
CHEM 121: Concepts for a Molecular View of Biology II ...
275
CHEM 121: CONCEPTS FOR A MOLECULAR VIEW OF BIOLOGY II Krista Cunningham Case Western Reserve University
-
Upload
khangminh22 -
Category
Documents
-
view
3 -
download
0
Transcript of CHEM 121: Concepts for a Molecular View of Biology II ...

CHEM 121: CONCEPTS FOR A MOLECULAR VIEW OF BIOLOGY II
Krista CunninghamCase Western Reserve University

CHEM 121: Concepts for a MolecularView of Biology II (Cunningham)

This text is disseminated via the Open Education Resource (OER) LibreTexts Project (https://LibreTexts.org) and like thehundreds of other texts available within this powerful platform, it is freely available for reading, printing and"consuming." Most, but not all, pages in the library have licenses that may allow individuals to make changes, save, andprint this book. Carefully consult the applicable license(s) before pursuing such effects.
Instructors can adopt existing LibreTexts texts or Remix them to quickly build course-specific resources to meet the needsof their students. Unlike traditional textbooks, LibreTexts’ web based origins allow powerful integration of advancedfeatures and new technologies to support learning.
The LibreTexts mission is to unite students, faculty and scholars in a cooperative effort to develop an easy-to-use onlineplatform for the construction, customization, and dissemination of OER content to reduce the burdens of unreasonabletextbook costs to our students and society. The LibreTexts project is a multi-institutional collaborative venture to developthe next generation of open-access texts to improve postsecondary education at all levels of higher learning by developingan Open Access Resource environment. The project currently consists of 14 independently operating and interconnectedlibraries that are constantly being optimized by students, faculty, and outside experts to supplant conventional paper-basedbooks. These free textbook alternatives are organized within a central environment that is both vertically (from advance tobasic level) and horizontally (across different fields) integrated.
The LibreTexts libraries are Powered by MindTouch and are supported by the Department of Education Open TextbookPilot Project, the UC Davis Office of the Provost, the UC Davis Library, the California State University AffordableLearning Solutions Program, and Merlot. This material is based upon work supported by the National Science Foundationunder Grant No. 1246120, 1525057, and 1413739. Unless otherwise noted, LibreTexts content is licensed by CC BY-NC-SA 3.0.
Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and donot necessarily reflect the views of the National Science Foundation nor the US Department of Education.
Have questions or comments? For information about adoptions or adaptions contact [email protected]. Moreinformation on our activities can be found via Facebook (https://facebook.com/Libretexts), Twitter(https://twitter.com/libretexts), or our blog (http://Blog.Libretexts.org).
This text was compiled on 01/11/2022
®

1 1/10/2022
TABLE OF CONTENTS
1: ORGANIC CHEMISTRY BASICS1.1: ORGANIC CHEMISTRY1.2: STRUCTURES AND NAMES OF ALKANES1.3: BRANCHED-CHAIN ALKANES1.4: CONDENSED STRUCTURAL AND LINE-ANGLE FORMULAS1.5: IUPAC NOMENCLATURE1.6: PHYSICAL PROPERTIES OF ALKANES1.7: CHEMICAL PROPERTIES OF ALKANES1.8: CYCLOALKANES1.9: ORGANIC CHEMISTRY: ALKANES1.10: ALKENES: STRUCTURES AND NAMES1.11: CIS-TRANS ISOMERS (GEOMETRIC ISOMERS)1.12: PHYSICAL PROPERTIES OF ALKENES1.13: CHEMICAL PROPERTIES OF ALKENES1.14: ALKYNES1.15: AROMATIC COMPOUNDS: BENZENE1.16: STRUCTURE AND NOMENCLATURE OF AROMATIC COMPOUNDS1.17: UNSATURATED AND AROMATIC HYDROCARBONS (SUMMARY)1.18: CHIRALITY AND STEREOISOMERS1.19: R-S SEQUENCE RULES1.20: ORGANIC CHEMISTRY: ALKANES1.21: UNSATURATED AND AROMATIC HYDROCARBONS (EXERCISES)
2: CARBOHYDRATES2.1: PRELUDE TO CARBOHYDRATES2.2: CARBOHYDRATES2.3: CLASSES OF MONOSACCHARIDES2.4: IMPORTANT HEXOSES2.5: CYCLIC STRUCTURES OF MONOSACCHARIDES2.6: PROPERTIES OF MONOSACCHARIDES2.7: DISACCHARIDES2.8: POLYSACCHARIDES2.9: CARBOHYDRATES (SUMMARY)
3: LIPIDS3.1: PRELUDE TO LIPIDS3.2: FATTY ACIDS3.3: FATS AND OILS3.4: MEMBRANES AND MEMBRANE LIPIDS3.5: STEROIDS3.6: LIPIDS (SUMMARY)3.7: EXERCISES
4: AMINO ACIDS, PROTEINS, AND ENZYMES4.1: PRELUDE TO AMINO ACIDS, PROTEINS, AND ENZYMES4.2: PROPERTIES OF AMINO ACIDS4.3: REACTIONS OF AMINO ACIDS4.4: PEPTIDES4.5: PROTEINS4.6: ENZYMES4.7: ENZYME ACTION4.8: ENZYME ACTIVITY4.9: ENZYME INHIBITION4.10: ENZYME COFACTORS AND VITAMINS

2 1/10/2022
4.11: AMINO ACIDS, PROTEINS, AND ENZYMES (SUMMARY)4.12: AMINO ACIDS, PROTEINS, AND ENZYMES (EXERCISES)
5: NUCLEIC ACIDS5.1: PRELUDE TO NUCLEIC ACIDS5.2: NUCLEOTIDES5.3: NUCLEIC ACID STRUCTURE5.4: REPLICATION AND EXPRESSION OF GENETIC INFORMATION5.5: PROTEIN SYNTHESIS AND THE GENETIC CODE5.6: MUTATIONS AND GENETIC DISEASES5.7: VIRUSES5.8: NUCLEIC ACIDS (SUMMARY)5.9: NUCLEIC ACIDS (EXERCISES)
6: ENERGY METABOLISMMetabolism is the set of life-sustaining chemical transformations within the cells of living organisms. The three main purposes ofmetabolism are the conversion of food/fuel to energy to run cellular processes, the conversion of food/fuel to building blocks forproteins, lipids, nucleic acids, and some carbohydrates, and the elimination of nitrogenous wastes. These enzyme-catalyzed reactionsallow organisms to grow and reproduce, maintain their structures, and respond to their environments.
6.1: PRELUDE TO ENERGY METABOLISM6.2: ATP: THE UNIVERSAL ENERGY CURRENCY6.3: STAGE I OF CATABOLISM6.4: OVERVIEW OF STAGE II OF CATABOLISM6.5: STAGE III OF CATABOLISM6.6: STAGE II OF CARBOHYDRATE CATABOLISM6.7: STAGE II OF LIPID CATABOLISM6.8: STAGE II OF PROTEIN CATABOLISM6.9: ENERGY METABOLISM (SUMMARY)6.10: ENERGY METABOLISM (EXERCISES)
7: CHEMICAL MESSENGERS: HORMONES, NEUROTRANSMITTERS, ANDDRUGS
7.1: MESSENGER MOLECULES7.2: HORMONES AND THE ENDOCRINE SYSTEM7.3: HOW HORMONES WORK - EPINEPHRINE AND FIGHT-OR-FLIGHT7.4: AMINO ACID DERIVATIVES AND POLYPEPTIDES AS HORMONES7.5: STEROID HORMONES7.6: NEUROTRANSMITTERS7.7: HOW NEUROTRANSMITTERS WORK: ACETYLCHOLINE, ITS AGONISTS AND ANTAGONISTS7.8: HISTAMINE AND ANTIHISTAMINES7.9: SEROTONIN, NOREPINEPHRINE, AND DOPAMINE7.10: NEUROPEPTIDES AND PAIN RELIEF7.11: DRUG DISCOVERY AND DRUG DESIGN
BACK MATTERINDEXGLOSSARY

1 1/10/2022
CHAPTER OVERVIEW1: ORGANIC CHEMISTRY BASICS
1.1: ORGANIC CHEMISTRYToday organic chemistry is the study of the chemistry of the carbon compounds, and inorganic chemistry is the study of the chemistryof all other elements. Organic chemistry is the study of carbon compounds, nearly all of which also contain hydrogen atoms.
1.2: STRUCTURES AND NAMES OF ALKANESSimple alkanes exist as a homologous series, in which adjacent members differ by a unit.
1.3: BRANCHED-CHAIN ALKANESAlkanes with four or more carbon atoms can exist in isomeric forms.
1.4: CONDENSED STRUCTURAL AND LINE-ANGLE FORMULASCondensed chemical formulas show the hydrogen atoms (or other atoms or groups) right next to the carbon atoms to which they areattached. Line-angle formulas imply a carbon atom at the corners and ends of lines. Each carbon atom is understood to be attached toenough hydrogen atoms to give each carbon atom four bonds.
1.5: IUPAC NOMENCLATUREAlkanes have both common names and systematic names, specified by IUPAC.
1.6: PHYSICAL PROPERTIES OF ALKANESAlkanes are nonpolar compounds that are low boiling and insoluble in water.
1.7: CHEMICAL PROPERTIES OF ALKANESThe alkanes and cycloalkanes, with the exception of cyclopropane, are probably the least chemically reactive class of organiccompounds. Alkanes contain strong carbon-carbon single bonds and strong carbon-hydrogen bonds. The carbon-hydrogen bonds areonly very slightly polar. Alkanes can be burned, alkanes can react with some of the halogens, breaking carbon-hydrogen bonds, andalkanes can crack by breaking the carbon-carbon bonds.
1.8: CYCLOALKANESMany organic compounds have cyclic structures.
1.9: ORGANIC CHEMISTRY: ALKANESSummary of Chapter.
1.10: ALKENES: STRUCTURES AND NAMESAlkenes are hydrocarbons with a carbon-to-carbon double bond.
1.11: CIS-TRANS ISOMERS (GEOMETRIC ISOMERS)Cis-trans (geometric) isomerism exists when there is restricted rotation in a molecule and there are two nonidentical groups on eachdoubly bonded carbon atom.
1.12: PHYSICAL PROPERTIES OF ALKENESThe physical properties of alkenes are much like those of the alkanes: their boiling points increase with increasing molar mass, andthey are insoluble in water.
1.13: CHEMICAL PROPERTIES OF ALKENESAlkenes undergo addition reactions, adding such substances as hydrogen, bromine, and water across the carbon-to-carbon doublebond.
1.14: ALKYNESAlkynes are similar to alkenes in both physical and chemical properties. For example, alkynes undergo many of the typical additionreactions of alkenes. The International Union of Pure and Applied Chemistry (IUPAC) names for alkynes parallel those of alkenes,except that the family ending is -yne rather than -ene. The IUPAC name for acetylene is ethyne. The names of other alkynes areillustrated in the following exercises.
1.15: AROMATIC COMPOUNDS: BENZENEAromatic hydrocarbons appear to be unsaturated, but they have a special type of bonding and do not undergo addition reactions.
CH2

2 1/10/2022
1.16: STRUCTURE AND NOMENCLATURE OF AROMATIC COMPOUNDSAromatic compounds contain a benzene ring or have certain benzene-like properties; for our purposes, you can recognize aromaticcompounds by the presence of one or more benzene rings in their structure.
1.17: UNSATURATED AND AROMATIC HYDROCARBONS (SUMMARY)A brief summary of the chapter.
1.18: CHIRALITY AND STEREOISOMERS1.19: R-S SEQUENCE RULES1.20: ORGANIC CHEMISTRY: ALKANESSelect problems and solutions to chapter.
1.21: UNSATURATED AND AROMATIC HYDROCARBONS (EXERCISES)Select problems and solutions for the chapter.

1.1.1 12/19/2021 https://chem.libretexts.org/@go/page/178734
1.1: Organic ChemistryLearning Objectives
To recognize the composition and properties typical of organic and inorganic compounds.
Scientists of the 18th and early 19th centuries studied compounds obtained from plants and animals and labeled themorganic because they were isolated from “organized” (living) systems. Compounds isolated from nonliving systems, suchas rocks and ores, the atmosphere, and the oceans, were labeled inorganic. For many years, scientists thought organiccompounds could be made by only living organisms because they possessed a vital force found only in living systems. Thevital force theory began to decline in 1828, when the German chemist Friedrich Wöhler synthesized urea from inorganicstarting materials. He reacted silver cyanate (AgOCN) and ammonium chloride (NH Cl), expecting to get ammoniumcyanate (NH OCN). What he expected is described by the following equation.
Instead, he found the product to be urea (NH CONH ), a well-known organic material readily isolated from urine. Thisresult led to a series of experiments in which a wide variety of organic compounds were made from inorganic startingmaterials. The vital force theory gradually went away as chemists learned that they could make many organic compoundsin the laboratory.
Today organic chemistry is the study of the chemistry of the carbon compounds, and inorganic chemistry is the study of thechemistry of all other elements. It may seem strange that we divide chemistry into two branches—one that considerscompounds of only one element and one that covers the 100-plus remaining elements. However, this division seems morereasonable when we consider that of tens of millions of compounds that have been characterized, the overwhelmingmajority are carbon compounds.
The word organic has different meanings. Organic fertilizer, such as cow manure, is organic in the original sense; it isderived from living organisms. Organic foods generally are foods grown without synthetic pesticides or fertilizers.Organic chemistry is the chemistry of compounds of carbon.
Carbon is unique among the other elements in that its atoms can form stable covalent bonds with each other and withatoms of other elements in a multitude of variations. The resulting molecules can contain from one to millions of carbonatoms. We previously surveyed organic chemistry by dividing its compounds into families based on functional groups. Webegin with the simplest members of a family and then move on to molecules that are organic in the original sense—that is,they are made by and found in living organisms. These complex molecules (all containing carbon) determine the forms andfunctions of living systems and are the subject of biochemistry.
Organic compounds, like inorganic compounds, obey all the natural laws. Often there is no clear distinction in thechemical or physical properties among organic and inorganic molecules. Nevertheless, it is useful to compare typicalmembers of each class, as in Table .
4
4
AgOCN +N Cl → AgCl +N OCNH4 H4 (1.1.1)
2 2
1.1.1

1.1.2 12/19/2021 https://chem.libretexts.org/@go/page/178734
Table : General Contrasting Properties and Examples of Organic and Inorganic CompoundsOrganic Hexane Inorganic NaCl
low melting points −95°C high melting points 801°C
low boiling points 69°C high boiling points 1,413°C
low solubility in water;high solubility in nonpolar
solvents
insoluble in water; solublein gasoline
greater solubility in water;low solubility in nonpolar
solvents
soluble in water; insolublein gasoline
flammable highly flammable nonflammable nonflammable
aqueous solutions do notconduct electricity
nonconductive aqueous solutions conductelectricity
conductive in aqueoussolution
exhibit covalent bonding covalent bonds exhibit ionic bonding ionic bonds
Keep in mind, however, that there are exceptions to every category in this table. To further illustrate typical differencesamong organic and inorganic compounds, Table also lists properties of the inorganic compound sodium chloride(common table salt, NaCl) and the organic compound hexane (C H ), a solvent that is used to extract soybean oil fromsoybeans (among other uses). Many compounds can be classified as organic or inorganic by the presence or absence ofcertain typical properties, as illustrated in Table .
1.1.1
1.1.1
6 14
1.1.1

1.2.1 1/5/2022 https://chem.libretexts.org/@go/page/178735
1.2: Structures and Names of AlkanesLearning Objectives
To identify and name simple (straight-chain) alkanes given formulas and write formulas for straight-chain alkanesgiven their names.
We begin our study of organic chemistry with the hydrocarbons, the simplest organic compounds, which are composed ofcarbon and hydrogen atoms only. As we noted, there are several different kinds of hydrocarbons. They are distinguished bythe types of bonding between carbon atoms and the properties that result from that bonding. Hydrocarbons with onlycarbon-to-carbon single bonds (C–C) and existing as a continuous chain of carbon atoms also bonded to hydrogen atomsare called alkanes (or saturated hydrocarbons). Saturated, in this case, means that each carbon atom is bonded to four otheratoms (hydrogen or carbon)—the most possible; there are no double or triple bonds in the molecules.
The word saturated has the same meaning for hydrocarbons as it does for the dietary fats and oils: the molecule has nocarbon-to-carbon double bonds (C=C).
We previously introduced the three simplest alkanes—methane (CH ), ethane (C H ), and propane (C H ) and they areshown again in Figure .
Figure : The Three Simplest Alkanes
The flat representations shown do not accurately portray bond angles or molecular geometry. Methane has a tetrahedralshape that chemists often portray with wedges indicating bonds coming out toward you and dashed lines indicating bondsthat go back away from you. An ordinary solid line indicates a bond in the plane of the page. Recall that the VSEPR theorycorrectly predicts a tetrahedral shape for the methane molecule (Figure ).
Figure : The Tetrahedral Methane Molecule
Methane (CH ), ethane (C H ), and propane (C H ) are the beginning of a series of compounds in which any two membersin a sequence differ by one carbon atom and two hydrogen atoms—namely, a CH unit. The first 10 members of this seriesare given in Table .
Table : The First 10 Straight-Chain AlkanesName Molecular Formula (C H ) Condensed Structural Formula Number of Possible Isomers
methane CH CH —
ethane C H CH CH —
propane C H CH CH CH —
butane C H CH CH CH CH 2
pentane C H CH CH CH CH CH 3
hexane C H CH CH CH CH CH CH 5
heptane C H CH CH CH CH CH CH CH 9
4 2 6 3 81.2.1
1.2.1
1.2.2
1.2.2
4 2 6 3 8
21.2.1
1.2.1
n 2n + 2
4 4
2 6 3 3
3 8 3 2 3
4 10 3 2 2 3
5 12 3 2 2 2 3
6 14 3 2 2 2 2 3
7 16 3 2 2 2 2 2 3

1.2.2 1/5/2022 https://chem.libretexts.org/@go/page/178735
Name Molecular Formula (C H ) Condensed Structural Formula Number of Possible Isomers
octane C H CH CH CH CH CH CH CH CH
18
nonane C H CH CH CH CH CH CH CH CH CH
35
decane C H CH CH CH CH CH CH CH CH CH CH
75
Consider the series in Figure . The sequence starts with C H , and a CH unit is added in each step moving up theseries. Any family of compounds in which adjacent members differ from each other by a definite factor (here a CH group)is called a homologous series. The members of such a series, called homologs, have properties that vary in a regular andpredictable manner. The principle of homology gives organization to organic chemistry in much the same way that theperiodic table gives organization to inorganic chemistry. Instead of a bewildering array of individual carbon compounds,we can study a few members of a homologous series and from them deduce some of the properties of other compounds inthe series.
Figure : Members of a Homologous Series. Each succeeding formula incorporates one carbon atom and twohydrogen atoms more than the previous formula.
The principle of homology allows us to write a general formula for alkanes: C H . Using this formula, we can write amolecular formula for any alkane with a given number of carbon atoms. For example, an alkane with eight carbon atomshas the molecular formula C H = C H .
Key TakeawaySimple alkanes exist as a homologous series, in which adjacent members differ by a CH unit.
n 2n + 2
8 183 2 2 2 2 2 2
3
9 203 2 2 2 2 2 2
2 3
10 223 2 2 2 2 2 2
2 2 3
1.2.3 3 8 2
2
1.2.3
n 2n + 2
8 (2 × 8) + 2 8 18
2

1.3.1 1/7/2022 https://chem.libretexts.org/@go/page/178736
1.3: Branched-Chain AlkanesLearning Objectives
To learn how alkane molecules can have branched chains and recognize compounds that are isomers.
We can write the structure of butane (C H ) by stringing four carbon atoms in a row,
–C–C–C–C–
and then adding enough hydrogen atoms to give each carbon atom four bonds:
The compound butane has this structure, but there is another way to put 4 carbon atoms and 10 hydrogen atoms together.Place 3 of the carbon atoms in a row and then branch the fourth one off the middle carbon atom:
Now we add enough hydrogen atoms to give each carbon four bonds.
Figure ).
Figure : Butane and Isobutane. The ball-and-stick models of these two compounds show them to be isomers; bothhave the molecular formula C H .
Notice that C H is depicted with a bent chain in Figure . The four-carbon chain may be bent in various waysbecause the groups can rotate freely about the C–C bonds. However, this rotation does not change the identity of thecompound. It is important to realize that bending a chain does not change the identity of the compound; all of thefollowing represent the same compound, butane:
The structure of isobutane shows a continuous chain of three carbon atoms only, with the fourth attached as a branch offthe middle carbon atom of the continuous chain, which is different from the structures of butane (compare the two
4 10
1.3.1
1.3.1
4 10
4 10 1.3.1

1.3.2 1/7/2022 https://chem.libretexts.org/@go/page/178736
structures in Figure .
Unlike C H , the compounds methane (CH ), ethane (C H ), and propane (C H ) do not exist in isomeric forms becausethere is only one way to arrange the atoms in each formula so that each carbon atom has four bonds.
Next beyond C H in the homologous series is pentane. Each compound has the same molecular formula: C H . (Table12.2 has a column identifying the number of possible isomers for the first 10 straight-chain alkanes.) The compound at thefar left is pentane because it has all five carbon atoms in a continuous chain. The compound in the middle is isopentane;like isobutane, it has a one CH branch off the second carbon atom of the continuous chain. The compound at the far right,discovered after the other two, was named neopentane (from the Greek neos, meaning “new”). Although all three have thesame molecular formula, they have different properties, including boiling points: pentane, 36.1°C; isopentane, 27.7°C; andneopentane, 9.5°C.
A continuous (unbranched) chain of carbon atoms is often called a straight chain even though the tetrahedralarrangement about each carbon gives it a zigzag shape. Straight-chain alkanes are sometimes called normal alkanes,and their names are given the prefix n-. For example, butane is called n-butane. We will not use that prefix here becauseit is not a part of the system established by the International Union of Pure and Applied Chemistry.
1.3.1
4 10 4 2 6 3 8
4 10 5 12
3

1.4.1 1/2/2022 https://chem.libretexts.org/@go/page/178737
1.4: Condensed Structural and Line-Angle FormulasLearning Objectives
Write condensed structural formulas for alkanes given complete structural formulas.Draw line-angle formulas given structural formulas.
We use several kinds of formulas to describe organic compounds. A molecular formula shows only the kinds and numbersof atoms in a molecule. For example, the molecular formula C H tells us there are 4 carbon atoms and 10 hydrogenatoms in a molecule, but it doesn’t distinguish between butane and isobutane. A structural formula shows all the carbonand hydrogen atoms and the bonds attaching them. Thus, structural formulas identify the specific isomers by showing theorder of attachment of the various atoms.
Unfortunately, structural formulas are difficult to type/write and take up a lot of space. Chemists often use condensedstructural formulas to alleviate these problems. The condensed formulas show hydrogen atoms right next to the carbonatoms to which they are attached, as illustrated for butane:
The ultimate condensed formula is a line-angle formula, in which carbon atoms are implied at the corners and ends oflines, and each carbon atom is understood to be attached to enough hydrogen atoms to give each carbon atom four bonds.For example, we can represent pentane (CH CH CH CH CH ) and isopentane [(CH ) CHCH CH ] as follows:
Parentheses in condensed structural formulas indicate that the enclosed grouping of atoms is attached to the adjacentcarbon atom.
Key TakeawaysCondensed chemical formulas show the hydrogen atoms (or other atoms or groups) right next to the carbon atoms towhich they are attached.Line-angle formulas imply a carbon atom at the corners and ends of lines. Each carbon atom is understood to beattached to enough hydrogen atoms to give each carbon atom four bonds.
4 10
3 2 2 2 3 3 2 2 3

1.5.1 11/28/2021 https://chem.libretexts.org/@go/page/178738
1.5: IUPAC NomenclatureLearning Objectives
To name alkanes by the IUPAC system and write formulas for alkanes given IUPAC names
As noted in previously, the number of isomers increases rapidly as the number of carbon atoms increases. There are 3pentanes, 5 hexanes, 9 heptanes, and 18 octanes. It would be difficult to assign unique individual names that we couldremember. A systematic way of naming hydrocarbons and other organic compounds has been devised by the InternationalUnion of Pure and Applied Chemistry (IUPAC). These rules, used worldwide, are known as the IUPAC System ofNomenclature. (Some of the names we used earlier, such as isobutane, isopentane, and neopentane, do not follow theserules and are called common names.) A stem name (Table ) indicates the number of carbon atoms in the longestcontinuous chain (LCC). Atoms or groups attached to this carbon chain, called substituents, are then named, with theirpositions indicated by numbers. For now, we will consider only those substituents called alkyl groups.
Table : Stems That Indicate the Number of Carbon Atoms in Organic MoleculesStem Number
meth- 1
eth- 2
prop- 3
but- 4
pent- 5
hex- 6
hept- 7
oct- 8
non- 9
dec- 10
An alkyl group is a group of atoms that results when one hydrogen atom is removed from an alkane. The group is namedby replacing the -ane suffix of the parent hydrocarbon with -yl. For example, the -CH group derived from methane (CH )results from subtracting one hydrogen atom and is called a methyl group. The alkyl groups we will use most frequently arelisted in Table . Alkyl groups are not independent molecules; they are parts of molecules that we consider as a unit toname compounds systematically.
Table : Common Alkyl Groups
Parent Alkane Alkyl Group Condensed StructuralFormula
methane methyl CH –
*There are four butyl groups, two derived from butane and two from isobutane. We will introduce the other three where appropriate.
1.5.1
1.5.1
3 4
1.5.2
1.5.2
3

1.5.2 11/28/2021 https://chem.libretexts.org/@go/page/178738
Parent Alkane Alkyl Group Condensed StructuralFormula
ethane ethyl CH CH –
propane propyl CH CH CH –
isopropyl (CH ) CH–
butane butyl* CH CH CH CH –
*There are four butyl groups, two derived from butane and two from isobutane. We will introduce the other three where appropriate.
Simplified IUPAC rules for naming alkanes are as follows (demonstrated in Example ).
1. Name alkanes according to the LCC (longest continuous chain) of carbon atoms in the molecule (rather than thetotal number of carbon atoms). This LCC, considered the parent chain, determines the base name, to which we add thesuffix -ane to indicate that the molecule is an alkane.
2. If the hydrocarbon is branched, number the carbon atoms of the LCC. Numbers are assigned in the direction thatgives the lowest numbers to the carbon atoms with attached substituents. Hyphens are used to separate numbers from thenames of substituents; commas separate numbers from each other. (The LCC need not be written in a straight line; forexample, the LCC in the following has five carbon atoms.)
3. Place the names of the substituent groups in alphabetical order before the name of the parent compound. If thesame alkyl group appears more than once, the numbers of all the carbon atoms to which it is attached are expressed. If thesame group appears more than once on the same carbon atom, the number of that carbon atom is repeated as many times asthe group appears. Moreover, the number of identical groups is indicated by the Greek prefixes di-, tri-, tetra-, and so on.These prefixes are not considered in determining the alphabetical order of the substituents. For example, ethyl is listedbefore dimethyl; the di- is simply ignored. The last alkyl group named is prefixed to the name of the parent alkane to formone word.
When these rules are followed, every unique compound receives its own exclusive name. The rules enable us to not onlyname a compound from a given structure but also draw a structure from a given name. The best way to learn how to usethe IUPAC system is to put it to work, not just memorize the rules. It’s easier than it looks.
Example Name each compound.
1.
3 2
3 2 2
3 2
3 2 2 2
1.5.1
1.5.1

1.5.3 11/28/2021 https://chem.libretexts.org/@go/page/178738
2.
3.
SOLUTION
1. The LCC has five carbon atoms, and so the parent compound is pentane (rule 1). There is a methyl group (rule 2)attached to the second carbon atom of the pentane chain. The name is therefore 2-methylpentane.
2. The LCC has six carbon atoms, so the parent compound is hexane (rule 1). Methyl groups (rule 2) are attached tothe second and fifth carbon atoms. The name is 2,5-dimethylhexane.
3. The LCC has eight carbon atoms, so the parent compound is octane (rule 1). There are methyl and ethyl groups (rule2), both attached to the fourth carbon atom (counting from the right gives this carbon atom a lower number; rule 3).The correct name is thus 4-ethyl-4-methyloctane.
Exercise Name each compound.
1.
2.
3.
Example Draw the structure for each compound.
a. 2,3-dimethylbutaneb. 4-ethyl-2-methylheptane
SOLUTION
In drawing structures, always start with the parent chain.
a. The parent chain is butane, indicating four carbon atoms in the LCC.
Then add the groups at their proper positions. You can number the parent chain from either direction as long as youare consistent; just don’t change directions before the structure is done. The name indicates two methyl (CH )groups, one on the second carbon atom and one on the third.
1.5.1
1.5.2
3

1.5.4 11/28/2021 https://chem.libretexts.org/@go/page/178738
Finally, fill in all the hydrogen atoms, keeping in mind that each carbon atom must have four bonds.
b. The parent chain is heptane in this case, indicating seven carbon atoms in the LCC.
–C–C–C–C–C–C–C–
Adding the groups at their proper positions gives
Filling in all the hydrogen atoms gives the following condensed structural formulas:
Note that the bonds (dashes) can be shown or not; sometimes they are needed for spacing.
Exercise
Draw the structure for each compound.
a. 4-ethyloctaneb. 3-ethyl-2-methylpentanec. 3,3,5-trimethylheptane
Key TakeawayAlkanes have both common names and systematic names, specified by IUPAC.
1.5.2

1.6.1 1/5/2022 https://chem.libretexts.org/@go/page/178739
1.6: Physical Properties of AlkanesLearning Objectives
To identify the physical properties of alkanes and describe trends in these properties.
Because alkanes have relatively predictable physical properties and undergo relatively few chemical reactions other thancombustion, they serve as a basis of comparison for the properties of many other organic compound families. Let’sconsider their physical properties first.
Table describes some of the properties of some of the first 10 straight-chain alkanes. Because alkane molecules arenonpolar, they are insoluble in water, which is a polar solvent, but are soluble in nonpolar and slightly polar solvents.Consequently, alkanes themselves are commonly used as solvents for organic substances of low polarity, such as fats, oils,and waxes. Nearly all alkanes have densities less than 1.0 g/mL and are therefore less dense than water (the density of H Ois 1.00 g/mL at 20°C). These properties explain why oil and grease do not mix with water but rather float on its surface.
Table : Physical Properties of Some Alkanes
Molecular Name Formula Melting Point (°C) Boiling Point (°C) Density (20°C)* Physical State (at20°C)
methane CH –182 –164 0.668 g/L gas
ethane C H –183 –89 1.265 g/L gas
propane C H –190 –42 1.867 g/L gas
butane C H –138 –1 2.493 g/L gas
pentane C H –130 36 0.626 g/mL liquid
hexane C H –95 69 0.659 g/mL liquid
octane C H –57 125 0.703 g/mL liquid
decane C H –30 174 0.730 g mL liquid
*Note the change in units going from gases (grams per liter) to liquids (grams per milliliter). Gas densities are at 1 atm pressure.
1.6.1
2
1.6.1
4
2 6
3 8
4 10
5 12
6 14
8 18
10 22

1.6.2 1/5/2022 https://chem.libretexts.org/@go/page/178739
Figure : Oil Spills. Crude oil coats the water’s surface in the Gulf of Mexico after the Deepwater Horizon oil rig sankfollowing an explosion. The leak was a mile below the surface, making it difficult to estimate the size of the spill. One literof oil can create a slick 2.5 hectares (6.3 acres) in size. This and similar spills provide a reminder that hydrocarbons andwater don’t mix. Source: Photo courtesy of NASA Goddard / MODIS Rapid Response Team,http://www.nasa.gov/topics/earth/features/oilspill/oil-20100519a.html.
Looking Closer: Gas Densities and Fire Hazards Table indicates that the first four members of the alkane series are gases at ordinary temperatures. Natural gas iscomposed chiefly of methane, which has a density of about 0.67 g/L. The density of air is about 1.29 g/L. Because naturalgas is less dense than air, it rises. When a natural-gas leak is detected and shut off in a room, the gas can be removed byopening an upper window. On the other hand, bottled gas can be either propane (density 1.88 g/L) or butanes (a mixture ofbutane and isobutane; density about 2.5 g/L). Both are much heavier than air (density 1.2 g/L). If bottled gas escapes into abuilding, it collects near the floor. This presents a much more serious fire hazard than a natural-gas leak because it is moredifficult to rid the room of the heavier gas.
Also shown in Table are the boiling points of the straight-chain alkanes increase with increasing molar mass. Thisgeneral rule holds true for the straight-chain homologs of all organic compound families. Larger molecules have greatersurface areas and consequently interact more strongly; more energy is therefore required to separate them. For a givenmolar mass, the boiling points of alkanes are relatively low because these nonpolar molecules have only weak dispersionforces to hold them together in the liquid state.
Looking Closer: An Alkane Basis for Properties of Other Compounds An understanding of the physical properties of the alkanes is important in that petroleum and natural gas and the manyproducts derived from them—gasoline, bottled gas, solvents, plastics, and more—are composed primarily of alkanes. Thisunderstanding is also vital because it is the basis for describing the properties of other organic and biological compoundfamilies. For example, large portions of the structures of lipids consist of nonpolar alkyl groups. Lipids include the dietaryfats and fatlike compounds called phospholipids and sphingolipids that serve as structural components of living tissues.These compounds have both polar and nonpolar groups, enabling them to bridge the gap between water-soluble and water-insoluble phases. This characteristic is essential for the selective permeability of cell membranes.
1.6.1
1.6.1
1.6.1

1.6.3 1/5/2022 https://chem.libretexts.org/@go/page/178739
Figure : Tripalmitin (a), a typical fat molecule, has long hydrocarbon chains typical of most lipids. Compare thesechains to hexadecane (b), an alkane with 16 carbon atoms.
Concept Review Exercises 1. Without referring to a table, predict which has a higher boiling point—hexane or octane. Explain.
2. If 25 mL of hexane were added to 100 mL of water in a beaker, which of the following would you expect to happen?Explain.
a. Hexane would dissolve in water.b. Hexane would not dissolve in water and would float on top.c. Hexane would not dissolve in water and would sink to the bottom of the container.
Answers
1. octane because of its greater molar mass
2. b; hexane is insoluble in water and less dense than water.
Key Takeaway Alkanes are nonpolar compounds that are low boiling and insoluble in water.
Exercises
1. Without referring to a table or other reference, predict which member of each pair has the higher boiling point.
a. pentane or butaneb. heptane or nonane
2. For which member of each pair is hexane a good solvent?
a. pentane or waterb. sodium chloride or soybean oil
Answer
a. 1. pentaneb. nonane
1.6.2

1.7.1 1/5/2022 https://chem.libretexts.org/@go/page/178740
1.7: Chemical Properties of AlkanesLearning Objectives
To identify the main chemical properties of alkanes.
Alkane molecules are nonpolar and therefore generally do not react with ionic compounds such as most laboratory acids,bases, oxidizing agents, or reducing agents. Consider butane as an example:
Neither positive ions nor negative ions are attracted to a nonpolar molecule. In fact, the alkanes undergo so few reactionsthat they are sometimes called paraffins, from the Latin parum affinis, meaning “little affinity.”
Two important reactions that the alkanes do undergo are combustion and halogenation. Nothing happens when alkanes aremerely mixed with oxygen ( ) at room temperature, but when a flame or spark provides the activation energy, a highlyexothermic combustion reaction proceeds vigorously. For methane (CH ), the reaction is as follows:
If the reactants are adequately mixed and there is sufficient oxygen, the only products are carbon dioxide ( ), water (), and heat—heat for cooking foods, heating homes, and drying clothes. Because conditions are rarely ideal, however,
other products are frequently formed. When the oxygen supply is limited, carbon monoxide ( ) is a by-product:
This reaction is responsible for dozens of deaths each year from unventilated or improperly adjusted gas heaters. (Similarreactions with similar results occur with kerosene heaters.)
Alkanes also react with the halogens chlorine ( ) and bromine ( ) in the presence of ultraviolet light or at hightemperatures to yield chlorinated and brominated alkanes. For example, chlorine reacts with excess methane ( ) togive methyl chloride ( ).
With more chlorine, a mixture of products is obtained: CH Cl, CH Cl , CHCl , and CCl . Fluorine ( ), the lightesthalogen, combines explosively with most hydrocarbons. Iodine ( ) is relatively unreactive. Fluorinated and iodinatedalkanes are produced by indirect methods.
Concept Review Exercises 1. Why are alkanes sometimes called paraffins?2. Which halogen reacts most readily with alkanes? Which reacts least readily?
Answers 1. Alkanes do not react with many common chemicals. They are sometimes called paraffins, from the Latin parum affinis,
meaning “little affinity.”2. most readily: ; least readily:
Key Takeaway Alkanes react with oxygen (combustion) and with halogens (halogenation).
O2
4
C +2 → C +2 O +heatH4 O2 O2 H2 (1.7.1)
CO2
OH2
CO
2C +3 → 2CO +4 OH4 O2 H2 (1.7.2)
Cl2 Br2
CH4
C ClH3
C +C → C Cl +HClH4 l2 H3 (1.7.3)
3 2 2 3 4 F2
I2
F2 I2

1.7.2 1/5/2022 https://chem.libretexts.org/@go/page/178740
Exercises 1. Why do alkanes usually not react with ionic compounds such as most laboratory acids, bases, oxidizing agents, or
reducing agents?2. Write an equation for the complete combustion of methane ( ), the main component of natural gas).3. What is the most important reaction of alkanes?4. Name some substances other than oxygen that react readily with alkanes.
Answers
1. Alkanes are nonpolar; they do not attract ions.
CH4

1.8.1 1/5/2022 https://chem.libretexts.org/@go/page/178741
1.8: CycloalkanesLearning Objectives
To name cycloalkanes given their formulas and write formulas for these compounds given their names.
The hydrocarbons we have encountered so far have been composed of molecules with open-ended chains of carbon atoms.When a chain contains three or more carbon atoms, the atoms can join to form ring or cyclic structures. The simplest ofthese cyclic hydrocarbons has the formula C H . Each carbon atom has two hydrogen atoms attached (Figure ) and iscalled cyclopropane.
Figure : Ball-and-Spring Model of Cyclopropane. The springs are bent to join the carbon atoms.
To Your Health: Cyclopropane as an Anesthetic With its boiling point of −33°C, cyclopropane is a gas at room temperature. It is also a potent, quick-acting anesthetic withfew undesirable side effects in the body. It is no longer used in surgery, however, because it forms explosive mixtures withair at nearly all concentrations.
The cycloalkanes—cyclic hydrocarbons with only single bonds—are named by adding the prefix cyclo- to the name of theopen-chain compound having the same number of carbon atoms as there are in the ring. Thus the name for the cycliccompound C H is cyclobutane. The carbon atoms in cyclic compounds can be represented by line-angle formulas thatresult in regular geometric figures. Keep in mind, however, that each corner of the geometric figure represents a carbonatom plus as many hydrogen atoms as needed to give each carbon atom four bonds.
Some cyclic compounds have substituent groups attached. Example interprets the name of a cycloalkane with asingle substituent group.
Example
Draw the structure for each compound.
a. cyclopentaneb. methylcyclobutane
SOLUTION
a. The name cyclopentane indicates a cyclic (cyclo) alkane with five (pent-) carbon atoms. It can be represented as apentagon.
b. The name methylcyclobutane indicates a cyclic alkane with four (but-) carbon atoms in the cyclic part. It can berepresented as a square with a CH group attached.
3 6 1.8.1
1.8.1
4 8
1.8.1
1.8.1
3

1.8.2 1/5/2022 https://chem.libretexts.org/@go/page/178741
Exercise Draw the structure for each compound.
a. cycloheptaneb. ethylcyclohexane
The properties of cyclic hydrocarbons are generally quite similar to those of the corresponding open-chain compounds. Socycloalkanes (with the exception of cyclopropane, which has a highly strained ring) act very much like noncyclic alkanes.Cyclic structures containing five or six carbon atoms, such as cyclopentane and cyclohexane, are particularly stable. Wewill see later that some carbohydrates (sugars) form five- or six-membered rings in solution.
The cyclopropane ring is strained because the C–C–C angles are 60°, and the preferred (tetrahedral) bond angle is109.5°. (This strain is readily evident when you try to build a ball-and-stick model of cyclopropane; see Figure .)Cyclopentane and cyclohexane rings have little strain because the C–C–C angles are near the preferred angles.
Concept Review Exercises1. What is the molecular formula of cyclooctane?
2. What is the IUPAC name for this compound?
Answers
1. C H
2. ethylcyclopropane
Key TakeawayMany organic compounds have cyclic structures.
Exercises 1. Draw the structure for each compound.
a. ethylcyclobutaneb. propylcyclopropane
2. Draw the structure for each compound.
a. methylcyclohexaneb. butylcyclobutane
3. Cycloalkyl groups can be derived from cycloalkanes in the same way that alkyl groups are derived from alkanes. Thesegroups are named as cyclopropyl, cyclobutyl, and so on. Name each cycloalkyl halide.
a.
1.8.1
1.8.1
8 16

1.8.3 1/5/2022 https://chem.libretexts.org/@go/page/178741
b.
4. Halogenated cycloalkanes can be named by the IUPAC system. As with alkyl derivatives, monosubstituted derivativesneed no number to indicate the position of the halogen. To name disubstituted derivatives, the carbon atoms arenumbered starting at the position of one substituent (C1) and proceeding to the second substituted atom by the shortestroute. Name each compound.
a.
b.
Answers
1. a.
b.
a. 3. cyclopentyl bromideb. cyclohexyl chloride

1.9.1 12/7/2021 https://chem.libretexts.org/@go/page/178742
1.9: Organic Chemistry: AlkanesTo ensure that you understand the material in this chapter, you should review the meanings of the following bold terms in
the summary and ask yourself how they relate to the topics in the chapter.
Organic chemistry is the chemistry of carbon compounds, and inorganic chemistry is the chemistry of all the otherelements. Carbon atoms can form stable covalent bonds with other carbon atoms and with atoms of other elements, andthis property allows the formation the tens of millions of organic compounds. Hydrocarbons contain only hydrogen andcarbon atoms.
Hydrocarbons in which each carbon atom is bonded to four other atoms are called alkanes or saturated hydrocarbons.They have the general formula C H . Any given alkane differs from the next one in a series by a CH unit. Any familyof compounds in which adjacent members differ from each other by a definite factor is called a homologous series.
Carbon atoms in alkanes can form straight chains or branched chains. Two or more compounds having the same molecularformula but different structural formulas are isomers of each other. There are no isomeric forms for the three smallestalkanes; beginning with C H , all other alkanes have isomeric forms.
A structural formula shows all the carbon and hydrogen atoms and how they are attached to one another. A condensedstructural formula shows the hydrogen atoms right next to the carbon atoms to which they are attached. A line-angleformula is a formula in which carbon atoms are implied at the corners and ends of lines. Each carbon atom is understoodto be attached to enough hydrogen atoms to give each carbon atom four bonds.
The IUPAC System of Nomenclature provides rules for naming organic compounds. An alkyl group is a unit formed byremoving one hydrogen atom from an alkane.
The physical properties of alkanes reflect the fact that alkane molecules are nonpolar. Alkanes are insoluble in water andless dense than water.
Alkanes are generally unreactive toward laboratory acids, bases, oxidizing agents, and reducing agents. They do burn(undergo combustion reactions).
Alkanes react with halogens by substituting one or more halogen atoms for hydrogen atoms to form halogenatedhydrocarbons. An alkyl halide (haloalkane) is a compound resulting from the replacement of a hydrogen atom of analkane with a halogen atom.
Cycloalkanes are hydrocarbons whose molecules are closed rings rather than straight or branched chains. A cyclichydrocarbon is a hydrocarbon with a ring of carbon atoms
n 2n + 2 2
4 10

1.10.1 1/2/2022 https://chem.libretexts.org/@go/page/178744
1.10: Alkenes: Structures and NamesLearning Objectives
To name alkenes given formulas and write formulas for alkenes given names.
As noted before, alkenes are hydrocarbons with carbon-to-carbon double bonds (R C=CR ) and alkynes are hydrocarbonswith carbon-to-carbon triple bonds (R–C≡C–R). Collectively, they are called unsaturated hydrocarbons because they havefewer hydrogen atoms than does an alkane with the same number of carbon atoms, as is indicated in the following generalformulas:
Some representative alkenes—their names, structures, and physical properties—are given in Table .
Table : Physical Properties of Some Selected Alkenes
IUPAC Name Molecular Formula Condensed StructuralFormula
Melting Point (°C) Boiling Point (°C)
ethene C H CH =CH –169 –104
propene C H CH =CHCH –185 –47
1-butene C H CH =CHCH CH –185 –6
1-pentene C H CH =CH(CH ) CH –138 30
1-hexene C H CH =CH(CH ) CH –140 63
1-heptene C H CH =CH(CH ) CH –119 94
1-octene C H CH =CH(CH ) CH –102 121
We used only condensed structural formulas in Table . Thus, CH =CH stands for
The double bond is shared by the two carbonnd does not involve the hydrogen atoms, although the condensed formuladoes not make this point obvious. Note that the molecular formula for ethene is C H , whereas that for ethane is C H .
The first two alkenes in Table , ethene and propene, are most often called by their common names—ethylene andpropylene, respectively (Figure ). Ethylene is a major commercial chemical. The US chemical industry producesabout 25 billion kilograms of ethylene annually, more than any other synthetic organic chemical. More than half of thisethylene goes into the manufacture of polyethylene, one of the most familiar plastics. Propylene is also an importantindustrial chemical. It is converted to plastics, isopropyl alcohol, and a variety of other products.
2 2
1.10.1
1.10.1
2 4 2 2
3 6 2 3
4 8 2 2 3
5 10 2 2 2 3
6 12 2 2 3 3
7 14 2 2 4 3
8 16 2 2 5 3
1.10.1 2 2
2 4 2 6
1.10.1
1.10.1

1.10.2 1/2/2022 https://chem.libretexts.org/@go/page/178744
Figure : Ethene and Propene. The ball-and-spring models of ethene/ethylene (a) and propene/propylene (b) showtheir respective shapes, especially bond angles.
Although there is only one alkene with the formula C H (ethene) and only one with the formula C H (propene), thereare several alkenes with the formula C H .
Here are some basic rules for naming alkenes from the International Union of Pure and Applied Chemistry (IUPAC):
1. The longest chain of carbon atoms containing the double bond is considered the parent chain. It is named using thesame stem as the alkane having the same number of carbon atoms but ends in -ene to identify it as an alkene. Thus thecompound CH =CHCH is propene.
2. If there are four or more carbon atoms in a chain, we must indicate the position of the double bond. The carbons atomsare numbered so that the first of the two that are doubly bonded is given the lower of the two possible numbers.Thecompound CH CH=CHCH CH , for example, has the double bond between the second and third carbon atoms. Itsname is 2-pentene (not 3-pentene).
3. Substituent groups are named as with alkanes, and their position is indicated by a number. Thus,
is 5-methyl-2-hexene. Note that the numbering of the parent chain is always done in such a way as to give thedouble bond the lowest number, even if that causes a substituent to have a higher number. The double bond alwayshas priority in numbering.
Example
Name each compound.
a.
b.
SOLUTION
a. The longest chain containing the double bond has five carbon atoms, so the compound is a pentene (rule 1). To givethe first carbon atom of the double bond the lowest number (rule 2), we number from the left, so the compound is a2-pentene. There is a methyl group on the fourth carbon atom (rule 3), so the compound’s name is 4-methyl-2-pentene.
b. The longest chain containing the double bond has five carbon atoms, so the parent compound is a pentene (rule 1).To give the first carbon atom of the double bond the lowest number (rule 2), we number from the left, so the
1.10.1
2 4 3 6
4 8
2 3
3 2 3
1.10.1

1.10.3 1/2/2022 https://chem.libretexts.org/@go/page/178744
compound is a 2-pentene. There is a methyl group on the third carbon atom (rule 3), so the compound’s name is 3-methyl-2-pentene.
Exercise
Name each compound.
1. CH CH CH CH CH CH=CHCH
2.
Just as there are cycloalkanes, there are cycloalkenes. These compounds are named like alkenes, but with the prefix cyclo-attached to the beginning of the parent alkene name.
Example Draw the structure for each compound.
1. 3-methyl-2-pentene2. cyclohexene
SOLUTION
1. First write the parent chain of five carbon atoms: C–C–C–C–C. Then add the double bond between the second andthird carbon atoms:
Now place the methyl group on the third carbon atom and add enough hydrogen atoms to give each carbon atom atotal of four bonds.
2. First, consider what each of the three parts of the name means. Cyclo means a ring compound, hex means 6 carbonatoms, and -ene means a double bond.
Exercise
Draw the structure for each compound.
a. 2-ethyl-1-hexeneb. cyclopentene
Concept Review Exercises
1. Briefly identify the important distinctions between a saturated hydrocarbon and an unsaturated hydrocarbon.
2. Briefly identify the important distinctions between an alkene and an alkane.
3. Classify each compound as saturated or unsaturated. Identify each as an alkane, an alkene, or an alkyne.
a.
1.10.1
3 2 2 2 2 3
1.10.2
1.10.2

1.10.4 1/2/2022 https://chem.libretexts.org/@go/page/178744
b. CH CH C≡CCH
c.
Answers
1. Unsaturated hydrocarbons have double or triple bonds and are quite reactive; saturated hydrocarbons have only singlebonds and are rather unreactive.
2. An alkene has a double bond; an alkane has single bonds only.
a. 3. saturated; alkaneb. unsaturated; alkynec. unsaturated; alkene
Key TakeawayAlkenes are hydrocarbons with a carbon-to-carbon double bond.
Exercises
1. Draw the structure for each compound.
a. 2-methyl-2-penteneb. 2,3-dimethyl-1-butenec. cyclohexene
2. Draw the structure for each compound.
a. 5-methyl-1-hexeneb. 3-ethyl-2-pentenec. 4-methyl-2-hexene
3. Name each compound according to the IUPAC system.
a.
b.
c.
4. Name each compound according to the IUPAC system.
a.
b.
3 2 3
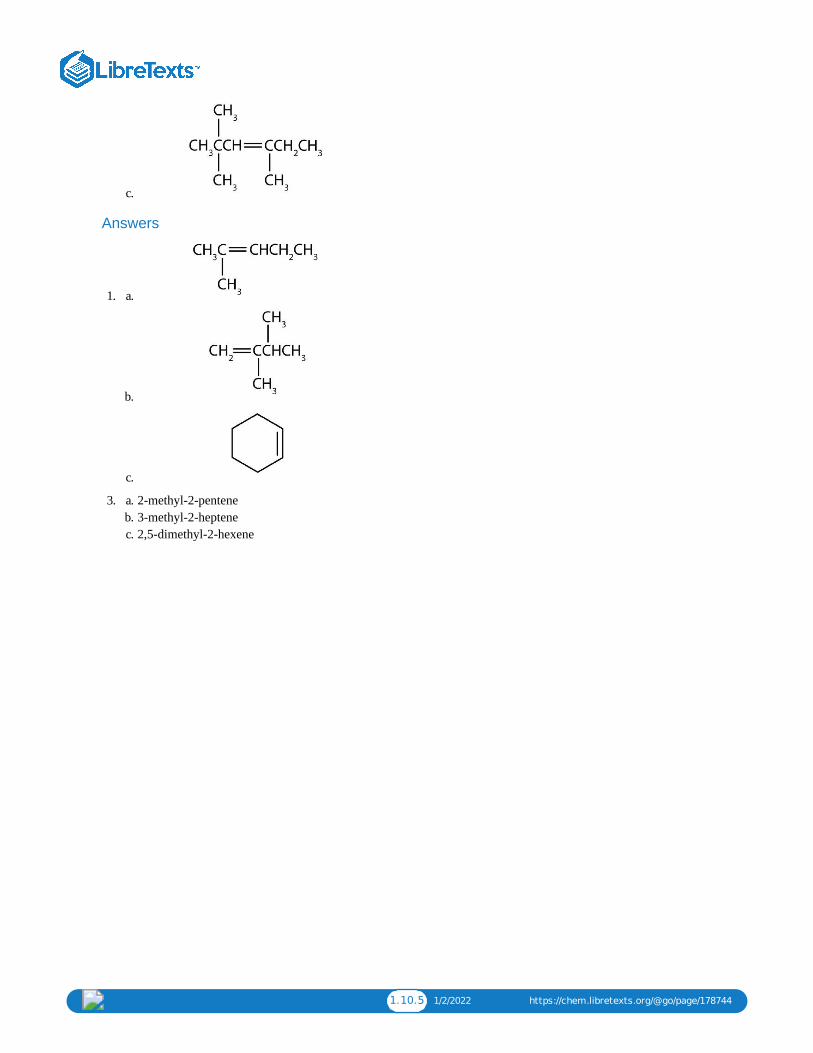
1.10.5 1/2/2022 https://chem.libretexts.org/@go/page/178744
c.
Answers
1. a.
b.
c.
a. 3. 2-methyl-2-penteneb. 3-methyl-2-heptenec. 2,5-dimethyl-2-hexene

1.11.1 12/26/2021 https://chem.libretexts.org/@go/page/178745
1.11: Cis-Trans Isomers (Geometric Isomers)Learning Objectives
Recognize that alkenes that can exist as cis-trans isomers.Classify isomers as cis or trans.Draw structures for cis-trans isomers given their names.
There is free rotation about the carbon-to-carbon single bonds (C–C) in alkanes. In contrast, the structure of alkenesrequires that the carbon atoms of a double bond and the two atoms bonded to each carbon atom all lie in a single plane, andthat each doubly bonded carbon atom lies in the center of a triangle. This part of the molecule’s structure is rigid; rotationabout doubly bonded carbon atoms is not possible without rupturing the bond. Look at the two chlorinated hydrocarbons inFigure .
Table : Rotation about Bonds. In 1,2-dichloroethane (a), free rotation about the C–C bond allows the twostructures to be interconverted by a twist of one end relative to the other. In 1,2-dichloroethene (b), restricted rotation
about the double bond means that the relative positions of substituent groups above or below the double bond aresignificant.
In 1,2-dichloroethane (part (a) of Figure ), there is free rotation about the C–C bond. The two models shownrepresent exactly the same molecule; they are not isomers. You can draw structural formulas that look different, but if youbear in mind the possibility of this free rotation about single bonds, you should recognize that these two structuresrepresent the same molecule:
In 1,2-dichloroethene (Figure ), however, restricted rotation about the double bond means that the relative positionsof substituent groups above or below the double bond become significant. This leads to a special kind of isomerism. Theisomer in which the two chlorine (Cl) atoms lie on the same side of the molecule is called the cis isomer (Latin cis,meaning “on this side”) and is named cis-1,2-dichloroethene. The isomer with the two Cl atoms on opposite sides of themolecule is the trans isomer (Latin trans, meaning “across”) and is named trans-1,2-dichloroethene. These two compoundsare cis-trans isomers (or geometric isomers), compounds that have different configurations (groups permanently indifferent places in space) because of the presence of a rigid structure in their molecule.
Consider the alkene with the condensed structural formula CH CH=CHCH . We could name it 2-butene, but there areactually two such compounds; the double bond results in cis-trans isomerism (Figure ).
1.11.1
1.11.1
1.11.1
1.11.1b
3 31.11.2

1.11.2 12/26/2021 https://chem.libretexts.org/@go/page/178745
Figure : Ball-and-Spring Models of (a) Cis-2-Butene and (b) Trans-2-Butene. Cis-trans isomers have differentphysical, chemical, and physiological properties.
Cis-2-butene has both methyl groups on the same side of the molecule. Trans-2-butene has the methyl groups on oppositesides of the molecule. Their structural formulas are as follows:
Figure : Models of (left) Cis-2-Butene and (right) Trans-2-Butene.
Note, however, that the presence of a double bond does not necessarily lead to cis-trans isomerism (Figure ). We candraw two seemingly different propenes:
Figure : Different views of the propene molecule (flip vertically). These are not isomers.
However, these two structures are not really different from each other. If you could pick up either molecule from the pageand flip it over top to bottom, you would see that the two formulas are identical. Thus there are two requirements for cis-trans isomerism:
1. Rotation must be restricted in the molecule.2. There must be two nonidentical groups on each doubly bonded carbon atom.
In these propene structures, the second requirement for cis-trans isomerism is not fulfilled. One of the doubly bondedcarbon atoms does have two different groups attached, but the rules require that both carbon atoms have two differentgroups. In general, the following statements hold true in cis-trans isomerism:
Alkenes with a C=CH unit do not exist as cis-trans isomers.Alkenes with a C=CR unit, where the two R groups are the same, do not exist as cis-trans isomers.Alkenes of the type R–CH=CH–R can exist as cis and trans isomers; cis if the two R groups are on the same side of thecarbon-to-carbon double bond, and trans if the two R groups are on opposite sides of the carbon-to-carbon doublebond.
Advanced Note: E/Z IsomerizationIf a molecule has a C=C bond with one non-hydrogen group attached to each of the carbons, cis/trans nomenclaturedescried above is enough to describe it. However, if you have three different groups (or four), then the cis/transapproach is insufficient to describe the different isomers, since we do not know which two of the three groups are beingdescribed. For example, if you have a C=C bond, with a methyl group and a bromine on one carbon , and an ethylgroup on the other, it is neither trans nor cis, since it is not clear whether the ethyl group is trans to the bromine or themethyl. This is addressed with a more advanced E/Z nomenclature discussed elsewhere.
Cis-trans isomerism also occurs in cyclic compounds. In ring structures, groups are unable to rotate about any of the ringcarbon–carbon bonds. Therefore, groups can be either on the same side of the ring (cis) or on opposite sides of the ring(trans). For our purposes here, we represent all cycloalkanes as planar structures, and we indicate the positions of thegroups, either above or below the plane of the ring.
1.11.2
1.11.3
1.11.4
1.11.4
2
2

1.11.3 12/26/2021 https://chem.libretexts.org/@go/page/178745
Example Which compounds can exist as cis-trans (geometric) isomers? Draw them.
1. CHCl=CHBr2. CH =CBrCH3. (CH ) C=CHCH CH4. CH CH=CHCH CH
SOLUTION
All four structures have a double bond and thus meet rule 1 for cis-trans isomerism.
1. This compound meets rule 2; it has two nonidentical groups on each carbon atom (H and Cl on one and H and Br onthe other). It exists as both cis and trans isomers:
2. This compound has two hydrogen atoms on one of its doubly bonded carbon atoms; it fails rule 2 and does not existas cis and trans isomers.
3. This compound has two methyl (CH ) groups on one of its doubly bonded carbon atoms. It fails rule 2 and does notexist as cis and trans isomers.
4. This compound meets rule 2; it has two nonidentical groups on each carbon atom and exists as both cis and transisomers:
Exercise
Which compounds can exist as cis-trans isomers? Draw them.
a. CH =CHCH CH CHb. CH CH=CHCH CHc. CH CH CH=CHCH CH
d.
e.
Concept Review Exercises
1. What are cis-trans (geometric) isomers? What two types of compounds can exhibit cis-trans isomerism?
2. Classify each compound as a cis isomer, a trans isomer, or neither.
1.11.1
2 3
3 2 2 3
3 2 3
3
1.11.1
2 2 2 3
3 2 3
3 2 2 3

1.11.4 12/26/2021 https://chem.libretexts.org/@go/page/178745
a.
b.
c.
d.
Answers 1. Cis-trans isomers are compounds that have different configurations (groups permanently in different places in space)
because of the presence of a rigid structure in their molecule. Alkenes and cyclic compounds can exhibit cis-transisomerism.
a. 2. trans (the two hydrogen atoms are on opposite sides)b. cis (the two hydrogen atoms are on the same side, as are the two ethyl groups)c. cis (the two ethyl groups are on the same side)d. neither (fliping the bond does not change the molecule. There are no isomers for this molecule)
Key Takeaway Cis-trans (geometric) isomerism exists when there is restricted rotation in a molecule and there are two nonidenticalgroups on each doubly bonded carbon atom.
Exercises1. Draw the structures of the cis-trans isomers for each compound. Label them cis and trans. If no cis-trans isomers exist,
write none.
a. 2-bromo-2-penteneb. 3-hexenec. 4-methyl-2-pentened. 1,1-dibromo-1-butenee. 2-butenoic acid (CH CH=CHCOOH)
2. Draw the structures of the cis-trans isomers for each compound. Label them cis and trans. If no cis-trans isomers exist,write none.
a. 2,3-dimethyl-2-penteneb. 1,1-dimethyl-2-ethylcyclopropanec. 1,2-dimethylcyclohexaned. 5-methyl-2-hexenee. 1,2,3-trimethylcyclopropane
Answer 1. a: none. There are two distinct geometric isomers, but since there are there are four different groups off the double
bond, these are both cis/trans isomers (they are technically E/Z isomers discussed elsewhere).
3

1.11.5 12/26/2021 https://chem.libretexts.org/@go/page/178745
b:
c:
d:
e:

1.12.1 1/7/2022 https://chem.libretexts.org/@go/page/178746
1.12: Physical Properties of AlkenesLearning Objectives
To identify the physical properties of alkenes and describe trends in these properties.
The physical properties of alkenes are similar to those of the alkanes. The table at the start of the chapter shows that theboiling points of straight-chain alkenes increase with increasing molar mass, just as with alkanes. For molecules with thesame number of carbon atoms and the same general shape, the boiling points usually differ only slightly, just as we wouldexpect for substances whose molar mass differs by only 2 u (equivalent to two hydrogen atoms). Like other hydrocarbons,the alkenes are insoluble in water but soluble in organic solvents.
Looking Closer: Environmental Note
Alkenes occur widely in nature. Ripening fruits and vegetables give off ethylene, which triggers further ripening. Fruitprocessors artificially introduce ethylene to hasten the ripening process; exposure to as little as 0.1 mg of ethylene for 24 hcan ripen 1 kg of tomatoes. Unfortunately, this process does not exactly duplicate the ripening process, and tomatoespicked green and treated this way don’t taste much like vine-ripened tomatoes fresh from the garden.
The bright red color of tomatoes is due to lycopene—a polyene.
Other alkenes that occur in nature include 1-octene, a constituent of lemon oil, and octadecene (C H ) found in fish liver.Dienes (two double bonds) and polyenes (three or more double bonds) are also common. Butadiene (CH =CHCH=CH ) isfound in coffee. Lycopene and the carotenes are isomeric polyenes (C H ) that give the attractive red, orange, and yellowcolors to watermelons, tomatoes, carrots, and other fruits and vegetables. Vitamin A, essential to good vision, is derivedfrom a carotene. The world would be a much less colorful place without alkenes.
Concept Review Exercises 1. Briefly describe the physical properties of alkenes. How do these properties compare to those of the alkanes?
2. Without consulting tables, arrange the following alkenes in order of increasing boiling point: 1-butene, ethene, 1-hexene, and propene.
Answers 1. Alkenes have physical properties (low boiling points, insoluble in water) quite similar to those of their corresponding
alkanes.
2. ethene < propene < 1-butene < 1-hexene
Key Takeaway The physical properties of alkenes are much like those of the alkanes: their boiling points increase with increasingmolar mass, and they are insoluble in water.
Exercises1. Without referring to a table or other reference, predict which member of each pair has the higher boiling point.
18 36
2 2
40 56

1.12.2 1/7/2022 https://chem.libretexts.org/@go/page/178746
a. 1-pentene or 1-buteneb. 3-heptene or 3-nonene
2. Which is a good solvent for cyclohexene, pentane or water?
Answer a. 1. 1-penteneb. 3-nonene

1.13.1 12/14/2021 https://chem.libretexts.org/@go/page/178747
1.13: Chemical Properties of AlkenesLearning Objectives
To write equations for the addition reactions of alkenes with hydrogen, halogens, and water
Alkenes are valued mainly for addition reactions, in which one of the bonds in the double bond is broken. Each of thecarbon atoms in the bond can then attach another atom or group while remaining joined to each other by a single bond.Perhaps the simplest addition reaction ishydrogenation—a reaction with hydrogen (H ) in the presence of a catalyst suchas nickel (Ni) or platinum (Pt).
The product is an alkane having the same carbon skeleton as the alkene.
Alkenes also readily undergo halogenation—the addition of halogens. Indeed, the reaction with bromine (Br ) can be usedto test for alkenes. Bromine solutions are brownish red. When we add a Br solution to an alkene, the color of the solutiondisappears because the alkene reacts with the bromine:
Another important addition reaction is that between an alkene and water to form an alcohol. This reaction, calledhydration, requires a catalyst—usually a strong acid, such as sulfuric acid (H SO ):
The hydration reaction is discussed later, where we deal with this reaction in the synthesis of alcohols.
Example Write the equation for the reaction between CH CH=CHCH and each substance.
a. H (Ni catalyst)b. Brc. H O (H SO catalyst)
SOLUTION
In each reaction, the reagent adds across the double bond.
a.
2
2
2
2 4
1.13.1
3 3
2
2
2 2 4

1.13.2 12/14/2021 https://chem.libretexts.org/@go/page/178747
b.
c.
Exercise
Write the equation for each reaction.
a. CH CH CH=CH with H (Ni catalyst)b. CH CH=CH with Clc. CH CH CH=CHCH CH with H O (H SO catalyst)
Concept Review Exercises 1. What is the principal difference in properties between alkenes and alkanes? How are they alike?2. If C H reacts with HBr in an addition reaction, what is the molecular formula of the product?
Answers1. Alkenes undergo addition reactions; alkanes do not. Both burn.2. C H Br
Key Takeaway Alkenes undergo addition reactions, adding such substances as hydrogen, bromine, and water across the carbon-to-carbon double bond.
Exercises 1. Complete each equation.
a. (CH ) C=CH + Br →
b.
c.
2. Complete each equation.
a.
b.
c.
1.13.1
3 2 2 2
3 2 2
3 2 2 3 2 2 4
12 24
12 24 2
3 2 2 2
C =C(C )C C +H2 H3 H2 H3 H2 −→Ni
C =CHCH=C +2H2 H2 H2 −→Ni
(C C=C(C + OH3)2 H3)2 H2 − →−−−SH2 O4

1.13.3 12/14/2021 https://chem.libretexts.org/@go/page/178747
Answera. 1. (CH ) CBrCH Brb. CH CH(CH )CH CH
c.
3 2 2
3 3 2 3

1.14.1 1/5/2022 https://chem.libretexts.org/@go/page/178748
1.14: AlkynesLearning Objectives
Describe the general physical and chemical properties of alkynes.Name alkynes given formulas and write formulas for alkynes given names.
The simplest alkyne—a hydrocarbon with carbon-to-carbon triple bond—has the molecular formula C H and is known byits common name—acetylene (Figure ). Its structure is H–C≡C–H.
Figure : Ball-and-Spring Model of Acetylene. Acetylene (ethyne) is the simplest member of the alkyne family.
Acetylene is used in oxyacetylene torches for cutting and welding metals. The flame from such a torch can be very hot.Most acetylene, however, is converted to chemical intermediates that are used to make vinyl and acrylic plastics, fibers,resins, and a variety of other products.
Alkynes are similar to alkenes in both physical and chemical properties. For example, alkynes undergo many of the typicaladdition reactions of alkenes. The International Union of Pure and Applied Chemistry (IUPAC) names for alkynes parallelthose of alkenes, except that the family ending is -yne rather than -ene. The IUPAC name for acetylene is ethyne. Thenames of other alkynes are illustrated in the following exercises.
Concept Review Exercises 1. Briefly identify the important differences between an alkene and an alkyne. How are they similar?2. The alkene (CH ) CHCH CH=CH is named 4-methyl-1-pentene. What is the name of (CH ) CHCH C≡CH?3. Do alkynes show cis-trans isomerism? Explain.
Answers 1. Alkenes have double bonds; alkynes have triple bonds. Both undergo addition reactions.2. 4-methyl-1-pentyne3. No; a triply bonded carbon atom can form only one other bond. It would have to have two groups attached to show cis-
trans isomerism.
Key Takeaway Alkynes are hydrocarbons with carbon-to-carbon triple bonds and properties much like those of alkenes.
Exercises
1. Draw the structure for each compound.
a. acetyleneb. 3-methyl-1-hexyne
2. Draw the structure for each compound.
a. 4-methyl-2-hexyneb. 3-octyne
3. Name each alkyne.
a. CH CH CH C≡CHb. CH CH CH C≡CCH
2 21.14.1
1.14.1
3 2 2 2 3 2 2
3 2 2
3 2 2 3

1.14.2 1/5/2022 https://chem.libretexts.org/@go/page/178748
Answers a. 1. H–C≡C–H
b.
a. 3. 1-pentyneb. 2-hexyne

1.15.1 1/7/2022 https://chem.libretexts.org/@go/page/178749
1.15: Aromatic Compounds: BenzeneLearning Objectives
To describe the bonding in benzene and the way typical reactions of benzene differ from those of the alkenes.
Next we consider a class of hydrocarbons with molecular formulas like those of unsaturated hydrocarbons, but which,unlike the alkenes, do not readily undergo addition reactions. These compounds comprise a distinct class, called aromatichydrocarbons, with unique structures and properties. We start with the simplest of these compounds. Benzene (C H ) is ofgreat commercial importance, but it also has noteworthy health effects.
The formula C H seems to indicate that benzene has a high degree of unsaturation. (Hexane, the saturated hydrocarbonwith six carbon atoms has the formula C H —eight more hydrogen atoms than benzene.) However, despite the seeminglow level of saturation, benzene is rather unreactive. It does not, for example, react readily with bromine, which, is a testfor unsaturation.
Benzene is a liquid that smells like gasoline, boils at 80°C, and freezes at 5.5°C. It is the aromatic hydrocarbonproduced in the largest volume. It was formerly used to decaffeinate coffee and was a significant component of manyconsumer products, such as paint strippers, rubber cements, and home dry-cleaning spot removers. It was removed frommany product formulations in the 1950s, but others continued to use benzene in products until the 1970s when it wasassociated with leukemia deaths. Benzene is still important in industry as a precursor in the production of plastics (suchas Styrofoam and nylon), drugs, detergents, synthetic rubber, pesticides, and dyes. It is used as a solvent for such thingsas cleaning and maintaining printing equipment and for adhesives such as those used to attach soles to shoes. Benzeneis a natural constituent of petroleum products, but because it is a known carcinogen, its use as an additive in gasoline isnow limited.
To explain the surprising properties of benzene, chemists suppose the molecule has a cyclic, hexagonal, planar structure ofsix carbon atoms with one hydrogen atom bonded to each. We can write a structure with alternate single and double bonds,either as a full structural formula or as a line-angle formula:
However, these structures do not explain the unique properties of benzene. Furthermore, experimental evidence indicatesthat all the carbon-to-carbon bonds in benzene are equivalent, and the molecule is unusually stable. Chemists oftenrepresent benzene as a hexagon with an inscribed circle:
The inner circle indicates that the valence electrons are shared equally by all six carbon atoms (that is, the electrons aredelocalized, or spread out, over all the carbon atoms). It is understood that each corner of the hexagon is occupied by onecarbon atom, and each carbon atom has one hydrogen atom attached to it. Any other atom or groups of atoms substitutedfor a hydrogen atom must be shown bonded to a particular corner of the hexagon. We use this modern symbolism, butmany scientists still use the earlier structure with alternate double and single bonds.
To Your Health: Benzene and UsMost of the benzene used commercially comes from petroleum. It is employed as a starting material for the productionof detergents, drugs, dyes, insecticides, and plastics. Once widely used as an organic solvent, benzene is now known tohave both short- and long-term toxic effects. The inhalation of large concentrations can cause nausea and even deathdue to respiratory or heart failure, while repeated exposure leads to a progressive disease in which the ability of the
6 6
6 6
6 14

1.15.2 1/7/2022 https://chem.libretexts.org/@go/page/178749
bone marrow to make new blood cells is eventually destroyed. This results in a condition called aplastic anemia, inwhich there is a decrease in the numbers of both the red and white blood cells.
Concept Review Exercises 1. How do the typical reactions of benzene differ from those of the alkenes?2. Briefly describe the bonding in benzene.3. What does the circle mean in the chemist’s representation of benzene?
Answers1. Benzene is rather unreactive toward addition reactions compared to an alkene.2. Valence electrons are shared equally by all six carbon atoms (that is, the electrons are delocalized).3. The six electrons are shared equally by all six carbon atoms.
Concept Review Exercises
Exercises1. Draw the structure of benzene as if it had alternate single and double bonds.2. Draw the structure of benzene as chemists usually represent it today.
Answer
1.

1.16.1 1/5/2022 https://chem.libretexts.org/@go/page/178750
1.16: Structure and Nomenclature of Aromatic CompoundsLearning Objectives
Recognize aromatic compounds from structural formulas.Name aromatic compounds given formulas.Write formulas for aromatic compounds given their names.
Historically, benzene-like substances were called aromatic hydrocarbons because they had distinctive aromas. Today, anaromatic compound is any compound that contains a benzene ring or has certain benzene-like properties (but notnecessarily a strong aroma). You can recognize the aromatic compounds in this text by the presence of one or morebenzene rings in their structure. Some representative aromatic compounds and their uses are listed in Table , wherethe benzene ring is represented as C H .
Table : Some Representative Aromatic CompoundsName Structure Typical Uses
aniline C H –NHstarting material for the synthesis of dyes,drugs, resins, varnishes, perfumes; solvent;
vulcanizing rubber
benzoic acid C H –COOHfood preservative; starting material for the
synthesis of dyes and other organiccompounds; curing of tobacco
bromobenzene C H –Brstarting material for the synthesis of many
other aromatic compounds; solvent; motor oiladditive
nitrobenzene C H –NOstarting material for the synthesis of aniline;
solvent for cellulose nitrate; in soaps and shoepolish
phenol C H –OHdisinfectant; starting material for the
synthesis of resins, drugs, and other organiccompounds
toluene C H –CH
solvent; gasoline octane booster; startingmaterial for the synthesis of benzoic acid,
benzaldehyde, and many other organiccompounds
Example Which compounds are aromatic?
1.
2.
3.
4.
1.16.1
6 5
1.16.1
6 5 2
6 5
6 5
6 5 2
6 5
6 5 3
1.16.1

1.16.2 1/5/2022 https://chem.libretexts.org/@go/page/178750
SOLUTION
1. The compound has a benzene ring (with a chlorine atom substituted for one of the hydrogen atoms); it is aromatic.2. The compound is cyclic, but it does not have a benzene ring; it is not aromatic.3. The compound has a benzene ring (with a propyl group substituted for one of the hydrogen atoms); it is aromatic.4. The compound is cyclic, but it does not have a benzene ring; it is not aromatic.
Exercise Which compounds are aromatic?
1.
2.
3.
In the International Union of Pure and Applied Chemistry (IUPAC) system, aromatic hydrocarbons are named asderivatives of benzene. Figure shows four examples. In these structures, it is immaterial whether the singlesubstituent is written at the top, side, or bottom of the ring: a hexagon is symmetrical, and therefore all positions areequivalent.
Figure : Some Benzene Derivatives. These compounds are named in the usual way with the group that replaces ahydrogen atom named as a substituent group: Cl as chloro, Br as bromo, I as iodo, NO as nitro, and CH CH as ethyl.
Although some compounds are referred to exclusively by IUPAC names, some are more frequently denoted by commonnames, as is indicated in Table .
When there is more than one substituent, the corners of the hexagon are no longer equivalent, so we must designate therelative positions. There are three possible disubstituted benzenes, and we can use numbers to distinguish them (Figure
). We start numbering at the carbon atom to which one of the groups is attached and count toward the carbon atomthat bears the other substituent group by the shortest path.
1.16.1
1.16.1
1.16.1
2 3 2
1.16.1
1.16.2

1.16.3 1/5/2022 https://chem.libretexts.org/@go/page/178750
Figure : The Three Isomeric Dichlorobenzenes
In Figure , common names are also used: the prefix ortho (o-) for 1,2-disubstitution, meta (m-) for 1,3-disubstitution, and para (p-) for 1,4-disubstitution. The substituent names are listed in alphabetical order. The firstsubstituent is given the lowest number. When a common name is used, the carbon atom that bears the group responsiblefor the name is given the number 1:
Example Name each compound using both the common name and the IUPAC name.
1.
2.
3.
SOLUTION
1. The benzene ring has two chlorine atoms (dichloro) in the first and second positions. The compound is o-dichlorobenzene or 1,2-dichlorobenzene.
2. The benzene ring has a methyl (CH ) group. The compound is therefore named as a derivative of toluene. Thebromine atom is on the fourth carbon atom, counting from the methyl group. The compound is p-bromotoluene or 4-bromotoluene.
3. The benzene ring has two nitro (NO ) groups in the first and third positions. It is m-dinitrobenzene or 1,3-dinitrobenzene.
Note: The nitro (NO ) group is a common substituent in aromatic compounds. Many nitro compounds are explosive,most notably 2,4,6-trinitrotoluene (TNT).
1.16.2
1.16.2
1.16.2
3
2
2

1.16.4 1/5/2022 https://chem.libretexts.org/@go/page/178750
Exercise Name each compound using both the common name and the IUPAC name.
1.
2.
3.
Sometimes an aromatic group is found as a substituent bonded to a nonaromatic entity or to another aromatic ring. Thegroup of atoms remaining when a hydrogen atom is removed from an aromatic compound is called an aryl group. Themost common aryl group is derived from benzene (C H ) by removing one hydrogen atom (C H ) and is called a phenylgroup, from pheno, an old name for benzene.
Polycyclic Aromatic Hydrocarbons Some common aromatic hydrocarbons consist of fused benzene rings—rings that share a common side. These compoundsare called polycyclic aromatic hydrocarbons (PAHs).
The three examples shown here are colorless, crystalline solids generally obtained from coal tar. Naphthalene has apungent odor and is used in mothballs. Anthracene is used in the manufacture of certain dyes. Steroids, a large group ofnaturally occurring substances, contain the phenanthrene structure.
To Your Health: Polycyclic Aromatic Hydrocarbons and Cancer The intense heating required for distilling coal tar results in the formation of PAHs. For many years, it has been known thatworkers in coal-tar refineries are susceptible to a type of skin cancer known as tar cancer. Investigations have shown that anumber of PAHs are carcinogens. One of the most active carcinogenic compounds, benzopyrene, occurs in coal tar and hasalso been isolated from cigarette smoke, automobile exhaust gases, and charcoal-broiled steaks. It is estimated that morethan 1,000 t of benzopyrene are emitted into the air over the United States each year. Only a few milligrams ofbenzopyrene per kilogram of body weight are required to induce cancer in experimental animals.
1.16.2
6 6 6 5

1.16.5 1/5/2022 https://chem.libretexts.org/@go/page/178750
Biologically Important Compounds with Benzene Rings
Substances containing the benzene ring are common in both animals and plants, although they are more abundant in thelatter. Plants can synthesize the benzene ring from carbon dioxide, water, and inorganic materials. Animals cannotsynthesize it, but they are dependent on certain aromatic compounds for survival and therefore must obtain them fromfood. Phenylalanine, tyrosine, and tryptophan (essential amino acids) and vitamins K, B (riboflavin), and B (folic acid)all contain the benzene ring. Many important drugs, a few of which are shown in Table , also feature a benzene ring.
So far we have studied only aromatic compounds with carbon-containing rings. However, many cyclic compounds havean element other than carbon atoms in the ring. These compounds, called heterocyclic compounds, are discussed later.Some of these are heterocyclic aromatic compounds.
Table : Some Drugs That Contain a Benzene RingName Structure
aspirin
acetaminophen
ibuprofen
amphetamine
sulfanilamide
Concept Review Exercises 1. Briefly identify the important characteristics of an aromatic compound.
2. What is meant by the prefixes meta, ortho, or para? Give the name and draw the structure for a compound thatillustrates each.
3. What is a phenyl group? Give the structure for 3-phenyloctane.
Answers1. An aromatic compound is any compound that contains a benzene ring or has certain benzene-like properties.
2. meta = 1,3 disubstitution; (answers will vary)
2 91.16.2
1.16.2

1.16.6 1/5/2022 https://chem.libretexts.org/@go/page/178750
ortho = 1,2 disubstitution
para = 1,4 disubstitution or 1-bromo-4-chlorobenzene
3. phenyl group: C H or
3-phenyloctane:
Key Takeaway Aromatic compounds contain a benzene ring or have certain benzene-like properties; for our purposes, you canrecognize aromatic compounds by the presence of one or more benzene rings in their structure.
Exercises1. Is each compound aromatic?
a.
b.
2. Is each compound aromatic?
a.
6 5

1.16.7 1/5/2022 https://chem.libretexts.org/@go/page/178750
b.
3. Draw the structure for each compound.
a. tolueneb. m-diethylbenzenec. 3,5-dinitrotoluene
4. Draw the structure for each compound.
a. p-dichlorobenzeneb. naphthalenec. 1,2,4-trimethylbenzene
5. Name each compound with its IUPAC name.
a.
b.
c.
d.
6. Name each compound with its IUPAC name.
a.
b.

1.16.8 1/5/2022 https://chem.libretexts.org/@go/page/178750
c.
d.
Answersa. 1. yesb. no
3. a.
b.
c.
a. 5. ethylbenzeneb. isopropylbenzenec. o-bromotoluened. 3,5-dichlorotoluene

1.17.1 12/7/2021 https://chem.libretexts.org/@go/page/178751
1.17: Unsaturated and Aromatic Hydrocarbons (Summary)To ensure that you understand the material in this chapter, you should review the meanings of the bold terms in the
following summary and ask yourself how they relate to the topics in the chapter.
Any hydrocarbon containing either a double or triple bond is an unsaturated hydrocarbon. Alkenes have a carbon-to-carbon double bond. The general formula for alkenes with one double bond is C H . Alkenes can be straight chain,branched chain, or cyclic. Simple alkenes often have common names, but all alkenes can be named by the system of theInternational Union of Pure and Applied Chemistry.
Cis-trans isomers (or geometric isomers) are characterized by molecules that differ only in their configuration around arigid part of the structure, such as a carbon–to-carbon double bond or a ring. The molecule having two identical (or closelyrelated) atoms or groups on the same side is the cis isomer; the one having the two groups on opposite sides is the transisomer.
The physical properties of alkenes are quite similar to those of alkanes. Like other hydrocarbons, alkenes are insoluble inwater but soluble in organic solvents.
More reactive than alkanes, alkenes undergo addition reactions across the double bond:
Addition of hydrogen (hydrogenation):
CH =CH + H → CH CH
Addition of halogen (halogenation):
CH =CH + X → XCH CH X
where X = F, Cl, Br, or I.
Addition of water (hydration):
CH =CH + HOH → HCH CH OH
Alkenes also undergo addition polymerization, molecules joining together to form long-chain molecules.
…CH =CH + CH =CH + CH =CH +…→…CH CH –CH CH –CH CH –…
The reactant units are monomers, and the product is a polymer.
Alkynes have a carbon-to-carbon triple bond. The general formula for alkynes is C H . The properties of alkynes arequite similar to those of alkenes. They are named much like alkenes but with the ending -yne.
The cyclic hydrocarbon benzene (C H ) has a ring of carbon atoms. The molecule seems to be unsaturated, but it does notundergo the typical reactions expected of alkenes. The electrons that might be fixed in three double bonds are insteaddelocalized over all six carbon atoms.
A hydrocarbon containing one or more benzene rings (or other similarly stable electron arrangements) is an aromatichydrocarbon, and any related substance is an aromatic compound. One or more of the hydrogen atoms on a benzene ringcan be replaced by other atoms. When two hydrogen atoms are replaced, the product name is based on the relative positionof the replacement atoms (or atom groups). A 1,2-disubstituted benzene is designated as an ortho (o-) isomer; 1,3-, a meta(m-) isomer; and 1,4-, a para (p-) isomer. An aromatic group as a substituent is called an aryl group.
A polycyclic aromatic hydrocarbon (PAH) has fused benzene rings sharing a common side.
n 2n
2 2 2 3 3
2 2 2 2 2
2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2
n 2n − 2
6 6

1.18.1 1/5/2022 https://chem.libretexts.org/@go/page/178752
1.18: Chirality and StereoisomersStereoisomers are isomers that differ in spatial arrangement of atoms, rather than order of atomic connectivity. One of theirmost interesting type of isomer is the mirror-image stereoisomers, a non-superimposable set of two molecules that aremirror image of one another. The existence of these molecules are determined by concept known as chirality.
Introduction
Organic compounds, molecules created around a chain of carbon atom (more commonly known as carbon backbone), playan essential role in the chemistry of life. These molecules derive their importance from the energy they carry, mainly in aform of potential energy between atomic molecules. Since such potential force can be widely affected due to changes inatomic placement, it is important to understand the concept of an isomer, a molecule sharing same atomic make up asanother but differing in structural arrangements. This article will be devoted to a specific isomers called stereoisomers andits property of chirality (Figure 1).
Figure 1: Two enantiomers of a tetrahedral complex.
The concepts of steroisomerism and chirality command great deal of importance in modern organic chemistry, as theseideas helps to understand the physical and theoretical reasons behind the formation and structures of numerous organicmolecules, the main reason behind the energy embedded in these essential chemicals. In contrast to more well-knownconstitutional isomerism, which develops isotopic compounds simply by different atomic connectivity, stereoisomerismgenerally maintains equal atomic connections and orders of building blocks as well as having same numbers of atoms andtypes of elements.
What, then, makes stereoisomers so unique? To answer this question, the learner must be able to think and imagine in notjust two-dimensional images, but also three-dimensional space. This is due to the fact that stereoisomers are isomersbecause their atoms are different from others in terms of spatial arrangement.
Spatial Arrangement
First and foremost, one must understand the concept of spatial arrangement in order to understand stereoisomerism andchirality. Spatial arrangement of atoms concern how different atomic particles and molecules are situated about in thespace around the organic compound, namely its carbon chain. In this sense, spatial arrangement of an organic molecule aredifferent another if an atom is shifted in any three-dimensional direction by even one degree. This opens up a very broadpossibility of different molecules, each with their unique placement of atoms in three-dimensional space .
Stereoisomers
Stereoisomers are, as mentioned above, contain different types of isomers within itself, each with distinct characteristicsthat further separate each other as different chemical entities having different properties. Type called entaniomer are thepreviously-mentioned mirror-image stereoisomers, and will be explained in detail in this article. Another type,diastereomer, has different properties and will be introduced afterwards.
Enantiomers
This type of stereoisomer is the essential mirror-image, non-superimposable type of stereoisomer introduced in thebeginning of the article. Figure 3 provides a perfect example; note that the gray plane in the middle demotes the mirrorplane.

1.18.2 1/5/2022 https://chem.libretexts.org/@go/page/178752
Figure 2: Comparison of Chiral and Achiral Molecules. (a) Bromochlorofluoromethane is a chiral molecule whosestereocenter is designated with an asterisk. Rotation of its mirror image does not generate the original structure. To
superimpose the mirror images, bonds must be broken and reformed. (b) In contrast, dichlorofluoromethane and its mirrorimage can be rotated so they are superimposable.
Note that even if one were to flip over the left molecule over to the right, the atomic spatial arrangement will not be equal.This is equivalent to the left hand - right hand relationship, and is aptly referred to as 'handedness' in molecules. This canbe somewhat counter-intuitive, so this article recommends the reader try the 'hand' example. Place both palm facing up,and hands next to each other. Now flip either side over to the other. One hand should be showing the back of the hand,while the other one is showing the palm. They are not same and non-superimposable.
This is where the concept of chirality comes in as one of the most essential and defining idea of stereoisomerism.
Chirality
Chirality essentially means 'mirror-image, non-superimposable molecules', and to say that a molecule is chiral is to say thatits mirror image (it must have one) is not the same as it self. Whether a molecule is chiral or achiral depends upon a certainset of overlapping conditions. Figure 4 shows an example of two molecules, chiral and achiral, respectively. Notice thedistinct characteristic of the achiral molecule: it possesses two atoms of same element. In theory and reality, if one were tocreate a plane that runs through the other two atoms, they will be able to create what is known as bisecting plane: Theimages on either side of the plan is the same as the other (Figure 4).
Figure 4.
In this case, the molecule is considered 'achiral'. In other words, to distinguish chiral molecule from an achiral molecule,one must search for the existence of the bisecting plane in a molecule. All chiral molecules are deprive of bisecting plane,whether simple or complex.
As a universal rule, no molecule with different surrounding atoms are achiral. Chirality is a simple but essential idea tosupport the concept of stereoisomerism, being used to explain one type of its kind. The chemical properties of the chiralmolecule differs from its mirror image, and in this lies the significance of chilarity in relation to modern organic chemistry.

1.18.3 1/5/2022 https://chem.libretexts.org/@go/page/178752
Compounds with Multiple Chiral Centers
We turn our attention next to molecules which have more than one stereocenter. We will start with a common four-carbonsugar called D-erythrose.
A note on sugar nomenclature: biochemists use a special system to refer to the stereochemistry of sugar molecules,employing names of historical origin in addition to the designators 'D' and 'L'. You will learn about this system if you takea biochemistry class. We will use the D/L designations here to refer to different sugars, but we won't worry about learningthe system.
As you can see, D-erythrose is a chiral molecule: C and C are stereocenters, both of which have the R configuration. Inaddition, you should make a model to convince yourself that it is impossible to find a plane of symmetry through themolecule, regardless of the conformation. Does D-erythrose have an enantiomer? Of course it does – if it is a chiralmolecule, it must. The enantiomer of erythrose is its mirror image, and is named L-erythrose (once again, you should usemodels to convince yourself that these mirror images of erythrose are not superimposable).
Notice that both chiral centers in L-erythrose both have the S configuration. In a pair of enantiomers, all of the chiralcenters are of the opposite configuration.
What happens if we draw a stereoisomer of erythrose in which the configuration is S at C and R at C ? This stereoisomer,which is a sugar called D-threose, is not a mirror image of erythrose. D-threose is a diastereomer of both D-erythrose andL-erythrose.
The definition of diastereomers is simple: if two molecules are stereoisomers (same molecular formula, same connectivity,different arrangement of atoms in space) but are not enantiomers, then they are diastereomers by default. In practicalterms, this means that at least one - but not all - of the chiral centers are opposite in a pair of diastereomers. By definition,two molecules that are diastereomers are not mirror images of each other.
L-threose, the enantiomer of D-threose, has the R configuration at C and the S configuration at C . L-threose is adiastereomer of both erythrose enantiomers.
2 3
2 3
2 3

1.18.4 1/5/2022 https://chem.libretexts.org/@go/page/178752
In general, a structure with n stereocenters will have 2 different stereoisomers. (We are not considering, for the timebeing, the stereochemistry of double bonds – that will come later). For example, let's consider the glucose molecule in itsopen-chain form (recall that many sugar molecules can exist in either an open-chain or a cyclic form). There are twoenantiomers of glucose, called D-glucose and L-glucose. The D-enantiomer is the common sugar that our bodies use forenergy. It has n = 4 stereocenters, so therefore there are 2 = 2 = 16 possible stereoisomers (including D-glucose itself).
In L-glucose, all of the stereocenters are inverted relative to D-glucose. That leaves 14 diastereomers of D-glucose: theseare molecules in which at least one, but not all, of the stereocenters are inverted relative to D-glucose. One of these 14diastereomers, a sugar called D-galactose, is shown above: in D-galactose, one of four stereocenters is inverted relative toD-glucose. Diastereomers which differ in only one stereocenter (out of two or more) are called epimers. D-glucose and D-galactose can therefore be refered to as epimers as well as diastereomers.
Example 3.10Draw the structure of L-galactose, the enantiomer of D-galactose.
Solution
Example 3.11Draw the structure of two more diastereomers of D-glucose. One should be an epimer.
Solution
Erythronolide B, a precursor to the 'macrocyclic' antibiotic erythromycin, has 10 stereocenters. It’s enantiomer is thatmolecule in which all 10 stereocenters are inverted.
In total, there are 2 = 1024 stereoisomers in the erythronolide B family: 1022 of these are diastereomers of the structureabove, one is the enantiomer of the structure above, and the last is the structure above.
We know that enantiomers have identical physical properties and equal but opposite degrees of specific rotation.Diastereomers, in theory at least, have different physical properties – we stipulate ‘in theory’ because sometimes thephysical properties of two or more diastereomers are so similar that it is very difficult to separate them. In addition, thespecific rotations of diastereomers are unrelated – they could be the same sign or opposite signs, and similar in magnitudeor very dissimilar.
n
n 4
10

1.18.5 1/5/2022 https://chem.libretexts.org/@go/page/178752
Constitutional isomersConstitutational isomers or structural isomers are molecules with the same chemical formula but different structures ofatoms and bonds. For example, both 3-methylpentane and hexane have the same chemical formula, C H , yet they clearlyhave different structures:
3-methylpentane hexane
Another example involves functional groups. Methoxy methane, an ether, and ethanol, an alcohol, both have the chemicalformula C H O:
Methoxy methane Ethanol
External Resources1. Further Details of Stereochemistry: For those interested in the topic further!2. MIT Online-Lecture including basic Organic Chemistry : Good background lecture to introduce Organic Chemistry.3. Chirality Rap: Good way to understand the concept? Decide for yourself!
References1. Anslyn, Eric V. and Dougherty, Dennis A. Modern Physical Organic Chemistry. Chicago, IL.: University Science. 20052. Hick, Janice M. The Physical Chemistry of Chirality. New York, N.Y.: An American Chemical Society Publication.
2001.3. Vollhardt, K. Peter C. and Schore, Neil E. Organic Chemistry: Structure and Function. Fifth Edition. New York, N.Y.:
W. H. Freeman Company, 2007.
Problems
Identify the following as either a constitutional isomer or stereoisomer. If stereoisomer, determine if it is an enantiomer ordiastereomer. Explain the reason behind the answer. Also mark chirality for each molecule.
1. 2. 3.
ContributorsDan ChongJonathan Mooney (McGill University)
6 14
2 6

1.19.1 12/14/2021 https://chem.libretexts.org/@go/page/178753
1.19: R-S Sequence RulesTo name the enantiomers of a compound unambiguously, their names must include the "handedness" of the molecule. Themethod for this is formally known as R/S nomenclature.
Introduction The method of unambiguously assigning the handedness of molecules was originated by three chemists: R.S. Cahn, C.Ingold, and V. Prelog and, as such, is also often called the Cahn-Ingold-Prelog rules. In addition to the Cahn-Ingoldsystem, there are two ways of experimentally determining the absolute configuration of an enantiomer:
1. X-ray diffraction analysis. Note that there is no correlation between the sign of rotation and the structure of a particularenantiomer.
2. Chemical correlation with a molecule whose structure has already been determined via X-ray diffraction.
However, for non-laboratory purposes, it is beneficial to focus on the R/S system. The sign of optical rotation, althoughdifferent for the two enantiomers of a chiral molecule,at the same temperature, cannot be used to establish the absoluteconfiguration of an enantiomer; this is because the sign of optical rotation for a particular enantiomer may change whenthe temperature changes.
Stereocenters are labeled R or S
The "right hand" and "left hand" nomenclature is used to name the enantiomers of a chiral compound. The stereocentersare labeled as R or S.
Consider the first picture: a curved arrow is drawn from the highest priority (1) substituent to the lowest priority (4)substituent. If the arrow points in a counterclockwise direction (left when leaving the 12 o' clock position), theconfiguration at stereocenter is considered S ("Sinister" → Latin= "left"). If, however, the arrow points clockwise,(Rightwhen leaving the 12 o' clock position) then the stereocenter is labeled R ("Rectus" → Latin= "right"). The R or S is thenadded as a prefix, in parenthesis, to the name of the enantiomer of interest.
Example 1(R)-2-Bromobutane
(S)-2,3- Dihydroxypropanal
Sequence rules to assign priorities to substituents
Before applying the R and S nomenclature to a stereocenter, the substituents must be prioritized according to the followingrules:
Rule 1
First, examine at the atoms directly attached to the stereocenter of the compound. A substituent with a higher atomicnumber takes precedence over a substituent with a lower atomic number. Hydrogen is the lowest possible prioritysubstituent, because it has the lowest atomic number.
1. When dealing with isotopes, the atom with the higher atomic mass receives higher priority.2. When visualizing the molecule, the lowest priority substituent should always point away from the viewer (a dashed line
indicates this). To understand how this works or looks, imagine that a clock and a pole. Attach the pole to the back ofthe clock, so that when when looking at the face of the clock the pole points away from the viewer in the same way thelowest priority substituent should point away.

1.19.2 12/14/2021 https://chem.libretexts.org/@go/page/178753
3. Then, draw an arrow from the highest priority atom to the 2nd highest priority atom to the 3rd highest priority atom.Because the 4th highest priority atom is placed in the back, the arrow should appear like it is going across the face of aclock. If it is going clockwise, then it is an R-enantiomer; If it is going counterclockwise, it is an S-enantiomer.
When looking at a problem with wedges and dashes, if the lowest priority atom is not on the dashed line pointing away, themolecule must be rotated. Remember that
Wedges indicate coming towards the viewer.Dashes indicate pointing away from the viewer.
Rule 2
If there are two substituents with equal rank, proceed along the two substituent chains until there is a point of difference.First, determine which of the chains has the first connection to an atom with the highest priority (the highest atomicnumber). That chain has the higher priority.
If the chains are similar, proceed down the chain, until a point of difference.
For example: an ethyl substituent takes priority over a methyl substituent. At the connectivity of the stereocenter, bothhave a carbon atom, which are equal in rank. Going down the chains, a methyl has only has hydrogen atoms attached to it,whereas the ethyl has another carbon atom. The carbon atom on the ethyl is the first point of difference and has a higheratomic number than hydrogen; therefore the ethyl takes priority over the methyl.
Rule 3
If a chain is connected to the same kind of atom twice or three times, check to see if the atom it is connected to has agreater atomic number than any of the atoms that the competing chain is connected to.
If none of the atoms connected to the competing chain(s) at the same point has a greater atomic number: the chainbonded to the same atom multiple times has the greater priorityIf however, one of the atoms connected to the competing chain has a higher atomic number: that chain has the higherpriority.
Example 2A 1-methylethyl substituent takes precedence over an ethyl substituent. Connected to the first carbon atom, ethyl onlyhas one other carbon, whereas the 1-methylethyl has two carbon atoms attached to the first; this is the first point ofdifference. Therefore, 1-methylethyl ranks higher in priority than ethyl, as shown below:
However:

1.19.3 12/14/2021 https://chem.libretexts.org/@go/page/178753
Remember that being double or triple bonded to an atom means that the atom is connected to the same atom twice. Insuch a case, follow the same method as above.
Caution!! Keep in mind that priority is determined by the first point of difference along the two similar substituent chains. Afterthe first point of difference, the rest of the chain is irrelevant.
When looking for the first point of difference on similar substituent chains, one may encounter branching. If there isbranching, choose the branch that is higher in priority. If the two substituents have similar branches, rank the elementswithin the branches until a point of difference.
After all your substituents have been prioritized in the correct manner, you can now name/label the molecule R or S.
1. Put the lowest priority substituent in the back (dashed line).2. Proceed from 1 to 2 to 3. (it is helpful to draw or imagine an arcing arrow that goes from 1--> 2-->3)3. Determine if the direction from 1 to 2 to 3 clockwise or counterclockwise.
i) If it is clockwise it is R. ii) if it is counterclockwise it is S.
USE YOUR MODELING KIT: Models assist in visualizing the structure. When using a model, make sure the lowestpriority is pointing away from you. Then determine the direction from the highest priority substituent to the lowest:clockwise (R) or counterclockwise (S).

1.19.4 12/14/2021 https://chem.libretexts.org/@go/page/178753
IF YOU DO NOT HAVE A MODELING KIT: remember that the dashes mean the bond is going into the screen and thewedges means that bond is coming out of the screen. If the lowest priority bond is not pointing to the back, mentally rotateit so that it is. However, it is very useful when learning organic chemistry to use models.
If you have a modeling kit use it to help you solve the following practice problems.
Problems Are the following R or S?
Solutions 1. S: I > Br > F > H. The lowest priority substituent, H, is already going towards the back. It turns left going from I to Br
to F, so it's a S.2. R: Br > Cl > CH > H. You have to switch the H and Br in order to place the H, the lowest priority, in the back. Then,
going from Br to Cl, CH is turning to the right, giving you a R.3. Neither R or S: This molecule is achiral. Only chiral molecules can be named R or S.4. R: OH > CN > CH NH > H. The H, the lowest priority, has to be switched to the back. Then, going from OH to CN to
CH NH , you are turning right, giving you a R.5. (5) S: > > > . Then, going from to to you are turning
left, giving you a S configuration.
References 1. Schore and Vollhardt. Organic Chemistry Structure and Function. New York:W.H. Freeman and Company, 2007.2. McMurry, John and Simanek, Eric. Fundamentals of Organic Chemistry. 6th Ed. Brooks Cole, 2006.
Contributors Ekta Patel (UCD), Ifemayowa Aworanti (University of Maryland Baltimore County)
3
3
2 2
2 2−COOH − OHCH
2C≡CH H −COOH − OHCH
2−C≡CH

1.20.1 1/10/2022 https://chem.libretexts.org/@go/page/178754
1.20: Organic Chemistry: Alkanes
12.1: Organic Chemistry
Concept Review Exercises
1. Classify each compound as organic or inorganic.
a. C H Ob. CaClc. Cr(NH ) Cld. C H O N
2. Which compound is likely organic and which is likely inorganic?
a. a flammable compound that boils at 80°C and is insoluble in waterb. a compound that does not burn, melts at 630°C, and is soluble in water
Answers
a. 1. organicb. inorganicc. inorganicd. organic
a. 2. organicb. inorganic
1. Classify each compound as organic or inorganic.
a. C Hb. CoClc. C H O
2. Classify each compound as organic or inorganic.
a. CH NHb. NaNHc. Cu(NH ) Cl
3. Which member of each pair has a higher melting point?
a. CH OH and NaOHb. CH Cl and KCl
4. Which member of each pair has a higher melting point?
a. C H and CoClb. CH and LiH
Answers
a. 1. organicb. inorganicc. organic
a. 3. NaOHb. KCl
12.2: Structures and Names of Alkanes
3 8
2
3 3 3
30 48 3
6 10
2
12 22 11
3 2
2
3 6 2
3
3
2 6 2
4

1.20.2 1/10/2022 https://chem.libretexts.org/@go/page/178754
Concept Review Exercises1. In the homologous series of alkanes, what is the molecular formula for the member just above C H ?2. Use the general formula for alkanes to write the molecular formula of the alkane with 12 carbon atoms.
Answers1. C H
2. C H
Exercises1. What compounds contain fewer carbon atoms than C H and are its homologs?
2. What compounds contain five to eight carbon atoms and are homologs of C H ?
Answer
1. CH and C H
12.3: Branched-Chain Alkanes
Concept Review Exercises1. In alkanes, can there be a two-carbon branch off the second carbon atom of a four-carbon chain? Explain.
2. A student is asked to write structural formulas for two different hydrocarbons having the molecular formula C H . Shewrites one formula with all five carbon atoms in a horizontal line and the other with four carbon atoms in a line, with aCH group extending down from the first attached to the third carbon atom. Do these structural formulas representdifferent molecular formulas? Explain why or why not.
Answers1. No; the branch would make the longest continuous chain of five carbon atoms.
2. No; both are five-carbon continuous chains.
Key TakeawayAlkanes with four or more carbon atoms can exist in isomeric forms.
Exercises
1. Briefly identify the important distinctions between a straight-chain alkane and a branched-chain alkane.
2. How are butane and isobutane related? How do they differ?
3. Name each compound.
a.
b.
4. Write the structural formula for each compound.
8 18
9 20
12 26
3 8
4 10
4 2 6
5 12
3

1.20.3 1/10/2022 https://chem.libretexts.org/@go/page/178754
a. hexaneb. octane
5. Indicate whether the structures in each set represent the same compound or isomers.
a. CH CH CH CH and
b. CH CH CH CH CH and
Answers
1. Straight-chain alkanes and branched-chain alkanes have different properties as well as different structures.
a. 3. pentaneb. heptane
a. 5. nob. yes
12.4: Condensed Structural and Line-Angle Formulas
Exercises
1. Write the condensed structural formula for each structural formula.
a.
b.
c.
2. A condensed structural formula for isohexane can be written as (CH ) CHCH CH CH . Draw the line-angle formulafor isohexane.
3. Draw a line-angle formula for the compound CH CH CH(CH )CH CH CH .
4. Give the structural formula for the compound represented by this line-angle formula:
3 2 2 3
3 2 2 2 3
3 2 2 2 3
3 2 3 2 2 3

1.20.4 1/10/2022 https://chem.libretexts.org/@go/page/178754
Answersa. 1. CH CHb. CH CH CHc. CH CH CH CH CH
3.
12.5: IUPAC Nomenclature
Concept Review Exercises1. What is a CH group called when it is attached to a chain of carbon atoms—a substituent or a functional group?2. Which type of name uses numbers to locate substituents—common names or IUPAC names?
Answers1. substituent
2. IUPAC names
Exercises
1. Briefly identify the important distinctions between an alkane and an alkyl group.
2. How many carbon atoms are present in each molecule?
a. 2-methylbutaneb. 3-ethylpentane
3. How many carbon atoms are present in each molecule?
a. 2,3-dimethylbutaneb. 3-ethyl-2-methylheptane
4. Draw the structure for each compound.
a. 3-methylpentaneb. 2,2,5-trimethylhexanec. 4-ethyl-3-methyloctane
5. Draw the structure for each compound.
a. 2-methylpentaneb. 4-ethyl-2-methylhexanec. 2,2,3,3-tetramethylbutane
6. Name each compound according to the IUPAC system.
a.
b.
7. Name each compound according to the IUPAC system.
3 3
3 2 3
3 2 2 2 3
3

1.20.5 1/10/2022 https://chem.libretexts.org/@go/page/178754
a.
b.
8. What is a substituent? How is the location of a substituent indicated in the IUPAC system?
9. Briefly identify the important distinctions between a common name and an IUPAC name.
Answers1. An alkane is a molecule; an alkyl group is not an independent molecule but rather a part of a molecule that we consider
as a unit.
a. 3. 6b. 10
5. a.
b.
c.
a. 7. 2,2,4,4-tetramethylpentaneb. 3-ethylhexane
9. Common names are widely used but not very systematic; IUPAC names identify a parent compound and name othergroups as substituents.
12.6: Physical Properties of Alkanes
12.7: Chemical Properties of Alkanes
12.8: Halogenated Hydrocarbons
12.9: Cycloalkanes
12.10: Chapter Summary

1.20.6 1/10/2022 https://chem.libretexts.org/@go/page/178754
Additional Exercises1. You find an unlabeled jar containing a solid that melts at 48°C. It ignites readily and burns readily. The substance is
insoluble in water and floats on the surface. Is the substance likely to be organic or inorganic?
2. Give the molecular formulas for methylcyclopentane, 2-methylpentane, and cyclohexane. Which are isomers?
3. What is wrong with each name? (Hint: first write the structure as if it were correct.) Give the correct name for eachcompound.
a. 2-dimethylpropaneb. 2,3,3-trimethylbutanec. 2,4-diethylpentaned. 3,4-dimethyl-5-propylhexane
4. What is the danger in swallowing a liquid alkane?
5. Distinguish between lighter and heavier liquid alkanes in terms of their effects on the skin.
6. Following is the line formula for an alkane. Draw its structure and give its name.
7. Write equations for the complete combustion of each compound.
a. propane (a bottled gas fuel)b. octane (a typical hydrocarbon in gasoline).
8. The density of a gasoline sample is 0.690 g/mL. On the basis of the complete combustion of octane, calculate theamount in grams of carbon dioxide (CO ) and water (H O) formed per gallon (3.78 L) of the gasoline when used in anautomobile.
9. Draw the structures for the five isomeric hexanes (C H ). Name each by the IUPAC system.
10. Indicate whether the structures in each set represent the same compound or isomers.
a.
b.
c.
11. Consider the line-angle formulas shown here and answer the questions.
a. Which pair of formulas represents isomers? Draw each structure.
2 2
6 14

1.20.7 1/10/2022 https://chem.libretexts.org/@go/page/178754
b. Which formula represents an alkyl halide? Name the compound and write its condensed structural formula.c. Which formula represents a cyclic alkane? Name the compound and draw its structure.d. What is the molecular formula of the compound represented by (i)?
Answers1. organic
a. 3. Two numbers are needed to indicate two substituents; 2,2-dimethylpropane.b. The lowest possible numbers were not used; 2,2,3-trimethylbutane.c. An ethyl substituent is not possible on the second carbon atom; 3,5-dimethylheptane.d. A propyl substituent is not possible on the fifth carbon atom; 3,4,5-trimethyloctane.
5. Lighter alkanes wash away protective skin oils; heavier alkanes form a protective layer.
a. 7. C H + 5O → 3CO + 4H Ob. 2C H + 25O → 16CO + 18H O
9. CH CH CH CH CH CH ; hexane
11. a. ii and iii; CH CH CH CH CH CH CH and
b. iv; 3-chloropentane; CH CH CHClCH CH
c. i; ethylcyclopentane;
d. C H
3 8 2 2 2
8 18 2 2 2
3 2 2 2 2 3
3 2 2 2 2 2 3
3 2 2 3
7 14

1.21.1 1/5/2022 https://chem.libretexts.org/@go/page/178756
1.21: Unsaturated and Aromatic Hydrocarbons (Exercises)
Additional Exercises
1. Classify each compound as saturated or unsaturated.
a. b. CH C≡CCH
2. Classify each compound as saturated or unsaturated.
a.
b.
3. Give the molecular formula for each compound.
a.
b.
4. When three isomeric pentenes—X, Y, and Z—are hydrogenated, all three form 2-methylbutane. The addition of Cl toY gives 1,2-dichloro-3-methylbutane, and the addition of Cl to Z gives 1,2-dichloro-2-methylbutane. Draw theoriginal structures for X, Y, and Z.
5. Pentane and 1-pentene are both colorless, low-boiling liquids. Describe a simple test that distinguishes the twocompounds. Indicate what you would observe.
6. Draw and name all the alkene cis-trans isomers corresponding to the molecular formula C H . (Hint: there are onlytwo.)
7. The complete combustion of benzene forms carbon dioxide and water:
C H + O → CO + H O
Balance the equation. What mass, in grams, of carbon dioxide is formed by the complete combustion of 39.0 g ofbenzene?
3 3
2
2
5 10
6 6 2 2 2

1.21.2 1/5/2022 https://chem.libretexts.org/@go/page/178756
8. Describe a physiological effect of some PAHs.
9. What are some of the hazards associated with the use of benzene?
10. What is wrong with each name? Draw the structure and give the correct name for each compound.
a. 2-methyl-4-hepteneb. 2-ethyl-2-hexenec. 2,2-dimethyl-3-pentene
11. What is wrong with each name?
a. 2-bromobenzeneb. 3,3-dichlorotoluenec. 1,4-dimethylnitrobenzene
12. Following are line-angle formulas for three compounds. Draw the structure and give the name for each.
a.
b.
c.
13. Following are ball-and-stick molecular models for three compounds (blue balls represent H atoms; red balls are Catoms). Write the condensed structural formula and give the name for each.
a.
b.
c.
Answers
a. 1. unsaturatedb. unsaturated
a. 3. C Hb. C H
5. Add bromine solution (reddish-brown) to each. Pentane will not react, and the reddish-brown color persists; 1-pentenewill react, leaving a colorless solution.
6 10
4 8

1.21.3 1/5/2022 https://chem.libretexts.org/@go/page/178756
7. 2C H + 15O → 12CO + 6H O; 132 g
9. carcinogenic, flammable
a. 11. number not neededb. can’t have two groups on one carbon atom on a benzene ringc. can’t have a substituent on the same carbon atom as the nitro group
a. 13. CH CH=CHCH CH CH ; 2-hexene
b.
c.
6 6 2 2 2
3 2 2 3

1 1/10/2022
CHAPTER OVERVIEW2: CARBOHYDRATES
2.1: PRELUDE TO CARBOHYDRATESPeople with diabetes are impaired in their ability to metabolize glucose, a sugar needed by the body for energy; as a result, excessivequantities of glucose accumulate in the blood and the urine. The characteristic symptoms of diabetes are weight loss, constant hunger,extreme thirst, and frequent urination (the kidneys excrete large amounts of water in an attempt to remove the excess sugar from theblood).
2.2: CARBOHYDRATESCarbohydrates are an important group of biological molecules that includes sugars and starches. Photosynthesis is the process bywhich plants use energy from sunlight to synthesize carbohydrates. A monosaccharide is the simplest carbohydrate and cannot behydrolyzed to produce a smaller carbohydrate molecule. Disaccharides contain two monosaccharide units, and polysaccharidescontain many monosaccharide units.
2.3: CLASSES OF MONOSACCHARIDESMonosaccharides can be classified by the number of carbon atoms in the structure and/or the type of carbonyl group they contain(aldose or ketose). Most monosaccharides contain at least one chiral carbon and can form stereoisomers. Enantiomers are a specifictype of stereoisomers that are mirror images of each other.
2.4: IMPORTANT HEXOSESThree abundant hexoses in living organisms are the aldohexoses D-glucose and D-galactose and the ketohexose D-fructose.
2.5: CYCLIC STRUCTURES OF MONOSACCHARIDESMonosaccharides that contain five or more carbons atoms form cyclic structures in aqueous solution. Two cyclic stereoisomers canform from each straight-chain monosaccharide; these are known as anomers. In an aqueous solution, an equilibrium mixture formsbetween the two anomers and the straight-chain structure of a monosaccharide in a process known as mutarotation.
2.6: PROPERTIES OF MONOSACCHARIDESMonosaccharides are crystalline solids at room temperature and quite soluble in water. Monosaccharides are reducing sugars; theyreduce mild oxidizing agents, such as Tollens’ or Benedict’s reagents.
2.7: DISACCHARIDESMaltose is composed of two molecules of glucose joined by an α-1,4-glycosidic linkage. It is a reducing sugar that is found insprouting grain. Lactose is composed of a molecule of galactose joined to a molecule of glucose by a β-1,4-glycosidic linkage. It is areducing sugar that is found in milk. Sucrose is composed of a molecule of glucose joined to a molecule of fructose by an α-1,β-2-glycosidic linkage. It is a nonreducing sugar that is found in sugar cane and sugar beets.
2.8: POLYSACCHARIDESStarch is a storage form of energy in plants. It contains two polymers composed of glucose units: amylose (linear) and amylopectin(branched). Glycogen is a storage form of energy in animals. It is a branched polymer composed of glucose units. It is more highlybranched than amylopectin. Cellulose is a structural polymer of glucose units found in plants. It is a linear polymer with the glucoseunits linked through β-1,4-glycosidic bonds.
2.9: CARBOHYDRATES (SUMMARY)To ensure that you understand the material in this chapter, you should review the meanings of the bold terms in the followingsummary and ask yourself how they relate to the topics in the chapter.

2.1.1 12/12/2021 https://chem.libretexts.org/@go/page/178758
2.1: Prelude to CarbohydratesIn the United States, 17.9 million people have been diagnosed with diabetes, and experts estimate that at least another 5.7million people have the disease but have not been diagnosed. In 2006, diabetes was the seventh leading cause of death,listed on 72,507 death certificates. Moreover, it was a contributing factor in over 200,000 deaths in which the cause waslisted as something else, such as heart or kidney disease.
People with diabetes are impaired in their ability to metabolize glucose, a sugar needed by the body for energy; as a result,excessive quantities of glucose accumulate in the blood and the urine. The characteristic symptoms of diabetes are weightloss, constant hunger, extreme thirst, and frequent urination (the kidneys excrete large amounts of water in an attempt toremove the excess sugar from the blood).
An important diagnostic test for diabetes is the oral glucose tolerance test, which measures the level of glucose in bloodplasma. A first measurement is made after a fast of at least 8 h, followed by another measurement 2 h after the persondrinks a flavored solution of 75 g of glucose dissolved in water. At the second measurement, the glucose plasma levelshould be no higher than 139 mg/dL. Individuals with a value between 140 and 199 mg/dL are diagnosed with prediabetes,while those with a value of 200 mg/dL or above are diagnosed with diabetes. Following a diagnosis of diabetes a personwill need to monitor his or her blood glucose levels daily (or more often) using a glucose meter.
Figure : Using a Glucose Meter to Test Blood Glucose Level. Image used with permission (Public Domain; Centersfor Disease Control and Prevention).
2.1.1

2.2.1 1/5/2022 https://chem.libretexts.org/@go/page/178759
2.2: CarbohydratesLearning Objectives
To recognize carbohydrates and classify them as mono-, di-, or polysaccharides.
All carbohydrates consist of carbon, hydrogen, and oxygen atoms and are polyhydroxy aldehydes or ketones or arecompounds that can be broken down to form such compounds. Examples of carbohydrates include starch, fiber, the sweet-tasting compounds called sugars, and structural materials such as cellulose. The term carbohydrate had its origin in amisinterpretation of the molecular formulas of many of these substances. For example, because its formula is C H O ,glucose was once thought to be a “carbon hydrate” with the structure C ·6H O.
Example
Which compounds would be classified as carbohydrates?
a.
b.
c.
d.
SOLUTION
a. This is a carbohydrate because the molecule contains an aldehyde functional group with OH groups on the other twocarbon atoms.
b. This is not a carbohydrate because the molecule does not contain an aldehyde or a ketone functional group.c. This is a carbohydrate because the molecule contains a ketone functional group with OH groups on the other two
carbon atoms.d. This is not a carbohydrate; although it has a ketone functional group, one of the other carbons atoms does not have
an OH group attached.
6 12 6
6 2
2.2.1

2.2.2 1/5/2022 https://chem.libretexts.org/@go/page/178759
Exercise
Which compounds would be classified as carbohydrates?
1.
2.
3.
4.
Green plants are capable of synthesizing glucose (C H O ) from carbon dioxide (CO ) and water (H O) by using solarenergy in the process known as photosynthesis:
(The 686 kcal come from solar energy.) Plants can use the glucose for energy or convert it to larger carbohydrates, such asstarch or cellulose. Starch provides energy for later use, perhaps as nourishment for a plant’s seeds, while cellulose is thestructural material of plants. We can gather and eat the parts of a plant that store energy—seeds, roots, tubers, and fruits—and use some of that energy ourselves. Carbohydrates are also needed for the synthesis of nucleic acids and many proteinsand lipids.
Animals, including humans, cannot synthesize carbohydrates from carbon dioxide and water and are therefore dependenton the plant kingdom to provide these vital compounds. We use carbohydrates not only for food (about 60%–65% by massof the average diet) but also for clothing (cotton, linen, rayon), shelter (wood), fuel (wood), and paper (wood).
The simplest carbohydrates—those that cannot be hydrolyzed to produce even smaller carbohydrates—are calledmonosaccharides. Two or more monosaccharides can link together to form chains that contain from two to several hundredor thousand monosaccharide units. Prefixes are used to indicate the number of such units in the chains. Disaccharidemolecules have two monosaccharide units, trisaccharide molecules have three units, and so on. Chains with manymonosaccharide units joined together are called polysaccharides. All these so-called higher saccharides can be hydrolyzedback to their constituent monosaccharides.
Compounds that cannot be hydrolyzed will not react with water to form two ormore smaller compounds.
2.2.1
6 12 6 2 2
6 +6 O+686 kcal → +6CO2 H2 C6H12O6 O2 (2.2.1)

2.2.3 1/5/2022 https://chem.libretexts.org/@go/page/178759
Summary
Carbohydrates are an important group of biological molecules that includes sugars and starches. Photosynthesis is theprocess by which plants use energy from sunlight to synthesize carbohydrates. A monosaccharide is the simplestcarbohydrate and cannot be hydrolyzed to produce a smaller carbohydrate molecule. Disaccharides contain twomonosaccharide units, and polysaccharides contain many monosaccharide units.
Concept Review Exercises 1. Why is photosynthesis important?
2. Identify the differences among monosaccharides, disaccharides, and polysaccharides.
Answers 1. Photosynthesis is the process by which solar energy is used to reduce carbon dioxide to carbohydrates, which are
needed for energy by plants and other living organisms that eat plants.
2. A monosaccharide is the simplest carbohydrate and cannot be hydrolyzed to produce a smaller carbohydrate; adisaccharide is composed of two monosaccharide units; and a polysaccharide contains many saccharide units.
Exercises 1. When an aqueous solution of trehalose is heated, two molecules of glucose are produced for each molecule of
trehalose. Is trehalose a monosaccharide, a disaccharide, or a polysaccharide?
2. When an aqueous solution of arabinose is heated, no other molecules are produced. Is arabinose a monosaccharide, adisaccharide, or a polysaccharide?
Answer 1. Trehalose is a disaccharide because it is hydrolyzed into two molecules of glucose (a monosaccharide).

2.3.1 1/5/2022 https://chem.libretexts.org/@go/page/178760
2.3: Classes of MonosaccharidesLearning Objectives
Classify monosaccharides as aldoses or ketoses and as trioses, tetroses, pentoses, or hexoses.Distinguish between a D sugar and an L sugar.
The naturally occurring monosaccharides contain three to seven carbon atoms per molecule. Monosaccharides of specificsizes may be indicated by names composed of a stem denoting the number of carbon atoms and the suffix -ose. Forexample, the terms triose, tetrose, pentose, and hexose signify monosaccharides with, respectively, three, four, five, and sixcarbon atoms. Monosaccharides are also classified as aldoses or ketoses. Those monosaccharides that contain an aldehydefunctional group are called aldoses; those containing a ketone functional group on the second carbon atom are ketoses.Combining these classification systems gives general names that indicate both the type of carbonyl group and the numberof carbon atoms in a molecule. Thus, monosaccharides are described as aldotetroses, aldopentoses, ketopentoses,ketoheptoses, and so forth. Glucose and fructose are specific examples of an aldohexose and a ketohexose, respectively.
Example
Draw an example of each type of compound.
a. a ketopentoseb. an aldotetrose
SOLUTION
a. The structure must have five carbon atoms with the second carbon atom being a carbonyl group and the other fourcarbon atoms each having an OH group attached. Several structures are possible, but one example is shown.
b. The structure must have four carbon atoms with the first carbon atom part of the aldehyde functional group. Theother three carbon atoms each have an OH group attached. Several structures are possible, but one example isshown.
Exercise
2.3.1
2.3.1

2.3.2 1/5/2022 https://chem.libretexts.org/@go/page/178760
Draw an example of each type of compound.
a. an aldohexoseb. a ketotetrose
The simplest sugars are the trioses. The possible trioses are shown in part (a) of Figure ; glyceraldehyde is analdotriose, while dihydroxyacetone is a ketotriose. Notice that two structures are shown for glyceraldehyde. Thesestructures are stereoisomers, and hence are isomers having the same structural formula but differing in the arrangement ofatoms or groups of atoms in three-dimensional space. If you make models of the two stereoisomers of glyceraldehyde, youwill find that you cannot place one model on top of the other and have each functional group point in the same direction.However, if you place one of the models in front of a mirror, the image in the mirror will be identical to the secondstereoisomer in part (b) of Figure . Molecules that are nonsuperimposable (nonidentical) mirror images of each otherare a type of stereoisomer called enantiomers (Greek enantios, meaning “opposite”).
NoteThese are another type of stereoisomers than the cis-trans (geometric) isomers previously discussed.
Figure : Structures of the Trioses. (a) D- and L-glyceraldehyde are mirror images of each other and represent a pair ofenantiomers. (b) A ball-and-stick model of D-glyceraldehyde is reflected in a mirror. Note that the reflection has the samestructure as L-glyceraldehyde.
A key characteristic of enantiomers is that they have a carbon atom to which four different groups are attached. Note, forexample, the four different groups attached to the central carbon atom of glyceraldehyde (part (a) of Figure ). Acarbon atom that has four different groups attached is a chiral carbon. If a molecule contains one or more chiral carbons, itis likely to exist as two or more stereoisomers. Dihydroxyacetone does not contain a chiral carbon and thus does not existas a pair of stereoisomers. Glyceraldehyde, however, has a chiral carbon and exists as a pair of enantiomers. Except for thedirection in which each enantiomer rotates plane-polarized light, these two molecules have identical physical properties.One enantiomer has a specific rotation of +8.7°, while the other has a specific rotation of −8.7°.
H. Emil Fischer, a German chemist, developed the convention commonly used for writing two-dimensional representationsof the monosaccharides, such as those in part (a) of Figure . In these structural formulas, the aldehyde group iswritten at the top, and the hydrogen atoms and OH groups that are attached to each chiral carbon are written to the right orleft. (If the monosaccharide is a ketose, the ketone functional group is the second carbon atom.) Vertical lines representbonds pointing away from you, while horizontal lines represent bonds coming toward you. The formulas of chiralmolecules represented in this manner are referred to as Fischer projections.
The two enantiomers of glyceraldehyde are especially important because monosaccharides with more than three carbonatoms can be considered as being derived from them. Thus, D- and L-glyceraldehyde provide reference points fordesignating and drawing all other monosaccharides. Sugars whose Fischer projections terminate in the same configurationas D-glyceraldehyde are designated as D sugars; those derived from L-glyceraldehyde are designated as L sugars.
2.3.1
2.3.1
2.3.1
2.3.1
2.3.1

2.3.3 1/5/2022 https://chem.libretexts.org/@go/page/178760
By convention, the penultimate (next-to-last) carbon atom has been chosen as thecarbon atom that determines if a sugar is D or L. It is the chiral carbon farthestfrom the aldehyde or ketone functional group.
Looking Closer: Polarized LightA beam of ordinary light can be pictured as a bundle of waves; some move up and down, some sideways, and others atall other conceivable angles. When a beam of light has been polarized, however, the waves in the bundle all vibrate in asingle plane. Light altered in this way is called plane-polarized light. Much of what chemists know about stereoisomerscomes from studying the effects they have on plane-polarized light. In this illustration, the light on the left is notpolarized, while that on the right is polarized.
Sunlight, in general, is not polarized; light from an ordinary light bulb or an ordinary flashlight is not polarized. Oneway to polarize ordinary light is to pass it through Polaroid sheets, special plastic sheets containing carefully orientedorganic compounds that permit only light vibrating in a single plane to pass through. To the eye, polarized light doesn’t“look” any different from nonpolarized light. We can detect polarized light, however, by using a second sheet ofpolarizing material, as shown here.
In the photo on the left, two Polaroid sheets are aligned in the same direction; plane-polarized light from the firstPolaroid sheet can pass through the second sheet. In the photo on the right, the top Polaroid sheet has been rotated 90°
and now blocks the plane-polarized light that comes through the first Polaroid sheet.
Certain substances act on polarized light by rotating the plane of vibration. Such substances are said to be optically active.The extent of optical activity is measured by a polarimeter, an instrument that contains two polarizing lenses separated by asample tube, as shown in the accompanying figure. With the sample tube empty, maximum light reaches the observer’s eyewhen the two lenses are aligned so that both pass light vibrating in the same plane. When an optically active substance isplaced in the sample tube, that substance rotates the plane of polarization of the light passing through it, so that thepolarized light emerging from the sample tube is vibrating in a different direction than when it entered the tube. To see themaximum amount of light when the sample is in place, the observer must rotate one lens to accommodate the change in theplane of polarization.

2.3.4 1/5/2022 https://chem.libretexts.org/@go/page/178760
Figure : Diagram of a Polarimeter
Some optically active substances rotate the plane of polarized light to the right (clockwise) from the observer’s point ofview. These compounds are said to be dextrorotatory; substances that rotate light to the left (counterclockwise) arelevorotatory. To denote the direction of rotation, a positive sign (+) is given to dextrorotatory substances, and a negativesign (−) is given to levorotatory substances.
Summary Monosaccharides can be classified by the number of carbon atoms in the structure and/or the type of carbonyl group theycontain (aldose or ketose). Most monosaccharides contain at least one chiral carbon and can form stereoisomers.Enantiomers are a specific type of stereoisomers that are mirror images of each other.
Concept Review Exercises 1. What is a chiral carbon?2. Describe how enantiomers differ.
Answers 1. A chiral carbon is a carbon atom with four different groups attached to it.2. Enantiomers are mirror images of each other; they differ in the arrangements of atoms around a chiral carbon.
Exercises 1. Identify each sugar as an aldose or a ketose and then as a triose, tetrose, pentose, or hexose.
a. D-glucose
2.3.2

2.3.5 1/5/2022 https://chem.libretexts.org/@go/page/178760
b. L-ribulose
c. D-glyceraldehyde
2. Identify each sugar as an aldose or a ketose and then as a triose, tetrose, pentose, or hexose.
a. dihydroxyacetone
b. D-ribose
c. D-galactose

2.3.6 1/5/2022 https://chem.libretexts.org/@go/page/178760
3. Identify each sugar as an aldose or a ketose and then as a D sugar or an L sugar.
a.
b.
4. Identify each sugar as an aldose or a ketose and then as a D sugar or an L sugar.
a.

2.3.7 1/5/2022 https://chem.libretexts.org/@go/page/178760
b.
Answers a. 1. aldose; hexoseb. ketose; pentosec. aldose; triose
a. 3. aldose; D sugarb. ketose; L sugar

2.4.1 12/7/2021 https://chem.libretexts.org/@go/page/178761
2.4: Important HexosesLearning Objectives
To identify the structures of D-glucose, D-galactose, and D-fructose and describe how they differ from each other.
Although a variety of monosaccharides are found in living organisms, three hexoses are particularly abundant: D-glucose,D-galactose, and D-fructose (Figure ). Glucose and galactose are both aldohexoses, while fructose is a ketohexose.
Figure : Structures of Three Important Hexoses. Each hexose is pictured with a food source in which it is commonlyfound. Source: Photos © Thinkstock.
Glucose
D-Glucose, generally referred to as simply glucose, is the most abundant sugar found in nature; most of the carbohydrateswe eat are eventually converted to it in a series of biochemical reactions that produce energy for our cells. It is also knownby three other names: dextrose, from the fact that it rotates plane-polarized light in a clockwise (dextrorotatory) direction;corn sugar because in the United States cornstarch is used in the commercial process that produces glucose from thehydrolysis of starch; and blood sugar because it is the carbohydrate found in the circulatory system of animals. Normalblood sugar values range from 70 to 105 mg glucose/dL plasma, and normal urine may contain anywhere from a trace to20 mg glucose/dL urine.
Figure : Fischer projection of D-glucose
The Fischer projection of D-glucose is given in Figure . Glucose is a D sugar because the OH group on the fifthcarbon atom (the chiral center farthest from the carbonyl group) is on the right. In fact, all the OH groups except the one onthe third carbon atom are to the right.
2.4.1
2.4.1
2.4.2
2.4.2

2.4.2 12/7/2021 https://chem.libretexts.org/@go/page/178761
GalactoseD-Galactose does not occur in nature in the uncombined state. It is released when lactose, a disaccharide found in milk, ishydrolyzed. The galactose needed by the human body for the synthesis of lactose is obtained by the metabolic conversionof D-glucose to D-galactose. Galactose is also an important constituent of the glycolipids that occur in the brain and themyelin sheath of nerve cells. For this reason it is also known as brain sugar. The structure of D-galactose is shown inFigure . Notice that the configuration differs from that of glucose only at the fourth carbon atom.
Fructose
D-Fructose, also shown in Figure , is the most abundant ketohexose. Note that from the third through the sixth carbonatoms, its structure is the same as that of glucose. It occurs, along with glucose and sucrose, in honey (which is 40%fructose) and sweet fruits. Fructose (from the Latin fructus, meaning “fruit”) is also referred to as levulose because it has aspecific rotation that is strongly levorotatory (−92.4°). It is the sweetest sugar, being 1.7 times sweeter than sucrose,although many nonsugars are several hundred or several thousand times as sweet (Table ).
Table : The Relative Sweetness of Some Compounds (Sucrose = 100)Compound Relative Sweetness
lactose 16
maltose 32
glucose 74
sucrose 100
fructose 173
aspartame 18,000
acesulfame K 20,000
saccharin 30,000
sucralose 60,000
Looking Closer: Artificial SweetenersAlthough sweetness is commonly associated with mono- and disaccharides, it is not a property found only in sugars.Several other kinds of organic compounds have been synthesized that are far superior as sweetening agents. These so-called high-intensity or artificial sweeteners are useful for people with diabetes or other medical conditions that requirethem to control their carbohydrate intake. The synthetic compounds are noncaloric or used in such small quantities thatthey do not add significantly to the caloric value of food.
The first artificial sweetener—saccharin—was discovered by accident in 1879. It is 300 times sweeter than sucrose, butit passes through the body unchanged and thus adds no calories to the diet. After its discovery, saccharin was used untilit was banned in the early 1900s. However, during the sugar-short years of World War I, the ban was lifted and was notreinstated at the war’s end. One drawback to the use of saccharin is its bitter, metallic aftertaste. The initial solution tothis problem was to combine saccharin with cyclamate, a second artificial sweetener discovered in 1937.
In the 1960s and 1970s, several clinical tests with laboratory animals implicated both cyclamate and saccharin ascarcinogenic (cancer-causing) substances. The results from the cyclamate tests were completed first, and cyclamate wasbanned in the United States in 1969. Then a major study was released in Canada in 1977 indicating that saccharinincreased the incidence of bladder cancer in rats. The US Food and Drug Administration (FDA) proposed a ban onsaccharin that raised immediate public opposition because saccharin was the only artificial sweetener still available. Inresponse, Congress passed the Saccharin Study and Labeling Act in 1977, permitting the use of saccharin as long as anyproduct containing it was labeled with a consumer warning regarding the possible elevation of the risk of bladder
2.4.1
2.4.1
2.4.1
2.4.1

2.4.3 12/7/2021 https://chem.libretexts.org/@go/page/178761
cancer. Today this warning is no longer required; moreover, the FDA is currently reviewing the ban on cyclamate, as 75additional studies and years of usage in other countries, such as Canada, have failed to show that it has any carcinogeniceffect.
A third artificial sweetener, aspartame, was discovered in 1965. This white crystalline compound is about 180 timessweeter than sucrose and has no aftertaste. It was approved for use in 1981 and is used to sweeten a wide variety offoods because it blends well with other food flavors. Aspartame is not used in baked goods, however, because it is notheat stable.
In the body (or when heated), aspartame is initially hydrolyzed to three molecules: the amino acids aspartic acid andphenylalanine and an alcohol methanol. Repeated controversy regarding the safety of aspartame arises partly from thefact that the body metabolizes the released methanol to formaldehyde. It should be noted, though, that a glass of tomatojuice has six times as much methanol as a similar amount of a diet soda containing aspartame. The only documentedrisk connected to aspartame use is for individuals with the genetic disease phenylketonuria (PKU); these individualslack the enzyme needed to metabolize the phenylalanine released when aspartame is broken down by the body. Becauseof the danger to people with PKU, all products containing aspartame must carry a warning label.
Acesulfame K, discovered just two years after aspartame (1967), was approved for use in the United States in 1988. Itis 200 times sweeter than sugar and, unlike aspartame, is heat stable. It has no lingering aftertaste.
One of the newest artificial sweeteners to gain FDA approval (April 1998) for use in the United States is sucralose, awhite crystalline solid approximately 600 times sweeter than sucrose. Sucralose is synthesized from sucrose and hasthree chlorine atoms substituted for three OH groups. It is noncaloric because it passes through the body unchanged. Itcan be used in baking because it is heat stable.
All of the extensive clinical studies completed to date have indicated that these artificial sweeteners approved for use inthe United States are safe for consumption by healthy individuals in moderate amounts.
SummaryThree abundant hexoses in living organisms are the aldohexoses D-glucose and D-galactose and the ketohexose D-fructose.

2.4.4 12/7/2021 https://chem.libretexts.org/@go/page/178761
Concept Review Exercises1. Describe the similarities and differences in the structures of D-glucose and D-galactose.2. Describe similarities and differences in the structures of D-glucose and D-fructose.
Answers1. Both monosaccharides are aldohexoses. The two monosaccharides differ in the configuration around the fourth carbon
atom.2. Both monosaccharides are hexoses. D-glucose is an aldohexose, while D-fructose is a ketohexose.
Exercises1. Identify each sugar by its common chemical name.
a. blood sugarb. levulose
2. Identify each sugar by its common chemical name.
a. dextroseb. brain sugar
3. Identify each sugar as an aldohexose or a ketohexose.
a. glucoseb. galactosec. fructose
4. What hexose would you expect to be most abundant in each food?
a. honeyb. milkc. cornstarch
Answersa. 1. D-glucoseb. D-fructose
a. 3. aldohexoseb. aldohexosec. ketohexose

2.5.1 1/2/2022 https://chem.libretexts.org/@go/page/178762
2.5: Cyclic Structures of MonosaccharidesLearning Objectives
Define what is meant by anomers and describe how they are formed.Explain what is meant by mutarotation.
So far we have represented monosaccharides as linear molecules, but many of them also adopt cyclic structures. Thisconversion occurs because of the ability of aldehydes and ketones to react with alcohols:
You might wonder why the aldehyde reacts with the OH group on the fifth carbon atom rather than the OH group on thesecond carbon atom next to it. Recall that cyclic alkanes containing five or six carbon atoms in the ring are the most stable.The same is true for monosaccharides that form cyclic structures: rings consisting of five or six carbon atoms are the moststable.
Figure : Cyclization of D-Glucose. D-Glucose can be represented with a Fischer projection (a) or three dimensionally(b). By reacting the OH group on the fifth carbon atom with the aldehyde group, the cyclic monosaccharide (c) isproduced.
When a straight-chain monosaccharide, such as any of the structures shown in Figure , forms a cyclic structure, thecarbonyl oxygen atom may be pushed either up or down, giving rise to two stereoisomers, as shown in Figure . Thestructure shown on the left side of Figure , with the OH group on the first carbon atom projected downward, representwhat is called the alpha (α) form. The structures on the right side, with the OH group on the first carbon atom pointedupward, is the beta (β) form. These two stereoisomers of a cyclic monosaccharide are known as anomers; they differ instructure around the anomeric carbon—that is, the carbon atom that was the carbonyl carbon atom in the straight-chainform.
It is possible to obtain a sample of crystalline glucose in which all the molecules have the α structure or all have the βstructure. The α form melts at 146°C and has a specific rotation of +112°, while the β form melts at 150°C and has aspecific rotation of +18.7°. When the sample is dissolved in water, however, a mixture is soon produced containing bothanomers as well as the straight-chain form, in dynamic equilibrium (part (a) of Figure ). You can start with a purecrystalline sample of glucose consisting entirely of either anomer, but as soon as the molecules dissolve in water, they opento form the carbonyl group and then reclose to form either the α or the β anomer. The opening and closing repeats
2.5.1
2.5.1
2.5.2
2.5.2
2.5.2

2.5.2 1/2/2022 https://chem.libretexts.org/@go/page/178762
continuously in an ongoing interconversion between anomeric forms and is referred to as mutarotation (Latin mutare,meaning “to change”). At equilibrium, the mixture consists of about 36% α-D-glucose, 64% β-D-glucose, and less than0.02% of the open-chain aldehyde form. The observed rotation of this solution is +52.7°.
Figure : Monosaccharides. In an aqueous solution, monosaccharides exist as an equilibrium mixture of three forms.The interconversion between the forms is known as mutarotation, which is shown for D-glucose (a) and D-fructose (b).
Even though only a small percentage of the molecules are in the open-chain aldehyde form at any time, the solution willnevertheless exhibit the characteristic reactions of an aldehyde. As the small amount of free aldehyde is used up in areaction, there is a shift in the equilibrium to yield more aldehyde. Thus, all the molecules may eventually react, eventhough very little free aldehyde is present at a time.
Commonly, (e.g., in Figures and ) the cyclic forms of sugars are depicted using a convention first suggested byWalter N. Haworth, an English chemist. The molecules are drawn as planar hexagons with a darkened edge representingthe side facing toward the viewer. The structure is simplified to show only the functional groups attached to the carbonatoms. Any group written to the right in a Fischer projection appears below the plane of the ring in a Haworth projection,and any group written to the left in a Fischer projection appears above the plane in a Haworth projection.
The difference between the α and the β forms of sugars may seem trivial, but such structural differences are often crucial inbiochemical reactions. This explains why we can get energy from the starch in potatoes and other plants but not fromcellulose, even though both starch and cellulose are polysaccharides composed of glucose molecules linked together.
Summary
Monosaccharides that contain five or more carbons atoms form cyclic structures in aqueous solution. Two cyclicstereoisomers can form from each straight-chain monosaccharide; these are known as anomers. In an aqueous solution, anequilibrium mixture forms between the two anomers and the straight-chain structure of a monosaccharide in a processknown as mutarotation.
Concept Review Exercises1. Define each term.
a. mutarotationb. anomerc. anomeric carbon
2. How can you prove that a solution of α-D-glucose exhibits mutarotation?
Answers1.
a. the ongoing interconversion between anomers of a particular carbohydrate to form an equilibrium mixture
2.5.2
2.5.1 2.5.2

2.5.3 1/2/2022 https://chem.libretexts.org/@go/page/178762
b. a stereoisomer that differs in structure around what was the carbonyl carbon atom in the straight-chain form of amonosaccharide
c. the carbon atom that was the carbonyl carbon atom in the straight-chain form of a monosaccharide
2. Place a sample of pure α-D-glucose in a polarimeter and measure its observed rotation. This value will change asmutarotation occurs.
Exercises
1. Draw the cyclic structure for β-D-glucose. Identify the anomeric carbon.
2. Draw the cyclic structure for α-D-fructose. Identify the anomeric carbon.
3. Given that the aldohexose D-mannose differs from D-glucose only in the configuration at the second carbon atom,draw the cyclic structure for α-D-mannose.
4. Given that the aldohexose D-allose differs from D-glucose only in the configuration at the third carbon atom, draw thecyclic structure for β-D-allose.
Answers
1.
3.

2.6.1 1/9/2022 https://chem.libretexts.org/@go/page/178763
2.6: Properties of MonosaccharidesLearning Objectives
To identify the physical and chemical properties of monosaccharides.
Monosaccharides such as glucose and fructose are crystalline solids at room temperature, but they are quite soluble inwater, each molecule having several OH groups that readily engage in hydrogen bonding. The chemical behavior of thesemonosaccharides is likewise determined by their functional groups.
An important reaction of monosaccharides is the oxidation of the aldehyde group, one of the most easily oxidized organicfunctional groups. Aldehyde oxidation can be accomplished with any mild oxidizing agent, such as Tollens’ reagent orBenedict’s reagent. With the latter, complexed copper(II) ions are reduced to copper(I) ions that form a brick-redprecipitate [copper(I) oxide; Figure ].
Any carbohydrate capable of reducing either Tollens’ or Benedict’s reagents without first undergoing hydrolysis is said tobe a reducing sugar. Because both the Tollens’ and Benedict’s reagents are basic solutions, ketoses (such as fructose) alsogive positive tests due to an equilibrium that exists between ketoses and aldoses in a reaction known as tautomerism.
Figure : Benedict’s Test. Benedict’s test was performed on three carbohydrates, depicted from left to right: fructose,glucose, and sucrose. The solution containing sucrose remains blue because sucrose is a nonreducing sugar.
These reactions have been used as simple and rapid diagnostic tests for the presence of glucose in blood or urine. Forexample, Clinitest tablets, which are used to test for sugar in the urine, contain copper(II) ions and are based on Benedict’stest. A green color indicates very little sugar, whereas a brick-red color indicates sugar in excess of 2 g/100 mL of urine.
Summary Monosaccharides are crystalline solids at room temperature and quite soluble in water. Monosaccharides are reducingsugars; they reduce mild oxidizing agents, such as Tollens’ or Benedict’s reagents.
Concept Review Exercises
1. Why are monosaccharides soluble in water?
2. What is a reducing sugar?
2.6.1
2.6.1

2.6.2 1/9/2022 https://chem.libretexts.org/@go/page/178763
Answers
1. Monosaccharides are quite soluble in water because of the numerous OH groups that readily engage in hydrogenbonding with water.
2. any carbohydrate capable of reducing a mild oxidizing agent, such as Tollens’ or Benedict’s reagents, without firstundergoing hydrolysis
Exercises
1. Which gives a positive Benedict’s test—L-galactose, levulose, or D-glucose?
2. Which gives a positive Benedict’s test—D-glyceraldehyde, corn sugar, or L-fructose?
3. D-Galactose can be oxidized at the sixth carbon atom to yield D-galacturonic acid and at both the first and sixth carbonatoms to yield D-galactaric acid. Draw the Fischer projection for each oxidation product.
4. D-Glucose can be oxidized at the first carbon atom to form D-gluconic acid, at the sixth carbon atom to yield D-glucuronic acid, and at both the first and sixth carbon atoms to yield D-glucaric acid. Draw the Fischer projection foreach oxidation product.
Answers 1. All three will give a positive Benedict’s test because they are all monosaccharides.
3.

2.7.1 1/5/2022 https://chem.libretexts.org/@go/page/178764
2.7: DisaccharidesLearning Objectives
Identify the structures of sucrose, lactose, and maltose.Identify the monosaccharides that are needed to form sucrose, lactose, and maltose
Previously, you learned that monosaccharides can form cyclic structures by the reaction of the carbonyl group with an OHgroup. These cyclic molecules can in turn react with another alcohol. Disaccharides (C H O ) are sugars composed oftwo monosaccharide units that are joined by a carbon–oxygen-carbon linkage known as a glycosidic linkage. This linkageis formed from the reaction of the anomeric carbon of one cyclic monosaccharide with the OH group of a secondmonosaccharide.
The disaccharides differ from one another in their monosaccharide constituents and in the specific type of glycosidiclinkage connecting them. There are three common disaccharides: maltose, lactose, and sucrose. All three are whitecrystalline solids at room temperature and are soluble in water. We’ll consider each sugar in more detail.
Maltose Maltose occurs to a limited extent in sprouting grain. It is formed most often by the partial hydrolysis of starch andglycogen. In the manufacture of beer, maltose is liberated by the action of malt (germinating barley) on starch; for thisreason, it is often referred to as malt sugar. Maltose is about 30% as sweet as sucrose. The human body is unable tometabolize maltose or any other disaccharide directly from the diet because the molecules are too large to pass through thecell membranes of the intestinal wall. Therefore, an ingested disaccharide must first be broken down by hydrolysis into itstwo constituent monosaccharide units.
In the body, such hydrolysis reactions are catalyzed by enzymes such as maltase. The same reactions can be carried out inthe laboratory with dilute acid as a catalyst, although in that case the rate is much slower, and high temperatures arerequired. Whether it occurs in the body or a glass beaker, the hydrolysis of maltose produces two molecules of D-glucose.
Maltose is a reducing sugar. Thus, its two glucose molecules must be linked in such a way as to leave one anomeric carbonthat can open to form an aldehyde group. The glucose units in maltose are joined in a head-to-tail fashion through an α-linkage from the first carbon atom of one glucose molecule to the fourth carbon atom of the second glucose molecule (thatis, an α-1,4-glycosidic linkage; see Figure ). The bond from the anomeric carbon of the first monosaccharide unit isdirected downward, which is why this is known as an α-glycosidic linkage. The OH group on the anomeric carbon of thesecond glucose can be in either the α or the β position, as shown in Figure .
12 22 11
maltose 2 D-glucose− →−−−−−−−or maltaseH+
(16.6.2)
2.7.1
2.7.1

2.7.2 1/5/2022 https://chem.libretexts.org/@go/page/178764
Figure : An Equilibrium Mixture of Maltose Isomers
Lactose
Lactose is known as milk sugar because it occurs in the milk of humans, cows, and other mammals. In fact, the naturalsynthesis of lactose occurs only in mammary tissue, whereas most other carbohydrates are plant products. Human milkcontains about 7.5% lactose, and cow’s milk contains about 4.5%. This sugar is one of the lowest ranking in terms ofsweetness, being about one-sixth as sweet as sucrose. Lactose is produced commercially from whey, a by-product in themanufacture of cheese. It is important as an infant food and in the production of penicillin.
Lactose is a reducing sugar composed of one molecule of D-galactose and one molecule of D-glucose joined by a β-1,4-glycosidic bond (the bond from the anomeric carbon of the first monosaccharide unit being directed upward). The twomonosaccharides are obtained from lactose by acid hydrolysis or the catalytic action of the enzyme lactase:
Many adults and some children suffer from a deficiency of lactase. These individuals are said to be lactose intolerantbecause they cannot digest the lactose found in milk. A more serious problem is the genetic disease galactosemia, whichresults from the absence of an enzyme needed to convert galactose to glucose. Certain bacteria can metabolize lactose,forming lactic acid as one of the products. This reaction is responsible for the “souring” of milk.
Example
For this trisaccharide, indicate whether each glycosidic linkage is α or β.
2.7.1
2.7.1

2.7.3 1/5/2022 https://chem.libretexts.org/@go/page/178764
SOLUTION
The glycosidic linkage between sugars 1 and 2 is β because the bond is directed up from the anomeric carbon. Theglycosidic linkage between sugars 2 and 3 is α because the bond is directed down from the anomeric carbon.
Exercise
For this trisaccharide, indicate whether each glycosidic linkage is α or β.
To Your Health: Lactose Intolerance and GalactosemiaLactose makes up about 40% of an infant’s diet during the first year of life. Infants and small children have one form ofthe enzyme lactase in their small intestines and can digest the sugar easily; however, adults usually have a less activeform of the enzyme, and about 70% of the world’s adult population has some deficiency in its production. As a result,many adults experience a reduction in the ability to hydrolyze lactose to galactose and glucose in their small intestine.For some people the inability to synthesize sufficient enzyme increases with age. Up to 20% of the US populationsuffers some degree of lactose intolerance.
In people with lactose intolerance, some of the unhydrolyzed lactose passes into the colon, where it tends to draw waterfrom the interstitial fluid into the intestinal lumen by osmosis. At the same time, intestinal bacteria may act on thelactose to produce organic acids and gases. The buildup of water and bacterial decay products leads to abdominaldistention, cramps, and diarrhea, which are symptoms of the condition.
The symptoms disappear if milk or other sources of lactose are excluded from the diet or consumed only sparingly.Alternatively, many food stores now carry special brands of milk that have been pretreated with lactase to hydrolyze thelactose. Cooking or fermenting milk causes at least partial hydrolysis of the lactose, so some people with lactoseintolerance are still able to enjoy cheese, yogurt, or cooked foods containing milk. The most common treatment forlactose intolerance, however, is the use of lactase preparations (e.g., Lactaid), which are available in liquid and tabletform at drugstores and grocery stores. These are taken orally with dairy foods—or may be added to them directly—toassist in their digestion.
Galactosemia is a condition in which one of the enzymes needed to convert galactose to glucose is missing.Consequently, the blood galactose level is markedly elevated, and galactose is found in the urine. An infant withgalactosemia experiences a lack of appetite, weight loss, diarrhea, and jaundice. The disease may result in impairedliver function, cataracts, mental retardation, and even death. If galactosemia is recognized in early infancy, its effectscan be prevented by the exclusion of milk and all other sources of galactose from the diet. As a child with galactosemiagrows older, he or she usually develops an alternate pathway for metabolizing galactose, so the need to restrict milk isnot permanent. The incidence of galactosemia in the United States is 1 in every 65,000 newborn babies.
Sucrose
Sucrose, probably the largest-selling pure organic compound in the world, is known as beet sugar, cane sugar, table sugar,or simply sugar. Most of the sucrose sold commercially is obtained from sugar cane and sugar beets (whose juices are
2.7.1

2.7.4 1/5/2022 https://chem.libretexts.org/@go/page/178764
14%–20% sucrose) by evaporation of the water and recrystallization. The dark brown liquid that remains after therecrystallization of sugar is sold as molasses.
The sucrose molecule is unique among the common disaccharides in having an α-1,β-2-glycosidic (head-to-head) linkage.Because this glycosidic linkage is formed by the OH group on the anomeric carbon of α-D-glucose and the OH group onthe anomeric carbon of β-D-fructose, it ties up the anomeric carbons of both glucose and fructose.
This linkage gives sucrose certain properties that are quite different from those of maltose and lactose. As long as thesucrose molecule remains intact, neither monosaccharide “uncyclizes” to form an open-chain structure. Thus, sucrose isincapable of mutarotation and exists in only one form both in the solid state and in solution. In addition, sucrose does notundergo reactions that are typical of aldehydes and ketones. Therefore, sucrose is a nonreducing sugar.
The hydrolysis of sucrose in dilute acid or through the action of the enzyme sucrase (also known as invertase) gives anequimolar mixture of glucose and fructose. This 1:1 mixture is referred to as invert sugar because it rotates plane-polarizedlight in the opposite direction than sucrose. The hydrolysis reaction has several practical applications. Sucrose readilyrecrystallizes from a solution, but invert sugar has a much greater tendency to remain in solution. In the manufacture ofjelly and candy and in the canning of fruit, the recrystallization of sugar is undesirable. Therefore, conditions leading to thehydrolysis of sucrose are employed in these processes. Moreover, because fructose is sweeter than sucrose, the hydrolysisadds to the sweetening effect. Bees carry out this reaction when they make honey.
The average American consumes more than 100 lb of sucrose every year. About two-thirds of this amount is ingested insoft drinks, presweetened cereals, and other highly processed foods. The widespread use of sucrose is a contributing factorto obesity and tooth decay. Carbohydrates such as sucrose, are converted to fat when the caloric intake exceeds the body’srequirements, and sucrose causes tooth decay by promoting the formation of plaque that sticks to teeth.
Summary Maltose is composed of two molecules of glucose joined by an α-1,4-glycosidic linkage. It is a reducing sugar that is foundin sprouting grain. Lactose is composed of a molecule of galactose joined to a molecule of glucose by a β-1,4-glycosidiclinkage. It is a reducing sugar that is found in milk. Sucrose is composed of a molecule of glucose joined to a molecule offructose by an α-1,β-2-glycosidic linkage. It is a nonreducing sugar that is found in sugar cane and sugar beets.
Concept Review Exercise 1. What monosaccharides are obtained by the hydrolysis of each disaccharide?
a. sucroseb. maltosec. lactose
Answer 1.
a. D-glucose and D-fructoseb. two molecules of D-glucosec. D-glucose and D-galactose

2.7.5 1/5/2022 https://chem.libretexts.org/@go/page/178764
Exercises
1. Identify each sugar by its common chemical name.
a. milk sugarb. table sugar
2. Identify each sugar by its common chemical name.
a. cane sugarb. malt sugar
3. For each disaccharide, indicate whether the glycosidic linkage is α or β.
a.
b.
4. For each disaccharide, indicate whether the glycosidic linkage is α or β.
a.

2.7.6 1/5/2022 https://chem.libretexts.org/@go/page/178764
b.
5. Identify each disaccharide in Exercise 3 as a reducing or nonreducing sugar. If it is a reducing sugar, draw its structureand circle the anomeric carbon. State if the OH group at the anomeric carbon is in the α or the β position.
6. Identify each disaccharide in Exercise 4 as a reducing or nonreducing sugar. If it is a reducing sugar, draw its structureand circle the anomeric carbon. State if the OH group at the anomeric carbon is in the α or β position.
7. Melibiose is a disaccharide that occurs in some plant juices. Its structure is as follows:
a. What monosaccharide units are incorporated into melibiose?b. What type of linkage (α or β) joins the two monosaccharide units of melibiose?c. Melibiose has a free anomeric carbon and is thus a reducing sugar. Circle the anomeric carbon and indicate whether
the OH group is α or β.
8. Cellobiose is a disaccharide composed of two glucose units joined by a β-1,4-glycosidic linkage.
a. Draw the structure of cellobiose.b. Is cellobiose a reducing or nonreducing sugar? Justify your answer.
Answers
1.
a. lactoseb. sucrose

2.7.7 1/5/2022 https://chem.libretexts.org/@go/page/178764
3.
a.
b.
5. 3a: nonreducing; 3b: reducing
7.
a. galactose and glucoseb. α-glycosidic linkage

2.7.8 1/5/2022 https://chem.libretexts.org/@go/page/178764
c.

2.8.1 11/28/2021 https://chem.libretexts.org/@go/page/178765
2.8: PolysaccharidesLearning Objectives
To compare and contrast the structures and uses of starch, glycogen, and cellulose.
The polysaccharides are the most abundant carbohydrates in nature and serve a variety of functions, such as energy storageor as components of plant cell walls. Polysaccharides are very large polymers composed of tens to thousands ofmonosaccharides joined together by glycosidic linkages. The three most abundant polysaccharides are starch, glycogen,and cellulose. These three are referred to as homopolymers because each yields only one type of monosaccharide (glucose)after complete hydrolysis. Heteropolymers may contain sugar acids, amino sugars, or noncarbohydrate substances inaddition to monosaccharides. Heteropolymers are common in nature (gums, pectins, and other substances) but will not bediscussed further in this textbook. The polysaccharides are nonreducing carbohydrates, are not sweet tasting, and do notundergo mutarotation.
Starch
Starch is the most important source of carbohydrates in the human diet and accounts for more than 50% of ourcarbohydrate intake. It occurs in plants in the form of granules, and these are particularly abundant in seeds (especially thecereal grains) and tubers, where they serve as a storage form of carbohydrates. The breakdown of starch to glucosenourishes the plant during periods of reduced photosynthetic activity. We often think of potatoes as a “starchy” food, yetother plants contain a much greater percentage of starch (potatoes 15%, wheat 55%, corn 65%, and rice 75%). Commercialstarch is a white powder.
Starch is a mixture of two polymers: amylose and amylopectin. Natural starches consist of about 10%–30% amylose and70%–90% amylopectin. Amylose is a linear polysaccharide composed entirely of D-glucose units joined by the α-1,4-glycosidic linkages we saw in maltose (part (a) of Figure ). Experimental evidence indicates that amylose is not astraight chain of glucose units but instead is coiled like a spring, with six glucose monomers per turn (part (b) of Figure
). When coiled in this fashion, amylose has just enough room in its core to accommodate an iodine molecule. Thecharacteristic blue-violet color that appears when starch is treated with iodine is due to the formation of the amylose-iodinecomplex. This color test is sensitive enough to detect even minute amounts of starch in solution.
Figure : Amylose. (a) Amylose is a linear chain of α-D-glucose units joined together by α-1,4-glycosidic bonds. (b)Because of hydrogen bonding, amylose acquires a spiral structure that contains six glucose units per turn.
Amylopectin is a branched-chain polysaccharide composed of glucose units linked primarily by α-1,4-glycosidic bonds butwith occasional α-1,6-glycosidic bonds, which are responsible for the branching. A molecule of amylopectin may containmany thousands of glucose units with branch points occurring about every 25–30 units (Figure ). The helical structureof amylopectin is disrupted by the branching of the chain, so instead of the deep blue-violet color amylose gives withiodine, amylopectin produces a less intense reddish brown.
2.8.1
2.8.1
2.8.1
2.8.2

2.8.2 11/28/2021 https://chem.libretexts.org/@go/page/178765
Figure : Representation of the Branching in Amylopectin and Glycogen. Both amylopectin and glycogen containbranch points that are linked through α-1,6-linkages. These branch points occur more often in glycogen.
Dextrins are glucose polysaccharides of intermediate size. The shine and stiffness imparted to clothing by starch are due tothe presence of dextrins formed when clothing is ironed. Because of their characteristic stickiness with wetting, dextrinsare used as adhesives on stamps, envelopes, and labels; as binders to hold pills and tablets together; and as pastes. Dextrinsare more easily digested than starch and are therefore used extensively in the commercial preparation of infant foods.
The complete hydrolysis of starch yields, in successive stages, glucose:
starch → dextrins → maltose → glucose
In the human body, several enzymes known collectively as amylases degrade starch sequentially into usable glucose units.
Glycogen
Glycogen is the energy reserve carbohydrate of animals. Practically all mammalian cells contain some storedcarbohydrates in the form of glycogen, but it is especially abundant in the liver (4%–8% by weight of tissue) and inskeletal muscle cells (0.5%–1.0%). Like starch in plants, glycogen is found as granules in liver and muscle cells. Whenfasting, animals draw on these glycogen reserves during the first day without food to obtain the glucose needed to maintainmetabolic balance.
Glycogen is structurally quite similar to amylopectin, although glycogen is more highly branched (8–12 glucose unitsbetween branches) and the branches are shorter. When treated with iodine, glycogen gives a reddish brown color.Glycogen can be broken down into its D-glucose subunits by acid hydrolysis or by the same enzymes that catalyze thebreakdown of starch. In animals, the enzyme phosphorylase catalyzes the breakdown of glycogen to phosphate esters ofglucose.
About 70% of the total glycogen in the body is stored in muscle cells. Although thepercentage of glycogen (by weight) is higher in the liver, the much greater mass ofskeletal muscle stores a greater total amount of glycogen.
Cellulose
Cellulose, a fibrous carbohydrate found in all plants, is the structural component of plant cell walls. Because the earth iscovered with vegetation, cellulose is the most abundant of all carbohydrates, accounting for over 50% of all the carbonfound in the vegetable kingdom. Cotton fibrils and filter paper are almost entirely cellulose (about 95%), wood is about50% cellulose, and the dry weight of leaves is about 10%–20% cellulose. The largest use of cellulose is in the manufactureof paper and paper products. Although the use of noncellulose synthetic fibers is increasing, rayon (made from cellulose)and cotton still account for over 70% of textile production.
2.8.2

2.8.3 11/28/2021 https://chem.libretexts.org/@go/page/178765
Like amylose, cellulose is a linear polymer of glucose. It differs, however, in that the glucose units are joined by β-1,4-glycosidic linkages, producing a more extended structure than amylose (part (a) of Figure ). This extreme linearityallows a great deal of hydrogen bonding between OH groups on adjacent chains, causing them to pack closely into fibers(part (b) of Figure ). As a result, cellulose exhibits little interaction with water or any other solvent. Cotton and wood,for example, are completely insoluble in water and have considerable mechanical strength. Because cellulose does nothave a helical structure, it does not bind to iodine to form a colored product.
Figure : Cellulose. (a) There is extensive hydrogen bonding in the structure of cellulose. (b) In this electronmicrograph of the cell wall of an alga, the wall consists of successive layers of cellulose fibers in parallel arrangement.
Cellulose yields D-glucose after complete acid hydrolysis, yet humans are unable to metabolize cellulose as a source ofglucose. Our digestive juices lack enzymes that can hydrolyze the β-glycosidic linkages found in cellulose, so although wecan eat potatoes, we cannot eat grass. However, certain microorganisms can digest cellulose because they make theenzyme cellulase, which catalyzes the hydrolysis of cellulose. The presence of these microorganisms in the digestive tractsof herbivorous animals (such as cows, horses, and sheep) allows these animals to degrade the cellulose from plant materialinto glucose for energy. Termites also contain cellulase-secreting microorganisms and thus can subsist on a wood diet. Thisexample once again demonstrates the extreme stereospecificity of biochemical processes.
Career Focus: Certified Diabetes EducatorCertified diabetes educators come from a variety of health professions, such as nursing and dietetics, and specialize inthe education and treatment of patients with diabetes. A diabetes educator will work with patients to manage theirdiabetes. This involves teaching the patient to monitor blood sugar levels, make good food choices, develop andmaintain an exercise program, and take medication, if required.
A certified diabetes educator at Naval Medical Center Portsmouth (left) and a registered dietician at the medical center(center), provide nutritional information to a diabetes patient and her mother at the Diabetes Boot Camp.
2.8.3
2.8.3
2.8.3

2.8.4 11/28/2021 https://chem.libretexts.org/@go/page/178765
Diabetes educators also work with hospital or nursing home staff to improve the care of diabetic patients. Educatorsmust be willing to spend time attending meetings and reading the current literature to maintain their knowledge ofdiabetes medications, nutrition, and blood monitoring devices so that they can pass this information to their patients.
Summary Starch is a storage form of energy in plants. It contains two polymers composed of glucose units: amylose (linear) andamylopectin (branched). Glycogen is a storage form of energy in animals. It is a branched polymer composed of glucoseunits. It is more highly branched than amylopectin. Cellulose is a structural polymer of glucose units found in plants. It is alinear polymer with the glucose units linked through β-1,4-glycosidic bonds.
Concept Review Exercises
1. What purposes do starch and cellulose serve in plants?
2. What purpose does glycogen serve in animals?
Answers
1. Starch is the storage form of glucose (energy) in plants, while cellulose is a structural component of the plant cell wall.
2. Glycogen is the storage form of glucose (energy) in animals.
Exercises
1. What monosaccharide is obtained from the hydrolysis of each carbohydrate?
a. starchb. cellulosec. glycogen
2. For each carbohydrate listed in Exercise 1, indicate whether it is found in plants or mammals.
3. Describe the similarities and differences between amylose and cellulose.
4. Describe the similarities and differences between amylopectin and glycogen.
Answers a. 1. glucoseb. glucosec. glucose
3. Amylose and cellulose are both linear polymers of glucose units, but the glycosidic linkages between the glucose unitsdiffer. The linkages in amylose are α-1,4-glycosidic linkages, while the linkages in cellulose they are β-1,4-glycosidiclinkages.

2.9.1 1/10/2022 https://chem.libretexts.org/@go/page/178766
2.9: Carbohydrates (Summary)To ensure that you understand the material in this chapter, you should review the meanings of the bold terms in the
following summary and ask yourself how they relate to the topics in the chapter.
Carbohydrates, a large group of biological compounds containing carbon, hydrogen, and oxygen atoms, include sugars,starch, glycogen, and cellulose. All carbohydrates contain alcohol functional groups, and either an aldehyde or a ketonegroup (or a functional group that can be converted to an aldehyde or ketone). The simplest carbohydrates aremonosaccharides. Those with two monosaccharide units are disaccharides, and those with many monosaccharide unitsare polysaccharides. Most sugars are either monosaccharides or disaccharides. Cellulose, glycogen, and starch arepolysaccharides.
Many carbohydrates exist as stereoisomers, in which the three-dimensional spatial arrangement of the atoms in space isthe only difference between the isomers. These particular stereoisomers contain at least one chiral carbon, a carbon atomthat has four different groups bonded to it. A molecule containing a chiral carbon is nonsuperimposable on its mirrorimage, and two molecules that are nonsuperimposable mirror images of each other are a special type of stereoisomer calledenantiomers. Enantiomers have the same physical properties, such as melting point, but differ in the direction they rotatepolarized light.
A sugar is designated as being a D sugar or an L sugar according to how, in a Fischer projection of the molecule, thehydrogen atom and OH group are attached to the penultimate carbon atom, which is the carbon atom immediately beforethe terminal alcohol carbon atom. If the structure at this carbon atom is the same as that of D-glyceraldehyde (OH to theright), the sugar is a D sugar; if the configuration is the same as that of L-glyceraldehyde (OH to the left), the sugar is an Lsugar.
Monosaccharides of five or more carbons atoms readily form cyclic structures when the carbonyl carbon atom reacts withan OH group on a carbon atom three or four carbon atoms distant. Consequently, glucose in solution exists as anequilibrium mixture of three forms, two of them cyclic (α- and β-) and one open chain. In Haworth projections, the alphaform is drawn with the OH group on the “former” carbonyl carbon atom (anomeric carbon) pointing downward; the betaform, with the OH group pointing upward; these two compounds are stereoisomers and are given the more specific term ofanomers. Any solid sugar can be all alpha or all beta. Once the sample is dissolved in water, however, the ring opens upinto the open-chain structure and then closes to form either the α- or the β-anomer. These interconversions occur back andforth until a dynamic equilibrium mixture is achieved in a process called mutarotation.
The carbonyl group present in monosaccharides is easily oxidized by Tollens’ or Benedict’s reagents (as well as others).Any mono- or disaccharide containing a free anomeric carbon is a reducing sugar. The disaccharide maltose contains twoglucose units joined in an α-1,4-glycosidic linkage. The disaccharide lactose contains a galactose unit and a glucose unitjoined by a β-1,4-glycosidic linkage. Both maltose and lactose contain a free anomeric carbon that can convert to analdehyde functional group, so they are reducing sugars; they also undergo mutarotation. Many adults, and some children,have a deficiency of the enzyme lactase (which is needed to break down lactose) and are said to be lactose intolerant. Amore serious problem is the genetic disease galactosemia, which results from the absence of an enzyme needed to convertgalactose to glucose.
The disaccharide sucrose (table sugar) consists of a glucose unit and a fructose unit joined by a glycosidic linkage. Thelinkage is designated as an α-1,β-2-glycosidic linkage because it involves the OH group on the first carbon atom of glucoseand the OH group on the second carbon atom of fructose. Sucrose is not a reducing sugar because it has no anomericcarbon that can reform a carbonyl group, and it cannot undergo mutarotation because of the restrictions imposed by thislinkage.
Starch, the principal carbohydrate of plants, is composed of the polysaccharides amylose (10%–30%) and amylopectin(70%–90%). When ingested by humans and other animals, starch is hydrolyzed to glucose and becomes the body’s energysource. Glycogen is the polysaccharide animals use to store excess carbohydrates from their diets. Similar in structure toamylopectin, glycogen is hydrolyzed to glucose whenever an animal needs energy for a metabolic process. Thepolysaccharide cellulose provides structure for plant cells. It is a linear polymer of glucose units joined by β-1,4-glycosidiclinkages. It is indigestible in the human body but digestible by many microorganisms, including microorganisms found inthe digestive tracts of many herbivores.

1 1/10/2022
CHAPTER OVERVIEW3: LIPIDS
3.1: PRELUDE TO LIPIDSLipids are not defined by the presence of specific functional groups, as carbohydrates are, but by a physical property—solubility.Compounds isolated from body tissues are classified as lipids if they are more soluble in organic solvents, such as dichloromethane,than in water. Hence, the lipid category includes not only fats and oils, which are esters of the trihydroxy alcohol glycerol and fattyacids, but also compounds derived from phosphoric acid, carbohydrates, amino alcohols and steroids.
3.2: FATTY ACIDSFatty acids are carboxylic acids that are the structural components of many lipids. They may be saturated or unsaturated. Most fattyacids are unbranched and contain an even number of carbon atoms. Unsaturated fatty acids have lower melting points than saturatedfatty acids containing the same number of carbon atoms.
3.3: FATS AND OILSFats and oils are composed of molecules known as triglycerides, which are esters composed of three fatty acid units linked toglycerol. An increase in the percentage of shorter-chain fatty acids and/or unsaturated fatty acids lowers the melting point of a fat oroil. The hydrolysis of fats and oils in the presence of a base makes soap and is known as saponification. Double bonds present inunsaturated triglycerides can be hydrogenated to convert oils (liquid) into margarine (solid).
3.4: MEMBRANES AND MEMBRANE LIPIDSLipids are important components of biological membranes. These lipids have dual characteristics: part of the molecule is hydrophilic,and part of the molecule is hydrophobic. Membrane lipids may be classified as phospholipids, glycolipids, and/or sphingolipids.Proteins are another important component of biological membranes. Integral proteins span the lipid bilayer, while peripheral proteinsare more loosely associated with the surface of the membrane.
3.5: STEROIDSSteroids have a four-fused-ring structure and have a variety of functions. Cholesterol is a steroid found in mammals that is needed forthe formation of cell membranes, bile acids, and several hormones. Bile salts are secreted into the small intestine to aid in thedigestion of fats.
3.6: LIPIDS (SUMMARY)To ensure that you understand the material in this chapter, you should review the meanings of the bold terms in the followingsummary and ask yourself how they relate to the topics in the chapter.
3.7: EXERCISESProblems and select solutions for the chapter.

3.1.1 1/7/2022 https://chem.libretexts.org/@go/page/178768
3.1: Prelude to Lipids
On July 11, 2003, the Food and Drug Administration amended its food labeling regulations to require thatmanufacturers list the amount of trans fatty acids on Nutrition Facts labels of foods and dietary supplements, effectiveJanuary 1, 2006. This amendment was a response to published studies demonstrating a link between the consumption oftrans fatty acids and an increased risk of heart disease. Trans fatty acids are produced in the conversion of liquid oils tosolid fats, as in the creation of many commercial margarines and shortenings. They have been shown to increase thelevels of low-density lipoproteins (LDLs)—complexes that are often referred to as bad cholesterol—in the blood. Inthis chapter, you will learn about fatty acids and what is meant by a trans fatty acid, as well as the difference betweenfats and oils. You will also learn what cholesterol is and why it is an important molecule in the human body.
Fats and oils, found in many of the foods we eat, belong to a class of biomolecules known as lipids. Gram for gram, theypack more than twice the caloric content of carbohydrates: the oxidation of fats and oils supplies about 9 kcal of energy forevery gram oxidized, whereas the oxidation of carbohydrates supplies only 4 kcal/g. Although the high caloric content offats may be bad news for the dieter, it says something about the efficiency of nature’s designs. Our bodies usecarbohydrates, primarily in the form of glucose, for our immediate energy needs. Our capacity for storing carbohydratesfor later use is limited to tucking away a bit of glycogen in the liver or in muscle tissue. We store our reserve energy inlipid form, which requires far less space than the same amount of energy stored in carbohydrate form. Lipids have otherbiological functions besides energy storage. They are a major component of the membranes of the 10 trillion cells in ourbodies. They serve as protective padding and insulation for vital organs. Furthermore, without lipids in our diets, we wouldbe deficient in the fat-soluble vitamins A, D, E, and K.
Lipids are not defined by the presence of specific functional groups, as carbohydrates are, but by a physical property—solubility. Compounds isolated from body tissues are classified as lipids if they are more soluble in organic solvents, suchas dichloromethane, than in water. By this criterion, the lipid category includes not only fats and oils, which are esters ofthe trihydroxy alcohol glycerol and fatty acids, but also compounds that incorporate functional groups derived fromphosphoric acid, carbohydrates, or amino alcohols, as well as steroid compounds such as cholesterol (Figure presentsone scheme for classifying the various kinds of lipids). We will discuss the various kinds of lipids by considering onesubclass at a time and pointing out structural similarities and differences as we go.
Figure : Lipid Organization Based on Structural Relationships
3.1.1
3.1.1
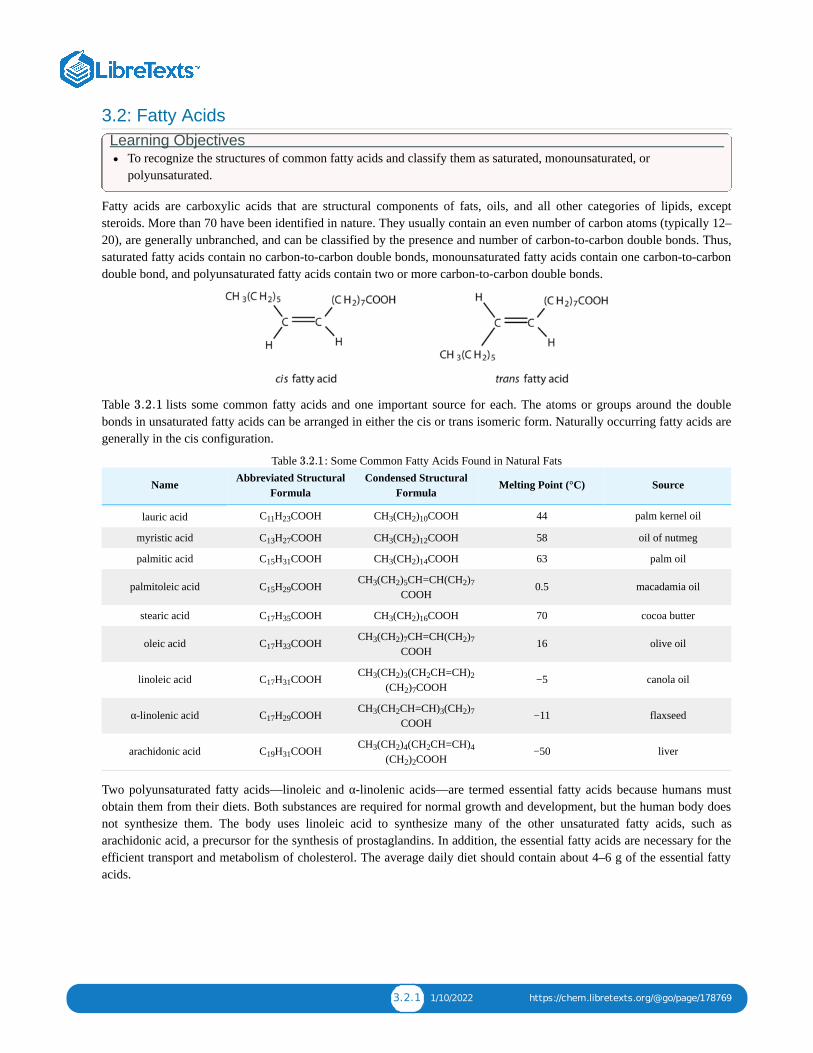
3.2.1 1/10/2022 https://chem.libretexts.org/@go/page/178769
3.2: Fatty AcidsLearning Objectives
To recognize the structures of common fatty acids and classify them as saturated, monounsaturated, orpolyunsaturated.
Fatty acids are carboxylic acids that are structural components of fats, oils, and all other categories of lipids, exceptsteroids. More than 70 have been identified in nature. They usually contain an even number of carbon atoms (typically 12–20), are generally unbranched, and can be classified by the presence and number of carbon-to-carbon double bonds. Thus,saturated fatty acids contain no carbon-to-carbon double bonds, monounsaturated fatty acids contain one carbon-to-carbondouble bond, and polyunsaturated fatty acids contain two or more carbon-to-carbon double bonds.
Table lists some common fatty acids and one important source for each. The atoms or groups around the doublebonds in unsaturated fatty acids can be arranged in either the cis or trans isomeric form. Naturally occurring fatty acids aregenerally in the cis configuration.
Table : Some Common Fatty Acids Found in Natural Fats
Name Abbreviated StructuralFormula
Condensed StructuralFormula
Melting Point (°C) Source
lauric acid C H COOH CH (CH ) COOH 44 palm kernel oil
myristic acid C H COOH CH (CH ) COOH 58 oil of nutmeg
palmitic acid C H COOH CH (CH ) COOH 63 palm oil
palmitoleic acid C H COOH CH (CH ) CH=CH(CH )COOH
0.5 macadamia oil
stearic acid C H COOH CH (CH ) COOH 70 cocoa butter
oleic acid C H COOH CH (CH ) CH=CH(CH )COOH
16 olive oil
linoleic acid C H COOH CH (CH ) (CH CH=CH)(CH ) COOH
−5 canola oil
α-linolenic acid C H COOH CH (CH CH=CH) (CH )COOH
−11 flaxseed
arachidonic acid C H COOH CH (CH ) (CH CH=CH)(CH ) COOH
−50 liver
Two polyunsaturated fatty acids—linoleic and α-linolenic acids—are termed essential fatty acids because humans mustobtain them from their diets. Both substances are required for normal growth and development, but the human body doesnot synthesize them. The body uses linoleic acid to synthesize many of the other unsaturated fatty acids, such asarachidonic acid, a precursor for the synthesis of prostaglandins. In addition, the essential fatty acids are necessary for theefficient transport and metabolism of cholesterol. The average daily diet should contain about 4–6 g of the essential fattyacids.
3.2.1
3.2.1
11 23 3 2 10
13 27 3 2 12
15 31 3 2 14
15 293 2 5 2 7
17 35 3 2 16
17 333 2 7 2 7
17 313 2 3 2 2
2 7
17 293 2 3 2 7
19 313 2 4 2 4
2 2

3.2.2 1/10/2022 https://chem.libretexts.org/@go/page/178769
To Your Health: ProstaglandinsProstaglandins are chemical messengers synthesized in the cells in which their physiological activity is expressed. Theyare unsaturated fatty acids containing 20 carbon atoms and are synthesized from arachidonic acid—a polyunsaturatedfatty acid—when needed by a particular cell. They are called prostaglandins because they were originally isolated fromsemen found in the prostate gland. It is now known that they are synthesized in nearly all mammalian tissues and affectalmost all organs in the body. The five major classes of prostaglandins are designated as PGA, PGB, PGE, PGF, andPGI. Subscripts are attached at the end of these abbreviations to denote the number of double bonds outside the five-carbon ring in a given prostaglandin.
The prostaglandins are among the most potent biological substances known. Slight structural differences give themhighly distinct biological effects; however, all prostaglandins exhibit some ability to induce smooth muscle contraction,lower blood pressure, and contribute to the inflammatory response. Aspirin and other nonsteroidal anti-inflammatoryagents, such as ibuprofen, obstruct the synthesis of prostaglandins by inhibiting cyclooxygenase, the enzyme needed forthe initial step in the conversion of arachidonic acid to prostaglandins.
Their wide range of physiological activity has led to the synthesis of hundreds of prostaglandins and their analogs.Derivatives of PGE are now used in the United States to induce labor. Other prostaglandins have been employedclinically to lower or increase blood pressure, inhibit stomach secretions, relieve nasal congestion, relieve asthma, andprevent the formation of blood clots, which are associated with heart attacks and strokes.
Although we often draw the carbon atoms in a straight line, they actually have more of a zigzag configuration (Figure ). Viewed as a whole, however, the saturated fatty acid molecule is relatively straight (Figure ). Such
molecules pack closely together into a crystal lattice, maximizing the strength of dispersion forces and causing fatty acidsand the fats derived from them to have relatively high melting points. In contrast, each cis carbon-to-carbon double bond inan unsaturated fatty acid produces a pronounced bend in the molecule, so that these molecules do not stack neatly. As aresult, the intermolecular attractions of unsaturated fatty acids (and unsaturated fats) are weaker, causing these substancesto have lower melting points. Most are liquids at room temperature.
2
3.2.2a 3.2.2b

3.2.3 1/10/2022 https://chem.libretexts.org/@go/page/178769
Figure : The Structure of Saturated Fatty Acids. (a) There is a zigzag pattern formed by the carbon-to-carbon singlebonds in the ball-and-stick model of a palmitic acid molecule. (b) A space-filling model of palmitic acid shows the overallstraightness of a saturated fatty acid molecule.
Waxes are esters formed from long-chain fatty acids and long-chain alcohols. Most natural waxes are mixtures of suchesters. Plant waxes on the surfaces of leaves, stems, flowers, and fruits protect the plant from dehydration and invasion byharmful microorganisms. Carnauba wax, used extensively in floor waxes, automobile waxes, and furniture polish, islargely myricyl cerotate, obtained from the leaves of certain Brazilian palm trees. Animals also produce waxes that serveas protective coatings, keeping the surfaces of feathers, skin, and hair pliable and water repellent. In fact, if the waxycoating on the feathers of a water bird is dissolved as a result of the bird swimming in an oil slick, the feathers become wetand heavy, and the bird, unable to maintain its buoyancy, drowns.
Summary Fatty acids are carboxylic acids that are the structural components of many lipids. They may be saturated or unsaturated.Most fatty acids are unbranched and contain an even number of carbon atoms. Unsaturated fatty acids have lower meltingpoints than saturated fatty acids containing the same number of carbon atoms.
Concept Review Exercises 1. Give an example of each compound.
a. saturated fatty acidb. polyunsaturated fatty acidc. monounsaturated fatty acid
2. Why do unsaturated fatty acids have lower melting points than saturated fatty acids?
Answers
a. 1. stearic acid (answers will vary)b. linoleic acid (answers will vary)c. palmitoleic acid (answers will vary)
2. Unsaturated fatty acids cannot pack as tightly together as saturated fatty acids due to the presence of the cis doublebond that puts a “kink” or bend in the hydrocarbon chain.
Exercises
1. Classify each fatty acid as saturated or unsaturated and indicate the number of carbon atoms in each molecule.
a. palmitoleic acid
3.2.2

3.2.4 1/10/2022 https://chem.libretexts.org/@go/page/178769
b. myristic acidc. linoleic acid
2. Classify each fatty acid as saturated or unsaturated and indicate the number of carbon atoms in each molecule.
a. stearic acidb. oleic acidc. palmitic acid
3. Write the condensed structural formula for each fatty acid.
a. lauric acidb. palmitoleic acidc. linoleic acid
4. Write the condensed structural formulas for each fatty acid.
a. oleic acidb. α-linolenic acidc. palmitic acid
5. Arrange these fatty acids (all contain 18 carbon atoms) in order of increasing melting point. Justify your arrangement.
a.
b.
c.
6. Arrange these fatty acids (all contain 16 carbon atoms) in order of increasing melting point. Justify your arrangement.
a. CH (CH ) COOH
b.
c.
3 2 14

3.2.5 1/10/2022 https://chem.libretexts.org/@go/page/178769
Answers
a. 1. unsaturated; 16 carbon atomsb. saturated; 14 carbon atomsc. unsaturated; 18 carbon atoms
a. 3. CH (CH ) COOHb. CH (CH ) CH=CH(CH ) COOHc. CH (CH ) (CH CH=CH) (CH ) COOH
5. c < a < b; an increase in the number of double bonds will lower the melting point because it is more difficult to closelypack the fatty acids together.
3 2 10
3 2 5 2 7
3 2 3 2 2 2 7

3.3.1 12/19/2021 https://chem.libretexts.org/@go/page/178770
3.3: Fats and OilsLearning Objectives
Explain why fats and oils are referred to as triglycerides.Explain how the fatty acid composition of the triglycerides determines whether a substance is a fat or oil.Describe the importance of key reactions of triglycerides, such as hydrolysis, hydrogenation, and oxidation.
Fats and oils are the most abundant lipids in nature. They provide energy for living organisms, insulate body organs, andtransport fat-soluble vitamins through the blood.
Structures of Fats and Oils
Fats and oils are called triglycerides (or triacylcylgerols) because they are esters composed of three fatty acid units joinedto glycerol, a trihydroxy alcohol:
If all three OH groups on the glycerol molecule are esterified with the same fatty acid, the resulting ester is called a simpletriglyceride. Although simple triglycerides have been synthesized in the laboratory, they rarely occur in nature. Instead, atypical triglyceride obtained from naturally occurring fats and oils contains two or three different fatty acid componentsand is thus termed a mixed triglyceride.
A triglyceride is called a fat if it is a solid at 25°C; it is called an oil if it is a liquid at that temperature. These differences inmelting points reflect differences in the degree of unsaturation and number of carbon atoms in the constituent fatty acids.Triglycerides obtained from animal sources are usually solids, while those of plant origin are generally oils. Therefore, wecommonly speak of animal fats and vegetable oils.
No single formula can be written to represent the naturally occurring fats and oils because they are highly complexmixtures of triglycerides in which many different fatty acids are represented. Table shows the fatty acid compositionsof some common fats and oils. The composition of any given fat or oil can vary depending on the plant or animal species itcomes from as well as on dietetic and climatic factors. To cite just one example, lard from corn-fed hogs is more highlysaturated than lard from peanut-fed hogs. Palmitic acid is the most abundant of the saturated fatty acids, while oleic acid isthe most abundant unsaturated fatty acid.
3.3.1

3.3.2 12/19/2021 https://chem.libretexts.org/@go/page/178770
Table : Average Fatty Acid Composition of Some Common Fats and Oils (%)*Lauric Myristic Palmitic Stearic Oleic Linoleic Linolenic
Fats
butter (cow) 3 11 27 12 29 2 1
tallow 3 24 19 43 3 1
lard 2 26 14 44 10
Oils
canola oil 4 2 62 22 10
coconut oil 47 18 9 3 6 2
corn oil 11 2 28 58 1
olive oil 13 3 71 10 1
peanut oil 11 2 48 32
soybean oil 11 4 24 54 7
*Totals less than 100% indicate the presence of fatty acids with fewer than 12 carbon atoms or more than 18 carbon atoms.
Coconut oil is highly saturated. It contains an unusually high percentage of the low-melting C , C , and C saturated fatty acids.
Terms such as saturated fat or unsaturated oil are often used to describe the fats or oils obtained from foods. Saturated fatscontain a high proportion of saturated fatty acids, while unsaturated oils contain a high proportion of unsaturated fattyacids. The high consumption of saturated fats is a factor, along with the high consumption of cholesterol, in increased risksof heart disease.
Physical Properties of Fats and Oils
Contrary to what you might expect, pure fats and oils are colorless, odorless, and tasteless. The characteristic colors, odors,and flavors that we associate with some of them are imparted by foreign substances that are lipid soluble and have beenabsorbed by these lipids. For example, the yellow color of butter is due to the presence of the pigment carotene; the taste ofbutter comes from two compounds—diacetyl and 3-hydroxy-2-butanone—produced by bacteria in the ripening creamfrom which the butter is made.
Fats and oils are lighter than water, having densities of about 0.8 g/cm . They are poor conductors of heat and electricityand therefore serve as excellent insulators for the body, slowing the loss of heat through the skin.
Chemical Reactions of Fats and Oils
Fats and oils can participate in a variety of chemical reactions—for example, because triglycerides are esters, they can behydrolyzed in the presence of an acid, a base, or specific enzymes known as lipases. The hydrolysis of fats and oils in thepresence of a base is used to make soap and is called saponification. Today most soaps are prepared through the hydrolysisof triglycerides (often from tallow, coconut oil, or both) using water under high pressure and temperature [700 lb/in (∼50atm or 5,000 kPa) and 200°C]. Sodium carbonate or sodium hydroxide is then used to convert the fatty acids to theirsodium salts (soap molecules):
3.3.1
†
†8 10 12
3
2

3.3.3 12/19/2021 https://chem.libretexts.org/@go/page/178770
Looking Closer: SoapsOrdinary soap is a mixture of the sodium salts of various fatty acids, produced in one of the oldest organic synthesespracticed by humans (second only to the fermentation of sugars to produce ethyl alcohol). Both the Phoenicians (600BCE) and the Romans made soap from animal fat and wood ash. Even so, the widespread production of soap did notbegin until the 1700s. Soap was traditionally made by treating molten lard or tallow with a slight excess of alkali inlarge open vats. The mixture was heated, and steam was bubbled through it. After saponification was completed, thesoap was precipitated from the mixture by the addition of sodium chloride (NaCl), removed by filtration, and washedseveral times with water. It was then dissolved in water and reprecipitated by the addition of more NaCl. The glycerolproduced in the reaction was also recovered from the aqueous wash solutions.
Pumice or sand is added to produce scouring soap, while ingredients such as perfumes or dyes are added to producefragrant, colored soaps. Blowing air through molten soap produces a floating soap. Soft soaps, made with potassiumsalts, are more expensive but produce a finer lather and are more soluble. They are used in liquid soaps, shampoos, andshaving creams.
Dirt and grime usually adhere to skin, clothing, and other surfaces by combining with body oils, cooking fats,lubricating greases, and similar substances that act like glues. Because these substances are not miscible in water,washing with water alone does little to remove them. Soap removes them, however, because soap molecules have a dualnature. One end, called the head, carries an ionic charge (a carboxylate anion) and therefore dissolves in water; theother end, the tail, has a hydrocarbon structure and dissolves in oils. The hydrocarbon tails dissolve in the soil; the ionicheads remain in the aqueous phase, and the soap breaks the oil into tiny soap-enclosed droplets called micelles, whichdisperse throughout the solution. The droplets repel each other because of their charged surfaces and do not coalesce.With the oil no longer “gluing” the dirt to the soiled surface (skin, cloth, dish), the soap-enclosed dirt can easily berinsed away.
The double bonds in fats and oils can undergo hydrogenation and also oxidation. The hydrogenation of vegetable oils toproduce semisolid fats is an important process in the food industry. Chemically, it is essentially identical to the catalytichydrogenation reaction described for alkenes.

3.3.4 12/19/2021 https://chem.libretexts.org/@go/page/178770
In commercial processes, the number of double bonds that are hydrogenated is carefully controlled to produce fats with thedesired consistency (soft and pliable). Inexpensive and abundant vegetable oils (canola, corn, soybean) are thustransformed into margarine and cooking fats. In the preparation of margarine, for example, partially hydrogenated oils aremixed with water, salt, and nonfat dry milk, along with flavoring agents, coloring agents, and vitamins A and D, which areadded to approximate the look, taste, and nutrition of butter. (Preservatives and antioxidants are also added.) In mostcommercial peanut butter, the peanut oil has been partially hydrogenated to prevent it from separating out. Consumerscould decrease the amount of saturated fat in their diet by using the original unprocessed oils on their foods, but mostpeople would rather spread margarine on their toast than pour oil on it.
Many people have switched from butter to margarine or vegetable shortening because of concerns that saturated animalfats can raise blood cholesterol levels and result in clogged arteries. However, during the hydrogenation of vegetable oils,an isomerization reaction occurs that produces the trans fatty acids mentioned in the opening essay. However, studies haveshown that trans fatty acids also raise cholesterol levels and increase the incidence of heart disease. Trans fatty acids donot have the bend in their structures, which occurs in cis fatty acids and thus pack closely together in the same way that thesaturated fatty acids do. Consumers are now being advised to use polyunsaturated oils and soft or liquid margarine andreduce their total fat consumption to less than 30% of their total calorie intake each day.
Fats and oils that are in contact with moist air at room temperature eventually undergo oxidation and hydrolysis reactionsthat cause them to turn rancid, acquiring a characteristic disagreeable odor. One cause of the odor is the release of volatilefatty acids by hydrolysis of the ester bonds. Butter, for example, releases foul-smelling butyric, caprylic, and capric acids.Microorganisms present in the air furnish lipases that catalyze this process. Hydrolytic rancidity can easily be prevented bycovering the fat or oil and keeping it in a refrigerator.
Another cause of volatile, odorous compounds is the oxidation of the unsaturated fatty acid components, particularly thereadily oxidized structural unit
in polyunsaturated fatty acids, such as linoleic and linolenic acids. One particularly offensive product, formed by theoxidative cleavage of both double bonds in this unit, is a compound called malonaldehyde.
Rancidity is a major concern of the food industry, which is why food chemists are always seeking new and betterantioxidants, substances added in very small amounts (0.001%–0.01%) to prevent oxidation and thus suppress rancidity.Antioxidants are compounds whose affinity for oxygen is greater than that of the lipids in the food; thus they function bypreferentially depleting the supply of oxygen absorbed into the product. Because vitamin E has antioxidant properties, ithelps reduce damage to lipids in the body, particularly to unsaturated fatty acids found in cell membrane lipids.
Summary Fats and oils are composed of molecules known as triglycerides, which are esters composed of three fatty acid units linkedto glycerol. An increase in the percentage of shorter-chain fatty acids and/or unsaturated fatty acids lowers the meltingpoint of a fat or oil. The hydrolysis of fats and oils in the presence of a base makes soap and is known as saponification.Double bonds present in unsaturated triglycerides can be hydrogenated to convert oils (liquid) into margarine (solid). Theoxidation of fatty acids can form compounds with disagreeable odors. This oxidation can be minimized by the addition ofantioxidants.

3.3.5 12/19/2021 https://chem.libretexts.org/@go/page/178770
Concept Review Exercises
1. What functions does fat serve in the body?
2. Which of these triglycerides would you expect to find in higher amounts in oils? In fats? Justify your choice.
Answers 1. Fats provide energy for living organisms. They also provide insulation for body organs and transport fat-soluble
vitamins.
2. The triglyceride on the left is expected to be present in higher amounts in fats because it is composed of a greaternumber of saturated fatty acids. The triglyceride on the right is expected to be present in higher amounts in oils becauseit is composed of a greater number of unsaturated fatty acids.
Exercises 1. Draw the structure for each compound.
a. trimyristinb. a triglyceride likely to be found in peanut oil
2. Draw the structure for each compound.
a. tripalmitinb. a triglyceride likely to be found in butter
3. Draw structures to write the reaction for the complete hydrogenation of tripalmitolein (Table for the condensedstructure of palmitoleic acid). Name the product formed.
4. Draw structures to write the reaction for the complete hydrogenation of trilinolein (Table for the condensedstructure of linoleic acid). Name the product formed.
5. Draw structures to write the reaction for the hydrolysis of trilaurin in a basic solution (Table for the condensedstructure of lauric acid).
6. Draw structures to write the reaction for the hydrolysis of tristearin in a basic solution (Table for the condensedstructure of stearic acid).
a. 7. What compounds with a disagreeable odor are formed when butter becomes rancid?b. How are these compounds formed?c. How can rancidity be prevented?
a. 8. What compound with a disagreeable odor is formed when unsaturated fatty acids react with oxygen in theatmosphere?
3.3.1
3.3.1
3.3.1
3.3.1
3.3.6 12/19/2021 https://chem.libretexts.org/@go/page/178770
b. How can this process be prevented?
Answers
1
3.
5.
a. 7. smaller carboxylic acids, such as butyric, caprylic, and capric acidsb. These compounds are formed by the hydrolysis of the triglycerides found in butter.c. Rancidity can be prevented by covering the butter (to keep out moisture) and storing it in a refrigerator. (Cold
temperatures slow down hydrolysis reactions.)

3.4.1 1/9/2022 https://chem.libretexts.org/@go/page/178771
3.4: Membranes and Membrane LipidsLearning Objectives
Identify the distinguishing characteristics of membrane lipids.Describe membrane components and how they are arranged.
All living cells are surrounded by a cell membrane. Plant cells (Figure ) and animal cells (Figure ) contain acell nucleus that is also surrounded by a membrane and holds the genetic information for the cell. Everything between thecell membrane and the nuclear membrane—including intracellular fluids and various subcellular components such as themitochondria and ribosomes—is called the cytoplasm. The membranes of all cells have a fundamentally similar structure,but membrane function varies tremendously from one organism to another and even from one cell to another within asingle organism. This diversity arises mainly from the presence of different proteins and lipids in the membrane.
Figure : (A) An Idealized Plant Cell. Not all the structures shown here occur in every type of plant cell. (B) AnIdealized Animal Cell. The structures shown here will seldom all be found in a single animal cell.
The lipids in cell membranes are highly polar but have dual characteristics: part of the lipid is ionic and therefore dissolvesin water, whereas the rest has a hydrocarbon structure and therefore dissolves in nonpolar substances. Often, the ionic partis referred to as hydrophilic, meaning “water loving,” and the nonpolar part as hydrophobic, meaning “water fearing”(repelled by water). When allowed to float freely in water, polar lipids spontaneously cluster together in any one of threearrangements: micelles, monolayers, and bilayers (Figure ).
3.4.1A 3.4.1B
3.4.1
3.4.2

3.4.2 1/9/2022 https://chem.libretexts.org/@go/page/178771
Figure : Spontaneously Formed Polar Lipid Structures in Water: Monolayer, Micelle, and Bilayer
Micelles are aggregations in which the lipids’ hydrocarbon tails—being hydrophobic—are directed toward the center ofthe assemblage and away from the surrounding water while the hydrophilic heads are directed outward, in contact with thewater. Each micelle may contain thousands of lipid molecules. Polar lipids may also form a monolayer, a layer onemolecule thick on the surface of the water. The polar heads face into water, and the nonpolar tails stick up into the air.Bilayers are double layers of lipids arranged so that the hydrophobic tails are sandwiched between an inner surface and anouter surface consisting of hydrophilic heads. The hydrophilic heads are in contact with water on either side of the bilayer,whereas the tails, sequestered inside the bilayer, are prevented from having contact with the water. Bilayers like this makeup every cell membrane (Figure ).
Figure : Schematic Diagram of a Cell Membrane. The membrane enclosing a typical animal cell is a phospholipidbilayer with embedded cholesterol and protein molecules. Short oligosaccharide chains are attached to the outer surface.
In the bilayer interior, the hydrophobic tails (that is, the fatty acid portions of lipid molecules) interact by means ofdispersion forces. The interactions are weakened by the presence of unsaturated fatty acids. As a result, the membranecomponents are free to mill about to some extent, and the membrane is described as fluid.
The lipids found in cell membranes can be categorized in various ways. Phospholipids are lipids containing phosphorus.Glycolipids are sugar-containing lipids. The latter are found exclusively on the outer surface of the cell membrane, actingas distinguishing surface markers for the cell and thus serving in cellular recognition and cell-to-cell communication.Sphingolipids are phospholipids or glycolipids that contain the unsaturated amino alcohol sphingosine rather than glycerol.Diagrammatic structures of representative membrane lipids are presented in Figure .
3.4.2
3.4.3
3.4.3
3.4.4

3.4.3 1/9/2022 https://chem.libretexts.org/@go/page/178771
Figure : Component Structures of Some Important Membrane Lipids
Phosphoglycerides (also known as glycerophospholipids) are the most abundant phospholipids in cell membranes. Theyconsist of a glycerol unit with fatty acids attached to the first two carbon atoms, while a phosphoric acid unit, esterifiedwith an alcohol molecule (usually an amino alcohol, as in part (a) of Figure ) is attached to the third carbon atom ofglycerol (part (b) of Figure ). Notice that the phosphoglyceride molecule is identical to a triglyceride up to thephosphoric acid unit (part (b) of Figure ).
Figure : Phosphoglycerides. (a) Amino alcohols are commonly found in phosphoglycerides, which are evident in itsstructural formula (b).
There are two common types of phosphoglycerides. Phosphoglycerides containing ethanolamine as the amino alcohol arecalled phosphatidylethanolamines or cephalins. Cephalins are found in brain tissue and nerves and also have a role inblood clotting. Phosphoglycerides containing choline as the amino alcohol unit are called phosphatidylcholines orlecithins. Lecithins occur in all living organisms. Like cephalins, they are important constituents of nerve and brain tissue.Egg yolks are especially rich in lecithins. Commercial-grade lecithins isolated from soybeans are widely used in foods asemulsifying agents. An emulsifying agent is used to stabilize an emulsion—a dispersion of two liquids that do notnormally mix, such as oil and water. Many foods are emulsions. Milk is an emulsion of butterfat in water. The emulsifyingagent in milk is a protein called casein. Mayonnaise is an emulsion of salad oil in water, stabilized by lecithins present inegg yolk.
3.4.4
3.4.5
3.4.5
3.4.5
3.4.5

3.4.4 1/9/2022 https://chem.libretexts.org/@go/page/178771
Sphingomyelins, the simplest sphingolipids, each contain a fatty acid, a phosphoric acid, sphingosine, and choline (Figure ). Because they contain phosphoric acid, they are also classified as phospholipids. Sphingomyelins are important
constituents of the myelin sheath surrounding the axon of a nerve cell. Multiple sclerosis is one of several diseasesresulting from damage to the myelin sheath.
Figure : Sphingolipids. (a) Sphingosine, an amino alcohol, is found in all sphingolipids. (b) A sphingomyelin is alsoknown as a phospholipid, as evidenced by the phosphoric acid unit in its structure.
Most animal cells contain sphingolipids called cerebrosides (Figure ). Cerebrosides are composed of sphingosine, afatty acid, and galactose or glucose. They therefore resemble sphingomyelins but have a sugar unit in place of the cholinephosphate group. Cerebrosides are important constituents of the membranes of nerve and brain cells.
Figure : Cerebrosides. Cerebrosides are sphingolipids that contain a sugar unit.
The sphingolipids called gangliosides are more complex, usually containing a branched chain of three to eightmonosaccharides and/or substituted sugars. Because of considerable variation in their sugar components, about 130varieties of gangliosides have been identified. Most cell-to-cell recognition and communication processes (e.g., blood
3.4.6
3.4.6
3.4.7
3.4.7

3.4.5 1/9/2022 https://chem.libretexts.org/@go/page/178771
group antigens) depend on differences in the sequences of sugars in these compounds. Gangliosides are most prevalent inthe outer membranes of nerve cells, although they also occur in smaller quantities in the outer membranes of most othercells. Because cerebrosides and gangliosides contain sugar groups, they are also classified as glycolipids.
Membrane ProteinsIf membranes were composed only of lipids, very few ions or polar molecules could pass through their hydrophobic“sandwich filling” to enter or leave any cell. However, certain charged and polar species do cross the membrane, aided byproteins that move about in the lipid bilayer. The two major classes of proteins in the cell membrane are integral proteins,which span the hydrophobic interior of the bilayer, and peripheral proteins, which are more loosely associated with thesurface of the lipid bilayer (Figure ). Peripheral proteins may be attached to integral proteins, to the polar head groupsof phospholipids, or to both by hydrogen bonding and electrostatic forces.
Small ions and molecules soluble in water enter and leave the cell by way of channels through the integral proteins. Someproteins, called carrier proteins, facilitate the passage of certain molecules, such as hormones and neurotransmitters, byspecific interactions between the protein and the molecule being transported.
SummaryLipids are important components of biological membranes. These lipids have dual characteristics: part of the molecule ishydrophilic, and part of the molecule is hydrophobic. Membrane lipids may be classified as phospholipids, glycolipids,and/or sphingolipids. Proteins are another important component of biological membranes. Integral proteins span the lipidbilayer, while peripheral proteins are more loosely associated with the surface of the membrane.
Concept Review Exercises
1. Name the structural unit that must be present for a molecule to be classified as a
a. phospholipid.b. glycolipid.c. sphingolipid.
2. Why is it important that membrane lipids have dual character—part of the molecule is hydrophilic and part of themolecule is hydrophobic?
3. Why do you suppose lecithins (phosphatidylcholines) are often added to processed foods such as hot cocoa mix?
Answers a. 1. a phosphate groupb. a saccharide unit (monosaccharide or more complex)c. sphingosine
2. The dual character is critical for the formation of the lipid bilayer. The hydrophilic portions of the molecule are incontact with the aqueous environment of the cell, while the hydrophobic portion of the lipids is in the interior of thebilayer and provides a barrier to the passive diffusion of most molecules.
3. Lecithin acts as an emulsifying agent that aids in the mixing of the hot cocoa mix with water and keeps the cocoa mixevenly distributed after stirring.
Exercises
1. Classify each as a phospholipid, a glycolipid, and/or a sphingolipid. (Some lipids can be given more than oneclassification.)
3.4.3

3.4.6 1/9/2022 https://chem.libretexts.org/@go/page/178771
a.
b.
2. Classify each as a phospholipid, a glycolipid, and/or a sphingolipid. (Some lipids can be given more than oneclassification.)
a.
b.
3. Draw the structure of the sphingomyelin that has lauric acid as its fatty acid and ethanolamine as its amino alcohol.
4. Draw the structure of the cerebroside that has myristic acid as its fatty acid and galactose as its sugar.
a. 5. Distinguish between an integral protein and a peripheral protein.b. What is one key function of integral proteins?
Answers
a. 1. phospholipidb. sphingolipid and glycolipid
3.

3.4.7 1/9/2022 https://chem.libretexts.org/@go/page/178771
a. 5. Integral proteins span the lipid bilayer, while peripheral proteins associate with the surfaces of the lipid bilayer.b. aid in the movement of charged and polar species across the membrane

3.5.1 1/5/2022 https://chem.libretexts.org/@go/page/178772
3.5: SteroidsLearning Objectives
To identify the functions of steroids produced in mammals.
All the lipids discussed so far are saponifiable, reacting with aqueous alkali to yield simpler components, such as glycerol,fatty acids, amino alcohols, and sugars. Lipid samples extracted from cellular material, however, also contain a small butimportant fraction that does not react with alkali. The most important nonsaponifiable lipids are the steroids. Thesecompounds include the bile salts, cholesterol and related compounds, and certain hormones (such as cortisone and the sexhormones).
Figure Steroids. (a) The four-fused-ring steroid skeleton uses letter designations for each ring and the numbering ofthe carbon atoms. (b) The cholesterol molecule follows this pattern.
Steroids occur in plants, animals, yeasts, and molds but not in bacteria. They may exist in free form or combined with fattyacids or carbohydrates. All steroids have a characteristic structural component consisting of four fused rings. Chemistsidentify the rings by capital letters and number the carbon atoms as shown in Figure . Slight variations in thisstructure or in the atoms or groups attached to it produce profound differences in biological activity.
Cholesterol
Cholesterol (Figure ) does not occur in plants, but it is the most abundant steroid in the human body (240 g is atypical amount). Excess cholesterol is believed to be a primary factor in the development of atherosclerosis and heartdisease, which are major health problems in the United States today. About half of the body’s cholesterol is interspersed inthe lipid bilayer of cell membranes. Much of the rest is converted to cholic acid, which is used in the formation of bilesalts. Cholesterol is also a precursor in the synthesis of sex hormones, adrenal hormones, and vitamin D.
Excess cholesterol not metabolized by the body is released from the liver and transported by the blood to the gallbladder.Normally, it stays in solution there until being secreted into the intestine (as a component of bile) to be eliminated.Sometimes, however, cholesterol in the gallbladder precipitates in the form of gallstones (Figure ). Indeed, the namecholesterol is derived from the Greek chole, meaning “bile,” and stereos, meaning “solid.”
Figure : Numerous small gallstones made up largely of cholesterol, all removed in one patient. Grid scale 1 mm
3.5.1
3.5.1a
3.5.1b
3.5.2
3.5.2

3.5.2 1/5/2022 https://chem.libretexts.org/@go/page/178772
To Your Health: Cholesterol and Heart DiseaseHeart disease is the leading cause of death in the United States for both men and women. The Centers for DiseaseControl and Prevention reported that heart disease claimed 631,636 lives in the United States (26% of all reporteddeaths) in 2006.
Scientists agree that elevated cholesterol levels in the blood, as well as high blood pressure, obesity, diabetes, andcigarette smoking, are associated with an increased risk of heart disease. A long-term investigation by the NationalInstitutes of Health showed that among men ages 30 to 49, the incidence of heart disease was five times greater forthose whose cholesterol levels were above 260 mg/100 mL of serum than for those with cholesterol levels of 200mg/100 mL or less. The cholesterol content of blood varies considerably with age, diet, and sex. Young adults averageabout 170 mg of cholesterol per 100 mL of blood, whereas males at age 55 may have cholesterol levels at 250 mg/100mL or higher because the rate of cholesterol breakdown decreases with age. Females tend to have lower bloodcholesterol levels than males.
To understand the link between heart disease and cholesterol levels, it is important to understand how cholesterol andother lipids are transported in the body. Lipids, such as cholesterol, are not soluble in water and therefore cannot betransported in the blood (an aqueous medium) unless they are complexed with proteins that are soluble in water,forming assemblages called lipoproteins. Lipoproteins are classified according to their density, which is dependent onthe relative amounts of protein and lipid they contain. Lipids are less dense than proteins, so lipoproteins containing agreater proportion of lipid are less dense than those containing a greater proportion of protein.
Research on cholesterol and its role in heart disease has focused on serum levels of low-density lipoproteins (LDLs)and high-density lipoproteins (HDLs). One of the most fascinating discoveries is that high levels of HDLs reduce aperson’s risk of developing heart disease, whereas high levels of LDLs increase that risk. Thus the serum LDL:HDLratio is a better predictor of heart disease risk than the overall level of serum cholesterol. Persons who, because ofhereditary or dietary factors, have high LDL:HDL ratios in their blood have a higher incidence of heart disease.
How do HDLs reduce the risk of developing heart disease? No one knows for sure, but one role of HDLs appears to bethe transport of excess cholesterol to the liver, where it can be metabolized. Therefore, HDLs aid in removingcholesterol from blood and from the smooth muscle cells of the arterial wall.
Dietary modifications and increased physical activity can help lower total cholesterol and improve the LDL:HDL ratio.The average American consumes about 600 mg of cholesterol from animal products each day and also synthesizesapproximately 1 g of cholesterol each day, mostly in the liver. The amount of cholesterol synthesized is controlled bythe cholesterol level in the blood; when the blood cholesterol level exceeds 150 mg/100 mL, the rate of cholesterolbiosynthesis is halved. Hence, if cholesterol is present in the diet, a feedback mechanism suppresses its synthesis in theliver. However, the ratio of suppression is not a 1:1 ratio; the reduction in biosynthesis does not equal the amount ofcholesterol ingested. Thus, dietary substitutions of unsaturated fat for saturated fat, as well as a reduction inconsumption of trans fatty acids, is recommended to help lower serum cholesterol and the risk of heart disease.

3.5.3 1/5/2022 https://chem.libretexts.org/@go/page/178772
Steroid HormonesHormones are chemical messengers that are released in one tissue and transported through the circulatory system to one ormore other tissues. One group of hormones is known as steroid hormones because these hormones are synthesized fromcholesterol, which is also a steroid. There are two main groups of steroid hormones: adrenocortical hormones and sexhormones.
The adrenocortical hormones, such as aldosterone and cortisol (Table ), are produced by the adrenal gland, which islocated adjacent to each kidney. Aldosterone acts on most cells in the body, but it is particularly effective at enhancing therate of reabsorption of sodium ions in the kidney tubules and increasing the secretion of potassium ions and/or hydrogenions by the tubules. Because the concentration of sodium ions is the major factor influencing water retention in tissues,aldosterone promotes water retention and reduces urine output. Cortisol regulates several key metabolic reactions (forexample, increasing glucose production and mobilizing fatty acids and amino acids). It also inhibits the inflammatoryresponse of tissue to injury or stress. Cortisol and its analogs are therefore used pharmacologically as immunosuppressantsafter transplant operations and in the treatment of severe skin allergies and autoimmune diseases, such as rheumatoidarthritis.
Table : Representative Steroid Hormones and Their Physiological EffectsHormone Effect
regulates salt metabolism; stimulates kidneys to retain sodium andexcrete potassium
stimulates the conversion of proteins to carbohydrates
regulates the menstrual cycle; maintains pregnancy
stimulates female sex characteristics; regulates changes during themenstrual cycle
stimulates and maintains male sex characteristics
3.5.1
3.5.1

3.5.4 1/5/2022 https://chem.libretexts.org/@go/page/178772
The sex hormones are a class of steroid hormones secreted by the gonads (ovaries or testes), the placenta, and the adrenalglands. Testosterone and androstenedione are the primary male sex hormones, or androgens, controlling the primary sexualcharacteristics of males, or the development of the male genital organs and the continuous production of sperm. Androgensare also responsible for the development of secondary male characteristics, such as facial hair, deep voice, and musclestrength. Two kinds of sex hormones are of particular importance in females: progesterone, which prepares the uterus forpregnancy and prevents the further release of eggs from the ovaries during pregnancy, and the estrogens, which are mainlyresponsible for the development of female secondary sexual characteristics, such as breast development and increaseddeposition of fat tissue in the breasts, the buttocks, and the thighs. Both males and females produce androgens andestrogens, differing in the amounts of secreted hormones rather than in the presence or absence of one or the other.
Sex hormones, both natural and synthetic, are sometimes used therapeutically. For example, a woman who has had herovaries removed may be given female hormones to compensate. Some of the earliest chemical compounds employed incancer chemotherapy were sex hormones. For example, estrogens are one treatment option for prostate cancer becausethey block the release and activity of testosterone. Testosterone enhances prostate cancer growth. Sex hormones are alsoadministered in preparation for sex-change operations, to promote the development of the proper secondary sexualcharacteristics. Oral contraceptives are synthetic derivatives of the female sex hormones; they work by preventingovulation.
Bile Salts Bile is a yellowish green liquid (pH 7.8–8.6) produced in the liver. The most important constituents of bile are bile salts,which are sodium salts of amidelike combinations of bile acids, such as cholic acid (part (a) of Figure ) and an aminesuch as the amino acid glycine (part (b) of Figure ). They are synthesized from cholesterol in the liver, stored in thegallbladder, and then secreted in bile into the small intestine. In the gallbladder, the composition of bile gradually changesas water is absorbed and the other components become more concentrated.
Figure Bile Acids. (a) Cholic acid is an example of a bile acid. (b) Sodium glycocholate is a bile salt synthesizedfrom cholic acid and glycine.
Because they contain both hydrophobic and hydrophilic groups, bile salts are highly effective detergents and emulsifyingagents; they break down large fat globules into smaller ones and keep those smaller globules suspended in the aqueousdigestive environment. Enzymes can then hydrolyze fat molecules more efficiently. Thus, the major function of bile salts isto aid in the digestion of dietary lipids.
Surgical removal is often advised for a gallbladder that becomes infected, inflamed, or perforated. This surgery does notseriously affect digestion because bile is still produced by the liver, but the liver’s bile is more dilute and its secretioninto the small intestine is not as closely tied to the arrival of food.
Summary Steroids have a four-fused-ring structure and have a variety of functions. Cholesterol is a steroid found in mammals that isneeded for the formation of cell membranes, bile acids, and several hormones. Bile salts are secreted into the smallintestine to aid in the digestion of fats.
Concept Review Exercises
1. Distinguish between a saponifiable lipid and a nonsaponifiable lipid.
2. Identify a key function for each steroid.
3.5.3
3.5.3
3.5.3

3.5.5 1/5/2022 https://chem.libretexts.org/@go/page/178772
a. bile saltb. cholesterolc. estradiol
Answers
1. A saponifiable lipid reacts with aqueous alkali to yield simpler components, while a nonsaponifiable lipid does notreact with alkali to yield simpler components.
a. 2. acts as an emulsifying agent to break down large fat globules and keep these globules suspended in the aqueousdigestive environment
b. a key component of mammalian cell membranes (answers will vary)c. stimulates female sex characteristics and regulates changes during the menstrual cycle
Exercises
1. Which of these compounds are steroids—tripalmitin, cephalin, or cholesterol?
2. Which of these compounds are steroids—vitamin D, cholic acid, or lecithin?
3. Draw the basic steroid skeleton and label each ring with the appropriate letter designation.
4. Identify each compound as an adrenocortical hormone, a female sex hormone, or a male sex hormone.
a. progesteroneb. aldosteronec. testosteroned. cortisol
Answers
1. cholesterol
3.

3.6.1 12/5/2021 https://chem.libretexts.org/@go/page/178773
3.6: Lipids (Summary)To ensure that you understand the material in this chapter, you should review the meanings of the bold terms in the
following summary and ask yourself how they relate to the topics in the chapter.
Lipids, found in the body tissues of all organisms, are compounds that are more soluble in organic solvents than in water.Many of them contain fatty acids, which are carboxylic acids that generally contain an even number of 4–20 carbon atomsin an unbranched chain. Saturated fatty acids have no carbon-to-carbon double bonds. Monounsaturated fatty acidshave a single carbon-to-carbon double bond, while polyunsaturated fatty acids have more than one carbon-to-carbondouble bond. Linoleic and linolenic acid are known as essential fatty acids because the human body cannot synthesizethese polyunsaturated fatty acids. The lipids known as fats and oils are triacylglycerols, more commonly calledtriglycerides—esters composed of three fatty acids joined to the trihydroxy alcohol glycerol. Fats are triglycerides that aresolid at room temperature, and oils are triglycerides that are liquid at room temperature. Fats are found mainly in animals,and oils found mainly in plants. Saturated triglycerides are those containing a higher proportion of saturated fatty acidchains (fewer carbon-to-carbon double bonds); unsaturated triglycerides contain a higher proportion of unsaturated fattyacid chains.
Saponification is the hydrolysis of a triglyceride in a basic solution to form glycerol and three carboxylate anions or soapmolecules. Other important reactions are the hydrogenation and oxidation of double bonds in unsaturated fats and oils.
Phospholipids are lipids containing phosphorus. In phosphoglycerides, the phosphorus is joined to an amino alcohol unit.Some phosphoglycerides, like lecithins, are used to stabilize an emulsion—a dispersion of two liquids that do not normallymix, such as oil and water. Sphingolipids are lipids for which the precursor is the amino alcohol sphingosine, rather thanglycerol. A glycolipid has a sugar substituted at one of the OH groups of either glycerol or sphingosine. All are highlypolar lipids found in cell membranes.
Polar lipids have dual characteristics: one part of the molecule is ionic and dissolves in water; the rest has a hydrocarbonstructure and dissolves in nonpolar substances. Often, the ionic part is referred to as hydrophilic (literally, “water loving”)and the nonpolar part as hydrophobic (“water fearing”). When placed in water, polar lipids disperse into any one of threearrangements: micelles, monolayers, and bilayers. Micelles are aggregations of molecules in which the hydrocarbon tailsof the lipids, being hydrophobic, are directed inward (away from the surrounding water), and the hydrophilic heads that aredirected outward into the water. Bilayers are double layers arranged so that the hydrophobic tails are sandwiched betweenthe two layers of hydrophilic heads, which remain in contact with the water.
Every living cell is enclosed by a cell membrane composed of a lipid bilayer. In animal cells, the bilayer consists mainly ofphospholipids, glycolipids, and the steroid cholesterol. Embedded in the bilayer are integral proteins, and peripheralproteins are loosely associated with the surface of the bilayer. Everything between the cell membrane and the membraneof the cell nucleus is called the cytoplasm.
Most lipids can be saponified, but some, such as steroids, cannot be saponified. The steroid cholesterol is found in animalcells but never in plant cells. It is a main component of all cell membranes and a precursor for hormones, vitamin D, andbile salts. Bile salts are the most important constituents of bile, which is a yellowish-green liquid secreted by thegallbladder into the small intestine and is needed for the proper digestion of lipids.

3.7.1 1/5/2022 https://chem.libretexts.org/@go/page/178774
3.7: Exercises
Additional Exercises
1. The melting point of elaidic acid is 52°C.
a. What trend is observed when comparing the melting points of elaidic acid, oleic acid, and stearic acid? Explain.
b. Would you expect the melting point of palmitelaidic acid to be lower or higher than that of elaidic acid? Explain.
2. Examine the labels on two brands of margarine and two brands of shortening and list the oils used in the variousbrands.
3. Draw a typical lecithin molecule that incorporates glycerol, palmitic acid, oleic acid, phosphoric acid, and choline.Circle all the ester bonds.
4. In cerebrosides, is the linkage between the fatty acid and sphingosine an amide bond or an ester bond? Justify youranswer.
5. Serine is an amino acid that has the following structure. Draw the structure for a phosphatidylserine that contains apalmitic acid and a palmitoleic acid unit.
6. Explain whether each compound would be expected to diffuse through the lipid bilayer of a cell membrane.
a. potassium chlorideb. CH CH CH CH CH CHc. fructose
7. Identify the role of each steroid hormone in the body.
a. progesteroneb. aldosteronec. testosteroned. cortisol
8. How does the structure of cholic acid differ from that of cholesterol? Which compound would you expect to be morepolar? Why?
a. 9. What fatty acid is the precursor for the prostaglandins?b. Identify three biological effects of prostaglandins.
10. Why is it important to determine the ratio of LDLs to HDLs, rather than just the concentration of serum cholesterol?
3 2 2 2 2 3

3.7.2 1/5/2022 https://chem.libretexts.org/@go/page/178774
Answersa. 1. Stearic acid has the highest melting point, followed by elaidic acid, and then oleic acid with the lowest melting
point. Elaidic acid is a trans fatty acid, and the carbon chains can pack together almost as tightly as those of thesaturated stearic acid. Oleic acid is a cis fatty acid, and the bend in the hydrocarbon chain keeps these carbon chainsfrom packing as closely together; fewer interactions lead to a much lower melting point.
b. The melting point of palmitelaidic acid should be lower than that of elaidic acid because it has a shorter carbonchain (16, as compared to 18 for elaidic acid). The shorter the carbon chain, the lower the melting point due to adecrease in intermolecular interactions.
3.
5.
a. 7. regulates the menstrual cycle and maintains pregnancyb. regulates salt metabolism by stimulating the kidneys to retain sodium and excrete potassiumc. stimulates and maintains male sex characteristicsd. stimulates the conversion of proteins to carbohydrates
a. 9. arachidonic acidb. induce smooth muscle contraction, lower blood pressure, and contribute to the inflammatory response

1 1/10/2022
CHAPTER OVERVIEW4: AMINO ACIDS, PROTEINS, AND ENZYMES
4.1: PRELUDE TO AMINO ACIDS, PROTEINS, AND ENZYMESInsulin is a hormone that is synthesized in the pancreas. Insulin stimulates the transport of glucose into cells throughout the body andthe storage of glucose as glycogen. People with diabetes do not produce insulin or use it properly. The isolation of insulin in 1921 ledto the first effective treatment for these individuals.
4.2: PROPERTIES OF AMINO ACIDSAmino acids can be classified based on the characteristics of their distinctive side chains as nonpolar, polar but uncharged, negativelycharged, or positively charged. The amino acids found in proteins are L-amino acids.
4.3: REACTIONS OF AMINO ACIDSAmino acids can act as both an acid and a base due to the presence of the amino and carboxyl functional groups. The pH at which agiven amino acid exists in solution as a zwitterion is called the isoelectric point (pI).
4.4: PEPTIDESThe amino group of one amino acid can react with the carboxyl group on another amino acid to form a peptide bond that links the twoamino acids together. Additional amino acids can be added on through the formation of addition peptide (amide) bonds. A sequenceof amino acids in a peptide or protein is written with the N-terminal amino acid first and the C-terminal amino acid at the end (writingleft to right).
4.5: PROTEINSProteins can be divided into two categories: fibrous, which tend to be insoluble in water, and globular, which are more soluble inwater. A protein may have up to four levels of structure. The primary structure consists of the specific amino acid sequence. Thepeptide chain can form an α-helix or β-pleated sheet, which is known as secondary structure and are incorporated into the tertiarystructure of the folded polypeptide. The quaternary structure describes the arrangements of subunits.
4.6: ENZYMESAn enzyme is a biological catalyst, a substance that increases the rate of a chemical reaction without being changed or consumed inthe reaction. A systematic process is used to name and classify enzymes.
4.7: ENZYME ACTIONA substrate binds to a specific region on an enzyme known as the active site, where the substrate can be converted to product. Thesubstrate binds to the enzyme primarily through hydrogen bonding and other electrostatic interactions. The induced-fit model saysthat an enzyme can undergo a conformational change when binding a substrate. Enzymes exhibit varying degrees of substratespecificity.
4.8: ENZYME ACTIVITYInitially, an increase in substrate concentration increases the rate of an enzyme-catalyzed reaction. As the enzyme molecules becomesaturated with substrate, this increase in reaction rate levels off. The rate of an enzyme-catalyzed reaction increases with an increasein the concentration of an enzyme. At low temperatures, an increase in temperature increases the rate of an enzyme-catalyzedreaction; at higher temperatures, the protein will denature. Enzymes have optimum pH ranges.
4.9: ENZYME INHIBITIONAn irreversible inhibitor inactivates an enzyme by bonding covalently to a particular group at the active site. A reversible inhibitorinactivates an enzyme through noncovalent, reversible interactions. A competitive inhibitor competes with the substrate for binding atthe active site of the enzyme. A noncompetitive inhibitor binds at a site distinct from the active site.
4.10: ENZYME COFACTORS AND VITAMINSVitamins are organic compounds that are essential in very small amounts for the maintenance of normal metabolism. Vitamins aredivided into two broad categories: fat-soluble vitamins and water-soluble vitamins. Most water-soluble vitamins are needed for theformation of coenzymes, which are organic molecules needed by some enzymes for catalytic activity.
4.11: AMINO ACIDS, PROTEINS, AND ENZYMES (SUMMARY)To ensure that you understand the material in this chapter, you should review the meanings of the bold terms in the followingsummary and ask yourself how they relate to the topics in the chapter.

2 1/10/2022
4.12: AMINO ACIDS, PROTEINS, AND ENZYMES (EXERCISES)Problems and select solutions for the chapter.

4.1.1 1/5/2022 https://chem.libretexts.org/@go/page/178776
4.1: Prelude to Amino Acids, Proteins, and EnzymesThe 1923 Nobel Prize in Medicine or Physiology was awarded to Frederick Grant Banting and John James RichardMacleod for their discovery of the protein insulin. In 1958, the Nobel Prize in Chemistry was awarded to Frederick Sangerfor his discoveries concerning the structure of proteins and, in particular, the structure of insulin. What is so importantabout insulin that two Nobel Prizes have been awarded for work on this protein?
Insulin is a hormone that is synthesized in the pancreas. Insulin stimulates the transport of glucose into cells throughout thebody and the storage of glucose as glycogen. People with diabetes do not produce insulin or use it properly. The isolationof insulin in 1921 led to the first effective treatment for these individuals.
Figure : Insulin pump, showing an infusion set loaded into spring-loaded insertion device. A reservoir is attached tothe infusion set (shown here removed from the pump). Image used with permission (Public Domain; User:David-i98 ).
4.1.1
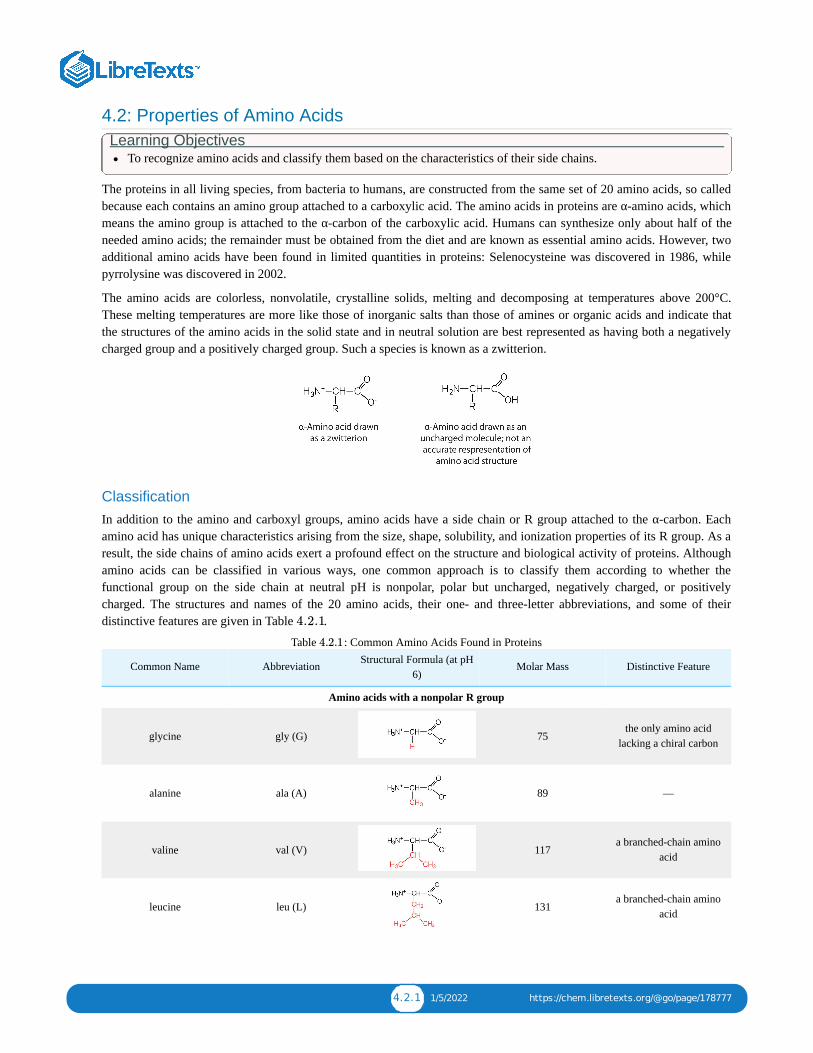
4.2.1 1/5/2022 https://chem.libretexts.org/@go/page/178777
4.2: Properties of Amino AcidsLearning Objectives
To recognize amino acids and classify them based on the characteristics of their side chains.
The proteins in all living species, from bacteria to humans, are constructed from the same set of 20 amino acids, so calledbecause each contains an amino group attached to a carboxylic acid. The amino acids in proteins are α-amino acids, whichmeans the amino group is attached to the α-carbon of the carboxylic acid. Humans can synthesize only about half of theneeded amino acids; the remainder must be obtained from the diet and are known as essential amino acids. However, twoadditional amino acids have been found in limited quantities in proteins: Selenocysteine was discovered in 1986, whilepyrrolysine was discovered in 2002.
The amino acids are colorless, nonvolatile, crystalline solids, melting and decomposing at temperatures above 200°C.These melting temperatures are more like those of inorganic salts than those of amines or organic acids and indicate thatthe structures of the amino acids in the solid state and in neutral solution are best represented as having both a negativelycharged group and a positively charged group. Such a species is known as a zwitterion.
ClassificationIn addition to the amino and carboxyl groups, amino acids have a side chain or R group attached to the α-carbon. Eachamino acid has unique characteristics arising from the size, shape, solubility, and ionization properties of its R group. As aresult, the side chains of amino acids exert a profound effect on the structure and biological activity of proteins. Althoughamino acids can be classified in various ways, one common approach is to classify them according to whether thefunctional group on the side chain at neutral pH is nonpolar, polar but uncharged, negatively charged, or positivelycharged. The structures and names of the 20 amino acids, their one- and three-letter abbreviations, and some of theirdistinctive features are given in Table .
Table : Common Amino Acids Found in Proteins
Common Name Abbreviation Structural Formula (at pH6)
Molar Mass Distinctive Feature
Amino acids with a nonpolar R group
glycine gly (G) 75the only amino acid
lacking a chiral carbon
alanine ala (A) 89 —
valine val (V) 117a branched-chain amino
acid
leucine leu (L) 131a branched-chain amino
acid
4.2.1
4.2.1

4.2.2 1/5/2022 https://chem.libretexts.org/@go/page/178777
Common Name Abbreviation Structural Formula (at pH6)
Molar Mass Distinctive Feature
isoleucine ile (I) 131
an essential amino acidbecause most animals
cannot synthesizebranched-chain amino
acids
phenylalanine phe (F) 165also classified as anaromatic amino acid
tryptophan trp (W) 204also classified as anaromatic amino acid
methionine met (M) 149side chain functions as a
methyl group donor
proline pro (P) 115contains a secondary
amine group; referred toas an α-imino acid
Amino acids with a polar but neutral R group
serine ser (S) 105found at the active site of
many enzymes
threonine thr (T) 119 named for its similarity tothe sugar threose
cysteine cys (C) 121oxidation of two cysteinemolecules yields cystine
tyrosine tyr (Y) 181also classified as anaromatic amino acid
asparagine asn (N) 132 the amide of aspartic acid
glutamine gln (Q) 146 the amide of glutamic acid
Amino acids with a negatively charged R group
aspartic acid asp (D) 132
carboxyl groups areionized at physiological
pH; also known asaspartate

4.2.3 1/5/2022 https://chem.libretexts.org/@go/page/178777
Common Name Abbreviation Structural Formula (at pH6)
Molar Mass Distinctive Feature
glutamic acid glu (E) 146
carboxyl groups areionized at physiological
pH; also known asglutamate
Amino acids with a positively charged R group
histidine his (H) 155the only amino acid whose
R group has a pK (6.0)near physiological pH
lysine lys (K) 147 —
arginine arg (R) 175almost as strong a base as
sodium hydroxide
The first amino acid to be isolated was asparagine in 1806. It was obtained from protein found in asparagus juice (hencethe name). Glycine, the major amino acid found in gelatin, was named for its sweet taste (Greek glykys, meaning “sweet”).In some cases an amino acid found in a protein is actually a derivative of one of the common 20 amino acids (one suchderivative is hydroxyproline). The modification occurs after the amino acid has been assembled into a protein.
Configuration Notice in Table that glycine is the only amino acid whose α-carbon is not chiral. Therefore, with the exception ofglycine, the amino acids could theoretically exist in either the D- or the L-enantiomeric form and rotate plane-polarizedlight. As with sugars, chemists use glyceraldehyde as the reference compound for the assignment of configuration to aminoacids. Its structure closely resembles an amino acid structure except that in the latter, an amino group takes the place of theOH group on the chiral carbon of the sugar.
We learned that all naturally occurring sugars belong to the D series. It is interesting, therefore, that nearly all known plantand animal proteins are composed entirely of L-amino acids. However, certain bacteria contain D-amino acids in their cellwalls, and several antibiotics (e.g., actinomycin D and the gramicidins) contain varying amounts of D-leucine, D-phenylalanine, and D-valine.
a
4.2.1

4.2.4 1/5/2022 https://chem.libretexts.org/@go/page/178777
Summary
Amino acids can be classified based on the characteristics of their distinctive side chains as nonpolar, polar but uncharged,negatively charged, or positively charged. The amino acids found in proteins are L-amino acids.
Concept Review Exercises 1. What is the general structure of an α-amino acid?
2. Identify the amino acid that fits each description.
a. also known as aspartateb. almost as strong a base as sodium hydroxidec. does not have a chiral carbon
Answers 1.
a. 2. aspartic acidb. argininec. glycine
Exercises 1. Write the side chain of each amino acid.
a. serineb. argininec. phenylalanine
2. Write the side chain of each amino acid.
a. aspartic acidb. methioninec. valine
3. Draw the structure for each amino acid.
a. alanineb. cysteinec. histidine
4. Draw the structure for each amino acid.
a. threonineb. glutamic acidc. leucine
5. Identify an amino acid whose side chain contains a(n)
a. amide functional group.b. aromatic ring.c. carboxyl group.
6. Identify an amino acid whose side chain contains a(n)
a. OH groupb. branched chain

4.2.5 1/5/2022 https://chem.libretexts.org/@go/page/178777
c. amino group
Answers
a. 1. CH OHb.
c.
2.
3. a.
b.
c.
4.
a. 5. asparagine or glutamineb. phenylalanine, tyrosine, or tryptophanc. aspartic acid or glutamic acid
2−

4.3.1 12/12/2021 https://chem.libretexts.org/@go/page/178778
4.3: Reactions of Amino AcidsLearning Objectives
To explain how an amino acid can act as both an acid and a base.
The structure of an amino acid allows it to act as both an acid and a base. An amino acid has this ability because at a certain pH value (different for each amino acid) nearly all the aminoacid molecules exist as zwitterions. If acid is added to a solution containing the zwitterion, the carboxylate group captures a hydrogen (H ) ion, and the amino acid becomes positivelycharged. If base is added, ion removal of the H ion from the amino group of the zwitterion produces a negatively charged amino acid. In both circumstances, the amino acid acts tomaintain the pH of the system—that is, to remove the added acid (H ) or base (OH ) from solution.
Example a. Draw the structure for the anion formed when glycine (at neutral pH) reacts with a base.b. Draw the structure for the cation formed when glycine (at neutral pH) reacts with an acid.
SOLUTION
a. The base removes H from the protonated amine group.
b. The acid adds H to the carboxylate group.
Exercise a. Draw the structure for the cation formed when valine (at neutral pH) reacts with an acid.b. Draw the structure for the anion formed when valine (at neutral pH) reacts with a base.
The particular pH at which a given amino acid exists in solution as a zwitterion is called the isoelectric point (pI). At its pI, the positive and negative charges on the amino acid balance, andthe molecule as a whole is electrically neutral. The amino acids whose side chains are always neutral have isoelectric points ranging from 5.0 to 6.5. The basic amino acids (which havepositively charged side chains at neutral pH) have relatively high examples. Acidic amino acids (which have negatively charged side chains at neutral pH) have quite low examples (Table
).
Table : ExampIes of Some Representative Amino AcidsAmino Acid Classification
alanine nonpolar
valine nonpolar
serine polar, uncharged
threonine polar, uncharged
arginine positively charged (basic)
histidine positively charged (basic)
lysine positively charged (basic)
aspartic acid negatively charged (acidic)
glutamic acid negatively charged (acidic)
Amino acids undergo reactions characteristic of carboxylic acids and amines. The reactivity of these functional groups is particularly important in linking amino acids together to formpeptides and proteins, as you will see later in this chapter. Simple chemical tests that are used to detect amino acids take advantage of the reactivity of these functional groups. An exampleis the ninhydrin test in which the amine functional group of α-amino acids reacts with ninhydrin to form purple-colored compounds. Ninhydrin is used to detect fingerprints because itreacts with amino acids from the proteins in skin cells transferred to the surface by the individual leaving the fingerprint.
Summary Amino acids can act as both an acid and a base due to the presence of the amino and carboxyl functional groups. The pH at which a given amino acid exists in solution as a zwitterion iscalled the isoelectric point (pI).
+
+
+ −
4.3.1
+
+
4.3.1
4.3.1
4.3.1

4.3.2 12/12/2021 https://chem.libretexts.org/@go/page/178778
Concept Review Exercises
1. Define each term.
a. zwitterionb. isoelectric point
2. Draw the structure for the anion formed when alanine (at neutral pH) reacts with a base.
3. Draw the structure for the cation formed when alanine (at neutral pH) reacts with an acid.
Answers a. 1. an electrically neutral compound that contains both negatively and positively charged groupsb. the pH at which a given amino acid exists in solution as a zwitterion
2.
3.
Exercises
1. Draw the structure of leucine and determine the charge on the molecule in a(n)
a. acidic solution (pH = 1).b. neutral solution (pH = 7).c. a basic solution (pH = 11)
2. Draw the structure of isoleucine and determine the charge on the molecule in a(n)
a. acidic solution (pH = 1).b. neutral solution (pH = 7).c. basic solution (pH = 11).
Answer
1. a.
b.
c.

4.4.1 1/5/2022 https://chem.libretexts.org/@go/page/178779
4.4: PeptidesLearning Objectives
Explain how a peptide is formed from individual amino acids.Explain why the sequence of amino acids in a protein is important.
Two or more amino acids can join together into chains called peptides. Previously, we discussed the reaction betweenammonia and a carboxylic acid to form an amide. In a similar reaction, the amino group on one amino acid molecule reactswith the carboxyl group on another, releasing a molecule of water and forming an amide linkage:
An amide bond joining two amino acid units is called a peptide bond. Note that the product molecule still has a reactiveamino group on the left and a reactive carboxyl group on the right. These can react with additional amino acids to lengthenthe peptide. The process can continue until thousands of units have joined, resulting in large proteins.
A chain consisting of only two amino acid units is called a dipeptide; a chain consisting of three is a tripeptide. Byconvention, peptide and protein structures are depicted with the amino acid whose amino group is free (the N-terminalend) on the left and the amino acid with a free carboxyl group (the C-terminal end) to the right.
The general term peptide refers to an amino acid chain of unspecified length. However, chains of about 50 amino acids ormore are usually called proteins or polypeptides. In its physiologically active form, a protein may be composed of one ormore polypeptide chains.
Figure : Space-filling model of bradykinin. Image used with permission (Public Domain; Fvasconcellos)
For peptides and proteins to be physiologically active, it is not enough that they incorporate certain amounts of specificamino acids. The order, or sequence, in which the amino acids are connected is also of critical importance. Bradykinin is anine-amino acid peptide (Figure ) produced in the blood that has the following amino acid sequence:
arg-pro-pro-gly-phe-ser-pro-phe-arg
4.4.1
4.4.1

4.4.2 1/5/2022 https://chem.libretexts.org/@go/page/178779
This peptide lowers blood pressure, stimulates smooth muscle tissue, increases capillary permeability, and causes pain.When the order of amino acids in bradykinin is reversed,
arg-phe-pro-ser-phe-gly-pro-pro-arg
the peptide resulting from this synthesis shows none of the activity of bradykinin.
Just as millions of different words are spelled with our 26-letter English alphabet, millions of different proteins are madewith the 20 common amino acids. However, just as the English alphabet can be used to write gibberish, amino acids can beput together in the wrong sequence to produce nonfunctional proteins. Although the correct sequence is ordinarily ofutmost importance, it is not always absolutely required. Just as you can sometimes make sense of incorrectly spelledEnglish words, a protein with a small percentage of “incorrect” amino acids may continue to function. However, it rarelyfunctions as well as a protein having the correct sequence. There are also instances in which seemingly minor errors ofsequence have disastrous effects. For example, in some people, every molecule of hemoglobin (a protein in the blood thattransports oxygen) has a single incorrect amino acid unit out of about 300 (a single valine replaces a glutamic acid). That“minor” error is responsible for sickle cell anemia, an inherited condition that usually is fatal.
Summary
The amino group of one amino acid can react with the carboxyl group on another amino acid to form a peptide bond thatlinks the two amino acids together. Additional amino acids can be added on through the formation of addition peptide(amide) bonds. A sequence of amino acids in a peptide or protein is written with the N-terminal amino acid first and the C-terminal amino acid at the end (writing left to right).
Concept Review Exercises 1. Distinguish between the N-terminal amino acid and the C-terminal amino acid of a peptide or protein.2. Describe the difference between an amino acid and a peptide.3. Amino acid units in a protein are connected by peptide bonds. What is another name for the functional group linking
the amino acids?
Answers 1. The N-terminal end is the end of a peptide or protein whose amino group is free (not involved in the formation of a
peptide bond), while the C-terminal end has a free carboxyl group.2. A peptide is composed of two or more amino acids. Amino acids are the building blocks of peptides.3. amide bond
Exercises
1. Draw the structure for each peptide.
a. gly-valb. val-gly
2. Draw the structure for cys-val-ala.
3. Identify the C- and N-terminal amino acids for the peptide lys-val-phe-gly-arg-cys.
4. Identify the C- and N-terminal amino acids for the peptide asp-arg-val-tyr-ile-his-pro-phe.
Answers

4.4.3 1/5/2022 https://chem.libretexts.org/@go/page/178779
1. a.
b.
3. C-terminal amino acid: cys; N-terminal amino acid: lys

4.5.1 1/10/2022 https://chem.libretexts.org/@go/page/178780
4.5: ProteinsLearning Objectives
Describe the four levels of protein structure.Identify the types of attractive interactions that hold proteins in their most stable three-dimensional structure.Explain what happens when proteins are denatured.Identify how a protein can be denatured.
Each of the thousands of naturally occurring proteins has its own characteristic amino acid composition and sequence thatresult in a unique three-dimensional shape. Since the 1950s, scientists have determined the amino acid sequences andthree-dimensional conformation of numerous proteins and thus obtained important clues on how each protein performs itsspecific function in the body.
Proteins are compounds of high molar mass consisting largely or entirely of chains of amino acids. Because of their greatcomplexity, protein molecules cannot be classified on the basis of specific structural similarities, as carbohydrates andlipids are categorized. The two major structural classifications of proteins are based on far more general qualities: whetherthe protein is (1) fiberlike and insoluble or (2) globular and soluble. Some proteins, such as those that compose hair, skin,muscles, and connective tissue, are fiberlike. These fibrous proteins are insoluble in water and usually serve structural,connective, and protective functions. Examples of fibrous proteins are keratins, collagens, myosins, and elastins. Hair andthe outer layer of skin are composed of keratin. Connective tissues contain collagen. Myosins are muscle proteins and arecapable of contraction and extension. Elastins are found in ligaments and the elastic tissue of artery walls.
Globular proteins, the other major class, are soluble in aqueous media. In these proteins, the chains are folded so that themolecule as a whole is roughly spherical. Familiar examples include egg albumin from egg whites and serum albumin inblood. Serum albumin plays a major role in transporting fatty acids and maintaining a proper balance of osmotic pressuresin the body. Hemoglobin and myoglobin, which are important for binding oxygen, are also globular proteins.
Levels of Protein Structure
The structure of proteins is generally described as having four organizational levels. The first of these is the primarystructure, which is the number and sequence of amino acids in a protein’s polypeptide chain or chains, beginning with thefree amino group and maintained by the peptide bonds connecting each amino acid to the next. The primary structure ofinsulin, composed of 51 amino acids, is shown in Figure .
Figure : Primary Structure of Human Insulin. Human insulin, whose amino acid sequence is shown here, is ahormone that is required for the proper metabolism of glucose.
4.5.1
4.5.1

4.5.2 1/10/2022 https://chem.libretexts.org/@go/page/178780
A protein molecule is not a random tangle of polypeptide chains. Instead, the chains are arranged in unique but specificconformations. The term secondary structure refers to the fixed arrangement of the polypeptide backbone. On the basis ofX ray studies, Linus Pauling and Robert Corey postulated that certain proteins or portions of proteins twist into a spiral ora helix. This helix is stabilized by intrachain hydrogen bonding between the carbonyl oxygen atom of one amino acid andthe amide hydrogen atom four amino acids up the chain (located on the next turn of the helix) and is known as a right-handed α-helix. X ray data indicate that this helix makes one turn for every 3.6 amino acids, and the side chains of theseamino acids project outward from the coiled backbone (Figure ). The α-keratins, found in hair and wool, areexclusively α-helical in conformation. Some proteins, such as gamma globulin, chymotrypsin, and cytochrome c, havelittle or no helical structure. Others, such as hemoglobin and myoglobin, are helical in certain regions but not in others.
Figure A Ball-and-Stick Model of an α-Helix. This ball-and-stick model shows the intrachain hydrogen bondingbetween carbonyl oxygen atoms and amide hydrogen atoms. Each turn of the helix spans 3.6 amino acids. Note that theside chains (represented as green spheres) point out from the helix.
Another common type of secondary structure, called the β-pleated sheet conformation, is a sheetlike arrangement in whichtwo or more extended polypeptide chains (or separate regions on the same chain) are aligned side by side. The alignedsegments can run either parallel or antiparallel—that is, the N-terminals can face in the same direction on adjacent chainsor in different directions—and are connected by interchain hydrogen bonding (Figure ). The β-pleated sheet isparticularly important in structural proteins, such as silk fibroin. It is also seen in portions of many enzymes, such ascarboxypeptidase A and lysozyme.
Figure : A Ball-and-Stick Model of the β-Pleated Sheet Structure in Proteins. The side chains extend above or belowthe sheet and alternate along the chain. The protein chains are held together by interchain hydrogen bonding.
Tertiary structure refers to the unique three-dimensional shape of the protein as a whole, which results from the folding andbending of the protein backbone. The tertiary structure is intimately tied to the proper biochemical functioning of theprotein. Figure shows a depiction of the three-dimensional structure of insulin.
4.5.2
4.5.2
4.5.3
4.5.3
4.5.4

4.5.3 1/10/2022 https://chem.libretexts.org/@go/page/178780
Figure : A Ribbon Model of the Three-Dimensional Structure of Insulin. The spiral regions represent sections of thepolypeptide chain that have an α-helical structure, while the broad arrows represent β-pleated sheet structures.
Four major types of attractive interactions determine the shape and stability of the tertiary structure of proteins. Youstudied several of them previously.
1. Ionic bonding. Ionic bonds result from electrostatic attractions between positively and negatively charged side chainsof amino acids. For example, the mutual attraction between an aspartic acid carboxylate ion and a lysine ammoniumion helps to maintain a particular folded area of a protein (part (a) of Figure ).
2. Hydrogen bonding. Hydrogen bonding forms between a highly electronegative oxygen atom or a nitrogen atom and ahydrogen atom attached to another oxygen atom or a nitrogen atom, such as those found in polar amino acid sidechains. Hydrogen bonding (as well as ionic attractions) is extremely important in both the intra- and intermolecularinteractions of proteins (part (b) of Figure ).
3. Disulfide linkages. Two cysteine amino acid units may be brought close together as the protein molecule folds.Subsequent oxidation and linkage of the sulfur atoms in the highly reactive sulfhydryl (SH) groups leads to theformation of cystine (part (c) of Figure ). Intrachain disulfide linkages are found in many proteins, includinginsulin (yellow bars in Figure ) and have a strong stabilizing effect on the tertiary structure.
4. Dispersion forces. Dispersion forces arise when a normally nonpolar atom becomes momentarily polar due to anuneven distribution of electrons, leading to an instantaneous dipole that induces a shift of electrons in a neighboringnonpolar atom. Dispersion forces are weak but can be important when other types of interactions are either missing orminimal (part (d) of Figure ). This is the case with fibroin, the major protein in silk, in which a high proportion ofamino acids in the protein have nonpolar side chains. The term hydrophobic interaction is often misused as a synonymfor dispersion forces. Hydrophobic interactions arise because water molecules engage in hydrogen bonding with otherwater molecules (or groups in proteins capable of hydrogen bonding). Because nonpolar groups cannot engage inhydrogen bonding, the protein folds in such a way that these groups are buried in the interior part of the proteinstructure, minimizing their contact with water.
4.5.4
4.5.5
4.5.5
4.5.5
4.5.1
4.5.5

4.5.4 1/10/2022 https://chem.libretexts.org/@go/page/178780
Figure : Tertiary Protein Structure Interactions. Four interactions stabilize the tertiary structure of a protein: (a) ionicbonding, (b) hydrogen bonding, (c) disulfide linkages, and (d) dispersion forces.
When a protein contains more than one polypeptide chain, each chain is called a subunit. The arrangement of multiplesubunits represents a fourth level of structure, the quaternary structure of a protein. Hemoglobin, with four polypeptidechains or subunits, is the most frequently cited example of a protein having quaternary structure (Figure ). Thequaternary structure of a protein is produced and stabilized by the same kinds of interactions that produce and maintain thetertiary structure. A schematic representation of the four levels of protein structure is in Figure .
Figure The Quaternary Structure of Hemoglobin. Hemoglobin is a protein that transports oxygen throughout thebody.
Source: Image from the RCSB PDB (www.pdb.org) of PDB ID 1I3D (R.D. Kidd, H.M. Baker, A.J. Mathews, T. Brittain,E.N. Baker (2001) Oligomerization and ligand binding in a homotetrameric hemoglobin: two high-resolution crystalstructures of hemoglobin Bart's (gamma(4)), a marker for alpha-thalassemia. Protein Sci. 1739–1749).
4.5.5
4.5.6
4.5.7
4.5.6

4.5.5 1/10/2022 https://chem.libretexts.org/@go/page/178780
Figure : Levels of Structure in Proteins
The primary structure consists of the specific amino acid sequence. The resulting peptide chain can twist into an α-helix,which is one type of secondary structure. This helical segment is incorporated into the tertiary structure of the foldedpolypeptide chain. The single polypeptide chain is a subunit that constitutes the quaternary structure of a protein, such ashemoglobin that has four polypeptide chains.
Denaturation of Proteins
The highly organized structures of proteins are truly masterworks of chemical architecture. But highly organized structurestend to have a certain delicacy, and this is true of proteins. Denaturation is the term used for any change in the three-dimensional structure of a protein that renders it incapable of performing its assigned function. A denatured protein cannotdo its job. (Sometimes denaturation is equated with the precipitation or coagulation of a protein; our definition is a bitbroader.) A wide variety of reagents and conditions, such as heat, organic compounds, pH changes, and heavy metal ionscan cause protein denaturation (Figure ).
Figure : Protein Denaturation MethodsMethod Effect on Protein Structure
Heat above 50°C or ultraviolet (UV) radiationHeat or UV radiation supplies kinetic energy to protein molecules,
causing their atoms to vibrate more rapidly and disrupting relativelyweak hydrogen bonding and dispersion forces.
Use of organic compounds, such as ethyl alcoholThese compounds are capable of engaging in intermolecular
hydrogen bonding with protein molecules, disrupting intramolecularhydrogen bonding within the protein.
Salts of heavy metal ions, such as mercury, silver, and leadThese ions form strong bonds with the carboxylate anions of the
acidic amino acids or SH groups of cysteine, disrupting ionic bondsand disulfide linkages.
Alkaloid reagents, such as tannic acid (used in tanning leather) These reagents combine with positively charged amino groups inproteins to disrupt ionic bonds.
Anyone who has fried an egg has observed denaturation. The clear egg white turns opaque as the albumin denatures andcoagulates. No one has yet reversed that process. However, given the proper circumstances and enough time, a protein thathas unfolded under sufficiently gentle conditions can refold and may again exhibit biological activity (Figure ). Suchevidence suggests that, at least for these proteins, the primary structure determines the secondary and tertiary structure. Agiven sequence of amino acids seems to adopt its particular three-dimensional arrangement naturally if conditions areright.
4.5.7
4.5.1
4.5.1
4.5.8

4.5.6 1/10/2022 https://chem.libretexts.org/@go/page/178780
Figure : Denaturation and Renaturation of a Protein. The denaturation (unfolding) and renaturation (refolding) of aprotein is depicted. The red boxes represent stabilizing interactions, such as disulfide linkages, hydrogen bonding, and/orionic bonds.
The primary structures of proteins are quite sturdy. In general, fairly vigorous conditions are needed to hydrolyze peptidebonds. At the secondary through quaternary levels, however, proteins are quite vulnerable to attack, though they vary intheir vulnerability to denaturation. The delicately folded globular proteins are much easier to denature than are the tough,fibrous proteins of hair and skin.
Summary
Proteins can be divided into two categories: fibrous, which tend to be insoluble in water, and globular, which are moresoluble in water. A protein may have up to four levels of structure. The primary structure consists of the specific aminoacid sequence. The resulting peptide chain can form an α-helix or β-pleated sheet (or local structures not as easilycategorized), which is known as secondary structure. These segments of secondary structure are incorporated into thetertiary structure of the folded polypeptide chain. The quaternary structure describes the arrangements of subunits in aprotein that contains more than one subunit. Four major types of attractive interactions determine the shape and stability ofthe folded protein: ionic bonding, hydrogen bonding, disulfide linkages, and dispersion forces. A wide variety of reagentsand conditions can cause a protein to unfold or denature.
Concept Review Exercises 1. What is the predominant attractive force that stabilizes the formation of secondary structure in proteins?
2. Distinguish between the tertiary and quaternary levels of protein structure.
3. Briefly describe four ways in which a protein could be denatured.
Answers
1. hydrogen bonding
2. Tertiary structure refers to the unique three-dimensional shape of a single polypeptide chain, while quaternary structuredescribes the interaction between multiple polypeptide chains for proteins that have more than one polypeptide chain.
3. (1) heat a protein above 50°C or expose it to UV radiation; (2) add organic solvents, such as ethyl alcohol, to a proteinsolution; (3) add salts of heavy metal ions, such as mercury, silver, or lead; and (4) add alkaloid reagents such as tannicacid
Exercises 1. Classify each protein as fibrous or globular.
a. albumin
4.5.8

4.5.7 1/10/2022 https://chem.libretexts.org/@go/page/178780
b. myosinc. fibroin
2. Classify each protein as fibrous or globular.
a. hemoglobinb. keratinc. myoglobin
3. What name is given to the predominant secondary structure found in silk?
4. What name is given to the predominant secondary structure found in wool protein?
5. A protein has a tertiary structure formed by interactions between the side chains of the following pairs of amino acids.For each pair, identify the strongest type of interaction between these amino acids.
a. aspartic acid and lysineb. phenylalanine and alaninec. serine and lysined. two cysteines
6. A protein has a tertiary structure formed by interactions between the side chains of the following pairs of amino acids.For each pair, identify the strongest type of interaction between these amino acids.
a. valine and isoleucineb. asparagine and serinec. glutamic acid and arginined. tryptophan and methionine
7. What level(s) of protein structure is(are) ordinarily disrupted in denaturation? What level(s) is(are) not?
8. Which class of proteins is more easily denatured—fibrous or globular?
Answers
a. 1. globularb. fibrousc. fibrous
3. β-pleated sheet
a. 5. ionic bondingb. dispersion forcesc. dispersion forcesd. disulfide linkage
7. Protein denaturation disrupts the secondary, tertiary, and quaternary levels of structure. Only primary structure isunaffected by denaturation.

4.6.1 12/7/2021 https://chem.libretexts.org/@go/page/178781
4.6: EnzymesLearning Objectives
Explain the functions of enzymes.Explain how enzymes are classified and named.
A catalyst is any substance that increases the rate or speed of a chemical reaction without being changed or consumed inthe reaction. Enzymes are biological catalysts, and nearly all of them are proteins. The reaction rates attained by enzymesare truly amazing. In their presence, reactions occur at rates that are a million (10 ) or more times faster than would beattainable in their absence. What is even more amazing is that enzymes perform this function at body temperature (~37°C)and physiological pH (pH ~7), rather than at the conditions that are typically necessary to increase reaction rates (hightemperature or pressure, the use of strong oxidizing or reducing agents or strong acids or bases, or a combination of any ofthese). In addition, enzymes are highly specific in their action; that is, each enzyme catalyzes only one type of reaction inonly one compound or a group of structurally related compounds. The compound or compounds on which an enzyme actsare known as its substrates.
Hundreds of enzymes have been purified and studied in an effort to understand how they work so effectively and with suchspecificity. The resulting knowledge has been used to design drugs that inhibit or activate particular enzymes. An exampleis the intensive research to improve the treatment of or find a cure for acquired immunodeficiency syndrome (AIDS).AIDS is caused by the human immunodeficiency virus (HIV). Researchers are studying the enzymes produced by thisvirus and are developing drugs intended to block the action of those enzymes without interfering with enzymes producedby the human body. Several of these drugs have now been approved for use by AIDS patients.
Table : Classes of EnzymesClass Type of Reaction Catalyzed Examples
oxidoreductases oxidation-reduction reactions
Dehydrogenases catalyze oxidation-reductionreactions involving hydrogen and reductases
catalyze reactions in which a substrate isreduced.
transferasestransfer reactions of groups, such as methyl,
amino, and acetyl
Transaminases catalyze the transfer of aminogroup, and kinases catalyze the transfer of a
phosphate group.
hydrolases hydrolysis reactions Lipases catalyze the hydrolysis of lipids, andproteases catalyze the hydrolysis of proteins
lyasesreactions in which groups are removed
without hydrolysis or addition of groups to adouble bond
Decarboxylases catalyze the removal ofcarboxyl groups.
isomerasesreactions in which a compound is converted
to its isomer
Isomerases may catalyze the conversion of analdose to a ketose, and mutases catalyzereactions in which a functional group is
transferred from one atom in a substrate toanother.
ligasesreactions in which new bonds are formed
between carbon and another atom; energy isrequired
Synthetases catalyze reactions in which twosmaller molecules are linked to form a larger
one.
The first enzymes to be discovered were named according to their source or method of discovery. The enzyme pepsin,which aids in the hydrolysis of proteins, is found in the digestive juices of the stomach (Greek pepsis, meaning“digestion”). Papain, another enzyme that hydrolyzes protein (in fact, it is used in meat tenderizers), is isolated frompapayas. As more enzymes were discovered, chemists recognized the need for a more systematic and chemicallyinformative identification scheme. In the current numbering and naming scheme, under the oversight of the NomenclatureCommission of the International Union of Biochemistry, enzymes are arranged into six groups according to the general
6
4.6.1

4.6.2 12/7/2021 https://chem.libretexts.org/@go/page/178781
type of reaction they catalyze (Table ), with subgroups and secondary subgroups that specify the reaction moreprecisely.
Figure : Structure of the alcohol dehydrogenase protein (E.C.1.1.1.1) (EE ISOZYME) complexed wtih nicotinamideadenini dinulceotide (NAD) and zinc (PDB: 1CDO).
Each enzyme is assigned a four-digit number, preceded by the prefix EC—for enzyme classification—that indicates itsgroup, subgroup, and so forth. This is demonstrated in Table for alcohol dehydrogenase. Each enzyme is also given aname consisting of the root of the name of its substrate or substrates and the -ase suffix. Thus urease is the enzyme thatcatalyzes the hydrolysis of urea.
Table : Assignment of an Enzyme Classification NumberAlcohol Dehydrogenase: EC 1.1.1.1
The first digit indicates that this enzyme is an oxidoreductase; that is, an enzyme that catalyzes an oxidation-reduction reaction.
The second digit indicates that this oxidoreductase catalyzes a reaction involving a primary or secondary alcohol.
The third digit indicates that either the coenzyme NAD or NADP is required for this reaction.
The fourth digit indicates that this was the first enzyme isolated, characterized, and named using this system of nomenclature.
The systematic name for this enzyme is alcohol:NAD oxidoreductase, while the recommended or common name is alcohol dehydrogenase.
Reaction catalyzed:
Summary
An enzyme is a biological catalyst, a substance that increases the rate of a chemical reaction without being changed orconsumed in the reaction. A systematic process is used to name and classify enzymes.
Concept Review ExerciseIn the small intestine, sucrose is hydrolyzed to form glucose and fructose in a reaction catalyzed by sucrase.
1. Identify the substrate in this reaction.2. Name the enzyme.
Answers1. sucrose2. sucrase
Exercises
1. Identify the substrate catalyzed by each enzyme.
a. lactaseb. cellulasec. peptidase
2. Identify the substrate catalyzed by each enzyme.
a. lipaseb. amylasec. maltase
3. Identify each type of enzyme.
a. decarboxylaseb. protease
4.6.1
4.6.1
4.6.2
4.6.2
+ +
+

4.6.3 12/7/2021 https://chem.libretexts.org/@go/page/178781
c. transaminase
4. Identify each type of enzyme.
a. dehydrogenaseb. isomerasec. lipase
Answersa. 1. lactoseb. cellulosec. peptides
a. 3. lyaseb. hydrolasec. transferase

4.7.1 11/28/2021 https://chem.libretexts.org/@go/page/178782
4.7: Enzyme ActionLearning Objectives
To describe the interaction between an enzyme and its substrate.
Enzyme-catalyzed reactions occur in at least two steps. In the first step, an enzyme molecule (E) and the substratemolecule or molecules (S) collide and react to form an intermediate compound called the enzyme-substrate (E–S) complex.(This step is reversible because the complex can break apart into the original substrate or substrates and the free enzyme.)Once the E–S complex forms, the enzyme is able to catalyze the formation of product (P), which is then released from theenzyme surface:
Hydrogen bonding and other electrostatic interactions hold the enzyme and substrate together in the complex. Thestructural features or functional groups on the enzyme that participate in these interactions are located in a cleft or pocketon the enzyme surface. This pocket, where the enzyme combines with the substrate and transforms the substrate to productis called the active site of the enzyme (Figure ).
Figure : Substrate Binding to the Active Site of an Enzyme. The enzyme dihydrofolate reductase is shown with oneof its substrates: NADP (a) unbound and (b) bound. The NADP (shown in red) binds to a pocket that is complementaryto it in shape and ionic properties.
The active site of an enzyme possesses a unique conformation (including correctly positioned bonding groups) that iscomplementary to the structure of the substrate, so that the enzyme and substrate molecules fit together in much the samemanner as a key fits into a tumbler lock. In fact, an early model describing the formation of the enzyme-substrate complexwas called the lock-and-key model (Figure ). This model portrayed the enzyme as conformationally rigid and able tobond only to substrates that exactly fit the active site.
Figure : The Lock-and-Key Model of Enzyme Action. (a) Because the substrate and the active site of the enzymehave complementary structures and bonding groups, they fit together as a key fits a lock. (b) The catalytic reaction occurswhile the two are bonded together in the enzyme-substrate complex.
Working out the precise three-dimensional structures of numerous enzymes has enabled chemists to refine the originallock-and-key model of enzyme actions. They discovered that the binding of a substrate often leads to a largeconformational change in the enzyme, as well as to changes in the structure of the substrate or substrates. The currenttheory, known as the induced-fit model, says that enzymes can undergo a change in conformation when they bind substrate
S+E →E–S (4.7.1)
E–S → P +E (4.7.2)
4.7.1
4.7.1+ +
4.7.2
4.7.2

4.7.2 11/28/2021 https://chem.libretexts.org/@go/page/178782
molecules, and the active site has a shape complementary to that of the substrate only after the substrate is bound, asshown for hexokinase in Figure . After catalysis, the enzyme resumes its original structure.
Figure : The Induced-Fit Model of Enzyme Action. (a) The enzyme hexokinase without its substrate (glucose, shownin red) is bound to the active site. (b) The enzyme conformation changes dramatically when the substrate binds to it,resulting in additional interactions between hexokinase and glucose.
The structural changes that occur when an enzyme and a substrate join together bring specific parts of a substrate intoalignment with specific parts of the enzyme’s active site. Amino acid side chains in or near the binding site can then act asacid or base catalysts, provide binding sites for the transfer of functional groups from one substrate to another or aid in therearrangement of a substrate. The participating amino acids, which are usually widely separated in the primary sequence ofthe protein, are brought close together in the active site as a result of the folding and bending of the polypeptide chain orchains when the protein acquires its tertiary and quaternary structure. Binding to enzymes brings reactants close to eachother and aligns them properly, which has the same effect as increasing the concentration of the reacting compounds.
Example a. What type of interaction would occur between an OH group present on a substrate molecule and a functional group
in the active site of an enzyme?b. Suggest an amino acid whose side chain might be in the active site of an enzyme and form the type of interaction
you just identified.
SOLUTION
a. An OH group would most likely engage in hydrogen bonding with an appropriate functional group present in theactive site of an enzyme.
b. Several amino acid side chains would be able to engage in hydrogen bonding with an OH group. One examplewould be asparagine, which has an amide functional group.
Exercise a. What type of interaction would occur between an COO group present on a substrate molecule and a functional
group in the active site of an enzyme?b. Suggest an amino acid whose side chain might be in the active site of an enzyme and form the type of interaction
you just identified.
One characteristic that distinguishes an enzyme from all other types of catalysts is its substrate specificity. An inorganicacid such as sulfuric acid can be used to increase the reaction rates of many different reactions, such as the hydrolysis ofdisaccharides, polysaccharides, lipids, and proteins, with complete impartiality. In contrast, enzymes are much morespecific. Some enzymes act on a single substrate, while other enzymes act on any of a group of related moleculescontaining a similar functional group or chemical bond. Some enzymes even distinguish between D- and L-stereoisomers,binding one stereoisomer but not the other. Urease, for example, is an enzyme that catalyzes the hydrolysis of a singlesubstrate—urea—but not the closely related compounds methyl urea, thiourea, or biuret. The enzyme carboxypeptidase, onthe other hand, is far less specific. It catalyzes the removal of nearly any amino acid from the carboxyl end of any peptideor protein.
4.7.3
4.7.3
4.7.1
4.7.1−

4.7.3 11/28/2021 https://chem.libretexts.org/@go/page/178782
Enzyme specificity results from the uniqueness of the active site in each different enzyme because of the identity, charge,and spatial orientation of the functional groups located there. It regulates cell chemistry so that the proper reactions occurin the proper place at the proper time. Clearly, it is crucial to the proper functioning of the living cell.
Summary A substrate binds to a specific region on an enzyme known as the active site, where the substrate can be converted toproduct. The substrate binds to the enzyme primarily through hydrogen bonding and other electrostatic interactions. Theinduced-fit model says that an enzyme can undergo a conformational change when binding a substrate. Enzymes exhibitvarying degrees of substrate specificity.
Concept Review Exercises 1. Distinguish between the lock-and-key model and induced-fit model of enzyme action.2. Which enzyme has greater specificity—urease or carboxypeptidase? Explain.
Answers 1. The lock-and-key model portrays an enzyme as conformationally rigid and able to bond only to substrates that exactly
fit the active site. The induced fit model portrays the enzyme structure as more flexible and is complementary to thesubstrate only after the substrate is bound.
2. Urease has the greater specificity because it can bind only to a single substrate. Carboxypeptidase, on the other hand,can catalyze the removal of nearly any amino acid from the carboxyl end of a peptide or protein.
Exercises 1. What type of interaction would occur between each group present on a substrate molecule and a functional group of the
active site in an enzyme?
a. COOHb. NHc. OHd. CH(CH )
2. What type of interaction would occur between each group present on a substrate molecule and a functional group of theactive site in an enzyme?
a. SHb. NHc. C Hd. COO
3. For each functional group in Exercise 1, suggest an amino acid whose side chain might be in the active site of anenzyme and form the type of interaction you identified.
4. For each functional group in Exercise 2, suggest an amino acid whose side chain might be in the active site of anenzyme and form the type of interaction you identified.
3+
3 2
2
6 5−

4.7.4 11/28/2021 https://chem.libretexts.org/@go/page/178782
Answers
a. 1. hydrogen bondingb. ionic bondingc. hydrogen bondingd. dispersion forces
a. 3. The amino acid has a polar side chain capable of engaging in hydrogen bonding; serine (answers will vary).b. The amino acid has a negatively charged side chain; aspartic acid (answers will vary).c. The amino acid has a polar side chain capable of engaging in hydrogen bonding; asparagine (answers will vary).d. The amino acid has a nonpolar side chain; isoleucine (answers will vary).

4.8.1 12/12/2021 https://chem.libretexts.org/@go/page/178783
4.8: Enzyme ActivityLearning Objectives
To describe how pH, temperature, and the concentration of an enzyme and its substrate influence enzyme activity.
The single most important property of enzymes is the ability to increase the rates of reactions occurring in livingorganisms, a property known as catalytic activity. Because most enzymes are proteins, their activity is affected by factorsthat disrupt protein structure, as well as by factors that affect catalysts in general. Factors that disrupt protein structureinclude temperature and pH; factors that affect catalysts in general include reactant or substrate concentration and catalystor enzyme concentration. The activity of an enzyme can be measured by monitoring either the rate at which a substratedisappears or the rate at which a product forms.
Concentration of Substrate
In the presence of a given amount of enzyme, the rate of an enzymatic reaction increases as the substrate concentrationincreases until a limiting rate is reached, after which further increase in the substrate concentration produces no significantchange in the reaction rate (part (a) of Figure ). At this point, so much substrate is present that essentially all of theenzyme active sites have substrate bound to them. In other words, the enzyme molecules are saturated with substrate. Theexcess substrate molecules cannot react until the substrate already bound to the enzymes has reacted and been released (orbeen released without reacting).
Figure : Concentration versus Reaction Rate. (a) This graph shows the effect of substrate concentration on the rate ofa reaction that is catalyzed by a fixed amount of enzyme. (b) This graph shows the effect of enzyme concentration on thereaction rate at a constant level of substrate.
Let’s consider an analogy. Ten taxis (enzyme molecules) are waiting at a taxi stand to take people (substrate) on a 10-minute trip to a concert hall, one passenger at a time. If only 5 people are present at the stand, the rate of their arrival at theconcert hall is 5 people in 10 minutes. If the number of people at the stand is increased to 10, the rate increases to 10arrivals in 10 minutes. With 20 people at the stand, the rate would still be 10 arrivals in 10 minutes. The taxis have been“saturated.” If the taxis could carry 2 or 3 passengers each, the same principle would apply. The rate would simply behigher (20 or 30 people in 10 minutes) before it leveled off.
Concentration of Enzyme When the concentration of the enzyme is significantly lower than the concentration of the substrate (as when the number oftaxis is far lower than the number of waiting passengers), the rate of an enzyme-catalyzed reaction is directly dependent onthe enzyme concentration (part (b) of Figure ). This is true for any catalyst; the reaction rate increases as theconcentration of the catalyst is increased.
4.8.1
4.8.1
4.8.1

4.8.2 12/12/2021 https://chem.libretexts.org/@go/page/178783
Temperature
A general rule of thumb for most chemical reactions is that a temperature rise of 10°C approximately doubles the reactionrate. To some extent, this rule holds for all enzymatic reactions. After a certain point, however, an increase in temperaturecauses a decrease in the reaction rate, due to denaturation of the protein structure and disruption of the active site (part (a)of Figure ). For many proteins, denaturation occurs between 45°C and 55°C. Furthermore, even though an enzymemay appear to have a maximum reaction rate between 40°C and 50°C, most biochemical reactions are carried out at lowertemperatures because enzymes are not stable at these higher temperatures and will denature after a few minutes.
Figure : Temperature and pH versus Concentration. (a) This graph depicts the effect of temperature on the rate of areaction that is catalyzed by a fixed amount of enzyme. (b) This graph depicts the effect of pH on the rate of a reaction thatis catalyzed by a fixed amount of enzyme.
At 0°C and 100°C, the rate of enzyme-catalyzed reactions is nearly zero. This fact has several practical applications. Westerilize objects by placing them in boiling water, which denatures the enzymes of any bacteria that may be in or on them.We preserve our food by refrigerating or freezing it, which slows enzyme activity. When animals go into hibernation inwinter, their body temperature drops, decreasing the rates of their metabolic processes to levels that can be maintained bythe amount of energy stored in the fat reserves in the animals’ tissues.
Hydrogen Ion Concentration (pH) Because most enzymes are proteins, they are sensitive to changes in the hydrogen ion concentration or pH. Enzymes maybe denatured by extreme levels of hydrogen ions (whether high or low); any change in pH, even a small one, alters thedegree of ionization of an enzyme’s acidic and basic side groups and the substrate components as well. Ionizable sidegroups located in the active site must have a certain charge for the enzyme to bind its substrate. Neutralization of even oneof these charges alters an enzyme’s catalytic activity.
An enzyme exhibits maximum activity over the narrow pH range in which a molecule exists in its properly charged form.The median value of this pH range is called the optimum pH of the enzyme (part (b) of Figure ). With the notableexception of gastric juice (the fluids secreted in the stomach), most body fluids have pH values between 6 and 8. Notsurprisingly, most enzymes exhibit optimal activity in this pH range. However, a few enzymes have optimum pH valuesoutside this range. For example, the optimum pH for pepsin, an enzyme that is active in the stomach, is 2.0.
Summary Initially, an increase in substrate concentration leads to an increase in the rate of an enzyme-catalyzed reaction. As theenzyme molecules become saturated with substrate, this increase in reaction rate levels off. The rate of an enzyme-catalyzed reaction increases with an increase in the concentration of an enzyme. At low temperatures, an increase intemperature increases the rate of an enzyme-catalyzed reaction. At higher temperatures, the protein is denatured, and therate of the reaction dramatically decreases. An enzyme has an optimum pH range in which it exhibits maximum activity.
Concept Review Exercises 1. The concentration of substrate X is low. What happens to the rate of the enzyme-catalyzed reaction if the concentration
of X is doubled?2. What effect does an increase in the enzyme concentration have on the rate of an enzyme-catalyzed reaction?
4.8.2
4.8.2
4.8.2

4.8.3 12/12/2021 https://chem.libretexts.org/@go/page/178783
Answers 1. If the concentration of the substrate is low, increasing its concentration will increase the rate of the reaction.2. An increase in the amount of enzyme will increase the rate of the reaction (provided sufficient substrate is present).
Exercises
1. In non-enzyme-catalyzed reactions, the reaction rate increases as the concentration of reactant is increased. In anenzyme-catalyzed reaction, the reaction rate initially increases as the substrate concentration is increased but thenbegins to level off, so that the increase in reaction rate becomes less and less as the substrate concentration increases.Explain this difference.
2. Why do enzymes become inactive at very high temperatures?
3. An enzyme has an optimum pH of 7.4. What is most likely to happen to the activity of the enzyme if the pH drops to6.3? Explain.
4. An enzyme has an optimum pH of 7.2. What is most likely to happen to the activity of the enzyme if the pH increasesto 8.5? Explain.
Answers
1. In an enzyme-catalyzed reaction, the substrate binds to the enzyme to form an enzyme-substrate complex. If moresubstrate is present than enzyme, all of the enzyme binding sites will have substrate bound, and further increases insubstrate concentration cannot increase the rate.
3. The activity will decrease; a pH of 6.3 is more acidic than 7.4, and one or more key groups in the active site may bind ahydrogen ion, changing the charge on that group.

4.9.1 12/26/2021 https://chem.libretexts.org/@go/page/178784
4.9: Enzyme InhibitionLearning Objectives
Explain what an enzyme inhibitor is.Distinguish between reversible and irreversible inhibitors.Distinguish between competitive and noncompetitive inhibitors.
Previously, we noted that enzymes are inactivated at high temperatures and by changes in pH. These are nonspecificfactors that would inactivate any enzyme. The activity of enzymes can also be regulated by more specific inhibitors. Manycompounds are poisons because they bind covalently to particular enzymes or kinds of enzymes and inactivate them (Table
).
Table : Poisons as Enzyme InhibitorsPoison Formula Example of Enzyme Inhibited Action
arsenateglyceraldehyde 3-phosphate
dehydrogenase substitutes for phosphate
iodoacetate triose phosphate dehydrogenase binds to cysteine group
diisopropylfluoro-phosphate(DIFP; a nerve poison)
acetylcholinesterase binds to serine group
Irreversible Inhibition: Poisons An irreversible inhibitor inactivates an enzyme by bonding covalently to a particular group at the active site. The inhibitor-enzyme bond is so strong that the inhibition cannot be reversed by the addition of excess substrate. The nerve gases,especially Diisopropyl fluorophosphate (DIFP), irreversibly inhibit biological systems by forming an enzyme-inhibitorcomplex with a specific OH group of serine situated at the active sites of certain enzymes. The peptidases trypsin andchymotrypsin contain serine groups at the active site and are inhibited by DIFP.
Reversible Inhibition A reversible inhibitor inactivates an enzyme through noncovalent, more easily reversed, interactions. Unlike an irreversibleinhibitor, a reversible inhibitor can dissociate from the enzyme. Reversible inhibitors include competitive inhibitors andnoncompetitive inhibitors. (There are additional types of reversible inhibitors.) A competitive inhibitor is any compoundthat bears a structural resemblance to a particular substrate and thus competes with that substrate for binding at the activesite of an enzyme. The inhibitor is not acted on by the enzyme but does prevent the substrate from approaching the activesite.
The degree to which a competitive inhibitor interferes with an enzyme’s activity depends on the relative concentrations ofthe substrate and the inhibitor. If the inhibitor is present in relatively large quantities, it will initially block most of theactive sites. But because the binding is reversible, some substrate molecules will eventually bind to the active site and beconverted to product. Increasing the substrate concentration promotes displacement of the inhibitor from the active site.Competitive inhibition can be completely reversed by adding substrate so that it reaches a much higher concentration thanthat of the inhibitor.
4.9.1
4.9.1
AsO3 −
4
ICH2COO
−SH
OH

4.9.2 12/26/2021 https://chem.libretexts.org/@go/page/178784
Studies of competitive inhibition have provided helpful information about certain enzyme-substrate complexes and theinteractions of specific groups at the active sites. As a result, pharmaceutical companies have synthesized drugs thatcompetitively inhibit metabolic processes in bacteria and certain cancer cells. Many drugs are competitive inhibitors ofspecific enzymes.
A classic example of competitive inhibition is the effect of malonate on the enzyme activity of succinate dehydrogenase(Figure ). Malonate and succinate are the anions of dicarboxylic acids and contain three and four carbon atoms,respectively. The malonate molecule binds to the active site because the spacing of its carboxyl groups is not greatlydifferent from that of succinate. However, no catalytic reaction occurs because malonate does not have a CH CH group toconvert to CH=CH. This reaction will also be discussed in connection with the Krebs cycle and energy production.
Figure : Competitive Inhibition. (a) Succinate binds to the enzyme succinate dehydrogenase. A dehydrogenationreaction occurs, and the product—fumarate—is released from the enzyme. (b) Malonate also binds to the active site ofsuccinate dehydrogenase. In this case, however, no subsequent reaction occurs while malonate remains bound to theenzyme.
To Your Health: PenicillinChemotherapy is the strategic use of chemicals (that is, drugs) to destroy infectious microorganisms or cancer cellswithout causing excessive damage to the other, healthy cells of the host. From bacteria to humans, the metabolicpathways of all living organisms are quite similar, so the search for safe and effective chemotherapeutic agents is aformidable task. Many well-established chemotherapeutic drugs function by inhibiting a critical enzyme in the cells ofthe invading organism.
An antibiotic is a compound that kills bacteria; it may come from a natural source such as molds or be synthesized witha structure analogous to a naturally occurring antibacterial compound. Antibiotics constitute no well-defined class ofchemically related substances, but many of them work by effectively inhibiting a variety of enzymes essential tobacterial growth.
Penicillin, one of the most widely used antibiotics in the world, was fortuitously discovered by Alexander Fleming in1928, when he noticed antibacterial properties in a mold growing on a bacterial culture plate. In 1938, Ernst Chain andHoward Florey began an intensive effort to isolate penicillin from the mold and study its properties. The large quantitiesof penicillin needed for this research became available through development of a corn-based nutrient medium that themold loved and through the discovery of a higher-yielding strain of mold at a United States Department of Agricultureresearch center near Peoria, Illinois. Even so, it was not until 1944 that large quantities of penicillin were beingproduced and made available for the treatment of bacterial infections.
Penicillin functions by interfering with the synthesis of cell walls of reproducing bacteria. It does so by inhibiting anenzyme—transpeptidase—that catalyzes the last step in bacterial cell-wall biosynthesis. The defective walls causebacterial cells to burst. Human cells are not affected because they have cell membranes, not cell walls.
Several naturally occurring penicillins have been isolated. They are distinguished by different R groups connected to acommon structure: a four-member cyclic amide (called a lactam ring) fused to a five-member ring. The addition of
4.9.1
2 2
4.9.1

4.9.3 12/26/2021 https://chem.libretexts.org/@go/page/178784
appropriate organic compounds to the culture medium leads to the production of the different kinds of penicillin.
The penicillins are effective against gram-positive bacteria (bacteria capable of being stained by Gram’s stain) and afew gram-negative bacteria (including the intestinal bacterium Escherichia coli). They are effective in the treatment ofdiphtheria, gonorrhea, pneumonia, syphilis, many pus infections, and certain types of boils. Penicillin G was the earliestpenicillin to be used on a wide scale. However, it cannot be administered orally because it is quite unstable; the acidicpH of the stomach converts it to an inactive derivative. The major oral penicillins—penicillin V, ampicillin, andamoxicillin—on the other hand, are acid stable.
Some strains of bacteria become resistant to penicillin through a mutation that allows them to synthesize an enzyme—penicillinase—that breaks the antibiotic down (by cleavage of the amide linkage in the lactam ring). To combat thesestrains, scientists have synthesized penicillin analogs (such as methicillin) that are not inactivated by penicillinase.
Some people (perhaps 5% of the population) are allergic to penicillin and therefore must be treated with otherantibiotics. Their allergic reaction can be so severe that a fatal coma may occur if penicillin is inadvertentlyadministered to them. Fortunately, several other antibiotics have been discovered. Most, including aureomycin andstreptomycin, are the products of microbial synthesis. Others, such as the semisynthetic penicillins and tetracyclines,are made by chemical modifications of antibiotics; and some, like chloramphenicol, are manufactured entirely bychemical synthesis. They are as effective as penicillin in destroying infectious microorganisms. Many of theseantibiotics exert their effects by blocking protein synthesis in microorganisms.
Initially, antibiotics were considered miracle drugs, substantially reducing the number of deaths from blood poisoning,pneumonia, and other infectious diseases. Some seven decades ago, a person with a major infection almost always died.Today, such deaths are rare. Seven decades ago, pneumonia was a dreaded killer of people of all ages. Today, it killsonly the very old or those ill from other causes. Antibiotics have indeed worked miracles in our time, but even miracledrugs have limitations. Not long after the drugs were first used, disease organisms began to develop strains resistant tothem. In a race to stay ahead of resistant bacterial strains, scientists continue to seek new antibiotics. The penicillinshave now been partially displaced by related compounds, such as the cephalosporins and vancomycin. Unfortunately,some strains of bacteria have already shown resistance to these antibiotics.
Some reversible inhibitors are noncompetitive. A noncompetitive inhibitor can combine with either the free enzyme or theenzyme-substrate complex because its binding site on the enzyme is distinct from the active site. Binding of this kind ofinhibitor alters the three-dimensional conformation of the enzyme, changing the configuration of the active site with one oftwo results. Either the enzyme-substrate complex does not form at its normal rate, or, once formed, it does not yieldproducts at the normal rate. Because the inhibitor does not structurally resemble the substrate, the addition of excesssubstrate does not reverse the inhibitory effect.

4.9.4 12/26/2021 https://chem.libretexts.org/@go/page/178784
Figure : Feedback Inhibition of Threonine Deaminase by Isoleucine. Threonine deaminase is the first enzyme in theconversion of threonine to isoleucine. Isoleucine inhibits threonine deaminase through feedback inhibition.
Feedback inhibition is a normal biochemical process that makes use of noncompetitive inhibitors to control someenzymatic activity. In this process, the final product inhibits the enzyme that catalyzes the first step in a series of reactions.Feedback inhibition is used to regulate the synthesis of many amino acids. For example, bacteria synthesize isoleucinefrom threonine in a series of five enzyme-catalyzed steps. As the concentration of isoleucine increases, some of it binds asa noncompetitive inhibitor to the first enzyme of the series (threonine deaminase), thus bringing about a decrease in theamount of isoleucine being formed (Figure ).
Summary An irreversible inhibitor inactivates an enzyme by bonding covalently to a particular group at the active site. A reversibleinhibitor inactivates an enzyme through noncovalent, reversible interactions. A competitive inhibitor competes with thesubstrate for binding at the active site of the enzyme. A noncompetitive inhibitor binds at a site distinct from the activesite.
Concept Review Exercises 1. What are the characteristics of an irreversible inhibitor?2. In what ways does a competitive inhibitor differ from a noncompetitive inhibitor?
Answers 1. It inactivates an enzyme by bonding covalently to a particular group at the active site.2. A competitive inhibitor structurally resembles the substrate for a given enzyme and competes with the substrate for
binding at the active site of the enzyme. A noncompetitive inhibitor binds at a site distinct from the active site and canbind to either the free enzyme or the enzyme-substrate complex.
Exercises 1. What amino acid is present in the active site of all enzymes that are irreversibly inhibited by nerve gases such as DIFP?2. Oxaloacetate (OOCCH2COCOO) inhibits succinate dehydrogenase. Would you expect oxaloacetate to be a
competitive or noncompetitive inhibitor? Explain.
Answer 1. serine
4.9.2
4.9.2

4.10.1 12/19/2021 https://chem.libretexts.org/@go/page/178785
4.10: Enzyme Cofactors and VitaminsLearning Objectives
To explain why vitamins are necessary in the diet.
Many enzymes are simple proteins consisting entirely of one or more amino acid chains. Other enzymes contain anonprotein component called a cofactor that is necessary for the enzyme’s proper functioning. There are two types ofcofactors: inorganic ions [e.g., zinc or Cu(I) ions] and organic molecules known as coenzymes. Most coenzymes arevitamins or are derived from vitamins.
Vitamins are organic compounds that are essential in very small (trace) amounts for the maintenance of normalmetabolism. They generally cannot be synthesized at adequate levels by the body and must be obtained from the diet. Theabsence or shortage of a vitamin may result in a vitamin-deficiency disease. In the first half of the 20th century, a majorfocus of biochemistry was the identification, isolation, and characterization of vitamins. Despite accumulating evidencethat people needed more than just carbohydrates, fats, and proteins in their diets for normal growth and health, it was notuntil the early 1900s that research established the need for trace nutrients in the diet.
Vitamin Physiological Function Effect of DeficiencyTable : Fat-Soluble Vitamins and Physiological Functions
vitamin A (retinol)formation of vision pigments; differentiation
of epithelial cellsnight blindness; continued deficiency leads to
total blindness
vitamin D (cholecalciferol) increases the body’s ability to absorb calciumand phosphorus
osteomalacia (softening of the bones); knownas rickets in children
vitamin E (tocopherol) fat-soluble antioxidant damage to cell membranes
vitamin K (phylloquinone) formation of prothrombin, a key enzyme inthe blood-clotting process
increases the time required for blood to clot
Because organisms differ in their synthetic abilities, a substance that is a vitamin for one species may not be so for another.Over the past 100 years, scientists have identified and isolated 13 vitamins required in the human diet and have dividedthem into two broad categories: the fat-soluble vitamins, which include vitamins A, D, E, and K, and the water-solublevitamins, which are the B complex vitamins and vitamin C. All fat-soluble vitamins contain a high proportion ofhydrocarbon structural components. There are one or two oxygen atoms present, but the compounds as a whole arenonpolar. In contrast, water-soluble vitamins contain large numbers of electronegative oxygen and nitrogen atoms, whichcan engage in hydrogen bonding with water. Most water-soluble vitamins act as coenzymes or are required for thesynthesis of coenzymes. The fat-soluble vitamins are important for a variety of physiological functions. The key vitaminsand their functions are found in Tables and .
Table : Water-Soluble Vitamins and Physiological FunctionsVitamin Coenzyme Coenzyme Function Deficiency Disease
vitamin B (thiamine) thiamine pyrophosphate decarboxylation reactions beri-beri
vitamin B (riboflavin) flavin mononucleotide or flavinadenine dinucleotide
oxidation-reduction reactionsinvolving two hydrogen atoms
—
vitamin B (niacin)nicotinamide adenine
dinucleotide or nicotinamideadenine dinucleotide phosphate
oxidation-reduction reactionsinvolving the hydride ion (H ) pellagra
vitamin B (pyridoxine) pyridoxal phosphate variety of reactions including thetransfer of amino groups
—
vitamin B (cyanocobalamin) methylcobalamin ordeoxyadenoxylcobalamin
intramolecular rearrangementreactions
pernicious anemia
biotin biotin carboxylation reactions —
folic acid tetrahydrofolate carrier of one-carbon units suchas the formyl group
anemia
4.10.1
4.10.1 4.10.2
4.10.2
1
2
3 −
6
12

4.10.2 12/19/2021 https://chem.libretexts.org/@go/page/178785
Vitamin Coenzyme Coenzyme Function Deficiency Disease
pantothenic Acid coenzyme A carrier of acyl groups —
vitamin C (ascorbic acid) noneantioxidant; formation of
collagen, a protein found intendons, ligaments, and bone
scurvy
Vitamins C and E, as well as the provitamin β-carotene can act as antioxidants in the body. Antioxidants prevent damagefrom free radicals, which are molecules that are highly reactive because they have unpaired electrons. Free radicals areformed not only through metabolic reactions involving oxygen but also by such environmental factors as radiation andpollution.
β-carotene is known as a provitamin because it can be converted to vitamin A inthe body.
Free radicals react most commonly react with lipoproteins and unsaturated fatty acids in cell membranes, removing anelectron from those molecules and thus generating a new free radical. The process becomes a chain reaction that finallyleads to the oxidative degradation of the affected compounds. Antioxidants react with free radicals to stop these chainreactions by forming a more stable molecule or, in the case of vitamin E, a free radical that is much less reactive (vitamin Eis converted back to its original form through interaction with vitamin C).
Summary Vitamins are organic compounds that are essential in very small amounts for the maintenance of normal metabolism.Vitamins are divided into two broad categories: fat-soluble vitamins and water-soluble vitamins. Most water-solublevitamins are needed for the formation of coenzymes, which are organic molecules needed by some enzymes for catalyticactivity.
Concept Review Exercises 1. What is the difference between a cofactor and a coenzyme?2. How are vitamins related to coenzymes?
Answers 1. A coenzyme is one type of cofactor. Coenzymes are organic molecules required by some enzymes for activity. A
cofactor can be either a coenzyme or an inorganic ion.2. Coenzymes are synthesized from vitamins.
Exercises 1. Identify each vitamin as water soluble or fat soluble.
a. vitamin Db. vitamin Cc. vitamin B
2. Identify each vitamin as water soluble or fat soluble.
a. niacinb. cholecalciferolc. biotin
3. What vitamin is needed to form each coenzyme?
a. pyridoxal phosphateb. flavin adenine dinucleotidec. coenzyme Ad. nicotinamide adenine dinucleotide
12

4.10.3 12/19/2021 https://chem.libretexts.org/@go/page/178785
4. What coenzyme is formed from each vitamin?
a. niacinb. thiaminec. cyanocobalamind. pantothenic acid
5. What is the function of each vitamin or coenzyme?
a. flavin adenine dinucleotideb. vitamin Ac. biotin
6. What is the function of each vitamin or coenzyme?
a. vitamin Kb. pyridoxal phosphatec. tetrahydrofolate
Answers
a. 1. fat solubleb. water solublec. water soluble
a. 3. vitamin B or pyridoxineb. vitamin B or riboflavinc. pantothenic acidd. vitamin B or niacin
a. 5. needed by enzymes that catalyze oxidation-reduction reactions in which two hydrogen atoms are transferredb. needed for the formation of vision pigmentsc. needed by enzymes that catalyze carboxylation reactions
6
2
3

4.11.1 12/19/2021 https://chem.libretexts.org/@go/page/178786
4.11: Amino Acids, Proteins, and Enzymes (Summary)To ensure that you understand the material in this chapter, you should review the meanings of the bold terms in the
following summary and ask yourself how they relate to the topics in the chapter.
A protein is a large biological polymer synthesized from amino acids, which are carboxylic acids containing an α-aminogroup. Proteins have a variety of important roles in living organisms, yet they are made from the same 20 L-amino acids.About half of these amino acids, the essential amino acids, cannot be synthesized by the human body and must beobtained from the diet. In the solid state and in neutral solutions, amino acids exist as zwitterions, species that are chargedbut electrically neutral. In this form, they behave much like inorganic salts. Each amino acid belongs to one of four classesdepending on the characteristics of its R group or amino acid side chain: nonpolar, polar but neutral, positively charged,and negatively charged. Depending on the conditions, amino acids can act as either acids or bases, which means thatproteins act as buffers. The pH at which an amino acid exists as the zwitterion is called the isoelectric point (pI).
The amino acids in a protein are linked together by peptide bonds. Protein chains containing 10 or fewer amino acids areusually referred to as peptides, with a prefix such as di- or tri- indicating the number of amino acids. Chains containingmore than 50 amino acid units are referred to as proteins or polypeptides. Proteins are classified globular or fibrous,depending on their structure and resulting solubility in water. Globular proteins are nearly spherical and are soluble inwater; fibrous proteins have elongated or fibrous structures and are not soluble in water.
Protein molecules can have as many as four levels of structure. The primary structure is the sequence of amino acids inthe chain. The secondary structure is the arrangement of adjacent atoms in the peptide chain; the most commonarrangements are α-helices or β-pleated sheets. The tertiary structure is the overall three-dimensional shape of themolecule that results from the way the chain bends and folds in on itself. Proteins that consist of more than one chain havequaternary structure, which is the way the multiple chains are packed together.
Four types of intramolecular and intermolecular forces contribute to secondary, tertiary, and quaternary structure: (1)hydrogen bonding between an oxygen or a nitrogen atom and a hydrogen atom bound to an oxygen atom or a nitrogenatom, either on the same chain or on a neighboring chain; (2) ionic bonding between one positively charged side chain andone negatively charged side chain; (3) disulfide linkages between cysteine units; and (4) dispersion forces betweennonpolar side chains.
Because of their complexity, protein molecules are delicate and easy to disrupt. A denatured protein is one whoseconformation has been changed, in a process called denaturation, so that it can no longer do its physiological job. Avariety of conditions, such as heat, ultraviolet radiation, the addition of organic compounds, or changes in pH can denaturea protein.
An enzyme is an organic catalyst produced by a living cell. Enzymes are such powerful catalysts that the reactions theypromote occur rapidly at body temperature. Without the help of enzymes, these reactions would require high temperaturesand long reaction times.
The molecule or molecules on which an enzyme acts are called its substrates. An enzyme has an active site where itssubstrate or substrates bind to form an enzyme-substrate complex. The reaction occurs, and product is released:
The original lock-and-key model of enzyme and substrate binding pictured a rigid enzyme of unchanging configurationbinding to the appropriate substrate. The newer induced-fit model describes the enzyme active site as changing itsconformation after binding to the substrate.
Most enzymes have maximal activity in a narrow pH range centered on an optimum pH. In this pH range, the enzyme iscorrectly folded, and catalytic groups in the active site have the correct charge (positive, negative, or neutral). For mostenzymes, the optimum pH is between 6 and 8.
Substances that interfere with enzyme function are called inhibitors. An irreversible inhibitor inactivates enzymes byforming covalent bonds to the enzyme, while a reversible inhibitor inactivates an enzyme by a weaker, noncovalentinteraction that is easier to disrupt. A competitive inhibitor is a reversible inhibitor that is structurally similar to thesubstrate and binds to the active site. When the inhibitor is bound, the substrate is blocked from the active site and no
E+S →E–S →E+P (4.11.1)

4.11.2 12/19/2021 https://chem.libretexts.org/@go/page/178786
reaction occurs. Because the binding of such an inhibitor is reversible, a high substrate concentration will overcome theinhibition because it increases the likelihood of the substrate binding. A noncompetitive inhibitor binds reversibly at asite distinct from the active site. Thus, it can bind to either the enzyme or the enzyme-substrate complex. The inhibitorchanges the conformation of the active site so that the enzyme cannot function properly. Noncompetitive inhibitors areimportant in feedback inhibition, in which the amount of product produced by a series of reactions is carefully controlled.The final product in a series of reactions acts as a noncompetitive inhibitor of the initial enzyme.
Simple enzymes consist entirely of one or more amino acid chains. Complex enzymes are composed of one or more aminoacid chains joined to cofactors—inorganic ions or organic coenzymes. Vitamins are organic compounds that are essentialin very small amounts for the maintenance of normal metabolism and generally cannot be synthesized at adequate levelsby the body. Vitamins are divided into two broad categories: fat-soluble vitamins and water-soluble vitamins. Many of thewater-soluble vitamins are used for the synthesis of coenzymes.

4.12.1 1/9/2022 https://chem.libretexts.org/@go/page/178787
4.12: Amino Acids, Proteins, and Enzymes (Exercises)
Additional Exercises
1. Draw the structure of the amino acid γ-aminobutyric acid (GABA). Would you expect to find GABA in the amino acidsequence of a protein? Explain.
2. Draw the structure of the amino acid homocysteine (R group = CH CH SH). Would you expect to find homocysteinein the amino acid sequence of a protein? Justify your answer.
3. Write equations to show how leucine can act as a buffer (that is, how it can neutralize added acid or base).
4. Write equations to show how isoleucine can act as a buffer (that is, how it can neutralize added acid or base).
5. Glutathione (γ-glutamylcysteinylglycine) is a tripeptide found in all cells of higher animals. It contains glutamic acidjoined in an unusual peptide linkage involving the carboxyl group of the R group (known as γ-carboxyl group), ratherthan the usual carboxyl group (the α-carboxyl group). Draw the structure of glutathione.
6. Draw the structure of the pentapeptide whose sequence is arg-his-gly-leu-asp. Identify which of the amino acids have Rgroups that can donate or gain hydrogen ions.
7. Bradykinin is a peptide hormone composed of nine amino acids that lowers blood pressure. Its primary structure is arg-pro-pro-gly-phe-ser-pro-phe-arg. Would you expect bradykinin to be positively charged, negatively charged, or neutralat a pH of 6.0? Justify your answer.
8. One of the neurotransmitters involved in pain sensation is a peptide called substance P, which is composed of 11 aminoacids and is released by nerve-cell terminals in response to pain. Its primary structure is arg-pro-lys-pro-gln-gln-phe-phe-gly-leu-met. Would you expect this peptide to be positively charged, negatively charged, or neutral at a pH of 6.0?Justify your answer.
9. Carbohydrates are incorporated into glycoproteins. Would you expect the incorporation of sugar units to increase ordecrease the solubility of a protein? Justify your answer.
10. Some proteins have phosphate groups attached through an ester linkage to the OH groups of serine, threonine, ortyrosine residues to form phosphoproteins. Would you expect the incorporation of a phosphate group to increase ordecrease the solubility of a protein? Justify your answer.
11. Refer to Table 18.5 and determine how each enzyme would be classified.
a. the enzyme that catalyzes the conversion of ethanol to acetaldehydeb. the enzyme that catalyzes the breakdown of glucose 6-phosphate to glucose and inorganic phosphate ion (water is
also a reactant in this reaction)
12. Refer to Table 18.5 and determine how each enzyme would be classified.
a. the enzyme that catalyzes the removal of a carboxyl group from pyruvate to form acetate
b. the enzyme that catalyzes the rearrangement of 3-phosphoglycerate to form 2-phosphoglycerate
2 2

4.12.2 1/9/2022 https://chem.libretexts.org/@go/page/178787
13. The enzyme lysozyme has an aspartic acid residue in the active site. In acidic solution, the enzyme is inactive, butactivity increases as the pH rises to around 6. Explain why.
14. The enzyme lysozyme has a glutamic acid residue in the active site. At neutral pH (6–7), the enzyme is active, butactivity decreases as the pH rises. Explain why.
15. The activity of a purified enzyme is measured at a substrate concentration of 1.0 μM and found to convert 49 μmol ofsubstrate to product in 1 min. The activity is measured at 2.0 μM substrate and found to convert 98 μmol of substrate toproduct/minute.
a. When the substrate concentration is 100 μM, how much substrate would you predict is converted to product in 1min? What if the substrate concentration were increased to 1,000 μM (1.0 mM)?
b. The activities actually measured are 676 μmol product formed/minute at a substrate concentration of 100 μM and698 μmol product formed/minute at 1,000 μM (1.0 mM) substrate. Is there any discrepancy between these valuesand those you predicted in Exercise 15a? Explain.
16. A patient has a fever of 39°C. Would you expect the activity of enzymes in the body to increase or decrease relative totheir activity at normal body temperature (37°C)?
17. Using your knowledge of factors that influence enzyme activity, describe what happens when milk is pasteurized.
Answers
1.
This amino acid would not be found in proteins because it is not an α-amino acid.

4.12.3 1/9/2022 https://chem.libretexts.org/@go/page/178787
3.
5.
7. Bradykinin would be positively charged; all of the amino acids, except for arginine, have R groups that do not becomeeither positively or negatively charged. The two arginines are R groups that are positively charged at neutral pH, so thepeptide would have an overall positive charge.
9. Carbohydrates have many OH groups attached, which can engage in hydrogen bonding with water, which increases thesolubility of the proteins.
a. 11. oxidoreductaseb. hydrolase
13. The enzyme is active when the carboxyl group in the R group of aspartic acid does not have the hydrogen attached(forming COO ); the hydrogen is removed when the pH of the solution is around pH 6 or higher.
a. 15. at 100 μM, you would predict that the rate would increase 100 times to 4,900 μmol of substrate to product in 1 min;at 1.0 mM, you would predict an increase to 49,000 μmol of substrate to product in 1 min.
b. There is a great discrepancy between the predicted rates and actual rates; this occurs because the enzyme becomessaturated with substrate, preventing a further increase in the rate of the reaction (the reaction is no longer linear withrespect to substrate concentration because it is at very low concentrations).
17. When milk is pasteurized, it is heated to high temperatures. These high temperatures denature the proteins in bacteria,so they cannot carry out needed functions to grow and multiply.
–

1 1/10/2022
CHAPTER OVERVIEW5: NUCLEIC ACIDS
5.1: PRELUDE TO NUCLEIC ACIDSIn the 1970s, an intense research effort began that eventually led to the production of genetically engineered human insulin—the firstgenetically engineered product to be approved for medical use. To accomplish this feat, researchers first had to determine how insulinis made in the body and then find a way of causing the same process to occur in nonhuman organisms, such as bacteria or yeast cells.Many aspects of these discoveries are presented in this chapter on nucleic acids.
5.2: NUCLEOTIDESNucleotides are composed of phosphoric acid, a pentose sugar (ribose or deoxyribose), and a nitrogen-containing base (adenine,cytosine, guanine, thymine, or uracil). Ribonucleotides contain ribose, while deoxyribonucleotides contain deoxyribose.
5.3: NUCLEIC ACID STRUCTUREDNA is the nucleic acid that stores genetic information. RNA is the nucleic acid responsible for using the genetic information in DNAto produce proteins. Nucleotides are joined together to form nucleic acids through the phosphate group of one nucleotide connectingin an ester linkage to the OH group on the third carbon atom of the sugar unit of a second nucleotide. Nucleic acid sequences arewritten starting with the nucleotide having a free phosphate group (the 5′ end).
5.4: REPLICATION AND EXPRESSION OF GENETIC INFORMATIONIn DNA replication, each strand of the original DNA serves as a template for the synthesis of a complementary strand. DNApolymerase is the primary enzyme needed for replication. In transcription, a segment of DNA serves as a template for the synthesis ofan RNA sequence. RNA polymerase is the primary enzyme needed for transcription. Three types of RNA are formed duringtranscription: mRNA, rRNA, and tRNA.
5.5: PROTEIN SYNTHESIS AND THE GENETIC CODEIn translation, the information in mRNA directs the order of amino acids in protein synthesis. A set of three nucleotides (codon) codesfor a specific amino acid.
5.6: MUTATIONS AND GENETIC DISEASESThe nucleotide sequence in DNA may be modified either spontaneously or from exposure to heat, radiation, or certain chemicals andcan lead to mutations. Mutagens are the chemical or physical agents that cause mutations. Genetic diseases are hereditary diseasesthat occur because of a mutation in a critical gene.
5.7: VIRUSESViruses are very small infectious agents that contain either DNA or RNA as their genetic material. The human immunodeficiencyvirus (HIV) causes acquired immunodeficiency syndrome (AIDS).
5.8: NUCLEIC ACIDS (SUMMARY)To ensure that you understand the material in this chapter, you should review the meanings of the bold terms in the followingsummary and ask yourself how they relate to the topics in the chapter.
5.9: NUCLEIC ACIDS (EXERCISES)Problems and select solutions for the chapter.

5.1.1 1/2/2022 https://chem.libretexts.org/@go/page/178789
5.1: Prelude to Nucleic AcidsFollowing the initial isolation of insulin in 1921, diabetic patients could be treated with insulin obtained from thepancreases of cattle and pigs. Unfortunately, some patients developed an allergic reaction to this insulin because its aminoacid sequence was not identical to that of human insulin. In the 1970s, an intense research effort began that eventually ledto the production of genetically engineered human insulin—the first genetically engineered product to be approved formedical use. To accomplish this feat, researchers first had to determine how insulin is made in the body and then find away of causing the same process to occur in nonhuman organisms, such as bacteria or yeast cells. Many aspects of thesediscoveries are presented in this chapter on nucleic acids.
Figure : A vial of insulin. It has been given a trade name, Actrapid, by the manufacturer. Image used with permission(Public Domain; Mr Hyde).
5.1.1

5.2.1 12/5/2021 https://chem.libretexts.org/@go/page/178790
5.2: NucleotidesLearning Objectives
To identify the different molecules that combine to form nucleotides.
The repeating, or monomer, units that are linked together to form nucleic acids are known as nucleotides. Thedeoxyribonucleic acid (DNA) of a typical mammalian cell contains about 3 × 10 nucleotides. Nucleotides can be furtherbroken down to phosphoric acid (H PO ), a pentose sugar (a sugar with five carbon atoms), and a nitrogenous base (a basecontaining nitrogen atoms).
If the pentose sugar is ribose, the nucleotide is more specifically referred to as a ribonucleotide, and the resulting nucleicacid is ribonucleic acid (RNA). If the sugar is 2-deoxyribose, the nucleotide is a deoxyribonucleotide, and the nucleic acidis DNA.
The nitrogenous bases found in nucleotides are classified as pyrimidines or purines. Pyrimidines are heterocyclic amineswith two nitrogen atoms in a six-member ring and include uracil, thymine, and cytosine. Purines are heterocyclic aminesconsisting of a pyrimidine ring fused to a five-member ring with two nitrogen atoms. Adenine and guanine are the majorpurines found in nucleic acids (Figure ).
Figure The Nitrogenous Bases Found in DNA and RNA
The formation of a bond between C1′ of the pentose sugar and N1 of the pyrimidine base or N9 of the purine base joins thepentose sugar to the nitrogenous base. In the formation of this bond, a molecule of water is removed. Table summarizes the similarities and differences in the composition of nucleotides in DNA and RNA.
The numbering convention is that primed numbers designate the atoms of the pentose ring, and unprimed numbersdesignate the atoms of the purine or pyrimidine ring.
9
3 4
nucleic acids nucleotides P +nitrogen base +pentose sugar− →−−−−−−−can be broken
down into− →−−−−−−−can be broken
down intoH3 O4 (5.2.1)
5.2.1
5.2.1
5.2.1

5.2.2 12/5/2021 https://chem.libretexts.org/@go/page/178790
Table : Composition of Nucleotides in DNA and RNAComposition DNA RNA
purine bases adenine and guanine adenine and guanine
pyrimidine bases cytosine and thymine cytosine and uracil
pentose sugar 2-deoxyribose ribose
inorganic acid phosphoric acid (H PO ) H PO
The names and structures of the major ribonucleotides and one of the deoxyribonucleotides are given in Figure .
Figure : The Pyrimidine and Purine Nucleotides
Apart from being the monomer units of DNA and RNA, the nucleotides and some of their derivatives have other functionsas well. Adenosine diphosphate (ADP) and adenosine triphosphate (ATP), shown in Figure , have a role in cellmetabolism. Moreover, a number of coenzymes, including flavin adenine dinucleotide (FAD), nicotinamide adeninedinucleotide (NAD ), and coenzyme A, contain adenine nucleotides as structural components.
5.2.1
3 4 3 4
5.2.2
5.2.2
5.2.3
+

5.2.3 12/5/2021 https://chem.libretexts.org/@go/page/178790
Figure : Structures of Two Important Adenine-Containing Nucleotides
SummaryNucleotides are composed of phosphoric acid, a pentose sugar (ribose or deoxyribose), and a nitrogen-containing base(adenine, cytosine, guanine, thymine, or uracil). Ribonucleotides contain ribose, while deoxyribonucleotides containdeoxyribose.
Concept Review Exercises
1. Identify the three molecules needed to form the nucleotides in each nucleic acid.
a. DNAb. RNA
2. Classify each compound as a pentose sugar, a purine, or a pyrimidine.
a. adenineb. guaninec. deoxyribosed. thyminee. ribosef. cytosine
Answersa. 1. nitrogenous base (adenine, guanine, cytosine, and thymine), 2-deoxyribose, and H POb. nitrogenous base (adenine, guanine, cytosine, and uracil), ribose, and H POa. 2. purineb. purinec. pentose sugard. pyrimidinee. pentose sugarf. pyrimidine
Exercises1. What is the sugar unit in each nucleic acid?
a. RNAb. DNA
2. Identify the major nitrogenous bases in each nucleic acid.
a. DNAb. RNA
3. For each structure, circle the sugar unit and identify the nucleotide as a ribonucleotide or a deoxyribonucleotide.
5.2.3
3 4
3 4

5.2.4 12/5/2021 https://chem.libretexts.org/@go/page/178790
a.
b.
4. For each structure, circle the sugar unit and identify the nucleotide as a ribonucleotide or a deoxyribonucleotide.
a.
b.
5. For each structure, circle the nitrogenous base and identify it as a purine or pyrimidine.
a.

5.2.5 12/5/2021 https://chem.libretexts.org/@go/page/178790
b.
6. For each structure, circle the nitrogenous base and identify it as a purine or pyrimidine.
a.
b.
Answersa. 1. riboseb. deoxyribose
3. a.
b.

5.2.6 12/5/2021 https://chem.libretexts.org/@go/page/178790
a.
b.

5.3.1 12/12/2021 https://chem.libretexts.org/@go/page/178791
5.3: Nucleic Acid StructureLearning Objectives
Identify the two types of nucleic acids and the function of each type.Describe how nucleotides are linked together to form nucleic acids.Describe the secondary structure of DNA and the importance of complementary base pairing.
Nucleic acids are large polymers formed by linking nucleotides together and are found in every cell. Deoxyribonucleicacid (DNA) is the nucleic acid that stores genetic information. If all the DNA in a typical mammalian cell were stretchedout end to end, it would extend more than 2 m. Ribonucleic acid (RNA) is the nucleic acid responsible for using thegenetic information encoded in DNA to produce the thousands of proteins found in living organisms.
Primary Structure of Nucleic Acids
Nucleotides are joined together through the phosphate group of one nucleotide connecting in an ester linkage to the OHgroup on the third carbon atom of the sugar unit of a second nucleotide. This unit joins to a third nucleotide, and theprocess is repeated to produce a long nucleic acid chain (Figure ). The backbone of the chain consists of alternatingphosphate and sugar units (2-deoxyribose in DNA and ribose in RNA). The purine and pyrimidine bases branch off thisbackbone.
Each phosphate group has one acidic hydrogen atom that is ionized atphysiological pH. This is why these compounds are known as nucleic acids.
Figure Structure of a Segment of DNA. A similar segment of RNA would have OH groups on each C2′, and uracilwould replace thymine.
Like proteins, nucleic acids have a primary structure that is defined as the sequence of their nucleotides. Unlike proteins,which have 20 different kinds of amino acids, there are only 4 different kinds of nucleotides in nucleic acids. For aminoacid sequences in proteins, the convention is to write the amino acids in order starting with the N-terminal amino acid. Inwriting nucleotide sequences for nucleic acids, the convention is to write the nucleotides (usually using the one-letterabbreviations for the bases, shown in Figure ) starting with the nucleotide having a free phosphate group, which isknown as the 5′ end, and indicate the nucleotides in order. For DNA, a lowercase d is often written in front of the sequenceto indicate that the monomers are deoxyribonucleotides. The final nucleotide has a free OH group on the 3′ carbon atom
5.3.1
5.3.1
5.3.1

5.3.2 12/12/2021 https://chem.libretexts.org/@go/page/178791
and is called the 3′ end. The sequence of nucleotides in the DNA segment shown in Figure would be written 5′-dG-dT-dA-dC-3′, which is often further abbreviated to dGTAC or just GTAC.
Secondary Structure of DNA
The three-dimensional structure of DNA was the subject of an intensive research effort in the late 1940s to early 1950s.Initial work revealed that the polymer had a regular repeating structure. In 1950, Erwin Chargaff of Columbia Universityshowed that the molar amount of adenine (A) in DNA was always equal to that of thymine (T). Similarly, he showed thatthe molar amount of guanine (G) was the same as that of cytosine (C). Chargaff drew no conclusions from his work, butothers soon did.
At Cambridge University in 1953, James D. Watson and Francis Crick announced that they had a model for the secondarystructure of DNA. Using the information from Chargaff’s experiments (as well as other experiments) and data from the Xray studies of Rosalind Franklin (which involved sophisticated chemistry, physics, and mathematics), Watson and Crickworked with models that were not unlike a child’s construction set and finally concluded that DNA is composed of twonucleic acid chains running antiparallel to one another—that is, side-by-side with the 5′ end of one chain next to the 3′ endof the other. Moreover, as their model showed, the two chains are twisted to form a double helix—a structure that can becompared to a spiral staircase, with the phosphate and sugar groups (the backbone of the nucleic acid polymer)representing the outside edges of the staircase. The purine and pyrimidine bases face the inside of the helix, with guaninealways opposite cytosine and adenine always opposite thymine. These specific base pairs, referred to as complementarybases, are the steps, or treads, in our staircase analogy (Figure ).
Figure DNA Double Helix. (a) This represents a computer-generated model of the DNA double helix. (b) Thisrepresents a schematic representation of the double helix, showing the complementary bases.
The structure proposed by Watson and Crick provided clues to the mechanisms by which cells are able to divide into twoidentical, functioning daughter cells; how genetic data are passed to new generations; and even how proteins are built torequired specifications. All these abilities depend on the pairing of complementary bases. Figure shows the two setsof base pairs and illustrates two things. First, a pyrimidine is paired with a purine in each case, so that the long dimensionsof both pairs are identical (1.08 nm).
5.3.1
5.3.2
5.3.2
5.3.3

5.3.3 12/12/2021 https://chem.libretexts.org/@go/page/178791
Figure Complementary Base Pairing. Complementary bases engage in hydrogen bonding with one another: (a)thymine and adenine; (b) cytosine and guanine.
If two pyrimidines were paired or two purines were paired, the two pyrimidines would take up less space than a purine anda pyrimidine, and the two purines would take up more space, as illustrated in Figure . If these pairings were ever tooccur, the structure of DNA would be like a staircase made with stairs of different widths. For the two strands of thedouble helix to fit neatly, a pyrimidine must always be paired with a purine. The second thing you should notice in Figure
is that the correct pairing enables formation of three instances of hydrogen bonding between guanine and cytosineand two between adenine and thymine. The additive contribution of this hydrogen bonding imparts great stability to theDNA double helix.
Figure Difference in Widths of Possible Base Pairs
Summary DNA is the nucleic acid that stores genetic information. RNA is the nucleic acid responsible for using the geneticinformation in DNA to produce proteins.Nucleotides are joined together to form nucleic acids through the phosphate group of one nucleotide connecting in anester linkage to the OH group on the third carbon atom of the sugar unit of a second nucleotide.Nucleic acid sequences are written starting with the nucleotide having a free phosphate group (the 5′ end).Two DNA strands link together in an antiparallel direction and are twisted to form a double helix. The nitrogenousbases face the inside of the helix. Guanine is always opposite cytosine, and adenine is always opposite thymine.
5.3.3
5.3.4
5.3.3
5.3.4

5.3.4 12/12/2021 https://chem.libretexts.org/@go/page/178791
Concept Review Exercises
a. 1. Name the two kinds of nucleic acids.b. Which type of nucleic acid stores genetic information in the cell?
2. What are complementary bases?
3. Why is it structurally important that a purine base always pair with a pyrimidine base in the DNA double helix?
Answers a. 1. deoxyribonucleic acid (DNA) and ribonucleic acid (RNA)b. DNA
2. the specific base pairings in the DNA double helix in which guanine is paired with cytosine and adenine is paired withthymine
3. The width of the DNA double helix is kept at a constant width, rather than narrowing (if two pyrimidines were acrossfrom each other) or widening (if two purines were across from each other).
Exercises 1. For this short RNA segment,
a. identify the 5′ end and the 3′ end of the molecule.b. circle the atoms that comprise the backbone of the nucleic acid chain.
c. write the nucleotide sequence of this RNA segment.
2. For this short DNA segment,
a. identify the 5′ end and the 3′ end of the molecule.b. circle the atoms that comprise the backbone of the nucleic acid chain.
c. write the nucleotide sequence of this DNA segment.

5.3.5 12/12/2021 https://chem.libretexts.org/@go/page/178791
3. Which nitrogenous base in DNA pairs with each nitrogenous base?
a. cytosineb. adeninec. guanined. thymine
4. Which nitrogenous base in RNA pairs with each nitrogenous base?
a. cytosineb. adeninec. guanined. thymine
5. How many hydrogen bonds can form between the two strands in the short DNA segment shown below?
5′ ATGCGACTA 3′ 3′ TACGCTGAT 5′
6. How many hydrogen bonds can form between the two strands in the short DNA segment shown below?
5′ CGATGAGCC 3′ 3′ GCTACTCGG 5′
Answers
1.

5.3.6 12/12/2021 https://chem.libretexts.org/@go/page/178791
c. ACU
a. 3. guanineb. thyminec. cytosined. adenine
5. 22 (2 between each AT base pair and 3 between each GC base pair)

5.4.1 1/5/2022 https://chem.libretexts.org/@go/page/178792
5.4: Replication and Expression of Genetic InformationLearning Objectives
Describe how a new copy of DNA is synthesized.Describe how RNA is synthesized from DNA.Identify the different types of RNA and the function of each type of RNA.
We previously stated that deoxyribonucleic acid (DNA) stores genetic information, while ribonucleic acid (RNA) isresponsible for transmitting or expressing genetic information by directing the synthesis of thousands of proteins found inliving organisms. But how do the nucleic acids perform these functions? Three processes are required: (1) replication, inwhich new copies of DNA are made; (2) transcription, in which a segment of DNA is used to produce RNA; and (3)translation, in which the information in RNA is translated into a protein sequence.
Replication
New cells are continuously forming in the body through the process of cell division. For this to happen, the DNA in adividing cell must be copied in a process known as replication. The complementary base pairing of the double helixprovides a ready model for how genetic replication occurs. If the two chains of the double helix are pulled apart, disruptingthe hydrogen bonding between base pairs, each chain can act as a template, or pattern, for the synthesis of a newcomplementary DNA chain.
The nucleus contains all the necessary enzymes, proteins, and nucleotides required for this synthesis. A short segment ofDNA is “unzipped,” so that the two strands in the segment are separated to serve as templates for new DNA. DNApolymerase, an enzyme, recognizes each base in a template strand and matches it to the complementary base in a freenucleotide. The enzyme then catalyzes the formation of an ester bond between the 5′ phosphate group of the nucleotideand the 3′ OH end of the new, growing DNA chain. In this way, each strand of the original DNA molecule is used toproduce a duplicate of its former partner (Figure ). Whatever information was encoded in the original DNA doublehelix is now contained in each replicate helix. When the cell divides, each daughter cell gets one of these replicates andthus all of the information that was originally possessed by the parent cell.
Figure : A Schematic Diagram of DNA Replication. DNA replication occurs by the sequential unzipping of segmentsof the double helix. Each new nucleotide is brought into position by DNA polymerase and is added to the growing strandby the formation of a phosphate ester bond. Thus, two double helixes form from one, and each consists of one old strandand one new strand, an outcome called semiconservative replications. (This representation is simplified; many moreproteins are involved in replication.)
5.4.1
5.4.1

5.4.2 1/5/2022 https://chem.libretexts.org/@go/page/178792
Example A segment of one strand from a DNA molecule has the sequence 5′‑TCCATGAGTTGA‑3′. What is the sequence ofnucleotides in the opposite, or complementary, DNA chain?
SOLUTION
Knowing that the two strands are antiparallel and that T base pairs with A, while C base pairs with G, the sequence ofthe complementary strand will be 3′‑AGGTACTCAACT‑5′ (can also be written as TCAACTCATGGA).
Exercise A segment of one strand from a DNA molecule has the sequence 5′‑CCAGTGAATTGCCTAT‑3′. What is the sequenceof nucleotides in the opposite, or complementary, DNA chain?
What do we mean when we say information is encoded in the DNA molecule? An organism’s DNA can be compared to abook containing directions for assembling a model airplane or for knitting a sweater. Letters of the alphabet are arrangedinto words, and these words direct the individual to perform certain operations with specific materials. If all the directionsare followed correctly, a model airplane or sweater is produced.
In DNA, the particular sequences of nucleotides along the chains encode the directions for building an organism. Just assaw means one thing in English and was means another, the sequence of bases CGT means one thing, and TGC meanssomething different. Although there are only four letters—the four nucleotides—in the genetic code of DNA, theirsequencing along the DNA strands can vary so widely that information storage is essentially unlimited.
Transcription
For the hereditary information in DNA to be useful, it must be “expressed,” that is, used to direct the growth andfunctioning of an organism. The first step in the processes that constitute DNA expression is the synthesis of RNA, by atemplate mechanism that is in many ways analogous to DNA replication. Because the RNA that is synthesized is acomplementary copy of information contained in DNA, RNA synthesis is referred to as transcription. There are three keydifferences between replication and transcription:
1. RNA molecules are much shorter than DNA molecules; only a portion of one DNA strand is copied or transcribed tomake an RNA molecule.
2. RNA is built from ribonucleotides rather than deoxyribonucleotides.3. The newly synthesized RNA strand does not remain associated with the DNA sequence it was transcribed from.
The DNA sequence that is transcribed to make RNA is called the template strand, while the complementary sequence onthe other DNA strand is called the coding or informational strand. To initiate RNA synthesis, the two DNA strands unwindat specific sites along the DNA molecule. Ribonucleotides are attracted to the uncoiling region of the DNA molecule,beginning at the 3′ end of the template strand, according to the rules of base pairing. Thymine in DNA calls for adenine inRNA, cytosine specifies guanine, guanine calls for cytosine, and adenine requires uracil. RNA polymerase—an enzyme—binds the complementary ribonucleotide and catalyzes the formation of the ester linkage between ribonucleotides, areaction very similar to that catalyzed by DNA polymerase (Figure ). Synthesis of the RNA strand takes place in the5′ to 3′ direction, antiparallel to the template strand. Only a short segment of the RNA molecule is hydrogen-bonded to thetemplate strand at any time during transcription. When transcription is completed, the RNA is released, and the DNA helixreforms. The nucleotide sequence of the RNA strand formed during transcription is identical to that of the correspondingcoding strand of the DNA, except that U replaces T.
5.4.1
5.4.1
5.4.2

5.4.3 1/5/2022 https://chem.libretexts.org/@go/page/178792
Figure : A Schematic Diagram of RNA Transcription from a DNA Template. The representation of RNA polymeraseis proportionately much smaller than the actual molecule, which encompasses about 50 nucleotides at a time.
Example A portion of the template strand of a gene has the sequence 5′‑TCCATGAGTTGA‑3′. What is the sequence ofnucleotides in the RNA that is formed from this template?
SOLUTION
Four things must be remembered in answering this question: (1) the DNA strand and the RNA strand being synthesizedare antiparallel; (2) RNA is synthesized in a 5′ to 3′ direction, so transcription begins at the 3′ end of the templatestrand; (3) ribonucleotides are used in place of deoxyribonucleotides; and (4) thymine (T) base pairs with adenine (A),A base pairs with uracil (U; in RNA), and cytosine (C) base pairs with guanine (G). The sequence is determined to be3′‑AGGUACUCAACU‑5′ (can also be written as 5′‑UCAACUCAUGGA‑3′).
Exercise
A portion of the template strand of a gene has the sequence 5′‑CCAGTGAATTGCCTAT‑3′. What is the sequence ofnucleotides in the RNA that is formed from this template?
Three types of RNA are formed during transcription: messenger RNA (mRNA), ribosomal RNA (rRNA), and transfer RNA(tRNA). These three types of RNA differ in function, size, and percentage of the total cell RNA (Table ). mRNAmakes up only a small percent of the total amount of RNA within the cell, primarily because each molecule of mRNAexists for a relatively short time; it is continuously being degraded and resynthesized. The molecular dimensions of themRNA molecule vary according to the amount of genetic information a given molecule contains. After transcription,which takes place in the nucleus, the mRNA passes into the cytoplasm, carrying the genetic message from DNA to theribosomes, the sites of protein synthesis. Elsewhere, we shall see how mRNA directly determines the sequence of aminoacids during protein synthesis.
Table : Properties of Cellular RNA in Escherichia coli
Type Function Approximate Number ofNucleotides
Percentage of Total Cell RNA
mRNA codes for proteins 100–6,000 ~3
rRNA component of ribosomes 120–2900 83
tRNA adapter molecule that brings theamino acid to the ribosome
75–90 14
Ribosomes are cellular substructures where proteins are synthesized. They contain about 65% rRNA and 35% protein, heldtogether by numerous noncovalent interactions, such as hydrogen bonding, in an overall structure consisting of two
5.4.2
5.4.2
5.4.2
5.4.1
5.4.1

5.4.4 1/5/2022 https://chem.libretexts.org/@go/page/178792
globular particles of unequal size.
Molecules of tRNA, which bring amino acids (one at a time) to the ribosomes for the construction of proteins, differ fromone another in the kinds of amino acid each is specifically designed to carry. A set of three nucleotides, known as a codon,on the mRNA determines which kind of tRNA will add its amino acid to the growing chain. Each of the 20 amino acidsfound in proteins has at least one corresponding kind of tRNA, and most amino acids have more than one.
Figure : Transfer RNA. (a) In the two-dimensional structure of a yeast tRNA molecule for phenylalanine, the aminoacid binds to the acceptor stem located at the 3′ end of the tRNA primary sequence. (The nucleotides that are notspecifically identified here are slightly altered analogs of the four common ribonucleotides A, U, C, and G.) (b) In thethree-dimensional structure of yeast phenylalanine tRNA, note that the anticodon loop is at the bottom and the acceptorstem is at the top right. (c) This shows a space-filling model of the tRNA.
The two-dimensional structure of a tRNA molecule has three distinctive loops, reminiscent of a cloverleaf (Figure ).On one loop is a sequence of three nucleotides that varies for each kind of tRNA. This triplet, called the anticodon, iscomplementary to and pairs with the codon on the mRNA. At the opposite end of the molecule is the acceptor stem, wherethe amino acid is attached.
Summary In DNA replication, each strand of the original DNA serves as a template for the synthesis of a complementary strand.DNA polymerase is the primary enzyme needed for replication.In transcription, a segment of DNA serves as a template for the synthesis of an RNA sequence.RNA polymerase is the primary enzyme needed for transcription.Three types of RNA are formed during transcription: mRNA, rRNA, and tRNA.
Concept Review Exercises 1. In DNA replication, a parent DNA molecule produces two daughter molecules. What is the fate of each strand of the
parent DNA double helix?2. What is the role of DNA in transcription? What is produced in transcription?3. Which type of RNA contains the codon? Which type of RNA contains the anticodon?
5.4.3
5.4.3

5.4.5 1/5/2022 https://chem.libretexts.org/@go/page/178792
Answers 1. Each strand of the parent DNA double helix remains associated with the newly synthesized DNA strand.2. DNA serves as a template for the synthesis of an RNA strand (the product of transcription).3. codon: mRNA; anticodon: tRNA
Exercises
1. Describe how replication and transcription are similar.
2. Describe how replication and transcription differ.
3. A portion of the coding strand for a given gene has the sequence 5′‑ATGAGCGACTTTGCGGGATTA‑3′.
a. What is the sequence of complementary template strand?b. What is the sequence of the mRNA that would be produced during transcription from this segment of DNA?
4. A portion of the coding strand for a given gene has the sequence 5′‑ATGGCAATCCTCAAACGCTGT‑3′.
a. What is the sequence of complementary template strand?b. What is the sequence of the mRNA that would be produced during transcription from this segment of DNA?
Answers 1. Both processes require a template from which a complementary strand is synthesized.
3.
a. 3′‑TACTCGCTGAAACGCCCTAAT‑5′b. 5′‑AUGAGCGACUUUGCGGGAUUA‑3′

5.5.1 1/7/2022 https://chem.libretexts.org/@go/page/178793
5.5: Protein Synthesis and the Genetic CodeLearning Objectives
describe the characteristics of the genetic code.describe how a protein is synthesized from mRNA.
One of the definitions of a gene is as follows: a segment of deoxyribonucleic acid (DNA) carrying the code for a specificpolypeptide. Each molecule of messenger RNA (mRNA) is a transcribed copy of a gene that is used by a cell forsynthesizing a polypeptide chain. If a protein contains two or more different polypeptide chains, each chain is coded by adifferent gene. We turn now to the question of how the sequence of nucleotides in a molecule of ribonucleic acid (RNA) istranslated into an amino acid sequence.
How can a molecule containing just 4 different nucleotides specify the sequence of the 20 amino acids that occur inproteins? If each nucleotide coded for 1 amino acid, then obviously the nucleic acids could code for only 4 amino acids.What if amino acids were coded for by groups of 2 nucleotides? There are 4 , or 16, different combinations of 2nucleotides (AA, AU, AC, AG, UU, and so on). Such a code is more extensive but still not adequate to code for 20 aminoacids. However, if the nucleotides are arranged in groups of 3, the number of different possible combinations is 4 , or 64.Here we have a code that is extensive enough to direct the synthesis of the primary structure of a protein molecule.
Video: NDSU Virtual Cell Animations project animation "Translation". For more information, seehttp://vcell.ndsu.nodak.edu/animations
The genetic code can therefore be described as the identification of each group of three nucleotides and its particular aminoacid. The sequence of these triplet groups in the mRNA dictates the sequence of the amino acids in the protein. Eachindividual three-nucleotide coding unit, as we have seen, is called a codon.
Protein synthesis is accomplished by orderly interactions between mRNA and the other ribonucleic acids (transfer RNA[tRNA] and ribosomal RNA [rRNA]), the ribosome, and more than 100 enzymes. The mRNA formed in the nucleusduring transcription is transported across the nuclear membrane into the cytoplasm to the ribosomes—carrying with it thegenetic instructions. The process in which the information encoded in the mRNA is used to direct the sequencing of aminoacids and thus ultimately to synthesize a protein is referred to as translation.
Figure : Binding of an Amino Acid to Its tRNA
2
3
TranslationTranslation
5.5.1

5.5.2 1/7/2022 https://chem.libretexts.org/@go/page/178793
Before an amino acid can be incorporated into a polypeptide chain, it must be attached to its unique tRNA. This crucialprocess requires an enzyme known as aminoacyl-tRNA synthetase (Figure ). There is a specific aminoacyl-tRNAsynthetase for each amino acid. This high degree of specificity is vital to the incorporation of the correct amino acid into aprotein. After the amino acid molecule has been bound to its tRNA carrier, protein synthesis can take place. Figure depicts a schematic stepwise representation of this all-important process.
Figure : The Elongation Steps in Protein Synthesis
Early experimenters were faced with the task of determining which of the 64 possible codons stood for each of the 20amino acids. The cracking of the genetic code was the joint accomplishment of several well-known geneticists—notablyHar Khorana, Marshall Nirenberg, Philip Leder, and Severo Ochoa—from 1961 to 1964. The genetic dictionary theycompiled, summarized in Figure , shows that 61 codons code for amino acids, and 3 codons serve as signals for thetermination of polypeptide synthesis (much like the period at the end of a sentence). Notice that only methionine (AUG)and tryptophan (UGG) have single codons. All other amino acids have two or more codons.
5.5.1
5.5.2
5.5.2
5.5.3

5.5.3 1/7/2022 https://chem.libretexts.org/@go/page/178793
Figure : The Genetic Code
Example : Using the Genetic CodeA portion of an mRNA molecule has the sequence 5′‑AUGCCACGAGUUGAC‑3′. What amino acid sequence doesthis code for?
SOLUTION
Use Figure to determine what amino acid each set of three nucleotides (codon) codes for. Remember that thesequence is read starting from the 5′ end and that a protein is synthesized starting with the N-terminal amino acid. Thesequence 5′‑AUGCCACGAGUUGAC‑3′ codes for met-pro-arg-val-asp.
Exercise
A portion of an RNA molecule has the sequence 5′‑AUGCUGAAUUGCGUAGGA‑3′. What amino acid sequence doesthis code for?
Further experimentation threw much light on the nature of the genetic code, as follows:
1. The code is virtually universal; animal, plant, and bacterial cells use the same codons to specify each amino acid (witha few exceptions).
2. The code is “degenerate”; in all but two cases (methionine and tryptophan), more than one triplet codes for a givenamino acid.
3. The first two bases of each codon are most significant; the third base often varies. This suggests that a change in thethird base by a mutation may still permit the correct incorporation of a given amino acid into a protein. The third baseis sometimes called the “wobble” base.
4. The code is continuous and nonoverlapping; there are no nucleotides between codons, and adjacent codons do notoverlap.
5. The three termination codons are read by special proteins called release factors, which signal the end of the translationprocess.
6. The codon AUG codes for methionine and is also the initiation codon. Thus methionine is the first amino acid in eachnewly synthesized polypeptide. This first amino acid is usually removed enzymatically before the polypeptide chain iscompleted; the vast majority of polypeptides do not begin with methionine.
Summary In translation, the information in mRNA directs the order of amino acids in protein synthesis. A set of three nucleotides(codon) codes for a specific amino acid.
5.5.3
5.5.1
5.5.3
5.5.4

5.5.4 1/7/2022 https://chem.libretexts.org/@go/page/178793
Concept Review Exercises 1. What are the roles of mRNA and tRNA in protein synthesis?2. What is the initiation codon?3. What are the termination codons and how are they recognized?
Answers 1. mRNA provides the code that determines the order of amino acids in the protein; tRNA transports the amino acids to
the ribosome to incorporate into the growing protein chain.2. AUG3. UAA, UAG, and UGA; they are recognized by special proteins called release factors, which signal the end of the
translation process.
Exercises
1. Write the anticodon on tRNA that would pair with each mRNA codon.
a. 5′‑UUU‑3′b. 5′‑CAU‑3′c. 5′‑AGC‑3′d. 5′‑CCG‑3′
2. Write the codon on mRNA that would pair with each tRNA anticodon.
a. 5′‑UUG‑3′b. 5′‑GAA‑3′c. 5′‑UCC‑3′d. 5′‑CAC‑3′
3. The peptide hormone oxytocin contains 9 amino acid units. What is the minimum number of nucleotides needed tocode for this peptide?
4. Myoglobin, a protein that stores oxygen in muscle cells, has been purified from a number of organisms. The proteinfrom a sperm whale is composed of 153 amino acid units. What is the minimum number of nucleotides that must bepresent in the mRNA that codes for this protein?
5. Use Figure to identify the amino acids carried by each tRNA molecule in Exercise 1.
6. Use Figure to identify the amino acids carried by each tRNA molecule in Exercise 2.
7. Use Figure to determine the amino acid sequence produced from this mRNA sequence:5′‑AUGAGCGACUUUGCGGGAUUA‑3′.
8. Use Figure to determine the amino acid sequence produced from this mRNA sequence:5′‑AUGGCAAUCCUCAAACGCUGU‑3′
Answers a. 1. 3′‑AAA‑5′b. 3′‑GUA‑5′c. 3′‑UCG‑5′d. 3′‑GGC‑5′
3. 27 nucleotides (3 nucleotides/codon)
5. 1a: phenyalanine; 1b: histidine; 1c: serine; 1d: proline
7. met-ser-asp-phe-ala-gly-leu
5.5.3
5.5.3
5.5.3
5.5.3

5.6.1 12/19/2021 https://chem.libretexts.org/@go/page/178794
5.6: Mutations and Genetic DiseasesLearning Objectives
To describe the causes of genetic mutations and how they lead to genetic diseases.
We have seen that the sequence of nucleotides in a cell’s deoxyribonucleic acid (DNA) is what ultimately determines thesequence of amino acids in proteins made by the cell and thus is critical for the proper functioning of the cell. On rareoccasions, however, the nucleotide sequence in DNA may be modified either spontaneously (by errors during replication,occurring approximately once for every 10 billion nucleotides) or from exposure to heat, radiation, or certain chemicals.Any chemical or physical change that alters the nucleotide sequence in DNA is called a mutation. When a mutation occursin an egg or sperm cell that then produces a living organism, it will be inherited by all the offspring of that organism.
Common types of mutations include substitution (a different nucleotide is substituted), insertion (the addition of a newnucleotide), and deletion (the loss of a nucleotide). These changes within DNA are called point mutations because onlyone nucleotide is substituted, added, or deleted (Figure ). Because an insertion or deletion results in a frame-shift thatchanges the reading of subsequent codons and, therefore, alters the entire amino acid sequence that follows the mutation,insertions and deletions are usually more harmful than a substitution in which only a single amino acid is altered.
Figure : Three Types of Point Mutations
The chemical or physical agents that cause mutations are called mutagens. Examples of physical mutagens are ultraviolet(UV) and gamma radiation. Radiation exerts its mutagenic effect either directly or by creating free radicals that in turnhave mutagenic effects. Radiation and free radicals can lead to the formation of bonds between nitrogenous bases in DNA.For example, exposure to UV light can result in the formation of a covalent bond between two adjacent thymines on aDNA strand, producing a thymine dimer (Figure ). If not repaired, the dimer prevents the formation of the doublehelix at the point where it occurs. The genetic disease xeroderma pigmentosum is caused by a lack of the enzyme that cutsout the thymine dimers in damaged DNA. Individuals affected by this condition are abnormally sensitive to light and aremore prone to skin cancer than normal individuals.
5.6.1
5.6.1
5.6.2

5.6.2 12/19/2021 https://chem.libretexts.org/@go/page/178794
Figure : An Example of Radiation Damage to DNA. (a) The thymine dimer is formed by the action of UV light. (b)When a defect in the double strand is produced by the thymine dimer, this defect temporarily stops DNA replication, butthe dimer can be removed, and the region can be repaired by an enzyme repair system.
Sometimes gene mutations are beneficial, but most of them are detrimental. For example, if a point mutation occurs at acrucial position in a DNA sequence, the affected protein will lack biological activity, perhaps resulting in the death of acell. In such cases the altered DNA sequence is lost and will not be copied into daughter cells. Nonlethal mutations in anegg or sperm cell may lead to metabolic abnormalities or hereditary diseases. Such diseases are called inborn errors ofmetabolism or genetic diseases. A partial listing of genetic diseases is presented in Figure , and two specific diseasesare discussed in the following sections. In most cases, the defective gene results in a failure to synthesize a particularenzyme.
Figure : Some Representative Genetic Diseases in Humans and the Protein or Enzyme ResponsibleDisease Responsible Protein or Enzyme
alkaptonuria homogentisic acid oxidase
galactosemia galactose 1-phosphate uridyl transferase, galactokinase, or UDPgalactose epimerase
Gaucher disease glucocerebrosidase
gout and Lesch-Nyhan syndrome hypoxanthine-guanine phosphoribosyl transferase
hemophilia antihemophilic factor (factor VIII) or Christmas factor (factor IX)
homocystinuria cystathionine synthetase
maple syrup urine disease branched chain α-keto acid dehydrogenase complex
McArdle syndrome muscle phosphorylase
Niemann-Pick disease sphingomyelinase
phenylketonuria (PKU) phenylalanine hydroxylase
sickle cell anemia hemoglobin
Tay-Sachs disease hexosaminidase A
tyrosinemia fumarylacetoacetate hydrolase or tyrosine aminotransferase
von Gierke disease glucose 6-phosphatase
Wilson disease Wilson disease protein
PKU results from the absence of the enzyme phenylalanine hydroxylase. Without this enzyme, a person cannot convertphenylalanine to tyrosine, which is the precursor of the neurotransmitters dopamine and norepinephrine as well as the skinpigment melanin.
5.6.2
5.6.1
5.6.1

5.6.3 12/19/2021 https://chem.libretexts.org/@go/page/178794
When this reaction cannot occur, phenylalanine accumulates and is then converted to higher than normal quantities ofphenylpyruvate. The disease acquired its name from the high levels of phenylpyruvate (a phenyl ketone) in urine.Excessive amounts of phenylpyruvate impair normal brain development, which causes severe mental retardation.
PKU may be diagnosed by assaying a sample of blood or urine for phenylalanine or one of its metabolites. Medicalauthorities recommend testing every newborn’s blood for phenylalanine within 24 h to 3 weeks after birth. If the conditionis detected, mental retardation can be prevented by immediately placing the infant on a diet containing little or nophenylalanine. Because phenylalanine is plentiful in naturally produced proteins, the low-phenylalanine diet depends on asynthetic protein substitute plus very small measured amounts of naturally produced foods. Before dietary treatment wasintroduced in the early 1960s, severe mental retardation was a common outcome for children with PKU. Prior to the 1960s,85% of patients with PKU had an intelligence quotient (IQ) less than 40, and 37% had IQ scores below 10. Since theintroduction of dietary treatments, however, over 95% of children with PKU have developed normal or near-normalintelligence. The incidence of PKU in newborns is about 1 in 12,000 in North America.
Every state in the United States has mandated that screening for PKU be providedto all newborns.
Several genetic diseases are collectively categorized as lipid-storage diseases. Lipids are constantly being synthesized andbroken down in the body, so if the enzymes that catalyze lipid degradation are missing, the lipids tend to accumulate andcause a variety of medical problems. When a genetic mutation occurs in the gene for the enzyme hexosaminidase A, forexample, gangliosides cannot be degraded but accumulate in brain tissue, causing the ganglion cells of the brain to becomegreatly enlarged and nonfunctional. This genetic disease, known as Tay-Sachs disease, leads to a regression indevelopment, dementia, paralysis, and blindness, with death usually occurring before the age of three. There is currentlyno treatment, but Tay-Sachs disease can be diagnosed in a fetus by assaying the amniotic fluid (amniocentesis) forhexosaminidase A. A blood test can identify Tay-Sachs carriers—people who inherit a defective gene from only one ratherthan both parents—because they produce only half the normal amount of hexosaminidase A, although they do not exhibitsymptoms of the disease.
Looking Closer: Recombinant DNA Technology
More than 3,000 human diseases have been shown to have a genetic component, caused or in some way modulated by theperson’s genetic composition. Moreover, in the last decade or so, researchers have succeeded in identifying many of thegenes and even mutations that are responsible for specific genetic diseases. Now scientists have found ways of identifyingand isolating genes that have specific biological functions and placing those genes in another organism, such as abacterium, which can be easily grown in culture. With these techniques, known as recombinant DNA technology, theability to cure many serious genetic diseases appears to be within our grasp.
Isolating the specific gene or genes that cause a particular genetic disease is a monumental task. One reason for thedifficulty is the enormous amount of a cell’s DNA, only a minute portion of which contains the gene sequence. Thus, thefirst task is to obtain smaller pieces of DNA that can be more easily handled. Fortunately, researchers are able to userestriction enzymes (also known as restriction endonucleases), discovered in 1970, which are enzymes that cut DNA atspecific, known nucleotide sequences, yielding DNA fragments of shorter length. For example, the restriction enzymeEcoRI recognizes the nucleotide sequence shown here and cuts both DNA strands as indicated:

5.6.4 12/19/2021 https://chem.libretexts.org/@go/page/178794
Once a DNA strand has been fragmented, it must be cloned; that is, multiple identical copies of each DNA fragment areproduced to make sure there are sufficient amounts of each to detect and manipulate in the laboratory. Cloning isaccomplished by inserting the individual DNA fragments into phages (bacterial viruses) that can enter bacterial cells andbe replicated. When a bacterial cell infected by the modified phage is placed in an appropriate culture medium, it forms acolony of cells, all containing copies of the original DNA fragment. This technique is used to produce many bacterialcolonies, each containing a different DNA fragment. The result is a DNA library, a collection of bacterial colonies thattogether contain the entire genome of a particular organism.
The next task is to screen the DNA library to determine which bacterial colony (or colonies) has incorporated the DNAfragment containing the desired gene. A short piece of DNA, known as a hybridization probe, which has a nucleotidesequence complementary to a known sequence in the gene, is synthesized, and a radioactive phosphate group is added to itas a “tag.” You might be wondering how researchers are able to prepare such a probe if the gene has not yet been isolated.One way is to use a segment of the desired gene isolated from another organism. An alternative method depends onknowing all or part of the amino acid sequence of the protein produced by the gene of interest: the amino acid sequence isused to produce an approximate genetic code for the gene, and this nucleotide sequence is then produced synthetically.(The amino acid sequence used is carefully chosen to include, if possible, many amino acids such as methionine andtryptophan, which have only a single codon each.)
After a probe identifies a colony containing the desired gene, the DNA fragment is clipped out, again using restrictionenzymes, and spliced into another replicating entity, usually a plasmid. Plasmids are tiny mini-chromosomes found inmany bacteria, such as Escherichia coli (E. coli). A recombined plasmid would then be inserted into the host organism(usually the bacterium E. coli), where it would go to work to produce the desired protein.

5.6.5 12/19/2021 https://chem.libretexts.org/@go/page/178794
Proponents of recombinant DNA research are excited about its great potential benefits. An example is the production ofhuman growth hormone, which is used to treat children who fail to grow properly. Formerly, human growth hormone wasavailable only in tiny amounts obtained from cadavers. Now it is readily available through recombinant DNA technology.Another gene that has been cloned is the gene for epidermal growth factor, which stimulates the growth of skin cells andcan be used to speed the healing of burns and other skin wounds. Recombinant techniques are also a powerful researchtool, providing enormous aid to scientists as they map and sequence genes and determine the functions of differentsegments of an organism’s DNA.
In addition to advancements in the ongoing treatment of genetic diseases, recombinant DNA technology may actually leadto cures. When appropriate genes are successfully inserted into E. coli, the bacteria can become miniature pharmaceuticalfactories, producing great quantities of insulin for people with diabetes, clotting factor for people with hemophilia, missingenzymes, hormones, vitamins, antibodies, vaccines, and so on. Recent accomplishments include the production in E. coliof recombinant DNA molecules containing synthetic genes for tissue plasminogen activator, a clot-dissolving enzyme thatcan rescue heart attack victims, as well as the production of vaccines against hepatitis B (humans) and hoof-and-mouthdisease (cattle).
Scientists have used other bacteria besides E. coli in gene-splicing experiments and also yeast and fungi. Plant molecularbiologists use a bacterial plasmid to introduce genes for several foreign proteins (including animal proteins) into plants.The bacterium is Agrobacterium tumefaciens, which can cause tumors in many plants, but which can be treated so that itstumor-causing ability is eliminated. One practical application of its plasmids would be to enhance a plant’s nutritionalvalue by transferring into it the gene necessary for the synthesis of an amino acid in which the plant is normally deficient(for example, transferring the gene for methionine synthesis into pinto beans, which normally do not synthesize high levelsof methionine).
Restriction enzymes have been isolated from a number of bacteria and are named after the bacterium of origin. EcoRI isa restriction enzyme obtained from the R strain of E. coli. The roman numeral I indicates that it was the first restrictionenzyme obtained from this strain of bacteria.
Summary The nucleotide sequence in DNA may be modified either spontaneously or from exposure to heat, radiation, or certainchemicals and can lead to mutations.Mutagens are the chemical or physical agents that cause mutations.Genetic diseases are hereditary diseases that occur because of a mutation in a critical gene.
Concept Review Exercises
a. 1. What effect can UV radiation have on DNA?b. Is UV radiation an example of a physical mutagen or a chemical mutagen?
a. 2. What causes PKU?b. How is PKU detected and treated?
Answers
a. 1. It can lead to the formation of a covalent bond between two adjacent thymines on a DNA strand, producing athymine dimer.
b. physical mutagen
a. 2. the absence of the enzyme phenylalanine hydroxylaseb. PKU is diagnosed by assaying a sample of blood or urine for phenylalanine or one of its metabolites; treatment calls
for an individual to be placed on a diet containing little or no phenylalanine.
Exercises
1. A portion of the coding strand of a gene was found to have the sequence 5′‑ATGAGCGACTTTCGCCCATTA‑3′. Amutation occurred in the gene, making the sequence 5′‑ATGAGCGACCTTCGCCCATTA‑3′.

5.6.6 12/19/2021 https://chem.libretexts.org/@go/page/178794
a. Identify the mutation as a substitution, an insertion, or a deletion.b. What effect would the mutation have on the amino acid sequence of the protein obtained from this mutated gene
(use Figure 19.14)?
2. A portion of the coding strand of a gene was found to have the sequence 5′‑ATGGCAATCCTCAAACGCTGT‑3′. Amutation occurred in the gene, making the sequence 5′‑ATGGCAATCCTCAACGCTGT‑3′.
a. Identify the mutation as a substitution, an insertion, or a deletion.b. What effect would the mutation have on the amino acid sequence of the protein obtained from this mutated gene
(use Figure 19.14)?
a. 3. What is a mutagen?b. Give two examples of mutagens.
4. For each genetic disease, indicate which enzyme is lacking or defective and the characteristic symptoms of the disease.
a. PKUb. Tay-Sachs disease
Answers
a. 1. substitutionb. Phenylalanine (UUU) would be replaced with leucine (CUU).
a. 3. a chemical or physical agent that can cause a mutationb. UV radiation and gamma radiation (answers will vary)

5.7.1 12/19/2021 https://chem.libretexts.org/@go/page/178795
5.7: VirusesLearning Objectives
To explain how viruses reproduce in cells.
Viruses are visible only under an electron microscope. They come in a variety of shapes, ranging from spherical to rodshaped. The fact that they contain either deoxyribonucleic acid (DNA) or ribonucleic acid (RNA)—but never both—allows them to be divided into two major classes: DNA viruses and RNA viruses (Figure ).
Figure : Viruses. Viruses come in a variety of shapes that are determined by their protein coats.
Most RNA viruses use their nucleic acids in much the same way as the DNA viruses, penetrating a host cell and inducing itto replicate the viral RNA and synthesize viral proteins. The new RNA strands and viral proteins are then assembled intonew viruses. Some RNA viruses, however, called retroviruses (Figure ), synthesize DNA in the host cell, in a processthat is the reverse of the DNA-to-RNA transcription that normally occurs in cells. The synthesis of DNA from an RNAtemplate is catalyzed by the enzyme reverse transcriptase.
Figure : Life Cycle of a Retrovirus
In 1987, azidothymidine (AZT, also known as zidovudine or the brand name Retrovir) became the first drug approved forthe treatment of AIDS. It works by binding to reverse transcriptase in place of deoxythymidine triphosphate, after which,because AZT does not have a 3′OH group, further replication is blocked. In the past 10 years, several other drugs havebeen approved that also act by inhibiting the viral reverse transcriptase.
5.7.1
5.7.1
5.7.2
5.7.2

5.7.2 12/19/2021 https://chem.libretexts.org/@go/page/178795
Raltegravir (Isentress) is a newer anti-AIDS drug that was approved by the FDA in October 2007. This drug inhibits theintegrase enzyme that is needed to integrate the HIV DNA into cellular DNA, an essential step in the production of moreHIV particles.
A major problem in treating HIV infections is that the virus can become resistant to any of these drugs. One way to combatthe problem has been to administer a “cocktail” of drugs, typically a combination of two reverse transcriptase inhibitorsalong with a protease inhibitor. These treatments can significantly reduce the amount of HIV in an infected person.
Career Focus: Genetics CounselorA genetics counselor works with individuals and families who have birth defects or genetic disorders or a family historyof a disease, such as cancer, with a genetic link. A genetics counselor may work in a variety of health-care settings(such as a hospital) to obtain family medical and reproductive histories; explain how genetic conditions are inherited;explain the causes, diagnosis, and care of these conditions; interpret the results of genetic tests; and aid the individual orfamily in making decisions regarding genetic diseases or conditions. A certified genetics counselor must obtain amaster’s degree from an accredited program. Applicants to these graduate programs usually have an undergraduatedegree in biology, psychology, or genetics.
Photo courtesy of the United States National Institutes for Health,http://commons.wikimedia.org/wiki/File:Geneticcounseling.jpg.
Summary
Viruses are very small infectious agents that contain either DNA or RNA as their genetic material. The humanimmunodeficiency virus (HIV) causes acquired immunodeficiency syndrome (AIDS).
Questions 1. Describe the general structure of a virus.2. How does a DNA virus differ from an RNA virus?3. Why is HIV known as a retrovirus?
4. Describe how a DNA virus invades and destroys a cell.
a. 5. Describe how an RNA virus invades and destroys a cell.

5.7.3 12/19/2021 https://chem.libretexts.org/@go/page/178795
b. How does this differ from a DNA virus?
6. What HIV enzyme does AZT inhibit?
7. What HIV enzyme does raltegravir inhibit?
Answers 1. A virus consists of a central core of nucleic acid enclosed in a protective shell of proteins. There may be lipid or
carbohydrate molecules on the surface.2. A DNA virus has DNA as its genetic material, while an RNA virus has RNA as its genetic material.3. In a cell, a retrovirus synthesizes a DNA copy of its RNA genetic material.4. The DNA virus enters a host cell and induces the cell to replicate the viral DNA and produce viral proteins. These
proteins and DNA assemble into new viruses that are released by the host cell, which may die in the process.5. -6. reverse transcriptase7. -

5.8.1 1/10/2022 https://chem.libretexts.org/@go/page/178796
5.8: Nucleic Acids (Summary)To ensure that you understand the material in this chapter, you should review the meanings of the bold terms in the
following summary and ask yourself how they relate to the topics in the chapter.
A cell’s hereditary information is encoded in chromosomes in the cell’s nucleus. Each chromosome is composed ofproteins and deoxyribonucleic acid (DNA). The chromosomes contain smaller hereditary units called genes, which arerelatively short segments of DNA. The hereditary information is expressed or used through the synthesis of ribonucleicacid (RNA). Both nucleic acids—DNA and RNA—are polymers composed of monomers known as nucleotides, which inturn consist of phosphoric acid (H PO ), a nitrogenous base, and a pentose sugar.
The two types of nitrogenous bases most important in nucleic acids are purines—adenine (A) and guanine (G)—andpyrimidines—cytosine (C), thymine (T), and uracil (U). DNA contains the nitrogenous bases adenine, cytosine, guanine,and thymine, while the bases in RNA are adenine, cytosine, guanine, and uracil. The sugar in the nucleotides of RNA isribose; the one in DNA is 2-deoxyribose. The sequence of nucleotides in a nucleic acid defines the primary structure of themolecule.
RNA is a single-chain nucleic acid, whereas DNA possesses two nucleic-acid chains intertwined in a secondary structurecalled a double helix. The sugar-phosphate backbone forms the outside the double helix, with the purine and pyrimidinebases tucked inside. Hydrogen bonding between complementary bases holds the two strands of the double helix together;A always pairs with T and C always pairs with G.
Cell growth requires replication, or reproduction of the cell’s DNA. The double helix unwinds, and hydrogen bondingbetween complementary bases breaks so that there are two single strands of DNA, and each strand is a template for thesynthesis of a new strand. For protein synthesis, three types of RNA are needed: messenger RNA (mRNA), ribosomal RNA(rRNA), and transfer RNA (tRNA). All are made from a DNA template by a process called transcription. The doublehelix uncoils, and ribonucleotides base-pair to the deoxyribonucleotides on one DNA strand; however, RNA is producedusing uracil rather than thymine. Once the RNA is formed, it dissociates from the template and leaves the nucleus, and theDNA double helix reforms.
Translation is the process in which proteins are synthesized from the information in mRNA. It occurs at structures calledribosomes, which are located outside the nucleus and are composed of rRNA and protein. The 64 possible three-nucleotide combinations of the 4 nucleotides of DNA constitute the genetic code that dictates the sequence in whichamino acids are joined to make proteins. Each three-nucleotide sequence on mRNA is a codon. Each kind of tRNAmolecule binds a specific amino acid and has a site containing a three-nucleotide sequence called an anticodon.
The general term for any change in the genetic code in an organism’s DNA is mutation. A change in which a single baseis substituted, inserted, or deleted is a point mutation. The chemical and/or physical agents that cause mutations are calledmutagens. Diseases that occur due to mutations in critical DNA sequences are referred to as genetic diseases.
Viruses are infectious agents composed of a tightly packed central core of nucleic acids enclosed by a protective shell ofproteins. Viruses contain either DNA or RNA as their genetic material but not both. Some RNA viruses, calledretroviruses, synthesize DNA in the host cell from their RNA genome. The human immunodeficiency virus (HIV) causesacquired immunodeficiency syndrome (AIDS).
3 4
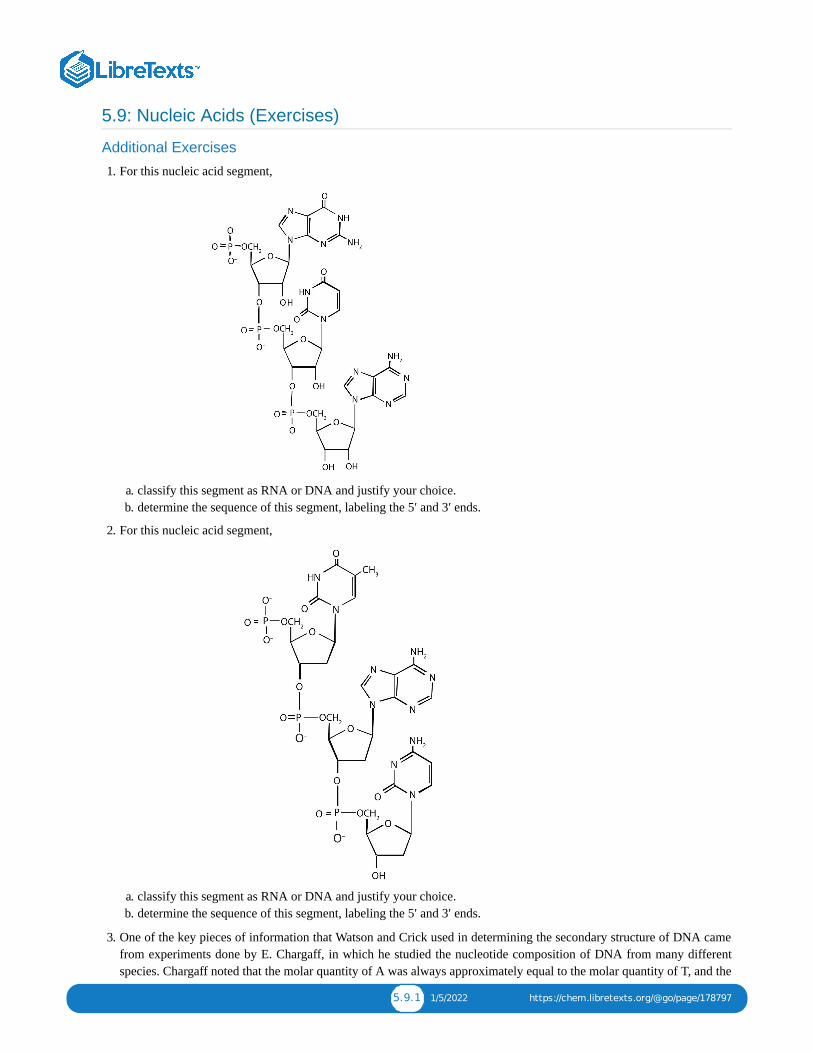
5.9.1 1/5/2022 https://chem.libretexts.org/@go/page/178797
5.9: Nucleic Acids (Exercises)
Additional Exercises
1. For this nucleic acid segment,
a. classify this segment as RNA or DNA and justify your choice.b. determine the sequence of this segment, labeling the 5′ and 3′ ends.
2. For this nucleic acid segment,
a. classify this segment as RNA or DNA and justify your choice.b. determine the sequence of this segment, labeling the 5′ and 3′ ends.
3. One of the key pieces of information that Watson and Crick used in determining the secondary structure of DNA camefrom experiments done by E. Chargaff, in which he studied the nucleotide composition of DNA from many differentspecies. Chargaff noted that the molar quantity of A was always approximately equal to the molar quantity of T, and the

5.9.2 1/5/2022 https://chem.libretexts.org/@go/page/178797
molar quantity of C was always approximately equal to the molar quantity of G. How were Chargaff’s results explainedby the structural model of DNA proposed by Watson and Crick?
4. Suppose Chargaff (see Exercise 3) had used RNA instead of DNA. Would his results have been the same; that is, wouldthe molar quantity of A approximately equal the molar quantity of T? Explain.
5. In the DNA segment
5′‑ATGAGGCATGAGACG‑3′ (coding strand) 3′‑TACTCCGTACTCTGC‑5′ (template strand)
a. What products would be formed from the segment’s replication?b. Write the mRNA sequence that would be obtained from the segment’s transcription.c. What is the amino acid sequence of the peptide produced from the mRNA in Exercise 5b?
6. In the DNA segment
5′‑ATGACGGTTTACTAAGCC‑3′ (coding strand) 3′‑TACTGCCAAATGATTCGG‑5′ (template strand)
a. What products would be formed from the segment’s replication?b. Write the mRNA sequence that would be obtained from the segment’s transcription.c. What is the amino acid sequence of the peptide produced from the mRNA in Exercise 6b?
7. A hypothetical protein has a molar mass of 23,300 Da. Assume that the average molar mass of an amino acid is 120.
a. How many amino acids are present in this hypothetical protein?b. What is the minimum number of codons present in the mRNA that codes for this protein?c. What is the minimum number of nucleotides needed to code for this protein?
8. Bradykinin is a potent peptide hormone composed of nine amino acids that lowers blood pressure.
a. The amino acid sequence for bradykinin is arg-pro-pro-gly-phe-ser-pro-phe-arg. Postulate a base sequence in themRNA that would direct the synthesis of this hormone. Include an initiation codon and a termination codon.
b. What is the nucleotide sequence of the DNA that codes for this mRNA?
9. A particular DNA coding segment is ACGTTAGCCCCAGCT.
a. Write the sequence of nucleotides in the corresponding mRNA.b. Determine the amino acid sequence formed from the mRNA in Exercise 9a during translation.
c. What amino acid sequence results from each of the following mutations?
a. replacement of the underlined guanine by adenineb. insertion of thymine immediately after the underlined guaninec. deletion of the underlined guanine
10. A particular DNA coding segment is TACGACGTAACAAGC.
a. Write the sequence of nucleotides in the corresponding mRNA.b. Determine the amino acid sequence formed from the mRNA in Exercise 10a during translation.
c. What amino acid sequence results from each of the following mutations?
a. replacement of the underlined guanine by adenineb. replacement of the underlined adenine by thymine
11. Two possible point mutations are the substitution of lysine for leucine or the substitution of serine for threonine. Whichis likely to be more serious and why?
12. Two possible point mutations are the substitution of valine for leucine or the substitution of glutamic acid for histidine.Which is likely to be more serious and why?
Answers
a. 1. RNA; the sugar is ribose, rather than deoxyriboseb. 5′‑GUA‑3′

5.9.3 1/5/2022 https://chem.libretexts.org/@go/page/178797
3. In the DNA structure, because guanine (G) is always paired with cytosine (C) and adenine (A) is always paired withthymine (T), you would expect to have equal amounts of each.
a. 5. Each strand would be replicated, resulting in two double-stranded segments.b. 5′‑AUGAGGCAUGAGACG‑3′c. met-arg-his-glu-thr
a. 7. 194b. 194c. 582
a. 9. 5′‑ACGUUAGCCCCAGCU‑3′b. thr-leu-ala-pro-ala
a. c. thr-leu-thr-pro-alab. thr-leu-val-pro-serc. thr-leu-pro-gin
11. substitution of lysine for leucine because you are changing from an amino acid with a nonpolar side chain to one thathas a positively charged side chain; both serine and threonine, on the other hand, have polar side chains containing theOH group.

1 1/10/2022
CHAPTER OVERVIEW6: ENERGY METABOLISMMetabolism is the set of life-sustaining chemical transformations within the cells of living organisms. The three main purposes ofmetabolism are the conversion of food/fuel to energy to run cellular processes, the conversion of food/fuel to building blocks forproteins, lipids, nucleic acids, and some carbohydrates, and the elimination of nitrogenous wastes. These enzyme-catalyzed reactionsallow organisms to grow and reproduce, maintain their structures, and respond to their environments.
6.1: PRELUDE TO ENERGY METABOLISMThe insulin receptor is located in the cell membrane and consists of four polypeptide chains: two identical chains called α chains andtwo identical chains called β chains. The α chains, positioned on the outer surface of the membrane, consist of 735 amino acids eachand contain the binding site for insulin. The β chains are integral membrane proteins, each composed of 620 amino acids.
6.2: ATP: THE UNIVERSAL ENERGY CURRENCYThe hydrolysis of ATP releases energy that can be used for cellular processes that require energy.
6.3: STAGE I OF CATABOLISMDuring digestion, carbohydrates are broken down into monosaccharides, proteins are broken down into amino acids, and triglyceridesare broken down into glycerol and fatty acids. Most of the digestion reactions occur in the small intestine.
6.4: OVERVIEW OF STAGE II OF CATABOLISMAcetyl-CoA is formed from the breakdown of carbohydrates, lipids, and proteins. It is used in many biochemical pathways.
6.5: STAGE III OF CATABOLISMThe acetyl group of acetyl-CoA enters the citric acid cycle. For each acetyl-CoA that enters the citric acid cycle, 2 molecules ofcarbon dioxide, 3 molecules of NADH, 1 molecule of ATP, and 1 molecule of FADH2 are produced. The reduced coenzymes produced by the citric acid cycle are reoxidized by the reactions of the electron transport chain. This series of reactions also producesa pH gradient across the inner mitochondrial membrane that drives the synthesis of ATP from ADP.
6.6: STAGE II OF CARBOHYDRATE CATABOLISMThe monosaccharide glucose is broken down through a series of enzyme-catalyzed reactions known as glycolysis. For each moleculeof glucose that is broken down, two molecules of pyruvate, two molecules of ATP, and two molecules of NADH are produced. In theabsence of oxygen, pyruvate is converted to lactate, and NADH is reoxidized to NAD+. In the presence of oxygen, pyruvate isconverted to acetyl-CoA and then enters the citric acid cycle. More ATP can be formed from the breakdown of glucose.
6.7: STAGE II OF LIPID CATABOLISMFatty acids, obtained from the breakdown of triglycerides and other lipids, are oxidized through a series of reactions known as β-oxidation. In each round of β-oxidation, 1 molecule of acetyl-CoA, 1 molecule of NADH, and 1 molecule of FADH2 are produced.The acetyl-CoA, NADH, and FADH2 are used in the citric acid cycle, the electron transport chain, and oxidative phosphorylation toproduce ATP.
6.8: STAGE II OF PROTEIN CATABOLISMGenerally the first step in the breakdown of amino acids is the removal of the amino group, usually through a reaction known astransamination. The carbon skeletons of the amino acids undergo further reactions to form compounds that can either be used for thesynthesis of glucose or the synthesis of ketone bodies.
6.9: ENERGY METABOLISM (SUMMARY)To ensure that you understand the material in this chapter, you should review the meanings of the bold terms in the followingsummary and ask yourself how they relate to the topics in the chapter.
6.10: ENERGY METABOLISM (EXERCISES)Problems and select solutions for the chapter.

6.1.1 1/5/2022 https://chem.libretexts.org/@go/page/178799
6.1: Prelude to Energy MetabolismThe discovery of the link between insulin and diabetes led to a period of intense research aimed at understanding exactlyhow insulin works in the body to regulate glucose levels. Hormones in general act by binding to some protein, known asthe hormone’s receptor, thus initiating a series of events that lead to a desired outcome. In the early 1970s, the insulinreceptor was purified, and researchers began to study what happens after insulin binds to its receptor and how those eventsare linked to the uptake and metabolism of glucose in cells.
The insulin receptor is located in the cell membrane and consists of four polypeptide chains: two identical chains called αchains and two identical chains called β chains. The α chains, positioned on the outer surface of the membrane, consist of735 amino acids each and contain the binding site for insulin. The β chains are integral membrane proteins, each composedof 620 amino acids. The binding of insulin to its receptor stimulates the β chains to catalyze the addition of phosphategroups to the specific side chains of tyrosine (referred to as phosphorylation) in the β chains and other cell proteins,leading to the activation of reactions that metabolize glucose. In this chapter we will look at the pathway that breaks downglucose—in response to activation by insulin—for the purpose of providing energy for the cell.
Figure : Model of the Structure of the Insulin Receptor (PDB code 4ZXB).
Life requires energy. Animals, for example, require heat energy to maintain body temperature, mechanical energy to movetheir limbs, and chemical energy to synthesize the compounds needed by their cells. Living cells remain organized andfunctioning properly only through a continual supply of energy. But only specific forms of energy can be used. Supplyinga plant with energy by holding it in a flame will not prolong its life. On the other hand, a green plant is able to absorbradiant energy from the sun, the most abundant source of energy for life on the earth. Plants use this energy first to formglucose and then to make other carbohydrates, as well as lipids and proteins. Unlike plants, animals cannot directly use thesun’s energy to synthesize new compounds. They must eat plants or other animals to get carbohydrates, fats, and proteinsand the chemical energy stored in them. Once digested and transported to the cells, the nutrient molecules can be used ineither of two ways: as building blocks for making new cell parts or repairing old ones or “burned” for energy.
6.1.1
GLmol

6.1.2 1/5/2022 https://chem.libretexts.org/@go/page/178799
Figure : Some Energy Transformations in Living Systems. Plants and animals exist in a cycle; each requires productsof the other.
The thousands of coordinated chemical reactions that keep cells alive are referred to collectively as metabolism. Ingeneral, metabolic reactions are divided into two classes: the breaking down of molecules to obtain energy is catabolism,and the building of new molecules needed by living systems is anabolism.
metaboliteAny chemical compound that participates in a metabolic reaction is a metabolite.
Most of the energy required by animals is generated from lipids and carbohydrates. These fuels must be oxidized, or“burned,” for the energy to be released. The oxidation process ultimately converts the lipid or carbohydrate to carbondioxide (CO ) and water (H O).
Carbohydrate:
Lipid:
These two equations summarize the biological combustion of a carbohydrate and a lipid by the cell through respiration.Respiration is the collective name for all metabolic processes in which gaseous oxygen is used to oxidize organic matterto carbon dioxide, water, and energy.
Like the combustion of the common fuels we burn in our homes and cars (wood, coal, gasoline), respiration uses oxygenfrom the air to break down complex organic substances to carbon dioxide and water. But the energy released in the burningof wood is manifested entirely in the form of heat, and excess heat energy is not only useless but also injurious to theliving cell. Living organisms instead conserve much of the energy respiration releases by channeling it into a series ofstepwise reactions that produce adenosine triphosphate (ATP) or other compounds that ultimately lead to the synthesis ofATP. The remainder of the energy is released as heat and manifested as body temperature.
6.1.2
2 2
+6 → 6 +6 O+670 kcalC6H12O6 O2 CO2 H2 (6.1.1)
+23 → 16 +16 O+2 , 385 kcalC16H32O2 O2 CO2 H2 (6.1.2)

6.2.1 12/26/2021 https://chem.libretexts.org/@go/page/178800
6.2: ATP: the Universal Energy CurrencyLearning Objectives
To describe the importance of ATP as a source of energy in living organisms.
Adenosine triphosphate (ATP), a nucleotide composed of adenine, ribose, and three phosphate groups, is perhaps the mostimportant of the so-called energy-rich compounds in a cell. Its concentration in the cell varies from 0.5 to 2.5 mg/mL ofcell fluid.
Energy-rich compounds are substances having particular structural features that lead to a release of energy after hydrolysis.As a result, these compounds are able to supply energy for biochemical processes that require energy. The structuralfeature important in ATP is the phosphoric acid anhydride, or pyrophosphate, linkage:
The pyrophosphate bond, symbolized by a squiggle (~), is hydrolyzed when ATP is converted to adenosine diphosphate(ADP). In this hydrolysis reaction, the products contain less energy than the reactants; there is a release of energy (> 7kcal/mol). One reason for the amount of energy released is that hydrolysis relieves the electron-electron repulsionsexperienced by the negatively charged phosphate groups when they are bonded to each other (Figure 20.1.1).
Figure : Hydrolysis of ATP to Form ADP
Energy is released because the products (ADP and phosphate ion) have less energy than the reactants [ATP and water(H O)].
The general equation for ATP hydrolysis is as follows:
If the hydrolysis of ATP releases energy, its synthesis (from ADP) requires energy. In the cell, ATP is produced by thoseprocesses that supply energy to the organism (absorption of radiant energy from the sun in green plants and breakdown offood in animals), and it is hydrolyzed by those processes that require energy (the syntheses of carbohydrates, lipids,proteins; the transmission of nerve impulses; muscle contractions). In fact, ATP is the principal medium of energyexchange in biological systems. Many scientists call it the energy currency of cells.
6.2.1
2
AT P + O → ADP + +7.4 kcal/molH2 Pi (6.2.1)

6.2.2 12/26/2021 https://chem.libretexts.org/@go/page/178800
is the symbol for the inorganic phosphate anions and .
ATP is not the only high-energy compound needed for metabolism. Several others are listed in Table . Notice,however, that the energy released when ATP is hydrolyzed is approximately midway between those of the high-energy andthe low-energy phosphate compounds. This means that the hydrolysis of ATP can provide energy for the phosphorylationof the compounds below it in the table. For example, the hydrolysis of ATP provides sufficient energy for thephosphorylation of glucose to form glucose 1-phosphate. By the same token, the hydrolysis of compounds, such ascreatine phosphate, that appear above ATP in the table can provide the energy needed to resynthesize ATP from ADP.
Table : Energy Released by Hydrolysis of Some Phosphate CompoundsType Example Energy Released (kcal/mol)
acyl phosphate1,3-bisphosphoglycerate (BPG) −11.8
acetyl phosphate −11.3
guanidine phosphatescreatine phosphate −10.3
arginine phosphate −9.1
pyrophosphates PP → 2P −7.8
ATP → AMP + PP −7.7
ATP → ADP + P −7.5
ADP → AMP + P −7.5
sugar phosphates glucose 1-phosphate −5.0
fructose 6-phosphate −3.8
AMP → adenosine + P −3.4
glucose 6-phosphate −3.3
glycerol 3-phosphate −2.2
*PP is the pyrophosphate ion.
Summary
The hydrolysis of ATP releases energy that can be used for cellular processes that require energy.
Concept Review Exercise
1. Why is ATP referred to as the energy currency of the cell?
Answer1. ATP is the principal molecule involved in energy exchange reactions in biological systems.
Exercises
1. How do ATP and ADP differ in structure?2. Why does the hydrolysis of ATP to ADP involve the release of energy?3. Identify whether each compound would be classified as a high-energy phosphate compound.
a. ATPb. glucose 6-phosphatec. creatine phosphate
Pi PH2 O−4 HPO
2−4
6.2.1
6.2.1
i* i
i
i
i
i
i

6.2.3 12/26/2021 https://chem.libretexts.org/@go/page/178800
4. Identify whether each compound would be classified as a high-energy phosphate compound.a. ADPb. AMPc. glucose 1-phosphate
Answers
1. ATP has a triphosphate group attached, while ADP has only a diphosphate group attached.
a. 3. yesb. noc. yes

6.3.1 1/5/2022 https://chem.libretexts.org/@go/page/178801
6.3: Stage I of CatabolismLearning Objectives
To describe how carbohydrates, fats, and proteins are broken down during digestion.
We have said that animals obtain chemical energy from the food—carbohydrates, fats, and proteins—they eat throughreactions defined collectively as catabolism. We can think of catabolism as occurring in three stages (Figure ). Instage I, carbohydrates, fats, and proteins are broken down into their individual monomer units: carbohydrates into simplesugars, fats into fatty acids and glycerol, and proteins into amino acids. One part of stage I of catabolism is the breakdownof food molecules by hydrolysis reactions into the individual monomer units—which occurs in the mouth, stomach, andsmall intestine—and is referred to as digestion.
In stage II, these monomer units (or building blocks) are further broken down through different reaction pathways, one ofwhich produces ATP, to form a common end product that can then be used in stage III to produce even more ATP. In thischapter, we will look at each stage of catabolism—as an overview and in detail.
Figure : Energy Conversions
6.3.1
6.3.1

6.3.2 1/5/2022 https://chem.libretexts.org/@go/page/178801
The conversion of food into cellular energy (as ATP) occurs in three stages.
Digestion of Carbohydrates
Carbohydrate digestion begins in the mouth (Figure ) where salivary α-amylase attacks the α-glycosidic linkages instarch, the main carbohydrate ingested by humans. Cleavage of the glycosidic linkages produces a mixture of dextrins,maltose, and glucose. The α-amylase mixed into the food remains active as the food passes through the esophagus, but it israpidly inactivated in the acidic environment of the stomach.
Figure : The Principal Events and Sites of Carbohydrate Digestion
The primary site of carbohydrate digestion is the small intestine. The secretion of α-amylase in the small intestine convertsany remaining starch molecules, as well as the dextrins, to maltose. Maltose is then cleaved into two glucose molecules bymaltase. Disaccharides such as sucrose and lactose are not digested until they reach the small intestine, where they areacted on by sucrase and lactase, respectively. The major products of the complete hydrolysis of disaccharides andpolysaccharides are three monosaccharide units: glucose, fructose, and galactose. These are absorbed through the wall ofthe small intestine into the bloodstream.
Digestion of Proteins Protein digestion begins in the stomach (Figure ), where the action of gastric juice hydrolyzes about 10% of thepeptide bonds. Gastric juice is a mixture of water (more than 99%), inorganic ions, hydrochloric acid, and various enzymesand other proteins.
The pain of a gastric ulcer is at least partially due to irritation of the ulcerated tissue by acidic gastric juice.
6.3.2
6.3.2
6.3.3

6.3.3 1/5/2022 https://chem.libretexts.org/@go/page/178801
Figure : The Principal Events and Sites of Protein Digestion
The hydrochloric acid (HCl) in gastric juice is secreted by glands in the stomach lining. The pH of freshly secreted gastricjuice is about 1.0, but the contents of the stomach may raise the pH to between 1.5 and 2.5. HCl helps to denature foodproteins; that is, it unfolds the protein molecules to expose their chains to more efficient enzyme action. The principaldigestive component of gastric juice is pepsinogen, an inactive enzyme produced in cells located in the stomach wall.When food enters the stomach after a period of fasting, pepsinogen is converted to its active form—pepsin—in a series ofsteps initiated by the drop in pH. Pepsin catalyzes the hydrolysis of peptide linkages within protein molecules. It has afairly broad specificity but acts preferentially on linkages involving the aromatic amino acids tryptophan, tyrosine, andphenylalanine, as well as methionine and leucine.
Protein digestion is completed in the small intestine. Pancreatic juice, carried from the pancreas via the pancreatic duct,contains inactive enzymes such as trypsinogen and chymotrypsinogen. They are activated in the small intestine as follows(Figure ): The intestinal mucosal cells secrete the proteolytic enzyme enteropeptidase, which converts trypsinogen totrypsin; trypsin then activates chymotrypsinogen to chymotrypsin (and also completes the activation of trypsinogen). Bothof these active enzymes catalyze the hydrolysis of peptide bonds in protein chains. Chymotrypsin preferentially attackspeptide bonds involving the carboxyl groups of the aromatic amino acids (phenylalanine, tryptophan, and tyrosine).Trypsin attacks peptide bonds involving the carboxyl groups of the basic amino acids (lysine and arginine). Pancreaticjuice also contains procarboxypeptidase, which is cleaved by trypsin to carboxypeptidase. The latter is an enzyme thatcatalyzes the hydrolysis of peptide linkages at the free carboxyl end of the peptide chain, resulting in the stepwiseliberation of free amino acids from the carboxyl end of the polypeptide.
6.3.3
6.3.4

6.3.4 1/5/2022 https://chem.libretexts.org/@go/page/178801
Figure : Activation of Some Pancreatic Enzymes in the Small Intestine
Aminopeptidases in the intestinal juice remove amino acids from the N-terminal end of peptides and proteins possessing afree amino group. Figure illustrates the specificity of these protein-digesting enzymes. The amino acids that arereleased by protein digestion are absorbed across the intestinal wall into the circulatory system, where they can be used forprotein synthesis.
Figure : Hydrolysis of a Peptide by Several Peptidases
This diagram illustrates where in a peptide the different peptidases we have discussed would catalyze hydrolysis thepeptide bonds.
Digestion of Lipids
Lipid digestion begins in the upper portion of the small intestine (Figure ). A hormone secreted in this regionstimulates the gallbladder to discharge bile into the duodenum. The principal constituents of bile are the bile salts, whichemulsify large, water-insoluble lipid droplets, disrupting some of the hydrophobic interactions holding the lipid moleculestogether and suspending the resulting smaller globules (micelles) in the aqueous digestive medium. These changes greatlyincrease the surface area of the lipid particles, allowing for more intimate contact with the lipases and thus rapid digestionof the fats. Another hormone promotes the secretion of pancreatic juice, which contains these enzymes.
6.3.4
6.3.5
6.3.5
6.3.6

6.3.5 1/5/2022 https://chem.libretexts.org/@go/page/178801
Figure : The Principal Events and Sites of Lipid (Primarily Triglyceride) Digestion
The lipases in pancreatic juice catalyze the digestion of triglycerides first to diglycerides and then to 2‑monoglycerides andfatty acids:
The monoglycerides and fatty acids cross the intestinal lining into the bloodstream, where they are resynthesized intotriglycerides and transported as lipoprotein complexes known as chylomicrons. Phospholipids and cholesteryl estersundergo similar hydrolysis in the small intestine, and their component molecules are also absorbed through the intestinallining.
The further metabolism of monosaccharides, fatty acids, and amino acids released in stage I of catabolism occurs in stagesII and III of catabolism.
Summary
During digestion, carbohydrates are broken down into monosaccharides, proteins are broken down intoamino acids, and triglycerides are broken down into glycerol and fatty acids. Most of the digestionreactions occur in the small intestine.
Concept Review Exercises
1. Distinguish between each pair of compounds.
a. pepsin and pepsinogenb. chymotrypsin and trypsinc. aminopeptidase and carboxypeptidase
6.3.6

6.3.6 1/5/2022 https://chem.libretexts.org/@go/page/178801
2. What are the primary end products of each form of digestion?
a. carbohydrate digestionb. lipid digestionc. protein digestion
3. In what section of the digestive tract does most of the carbohydrate, lipid, and protein digestion take place?
Answersa. 1. Pepsinogen is an inactive form of pepsin; pepsin is the active form of the enzyme.b. Both enzymes catalyze the hydrolysis of peptide bonds. Chymotrypsin catalyzes the hydrolysis of peptide bonds
following aromatic amino acids, while trypsin catalyzes the hydrolysis of peptide bonds following lysine andarginine.
c. Aminopeptidase catalyzes the hydrolysis of amino acids from the N-terminal end of a protein, whilecarboxypeptidase catalyzes the hydrolysis of amino acids from the C-terminal end of a protein.
a. 2. glucose, fructose, and galactoseb. monoglycerides and fatty acidsc. amino acids
3. the small intestine
Exercises
1. What are the products of digestion (or stage I of catabolism)?
2. What is the general type of reaction used in digestion?
3. Give the site of action and the function of each enzyme.
a. chymotrypsinb. lactasec. pepsind. maltase
4. Give the site of action and the function of each enzyme.
a. α-amylaseb. trypsinc. sucrased. aminopeptidase
a. 5. What is the meaning of the following statement? “Bile salts act to emulsify lipids in the small intestine.”b. Why is emulsification important?
6. Using chemical equations, describe the chemical changes that triglycerides undergo during digestion.
7. What are the expected products from the enzymatic action of chymotrypsin on each amino acid segment?
a. gly-ala-phe-thr-leub. ala-ile-tyr-ser-argc. val-trp-arg-leu-cys
8. What are the expected products from the enzymatic action of trypsin on each amino acid segment?
a. leu-thr-glu-lys-alab. phe-arg-ala-leu-valc. ala-arg-glu-trp-lys
Answers
1. proteins: amino acids; carbohydrates: monosaccharides; fats: fatty acids and glycerol

6.3.7 1/5/2022 https://chem.libretexts.org/@go/page/178801
a. 3. Chymotrypsin is found in the small intestine and catalyzes the hydrolysis of peptide bonds following aromaticamino acids.
b. Lactase is found in the small intestine and catalyzes the hydrolysis of lactose.c. Pepsin is found in the stomach and catalyzes the hydrolysis of peptide bonds, primarily those that occur after
aromatic amino acids.d. Maltase is found in the small intestine and catalyzes the hydrolysis of maltose.
a. 5. Bile salts aid in digestion by dispersing lipids throughout the aqueous solution in the small intestine.b. Emulsification is important because lipids are not soluble in water; it breaks lipids up into smaller particles that can
be more readily hydrolyzed by lipases.
a. 7. gly-ala-phe and thr-leub. ala-ile-tyr and ser-argc. val-trp and arg-leu-cys
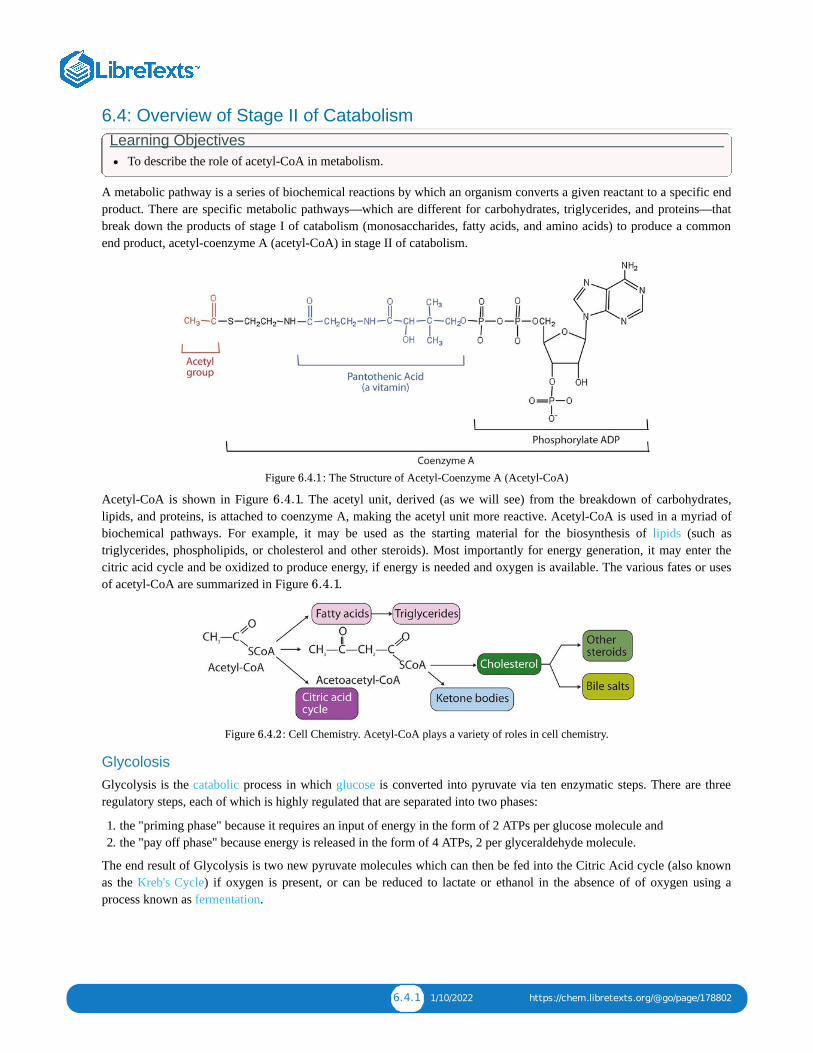
6.4.1 1/10/2022 https://chem.libretexts.org/@go/page/178802
6.4: Overview of Stage II of CatabolismLearning Objectives
To describe the role of acetyl-CoA in metabolism.
A metabolic pathway is a series of biochemical reactions by which an organism converts a given reactant to a specific endproduct. There are specific metabolic pathways—which are different for carbohydrates, triglycerides, and proteins—thatbreak down the products of stage I of catabolism (monosaccharides, fatty acids, and amino acids) to produce a commonend product, acetyl-coenzyme A (acetyl-CoA) in stage II of catabolism.
Figure : The Structure of Acetyl-Coenzyme A (Acetyl-CoA)
Acetyl-CoA is shown in Figure . The acetyl unit, derived (as we will see) from the breakdown of carbohydrates,lipids, and proteins, is attached to coenzyme A, making the acetyl unit more reactive. Acetyl-CoA is used in a myriad ofbiochemical pathways. For example, it may be used as the starting material for the biosynthesis of lipids (such astriglycerides, phospholipids, or cholesterol and other steroids). Most importantly for energy generation, it may enter thecitric acid cycle and be oxidized to produce energy, if energy is needed and oxygen is available. The various fates or usesof acetyl-CoA are summarized in Figure .
Figure : Cell Chemistry. Acetyl-CoA plays a variety of roles in cell chemistry.
Glycolosis Glycolysis is the catabolic process in which glucose is converted into pyruvate via ten enzymatic steps. There are threeregulatory steps, each of which is highly regulated that are separated into two phases:
1. the "priming phase" because it requires an input of energy in the form of 2 ATPs per glucose molecule and2. the "pay off phase" because energy is released in the form of 4 ATPs, 2 per glyceraldehyde molecule.
The end result of Glycolysis is two new pyruvate molecules which can then be fed into the Citric Acid cycle (also knownas the Kreb's Cycle) if oxygen is present, or can be reduced to lactate or ethanol in the absence of of oxygen using aprocess known as fermentation.
6.4.1
6.4.1
6.4.1
6.4.2

6.4.2 1/10/2022 https://chem.libretexts.org/@go/page/178802
Video : Glycolysis: An Overview. Glycolysis is a series of 10 reactions that converts sugars, like glucose, into 3-carbon molecules called pyruvate. This animation provides an overview of the energy consumed and produced by the
pathway. NDSU VCell Production's animation; for more information please see http://vcell.ndsu.edu/animations.
Glycolysis occurs within almost all living cells and is the primary source of Acetyl-CoA, which is the moleculeresponsible for the majority of energy output under aerobic conditions. The structures of Glycolysis intermediates can befound in Figure .
Figure : Glycolysis pathway. Image used with permission from Wikipedia.
Phase 1: The "Priming Step"
The first phase of Glycolysis requires an input of energy in the form of ATP (adenosine triphosphate).
1. alpha-D-Glucose is phosphorolated at the 6 carbon by ATP via the enzyme Hexokinase (Class: Transferase) to yieldalpha-D-Glucose-6-phosphate (G-6-P). This is a regulatory step which is negatively regulated by the presence ofglucose-6-phosphate.
2. alpha-D-Glucose-6-phosphate is then converted into D-Fructose-6-phosphate (F-6-P) by Phosphoglucoisomerase(Class: Isomerase)
3. D-Fructose-6-phosphate is once again phosphorolated this time at the 1 carbon position by ATP via the enzymePhosphofructokinase (Class: Transferase) to yield D-Fructose-1,6-bisphosphate (FBP). This is the committed step ofglycolysis because of its large value.
Glycolysis: An OverviewGlycolysis: An Overview
6.4.1
6.4.3
6.4.3
ΔG

6.4.3 1/10/2022 https://chem.libretexts.org/@go/page/178802
4. D-Fructose-1,6-bisphosphate is then cleaved into two, three carbon molecules; Dihydroxyacetone phosphate (DHAP)and D-Glyceraldehyde-3-phosphate (G-3-P) by the enzyme Fructose bisphosphate aldolase (Class: Lyase)
5. Because the next portion of Glycolysis requires the molecule D-Glyceraldehyde-3-phosphate to continueDihydroxyacetone phosphate is converted into D-Glyceraldehyde-3-phosphate by the enzyme Triose phosphateisomerase (Class: Isomerase)
Phase 2: The "Pay Off Step"
The second phase of Glycolysis where 4 molecules of ATP are produced per molecule of glucose. Enzymes appear in red:
1. D-Glyceraldehyde-3-phosphate is phosphorolated at the 1 carbon by the enzyme Glyceraldehyde-3-phosphatedehodrogenase to yield the high energy molecule 1,3-Bisphosphoglycerate (BPG)
2. ADP is then phosphorolated at the expense of 1,3-Bisphosphoglycerate by the enzyme Phosphoglycerate kinase (Class:Transferase) to yield ATP and 3-Phosphoglycerate (3-PG)
3. 3-Phosphoglycerate is then converted into 2-Phosphoglycerate by Phosphoglycerate mutase in preparation to yieldanother high energy molecule
4. 2-Phosphoglycerate is then converted to phosphoenolpyruvate (PEP) by Enolase. H O, potassium, and magnesium areall released as a result.
5. ADP is once again phosphorolated, this time at the expense of PEP by the enzyme pyruvate kinase to yield anothermolecule of ATP and and pyruvate. This step is regulated by the energy in the cell. The higher the energy of the cell themore inhibited pyruvate kinase becomes. Indicators of high energy levels within the cell are high concentrations ofATP, Acetyl-CoA, Alanine, and cAMP.
Because Glucose is split to yield two molecules of D-Glyceraldehyde-3-phosphate, each step in the "Pay Off" phase occurstwice per molecule of glucose.
Beta-Oxidation
The best source of energy for eukaryotic organisms are fats. Glucose offers a ratio 6.3 moles of ATP per carbon whilesaturated fatty acids offer 8.1 ATP per carbon. Also the complete oxidation of fats yields enormous amounts of water forthose organisms that do not have adequate access to drinkable water. Camels and killer whales are good example of this,they obtain their water requirements from the complete oxidation of fats.
Video : Fatty acid metabolism / beta oxidation / β-Oxidation
There are four distinct stages in the oxidation of fatty acids. Fatty acid degradation takes place within the mitochondria andrequires the help of several different enzymes. In order for fatty acids to enter the mitochondria the assistance of twocarrier proteins is required, Carnitine acyltransferase I and II. It is also interesting to note the similarities between the foursteps of beta-oxidation and the later four steps of the TCA cycle.
Entry into Beta-oxidationMost fats stored in eukaryotic organisms are stored as triglycerides as seen below. In order to enter into beta-oxidationbonds must be broken usually with the use of a Lipase. The end result of these broken bonds are a glycerol molecule and
2
Beta oxidation | Beta oxidation | β-Oxidationβ-Oxidation
6.4.2

6.4.4 1/10/2022 https://chem.libretexts.org/@go/page/178802
three fatty acids in the case of triglycerides. Other lipids are capable of being degraded as well.
Figure : Key molecules in beta-oxidation: (left) A triglyceride molecule, (middle) Glycerol, (right) Fatty Acids(unsaturated)
Activation StepOnce the triglycerides are broken down into glycerol and fatty acids they must be activated before they can enter intothe mitochondria and proceed on with beta-oxidation. This is done by Acyl-CoA synthetase to yield fatty acyl-CoA.After the fatty acid has been acylated it is now ready to enter into the mitochondria.There are two carrier proteins (Carnitine acyltransferase I and II), one located on the outer membrane and one on theinner membrane of the mitochondria. Both are required for entry of the Acyl-CoA into the mitochondria.Once inside the mitochondria the fatty acyl-CoA can enter into beta-oxidation.
Oxidation Step
A fatty acyl-CoA is oxidized by Acyl-CoA dehydrogenase to yield a trans alkene. This is done with the aid of an [FAD]prosthetic group.
Hydration Step
The trans alkene is then hydrated with the help of Enoyl-CoA hydratase
6.4.4

6.4.5 1/10/2022 https://chem.libretexts.org/@go/page/178802
Oxidation Step
The alcohol of the hydroxyacly-CoA is then oxidized by NAD to a carbonyl with the help of Hydroxyacyl-CoAdehydrogenase. NAD is used to oxidize the alcohol rather then [FAD] because NAD is capable of the alcohol while[FAD] is not.
Cleavage
Finally acetyl-CoA is cleaved off with the help of Thiolase to yield an Acyl-CoA that is two carbons shorter than before.The cleaved acetyl-CoA can then enter into the TCA and ETC because it is already within the mitochondria.
Summary Acetyl-CoA is formed from the breakdown of carbohydrates, lipids, and proteins. It is used in many biochemicalpathways.
References 1. Garrett, H., Reginald and Charles Grisham. Biochemistry. Boston: Twayne Publishers, 2008.2. Raven, Peter. Biology. Boston: Twayne Publishers, 2005.
Concept Review Exercises 1. What is a metabolic pathway?2. What vitamin is required to make coenzyme A?3. What is the net yield of Glycolysis as far as ATP?4. Name the enzymes that are key regulatory sites in Glycolysis.5. Why are the enzymes in the previous question targets for regulation?6. Why is the priming phase necessary?7. Draw the entire pathway for glycolysis including enzymes, reactants and products for each step.8. Where does beta-oxidation occur?9. What is the average net yield of ATP per carbon?
10. Where exactly is water formed during the process of fatty acid degradation? (Hint: H O is formed when when the oneof the products of beta-oxidation is passed through another of the metabolic pathways)
11. During the process of beta-oxidation, why is it that [FAD] is used to oxidize an alkane to an alkene while NAD is usedto oxidize an alchol to a carbonyl
12. Draw out the entire process of the degradation of a triglyceride, include enzymes and products and reactants for eachstep.
Answers 1. A metabolic pathway is a series of biochemical reactions by which an organism converts a given reactant to a specific
end product.2. pantothenic acid
Contributors Darik Benson, (University California Davis)
+
+ +
2
+

6.5.1 12/26/2021 https://chem.libretexts.org/@go/page/178803
6.5: Stage III of CatabolismLearning Objectives
Describe the reactions of the citric acid cycle.Describe the function of the citric acid cycle and identify the products produced.Describe the role of the electron transport chain in energy metabolism.Describe the role of oxidative phosphorylation in energy metabolism.
The acetyl group enters a cyclic sequence of reactions known collectively as the citric acid cycle (or Krebs cycle ortricarboxylic acid [TCA] cycle). The cyclical design of this complex series of reactions, which bring about the oxidation ofthe acetyl group of acetyl-CoA to carbon dioxide and water, was first proposed by Hans Krebs in 1937. (He was awardedthe 1953 Nobel Prize in Physiology or Medicine.) Acetyl-CoA’s entrance into the citric acid cycle is the beginning of stageIII of catabolism. The citric acid cycle produces adenosine triphosphate (ATP), reduced nicotinamide adenine dinucleotide(NADH), reduced flavin adenine dinucleotide (FADH ), and metabolic intermediates for the synthesis of neededcompounds.
Steps of the Citric Acid Cycle
At first glance, the citric acid cycle appears rather complex (Figure ). All the reactions, however, are familiar types inorganic chemistry: hydration, oxidation, decarboxylation, and hydrolysis. Each reaction of the citric acid cycle isnumbered, and in Figure , the two acetyl carbon atoms are highlighted in red. Each intermediate in the cycle is acarboxylic acid, existing as an anion at physiological pH. All the reactions occur within the mitochondria, which are smallorganelles within the cells of plants and animals.
Figure : Reactions of the Citric Acid Cycle
1. In the first step, acetyl-CoA enters the citric acid cycle, and the acetyl group is transferred onto oxaloacetate, yieldingcitrate. Note that this step releases coenzyme A. The reaction is catalyzed by citrate synthase.
2. In the next step, aconitase catalyzes the isomerization of citrate to isocitrate. In this reaction, a tertiary alcohol, whichcannot be oxidized, is converted to a secondary alcohol, which can be oxidized in the next step.
3. Isocitrate then undergoes a reaction known as oxidative decarboxylation because the alcohol is oxidized and themolecule is shortened by one carbon atom with the release of carbon dioxide (decarboxylation). The reaction is
2
6.5.1
6.5.1
6.5.1

6.5.2 12/26/2021 https://chem.libretexts.org/@go/page/178803
catalyzed by isocitrate dehydrogenase, and the product of the reaction is α-ketoglutarate. An important reaction linkedto this is the reduction of the coenzyme nicotinamide adenine dinucleotide (NAD ) to NADH. The NADH is ultimatelyreoxidized, and the energy released is used in the synthesis of ATP, as we shall see.
4. The fourth step is another oxidative decarboxylation. This time α-ketoglutarate is converted to succinyl-CoA, andanother molecule of NAD is reduced to NADH. The α-ketoglutarate dehydrogenase complex catalyzes this reaction.This is the only irreversible reaction in the citric acid cycle. As such, it prevents the cycle from operating in the reversedirection, in which acetyl-CoA would be synthesized from carbon dioxide.
So far, in the first four steps, two carbon atoms have entered the cycle as an acetyl group, and two carbon atoms havebeen released as molecules of carbon dioxide. The remaining reactions of the citric acid cycle use the four carbon atomsof the succinyl group to resynthesize a molecule of oxaloacetate, which is the compound needed to combine with anincoming acetyl group and begin another round of the cycle.
In the fifth reaction, the energy released by the hydrolysis of the high-energy thioester bond of succinyl-CoA is used toform guanosine triphosphate (GTP) from guanosine diphosphate (GDP) and inorganic phosphate in a reaction catalyzed bysuccinyl-CoA synthetase. This step is the only reaction in the citric acid cycle that directly forms a high-energy phosphatecompound. GTP can readily transfer its terminal phosphate group to adenosine diphosphate (ADP) to generate ATP in thepresence of nucleoside diphosphokinase.
Succinate dehydrogenase then catalyzes the removal of two hydrogen atoms from succinate, forming fumarate. Thisoxidation-reduction reaction uses flavin adenine dinucleotide (FAD), rather than NAD , as the oxidizing agent. Succinatedehydrogenase is the only enzyme of the citric acid cycle located within the inner mitochondrial membrane. We will seesoon the importance of this.
In the following step, a molecule of water is added to the double bond of fumarate to form L-malate in a reaction catalyzedby fumarase.
One revolution of the cycle is completed with the oxidation of L-malate to oxaloacetate, brought about by malatedehydrogenase. This is the third oxidation-reduction reaction that uses NAD as the oxidizing agent. Oxaloacetate canaccept an acetyl group from acetyl-CoA, allowing the cycle to begin again.
+
+
+
+
The Citric Acid Cycle: An OverviewThe Citric Acid Cycle: An Overview

6.5.3 12/26/2021 https://chem.libretexts.org/@go/page/178803
Video: "The Citric Acid Cycle: An Overview". In the matrix of the mitochondrion, the Citric Acid Cycle uses Acetyl CoAmolecules to produce energy through eight chemical reactions. This animation provides an overview of the pathway and its
products. NDSU VCell Production's animation; for more information please see http://vcell.ndsu.edu/animations.
Cellular Respiration
Respiration can be defined as the process by which cells oxidize organic molecules in the presence of gaseous oxygen toproduce carbon dioxide, water, and energy in the form of ATP. We have seen that two carbon atoms enter the citric acidcycle from acetyl-CoA (step 1), and two different carbon atoms exit the cycle as carbon dioxide (steps 3 and 4). Yetnowhere in our discussion of the citric acid cycle have we indicated how oxygen is used. Recall, however, that in the fouroxidation-reduction steps occurring in the citric acid cycle, the coenzyme NAD or FAD is reduced to NADH or FADH ,respectively. Oxygen is needed to reoxidize these coenzymes. Recall, too, that very little ATP is obtained directly from thecitric acid cycle. Instead, oxygen participation and significant ATP production occur subsequent to the citric acid cycle, intwo pathways that are closely linked: electron transport and oxidative phosphorylation.
All the enzymes and coenzymes for the citric acid cycle, the reoxidation of NADH and FADH and the production of ATPare located in the mitochondria, which are small, oval organelles with double membranes, often referred to as the “powerplants” of the cell (Figure ). A cell may contain 100–5,000 mitochondria, depending on its function, and themitochondria can reproduce themselves if the energy requirements of the cell increase.
Figure : Respiration
Cellular respiration occurs in the mitochondria
Figure shows the mitochondrion’s two membranes: outer and inner. The inner membrane is extensively folded into aseries of internal ridges called cristae. Thus there are two compartments in mitochondria: the intermembrane space, whichlies between the membranes, and the matrix, which lies inside the inner membrane. The outer membrane is permeable,whereas the inner membrane is impermeable to most molecules and ions, although water, oxygen, and carbon dioxide canfreely penetrate both membranes. The matrix contains all the enzymes of the citric acid cycle with the exception ofsuccinate dehydrogenase, which is embedded in the inner membrane. The enzymes that are needed for the reoxidation ofNADH and FADH and ATP production are also located in the inner membrane. They are arranged in specific positions sothat they function in a manner analogous to a bucket brigade. This highly organized sequence of oxidation-reductionenzymes is known as the electron transport chain (or respiratory chain).
Electron Transport Figure illustrates the organization of the electron transport chain. The components of the chain are organized intofour complexes designated I, II, III, and IV. Each complex contains several enzymes, other proteins, and metal ions. Themetal ions can be reduced and then oxidized repeatedly as electrons are passed from one component to the next. Recall thata compound is reduced when it gains electrons or hydrogen atoms and is oxidized when it loses electrons or hydrogenatoms.
+2
2,
6.5.2
6.5.2
6.5.2
2
6.5.3

6.5.4 12/26/2021 https://chem.libretexts.org/@go/page/178803
Figure : The Mitochondrial Electron Transport Chain and ATP Synthase. The red line shows the path of electrons.
Electrons can enter the electron transport chain through either complex I or II. We will look first at electrons entering atcomplex I. These electrons come from NADH, which is formed in three reactions of the citric acid cycle. Let’s use step 8as an example, the reaction in which L-malate is oxidized to oxaloacetate and NAD is reduced to NADH. This reactioncan be divided into two half reactions:
Oxidation half-reaction:
Reduction half-reaction:
In the oxidation half-reaction, two hydrogen (H ) ions and two electrons are removed from the substrate. In the reductionhalf-reaction, the NAD molecule accepts both of those electrons and one of the H ions. The other H ion is transportedfrom the matrix, across the inner mitochondrial membrane, and into the intermembrane space. The NADH diffuses throughthe matrix and is bound by complex I of the electron transport chain. In the complex, the coenzyme flavin mononucleotide(FMN) accepts both electrons from NADH. By passing the electrons along, NADH is oxidized back to NAD and FMN isreduced to FMNH (reduced form of flavin mononucleotide). Again, the reaction can be illustrated by dividing it into itsrespective half-reactions.
Oxidation half-reaction:
Reduction half-reaction:
Complex I contains several proteins that have iron-sulfur (Fe·S) centers. The electrons that reduced FMN to FMNH arenow transferred to these proteins. The iron ions in the Fe·S centers are in the Fe(III) form at first, but by accepting an
6.5.3
+
+
+ + +
+
2
2

6.5.5 12/26/2021 https://chem.libretexts.org/@go/page/178803
electron, each ion is reduced to the Fe(II) form. Because each Fe·S center can transfer only one electron, two centers areneeded to accept the two electrons that will regenerate FMN.
Oxidation half-reaction:
Reduction half-reaction:
Electrons from FADH , formed in step 6 of the citric acid cycle, enter the electron transport chain through complex II.Succinate dehydrogenase, the enzyme in the citric acid cycle that catalyzes the formation of FADH from FAD is part ofcomplex II. The electrons from FADH are then transferred to an Fe·S protein.
Oxidation half-reaction:
Reduction half-reaction:
Electrons from complexes I and II are then transferred from the protein to coenzyme Q (CoQ), a mobile electroncarrier that acts as the electron shuttle between complexes I or II and complex III.
Coenzyme Q is also called ubiquinone because it is ubiquitous in living systems.
Oxidation half-reaction:
Reduction half-reaction:
Complexes III and IV include several iron-containing proteins known as cytochromes. The iron in these enzymes islocated in substructures known as iron porphyrins (Figure ). Like the Fe·S centers, the characteristic feature of thecytochromes is the ability of their iron atoms to exist as either Fe(II) or Fe(III). Thus, each cytochrome in its oxidized form—Fe(III)—can accept one electron and be reduced to the Fe(II) form. This change in oxidation state is reversible, so thereduced form can donate its electron to the next cytochrome, and so on. Complex III contains cytochromes b and c, as wellas Fe·S proteins, with cytochrome c acting as the electron shuttle between complex III and IV. Complex IV containscytochromes a and a in an enzyme known as cytochrome oxidase. This enzyme has the ability to transfer electrons tomolecular oxygen, the last electron acceptor in the chain of electron transport reactions. In this final step, water (H O) isformed.
Oxidation half-reaction:
Reduction half-reaction:
O + 4H + 4e → 2H O
F MN → F MN +2 +2H2 H + e− (6.5.1)
2F e(III) ⋅ S +2 → 2F e(II) ⋅ Se− (6.5.2)
2
2
2
F AD → F AD +2 +2H2 H + e− (6.5.3)
2F e(III) ⋅ S +2 → 2F e(II) ⋅ Se− (6.5.4)
F e ⋅ S
2F e(II) ⋅ S → 2F e(III) ⋅ S +2e− (6.5.5)
6.5.4
3
2
4Cyt – F e(II) → 4Cyt – F e(III) +4a3 a3 e− (6.5.6)
2+ −
2

6.5.6 12/26/2021 https://chem.libretexts.org/@go/page/178803
Figure : An Iron Porphyrin. Iron porphyrins are present in cytochromes as well as in myoglobin and hemoglobin.
Video: Cellular Respiration (Electron Transport Chain). Cellular respiration occurs in the mitochondria and provides bothanimals and plants with the energy needed to power other cellular processes. This section covers the electron transport
chain.NDSU Virtual Cell Animations Project animation; ror more information please see http://vcell.ndsu.edu/animations
Oxidative Phosphorylation Each intermediate compound in the electron transport chain is reduced by the addition of one or two electrons in onereaction and then subsequently restored to its original form by delivering the electron(s) to the next compound along thechain. The successive electron transfers result in energy production. But how is this energy used for the synthesis of ATP?The process that links ATP synthesis to the operation of the electron transport chain is referred to as oxidativephosphorylation.
Electron transport is tightly coupled to oxidative phosphorylation. The coenzymes NADH and FADH are oxidized by therespiratory chain only if ADP is simultaneously phosphorylated to ATP. The currently accepted model explaining howthese two processes are linked is known as the chemiosmotic hypothesis, which was proposed by Peter Mitchell, resultingin Mitchell being awarded the 1978 Nobel Prize in Chemistry.
Looking again at Figure , we see that as electrons are being transferred through the electron transport chain, hydrogen(H ) ions are being transported across the inner mitochondrial membrane from the matrix to the intermembrane space. Theconcentration of H is already higher in the intermembrane space than in the matrix, so energy is required to transport theadditional H there. This energy comes from the electron transfer reactions in the electron transport chain. But how doesthe extreme difference in H concentration then lead to ATP synthesis? The buildup of H ions in the intermembrane spaceresults in an H ion gradient that is a large energy source, like water behind a dam (because, given the opportunity, theprotons will flow out of the intermembrane space and into the less concentrated matrix). Current research indicates that theflow of H down this concentration gradient through a fifth enzyme complex, known as ATP synthase, leads to a change inthe structure of the synthase, causing the synthesis and release of ATP.
In cells that are using energy, the turnover of ATP is very high, so these cells contain high levels of ADP. They musttherefore consume large quantities of oxygen continuously, so as to have the energy necessary to phosphorylate ADP toform ATP. Consider, for example, that resting skeletal muscles use about 30% of a resting adult’s oxygen consumption, but
6.5.4
Cellular Respiration (Electron TranspCellular Respiration (Electron Transp……
2
6.5.3+
+
+
+ +
+
+

6.5.7 12/26/2021 https://chem.libretexts.org/@go/page/178803
when the same muscles are working strenuously, they account for almost 90% of the total oxygen consumption of theorganism.
Experiment has shown that 2.5–3 ATP molecules are formed for every molecule of NADH oxidized in the electrontransport chain, and 1.5–2 ATP molecules are formed for every molecule of FADH oxidized. Table summarizes thetheoretical maximum yield of ATP produced by the complete oxidation of 1 mol of acetyl-CoA through the sequentialaction of the citric acid cycle, the electron transport chain, and oxidative phosphorylation.
Table : Maximum Yield of ATP from the Complete Oxidation of 1 Mol of Acetyl-CoAReaction Comments Yield of ATP (moles)
Isocitrate → α-ketoglutarate + CO produces 1 mol NADH
α-ketoglutarate → succinyl-CoA + CO produces 1 mol NADH
Succinyl-CoA → succinate produces 1 mol GTP +1
Succinate → fumarate produces 1 mol FADH
Malate → oxaloacetate produces 1 mol NADH
1 FADH from the citric acid cycle yields 2 mol ATP +2
3 NADH from the citric acid cycle yields 3 mol ATP/NADH +9
Net yield of ATP: +12
Concept Review Exercises1. What is the main function of the citric acid cycle?2. Two carbon atoms are fed into the citric acid cycle as acetyl-CoA. In what form are two carbon atoms removed from
the cycle?3. What are mitochondria and what is their function in the cell?
Answers1. the complete oxidation of carbon atoms to carbon dioxide and the formation of a high-energy phosphate compound,
energy rich reduced coenzymes (NADH and FADH ), and metabolic intermediates for the synthesis of othercompounds
2. as carbon dioxide3. Mitochondria are small organelles with a double membrane that contain the enzymes and other molecules needed for
the production of most of the ATP needed by the body.
Key Takeaways The acetyl group of acetyl-CoA enters the citric acid cycle. For each acetyl-CoA that enters the citric acid cycle, 2molecules of carbon dioxide, 3 molecules of NADH, 1 molecule of ATP, and 1 molecule of FADH are produced.The reduced coenzymes (NADH and FADH ) produced by the citric acid cycle are reoxidized by the reactions of theelectron transport chain. This series of reactions also produces a pH gradient across the inner mitochondrial membrane.The pH gradient produced by the electron transport chain drives the synthesis of ATP from ADP. For each NADHreoxidized, 2.5–3 molecules of ATP are produced; for each FADH reoxidized, 1.5–2 molecules of ATP are produced.
Exercises 1. Replace each question mark with the correct compound.
a.
b.
2 6.5.1
6.5.1
2
2
2
2
2
2
2
2
? isocitrate− →−−−−aconitase
? + ? citrate +coenzyme A− →−−−−−−−−citrate synthase

6.5.8 12/26/2021 https://chem.libretexts.org/@go/page/178803
c.
d.
2. Replace each question mark with the correct compound.
a.
b.
c.
d.
3. From the reactions in Exercises 1 and 2, select the equation(s) by number and letter in which each type of reactionoccurs.
a. isomerizationb. hydrationc. synthesis
4. From the reactions in Exercises 1 and 2, select the equation(s) by number and letter in which each type of reactionoccurs.
a. oxidationb. decarboxylationc. phosphorylation
5. What similar role do coenzyme Q and cytochrome c serve in the electron transport chain?
6. What is the electron acceptor at the end of the electron transport chain? To what product is this compound reduced?
7. What is the function of the cytochromes in the electron transport chain?
8.
a. What is meant by this statement? “Electron transport is tightly coupled to oxidative phosphorylation.”b. How are electron transport and oxidative phosphorylation coupled or linked?
Answersa. 1. citrateb. oxaloacetate + acetyl-CoAc. malated. α-ketoglutarate hydrogenase complex
a. 3. reaction in 1ab. reaction in 1cc. reaction in 1b
5. Both molecules serve as electron shuttles between the complexes of the electron transport chain.
7. Cytochromes are proteins in the electron transport chain and serve as one-electron carriers.
fumarate ?− →−−−−fumarase
isocitrate +NA α-ketoglurate +NADH +CD+ →?
O2
malate +NA oxaloacetate +NADHD+ →?
? + ? GDP +ATP− →−−−−−−−−−−−−−−nucleoside diphosphokinase
succinyl-CoA ? + ?− →−−−−−−−−−−−−succinyl-CoA synthetase
succinate +FAD ? +FAD− →−−−−−−−−−−−−succinate dehydrogenase
H2

6.6.1 12/5/2021 https://chem.libretexts.org/@go/page/178804
6.6: Stage II of Carbohydrate CatabolismLearning Objectives
Describe the function of glycolysis and identify its major products.Describe how the presence or absence of oxygen determines what happens to the pyruvate and the NADH that areproduced in glycolysis.Determine the amount of ATP produced by the oxidation of glucose in the presence and absence of oxygen.
In stage II of catabolism, the metabolic pathway known as glycolysis converts glucose into two molecules of pyruvate (athree-carbon compound with three carbon atoms) with the corresponding production of adenosine triphosphate (ATP). Theindividual reactions in glycolysis were determined during the first part of the 20th century. It was the first metabolicpathway to be elucidated, in part because the participating enzymes are found in soluble form in the cell and are readilyisolated and purified. The pathway is structured so that the product of one enzyme-catalyzed reaction becomes thesubstrate of the next. The transfer of intermediates from one enzyme to the next occurs by diffusion.
Steps in Glycolysis
The 10 reactions of glycolysis, summarized in Figures and , can be divided into two phases. In the first 5reactions—phase I—glucose is broken down into two molecules of glyceraldehyde 3-phosphate. In the last five reactions—phase II—each glyceraldehyde 3-phosphate is converted into pyruvate, and ATP is generated. Notice that all theintermediates in glycolysis are phosphorylated and contain either six or three carbon atoms.
Figure : Phase 1 of Glycolysis
When glucose enters a cell, it is immediately phosphorylated to form glucose 6-phosphate, in the first reaction of phaseI. The phosphate donor in this reaction is ATP, and the enzyme—which requires magnesium ions for its activity—ishexokinase. In this reaction, ATP is being used rather than being synthesized. The presence of such a reaction in acatabolic pathway that is supposed to generate energy may surprise you. However, in addition to activating the glucosemolecule, this initial reaction is essentially irreversible, an added benefit that keeps the overall process moving in theright direction. Furthermore, the addition of the negatively charged phosphate group prevents the intermediates formedin glycolysis from diffusing through the cell membrane, as neutral molecules such as glucose can do.
6.6.1 6.6.2
6.6.1

6.6.2 12/5/2021 https://chem.libretexts.org/@go/page/178804
In the next reaction, phosphoglucose isomerase catalyzes the isomerization of glucose 6-phosphate to fructose 6-phosphate. This reaction is important because it creates a primary alcohol, which can be readily phosphorylated.The subsequent phosphorylation of fructose 6-phosphate to form fructose 1,6-bisphosphate is catalyzed byphosphofructokinase, which requires magnesium ions for activity. ATP is again the phosphate donor.
When a molecule contains two phosphate groups on different carbon atoms, the convention is to use the prefix bis.When the two phosphate groups are bonded to each other on the same carbon atom (for example, adenosinediphosphate [ADP]), the prefix is di.
Fructose 1,6-bisphosphate is enzymatically cleaved by aldolase to form two triose phosphates: dihydroxyacetonephosphate and glyceraldehyde 3-phosphate.Isomerization of dihydroxyacetone phosphate into a second molecule of glyceraldehyde 3-phosphate is the final step inphase I. The enzyme catalyzing this reaction is triose phosphate isomerase.
In steps 4 and 5, aldolase and triose phosphate isomerase effectively convert one molecule of fructose 1,6-bisphosphateinto two molecules of glyceraldehyde 3-phosphate. Thus, phase I of glycolysis requires energy in the form of twomolecules of ATP and releases none of the energy stored in glucose.
Figure : Phase 2 of Glycolysis
In the initial step of phase II (Figure ), glyceraldehyde 3-phosphate is both oxidized and phosphorylated in a reactioncatalyzed by glyceraldehyde-3-phosphate dehydrogenase, an enzyme that requires nicotinamide adenine dinucleotide(NAD ) as the oxidizing agent and inorganic phosphate as the phosphate donor. In the reaction, NAD is reduced toreduced nicotinamide adenine dinucleotide (NADH), and 1,3-bisphosphoglycerate (BPG) is formed.
BPG has a high-energy phosphate bond (Table ) joining a phosphate group to C1. This phosphate group is nowtransferred directly to a molecule of ADP, thus forming ATP and 3-phosphoglycerate. The enzyme that catalyzes thereaction is phosphoglycerate kinase, which, like all other kinases, requires magnesium ions to function. This is the firstreaction to produce ATP in the pathway. Because the ATP is formed by a direct transfer of a phosphate group from ametabolite to ADP—that is, from one substrate to another—the process is referred to as substrate-levelphosphorylation, to distinguish it from the oxidative phosphorylation discussed in Section 20.4.In the next reaction, the phosphate group on 3-phosphoglycerate is transferred from the OH group of C3 to the OHgroup of C2, forming 2-phosphoglycerate in a reaction catalyzed by phosphoglyceromutase.A dehydration reaction, catalyzed by enolase, forms phosphoenolpyruvate (PEP), another compound possessing a high-energy phosphate group.
6.6.2
6.6.2
+ +
6.6.1

6.6.3 12/5/2021 https://chem.libretexts.org/@go/page/178804
The final step is irreversible and is the second reaction in which substrate-level phosphorylation occurs. The phosphategroup of PEP is transferred to ADP, with one molecule of ATP being produced per molecule of PEP. The reaction iscatalyzed by pyruvate kinase, which requires both magnesium and potassium ions to be active.
Table : Maximum Yield of ATP from the Complete Oxidation of 1 Mol of GlucoseReaction Comments Yield of ATP (moles)
glucose → glucose 6-phosphate consumes 1 mol ATP −1
fructose 6-phosphate → fructose 1,6-bisphosphate
consumes 1 mol ATP −1
glyceraldehyde 3-phosphate → BPG produces 2 mol of cytoplasmic NADH
BPG → 3-phosphoglycerate produces 2 mol ATP +2
phosphoenolpyruvate → pyruvate produces 2 mol ATP +2
pyruvate → acetyl-CoA + CO produces 2 mol NADH
isocitrate → α-ketoglutarate + CO produces 2 mol NADH
α-ketoglutarate → succinyl-CoA + CO produces 2 mol NADH
succinyl-CoA → succinate produces 2 mol GTP +2
succinate → fumarate produces 2 mol FADH
malate → oxaloacetate produces 2 mol NADH
2 cytoplasmic NADH from glycolysis yields 2–3 mol ATP per NADH (dependingon tissue)
+4 to +6
2 NADH from the oxidation of pyruvate yields 3 mol ATP per NADH +6
2 FADH from the citric acid cycle yields 2 ATP per FADH +4
3 NADH from the citric acid cycle yields 3 ATP per NADH +18
Net yield of ATP: +36 to +38
In phase II, two molecules of glyceraldehyde 3-phosphate are converted to two molecules of pyruvate, along with theproduction of four molecules of ATP and two molecules of NADH.
To Your Health: DiabetesAlthough medical science has made significant progress against diabetes , it continues to be a major health threat. Someof the serious complications of diabetes are as follows:
It is the leading cause of lower limb amputations in the United States.It is the leading cause of blindness in adults over age 20.It is the leading cause of kidney failure.It increases the risk of having a heart attack or stroke by two to four times.
Because a person with diabetes is unable to use glucose properly, excessive quantities accumulate in the blood and theurine. Other characteristic symptoms are constant hunger, weight loss, extreme thirst, and frequent urination becausethe kidneys excrete large amounts of water in an attempt to remove excess sugar from the blood.
There are two types of diabetes. In immune-mediated diabetes, insufficient amounts of insulin are produced. This typeof diabetes develops early in life and is also known as Type 1 diabetes, as well as insulin-dependent or juvenile-onsetdiabetes. Symptoms are rapidly reversed by the administration of insulin, and Type 1 diabetics can lead active livesprovided they receive insulin as needed. Because insulin is a protein that is readily digested in the small intestine, itcannot be taken orally and must be injected at least once a day.
In Type 1 diabetes, insulin-producing cells of the pancreas are destroyed by the body’s immune system. Researchers arestill trying to find out why. Meanwhile, they have developed a simple blood test capable of predicting who will developType 1 diabetes several years before the disease becomes apparent. The blood test reveals the presence of antibodiesthat destroy the body’s insulin-producing cells.
6.6.1
2
2
2
2
2 2

6.6.4 12/5/2021 https://chem.libretexts.org/@go/page/178804
Type 2 diabetes, also known as noninsulin-dependent or adult-onset diabetes, is by far the more common, representingabout 95% of diagnosed diabetic cases. (This translates to about 16 million Americans.) Type 2 diabetics usuallyproduce sufficient amounts of insulin, but either the insulin-producing cells in the pancreas do not release enough of it,or it is not used properly because of defective insulin receptors or a lack of insulin receptors on the target cells. In manyof these people, the disease can be controlled with a combination of diet and exercise alone. For some people who areoverweight, losing weight is sufficient to bring their blood sugar level into the normal range, after which medication isnot required if they exercise regularly and eat wisely.
Those who require medication may use oral antidiabetic drugs that stimulate the islet cells to secrete insulin. First-generation antidiabetic drugs stimulated the release of insulin. Newer second-generation drugs, such as glyburide, do aswell, but they also increase the sensitivity of cell receptors to insulin. Some individuals with Type 2 diabetes do notproduce enough insulin and thus do not respond to these oral medications; they must use insulin. In both Type 1 andType 2 diabetes, the blood sugar level must be carefully monitored and adjustments made in diet or medication to keepthe level as normal as possible (70–120 mg/dL).
Metabolism of PyruvateThe presence or absence of oxygen determines the fates of the pyruvate and the NADH produced in glycolysis. Whenplenty of oxygen is available, pyruvate is completely oxidized to carbon dioxide, with the release of much greater amountsof ATP through the combined actions of the citric acid cycle, the electron transport chain, and oxidative phosphorylation.However, in the absence of oxygen (that is, under anaerobic conditions), the fate of pyruvate is different in differentorganisms. In vertebrates, pyruvate is converted to lactate, while other organisms, such as yeast, convert pyruvate toethanol and carbon dioxide. These possible fates of pyruvate are summarized in Figure . The conversion to lactate orethanol under anaerobic conditions allows for the reoxidation of NADH to NAD in the absence of oxygen.
Figure : Metabolic Fates of Pyruvate
6.6.2+
6.6.2

6.6.5 12/5/2021 https://chem.libretexts.org/@go/page/178804
ATP Yield from GlycolysisThe net energy yield from anaerobic glucose metabolism can readily be calculated in moles of ATP. In the initialphosphorylation of glucose (step 1), 1 mol of ATP is expended, along with another in the phosphorylation of fructose 6-phosphate (step 3). In step 7, 2 mol of BPG (recall that 2 mol of 1,3-BPG are formed for each mole of glucose) areconverted to 2 mol of 3-phosphoglycerate, and 2 mol of ATP are produced. In step 10, 2 mol of pyruvate and 2 mol of ATPare formed per mole of glucose.
For every mole of glucose degraded, 2 mol of ATP are initially consumed and 4 mol of ATP are ultimately produced. Thenet production of ATP is thus 2 mol for each mole of glucose converted to lactate or ethanol. If 7.4 kcal of energy isconserved per mole of ATP produced, and the total amount of energy that can theoretically be obtained from the completeoxidation of 1 mol of glucose is 670 kcal (as stated in the chapter introduction), the energy conserved in the anaerobiccatabolism of glucose to two molecules of lactate (or ethanol) is as follows:
Thus anaerobic cells extract only a very small fraction of the total energy of the glucose molecule.
Contrast this result with the amount of energy obtained when glucose is completely oxidized to carbon dioxide and waterthrough glycolysis, the citric acid cycle, the electron transport chain, and oxidative phosphorylation as summarized inTable . Note the indication in the table that a variable amount of ATP is synthesized, depending on the tissue, fromthe NADH formed in the cytoplasm during glycolysis. This is because NADH is not transported into the innermitochondrial membrane where the enzymes for the electron transport chain are located. Instead, brain and muscle cellsuse a transport mechanism that passes electrons from the cytoplasmic NADH through the membrane to flavin adeninedinucleotide (FAD) molecules inside the mitochondria, forming reduced flavin adenine dinucleotide (FADH ), which thenfeeds the electrons into the electron transport chain. This route lowers the yield of ATP to 1.5–2 molecules of ATP, ratherthan the usual 2.5–3 molecules. A more efficient transport system is found in liver, heart, and kidney cells where theformation of one cytoplasmic NADH molecule results in the formation of one mitochondrial NADH molecule, which leadsto the formation of 2.5–3 molecules of ATP.The total amount of energy conserved in the aerobic catabolism of glucose inthe liver is as follows:
Conservation of 42% of the total energy released compares favorably with the efficiency of any machine. In comparison,automobiles are only about 20%–25% efficient in using the energy released by the combustion of gasoline.
As indicated earlier, the 58% of released energy that is not conserved enters the surroundings (that is, the cell) as heat thathelps to maintain body temperature. If we are exercising strenuously and our metabolism speeds up to provide the energyneeded for muscle contraction, more heat is produced. We begin to perspire to dissipate some of that heat. As theperspiration evaporates, the excess heat is carried away from the body by the departing water vapor.
SummaryThe monosaccharide glucose is broken down through a series of enzyme-catalyzed reactions known as glycolysis.For each molecule of glucose that is broken down, two molecules of pyruvate, two molecules of ATP, and twomolecules of NADH are produced.In the absence of oxygen, pyruvate is converted to lactate, and NADH is reoxidized to NAD+. In the presence ofoxygen, pyruvate is converted to acetyl-CoA and then enters the citric acid cycle.More ATP can be formed from the breakdown of glucose when oxygen is present.
Concept Review Exercises
1. In glycolysis, how many molecules of pyruvate are produced from one molecule of glucose?
2. In vertebrates, what happens to pyruvate when
a. plenty of oxygen is available?b. oxygen supplies are limited?
×100 = 2.2%2×7.4 kcal
670 kcal(6.6.1)
6.6.1
2
×100 = 42%38×7.4 kcal
670 kcal(6.6.2)

6.6.6 12/5/2021 https://chem.libretexts.org/@go/page/178804
3. In anaerobic glycolysis, how many molecules of ATP are produced from one molecule of glucose?
Answers1. two
2.
a. Pyruvate is completely oxidized to carbon dioxide.b. Pyruvate is reduced to lactate, allowing for the reoxidation of NADH to NAD .
3. There is a net production of two molecules of ATP.
Exercises1. Replace each question mark with the correct compound.
a.
b.
c.
d.
2. Replace each question mark with the correct compound.
a.
b.
c.
d.
3. From the reactions in Exercises 1 and 2, select the equation(s) by number and letter in which each type of reactionoccurs.
a. hydrolysis of a high-energy phosphate compoundb. synthesis of ATP
4. From the reactions in Exercises 1 and 2, select the equation(s) by number and letter in which each type of reactionoccurs.
a. isomerizationb. oxidation
5. What coenzyme is needed as an oxidizing agent in glycolysis?
6. Calculate
a. the total number of molecules of ATP produced for each molecule of glucose converted to pyruvate in glycolysis.b. the number of molecules of ATP hydrolyzed in phase I of glycolysis.c. the net ATP production from glycolysis alone.
7. How is the NADH produced in glycolysis reoxidized when oxygen supplies are limited in
a. muscle cells?b. yeast?
8.
a. Calculate the number of moles of ATP produced by the aerobic oxidation of 1 mol of glucose in a liver cell.
b. Of the total calculated in Exercise 9a, determine the number of moles of ATP produced in each process.
a. glycolysis aloneb. the citric acid cycle
+
fructose 1, 6-bisphosphate ?+?− →−−−aldolase
?+ADP pyruvate+ATP− →−−−−−−−−pyruvate kinase
dihydroxyacetone phosphate glyceraldehyde 3-phosphate→?
glucose+ATP ?+ADP− →−−−−−hexokinase
fructose 6-phosphate+ATP fructose 1, 6-bisphosphate+ADP→?
? fructose 6-phosphate− →−−−−−−−−−−−−−phosphoglucose isomerase
glyceraldehyde 3-phosphate+NA + 1, 3-bisphosphoglycerate+NADHD+ Pi →?
3-phosphoglycerate ?− →−−−−−−−−−−−phosphoglyceromutase

6.6.7 12/5/2021 https://chem.libretexts.org/@go/page/178804
c. the electron transport chain and oxidative phosphorylation
Answersa. 1. glyceraldehyde 3-phosphate + dihydroxyacetone phosphateb. phosphoenolpyruvatec. triose phosphate isomerased. glucose 6-phosphate
a. 3. reactions 1b, 1d, and 2ab. reaction 1b
5. NAD
a. 7. Pyruvate is reduced to lactate, and NADH is reoxidized to NAD .b. Pyruvate is converted to ethanol and carbon dioxide, and NADH is reoxidized to NAD .
+
+
+

6.7.1 1/10/2022 https://chem.libretexts.org/@go/page/178805
6.7: Stage II of Lipid CatabolismLearning Objectives
To describe the reactions needed to completely oxidize a fatty acid to carbon dioxide and water.
Like glucose, the fatty acids released in the digestion of triglycerides and other lipids are broken down in a series ofsequential reactions accompanied by the gradual release of usable energy. Some of these reactions are oxidative andrequire nicotinamide adenine dinucleotide (NAD ) and flavin adenine dinucleotide (FAD). The enzymes that participate infatty acid catabolism are located in the mitochondria, along with the enzymes of the citric acid cycle, the electron transportchain, and oxidative phosphorylation. This localization of enzymes in the mitochondria is of the utmost importancebecause it facilitates efficient utilization of energy stored in fatty acids and other molecules.
Fatty acid oxidation is initiated on the outer mitochondrial membrane. There the fatty acids, which like carbohydrates arerelatively inert, must first be activated by conversion to an energy-rich fatty acid derivative of coenzyme A called fattyacyl-coenzyme A (CoA). The activation is catalyzed by acyl-CoA synthetase. For each molecule of fatty acid activated, onemolecule of coenzyme A and one molecule of adenosine triphosphate (ATP) are used, equaling a net utilization of the twohigh-energy bonds in one ATP molecule (which is therefore converted to adenosine monophosphate [AMP] rather thanadenosine diphosphate [ADP]):
The fatty acyl-CoA diffuses to the inner mitochondrial membrane, where it combines with a carrier molecule known ascarnitine in a reaction catalyzed by carnitine acyltransferase. The acyl-carnitine derivative is transported into themitochondrial matrix and converted back to the fatty acyl-CoA.
Steps in the β-Oxidation of Fatty Acids Further oxidation of the fatty acyl-CoA occurs in the mitochondrial matrix via a sequence of four reactions knowncollectively as β-oxidation because the β-carbon undergoes successive oxidations in the progressive removal of two carbonatoms from the carboxyl end of the fatty acyl-CoA (Figure ).
+
6.7.1

6.7.2 1/10/2022 https://chem.libretexts.org/@go/page/178805
Figure : Fatty Acid Oxidation. The fatty acyl-CoA formed in the final step becomes the substrate for the first step inthe next round of β-oxidation. β-oxidation continues until two acetyl-CoA molecules are produced in the final step.
6.7.1

6.7.3 1/10/2022 https://chem.libretexts.org/@go/page/178805
The first step in the catabolism of fatty acids is the formation of an alkene in an oxidation reaction catalyzed by acyl-CoAdehydrogenase. In this reaction, the coenzyme FAD accepts two hydrogen atoms from the acyl-CoA, one from the α-carbon and one from the β-carbon, forming reduced flavin adenine dinucleotide (FADH ).
The FADH is reoxidized back to FAD via the electron transport chain that supplies energy to form 1.5–2 molecules ofATP.
Next, the trans-alkene is hydrated to form a secondary alcohol in a reaction catalyzed by enoyl-CoA hydratase. Theenzyme forms only the L-isomer.
The secondary alcohol is then oxidized to a ketone by β-hydroxyacyl-CoA dehydrogenase, with NAD acting as theoxidizing agent. The reoxidation of each molecule of NADH to NAD by the electron transport chain furnishes 2.5–3molecules of ATP.
The final reaction is cleavage of the β-ketoacyl-CoA by a molecule of coenzyme A. The products are acetyl-CoA and afatty acyl-CoA that has been shortened by two carbon atoms. The reaction is catalyzed by thiolase.
The shortened fatty acyl-CoA is then degraded by repetitions of these four steps, each time releasing a molecule of acetyl-CoA. The overall equation for the β-oxidation of palmitoyl-CoA (16 carbon atoms) is as follows:
Because each shortened fatty acyl-CoA cycles back to the beginning of thepathway, β-oxidation is sometimes referred to as the fatty acid spiral.
The fate of the acetyl-CoA obtained from fatty acid oxidation depends on the needs of an organism. It may enter the citricacid cycle and be oxidized to produce energy, it may be used for the formation of water-soluble derivatives known asketone bodies, or it may serve as the starting material for the synthesis of fatty acids. For more information about the citricacid cycle, see Section 20.4.
Looking Closer: Ketone BodiesIn the liver, most of the acetyl-CoA obtained from fatty acid oxidation is oxidized by the citric acid cycle. However,some of the acetyl-CoA is used to synthesize a group of compounds known as ketone bodies: acetoacetate, β-hydroxybutyrate, and acetone. Two acetyl-CoA molecules combine, in a reversal of the final step of β-oxidation, toproduce acetoacetyl-CoA. The acetoacetyl-CoA reacts with another molecule of acetyl-CoA and water to form β-hydroxy-β-methylglutaryl-CoA, which is then cleaved to acetoacetate and acetyl-CoA. Most of the acetoacetate isreduced to β-hydroxybutyrate, while a small amount is decarboxylated to carbon dioxide and acetone.
2
2
+
+

6.7.4 1/10/2022 https://chem.libretexts.org/@go/page/178805
The acetoacetate and β-hydroxybutyrate synthesized by the liver are released into the blood for use as a metabolic fuel(to be converted back to acetyl-CoA) by other tissues, particularly the kidney and the heart. Thus, during prolongedstarvation, ketone bodies provide about 70% of the energy requirements of the brain. Under normal conditions, thekidneys excrete about 20 mg of ketone bodies each day, and the blood levels are maintained at about 1 mg of ketonebodies per 100 mL of blood.
In starvation, diabetes mellitus, and certain other physiological conditions in which cells do not receive sufficientamounts of carbohydrate, the rate of fatty acid oxidation increases to provide energy. This leads to an increase in theconcentration of acetyl-CoA. The increased acetyl-CoA cannot be oxidized by the citric acid cycle because of adecrease in the concentration of oxaloacetate, which is diverted to glucose synthesis. In response, the rate of ketonebody formation in the liver increases further, to a level much higher than can be used by other tissues. The excessketone bodies accumulate in the blood and the urine, a condition referred to as ketosis. When the acetone in the bloodreaches the lungs, its volatility causes it to be expelled in the breath. The sweet smell of acetone, a characteristic ofketosis, is frequently noticed on the breath of severely diabetic patients.
Because two of the three kinds of ketone bodies are weak acids, their presence in the blood in excessive amountsoverwhelms the blood buffers and causes a marked decrease in blood pH (to 6.9 from a normal value of 7.4). Thisdecrease in pH leads to a serious condition known as acidosis. One of the effects of acidosis is a decrease in the abilityof hemoglobin to transport oxygen in the blood. In moderate to severe acidosis, breathing becomes labored and verypainful. The body also loses fluids and becomes dehydrated as the kidneys attempt to get rid of the acids by eliminatinglarge quantities of water. The lowered oxygen supply and dehydration lead to depression; even mild acidosis leads tolethargy, loss of appetite, and a generally run-down feeling. Untreated patients may go into a coma. At that point,prompt treatment is necessary if the person’s life is to be saved.
ATP Yield from Fatty Acid Oxidation
The amount of ATP obtained from fatty acid oxidation depends on the size of the fatty acid being oxidized. For ourpurposes here. we’ll study palmitic acid, a saturated fatty acid with 16 carbon atoms, as a typical fatty acid in the humandiet. Calculating its energy yield provides a model for determining the ATP yield of all other fatty acids.
The breakdown by an organism of 1 mol of palmitic acid requires 1 mol of ATP (for activation) and forms 8 mol of acetyl-CoA. Recall from Table 20.4.1 that each mole of acetyl-CoA metabolized by the citric acid cycle yields 10 mol of ATP.

6.7.5 1/10/2022 https://chem.libretexts.org/@go/page/178805
The complete degradation of 1 mol of palmitic acid requires the β-oxidation reactions to be repeated seven times. Thus, 7mol of NADH and 7 mol of FADH are produced. Reoxidation of these compounds through respiration yields 2.5–3 and1.5–2 mol of ATP, respectively. The energy calculations can be summarized as follows:
1 mol of ATP is split to AMP and 2P −2 ATP
8 mol of acetyl-CoA formed (8 × 12) 96 ATP
7 mol of FADH formed (7 × 2) 14 ATP
7 mol of NADH formed (7 × 3) 21 ATP
Total 129 ATP
The number of times β-oxidation is repeated for a fatty acid containing n carbonatoms is n/2 – 1 because the final turn yields two acetyl-CoA molecules.
The combustion of 1 mol of palmitic acid releases a considerable amount of energy:
The percentage of this energy that is conserved by the cell in the form of ATP is as follows:
The efficiency of fatty acid metabolism is comparable to that of carbohydrate metabolism, which we calculated to be 42%.For more information about the efficiency of fatty acid metabolism, see Section 20.5.
The oxidation of fatty acids produces large quantities of water. This water, whichsustains migratory birds and animals (such as the camel) for long periods of time.
Summary Fatty acids, obtained from the breakdown of triglycerides and other lipids, are oxidized through a series of reactionsknown as β-oxidation.In each round of β-oxidation, 1 molecule of acetyl-CoA, 1 molecule of NADH, and 1 molecule of FADH areproduced.The acetyl-CoA, NADH, and FADH are used in the citric acid cycle, the electron transport chain, and oxidativephosphorylation to produce ATP.
Concept Review Exercises
1. How are fatty acids activated prior to being transported into the mitochondria and oxidized?
2. Draw the structure of hexanoic (caproic) acid and identify the α-carbon and the β-carbon.
Answers
1. They react with CoA to form fatty acyl-CoA molecules.
2.
Concept Review Exercises
Exercises
1. For each reaction found in β-oxidation, identify the enzyme that catalyzes the reaction and classify the reaction asoxidation-reduction, hydration, or cleavage.
2
i
2
+23 → 16C +16 O +2, 340 kcalC16H32O2 O2 O2 H2 (6.7.1)
×100 = ×100 = 41%energy conserved
total energy available
(129 ATP)(7.4 kcal/ATP)
2, 340 kcal(6.7.2)
2
2

6.7.6 1/10/2022 https://chem.libretexts.org/@go/page/178805
a.
b.
c.
2. What are the products of β-oxidation?
3. How many rounds of β-oxidation are necessary to metabolize lauric acid (a saturated fatty acid with 12 carbon atoms)?
4. How many rounds of β-oxidation are necessary to metabolize arachidic acid (a saturated fatty acid with 20 carbonatoms)?
5. When myristic acid (a saturated fatty acid with 14 carbon atoms) is completely oxidized by β-oxidation, how manymolecules of each are formed?
a. acetyl-CoAb. FADHc. NADH
6. When stearic acid (a saturated fatty acid with 18 carbon atoms) is completely oxidized by β-oxidation, how manymolecules of each are formed?
a. acetyl-CoAb. FADHc. NADH
7. What is the net yield of ATP from the complete oxidation, in a liver cell, of one molecule of myristic acid?
8. What is the net yield of ATP from the complete oxidation, in a liver cell, of one molecule of stearic acid?
Answers1.
a. enoyl-CoA hydratase; hydrationb. thiolase; cleavagec. acyl-CoA dehydrogenase; oxidation-reduction
3. five rounds
5.
a. 7 moleculesb. 6 moleculesc. 6 molecules
7. 112 molecules
2
2

6.8.1 1/5/2022 https://chem.libretexts.org/@go/page/178806
6.8: Stage II of Protein CatabolismLearning Objectives
To describe how excess amino acids are degraded.
The liver is the principal site of amino acid metabolism, but other tissues, such as the kidney, the small intestine, muscles,and adipose tissue, take part. Generally, the first step in the breakdown of amino acids is the separation of the amino groupfrom the carbon skeleton, usually by a transamination reaction. The carbon skeletons resulting from the deaminated aminoacids are used to form either glucose or fats, or they are converted to a metabolic intermediate that can be oxidized by thecitric acid cycle. The latter alternative, amino acid catabolism, is more likely to occur when glucose levels are low—forexample, when a person is fasting or starving.
Transamination
Transamination is an exchange of functional groups between any amino acid (except lysine, proline, and threonine) and anα-keto acid. The amino group is usually transferred to the keto carbon atom of pyruvate, oxaloacetate, or α-ketoglutarate,converting the α-keto acid to alanine, aspartate, or glutamate, respectively. Transamination reactions are catalyzed byspecific transaminases (also called aminotransferases), which require pyridoxal phosphate as a coenzyme.
Figure ).
In an α-keto acid, the carbonyl or keto group is located on the carbon atomadjacent to the carboxyl group of the acid.
Figure : Two Transamination Reactions. In both reactions, the final acceptor of the amino group is α-ketoglutarate,and the final product is glutamate.
6.8.1
6.8.1

6.8.2 1/5/2022 https://chem.libretexts.org/@go/page/178806
Oxidative Deamination
In the breakdown of amino acids for energy, the final acceptor of the α-amino group is α-ketoglutarate, forming glutamate.Glutamate can then undergooxidative deamination, in which it loses its amino group as an ammonium (NH ) ion and isoxidized back to α-ketoglutarate (ready to accept another amino group):
This reaction occurs primarily in liver mitochondria. Most of the NH ion formed by oxidative deamination of glutamateis converted to urea and excreted in the urine in a series of reactions known as the urea cycle.
The synthesis of glutamate occurs in animal cells by reversing the reaction catalyzed by glutamate dehydrogenase. For thisreaction nicotinamide adenine dinucleotide phosphate (NADPH) acts as the reducing agent. The synthesis of glutamate issignificant because it is one of the few reactions in animals that can incorporate inorganic nitrogen (NH ) into an α-ketoacid to form an amino acid. The amino group can then be passed on through transamination reactions, to produce otheramino acids from the appropriate α-keto acids.
The Fate of the Carbon Skeleton Any amino acid can be converted into an intermediate of the citric acid cycle. Once the amino group is removed, usuallyby transamination, the α-keto acid that remains is catabolized by a pathway unique to that acid and consisting of one ormore reactions. For example, phenylalanine undergoes a series of six reactions before it splits into fumarate andacetoacetate. Fumarate is an intermediate in the citric acid cycle, while acetoacetate must be converted to acetoacetyl-coenzyme A (CoA) and then to acetyl-CoA before it enters the citric acid cycle.
Figure : Fates of the Carbon Skeletons of Amino Acids
Those amino acids that can form any of the intermediates of carbohydrate metabolism can subsequently be converted toglucose via a metabolic pathway known as gluconeogenesis. These amino acids are called glucogenic amino acids. Aminoacids that are converted to acetoacetyl-CoA or acetyl-CoA, which can be used for the synthesis of ketone bodies but notglucose, are called ketogenic amino acids. Some amino acids fall into both categories. Leucine and lysine are the only
4+
4+
4+
6.8.2

6.8.3 1/5/2022 https://chem.libretexts.org/@go/page/178806
amino acids that are exclusively ketogenic. Figure summarizes the ultimate fates of the carbon skeletons of the 20amino acids.
Career Focus: Exercise PhysiologistAn exercise physiologist works with individuals who have or wish to prevent developing a wide variety of chronicdiseases, such as diabetes, in which exercise has been shown to be beneficial. Each individual must be referred by alicensed physician. An exercise physiologist works in a variety of settings, such as a hospital or in a wellness programat a commercial business, to design and monitor individual exercise plans. A registered clinical exercise physiologistmust have an undergraduate degree in exercise physiology or a related degree. Some job opportunities require amaster’s degree in exercise physiology or a related degree.
Ergospirometry laboratory for the measurement of metabolic changes during a graded exercise test on a treadmill.Image used with permission from Wikipedia.
Summary
Generally the first step in the breakdown of amino acids is the removal of the amino group, usually through a reactionknown as transamination. The carbon skeletons of the amino acids undergo further reactions to form compounds that caneither be used for the synthesis of glucose or the synthesis of ketone bodies.
Concept Review Exercises
a. 1. Write the equation for the transamination reaction between alanine and oxaloacetate.b. Name the two products that are formed.
2. What is the purpose of oxidative deamination?
Answers
1. a. b. pyruvate and aspartate
2. Oxidative deamination provides a reaction in which the amino group [as the ammonium (NH ) ion] is removed from amolecule, not simply transferred from one molecule to another. Most of the NH ion is converted to urea and excretedfrom the body.
6.8.2
4+
4+

6.8.4 1/5/2022 https://chem.libretexts.org/@go/page/178806
Exercises
1. Write the equation for the transamination reaction between valine and pyruvate.
2. Write the equation for the transamination reaction between phenylalanine and oxaloacetate.
3. What products are formed in the oxidative deamination of glutamate?
4. Determine if each amino acid is glucogenic, ketogenic, or both.
a. phenylalanineb. leucinec. serine
5. Determine if each amino acid is glucogenic, ketogenic, or both.
a. asparagineb. tyrosinec. valine
Answers
1.
3. α-ketoglutarate, NADH, and NH
a. 5. glucogenicb. bothc. glucogenic
4+

6.9.1 12/12/2021 https://chem.libretexts.org/@go/page/178807
6.9: Energy Metabolism (Summary)To ensure that you understand the material in this chapter, you should review the meanings of the bold terms in the
following summary and ask yourself how they relate to the topics in the chapter.
Metabolism is the general term for all chemical reactions in living organisms. The two types of metabolism arecatabolism—those reactions in which complex molecules (carbohydrates, lipids, and proteins) are broken down to simplerones with the concomitant release of energy—and anabolism—those reactions that consume energy to build complexmolecules. Metabolism is studied by looking at individual metabolic pathways, which are a series of biochemicalreactions in which a given reactant is converted to a desired end product.
The oxidation of fuel molecules (primarily carbohydrates and lipids), a process called respiration, is the source of energyused by cells. Catabolic reactions release energy from food molecules and use some of that energy for the synthesis ofadenosine triphosphate (ATP); anabolic reactions use the energy in ATP to create new compounds. Catabolism can bedivided into three stages. In stage I, carbohydrates, lipids, and proteins are broken down into their individual monomerunits—simple sugars, fatty acids, and amino acids, respectively. In stage II, these monomer units are broken down byspecific metabolic pathways to form a common end product acetyl-coenzyme A (CoA). In stage III, acetyl-CoA iscompletely oxidized to form carbon dioxide and water, and ATP is produced.
The digestion of carbohydrates begins in the mouth as α-amylase breaks glycosidic linkages in carbohydrate molecules.Essentially no carbohydrate digestion occurs in the stomach, and food particles pass through to the small intestine, whereα-amylase and intestinal enzymes convert complex carbohydrate molecules (starches) to monosaccharides. Themonosaccharides then pass through the lining of the small intestine and into the bloodstream for transport to all body cells.
Protein digestion begins in the stomach as pepsinogen in gastric juice is converted to pepsin, the enzyme that hydrolyzespeptide bonds. The partially digested protein then passes to the small intestine, where the remainder of protein digestiontakes place through the action of several enzymes. The resulting amino acids cross the intestinal wall into the blood and arecarried to the liver.
Lipid digestion begins in the small intestine. Bile salts emulsify the lipid molecules, and then lipases hydrolyze them tofatty acids and monoglycerides. The hydrolysis products pass through the intestine and are repackaged for transport in thebloodstream.
In cells that are operating aerobically, acetyl-CoA produced in stage II of catabolism is oxidized to carbon dioxide. Thecitric acid cycle describes this oxidation, which takes place with the formation of the coenzymes reduced nicotinamideadenine dinucleotide (NADH) and reduced flavin adenine dinucleotide (FADH ). The sequence of reactions needed tooxidize these coenzymes and transfer the resulting electrons to oxygen is called the electron transport chain, or therespiratory chain. The compounds responsible for this series of oxidation-reduction reactions include proteins known ascytochromes, Fe·S proteins, and other molecules that ultimately result in the reduction of molecular oxygen to water.Every time a compound with two carbon atoms is oxidized in the citric acid cycle, a respiratory chain compound acceptsthe electrons lost in the oxidation (and so is reduced) and then passes them on to the next metabolite in the chain. Theenergy released by the electron transport chain is used to transport hydrogen (H ) ions from the mitochondrial matrix tothe intermembrane space. The flow of H back through ATP synthase leads to the synthesis and release of ATP fromadenosine diphosphate (ADP) and inorganic phosphate ions (P ) in a process known as oxidative phosphorylation.Electron transport and oxidative phosphorylation are tightly coupled to each other. The enzymes and intermediates of thecitric acid cycle, the electron transport chain, and oxidative phosphorylation are located in organelles called mitochondria.
The oxidation of carbohydrates is the source of over 50% of the energy used by cells. Glucose is oxidized to two moleculesof pyruvate through a series of reactions known as glycolysis. Some of the energy released in these reactions is conservedby the formation of ATP from ADP. Glycolysis can be divided into two phases: phase I consists of the first five reactionsand requires energy to “prime” the glucose molecule for phase II, the last five reactions in which ATP is produced throughsubstrate-level phosphorylation.
The pyruvate produced by glycolysis has several possible fates, depending on the organism and whether or not oxygen ispresent. In animal cells, pyruvate can be further oxidized to acetyl-CoA and then to carbon dioxide (through the citric acidcycle) if oxygen supplies are sufficient. When oxygen supplies are insufficient, pyruvate is reduced to lactate. In yeast and
2
+
+
i

6.9.2 12/12/2021 https://chem.libretexts.org/@go/page/178807
other microorganisms, pyruvate is not converted to lactate in the absence of oxygen but instead is converted to ethanol andcarbon dioxide.
The amount of ATP formed by the oxidation of glucose depends on whether or not oxygen is present. If oxygen is present,glucose is oxidized to carbon dioxide, and 36–38 ATP molecules are produced for each glucose molecule oxidized, usingthe combined pathways of glycolysis, the citric acid cycle, the electron transport chain, and oxidative phosphorylation.Thus, approximately 42% of the energy released by the complete oxidation of glucose is conserved by the synthesis ofATP. In the absence of oxygen, only 2 molecules of ATP are formed for each molecule of glucose converted to lactate (2molecules), and the amount of energy conserved is much less (2%).
Fatty acids, released by the degradation of triglycerides and other lipids, are converted to fatty acyl-CoA, transported intothe mitochondria, and oxidized by repeated cycling through a sequence of four reactions known as β-oxidation. In eachround of β-oxidation, the fatty acyl-CoA is shortened by two carbon atoms as one molecule of acetyl-CoA is formed. Thefinal round of β-oxidation, once the chain has been shortened to four carbon atoms, forms two molecules of acetyl-CoA. β-oxidation also forms the reduced coenzymes FADH and NADH, whose reoxidation through the electron transport chainand oxidative phosphorylation leads to the synthesis of ATP. The efficiency of fatty acid oxidation in the human body isapproximately 41%.
Amino acids from the breakdown of proteins can be catabolized to provide energy. Amino acids whose carbon skeletonsare converted to intermediates that can be converted to glucose through gluconeogenesis are known as glucogenic aminoacids. Amino acids whose carbon skeletons are broken down to compounds used to form ketone bodies are known asketogenic amino acids.
The first step in amino acid catabolism is separation of the amino group from the carbon skeleton. In a transamination,the amino acid gives its NH to pyruvate, α-ketoglutarate, or oxaloacetate. The products of this reaction are a new aminoacid and an α-keto acid containing the carbon skeleton of the original amino acid. Pyruvate is transaminated to alanine, α-ketoglutarate to glutamate, and oxaloacetate to aspartate. The amino groups used to form alanine and aspartate areultimately transferred to α-ketoglutarate, forming glutamate. The glutamate then undergoes oxidative deamination toyield α-ketoglutarate and ammonia.
Template:HideOrg
2
2

6.10.1 1/5/2022 https://chem.libretexts.org/@go/page/178808
6.10: Energy Metabolism (Exercises)
Additional Exercises
1. Hydrolysis of which compound—arginine phosphate or glucose 6-phosphate—would provide enough energy for thephosphorylation of ATP? Why?
2. If a cracker, which is rich in starch, is chewed for a long time, it begins to develop a sweet, sugary taste. Why?
3. Indicate where each enzymes would cleave the short peptide ala-ser-met-val-phe-gly-cys-lys-asp-leu.
a. aminopeptidaseb. chymotrypsin
4. Indicate where each enzymes would cleave the short peptide ala-ser-met-val-phe-gly-cys-lys-asp-leu.
a. trypsinb. carboxypeptidase
5. If the methyl carbon atom of acetyl-CoA is labeled, where does the label appear after the acetyl-CoA goes through oneround of the citric acid cycle?
6. If the carbonyl carbon atom of acetyl-CoA is labeled, where does the label appear after the acetyl-CoA goes throughone round of the citric acid cycle?
7. The average adult consumes about 65 g of fructose daily (either as the free sugar or from the breakdown of sucrose). Inthe liver, fructose is first phosphorylated to fructose 1-phosphate, which is then split into dihydroxyacetone phosphateand glyceraldehyde. Glyceraldehyde is then phosphorylated to glyceraldehyde 3-phosphate, with ATP as the phosphategroup donor. Write the equations (using structural formulas) for these three steps. Indicate the type of enzyme thatcatalyzes each step.
8. What critical role is played by both BPG and PEP in glycolysis?
9. How is the NADH produced in glycolysis reoxidized when oxygen supplies are abundant?
10. When a triglyceride is hydrolyzed to form three fatty acids and glycerol, the glycerol can be converted to glycerol 3-phosphate and then oxidized to form dihydroxyacetone phosphate, an intermediate of glycolysis. (In this reaction,NAD is reduced to NADH.) If you assume that there is sufficient oxygen to completely oxidize the pyruvate formedfrom dihydroxyacetone phosphate, what is the maximum amount of ATP formed from the complete oxidation of 1 molof glycerol?
11. How is the FADH from β-oxidation converted back to FAD?
12. If 1 mol of alanine is converted to pyruvate in a muscle cell (through transamination) and the pyruvate is thenmetabolized via the citric acid cycle, the electron transport chain, and oxidative phosphorylation, how many moles ofATP are produced?
13. If the essential amino acid leucine (2-amino-4-methylpentanoic acid) is lacking in the diet, an α-keto acid can substitutefor it. Give the structure of the α-keto acid and the probable reaction used to form leucine from this α-keto acid.
Answers1. The hydrolysis of arginine phosphate releases more energy than is needed for the synthesis of ATP, while hydrolysis of
glucose 6-phosphate does not.
a. 3. The enzyme will cleave off amino acids one at a time beginning with alanine (the N-terminal end).b. following phenylalanine
5. Half of the label will be on the second carbon atom of oxaloacetate, while the other half will be on the third carbonatom.
+
2

6.10.2 1/5/2022 https://chem.libretexts.org/@go/page/178808
7.
9. When oxygen is abundant, NADH is reoxidized through the reactions of the electron transport chain.
11. FADH is reoxidized back to FAD via the electron transport chain.
13.
2

1 1/10/2022
CHAPTER OVERVIEW7: CHEMICAL MESSENGERS: HORMONES, NEUROTRANSMITTERS, ANDDRUGS
An GOB Chemistry Textmap organized around the textbook Fundamentals of General Organic & Biological Chemistry by John McMurry, Virginia Peterson, and Carl Hoegar
Thumbnail: A ball-and-stick model of testosterone. Testosterone is the primary male sex hormone and an anabolic steroid. Image usedwith perspective (Public Domain; Ben Mills).
7.1: MESSENGER MOLECULES7.2: HORMONES AND THE ENDOCRINE SYSTEM7.3: HOW HORMONES WORK - EPINEPHRINE AND FIGHT-OR-FLIGHT7.4: AMINO ACID DERIVATIVES AND POLYPEPTIDES AS HORMONES7.5: STEROID HORMONES7.6: NEUROTRANSMITTERS7.7: HOW NEUROTRANSMITTERS WORK: ACETYLCHOLINE, ITS AGONISTS AND ANTAGONISTS7.8: HISTAMINE AND ANTIHISTAMINES7.9: SEROTONIN, NOREPINEPHRINE, AND DOPAMINE7.10: NEUROPEPTIDES AND PAIN RELIEF7.11: DRUG DISCOVERY AND DRUG DESIGN

7.1.1 1/5/2022 https://chem.libretexts.org/@go/page/178810
Edit page
Drag and drop
Classifications
Working with templates
7.1: Messenger Molecules
Your page has been created!Remove this content and add your own.
Click the Edit page button in your user bar. You will see a suggested structure for your content. Add your content andhit Save.
Tips:
Drag one or more image files from your computer and drop them onto your browser window to add them to yourpage.
Tags are used to link pages to one another along common themes. Tags are also used as markers for the dynamicorganization of content in the CXone Expert framework.
CXone Expert templates help guide and organize your documentation, making it flow easier and more uniformly.Edit existing templates or create your own.
Visit for all help topics.

7.2.1 12/12/2021 https://chem.libretexts.org/@go/page/178811
Edit page
Drag and drop
Classifications
Working with templates
7.2: Hormones and the Endocrine System
Your page has been created!Remove this content and add your own.
Click the Edit page button in your user bar. You will see a suggested structure for your content. Add your content andhit Save.
Tips:
Drag one or more image files from your computer and drop them onto your browser window to add them to yourpage.
Tags are used to link pages to one another along common themes. Tags are also used as markers for the dynamicorganization of content in the CXone Expert framework.
CXone Expert templates help guide and organize your documentation, making it flow easier and more uniformly.Edit existing templates or create your own.
Visit for all help topics.

7.3.1 1/5/2022 https://chem.libretexts.org/@go/page/178812
Edit page
Drag and drop
Classifications
Working with templates
7.3: How Hormones Work - Epinephrine and Fight-or-Flight
Your page has been created!Remove this content and add your own.
Click the Edit page button in your user bar. You will see a suggested structure for your content. Add your content andhit Save.
Tips:
Drag one or more image files from your computer and drop them onto your browser window to add them to yourpage.
Tags are used to link pages to one another along common themes. Tags are also used as markers for the dynamicorganization of content in the CXone Expert framework.
CXone Expert templates help guide and organize your documentation, making it flow easier and more uniformly.Edit existing templates or create your own.
Visit for all help topics.

1 12/7/2021 https://chem.libretexts.org/@go/page/178813
Welcome to the Chemistry Library. This Living Library is a principal hub of the LibreTexts project, which is a multi-institutional collaborative venture to develop the next generation of open-access texts to improve postsecondary educationat all levels of higher learning. The LibreTexts approach is highly collaborative where an Open Access textbookenvironment is under constant revision by students, faculty, and outside experts to supplant conventional paper-basedbooks.
Campus Bookshelves Bookshelves
Learning Objects

7.5.1 12/26/2021 https://chem.libretexts.org/@go/page/178814
Edit page
Drag and drop
Classifications
Working with templates
7.5: Steroid Hormones
Your page has been created!Remove this content and add your own.
Click the Edit page button in your user bar. You will see a suggested structure for your content. Add your content andhit Save.
Tips:
Drag one or more image files from your computer and drop them onto your browser window to add them to yourpage.
Tags are used to link pages to one another along common themes. Tags are also used as markers for the dynamicorganization of content in the CXone Expert framework.
CXone Expert templates help guide and organize your documentation, making it flow easier and more uniformly.Edit existing templates or create your own.
Visit for all help topics.

7.6.1 1/10/2022 https://chem.libretexts.org/@go/page/178815
Edit page
Drag and drop
Classifications
Working with templates
7.6: Neurotransmitters
Your page has been created!Remove this content and add your own.
Click the Edit page button in your user bar. You will see a suggested structure for your content. Add your content andhit Save.
Tips:
Drag one or more image files from your computer and drop them onto your browser window to add them to yourpage.
Tags are used to link pages to one another along common themes. Tags are also used as markers for the dynamicorganization of content in the CXone Expert framework.
CXone Expert templates help guide and organize your documentation, making it flow easier and more uniformly.Edit existing templates or create your own.
Visit for all help topics.

7.7.1 12/19/2021 https://chem.libretexts.org/@go/page/178816
7.7: How Neurotransmitters Work: Acetylcholine, Its Agonists and Antagonists

7.8.1 12/26/2021 https://chem.libretexts.org/@go/page/178817
7.8: Histamine and Antihistamines
7.9.1 12/11/2021 https://chem.libretexts.org/@go/page/178818
7.9: Serotonin, Norepinephrine, and Dopamine

7.10.1 12/19/2021 https://chem.libretexts.org/@go/page/178819
7.10: Neuropeptides and Pain Relief

7.11.1 12/5/2021 https://chem.libretexts.org/@go/page/178820
7.11: Drug Discovery and Drug Design

Index
Bbile
3.5: Steroids
Cchirality
1.18: Chirality and Stereoisomers cholesterol
3.5: Steroids
DDenaturation
4.5: Proteins Diisopropyl fluorophosphate (DIFP)
4.9: Enzyme Inhibition
EEnergy Metabolism
6: Energy Metabolism Enzyme Classification Number
4.6: Enzymes Enzyme Inhibition
4.9: Enzyme Inhibition enzymes
4.6: Enzymes
Ffats
3.3: Fats and Oils fatty acids
3.2: Fatty Acids
Iinsulin
4.1: Prelude to Amino Acids, Proteins, andEnzymes
Mmembrane lipids
3.4: Membranes and Membrane Lipids Membranes
3.4: Membranes and Membrane Lipids
Nnucleotide
5.2: Nucleotides
Ooils
3.3: Fats and Oils
PPoisons
4.9: Enzyme Inhibition purine
5.2: Nucleotides pyrimidine
5.2: Nucleotides
RRenaturation
4.5: Proteins
Sstereoisomers
1.18: Chirality and Stereoisomers Steroids
3.5: Steroids
Ttriglyceride
3.3: Fats and Oils
Wwaxes
3.2: Fatty Acids

Glossary
Sample Word 1 | SampleDefinition 1




















