
An Efficient Feature Selection Method for Object Detection
8
An Efficient Feature Selection Method for Object Detection Duy-Dinh Le 1 and Shin’ichi Satoh 1,2 1 The Graduate University for Advanced Studies, Shonan Village, Hayama, Kanagawa, Japan 240-0193 [email protected] 2 National Institute of Informatics, 2-1-2 Hitotsubashi, Chiyoda-ku, Tokyo, Japan 101-8430 [email protected] Abstract. We propose a simple yet efficient feature-selection method — based on principle component analysis (PCA) — for SVM-based clas- sifiers. The idea is to select features whose corresponding axes are closest to the principle components computed from a data distribution by PCA. Experimental results show that our proposed method reduces dimension- ality similar to PCA, but maintains the original measurement meanings while decreasing the computation time significantly. 1 Introduction In many object-detection systems, feature selection — which is generally con- sidered as the selection of a smaller subset of features from a large set of features — is one of the critical issues for the following three reasons. First, there are many ways to represent a target object, leading to a huge input feature set. For example, Haar wavelet features used in [1] are in the order of thousands. However, only small and incomplete training sets are available. As a result, systems will suffer from the curse of dimensionality and overfitting. Second, a large feature set includes many irrelevant and correlated features that can degrade the generalization performance of classifiers [2,3]. Third, selecting an optimal feature subset from a large input feature set can improve the performance and speed of classifiers. In face detection, the success of systems such as those in [1,4] comes mainly from efficient feature-selection methods. Most work, however, only focuses on feature-extraction methods, such as principle-component analysis (PCA), linear discriminant analysis (LDA), and independent-component analysis (ICA) [5,6,7], which try to map data from high- dimensional space to lower-dimensional space. This might be because feature- selection methods, such as sequential forward selection (SFS), sequential back- ward selection (SBS), and sequential forward floating search (SFFS) [8,9], incur very high computational cost. In this paper, to address these problems, we propose a simple yet efficient feature-selection method for object detection. The main idea is to select features S. Singh et al. (Eds.): ICAPR 2005, LNCS 3686, pp. 461–468, 2005. c Springer-Verlag Berlin Heidelberg 2005
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of An Efficient Feature Selection Method for Object Detection

An Efficient Feature Selection Method for
Object Detection
Duy-Dinh Le1 and Shin’ichi Satoh1,2
1 The Graduate University for Advanced Studies,Shonan Village, Hayama, Kanagawa, Japan 240-0193
[email protected] National Institute of Informatics,
2-1-2 Hitotsubashi, Chiyoda-ku, Tokyo, Japan [email protected]
Abstract. We propose a simple yet efficient feature-selection method— based on principle component analysis (PCA) — for SVM-based clas-sifiers. The idea is to select features whose corresponding axes are closestto the principle components computed from a data distribution by PCA.Experimental results show that our proposed method reduces dimension-ality similar to PCA, but maintains the original measurement meaningswhile decreasing the computation time significantly.
1 Introduction
In many object-detection systems, feature selection — which is generally con-sidered as the selection of a smaller subset of features from a large set offeatures — is one of the critical issues for the following three reasons.
First, there are many ways to represent a target object, leading to a hugeinput feature set. For example, Haar wavelet features used in [1] are in the orderof thousands. However, only small and incomplete training sets are available. Asa result, systems will suffer from the curse of dimensionality and overfitting.
Second, a large feature set includes many irrelevant and correlated featuresthat can degrade the generalization performance of classifiers [2,3].
Third, selecting an optimal feature subset from a large input feature set canimprove the performance and speed of classifiers. In face detection, the successof systems such as those in [1,4] comes mainly from efficient feature-selectionmethods.
Most work, however, only focuses on feature-extraction methods, such asprinciple-component analysis (PCA), linear discriminant analysis (LDA), andindependent-component analysis (ICA) [5,6,7], which try to map data from high-dimensional space to lower-dimensional space. This might be because feature-selection methods, such as sequential forward selection (SFS), sequential back-ward selection (SBS), and sequential forward floating search (SFFS) [8,9], incurvery high computational cost.
In this paper, to address these problems, we propose a simple yet efficientfeature-selection method for object detection. The main idea is to select features
S. Singh et al. (Eds.): ICAPR 2005, LNCS 3686, pp. 461–468, 2005.c© Springer-Verlag Berlin Heidelberg 2005

462 D.-D. Le and S. Satoh
whose corresponding axes are closest to principle components computed by PCAfrom the data distribution. This is a very naive feature-selection method, butexperimental results on different kinds of features show that when working withsupport vector machine (SVM)-based classifiers, our proposed method has com-parable performance, but faster speed, compared to a feature-selection methodbased on PCA directly.
The rest of the paper is organized as follows: In section 2, feature extractionby PCA is presented. Our feature selection method is introduced in section 3.Experimental results are showed in section 4. Finally, section 5 concludes thepaper.
2 Feature Extraction Using PCA
The main steps to extract features using PCA are summarized in the following.The details are given in [5].
Each face image I(x, y) is represented as an N × N vector Γi.The average face Ψ is computed as: Ψ = 1
M ΣMi=1Γi where M is the number
of face images in the training set.The difference between each face and the average face is given as: Φi = Γi−Ψ .
A covariance matrix is then estimated as: C = 1M ΣM
i=1ΦiΦTi = AAT where
A = [Φ1Φ2...ΦM ].Eigenvectors ui and corresponding eigenvalues λi of the covariance matrix
C can be evaluated by using a Singular Value Decomposition (SVD) method[5]: Cui = λiui. Because matrix C is usually very large (N2 × N2), evaluatingeigenvectors and eigenvalues is very expensive. Instead, eigenvectors vi and cor-responding eigen values µi of matrix AT A (M × M) can be computed. Afterthat, ui can be computed from vi as follows: ui = Avi, j = 1, ..., M .
To reduce dimensionality, only a smaller number of eigenvectors K(K << M)corresponding to the largest eigenvalues are kept. A new face image Γ , aftersubtracting the mean (Φ = Γ − Ψ) can then be reconstructed in eigenspace bythe formula: Φ̃ = ΣK
i=1wiui where wi = uTi Ψ are coefficients of the projection and
can be considered as a new representation of the original face in this eigenspace.
3 The Proposed PCA-Based Feature Selection
The main idea of our naive feature-selection method is to investigate the principlecomponents computed by PCA in the projection space to select correspondingaxes in the original space. Selected axes are those closest to these principle com-ponents. Specifically, starting from each principle component ei in the projectionspace, we try to find the principle axis xj in the original space closest to ei. Asa result, the jth feature will be selected.
The method is illustrated in Figure 1. According to the data distribution,e1 and e2 are principle components sorted by their corresponding eigen values.By using PCA for feature extraction, we can map data from (x1, x2) to (y1, y2).

An Efficient Feature Selection Method for Object Detection 463
Fig. 1. Feature extraction by using PCA
And by using the proposed feature-selection method, starting from e1, x1, whichis the closest to e1, is found. Hence, the first feature, i.e, x1, will be selected.The proposed algorithm is summarized as follows:
– Step 1: Compute principle components {e1, e2, ..., eN} from the data dis-tribution by PCA and sort them in the order of the magnitude of eigenvalues.
– Step 2: For each principle component ei, find the axis xj that is closest toei.
– Step 3: Select feature jth.
4 Experimental Results
4.1 Training Data
We demonstrated efficiency of our feature-selection method by building a facedetector based on SVM. For training, we used 7,000 face samples and 7,000 non-face samples. Face samples are collected from the Internet, cropped and resizedto a size of 24x24 pixels. Non-face samples are generated from 6,278 images withvarious subjects such as rocks, trees, buildings, scenery, and flowers that containno faces. Figure 2 shows some of the face and non-face samples. For comparison,2,450 face samples and 7,000 non-face samples different from the training setwere also used.
4.2 Pixel-Based Features
In this experiment, we used the intensity of pixels as features. LibSVM [10] wasused to train SVM classifiers with a RBF kernel on selected feature subsets. Wecompared the performances of SVM classifiers trained on subset features selectedby our method and subset features selected from PCA-based feature extractionin which the top-100 and top-200 eigenvectors were used. The results in Figure 3shows that the performances of the SVM classifiers are comparable, particularly
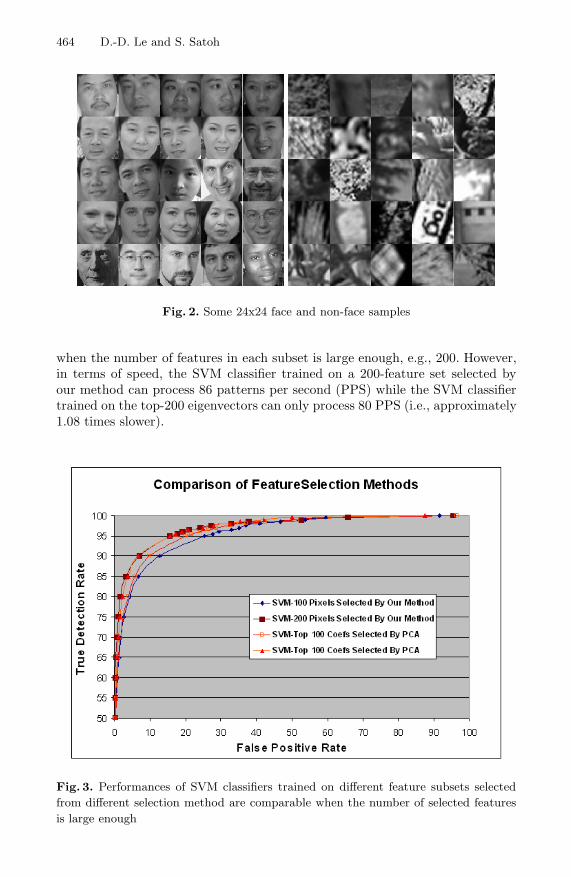
464 D.-D. Le and S. Satoh
Fig. 2. Some 24x24 face and non-face samples
when the number of features in each subset is large enough, e.g., 200. However,in terms of speed, the SVM classifier trained on a 200-feature set selected byour method can process 86 patterns per second (PPS) while the SVM classifiertrained on the top-200 eigenvectors can only process 80 PPS (i.e., approximately1.08 times slower).
Fig. 3. Performances of SVM classifiers trained on different feature subsets selected
from different selection method are comparable when the number of selected features
is large enough

An Efficient Feature Selection Method for Object Detection 465
Fig. 4. Image of 200 pixels (depicted in white) selected by the proposed selection
method
Figure 4 shows 200 pixel features selected by our method. It is easy to seethat selected pixels belong to major parts of facial features such as eyes, mouth,and nose.
4.3 Haar Wavelet Features
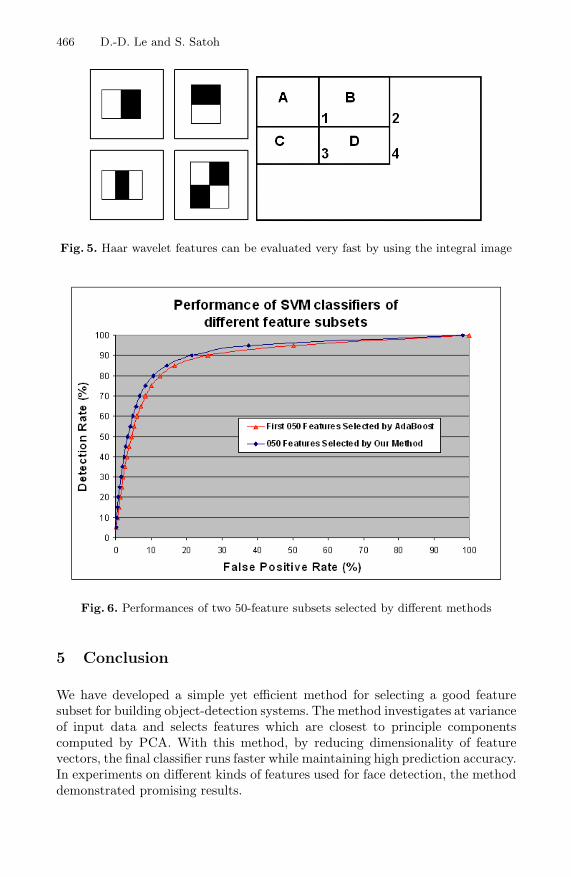
In recent face detectors based on AdaBoost [1,11,12], Haar wavelet features areused quite extensively because they are rich and can be evaluated very quickly.In our experiment, we used the same three kinds of Haar wavelet features as in[1] which are modeled from adjacent rectangles with the same size and shape.The feature value is defined as the difference of the sum of the pixels withinrectangles (see Figure 5).
By using integral image definition [1], these feature rectangle values canbe computed very quickly. The integral image at location (x, y) is defined asii (x, y) =
∑x′<=x,y′<=y i (x′, y′) where ii (x, y) is the integral image and i (x, y)
is the original image. In practice, ii (x, y) can be computed simply by usingthe following recurrent function: ii (x, y) = ii (x, y − 1) + ii (x − 1, y)+ i (x, y)−ii (x − 1, y − 1) and sum of the pixels within a rectangle can be computed fromfour integral image values of its vertices, for example, Sum(D) = 1+4− (2+3).
Because the Haar wavelet feature set defined above is over-complete (closeto 200,000 features), to use it with SVM [13], first, the maximum 200 featuresare selected by AdaBoost [14,1]. Then, from the same feature set, the first-50features are selected in the order they are added in the training process, andanother first-50 features are selected by using our method. The performancesof the SVM classifiers trained on these two subsets are shown in Figure 6.Thisfigure indicates that, in terms of performance, using our feature-selection methodis slightly better than not using it. In terms of speed, the SVM classifier trainedon the feature subset selected by our method has 3,405 support vectors andruns at a speed of 538 PPS, while that trained on the first-50-feature subset has4,017 support vectors and runs at a speed of 469 PPS (approximately 1.15 timesslower). In Figure 7, some face-detection results are shown.
466 D.-D. Le and S. Satoh
Fig. 5. Haar wavelet features can be evaluated very fast by using the integral image
Fig. 6. Performances of two 50-feature subsets selected by different methods
5 Conclusion
We have developed a simple yet efficient method for selecting a good featuresubset for building object-detection systems. The method investigates at varianceof input data and selects features which are closest to principle componentscomputed by PCA. With this method, by reducing dimensionality of featurevectors, the final classifier runs faster while maintaining high prediction accuracy.In experiments on different kinds of features used for face detection, the methoddemonstrated promising results.

An Efficient Feature Selection Method for Object Detection 467
Fig. 7. Some face detection results

468 D.-D. Le and S. Satoh
Acknowledgments
The authors thank the anonymous reviewers for their helpful comments on im-proving this paper.
References
1. Viola, P., Jones, M.: Rapid object detection using a boosted cascade of simple fea-tures. In: Proc. Intl. Conf. on Computer Vision and Pattern Recognition (CVPR).Volume 1. (2001) 511–518
2. Bins, J., Draper, B.A.: Feature selection from huge feature sets. In: Proc. Intl.Conf. on Computer Vision (ICCV). Volume 2. (2001) 159–165
3. Sun, Z., Bebis, G., Miller, R.: Object detection using feature subset selection.Pattern Recognition 37 (2004) 2165–2176
4. Li, S., Zhang, Z.: Floatboost learning and statistical face detection. IEEE Trans-actions on Pattern Analysis and Machine Intelligence 26(9) (2004) 23–38
5. Turk, M., Pentland, A.: Face recognition using eigenfaces. In: Proc. Intl. Conf. onComputer Vision and Pattern Recognition (CVPR). (1991)
6. Martinez, A., Kak, A.: Pca versus lda. IEEE Transactions on Pattern Analysisand Machine Intelligence 23(2) (2001) 228–233
7. Bartlett, M., Movellan, J., Sejnowski, T.: Face recognition by independent compo-nent analysis. IEEE Transactions on Neural Networks 13(6) (2002) 1450–1464
8. Jain, A., Zongker, D.: Feature selection: Evaluation, application, and small sampleperformance. IEEE Transactions on Pattern Analysis and Machine Intelligence19(2) (1997) 153–158
9. Pudil, P., Novovicova, J., Kittler, J.: Floating search methods in feature selection.Pattern Recognition Letter 15(11) (1994) 1119–1125
10. Chang, C.C., Lin, C.J.: LIBSVM: a library for support vector machines. (2001)Software available at http://www.csie.ntu.edu.tw/~cjlin/libsvm.
11. Liu, C., Shum, H.: Kullback-leibler boosting. In: Proc. Intl. Conf. on ComputerVision and Pattern Recognition (CVPR). Volume 1. (2003) 587–594
12. Lin, Y.Y., Liu, T., Fuh, C.S.: Fast object detection with occlusions. In: Proc. Intl.European Conference on Computer Vision (ECCV). Volume 3021. (2004) 402–413
13. Le, D.D., Satoh, S.: Fusion of local and global features for efficient object detection.In: Applications of Neural Networks and Machine Learning in Image ProcessingIX, IS&T/SPIE Symposium on Electronic Imaging. (2005)
14. Freund, Y., Schapire, R.E.: A short introduction to boosting. Journal of JapaneseSociety for Artificial Intelligence 14(5) (1999) 771–780



















