
A stream compiler for communication-exposed architectures
13
A Stream Compiler for Communication-Exposed Architectures Michael I. Gordon, William Thies, Michal Karczmarek, Jasper Lin, Ali S. Meli, Andrew A. Lamb, Chris Leger, Jeremy Wong, Henry Hoffmann, David Maze, and Saman Amarasinghe MIT Laboratory for Computer Science 200 Technology Square Cambridge, MA 02139 {mgordon, thies, karczma, jasperln, saadat, aalamb, clleger, jnwong, hank, dmaze, saman}@lcs.mit.edu ABSTRACT With the increasing miniaturization of transistors, wire de- lays are becoming a dominant factor in microprocessor per- formance. To address this issue, a number of emerging archi- tectures contain replicated processing units with software- exposed communication between one unit and another (e.g., Raw, SmartMemories, TRIPS). However, for their use to be widespread, it will be necessary to develop compiler technol- ogy that enables a portable, high-level language to execute efficiently across a range of wire-exposed architectures. In this paper, we describe our compiler for StreamIt: a high-level, architecture-independent language for streaming applications. We focus on our backend for the Raw proces- sor. Though StreamIt exposes the parallelism and communi- cation patterns of stream programs, some analysis is needed to adapt a stream program to a software-exposed processor. We describe a partitioning algorithm that employs fission and fusion transformations to adjust the granularity of a stream graph, a layout algorithm that maps a stream graph to a given network topology, and a scheduling strategy that generates a fine-grained static communication pattern for each computational element. We have implemented a fully functional compiler that par- allelizes StreamIt applications for Raw, including several load-balancing transformations. Using the cycle-accurate Raw simulator, we demonstrate that the StreamIt compiler can automatically map a high-level stream abstraction to Raw without losing performance. We consider this work to be a first step towards a portable programming model for communication-exposed architectures. * This version of the paper is dated August 9, 2002 and corrects some typos in the ASPLOS £nal copy. More information on the StreamIt project is available from http://compiler.lcs.mit.edu/streamit Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. ASPLOS X 10/02 San Jose, CA, USA Copyright 2002 ACM 1-58113-574-2/02/0010 ...$5.00 1. INTRODUCTION As we approach the billion-transistor era, a number of emerging architectures are addressing the wire delay prob- lem by replicating the basic processing unit and exposing the communication between units to a software layer (e.g., Raw [35], SmartMemories [23], TRIPS [29]). These ma- chines are especially well-suited for streaming applications that have regular communication patterns and widespread parallelism. However, today’s communication-exposed architectures are lacking a portable programming model. If these machines are to be widely used, it is imperative that one be able to write a program once, in a high-level language, and rely on a compiler to produce an efficient executable on any of the candidate targets. For von-Neumann machines, imperative programming languages such as C and FORTRAN served this purpose; they abstracted away the idiosyncratic details between one machine and another, but encapsulated the common properties (such as a single program counter, arith- metic operations, and a monolithic memory) that are neces- sary to obtain good performance. However, for wire-exposed targets that contain multiple instruction streams and dis- tributed memory banks, a language such as C is obsolete. Though C can still be used to write efficient programs on these machines, doing so either requires architecture-specific directives or an impossibly smart compiler that can extract the parallelism and communication from the C semantics. Both of these options disqualify C as a portable machine language, since it fails to hide the architectural details from the programmer and it imposes abstractions which are a mismatch for the domain. In this paper, we describe a compiler for StreamIt [33], a high level stream language that aims to be portable across communication-exposed machines. StreamIt contains basic constructs that expose the parallelism and communication of streaming applications without depending on the topol- ogy or granularity of the underlying architecture. Our cur- rent backend is for Raw [35], a tiled architecture with fine- grained, programmable communication between processors. However, the compiler employs three general techniques that can be applied to compile StreamIt to machines other than Raw: 1) partitioning, which adjusts the granularity of a stream graph to match that of a given target, 2) layout, 1
-
Upload
independent -
Category
Documents
-
view
4 -
download
0
Transcript of A stream compiler for communication-exposed architectures

A Stream Compiler forCommunication-Exposed Architectures
Michael I. Gordon, William Thies, Michal Karczmarek, Jasper Lin, Ali S. Meli,Andrew A. Lamb, Chris Leger, Jeremy Wong, Henry Hoffmann,
David Maze, and Saman Amarasinghe
MIT Laboratory for Computer Science200 Technology SquareCambridge, MA 02139
{mgordon, thies, karczma, jasperln, saadat, aalamb, clleger, jnwong, hank, dmaze, saman}@lcs.mit.edu
ABSTRACTWith the increasing miniaturization of transistors, wire de-lays are becoming a dominant factor in microprocessor per-formance. To address this issue, a number of emerging archi-tectures contain replicated processing units with software-exposed communication between one unit and another (e.g.,Raw, SmartMemories, TRIPS). However, for their use to bewidespread, it will be necessary to develop compiler technol-ogy that enables a portable, high-level language to executeefficiently across a range of wire-exposed architectures.In this paper, we describe our compiler for StreamIt: a
high-level, architecture-independent language for streamingapplications. We focus on our backend for the Raw proces-sor. Though StreamIt exposes the parallelism and communi-cation patterns of stream programs, some analysis is neededto adapt a stream program to a software-exposed processor.We describe a partitioning algorithm that employs fissionand fusion transformations to adjust the granularity of astream graph, a layout algorithm that maps a stream graphto a given network topology, and a scheduling strategy thatgenerates a fine-grained static communication pattern foreach computational element.We have implemented a fully functional compiler that par-
allelizes StreamIt applications for Raw, including severalload-balancing transformations. Using the cycle-accurateRaw simulator, we demonstrate that the StreamIt compilercan automatically map a high-level stream abstraction toRaw without losing performance. We consider this work tobe a first step towards a portable programming model forcommunication-exposed architectures.
∗ This version of the paper is dated August 9, 2002 and corrects some typosin the ASPLOS £nal copy. More information on the StreamIt project isavailable from http://compiler.lcs.mit.edu/streamit
Permission to make digital or hard copies of all or part ofthis work for personal or classroom use is granted without feeprovided that copies are not made or distributed for profit orcommercial advantage and that copies bear this notice and thefull citation on the first page. To copy otherwise, to republish, topost on servers or to redistribute to lists, requires prior specificpermission and/or a fee.ASPLOS X 10/02 San Jose, CA, USACopyright 2002 ACM 1-58113-574-2/02/0010 ...$5.00
1. INTRODUCTIONAs we approach the billion-transistor era, a number of
emerging architectures are addressing the wire delay prob-lem by replicating the basic processing unit and exposingthe communication between units to a software layer (e.g.,Raw [35], SmartMemories [23], TRIPS [29]). These ma-chines are especially well-suited for streaming applicationsthat have regular communication patterns and widespreadparallelism.However, today’s communication-exposed architectures are
lacking a portable programming model. If these machinesare to be widely used, it is imperative that one be able towrite a program once, in a high-level language, and rely ona compiler to produce an efficient executable on any of thecandidate targets. For von-Neumann machines, imperativeprogramming languages such as C and FORTRAN servedthis purpose; they abstracted away the idiosyncratic detailsbetween one machine and another, but encapsulated thecommon properties (such as a single program counter, arith-metic operations, and a monolithic memory) that are neces-sary to obtain good performance. However, for wire-exposedtargets that contain multiple instruction streams and dis-tributed memory banks, a language such as C is obsolete.Though C can still be used to write efficient programs onthese machines, doing so either requires architecture-specificdirectives or an impossibly smart compiler that can extractthe parallelism and communication from the C semantics.Both of these options disqualify C as a portable machinelanguage, since it fails to hide the architectural details fromthe programmer and it imposes abstractions which are amismatch for the domain.In this paper, we describe a compiler for StreamIt [33], a
high level stream language that aims to be portable acrosscommunication-exposed machines. StreamIt contains basicconstructs that expose the parallelism and communicationof streaming applications without depending on the topol-ogy or granularity of the underlying architecture. Our cur-rent backend is for Raw [35], a tiled architecture with fine-grained, programmable communication between processors.However, the compiler employs three general techniques thatcan be applied to compile StreamIt to machines other thanRaw: 1) partitioning, which adjusts the granularity of astream graph to match that of a given target, 2) layout,
1

float->float filter FIRFilter (float sampleRate, int N) {float[N] weights;
init {weights = calcImpulseResponse(sampleRate, N);
}
prework push N-1 pop 0 peek N {for (int i=1; i<N; i++) {
push(doFIR(i));}
}
work push 1 pop 1 peek N {push(doFIR(N));pop();
}
float doFIR(int k) {float val = 0;for (int i=0; i<k; i++) {
val += weights[i] * peek(k-i-1);}return val;
}}
float->float pipeline Equalizer (float samplingRate, int N) {add splitjoin {
int bottom = 2500;int top = 5000;split duplicate;for (int i=0; i<N; i++, bottom*=2, top*=2) {
add BandPassFilter(sampleRate, bottom, top);}join roundrobin;
}add Adder(N);
}
void->void pipeline FMRadio {add DataSource();add FIRFilter(sampleRate, N);add FMDemodulator(sampleRate, maxAmplitude);add Equalizer(sampleRate, 4);add Speaker();
}
Figure 1: Parts of an FM Radio in StreamIt.
which maps a partitioned stream graph to a given networktopology, and 3) scheduling, which generates a fine-grainedstatic communication pattern for each computational ele-ment. We consider this work to be a first step towardsa portable programming model for communication-exposedarchitectures.The rest of this paper is organized as follows. Section 2
provides an introduction to StreamIt, Section 3 contains anoverview of Raw, and Section 4 outlines our compiler forStreamIt on Raw. Sections 5, 6, and 7 describe our algo-rithms for partitioning, layout, and communication schedul-ing, respectively. Section 8 describes code generation forRaw, and Section 9 presents our results. Section 10 consid-ers related work, and Section 11 contains our conclusions.
2. THE STREAMIT LANGUAGEStreamIt is a portable programming language for high-
performance signal processing applications. The current ver-sion of StreamIt is tailored for static-rate streams: it requiresthat the input and output rates of each filter are knownat compile time. In this section, we provide a very briefoverview of the syntax and semantics of StreamIt, version1.1. A more detailed description of the design and rationalefor StreamIt can be found in [33], which describes version
DataSource
FIRFilter
FM Demodulator
Equalizer
Speaker
duplicate splitter
BandPass 1 BandPass N
roundrobin joiner
Adder
Figure 2: Block diagram of the FM Radio.
stream
stream
stream
stream
splitter
����� �am
����� �am
joiner
joiner
stream
splitter
stream
(a) A pipeline. (b) A splitjoin. (c) A feedbackloop.
Figure 3: Stream structures supported by StreamIt.
1.0; the most up-to-date syntax specification can always befound on our website [1].
2.1 Language ConstructsThe basic unit of computation in StreamIt is the filter.
A filter is a single-input, single-output block with a user-defined procedure for translating input items to output items.An example of a filter is the FIRFilter, a component ofour software radio (see Figure 1). Each filter contains aninit function that is called at initialization time; in thiscase, the FIRFilter calculates weights, which representsits impulse response. The work function describes the mostfine grained execution step of the filter in the steady state.Within the work function, the filter can communicate withits neighbors via FIFO queues, using the intuitive opera-tions of push(value), pop(), and peek(index), where peekreturns the value at position index without dequeuing theitem. The number of items that are pushed, popped, andpeeked1 on each invocation are declared with the work func-tion.In addition to work, a filter can contain a prework function
that is executed exactly once between initialization and thesteady-state. Like work, prework can access the input andoutput tapes of the filter; however, the I/O rates of work andprework can differ. In an FIRFilter, a prework function isessential for correctly filtering the beginning of the inputstream. The user never calls the init, prework, and work
functions–they are all called automatically.The basic construct for composing filters into a commu-
nicating network is a pipeline, such as the FM Radio inFigure 1. A pipeline behaves as the sequential compositionof all its child streams, which are specified with successivecalls to add from within the pipeline. For example, the out-put of DataSource is implicitly connected to the input ofFIRFilter, who’s output is connected to FMDemodulator,and so on. The add statements can be mixed with regu-lar imperative code to parameterize the construction of thestream graph.
1We define peek as the total number of items read, includingthe items popped. Thus, we always have that peek ≥ pop.
2

There are two other stream constructs besides pipeline:splitjoin and feedbackloop (see Figure 3). From now on,we use the word stream to refer to any instance of a filter,pipeline, splitjoin, or feedbackloop.A splitjoin is used to specify independent parallel streams
that diverge from a common splitter and merge into a com-mon joiner. There are two kinds of splitters: 1) duplicate,which replicates each data item and sends a copy to eachparallel stream, and 2) roundrobin(w1, . . . , wn), which sendsthe first w1 items to the first stream, the next w2 items tothe second stream, and so on. roundrobin is also the onlytype of joiner that we support; its function is analogous toa roundrobin splitter. If a roundrobin is written withoutany weights, we assume that all wi = 1. The splitter andjoiner type are specified with the keywords split and join,respectively (see Figure 1); the parallel streams are specifiedby successive calls to add, with the i’th call setting the i’thstream in the splitjoin.The last control construct provides a way to create cycles
in the stream graph: the feedbackloop. Due to space con-straints, we omit a detailed discussion of the feedbackloop.
2.2 Design RationaleStreamIt differs from other stream languages in that it
imposes a well-defined structure on the streams; all streamgraphs are built out of a hierarchical composition of filters,pipelines, splitjoins, and feedbackloops. This is in contrastto other environments, which generally regard a stream asa flat and arbitrary network of filters that are connectedby channels. However, arbitrary graphs are very hard forthe compiler to analyze, and equally difficult for a program-mer to describe. The comparison of StreamIt’s structurewith arbitrary stream graphs could be likened to the differ-ence between structured control flow and GOTO statements:though the programmer might have to re-design some codeto adhere to the structure, the gains in robustness, readabil-ity, and compiler analysis are immense.
3. THE RAW ARCHITECTUREThe Raw Microprocessor [9, 35] addresses the wire delay
problem [15] by providing direct instruction set architecture(ISA) analogs to three underlying physical resources of theprocessor: gates, wires and pins. Because ISA primitives ex-ist for these resources, a compiler such as StreamIt has directcontrol over both the computation and the communicationof values between the functional units of the microprocessor,as well as across the pins of the processor.The architecture exposes the gate resources as a scalable
2-D array of identical, programmable tiles, that are con-nected to their immediate neighbors by four on-chip net-works. Each network is 32-bit, full-duplex, flow-controlledand point-to-point. On the edges of the array, these net-works are connected via logical channels [13] to the pins.Thus, values routed through the networks off of the side ofthe array appear on the pins, and values placed on the pinsby external devices (for example, wide-word A/Ds, DRAMS,video streams and PCI-X buses) will appear on the net-works.Each of the tiles contains a compute processor, some mem-
ory and two types of routers–one static, one dynamic–thatcontrol the flow of data over the networks as well as intothe compute processor (see Figure 4). The compute proces-sor interfaces to the network through a bypassed, register-
SMEM
Switch
Registers
DMEM
PC
PC
ALU
IMEM
Figure 4: Block diagram of the Raw architecture.
mapped interface [9] that allows instructions to use the net-works and the register files interchangeably. In other words,a single instruction can read up to two values from the net-works, compute on them, and send the result out onto thenetworks, with no penalty. Reads and writes in this fash-ion are blocking and flow-controlled, which allows for thecomputation to remain unperturbed by unpredictable tim-ing variations such as cache misses and interrupts.Each tile’s static router has a virtualized instruction mem-
ory to control the crossbars of the two static networks. Col-lectively, the static routers can reconfigure the communica-tion pattern across these networks every cycle. The instruc-tion set of the static router is encoded as a 64-bit VLIWword that includes basic instructions (conditional branchwith/without decrement, move, and nop) that operate onvalues from the network or from the local 4-element registerfile. Each instruction also has 13 fields that specify the con-nections between each output of the two crossbars and thenetwork input FIFOs, which store values that have arrivedfrom neighboring tiles or the local compute processor. Theinput and output possibilities for each crossbar are: North,East, South, West, Processor, to the other crossbar, andinto the static router. The FIFOs are typically four or eightelements large.To route a word from one tile to another, the compiler in-
serts a route instruction on every intermediate static router[22]. Because the routers are pipelined and compile-timescheduled, they can deliver a value from the ALU of onetile to the ALU of a neighboring tile in 3 cycles, or moregenerally, 2+N cycles for an inter-tile distance of N hops.The results of this paper were generated using btl, a cycle-
accurate simulator that models arrays of Raw tiles identi-cal to those in the .15 micron 16-tile Raw prototype ASICchip. With a target clock rate of 250 MHz, the tile em-ploys as compute processor an 8-stage, single issue, in-orderMIPS-style pipeline that has a 32 KB data cache, 32 KBof instruction memory, and 64 KB of static router memory.All functional units except the floating point and integerdividers are fully pipelined. The mispredict penalty of thestatic branch predictor is three cycles, as is the load latency.The compute processor’s pipelined single-precision FPU op-erations have a latency of 4 cycles, and the integer multiplierhas a latency of 2 cycles.
4. COMPILING STREAMIT TO RAWThe phases of the StreamIt compiler are described in Ta-
ble 1. The front end is built on top of KOPI, an open-sourcecompiler infrastructure for Java [12]; we use KOPI as ourinfrastructure because StreamIt has evolved from a Java-based syntax. We translate the StreamIt syntax into the
3

Phase Function
KOPI Front-end Parses syntax into a Java-like abstract syntax tree.SIR Conversion Converts the AST to the StreamIt IR (SIR).Graph Expansion Expands all parameterized structures in the stream graph.Scheduling Calculates initialization and steady-state execution orderings for filter firings.Partitioning Performs fission and fusion transformations for load balancing.Layout Determines minimum-cost placement of filters on grid of Raw tiles.Communication Scheduling Orchestrates fine-grained communication between tiles via simulation of the stream graph.Code generation Generates code for the tile and switch processors.
Table 1: Phases of the StreamIt compiler.
KOPI syntax tree, and then construct the StreamIt IR (SIR)that encapsulates the hierarchical stream graph. Since thestructure of the graph might be parameterized, we propa-gate constants and expand each stream construct to a staticstructure of known extent. At this point, we can calculatean execution schedule for the nodes of the stream graph.
The automatic scheduling of the stream graph is one of theprimary benefits that StreamIt offers, and the subtleties ofscheduling and buffer management are evident throughoutall of the following phases of the compiler. The scheduling iscomplicated by StreamIt’s support for the peek operation,which implies that some programs require a separate sched-ule for initialization and for the steady state. The steadystate schedule must be periodic–that is, its execution mustpreserve the number of live items on each channel in thegraph (since otherwise a buffer would grow without bound.)A separate initialization schedule is needed if there is a filterwith peek > pop, by the following reasoning. If the initial-ization schedule were also periodic, then after each firing itwould return the graph to its initial configuration, in whichthere were zero live items on each channel. But a filter withpeek > pop leaves peek − pop (a positive number) of itemson its input channel after every firing, and thus could not bepart of this periodic schedule. Therefore, the initializationschedule is separate, and non-periodic.
In the StreamIt compiler, the initialization schedule isconstructed via symbolic execution of the stream graph, un-til each filter has at least peek−pop items on its input chan-nel. For the steady state schedule, there are many tradeoffsbetween code size, buffer size, and latency, and we are devel-oping techniques to optimize different metrics [34]. In thispaper, we use a simple hierarchical scheduler that constructsa Single Appearance Schedule (SAS) [5] for each filter. ASAS is a schedule where each node appears exactly once inthe loop nest denoting the execution order. We constructone such loop nest for each hierarchical stream construct,such that each component is executed a set number of timesfor every execution of its parent. In later sections, we referto the “multiplicity” of a filter as the number of times thatit executes in one steady state execution of the entire streamgraph.
Following the scheduler, the compiler has stages that arespecific for communication-exposed architectures: partition-ing, layout, and communication scheduling. The next threesections of the paper are devoted to these phases.
5. PARTITIONINGStreamIt provides the filter construct as the basic abstract
unit of autonomous stream computation. The programmershould decide the boundaries of each filter according to whatis most natural for the algorithm under consideration. Whileone could envision each filter running on a separate machinein a parallel system, StreamIt hides the granularity of the
KEY
Blocked on send or receive
(a) Original (runs on 64 tiles).
(b) Partitioned (runs on 16 tiles).
Figure 5: Execution traces for the (a) original and (b)
partitioned versions of the Radar application. The x
axis denotes time, and the y axis denotes the proces-
sor. Dark bands indicate periods where processors are
blocked waiting to receive an input or send an output;
light regions indicate periods of useful work. The thin
stripes in the light regions represent pipeline stalls. Our
partitioning algorithm decreases the granularity of the
graph from 53 unbalanced tiles (original) to 15 balanced
tiles (partitioned). The throughput of the partitioned
graph is 2.3 times higher than the original.
4

null
InputGenerate12
FIRFilter (64)12
FIRFilter (16)12
InputGenerate
FIRFilter (64)1
FIRFilter (16)1
VectorMultiply
null
duplicate
roundrobin
VectorMultiply
FIRFilter (64)1
1 2
1 2
Magnitude Magnitude
DetectionDetection
FIRFilter (64)2
VectorMultiply3
3
Magnitude
Detection
FIRFilter (64)3
VectorMultiply4
4
Magnitude
Detection
FIRFilter (64)4
1
a
b
a
b
c c c c
1 2 3 4
Figure 6: Stream graph of the original 12x4 Radar ap-
plication. The 12x4 Radarapplication has 12 channels
and 4 beams; it is the largest version that fits onto 64
tiles without filter fusion.
null
5
1
InputGenerate
FIRFilter (64)
FIRFilter (16)
1
InputGenerate
FIRFilter (64)
FIRFilter (16)
null
duplicate
roundrobin
FIRFilter (64)
VectorMultiply1
VectorMultiply2
Magnitude
Magnitude
2Detection
1Detection
FIRFilter (64)
VectorMultiply3
Magnitude
3Detection
FIRFilter (64)
VectorMultiply4
Magnitude
4Detection
FIRFilter (64)
1 12
1 12
1 12
a a
b b
1c
3c
2c
4c
1 3
2 4
Figure 7: Stream graph of the load-balanced 12x4
Radar application. Vertical fusion is applied to col-
lapse each pipeline into a single filter, and horizontal fu-
sion is used to transform the 4-way splitjoin into a 2-way
splitjoin. Figure 5 shows the benefit of these transfor-
mations.
target machine from the programmer. Thus, it is the re-sponsibility of the compiler to adapt the granularity of thestream graph for efficient execution on a particular architec-ture.We use the word partitioning to refer to the process of
dividing a stream program into a set of balanced computa-tion units. Given that a maximum of N computation unitscan be supported, the partitioning stage transforms a streamgraph into a set of no more than N filters, each of which per-forms approximately the same amount of work during theexecution of the program. Following this stage, each filtercan be run on a separate processor to obtain a load-balancedexecutable.
5.1 OverviewOur partitioner employs a set of fusion, fission, and re-
ordering transformations to incrementally adjust the streamgraph to the desired granularity. To achieve load balancing,the compiler estimates the number of instructions that areexecuted by each filter in one steady-state cycle of the en-tire program; then, computationally intensive filters can besplit, and less demanding filters can be fused. Currently, asimple greedy algorithm is used to automatically select thetargets of fusion and fission, based on the estimate of thework in each node.For example, in the case of the Radar application, the
original stream graph (Figure 6) contains 52 filters. Thesefilters have unbalanced amounts of computation, as evi-denced by the execution trace in Figure 5(a). The parti-tioner fuses all of the pipelines in the graph, and then fusesthe bottom 4-way splitjoin into a 2-way splitjoin, yieldingthe stream graph in Figure 7. As illustrated by the executiontrace in Figure 5(b), the partitioned graph has much bet-ter load balancing. In the following sections, we describe inmore detail the transformations utilized by the partitioner.
5.2 Fusion TransformationsFilter fusion is a transformation whereby several adjacent
filters are combined into one. Fusion can be applied to de-crease the granularity of a stream graph so that an applica-tion will fit on a given target, or to improve load balancingby merging small filters so that there is space for largerfilters to be split. Analogous to loop fusion in the scien-tific domain, filter fusion can enable other optimizations bymerging the control flow graphs of adjacent nodes, therebyshortening the live ranges of variables and allowing indepen-dent instructions to be reordered.
5.2.1 Unoptimized Fusion AlgorithmIn the domain of structured stream programs, there are
two types of fusion that we are interested in: vertical fu-
sion for collapsing pipelined filters into a single unit, andhorizontal fusion for combining the parallel components ofa splitjoin into one. Given that each StreamIt filter has aconstant I/O rate, it is possible to implement both verticaland horizontal fusion as a plain compile-time simulation ofthe execution of the stream graph. A high-level algorithmfor doing so is as follows:
1. Calculate a legal initialization and steady-state sched-ule for the nodes of interest.
2. For each pair of neighboring nodes, introduce a circu-lar buffer that is large enough to hold all the items
5

produced during the initial schedule and one iterationof the steady-state schedule. For each buffer, maintainindices to keep track of the head and tail of the FIFOqueue.
3. Simulate the execution of the graph according to thecalculated schedules, replacing all push, pop, and peekoperations in the fused region with appropriate ac-cesses to the circular buffers.
That is, a naive approach to filter fusion is to simply im-plement the channel abstraction and to leverage StreamIt’sstatic rates to simulate the execution of the graph. How-ever, the performance of fusion depends critically on theimplementation of channels, and there are several high-leveloptimizations that the compiler employs to improve uponthe performance of a general-purpose buffer implementa-tion. We describe a few of these optimizations in detailin the following sections.
5.2.2 Optimizing Vertical FusionFigure 8 illustrates two of our optimizations for vertical fu-
sion: the localization of buffers and the elimination of mod-ulo operations. In this example, the UpSampler pushes K
items on every step, while the MovingAverage filter peeksat N items but only pops 1. The effect of the optimizationsare two-fold. First, buffer localization splits the channel be-tween the filters into a local buffer (holding items that aretransfered within work) and a persistent peek buffer (hold-ing items that are stored between iterations of work). Sec-ond, modulo elimination arranges copies between these twobuffers so that all index expressions are known at compiletime, preventing the need for a modulo operation to wraparound a circular buffer.The execution of the fused filter proceeds as follows. In
the prework function, which is called only on the first in-vocation, the peek buffer is filled with initial values fromthe UpSampler. The steady work function implements asteady-state schedule in which LCM(N, K) items are trans-ferred between the two original filters–these items are com-municated through a local, temporary buffer. Before andafter the execution of the MovingAverage code, the con-tents of the peek buffer are transferred in and out of thebuffer. If the peek buffer is small, this copying can beeliminated with loop unrolling and copy propagation. Notethat the peek buffer is for storing items that are persistentfrom one firing to the next, while the local buffer is just forcommunicating values during a single firing.
5.2.3 Optimizing Horizontal FusionThe naive fusion algorithm maintains a separate input
buffer for each parallel stream in a splitjoin. However, in thecase of a duplicate splitter, the input buffer can be shared be-tween the streams, as illustrated in Figure 9. As in pipelinefusion, the code of the component filters is inlined into asingle filter with repetition according to the steady-stateschedule. However, there are some modifications: all popstatements are converted to peek statements, and the pop’sare performed at the end of the fused work function. Thisallows all the filters to see the data items before they areconsumed. Finally, the roundrobin joiner is simulated by areorder-roundrobin filter that re-arranges the output of thefused filter according to the weights of the joiner. Separat-ing this reordering phase from the fused filter also decreases
UpSampler (K)
int val = pop();
for (int i=0; i<K; i++)
push(val);
MovingAverage (N)
int sum = 0;
for (int i=0; i<N; i++)
sum += peek(i);
push(sum/N);
pop();
(a) Original
int i, j, val;
for (i=0; i<CEIL(N/K); i++) {
val = pop();
for (j=0; j<K; j++)
peek_buffer[i*K+j] = val;
}
UpSamplingMovingAverage (K, N)
int i, j, sum, val;
int buffer[PEEK_SIZE+LCM(N,K)];
for (i=0; i<LCM � ����������� ��������� val = pop();����
� ������ ������ ������� buffer[PEEK_SIZ ������������� !�#"�$�%��}
for (i=0; i<PEEK_SIZE; i++)&�' ���(��*) �� !�#+(�(�,
- &�'���(��
[i];
for (i=0; i<LCM � ��������.�/� ��������� sum = 0;����
� ������ ������ ������� sum ��� &�' ���(��*) ���.������ �� push(sum/N);
for (i=0; i<PEEK_SIZE; i++)
+(�(�,
- &�'���(��*)
�� !� &�' ���(��[i+LCM(N,K)];
int PEEK_SIZE = K*CEIL(N/K);
int peek_buffer[PEEK_SIZE];
prework
work
(b) Fused
Figure 8: Vertical fusion with buffer localization and
modulo-division optimizations.
duplicate
roundrobin (N, N)
push(pop() - pop());
Subtractpush(pop() + pop());
Add
(a) Original
AddSubtract
push(peek(0) + peek(1));
push(peek(0) - peek(1));
for (int i=0; i<2; i++)
pop();
ReorderRoundRobin (N)
int i, j;
for (i=0; i<2; i++)
for (j=0; j<N; j++)
push(peek(i+2*j));
for (i=0; i<2; i++)
for (j=0; j<N; j++)
pop();
(b) Fused
Figure 9: Horizontal fusion of a duplicate splitjoin con-
struct with buffer sharing optimization.
6

MovingAverage (N)
int sum = 0;
for (int i=0; i<N; i++)
sum += peek(i);
push(sum/N);
pop();
MovingAverage (N)
roundrobin
duplicate
1 MovingAverage (N)K
JMovingAverage (N)
for (int i=0; i<J-1; i++)
pop();
prework
int i, sum = 0;
for (i=0 ; i<N; i++)
sum += peek(i);
push(sum/N);
pop();
for (i=0; i<K-1; i++)
pop();
work
(a) Original (b) Fused
Figure 10: Fission of a filter that peeks.
the buffer requirements within the fused node. When ap-propriate, pipeline fusion can be applied to fuse these twonodes into a single filter that represents the entire splitjoin.
5.3 Fission TransformationsFilter fission is the analog of parallelization in the stream-
ing domain. It can be applied to increase the granularity ofa stream graph to utilize unused processor resources, or tobreak up a computationally intensive node for improved loadbalancing.
5.3.1 Vertical FissionSome filters can be split into a pipeline, with each stage
performing part of the work function. In addition to theoriginal input data, these pipelined stages might need tocommunicate intermediate results from within work, as wellas fields within the filter. This scheme could apply to fil-ters with state if all modifications to the state appear at thetop of the pipeline (they could be sent over the data chan-nels), or if changes are infrequent (they could be sent viaStreamIt’s messaging system.) Also, some state can be iden-tified as induction variables, in which case their values canbe reconstructed from the work function instead of stored asfields. We have yet to automate vertical filter fission in theStreamIt compiler.
5.3.2 Horizontal FissionWe refer to “horizontal fission” as the process of dis-
tributing a single filter across the parallel components ofa splitjoin. We have implemented this transformation for“stateless” filters–that is, filters that contain no fields thatare written on one invocation of work and read on later in-vocations. Let us consider such a filter F with steady-stateI/O rates of peek, pop, and push, that is being parallelizedinto an K-way splitjoin. There are two cases to consider:
1. If peek = pop, then F can simply be duplicated K
ways in the splitjoin. The splitter is a roundrobin thatroutes pop elements to each copy of F , and the joiner is
roundrobin( w , w )
1
2 3
roundrobin( w w + w )2 3
1 roundrobin( w + w w )
2,
,
3
roundrobin( w , w )21
Figure 11: Synchronization removal. If there are neigh-
boring splitters and joiners with matching rates, then the
nodes can be removed and the component streams can
be connected. The example above is drawn from a sub-
graph of the 3GPP application; the compiler automati-
cally performs this transformation to expose parallelism
and improve the partitioning. Synchronization removal
is especially valuable in the context of libraries–many
distinct components can employ splitjoins for processing
interleaved data streams, and the modules can be com-
posed without having to synchronize all the streams at
each boundary.
a roundrobin that reads push elements from each com-ponent. Since F does not peek at any items which itdoes not consume, its code does not need to be modi-fied in the component streams–we are just distributingthe invocations of F .
2. If peek > pop, then a different transformation is ap-plied (see Figure 10). In this case, the splitter is aduplicate, since the component filters need to exam-ine overlapping parts of the input stream. The i’thcomponent has a steady-state work function that be-gins with the work function of F , but appends a seriesof (K − 1) ∗ pop pop statements in order to accountfor the data that is consumed by the other compo-nents. Also, the i’th filter has a prework function thatpops (i− 1) ∗ pop items from the input stream, to ac-count for the consumption of previous filters on thefirst iteration of the splitjoin. As before, the joiner isa roundrobin that has a weight of push for each stream.
5.4 Reordering TransformationsThere are a multitude of ways to reorder the elements of
a stream graph so as to facilitate fission and fusion transfor-mations. For instance, neighboring splitters and joiners withmatching weights can be eliminated (Figure 11); a splitjoinconstruct can be divided into a hierarchical set of splitjoinsto enable a finer granularity of fusion (Figure 12); and identi-cal stateless filters can be pushed through a splitter or joinernode if the weights are adjusted accordingly.
5.5 Automatic PartitioningIn order to drive the partitioning process, we have im-
plemented a simple greedy algorithm that performs well onmost applications. The algorithm analyzes the work func-tion of each filter and estimates the number of cycles re-quired to execute it. Because of the static I/O rates inStreamIt, most loops within work can be unrolled, allowinga close approximation of the actual cycle count. Multiply-ing this cycle count by the multiplicity of the filter in the
7

duplicate
roundrobin(w1,w2,w3,w4)
duplicate
roundrobin(w1+w2,w3+w4)
duplicate duplicate
roundrobin(w1,w2) roundrobin(w3,w4)
Figure 12: Breaking a splitjoin into hierarchical units.
Though our horizontal fusion algorithms work on the
granularity of an entire splitjoin, it is straightforward
to transform a large splitjoin into a number of smaller
pieces, as shown here. Following this transformation, the
fusion algorithms can be applied to obtain an intermedi-
ate level of granularity. This technique was employed to
help load-balance the Radar application (see Section 9).
steady-state schedule, the algorithm obtains an estimate ofthe steady-state computational requirements for each filter.In the case where there are fewer filters than tiles, the
partitioner considers the filters in decreasing order of theircomputational requirements and attempts to split them us-ing the filter fission algorithm described above. Fission pro-ceeds until there are enough filters to occupy the availablemachine resources, or until the heaviest node in the graph isnot amenable to a fission transformation. Generally, it is notbeneficial to split nodes other than the heaviest one, as thiswould introduce more synchronization without alleviatingthe bottleneck in the graph.If the stream graph contains more nodes than the tar-
get architecture, then the partitioner works in the oppositedirection and repeatedly fuses the least demanding streamconstruct until the graph will fit on the target. The workestimates of the filters are tabulated hierarchically and eachconstruct (i.e., pipeline, splitjoin, and feedbackloop) is rankedaccording to the sum of its children’s computational require-ments. At each step of the algorithm, an entire stream con-struct is collapsed into a single filter. The only exceptionis the final fusion operation, which only collapses to the ex-tent necessary to fit on the target; for instance, a 4-elementpipeline could be fused into two 2-element pipelines if nomore collapsing was necessary.Despite its simplicity, this greedy strategy works well in
practice because most applications have many more filtersthan can fit on the target architecture; since there is a longsequence of fusion operations, it is easy to compensate froma short-sighted greedy decision. However, we can constructcases in which a greedy strategy will fail. For instance,graphs with wildly unbalanced filters will require fission ofsome components and fusion of others; also, some graphshave complex symmetries where fusion or fission will not bebeneficial unless applied uniformly to each component of thegraph. We are working on improved partitioning algorithmsthat take these measures into account.
6. LAYOUTThe goal of the layout phase is to assign nodes in the
stream graph to computation nodes in the target architec-ture while minimizing the communication and synchroniza-tion present in the final layout. The layout assigns exactlyone node in the stream graph to one computation node inthe target. The layout phase assumes that the given stream
graph will fit onto the computation fabric of the target andthat the filters are load balanced. These requirements aresatisfied by the partitioning phase described above.The layout phase of the StreamIt compiler is implemented
using simulated annealing [19]. We choose simulated anneal-ing for its combination of performance and flexibility. Toadapt the layout phase for a given architecture, we supplythe simulated annealing algorithm with three architecture-specific parameters: a cost function, a perturbation func-tion, and the set of legal layouts. To change the compilerto target one tiled architecture instead of another, these pa-rameters should require only minor modifications.The cost function should accurately measure the added
communication and synchronization generated by mappingthe stream graph to the communication model of the tar-get. Due to the static qualities of StreamIt, the compilercan provide the layout phase with exact knowledge of thecommunication properties of the stream graph. The termsof the cost function can include the counts of how manyitems travel over each channel during an execution of thesteady state. Furthermore, with knowledge of the routingalgorithm, the cost function can infer the intermediate hopsfor each channel. For architectures with non-uniform com-munication, the cost of certain hops might be weighted morethan others. In general, the cost function can be tailored tosuit a given architecture.
6.1 Layout for RawFor Raw, the layout phase maps nodes in the stream graph
to the tile processors. Each filter is assigned to exactly onetile, and no tile holds more than one filter. However, theends of a splitjoin construct are treated differently; eachsplitter node is folded into its upstream neighbor, and neigh-boring Joiner nodes are collapsed into a single tile (see Sec-tion 7.1). Thus, Joiners occupy their own tile, but splittersare integrated into the tile of another filter or Joiner.Due to the properties of the static network and the com-
munication scheduler (Section 7.1), the layout phase doesnot have to worry about deadlock. All assignments of nodesto tiles are legal. This gives simulated annealing the flexi-bility to search many possibilities and simplifies the layoutphase. The perturbation function used in simulated anneal-ing simply swaps the assignment of two randomly chosentile processors.After some experimentation, we arrived at the following
cost function to guide the layout on Raw. We let channels
denote the pairs of nodes {(src1, dst1) . . . (srcN , dstN )} thatare connected by a channel in the stream graph; layout(n)denote the placement of node n on the Raw grid; androute(src, dst) denote the path of tiles through which a dataitem is routed in traveling from tile src to tile dst. In ourimplementation, the route function is a simple dimension-ordered router that traces the path from src to dst by firstrouting in the X dimension and then routing in the Y di-mension. Given fixed values of channels and route, our costfunction evaluates a given layout of the stream graph:
cost(layout) =∑
items(src, dst) · (hops(path) + 10 · sync(path))(src,dst) ∈ channels
where path = route(layout(src), layout(dst))
In this equation, items(src, dst) gives the number of data
8

21
22
23
15
17
19
roundrobin(1, 1)
roundrobin (11, 11)
push(pop())
Identitypush(pop())
Identity
20
24
68
12
10
1416
18
Figure 13: Example of deadlock in a splitjoin. As
the joiner is reading items from the stream on the left,
items accumulate in the channels on the right. On Raw,
senders will block once a channel has four items in it.
Thus, once 10 items have passed through the joiner, the
system is deadlocked, as the joiner is trying to read from
the left, but the stream on the right is blocked.
21
22
23
15
17
19
roundrobin(1, 1)
buffering_roundrobin (11, 11)
push(pop())
Identitypush(pop())
Identity
buffering_roundrobin (11, 11)
buf
int i;
for (i=0; i<11; i++) {
push(input1.pop());
buf[i] = input2.pop();
}
for (i=0; i<11; i++) {
push(buf[i]);
}
20
2
4
6
8
12
10
14
16
18
Figure 14: Fixing the deadlock with a buffering joiner.
The buffering roundrobin is an internal StreamIt con-
struct (it is not part of the language) which reads items
from its input channels in the order in which they ar-
rive, rather than in the order specified by its weights.
The order of arrival is determined by a simulation of the
stream graph’s execution; thus, the system is guaranteed
to be deadlock-free, as the order given by the simulation
is feasible for execution on Raw. To preserve the seman-
tics of the joiner, the items are written to the output
channel from the internal buffers in the order specified
by the joiner’s weights. The ordered items are sent to
the output as soon as they become available.
words that are transfered from src to dst during each steadystate execution, hops(p) gives the number of intermediatetiles traversed on the path p, and sync(p) estimates the costof the synchronization imposed by the path p. We calculatesync(p) as the number of tiles along the route that are as-signed a stream node plus the number of tiles along the routethat are involved in routing other channels.With the above cost function, we heavily weigh the added
synchronization imposed by the layout. For Raw, this metricis far more important than the length of the route becauseneighbor communication over the static network is cheap. Ifa tile that is assigned a filter must route data items throughit, then it must synchronize the routing of these items withthe execution of its work function. Also, a tile that is in-volved in the routing of many channels must serialize theroutes running through it. Both limit the amount of paral-lelism in the layout and need to be avoided.
7. COMMUNICATION SCHEDULERWith the nodes of the stream graph assigned to compu-
tation nodes of the target, the next phase of the compilermust map the communication explicit in the stream graphto the interconnect of the target. This is the task of the com-munication scheduler. The communication scheduler mapsthe infinite FIFO abstraction of the stream channels to thelimited resources of the target. Its goal is to avoid deadlockand starvation while utilizing the parallelism explicit in thestream graph.The exact implementation of the communication sched-
uler is tied to the communication model of the target. Thesimplest mapping would occur for targets implementing anend-to-end, infinite FIFO abstraction, in which the sched-uler needs only to determine the sender and receiver of eachdata item. This information is easily calculated from theweights of the splitters and joiners. As the communicationmodel becomes more constrained, the communication sched-uler becomes more complex, requiring analysis of the streamgraph. For targets implementing a finite, blocking nearest-neighbor communication model, the exact ordering of tileexecution must be specified.Due to the static nature of StreamIt, the compiler can
statically orchestrate the communication resources. As de-scribed in Section 4, we create an initialization schedule anda steady-state schedule that fully describe the execution ofthe stream graph. The schedules can give us an order forexecution of the graph if necessary. One can generate or-derings to minimize buffer length, maximize parallelism, orminimize latency.Deadlock must be carefully avoided in the communication
scheduler. Each architecture requires a different deadlockavoidance mechanism and we will not go into a detailedexplanation of deadlock here. In general, deadlock occurswhen there is a circular dependence on resources. A circu-lar dependence can surface in the stream graph or in therouting pattern of the layout. If the architecture does notprovide sufficient buffering, the scheduler must serialize allpotentially deadlocking dependencies.
7.1 Communication Scheduler for RawThe communication scheduling phase of the StreamIt com-
piler maps StreamIt’s channel abstraction to Raw’s staticnetwork. As mentioned in Section 3, Raw’s static networkprovides optimized, nearest neighbor communication. Tiles
9

lines of # of constructs in the program # of filters in theBenchmark Description code filters pipelines splitjoins feedbackloops expanded graph
FIR 64 tap FIR 125 5 1 0 0 132Radar Radar array front-end[20] 549 8 3 6 0 52Radio FM Radio with an equalizer 525 14 6 4 0 26Sort 32 element Bitonic Sort 419 4 5 6 0 242FFT 64 element FFT 200 3 3 2 0 24Filterbank 8 channel Filterbank 650 9 3 1 1 51GSM GSM Decoder 2261 26 11 7 2 46Vocoder 28 channel Vocoder [30] 1964 55 8 12 1 1013GPP 3GPP Radio Access Protocol [3] 1087 16 10 18 0 48
Table 2: Application Characteristics.
250 MHz Raw processor C on a 2.2 GHzBenchmark StreamIt on 16 tiles C on a single tile Intel Pentium IV
Utilization# of tiles
usedMFLOPS
Throughput(per 105 cycles)
Throughput(per 105 cycles)
Throughput(per 105 cycles)
FIR 84% 14 815 1188.1 293.5 445.6Radar 79% 16 1,231 0.52 app. too large 0.041Radio 73% 16 421 53.9 8.85 14.1Sort 64% 16 N/A 2,664.4 225.6 239.4FFT 42% 16 182 2,141.9 468.9 448.5Filterbank 41% 16 644 256.4 8.9 7.0GSM 23% 16 N/A 80.9 app. too large 7.76Vocoder 17% 15 118 8.74 app. too large 3.353GPP 18% 16 44 119.6 17.3 65.7
Table 3: Performance Results.
communicate using buffered, blocking sends and receives. Itis the compiler’s responsibility to statically orchestrate theexplicit communication of the stream graph while prevent-ing deadlock.To statically orchestrate the communication of the stream
graph, the communication scheduler simulates the firing ofnodes in the stream graph, recording the communication asit simulates. The simulation does not model the code insideeach filter; instead it assumes that each filter fires instan-taneously. This relaxation is possible because of the flowcontrol of the static network–since sends block when a chan-nel is full and receives block when a channel is empty, thecompiler needs only to determine the ordering of the sendsand receives rather than arranging for a precise rendezvousbetween sender and receiver.Special care is required in the communication scheduler to
avoid deadlock in splitjoin constructs. Figure 13 illustratesa case where the naive implementation of a splitjoin wouldcause deadlock in Raw’s static network. The fundamentalproblem is that some splitjoins require a buffer of values atthe joiner node–that is, the joiner outputs values in a dif-ferent order than it receives them. This can cause deadlockon Raw because the buffers between channels can hold onlyfour elements; once a channel is full, the sender will blockwhen it tries to write to the channel. If this blocking propa-gates the whole way from the joiner to the splitter, then theentire splitjoin is blocked and can make no progress.To avoid this problem, the communication scheduler im-
plements internal buffers in the joiner node instead of ex-posing the buffers on the Raw network (see Figure 14). Asthe execution of the stream graph is simulated, the schedulerrecords the order in which items arrive at the joiner, and thejoiner is programmed to fill its internal buffers accordingly.At the same time, the joiner outputs items according to theordering given by the weights of the roundrobin. That is,the sending code is interleaved with the receiving code in thejoiner; no additional items are input if a buffered item can
be written to the output stream. To facilitate code gener-ation (Section 8), the maximum buffer size of each internalbuffer is recorded.Our current implementation of the communication sched-
uler is overly cautious in its deadlock avoidance. All feed-backloops are serialized by the communication scheduler toprevent deadlock. More precisely, the loop and body streamsof each feedbackloop cannot execute in parallel. Crossedroutes in the layout of the graph are serialized as well, forc-ing each path to wait its turn at the contention point.
8. CODE GENERATIONThe final phase in the flow of the StreamIt compiler is code
generation. The code generation phase must use the resultsof each of the previous phases to generate the complete pro-gram text. The results of the partitioning and layout phasesare used to generate the computation code that executes ona computation node of the target. The communication codeof the program is generated from the schedules produced bythe communication scheduler.
8.1 Code Generation for RawThe code generation phase of the Raw backend generates
code for both the tile processor and the switch processor.For the switch processor, we generate assembly code directly.For the tile processor, we generate C code that is compiledusing Raw’s GCC port. First we will discuss the tile pro-cessor code generation. We can directly translate the inter-mediate representation of most StreamIt expressions into Ccode. Translations for the push(value), peek(index), andpop() expressions of StreamIt require more care.In the translation, each filter collects the data necessary
to fire in an internal buffer. Before each filter is allowed tofire, it must receive pop items from its switch processor (peekitems for the initial firing). The buffer is managed circularlyand the size of the buffer is equal to the number of itemspeeked by the filter. peek(index) and pop() are translated
10
0
4
8
12
16
20
24
28
32
FIR Radio Sort FFT Filterbank 3GPP
����� ����� ���� ��� � �� ���
������������ ���� �� ��
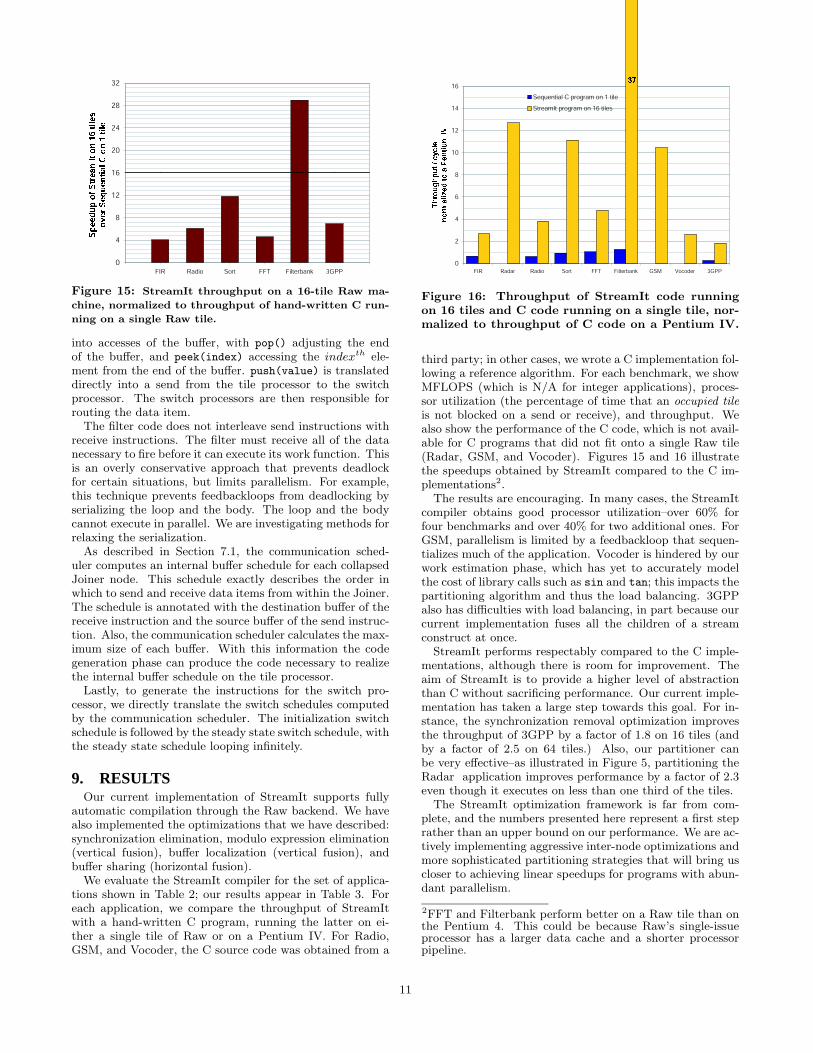
Figure 15: StreamIt throughput on a 16-tile Raw ma-
chine, normalized to throughput of hand-written C run-
ning on a single Raw tile.
into accesses of the buffer, with pop() adjusting the endof the buffer, and peek(index) accessing the indexth ele-ment from the end of the buffer. push(value) is translateddirectly into a send from the tile processor to the switchprocessor. The switch processors are then responsible forrouting the data item.The filter code does not interleave send instructions with
receive instructions. The filter must receive all of the datanecessary to fire before it can execute its work function. Thisis an overly conservative approach that prevents deadlockfor certain situations, but limits parallelism. For example,this technique prevents feedbackloops from deadlocking byserializing the loop and the body. The loop and the bodycannot execute in parallel. We are investigating methods forrelaxing the serialization.As described in Section 7.1, the communication sched-
uler computes an internal buffer schedule for each collapsedJoiner node. This schedule exactly describes the order inwhich to send and receive data items from within the Joiner.The schedule is annotated with the destination buffer of thereceive instruction and the source buffer of the send instruc-tion. Also, the communication scheduler calculates the max-imum size of each buffer. With this information the codegeneration phase can produce the code necessary to realizethe internal buffer schedule on the tile processor.Lastly, to generate the instructions for the switch pro-
cessor, we directly translate the switch schedules computedby the communication scheduler. The initialization switchschedule is followed by the steady state switch schedule, withthe steady state schedule looping infinitely.
9. RESULTSOur current implementation of StreamIt supports fully
automatic compilation through the Raw backend. We havealso implemented the optimizations that we have described:synchronization elimination, modulo expression elimination(vertical fusion), buffer localization (vertical fusion), andbuffer sharing (horizontal fusion).We evaluate the StreamIt compiler for the set of applica-
tions shown in Table 2; our results appear in Table 3. Foreach application, we compare the throughput of StreamItwith a hand-written C program, running the latter on ei-ther a single tile of Raw or on a Pentium IV. For Radio,GSM, and Vocoder, the C source code was obtained from a
0
2
4
6
8
10
12
14
16
FIR Radar Radio Sort FFT Filterbank GSM Vocoder 3GPP
�� ����� ������� !
"��#$ %&!'� �$( !"�% �#)*
Sequential C program on 1 tile
StreamIt program on 16 tiles
+-,
Figure 16: Throughput of StreamIt code runningon 16 tiles and C code running on a single tile, nor-malized to throughput of C code on a Pentium IV.
third party; in other cases, we wrote a C implementation fol-lowing a reference algorithm. For each benchmark, we showMFLOPS (which is N/A for integer applications), proces-sor utilization (the percentage of time that an occupied tile
is not blocked on a send or receive), and throughput. Wealso show the performance of the C code, which is not avail-able for C programs that did not fit onto a single Raw tile(Radar, GSM, and Vocoder). Figures 15 and 16 illustratethe speedups obtained by StreamIt compared to the C im-plementations2.The results are encouraging. In many cases, the StreamIt
compiler obtains good processor utilization–over 60% forfour benchmarks and over 40% for two additional ones. ForGSM, parallelism is limited by a feedbackloop that sequen-tializes much of the application. Vocoder is hindered by ourwork estimation phase, which has yet to accurately modelthe cost of library calls such as sin and tan; this impacts thepartitioning algorithm and thus the load balancing. 3GPPalso has difficulties with load balancing, in part because ourcurrent implementation fuses all the children of a streamconstruct at once.StreamIt performs respectably compared to the C imple-
mentations, although there is room for improvement. Theaim of StreamIt is to provide a higher level of abstractionthan C without sacrificing performance. Our current imple-mentation has taken a large step towards this goal. For in-stance, the synchronization removal optimization improvesthe throughput of 3GPP by a factor of 1.8 on 16 tiles (andby a factor of 2.5 on 64 tiles.) Also, our partitioner canbe very effective–as illustrated in Figure 5, partitioning theRadar application improves performance by a factor of 2.3even though it executes on less than one third of the tiles.The StreamIt optimization framework is far from com-
plete, and the numbers presented here represent a first steprather than an upper bound on our performance. We are ac-tively implementing aggressive inter-node optimizations andmore sophisticated partitioning strategies that will bring uscloser to achieving linear speedups for programs with abun-dant parallelism.
2FFT and Filterbank perform better on a Raw tile than onthe Pentium 4. This could be because Raw’s single-issueprocessor has a larger data cache and a shorter processorpipeline.
11

10. RELATED WORKThe Transputer architecture [2] is an array of processors,
where neighboring processors are connected with unbufferedpoint-to-point channels. The Transputer does not includea separate communication switch, and the processor mustget involved to route messages. The programming languageused for the Transputer is Occam [17]: a streaming languagesimilar to CSP [16]. However, unlike StreamIt filters, Oc-cam concurrent processes are not statically load-balanced,scheduled and bound to a processor. Occam processes arerun off a very efficient runtime scheduler implemented inmicrocode [24].DSPL is a language with simple filters interconnected in
a flat acyclic graph using unbuffered channels [25]. Unlikethe Occam compiler for the Transputer, the DSPL compilerautomatically maps the graph into the available resourcesof the Transputer. The DSPL language does not expose acyclic schedule, thus the compiler models the possible exe-cutions of each filter to determine the possible cost of exe-cution and the volume of communication. It uses a searchtechnique to map multiple filters onto a single processor forload balancing and communication reduction.The Imagine architecture is specifically designed for the
streaming application domain [28]. It operates on streamsby applying a computation kernel to multiple data itemsoff the stream register file. The compute kernels are writ-ten in Kernel-C while the applications stitching the kernelsare written in Stream-C. Unlike StreamIt, with Imagine theuser has to manually extract the computation kernels thatfit the machine resources in order to get good steady stateperformance for the execution of the kernel [18]. On theother hand, StreamIt uses fission and fusion transforma-tions to create load-balanced computation units and filtersare replicated to create more data parallelism when needed.Furthermore, the StreamIt compiler is able to use globalknowledge of the program for layout and transformationsat compile-time while Stream-C interprets each basic blockat runtime and performs local optimizations such as streamregister allocation in order to map the current set of streamcomputations onto Imagine.The iWarp system [7] is a scalable multiprocessor with
configurable communication between nodes. In iWarp, onecan set up a few FIFO channels for communicating betweennon-neighboring nodes. However, reconfiguring the commu-nication channels is more coarse-grained and has a highercost than on Raw, where the network routing patterns canbe reconfigured on a cycle-by-cycle basis [32]. ASSIGN [26]is a tool for building large-scale applications on multiproces-sors, especially iWarp. ASSIGN starts with a coarse-grainedflow graph that is written as fragments of C code. LikeStreamIt, it performs partitioning, placement, and routingof the nodes in the graph. However, ASSIGN is implementedas a runtime system instead of a full language and compilersuch as StreamIt. Consequently, it has fewer opportunitiesfor global transformations such as fission and reordering.SCORE (Stream Computations Organized for Reconfig-
urable Execution) is a stream-oriented computational modelfor virtualizing the resources of a reconfigurable architec-ture [8]. Like StreamIt, SCORE aims to improve portabil-ity across reconfigurable machines, but it takes a dynamicapproach of time-multiplexing computations (divided into“compute pages”) from within the operating system, ratherthan statically scheduling a program within the compiler.
Ptolemy [21] is a simulation environment for heteroge-neous embedded systems, including the domain of SynchronousDataflow (SDF) that is similar to the static-rate streamgraphs of StreamIt. While there are many well-establishedscheduling techniques for SDF [5], the round-robin nodes inour stream graph require the more general model of Cyclo-Static Dataflow (CSDF) [6] for which there are fewer re-sults. Even CSDF does not have a notion of an initializationphase, filters that peek, or a dynamic messaging system assupported in StreamIt. In all, the StreamIt compiler differsfrom Ptolemy in its focus on optimized code generation forthe nodes in the graph, rather than high-level modeling anddesign.Proebsting and Watterson [27] present a filter fusion al-
gorithm that interleaves the control flow graphs of adja-cent nodes. However, they assume that nodes communicatevia synchronous get and put operations; StreamIt’s asyn-chronous peek operations and implicit buffer managementfall outside the scope of their model.A large number of programming languages have included
a concept of a stream; see [31] for a survey. Synchronouslanguages such as LUSTRE [14], Esterel [4], and Signal [11]also target the embedded domain, but they are more control-oriented than StreamIt and are not aggressively optimizedfor performance. Sisal (Stream and Iteration in a Single As-signment Language) is a high-performance, implicitly par-allel functional language [10]. The Distributed OptimizingSisal Compiler [10] considers compiling Sisal to distributedmemory machines, although it is implemented as a coarse-grained master/slave runtime system instead of a fine-grainedstatic schedule.
11. CONCLUSIONIn this paper, we describe the StreamIt compiler and a
backend for the Raw architecture. Unlike other stream-ing languages, StreamIt enforces a structure on the streamgraph that allows a systematic approach to optimization andparallelization. The structure enables us to define multipletransformations and to compose them in a hierarchical man-ner.We introduce a collection of optimizations–vertical and
horizontal filter fusion, vertical and horizontal filter fission,and filter reordering–that can be used to restructure streamgraphs. We show that by applying these transformations,the compiler can automatically convert a high-level streamprogram, written to reflect the composition of the applica-tion, into a load-balanced executable for Raw.The stream graph of a StreamIt program exposes the data
communication pattern to the compiler, and the lack ofglobal synchronization frees the compiler to reorganize theprogram for efficient execution on the underlying architec-ture. The StreamIt compiler demonstrates the power of thisflexibility by partitioning large programs for execution onRaw. However, many of the techniques we describe are notlimited to Raw; in fact, we believe that the explicit paral-lelism and communication in StreamIt is essential for ob-taining high performance on other communication-exposedarchitectures. In this sense, we consider the techniques de-scribed in this paper to be a first step towards establishinga portable programming model for communication-exposedmachines.
12

12. ACKNOWLEDGEMENTSWe are very grateful to Anant Agarwal, Michael Taylor,
David Wentzlaff, Walter Lee, Matt Frank, and the rest ofthe Raw group for developing the Raw infrastructure and forinvesting a lot of time supporting us. We also thank AndyOng, John Chapin, Vanu Bose, and Stephanie Seneff forvaluable conversations regarding applications for StreamIt.Our thanks to Mani Narayanan as well for implementing theBitonicSort application and helping to debug the compiler.This work is supported in part by a grant from DARPA(PCA F29601-04-2-0166), an award from NSF (CISE EIA-0071841), and fellowships from the Singapore-MIT Allianceand the MIT-Oxygen Project.
13. REFERENCES[1] Streamit homepage.
http://compiler.lcs.mit.edu/streamit.
[2] The Transputer Databook. Inmos Corporation, 1988.
[3] 3rd Generation Partnership Project. 3GPP TS 25.201,
V3.3.0, Technical Specification, March 2002.
[4] G. Berry and G. Gonthier. The Esterel SynchronousProgramming Language: Design, Semantics,
Implementation. Science of Computer Programming, 19(2),1992.
[5] S. S. Bhattacharyya, P. K. Murthy, and E. A. Lee. SoftwareSynthesis from Dataflow Graphs. Kluwer AcademicPublishers, 1996.
[6] G. Bilsen, M. Engels, R. Lauwereins, and J. Peperstraete.Cyclo-static dataflow. IEEE Trans. on Signal Processing,1996.
[7] S. Borkar, R. Cohn, G. Cox, S. Gleason, T. Gross, H. T.Kung, M. Lam, B. Moore, C. Peterson, J. Pieper,
L. Rankin, P. S. Tseng, J. Sutton, J. Urbanski, andJ. Webb. iWarp: An integrated solution to high-speed
parallel computing. In Supercomputing, 1988.
[8] E. Caspi, M. Chu, R. Huang, J. Yeh, J. Wawrzynek, and
A. DeHon. Stream Computations Organized forReconfigurable Execution (SCORE): Extended Abstract. In
Proceedings of the Conference on Field ProgrammableLogic and Applications, 2000.
[9] M. B. T. et. al. The Raw Microprocessor: A ComputationalFabric for Software Circuits and General Purpose
Programs. IEEE Micro vol 22, Issue 2, 2002.
[10] J. Gaudiot, W. Bohm, T. DeBoni, J. Feo, and P. Mille”.
The Sisal Model of Functional Programming and itsImplementation. In Proceedings of the Second Aizu
International Symposium on ParallelAlgorithms/Architectures Synthesis, 1997.
[11] T. Gautier, P. L. Guernic, and L. Besnard. Signal: A
declarative language for synchronous programming of
real-time systems. Springer Verlag Lecture Notes in
Computer Science, 274, 1987.
[12] V. Gay-Para, T. Graf, A.-G. Lemonnier, and E. Wais. Kopi
Reference manual.http://www.dms.at/kopi/docs/kopi.html, 2001.
[13] T. Gross and D. R. O’Halloron. iWarp, Anatomy of aParallel Computing System. MIT Press, 1998.
[14] N. Halbwachs, P. Caspi, P. Raymond, and D. Pilaud. The
synchronous data-flow programming language LUSTRE.
Proc. of the IEEE, 79(9), 1991.
[15] R. Ho, K. Mai, and M. Horowitz. The Future of Wires. In
Proc. of the IEEE, 2001.
[16] C. A. R. Hoare. Communicating sequential processes.
Communications of the ACM, 21(8), 1978.
[17] Inmos Corporation. Occam 2 Reference Manual. PrenticeHall, 1988.
[18] U. J. Kapasi, P. Mattson, W. J. Dally, J. D. Owens, and
B. Towles. Stream scheduling. In Proc. of the 3rd
Workshop on Media and Streaming Processors, 2001.
[19] S. Kirkpatrick, J. C.D. Gelatt, and M. Vecchi. Optimization
by Simulated Annealing. Science, 220(4598), May 1983.
[20] J. Lebak. Polymorphous Computing Architecture (PCA)
Example Applications and Description. External Report,
Lincoln Laboratory, Mass. Inst. of Technology, 2001.
[21] E. A. Lee. Overview of the Ptolemy Project. UCB/ERL
Technical Memorandum UCB/ERL M01/11, Dept. EECS,
University of California, Berkeley, CA, March 2001.
[22] W. Lee, R. Barua, M. Frank, D. Srikrishna, J. Babb,V. Sarkar, and S. P. Amarasinghe. Space-Time Scheduling
of Instruction-Level Parallelism on a Raw Machine. In
Architectural Support for Programming Languages and
Operating Systems, 1998.
[23] K. Mai, T. Paaske, N. Jayasena, R. Ho, W. Dally, and
M. Horowitz. Smart memories: A modular recongurable
architecture. In ISCA 2000, Vancouver, BC, Canada.
[24] D. May, R. Shepherd, and C. Keane. CommunicatingProcess Architecture: Transputers and Occam. FutureParallel Computers: An Advanced Course, Pisa, LectureNotes in Computer Science, 272, June 1987.
[25] A. Mitschele-Thiel. Automatic Configuration andOptimization of Parallel Transputer Applications.Transputer Applications and Systems ’93, 1993.
[26] D. R. O’Hallaron. The ASSIGN Parallel ProgramGenerator. Carnegie Mellon Technical ReportCMU-CS-91-141, 1991.
[27] T. A. Proebsting and S. A. Watterson. Filter Fusion. In
POPL, 1996.
[28] S. Rixner, W. J. Dally, U. J. Kapasi, B. Khailany,
A. Lopez-Lagunas, P. R. Mattson, and J. D. Owens. Abandwidth-efficient architecture for media processing. In
International Symposium on Microarchitecture, 1998.
[29] K. Sankaralingam, R. Nagarajan, S. Keckler, andD. Burger. A Technology-Scalable Architecture for Fast
Clocks and High ILP. University of Texas at Austin, Dept.of Computer Sciences Technical Report TR-01-02, 2001.
[30] S. Seneff. Speech transformation system (spectrum and/orexcitation) without pitch extraction. Master’s thesis,Massachussetts Institute of Technology, 1980.
[31] R. Stephens. A Survey of Stream Processing. ActaInformatica, 34(7), 1997.
[32] M. B. Taylor, W. Lee, S. Amarasinghe, and A. Agarwal.
Scalar Operand Networks: On-Chip Interconnect for ILP in
Partitioned Architectures. Technical Report
MIT-LCS-TR-859, Mass. Inst. of Technology, July 2002.
[33] W. Thies, M. Karczmarek, and S. Amarasinghe. StreamIt:
A Language for Streaming Applications. In Proceedings ofthe International Conference on Compiler Construction, to
appear, Grenoble, France, 2002.
[34] W. Thies, M. Karczmarek, M. Gordon, D. Maze, J. Wong,
H. Hoffmann, M. Brown, and S. Amarasinghe. StreamIt: ACompiler for Streaming Applications. MIT-LCS Technical
Memo LCS-TM-622, Cambridge, MA, 2001.
[35] E. Waingold, M. Taylor, D. Srikrishna, V. Sarkar, W. Lee,
V. Lee, J. Kim, M. Frank, P. Finch, R. Barua, J. Babb,
S. Amarasinghe, and A. Agarwal. Baring it all to software:
Raw machines. IEEE Computer, 30(9), 1997.
13




















