
Accurate and Efficient HTML Differencing
10
Accurate and Efficient HTML differencing Rimon Mikhaiel and Eleni Stroulia Computing Science Department University of Alberta Edmonton AB, T6G 2H1, Canada {rimon, stroulia} @cs.ualberta.ca Abstract Recognizing the differences between subsequent versions of HTML documents is an important problem. It is useful for managers of multi-authored web sites who need to review and approve the changes to their web-site content. It is also necessary for users who want to be able to easily recognize changes to the pages they visit regularly. Comparing HTML documents at the lexical level, as if they were regular text documents, is neither informative nor intuitive. Instead, their internal tree structure has to be taken into account. In this paper, we discuss VDiff, an algorithm we have developed for HTML differencing, based on the Zhang-Shasha tree-edit distance algorithm. Our algorithm reports which nodes in the two compared documents match, have been deleted(inserted) from(in) the original(subsequent) document, or have been, moved in the HTML structure. We have evaluated the accuracy and performance of our algorithm with a case study. 1. Introduction HTML differencing, i.e., comparing two HTML documents in order to identify the differences between them, is an interesting problem with a variety of useful applications. It is relevant to web-site maintenance, where a manager may wish to periodically review the changes made by the various web-site users in order to approve their publication. It is also useful to recurring web-site visitors who may want to quickly assess whether or not an interesting change has been made to their page of interest. It is essential for web-content warehouses where documents are periodically collected by crawlers; upon receiving new versions of an existing document, the warehouse manager may want to track the changes that occurred since the last received version [5]. Finally, it is a necessary step for automatic web wrapping [13] [22] [10] where document comparison is used to automatically extract data from the web. One way of comparing HTML documents is to simply compare the textual content of these pages, e.g. using traditional UNIX text-diff approaches. For example, applying text-diff to the two documents, shown in Figure 1(a), would produce the result shown in Figure 1(b) reporting that text portion "<i>test text</i>" was replaced by a new text "<b>test text</b>". However, as shown Figure 1(c), a more intuitive result would be to report that both documents have the same content with only one structure change, i.e., a <i> element was changed to <b>. To deliver such a more “natural” comparison result, one would have to recognize the internal tree structure of HTML documents. In this work, we view HTML documents as labeled ordered trees and we have developed, VDiff, an algorithm for recognizing insertion, deletion and move operations of HTML elements from one version of an HTML document to another. We have implemented VDiff in the context of VTracker, a visualization tool for delivering the algorithm’s results to users. The rest of this paper is organized as follows. First, we review the problem of HTML document comparison as comparison of labeled ordered trees, and we briefly review the research in this area, including the original Zang-Shasha algorithm, in Section 2. Next, in Section 3, we present our extensions to this algorithm for designing VDiff: the construction of the candidacy matrix that records all the possible edit sequences, the matrix clean- up to discard irrelevant edit sequences, the selection of the best of the remaining candidates, and the post processing for recognizing movement operations. In Section 4, we place our work in the context of related work, we report on our evaluation of the algorithm’s run- time performance and we compare VTracker’s visualization against the state-of-the-art tools in this domain. Finally, in Section 5, we draw some initial conclusions and outline the direction of our research in the future. (a) HTML documents (b) Lexical differencing (as text) Proceedings of the 13th IEEE International Workshop on Software Technology and Engineering Practice (STEP'05) 0-7695-2639-X/05 $20.00 © 2005
-
Upload
independent -
Category
Documents
-
view
4 -
download
0
Transcript of Accurate and Efficient HTML Differencing

Accurate and Efficient HTML differencing
Rimon Mikhaiel and Eleni Stroulia Computing Science Department
University of Alberta Edmonton AB, T6G 2H1, Canada {rimon, stroulia} @cs.ualberta.ca
Abstract
Recognizing the differences between subsequent versions of HTML documents is an important problem. Itis useful for managers of multi-authored web sites who need to review and approve the changes to their web-sitecontent. It is also necessary for users who want to be ableto easily recognize changes to the pages they visitregularly. Comparing HTML documents at the lexicallevel, as if they were regular text documents, is neither informative nor intuitive. Instead, their internal treestructure has to be taken into account. In this paper, wediscuss VDiff, an algorithm we have developed for HTMLdifferencing, based on the Zhang-Shasha tree-edit distance algorithm. Our algorithm reports which nodes inthe two compared documents match, have been deleted(inserted) from(in) the original(subsequent)document, or have been, moved in the HTML structure. We have evaluated the accuracy and performance of our algorithm with a case study.
1. Introduction
HTML differencing, i.e., comparing two HTMLdocuments in order to identify the differences betweenthem, is an interesting problem with a variety of usefulapplications. It is relevant to web-site maintenance, wherea manager may wish to periodically review the changesmade by the various web-site users in order to approvetheir publication. It is also useful to recurring web-sitevisitors who may want to quickly assess whether or notan interesting change has been made to their page ofinterest. It is essential for web-content warehouses where documents are periodically collected by crawlers; upon receiving new versions of an existing document, the warehouse manager may want to track the changes thatoccurred since the last received version [5]. Finally, it is anecessary step for automatic web wrapping [13] [22] [10]where document comparison is used to automaticallyextract data from the web.
One way of comparing HTML documents is to simplycompare the textual content of these pages, e.g. usingtraditional UNIX text-diff approaches. For example,applying text-diff to the two documents, shown in Figure
1(a), would produce the result shown in Figure 1(b) reporting that text portion "<i>test text</i>" was replaced by a new text "<b>test text</b>".
However, as shown Figure 1(c), a more intuitive resultwould be to report that both documents have the samecontent with only one structure change, i.e., a <i>element was changed to <b>. To deliver such a more“natural” comparison result, one would have to recognizethe internal tree structure of HTML documents.
In this work, we view HTML documents as labeledordered trees and we have developed, VDiff, an algorithm for recognizing insertion, deletion and moveoperations of HTML elements from one version of an HTML document to another. We have implementedVDiff in the context of VTracker, a visualization tool fordelivering the algorithm’s results to users.
The rest of this paper is organized as follows. First, we review the problem of HTML document comparison ascomparison of labeled ordered trees, and we brieflyreview the research in this area, including the original Zang-Shasha algorithm, in Section 2. Next, in Section 3,we present our extensions to this algorithm for designingVDiff: the construction of the candidacy matrix thatrecords all the possible edit sequences, the matrix clean-up to discard irrelevant edit sequences, the selection of the best of the remaining candidates, and the postprocessing for recognizing movement operations. In Section 4, we place our work in the context of relatedwork, we report on our evaluation of the algorithm’s run-time performance and we compare VTracker’svisualization against the state-of-the-art tools in thisdomain. Finally, in Section 5, we draw some initialconclusions and outline the direction of our research inthe future.
(a) HTML documents
(b) Lexical differencing (as text)
Proceedings of the 13th IEEE International Workshop on Software Technology and Engineering Practice (STEP'05)0-7695-2639-X/05 $20.00 © 2005

• change(i, j) = map(i, j) and T1[i] T2[j]: Asshown in Figure 3(a), a change operation issimilar to a matching operation except that thelabel of the counterpart node T2[j] is not identicalto the node in the label of T1[i].(c) HTML structural differencing
Figure 1: Comparing HTML documents with Text-diff and HTML-diff
• delete(i) = map(i, -): As shown in Figure 3(b), adelete operation is an edit operation where anode T1[i], has no counterpart at T2.
2. HTML differencing as labeled-ordered tree comparison
• insert(j) = map(-, j): As shown in Figure 3(c), isthe inverse of the deletion operation where anode, in T2, has no counterpart in T1. In otherwords, a deletion operation at T1 is conceived as an insertion operation at T2.
In our work, we view HTML documents as labeledordered trees. The document’s internal structure is a tree whose nodes correspond to the HTML elements and theircontent data. Nodes corresponding to some HTMLelement are labeled with the element’s HTML tag (e.g. TABLE, BR, DIV, etc). Nodes corresponding to the datacontent of an inline HTML element are labeled with thedata itself. Nodes are related through sibling and ancestorrelations reflecting the containment relations of theircorresponding elements. Order is significant since itspecifies the display order of the contents of that HTML.
• move(i, j) = delete(i), insert(j), and T1[i] T2[j]:As shown in Figure 3(d), a move operation is an edit operation where a node in T2 has a counterpart in T1, but in a different context. Thisoperation is equivalent to deleting that nodefrom T1 and inserting it in a different place at T2.
Figure 2: Tree-Diff(T1, T2) (borrowed from [5])
Thus, the result of a comparison between two HTMLdocument trees – T1 and T2 – is a tree-edit sequence, i.e.,a sequence M of mappings, map(i, j), where i is a node inT1, and j is a node in T2, such that for all (i1, j1) and (i2,j2)∈ M [23]:
• i1 = i2 iff j1 = j1; each node can not be involved in more than one edit operation;
• T1[i1] is on the left of T1[i2] iff T2[j1] is on the left of T2[j2]; the mapping preserves the originalsibling order;
(a) Change (b) Delete
(c) Insert (d) MoveFigure 3: Edit Operations
• T1[i1] is an ancestor of T1[i2] iff T2[j1] is anancestor of T2[j2]; it also preserves the ancestor-child order.
Let us illustrate the properties of the labeled-orderedtree-differencing algorithm with an example. The difference of trees T1 and T2 shown in Figure 2 is the editsequence M={(b, b), (d, d), (e, e), (c, -), (-, l), (a, a')}.This sequence consists of the following edits: node a is changed to a', node c is deleted, node l is inserted, andnode d is moved. Both nodes b and e are unchanged at thesecond tree. This solution obeys the above constraints as it maps (a, a') where both a and a' are ancestors of all other nodes; additionally, (b, b) and (e, e) preserve the sibling order where in both trees, node b is on the left ofnode e. Clearly, moved nodes do not preserve the originalordering relations.
There has been a substantial body of research on treecomparison, under many titles, e.g. tree-to-tree correction [19] and [16], tree alignment [9], [20], [14], [23], treecomparison [11]. Zhang-Shasha's tree edit-distance algorithm [23] is a fast algorithm that, given a cost forchange, insertion, and deletion operations, computes the
Edit operations are defined with the following booleanfunctions:
• match(i, j) = map(i, j) and T1[i]=T2[j]: It is thesimplest edit operation and implies that nodeT1[i] has an identical counterpart at T2[j].
Proceedings of the 13th IEEE International Workshop on Software Technology and Engineering Practice (STEP'05)0-7695-2639-X/05 $20.00 © 2005

minimum cost of a sequence of such operations that can transform one tree to the other with an average complexity |T2|3/2.|T2|3/2 [5].
In this work, we have used this algorithm as a startingpoint and we have extended it in two ways. First, ourVDiff algorithm produces a minimum-cost sequence of tree-edit operations, which is also optimal in terms ofsimplicity heuristics (i.e. similar editing happens incontiguous nodes). Second, it allows for move operations,through a subsequent phase of mapping deleted sub-treesfrom the first tree to inserted sub-trees of the other.
3. The HTML-differencing process
The Zhang-Shasha algorithm [23] calculates the tree-edit distance between two trees T1 and T2. This algorithmassumes that the nodes of both trees are numbered in a post-ordered manner: where tree T1 is represented as
where the first node – T[ ||..1 11 TT
l(1
]
]
1[1] – is the leftmost leaf of T1, and the last node - T1[|T1|] – is the root node1 of T1.Then, according to [8], the tree distance between two trees T and T is: [ ii).. [ ]jjl )..(2
−+−−+−
+−−=
),(])1)..([],)..([(),(]))..([],1)..([(,(])1)..([],1)..([(
]))..([],)..([(
21
21
21
21
jjjlTiilTfdistijjlTiilTfdist
jijjlTiilTfdistjjlTiilTtdist
γγ
γ )
and the distance between two forests is:
−+−−+−
+−−=
),(])1)..([],)..([(),(]))..([],1)..([(
]))..([],)..([(])1)()..([],1)()..([(]))..([],)..([(
1211
1211
211211
1211
jjjlTiilTfdistijjlTiilTfdist
jjlTiilTtdistjljlTililTfdistjjlTiilTfdist
γγ
)(nlwhere is the leftmost node leaf child of node n, andγ is the cost function. For a more detailed discussion on this cost function, the reader may review [23].
As shown in Figure 4(a), the edit-distance between sub-tree T1[l(i)…i] and T2[l(j)…j] is the minimumbetween the following three options:1) the cost of mapping i (the root of T1) to j (the root of
T2) plus the cost of mapping the forests Tand T ;
[ ]1)..(1 −iil[ ]1)..(2 −jjl
2) the cost of deleting the node i from T1 plus the cost of mapping the remaining forest of T1 T to thesecond tree T ;
[ 1)..(1 −iil ]
]
[ ]jjl )..(2
3) the cost deleting node j from T2 plus the cost of mapping the first tree T to the remaining forestof T
[ iil )..(1
]1−j2 which is T . We have to review that adeletion at T
[ )..(2 jl2 is considered an insertion at T1.
Similarly, as shown in Figure 4(b), the distancebetween two forests F1 and F2, represented as T [ ]iil )..( 11
and ] respectively, is also the minimum amongthe costs associated with the following three options:
[ jjlT )..( 12
[ jl(2
()..( 12 jljlT
]
]
1) the cost of mapping the right-most sub-trees Tand T to each other plus the cost of mappingthe remaining forests T and
;
[ ]iil )..(1
]j)..
[ ]1) −[ 1)()..( 11 −ilil
2) the cost of deleting node i from F1 plus the cost of mapping the remaining forest T to F[ 1)..( 11 −iil 2.;
3) the cost of deleting node j from F2 plus the cost of mapping the remaining forest T to F[ ]1)..(2 −jjl 1.
It is based on a 2D dynamic-programming distancematrix. Its rows represent the post-ordered nodes of T1, its columns represent the post-ordered nodes of T2, and each cell, Dist[i,j], represents the minimum edit-distancebetween the sub-tree rooted at node T1[i] and the sub-treerooted at T2[j]. This matrix is recursively calculated:distances between children sub-trees are calculated before the distance between their ancestors. In order to calculatethe value of Dist[i, j], according to the calculated costs, tdist decides on which operation(s) is preferred at thatpoint, i.e. it decides whether to match, to delete, or toinsert. After calculating the entire distance matrix, thevalue at the lower-right corner of the matrix (i.e. Dist[|T1|,|T2|]) represents the total edit-distance between T1 and T2.
(a) Tree-to-Tree Cost
(b) Forest-to-Forest CostFigure 4: Tree Comparison [5]
3.1.The candidacy matrix
The Zhang-Shasha algorithm does not report thesequence of edit operations associated with the calculated edit-distance. In order to address this issue, upon calculating a value of every Dist[i, j] at the distance matrix, one must also record the chosen operation thatcorresponds to this cost. It is interesting to note here that,there may be more than one edit operation having thesame minimum edit cost. In this case, our VDiff
1 |T| is the size of that tree; which is the number of nodes at T.
Proceedings of the 13th IEEE International Workshop on Software Technology and Engineering Practice (STEP'05)0-7695-2639-X/05 $20.00 © 2005

algorithm records all of them as candidates for an edit operation associated with that Dist[i, j].
More specifically, in parallel with the distance matrix,VDiff maintains a candidacy matrix. This candidacy matrix stores candidate operations for each corresponding cell in the distance matrix, i.e. Cand[i,j] at the candidacy matrix stores the set of candidate operations associatedwith Dist[i, j] at the distance matrix. Formally, Cand[i,j]at a candidacy matrix is definedas: c .{ }insertdeletechangematchji ,,/),( ⊆
In order to produce more intuitive tree-edit sequences,we have modified the Zhang-Shasha algorithm to use an affine-cost policy, inspired by similar work in the string-alignment research. In that context, an affine-cost policyapplies when deleting/inserting more than oneconsecutive characters: the cost of a sequence of consecutive deletion/insertion operations equals the costof opening a gap plus an extra affine cost for each character to be deleted/inserted. Because the affine cost is less than the regular deletion cost, the total cost of a sequence of consecutive deletions/insertions is less thanthe sum of the independent deletion/insertion costs.Similarly, in the VDiff algorithm, a node'sdeletion/insertion cost is context sensitive: for a node, if all of its children nodes are also candidates for deletion,this node is more likely to be deleted as well, and then thedeletion cost of that node is less than the regular deletioncost. The same is true for the insertion cost of a nodewhose children are also candidates for insertion. To reflect this heuristic, the cost of the deletion/insertion ofsuch a node is a small addition to the cost ofdeleting/inserting its children.
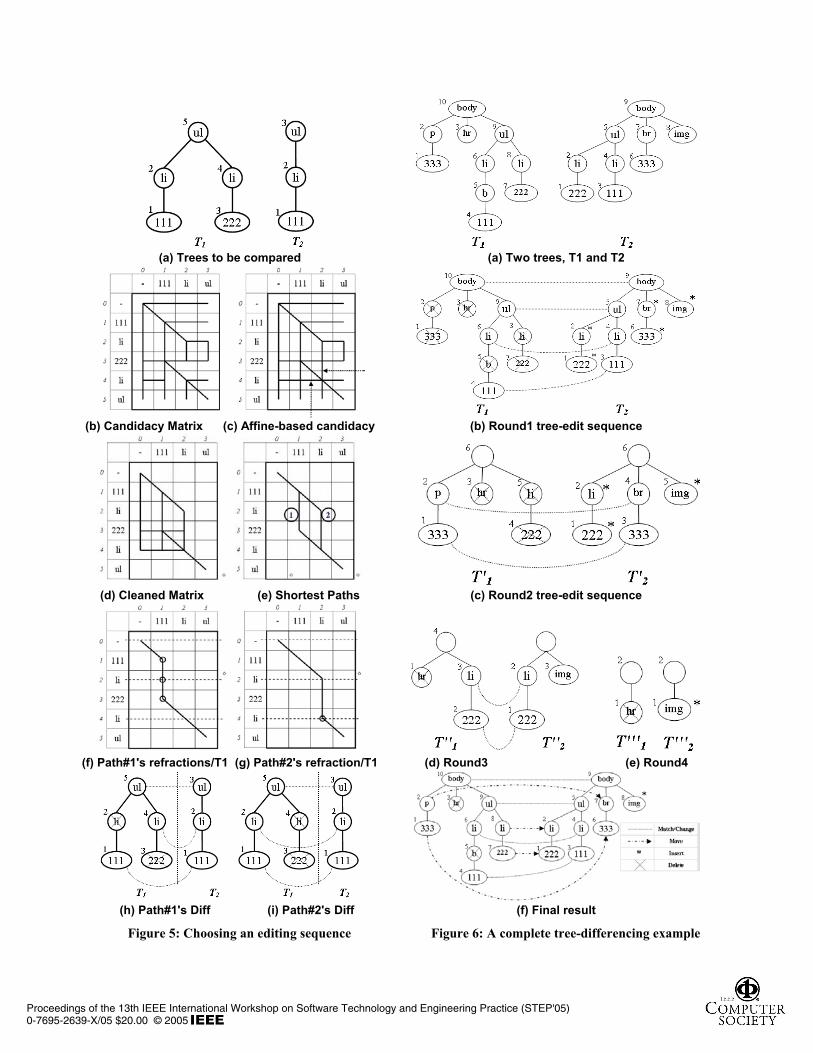
Figure 5(b) shows a candidacy matrix resulting fromcomparing the trees shown in Figure 5(a). At each Distcell a delete operation is represented by a verticalsegment, an insert operation is represented by a horizontalsegment, and a match/change operation is represented bya diagonal segment, moving upwards and to the left. Thedepicted candidacy matrix also shows whether a certainnode has more than one candidate operation. The candidacy matrix records different possible sequences ofedit operations. A complete path connecting the lower-right corner of a candidacy matrix to the upper-left corner represents a possible sequence of edit operations thattransform T1 into T2. Note that, all possible completepaths have the same total edit-distance. Therefore, the challenge becomes to decide which of these completepaths is the “best one” to report.
Formally, for a node T1[i] (at Cand[i,j]) to be eligiblefor a affine deletion cost, it should not be a leaf node, and all nodes starting at T1[l(i)] up to T1[i-1] should be eligible for deletion. This implies that, in the candidacymatrix, there should be a vertical segment starting atCand[l(i), j] going down to Cand[i-1, j].3.2.Affine cost
∈>−∈=
=),(&),,1(),(&
),,(
jicdeleteleftileftjieligiblejicdeleteleftitrue
leftjieligible
delete
delete
The original algorithm assumes that the cost of any deletion/insertion operation is independent of theoperation's context, i.e., the node to which this operationis applied and what other operations may have beenapplied in this node’s neighborhood. Thus, it assigns thesame cost to when inserting/deleting a node regardlessthat node's children are also deleted/inserted, or not. Thisillustrates an important shortcoming of such “context-free” – called non-affine– cost functions: they don't give any preferences for consecutive deletions/insertions, i.e. the cost of deleting/inserting an entire sub-tree equals thesummation of deleting/inserting costs of all of them,which is non-intuitive.
where is the set of candidate operations ofCand[i, j]. Similarly, for a Cand[i,j] to be eligible for anaffine insertion cost, there should be a straight horizontalsegment beginning at (i, j-1) to (i, l(j)).
),( jic
The tree and forest distance formulas should also bemodified correspondingly:
−−
+−
−−
+−
+−−
=
otherwisejyjljieligiblej
jjlTiilTfdist
otherwiseiiljieligiblei
jjlTiilTfdist
jijjlTiilTfdist
jjlTiilTtdist
insertaffine
deleteaffine
),())(,,(),(
])1)..([],)..([(
),())(,,(),(
]))..([],1)..([(
),(])1)..([],1)..([(
]))..([],)..([(
21
21
21
21
γγ
γγ
For example, the candidacy matrix shown in Figure5(b) depicts the result of such a non-affine cost function.At this candidacy matrix, all complete paths report thatnode T1[4] is matched to node T2[2], and that both nodes T1[2] and T1[3] are deleted. However, all of thesetransformations are less intuitive than reporting that nodes T1[3] and T1[4] are to be deleted instead of nodes T1[2]and T1[3]. In other words, according to the non-affinepolicy depicted in the candidacy matrix Figure 5(b), atransformation like the one shown in Figure 5(h) isexpected while it is impossible to reach the transformation of Figure 5(i).
−−
+−
−−
+−
+−−
=
otherwisejjljieligiblej
jjlTiilTfdist
otherwiseiiljieligiblei
jjlTiilTfdist
jjlTiilTtdistjljlTililTfdist
jjlTiilTfdist
insertaffine
deleteaffine
),())(,,(),(
])1)..([],)..([(
),())(,,(),(
]))..([],1)..([(
]))..([],)..([(])1)()..([],1)()..([(
]))..([],)..([(
1211
1211
211211
1211
γγ
γγ
Figure 5(c) shows the candidacy matrix for an affine-based comparison of the two trees in Figure 5(a). Notethat the two segments indicated by the arrows did not
Proceedings of the 13th IEEE International Workshop on Software Technology and Engineering Practice (STEP'05)0-7695-2639-X/05 $20.00 © 2005

exist in the former candidacy matrix. The new candidacy matrix shows that Cand[4,2] is eligible for both insertion and deletion affine cost which helps it to be a candidate for both deletion and insertion operations. This cell was eligible for deletion affine cost because its only child, Cand[3,2], was also candidate for deletion. This cell was also eligible for insertion affine cost because its only child, Cand[4,1] is candidate for insertion.
At this point, it should be clear how this affine cost policy could be used to enhance the result quality: it essentially provides a mechanism for a batch discount that can be used to effectively define the minimum cost of the tree-edit distance. The following sub-sections discuss how our algorithm selects the best of the candidate paths, using this cost policy.
4. Edit Sequence recovery
As the candidacy matrix is built, it includes segments that cannot possibly belong to any candidate path. A candidate path is a sequence of connected segments that connect the matrix's lower-right corner to the upper-left one. For example, discarding such segments from Figure 5(c) would result in full paths shown in Figure 5(d).
Each of the remaining candidate paths represents a different tree-edit sequence. Therefore, the next step is to select the path representing the best – according to some optimality criteria – sequence.
4.1.Shortest tree-edit sequences
One potential optimality criterion is minimizing the edit-sequence length, i.e. the number of editing operations represented in the sequence. Editing minimality is always among the objectives of a tree-differencing result: a shorter editing sequence is better. Thus, the objective becomes to find a shortest path that connects the lower-right corner of the candidacy matrix to the upper-left corner. To that end, the algorithm discards the non-shortest ones by eliminating irrelevant segments from the candidacy matrix. At a certain cell of the candidacy matrix, an irrelevant segment is defined as the segment that does not lead to a shortest path connecting that cell to the upper-left corner of the matrix.
For example, Figure 5(e) shows the candidacy matrix of Figure 5(d) after discarding the non-shortest paths. The result of discarding such non-shortest paths is one (or more) shortest candidate edit sequences; all of them have the same number of editing operations with an equivalent associated edit-distance.
For example, the first path of Figure 5(e) would result in the edit sequence shown in Figure 5(h), while the second path results in the edit sequence shown in Figure
5(i). As is clearly visible, the second sequence differs from the first one, as it simply deletes a whole sub-tree instead of deleting dispersed nodes. Hence, another step is needed to decide on which edit sequence is preferable.
4.2. Simplest paths
As illustrated by the example in the last subsection, 'path minimality' is not a sufficient criterion for identifying a unique tree-edit sequence. Looking at Figure 5, the sequence shown in (h) is preferable than the one shown in (i), as it is much simpler: it applies the same editing operations on nodes belonging to the same sub-tree. Visually, the tree-edit sequence that has the least number of refraction points is better, where a refraction point is a node that has an editing operation that is different from its parent's editing operation.
For example, in the Figure 5(h) sequence, both nodes 2 and 3 cause refraction points: as they are both deleted while their parents are not. However, in the transformation shown in Figure 5(i), only node 4 causes refraction points.
The number of refraction points of a tree-edit sequence has to be calculated with respect to both T1 and T2, i.e. number of horizontal refractions plus the number of vertical ones. For example, Figure 5(f) and (g) show the refraction points associated with the two shortest paths of Figure 5(e), path1 and path2 respectively. Path1 with respect to T1 (horizontally) has three refraction points; the first is that node T1[3] is to be deleted (represented by that vertical segment) while its parent is to be matched (represented by that diagonal segment). There is another refraction point at T1[2] which is also deleted while its parent does not. Node T1[2] also causes another refraction point at T1[1]. On the other hand, Path2 with respect to T1has only one refraction point; both nodes T1[3] and T1[4] are to be deleted, while both nodes T1[1] and T1[2] are to be matched. Because these transformations have no insertion operations, both Path1 and Path2 (vertically) with respect to T2 have zero refraction points. However, we have to check the refraction points against both T1 and T2, if applicable.
After applying the above simplicity filtering criterion to the set of shortest paths, the candidacy matrix is left to include only paths that are with both minimum length and least number of refraction points. However, we have to emphasis that it may happen that that there are more than one such best paths; in this case, the algorithm randomly selects one of them.
Proceedings of the 13th IEEE International Workshop on Software Technology and Engineering Practice (STEP'05)0-7695-2639-X/05 $20.00 © 2005
(a) Trees to be compared (a) Two trees, T1 and T2
(b) Candidacy Matrix (c) Affine-based candidacy (b) Round1 tree-edit sequence
(d) Cleaned Matrix (e) Shortest Paths (c) Round2 tree-edit sequence
(f) Path#1's refractions/T1 (g) Path#2's refraction/T1 (d) Round3 (e) Round4
(h) Path#1's Diff (i) Path#2's Diff (f) Final result
Figure 5: Choosing an editing sequence Figure 6: A complete tree-differencing example
Proceedings of the 13th IEEE International Workshop on Software Technology and Engineering Practice (STEP'05)0-7695-2639-X/05 $20.00 © 2005

4.3. Recognizing Move Operations In order to recognize move operations, the algorithm
does not repeat the comparison of the whole couple of trees. It only considers a few number of nodes to be movecandidates. Hence, the complexity of the originalalgorithm has not been increased too much. Additionally,as will be shown in the next section, even with very largetrees, the algorithm does not need many rounds tocomplete.
Many tree-differencing algorithms – including theoriginal Zhang-Shasha algorithm – report tree-editsequences consisting only of change, insertion, and deletion operations. Frequently, however, nodes are reported as deleted from T1 while similar nodes are reported as inserted in a different sub-tree of T2. Such cases should be more intuitively recognized as moves. In this work, we require that the move operation should be applied to entire sub-trees; i.e., the entire sub-tree isdeleted from T1 and inserted in a different position in T2.Hence, a move operation can be redefined as
andjTiTjinsertideletejimove ],[][),(),(),( 21 ≈=ccmovejchildrencichildrenc iji ∃→∈∀∈∀ ,()(),( Mj ∈)
5. Evaluation
In this section, we report on our evaluation of ourHTML-differencing algorithm, in terms of its run-timeperformance and the accuracy of its reported results.
For example, applying the tree-differencing algorithmon the couple of tree shown in Figure 6(a) reports Figure6(b) where a sub-tree (<li>222</li>) was deleted from T1while another sub-tree (<li>222</li>) was inserted. However, a more intuitive edit sequence would havereported that a sub-tree (<li>222</li>) was moved before the sub-tree (<li>111</li>). Thus, the next objective is torecognize move operations with a post-processing phase whose objective is to match sub-trees deleted from T1 tosub-trees inserted to T2.
5.1. Run-time Performance
We collected 24 web pages from the University of Alberta web site (www.cs.ualberta.ca). For each of thesedocuments, four additional documents were created byartificially modifying the original. Our automatedmodification process edits a page by randomly changing,deleting, inserting, and moving a number of HTMLnodes. The produced variants contained 10%, 25%, 50%,and 75% of the original document nodes modified.In order to recognize move operations, the VDiff
algorithm goes in another comparison round between only the sub-trees deleted from T1, and those inserted inT2. If any matching pairs are found, move operations arereported for these nodes. The algorithm keeps repeatingthis scenario (going in comparison rounds) until thereexist no more deleted/inserted nodes, or no moveoperations are recognized.
We then compared each of these variants to the original documents, for all 24 pages, using both astandard cost function and an affine cost policy. Theexperiment was carried out on an Intel Pentium IVmachine with a 512M main memory and 1M cache memory.
The average complexity of the Zhang-Shasha tree edit algorithm for two trees |T1| and |T2| is of the order of |T2|3/2.|T2|3/2 [5]. Figure 7(a) shows the time needed to carry out the tree edit-distance algorithm against the corresponding grid size, i.e. (|T1|.|T2|). That figure shows that applying affine cost policy to the basic tree edit-distance does not affect its run time too much. It onlyadds a semi-linear overhead to the time required to carry out the differencing process with a standard cost policy.
For example, comparing the two trees of Figure 6(a), the first round reports the editing of Figure 6(b) where allmatch/change operations are reported as final results;while whole deleted and inserted sub-trees go in a second round trying to match them aiming to recognize moveoperations. We have to note that not all deleted/insertednodes are candidate for move operations. For example,node T1[5] was not considered for a second round because its only child (node T1[4]) was not also deleted.Figure 6(c) shows the result of the second round where T'1[2] matches T'2[4], and T'1[1] matches T'2[3]. Such matches are reported as move(2, 4) and move(1, 3) to thefinal result. The algorithm keeps a mapping from each round indices to the original tree indices, i.e. move(2, 4)is translated to move(2, 7). Similarly, Figure 6(d) showsthe result of the third round which result in addingmove(3, 2) and move(2, 1) to the final result. After goingin a fourth round, shown Figure 6(e), the algorithm stopsbecause there is no more move operation recognized. Finally, the algorithm reports the result shown in Figure6(f).
Both Figure 7(b) and Figure 7(c) show the timerequired for performing the two distinct phases on trees of different sizes (|T1|.|T2|) either using non-affine or affinecost policy respectively. From these figures, it is clear that the neither the path recovery mechanism, nor move-recognition rounds significantly increase the complexityof the basic algorithm.
Additionally, Figure 7(d) shows that only a smallnumber of rounds is sufficient for recognizing all moveoperations because each round radically decreases the number of move candidate nodes for the next round.
Proceedings of the 13th IEEE International Workshop on Software Technology and Engineering Practice (STEP'05)0-7695-2639-X/05 $20.00 © 2005

5.2. Accuracy
(a) Affine vs non-affine cost
(b) Run-time cost of the VDiff phases - non-affine cost
(c) Run-time cost of the VDiff phases - affine cost
(d) Number of rounds required for movesrecognition
Figure 7 Run-time Performance
We have developed an HTML-difference visualization system based on our VDiff algorithm called VTracker.We have compared its usability and the intuitiveness ofits results against several comparable tools.
Figure 8 shows the result of VTracker given two realsnapshots of the BBC news home page (bbcnews.com).Moved elements are highlighted with green background,deleted elements are highlighted with red and insertedwith yellow. In the latter page, the top story swappedpositions with one of the stories below. Some morestories were shifted around in the right column and twonew stories appeared in the center of the page.
Figure 9 shows the result of comparing two pages(shown in Figure 9(a)) coming out from our VTracker Figure 9(b), HTMLMatch version 1.2.8 [http://www.htmlmatch.com] Figure 9(c), and Diff Docversion 3.18 [http://www.softinterface.com] Figure 9(d). As shown in Figure 9(b), unlike all other tools, VTracker is capable of recognizing moved portions like“<li>444</li>”. Furthermore, it is capable of recognizingthe movement of “<h1>Home Page</h1>” even it as been modified, i.e. h1 is changed to h3. Additionally, unlikeHTML Match (shown Figure 9(c)), VTracker is capableof recognizing the text “222” although it has a new parent“<a href=”#”>”. Additionally, unlike Diff Doc, VTracker recognizes that there is a slight change in the structure of the bullet list, i.e. a bullet “ul” was changed to a numbered list “ol”; which is represented in VTrackervisual result by that gray background of the list elementsindicating that there is an internal (unseen) structurechange.
6. Conclusions and future work
In this paper, we discussed, VDiff, an algorithm for comparing HTML documents. VDiff views HTMLdocuments as labeled ordered trees, and reports thedifferences between them as a sequence of insertion,deletion and move operations. VDiff uses an affine-costpolicy for calculating the minimum cost for the reportedtree-edit sequence, to prefer sequences of consecutivesimilar operations applied to branches of nodes and theirdescendants.
VDiff has been implemented in the context ofVTracker, a system providing a suite of complementaryvisualizations of the reported tree-edit sequences betweentwo versions of an HTML document. VTracker can beused by users who want to have a quick overview of “what’s new” in the pages they visit regularly or by web-site managers who want to maintain a global knowledgeof how their web-site contents evolve as they are been authored by the various web-site authors.
Proceedings of the 13th IEEE International Workshop on Software Technology and Engineering Practice (STEP'05)0-7695-2639-X/05 $20.00 © 2005

Our evaluation of VDiff’s performance has shown that its our extensions to the original Zhang-Sasha algorithm(affine-cost policy and post-processing phase for moverecognition) only incur a small linear additional cost.
Our evaluation of VTracker against the state-of-the-artHTML comparison tools has given us confidence thatindeed it produces more intuitive and easier to understand reports of the nature of the change between the twocompared documents. In the immediate future, we plan to conduct an extensive usability study to more conclusivelyassess the system’s usability and to identify its potentiallimitations.
(a) BBCNews.com (November 8 2005, 06:52 GMT)
(b) BBCNews.com (November 8 2005, 07:54 GMT)
(c) VDiff result in VTrackerFigure 8 HTML-differencing
(a-1) Page 1 (a-2) Page 2
(a-3) Source Code 1 (a-4) Source Code 2(a) Two HTML pages to compare
(b-1) Rendered results (b-2) Tree-based results
(b) Results from (our) “VDiff”
(c-1) Source code comparison results(c) Results from “HTML Match”
Proceedings of the 13th IEEE International Workshop on Software Technology and Engineering Practice (STEP'05)0-7695-2639-X/05 $20.00 © 2005

[6] S. Dulucq, and L. Tichit, “RNA Secondary structure comparison:exact analysis of the Zhang–Shasha tree edit algorithm”,Theoretical Computer Science, Volume 306, Issue 13: 471 – 484,September 2003.
(d) Results from “HTML Compare”
(e-1) Source code comparison results
(e-2) Rendered results(e) results from “Diff Doc”
Figure 9 Comparison results from related work
[7] M. Hajiaghayi, “Comparing of SGML documents”, April 2001,http://www-math.mit.edu/~hajiagha/treecor1.pdf.
[8] C. Isert, “The Editing Distance Between Trees”.citeseer.ist.psu.edu/isert99editing.html
[9] T. Jiang, L. Wang, and K. Zhang, “Alignment of trees---analternative to tree edit”, Theoretical Computer Science,143(1):137--148, July 1995.
[10] Y. Jiang, E. Stroulia, “Towards Reengineering Web Sites to Web-services Providers”, Eighth Euromicro Working Conference on Software Maintenance and Reengineering (CSMR), p. 296, 2004.
[11] T. Munzner, F. Guimbretiere, S. Tasiran, L. Zhang, and Y. Zhou.“TreeJuxtaposer: Scalable Tree Comparison using Focus+Context with Guaranteed Visibility”. SIGGRAPH 2003, published as ACMTransactions on Graphics 22(3), pages 453–462
[12] B. Nguyen, S. Abiteboul, G.Cobena, and M. Preda, “MonitoringXML Data on the Web”, In Proceedings of the ACM SIGMOD Conference, Santa Barbara, CA, USA, 2001.
[13] D. Reis, P. Golgher, A. Silva, and A. Laender, “Automatic web news extraction using tree edit distance”, In Proceedings of the13th International Conference on the World Wide Web, pages 502–511, New York, NY, 2004.
[14] D. Sankoff and R. Cedergren, “Simultaneous comparison of tree ormore sequences related by a tree”. In D. Sankoff and G. Kruskal, editors, Time Warps, String Edits, and Marcomolecules: theTheory and Practice of Sequence Comparison, volume 28, pages 253 - 263. Addison Wesley, Reading MA, 1983.
[15] W. Schmitt and M. Waterman, “Linear trees and RNA secondarystructures”, In Discrete Applied Mathematics 51, pages 317-323,1994.
[16] S. Selkow, “The tree-to-tree editing problem”, InformationProcessing Letters, 6:184–186, Dec. 1977.
[17] B. Shaprio, “An algorihtm for computing multiple RNA secondarystructures” In Comput. Appl. Biosci., pages 387-393, 1988.
[18] B. Shaprio and K. Zhang, “Comparing multiple RNA secondarystructures using tree comparisons”, In Comput. Appl. Biosci. 6(4),pages 309-318, 1990.
[19] K.-C. Tai, “The tree-to-tree correction problem”, Journal of the ACM (JACM), 26(3):422--433, July 1979.
[20] L. Wang and D. Gusfield, “Improved approximation algorithms fortree alignment”, Proceedings of 7th Symp. on Combinatorial Pattern Matching, pages 220 - 33, 1996.
[21] Y. Wang, D. DeWitt and J.Cai, “X-Diff: A Fast Change DetectionAlgorithm for XMLDocuments” Proceedings of 19th IEEE International Conference on Data Engineering, March 2003.7. References
[22] Y. Zhai , B. Liu, “Web data extraction based on partial treealignment”, Proceedings of the 14th international conference on World Wide Web, May 10-14, 2005, Chiba, Japan.
[1] M. Altinel and M. Franklin, “Efficient Filtering of XML Documents for Selective Dissemination of Information”, InProceedings of the 26th International Conference on Very Large Data Bases, pages 53--64, 2000.
[23] K. Zhang, R. Stgatman, and D. Shasha, “Simple fast algorithm forthe editing distance between trees and related problems”, SIAMJournal on Computing, 18(6):1245–1262, 1989.[2] S. Chawathe, S. Abiteboul, and J. Widom, “Managing Historical
Semistructured Data”, Theory and Practice of Object Systems 5(3),143—162, 1999.
[24] K. Zhang, D. Shasha, and J. T. L. Wang. “Approximate treematching in the presence of variable length don't cares”, Journal of Algorithms, 16(1):33–66, 1994.[3] J. Chen, D. DeWitt, F. Tian, Y. Wang, “NiagaraCQ: a scalable
continuous query system for Internet databases”, InternationalConference on Management of Data, Proceedings of the 2000 ACM SIGMOD international conference on Management of data,2000, pp. 379--390.
[4] A. M. G. Cobena, S. Abiteboul, “Detecting changes in xmldocuments”, In Proceedings of the 18th International Conferenceon Data Engineering, IEEE Computer Society, 2002.
[5] G. Cobena, T. Abdessalem and Y. Hinnach, “A comparative studyfor XML change detection” Technical Report, INRIA, France, 2000.
Proceedings of the 13th IEEE International Workshop on Software Technology and Engineering Practice (STEP'05)0-7695-2639-X/05 $20.00 © 2005




















