
Answer Selection and Validation for Arabic Questions
73
Arab Academy for Science, Technology and Maritime Transport College of Computing and Information Technology Department of Computer Science Answer Selection and Validation Answer Selection and Validation for Arabic Questions for Arabic Questions By Ahmed Magdy Ezzeldin Egypt Submitted to Arab Academy for Science, Technology and Maritime Transport in partial fulfillment of the requirements for the degree of Master of Computer Science Supervised by Prof. Dr. Yasser El-Sonbaty College of Computing & Information Technology Arab Academy for Science, Technology and Maritime Transport Dr. Mohamed Hamed Kholief College of Computing & Information Technology Arab Academy for Science, Technology and Maritime Transport 2014
Transcript of Answer Selection and Validation for Arabic Questions

Arab Academy for Science, Technology and Maritime Transport
College of Computing and Information Technology
Department of Computer Science
Answer Selection and ValidationAnswer Selection and Validation
for Arabic Questionsfor Arabic QuestionsBy
Ahmed Magdy EzzeldinEgypt
Submitted to Arab Academy for Science, Technology and Maritime
Transport in partial fulfillment of the requirements for the degree of
Master of Computer Science
Supervised by
Prof. Dr. Yasser El-Sonbaty
College of Computing & Information Technology
Arab Academy for Science, Technology and Maritime
Transport
Dr. Mohamed Hamed Kholief
College of Computing & Information Technology
Arab Academy for Science, Technology and Maritime
Transport
2014

DECLARATION
I certify that all the material in this thesis that is not my own work has been identified, and that no material
is included for which a degree has previously been conferred on me. The contents of this thesis reflect my own
personal views, and are not necessarily endorsed by the University.
Signature:
Date: 23/9/2014
2

3

Abstract
Arabic is the 6th most wide-spread natural language in the world with more than 350 million native speakers.
Arabic question answering systems are gaining great significance due to the increasing amounts of Arabic un-
structured content on the Internet and the increasing demand for information that regular information retrieval
techniques do not satisfy. Question answering systems generally, and Arabic systems are no exception, hit an up-
per bound of performance due to the propagation of error in their pipeline. This increases the significance of an-
swer selection and validation systems as they enhance the certainty and accuracy of question answering systems.
Very few works tackled the Arabic answer selection and validation problem, and they used the same question an-
swering pipeline without any changes to satisfy the requirements of answer selection and validation. That is why
they did not perform adequately well in this task. In this dissertation, a new approach to Arabic answer selection
and validation is presented through “ALQASIM”, which is a QA4MRE (Question Answering for Machine Read-
ing Evaluation) system. ALQASIM analyzes the reading test documents instead of the questions, utilizes sen-
tence splitting, root expansion, and semantic expansion using an ontology built from the CLEF 2012 background
collections. Our experiments have been conducted on the test-set provided by CLEF 2012 through the task of
QA4MRE. This approach led to a promising performance of 0.36 Accuracy and 0.42 C@1, which is double the
performance of the best performing Arabic QA4MRE system.
4

Acknowledgements
In the name of Allah, Who helped and guided me through the journey of my studies and my life ( لله .(الحمد
Special thanks to my supervisors, Prof. Dr. Yasser El-sonbaty and Dr. Mohamed Kholief, who guided me with
their experience and sense of perfection throughout the thesis, which improved the results of our research and the
papers dramatically.
I also thank all the doctors who taught me and helped me through out my studies in AASTMT. With their
hard work, I learned a lot that helped me to choose my field of research and develop a scientific way of thinking.
And a special thank you for Dr. Mohamed Shaheen who taught me a lot about academic writing and guided me
through writing my first paper. I would also like to thank Prof. Dr. Mohamed Ismail who accepted to award me
this privilege by examining and accepting my thesis.
I would have never accomplished this work without the support of my family. My mother and father who
taught me everything they could in my early years and who gave me the sense of perfection that helped me
through out the years of my study and life. Thank you my dear beloved wife Shimaa, who were there for me in
every moment, provided me with all the support to help me rise against all the hardships of this journey. May Al-
lah bless you Shimaa and bless our beloved child Mariam.
5

Table of Contents
Abstract................................................................................................................................................................ 4
List of Figures.......................................................................................................................................................8
List of Abbreviations............................................................................................................................................ 9
Chapter One Introduction…................................................................................................................................10
1.1. Background and Context............................................................................................................................11
1.1.1. Arabic Specific Difficulties.................................................................................................................11
1.1.2. Question Answering and its significance............................................................................................13
1.1.3. Pipeline of QA.....................................................................................................................................14
1.1.4. Question Answering for Machine Reading Evaluation (QA4MRE)...................................................14
1.2. Scope and Objectives.................................................................................................................................15
1.3. Achievements.............................................................................................................................................15
1.4. Overview of Dissertation...........................................................................................................................16
Chapter Two Related Works................................................................................................................................17
2.1. Arabic QA systems....................................................................................................................................18
2.1.1. Question Analysis...............................................................................................................................22
2.1.2. Passage Retrieval................................................................................................................................23
2.1.3. Answer Extraction and Validation.....................................................................................................25
2.2. The Best Performing English QA System................................................................................................27
2.3. Answer Selection and QA4MRE systems................................................................................................27
Chapter Three Tools, Test-set and Evaluation Metrics…...................................................................................31
3.1. Tools and Resources..................................................................................................................................32
3.1.1. MADA+TOKAN PoS tagger..............................................................................................................32
3.1.2. Root Stemmers...................................................................................................................................34
3.1.2.1. Khoja Root Stemmer...................................................................................................................34
3.1.2.2. ISRI Root Stemmer.....................................................................................................................34
3.1.2.3. Tashaphyne Root Stemmer..........................................................................................................34
3.1.3. Arabic WordNet.................................................................................................................................35
3.2. Test-set......................................................................................................................................................35
3.3. Evaluation metrics....................................................................................................................................36
3.3.1. Accuracy.............................................................................................................................................36
3.3.2. C@1...................................................................................................................................................37
6

Chapter Four System Architecture......................................................................................................................38
4.1. ALQASIM 1.0 Initial Architecture............................................................................................................39
4.1.1. Document Analysis.............................................................................................................................40
4.1.2. Locating Questions & Answers..........................................................................................................41
4.1.3. Answer Selection................................................................................................................................41
4.1.4. Evaluation of ALQASIM 1.0..............................................................................................................41
4.2. ALQASIM 2.0 Architecture......................................................................................................................43
4.2.1. Document Analysis.............................................................................................................................43
4.2.1.1. Inverted Index...............................................................................................................................44
4.2.1.2. Morphological analysis module...................................................................................................45
4.2.1.3. Sentence splitting module............................................................................................................45
4.2.1.4. Root Expansion module...............................................................................................................46
4.2.1.5. Numeric Expansion module........................................................................................................46
4.2.1.6. Ontology-based Semantic Expansion module.............................................................................47
4.2.2. Question Analysis..............................................................................................................................48
4.2.3. Answer Selection...............................................................................................................................49
Chapter Five Results and Analysis.....................................................................................................................50
5.1. Results.......................................................................................................................................................51
5.2. Analysis....................................................................................................................................................55
Chapter Six Conclusion and Future Work..........................................................................................................59
6.1. Summary...................................................................................................................................................60
6.2. Evaluation.................................................................................................................................................61
6.3. Future Work..............................................................................................................................................61
6.3.1. Rule-based techniques........................................................................................................................62
6.3.2. Anaphora Resolution.........................................................................................................................62
6.3.3. Semantic Parsing and Semantic Role Labeling.................................................................................62
6.3.4. More Automatically Generated Ontologies.......................................................................................63
References............................................................................................................................................................64
Appendix A..........................................................................................................................................................68
7

List of Figures
Figure 1. Example Arabic Derivation...................................................................................................................... 12
Figure 2. Example Arabic Inflection....................................................................................................................... 13
Figure 3. Arabic Question Answering Subtasks...................................................................................................... 14
Figure 4. The architecture of ArabiQA (Benajiba & Rosso, 2007)......................................................................... 19
Figure 5. QASAL architectural components Brini et al., 2009............................................................................... 20
Figure 6. JIRS Passage Retrieval System Architecture (Benajiba et al., 2007)....................................................... 24
Figure 7. Example of the Answer Extraction module's performance steps Benajiba et al., 2007...........................26
Figure 8. Performance of QA4MRE systems @ CLEF 2012.................................................................................. 29
Figure 9. Overview of ALQASIM architecture ..................................................................................................... 39
Figure 10. Detailed Architecture of ALQASIM...................................................................................................... 40
Figure 11. The performance of ALQASIM 1.0 versus the other two Arabic QA4MRE systems...........................42
Figure 12. Example for failure of ALQASIM 1.0 while trying to locate the question snippet...............................42
Figure 13. ALQASIM 2.0 Architecture.................................................................................................................. 43
Figure 14. Document Analysis module architecture............................................................................................... 44
Figure 15. The intuition behind extracting the background collection ontology..................................................... 47
Figure 16. Question Analysis module architecture.................................................................................................. 48
Figure 17. Answer Selection module architecture................................................................................................... 49
Figure 18. Comparison between QA4MRE systems............................................................................................... 53
Figure 19. Performance in terms of answered questions counts.............................................................................. 53
Figure 20. Ratio between correctly answered, wrongly answered and unanswered questions in run 4..................54
Figure 21. An example showing the effect of sentence splitting in ALQASIM 2.0................................................ 55
Figure 22. An example of the effect of ontology expansion in ALQASIM 2.0...................................................... 56
Figure 23. An example showing the effect of root expansion in ALQASIM 2.0.................................................... 57
ALQASIM platform main screen showing results.................................................................................................. 68
Screen showing a correctly answered question with the question answer colored.................................................68
Screen showing a wrongly answered question........................................................................................................ 69
Schema of the input questions after applying morphological analysis................................................................... 69
8

List of Abbreviations
• AVE: Answer Validation Exercise
• AWN: Arabic WordNet
• CLEF: Conference and Labs of the Evaluation Forum
• IR: Information Retrieval
• JIRS: Java Information Retrieval System
• ML: Machine Learning
• MRE: Machine Reading Evaluation
• MRR: Mean Reciprocal Rank
• MSA: Modern Standard Arabic
• MT: Machine Translation
• NE: Named Entity
• NER: Named Entity Recognition
• NLP: Natural Language Processing
• PoS: Part-of-Speech
• QA: Question Answering
• QA4MRE: Question Answering for Machine Reading Evaluation
• TREC: Text REtrieval Conference
9

Chapter OneChapter One
IntroductionIntroduction
10

Chapter 1Chapter 1
IntroductionIntroduction
Arabic is the 6th most wide-spread natural language in the world with more than 350 million native speakers.
Arabic is a highly inflectional, derivational, and morphologically rich language that requires special handling on
the different Natural Language Processing tools and tasks. Arabic question answering systems are gaining great
importance due to the increase of Arabic content on the Internet and the increasing need for information that the
traditional information retrieval systems cannot satisfy.
In this chapter, “Question Answering” (QA) as a task is defined and its significance is highlighted. Arabic
language specific difficulties that emerge from its rich morphology are also demonstrated. Then the QA subtasks
and pipeline is explained. The scope of the dissertation is then explained.
1.1. Background and Context
In this section, Arabic specific difficulties are explained. The definition of QA and its significance are
demonstrated, and the significance of this dissertation to Arabic QA is then highlighted.
1.1.1. Arabic Specific Difficulties
Arabic is a very rich language; however, this richness needs special handling, which makes regular Natural
Language Processing (NLP) systems, designed for other languages, unable to handle it. In the field of QA, Eng-
lish and other Latin-based languages benefited a lot from the advancement in NLP. However, Arabic Question
Answering systems are lagging behind when compared to their English and Latin-based counterparts due to the
Arabic specific difficulties.
One of the Arabic specific difficulties is the lack of diacritics in Modern Standard Arabic (MSA), which adds
to the ambiguity of the question and the searched documents. For example the word “علم” can have different
meaning according to the application of different diacritics as shown in Table 1. However, much interest has been
given to diacritizing MSA to resolve this ambiguity.
11

Table 1: Different meanings for the word “علم” due to different diacritics
Undiacritized word Diacritized word English Pronunciation Meaning
علم ْم َل َع Alam Flag
علم ْم ْل ِع Elm Science
علم َم َّل َع Allama Taught
علم َم ِل َع Alema Knew
Arabic is a highly derivational language as the vocabulary of Arabic words are essentially built from about
10,000 three or four letters roots, and derivations of these roots are created by adding affixes (prefix, infix, or
suffix) to each root according to about 120 patterns. As illustrated in Figure 1, derivations in Arabic are almost
always like this: Lemma = Root + Pattern (Abdelbaki & Shaheen, 2011). This derivational nature increases the
size of the Arabic vocabulary dramatically and makes building a high coverage semantic Language Resource
(LR) very challenging.
Arabic language morphology is challenging when compared to English and other Latin-based languages. This
is because Arabic is a highly inflectional language where a word token can consist of multiple morphemes. As il-
lustrated in Figure 2, an Arabic word may take this form "Word = Lemma + affixes (prefix, infix, and suffix)".
The prefixes can be articles, prepositions or conjunctions, which causes a lot of sparseness in index documents
and makes query expansion harder. This inflectional nature needs special handling for different Arabic NLP
tasks like stemming, lemmatization, morphological analysis, PoS tagging and even tokenization. Various tools
were developed to address this need as described shortly.
Unlike English and most Latin-based languages, Arabic does not have capital letters which makes Named En-
tity Recognition (NER) harder. In the next section, we will review the different approaches to the NER task.
Figure 1. Example Arabic Derivation
12

Figure 2. Example Arabic Inflection
1.1.2. Question Answering and its significance
In Information Retrieval (IR) and Natural Language Processing (NLP), Question Answering (QA) is the task
of automatically providing an answer for a question posed by a human in natural language. QA as a task can be
divided into three main distinct subtasks, which are: Question Analysis, Passage Retrieval and Answer Extrac-
tion. Most QA systems follow these three subtasks; however they may differ in how they implement every sub-
task.
QA as a task deals with many types of questions. Factoid questions are one type that is concerned with ques-
tions that ask mainly about Named Entities (NEs) like questions using the words: When, Where, How
much/many, Who, and What, which ask about a date/time, a place, a person, and an organization respectively.
QA systems are more capable of handling natural language queries than regular IR systems. On the other
hand, regular IR systems like search engines yield better results when the query is in Boolean formula (Laurent
et al., 2006). QA systems are also easier to use and have higher recall than ordinary IR systems, which means
that QA systems return an answer if it exists, unlike regular IR systems that sometimes return irrelevant docu-
ments which may not contain the answer (Smuckeret al., 2008).
13

1.1.3. Pipeline of QA
Arabic Question Answering as a task is made up of three distinct subtasks, which are: Question Analysis,
Document / Passage Retrieval, and Answer Extraction. In this section, we will show how each subtask is imple-
mented and the variations among different systems and implementations of Arabic QA in implementing these
subtasks.
Figure 3. Arabic Question Answering Subtasks
As illustrated in Figure 3, QA consists of three main phases: question analysis, passage retrieval and answer
extraction. In the question analysis phase, the expected answer type is determined according to the question
words, and the question is formulated into a query to be ready for passage retrieval. In the passage retrieval
phase, documents are separated into passages, and query formulated in the question analysis phase is used to
search for the most relevant passages and rank them according to relevance. In the answer extraction phase, the
retrieved passages are reranked according to the expected answer type detected in the question analysis phase,
and the system responds with the first ranked answer. In chapter two, the different Arabic QA systems are
demonstrated highlighting the achievements of each system in these three subtasks.
1.1.4. Question Answering for Machine Reading Evaluation (QA4MRE)
Question Answering for Machine Reading Evaluation (QA4MRE) is another type of QA that evaluates how
the computer understands a comprehension passage by posing a list of multiple choice questions that can be an-
swered by understanding this comprehension passage. It was introduced in an initiative to give more attention to
answer selection and validation over the IR based tasks of passage retrieval.
14

1.2. Scope and Objectives
In 2005, it was noticed in CLEF (Conference and Labs of the Evaluation Forum) that the greatest accuracy
reached by the different Question Answering (QA) systems was about 60%, where on the other hand 80% of the
questions were answered by at least one participating system. This is due to the error that propagates through the
QA pipeline layers: (i) Question Analysis, (ii) Passage Retrieval, (iii) and Answer Extraction. This led to the in-
troduction of the Answer Validation Exercise (AVE) pilot task, in which systems were required to focus on an-
swer selection and validation, leaving answer generation aside. However, all the QA systems from CLEF 2006 to
2010 used the traditional IR based techniques and hit the same accuracy upper bound of 60%. By 2011, it was a
must to devise a new approach to QA evaluation that forces the participating systems to focus on answer selec-
tion and validation, instead of focusing on passage retrieval. This was achieved by answering questions from one
document only. This new approach, which was named Question Answering for Machine Reading Evaluation
(QA4MRE), skips the answer generation tasks of QA, and focuses only on the answer selection and validation
subtasks (Penas et al., 2011). The questions used in this evaluation are provided with five answer choices each,
and the role of the participating systems is to select the most appropriate answer choice. The QA4MRE systems
may leave some questions unanswered, in case they estimate that the answer is not certain. Arabic QA4MRE was
then introduced for the first time in CLEF 2012 by two Arabic systems. A new test-set and a metric named
“C@1” were introduced for that reason. The evaluation test-set and metrics are explained thoroughly in chapter
three.
We introduce ALQASIM which is an Answer Selection and Validation system built on the QA4MRE test-set.
The main purpose of our research is to provide a reliable answer selection and validation module which will im-
prove the performance and reliability of any Arabic QA system. Through out this dissertation, the term
“QA4MRE” will be used interchangeably with “Answer Selection and Validation” as they serve the same pur-
pose.
1.3. Achievements
We provided two versions of our answer selection and validation system. The first version depends mainly on
answer keywords proximity to question keywords in the test document. The second version uses sentence split-
ting as a natural boundary to search for answers in the test document and introduces root expansion and semantic
expansion using an automatically generated ontology created from the background collection documents pro-
vided with the test-set.
15

The first version achieved an accuracy of 0.31 and a c@1 of 0.36. The second version achieved an accuracy of
0.36 and a c@1 of 0.42, which is double the performance of the best performing Arabic QA4MRE system.
1.4. Overview of Dissertation
In the next chapter, the Arabic QA related works are reviewed. The best performing English QA system is
also demonstrated. Then the best performing Arabic QA4MRE systems are explained.
In chapter three, the tools and language resources that were used in ALQASIM are demonstrated. The ex-
plained tools and language resources are the morphological analysis tool kit, stemmers and the Arabic WordNet
(AWN). The test-set and evaluation metrics that were used to evaluate ALQASIM are also demonstrated in the
same chapter.
In chapter four, the architecture of the two versions of our answer selection and validation system
(ALQASIM) are explained in detail. Then the results are demonstrated and discussed in chapter five. In chapter
six, the research is concluded and future work is highlighted.
16

Chapter TwoChapter Two
Related WorksRelated Works
17

Chapter 2Chapter 2
Related WorksRelated Works
2.1. Arabic QA systems
In this section, the Arabic QA systems are reviewed and compared. The first known Arabic QA system is
AQAS, which is created by Mohammed et al., 1993 to answer questions in the radiation domain. It handles ques-
tions and declarative sentences posed by humans in Arabic natural language and uses a knowledge base in the
form of frames to answer these questions. It analyzes user questions and formulates a query from them and
searches a structured set of data. However, the performance of this system was not reported and it is criticized
for being just a natural language interface for an ordinary database.
The second Arabic system is created by Hammo et al., 2002 and 2004 under the name of QARAB. It searches
in the corpus of news articles extracted from Al-Raya newspaper, using a Passage Retrieval (PR) module based
on Salton’s vector space model, and treats the document as a "bag of words". The system removes stop words,
uses a lexicon-based stemmer to stem questions and documents words, and implements PoS tagging and NER us-
ing the system created by Abuleil & Evens, 1998. It also determines the expected answer type by question words
and extracts Named Entities (NEs) as the answer. QARAB reports a precision of 97.3%; however, this perfor-
mance is skeptically high as it is much higher than the best performing English QA system (Lymba’s PowerAn-
swer 4), created in 2007 which performed at a precision of 70.6% (Moldovan et al., 2007). It is also worth men-
tioning that the test-set was composed of only 113 question which are only factoid questions and that these ques-
tions were posed by the system creators themselves, and that the corpus and questions that were used are not pub-
licly available.
Rosso et al., 2005 experimented with cross-language IR to answer Arabic questions from English documents.
They translated the questions then made five different formulations to them by verb and noun movement. Their
cross-language QA system has a precision of 10.7% and an MRR (Mean Reciprocal Rank) of 0.08. This poor
performance is due to the ambiguity incurred by translation. They found out that the best results came out from
verb reformulation in the translated question.
Awadallah & Rauber, 2006 created a QA system that ranks passages according to Answer and Question words
Count (AQC) and Answer and Question words Association (AQA). AQC is the number of found question key-
words in the passage and AQA is the co-occurrence of question and answer choice keywords within the same re-
18

sult snippet’s context. They held their experiments on the question of the Arabic TV show “Who's gonna be a
millionaire?” and TREC-2002 QA track questions. Their experiments revealed an average accuracy of 55% to
62%. The AQA strategy had better performance on the Arabic language questions while AQC was better for
English language tasks, which may be due to the morphological complexity of Arabic that resulted in retrieving
only precise phrases if they exist, rather than retrieving split segments (Awadallah & Rauber, 2006).
Rosso et al., 2006 created an Arabic QA system under the name of ArabiQA in 2006, which was completed
by Benajiba et al., 2007, Benajiba & Rosso, 2007 and Benajiba et al., 2007. They created their own corpus and
questions, following CLEF guidelines. They removed stop words from the question and documents and extracted
the named entities. They also classified the questions into Name, Date, Quantity, and Definition questions ac-
cording to the question words. ArabiQA use the Distance Density N-gram model, which assigns a higher rank for
passages that have a smaller distance between its keywords. Their answer extraction module tagged NEs in re-
trieved passages, selected the answers with the expected type of NEs and applied pattern matching to select the
final list of answers. The architecture of ArabiQA is illustrated in figure 4.
Figure 4. The architecture of ArabiQA (Benajiba & Rosso, 2007)
19

Brini et al., 2009 created QASAL Arabic QA system that answers the definition questions. QASAL uses
NooJ local grammars to formulate the user question into a query. It extracts the expected answer type, question
focus and important question keywords and uses Google as a PR system. It achieved a recall of 100% and a preci-
sion of 94%. However, the size of the test-set is too small as it is only 100 Factoid questions and 43 Definition
questions. The architecture of QASAL is illustrated in Figure 5.
Figure 5. QASAL architectural components Brini et al., 2009
Another QA system is the system created by Kanaan et al., 2009. They analyzed the question by tokenizing
the question text and the question focus, and extracting the root of each non-stop word in the question. They also
determined the question type using the question words as shown in Table 2. They also used a passage retieval
module based on Salton’s vector space model and achieved a precision of 43%. However, the test-set that they
used is very small as it contains only 25 documents gathered from the Internet, and 12 questions.
Table 2: Determining the question type according to question words as
suggested by Kanaan et al., 2009
Question words in Arabic Question Words in English Question Type
من Who, Whose Person, Group
متى When Date, Time
ماذا What Organization, Product, Event
أين Where Location
كم How much, How many Number, Quantity
20

DefArabicQA is another Arabic QA system created by Trigui et al., 2010 that tackles the definition type of
questions. They identified the candidate definitions using manual lexical patterns of sequence of words, letters
and punctuation symbols. They also used heuristic rules that they deduced from observing the form of some cor-
rect and incorrect definitions to enhance their algorithm, and ranked the candidate definitions according to the
weight of the definition pattern, snippet position and the sum of word frequencies in the candidate definition.
DefArabicQA has an MRR of 0.7, and 54% of the questions were answered by the first candidate answer re-
turned. Yet its main criticism is that the corpus size is too small as it contains only 50 organization definition
questions and the answers were assessed by only one Arabic native speaker.
Abouenour et al., 2009, 2010, 2011 created an Arabic QA system that answers the translated CLEF and TREC
questions. Their system uses Yahoo search engine and JIRS (Java Information Retrieval System) for passage re-
trieval. The system applies morphological and semantic query expansion using the Arabic WordNet. Abouenour
et al. enriched AWN to help the query expansion of their system. They ranked the passages based on distance
density n-gram model, and used Amine Platform to score and rank the retrieved passages semantically using con-
cept graphs. Their QA system achieved a poor accuracy of 20.20%, which may have occured because the number
of passages in JIRS was less than 1000 which did not enable structure based techniques to have great effect on
the results.
AQuASys is an Arabic QA system created by Bekhti et al., 2011. It segmented the question into interrogative
noun, question’s verb and keywords, and it did not use a Named Entity Recognition (NER) system. It performed
at a recall of 97.5% and at a precision of 66.25%. Yet, it is fatal drawback is that it cannot be used as it is on an
untagged raw text corpus as it uses the 316 documents provided by ANERcorp (Arabic NER corpus) with its
150,000 tagged words and posed 80 questions on that corpus.
Abdelbaki & Shaheen, 2011 also analyzed the question in their Arabic QA system by applying tokenization,
normalization and NER. They also determined the expected answer type and question focus and applied keyword
extraction and expansion. They applied stemming using Khoja’s Stemmer, then used semantic similarity between
the question’s focus and the candidate answer and made matching using N-grams. Finally, they validated the an-
swers using accuracy scoring and ranking. The test-set that they used to test their system is the 316 document
provided by ANERCorp and they posed 240 questions on this test-set. The accuracy of their system is 86.25%.
and the system also has an MRR of 0.87. However, the main criticism against this system is that it used ANER-
Corp for both training the NER module and as a document corpus which makes the results biased due to over-fit-
ting.
21

The best performing, published system in English QA is Lymba’s Power Answer 4 created by Moldovan et al.,
2007. They used TREC 2007 questions, 175 GB collection of blog entries and 2.5 GB newswire articles. Power
Answer 4 integrated semantic relations, advanced inferencing abilities, syntactically constrained lexical chains,
and temporal contexts. It used strategies to answer each class of questions, where each strategy has the three
components of (i) Question Processing, (ii) Passage Retrieval and (iii) Answer Processing. It also resolved fuzzy
temporal expressions and integrated with a syntactic parser, an NER, a semantic parser, ontologies, and a logic
prover for textual inference in answer selection. It could also detect event-event relations as it used a concept tag-
ger. Lymba’s Power Answer 4 performed at an accuracy of 70.6% in factoid questions and at an accuracy of
47.9% in list questions.
2.1.1. Question Analysis
In an attempt to perform a better Question Analysis, Hammo et al., 2004 parsed the question to extract its cat-
egory and the type of answer required whether it is a name, a place, a quantity or a date, which makes it easier
later in the Answer Extraction phase to select the right answer.
Rosso et al. 2005 experimented with cross-language IR to answer Arabic questions from English documents.
To analyze the question, they translated it then made 5 different formulations to the question by verb and noun
movement. They found out that the best results came out from verb reformulation in the translated question.
However, the results were not promising as the precision decreased by about 20% due to the ambiguity that trans-
lation adds to the question.
Rosso et al. 2006 analyzed Arabic questions by eliminating stop words, extracting named entities and classi-
fied the questions into Name, Date, Quantity, and Definition questions according to the question word used.
Brini et al., 2009 made some query formulation and extracted the expected answer type, question focus and
important question keywords. The question focus is the main noun phrase of the question that the user wants to
ask about. For example, if the user's query is "What is the capital of Tunis?" then the question focus is "Tunis"
and the keywords are "capital" and the expected answer type is a named entity for a location. Unfortunately, this
work had only 100 questions which made it biased and unable to generalize (Brini et al., 2009).
Kanaan et al., 2009 made four steps to analyze the question. They tokenized the question, then determined its
type, then determined its focus which is the proper noun phrase and extracted the root of each non-stop word in
the question.
22

Abdelbaki and Shaheen 2011 analyzed the question by:
a. Tokenization & Normalization
• Replacing initial إ, آ, أ by اand the letter ئ by the sequence ىء
• Replacing final ى by ي and replace final ة by ه
b. Determining answer type by question words (who, when...)
c. Named Entity Recognition (gazetteer, maxent model)
d. Focus determination by extracting the main NE
e. Keywords Extraction by removing stop words using the Khoja stop list, which has 168 words and the 1,131
words translated from English.
f. Keywords Expansion using the Arabic dictionary of synonyms. NEs are not expanded to avoid ambiguity.
g. Stemming by Khoja’s Stemmer and NEs are not stemmed
h. Query generation of keywords into a Boolean formula (Abdelbaki & Shaheen, 2011).
Bekhti et al., 2011 segmented the question into interrogative noun, question’s verb and question’s keywords.
2.1.2. Passage Retrieval
Awadallah and Rauber 2006 experimented with Arabic and English QA and introduced two techniques to
rank retrieved passages to select the best answer. The first technique is Answer and Question words Count (AQC)
which is based on the number of questions and/or answer choice keywords occurring in result snippets. The sec-
ond technique is Answer and Question words Association (AQA) which is the co-occurrence of question and an-
swer choice keywords within the same result snippet’s context. In other words, if there is a question with 5 candi-
date answers, then each candidate answer is joined with the question and passed to the passage retrieval module.
A retrieved passage is then assigned a higher ranking if it contains more question and candidate answer keywords
(AQC). If the candidate answer and question keywords appear nearer to each other in the retrieved passage it is
also assigned a higher ranking (AQA). They held their experiments on the question of the famous Arabic TV
show “Who's gonna be a millionaire?” and TREC-2002 QA track questions. Their experiments revealed an aver-
age performance of 55% to 62%. The AQA strategy had better performance on the Arabic language questions
while AQC was better for English language tasks. This may be due to the morphological complexity of Arabic
23

that resulted in retrieving only precise phrases if they exist, rather than retrieving split segments (Awadallah &
Rauber, 2006).
Benajiba et al., 2007 ranked the retrieved passages according to the relevant question terms appearing in the
passage, and assigned a higher rank for the passages that have a smaller distance between keywords which is
called the Distance Density model as shown in figure 6.
Figure 6. JIRS Passage Retrieval System Architecture (Benajiba et al., 2007)
Kanaan et al., 2009 used a passage retrieval system following Salton’s vector space model using query words
weight, and cosine similarity between documents words and question words. Their system tokenized every docu-
ment, removed the stop words, and carried out root extraction and term weighting. However, their test-set was
only 25 documents gathered from the Internet, 12 queries (questions) and some relevant documents provided by
themselves (Kanaan et al., 2009).
Abouenour explained an enhanced passage retrieval built on the JIRS passage retrieval system. He followed a
three level approach in his passage retrieval system: (Abouenour et al., 2009, 2010, 2011)
24

a- Keyword-based level: morphological and semantic query expansion using the Arabic WordNet including
the concept hypernyms, hyponyms, synonyms and definition.
b- Structure-based level: ranking the passages based on Distance Density n-gram Model giving higher rank to
passages that have the question words appear nearer one another.
c- Semantic Reasoning level: where he used Amine Platform to score and rerank the retrieved passages se-
mantically using concept graphs to find the most relevant answer passage.
However, the number of processed passages in JIRS was less than 1000 which did not enable structure based
techniques to have great effect.
The CLEF 2012 campaign had 2 Arabic QA attempts. The first attempt, is IDRAAQ by Abouenour et al. Its
NER is achieved by mapping the YAGO1 ontology and Arabic WordNet. The Passage Retrieval module of
IDRAAQ is based on 2 levels:
1. Keyword-based level: based on Query Expansion process relying on Arabic WordNet semantic relations
2. Structure-based level: based on a Distance Density N-gram Model passage retrieval system which is JIRS
2.1.3. Answer Extraction and Validation
Trigui et al., 2010 tackled the definition type of questions. They first identified the candidate definitions using
manual lexical patterns of sequence of words, letters and punctuation symbols. Then they used some heuristic
rules that they deduced from observing the form of some correct and incorrect definitions. After they extracted
the candidate definitions, they ranked them according to three criteria which are (i) Pattern weight of the pattern
that matched the candidate definition, (ii) Snippet position of the snippet that contains the candidate definition in
the snippets collection and (iii) the sum of word frequencies in the candidate definition. However, their evalua-
tion was not good enough as they tested on 50 organization definition questions only and the answers were as-
sessed by only one Arabic native speaker.
Abdelbaki & Shaheen, 2011 used semantic similarity between the question’s focus and the candidate answer
and made matching using n-grams. After that they validated the answers using accuracy scoring and ranking.
The results they achieved where 86.25% accuracy and an Mean Reciprocal Rank (MRR) of 0.87. They also pro-
vided the average response time which was 2262 ms on a machine with low specs (CPU: Intel® 1.60 GHz,
RAM: 512 MB) (Abdelbaki & Shaheen, 2011). However this work used the ANERCorp 316 articles as a QA cor-
pus and posed 240 questions on this small corpus which makes the redundancy passages not enough to test the
1 Yet Another Great Ontology: http://www.mpi-inf.mpg.de/YAGO-naga/YAGO/downloads.html
25

passage retrieval and the answer extraction modules. It is also noticed that by using ANERCorp corpus for train-
ing the Arabic Named Entity Recognition (NER) classifier then using it as the QA corpus will make the system
over-fitted for this corpus and may not reach the same results on other unseen texts.
Figure 7. Example of the Answer Extraction module's performance steps Benajiba et al., 2007
Benajiba et al., 2007, in their system named ArabiQA, approached the Answer Extraction task in three steps
as shown in Figure 7:
a- Using an NER system to tag all NEs in the retrieved passages.
b- Selecting candidate answers NEs that has the same expected answer type only.
c- Applying a set of patterns to select the final list of answers.
Moreover, they created a test-set solely to evaluate their Answer Extraction module in separation from the rest
of the system. This test-set was made up of four lists:
a- List of the questions
b- List containing the type of each question
26

c- List of manually selected passages that contain the right answers for the questions
d- List of correct answers
Their AE (Answer Extraction) module performed at a precision of 83.3% where the precision here is calculated
by dividing the number of correct answers over the number of questions (Benajiba et al., 2007).
2.2. The Best Performing English QA System
On the other hand, the best performing English QA system Lymba’s Power Answer 4, created by Moldovan et
al., 2007 performed at an accuracy of 70.6% in factoid questions and 47.9% in list questions. Lymba’s Power An-
swer 4 used the test-set of TREC 2007 and integrated semantic relations, advanced inference abilities, syntacti-
cally constrained lexical chains, and temporal contexts. It used strategies to answer each class of questions: each
strategy has the 3 components of (i) Question Processing (ii) Passage Retrieval (iii) Answer Processing. It also
resolved fuzzy temporal expressions, and it was integrated with a syntactic parser, an NER, a semantic parser,
ontologies, and a logic prover for textual inference in answer selection, and used Concept Tagger to detect event-
event relations.
2.3. Answer Selection and QA4MRE systems
Answer selection is concerned with selecting the best answer choice from multiple choices suggested by the
answer generation tasks which are question analysis and passage retrieval. A few works tackled the answer selec-
tion task in QA and most of these works used redundancy IR based approaches. Most of them also depended on
external sources like Wikipedia or different public Internet search engines. For example, Ko et al., 2007 used
Google search engine and Wikipedia to score answer choices according to redundancy, using a corpus of 1760
factoid questions from Text Retrieval Conference (TREC). Another similar attempt was carried out by Mendes &
Coheur, 2011 who explored the effects of different semantic relations between answer choices and the perfor-
mance of a redundancy-based QA system, also using the corpus of factoid questions provided by TREC. How-
ever, these approaches proved to be more effective in factoid questions. This is because factoid questions ask
about date/time, number or named entities, which could be searched easily on the Internet and aligned with the
answer choices. These kinds of answers are also repeated multiple times in almost the same format in different
documents. On the other hand, QA4MRE supports the answer choices of each question with a document and de-
pends on language understanding to select the correct answer choice, which can generalize for other kinds of
questions like causal, method, list and purpose questions.
27

In CLEF 2012, Arabic QA4MRE was introduced for the first time. Two Arabic systems participated in this
campaign. The first system is IDRAAQ which is created by Abouenour et al., 2012, achieved a 0.13 accuracy and
a 0.21 c@1. It used JIRS for passage retrieval, which uses the Distance Density N-gram Model, and semantic ex-
pansion using Arabic WordNet (AWN). IDRAAQ did not use the CLEF background collections. However, its de-
pendence on the traditional QA pipeline, to tackle QA4MRE, is the main reason behind its poor performance.
This is because the system depends mainly on the passage retrieval module, when the focus should have been on
the answer selection module as the right passages were already provided by the test-set. The use of AWN may
have also reduced performance due to its general purpose nature, which adds ambiguity by blurring the differ-
ences between the answer choices.
The second system by Trigui et al., 2012 achieved the accuracy and c@1 of 0.19 with their system. Thus, their
system has not marked any questions as unanswered, and attempted to answer all the test-set questions. Their sys-
tem uses an IR based approach. It collects the passages that have the question keywords and aligns them with the
answer choices, then searches for the best answer choice in the retrieved passages. It then employs semantic ex-
pansion, using some inference rules on the background collection, to expand the answer choices that could not be
found in the retrieved passages. The main reason behind the poor performance of that approach is that it depends
on the background collection as it offers enough redundancy for the passage retrieval module. This makes the
system very similar to traditional question answering systems, and does not attempt to analyze the reading test
document.
However, these two Arabic systems do not compare to the best performing system in the same campaign,
which was created by Bhaskar et al., 2012, which used the English test-set and performed at an accuracy of 0.53
and c@1 of 0.65. This system combined each answer choice with the question in a hypothesis and searched for
the hypothesis keywords in the document, then ranked the retrieved passages according textual entailment, which
proves that analyzing the reading test document, yields a much better performance. A comparison of the two
Arabic QA4ME systems and the best performing English system is illustrated in Table 3. Then the implemented
techniques of the best performing Arabic and English QA4MRE systems are compared in Table 4. The results of
the three QA4MRE systems are compared in the chart in figure 8.
28

Figure 8. Performance of QA4MRE systems @ CLEF 2012
Table 3: Comparison between Arabic QA4MRE @ CLEF 2012 and the best performing English System
QA4MRE System Deployed Components Performance
IDRAAQ Abouenour et
al., 2012
- NER by mapping the YAGO ontology and Arabic
WordNet.
- Did not use CLEF background collections
- PR based on Query Expansion using AWN semantic re-
lations, and Distance Density N-gram Model of JIRS
C@1 : 0.21
Accuracy : 0.13
Trigui et al., 2012 - Determine question focus
- PR retrieved passages are aligned with the multiple answer
choices of the question.
- Semantic expansion using inference rules on the back-
ground collection.
C@1 : 0.19
Accuracy : 0.19
English QA4MRE @
CLEF 2012
Bhaskar et al., 2012
- Combined each answer choice with the question in a hy-
pothesis
- PR searched for hypothesis keywords.
- Ranked passages according textual entailment. .
C@1 : 0.65
Accuracy : 0.53
29
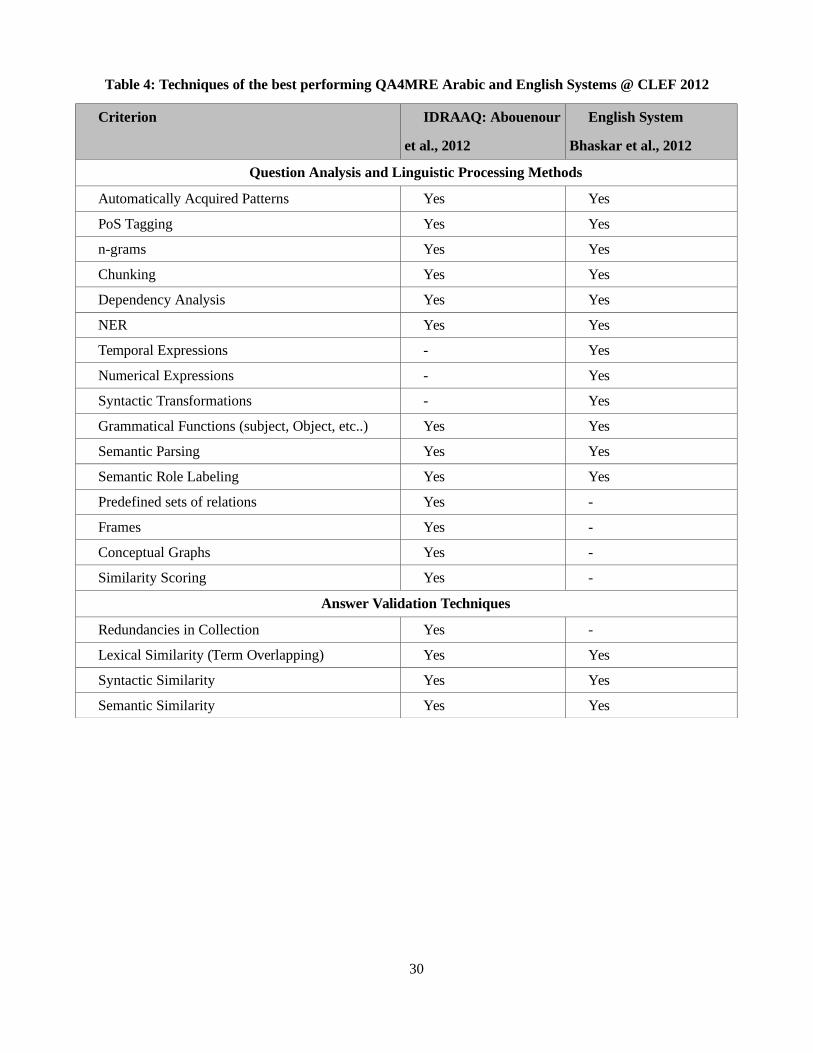
Table 4: Techniques of the best performing QA4MRE Arabic and English Systems @ CLEF 2012
Criterion IDRAAQ: Abouenour
et al., 2012
English System
Bhaskar et al., 2012
Question Analysis and Linguistic Processing Methods
Automatically Acquired Patterns Yes Yes
PoS Tagging Yes Yes
n-grams Yes Yes
Chunking Yes Yes
Dependency Analysis Yes Yes
NER Yes Yes
Temporal Expressions - Yes
Numerical Expressions - Yes
Syntactic Transformations - Yes
Grammatical Functions (subject, Object, etc..) Yes Yes
Semantic Parsing Yes Yes
Semantic Role Labeling Yes Yes
Predefined sets of relations Yes -
Frames Yes -
Conceptual Graphs Yes -
Similarity Scoring Yes -
Answer Validation Techniques
Redundancies in Collection Yes -
Lexical Similarity (Term Overlapping) Yes Yes
Syntactic Similarity Yes Yes
Semantic Similarity Yes Yes
30

Chapter Three Chapter Three
Tools, Test-set and Evaluation MetricsTools, Test-set and Evaluation Metrics
31

Chapter 3Chapter 3
Tools, Test-set and Evaluation MetricsTools, Test-set and Evaluation Metrics
In this chapter, the tools that were used in ALQASIM 1.0 and 2.0 are demonstrated. These tools include a
morphological analysis toolkit, an Arabic ontology (Arabic WordNet) and three different root stemmers. The
test-set that is used in this research is also explained in detail, which is a list of documents, questions and answer
choices for these questions that cover various domains and types of questions. Last but not least, the evaluation
metrics used to evaluate ALQASIM are explained to set the grounds for the upcoming chapters that will explain
the architecture, results and discussion of ALQASIM 1.0 and 2.0.
3.1. Tools and Resources
Natural Language Processing tools and resources are very crucial for question answering systems. These tools
should be language specific due to the fact that every language has its own set of rules that do not generalize for
other languages. Among the important tools used by any question answering system are the morphological analy-
sis toolkits and stemmers. Other language specific resources like lexicons and ontologies are very important as
they provide a semantic dimension to the question answering process.
3.1.1. MADA+TOKAN PoS tagger
Habash et al., 2009 created MADA+TOKAN, which one of the best performing Arabic morphological analy-
sis toolkits. Its main advantages are that it is a freely available toolkit that performs at a high accuracy.
MADA+TOKAN offers various Arabic NLP services:
– Tokenization: splitting the stream of Arabic text into separate tokens. Separating tokens requires classi-
fication to separate different clitics in the same word token.
– Diacritization: adding diacritics to MSA words to disambiguate their meanings and way of pronuncia-
tion. Diacritics are very important in Arabic as they are very similar to vowels for English.
– Part-of-speech (PoS) tagging: finding the PoS of each word whether it is a verb, a noun, a proposition
etc.
32

– Light stemming: removing prefixes and suffixes from Arabic words and returning them to their stems.
This is different from root stemming because it changes only the inflectional form of the word and not
the derivation form of it.
– Word number identification: finding whether a word is a singular, a plural or a dual word.
– Word gender identification: finding the word gender whether it is a masculine or a feminine word.
MADA examines all possible analyses for each word, and then selects the analysis that matches the current
context using Support Vector Machine (SVM) models classification for 19 distinct, weighted morphological fea-
tures as shown in Table 5. TOKAN then takes the output of MADA and generates tokenized output in a custom-
izable format. MADA has over 86% accuracy in predicting full diacritization.
Table 5. The 19 features used by MADA
Feature AKA Description Predicted With
pos POS Part-of-Speech (e.g., noun, verb, preposition, etc.) SVM
conj CNJ Presence of a conjunction (w+ or f+) SVM
part PRT Presence of a particle clitic (b+, k+, l+) SVM
clitic PRO Presence of a pronominal clitic (object or possessive) SVM
art DET Presence of definite article (Al+) SVM
gen GEN Gender (feminine or masculine) SVM
num NUM Number (singular, dual, plural) SVM
per PER Person (first, second, or third person) SVM
voice VOX Voice (passive or active) SVM
aspect ASP Aspect (perfective, imperfective) SVM
mood MOD Mood (imperative, nominative, etc ...) SVM
def NUN Presence of nunation (Definite or Indefinite) SVM
idafa CON Construct state (Possessive or Non-possessive) SVM
case CAS Case (Nominative , Accusative, Genitive) SVM
unigramlex Lexeme predicted by a unigram model of lexemes N-gram
unigramdiacDiacritic form predicted by a unigram model of diacritic
formsN-gram
ngramlex Lexeme predicted by an N-gram model of lexemes N-gram
isdefaultBoolean: Whether the analysis is a default BAMA (Buck-
walter Arabic Morphological Analyzer) outputDeterministic
spellmatchBoolean: Whether the diacritic form is a valid spelling
matchDeterministic
33

3.1.2. Root Stemmers
Root stemmers are used to extract the three or four letters root of an Arabic word. Thus if the word assumes
any inflectional or derivational form other than its root, this form is changed back to its original root form. This
is done by removing any prefixes, suffixes or infixes and checking the derivational pattern of a word to return it
back to its root. Three root stemmers have been tested in ALQASIM 2.0, which are (I) Khoja, (ii) ISRI, and (iii)
Tashaphyne root stemmers.
3.1.2.1. Khoja Root Stemmer
The Khoja2 root stemmer is a Java Arabic root stemmer, created by Khoja & Garside, 1999. It removes the
longest suffix and prefix, and then matches the retrieved stem with the verb and noun patterns, to extract the root.
Khoja Arabic stemmer handles weak letters, which may change their form in an Arabic word root (i.e. alif, waw
or yah). It also identifies words that do not have roots like the Arabic words for “we”, “under”, “after”, and so on.
Khoja stemmer also produces the right root if a letter is deleted from the root during derivation due to duplicate
letters (i.e. the last two letters are the same) (Khoja & Garside, 1999). Taghva et al., 2005 reported that Khoja
stemmer has an Average Precision of 46.3%. Khoja Stemmer was also used by Larkey & Connell, 2006 in an
Arabic information retrieval system, which helped them to improve the Average Precision of their system by 49%
over the non-stemmed technique.
3.1.2.2. ISRI Root Stemmer
ISRI (Information Science Research Institute) root stemmer is a Python Arabic root stemmer, created by
Taghva et al., 2005. The ISRI stemmer has many features in common with the Khoja stemmer; however, it does
not use a root dictionary, which makes the ISRI stemmer more capable of stemming rare and new words. It nor-
malizes unstemmed words, has more stemming patterns than Khoja stemmer, and more than 60 stop words. ISRI
stemmer has an Average Precision of 48% (Taghva et al., 2005).
3.1.2.3. Tashaphyne Root Stemmer
The Tashaphyne Light Arabic Stemmer works by first normalizing words in preparation for the “search and
index” tasks required for stemming, including removing diacritics and elongation from input words. Next, seg-
mentation and stemming of the input is performed using a default Arabic affix lookup list, allowing for various
levels of stemming and rooting (Oraby et al., 2012).
2 Shereen Khoja Research: http://zeus.cs.pacificu.edu/shereen/research.htm
34

3.1.3. Arabic WordNet
Elkateb et al., 2006 introduced the Arabic WordNet and described the challenges they faced to create it. Ara-
bic WordNet is a lexical resource for MSA based on the widely used Princeton WordNet for English. Arabic
WordNet was also enriched by Abouenour et al., 2009, 2010, 2011 by adding new named entities, new verbs and
new nouns which enriched the hyponymy relation between concepts.
3.2. Test-set
Using a test-set that is well developed and used by several other systems lays out the rules for the developed
system and sets the grounds for an objective means of research. In this section, the test-set that was used to vali-
date ALQASIM 1.0 and 2.0 is explained in detail to highlight its form and coverage for different kinds of ques-
tions.
The test-set used to evaluate ALQASIM 1.0 and 2.0 is provided by the QA4MRE task at CLEF 2012.
QA4MRE at CLEF 2012 is the fourth campaign of its kind (Penas et al., 2012); however, the Arabic QA4MRE
test-set was introduced for the first time in 2012. It is composed of four topics: (i) "AIDS", (ii) "Climate change",
(iii) "Music and Society", and (iv) "Alzheimer". Each topic consists of four reading tests, and every reading test
has ten questions, where each questions has five answer options:
• 16 test documents (4 documents for each of the 4 topics)
• 160 questions (10 questions for each document)
• 800 answer choices/options (5 for each question)
QA4MRE questions are designed to test the comprehension of only one document. The questions test the rea-
soning capabilities of the participating QA systems which may include inference, relative clauses, elliptic expres-
sions, meronymy, metonymy, temporal and spatial reasoning, and reasoning on quantities. The questions may
also need some background knowledge that is not present in the test document. That is why “Background Collec-
tions” are provided by CLEF to fill this need. The questions types are:
(i) Factoid: (where, when, by-whom)
(ii) Causal: (what was the cause/result of event X?)
(iii) Method: (how did X do Y? or in what way did X come about?)
(iv) Purpose: (why was X brought about? or what was the reason for doing X?)
(v) Which is true: (what can a 14 year old girl do?)
35

Questions are also classified according to their information requirements as follows:
(i) 75 questions do not need extra knowledge (from background collections).
(ii) 46 questions need background knowledge.
(iii) 21 questions need inference.
(iv) 20 questions need information to be gathered from different sentences or paragraphs.
3.3. Evaluation metrics
Using the appropriate evaluation metrics makes it easy for other researchers to compare the developed system
with its alternatives and sets a solid ground for comparing different approaches to solving the question answer se-
lection and validation problem. In this section, the metrics used to evaluate ALQASIM 2.0 are explained. Accu-
racy and c@1 are the metrics used to evaluate the performance of QA4MRE systems.
3.3.1. Accuracy
Accuracy is used by many information retrieval systems to evaluate their performance in terms of the ability
of these systems to retrieve relevant data items and ignore irrelevant ones. It is calculated by dividing the number
of retrieved relevant items plus the number of irrelevant items that are not retrieved by the number of all items
(Manning et al., 2008). Table 6 introduces a contingency matrix that shows the relation between retrieval and rel-
evance of data items, introducing the notions of true positives (tp), true negatives (tn), false positives (fp) and
false negatives (fn), then equation 1 uses these notions to show how accuracy is calculated.
Table 6. Information Retrieval contingency table
Retrieved Not Retrieved
Relevant true positives (tp) false negative (fn)
Not Relevant false positives (fp) true negative (tn)
36

Accuracy=tp+tntp+fp+tn+fn
(1)
Where:
• tp: True Positives
• tn: True Negatives
• fp: False Positives
• fn: False Negatives
3.3.2. C@1
There was an urgent need for a metric that gives partial credit for systems that leave some questions unan-
swered in case of uncertainty to encourage researchers in the field of question answer selection and validation to
improve the quality of their systems. Due to the emergence of this need, C@1 was introduced in the QA4MRE
task at CLEF 2011 by Penas et al., 2011. C@1 is a metric that encourages systems to leave some questions unan-
swered to reduce the amount of incorrect answers, as it gives partial credit for systems that leave some questions
unanswered in cases of uncertainty, instead of attempting to answer them incorrectly (Penas et al., 2011), which
is shown in equation 2.
C@1=1n (nR +nU
nR
n ) (2)
Where:
• nR: number of correctly answered questions
• nU: number of unanswered questions
• n: total number of questions
37

Chapter FourChapter Four
System ArchitectureSystem Architecture
38

Chapter 4Chapter 4
System ArchitectureSystem Architecture
In CLEF 2013, we introduced ALQASIM 1.0, which is a QA4MRE system that analyzes the reading test doc-
uments, where answer choices are scored according to the occurrence of their keywords, their keywords weights,
and the keywords distance from the question keywords. In the first section of this chapter, the architecture of
ALQASIM 1.0 (the first version) is explained. In the second section of this chapter, the architecture of the
ALQASIM 2.0 is explained in detail.
4.1. ALQASIM 1.0 initial architecture
Most Question Answering systems are composed of three main phases, which are: Question Analysis, Passage
Retrieval and Answer Extraction. However, these systems are mainly targeted at searching for answers in a large
collection of documents or on the Internet, which makes passage retrieval efficient (Ezzeldin & Shaheen, 2012).
QA4MRE is different in that aspect because the answer to a question is found in only one document, so there is
no enough information redundancy to help the IR statistical approaches of passage retrieval. Thus, we think that
the ordinary QA pipeline is not the best approach to QA4MRE; the best approach is the one used by human be-
ings in reading tests. A person would normally read and understand a document thoroughly, and then begins to
tackle the questions one by one. So, we divided the QA4MRE process into three phases: (i) Document Analysis,
(ii) Locating Questions & Answers, and (iii) Answer Selection. See Figure 9 and 10.
Figure 9. Overview of ALQASIM architecture
39

4.1.1. Document Analysis
In the Document Analysis phase, the reading tests documents are analyzed using MADA+TOKAN (Habash
et al., 2009) morphological analyzer to stem each word in the documents and get its Part-of-Speech (PoS). The
stop words are then removed, and an inverted index is created for the remaining words stems that contains the lo-
cations of each stem and its weight. Arabic WordNet (AWN) is also used to expand the words semantically by
adding the synonyms of each word to the inverted index of that document. The weight of each word in the in-
verted index is assigned according to its PoS and repetition. So that, nouns, verbs, adjectives, adverbs, proper
nouns and the other parts of speech are assigned different weights. Then the weight of a word is divided by its
count in the document, thus, the more a word is repeated the less its weight will be. These weights mark the im-
portance of keywords so that the higher the weight of a word the more important it is in the document. We have
carried out the morphological analysis phase in an off-line step to increase the speed of the system while testing
the questions.
Figure 10. Detailed Architecture of ALQASIM
40

4.1.2. Locating Questions & Answers
In the second phase, every question and answer choice is handled as follows. Keywords are identified by
stemming and removing stop words. The inverted index is then searched to find the best scoring three locations
for each question and answer choice keywords. This score is calculated according to: (i) the number of keywords
found within a distance threshold, (ii) the weights of all found keywords and (iii) the distance between these key-
words. The impact of keywords count and weights is positive while the impact of distance is negative which
means that locations scores are penalized for higher distance among its keywords.
4.1.3. Answer Selection
By now, the question and its five answer choices have three scored locations each. In this phase, answer
choices locations are scored with respect to the question locations. This score is generated by summing the
scores of one question location and one answer choice location and subtracting the distance between them. The
maximum of these scores is selected as the answer choice score. After that the maximum scoring answer choice
of the five choices is selected as the question answer. If there is more than one best scoring answer choice, then
the answer is not certain and the question is marked as unanswered.
4.1.4. Evaluation of ALQASIM 1.0
ALQASIM 1.0 searches for the answer choices within proximity to the question snippets. Keywords weights
are calculated according to their repetition in the document and their PoS tags, where the keywords weights de-
crease, the more they are repeated in the document. This approach leads to a promising performance of 0.31 ac-
curacy and 0.36 C@1, without using CLEF background collections (Ezzeldin et al., 2013). It is very promising
when compared to the other two Arabic QA4MRE system (Abouenour et al. 2012) and (Trigui et al. 2012) as
shown in figure 11, taking into consideration that it did not use CLEF background collections.
However, it does not take into consideration the natural boundary of sentences. Thus, if a weak answer choice
(in terms of keywords count and weight) is nearer to the question snippet, it may be selected as the correct an-
swer choice; even if there is a stronger answer choice that is a little bit further but still in the same sentence or the
sentence next to it. It also contains many manually adjusted weights that may make the system over-fit for the
test-set. Another disadvantage of ALQASIM 1.0 is that it finds the best three question snippets and three answer
snippets, then searches for the nearest and best scoring pair of question and answer choice snippets to choose the
correct answer choice. Thus, it may mistake an answer choice as the correct one if a sub-optimum question snip-
pet is chosen due to its high aggregate score with its associated answer choice snippet, which may happen with
41

answer choices that have many keywords. As an example, figure 12 shows how ALQASIM 1.0 could not mark
that all question keywords (marked in cyan) as the question snippet keywords because they are a little further
from each other, in fact they are only farther than the threshold that is set to identify related words. On the other
hand, if this threshold is increased, it affects the results negatively as it marks words from different snippets,
which produces more false positives.
Figure 11. The performance of ALQASIM 1.0 versus the other two Arabic QA4MRE systems
Figure 12. Example for failure of ALQASIM 1.0 while trying to locate the question snippet.
42

4.2. ALQASIM 2.0 Architecture
In ALQASIM 2.0, sentence splitting is utilized as a natural boundary to separate related units of meaning. So,
the question and answer choice snippets are considered related if they co-occur in the same sentence or share the
same sentence boundary. Thus, it searches for the answer choice in three sentences only: the sentence before the
question snippet, the sentence after it and the question snippet sentence itself.
In this section, ALQASIM 2.0 components and their integration will be explained in detail. As illustrated in
figure 13, the system consists of three main modules: (i) Document Analysis, (ii) Question Analysis, and (iii) An-
swer Selection.
Figure 13. ALQASIM 2.0 Architecture
4.2.1. Document Analysis
The document analysis module is crucial for the answer selection process. It gives context for morphological
analysis, and makes relating the question snippet to the answer choice snippet easier. In this module, the docu-
ment is split into sentences, and the sentences indexes are saved in an inverted index for future reference. The text
words are then tokenized, stemmed, and part-of-speech (PoS) tagged using MADA+TOKAN morphological
analysis toolkit. MADA+TOKAN performs light stemming and PoS tagging, and determines the number, and
gender of each word. ISRI Arabic root stemmer (Taghva et al., 2005) is then used to retrieve the root of each
word. Textual numeric expressions are rewritten in digits. The word, light stem, root, and numeric expansion are
43

all saved in an inverted index that marks the position of each word occurrence. The words are also expanded us-
ing an ontology of hypernyms and their hyponyms extracted from the background documents collection provided
by CLEF 2012. See figure 14.
Figure 14. Document Analysis module architecture
In the previous paragraph, we mentioned some modules and components that we have not explained yet:
i. Inverted Index
ii. Morphological analysis
iii. Sentence splitting
iv. Root expansion
v. Numeric expansion
vi. Ontology-based semantic expansion
These modules will be explained in detail in the following six subsections.
4.2.1.1. Inverted Index
The inverted index is an in-memory hash map data structure, created for each document. The key of this hash
map is a string token that could be a word stem, root, semantic expansion, or digit representation of a numeric
expression. The value of the hash map consists of a set of locations (a location is the index number of a word in
the text) where this token occurs. The inverted index also has another hash map that holds the weight of each to-
ken that is determined according to its part-of-speech (PoS) tag and whether it is a named entity (NE). See table
7. The intuition behind setting tokens weights is to give higher weights for tokens that are more informative.
Named Entities (NEs) are considered keywords that can mark a question or an answer snippet easily. That is why
44

NEs hold the highest weight. Nouns convey most of the meaning in Arabic sentences. This is because most of the
Arabic sentences are nominal ones. Adjectives and adverbs come in the third place in terms of weight after NEs
and nouns because they qualify nouns and verbs and help convey meaning. Verbs weight is less than adjectives
and adverbs as they are less informative. The least weight is then assigned to any other PoS tag. Prepositions,
conjunctions and interjections were already removed in the stop words removal process before saving the words
to the inverted index.
Table 7: Weights determined according to PoS tags and NEs
PoS Tag / Named Entity WeightNamed Entity (person, location, organization) 300Nouns 100Adjectives and Adverbs 60Verbs 40Other PoS tags 20Prepositions, conjunctions, interjections and stop words N/A (Not saved in the inverted index)
4.2.1.2. Morphological analysis module
The morphological analysis module is the most important module in the system as it provides the required in-
formation for the rest of the modules to work with. MADA+TOKAN has been used in this module to provide to-
kenization, part-of-speech (PoS) tagging, light stemming, and number determination of each word.
MADA+TOKAN is an open source morphological analysis toolkit, created by Habash et al., 2009. It provides
many Arabic NLP services like tokenization, diacritization, morphological disambiguation, gender and number
determination, part-of-speech (PoS) tagging, stemming and lemmatization. MADA also takes the current word
context into consideration, as it examines all possible analyses for each word, and selects the analysis that
matches the current context using Support Vector Machine (SVM) classification for 19 weighted morphological
features. TOKAN generates a customizable tokenized output from MADA output. MADA+TOKAN has an accu-
racy of 86% in predicting full diacritization (Habash et al., 2009). The morphological analysis module also saves
the stem of each word in the search inverted index, with a weight that is determined by the word PoS tag as men-
tioned in the previous subsection.
4.2.1.3. Sentence splitting module
The sentence splitting module marks the end of each sentence by the period punctuation mark that is recog-
nized by MADA PoS tagger. MADA helps the sentence splitting module by differentiating between the punctua-
tion period mark and other similar marks, like the decimal point. The sentence splitting process is very important
for locating question and answer snippets.
45

4.2.1.4. Root Expansion module
Arabic is a highly derivational language. This results in term sparseness that cannot be solved by only using a
light stemmer. Thus, using a root stemmer to expand words proved to be effective in many natural language pro-
cessing tasks on morphologically rich and complex languages like Arabic (Oraby et al., 2012).
The root expansion module uses an Arabic root stemmer to extract each word root and save it to the inverted
index as an expansion to the word itself. Three root stemmers were tested with ALQASIM 2.0: (I) Khoja, (ii)
ISRI and (iii) Tashaphyne root stemmers.
The Khoja root stemmer is a Java Arabic root stemmer, created by Khoja & Garside, 1999. It removes the
longest suffix and prefix, and then matches the retrieved stem with the verb and noun patterns, to extract the root.
Khoja Arabic stemmer handles weak letters, which may change their form in an Arabic word root (i.e. alif, waw
or yah). It also identifies words that do not have roots like the Arabic words for “we”, “under”, “after”, and so on.
Khoja stemmer also produces the right root if a letter is deleted from the root during derivation due to duplicate
letters (i.e. the last two letters are the same) (Khoja & Garside, 1999). Taghva et al., 2005 reported that Khoja
stemmer has an Average Precision of 46.3%. Khoja Stemmer was also used by Larkey & Connell, 2006 in an
Arabic information retrieval system, which helped them to improve the Average Precision of their system by 49%
over the non-stemmed technique.
ISRI (Information Science Research Institute) root stemmer is a Python Arabic root stemmer, created by
Taghva et al., 2005. The ISRI stemmer has many features in common with the Khoja stemmer; however, it does
not use a root dictionary, which makes the ISRI stemmer more capable of stemming rare and new words. It nor-
malizes unstemmed words, has more stemming patterns than Khoja stemmer, and more than 60 stop words. ISRI
stemmer has an Average Precision of 48% (Taghva et al., 2005).
The Tashaphyne Light Arabic Stemmer works by first normalizing words in preparation for the “search and
index” tasks required for stemming, including removing diacritics and elongation from input words. Next, seg-
mentation and stemming of the input is performed using a default Arabic affix lookup list, allowing for various
levels of stemming and rooting (Oraby et al., 2012).
4.2.1.5. Numeric Expansion module
The numeric expansion module extracts numeric textual expressions, and saves their digit representation in
the inverted index. It also takes word number tags, provided by the morphological analysis module, and adds the
number 2 with each dual word. For example, the word "شهادتين" that means "2 Certificates" is saved to the in-
verted index as two words in the same location: "2" and "شهادة" / “certificate”.
46

4.2.1.6. Ontology-based Semantic Expansion module
ALQASIM 2.0 uses the background collection documents provided with the QA4MRE corpus from CLEF
2012, which is a group of documents related to the main topic of the reading test document. The QA4MRE cor-
pus will be explained in detail in chapter three. The ontology-based semantic expansion module expands any hy-
pernym in the document with its hyponyms extracted from the background collection ontology. A hyponym has a
"type-of" relationship with its hypernym. For example, in the bi-gram “ الإيدز مرض ” (“AIDS disease”), the word “
.is a hyponym because AIDS is a type of disease (”AIDS”) ”الإيدز“ is a hypernym and the word (”disease“) ”مرض
The ontology is extracted from the background documents collection using bi-grams collected according to two
rules:
1. Collect all hypernyms from all documents by collecting all the Demonstrative Pronouns (e.g. هذا, هذه,
أولئك, أولئك, تلك, ذلك, هؤلء ) followed by the noun that starts with "Al" determiner. This noun is marked
as a hypernym.
2. Collect any hypernym of the extracted list followed by a proper noun and considering the proper noun as
the hyponym of the respective hypernym. This relation in Arabic is named “Modaf”-“Modaf Elaih” rela-
tionship, which often denotes a hypernym-hyponym relationship, where the “Modaf” (the indeterminate
noun) is the hypernym and the “Modaf Elaih” (the proper noun) is the hyponym. See figure 15.
Figure 15. The intuition behind extracting the background collection ontology
47

4.2.2. Question Analysis
The main purpose of the question analysis module is to extract the question keywords, search for them in the
inverted index of the test document and return the found question snippets with their scores and sentences in-
dexes. It starts by tokenizing, light-stemming, and PoS tagging of the question text using MADA+TOKAN mor-
phological analysis toolkit. Stop words are removed from the question words, and the remaining keywords roots
are then extracted, using ISRI root stemmer, and added to the question keywords. Some question patterns are also
identified and a boost factor is applied for some keywords in them. For example, the pattern “ ال ما ” or “What is
the” is most of the times followed by a hypernym that is the focus of the question, so a boost multiplier was ap-
plied to the weight of that hypernym (focus) to mark its importance. The inverted index is then searched for the
question keywords to find the question scored snippets and sentences indexes, which will be used in the answer
selection module. See figure 16. Question snippets are scored according to the number of keywords and key-
words weights found in each snippet. See equation 3.
Figure 16. Question Analysis module architecture
48

Score=(∑i=1
N
W i)+( N−K ) (3)
Where:
• Score: score of a question or answer snippet
• N: number of found keywords
• wi: weight of each keyword
• K: number of all keywords
4.2.3. Answer Selection
In the question analysis module, the best question snippets and their sentences indexes are retrieved, accord-
ing to score. Only the snippets with the best score are retrieved. In this module, each answer choice is analyzed
exactly like the question, and the answer choice keywords are located in the inverted index. The search for answer
snippets is constrained to the sentence of the question snippet and the two sentences around it. In other words, if
the answer choice snippet is found in the question sentence or in the sentence after or before the question sen-
tence, then it is taken into consideration for further answer selection processing. The best scoring “found” answer
choice is selected as the question answer. If there are no “found” answers choices, or the scores of the highest
two or more answer choices are equal, then this means that the system is not sure which is the most appropriate
answer choice, and the question is marked as unanswered. See figure 17.
Figure 17. Answer Selection module architecture
49

Chapter FiveChapter Five
Results and AnalysisResults and Analysis
50

Chapter 5Chapter 5
Results and AnalysisResults and Analysis
This chapter explains the different experiments that were carried out on ALQASIM 2.0 platform and their re-
sults. The results of these experiments are then analyzed to highlight our findings and show how significant these
findings are.
5.1. Results
ALQASIM 2.0 performance in terms of speed has been tested on a PC with 8 CPUs and 6GB of RAM, and it
could answer the 160 questions in 3 seconds. However, some preprocessing have been carried out offline like
morphological analysis of the documents and the background collection, ISRI and Tashaphyne stemmer root ex-
traction and the background collection ontology generation.
ALQASIM 2.0 performed at a promising performance that is more than double the performance of the best
performing Arabic QA4MRE system created by Abouenour et al. Four different expeiments have been carried
out on ALQASIM 2.0 platform. These four experiments highlight the effect of sentence splitting, AWN semantic
expansion, custom background ontology semantic expansion, and root expansion. The results also highlight the
difference between the effect of the three root stemmers (i) Khoja, (ii) ISRI, and (iii) Tashaphyne.
The first run uses the baseline approach without any type of root or semantic expansion. In other words, it
uses sentence splitting, light stemming, numeric expansion, weights according to PoS tagging, and boost multi-
pliers for some question patterns. This run is mainly meant to highlight the effect of sentence splitting in answer
selection and validation. The results of this run will demonstrate how effective is sentence splitting in selecting
the correct answer choice and more importantly ignoring the wrong ones.
The second run applies the baseline approach mentioned above, in addition to applying Arabic WordNet se-
mantic expansion. A dictionary of synonyms is generated from AWN to expand a word by adding its synonyms
in the inverted index, and marking these synonyms with the same location of the original word. When this run is
compared with the first run, the effect of AWN semantic expansion using synonyms will be evident.
The third run applies semantic expansion using the background collection ontology to the baseline approach.
The stem of each word in the document is expanded with its hyponyms if it is a hypernym, according to the ex-
planation of the hypernym / hyponym relationship in section 5.1.6. The effect of semantic expansion from the on-
51
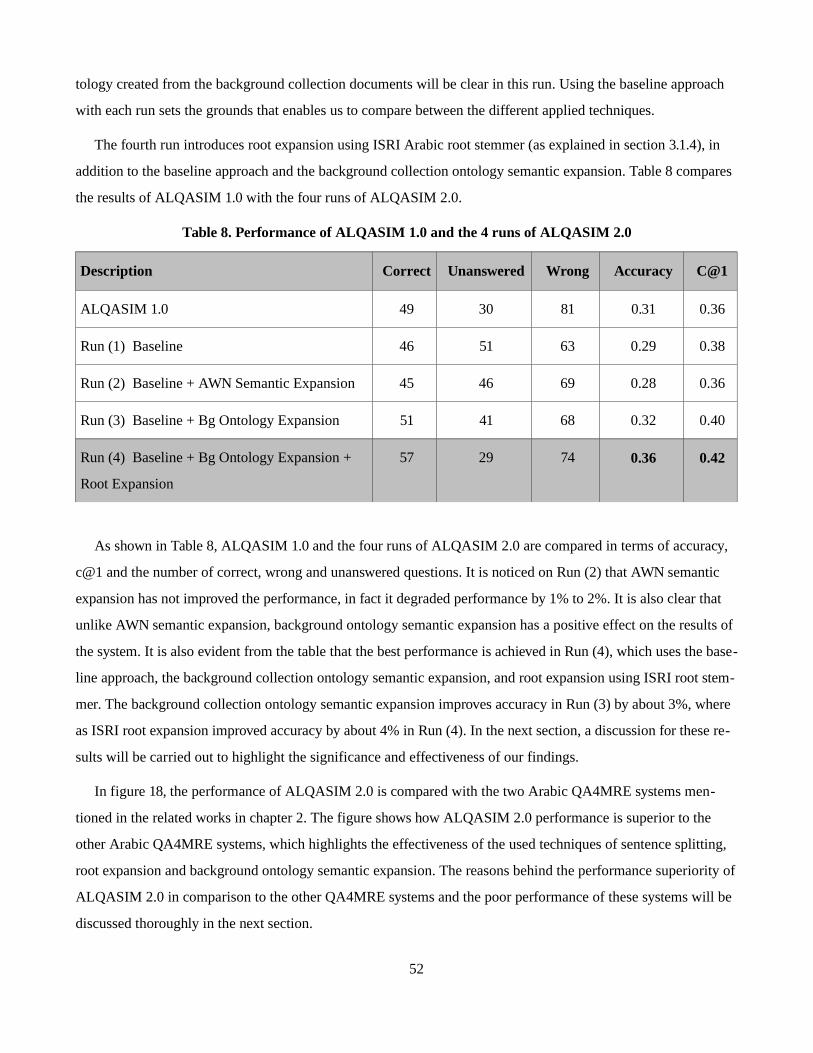
tology created from the background collection documents will be clear in this run. Using the baseline approach
with each run sets the grounds that enables us to compare between the different applied techniques.
The fourth run introduces root expansion using ISRI Arabic root stemmer (as explained in section 3.1.4), in
addition to the baseline approach and the background collection ontology semantic expansion. Table 8 compares
the results of ALQASIM 1.0 with the four runs of ALQASIM 2.0.
Table 8. Performance of ALQASIM 1.0 and the 4 runs of ALQASIM 2.0
Description Correct Unanswered Wrong Accuracy C@1
ALQASIM 1.0 49 30 81 0.31 0.36
Run (1) Baseline 46 51 63 0.29 0.38
Run (2) Baseline + AWN Semantic Expansion 45 46 69 0.28 0.36
Run (3) Baseline + Bg Ontology Expansion 51 41 68 0.32 0.40
Run (4) Baseline + Bg Ontology Expansion +
Root Expansion
57 29 74 0.36 0.42
As shown in Table 8, ALQASIM 1.0 and the four runs of ALQASIM 2.0 are compared in terms of accuracy,
c@1 and the number of correct, wrong and unanswered questions. It is noticed on Run (2) that AWN semantic
expansion has not improved the performance, in fact it degraded performance by 1% to 2%. It is also clear that
unlike AWN semantic expansion, background ontology semantic expansion has a positive effect on the results of
the system. It is also evident from the table that the best performance is achieved in Run (4), which uses the base-
line approach, the background collection ontology semantic expansion, and root expansion using ISRI root stem-
mer. The background collection ontology semantic expansion improves accuracy in Run (3) by about 3%, where
as ISRI root expansion improved accuracy by about 4% in Run (4). In the next section, a discussion for these re-
sults will be carried out to highlight the significance and effectiveness of our findings.
In figure 18, the performance of ALQASIM 2.0 is compared with the two Arabic QA4MRE systems men-
tioned in the related works in chapter 2. The figure shows how ALQASIM 2.0 performance is superior to the
other Arabic QA4MRE systems, which highlights the effectiveness of the used techniques of sentence splitting,
root expansion and background ontology semantic expansion. The reasons behind the performance superiority of
ALQASIM 2.0 in comparison to the other QA4MRE systems and the poor performance of these systems will be
discussed thoroughly in the next section.
52

Figure 18. Comparison between QA4MRE systems
Figure 19. Performance in terms of answered questions counts
53
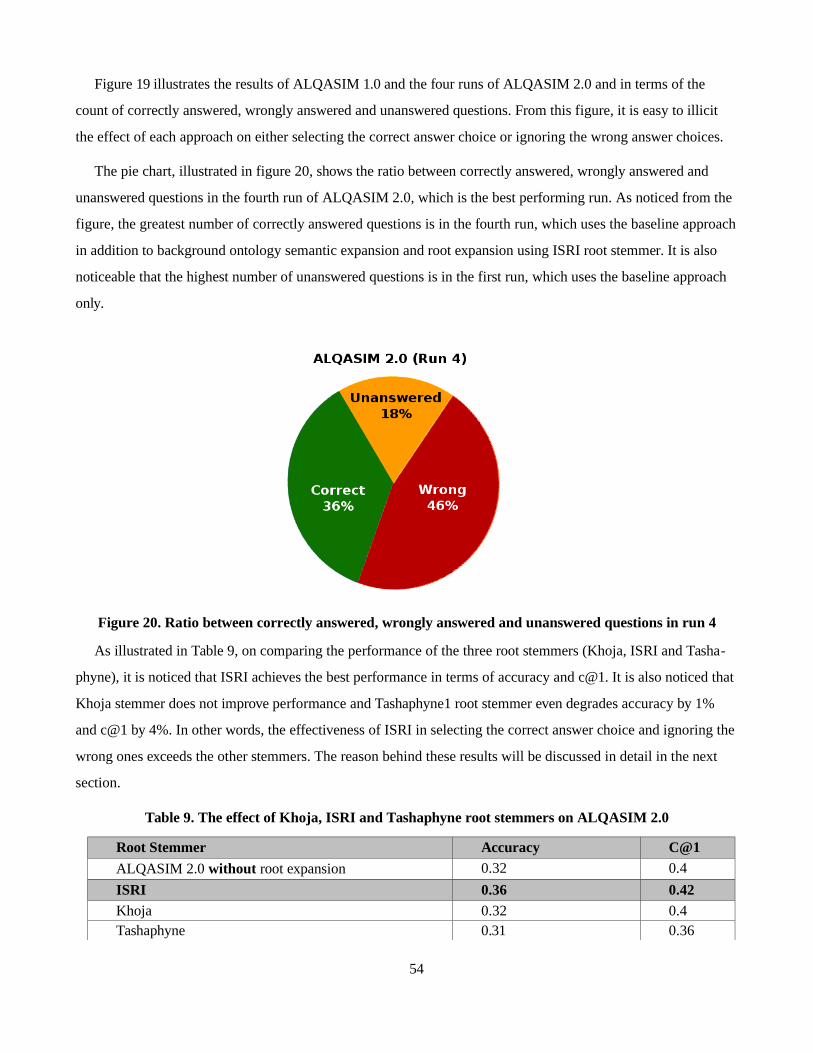
Figure 19 illustrates the results of ALQASIM 1.0 and the four runs of ALQASIM 2.0 and in terms of the
count of correctly answered, wrongly answered and unanswered questions. From this figure, it is easy to illicit
the effect of each approach on either selecting the correct answer choice or ignoring the wrong answer choices.
The pie chart, illustrated in figure 20, shows the ratio between correctly answered, wrongly answered and
unanswered questions in the fourth run of ALQASIM 2.0, which is the best performing run. As noticed from the
figure, the greatest number of correctly answered questions is in the fourth run, which uses the baseline approach
in addition to background ontology semantic expansion and root expansion using ISRI root stemmer. It is also
noticeable that the highest number of unanswered questions is in the first run, which uses the baseline approach
only.
Figure 20. Ratio between correctly answered, wrongly answered and unanswered questions in run 4
As illustrated in Table 9, on comparing the performance of the three root stemmers (Khoja, ISRI and Tasha-
phyne), it is noticed that ISRI achieves the best performance in terms of accuracy and c@1. It is also noticed that
Khoja stemmer does not improve performance and Tashaphyne1 root stemmer even degrades accuracy by 1%
and c@1 by 4%. In other words, the effectiveness of ISRI in selecting the correct answer choice and ignoring the
wrong ones exceeds the other stemmers. The reason behind these results will be discussed in detail in the next
section.
Table 9. The effect of Khoja, ISRI and Tashaphyne root stemmers on ALQASIM 2.0
Root Stemmer Accuracy C@1
ALQASIM 2.0 without root expansion 0.32 0.4
ISRI 0.36 0.42Khoja 0.32 0.4Tashaphyne 0.31 0.36
54
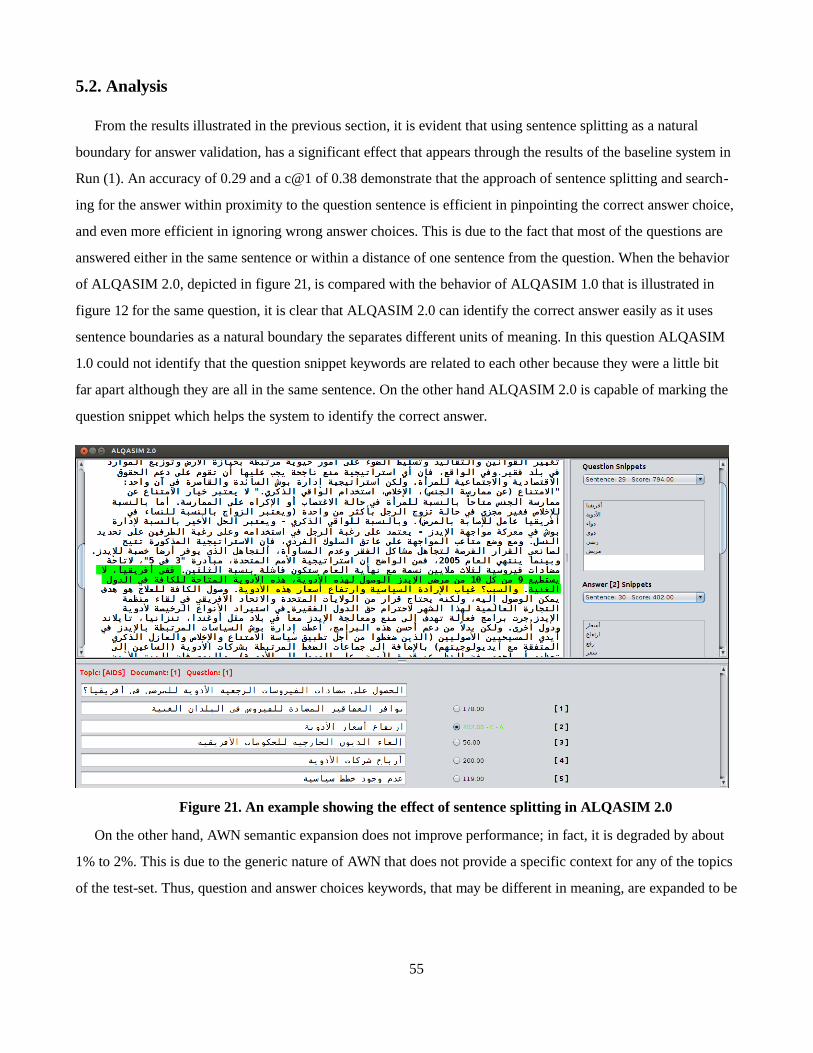
5.2. Analysis
From the results illustrated in the previous section, it is evident that using sentence splitting as a natural
boundary for answer validation, has a significant effect that appears through the results of the baseline system in
Run (1). An accuracy of 0.29 and a c@1 of 0.38 demonstrate that the approach of sentence splitting and search-
ing for the answer within proximity to the question sentence is efficient in pinpointing the correct answer choice,
and even more efficient in ignoring wrong answer choices. This is due to the fact that most of the questions are
answered either in the same sentence or within a distance of one sentence from the question. When the behavior
of ALQASIM 2.0, depicted in figure 21, is compared with the behavior of ALQASIM 1.0 that is illustrated in
figure 12 for the same question, it is clear that ALQASIM 2.0 can identify the correct answer easily as it uses
sentence boundaries as a natural boundary the separates different units of meaning. In this question ALQASIM
1.0 could not identify that the question snippet keywords are related to each other because they were a little bit
far apart although they are all in the same sentence. On the other hand ALQASIM 2.0 is capable of marking the
question snippet which helps the system to identify the correct answer.
Figure 21. An example showing the effect of sentence splitting in ALQASIM 2.0
On the other hand, AWN semantic expansion does not improve performance; in fact, it is degraded by about
1% to 2%. This is due to the generic nature of AWN that does not provide a specific context for any of the topics
of the test-set. Thus, question and answer choices keywords, that may be different in meaning, are expanded to be
55

semantically similar, which makes it harder for the system to pinpoint the correct answer among all the false pos-
itives introduced by the semantic expansion process.
Figure 22. An example of the effect of ontology expansion in ALQASIM 2.0
AWN also expands only well-known words like “ / سياسةpolicy or politics” and “ نظام / system or
arrangement” without any sense disambiguation according to context, and fails to expand context specific words
like “ / اإليدزAIDS” and “ / الزهايمرAlzheimer”. On the other hand, the automatically generated background collec-
tions ontology improves performance by about 3% and proves that it is more effective in the semantic expansion
of document specific terms. For example, the ontology states that “Alzheimer” is a “disease”, and that “AIDS” is
a “disease”, an “epidemic” and a “virus”.
However, building an ontology from the background collection to define the hypernym / hyponym semantic
relationship of document related terms is more efficient as it improves performance by about 3%. The approach
of automatically generating the ontology from the background collection as explained above is most of the time
capable of defining the right hypernym / hyponym pair. This semantic relationship helps to disambiguate many
questions that ask about the hyponym and has the hypernym among the question keywords. This approach in-
creases the overlap between the question and the answer terms, and makes it possible to boost the weight of the
hypernym in some question patterns to imply its importance. For example, figure 22 shows a question snippet,
marked in green, for the question that asks “What is the biggest obstacle against economic development in the
56

black continent?” and the answer snippet, marked in yellow, is a sentence that contains the words “this epidemic”
which denotes “AIDS”. Thus, ALQASIM 2.0 is able to identify that the hypernym “epidemic” in this context
stands for the hyponym “AIDS” and expands “epidemic” with “AIDS” in the inverted index.
Figure 23. An example showing the effect of root expansion in ALQASIM 2.0
The last Run shows the effect of root expansion on answer selection and validation. An improvement in per-
formance of about 4% was achieved by using ISRI root stemmer. Through this run it was clear that root expan-
sion makes it easier to pinpoint the correct answer especially when light stemming is not enough. This happens
when the question or answer and the document have the keywords of the same root but in different derivational
forms. For example, the question may ask about a noun, and the question snippet in the document has its verb
which has a different derivation. This is evident in figure 23 that illustrates that the answer choice has the word “
increase”, which enables ALQASIM 2.0 to align the / زيادة“ more” and the answer sentence has the word / المزيد
answer choice with its sentence in the document because these two words have the same root “زيد”.
Table 10 illustrates how over stemming using Tashaphyne stemmer actually degrades performance as it gives
the same root for some terms that should be semantically different. On the other hand, table 11 explains why
Khoja stemmer does not affect performance because it is not capable of stemming new words that are not found
in its dictionary. Thus, in most cases, it either returns the original word or its light stem, which means no expan-
57

sion is being carried out, taking into consideration that the light stem (provided by MADA+TOKAN) and the
original word are already saved in the inverted index.
Table 10: Sample Output of Tashaphyne root stemmer
Tashaphyne Root Original Words English Translation
ء " وباء"، " سواء"، " سوءا"، "ماء " “water”, “worse”, “alike”, “epidemic”
آا " آفات"، " آلت " “machinery”, “pests”
أ " أتى"، " أي " “any”, “came”
Table 11: Comparison between the performance of Khoja and ISRI root stemmers
Stemmer Output Khoja ISRI
Possible root (a token that is not equal to the light stem
or the original word)
36 0.23% 11324 74.68%
Light stem (already generated by MADA) 3647 24.05% 3204 21.13%
Original Word 11480 75.71% 635 4.18%
58

Chapter SixChapter Six
Conclusion and Future WorkConclusion and Future Work
59

Chapter 6Chapter 6
Conclusion and Future WorkConclusion and Future Work
In this chapter, a summary of the whole dissertation is provided. The research is then evaluated and the future
work is highlighted.
6.1. Summary
The dissertation tackled the Arabic answer selection and validation problem. Answer selection and validation
is very important for question answering as it enhances their quality. In other words, QA system generally gener-
ate answers choices for every question and the main task of answer selection and validation is to select the best
answer choice if any and marks the question as unanswered if there is no answer or the system is not certain of
the best answer. Question Answering for Machine Reading Evaluation (QA4MRE) is an organized approach of
creating and testing answer selection and validation systems. It works by selecting the best answer choice among
a list of provided choices and supports the selection with one document. This is exactly like reading comprehen-
sion where a document is provided to a human and a group of questions with answer choices for each questions
to choose from. Thus, the answer selection and validation task can be compared and evaluated with QA4MRE as
it provides the documents, questions and answer choices that are the traditional output of any QA generative
process (question analysis and passage retrieval).
In this dissertation, we introduced ALQASIM, which is a QA4MRE system that mimics the human behaviour
by analyzing the reading test document and selecting the best answer choice for every question according to sen-
tence splitting, background ontology semantic expansion and root expansion. The Arabic QA4MRE test-set used
by ALQASIM was introduced by CLEF 2012 and two Arabic systems attempted to tackle this task using the
same test-set. These systems are IDRAAQ and the system created by Trigui et al. In this dissertation, we showed
that the performance of ALQASIM is about double the performance of the best performing Arabic system which
is IDRAAQ. This performance increase is mainly due to the approach of analyzing the reading test documents
instead of following the ordinary QA pipeline used in the other two systems.
ALQASIM 1.0 was introduced in CLEF 2013 and it mainly used the notion of keywords weights and dis-
tances to pinpoint the question and answer choices in the reading test documents. In the next version, ALQASIM
2.0, three better techniques were used the improved performance in a more sound approach. These techniques are
sentence splitting, background ontology semantic expansion and root expansion. The intuition behind sentence
60

splitting is that sentences hold words that are connected to each other to form a stream of meaning, thus it is bet-
ter to connect the words of a single sentence togther and consider them related instead of using the notion of dis-
tance as it may not be accurate. Using the background ontology semantic expansion also proved to be effective
because it expands the document words with words from the same domain and this is much better than using a
general ontology like Arabic WordNet as it provides context to give a better understanding for the document and
the questions. Last but not least, root expansion provided a significant improvement in performance because Ara-
bic is a very morphologically rich, inflectional and derivational language and its derivational nature can be chal-
lenging in the information retrieval tasks ask a single word can appear in different derivational forms in the ques-
tion, answer or in the document.
6.2. Evaluation
The results of ALQASIM 1.0 illustrate the effect of keywords count, weight and distance on answer selection
and validation. ALQASIM 2.0 improves the notion of keyword distance by constraining the search for question
and answer snippets within sentence boundaries which makes use of the natural sentence boundaries and its rela-
tion with meaning.
ALQASIM 2.0 also makes use of root expansion to come over derivationally challenging snippet search. For
example, when the system needs to locate the question or answer snippets in the reading test document, and some
of the question keywords are in a different derivational form from its corresponding snippet in the test document.
An ontology created from the CLEF background document collection helped ALQASIM 2.0 to reach better
performance as it augments some document hypernyms with their hyponyms, which enables the system to an-
swer some questions that ask about a hyponym and mentions the hypernym in the question.
These deployed techniques make the performance of ALQASIM better than its best performing predecessor
on the same test-set by about 21% to 23%. This is considered very promising and encourages other works to take
these techniques as a baseline and build on top of them to reach better performance. Providing better answer se-
lection and validation systems will eventually provide smarter QA systems that can serve the demanding market
for fast and precise information. In the next section, the future work that can be carried out to improve perfor-
mance of ALQASIM is highlighted.
6.3. Future Work
This section points out some opportunities for future work on ALQASIM. These future work opportunities in-
clude applying rule-based techniques that depend on Arabic specific syntactic and semantic rules and making
61

use of textual entailment. They also include using other natural language processing tools like semantic parsing,
semantic role labeling, and anaphora resolution tools.
6.3.1. Rule-based techniques
Arabic specific rules are very rich and convey not only syntactic features but also some semantic features. Ac-
cording to the derivational pattern applied to an Arabic three or four letters root, a different meaning is conveyed.
However, these semantic differences could be inferred by Arabic native speakers by knowing the pattern and the
meaning of the root only. For example, applying the pattern “فاعول” to a three letter root in Arabic gives the
meaning of an instrument that does the action of the root. Also applying the pattern “استفعال” to a three letter root
gives the meaning of requesting the action of the root. In our future research, we will focus on applying rule-
based techniques that depend on Arabic specific syntactic and semantic rules, which proved to be effective in
other natural language processing tasks like Arabic sentiment analysis (Oraby et al., 2013).
6.3.2. Anaphora Resolution
A good writing style in any language requires the authors to refrain from repeating a word and to use anaphora
instead. Thus, most Arabic documents contain many anaphora that increases the ambiguity of Arabic sentences.
Applying anaphora resolution in Arabic answer selection and validation will definitely increase the overlap be-
tween the question or answer keywords and the document keywords, which will improve performance and make
it easier to pinpoint the right question and answer snippets.
6.3.3. Semantic Parsing and Semantic Role Labeling
The more the computer understands the human speech, the more it is capable to answer question posed by
them. Semantic parsers make it easier to add a semantic dimension to the task of answer selection and validation,
as it helps the machine to draw semantic graphs for the document, question and answer text. They can also help
to match question or answer choice semantic graph against a partial graphs in the document, which will help to
answer more complex questions. Semantic role labeling can also be used to further constrain the area to search
for answers and make it easier and more accurate to align the answer choices with the reading test document
snippets.
62

6.3.4. More Automatically Generated Ontologies
According to the positive effect that was explored in using an automatically generated ontology, we will also pay
more attention to automatic the generation of domain specific ontologies and knowledge-bases, which may help
to enrich the semantic aspect of language understanding as a whole and specifically question answering. Increas-
ing more relations in the ontology and improving the accuracy of these relation should impact the performance
of any answer selection and validation system as it will provide a better organized domain knowledge.
63

ReferencesReferences
(Abdelbaki & Shaheen, 2011) Abdelbaki, H., Shaheen, M., & Badawy, O. (2011, October). ARQA High-Perfor-
mance
(Abouenour et al., 2009) Abouenour, L., Bouzoubaa, K., & Rosso, P. (2009, May). Three-level Approach for Pas-
sage Retrieval in Arabic Question/Answering Systems. In Proc. Of the 3rd International Conference on Arabic
Language Processing CITALA2009, Rabat, Morocco.
(Abouenour et al., 2010) Abouenour, L., Bouzouba, K., & Rosso, P. (2010). An Evaluated Semantic Query Ex-
pansion and Structure-Based Approach for Enhancing Arabic Question/Answering.
(Abouenour et al., 2011) Abouenour, L. (2011). On the Improvement of Passage Retrieval in Arabic Question/An-
swering (Q/A) Systems. Natural Language Processing and Information Systems, 336-341.
(Abouenour et al., 2012) Abouenour, L., Bouzoubaa, K., & Rosso, P. (2012, September). IDRAAQ: New Arabic
Question Answering System Based on Query Expansion and Passage Retrieval. In CLEF 2012 Workshop on
Question Answering For Machine Reading Evaluation (QA4MRE).
(Abuleil & Evens, 1998) Abuleil, S., and Evens, M., (1998). Discovering Lexical Information by Tagging Arabic
Newspaper Text. Workshop on Semantic Language Processing. COLING-ACL '98, University of Montreal, Mon-
treal, PQ, Canada, Aug. 16 1998, pp. 1--7.
(Awadallah & Rauber, 2006) Awadallah, R., & Rauber, A. (2006). Web-based multiple choice question answer-
ing for English and Arabic questions. Advances in Information Retrieval, 515-518.
(Bekhti et al., 2011) Bekhti, S., Rehman, A., Al-Harbi, M., & Saba, T. (2011). AQuASys an Arabic Question-An-
swering System Based on Extensive Question Analysis and Answer Relevance Scoring. Inf Comput Int J Acad
Res, 3(4), 45-54.
(Benajiba et al., 2007) Benajiba, Y., Rosso, P., & Gómez Soriano, J. (2007). Adapting the JIRS Passage Retrieval
System to the Arabic Language. Computational Linguistics and Intelligent Text Processing, 530-541.
(Benajiba et al., 2007) Benajiba, Y., Rosso, P., & Lyhyaoui, A. (2007, April). Implementation of the ArabiQA
Question Answering System's components. In Proc. Workshop on Arabic Natural Language Processing, 2nd In-
formation Communication Technologies Int. Symposium, ICTIS-2007, Fez, Morroco, April (pp. 3-5).
(Benajiba & Rosso, 2007) Benajiba, Y., & Rosso, P. (2007). Arabic Question Answering. Diploma of advanced
studies. Technical University of Valencia, Spain.
(Bhaskar et al., 2012) Bhaskar, P., Pakray, P., Banerjee, S., Banerjee, S., Bandyopadhyay, S., & Gelbukh, A.
(2012, September). Question Answering System for QA4MRE@CLEF 2012. In CLEF 2012 Workshop on Ques-
tion Answering For Machine Reading Evaluation (QA4MRE).
64

(Brini et al., 2009) Brini, W., Ellouze, M., Mesfar, S., & Belguith, L. H. (2009, September). An Arabic Question-
Answering System for Factoid Questions. In Natural Language Processing and Knowledge Engineering, 2009.
NLP-KE 2009. International Conference on (pp. 1-7). IEEE.
(Brini et al., 2009) Brini, W., Ellouze, M., Trigui, O., Mesfar, S., Belguith, H. L., & Rosso, P. Factoid and Defini-
tional Arabic Question Answering System. Post-Proc. NOOJ-2009, Tozeur, Tunisia, June, 8-10. (2009).
(Elkateb et al., 2006) Elkateb, S., Black, W., Vossen, P., Farwell, D., Rodríguez, H., Pease, A., & Alkhalifa, M.
(2006, October). Arabic WordNet and the Challenges of Arabic. In Proceedings of Arabic NLP/MT Conference,
London, UK.
(Ezzeldin et al., 2013) Ezzeldin, A. M., Kholief, M. H., & El-Sonbaty, Y. (2013). ALQASIM: Arabic language
question answer selection in machines. In Information Access Evaluation. Multilinguality, Multimodality, and
Visualization (pp. 100-103). Springer Berlin Heidelberg.
(Ezzeldin & Shaheen, 2012) Ezzeldin, A. M., & Shaheen, M. (2012, December). A Survey Of Arabic Question
Answering: Challenges, Tasks, Approaches, Tools, And Future Trends. In Proceedings of the 13th International
Arab Conference on Information Technology ACIT'2012. ISSN: 1812-0857.
(Habash et al., 2009) Habash, N., Rambow, O., & Roth, R. (2009). MADA+TOKAN: A Toolkit for Arabic Tok-
enization, Diacritization, Morphological Disambiguation, PoS Tagging, Stemming and Lemmatization. In Pro-
ceedings of the 2nd International Conference on Arabic Language Resources and Tools (MEDAR), Cairo, Egypt
(pp. 102-109).
(Hammo et al., 2002) Hammo, B., Abu-Salem, H., & Lytinen, S. (2002, July). QARAB: a Question Answering
System to Support the Arabic Language. In Proceedings of the ACL-02 workshop on Computational approaches
to semitic languages (pp. 1-11). Association for Computational Linguistics.
(Hammo et al., 2004) Hammo, B., Abuleil, S., Lytinen, S., & Evens, M. (2004). Experimenting with a Question
Answering System for the Arabic Language. Computers and the Humanities, 38(4), 397-415.
(Kanaan et al., 2009) Kanaan, G., Hammouri, A., Al-Shalabi, R., & Swalha, M. (2009). A New Question An-
swering System for the Arabic Language. American Journal of Applied Sciences, 6(4), 797-805.
(Khoja & Garside, 1999) Khoja, S., & Garside, R. (1999). Stemming Arabic Text. Lancaster, UK, Computing
Department, Lancaster University.
(Ko et al., 2007) Ko, J., Si, L., & Nyberg, E. (2007). A Probabilistic Framework for Answer Selection in Ques-
tion Answering. In HLT-NAACL (pp. 524-531).
(Larkey & Connell, 2006) Larkey, L. S., & Connell, M. E. (2006). Arabic Information Retrieval at UMass in
TREC-10. Massachusetts Univ Amherst Center for Intelligent Information Retrieval.
(Laurent et al., 2006) Laurent, D., Séguéla, P., & Nègre, S. (2006, April). QA Better than IR?. In Proceedings of
the Workshop on Multilingual Question Answering (pp. 1-8). Association for Computational Linguistics.
65

(Manning et al., 2008) Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to information retrieval
(Vol. 1). Cambridge: Cambridge University Press.
(Mendes & Coheur, 2011) Mendes, A. C., & Coheur, L. (2011, June). An Approach to Answer Selection in Ques-
tion-Answering Based on Semantic Relations. In IJCAI (pp. 1852-1857).
(Mohammed et al., 1993) Mohammed, F. A., Nasser, K., & Harb, H. M. (1993). A Knowledge Based Arabic
Question Answering System (AQAS). ACM SIGART Bulletin, 4(4), 21-30.
(Moldovan et al., 2007) Moldovan, D., Clark, C., & Bowden, M. (2007, November). Lymba’s PowerAnswer 4 in
TREC 2007. In Proceedings of the Sixteenth Text REtrieval Conference (TREC 2007). Gaithersburg, MD.
(Oraby et al., 2012) Oraby, S. M., El-Sonbaty, Y., & El-Nasr, M. A. (2012). Exploring the Effects of Word Roots
for Arabic Sentiment Analysis.
(Oraby et al., 2013) Oraby, S., El-Sonbaty, Y., & El-Nasr, M. A. (2013). Finding Opinion Strength Using Rule-
Based Parsing for Arabic Sentiment Analysis. In Advances in Soft Computing and Its Applications (pp. 509-
520). Springer Berlin Heidelberg.
(Penas et al., 2011) Penas, A., Hovy, E. H., Forner, P., Rodrigo, Á., Sutcliffe, R. F., Forascu, C., & Sporleder, C.
(2011). Overview of QA4MRE at CLEF 2011: Question Answering for Machine Reading Evaluation. In CLEF
(Notebook Papers/Labs/Workshop).
(Penas et al., 2011) Penas, A., Rodrigo, A., & del Rosal, J. (2011, June). A simple Measure to Assess Non-re-
sponse. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human
Language Technologies (Vol. 1, pp. 1415-1424).
(Penas et al., 2012) Penas, A., Hovy, E., Forner, P., Rodrigo, A., Sutcliffe, R., Sporleder, C., Forascu, C., Bena-
jiba, Y., & Osenova, P. (2012, September). Overview of QA4MRE at CLEF 2012: Question Answering for Ma-
chine Reading Evaluation. In CLEF 2012 Workshop on Question Answering For Machine Reading Evaluation
(QA4MRE).
(Rosso et al., 2005) Rosso, P., Lyhyaoui, A., Peñarrubia, J., y Gómez, M. M., Benajiba, Y., & Raissouni, N.
(2005, June). Arabic-English Question Answering. In Proc. Symposium on Information Communication Tech-
nologies Int., Tetuan, Morocco.
(Rosso et al., 2006) Rosso, P., Benajiba, Y., & Lyhyaoui, A. (2006, December). Towards an Arabic Question An-
swering System. In Proc. 4th Conf. on Scientific Research Outlook & Technology Development in the Arab
world, SROIV, Damascus, Syria (pp. 11-14).
(Smuckeret al., 2008) Smucker, M. D., Allan, J., & Dachev, B. (2008). Human Question Answering Performance
Using an Interactive Information Retrieval System. Center for Intelligent Information Retrieval Technical Report
IR-655, University of Massachusetts.
66

(Taghva et al., 2005) Taghva, K., Elkhoury, R., & Coombs, J. (2005, April). Arabic Stemming without a Root
Dictionary. In Information Technology: Coding and Computing, 2005. ITCC 2005. International Conference on
(Vol. 1, pp. 152-157). IEEE.
(Trigui et al., 2010) Trigui, O., Belguith, H. L., & Rosso, P. (2010). DefArabicQA: Arabic Definition Question
Answering System. In Workshop on Language Resources and Human Language Technologies for Semitic Lan-
guages, 7th LREC, Valletta, Malta (pp. 40-45).
(Trigui et al., 2012) Trigui, O., Belguith, L. H., Rosso, P., Amor, H. B., Gafsaoui, B. (2012, September). Arabic
QA4MRE at CLEF 2012: Arabic Question Answering for Machine Reading Evaluation. In CLEF 2012 Work-
shop on Question Answering For Machine Reading Evaluation (QA4MRE).
67
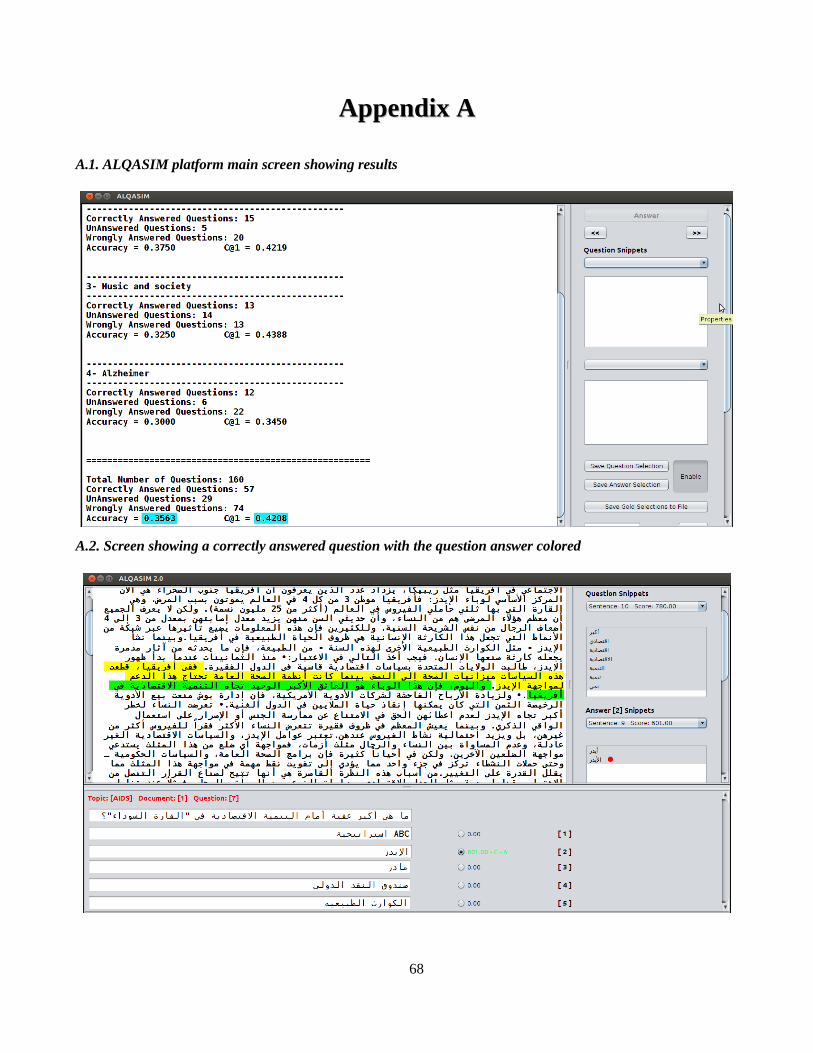
Appendix AAppendix A
A.1. ALQASIM platform main screen showing results
A.2. Screen showing a correctly answered question with the question answer colored
68

A.3. Screen showing a wrongly answered question with the gold answer to identify the reason for failure
A.4. Schema of the input questions after applying morphological analysis
69

A.5. Sample hypernym / hyponym pairs automatically generated from the CLEF background collection of the
AIDS topic
Frequency Possible Hypernym Possible Hyponym
3322 مرض أيدز
2127 فيروس أيدز
1168 مريض أيدز
426 وباء أيدز
361 جمهوري صين
351 شبكة إنترنت
338 منطقة شرق
317 قطاع غزة
275 جمهوري كونغو
260 إذن الله
256 ضد أيدز
208 دولة رياض
203 دولة كويت
194 شكل أكبر
190 مرض ألزهايمر
187 شمال أفريقيا
174 برنامج أمم
166 قدر أكبر
165 جائزة نوبل
157 علج أيدز
154 انتشار أيدز
153 إقليم شرق
152 تنظيم قاعدة
151 حرب خليج
147 يوم اثنين
146 رسول الله
142 يوم جمعة
140 سبب أيدز
133 عدد أكبر
133 حاكم شارقة
70

132 شهر رمضان
129 حول أيدز
127 مكتب يونيسكو
عدوى 126 أيدز
يوم 121 ثلثاء
شمال 114 شرق
71

الخلصة
تعدي على قادرة غير يجعلها مما طبقاتها في الأخطاء تراكم من غيرها أو العربية اللغة في سواءا الأسئلة إجابة أنظمة أغلب تعاني
. بينهم المفاضلة و سويا نظام من بأكثر الستعانة ليمكن الصحيحة الإجابات من للتأكد طريقة من بد ل كان لذلك الكفاءة من معين قدر
. . العربية باللغة الأسئلة إجابات من التأكد و باختيار يعنى الذي البحث هذا أهمية كانت لذا الأصح الإجابة من بالتأكد
ومختبرات " مؤتمر قبل من الغرض لهذا خصيصا معدة اختبار مجموعة على التجارب تمت و للبحث التجريبية المنهجية اختيار تم
التقييم " ( البحث) CLEFمنتدى مقارنة ليمكن ذلك و الختيارات متعددة الأسئلة و القراءة قطع من مجموعة من تتكون التي و ،
المتعارف الأسئلة أنواع أغلب ليمثل منهجي بشكل مكونة تلك الختبار مجموعة لأن و المماثلة الأبحاث من غيره مع به قمنا الذي
يسمى. " جديد مقياس و الدقة هي و المؤتمر نفس قبل من المستخدمة بالمقاييس أنشأناها التي النظم أداء قياس أيضا تم و عليها
C@1 . إجابتها" من متأكدة غير تكون التي الأسئلة عن تجيب ل التي للأنظمة أفضل درجة يعطي الذي و
العربي " الصرفي المحلل استخدام إيجاد" Mada+Tokanتم على يساعد الذي و النوع و العدد و الكلمة جذع يستخرج الذي و
" . الشجري القاموس استخدام أيضا تم فاعلية أكثر بطريقة الجواب و و" Arabic WordNetالسؤال المترادفات منه استخرج الذي و
هي " و العربية الكلمات جزر لستخراج أدوات ثلث إلى بالإضافة به قمنا" Tashaphyneو" "ISRIو" "Khojaالستعانة التي و
. نتائجها بين المقارنة و جميعا بتجربتها
التي التحديات و المستخدمة بالمصطلحات التعريف متناول البحث لموضوع اللزمة الخلفية تشرح مقدمة عن عبارة هو الأول الفصل
. إجابة نظام لأي العام للشكل شرح يتناول ثم خاصة بصفة العربية الأسئلة إجابة و عامة بصفة الطبيعية اللغات تحليل أنظمة تواجه
بالنسبة أهميتها و نشأتها بداية و الإجابات اختيار في البحث نقطة عن مقدمة ثم للمستخدم بالنسبة الأسئلة إجابة أهمية و أسئلة
. . التي الأعمال أهم يتناول الثاني الفصل الرسالة موضوع عن عامة نظرة و الإنجازات و البحث أهداف تناول أيضا تم الأسئلة لإجابة
أفضل شرح أيضا تم و ، المكونات لتلك عمل كل تناول و الأسئلة إجابات مكونات حسب مفصلة العربية باللغة الأسئلة إجابة تناولت
. اللغوية الموارد و الأدوات يسرد الثالث الفصل قبل من العربية الإجابات احتيار تناولت التي الأعمال و الأخرى اللغات في الأعمال
و " الدقة هي و باستخدامها قمنا التي المقاييس ّا أيض يتناول و قواميس، و نحوية و صرفية محللت من البحث في المستخدمة
C@1 . و" الأول البحث في بنشره قمنا الذي المبدئي النظام يشرح الرابع الفصل عليها النظام بتجربة قمنا التي الختبار مجموعة و
. مع عليه بها قمنا التي التعديلت بعد الجديد النظام مكونات بالشرح يتناول ثم ، السابقة بالأعمال مقارنتها و نتائجه ثم مكوناته
. أسباب لمعرفة مناقشتها و النتائج و أجريناها التي التجارب يشرح الخامس الفصل أجزائه و النظام هذا عمل لكيفية تفصيلي شرح
. لما تقييم و الرسالة في تناولناه عما ملخص يتضمن و الستنتاج فهو الأخير الفصل أما بها قمنا التي التجارب في الفشل أو النجاح
. العمل هذا لتكملة المستقبل في به نقوم أن يمكن لما عرض ثم فيها جاء
بمقدار % دقة إلى البحث هذا "36أدى مجال 42بمقدار” C@1%و في المماثلة الأعمال إليه توصلت ما ضعف حوالي ذلك و
تعرفنا أيضا و الأسئلة لإجابات بالنسبة الصرفية المحللت أفضل معرفة من تمكنا البحث خلل من و العربية للأسئلة الإجابات اختيار
بصلة تمت ل التي الأخرى العامة القواميس على أفضليتها و الختبار مجموعة من مباشرة الشجرية القواميس استخراج أهمية على
أهمية و الجواب و السؤال عن فيها البحث و جمل إلى عليها المختبر القطع تقسيم أهمية إلى التوصل أيضا و عليها المختبر للأسئلة
. السؤال جملة من مقربة على الإجابات عن البحث
72

البحري النقل و تكنولوجيا ل ا و لعلوم ل العربية أكاديمية ل ا
المعلومات ا تكنولوجي و الحاسبات ية ل ك
الحاسب علوم قسم
لإجابات ا صحة من تأكد ل ا و لإجابات اختيار ا صحة من تأكد ل ا و اختيار
العربية باللغة لأسئلة العربية ل باللغة لأسئلة لإعداد
الدين عز محمد مجدي أحمدمصر
ا تكنولوجي ل ا و لعلوم ل العربية أكاديمية ل ل مقدمة رسالة
درجة متطلبات لستكمال لبحري ا النقل و
الحاسب علوم ماجستير
إشراف تحت
خليف. حامد محمد د
المعلومات تكنولوجيا و الحاسبات كلية
البحري النقل و التكنولوجيا و للعلوم العربية الأكاديمية
. السنباطي. ياسر د أ
المعلومات تكنولوجيا و الحاسبات كلية
البحري النقل و التكنولوجيا و للعلوم العربية الأكاديمية
2014




















