
Conditional visuo-motor learning and dimension reduction
10
RESEARCH REPORT Fadila Hadj-Bouziane He´ le` ne Frankowska Martine Meunier Pierre-Arnaud Coquelin Driss Boussaoud Conditional visuo-motor learning and dimension reduction Received: 29 August 2005 / Revised: 3 December 2005 / Accepted: 7 December 2005 / Published online: 28 January 2006 Ó Marta Olivetti Belardinelli and Springer-Verlag 2006 Abstract Conditional visuo-motor learning consists in learning by trial and error to associate visual cues with correct motor responses, that have no direct link. Con- verging evidence supports the role of a large brain net- work in this type of learning, including the prefrontal and the premotor cortex, the basal ganglia (BG) and the hippocampus. In this paper we focus on the role of a major structure of the BG, the striatum. We first present behavioral results and electrophysiological data re- corded from this structure in monkeys engaged in learning new visuo-motor associations. Visual stimuli were presented on a video screen and the animals had to learn, by trial and error, to select the correct movement of a joystick, in order to receive a liquid reward. Behavioral results revealed that the monkeys used a sequential strategy, whereby they learned the associa- tions one by one although they were presented ran- domly. Human subjects, tested on the same task, also used a sequential strategy. Neuronal recordings in monkeys revealed learning-related modulations of neu- ral activity in the striatum. We then present a mathe- matical model inspired by viability theory developed to implement the use of strategies during learning. This model complements existing models of the BG based on reinforcement learning (RL), which do not take into account the use of strategies to reduce the dimension of the learning space. Keywords Basal ganglia Learning strategy Electrophysiology Monkey Viability theory Dimension reduction Introduction Conditional associative behavior, one type of non- standard sensori-motor mapping as opposed to standard mapping (such as grasping a cup of tea), relies on abstract rules that allow the primate brain to associate any sensory cue with a variety of behavioral responses (Wise et al. 1996a, b). The most sophisticated form of this capacity is reading, which depends on learned associations between the visual form of letters and the movements necessary to pronounce them. Studies of arbitrary visuo-motor learning in labora- tory situations have generally used a set of stimuli taken from the same category (colors, pictures, positions, etc.) and a set of motor responses (hand postures, lever dis- placements, etc.). Subjects are required to learn by trial and error, and then execute arbitrary rules such as ‘if green go right, if red go left’. Hence, these tasks are often referred to as ‘conditional’ associative tasks. Because all stimuli are equally associated with reward (or success) in these tasks, learning cannot be driven by simple stimu- lus–reward bonds. Instead, subjects must link a stimulus with a response which in turn leads to reward. This learning phase, thus, requires stimulus discrimination, response selection, but also on-line monitoring of the associations already tried and of their outcome (correct or incorrect). With large sets of items and actions to associate, this monitoring represents a high memory load, which can be decreased by using specific learning strategies. Several reviews have appeared in recent years on conditional visuo-motor learning (see for example Communicated by Richard Walker F. Hadj-Bouziane M. Meunier D. Boussaoud (&) INCM UMR6193, CNRS& Aix-Marseille Universite´, 31 Chemin Jospeh Aiguier, 13402 Marseille, France E-mail: [email protected] E-mail: [email protected] Tel.: +33-491-164121 Fax: +33-491-774969 H. Frankowska P.-A. Coquelin CNRS, CREA, Ecole Polytechnique, 1 rue Descartes, 75005 Paris, France E-mail: [email protected] E-mail: [email protected] Present address: F. Hadj-Bouziane Laboratory of Brain and Cognition, NIMH, Bethesda, MD, USA E-mail: [email protected] Cogn Process (2006) 7: 95–104 DOI 10.1007/s10339-005-0028-4
Transcript of Conditional visuo-motor learning and dimension reduction

RESEARCH REPORT
Fadila Hadj-Bouziane Æ Helene Frankowska
Martine Meunier Æ Pierre-Arnaud Coquelin
Driss Boussaoud
Conditional visuo-motor learning and dimension reduction
Received: 29 August 2005 / Revised: 3 December 2005 / Accepted: 7 December 2005 / Published online: 28 January 2006� Marta Olivetti Belardinelli and Springer-Verlag 2006
Abstract Conditional visuo-motor learning consists inlearning by trial and error to associate visual cues withcorrect motor responses, that have no direct link. Con-verging evidence supports the role of a large brain net-work in this type of learning, including the prefrontaland the premotor cortex, the basal ganglia (BG) and thehippocampus. In this paper we focus on the role of amajor structure of the BG, the striatum. We first presentbehavioral results and electrophysiological data re-corded from this structure in monkeys engaged inlearning new visuo-motor associations. Visual stimuliwere presented on a video screen and the animals had tolearn, by trial and error, to select the correct movementof a joystick, in order to receive a liquid reward.Behavioral results revealed that the monkeys used asequential strategy, whereby they learned the associa-tions one by one although they were presented ran-domly. Human subjects, tested on the same task, alsoused a sequential strategy. Neuronal recordings inmonkeys revealed learning-related modulations of neu-ral activity in the striatum. We then present a mathe-matical model inspired by viability theory developed toimplement the use of strategies during learning. Thismodel complements existing models of the BG based on
reinforcement learning (RL), which do not take intoaccount the use of strategies to reduce the dimension ofthe learning space.
Keywords Basal ganglia Æ Learning strategy ÆElectrophysiology Æ Monkey Æ Viability theory ÆDimension reduction
Introduction
Conditional associative behavior, one type of non-standard sensori-motor mapping as opposed to standardmapping (such as grasping a cup of tea), relies onabstract rules that allow the primate brain to associateany sensory cue with a variety of behavioral responses(Wise et al. 1996a, b). The most sophisticated form ofthis capacity is reading, which depends on learnedassociations between the visual form of letters and themovements necessary to pronounce them.
Studies of arbitrary visuo-motor learning in labora-tory situations have generally used a set of stimuli takenfrom the same category (colors, pictures, positions, etc.)and a set of motor responses (hand postures, lever dis-placements, etc.). Subjects are required to learn by trialand error, and then execute arbitrary rules such as ‘ifgreen go right, if red go left’. Hence, these tasks are oftenreferred to as ‘conditional’ associative tasks. Because allstimuli are equally associated with reward (or success) inthese tasks, learning cannot be driven by simple stimu-lus–reward bonds. Instead, subjects must link a stimuluswith a response which in turn leads to reward. Thislearning phase, thus, requires stimulus discrimination,response selection, but also on-line monitoring of theassociations already tried and of their outcome (corrector incorrect). With large sets of items and actions toassociate, this monitoring represents a high memoryload, which can be decreased by using specific learningstrategies.
Several reviews have appeared in recent years onconditional visuo-motor learning (see for example
Communicated by Richard Walker
F. Hadj-Bouziane Æ M. Meunier Æ D. Boussaoud (&)INCM UMR6193, CNRS& Aix-Marseille Universite,31 Chemin Jospeh Aiguier, 13402 Marseille, FranceE-mail: [email protected]: [email protected].: +33-491-164121Fax: +33-491-774969
H. Frankowska Æ P.-A. CoquelinCNRS, CREA, Ecole Polytechnique,1 rue Descartes, 75005 Paris, FranceE-mail: [email protected]: [email protected]
Present address: F. Hadj-BouzianeLaboratory of Brain and Cognition, NIMH, Bethesda, MD, USAE-mail: [email protected]
Cogn Process (2006) 7: 95–104DOI 10.1007/s10339-005-0028-4

Passingham 1993; Passingham et al. 2000; Wise et al.1996a, b; Wise and Murray 2000; Hadj-Bouziane et al.2003; Brasted and Wise 2004b). The purpose of thepresent paper is to bring new insights to basal ganglia(BG) models in learning, building on behavioral obser-vations and neuronal activity. The question at hand iswhether learning can be fully explained as the result ofimprovement of the cumulative reward as it is doneusing reinforcement learning (RL) algorithms. Here weget inspiration from viability theory based on investi-gation of boundaries of sets. Such investigation may beseen as an artificial reduction of the dimension of thelearning space, thereby simplifying the action selection.The idea put forward here is that the use of strategiesduring learning is a way to reduce the dimension oflearning space.
The role of the basal ganglia in arbitrary visuo-motorassociations
Converging evidence indicates that conditional associa-tive learning is based on neuronal operations throughwhich the posterior sensory cortices, the lateral pre-frontal cortex (PF) and the hippocampal region interactwith the loop linking the BG to the lateral premotorcortex, via the thalamus (see for example Wise andMurray 2000; Passingham 1993). BG represent a centralnode within this large network, and are believed to playa key role in learning.
The BG form an anatomical system consisting ofseveral structures: the striatum, composed of the caudatenucleus and the putamen, the globus pallidus (inter-nal—GPi; external—GPe; and ventral segments), thesubstantia nigra (pars compacta—SNc; and pars retic-ulata—SNr) and the subthalamic nucleus. The striatumconstitutes the main input stage of the BG, whereas theGPi and SNr constitute the principal output stages. Thestriatum receives projections from almost all corticalareas, as well as from subcortical structures, includingthe thalamus and most neuromodulatory systems(Alexander et al. 1986; Parent and Hazrati 1995).Among these afferent inputs, the projections arisingfrom the cortex are by far the most prominent. Thestriatum has been subdivided into three functional do-mains: a sensori-motor, an associative and a limbic do-main (Parent 1990; Joel and Weiner 1994), based on thetopographical organization of the corticostriatal pro-jections. The sensori-motor striatum receives inputsfrom the premotor and motor cortical areas, the asso-ciative striatum receives inputs from the PF, whereas thelimbic striatum receives extensive inputs from limbicstructures, such as the hippocampus, amygdala, the or-bitofrontal cortex and anterior cingulate areas (for areview see Parent and Hazrati 1995). Another importantinput to the striatum is the massive dopaminergic inputsfrom the midbrain systems (for reviews see Prensa et al.2000; Smith and Kieval 2000). Schultz and colleaguessuggested that these dopaminergic neurons could deliver
reward-predicting signals to the striatum (Fiorillo et al.2003; Hollerman et al. 1998; Ljungberg et al. 1992;Schultz et al. 1993). It reinforces behaviors bystrengthening associations between stimuli and behav-ioral responses, and is thus of particular interest for non-standard mapping, which requires to link a stimuluswith a response, based on outcome.
Due to its connectivity and its particular architecture,the striatum has long been considered as an ideal site forintegration of sensory, motor and reward information.We and others (Passingham et al. 2000; Bussey et al.2001) suggested that, under PF influence, this structurecould link various types of information through arbi-trary rules. PF’s contribution might be to hold inmemory the stimuli presented, as well as the conse-quences of the already tried associations, and to imple-ment specific strategies to facilitate learning. In thisview, the PF plays a prominent role during early learn-ing phases (Petrides 1985; Bussey et al. 2001). Finally,information flow from the BG, via the thalamus, influ-ences the dorsal premotor cortex (PMd), an output stagewhere associative rules are mapped onto actions, whe-ther the rules are learned or under the process oflearning. Once learned, the use of the visuo-motor rulesrequires particularly the striatum as well as PMd, whoselesion affects severely the execution of learned associa-tions both in humans (Petrides 1985; Halsband andFreund 1990) and monkeys (Petrides 1985; Passingham1993; Kurata and Hoffman 1994). This hypothesis isstrengthened by neurophysiological recordings in mon-keys during execution of a well-learned task. Indeed,Boussaoud and Kermadi (1997) found that the striatumcontains an important proportion of neurons coding aspecific association between a stimulus and a movement,i.e. a representation of these rules.
Conditional associative learning: behavioral and neuronaldata
In a recent study, we recorded single cell activity in thestriatum of two rhesus monkeys during learning of aconditional visuo-motor task that required to associ-ate complex visual cues with joystick movements(Hadj-Bouziane and Boussaoud 2003). We will describebehavioral results and neuronal changes in the striatumduring learning.
Behavioral results
The monkeys were first trained with a set of four stim-ulus/movement associations, until they reached at least80% correct responses. These familiar associations re-mained unchanged throughout the whole experiment.Then, the animals were taught to search, by trial anderror, for the correct joystick movements associated withnovel sets of four cues. Figure 1 illustrates thesequencing of events during the task. For both the
96
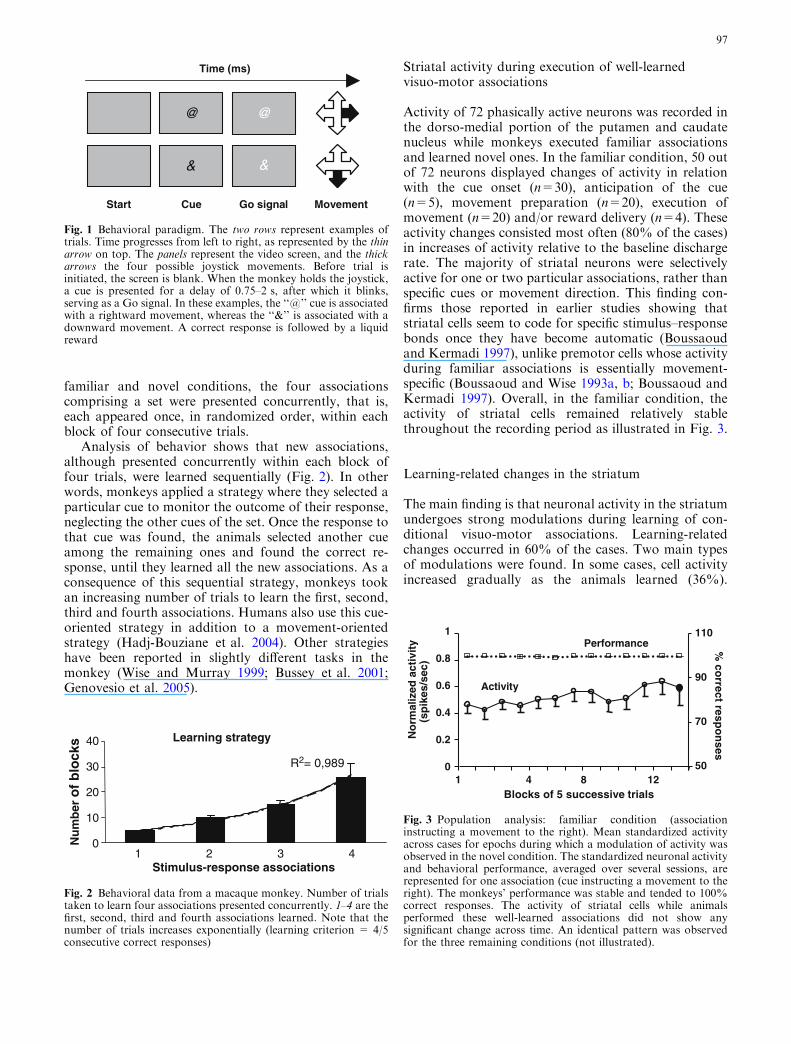
familiar and novel conditions, the four associationscomprising a set were presented concurrently, that is,each appeared once, in randomized order, within eachblock of four consecutive trials.
Analysis of behavior shows that new associations,although presented concurrently within each block offour trials, were learned sequentially (Fig. 2). In otherwords, monkeys applied a strategy where they selected aparticular cue to monitor the outcome of their response,neglecting the other cues of the set. Once the response tothat cue was found, the animals selected another cueamong the remaining ones and found the correct re-sponse, until they learned all the new associations. As aconsequence of this sequential strategy, monkeys tookan increasing number of trials to learn the first, second,third and fourth associations. Humans also use this cue-oriented strategy in addition to a movement-orientedstrategy (Hadj-Bouziane et al. 2004). Other strategieshave been reported in slightly different tasks in themonkey (Wise and Murray 1999; Bussey et al. 2001;Genovesio et al. 2005).
Striatal activity during execution of well-learnedvisuo-motor associations
Activity of 72 phasically active neurons was recorded inthe dorso-medial portion of the putamen and caudatenucleus while monkeys executed familiar associationsand learned novel ones. In the familiar condition, 50 outof 72 neurons displayed changes of activity in relationwith the cue onset (n=30), anticipation of the cue(n=5), movement preparation (n=20), execution ofmovement (n=20) and/or reward delivery (n=4). Theseactivity changes consisted most often (80% of the cases)in increases of activity relative to the baseline dischargerate. The majority of striatal neurons were selectivelyactive for one or two particular associations, rather thanspecific cues or movement direction. This finding con-firms those reported in earlier studies showing thatstriatal cells seem to code for specific stimulus–responsebonds once they have become automatic (Boussaoudand Kermadi 1997), unlike premotor cells whose activityduring familiar associations is essentially movement-specific (Boussaoud and Wise 1993a, b; Boussaoud andKermadi 1997). Overall, in the familiar condition, theactivity of striatal cells remained relatively stablethroughout the recording period as illustrated in Fig. 3.
Learning-related changes in the striatum
The main finding is that neuronal activity in the striatumundergoes strong modulations during learning of con-ditional visuo-motor associations. Learning-relatedchanges occurred in 60% of the cases. Two main typesof modulations were found. In some cases, cell activityincreased gradually as the animals learned (36%).
Cue Go signal Movement
@
&
@
&
Time (ms)
Start
Fig. 1 Behavioral paradigm. The two rows represent examples oftrials. Time progresses from left to right, as represented by the thinarrow on top. The panels represent the video screen, and the thickarrows the four possible joystick movements. Before trial isinitiated, the screen is blank. When the monkey holds the joystick,a cue is presented for a delay of 0.75–2 s, after which it blinks,serving as a Go signal. In these examples, the ‘‘@’’ cue is associatedwith a rightward movement, whereas the ‘‘&’’ is associated with adownward movement. A correct response is followed by a liquidreward
R2= 0,989
0
10
20
30
40
1 3
Nu
mb
er o
f b
lock
s
Stimulus-response associations
Learning strategy
42
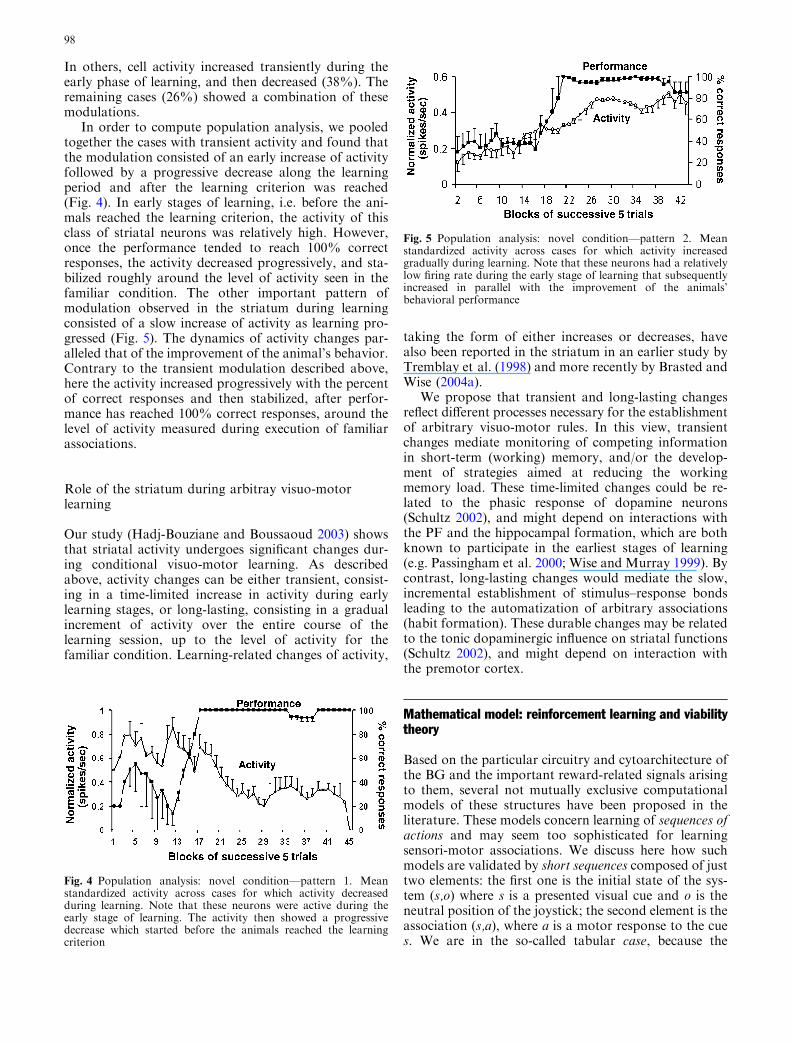
Fig. 2 Behavioral data from a macaque monkey. Number of trialstaken to learn four associations presented concurrently. 1–4 are thefirst, second, third and fourth associations learned. Note that thenumber of trials increases exponentially (learning criterion = 4/5consecutive correct responses)
0
0.2
0.4
0.6
0.8
1
1 8 1250
70
90
110
Blocks of 5 successive trials
No
rmal
ized
act
ivit
y(s
pik
es/s
ec)
% co
rrect respo
nses
Activity
Performance
4
Fig. 3 Population analysis: familiar condition (associationinstructing a movement to the right). Mean standardized activityacross cases for epochs during which a modulation of activity wasobserved in the novel condition. The standardized neuronal activityand behavioral performance, averaged over several sessions, arerepresented for one association (cue instructing a movement to theright). The monkeys’ performance was stable and tended to 100%correct responses. The activity of striatal cells while animalsperformed these well-learned associations did not show anysignificant change across time. An identical pattern was observedfor the three remaining conditions (not illustrated).
97
In others, cell activity increased transiently during theearly phase of learning, and then decreased (38%). Theremaining cases (26%) showed a combination of thesemodulations.
In order to compute population analysis, we pooledtogether the cases with transient activity and found thatthe modulation consisted of an early increase of activityfollowed by a progressive decrease along the learningperiod and after the learning criterion was reached(Fig. 4). In early stages of learning, i.e. before the ani-mals reached the learning criterion, the activity of thisclass of striatal neurons was relatively high. However,once the performance tended to reach 100% correctresponses, the activity decreased progressively, and sta-bilized roughly around the level of activity seen in thefamiliar condition. The other important pattern ofmodulation observed in the striatum during learningconsisted of a slow increase of activity as learning pro-gressed (Fig. 5). The dynamics of activity changes par-alleled that of the improvement of the animal’s behavior.Contrary to the transient modulation described above,here the activity increased progressively with the percentof correct responses and then stabilized, after perfor-mance has reached 100% correct responses, around thelevel of activity measured during execution of familiarassociations.
Role of the striatum during arbitray visuo-motorlearning
Our study (Hadj-Bouziane and Boussaoud 2003) showsthat striatal activity undergoes significant changes dur-ing conditional visuo-motor learning. As describedabove, activity changes can be either transient, consist-ing in a time-limited increase in activity during earlylearning stages, or long-lasting, consisting in a gradualincrement of activity over the entire course of thelearning session, up to the level of activity for thefamiliar condition. Learning-related changes of activity,
taking the form of either increases or decreases, havealso been reported in the striatum in an earlier study byTremblay et al. (1998) and more recently by Brasted andWise (2004a).
We propose that transient and long-lasting changesreflect different processes necessary for the establishmentof arbitrary visuo-motor rules. In this view, transientchanges mediate monitoring of competing informationin short-term (working) memory, and/or the develop-ment of strategies aimed at reducing the workingmemory load. These time-limited changes could be re-lated to the phasic response of dopamine neurons(Schultz 2002), and might depend on interactions withthe PF and the hippocampal formation, which are bothknown to participate in the earliest stages of learning(e.g. Passingham et al. 2000; Wise and Murray 1999). Bycontrast, long-lasting changes would mediate the slow,incremental establishment of stimulus–response bondsleading to the automatization of arbitrary associations(habit formation). These durable changes may be relatedto the tonic dopaminergic influence on striatal functions(Schultz 2002), and might depend on interaction withthe premotor cortex.
Mathematical model: reinforcement learning and viabilitytheory
Based on the particular circuitry and cytoarchitecture ofthe BG and the important reward-related signals arisingto them, several not mutually exclusive computationalmodels of these structures have been proposed in theliterature. These models concern learning of sequences ofactions and may seem too sophisticated for learningsensori-motor associations. We discuss here how suchmodels are validated by short sequences composed of justtwo elements: the first one is the initial state of the sys-tem (s,o) where s is a presented visual cue and o is theneutral position of the joystick; the second element is theassociation (s,a), where a is a motor response to the cues. We are in the so-called tabular case, because the
Fig. 4 Population analysis: novel condition—pattern 1. Meanstandardized activity across cases for which activity decreasedduring learning. Note that these neurons were active during theearly stage of learning. The activity then showed a progressivedecrease which started before the animals reached the learningcriterion
Fig. 5 Population analysis: novel condition—pattern 2. Meanstandardized activity across cases for which activity increasedgradually during learning. Note that these neurons had a relativelylow firing rate during the early stage of learning that subsequentlyincreased in parallel with the improvement of the animals’behavioral performance
98

number of both states and actions is small. Computa-tional models of BG state that reward-related signals inthe BG postulate that the reward should be a naturalpart of any of its computational models. However, as itis shown above, the strategy of learning is another objectthat should be considered.
Reinforcement learning
Reinforcement learning computational model in theframework of actor-critic model (Houk et al. 1995;Barto 1995) contains two basic components. The firstcomponent is a control system (where actions of anactor are considered as controls) that maps actualstates of the system to new states, and the secondcomponent is the cumulative reward (cost functionwhich sums a temporal sequence of rewards). Thesecond component leads to the problem of choice ofpolicies to maximize accumulated reward. There is anextensive literature devoted to RL, where the aim ofan agent is to maximize the cumulative reward usingdifferent types of action selections (cf. greedy, e-greedy,softmax, etc.). The role of an adaptive critic is to learnhow to provide an effective reinforcement, signal sothat when the actor learns according to the tacticalobjective of maximizing immediate effective reinforce-ment, it is actually learning according to the strategicobjective of maximizing a long-term measure ofbehavior (Barto 1995). In these models, the critic actsas a predictor of the maximal cost function. RLalgorithms (see for instance Sutton and Barto 1998and the comprehensive bibliography contained therein)are related to ideas of dynamic programming methodsdeveloped by Bellman to deal with problems of opti-mal control. In neurosciences, RL algorithms wereused for modeling learning processes in the BG forboth discrete and continuous time models (see Doya1999; 2000).
Let us first examine, from the point of view of RL,our particular task of learning of sensori-motor associ-ations, when a reward follows only each correct re-sponse. We consider the state space S of all visual cues sto which an action should be associated, the set of ac-tions A of all allowed motor responses a and define thenumerical reward r(s,a) to be positive when (s,a) is acorrect association and non-positive otherwise. Thepolicy p is a mapping from pairs (s,a)2S·A to theprobability p (s,a) of taking action a when in state s. Thecost function of a policy p is:
V pðsÞ ¼ Ep
X1
k¼0ckrtþkþ1jst ¼ s
( )
(see for instance Sutton and Barto 1998) where Epde-notes the expected value given that the agent followspolicy p, rt+k+1, the reward obtained at time t+k+1and the constant 0 £ c < 1 is fixed. The action valuefunction for policy p is:
Qpðs; aÞ ¼ Ep
X1
k¼0ckrtþkþ1jst ¼ s; at ¼ a
( ):
Its role is to maintain a record of all rewards that havefollowed the selection of the action a when the systemwas at state s. In the task of learning sensori-motorassociations, since cues are presented in blocks in whichthey are randomly distributed, action at does not inreality influence the change from state st to st+1, and it isalso clear that the best cumulative reward is achievedonly for correct choices. For this reason it is enough toconsider in the above expressions k=0 corresponding tothe choice c=0. The Bellman equation for the optimalvalue function then becomes V optðsÞ ¼ maxarðs; aÞ: Inthis way, the temporal difference (TD) signal for thevalue function is given by dV (st, at)=r(st, at) � V(st).For the action value function the TD signal is dQ (st,at)=r(st, at) � Q(st, at). The estimates of the value andaction value functions are updated in the following way:
V ðstÞ V ðstÞ þ adV ðst; atÞ
and
Qðst; atÞ Qðst; atÞ þ adQðst; atÞ;
where a 2[0,1] is a fixed learning rate. If this value isequal to zero, then no learning occurs. If it is equal toone, then the elements of the action value are immedi-ately updated to their final value. The objective ofassociative learning is to derive the optimal policy p opt
in such way that p opt (s,a)=1 when (s,a) is a correctassociation and p opt (s,a)=0, otherwise.
The most common softmax action selection methoduses a Gibbs distribution. It chooses action �a at state stwith probability:
P ðat ¼ �ajstÞ ¼ebQðst ;�aÞ
Pa2A ebQðst;atÞ
where b is the inverse temperature. This coefficient b isrelated to optimality: if it is high, then the best action ischosen among those learned before, and the explorationis low; if b is low, then the action is chosen randomly.
Other common action selections are for instance thegreedy action selection (at state s an action �a that max-imizes Q(s,a) is preferred to others) and the e-greedyaction selection (when an action �a that has the highestQ(s,a) is chosen with probability (1� e) whereas otheractions could be chosen with probability e.
In our task we observed that the associations werelearned sequentially and that the number of trials in-creased exponentially (see Fig. 2). Note that if cues werelearned sequentially and independently one from other,then a linear dependence would result. By contrast, ifthey were learned simultaneously, then one would expectlogarithmic curves, since, while learning the first associ-ation, some information about the other associationswould also be retained, thereby shortening the timeelapsed between acquisitions of other associations.
99
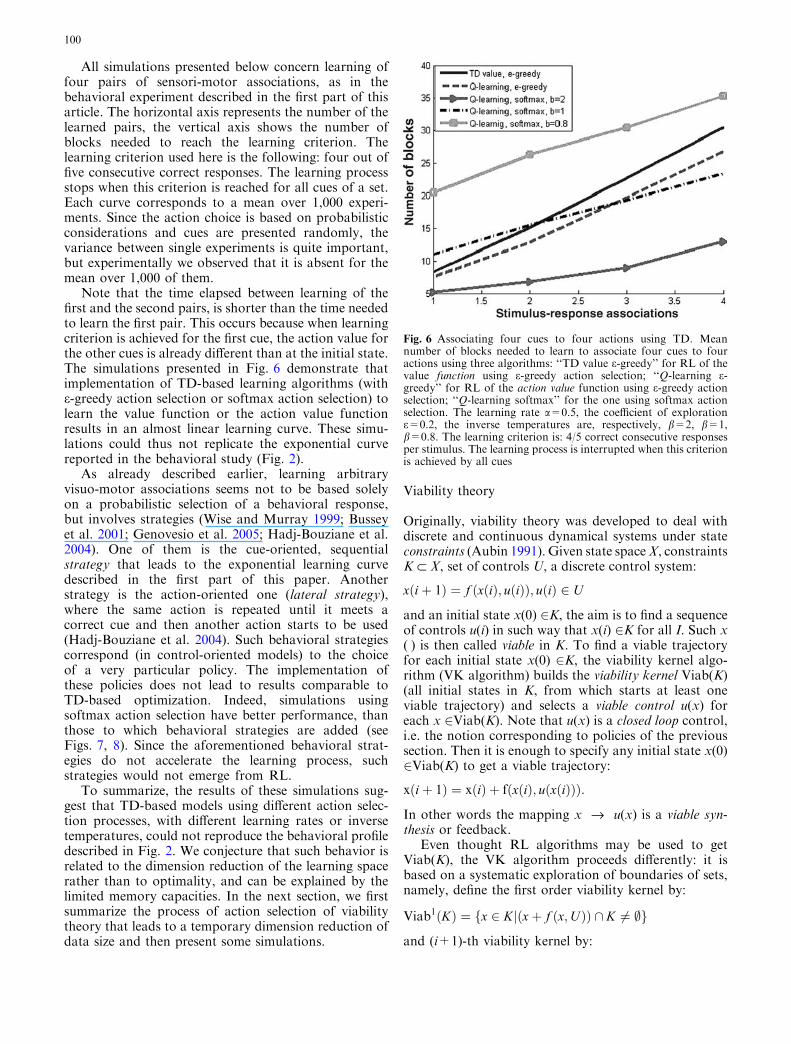
All simulations presented below concern learning offour pairs of sensori-motor associations, as in thebehavioral experiment described in the first part of thisarticle. The horizontal axis represents the number of thelearned pairs, the vertical axis shows the number ofblocks needed to reach the learning criterion. Thelearning criterion used here is the following: four out offive consecutive correct responses. The learning processstops when this criterion is reached for all cues of a set.Each curve corresponds to a mean over 1,000 experi-ments. Since the action choice is based on probabilisticconsiderations and cues are presented randomly, thevariance between single experiments is quite important,but experimentally we observed that it is absent for themean over 1,000 of them.
Note that the time elapsed between learning of thefirst and the second pairs, is shorter than the time neededto learn the first pair. This occurs because when learningcriterion is achieved for the first cue, the action value forthe other cues is already different than at the initial state.The simulations presented in Fig. 6 demonstrate thatimplementation of TD-based learning algorithms (withe-greedy action selection or softmax action selection) tolearn the value function or the action value functionresults in an almost linear learning curve. These simu-lations could thus not replicate the exponential curvereported in the behavioral study (Fig. 2).
As already described earlier, learning arbitraryvisuo-motor associations seems not to be based solelyon a probabilistic selection of a behavioral response,but involves strategies (Wise and Murray 1999; Busseyet al. 2001; Genovesio et al. 2005; Hadj-Bouziane et al.2004). One of them is the cue-oriented, sequentialstrategy that leads to the exponential learning curvedescribed in the first part of this paper. Anotherstrategy is the action-oriented one (lateral strategy),where the same action is repeated until it meets acorrect cue and then another action starts to be used(Hadj-Bouziane et al. 2004). Such behavioral strategiescorrespond (in control-oriented models) to the choiceof a very particular policy. The implementation ofthese policies does not lead to results comparable toTD-based optimization. Indeed, simulations usingsoftmax action selection have better performance, thanthose to which behavioral strategies are added (seeFigs. 7, 8). Since the aforementioned behavioral strat-egies do not accelerate the learning process, suchstrategies would not emerge from RL.
To summarize, the results of these simulations sug-gest that TD-based models using different action selec-tion processes, with different learning rates or inversetemperatures, could not reproduce the behavioral profiledescribed in Fig. 2. We conjecture that such behavior isrelated to the dimension reduction of the learning spacerather than to optimality, and can be explained by thelimited memory capacities. In the next section, we firstsummarize the process of action selection of viabilitytheory that leads to a temporary dimension reduction ofdata size and then present some simulations.
Viability theory
Originally, viability theory was developed to deal withdiscrete and continuous dynamical systems under stateconstraints (Aubin 1991). Given state spaceX, constraintsK � X, set of controls U, a discrete control system:
xðiþ 1Þ ¼ f ðxðiÞ; uðiÞÞ; uðiÞ 2 U
and an initial state x(0) 2K, the aim is to find a sequenceof controls u(i) in such way that x(i) 2K for all I. Such x(Æ) is then called viable in K. To find a viable trajectoryfor each initial state x(0) 2K, the viability kernel algo-rithm (VK algorithm) builds the viability kernel Viab(K)(all initial states in K, from which starts at least oneviable trajectory) and selects a viable control u(x) foreach x 2Viab(K). Note that u(x) is a closed loop control,i.e. the notion corresponding to policies of the previoussection. Then it is enough to specify any initial state x(0)2Viab(K) to get a viable trajectory:
xðiþ 1Þ ¼ xðiÞ þ fðxðiÞ; uðxðiÞÞÞ:
In other words the mapping x fi u(x) is a viable syn-thesis or feedback.
Even thought RL algorithms may be used to getViab(K), the VK algorithm proceeds differently: it isbased on a systematic exploration of boundaries of sets,namely, define the first order viability kernel by:
Viab1ðKÞ ¼ fx 2 Kjðxþ f ðx;UÞÞ \ K 6¼ ;g
and (i+1)-th viability kernel by:
Fig. 6 Associating four cues to four actions using TD. Meannumber of blocks needed to learn to associate four cues to fouractions using three algorithms: ‘‘TD value e-greedy’’ for RL of thevalue function using e-greedy action selection; ‘‘Q-learning e-greedy’’ for RL of the action value function using e-greedy actionselection; ‘‘Q-learning softmax’’ for the one using softmax actionselection. The learning rate a=0.5, the coefficient of exploratione=0.2, the inverse temperatures are, respectively, b=2, b=1,b=0.8. The learning criterion is: 4/5 correct consecutive responsesper stimulus. The learning process is interrupted when this criterionis achieved by all cues
100

Viabiþ1ðKÞ ¼ Viab1ðViabiðKÞÞ
Then Viabi (K) is a decreasing sequence of sets and theviability kernel of K is the set:
ViabðKÞ ¼\
i�1ViabiðKÞ:
Note that when f is small with respect to the size of Viabi
(K), then every x 2Viabi (K) that is far from theboundary of Viabi (K) belongs to the set Viabi+1 (K).For this reason the verification of the criterion ðxþf ðx;UÞÞ \ ViabiðKÞ 6¼ ; needs to be performed only forx lying near the boundary of Viabi (K). When dealingwith continuous control systems, such verification islimited only to the boundary of Viabi (K) and takes theform f ðx;UÞ \ TViabiðKÞðxÞ 6¼ ;: where TViabiðKÞðxÞ denotesthe tangent (cone) to Viabi (K) at a boundary point x(Frankowska and Quincampoix 1991; Aubin 1996, 2001;Saint-Pierre 2001). These algorithms were developedeven when the precise dynamics are not known and thedynamical system has the form of differential inclusionx(i+1) 2x(i)+F(x(i)), where F, instead of being a point-valued map, is a mapping taking values in subsets of Rn.This approach helps to treat problems in higherdimensions. Indeed, when we investigate the boundaryof a set, instead of the set itself, we reduce the dimensionof the state space. Furthermore the verification criterionis local. Instead of applying exploration type argumentsand trying different controls from the same initial con-dition, the VK algorithms consider the boundary of theset of constraints and take out points near the boundarythat are not viable. VK algorithms were developed forboth continuous and discrete time systems and also forhybrid systems, a combination of continuous andimpulse systems (Saint-Pierre 2001, 2002), and weresuccessfully used in investigation of control systems,differential games, neural networks, dynamical eco-nomics and portfolio management (Aubin 1996).
Although, at first glance, viability kernel seems not tobe related to optimization, this notion was applied alsoin optimal control; namely, optimal control problemsmay be stated in the form of search of a viability kernel.Such viability kernel is then the epigraph of the valuefunction (see for instance Aubin and Frankowska(1996) for an infinite horizon optimal control problem;Cardaliaguet et al. (1999) for the time optimal controlproblem of reaching a target; and Aubin (2001) for finitehorizon optimal control problems). This approach may berelated to the actor-critic paradigm by providing the criticwith an overestimated value function. The VK algorithmreduces this function to the true value function.
Mathematically, learning of a sequence of actions toachieve a desired goal leads also to the so-called targetproblem of control theory. Let us consider C0, a giventarget, / (x), a mapping defined on the state space andthe discrete control system, as described before. In theconstrained target problem one looks at each initial statex0 2K for a discrete trajectory x(i), i=0,...,j such that
x(0)=x0, x(i) 2K for all i < j and / (x(j)) 2C0, i.e. x(Æ)reaches the set C ¼ u�1ðC0Þ at some time j.
There are different tools, cf. time optimal control,adaptive control, viability and capture basin (CB) algo-rithms, that allow to find a synthesis in such a way thatthe corresponding trajectories reach the target andrespect constraints. In order to find a solution to thetarget problem, the CB algorithm constructs the capturebasin (all initial states in K from which the target can bereached in finite time). The first-order capture basin is:
Capt1ðK;CÞ ¼ fx 2 KjCjðxþ f ðx;UÞÞ \ C 6¼ ;g
and (i+1)-th capture basin is:
Captiþ1ðK;CÞ ¼ Capt1ðK;CaptiðK;CÞÞ
Then CaptiðK;CÞ is an increasing sequence of sets andthe capture basin for the target C under constraints K isgiven by:
CaptðK;CÞ ¼[
i�1CaptiðK;CÞ:
Notice that when f is small with respect to the size ofCapti (K,C), then every x 2K that is far from the setCapti (K,C) is not in the set Capti+1 (K,C). Thus, onlypoints close to the boundary of Capti (K,C) should betaken into consideration.
Viability kernel (respectively CB) algorithms arebased on elimination: taking out points from whichwhatever control is chosen it is impossible to stay in K(to get to a target while respecting constraints, respec-tively). In the same time, these algorithms construct thesynthesis (action selection corresponding to each state)that allows to remain in K (to reach the target understate constraints, respectively).
We consider now our particular task of learning ofsensori-motor associations in this paradigm, where o is aneutral element (joystick position at the initial time).Now consider the set X of all pairs x =(s,a), where sdenotes a visual cue, and a denotes a motor responseaugmented by the elements (s,o) and define the numer-ical reward r(s,a) to be positive when (s,a) is a correctassociation and non-positive otherwise. The initial stateof the system is (s,o). The choice of an action a leads tothe new pair (s,a). In the task of learning of sensori-motor associations the constraints are:
K ¼ fðs; aÞ; ðs; oÞjs 2 S; a 2 Ag
and target is made of pairs for which r(s,a) >0.Sequences have length two {(s,o), (s,a)}. So if a cue s isso that whatever action a is chosen r(s,a) £ 0, then (s,o)does not belong to the capture basin. The synthesisleading to the target is then the feedback a(s) 2A satis-fying r(s,a(s))>0.
Experimentally, the use of cue-oriented strategies tofacilitate learning of associations could correspond toinvestigation of lower dimensional subsets (boundaries).Specifically, consider that two elements of K, (s1,a1) and
101
(s2,a2), belong to the same boundary of K if either s1=s2or a1=a2. In the cue-oriented strategy, one of the cues �sis privileged and different actions are tried for this cue,while other cues are learned more slowly. This corre-sponds to the boundary elements fð�s; ajÞgj�1: In the caseof lateral strategy, the same action �a is repeated withdifferent cues before switching to another action. Thiscorresponds to the boundary elements fðsi; �aÞgi�1:
Implementation of cue-oriented strategies in Q-learning
How such dimension reduction (boundary verificationsof VK and CB algorithms) can be numerically imple-mented in learning of associations, keeping in mind thespecificity of our task?
For the cue-oriented strategy, every cue appears ineach block randomly, and an action has to be tried eachtime a cue is presented. For this reason, it is more nat-ural to implement the dimension reduction in the Q-learning process. We accomplish it by introducing state-dependent learning rates. Firstly, we fix a learning level ofa cue K: a cue �s is considered as learned with respect tothis level when the probability of an action �a to bechosen for this cue, Pð�a;�sÞbecomes higher than K. At thebeginning of the learning process, all cues get the same(low) learning rate a1
l until for some cue s(1) and an
action a(1) the probability P(a(1) | s(1)) > K. Then s(1)gets a higher learning rate a1
h, while all other cues obtaina lower learning rate a2
l . Once an action a(2) corre-sponding to some cue s(2) „ s(1) obtains P(a(2) | s(2))> K, then s(2) gets the learning rate a h
2 and all thosedifferent from s(1), s(2)—a lower learning rate a3
l , etc. Ifaih and ai
l are independent from i, then the simulations donot match the behavioral data reported in Fig. 2 (seeFig. 7). However, reaching the level K for a cue �s and anaction �a does not mean that the learning criterion hasbeen achieved for the association ð�s; �aÞ; and so, whilelearning the next cue, the learning process of the previ-ous cues still continues. It is thus more natural to con-sider decreasing sequences a1
l ‡ a2l ‡ ... and a1
h ‡ a2h ‡ ...
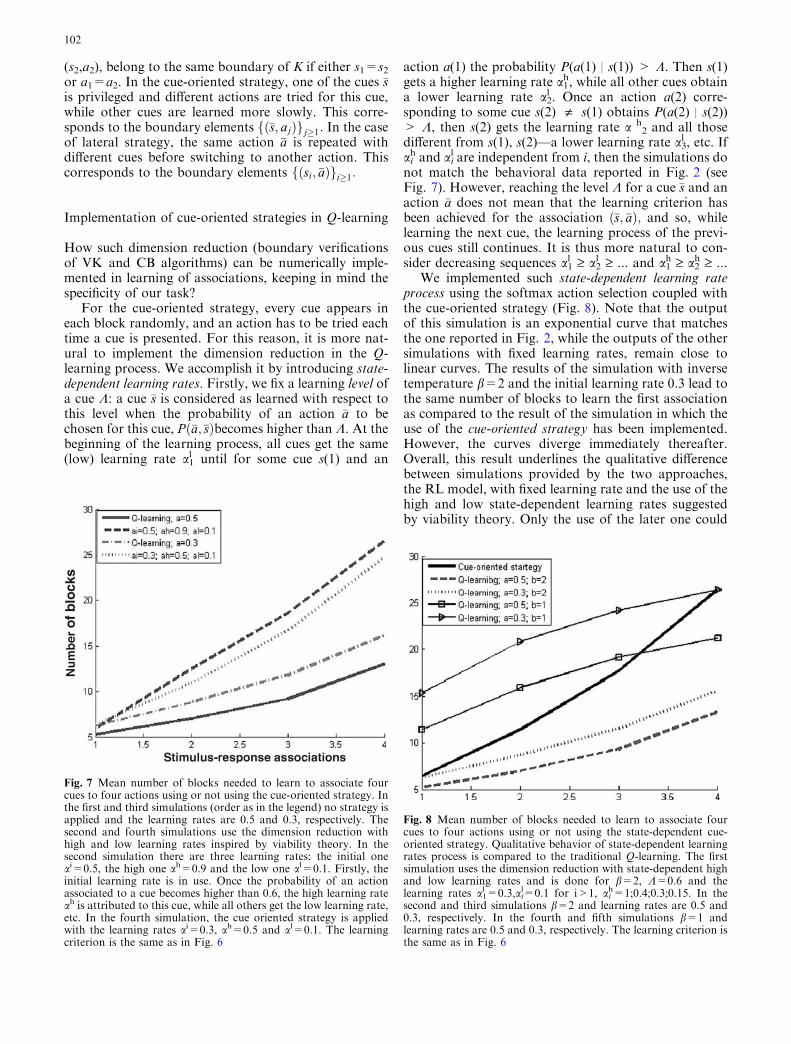
We implemented such state-dependent learning rateprocess using the softmax action selection coupled withthe cue-oriented strategy (Fig. 8). Note that the outputof this simulation is an exponential curve that matchesthe one reported in Fig. 2, while the outputs of the othersimulations with fixed learning rates, remain close tolinear curves. The results of the simulation with inversetemperature b=2 and the initial learning rate 0.3 lead tothe same number of blocks to learn the first associationas compared to the result of the simulation in which theuse of the cue-oriented strategy has been implemented.However, the curves diverge immediately thereafter.Overall, this result underlines the qualitative differencebetween simulations provided by the two approaches,the RL model, with fixed learning rate and the use of thehigh and low state-dependent learning rates suggestedby viability theory. Only the use of the later one could
Fig. 7 Mean number of blocks needed to learn to associate fourcues to four actions using or not using the cue-oriented strategy. Inthe first and third simulations (order as in the legend) no strategy isapplied and the learning rates are 0.5 and 0.3, respectively. Thesecond and fourth simulations use the dimension reduction withhigh and low learning rates inspired by viability theory. In thesecond simulation there are three learning rates: the initial oneai=0.5, the high one ah=0.9 and the low one al=0.1. Firstly, theinitial learning rate is in use. Once the probability of an actionassociated to a cue becomes higher than 0.6, the high learning rateah is attributed to this cue, while all others get the low learning rate,etc. In the fourth simulation, the cue oriented strategy is appliedwith the learning rates ai=0.3, ah=0.5 and al=0.1. The learningcriterion is the same as in Fig. 6
Fig. 8 Mean number of blocks needed to learn to associate fourcues to four actions using or not using the state-dependent cue-oriented strategy. Qualitative behavior of state-dependent learningrates process is compared to the traditional Q-learning. The firstsimulation uses the dimension reduction with state-dependent highand low learning rates and is done for b=2, K=0.6 and thelearning rates a1
l=0.3,ail=0.1 for i>1, ai
h=1;0.4;0.3;0.15. In thesecond and third simulations b=2 and learning rates are 0.5 and0.3, respectively. In the fourth and fifth simulations b=1 andlearning rates are 0.5 and 0.3, respectively. The learning criterion isthe same as in Fig. 6
102

reproduce the behavioral profile depicted in Fig. 2. Thehigh learning rate coefficient that decreases during thelearning process may be seen as an additional rein-forcement of one cue with respect to others at each stageof learning. Then the corresponding column of theaction-value matrix is updated much quicker than othercolumns. We would like to underline here that if threeout of four cues are already learned, then the rein-forcement of the last cue is not necessary, because thelearning space has already a reduced dimension (theremaining matrix to be learned is of dimension 1·4,instead of 4· 4 at the beginning of the experience).
We propose that the transient modifications ofactivity described in the striatum during learning couldbe associated to such additional reinforcement, seeFig. 4. On the other hand, some elements of action valueincrease during the learning process and depend on thedegree of learning. This suggests that the increasingmean standardized activities of Fig. 5 reflect the degreeof learning of elements of action-value in long-termmemory.
The idea of elimination of some states or actionsdeveloped here may be linked to Bar-Gad et al. (2003).Indeed, these states or actions may be considered asthose that should be neglected, while pairs that areretained and pass a local test are reinforced by a rein-forcement signal and encoded. In the model proposed byBar-Gad et al. (2003) the main objective is to compressthe information to be encoded by the output neuronsusing a reinforcement signal. Such decrease in thenumber of encoded inputs simplifies the selection fromstate to actions. In our model, the learning strategiesartificially reduce the dimension of learning space(number of actions or number of cues), a process thatsimplifies the learning task. At the neuronal level theboundary encodings may be accomplished using therules proposed in Bar-Gad et al. (2003), and local veri-fication done using the reinforcement signal. We thussuggest that the BG play an additional role in learning,that of reducing the dimension of learning space, therebyincreasing the learning rate.
Summary and conclusions
Learning arbitrary visuo-motor associations implies tolearn the correct stimulus–movement associations andthen to store them in long-term memory. One has tolearn by trial and error to select the appropriate move-ment according to the stimulus presented. During earlystages of learning, not only processes such as discrimi-nation, recognition and memorization of the stimuli arerequired, but also monitoring of events and behavioraloutcome. Learning time can be reduced by the use ofparticular strategies such as focusing on a single cue at atime, or repeating a motor response until correct.
Within the BG, the striatum receives various signalsincluding sensory, motor and motivational (feedback-
related) signals, and its particular architecture is suitablefor complex integration of these incoming signals.During early stages, probably under the influence of PF,the transient modifications of the activity in the striatumcould underlie the on-line monitoring of the associationsalready tried and of their consequences as well as thedevelopment and use of learning strategies. In parallel,long-lasting changes in the activity of the striatum couldbe responsible for long-term storage of the correctassociations, possibly through a strengthening of theconnections between the striatum and the PMd as sug-gested by fMRI (Toni et al. 2002) and lesion (Canavanet al. 1989; Nixon et al. 2004) studies.
We propose here a computational model based onboth reinforcement learning and boundary strategies ofviability theory, behavioral data showing the use ofparticular learning strategies, and on the possible cor-relates found in the dynamics of neuronal changes in thestriatum. This model complements existing ones, bytaking into account the presence of strategies. We thussuggest an additional role for the basal ganglia inlearning: reducing the dimension of learning space.
Acknowledgements This work was supported by the FrenchMinistry of Research (ACI Cognition et traitement de l’informationfor HF, and ACI Neurosciences Integratives et computationnellesfor DB), Interdisciplinary Program TCAN of CNRS, and aBettencourt-Schuller foundation fellowship for FHB.
References
Alexander GE, DeLong MR, Strick PL (1986) Parallel organiza-tion of functionally segregated circuits linking basal ganglia andcortex. Annu Rev Neurosci 9:357–381
Aubin J-P (1991) Viability theory. Birkhauser, BostonAubin J-P (1996) Neural networks and qualitative physics: a via-
bility approach. University Press, CambridgeAubin J-P (2001) Viability kernels and capture basins of sets under
differential inclusions. SIAM J Control 40:853–881Aubin J-P, Frankowska H (1996) The viability kernel algorithm for
computing value functions of infinite horizon optimal controlproblems. J Math Anal Appl 201:555–576
Bar-Gad I, Morris G, Bergman H (2003) Information processing,dimensionality reduction and reinforcement learning in thebasal ganglia. Prog Neurobiol 71:439–473
Barto A (1995) Adaptive critics and the basal ganglia. In: Houk JC,Davis JL, Beiser DG (eds) Models of information processing inthe basal ganglia. MIT Press, Cambridge, pp 215–232
Boussaoud D, Wise SP (1993a) Primate frontal cortex: neuronalactivity following attentional versus intentional cues. Exp BrainRes 95:15–27
Boussaoud D, Wise SP (1993b) Primate frontal cortex: effects ofstimulus and movement. Exp Brain Res 95:28–40
Boussaoud D, Kermadi I (1997) The primate striatum: neuronalactivity in relation to spatial attention versus motor prepara-tion. Eur J Neurosci 9:2152–2168
Brasted PJ, Wise SP (2004a) Comparison of learning-related neu-ronal activity in the dorsal premotor cortex and striatum. Eur JNeurosci 19(3):721–740
Brasted PJ, Wise SP (2004b) The arbitrary mapping of sensoryinputs to voluntary and involuntary movement: learning-dependant activity in the motor cortex and other telencephalicnetworks. In: Riehle A, Vaadia E (eds) Motor cortex in vol-untary movements. pp 259–293
103

Bussey TJ, Wise SP, Murray EA (2001) The role of ventral andorbital prefrontal cortex in conditional visuomotor learningand strategy use in rhesus monkeys (Macaca mulatta). BehavNeurosci 115:971–982
Canavan AGM, Nixon PD, Passingham RE (1989) Motor learningin monkeys (Macaca fascicularis) with lesions in motor thala-mus. Exp Brain Res 77:113–126
Cardaliaguet P, Quincampoix M, Saint-Pierre P (1999) Set-valuednumerical methods for optimal control and differential games,in Stochastic and differential games: theory and numericalmethods. Annals of the International Society of DynamicalGames, Birkhauser, pp 177–247
Doya K (1999) What are the computations of the cerebellum, thebasal ganglia, and the cerebral cortex. Neural Netw 12:961–974
Doya K (2000) Reinforcement learning in continuous time andspace. Neural Comput 12:219–245
Fiorillo CD, Tobler PN, Schultz W (2003) Discrete coding of re-ward probability and uncertainty by dopamine neurons. Science299:1898–1902
Frankowska H, Quincampoix M (1991) Viability kernels of dif-ferential inclusions with constraints: algorithm and applica-tions. J Math Syst Estim Control 1:371–388
Genovesio A, Brasted PJ, Mitz AR, Wise SP (2005) Prefrontalcortex activity related to abstract response strategies. Neuron47(2):307–20
Hadj-Bouziane F, Boussaoud D (2003) Activity of neurons in thestriatum during learning of arbitrary visuo-motor associations.Exp Brain Res 18:269–277
Hadj-Bouziane F, Meunier M, Boussaoud D (2003) Conditionalvisuo-motor learning in primates: a key role for the basalganglia. J Physiol Paris 97:567–579
Hadj-Bouziane F, Benatru I, Klinger H, Brousolle E, BoussaoudD, Meunier M (2004) Conditional associative learning inadvanced Parkinson’s disease. Soc Neurosci Abstr 710:4
Halsband U, Freund HJ (1990) Premotor cortex and conditionalmotor learning in man. Brain 113:207–222
Hollerman JR, Tremblay L, Schultz W (1998) Influence of rewardexpectation on behavior-related neuronal activity in primatestriatum. J Neurophysiol 80:947–963
Houk JC, Adams JL, Barto AG (1995) A model of how the basalganglia generate and use reward signals that predict reinforce-ment. In: Houk JC, Davis JL, Beiser DG (eds) Models ofinformation processing in the basal ganglia. MIT Press,Cambridge, pp 249–270
Joel D, Weiner I (1994) The organization of the basal ganglia-thalamocortical circuits: open interconnected rather than closedsegregated. Neuroscience 63:363–379
Kurata K, Hoffman DS (1994) Differential effects of muscimolmicroinjection into dorsal and ventral aspects of the premotorcortex of monkeys. J Neurophysiol 71:1151–1164
Ljungberg T, Apicella P, Schultz W (1992) Responses of monkeydopamine neurons during learning of behavioral reactions.J Neurophysiol 67:145–163
Nixon PD, McDonald KR, Gough PM, Alexander IH, Passing-ham RE (2004) Cortico-basal ganglia pathways are essential forthe recall of well-established visuomotor associations. Eur JNeurosci 20(11):3165–78
Parent A (1990) Extrinsic connections of the basal ganglia. TrendsNeurosci 13:254–258
Parent A, Hazrati LN (1995) Functional anatomy of the basalganglia. I. The cortico-basal gangliathalamo-cortical loop.Brain Res Brain Res Rev 20:91–127
Passingham RE (1993) The frontal lobe and voluntary action.Oxford University Press, Oxford
Passingham RE, Toni I, Rushworth MF (2000) Specializationwithin the prefrontal cortex: the ventral prefrontal cortex andassociative learning. Exp Brain Res 133:103–113
Petrides M (1985) Conditional learning and the primate frontalcortex. In: Perecman E (ed) The frontal lobe revisited. IBRNpress, New York, pp 91–108
Prensa L, Cossette M, Parent A (2000) Dopaminergic innervationof human basal ganglia. J Chem Neuroanat 20:207–213
Saint-Pierre P (2001) Approximation of viability kernels and cap-ture basin for hybrid systems. In: Martins de Carvalho JL (ed)Proceedings of the European Control Conference ECC 2001, pp2776–2783
Saint-Pierre P (2002) Hybrid kernels and capture basins for impulseconstrained systems, Communication at International Confer-ence HSCC02, Stanford
Schultz W (2002) Getting formal with dopamine and reward.Neuron 36:241–263
Schultz W, Apicella P, Ljungberg T, Romo R, Scarnati E (1993)Reward-related activity in the monkey striatum and substantianigra. Prog Brain Res 99:227–235
Smith Y, Kieval JZ (2000) Anatomy of the dopamine system in thebasal ganglia. Trends Neurosci 23(Suppl 10):S28–S33
Sutton R, Barto A (1998) Reinforcement learning: an introduction.MIT Press, Cambridge
Toni I, Rowe J, Stephan KE, Passingham RE (2002) Changes ofcortico-striatal effective connectivity during visuomotor learn-ing. Cereb Cortex 12:1040–1047
Tremblay L, Hollerman JR, Schultz W (1998) Modifications ofreward expectation-related neuronal activity during learning inprimate striatum. J Neurophysiol 80:964–977
Wise SP, Murray EA (1999) Role of the hippocampal system inconditional motor learning: mapping antecedents to action.Hippocampus 9:101–117
Wise SP, Murray EA (2000) Arbitrary associations between ante-cedents and actions. Trends Neurosci 23(6):271–276
Wise SP, Murray EA, Gerfen CR (1996a) The frontal cortex basalganglia system in primates. Crit Rev Neurobiol 10:317–356
Wise SP, di Pellegrino G, Boussaoud D (1996b) The premotorcortex and nonstandard sensorimotor mapping. Can J PhysiolPharmacol 74:469–482
104



















