A STUDY OF VARIOUS TRAINING ALGORITHMS ON NEURAL NETWORK FOR ANGLE BASED TRIANGULAR PROBLEM
10
International Journal of Computer Applications (0975 – 8887) Volume *– No.*, ___________ 2013 A STUDY OF VARIOUS TRAINING ALGORITHMS ON NEURAL NETWORK FOR ANGLE BASED TRIANGULAR PROBLEM Amarpal Singh M.Tech (CS&E) Amity University Noida, India [email protected] Piyush Saxena M.Tech (CS&E) Amity University Noida, India [email protected] Sangeeta Lalwani M.Tech (CS&E) Amity University Noida, India sangeeta.lalwani29@gmail .com ABSTRACT This paper examines the study of various feed forward back-propagation neural network training algorithms and performance of different radial basis function neural network for angle based triangular problem. The training algorithms in feed forward back- propagation neural network comprise of Scale Gradient Conjugate Back-Propagation (BP), Conjugate Gradient BP through Polak-Riebre updates, Conjugate Gradient BP through Fletcher-Reeves updates, One Secant BP and Resilent BP. The final result of each training algorithm for angle based triangular problem will also be discussed and compared. General Terms Artificial Neural Network (ANN), Feed Forward Backpropogation (FFB), Training Algorithm. Keywords Feed-forward back-propagation neural network, radial basis function, generalized regression neural network. 1. INTRODUCTION Artificial Neural Network (ANN) learns by adjusting the weights so as to be able to correctly categorize the training data and hence, after testing phase, to classify unknown data. It needs long time for training. It has a high tolerance to noisy and incomplete data. Some Salient Features of ANN are as follow: Adaptive learning, Self- organization Real-time operation, Massive parallelism Error acceptance by means of redundant information coding Learning and generalizing ability Distributed representation There are many different definitions of neural networks that are quoted by some famous researcher as follow: DARPA Neural Network (NN) Study: A NN is a taxonomy collected of various straightforward dispensations of fundamentals in commission of parallel whose purpose is unwavering by network configuration, connection strengths, as well as the dispensation executed at computing fundamentals or nodes. According to Haykin (1994): A Neural Network is a vast analogous scattered processor which has an expected tendency for storing practical knowledge and making it available for use. It is similar to the brain in two aspects [1]: • Knowledgebase is acquired by the network through a training process. 1
Transcript of A STUDY OF VARIOUS TRAINING ALGORITHMS ON NEURAL NETWORK FOR ANGLE BASED TRIANGULAR PROBLEM

International Journal of Computer Applications (0975 – 8887) Volume *– No.*, ___________ 2013
A STUDY OF VARIOUS TRAINING ALGORITHMS ONNEURAL NETWORK FOR ANGLE BASED TRIANGULAR
PROBLEM
Amarpal SinghM.Tech (CS&E)
Amity UniversityNoida, India
Piyush SaxenaM.Tech (CS&E)
Amity UniversityNoida, India
Sangeeta LalwaniM.Tech (CS&E)
Amity UniversityNoida, India
ABSTRACTThis paper examines the study of variousfeed forward back-propagation neuralnetwork training algorithms andperformance of different radial basisfunction neural network for angle basedtriangular problem. The trainingalgorithms in feed forward back-propagation neural network comprise ofScale Gradient Conjugate Back-Propagation(BP), Conjugate Gradient BP throughPolak-Riebre updates, Conjugate GradientBP through Fletcher-Reeves updates, OneSecant BP and Resilent BP. The finalresult of each training algorithm forangle based triangular problem will alsobe discussed and compared.
General TermsArtificial Neural Network (ANN), FeedForward Backpropogation (FFB), TrainingAlgorithm.
KeywordsFeed-forward back-propagation neuralnetwork, radial basis function,generalized regression neural network.
1. INTRODUCTIONArtificial Neural Network (ANN) learns byadjusting the weights so as to be able tocorrectly categorize the training dataand hence, after testing phase, toclassify unknown data. It needs long timefor training. It has a high tolerance tonoisy and incomplete data.
Some Salient Features of ANN are asfollow:
Adaptive learning, Self-organization
Real-time operation, Massiveparallelism
Error acceptance by means ofredundant information coding
Learning and generalizingability
Distributed representation
There are many different definitions ofneural networks that are quoted by somefamous researcher as follow:
DARPA Neural Network (NN) Study:
A NN is a taxonomy collected of variousstraightforward dispensations offundamentals in commission of parallelwhose purpose is unwavering by networkconfiguration, connection strengths, aswell as the dispensation executed atcomputing fundamentals or nodes.
According to Haykin (1994):
A Neural Network is a vast analogousscattered processor which has an expectedtendency for storing practical knowledgeand making it available for use. It issimilar to the brain in two aspects [1]:
• Knowledgebase is acquired by thenetwork through a training process.
1

International Journal of Computer Applications (0975 – 8887) Volume *– No.*, ___________ 2013
• Inter-neuron connection strengthsknown as synaptic weights are usedto accumulate the knowledge.
According to Nigrin (1993):
• A NN is a circuit composed of avery large number of simpleprocessing elements that areneurally based. Each elementoperates only on local information.
According to Zurada (1992):
• Artificial neural systems, orneural networks, are physicalcellular systems which can acquire,store and utilize experientialknowledge.
This paper examines how the artificialneural network is implemented for anglebased triangle problem. The performance(speed processing and high accuracyresult) of training algorithm that beenused in this problem is the researchtarget. The following figure (Fig. 1)shows the system architecture for anglebased triangular problem.
System structural design
System structural design starts withcreating training database. After thatneural network model such as trainingfunction, design and constraint wereinitialized.
Input an
Fig 1: Block Diagram for Angle BasedTriangular Problem
Fig 2: Block diagram for neural network
2. LITERATURE REVIEWEDIn this section of paper, the varioustypes of neural networks are discussed.Basic Models of Artificial NeuralNetworks:
Single-Layer Feed-Forward Network: When a layer of the processing nodes isformed, the inputs can be connected tothese nodes with various weights,resulting in a series of outputs, one pernode.
Multilayer Feed-Forward Network:A Multilayer feed-forward network isformed by the interconnection of severallayers. The input layer is that whichreceives the input and this layer has nofunction except buffering the inputsignal.
Single Node with its own Feedback:Single node with its own feedback issimple recurrent neural network having asingle neuron with feedback itself.
Single-Layer Recurrent Network:Single-layer recurrent network with afeedback connection in which a processingelement’s output can be directed back tothe processing element itself or theother processing element or to both.
Multilayer Recurrent Network:In Multilayer recurrent network, aprocessing element output can be directedback to the nodes in a preceding layer,forming a Multilayer recurrent network:
2
INPUTANGLEOF
TRIANGL
NEURALNETWORK
CLASSIFICAT
OUTPUT(MARE& MRE)
CREATETRAINING DATA
NETWORKPARAMETER AND
DESIGNIN
TRAINAND
SIMULATENETWORK

International Journal of Computer Applications (0975 – 8887) Volume *– No.*, ___________ 2013
Fig 3: Basic Models of ANN
Feed-forward Back-Propagation (FFBP)Neural Network
This neural network was trained andvalidated for various feed-forwardbackprop training algorithms available inMatlab Neural Network toolbox [2].
SUPPORTED TRAINING FUNCTIONS IN FFBPNEURAL NETWORK [10]
There are many supported trainingfunctions as follow : Trainb (Batchtraining with weight and bias learningrules) , Trainbfg (BFGS quasi-NewtonBP ), Trainbr (Bayesian regularization) ,Trainc ( Cyclical order incrementalupdate) , Traincgb ( Powell-Bealeconjugate gradient BP), Traincgf(Fletcher-Powell conjugate gradient BP ),Traincgp (Polak-Ribiere conjugategradient BP), Traingd (Gradient descentBP), Traingda (Gradient descent withadaptive learning rate BP), Traingdm(Gradient descent with momentum BP),Traingdx (Gradient descent with momentum& adaptive linear BP), Trainlm(Levenberg-Marquardt BP), Trainoss (Onestep secant BP), Trainr (Random orderincremental update), Trainrp (Resilientbackpropagation (Rprop)), Trains(Sequential order incremental update),Trainscg (Scaled conjugate gradient BP)
SUPPORTED LEARNING FUNCTIONS IN FFBPNEURAL NETWORK [10]
There are many supported learningfunctions as follow : learncon(Conscience bias learning), learngd(Gradient descent weight/bias learning),learngdm (Gradient descent with momentumweight/bias learning), learnh (Hebbweight learning), learnhd (Hebb withdecay weight learning rule ), learnis(Instar weight learning), learnk (Kohonenweight learning), learnlv1 (LVQ1 weightlearning), learnlv2 (LVQ2 weightlearning), learnos (Outstar weightlearning), learnp (Perceptron weight andbias learning) learnpn (Normalizedperceptron weight and bias learning),learnsom (Self-organizing map weightlearning), learnwh (Widrow-Hoff weightand bias learning rule).
TRANSFER FUNCTIONS IN FFBP NEURAL NETWORK[10]
There are many transfer functions asfollow : compet (Competitive), hardlim(Hard limit transfer), hardlims(Symmetric hard limit), logsig (Logsigmoid), poslin (Positivelinear),purelin (Linear), radbas (Radialbasis),satlin (Saturating linear)satlins(Symmetric saturating linear), tansig(Hyperbolic tangent sigmoid), tribas(Triangular basis)
TRANSFER DERIVATIVE FUNCTIONS [10]
There are many transfer derivativefunctions as follow : dhardlim (Hardlimit transfer derivative), dhardlms(Symmetric hard limit transfer derivative), dlogsig (Log sigmoid transferderivative), dposlin (Positive lineartransfer derivative), dpurelin (Hardlimit transfer derivative), dradbas(Radial basis transfer derivative),dsatlin (Saturating linear transferderivative), dsatlins (Symmetricsaturating linear transfer derivative),dtansig (Hyperbolic tangent sigmoidtransfer derivative), dtribas (Triangularbasis transfer derivative ).
WEIGHT & BIAS INITIALIZATION FUNCTIONS[10]
There are many weight and biasinitialization functions as follow:
3

International Journal of Computer Applications (0975 – 8887) Volume *– No.*, ___________ 2013
initcon (Conscience bias initialization),initzero (Zero weight/biasinitialization), midpoint (Midpointweight initialization), randnc(Normalized column weightinitialization), randnr (Normalized rowweight initialization), rands (Symmetricrandom weight/bias initialization)
WEIGHT DERIVATIVE FUNCTIONS [10]
The weight derivative function in ANN isDdotprod (Dot product weight derivativefunction).
In this paper, fifteen trainingalgorithms and two learning functionnamely “learngd” and “learngdm” are used. RBF Neural Network
RBF’s are embedded in a two layer neuralnetwork where each hidden unit implementsa radial activated function. The outputunits implement a weighted sum of hiddenunit outputs. The input into an RBFnetwork is non linear while the output islinear. In order to use RBF network itneed to specify the hidden unitactivation function, the number ofprocessing units, a criterion formodeling a given task and a trainingalgorithm for finding the parameters ofthe network. After training the RBFnetwork can be used with data whoseunderlying statistics is comparable tothat of the training set. RBF networkshave been successfully applied to a largediversity of applications includinginterpolation, time series modeling,speech recognition etc.
HIDDEN UNIT
INPUT OUTPUT
Fig 4: Network topology of RBF
GRNN Generalized Regression NeuralNetwork
GRNN is consists of a RBF layer with aunique linear layer used for functionapproximation with adequate amount ofunseen neurons. The MATLAB Neural NetworkToolbox Function (newgrnn) has been usedfor testing and training the networkperformance via measure of GRNN forcorresponding to validation data.
Fig 5 shows architecture of GRNN. It iscomparable to the RBF network, but it hasa somewhat dissimilar second layer.
Fig. 5: GRNN Network Topology
Some researcher use these neural networkfundamental to propose their own metricsregarding to their research areas.Khoshgoftarr et al. [3] introduced toapply the concept of the NN as a tool forpredicting software quality. Theypresented a discriminated model and a NNrepresentation of the largetelecommunications system, classifyingmodules as not fault-prone or fault-prone. They compared the neural-networkmodel with a non parametric disciminantmodel, and found the neural network modelhad better predictive accuracy. Specht[4] has stated that it is a memory-basednetwork that provides estimates ofcontinuous variables and converges to theunderlying (linear or nonlinear)regression surface. This is a one-passlearning algorithm with a highly parallelstructure. Even with sparse data is amultidimensional measurement space; thealgorithm provides smooth transitionsfrom one observed value to another.
3. RESEARCH METHODOLOGY
4

International Journal of Computer Applications (0975 – 8887) Volume *– No.*, ___________ 2013
In this section of paper, the researchmethodology for the implementation of theproblem is provided. Feed-forward Back-propagation NeuralNetworks
Backprop implements a gradient descentsearch through a space of possiblenetwork weight, iteratively reducing theerror E, between training example andtarget value and network output. Itguaranteed to converge only towards somelocal minima. A training procedure whichallows multilayer feed forward NeuralNetworks to be trained.
Fig 6: Architecture of Feed ForwardNetwork
However, the major disadvantages of BPare its convergence rate relativelyslow [11] and being trapped at thelocal minima.many powerful optimization algorithmshave been devised, most of which havebeen based on simple gradient descentalgorithm as explain by C.M. Bishop[12] such as conjugate gradient decent,scaled conjugate gradient descent,quasi-Newton BFGS and Levenberg-Marquardt methods.For feed forward networks:
A continuous function can be differentiated allowing Gradient-descent. Back propagation is an example of a
gradient-descent technique.
Uses sigmoid (binary or bipolar)activation function.
In multilayer networks, the activationfunction is usually more complex thanjust a threshold function, like1/[1+exp(-x)] or even 2/[1+exp(-x)] – 1to allow for inhibition, etc.
Gradient Descent
Gradient-Descent(training_examples,h)
Each training example is a pair ofthe form <(x1,…xn),t> where (x1,…,xn) is the vector of inputvalues, and t is the target outputvalue, h is the learning rate (e.g.0.1)
Initialize each wi to some smallrandom value
Until the termination condition ismet, Do
• Initialize each Dwi to zero• For each <(x1,…xn),t> in
training_examples Do• Input the instance (x1,…,xn)
to the linear unit andcompute the output o
• For each linear unit weightwi Do
Dwi= Dwi + h (t-o) xi For each linear unit weight wi Do wi=wi+Dwi
Sigmoid Activation Function
W1 X0=1
W2
O=σ(net)=1/(1+e-net)
. .
. Wn
net=∑i=0nWiXi
5
X1
X2
Xn
∑ ƒ
O

International Journal of Computer Applications (0975 – 8887) Volume *– No.*, ___________ 2013
Fig. 7: Sigmoid Activation Function
Derive gradient decent rules to train:• one sigmoid function
¶E/¶wi = -Sd(td-od) od (1-od) xi• Multilayer networks of sigmoid
units backpropagation
Conjugate gradientThis is the well accepted iterativetechnique for solving huge systems oflinear equations [6]. In the 1st
iteration, the conjugate gradientalgorithm will find the steep descentdirection. Description of 3 types of conjugateGradient Algorithms:- Scaled Gradient Conjugate
Backpropogation(SCG), Conjugate Gradient BP with Polak-
Riebre Updates(CGP) and Conjugate Gradient BP with
Fletcher-Reeves updates(CGF).
Approximate solution, xk for conjugategradient iteration is described asformulas below [7]:
Xk=Xk-1+αkdk-1
Scaled Gradient Conjugate Backpropogation(SCG)
SCG calculate the second order ConjugateGradient Algorithm that will help toreduce goal functions for some variables.Moller [7] proved this theoreticalfoundation in which remain its firstorder techniques in first derivativeslike standard backpropogation. This helpsto find way for local minimum in secondorder techniques in second derivatives. Conjugate Gradient Backpropagation withFletcher-Reeves Updates (CGF)
The 2nd edition for Conjugate Gradientalgorithm was projected by Fletcher-Reeves. As with the Polak and Ribiérealgorithm, the explore path at periteration is computed by equation below.
Conjugate Gradient Backpropagation withPolak-Riebre Updates (CGP)
One more edition of the ConjugateGradient algorithm was projected by Polakalong with Ribiére. The explore path atper iteration is same like SCG searchdirection equation. However for thePolak-Ribiére update, the constant beta,βk is computed by equation below.
Quasi-Newton Algorithms (One-Step SecantBackpropagation (OSS))
An alternative way to speed up theconjugate gradient optimization isNewton’s method. The fundamental footstepof Newton's technique shows in equationfollowing.
Heuristics Algorithms (ResilentBackpropagation(RP))
The reason for resilient backpropagationtraining algorithm is to get rid of thesedestructive sound effects of themagnitudes of the fractional derivatives[5].Performance evaluation Using Feed-ForwardBack-propagation Neural Networks [8]:
The first examination was to contrast thepredictive accuracy of Feed – ForwardNeural Network trained with various back-propagation training algorithms. Thisneural network was trained and validatedfor various feedforward backprop trainingalgorithms available in Matlab NeuralNetwork toolbox [2].The predictive accuracy of trainingalgorithms was compared:Mean Absolute relative error (MARE) [9]:This is the preferred measure used bysoftware engineering researchers and isgiven as
Mean Relative Error (MRE) [9]: Thismeasure is used to estimate whethermodels are biased and tend to
6

International Journal of Computer Applications (0975 – 8887) Volume *– No.*, ___________ 2013
overestimate or underestimate and isdesigned as follows
Radial Basis Function (RBF) NeuralNetwork
The RBF is a classification andfunctional approximation neural networkdeveloped by M.J.D. Powell. The networkuses the most common nonlinearities suchas sigmoidal and Gaussian kernelfunctions. The Gaussian functions arealso used in regularization networks. TheGaussian function is generally defined as
Fig 8: Gaussian function
Performance evaluation using RadialBasis Function (RBF) Neural Networks [8]:
The second investigation was to constructperformance prediction models and comparetheir predictive accuracy using differentradial basis function neural networksavailable in Matlab Neural Networktoolbox [2]. Three radial basis functionsare available in the toolbox. They are
i. Exact design radial basis networks
ii. Efficient design radial basisnetworks
iii. Generalized Regression NeuralNetwork
4. PROBLEM STATMENT
This part of paper will explore theproblem statement for the implementationof neural network in feed-forward
backpropogation and radial basisfunction. In this problem triangle isidentified based on their angle input. Inthis problem different types of anglebased triangle is identified using radialbasis function neural networks and feed-forward back-propagation neural network.For neural networks the training data,test data and target data is given to asinput. Input is given in form ofmatrices. For this problem the trainingdata is given as learning set for thenetwork. The learning data can be changedaccording to different problem statement.
5. IMPLIMENTATION
Feed-forward backpropogation NN usingMatlab
On Training Info, choose Inputs andTargets. lying on Training Parameters, specify:
epochs = 1000 (as the learning would bebetter when there are large no. of epochsand long durations of training) goal = 0.000000000000001
max_fail = 50 This will give you a learning andperformance graph.Once graph is decomposed (since you aretrying to minimize the error) similar tothat in figure 9.
7

International Journal of Computer Applications (0975 – 8887) Volume *– No.*, ___________ 2013
Fig 9: Train Network
Radial basis function Neural Networksusing Matlab
Make sure the parameters are as follows:
Network Type = radial basis function(exact fit)Spread constant = 1.0
Network Training:
on clicking the Create button, thenetwork is automatically trained whichconcludes the network implementationphrase.Network Simulation:
Now, test the test_data S on the NNNetwork Manager and track the identicalmethod indicated before (like for inputP).
Now perform the same steps with radialbasis function (fewer neurons) neuralnetwork and Generalized Regression NeuralNetwork (GRNN).
6. OBSERVATIONS AND RESULTS
The Observations through DifferentTraining Functions is formulated in formof table. Here all training algorithmswith “LEARNGDM” Adaption Learning
Function, Performance Function is “MSE”and Numbers of Layers = 2 are used :
No. of neurons= 10 Transfer function=tansig
Trainingfunction
No. ofiterations
MARE MRE
TRAINBFG 1 0.36 -0.192
TRAINBR 6 1.3 -0.21
TRAINCGB 2 0.07 0.09
TRAINCGF 3 0.14 -0.24
TRAINGD 7 1.03 0.16
TRAINGDM 8 35.7 -0.06
TRAINGDA 7 0.07 0.12
TRAINGDX 6 8.5 0.34
TRAINLM 1000 39.3 0.18
TRAINOSS 2 0.58 0.15
TRAINRP 6 0.3 -0.29
TRAINR 1000 0.36 -0.12
TRAINSCG 206 67.2 0.091
TRAINCGP 3 8.59 -0.4
TABLE 1: Results of error Prediction withdifferent training function
Adaption Learning Function = LEARNGD No. of neurons= 10 Transfer function= pure liner
Trainingfunction
No. ofiterations
MARE MRE
TRAINBFG 2 0.0018 0.2
TRAINBR 7 0.27 0.005
TRAINCGB 27 48.05 0.028
TRAINCGF 5 55.9 88.7
TRAINGD 68 0.38 0.14
TRAINGDM 6 1.18 0.14
TRAINGDA 6 8.3 0.42
TRAINGDX 6 3.1 0.14
TRAINLM 1000 416.4 0.28
8
International Journal of Computer Applications (0975 – 8887) Volume *– No.*, ___________ 2013
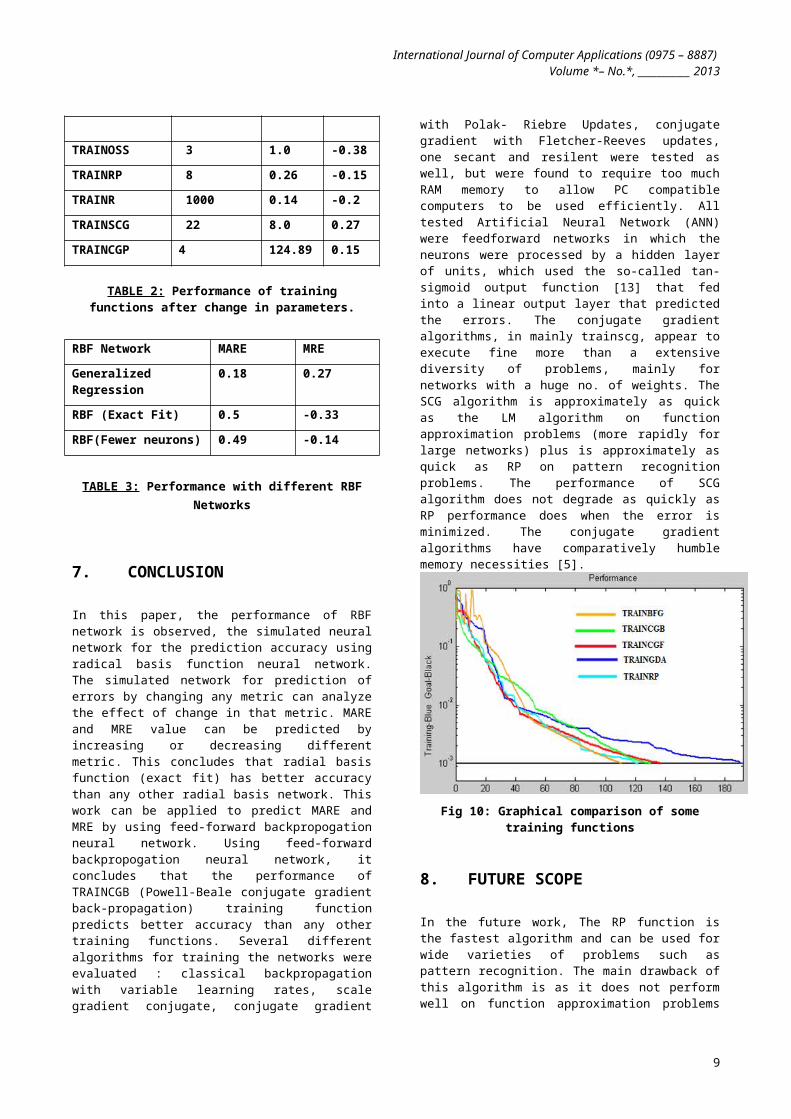
TRAINOSS 3 1.0 -0.38
TRAINRP 8 0.26 -0.15
TRAINR 1000 0.14 -0.2
TRAINSCG 22 8.0 0.27
TRAINCGP 4 124.89 0.15
TABLE 2: Performance of trainingfunctions after change in parameters.
RBF Network MARE MRE
GeneralizedRegression
0.18 0.27
RBF (Exact Fit) 0.5 -0.33
RBF(Fewer neurons) 0.49 -0.14
TABLE 3: Performance with different RBFNetworks
7. CONCLUSION
In this paper, the performance of RBFnetwork is observed, the simulated neuralnetwork for the prediction accuracy usingradical basis function neural network.The simulated network for prediction oferrors by changing any metric can analyzethe effect of change in that metric. MAREand MRE value can be predicted byincreasing or decreasing differentmetric. This concludes that radial basisfunction (exact fit) has better accuracythan any other radial basis network. Thiswork can be applied to predict MARE andMRE by using feed-forward backpropogationneural network. Using feed-forwardbackpropogation neural network, itconcludes that the performance ofTRAINCGB (Powell-Beale conjugate gradientback-propagation) training functionpredicts better accuracy than any othertraining functions. Several differentalgorithms for training the networks wereevaluated : classical backpropagationwith variable learning rates, scalegradient conjugate, conjugate gradient
with Polak- Riebre Updates, conjugategradient with Fletcher-Reeves updates,one secant and resilent were tested aswell, but were found to require too muchRAM memory to allow PC compatiblecomputers to be used efficiently. Alltested Artificial Neural Network (ANN)were feedforward networks in which theneurons were processed by a hidden layerof units, which used the so-called tan-sigmoid output function [13] that fedinto a linear output layer that predictedthe errors. The conjugate gradientalgorithms, in mainly trainscg, appear toexecute fine more than a extensivediversity of problems, mainly fornetworks with a huge no. of weights. TheSCG algorithm is approximately as quickas the LM algorithm on functionapproximation problems (more rapidly forlarge networks) plus is approximately asquick as RP on pattern recognitionproblems. The performance of SCGalgorithm does not degrade as quickly asRP performance does when the error isminimized. The conjugate gradientalgorithms have comparatively humblememory necessities [5].
Fig 10: Graphical comparison of sometraining functions
8. FUTURE SCOPE
In the future work, The RP function isthe fastest algorithm and can be used forwide varieties of problems such aspattern recognition. The main drawback ofthis algorithm is as it does not performwell on function approximation problems
9

International Journal of Computer Applications (0975 – 8887) Volume *– No.*, ___________ 2013
and performance also degrades as theerror goal is reduced. The memorynecessities for this algorithm arecomparatively less in contrast with otheralgorithms considered. In this workneural networks (based on neural networksalgorithms), further can design by owntraining algorithm for better resultsfocusing on accuracy, those may be basedon Fuzzy Logic algorithms, ArtificialIntelligence based algorithms or Supportvector based algorithms etc.
9. REFERENCES
[1] S. Haykins, “A ComprehensiveFoundation on Neural Networks,” PrenticeHall, 1999 .
[2] Neural network specification,available at URL:http://www.mathworks.in/products/neuralnetwork/description3.html
[3] T.M. Khoshgoftaar, E.B. Allen, J.P.Hudepohl, and S.J. Aud, “Application ofneural networks to software qualitymodeling of a very largetelecommunications system”, IEEETransactions on Neural Network, vol. 8,pp. 902-909, 1997.[4] D.F, Specht, “A general regressionneural network”.IEEE Transactions onNeural Networks, vol. 2, Issue: 6, pp.568-576, 1991.[5] Mathworks Online. Available:http://www. www.mathworks.com, 2009.[6] Jonathan Richard Shewchuk, anIntroduction to the Conjugate GradientMethod without the Agonizing Pain, August1994.[7] Martin Fodslette Moller, A ScaledConjugate Gradient Algorithm for FastSupervised Learning. Neural Networks,6:525-533, 1993.[8] S.N. Sivanadam, S. Sumathi, S.N.Deepa ,“Introduction to Neural NetworksUsing Matlab 6.0 “ , Tata McGraw Hill ,NewDelhi, 2006.[9] G.Finnie and G. witting, “AI toolsfor software Devlopment Effort
Estimation”, International Conference onSoftware Engineering: Education andpractice, 1996. [10] S.N. Sivanandam & S.N. Deepa,Principles of Soft Computing, WileyPublications
[11] Zweiri, Y.H., Whidborne, J.F. and Sceviratne, L.D. A Three-term Backpropagation Algorithm. Neurocomputing. 50: 305-318. 2002.
[12] 10. C.M. Bishop. Neural Networks forPattern Recognition. Chapter 7, pp.253-294. Oxford University Press. 1995.
[13] Demuth, H., Beale, M. Neural NetworkToolbox (Mathworks, Natick,Massachusetts,1998). World Academy of Science,Engineering and Technology
10