
Movement trajectory classification using supervised machine ...

ARTICLE IN PRESS
Contents lists available at ScienceDirect
Signal Processing
Signal Processing 89 (2009) 2400–2414
0165-16
doi:10.1
� Cor
E-m
URL
journal homepage: www.elsevier.com/locate/sigpro
A supervised learning approach to automate the acquisition ofknowledge in surveillance systems
J. Albusac �, J.J. Castro-Schez, L.M. Lopez-Lopez, D. Vallejo, L. Jimenez-Linares
Department of Information Technologies and Systems, University of Castilla-La Mancha, Paseo de la Universidad 4, Ciudad Real 13071, Spain
a r t i c l e i n f o
Article history:
Received 8 November 2008
Received in revised form
20 March 2009
Accepted 6 April 2009Available online 16 April 2009
Keywords:
Automated video surveillance
MPEG video analysis
Machine learning
Soft computing
Anomalous behaviour detection
84/$ - see front matter & 2009 Elsevier B.V. A
016/j.sigpro.2009.04.008
responding author.
ail address: [email protected] (J.
: http://personal.oreto.inf-cr.uclm.es/jalbusac
a b s t r a c t
This paper presents a machine learning-based method to build knowledge bases used to
carry out surveillance tasks in environments monitored with video cameras. The
method generates three sets of rules for each camera that allow to detect objects’
anomalous behaviours depending on three parameters: object class, object position, and
object speed. To deal with uncertainty and vagueness inherent in video surveillance we
make use of fuzzy logic. Thanks to this approach we are able to generate a set of rules
highly interpretable by security experts. Besides, the simplicity of the surveillance
system offers high efficiency and short response time. The process of building the
knowledge base and how to apply the generated sets of fuzzy rules is described in depth
for a real environment.
& 2009 Elsevier B.V. All rights reserved.
1. Introduction
At present, critical questions related to terrorist attacksor crimes both in public and private spaces are importantissues of concern for society. In fact, many governmentshave just decided to increase the number of computer-based solutions in order to improve security as much aspossible. For instance, more than four million of camerashave been deployed in London. The improvement of thesesecurity measures involves the deployment and config-uration of more sophisticated surveillance systems.
A typical surveillance scenario consists of a set of videocameras deployed in different places in order to allowexplicit surveillance on behalf of people and informationstorage to carry out forensic analysis if needed. When asecurity guard keeps watch an environment by means ofvideo cameras, he is able to detect if something is goingwrong. In other words, he perceives video events andclassifies them as normal or anomalous. If he detects ananomalous behaviour or event, he makes the appropriate
ll rights reserved.
Albusac).
(J. Albusac).
decisions to solve the problem as soon as possible. So, ifwe simplify the problem, video events represent the inputand behaviour classification represents the output. How-ever, the system depends on the human component toclassify events and to continuously pay attention to thevideo stream, which is a very tired task and, therefore,error-prone.
In the last few years, many researchers have proposedmodels and techniques for event and behaviour under-standing. Thanks to these proposals, software prototypesand systems have been developed and tested over realscenes, such as VSAM [7], W4 [9], Hudelot et al. [10],Bauckhage et al. [2] or Vallejo et al. [24]. Generally, thesesystems consist of different layers [25]. The moreimportant ones are as follows: (i) environment modellingto provide the system with the knowledge needed to carryout surveillance, (ii) segmentation and tracking of objects,(iii) multi-modal sensor fusion and behaviour/eventunderstanding, (iv) decision-making and crisis manage-ment and, finally, (v) multimedia content-based retrievalto perform forensic analysis. Every layer implies a widefield of investigation and, for this reason, most researchersfocus their work on one of these layers. Some examples ofinteresting work that solve specific surveillance tasks arepath detection in video surveillance [11,15,16,29], facial

ARTICLE IN PRESS
J. Albusac et al. / Signal Processing 89 (2009) 2400–2414 2401
recognition and tracking algorithms [3,14,12], human gaitrecognition [21,22,26] or network intrusion detection[13,23,28], amongst other issues.
Usually, these suggested systems are very specific tothe problem which is addressed. To overcome thislimitation, a conceptual framework based on the analysisof normality to detect anomalous behaviours in mon-itored environments has been suggested [1]. In thisframework, normality concepts are attached to objecttype and are used to model the environment normalityand to specify how a certain object must ideally behave.Moreover, it provides a scalable mechanism for dealingwith surveillance depending on different concepts andperceptions of the global environment provided by severalvideo cameras with different perspectives. There are manysimple events which can be identified from video data andanalysed into this framework. For instance, allowedproximity relationships between areas (i.e., the concept)and object type of the scene monitored by cameras can beanalysed. The work introduced in this paper is placedwithin the context of environment modelling and knowl-edge base building to determine whether identified eventsare normal or not according to the proximity relationsbased on the following information: object type, how theobject is moving along the scenario, and where it islocated.
Several authors have addressed these issues in theliterature [4,8,11]. Their work is based on the use ofconcise models for signal processing (e.g. probabilisticmodels) which are generally difficult to understand. Weare interested in systems with the ability of describingwhat is happening in scenes and detecting unusualbehaviour. This description should be readable and usefulfor the security expert. Moreover, the detection processshould be efficient and understandable by human securityguards.
This is our motivation to face the design of surveillancesystems able to do this kind of analysis in dynamic sceneswith a short response time from MPEG motion vectors.Our main interest is to suggest a method to build theknowledge base that easily defines the concept ofproximity relations. These automatic surveillance systemscould be embedded into each camera and used in differentdomains and scenarios. A machine learning algorithm willbe suggested to facilitate the deployment of knowledgebases to each new camera by using the data acquired fromMPEG motion vectors [18].
The machine learning algorithm is based on fuzzy logicbecause it allows us to deal with uncertainty in real-timeand to obtain good classification results by only using themotion information stored in backward motion vectors.Moreover, it generates a set of highly interpretable rules toclassify real-time events, which is useful to explain theresults. To do that, the system analyses spatial data from2D images obtained from cameras placed in outdoor/indoor environments and generates sets of fuzzy rules.Moreover, the proposed system is robust and obtains goodresults in the event classification process. Fuzzy logic hasalready been used for describing human activity in naturallanguage [20]. This description is made by studying thepossible relations among objects in a monitored environ-
ment. To do that, linguistic labels and fuzzy rules aredefined by an expert to classify people behaviour. In thispaper, we suggest to learn these rules.
The remainder of this paper is organised as follows.Section 2 describes the problem statement and overviewsthe processes needed to build the knowledge base of acamera and how to apply this knowledge to classifybehaviour. Section 3 discusses in depth the machinelearning algorithm employed to build the different sets offuzzy rules that compose the knowledge base. Section 4studies how to apply the system in a well-definedenvironment. Section 5 discusses the results obtainedin this environment and the efficiency of thealgorithm proposed. Finally, the conclusions are presentedin Section 6.
2. System overview
As previously described, we are concerned with theproblem of classifying events and behaviours whencarrying out video surveillance. In this context, classifyingmeans to differ if a certain behaviour is normal oranomalous in order to make adequate decisions. Sincethis task covers several research areas, we attack two ofthem: (i) how to build the surveillance knowledge base ofthe concrete scenario and (ii) how to apply this knowledgeto classify behaviours and events as normal or abnormal.
2.1. Knowledge base construction
In this work, we are interested in inferring suspiciousobjects’ behaviour depending on three factors: (i) theobject class, (ii) the object speed, that is, how fast a certainobject moves along the environment, and (iii) the objectposition regarding the camera, i.e., if it is located in anallowed zone according to its class. Therefore, thesurveillance knowledge base consists of three sets of ruleswhich are used to detect if a certain behaviour or simpleevent is normal or anomalous.
Firstly, the artificial system needs to know the class ofeach object in order to study the normality of the currentsituation. This information is critical when classifyingevents because it defines how the object should normallybehave. The object speed is another very interestingparameter to detect anomalous behaviours when carryingout surveillance. This parameter is directly related to theobject type and the distance from the camera. Forinstance, short movements made by vehicles which arefar away from the camera may involve speeding. On thecontrary, medium or large movements closed to thecamera may imply a normal speed. Finally, the thirdimportant factor is the object location from a 2D image,that is, the system needs to know in which type of zonesthe object is located. In this context, the camera position isvery relevant when determining this information becauseseveral camera parameters, such as height, angle, andzoom must be taken into account. In fact, two objects ofthe same size but different type in the camera image donot share the same distance from the camera.

ARTICLE IN PRESS
Fig. 1. Learning and classification processes.
J. Albusac et al. / Signal Processing 89 (2009) 2400–24142402
There are two alternatives to generate the knowledgebase of the surveillance system attached to a specificcamera: (i) to manually build it or (ii) to use a mechanismthat automates this task as much as possible. However, ifthere is a high number of possible situations in theenvironment, the first option is not suitable because itlacks of scalability. To overcome this challenge, we use amachine learning algorithm that aims at generating a setof rules from a training set. Besides, we have to addressuncertainty and imprecision inherent to object classifica-tion, to determine the object location, and to infer thespeed all from the data captured by fixed cameras in themonitored environment. Our approach is based on fuzzylogic [27,30] not only to deal with these issues but also tomake more understandable the rules that govern thesystem behaviour. This fact becomes relevant if thesecurity expert needs to adjust some concrete rule. Inthe stage of building the knowledge base, the three set ofrules are individually generated by independent trainingsets (see Fig. 1). Section 4 describes in depth the process ofgenerating these three sets of rules from the training sets.
2.2. Classification process
Once the knowledge base has been built and the threesets of fuzzy rules have been generated, the next stepconsists in applying this knowledge, that is, to use thesesets of rules to eventually infer if a certain event is normalin a concrete environment. To achieve this goal, we haveto take into account the output from each set of rules forevery monitored object. In other words, the normality ofan object behaviour in every instant depends on its class,speed, and location from the camera point of view (seeFig. 1).
The classification subsystem input is the output of thesegmentation algorithm used in Rodriguez et al. work[18]. This information is directly obtained from theanalysis of the MPEG video streams generated by an AXISIP 207w camera. Thus, the system uses the first set of rulesto obtain the class of each moving object as output. Next,this output is used together with the second set of rules todetermine the speed of each object. Thirdly, the system
estimates where each object is located. Finally, the systemhas all the information needed to classify behaviours bymaking use of the third set of rules. That is, theclassification process can be defined as the chaining ofthree sets of fuzzy if–then rules in which the knowledgegenerated by a set is employed by the next one.
3. Suggested machine learning algorithm
In this section, we propose a method to automaticallybuild the knowledge base of a camera in a surveillancesystem. The proposed method is based on a machinelearning algorithm and it is structured into three phases.The algorithm input is a collection of data contained in 2Dimages provided by one camera, and the three sets of rulesmentioned before represent the algorithm output. On theother hand, the proposed method deals with the un-certainty and vagueness contained in the input data and itis able to generate highly interpretable rules. This fact isvery important in surveillance system in order to justifythe system output, i.e., the output of a surveillance systemshould be easily interpretable. In this way, the securityagents can act quickly to solve problems.
From the great amount of automatic or semi-automaticmachine learning methods which are proposed in theliterature, we have decided to employ the fuzzy machinelearning algorithm proposed by Castro et al. [5]. Thismethod learns a set of maximal structure fuzzy if–thenrules from a set of training data instances. Such choice hasbeen motivated by the following reasons [5]:
�
Fuzzy logic provides a well-defined mathematicalframework to deal with the uncertainty and vaguenessinherently contained in the visual information used asinput data. � Inferred knowledge is represented by means of a set ofhighly interpretable IF–THEN rules and is expressed interms of linguistic variables.
� Experimental results show that the algorithm producesbetter classification results than other algorithms.
� The classification time is very short and the trainingtime is reasonable.

ARTICLE IN PRESS
J. Albusac et al. / Signal Processing 89 (2009) 2400–2414 2403
the first one, each example of a training set is converted
Basically, Castro’s algorithm works in two phases. Ininto a specific rule which describes how to act in aconcrete situation, that is, how this example must beclassified. Therefore, there will be so many particular rulesas examples in the worst case. In a second phase, thealgorithm generalises these particular rules in order to actin a wide range of possibilities, that is to say, manyexamples of a class can be correctly classified by using onegeneralised rule. To do that, an amplification processextends the particular rules by covering situations of thespace of possible situations, which have not been coveredbefore.
Formally, the original algorithm starts out the trainingphase from a set of data instances Y ¼ fe1; . . . ; emg. Eachei ¼ ððxi1; . . . ; xinÞ; yjÞ is a data example which is conveni-ently described through the set of input variables V ¼
fv1; . . . ;vng and one output variable yj, which is named theclass of ei. The elements ðxi1; . . . ; xinÞ are the concretevalues that the example ei takes for each variable vk 2 V .Besides, there is a domain definition DDVi for eachvariable in V , being DDV ¼ fDDV1; . . . ;DDVng the set ofall domains. Each DDVi ¼ fL1; . . . ; Lpg is composed of a setof linguistic labels which correspond to the fuzzy setsrepresented by means of trapezoidal functions as specifiedbelow:
Yðu; a; b; c; dÞ ¼
0; uoaðu� aÞ
ðb� aÞ; apuob
1; bpupc
ðd� uÞ
ðd� cÞ; coupd
0; u4d
8>>>>>>>>>><>>>>>>>>>>:
(1)
In this way, each DDVi must verify the followingproperties:
1.
8Lx 2 DDVi, heightðLxÞ ¼ 1. 2. 8Lx; Ly 2 DDVi, nucleusðLxÞ \ nucleusðLyÞ ¼ ;.P 3. 8x 2 Xi;jDDVij
j¼1 mLjðxÞ ¼ 1, being Xi the domain where vi
is defined.
In our particular application, there are three trainingsets, where every one of them consists of a set of exampleswhich are made up from the features extracted from 2Dimages. In relation to the outputs, the object class (y1) isthe output of the first set, the object speed (y2) is theoutput for the second one, and finally, the situation class(y3) is the output for the third one, which is used todistinguish whether it is normal or not.
The generated fuzzy IF–THEN rules by the algorithmare as follows:
if v0 is ZD0 ^ � � � ^ vn is ZDn then yj (2)
where vi 2 V and ZDi � DDVi is a subset of the linguisticlabels defined in DDVi for the variable vi.
Although a description in detail of the originalalgorithm by Castro et al. can be found in [5], we brieflydescribe the main steps here for convenience:
1.
Convert each training example into an initial fuzzy rule(translation into the fuzzy domain). Each element ei 2Y is translated into a fuzzy rule in which the value ofeach input variable is represented by means of alinguistic label.This step creates the set of initial rules and an emptyset of definitive rules.
2.
Take a rule from the set of initial rules. Let Ri be thatrule, Ri : if v0 is ZDi0 ^ � � � ^ vn is ZDin then yp.3.
Try to subsume the taken rule Ri in some rule of the setof definitive rules. If that happens so, ignore the takenrule and go back to step 2.4.
If the taken rule does not subsume in any rule of thedefinitive set, try to amplify it. For each variable vk:(a) For each unconsidered label Lx:(i) Try to amplify the rule ZDi0k ¼ ZDik [ Lx. If it isnot possible, go to step 4(a); otherwise,proceed to step 4(a) (ii). One rule can beamplified only if:(A) There is no Rj : if v0 is ZDj0 ^ � � � ^
vn is ZDjn then yq in the set of initial rules,such that 8k 2 ½0; jV j� ZDjk � ZDi0k andypayq.
(ii) Amplify the rule.
5. If the taken rule has been amplified, then include therule in the set of definitive rules.
6. If there are still unconsidered rules in the initial set ofrules, go to step 2. Otherwise, END.
Next, we briefly remember the concepts of subsume andamplification in order to facilitate the understanding of thealgorithm. A rule Ri ((ZDi0, ZDi1; . . . ; ZDin) yp) subsumes inthe rule Rk ((ZDk0, ZDk1; . . . ; ZDkn) yq) if ZDi0 � ZDk0, ZDi1 �
ZDk1; . . . ; ZDin � ZDkn and yp ¼ yq. For instance, the rule((VU, CH, ME, SH, HI, LA ) y1) subsumes in the rule: if X5 isfHI;VHg then Y is y1. It is important to remark that whenan input variable does not appear in the rule, it means thatit takes all the values of the set of labels. On the otherhand, the amplification process consists in incorporatingnew labels to one variable. This process starts out from aninitial rule ððZD0; ZD1; . . . ; ZDnÞypÞ and it goes on perform-ing amplifications in each variable, that is, it amplifieseach ZDi, i ¼ 1; . . . ;n with the labels that still have notbeen considered for it. An amplification is possiblewhenever there is no counterexample in another classthat conflicts with the amplified rule.
Despite the advantages listed before, this algorithmmay cause troubles when applied in the surveillancecontext due to the production of rules that are over-generalised. With over-generalised, we refer to the ten-dency of the definitive rules to cover spaces for whichthere are not counterexamples. For example, let ussuppose a simple rule for classifying a moving objectclass according to its size and distance from the camera(see Fig. 2(a)):
Ri:
if size is fSMALLg ^ distance is fMEDIUMg then y ispeople and two more rules as:Rj:
if size is fMEDSMALLg ^ distance is fMEDIUMg then yis motorbike

ARTICLE IN PRESS
Fig. 2. (a) Example of the over-generalisation of Ri0 . The variable distance from the camera is not shown because it does not change. (b) Dissimilarity
measure between fuzzy sets Li and Lj .
J. Albusac et al. / Signal Processing 89 (2009) 2400–24142404
Rk:
if size is fMEDBIGg ^ distance is fMEDIUMg then y iscar all of them contained in the set of initial rules. LetDDVsize ¼ fVSMALL, SMALL, MEDSMALL, MEDBIG;BIG;VBIGg, if we try to amplify the rule Ri to achieveRi0 , according to the variable size it would result in:
Ri0 :
if size is fVSMALL, SMALL, BIG, VBIGg ^ distance isfMEDIUMgthen y is peopleNote that Ri0 means that, if an object is at a medium
distance from the camera and its size is very small, small,big, or very big, it certainly belongs to the class people.However, Rj and Rk mean that if an object is at a medium
distance from the camera and its size is medium small ormedium big, the object is a motorbike or a car, respectively.Obviously, Ri0 lacks of any sense and it might causeproblem because of the miss classification of objects. Thishappens because when amplifying Ri to Ri0 , the labelsVSMALL, BIG, and VBIG are added to Ri0 as there are nocounterexamples in the set of rules that conflict with it.However, Rj and Rk take MEDSMALL and MEDBIG as valuesfor their respective size variables and they both target atdifferent classes.
To solve this issue, we have modified the originalalgorithm to restrict the amplification process. Accordingto the introduced modification, an amplification of a ruleRi to a rule Ri0 , being Ri0 : if v0 is ZDi00 ^ � � � ^ vn is
ZDi0n then yp, is possible if and only if the following twoconditions are satisfied:
1.
There is no Rj : if v0 is ZDj0 ^ � � � ^ vn is ZDjn then yqin the set of initial rules such that for all k belong 0 tojV j, ZDjk � ZDi0k and ypayq (we maintain the constraintof the original algorithm).
2.
The separability between the last label added to therule and the label being considered for amplifying therule does not exceed a separability threshold.We are interested in amplifying a rule only if the lastlabel added to the rule in the last amplification step andthe label being considered to be added are not too far fromeach other. Thus, we need to use a measure of separabilityto estimate the dissimilarity of linguistic labels, which areexpressed in terms of fuzzy sets. According to the selectedseparability measurement, the separability between twofuzzy sets Li and Lj, such that LioLj, is defined as theexisting area of the fuzzy set BetweenðLi; LjÞ (see Fig.2(b).c). The BetweenðLi; LjÞ fuzzy set is calculated as theintersection between the GreaterðLiÞ (Fig. 2(b).a) and theLessðLjÞ (Fig. 2(b).b) fuzzy sets. Expression (3) shows howthe value of distance between Li and Lj is calculated:
similarityðLi; LjÞ ¼ðbLj � cLiÞ þ ðaLj � dLiÞ
2(3)
being ðaLi; bLi; cLi; dLiÞ and ðaLj;bLj; cLj; dLjÞ the trapezoids thatdefine the fuzzy sets Li and Lj, respectively, and verifyingthat dLioaLj. If dLi ¼ aLj or dLi4aLj, then sðLi; LjÞ ¼ 0, as thearea of the fuzzy set similarityðLi; LjÞ is not significantenough. The separability threshold is empirically calcu-lated by observing how the algorithm selects the differentvalues of percentage of the maximum separabilitybetween the fuzzy sets of a given linguistic variable. Ifwe apply expression (3) with Li being the first label and Lj
the last label of a linguistic variable, we obtain themaximum possible distance value for that variable. Then,it is possible to choose the 25% or the 10% of suchseparability as the threshold for amplifying a rule.

ARTICLE IN PRESS
Fig. 3. Examples of results obtained in the segmentation process. Each moving object is represented by one blob, which is composed of several
macroblocks and motion vectors.
J. Albusac et al. / Signal Processing 89 (2009) 2400–2414 2405
Another modification made in this work over theoriginal algorithm is that the variance value of a variablewill be taken into account in the amplification process.The original algorithm amplifies the variables in order andwithout any special criterion. This fact may affect the finalquality of the definitive rules. For this reason, we proposethat the order, in which the variables are amplified, isgiven from the variance value of each variable. Thevariance is a measure of dispersion an it is calculated asfollows:
s2ðvÞ ¼1
n
Xn
i¼1
ðvi � vÞ2 (4)
being vi every value of the variable v, v is the averagevalue of v, and n is the number of instances of the variablev. The variables that have a high value of variance arefirstly amplified. These variables do not clearly discrimi-nate against the elements of one class and it is probablythat they are amplified by a great number of labels. Whena variable vi is amplified by all labels defined in DDVi, thenit is ignored and not included in the definitive rule. Forthis reason, we first are interested in removing suchvariables.
4. Applying the suggested machine learning algorithm toa real scene
In this section, we describe in detail how the rules forobject class, speed, and behaviour classification arelearned according to the scene chosen to test thesuggested machine learning algorithm (see Fig. 3). The
scenario is composed of buildings, roads, gardens, trafficsignals, and so on. There are also pedestrian areas wherevehicles are not allowed to drive. In the same way, thereare only vehicle areas where pedestrians should not walk.
4.1. Learning of rules to determine the object class
As previously explained, the suggested machine learn-ing algorithm needs a training set for generating the rules.In this stage, each example of the training set represents asituation of a moving object in a concrete time instant orframe. These examples are built from the informationgenerated by a segmentation algorithm which analyses anMPEG video stream [18]. Concretely, the examples arecomposed of numeric values for the following variables:
ððVP;HP; SMB;DMV ;DISÞy1Þ (5)
A brief description of each variable vi and theirdefinition domains DDVi is given in Table 1.
The segmentation algorithm determines the set ofmacroblocks in each frame. A macroblock is the basic unitin an MPEG stream and it is an area of 16 by 16 pixels inwhich the motion vectors are stored. The displacementbetween two macroblocks in different frames gives themotion vector and it specifies a distance and a direction.Subsequently, the macroblocks are grouped by means of aclustering function. Each object is represented by a set ofmacroblocks, and this set is known as blob. In other words,a blob is the set of macroblocks that represents a movingobject. In order to determine the horizontal and verticalposition of each macroblock, we divide the scene into

ARTICLE IN PRESS
Table 1Set of variables used to create the rules that determine the object class.
Vi Description DDVi
VP Vertical position fVP: very up, UP: up, LU: low up, VC: vertical centre, LD: low down, DO: down, VD: very
downg
HP Horizontal position fVL: very left, LE: left, LL: low left, HC: horizontal centre, LR: low right, RI: right, VR: very
rightg
SMB The object’s size according to the number of
macroblocks
fVS: very short, SH: short, ME: medium, LA: large, VR: very largeg
DMV The dispersion degree of the motion vectors fVL: very low, LO: low, ME: medium, HI: high, VH: very highg
DIS The object’s displacement between consecutive
frames
fVS: very short, SH: short, ME: medium, LA: large, VL: very largeg
y1 Output variable fperson, group of people, motorbike/bicycle, car, truck (or any vehicle with a big size)g
The domain partition and the fuzzy set sizes of each variable are defined by using a knowledge acquisition tool and according to the analysed scene.
Table 2Subset of variables used to create the rules that determine the object speed.
Variable
Vi
Description DDVi
HS Object horizontal
speed
fVFR: very fast right, FR: fast right, NR: normal right, LR: low right, VLR: very low right, NM: no motion, VLL: very low left,
LL: low left, NL: normal left, FL: fast left, VFL: very fast leftg
VS Object vertical
speed
fVFD: very fast down, FD: fast down, ND: normal down, LD: low down, VLD: very low down, NM: no motion, VLU: very low
up, LU: low up, NU: formal up, FU: fast up, VFU: very fast upg
y2 Output variable fno motion, slow, medium, fast)g
The variables VP, HP, and y1 are not included (see Table 1).
J. Albusac et al. / Signal Processing 89 (2009) 2400–24142406
rows and columns. Each image sector corresponds to afuzzy set defined in the domain definition of the variablesVP and HP. All the macroblocks are always located at arow N and a column M, and their positions are determinedby fuzzifying these values. In the macroblock groupingprocess, an aggregation function is used each time that amacroblock is included in a blob. This function updatesthe vertical and horizontal position of the blob, calculatingthe average of all macroblock locations. Fig. 3 illustrates amosaic of frames obtained from the real scene used in thiswork. In each frame, the moving objects are marked bymeans of several macroblocks.
The third parameter SMB determines the size of anobject in a frame by taking into account the number ofmacroblocks and motion vectors. One of our mainobjectives is to classify objects by studying the relation-ship between size and location.
The parameter DMV specifies the dispersion degree ofthe motion vectors of an object. Each motion vector hastwo components:~vðx; yÞ, and they are used to estimate thehorizontal (HS) and vertical speed (VS), respectively (seeTable 2). Thus, the average of all x and y values determinesa single vector ~vgðgx; gyÞ, which represents the globalobject orientation and speed:
gx ¼
PjSMBji¼1
~viðxÞ
jSMBj(6)
gy ¼
PjSMBji¼1
~viðyÞ
jSMBj(7)
The value of DMV is low when most vectors are orientedin the same way. This parameter is interesting to
differentiate between a group of people and the rest ofobjects. In the case of a group of people, the dispersiondegree (DMV) is usually high due to the nature of theirnon-uniform movements. This value is calculated fromthe global orientation of the blob ~vg and the particularorientation of each motion vector:
DMVðobjÞ ¼XjSMBj
i¼1
distanceðLBv; LVMiÞ þ distanceðLBh; LHMiÞ
(8)
where LBv 2 DDVVS is the linguistic label that representsthe global vertical speed of the blob, LBh 2 DDVHS is theglobal horizontal speed, LVMi 2 DDVVS and LHMi 2 DDVHS
are the linguistic labels that represent the vertical andhorizontal speed of the motion vector i. The functiondistance determines the number of labels that existsbetween two specific labels. For instance, let DDV be adomain definition composed of the following linguisticlabels: {FR, NR, LR, NM, LL, NL, FL}, the distance betweenNR and LL is two, because there are two linguistic labelsbetween them (LR and NM). The final value of the DMV
variable is the total sum of all distances.Finally, the displacement DIS is also a key parameter to
differentiate between people and vehicles. For instance, aperson or group of people cannot be able to make largedisplacements between consecutive frames without usinga vehicle. The numeric value of this variable is the lengthof the vector ~vg and it is calculated by means of thefollowing expression:
DISðobjÞ ¼ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffig2
x þ g2y
q(9)

ARTICLE IN PRESS
J. Albusac et al. / Signal Processing 89 (2009) 2400–2414 2407
We show an example of the person class used to learnwith the aim at illustrating our initial point:ð30:3;18:2;4;5;2:0Þ fuzzified as (VD, LL, SH, ME, VS). Thecomplete set of examples used to learn in our scene can beconsulted in http://raro.oreto.inf-cr.uclm.es/apps/learn-ing/index.html. Next, we show some examples of rulesobtained in this stage after applying the machine learningalgorithm to the set of examples:
R1:
if VP is not fVU, UP, LUg ^ SMB is fVS, SHg ^ DMV isfVL, LOg then y1 is personR2:
if VP is fDO, VDg ^ HP is not fVL, LEg ^ SMB is notfVL, LAg ^ DMV is fLOg ^ DIS is fSH, MEg then y1 ispersonR3:
if SMB is not fVLg ^ DMV is fVH, HIg ^ DIS is fVS, SHgthen y1 is group of peopleR4:
if VP is fCV, LDg ^ HP is not fRI, VRg ^ SMB is fMEg ^DMV is fVL, LOg then y1 is motorbike/bicycleR5:
if VP is not fVD, DOg ^ SMB is fLAg ^ DMV is notfHI, VHg ^ DIS is not fVS, SHg then y1 is carR6:
if VP is not fDO, VDg ^ SMB is fVL, LAg ^ DMV is notfVL, LOg then y1 is truck4.2. Learning the rules to determine the object speed
In any urban environment, the analysis of speed datacan be a determining factor to detect anomalies. Forinstance, vehicles going so fast or people running in alldirections. The second phase of the suggested machinelearning algorithm aims at learning a set of rules toroughly estimate the real speed of an object. To do that,we have built a training set in which each example is atuple consisting of the following elements:
ððVP;HP; y1;VS;HSÞy2Þ (10)
The variables VP, HP, and y1 have also been used in thefirst phase and represent the vertical and horizontalposition, and the object class (see Section 4.1). The restof variables, VS, HS and y2, are summarised in Table 2. Thevalues of the variables VS and HS are directly obtainedfrom ~vgðgx; gyÞ. Specifically, HS is equal to gx and VS to gy.
Actually, two different set of rules are generated in thisphase for people (person and group of people) andvehicles (bicycle/motorbike, car and truck). This isbecause equal movements done by people and vehiclesmay imply different speed. For instance, a mediummovement for one person may involve high speed andfor a car may involve low or medium speed. Theclassification module uses the variable y1 as the discri-mination factor for choosing the adequate set of rules.
Some examples of rules obtained in this stage are thefollowing:
R1:
if y1 is fperson, group of peopleg ^ VS is fVLD, NMg ^HS is fNMg then y2 is no motionR2:
if VP is fDO, VDg ^ y1 is fperson, group of peopleg ^VS is fND, LD, VLDg ^ HS is fVLR, LRg then y2 is slowR3:
if VP is fVU, UP, LUg ^ y1 is fmotorbike, car, truckg ^HS is fLLg then y2 is mediumR4:
if HP is not fVL, LEg ^ y1 is fmotorbike, car, truckg^VSis fVFD, FDg then y2 is fast4.3. Learning of rules to determine the object behaviour
Finally, the last step in the general learning processconsists in generating a set of rules that allows thesurveillance system to detect if an object behavesnormally or anomalously depending on the object class,its speed, and the zones in which it is located. Note thatthis last factor is also important to detect anomaliesbecause in any urban environment there are reservedareas for pedestrians and vehicles. Thus, a vehicle movingover a pedestrian area clearly represents an anomalousbehaviour.
In order to determine the object location from a 2Dimage, we carry out a spatial study of the scene. Firstly,this study consists in defining and categorising theenvironment areas. To do that, we establish the limits ofan area by means of a set of points, i.e., each zone isrepresented by a polygon. Fig. 4 shows the set of areasdefined for the environment analysed in this work. The setof polygons and classes are internally represented in thesystem through a data structure. The system uses thisstructure and the object information to estimate itslocation.
Once the areas have been defined, the system cancalculate the intersection that exists between an object orblob, and the categorised areas. The intersection betweenan object and an area is the percentage of pixels that theyshare. To determine if a point lies within a polygon, we usethe algorithm created by Randolph Franklin [17], which isbased on earlier work [19]:
int pnpoly(int nvert, float *vertx, float *verty, float testx,
float testy)
f
int i, j, c ¼ 0;
for (i ¼ 0;j ¼ nvert� 1;ionvert;j ¼ iþþ) f
if ( ((verty[i]4testy) ! ¼ (verty[j]4testy)) &&
(testxo(vertx[j]� vertx[i]) � (testy-verty[i])
=(verty[j]� verty[i])þ vertx[i]) )
c ¼ !c;
g
return c;
g
where nvert is the number of vertices in the polygon, vertx
and verty the arrays containing the x- and y-coordinates ofthe polygon’s vertices and, finally, testx and testy are the x-and y-coordinate of the test point.
However, not all the pixels are used to estimate the realobject location, but those that represent the points ofsupport. The system chooses this set of points accordingto the movement and orientation of the object, bothobtained from its motion vectors (see Section 4.1).Normally, the selected points correspond to the med-ium–low part of the object. Fig. 5 shows some examples ofobjects with different orientations, where each object hasa size of 16 macroblocks.
In this phase, each example of the training set isdefined as follows:
ðy1; y2;RO; PC; SW ; PAÞy3Þ (11)

ARTICLE IN PRESS
J. Albusac et al. / Signal Processing 89 (2009) 2400–24142408
being y1 the object class, y2 the object speed, and RO, PC,SW , and PA the intersection degrees for the types of areasroad, pedestrian crossing, sidewalk, and parking, respec-tively. Finally, y3 is the output variable and it can benormal or anomalous situation. Table 3 summarises thevariables and its definition domains used in this phase.
If we take into account the perspective of the camera,the proposed method might wrongly conclude that part ofan object is located in an area when it actually is not there.The learning method proposed in this work is able to dealwith this kind of noise in the analysis of proximitybetween objects and areas. For example, let us supposethat in some environment vehicles are not allowed to runover sidewalk areas. If there is an example classified as a
Fig. 4. Categorisation of the environment areas. The areas 1, 7, 8, 9 are
categorised as road; 3 and 5 as pedestrian crossing; 2, 4, 6, and 10 as
sidewalk; 11 and 12 as parking.
Fig. 5. Each case shows the set of macroblocks and pixels used to study the obje
by a set of 16 macroblocks.
normal situation in the training data set in which a vehiclehas a high amount of points in common with a road zone,and a very low amount of points in common with asidewalk area, the learning method might generate a ruleby which this activity could be considered as a normalsituation. In other words, the surveillance system wouldnot consider as anomalous an invasion of a sidewalk by avehicle unless it is clear enough.
To end this section, we enumerate the possibleanomalous situations that can be automatically detectedby employing the class, speed, and proximity relationshipsof the objects:
�
ct lo
TabSub
beh
Var
Vi
y1
y2
RO,
SW
y3
Pedestrian or group of people over the road.
� Group of people running fast. � Bicycle moving on a sidewalk. � Vehicle parked or moving on a sidewalk. � Vehicle stopped on a pedestrian crossing. � Vehicle moving fast.cation according to its orientation. In all case, the object is composed
le 3set of variables used to create the rules that determine the object
aviour.
iable Description DDVi
Object class fperson, group of people,
motorbike/bicycle, car, truck
(or any vehicle with a big size)g
Object speed fslow, medium, fast)g
PC,
, PA
Intersection degree for the
type of areas road, pedestrian
crossing, sidewalk, parking
VO : void, VL: very low, LO: low,
ME: medium, HI: high, VH: very
high
Output variable fnormal/anomalous situationg

ARTICLE IN PRESS
J. Albusac et al. / Signal Processing 89 (2009) 2400–2414 2409
distinguishing between normal and anomalous situations
Some examples of rules generated in this stage forare the following:
R1:
if y1 is not fperson, group of peopleg ^ y2 is fSL,MEg ^ SW is fVL, LOg then y3 is normalR2:
if y1 is fperson, group of peopleg ^ y2 is not fFAg ^ PCis not fVOg then y3 is normal
R3:
if y1 is fpersong ^ y2 is fSLg ^ PA is fVHg then y3 isnormalR4:
if y1 is not fpersong ^ y2 is fFAg then y3 is anomalousR5:
if y1 is fmotorbike, car, trackg ^ y2 is fNMg ^ PC is notfVOg then y3 is anomalousR6:
if y1 is fperson, group of peopleg ^ RO is not fVO, VLgthen y3 is anomalous4.4. Classification process
In each instant, the classification module makes use ofthe low data from the segmentation process and the threeset of rules to finally infer if the behaviour of each object isnormal or anomalous. This module calculates in whichrules every instance subsumes. The following two casesmay arise [5]:
1.
The instance subsumes in one or more rules of thesame class. In this case, the instance is classified as anelement of the class.2.
The instance subsumes in two or more different classesof rules. In this case, the system must examine thedegree of convenience between the instance and therules in which it is included. The instance is classifiedas an element of the class of the rule with the greatestdegree of convenience.The degree of convenience of a rule (dc) is calculated asthe lowest value of the functions that are associated witheach input variable of the rule.
dc ¼minfjiðxiÞg (12)
where ji are the membership functions associated witheach input variable vi. The function ji is defineddepending on the labels presented in the rule for theinput variable vi, and it is different for each rule [5].
Next, we explain the global classification process bymeans of an example in which a person is slowly movingalong the road in a concrete instant.
First, the segmentation process determines the set ofblobs in the current frame, where each blob has associateda set of macroblocks and motion vectors. From thisinformation, the segmentation algorithm provides nu-meric values for the variables VP (vertical position), HP
(horizontal position), SMB (size in macroblocks), DMV
(dispersion degree), DIS (displacement), VS (verticalspeed) and HS (horizontal speed), being the first five ofthem used as the input for the first set of rules. Let ussuppose that these numeric values are fuzzified asfollows: (DO, LE, SH, LO, VS).
The previous tuple of linguistic labels means that theobject location is down (DO) and left (LE), its size in terms
of macroblocks and motion vectors is short (SH), thedispersion degree is low (LO), and, finally, the displace-ment is very short (VS). This case may be perfectlyclassified as person by the following rule:
Ri: IF VP is fVD; LD;DOg ^ HP is fVL; LEg ^ SMB isfVS; SHg ^ DIS is fVS} THEN y1 is person.
Later, the system uses the output variable y1 to decidewhich set of rules must be employed in the second phasein order to determine the object speed. As we discussed inSection 4.2, different sets of rules for people and vehiclesare generated. In this case, the system would choose theset of rules that classifies the people speed. Moreover, theinput of this phase is a 5-tuple consisting of numericvalues for the following variables: VP, HP, y1, VS and HS.Let us suppose that these numeric values are fuzzified asfollows: (DO, LE, person, LU, LR).
The previous tuple of linguistic labels means that theobject location is down (DO) and left (LE), the object is aperson, and its vertical and horizontal speed is low up(LU) and low right (LR), respectively. It is important toremark that VS and HS is the speed given by the motionvectors, but it is not the true object speed. Let us supposethat this tuple is classified as slow speed by the followingrule:
Rj: IF VP is fVD; LD;DOg ^ HP is fVL; LEg ^ y1 is {person,group of peopleg ^ VS is fLD; LUg ^ HS is fLR; LLg THEN y2
is slow.
Until now, the system knows that the moving object is aperson and its speed is slow. The next step consists inanalysing the intersection degree between the object andthe categorised areas, and classifying the object’s beha-viour. If the object is totally located over the road, thesystem will build the following tuple: (person, slow, VH,VO, VO, VO).
Finally, the following rule may determine that theobject’s behaviour is anomalous:
Rk: IF y1 is {person, group of peopleg ^ RO is fME;HI;VHg
THEN y3 is anomalous.
Note that the above rule is highly interpretable andjustifies itself why the current situation is anomalous. Rk
means that if an object is a person or a group of people,and he/she or they are in a road area (the intersectionbetween them and a road area is medium (ME), high (HI),or very high (VH)), then the current situation is anom-alous.
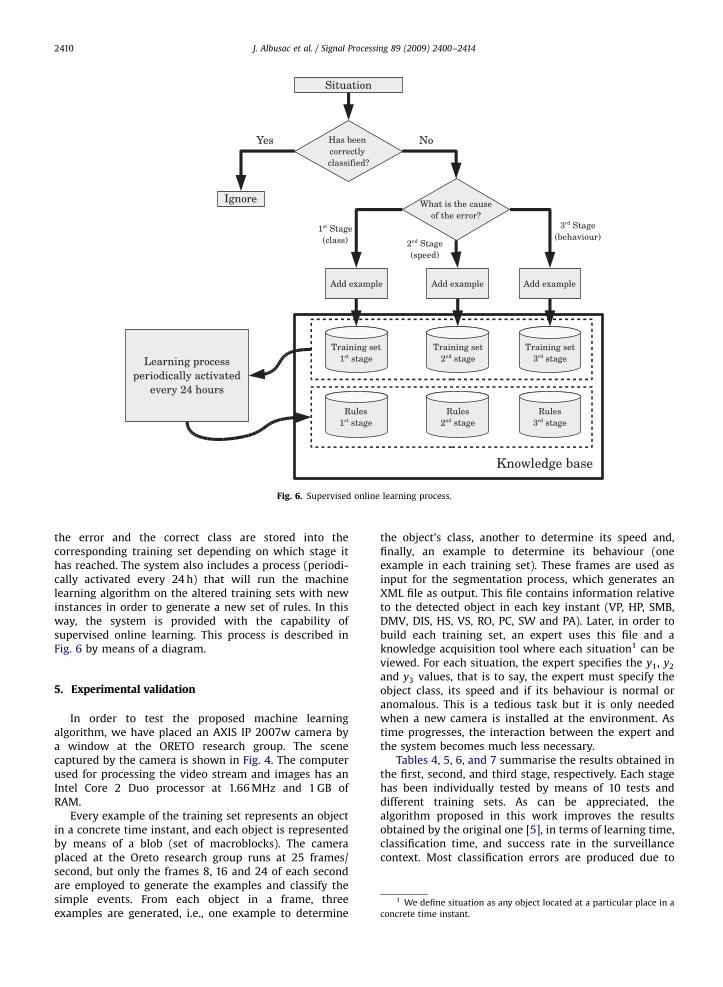
The number of errors in the classification processdecreases when the system refines the knowledge base.Anomalous situations involve the activation of alarms.When this takes place, the user can specify whether thealarm activation was correct or, on the other hand, it was amistake. Besides, if a certain situation was incorrectlyclassified, the user can specify through the system inter-face which stage of the global process made the mistakeand which is the correct class. The situation that produced
ARTICLE IN PRESS
Fig. 6. Supervised online learning process.
J. Albusac et al. / Signal Processing 89 (2009) 2400–24142410
the error and the correct class are stored into thecorresponding training set depending on which stage ithas reached. The system also includes a process (periodi-cally activated every 24 h) that will run the machinelearning algorithm on the altered training sets with newinstances in order to generate a new set of rules. In thisway, the system is provided with the capability ofsupervised online learning. This process is described inFig. 6 by means of a diagram.
1 We define situation as any object located at a particular place in a
concrete time instant.
5. Experimental validation
In order to test the proposed machine learningalgorithm, we have placed an AXIS IP 2007w camera bya window at the ORETO research group. The scenecaptured by the camera is shown in Fig. 4. The computerused for processing the video stream and images has anIntel Core 2 Duo processor at 1.66 MHz and 1 GB ofRAM.
Every example of the training set represents an objectin a concrete time instant, and each object is representedby means of a blob (set of macroblocks). The cameraplaced at the Oreto research group runs at 25 frames/second, but only the frames 8, 16 and 24 of each secondare employed to generate the examples and classify thesimple events. From each object in a frame, threeexamples are generated, i.e., one example to determine
the object’s class, another to determine its speed and,finally, an example to determine its behaviour (oneexample in each training set). These frames are used asinput for the segmentation process, which generates anXML file as output. This file contains information relativeto the detected object in each key instant (VP, HP, SMB,DMV, DIS, HS, VS, RO, PC, SW and PA). Later, in order tobuild each training set, an expert uses this file and aknowledge acquisition tool where each situation1 can beviewed. For each situation, the expert specifies the y1, y2
and y3 values, that is to say, the expert must specify theobject class, its speed and if its behaviour is normal oranomalous. This is a tedious task but it is only neededwhen a new camera is installed at the environment. Astime progresses, the interaction between the expert andthe system becomes much less necessary.
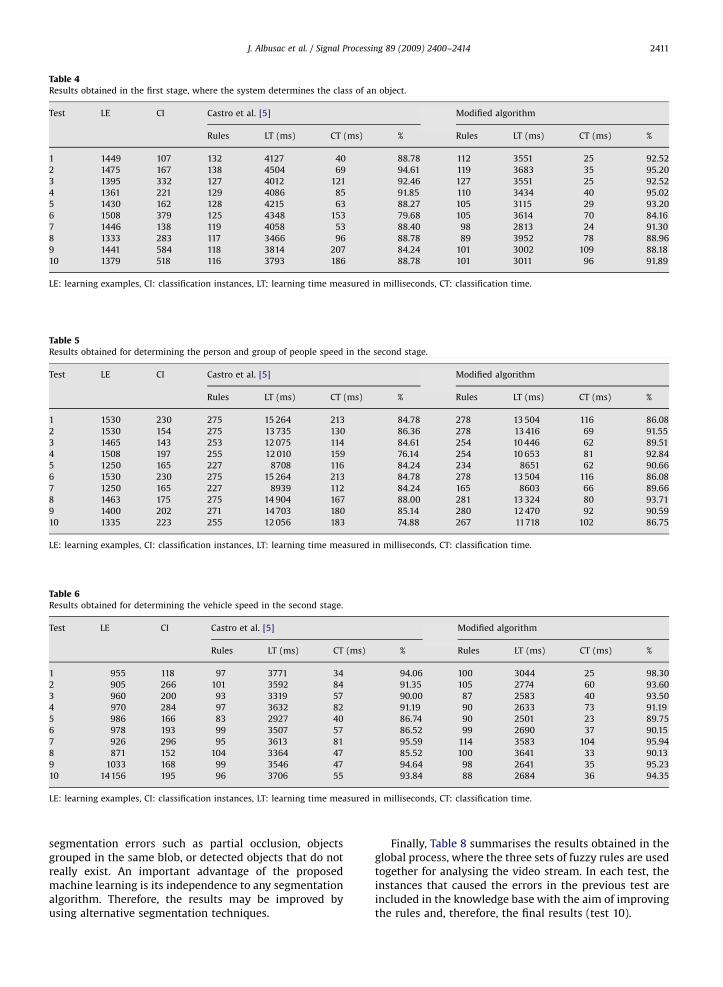
Tables 4, 5, 6, and 7 summarise the results obtained inthe first, second, and third stage, respectively. Each stagehas been individually tested by means of 10 tests anddifferent training sets. As can be appreciated, thealgorithm proposed in this work improves the resultsobtained by the original one [5], in terms of learning time,classification time, and success rate in the surveillancecontext. Most classification errors are produced due to
ARTICLE IN PRESS
Table 4Results obtained in the first stage, where the system determines the class of an object.
Test LE CI Castro et al. [5] Modified algorithm
Rules LT (ms) CT (ms) % Rules LT (ms) CT (ms) %
1 1449 107 132 4127 40 88.78 112 3551 25 92.52
2 1475 167 138 4504 69 94.61 119 3683 35 95.20
3 1395 332 127 4012 121 92.46 127 3551 25 92.52
4 1361 221 129 4086 85 91.85 110 3434 40 95.02
5 1430 162 128 4215 63 88.27 105 3115 29 93.20
6 1508 379 125 4348 153 79.68 105 3614 70 84.16
7 1446 138 119 4058 53 88.40 98 2813 24 91.30
8 1333 283 117 3466 96 88.78 89 3952 78 88.96
9 1441 584 118 3814 207 84.24 101 3002 109 88.18
10 1379 518 116 3793 186 88.78 101 3011 96 91.89
LE: learning examples, CI: classification instances, LT: learning time measured in milliseconds, CT: classification time.
Table 5Results obtained for determining the person and group of people speed in the second stage.
Test LE CI Castro et al. [5] Modified algorithm
Rules LT (ms) CT (ms) % Rules LT (ms) CT (ms) %
1 1530 230 275 15 264 213 84.78 278 13 504 116 86.08
2 1530 154 275 13 735 130 86.36 278 13 416 69 91.55
3 1465 143 253 12 075 114 84.61 254 10 446 62 89.51
4 1508 197 255 12 010 159 76.14 254 10 653 81 92.84
5 1250 165 227 8708 116 84.24 234 8651 62 90.66
6 1530 230 275 15 264 213 84.78 278 13 504 116 86.08
7 1250 165 227 8939 112 84.24 165 8603 66 89.66
8 1463 175 275 14 904 167 88.00 281 13 324 80 93.71
9 1400 202 271 14 703 180 85.14 280 12 470 92 90.59
10 1335 223 255 12 056 183 74.88 267 11718 102 86.75
LE: learning examples, CI: classification instances, LT: learning time measured in milliseconds, CT: classification time.
Table 6Results obtained for determining the vehicle speed in the second stage.
Test LE CI Castro et al. [5] Modified algorithm
Rules LT (ms) CT (ms) % Rules LT (ms) CT (ms) %
1 955 118 97 3771 34 94.06 100 3044 25 98.30
2 905 266 101 3592 84 91.35 105 2774 60 93.60
3 960 200 93 3319 57 90.00 87 2583 40 93.50
4 970 284 97 3632 82 91.19 90 2633 73 91.19
5 986 166 83 2927 40 86.74 90 2501 23 89.75
6 978 193 99 3507 57 86.52 99 2690 37 90.15
7 926 296 95 3613 81 95.59 114 3583 104 95.94
8 871 152 104 3364 47 85.52 100 3641 33 90.13
9 1033 168 99 3546 47 94.64 98 2641 35 95.23
10 14156 195 96 3706 55 93.84 88 2684 36 94.35
LE: learning examples, CI: classification instances, LT: learning time measured in milliseconds, CT: classification time.
J. Albusac et al. / Signal Processing 89 (2009) 2400–2414 2411
segmentation errors such as partial occlusion, objectsgrouped in the same blob, or detected objects that do notreally exist. An important advantage of the proposedmachine learning is its independence to any segmentationalgorithm. Therefore, the results may be improved byusing alternative segmentation techniques.
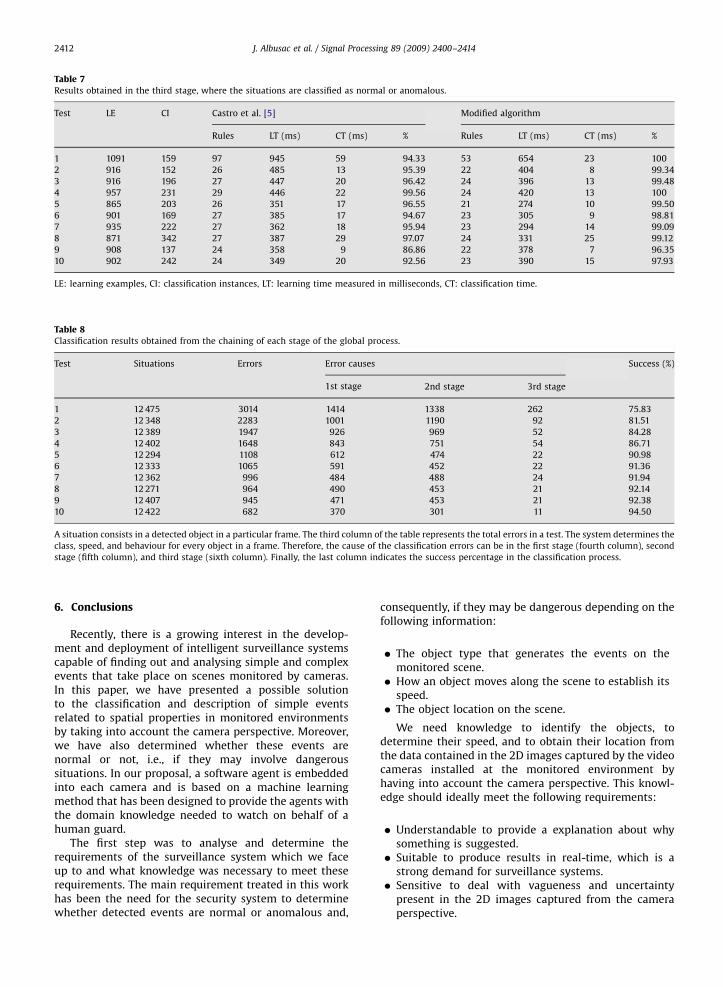
Finally, Table 8 summarises the results obtained in theglobal process, where the three sets of fuzzy rules are usedtogether for analysing the video stream. In each test, theinstances that caused the errors in the previous test areincluded in the knowledge base with the aim of improvingthe rules and, therefore, the final results (test 10).
ARTICLE IN PRESS
Table 7Results obtained in the third stage, where the situations are classified as normal or anomalous.
Test LE CI Castro et al. [5] Modified algorithm
Rules LT (ms) CT (ms) % Rules LT (ms) CT (ms) %
1 1091 159 97 945 59 94.33 53 654 23 100
2 916 152 26 485 13 95.39 22 404 8 99.34
3 916 196 27 447 20 96.42 24 396 13 99.48
4 957 231 29 446 22 99.56 24 420 13 100
5 865 203 26 351 17 96.55 21 274 10 99.50
6 901 169 27 385 17 94.67 23 305 9 98.81
7 935 222 27 362 18 95.94 23 294 14 99.09
8 871 342 27 387 29 97.07 24 331 25 99.12
9 908 137 24 358 9 86.86 22 378 7 96.35
10 902 242 24 349 20 92.56 23 390 15 97.93
LE: learning examples, CI: classification instances, LT: learning time measured in milliseconds, CT: classification time.
Table 8Classification results obtained from the chaining of each stage of the global process.
Test Situations Errors Error causes Success (%)
1st stage 2nd stage 3rd stage
1 12 475 3014 1414 1338 262 75.83
2 12 348 2283 1001 1190 92 81.51
3 12 389 1947 926 969 52 84.28
4 12 402 1648 843 751 54 86.71
5 12 294 1108 612 474 22 90.98
6 12 333 1065 591 452 22 91.36
7 12 362 996 484 488 24 91.94
8 12 271 964 490 453 21 92.14
9 12 407 945 471 453 21 92.38
10 12 422 682 370 301 11 94.50
A situation consists in a detected object in a particular frame. The third column of the table represents the total errors in a test. The system determines the
class, speed, and behaviour for every object in a frame. Therefore, the cause of the classification errors can be in the first stage (fourth column), second
stage (fifth column), and third stage (sixth column). Finally, the last column indicates the success percentage in the classification process.
J. Albusac et al. / Signal Processing 89 (2009) 2400–24142412
6. Conclusions
Recently, there is a growing interest in the develop-ment and deployment of intelligent surveillance systemscapable of finding out and analysing simple and complexevents that take place on scenes monitored by cameras.In this paper, we have presented a possible solutionto the classification and description of simple eventsrelated to spatial properties in monitored environmentsby taking into account the camera perspective. Moreover,we have also determined whether these events arenormal or not, i.e., if they may involve dangeroussituations. In our proposal, a software agent is embeddedinto each camera and is based on a machine learningmethod that has been designed to provide the agents withthe domain knowledge needed to watch on behalf of ahuman guard.
The first step was to analyse and determine therequirements of the surveillance system which we faceup to and what knowledge was necessary to meet theserequirements. The main requirement treated in this workhas been the need for the security system to determinewhether detected events are normal or anomalous and,
consequently, if they may be dangerous depending on thefollowing information:
�
The object type that generates the events on themonitored scene. � How an object moves along the scene to establish itsspeed.
� The object location on the scene.We need knowledge to identify the objects, todetermine their speed, and to obtain their location from
the data contained in the 2D images captured by the videocameras installed at the monitored environment byhaving into account the camera perspective. This knowl-edge should ideally meet the following requirements:�
Understandable to provide a explanation about whysomething is suggested. � Suitable to produce results in real-time, which is astrong demand for surveillance systems.
� Sensitive to deal with vagueness and uncertaintypresent in the 2D images captured from the cameraperspective.

ARTICLE IN PRESS
J. Albusac et al. / Signal Processing 89 (2009) 2400–2414 2413
mined, the next stage was to assemble the sequence of
Once the problem requirements were clearly deter-steps to learn the knowledge. We have proposed amachine learning algorithm to get the necessary knowl-edge from examples and a method that makes use of thisalgorithm. The proposed method includes three calls tothe algorithm as explained in Section 2 (see Fig. 1).
The heart of the suggested machine learning algorithmis suggested in [5]. This algorithm is appropriate since ithas a good history of use in machine learning contextswhere the systems have to express relationships betweenthe input variables and an output variable, it gets knowl-edge represented by means of IF–THEN fuzzy rules withthe features previously mentioned, and it generates goodclassification results. Moreover, it has another importantcharacteristic, it is capable of making explicit what is oftenimplicit or tacit knowledge that a human may haveregarding objects in the real world.
The linguistic variables used in this algorithm aredefined as fuzzy sets with appropriate membershipfunctions. These functions need to be predefined beforefuzzy rule bases will be built. In order to obtain these,some automatic methods of fuzzy clustering could beused. These methods divide the m data points into c fuzzyclusters and determine the locations of these cluster in theappropriate space as well as the associated degrees ofmembership. Also a knowledge-acquisition facilities couldbe used for helping the expert to define the linguisticvariables and their membership functions [6]. The defini-tion of these functions depends on the scene and they areactually defined by human experts or experienced users.Even though, last approach could be considered as analgorithm drawback, it is suggested when we are inter-ested in obtaining rules expressed in the same terminol-ogy as that used by the expert involved with the process.We insist on the importance that the expert understandthe system output.
In this paper, a key innovation has been added to thisalgorithm with the aim of adapting it to the new needs ofour surveillance problem. This was mainly motivatedsince several generated rules with different consequencescould be applied to the same premises, generally scenariosthat are not present in the training data. This is due to thegeneralisation of each particular rule into a definitive rule.Consequently, we pretend to prune the over-general-isation of a definitive rule during the amplificationprocess. As has been shown in the previous section, theover-generalisation is not desirable to us and it will becontrolled by means of a separability measurement. Thismeasurement allows one definitive rule to capture thepremises that are not present in the training data butclose to those evidences in the data that justify that rule.Thanks to this separability measurement the resultsobtained are improved.
Another modification suggested in this work is that wegive an order to the variables before the amplificationprocess start, the variables will be amplified according tothat order.
In the example discussed in this paper, it is clear howthe steps of the method proceeds and how the knowledgelearned maps to the knowledge requirements of the
surveillance system. Moreover, we show in a surveillanceproblem how the system identifies the objects beingtracked, establishes their location and speed from theperspective camera, and determines the normality of theevents that take place in the scene.
The results obtained are very promising especiallyregarding further integration of the knowledge learned foreach machine learning algorithm with the aim todetermine the simple events captured by the camera.The algorithm suggested presents better classificationresults than the original one. Furthermore, the ruleslearned are very understandable since they capture thesemantics of the terms that are used in the particulardomain and allow the security guard to examine the resultobtained by the method.
We have only modelled the process of acquiring thedomain knowledge for our particular problem, i.e.,classifying events as normal or abnormal depending onthe spatial information from 2D images captured by acamera. When we go through related surveillance pro-blems, we will have to consider the new knowledgerequirements in order to bring a wider range of knowledgeacquisition techniques. In this way, we will be able to dealwith the problem of populating the new knowledge basesof our agents and customising their behaviour.
Acknowledgements
The authors would like to thank the anonymousreviewers for their insightful comments that have sig-nificantly improved the quality of this paper. This workhas been founded by the Spanish Ministry of Industry(MITYC) under Research Project HESPERIA (CENIT Project).
References
[1] J. Albusac, D. Vallejo, L. Jimenez-Linares, J.J. Castro-Schez, L.Rodriguez-Benitez, Intelligent surveillance based on normalityanalysis to detect abnormal behaviors, International Journal ofPattern Recognition and Artificial Intelligence (2009), accepted forpublication.
[2] C. Bauckhage, M. Hanheide, S. Wrede, G. Sagerer, A cognitive visionsystem for action recognition in office environments, in: Proceed-ings of the 2004 IEEE Computer Society Conference on ComputerVision and Pattern Recognition, vol. 2, 2004, pp. 827–833.
[3] K. Bowyer, K. Chang, P. Flynn, A survey of approaches and challengesin 3D and multi-modal 3Dþ 2D face recognition, Computer Visionand Image Understanding 101 (1) (2006) 1–15.
[4] H. Buxton, S. Gong, Visual surveillance in a dynamic and uncertainworld, Artificial Intelligence 78 (1–2) (1995) 431–459.
[5] J.L. Castro, J.J. Castro-Schez, J.M. Zurita, Learning maximal structurerules in fuzzy logic for knowledge acquisition in expert systems,Fuzzy Sets and Systems 101 (3) (1999) 331–342.
[6] J.J. Castro-Schez, J.L. Castro, J.M. Zurita, Fuzzy repertory table: amethod for acquiring knowledge about input variables to machinelearning algorithm, IEEE Transactions on Fuzzy Systems 12 (1)(2004) 123–139.
[7] R. Collins, A. Lipton, T. Kanade, H. Fujiyoshi, D. Duggins, Y. Tsin, D.Tolliver, N. Enomoto, O. Hasegawa, A System for Video Surveillanceand Monitoring, Technical Report CMU-RI-TR-00-12, RoboticsInstitute, Carnegie Mellon University, 2000.
[8] G.L. Foresti, C. Micheloni, L. Snidaro, Event classification forautomatic visual-based surveillance of parking lots, in: Proceedingsof the 17th International Conference on Pattern Recognition, vol. 3,2004, pp. 314–317.

ARTICLE IN PRESS
J. Albusac et al. / Signal Processing 89 (2009) 2400–24142414
[9] I. Haritaoglu, D. Harwood, L.S. Davis, W4: real-time surveillance ofpeople and their activities, Pattern Analysis and Machine Intelli-gence 22 (8) (2000) 809–830.
[10] C. Hudelot, M. Thonnat, A cognitive vision platform for automaticrecognition of natural complex objects, in: International Conferenceon Tools with Artificial Intelligence, ICTAI, Sacramento, 2003, pp.398–405.
[11] N. Johnson, D. Hogg, Learning the distribution of object trajectoriesfor event recognition, Image and Vision Computing 14 (8) (1996)609–615.
[12] Y. Lee, C. Han, J. Shim, Fuzzy neural networks and fuzzy integralapproach to curvature-based component range facial recognition,in: 16th International Conference on Pattern Recognition (ICPR’02),vol. 2, 2007, pp. 1334–1339.
[13] J. Li, H. Wang, J. Yu, Research on the application of CRFs based onfeature sets in network intrusion detection, in: InternationalConference on Security Technology, 2008, pp. 194–197.
[14] Y. Lu, Y. Wang, X. Tong, Z. Zhao, H. Jia, J. Kong, Face tracking in videosequences using particle filter based on skin color model and facialcontour, in: Intelligent Information Technology Application, IITA’08,vol. 1, 2008, pp. 457–461.
[15] D. Makris, T. Ellis, Path detection in video surveillance, Image andVision Computing 12 (20) (2002) 895–903.
[16] C. Piciarelli, G.L. Foresti, L. Snidaro, Trajectory clustering and itsapplications for video surveillance, in: IEEE Conference on Ad-vanced Video and Signal Based Surveillance, 2005, pp. 40–45.
[17] W. Randolph, PNPOLY—point inclusion in polygon test, 2008hwww.ecse.rpi.edu/Homepages/wrf/Research/Short_Notes/pnpoly.htmli.
[18] L. Rodriguez-Benitez, J. Moreno-Garcia, J.J. Castro-Schez, J. Albusac,L. Jimenez-Linares, Automatic objects behaviour recognition fromcompressed video domain, Image and Vision Computing 27 (6)(2009) 648–657.
[19] M. Shimrat, Algorithm 112: position of point relative to polygon,Communications of the ACM 5 (8) (1962) 425.
[20] H. Stern, U. Kartoun, A. Shmilovici, A prototype fuzzy system forsurveillance picture understanding, in: IASTED International Con-ference Visualization, Imaging, and Image Processing (VIIP’01),2001, pp. 624–629.
[21] D. Tao, X. Li, X. Mayban, S. Wu, Elapsed time in human gaitrecognition: a new approach, in: IEEE International Conference onAcoustics, Speech, and Signal Processing, vol. 2, 2006.
[22] D. Tao, X. Li, X. Wu, S. Maybank, General tensor discriminantanalysis and Gabor features for gait recognition, IEEE Transactionson Pattern Analysis and Machine Intelligence 29 (10) (2007)1700–1715.
[23] T. Uribe, S. Cheung, Automatic analysis of firewall and networkintrusion detection system configurations, Journal of ComputerSecurity 15 (6) (2007) 691–715.
[24] D. Vallejo, J. Albusac, L. Jimenez-Linares, C. Gonzalez-Morcillo, J.Moreno, A cognitive surveillance system for detecting incorrecttraffic behaviors, Expert System with Applications 46 (3) (2010),doi:10.1016/j.eswa.2009.01.034.
[25] W. Wang, S. Maybank, A survey on visual surveillance of objectmotion and behaviors, IEEE Transactions on Systems, Man andCybernetics, Part C 34 (3) (2004) 334–352.
[26] D. Xu, S. Yan, D. Tao, L. Zhang, X. Li, H. Zhang, Human gaitrecognition with matrix representation, IEEE Transactions onCircuits and Systems for Video Technology 16 (7) (2006) 896–903.
[27] L.A. Zadeh, Fuzzy sets, Information and Control 8 (3) (1965)338–353.
[28] S. Zanero, S. Savaresi, Unsupervised learning techniques for anintrusion detection system, in: Proceedings of the 2004 ACMSymposium on Applied Computing, 2004, pp. 412–419.
[29] Z. Zhang, K. Huang, T. Tan, L. Wang, Trajectory series analysis basedevent rule induction for visual surveillance, in: InternationalConference on Computer Vision and Pattern Recognition, CVPR’07,2007, pp. 1–8.
[30] H.J. Zimmermann, Fuzzy Set Theory and its Applications, KluwerAcademic Publishers, Dordrecht, 2001.
Copyright © 2022 FDOKUMEN




















