, underthe assumption that the available incomplete training samplesfrom the elliptic populations are characterized by a monotonemissing pattern. In this context, two classification rules arestated, studied and compared. Namely, the plug-in classifica-tion rule and the linear combination classification rule proposedby Chung and Han (2000). Simulated data from a multivariatet−distribution are obtained and used in order to illustrate theresults.References[1] Cacoullos, T. and Koutras, M. (1997) On the performance ofminimum-distance classification rules for Kotz-type elliptical distribu-tions, Advances in the theory and practice of statistics: A volume inhonor of Samuel Kotz,Edited by N.L. Johnson and N. Balakrishnan,Wiley, New York.[2] Chung, H.C. and Han, C.P. (2000) Discriminant analysis when ablock of observations is missing,Ann. Inst. Statist. Math. 52, 544-556.[3] Koutras, M. (1987). On the performance of the linear discriminantfunction for spherical distributions.J. Multivariate Anal.22, 1–12.[4] Sutradhar, B.C. (1990) Discrimination of observations into one oftwo t populationsBiometrics46, 827–835.[5] Twedt, D.J. and Gill, D.S. (1992) Comparison of algorithm for re-placing missing data in discriminant analysis,Commun. Statist. TheoryMeth. 21, 1567–1578.

Directoryof participants


Directory 209
AALEN, Odd O.
UNIVERSITY OF OSLO, IMB
P.O.Box 1122 Blindern
Oslo
N-0317 Norway
ABAURREA, Jesús
UNIVERSIDAD DE ZARAGOZA
C/ P. Cerbuna, 9.
Zaragoza
50005 Spain
[email protected][Session P1 (page 21), Abstracts 64 and
15]
ACOSTA, Lesly
UNIVERSITAT POLITECNICA DE
CATALUNYA
Pau Gargallo, 5
Barcelona
08028 Spain
[email protected][Session C56 (page 47), Abstract 1]
ADELL, J.Antonio
DEP.METODOS ESTADISTICOS, FAC.
CIENCIAS, UNIV. DE ZARAGOZA
Pedro Cerbuna, 12, Zaragoza
50009 Spain
[email protected][Sessions C7 and M2 (pages 44 and 41),
Abstracts 2 and 369]
ADLER, Robert
INDUSTRIAL ENGINEERING
Technion
Haifa
32000 Israel
[email protected][Session Inv. 7 (page 32), Abstract 3]
AGUIRRE TORRES, Victor
ITAM
Rio Hondo 1
Mexico, DF
01000 Mexico
[email protected][Session C45 (page 14), Abstract 4]
AÏT-SAHALIA, Yacine
Princeton University,
Bendheim Center for Finance
26 Prospect Avenue
Princeton
NJ 08540-5296 USA
[email protected][Session Inv. 30 (page 43), Abstract 5]
ALBERS, Willem
APPL. MATH. DEPT., UNIVERSITY OF
TWENTE
P.O BOX 217
Enschede
7521 AV The Netherlands
[email protected][Session M4 (page 37), Abstract 6]
ALCALA NALVAIZ, Jose Tomas
DPTO. METODOS ESTADISTICOS,
UNIVERSIDAD DE ZARAGOZA
Fac. de Ciencias (Edif. B) Campus
50009 Zaragoza, Spain
[email protected][Sessions C5 and C14 (pages 18 and 16),
Abstracts 12 and 307]
ALDOUS, David
UNIVERSITY OF CALIFORNIA
367 Evans Hall, Berkeley
CA94720 USA
[email protected][Sessions Kolmogorov Lect., C1 and C35
(pages 13, 15 and 25) , Abstracts 7, 337
and 20]
ALLAART, Pieter
UNIVERSITY OF NORTH TEXAS
Mathematics Department, P.O.
Denton Tx
76203-1430 USA
[email protected][Session M5 (page 27), Abstract 8]
ALONSO, Andrés M.
UNIVERSIDAD AUTONOMA
DE MADRID
Campus de Cantoblanco, Madrid
28049 España
[email protected][Sessions C48 and P1 (pages 40 and 22),
Abstracts 9 and 10]
ALOS, Elisa
UNIVERSITAT POMPEU FABRA
C/ Ramón Trias Fargas, 25-27
Barcelona
08005 Spain
[email protected][Session P2 (page 31), Abstract 11]
ALZAID, Munther
INSTITUTE OF PUBLIC
ADMINISTRATION
P.O. Box 205
Riyadh
11141 Saudi Arabia
AMARAL TURKMAN, Antonia
FUNDAÇAO DE FCUL
Faculdade de Ciencias, Univ. of Lisboan
Lisbon
1749-016 Portugal
AMIR, Gideon
WEIZMANN INSTITUTE OF SCIENCE
P.O.Box 26
Rehovot
76100 Israel
ANDRES ESTEBAN, Eva María
DPTO. METODOS ESTADISTICOS,
UNIVERSIDAD DE ZARAGOZA
Fac. de CCEEyEE. C/ Dr. Cerrada 1-3
Zaragoza
50005 Spain
[email protected][Session C5 (page 18), Abstract 12]
ANISIMOV, Vladimir
GLAXOSMITHKLINE
RESEARCH STATISTICS UNIT
NFSP-South,Third Avenue
Harlow, Essex
CM19 5 AW UK
[email protected][Session C40 (page 37), Abstract 13]

210 6th BS/ IMSC
ANTONELLI, Fabio
MATH. DEPT. UNIVERSITY OF L’AQUILA
Via Vetoio loc. Coppito
L’Aquila
67100 Italy
ANTONIADIS, Anestis
UNIVERSITY JOSEPH FOURIER
BP 53
Grenoble
38041 France
ANTONIOU, Efi
THE PENNSYLVANIA STATE UNIVER-
SITY
326 Thomas Bldg
University Park PA
16802 USA
[email protected][Session C43 (page 26), Abstract 14]
AREDE, Maria Teresa
ENGINEERING FACULTY - O’PORTO
UNIVERSITY
Faculdade de Engenharia, R. Dr. Roberto
Porto
4200-465 Portugal
ASSELAH, Amine
UNIVERSITE DE PROVENCE
39 Rue Joliot Curie, CMI
Marseille Cedex 13
13453 France
[email protected][Session C9 (page 20), Abstract 16]
ASTIC, Fabian
CREST AND UNIVERSITY OF PARIS-
DAUPHINE
15 bd. Gabriel Peri
Malakoff
92245 France
ASÍN, Jesús
UNIVERSIDAD DE ZARAGOZA
CPS, C/ María de Luna
Zaragoza
50010 Spain
[email protected][Session P1 (page 21), Abstract 15]
ATCHADE, Yves
HARVARD UNIVERSITY
Dept. of Statistics, Harvard Univ.
Cambridge
02138 USA
ATIENZA MARTINEZ, Nieves
DEP. CIENCIAS SOCIO-SANITARIAS
UNIVERSIDAD DE SEVILLA
Facultad de Medicina Av. Sánchez
Sevilla
41009 Spain
[email protected][Sessions P3 and P1 (pages 41 and 22),
Abstracts 119 and 17]
AUBIN, Jean-Baptiste
UNIV. PARIS 6
9 Rue Vulpian
Paris
75013 France
[email protected][Session C6 (page 38), Abstract 18]
BAILLO, Amparo
UNIVERSIDAD CARLOS III DE MADRID
Depto. Estadística; C/ Madrid 126
Getafe
28903 Spain
[email protected][Session C6 (page 38), Abstract 19]
BALOGH, Jozsef
THE OHIO STATE UNIVERSITY
231 West 18th Street
Columbus
43210 USA
BANDYOPADHYAY, Antar
INSTITUTE FOR MATHEMATICS AND
ITS APPLICATIONS,
UNIV. OF MINNESOTA
400 Lind Hall, 207 Church Street SE
Minneapolis, Minnesota
55414 USA
[email protected][Session C35 (page 25), Abstract 20]
BANK, Peter
COLUMBIA UNIVERSITY
2990 Broadway
New York
10027 USA
[email protected][Session Inv. 3 (page 19), Abstract 21]
BARDINA, Xavier
UNIVERSITAT AUTONOMA DE
BARCELONA
Facultat de Ciències
Bellaterra
08193 Catalonia
[email protected][Session P2 (page 31), Abstract 22]
BARGER, Noam
CALTECH
Mathematics 253-37 Caltech
Pasadena
CA 91125 USA
BARLOW, Martin
UNIVERSITY OF BRITISH COLUMBIA
dept. of math, UBC
Vancouver
V6T 1Z2 Canada
[email protected][Session Inv. 18 (page 23), Abstract 23]
BARNDORFF-NIELSEN, Ole E.
UNIVERSITY OF AARHUS
Department of Mathematical Sciences
Aarhus
DK-8000 Denmark
[email protected][Session C13 (page 45), Abstracts 264,
320 and 371]

Directory 211
BARRANCO-CHAMORRO, Inmaculada
UNIVERSISDAD DE SEVILLA,
FAC. DE MATEMATICAS,
DPTO.DE ESTADISTICA
C/Tarfia, s/n, Sevilla
41012 Spain
[email protected][Session P3 (pages 41 and 42), Abstracts
24, 119 and 120]
BARRIEU, Pauline
LONDON SCHOOL OF ECONOMICS
Houghton Street
London
WC2A2AE UK
[email protected][Session Inv. 9 (page 23), Abstract 25]
BARTROFF, Jay
CALTECH
Caltech 253-37
Pasadena, CA
91125 USA
[email protected][Session C63 (page 39), Abstract 27]
BATSIDIS, Apostolos
UNIVERSITY OF IOANNINA
Univ. Ioannina, Dpt. Mathematics
Ioannina
451 10 Greece
[email protected][Session C41 (page 46), Abstracts 479
and 28]
BECHERER, Dirk
IMPERIAL COLLEGE LONDON
South Kensington campus
London
SW7 2AZ UK
[email protected][Session M5 (page 27), Abstract 29]
BEFFARA, Vincent
ENS LYON
46, Allee d’Italie
Lyon Cedex 07
69364 France
[email protected][Session Inv. 10 (page 39), Abstract 30]
BENEŠ, Christian
DUKE UNIVERSITY,
DPT. MATHEMATICS
Duke University
Durham, NH
27705 USA
[email protected][Session C15 (page 53), Abstract 31]
BENJAMINI, Yoav
Department of Statistics and
Operations Research
Tel Aviv University
Tel Aviv
Israel
[email protected][Session Inv. 27 (page 43), Abstract 32]
BERAN, Jan
UNIVERSITY OF KONSTANZ
Universitaetsstr. 10
Konstanz
78457 Germany
[email protected][Session C30 (page 54), Abstract 33]
BERESTYCKI, Julien
UNIVERSITE DE PARIS VI ET PARIS X
47, bvd de la villette
Paris
75010 France
[email protected][Session C38 (page 38), Abstract 35]
BERESTYCKI, Nathanael
CORNELL UNIVERSITY, ECOLE NOR-
MALE SUPERIEURE
118, Lake Avenue, Apt. 1
Ithaca, NY
14850 USA
[email protected][Session C15 (page 53), Abstract 34]
BERGER, Noam
Caltech
Pasadena
CA 91125 USA
[email protected][Session Inv. 22 (page 39), Abstract 36]
BERTAIL, Patrice
CREST - LAB. DE STATISTIQUE
18 Bd Adolphe Pinard
Paris
75675 France
[email protected][Sessions C47 and C5 (pages 17 and 18),
Abstracts 37 and 168]
BERTHET, Philippe
IRMAR, Université Rennes 1
Rennes
35042 France
[email protected][Session C14 (page 15), Abstract 38]
BERTOIN, Jean
LABORATOIRE DE PROBABILITES,
UNIVERSITE PARIS
175 rue du Chevaleret
Paris
75013 France
[email protected][Session C38 (page 38), Abstract 154]
BEUTNER, Eric
INSTITUT FUER STATISTIK UND
WIRTSCHAFTSMATHEMATIK
Wuellnerstrasse 3
Aachen
52062 Germany
BIBBY, Bo Martin
ROYAL VETERINARY AND
AGRICULTURAL UNIVERSITY
Department of Maths and Physics
Frederiksberg C
1871 Denmark
[email protected][Session M1 (page 17), Abstract 39]
BICKEL, Peter
UNIVERSITY OF CALIFORNIA,
BERKELEY 357 Evans Hall
Berkeley, Ca 94720, USA
[email protected][Bernoulli Lect. and session C29 (pages
52 and 56), Abstracts 71 and 135]

212 6th BS/ IMSC
BICKIS, Mikelis
UNIVERSITY OF SASKATCHEWAN
106 Wiggins Road
Saskatoon
S7J 2B8 Canada
[email protected][Session C46 (page 46), Abstract 41]
BIRGE, Lucien
LABORATOIRE DE PROBABILITÉS,
UNIVERSITY PARIS VI
Boite 188, 4 Place Jussieu
Paris Cedex 05
75252 France
[email protected][Session Inv. 23 (page 49), Abstract 42]
BIZJAJEVA, Svetlana
LUND UNIVERSITY
Sölvegatan 18
Lund
221 00 Sweden
BLATH, Jochen
UNIVERSITY OF OXFORD
DEPARTMENT OF STATISTICS
Oxford
OX1 3TG UK
[email protected][Session C1 (page 15), Abstract 43]
BOBKOV, Sergey
UNIVERSITY OF MINNESOTA
SCHOOL OF MATHEMATICS
Minneapolis
55455 USA
BOJDECKI, Tomasz
UNIVERSITY OF WARSAW
Institute of Mathematics
Warsaw
02-097 Poland
[email protected][Session C25 (page 36), Abstract 44]
BOLTHAUSEN, Erwin
Institute of Mathematics
University of Zurich
Winterthurerstrasse 190
Zurich
CH-8057 Switzerland
[email protected][Session Inv. 14 (page 33), Abstract 45]
BONDON, Pascal
CNRS
Laboratoire des Signaux et Systema
Gif -sur-Yvette
91192 France
[email protected][Session C30 (page 54), Abstract 46]
BORISOV, Igor
SOBOLEV INSTITUTE OF MATHEMAT-
ICS
Koptyug avenue, 4
Novosibirsk
630090 Russian Federation
[email protected][Session C11 (page 15), Abstract 47]
BORODIN, Alexei
CALTECH
1200 East California Boulevard
Pasadena
CA 91125 USA
[email protected] edu[Session Inv. 20 (page 29), Abstract 48]
BOUCHARD-DENIZE, Bruno
LPMA, UNIVERSITY PARIS 6
Tour 56- 4, PLace Jussieu
Paris
75252 France
[email protected][Session C36 (page 16), Abstract 49]
BOUDRAHEM, Nassim
UNIVERSITY FES
88 Rue Didadou
FES
08001 Tunisia
BOVIER, Anton
WEIERSTRASS-INSTITUTE
Mohrenstrasse 39
Berlin
10117 Germany
[email protected][Session Inv. 16 (page 14), Abstract 50]
BREMAUD, Pierre
EPFL
EPFL/IC
Ecublens
1015 Switzerland
[email protected][Session C62 (page 18), Abstract 51]
BROWN, Lawrence
UNIV OF PENN
Statistics Department
Philadelphia
19104 USA
[email protected][Session Inv. 23 (page 49), Abstract 52]
BROWN, Tim
AUSTRALIAN NATIONAL UNIVERSITY
Faculty of Science,
Canberra
ACT 0200 Australia
[email protected][Session Inv. 23 (page 49), Abstract 52]
BUNEA, Florentina
FLORIDA STATE UNIVERSITY
Corner of Call St. and Woodward Ave.
Tallahassee
32306-4330 USA
[email protected][Session C48 (page 40), Abstract 53]
CABALLERO, Maria Emilia
UNIVERSIDAD DE MEXICO UNAM,
UNIV. DE PARIS X
28 Rue des Fosses St. Bernard
Paris
75005 France
[email protected][Session C32 (page 50), Abstract 72]

Directory 213
CABALLERO-AGUILA, Raquel
UNIVERSIDAD DE JAEN
Paraje Las Lagunillas s/n
Jaén
23071 Spain
[email protected][Session P1 (page 21), Abstract 54]
CABAÑA NIGRO, Ana Alejandra
UNIVERSIDAD DE VALLADOLID
Fac. de Ciencias
Valladolid
47005 Spain
[email protected][Session C22 (page 40), Abstract 55]
ÇAGLAR, Mine
KOC UNIVERSITY
Rumelifeneri Yolu, Sariyer
Istanbul
34450 Turkey
[email protected][Session C25 (page 36), Abstract 56]
CAI, Yuzhi
University of Wisconsin
Sheboygan
WI 53081 USA
CAMPILLO, Fabien
INRIA RENNES / IRISA
Campus de Beaulieu
Rennes
35042 France
[email protected][Session C20 (page 35), Abstract 57]
CANEPA, Alessandra
UNIVERSITY OF YORK
Dpt. of Economics, Heslington
York
YO10 5DD UK
[email protected][Session P3 (page 42), Abstract 58]
CAO, Ricardo
UNIVERSIDADE DA CORUÑA
Facultad Informática Campus de Elviña
A Coruña
15071 Spain
[email protected][Sessions Inv. 28 and C54 (pages 43 and
46), Abstracts 59 and 190]
CAPALDO, Marcella
DEPT. OF STATISTICS
1, South Parks Road
Oxford
OX1 3TG UK
ÇAPAR, Ulu g
EASTERN MEDITERRANEAN
UNIVERSITY
Department of Mathematics
Mersin
MERSIN-10 Turkey
[email protected][Session C4 (page 53), Abstract 60]
CAPPE, Olivier
ENST / CNRS
46 Rue Barrault
Paris
75634 France
CÁRCAMO, Javier
UNIVERSITY OF THE BASQUE COUN-
TRY
Departamento de Economía Aplicada V
Bilbao
48008 Spain
[email protected][Session C2 (page 24), Abstract 61]
CASADO, David
SPANISH NATIONAL CANCER CENTER
(CNIO)
Melchor Fernández Almagro, 3
MADRID
28029 Spain
CASANOVA DEL ANGEL, Francisco
INSTITUTO POLITÉCNICO NACIONAL
Andador nž6, Edificio 4-C-305
México D.F.
07270 Mexico
CASCOS FERNANDEZ, Ignacio
PUBLIC UNIVERSITY OF NAVARRE
Campus Arrosadía, s/n
Pamplona
31006 España
[email protected][Session C2 (page 24), Abstract 62]
CASTELO, Robert
UNIVERSITAT POMPEU FABRA
Psg. Maritim 37-49
Barcelona
08003 Spain
[email protected][Session Inv. 6 (page 23), Abstract 162]
CAVALIER, Laurent
UNIVERSITE AIX-MARSEILLE 1
CMI 39 Rue Joliot-Curie
Marseille
13453 France
[email protected][Session C53 (page 28), Abstract 63]
CEBRIÁN, Ana C.
UNIVERSIDAD DE ZARAGOZA
C/ P. Cerbuna, 9
Zaragoza
50005 Spain
[email protected][Session P1 (page 21), Abstract 64]
CENTANNI, Silvia
DEPARTMENT OF ECONOMICS,
UNIVERSITY OF PERUGIA
Via Pascoli
Perugia
06100 PERU Italy
[email protected][Session M6 (page 29), Abstract 65]

214 6th BS/ IMSC
CENTELLES, Alberto
UNIVERSIDAD DE ZARAGOZA
C/ P. Cerbuna, 9.
Zaragoza
50005 Spain
CERQUETTI, Annalisa
BOCCONI UNIVERSITY
Viale Isonzo, 25
Milan
20135 Italy
[email protected][Session P2 (page 31), Abstract 66]
CETIN, Umut
VIENNA UNIVERSITY OF TECHNOL-
OGY
WIEDNER HAUPTSTR. 8-10/105
Vienna
A-1040 Austria
[email protected][Session M4 (page 37), Abstract 67]
CHAGANTY, Narasinga Rao
OLD DOMINION UNIVERSITY
1309 Links Court
Chesapeake, Virginia
23320 USA
[email protected][Session C33 (page 45), Abstract 68]
CHALEYAT-MAUREL, Mireille
UNIVERSITÉ RENÉ DESCARTES
45, Rue des Saints Pères
Paris
75006 France
CHANDLER, Richard E.
Department of Statistical Science,
University College London
Gower St
London
WC1E 6BT UK
[email protected][Session Inv. 2 (page 13), Abstract 69]
CHANG, Chih-Chung
MATH DEPT.
National Taiwan University
Taipei
106 Taiwan
[email protected][Session C9 (page 20), Abstract 70]
CHAUDHURI, Sanjay
UNIVERSITY OF WASHINGTON
B313 Padelford Hall, Box 354322
Seattle
98195 USA
[email protected][Session C24 (page 36), Abstract 71]
CHAUMONT, Loic
UNIVERSITE PARIS 6
4, Place Jussieu
Paris
75252 France
[email protected][Session C32 (page 50), Abstract 72]
CHEN, Dayue
PEKING UNIVERSITY
School of Mathematical Sciences
Beijing
100871 China
[email protected][Session Inv. 19 (page 49), Abstract 73]
CHEN, Louis
INSTITUTE FOR MATHEMATICAL
SCIENCES
National Univ. of Signapore
Singapore
118042 Singapore
CHENG, Yebin
TINBERGEN INSTITUTE
Dept. of Quantitative Economics,
Amsterdam
1018 WB AM The Netherlands
[email protected][Session C54 (page 46), Abstract 74]
CHIANG, Tzuu-Shuh
INSTITUTE OF MATHEMATICS
Academia Sinica
Taipei
115 Taiwan
[email protected][Session C12 (page 25), Abstract 75]
CHIAROMONTE, Francesca
Department of Statistics,
The Pennsylvania State University
326 Thomas Building, University Park
PA 16802 USA
[email protected][Session Inv. 6 (page 23), Abstract 76]
CHIVORET, Sebastien
UNIVERSITY OF MICHIGAN
525 East University Avenue
Michigan
48109-1109 USA
CHOIRAT, Christine
UNIVERSITA DEGLI STUDI
DELL’INSUBRIA
Via Ravasi 2, Varese
2100, Italy
[email protected][Sessions P3 and C8 (pages 35 and 42),
Abstracts 77, 78, 386 and 387]
CLAESKENS, Gerda
UNIVERSITE CATHOLIQUE
DE LOUVAIN
INSTITUT DE STATISTIQUE
Louvain-La-Neuve
1348 Belgium
[email protected][Session C57 (page 34), Abstract 79]
CLAYTON, David
CAMBRIDGE UNIVERSITY
Wellcome Trust/MRC Building,
Cambridge
CB2 2XY UK
[email protected][Session Inv. 5 (page 29), Abstract 80]

Directory 215
COLLAMORE, Jeffrey
UNIVERSITY OF COPENHAGEN
Lab. of Actuarial Mathematics,
Copenhagen OE
DK-2100 Denmark
[email protected][Session M2 (page 41), Abstract 81]
COMMENGES, Daniel
INSERM E03 38
ISPED, 146 rue Léo Saignat
Bordeaux
33076 France
[Session C20 (page 35), Abstract 82]
CONÇALVEZ FIGUEIRINHA, Rita
Marisa
FACULDADE DE CIENCIAS E
TECNOLOGIA DE COIMBRA
Rua Principal, n. 112 Mata Mourisca
Pombal
3105-198 Portugal
COQUET, Francois
LMAH, UNIVERSITE DU HAVRE
25, rue Philippe Lebon
LE HAVRE
76600 France
[email protected][Session C11 (page 15), Abstract 83]
CORCUERA, José Manuel
UNIVERSITY OF BARCELONA
Gran Via 585
Barcelona
08007 Spain
COX, Alexander
UNIVERSITY OF BATH
Dpt. of Mathematics, Univ. of Bath
Bath
BA2 7AY UK
[email protected][Session C10 (page 44), Abstract 84]
COX, Ted
SYRACUSE UNIVERSITY
Mathematics Department, Syracuse
Univers
Syracuse
13244 USA
CRISAN, Dan
IMPERIAL COLLEGE LONDON
180 Queen’s Gate
London
SW7 2AZ UK
[email protected][Session C3 (page 50), Abstract 85]
CUADRAS, Carles M.
UNIVERSITY OF BARCELONA
Diagonal 645
Barcelona
08028 Spain
[email protected][Session C41 (page 46), Abstract 86]
CUESTA-ALBERTOS, Juan A.
UNIVERSIDAD DE CANTABRIA
Facultad de Ciencias
Santander
39005 Spain
[email protected][Session C61 (page 48), Abstract 275]
CUREG, EDGARDO
UNIVERSITY OF SOUTH FLORIDA
9209 Seminole Blvd Apt 121
Seminole
33772 USA
DALEN, Ingvild
UNIVERSITY OF OHIO
Department of Statistics, IBM, PB 1122 B
Oslo
0317 Norway
DAMILANO, Gabriela
UNIVERSITAT AUTÒNOMA
DE BARCELONA
Departament de Matemàtiques
Cerdanyola del Vallés
08193 Spain
[email protected][Session C49 (page 26), Abstract 87]
DAOUDI, Jalila
UAB
Cerdanyola del Vallès
Barcelona
08193 Spain
DARLING, R W R
U. S. GOVERNMENT
P.O.Box 535
Annapolis Junction, MD
20701 USA
[email protected][Session C16 (page 52), Abstract 88]
DAUXOIS, Jean-Yves
CREST-ENSAI
Campus de Ker-Lann
Bruz
35170 France
[email protected][Session C27 (page 36), Abstracts 89 and
163]
DAWSON, Donald
CARLETON UNIVERSITY
6 Leyland Private
Ottawa
K1V0X8 Canada
DE HAAN, Laurens
ERASMUS UNIVERSITEIT
Postbus 1738
Rotterdam
3000 DR The Netherlands
[email protected][Sessions Inv. 4 and C59 (pages 23 and
48), Abstracts 90 and 245]

216 6th BS/ IMSC
DE JONG, Hidde
INRIA RHONE-ALPES
655, Avenue de l’Europe, Montbonnot
St. Ismier Cedex
38334 France
[email protected][Session Inv. 1 (page 19), Abstract 91]
DE LUNA, Xavier
UMEA UNIVERSITY
Department of Statistics, Umea Universit
Umea
90187 Sweden
[email protected][Session C39 (page 33), Abstract 92]
DEBOWSKI, Łukasz
INSTITUTE OF COMPUTER SCIENCE
POLISH ACADEMY OF SCIENCES
ul. Ordona 21
Warsaw
01-237 Poland
[email protected][Session P2 (page 32), Abstract 93]
DEL CASTILLO, Joan
UAB
Campus de la UAB, Bellaterra
Cerdanyola del Vallés
08193 Spain
DEL MORAL, Pierre
Laboratoire de Statistique et Probabilités
118 route de Narbonne
TOULOUSE
31062 France
[email protected][Session Inv. 24 (page 51), Abstract 94]
DELAIGLE, Aurore
UNIVERSITY OF CALIFORNIA, DAVIS
DPT. STATISTICS
Kerr Hall, One Shields Avenue
Davis
95616 USA
[email protected][Session C54 (page 46), Abstract 95]
DELGADO, Miguel A.
UNIVERSIDAD CARLOS III
Madrid, 126-128
Getafe
28903 España
[email protected][Session Inv. 28 (page 43), Abstract 257]
DELGADO, Rosario
UAB
Edifici C- Facultat de Ciències
Bellaterra
08193 España
[email protected][Session Inv. 28 (page 43), Abstract 257]
DELICADO, Pedro
UNIVERSITAT POLITECNICA
DE CATALUNYA
Pau gargallo 5
Barcelona
08005 Spain
[email protected][Session C65 (page 48), Abstract 97]
DELIGERO, Eveyth
KEIO UNIVERSITY
3-14-1 Hiyoshi, Kohoku-ku,
Kanagawa
223-8522 Japan
[email protected][Session C7 (page 44), Abstract 98]
DELMAS, Jean-François
CERMICS-ENPC
6-8, Av. Blaise Pascal
Champs sur Marne
77445 France
DEN HOLLANDER, Frank
EURANDOM
Postbus 513
EINDHOVEN
5600 MB The Netherlands
DETTE, Holger
FAKULTAET FUER MATHEMATIK
Ruhr Universitaet Bochum
Bochum
44780 Germany
[email protected][Session C19 (page 30), Abstract 99]
DI PERSIO, Luca
UNIVERSITY OF TRENTO,
DPT. MATHEMATICS
Via Sommarive, 14
Povo (Trento)
38050 Italy
DI SCALA, Lilla
UNIVERSITY OF PAVIA
Dip. Matematica, Via Ferrata 1
Pavia
27100 Italy
DIDELEZ, Vanessa
UNIVERSITY COLLEGE LONDON,
DEPT. OF STATISTICAL SCIENCE
Gower Street
London
WC1E6BT UK
[email protected][Session C39 (page 33), Abstract 100]
DIECKMANN, Ulf
International Institute for
Applied Systems Analysis (IIASA)
Laxenburg
Austria
[email protected][Session Inv. 2 (page 13), Abstract 101]
DIPPON, Jurgen
UNIVERSITY OF STUTTGART
Pfaffenwaldring 57
Stuttgart
70550 Germany

Directory 217
DOMANSKI, Czeslaw
UNIVERSITY OF LODZ, CHAIR OF
STATISTICAL METHODS
Rewolucji 1905r.str. No 41
LODZ
90-214 Poland
DOMENACH, Florent
INSTITUTE OF POLICY AND PLANNING
SCIENCES
1-1-1 Tenno-dai
Tsukuba, Ibaraki
305-8573 Japan
[email protected][Session C55 (page 21), Abstract 102]
DORAY, Louis
DEPT OF MATH & STAT
UNIVERSITY OF MONTREAL
P.O. Box 6128, succursale Centre-ville
Montreal, P.Q.
H3C 3J7 Canada
[email protected][Session C33 (page 45), Abstract 103]
DOUC, Randal
ECOLE POLYTECHNIQUE
CMAP, route de Saclay
Palaiseau
91128 France
[email protected][Sessions C18 and C36 (pages 54 and
16), Abstracts 104, 292 and 300]
DOWNIE, Tim
UNIVERSITY COLLEGE LONDON
Gower Street
London
WC1E 6BT UK
[email protected][Session C21 (page 50), Abstract 105]
DROZDENKO, Myroslav
MATHEMATICS AND PHYSICS
Box 883
Vasteras
72123 Sweden
[email protected][Session M2 (page 41), Abstract 106]
DRTON, Mathias
UNIVERSITY OF WASHINGTON
Dpt. Statistics, Box, 354322
Seattle
98195-4322 USA
[email protected][Session Inv. 35 (page 30), Abstract 107]
DRYDEN, Ian
UNIVERSITY OF NOTTINGHAM
School of Mathematical Sciences, Univers
Nottingham
NG7 2RD UK
[email protected][Sessions C28 and C17 (pages 25 and
53) , Abstracts 222, 233 and 108]
DUBEDAT, Julien
UNIVERSITE PARIS-SUD
Laboratoire de Mathematiques
Orsay
91405 France
[email protected][Session Inv. 13 (page 20), Abstract 109]
DUMITRIU, Ioana
UNIVERSITY OF CALIFORNIA AT
BERKELEY
Dept. of Math. , 751 Evans Hall
Berkeley
94709 USA
[email protected][Session Inv. 20 (page 29), Abstract 110]
EATON, Morris
UNIVERSITY OF MINNESOTA
School of Statistics
Minneapolis, MN
55455 USA
EDELMAN, Alan
M.I.T.
77 Massachusetts Ave 2-343
Cambridge
02139 USA
[email protected][Sessions C8 and Inv. 21 (pages 34 and
33), Abstracts 299 and 111]
EEROLA, Mervi
UNIVERSITY OF HELSINKI,
DEPT. OF MATHEMATICS AND STATIS-
TICS
P.O.Box 4
Helsinki
00014 Finland
EICHELSBACHER, Peter
FACULTY OF MATHEMATICS
RUHR-UNIVERSITY OF BOCHUM
BOCHUM
44780 Germany
[email protected][Session C35 (page 26), Abstract 112]
EKSTROM, Magnus
CENTRE OF BIOSTOCHASTICS
Swedish Univ. of Agricultural Scienes
Umea
903 38 Sweden
[email protected][Session C45 (page 14), Abstract 113]
ELIE, Romuald
CREST-ENSAE
3, avenue Pierre Larousse
Malakoff Cedex
92245 France
ELORANTA, Kari
HELSINKI UNIVERSITY
espoo
Finland
paula.latvalaÇ@hut.fi[Session C23 (page 16), Abstract 114]
EMBRECHTS, Paul
ETH ZURICH
Raemistrasse 101
Zurich
8092 Switzerland
[email protected][Session Inv. 9 (page 23), Abstract 115]

218 6th BS/ IMSC
ENGELBERT, Hans-Jürgen
UNIVERSITY OF JENA,
INSTITUTE FOR STOCHASTICS
Ernst-Abbe-Platz 1-4, Jena
D-07743 Germany
[email protected][Session C4 (page 53), Abstract 116]
ENGLANDER, Janos
UNIVERSITY OF CALIFORNIA
Dept. of Statistics, South Hall, UCSB
Santa Barbara
CA 93106 USA
[email protected][Session C37 (page 24), Abstract 117]
ENGUIX-GONZALEZ, Alicia
UNIVERSIDAD DE SEVILLA
C/ Tarfia s/n
Sevilla
41012 Spain
[email protected][Session P3 (pages 41 and 42), Abstracts
118, 119 and 120]
EPIFANI, Ilenia
POLITECNICO DI MILANO
Piazza L. da Vinci 32
Milan
20133 Italy
ERIKSSON, Jonatan
DEPARTMENT OF MATHEMATICS,
UPPSALA UNIVERSITY
Box 408
Uppsala
75106 Sweden
[email protected][Session P2 (page 32), Abstract 121]
ESCANCIANO, Juan Carlos
UNIVERSIDAD CARLOS III DE MADRID
Calle Madrid 126
Madrid
28903 Spain
[email protected][Session C53 (page 28), Abstract 122]
ESTUDILLO MARTINEZ, Maria Dolores
UNIVERSITY OF JAEN
Paraje Las Lagunillas s/n
Jaen
23071 Spain
[email protected][Session P3 (page 42), Abstract 123]
ETHERIDGE, Alison
OXFORD UNIVERSITY
Department of Statistics
Oxford
OX1 4AU UK
[email protected][Sessions Medaillon Lect. and C1 (pages
32 and 15), Abstracts 124 and 43]
FAN, Jianqing
PRINCETON UNIVERSITY
Dpt. of Oper Res. & Fin. Eng.
Princeton
NJ 08540 USA
[email protected][Session Inv. 8 (page 13), Abstract 125]
FARRINGTON, Paddy
OPEN UNIVERSITY
Walton Hall
Milton Keynes
MK7 6AA UK
[email protected][Session Inv. 34 (page 44), Abstract 126]
FASEN, Vicky
MUNICH UNIVERSITY OF
TECHNOLOGY
Boltzmannstraße 3
Garching
85747 Germany
[email protected][Session P2 (page 32), Abstract 127]
FEIGIN, Paul
TECHNION - ISRAEL INSTITUTE OF
TECHNOLOGY
Faculty of Industrial Eng. & Management
Haifa
32000 Israel
FERKINGSTAD, Egil
DEPARTMENT OF STATISTICS,
FACULTY OF MEDICINE,
UNIVERSITY OF OSLO
Sognsvannsveien 9
Oslo
N-0317 Norway
FERNANDES, Marcelo
CETULIO VARGAS FOUNDATION
Praia de Botafogo, 190/1113
Rio de Janeiro
22230-000 Brazil
[email protected][Session M6 (page 28), Abstract 128]
FERNANDEZ MARTINEZ, Daniel
CIMAT CENTRO DE INVESTIGACION
EN MATEMATICAS AC
Jalisco s/n, Mineral de Valenciana
Guanajuato
36240 Mexico
FERNANDEZ PASCUAL, Rosaura
UNIVERSIDAD DE JAEN
Virgen de la Cabeza s/n
Jaén
23071 Spain
[email protected][Session C19 (page 30), Abstract 129]
FERRARI, Pablo
IME- UNIVERSIDADE DE SAO PAULO
Cx Postal 66281
Sao Paulo
05311970 Brazil
[email protected][Session Inv. 18 (page 23), Abstract 131]
FERRIGNO, Sandie
LABORATOIRE PROBABILITES ET
STATISTIQUE
Université Montpellier II
Montpellier
34095 France
[email protected][Session P3 (page 41), Abstract 132]

Directory 219
FILATOVA, Daria
UNIVERSITY OF KIELCE
ul. Krakowska 11
Kielce
25-029 Poland
[email protected][Session C19 (page 30), Abstract 133]
FILINKOV, Alexei
DSTO
PO Box 1500
Edinburgh
5111 Australia
FINNER, Helmut
Leibniz-Institut an der
Heinrich-Heine-Universität
Düsseldorf
Germany
[email protected][Session Inv. 27 (page 43), Abstract 134]
FORTINI, Sandra
BOCCONI UNIVERSITY
Viale Isonzo 25
Milano
20135 Italy
[email protected][Session P2 (page 31), Abstract 66]
FROSINI, Benito
UNIVERSITA CATTOLICA DI MILANO
Largo Gemelli 1
Milano
20123 Italy
GALLIZO LARRAZ, Jose Luis
FACULTAT DE DRET I ECONOMIA,
UNIVERSITAT DE LLEIDA
Jaume II, 73 (Capont)
Lleida
25001 Spain
[email protected][Session P1 (page 21), Abstract 142]
GAMST, Anthony
UNIVERSITY OF CALIFORNIA
UCSD, Biostatistics - 0717, La Jolla
CA 92093-0717 USA
[email protected][Sessions C31, C29 and P3 (pages 30,
52 and 42) , Abstracts 135, 136 and 137]
GANESH, Ayalvadi
MICROSOFT RESEARCH
7 J J Thomson Avenue
Cambridge
CB3 0FB UK
[email protected][Session C16 (page 52), Abstract 138]
GANTERT, Nina
UNIVERSITAET KARLSRUHE
Englerstr. 2
Karlsruhe
76128 Germany
[email protected][Session Inv. 22 (page 39), Abstract 36]
GAPEEV, Pavel
RUSSIAN ACADEMY OF SCIENCES
Profsoyuznaya Street 65
Moscow
117997 Russian Federation
[email protected][Session C12 (page 25), Abstract 139]
GARCIA, Gloria
AUTONOMA UNIVERSITY
OF BARCELONA
Edifici ciències, c1/306
Bellaterra-Barcelona
08193 Spain
[email protected][Session P3 (page 42), Abstract 140]
GAREL, Bernard
NATIONAL POLYTECHNICS INSTITUTE
2 rue Camichel
TOULOUSE
31071 France
[email protected][Session C44 (page 52), Abstract 141]
GARGALLO VALERO, Pilar
ESCUELA UNIVERSITARIA DE
ESTUDIOS EMPRESARIALES,
UNIV. DE ZARAGOZA
c/Maria de Luna, Edif. Lorenzo Norman
50018 Zaragoza, Spain
[email protected][Session P1 (page 21), Abstract 142]
GARRICK, SAMUEL
WISE KIDDIES SCHOOL
12 SOKEYE STREET,
OLORUNSOGO,MOLETE
IBADAN.OYO STATE.
200001 Nigeria
GARRIDO-ATIENZA, María José
UNIVERSIDAD DE SEVILLA
Apartado de Correos 1160
SEVILLA
41080 Spain
[email protected][Session C12 (page 25), Abstract 143]
GASSIAT, Elisabeth
UNIVERSITE PARIS SUD
Batiment 425
Orsay
91405 France
[email protected][Session C34 (page 28), Abstract 144]
GAUDILLIÈRE, Alexandre
University of Roma Tor Vergata
Roma
Italy
[email protected][Session C35 (page 26), Abstract 145]
GEISS, Stefan
UNIVERSITY OF JYVÄSKYLÄ
DPT OF MATHEMATICS AND STATIS-
TICS
Jyväskylä
FIN-40520 Finland
[email protected][Session C11 (page 15), Abstract 146]

220 6th BS/ IMSC
GEMO, Sabrina
UNIVERSITAT DE BARCELONA
Gran Via de les Corts Catalanes
BARCELONA
08007 Spain
GENOVESE, Christopher
CARNEGIE MELLON UNIVERSITY
5000 Forbes Avenue
Pittsburgh, PA
15213 USA
[email protected][Session Inv. 27 (page 43)]
GHOMRASNI, Raouf
DEPT DE MATEMATICA APLICADA Y
ESTADISTICA
Univ. Politécnica de Cartagena
Cartagena
E-30203 Spain
GHOSH, Sucharita
SWISS FEDERAL RESEARCH
INSTITUTE WSL
Zuercherstrasse 111
Birmensdorf
CH-8903 Switzerland
[email protected][Session C30 (page 54), Abstract 147]
GIACOMIN, Giambattista
UNIVERSITé PARIS 7
2 place Jussieu, Case 7012
Paris Cedex 05
75251 France
[email protected][Session Inv. 14 (page 33), Abstract 148]
GINÉ, Evarist
UNIVERSITY OF CONNECTICUT
Department of Mathematics, U-3009
Storrs, CT
06269 USA
[email protected][Session Medaillon Lect. (page 51), Ab-
stract 149]
GINEBRA, Josep
UNIVERSITAT POLITECNICA DE
CATALUNYA
Avgda. Diagonal 647, 6ł Planta
BARCELONA
08028 Spain
[email protected][Session C34 (page 28), Abstract 150]
GIRAUDO, Maria Teresa
DEPT. OF MATHEMATICS
UNIVERSITY OF TORINO
Via Carlo Alberto 10
Torino
10128 Italy
[email protected][Session P2 (page 31), Abstract 151]
GLATT-HOLTZ, Nathan
UNIVERSITY OF SOUTHERN
CALIFORNIA
234 South Figueroa St 1339
Los Angeles
90012 USA
GLUHOVSKY, Ilya
SUN MICROSYSTEMS LABORATORIES
2600 Casey Ave MTV29-120
Mountain View, CA
94043 USA
[email protected][Session C58 (page 55), Abstract 152]
GOBET, Emmanuel
ECOLE POLYTECHNIQUE - CMAP
Route de Saclay
Palaiseau
91120 France
[email protected][Session C10 (page 44), Abstracts 153,
279 and 237]
GOLDSCHMIDT, Christina
LABORATOIRE DE PROBABILITES ET
MODELES ALEATOIRES
UNIV. PARIS 6
175 rue du Chevaleret, Paris
75013 France
[email protected][Session C38 (page 38), Abstract 154]
GÓMEZ GÓMEZ, Mł Teresa
UNIVERSIDAD DE SEVILLA
Tarfia s/n
Sevilla
41012 España
[email protected][Session P3 (page 41), Abstract 130]
GONZÁLEZ MANTEIGA, Wenceslao
UNIVERSITY OF SANTIAGO DE
COMPOSTELA
Departamento de Estadistica e I.O.
Santiago de Compostela
15782 Spain
[email protected][Sessions C22 and C5 (pages 40 and 18),
Abstracts 156, 444 and 312]
GONZÁLEZ VELASCO, Miguel
UNIVERSIDAD DE EXTREMADURA
Dpto. Matemáticas Facultad de Ciencias
Badajoz
06071 Spain
[email protected][Session P2 (page 31), Abstract 155]
GORDIENKO, Evgueni
UNIVERSIDAD AUTONOMA
METROPOLITANA - IZTAPALAPA
Av. San Rafael Atlixco, 186 Col. Vicenti
Mexico D.F.
09340 Mexico
[email protected][Session M2 (page 41), Abstract 157]
GOROSTIZA, Luis
CINVESTAV
A. P. 14-740
Mexico D.F.
07000 Mexico
[email protected][Session C25 (page 36), Abstract 44]
GOTTARDO, Raphael
UNIVERSITY OF WASHINGTON
University of Washington Dept. of
Seattle
98195-4322 USA
[email protected][Session C40 (page 37), Abstract 158]

Directory 221
GOTZE, Friedrich
UNIVERSITY OF BIELEFELD
Department of Mathematics
Bielefeld
33501 Germany
GRANOVSKY, Boris
TECHNION
Technion -city
Haifa
32000 Israel
[email protected][Sessions C8 and C38 (pages 35 and 38),
Abstracts 401 and 160]
GREEN, Peter
UNIVERSITY OF BRISTOL
School of Mathematics
Bristol
BS8 1TW UK
GREVEN, Andreas
MATHEMATISCHES INSTITUT
ERLANGEN
Bismarckstrasse 1 1/2
91054 Germany
GRIFFITHS, Robert
UNIVERSITY OF OXFORD
Lady Margaret Hall
Oxford
OX2 6QA UK
[email protected][Session C1 (page 15), Abstracts 161 and
399]
GUERRA, Joao
UNIVERSITAT DE BARCELONA
Gran Via de les corts catalanes, 585
Barcelona
08007 Spain
GUIGÓ, Roderic
IMIM
Pg. Maritim de la Barceloneta, 37-49
Barcelona
08003 Spain
[email protected][Session Inv. 6 (page 23), Abstract 162]
GUILLOUX, Agathe
CREST-ENSAI
Campus de Ker Lann
BRUZ
35170 France
[email protected][Session C27 (page 36), Abstracts 89 and
163]
GUNNES, Nina
UNIVERSITY OF OSLO
IBM, Department of Statistics, PB 1122 B
Oslo
0317 Norway
GUO, Meihui
NATIOANL SUN YAT-SEN UNIVERSITY
Dept. of Appied Math.
Kaohsiung, Taiwan
804 Taiwan
[email protected][Sessions Inv. 3, C34 and C30 (pages 19,
28 and 54) , Abstracts 326, 183 and 164]
GUSTAFSON, Elyse
Institute of Mathematical Statistics
PO Box 22718
Beachwood
OH 44122 USA
GUT, Allan
UPPSALA UNIVERSITY
Dpt. of Mathematics
Uppsala
SE 751 06 Sweden
[email protected][Session C2 (page 24), Abstract 165]
GUYADER, Arnaud
UNIVERSITE DE RENNES 2
Campus de Villejean
Rennes
35043 France
[email protected][Session Inv. 24 (page 51), Abstract 236]
HAAG, Berthold
UNIVERSITY OF MANNHEIM
L7, 3-5
Mannheim
68131 Germany
HALL, W. J.
UNIVERSITY OF ROCHESTER
Medical Center
NY
14642-8630 USA
HALL, Peter
AUSTRALIAN NATIONAL UNIVERSITY
Centre for Mathematics and its Applicati
Canberra, A.C.T.
0200 Australia
[email protected][Sessions C37 and C51 (pages 24 and
27), Abstracts 166 and 365]
HANDA, Kenji
SAGA UNIVERSITY
Honjo-machi 1
Saga
840-8502 Japan
[email protected][Session C1 (page 15), Abstract 167]
HARARI-KERMADEC, Hugo
INRA-CORELA
65 bd de Brandebourg
Ivry-Sur-Seine
94205 France
[email protected][Session C5 (page 18), Abstract 168]

222 6th BS/ IMSC
HASHEMIPARAST, Moghtada
K.N.T.UNIVERSITY OF TECHNOLOGY
Seyed Khandan Jolfa Ave.
Tehran
2751325 Iran
HAUSENBLAS, Erika
Institut für Mathematik
Universität Salzburg
Hellbrunnerstr. 34
Salzburg
A-5020 AUSTRIA
[email protected][Session C3 (page 50), Abstract 169]
HAYASHI, Takaki
COLUMBIA UNIVERSITY / UNIVERSITY
OF TOKIO
3-8-1 Komaba, Meguro-ku
Tokyo
153-8914 Japan
[email protected][Session M6 (page 28), Abstract 170]
HELD, Leonhard
UNIVERSITY MUNICH
DEPARTMENT OF STATISTICS
Munich
80539 Germany
[email protected][Session Inv. 34 (page 43), Abstract 171]
HENGARTNER, Nicolas
LOS ALAMOS NATIONAL LABORATORY
MS F600, D-1 Statistical Science
Los Alamos
87545 USA
[email protected][Sessions C24 and C31 (pages 36 and
30), Abstracts 413 and 172]
HEUCHENNE, Cédric
INSTITUT DE STATISTIQUE (UCL)
Voie du Roman Pays, 20
Louvain-la-Neuve
1348 Belgium
[email protected][Session C27 (page 36), Abstract 174]
HINOJOSA LUNA, Adrian Pablo
UNIVERSIDADE FEDERAL DE
MINAS GERAIS
Av. Antonio Carlos 6627
Belo Horizonte
31270-901 Brazil
[email protected][Session C37 (page 24), Abstract 175]
HOFFMANN, Marc
CNRS-UMR
France
[email protected][Session Inv. 32 (page 33), Abstract 176]
HOLMSTRÖM, Lasse
UNIVERSITAT OF OULU
DEPARTMENT OF MATHEMATICAL SCI-
ENCES
P.O Box 3000
Oulu
FIN-90014 Finland
[email protected][Session C56 (page 47), Abstract 177]
HOLROYD, Alexander
UNIVERSITY OF BRITISH COLUMBIA
121-1984 Mathematics Road
Vancouver, BC
V6T 1Z2 Canada
[email protected][Session Inv. 18 (page 24), Abstract 178]
HOOKER, Giles
DEPARTMENT OF STATISTICS
Stanford University
Stanford
94305 USA
[email protected][Session C51 (page 27), Abstract 179]
HOTTA, Luiz
STATE UNIVERSITY OF CAMPINAS
IMECC-UNICAMP CP 6065
Campinas
13083-970 Brazil
[email protected][Session P2 (page 32), Abstract 181]
HOUDRÉ, Christian
School of Mathematics,
Georgia Institute of Technology
Atlanta, Georgia
30332 USA
[email protected][Session Inv. 12 (page 20), Abstract 182]
HOWELL, Tati
IMS BULLETIN
20 Shadwell, Uley
Dursley
GL11 5BW UK
HUANG, Yu-Jung
I-SHOU UNIVERSITY
1,SECTION 1,HSUEH-CHENG RD
Kaohsiung
840 Taiwan
[email protected][Session C34 (page 28), Abstract 183]
HUEBNER, Marianne
MICHIGAN STATE UNIVERSITY
Dpt. of Statistics and Probability
East Lansing
MI 48824 USA
[email protected][Session Inv. 1 (page 19), Abstract 184]
HULT, Henrik
DEPT. OF APPLIED MATHEMATICS
AND STATISTICS,
UNIVERSITY OF COPENHAGEN
Universitetsparken, 5
Copenhagen
DK 2100 Denmark
[email protected][Session Inv. 4 (page 23), Abstract 185]
HUSKOVA, Marie
CHARLES UNIVERSITY
Department of Statistics
Prague
18675 Czech Republic
[email protected][Session C58 (page 55), Abstract 186]

Directory 223
IONIDES, Edward
UNIVERSITY OF MICHIGAN
Department of Statistics
Ann Arbor, MI
48109 USA
[email protected][Session P2 (page 32), Abstract 187]
ISHAM, Valerie
UCL
Gower Street
London
WC1E 6BT UK
ISHWARAN, Arti
IMS
22025 Rye Rd.
Ohio
44122 USA
[email protected][Session C23 (page 16), Abstract 188]
ISHWARAN, Hemant
CLEVELAND CLINIC FOUNDATION
Dept of Biostatsitcs, Wb4
Cleveland, Ohio
44195 USA
[email protected][Session C23 (page 16), Abstract 188]
JACOD, Jean
UNIVERSITE PARIS 6
4 Place Jussieu
Paris
75252 France
[email protected][Session Inv. 8 (page 14), Abstract 189]
JACOME PUMAR, Mł Amalia
UNIVERSIDAD DE VIGO
Facultad de Ciencias Empresariales
Vigo
32004 España
[email protected][Session C54 (page 46), Abstract 190]
JAGERS, Peter
CHALMERS AND GOTHENBURG UNI-
VERSITIES
Chalmers
Gothenburg
SE41296 Sweden
[email protected][Session C1 (page 15), Abstract 191]
JAKUBOWICZ, Jérémie
ENS CACHAN
61, avenue du Président Wilson
Cachan
94235 France
JAKUBOWSKI, Adam
NICOLAUS COPERNICUS UNIVERSITY
ul. Chopina 12/18
Torun
87-100 Poland
[email protected][Session C11 (page 15), Abstracts 193
and 83]
JANSEN, Maarten
TU EINDHOVEN, DEPT. OF MATH. & CS
PO Box 513 office HG 9.25
Eindhoven
NL5600MB The Netherlands
[email protected][Session C37 (page 24), Abstract 194]
JASKIEWICZ, Anna
INSTYTUT MATEMATYKI POLITECH-
NIKA WROCLAWSKA
Wybrzeze Wyspianskiego 27
Wroclaw
50-370 Poland
[email protected][Session C23 (page 16), Abstract 195]
JIANG, Yiwen
WUCNRS-UNIVERSITE PARIS VIIHAN
ECONOMICS ACADEMY
Luojiadun 122
Wuhan
430035 China
[email protected][Session P2 (page 31), Abstract 418]
JIMÉNEZ GÁMERO, M. Dolores
DPTO.ESTADISTICA E I.O.,
UNIVERSIDAD DE SEVILLA
Faculdad de matematicas, C/ Tarfia, s/n
Sevilla
41012 Spain
[email protected][Sessions P3 and P1 (pages 41 and 22),
Abstracts 197 and 331]
JIMÉNEZ-LÓPEZ, José Domingo
UNIVERSIDAD DE JAEN
Paraje Las Lagunillas s/n
Jaén
23071 Spain
[email protected][Session P1 (page 22), Abstract 198]
JOFFE, Anatole
DEPT. MATHEMATIQUES,
UNIVERSITE DE MONTREAL
C.P.6182 suc centre ville
Montreal P.Q.
H3C 3J7 France
JOHNSTONE, Iain
Department of Statistics
STANDFORD UNIVERSITY
Standford
CA 94305-4065, USA
[email protected][Wald Lectures I, II and III (pages 28, 38
and 48), Abstract 199]
JOLEVSKA-TUNESKA, Biljana
FACULTY OF ELECTRICAL
ENGINEERING
Karpos 2 bb
Skopje
1000 Macedonia
JOLIS, Maria
UNIVERSITAT AUTÒNOMA DE
BARCELONA
Departament de matemàtiques
Cerdanyola del Vallès
08193 Spain
[email protected][Session P2 (page 31), Abstract 22]

224 6th BS/ IMSC
JÖNSSON, Henrik
MALARDALEN UNIV.
DEPT. MATHEMATICS AND PHYSICS
Box, 883
Vasteras
721 23 Sweden
[email protected][Session M3 (page 34), Abstract 200]
JORDAN, Michael
UNIVERSITY OF CALIFORNIA,
BERKELEY
731 Soda Hall
CALIFORNIA
94720-1776 USA
[email protected][Session Inv. 29 (page 29), Abstract 201]
JÖRNSTEN, Rebecka
RUTGERS UNIVERSITY
501 Hill Center
Piscataway
08854 USA
[email protected][Session C40 (page 37), Abstract 202]
JOSA FOMBELLIDA, Ricardo
UNIVERSIDAD DE VALLADOLID
Paseo Prado de la Magdalena
Valladolid
47005 Spain
[email protected][Session P2 (page 31), Abstract 203]
JOULIN, Aldéric
UNIVERSITY OF LA ROCHELLE
Avenue Michel Crépeau
La Rochelle
17042 France
JULIÀ DE FERRAN, Olga
UNIVERSITAT DE BARCELONA
Gran Via 585
Barcelona
08007 Spain
JUNG, Paul
Cornell University
3100 Malot Hall
Ythaca
NY 14853-4201 USA
[email protected][Session C9 (page 20), Abstract 204]
JURECKOVA, Jana
CHARLES UNIVERSITY IN PRAGUE
Department of Statistics
Prague 8
CZ-196 75 Czech Republic
[email protected][Session C49 (page 26), Abstract 205]
KARGIN, Vladislav
CORNERSTONE RESEARCH
599 Lexington Ave. fl.43
New York
10022 USA
[email protected][Sessions C46 and M8 (pages 46 and 31),
Abstracts 206 and 309]
KARIMA, Belaide
University of Bejaia
Department of Matehmatics
06000 Algeria
[email protected][Session C30 (page 54), Abstract 207]
KARR, Alan
NISS
PO Box 14006
Research Triangle Park
27709-4006 USA
KASPI, Haya
TECHNION
Faculty of Industrial Engineering and Ma
Haifa
32000 Israel
KAWCZAK, Janusz
THE UNIVERSITY OF NORTH
CAROLINA AT CHARLOTTE
Dpt. of Mathematics and Statistics
Charlotte
28223 USA
[email protected][Session C18 (page 54), Abstract 208]
KEIDING, Niels
BIOSTATISTICS, UNIV. COPENHAGEN
Blegdamsvej 3
Copenhagen N
2200 Denmark
KENDALL, Wilfrid
UNIVERSITY OF WARWICK
Gibbet Hill Road
Coventry
CV4 7AL UK
[email protected][Session C38 (page 38), Abstract 209]
KESSLER, Mathieu
TECNICAL UNIVERSITY OF
CARTAGENA
Paseo Alfonso XIII
CARTAGENA
30203 Spain
KHARIN, Yurij
BELARUSIAN STATE UNIVERSITY
Skorina Ave, 4
Minsk
220050 Belarus
[email protected][Session C49 (page 26), Abstract 210]
KHOKHLOV, Vladimir
STEKLOV MATH. INST.
Gubkin Str. 8
Moscow
119991 Russian Federation
[email protected][Session C8 (page 35), Abstract 211]

Directory 225
KLÜPPELBERG, Claudia
MUNICH UNIVERSITY OF
TECHNOLOGY
Center for Mathematical Sciences
Garching
85747 Germany
KOCH, Inge
UNIVERSITY OF NEW SOUTH WALES
School of Mathematics
Sydney
2052 Australia
KOHATSU-HIGA, Arturo
UNIVERSITAT POMPEU FABRA
Ramon trias fargas 25-27
Barcelona
08012 Spain
KOHLER, Michael
UNIVERSITY OF STUTTGART
INSTITUTE OF STOCHASTICS
Stuttgart
70569 Germany
[email protected][Sessions C29 and C51 (pages 52 and
27), Abstracts 212 and 220]
KOLACZYK, Eric
BOSTON UNIVERSITY
111 Cummington Street
Boston
02215 USA
[email protected][Session C28 (page 25), Abstract 216]
KOLTCHINSKII, Vladimir
UNIVERSITY OF NEW MEXICO
USA
[email protected][Session Medaillon Lect. (page 42), Ab-
stract 217]
KONECNY, Franz
BOKU-UNIVERSITY OF NATURAL
RESOURCES AND APPLIED
LIFE SCIENCES
Vienna
A-1190 Austria
KOREISHA, Sergio
UNIVERSITY OF OREGON
Lundquist College of business
Eugene
97403 USA
[email protected][Session C48 (page 40), Abstract 213]
KORMOS, János
UNIVERSITY OF DEBRECEN
Egyetem ter. 1, POB 12
Debrecen
4010 Hungary
[email protected][Session C28 (page 25), Abstract 218]
KOUL, Hira L.
MICHIGAN STATE UNIVERSITY
East Lansing
East Lansing
MI 48824 USA
[email protected][Session Inv. 28 (page 43), Abstract 214]
KOZDRON, Michael
UNIVERSITY OF REGINA
Depart. of Mathematics, College West
Regina SK
S4S 0A2 Canada
KOZEK, Andrzej
MACQUARIE UNIVERSITY
Department of Statistics, DEFS
North Ryde, NSW
2109 Australia
[email protected][Session C54 (page 46), Abstract 219]
KUMAR , R. Suresh
Department of Statistics
University of Madras
Chennai
600 005 India
[email protected][Session C23 (page 16), Abstract 221]
KUME, Alfred
UNIVERSITY OF NOTTINGHAM
School of Mathematical Sciences
Nottingham
NG7 2RD UK
[email protected][Sessions C28 and C17 (pages 25 and
53), Abstracts 222 and 233]
KUNSCH, Hans R.
ETH ZURICH
Seminar fur Statistik,
Zurich
CH-8092 Switzerland
KURTZ, Thomas G.
UNIVERSITY OF WISCONSIN -
MADISON
MATHEMATICS
Madison, WI
53706-138 USA
LA ROCCA, Luca
UNIVERSITY OF MODENA AND
REGGIO EMILIA
Dipartimento SSCQ, Via G. Giglioli Valle
Reggio Emilia
42100 Italy
LACERDA, Ana
FACULDADE DE ECONOMIA-CENTRO
MATEMATICA E APLICAÇOES
Travessa Estevao Pinto
Lisbon
1099-032 Portugal
[email protected][Session M3 (page 34), Abstract 223]

226 6th BS/ IMSC
LACRUZ, Beatriz
UNIVERSIDAD DE ZARAGOZA
Dpt. de Métodos Estadísticos.
Zaragoza
50009 España
LADELLI, Lucia
POLITECNICO DI MILANO
Piazza L. da Vinci 32
Milan
20133 Italy
LAFFERTY, JOHN
CANEGIE MELLON UNIVERSITY
5000 FORBES AVENUE
PITTSBURGH
15213 USA
[email protected][Session Inv. 29 (page 29)]
LAI, PIK YING
THE UNIVERSITY OF HONG KONG
Rm 518, Meng Wah Complex
Hong Kong
N/A China
[email protected][Session C53 (page 28), Abstract 224]
LAMBERT, Alexandre
INSTITUT DE STATISTIQUE (UCL)
Voie du Roman Pays, 20
Louvain-la-Neuve
1348 Belgium
[email protected][Session C58 (page 55), Abstract 225]
LANDIM, Claudio
IMPA
Estrada Dona Castorina 110
Rio de Janeiro
22460-320 Brazil
[email protected][Session Inv. 14 (page 33), Abstract 226]
LAROCQUE, Denis
HEC MONTREAL
3000, chemin de la Cote-Sainte-
Catherine
Montreal
H3T 2A7 Canada
[email protected][Session C46 (page 46), Abstract 227]
LARSEN, Havard André
UNIVERSITY OF BERGEN
Johannes Brunsgate 12
Bergen
5035 Norway
LARSSON, Karl
LUND UNIVERSITY
DEPARTMENT OF ECONOMICS
LUND
22007 Sweden
LASIECKI, Pawel
UNIVERSITY OF CALIFORNIA
AT BERKELEY
367 Evans Hall 3860 Univ. of California
Berkeley
94720 USA
LATAŁA, Rafał
WARSAW UNIVERSITY
INSTITUTE OF MATHEMATICS
Warszawa
02-097 Poland
[email protected][Session Inv. 12 (page 20), Abstract 228]
LAU, Wai Kwong John
HONG KONG UNIVERSITY OF
SCIENCE AND TECHNOLOGY
Information and Syst. Management Dpt.
Hong Kong
852 Hong Kong
[email protected][Session C57 (page 34), Abstract 229]
LAURITZEN, Steffen
DEPARTMENT OF STATISTICS
UNIVERSITY OF OXFORD
Oxford
OX1 3TG UK
[email protected][Session Laplace Lect. (page 56), Ab-
stract 230]
LAVANCIER, Frédéric
CREST AND UNIVERSITé LILLE 1
Timbre J340
Malakoff
92240 France
[email protected][Session P2 (page 32), Abstract 231]
LAWI, Stephan
UNIVERSITY OF TORONTO
144 Route de Florissant
Geneva
1231 Switzerland
[email protected][Session C11 (page 15), Abstract 232]
LE, Huiling
UNIVERSITY OF NOTTINGHAM
School of Mathematical Sciences
Nottingham
NG7 2RD UK
[email protected][Sessions C28 and C17 (pages 25 and
53), Abstracts 222 and 233]
LE GALL, Jean Francois
DMA - ECOLE NORMALE SUPERIEURE
45 rue d’Ulm
PARIS
75005 France
LE GLAND, François
IRISA / INRIA
Campus de Beaulieu
Rennes
35042 France
[email protected][Session Inv. 24 (page 51), Abstract 236]

Directory 227
LEBLANC, Frederique
UNIVERSITE JOSEPH FOURIER
LMC-IMAG BP 53
Grenoble Cedex 9
38041 France
[email protected][Session C52 (page 20), Abstract 241]
LEDOUX, Michel
Institut de Mathématiques, LSP,
Université Paul-Sabatier
Toulouse
France
[email protected][Session Inv. 12 (page 19), Abstract 234]
LEE, Stephen M.S.
THE UNIVERSITY OF HONG KONG
Depart. of Statistics & Actuarial Scienc
Hong Kong
Hong Kong
[email protected][Sessions C45 and C53 (pages 14 and
28), Abstracts 235 and 224]
LEEDUN, Jack
DELACKER L.T.D
206 Lakewood Drive
STAFFORD
22336 USA
LEKUONA, Alberto
DEP.METODOS ESTADISTICOS,
FACULTAD DE CIENCIAS,
UNIV. DE ZARAGOZA
Pedro Cerbuna, 12
Zaragoza
50009 Spain
LEMOR, Jean-Philippe
CENTRE DE MATHEMATIQUES
APPLIQ.- ECOLE POLYTECHNIQUE
Ecole Polytechnique
Palaiseau Cedex
91128 France
[email protected][Session C10 (page 44), Abstract 237]
LEONI, Samuela
UNIV. DI PADOVA UNIV. DI REIMS
9 Rue Vulpian
Paris
75013 France
[email protected][Session C31 (page 30), Abstract 238]
LEPSKI, Oleg
University of Aix-Marselle 1
France
[email protected][Session Inv. 23 (page 49), Abstract 239]
LETAC, Gerard
UNIV. P. SABATIER
Lab. de Stat et Probab.
Algans
81470 France
[email protected][Session C24 (page 35), Abstract 240]
LETUE, Frederique
LMC/ IMAG AND LABSAD / UPMF
51, rue des Mathematiques, BP 53
Grenoble
38041 France
[email protected][Session C52 (page 20), Abstract 241]
LEVEQUE, Olivier
Ecole Polytechnique Fédérale
de Lausanne
Lausanne
CH-1015 Switzerland
[email protected][Session Inv. 21 (page 33), Abstract 242]
LEVINA, Elizaveta
UNIVERSITY OF MICHIGAN
Department of Statistics
Ann Arbor, MI
48109 USA
[email protected][Session C29 (page 52), Abstract 243]
LËVY-LEDUC, CÉLINE
UNIVERSITE PARIS-SUD
Labo de Maths, Bat 425
Orsay
91405 France
[email protected][Session C48 (page 40), Abstract 244]
LI, Deyuan
ECONOMETRIC INSTITUTE, ERASMUS
UNIVERSITY ROTTERDAM
P.O.Box 1738
Rotterdam
3000 The Netherlands
[email protected][Session C59 (page 48), Abstract 245]
LI, Guangshan
WUHAN ECONOMICS ACADEMY
Luojiadun 122
Wuhan
430035 China
[email protected][Session P2 (page 31), Abstract 196]
LI, Guo-ying
INSTITUTE OF SYSTEMS SCIENCE
CHINESE ACADEMY OF SCIENCES
No.55, Zhong-guan-cun East Road
Beijing
100080 China
[email protected][Session C52 (page 21), Abstract 246]
LI, Ker-Chau
UCLA, Mathematics Department
Box 951555
Los Angeles
CA 90095-1555 USA
[email protected][Session Inv. 26 (page 50), Abstract 248]
LI, Linxiong
UNIVERSITY OF NEW ORLEANS
Department of Mathematics
New Orleans
70148 USA
[email protected][Session P1 (page 21), Abstract 247]

228 6th BS/ IMSC
LIGGETT, Thomas
UCLA
12310 Stanwood Drive
Los Angeles
90066 USA
LILLESTOL, Jostein
NORWEGIAN SCHOOL OF
ECONOMICS AND BUS ADM
Helleveien 30
Bergen
N-5045 Norway
LIMIC, Vlada
UNIVERSITY OF BRITISH COLUMBIA
121-1984 Mathematics Road
Vancouver
V6T 1Z4 Canada
[email protected][Session Inv. 19 (page 49), Abstract 250]
LINDNER, Alexander
CENTER FOR MATHEMATICAL
SCIENCES
MUNICH TECHNICAL UNIVERSITY
Garching
85747 Germany
[email protected][Session M9 (page 19), Abstract 251]
LIU, Jun
HARVARD UNIVERSITY
1 Oxford Street
Cambridge
MA USA
[email protected][Session Bernoulli Lect. (page 13), Ab-
stract 252]
LIU, Regina
RUTGERS UNIVERSITY
Dept of Statistics, Hill Center
Piscataway
08854-8019 USA
[email protected][Sessions C40 and C55 (pages 37 and
21) , Abstracts 202, 253 and 249]
LOADER, Catherine
CASE WESTERN RESERVE
UNIVERSITY
26800 Amhearst Circle 107
Beachwood
OH 44122 USA
[email protected][Session C44 (pages 52 and 53), Ab-
stracts 329 and 254]
LOEBUS, Joerg-Uwe
UNIVERSITY OF DELAWARE
University of Delaware
Neware
19716 USA
[email protected][Session C9 (page 20), Abstract 255]
LOECHERBACH, Eva
UNIVERSITY OF PARIS XII-VAL DE
MARNE
61 avenue du General de Gaulle,
Creteil CEDEX
94010 France
LOPEZ, F. Javier
UNIVERSIDAD DE ZARAGOZA
Dpto. Met. Estadisticos. Fac de Ciencias
Zaragoza
50009 Spain
[email protected][Session C9 (page 20), Abstract 257]
LÓPEZ SANJUAN, Eva T.
UNIV. DE EXTREMADURA
Dpto. de Matematicas. Fac. de Ciencias
Badajoz
06071 Spain
LÓPEZ-PINTADO, Sara
UNIVERSIDAD CARLOS III DE MADRID
Calle Madrid, 126
Getafe
28903 Spain
[email protected][Session C55 (page 21), Abstract 357]
LÓPEZ-RATERA, Anna
UNIVERSITAT AUTONOMA DE
BARCELONA
Campus de Bellaterra
Barcelona
08290 Spain
LOUBES, Jean-Michel
CNRS AND UNIVERSITÉ PARIS-SUD
Département de mathématiques, equipe
Orsay
91425 France
[email protected][Session C5 (page 18), Abstract 258]
LOUREIRO NUNES, Ana Filipa
FACULDAE DE CIENCIAS E TECNOLO-
GIA DA UNIVERSIDADE DE COIMBRA
Rua Sto Antonio, nž 59. 1ž drt, Repeses
Voseu
3500 Portugal
LU, Yingdong
IBM T.J. WATSON RESEARCH CENTER
1101 Kitchawan RD
Yorktown Heights
10598 USA
[email protected][Session C4 (page 53), Abstract 259]
LUDENA, Carenne
IVIC
Apartado 21827
Caracas
1020-A Venezuela
[email protected][Session C25 (page 36), Abstract 260]
LUENGO MERINO, Inmaculada
UNIVERSIDAD DE LAS PALMAS DE
GRAN CANARIA
Edificio de Informática Campus de Tafira
Las Palmas de Gran Canaria
35017 Spain
[email protected][Session P1 (page 22), Abstracts 173 and
261]

Directory 229
LUGOSI, Gabor
UNIVERSITAT POMPEU FABRA
Ramon Trias Fargas 25-27
Barcelona
08005 Spain
[email protected][Sessions Inv. 29, C51 and M8 (pages
29, 27 and 31) , Abstracts 262, 460 and
439]
LWAMBA, Marcel
BERNOUILLI SOCIETY
99 avenue Kassi, Bandal Moulaert
Kinsasha
00 Congo
LÉVÊQUE, Olivier
EPF LAUSANNE
LTHI - ISC -I&C
Lausanne
1015 Switzerland
[email protected][Session Inv. 21 (page 33), Abstract 242]
MAEJIMA, Makoto
KEIO UNIVERSITY
3-14-1 Hiyoshi, Kohoku-ku
Yokohama
223-8522 Japan
[email protected][Session C13 (page 45), Abstracts 264
and 371]
MAJOR, Peter
MATHEMATICAL INST OF THE
HUNGARIAN ACADEMY OF SCIENCES
H-1053 Realtanoda str. 13-15
Budapest
H-1364 127 Hungary
MAKAROV, Nikolai
CALTECH
1200 East California Boulevard
Pasadena
CA 91125 USA
[email protected][Session Inv. 13 (page 20), Abstract 265]
MALYARENKO, Anatoliy
MALARDALEN UNIVERSITY
Box 883
Vasteras
SE 721 23 Sweden
[email protected][Sessions C25 and M5 (pages 36 and 27),
Abstracts 266 and 391]
MAMMEN, Enno
DEPARTMENT OF ECONOMICS
L7, 3-5
Mannheim
68131 Germany
MAMMITZSCH, Volker
DEPT MATHEMATICS AND COMPUT-
ERSCIENCE
Hans Meerwein St
Marburg
D-35032 Germany
MANSTAVICIUS, Martynas
UNIVERSITY OF CONNECTICUT
196 Auditorium Road U-3009
Storrs
06269 USA
[email protected][Session C21 (page 50), Abstract 267]
MARCHIS, Iuliana
WARWICK UNIVERSITY
Mathematics Institute
Coventry
CV4 7AL UK
MARINELLI, Carlo
UNIVERSITAET BONN
Wegelerstr 6
Bonn
D-53115 Germany
[email protected][Session M5 (page 27), Abstract 268]
MARINUCCI, Domenico
DIPARTAM. MATEMATICA, UNIVERSITA
DI ROMA
Via Della Ricerca Scientifica, 1
Roma
00133 Italy
[email protected][Session C23 (page 16), Abstract 269]
MARKUS, László
EöTVöS LORáND UNIVERSITY
Pázmány Péter st. 1/C
Budapest
1117 Hungary
[email protected][Session P1 (page 22), Abstract 270]
MARQUEZ-CARRERAS, David
UNIVERSITAT DE BARCELONA
FACULTAT DE MATEMÀTIQUES
Barcelona
08007 Spain
[email protected][Session C35 (page 26), Abstract 425]
MARTINEZ-RODRIGUEZ, Ana M.
UNIVERSITY OF JAÉN
Paraje Las Lagunillas s/n Edf. D-3
Jaén
23071 Spain
[email protected][Session P1 (page 21), Abstract 271]
MARTINUSSEN, Torben
ROYAL VET. AND. AGRI. UNIVERSITY
Department of Maths and Physics
Frederiksberg C
1871 Denmark
[email protected][Session Inv. 34 (page 44), Abstract 272]
MASSAM, Helene
YORK UNIVERSITY
4700 Keele Street
toronto
M3J 1P3 Canada
[email protected][Session C24 (page 35), Abstracts 240
and 273]

230 6th BS/ IMSC
MATIAS, Catherine
CNRS
LABORATOIRE STATISTIQUE ET
GENOME
Evry
91000 France
[email protected][Session C31 (page 30), Abstract 274]
MATRAN, Carlos
UNIVERSIDAD DE VALLADOLID
Departamento de Estadística
Valladolid
47002 Spain
[email protected][Session C61 (page 48), Abstract 275]
MAYO, Agustin
FACULTAD DE MEDICINA
UNIVERSIDAD DE VALLADOLID
C/Ramon y Cajal s/n
Valladolid
47011 Spain
[email protected][Session C61 (page 48), Abstract 275]
MCKEAGUE, Ian W.
Florida State University
USA
MEDA, Ana
UNIVERSIDAD NACIONAL AUTONOMA
DE MEXICO
Cub. 123, Dpto. de Matematicas, Fac. de
Mexico
04510 Mexico
[email protected][Session M4 (page 37), Abstract 276]
MEINSHAUSEN, Nicolai
ETH ZURICH
Leonhardstrasse 27
Zurich
8032 Switzerland
[email protected][Session C51 (page 27), Abstract 277]
MEISTER, Kadri
DEPARTMENT OF MATHEMATICAL
STATISTICS
Umea University
Umea
90187 Sweden
[email protected][Session C49 (page 26), Abstract 278]
MENOZZI, Stephane
UNIVERSITY PARIS VI AND
ECOLE POLYTECHNIQUE
98 Rue la Bruyere
Poissy
78300 France
[email protected][Session C10 (page 44), Abstract 279]
MEREDITH, Mark
DEPT. OF STATISTICS,
UNIVERSITY OF OXFORD
1 South Parks Road
Oxford
OX1 3TG UK
[email protected][Session C1 (page 15), Abstract 43]
MERHI, Amal
KING’S COLLEGE LONDON
Strand
London
WC2R 2LS UK
MERKL, Franz
MATHEMATICAL INSTITUTE
UNIVERSITY OF LEIDEN
Postbus 9512
Leiden
2300 RA The Netherlands
[email protected][Session Inv. 22 (page 39), Abstract 280]
MERKLE, Milan
FACULTY OF ELECTRICAL
ENGINEERING
P.O Box 35-54
Belgrade
11120 Yugoslavia
[email protected][Session C7 (page 44), Abstract 281]
MESSAOUD, Marouen
INRIA ROCQUENCOURT
Domaine de Volulceau - BP 105
Le Chesnay
78153 France
[email protected][Session C10 (page 44), Abstract 282]
MIERMONT, Grégory
ECOLE NORMALE SUPERIEURE
45, rue d’Ulm
Paris
75005 France
[email protected][Session Inv. 11 (page 42), Abstract 283]
MININNI, Rosa Maria
UNIVERSITA DI BARI
DIPARTIMENTO DI MATEMATICA
BARI
70125 Italy
[email protected][Session C20 (page 35), Abstract 284]
MINOZZO, Marco
DEPARTMENT OF STATISTICAL SCI-
ENCE
UNIV. OF PERUGIA
Via A. Pascoli, Perugia
06100 Italy
[email protected][Session M6 (page 29), Abstract 65]
MISCHLER, Stéphane
Laboratoire de Mathématiques Appl.,
Université de Versailles Saint-Quentin
France
[email protected][Session Inv. 11 (page 42), Abstract 285]
MOERTERS, Peter
UNIVERSITY OF BATH
Claverton Down
Bath
BA2 6PA UK

Directory 231
MOGER, Tron Anders
IMBA/DEPARTMENT OF STATISTICS
University of Oslo
Oslo
0317 Norway
MOGULSKII, Anatolii
SOBOLEV INSTITUTE OF
MATHEMATICS
Koptyug pr. 4
630090 Russian Federation
[email protected][Session C15 (page 53), Abstract 286]
MOHAMMADI, Leila
MATHEMATICAL INSTITUTE,
LEIDEN UNIVERSITY
Morsweg 28
Leiden
2312 AD The Netherlands
MOHTASHAMI BORZADARAN, G.R.
UNIVERSITY OF BIRJAND
Dept. of Statistics
Birjand
Iran
[email protected][Session C34 (page 28), Abstract 287]
MOKKADEM, Abdelkader
UNIVERSITE DE VERSAILLES
45 avenue des Etats Unis
Versailles
78035 France
[email protected][Session C6 (page 38), Abstract 318]
MOLER, Jose Antonio
UNIVERSIDAD PUBLICA DE NAVARRA
Campos de Arrosadia, s/n
Pamplona
31006 Spain
[email protected][Session C63 (page 38), Abstract 288]
MOLLER, Jesper
AALBORG UNIVERSITY
F. Bajers Vej 7G
Aalborg
DK-9220 Denmark
[email protected][Session Inv. 31 (page 39), Abstract 289]
MORENO REBOLLO, Juan Luis
DEPARTMENT OF STATISTICS AND
OPERATIONAL RESEARCH
C/ Tarfia s.n.
Seville
41012 Spain
[email protected][Session P3 (pages 41 and 42), Ab-
stract 120]
MORI, Tamás
EöTVöS LORáND UNIVERSITY
Pázmány Péter s. 1/c
Budapest
1117 Hungary
MORROW, Gregory
UNIVERSITY COLORADO
AT COLORADO SPRINGS
1420 Austin Bluffs Pkwy
Colorado Springs, CO
80933-7150 USA
MÖRTERS, Peter
Department of Mathematical Sciences,
University of Bath
Claverton Down
Bath
BA2 7AY United Kingdom
[email protected][Session Inv. 10 (page 39), Abstract 290]
MOUHOUBI, Zahir
UNIVERSITY A/MIRA
Route Targa Ouzemour University A/Mira
Bejaia
06000 Algeria
[email protected][Session C18 (page 54), Abstract 291]
MOULINES, Eric
ECOLE NATIONALE DE
TELECOMMUNICATIONS
46, Rue Barrault, Paris
75643 France
[email protected][Session C18 (page 54), Abstracts 104
and 292]
MOUNTFORD, Thomas
E.P.F.L
Department of Mathematiques
Escublens
1015 Switzerland
MÜLLER, Alfred
UNIVERSITY KARLSRUHE
Kaiserstr. 12, Geb. 20.21
Karlsruhe
76128 Germany
[email protected][Session C2 (page 24), Abstract 293]
MÜLLER, Gernot
MUNICH UNIVERSITY OF
TECHNOLOGY
Zentrum Mathematik, M4, Boltzmannstr.3
Garching bei Muenchen
85747 Germany
[email protected][Session M1 (page 17), Abstract 294]
MURPHY, Susan
UNIVERSITY OF MICHIGAN
Dept. of Statistics
Ann Arbor
48109-1092 USA
[email protected][Session Inv. 25 (page 14), Abstract 295]
MUÑOZ PICHARDO, Juan M
UNIVERSIDAD DE SEVILLA
Avd. Reina Mercedes s/n
Sevilla
41012 Spain
[email protected][Sessions P1 and P3 (pages 22 and 41) ,
Abstract 331]

232 6th BS/ IMSC
MYKLAND, Per
Department of Statistics
The University of Chicago
5734 University Avenue
Chicago, Illinois
60637 USA
[email protected][Session Inv. 8 (page 14), Abstract 296]
MYTNIK, Leonid
Technion - Israel Institute of Technology
Technion City, Haifa 32000
Israel
[email protected][Session Inv. 15 (page 51), Abstract 297]
NACU, Serban
UC BERKELEY
367 Evans Hall 3860
Berkeley, CA
94720-3860 USA
[email protected][Session C45 (page 14), Abstract 298]
NADAKUDITI, Raj Rao
MASSACHUSETTS INSTITUTE OF
TECHNOLOGY
77 Massacusetts Avenue
Cambridge
02142 USA
[email protected][Session C8 (page 34), Abstract 299]
NAJIM, Jamal
CNRS
ENST, 46 Rue Barrault
Parist’
75013 France
[email protected][Session C36 (page 16), Abstract 300]
NARDI, Francesca Romana
UNIVERSITY OF ROMA 1
Via Posidippo 9
Roma
00125 Italy
[email protected][Session P2 (page 32), Abstract 301]
NAVEAU, Philippe
DEPARTMENT OF APPLIED
MATHEMATICS
University of Colorado
Boulder
CO 80309-5 USA
[email protected][Session Inv. 4 (page 23), Abstract 302]
NGUYEN-NGOC, Laurent
UNIVERSITE PARIS 6
57 Rue Greneta
Paris
75002 France
NOLSOEE, Kim
IMM
Kildemosevej, 36
Espergaerde
3060 Denmark
NORBERG, Ragnar
LONDON SCHOOL OF ECONOMICS
Statistics Dept.
London
WC2A 2AE UK
NOVIKOV, Andrey
UNIVERSIDAD AUTONOMA
METROPOLITANA- IZTAPALAPA
San Rafael Atlixco 186, col. Vicentina
Mexico
09340 Mexico
[email protected][Session C63 (page 38), Abstract 303]
NUALART, David
UNIVERSITAT DE BARCELONA
Gran Via 585
Barcelona
08007 Spain
NUALART, Eulalia
UNIVERSITÉ DE PARIS
4 Place Jussieu
Paris
75252 France
NURMINEN, Tommi
BIOTIE THERAPIES CORP.
Tykistokatu 6
Turku
20520 Finland
[email protected][Session P3 (page 41), Abstract 304]
NYKYRI, Erkki
INSTITUTE OF OCCUPATIONAL
HEALTH
Topeliuksenkatu 41 a A
Helsinki
00250 Finland
OBLOJ, Jan
LABORATOIRE PROBABILITE,
UNIVERSITE DE PARIS 6
4, Pl. Jussieu Boite 188 Cedex 05
Paris
75252 France
[email protected][Session C12 (page 25), Abstract 305]
OGATA, Yosihiko
INSTITUTE OF STATISTICAL
MATHEMATICS
Minato-Ku, Minami-Azabu 4-6-7
Tokyo
106-8569 Japan
[email protected][Session Inv. 2 (page 13), Abstract 306]
OJEDA CABRERA, Jorge Luis
UNIVERSIDAD DE ZARAGOZA
Fac. de Ciencias, Ed. Matemáticas
Zaragoza
50009 Spain
[email protected][Session C14 (page 16), Abstract 307]

Directory 233
OJO, WILLIAMS
IITA
Maize Micronutrient Research and Dev.
Nigeria
OKUMURA, Hidenori
CHUGOKU JUNIOR COLLEGE
83, Niwase
Okayama
701-0197 Japan
[email protected][Session C52 (page 20), Abstract 308]
OLSSON, Jimmy
LUND UNIVERSITY
Box 118
Lund
22100 Sweden
ONATSKI, Alexei
COLUMBIA UNIVERSITY
Economics Dept., 420 West, 118th St
New York, NY
10027 USA
[email protected][Session M8 (page 31), Abstract 309]
ORDOÑEZ CABRERA, Manuel
UNIVERSIDAD DE SEVILLA
Dpto. Análisis Matemático
Sevilla
41080 Spain
[email protected][Session C7 (page 44), Abstracts 456 and
310]
ÖRJAN, Stenflo
DEPARTMENT OF MATHEMATICS
Stockholm University
Stockholm
10691 Sweden
ORTIZ-LATORRE, Salvador
UNIVERSITAT DE BARCELONA
Paseig de Pujades 21-23, 2-3
Barcelona
08018 Spain
PAPARODITIS, Efstathios
Department of Mathematics and
Statistics, University of Cyprus
P.O.Box 20537
Nicosia
1678 Cyprus
PAPAVASILIOU, Anastasia
COLUMBIA UNIVERSITY
200 S.W. Mudd Building, MC-4701
New York
10027 USA
[email protected][Session C36 (page 16), Abstract 311]
PARDO-FERNANDEZ, Juan Carlos
UNIVERSIDADE DE VIGO
E.U.E.T.I. Rúa Torrecedeira, 86
Vigo
36208 Spain
[email protected][Session C22 (page 40), Abstract 312]
PARNA, Kalev
UNIVERSITY OF TARTU
Liivi, 2
Tartu
50409 Estonia
[email protected][Session C61 (page 48), Abstract 313]
PARYS, DARIUSZ
UNIVERSITY OF LODZ,
CHAIR OF STATISTICAL METHODS
REWOLUCJI1905r. Str.No.41
LODZ
90-214 Poland
PASQUALI, Sara
CNR - IMATI
Via Bassini, 15
Milano
20133 Italy
[email protected][Session C20 (page 35), Abstract 314]
PATILEA, Valentin
CREST-ENSAI
Campus de Ker-Lann, Rue Blaise Pascal
Bruz
35172 France
[email protected][Session C27 (page 36), Abstract 315]
PATOUILLE, Brigitte
UNIVERSITé BORDEAUX 1
351 Cours de la Libération
Talence
33405 France
PAUL, Debashis
StANDFORD UNIVERSITY
390 Serra Mall,Department of Statisctics
Standford
CA 94305 USA
[email protected][Session C29 (page 52), Abstract 316]
PECCATI, Giovanni
UNIVERSITE DE PARIS IV
5, rue de la Butte aux Cailles
Paris
75013 France
[email protected][Session C11 (page 15), Abstract 317]
PEDERSEN, Jesper Lund
UNIVERSITY OF COPENHAGEN
Dpt. of Applied Math. and Statistics
Copenhagen
2100 Denmark

234 6th BS/ IMSC
PELLETIER, Mariane
UNIVERSITE VERSAILLES-
ST. QUENTIN
45 avenue des Etats-Unis
VERSAILLES
78035 France
[email protected][Session C6 (page 38), Abstract 318]
PEÑA, Daniel
Universidad Carlos III
Madrid
SPAIN
[email protected][Session Inv. 26 (page 49), Abstract 319]
PEREZ, Marta
UNIVERSITAT POLITECNICA DE
CATALUNYA
Pau Gargallo, 5
Barcelona
08028 Spain
PEREZ ABREU, Victor
CENTRO DE INVESTIGACIÓN EN
MATEMÁTICAS
Apartado Postal 402
Guanajuato
36000 Mexico
[email protected][Session C13 (page 45), Abstract 320]
PEREZ PALOMARES, Ana
UNIVERSIDAD DE ZARAGOZA
Dept. Mét. Estadísticos. Fac. Ciencias
Zaragoza
50009 Spain
PERKINS, Ed
U. BRITISH COLUMBIA
Mathematics Dept.
vancouver
V6T1Z2 Canada
[email protected][Session Inv. 15 (page 51), Abstract 321]
PERLMAN, Michael
UNIVERSITY OF WASHINGTON
Dept. of Statistics 35-4322
Seattle WA
98195 USA
[email protected][Session C24 (page 35), Abstract 322]
PETE, Gabor
UNIV. OF CALIFORNIA BERKELEY
Dept. of Statistics 367 Evans Hall
Berkeley
94720 USA
[email protected][Session C35 (page 25), Abstract 323]
PETERSON, Herman
DEPARTMENT OF MATHEMATICS
Box 480
Uppsala
751 06 Sweden
PETTERSSON, Roger
MATEMATISKA & SYSTEMTEKNISKA
INST
Växjö University
Växjö
351 95 Sweden
[email protected][Session C3 (page 50), Abstract 324]
PEWSEY, Arthur
UNIVERSIDAD DE EXTREMADURA
Escuela Politécnica, Avda. de la Univers
Cáceres
10071 Spain
[email protected][Session C46 (page 46), Abstract 325]
PEÑA, Daniel
UNIVERSIDAD CARLOS III DE MADRID
Madrid 126
Getafe
28903 Spain
[email protected][Session Inv. 26 (page 49), Abstract 319]
PFAFFELHUBER, Peter
UNIVERSITY OF MUNICH
Luisentr. 14
Munich
80333 Germany
PHAM, Huyen
UNIVERSITY PARIS 7 AND CREST
2 Place Jussieu
Paris
75251 France
[email protected][Session Inv. 3 (page 19), Abstract 326]
PICARD, Dominique
CNRS-UNIVERSITE PARIS VII
175 rue du chevaleret
Paris
75013 France
[email protected][Session Medaillon Lect. (page 13), Ab-
stract 327]
PICCIONI, Mauro
DIPARTIMENTO DI MATEMATICA
UNIVERSITA ROMA LA SAPIENZA
Piazzale Aldo Moro
Roma
00185 Italy
[email protected][Session C39 (page 33), Abstract 328]
PILLA, Ramani
CASE WESTERN RESERVE
UNIVERSITY
10900 Euclid Avenue
Cleveland
44106-7054 USA
[email protected][Session C44 (pages 52 and 53), Ab-
stracts 329 and 254]
PILZ, Kay Frederik
RUHR - UNIVERSITAET BOCHUM
FAKULTÄT FÜR MATHEMATIK
Bochum
44801 Germany
[email protected][Session C58 (page 55), Abstract 330]

Directory 235
PINO MEJIAS, Rafael
UNIVERSIDAD DE SEVILLA
Facultad de Matemáticas
Sevilla
41012 Spain
[email protected][Sessions P1 and P3 (pages 22 and 41) ,
Abstracts 331, 130 and 197]
PISTORIUS, Martijn
KING’S COLLEGE LONDON
Strand
London
WC2R 2LS UK
[email protected][Session C32 (page 51), Abstract 332]
PITT, Michael K.
Economics Department,
University of Warwick
Warwick
UK
[email protected][Session Inv. 24 (page 51)]
PITTS, Susan
UNIVERSITY OF CAMBRIDGE
Statistical Laboratory, CMS
Cambridge
CB3 0WB UK
[email protected][Session M4 (page 37), Abstract 333]
PLO, Fernando
UNIVERSIDAD DE ZARAGOZA
Pedro Cerbuna, 12
Zaragoza
50009 Spain
[email protected][Session C63 (page 38), Abstract 288]
POLONIK, Wolfgang
UNIVERSITY OF CALIFORNIA, DAVIS
One Shields Ave.
Davis, CA
95616 USA
[email protected][Session Inv. 30 (page 43), Abstract 334]
POLZEHL, Joerg
WIAS
Mohrenstr. 39
Berlin
10117 Germany
[email protected][Session C28 (page 25), Abstract 335]
POPOV, Serguei
UNIVERSIDADE DE SÃO PAULO
IME/USP, r. do Matõ 1010
São Paulo
05508-090 Brazil
[email protected][Session C15 (page 53), Abstract 336]
POPOVIC, Lea
IMA
400 Lind Hall, 207, Curch St. SE
Minneapolis
55455 USA
[email protected][Session C1 (page 15), Abstract 337]
POSKITT, Don
ECONOMETRICS & BUSINESS STATIS-
TICS
Monash University
Clayton
Vic 3800 Australia
POSTAN, Mikhail
ODESSA NATIONAL MARITIME UNIV.
34, Mechnikov Str.
Odessa
65029 Ukraine
[email protected][Session C8 (page 35), Abstract 338]
PRASKOVA, Zuzana
CHARLES UNIVERSITY
Department of Statistics
Prague
18675 Czech Republic
[email protected][Session C33 (page 45), Abstract 339]
PRITCHARD, Geoffrey
UNIVERSITY OF AUCKLAND
Department of Statistics, Private Bag 92
Auckland
New Zealand
PRÜNSTER, Igor
UNIVERSITY OF PAVIA
Via S.Felice 5
Pavia
27100 Italy
[email protected][Session C57 (page 34), Abstract 340]
PUIG, Pedro
UNIVERSITAT AUTONOMA DE
BARCELONA
Campus UAB, Edifici C
Cerdanyola del Valles
08193 España
[email protected][Session C49 (page 26), Abstracts 87 and
341]
PUKELSHEIM, Friedrich
INSTITUT FUER MATHEMATIK
Universitaet Augsburg
Augsburg
86135 Germany
[email protected][Session C43 (page 26), Abstract 342]
QUER I SARDANYONS, Lluis
UNIVERSITAT DE BARCELONA
Gran Via de les Corts Catalanes 585
BARCELONA
08007 Spain
QUESADA-RUBIO, Jose Manuel
UNIVERSIDAD GRANADA
Facultad de Ciencias.
Granada
18071 Spain
[email protected][Session P3 (page 41), Abstract 343]

236 6th BS/ IMSC
RADCHENKO, Peter
YALE UNIVERSITY
24 Hillhouse Ave
New Haven CT
06511 USA
[email protected][Session C14 (page 16), Abstract 345]
RAHMANN, Sven
UNIVERSITY OF BIELEFELD
Faculty of Technology
Bielefeld
D-33594 Germany
[email protected][Session C40 (page 37), Abstract 344]
RASEKH, Abdolrahman
SHAHID CHAMRAN UNIVERSITY
Department of Statistics
Ahwaz
61357 Iran
[email protected][Session C14 (page 16), Abstract 346]
RAY, Surajit
UNIVERSITY OF NORTH CAROLINA AT
CHAPEL HILL
3125 Mc Gv Bldg CB 7420
Chapel Hill
27599-7240 USA
[email protected][Session C29 (page 52), Abstract 347]
REINERT, Gesine
UNIVERSITY OF OXFORD
DEPARTMENT OF STATISTICS
Oxford
OX1 3TG UK
[email protected][Session Inv. 1 (page 19), Abstract 348]
REMILLARD, Bruno
HEC MONTREAL
3000 Cote-Sainte-Catherine
Montreal
H3T 2AT Canada
RIGOLLET, Philippe
UNIVERSITE PARIS 6
175, rue du Chevaleret
Paris
75013 France
RINCON, Luis
FACULTAD DE CIENCIAS UNAM
Departamento de Matemáticas Facul. de
México City
04510 Mexico
[email protected][Session C3 (page 50), Abstract 350]
RITZ, Christian
DEPT OF NATURAL SCIENCES,
ROYAL VETERINARY AND
AGRICULTURAL UNIVERSITY
Thorvaldensvej 40
Frederiksberg C
DK 1871 Denmark
[email protected][Session C44 (page 52), Abstract 351]
RIVERO MERCADO, Victor
UNIVERSITE PARIS VI ET
UNIVERSITE PARIS X
4, Place Jussieu Case 188
Paris
75005 France
[email protected][Session C32 (page 51), Abstract 352]
ROBERTS, Gareth
LANCASTER UNIVERSITY
Bailrigg
Lancaster
LA1 4YF UK
[email protected][Session Inv. 32 (page 33), Abstract 349]
ROBINS, James
Harvard University
Harvard School of Public Health
677 Huntington Avenue
Boston
MA 02115 USA
[email protected][Session Inv. 35 (page 30), Abstract 353]
ROBINSON, John
UNIVERSITY OF SYDNEY
33 Barons Crescent
NSW
2110 Australia
[email protected][Sessions C61 and C44 (pages 48 and
52), Abstracts 354 and 406]
RODRIGUEZ CASAL, Alberto
UNIVERSIDAD DE VIGO
Fac. Ciencias Económicas.
Campus Lagoas
36310-Vigo, España
[email protected][Session C17 (page 54), Abstract 356]
RODRIGUEZ GRIÑOLO, Rosario
UNIVERSIDAD DE SEVILLA
Tarfia s/n
Sevilla
41012 España
ROLLES, Silke
UNIVERSITY OF BIELEFELD
Karlstrasse 17
Voelklingen
66333 Germany
[email protected][Session Inv. 22 (page 39), Abstract 280]
ROMO, Juan
UNIVERSIDAD CARLOS III DE MADRID
Madrid, 126
Getafe
28903 Spain
[email protected][Session C55 (page 21), Abstract 357]
ROQUE DUARTE, Marta Gabriela
FACULDAE DE CIENCIAS E
TECNOLOGIA DA UNIVERDIDADE DE
COIMBRA
Casal de Faia. nž 1 Brogueira
Torres Novas
2350-054 Portugal

Directory 237
ROSEN, Jay
Mathematics Department,
The City University of New York
2800 Victory Blvd.
Staten Island
NY 10314 USA
[email protected][Session Inv. 10 (page 39), Abstract 358]
ROSENTHAL, Jeffrey
UNIVERSITY OF TORONTO
Dept. of Statistics, University of Toron
Toronto
M5S 3G3 Canada
ROSS, Joshua
THE UNIVERSITY OF QUEENSLAND
Saint Lucia
Brisbane
4072 Australia
[email protected][Session P2 (page 32), Abstract 359]
ROUEFF, François
TELECOM PARIS
46 rue Barrault
Paris cedex 13
75634 France
[email protected][Session C28 (page 25), Abstract 360]
ROVERATO, Alberto
DIPARTIMENTO DI SCIENZE SOCIALI
COGNITIVE E QUANTITATIVE
Via Giglioli Valle 9
Reggio Emilia
I-42100 Italy
[email protected][Session C24 (page 35), Abstract 408]
ROVIRA ESCOFET, Carles
UNIVERSITAT DE BARCELONA
Gran Via 585
BARCELONA
08007 Spain
[email protected][Session C35 (page 26), Abstract 425]
ROZENHOLC, Yves
LAB. DE PROBABILITÉS ET MODELES
ALEATOIRES
Université Pierre et Marie Curie
Paris
75252 France
RUFO BAZAGA, María Jesús
UNIVERSIDAD DE EXTREMADURA
C/ Antonio Hurtado nž 20
Cáceres
10002 Spain
[email protected][Session C56 (page 47), Abstract 362]
RUIZ ESPEJO, Mariano
UNED
c/ Chile 5 - 4 H
Madrid
28016 Spain
[email protected][Session P3 (page 42), Abstract 363]
RYDEN, Tobias
CENTRE FOR MATHEMATICAL SCI-
ENCES, LUND UNIVERSITY
Box 118
Lund
22100 Sweden
SAEZ-CASTILLO, Antonio José
UNIVERSIDAD DE JAEN
EUP
Linares
23700 España
[email protected][Session P1 (page 22)]
SAGITOV, Serik
SCHOOL OF MATHEMATICAL SCI-
ENCES
Chalmers University of Technology
Gothenburg
S-412 96 Sweden
SALMERON, Diego
UNIVERSIDAD DE MURCIA
Av. Europa, Edf Roma, nž 8 4ž B
Murcia
30006 Spain
SAMAROV, Alexander
UMASS AND MIT
Sloan School NE20-336
Cambridge MA
02139 USA
[email protected][Session C41 (page 45), Abstract 364]
SAMWORTH, Richard
UNIVERSITY OF CAMBRIDGE
St John’s College
Cambridge
CB2 1TP UK
[email protected][Session C51 (page 27), Abstract 365]
SANCHEZ, Juana
UNIVERSITY OF CALIFORNIA LOS AN-
GELES
Department of Statistics, 8130 Math Scie
Los Angeles
CA 91325 USA
[email protected][Session C47 (page 17), Abstract 366]
SANCHEZ, Maria Isabel
UNIVERSIDAD DE GRANADA
Campus Fuentenueva, s/n
Granada
18071 Spain
SANCHEZ PLA, Alex
UNIVERSITAT DE BARCELONA
Departament d’Estadística. Facultat de B
Barcelona
08028 Spain
[email protected][Session C40 (page 37), Abstract 367]

238 6th BS/ IMSC
SANGÜESA, Carmen
DEP.METODOS ESTADISTICOS,
FACULTAD DE CIENCIAS,
UNIV. DE ZARAGOZA
Pedro Cerbuna, 12, ZARAGOZA
50009 Spain
[email protected][Session M2 (page 41), Abstract 369]
SANTACROCE, Marina
POLITECNICO DI TORINO
Corso Duca degli Abruzzi, 24
Torino
10129 Italy
SANZ, Gerardo
UNIVERSITY OF ZARAGOZA
C/ Pedro Cerbuna, 12
ZARAGOZA
50009 Spain
[email protected][Session C9 (page 20), Abstract 257]
SANZ-SOLE, Marta
UNIVERSITAT DE BARCELONA
Gran Via 585
BARCELONA
08007 Spain
[email protected][Session C12 (page 25), Abstract 370]
SATO, Ken-Iti
Hachiman-yama 1101-5-103
Nagoya
468-0074 Japan
[email protected][Session C13 (page 45), Abstracts 264
and 371]
SATORRA, Albert
UNIVERSITAT POMPEU FABRA
Ramon Trias Fargas, 25-27
Barcelona
08005 Spain
[email protected][Session M8 (page 31), Abstract 372]
SAUNDERS, David
UNIVERSITY OF PITTSBURGH
301 Thackeray Hall
Pittsburgh
15260 USA
[email protected][Session M3 (page 34), Abstract 373]
SAURA, Fuensanta
UNIVESITAT JAUME I
C/ La Vall dt’Uixo 13
Nules (Castellon)
12520 Spain
SCHBATH, Sophie
INSTITUT NATIONAL DE LA
RECHERCHE AGRONOMIQUE
Domaine de Vilvert
Jouy-en-Josas
78352 France
[email protected][Session Inv. 6 (page 23), Abstract 374]
SCHMID, Friedrich
UNIVERSITAET ZU KOELN
Albertus-Magnus-Platz
Koeln
D-50 923 Germany
[email protected][Session P1 (page 22), Abstract 375]
SCHMIDLER, Scott
DUKE UNIVERSITY
223 Old Chem Bldg, Box 90251
Durham, NC
27705-0251 USA
[email protected][Session C56 (page 47), Abstract 376]
SCHOENBERG, Frederic
UCLA
8142 Math-Science Building
Los Angeles, CA
90095-1554 USA
SCHWEINBERGER, Michael
UNIVERSITY OF GRONINGEN
Grote Rozenstraat 31
Groningen
9712 TG The Netherlands
[email protected][Session C19 (page 30), Abstract 378]
SCHWEINSBERG, Jason
UNIV. OF CALIFORNIA AT SAN DIEGO
Department of Mathematics
Ithaca, NY
14853-4201 USA
[email protected][Session Inv. 11 (page 43), Abstract 377]
SCOPPOLA, Elisabetta
DIP: MATEMATICA_UNIVERSITA
ROMA TRE
Roma
00146 Italy
[email protected][Session P2 (page 32), Abstract 379]
SCOTT, David
RICE UNIVERSITY
4143 Marlowe St
Houston
77005-1953 USA
[email protected][Session C55 (page 21), Abstract 380]
SCOTTO, Manuel
UNIVERSIDADE DE AVEIRO
Campus de Santiago
Aveiro
381-193 Portugal
[email protected][Session C59 (page 48), Abstract 381]
SELEZNJEV, Oleg
UNIVERSITY OF UMEA
Institute of Mathematical Statistics
Umea
SE90187 Sweden
[email protected][Session C21 (page 50), Abstract 382]

Directory 239
SEN, Arusharka
CONCORDIA UNIVERSITY
7141 Sherbrooke Street West
Montreal
H4B 1R6 Canada
[email protected][Sessions C27 and C22 (pages 36 and
40), Abstracts 384 and 383]
SEPP, Artur
UNIVERSITY OF TARTU, INSTITUTE OF
MATHEMATHICAL STATISTICS
J. Livii 2
Tartu
50409 Estonia
[email protected][Session M3 (page 34), Abstract 385]
SERI, Raffaello
UNIVERSITA DEGLI STUDI
DELL’INSUBRIA
Via Ravasi 2, Varese
2100, Italy
[email protected][Sessions P3 and C8 (pages 35 and 42),
Abstracts 77, 78, 386 and 387]
SERRANO PERDOMO, Rafael Antonio
UNIVERSITY OF KAISERSLAUTERN
Friedrich-Engels Strasse 8
Kaiserslautern
67655 Germany
SHAMAN, Paul
UNIVERSITY OF PENNSYLVANIA
Department of Statistics
Philadephia, PA
19104-6302 USA
SHEFFIELD, Scott
University of California at Berkeley
Berkeley
USA
[email protected][Session Inv. 13 (page 20), Abstract 388]
SHI, Zhan
UNIVERSITE PARIS VI
Laboratoire de Probabilites
Paris Cedex 05
75252 France
[email protected][Session Inv. 22 (page 39), Abstract 389]
SILVERMAN, Bernard
OXFORD UNIVERSITY
St. Peter’s College
Oxford
OX1 2DL UK
[email protected][Session Inv. 33 (page 40)]
SILVESTROV, Dmitrii
MÄLARDALEN UNIVERSITY, Hogskole-
plan
Västerås, SE-721 23 Sweden
[email protected][Sessions M1, M2, M3, M5 and C37,
(pages 17, 24, 27, 34 and 41), Abstracts
15, 34, 41, 61 and 79]
SILVESTROVA, Evelina
MÄLARDALEN UNIVERSITY
Hogskoleplan
Västerås
SE-721 23 Sweden
[email protected][Sessions M5 and P2 (pages 27 and 32),
Abstracts 391 and 392]
ŠIMECEK, Petr
UTIA AV CR
Pod Vodarenskou vezi 4
Prague
18208 Czech Republic
[email protected][Session C39 (page 34), Abstract 393]
SINCLAIR, Alistair
Computer Science Division,
University of California
Berkeley
CA 94720-1776 USA
[email protected][Session Inv. 17 (page 49), Abstract 394]
SINHA, Kumar Ashoke
TILBURG UNIVERSITY
Warandelaan 2, Postbus 90153
Tilburg
5000 LE The Netherlands
[email protected][Session C59 (page 48), Abstract 395]
SKOLD, Martin
CENTRE FOR MATHEMATICAL
SCIENCES
Lund University Box 118
Lund
SE-22100 Sweden
SO, Mike
HONG KONG UNIVERSITY OF
SCIENCE AND TECHNOLOGY
Clear Water Bay
Hong Kong
[email protected][Session C57 (page 34), Abstracts 229
and 396]
SOLE I CLIVILLES, Josep Lluís
UNIVERSITAT AUTONOMA DE
BARCELONA
Departament de Matemàtiques.
Bellaterra
08193 Spain
[email protected][Session C32 (page 51), Abstract 454]
SONIN, Isaac
UNIV. OF NORTH CAROLINA
AT CHARLOTTE
Dept. of Mathematics
Charlotte NC
28 223 USA
[email protected][Session C16 (page 52), Abstract 397]
SOOS, Anna
BABES BOLYAI UNIVERSITY,
FACULTY OF MATHEMATICS AND
COMPUTER SCIENCE
Str, Kogalniceanu, nr. 1
Cluj-Napoca
3400 Romania

240 6th BS/ IMSC
SORENSEN, Helle
ROYAL VETERINARY AND
AGRICULTURAL UNIVERSITY
Dpt. of Chemistry, Physics and Mathema
Frederiksberg C
1871 Denmark
[email protected][Session Inv. 32 (page 33), Abstract 398]
SORENSEN, Michael
UNIVERSITY OF COPENHAGEN
universitetsparken 5
copenhagen
DK-2100 Denmark
[email protected][Session Inv. 32 (page 33), Abstract 398]
SOSHNIKOV, Alexander
UNIVERSITY OF CALIFORNIA AT DAVIS
One Shields Avenue
Davis, California
95616 USA
SOULIER, Philippe
UNIVERSITE PARIS X
200 Avenue de la Republique
Nanterre
92100 France
[email protected][Session C18 (page 54), Abstract 104]
SPANO, Dario
UNIVERSITY OF OXFORD
1 South Parks Road
Oxford
OX1 3TG UK
[email protected][Session C1 (page 15), Abstract 399]
SPEED, Terry
UNIVERSITY OF CALIFORNIA
Department of Statistics
Berkeley, CA
94720 USA
SPREIJ, Peter
UNIVERSITEIT VAN AMSTERDAM
Plantage Muidergracht 24
Amsterdam
1018TV The Netherlands
[email protected][Session C18 (page 54), Abstract 400]
STADTMUELLER, Ulrich
UNIVERSITY OF ULM
Dept. of Number hteory and Probability T
Ulm
89069 Germany
STARK, Dudley
QUEEN MARY,
UNIVERSITY OF LONDON
Mile End, London
E1 4NS UK
[email protected][Session C8 (page 35), Abstract 401]
STEFANESCU, Catalina
LONDON BUSINESS SCHOOL
Regent’s Park
London
NW1 4SA UK
[email protected][Session M9 (page 19), Abstract 402]
STEFFENSEN, Mogens
UNIVERSITY OF COPENHAGEN
Institute of Mathematical Sciences
Copenhagen
2100 Denmark
[email protected][Session Inv. 9 (page 23), Abstract 403]
STEIF, Jeffrey
CHALMERS UNIVERSITY OF
TECHNOLOGY
Eklandagatan 86
Gothenburg
41296 Sweden
STENBERG, Frederik
DEPARTMENT OF MATHEMATICS
AND PHYSICS
Box 883
Vasteras
72123 Sweden
[email protected][Session M1 (page 17), Abstract 404]
STENFLO, Örjan
DEPARTMENT OF MATHEMATICS
Stockholm University
Stockholm
10691 Sweden
[email protected][Session C17 (page 54), Abstract 405]
STEWART, Michael
UNIVERSITY OF SYDNEY
Parramatta Rd
Camperdown
2006 Australia
[email protected][Session C44 (page 52), Abstract 406]
STOVE, Bard
UNIVERSITY OF BERGEN
Johannes Brunsgate 12
Bergen
5008 Norway
STOYAN, Dietrich
TU BERGAKADEMIE FREIBERG
Institut fuer Stochastik
Freiberg
09596 Germany
[email protected][Session Inv. 31 (page 39), Abstract 407]
STUDENY, Milan
UTIA AV CR
Pod vodarenskou vezi 4
Prague
18208 Czech Republic
[email protected][Session C24 (page 35), Abstract 408]

Directory 241
STUTE, Winfried
UNIVERSITY OF GIESSEN
Mathematical Institute
Giessen
D-35392 Germany
STYAN, George
MCGILL UNIVERSITY
Burnside Hall Room 1005,
Montreal
H3A 2K6 Canada
SUDBURY, Aidan
MONASH UNIVERSITY
WELLINGTON ROAD
CLAYTON
3180 Australia
SUN, Jiayang
CASE WESTERN RESERVE
UNIVERSITY
10900 Euclid Avenue
Cleveland, OH
44106 USA
SVENSSON, Åke
DEPARTMENT OF MATHEMATICS
Stockholm University
Stockholm
SE-10691 Sweden
SWENSEN, Anders Rygh
UNIVERSITY OF OSLO
DEPT. OF MATH
Oslo
N-0316 Norway
[email protected][Session C47 (page 17), Abstract 409]
SWISHCHUK, Anatoliy
Department of Mathematics and
Statistics, York University
4700 Keele str
Toronto
ON M3J 1P3 Canada
[email protected][Session M1 (page 17), Abstract 410]
SZATZSCHNEIDER, Wojciech
ANAHUAC UNIVERSITY
Av. Lomas Anahuac
Huixquilucan
52786 Mexico
[email protected][Session M5 (page 27), Abstract 411]
TAKEMURA, Akimichi
UNIVERSITY OF TOKYO
Hongo 7-3-1, Bunkyo-ku
Tokyo
113-0033 Japan
[email protected][Session C43 (page 26), Abstract 412]
TALIH, Makram
CITY UNIVERSITY OF NEW YORK
DEPT OF MATHEMATICS AND STATIS-
TICS
695 Park Avenue, Room 905 HE
New York, NY
10021 USA
[email protected][Session C24 (page 36), Abstract 413]
TANKOV, Peter
ECOLE POLYTECHNIQUE
Route de Saclay
Palaiseau
91128 France
[email protected][Sessions C13 and P2 (pages 45 and 31),
Abstracts 414 and 415]
TAQQU, Murad
BOSTON UNIVERSITY
111 Cummington St.
Boston, MA
02215 USA
[email protected][Session C12 (page 24), Abstract 416]
TARTAKOVSKY, Alexander
UNIVERSITY OF SOUTHERN CALIFOR-
NIA
3620 S. Vermont Avenue, KAP 108
Los Angeles, CA
90089-2532 USA
[email protected][Session C63 (page 39), Abstract 417]
TAUPIN, Marie-luce
UNIVERSITE PARIS 11
Orsay
91400 France
TAVARE, Simon
UNIVERSITY OF SOUTHERN CALIFOR-
NIA
Department of Biological Sciences
Los Angeles, CA
90089-1113 USA
[email protected][Session Inv. 5 (page 29), Abstract 418]
TAYLOR, Jonathan
Department of Statistics, Stanford Univer-
sity
390 Serra Mall
Stanford
CA 94305 USA
[email protected][Session Inv. 7 (page 32), Abstract 419]
TEHRANCHI, Michael
UNIVERSITY OF TEXAS AT AUSTIN
Dept. of Mathematics, 1 University
Austin
78712 USA
[email protected][Session M5 (page 27), Abstract 420]
TER HORST, Enrique
DUKE UNIVERSITY
12 Ionian Building, 45 Narrow St
London
E14 8DW UK
[email protected][Session P2 (page 31), Abstract 180]

242 6th BS/ IMSC
TERAN, Pedro
UNIVERSIDAD DE ZARAGOZA
Fac. Económicas,
Dpto. Métodos Estadísiticos
Zaragoza
50005 España
[email protected][Session C14 (page 16), Abstract 421]
TETALI, Prasad
School of Mathematics, Georgia Institute
of Technology
Atlanta
Ga 30332-0160
[email protected][Session Inv. 17 (page 49), Abstract 422]
THOMAS, Alun
UNIVERSITY OF UTAH
Genetic Epidemiology,
391 Chipeta Way Su
Salt Lake City
UT 84108 USA
[email protected][Session Inv. 5 (page 29), Abstract 423]
TIMAR, Adam
INDIANA UNIVERSITY,
DPT. MATHEMATICS
Rawles Building
Bloomington, IN
47405 USA
[email protected][Session C62 (page 18), Abstract 424]
TINDEL, Samy
UNIVERSITY OF NANCY
IECN, BP 239
Vandoeuvre-lès-Nancy
54506 France
[email protected][Session C35 (page 26), Abstract 425]
TOLDO, Sandrine
UNIVERSITE RENNES 1
Campus de Beaulieu
Rennes
35042 France
[email protected][Session C36 (page 16), Abstract 426]
TOMA, Aida
ACADEMY OD ECONOMIC STUDIES
Piata Romana no. 6
Bucharest
70000 Romania
[email protected][Session P3 (page 42), Abstract 427]
TOMASZ, Michalski
DEPART. OF ECONOMIC INSURANCE,
WARSAW SCHOOL OF ECONOMICS
Al. Niepodleg & 322, 347, ci 164
Warsaw
02-554 Poland
TOROKHTI, Anatoli
UNIVERSITY OF SOUTH AUSTRALIA
Mawson Lakes Boulevard
Mawson Lakes
5095 Australia
[email protected][Sessions P1 and C41 (pages 22 and 46),
Abstracts 428, 429 and 430]
TORRECILLA, Ivan
FACULTAD DE MATEMATIQUES
Gran Via de les Corts Catalanes, 585
BARCELONA
08007 Spain
TORRISI, Giovanni Luca
CNR-ISTITUTO PER LE APPLICAZIONI
DEL CALCOLO
Viale del Policlinico 137, Rome
00161 Italy
[email protected][Sessions P2 and M2 (pages 31 and 41),
Abstracts 263 and 431]
TOUZI, Nizar
CREST, Laboratoire de Finance et
Assurance
15 Bd Gabriel Péri, Malakoff
92245 FRANCE
[email protected][Sessions C36 and Inv. 3 (pages 16 and
19), Abstract 49]
TRACY, Craig
UC DAVIS
Department of Mathematics
Davis
95616 USA
[email protected][Session Inv. 20 (page 29), Abstract 432]
TRANBARGER, Katherine
UCLA DEPARTMENT OF STATISTICS
8130 Math Sciences Bldg. Box 951554
Los Angeles, CA
90095-1554 USA
TRIBE, Roger
WARWICK UNIVERSITY
Mathematics Department
Coventry
CV4 7AL UK
[email protected][Session Inv. 15 (page 51), Abstract 433]
TRINDADE, Adao Alexandre
7832 N.W. 50 Street Gainesville
Gainesville
FL 32653 USA
[email protected][Session C33 (page 45), Abstract 434]
TSANGARI, Haritini
INTERCOLLEGE
16 LOUKIS AKRITAS STREET
NICOSIA
2064 Cyprus
[email protected][Session M8 (page 31), Abstract 435]
TSYBAKOV, Alexandre
Laboratoire de Probabilités et Modèles
Aléatoires, Université Paris VI
4, Place Jussieu, B.P. 188
PARIS
75252 France
[email protected][Session C41 (page 45), Abstract 436]

Directory 243
TULINO, Antonia M.
Universitá degli Studi di
Napoli “Federico II"
Napoli
Italy
[email protected][Session Inv. 21 (page 33), Abstract 450]
TUNESKI, Nikola
FACULTY OF MECHANICAL
ENGINEERING
Karpos 2 bb
Skopje
1000 Macedonia
TURKMAN, Kamil
FUNDAÇAO DE FCUL
Faculdade de Ciencias, Univ. of Lisbon
Lisbon
1749-016 Portugal
TURNER, Amanda
CAMBRIDGE UNIVERSITY
St John’s College
Cambridge
CB2 1TP UK
[email protected][Session C21 (page 50), Abstract 437]
TWARDOWSKA, Krystyna
FACULTY OF MATHEMATICS AND IN-
FORMATION SCIENCE
WARSAW UNIVERS. OF TECHNOLOGY
Warsaw
00-661 Poland
[email protected][Session M4 (page 37), Abstract 438]
UDINA, Frederic
UNIVERSITAT POMPEU FABRA
Ramon Trias Fragas 25
Barcelona
08005 Spain
[email protected][Session M8 (page 31), Abstract 439]
URMENETA, Henar
PUBLIC UNIVERSITY OF NAVARRA
Dep of Statistics and Operations Researc
Pamplona
31006 España
[email protected][Session C8 (page 35), Abstract 440]
UTZET, Frederic
UNIVERSITAT AUTÒNOMA DE
BARCELONA
Dpt. de Matematiques
Bellaterra (Barcelona)
08193 Spain
UUSIPAIKKA, Esa
UNIVERSITY OF TURKU
Assistentinkatu 7
Turku
20014 Finland
[email protected][Session P3 (page 41), Abstract 304]
VACHKOVSKAIA, Marina
UNIVERSIDADE DE CAMPINAS
IMECC / UNICAMP Caixa Postal 6065
Campinas
13083-970 Brazil
[email protected][Session C15 (page 53), Abstract 441]
VALDÉS SOSA, Pedro A.
Cuban Neuroscience Center
Apartado 6880
La Habana
Cuba
[email protected][Session Inv. 7 (page 32), Abstract 442]
VALERO, Jordi
ESCOLA SUPERIOR D’AGRICULTURA
DE BARCELONA
C. Comte Urgell 187
Barcelona
08036 Spain
[email protected][Session C49 (page 26), Abstract 341]
VAN DEN AKKER, Ramon
TILBURG UNIVERSITY
Postbus, 90153, Dpt. Econometrie & OR
B6
Tilburg
5000 LE The Netherlands
VAN ES, Bert
UNIVERSITY VAN AMSTERDAM
Plantage Muidergracht 24
Amsterdam
1018 TV The Netherlands
[email protected][Session C54 (page 46), Abstract 443]
VAN KEILEGOM, Ingrid
UNIVERSITE CATHOLIQUE DE
LOUVAIN
Institute de Statistique
Louvain-la-Neuve
1348 Belgium
[email protected][Session C27 (page 36), Abstract 174]
VAN LIESHOUT, Marie-Colette
CWI
Kruislaan 413
Amsterdam
1098 SJ The Netherlands
[email protected][Session Inv. 31 (page 39), Abstract 445]
VAN ROY, Benjamin
Stanford University
Terman 315
Stanford
CA 94305-4023 USA
[email protected][Session Inv. 25 (page 14), Abstract 446]
VARADHAN, Srinivasa
COURANT INSTITUTE
NEW YORK UNIVERSITY
New York, NY
10012 USA

244 6th BS/ IMSC
VEEN, Alejandro
UCLA DEPARTMENT OF STATISTICS
8130 Math Sciences Building,
Box 951554
Los Angeles, CA
90095 USA
[email protected][Session P1 (page 21), Abstract 447]
VELILLA, Santiago
UNIVERSIDAD CARLOS III DE MADRID
C/ Madrid 126
Getafe
28903 Spain
[email protected][Session C41 (page 45), Abstract 448]
VENGEROV, David
SUN MICROSYSTEMS
2600 Casey Ave
Mountain View
94086 USA
[email protected][Session C58 (page 55), Abstract 152]
VERAVERBEKE, Noël
LIMBURGS UNIVERSITAIR CENTRUM
University Campus
Diepenbeek
B 3590 Belgium
[email protected][Session C27 (page 36), Abstract 449]
VERDÚ, Sergio
Department of Electrical Engineering,
Princeton University
Princeton, -New Jersey
08544 USA
[email protected][Session Inv. 21 (page 33), Abstract 450]
VIEIRA MENDES CALISTO, Paula
Cristina
FACULDADE DE CIENCIAS E
TECNO-LOGIA DA UNIVERS. DE COIM-
BRA
Rua Dra Maria Espirito Santo Simoes 9
3200 Lousa, Portugal
[email protected],[email protected]
VIGODA, Eric
UNIVERSITY OF CHICAGO &
TOYOTA TECHNOLOGICAL UNIVER-
SITY
1100 E. 58th St.
Chicago
60615 USA
[email protected][Session Inv. 17 (page 49), Abstract 451]
VILES CUADROS, Noèlia
UAB
Departament de Matemàtiques
Bellaterra
08193 Spain
VIRÁG, Bálint
Department of Mathematics,
University of Toronto
100 St George St.
Toronto, ON
M5S 3G3 Canada
[email protected].[Session Inv. 19 (page 49), Abstract 452]
VISEK, Jan Amos
CHARLES UNIVERSITY
Fac. Social Sciences, Ins. Economic Stud
Prague
11001 Czech Republic
[email protected][Session C61 (page 48), Abstract 453]
VITALE, Richard
UNIVERSITY OF CONNECTICUT
11 Glen Hollow
West Hartford
06117-3023 USA
VIVES, Josep
UNIVERSITAT AUTONOMA DE
BARCELONA
Campus de Bellaterra
Cerdanyola
08193 España
[email protected][Session C32 (page 51), Abstract 454]
VIVO MOLINA, Juana María
UNIVERSIDAD DE MURCIA
Dpto. Métodos Cuantitativos
Murcia
30100 Spain
[email protected][Session P3 (page 42), Abstract 455]
VOLODIN, Andrei
UNIVERSITY OF REGINA
Department of Mathematics and Statistics
Regina
S4S 0A2 Canada
[email protected][Session C7 (page 44), Abstracts 310 and
456]
VONDRACEK, Zoran
UNIVERSITY OF ZAGREB
Department of Mathematics
Zagreb
10000 Croatia
VYSOTSKY, Vladislav
Saint-Petersburg State University
Russia
[email protected][Session C9 (page 20), Abstract 457]
WADE, Andrew
UNIVERSITY OF DURHAM
South Road
Durham
DH1 3LE UK
[email protected][Session C16 (page 52)]
WAKOLBINGER, Anton
GOETHE-UNIVERSITY FRANKFURT
AM MAIN
Robert-Mayer-Str. 10
Frankfurt am Main
60054 Germany

Directory 245
WANG, Yuedong
UNIVERSITY OF CALIFORNIA -
SANTA BABARA
Dept of Statistics and
Santa Barbara
93106 USA
[email protected][Session C58 (page 55), Abstract 458]
WANNTORP, Henrik
DEPARTMENT OF MATHEMATICS
Box 480
Uppsala
751 06 Sweden
WEBER, Stefan
HUMBOLDT-UNIVERSITAT ZU BERLIN
Unter den Linden 6
Berlin
10099 Germany
[email protected][Session M4 (page 37), Abstract 459]
WEE, In-Suk
KOREA UNIVERSITY
DEPT. OF MATHEMATICS
Seoul
136-701 Korea, South
WEGKAMP, Marten
FLORIDA STATE UNIVERSITY
Westerscheldelaan 3
Koudekerke
4371 PP The Netherlands
[email protected][Session C51 (page 27), Abstract 460]
WERNER, Wendelin
UNIVESITY PARIRS-SOUTH
Laboratoire de Mathématiques
Orsay Cedex
91405 France
[email protected][Session Levy Lect. (page 18), Ab-
stract 461]
WESOLOWSKI, Jacek
POLITECHNIKA WARSZAWSKA
Pl. Politechniki 1
Warszawa
00-661 Poland
[email protected][Sessions C32 and C24 (pages 50 and
35), Abstracts 462 and 273]
WIERMAN, John
JOHNS HOPKINS UNIVERSITY
Applied Mathematics and Statistics Dept.
Baltimore, Maryland
21218 USA
[email protected][Session C35 (page 25), Abstract 463]
WINTER, Anita
MATHEMATISCHES INSTITUT, FAU ER-
LANGEN
Bismarckstr 1 1/2
Erlangen
91054 Germany
[email protected][Session C37 (page 24), Abstract 117]
WINTER, Stefan
INSTITUT FüR STOCHASTIK UND
ANWENDUNGEN
Pfaffenwaldring 57
Stuttgart
70569 Germany
[email protected][Session P3 (page 42), Abstract 464]
WOOD, Andrew
UNIVERSITY OF NOTTINGHAM
School of Mathemathical Sciences, Univer
Nottingham
NG7 2RD UK
[email protected][Session C47 (page 17), Abstract 465]
WU, Qiguang
INSTITUTE OF SYSTEMS SCIENCE
CHINESE ACADEMY OF SCIENCES
55, Zhong-gun-cun East Road
Beijing
100080 China
[email protected][Session C43 (page 26), Abstract 466]
XIA, Yingcun
NATIONAL UNIVERSITY OF SINGA-
PORE
Department of Statistics and Applied
Singapore
117543 Singapore
[email protected][Session Inv. 30 (page 43), Abstract 468]
XIAMIN, Li
BEIJING POLYTECHNIC UNIVERSITY
Peking University Cheng-Ze-Yuan
BL.106,N
Beijing
100871 China
YAO, Qiwei
LONDON SCHOOL OF ECONOMICS
Dept of Statistics, Houghton Street
London
WC2 2AE UK
YEVGENIY, Kovchegov
UNIVERSITY OF CALIFORNIA, LOS
ANGELES
2734 Coneho Canyon Ct.
Thousand Oaks
91362 USA
YU, LONG
CORNELL UNIVERSITY
1206 Hasbrouck Apts.
Ithaca, New York
14850 USA
[email protected][Session P2 (page 32), Abstract 470]
YUKICH, Joseph
LEHIGH UNIVERSITY
Packer Ave
Bethlehem
18017 USA
[email protected][Session C62 (page 18), Abstract 471]

246 6th BS/ IMSC
YUN, Seok Hoon
UNIVERSITY OF SUWON
Department of Applied Statistics
Suwon, Kyonggi-do
445-743 Korea, South
XIE, Zhongjie
Department of Probability and Statistics
Peking University
Beijing
China
[email protected][Session C21 (page 50), Abstract 469]
ZAIATS, Vladimir
UNIVERSITAT DE VIC and
UNIVERSITAT AUTONOMA DE
BARCELONA
EPS,C/ de la Laura, 13
Vic and Bellaterra
08500 Spain
[email protected][Session C20 (page 35), Abstract 472]
ZAITSEV, Andrei
ST. PETERSBURG DEPARTMENT OF
THE STEKLOV MATHEMATICAL INSTI-
TUTE
Fontanka 27, St. Petersburg
191023 Russian Federation
[email protected][Session C65 (page 48), Abstract 473]
ZAMFIRESCU, Ingrid-Mona
BARUCH COLLEGE - CUNY
One Bernard Baruch Way
New York, NY
10010 USA
ZARZO, Manuel
POLYTECHNIC UNIVERSITY OF
VALENCIA
Camino de Vera s/n - edificio I3
Valencia
46022 Spain
[email protected][Session P1 (page 22), Abstract 474]
ZEMPLENI, Andrés
EOTVOS LORAND UNIVERSITY
Dept.Of Probability Theory and Statistic
Budapest
1117 Hungary
[email protected][Session C22 (page 40), Abstract 475]
ZHANG, Cun-Hui
RUTGERS UNIVERSITY
Department of Statistics
New Brunswick, NJ
08854 USA
[email protected][Session Medaillon Lect. (page 22), Ab-
stract 476]
ZHANG, Heping
YALE UNIVERSITY SCHOOL
OF MEDICINE
60 College St
New Haven
06511 USA
[email protected][Session Inv. 26 (page 49), Abstract 477]
ZHOU, Xiaowen
DEPT. OF MATHEMATICS,
CONCORDIA UNIVERSITY
7141 Sherbrooke Street W.
Montreal
H4B 1R6 Canada
[email protected][Session C13 (page 45), Abstract 478]
ZIGLIO, Giacomo
UNIVERSITA DEGLI STUDI DI TRENTO
Via H. Gmeiner 7
Trento
38100 Italy
ZINE, Raoudha
FACULTE DES SCIENCES DE SFAX
B. P. 802
Sfax
3018 Tunisia
ZOGRAFOS, Konstantinos
UNIVERSITY OF IOANNINA
Univ. Ioannina, Dpt. Mathematics
Ioannina
451 10 Greece
[email protected][Session C41 (page 46), Abstract 479]

GeneralInformations


General Information 249
Congress Venue
All the activities of the 6th BS/IMS Congress willtake place in the main building of the University ofBarcelona except for some sessions on MathematicalFinance that will take place at the Borsa de Barcelona(Barcelona Stock Market). The main building of theUniversity of Barcelona houses the Rector's oce, theFaculty of Mathematics and the Faculty of Philology.This building is located in the city center in front ofPlaça Universitat (see Figure 1). Metro lines L1 (red)and L2 (violet) take you to Universitat station, andthe exits lead to Plaça Universitat.
Borsa de Barcelona
Some sessions on Mathematical Finance (Monday andTuesday) will take place at the Borsa de Barcelona(Barcelona Stock Market) which is located at Passeigde Gracia 19 (see Figure 1). This is a ve minutewalk from the University of Barcelona. Metro stationPasseig de Gracia is close to the stock market. Thisstation can be reached using lines L4 (yellow) and L3(green).
Congress Secretariat
The Congress Secretariat is located on the rst oor of
the building of the University of Barcelona (see Figure5 on page 253).
Opening Hours:
Monday, July 26, 8:00 - 18:00
Tuesday through Friday, 9:00 - 18:00
Saturday, July 31, 9:00 - 13:00
Participants may obtain information about lodging,travel, excursions, registration payment, tourist infor-mation, restaurants, museums, etc.
Daily Announcements and Program Changes
Every morning, an information sheet, containing last-minute announcements, programme changes, or infor-mation will be available at the Congress Secretariat.Boards conveniently located will also show this in-formation. Other late announcements may be ac-cepted. The appropriate forms will be available atthe Congress Secretariat. Note that only forms sub-mitted before 16:00 will appear the next day on theannouncement sheet.
Organizers and Volunteers
Members of the Organizing Committee can be iden-tied by special badges. A number of volunteer stu-dents will wear a special 6th BS/IMS T-shirt.
Figure 1. Map showing the location of the main building of the Universitat of Barcelona and Borsa deBarcelona (Barcelona Stock Market)

250 6th BS/ IMSC
Grants
Recipients of the grants oered by the Local Com-mittee (this excludes the holders of Laha grants) areasked to bring their passport or identity card. Con-tact the Congress Secretariat in order to process yourrefunds. The grants that only cover the registrationfees have already been processed directly by the localorganization committee.
Computer Room
Three computer rooms will be available for your useduring the period of the congress. These rooms (A,B, C) are located in the Faculty of Mathematics (seeFigure 4 on page 253).
Opening Hours:
Monday through Friday, 10:00 18:00
Software and Equipment
Access to Internet, including telnet and SSH.Acrobat Reader viewerEthernet plugs for portable computers.Printing (this service is not free of charge)
Instructions for speakers
Time allotted for the talks is as follows:
• Special Lectures: 1 hour.
• Individual talks within Invited Sessions: 30 min-utes plus 5 minutes for discussion.
• Individual talks within Contributed Sessions: 20minutes including discussion.
Poster Exhibition
The poster exhibition area will be located in the MainEntrance Hall (see Figure 4 on page 253) of the Uni-versity of Barcelona. The maximum size for postersis 0.9 meters (width) and 1.5 meters.
Display Schedule: Tuesday, Wednesday andThursday, 12:30 - 18:30. From 14:00 to 15:00, posterauthors will be available for questions and discussionnext to their posters.
Exhibitor Stands
Various publishing houses and other companies willhave exhibitions of their products. These will be lo-cated around the Main Entrance Hall of the Universityof Barcelona.
Location of Rooms
• Paranimf and Aula Magna where the open-ing ceremony and the plenary lectures will takeplace are located in the rst oor of the build-ing of the main building of the University ofBarcelona (see Figures 4 and 5 on page 253).
• Rooms for various sessions will be located in theEdici Aribau which is a recent attachment to
the main building of the University of Barcelona(see Figures 2 and 3 on page 252). These roomsare noted by 0.1, 0.3, 1.1, 2.1, 2.2, 3.1 and 4.1.
• The Monday and Tuesday sessions on Mathe-matical Finance will take place at the Borsa deBarcelona (Barcelona Stock Market).
Discussion Rooms
Participants may use freely rooms 10 and 11 in theFaculty of Mathematics (see Figure 4 on page 253)for informal discussions.
Coee Breaks
Coee and refreshments will be oered at the Hallvenue (see Figure 4 on page 253 during the breaksestablished in the program of the Congress. The ses-sions at the Borsa de Barcelona will also have coeebreaks outside the session room.
Phones and Stamps.
Phones work with coins or with phone cards. Phonecards and stamps can be bought at tobacco stores.
Fax Service
There is a fax service on the second oor of the Facultyof Mathematics building at the oce of the Instituteof Mathematics (IMUB), see Figure 6 on page 254.These services are not free.
Libraries and Others Facilities
The mathematical library is located on the secondoor of Faculty of Mathematics (see Figure 6 on page254). The library is open from 9:00h to 17:00h. Pho-tocopy machines are available for photocopying; youcan buy a card for 10 photocopies by 1.20 e froma vending machine near the photopier, and you canrecharge this card for 0.04 e each copy.
Opening and Reception
A reception will take place in the Gardens of the Uni-versity of Barcelona on Monday July 26, at 19:15 (seemap).
Congress Gala Dinner
The Congress dinner will take place on Thursday 29,at 21:00, at the Palauet Luca which is a ve minuteswalk from the venue.
Lunch Time
There are many restaurants with a variety of pricesnear the venue. A list of restaurants and their loca-tion will be included the welcome package.
Late Registration
Participants wishing to pay their registration fee dur-ing the Congress are asked to contact the Secretariat.
Bank Services
You can obtain cash using major credit cards at cashmachines at the university. Also there is a branch

General Information 251
of La Caixa Bank at the Hall of the University ofBarcelona building. Opening hours are 8:1514:00from Monday to Friday. They can also exchange cur-rencies.
First Aid and Insurance
The registration fee does not include insurance forparticipants against accidents, sickness, or personalproperty losses. Participants are strongly advised tomake arrangements for health and accident insurancein advance. In case of an emergency, please contactthe Congress Secretariat.
Shopping Hours
Most shops in Barcelona are open from 10:00 to 20:00,possibly closing during lunch time. Some big storesstay open until 21:00 or 21:30, even on Saturdays.On Sundays most stores are closed. In tourist areasrestaurants remain open on Sundays.
Climate and Clothing
The temperature in Barcelona is around 28 degrees
Celsius in July during the day, and 20 degrees Celsiusat night. The weather is hot and humid.
Transportation
Barcelona has an extended network of buses, metroand train lines and taxis. We recommend using themetro because it is reliable and fast. There are conve-nient transportation cards, called T-10, which can beused for 10 trips covering all changes in transporta-tion within a time limit of 75 minutes. The price of aT-10 for central Barcelona (1 zone) is 6 e. There isan extensive bus system. Taxis charge two dierentfares per kilometer according to the hour. One from6:00-22:00 on weekdays and the other for the rest ofthe times. All taxis should run a taxi-meter systemwhen charging for a trip. The charge from the airportto the city center is about 20 euros. There is a chargeof 0.78 euros per bag and 1.92 for airport charges.
Useful Phone Numbers
Information Service 11818 Taxis 933 003 811City Hall Information 010 Taxi Radio Movil 933 581 111Tourist Information 807 117 222 Taxi Miramar 934 331 020Police (theft) 091 Ambulance 933 002 020City Police 092 Information on duty pharmacies 934 810 060Post Oce 933 183 831 Lost bank cardsAirport 933 170 178 Visa - Master Card - Servired 933 152 512RENFE (train) 934 900 202 915 192 100Medical Emergencies 061 American Express 915 720 320General Emergencies 112 Dinner's Club 902 401 112

252 6th BS/ IMSC
Figure 2. Edici Aribau, ground oor
Figure 3. Edici Aribau, 1th, 2nd, 3th and 4th oor

General Information 253
Figure 4. Main building, ground oor
Figure 5. Main building, 1th oor

254 6th BS/ IMSC
Figure 6. Main building, 2nd oor
AcknowledgementsThe local organizing committee would like to thank the following people for their support as reviewers ofcontributed papers.
S. Bayarri (Universitat de València) D. Nualart (UB)
J. M. Corcuera (UB) J. M. Oller (UB)
C. Cuadras (UB) P. Puig (UAB)
J. del Castillo (UAB) C. Rovira (UB)
J. Fortiana (UB) A. Sànchez (UB)
M. Greenacre (UPF) M. Sanz (UB)
A. Kohatsu (UPF) S. Tindel (Université de Nancy)
G. Lugosi (UPF) M. Wolf (UPF)
D. Màrquez-Carreras (UB) V. Zaiats (Universitat de Vic and UAB)
J. Niño Mora (Universidad Carlos III)