
최종 연구보고서 고성능 인터넷 서비스를 위한 JAVA 기반 기술 ...
266
산.학.연 공동기술개발사업 최종 연구보고서 고성능 인터넷 서비스를 위한 JAVA 기반 기술 구축 (Java development system for high performance internet application) 연구수행기관 : 이화여자대학교 정보통신부
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of 최종 연구보고서 고성능 인터넷 서비스를 위한 JAVA 기반 기술 ...

산.학.연 공동기술개발사업
최종 연구보고서
고성능 인터넷 서비스를 위한 JAVA 기반 기술 구축
(Java development system for high performance internet
application)
연구수행기관 : 이화여자대학교
정 보 통 신 부

제 출 문
정보통신부 장관 귀하
본 보고서를 산.학.연 공동기술개발사업
고성능 인터넷 서비스를 위한 JAVA 기반 기술 구축 과제의 최종연구보고서로 제출합니다.
2000년 2월 18일
연구수행기관 : 이화여자대학교
연구개발책임자 : 조 동 섭
참여 연구원 강민숙
김창범
이연수
공문표
김은영
김혜연
한지선
이은영

요 약 문
1. 제 목
산.학.연 공동기술개발사업 고성능 인터넷 서비스를 위한 JAVA 기반 기술 구축 개발 과제
2. 연구개발의 목적 및 중요성
가. 연구개발의 목적
하드웨어 기술이 급변하면서 응용프로그램의 사용은 질적인 변화를 요구하고 있고 개발된
프로그램의 소스 코드의 재사용과 분배에 관한 시장 원리가 새로운 컴퓨터 시스템 환경을
요구하고 있다. 본 연구팀에서는 차세대가 요구하는 새로운 응용프로그램 환경을 조사 연구
하고, 차세대의 마이크로프로세서를 근간으로 128비트 아키텍처를 지향하는 하드웨어/소프
트웨어 연구를 목적으로 하였다. 본 연구의 목적을 다음과 같이 분류할 수 있다.
.Java 고성능 Architecture 연구
.Java 고성능 인터넷 서비스 개발 환경 구축
나. 연구개발의 중요성
Java기반 컴퓨터 환경은 현재의 어느 시스템보다 사용자에게 대한 친화력을 갖고 있으며
사용하기 쉬운 관리환경 및 개발환경을 제공한다. Java의 컴퓨팅 기술은 단순성, 보안성, 신
뢰성, 적응성 등의 특성 때문에 대형 컴퓨터로부터 스마트카드에 이르기까지 그 적용분야가
크게 확대되고 있다. 따라서 이에 관련된 기반 기술을 연구한다는 것은 해외 컴퓨터 업계보
다 많이 뒤쳐져 있는 Java관련 기술을 확보할 수 있는 계기가 될 수 있다.

시스템에 무관한 사용자 명령과 작업 지시의 실행이 Java나 여러 미들웨어의 사용을 통해
가능해지고 있다. 이와 같은 기술 독립적인 기계의 인터페이스는 매우 중요하다.
Java가 갖고 있는 잠재적인 가능성은 여러 표준을 적극 수용하는 인터넷 환경에서 더욱 두
드러진다. Java는 소프트웨어의 이식이 거의 필요 없는 새로운 소프트웨어의 개발을 주도
하고 있다. 사용자는 이제 시스템을 사는 것이 아니라 자기 업무 수행에 필요한 소프트웨어
를 사는 것이 된다. 결국 최종 사용자에서 하드웨어의 의존도를 줄여 가는 것이다. 따라서,
소프트웨어의 서비스에 많은 시간을 투여할 수 있으며 양질의 소프트웨어를 만들 수 있다.
3. 연구개발의 내용 및 범위
2차 년도 주요 연구 내용은 Java 고성능 Architecture 연구와 Java고성능 인터넷 서비스 개
발 환경 구축에 관한 연구이다. 1차 년도의 기본적 설계를 바탕으로 Java virtual Machine
설계, debugger의 구현, Java OS의 기능 연구 등의 고성능 아키텍처 구조 연구를 수행하고,
Database Java 환경, Web 환경 기반 DB 연동 환경, Java Web Server/Browser의 성능 개
선을 통한 Java 고성능 인터넷 서비스 개발 환경을 구축한다.
Java 고성능 Architecture 연구ㆍJava Virtual Machine 설계, 연구ㆍJava Interpreter/debugger 구현ㆍJava OS의 기능 연구
Java 고성능 인터넷 서비스 개발 환경 구축ㆍDatabase Java 환경 구축ㆍWeb 환경 기반 DB 연동 환경 구축ㆍJava Web Server/Browser 성능 개선

4. 연구개발 결과 및 활용에 대한 건의
가. 연구개발 결과
기존에 공개되어 있는 운영 체제들의 내부 구조를 연구하고 공개된 운영 체제 상에서 자바
가상 머신이 잘 수행되는 것을 테스트하였다. 자바 라이브러리 패키지를 추가함으로써 OS
의 기능을 확장하였다.
그리고 Java Web Server의 기능을 확장하여 인터넷 강의 시스템과 같은 특정한 목적의 시
스템에서 성능이 향상되도록 하였다. 즉 간단한 스크립트를 정의하여 쉽게 HTML파일을 생
성하고 브라우저만을 사용해 서버의 디렉토리 관리 기능을 수행할 수 있도록 하였다.
이동 에이전트 기술을 기존의 원격 프로시저 호출등의 방법처럼 지속적으로 많은 데이터를
주고받는 것이 아니기 때문에 성능이 그다지 좋지 않은 네트워크에서도 비용이나 자원을 효
과적으로 이용할 수 있다. 이러한 이동 에이전트의 장점을 분산 XML 문서 검색에 적용함
으로써 현재 XML 검색 시스템 구조의 개선하였으며 이를 통해 검색의 효율성을 다른 각
도에서 해결하였다.
또한 Security 부분에서는, 사용자가 원하는 security 정책을 세울 수 있도록 하여 security
의 다양성과 유연성을 보장하였고, 차후에 등장할 IPv6망에 적합한 application 작성을 가능
하게 하는 간단한 Java API를 설계하고 구현하였다.
나. 활용에 대한 건의
인터넷상에서 사용되는 최상의 서버와 클라이언트를 구축할 수 있다. 개발된 애플리케이션
은 요소 제품들로 판매될 수 있으며, 컴포넌트 기술을 적용하여 기존의 클래식에서 지원하
지 않는 부분들을 사용자에게 제공할 수 있다.
기대 효과

본 시스템은 기본적으로 Java로 되어 있는 시스템이기 때문에 어떠한 하드웨어에서도 동작
한다. 따라서 기존의 특정 시스템에 고정된 커널의 최하위 부분을 제외하고 모든 시스템이
같은 방식으로 동작하게 되므로 유지 보수를 위한 기술과 자금이 절약된다. 또한 일괄적인
인터페이스를 가지고 있으므로 사용자가 편리하게 사용할 수 있고 Java 언어 자체가 지원
하는 여러 가지 예외 상황의 기술과 메모리 관리 기법에 의해 시스템의 신뢰도가 증가할 수
있다. Java는 하드웨어나 소프트웨어 신기술의 복잡한 변화에 대응해 표준 개발 툴을 지원
해야 하므로 프로그램의 재사용률이 대폭 향상된다.

Summary
1. Subject
The industrial-educational cooperation project; Establishment of cutting edge Java
technology for high performing Internet service
2. Purpose and Content
Research on Java high-performance architecture
ㆍJava Virtual Machine research & design
ㆍJava Interpreter/debugger implementation
ㆍJava OS function research
Environmental set up for the Internet service using high preforming Java technology
ㆍimplementation of environment for the Java Database
ㆍimplementation of DB interlocking environment based on Web interface
ㆍJava Web Server/Browser performance improvement
3. Results
-Java OS which enhances the speed of Java processing is implemented by adding the
Java library to existing Java OS.
-Java Web Server which is tuned for specific-purpose system is implemented by
expanding features of general Java Web Server.
-Applying agent technology to distributed XML document searching system,
effectiveness of XML document searching
architecture is achieved.

-By reducing the number of network passing, the service became more effective.
-It allows users to develop their own security strategy and provides diversity and
flexibility of security.
-Java API which enables users to develop IPv6-supporting applications is implemented.
4. Expectation
This Java based system will work on any hardware plarform. Thus one can reduce the
cost of system maintenance. And it has a
consistent interface that provides convenience to the users. It will provide the better
reliability on the system because of
exception handing technology and its memory management method of Java language.
Java is less affected by the industry
shifting in hardware and software fields, so reusability of software will increase.

CONTENTS
1. Introduction
1.1 Research Background
1.2 Research Object
1.3 Research Scope
2. Content of Research
2.1 Java Virtual Machine research
2.2 Java Debugger research
2.3 Java Database search Engine research
2.4 Java Web Server/Browser research
2.5 Java O/S programming tools research
2.6 Java Application research
2.7 Java IPv6 Protocol and Security research
3. Conclusion of Research
3.1 Result of research on Java Debugger
3.2 Result of research on Java Database Search Engine
3.3 Result of research on Java WebServer/Browser
3.4 Result of research on Java Application
3.5 Result of research on Java IPv6 Protocol and Security

4. Conclusion
4.1Result of Research
4.2Achievement of Research Object and Self-estimation
4.3Research Performance
References

목 차
제 1 장 서 론
제 1 절 연구 배경
제 2 절 연구 목적
제 3 절 연구 범위
제 2 장 연구 내용
제 1 절Java 가상 머신 연구
제 2 절Java 디버거의 연구
제 3 절Java 데이터베이스 검색 엔진의 연구
제 4 절Java 웹 서버/브라우저의 연구
제 5 절Java 운영체제 프로그래밍 툴의 연구
제 6 절Java Application의 연구
제 7 절Java IPv6 프로토콜 및 Security 연구
제 3장 연구결과
제 1 절Java 디버거의 연구 결과
제 2 절Java 데이터베이스 검색 엔진의 연구 결과
제 3 절Java 웹 서버/브라우저의 연구 결과
제 4 절Java Application의 연구 결과
제 5 절 Java IPv6 프로토콜 및 Security 연구 결과

제 4 장 결과
제 1절 연구결과
제 2절 연구개발의 달성도 및 자체평가
제 3절 연구 성과
참고문헌

제 1장 서 론
제 1절 연구 배경
자바가 프로그래머 사이에서 대중화되고 있는 요즘, 자바로 실제 사용 가능한 애플리케이션
을 작성하는 것도 필요하겠지만, 자바로 만들어진 자바ㆍ운영체제나 가상 머신 등을 통해서
접할 수 있는 새로운 개념과 기술도 필요하다.
여기서 말하는 자바 운영 체제는 자바 프로그램을 직접 하드웨어 장치에 실행시키게 해주며
작고 효능이 높은 운영체제로 성능, 이식성, 동시동작, 네트워크 중심등의 면에서 유연성과
용이성을 제공한다. 성능이나 크기에 따라서 다양한 기능을 제공할 수 있으며 적은 크기로
도 큰 영향력을 발휘할 수 있다.
또한 Java(이하 자바)는 썬 마이크로프로세서 사에서 개발한 프로그래밍 언어이다. 그러나
단순한 언어에 그치지 않고 Java Virtual Machine(이하 자바 가상 머신)이란 개념을 도입하
여 장치에 무관하게 프로그램을 실행할 수 있게 만들었다. 특히 최근 인터넷의 폭발적인 발
전을 등에 업고 네트워크상에서 서로 물려 있는 각양각색의 컴퓨터들에서 모두 실행 가능하
다는 점이 자바가 인기 있는 원인이다.
자바 가상 머신이란 개념은 프로그램이 실행될 때 하드웨어의 CPU를 사용하는 것이 아니
라 어떤 가상적인 머신을 사용한다는 것을 의미한다. (물론 실제적으로는 하드웨어 CPU를
통해서 실행된다.) 그러므로 특정 머신에 관계없이 어떤 머신에게도 실행이 가능하게 된다.
즉 일종의 소프트웨어적인 머신 되는 것이다. 이 자바 가상 머신은 자바 언어에 대헤서는
알지 못하며 프로그램을 실행하기 위해 8비트 문자열로 구성되어 있는 클래스 파일이라는
형태로 된 바이트 코드를 확인ㆍ해석하여 실행한다.
또한 자바 운영체계의 다른 부분을 위한 기반구조를 제공한다. 또 예의사항을 처리하며 시
스템에 있는 거의 모든 메모리들을 관리하고 여러 쓰레드를 동시에 실행하기 위해 필요한
처리를 한다.

그러나 위와 같은 자바 가상 머신의 장점에도 불구하고 자바 언어 사용이 활발하지 않은 이
유가 있다. 애플릿을 실행하는 경우 웹으로부터 다운로드받아 자바 가상 머신을 수행시켜
브라우저 상에서 애플릿을 보는 과정까지가 상당히 긴 시간을 필요로 한다. 네트워크상의
문제도 있으나 자바 가상 머신 자체의 문제점도 있다. 본 연구의 목적은 기존의 자바 가상
머신의 연구를 통해 문제점들을 찾아내고 개선하여, 고성능 인터넷 서비스를 위한 자바 기
반 기술의 확보를 위한 자바 가상 머신의 효율적인 운영을 위한 설계를 하는 것이다.
자바 운영 체제나 가상 머신 이외의 새로운 기술을 살펴보면 최근 급격한 분산 컴퓨팅 환경
으로의 변화에 적응하기 위한 여러 가지 기술이 발전되어 왔다. 이동 에이전트(Mobile
Agent) 기술은 네트워크상에서 로드부담을 줄이기 위해 오브젝트 패싱(Object Passing)이라
는 새로운 개념을 적용시키므로써 분산된 데이터베이스를 관리를 하는 방식이며,
XML(extensible Markup Language)은 W3C(World Web Consortium)에서 표준화한 웹 기
반의 구조화된 문서를 기술하는 방법에 대한 표준이다. xml문서는 구조적 특성상 네트워크
상에서 분산되어 있는 데이터 베이스로 간주될 수 있는데, 이러한 분산된 환경에서의 xml문
서를 검색을 위해 자바 기반의 이동 에이전트 기술을 적용시키므로써 증가되고 있는 XML
문서의 효율적인 저장 및 검색 시스템에 관한 연구를 제시할 수 있다.
이동 에이전트의 개념은 프로세스간의 통신(IPC: Inter-Process Communication)으로 분산처
리를 하는 것이 아니라 실행 프로그램이 네트워크를 이동하며 목적을 수행하는 기술이며,
소프트웨어 에이전트(Software Agent), 혹은 지능 에이전트(Intelligent Agent)로 총칭되는
에이전트 기술중의 한 분야이다. 통신망을 이용한 정보의 교류가 활성화되고, 컴퓨터 네트워
크에 저장된 정보의 내용이 폭발적으로 증가하면서, 이동 에이전트 기술은 사용자 대행 능
력과 유연한 서비스구성 기능 때문에 관심의 대상이 되고 있다. 전통적인 클라이언트 서버
모델에서 클라이언트와 서버간의 대화가 많이 필요한 경우에는 상대적으로 느린 통신이 처
리시간의 대부분을 차지하게 되는데 이동 에이전트는 중간에서 사용자가 하는 일을 대신하
므로써 느린 통신처리 문제를 해결한다.

이동 에이전트 모델은 전통적인 클라이언트/서버 모델의 확장형으로서 특히 복잡한 시스템
개발에 적합하다.
분산된 XML문서를 효율적으로 검색하고 응용하는데 새로운 이동 에이전트 기술을 적용하
여 기존의 검색 시스템을 대체할 수 있는 보다 효율적인 검색 시스템에 관한 연구가 필요
하다.
플랫폼 독립적인 JAVA기반의 이동 에이전트 기술을 도입하여 차세대 검색 시스템을 통합
운용 관리할 수 있는 기반 기술을 확보하고자 한다.
그리고 자바 애플릿과 같은 실행 가능한 응용(executable contents)은 네트워크를 통해 전송
(download)되어 원격지에 있는 사용자의 컴퓨터에서 실행되어지는데 이와 같은 자바 기술
은 네트워크를 기반으로 하는 컴퓨팅의 능력을 증가시키지만 새로운 보안 문제를 발생시킨
다. 이것을 자바 security라고 한다. 자바 security가 심각하게 부각되고 있는 이유는 자바
자체가 웹 기반 언어인 데다가, 이것은 코드 자체가 다운로드 되기 때문에 악의적인 애플릿
을 실행시켰을 경우 사용자의 컴퓨터에 치명적인 손상을 입힐 수 있기 때문이다. 이러한 자
바 security 문제를 해결하기 위해서는 썬사 및 security 연구기관의 노력이 있어 왔다. 이러
한 노력의 일환으로 security 기술은 단순히 방어적인 태도에서 벗어나 security manager,
메시지 다이제스트, 전자서명 등 자바 라이브러리에서 제공하는 다양한 security 기술을 이
용하여 시스템 자원 접근에 있어 유연하고 다양한 방법을 제시하고 있다.
따라서, 본 연구에서는 security 요구사항을 분석하고, 현재 자바에서 제공되고 있는
security 기술에 대해 자세히 논한 후에, 이러한 security 기술을 이용한 웹 브라우저 상에서
의 security 구현을 제시하겠다.

제 2절 연구목적
본 연구의 목적은 초고속 환경에서의 자바의 새로운 개념과 기술을 개발하고 발전시키기 위
해서 Java 운영 체제, Java가상 머신, Java 데이터베이스 검색 엔진, Java 웹 서버, Java 웹
브라우저, Java Security등에 관한 연구를 하고 연구 내용을 기반으로 각각을 설계하고 구
현하는 것을 목표로 한다. 세부 목표와 평가 착안점을 살펴보면 다음과 같다.
1. 연구개발 목표
-Java 가상 머신의 설계, 연구
-Java Debugger의 연구 및 구현
-Database Java 환경구축
-Java Web Server/browser 성능 개선
-Portable Java OS 설계
-Java Security 구현
2. 연구개발 평가 착안점
-Java 시스템 기능의 분석
-Java 시스템의 환경 구축 정도 조사
-Java 가상 머신의 기능
-Java Database 환경의 구축
-Java Web server/browser의 개선된 성능
-Java OS의 구현
-Java Security
3. 연도별 목표 및 내용
이번 연차의 주요 연구 범위는 Java 가상 머신의 기능 연구와 구형, Java Database 환경의
구축, Java Web server/browser의 성능 개선, Java OS의 구현이었다. 즉 시스템적 측면에
서 Java를 이해하고 Java전용 컴퓨터란 무엇인가를 이해하며 Java 언어 체계를 현재의 시
스템보다 좀 더 효율적으로 수행할 수 있는 하드웨어를 설계한다. 이러한 하드웨어에 적합
한 Java 가상 머신의 설계도 되어져야 한다.
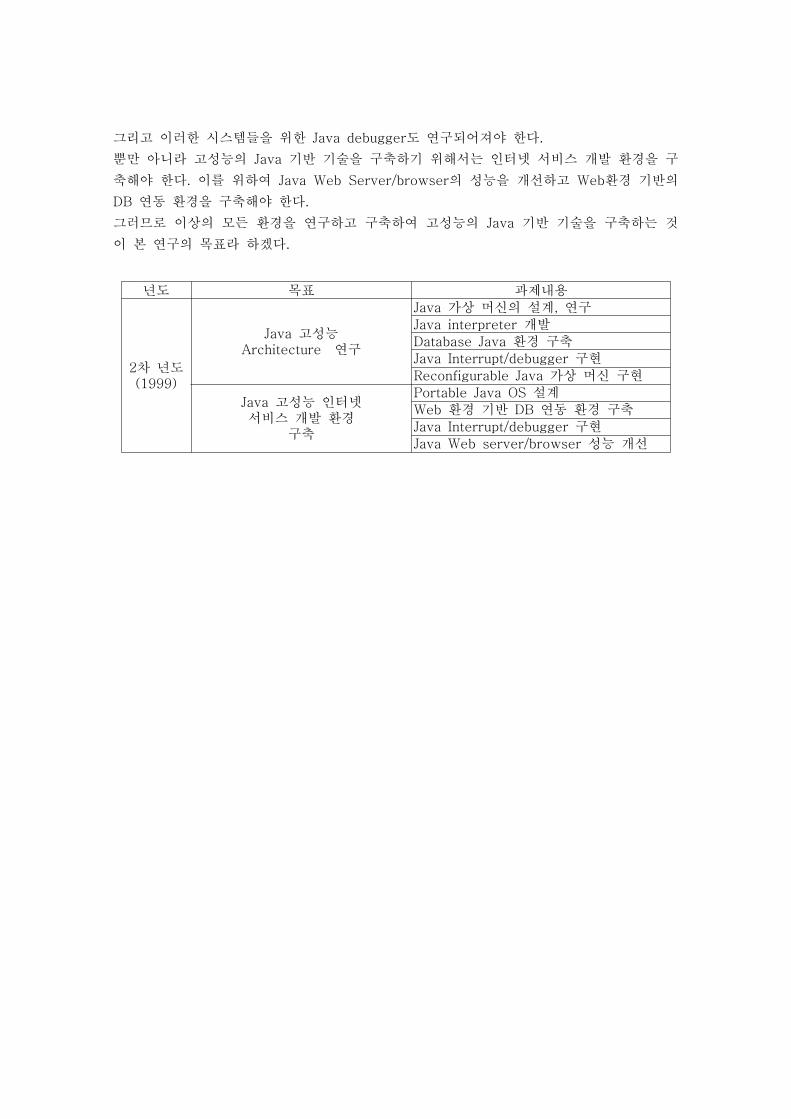
그리고 이러한 시스템들을 위한 Java debugger도 연구되어져야 한다.
뿐만 아니라 고성능의 Java 기반 기술을 구축하기 위해서는 인터넷 서비스 개발 환경을 구
축해야 한다. 이를 위하여 Java Web Server/browser의 성능을 개선하고 Web환경 기반의
DB 연동 환경을 구축해야 한다.
그러므로 이상의 모든 환경을 연구하고 구축하여 고성능의 Java 기반 기술을 구축하는 것
이 본 연구의 목표라 하겠다.
년도 목표 과제내용
2차 년도(1999)
Java 고성능Architecture 연구
Java 가상 머신의 설계, 연구
Java interpreter 개발
Database Java 환경 구축
Java Interrupt/debugger 구현
Reconfigurable Java 가상 머신 구현
Java 고성능 인터넷서비스 개발 환경
구축
Portable Java OS 설계
Web 환경 기반 DB 연동 환경 구축
Java Interrupt/debugger 구현
Java Web server/browser 성능 개선
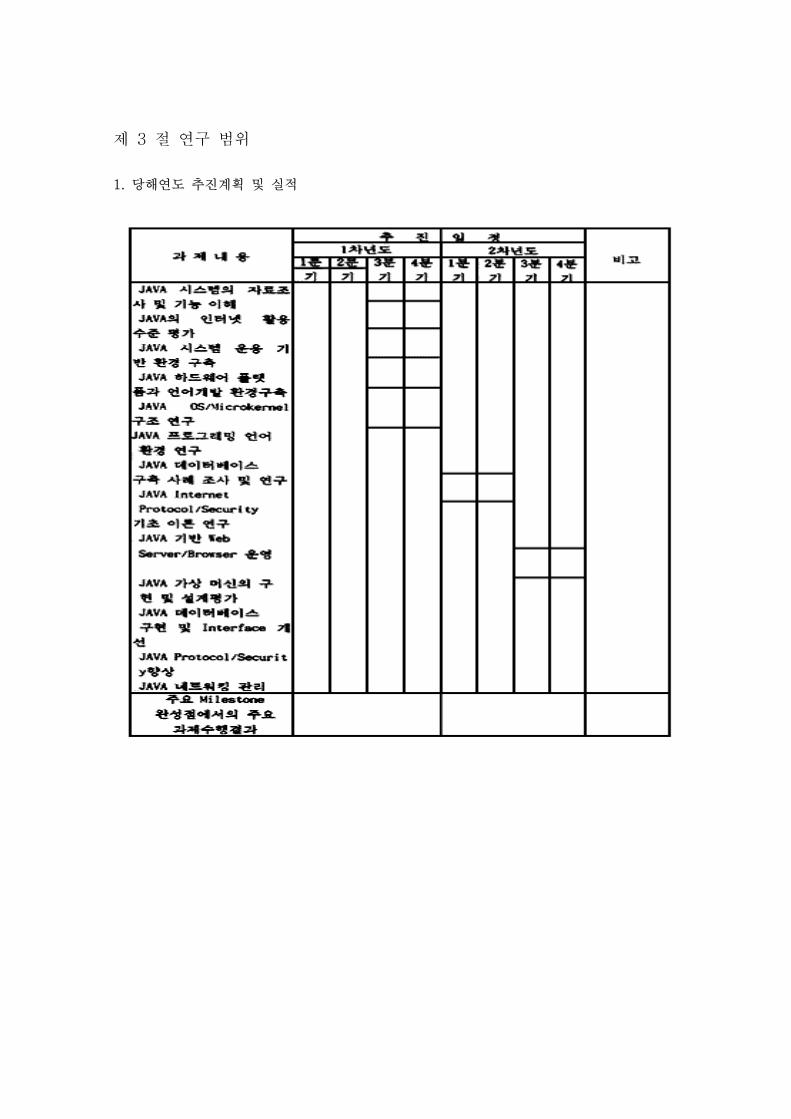
제 3 절 연구 범위
1. 당해연도 추진계획 및 실적
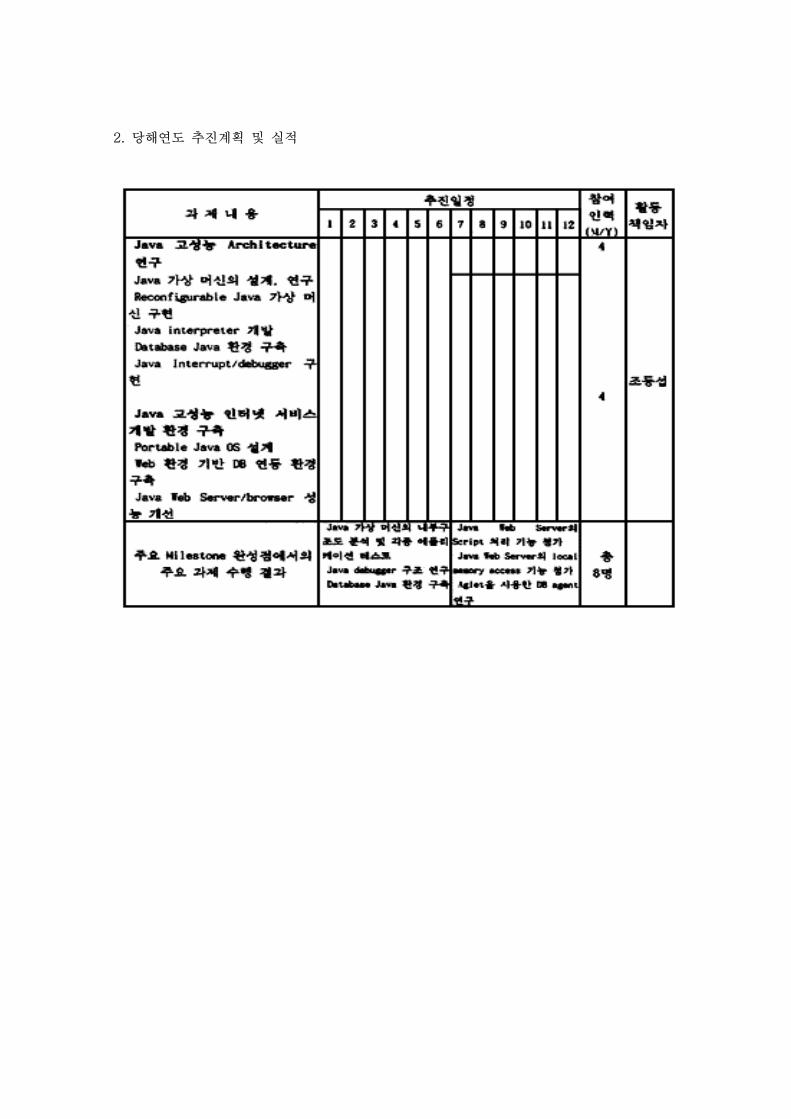
2. 당해연도 추진계획 및 실적

3. 당해연도 세부목표의 달성도
목 표 계 획 실 직 달성도(%)
Java 고성능Architecture 연구Java 가상 머신의 설계, 연구Reconfigurable Java가상 머신 구현Java interpreter 개발Database Java 환경 구축Java Interrupt/debugger 구현Java Security 구현zJava 고성능 인터넷서비스 개발 환경 구축Portable Java OS 설계Web 환경 기반 DB 연동환경 구축Java Web Server/browser 성능 개선
Java 고성능Architecture 연구Java 가상 머신의 설계, 연구Reconfigurable Java가상 머신 구현Java interpreter 개발Database Java 환경 구축Java Interrupt/debugger 구현Java Security 구현 Java 고성능 인터넷서비스 개발 환경 구축Portable Java OS 설계Web 환경 기반 DB 연동환경 구축Java Web Server/browser 성능 개선
Java 고성능Architecture 연구Java 가상 머신의 설계, 연구Reconfigurable Java가상 머신 연구, 조사Java interpreter 개발Database Java 환경 구축Java Interrupt/debugger 연구 조사Java Security 구현 Java 고성능 인터넷서비스 개발 환경 구축Portable Java OS 연구Web 환경 기반 DB 연동환경 구축Java Web Server/browser 성능 개선
90%
90%

제 2 장 연구 내용
제 1 절 Java 가상머신 연구
1. 자바 가상 머신
가. 자바 가상 머신의 소개
자바 네트워크 기반인 자바 가상 머신은 장치 독립적이고, 보안성이 뛰어나다. 또한 자바 가
상 머신의 네트워크 이동성은 자바의 네트워크 기반구조의 프로그램을 지원한다.
자바 가상 머신의 주된 기능을 클래스 파일을 로드(load)하고, 그 안의 바이트코드들을 실행
시킨다. [그림 2-1-1]에서의 같이 클래스 로더는 프로그램이나 자바 API로부터 클래스 파일
을 로드하는 역할을 한다. 소프트웨어적 자바 가상 머신의 실행 엔진의 경우 한번에 한 바
이트 코드씩 인터프리트하는 단순한 실행 엔진이며, 어떤 메소드가 처음 호출되었을 때 그
바이트 코드가 원시 기계어 코드로 컴파일 되어 캐쉬 되고, 그 메소드가 재귀 호출되었을
때는 이를 재사용 하여 보다 빠르지만 메모리 요구가 더 큰 JIT 컴파일러를 사용한다. 하드
웨어적 자바 가상머신의 실행 엔진은 칩에 내장되어 있다.

[그림 2-1-1 Host O/S위에 소프트웨어로 구현된 자바가상머신]
자바 프로그램은 원시 메소드를 호출함으로써 호스트(host)와 상호작용을 한다. 자바의 두
가지 메소드는 자바 메소드와 원시 메소드가 있다. 자바 메소드는 자바 언어로 작성되어 바
이트 코드로 컴파일 되고, 클래스 파일에 저장되며, 장치에 독립적이다. 원시 메소드는 다른
언어 즉, C, C++ 등의 언어로 작성되어 특성 프로세서의 원시 기계어 코드로 컴파일 된다.
이는 동적 링크된 라이브러리에 저장되며, 장치에 의존적이다. 실행중인 자바 프로그램이 원
시 메소드를 호출하면 자바 가상 머신은 그 원시 메소드를 가진 동적 라이브러리를 읽어서
그를 호출한다.

나. 자바 가상 머신의 구조
자바 가상 머신의 내부구조는 [그림 2-1-2]과 같다.
[그림 2,-1-2 자바 가상 머신의 내부 구조]
(1) 자바 가상 머신 인스턴스
자바 가상 머신 인스턴스는 서브시스템, 메모리 영역, 데이터 타입, 명령어로 구성되어있다.
클래스 로더 서브시스템은 타입(클래스, 인터페이스)을 읽어들이는 메카니즘이다. 실행 엔진
은 불려진 클래스의 메소드에 포함되어 있는 명령어를 수행하는 책임을 가지고 있다. 실행
데이터의 접근을 수행함으로써 프로그램 실행에 필요한 메모리를 구성한다. 모든 자바 가상
머신의 일부분에는 실행 데이터 영역이 있는데도 불구하고 스펙은 추상적이다. 스펙이 추상
적인 성질을 가지므로 다양한 컴퓨터와 디바이스에 자바 가상 머신을 구현하기 쉽다.
(2) 서브시스템
클래스 로더 서브시스템에서 원시 클래스 로더는 가상 머신 구현의 부분이다. 클래스 로더
객체는 자바 애플리케이션이 실행되는 부분이고, 다른 클래스 로더에 의해 로드된 클래스들
은 각각의 이름 공간에 놓여진다.

클래스 로더 서브시스템은 java, lang 라이브러리로부터의 몇몇 클래스를 포함한다. 예를 들
면 클래스로더 객체는 java, lang. ClassLoader로부터 계승된 정규 자바 객체이다. 모든 객
체, 클래스 로더 객체, 클래스의 인스턴스들은 힙에 놓여지고, 로드된 타입의 데이터는 메소
드 영역에 놓여진다. 클래스 로더 서브시스템이 해야할 일은 [그림2-1-3]과 같다.
[그림2-1-3 클래스 로더 서브시스템이 일하는 과정]
우선 로딩(Loading)을 한다. 로딩이란 바이너리 데이터(타입)를 찾고 가져오는 것이다. 그
다음으로 링킹(Linking)을 한다. 링킹이란 중요한 타입의 정확성을 보증하고, 변수를 메모리
에 할당하고 기본 값으로 초기화하며 심볼 참조를 직접 참조로 변형하는 것이다. 끝으로 초
기화를 해야한다. 초기화란 클래스 변수를 고유한 시작 값으로 초기화하는 자바 코드를 불
러내는 것이다.
원시 클래스 로더는 클래스와 인터페이스를 인식하고 로드한다. 모든 자바 가상 머신 구현
은 원시 클래스 로더를 가지며, 어떻게 신뢰받는 클래스(자바 API의 클래스 포함)를 로드
할지 알고 있다. 클래스(type name. class)는 클래스패스에 나온 순서대로 찾고, 없으면 부
디렉토리를 찾는다. 예를 들어 java, lang, Object를 찾는다면, 자바라는 부디렉토리에서
Object, class를 찾는다.
클래스로더 객체는 클래스 로더 클래스에 포함되어 있다.
클래스 로더 클래스에는 3개의 메소드가 있다.
첫째, defineClass()이라는 메소드로서 배열 안에 오프셋에서 시작해서 길이 바이트만큼 바
이너리 데이터가 자비 클래스 애플리케이션에 합치는 메소드, 자바 가상 머신은 이 메소드
에서 메소드 영역에 가져 가게될 새로운 타입이 발생할 수 있다는 것을 확인해야 한다.

둘째, findSystemClass()라는 메소드로서 가상 머신으로 하여금 원시 클래스 로더를 경유하
여 명령된 타입을 로드 하도록 요구한다. 타입을 성공적으로 로드하면 타입을 표현하는 클
래스 객체로의 참조를 반환한다.
셋째, resolveClass()라는 메소드로서 클래스 인스턴스로의 참조를 받는다. 클래스 인스턴스
가 링크 되고 초기화되어 다시 표현된 타입을 발생시킨다. 클래스 인스턴스를 반환한다.
(3) 메모리 영역
클래스 로더마다 각자의 이름 공간을 유지한다. 클래스 로더가 각각의 이름 공간을 갖기 때
문에 하나의 자바 애플리케이션은 같은 이름을 가진 여러 개의 타입을 로드할 수 있다. 따
라서 자바 가상 머신 인스턴스 안에서는 같은 이름을 가진 여러 타입을 구분할 수 없다. 만
약 같은 이름의 여러 타임이 다른 이름 공간에 로드되면, 그 타입을 로드한 클래스 로더의
정체성은 그 타입을 유일하게 구별하기 위해 필요하게 된다.
로드된 타입들은 메소드 영역이라고 불리는 메모리의 논리적 영역에 저장된다. 타입 정보를
내부적으로 저장하는데는 big-endian또는 little-endian 방식이 사용된다. (설계자가 시설의
속도와 압축성을 고려하여)모든 쓰레드가 같은 메소드 영역을 공유하기 때문에 메소드 영역
에 접근할 때 쓰레드가 안전 해야한다. 예를 들어 만약 두 쓰레드가 라바(Lava)라는 클래스
를 찾았는데 아직 로드되지 않았다면 하나의 쓰레드만 그 클래스를 로드하는 것을 허가받아
야 한다. (다른 하나는 기다려 한다.)
메소드 영역도 가비지 수집이 되어야 한다. 왜냐하면 클래스 로더 객체를 통해 자바 프로그
램이 동적으로 확장되기 때문이다. 메소드 영역에 저장되는 것들은 타입 이름, 타입의 상위
클래스, 타입이 클래스인지 인터페이스인지, 그 타입 검증자(public, abstract, final)등의 타
입정보, 타입에 의해 사용되는 상수의 정렬된 집합의 상수 저장소 (예를 들어
constant_String의 tag =0, constant_Int =1, ... 와 같은 것을 말한다.), 타입 안에서 선언된
필드에 대해 필드 이름, 타입, 수정자 등의 필드 정보 등이 있다.

또 타입 안에서 선언된 메소드에 대해 이름, 결과 타입, 파라메터, 검증자 등의 메소드 정보
가 있다. 이것은 메소드가 추상화나 원시가 아닌 경우에는 메소드의 바이트 코드 등을 더
포함한다. 클래스의 모든 인스턴스가 공유하는 클래스 변수들, 클래스 로더 객체를 거쳐 로
드된 타입에 대해 자바 가상 머신은 그 타입을 로드한 클래스 로더 객체의 참조를 저장해야
한다. 따라서 하나의 타입이 다른 타입을 참조할 때 자바 가상 머신은 그 타입을 로드한 클
래스 로더에게 참조 타입을 요구하는 클래스 로더에 대한 참조 등의 더 있다. 그리고 클래
스 로더에 대한 참조도 있는데. 예를 들면 public static class forname("java, lang, Object")
이 java, lang, Object 로의 참조를 얻는 것을 말한다.
타입이 현재 이름 공간에 있는 한 forname()을 사용하여 클래스 참조를 얻을 수 있다. 뿐만
아니라 메소드 테이블들은 빨리 접근할 수 있게 모든 인스턴스 메소드로의 직접 참조를 배
열로 만들어 놓았다. 메소드 영역 사용 예는 main()에서 볼 수 있는데 main()을 실행하기
잔에 애플리케이션에 사용되는 모든 클래스가 로드되기를 기다리지 않고, 필요 할 때 로드
한다.
(가) 상수 저장소 해석 - Volcano의 상수 저장소에서 심볼 참조 “Lava"의 클래스를 데이터
포인터로 대신하는 것.
(나) 이제 새로운 Lava 객체를 위한 memory를 할당한 준비가 됨.
(다) Lava 객체에 필요한 heap 공간을 알아낸다. (Lava 데이터 포인터를 사용한다)
(라) speed를 0으로 초기화한다. 다른 모든 변수를 초기화함.
(마) main()에서 Lava 객체로의 참조를 스택에 푸시 ( 이 참조는 speed를 5로 초기화하는데
쓰이고, 참조된 Lava 객체에서 flow() 메소드를 불러내기 위해서도 쓰인다.)
모든 쓰레드들이 공유하는 영역은 타입과 메them 정보, 클래스 변수등이 사용하는 메소드
영역, 모든 객체들이 사용하는 힙을 들 수 있다.

각각의 쓰레드에 유일한 영역에는 자바 메소드 (원시 메소드가 아닌)를 실행중이라면 다음
에 실행될 명령어를 가리키는 pc 레지스터, 쓰레드마다 포함된 자바 메소드 상태를 저장하
는 자바 스택이 있다. 자바 스택의 경우 지역 변수, 파라메터, 결과 값, 중간 계산결과 산출
등에 사용되며, 쓰레드가 메소드를 호출하면 새로운 프레임을 그 쓰레드의 자바 스택에 푸
시 한다. 레지스터가 없어서 중간 계산결과를 자바 스택에 저장하기도 한다. 원시 메소드 스
택에는 원시 메소드의 포함상태를 저장한다.
자바 가상 머신 인스턴스에는 모든 쓰레드가 공유하는 하나의 힙만 존재한다. 하나의 애플
리케이션 안에 있는 쓰레드사이에서는 힙 데이터의 접근의 적당한 동기화가 필요하다. 힙에
서 일어나는 일은 가비지 컬렉션, 객체표현, 배열표현 등이 있다. 가비지 컬렉션은 현재 실
행중인 애플리케이션에 의해 더 이상 참조되지 않는 객체가 사용하는 메모리를 회수한다.
그러므로 힙 분할을 줄이기 위해 객체를 이동한다. 힙을 유지하기 위한 방법으로는 항상 일
정량의 메모리를 확보하는 방법이 있지만 고정된 사용 가능한 힙 영역이 없으면
OutOfMemory 예외에 빠진다는 단점이 있다. 객체로의 참조가 자바 스택, 힙 메소드 영역,
원시 메소드 스택 등에 모두 존재하기 때문에 가비지 컬렉션이 어렵다. 객체표현은 handle
pool과 객체 pool로 나눔으로써 힙 분할을 줄인다는 장점이 있다. 그러나 객체의 인스턴스에
접근할 때마다 포인터를 두 번씩 참조해야한다는 단점이 있다. 객체 데이터를 한 곳에 모아
두는 방법이 있는데 이것은 포인터를 한 번만 참조하면 된다는 장점과 힙 분할을 줄이기 위
해 객체를 옮기는 것이 복잡하다는 단점이 있다. 메소드 테이블로의 포이터를 가지는 방법
은 동적 바인딩이 필요가 없기 때문에 시간이 적게든다는 장점은 있으나 공간이 많이 필요
하다는 단점이 있다. 공유 데이터에 접근하기 위해 객체 잠금이 필요하다. 배열표현은 힙에
서 배열을 표현하기 위한 방법으로서 1차원 정수 배열은 ‘[Ⅰ‘ 와 같이 3차원 바이트 배열은
’[[[B'와 같이 표현한다.
자바 스택은 새 쓰레드가 생성되면 그에 대한 새 자바 스택이 자바 가상 머신에 의해 생성
되고 자바 스택은 쓰레드의 상태를 분산 프레임에 저장하며 연산으로는 푸시, 팝 등이 있다.

현행 메소드는 쓰레드에 의해 현재 수행중인 메소드를 말한다. 현행 프레임은 현행 메소드
에 대한 스택 프레임, 스택 프레임에 저장된 데이터에 대한 연산은 여기에서 수행된다. 현행
클래스는 현행 메소드들을 정의하고 있는 클래스이고, 현행 상수 저장소는 현행 메소드들을
정의하고 있는 클래스이고, 현행 상수 저장소는 현행 클래스의 현행 풀, 메소드 수행 시 자
바 가상 머신이 현행 클래스를 유지, track하는 곳이다.
스택 프레임은 자바 스택을 관리하는 데이터 구조로서 지역 변수들, 연산자 스택, 프레임 데
이터 세 부분으로 구성되어진다. 자바 가상 머신은 자바 메소드를 호출할 때, 지역 변수가
연산자 스택에서 그 메소드에 의해 요구되는 워드 수를 결정하기 위해 클래스 데이터를 확
인한다. 그 메소드에 알맞은 크기의 스택 프레임을 생성하고 이를 자바 스택에 푸시 한다.
지역 변수들의 경우는 스택 프레임을 시작하고 호출한 메소드의 파라메터들을 가진다. 그리
고 메소드에서 지역적으로 명시된 변수들이 할당된다.
(4) 데이터 타입
데이터 타입으로는 크게 초기 타입, 참조 타입으로 나눌 수 있다. 초기 타입은 참조하는 객
체가 없는 값이고 참조 타입은 객체를 참조하는 값이다. 불리언 타입은 원시 타입에 포함되
지 않는다. boolean이 포함된 연산은 int로, 불리언의 배열은 바이트 배열로 표현된다. 워드
크기는 long, double을 제외한 모든 타입을 포함할 수 있어야 한다. 2워드는 long, double을
포함할 수 있어야 한다. 따라서 워드 크기를 적어도 32비트로 해야한다.
런타임 데이터 영역은 워드의 추상화 개념에 기초한다. 예를 들면 자바 스택 프레임 - 지역
변수와 연산자 스택 - 은 워드로 정의된다.
프로그램 카운터는 수행 프로그램의 각 쓰레드마다 존재한다. 이것의 생성시기는 쓰레드가
시작될 때 생성된다. 크기는 1 워드이고, 이것의 내용은 현재 그 쓰레드에 의해 수행되는 명
령어의 주소가 있다. (원시 메소드 수행시, PC값은 정해지지 않음)

다. 자바 바이트 코드 해석
우선 클랙스 파일의 바이트코드를 원시 로더에 의해서나 클래스로더 객체에 의해 얻는다.
원시 로더는 가상 머신의 일부로서, 믿을 수 있는 클래스, 자바API의 클래스들을 대개 지역
하드로부터 읽는다. 클래스 파일이 클래스 로더에 의해 읽혀져서 사용되어 지는 과정은 [그
림 2-1-4]와 같다.
[그림 2-1-4 자바 바이트코드의 해석과정]
ClassLoader 객체는 자바 애플리케이션이 실행 시에 설치되고, 네트워크를 통해 다운로드받
는 동의 일반적 방법으로 클래스들을 읽는다.
그 다음 클래스 파일을 링킹 한다. 링킹 한다는 것은 바이트 코드를 자바 가상 머신이 사용
할 수 있는 런타임 형태로 변환하는 것이다. 이 작업은 다른 클래스 파일의 링킹을 필요로
할 수도 있다. 또한 검증, 준비, 해결 등이 필요하다.
세 번째로 클래스 파일을 검증한다. 클래스 파일의 형태를 확인하고, 안전한 실행을 확인한
다. 네 번째로 클래스 파일을 위해서 준비를 한다. 정적인 필드들이 기본 값으로 초기화된
다. 추상화되지 않은 클래스로부터의 추상화 메소드가 있는지 확인한다.
다섯 번째로 클래스 파일을 초기화한다. 초기화는 클래스 파일을 처음 참조할 때만 이루어
진다. 상위 클래스가 초기화되었는지 먼저 확인하고, 정적 initializar <clint>을 호출한다.

여섯 번째로 클래스 필드 해석을 한다. 이때 상징적 참조가 실제 주소로 변환된다. 이 과정
은 자바 가상 머신 구현에 따라 걸기는 시간이 다르다.
참고로 클래스 파일에 대해 살펴보면 이것은 장치 독립성과 네트워크 이동성을 강화하여 자
바가 네트워크에 적합한 언어이게 한다. 장치 독립성은 자바 클래스 파일이 자바 가상 머신
이 있는 어디에서나, 운영체제나 하드웨어 장치에 무관하게 실행될 수 있는 바이너리파일로
되어져 있고, 자바 컴파일러가 자바 소스의 명령어들을, 자바 가상 머신의 기계 언어인 바이
트 코드로 번역하며, 자바 클래스 파일에서는 어떤 장치가 파일을 생성하고 이를 사용하는
지에 상관없어 big-endian으로 작성되므로 가능하다. 네트워크 이동성은 클래스 파일은 아
주 압축하여하여 네트워크 상에서 쉽게 이동할 수 있다는 점을 이용한 결과라 할 수 있다.
자바 프로그램은 동적으로 링크되어 있고, 동적으로 확장되므로, 클래스 파일에 필요에 따라
다운로드 된다.
2. 자바 API
자바 API는 장치 독립성과 보안성을 지원하여 자바가 네트워크에 적합한 언어이게 한다. 장
치 독립성에서 보면 non-Java OS system상에 소프트웨어로 구현된 가상 머신이 있는 경우
에는 자바 API의 클래스 파일은 원시 메소드 들을 호출하여 그 호스트의 자원들에 접근하
므로 자바 API의 클래스 파일들은 호스트에 대해 표준적이고, 장치 독립적인 인터페이스로
자바 프로그램을 제공한다. 즉 자바 API의 내부 설계가 장치 독립성을 지향한다.
보안성을 살펴보면 자바 API의 메소드 들은 그들이 잠재적인 악영향을 미칠만한 행동을 취
하기 전에 보안 관리자로부터 허가를 확인한다. 그리고 보안 관리자는 그 애플리케이션에
대한 일반적인 보안정책을 정의한다.

3. 자바 네트워크
자바 네트워크에 적합하게 설계된 언어지만, 법용으로 쓰이는 경우가 있다. 프로그래밍 언어
로서 객체 기반 언어, 멀티 쓰레딩 가능, 구조적 에러 핸들링이 용이, 가비지 컬렉션 지원,
동적 링크, 동적 확정 등의 장점이 있다.
이러한 장점들은 자바 프로그래밍 언어를 다양한 상황에 대해, 네트워크에 관계없이 쓸 수
있는 강력한 범용 툴 로서 만들어 준다. 자바 프로그래밍 언어의 최대장점으로는 개발자의
생산성을 확대시킨다는 것, 최대 단점으로는 수행 속도가 느리다는 것을 들 수 있다.
자바 프로그래밍 언어(이하 자바언어)의 특징을 살펴보면 객체 기반 언어이고, 메몰 직접 조
작 금지하여 개발자의 생산성을 향상시키는 주목할만한 특징을 가지고 있다.
자바언어에서 메모리 붕괴를 막는 방법으로는 첫째, 다른 타입을 마음대로 지정하는 포인터
에 의한, 혹은 포인터 연산에 의한 메모리 직접 접근이 불가능하게 한다. 둘째, 메모리 붕괴
를 야기할만한 직접적인 메모리 조작이 방지된다. 셋째, 자동 가비지 컬렉션을 하기 때문에
풀어 주어야 할 객체를 명시적으로 지정할 필요가 없다. 넷째, array bounds checking을 한
다. 즉 완전한 객체 참조를 확인한다. 그러나 널 값 참조는 예외이다. 자바 언어의 트레이드
오프로는 수행속도를 들 수 있다. 배열 경계 확인, 타입-safe reference casting, 널 참조에
대한 확인, 가비지 컬렉션 등으로 소비시간 많어져 속도가 저하된다. 또한 인터프리트 언어
라는 특성에서 오는 속도문제가 있다. 이 문제는 JIT 컴파일 등으로 성능 향상이 가능하다.
그러나 네트워크에서의 대기시간 등과 자바가 네트워크에서 가지는 강점 등을 따져보면 그
리 나쁘지 않다. 그러므로 수행속도가 중요한 경우를 위한 방법은 하드웨어로 구현된 가상
머신 위에 클래스 파일을 실행하거나 수행속도가 중요한 부분만 원시 메소드로 구현하는 방
법도 있다. 그리고 자바 프로그램을 장치-의존적으로 컴파일 할 수도 있다.
만약 수행속도와 장치-독립성을 모두 얻고자 하는 경우라면 인스톨 시에 컴파일링 하는 방
법이 있다. 이 방법은 인스톨 시에 장치-의존적으로 컴파일 되는 장치-독립성 클래스 파일
을 배포하고, 배포한 이진 형식은 장치-독립적이나, 말단 사용자가 실행하는 이진형식은 장
치-특성화c하게 즉, 말단 사용자의 시스템에 설치되는 동안 장치-의존적으로 컴파일 되는
것이다.

위의 사항들을 살펴보았을 때 자바는 이렇게 다양한 옵션으로 배포, 수행될 수 있다. 네트워
크-기반 기능들로 인한 트레이드 오프로는 수행속도의 저하, 메모리 관리 제어력 손실 등을
들 수 있다.
4. 자바 장치 독립성
장치-독립성 목적으로 인한 트레이드 오프로는 lowest-common-denominator problem을 들
수 있다. 이 문제는 동적으로 링크된다는 자바 프로그램의 속성에 따라, 한 클래스에서 다른
클래스의 참조가 심볼화 되는 경우에 발생하며, 장치-독립적인 API를 설계하는 사람에게
골칫거리일 뿐 아니라, 그 API를 사용하는, 프로그램 설계자에게도 문제가 된다.
자바는 다양한 형태의 기종에도 수정 없어 그대로 실행 할 수 있게 바이너리 코드를 생성하
므로 어떠한 네트워크 컴퓨터에서도 실행할 수 있다. 그러므로 관리자의 일이 줄어들고 개
발자 관점에서는 여러 컴퓨터에 맞춰 개발하는 시간과 비용이 절약되며 소프트웨어는 좀더
많은 소비자를 얻는 반면 많은 경쟁자도 생기게 된다.
자바의 장치 독립성은 옵션이다. 자바는 하드웨어와 운영체제의 기초적인 부분과 자바 프로
그램이 동작하는 사이에서 버퍼처럼 행동한다. 자바 프로그램은 자바 API 클래스들 (컴퓨터
의 실제 자원들에 접근) 이 실시간으로 사용이 가능하다는 전제하에서 자바 가상 머신에서
실행된다. 그러므로 자바 프로그램이 실행되기 위해서 자바 장치와의 상호작용이 필요하기
때문에 결국 하부의 운영체제와 하드웨어에 상관없다. 자바 언어는 자바의 장치독립성을 원
칙적으로 표현한다. 기본적인 타입(형)들의 범위(크기)와 특성들이 언어에 의해 정해진다.
다른 언어의 경우 하드웨어의 워드형에 의해 결정되기 때문에 각각에 다른 동작을 한다. 그
러나 자바에서의 기본 타입들은 하드웨어에 상관없이 같은 동작을 한다. 자바 가상 머신에
서 정의된 바이너리 형식으로서 (big-endian order multibyte value) 가상 머신에서 실행되
기 때문에 장치 독립적이다.

정량 성을 보면 자바 장치는 embedded 장치부터 컴퓨터까지 다양한 범위에서 구현될 수 있
다. 초기자바는 embedded 장치를 위한 기술로 발전되었다. 어떤 시스템이든지 상관없이 소
프트웨어가 네트워크를 통해서 전송되어 실행되었다. 시스템의 가능한 자원을 사용하여 소
프트웨어를 구현하기에 충분히 치 하고 간결해야 한다.
자바 장치의 종류는 The Java Embedded Platform, The Java Personal Platform, The Java
Card Platform,등이 있으며, 자바 장치는 압축하기 때문에 여러 시스템에 적용하기 좋다. 자
바 장치 전개는 장치 독립성을 결정짓는 요소 여러 컴퓨터에서 platform이 동작하는가를 고
려해볼 수 있다. 그러나 현재 여러 가지 기술(자바 정용 칩, 장치들..)의 발전으로 쉽게 가능
해지고 있다.
모든 runtime 라이브러리들이 모든 자바 장치에서 실행된다는 보장을 못하기 때문에 자바
장치는 점점 복잡해 질 것이다.
자바 Core API는 모든 자바 장치에서 실행되는 것을 보장하는 기본적인 라이브러리 집합이
다. 자바 코어장치는 코어 API로 구성된 클래스 파일들에 동반되는 자바 가상 머신을 가진
다.
자바 장치는 계속 바뀐다. 왜냐하면 시간이 지날수록 새로운 기능이 API들에 추가되고 삭제
되어지기 때문이다. 따라서 버전에 따라 이전 버전의 프로그램이 실행되지 않을 수도 있음
에 유의해야한다. 그리고 개발자는 프로그램 개발의 기존이 될 버전과 에디션을 결정해야
한다.
자바 장치를 확장하는 하나의 방법으로 원시 메소드를 사용한다. 장치 독립적인 자바 프로
그램은 직ㆍ간접적으로 원시 메소드를 사용 못한다. 그러므로 장치 의존적으로 만들고자 할
때 사용하는 것이 원시 메소드이다. 원시 메소드는 자바 API를 통해서 접근되지 못하는 장
치 하부의 기능을 접근할 때, 자바에 구현되지 않은 이미 존재하는 라이브러리에 접근할 때,
프로그램의 성능을 높이고자할 때,
원시 메소드를 사용하면서 장치 독립적으로 구현하고자 할 때 유용하다. 그러나 적용하고자
하는 모든 장치에 원시 메소드를 포팅 해야 한다.
비표준화 실행시간 라이브러리는 vendor에 의해 제공되는 확장된 라이브러리이다.

원시 메소드를 호출하지 않는 라이브러리로서 장치 독립성에 영향을 주지 않고 라이브러리
를 시행시키기 위해서는 실행 될 자바 장치에 클래스 라이브러리들을 전송 해준다. 예를 들
어 AFC는 마이크로소프트사에서 만든 클래스, 익스플로러가 아닌 다른 브라우저들은 실행
할 때마다 다운받아야 한다. 원시 메소드를 호출하는 라이브러리는 장치 의존적 원시 메소
드처럼 자바의 능력을 향상시키지만 장치독립성은 떨어진다. 예를 들면 마이크로소트사의
톨을 이용하여 COM 객체와 상호 작용하는 클래스를 만들 수 있지만 다른 운영체제에서 불
가능하다.
장치 독립적인 프로그램을 짜기 위해서 가상 머신에서 고려해야할 사향은 다음과 같다.
첫째, 프로그램의 정확성을 위해 시간적으로 결말에 관여하지 않는다
둘째, 가비지 콜렉터가 된 힙을 사용하는 것은 동일하지만 어떻게 구현되는 가는 가상 머신
에 따라 다르다는 것이 그 예이다.
셋째, 프로그램의 정확성을 위해 쓰레드의 우선 순위에 관여하지 않는다. 가상머신마다 쓰레
드의 우선 순위 관리 방식이 다르다. 따라서 쓰레드 사이의 상호작용을 동기화로 구현해야
한다.
AWT 사용자 인터페이스 라이브러리는 각 장치의 원시 구성요소에 접근하는 사용자 인터
페이스 구성요소의 집합이다. 여러 장치에서 동작하는 인터페이스를 만드는 것은 쉬운 일이
나 장치에서 제대로 동작하는 디바이스를 만들기는 어렵다 자바 구조는 어떤 의미로 보면
선택이 가능하다. 자바에서 할 수 없는 장치 독립적인 기능을 사용하고자 할 때,
기존의 시스템과 상호 작용을 하고자 할 때, 기존에 존재하는 라이브러리를 사용하고자 할
때, 프로그램의 실행을 최대화 하고자 할 때 우리는 자바 구조를 선택해야 할 것이다. 장치
독립적으로 구현하고자 할 때의 개발 7단계는 [그림2-1-5]과 같다.

[그림 2-1-5 자바 장치 독립성 개발 7단계]
자바 장치는 확장이 가능하다. 모든 벤더는 자바 가상 머신과 자바 API의 수준에서 적합성
을 반드시 따라야 하지만 확장과 성능은 달라도 된다. 표준 구성요소를 지원한다는 것은 장
치독립성 지원한다는 것이다. 또한 벤더에 의한 확장 호스트의 특별한 기능을 사용하여 장
치 의존적으로 프로그램을 확장 가능하다. 이것은 개발자의 선택에 달려있다. 그러나 향상된
운영체제의 개발이 저조하게 되고, 실행파일 형식이 이진이기 때문에 새로운 하드웨어 개발
이 저조하게 된다.
5. 자바 가상 머신 보안성
자바 가상 머신의 보안성은 샌드박스를 사용한다. 보안성은 로컬디스크(지역 디스크)를 읽거
나 쓰는 일, 애플릿이 오는 곳과 네트워크 연결, 새로운 프로세스의 생성, 새 동적 라이브러
리의 로드와 원시 메소드의 직접적인 호출 수행 등의 일을 할 때 필요한 작업이다. 자바언
어의 보안기능으로는 포인터 삭제, 강력한 타입 검사 등을 들 수 있고, 컴파일러의 보안 기
능으로는 배열 연산 검사, 언어의 강력한 타입 검사 등을 들 수 있다.

샌드박스라는 것은 컴퓨터 메모리에서 애플리케이션(일반적으로 자바 기반의) 호스트 시스
템에 해를 끼치지 않고 작동하는 것이 허락되는 보호받는 구역을 말한다. 어떤 소스를 제한
하지는 않는다. 그리고 실행 시에 시스템에 해가 될 행동을 제한한다. 샌드박스 구성요소는
클래스로더 구조, 클래스 파일 검증자, 자바 가상 머신 내에서 만들어진 안전성, 보안 매니
저와 자바 API가 있다.
클래스 로더는 자바 가상 머신으로 코드를 가져오는 역할을 수행한다. 여기서도 역시 보안
성이 확인되는데 신뢰성 있는 클래스 라이브러리의 경계를 알기, 부당한 코드를 방지, 클래
스 로더는 믿을 수 없는 코드로부터 경계를 지정 등의 일을 한다. 참고로 애플릿은 클래스
로더를 통해 웹에 로드되므로 클래스 로더는 네트워크를 통해 로드되는 클래스가 자신을 가
장하거나 지역 파일 시스템의 클래스와 충돌하는 것을 방지한다. 자바 API의 보안에 중요한
클래스가 네트워크를 통해 신뢰할 수 없는 클래스로 대치되지 않도록 한다. 클래스 로더는
특정 네트워크 호스트로부터 로드되는 클래스가 호스트에 따른 독특한 이름을 가지도록 하
여 지역과 네트워크에서 로드되는 클래스를 분리한다.
이름 공간은 로드된 클래스들의 고유한 이름 집합이다. 이것은 자바 가상 머신에 의해 유지
된다. 하나의 이른 공간에는 같은 이름의 클래스를 중복되게 사용할 수 없다. 여러 개의 이
름 공간을 사용, 다른 클래스 로더에 의해 다른 이른 공간에 로드된다. 서로 다른 이른 공간
간에 클래스를 로드하는 것을 방지한다. 자바 가상 머신에서 같은 이름 공간의 클래스는 다
른 것들과 서로 상호작용 한다. 클래스 로더 사용 시, 사용자는 로드된 코드의 실행의 새 환
경을 만든다.
보안성을 고려한 클래스 로더 만들려면
- 클래스 로더가 로드할 수 없는 패키지가 있으면 클래스 로더는 요구된 클래스가 금지된
패키지인지 확인하여 그러면 보안성 예외로 처리하고 아니면 step2를 수행한다.
- 원시 클래스 로더가 성공적으로 반환하는지 보고 아니면 step3을 수행한다.

- 클래스 로더가 제한 받은 클래스를 add하는지 검사하여 그렇다면 보안성 예외 아니면
step4을 수행한다.
- 클래스 로더는 일반적인 방법으로 로드하려고 시도하여 성공하면 리턴, 아니면 “no class
definition found error"메시지를 출력한다.
클래스 파일 검증기 로드된 클래스 파일이 적절한 내부 구조를 가졌는지 검사한다. 프로그
램 견고성을 검사하면, 수행 전에 바이트 코드를 분석한다. 그리고 로드된 클래스가 정확하
게 구성되고 타입과 이름 공간의 제약을 위반하지 않는지를 검사한다. 작은 정리 증명기를
사용하여, 클래스 파일이 초기에 특정의 보안 제약을 만족하며 실행되면 언제나 보안 제약
이 만족되는 상태로 전환됨을 검증한다. 검증기는 타입간의 잘못된 변환이 없고 메소드에
전달되는 인수와 작용되는 명령이 정확하고 스택 연산이 오버플로우나 언더플로우를 발생
하지 않고 액세스 변환자가 잘 지켜지고 위조 포인터가 만들어지지 않고 레지스터 연산이
에러를 발생하지 않는 것을 시험한다.
[표 2-5-1 검증기의 분류]
Phase Phase T재
내부검사 심볼 참조의 검증
바이트 코드의 완전성을 포함하며클래스 파일의 내부구조를 체크한다.
바이트 코드가 수행될 때 클래스파일 검증자가 관련된 클래스,필드, 메소드의 존재 확인한다.
자바 가상 머신은 built in 보안성 기법을 사용한다. 기법으로는 타입 안전 참조 변환, 구조
화된 메모리 접근 (포인터 없음), 자동화된 가비지 컬렉션, 배열의 경계 확인, 널 참조 등이
있다.
보안성 관리를 하기 위해서는 샌드박스의 한계를 결정하고 보안성 전략에 따라 어떤 행동이
안전하지 않은 지 확인한다. 보안성 관리자를 수행하는 자바 API는 확인으로 시작하는 메소
드를 가진다.

애플릿의 제한 규정은 다음과 같다.
ㆍ애플릿은 클래스로더나 보안성 관리자를 만들거나 설치할 수 없다.
ㆍ애플릿은 지역 클래스의 이름 공간 안에 클래스를 생성할 수 없다.
ㆍ애플릿은 자바 API의 표준 패키지 바깥의 지역 패키지를 접근할 수 없다.
ㆍ애플릿은 지역 시스템의 파이이나 디렉토리를 어떤 방법으로든 접근 할 수 없다.
ㆍ애플릿은 로드된 호스트 시스템에는 네트워크 연결을 할 수 없다.
ㆍ애플릿은 상수 핸들러, 프로토콜 핸들러, 소켓 구현을 할 수 없다.
ㆍ애플릿은 사용자에 대한 정보를 갖는 시스템 특성을 읽을 수 없다
ㆍ애플릿은 시스템 특성을 변경할 수 없다.
ㆍ애플릿은 지역 시스템의 다른 프로그램을 로드하거나 DLL을 로드할 수 없다.
ㆍ애플릿은 실행되는 시스템이나 다른 프로그램을 종료할 수 없다.
ㆍ애플릿은 자신이 쓰레드 그룹 밖의 쓰레드를 접근할 수 없다.
ㆍ애플릿에 의해 생성된 모든 윈도우는 신뢰받지 않는다는 제목을 가져야만 한다.
자바의 보안 규칙을 구현하는 중앙 결정 점을 제공한다.
java.lang 패키지의 보안성 관리자는 네트워크에서 로드된 클래스에 의해 만들어지거나 불
려지거나 접근될 수 없다. 따라서 실행 시에 자바 애플릿이 보안성 관리자 객체에 의해 구
현된 보안 규칙을 변경할 수 없도록 한다.
서비스의 부정은 수행 종료 전 메모리 할당, 수행 마치기전에 쓰레드 넘기기, 이 메일로 애
플릿 보내기, 웹에서 배열 잡음, 모욕적인 이미지나 애니메이션 등의 경우에 실행된다.
넷스케이프에 따르면 자바는 모든 문제의 해결책이다. 네비게이터 3.x와 인터넷 익스플로러
3.x에서 자바 애플릿들은 “샌드박스”라 불리는 곳에서 실행된다. 이 샌드박스는 지역 드라이
브를 제한적인 사용만을 허가한다. 보안의 차원에서 볼 때 이것은 좋은 일이다.

바이러스나 해로운 애플릿이 램이나 하드드라이브를 건드릴 수 없기 때문에 시스템에 악영
향을 미칠 수가 없기 때문이다. 단점이라면 좋은 애플릿도 이런 식으로 제한된다는 것이다.
그래서 커뮤니케이터 4.x의 새로운 자바 “인증”제도가 등장하게 되었다. 이 방법으로 자바
애플릿은 지역 하드웨어 사용을 승인해달라고 요청한다. 사용자가 승인을 할 경우 애플릿은
샌드박스 밖에서 작동할 수 있게 된다. 예를 들면 특정 회사의 애플릿을 믿는다면 하드 드
라이브를 사용하도록 허가할 수 있다.
이러한 기능을 추가하면서 넷스케이프는 기존의 자바 보안 모델에 있는 문제를 해결해야만
했다. 지난 해 8월, 미국 콜로라도에 사는 한 프로그래머는 특정 자바 애플릿을 샌드박스 밖
에서 작동할 수 있게 하는 버그를 발견했다. 이 버그는 사용자가 원하지 않는 이미지나 사
운드를 다운로드받게끔 했고 넷스케이프와 마이크로소프트 브라우저 모두에 영향을 끼쳤다.
넷스케이프는 또한 자바스크립트에 있어서의 보안 문제를 해결해야 했다. 자바스크립트는
웹 상에서 HTML 양식에 있는 데이터를 확인하는 데 쓰이는 프로그래밍 언어이다. 몇몇 자
바스크립트 보안 문제점은 “나쁜” 웹사이트로 하여금 HTML 양식에 입력된 사용자들의 사
적인 정보를 가로챌 수 있도록 했다. 넷스케이프는 이러한 버그를 수정하기 위해 재빠르게
행동했지만 4.04버전까지 내놓았는데도 불구하고 업데이트가 앞으로 더 나올 가능성이 남아
있다. 네트워크 보안은 인터넷 사용자와 특별하게 인터넷 상업의 성장에 출현한 사용자에게
제일 중요하다. 네트워크에 기발한 응용프로그램은 실제의 잡동사니들인 네트워크 바이러스,
웜(Worm), 트로이 목마와 다른 형태의 침입자들로부터 자신을 보호해야 한다. 이 부분은
자바, 런타입 시스템, 핫자바의 고수준 프로토콜이 제공하는 방어영역에서 다루어야한다. 핫
자바와 같은 시스템을 만드는데 있어 가장 중요한 기술적인 도전은 보안이다. 네트워크를
가로질러 온 수입된 코드를 설치하고 실해하는 것은 모든 종류의 문제에 대해 개방적이다.
한편에서 그런 요소가 매우 가치 있는 목적을 성취하는데 쓰이는 강력한 힘을 제공한다면,
다른 편에서는 컴퓨터 바이러스를 위한 토양의 성장을 타도한다.

안전성의 주제는 매우 광범위하고 단일한 답이 없다. 핫자바는 높은 안전성을 제공하는 연
속된 층과 연동 요소를 제공한다.
[표 2-1-2 클래스 접근 방식]
종류 제한적 비제한적
내용 ㆍ기본값ㆍ애플릿들이 썬 사의 내부 패키지의클래스들에 접근할 수 없음ㆍ애플리케이션 서버는 sun 패키지에 접근할 수 없으므로 중계 서버를 이용하여 sun패키지를 활용하는 것을 생각.
ㆍ애플릿들이 썬 사의 패키지의클래스들에 접근 할 수 있음.
네트워크 접근 방식과 클래스 접근 방식은 [표 2-6-2]와 [표 2-6-3]과 같다“
[표 2-1-3] 네트워크 접근 방식
종류 Applet Host Unrestricted None
내용 ㆍ기본값.ㆍ애플릿들이 자신이 소재한 호스트에만 접속할 수 있음.ㆍ넷스케이프 네비게이터는 이 옵션만을 선택하므로 다른 호스트에서 서버가 구동하는 환경의 클라이언트 애플릿을 제대로구동시킬 수 없음.
ㆍ애플릿들이 어떤 호스트에든지 접속할 수 있음.ㆍ어떤 네트워크 환경에서는 위험.ㆍ양쪽 호스트에서 서버를구성하여 (중계 서버의 구성) 애플릿 보안을
ㆍ애플릿들에게 어떤 네트워크 연결도 허용치 않음.ㆍ일부 애플릿의 실행을 막을 수도 있음.
첫 번째 층 - 자바 인터프리터

자바 응용프로그램에서 보안성의 첫 번째 층은 자바의 기본 규칙에서 비롯된다. 핫자바가
코드를 수입할 때, 지역 자바 컴파일러에 의해 만들어지지 않았기 때문에, 핫자바는 코드가
안전성을 위한 자바 규칙을 따르는지 아닌지를 실제로 모른다. 앞에서 설명한 대로, 코드의
형식이 바른가하는 직접적인 검사에서 시작하여 인증기에 의한 연속된 계속적인 검사로 시
작하여 인증기에 의한 연속된 계속적인 검사로 끝나는 검사의 연속에 수입된 코드는 지배된
다.
다음 층 - 고수준 프로토콜
인터페이스가 위반하지 않을 거이라는 확신이 주어지면, 시스템의 고수준은 자신을 지키는
메커니즘을 구현한다. 예로, 파일접근은 수입된 코드에 의해(또는 수입된 코드가 호출한 코
드에 의해) 파일을 읽고 쓰는 접근을 제어하는 접근 제어 목록을 구현한다. 이 접근제어의
내정값은 매우 제한적이다. 접근이 허락되지 않은 파일에 접근하는 수입된 코드의 사용자
에게 결정하게 만든다.
이런 접근 제한은 보수적인 측면에서 틀린 것이다. 매우 유용한 확장을 불가능하게 하거나
다루기 곤란하게 한다. 공개키는 더 적은 제한을 하는 인증 된 공개키를 사용한 코드를 허
락하는 코드의 부분으로 접근하는 메커니즘이 있다. (역주. 공개 키 알고리즘은 암호학에서
새롭게 부각하는 알고리즘으로 암호화로 암호화키는 공개하고 복호화 키는 비 로 하여 통
신을 하게 된다. 네트스케이프에서도 공개키를 이용한다고 한다. 그리고 공개키는 계산량 적
으로 풀 수 없는 안전성을 가진다. 따라서 풀리기는 풀린다. 지난해 프랑스 대학원생 한 명
이 워크스테이션 3대와 개인용 컴퓨터 100대를 연결하여 3달에 걸쳐 한 줄의 공개키로 암호
화된 암호문을 푼 적이 있다. 그러나 내용은 몇 개월 전의 것이었다. 그리고 키가 겨우 40비
트였다. 미국 내에서 사용하는 네트스케이프의 공개키는 128비트이다.) 이 메커니즘은 법적
인 이유로 공개적인 판에 포함되지 않았다.

네트워크 이동성은 기존의 컴퓨팅 모델보다 한 단계 더 진화된 모델이다. 한 시스템에서 처
리 작업수행 후 분산 프로세싱에 의한 분산 작업수행, 네트워크를 통한 분산 작업(소프트웨
어의 작업 분리가 쉽게 이루어짐)을 수행한다.
네트워크 이동에 대한 설명과 이를 구현하는 새로운 패러다임을 [표 2-1-4]에서와 같이 제
시하고자 한다.
[표 2-1-4 구형모델과 신형모델의 비교]
모델 구형모델 신형모델
차이점 ㆍ지역 디스크에서 실행된 소프트웨어가 데이터를 호출하는 행위ㆍ소프트웨어 애플리케이션은 별개의 실체로 취급ㆍ데이터에 의해 쉽게 구분할 수 없음
ㆍ소프트웨어 전송시 데이터도 함께 전송ㆍ소프트웨어와 데이터가 하나의 내용 형식으로 전송
메인 프레임모델에서 분산 프로세싱 모델로 바뀌었고 여기서 다시 네트워크 이동 모델로 바
뀌었다. 메인프레임 모델에서 분산 프로세싱 모델로 바뀐 이유는 작업 능률이 향상되었고,
프로세서 가격이 하락하였기 때문이다. 분산 프로세싱 모델에서 네트워크 이동 모델로 바뀐
이유는 작업 능률이 향상되었고, 네트워크 대역폭 가격이 하락하였다. 점차 네트워크 통해
전달되는 다양한 정보량이 많이 질수록 대역폭을 확장 해야한다. 네트워크 이동 코드는 사
용자가 소프트웨어를 편리하게 사용하게 하기 위해 코드 작성을 쉽게 하고, 소프트웨어가
전송될 때 데이터도 함께 전송한다.
결론적인 새로운 패러다임은 소프트웨어 응용성을 고려하고, 설치, 버전 수, 업그레이드에
큰 영향을 주지 않는 형태로써, 소프트웨어와 데이터가 함께 네트워크 전송되어 소프트웨어
의 전송과 업데이트가 자동으로 이루어지는 것이다. 이러한 새로운 패러다임이 자바의 개발
과 이용을 발전시킬 것이다. 그러면 이러한 네트워크를 통해 이동하는 애플릿에 대하여 살
펴보자.

모든 애플릿은 애플릿 클래스의 서브 클래스를 생성함으로써 구현된다. 자바 애플릿은 웹
브라우저 내에서 실행되며 자바의 모든 특징을 보여준다. 예를 들면 장치 독립성, 네트워크
이동성, 보안성 등을 들 수 있다. 또 애플릿은 어떤 장치에서도 실행 가능하고, 애플릿은 보
안성을 보장하여 샌드박스 내에서 실행이 된다. 그러나 네트워크를 통해 적재된 애플릿은
몇 가지 제약을 가지게 되는데 그것은 보안문제 때문이다. 즉 자신이 수행되고 있는 컴퓨터
의 상의 파일들을 읽거나 쓰지 못한다는 것, 자신이 다운로드 된 호스트 이외의 다른 호스
트와는 통신 할 수 없다는 것 등의 문제가 있다.
애플릿클래스 상속 계층 구조는 [그림 2-1-6]과 같다.
애플릿의 수행 과정은 위의 [그림 2-1-7]과 같다.
[그림2-1-6 애플릿클래스 상속계층 구조]
[그림2-1-7 애플릿 수행과정]

자바 애플릿 수행예제는 다음과 같다.
<applet CODE="HeapofFish.class" CODEBASE="gcsuppore/classes"WIDTH=525 HEIGHT=360>m/applet>

CODE : 애플릿의 시작 클래스 파일을 지정 → HeapofFish.class
CODEBASE : 클래스 파일의 위치
WIDTH/HEIGHT : 애플릿 패널의 픽셀 크기
이상의 기능을 수행하는 자바 가상 머신에서 실행하는 시간 인스턴스의 임무는 자바 애플리
케이션 실행하는 것이다. 초기화 클래스의 main() 메소드는 초기 쓰레드의 시작 지점이다.
초기 쓰레드는 다른 쓰레드들을 만들어 낼 수 있다. 쓰레드는 대몬 쓰레드와 비 대몬 쓰레
드로 나눌 수 있다. 대몬 쓰레드는 가상 머신에서 사용되는 쓰레드로서 가비지 컬렉션이 그
예이다. 비대몬 쓰레드는 애플리케이션의 초기화 쓰레드로써 main()이 그 예이다. 자바 애플
리케이션은 비대몬 쓰레드가 실행되는 한 계속 살아 남아 있다. 또한 자바 애플리케이션의
비 대몬 쓰레드가 종료되면 가상 머신 인스턴스를 종결한다. 예에서 main()은 다른 쓰레드
를 호출하지 않고 출력이 끝나면main()은 리턴하고, 비대몬이 종결되면 가상 머신 인스턴스
가 종료한다.
6. 자바 클래스 파일
자바 클래스 파일이란 자바 프로그램을 위한 이진 파일 형태이다. 포맷이 정 하기 때문s에
어떠한 기계에서도 수행될 수 있다. 8-비트의 이진 문자열(1 바이트가 넘어가면 big-endian
순으로 자름)이 순서대로 저장된다. 하나의 클래스 파일에는 아이템, 필드 등의 개수나 크기
에 상관없다. 클래스 파일에는 가상 머신이 자바 클래스 또는 인터페이스에 대해 알아야 할
모든 정보가 들어있다.
magic, 이것이 자바 클래스 파일임을 명시하는 용어이다. 파일의 시작에 4바이트로
oxCAFEBABE값을 준다. minor_version과 major_version은 클래스 파일의 버전을 명시한
다. 두 번째 4바이트에 각각 2바이트씩 기록한다. 버전과 함께 클래스 포맷도 바뀌었기 때문
에 가상머신은 자신이 지원할 수 있는 버전인지 체크한다.
상수 저장소는 클래스 파일과 관련된 상수이고 상수 저장소 개수는 그들 전체의 개수를 나
타낸다.

예로서 메소드의 이름, 클래스 이름, 마지막 변수 값, 문자열을 들 수 있다. 상수 저장소에
있는 입력 값들은 서로 가른 입력 값들을 참조한다. 각 entry는 자신의 타입을 가리키는 1
바이트의 태그 값을 가진다. 각 태그별로 자신과 일치하는 테이블을 가진다. 예를 들면
CONSTANT_Class는 CONSTANT_Class_info를 가진다.
문자상수값은 완전히 분류된 클래스와 인터페이스들의 이름을 갖는다.
필드 names and 설명자, 메소드 이름과 설명자의 3가지 종류가 있다. 필드는 클래스나 인터
페이스의 가변적인 이름을 나타낸다. 필드 설명자는 필드의 형을 가리키는 문자열이다. 메소
드 설명자는 반환 타입과 파라메터의 수, order, 타입들을 가리키는 문자열이다.
상수저장소는 fully qualified name과 메소드, 필드 설명자는 자신의 클래스나 interface에 외
부의 것을 linking하기 위해서 runtime시간에 사용한다. 클래스자체에는 calss, 필드, 메소드
에 대한 정보가 없다. 또한 가상 머신은 과 runtime에 상수저장소의 정보를 얻어와 분석한
다. access_flags는 파일 안에 정의되어 있는 클래스들과 인터페이스에 대한 정보를 나타낸
다. 두 byte를 사용한다. 파일이 클래스들이나 인터페이스들을 정의했는지 안 했는지 나타내
며 수정자들이 클래스나 인터페이스의 정의로 사용되는지 안 되는지를 “Classes can be
final", "interfaces cant be final"로 나타낸다. 사용되는 플래그 비트들은 다음과 같다.
[표 2-1-5 플래그의 예]
Flag 내용
ACC_SUPER flag
ㆍ오래된 VM의 자바 컴파일러를 위한것인지 새로운 자바 컴파일러를 위한 것인지 화인ㆍ오래된 자바 컴파일러인 경우 0

[표 2-1-6 클래스 구분]
Class 종류 차이점
this_class
ㆍCONSTANT_constant pool의 인데스로서2바이트의 크기ㆍClass_ingo tag, name_index 등의 속성을가진다ㆍ태그는 상수 자장소 entry를 나타내고name_index는 클래스나 interface의 전체 이름을 포함하는 테이블인CONSTANT_uf8_info를 나타낸다.
super_class
ㆍ2 byte의 크기ㆍ해당 클래스의 슈퍼 클래스의 전체 이름을포함하는 CONSTANT_Class_ingo을 속성ㆍ모든 객체의 슈퍼 클래스는java,lang.object이고 객체 클래스인 경우는 0값을 가진다

[표 2-1-7 Counter 구분]
Counter 종류 차이점
interfaces_count
ㆍ파일에 정의된 클래스나 interface에 의해직접 구현된 superinterface들의 수ㆍinterface는 각각의 superinterface를 위한상수 저장소의 인덱스를 포함하고 있는arrayㆍ직접적인 superinterface절 만이 이 array에 나타남.ㆍ예:interface선언의 확장절, 클래스의 도구절
fields_count
ㆍ클래스와 interface를 포함한 필드들의 수ㆍ필드는 file에 클래스와 interface 정의에의해 선언된 필드 리스트로서 길이가 가변적ㆍfield_info 테이블에서 정보를 찾을 수 있음ㆍfield_info 테이블이란 필드의 정보(이름,설명자, 수정자), 필드가 끝인지 알 수 있다.
메소드는 클래스나 인터페이스에 정의된 메소드의 정보, 메소드 정보테이블, 사위 클래스나
상위 인터페이스의 메소드는 가지고 있지 않는다. 메소드 개수는 메소드 정보 테이블의 개
수를 말하고, 메소드 정보는 이름, 설명자, 반환 타입, 변수 타입 등의 메소드에 대한 여러
정보 포함한다.
상수저장소에 포함되어 있는 심볼 참조는 전적으로 적격인 이름, 간단한 이름, 설명자인 세
가지 특수한 문자 형태를 포함하며 필드의 심볼 참조는 전적으로 적격인 타입 이름, 간단한
필드 이름, 필드 설명자를 포함한다. 메소드의 심볼 참조도 역시 전적으로 적격인 이름, 간
단한 메소드 이름, 메소드 설명자 정보를 포함한다. 상수 저장소 요소가 클래스나 인테페이
스를 참조할 때마다 그것의 전적으로 적격인 이름을 사용한다.

java,lang,Object가 java/lang/Object로 바뀌듯이 점(.)은 슬래쉬(/)로 바뀐다. 설명자는 필드
와 메소드의 심볼 참조로서 필드 설명자, 메소드 설명자 드의 속성을 가진다. 필드 설명자는
필드이 타입을 나타내고 메소드 설명자는 메소드 인자의 타입, 수, 반환 값의 타입을 나타낸
다. 이것은 context-free grammar에 의해 정의되어진다. 상수 저장소는 기본적인 사수 정보
테이블의 형태이고 내용은 아래와 같다.
태그 테이블의 특성과 형태를 나타냄
바이트 자료 저장
CONSTANT_utf8_info 테이블은 상수문자열 값 저장하며, 정의된 클래스나 인터페이스의
실명자이고, 다른 클래스와 인터페이스의 심볼 참조이다. 또한 특성과 결합된 문자열이다.
테이블 형태는 아래와 같다.
u1 태그
u2 길이
u1 바이트[길이] 바이트 범위 : 1바이트 3바이트 표현
바이트의 인코딩 방법이 UTF_8 인코딩 방법과 다른점은 널을 표현할 때 2바이트를 사용함
으로써 0과 차이를 둔다는 점과 3바이트만으로 한정해서 표현(UTF_8은 더 긴것도 지원)한
다는 것이다.
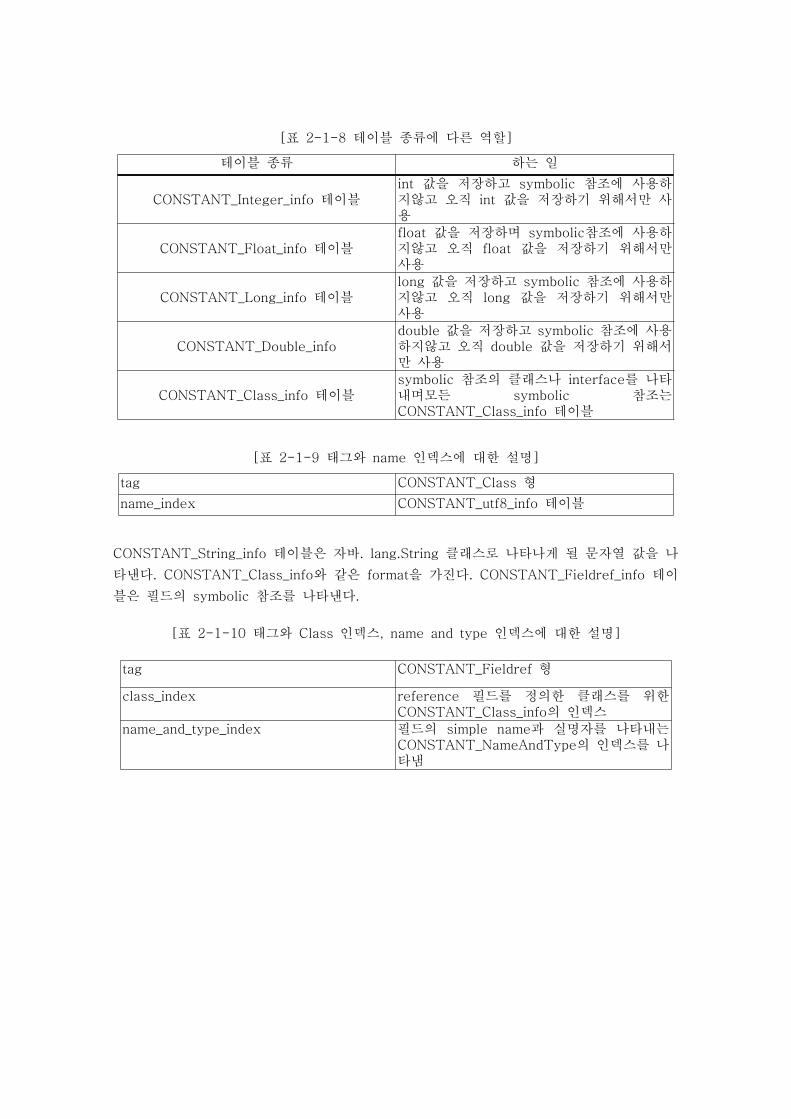
[표 2-1-8 테이블 종류에 다른 역할]
테이블 종류 하는 일
CONSTANT_Integer_info 테이블int 값을 저장하고 symbolic 참조에 사용하지않고 오직 int 값을 저장하기 위해서만 사용
CONSTANT_Float_info 테이블float 값을 저장하며 symbolic참조에 사용하지않고 오직 float 값을 저장하기 위해서만사용
CONSTANT_Long_info 테이블long 값을 저장하고 symbolic 참조에 사용하지않고 오직 long 값을 저장하기 위해서만사용
CONSTANT_Double_infodouble 값을 저장하고 symbolic 참조에 사용하지않고 오직 double 값을 저장하기 위해서만 사용
CONSTANT_Class_info 테이블symbolic 참조의 클래스나 interface를 나타내며모든 symbolic 참조는CONSTANT_Class_info 테이블
[표 2-1-9 태그와 name 인덱스에 대한 설명]
tag CONSTANT_Class 형
name_index CONSTANT_utf8_info 테이블
CONSTANT_String_info 테이블은 자바. lang.String 클래스로 나타나게 될 문자열 값을 나
타낸다. CONSTANT_Class_info와 같은 format을 가진다. CONSTANT_Fieldref_info 테이
블은 필드의 symbolic 참조를 나타낸다.
[표 2-1-10 태그와 Class 인덱스, name and type 인덱스에 대한 설명]
tag CONSTANT_Fieldref 형
class_index reference 필드를 정의한 클래스를 위한CONSTANT_Class_info의 인덱스
name_and_type_index 필드의 simple name과 실명자를 나타내는CONSTANT_NameAndType의 인덱스를 나타냄

CONSTANT_Methodref_info 테이블은 인터페이스가 아닌 클래스에 선언된 메소드의 심볼
참조를 참조한다. CONSTANT_Fieldref_info와 같은 형태를 가진다.
CONSTANT_InterfaceMethodref_info 테이블은 클래스가 아닌 인터페이스에 선언된 메소드
의 심볼 참조를 참조한다.
CONSTANT_Fieldref_info와 같은 형태를 가진다.
CONSTANT_NameAndType 테이블은 filed 나 메소드의 심볼 참조의 부분 정보를 나타낸
다.
[표 2-1-11 태그와 Class 인덱스, name and type 인덱스에 대한 설명]
tag CONSTANT_NameAndType 형
name_index 필드나 메소드의 이름을 나타내는 CONSTANT_Utf8_info의 인덱스
descriptor_index 필드나 메소드의 실명자를 나타내는 CONSTANT_Utf8_info의인덱스
필드는 “클래스나 인터페이스에 선언된 각 필드는 필드 정보 테이블에 묘사되었다. 자바 클
래스 파이에 새로운 특성을 추가하려면 명세에 의해 미리 정의되지 않은 특성은 클래스나
인터페이스 타입의 의미에 영향을 줄 수 없다. 새 특성은 클래스 파일에 새로운 정보를 추
가할 수만 있으며, 디버깅 등에서 이 정보는 사용된다. 그리고 이진 타입 데이터가 자바 가
상 머신(자바가상머신)에 import되어 시작부터 종료될 때까지에 해당되는 실행되는 주기인
”life time"에 대해 설명한다. 주로 클래스 또는 인터페이스 생명주기에 대해 설명한다.
클래스 생명주기의 초기 단계에서는 로딩 후 링킹을 수행하고 초기화를 수행한다. 클래스
생명주기의 중간 단계에서는 가비지 컬렉션을 수행한 후 finalization을 수행한다. 클래스
생명주기의 마지막 단계에서 finalization을 수행한 후, unloading을 수행한다.
자바 가상 머신에서는 로딩. 링킹, 초기화를 통해 프로그램을 자바 가상 머신에서 실행 가능
한 바이트 코드 타입으로 만들면 활동적인 사용상태가 된다. 활동적인 사용상태는 초기 클
래스 생명주기 단계로서 로딩은 이진 타입 데이터를 실행시키기 위해 자바 가상 머신으로
로드하는 작업이고. 링킹은 이진 타입 데이터를 실행 단계로 통합하기 의해 링크하는 작업
이며 초기화는 활동적인 사용의 마지막 단계로 프로그래머가 제안한 초기 값으로 클래스 값
을 세팅하는 작업이다.

초기화동안 클래스 변수의 proper 초기 값이 세팅된다. 초기 proper 값은 프로그래머에 의
해 주어진다.
링킹은 검증, 준비, 해석의 세 가지 작업으로 분할한다. 검증은 로드된 클래스 파일이 자바
가상 머신에서 실행 가능한 적절한 이진 타입 코드의 형태인지 즉, 내부 구조인지 검사하는
단계이다. 준비는 전처리 단계, 메모리 할당을 위해 클래스 파일 타입을 미리 호출하는 단계
이다. 해석은 심볼 참조를 직접 참조로 변경시키는 단계이다.
활동적인 사용상태에서는 이진 코드의 실행을 위해 반드시 각 클래스와 인터페이스에 대한
초기화가 미리 되어 있어야한다. 클래스는 새로운 클래스에 대한 구조를 호출한다. 해당 클
래스의 배열을 생성한다. 상위 클래스로부터 상속되지 않은 클래스에 의해 선언된 메소드를
호출하고 상위 클래스 또는 상위 인터페이스로부터 상속되지 않은 클래스의 필드를 할당하
고 이용한다. 단, 검파일시 초기화하는 static, final 필드는 제외한다.
인터페이스 상위 인터페이스로부터 상속되지 않은 인터페이스에 의해 선언된 필드를 할당하
고 이용한다. 단, 컴파일시 초기화된 필드는 제외한다.
로딩시에는 자바 가상 머신에서 이진 데이터를 로드하기 위해선 기본 적인 세 가지 작업이
요구된다. 첫째, 다운로드된 자료로 부터 이진 데이터를 생성한다. 둘째, 로드된 이진 데이터
를 자바 가상 머신에서 처리할 수 있는 내부 데이터 구조로 파싱한다. 셋째, 최종적으로 내
부 데이터로 java. lang. Class를 생성한다. 그러므로 , 자바 가상 머신은 로딩 단계에서 만
들어진 클래스는 프로그램과 내부 데이터 구조 사이의 인터페이스를 형성한다. 다운로드된
정보를 접근하고 먼저 내부 데이터 구조에 저장한 후 프로그램은 저장된 데이터를 로드하기
위해 클래스의 메소드를 호출한다.

검증은 링크의 첫 번쨰 단계이다. 이진 코드가 자바 가상 머신에서 실행 가능한 내부 구조
로 로드되어서 링크 단계로 넘어간다. 로드된 클래스 파일이 자바 가상 머신에서 실행 가능
한 적절한 이진 타입 코드의 형태인지 즉, 내부 구조인지 검사하는 단계이다. 자바 가상 머
신 내에는 인증 작업이 언제 어떻게 이루어질 것인가에 대해 리스트로 명시한다. 예를 들면
로드 단계이후 이진 데이터 해석하고 내부 데이터 구조로 변경한다. 이때 검증 확인이 이루
어진다.
준비는 링크의 두 번째 단계이다. 클래스 로드 후 클래스에 대한 검증을 한다. 준비 단계 전
에 준비 단계에서 자바 가상 머신은 클래스 변수에 메모리를 할당받거나 다른 클래스 변수
값을 설정한다. 원시 데이터에 “default"초기 값을 설정한다. 준비에서 이루어지는 작업은 새
롭게 할당된 메모리 값을 세팅한다. 그리고 프로그램 수행 중 할당된 메모리 값을 세팅한다.
해석은“ 링크의 세 번째 단계이다. 해석에서 클래스, 인터페이스, 필드, 메소드의 심볼 참조
를 직접 참조로 변경시키는 단계이다.
초기화는 클래스 변수를 proper된 초기값으로 세팅하는 단계이다. proper 값은 프로그래머에
의해 지정된다. 다음은 초기화의 예문이다.
class value initializerclass Example//variable initializerstatci int size = 3*(int) (Math.randow()*5.0) ; static value initializerclass Examplelbstatic int size;// static initializerstaticsize = 3*(int) (Math.randow()*5.0) ;

객체의 생명주기는 클래스 실증과 초기화, 객체 생명주기의 시작에 발생하는 활동성, 가비지
컬렉션, 승인 , 객체 생명주기의 끝에 표하는 활동성에 의해 결정한다.
클래스 초기화는 프로그램 안에서 new operation, newInstance(), clone()등의 작업 수행한
다. 자바 애플리케이션의 첫 번째 instantiated 객체는 command line argument를 사용하여
전달되는 문자열 객체이다. 클래스 로딩 시에 instantiate되는 클래스는 자바 가상 머신에 모
든 타입이 로드될 때 타입을 나타내는 새로운 클래스를 instantiate한다. 상수 저장소의
CONSTANT_String_info entry를 포함한 클래스를 로드할 때, new String 객체가
instantiate된다. 상수 저장소 resolution은 메소드 area의 CONSTANT_String_infoentry를
heap의 string 인스턴스로 transforming하는 작업이다.
표현 평가 수행 주에 생성되는 객체는 표현이 컴파일 상수가 아닌 경우이다. <init>메소드
는<init>() 메소드를 호출하는부분, 인스턴스 변수를 초기화하는 코드 구현 부분, 건설자의
코드 부분을 포함한다. 같은 클래스 안에서 명시적 호출로 this()를 호출하는 경우 <init>메
소드는 <init>() 메소드를 호출하는부분과 건설자에 해당하는 구현 몸체의 바이트코드의 두
부분으로 구성된다.
this()를 사용하지 않는 경우는 사위 클래스 <init>() 메소드를 호출하는 부분, 인스턴스 변
수를 초기화하는 코드 구현 부분, 건설자의 코드 부분이 있는 경우이다. 힙에 대해 자동으로
저장소를 관리하는 전략이 필요하다. 명시적/함축적 메모리 할당은 객체 인스턴스 변수을
저장할 힙 공간을 할당한다. 상위 클래스의 변수 모두를 할당한다. 구현 독립적인 포인터이
다. 클래스 데이터로의 저장을 한다. 메소드 영역에 있다. 힙 메모리와는 별도로 인스턴스
변수을 기본값으로 초기화한다. proper 초기 값을 준다.
인스턴스 초기화 메소드는 <init>이다. 외부적으로 건설자를 선언하지 않으면 기본으로
<init>() 메소드를 호출한다. 동적 링킹과 해석은 자바 컴파일시 프로그램에 관련된 클래스
파일들을 얻어온다.

자바 실행시에 자바 가상 머신은 동적 링킹 시점에 관련 클래스, 인터페이스, hook등을 로
드한다. 상수 저장소는 클래스의 모든 심볼 참조가 있다. 초기에 한번 로드한 뒤에 , 다음부
터는 내부의 상수 저장소를 참조한다. 상수 저장소 해석된 프로그램 중 실행 중에 사용되려
면 반드시 해석되어야 한다. 해석은 심볼 참조에 의해 명확해지는 실체를 찾고, 직접 참조로
대치시키는 것이다. 모든 심볼 참조가 상수 저장소에 있으므로 이러한 작업을 상수 저장소
에 접근할 수 있지만, 각각은 오직 한번만 해석됨. 심볼 참조는 상수 저장소에 있는 아이템
의 한 종류이다. 이것을 참조하는 가상머신 명령어는 상수 저장소에서 어디에 있는지에 대
한 인덱스를 명시한다. 링킹은 심볼 참조를 직접 참조로 대치한다. 해석하는 동안에 접근 인
증허가와 접합성을 포함한다. 예를 들면 다른 클래스 필드의 명령어를 해석한다면 가상 머
신이 체크하는 것을 들 수 있다.
다음 중 확인 실패한 것이 있으면 에러를 반환하고 해석을 실패한다.
- 다른 클래스의 존재
- 그 클래스가 다른 클래스의 접근을 허용하는가
- 다른 클래스에 이름 붙어진 필드가 있는가
- 적합한 타입을 가졌는가
- 이 클래스가 필드 접근을 위한 허가를 가졌는가
- 필드가 정적인가
가상 머신마다 언제 링킹를 하는지 결정할 수 있다. 초기 해석은 main()이 시작되기 전에
모든 심볼을 링크한다. 프로그램이 시작하기 전에 에러를 찾아 낼 수 있다. 말기해석은 심볼
이 불려질 때 링크, 대부분의 가상 머신이 나아가는 방향이다. 에러가 있는 클래스가 있더라
도 호출하지 않으면 에러가 나지 않는다.
동적 확장은 프로그램이 실행시에 클래스들을 링크하여 그 안의 메소드들을 이용할 수 있
다. 클래스 로더를 포함해야 한다.

java. lang. classLoader의 loadClass()를 이용하여 로드한다. 클래스 로더는 로딩, 링킹, 초기
화를 수행한다. ClassLoader 는 로드만을 한다. 클래스 로더 링커와 초기화자는 링킹과 초
기화도 기본으로 수행한다. 자신의 클래스 로더를 생성하는 이유는 로드하는 단계를 사용자
설정하기 위한 것이다. 각 클래스 로더는 링크하고 초기화하는 것은 다르지만 로드하는 것
은 같다. loadClass() 메소드는 로딩, 링킹, 초기화의 세 단계를 포함한다. 파라메터 이름은
요구되는 클래스의 전체 적격 이름을 넘긴다. 파라메터 해석이 진실이면 링킹과 초기화는
수행하고, 거짓이면 수행하지 않는다. 해석할 때 에러가 발생하면 명령어에서 에러가 난 것
처럼 보인다.
CONSTANT_Class_info Entries의 해석은 해석하기 가장 어렵다. CONSTANT_Class_info
는 클래스와 인터페이스의 심볼 참조를 참조하기 위해 사용한다. new, anewarray와 같은
명령들은 entry들을 직접 참조한다. put 필드, invoke virtual과 같은 명령들은 다른 타입의
entry를 통해서 간접적으로 참조한다. CONSTANT_Class_info의 해석하는 세부사항은 타입
이 배열인지, 참조될 타입이 기본의 클래스 로더나 클래스로더 간접적으로 참조한다.
CONSTANT_Class_info의 해석하는 세부 사항은 타입이 배열인지, 참조될 타입이 기본의
클래스 로더나 클래스 로더 객체를 통해서 로드가 됐는지에 따라 바뀐다.
배열 클래스는 name_index가 [로 시작하는CONSTANT_Utf8_info를 참조한다면
CONSTANT_Class_info entry가 배열 클래스를 가리킨다. 요소 타입이 L로 시작한다면 배
열이 이면 배열이 가상 머신이 해석하는 것이다. 요소 타입이 기본 타입이면 배열이 기본
타입이 배열이다.
NONARRAY CLASSES AND INTERFACES 는 name_index가 [로 시작하지 않는
CONSTANT_Utf8_info를 참조한다면 비 배열 클래스이거나 인터페이스를 나타낸다. 심볼
참조를 해석하는 단계 즉 step1에서 타입 로드를 하고 step2a-2e에서 링킹, 초기화한다. 가
상 머신이 이들 step을 수행하는 것은 참조 타입이 기본 클래스 로더 또는 클래스 로더 객
체를 통해서 로드되는 것에 따라서 변할 수 있다.
step1에서 타입과 상위 클래스를 로드한다. 인터페이스나 배열이 아닌 클래스의 해석은 현
재 이름 공간에 로드된다. 클래스 로더는 타입을 로드, 이진 데이터를 내부 데이터 구조로
파스, 클래스 인스턴스를 생성한다.

java. lang. object가 아닌 클래스라면 자신의 superclass의 full qualified name을 체크한다.
자신의 상위 클래스가 로드되지 않았으면 로드해온다. 상위 클래스가 java. lang. Object가
될 때가지 반복한다. class가 로드된 방법에 따라 상위 클래스의 로드 법이 결정한다. 원시
클래스 로더인지, 클래스 로더 객체인지를 결정한다. 해석동안에 어떤 로더에 의해 이미 로
드되었는지의 여부를 저장하고 있는 리스트를 이용한다. 참조 타입이 원시 클래스 로더를
통해 로드되었다면 이미 로드가 되었는지 체크하기 위해 원시 클래스 로더 이름 공간을 참
조한다. 만약 로드되어 있지 않으면 원시 클래스 로더가 가상 머신의 나름대로의 방법대로
로드한다. 참조 타입이 클래스 로더 객체를 통해 로드되었다면 로드하기 위해 클래스 로드
객체의 loadClass()를 호출한다. 파라메터로 참조 타입의 fully qualified name과 true를 넘겨
준다. 클래스 로더 객체의 두 가지 방식은 원시 클래스 로더가 요청된 타입을 로드, 링크,
초기화하는 findSystemClass()의 호출에 의해 원시 클래스 로더를 사용하는 방법과 resolve
parameter가 true인 경우 resolveClass()를 호출하는 defineClass()를 호출함으로써 자신의
방법으로이진 데이터를 처리하는 방법이 있다.
다음의 클래스의 예이다.
protected final Class findSystemClass (String name) throws ClassNotFoundException;
protected final Class defineClass (String name, byte data[], int offset, int length);
protected final void resoveClass(Class c);
findSystemClass()에서 name은 resolve하기 위한 타입의 fully qualified이고, 반환 값은 원
시 클래스 로더가 성공적으로 로드했다면 참조 타입의 클래스 인스턴스를 수행한다. 오류가
났을 때 ClassNotFoundException 발생하고, defineClass(), 가상 머신이 이진 데이터를 내부
적 데이터 구조로 parse하고 타입을 나타낼 클래스 인스턴스를 생성한다.

타입이 java. lang. object가 아닌 클래스일 경우 상위클래스도 생성한다. 여기서 이름은 해
석하기 위한 타입의fully qualified name이다. 해석은 링킹, 초기화의 수행 여부를 true/false
값으로 리턴 한다.
ㆍstep 1동안 생기는 예외를 보면[표 2-1-12]와 같다.
[표 2-1-12 step 1에서 발생하는 예외]
예외 발생상황
NoClassDefFoundError
ㆍ적당한 이름의 클래스 파일을 찾을 수 없을 때ㆍ클래스의 version이 적당하지 않을 때ㆍ클래스 파일 안에 클래스 이름이 같지 않을 때
NoClassDefFoundErrorㆍ지신이 객체가 아니면서 superclass를 포함하지 않을 때
ClassCircularityError ㆍ자신이 자신의 superclass처럼 보일 때
ㆍstep 2 LINK AND INITIALIZE THE TYPE AND ANY SUPERCLASSES부 클래스 전
에 모든 상위 클래스들은 초기화되어야 함.
가. step 2a 타입 검증
검증하는 과정은 가상머신이 새로운 타입을 로드하길 요구한다. 타입에 적합한 이진인지 체
크하기 위해 상위클래스와 상위 인터페이스를 모두 검사한다. superinterface이면 새로 로드
하면서 가능한 링크를 한다. 타입이 언어 문법상 맞는지 검사한다. 예를 들어 다른 클래스의
메소드를 부를 때 둘 다 로드되어야 한다. 예외 상황 시 검증에러가 발생한다.
나. step 2.b 타입 준비
메소드 테이블 같은 클래스 변수들이나 구현 의존적인 데이터 구조를 위한 메모리를 설정한
다. 예외 상황 시 추상메소드에러가 발생한다.

다. step 2c 타입 해석
참조 타입이 아닌 참조된 타입을 포함하는 심볼 참조의 해석이다.
그러나, 실행 시에 에러의 여부를 체크할 수 있다.
“NoClassDefFound”가 발생한다.
라. step 2d 타입 초기화
타입이 상위 클래스가 있다면 top_down방식으로 초기화한다. 실행 중 에러가 발생하면
"Exception In Initializer Error"가 발생한다. 메모에러가 발생하면 "Exception In Initializer
Error"를 생성할 수 없으면 OutOfMemoryError가 발생한다.
마. step 2e 접근 허가
참조 타입의 접근 권한을 체크하여 불법액세스에러를 발생시킨다. 이 단계에서는 에러가 발
생하더라도 일반적으로 아직은 사용 가능하다.
CONSTANT_Fieldref_info Entries의 Resolution은 class_index가 가리키고 있는
CONSTANT_Class_info가 먼저 해석되어야 한다.
NoSuchFieldError는 참조된 클래스에 존재하는 타입, 이름 등을 가진 필드가 없을 때 발생
한다. I11ega1AccessError는 필드는 존재하는데 접근권한이 없을 때 발생한다.
7. 자바 스택
가비지 컬렉션을 하는 이유는 고정분할 메모리 기법, 가변분할 메모리 기법으로 주기억장치
를 관리할 때 메모리의 단편화가 발생한다. 단편화의 해결책으로 통합기법과 압축기법이 있
다. 여기서 말하는 가비지 컬렉션은 압축기법이다. 분할에 대한 가비지 컬렉션을 자동을 실
행한다.

가비지 컬렉션은 분할 발생으로 주기억장치에 넓게 퍼진 메모리들을 사용하기 위해 한 구역
으로 모으는 작업이다. 특히 자바 개발에 있어서 장점은 메모리 효율성을 들 수 있다. 그러
나 가비지 컬렉션의 단점은 속도와 성능 저하를 들 수 있다.
고전적인 가비지 컬렉션은 알고리즘은 참조 카운팅과 트레이싱, 두 가지가 있다. 그 중에서
크레이싱은 마크-스윕과 복사가 있다.
참조 카운팅은 루트와 힙은 포인터로 연결되어 있다. 참조계수가 0이면 가비지 컬렉션을 실
행한다. 참조 카운팅의 장점은 실행이 쉽고, 즉각적인 메모리 재사용이 가능하며. 루트 영역
과 힙 영역이 독립되어 있다. 그러나 이 것의 단점은 참조계수를 위함 메모리영역이 필요하
고, 업데이트를 위한 오버헤드가 높으며, 포인터로 연결되어 있어 사이클에 대한 오버헤드가
발생할 수 있다.
마킹은 사용되지 않는 메모리와 사용되는 메모리 영역을 분리하여 마크하는 것이다. 수윕은
모두 모인 가비지 셀들을 하나의 프리 저장소로 재구성하는 것이다. 이런 작업들의 장점은
효율적인 관리가 가능하고 포인터를 사용했던 RC에 비해 오버헤드가 감소된다는 것을 들
수 있다. 마크/스윕(스탑/스타트)에 의한 오버헤드로는 비트맵 마킹과 게으른 스위핑을 들
수 있다.
복사는 힙을 세미 공간으로 구성하여 두 개의 영역으로 분할한다. 그 두 개의 영역이란 현
재 데이터와 폐용 된 데이터 영역이다.
컬렉터는 활동적 데이터 공간을 발견하여 비어있는 세미 공간으로 복사한다. 이것의 장점은
자동으로 간결화가 이루오지고 배당에 따른 메모리 영역 낭비를 막을 수 있다. 단점은 복사
의 오버헤드가 크고 두 개의 영역으로 나누어진 세미 공간에 대한 오버헤드가 있다.
가비지 컬렉션 자바 또는 자바 가상 머신의 이슈는 발달 정책과 힙 기관과 효율적인 컬렉션
스케쥴링을 한다.
자바 가상 머신은 스택기반 머신이다. 대부분의 명령어는 피연산자 스택을 포함한다. 푸시
값, 팝 값, 또는 둘 모두를 수행한다. 상수를 스택에 푸시하고 일반적인 스택 연산자를 수행
하는 정도가 피연산자 스택과 지연 변수 사이의 값 변형을 일으키기도 한다.
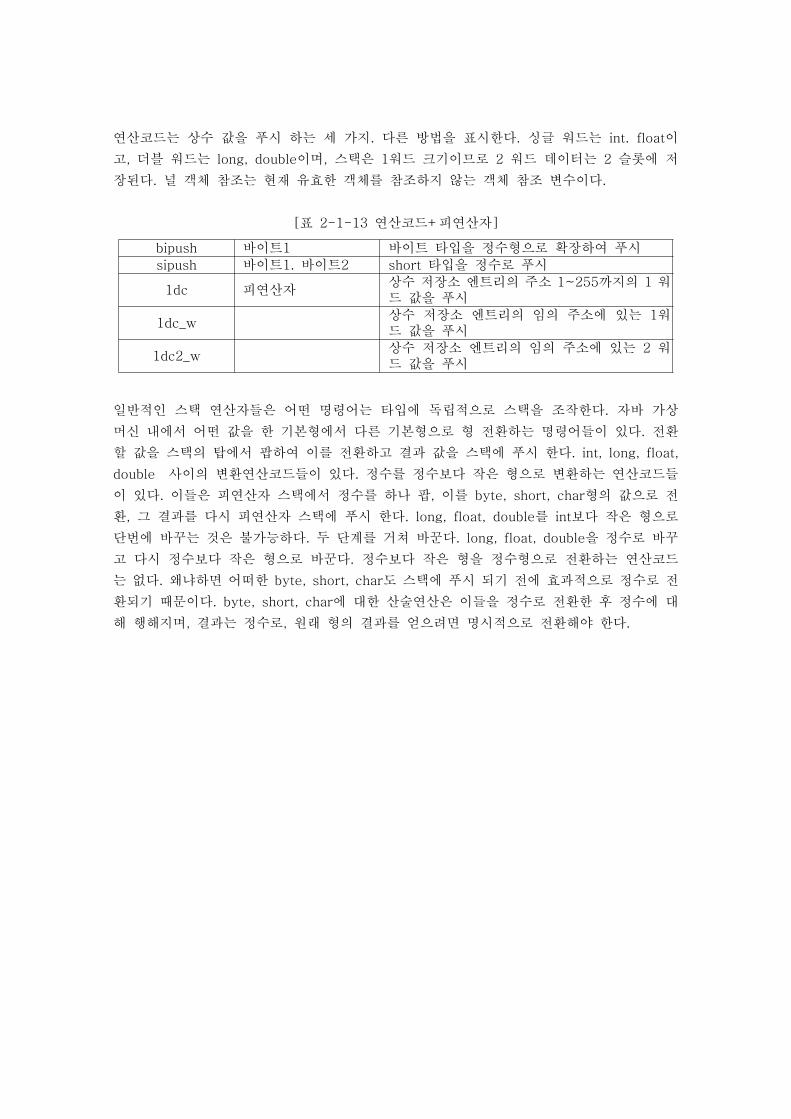
연산코드는 상수 값을 푸시 하는 세 가지. 다른 방법을 표시한다. 싱글 워드는 int. float이
고, 더블 워드는 long, double이며, 스택은 1워드 크기이므로 2 워드 데이터는 2 슬롯에 저
장된다. 널 객체 참조는 현재 유효한 객체를 참조하지 않는 객체 참조 변수이다.
[표 2-1-13 연산코드+피연산자]
bipush 바이트1 바이트 타입을 정수형으로 확장하여 푸시
sipush 바이트1. 바이트2 short 타입을 정수로 푸시
1dc 피연산자상수 저장소 엔트리의 주소 1~255까지의 1 워드 값을 푸시
1dc_w상수 저장소 엔트리의 임의 주소에 있는 1워드 값을 푸시
1dc2_w상수 저장소 엔트리의 임의 주소에 있는 2 워드 값을 푸시
일반적인 스택 연산자들은 어떤 명령어는 타입에 독립적으로 스택을 조작한다. 자바 가상
머신 내에서 어떤 값을 한 기본형에서 다른 기본형으로 형 전환하는 명령어들이 있다. 전환
할 값을 스택의 탑에서 팝하여 이를 전환하고 결과 값을 스택에 푸시 한다. int, long, float,
double 사이의 변환연산코드들이 있다. 정수를 정수보다 작은 형으로 변환하는 연산코드들
이 있다. 이들은 피연산자 스택에서 정수를 하나 팝, 이를 byte, short, char형의 값으로 전
환, 그 결과를 다시 피연산자 스택에 푸시 한다. long, float, double를 int보다 작은 형으로
단번에 바꾸는 것은 불가능하다. 두 단계를 거쳐 바꾼다. long, float, double을 정수로 바꾸
고 다시 정수보다 작은 형으로 바꾼다. 정수보다 작은 형을 정수형으로 전환하는 연산코드
는 없다. 왜냐하면 어떠한 byte, short, char도 스택에 푸시 되기 전에 효과적으로 정수로 전
환되기 때문이다. byte, short, char에 대한 산술연산은 이들을 정수로 전환한 후 정수에 대
해 행해지며, 결과는 정수로, 원래 형의 결과를 얻으려면 명시적으로 전환해야 한다.

자바 가상 머신이 지원하는 모든 정수형 즉, byte, short, int, long은 부호화 2의 보수이다.
2의 보수법은 양수, 음수를 모두 표현할 수 2의 보수에서 most significant bit은 부호 비트
의 값이 1이면 음수, 0이면 양수이다.
2의 보수로 표현 가능한 수의 개수 : 2 sup (비트수)
2의 보수에 대한 덧셈은 비 부호화 이진수에 대한 덧셈처럼 더해진 후 오버플로는 무시되고
결과는 2의 보수로 저장한다.
예외가 발생하는 경우는 다음과 같다.
- 정수연산시의 오버플로는 자바 가상 머신에서 예외상황을 발생시키지 않는다. 단지 결과
가 잘려나갈 뿐이다.
- 정수를 0으로 나누는 경우에는 수학적인 예외상황이 발생한다.
- long이 충분히 길지 않은 경우는 java. math패키지의 BigInteger 클래스를 사용한다.
BigInteger 클래스는 길이가 정해지지 않은, 기본형에서 가능한 연산을 모두 허용한다. 자바
가상 머신은 정수와 long에 대해 정수 산술연산을 하는 연산코드들을 몇 가지 제공한다. 스
택의 탑에서 두 값을 팝 하여 연산하고 결과를 푸시 한다. 더해질 값들은 이전 명령어에 의
해 스택에 푸시 되어 있어야 한다. 값의 형은 연산코드에 의해 지시되고 결과는 더해진 숫
자들과 같은 형이다. 예외상황 발생 없으며, 오버플로는 무시된다. 수학적 연산코드가 스택
으로부터 가져온 피연산자를 취하는데 대한 예외 규칙이다. iinc 다음 첫 번째 바이트에 증
가시킬 지역 변수가 온다. 이에 더할 양이 iinc 다음 두 번째 바이트에 온다. 위 두 수의 더
해진 결과가 지역 변수에 되 쓰인다. 오버플로는 무시되고, 예외상황은 발생하지 않는다. 와
이드는 iinc의 와이드 변형이다. 인덱스를 8비트에서 16비트로 확장한다.
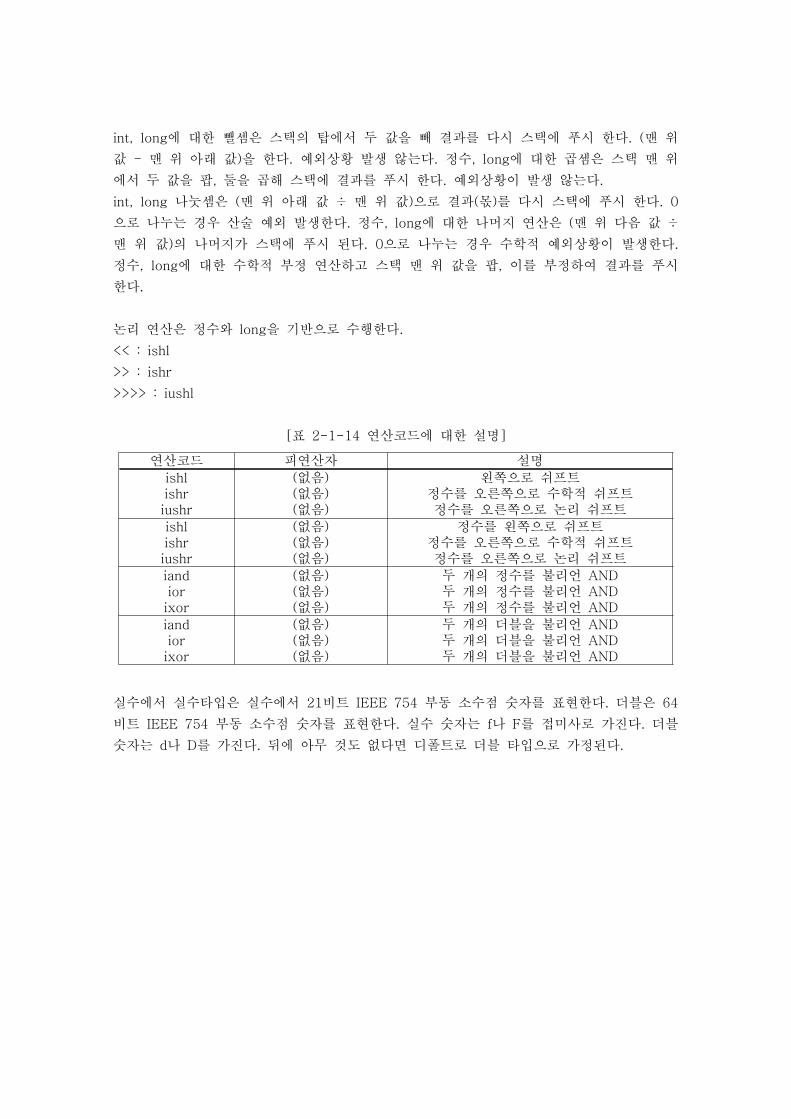
int, long에 대한 뺄셈은 스택의 탑에서 두 값을 빼 결과를 다시 스택에 푸시 한다. (맨 위
값 - 맨 위 아래 값)을 한다. 예외상황 발생 않는다. 정수, long에 대한 곱셈은 스택 맨 위
에서 두 값을 팝, 둘을 곱해 스택에 결과를 푸시 한다. 예외상황이 발생 않는다.
int, long 나눗셈은 (맨 위 아래 값 ÷ 맨 위 값)으로 결과(몫)를 다시 스택에 푸시 한다. 0
으로 나누는 경우 산술 예외 발생한다. 정수, long에 대한 나머지 연산은 (맨 위 다음 값 ÷
맨 위 값)의 나머지가 스택에 푸시 된다. 0으로 나누는 경우 수학적 예외상황이 발생한다.
정수, long에 대한 수학적 부정 연산하고 스택 맨 위 값을 팝, 이를 부정하여 결과를 푸시
한다.
논리 연산은 정수와 long을 기반으로 수행한다.
<< : ishl
>> : ishr
>>>> : iushl
[표 2-1-14 연산코드에 대한 설명]
연산코드 피연산자 설명
ishlishriushr
(없음)(없음)(없음)
왼쪽으로 쉬프트정수를 오른쪽으로 수학적 쉬프트정수를 오른쪽으로 논리 쉬프트
ishlishriushr
(없음)(없음)(없음)
정수를 왼쪽으로 쉬프트정수를 오른쪽으로 수학적 쉬프트정수를 오른쪽으로 논리 쉬프트
iandiorixor
(없음)(없음)(없음)
두 개의 정수를 불리언 AND두 개의 정수를 불리언 AND두 개의 정수를 불리언 AND
iandiorixor
(없음)(없음)(없음)
두 개의 더블을 불리언 AND두 개의 더블을 불리언 AND두 개의 더블을 불리언 AND
실수에서 실수타입은 실수에서 21비트 IEEE 754 부동 소수점 숫자를 표현한다. 더블은 64
비트 IEEE 754 부동 소수점 숫자를 표현한다. 실수 숫자는 f나 F를 접미사로 가진다. 더블
숫자는 d나 D를 가진다. 뒤에 아무 것도 없다면 디폴트로 더블 타입으로 가정된다.

부동 소숫점은 다음 네 가지 형태로 표현한다. 네 가지 형태는 digits. digits exponent part
suffix, digits exponent part suffix, digits exponent part suffix, NaN이다. 부호를 보면 0은
+, 1은 -이다. 지수는 처음 두 형태에서는 없어도 상관없지만 세 번째 형태에서는 꼭 필요
하다. 지수는 e 또는 E뒤에 양의 정수 또는 음의 정수로 구성된다. 지수는 과학적 표현으로
쓰여진 숫자에서 10의 지수를 구분하는데 쓰인다. 예를 들어 1000000.0은 1.0E6으로 표현된
다. NaN은 0으로 나누는 것과 같은 수학적으로 정의되지 않은 연산 결과를 나타내는 수가
아닌 값을 표현하는데 쓰인다.
객체와 배열상의 재생자는 다음과 같은 특징을 지닌다. 첫째, 객체만 가비지 컬렉터가 되는
힙에 할당된다. 원시 타입을 힙에 할당할 수 없다. 둘째, 객체 참조와 원시 타입만이 자바
스택에 놓여진다. 객체는 자바 스택에 놓여질 수 없다. 셋째, 자바에서의 배열은
full-fledged 객체이다. 다른 객체처럼 동적으로 생성된다. 넷째, 배열 연산자는 특별한 바이
트 코드에 의해 조작된다. 다음 [표2-1-14], [표 2-1-16], [표 2-1-17]을 보면 객체 생성과
클래스, 인스턴스 변수 접근을 알 수 있다.
[표 2-1-15 객체 생성]
연산코드 피연산자 설명
new인덱스바이트 1,인덱스바이트 2
힙에 새로운 객체를 생성하고 새로운 참조를푸시한다.
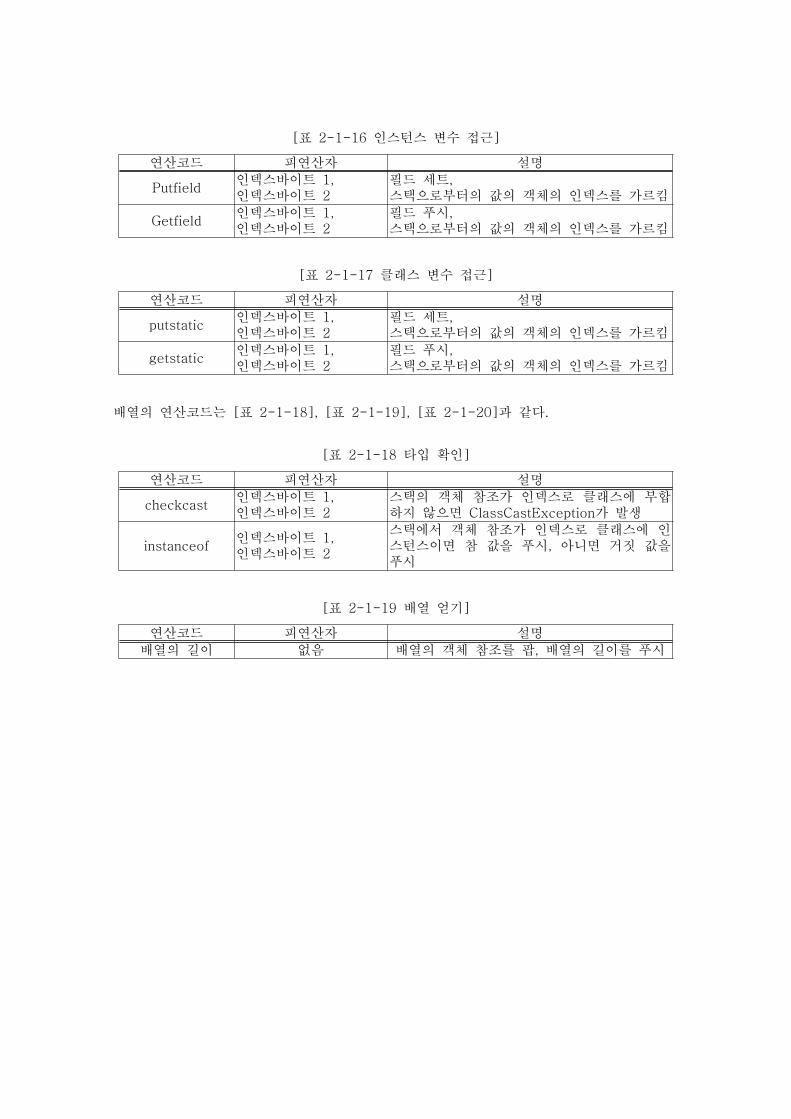
[표 2-1-16 인스턴스 변수 접근]
연산코드 피연산자 설명
Putfield인덱스바이트 1,인덱스바이트 2
필드 세트,스택으로부터의 값의 객체의 인덱스를 가르킴
Getfield인덱스바이트 1,인덱스바이트 2
필드 푸시,스택으로부터의 값의 객체의 인덱스를 가르킴
[표 2-1-17 클래스 변수 접근]
연산코드 피연산자 설명
putstatic인덱스바이트 1,인덱스바이트 2
필드 세트,스택으로부터의 값의 객체의 인덱스를 가르킴
getstatic인덱스바이트 1,인덱스바이트 2
필드 푸시,스택으로부터의 값의 객체의 인덱스를 가르킴
배열의 연산코드는 [표 2-1-18], [표 2-1-19], [표 2-1-20]과 같다.
[표 2-1-18 타입 확인]
연산코드 피연산자 설명
checkcast인덱스바이트 1,인덱스바이트 2
스택의 객체 참조가 인덱스로 클래스에 부합하지 않으면 ClassCastException가 발생
instanceof인덱스바이트 1,인덱스바이트 2
스택에서 객체 참조가 인덱스로 클래스에 인스턴스이면 참 값을 푸시, 아니면 거짓 값을푸시
[표 2-1-19 배열 얻기]
연산코드 피연산자 설명
배열의 길이 없음 배열의 객체 참조를 팝, 배열의 길이를 푸시
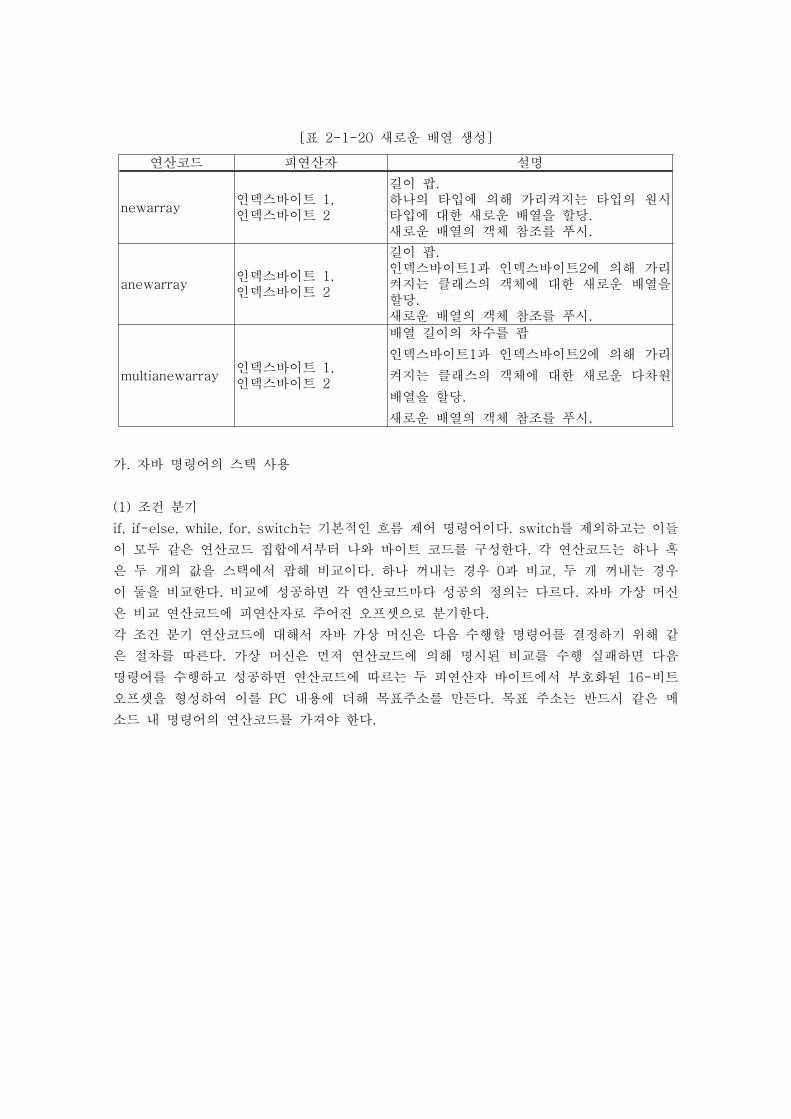
[표 2-1-20 새로운 배열 생성]
연산코드 피연산자 설명
newarray인덱스바이트 1,인덱스바이트 2
길이 팝.하나의 타입에 의해 가리켜지는 타입의 원시타입에 대한 새로운 배열을 할당.새로운 배열의 객체 참조를 푸시.
anewarray인덱스바이트 1,인덱스바이트 2
길이 팝.인덱스바이트1과 인덱스바이트2에 의해 가리켜지는 클래스의 객체에 대한 새로운 배열을할당.새로운 배열의 객체 참조를 푸시.
multianewarray인덱스바이트 1,인덱스바이트 2
배열 길이의 차수를 팝
인덱스바이트1과 인덱스바이트2에 의해 가리
켜지는 클래스의 객체에 대한 새로운 다차원
배열을 할당.
새로운 배열의 객체 참조를 푸시.
가. 자바 명령어의 스택 사용
(1) 조건 분기
if, if-else, while, for, switch는 기본적인 흐름 제어 명령어이다. switch를 제외하고는 이들
이 모두 같은 연산코드 집합에서부터 나와 바이트 코드를 구성한다. 각 연산코드는 하나 혹
은 두 개의 값을 스택에서 팝해 비교이다. 하나 꺼내는 경우 0과 비교, 두 개 꺼내는 경우
이 둘을 비교한다. 비교에 성공하면 각 연산코드마다 성공의 정의는 다르다. 자바 가상 머신
은 비교 연산코드에 피연산자로 주어진 오프셋으로 분기한다.
각 조건 분기 연산코드에 대해서 자바 가상 머신은 다음 수행할 명령어를 결정하기 위해 같
은 절차를 따른다. 가상 머신은 먼저 연산코드에 의해 명시된 비교를 수행 실패하면 다음
명령어를 수행하고 성공하면 연산코드에 따르는 두 피연산자 바이트에서 부호화된 16-비트
오프셋을 형성하여 이를 PC 내용에 더해 목표주소를 만든다. 목표 주소는 반드시 같은 메
소드 내 명령어의 연산코드를 가져야 한다.

if 연산코드 류0에 대한 비교자바 가상 머신이 이들 만나면 스택에서 하나의 값을 팝하여 0과 비교한다.
두 개의 값을 스택에서 팝하여 이들을 비교하고 가상 머신은 비교에 성공하면 분기한다. 이
연산코드를 수행하기 전에 값2는 스택 탑에 값1은 그 밑에 있다. 정수에 대해 행해진다.
short, byte, char에 대해서도 가능하다. 자바 가상 머신은 언제나 이러한 형들을 정수로 전
환한 후 다룬다. long, float, double에 대한 비교한다. 이들 연산코드 자체로는 분기 일어나
지 않는다. 대신, 비교결과를 나타내는 정수 값을 푸시하고 정수 비교 연산코드를 통해 실질
적인 분기가 이루어진다. 객체 참조를 스택에서 팝하여 이를 널과 비교하고 비교에 성공하
면 분기한다. 스택에서 객체 참조를 두 개 팝하여 이들을 비교하여 둘이 같으면 이들이 같
은 객체를 참조하는 것이고 다르면 다른 객체를 참조하는 것이다. 성공하면 분기한다.
(2) 무조건 분기문
가상 머신은 goto 연산코드의 두 피연산자로부터 부호화된 16-비트의 오프셋을 만들어
(goto_w의 경우 32-bit) 가상 머신은 이를 PC의 현재 값에 더해 결과 주소를 구한다.
(3) 테이블을 가진 조건 분기문
switch를 위한 자바 가상 머신은 특별한 연산코드는 tableswitch과 lookup switch이 있다.
tableswitch, lookupswitch 명령어는 기본 분기 오프셋 하나와 가변길이의 경우 값/분기 오
프셋 집합을 가진다. 스택에서 키를 꺼내 이를 모든 경우 값들과 비교하고 match가 있으면
그 경우 값에 해당하는 분기 오프셋을 취하고 없으면 기본 분기 오프셋을 취한다. 두 명령
어의 차이점은 경우 값을 지시하는 방법이 다르다는 것이다. lookupswitch가 tablesswitch보
다 범용이나, tableswitch가 대개의 경우 보다 효율적이다.

둘 다 뒤에는 0~3byte의 padding이 오고 그 다음에는 기본 분기 오프셋(4 bytes)가 온다.
그 다음에는 lookupswitch를 한다. 값(int형)-npair의 쌍이 온다. tableswitch는 low, high int
값이 온다. 다음에는 범위보다 high한 경우의 분기 오프셋, 보다 low한 경우의 분기 오프셋,
범위내인 경우의 분기 오프셋이 온다. Throwing and Catching Exceptions을 보면 예상치
못한 상황(unexpected condition)을 제어하기 위해 예외상황(exception)을 사용한다.
NitPickyMath라는 덧셈, 뺄셈, 곱셈, 나눗셈을 하는 클래스에서 예외상황(Exception)을 보인
다. 오버플로우(overflow), 언더플로우(underflow), devided by zero(0으로 나누는 경우)의 경
우에는 예외 에러가 발생한다. 수학적 예외상황은(Arithmetic Exception)은 클래스
OverflowException extends Exception, class UnderflowException extends Exception, class
DevideByZero
Exception extends Exception이다. 각 연산에서 검사하여 에러 발생 시 제어를 예외처리로
이동한다.
8. 자바 모니터
모니터는 두 종류의 쓰레드 동기화를 지원한다. 상호 배척은 객체를 잠금으로 여러 쓰레드
가 서로 간섭하지 않고 독립적으로 공유 데이터를 사용하여 동작한다. 상호 작용은 클래스
객체의 메소드들을 알리고 기다리게 해서 쓰레드들이 공동의 목적을 위해 함께 동작하는 것
을 가능하게 해준다. 모니터란 특별한 방(어떤 시점에 단지 하나의 쓰레드만이 점령하는)을
가지는 건물과 같다. 객체 잠금은 자바 가상 머신의 실행 시 데이터 영역 중 일부는 모든
쓰레드에 의해 공유되고 나머지는 각각의 쓰레드에 소속되어 있다.

9. 시스템의 구현
가. 자바 가상 머신 카페(kaffe : 이하 카페)
(1) 카페
카페는 장치 독립적이고, 자신의 표준 클래스 라이브러리와 원시 라이브러리, 그리고 고도의
구성력을 가진 가상머신 Just-In-Time(JIT) 컴파일러이다. 카페는 가상 머신 모듈과 목적
장치들에 대해 구현되어진 원시 라이브러리의 집합을 그 구성 요소로 가진다.
또한 “run-anywhere"자바 수행을 제공하며, 어떤 인터넷 어플리케이션 또는 내장된
(embedded) 시스템에서도 가상적으로 작동한다. 또한 Sun 과 Microsoft 의 자바 둘 다 어
떤 플랫폼에서도 실행시킬 수 있는 JVM이다. 카페는 완전히 독립적인 수행을 하고, 그래픽,
파일 관리, 입/출력 클래스들을 포함한다.
(2) 카페의 특징
(가) 완벽한 가상머신으로 PersonalJava(JDK1. 1. 1) 명세
ㆍ인터프리터, “Just-In-Time"(JIT) 편집물 또는 사전 편집 코드
ㆍ표준 JNI 인터페이스로 고유 코드
ㆍ호출 인터페이스로 쉽게 다른 소프트웨어 안에서 통합된다.
ㆍ주문가능 인터페이스로 운영체제, 클래스 로더, 파일 시스템, 네트웍과 그래픽 하부 시스
템에 간단하게 이식된다.
ㆍ고유의 운영체제 쓰레드 또는 그 자신의 내부 쓰레드 시스템에 대해 지원
ㆍ혼합된 사전 편집과 JIT 편집 자바 코드에 대해 지원
ㆍ다른 응용과 함께 간단하고 쉬운 통합(예. 웹 브라우저와 서버)
ㆍMicrosoft 자바 확장에 대해 지원
(나) PersonalJava 클래스 라이브러리에 관한 완벽한 실행
java. lang, java. io, java. util, java. net, java. net, java. beans, java. awt, java. applet,
java. lang. relect, java. util. zip, java.
awt. datatransfer, java. awt. event, java. awt. image

(다) 완전한 AWT 1.1 실행
ㆍ표준 windowing 시스템에 대해 AWT 지원(X-windows와 같음)
ㆍnon-windowing 플랫폼(예. 프레임버퍼) 사용하는 그 자신의 자바기반 windowing 시스템
에 대해 AWT지원
ㆍSun's Swing에 대해 메모리와 실행 비용 없이 주문가능한 "look and feel"
ㆍ유례 없는 모든 자바 AWT 디자인이 제공하는 보다 적은 공간에서의 더 나은 이식과, 아
직은 동등 기반과 Swing 기반에 대신하는 빠른 실행을 제공
ㆍAWT1.0에 대해 역행 지원
ㆍJavaSoft's Swing 그래픽 라이브러리에 대한 지원
(라) 모든 소스
ㆍSun 소스 또는 다른 어떤 밴더로 부터의 소스도 없다.
ㆍSun 라이센스를 요구하지도 않는다.
ㆍ모든 소스 코드는 표준 라이센스 부분으로 제공된다.
(마) 디스크보다 작은 실행
고유의 파일 시스템을 필요로 하지 않고 디스크보다 작은 용량 내에서 실행된다. 클래스는
RAM, ROM 또는 flash 메모리로부터 로드된다.
(3) 카페의 장점
(가) 이식성
kaffe는 30개 이상의 운영체제에 포트 되어 있고, 8개의 다른 프로세서에서 실행된다. 제공
되는 플랫폼 영역에서 보여지는 사용자 환경이 이미 제공되어진다. 새로운 포트는 완벽하게
약 3개월 이상 사용되지 않고 상당히 쉽다. 이것은 보기에 쉽고 kaffe는 플랫폼의 넓은 영역
에 사용된다.

(나) 확장성
사용자가 본문 끝에 그래픽을 필요로 한다면? 사용자가 독립적으로 포함된 컨트롤러를 네트
웍 지원에 필요로 한다면? 사용자는 많은 다른 시스템에서 소규모의 내재된 제어를 강력한
그래픽 웍스테이션으로부터 kaffe를 찾을 수 있다. 많은 다른 환경들에서 단일 장치와 함께
공급되어지는 느낌을 만들지는 못한다. 결과로써, kaffe는 쉽게 포함되어 만들어지고 변환
사이에 들어오지 못하게 한다.
ㆍ그래픽(AWT) 지원
ㆍJIT/인터프리터 모드
ㆍ사용자/커널 쓰레드
ㆍkaffe/JNI 고유 인터페이스
이것은 완벽한 리스트가 아니다. 그러나 주어지는 개념은 사용자가 kaffe를 구축하고 실행함
에 있어 적어요 100KB이어야 한다.
(다) 유효성
유효성은 없고 단지 약간의 실행시의 속도가 있다. 그러나 kaffe‘s JIT는 빠른 스피드가 있
다. 자바 코드가 실행되는데 오직 30% C로 짜여진 것보다 느리다는 것이다. 그러한 이유로
메모리에서 소비되는 JIT가능한 그래픽적 kaffe 또한 중요하다. 여기서 우리가 실행 가능한
완벽한 시스템은 DOS 시스템에서 4MB, 가상머신과 라이브러리 최소한 1MB를 넘지 않아
야 한다. 우리의 완벽한 소스는 1.4MB 단일 플로피에 tree에 맞다. 이러한 이유로 우리는
유효성이라 한다.

나. 카페의 구조
(1) 기본적인 카페의 구조
(2) 카페의 모듈
다음 그림은 자바1.1에 따른 가상머신 카페의 모듈을 나타낸다.
가상머신은 한 덩어리로 뭉친 조각의 코드이다. 이식성과 확장성이 함께 디자인되었기 때문
에 서브시스템을 나누는데 중요하게 사용된다.

(가) 쓰레딩
내부의 자바의 명확한 사용자 단계 쓰레드 시스템(j 쓰레드 시스템이라 부름)과 고유한 커
널 단계 쓰레딩 시스템( 예. POSIX 에 따른 p 쓰레드)사이에서 어떤 플랫폼에서든지 가능
하게 선택된다. 첫 번째 선택은 많은 이식과 non-I/O 운영에서 빠른 사용성으로 (정당한 적
은 문맥 변경의 오버헤드),나중의 사용 시 만약 많은 오버래핑, 비동기적 입출력, kaffe가 멀
티프로세스를 사용 할 때까지이다.
(나) 메모리 관리
kaffe는 mark- and-sweep 가비지 콜렉터(GC)와 함께 자신의 heap 관리 시스템을 가지고
있다. 왜냐하면, 그것은 “이상의” 가비지 관리 개념이 아니다. 그래서 kaffe는 하나 이상의
응용의 사용에 쓰는 GC에 교체 가능한 것을 제공한다. -빠른 할당에 대해 원격 참조 계수
계획, 한세대의 수집이나 복사 수집한다.
(다) java Native Interface
고유 방식의 실행에 대해 두 가지가 있다.-표준 자바 고유 인터페이스(JNI)와 kaffe 명세의
고유 인터페이스(KNI). JNI는 고유 라이브러리에 사용자가 쓸 수 있으며 다른 가상머신 사
이에서 언제든지 이식이 가능하다. KNI는 빠르지만, 자바 필드에 사용자 고유 코드에 자주
접근한다면 이식되지는 않는다.
(라) Native system call
이식성의 이유에 대해 목적 명세 시스템을 간접 디렉토리를 경유하며 운영체제 인터페이스
를 부른다.
(3) JIT 의 구조
가상머신에서 가장 흥미있는 부분은 실행 엔진으로 인터프리터와 JIT가 있다. 인터프리터는
포트에 작고 쉽지만 실행 코드가 상당히 느리다. JIT는 매크로의 쓰여지는 부분을 요구하
고, 실제 어셈블러 명령어들을 제의한다.

고유 코드에 C로 컴파일된 속도를 차단하여 “on-demand" 가능한 코드 실행에 변환되는 바
이트코드를 허락한다.
java lang/io/net/util packagesjava. awt packages
native window system/standalone
[그림 2-1-8 Persona1Java 1.1 에 따른 자바 클래스 라이브러리]1
(가) JRE (The Java Runtime Interpreter (Win32)
jre interprets (executes) Java bytecodes.
(나) JIT 컴파일러
실행시에 원시코드를 자바 바이트코드를 변환하는 컴파일러이다. 실행시에 극적으로 프로그
램의 수행속도를 증가시킬 수 있다. 그러나 최적화는 실행시간에 일어나기 때문에 수행하는
최적화 단계는 많은 부하를 가져온다. 따라서 JIT 컴파일러는 코드를 빠르게 생성하는데 많
은 관심을 가진다.
카페에서는 직접 자체 제작한 ‘자바 JIT 컴파일러’를 탑재하여 자바 애플릿의 실행속도를
10에서 15배까지 향상시켰다. JIT는 자바가 가상 머신에서 인터프리팅 되던 점을 보완하여
자바 바이트 코드를 인터프리팅하지 않고 바로 내부적으로 컴파일 되어있어 기계적으로 속
도를 향상 시켰다.
다음 그림은 카페에서 JIT 컴파일러의 수행과정을 나타내고 있다.
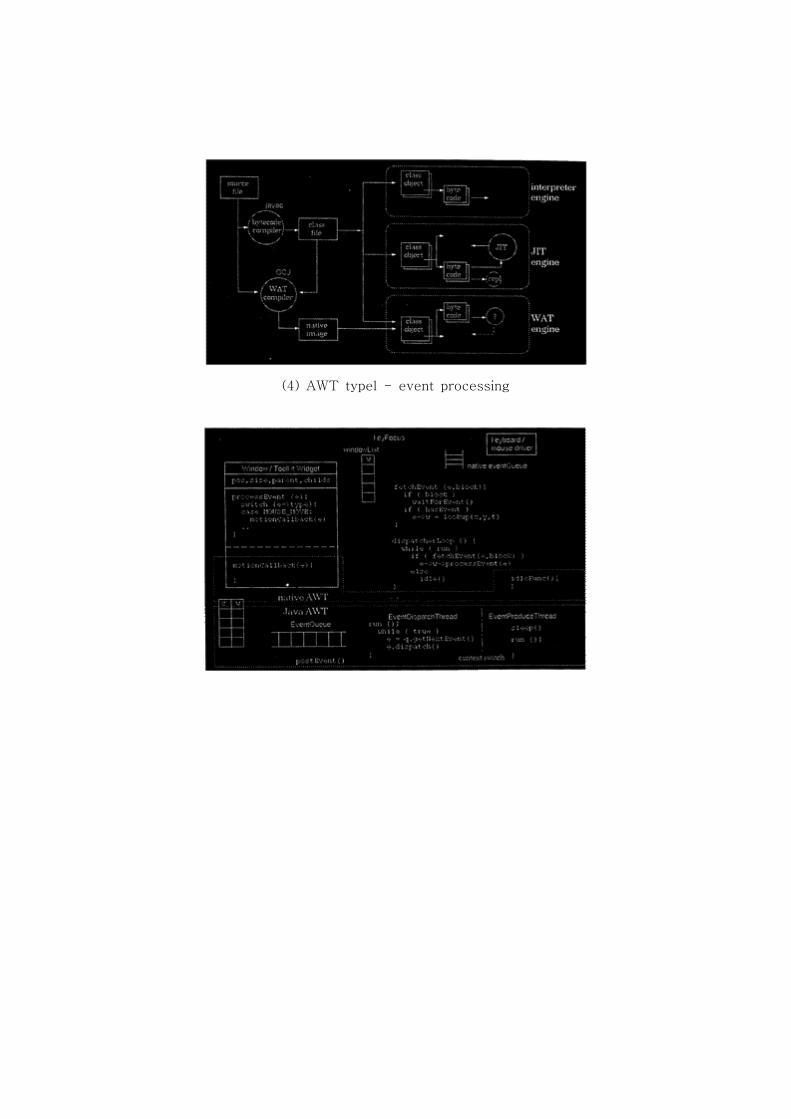
(4) AWT typel - event processing

① AWT type2 - event processing
제 2 절 Java Debugger의 연구
Java 디버거는 Java 애플리케이션을 디버그할 수 있는 Java 도구이다. 디버거라는 말은 기
존의 프로그램들에서도 많이 사용되어 왔기 때문에 잘 알고 있겠지만, 코드의 실행을
command-line방식으로 한 라인씩 추적해 가면서 소스코드의 잘못된 곳이나 특정 상황에서
어떻게 작동을 하는지 알아 볼 수 있는 프로그램을 말한다.
Java Virtual Machine Debugger Interface (JVMDI)는 하위레벨의 디버깅 API이다. 가능한
사용을 위해 JVMDI가 포함하는 것은, - 프로세스내의 디버거 도구 : 디버거와의 의사전달
을 위해 직접 JVM과 함께 JVMDI를 사용한다.

-프로세스내의 out-of-process를 위한 back-end 디버거 도구 : back-end 를 사용한 JVMDI
는 상위레벨 디버깅 인터페이스 도구이다.
JVMDI는 하위레벨 API로 JVMDI는 직접 디버깅 툴을 지원하는 것을 의미하지 않고, 다양
한 상위레벨 디버깅 API들을 지원하는 것을 의미한다.
이런 API들은 다양한 종류의 디버거들을 지원하기를 바란다.
JVMDI는 Java Native Interface(JNI)를 사용한다. 각각의 디버거는 Java 쓰레드와 같이 쓰
레드를 생성하지만, 네이티브 방법들을 호출하는 것처럼 JVMDI와 JNI를 호출하는 것은 문
제가 된다. 모든 네이티브 방법들은 JNIEnv 포인터를 갖는다. JNIEnv 포인터는 쓰레드에
대해 상세한데, 그것은 네이티브 방법이라 불리고 모든 JVMDI 함수들에 적합하다.
1. JVMDI 함수들
가. 쓰레드 실행 함수
(1) 쓰레드 상태 가져오기
(2) 쓰레드 중지
(3) 쓰레드 다시 시작하기
(4) 단일 단계 모드 설정하기
나. 스택 프레임 접근 함수
(1) 쓰레드의 현재 프레임 가져오기 - 쓰레드 중지되어야 하고, 반환하는 값은 확실하게 남
아있어야 하는데, 오직 오랫동안 중지되어 남아있는 쓰레드를 말하며, 쓰레드는 Java 또는
JNI 방법이다.
(2) 방문 프레임 가져오기 - 프레임을 가져오는 것은 방문 프레임과 반환되는 프레임 포인
터에 의해서이고, 호출과 방문 모두 Java 또는 JNI 방법이다.

(3) 프레임 방법 가져오기 - 가져온 정보를 확인하는 것은 프레임내서의 액티브 방법이다.
반환되는 액티브 방법의 클래그는 포인터 내에 위치하고, 반환되는 방법은 스스로 메소드
포인터를 경유한다.
(4) 프레임에서 바이트코드 인덱스 가져오기 - 바이트코드 인덱스를 정의하는 것은 프레임
의 현재 실행 명령을 뜻한다. 바이트코드 포인터를 경유한 바이트코드 인덱스를 반환한다.
(5) 제거된 프레임의 표기 - 프레임이 스택으로부터 제거되었을 때
JVMDI_EVENT_FRAME_POP 이 생성된다.
다. 지역변수 접근 함수
(1) 지역변수 가져오기- 프레임과 슬롯이 가리키는 지역변수의 값을 가져온다. 값의 포인터
에 의해 가리켜지는 값을 복사 해온다. 이러한 함수들은 새로운 전역 객체로 생성된다.
(2) 지역변수 설정하기 - 값을 설정한다는 것은 프레임과 슬롯에 의해 가리켜지는 지역변수
의 값을 설정하는 것이다.
라. 구분점 함수
(1) 하나의 구분점 설정 - 구분점 설정은 clazz, 메소드 바이트코드 인덱스가 가리키는 바
이트코드에 설정하는 것이다. 지정된 바이트코드를 실행할 때는 언제나, JVMDI_E
VENT_BREAKPOINT 이벤트가 생성된다.
(2) 하나의 구분점 지우기 - clazz, 메소드, 바이트코드 인덱스에 의해 바이트코드에 설정된
구분점을 지우는 것이다.

(3) 모든 구분점 지우기 - JVM내에 설정된 모든 구분점 지운다.
마. 메소드 정보 함수
(1) 메소드 명칭과 기호 - clazz와 메소드에 의해 지칭되는 Java 메소드에 대해 반환되는
이름포인터를 경우한 메소드 이름과 기호 포인터를 경우한 메소드 기호이다. 반환되는 두
개의 값은 새로운 전역 객체로 사용자는 확실하게 JNI 함수인 DeleteGloba1Ref()와 함께 반
환해야 한다.
(2) 메소드 정의 클래스 - clazz와 메소드에 의해 지칭되는 메소드에 대해 반환되는 클래스
definingClassPtr를 경유한다. 반환되는 값은 새로운 전역 객체로 사용자는 확실하게 JNI 함
수인 DeleteGloba1ref()와 함께 반환해야 한다.
(3) 네이티브 메소드 - clazz와 메소드에 의해 지칭되는 메소드에 대해 반환되는 값이
isNativeptr를 경유하는 네이티브 메소드인지 아닌지를 지칭한다.
바. 이벤트 함수
쓰레드는 실행되는 상태가 변하지 않는 이벤트를 생성한다. 만약 이벤트가 쓰레드가 정지되
는 것을 야기 시킨다면, 이벤트 훅 함수를 정지시키는 문제일 것이다. 이벤트 훅 함수는 쓰
레드 생성 이벤트에 의해 호출된다. 그것은 Java 객체 또는 Java 메소드 호출에 의해 생성
되는 것이 아니다.
사. 그 외의 함수들
(1) 적재된 클래스 가져오기 - 반환하는 배열의 모든 클래스들의 적재는 Java 가상머신의
classesptr를 경유한다. 반환되는 값은 새로운 전역 객체로 사용자는 확실하게 JNI
DeleteGlobalRef()함께 반환해야 한다.

(2) 버전 정보 가져오기 - JVMDI의 버전은 version Ptr에 의해 반환된다. 반환되는 값은
확실하게 큰 쪽의 상위 순서 16비트와 작은 쪽의 하위 순서 16비트로 되어 있다.
2. 디버거 사용법
디버거의 처리는
- 디버그 처리
- 오류설명, 디버그 개념 그리고 디버그 세션 시작
- 프로그램 수행 제어
- 실행시에 이용하는 방법, 특정한 위치에서 수행, 코드를 이용한 단계별 수행
- 정지점 이용
- 정지점 설정과 제거하는 방법, 조건과 예외 정지점 설정 그리고 정지점 그룹
- 이용하는 방법
- 프로그램 데이터 값 검사
- Inspector와 보기 이용 방법, 식 계산 방법에 대한 설명.
- 디버거 설정
- 색상 설정과 패널에 출력될 제어 설명 Debugger 이다.
디버거는
- 정지점으로 수행
- 메소드 호출로 가기
- 메소드 호출 추적
- 커서 위치 수행
- 메소드 끝 수행
- 어떤 위치에서 프로그램 정지
- 어떤 조건을 만났을 때 프로그램 정지를 이용해서 프로그램을 제어한다.

프로그램이 정지 할 때, 프로그램 데이터 항목의 현재 값, 포함한 클래스, 인트턴스 그리고
지역 변수, 메소드 인자 그리고 속성값을 볼 수 있다.
- 쓰레드와 스택 창
- 데이터 창
- 보기 창
- Inspector 창
- 대화 상자 계산/ 변경 등을 이용해서 데이터 항목값을 검사 변경 할 수 있다.
디버거 중에 프로그램 데이터 값을 변경하는 것은 프로그램 수행중 버그를 가상적으로 수정
하고 검사하는 방법으로, 디버거를 중단하고 프로그램을 오류 코드를 변경하고 다시 컴파일
한다. 많은 디버그 특성은 실행과 보기메뉴에 의해 설정된다.
제 3 절 Java Database search engine 의 연구
1. XML : 저장 및 검색 방식
가. XML 개요 및 구조
XML은 extensible Markup Language의 약자로 1996년 W3C(world Wide Web
Consortium)에서 제안한 것으로써, 웹상에서 구조화된 문서를 전송 가능하도록 설계된 표준
화된 텍스트 형식이다.

이는 인터넷에서 기존에 사용하던 HTML의 한계를 극복하고 SGML의 복잡함을 해결하는
방안으로써 HTML에 사용자가 새로운 태그(tag)를 정의할 수 있는 기능이 추가된 것이라고
볼 수 있다. 즉, XML 이 나오기까지는 SGML(Standard Generalized Markup Language)의
배경과 HTML(HyperText Markup Language)의 기능적 측면들을 살펴볼 필요가 있다.
(1) HTML
현재 웹에서 사용되고 있는 문서로써, 하이퍼텍스트나 하이퍼미디어의 기능을 지원하는 간
단하고 단순한 텍스트로 이식성과 사용이 편리하다. HTML은 SGML을 기반으로 한 DTD
를 정의하고, 그 정의를 따르는 웹브라우저를 사용하여 사용자가 만든 HTML 인스턴스
(HTML 파일)을 보여주는 방식으로 사용되고 있다. HTML의 문제점으로는 대용량 온라인
출판이 어렵고, 단순히 화면상에 보여지는 기능만을 한다는 점과, 사용자는 정의된 태그만을
사용할 수 있으며, 페이지 레이아웃 형태를 임으로 지정할 수 없다는 점 등이 있다. 이러한
문제점들은 CSS(cascading Style Sheet)로 얼마만큼 해결 될 수도 있지만, 근본적으로 고정
적인 태그 셋 (tag set)에서 발생하는 문제나 HTML 문서에 구조적 정보를 담을 수 없는
점 등 은 여전히 발생한다.
이를 해결하기 위해서는 태그에 대한 정의를 할 수 있는 기능이 있어야 하며, 브라우저에서
는 DTD를 읽고, 또 DTD를 이용하여 만든 문서를 DTD에 맞게 해석할 수 있고, 또 브라우
저에 보여줄 수 있어야 하는데 그러한 요구를 수용하려는 시도가 바로 XML이 등장하게 된
이유중의 하나이다.
(2) SGML : Standard Generalized Markup Language
상이한 시스템간의 여러 가지 문서 정보들을 공통적으로 표현하기 위하여 만든 국제 표준
규약으로, 국제표준기구(ISO : International Standard Organization)에서는 1986년 데이터
객체 양식의 표준으로서 ISO 8879 : Information Processing Text and Office
Systems-Standard Generalized Markup Language (SGML)을 제정하였다.

SGML은 문서의 지능적 내용이나 체계를 정의하기 위한 언어로서 그 특성상 객체지향적 메
타언어(Object Oriented Mata Language)라 할 수 있다. SGML은 계층화된 논리구조와 내
용구조를 표현할 수 있기 때문에 텍스트, 그래픽, 멀티미디어 정보, 데이터베이스 정보 등을
명확하고 효과적으로 표현할 수 있으며, 각 소프트웨어와 하드웨어 독립적이고 어떠한 시스
템 간에도 상호 호환과 공유가 가능하다.
(3) xML : Extensible Markup Language
"XML는 SGML의 간략화된 버전이다. XML의 목적은 일반적인 SGML을 마치 HTML이
웹에서 동작하는 것처럼 사용하고자 하는 것이다. XML은 HTML과 SGML의 공동이용을
가능하게 하고자 제작된 언어이다.“
XML이란 개발자들이 클라이언트 어플리케이션에서 데이터를 디스플레이하고 조작하기 위
해 구조화된 데이터를 표현하고 전달하고 교환할 수 있는 텍스트 기반 포맷으로, 구조화된
데이터의 서버간 전송을 가능하게 하며 서로 호환되지 않는 분산된 데이터베이스에 방대한
양의 기존 데이터가 존재하고 있을 때 데이터의 동일성을 유지하면서 상호 이해 가능한 방
법으로 데이터를 교환하고자 처리하게 할 수 있다.
XML은 SGML의 장점을 계승한 언어이기 때문에 SGML이 가지고 있는 확장
(Extensibility), 구조(Structure), 검증(Validation)의 특성을 모두 계승하는데, 대표적인 특징
들로는 다음과 같은 것들이 있다.
- 사용자가 임의로 새로운 태그 세트와 속성을 정의할 수 있다.
- 문서의 구조는 연속적인 중첩을 허용한다. : 객체 지향적 구조 혹은 데이터베이스 스키마
의 구성을 위해 필요한 여러번의 중첩을 허용한다.
- 문법적인 구별을 문서 안에서 제공하므로써 문서 구조의 검증이 필요한 어플리케이션의
경우 문서 오류를 쉽게 판단할 수 있다.
- 서로 다른 소스의 데이터 통합, 다양한 어플리케이션의 데이터의 활용이나 로컬에서 조작
및 계산작업, 다양한 형태로 데이터 표시 기능 등 융통성 있는 웹 어플리케이션 개발이 가
능하다.
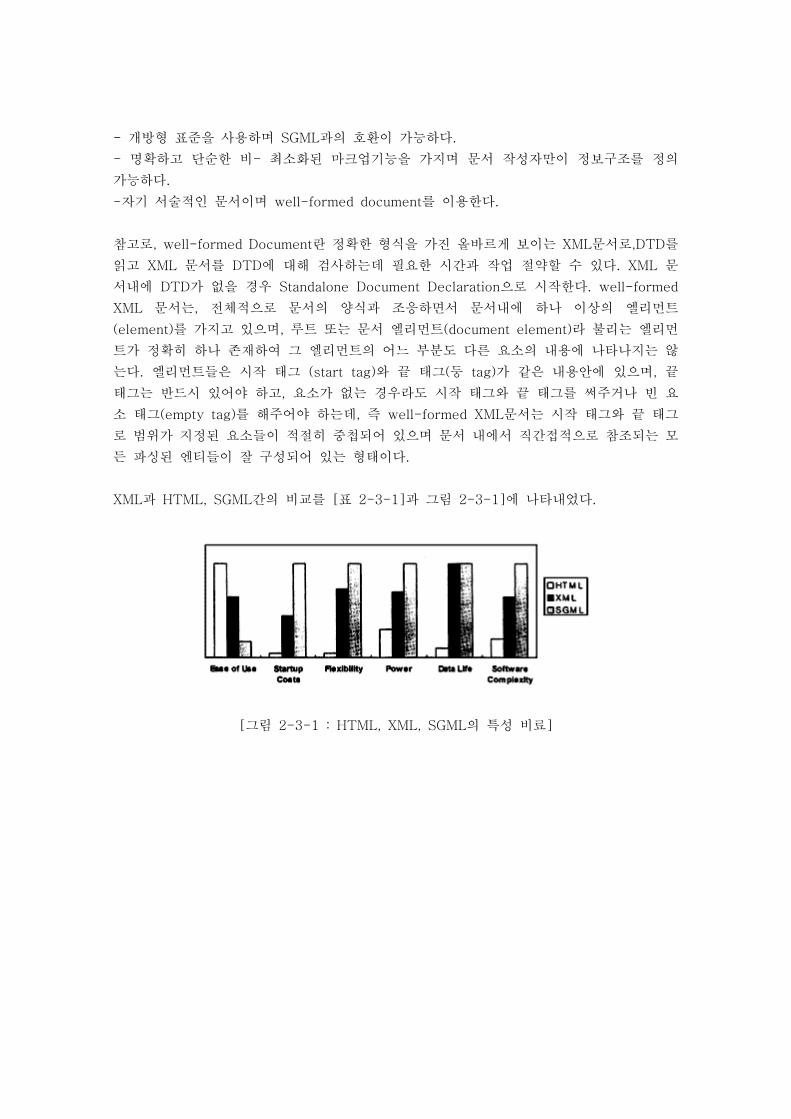
- 개방형 표준을 사용하며 SGML과의 호환이 가능하다.
- 명확하고 단순한 비- 최소화된 마크업기능을 가지며 문서 작성자만이 정보구조를 정의
가능하다.
-자기 서술적인 문서이며 well-formed document를 이용한다.
참고로, well-formed Document란 정확한 형식을 가진 올바르게 보이는 XML문서로,DTD를
읽고 XML 문서를 DTD에 대해 검사하는데 필요한 시간과 작업 절약할 수 있다. XML 문
서내에 DTD가 없을 경우 Standalone Document Declaration으로 시작한다. well-formed
XML 문서는, 전체적으로 문서의 양식과 조응하면서 문서내에 하나 이상의 엘리먼트
(element)를 가지고 있으며, 루트 또는 문서 엘리먼트(document element)라 불리는 엘리먼
트가 정확히 하나 존재하여 그 엘리먼트의 어느 부분도 다른 요소의 내용에 나타나지는 않
는다. 엘리먼트들은 시작 태그 (start tag)와 끝 태그(둥 tag)가 같은 내용안에 있으며, 끝
태그는 반드시 있어야 하고, 요소가 없는 경우라도 시작 태그와 끝 태그를 써주거나 빈 요
소 태그(empty tag)를 해주어야 하는데, 즉 well-formed XML문서는 시작 태그와 끝 태그
로 범위가 지정된 요소들이 적절히 중첩되어 있으며 문서 내에서 직간접적으로 참조되는 모
든 파싱된 엔티들이 잘 구성되어 있는 형태이다.
XML과 HTML, SGML간의 비교를 [표 2-3-1]과 그림 2-3-1]에 나타내었다.
[그림 2-3-1 : HTML, XML, SGML의 특성 비료]

[표 2-3-1 HTML과 XML 비교]
HTML XML
SGML의 어플리케이션 SGML의 축소된 버전(부분집합)
하이퍼텍스트, 멀티미디어 지원 광범위한 영역의 어플리케이션
하나로 정해진 문서 타입 자신만의 문서 타입 정의 기능
SGML을 사용하여 설계된 언어로, 설계목적은 웹상에서 사용되는 데이터 문서로 사용하기 위함이므로 SGML의 응용이라 할 수 있다.
SGML의 복잡성을 줄여 유저들이 쉽게 사용할 수 있다.
XML 관련 표준으로는 다음과 같은 것들이 있다.
-xML(Extensible Markup Language) : SGML의 subset으로 Content를 포함하는 부분이며
1.0이 98년 2월 10일 W3C에 의해 recommendation된 상태이다.
-XSL(Extensible Style Language) : Displaying 정보를 포함하는 부분이며, XML 기반 데
이터를 HTML이나 다른 프리젠테이션 포맷으로 변환하는데 쓰이고, 기존의 CSS(Cascading
Style Sheets)보다 더 많은 기능을 제공하여 데이터 구조와 다른 프리젠테이션 구조를 만들
수 있게 한다.
-XML(Extensible Linking Language) : Hypertext 즉, link 정보를 포함하는 부분으로 XML
링크용 언어로 볼 수 있다. XML을 사용하면 링크는 다중방향성을 가질 수 있고 페이지 레
블 뿐 아니라 오브젝트 레블의 링크도 가능하게 한다.
-DOM(Document Object Model) : 문서 안에 스크립트를 끼워 넣는 표준으로 스크립트를
통해 구조화된 데이터에 프로그램식 접근을 가능하게 하므로써 XML 기반 데이터를 지속적
으로 가지고 계산할 수 있게 한다. 프로그램과 스크립트들이 컨벤트와 구조, 문서의 스타일
을 다이나믹하면서 표준적으로 접근 할 수 있게 한다.
-DTD : XML tag와 구조 정보를 포함하는 부분이다.

XML 문서를 만들기 위해서는 원하는 문서의 논리적 구조를 파악한 후 이를 표현할 수 있
는 문헌정의부(DTD)를 만들고, 정의한 태그들을 이용하여 실제 문헌부(XML document
instance)를 만드는 순서를 가진다. 이때 [그림 2-3-2]같이 DTD를 하나의 문서 파일에 함께
두는 방법과 [그림 2-3-3]처럼 DTD와 Instance를 따로 두는 방법이 있다. 이후 만들어진
문서에 대해 style sheet을 적용하므로써 원하는 형식대로 보여지게 한다. XML문서 제작을
위한 전체적인 과정을 표현한 그림이 [그림 2-3-4]에 나타나 있다.
<?XML version="1.0" encoding = "UTF-8" RDM= 'INTERNAL'?><!DOCTYPE greeting SYSTEM "hello.dtd"><greeting> Hello. world!</greeting>
[그림 2-3-2 DTD를 하나의 파일 안에 두는 방식]
<?XML version="1.0" encoding = "UTF-8" RDM= 'INTERNAL'?><!DOCTYPE greeting<!ELEMENT greeting (#PCDATA)]><greeting> Hello. world!</greeting>
[그림 2-3-3 DTD를 서로 다른 파일 안에 두는 방식]
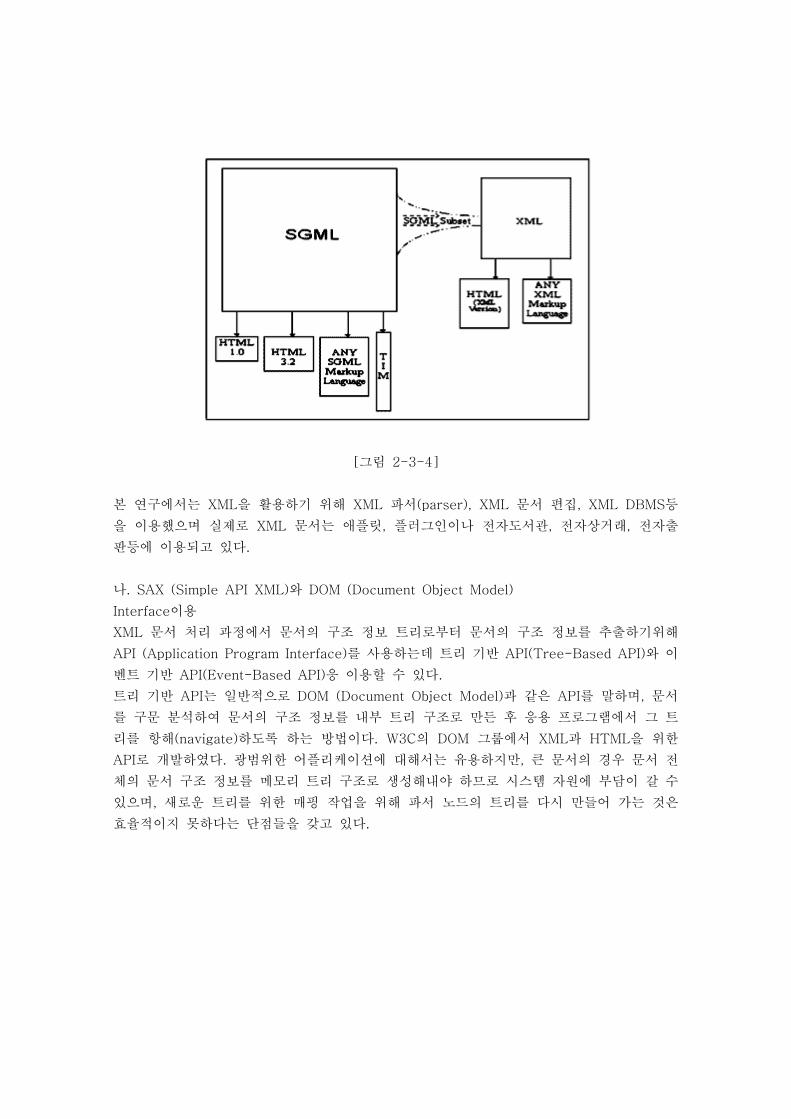
[그림 2-3-4]
본 연구에서는 XML을 활용하기 위해 XML 파서(parser), XML 문서 편집, XML DBMS등
을 이용했으며 실제로 XML 문서는 애플릿, 플러그인이나 전자도서관, 전자상거래, 전자출
판등에 이용되고 있다.
나. SAX (Simple API XML)와 DOM (Document Object Model)
Interface이용
XML 문서 처리 과정에서 문서의 구조 정보 트리로부터 문서의 구조 정보를 추출하기위해
API (Application Program Interface)를 사용하는데 트리 기반 API(Tree-Based API)와 이
벤트 기반 API(Event-Based API)응 이용할 수 있다.
트리 기반 API는 일반적으로 DOM (Document Object Model)과 같은 API를 말하며, 문서
를 구문 분석하여 문서의 구조 정보를 내부 트리 구조로 만든 후 응용 프로그램에서 그 트
리를 항해(navigate)하도록 하는 방법이다. W3C의 DOM 그룹에서 XML과 HTML을 위한
API로 개발하였다. 광범위한 어플리케이션에 대해서는 유용하지만, 큰 문서의 경우 문서 전
체의 문서 구조 정보를 메모리 트리 구조로 생성해내야 하므로 시스템 자원에 부담이 갈 수
있으며, 새로운 트리를 위한 매핑 작업을 위해 파서 노드의 트리를 다시 만들어 가는 것은
효율적이지 못하다는 단점들을 갖고 있다.

이벤트 기반을 API는 문서의 구조 정보를 내부 트리 구조로 만드는 대신 구문 분석 이벤트
를 직접 응용프로그램에 전달하는 방법으로 트리 기반 API에서 시스템 자원이 많이 사용되
는 문제를 해결한 방법이다. 파싱 이벤트를 바로 콜백(callback)하여 어플리케이션에 기록하
며 내부 트리는 만들지 않는다. 서로 다른 이벤트에 대해 비슷한 핸들러(handler)를 두어 다
루게 하므로써 간단하게 구현될 수 있고, XML문서의 하위레벨 접근을 제공하므로써 실제
유용한 시스템 메모리보다 큰문서의 파싱도 가능하고 이벤트 핸들러를 사용하여 자신만의
데이터 구조를 설립시킬 수 있다.
예를 들어, “Ottawa를 포함하는 레코드 요소의 위치는?”라는 사용자 질의에 대한 정보를 찾
을때,XML 문서가 20MB 정도라면 문맥상 정보 하나를 위치시키기 위해 내부메모리 파스트
리(parse tree)를 만들고 운행하는 것은 비효율적일 것이며 이벤트 기반 인터페이스를 통해
적은 메모리를 사용하여 단일 패스내에 찾도록 하는 방법이 효율적일 것이다.
SAX(Simple API XML)는 XPI-J와 XML-DEV 메일링 리스트의 멤버들에 의해 개발된 이
벤트 기반 XML 파싱을 위한 표준 인터페이스, 현재 파서와 응용프로그램 양쪽으로 지원되
고 있다. 처음에는 JUMBO 가 세 개의 서로 다른 API를 가지는 XML파서를 지원하기 시작
하면서 자바 이벤트 기반 API 파서 (YAXPAPI : Yet Another XML parser API)를 생성했
으며, XML 파서를 위한 독립적이고 표준적인 이벤트 기반 API로써는 자바 패키지 이름이
org.xml sax xml.org. domain을 사용하여 본격적으로 이용되기 시작했다.
SAX 1.0드라이버를 기반으로 만들어진 100% 순수 자바 기반의 파서로는 IBM's XML for
Java, James Clark's XP, DataChannels and Microsofts XJParser, Microstars Aelfred,
Silfides SXP, Suns XML
Library, Oracless XML Parser for Java 등이 있으며 세부적 특징은 다음절에서 설명한다.

다. 100% Pure Java 기반 XML Parser를 이용한XML 문서 검색
“XML 파서(프로세스)는 XML 문서를 읽고 문서의 내용과 구조를 알 수 있게 해주는데 이
런 점에서 XML 프로세서는 애플리케이션의 기능을 대신하는 것으로 간주된다.”
파서는 문서의 내용과 구조를 파악해 애플리케이션에 전달해 주는 역할을 하며 주요 기능은
다음과 같다.
- XML 문서의 선언부와 프롤로그 정보를 이용해 문서를 해석한다.
- XML 문서는 DTD(Document Type Definition)을 참조해 만든 유효한 (Valid) 문서와
DTD 참조 없이 만든 잘 구성된 (well-formed)문서로 구분할 수 있는데 각 문서에 따른 오
류 검사 기능을 제공하며, 발견된 오류의 위치와 종류, 수정방법 등에 대한 정보를 제공한
다.
- 문서의 파싱을 통해 얻어진 각종 정보를 제공한다. 즉, 엘리먼트나 엔터티의 구성정보, 현
재 파싱되고 있는 문서의 위치 및 파싱 상태 정보, 파싱이 끝난 후 재가공 된 문서 정보(문
서의 트리나 DTD 트리 등)를 제공해, XML 데이터 구조를 XML 애플리케이션에서 활용하
게 한다. 애플리케이션에 전달하는 과정에서 때로 SAX 혹은 DOM 같은 표준 인터페이스를
사용한다.
XML Parser의 종류로는 현재 C++를 이용해 구현된 것과 순수 Java를 사용해 구현된 것
등이 있으며 주요 업계에서 내높은 제품과 그 특징들은 다음[표 2-3-3], [표2-3-4], [표
2-3-5]와 같이 정리할 수 있다.
V : Validation Parser
S : Source Available

[표 2-3-3 xml parser in C++]
시스템 특징 V S
expat(James Clark) Mozilla 5.0에서 사용, 완전한 well-formedness 파서 X 0
LTXML
파서와 함께 다양한 종류의 파서들 포함모든 xml 마크업을 strip-out 시키는 프로그램, xmlnormalizer(주로 well-formed 체크에 쓰임), ESISoutputter, 엘리먼트 발생 카운터, tokenizer,down-translation 도구, grep tool, sorting tool 등
X 0
WindowsFoundation Classes
simple XML parser X 0
[표 2-3-4 : xml parser in JAVA]
시스템 특징 V S
Lark(Tim Bray) 작고 빠름, sax 드라이버 사용 0 0
Alfred(Microstar) 작고 빠름, sax 드라이버 사용 X 0
Microsoft XMLParser
well-defined 클래스, sax 드라이버 사용 0 0
IBM XML for JavaDOM 인터페이스, SAX 드라이버 namespace 구현,Xpointer구현하여 DTD 접근
0 0
XP(James Clark) 높은 성능, XML 1.0 스펙과의 완벽한 호환 X 0
DXP(Data ChannelXML Parser)
NXP(Nober Mikula)에 기반한 sax 드라이버, DOM 인터페이스 사용
0 0
[표 2-3-5 : xml parser (기타)]
시스템 특징 언어 S
Xparse 웹상에서 XML 문서를 파싱해서 보여줌 Java Script X
Pyexpatpython모듈로써 싸여져 있는 James Clarkexpat C parser
Python x
xmlproc dtd에 대한 접근 제공 Python X
xml-check perl X
Tcl support forXML
tcl 0

특히, 순수 자바로 만들어진 제품들의 특징에 대해서 좀더 자세히 살펴보면 다음과 같다.
(1) IBM의 XML for Java(Version 2)
- XML1.0 Recommendation, DOM1.0 Recommendation, SAX1.0
- 구성가능하고 모듈러식 구조를 갖고 있으며 높은 성능, 재유효화등 지원
- 순수 자바로 구현되어 있어 com.ibm.XML.parser package내에 XML문서등 파싱, 생성,
조작, 유효화를 위한 모든 클래스와 메쏘드를 함유하고 있다.
(2) Oracle의 XML Parser for Java
- XML1.0 Recommendation, 통합된 문서 객체모델 DOM1.0 Recommendation, SAX1.0
- 유효화/ 비유효화 모드 선택 가능하며 XSLT지원하여 성능 최적화
- 에러 회복 유틸 지원
- XML Namespace를 위해 제안된 recommendation 지원
- 15가지의 encoding 지원 : UTF-8, UTF-16, ISO-10646-UCS-2, ISO-10646-UCS-4,
US-ASCII, ISO-8859-1+0-9, Shift_JIS, EBCDIC-CP-*, BIG5, GB2312, EUC-KR, KO18-R,
ISO_2022_JP, ISO_2022_KR
(3) James Clark
- non-well formed 문서 감지
- 모든 외부객체 파싱 가능 : 외부 DTD subset, 외부 파라미터 개체등
- 4개의 encoding 지원 : UTF-8, UTF-16, ISO-8859-1, US-ASCII
(4) Slifides SXP
- 클라이언트/서버 환경에서 분산 언어 자원들을 위한 파서
- 문서자원의 일시적 메시지를 인코딩함(서버/서버, 서버/클라이언트)

- 서버측 툴과 클라이언트 작업공간을 구현하기 위함
- 구성 : SXP(Silfide XML Parser), NMU(Network Management Unit),
XQL(Silfide Query Language), SilDB(Silfide Database),
SIL(Silfide Interface Language),
Silver(Java web Server)
(5) Datachannel
- W3C의 XML1.0 Recommendation, DOM1.0 Recommendation, SAX1.0
- DTD와 Data-Schema 타입의 정의와 유효성, 명백한 데이터 타입 정의와 조작,
namespace가 부여된 요소와 어트리뷰트, Extensible Style Language(XSL)등 지원
- 질의, 패턴 매칭, 변형등을 통한 지원
그 밖의 Ms의 XJParser, Microstar의 Aelfred, SUN의 XML Library가 있다.
라. XML 문서 편집기를 이용한 XML Instance 생성
본 연구과제를 수행하기 위해 사용한 XML문서 편집기는 Clip를 이용했으며 [그림 2-3-5]는
Clip의 사용자 인터페이스를 나타낸다. Clip XML 문서 편집기는 다양한 문서 인코딩 지원,
실시간 유효성 검사, Tree기반 문서 편집 기능, 간단한 DTD 구조 편집 기능 등과 문서 구
조 정보를 이용한 검색 수행이 가능하다는 특징들을 갖고 있다.

[그림 2-3-5 CLIP XML 문서 편집기 실행 화면]
마. XML 저장 및 검색 방식
XML DBMS는 XML문서와 관계형 데이터베이스 사이의 데이터를 전송하는 시스템으로 다
음과 같은 특징을 갖는다.
- XML 문서를 트리 모양의 객체로 나타내며 이러한 객체를 RDB에 매핑하기 위해 객체-
관계 매핑을 사용
- 엘리먼트 타입은 클래스, 애트리뷰트와, PDATA은 클래스들의 속성들로 정의한다.
- 객체의 트리형은 DOM이 아닌데, 그 이유는 그 자체로 모델이 되지 그 문서의 데이터가
모델화 되지 않기 때문이다.
- 문서에 있는 데이터뿐만 아니라 XML문서의 계층구조도 까지 보존시키므로써 계층이 나
타나는 주어진 레벨에서 children내의 순서도도 보존한다.
- 문서 전송이 아닌 데이터 전송을 추구하므로, DTD룰 보존하지 않으며, entity사용,
CDATA구역, 문서 encoding과 같은 물리적 구조 보존 안한다.
- RDB의 top에서 문서관리 시스템구현까진 시도되지 못한 실정이다.

바. 기존의 데이터 베이스 시스템으로부터 XML 문서 검색 방식
XML 문서 표준안에 맞춰 이를 활용하는데 있어서 기존의 다양한 정보시스템을 XML을 매
개로 하여 통합하는 연구로 몇 가지 방안이 연구되고 있다. 즉, 기존의 RDB(Relational
Database)내에 구축되어진 많은 데이터들을 사용하기 위해 ODBC 로부터 XML 문서로 변
환시킬 수 있는 작업이나, OODB(Object Oriented Database)로부터 직접 XML 문서로 변환
시키기 위한 방안들이 이미 연구되어 있다. 분산 환경에서 각자 고유한 스키마를 가지고 운
영되고 있는 기존의 정보 시스템들을 XML이라는 공통 데이터 모델을 사용하여 표현함으로
써 통합된 정보를 제공할 수 있는데, 이를 위해 기존의 정보시스템의 데이터에 대한 XML
화된 질의 방법을 제시하며 이러한 질의에 대한 결과도 역시 XML으로 표현하기 위한 연구
이다.
이와 같은 방법을 통해 XML 문서를 위한 데이터 구축이 아닌 이미 구축되어진 DB 내의
데이터를 재사용 한다는 점과 데이터베이스내의 데이터를 원하는 대로 구조적으로 생성가능
하다는 점, 이미 만들어진 db의 내용을 손쉽게 꺼내 사용하므로 XML 인스턴스를 일일이
새로 정의해 주는 절차를 생략할 수 있어 새로 만들어야 할 XML 문서내의 크기를 줄일 수
있다는 점등을 이점으로 가질 수 있다. 이에 대해 간략히 소개하면 다음과 같다.
(1) ODBC2XML
ODBC2XML 은 복잡한 XML 문서의 생성을 간략화 시키고 비 프로그래머들도 스크립트
언어나 다른 복잡한 처리도구들을 사용하지 않고서도 XML 파일들을 생성가능하게 하는 방
안으로, Oracle, SQL 서버, Microsoft Access, Excel spreadsheets나 다른 모든 ODBC 드라
이버를 사용하는 데이터 소스를 XML 파일로 병합시켜 나타내는 프로그램이며 실행과정은
① ODBC DSN Connection, ② 템플릿 파일(sample.xml)을 읽어들여 질의문 인식, ③ fetch
된 질의문을 ODBC DSN으로 전송후 프로세스 수행 ④결과를 XML 문서로 내보내기 와 같
은 절차를 거치게 되어있다.

(2) OODB2XML
사용자로부터 XQL 질의를 입력받고, 결과를 XML 문서로 넘겨줌으로써 사용자가 임의의
DBMS를 XML 저장소와 같이 사용할 수 있도록 하는 방식이다. 실제적인 데이터는 객체지
향 DBMS에 저장되어 있는 객체들이며 사용자가 질의한 XQL은 OQL로 변화되어 DBMS에
질의되고 결과로 나온 객체의 집합은 다시 XML 문서로 변환되어 사용자에게 전달되는 방
식을 가진다. 전체적인 시스템 구조를 [그림 2-3-6]에 나타내었다.
[그림 2-3-6 OODB2XML 시스템 구조]
- XQL2OQL변환기 : 사용자로부터 XQL를 입력받아 객체 지향 DBMS가 이해할 수 있는
OQL로 변환하는 모듈. XQL을 OQL로 변환할 때 XQL표현식에서 나오는 각 엘리먼트들은
객체의 속성, 또는 그 객체가 가리키는 또 다른 객체로 매핑된다. 즉, XSQL
'novel/front/author'를 OQL로 변환하면 ‘SELECT x.front.author FROM x in novel'로 나
타낼 수 있다.

- Object2XML : 객체 지향 DBMS에 대한 질의 결과로 얻어지는 객체를 XML 형태의 문
서로 변환하는 모듈이다. 즉, 객체지향 DBMS에 대한 OQL 질의를 입력으로 받아 질의를
수행하고 결과로 XML 문서를 출력한다. 따라서 변환기 모듈은 질의의 대상이 되는 DBMS
의 OQL과 질의 결과 형태에 의존적인 모듈로서 개발되어진다.
(3) JDBC2XML
본 연구 수행 과정 중에는 이미 연구된 바 있는 ODBC2XML 변환 프로그램이 Microsoft
관련 database 제품에 대해서만 사용가능 하다는 제약점을 갖는데 대해 그 해결을 위한 방
안으로 플랫폼 독립적이며 어떤 DBMS에도 상관없이 XML 문서 시스템으로 변환 가능한
프로그램을 작성하였으며 그 이름을 임의로 JDBC2XML 이라 칭했다.
실행방식은
① 읽어들일 XML파일을 FileInputStream으로 읽어들인후,
② 파일내 문장들을 StringTokenize하여 질의문을 인식한다.
③ JDBC를 사용하여 사용될 DB Connection 작업을 거친다.
④ 인식된 질의문을 수행시킨다.
⑤ 결과를 화면에 가져온다. 와 같은 절차를 거치게 되어있다. 자세한 시스템 구성도와 구현
내용 및 데모화면은 [Appendix B]에 실었다.

2. 이동 에이전트를 이용한 검색 시스템
가. 에이전트의 개념 및 분류
에이전트란 사전적 의미로 ‘대행자’, ‘대리인’이란 뜻이며, 컴퓨터 분야에서는 ‘작업을 대행해
주는 프로그램’으로 이해될 수 있다. 에이전트를 다음과 같이 분류할 수 있다.
(1) 다중 에이전트 시스템(Multi Agent System)
에이전트끼리 대화한다는 것은 정해진 언어 규약에 따라 메시지를 주고받음을 의미한다. 에
이전트는 다른 에이전트에게 서비스를 요청하기 위해 정해진 언어 규약에 따라 요구 사항을
메시지 형태로 바꾼 후 해당 에이전트에게 전달한다. 다른 에이전트로부터 서비스 요청을
받은 에이전트는 그 메시지를 분석해 내부에서 처리할 수 있는 형태로 변환해서 이를 처리
한다. 에이전트는 그 결과를 다시 메시지 형태로 바꿔 이를 요청한 에이전트에게 전달한다.
이와 같이 에이전트끼리 대화를 하려면 내부적인 통신 규약이 필요하다. 이에 대한 연구로
는 미국방부의 ‘Knowledge Sharing Effort'하에 이뤄지는 ACL(Agent Communication
Language)이나 SRI(Stanford Research Institute)의 ICL(Inter-Agent Communication
Language) 등이 있다.

cf) 에이전트 통신규약(ACL) : ACL은 일부 그룹에서는 ‘ACL로 통신하는 프로그램’을 에이전트라고 부를 만큼 다중 에이전트 시스템 연구에 있어 중요하다. ACL은 크게 어휘(Ontology)와 내부 언어인 KIF(Knowledge Interface Format), 외부 언어인KQML(Knowledge query and Manipulation Language)로 이뤄져 있다. 어휘는 에이전트끼리 서로 이해하고 있는 단어를 의미하며, KIF는 지식을 표현하기 위한 규칙으로 확장된 1차 서술 논리문(first-order predicate calculus)이다. KQML은 에이전트간에 통신을지원하기 위한 언어로 문법적인 구조와 통신 프로토콜을 포함한다. KQML은 내용 계층(Content layer). 메시지 계층(Message layer), 통신 계층(Communication layer)의 3계층구조로 이뤄져 있는데 내용 계층은 전달될 지식, 메시지 계층은 전달할 내용의 특성, 통신계층은 통신을 위한 특성이 표현된다. 이중에서 내용 계층의 표현 형태는 특별히 제한하지 않으며, 지식 표현 방법인 KIF의 사용을 권하고 있다.
다중 에이전트의 특징으로는 에이전트 간 대화기능과, 대화내용을 전달하기 위한 에이전트
간 통신 구조(Agent Communication Architecture)를 들 수 있다. 에이전트 간 통신 구조로
는 QMW(Queen Mary and Westfield College) 대학의 ARCHON과 한국전자통신연구소의
EAMF(Extensible Multi-Agent Framework)가 있는데 ARCHON은 모든 에이전트가 다른
에이전트에 대한 정보를 갖고 이를 바탕으로 다른 에이전트에게 자신이 원하는 서비스를 직
접 요청하는 방식이며 EMAF는 조정자 역할을 하는 조정 에이전트(Broker, Coordinating
Agent)를 통해 에이전트들이 서비스를 주고받는 구조이다. EMAF 구조에서는 다른 에이전
트에게 서비스를 요청할 때 서비스를 제공할 에이전트에 대한 지정없이 필요한 서비스만을
요구한다. 조정 에이전트는 요청한 서비스 내용을 분석해 이를 수행할 에이전트를 선정하고,
해당 에이전트는 요구받은 사항을 수행하고 결과를 조정 에이전트에 전달하며 조정 에이전
트는 수행 결과를 처음 요청한 에이전트에 전달한다. 이때 서비스를 요청한 에이전트나 서
비스를 제공한 에이전트는 상대방이 누구인지 모르고 동작하게 된다.

다중 에이전트 시스템의 에이전트가 갖는 가장 큰 장점은 독립적인 응용 프로그램의 집합으
로는 해결할 수 없는 보다 복잡한 서비스를 다른 에이전트와의 협력을 통해 제공할 수 있
다는 점이다. 그 외에도 사용자는 컴퓨터에 있는 많은 에이전트의 존재나 사용법을 모르더
라도 주로 이용하는 에이전트를 통해 자신도 모르게 다른 에이전트를 사용한다는 장점이 있
다. 현재 대부분의 컴퓨터에는 수많은 응용 프로그램이 있고 이런 프로그램은 시간이 지남
에 따라 사용 빈도가 적어진다. 이는 사용자가 응용 프로그램을 제대로 관리하기 힘들며 사
용법을 잘 모르기 때문이다. 그래서 때로는 자신이 원하는 기능을 가진 응용 프로그램을 갖
고 있음에도 불구하고, 이런 기능을 제공하는 프로그램을 찾기 위해 애를 쓰는 경우도 있다.
하지만 다중 에이전트 시스템에는 서로 협력하는 에이전트가 있기 때문에 사용자 자신도 모
르게 많은 에이전트를 사용하게 된다.
다중 에이전트 시스템이 갖는 또 하나의 장점은 기능 확장이 용이하다는 것이다. 기존 프로
그램은 기능이 확장될 때마다 개발자가 새로운 프로그램을 만들고 사용자는 업그레이드해야
했다. 하지만 다중 에이전트 시스템에서는 에이전트의 기능이 확장되면 새로운 기능을 가진
에이전트를 붙여 주기만 하면 되는 장점이 있다.
(2) 보조 에이전트(Assignment Agent)
보조 에이전트는 ‘사용자의 작업을 돕는 프로그램’이다. 인공지능 분야의 거장 마빈 민스키
(Marvin Minsky)는 에이전트를 ‘어떤 문제를 해결하는 블랙박스와 같은 것으로 인간을 대
신해 일을 처리해 주는 프로세스’라고 정의하고 있다. 이와 같은 견해에 의해 응용 프로그램
의 하나로 전보다 편리한 컴퓨터 사용 환경을 제공하는 프로그램이란 의미에 많은 사람은
수긍하고 있다.

이에 대한 예로는 네트웍에서 자신이 원하는 자료를 찾아 주는 아키(Archie)나 뉴스그룹 프
로그램인 프리 에이전트(Free Agent)를 에이전트라고 부르는 경우를 둘 수 있다.
하지만 단지 기존 프로그램과 같이 사용자 작업을 대신하는 프로그램보다는 능동적인 특성
을 갖고 사용자의 작업을 대행하는 프로그램을 보조 에이전트라고 부른다. 따라서 몇몇 사
람은 보조 에이전트의 능동적인 특성을 반영하기 위해 로봇(Robot)이라 부르기도 한다. 로
봇에 대한 사용 예로는 사용자의 지식을 기반으로 전자우편을 정리해 주고 자동으로 답장해
주는 메일봇(MailBot)이나 ftp, 아키, netfind 등과 같은 인터넷 관련 작업을 도와주는 소프
로봇(Softbot), 그리고 웹에 있는 정보를 찾아 주는 웹 에이전ㅌ(웹로봇이라도 함) 등을 들
수 있다.
여기서 정보는 정보 검색 웹 에이전트와 정보 검색 이동 에이전트는 웹을 통해 사용자가 원
하는 정보를 가져온다는 기능적인 면은 유사하다. 하지만 정보 검색 웹 에이전트는 자신이
수행된 컴퓨터를 중심으로 다른 컴퓨터에서 정보를 가져와 검색하며 정보 검색 이동 에이전
트는 에이전트 프로그램이 정보가 있는 컴퓨터로 이동해 정보를 검색한다는 점에서 차이가
있다.
(3) 사용자 인터페이스 에이전트(User Interface Agent)
사용자 인터페이스 에이전트는 ‘사용자가 컴퓨터를 쓰기 편리하도록 지원하는 에이전트’이
다. 컴퓨터 모니터에 사람이나 동물이 나타나 사람에게 말로 묻고 말로 지시한 내용을 인식
해 처리한 후, 수행 결과를 말이나 영상으로 제시해 준다면 컴퓨터에 익숙하지 않은 사람에
게는 지금보다 훨씬 편리해질 것이다. 사용자 인터페이스 에이전트의 예로는 마이크로소프
트 연구소가 수행하고 있는 퍼소나(Persona) 프로젝트의 페디(Peedy)를 들 수 있다. 페디는
사람의 말을 알아듣고 그에 따라 3차원 동영상으로 반응하며 음성으로 대답하기도 한다.

사용자 인터페이스 에이전트는 컴퓨터 프로그램이 학습 능력을 가짐으로써 사용자가 컴퓨터
를 보다 쉽게 사용할 수 있도록 지원하는 역할도 한다. 예를 들어 어떤 사용자가 매일같이
수십 개의 전자우편을 읽는데 만도 많은 시간을 보내게 될 것이다. 이런 상황에서 전자우편
에이전트는 사용자가 전자우편을 읽는 과정을 관찰, 사용자의 습관을 학습해 전자우편 관리
를 도와준다. 사용자 인터페이스 에이전트는 기술적으로 3차원 애니메이션, 음성 인식, 자연
어 처리, 음성 합성, 멀티모달 입력 및 멀티미디어 출력 등의 사용자 인터페이스 기술과 학
습 능력과 같은 인공지능 기술이 융합된 종합 응용 분야이다.
(4) 지능형 에이전트(Intelligent Agent)
지능형 에이전트는 에이전트 중에서 ‘학습 능력이나 추론 능력, 계획 능력과 같은 지능적인
특성을 갖는 에이전트’를 말한다. 지능형 에이전트의 예로는 코치(COACH : Cognitive
Adaptive Computer Help) 시스템을 들 수 있다. 코치 시스템은 사용자가 리스프 프로그램
을 작성하는 작업 형태를 관찰해 적응 사용자 모델(AUM : Adaptive User Model)을 만들
고 작업 지식과 적응 사용자 모델에 따라 사용자가 앞으로 하려는 일을 추론해 능력에 맞는
도움말을 제시해 주는 역할을 한다. 코치 시스템은 학습 기능과 추론 기능을 갖는 지능형
에이전트이며, 컴퓨터 작업 환경을 돕는다는 측면에서는 사용자 인터페이스 에이전트이다.
이와 같이 지능형 에이전트는 사용자 인터페이스 에이전트와 접한 관계가 있다. 또한 지
능형 에이전트는 지능적인 특성이 있는 에이전트를 지칭하는 경우 외에 일반적인 에이전트
와 동일한 의미로 사용되기도 한다.

(5) 이동 에이전트(Mobile Agent)
이동 에이전트는 네트웍 에이전트(Network Agent) 또는 순회 에이전트(Itinerant Agent)라
고 하며, ‘프로그램 자체가 네트웍을 돌아다니며 수행되는 프로그램’을 말한다. 이동 에이전
트와 유사한 예로는 자바 애플릿을 들 수 있다. 하지만 자바는 웹브라우저에서 요구할 때
서버에 있는 애플릿이 브라우저로 이동하는 반면, 이동 에이전트는 자신의 판단에 의해 이
동하는 것이 다르다. 이동 에이전트는 크게 코드 마이그레이션(Code migration)과 상태 마
이그레이션(State migration)으로 구분 지어 강한 마이그레이션(Strong Migration)과 약한
(Weak Migration)으로 나뉘어 진다. 이동 에이전트에서 코드 마이그레이션은 일반 프로그
램에서 데이터 이동을 보완하여 네트웍 오버헤드를 줄일 뿐 아니라 원격지에서 실행하여 그
상태와 결과만을 리턴하기 때문에 강한 마이그레이션이 이동 에이전트가 지향하는 방향이
다. 참고로, 코드 모빌러티는 다음과 같이 정의된다.
“네트웍 환경에서 컴퓨터의 물리적인 위치에 상관없이 응용프로그램의 소프트웨어 콤포넌트
간의 바인딩을 다이나믹하게 런타임시에 재인식 할 수 있는 능력”
위에서 언급했듯이 코드나 상태의 이동 정도에 따라 강한 마이그레이션, 약한 마이그레이션
으로 구분된다. 아래 표는 이를 기준으로 분류된 그림이다.
[그림 2-3-7]

[표 2-3-7 : 이동 코드를 지원하는 언어의 코드 이동성의 정도]
Type of Mobility System
Remote ExecutionCode on DemandWeak MigrationStrong Migration
JavaServlets(push[Sun96])ActiveX[AarAar97]Aglets[IBM96]AgentTcl[Gray95]
Remote Evaluation[Stam os86]JavaServlets(pull[Sun96])MoleAra[Peine97]
Tacoma[JovRSc95]Java Applets[Sun94]Odyssey[GenMag97]Telescript[GenMag96]
이동 에이전트는 별도의 실행 환경(Runtime Environment)을 통해 생성되어 그 안에서 수행
되며, 때로는 다른 실행 환경으로 이동하기도 한다. 이동 에이전트는 이동 에이전트 실행 환
경을 중심으로 하는 생명주기(Life Cycle)를 갖는다. 즉, 이동 에이전트 실행 환경은 이동 에
이전트를 생성하고 실행하며 다른 곳으로의 이동을 지원한다. 일반적으로 이러한 이동 에이
전트 실행환경은 자체에서 활동할 수 있는 이동 에이전트를 만들기 위한 프레임 워크나 라
이브러리, 또는 제작 툴킷 등과 여러 가지 지원 유틸리티를 필요로 한다. 본 연구에서는 이
들을 통합적으로 이동 에이전트 시스템이라 한다.
나. 이동 에이전트으 특징
이동 에이전트는 이동 컴퓨팅(Mobile Computing)분야에 효과적인 기술이다. 이동 컴퓨팅이
란 사용자가 노트북이나 PDA(Personal Digital Assistant)를 들고 다니면서 사용하는 환경
으로, 이런 컴퓨터는 이동성 때문에 다른 컴퓨터와의 통신이 취약하다.
이동 에이전트는 사용자 요구에 따라 에이전트가 컴퓨터 사이를 이동하므로 사용자는 서비
스를 제공받기 위해 지속적으로 연결 상태를 유지할 필요가 없으며 단지 나중에 두 컴퓨터
를 연결해 처리된 결과를 가져오기만 하면 된다.
이동 에이전트가 갖는 가장 큰 문제점은 보안인데, 자신의 컴퓨터에서 수행되는 다른 사람
의 이동 에이전트는 바이러스처럼 나쁜 영향을 끼칠 수 있다.

또 다른 문제점으로는 수많은 서버 중에서 자신이 원하는 서비스를 제공하는 서버를 어떻게
효율적으로 찾는가에 대한 문제와 찾았을 경우에도 이동 에이전트 서버가 있는 시스템으로
의 이동만이 가능하다는 점이다. 이동 에이전트는 스크립트로 구성되기 때문에 자신을 수행
시켜 줄 인터프리터가 없으면 무용지물이 되므로 이동 에이전트 서버가 얼마나 많이 깔릴
수 있는가가 중요하다.
이동 에이전트의 일반적인 특징으로는 다음과 같은 것들이 있다.
- Object Passing : 이동할 때 자체의 코드, 데이터 모두 이동 가능하다.
- Autonomous : 맡은 임무와 목적지에 대한 정보를 가지고 있다.
- Asynchronous : 자기 자신의 실행 쓰레드를 가지고 있으며 다른 에이전트와는 독립적으
로 실행할 수 있다.
- Local Interaction : 다른 이동 에이전트 및 지역 내부에 있는 정적인 오브젝트와 통신이
가능하고, 필요한 경우 통신을 위해 새로운 이동 에이전트를 파견할 수 있다.
- Parallel Execution : 동시 다발적인 임무 수행을 위해 여러 개의 에이전트를 여러 개의
장소로 보내어져 실행 할 수 있다.
다. 이동 에이전트 지원 언어 및 언어별 특징
[표 2-3-8]은 이동 에이전트를 지원하는 언어의 특징을 간략하게 정리한 것이다.

[표 2-3-8 : 이동 에이전트 지원 언어]
Name of thesystem
supported Languages company Availability
ARAffMAINTacomaAgentTclAgletsConcordiaSyberagentsJava-2-goKafkamessengersMOAMoleMonJaOdysseyTelescriptVoyager
Tcl,C,JavaTcl,Perl,JavaTcl,C,Python,Scheme,PerlTclJavaJavaJavaJavaJavaM0JavaJavaJavaJavaTelescriptJava
University of Kaiserslautern, GermanyUniversity of Frankfurt, GemanyCormell(USA),Tromso, NorwayDartmouth college, USAIBM, JapanMitsubishi, USAFTP Software,Inc., USAUniversity of California at Berkeley, USAFujitsu, JapanUniversity of Zurich, SwitzerlandThe Open Group, USAUniversity of Stuttgart, GermanyMitsubishi, JapanGeneral magic, USAGeneral magic, USAObjectspace,Inc.,USa
freenofreefreebinary onlybinary onlyno longerfreebinary onlyfreenofreebinary onlybinary onlybinary onlybinary only
(1) Aglets Workbench
Aglets Workbench(AWB)는 IBM사의 Tokyo Research Lab(TRL).에서 개발한 MAS로 자
바 기술을 기반으로 한다. 실행환경과 함께 이동 에이전트 (Aglets) 프레임 워크를 자바 클
래스 라이브러리 형태로 제공하여 개발을 쉽게 하였다. 다음 실행 환경은 Tahiti라 불리는
GUI기반의 자바 애플리케이션으로 이동 에이전트의 관리를 쉽게 하려는데 초점을 두었으
며, 현재 웹 페이지 내에 존재할 수 있는 실행 환경인 Fiji의 출시를 앞두고 있다.

에이전트간의 동기 및 비동기 메시지 전송을 지원하지만 Naming Service나 프락시를 통한
위치 투명성을 보장하지는 못한다.
IBM사의 TRL에서는 곧 에이전트의 전송을 위한 고유 프로토콜인 ATP(Agent Transfer
Protocol)과 프레임 워크인 J-AAPI(Java Agletss API) 가 표준으로 채택되도록 하기 위해
노력하고 있다. 다음 [그림 2-3-8]은 Aglets Runtime Framework와 [그림 2-3-9]는 Aglets
Transfer Protocol을 설명하는 그림이다.
[그림 2-3-8 : Aglet runtime framework]
[그림 2-3-9 : Aglet 전송 프로토콜]
ATP(Aglets Transfer Protocol)는 분산 에이전트 기반 시스템들을 위한 응용 계층 프로토
콜이다. 이것은 네트워크를 통해 에이전트를 주고받기 위한 에이전트 서버에 상주하는 것으
로써 인터넷상에서 네트워크에 연결된 컴퓨터 사이를 에이전트들이 이동하기 위한 간단하고
플랫폼 독립적인 프로토콜이다. Aglet을 이용한 분산 응용프로그램 프로젝트는 현재 활발히
진행중이다.

(2) Voyager
Voyager는 ObjectSpace사의 이동 에이전트 기능을 갖춘 orb(Object Request Broker) 제품
으로, 역시 순수 자바 기술로 구현되어 있다.
Voyager에는 실행 환경인 Voyager가 있고, 프락시 기능을 지원하는 VCC(Virtual Class)와
웹 환경을 지원하는 Hub등의 유틸리티가 있다.
또, Voyager의 에이전트를 작성하기 위한 클래스 라이브러리와 자사의 기존제품인
JGL(Java Generic Library)이 포함된다. 설계초기부터 이동 에이전트와 ORB를 동시에 고려
한 듯한 많은 편의 기능이 존재한다.
또, 실행환경은 처음부터 웹에서의 이용을 염두에 두어 만들어 졌으며, GUI기능을 지원하지
않는다. 실행환경을 통하지 않고 직접 원격 객체의 레퍼런스를 이용할 수 있는 기능, 여러
가지 통신 방법 지원 등의 다양한 특성을 가지고 있으나 안정화 기간이 다소 필요하다고 보
여진다.
(3) Odyssey
Odyssey는 Telescrip로 유명한 General Magic 사에서 개발한 이동 에이전트 시스템으로,
Telescrip의 개념과 기능이 최대한 자바 기반으로 이식되었다. 자사의 Telescrip가 뛰어난
기술임을 인정받고도 급부상한 자바의 경쟁에서 리게 되자, 결국은 Telescrip를 시장에서
공식적으로 철수한 후 내세운 제품이다. 또한, IBM사의 AWB의 설계 및 개발을 총괄했던
엔지니어를 영입하는 작업을 진행하기도 했다. 그러나, 다른 제품에 비해 늦게 출발하여 아
직은 개발작업이 진행 중이며 자세한 구조가 공개되지는 않았다.

순수 자바 기술로 개발되었으며, 실행 환경으로는 Agent Systems가 있고 이 위에 논리적인
공간인 Place가 위치하는 2계층 구조를 가진다. 에이전트 클래스와 이것을 상속하는
Worker는 항상 이 Place 위에서 활동하게 된다. 자바의 PMI(Remote Mothod Ivocation)를
기본통신 메커니즘으로 사용하지만 마이크로소프트사의 DCOM(Disctibutedd Common
Object Mode)과 OMG(Object Management Group) CORBA(Common Object Request
Broker Architecture)의 IIOP(Internet InternetORB Protocol)를 이용할 수도 있다.
라. 이동 에이전트 활용분야
(1) 전자상거래(Electronic Commerce) : 에이전트가 상점 서버를 돌아다니면서 조건이 가장
좋은 서버를 찾아 거래한다.
(2) 정보검색(Information Search & Retrieval) : 에이전트가 여러 데이터베이스 서버사이를
움직이면서 사용자가 원하는 정보를 찾아온다.
(3) 네트웍 관리(Network Management) : 에이전트가 네트웍을 이동하면서 트래픽이 많은
곳을 찾아 문제를 해결하거나 전문가에게 상황을 정리, 알려 줌으로써 문제를 해결하도록
한다.
제 4 절 Java Web Server/Browser의 연구
1. 웹 서버(Web Server)
웹 서버란 브라우저(클라이언트) 요구하는 웹페이지(서비스)를 제공할 수 있는 환경을 구축
하기 위해 사용되는 서버로 병행적, 연결지향 서버가 일반적이다. 가장 많이 사용되는 웹 서
버로는 apache server를 예로 들 수 있는데 이러한 서버들은 OS의 부담을 덜어주기 위해
프로세서를 사전 할당하여 필요할 때 할당하는 방식을 취하고있다.

그러나 자바에서는 시스템의 부담을 줄이기 위해 프로세스가 아닌 쓰레드(Thead) 개념을
가지고 서버를 구축할 수 있다. 쓰레드란 현재 작동 중인 한 태스크(task, 작업)에서 작동할
수 있는 태스크보다 더 작은 하나의 작업단위를 말하는 것으로 작은 서브 모듈을 말한다.
일반적으로 이것은 동일한 문맥을 사용하는 작업의 단위를 의미하는데, 하나의 프로세스 안
에서 각각의 쓰레드는 동일한 문맥을 사용하기 때문에 보다 빠르게 작업을 교체하여 실행시
킬 수 있다는 특징을 가지고 있다.
쓰레드 개념의 웹서버는 클라이언트의 connection이 요청될 때 새로운 프로세스를 생성하는
것이 아니라 connection에 대한 쓰레드를 생성시킴으로써 시스템의 부담을 줄일 수 있다.
그러므로 쓰레드를 사용하는 Java Web Server를 구축하는 것이 의미가 있다.
가. 사이버 강의 스크립트
스크립트란 응용프로그램이나 유틸리티 프로그램에 대한 명령어의 조합으로 구성된 일종의
간단한 프로그램으로 대개 루프나 if-then과 같은 간단한 제어구조를 사용하여 작성된다. 또
한 스크립트는 구조가 간단하기 때문에 사용자가 사용하기 편하다. 사이버 강의 스크립터란
인터넷 환경에서 교육용 시스템을 보다 편리하게 구축하기 위해 정의한 스크립트언어다. 이
언어는 기존의 HTML에 원하는 기능의 스크립트를 추가시키는 방법으로 구현되므로 사용
자가 간편하게 구현, 작성할 수 있도록 해준다. 또한 교육용 시스템이기 때문에 다른 시스템
과 비교할 때 데이터베이스에 접근하거나 파일 다운로드나 업로드가 많기 때문에 이와 관련
된 문법이 많다. 이에 사이버 강의 스크립트를 처리하기 위한 웹서버의 구현이 의의가 있다
고 할 수 있다.

2. Java Browser
가. 브라우저 구현 원리
(1) 브라우저의 애플릿 처리
<applet code="Clock2.class" width=170 height=150>
위의 예에서 브라우저는 웹 문서에 지정된 애플릿 주 클래스의 객체(인스턴트)를 생성한다.
주 클래스가 실행하는 도중 참조하는 클래스를 넷스케이프 4.x와 인터넷 익스플로러 4.x는
다음과 같은 순서로 찾아서 메모리 내 적재한다.
(가) 안전을 위해서 해당 설치 디렉토리 내에 제공하는 패키지 디렉토리를 먼저 찾는다.
(나) 없을 경우, 웹 브라우저 컴퓨터 내에서 CLASSPATH 환경변수 값에 따라 찾는다.
(다) 그래도 없을 경우, codebase 속성 값을 나타내는(웹서버의) 디렉토리를 찾는다.
(2) 클래스 로더
클래스 로더는 현재의 컴퓨터 혹은 네트워크로부터 클래스 파일을 로드한다. 자바 가상 머
신에는 디폴스 클래스 로더가 존재하며, 부가적으로 다른 클래스 로더가 존재할 수 있다. 디
폴스 클래스 로더(혹은 파일 시스템 클래스 로더)는 현재의 컴퓨터의 CLASSPATH로부터
클래스를 로드한다. 디폴트 클래스 로드를 제외한 모든 클래스 로더는 ClassLoader의 하위
클래스 객체이다.

클래스 로드의 주요한 메소드를 살펴보자.
(가) abstract Class loadClass (String name, boolean resolve)
① 주어진 이름의 클래스를 로드하는 메소드의 프로토타입이다.
② 이 클래스 로더 객체에 의해 로드된 클래스가 다른 로드되지 않은 클래스를 참조하면 자
가 가상 머신이 자동적으로 이 객체의 이 메소드를 호출해 준다.
(나) Class loadClass(String name) : resolve = true
(다) protected final Class loadSystemClass(String name)
- 디폴트 클래스 로더에 의해 주어진 이름의 클래스를 로드한다.
(라) protected final void resolveClass(String name)
- loadClass(. . . )메소드에 의해 호출되어야 한다.
(마) protected final void defineClass(String name, byte data[], int offset, int length)
(3) 애플릿 클래스 로더
각 브라우저는 자신만의 애플릿 클래스 로더를 갖는다. 애플릿과 애플릿이 참조하는 클래스
를 로드한다. 그러나 브라우저가 제공하는 클래스는 디폴트 클래스 로더를 이용하여 로드
한다. 두 클래스가 서로 다른 컴퓨터로부터 로드되었으며 이름 충돌을 피하기 위해 패키지
이름이 같아도 다른 패키지에 속한다. 애플릿 클래스 로더에 의해 직접 로드된 클래스는 바
이트 코드 검증기(Bytecode verifier)에 의해 검증된다. 바이트 코드 검증기는 클래스 파일이
바르게 컴파일 되어 있는지 확인한다.
(4) 보안 관리자
파일 시스템 클래스 로더에 의해 로드된 클래스는 어떠한 제약도 받지 않는다. 자바 표준
패키지(java.*)의 클래스는 보안 관리자 객체의 허락을 얻어서 연산(파일 입출력, 네트워킹,
. . . )을 수행한다. 보안 관리자 클래스는 연산의 종류에 따른 checkXXX()형태의 메쏘드들
을 갖는다.

checkXXX()메쏘드가 연산을 허락하지 않을 때는 SecuritiyException을 발생시킨다. 보안 관
리자 객체는 1개의 자바 가상머쉰(웹 브라우저나 자바 인터프리터등)에서 최대 1개 존재할
수 있다.
웹 브라우저는 자신만의 보안 관리자를 갖는다. (보통 AppletSecurity라는 이름의 클래스 객
체) 애플릿 클래스 로더에 의해 직접 로드된 클래스는 애플릿 보안 관리자에 의해 제한이
가해진다.
(5) 브라우저의 애플릿 처리 과정
웹 브라우저는 애플릿을 포함하는 웹 문서를 방문할 때, 지정된 애플릿의 객체를 생성한 후
다음 메소드를 적절한 시험에 호출해 준다.
(가) init() - 초기화
애플릿 객체를 생성한 직후에 한번 호출한다.
(나) start() - 재시작
init()이 실행된 직후 혹은 사용자가 이 애플릿을 포함하는 웹 문서로 되돌아 올 때 호출해
준다.
(다) stop() - 일시 정지
사용사가 이 웹 문서를 떠날 대 호출됨
(라) destroy() - 소멸
브라우저가 정상적으로 실행을 끝낼 때 호출됨
Sun사에서 만든 핫자바는 자바로 만든 대표적인 웹 브라우저이다. Java로 만든 웹 브라우
저의 특징을 알아보기 위하여 핫자바의 특성에 대한 조사를 하였다.

나. HotJava
[그림 2-4-1 핫자바 실행화면]
핫자바는 자바로 짜여져 있으며 자바 런타임 시스템의 위에서 실행되고 있는데, 자바 인터
프리터 위에서 핫자바가 실행되고, 핫자바가 현재 브라우징하고 있는 웹페이지에 포함된 애
플릿 프로그램은 인터프리터가 동적으로 바인드 시켜 실행을 하게 된다. 따라서 핫자바 또
한 자바 런타임 시스템이 구현된 어떤 환경에서도 실행이 가능하다. 이는 핫자바의 강력한
이식성과 호환성을 보장하는 한편으로 빠르게 변화하는 네트웍 환경에서 새롭게 등장하는
모든 프로토콜 등을 아주 쉽게 처리할 수 있도록 하는 확장성이 용이한 것을 말한다.
(1) HotJava의 의의
HotJava는 Java로 짜여진 Web browser이기 때문에 HTML 외에 Java로 만들어진 Applet
을 실행할 수 있다. Java Applet은 사운드와 애니메이션과 같은 Dynamic Content를 포함하
는 생동감 있는 web page를 구성할 수 있게 하여준다. Java의 dynamic한 성질은 network
을 통해서 어떤 object라도 access할 수 있게 해주므로 상당히 유연한 program을 작성할 수
있다.

[그림 2-4-2 hotjava의 dynamic loading]
[그림 2-4-2]는 HotJava가 web을 browsing하는 도중에 처리할 수 없는 Object를 만났을
경우 어떻게 이를 처리하는가를 보여주고 있다.
만일 server가 이 object를 처리할 수 있는 routine의 위치를 알고 있다면, HotJava는 그
resource를 access해서 그 object를 runtime에 handling할 수 있다. 그러나 다른 browser의
경우에는 그 object를 처리할 수 있는 routine을 작성한 다음 다시 compile하여야 하므로 이
런 hard-coded 환경보다 훨씬 유연하게 확장이 가능한 것을 알고 있다.
그리고 program의 install의 개념도 상당히 많이 달라질 수 있다.
Java를 기반으로 한다면, 기본적으로 compatibility의 문제가 사라지게 되고, 사용자는 단지
web page를 browsing하는 것으로 install 없이 프로그램을 사용할 수 있게 l는 것이다.
(2) 기존 브라우저의 한계
WWW이 가지는 다양한 데이터와 프로토콜의 지원은 모든 인터넷 응용(파일 전송, 전자 메
일 등)을 하나의 사용자 인터페이스로 통합하는 변화를 가져왔고, 현재 종이를 이용하여 주
로 발표되었던 출판이라는 분야를 네트워크를 통하여 가능하게 하였다

하지만, 현재의 브라우저들은 기본적으로 지원하는 인터넷 응용들이 고정되어 있다. 곧 브라
우저 제공자들이 만들어 놓은 인터넷 응용에 대해서만 동작할 수 있고, 새로운 응용이 생겼
을 경우 브라우저를 새로 제작해야 한다.
인터넷 응용뿐만 아니라 데이터의 형태에 대해서도 현재의 브라우저는 한계를 가지고 있다.
Netscape나 Mosaic과 같은 브라우저에서는 GIF나 jpeg과 같은 자주 쓰이는 그림 형식에 대
해서는 브라우저 내부에서 처리를 하여 예쁘게 그림을 그려준다. 하지만 새로운 형태나 자
주 쓰이지 않는 형식에 대해서는 외부 viewer를 사용한다. 이건 전문가에게는 손쉬운 일이
지만, 초보자들이 이용을 포기하는 약점이 되고 있다. 현재의 브라우저에서는 문서의 동적인
면을 이용하기가 힘들다. 문서의 일부분에 대해서 애니메이션이 이루어진다거나, 문자들이
움직이는 동적인 문서를 만드는 데에는 한계가 있다.
(3) 핫자바가 WWW 브라우저로서 가지는 장점
정적인 web page에 생동감 넘치는 애니메이션과 사운드를 곁들일 수 있으며, Dynamic
feature는 변화하는 환경에 유연하게 적응해 나갈 수 있다. 핫자바는 다른 여타의 브라우저
와는 다르게 핫자바에서 다루어야 하는 프로토콜이나 오브젝트 등에 대한 내용을 가지고 있
지 않다. 대신 핫자바는 현재 자신이 다룰 수 없는 내용이 무엇인지 지적할 수 있는데, 이는
핫자바에게 상당한 유연성과 새로운 기능을 더할 수 있는 능력을 준다. 즉 핫자바는 조정자
(coordinator)로서의 기능을 하고 있고, 각각의 프로토콜이나 오브젝트에 대한 처리는 서로
다른 부분이 처리한다. 만일 이러한 처리부분이 없다면 핫자바는 네트웍을 통해 이를 처리
하기 위한 루틴을 다운로드하여 사용할 수 있다.
핫자바를 사용할 때 가장 눈에 두드러지게 보이는 것은, 바로 핫자바 API를 사용하여 만든
프로그램이다. 이것은 다이나믹 콘텐트(Dynamic Content)라고 불리며, 이를 사용하여 사용
자와의 대화가 가능한 동적인 웹 페이지를 구성할 수 있다.

여기에 프로그래머는 각종 멀티미디어 기능을 쉽게 더할 수 있다.
핫자바의 동적인 이러한 일련의 특징은 핫자바가 여러 가지 다른 종류의 형식을 가지는 오
브젝트를 처리할 수 있는 기능을 더 하는데 사용한다. 예를 들면, 현재 대부분의 WWW 브
라우저는 GIF, X11 pixmap, X11 bitmap등의 이미지 파일을 처리할 수 있다. 만일 새로운
효율이 향상된 이미지 저장 형식이 개발되었다고 하자. 다른 브라우저는 브라우저가 이 이
미지를 처리하게 하기 위해 전체 프로그램을 다시 컴파일 해야 한다. 그러나 핫자바의 동적
인 특성은 현재 자신이 처리할 수 없는 타입을 만날 경우 이를 처리할 수 있는 루틴에 해당
하는 코드를 네트웍을 통해 서버에서 다운로드 하기만 하면 그대로 이를 핫자바 내에서 처
리 할 수 있게 된다. 이는 또한 다양한 현존하는 프로토콜이나 새로 이 이후에 개발될 프로
토콜에 대해서도 마찬가지로 적용된다. 이것은 핫자바가 빠르게 변화하는 네트웍 환경에서
얼마나 효과적으로 이러한 변화에 대처할 수 있는가를 설명해 준다.
제 5 절 Java Operating System programming tools의 연구
1. 자바 운영체제
가. 자바 운영체제의 소개
자바라는 언어는 프로그래밍 언어이지만 다른 프로그래밍 언어와는, 자바 가상 머신이라는
가상의 기계에서 실행된다는 뚜렷한 차이점을 가진다. 자바 가상 머신은 바이트 코드라는
일종의 기계어를 실행한다. 즉 자바 언어로 구현된 프로그램들은 바이트 코드로 번역된 후
에 실행이 되는 것이다.
이러한 자바 가상 머신을 구현하는 방법은 다음과 같은 세 가지가 있다.

첫째, 윈도우즈 95나 98, 윈도우즈 NT와 같은 기존의 운영체제 위에 자바 가상 머신을 구
현하는 것이다.
둘째, 넷스케이프 네비게이터나 마이크로소프트 익스플로러와 같은 웹 브라우저 내에 구현
하는 것이다.
셋째, 자바 가상 머신을 아예 운영체제에 기본적으로 포함시킨 새로운 운영체제를 만드는
것이다.
자바 운영체제는 위의 세 가지 경우 중 마지막 경우에 해당하며 위의 첫째 경우처럼 별도의
운영체제가 없이 처음부터 자바 운영체제가 없이 처음부터 자바 애플릿이나 애플리케이션만
을 실행하는 것을 목적으로 개발되었다. 자바 운영체제는 처음부터 인터넷이나 인트라넷에
서 사용될 네트워크 컴퓨터를 위해 디자인된 운영체제로 윈도우즈95와 같이 다양한 기능을
갖춘 일반 운영체제에서 자바 프로그램을 실행하는데 사용되는 불필요한 기능을 제거하여
자바 환경에 가장 적합하도록 만든 운영체제이다.
자바 프로그램을 실행할 수 있는 환경을 자바 플랫폼이라고 한다. 추기에는 자바 플랫폼이
브라우저와 같은 응용 프로그램에 JVM과 자바 응용 프로그램 개발자들을 위한 프로그램
작성 통합 틀에 해당하는 자바기본 클래스(Java Foundation Class, JFC)들은 삽입하여 지원
되었다. 많은 운영체제들이 자바를 지원하게 되면서 기존의 운영체제에 자바 가상 머신과
자바 기본 클래스들을 삽입하였다. 이러한 경우의 구조는 [그림2-5-1]과 같다.

[그림 2-5-1 기존 운영체제에서 자바를 자원할 경우의 구조도]
자바 운영체제는 기존에 존재하는 운영체제의 도움을 받을 수 없거나 또는 별도의 운영체제
가 필요 없도록 처음부터 자바가상머신이 곧바로 하드웨어에서 동작하도록 설계되었다. 따
라서 자바 운영체제는 자바 프로그램만을 지원하도록 설계됨으로써 더욱 작고 효율적으로
구현되었다. 현재 자바 운영체제에는 자체 파일 시스템이 없고 가상 메모리를 사용하지 않
으므로 메모리 공간을 사용자가 사용하는 공간과 운영체제만이 사용할 수 있는 공간으로 구
분 할 필요가 없다. 모든 동작이 프로세서의 관리자 모드나 보호 모드에서 이루어 질 수 있
어 크기가 기존의 운영체제의 비해 작다. 자바 운영체제와 일반 운영체제의 비교를 다음[표
2-5-7]에서 볼 수 있다.
[표 2-5-7 일반 운영체제와 자바 운영체제의 비교]
운영체제 차이점 공통점
일반 운영체제ㆍ지역 파일 시스템 제공ㆍ가상 메모리 지원ㆍ메모리 공간 구분
ㆍ부팅 지원ㆍ사용자 확인/인증ㆍ장치 구동기ㆍ네트워크 프로토콜ㆍ쓰레드/애플릿다중실행ㆍ윈도우즈 시스템ㆍ기타 API 지원
자바 운영체제
ㆍ지역 파일 시스템 /가상 메모리 지원 안함ㆍ메모리 공간 구분 없음ㆍ단일 프로그래밍 언어ㆍ자체 시스템 콜이 없음
나. 자바 운영체제의 기능
자바는 다른 언어와는 달리 처음부터 클래스 라이브러리 집합이 몇 개의 응용 프로그램 인
터페이스로 제공되고 이 때문에 API집합들의 표준화되었다. 이러한 표준 클래스 라이브러리
를 자바 컴파일러, 자바가상 머신과 함께 윈도우즈 자바 개발자 도구(Java Developer's Kit,
JDK)로 배포한다. 즉 자바 운영체제는 특정 JDK 배포판과 접한 연관이 있다.
자바 소프트에서 만든 자바 운영체제와 JDK의 연관 관계를 살펴보면 다음 [표 2-5-2]와 같
다.
[표 2-5-2 자바 운영체제와 JDK의 연관관계]
자바 운영체제 배포판 JDK의 배포판
자바 운영체제1.0 JDK1.0.2
자바 운영체제1.1 JDK1.1
[표2-5-2]에 따르면 자바 운영체제는 JDK에 많은 영향을 받는다. 자바 운영체제의 기능을
JDK 자바 애플릿 API와 핫자바 브라우저 지원하고 다양한 네트워크 프로토콜 지원하며 자
바 운영체제 윈도우와 그래픽 시스템 지원한다. 그리고 자바로 작성된 장치 구동기 (디바이
스 드라이버)를 가지고 있으며 네트워크 정보 시스템을 이용한 네트워크 프린팅과 시스템
재구성할 수 있다.

또한 폰트나 인풋 메소드등의 저 수준 인터내셔널라이제이션 지원하며 저스트 인 타임(JIT)
컴파일러 지원한다. 모뎀이나 PPP, 자테 프린팅을 자체 시리얼 포트 지원하고 네이밍 서비
스가 가능하다. PCI버스를 지원하고 성능 향상과 최적화가 가능하며 다운로드가 가능하다.
자바 운영체제 플랫폼 부트 인터페이스 정의할 수 있고 자바 운영체제를 모듈화할 수 있다.
그 외에도 PC카드 지원, 네트워크 프로토콜 추가기능, 다이나믹하게 링크할 수 있는 라이브
러리 지원 등을 자바 운영체제의 기능으로 말할 수 있다.
다. 자바 운영체제의 아키텍쳐
자바 운영체제의 내부를 살펴보면 다음 [그림 2-5-2]와 같다.
[그림 2-5-2 자바 운영체제의 구조도]
자바 운영체제에서는 CPU, 물리적인 메모리 구성 그리고 항상 CPU에 연결되어 있는 장치
나 버스, 슬롯 등을 통틀어 윈도우 플랫폼이라 한다. 자바 운영체제는 플랫폼과 연관이 있는
부분 즉 하드웨어를 하기 위해 필요한 부분을 코드와 플랫폼에 관련 없는 부분을 다루는 자
바 언어로 구성된 부분으로 나눌 수 있다.

플랫폼에 관계가 있는 부분은 네이티브 코드로 작성되어 있으며 이 부분을 자바 운영체제의
윈도우 마이크로 커널이라고 한다. 플랫폼에 무관한 부분은 자바 운영체제의 윈도우 실행부
분이라고 하며 둘 사이의 인터페이스를 윈도우 자바 플랫폼 인터페이스라고 한다.
자바 플랫폼 인터페이스에는 자바 가상 머신, 애플리케이션 윈도우즈 툴킷, 네트워킹 그리고
파일 관련 입출력 코드등이 포함되어 있다. 또한 장치 구동기를 지원하기 위한 코드로 들어
있다.
좁은 의미의 자바 운영체제는 자바 운영체제의 마이크로 커널만을 가리킬 때도 있다. 마이
크로 커널은 자바 가상 머신에 일반 운영체제가 제공하는 서비스를 제공하며 멀티쓰레딩을
위하여 썬에서 개발된 그린tm레딩 패키지에 해당하는 부분이 포함되어 있다.
자바 플랫폼 인터페이스의 측면에서 불 때 이 것의 상위에 있는 자바 가상 머신이나 장치
구동기, 기타 소프트웨어들은 윈도우 자바 플랫폼 인터페이스 클라이언트이다. 이렇게 자바
실행부분과 마이크로커널을 명확히 구분하는 것은 자바 운영체제가 내장될 실제 시스템의
요구 조건에 따라 실행부분과 마이크로커널을 몇 개의 칩이나 회사가 동시에 개발하여 적
절히 조합하여 사용할 수 있게 하기 위함이다.
자바 운영체제는 그 크기나 성능에 따라서 엔터프라이즈 자바, 퍼스널 자바, 임베디드 자바
의 세 가지로 나눌 수 있다.
엔터프라이즈 자바는 기존의 모든 API를 지원하는 자바에 해당하며 시스템은 약 4MB의
롬과 약 4MB의 램을 필요로 한다. 4MB의 롬에서 시스템을 부팅 시키기 위한 코드, 자바
운영체제, 그리고 핫자바 브라우저, 1MB의 폰트 등이 모두 들어갈 수 있다.
퍼스널 자바는 엔터프라이즈 자바가 제공하는 수준의 기능을 필요로 하지 않는 단말기들을
위하여 엔터프라이즈 자바의 애플리케이션 윈도우즈 툴킷과 자바 APi가 제공하는 클래스들
중에서 이러한 단말기에서 잘 쓰이지 않는 부분들을 삭제하여 더욱 작은 메모리와 낮은 성
능의 프로세서에서도 동작 할 수 있게 만든 것이다. 퍼스널 자바의 크기는 롬과 램을 합하
여 약 2MB정도이고 실시간 운영체제를 마이크로 커널로 사용하며 셋탑박스, 개인 휴대 정
보 단말기, 스크린 전화기, 휴대전화기, 인터넷 TV등을 대상으로 한다.

임베디드 자바는 퍼스널 자바보다 더욱 작은 크기의 자바 환경을 제공하며 산업계에서 쓰이
는 제어기나 장비, 프린터, 복사기, 라우터, 스위치, 허브, 삐삐, 전화기 등을 대상으로 한다.
임베디드 자바는 롬과 램을 합하여 1MB이하의 크기를 가지며 값이 싸고 성능이 다소 뒤떨
어지는 프로세서에서도 동작하도록 만든 것이다.
자바 운영체제가 동작하기 위해 필요한 조건은 자바 가상 머신의 요구조건을 포함한다. 자
바 운영체제는 상당히 제약적인 하드웨어에서도 동작하도록 설계되었다.
라. 자바 커널
자바 운영체제의 가장 하위 부분을 담당하며 자바 가상머신이 필요로 하는 여러 가지 시스
템 기능, 여러 가지 디버깅 API, 자바 운영체제 실행 부분을 지원하기 위한 코드등이 있다.
이 부분은 다른 운영체제에서는 마이크로 커널이나 나노 커널 등이 말고 있다 그러나 자바
운영체제에서는 자바 프로그램을 실행하는 것이 목적이므로 윈도우즈 자바 커널이라는 지칭
한다.
자바 커널이 담당하는 대표적인 일은 부팅, 트랩, 인터럽트, 쓰레드처리 등이 있다. 트랩과
인터럽트 처리는 트랩과 인터럽트가 발생하였을 때 이를 해당 자바 장치 구동기가 알 수 있
게 해 주는 것이다. 쓰레드를 처리는 시스템에서 실행되고 있는 많은 쓰레드들 사이에서 자
바 가상 머신이 컨텍트 스위칭을 할 수 있게 해 준다.
시스템 부팅 초기에 실행되는 부트스트랩 코드는 자바 힙과 여러 가지 입출력 장치들의 레
지스터와 DMA 동작을 위한 메모리 영역을 할당한다. 또한 각종 하드웨어 장치들을 해당
장치 구동기에 연결시킨다.
자바 운영체제는 스케쥴링 방법으로 우선순위 기반의 선점형 스케쥴링 방법을 사용한다. 이
는 항상 어느 시점에 있어 우선 순위가 가장 높은 쓰레드가 실행된다. 자바는 이런 쓰fp드
간의 동기화와 통신을 위하여 모니터라는 상위 객체를 사용한다.

마. 디바이스 드라이버
자바 운영체제의 모든 장치들의 구동기들은 자바 언어로 작성된다. 그러나 자바 언어가 포
인터를 지원하지 않는 등의 이유로 인해 자바 코드로 작성할 수 없는 부분은 추출하여 두
개의 작은 지원 클래스로 C++을 사용하여 작성되었다.
하나는 구동기들이 메모리의 특정 바이트나 워드를 읽거나 변경할 수 있도록 하기 위한 윈
도우 메모리 객체 클래스이고 다른 하나는 인터럽트가 발생했을 때 이를 해당 구동기로 전
달하기 위한 부분이다. 장치 구동기를 작성하기 위한 인터페이스는 윈도우 자바 장치 구동
기 인터페이스라고 한다.
현재 구현되어 있는 구동기는 이더넷 카드, 키보드, 마우스, 시리얼 포트, 클락, 프레임 버퍼,
오디오 카드등에 대한 것들이 있다.
바. 네트워크 프로토콜
자바 운영체제는 다양한 네트워크 프로토콜을 구현하였다. 이는 모두 자바 언어로 작성되어
있다. 기본적인 전송과 라우팅 프로토콜들이 포함되어 있다.
자바 운영체제는 호스트 이름을 찾기 위해 DNS를 사용하며 로그인 시 사용자 이름과 패스
워드를 확인하고 사용자의 홈 디렉토리를 찾고 네트워크에 존재하는 프린터에 접속하여 사
용하기 위해서는 NIS를 사용한다.
자바 운영체제는 부팅과 시스템의 네트워크 주소를 찾기 위해 리버스 ARP와 DHCP,
TFTP등을 사용한다. 이 외에도 핫자바 브라우저에서 각 사용자의 개별적인 구성정보를 나
타내는 윈도우 프로퍼티를 저장하기 위해 NFS를 사용하며 네트워크에서 각 시스템의 관리
를 용이하게 하기 위해 SNMP를 지원한다. 또 부팅을 할 때 시스템간의 정보를 네트워크
서버로부터 가져와 설정하는데 이렇게 함으로써 설치와 관리를 더욱 쉽게 할 수 있다.

2. 자바 네트워크 컴퓨터 (NC)
자바 컴퓨터는 응용 프로그램을 필요할 때 제공받아 수행하는 새로운 지능형 단말기이다.
인터넷과 인트라넷 단말은 물론 온라인 DB검색과 메인프레임 접속용 단말등 단순 작업용
PC의 대용으로 사용할 수 있는 단순 구조의 고성능 네트워크 접속기이다. 또한 다른 컴퓨
터와는 달리 자바 프로세서가 내장되어 있다.
자바 프로세서는 자바 해석 소프트웨어를 하드웨어로 구현한 CPU이다. 기존에는 사용자측
에 있는 자바 가상 머신이라는 소프트웨어가 컴파일된 자바 바이트 코드를 해석하여 디스플
레이 할 수 있었으나 자바 프로세서는 자바 환경에 적합하게 구현 할 수 있다. 자바 프로세
서는 네트워크 컴퓨터, 인터넷 TV, 인터넷 셋탑 박스 등 네트워크 환경의 모든 정보기기에
채용될 수 있다.
3. TeaPot 자바 운영 체제
TeaPot은 컴퓨터 내장 기기용으로 개발된 자바 전용 운영체제이다. 그리고 휴대용 통신기
기, 인터넷 셋탑 박스, 웹 터미널, 차량용 향법치, 웹 스크린 폰 등에 가장 적합하다. TeaPot
는 완전한 컴포넌트 구조와 개방형 개발 환경에 기인한 빠른 개발, 손쉬운 유지/보수가 가
능하다. JDK1.1x에서 동작하는 자바 응용프로그램은 TeaPot 운영체제에서도 돌아간다.
자바 운영체제는 그 사용 용도로서 네트워크 컴퓨터와 임베디드된 장치를 위해 개발되었으
나 네트워크 컴퓨터를 중심으로 발전되어 왔다. 네트워크 TeaPot 운영체제도 자바 응용프로
그램이 동작하는 실행 환경 중 하나이다. 네트워크 컴퓨터 개념은 확장한 자바PC개념으로
만들어졌다.
TeaPot의 설치방법은 아래와 같다.
(1) TeaPot 부팅 이미지를 구한다.
(2) rawrite 로 부팅 이미지를 플로피에 기록한다.
rawrite
insert your boot image : tpimg
insert your destination drive -- ENTER -- : a:

(3) 새로운 부팅 디스켓을 통해서 다시 부팅하면 TeaPot 운영체제 환경이 뜬다.
나. 유닉스 계열
(1) 이미지를dd나 cat 명령을 통해서 플로피에 저장한다.
dd if=(부팅이미지이름) of=/dev/fd0
TeaPot은 자바를 상징하는 Tea와 환경을 나타내는 운영체제인 Pot을 더한 합성어로 Pot
운영체제 위에 자바가상 머신이 있는 것을 나타냈다.
[그림 2-5-3 TeaPot 구조]
TeaPot이 수행되어지는 시스템사양을 보면 S3 모니터, PS/2 마우스가 필수적으로 필요하
다. 이외의 하드웨어는 별 상관없다. 그리고 자바 칩 상에서 최적의 효과를 낸다.
TeaPot의 특징을 살펴보면 다음과 같다.
첫째, 카페 가상 머신을 보완한다.
둘째, 자바 클래스 라이브러리 패키지를 추가하기 용이하다.

셋째, 자바를 쓰면서 C로 짤 수 있다.
넷째, 임베디드된 환경에 적합하다.
다섯째, 자바 애플리케이션뿐만 아니라 C 애플리케이션도 수행이 가능하다.
TeaPot의 부팅 히 스토리는 일반적인 부팅 히 스토리와 비슷하다. 그러나 메모리상의 1M이
상의 지점에 TeaPot 운영체제를 적재하는 프로텍티드 리얼 모드를 사용한다는 점이 다른
일반 운영체제와 다르다. 부팅 히 스토리를 살펴보면 [그림 2-5-4]과 같다.
[그림2-5-4 TeaPot의 부트시 히스토리]
아래의 [그림 2-5-5]에서 보이는 1MB위에 점프명령어를 통해 롬 바이오스가 적재된 메모
리로 가게 된다. 운영체제가 탑재될 메모리를 확인하고 플로피나 시스템 시계 등을 초기화
한 다음 운영체제를 메모리에 탑재하고 운영체제 자체의 커널을 탑재하게 된다. 그리고 시
스템 추상화 계층을 탑재하고 원시 커널을 탑재함으로서 부팅이 끝나게 된다.
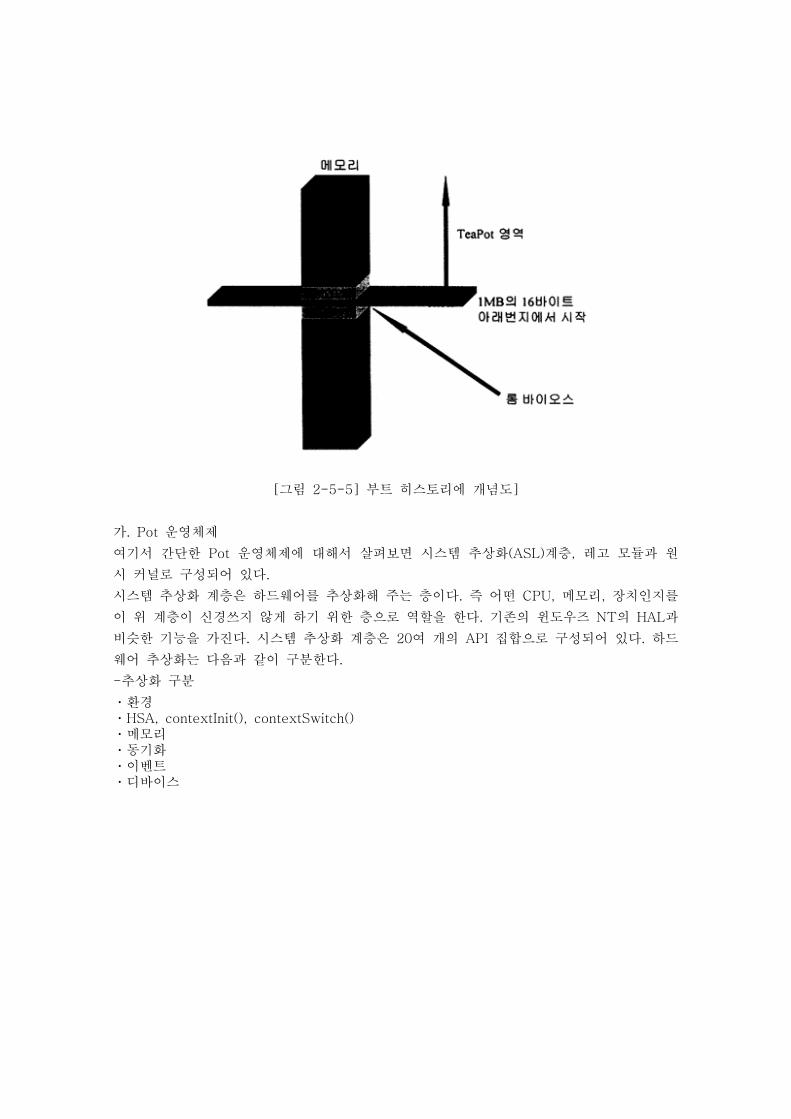
[그림 2-5-5] 부트 히스토리에 개념도]
가. Pot 운영체제
여기서 간단한 Pot 운영체제에 대해서 살펴보면 시스템 추상화(ASL)계층, 레고 모듈과 원
시 커널로 구성되어 있다.
시스템 추상화 계층은 하드웨어를 추상화해 주는 층이다. 즉 어떤 CPU, 메모리, 장치인지를
이 위 계층이 신경쓰지 않게 하기 위한 층으로 역할을 한다. 기존의 윈도우즈 NT의 HAL과
비슷한 기능을 가진다. 시스템 추상화 계층은 20여 개의 API 집합으로 구성되어 있다. 하드
웨어 추상화는 다음과 같이 구분한다.
-추상화 구분
ㆍ환경ㆍHSA, contextInit(), contextSwitch()ㆍ메모리ㆍ동기화ㆍ이벤트ㆍ디바이스

그리고 하드웨어 제어를 위한 약간의 어셈블 리가 첨가되어 있다.
레고 모듈은 장치에 대한 드라이버 제어 모듈로써 API 형식으로 구성되어 있다.
각 API들을 살펴보자.
[그림 2-5-6] 자바 API들
[그림 2-5-6]에서의 API들의 특징은 [표 10503]에 정리되어 있다.
[표 2-5-3 각 API의 특징]
API 종류 특징
lang 원시 가상 머신의 필요
io파일, 파일 시스템 관련(자바의 모든 입출력)
util 독자적 수행
net TCP/IP 기반
awt Xwindows가 동기가 되었음
원시 커널은 일반적인 커널과 비슷한 기능을 한다. 그 세부 기능을 살펴보면 다음과 같다.
-원시 커널의 기능
ㆍ쓰레드ㆍ메모리ㆍSemaphore - 동기적ㆍ시그널 - 비동기적원시 커널은 폰노이만 방식으로 CPU, 메모리, 장치를 제어한다.
나. Tea 가상 머신
자바 가상 머신인 Tea 가상 머신에서는 클래스 로더와 가비지 컬렉터, SoftCPU부분이 있
다. 클래스 로더는 네트워크/원격상의 클래스 로더와 로컬에서 파일 시스템상의 클래스 로
더를 들 수 있다. 가비지 컬렉터 스택을 사용한다.

SoftCPU는 바이트 코드 인터프리터가 CPU내에 탑재된 CPU를 말한다. 바이트 코드 인터프
리터는 여기서는 JIT라는 것을 사용하였는데 바이트 코드는 일반 CPU에서 사용하는 머신
코드정도로 생각하면 된다. SoftCPU의 예로는 핫스팟, 어셈블리, 인터프리터, 자바 칩(바이
트 코드 인터프리터만 칩에 탑재된 CPU)등을 들 수 있다.
시중에 판매되고 있는 자바 가상머신으로는 썬사의 P-자바, 트랜스폼사의 Kaffe, 휴렛패커
드사의 차이(chai) 가상 머신이 있다.
표준 자바 API는 p-자바로 구성되어 있다.
TeaPot은 디버거로 원격 디버거를 사용하는데 임베디드 환경에서 많이 사용된다.
목적지에서 디버그 에이전트가 있고 직렬회로이나 네트워크로 연결되어 있는 호스트에는
GDB가 있다. 호스트의 gdb는 목적지의 디버그 에이전트로부터 정보를 받아서 디버깅을 한
다. 디버그 프로토콜로는 메모리 읽기/쓰기 등이 필요하다. 또한, 주소 크기, 레지스터 등도
필요하다. 소스디버거는 심볼 테이블에 심볼을 가지고 있다.
다. TeaPot의 커널
TeaPot의 커널은 아래의 [그림2-5-7]과 같이 정적 커널과 동적 커널로 구성되어 있다.

[그림 2-5-7 TeaPot의 커널 구조도]
정적 커널은 자바 바이트 코드를 수행할 수 없는 환경에서 동적 커널이 수행될 수 있는 역
할을 한다. 정적 커널 내에는 하드웨어 추상화 계층, 나노 커널, 자바 가상 머신의 세 가지
계층이 있다. 하드웨어 추상화 계층(Abstract Support Layer, ASL)은 Teapot이 하드웨어
독립적으로 동작하도록 구현되어 있다. 하드웨어를 추상화하는 계층으로 TeaPot 정적 커널
의 모든 기능은 이 계층상에서 구현되어 진다. 나노 커널은 자바 가상 머신이 수행되기 위
한 최소한의 환경을 만들어 주기 위한 커널이다. 자바 가상 머신은 이전에는 Kaffe를 사용
하였으나 지금은 자신의 가상 머신을 개발한 단계이다. 이전 Kaffe 사용 시 순수 Kaffe와는
쓰레드 처리, 신호 처리 등의 일부분을 변경하여 사용하였다.
동적 커널은 장비 드라이버, 파일 시스템, 커널 등 컴포넌트 객체의 집합이다. 보편적으로
말하는 운영체제의 대부분 기능이 여기서 구현되어진다.

제 6 절 Java Applications의 연구
1. Java Telnet
컴퓨터 원격접속은 특정지역의 사용자가 다른 곳에 위치한 컴퓨터를 온라인으로 연결하여
사용하는 서비스를 말한다. 일단 원격 시스템에 연결되면 이용자는 마치 하드웨어적으로 직
접 연결된 단말기와 다름없이, 연결한 원격 컴퓨터를 사용할 수 있다. TCP/IP 프로토콜 체
계에서 이러한 기능을 “Telnet"이라 하는데, 인터넷 사용자는 Telnet을 이용해 전 세계의
BBS, 다양한 도서 데이터베이스와 여러 대학의 정보 시스템, 문제전용 데이터 베이스, 데이
터 파일 및 기타 다양한 온라인 서비스를 제공받을 수 있다.
인터넷의 일반 사용자들은 자기의 고유 계정이 없이도 이와 같은 다양한 서비스를 제공하는
많은 시스템들을 접속할 수가 잇다. 이 응용 서비스가 매우 효과적인 이유는 거리에 관계없
이 쉽게 원격시스템에 접속할 수 있기 때문이다. 인터넷 사용자는 마치 옆 건물의 시스템에
접속하듯이 지구의 어느 시스템이든 쉽고 적당한 속도로 접속할 수 있고, 현재로서는 대부
분의 인터넷 사용자들이 자기들이 속한 기관에 별도의 사용비용을 지불하거나 혹은, 사용자
레벨에 따라 요금이 산정 되지 않고 있기 때문에 사용요금 혹은 비용은 대개의 경우 인터넷
사용의 중요한 제약 조건이 아니다. 따라서 다른 형태의 전자통신과 비교해 볼 때, 인터넷
환경에서는 거리와 시간 및 비용의 장벽이 매우 낮은 반면에, 인터넷은 초기에 연결을 하기
위한 비용이 상대적으로 많이 들고 여러 기술적인 지식이 필요하다.
보통 원거리에 있는 host로 Telnet을 이용해 log-in하기 위해서는 그 host상에 계정을 가지
고 있어야 하지만, 몇 몇 공개서비스를 제공하는 host들은 개인적인 계정을 갖지 않아도 무
방하다. 또한, TCP/IP를 바탕으로 한 응용 서비스 중에는 특정 포트번호를 통하여 서비스를
제공하는데, 이 경우에는 계정이 필요 없다.
Telnet으로 연결되면 키보드로 주어지는 모든 문자입력은 자신의 시스템은 그냥 통과하여
연결된 원격 시스템에게 받아들여진다. 그러면 원격 시스템과 연결을 끊지 않고 자신의 시
스템에게 명령을 내리는 방법으로 탈출문자가 있다.

탈출문자는 메시지를 원격 시스템에서 자신의 시스템으로 돌아오게 해주는 의미이다.
Telnet 다음에 기계의 이름(또는 IP번호)을 지정한다고 하였는데, 그냥 telnet만을 입력하면
telnet 명령어 상태(command mode)로 들어가게 된다. 이 상태는 ‘telnet>'이란 프롬프트로
표시되며, telnet 프로그램이 우리의 다음 명령을 기다리고 있다는 의미로 이 상태에서 ’물음
표(?)‘ 또는 ’help'를 입력하면 사용 가능한 명령어 목록이 나온다.
가. Telnet 포트번호
TCP/IP 프로토콜을 바탕으로 한 인터넷의 응용서비스들은 모두 고유의 포트번호를 가지고
있는데, telnet의 경우도 마찬가지로 23번이라는 고유의 포트번호를 가지고 있다. 일반적으로
telnet을 사용할 때는 이 포트를 사용하지만 telnet을 이용해 특별한 게임이나 채팅 등의 특
별한 서비스 제공이나 문제 해결을 위한 디버깅을 위해서 별도의 포트번호를 이용할 수 있
다. 새로운 많은 인터넷 서비스가 등장하면서 서비스별로 고유의 포트번호가 부여된다.
나. Telnet 프로그램 선택하기
Telnet 프로그램을 선택하기 위해서는 몇 가지 알아두어야 할 것이 있다. 사용자의 telnet
사용 용도가 대체적으로 어떤 것인지 다음과 같은 목록에서 생각해 봐야 한다.
ㆍ한글 채팅
ㆍ프로그램 받기
ㆍ통신/telnet 모두 사용
ㆍ자체 한글 지원
ㆍ무료/상업용
통신 프로그램과 telnet 프로그램의 차이를 설명하면, 통신만을 지원하는 프로그램은 전화를
걸어 통신 서비스 업체에 연결한 후 통신 업체에서 제공되는 서비스만을 사용할 수 있다.

일부 통신 프로그램은 telnet도 지원한다. 반면 telnet 지원 프로그램은 전화를 걸기 위한 기
능이 없이 인터넷이나 통신에 연결되어 있는 경우만 사용 가능하다. 통신과 telnet을 모두
지원한다면 먼저 윈도우 95, 98에서 윈속 프로그램으로 인터넷 서비스에 연결을 한다. 그런
후 인터넷을 넷스케이프 네비게이터로 사용하면서 동시에 telnet을 사용해 원하는 통신 업체
서비스를 사용할 수 있다. 이런 면에서 본다면 telnet 프로그램 선택 시 통신과 telnet을 모
두 지원하는 것을 선택하는 것이 이중의 효과를 얻을 수 있다.
(1) 어떤 웹 페이지는 telnet을 필요로 한다. 애플릿은 충분히 telnet 과 터미널 에뮬레이터
를 특징으로 한다. 그러나 보통 사용자가 더욱 자주 사용하는 프로그램으로 사용자의 시스
템과 함께 사용된다. 대부분의 유닉스기반 시스템은 매우 우수한 터미널 에뮬레이터(xterm)
와 항상 telnet 에플리케이션을 가지고 있다. 윈도우 95는 telnet 과 함께 사용자에게 네트웍
자료가 있을 경우 C:₩windows₩telnet .exe에 설치된다. 이것은 충분하지만, 만약 사용자가
더 나은 터미널 에뮬레이션과 색상을 원하는 경우 Java Telnet Applet이 더 나은 선택이 된
다.
(2) Java 애플릿은 각각의 방법들에 대해 제한되어 있다. 하나의 제한방법은 웹서버로부터
다운로드받는 것으로 사용자가 애플릿을 www.where.com에 놓는다면 “주소”필드를 설정하
지 않으면 some.where.com으로부터 연결을 가질 수 없다.
(3) HTML 파일을 하드디스크가 작업을 하지 않는 한 하드디스크로부터 받을 수 있다. 네
스케이프와 인터넷 익스플로러는 사용자의 하드디스크의 안전한 영역에서의 접근을 받아들
이지 않는다. 그래서 그것들은 어떤 자원의 접근들을 네트웍에서처럼 애플릿으로 제공할 것
이다. 사용자가 애플릿 저장할 곳의 디렉토리를 추가하고자 할 경우 사용자는
“CLASSPATH"환경변수를 브라우저 실행 정에 설정하여야 한다.

2. Java Ftp
[그림 3-6-2 FTP로 전 세계의 정보를 온라인으로 입수]
인터넷의 대표적인 응용서비스로서 인터넷에 접속된 컴퓨터들간의 파일 전송이 있다. 이 서
비스는 TCP/IP 환경에서 Ftp에 의해서 제공되는데, Telnet과 비슷하게 통신망 이용자들은
인터넷의 다른 컴퓨터의 다른 컴퓨터에 Ftp를 통하여 온라인으로 접속하는데 Telnet과는 달
리 Ftp의 단순히 파일의 위치변경과 송수신에 관련된 기능만을 수행할 수 있다. Ftp의 기능
중에는 디렉토리 변경, 파일목록보기 및 파일 수신과 같은 기타 기능 등이 있다.
Ftp는 file transfer Protocol의 약자이며 이름이 의미하듯이, 인터넷에서의 파일 전송 규약으
로서 근거리 시스템과 원격 시스템간의 파일 전송 프로토콜 기능을 제공하는 TCP/IP 규약
계열 중의 하나이다. 따라서 Ftp의 목적은 인터넷에 연결되어 있는 컴퓨터들 사이의 파일들
을 쉽고, 빠르게 하기 위한 것이다. 물론 Ftp는 파일 전송 프로그램(File transfer Program)
을 의미하기도 한다. 대부분의 인터넷 서비스와 마찬가지로, ftp도 클라이언트 프로그램을
사용하여 접속하고자 하는 시스템에 있는 서버 프로그램에 연결한다. 사용자는 클라이언트
프로그램을 이용하여 서버에게 명령을 내리고, 서버는 사용자의 명령을 충실히 실행할 것이
다.

FTP는 TCP/IP 프로토콜에서 파일을 전송하는 메커니즘으로 인터넷상에 있는 거의 모든 파
일의 전송에 - FTP 클라이언트를 통한 것이든, 코퍼 메뉴나 웹 링크를 통한 것이든 간에 -
실제로는 FTP 프로토콜이 사용되어 이루어진다. FTP 서버는 다운로드 할 수 있는 파일들
의 리스트와 디렉토리를 준비하여 표시해 준다. 이러한 서버들은 익명(anonymous) FTP 로
그인을 허용하기 때문에 암호나 사용자 ID가 필요 없이 파일을 다운로드 한다.
Ftp를 이용한 파일 송수신 속도는 네트웍을 연결한 링크의 전송속도와 그 링크를 통해 전
송되는 데이터의 트래픽 양에 따라 가변적이다. 또한, 한 시스템에 대하여 여러 명이 접속하
여 Ftp로 파일 송수신 할 경우 시스템의 시스템에 과부하가 걸려 실제 전송속도가 떨어질
수 있다.
가. Ftp 포트번호
TCP/IP 프로토콜을 바탕으로 한 인터넷의 응용서비스들은 모두 고유의 포트번호를 가지고
있는데, ftp의 경우도 마찬가지로 21번이라는 고유의 포트번호를 가지고 있다. 일반적으로
ftp를 사용할 때는 이 포트를 사용한다.
나. Ftp 명령 구조
파일 전송 규약은 컨트롤 연결을 지나는 모든 통신을 위한 Telnet 규약의 내역을 따르므로,
모든 Ftp 명령은 Telnet end of line code에 의해 종결되는 Telnet strings이다.
Ftp 명령은 세 부분으로 나뉜다.
- 접근 제어 인증 자
- 전송 매개변수
- FTP 서비스 요구
명령은 인자에 따른 명령 코드로 시작되는데, 명령 코드는 4이하의 알파벳 문자이다.

제 7 절 Java IPv6 프로토콜 및 Security 연구
1. IPv6 프로토콜
Java 설계의 목적 중 하나가 복잡하지만 작고 버그가 없으며 이해하기 쉬운 컴퓨터 개발을
지원하는 것이다. Java는 프로그래밍 언어에서 가장 단순한 네트웍 작업의 수행도 단지 몇
페이지에 달하는 코드를 요구한다. 이렇게 네트웍 환경에 적합한 java는 현재 네트워크를
하기 위해서 TCP/IP중에서 Ipv4를 사용한다. 그러나 현재의 Ipv4에서는 인터넷에 접속되는
장치의 증가로 할당 주소가 부족한 상태와 멀티미디어 서비스에 완벽한 제공을 하지 못함으
로 이에 대한 보안으로 128bit주소를 가진 IPv6가 나오게 되었다. 차후에 등장한 IPv6망에
적합하게 application이 쓰여질 수 있으려면 그에 맞는 API가 필요하게 된다. 이에 이 연구
에서는 IPv6에 맞는 JAVA API가 목적이다. TCP/IP application을 위한 application
program interface(api)는 socket interface이다. 이 API는 1980년대 초에 unix system에서
개발되었다. 그것은 다양하게 non-UNIX system의 다양한 system에서 구현되어졌다.
Socket API를 사용하기 위해 쓰여진 TCP/IP application은 높은 이식성을 가지고 우리는
iPv6에서도 같은 이식성을 갖기를 바란다. 그러나 socket API는 IPv6를 지원하기 위해 변화
를 필요로 하게된다. 이는 IPv6주고를 전달하는 새로운 socket 주소 구조, 새로운 주소변환
함수, 새로운 소켓 옵션들을 포함하고 있다. 이러한 연장은 멀티캐스팅을 포함하여 시스템에
최소한의 변화를 주면서 기본 IPv6특징에 접근하기 위해 제공되도록 디자인되어졌다.

2. JAVA NETWORK이란?
네트웍 프로그래밍을 작성하는데 주로 사용되는 클래스들은 JAVA. NET 패키지에 정의되
어 있는데 JAVA. NET 패키지에는 연결형 서비스(TCP)를 위하여 SOCKET과
SERVERSOCKET 클래스가 정의되어있으며 비 연결형 서비스(UDT)를 위하여 데이터그램
socket과 데이터 그램 packet 클래스가 정의되어 있다. 한편 웹 서비스를 위한 http 프로토
콜에서 사용하는 URL 주소를 지정하거나 임의의 URL로 연결하는데 상용하기 위하여 URL
과 URLCONNECTION 클래스가 있다.
SOCKET은 클라이언트에서 필요한 클래스이고 SERVERSOCKET은 서버에서 필요한 클래
스이다.
가. SOCKET 클래스
자바와 같은 객체지향 프로그램에서 어떤 클래스를 처음 불러 사용하면 그 클래스의 생성자
메소드를 호출하게 된다. 생성자 메소드는 항상 클래스 이름과 같은 이름을 가져야하는데
생성자 메소드 인자(ARGUMENT)의 패턴을 다르게 하여 여러 종류의 생성자 메소드를 정
의할 수 있으며, 사용자는 자신이 원하는 종류의 생성자를 선택할 수 있다.
Public final Socket extends object /*생성자 메소드*/
Socket(string host, int port) /*호스트 이름과 포트번호 지정*/
Socket("String host, int port, boblean stream): /*서비스 종류(Stream, 데이터그램)지정*/
Socket(InterAdsress addr, int port):/*인터넷 주소와 포트번호 지정*/
Socket(InterAdsress addr, int port, boblean stream): /*서비스 종류지정*/
/*주요 public 메소드*/
inputStream getInputStream(); /*inputStream 형태의 읽기*/
OutputStream getOutputStream(); /*outputStream 형태의 쓰기*/
InetAddress getInetAddress(); /*상대방의 인터넷 주소를 리턴*/

String getHost(); /*호스트의 이름을 얻기*/
int getPort(); /*상대방의 포트번호를 리턴*/
int getLocalPort */자신의 포트번호를 리턴*/
String toString(0; /*소켓 객체를 스트링 형태로 변환*/
synchronizes void close(); /*소켓 닫기*/
자바 Socket 생성자에는 네 가지 종류가 있는데 각 생성자가 사용하는 인자는 다음과 같다.
- host : 호스트 이름을 나타내는 스트링
- port : 포트번호
- sream : 프로토콜을 구분(스트림, 데이터그램)
- address : 인터넷 소켓주소 구조체
나. ServerSocket 클래스
서버에서 소켓을 구축하기 위해서는 java.net.ServerSocket 클래스를 사용한다.
ServerSocket은 아래와 같이 두 가지의 생성자 메소드를 지원하고 있는데 인자 port는 접속
에 사용할 포트번호이고 count는 대기시킬 수 있는 클라이언트의 접속 요청 수이다.
Serversocket은 아래와 같이 다섯 가지의 public 인스턴스 메소드를 지원한다.
public final class ServerSocket extends Object(
/*생성자 메소드*/
ServerSocket(int port); /*포트번호 지정*/
ServerSocket(int port, int count); /* 포트번호와 연결대기 최대치 지정*/
/*주요 public 메소드*/
Socket accept(); /*클라이언트의 접속요구를 받아들이며 새로운 Socket객체를 리턴*/
inetAddress getInetAddress(); /*상대방의 인터넷 주소를 리턴*/
int getLocalPort(); /*자신의 포트번호를 리턴*/

String toString(); /*소켓 객체를 스트링 형태로 변환
synchronized void close(); /*소켓 닫기*/
3. IPv4에서 IPv6로 변형하면서 주소 변형 함수에서 생긴 점
IPv4주소는 32bit이고 IPv6는 128bit이다. socket 인터페이스는 IP주소의 사이즈를
application에 visible하게 만든다. 가상적으로 모든 TCP/IP application은 IPwnthdml 사이즈
에 고나한 정보를 가지고 있다. 주소를 표현하는 API의 부분들은 더 큰 IPv6주소 사이즈를
적용하기 위해 변화된다. (즉 flow label과 priority)
가. 디자인 고려사항
IPv4에서 IPv6변화에 따른 API변화를 디자인하기 위해서는 몇 가지 고려사항이 있다.
(1) API 변화는 source와 binary compatibility 모두에 제공되어야 한다. 즉 기존 program
binary 들이 새로운 API를 위한 시스템이 동작하는 동안 계속 수행 되야 한다. 또한 기존의
application들이 계속 수행될 수 있어야 한다. 간단히 말하여 IPv6인한 API 변화는 기존의
프로그램을 멈추게 하지 않아야 한다.
(2) API에 변화는 기존의 IPv4 application을 IPv6로 변경하는 작업이 가능한 적은 부분이어
야 한다.
(3) 가능하면 application들은 IPv6와 IPv6 host에서 모두 동작 할 수 있게 사용할 수 있어
야 한다. application들은 그들이 통신하는 호스트의 타입에 대해 알 필요는 없다.
(4) 데이터 구조 안에서 전달되는 IPv6 주소는 64bit로 할당되어진다. 이는 64bit 머신 구조
에서 최적의 성능을 얻기 위해서이다.
API에서 IPv4 compatibility(양립성) 제공의 중요성 때문에, 확장은 확실히 IPv4, IPv6 모두
가 지원하는 기계에서 수행되도록 디자인되었다.

나. 변화를 위해 필요로 하는 것(What needs to be changed) socket inter face API는 몇
개의 특정적인 부분으로 구성되어져 있다.
- Core socket 함수
- Address data 구조
- Name-to-address 변환 함수
- Address conversion 함수
COre socket 함수 - TCP 연결을 설정하고 끊고, UDP packet을 받고 보내는 일을 다루는
함수이다. - transport에 독립적으로 디자인한다. 프로토콜 주소가 함수 매개변수로서 전달
되어 질 때 그들은 opaque pointer를 통해 전달된다.
Address data(특정주소)데이터 구조는 소켓 함수들이 지원하는 각각의 프로토콜로 정의된
다. application은 address structure에 pointer를 준다. 이 함수들은 IPv6를 위해 변화 할 필
요는 없다. 그러나 IPv6 특정주소 data 구조는 필요로 하다.
sockaddr_in은 IPv4를 위한 data구조이다. 이 데이터 구조는 8옥텟의 사용되지 않는 공간을
포함하고 있다. 이 공간을 IPv6에 구조를 적용하기 위해 사용하려한다. 불행히 sockaddr_in
구조는 16옥텟 IPv6주소와 다른 정보를 (address family and port number) 유지할 만큼 넓
은 공간이 아니다. 그래서 새로운 데이터 구조가 IPv6에 정의되게 된다.
Name-to-address 변환 함수는 gethostbyname()과 gethostbyaddr()이다. 이들은 IPv6를 지
원하기 위해 수정되어야 한다. Address conversion 함수(), inet-ntoa()과 inet-addr(), IPv4
주소를 binary와 도메인 네임으로 변하게 한다. 이 함수들은 32bit IPv4주소를 가진다. 여기
서는 IPv4와 IPv6 주소를 모두 변환할 수 있는 두 개의 유사한 함수를 디자인하고 주소 타
입 파라미터를 전달하게 한다.

마지막으로 IPv6를 지원하기 위해서는 몇 가지 특성을 필요로 한다. IPv6 flow lable,
priority, hop-limit)를 지원하기 위해 새로운 인터페이스가 필요하다. 새로운 옵션들은 IPv6
멀티캐스트 패킷의 주고받는 것을 조절하기 위해 필요로 하다.
다. 소켓 인터페이스
이 절에서는 IPv6를 위해 소켓 인터페이스 변환을 기술한다.
(1) IPv6 address family and protocol family
새 address family name - AF_INET6 - 는<sys/socket.h>에서 정의된다. 다른 protocol
family name과 마찬가지로 이것은 일반적으로 대응되는 address family name 같은 변수로
정의된다.
#define PF_INET6 AF_INET6
PF_INET6는 IPv6 소켓이 생성되는 것을 나타내는 socket() 함수의 첫 번째 argument이다.
(2) IPv6 address structure
하나의 IPv6 주소를 유지하는 새로운 데이터 구조는 다음과 같이 정의된다.
#include<-addr{
netinet/in.h>
struct in6_addr{
u_int8_t s6_assr[16]; /*IPv6 address*/
이 데이터 구조는 128bit IPv6 주소를 이루는 16개의 8bit요소의 배열로 구성된다. IPv6주소
는 network byte순서로 저장된다.

(3) Socket address structure for 4. 3 BSD-Based System
소켓 인터페이스에서 different specific data structure는 각각의 프로토콜 쌍을 위하여 주소
를 전달하기 위해 정의된다. 각 프로토콜의 특정 데이터구조는 pointer를 sockaddr 구조에
놓는다.
sockaddr_in 구조는 IPv4를 위한 protocol specific address data구조이다. 그것은 소켓함수
에 있는 시스템과 응용프로그램 사이에서 주소를 넘기는데 사용된다. 다음 구조는 IPv6주소
를 전달하기 위해 사용되는 것이다.
include <netinet/in.h>
struct sockaddr_in6
u_int16m_t sin6_family /*AF_INET6*/
u_int16m_t sin6_port /*transport layer port#*/
u_int32m_t sin6_addr /* IPv6 flow information*/
struct in6_addr sin6_addr; /* IPv6 address*/
이 구조는 4. 3BSD에서도 사용될 수 있게 sockaddr data 구조와 양립할 수 있게 디자인되
었다. sin6_family 필드는 sockaddr_in6 구조로서 이를 확인한다. 이 필드는 버퍼가
sockaddr데이터 구조에 cast할 때, sa_family 필드를 오버레이한다. 이 필드의 변수는
AF_INET6이다.
SIN6_PORT 필드는 16bkt UDT도는 TCP포트 숫자를 포함한다. 이 필드는 sockaddr_in 구
조의 sin_port 필드에서도 같은 방식으로 사용된다. 포트 숫자는 network byte순서로 저장
된다.
sin6_flowinfo 필드는 24bit IPv6 flow label과 4bit priority 필드 정보를 포함하는 32bit필드
이다.
sin6_addr 필드는 하나의 in6_addr 구조이다. 이 필드는 128bkt IPv6 주소를 가지고 있다.
주소는 network byte 순서로 저장된다.

이 구조에서 구성 요소의 순서는 명확하게 디자인된다. 그래서 sin6_addra 필드는 64bit 영
역이 할당된다. 이것은 64bit 구조에서 최적의 성능을 가질 것이다.
sockaddr_in6 구조는 일반적인 sockaddr 구조보다 일반적으로 더 크다. sizeof(strucaddr_in)
구현은 sizeof(sockaddr)와 같다. 이런 가정을 만드는 기존의 코드는 IPv6로 변경할 때 주의
깊게 하여야 한다.
(4) Socket Address Structure for 4. 4BSD-Based system
4BSD release는 적은 그러나 socket 인터페이스와 양립할 수 없는 변화를 포함한다.
sockaddr데이터 구조의 sa_family 필드는 16bit 변수로부터 8bit 변수로 변경되었다. 그리고
절약된 공간은 sa_len이라는 길이 필드를 유지하는데 사용된다. sockaddr_in6 데이터 구조는
정확하게 새로운 sockaddr 데이터 구조로 casta 되지 않는다. 때문에 IPv6주소데이터 구조
는 4. 4BSD를 기반으로 하는 시스템에 사용되어지게 제공되어진다.
#include <netinet/in.h>
#define SIN6_LEN
struct sockaddr_in6
u_char sin6_len; /*length of this struct*/
u_char sin6_family; /*AF_INET6*/
u_int16m_t sin6_port; /*transport layer port#*/
u_int32m_t sin6_flowinfo; /*IPv6 flow information*/
struct in6_addr sin6_addr; /*IPv6 address*/
이 데이터 구조와 4.3BSD 변형사이에 차이는 길이 필드의 포함과 8bit 데이터 타입의
family field로의 변화이다. 모든 다른 필드의 정의는 앞 절과 같다.

sockaddr_in6 데이터 구조의 버전을 제공하는 시스템은 <netinet/in.h>를 포함하는 결과로서
SIN6_LEN을 선언한다. 이 마크로는 application이 4. 3BSD 또는 4. 4BSD 변형을 지원하는
시스템을 만드는지 아닌지를 결정하게 한다.
(5) The socket function
Application은 통신의 종단을 나타내는 소켓 descriptor을 생성하는 socket 함수를 부른다.
socket 함수에 대한 argument는 어떤 프로토콜이 사용되며 어떤 포맷주소 구조가 사용되는
지를 보인다.
예를 들어,
IPv4/TCP 소켓을 생성하기 위하여 application은 다음 call을 만든다;
s=socket(PF_INET, SOCK_STREAM, 0);
IPv4/UDP 소켓을 생성하기 위하여 application은 다음과 같은 call을 만든다.
s=socket(PF_INET6, SOCK_DGRAM, 0);
일단 application이 PF_inet6 소켓을 생성하고 나면, 시스템에 주소를 전달할 때
sockaddr_in6 주소 구조를 사용해야 한다. application이 주소를 전달하기 위하여 사용하는
함수에는 다음과 같은 것이 있다.
bind()
connetct()
sendmsg()
sendto()
시스템은 PF_INET6 socket을 사용하는 application에 주소를 돌려주는 sockaddr_in6 구조를
사용한다. 시스템으로부터 application에 주소를 돌려주는 함수에는 다음과 같은 것이 있다.

accept()
recvfrom()
recvmsg()
getpeername()
getsockname()
주소 변환 함수의 모든 것이 불특정 주소 포인터를 사용하며 함수의 변수로서 주소길이를
전달하기 때문에 IPv6를 지원하기 위해 socket 함수의 구문에는 아무런 변화가 필요로 하지
않다.
]
(6) compatibility with Ipv4 application
기존의 api를 사용하여 application의 큰 기본을 지원하기 위하여 시스템 구현은 기존의 api
와 완벽한 source, binary를 양립할 수 있게 제공돼야 한다. 이것은 시스템이 pf_inet socket
과 socket_in주소 구조를 계속하여 지원해야 한다는 것을 의미한다. application은 socket 함
수 안에 있는 PF_inet 상수를 사용하여 IPV4/TCP와 IPV4/UDP 소켓을 생성한다.
application은 같은 프로세스 내에서 동시적으로 IPV4/TCP, IPV4/UDP, IPV6/TCP
IPV6/UDP 소켓의 조합을 유지 할 수 있어야 한다.
기존의 API를 사용하는 application은 단지 IPv4를 지원하는 시스템인 것처럼 계속해서 운
영되어야 한다. 즉 그들은 IPv4 노드들과 함께 계속해서 상호 운영되도록 해야 한다.
(7) compatibility with Ipv4 nodes
API는 양립성의 다른 타입을 제공한다. 이 특징은 IPv6 addressing specification내에서
IPv4 mapped IPv6 주소로 정의된 주소 형식을 사용하게 된다. 이 주소 형식은 IPv4노드의
IPv4주소가 IPv6주소처럼 나타나게 된다. IPv4주소는 IPv6 주소의 lower-order 32bit로
encode 되게 하고 high-order 96bit 는 고정된 prefix 0:0:0:FFFF IPv4 mapped 주소는 다음
과 같이 쓰여진다.

: : FFFF: (IPv4-address)
이 주소들은 특정 호스터가 IPv4주소를 단지 가질 때 gethostbyname() 함수에 의해 자동으
로 생성된다 application은 도착지의 IPv4주소를 IPv4-mapped IPv6 주소로 encoded하고 그
주소를 connect(0또는 send-to(0안에 있는 sockaddr_in6구조에 전달함으로써 IPv4노드에 연
결되는 TCP를 열기 위하여 IPv4노드에 UDP패킷을 보내기 위하여 PF_INET6 소켓을 사용
한다. application이 IPv4노드로부터 TCP연결을 받아들이거나 또는 IPv4노드로부터 UDP 패
킷을 받아들이는 PF_INET6를 사용할 때 시스템은 accept(), recvfrom(), getpeername()에
있는 applicaior에 peer의 주소를 return한다. application은 그들이 상호 운영하는 노드의 타
입이 무엇인지를 알 필요가 없다.
(8) IPv6 wirdcard address
bind() 함수는 application이 UDP 패킷과 TCP 연결의 source IP 주소를 선택하는
application을 허용하는 동안 시스템이 source 주소를 선택하게 하는 함수이다. 주소를 심볼
상수로 명시한다.
IPv6 주소타입이 구조이기 때문에 심볼 상수가 IPv6주소 변수를 초기화하는데 사용되어진
다. 그러나 할당하여 사용할 수는 없다. 그러기 때문에 시스템은 IPv6 wirdcard 주소를 두
가지 형태로 제공한다.
첫 번째 버전은 in6_addr 구조를 가지고 있는 in6addr_any라 명명된 global변수이다. 이 변
수에 대한 선언은 <netonet/in.h>에 정의되어 있다.
extern const struct in6_addr in6addr_any;
application은 IPv4에서 INADDR_ANY를 사용하는 것과 유사한 방법으로 in6addr_any를 사
용한다. 예를 들어 소켓을 포트번호 23번에 bind하기 위해 시스템은 source 주소를 선택하
지 않게 하고 applicario은 다음과 같은 코드를 사용한다.

(9) IPv6 lookback address
application은 UDR패킷, originate TCP 연결을 local 노드에 있는 서비스에 보낼 필요가 있
다. IPV4에서 이 일은connect(), sendto(0, sendmesg() call에 있는 IPv4address
INADDR_LOOKBACK 상수를 사용하여 동작한다.
IPv6는 또한 로컬 TCP와 UDP서비스에 연결하기 위하여 lookback 주소를 제공한다. 언급되
지 않은 주소는 IPv6lookback 주소가 두 가지 형태로 제공된다.
global 변수는 in6addr_loopback이라고 불리는 in6_addr 주소 구조를 가진다. 이 변수에 대
한 외부선언은 <netonet/in.h>에 정의된다.
extern const struct struct in6_Addr in6addr_loopback;
application은 IPv4 application에서 INADDR_LOOPBACK을 사용하는 것처럼
in6addr_loopback을 사용한다.
라. interface identification
이 API는 멀티 캐스트 그룹이 어디에 속해 있는지에 대한 로컬 인터페이스를 확인하기 위
하여 인터페이스 인덱스를 사용한다. 부가적으로 발전된 API는 데이터그램이 받는 인터페이
스를 확인하기 위하여 또는 데이터그램이 보내지는 인터페이스를 기술하기 위하여 같은 인
터페이스를 사용한다.
인터페이스는 보통 “le0:, :sl1;m;ppp2" 같은 이름으로 알려져 있다. berkery-derived 구현에
서 인터페이스가 시스템에 알려질 때 만들어지면, 커널은 특정 숫자를 할당하나, 이것은 1부
터 시작하는 작은 숫자이어서 어떤 갭이 있을 수도 있다. 특정 향후 인터페이스 인덱스를
위한 인터페이스는 현재 없다. 이 API는 인터페이스 이름과 인덱스 사이에서 매핑하는 두
가지의 함수 모든 인터페이스 이름과 인덱스를 돌려주는 세 번째의 함수 앞의 함수에 의해
동적으로 할당된 메모리를 돌려주는 네 번째 함수를 정의한다.
(1) Name-to-index
첫 번째 함수는 인터페이스 이름을 그것에 대응하는 인덱스로 매핑 한다.

#include <net/if.h>
unsigned int if_nametoindex(const char *ifname);
특정 인터페이스 인덱스가 존재하지 않으면 리턴 변수는 0이다.
(2) index-to-name
두 번째 함수는 인터페이스 인덱스를 대응하는 이름으로 매핑 하는 함수이다.
#include <net/if.h>
char *if_indextoname(unsigned int ifindex, char *ifname);
ifnaem 매개변수는 특정 인덱스에 대응하는 특정 인터페이스 이름이 리턴 되는
IFNAMSIZE 바이트 크기의 버퍼를 가리킨다. 이 포인터는 또한 함수의 리턴변수이다. 특정
인덱스에 대응하는 인터페이스 가 없다면 NULL이 리턴 된다.
(3) Library FUNCTION
새 함수는 IPv6 주소와 함께 동작의 다양함을 수행할 필요가 있다. 함수들은 DNA에 있는
IPV6주소를 loopback할 필요가 있다. forward lookup과 reverse lookup이 지원돼야 한다. 함
수들은 IPv6 주소를 binary와 text 형식으로 전환할 필요가 있다.
(가) HOSTNAME-TO-ADDRESS TRANSLATION
일반적으로 사용되는 함수 gethostbyname()은 포인터를 돌려주는 hostent구조처럼 아무런
변화가 없이 있다. 이 함수를 부르는 기존의 application은 A 레코드를 위한 DNA 에 있는
질의의 결과인 IPv4주소 받는 것을 계속한다. 두 가지의 새로운 변화가 IPv6주소를 지원하
기 위해 만들어진다. 첫째 다음과 같은 함수가 변형이다.

#Include<sys/socket.h>
#include<netdb.h>
struct hostnet *gethostbyname2(constchar *name, int af);
af매개변수는 address family를 기술한다. 이 함수의 default 작동은 간단하다. IPv4주소가
리턴되고 hostent 구조의 h_length 멤버는 4가 될 것이다. 그렇지 않으면 MULL 포인터를
리턴한다.
부가 기능을 제공하는 두 번째 변화는 <resolv.h> 헤더를 포함하면서 결과로서 정의된
새로운 해결 자 사양 RES_USE_INET6이다.
이 옵션을 설정에는 세 가지 방법이 있다.
- 첫 번째 방법은
res_init();
_res.options = RES_USE_INET6;
그리고 gethostbyname() 또는 gethostbyname2()를 부르는 것이다. 이 사양은 해결 자를
부르는 프로세스에 단지 영향을 준다.
- 두 번째 방법은 RES_OPTION=inet6처럼 환경변수 RES_OPTIONS를 설정하는 것이다.
이 방법은 이 환경변수를 참조하는 프로세스들에 영향을 준다.
- 세 번째 방법은 해결 자 위치 파일에 이 사양을 설정하고, 이는 호스트의 모든
application이 IPv6 주소를 다룰 수 있을 때까지 동작하지 않는다.
이 세 가지 방법들 사이에는 어떤 우선 순위도 없다. RES_USE_INET6 사양이 설정될 때
두 가지 변화가 일어난다.
- gethostbyname(host) 첫 번째는 AAA레코드를 찾는 gethostbyname2(host, AF_INET)을
부른다.
- gethostbyname2(host, AF_INET)은 16으로 설정된 hostent 구조의 h_length 멤버와 함께
항상 IPV4-mapped IPv6주소를 리턴 한다.

application은 리턴되는 hostent 구조안에 16byte 주소를 다루는 것이 준비될 때까지 RES_
USE_ INET6 사양을 가능하게 할 수 없다.
다음 테이블은 기존의 gethostbyname() 함수, gethostbyname2()의 작동을 요약한 것이다.
[표 7-1-1]
RES_USE_ INET6 option
off on
gethostbyname(host)
-A 레코드를 찾는다.- 발견되면 IPv4 주소를 리턴한다.- 기존의 IPv4 appls와 함께backward 양립성을 제공한다.
-AAA 레코드를 찾는다.-발견되면 IPv6주소를 돌려주고 그렇지 않으면 A레코드를 찾는다.-발견되면 IPv4mapped IPv6주소를돌려준다. 그렇지 않으면 error
gethostbyname2(host, AF_INET)
-A레코드를 찾는다. 발견되면 IPv6주소를 리턴하고 그렇지 않으면error
-A레코드를 찾는다. 만약 발견되면IPv4-mapped IPv6를 돌려준다. 그렇지 않으면 error
gethostbyname2(host, AF_INET6)
-AAA레코드를 찾는다. 발견되면 IPv6주소를 리턴하고 그렇지 않으면error
-AAA레코드를 찾는다. 발견되면IPv6주소를 리턴하고 그렇지 않으면error
(나) Address Conversion 함수
두 함수 inet_addr()와 inet_ntoa 각각은 IPv4 주소를 바이너리와 텍스트 형태로 변경한다.
IPv6 application 역시 유사한 함수가 필요하다. 다음과 같은 두 함수가 IPv6와 IPv4 주소
모두를 변경한다.

#include <sys. socket. h>
#include <arpa/inet. h>
int inet_(int af, char *src, void *dst):
const shar *inet_ ntop( int af, const void ㆍ*src, char *dst, size_t size):
inet_pton() 함수는 주소를 그것의 표준, 텍스트 형태에서 바이너리 형태로 변경한다. af매개
변수는 주소의 family를 언급한다. 현재 AF_INET과 AF_INET6 주소가 지원된다. src 매개
변수는 전달되는 스트링을 가르친다. dst 매개변수는 함수가 numeric 주소를 저장하는 버퍼
를 가리킨다. 주소는 network byte order로 돌아온다. Inet_pton()은 변형이 성공하면 1, 입
력이 명확한 IPv4 주소형태, IPv6 주소 형태가 아니면 0을, 매개변수가 알려지지 않은 값이
라면 error와 함께 -1을 리턴한다. calling application은 dst에 의해 참조되는 buffer가
numeric 주소를 유지 할 수 있을 만큼 충분한 공간을 가지고 있어야 한다. (즉 AF_INET를
위한 4바이트나 AF_INET6를 위한 16바이트)
ddd.ddd.ddd.ddd
ddd는 0과 255사이에서 3digit decimal 숫자 중의 하나이다. 기존의 inet_adder()과
inet_adder() 함수의 구현에서 비 표준 입력을 받아들이는 것을 주의해야 한다. 8진수, 16진
수, fewer than four numbers, inet_pton은 이 세 가지 형태를 받아들이지 않는다. af 매개
변수가 AF_INET6이면, 함수는 표준 IPv6 텍스트 형식의 하나인 string을 받아들인다.
inet_ntop() 함수는 numeric 주소를 presentation 하기에 적당한 텍스트 스트링으로 변환시
킨다. af 매개변수는 주소의 family를 기술한다. 이것은 AF_INET 또는 AF_INET6일 것이
다. src 매개변수는 af 매개변수가 AF_INET 이라면, IPv4 주소를 유지하는 버퍼를 가리키
고 af 매개변수가 AF_INET6이라면 IPv6주소를 가리킨다.

dst 매개변수는 결과 텍스트 스트링을 저장하는 버퍼를 가리킨다. application은 non_NULL
dst 매개변수에 대해서 기술해야 된다. IPv6 주소에 대해서 버퍼는 적어도 46옥텟이어야 한
다. IPv4 주소에 대해서 버퍼는 적어도 16옥텟이어야 한다. application이 쉽게 스트링 형태
에 IPv4, IPv6 주소를 저장하기 위한 적당한 사이즈의 버퍼를 선언하기 위하여, 다음과 같
은 두 가지 상수가 <netinet/in.h> 정의되어야 한다.
#define INET_ADDRSTRLEN 16
#define INET_ADDRSTRLEN 46
inet_ntop 함수는 변환이 성공한다면 텍스트 스트링을 포함하는 버퍼를 가리키는 포인터를
리턴하고 그렇지 않으면 NULL을 리턴한다. 실패하면 error는 af 매개변수가 무효하다면
EAFNOSUPPORT를 설정하고, 결과 버퍼의 사이즈가 적당하지 않으면 ENOSPC을 설정한
다.
4. java API
자바 API패키지는 JDK 1.0에서 java. applet, java.awt, java. awt. image, java. awt. peer,
Java. lang, java. util, java. net이 있으며 그 외에 선마이크로시스템에서 자체적으로 제공하
는 패키지들로 구분된다. 선 마이크로 시스템에서 제공하는 패키지의 경우 자바 api표준으
로 정해지지는 않았으나 선 자체적으로 유용하다고 생각되는 클래스만을 따로 제공하는 것
으로, 특히 알파 버전의 경우에 java. net에서 제공되던 유용한 클래스들이 베타 이후로 변
환되면서 표준 api에서 삭제되고, sun, net 패키지로 옮겨왔다. 또 한가지 주의해야 할 점은
클래스 계층 구조와 클래스 패키지가 완벽히 일치하지는 않는다는 점이다. 그 이유는 베타
이후 버전부터 클래스 계층 구조에 따른 메소드 재사용을 최대화하기 위해 특히 예외 부분
에 대한 내용들이 askg이 수정되었다. 주의해야 할 점은 전의 알파 버전에서 제공되었던 네
트웍을 위한 networkclient/networkserver 클래스들이 sun. net패키지로 옮겨졌다는 점이다.
이와는 관계없이 이 클래스들을 사용하고 싶으면 java. net. *과 sun. net. *을 함께 사용하
면 된다.

가. java. net. 패키치
네트웍에 관련된 클래스들로 소켓연결과 URL 처리를 위한 클래스들로 구성되어 있다. 주의
해야 할 점은 이전의 알파버전에서 제공되었던 네트웍을 위한 networkclient/networkserver
클래스들이 sun. net 패키지로 옮겨졌다는 점이다. 이와는 관계없이 이 클래스들을 사용하고
싶으면 java. net*과 sun. net*을 함께 import하여 사용하면 된다.
(1) java. net. inetaddress
인터넷 ip 주소를 다루는 클래스이다. 패키지 안의 다른 클래스들은 직접적으로 관련되지
않고 이 클래스를 이용하게 된다. 이 클래스의 장점은 4byte address를 32bitwjdtnfg 표현하
는데 있다. 따라서 본 연구에서는 IP 주소를 다루는 클래스인 java, net. inetaddress를 중심
으로 주소 bit 화장에 따른 변화를 알아보고 실제 IPv6에서 주소변환이 되는 과정을 보여준
다.
(2) JAVA API for IPv4에서 관련된 부분
java 프로그램에서 inetaddress 객체를 사용해서 인터넷 주소를 지정한다. Inetaddress 클래
스는 java. net 패키지 내에 있다. 이 클래스를 사용해서 인터넷을 통해 연결하고 싶은 컴퓨
터를 지정한다. Inetaddress 객체를 작성하기 inetaddress 구성자 메소드를 사용하지는 않는
다. 단지 변수를 선언하고 inetaddress 객체를 리턴하는 inetaddress클래스 메소드 중 하나를
사용하면 된다.
(3) 로컬 호스트에서 ip 주소 얻기
예를 들어 자신의 컴퓨터에서 ip 주소를 판별하고 싶다고 사정한다. 이때 inetaddress 클래
스 static getlocalhost메소드를 사용해서 컴퓨터의 inetaddress 객체를 리턴할 수 있다.

(4) 도메인 이름에서 ip 주소 얻기
inetaddress 클래스 getbyname메소드는 도메인 이름에서 inetaddress 객체를 작성한다. 프로
그램이 getbyname을 호출하면 메소드는 도메인 네임서버와 연결하여 지정된 이름의 ip 주
소를 알아낸다.
5. IPv6에 대해서
IPv6 가 주목받는 것은 인터넷 가입자가 폭발적으로 증가하고 있지만 IPv4 기반의 TCP/IP
는 이 같은 환경에 적절하게 대응할 수 없다는 한계 때문이다. 현재의 IPv4에서는 폭증하는
인터넷 프로토콜의 어드레스 수요가 멀티미디어 실시간 처리 및 보단 대처 능력에 분명한
기술적, 물리적 한계를 지니고 있다고 지적하고 있다. IPv6는 바로 이 같은 IPv4의 한계를
극복한 차세대 IP라 할 수 있다. 더욱 중요한 것은 IPv6의 모든 규격이 각종 인터넷 표준을
정의하는 IETF의 권고안대로 설계돼 처음부터 업계표준 IP로서 대우를 받고 있다는 점이
다.
가장 두드러진 특징으로 꼽히는 128비트 주소 구조는 기존 IPv4에서 주소 할당 요구가 증
가할수록 관리가 복잡하고 비효율적이 되는 한계를 완전 극복한 것으로 평가되고 있다. 인
터넷 정보 전송은 보통 패킷단위로 이루어지는데 이 패킷은 발신자 주소와 수신자 주소를
비롯하여 전송하는 정보의 성격을 규정하는 헤더 등 세 부분으로 구성돼 있다. 어드레스는
발신자와 수신자 주소를 통칭하는 것이다.
IPv6에서는 발신자 및 수신자 주소 부문 정보의 길이가 32비트에서 128비트로 늘어났는데
이는 IP어드레스를 표기할 수 있는 숫자가 지금까지는 2의 32승 개였지만 이제는 2의 128승
개로 증가했다는 의미를 지닌다.
가. IPv6 주소 체계
IPv6 address는 128비트로 인터페이스들의 집합을 지정한다. IPv6주소는 다음과 같은 3가지
유형을 갖는다.

-Unicast 주소: 단일 인터페이스를 지정하며 unicast 주소로 보내진 패킷은 그 어드레스에
해당하는 인터페이스에 전달된다.
-Anycast 주소: 여러 노드들에 속한 인터페이스의 집합을 지정하며 anycast 주소로 보내진
패킷은 그 어드레스에 해당하는 인터페이스들 중 하나의 인터페이스에 전달된다.
-Multicast 주소: 여러 노드들에 속한 인터페이스의 집합을 지정하며 multicast 주소로 보내
진 패킷은 그 어드레스에 해당하는 모든 인터페이스들에 전달된다. IPv6에는 broadcast 주
소는 없고 그 기능은 multicast 주소로 대체 됐다. 현재 어드레스 공간의 15%는 초기 할당
되어 졌고 나머지 85%는 미래를 위해 예약되어 있다.
(1)addressing 모델
모든 유형의 IPv6 주소들은 노드에 할당되는 것이 아니라 인터페이스에 할당된다. 각각의
인터페이스는 단일 노드에 속하기 때문에 어떤 노드의 인터페이스 unicast 주소를 그 노드
를 지정하는데 사용된다. 단일 인터페이스에는 3가지 유형의 어드레스들이 모두 할당되어질
수 있다. 이 addressing 모델에서 다음과 같은 두 가지 예외가 있다. 첫째로 만일 구현된 것
이 다수의 물리적 인터페이스를 인터넷 계층에서 하나의 인터페이스로 취급할 때 다수의 물
리적 인터페이스는 하나의 어드레스만 할당받는다. 이것은 다수의 물리적 인터페이스에 대
한 로드 분산에 유용한다. 둘째로 포인트 두 포인트 링크에서 라우터는 IPv6 어드레스를 할
당받지 않는다. 라우터에서 point-to-point 인터페이스들이 IPv6 패킷의 소스나 목적지로 사
용되지 않는다면, 이 인터페이스에 대한 주소는 필요치 않기 때문이다.
나. 주소 표현 방식
IPv6 주소를 문자열로 표현하는 3가지 일반적인 형식이 있다.
개선된 형식
X:X:X:X:X:X:X:X

여기서 X는 16비트이고 4개의 16진수로 표현된다.
IPv4와 IPv6 node의 혼합환경을 취급하는 형식
X:X:X:X:X:X:d.d.d.d
여기서 X는 16비트이고 4개의 16진수 값이고 d는 8bit10진수 값이다.
6. java. net. inetaddress 변환모습
ip 주소 32비트를 128비트로 변환하였다. IPv6에서 데이터그램 형식의 변환은 망 계층에서
처리하므로 api 변환에서는 신경쓰지 않았다.
변환전(ipuv4)
address = addr[3]&0× FF:
address = ((addr[2] <<8)&0× FF00):
address = ((addr[1]<<16&0× FF0000):
address =((addr[0]<<24)&0× FF000000):
변환후(IPv6)
address = addr[15]&0× FF:
address = ((addr[14]<<8)&0× FF00):
address = ((addr[13]<<16)&0× FF0000):
address = ((addr[12]<<24)&0× FF000000):
address = ((addr[11]<<32)&0× FF00000000):
address = ((addr[10]<<40)&0× FF0000000000):
address = ((addr[9]<<48)&0× FF000000000000):
address = ((addr[8]<<56)&0× FF00000000000000):
address = ((addr[7] <<64)&0× FF0000000000000000):
address = ((addr[6]<<72)&0× FF0000000000000000000):
address = ((addr[5]<<80)& 0× FF000000000000000000000000):
address = ((addr[4] <<88)& 0× FF0000000000000000000000000):

address = ((addr[3]<<96)0× FF00000000000000000000000000):
address = ((addr[2]<<104)&0× FF0000000000000000000000000000):
address = ((addr[1]<<112)&0× DD000000000000000000000000000000):
address = ((addr[0]<<120)&0× FF00000000000000000000000000000000):
변환전
public byte[]getaddress() [
byte[]addr=new byte[4]:
addr[0]=(byte)((address>>>24)&0×FF):
addr[1]=(byte)((address>>>16)&0×FF):
addr[2]=(byte)((address>>>8)&0×FF):
addr[0]=(byte)(address&0×FF):
return addr:
}
변환후
public byte[]getaddress()[
byte[]addr=new byte[16]:
addr[0]=(byte)((address>>>120)&0×FF):
addr[1]=(byte)((address>>>112)&0×FF):
addr[2]=(byte)((address>>>104)&0×FF):
addr[3]= (byte)((address>>>96)&0×FF):
addr[4]= (byte)((address>>>88)&0×FF):
addr[5]=(byte)((address>>>80)&0×FF):
addr[6]=(byte)((address>>>72)&0×FF):
addr[7]=(byte)((address>>>64)&0×FF):
addr[8]=(byte)((address>>>56)&0×FF):
addr[9]=(byte)((address>>>48)&0×FF):
addr[11]=(byte)((address>>>32)&0×FF):
addr[12]=(byte)((address>>>24)&0×FF):

addr[13]=(byte)((address>>>16)&0×FF):
addr[14]=(byte)((address>>>8)&0×FF):
addr[15]=(byte)((address&0×FF):
return addr:
}
변환전
public string gethostaddress(){
return((address >>>24)&0Xff)+.+
((address >>>16)&0Xff)+.+
((address >>>8)&0Xff)+.+
((address >>>0)&0Xff):
변환후
public string gethostaddress(){
return((address >>>120)&0Xff)+.+
((address >>>112)&0Xff)+.+
((address >>>104)&0Xff)+.+
((address >>>112)&0Xff)+.+
((address >>>104)&0Xff)+.+
((address >>>96)&0Xff)+.+
((address >>>88)&0Xff)+.+
((address >>>72)&0Xff)+.+
((address >>>64)&0Xff)+.+
((address >>>56)&0Xff)+.+
((address >>>48)&0Xff)+.+
((address >>>40)&0Xff)+.+
((address >>>32)&0Xff)+.+
((address >>>24)&0Xff)+.+
((address >>>16)&0Xff)+.+
((address >>>8)&0Xff)+.+
((address >>>0)&0Xff):

2. Java Security 연구
실행 가능한 응용이 네트워크를 통해 원격지 컴퓨터에서 실행될 경우 시스템내의 특정한 자
원에 대한 접근이 요구된다. 그러나, 실행 가능한 응용 프로그램은 기본적으로 보안 문제를
신뢰할 수 없기 때문에 컴퓨터 시스템의 자원 접근에 대한 제어가 필요하다.[2]. 따라서, 자
바 애플릿과 같은 실행 가능한 응용 프로그램을 원격지 컴퓨터에서 실행할 경우 컴퓨터 시
스템 자원들에 대한 제어할 수 있는 Security 기술이 필요하다. 일반적인 시스템 자원에 대
한 위험 요소로는 노출, 활용성, 무결성, 그리고 불쾌감이 있다. 이들 위함 요소들에 대한 예
는 표 1과 같다.

[표 2-7-1 시스템 자원에 대한 위험요소들]
위험요소 내용
노출(Disclosure)
- 개인적인 정보 유출- 기계에 대한 정보 유출(etc/passwd 파일을 훔쳐가는 것)- 네트워크를 통해 적이나 경쟁자에게 개인이나 회사의파일을 전송하는 행위
활용성(Usability)
- 과도한 메모리 할당- 수천개의 실행 윈도우 생성-우선 순위가 높은 프로세스 혹은 쓰레드(thread) 생성
무결성(Integrity)
-파일의 수정/삭제- 사용중인 컴퓨터 시스템내의 메모리 변경 내용- 사용중인 프로세스 혹은 쓰레드의 실행 종결
불쾌감(Annoyance)- 모니터에 음란물 표시- 스피커를 통해 원하지 않는 소리 생성
그리고 [표 2-7-2-1]은 [표 2-7-2-2]에서 살펴본 컴퓨터 시스템 자원에 대한 위함 요소에
대해 자바 애플릿과 같은 실행 가능한 응용 프로그램이 접근할 수 있는 시스템의 자원 요소
들을 보여 준다.
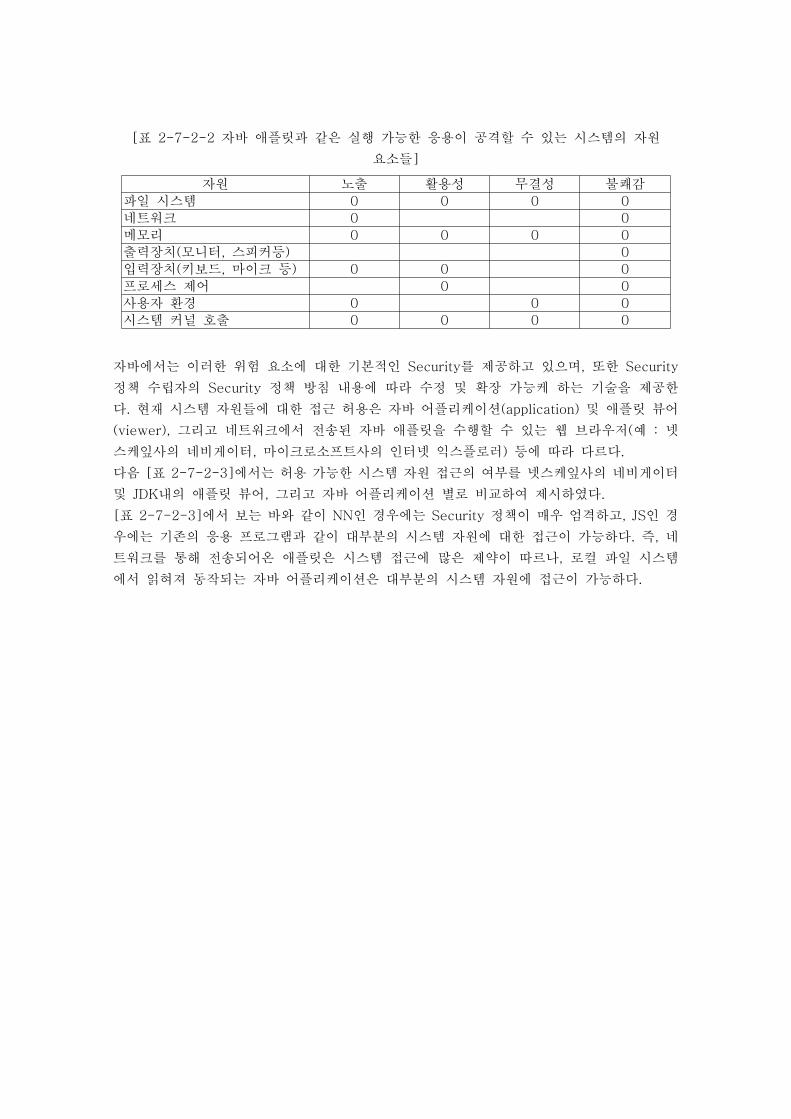
[표 2-7-2-2 자바 애플릿과 같은 실행 가능한 응용이 공격할 수 있는 시스템의 자원
요소들]
자원 노출 활용성 무결성 불쾌감
파일 시스템 0 0 0 0
네트워크 0 0
메모리 0 0 0 0
출력장치(모니터, 스피커등) 0
입력장치(키보드, 마이크 등) 0 0 0
프로세스 제어 0 0
사용자 환경 0 0 0
시스템 커널 호출 0 0 0 0
자바에서는 이러한 위험 요소에 대한 기본적인 Security를 제공하고 있으며, 또한 Security
정책 수립자의 Security 정책 방침 내용에 따라 수정 및 확장 가능케 하는 기술을 제공한
다. 현재 시스템 자원들에 대한 접근 허용은 자바 어플리케이션(application) 및 애플릿 뷰어
(viewer), 그리고 네트워크에서 전송된 자바 애플릿을 수행할 수 있는 웹 브라우저(예 : 넷
스케잎사의 네비게이터, 마이크로소프트사의 인터넷 익스플로러) 등에 따라 다르다.
다음 [표 2-7-2-3]에서는 허용 가능한 시스템 자원 접근의 여부를 넷스케잎사의 네비게이터
및 JDK내의 애플릿 뷰어, 그리고 자바 어플리케이션 별로 비교하여 제시하였다.
[표 2-7-2-3]에서 보는 바와 같이 NN인 경우에는 Security 정책이 매우 엄격하고, JS인 경
우에는 기존의 응용 프로그램과 같이 대부분의 시스템 자원에 대한 접근이 가능하다. 즉, 네
트워크를 통해 전송되어온 애플릿은 시스템 접근에 많은 제약이 따르나, 로컬 파일 시스템
에서 읽혀져 동작되는 자바 어플리케이션은 대부분의 시스템 자원에 접근이 가능하다.

한편, [표 2-7-2-3]에서는 [표 2-7-2-2]에서 언급한 시스템 자원 중 메모리, 출력장치, 입력
장치, 프로세스 제어, 시스템 커널 호출 등과 같은 부분의 내용이 빠져 있다. 이들 각각에
대하여 살펴보면 다음과 같다.
먼저 메모리에 대한 보호는 자바 언어 명세에 의해 기본적으로 이루어진다. 이미 할당된 메
모리에 대한 애플릿의 접근은 가능하지 않으나, 애플릿이 객체를 생성하여 현재의 이용 가
능한 메모리를 과다하게 할당하는 위협 요소에 대한 보호 작용은 존재하지 않는다. 그러나
이러한 애플릿의 과다한 메모리 할당 요구는 직접적인 위협을 제공하지 못한다. 일반적으로
웹 브라우저는 자바가 사용 가능한 메모리의 양을 제한하기 때문에 애플릿의 과다한 메모리
할당 요구는 치명적 위협 요소는 아니며, 또한 웹 브라우저는 네트워크를 통해 전송된 애플
릿이 과도한 메모리 할당을 요구하는 경우, 애플릿을 종결시키는 메쏘드를 가지고 있기 때
문에 애플릿의 과도한 메모리 할당 요구를 막을 수 있다. 한편 애플릿은 직접적으로 출력장
치에 접근할 수 없으며, 대신에 자바 라이브러리에서 제공하는 방법만을 사용함으로써 출력
장치에 접근할 수 있다. 그리고, 애플릿은 키보드 입력이나 마우스 장치를 통해서만 접근할
수 있으며, 입력에 대한 특별한 접근 제한은 없다.
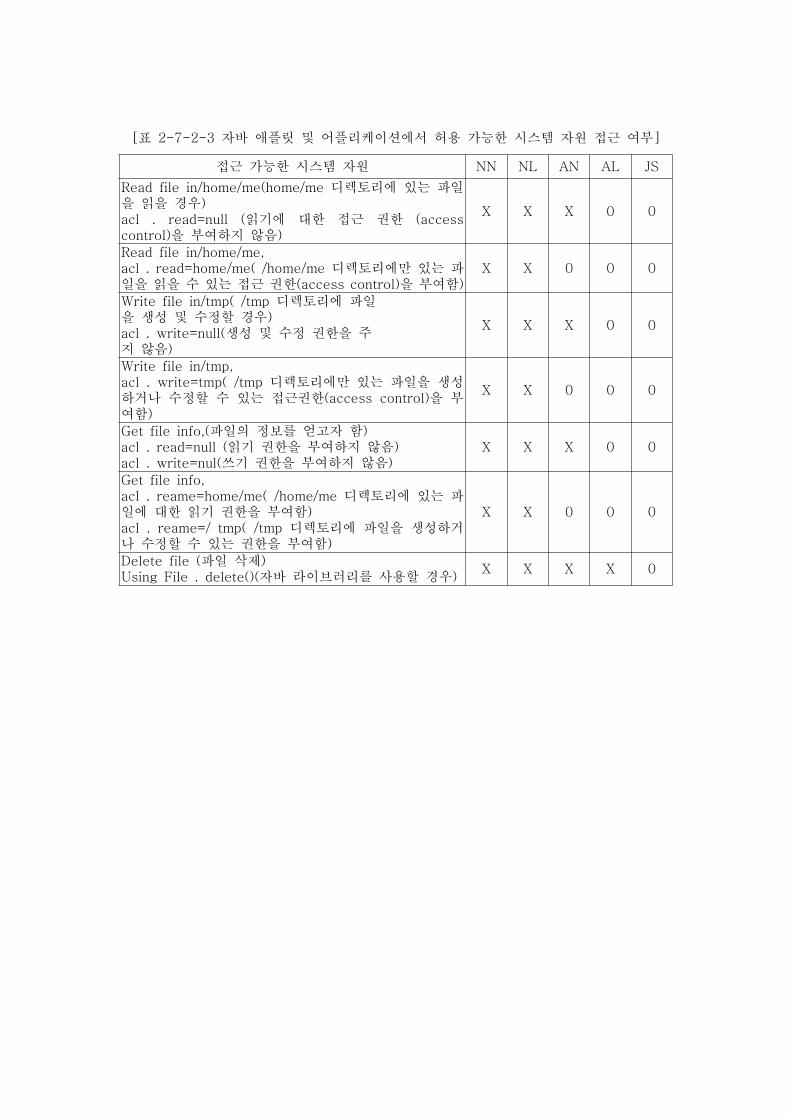
[표 2-7-2-3 자바 애플릿 및 어플리케이션에서 허용 가능한 시스템 자원 접근 여부]
접근 가능한 시스템 자원 NN NL AN AL JS
Read file in/home/me(home/me 디렉토리에 있는 파일을 읽을 경우)acl . read=null (읽기에 대한 접근 권한 (accesscontrol)을 부여하지 않음)
X X X 0 0
Read file in/home/me,acl . read=home/me( /home/me 디렉토리에만 있는 파일을 읽을 수 있는 접근 권한(access control)을 부여함)
X X 0 0 0
Write file in/tmp( /tmp 디렉토리에 파일을 생성 및 수정할 경우)acl . write=null(생성 및 수정 권한을 주지 않음)
X X X 0 0
Write file in/tmp,acl . write=tmp( /tmp 디렉토리에만 있는 파일을 생성하거나 수정할 수 있는 접근권한(access control)을 부여함)
X X 0 0 0
Get file info,(파일의 정보를 얻고자 함)acl . read=null (읽기 권한을 부여하지 않음)acl . write=nul(쓰기 권한을 부여하지 않음)
X X X 0 0
Get file info,acl . reame=home/me( /home/me 디렉토리에 있는 파일에 대한 읽기 권한을 부여함)acl . reame=/ tmp( /tmp 디렉토리에 파일을 생성하거나 수정할 수 있는 권한을 부여함)
X X 0 0 0
Delete file (파일 삭제)Using File . delete()(자바 라이브러리를 사용할 경우)
X X X X 0

Delete file,Using exec /usr/bin/rm(외부 exec를 이용하여 실행 명령인 rm을 사용한 경우)
X X X 0 0
Read the user . nameProperty (사용자 정보 얻기)
X 0 X 0 0
Make network connections except to the host that itcame from(애플릿이 실행되는 클라이언트에서 시스템과 통신을 하고자 할 경우)
X 0 X 0 0
Load library(시스템 라이브러리를 사용함) X 0 X 0 0
Exit() (애플릿 시스템 호출 명령인 Exit를 호출할 경우에 애플릿이 동작되고 있는 웹 브라우저 자체가 종결되는 결과를 발생시킴)
X X X 0 0
Create a popup window without a warning (popup 윈도우를 생성하고자 할 경우)
X 0 X 0 0
구분 :
① NN :네트워크를 통해 전송된 애플릿이 넷스케이프 네비게이터에서 실행되는 경우
② NL : 로컬 파일 시스템에서 읽은 애플릿이 넷스케이프 네비게이터에서 실행되는 경우
③ AN : 네트워크를 통해 전송된 애플릿이 JDK 1 . x에 있는 애플릿 뷰어에서 실행되는
경우
④ AL : 로컬 파일 시스템에서 읽은 애플릿이 JDK 1 . x에 있는 애플릿 뷰어에서 실행되
는 경우
⑤ JS : 자바 어플리케이션이 실행되는 경우

애플릿의 쓰레드에 대한 접근은 매우 제한적이어서 애플릿은 쓰레드에 대한 제어 권한을
가지지 못한다. 또한, 애플릿의 시스템의 커널 호출 부분에 대한 접근도 매우 제한적이다.
이와 같이 애플릿은 매우 제한된 시스템 자원에 대한 접근 권한만을 가지고 실행됨으로써,
Security에 대한 안전성을 제공한다.
나. 자바 Security 메커니즘
(1) Java Security Model 의 단계별 발전 현황
자바는 JDK 1.0부터 JDK 1.2까지 발전하면서 security 부분에 대한 많은 변화가 있었다.
표 4는 자바 security 모델의 단계별 발전 현황을 보여준다.
[표 2-7-2-4 자바 security 모델의 단계별 발전 현황]
JDK 1.0 JDK 1.1 JDK 1.2
-샌드박스 기술
-DSA, MD5, 그리고 SHA를 이용한 전자서명(Digital Signature) 기술-X. 509vl 인증서(Certificate)네트워크 security (자바 웹 서버및 HotJava에서 SSL 지원)-제 3의 업체에서 제공하는 암호와 알고리즘을 수용하는 확장기능
-Protection domain 기술향상된 접근제어(access control)기술-보다 유연한 시스템 자원 관리-툴 기반의 security 환경설정 기능-감시(Auditing) 기능-X.509v3 기반의 인증서 및 온라인인증 서버 지원

JDK 1.0 모델에서는 외부의 애플릿은 전혀 로컬 시스템 자원을 접근할 수 없다. 이들은 보
안 관리자에 의해, 샌드박스라는 논리적인 공간에서 제한된 환경만이 허용된다. (그림
2-7-2-1 참조)
JDK 1.1에서는 인증된 애플릿(Signed Applet)이라는 개념을 도입하였다. 이는 로컬 코드와
동일한 권한을 지닌다. 그러나, 인증되지 않은(unsigned) 애플릿은 여전히 샌드박스 내에서
만 동작한다. (그림 2-7-2-2 참조)
[그림 2-7-2-1 JDK 1.0에서의 security 모델]
[그림 2-7-2-2 JDK 11에서의 security 모델]

JDK 1.2에서 일어난 변화 중 가장 중요한 것이 보안 정책 설정이 가능해졌다는 것이다. 애
플릿의 인증여부나 로컬 어플리케이션에 상관없이 보안 정책을 세세한 단위로 나누어 설정
할 수 있게 되었다. 이러한 security 정책은 사용자나 시스템 관리자에 의해서 permission
set으로 정의되어 이 정의에 따라 다양한 domain으로 분류된다. 런타임 시스템은 코드를 각
각의 domain으로 보내는데, 이 domain은 같은 permission 레벨을 갖는 클래스들의 집합으
로 이루어진다.
[그림 2-7-2-3 JDK 1.2에서의 security 모델]
(2) Language-level security
자바 프로그래밍 언어는 종종 안전한 언어(secure language)라 불리운다. 이를 이해하려면
컴퓨터 언어들이 어플리케이션, 커뮤니케이션(communication), 그리고 데이터 무결성에 있
어서 취약점을 일으킬 수 있는 방법을 이해해야 한다. 대게 이러한 방법에는, 포인터 연산의
제거, 참조되지 않은 메모리의 자동 교정, 그리고 틀린 배열 오프셋(offset)의 자동점검이
있다.

자바는 C++와 비슷한, 그러나 약간 다른 문법적 특성을 가진 객체 지향 언어이다. 시큐리티
관점에서 본 중요한 언어적 특징은 변수와 메소드에 대해서 클래스 내부에서 접근제어를 사
용하는 것, 타임 정의들의 안정성, 언어의 데이터형으로서 포인터의 부재, 가비지 콜렉션
(garbage collection)의 사용(자동적으로 메모리를 재분배), 분리된 이름공간(name space)의
사용 등이다.
(가) 가비지 콜렉션(Garbage Collection)
가비지 콜렉션이란 런타임 환경에서 자동적으로 더 이상 참조되지 않는 메모리를 방출하는
능력이다. 모든 동적 할당 메모리 요구가 힙(heap)으로부터 할당되기 때문에 가비지 콜렉터
는 힙 안에서 일어나는 참조들을 감시하기만 하면 된다. 더 이상 참조되지 않는 메모리 영
역이 발생하면 가비지 콜렉터는 메모리를 방출한다. 이렇게 해서 이러한 메모리들은 프로그
램의 다른 부분에 의해 재할당될 수 있도록 하는 자유 메모리 블록(freed memory block)으
로 두어 효과적으로 사용될 수 있게 한다.
자바 언어는 또한 메모리 할당에 대한 스택의 개념도 갖고 있다. 사실, 프로그램 내에는 여
러 개의 스택이 있을 수 있다. 그러나 스택에 할당되는 메모리는 고작 메쏘드의 지역 변수
를 위한 것뿐이다. 메쏘드가 종료되면 가용 공간은 버려진다.
가비지 콜렉터의 도움으로, 자바 프로그래머는 더 이상 언제 메모리를 방출하는 것이 안전
한가를 결정할 필요가 없어졌다. 가비지 콜렉터는 메모리가 더 이상 참조되지 않고 안전하
다고 판단했을 때 메모리를 방출한다.
(나) 맞지 않는 메모리 접근(Invalid Memory Access)
자바 프로그래밍 언어가 security에 기여하는 주요한 작용은, 포인터 연산을 수행하지 않는
다는 것이다.

이것은 자바 언어의 안전성에 가장 중요한 기여를 하는 특징으로 볼 수 있다.
포인터 연산을 수행하지 않는다는 것이 자바 프로그래밍 언어가 포인터를 지원하지 않는다
는 것을 얘기하는 것은 아니다. 사실 자바 프로그래밍 언어에서의 포인터는 참조(reference)
라 불리우고 이것은 충분히 지원된다. 참조 변수의 존재는 연결 리스트, 이진 트리, 혹은 C
나 C++와 같은 언어에서 포인터 변수를 사용하는 것과 같은 자료 구조를 생성할 수 있게
한다.
(다) 그 밖의 언어적 특징들
C++와 마찬가지로 자바는 객체들의 변수와 메쏘드에 대해서 접근을 제어할 능력을 가지고
있다. 이러한 접근 제어는 신용할 수 없는 코드에 대해 객체가 부적절하게 사용되지 않는다
는 보장을 가능하게 한다.
예를 들면, 자바 라이브러리는 파일 객체에 대한 정의를 포함하는데, 파일 객체는 읽기용으
로 public 메쏘드(누구나 호출가능)를 가지고 있고 또한 읽기용으로 저수준의 private 메쏘
드(객체 메쏘드에 의해서만 호출 가능한)를 가지고 있다. public 호출은 우선 security에 대
한 체크를 수행하고 난 다음에 private 읽기를 호출한다. 자바는 신뢰도지 않은 코드가 파일
객체를 안전하게 조정하는 것을 public 메쏘드에 대한 접근만을 허용함으로써 보장하는 것
이다. 그러므로, 접근 제어 능력은 프로그래머들이 라이브러리에 대한 접근제어를 정확히 명
시함으로써 언어에 security가 보장된 라이브러리 작성을 가능하게 한다.
접근제어를 보장하는 다른 능력은 final로서 클래스나 메쏘드를 선언하는 것이다. 이것은 악
의적인 프로그래머가 핵심적인 라이브러리 클래스를 서브 클래스로 사용하거나, 한 클래스
의 메쏘드를 오버라이딩 하는 것을 막아준다. 그러므로, 자바는 실제 메쏘드가 어떤 객체에
관계되었을 때 객체의 컴파일시 타입에 맞게 쓰여진 final 메쏘드임을 보장한다. 이는 또한
객체의 행동의 특정한 부분이 수정되지 않았음을 보장하는 것이다.

자바는 또한 타입에 안전하게 설계되었다. 이것은 컴파일시 타입과 변수의 실행 시 타입의
호환성이 보장됨을 의미한다. 이는 캐스트(cast)가 컴파일과 실행하는 경우에 그들이 유효한
지를 확인하기 위해서 모두 체크됨을 의미한다. 이는 접근제어를 비껴가기 위해서 객체에
대한 접근을 가장하는 것을 예방해준다.
(3) Java Virtual Machine-level Security
JVM(Java virtual machine)은 자바 프로그램이 실행될 때 샌드박스 기술에 의존한다. 자바
가 제공하는 기본적인 security 모델인 샌드박스는 미국의 가정집 뒤뜰에서 장난치는 어린
이들의 물리적인 부상을 막기 위한 모래통에서 의미를 가져왔다. 이와 같이 자바에서도 시
스템 지원에 대한 접근 제한을 위해 JVM 영역 내에 샌드박스를 만들어 안전한 security를
제공한다.
자바는 기본적으로 로컬 파일 시스템에서 실행되는 애플릿과 어플리케이션은 신뢰성이 있는
실행 가능한 응용 프로그램으로 간주하여 시스템 자원에 대한 접근이 가능하지만, 네트워크
를 통해 전송된 애플릿은 신뢰성이 없는 것으로 간주하여 반드시 샌드박스 내에 있는
security 정책에 따라 시스템 자원에 대한 접근을 제한한다. 즉, 샌드박스에 의해 접근이 허
용된 애플릿은 자신의 작업을 수행할 수 있지만, 샌드박스에 의해 로컬 파일 시스템의 접근
이 허용되지 않는 애플릿은 로컬 파일을 읽거나 변경할 수 없기 때문에 로컬 시스템에 대한
손상을 입히지 않는다. 자바에서는 security 책임자들이 샌드박스를 시스템의 고유 특성에
적합한 security 정책을 수용할 수 있는 플랫폼으로 전환할 수 있는 기술을 제공한다.
한편, 애플릿의 자원 접근에 대한 부분은 자동적으로 샌드박스를 통해 제한되어지므로 사용
자는 시스템 내의 보안을 고려할 필요가 없다. 따라서 앞서 살펴본 바와 같이 자바 security
모델은 사용자가 직접 security 정책을 고려해야 하는 기존의 security 모델보다 사용자 편
리성 측면에서 훨씬 우수함을 보여준다.

(가) 샌드박스의 구성
샌드박스는 Class Loader, Bytecode Verifier, 그리고 Security Manager의 세 가지 컴포넌
트로 구성되어 있다. 각 컴포넌트는 시스템의 신뢰성을 유지하는데 중요한 역할을 수행하며,
다음과 같은 기능들을 제공한다.
● 정확한 클래스가 로드되었는지 검사한다.
● 로드된 클래스가 정확한 바이트 코드(bytecode) 포맷(format)인지를 검증한다.
● 신뢰성이 없는 클래스가 위험한 메쏘드를 실행시켜 보호된 시스템 자원을 접근하지 못하
도록 한다.
이들 세 가지 컴포넌트를 통해 네트워크에서 전송된 애플릿의 security 처리과정은 [그림
2-7-2-4]와 같다.
[그림 2-7-2-4 네트워크에서 전송된 애플릿의 security 처리 과정]

① 클래스 로더(Class Loader)
먼저, 클라이언트의 웹 브라우저는 네트워크에 연결되어 있는 서버로부터 전송된 애플릿을
자신의 웹 브라우저내에서 실행시키기 위한 첫 번째 단계로 클래스 로더를 호출하며 다음과
같은 기능 수행을 통하여 애플릿이 클래스를 언제 어떻게 로드할 수 있는가를 결정한다.
● 웹 브라우저 내의 클래스 로더는 원격지의 서버로부터 애플릿을 가져온다.
● 웹 브라우저 내의 클래스 로더는 전송된 애플릿이 실행 시에 시스템 자원에 접근하지 않
도록 하기 위하여 애플릿에 대한 이름 공간을 생성하고 관리한다. 특히, 애플릿이 자신에
대한 새로운 클래스 로더를 생성 못하게 한다.
● 웹 브라우저 내의 클래스 로더는 전송된 애플릿이 시스템 클래스 로더 내에 있는 메쏘드
호출을 못하게 한다.
클래스 로더는 [그림 2-7-2-5]와 같이 클래스가 발생한 위치를 기반으로 하여 이름 공간을
관리 및 이용하여 클래스가 로컬 클래스인가 혹은 네트워크를 통하여 온 클래스인가를 구분
하고 클래스의 신뢰성 여부를 판단한다. 이렇게 항으로써 클래스 로더는 신뢰성이 없는 애
플릿이 허가받지 않은 시스템 자원에 대한 접근을 못하게 한다.
[그림 2-7-2-5 Class Loader내에 생성되는 이름 공간 구조]

② 바이트 코드 검증기(Bytecode Verifier)
한편 바이트 코드(Bytecode)로 구성된 애플릿은 클래스 로더에 의해 실행되기 이전에 바이
트 코드 검증기에 의해 검증을 받는다. 바이트 코드 검증기는 클래스 파일이 올바른 형태로
구성되어 있는지를 확인하여 자바 컴파일러의 적법한 사양에 따라 바이트 코드가 시스템 내
에서 스택 오버플로우, 혹은 언더플로우가 발생되는지를 검사하고, 명령어 및 파라미터가 올
바른지를 확인하며, 부적절한 레지스터 접근 여부를 검사한다. 바이트 코드 검증 과정을 통
해 1차적인 security 처리 과정이 끝나면, 앞서 기술한 것처럼 클래스 로더에 의해서 또 한
번 security 처리 과정을 거친다. 클래스 로더를 통한 두 번째 단계인 security 처리 과정이
끝나면, 세 번째 단계인 Security manager가 수행된다.
③ Security Manager
Security manager는 애플릿 실행시 컴퓨터 시스템 자원에 대한 접근을 제어하며, 또한 위험
스러운 메쏘드에 대한 검증을 한다. 위험스러운 메쏘드란 파일 입출력, 네트워크 접근이 요
구되는 메쏘드나 새로운 클래스 로더를 정의하고자 하는 메쏘드 등을 말한다. 어느 경우에
나 Security manager는 거부권을 행사하는데 예로써, 애플릿이 “read" 메쏘드를 호출하면,
JVM은 security manager를 참조하여 그 애플릿이 신뢰성이 있다고 판단되면 “read" 메쏘
드는 애플릿을 실행시키고, 그렇지 않은 경우에는 에러가 발생되어 중지시킨다. 이러한
security manager를 통한 접근 제어는 기존의 security 기능을 확장하거나 새로운 security
기능으로 구현되어 처리될 수 있다. 만약 security manager가 구현되어 있지 않을 경우에는
애플릿은 자바 어플리케이션과 같은 접근 권한을 가질 수 있다. 표 3에서 보는 바와 같이
네비게이터와 같은 웹 브라우저가 애플릿의 파일 시스템에 대한 접근을 허용하지 않는 것은
네비게이터 JVM내에 있는 security manager가 파일 시스템에 대한 접근을 허용하지 않기
때문이다. 이외에도 security manager에서는 소켓(soket)작동 관리, 클래스 로더 관리 등과
같은 기능들을 수행한다.

이러한 security manager를 구현하기 위해서는 JDK에서 제공하는 Security Manager 클래
스와 Security Manager 클래스에서 제공되는 checkXXX() 메쏘드를 이용한다. 자바에서는
파일 시스템, 소켓, 쓰레드, 클래스 로더 등 시스템 자원의 종류에 따라 제공되는
checkXXX() 메쏘드의 종류가 다르다. 예로써, 파일 시스템 자원에 대한 접근 제어를 수행
하는 checkXXX() 메쏘드의 종류로는 checkWrite(), checkRead() 그리고 checkDelete() 등이
있다. 이들 메쏘드의 기능을 살펴보면, checkWrite()는 네트워크를 통해 클라이언트에 전송
된 애플릿이 클라이언트내의 로컬 파일 tlymxpa에 접근하여 파일 생성에 대한 실행을 제어
하고자 할 때 사용되어지며, checkRead()는 파일 읽기에 대한 실행을 제어하고,
checkDelete()는 파일 삭제에 대한 실행을 제어하고자 할 때 수행되어진다.
다음은 security 체크의 예사이다. 이 예는 기본적인 접근 방식을 보여준다.
public boolean mkdir(String path) throw IOException {
Security Manager security =
System. get Security Manager() ;
if (security ! = null) {
security. checkWrite(path) ;
}
return mkdiro() ;
}
한편, 바이코드 검증기, 클래스 로더, 그리고 security manager를 통한 security 처리 과정이
끝나면, JVM은 운영체제와의 인터페이스를 통해 시스템내의 하드웨어 자원을 사용하면서
전송 받은 실행 가능한 응용인 애플릿을 동작시킨다.

(4) API-level Security
JDK 1.0에서의 security 기술 외에 JDK 1.1부터는 전자 서명, 메시지 다이제스트(Message
Digest), X.509 기반의 인증서 관리, 키(key)관리, 그리고 접근 제한 권한을 제공하는
Security API를 제공한다.
(가) 메시지 다이제스트(Message Digest)
메시지 다이제스트는 네트워크를 통해 전송되어온 애플릿의 내용이 변하지 않았음을 증명하
는데 사용되어진다. 이 메시지 다이제스트 알고리즘은 정보 내용의 체크섬(CheckSum)을 구
하듯이 정보를 해쉬(hash) 처리한 후 각 정보에 대응되는 일정 길이의 해쉬를 구하는 알고
리즘이다 메시지 다이제스트는 해당 정보와 일대일로 매핑도기 때문에 정보의 내용을 증명
할 수 있는 코드로서 활용된다. 즉 어떤 정보를 해수함수를 통해 메시지 다이제스트를 구하
면 해당 메시지 다이제스트를 이용해 자료의 수정, 순서 변경, 삭제, 첨가 등 정보의 통합성
을 체크할 수 있다.
특히, 메시지 다이제스트를 구하는 해쉬 함수는 단방향 해쉬 함수로서 생성된 메시지 다이
제스트로부터 원래의 정보를 추론할 수 없는 해쉬를 사용하기 때문에 안전하다고 할 수 있
다. 이 해쉬 함수는 임의의 길이를 가지고 있는 정보를 입력받아 일정한 길이의 결과로 전
해주는 함수이다. 원래의 정보 X에 대하여 해쉬 함수 f를 사용하여 나온 결과가 X'인 경우
에 식으로 나타내면 f(X) = X'이며, 안전한 해쉬 함수가 되기 위해서는 다음의 조건을 만족
해야 한다.
조건 1 : 임의의 길이의 정보를 입력으로 받을 수 있어야 한다.
조건 2 : 고정된 길이의 출력을 만들어야 한다.
조건 3 : 모든 X에 대해서, f(X)의 계산이 쉬워야 한다.
조건 4 : 주어진 X' 대해서 원래의 X를 구할 수 없어야 한다.
조건 5 : X, Y가 같지 않을 때 f(X), f(Y)는 같을 수 없다.
조건 6 : f(X) = f(Y)인 X, Y를 구하기가 어려워야 한다.

이러한 암호와 해수 함수의 종류는 128비트의 출력을 생성하는 MD5와 160 비트 출력의
SHA(Secure Hash Algorithm)가 있다. 다음 [그림 2-7-2-6]은 메시지 다이제스트의 생성과
정을 보여준다.
[그림 2-7-2-6 메시지 다이제스트의 생성과정]
다음은 메시지 다이제스트를 이용하는 방법이다.
① byte[]로서 메시지를 얻는다. 만약 파일로 전송되었을 경우
FileInputStream으로부터 ByteArrayOutputStream으로 바이트를 읽는다.
FileInputStream file = new FileInputStream(filename) ;
BufferedInputStream bis = new BufferedInputStream (fis) ;
ByteArrayOutputStream baos = new ByteArrayOutputStream () ;
int ch ;
while ((ch = bis. read()) ! =-1) {
baos. wite (ch) ;
}
byte buffer[] = baos. toByteArray() ;
② 적당한 알고리즘을 이용하여 메시지 다이제스트를 얻는다.
MessageDigest algorithm = MessageDigest. getInstance
("SHA-1") ;
or
MessageDigest algorithm = MessageDigest. getInstance
("MD5") ;

③ 다이제스트의 버퍼가 비어 있다고 확신한다. 이렇게 하면 나중에 재사용할 때 좋다.
algorithm. reset() ;
④ 앞서 얻은 메시지 다이제스트로부터 얻은 데이터를 가지고 다이제스트의 버퍼를 채운다.
algorithm. update (buffer) ;
⑤ 다이제스트를 가져온다.
byte digest[] = algorithm. digest() ;
⑥ 다이제스트 바이트를 저장하고 인쇄한다. 인쇄할 경우에는 Integer. toHexString() 함수
를 사용하면 된다.
StringBuffer hexString = new StringBuffer() ;
for (int i=0; i<digest. length; I++) {
hexString. append (
Interger. toHexString(0xFF &
digest[i])) ;
hexString. append ( " ") ;
}
System. out. println
(hexString . toString()) ;
(나) 전자 서명 (Digital Signature)
먼저 전자 서명에 대해 살펴보면, 전자 서명은 애플릿 어플리케이션을 신뢰하는데 사용되어
진다.

전자 서명을 구현하기 위해서는 공개키 암호화 방식을 이용하는데, 공개키 암호화 방식은
암호키와 복호화 키가 동일하여 교환되는 정보에 대한 인증을 제공하지 못하는 대칭형 암호
와 기술과 달리 암호화에 사용되는 키와 복호화에 사용되는 키가 서로 다르다. 일반적으로
복호화 키는 공개를 하기 때문에 공개키(public key)로 정의되어지며, 암호화하는데 사용되
는 키는 비 로 간직하기 때문에 개인키(private key)로 정의되어진다. 공개키 암호화 방식
은 암호화 알고리즘 특성상 개인키로 암호화된 정보는 개인키에 대응되는 공개키를 반드시
사용하여 복호화 할 수 있다. 공개키 암호화 방식의 절차는 [그림 2-7-2-7]과 같다.
[그림 2-7-2-7]에서 보는 바와 같이 송신자는 A는 개인키 KRa를 가지고 평문 M 에 대한
암호문을 구성하고, 수신자 B는 A의 개인키로 암호화된 M'를 받고 암호화된 M'를 복호화
하기 위해서 A의 공개키 AUa를 이용한다. [그림 2-7-2-6]과 같은 공개키 암호화 절차 과
정은 결과적으로는 송신자 A가 암호화하기 위한 평문 M에 자신의 개인키를 사용하여 전자
서명한 효과이다. 이와 같은 공개키 암호화의 특성 때문에 정보 인증을 위해서는 공개키의
암호화 방식을 근간으로 하는 전자 서명을 사용한다.
[그림 2-7-2-7 공개키 암호화 절차]
대표적인 공개키 암호화 알고리즘으로는 DSA(Digital Signature Algorithm)와 RSA(RSA를
만든 Ronald Rivest, Adir Shamir, Leonard Adleman에 의해 명명되어짐)가 있다.
API를 이용한 키 쌍(key pair)을 산출하기 위해서는 KeyPairGenerator클래스를 이용한다.
다음 예는 DSA 알고리즘을 이용하여 키를 산출하는 방법을 제시하였다.

KeyPairGenerator kpg = KeyPairGenerator . getInstance
( "DSA") ;
그리고 나서 이것을 초기화시킨다. DSA 키 쌍의 경우에는 512나 1024비트와 같은 길이를
정의해주면 된다.
kpg . initialize(1024) ;
DSAKey PairGenerator는 DSAParams의 집합과 함께 초기화될 수 있다.
이러한 값들은 p, q, 그리고 g값으로 표현되는데 p는 산출 프로세서에서 주로 사용되는 것
이고 q는 그 다음으로, 그리고 g는 기본으로 사용되어지는 값이다. 미리 정해놓지 않았다면
디폴트 값들이 사용된다.
DSAKeyPariGenerator dkpg = ( DSAKeyPariGenerator )
KeyPariGenerator . getInstance ( " DSA") ;
DSAParams params = new DSAParams (ap, aq,
aG) ;
dkpg . initialize (1024, params, new
SecureRandom()) ;
이제 generateKeyPair() 메쏘드를 이용하여 실제 키 쌍을 산출하고 이것을 디스크에 저장한
다.
KeyPair kp = kpg . generateKeyPair() ;
① 자료 암호(Signing Data)
키 쌍이 생성되면 메시지를 암호화 할 수 있다. 암호화하는 데에는 네 단계의 과정이 필요
하다.

㉮ DSA를 이용하여 Signature 오브젝트를 얻는다.
Signature sig = Signature . getInstance( "DSA") ;
㉯ 메시지를 암호화하기 위해서 키 쌍으로부터 개인키를 얻어 Signature를 초기화한다.
PrivateKey priv = kp . getPrivate() ;
sig . initSign(priv) ;
㉰ 암호화를 위해서 메시지와 함께 Signature를 제공한다.
sig . update (aByteArray) ;
㉱ 암호화하고 다이제스트를 얻는다. 전형적으로 이것은 원시 메시지에 덧 붙여져 받는 사
람에게 전달된다.
byte digest{} = sig . sign() ;
② 자료 검증 (Verifying Data)
전자 서명화된 메시지를 받으면 이것을 검증하여야 한다. 이를 위해서는 3 단계의 과정이
필요하다.
㉮ DSA를 이용하여 Signature 오브젝트를 얻는다.
Signsature sig = Signature . getInstance( “DSA") ;

㉯ 자료를 검증하기 위해서, 보내는 이의 공개키를 이용하여 Signature를 초기화한다.
PublicKey pub = kp.getPublic():
sig. initVerify(pub);
㉰ 마지막으로, 메시지 내용과 다이제스트를 이용하여 자료를 검증한다.
sig. update (content);
if (sig. verify (digest)) {
System. out. println ("Valid");
} else {
System. out. println ("Invalid");
}
(다) JAR 파일과 전자 서명
웹에서 사용되어지는 GTTP 프로토콜은 정보를 전송하는데 있어 파일 하나를 보낼 때마다
송수신자간의 새로운 연결이 필요하다. 이러한 방식은 실행 가능한 응용인 애플릿이 클라이
언트의 웹 브라우저에서 수행되기 위해서 일반적으로 많은 소리 파일 및 그림 파일을 포함
하고 있기 때문에 애플릿을 구성하고 있는 각각의 파일들을 전송하는데 많은 시간이 요구되
어 HTTP를 통한 전송 효율이 급격히 떨어지게 된다. 이에 자바에서는 ZIP기반의 압축 및
복원을 지원하는 JAR 파일 방식을 제공한다.
JAR 방식은 여러 개의 파일로 되어 있는 애플릿을 하나의 통합된 파일로, 한번에 HTTP
프로토콜을 통해 전송하기 때문에 HTTP 프로토콜의 전송 효율을 개선시킬 수 있다.
이러한 JAR 파일 방식의 특성은 애플릿에 필요한 파일들을 함께 묶어 전송할 수 있기 때문
에 애플릿을 구성하고 있는 각각의 파일에 대한 전자 서명을 할 필요 없이 애플릿을 구성하
고 있는 전체 내용을 인증할 수 있다.

전자서명은 파일의 압축 및 복원을 담당하는 JAR 툴과 전자 서명에 필요한 키 생성을 담당
하는 자바키(javakey)를 이용한다. 그리고, 전자 서명을 위해 DSA와 MD5, 그리고 SHA 암
호화 알고리즘과 X, 509v1 기반의 인증서를 사용한다.
여러개의 파일들로 구성되어 있는 애플랫은 JAR 툴과 자비키를 이용하여 하나의 JAR 파일
로 묶여지며, JAR 파일내에는 원래의 파일과 전자서명을 통해 생성된 Manifest 파일 및
Signature 파일 , 그리고 전자 서명의 내용이 담겨져 있는 DSA 파일이 생성된다. Manifest
파일의 확장자는 .MF이며, Signature 파일의 확장자는 .SF이고, 마지막으로 DSA 파일의 확
장자는 .DSA가 된다. [그림 2-7-2-8]은 애플릿의 전자 서명 과정을 보여준다.
[그림 2-7-2-8 애플릿의 전자 서명 절차]

그림 8에서의 동작 과정을 살펴보면 송신자는 JAR 툴을 이용하여 여러개의 파일로 구성된
파일을 하나로 묶어 JAR 파일을 생성하고 생성된 JAR 파일의 전자 서명을 초기화한다. 초
기화하는 과정은 JAR 파일내에 포함되어 있는 각 클래스마다 별도로 수행되는데 먼저 클래
스의 메시지 다이제스트를 구하여 .MF 확장자를 가지는 파일을 생성하여 저장하고, MF 파
일의 메시지 다이제스트를 구하여 .SF 확장자를 가지는 파일을 생성하여 저장한다. 이와 같
이 수행하는 이유는 .MF 파일의 무결성을 보장하기 위해서 이다. 그리고 생성된 .MF 파일
은 X. 509v1 인증서와 생성된 공개키 및 비 키를 이용하여 전자 서명된 후에 .DSA 확장자
를 가지는 파일을 생성한다.
송신자는 생성된 .MF 파일 및 DSA 파일, 그리고 .SF 파일을 다시 묶어 전자 서명화된 새
로운 JAR 파일을 생성하여 수신자에게 전송한다. 수신자는 전자 서명화된 파일을 수신 받
은 뒤 세 개의 .MF 파일 및 .DSA 파일, 그리고 .SF 파일을 추출한 후, .MF 파일의 메시지
다이제스를 구하여 .SF 파일을 추출한 후, .MF 파일의 복호화한다.
DSA 파일이 복호화되면 .MF 파일과의 내용과 비교하여 결과가 일치하면, JAR 파일을 복
원하여 JAR 파일내에 포함되어 있는 클래스 파일들을 실행시킨다. 이러한 과정을 통해 신
뢰성을 보장하는 전자 서명화된 애플릿을 실행시킬 수 있다.
한편, 전자 성명과 JAR 파일은 자바 어플리케이션에도 이용되어 질 수 있다. 물론 자바 어
플리케이션은 대부분의 시스템 자원 접근에 대한 제한이 없기 때문에 애플릿의 전자 서명
효과와 조금 달라질 수 있으나, 전자 서명을 통해 컴퓨터 시스템내에 바이러스를 감염시킨
사용자에 대해 자바 어플리케이션 배포 유무의 책임을 판단할 수 있는 효과를 가져온다.
(5) Protection Domain
Protection Domain은 실행 가능한 응용인 애플릿 혹은 어플리케이션의 특징에 따라 시스템
자원에 접근할 수 있는 부분을 분리시켜 한 시스템 영역내에 가상적인 Protection Domain
을 여러 개로 두는 기술이다.

예를 들어 전자 서명을 이용하여 신뢰성을 제공하는 애플릿 혹은 어플리케이션이 접근할 수
있는 시스템 자원 부분과 그렇지 않은 경우에 대한 부분을 Protection domain 기술을 이용
하여 차별화 시킬 수 있다. 이러한 기술은 기존의 방식에서 제공하는 샌드박스 기술의 기능
중 Fine-grained Control로 명명되어지는 시스템 자원에 대한 접근 제한 기술을 확장하여
응용 프로그램의 특성에 딸 다중 security 정책을 세울 수 있음으로써 유연성 및 안정성을
강화시켰다.
자바에서 정의되고 있는 Protection domain은 시스템 자원 부분과 응용 프로그램으로 나
누어진다. 시스템 자원 부분으로는 파일 시스템, 네트워크, 모니터, 키보드 등이며, 응용 프
로그램으로는 자바 애플릿 및 어플리케이션이 있다. Protection domain 구조는 [그림
2-7-2-9]과 같다.
[그림 2-7-2-9]에서 보는 바와 같이 Protection domain 구조는 한 시스템 영역내에 다중
Protection domain 을 두어 해당되는 Protection domain 에 domain ID(그림 예: A, B)를 부
여하여 구분하며 이러한 방식을 통해 기존의 자바에서 사용되던 단일 시스템 영역 기술에서
발생되어온 문제점인 하나의 에러가 전체적인 시스템 자원 관리 부분에 치명적인 위협이 되
는 것을 해결할 수 있다.
[그림 2-7-2-9 Protection Domain 구조 ]

(6) 자바 가능 브라우저 (Java Enalbed Browser)
웹 브라우저 또한 시스템의 보안에 있어서 중요한 역할을 한다. 웹 브라우저는 다운로드된
자바 코드를 실행하는 보안 정책을 정의하고 구현한다. 자바 가능 브라우저는 자바 인터프
리터와 실행 시간 라이브러리와 Security manager 및 다양한 클래스 로더를 포함할 것이다.
Security 관점에서 본다면 Security manager의 웹 브라우저상의 구현이 클래스 로더의 구현
보다 더욱 중요하다.
Security manager는 핵심적인 시스템 자원에 대한 접근을 통제한다. 이것은 자바 가능 브라
우저의 구현자가 Security manager를 서브 클래싱하고 특정한 메쏘드를 오버라이딩하거나
새로운 버전을 시스템Security manager로써 설치하는 것에 의해 특정한 보안 정책을 구현
하는 것을 가능하게 해준다. 서브 클래스된 Security manager는 보안 정책을 구현하기 때문
에, 웹 브라우저의 Security manager버전이 정확히 구현되는 것이 매우 중요하게 된다. 극
단적으로, 자바 가능 브라우저가 시스템 Security manager를 설치하지 않았을 경우에는 애
플릿은 로컬자바 어플리케이션과 같은 접근 권한을 가지게 될 것이다.
웹 브라우저의 security 정책은 Security manager의 수단들이 매우 유연한 인터페이스를
제공하기 때문에 임의적으로 복잡해질 수 있다. 프로그램 될 수 있다면 어떠한 Security 정
책도 사용될 수 있는 것이다. 예를 들어, Security 정책은 Security manager가 어떤 사용자
가 어떤 접근을 시도했는지에 대해서도 조사할 수 있다.

제 3 장 연구 결과
제 1 절 Java Debugger의 연구 결과
1. 디버거 수행
다음은 Java 코드를 디버그 하는 완전한 수행에 대한 것으로, 디버거를 이용하기 전에 디
버거 정보를 가지고 컴파일 해야 한다.
가. 클래스 컴파일과 디버거 시작
(1) 프로젝트를 연다. 그러면 프로젝트 AppBrowser 나온다.
(2) File|Project를 선택하고 디버거 정보 체크박스를 선택한다.
(3) 네비게이트 창에서 .jpr 프로젝트 노드를 선택한다. 그리고 Run|Debug를 선택하거나 디
버그 아이콘을 클릭한다.
(4) 노드는 자동적으로 Make를 이용하면 컴파일 된다. 프로젝트 또는 클래스 번역이 성공
적으로 되면 디버거가 나타난다. 디버거 창의 왼 쪽에 추가 탭이 있다.
디버거 또는 “D" 탭 (쓰레드, 스택 그리고 데이터 페인 )
보기 또는 “W" 탭 (창기 창)
나. 정지점 설정과 코드 위 지나가기
(1) 소스의 수행문에 정지점은 문장의 끝부분을 클릭 함으로써 설정 한다.
(2) 왼쪽 부분에 케크 표시를 가진 빨간 원이 생긴다.
(3) Run|Debug 선택
(4) 클레스를 수행하고 정지점에 멈춘다.
(5) 메소드 호출의 추적을 위해 Run|Trace를 선택한다. 또는 메소드 호출을 지나가기 위해
Run|Step 를 선택한다.
(6) 모든 프로그램의 상태와 각 호출된 메소드의 스택을 검사하기 위해 쓰레드와 스택판을
본다.
(7) 연관된 소스코드를 보기 위해서 스택 안의 메소드를 더블-클릭 한다.

다. 편집과 재 컴파일
(1) 변경할 코드를 발견하면, 왼쪽 위의 빨간 정지 아이콘을 눌러서 디버거를 정지시킨다.
또는 Run|Program Reset 을 선택한다.
(2) 소스 판에서 코드를 편집한다.
. java 노드를 오른 쪽 클릭하고, 주메뉴에서 Build|Make를 선택한다. 변경된 프로젝트 파일
을 다시 컴파일하고, 디버거를 다시 실행시킨다.
2. 오류 형태
디버거는 프로그램 오류의 기본적인 두 가지 형태를 찾는데, 그것은 실행 시 오류와 기본
오류(컴파일러는 문법 오류를 찾아낸다.)로 프로그램 실행 또는 논리 오류가 발견되면, 디버
거 제어에서 프로그램을 수행해 디버거 세션을 시작할 수 있다.
가. 실행시 오류
프로그램이 성공적으로 컴파일 되었어도, 프로그램을 실행하면 실행 오류가 발생할 구 있다.
옳은 문장을 가지고 있어도 실행시 에러가 발생할 수 있는데, 예를 들어, 존재하지 않는 파
일을 열려고 하나 0으로 나누기를 할 경우에 발생한다. 디버거가 없으면 실행시 오류를 찾
는 것은 어렵다. 왜냐하면 컴파일러가 소스 코드 위치를 알려 주지 않기 때문이다. 프로그램
소스 코드를 통해 찾음으로써 실행시 오류를 찾을 수 있지만 디버거는 오류의 유형을 알려
줌으로써 쉽게 해 준다. 디버거를 이용하면, 특정 프로그램을 수행할 수 있다. 그러므로 어
떤 특정시간에 한 문장에서 프로그램을 수행할 수 있다. 각 단계마다. 프로그램의 상태를 볼
수도 있다. 프로그램을 멈추게 하는 문장에서 수행할 때 그 오류를 정확하게 지적한다. 따라
서 오류를 소스 코드에서 고치고 프로그램을 재 컴파일 한 후 프로그램을 다시 테스트한다.

나. 로직 오류
로직 오류는 프로그램 설계, 구현 오류이다. 프로그램이 옳지만 프로그램 수행은 처음에 원
했던 데로 수행되지 않을 수도 있다. 예를 들어, 논리 오류는 부정확한 값을 가진 변수가 있
을 때 발생한다. 그래픽 이미지가 정확하게 보이지 않거나, 프로그램 결과가 부정확하지 않
을 때이다. 로직 오류는 찾기에 어렵다. 왜냐하면 예상하지 못했던 곳에서 발생하기 때문이
다. 그러므로 프로그램이 정확하게 설계되었을 때 여러 측면에서 다양한 테스트를 해야 한
다. 실행 오류를 가지고 있을 때 디버거는 프로그램 변수의 값과 데이터 객체를 보여줌으로
서 로직 오류를 찾을 수 있도록 한다.
3. 디버거 세션 시작
프로그램 설계 후, 프로그램 개발은 프로그램 코딩과 디버깅의 순환으로 이루어진다. 철저
하게 프로그램을 테스트한 후 사용자에게 프로그램을 넘긴다. 모든 측면에서 프로그램을 테
스트해야하고 그것은 테스트와 디버그에 의해서만 가능하다.
좋은 디버그 방법은 알맞게 디버그할 수 있도록 여러 부분으로 프로그램을 나누는 것이다.
각 프로그램에서 문자를 보면서 프로그램을 검증할 수 있는데, 프로그램 오류가 발생하면
소스 코드를 보고 문제를 해결하면 된다. 그리고 다시 테스트한다. 프로그램의 부분을 검사
해 가면서 프로젝트의 모든 파일에서 추적을 제거한다. 그러면 모든 파일을 추적할 수 있다.
이때, 클래스 추적 가능과 불가능을 참조한다.
사용자는 Java API 클래스들을 디버그 할 수 없다는 점에 유의해야 한다. 이 클래스들이
디버그 정보와 함께 컴파일 되지 않았기 때문이다. 그러나 사용자는 그 클래스들에 대해
trace into 메뉴 명령을 실행 할 수 있다. 이런 클래스들에 대한 trace into 방법을 배우기
위해서는, 클래스들에 대한 trace into 설정하기 (Enabling) 와 설정 안하기 (disabling)부분
을 보면 된다.

4. 디버그 정보를 이용한 컴파일
디버그 세션을 시작하기 전에 기호 디버그 정보를 가지고 프로젝트를 컴파일해야 한다. 기
호 테이블을 가진 기호 디버그 정보는 디버거가 프로그램 소스와 컴파일기에 의해 생성된
java 바이트 코드를 연결한다.
이 연결은 프로그램 수행시 디버그하는 동안 소스 코드를 볼 수 있도록 한다. 그리고 또한
데이터 값을 볼 수 있다.
기본적으로 JBuilder는 컴파일 할 때 기호 디버거 정보를 가지고 있다. 프로그램에서 기호
디버거 정보를 포함하기 위해서는
-속성 다이얼 박스를 열기 위해 File|Project Properties를 선택한다.
- 포함 디버거 정보 선택 박스를 선택한다.
기호 디버거 정보를 생성했을 때, 컴파일러는 기호 테이블을 연관된.class 파일에 저장한다.
5. 프로그램 실행
디버거 정보를 가지고 프로그램을 컴파일한 후, JBuilder 디버거에서 프로그램을 실행함으로
써 디버거 세션을 시작한다. 디버거, 추적, 넘어가기를 선택할 때마다 디버거는 제어를 가진
다. 디버거 제어가 프로그램을 실행할 때, 윈도우를 생성, 사용자 값을 입력받기, 결과 출력
과 같은 동작을 한다. 추가적으로 디버거가 프로그램을 정지시킨다. 이때 프로그램의 현재
상태를 조사할 수 있다. 변수의 값, 호출 스택의 방법, 그리고 프로그램의 결과를 보고 프로
그램 결과가 설계할 때와 같은 지 검사할 수 있다.
디버거를 이용해 프로그램을 수행할 때, 응용프로그램의 동작을 볼 수 있다. 디버그할 때 디
버그와 응용 프로그램의 두개의 윈도우의 위치를 정할 수 있다. 응용 프로그램 윈도우와 디
버그 윈도우가 겹치지 않게 해서 두 윈도우를 보면서 작업할 수 있다.

6. 프로그램에 명령 인자 보내기
Java 응용 프로그램을 디버그할 때, 명령 인자를 이용할 수 있는데, IDE를 가지고 Java 응
용 프로그램에 명령 인자를 설정하기 위해서는
- Run: Parameters를 선택한다.
- 실행 인자 대화 상자 박스에서 디버그 할 때 프로그램에 전달한 인자를 입력한다.
- OK를 누른다.
- Run: Debug를 선택한다.
7. 애플릿 디버그
애플릿 을 디버깅하기 위해서는
- 네비게이트에서 <APPLET> 태그를 포함하고 있는 .html파일을 선택한다.
- Run: step over 를 선택한다.
- 디버그 모드에서 애플릿 보기로 애플릿을 수행한다. 소스 파일의 수행 코드의 첫 번째 줄
이 밝게 된다. 애플릿 코드에 init() 메소드가 있으면 거기서 정지한다.
가. 인자를 저장하는 HTML 파일 이용
애플릿의 출력 크기와 인자를 얻기 위해서 애플릿을 HTML 페이지에서 실행한다. JBuilder
에서 애플릿을 수행하거나 디버그하기 위해서는 .html파일 안에 적당한 APPLET 태그를 가
지고 있어야 한다. AppBrowser 의 프로젝트 트리에서 .html을 선택하고 Run|Run 또는
Run|Debug를 선택한다.
인자이름은 각각 의미가 있다.
<applet CODE="foo. class" width=200 height=20>
</applet>
<Param> 태그를 포함하는 애플릿에 인자를 보낼 수 있다. 즉, 다음과 같은 <applet> 과
</applet>, 태그이다.
<param name=foo value=true>
인자를 보내기 위해 사용되는 HTML 파일

<title>Test File</title>
<hr>
<applet code="Test3. class" width=500 height=120>
<param name=level value="8">
<param name=angle value="45">
<param name=delay value="1000">
<param name=axiom value="F">
<param name=incremental value="true">
<param name=border value="2">
</applet>
<hr>
<a HREF="#Test3. java"> The source. </a>
나. 다른 프로젝트로 디버거 이동
어떤 특정 시간에는 한 프로젝트만 디버그 한다. 이미 디버그 세션이 열려져 있을 때 다른
프로젝트를 디버그 하기 위해서는
(1) Reset 버튼을 클릭한다.
디버거 윈도우를 닫고, 현재 프로젝트 AppBrowser를 나타낸다.
(2) 다른 AppBrowser를 선택한다.
(3) 디버깅을 시작한다.

제 2 절 Java Database search engine 의 연구
1. 이동 에이전트를 이용한 XML 문서의 저장 및 검색 방법
가. 구성도
네트워크로 연결된 세 개의 사이트에 XML문서가 분산되어 있을 때, 한 클라이언트에서
XML문서 내의 원하는 검색어를 질의하면 에이전트는 네트워크를 돌아다니며 원하는 결과
값을 찾아내게 한다. 설명을 돕기 위해 XML문서를 검색하기 위한 이동 에이전트의 구성도
를 다음과 같이 나타내었다.
[그림 3-2-1 : 자바 이동 에이전트를 이용한 XML 문서 검색시스템 구성도]
본 연구에서 구현한 자바 이동 에이전트를 이용한 XML 문서 검색 시스템은 DBMS내에 저
장된 XML문서를 검색하는 기존의 방식과는 다르다.
이동 에이전트 개념은 적용하여 분산 환경에서 활용될 수 있도록 하였으며, 클라이언트로부
터 질의를 받아들이고 적절한 결과 값을 응답해 주기 위해 XML문서를 파싱하도록 설계되
었다. 클라이언트로부터 질의를 받아들인 에이전트는 지정된 곳으로 이동하여 XML 문서를
검색한 후 해당 XML문서 내에 원하는 적절한 값을 찾아낸 후 다시 다른 사이트로 이동하
여 원하는 질의를 다시 수행한 후 적절한 결과가 있을 경우 전에 검색된 결과와 함께 병합
하여 클라이언트에게 결과를 돌려주게 된다.

나. 접근 방법
[1단계] Aglet 을 용한 이동 에이전트 시스템
[2단계] Data channel XML Parser 라이브러리 통합
[3단계] sample XML 문서로 food. XML 사용[Appendix C]
[4단계] 서버측에 인터페이스 에이전트 통한 접근
다. 사용자 인터페이스 설계
사용자 인터페이스 에이전트는 분산된 XML문서를 검색하는데 [그림 3-2-2]와 같은 인터페
이스를 가지도록 설계하였다.
[그림 3-2-2 분산된 XML 문서 검색을 위한 사용자 인터페이스 에이전트]
사용자 인터페이스 에이전트를 비롯한 Aglet 으로 구현된 대부분의 에이전트들은 서버 또는
다른 에이전트를 통해 생성이 된다. 서버를 통해 사용자 인터페이스 에이전트를 생성하는
이유는 신뢰할 수 있는 코드만 을 네트워크로 배출하기 위해서 인데 이것은 에이전트의 보
안을 유지하는데도 상당한 영향을 미친다.

라. 실행 결과
문서 내에서 단순질의 작업과 일정한 조건을 만족시키는 값만을 출력하는 질의를 수행하도
록 다음과 같은 예제 질의를 실행하였으며. 이에 대한 질의 화면과 결과 화면은 다음과 같
다.
▣ [실행 1] 주어진 XML 문서 내에서 원하는 FOOD의 가격(Price)를 검색한다.
[그림 3-2-3 {질의 1}화면]
[그림 3-2-4 {결과 1}화면]

▣ [실행 2] 음식의 가격이 $6 미만인 음식의 이름을 보여라
[그림 3-2-5 {질의 2} 화면]
[그림 3-2-6 {결과 2} 화면]
▣ [실행 3] 음식의 가격이 $7보다 작고 star가 3보다 큰 음식의 이름을 보여라

[그림 3-2-7 {질의 3}의 화면]
[그림 3-2-8 {결과 3}의 화면]
이를 구현하는데 사용된 소스는 [Appendix 2]내에 실었다.

제 3 절 Java Web Server/Browser 의 연구
최근 인터넷 사용의 증가와 함께 브라우저만을 이용한 교육 프로그램이 많이 사용되고 있
다. 현재 가상대학 시스템, 원격 교육 시스템, 평생교육 시스템 등이 이러한 예이며 앞으로
이 분야에 대한 수요는 점차 늘어갈 것으로 보인다. 그러나 가상대학 시스템으로 사용되고
있는 대부분의 웹 서버들은 정형화된 인터페이스로 사용자와 관리자에게 있는 대부분의 웹
서버들은 정형화된 인터페이스로 사용자와 관리자에게 일방적으로 제공되는 기능만을 사용
하게 되어있으며, 특정 OS에 종속적이다. 또한 사용자에게 보다 능동적인 수업효과를 제공
하기 위해 멀티미디어 데이터의 사용이 증가되고 잇기 때문에 서버의 기능이 커지고 있다.
앞으로도 인터넷 환경에서 교육 프로그램이 점점 증가하고 이를 이용하는 학생 수 또한 증
가할 것으로 보이기 때문에 Web Server를 보다 효과적으로 구현할 필요성이 증가되고 있
으며, 보다 빠르게 원하는 형태의 교육 시스템을 구축하고자 하는 요구가 증가할 것으로 보
인다.
이에 Java Web Server에 가상 강의 시스템에 사용될 수 있는 Script처리 기능을 추가하여
이를 효과적으로 운영하도록 설계 구현하였다.
또한 웹서버에 디렉토리 관리 기능을 추가하여 보다 빠르게 파일처리를 할 수 있도록 하고
시스템 부하를 줄여 동시에 많은 사용자들의 요청을 받아들일 수 있도록 하였다. 이것은 디
렉토리 및 파일 관리를 위해 ftp server나 ftp client프로그램을 설치하지 않아도 브라우저만
으로 이러한 기능을 수행할 수 있다는 장점이 있다.
1. 구현 시스템 및 시나리오
가. 웹 서버에 script 처리기능 추가
자바 웹 서버에서의 script처리는 다음 세 가지 형태로 구현될 수 있다.
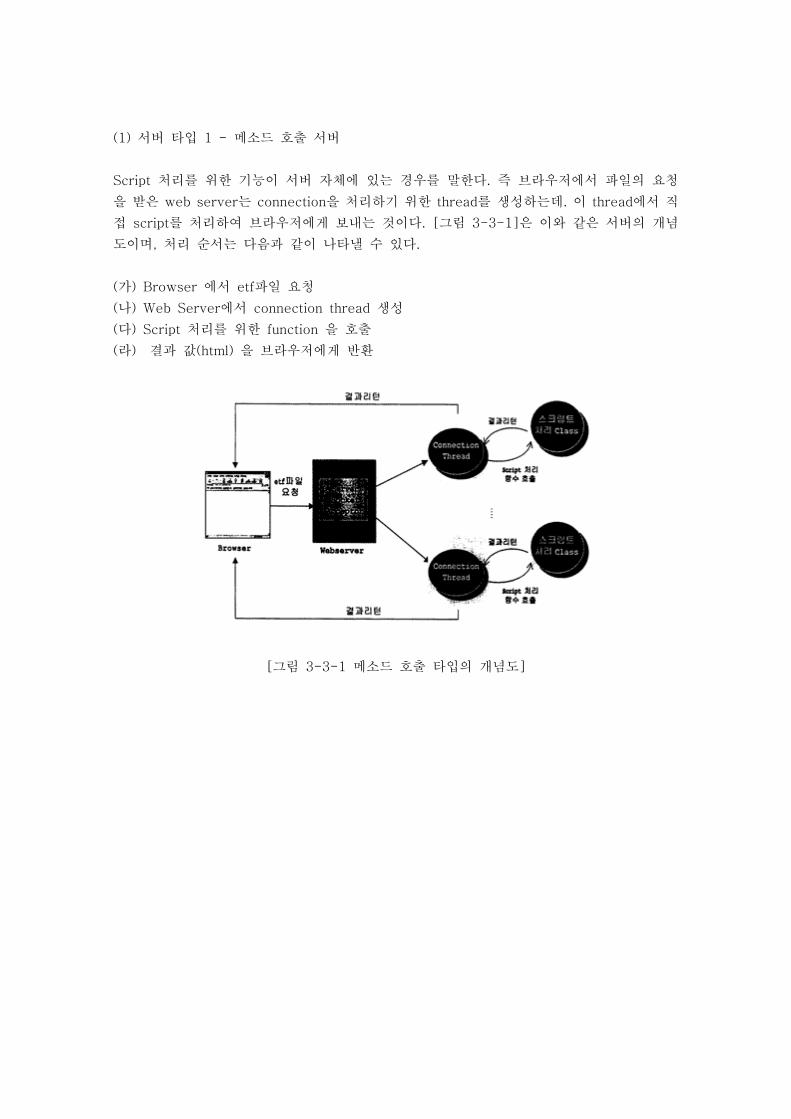
(1) 서버 타입 1 - 메소드 호출 서버
Script 처리를 위한 기능이 서버 자체에 있는 경우를 말한다. 즉 브라우저에서 파일의 요청
을 받은 web server는 connection을 처리하기 위한 thread를 생성하는데. 이 thread에서 직
접 script를 처리하여 브라우저에게 보내는 것이다. [그림 3-3-1]은 이와 같은 서버의 개념
도이며, 처리 순서는 다음과 같이 나타낼 수 있다.
(가) Browser 에서 etf파일 요청
(나) Web Server에서 connection thread 생성
(다) Script 처리를 위한 function 을 호출
(라) 결과 값(html) 을 브라우저에게 반환
[그림 3-3-1 메소드 호출 타입의 개념도]
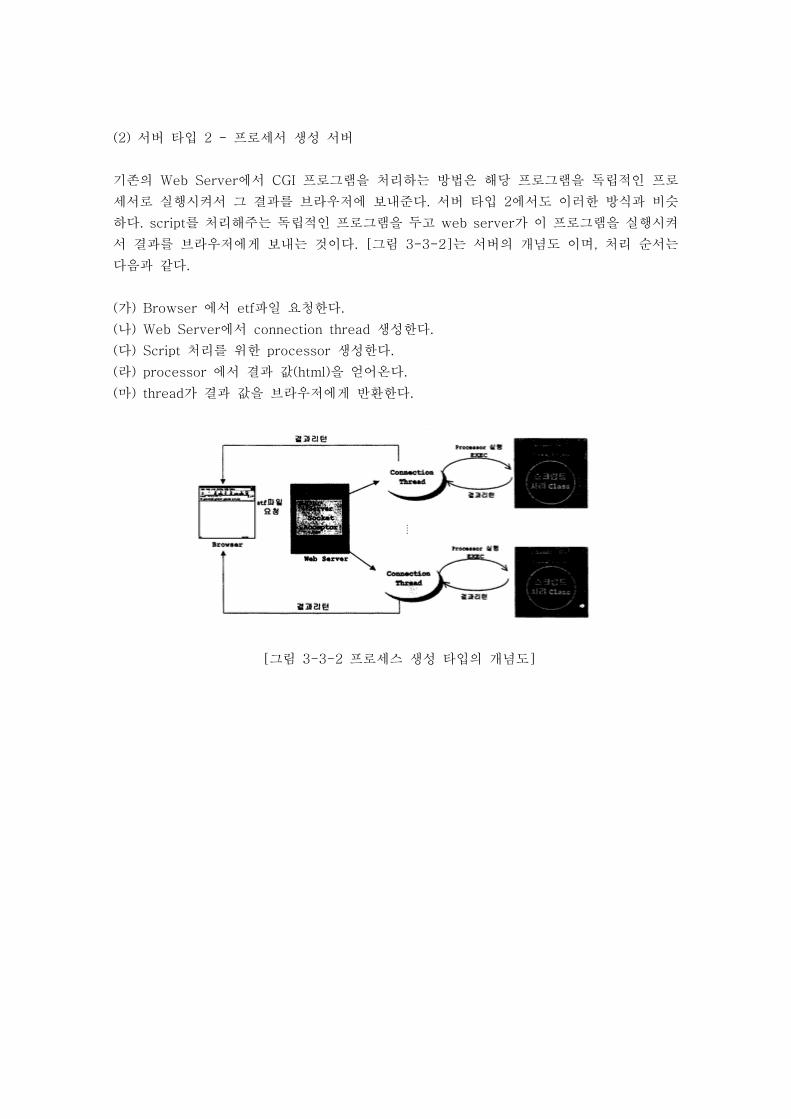
(2) 서버 타입 2 - 프로세서 생성 서버
기존의 Web Server에서 CGI 프로그램을 처리하는 방법은 해당 프로그램을 독립적인 프로
세서로 실행시켜서 그 결과를 브라우저에 보내준다. 서버 타입 2에서도 이러한 방식과 비슷
하다. script를 처리해주는 독립적인 프로그램을 두고 web server가 이 프로그램을 실행시켜
서 결과를 브라우저에게 보내는 것이다. [그림 3-3-2]는 서버의 개념도 이며, 처리 순서는
다음과 같다.
(가) Browser 에서 etf파일 요청한다.
(나) Web Server에서 connection thread 생성한다.
(다) Script 처리를 위한 processor 생성한다.
(라) processor 에서 결과 값(html)을 얻어온다.
(마) thread가 결과 값을 브라우저에게 반환한다.
[그림 3-3-2 프로세스 생성 타입의 개념도]

(3) 서버 타입 3 - 독립기능 서버
Script 처리를 자바의 서블릿(servlet)과 비슷한 방식으로 처리한다.
기존 웹 서버들은 서블릿을 실행시키기 위해 서블릿 처리를 위한 서블릿 엔진을 실행시킨
다. 이 서블릿 엔진은 웹 서버에 등록된 서블릿들에 대한 정보를 알고 있다가 웹 서버의 요
청이 들어오면 해당 서블릿을 실행시키고 그 결과를 웹 서버에게 돌려준다. 이때 웹 서버와
서블릿은 TCP-IP로 연결이 되기 때문에 서블릿 엔진의 다른 사이트의 웹 서버의 요청을
받아 실행시킬 수도 있다.
우리가 구현하고자하는 서버는 스크립트만을 처리하는 Script 처리 Engine을 두고 서버가
필요할 때마다 이 Engine에 처리를 요청하고 받는 형태를 취할 수 있다.
(가) Browser에서 etf파일 요청
(나) Web Server에서 connection thread 생성
(다) Script Server에 TCP-IP 접속
(라) script server에서 connection에 대한 thread 생성
(마) script server의 thread가 etf파일 처리
(바) 결과 값(html) 을 web server의 thread에게 반환
(사) web server의 thread가 결과 값(html)을 브라우저에게 반환

[그림 3-3-3 통신에 의한 분산 타입의 개념도]
나. 웹 서버에 서버 시스템의 파일 관리 기능 추가
웹 브라우저에서 서버시스템의 파일을 read/write 하는 기능을 추가하였다. 즉 서버시스템의
디렉토리 추가, 삭제, 옮기기 및 파일 리스트를 보는 기능을 Applet을 통해 할 수 있도록 한
것이다. 이것은 서버와 Applet간의 소켓 통신을 통하여 구현되었다. 사용자의 요구가 소켓을
통하여 서버에 전달되고 서버가 실제적으로 자신의 시스템의 파일에 대해 이러한 기능들을
수행한다.
이 기능은 웹서버만 설치하면 따로 ftp 서버를 띄우지 않아도 파일에 대한 정보 및 처리를
서버 할 수 있다는 장점이 있다. 즉 ftp 서버를 띄워서 파일 조작을 하면 서버의 부담이 커
지는 단점이 있는데 우리는 웹 서버에 쓰레드를 띄우는 것에 의해 이 기능을 수행하도록 하
여 서버의 부담을 줄였다. 그리고 브라우저만 가지고 있는 사용자는 어디에서든 접속해서
기능을 수행할 수 있다.
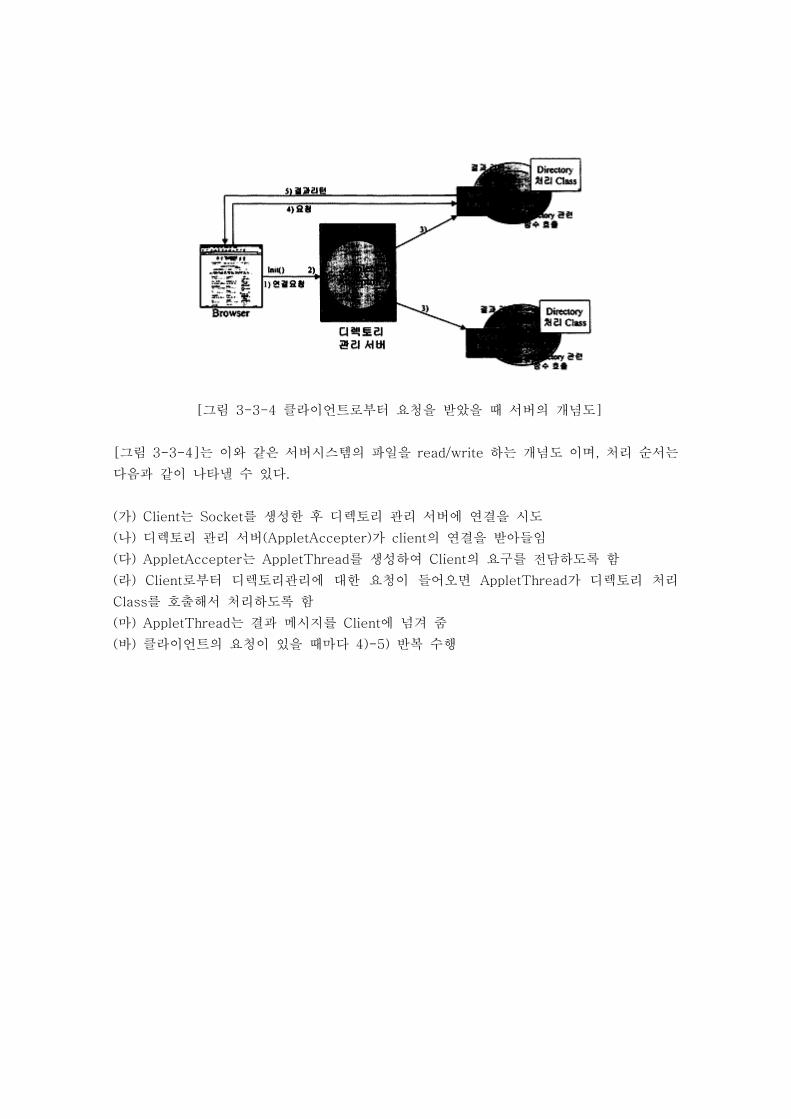
[그림 3-3-4 클라이언트로부터 요청을 받았을 때 서버의 개념도]
[그림 3-3-4]는 이와 같은 서버시스템의 파일을 read/write 하는 개념도 이며, 처리 순서는
다음과 같이 나타낼 수 있다.
(가) Client는 Socket를 생성한 후 디렉토리 관리 서버에 연결을 시도
(나) 디렉토리 관리 서버(AppletAccepter)가 client의 연결을 받아들임
(다) AppletAccepter는 AppletThread를 생성하여 Client의 요구를 전담하도록 함
(라) Client로부터 디렉토리관리에 대한 요청이 들어오면 AppletThread가 디렉토리 처리
Class를 호출해서 처리하도록 함
(마) AppletThread는 결과 메시지를 Client에 넘겨 줌
(바) 클라이언트의 요청이 있을 때마다 4)-5) 반복 수행

2. 구현 설계
가. Webserver
(1) 스크립트 처리 기능
스크립트를 처리하기 위해서는 웹서버가 스크립트를 사용자에게 제공하기 위한 Script
Engine을 포함하고 있어야 하는데, 이러한 Script Engine이 Web Server와 어떻게 상호작용
하는가에 따라 성능이 좌우된다. 상호 작용하는 방법에는 Script Engine이 Web Server 자
체에 포함된 경우, 독립적인 프로세서를 띄워서 처리하는 방법, 스크립트만을 처리하는 별도
의 서버를 두어 처리하는 방법이 있다. 이 세 타입의 성능을 비교하기 위해 ETF라는 스크
립트를 사용한다.
(가) ETF 스크립트 문법
새로 정의한 스크립트언어를 etf(Ewha Tag Format)라 정한다. 다음은 초기 프로토타입에서
구현한 스크립트의 문법으로 매크로, 파일 첨부, 루프에 관한 구문이 있다.
① 매크로
기능 : 서버에 미리 정의되어 있는 일련의 값으로 치환시킬 수 있는 기능으로 “매크로의 매
크로”와 같은 이중 매크로도 처리 가능하다. 서버에 macro. prf파일에 정의되어 있다.
문법 : <%$매크로변수>
② 파일 첨부
기능 : etf 스크립트 파일에 다른 text나 html파일을 추가시킬 수 있는 기능으로 주로 파일
의 머리말이나 꼬리말을 추가시킬 때 사용 가능하다.
문법 : <%InsertFile=파일 이름>
③ Loop
기능 : 특성 부분을 반복할 수 있는 기능이다.
문법 : <%Loop=횟수> ~<%EndLoop>

(나) 스크립트 구현
스크립트의 처리 순서는 [그림 3-3-5]와 같이 나타낼 수 있다.
[그림 3-3-5 스크립트 처리의 흐름도]
① 스크립트가 포함된 etf파일을 읽어들인다.
② 매크로 정보가 들어있는 hash 테이블을 바탕으로 각 매크로를 치환한다.
③ InsertFile, Loop 루틴을 html file을 만든다.
매크로 처리는 매크로를 정의해 놓은 파일을 참조해서 수행한다. 그 파일에는 매크로 변수
와 매크로 변수의 값이 들어가 있다. 그 파일 이름은 Macro. prf로 한다.
다음은 Macro. prf 파일의 예이다.
Webserver/0.9/macroprefsAdmin=AdministratorSeAdmin=Second$Admintest=merong2%end%
매크로를 정의해 놓은 Macro. prf 파일
항상 첫 번째 라인은 Webserver/0.9/macroprefs 이어야 한다. 다음 줄부터 매크로 변수를
정의하는데 한 줄에 하나의 매크로 변수와 값이 정의되어 있다. 파일의 끝은 %end% 로 한
다.

위 예는 Admin이라는 매크로를 만나면 Administrator로 치환한다. 즉 매크로 변수는
Admin, Admin의 치환 값이 Administrator가 된다. 다음 줄의 SeAdmin은 2중 매크로를 보
여주고 있다. 매크로 값 안에 매크로 변수가 들어가 있는데 이것을 변환하면
SecondAdministrator 가 된다.
[그림 3-3-6]은 웹 서버를 띄웠을 때 모니터링 해주는 차이고 [그림 3-3-7]은 웹 서버를 띄
운 시스템에 접속한 브라우저의 모습을 나타내고 있다.
[그림 3-3-6 웹 서버 실행 화면]
[그림 3-3-7 웹 서버가 떠있는 시스템에 접속한 브라우저의 모습]

(다) 스크립트 처리하는 방식에 따른 성능을 비교 분석된 결과는 다음과 같다.
① connection thread 생성
스크립트 처리 엔진이 Web Server 자체에 포함된 경우 생성되는 connection thread는 쓰레
드 자체에 스크립트처리 루틴을 포함하기 때문에 독립적인 프로세서를 띄워서 처리하는 방
법, 별도의 서버를 두어 스크립트를 처리하는 방법보다 부하가 클 것이라는 예상과는 달리
세 타입 모두 connection thread 생성에 대해 동일한 시간이 걸렸다. 따라서 서버에서 쓰레
드를 생성하는 것은 서버의 성능을 크게 좌우하지는 않는다는 결론을 얻었다.
② 스크립트 처리
처리 시간 순으로 보면 스크립트 처리 엔진이 Web Server 자체에 포함된 경우가 가장 빠
르고 독립적인 프로세스를 띄워서 처리하는 방법이 제일 느렸다. 이것은 쓰레드에 비해 새
로운 프로세스를 생성시키는 것은 서버에 많은 부담을 줄 수 있다는 것을 알려준다. 별도의
서버를 두어 스크립트를 처리하는 방법은 Web Server 자체에 스크립트 처리 엔진이 포함
된 경우와 같은 형태로 스크립트 처리 쓰레드를 생성시키기 때문에 처리 속도가 빠르다. 하
지만 connection thread가 스크립트 서버에 TCP-IP로 접근하기 때문에 네트워크 상황에 따
라 성능이 크게 좌우 될 수 있다.
③ 분산 환경
프로세스를 띄워서 처리하는 방법은 웹 서버와 TCP-IP로 연결되기 때문에 같은 사이트에
있을 수도 있고 다른 사이트에 있을 수도 있다. 따라서 네트워크 상황이 좋다면 웹 서버에
만 집중될 수 있는 처리량을 다른 서버로 분산시킬 수 있기 때문에 대용량 서버를 구현할
때 좋은 방법이 될 것이다.

(2) 서버 시스템의 파일 관리 기능
(가) 파일 관리의 기능
구현된 파일 관리 기능은 다음과 같다.
① refresh - 현재 디렉토리 밑의 파일 리스트를 보여준다.
② access - 특정 디렉토리 밑의 파일 리스트를 보여준다.
③ delete - 특정 디렉토리 및 파일을 지운다. 단 디렉토리가 비어있지 않으면 지울 수 없
다.
④ add - 특정 디렉토리를 만들어 준다.
⑤ move - 디렉토리를 다른 경로로 옮겨준다.
(나) 프로토콜
프로토콜은 서버와 클라이언트가 통신하는 규약이다. 디렉토리 관리 서버와 클라이언트의
프로토콜은 [그림 3-3-8]과 같다.
[그림 3-3-8 디렉토리 관리 서버와 클라이언트와의 통신]
클라이언트가 서버한테 파일처리를 위한 메시지를 주면 서버는 해당하는 처리를 한 후 결과
를 클라이언트한테 넘겨준다. 클라이언트는 넘어온 결과를 보고 성공인지 실패인지를 알 수
있다.
서버에서 클라이언트로 리턴해 주는 Return Message는 [표 3-3-1], [표 3-3-2]와 같다.

[표 3-3-1 delete, add, move 일 때의 Return Message]
add, delete, move 성공 add, delete, move 실패
현재디렉토리 refresh 성공 현재디렉토리 refresh 실패"0\n에러메시지\n"
"1\n1\n디렉토리리스트/end\n" "1\n0\n에러메시지\n"
[표 3-3-2 add, refresh 일 때의 Return Message]
acess, refresh 성공 acess, refresh 실패
“1\n디렉토리리스트/end" "0\n에러메시지\n“
delete, move, make는 수행 후 현재 디렉토리 리스트를 서버로 전송하여 바뀐 파일 시스템
에 대한 리스트를 클라이언트가 나타낼 수 있도록 해 준다.
[표 3-3-1]은 add, delete, add, move를 수행한 후 결과에 따른 클라이언트한테 되돌려지는
메시지를 나타내 준다. add, delete, add, move명령이 들어오면 해당하는 기능을 수행한 후
제대로 수행이 되면 현재 디렉토리를 refresh한다. refresh도 성공하면 [표 3-3-1]의 왼쪽 하
단에 있는 것 같은 메시지를 클라이언트한테 넘겨준다. add, delete, add, move는 성공했는
데 현재 디렉토리 refresh는 실패한 경우 [표 3-3-1]의 왼쪽에서 두 번째와 같은 메시지를
넘겨준다. add, delete, add, move도 실패한 경운 [표 3-3-1]의 오른쪽과 같은 메시지를 넘
겨준다.
[표 3-3-2] 는 access, refresh를 수행한 후 클라이언트한테 전송되는 return 메시지를 나타
내 준다. access, refresh를 성공적으로 수행한 후의 메시지는 [표 3-3-2]의 왼쪽 아래의 표
시된 메시지를 클라이언트한테 넘겨준다. 실패했을 경우에는 오른쪽과 같다. access, refresh
는 수행한 후 또 한번 refresh 기능을 수행할 필요가 없다.

[그림 3-3-9]는 웹서버가 실행되었을 때의 화면이다.
[그림 3-3-9 웹서버의 실행화면]
[그림 3-3-10]은 웹 브라우저에서 디렉토리 관리 기능을 수행하는 화면이다.
[그림 3-3-10 서버의 파일 관리를 위한 애플릿]

3. 상세 설명
가. 웹서버의 스크립트 처리 기능
태그가 .etf 인 파일은 etf 스크립트 파일이라고 보고 스크립트 문법에 맞는 처리를 해준다.
주요한 클래스들은 다음과 같다.
(1) ConnectionThread 클래스
클라이언트와의 설정을 유지하는 클래스인 ConnectionThread의 일부분이다. Thread를 상속
해서 만들었다.
class ConnectionThread extends Thread
{
public void run()
{ try
{ :
:
if (cmd.equals("GET"" /*If the command is a GET*/
{
:
:
if (!withinSecurityLimits(inputFile, prefs))
sendForbidden(out) ;
else
{
if (!(inputFile.canRead()))//읽을 수 있는 파일인지 체크
sendNotFound(out, inputFile) ;
else // 읽을 수 있는 파일일 경우
{
String mime = (String)mineTypes.get(extension.toLowerCase()) ;

//mine hash table로부터 mime type을 얻는다.
if(mime==null) //hash table에서 mime type이 발견되지 않았다면
sendNotImplemented(out) ;
else { // hash table에서 mime type이 발견되었다면
if(extension. equals("etf")){ //etf 스크립트 파일인지 체크
StringBffer firstBuf = new StringBuffer(); // 단순치환한 결과
StringBffer secondBuf = new StringBuffer(); // 나머지 Script 처리 결과
MacroPreferences
MacroPreferences(prefs.getRootDir()); // 매크로 처리를 위한 클래스를 만든다.
a.loadMacroFile(); // 치환되어야 할 매크로가 정의되어 있는 macro hash table을 load한다.
firstBuf = a.getHTML(inputFile); // 매크로 치환을 수행함
etfScript gen = new etfScript(prefs. getRootDir()); // loop 및, 파일 첨부에 대한 처리를 위
함 메소드를 만듦
secondBuf = gen.generate HTMS(firstBuf); // 스크립트 처리를 해 줌
sendBuffer(secondBuf, out, mime); // 결과 파일을 클라이언트한테 전송해 준다. }else{
//etf 스크립트 파일이 아니면 sendFile 메소드를 호출한다.
sendFile(inputFile, out, mime);
}
}
}
}

}
}
connection. close();
}
catch(Exception e)
{
:
:
}
}
(2) MacroPreferences 클래스
etf 파일을 받아서 매크로 처리를 해주는 클래스이다. MacroPreferences에 속해 있는 주여
메소드들을 살펴보면 다음과 같다.
(가) loadMacroFile()
매크로가 정의되어 있는 macro.prf 파일을 가져와서 hashtable을 만들어주는 메쏘드이다. 매
크로를 추가하고 싶으면 macro.prf파일에 내용을 추가하면 된다.
public void loadMacroFile()
{
File MacroFile=new File("macro. prf") ; // 매크로가 정의되어 있는 파일
if (!MacroFile.isFile())
{
System.out.print1n("Could not find file: " + MacroFile); return:
}
String line=null, variable="",value="";
try
{

FileInoutStream fileTypesFileInputStrram = new FileInoutStream(MacroFile) ;
DataInputStream fileTypesInputStream = new DataInputStream(fileTypesFileInputStream);
int 1 = (int)MacroFile. length();
byte[] buffer - new byte[1];
fileTypesInputStream.read(buffer) ;
StringTokenizer bufferST = new StringTokenizer(new String(buffer), "\r\n");//\n나\r
으로 토큰을 분리한다.
if (bufferST.hasMoreTokens())
line = (String)bufferST. nextToken();
else {
System.out.print1n(MacroFile +" is not a Macro File. No Entries read.");
return ;
}
if (!(line.equals("Webserver/0.9/macroprefs"))) // 파일의 첫 라인은
Webserver/0.9/macroprefs로 시작해야 한다.
{
System. out. print1n(MacroFile +" is not a Macro File. No entries read.");
return ;
}
StingTokenizer st = null;
System. out. print1n("Loading macro file ...");
while(bufferST.hasMoreTokens() && !((1ine=(String)bufferST.nextElemet()).startsWith
("%end%"))) // %end%일 때까지 라인을 읽어들인다.
{
st = new StringTokenizer(line,"="); 각 line을 =을 중심으로 분리한다.

if ( st. countTokens()==2)
{
variable = st. nextToken(); // 매크로 변수
value = st. nextToken(); // 대치할 매크로 값
macroTable.put(variable, value); // 각 값을 hash table에 넣는다.
System. out. print1n(variable + " " + value);
}
}
fileTypesInputStream. close();
}
catch(Exception e)
{
System.out.print1n("An error occured while reading the macro file. No more macro file
will be read.");
}
}
(나) getHTML
etf스크립트 파일을 읽어서 매크로 처리를 한 후의 text를 StrigBuffer 형으로 return 해주는
메쏘드이다.
public StringBuffer getHTML(File inputFile)
{
try
{
//테스트 구문
System. out. print1n("here getHtml");

char c, d;
StringBurrer inbuf = new StringBurrer();
BurreredReader inb = new BufferedReader(new FileReader(inputFile));
String s=" ";
while((s=inb. readLine()) ! = null1){
inbuf. append(s). append((char)'\n');
}
inb.close();
src = inbuf. toString();
PARSING : for(;;){// '<'라면 매크로처리의 시작일 수 있음
if(parseInNoneOrHtml State()){ // 매크로라면 처리 한 후 continue PARSING ; // parsing
을 계속 함
}
}
scriptletsCode.append((char) c); // 매크로가 아니면 아무처리 안해주고 char c를 append해
줌
srcPos++;
}
} // try
catch(Exception e)
{
/*kill this thread, connection lost. */
}
return scriptletsCode;
}

(다) paresInNoneOrHtmlState
매크로가 있다면 매크로 처리를 해 주는 메쏘드이다.
private boolean paresInNoneOrHtmlState() throws StringIndexOutOfBoundsException
{
char c, d;
String[] keyAndValue;
int id;
boolean boo;
int pos;
id = 0;
if(srcPos < src. length() -3 && src.charAt(srcPos +1) == '%'){ // start of expression
pos = srcPos;
srcPos +=2;
skipWhitespace();
if((c=src. charAt(srcPos)) == '$'){
boo = changeMacro(); // 매크로 변수에 해당하는 값으로 바꿔준다.
if (boo == true) { // 매크로 치환이 제대로 된 경우
srcPos +=1;
return true;
}
else {
srcPos -= 2;
return false ;
}
// System. out. print1n(keyAndValue[1]);

}
else { // 매크로 변수가 아닌 경우
srcPos = pos;
return false;
}
}
return false;
}
(라) changeMacro
hash table에서 해당하는 변수를 찾아 해당하는 값으로 변화시켜주는 메쏘드이다.
private boolean changeMacro() {
int index;
char c;
String tmp, tmp2, value;
int pos;
index = 0;
tmp = null;
tmp2 = null;
value = null;
pos = srcPos;
srcPos+= 1;
srcPos = src. indexOf(">", srcPos);
tmp = src. substring(pos+1, srcPos). trim();
value =(String) macroTable.get(tmp); // 매크로 테이블에서 tmp에 해당하는 값을 찾는다.
if (value !=null) { //해당하는 값이 있을 경우
if ((index=value.indexOf("$")) >=) { //이중 매크로인 경우 이중 매크로 처리

tmp = value.substring(0, index);
scriptletsCode.append(tmp2);
tmp = value. substring(index+1, value. length());
value = (String) macroTable.get(tmp);
scriptletsCode.append(value);
}
else {// 이중 매크로가 아닌 경우 매크로 변수의 값을 찾아 그 값을 append해 준다.
scriptletaCode.append(value);
}
return true;
}
else {
srcPos = pos;
return false;
}
}
(3) etfScript 클래스
파일 첨부 loop 기능을 수행하는 메쏘드이다. 이 클래스 중 주요한 메쏘드들을 살펴보면
다음과 같다.
(가) generateHTML
매크로처리가 된 것을 입력으로 받아 look 및 파일 첨부에 대한 처리를 해 준 후에 결과를
htm1형식으로 만들어서 출력해 준다.
public StringBuffer generateHTML(StringBuffer inbuf)
{
try

{
char c, d;
src = inbuf. toString();
String s="";
PARSING : for(;;){// inbuf에 있는 내용을 한 character씩 position을 옮겨가면서 읽는다.
c=src. charAt(srcPos);
if (c == '<') { // <가 있으면 특수한 처리를 위한 것일 수 있다.
if (parseInNoneOrHtmlState()){ // 스크립트처리를 위한 태그인지 체크
continue PARSING ; // 다시 파싱을 계속한다.
}
}
switch(paresState){
case PARSE+INLOOP : //현재 position 이 loop body에 속한다면
loopbody.append((char) c); //loopbody라는 buffer에 현재 character를 넣는다.
default :
scriptletsCode.append((char) c);
break;
}
srcPos++;
}
} //try 끝
catch(Exception e)
{
/*kill this thread, connection lost. */

}
return scriptletsCode;
}
(나) loopFunc
loop 기능을 수행해 주는 메쏘드이다.
private void loopFunc()
{
int end;
int endloop1, endloop2;
String loopnum;
String body="";
int num;
body=loopbody.toString(); //loopbody의 내용
for(int i=0; i < numofLoop; I++){ //numofLoop 만큼 반복해서 써준다.
scriptletsCode.append(body);
}
}
(다) fileAttach
파일 첨부를 수행해 주는 메쏘드이다.
private void fileAttach(String filename)
{
BufferedReader in;
String s="";
try{
String temp="\\"; //파일 분리자
File inputFile = new File(rootDirectory + temp + filename);

inputFile = new File(inputFile.getCanonicalPath());
in = new BufferedReader(new FileReader(inputFile)); // 첨부할 파일
try {
while((s=in. readLine()) ! = null) { // 파일의 끝까지 읽어서 내용을 써준다.
scriptletsCode.append(s).append((char)'\n');
}
} finally {
in. colse();
}
} catch(FileNotFoundException fnfexc){
sendMessage("Could not found");
} catch(I0Exception ioexc){
}
}
(라) parseKeyAndValue
메쏘드는 Key 와 value 값을 추출하는 메쏘드이다.
private Sting[] parseKeyAndValue() throws
StringIndexOutOfBoundsException {
char c;
int pos;
String[] keyAndValue = new String[2];
pos = srcPos;
if(parseState == PARSE_INLOOP){ // loop 구문 수행중일 때
srcPos = src.indexOf(">", srcPos); //>를 loop 구문의 끝으로 인식함
keyAndValue[0] = src. substring(pos, srcPos).trim();

keyAndValue[1] = keyAndValue[0];
}else{
srcPos = src.indexOf("=", srcPos);
if(srcPos < 0) { // 스크립트 구문이 아니다.
srcPos = pos-2; //position을 원래대로
parseState = PARSE_NOTSCRIPT; //스크립트가 아니라는 표시
return keyAndValue;
}
keyAndValue[0] = src.substring(pos, srcPos).trim();
if(keyAndValue[0].equalsIgnoreCase("ATTACHFILE") ¦¦
keyAndValue[0].eqyaksIgnoreCase("LOOP")){ // 스크립트 키워드일 때
srcPos++;
pos = srcPos ;
srcPos = src. indexOf(">", srcPos); //positionn을 옮김
keyAndValue[1] = src.substring(pos, srcPos). trim(); //value 값을 넣어준다.
} else { //스크립트 키워드가 아닐 때
srePos = pos-2; // position을 원래대로
parseState = PARSE_NOTSCRIPT;
return keyAndValue;
}
}
srcPos++;
return keyAndValue;
}

나. 서버 시스템의 파일 관리 기능
클라이언트 프로그램은 웹 브라우저에 의해 수행될 수 있는 애플릿으로 구현했고, 디렉토리
관리서버는 Java 의 쓰레드를 사용하여 구현하였다. 서버와 클라이언트는 소켓 통신으로 메
시지를 주고받는다. 쓰레드는 프로세스보다 생성되는 크기가 작기 때문에 서버의 부하도 적
다. 그렇게 때문에 쓰레드로 구현한 디렉토리 관리 서버는 클라이언트가 요청했을 때 응답
시간 및 수행시간이 빠르다.
웹서버가 시작되면 디렉토리 관리 서버도 같이 시작된다.
다음은 주요 클래스 설명이다.
(1) Client 프로그램
Java의 애플릿으로 구현하였다. 소켓을 생성. 디렉토리 관리 서버와 연결을 시도한 후 디렉
토리관리 서버가 연결요청을 받아들이면 클라이언트와 서버와의 연결이 설정된다. 서버에
파일 처리 관련된 기능을 요청할 수 있다.
(가) init
애플릿이 load 되면 초기화를 위해 가장 먼저 불리는 메쏘드이다. 이 메소드는 애플릿을 초
기화한 후 소켓을 생성해서 서버와 연결을 한다. 그리고 서버와 서버로부터 디렉토리 리스
트를 얻어와서 애플릿의 List 에 보여준다.
다음은 서버와 연결하고 리스트를 받아오는 일을 하는 부분의 코드이다.
// 소켓 연결하기
try{
k = new Socket( "movie. ewha. ac. kr", 8089); //
movie. ewha.ac.kr의 주소의 8089 port에 연결을 시도한다.
os = new DateOutputStream(k.getOutputStream());

is = new BufferedReader(new InputStreamReader(k.getInputStream(), "KSC5601"));
}catch(UnknownHostException uh)
{
}
catch(UnsupporthdEncodingException us)
{
}
catch(I0Exception ie)
{
}
//서버로부터 list 받음
try{
String fromSerer = is.readLine();
if(!fromSerer.equals("error")){//에러가 아니면 디렉토리 리스트를 출력한다.
txtPath.setText(fromServer);
while(!(fromServer = is.readLine()).equals("end")){
System.out.println(fromServer);
ListShow.addItem(fromServer);
} // end of while
}
else { //에러일 때 에러 메시지 출력해 준다.
fromServer = "Local disk가 존재하지 않다.
errMsg(fromServer);
} //end of if
}catch(Exception e){}

(나) ListShow_ActionPerformed
파일이나 디렉토리를 보여주는 리스트를 더블클릭 했을 때 수행되는 메쏘드 이다. 사용자가
list를 더블클릭 하면 더블클릭 한 이름의 디렉토리 하위에 있는 파일들을 보여준다.
이 메쏘드의 처리 절차는 다음과 같다.
① 선택된 디렉토리 명을 list에서 얻는다.
② 메시지를 생성해서 서버에 전달한다.
③ 서버는 디렉토리의 하위에 있는 디렉토리나 파일 이름을 얻는다
④ 에러 없이 수행이 되었으면 1을 클라이언트한테 전달한 후 디렉토리 리스트를 넘겨준다.
사행시 에러가 있다면 0과 에러 메시지를 Client한테 보내준다.
⑤ 클라이언트는 메시지를 받아서 성공이면 서버로부터 받은 파일 및 디렉토리에 대한 정보
를 Applet의 List에 보여주고 실패했으면 에러 메시지를 출력해 준다.
다음은 구현된 코드이다.
st = ListShow.getSelectedI tem(); 리스트 중에서 선택된 리스트의 item을 얻어온다.
if ( ((index = st. index0f("₩₩")) >=0) : : ((index =
st.index0f{".")) >=0)){
if ((index = st. index0f("..")) >=0 { // ..이라면 부모 디렉토리의 리스트를 보여준다.
try{
StringTokenizer myToken = new
StringTokenizer(st, " ");
File current = new

File(txtPath.getText(). trim());
String msg = "access :"+
current.getParent();
sendToServer(msg) ;
getDirectoryList();
}
catch(Exception e) {}
}
else if ( (index = st. index0f("₩₩")) >=0) { // 파일 이름 끝에 ₩가 있으면 디렉토리를 의
미한다. 즉 디렉토리라면 그 디렉토리 하위의 파일 리스트를 보여준다.
try{
StringTokenizer myToken = new
StringTokenizer(st, "₩₩");
String msg = "access :"+
txtPath.getText(). trim() +"₩₩"+
myToken.nextToken().substring(0,index);
sendToServer(msg); //서버한테 메시지를 보내는 메쏘드이다.
getDirectioryList(); //서버로부터 디렉토리 리스트를 받아오는 메쏘드이다.
}
catch(Exception e ) {}
}
}
(다) ButtonRefresh_MouseClicked
현재 디렉토리의 리스트를 refresh해서 보여주는 기능을 한다.

처리 절차는 다음과 같다.
① 현재 디렉토리 명 Applet의 textbox에서 얻는다.
② 메시지를 생성해서 서버에 전달한다.
③ 서버는 현재 디렉토리의 하위에 있는 디렉토리나 파일 이름을 얻는다.
④ 에러 없이 수행이 되었으면 1을 클라이언트한테 전달한 후 디렉토리 리스트를 넘겨준다.
수행 시 에러가 있다면 0과 에러 메시지를 Client한테 보내준다.
⑤ 클라이언트는 메시지를 받아서 성공이면 서버로부터 받은 파일 및 디렉토리에 대한 정보
를 Applet의 List에 보여주고 실패했으면 에러 메시지를 출력해 준다.
구현된 코드는 다음과 같다.
String msg = "access :"+ txtPath.getText(). trim(); //메시지를 생성한다.
sendTo Server(msg); //서버한테 메시지를 전송하는 메쏘드이다.
getdirectoryList(); //서버에서 디렉토리 리스트를 얻어오는 메쏘드이다.
(라) sendToServer
서버한테 메시지를 전달해 준다.
코드는 다음과 같다.
try{
String sendMsg= msg + "₩n"; //인자로 들어온 메시지에 리턴문자를 붙여서 메시지를 만든
다.
os.write(sendMsg.getBytes()); //메시지를 서버로 전달해 준다.
os.flush();
System.out.println(sendMsg);

}catch(IOException e){
System.out.println("this");
}
(마) getDirectoryList
서버로부터 디렉토리 및 파일에 대한 정보를 받아온다.
코드는 다음과 같다.
try{
String fromServer="";
fromServer = is.readLine();
if ( fromServer.equals("1") ) { //서버에서 1을 받았다면 성공한 것이다.
ListShow.clear(); // 그러므로 디렉토리를 clear시키고
txtpath.setText(is.readLine()); //디렉토리에 대한 정보를 리스트에 나타내 준다.
while(!(fromServer = is.readLine()).equals("/end"))
{ // '/end'는 메시지의 끝임을 나타낸다.
ListShow.addItem(fromServer);
}
}else { //에러라면 에러 메시지 출력
fromServer = is.readLine();
errMsg(fromServer);
}
}catch(IOException e) {
}

(바) ButtonDelete_MouseClicked
선택된 디렉토리나 파일을 지운다.
메쏘드의 처리절차는 다음과 같다.
① 지울 디렉토리 명을 list에서 얻는다.
② 메시지를 생성해서 서버에 전달한다.
③ 서버에서 해당 파일이나 디렉토리를 지운다.
④ 파일이나 디렉토리를 지우는 일을 제대로 수행했으면 1을 아니면 0과 에러 메시지를
Client한테 보내준다.
⑤ 클라이언트는 메시지를 받아서 성공이면 현재 디렉토리의 변경된 리스트를 보여주고 실
패했으면 에러 메시지를 출력해 준다.
프로그램 코드는 다음과 같다.
try{
int index;
String msg ="";
String dirName = ListShow. getSelectedI tem();;
// 지울 디렉토리 명을 얻는다.
StringTokenizer mytoken = new
StringTokenizer(dirName,"");
dirName = myToken.nextToken();
dirName =
dirName.substring(0,dirName.Length(0-1); // 파일명의 끝의 ‘₩’를 뗀 것을 디렉토리 이름으
로 한다.
msg = "delete:" + txtPath.getText() + "//" +
dirName ; //서버에 보낼 메시지 생성
sendToServer(msg); 서버에 메시지를 보냄
String fromServer = is. readLine();
if ( fromServer.equals("1") ) { // 서버에서 받은 메시지가 1일라면 delete 성공
getDirectoryList(); // 현재 디렉토리 리스트를 refresh함

}
else { 실패하면 에러 메시지 출력
fromServer = is.readLine();
errMsg(fromServer);
}
}catch(Exception e ) {}
디렉토리 만들기 및 디렉토리 옮기기의 구현은 위의 코드와 비슷하다.
(2) 서버 프로그램
(가) 디렉토리관리서버(AppletAccepter)
Java의 쓰레드를 사용하며 웹 서버가 살아있는 한 메모리에 상주하여 사용자의 요청을 기
다리고 있다. 사용자의 연결 요청이 오면 받아들이고 그 일을 전담하는 쓰레드
(AppletThread)를 할당해 준다. 즉 사용자와 새로운 Connection을 생성해 준다.
‘fileAccess.prf'라는 파일은 사용자가 root 디렉토리를 정의해 놓은 파일이다. 이 파일에서
root 디렉토리를 얻어와서 rootDirectory라는 변수에 넣는다.
AppletAcceptor()
{
File prefFile = new ("fileAccess.prf"); // 파일을 읽음
FileInputStream prefInputStream = new
FileInputStream(prefFile);

int 1 = (int) prefFile.length(); // 파일의 길이
byte[] buffer = new byte[1]; // 파일의 길이만큼 byte 버퍼를 설정
prefInputStream.read(buffer);
StringTokenizer bufferST = new StringTokenizer(new String(buffer), "₩r₩n"); // ₩r 이나
₩n으로 토큰 분리
StringTokenizer st = new
StringTokenizer(bufferST.nextToken(), "="); // = 로 토큰 분리
String variable = st.nexttoken();
String value = st.nextToken();
if(variable.equals("rootdir")) { //키워드라 rootDir라면 rootDirectory에 값을 설정
rootDirectory = value;
System.out.printIn(value);
}
File rootDirFile = new File(rootDirectory);
rootDirFile = new File(rootDirFile.getCanonicalPath());
}
다음은 AppletAcceptor 쓰레드가 실행될 때의 코드이다. 클라이언트의 연결을 기다리고 있
다가 연결이 요청되면 연결을 받아들인다. 그리고 연결된 후의 일을 전담하기 위한
AppletThread라는 새로운 쓰레드를 생성시킨다.
public void run()
{
connectionList = new ConnectionManager();

try
{
s = new ServerSocket(8089, 30); // port 8089으로 연결을 기다린다.
}
catch(Exception e)
{
stop();
}
int connectionNumer = 0; /* AppletThreads를 위한 connection ID*/
try
{
while (!done)
{
Socket connection = s.accept(); //다음 연결을 기다린다.
AppletThread t = new AppletThread(
connectionList, connection, rootDirectory, "Connection number: "+ connectionNumber);
//쓰레드를 생성한다.
t.start(); /*쓰레드를 시작시킴
connectionNumber++;// thread ID number를 증가시킴
yield();
}
}
catch(Exception 2)
{
stop();
}
}

(나) AppletThread - 쓰레드를 사용한다.
클라이언트와의 연결을 유지하고 있으면서 클라이언트의 요청에 대한 처리를 수행을 위해
Directory처리 클래스를 호출한다. 클라이언트 프로그램이 종료되면 이 쓰레드는 자동 종료
된다.
① AppletThread
생성 자이다.
AppletThread(ThreadGroup tg, Socket c, String root, String str)
{
super(tg, str); /*add this Thread to the ThreadGroup tg */ rootDirectory = root;
connection = c; /*The Socket to send and receive data*/
//setPriority(Thread.MAX_PRIORITY_2); /*We want a responsive connection. */
}
② run
쓰레드가 시작될 때 불려지는 메쏘드이다. 클라이언트와 프로토콜에 의해 통신을 한다.
public void run()
{
try
{
/*initialize input and output streams*/
out = new DataOutputStream(connection.getOutputStream());

in = new BufferedReader(new InputStreamReader(connection.getInputStream(),
"KSC5601"));
String cmd=“”, file1 ="",file2="";
// 먼저 client한테 root 디렉토리에 있는 파일 리스트를 뿌려준다.
rootAccess(rootDirectory);
while(connection != null) { //커넥션이 끊어지지 않는 동안 다음을 반복한다.
String commands = in.readLine();
StringTokenzer st = new StringTokenizer(commands,":");
cmd = st.nextToken();
file1 = st.nextToken(); // 첫 번째 파라미터
if (cmd.equals(access")) // 디렉토리 access
{
access(file1);
}else if(cmd.equals("move")"{ //디렉토리 move
file2 = st.nextToken();
move(file1, file2);
}else if(cmd.equals("add")"{ //디렉토리 add
add(file1);
}else if(cmd.equals("delete")"{ //디렉토리 delete
delete(file1);
}// if문 끝
} // while 의 끝
}
catch(IOException e) // client와의 연결이 끊어지면 IOException이 발생하고 다음 코드를
실행한다.
{

try // 연결을 끊고 쓰레드를 죽이다.
{
connection.close();
System.out.println("AppletThread is closed");
stop(); /*kill the thread*/
}
catch(I0Exception ex)
{
stop();
}
}
③ delete
서버의 파일 시스템에서 인자로 들어온 file1을 지운다.
private void delete(String file1)
{
DirAction dir = new DirAction(); // directory 처리를 위한 클래스
String errMsg ="";
String success = "";
try{
errMsg = dir.deleteDir(filel);
if(errMsg== null){//파일을 지우는데 성공했을 때
System.out.println("delete success");
out.write(success.getBytes());
out.flush();
refresh(file1); //변경된 파일 리스트를 다시 한번 클라이언트한테 보내준다.

}
else{ //파일을 지우는데 실패했을 때 실패한 코드 0과 에러 메시지를 클라이언트한데 보내
준다.
System. out. println(errMsg);
success =“0\n";
out, write(success. getBytes());
out. flush();
System. out. println(success);
out. write(errMsg. getBytes());
out. flush();
}
}catch(I0Exception e){}
}
④ add
인자로 들어온 file1 디렉토리를 추가한다.
private void add(String file1)
{
DirAction dir = new DirAction(); // directory 처리를 위한 클래스
String errMsg ="";
String success = "";
try{
errMsg = dir.mkDir(file1);
if(errMsg== null){//파일을 지우는데 성공했을 때
System. out. println("delete success");
out. write(success.getBytes());
out. flush();
refresh(file1);
}

else{ //디렉토리 추가에 실패했을 때
System. out. println(errMsg);
success =“0\n";
out. write(success.getBytes());
out. flush();
out, write(errMsg. getBytes());
out. flush();
}
}catch(I0Exception e){}
}
⑤ access
file1 디렉토리 밑에 있는 파일 리스트를 보여주는 메쏘드이다.
private void access(String file1)
{
DirAction dir = new DirAction(); // directory 처리를 위한 클래스
DirListMsg retMsg = new DirListMsg();
String success = "";
try{
retMsg = dir.getDir(file1);
if(errMsg.errorCheck() ==true){ // 성공했을 때
System. out. println(retMsg.getMessage());
success =“1\n";
out. write(success.getBytes());
out. flush();

out. write(retMsg.getMessage().getBytes());
out. flush();
String and ="/end\n";
out. write(end.getBytes());
out. flush();
}
else{ // 실패했을 때
success =“0\n";
out. write(success.getBytes());
System. out. println(retMsg.getMessage());
out. write(retMsg.getMessage().getBytes());
out. flush();
}
}catch(I0Exception e){}
}
⑥ rooAccess
root 디렉토리 하위의 파일 리스트를 보여주는 메쏘드이다.
private void rooAccess(String file1)
{
DirAction dir = new DirAction(); // directory 처리를 위한 클래스
DirListMsg retMsg = new DirListMsg();
String success = "";
try{
retMsg = dir.getDir(file1);
if(retMsg.errorCheck() ==true){ // 성공했을 때
System. out. println(retMsg. getMessage());
out. write(retMsg.getMessage().getBytes());
out. flush();

} else{ // 실패했을 때
retMsg= dir.getDir("c:\\"); //디폴트로 c:\를 access
if(errMsg.errorCheck() ==true){
out. write(retMsg.getMessage().getBytes());
out. flush();
} else{
String tmp ="error\n"; //local disk가 존재하지 않을
out. write(tmp.getBytes());
out. flush();
}
}
String end ="/end\n"; //메시지의 끝을 나타냄
out. write(end. getBytes());
out. flush();
}catch(I0Exception e){}
}
⑦ move
file1을 file2로 바꾸는 메쏘드이다.
private void move(String file1,String file2 )
{
DirAction dir = new DirAction(); // directory 처리를 위한 클래스
String success = "";
String errMsg ="";

try{
errMsg = dir.mvDir(file1, file2); //file1을 file2로 바꾸는 메쏘드이다.
if(errMsg== null){// 성공했을 때
System.out.println("move success");
success =“1\n";
out. write(success.getBytes());
out. flush();
refresh(file1);
}
else{ //실패했을 때
success =“0\n";
System. out. println(errMsg);
out. write(success.getBytes());
out. flush();
out. write(errMsg.getBytes());
out. flush();
}
}catch(I0Exception e){}
}
⑧ refresh
filename파일의 루트 디렉토리를 얻어서 그 밑의 파일 리스트를 보여 주는 메쏘드이다.
private void refresh(String filename)
{
DirAction dir = new DirAction(); // directory 처리를 위한 클래스
DirListMsg retMsg = new DirListMsg();
String success = "";

try{
File myfile = new File(filename);
String parent = newFile(myfile. getCanonicalPath()). getParent(); //파일의 루트 디렉토리
이름을 얻는다.
retMsg = dir, getDir(Parent); //이 디렉토리 밑의 파일 리스트를 보여주는 메쏘드
if(retMsg== true){//파일 리스트를 보여주는데 성공했다면
success =“1\n";
out. write(success.getBytes());
out. flush();
out. write(retMsg.getMessage().getBytes());
out. flush();
String end ="/end\n"; //메시지의 끝을 나타냄
out. write(end.getBytes());
out. flush();
}else{ //실패했다면 에러 메시지 출력
System, out. println(retMsg.msg);
success =“0\n";
out. write(success.getBytes());
out. flush();
out. write(retMsg.getMessage().getBytes());
out. flush();
}
}catch(I0Exception e){}
}

(다) Directory 처리 Class
디렉토리 처리에 관한 일 전담한다. 디렉토리에 관련된 실제적인 처리(delete, create, move
등)를 한 후 결과를 AppletThread에 넘겨준다.
제 4 절 Java Application의 연구 결과
1. Java Telnet
[그림 3-4-1-1 Telnet Applet 실행화면]
가. 장치 설명
(1) Telnet Applet의 설치
다운로드 페이지의 기록에 따라 어떻게 그것을 얻고 어떻게 파일을 실행시키는지 알 수 있
다. 성공적인 실행 후에 완벽한 패키지를 사용자의 디렉토리에 가질 수 있다.
Telnet/ *.html, *.java와 *.class 파일들의 디렉토리와 Documentation/, display/, modules/,
socket/와 툴들이다.
applet의 인스톨은 최근의 파일들과 디렉토리들 다음에 계속되는 사용자의 웹 페이지를 필
요로 한다. 모든 파일들과 디렉토리들은 다른 사용자에 의해 읽기 쉽게 만들어진다.

telnet applet은 다음에 명시된 파라미터들에 의한 주문에 의해서 사용한다.
<PARAM NAME = address VALUE = "tanis.first.gmd.de">
<PARAM NAME = port VALUE = "23">
<PARAM NAME = emulation VALUE = "vt320">
<PARAM NAME = proxy VALUE = "www.first.gmd.de">
<PARAM NAME = proxyport VALUE = "31415">
프록시와 프록시 포트 파라미터들은 좌측의 바깥쪽이다. 그것들은 사용자의 목적지 호스트
를 필요로 하는데, 사용자의 웹 서버와 사용하는 대체 데몬과 같아서는 안 된다.
(2) 터미널 에뮬레이션 설치하기.
터미널 에뮬레이션은 telnet applet에서는 매우 중요한 파트이다. 그것은 확실한 VT100 이나
ANSI와 같이 하드웨어 터미널들을 사용하여 사용자 프로그램을 가능하게 만들기 때문이다.
공급되는 패키지는 거의 VT320의 유순한 터미널 에뮬레이션으로 VT100과 ANSI를 포함하
고 있다. 그 의미는 applet이 만약 원래의 VT320 터미널이 할 수 없는 컬러지정조치 가능하
다는 것이다. applet은 TV 터미널에서 특별한 그래픽 문자 집합을 지원한다. 작은 결점들과
함께 모든 그래픽 문자들이 새로이 실행되도록 지원한다. 더 많은 그래픽 문자들을 스트린
에 느리게 출력한다. 우리는 현재의 실행을 UNICODE를 지원하여 모든 브라우저들이 활성
화될 때 제거할 것이다.
(3) 모듈 설치하기
Java telnet applet의 또 다른 특징은 모듈의 동적 로드가 가능하다는 것이다.

모듈은 Java 클래스 로드 된 후에 applet이 가지고 있는 초기값을 사용자 인터페이스 또는
배경작업의 어떤 방법들을 사용하는데 강화할 것이다.
(가) 스크립트 모듈
스크립트 모듈은 매우 단순한 실행을 입력 트리거 스크립트 수행자에게 준다. 텍스트를 보
내고 원격 호스트가 텍스트를 받을 때 일치되는 패턴을 프로그램 하도록 한다. 각 패턴의
상과 텍스트로 단지 하나와 중지된 작업이 모든 패턴의 매치된 후에 실행된다. 그것은 새로
운 연결에 다시 작업을 시작할 때이다.
(나) 머드컨넥터
이 모듈은 머드 컨넥터를 위한 특별한 편집기이다. 특징은 MUDs의 리스트와 작은 버튼들
의 비연결, MUDs에 대한 정보를 얻는 것이다. 전문화된 모듈에 대한 매우 좋은 예제이다.
html 파일 안에 다음에 계속되는 태그를 포함한 모듈을 로드한다.
(4) applet을 포장하여 설치하기.
applet을 포장한다는 것은 applet에 대해 로딩, 예제, telnet applet외의 아무것도 하지 않는
다는 것이다. 이해를 위하여 “왜 우리가 만들어서 가지고 있는가”를 사용자가 경험적인 보
고가 필요로 하기 때문이다.
(5) 프록시 서버 설치하기.
telnet applet과 함께 두 개의 프록시 서버가 제공된다. 첫 번째 하나의 java내에 쓰고 하나
의 호스트에 연결을 지원하기 위해서이고, 두 번째는 C 내에 쓰고 다른 목적 호스트(대체
데몬이라 부른다)를 지원하기 위해서이다.

(가) Java 프록시 서버
프록시 서버는 작은 Java 프로그램으로 Java의 보안 제한을 넘어서 웹 브라우저를 가능하
게 한다. 프록시는 연결을 새 방향으로 돌려서 사용하도록 호스트에게 주어진다. 보통
applet은 오직 웹 서버에 연결이 가능하도록 로드된다. 프록시를 사용자의 웹 서버에 설치할
때 사용자가 연결되기를 바라는 것과 같이 applet을 호스트에 연결시킨다.
① 프록시 어플리케이션을 실행시키기 위해서는 다음의 두 가지 요소가 필요하다.
- java interpreter(JDK를 포함한 것)
- 프록시의 번역된 버전 (proxy. class)
2. Java Ftp
[ 그림 3-4-2-1 FTP Applet 실행하면]

가. Ftp 관련 함수
Ftp와 관련된 함수들은 두 가지로 분류되는데, 첫째는 다른 widow를 띄우고 따로 동작하는
함수, 둘째는 telnet 프로그램에 맞물려 돌아가서 ftp로 파일을 다 받은 때까지 아무 일도 못
하게 하는 함수들이다. FTPform. java는 widow frame을 새로 만드는 함수들과, 그것을 이
용해 output을 textarea로 잡고 프로그램을 수행하도록 하는 또 개별적으로 실행도 시킬 수
있는 프로그램이고, miniftp는 telnet프로그램에서 실행하였을 때 아무런 message도 뜨지 않
고 그냥 get과 put이 되게 하는 함수들이다.
제 5 절 Java IPv6 프로토콜 및 Security 연구 결과
1. IPv6 프로토콜
가. 실험환경
IPv6주소 변환을 보여주기 위한 환경은 pc기반 unix인 freeBSD2.2.8에 queuing과 관련된
Altp 1.1.3자원예약을 위해 사용되는 revpd, IPv6 패키지인 KANE그리고 라우팅과 관련된
IPv6용 gatesD를 설치함으로 환경을 구성한다.
나. 6bone-KR이란?
6bone(IPv6 BACKBONE)이란 기존 인터넷상에서 IPv6를 지원하는 라우터와 호스트로 구성
된 가상망을 가리킨다.
IPv6란 1992년 IETF의 ipngwg에서 개발하기 시작한 128비트 주소 체계를 갖는 차세대 ip
프로토콜로써 현재 대부분의 규격이 완료된 상태이며, CISCO를 비롯한 여러 업체 연구소
등에서 IPv6가 지원되는 라우터 호스트를 등을 개발하였거나 개발 중에 있다. 6bone이란 이
러한 IPv6를 동작하고 실험하기 위한 국제적인 실험망으로써 IETF WG에서 6bone의
transition에 대한 여러 가지 작업을 수행 중에 있다.

현재 국내에서는 국제 6bone에 연결되어 국내의 IPv6개발과 연구 촉진 network
deployment를 위한 실험망인 6bonek이 있으면 Ptla인 etri/kr, 3ffe:2e00: : /24를 기반으로
국내 transition을 체계적으로 추진중이다.
2. Java Security의 구현
본 연구에서 구현한 것은 다음과 같다.
● 웹 브라우저인 핫자바 브라우저에서의 사용자 security 환경설정 인터페이스
핫자바 버전 1.0 알파 3에서의 보안 환경은 인터넷 방화벽을 이용한 것이었다. 그러므로, 현
재 자바에서 제공하고 있는 다양한 security 정책을 효과적으로 이용할 수 없었다. 따라서
본 연구에서는 JDK가 제공하는 security manager 및 툴을 사용하여 security 환경을 새롭
게 구성해보았다.
가. Security 환경 설정 인터페이스
다음 그림은 security 환경 설정 인터페이스이다. 그림 10에서 보는 바와 같이 사용자가 설
정해 줄 수 있는 영역은 네 가지가 있다.
● Security Level
● Policy Tool
● Signed Applet
● Password

첫째, ‘Security Level’ 은 보안 수준을 세 단계로 정할 수 있다. 수준의 엄격함, 보통, 낮음
으로 설정 가능하다. 이것은 JDK에서 제공하는 security manager를 보안 수준의 단계에 맞
는 서브 클래스로 작성하여 가능하게 하였다. (그림 3-6-2-1 참조)
[그림 3-5-2-1 Security 레벨 설정]
둘째, ‘Policy Tool’은 웹 상에서 policytool이라는 응용프로그램을 실행할 수 있도록 하였다.
다음 그림에서 보는 바와 같이 버튼을 클릭하면 [그림 3-6-2-2]과 같은 policytool 창이 뜬
다.

[그림 3-5-2-2 Policytool의 실행]
policytool은 특징 URL에 대하여 퍼미션을 줌으로써, 기존에 네트워크를 통해 전송되어진
애플릿이 시스템 자원에 접근하지 못하도록 한 것을 보다 유연하게 한 것이다. 이를 사용하
면 특정한 사람이 인증한 특정한 URL에 있는 애플릿에게 읽기, 쓰기 혹은 모든 퍼미션을
줄 수 있다.

[그림 3-5-2-3 Policytool]
셋째, ‘Signed Applet’은 인증된 애플릿의 실행을 제어하는 것이다. 인증된 애플릿이라고 할
지라도 이것을 사용하는데 안전하다는 보장을 할 수 없기 때문에 실행에 관련하여 사용자는
고유의 정책을 마련 할 수 있다. 인증된 애플릿을 엄격하게 다룰 것인가, 혹은 애플릿을 실
행하기 전에 경고 문구를 보여줄 것인가로 설정할 수 있다.

[그림 3-5-2-4 Signed applet 제어]
넷째, ‘Password’ 는 브라우저에 암호를 심어주는 것이다. 사용자 컴퓨터가 물리적 혹은 네
트워크를 통해서 다른 사용자에게 개방되어 있는 경우, 브라우저에 암호를 심어줌으로써 사
용 권한을 제한할 수 있다.
즉, 브라우저를 띄우기 전에 사용자 암호를 입력하게 하여 암호가 맞으면 브라우저를 실행
하고 그렇지 않으면 브라우저를 실행하지 않는다.

[그림 3-5-2-5 Password 설정]

제 4 장 결론
제 1 절 연구결과
본 연구에서는 당해 년도에 Java 가상머신에 대한 연구 및 설계, Java 데이터베이스 환경의
구축, Java 웹서버/브라우저의 성능 개선, Java 운영체제의 구현, Java 디버거에 대한 연구
등을 수행하였다. 연구수행의 결과는 다음과 같다.
Java 가상머신은 내부 구조가 복잡하고 내용이 다양하며 하위레벨과의 상호연관성을 알기
위해서는 하드웨어적인 지식을 많이 요구한다.
기존의 Japhar, Kaffe, Electrical Fire 등의 공개된 Java 가상머신의 성능을 테스트해 보았
다. 테스트 결과 기능상의 문제점이 없음을 알았고, 프로그램으로 구현하기보다는 내부 구조
를 분석하고 수행 가능한 애플리케이션을 알아보기 위해 각종 프로그램으로 Java 가상머
신을 테스트해 보았다. 이와 같은 테스트를 통하여 위에서 언급한 3가지 Java 가상머신 중
에서 Kaffe가 설치도 용이하고 성능도 뛰어남을 알 수 있었다.
현존하는 Java 디버거는 프로그램의 세부모듈을 검사해가면서 프로젝트의 모든 파일을 추
적을 할 수 있는 장점을 가지고 클래스 추적 가능과 불가능을 참조하며, 디버거를 이용해
프로그램을 수행 시, 응용 프로그램의 동작을 볼 수 있다는 장점을 가지고 있다. 이와 같은
Java 디버거는 기능상의 문제는 없으나 사용자를 위한 graphical한 interface를 제공하지 않
는다. 그러므로 사용자 편의를 위한 graphical interface를 제공하기 위해서 기존 Java 디버
거를 비쥬얼한 통합 툴로 업그레이드하는 것이 필요하다.
웹서버의 기능을 확장하였다. 즉 웹서버에 디렉토리 처리기능과 스크립트 처리기능을 추가
하였다. 간단한 ETF(Ewha tag Format)를 정의하여 여러 타입의 서버를 만들어 성능을 테
스트하는데 사용하였다. 같은 프로그램 내에서 쓰레드를 생성하여 스크립트를 처리하는 방
식이 독립된 프로세스를 생성시켜 스크립트를 처리하는 것보다 시간이 적게 걸렸다.

즉 쓰레드 생성이 프로세스 생성보다 부하가 적다는 것을 볼 수 있다. 그리고 분산환경일
때는 스크립트 처리 기능을 하는 독립된 서버를 두어 부담을 분산시키는 것이 많은 사용자
의 요구를 동시에 처리해야 하는 웹서버를 고려할 때 유용하다고 할 수 있다.
Java 웹 서버의 디렉토리 관리 기능은 파일 업로드 및 다운로드가 많은 인터넷 강의의 특
성을 고려할 때 유용성이 있다. 웹서버에 파일 및 디렉토리 관리를 전담하는 서버(디렉토리
관리서버)를 따로 유지함으로써 사용자에게 일관된 인터페이스를 제공하고 시스템의 부하를
줄이게 되었다. 즉 사용자는 비슷한 기능을 하는 ftp client와 같은 별도의 프로그램을 설치
할 필요 없이 웹브라우저만을 가지고 어디서든 파일 관리를 할 수 있다. 또한 서버 시스템
에도 ftp server와 같은 별도의 프로그램을 설치할 필요가 없다. 자바 웹서버 및 디렉토리
관리서버는 자바의 쓰레드를 사용하여 사용자의 연결을 받아들이기 때문에 일반적인 웹서버
보다 연결 요청 시에 반응속도 및 실행속도가 빠르다는 장점이 있다. 또한 구현된 자바 웹
서버는 애플릿의 제약사항이었던 서버의 디렉토리 액세스를 한정된 사용자한테 가능하도록
하였다는데 의의를 둘 수 있다.
제 2 장 제 5 절에서 살펴본 운영체제는 기능이 복잡하고 구현해야될 것들도 많다. 뿐만 아
니라 각종 하드웨어 드라이브에 관한 지식이나 하드웨어 자체에 지식이 너무나 방대하여 구
현하기 힘든 부분이였다. 그러므로 본 연구에서는 기존에 공개되어 있는 운영체제들의 내부
구조를 연구하였고, 공개된 운영체제상에서 자바 가상머신이 별 무리 없이 잘 수행되는 것
을 테스트하였다.
Java 데이터베이스 환경 구축을 위한 이동 에이전트의 기술은 기존의 원격 프로시저 호출
과 같은 방법처럼 지속적으로 많은 데이터를 주고받는 것이 아니기 때문에 성능이 그다지
좋지 않은 네트워크에서도 비용이나 자원을 효과적으로 이용할 수 있다. 이런 이동 에이전
트의 장점을 분산 XML문서 검색에 적용시킴으로써 현재 XML 검색 시스템 구조의 개선을
통한 검색의 효율성을 다른 각도에서 해결 할 수 있다.

서로 다른 호스트들이 산재되어 있는 분산환경에서 XML문서를 질의하면 이동 에이전트의
LightWeight의 특성에 맞게 신뢰성 있는 결과를 사용자에게 즉각적으로 제공해 줄 수 있으
며, 네트워크상의 불필요한 메시지 패싱을 줄이고 능동적인 행동능력을 갖춘 에이전트의 이
동으로 효율적으로 네트워크를 사용할 수 있다.
앞으로 좀 더 발전된 형태로 이동 에이전트 서버가 질의 기능도 포함함으로써 클라이언트
쪽의 기능은 축소시키고 서버 쪽 기능을 확대시켜 나가는 방안은 모색해 볼 수 있으며 더
나아가 JAVA Virtual Machine내에 이동 에이전트의 질의 기능을 추가시킴으로써 서버 쪽
에서 원하는 사용자 검색에 관한 모든 일들을 처리할 수 있도록 개선 가능하다.
제 2절 연구개발의 달성도 및 자체평가
1. 연구개발 목표의 달성도
- Java 시스템 기능의 분석
- Java 시스템의 환경구축 정도 조사
- Java 가상머신의 기능
- Java Database 환경의 구축
- Java Web server/browser의 개선된 성능
- Java OS의 구현

다음은 연구개발 목표에 따른 달성도를 도표로 표시한 것이다.
목표달성도(%)
과제 내용
Java 고성능Architecture 연구
90%
Java 가상머신의 설계, 연구
Java interpreter 개발
Database Java 환경구축
Java Interrupt/debugger 구현
Reconfigurable Java 가상머신 구현
Java 고성능 인터넷 서비스개발환경 구축
90%
Portable Java OS설계
Web 환경기반 DB 연동 환경 구축
Java Interrupt/debugger 구현
Java Web server/browser 성능 개선
2. 연구개발에 따른 목표 달성도에 대한 평가
본 연구는 1998년 상반기에 Java 가상머신의 기능 연구와 Java 프로세서 구조 연구 및 바
바 운영체제 구조연구가 완료되었고, 후반기에 는 Java 프로그래밍 언어 환경연구, Java 데
이터베이스 구축 사례 및 연구, Java 인터넷 프로토콜/보안의 기초 이론 연구가 완료되었다.
또한 2차 년도인 1999년에는 1998년 1차 년도의 연구내용을 기반으로 하여 Java 가상머신
의 효율적인 운영을 위한 자바 운영체제를 구현하기 위해 연구, 설계해 보았다. 또한 이렇게
설계된 자바 운영체제 상에서 잘 수행되는 자바 가상머신의 내부구조를 연구하고 분석해 보
았으며 Java 웹서버의 성능을 개선해 보았다. 그리고, Java 데이터베이스 환경 구축은
Aglet이라는 이동 에이전트를 사용하여 DB Search를 구현해 보았다.
제 3 절 연구 성과
연구성과 내 용
논문발표
명 칭 저널ㆍ학회명 발표일 비고
Web Lecture Script를 위한 Java WebServer 구현
전기학회 1999년 7월 20일
디렉토리 관리 기능을 추가한 자바 웹서버의 설계 및 구현
정보과학회 1999년 10월 23일
연구성과 내 용
프로그램등록
명 칭 등록일 등록번호
ETF(Ewha Tag Format)script처리를 위한 JavaWeb Server
1999년 7월 28일 99-01-15-3508
위의 프로그램등록을 증명하는 프로그램등록증서의 사본을 본 보고서 뒤에 별지로 첨부한
다.

참고문헌
[1] James Gosling, Frank Yellin, The Java Application Programming Interface, Volume 1,
Addison Wesley, 1996.
[2] James Gosling, Frank Yellin, The Java Application Programming Interface, Volume 2,
Addison Wesley, 1996.
[3] Hamilton Cattel1 Fisher저, 박재진, 손진국 역, 자바로 처리하는 JDBC 데이터베이스, 대
림, 1997
[4] http://eesri.snu.ac.kr/trans/english/information/techinfo/techinfo.html
[5] http://caic.chungnam.ac.kr/youngsik/index1.html
[6] http://polaris.cs.uiuc.edu/~pengwu/java-group.html
[7] http://www.icesoft.no/DOWNLOAD/index.html
[8] http://www.jars.com/
[9] http://his.etri.re.kr/share.1html.html
[10] http://www.artima.com/insidejvm/index.html
[11] Peter Coad, Mark MayField, JAVA DESIGN(Building Better Apps & Applets),
Yourdon Press, 1996
[12] Philip Heller, Simon Roberts, Peter Seymour, Tom McGinn, Inside Secrets Java 1.1,
삼각형, 1997
[13] Feather저, 김중환역, 예제로 배우는 자바스크립트, 인포북,1997
[14] Mark Grand, Jonathan Knudsen, JAVA Fundamental Classes Reference, O' REILLY,
1997
[15] Dan Brookshier저, 윤경구역, 자바빈즈 개발자 레퍼런스, 대림, 1997
[16] Noel Enete, JAVA JUMP START, Prentice Hall PTR, 1997
[17] Chris Laffra, Advanced JAVA, Prentice Hall PTR, 1997
[18] Robert Orfali, Dan Harkey, Client/Server Programming with JAVA and CORBA,
WILEY COMPUTER PUBLISHING, 1997
[19] Campione, Walrath, 자바 튜토리얼, 에드텍, 1997

[20] Mark C. Chan, Steven W. Griffith, Anthony F. Iasi, 1001JAVA PROGRAMMER'S
TIPS, 성안당, 1997
[21] http://www.cs.berkeley.edu/~jfoster/cs252-project/benchmarks
[22] http://www.javalobby.org/
[23] http://www.javagrande.org/
[24] http://javaboutique.internet.com/new.html
[25] http://myhome.shinbiro.com/~bonde1/java/java.htm
[26] http://computing.soongsil.ac.kr/vmspec/VMSpecTOC.doc.html
[27] David Flanagan, JAVA IN A NUTSHELL, O' REILLY, 1997
[28] John A. Pew, Instant JAVA, Prentice Hall PTR, 1997
[29] Jerry R. Jackson, Alan L. McClellan, JAVA by example, Prentice Hall PTR, 1997
[30] Doug Lea, Concurrent Programming in Java, Addison Wesley, 1996
[31] Patrick Naughton, Herbert Schildt, The Complete Reference JAVA, McGraw-Hill,
1997
[32] Gay S. Horstmann, Core JAVA, Gray Cornel1, Prentice Hall PTR, 1997
[33] 박지훈, 네트워크 컴퓨팅의 핵심 기술 최신자바 1.1, 사이버출판사, 1997
[34] Mark Watson, INTELLIGENT JAVA APPLICATIONS, Morgan Kaufmann
Publishers, 1997
[35] Joseph P. Bigus, Jennifer Bigus, Constructing intelligent Agents with Java, WILEY
COMPUTER PUBLISHING, 1997
[36] CampioneㆍWalrathㆍHumlㆍTutorial Team, The Java Tutorial Continued, Addison
Wesley, 1998
[37] Chan Lee Kramer, The Java Class Libraries Second Edition, Addison Wesley, 1998
[38] Mike Cohn, Bryan Morgan, Michael Morrison, Michael T. Nygard, Can Joshi, Tom
Trinko, JAVA 레퍼런스, 정보문화사, 1998

[39] Mark Grand, Patterns in Java Volume 1, WILEY COMPUTER PUBLISHING, 1998
[40] Scott R. Weiner, Stephen Asbury, Programming with JFC, WILEY COMPUTER
PUBLISHING, 1998
[41] Steve Potts, Java 1.2 How-To, SAMS, 1998
[42] Robert Orfali, Dan Harkey, Client/Server Programming with JAVA and CORBA,
WILEY COMPUTER PUBLISHING, 1998
[43] Bill Venners, INSIDE the JAVA Virtual Machine, McGraw-Hill, 1998
[44] Robert Eckstein, Marc Loy, Dave Wood, JAVA Swing, O' REILLY, 1998
[45] Campione Walrath, The Java Tutorial Second Edition, Addison Wesley, 1998
[46] Cay S. Horstmann, Gary Cornel1, Core JAVA 1.2, Prentice Hall, 1999
[47]Philip Heller, Simon Roberts, Java 2 개발자 핸드북, 삼각형프레스, 1999
[48] http://race.gsnu.ac.kr/~hwa/java/jdk1.2/docs/guide/jvmdi/jvmdi.html
[49] http://pl.changwon.ac.kr/seminar/jvm/notes/seminar_sam.ntml
[50] http://www.sys-con.com/java/index2.html
[51] http://davinci.snu.ac.kr/lab/seminar/jvm.html
[52] http://cselab.snu.ac.kr/project/ipctv/workshop.html
[53] http://latte.snu.ac.kr/
[54] Stephen Asbury, Scott R. Weiner, Java Enterprise Applications, WILEY
COMPUTER PUBLISHING, 1999
[55] Jonathan Knudsen, JAVA 2D Graphics, O' REILLY, 1999
[56] 최재영, 최종명, 유재우, 프로그래머를 위한 Java2, 홍릉과학출판사, 1999
[57] David M. Geary, Graphic JAVA Mastering the JFC, Prentice Hall, 1999

[58] Douglas A. Lyon, IMAGE PROCESSING in JAVA, A Lyon Book, 1999
[59] Merlin Hughes, Michael Shoffner, Derek Hamner, with Umesh Bellur, JAVA
Network Programming, MANNING, 1999
[60] David Flanagan, 예제로 배우는 자바 프로그래밍, 한빛미디어, 1999
[61] Daniel Groner, K.C. Hopson, Harish Prabandham, Todd Sundsted, Java API
Programming, 삼각형, 1997
[62] Gary McGraw, Edward Felten, JAVA SECURITY, WILEY COMPUTER
PUBLISHING, 1997
[63] Dan Woods, Larne Pekowsky, Tom Snee, The Developer's Guide to the Java Web
Server, Addison-Wesley, 1999
[64] Richard Monson-Haefel, Enterprise JAVA BEANS, O' REILLY, 1999
[65] Tom Valesky, Enterprise JavaBeans Developing Component-Based Distributed
Applications, Addison-Wesley, 1999
[66] 김석주, 자바스크립트의 유혹, 가남사, 1996
[67] Laura Lemay, Rogers Cadengead, Java1.2(21일 완성), 인포북, 1998
[68] Dustin R. Callaway, Inside Servelets, Addison-Wesley, 1999
[69] Marco Pistoia, Duane F. Reller, Deepak Gupta, MilindNagnur Ashok K. Ramani,
JAVA 2 NETWORD SECURITY, Prentice
Hall PTR, 1999
[70] James Goodwill, Developing Java Servlets, SAMS, 1999
[71] http://www.transvirtual.com/presentations/one4all/kaffe-dav.html
[72] http://www.javasoft.com/nav/business/source_form.html
[73] http://www.blackdown.org/java-linux/mirrors.html
[74] http://www.elim.net/~hwlee/TeaPot/
[75] http://pec.etri.re.kr/~qkim/HTTP/
[76] www.sun.com/software/embeddedserver/index.html
[77] http://webservercompare.internet.com/cgi-bin/servdir.pl
[78] http://www.first.gmd.de/persons/leo/java/Telnet/

[79] J. steven Fritzinger, and Marianne Mueller, 'Java Security', Sun microsystems, Inc.
1997.
[80] Joseph A. Bank, 'Java Security', 1995.
http://swissnet.ai.mit.edu/~jbank/javapaper/javapaper.html
[81] Sun Microsystems, "Frequently Asked Questions-Java Security', 1997
[82] Gary McGraw, Edward Felten, 'Java Security', John Wiley, Sons, Inc. 1997
[83] Sun Microsystems, 'Secure Computing With Java', White papers, 1997
[84] Java Security 기술, 탁성우, 1998
[85] 자바 시큐리티에 대한 고찰, 임영주
http://cybers.yonsei.ac.kr/
[86] Fritz Hohl, Peter Klar, Joachim Baumann. Efficient Code Migration for Modular
Mobile Agents. Institute of parallel and
Distributed High-Performance System(IPVR), University of Stuttgart, Germany.
[87] Alberto Silva, Miguel Mira da Silva and jose Delgado. An Overview of AgentSpace
: A Next-Generation Mobile Agent Systems.
In Proceeding of the Mobile Agent 98.
[88] Frederick Knabe. An Overview of Mobile Agent Programming. P. University
Catolica de Chile, Casilla 306, Santiago 22, Chile.
[89] Chong Xu, Dongbin Tao. Bulding Distributed Application with Aglet.
[90] Evaggelia Pitoura and Bharat Bharagava. Dealing with Mobility: Issues and
Research Challenges.
[91] Arnaud Sahuguet. About agents and databases.
[92] Gunter Karjoth. A Security Model and Aglets.
[93] David Wong, Noemi Pacior다 Dana Moore. Java-based Mobile Agents

[94] P. E. Clements, Todd Papioannou and John Edwards. Aglets : Enabling the virtual
Enterprise. Managing Enterprises Stakeholders,
Engineering, Logistics and Achievement (ME-SELA 97)
[95] Todd Papaioannou and John Edwards. Mobile Agent Technology Enabling The
Virtual Enterprise : A Pattern for Database
Query.
[96] 분산 멀티미디어 정보 관리를 위한 이동 에이전트 기술.
http://D bdoc.ajou.ac.kr/~gremrin/research/agent.html
[97] 조영환, 강지훈. SAX를 이용한 XML문서 편집기, 1999년도 한국 정보과학회 춘계 학술
발표 논문집.
[98] 연제원, 조정수, 이강찬, 이규철. XML문서 구조 검색을 위한 저장 시스템 설계, 1999년
도 한국 정보과학회 춘계 학술 발표 논문집.
[99] 최한석, 김동욱. XML 구조 문서 편집기의 설계 및 구현. 1999년도 한국 정보과학회 춘
계 학술 발표 논문집.
[100] http://xdev.datachannel.com/
[101] http://www.megginson.com/SAX/index.html
[102] http://msdn.microsoft.com/XML/c-frame.htm#/XML/default.asp
[103] http://www.XML.com/XML/pub
[104] http://XMLinfo.com
[105] http://saxsoft.com
[106] http://XML 1.0 W3C Recommendation 10-Feb-1998
[107] http://www.w3.org/TR/REC-XML-19980210.html
[108] 최중민, 에이전트의 개요와 연구방향, 1997년도 정보과학회지
[109] 최지영, 이동 에이전트를 이용한 분산 전문가 시스템 개발환경의 설계 및 구현, 1997
년 석사학위 청구논문
[110] http://www.trl.co.jp/aglets
[111] 표순규, 윤기병, 유대균, 모바알 에이전트 서비스 시스템의 설계와 구현
[112] http://www.genmagic.com
[113] 김태현, 김경일, 이강찬, 이규철, xml기반의 정보 통합을 위한 OODB2XML 래퍼의 설
계 및 구현.

import com.datachannel.xql.query.*;import com.datachannel.xml.om.IXMLDOMNode;import com.datachannel.xml.om.IXMLDOMNodeList;
[Appendix A] Data channel 라이브러리를 이용한 이동 에이전트 구현
n XML 문서를 파싱 하기 위한 자바 파서 IMPORT
n XML 문서를 파싱 하기 위한 Datachannel의 Library사용

public void XMLParsing(Message msg) {setText(message);String fileQueried ="c:\\agletsl.lbl\\public\\thai_food.xml“;String urlString = fileQueriedString queryString = messige; com.datachannel.xml.om.Document doc = new com.datachannel.xml.om.Document();doc.setValidateOnParse(false);StringBuffer result = new StringBuffer();try{doc. load(urlString);IXMLDOMNodeList selectedNodes =((IXMLDOMNsde)doc.getDocumentElement()).selectNodes(queryString);IXMLDOMNode node = selectedNondes.nextNode();while (node !=null)node = selectedNondes.nextNode()}setText(result.toString());if(result. length() == 0){setText("The result is empty.\n");}catch(Exception e){ setText("The result is empty.\n");}}
[Appendix B] 사용된 XML 문서 : food.xml





















