
A pitch synchronous approach to design voice conversion system using source-filter correlation
13
Int J Speech Technol (2012) 15:419–431 DOI 10.1007/s10772-012-9164-2 A pitch synchronous approach to design voice conversion system using source-filter correlation Rabul Hussain Laskar · Kalyan Banerjee · Fazal Ahmed Talukdar · K. Sreenivasa Rao Received: 9 March 2012 / Accepted: 12 June 2012 / Published online: 26 June 2012 © Springer Science+Business Media, LLC 2012 Abstract We propose a pitch synchronous approach to de- sign the voice conversion system taking into account the cor- relation between the excitation signal and vocal tract system characteristics of speech production mechanism. The glottal closure instants (GCIs) also known as epochs are used as an- chor points for analysis and synthesis of the speech signal. The Gaussian mixture model (GMM) is considered to be the state-of-art method for vocal tract modification in a voice conversion framework. However, the GMM based models generate overly-smooth utterances and need to be tuned ac- cording to the amount of available training data. In this pa- per, we propose the support vector machine multi-regressor (M-SVR) based model that requires less tuning parameters to capture a mapping function between the vocal tract char- acteristics of the source and the target speaker. The prosodic features are modified using epoch based method and com- pared with the baseline pitch synchronous overlap and add (PSOLA) based method for pitch and time scale modifica- tion. The linear prediction residual (LP residual) signal cor- responding to each frame of the converted vocal tract trans- fer function is selected from the target residual codebook R. Hussain Laskar ( ) · K. Banerjee · F.A. Talukdar Department of Electronics & Communication Engineering, National Institute of Technology, Silchar, Assam, India e-mail: [email protected] K. Banerjee e-mail: [email protected] F.A. Talukdar e-mail: [email protected] K.S. Rao School of Information Technology, IIT Kharagpur, Kharagpur 721302, West Bengal, India e-mail: [email protected] using a modified cost function. The cost function is calcu- lated based on mapped vocal tract transfer function and its dynamics along with minimum residual phase, pitch period and energy differences with the codebook entries. The LP residual signal corresponding to the target speaker is gen- erated by concatenating the selected frame and its previous frame so as to retain the maximum information around the GCIs. The proposed system is also tested using GMM based model for vocal tract modification. The average mean opin- ion score (MOS) and ABX test results are 3.95 and 85 for GMM based system and 3.98 and 86 for the M-SVR based system respectively. The subjective and objective evaluation results suggest that the proposed M-SVR based model for vocal tract modification combined with modified residual selection and epoch based model for prosody modification can provide a good quality synthesized target output. The results also suggest that the proposed integrated system per- forms slightly better than the GMM based baseline system designed using either epoch based or PSOLA based model for prosody modification. Keywords Gaussian mixture model · SVM multi-regressor · Prosody · Pitch contour · Duration patterns · Energy profiles · Residual modification · Glottal closure instants · Correlation 1 Introduction The voice conversion (VC) is to modify the acoustic charac- teristics of the speech signal spoken by the source speaker to be perceived as if target speaker has spoken it (Arslan 1999). The basic objective of the voice conversion system is to implant the speaker-specific acoustics cues in the source speech signal so that the synthesized speech signal carries
Transcript of A pitch synchronous approach to design voice conversion system using source-filter correlation

Int J Speech Technol (2012) 15:419–431DOI 10.1007/s10772-012-9164-2
A pitch synchronous approach to design voice conversion systemusing source-filter correlation
Rabul Hussain Laskar · Kalyan Banerjee ·Fazal Ahmed Talukdar · K. Sreenivasa Rao
Received: 9 March 2012 / Accepted: 12 June 2012 / Published online: 26 June 2012© Springer Science+Business Media, LLC 2012
Abstract We propose a pitch synchronous approach to de-sign the voice conversion system taking into account the cor-relation between the excitation signal and vocal tract systemcharacteristics of speech production mechanism. The glottalclosure instants (GCIs) also known as epochs are used as an-chor points for analysis and synthesis of the speech signal.The Gaussian mixture model (GMM) is considered to be thestate-of-art method for vocal tract modification in a voiceconversion framework. However, the GMM based modelsgenerate overly-smooth utterances and need to be tuned ac-cording to the amount of available training data. In this pa-per, we propose the support vector machine multi-regressor(M-SVR) based model that requires less tuning parametersto capture a mapping function between the vocal tract char-acteristics of the source and the target speaker. The prosodicfeatures are modified using epoch based method and com-pared with the baseline pitch synchronous overlap and add(PSOLA) based method for pitch and time scale modifica-tion. The linear prediction residual (LP residual) signal cor-responding to each frame of the converted vocal tract trans-fer function is selected from the target residual codebook
R. Hussain Laskar (�) · K. Banerjee · F.A. TalukdarDepartment of Electronics & Communication Engineering,National Institute of Technology, Silchar, Assam, Indiae-mail: [email protected]
K. Banerjeee-mail: [email protected]
F.A. Talukdare-mail: [email protected]
K.S. RaoSchool of Information Technology, IIT Kharagpur,Kharagpur 721302, West Bengal, Indiae-mail: [email protected]
using a modified cost function. The cost function is calcu-lated based on mapped vocal tract transfer function and itsdynamics along with minimum residual phase, pitch periodand energy differences with the codebook entries. The LPresidual signal corresponding to the target speaker is gen-erated by concatenating the selected frame and its previousframe so as to retain the maximum information around theGCIs. The proposed system is also tested using GMM basedmodel for vocal tract modification. The average mean opin-ion score (MOS) and ABX test results are 3.95 and 85 forGMM based system and 3.98 and 86 for the M-SVR basedsystem respectively. The subjective and objective evaluationresults suggest that the proposed M-SVR based model forvocal tract modification combined with modified residualselection and epoch based model for prosody modificationcan provide a good quality synthesized target output. Theresults also suggest that the proposed integrated system per-forms slightly better than the GMM based baseline systemdesigned using either epoch based or PSOLA based modelfor prosody modification.
Keywords Gaussian mixture model · SVMmulti-regressor · Prosody · Pitch contour · Durationpatterns · Energy profiles · Residual modification · Glottalclosure instants · Correlation
1 Introduction
The voice conversion (VC) is to modify the acoustic charac-teristics of the speech signal spoken by the source speakerto be perceived as if target speaker has spoken it (Arslan1999). The basic objective of the voice conversion system isto implant the speaker-specific acoustics cues in the sourcespeech signal so that the synthesized speech signal carries

420 Int J Speech Technol (2012) 15:419–431
the identity of the desired target speaker. There are manyapplications of voice conversion such as customization oftext-to-speech system, movie dubbing, karaoke, speaker ver-ification and security related systems that uses speech asbiometric feature (Arslan 1999; Kain and Macon 1998;Turk and Arslan 2006; Mousa 2010; Lee 2007).
Speaker identity lies in all the acoustic cues with varyingdegree of importance (Kain and Macon 1998). The speaker-specific information lies at vocal tract transfer function,source excitation signal, prosodic features and in linguis-tic cues of the speech signal (Yegnanarayana et al. 2001;Kuwabara and Sagisaka 1995; Prasanna et al. 2006). There-fore, mapping and modification of acoustic cues having highdegree of speaker-specific information is crucial in a voiceconversion system.
There are various speech features used to represent thevocal tract transfer function. These are spectral lines (Suen-dermann et al. 2003), formant frequencies and formantbandwidths (Kuwabara 1984), linear prediction coefficients(LPCs) (Abe et al. 1988), reflection coefficients (RCs) (Ver-helst and Mertens 1996), log-area ratios (LARs) (Rao et al.2007), line spectral frequencies (LSFs) (Arslan 1999; Kainand Macon 1998; Lee 2007; Rao 2010; Rao et al. 2007),cepstral coefficients (Stylianou et al. 1998), mel cepstralfrequencies (Desai et al. 2010) and mel-generated cepstra(MGC) (Helander et al. 2012). The acoustic features usedto represent the vocal tract transfer function should possessinterpolation property and ensure stable filter. The LSFs, aderived acoustic parameter set from LPCs is a good choiceto represent the vocal tract characteristics in a voice conver-sion system (Arslan 1999).
Nonlinear relation exists between the vocal tract char-acteristics of two speakers. To model these nonlinearities,various models have been explored in the literature. Thesemodels may capture either discrete or continuous map-ping functions. These models are specific to the kind offeatures used for mapping. For instance, vector quantiza-tion (VQ) (Abe et al. 1988), fuzzy vector quantization(FVQ) (Verhelst and Mertens 1996), dynamic frequencywarping (DFW) (Toda et al. 2001; Baudoin and Stylianou1996), linear multivariate regression (LMR) (Baudoin andStylianou 1996), artificial neural network (ANN) (Rao 2010;Rao et al. 2007; Narendranath et al. 1995; Desai et al. 2010),radial basis function network (RBFN) (Rao et al. 2007),Gaussian mixture models (GMM) (Kain and Macon 1998;Stylianou et al. 1998; Toda et al. 2001; Desai et al. 2010;Mesbahi et al. 2007), dynamic kernel partial least square re-gression (DKPLS) (Helander et al. 2012) etc., are widelyused for mapping the vocal tract characteristics. To capturethe nonlinear relation present in the vocal tract character-istics of two speakers, the support vector machine multi-regressor (M-SVR) (Cruz et al. 2002; Fernandez et al. 2004)has been proposed in this paper. In case of M-SVR, the ap-proximation of the classical quadratic loss function used in
SVR is solved using weighted least square regression algo-rithm known as iterative re-weighted least square algorithm(IRWLS) (Cruz et al. 2005). This is a fast and efficient al-gorithm for training SVR in case of multiple-input multiple-output (MIMO) scenarios to capture a nonlinear mappingfunction.
The prosodic features carries significant speaker-specificinformation (Chappel and Hansen 1998). In contrast to av-erage pitch, the pitch contour carries significant speaker-specific information (Akagi and Ienaga 1995). In a highquality voice conversion system, the global and local dy-namics of source pitch contour needs to be modified accord-ing to the desired target pitch contour (Inanoglu 2003). TheGaussian normalization, scatter plots, GMM based models,ANN based models, sentence contour codebook, segmentcontour codebook and pitch contour stylization are usedfor mapping and modification of pitch contours at gross orfine levels (Rao 2010; Chappel and Hansen 1998; Inanoglu2003; Turk and Arslan 2006; Ghosh and Narayanan 2009). Ithas been observed that the performance of codebook basedmodel is better than linear, cubic and GMM based models incapturing the local variations in the intonation patterns of thetarget speaker. In case of ANN based model, capturing thenetwork structure for proper mapping and manipulation ofpitch contour is a difficult task. The codebook based modeldesigned at segment level can capture the local dynamicsof the target pitch contour in a better manner as comparedto sentence level codebook based model (Inanoglu 2003;Chappel and Hansen 1998). Therefore, we propose to use acodebook based model at voiced segment level for mappingthe source pitch contour according to the desired target pitchcontour. The duration patterns of the source speech signal isalso modified at the segmental level to adjust the speakingrate according to the desired target speaker (Toth and Black2008).
The residual signal contain significant speaker-specificinformation (Kain and Macon 2001). Therefore, propermodification of the residual signal is required to synthesizehigh quality target speaker’s voice (Kain and Macon 2001;Suendermann et al. 2005a). Residual copying, residual pre-diction, residual selection and unit (single speech frame) se-lection methods are some of the existing methods to modifythe residual signal of the source speaker according to targetspeaker (Kain and Macon 2001; Suendermann et al. 2005a,2005b; Drugman et al. 2009; Suendermann et al. 2005b; Leeet al. 1996). The residual copying is a trivial solution andusually converted speech seems like a third speaker’s voice(Suendermann et al. 2005a). Residual prediction using code-book based model (Kain and Macon 2001) has the drawbackof over-smoothing the residual signal due to averaging oper-ation. The ANN based model applied at epoch level to modeland modify the residual signal can provide a better mappingof the residual signal as most of speaker-specific informa-tion lies around the epochs (Rao 2010). However, in case of

Int J Speech Technol (2012) 15:419–431 421
ANN based model the network structure needs to be cap-tured empirically. As both the vocal tract characteristics andresidual signals are predictive in nature, the correlation be-tween them may be lost, resulting in degradation of speechquality. The methods based on residual selection and unitselection can capture the correlation present in speech pro-duction mechanism of a particular speaker. The target costto select the appropriate residual frame is usually calculatedbased on similarity between the predicted vocal tract transferfunction and its transitions along with pitch and normalizedresidual energy difference between the source test frameand the residual frames in the target codebook (Suender-mann et al. 2005a). The subjective evaluation results suggestthat the residual selection and unit selection method com-bined with residual smoothing outperforms the other meth-ods (Suendermann et al. 2005a, 2005b). Therefore, we pro-pose a modified residual selection method combined withepoch based concatenation to retain the information aroundGCIs to generate the target residual signal. The combinationof the residual selection method and epoch based concate-nation may help to capture the correlation between the exci-tation signal and vocal tract system to deliver a high qualityoutput.
For extraction of acoustic features, the analysis of speechsignal may be carried out at segmental level. It has beenreported that block processing (segmental analysis) smearsthe information within the analysis frame and estimate thespectrum corresponding to some average behavior withinthe analysis window (Yegnarayana and Veldhuis 1998). Thefundamental frequency as well as the shape, size and po-sition of analysis window has significant effect on spectralestimation of the signal (Yegnarayana and Veldhuis 1998;Rao 2010). In addition, the block processing based methodfails to track the natural variations in the formant parame-ters of speech production mechanism. To obviate this prob-lem, we propose a pitch synchronous approach based onGCIs (epochs) to design the voice conversion system. Theepochs are extracted using the group delay analysis whichis a robust method and is insensitive to mild degradationdue to noise and reverberation (Rao and Yegnanarayana2006). The epoch interval, the interval between two suc-cessive epochs carries the information about the pitch peri-ods in the voiced segments of the speech signal. The epochsmay help to position the analysis window and track the nat-ural spectral variations in the speech signal. It has been ob-served that the residual signal around the GCIs carries sig-nificant speaker-specific information and is crucial for syn-thesizing high quality target output signal (Rao et al. 2007;Rao 2010). Since the epoch intervals in the voiced segmentsare nothing but the pitch periods, we propose to modify theprosodic features (pitch contour and duration pattern) of thesignal using epoch based method.
The pitch synchronous approach to design the voice con-version system has been explored by different researchers
(Rao 2010; Sundermann et al. 2004; Ye and Young 2004;Kain and Macon 1998). The ANN based predictive mod-els proposed in Rao (2010) fails to capture the correla-tion between the excitation signal and the system charac-teristics. In most of the studies related to voice conversionemphasis is given to spectral transformation while convert-ing the prosodic features using linear mapping function forpitch and time scale modification. These transformationsleads to degradation in speech conversion quality, especiallywhen the speaking styles of the source and target speak-ers are different. In this paper, we propose a method ca-pable of jointly converting prosodic features, spectral en-velope and residual signal maintaining the correlation be-tween them. The proposed approach is different from theexisting pitch synchronous methods in terms of the follow-ing points: (a) group delay analysis is used for automaticextraction of pitch marks (Rao and Yegnanarayana 2006;Rao 2010), (b) the vocal tract characteristics is modified us-ing M-SVR based model in addition to the baseline GMMbased model, (c) the modified residual selection methodcombined with epoch based concatenation to generate thetarget residual signal and (d) modification of prosodic fea-tures (pitch contours and duration patterns) at voiced seg-ment level using epoch based approach to adjust the intona-tion patterns and speaking rate of the desired target speaker.The functional block diagram of the proposed voice conver-sion system is given in Fig. 1.
The paper is organized as follows. In Sect. 2, the databaseused in this paper and the extraction of acoustic features arediscussed. In Sect. 3, we have discussed the baseline GMMbased model and proposed M-SVR based model for spec-tral transformation. The modified residual selection and con-catenation method to generate the target residual signal hasbeen discussed in Sect. 4. Mapping of prosodic features atsegmental level is discussed in Sect. 5. The integrated sys-tem to synthesize the target speech signal is discussed inSect. 6. Performance evaluation of synthesized target speechsignal using both the subjective and objective measures aregiven in Sect. 7. Conclusion and future direction of work arehighlighted in Sect. 8.
2 Database preparation and feature extraction
Four speakers, the BDL (US male: M1), RMS (US male:M2), SLT (US female: F1), CLB (US female: F2) from theCMU arctic database has been used to develop the voiceconversion system. The speaker combinations are: M1-F1,F2-M2, M1-M2 and F1-F2. For each of the speaker pairs50 parallel sentences are used for training the system and30 sentences are used for evaluation. Since, the speech sam-ples involved are based on same text material and same lan-guage, therefore, the proposed system is an intra-lingual,text-dependent voice conversion system.

422 Int J Speech Technol (2012) 15:419–431
Fig. 1 Functional block diagram of the proposed voice conversion system
The GCIs are used as anchor points for the proposedpitch synchronous voice conversion system. The GCIs areextracted from the residual signal using group delay analy-sis (Rao and Yegnanarayana 2006). For processing in a pitchsynchronous manner, the GCIs in the nonvoiced segmentsof a particular speaker are generated at an interval of meanpitch period of that speaker. The extracted speech framesof the speaker pairs are time aligned using dynamic timewarping (DTW) algorithm. The LPCs are extracted fromthe time aligned speech frames from which the LSFs arederived. The LSFs requires less coefficients to efficientlycapture the formant structure and it has better interpolationproperties. The 32nd order LSFs along with the residual sig-nals are stored in the codebooks for both the source and thetarget speakers. It is to be noted that the LSF codebook is afixed length codebook, whereas the residual codebook is ofvariable length. The resampled pitch contour segments (100pitch periods) derived from the voiced segments of speechsignals of the speaker pairs are stored in the pitch contourcodebooks. There are around 30000 LSF vectors and resid-ual frames in the respective codebooks and around 10000pitch contour segments in the pitch contour codebooks fortraining the system.
3 Mapping the vocal tract characteristics
Various model exists for mapping the vocal tract characteris-tics of a source speaker according to the target speaker. TheGMM and ANN are the two widely used models for spec-tral mapping in a voice conversion system (Desai et al. 2010;
Mesbahi et al. 2007). The ANN provides a nonlinear map-ping function. It has been observed that ANN suffers fromoverfitting and overtraining. Moreover, the ANN based sys-tem needs sufficient amount of data to build a speaker model(Desai et al. 2010). The GMM based model outperforms theother models for spectral mapping in a voice conversion sys-tem (Chen et al. 2003). Therefore, we have used GMM jointdensity based model as the baseline system for mapping thevocal tract characteristics between the speaker pairs.
3.1 GMM based model
In the GMM based model, a locally linear mapping functionis captured by training the system using joint density esti-mation (Kain and Macon 1998). The GMM allows the prob-ability distribution of a random variable z to be modeled asthe sum of Q Gaussian components known as mixtures. Theprobability density function is given by
p(z) =Q∑
i=1
αiN(z;μi ,Σ i )
Q∑
i=1
αi = 1 αi ≥ 0 (1)
If X = [x1;x2; . . . ;xN ] be a sequence of N feature vec-tors describing the source speaker and Y = [y1;y2; . . . ;yN ]be the corresponding sequence as produced by the targetspeaker, then z = [XT YT ] is an augmented feature vector ofinput X and output Y. The N(z;μi ,Σ i ) denotes the Gaus-sian distribution with mean vector μi , covariance matrix Σ i
and αi denotes the prior probability that vector z belongsto the ith class. The model parameters (α;μ;Σ) are esti-mated using the expectation maximization (EM) algorithm

Int J Speech Technol (2012) 15:419–431 423
which is an iterative method for computing maximum like-lihood parameter estimates. During the training phase, it isrequired to compute the Gaussian distribution parameters.
The testing process involves regression, i.e., given the in-put vectors, X, we need to predict Y using GMMs, which iscalculated as follows
F(xi ) = E[yi |xi] =Q∑
i=1
hi(x)[μ
yi + Σ
yxi
(Σxx
i
)−1(x − μxi
)]
(2)
and hi(x) is given by
hi(x) = αiN(z;μxi ;Σxx
i )∑Q
j=1 αjN(z;μxj ;Σxx
j )(3)
The hi(x) represents the aposterior probability that agiven input vector x belongs to the ith class. μx
i and μyi de-
note mean vectors of class i for the source and target speak-ers respectively. Σxx
i is the covariance matrix of class i forsource speaker and Σ
yxi denotes the cross-covariance matrix
of class i for the source and target speakers.The GMM based model has been developed to capture
a locally linear globally nonlinear mapping function. Thenumber of mixtures selected for this study is 64. Since, theGMM with diagonal covariance do not work well with thehighly correlated data (intra-frame correlation) like LSFs(Han et al. 2011), therefore, we have used the full diago-nal covariance matrix (Stylianou et al. 1998). The mappingfunction captured during the training phase is used to predictthe vocal tract characteristics of the desired target speaker.The predicted LSFs are converted to LPCs that represent thedesired target speaker’s vocal tract characteristics.
3.2 M-SVR based model
The GMM based models are more efficient and robust thanthe various other models used for spectral mapping (Chenet al. 2003). However, the GMM based models generateoverly-smooth utterances and need some post processing toreduce the artifacts. The GMM based systems work on aframe-by-frame basis without taking the dynamics of realspeech production mechanism into account (Helander et al.2012). To build a speaker model, the GMM based system re-quires sufficient amount of training data. The models need tobe tuned according to the amount of available training data(Desai et al. 2010; Mesbahi et al. 2007). In this paper, wepropose a SVM multi-regressor (M-SVR) (Cruz et al. 2002;Fernandez et al. 2004) based approach that requires lesstuning parameters to capture a mapping function betweenthe acoustic spaces of two speakers. The M-SVR is solvedusing IRWLS (Cruz et al. 2005) algorithm to capture the
model parameters. In case of data-aided MIMO channel es-timation, the M-SVR provides some advantages in terms ofbit error rate (BER) and complexity as compared to RBFNand uni-dimensional SVR (Fernandez et al. 2004). For func-tion estimation using real and synthetic data, the M-SVRshows better and robust prediction performance as comparedto uni-dimensional SVR (Cruz et al. 2005). The M-SVRcan address the dependencies between input and output fea-tures in a MIMO system. The LSFs used to represent thevocal tract characteristics possess high intra-frame correla-tion. The multidimensional regression may exploit the intra-frame dependencies in the vocal tract system to deliver arobust mapping function.
The classical SVM minimizes a quadratic cost functionthat is solved using Quadratic Programming (QP). The IR-WLS is considered to be the fastest SVM solver (Cruz et al.2005). It solves a sequence of weighted least square prob-lems that converges to QP solution. It is a quasi-Newtonapproach in which each iteration has same computationalcomplexity as that of a least square procedure for each com-ponent of the vector. Being weighted least square based ap-proach, the number of iterations required to obtain the finalsolution is small (Cruz and Rodríguez 2004).
In case of voice conversion, the input and output vectorsare d dimensional. The classical uni-dimensional SVR maybe used to capture the nonlinear mapping function for eachof the output dimension. However, it may lead to individ-ual mapping function for each of the output dimension. Theintra-frame correlation of the LSF vectors may not be ex-ploited by such kind of mapping functions leading to audi-ble distortion. The classical methods for training the SVMs,such as decomposition methods used in SVM-Light, LIB-SVM and SVMTorch can handle large scale problems quiteefficiently, but their super-linear-behavior makes their useinefficient or even intractable for large number of samples(Joachims 1999; Platt 1999; Collobert and Bengio 2001;Cruz et al. 2002). The M-SVR can handle all the output di-mension together leading to a single mapping function forall the dimension. However, the M-SVR can not be appliedto large scale learning problem because of memory insuffi-ciency problem. Therefore, it is required to recast the largescale learning problem (>10000 data points) to a mediumscale learning problem (within 1000 to 10000 data points)(Cruz and Rodríguez 2004). For that, we have used an algo-rithm known as sample reduction using recursive and seg-mented data structure analysis (SR-RSDSA) (Laskar et al.2011; Wang and Shi 2008) to select the valuable data pointsto train the M-SVR.
To capture the nonlinear relation between the acousticcharacteristics of two speakers, the M-SVR is applied in fea-ture space (kernel space). The Gaussian RBFN kernel func-

424 Int J Speech Technol (2012) 15:419–431
tion k(xi ,xj ) = φT (xi )φT (xj ) is given by
k(x,xi ) = exp
(−‖x − xi‖2
2σ 2
)(4)
For ε-insensitive loss function, with nonzero ε, the M-SVR takes every output dimension to construct each individ-ual regressor and bounds all the outputs together, a desirablefeature for mapping the vocal tract characteristics betweentwo speaker pairs. If β = [β1,β2, . . . ,βd ] denote the modelparameters of M-SVR and Kx is a vector that contains thekernel of the input vector x and the training samples, then theoutput vector y may be written as (Fernandez et al. 2004)
y = φT (x)ΦT β = Kxβ (5)
where, Φ = [φ(x1), . . . ,φ(xN)]T .
4 Modification of the residual signal
The residual signal carries significant speaker-specific infor-mation. Therefore, appropriate mapping and modification ofresidual signal is required to achieve a high quality synthe-sized target speech signal. We propose a modified residualselection and epoch based concatenation method to selectthe appropriate target residual frame corresponding to themapped vocal tract transfer function.
During the training stage, the target residual frame corre-sponding to each training speech frames are stored in a vari-able length residual codebook along the target LSF vectors.The residual phase vectors are extracted from the source andtarget residual frames that are resampled to a length of 200to store in the residual phase codebooks (Kain and Macon2001). The residual phase information is extracted from theresidual signal and its Hilbert envelope (Murthy and Yeg-nanarayana 2006). The residual phase information for thetarget residual frame is given by
cos(θ) = rt
ht
(6)
where, rt is LP residual signal and ht is Hilbert envelope ofthe analytic signal corresponding to rt .
We propose a modified cost function to select the appro-priate target residual signal from the converted vocal tracttransfer function and the residual phase vector. During thetransformation stage, the LSFs and residual signal are ex-tracted for each frame of the source speaker’s speech signal.The LSFs are mapped using the mapping function capturedduring the training stage. The residual signal correspondingto a mapped LSF vector is selected from the target residualcodebook using the criteria given in (7) and (8).
Let xt represents the mapped LSF vector correspondingto a source speaker’s LSF vector xt . We consider, �xt−1
and �xt+1 represents the vocal tract transition between cur-rent frame and its previous frame and between the currentframe and the following frame respectively. Thus the ex-tended vector xt = [�xt−1 : xt : �xt+1] may contain the dy-namics of the vocal tract transfer function. The [�xtest−1 :xtest : �xtest+1] represents the vocal tract transfer functionand its dynamics corresponding to a test LSF vector of thesource speaker. The vector yt i = [�y(t−1)i : yt i : �y(t+1)i],for i = 1,2, . . . ,N , represents the LSFs and its dynamics inthe target training database. The rtest represents the sourcespeaker’s residual signal corresponding to source speaker’sLSF vector xtest . The rti for i = 1,2, . . . ,N representsthe entries in the residual codebook corresponding to eachyti , for i = 1,2, . . . ,N . The cos(θ test ) represents resam-pled phase vector of source residual test frame and cos(θ si ),cos(θ ti ), for i = 1,2, . . . ,N , represents the entries in thesource and target residual phase codebooks respectively. Thetarget cost function (Ct ) is given by
Ct = w1‖yt i − xt‖2 + w2[∣∣cos(θ si ) − cos(θ test )
∣∣]
+ w3[|ηftest − fti |
] + w4[∣∣E(rti ) − E(rs)
∣∣] (7)
where, E(.) represents the energy of the residual frame. Theparameters fti is the fundamental frequency of the targetspeaker’s residual frames stored in the codebook and ftest
is that of the source speaker’s residual frame under consid-eration. The η is a pitch scaling factor derived at the utter-ance level. The weights w1, w2, w3 and w4 are determinedexperimentally and should satisfy the following constraints
w1 + w2 + w3 + w4 ≤ 1; w1,w2,w3,w4 ≥ 0 (8)
If k represent the index for which the cost is minimum,then rtk represents the best match with the mapped LSF vec-tor xt . This may help to maintain good correlation betweenthe mapped vocal tract transfer function and the target resid-ual signal (Suendermann et al. 2005b). It may be noted thatthe target cost is calculated by jointly exploiting the sourceand target codebooks. The vocal tract transfer function andits transitions along with the residual energy differences areminimized using the target codebooks, whereas the resid-ual phase difference is minimized using the residual sourcecodebook. The phase of the residual signal carries most ofthe speaker-specific information than its magnitude. There-fore, it can be thought of as looking for the residual sig-nal from the source codebook that has the phase similaritywith the residual test frame under consideration. The valuesof w1,w2, w3 and w4 used in this study are 0.6, 0.25, 0.1and 0.05 respectively. The residual signal around the GCIsare crucial to obtain the naturalness in the synthesized targetspeech signal (Rao and Yegnanarayana 2006). Therefore, wemade use of the residual frames rtk and rtk−1 during synthe-sis to retain the maximum information around the GCIs.

Int J Speech Technol (2012) 15:419–431 425
5 Mapping the prosodic features
The intonation patterns (pitch contour) is one of the impor-tant acoustic cues related to identity of a particular speaker.In a voice conversion system, it needs to capture both theglobal and local variations of the pitch contour to improvethe naturalness of the target speech signal. Various modelshave been proposed in the literature to capture the intonationpatterns of the desired target speaker. We have used a code-book based model at voiced segment level to capture theglobal and local variations of the target pitch contour. TheGCIs in the voiced segments of the speech signal are usedto derive the epoch intervals. The epoch intervals in voicedsegments of the speech signal are nothing but the pitch peri-ods. The epoch intervals corresponding to voiced segmentsare retained and that for the nonvoiced segments are dis-carded by running the voiced/nonvoiced detection algorithm(Dhananjaya and Yegnarayana 2010).
5.1 Mapping the pitch contour
The database containing sufficient number of pitch segmentshaving rises and falls may capture the intonation patterns ofthe target pitch contour from the source pitch contour. Thepitch contours are extracted at the voiced segment level fromthe parallel utterances of the source and target speakers.Since the voiced segments are of varying durations withina sentence and across the sentences in a database, the pitchcontours are resampled to a length of 100 pitch periods tostore in the codebooks.
In the training phase, the pitch contours are extractedfrom the time aligned (using DTW algorithm) parallel ut-terances of the source and the target speakers. The targetpitch contour is linearly interpolated in the non-voiced re-gions. For each pitch contour segment of the source speaker,the corresponding target pitch contour segment is extractedfrom the interpolated and aligned target pitch contour. Sincethe pitch contour segments are of varying length within asentence and across the sentences, therefore, the segmentsof pitch contours are resampled to make their length equal.Two parallel codebooks having one-to-one relation are pre-pared for the source and target speaker pairs. This processis repeated for all the voiced segments in a particular sen-tence and then for all the sentences in the database. Dur-ing the transformation, the resampled voiced segments ofsource pitch contour is coded with the source pitch contourcodebook and decoded as the weighted average of the tar-get pitch contour codebook. If D is the Euclidean distancevector with Di , i = 1,2, . . . ,M as the elements, then thenormalized weight vector w, whose elements are given bywk = Dk∑M
i=1 Di
; k = 1,2, . . . ,M .
The proposed algorithm is used to map the pitch contoursfor all the speaker pairs, i.e., M1-F1, F2-M2, M1-M2 and
Fig. 2 Modification of epoch interval plot from Male to Female(M1-F1) using codebook based model
F1-F2. The mapped epoch interval plot for Male to Female(M1-F1) conversion is shown in Fig. 2. It is observed thatthe proposed codebook based model can capture the globalnature of the pitch contour in addition to local variations.However, it fails to capture the sudden jumps in the targetpitch contour. This method work well for mapping of crossgender pitch contour conversion, as there are wide variationsin their mean values and dynamic ranges. For intra-gendermapping this method can also capture the global variationsin general along with the local variations to certain extent. Ithas been observed that the increase in codebook size leadsto processing distortion due to large amount of modifica-tions performed. Because of the averaging operation, thepitch contour loses the local variations and hence there isa degradation of quality of the synthesized speech signal.
5.2 Mapping the duration patterns
To adjust the speaking rate of the synthesized speech signal,it is required to modify the duration pattern of the sourcespeaker according to the target speaker. In the proposed ap-proach, a transformation ratio is calculated at the utterancelevel by dividing the average target speaker’s speech dura-tion by the average source speaker’s speech duration (Tothand Black 2008). If ds and dt represent the average durationsof the speech signals of the source and the target speakersrespectively, then the duration modification factor is givenby g = dt
ds. In the testing phase, we derive the epoch inter-
vals from the mapped target pitch contour. The epoch in-tervals in the voiced segments are scaled by the durationmodification factor (g) to obtain the modified epoch inter-vals. The epoch intervals in the nonvoiced segments (Raoand Yegnanarayana 2006) are replaced by the mean pitchperiod (epoch interval) of the desired target speaker. Finally,the new target epoch sequences are generated from the pitchcontour and duration modified epoch intervals.

426 Int J Speech Technol (2012) 15:419–431
6 Synthesizing the target speech signal
The new target epoch sequences are used to synthesize thedesired target speech signal. For each new target epoch,the corresponding nearest source epoch is identified for thesource speech signal to be converted. The mapped vocaltract characteristics corresponding to source speech segmentis used to update the vocal tract transfer function at the newtarget epoch. The LP residual signal of the source speechsegment along with the mapped vocal tract transfer func-tion is used to select the appropriate LP residual frame forthe desired target speaker using the criterion discussed inSect. 4. For example, if rtk represents the selected LP resid-ual frame, then we also consider the previous LP residualframe rtk−1 along with rtk for concatenation. The initial 40 %of LP residual samples of rtk are retained and put on rightside of new target epoch and same number of samples fromthe tail of the rtk−1 are substituted on the left side of thenew target epoch. The remaining samples of rtk are resam-pled and placed in the rest of the interval between the targetepoch under consideration and its next epoch. This processis repeated for all the new target epoch sequences to gener-ate the target LP residual signal. The modified LP residualsignal along with the mapped vocal tract transfer functionand the new target epoch sequences are used to synthesizethe target speech signal on a frame by frame basis. To mit-igate the formant broadening effect, the perceptual filteringis applied to the synthesized speech frames (Ye and Young2004). It has been observed that this post-filtering reducesthe audible artifacts and improves the quality of the synthe-sized target speech signal.
7 Results and discussion
The performance of the proposed voice conversion systemis evaluated using both the objective and subjective mea-sures. The normalized cepstral distortion (NCD) (Mesbahiet al. 2007) and root mean square log-spectral distortion(SD) (Stylianou et al. 1998) are used for objective evaluationof the proposed systems. The result of objective evaluation issubstantiated by the perceptual evaluation. The mean opin-ion score (MOS) and ABX (A: source, B: target, X: neithersource nor target) tests are carried out for subjective evalua-tion of the proposed voice conversion systems.
The root mean Square error (RMSE) between the desiredand predicted LSFs is given by
RMSE =∑N
j=1
√∑di=1(xti − yti )
2
N(9)
where xti and yti are the predicted and desired LSF vectors,d is the dimension of the LSF vectors and N is the number
of speech frames. The normalized cepstral distortion and logspectral distortion are often used for performance evaluationof VC system. The NCD is given by
e(ct , ct
) =∑N
i=1∑13
j=2(ctij − ct
ij )2
∑Ni=1
∑13j=2(c
sij − ct
ij )2(10)
The 12th dimensional MFCCs obtained by discarding thefirst coefficient has been used for calculation of NCD. Thect , ct and cs represent the predicted target, desired targetand source MFCCs respectively. The root mean square log-spectral distortion (drms ) in dB is given as
d2rms = 1
2π
∫ π
−π
∣∣10 log10(S1(ω)
) − 10 log10(S2(ω)
)∣∣2dω
(11)
where, S1(ω) and S2(ω) are the power spectral density ofthe desired target signal and the synthesized target signalrespectively.
The results shown in Table 1 suggest that the perfor-mance of the proposed M-SVR based model is slightlybetter than the GMM based model for mapping the vocaltract characteristics between the speaker pairs. The RMSEbetween the desired and predicted LSFs for GMM basedmodel is less than that of M-SVR based model. But, theRMSE always do not give clear information about the spec-tral distortion. Therefore, the NCD and SD are used as ob-jective measure for evaluating the spectral distortion be-tween the desired and predicted acoustic spaces. The resultsshow that NCD and SD for M-SVR based model is slightly(within 10 to 25 %) less than that of the GMM based model.
The predicted LSFs are converted to LPCs. The roots ofthe LPCs in polar form contain the information about themagnitude and angle of the poles. The angular componentof the poles carry the information about the formant fre-quencies. The scatter plots for the first (F1), second (F2) andthird (F3) order formant frequencies for two different mod-els are shown in Fig. 3. The compact clusters formed aroundthe diagonal shows the efficacy of both the mapping func-tions. However, the clusters are slightly dense in case of M-SVR based model as compared to GMM based model. Thus,we can infer that the M-SVR based model can capture theformant structures of the desired target speaker in a bettermanner as compared to GMM based model. It has been ob-served that clusters are more aligned along the diagonal linefor higher order formant (F3) indicating speaker-specific in-formation is embedded in higher order formant. The spectralenvelopes for both the models are shown in Fig. 4. The de-sired target spectral envelope are plotted along with the pre-dicted spectral envelopes. It may be observed that the pre-dicted spectral envelopes follow the pattern of desired spec-tral envelope. Even though the location of the spectral peaks

Int J Speech Technol (2012) 15:419–431 427
Table 1 The RMSE, NCD and SD for VC systems designed using GMM and M-SVR based models (SP: Speaker pairs)
SP GMM M-SVR
RMSE NCD SD RMSE NCD SD
M1-F1 0.1075 0.5101 1.9183 0.1121 0.5008 1.9021
F2-M2 0.1006 0.6518 2.1994 0.1026 0.6508 1.9482
M1-M2 0.0941 0.6474 1.7344 0.0411 0.6199 1.3291
F1-F2 0.1540 0.6518 1.2286 0.0852 0.6313 1.1723
Fig. 3 Desired and predictedvalues of the formantfrequencies (a) first formantsusing M-SVR, (b) first formantsusing GMM, (c) secondformants using M-SVR,(d) second formants usingGMM, (e) third formants usingM-SVR, (f) third formants usingGMM
are almost similar in both the models but the amplitude ofthe spectral peaks seems to be more closer to desired patternin case of M-SVR based model as compared to GMM basedmodel.
The percentage change in predicted formant frequencies(Fp) with respect to desired formant frequencies (Fd ) is de-
noted as PDi (Rao 2010). It indicates the percentage of test
frames that lie within a given deviation and is given by
PDi = |Fdi − Fpi|
Fdi
× 100 (12)

428 Int J Speech Technol (2012) 15:419–431
Fig. 4 Desired and predictedspectral envelopes of the targetspeaker using M-SVR andGMM based models. (a) whenboth the models are working,(b) when both the models arenot working
The root mean square error (μR) is computed in terms ofpercentage of the mean of the desired values.
μR =
√∑i |Fd i−Fpi |2
N1
Fd
× 100 (13)
σE =√∑
i de2i
N1, dei = efi − μE, efi = Fdi − Fpi
,
μE =∑
i |Fdi − Fpi|
N1(14)
The parameter efi is the error between the desired andpredicted formant values. The deviation in error is dei , andN1 is the number of observed formant values of the speechframes.
The correlation coefficient between the desired and pre-dicted formant frequencies is given by
γ = V
σFd.σFp
, where V =∑
i |Fdi − Fd |.|Fpi− Fp|
N1
(15)
The quantities σFd, σFp are the standard deviations for
the desired and predicted formant values respectively, and V
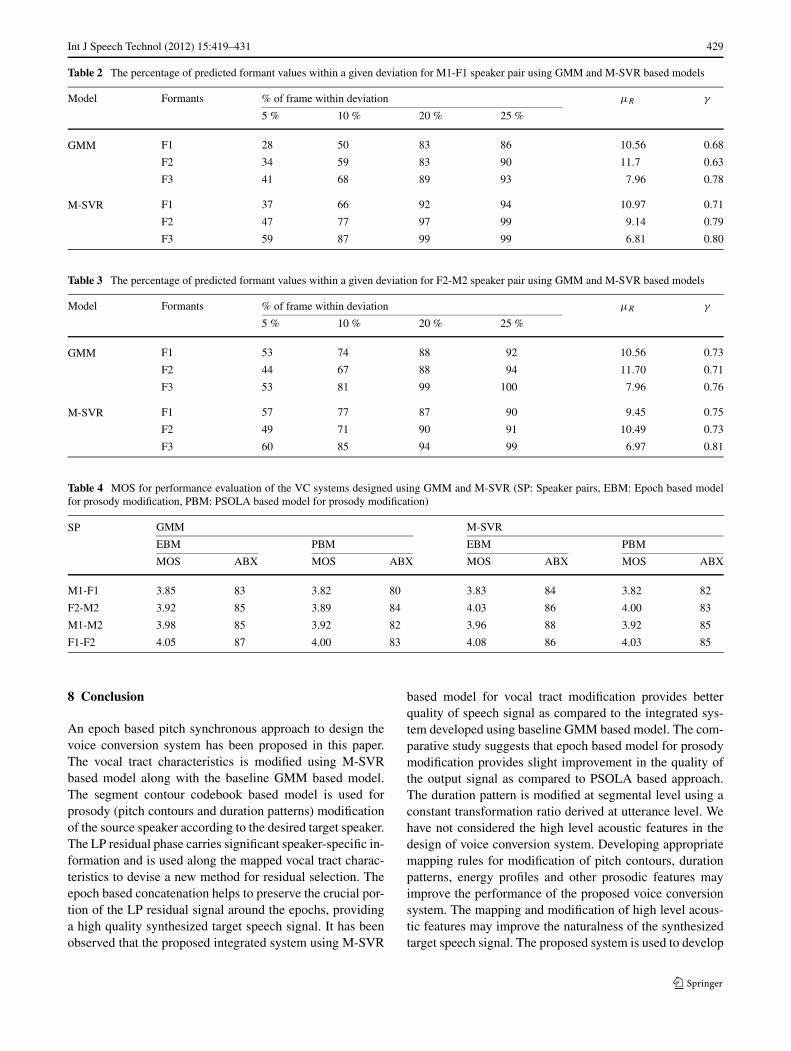
is the covariance between the desired and predicted formantvalues. The PDi , μR and γ for M1-F1 and F2-M2 speakercombinations are shown in Tables 2 and 3.
The proposed system is evaluated using listening tests toassess the quality of the synthesized signal and the identityof the desired target speaker contained in it. In MOS test, thelisteners are exposed to the synthesized target speech signalsto judge the quality on a 5-point scale. The rating 5 indi-cates the excellent match between the target speaker’s origi-nal speech signal and the synthesized speech signal. The rat-ing 4 indicates a good match between the two. The rating 3and 2 indicates fair and poor quality of the synthesized targetspeech signal, whereas the rating 1 indicates bad (very poor)match between the two utterances. In case of ABX test, thelisteners are exposed to original utterances of the source and
target speakers along with the synthesized speech signal togive their opinion towards a ternary decision.
The speech signals are synthesized using proposed in-tegrated system with M-SVR and GMM based models forvocal tract modification. The speech signals are also synthe-sized using M-SVR and GMM based model for vocal tractmodification combined with LP residual selection methodand PSOLA based model for pitch and duration modifi-cation. We have synthesized 20 sentences for each of thespeaker pairs. There are altogether 80 sentences availablefor perceptual evaluation of every speaker pair conversion.The MOS scores (Table 4) indicates the efficacy of the map-ping functions in transforming the speaker-specific acousticfeatures of the source speaker according to a desired targetspeaker. The variations in MOS score with respect to genderis due to the variation in the shapes of the vocal tract char-acteristics and intonation patterns between the source andthe target speakers. These variations are large in the case ofsource and target speakers belonging to different genders.The listeners are exposed to the original utterances of thesource and target speakers along with the synthesized speechsignal of the desired target speaker. The listeners has givenbetter ratings for M1-M2 and F1-F2 as compared to othertwo combinations. This may be due to better mapping ofthe vocal tract characteristics and prosodic features for intra-gender speakers as compared to cross-gender speakers.
In the proposed models, the listeners has shown slightpreferences towards the M-SVR based system as com-pared to GMM based voice conversion system. This maybe due to overly-smooth utterances obtained from the GMMbased models. The listeners have shown slight preferencetowards M-SVR/GMM based VC system developed usingepoch based model as compared to PSOLA based model forprosodic modification. The reason may be due to modifica-tion of pitch contours and duration patterns in the residualdomain rather than manipulating the speech signal directly.This may also be due to appropriately implanting the pitchcontours and duration patterns in the converted speech sig-nal. The ABX evaluation results suggest that the developedmapping functions can convert the identity of one speaker toanother with a suitable degree of acceptability.
Int J Speech Technol (2012) 15:419–431 429
Table 2 The percentage of predicted formant values within a given deviation for M1-F1 speaker pair using GMM and M-SVR based models
Model Formants % of frame within deviation μR γ
5 % 10 % 20 % 25 %
GMM F1 28 50 83 86 10.56 0.68
F2 34 59 83 90 11.7 0.63
F3 41 68 89 93 7.96 0.78
M-SVR F1 37 66 92 94 10.97 0.71
F2 47 77 97 99 9.14 0.79
F3 59 87 99 99 6.81 0.80
Table 3 The percentage of predicted formant values within a given deviation for F2-M2 speaker pair using GMM and M-SVR based models
Model Formants % of frame within deviation μR γ
5 % 10 % 20 % 25 %
GMM F1 53 74 88 92 10.56 0.73
F2 44 67 88 94 11.70 0.71
F3 53 81 99 100 7.96 0.76
M-SVR F1 57 77 87 90 9.45 0.75
F2 49 71 90 91 10.49 0.73
F3 60 85 94 99 6.97 0.81
Table 4 MOS for performance evaluation of the VC systems designed using GMM and M-SVR (SP: Speaker pairs, EBM: Epoch based modelfor prosody modification, PBM: PSOLA based model for prosody modification)
SP GMM M-SVR
EBM PBM EBM PBM
MOS ABX MOS ABX MOS ABX MOS ABX
M1-F1 3.85 83 3.82 80 3.83 84 3.82 82
F2-M2 3.92 85 3.89 84 4.03 86 4.00 83
M1-M2 3.98 85 3.92 82 3.96 88 3.92 85
F1-F2 4.05 87 4.00 83 4.08 86 4.03 85
8 Conclusion
An epoch based pitch synchronous approach to design thevoice conversion system has been proposed in this paper.The vocal tract characteristics is modified using M-SVRbased model along with the baseline GMM based model.The segment contour codebook based model is used forprosody (pitch contours and duration patterns) modificationof the source speaker according to the desired target speaker.The LP residual phase carries significant speaker-specific in-formation and is used along the mapped vocal tract charac-teristics to devise a new method for residual selection. Theepoch based concatenation helps to preserve the crucial por-tion of the LP residual signal around the epochs, providinga high quality synthesized target speech signal. It has beenobserved that the proposed integrated system using M-SVR
based model for vocal tract modification provides betterquality of speech signal as compared to the integrated sys-tem developed using baseline GMM based model. The com-parative study suggests that epoch based model for prosodymodification provides slight improvement in the quality ofthe output signal as compared to PSOLA based approach.The duration pattern is modified at segmental level using aconstant transformation ratio derived at utterance level. Wehave not considered the high level acoustic features in thedesign of voice conversion system. Developing appropriatemapping rules for modification of pitch contours, durationpatterns, energy profiles and other prosodic features mayimprove the performance of the proposed voice conversionsystem. The mapping and modification of high level acous-tic features may improve the naturalness of the synthesizedtarget speech signal. The proposed system is used to develop

430 Int J Speech Technol (2012) 15:419–431
intra-lingual, text-dependent voice conversion system. How-ever, the performance of the proposed system may be evalu-ated for text-independent and cross-lingual voice conversionsystem. Studies have been carried out to identify whethervoice conversion is a threat to speaker verification system.Research work has also been carried out to identify the ef-fect of voice conversion to trick the human ear or an auto-matic system (Perrot et al. 2007). It may be concluded thatthe advances in voice conversion techniques may open upnew avenues of research to study the attack and defense incase of speaker recognition system.
References
Abe, M., Nakanura, S., Shikano, K., & Kuwabara, H. (1988). Voiceconversion through vector quantization. In Proc. of int. conf. onacoustics, speech, and signal process (Vol. 1, pp. 655–658). NewYork: IEEE.
Akagi, M., & Ienaga, T. (1995). Speaker individualities in fundamentalfrequency contours and its control. In Proc. of Eurospeech (pp.439–442).
Arslan, L. M. (1999). Speaker transformation algorithm using segmen-tal code books (STASC). Speech Communication, 28(3), 211–226.
Baudoin, G., & Stylianou, Y. (1996). On the transformation of speechspectrum for voice conversion. In Proc. of int. conf. on spokenlanguage process (Vol. 3, pp. 1045–1048).
Chappel, D. T., & Hansen, J. H. (1998). Speaker specific pitch contourmodeling and modification. In Proc. of int. conf. on acoustics,speech, and signal process (Vol. 2, pp. 885–888). Seattle: IEEE.
Chen, Y., Chu, M., Chang, E., Liu, J., & Runsheng, L. (2003). Voiceconversion using smooth GMM and MAP adaptation. In Proc. ofEurospeech, Geneva (pp. 2413–2416).
Collobert, R., & Bengio, S. (2001). SVMTorch: support vector ma-chines for large scale regression problems. Journal on MachineLearning, 1, 143–160.
Cruz, F. P., & Rodríguez, A. A. (2004). Speeding up the IRWLS con-vergence to the SVM solution. In Proc. of int. joint conf. on neuralnetworks, IEEE, special session on least squares support vectormachines (Vol. 4, pp. 555–560).
Cruz, F. P., Camps, G., Soria, E., Perez, J., Vidal, A. R. F., & Rodriguez,A. A. (2002). Multi-dimensional function approximation and re-gression estimation. In Proc. of int. conf. on artificial neural net-works, Madrid, Spain (Vol. 2, pp. 757–762).
Cruz, F. P., Calzon, C. B., & Rodriguez, A. A. (2005). Convergenceof the IRWLS procedure to the support vector machine solution.Neural Computation, 17(1), 7–18.
Desai, S., Black, A. W., Yegnanarayana, B., & Prahallad, K. (2010).Spectral mapping using artificial neural networks for voice con-version. IEEE Transactions on Audio, Speech, and Language Pro-cessing, 18(5), 954–964.
Dhananjaya, N., & Yegnarayana, B. (2010). Voiced/nonvoiced detec-tion based on robustness of voiced epochs. IEEE Signal Process-ing Letters, 17(3), 273–276.
Drugman, T., Moinet, A., Dutoit, T., & Wilfart, G. (2009). Usinga pitch synchronous residual codebook for hybrid HMM/frameselection speech synthesis. In Proc. of int. conf. on acoustics,speech, and signal process (pp. 3793–3796). Taipei: IEEE.
Fernandez, M. S., Cumplido, M. P., García, J. A., & Cruz, F. P.(2004). SVM multi-regression for nonlinear channel estimationin multiple-input multiple-output systems. IEEE Transactions onSignal Processing, 52(8), 2298–2307.
Ghosh, P. K., & Narayanan, S. S. (2009). Pitch contour stylization us-ing an optimal piecewise polynomial approximation. IEEE SignalProcessing Letters, 16(9), 810–813.
Han, X., Zhao, X., Fang, T., & Jia, X. (2011). Research on EEDSVQof LSF parameters based on voiced and unvoiced classification.Journal of Convergence Information Technology, 6(1), 116–125.
Helander, E., Silen, H., Virtanen, T., & Gabbouj, M. (2012). Voiceconversion using dynamic kernel partial least squares regression.IEEE Transactions on Speech and Audio Processing, 20(3), 806–817.
Inanoglu, Z. (2003). Transforming pitch in a voice conversion frame-work. M.Phil. thesis, St. Edmund’s College University of Cam-bridge. July, 2003.
Joachims, T. (1999). Making large-scale SVM learning practical. InB. Scholkopf, C. Burges & A. Smola (Eds.), Advances in kernelmethods-support vector learning (pp. 169–184). Cambridge: MITPress.
Kain, A., & Macon, M. (1998). Spectral voice conversion for text-to-speech synthesis. In Proc. of int. conf. on acoustics, speech, andsignal process (Vol. 1, pp. 285–288). New York: IEEE.
Kain, A., & Macon, M. W. (2001). Design and evaluation of a voiceconversion algorithm based on spectral envelop mapping andresidual prediction. In Proc. of int. conf. on acoustics, speech, andsignal process (Vol. 2, pp. 813–816). New York: IEEE.
Kuwabara, H. (1984). A pitch-synchronous analysis/synthesis to inde-pendently modify formant frequencies and bandwidth for voicedspeech. Speech Communication, 3(3), 211–220.
Kuwabara, H., & Sagisaka, Y. (1995). Acoustics characteristics ofspeaker individuality: control and conversion. Speech Communi-cation, 16(2), 165–173.
Laskar, R. H., Talukdar, F. A., Paul, B., & Chakrabarty, D. (2011).Sample reduction using recursive and segmented data structureanalysis. Journal of Engineering and Computer Innovations, 2(4),59–67.
Lee, K.-S. (2007). Statistical approach for voice personality transfor-mation. IEEE Transactions on Audio, Speech, and Language Pro-cessing, 15(2), 641–651.
Lee, K. S., Youn, D. H., & Cha, I. W. (1996). A new voice personal-ity transformation based on both linear and non-linear predictionanalysis. In Proc. of int. conf. on spoken language process (pp.1401–1404).
Mesbahi, L., Barreaud, V., & Boeffard, O. (2007). GMM-based speechtransformation system under data reduction. In Proc. of int.speech comm. assoc., speech synthesis workshop (pp. 119–124).Bonn, Germany.
Mousa, A. (2010). Voice conversion using pitch shifting algorithm bytime stretching with PSOLA and re-sampling. Journal of Electri-cal Engineering, 61(1), 57–61.
Murthy, K. S. R., & Yegnanarayana, B. (2006). Combining evidencefrom residual phase and MFCC features for speaker recognition.IEEE Signal Processing Letters, 13(1), 52–56.
Narendranath, M., Murthy, H. A., Rajendran, S., & Yegnanarayana, B.(1995). Transformation of formants for voice conversion using ar-tificial neural networks. Speech Communication, 16(2), 206–216.
Perrot, P., Aversano, G., & Chollet, G. (2007). Voice disguise and auto-matic detection review and perspective. In Lecture notes in com-puter science (Vol. 4391, pp. 101–117). Berlin: Springer.
Platt, J. (1999). Fast training of support vector machines using sequen-tial minimal optimization. In B. Scholkopf, C. Burges & A. Smola(Eds.), Advances in kernel methods-support vector learning (pp.185–208). Cambridge: MIT Press.
Prasanna, S. R. M., Gupta, C. S., & Yegnanarayana, B. (2006). Extrac-tion of speaker-specific information from linear prediction resid-ual of speech. Speech Communication, 48(10), 1243–1261.
Rao, K. S. (2010). Voice conversion by mapping the speaker-specificfeatures using pitch synchronous approach. Computer Speech &Language Processing, 24(3), 474–494.

Int J Speech Technol (2012) 15:419–431 431
Rao, K. S., & Yegnanarayana, B. (2006). Prosody modification us-ing instants of significant excitation. IEEE Transactions on Audio,Speech, and Language Processing, 14(3), 972–980.
Rao, K. S., Laskar, R. H., & Koolagudi, S. G. (2007). Voice transfor-mation by mapping the features at syllable level. In Lecture notesin computer sciences (Vol. 4815, pp. 479–486). Berlin: Springer.
Stylianou, Y., Cappe, Y., & Moulines, E. (1998). Continuous prob-abilistic transform for voice conversion. IEEE Transactions onSpeech and Audio Processing, 6(2), 131–142.
Suendermann, D., Ney, H., & Hoege, H. (2003). VTLN-based cross-language voice conversion. In Proc. of automatic speech recog-nition and understanding workshop (pp. 676–681). New York:IEEE.
Sundermann, D., Bonafonte, A., Hoge, H., & Ney, H. (2004). Voiceconversion using exclusively unaligned training data. In Proc. ofACL/SEPLN 2004, 42nd annu. meeting assoc. for comput. Lin-guistics/XX congreso de la sociedad espanola para el proce-samiento del lenguaje natural, Barcelona, Spain, July, 2004.
Suendermann, D., Bonafonte, A., Ney, H., & Hoege, H. (2005a). Astudy on residual prediction techniques for voice conversion. InProc. of int. conf. on acoustics, speech, and signal process (pp.13–16). New York: IEEE.
Suendermann, D., Hoege, H., Bonafonte, A., Ney, H., & Black, A.(2005b). Residual prediction based on unit selection. In Proc. ofautomatic speech recognition and understanding workshop (pp.369–374). New York: IEEE.
Toda, T., Saruwatari, H., & Shikano, K. (2001). Voice conversion algo-rithm based on Gaussian mixture model with dynamic frequency
warping of STRAIGHT spectrum. In Proc. of int. conf. on acous-tics, speech, and signal process (Vol. 2, pp. 841–844). New York:IEEE.
Toth, A., & Black, A. W. (2008). Incorporating durational modifica-tion in voice transformation. In Proc. of interspeech, Brisbane,Australia (pp. 1088–1091).
Turk, O., & Arslan, L. M. (2006). Robust processing techniques forvoice conversion. Computer Speech & Language Processing,20(4), 441–467.
Verhelst, W., & Mertens, J. (1996). Voice conversion using partitions ofspectral feature space. In Proc. of int. conf. on acoustics, speech,and signal process (Vol. 1, pp. 365–368). New York: IEEE.
Wang, D., & Shi, L. (2008). Selecting valuable training samples forSVMs via data structure analysis. Neurocomputing, 71(13), 2772–2781.
Ye, H., & Young, S. (2004). High quality voice morphing. In Proc.of int. conf. on acoustics, speech, and signal process (Vol. I, pp.9–12). New York: IEEE.
Yegnanarayana, B., Reddy, K. S., & Kishore, S. P. (2001). Source andsystem features for speaker recognition using AANN models. InProc. of int. conf. on acoustics, speech, and signal process (Vol. 1,pp. 409–412). New York: IEEE.
Yegnarayana, B., & Veldhuis, R. N. J. (1998). Extraction of vocal-tractsystem characteristics from speech signals. IEEE Transactions onSpeech and Audio Processing, 6(4), 313–327.




















