
kompresi_04
30
Topic 4 Dictionary Method Aditya Wikan M., S.Kom Dictionary Method Kompresi Data
-
Upload
dwi-prasetiyo -
Category
Documents
-
view
53 -
download
2
Transcript of kompresi_04

Topic 4Dictionary Method
Aditya Wikan M., S.Kom
Dictionary Method
Kompresi Data

Dictionary Method
� Dictionary method / metode kamus menggunakan sebuah kamus yang disusun untuk menentukan codewordkompresi dan dekompresi (hampir sama dengan symbol table)dengan symbol table)� Disebut juga dictionary coding (Zeeh:
2003)

Dictionary Method
� Teknik dictionary coding bergantung pada pengamatan bahwa terdapat korelasi antara bagian-bagian data yang akan dikompresi:Ada pola yang muncul kembali / berulang � Ada pola yang muncul kembali / berulang (recurring patterns)� Ide dasarnya adalah mengganti
perulangan tersebut dengan referensi (yang seharusnya lebih pendek) ke kamus yang menyimpan bentuk aslinya

Static Dictionary
� Kamus ditentukan terlebih dahulu� Mengandung simbol yang biasanya
muncul berulang-ulang, baik dalam bentuk frase, digram, atau n-gramfrase: oleh karena itudigram: ng, nj, au, eu, ai, 3-gram: nya, itu, lah� Membutuhkan pengetahuan mengenai
teks yang akan dikompresi, misal teks Bahasa Indonesia.

Static Dictionary
� Static dictionary hanya menghasilkan sedikit kompresi terhadap data yang bervariasi, malah bisa menimbulkan perbesaran ukuranMisal dictionary semua digram dan 3-gram � Misal dictionary semua digram dan 3-gram bahasa Indonesia, digunakan untuk mengkompresi teks bahasa Inggris �tidak optimal

Semi-Adaptive Dictionary
� Menghindari masalah pada static dictionary� Data input dibaca dahulu seluruhnya,
kemudian dilihat pola data yang ada, dan disusun kamusnyadisusun kamusnya� Dua kali kerja: membuat kamus dahulu
baru mengkompres data� Membutuhkan metode lain untuk
membantu menyusun kamus yang optimal (analisis heuristik dsb.)

Adaptive Dictionary
� Data input dibaca sambil menyusun kamus, sambil melakukan kompresi� Tidak perlu menyimpan kamus bersama
dengan data hasil kompresi� Decoder (dekompresor) bisa menyusun
kamus dengan cara yang sama seperti encoder (kompresor)� Metode inilah yang paling banyak dipakai
saat ini (Zeeh: 2003, Munro)

Algoritma Lempel-Ziv
� Adalah algoritma kompresi data lossless, dikembangkan oleh Abraham Lempel dan Jacob Ziv� Istilah Lempel-Ziv biasanya merujuk pada
sebuah keluarga algoritma yang terbagi sebuah keluarga algoritma yang terbagi menjadi dua keluarga besar, diberi nama sesuai tahun pengajuan paper mereka, yaitu 1977 (LZ77) dan 1978 (LZ88)� Algoritma dictionary coding yang banyak
dipakai
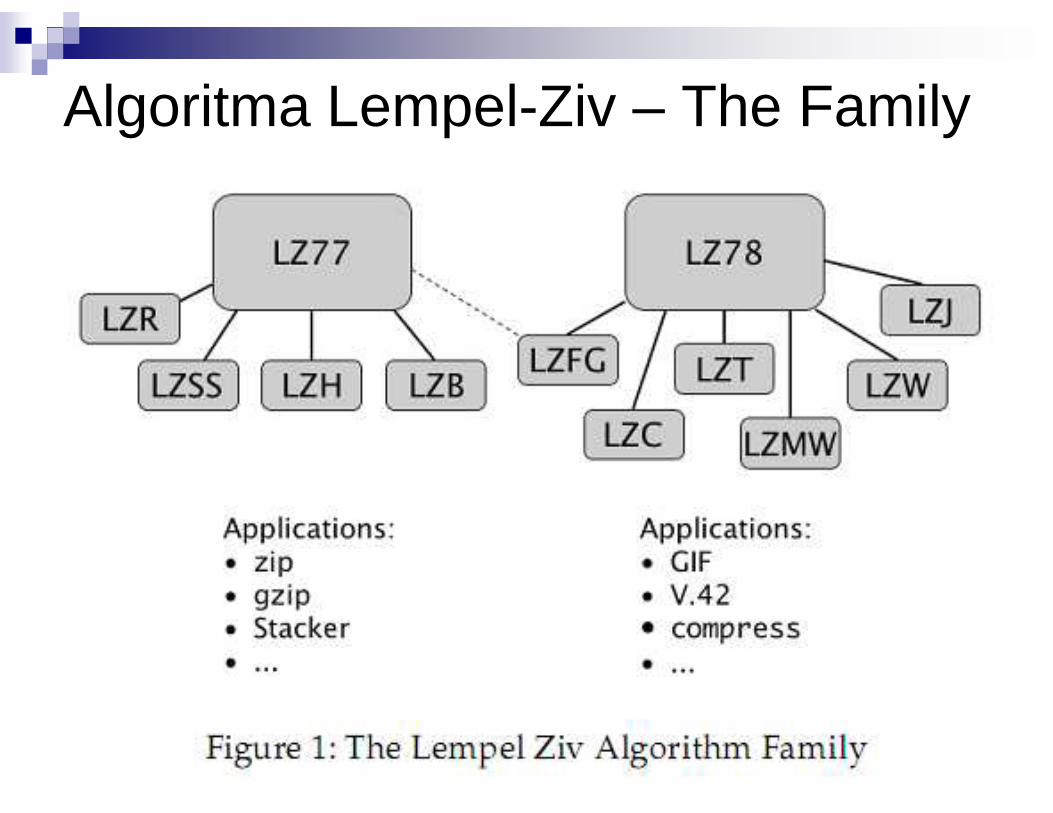
Algoritma Lempel-Ziv – The Family

LZ77 - Principle
� Dikenal juga dengan algoritma sliding window.� Mengintip rangkaian data melalui sebuah
jendela geser sepanjang n data� Jendela tersebut kemudian dibagi menjadi
2 bagian:Looakhead buffer sepanjang L dataSearch buffer (S) sepanjang (n – L) data� Terapkan algoritma LZ77 pada jendela
tersebut

LZ77 - Principle
� Search buffer digunakan sebagai kamus� Ukuran kedua buffer menjadi parameter
untuk implementasi. � Asumsi: pola dalam teks akan muncul
sepanjang range dari search buffer.

LZ77 – Encoding Algorithm
Output code: sebuah tupel yang terdiri dari:(Posisi, panjang, simbol berikutnya)

LZ77 – Encoding Sample
NOT USED!!!TO UNDERSTAND MUST READTHE ORIGINAL LEMPEL-ZIV PAPER FIRST

LZ77 – Decoding Sample
NOT USED!!!TO UNDERSTAND MUST READTHE ORIGINAL LEMPEL-ZIV PAPER FIRST

LZ77 – Encoding Sample

LZ77 – Decoding Algorithm
LZ77 bersifat asimetrik, encoding lebih sulit daripada decoding karena harus menemukan rangkaian simbol terpanjang yang cocok
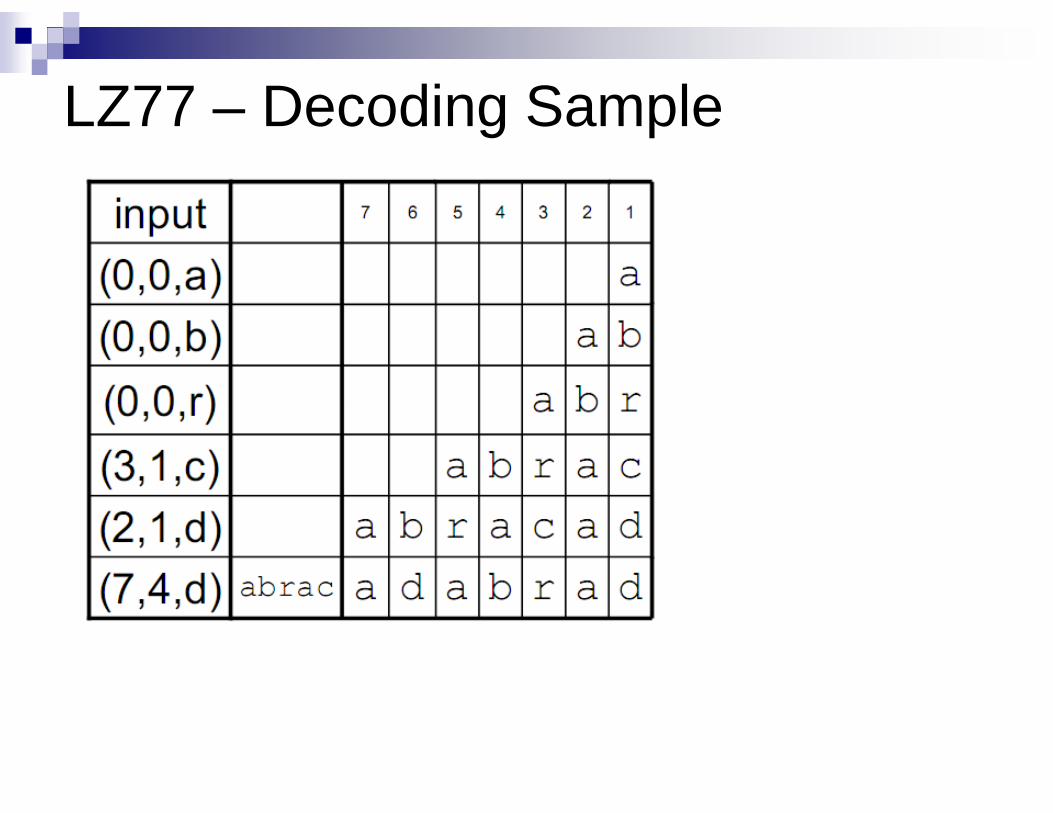
LZ77 – Decoding Sample

LZ77 – Applications� Tidak seperti LZ78, LZ77 belum dipatenkan.
Oleh karena itu banyak sekali turunan LZ77 (LZSS, LZB, LZH, LZR, LZFG, LZMA, Deflate) yang digunakan misal:� Deflate adalah kombinasi LZSS dengan
Huffman encoding dan memakai ukuran window Huffman encoding dan memakai ukuran window 32kB.� This algorithm is open source and used in what
is widely known as ZIP compression (although the ZIP format itself is only a container format, like AVI and can be used with several algorithms), and by the formats PNG, TIFF, PDF and many others

LZ78 - Principle� Membaca input string kemudian mendeteksi
apakah simbol yang dibaca sudah ada dalam kamus, jika tidak:� Menyimpan pola simbol berupa satu karakter
atau multi karakter yang distinct (tidak ada yang atau multi karakter yang distinct (tidak ada yang sama) ke dalam kamus� Menghasilkan dua elemen codeword:� Sebuah indeks yang merujuk pada kamus untuk
entry terpanjang yang cocok dan tersimpan di dalam kamus (matching dictionary entry)� dan sebuah simbol pertama berikutnya yang
tidak cocok (non-matching symbol)

LZ78 - Principle
� Output:

LZ78 – Algorithm

LZ78 – Encoding Sample

LZ78 – Decoding Sample

LZ78 – What’s transmitted?
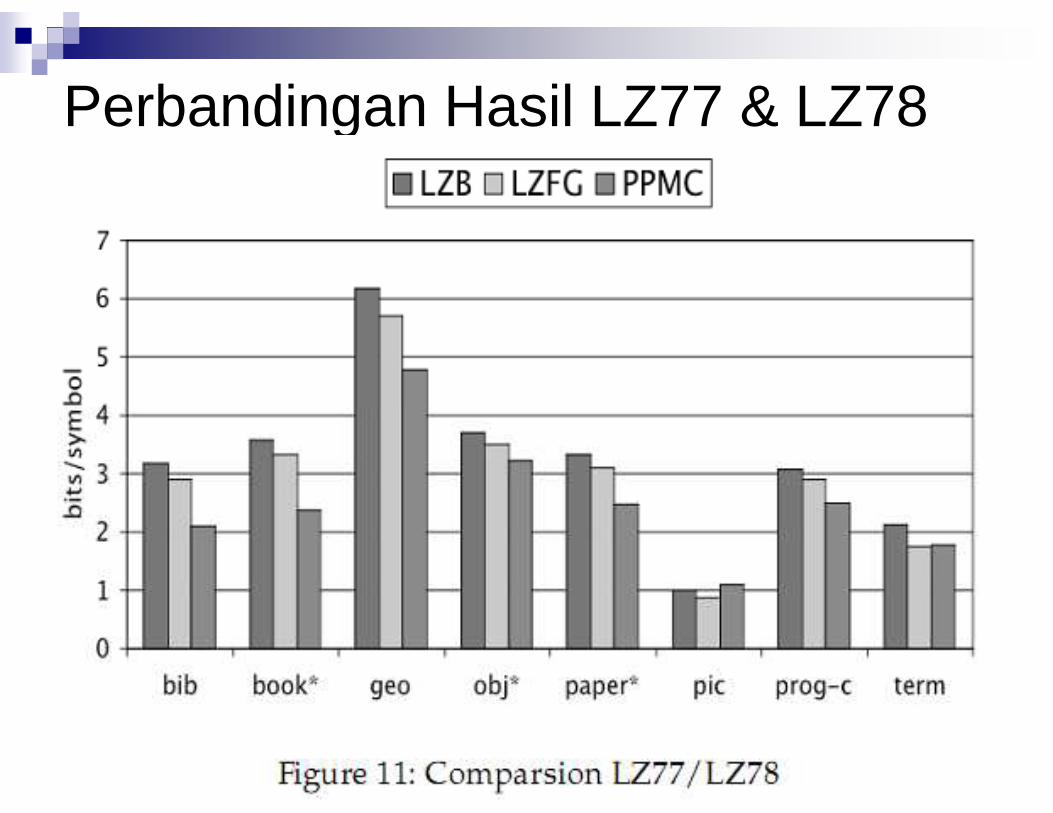
Perbandingan Hasil LZ77 & LZ78

LZW - Principle� Adalah pengembangan dari LZ78 yang oleh
Terry Welch pada 1984� LZW (Lempel-Ziv-Welch) uses a dictionary with
4096 entries. In the beginning the entries 0-255 refer to individual bytes, and the rest 256-4095 refer to individual bytes, and the rest 256-4095 refer to longer strings� LZW compression replaces strings of characters
with single codes. It does not do any analysis of the incoming text. Instead, it just adds every new string of characters it sees to a table of strings. Compression occurs when a single code is output instead of a string of characters.

LZW – Algorithm

LZW – Encoding Sample

LZW – Decoding Sample

That’s all for today
Terima kasih ☺




















