
Broad-Specificity mRNA–rRNA Complementarity in Efficient Protein Translation
Upload
independentCategory
view
0download
0
J Mol Evol (1985) 21:259-269 Journal of Molecular Evolution �9 Springer-Verlag 1985
Comparison of the Nucleotide Sequence of Soybean 188 rRNA with the Sequences of Other Small-Subunit rRNAs
Virginia K. Eckenrode I*, Jonathan Arnold 2, and Richard B. Meagher 2
Department of Biochemistry, University of Georgia, Athens, Georgia 30602, USA Department of Genetics, University of Georgia, Athens, Georgia 30602, USA
Suramary. We present the sequence of the nuclear- encoded ribosomal small-subunit RNA from soy- bean. The soybean 18S rRNA sequence of 1807 aUeleotides (nt) is contained in a gene family of aPProximately 800 closely related members per haploid genome. This sequence is compared with the ribosomal small-subunit RNAs of maize (1805 nt), yeast (1789 nt), Xenopus (1825 nt), rat (1869 nt), and Escherichia coli (1541 nO. Significant se- quence homology is observed among the eukaryotic snlall-subunit rRNAs examined, and some se- quence homology is observed between eukaryotic and prokaryotic small-subunit rRNAs. Conserved regions are found to be interspersed among highly ~liVerged sequences. The significance of these com- l~arisons is evaluated using computer simulation of a random sequence model. A tentative model of the SeCOndary structure of soybean 18S rRNA is pre- sented and discussed in the context of the functions of the various conserved regions within the se- quence. On the basis of this model, the short base- Paired sequences defining the four structural and ~ c t i o n a l domains of all 18S rRNAs are seen to be Well conserved. The potential roles of other con- Served soybean 18S rRNA sequences in protein syn- thesis are discussed.
i~ey words: Eukaryot ic rRNA -- Small-r ibo- SOraal-subunit rRNA -- Secondary structure -- COrnputer simulation
reauests to: R.B. Meagher trent ~dress: Department of Genetics, North Carolina State
niversity, Raleigh, North Carolina 27695, USA
Introduction
Ribosomes from all prokaryotic, archaebacterial, and eukaryotic sources are composed of small and large subunits. These complexes of R N A and protein molecules have conserved overall structures and perform similar biological functions during protein synthesis (Wool 1980; Liljas 1982; Lake 1983). The ribosomal complex has been studied as an example of R N A - R N A and RNA-protein interactions. These interactions are reflected in a conserved structure for the ribosomal RNAs (rRNAs) (Noller and Woese 1981).
The rRNA molecule associated with the small ribosomal subunit from any source is referred to as the small-subunit rRNA. Small-subunit rRNAs are often grouped according to source and size: 18S rRNAs from eukaryotic cytoplasms, 16S rRNAs from prokaryotic sources, 12S rRNAs from animal mitochondria, etc. Although their lengths vary ap- proximately twofold, from 954 nucleotides (nt) [12S from human mitochondria (Eperon et al. 1980)] to 1962 nt [18.5S from maize mitochondria (Chao et al. 1984)], small-subunit rRNAs contain certain structures that can be identified as shared by all. All the nuclear-encoded 18S rRNAs have lengths of close to 1800 nt and share significant nucleotide sequence homology. However, the eukaryotic I8S and pro- karyotic 16S small-subunit rRNAs differ in length by about 300 nt and share little overall nucleotide sequence homology.
Relatively little is known about plant cytoplasmic ribosomes and rRNAs. The sequence of the small rRNA from maize, a monocotyledon, has recently been reported (Messing et al. 1984). To extend struc-
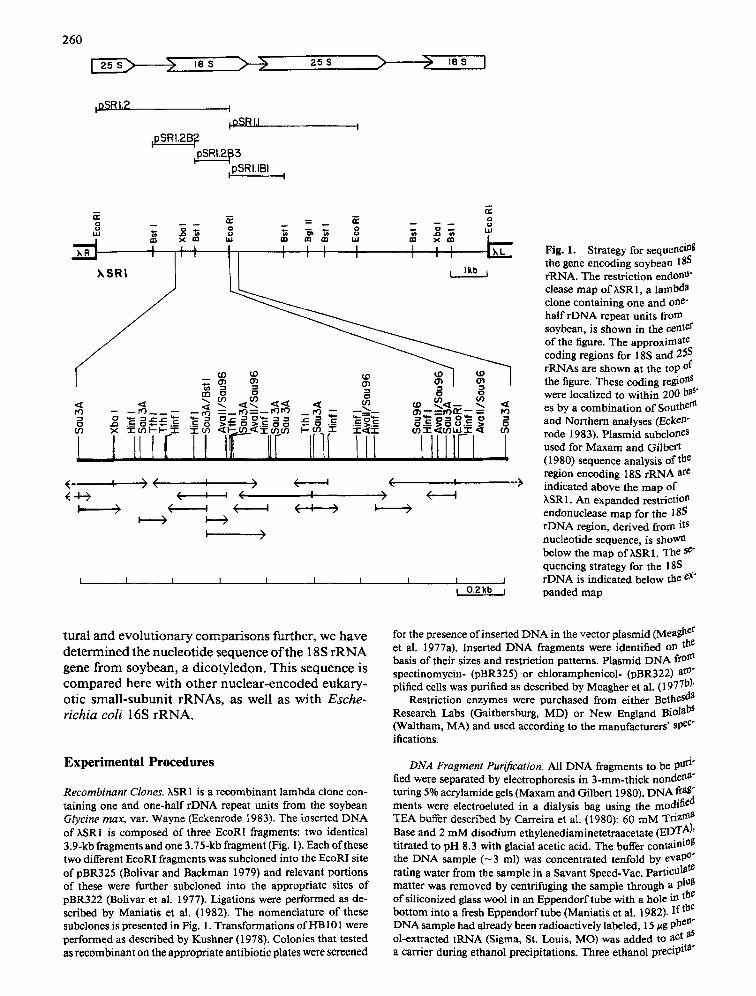
260
2 5 S 18s I
~oSR ~.2 I ,, vSR I,I
IpSRI.2B~- ~pSRI.21~3
)pSRI.IBI
m
I I II I I I I I I I Ix,
~ ~ ~ ~I ~ ,
v * - = - - " - ~ . ~ = _ m = - - m m _ m ~. ~ _ ~ m - - = m u : - =
I ( - ) ) ( I ) ( l < , (-4-) ( ) ) ~. : ~ ( l
) < ) ( i ( ! ) ) ) ) ) J )
I )
I ) I I I I I I I I O , 2 k b
Fig. 1. Strategy for sequenci~ the gene encoding soybean 185 rRNA. The restriction endonU" clease map of;~SRl, a lambda clone containing one and one- half rDNA repeat units from soybean, is shown in the center of the figure. The approximate coding regions for 18S and 25S rRNAs are shown at the top of the figure. These coding regiolaS were localized to within 200 has" es by a combination of Souther~ and Northern analyses (Ecken" rode 1983). Plasmid subcloneS used for Maxam and Gilbert (1980) sequence analysis of the region encoding 18S rRNA are indicated above the map of hSR 1. An expanded restriction endonuclease map for the 18S rDNA region, derived from its nucleotide sequence, is shoWn below the map ofhSR1. The r quencing strategy for the 18S rDNA is indicated below the r panded map
tu r a l a n d e v o l u t i o n a r y c o m p a r i s o n s f u r t h e r , w e h a v e
d e t e r m i n e d t h e n u c l e o t i d e s e q u e n c e o f t h e 18S r R N A
g e n e f r o m s o y b e a n , a d i c o t y l e d o n . T h i s s e q u e n c e is
c o m p a r e d h e r e w i t h o t h e r n u c l e a r - e n c o d e d e u k a r y -
o t i c s m a l l - s u b u n i t r R N A s , as w e l l a s w i t h Esche - richia coli 16S r R N A .
E x p e r i m e n t a l P r o c e d u r e s
Recombinant Clones. hSR1 is a recombinant lambda clone con- mining one and one-half rDNA repeat units from the soybean Glycine max, var. Wayne (Eckenrode 1983). The inserted DNA of ~,SRI is composed of three EcoRI fragments: two identical 3.9-kb fragments and one 3.75-kb fragment (Fig. 1). Each of these two different EcoRI fragments was subcloned into the EcoRI site of pBR325 (Bolivar and Backman 1979) and relevant portions of these were further subcloned into the appropriate sites of pBR322 (Bolivar et al. 1977). Ligations were performed as de- scribed by Maniatis et al. (1982). The nomenclature of these subclones is presented in Fig. 1. Transformations of liB101 were performed as described by Kushner (1978). Colonies that tested as recombinant on the appropriate antibiotic plates were screened
for the presence of inserted DNA in the vector plasmid (Meag, laer et al. 1977a). Inserted DNA fragments were identified on the basis of their sizes and restriction patterns. Plasmid DNA fro# spectinomycin- (pBR325) or chloramphenicol- (pBR322) a~" plified cells was purified as described by Meagher et al. (19773)'
Restriction enzymes were purchased from either Bethesda Research Labs (Gaithersburg, MD) or New England BiolabS (Waltham, MA) and used according to the manufacturers' speC" ifications.
DNA Fragment Purification. All DNA fragments to be P tffi" fled were separated by eleetrophoresis in 3-ram-thick nond erda~ turing 5% acrylamide gels (Maxam and Gilbert 1980). DNA fraud ments were electroeluted in a dialysis bag using the modifir TEA buffer described by Carreira et al. (1980): 60 mM Triz t~ Base and 2 mM disodium ethylenediaminetetraacetate (EDTA), titrated to pH 8.3 with glacial acetic acid. The buffer containing the DNA sample ( - 3 ml) was concentrated tenfold by e yap~ rating water from the sample in a Savant Speed-Vat. Particulate matter was removed by centrifuging the sample through a plU~ of siliconized glass wool in an Eppendorf tube with a hole in the bottom into a fresh Eppendorftube (Maniatis et al. 1982). iftlae DNA sample had already been radioactively labeled, 15/~g phela- ol-extracted tRNA (Sigma, St. Louis, MO) was added to act as a carrier during ethanol precipitations. Three ethanol precipita"

tions were performed prior to sequencing (Maxam and Gilbert 1980).
Labeling the DNA. Recessed 3' ends of restriction fragments Were filled in using (a-32p]dNTPs and the Klenow fragment of E. co6 DNA polymerase I (both from New England Nuclear CorD., Boston, MA). The reaction conditions were as described by Shah et al. (1982), with the modification that the reaction ~ixtures contained no more than 10 pmol of fragment ends and aPProximately 12 pmol of the appropriate radioactive nucleotide (USUally 50 ~Ci, with a specific activity of >- 3000 Ci/mmol).
DNA Sequence Determination. Purified DNA fragments were Sequenced by the method of Maxam and Gilbert (1980), with the modification that the "G + A" reaction was performed in 70% formic acid for 5 rain, as described by Krayev et aL (1980). Sequencing gels were run as described by Maxam and Gilbert (I 98% except that high gel temperatures (> 65"C) were necessary for obtaining reproducible DNA sequence patterns of this ~ibo- Sornal gene region, most likely because of the high degree of l~tential secondary structure in rDNA. Because the rRNA tran- scril~ts from this gene probably have approximately 50% of their bases in a base-paired configuration (see Discussion), each DNA strand can also form intrastrand duplexes, which could cause aberrent sequencing patterns. Elevating the temperature probably Cenatured the intrastrand duplexes. Typical gels (43 cm long, 35 en~ Wide, 0.3 mm thick) were run at 150 W constam power.
Computer Analysis of the DATA Sequence Data. Sequencing data were stored and analyzed using the Stanford Gene Molgen Project with NIH SUMEX-AIM Facility (Stanford, CA). An Ap- l~le II Plus computer and a Zenith Z-19 terminal were used to interact with the Stanford computer via the TYMNET satellite .e~ system. Additional analyses were performed us- ing the Intelligenetics system (Falo Alto, CA) and the same ter- minals. Files were transferred from the remote system to the APple II Plus system using a BITS program (SoRware Sorcery, MCLean, VA).
A program developed by Arnold et al. (J. Arnold, V.K. Eck- enrode, K. Lemke, G.J. Phillips, and S.W. Schaeffer, manuscript Submitted to Nucleic Acids Research) for a PDP 11/34A com- bo uter (Digital Equipment Corporation, Maynard, MA) was used
r the final pairwise intergenic comparisons of the sma11-subunit rRNA nucleotide sequences. The program implements a dynamic l~rogramming algorithm described by Ksuskai (1983) and origi- ~tlly proposed by Needleman and Wunsch (1970). This algo- rithrn specifies a weight for each type of nucleotide mutation: ~a? sition, transversion, and insertion/deletion. A perfect match ~ s no weight. A transition is defined as having a weight of 1.
lher, less likely mutations are given higher weights. The optimal alignment of two sequences involves minimizing the sum of these weights; this minimum sum is defined as the evolutionary dis- ta~ee. Sankofr et at. (1976) suggested giving insertions/deletions Weights of 2.25 and transversions weights of 1.75. Tgese numbers Were based on the results of multiway sequence comparisons ~ ra~ng 5S rRNAs. We found that weighting transversions more i eavily than transitions, as suggested by Brown and Clegg (1983), a0 little effect on our pairwise alignments. Therefore, transitions
and transversions were both given weights of 1, as in the work ~ Erickson and Sellers (1983). For the sake of simplicity, laser- li~ were weighted twice as heavily as transitions and transversions, i.e., were given a weight of 2. Mismatches were therefore favored over insertion/deletion events. All nucleotide Sequence comparisons in Fig. 2 represent optimal pairwise align- t~ents against the soybean 18S rRNA. Percentage homology be- tween any two nucleotide sequences was calculated as the number of l~sitions with the same nucleotide divided by 1919, the total
261
number of positions needed to make the six-way match shown in Fig. 2.
To test the significance of the evolutionary distances, the dis- tribution of evolutionary distances between pairs of random se- quences was determined. Five hundred pairs of random se- quences with lengths of 1819 nt and an average G + C composition of 51% (see Table 1) were generated using a multiplicative ran- dom-number generator with period 2 a~ - 1 and multiplier 7 s (I~uth 1981). The generator was tested as in Knuth (1981).
Generation of a Secondary-Structure Model To facilitate the analysis of conserved structural regions and regions of signifi- cance in the soybean 18S rRNA sequence, we devised a potential secondary structure based on a secondary-structure model for yeast and Xenopus 18S rRNAs (Zwieb et aL I981). Changes in the lengths and relative placements of duplex regions were made from the model for the yeast 18S rRNA to accommodate the soybean 18S rRNA sequences. The base pairing and structure rules of Erdmann et at. (i983) were followed for the determi- nation of duplex regions.
Analysis of Soybean Genomic DNA for Small-Subuntt rRNA- Encoding Sequences. Soybean genomic DNA was analyzed (Southern 1975) for small-subunit rDNA sequences hybridizing to the small-subunit rDNA insert contained in pSR1.2B3. This 1.05-kb BstI-EcoRI fragment encodes nucleofides 544-1583 of the 18S rRNA gene of ASRI. Filters were prehybridized and hybridized in 50% formamide, 5 x SSC, 5 x Denhardt's solution (Denhardt 1966), at 56"C. Filters were washed three times in 0.2 • SSC, 0.2% sodium dodecyl sulfate (SDS), at 56"C for 10 rain each and exposed overnight to film.
Results
Description o f the Soybean 18S rRNA Sequence
T h e n u c l e o t i d e s e q u e n c e o f a s o y b e a n 18S r R N A m o l e c u l e , as i n f e r r e d f r o m t h e gene s e q u e n c e c o n - t a i n e d in r e c o m b i n a n t p h a g e h S R 1, is p r e s e n t e d in full on the t o p l ine o f Fig . 2. A l s o s h o w n in Fig . 2 is a c o m p a r i s o n o f the s e q u e n c e o f t he s o y b e a n 18S r R N A w i t h the s equences o f f ou r o t h e r e u k a r y o t i c 18S r R N A s [ m a i z e (Mess ing et al. 1984), y e a s t ( R u b s t o v et al . 1980), f rog ( S a l i m a n d M a d e n 1981), a n d r a t ( T o r c z y n s k i e t al. 1983)] a n d w i t h the se- q u e n c e o f one p r o k a r y o t i c 16S r R N A [E. coli ( N o l l e r a n d W o e s e 1981)]. Because the 5' a n d 3' e n d s o f the 18S r R N A s f r o m y e a s t ( K r a y e v et al. 1980), f rog (Sa l im a n d M a d e n 1981), a n d r a t ( T o r c z y n s k i e t al . 1983) h a v e been e x p e r i m e n t a l l y d e t e r m i n e d a n d be- cause o f t h e pe r f ec t h o m o l o g y o f t he e n d n u c l e o t i d e s a n d the n e a r l y pe r f ec t s e q u e n c e h o m o l o g y o f the f irst 70 a n d las t 50 nt , the l i m i t s o f t he m a t u r e soy - b e a n 18S r R N A s e q u e n c e were o p e r a t i o n a l l y de - f ined by t h e i r a g r e e m e n t w i t h t h o s e o f t he se t h r e e o t h e r r D N A genes. T h e m a t u r e 18S r R N A f r o m s o y b e a n is 1807 n t long, T h i s is w i t h i n t he l eng th range o f t h e k n o w n e u k a r y o t i c 18S r R N A s , f r o m 1789 [yeas t ( K r a y e v et al. 1980)] to 1869 [ ra t (Tor - c z y n s k i e t al , 1983)] nt ,
The average G + C content of the eukaryotic 18S

262
i0 20 30 40 50 60 70 80 90 100 ii0 120
......... I ......... I ......... I ......... I ........ I ......... I ......... I ......... I ......... I ......... I ........ I ......... I
= I o 20
Z.m. ---C-xxxxx ...................................................... C ............... -GA .... x ..... x---x ..................... 111
S.c. --UC-xxxxx ..................................................... C ....... x--GC .... U-U--A-I( ..... x---x ...................... 110
X.l. ---C-xxxxx .................. I( .............................. C ......... C-C--xGGCCGGU--A-x ..... x---x ...................... Ii0
R. r . - - -C -xxxx i ( . . . . . . . . . . . . . . . . . . x . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . C . . . . . . C-C--xGGCCGGU--A-x . . . . . x - - - x . . . . . . . . . . . . . . . . . . . . . . E.C. A-A--GAAGA-U ...... A--G-U CAGA-UGA-C---G-CGG--xG-CC---CA ...... A--CG- -CGG-A-CAGC,-AGA--CU --C-CUUUG---A-- -G .... GG-xCGGG-G---A 118
3
I G.m. AUAGUUUGUUt~G XxAxUCW~xU xxAUCUACUACU OGG xAU AACOGUAGUAAUUCU AGAGCU AAUACGUG xCAACAAACCC~AC xx xxx ~Cxxx ~ A x x x xUG~UUUA~AGA 212
Z.m. - ........... xx-x---X-xx-CG-G ....... x ............................... x .............. Xxxxx---xxxC--G .... GxxxxC ............ 215
S.C. --C .... A .... XX-x-A-U-xCC-H ...... AU--U ........ G ................... A--x-UUA---U-U .... CxxxxC-Uxxx ...... A--xxxx--U .......... 215
X. 1. -, -- -,--,- xI( - X-,-,-CC----GH .... U--x .... U--G .................. A--C-G--G-G-G-U---xxxxxCC-xxCA--G-U-CGxxxx ......... C--- 228
R. r �9 -"G---CC .... UCGC-C-C-xCC---C ..... U--x ..... U--G ................... ,--,-,-,-,-,---,,,,,---,,---, .... OGCG ......... C---
E.C. - - I(--C--GGAAxx - xCO -xC xxC-GAUGG'~GG - - x ..... UACU-G--xA-GGU ......... xC-x - - I(i( U- - -GU - -CA I( I(x I(xAGAx xi(CCA-- - A-G I( xi(xG-G- CC-x- CG-G 212
I G.m. UxAAAA XX x x xx xGGUCRxi( XXX XX XX xACACAGGCxxi( x I( I(UCxx xUGCCU xG I(UUGCU UUGAUGA~CAUGAUAAxCUCGU xCGGAUCGCACC-GCCUUUGUGCCGGCGACGxCAUCAU 300 Z.m. -X .... I(I(I(XXXX--CIJGxxxxxxxxxx--G-G---XXXXXX--XXX .... CI(-I(CC-A- CC ............... x--U-AX ................ C ............ X ...... 300
296 S . C . -X . . . . XXXI(I (xxAA---xxxi (xxxxxi( -Uxxx-U-xi ( I ( I (XX-XXXX-X-GGXAxC-x . . . . . . . . . . . . . . A . . . . x - - U U - x - - A . . . . . . U . . . . I( . . . . . . U . . . . . U-xGU . . . . 309 X. i . CxC --- xxxxx xxACCA-xxxxxx Xx xxU-CGG--- Xi( I( x xi(C- CCGC-- -CC-GCC . . . . . . G- - -C- -UA . . . . . C . . . . GG-C . . . . . . . . . U- -xCC-- -A . . . . . . . . XAUA--- 346 R. r. -C .... CCAACCC ..... GCCCCCUCCCG- U-C---~--GGGC---Gx -AOG ..... G---C--UA ..... C .... GG-C ......... C---CC---G ........ xACC---
E.C. CI(CUCUxxxXXXXU-C--xxxxxxxxxxU-GG-U-xxxxwxx-XXI(XGC--Ax-xA---GG A-U - x - C-AGUA-G-GG xGGU AAx - --C- -A-CUA-G-GAC-AU--CUA-CU-GUC-G-G 298
2b
I G .m. UCAAAUUUCUGCCCUAxUCxAACUUUCGAUC.C4JAGGAUAGUGGCCUACCAUGGUGGUGAC GGGUGACGGAGAAUUAGGGUUCGAUUCCGGAGAGGGAGC~CUACCACAUC 418 418
Z .m. - ............... I(--i( .................... G ............................................................................... 414
S.c. - ............... x--i( .................................. UUCA ...... A .... G .... A ............................................. 427
X.l. --GG--G ......... X--i( .............. CUU-CUGC ............. ACC ...... A .... G .... C ............................................. 464
R. r. --G--CG ......... I( --i( ............... UCGCOGU ............. ACC ..... A .... G .... C .............................................
E.C. AGG-UGAC-A---AC-C-GG .... xxx --x-AC-C-G-xCCA-A--I(--x-ACG--A-G- A-CA- xU--G---x--UU-CA-x-A-I(I( --I(-C-CA ....... DGC-GCCA-G--G-G-G 405
535 I G.m. ~AAGGCAGCAGGCGCGCAAAUUACCCAAUCCUGACAI(CGGC~AGGUAGUGACAAUA AA UAACAA UACCGGGCUCAUU I(GAxGUCUGGUAAUUGGAAUGAGUACAAUC UAAAUCCCU 536 Z .m, - ....................................... x ................................... G-G--A-Ux ...................................
S.C. - .................................. A-UUI(-A ....................... G .... A .... C .... C-GI( .... U .................... G ..... A--- 532 546
X.I. - .............................. C---C---Gx ............... G-A ............ A--A---U--C--G-C-CU .................. C-U ....... U- 583
R. r �9 - .............................. C---C---Cx ............... G-A ............ A--A---U--C--G-C-CU ............... C--C-U ....... U-
E.C. U-U-x---XX-XI( .... CUU-GGG--GUAA-G-A- -IXI --G ........ A--X-GX-G-- --I(GUU ..... xxxi( --i(i( --XXXI(-W-XI(I(-C---I(-x-C-xU---xxx-xxi(WX-G-A 492
4 Ib 5o
I/IT G.m. ~G^uc~A~ccAuuce~GGGcA~cud~UGcc~GcA~c~scGG~AA~c~Gc~ccA^~~u~-G6-6 -~~ucG~u~c~u~u~ ~s5 655 Z.m. - .... x ......... -G .............................................................................................. CC---C-- 651
S.C. - .... x---A-A----G ...................................................... A .............................. A--U ..... CCC---U- 665
A X �9 1 �9 - .... x ..... U----G ...................................................... A ...... C ......................... U ...... A-C-AG-U 702
R. r. - .... x ........ -G ...................................................... A ...... C ......................... U ...... AGC--G-- 581
E.c. G--x--A-C-x --xxxxxi(--CU--C--Cx .................... A-GGAGGGUG CA ..... UA-- CGG-A- -AC-- I( x -GCGU ..... I(i(xi(xxxx-C-x-xi(i(xxxxxx-i(-x
10 20 30 40 50 60 70 80 90 100 110 ]20 . . . . . . . . . / . . . . . . . . . / . . . . . . . . . / . . . . . . . . . / . . . . . . . . . / . . . . . . . . . / . . . . . . . . . / . . . . . . . . . / . . . . . . . . . 1 . . . . . . . . . / . . . . . . . . . / . . . . . . . . . /
Z .m. GGU-CCG ..... G-A-x--GCA-xA .... ACx ...... x-A ..... Xx .................. x--G .................. x ......... x--C ................... 760
S.C. GC .... X---AUU-UUUC .... ACUGGAUU-C-AA-GGx-G--U--I(C--U-U---U-xA-x --UGXA ...... Gxx .... UxCU-G- xC-AAx--A-GA-- U .......... A ...... 778
X.I. GG .... x ..... xG-GA--C-GCI(U .... CCxU-U-C-A-C----GxC--CU ..... CCU-x-C-GA--CU---G .... AGU-U CC--xG-GGC-- - AA- -GU .......... A ...... 818
R. r. GG .... x ..... xG-GA--C-A-U ..... CCx--U-C-C-C ..... GC--CU ..... CCC-x---GA--CU .... G- -- AGU- UCC --CG-GGC- - - AA- -GU .......... A ......
E,c. - x x x - x x x x - x x x x x - x x - x - - x x x x x x x x - x x x x x - x x - x x x x - - x x A A - U - A x x - - - x x - x x x x x - - x x x x x - - x x x x x x x x x x x A x - x - - x . . . . x - - x x x - x - x x x x x x x - - C C - x 624
T[ G,m. GAGUGCUCAAAGCAAGCCUAC xGCxxUCUGUAUACAUUAGCAUGC~AUAACAC CACAGGA xUUCUGAU CC U AUUGUG UUGGCC UU CC-GGAUCGGAGUAAUGAUUAACAGGGACAGUCGGG 881 Z .m. - ................. AU-x--xx .... G ..................... U--U .... x---C-G ....................................... U .............. 882
077 S.c. - .... U ........ ,--,--,,--,,--,-,---, .......... A .... U-GA-U .... CG-U--G-U ..... U ....... UU-CUA---C-AUC ........... U ...... G ...... 895
X. 1. - .... U--C ..... G---GCGxU-xGC---G .... U-C---UA--A .... UGGA-U .... xC--C-G-U ..... U ...... UU ..... A-CU--G-CC ........ G ...... G-C ....
R.r. - .... U ........ G---OGAx--CGC--AG .... CGC---UA--A .... UGGA- U .... xCCGC-G-U ..... U ...... UU ..... A-CU-AG-CC ........ G ...... G-C .... 936
E,C, - x - x - x x x x - - x - x U - x - x - x x x x x x . . . . x . . . . x - x x - x x x - x x x x x x - - x x - x x - C x x - - x x - - x x x x x x x - - x x x x x x - - x - - x x x - x x x - - x - x x - x x x x x x x x x x x x x x x x - - - 668
IT G.m. GGCA UUCGUAUUUCAUAGUCAGAGGUGA~AUUCUUGGAUUU AUGNIAGACGAACAACUGC GAAAGCAUUUGCCAAGG AUG UUU UC xAUU AAUC~u~GAACGAAAG UUGCeGGGCUCGAAGAC 1000 Z.m. - .................................................................................... x .................................... 1001
985 S.c. - .... CG ..... CA--U---x ...................... UG ..... U---u ........... u ............ C ...... xG .................... A--xxxxxxxxxx
X.I. - ........... GDGCC-CU .................. CCGGC-C ......... C-AA .................. A ........ x ................... C--A--U ........ 1014
R.r. - ........... G-C, CC-CU .................. CCGGC-C ...... G--C-GA .................. A ........ x ................... C--A--U ........ iu95
E.c. --U-xxx-A---C--GGUGU--C ........ G-G-A- -GA-C--G-G- -AU -C-GGUG ..... G- -GGCCC--Ux---C-DAGA-UGACGC---G- UG ...... CGU .... AG-A--C-G 784
5b
IT G.m. GAUCAGAUACCGUCCUAGUCUCAACCAUAAACGAUGCCGACCAGGGAUxCAGCGGAUG U U GCUUU U AGG ACUCCGCUGG xCACCUU AUGAGAAAUCAAAGU C~U UGGGUUCCGG~GGGAG ii18
Z.m. - ............................................... x ...... x .... A--AA ...... C ....... C ......................................... 1119
S.c. ----U ......... G ...... U .......... U ........ U-XX---x-G-GU-G .... ,,---,-,---,--,--,-,, ...... C ....................... U ........ ii01
X.I. - ............. G .... UC-C .................. U--C---x-C-GC-GC--- AU-CCC-U ---x .... C-AG--G---CC-G .... C ......................... 1132
R.r. - ............. G .... UC-G .................. UG-C---G-G .... xC--- AU-CCC-U---C-GC-G- -x --G---CC-G .... C ......................... 1173
E.c. ---U ....... C-GG ..... CACG--G ......... U .... xuu---xxxxxx--U--x- --CC--xx--G xG--x --- xxx-U-CCG---CU-A-CCGU-AAG-C-ACCG-CU ...... 889
~ 6 7a 8a 9a T T / ~ I G.m. UAUGGUCGCAAxGGCUGAAACUU/~A~GAAUUGAC~GAAC~GC~CCACC~'~-~]GG~GC CUGCGGCU xAAUU~GAC U CAACACGGGGAAACUU ACCAGGUCCAGACAU x xAGUAAC43 xU 1233
~.m. - .......... x ........................................ C ............... U ........................................ xx--C .... A- 1236
S.c. - .......... A .................................... O ................... x ........................ C .............. Cxx-A ..... A- 1218
X.I. - ..... U .... xA ....................................................... U .................. A--C--C---C--C--G .... CxxG-A .... A- 1249 R.r. - ..... U .... xA ............................................ x .......... U ---~ .............. A--C--C---C--C--G .... CxxG-AC---A- 1289 E.c. --C--C ..... x--U-A ..... C---U .......... xG--C-CC---A--CG ....... A--U--U-U .... C--UG .... G--AA---C ...... U .... bXJ ..... CC-CCKI-A-x- 1006
IT[ G.m. I)GACAGAxCUGAGAX xGCUCUUUCUUGAUUC xUAUGGGUGG UGGUGCAUGGCCC UU xCUU AGUUGGUGG AGCGAUUUG UCUGGU UAAUUCOGUUAACG AACGAGACCUCAGCCUGC U ~ 1340 Z.m. - ...... x ...... xx ............... X ................... U .... x .............................................................. C 1351
S.c. - ...... xU ..... xx .............. UX--G ...................... U--C ........... U .......... C ...... G--A ............... U-A---A ..... IJ34
X. 1. - ...... xU---U-xx ......... C ..... x-G ...................... x ................................... A ............. UC-UC-A ...... C 1364
B R. r. - ...... xU---U-xx ......... C ..... xCG ...................... x ................................... A ............. UCUG--A ...... C 1404
E.C. -UU----GA ..... AU-UG-C---GG- -AC-G-GA-ACA .... C ........ U--CxG-C --C-C---UU-U--AA---UG ...... G---xxxxCGC ...... xx-G--A--xx--xU- ~i16

263
I0 20 30 40 50 60 70 80 90 i00 ii0 120
......... I ......... I ......... / ......... I ......... / ......... / ......... / ......... / ......... / ......... / ......... / ......... /
IZ
C
G.m. UAGCUAUG UGG xAGGUAACCC xU CCACGGCC xx xAGCUU CUUAGAGG xGACUAUGGCCGC UUAGGCCACGGAAGU UUGAGGCAAHAA~UCUGUGA~CCCUU AGAx0GUUCH~CC 1461
Z .m. - ....... C--x--CC-U---X ---GUA-UUxxx ............. x ........... U ....... G--x ..................................... x ........... 1463
S.C. ---UGG--CUxx --C.AUUUG-x-GGUUAU--XXX-X ......... ~-X ...... C-GUUU CA--C-G-U ....................................... AC .......... 144b
X.I. ---U--C-C-ACCCCCGG-GGx--GG--U --xXX-A ........... X---A-GU-G--U-C--x .... ACG--A-C---x ........................... X---C-G .... U 1476
R �9 r. - -- U--C- C- ACCCCCG--G-GG--GG- - U -- CCC- A ........... x---A-GU-G--U -C--x .... CCG--A ..... x ........................... X---C-G .... U 1520
E.c. -xC--x -X--UxU-CC-G--GGx -x-x ..... x xxG-GAA--C-A---A- ---GCCAGU-A -A-ACUGGA ..... G-G-G-AUG-CGU--A---rdI-C---G--C-xU-xC-AC-A .... U 1223
G.m. GCACGCGCGCUACACUGAUGUAUU CAACGAG UCUAUAGCCUUGGCCGACAGGUCCGGG(JA AUCUU xUGAAA~JUUCAU xCGUGAU~ AU ~AU~U U G ~ UUGU~ UCUU~CGAG 1579
Z.m. - ...................... C ........ A ................... x--x ......... GG .......... G---x ................................... x-- 1579
S.c. - ................. C-G-GC--G ........ x-x .......... G ..... UU ........ G ..... C-C-G-x .... C .......... G ..... U .... A---C ........... 1963
X.1. - ................. ,,-----,--,--,-,--,--,, .......... G ....... C-CGC .... CCCCGU-x ...... A ..... C-GGG ......... A--UCC-A-G ...... 1595
R. r. _ ................. ,,,---,--,---,--,---,,---, .... CG ....... C-OGU .... CCCCAH-x ............ C-C~G ......... A--CCC-A-G ...... 1639
E.c. A---A--U ...... A--GC-C--A---A---~Ax-GC-A-C-C-x---G-x-x-AA-CGG -C--CxAU---G-G-GUx---AG-CC .... U-GAGUC ..... C-CGACUC-A-G--GUC- 1336
8b 7b--,- .,,- { 0 G,m. C~'6"6"6~AGUAAGCGCGAGUCAUCAGCUOGCGU UGACUACGUCCC~GCCCUUL~G UACAC ACOGCCCGUC(~CUCCUACCGAUUGAAUGGUCCGGUGAAGUGUUCGGAH xHGCGGxCG ~C 1696
Z .m, ----G ......... x--x .............. C ........................................................................ -GC-x ---C--C-- 1696
S.C. - ................ A ........... U ....... U ................................... AG .............. CUHA .... G-CC-CA .... C---b-OxA-x-X 1680
X.l. - ...... C ...... U---G ..... A ............ U--A ............................... A .......... G ..... UUA .... G--CC ...... CG--CCx--)~C- 1713
R.r. - ...... C ...... U---G ..... A .... U ....... U--A ............................... A .......... G ..... UUA .... G-CCC ...... CG--CCx--xC- 1757
E.C. ----CG ....... '--'-''---''-'-'--'---" ..... U--C-GG-C .................. A-A--AHGG- -G--GG-U-x -AAAA ..... AGGUA-C-x-AACxx-UxU- 1451
II 12a + 9b 12b I.5 g.m. GUGAGCGGUU xCGCUGCCC xx GCGACGUUGUGAGAAG uCCACUGAACCUUAUCAUUUAGA GGAAGG~GAAGUCGUAACAAGG~UUCCGU A G ~ G A ~ C U G ~ A U ~ xx xxxUOGJ 1807
Z.m CG-IFd -- CCGC- C-C-A-- x XxGOCC- xxCC .......... U ..................................................................... xxxxx--- 1805
S.c. -xA- -G- -GC xAA--x --AXXU-UCA -AGCG ..... U-UGGACA--- U-C4~ ...... G ...... CU-A ........................................... xxxxx--A 1789
X. 1. -G-GU---xCx-A-G .... UG---GA-CGCC ...... A-G-UCA---U-G-CU--C ......... U-A ........................................... xxxxx--A 1825
R. r. -G-GU- --CCx-A-G---UUx ---GA-CGC ....... A-GGUC .... U-G-CU--C ......... U-A ........................................... xxxxx--A 1869
E.c. -G---x--xxx .... U A - - x x x x x - - U ...... UXXX--X-X ---X-X-XXXXXXXXX-X - - x x - x U ................ AA ....... G .......... D-d ...... CCUCC--A 1541
Fig. 2. Comparison of the soybean 18S rRNA nucleotide sequence with those of four eukaryotic 18S rRNAs and of one prokaryotic 16S rRNA. The nucleotide sequence of 18S rRNA from soybean (G.m.) was predicted from 8enomic DNA sequences. It is compared ~ith the nucleotide sequences for the 18S rRNAs from maize (Z.m.), yeast (S.c.), Xenopus leavis (X.1.), and rat (R.r.), and the 16S rRNA from E. coli (E.c.). All nucleotide sequence comparisons were optimized for homology with the soybean sequence. A nucleotide in any of the other 18S rRNAs that is identical to that in the soybean sequence in that position is indicated by a dash. A nucleotide different from that in the soybean sequence is indicated by writing the letter symbol for the differing nucleotide in the appropriate I)osition of the other 18S r R N A sequence. A deletion in any sequence is indicated by an "x" in the appropriate position. The four I)redicted structural domains of the soybean sequence are indicated by roman numerals on the left side of the figure and are roughly Separated by opposing arrows. The total number ofnucleotides presented for each sequence is tallied at the end of each line. Regions ~f particular interest are enclosed and numbered (see Discussion)
Table 1. Nucleotide compositions and lengths of various small- SUbunit rRNAs
~laecies,
G + C Number ofnucleotides Length con-
A U G C (nt) tent
Soybean (G.m.) 451 469 491 396 1807 49% Maize (Z.m.) 447 439 500 419 1805 51% Yeast (S.c.) 475 509 458 347 1789 45% Xenopus (X.1.) 432 411 516 466 1825 54% Rat (R.r.) 421 408 543 497 1869 56% E. coli (E.c.) 389 313 487 352 1541 54% l~ukaryotic
average 445 447 502 425 1819 51%
Abbreviations for organisms are as given in Fig. 2
rRNAs examined is 51% (Table 1), with a variation of 5% from this average. The G + C content of the mature 18S rRNA from soybean, 49%, is close to this average. Although the high degree of variation OfG + C content among the eukaryotic 18S rRNAs has been noted previously (Salim and Maden 1981; Torczynski et al. 1983; Messing et al. 1984), the significance of this variation is unknown. Salim and Maden (1981) have noted, however, that this vari- ation of G + C content is confined to the regions of low homology among the 18S rRNAs (see next Section).
Sequence Comparisons among the Eukaryotic 18S rRNA Sequences
An examination of Fig. 2 reveals extensive nucleo- tide sequence homology among the eukary0tic 18S rRNAs. All of the eukaryotic 18S rRNAs examined share at least 74% nucleotide sequence homology with the soybean 18S rRNA (Table 2). Soybean 18S rRNA is more homologous (93.5%) in nucleotide sequence to maize 18S rRNA than to the 18S rRNAs from the organisms from other kingdoms. Similarly, even when they are optimized for alignment with the soybean sequence, Xenopus 18S rRNA is more homologous (91.6%) in nucleotide sequence to rat 18S rRNA than to the other sequences analyzed.
It is apparent from Fig. 2 that the five eukaryotic 18S rRNAs presented are collinear. In any pairwise comparison of the eukaryotic rRNAs, there are stretches of high sequence homology (greater than 90%) separated by stretches of low homology (less than 45%). For example, soybean nucleotides 1-65 and 81-124 are conserved in all eukaryotic 18S rRNAs. They are separated by 13 nucleotides that are nonhomologous among the various sequences. Other regions of shared high sequence homology include soybean nucleotides 135-170, 358-490, 505-647, 748-780, 860-895, 902-919, and 950-

264
Table 2. Percentage homologies (below the diagonal of null values) and evolutionary distances (above diagonal) between various small-subunit rRNAs ._...
G.m. Z.m. S.c.
[ G.m. 0/100% 138 383 Z.m. 93.5% 0/100% 412
S.c. 82.8% 80.8% 0/100%
X.1. R.r.
419 497 416 496
464 542
X.I. 79.9% 79.4% 76.7% 0/100% 177 R.r. 78.2% 77.3% 74.8% 91.6% 0/100%
E.c. 53.3% 51.4% 47.8% 47.2% 44.4%
E.c.
1126 1132
1117
1154 1230
0/100%
All percentages were calculated by taking the total number of similarities between two sequences (using the alignment of Fig. 2) and dividing by 1919, the total number of positions necessary to accommodate all base insertions. In this way, all the pairwise comparisons were normalized to the same length. The upper half of the matrix gives the evolutionary distances based on the weighted values for transitions/transversions and insertions/deletions. An evolutionary tree for the rRNA family can be constructed by single linkage (Hartigan 1975) based on either percentage homology or evolutionary distance. The resulting trees are identical, and the common tree is superimposed on the matrix using boxes. The species abbreviations are as defined in the legend to Fig. 2
990. In all pairwise sequence comparisons, most of the regions of sequence divergence occur in the same relative positions. This pattern of 18S rRNA se- quence conservation was first observed by Salim and Maden (1981) in a comparison between the Xenopus and yeast 18S rRNAs and was described by them as "extensive but interrupted" or "inter- spersed" homology. Our five-way comparison ex- tends and confirms their observation.
Most striking is the 93.5% homology between the soybean and maize 18S rRNA sequences, which is accounted for by the fact that there are only 129 nucleotide replacements between the two genes, which are scattered throughout the sequences. In contrast, both the rat and frog sequences are less than 80% homologous with the soybean sequence, while being 91.6% homologous with each other. In fact, the rat 18S rRNA is 62 nt longer than the soybean 18S rRNA molecule. Most of the additional nucleotides in the rat 18S rRNA occur in region 3, rat nucleotides 119-306 (Figs. 2 and 5), in which the nucleotide sequences also vary among the other four sequences. The differences in length among the non-rat rRNA molecules are much less dramatic and are scattered throughout the whole sequence.
Sequence Homology Between the Soybean and E. coil Smatl-Subunit rRNAs
Comparison of the soybean and E. coli sequences provides examples of the degrees and types of se- quence homology between eukaryotic and prokary- otic small-subunit rRNAs. In contrast to the high degree ofnucleotide sequence homology among the eukaryotic small-subunit rRNAs, the homology be- tween the soybean 18S rRNA sequence and the E. coli 16S rRNA sequence is only 53%. This calcu- lation was based on a total length of 1919 nucleo-
tides, with insertions placed where necessary to maximize the homology. Because the total length used for the match was longer than the soybeat~ sequence and far longer than the E. coli 16S se- quence, this percentage is undoubtedly an overeS- timate of the actual homology. The percentage ho- mology between two random sequences of approximate length 1800 is 50% using our matching program. Therefore, the actual homology between the soybean and E. coli small-subunit rRNAs is not very different from the homology between two ran" dora sequences. What is significant is that there are short stretches of high sequence homology betwee~ the soybean and E. coli small-subunit rRNAs. For example, there are five perfect matches of ten bases or more, represented by soybean nucleotides 565 ~ 584 (region 4), 1146-1155 (region 6), 1631-1649 (region 10), 1760-1769 (region 11), and 1785-1794 (region 12). As in the work of Brown and Clegg (1983, p. 118), the probability of finding a run of ten perfect matches between E. coli and soybean ila 1807 bases is estimated to be (266/1807)(1541/ 1807) 1~ = 0.030, where the length difference be- tween E. coli and soybean is 266 bases. The fact that all five matches occur in an order consistent with collinear alignment of the two sequences makes it highly improbable that these homologies arose bY chance. It is also notable that these homologies oc- cur in regions that are conserved among all the eu- karyotic 18S rRNA sequences. The potential struc" rural and functional significance of some of the conserved regions within the small-subunit rRNA sequences will be addressed in the Discussion.
Statistical Significance of Homologies
The evolutionary distance between each pair ofeU" karyotic 18S rRNAs was calculated using the pro-
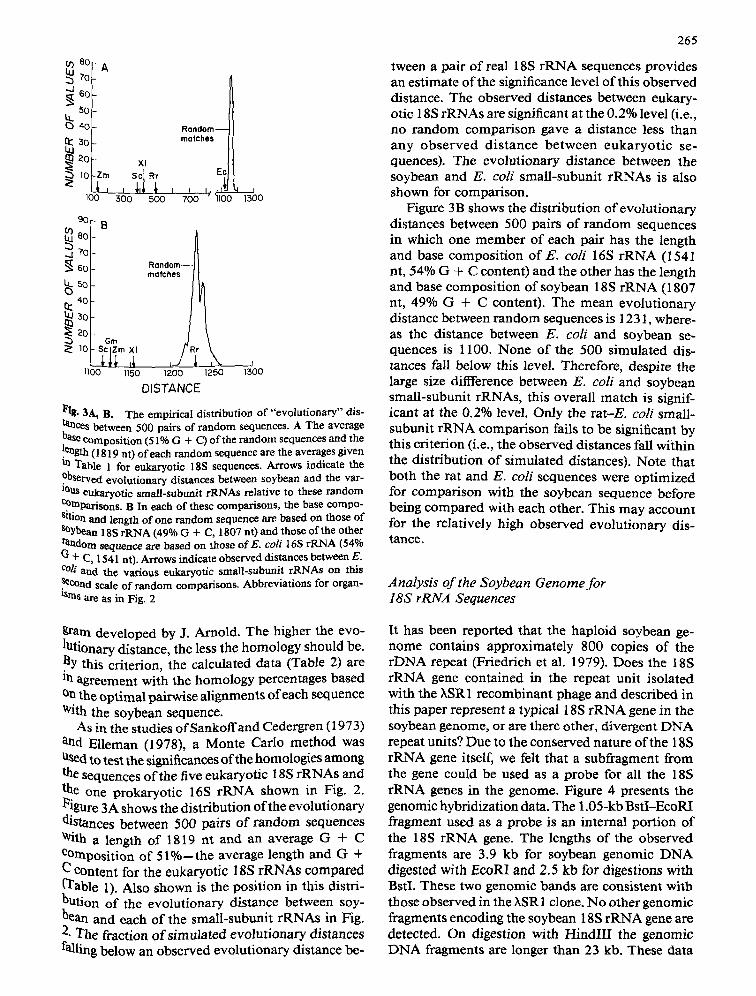
70 --.1 6o
Rondom-- marches
~ 20 Xl I0 Ec
lOO 5oo 5oo 700 " lloo
9~ I B ..j 70
-
~ Gm
1100 1150 1200 1250
DISTANCE
1500
1500
l~ig. 3A, B. The empirical distribution of "evolutionary" dis- tances between 500 pairs of random sequences. A The average base composition (51% G + C) of the random sequences and the !ength (1819 nt) of each random sequence are the averages given ua Table 1 for eukaryotic 18S sequences. Arrows indicate the .Observed evolutionary distances between soybean and the var- Ious eukaryotic small-subtmit rRNAs relative to these random e~raparisons. B In each of these comparisons, the base compo- sition and length of one random sequence are based on those of soybean 18S rRNA (49% G + C, 1807 nO and those of the other razdom sequence are based on those orE. coli 16S rKNA (54% G + C, 1541 at). Arrows indicate observed distances between E. COil and the various ettkaryotic small-subunit rRNAs on this ~COnd scale of random comparisons. Abbreviations for organ- tsrns are as in Fig. 2
265
tween a pair of real 18S rRNA sequences provides an estimate of the significance level of this observed distance. The observed distances between eukary- otic 18S rRNAs are significant at the 0.2% level (i.e., no random comparison gave a distance less than any observed distance between eukaryot ic se- quences). The evolutionary distance between the soybean and E. coti small-subunit rRNAs is also shown for comparison.
Figure 3B shows the distribution of evolutionary distances between 500 pairs of random sequences in which one member of each pair has the length and base composition o f E . coli 16S r R N A (1541 nt, 54% G + C content) and the other has the length and base composition of soybean 18S rRNA (1807 nt, 49% G + C content). The mean evolutionary distance between random sequences is 1231, where- as the distance between E. coli and soybean se- quences is 1100. None of the 500 simulated dis- tances fall below this level. Therefore, despite the large size difference between E. coli and soybean small-subunit rRNAs, this overall match is signif- icant at the 0.2% level. Only the r a t E . coli small- subunit rRNA comparison fails to be significant by this criterion (i.e., the observed distances fall within the distribution of simulated distances). Note that both the rat and E. coli sequences were optimized for comparison with the soybean sequence before being compared with each other. This may account for the relatively high observed evolutionary dis- tance.
Analysis of the Soybean Genome for 18S rRNA Sequences
gram developed by J. Arnold. The higher the evo- lutionary distance, the less the homology should be. l~y this criterion, the calculated data (Table 2) are ha agreement with the homology percentages based t~n the optimal pairwise alignments of each sequence With the soybean sequence.
As in the studies ofSankoffand Cedergren (1973) and Elleman (1978), a Monte Carlo method was used to test the significances of the homologies among the sequences of the five eukaryotic 18S rRNAs and the one prokaryotic 16S rRNA shown in Fig. 2. l~igure 3A shows the distribution of the evolutionary distances between 500 pairs of random sequences With a length of 1819 nt and an average G + C COmposition of 5 l%--the average length and G + C COntent for the eukaryotic 18S rRNAs compared (q~able 1). Also shown is the position in this distri- bution of the evolutionary distance between soy- hean and each of the small-subunit rRNAs in Fig. 2. The fraction o f simulated evolutionary distances falling below an observed evolutionary distance be-
It has been reported that the haploid soybean ge- home contains approximately 800 copies of the rDNA repeat (Friedrich et al. 1979). Does the 18S rRNA gene contained in the repeat unit isolated with the XSR 1 recombinant phage and described in this paper represent a typical 18S rRNA gene in the soybean genome, or are there other, divergent DNA repeat units? Due to the conserved nature of the 18S rRNA gene itself, we felt that a subfragment from the gene could be used as a probe for all the 18S rRNA genes in the genome. Figure 4 presents the genomic hybridization data. The 1.05-kb BstI-EcoRI fragment used as a probe is an internal portion of the 18S rRNA gene. The lengths of the observed fragments are 3.9 kb for soybean genomic DNA digested with EcoRI and 2.5 kb for digestions with BstI. These two genomic bands are consistent with those observed in the ~SR 1 done. No other genomic fragments encoding the soybean 18S rRNA gene are detected. On digestion with HindIII the genomic DNA fragments are longer than 23 kb. These data

266
r~ o
I.=J
- - " 0
m - r
B
0 0 0 03
U
g
- 2 3 . 7 ? - kb
- 9 . 4 6 k b
- 6 . 6 7 k b
- 4 2 6 k b
- P . 2 5 k b
- 1 . 9 6 k b
- 1 . 0 5 k b
Fig. 4A, B. Analysis of soybean genomic DNA for 18S rRNA sequences. The A lanes contain 5 ~g soybean DNA digested with EcoRI, BstI, and HindIII, respectively. The B lanes represent copy-number reconstructions and contain pSR1.2B3 plasmid DNA digested with BstI and EcoRI to yield the 1.05-kb insert fragment containing an internal portion of the soybean 18S rRNA gene described in this paper: 2 ng plasmid or 90 copies, 4 ng plasmid or 180 copies, and 20 ng or 900 copies, respectively. Based on a haploid genome size of 1.2 • 109 bp for soybean, each copy of the 18S gene would represent approximately 7 pg of the 5/zg of DNA loaded
are consistent with there being no observed HindIII sites in the typical 7.7-kb soybean rDNA repeat. Varsanyi-Breiner et al. (1979) and Jackson and Lark (1982) also observed no HindIII sites in soybean genomic rDNA, although Friedrich et al. (1979) re- ported the existence at one HindII] per soybean rDNA repeat unit.
It can be seen from this experiment that the 18S rRNA genes are present in about 500-800 copies per haploid genome, as reported by Friedrich et al. (1979). We conclude that the clone XSR1 examined in this paper is representative of the multigene fam- ily encoding soybean rRNA.
D i s c u s s i o n
Secondary Structure
The high degree of sequence conservation within the eukaryotic 18S rRNAs implies a high degree of similarity of potential secondary structure (Noller and Woese 1981; Stiegler et al. 1981; Zwieb et al. 1981). To provide a perspective on the types of sequence homology in small-subunit RNAs, we pre-
sent in Fig. 5 a rough proposal for the secondary structure of the soybean 18S rRNA, constructed by using as a guide the proposed secondary structures for the yeast and Xenopus 18S rRNAs (Zwieb et al. 1981).
Despite the limited sequence homology betweerl the eukaryotic 18S rRNA class and the prokaryotic 16S rRNA class [e.g., the 53% homology between the soybean 18S and the E. coli 16S rRNAs (Fig, 2)], there is a great deal of secondary-structure sim- ilarity between the small-subunit rRNAs of the two different classes (Kiintzel and KSchel 1981; Stiegler et al. 1981; Zwieb et al. 1981).
Description of the Model
The model of the soybean 18S rRNA presented in Fig. 5 contains 53% of its nucleotides in base-paired configurations. This is comparable to the percentage proposed by Zwieb et at. (1981) for both the yeast and Xenopus 18S rRNA secondary structures. Fur- therrnore, there are no extended perfect duplexes in the proposed secondary structure of soybean 18S rRNA. The longest perfect duplex is 14 bp long (nucleotides 117-130 pair with nucleotides 203- 210). This, too, is comparable in length to the long- est proposed perfect duplex of 13 bp in yeast 18S rRNA (Zwieb et al. 1981) and the longest proposed perfect duplex in the E. coli 16S rRNA of 12 bP (Noller and Woese 1981; Zwieb et al. 1981). Noller and Woese (1981) have suggested that this lack of extended perfect duplexes in small-subunit rRNAS provides them with increased structural flexibility when packaged in the small ribosomal subunit.
More significantly, examination of Fig. 5 reveals that the proposed secondary structure of soybean 18S rRNA can be geometrically divided into four structural domains, I-IV. These are comparable to the four structural domains in Stiegler et al.'s (1981) proposed generalized secondary structure for small- subunit rRNAs. These structural domains are be- lieved to be related to the four functional domains determined by Herr et al. (1979) from biochemical data prior to the development of reliable secondary" structure models for E. coli 16S rRNA. Herr et al. (1979) suggested that domain I functions in the structural organization and assembly of the small ribosomal subunit, that domain II functions in the contact of the small ribosomal subunit with the large ribosomal subunit, that domain III lines the pocket created at the interaction with the large ribosomal subunit, and that domain IV functions in the inter- action with the large ribosomal unit and plays a keY role in the initiation of protein synthesis.
The four domains are separated from each other and stabilized by a core of five central duplex regions (regions 1, 2, 5, 7 and 8 in Figs. 2 and 5). Ther~
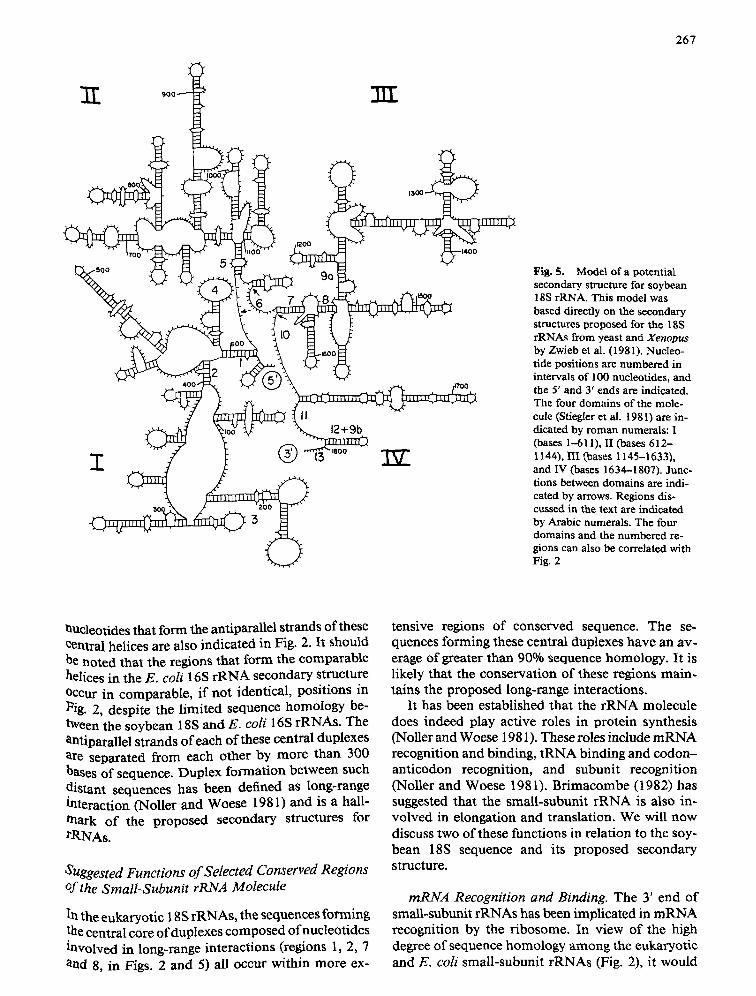
267
I |
9(3
33T
12+9b
7ST
FiR. 5. Model of a potential secondary structure for soybean 18S rRNA. This model was based directly on the secondary structures proposed for the 18S rRNAs from yeast and Xenopus by Zwieb et al. (1981). Nucleo- tide positions are numbered in intervals of 100 nucleotides, and the 5' and 3' ends are indicated. The four domains of the mole- cule (Stiegler et al. 1981) are in- dicated by roman numerals: I (bases 1-611), II (bases 612- 1144), III (bases 1145-1633), and IV (bases 1634-1807). Junc- tions between domains are indi- cated by arrows. Regions dis- cussed in the text are indicated by Arabic numerals. The four domains and the numbered re- gions can also be correlated with Fig. 2
Uucleotides that form the antiparaUel strands of these central helices are also indicated in Fig. 2. It should he noted that the regions that fo rm the comparable helices in the E. coli 16S r R N A secondary structure OCcur in comparable , i f not identical, posit ions in Pig. 2, despite the l imited sequence homology be- tween the soybean 18S and E. coli 16S rRNAs. The antiparallel strands o f each o f these central duplexes are separated f rom each other by more than 300 bases o f sequence. Duplex format ion between such distant sequences has been defined as long-range interaction (Noller and Woese 1981) and is a hall- ~aark o f the proposed secondary structures for rRNAs.
Suggested Functions of Selected Conserved Regions of the Srnall-Subunit rRNA Molecule
In the eukaryotic 18S rRNAs, the sequences forming the central core o f duplexes composed ofnucleot ides involved in long-range interactions (regions 1, 2, 7 and 8, in Figs. 2 and 5) all occur within more ex-
tensive regions o f conserved sequence. The se- quences forming these central duplexes have an av- erage o f greater than 90% sequence homology. It is likely that the conservat ion o f these regions main- rains the proposed long-range interactions.
It has been established that the r R N A molecule does indeed play active roles in protein synthesis (Noller and Woese 1981). These roles include m R N A recognit ion and binding, t R N A binding and c o d o n - ant icodon recognition, and subunit recognition (Noller and Woese 1981). Br imacombe (1982) has suggested that the small-subunit r R N A is also in- vo lved in elongation and translation. We will now discuss two o f these functions in relat ion to the soy- bean 18S sequence and its proposed secondary structure.
mRNA Recognition and Binding. The 3' end o f small-subunit rRNAs has been implicated in m R N A recognit ion by the r ibosome. In view of the high degree o f sequence homology among the eukaryotic and E. coli small-subunit rRNAs (Fig. 2), it would

268
not be surprising i f a significant funct ion was per- f o rmed by this region. Shine and Dalgarno (1974) p roposed that a specific sequence (CCUCC) at the 3' end of E. coil 16S r R N A is an m R N A recognit ion site [E. coli nueleotides 1534-1538, in region 13 (Figs. 2 and 5)]. Steitz and Jakes (197 5) have shown that there is a sequence homologous to the Sh ine- Dalgarno sequence at the 5' ends o f the major i ty o f E. coil m R N A s . However , the Sh ine-Dalgarno se- quence is miss ing in all the eukaryot ie 18S r R N A s we have examined (Fig. 2, be tween the soybean bas- es 1804 and 1805). The m e c h a n i s m o f m R N A rec- ognit ion in eukaryotes m a y rely on another specific sequence at the 3' end o f 18S rRNAs . This theory has been tested (Kozak 1983) by compar ing the se- quence at the 3' end o f 18S r R N A s with that at the 5' end o feuka ryo t i c m R N A s . To date, no consistent conclusions have been drawn f rom these data. Noll- er (1980) has p roposed that there m a y be switches between two al ternate base-pair ing schemes that permi t the binding o f specific molecules at specific stages dur ing prote in synthesis. Based on psoralen cross-l inking studies, T h o m p s o n and Hears t (1983) have suggested that a specific switch between two al ternate base-pai red conformat ions , one consisting o f region 12 paired as shown, and the o ther o f region 9a pai red with region 9b (Figs. 2 and 5), permi t s m R N A recognit ion by E. coli 16S rRNA. In view o f the high degree o f conservat ion between E. coli and the eukaryot ic smal l -subuni t r R N A s in these regions, bo th in sequence and in potent ia l secondary structure, this interact ion m a y also take place in eukaryot ic 18S rRNAs .
tRNA Binding and Codon-Anticodon Recogni- tion. Ofengand et al. (1982) have demons t r a t ed tha t t R N A in the P site o f a preini t ia t ion complex in- eluding m R N A , tRNA, and the small r i bosomal subunit covalent ly binds a nucleotide in a conserved region corresponding to region 10 (soybean nucleo- t ide 1642). This happens with bo th E. coli and yeast small r ibosomal subunits. In view o f the high degree of nucleotide conserva t ion of this region, it is pos- sible tha t it plays the role in t R N A binding suggested by Ofengand et al. in all smal l -subuni t rRNAs .
Summary
I t can be seen f rom our da ta that soybean 18S r R N A is typical o f smal l -subuni t rRNAs . Consider ing the degree o f sequence conservat ion, potent ia l conser- va t ion o f secondary structure, and conserva t ion o f function, it is likely that the m a j o r aspects o f r ibo- somal funct ion in highei plants are very s imilar to those in other eukaryotes. The data presented here showing part ial conservat ion o f sequence between soybean and E. coil smal l -subuni t r R N A s and a high
degree o f potent ial secondary-s t ructure homologY suggest that m a n y o f the extensive genetic and bio- chemical studies on prokaryot ic r ibosomes are ap- plicable to eukaryot ic r ibosomes . Fur ther exami- nat ion o f plant r R N A structures should be helpful in this regard.
Dur ing the p repara t ion and review o f this manu- script the comple te sequences o f two eukaryot ic smal l -subuni t r R N A s were publ ished [rabbit (Con- naughton et al. 1984) and Dictyostelium (McCarroll et al. 1983)]. The rabbi t 18S r R N A sequence is quite s imilar to the rat sequence we have examined. A detailed compar i son o f these new sequences to soy- bean has not yet been done.
Acknowledgments. We wish to acknowledge the continuing in- terest and encouragement of D.M. Shah, R.C. Hightower, R.T. Nagao, and J.L. Key. We would specifically like to thank R.C. Hightower for her help with the genomie blot and B. Rufledge for her assistance .with the manuscript. This research was done in partial fulfillment of the requirements for a Ph.D. by V.K.E. It was supported in part by the Genetics Mechanisms section of USDA-SEA grant No. 83CRCR-I-1254 and grant No. $901- 0410-8-0068-0, and by the U.S. Army Research Office under Training Grant No. DAA G29-83-G-0111.
References
Bolivar F, Rodriguez RL, Greene PJ, Betlach MC, Heyneker HL, Boyer HW (1977) Construction and characterization of new cloning vehicles: II. A multipurpose cloning system. Gene 2:95-113
Bolivar F, Backman K (1979) Plasmids of E. coli as cloning vectors. Methods Enzymol 68:245-267
Brimacombe R (1982) The secondary structure of ribosomal RNA, and its organization within the ribosomal subunits. Biochem Soc Syrup 47:49-60
Brown AHD, Clegg MT (1983) Analysis of variation in related DNA sequences. In: Weir BS (ed) Statistical analysis of DNA sequence data. Marcel Dekker, New York, pp 107-132
Carreira LH, Carlton BC, Bobbio SM, Nagao RT, Meagher RB (1980) Construction and application of a modified "Gene Machine": A circular concentrating preparative gel electro- phoresis device employing discontinuous elution. Anal Bio o them 106:455-468
Cliao S, Sederoff RR, Levings CS III (1984) Nucleotide se ~ quence and evolution of the 18S ribosomal RNA gene in maize mitochondria. Nucleic Acids Res 12:6629-6644
Connaughton JF, Rairkar A, Lockard RE, Kumar A (1984) pri- mary structure of rabbit 18S ribosomal RNA determined bY direct RNA sequence analysis. Nucleic Acids Res 12:4731 - 4745
Denhardt D (1966) A membrane-filter technique for the de- tection of complementary DNA. Biochem Biophys Res Cona- mun 23:641-646
Eckenrode VK (1983) Sequence analysis of an 18S rRNA gene and physical mapping of an rDNA repeat unit from soybean. Ph.D. dissertation, University of Georgia, Athens, Georgia
Elleman TC (1978) A method for detecting distant evolutionary relationships between protein or nucleic acid sequences in the presence of deletions and insertions. J Mol Evol 11:143-161
Eperon IC, Anderson S, Nierlich DP (1980) Distinctive se- quence of human mitochondrial ribosomal RNA genes. Na- ture 286:460-467
Erdmann VA, Huysmens E, Vandenberghe A, De Wachter g

(1983) Collection of published 5S and 5.8S ribosomal RNA sequences. Nucleic Acids Res 1 l:r105-r133
Eriekson BW, Sellers PH (1983) Recognition of patterns in genetics sequences. In: Sankoff D, Kruskal JB (eds) Time warps, string edits, and macromolecules. Addison-Wesley, Reading, Massachusetts, pp 55-91
Friedrich H, Hemleben V, Meagher RB, Key JL (1979) Puri- fication and restriction endonuclease mapping of soybean 18S and 25S ribosomal RNA genes. Planta 146:467-473
tIartigan JA (1975) Clustering algorithms. John Wiley & Sons, New York, pp 191-215
Herr W, Chapman NM, Noller HF (1979) Mechanism of ri- bosomal subanit association: discrimination of specific sites in 16S RNA essential for association activity. J Mol Biol 130: 433-449
Jackson pJ,/.ark KG (1982) Ribosomal RNA synthesis in soy- bean suspension cultures growing in different media. Plant Physiol 69:234-239
Knuth D (1981) The art of computer programming. In: Semi- numerical algorithms, 2nd ed vol 2. Addison-Wesley, Read- ing, Massachusetts, pp 1-77
Kozak M (I 983) Comparison of initiation of protein synthesis in procaryotes, eucaryotes, and organelles. Microbiol Rev 47: 1-45
Krayev AS, Kramerov DA, Skryabin KG, Ryskov AP, Bayev AA, Georgiev GP (1980) The nucleotide sequence of the ubiquitous repetitive DNA sequence B1 complementary to the most abundant class of mouse foldback RNA. Nucleic Acids Res 8:1201-1215
Kruskal JB (1983) An overview of sequence comparison. In: Sankoff D, Kruskal JB (eds) Time warps, string edits, and macromolecules. Addison-Wesley, Reading, Massachusetts, pp 1-40
Kitntzel H, K~chel HG (1981) Evolution ofrRNA and origin of mitochondria. Nature 293:751-755
Kushner SR (1978) An improved method for transformation of Escherichia coli with colE1 derived plasmids. In" Boyer HW, Nicosia S (eds) Genetic engineering. Elsevier/North Hol- land, New York, pp 17-23
Lake JA (1983) Evolving ribosome structure: domains in ar- chaebacteria, eubacteria, and eucaryotes. Cell 33:318-319
Liljas A (1982) Structural studies of ribosomes. Prog Biophys Mol Biol 40:161-228
Maniatis T, Fritseh EF, Sambrook J (1982) Molecular cloning: a laboratory manual. Cold Spring Harbor Laboratory Press, Cold Spring Harbor, New York
Maxam AM, Gilbert W (1980) Sequencing end-labeled DNA with base-specific chemical cleavages. Methods Enzymol 65: 499-560
McCarroll R, Olfen GJ, Stahl YD, Woese CR, Sogin ML (1983) Nucleotide sequence of the Dictyostelium discoideum small- subunit ribosomal ribonucleic acid inferred from the gene sequence: evolutionary implications. Biochemistry 22:5858- 5868
Meagher RB, Tait RC, Betlach M, Boyer HW (1977a) Protein expression in E. coli minicells by recombinant plasmids. Cell 10:521-536
Meagher RB, Shepherd RJ, Boyer HW (1977b) The structure of cauliflower moisaic virus: I. A restriction endonuclease map of cauliflower mosaic virus DNA. Virology 80:362-375
Messing j, Carlson J, Hagen G, Rubenstein I, Oleson A (1984) Cloning and sequencing of the ribosomal RNA genes in maize: the 17S region. DNA 3:31--40
Needleman SB, Wunsch CD (1970) A general method appli- cable to the search for similarities in the amino-acid sequence of two proteins. J Mol Biol 48:443-453
269
Noller HF (1980) Structure and topography of ribosomal RNA. In: Chambliss G, Craven GR, Davies J, Davis K, Kahan L, Nomura M (eds) Ribosomes: structure, function and genetics. University Park Press, Baltimore, Maryland, pp 3-22
Noller HF, Woese CR (1981) Secondary structure of 16S ri- bosomal RNA. Science 212:403-411
Ofengand J, Gornicki P, Chakraburtty K, Nurse K (1982) Func- tional conservation near the 3' end ofeukaryotic small subunit RNA: photochemical crosslinking of P site-bound acetylvalyl- tRNA to 18S RNA of yeast ribosomes. Proc Natl Acad Sci USA 79:2817-2821
Rubstov PM, Musakhonov MM, Zakharyev VM, Krayev AS, Skryabin KG, Bayev AA (1980) The structure of the yeast ribosomal RNA genes: I. The complete nucleotide sequence of the 18S ribosomal RNA gene from Saccharomyces cere- visiae. Nucleic Acids Res 8:5779-5794
Salim M, Maden BEH (1981) Nucleotide sequence of Xenopus laevis 18S ribosomal RNA inferred from the gene sequence. Nature 291:205-208
SankoffD, Cedergren RJ (1973) A test for nueleotide sequence homology. J Mol Biol 77:159-164
SankoffD, Cedergren RJ, Lapalme G (1976) Frequency ofin- sertion--deletion, transversion, and transition in the evolution of 5S ribosomal RNA. J Mol Evol 7:133-149
Shah DM, Hightower RC, Meagher RB (1982) Complete nu- cleotide sequence of a soybean actin gene. Proc Natl Acad Sci USA 79:1022-1026
Shine J, Dalgarno L (1974) The 3'-terminal sequence of Esch- erichia coli 16S ribosomal RNA: complementarity to non- sense triplets and ribosome binding sites. Proc Natl Acad Sci USA 71:1342-1346
Southern EM (1975) Detection of specific sequences among DNA fragments separated by gel electrophoresis. J Mol Biol 98:503-517
Steitz JA, Jakes K (1975) How ribosomes select initiator regions in mRNA: base pair formation between the 3' terminus of 16S rRNA and the mRNA during initiation of protein syn- thesis in Escherichia coil Proc Natl Acad Sci USA 72:4734- 4738
Stiegler P, Carbon P, Ebel J-P, Ehresmann C (1981) A general secondary-structure model for prokaryotic and eucaryotic RNAs of the small ribosomal subunits. Eur J Biochem 120: 487--495
Thompson JF, Hearst JE (1983) Structure-function relations in E. coli 16S RNA. Cell 33:19-24
Torczynski R, Bollon AP, Fuke M (1983) The complete nu- cleotide sequence of the rat 18S ribosomal RNA gene and its comparison with the respective yeast and frog genes. Nucleic Acids Res 11:4879-4890
Varsanyi-Breiner A, Gusella JF, Keys C, Honsman DE, Sullivan D, Brisson N, Verma DPS (1979) The organization of a nuclear DNA sequence from a higher plant: molecular cloning and characterization of soybean ribosomal DNA. Gene 7: 317-334
Wool IG (1980) The structure and function of eucaryotic ri- bosomes. In: Chambliss G, Craven GR, Davies J, Davis K, Kahan L, Nomura M (eds) Ribosomes: structure, function and genetics. University Park Press, Baltimore, Maryland, pp 797-824
Zwieb C, Glotz C, Brimacombe R (1981) Secondary structure comparisons between small subunit ribosomal RNA mole- cules from six different species. Nucleic Acids Res 9:3621- 3640
Received July 23, 1984/Revised December 4, 1984
Copyright © 2022 FDOKUMEN




















