
KAJIAN PENGARUH PENAMBAHAN INFORMASI GEROMBOL … · Dengan ini saya melimpahkan hak cipta dari...
70
KAJIAN PENGARUH PENAMBAHAN INFORMASI GEROMBOL TERHADAP HASIL PREDIKSI AREA NIRCONTOH (Studi Kasus Pengeluaran per Kapita Kecamatan di Kota dan Kabupaten Bogor) RAHMA ANISA SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR BOGOR 2014
Transcript of KAJIAN PENGARUH PENAMBAHAN INFORMASI GEROMBOL … · Dengan ini saya melimpahkan hak cipta dari...

KAJIAN PENGARUH PENAMBAHAN
INFORMASI GEROMBOL TERHADAP HASIL
PREDIKSI AREA NIRCONTOH
(Studi Kasus Pengeluaran per Kapita Kecamatan di Kota dan
Kabupaten Bogor)
RAHMA ANISA
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2014


PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa tesis berjudul Kajian Pengaruh
Penambahan Informasi Gerombol terhadap Hasil Prediksi Area Nircontoh (Studi
Kasus Pengeluaran per Kapita Kecamatan di Kota dan Kabupaten Bogor) adalah
benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan
dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang
berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari
penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di
bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut
Pertanian Bogor.
Bogor, Maret 2014
Rahma Anisa
NIM G151110011

RINGKASAN
RAHMA ANISA. Kajian Pengaruh Penambahan Informasi Gerombol terhadap
Hasil Prediksi Area Nircontoh (Studi Kasus Pengeluaran per Kapita Kecamatan di
Kota dan Kabupaten Bogor). Dibimbing oleh ANANG KURNIA dan
INDAHWATI.
Metode Prediksi Takbias Linear Terbaik Empirik atau Empirical Best
Linear Unbiased Prediction (EBLUP) telah banyak digunakan untuk memprediksi
parameter pada area dengan ukuran contoh yang kecil atau bahkan area nircontoh
(non-sample area). Permasalahan yang terjadi adalah ketika model ini digunakan
untuk memprediksi parameter area nircontoh. EBLUP baku memprediksi
parameter menggunakan model sintetik yang mengabaikan pengaruh acak area
karena kurangnya informasi pada area nircontoh. Akibatnya, seluruh nilai
penduga parameter yang dihasilkan untuk area nircontoh akan terdistorsi pada
satu garis model sintetik. Salah satu gagasan yang dikembangkan dalam penelitian
ini adalah dengan menganggap bahwa terdapat kemiripan karakteristik antar-area
tertentu. Hubungan antar-area tersebut dapat dianalisis dengan teknik
penggerombolan (clustering). Informasi dari hasil penggerombolan ini
ditambahkan ke dalam model untuk memodifikasi titik potong model prediksi
EBLUP baku atau memodifikasi baik titik potong maupun kemiringan model
EBLUP baku. Modifikasi ini dilakukan dengan menambahkan nilai tengah
penduga pengaruh acak dari area dan peubah penyerta (auxiliary variable) pada
setiap gerombol. Pada penelitian ini, kebaikan model yang diusulkan
dibandingkan dengan model EBLUP baku berdasarkan simulasi. Seluruh model
dievaluasi berdasarkan nilai Bias Relatif atau Relative Bias (RB) dan Akar
Kuadrat Tengah Galat Relatif atau Relative Root Mean Squares Error (RRMSE).
Hasil simulasi menunjukkan bahwa penambahan informasi gerombol dapat
meningkatkan kebaikan model dalam memprediksi parameter pada area nircontoh.
Pendugaan ragam pada model linier campuran EBLUP umumnya
menggunakan pendekatan Kemungkinan Maksimum Terbatas atau Restricted
Maximum Likelihood (REML) yang memerlukan asumsi kenormalan. Pelanggaran
asumsi ini banyak ditemukan pada kasus-kasus terapan. Skenario yang berbeda,
yaitu salah satu atau seluruh komponen acak tidak berasal dari sebaran normal,
ditambahkan kedalam simulasi untuk mengkaji kebaikan model yang diusulkan
pada kondisi tersebut. Hasilnya menunjukkan bahwa pada kondisi tersebut, model
yang diusulkan mampu memprediksi dengan nilai RB dan RRMSE yang lebih
kecil dibandingkan dengan EBLUP baku, terutama pada area nircontoh.
Data SUSENAS 2010 dan PODES 2011 digunakan sebagai studi kasus
untuk memprediksi rata-rata pengeluaran per kapita kecamatan di kota dan
kabupaten Bogor. Penerapan model modifikasi EBLUP menghasilkan nilai
prediksi yang berbeda, namun terlihat adanya kemiripan pola. Penggerombolan
memegang peranan penting dalam menerapkan model yang diusulkan pada studi
kasus. Pola penggerombolan yang cenderung tidak linier terhadap peubah respon
dapat menyebabkan prediksi kecamatan nircontoh yang dihasilkan model yang
diusulkan menjadi tidak lebih baik dibandingkan model EBLUP baku. Namun
demikian, masih terdapat model dengan penambahan informasi gerombol yang

menunjukkan kemampuan yang lebih baik dibandingkan dengan EBLUP baku
dalam memprediksi nilai tengah kecamatan nircontoh.
Kata kunci: Analisis Gerombol, EBLUP, Model Campuran Linier


SUMMARY
RAHMA ANISA. Study on the Effects of Cluster Information in Prediction of
Non-sampled Area (A Case Study of per Capita Expenditures at Subdistrict Level
in Regency and Municipality of Bogor). Supervised by ANANG KURNIA and
INDAHWATI.
Empirical Best Linear Unbiased Predictor (EBLUP) has been widely used to
predict parameters in area with small or even zero sample size, known as non-
sampled area. It has been noted that there is a problem when this model will be
used to predict the parameters of non-sampled area. Usually EBLUP is used to
predict the parameters using a synthetic model ignoring the area random effects
due to lack of non-sampled area information. Hence, this prediction will be
distorted based on a single line of the synthetic model. The idea developed in this
thesis is to modify the prediction model by adding cluster information assuming
that there are similiarities among particular areas. These information have been
incorporated into the model to modify the intercept of prediction models as well
as both intercept and slope of the prediction model. In this paper, a simulation is
carried out to study the performance of the proposed models compared with
ordinary EBLUP. All models were evaluated based on the value of Relative Bias
(RB) and Relative Root Mean Squares Error (RRMSE). It was shown, by mean of
simulation, that the addition of cluster information has improved the ability of the
model to predict non-sampled areas.
Restricted Maximum Likelihood (REML), a common method for estimating
variance component in EBLUP models, requires normality assumption. But the
conditions in which the area random effects or sampling error are not normally
distributed may encountered in many applications. Therefore we also used
different scenarios, such as either one of random component was not normally
distributed or both of area random effects and sampling error area were not
normally distributed, to study the performance of the proposed models when the
area random effects or auxiliary variables are not normally distributed. The result
showed that under these conditions, the proposed models has been able to
estimate the parameter with smaller Relative Bias (RB) and Relative Root Mean
Squares Error (RRMSE) than ordinary EBLUP, especially in non-sampled areas.
It was shown that all models could be used to predict average per capita
expenditures per month at subdistrict level in regency and municipality in Bogor.
The analysis was based on SUSENAS 2010 and PODES 2011 data sets. Even
though the resulting predictions of the models were different, similar pattern
among them has been observed. Clustering technique played an important role in
implementing the proposed model in the case study. Clustering pattern which tend
not to be linearly correlated with response variable can lead to the result that
proposed model was not better than standard EBLUP model. However, there were
some proposed models that showed a better accuracy than the standard EBLUP
prediction of non-sampled subdistrict parameter.
Keywords: EBLUP, Clustering, Linear Mixed Models

© Hak Cipta Milik IPB, Tahun 2014
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan
atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan,
penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau
tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan
IPB
Dilarang mengumumkan dan memperbanyak sebagian atau seluruh karya tulis ini
dalam bentuk apa pun tanpa izin IPB

Tesis
sebagai salah satu syarat untuk memperoleh gelar
Magister Sains
pada
Program Studi Statistika
KAJIAN PENGARUH PENAMBAHAN
INFORMASI GEROMBOL TERHADAP HASIL
PREDIKSI AREA NIRCONTOH
(Studi Kasus Pengeluaran per Kapita Kecamatan di Kota dan
Kabupaten Bogor)
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2014
RAHMA ANISA

Penguji pada Ujian Sidang: Prof. Dr. Ir. Khairil Anwar Notodiputro, MS

Judul Tesis : Kajian Pengaruh Penambahan Informasi Gerombol terhadap Hasil
Prediksi Area Nircontoh (Studi Kasus Pengeluaran per Kapita
Kecamatan di Kota dan Kabupaten Bogor)
Nama : Rahma Anisa
NIM : G151110011
Disetujui oleh
Komisi Pembimbing
Dr. Anang Kurnia
Ketua
Dr. Ir. Indahwati, MSi
Anggota
Diketahui oleh
Ketua Program Studi
Magister Statistika
Dr. Ir. Anik Djuraidah, MS
Dekan Sekolah Pascasarjana
Dr. Ir. Dahrul Syah, MSc.Agr.
Tanggal Ujian: 21 Januari 2014
Tanggal Lulus:

JuduJ Tesis
Nama NIM
: Kajian Pengaruh Penambahan Inforrnasi Gerombol terhadap Hasil Prediksi Area Nircontoh (Studi Kasus Pengeluaran per Kapita Kecamatan di Kota dan Kabupaten Bogor)
: Rahma Anisa : G 151110011
Disetujui oleh
Komisi Pembimbing
Dr. Anan Kurnia Ketla Anggota
Dr. Ir. Indahwati, MSi
Diketahui o]eh
Ketua Program Studi Magister Statistika
Dr.lr. Anik Djuraida~ MS
Tanggal Ujian: 21 Januari 2014 Tanggal Lulus: 0 7 APR 20 14

PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas
segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Sholawat serta
salam semoga selalu tercurah kepada pemimpin umat nabi Muhammad SAW,
beserta keluarga, sahabat, dan umatnya. Karya ilmiah ini “Kajian Pengaruh
Penambahan Informasi Gerombol terhadap Hasil Prediksi Area nircontoh (Studi
Kasus Pengeluaran per Kapita Kecamatan Kota dan Kabupaten Bogor)”.
Terima kasih yang sebesar-besarnya kepada semua pihak yang telah turut
peran serta dalam penyusunan karya ilmiah ini, terutama kepada :
1. Bapak Dr. Anang Kurnia dan Ibu Dr. Ir. Indahwati, MSi selaku dosen
pembimbing,
2. Bapak Prof. Dr. Ir. Khairil Anwar Notodiputro, MS sebagai dosen
penguji pada ujian sidang tesis,
3. Badan Pusat Statistik (BPS), atas segala informasi yang telah diberikan,
4. Keluarga Besar Program Studi Statistika IPB,
5. Ayah, ibu, serta seluruh keluarga dan sahabat, atas segala dukungan, doa
dan kasih sayangnya.
Semoga semua bantuan yang diberikan kepada penulis mendapatkan balasan
dari Allah SWT, dan semoga karya ilmiah ini dapat bermanfaat bagi semua pihak
yang membutuhkan.
Bogor, Maret 2014
Rahma Anisa

DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vii
1 PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
2 TINJAUAN PUSTAKA 2
Pendugaan Area Kecil (Small Area Estimation (SAE)) 2
Empirical Best Linear Unbiased Predictor (EBLUP) 3
Restricted Maximum Likelihood (REML) 4
Analisis Gerombol (Clustering) 4
3 METODE 5
Pengembangan Model 6
Kajian Simulasi 7
Studi Kasus 10
4 HASIL DAN PEMBAHASAN 11
Kajian Simulasi 11
Studi Kasus 15
5 SIMPULAN DAN SARAN 20
Simpulan 20
Saran 20
DAFTAR PUSTAKA 20
LAMPIRAN 23

DAFTAR TABEL
1 Titik potong dan kemiringan pada populasi skenario 1 8 2 Titik potong dan kemiringan pada populasi skenario 2 8
3 Jumlah area contoh dan nircontoh pada gerombol ke- 9 4 Kuadrat tengah sisaan prediksi area nircontoh 12 5 Median dari Relative Bias (RB) pada area contoh (%) 13 6 Median dari RRMSE pada area contoh (%) 13 7 Median dari Relative Bias (RB) pada area nircontoh (%) 14 8 Median dari RRMSE pada area nircontoh (%) 14
9 Uji Kenormalan Anderson-Darling 17 10 Penggerombolan kecamatan di Kota dan Kabupaten Bogor 17 11 Prediksi rata-rata pengeluaran per kapita dan evaluasi pemodelan
pada kecamatan nircontoh 19
DAFTAR GAMBAR
1 Garis prediksi area nircontoh skenario 1 untuk hubungan peubah
penyerta terhadap peubah respon yang dihasilkan oleh Model-0,
Model-1, Model-2, Model-3, Model-4, dan Model-5 11 2 Boxplot nilai RB dari prediksi nilai tengah area nircontoh skenario 2 14 3 Nilai RRMSE (%) prediksi area nircontoh model modifikasi EBLUP
pada seluruh skenario simulasi 15 4 Nilai RB (%) prediksi area nircontoh model modifikasi EBLUP pada
seluruh skenario simulasi 15
5 Kepekatan peluang peubah , yaitu rata-rata pengeluaran per kapita
per bulan dan bentuk tranformasi logaritma peubah Y 16
6 Plot kuantil-kuantil peubah 16 7 Hubungan antara peubah penyerta jumlah poliklinik dan jumlah
minimarket terhadap peubah respon 18
DAFTAR LAMPIRAN
1 Garis prediksi area nircontoh skenario 2 untuk hubungan peubah
penyerta terhadap peubah respon yang dihasilkan seluruh
model 23
2 Garis prediksi area nircontoh skenario 3 untuk hubungan peubah
penyerta terhadap peubah respon yang dihasilkan seluruh
model 24
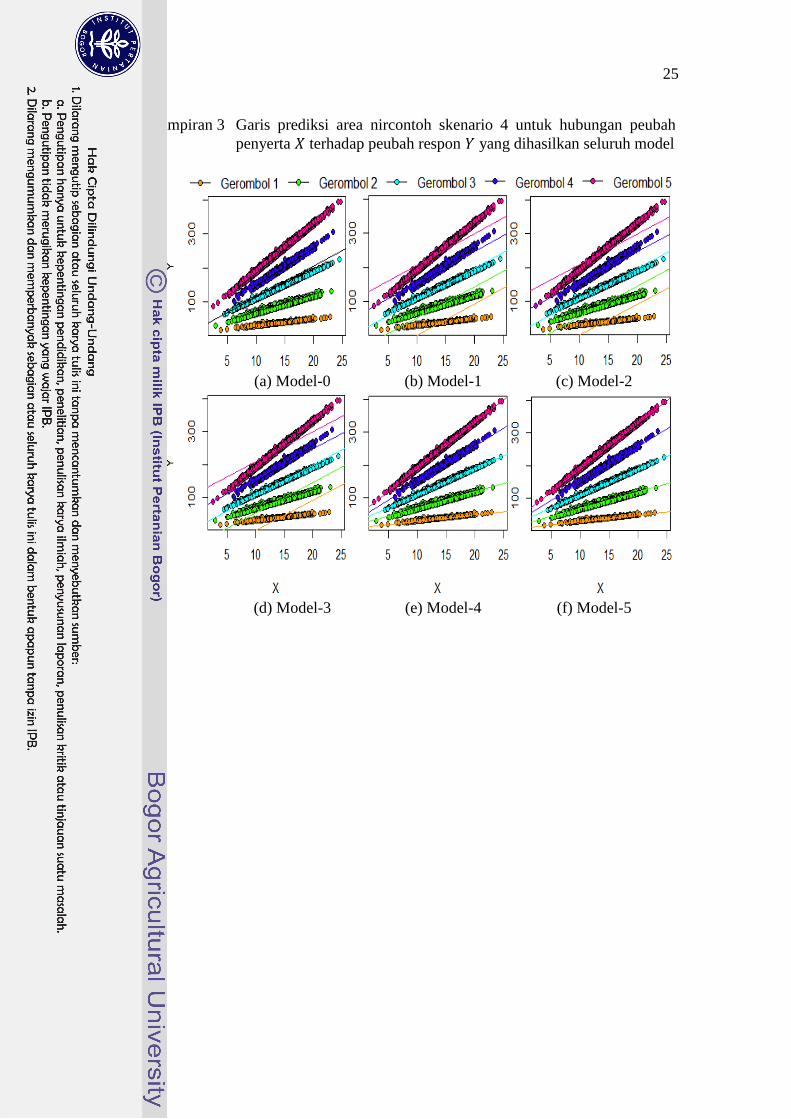
3 Garis prediksi area nircontoh skenario 4 untuk hubungan peubah
penyerta terhadap peubah respon yang dihasilkan seluruh
model 25
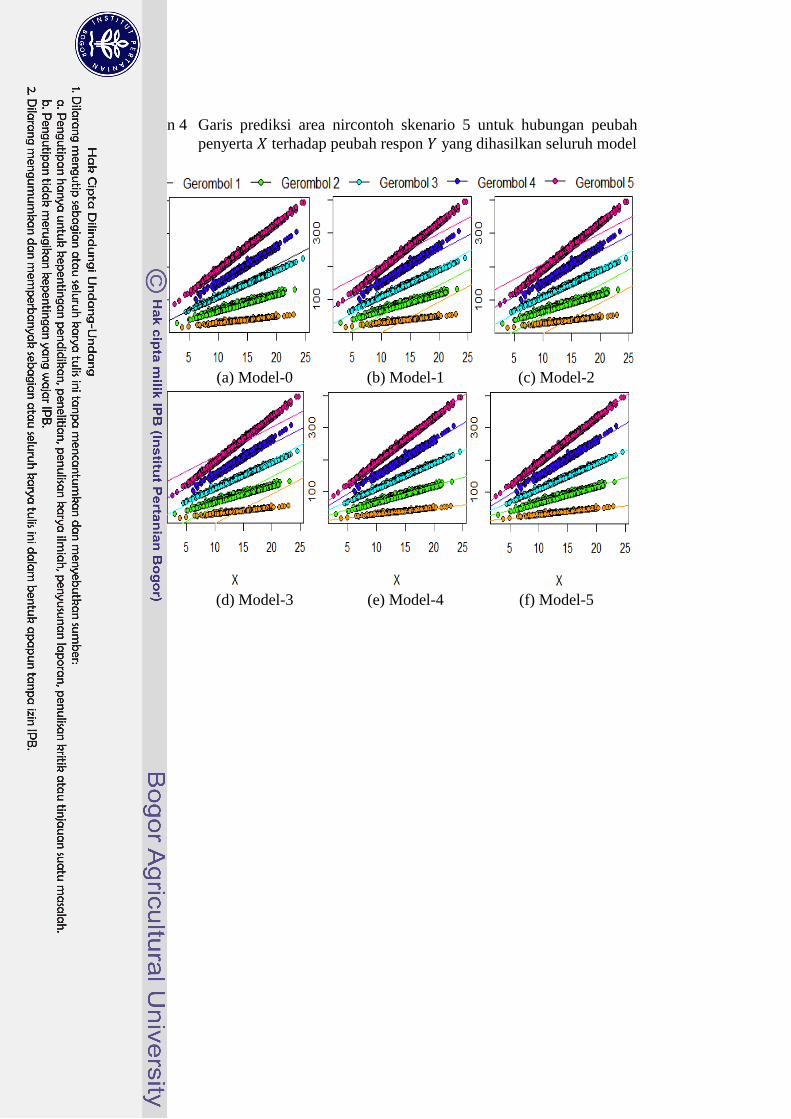
4 Garis prediksi area nircontoh skenario 5 untuk hubungan peubah
penyerta terhadap peubah respon yang dihasilkan seluruh
model 26
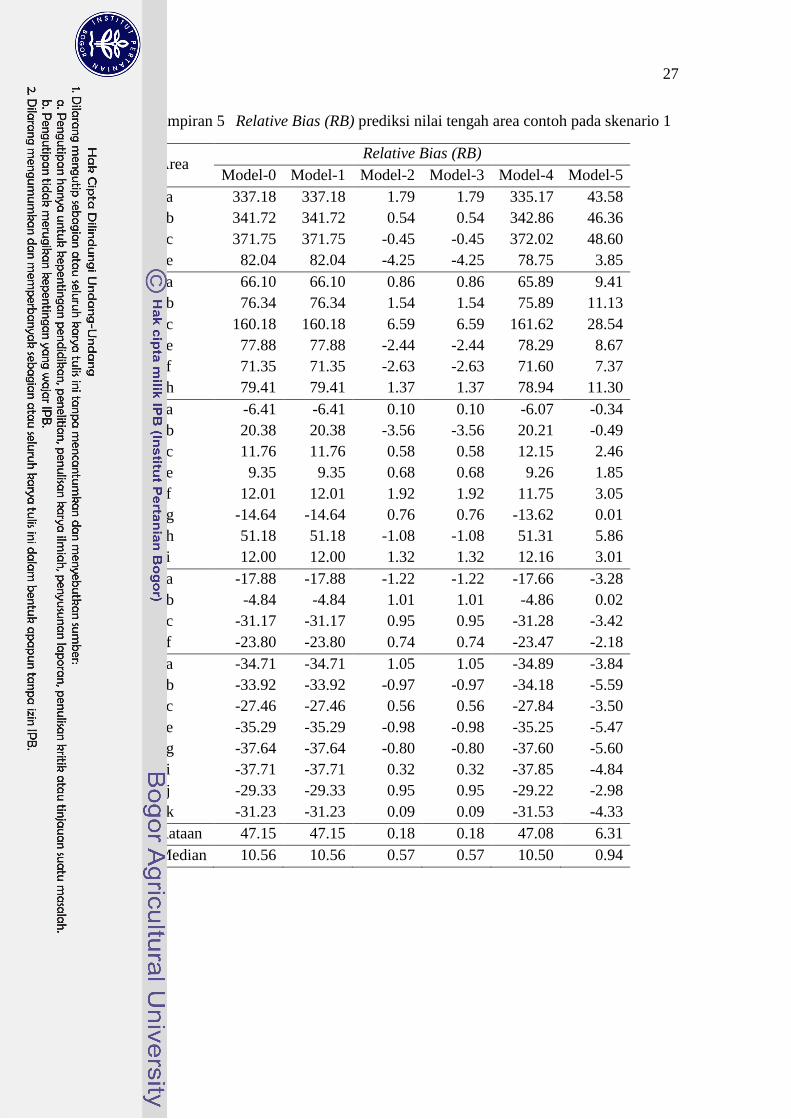
5 Relative Bias (RB) prediksi nilai tengah area contoh pada
skenario 1 27
6 Relative Root Mean Squares Error (RRMSE) prediksi nilai
tengah area contoh pada skenario 1 28
7 Relative Bias (RB) prediksi nilai tengah area contoh pada
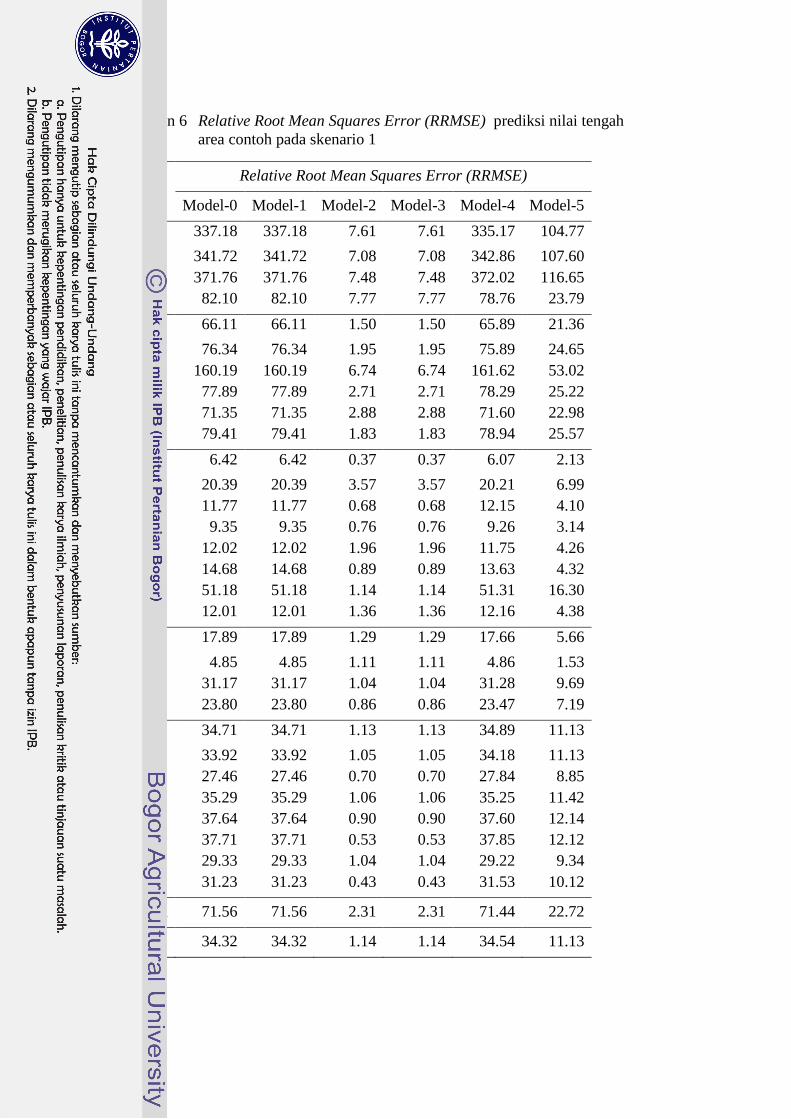
skenario 2 29
8 Relative Root Mean Squares Error (RRMSE) prediksi nilai
tengah area contoh pada skenario 2 30
9 Relative Bias (RB) prediksi nilai tengah area contoh pada
skenario 3 31
10 Relative Root Mean Squares Error (RRMSE) prediksi nilai
tengah area contoh pada skenario 3 32
11 Relative Bias (RB) prediksi nilai tengah area contoh pada
skenario 4 33
12 Relative Root Mean Squares Error (RRMSE) prediksi nilai
tengah area contoh pada skenario 4 34
13 Relative Bias (RB) prediksi nilai tengah area contoh pada
skenario 5 35
14 Relative Root Mean Squares Error (RRMSE) prediksi nilai
tengah area contoh pada skenario 5 36
15 Relative Bias (RB) prediksi nilai tengah area nircontoh pada
skenario 1 37
16 Relative Root Mean Squares Error (RRMSE) prediksi nilai
tengah area nircontoh pada skenario 1 37
17 Relative Bias (RB) prediksi nilai tengah area nircontoh pada
skenario 2 38
18 Relative Root Mean Squares Error (RRMSE) prediksi nilai
tengah area nircontoh pada skenario 2 38
19 Relative Bias (RB) prediksi nilai tengah area nircontoh pada
skenario 3 39
20 Relative Root Mean Squares Error (RRMSE) prediksi nilai
tengah area nircontoh pada skenario 3 39

21 Relative Bias (RB) prediksi nilai tengah area nircontoh pada
skenario 4 40
22 Relative Root Mean Squares Error (RRMSE) prediksi nilai
tengah area nircontoh pada skenario 4 40
23 Relative Bias (RB) prediksi nilai tengah area nircontoh pada
skenario 5 41
24 Relative Root Mean Squares Error (RRMSE) prediksi nilai
tengah area nircontoh pada skenario 5 41
25 Peubah yang terpilih sebagai dasar penggerombolan kecamatan di
Kota dan Kabupaten Bogor 42
26 Korelasi antar peubah dasar penggerombolan kecamatan di Kota
dan Kabupaten Bogor 43
27 Dendogram analisis gerombol kecamatan di Kota dan Kabupaten
Bogor 44
28 Rataan setiap peubah pada masing-masing gerombol 45
29 Pemilihan peubah untuk pemodelan dengan seleksi model regresi
stepwise 46
30 Prediksi rata-rata pengeluaran per kapita per bulan pada
kecamatan contoh di Kota dan Kabupaten Bogor 47
31 Prediksi rata-rata pengeluaran per kapita kecamatan contoh pada
masing-masing gerombol 48
32 Root Mean Squares Error (RMSE) dari prediksi rata-rata
pengeluaran per kapita per bulan pada kecamatan contoh di Kota
dan Kabupaten Bogor 49
32 Root Mean Squares Error (RMSE) dari prediksi rata-rata
pengeluaran per kapita per bulan pada kecamatan contoh di Kota
dan Kabupaten Bogor ( Lanjutan ) 50
33 Prediksi rata-rata pengeluaran per kapita pada kecamatan
nircontoh menggunakan seluruh model 50
34 Evaluasi pemodelan pada kecamatan nircontoh menggunakan
seluruh model 50

1 PENDAHULUAN
Latar Belakang
Pengumpulan data banyak dilakukan melalui survei contoh karena dapat
memperkecil biaya dibandingkan apabila melakukan sensus. Pendugaan
parameter berdasarkan informasi yang diperoleh dari suatu survei dapat dilakukan
dengan pendugaan langsung (direct estimation). Pendugaan langsung akan
memberi hasil yang baik ketika ukuran contoh untuk setiap area cukup besar.
Namun, survei untuk memperoleh informasi rinci pada setiap area akan
memerlukan waktu dan biaya yang besar. Ketika terdapat area contoh dengan
ukuran yang sangat kecil atau bahkan nol, maka pendugaan langsung tidak lagi
baik untuk digunakan karena dapat menghasilkan galat baku yang sangat besar
(Rao 2003). Oleh karenanya, telah dikembangkan metode pendugaan tidak
langsung (indirect estimation) yang diperoleh dengan memanfaatkan peubah lain
(auxiliary variable), serta menambahkan pengaruh acak dari area. Pendekatan ini
dikenal sebagai metode Empirical Best Linear Unbiased Prediction (EBLUP).
Permasalahan lain yang muncul adalah ketika melakukan pendugaan
parameter untuk area yang tidak disurvei (nircontoh). Penduga EBLUP baku
untuk area nircontoh menggunakan model sintetik yang bersifat global. Model
sintetik akan mengabaikan pengaruh acak area karena tidak adanya informasi
pengaruh acak pada area nircontoh (Saei dan Chambers 2005). Akibatnya, nilai
prediksi yang dihasilkan untuk semua area nircontoh akan terdistorsi menuju satu
garis model sehingga memungkinkan terjadi bias yang cukup besar.
Salah satu gagasan yang dikembangkan pada penelitian ini adalah dengan
mengasumsikan bahwa suatu area memiliki pola kedekatan hubungan dengan area
lain. Pola kedekatan tersebut dapat dianalisis berdasarkan karakteristik peubah
tertentu untuk setiap area. Informasi dari pola hubungan tersebut akan
ditambahkan ke dalam model sehingga diharapkan mampu memperbaiki
pendugaan pada area nircontoh. Salah satu pendekatan untuk menganalisis pola
hubungan antar-area tersebut adalah dengan teknik penggerombolan (clustering).
Pendekatan lain yang dikembangkan pada penelitian ini adalah dengan
menambahkan nilai tengah penduga pengaruh acak dari area dan peubah penyerta
pada setiap gerombol ke dalam model prediksi. Penambahan pengaruh tetap
gerombol serta pengaruh acak area dan peubah penyerta secara bersamaan pada
model diharapkan mampu menghasilkan penduga yang lebih baik, terutama untuk
area nircontoh.
Penerapan dari metode yang dikembangkan dalam penelitian ini adalah
untuk menduga rata-rata pengeluaran per kapita per bulan pada kecamatan
nircontoh berdasarkan data SUSENAS tahun 2010 dan PODES tahun 2011 yang
diperoleh dari Badan Pusat Statistik (BPS). Data SUSENAS hanya mencakup
sebagian desa/keluharan dan kecamatan pada setiap kota dan kabupaten.
Pembentukan gerombol berdasarkan data PODES, yang mencakup seluruh
desa/kelurahan dan kecamatan, dapat menambah informasi untuk menduga
parameter yang ingin diamati. Hal ini diperlukan terutama pada saat menduga
parameter dari area yang tidak disurvei pada SUSENAS. Pada kasus ini
pendugaan yang dilakukan dibatasi untuk wilayah Kota dan Kabupaten Bogor.

2
Tujuan Penelitian
Tujuan yang ingin dicapai pada penelitian ini adalah:
1. memodifikasi model prediksi EBLUP baku dengan menambahkan informasi
gerombol, dengan pendekatan sebagai pengaruh tetap maupun sebagai
pengaruh acak,
2. mengkaji kebaikan model yang diusulkan dibandingkan dengan model dasar
yaitu EBLUP baku,
3. menerapkan model yang diusulkan untuk menduga rata-rata pengeluaran per
kapita per kapita per bulan pada kecamatan nircontoh di Kota dan Kabupaten
Bogor.
2 TINJAUAN PUSTAKA
Pendugaan Area Kecil (Small Area Estimation (SAE))
Menurut Rao (2003), suatu area dikatakan besar apabila ukuran contoh pada
area tersebut mampu menghasilkan presisi pendugaan yang baik dengan penduga
langsung. Sebaliknya, suatu area dikatakan “kecil” apabila ukuran contoh pada
area tersebut tidak cukup untuk menunjang penduga langsung agar mampu
menghasilkan presisi pendugaan yang baik. Pendekatan lain seringkali diperlukan
untuk mengatasi permasalahan tersebut, salah satunya adalah penduga tak
langsung. Penduga tak langsung “meminjam informasi” dengan menggunakan
nilai peubah dari contoh pada area lain yang terkait dengan area yang diamati.
Model pendugaan area kecil terdiri dari Model Level Area (Tipe-A) dan Model
Level Satuan (Tipe-B).
a. Model Level Area (Tipe-A)
Model ini digunakan ketika informasi peubah penyerta pada level satuan
tidak diketahui dengan mengasumsikan bahwa ( ) untuk ( ) tertentu
berhubungan dengan peubah penyerta pada area, yaitu ( )
,
melalui model linier berikut:
dengan ( ) merupakan pengaruh acak pada area ke-i. Penduga langsung
diasumsikan diketahui untuk menarik kesimpulan tentang nilai tengah area
kecil , yaitu:
. /
dengan menganggap bahwa adalah galat penarikan contoh yang menyebar
normal ( ), dan
diketahui.
Model deterministik pada diperoleh dengan menetapkan bahwa .
Model tersebut mengarah pada model sintetik yang tidak memperhitungkan
keragaman lokal selain dari keragaman yang bersumber pada peubah penyerta .
Model berikut diperoleh dengan menggabungkan kedua model di atas:

3
b. Model Level Satuan (Tipe-B)
Model ini digunakan dengan asumsi bahwa data peubah penyerta untuk
setiap satuan ( )
tersedia. Peubah yang diamati
berhubungan dengan peubah penyerta melalui model regresi galat tersarang
berikut:
Anggapan yang digunakan pada model ini adalah terdapat satuan yang
disurvei (contoh) dan satuan yang tidak disurvei (nircontoh) sehingga model di
atas dapat diuraikan menjadi:
0
1 [
] [
] 0
1
dan penduga nilai tengah area kecil dapat dituliskan sebagai berikut:
( )
dengan ⁄ , serta dan berturut-turut adalah nilai tengah untuk
satuan contoh dan satuan nircontoh. Penduga nilai tengah area dengan ukuran
contoh nol dapat dinyatakan sebagai .
Empirical Best Linear Unbiased Predictor (EBLUP)
Menurut Das et al. (2004), secara umum, model campuran linear (linear
mixed model) dapat dituliskan dalam bentuk berikut:
(1)
dengan merupakan vektor berukuran yang berisi nilai pengamatan
contoh, dan adalah matriks yang nilainya diketahui, serta dan merupakan
pengaruh acak yang bersebaran saling bebas dengan nilai tengah nol dan matriks
ragam koragam masing-masing adalah dan , yang bergantung pada suatu
parameter yang disebut komponen ragam. Model ini menganggap bahwa
berpangkat penuh p ( ), dengan catatan bahwa ragam dari peubah adalah
( ) . Salah satu kasus khusus dari model (1) untuk area ke- dan satuan ke-
adalah sebagai berikut:
dengan ( ) dan (
) , yang bergantung pada suatu
parameter yaitu komponen ragam (
).
Menurut Das et al. (2004), penduga EBLUP adalah suatu penduga dua tahap
yang digunakan dalam menduga suatu parameter ( ) yang bergantung pada
yang tidak diketahui. Pendekatan ini dilakukan dengan mengganti parameter
dengan penduganya, yaitu , sehingga pendugaan dilakukan terhadap parameter
( ). Jika didefinisikan bahwa terdapat pendugaan untuk kombinasi linier dari
dan yaitu:
dengan dan adalah suatu vektor konstanta, maka dapat diperoleh prediktor tak
bias terbaik atau Best Linear Unbiased Predictor (BLUP) bagi adalah:
( ) ( )
( ) ( ) ( )

4
dengan
( ) ( )
adalah penduga kuadrat terkecil terampat (generalized least square), atau penduga
takbias terbaik (Best Linear Unbiased Estimator (BLUE)) dari , dengan
penduga dari pengaruh acak adalah ( ) ( ) , dan
( ) . Penduga EBLUP diperoleh dengan mengganti menjadi
( ) , sehingga diperoleh ( ) (Rao 2003). Kackar dan Harville
(1981) dalam Das et al. (2004) menyatakan bahwa penduga dua tahap ( )
merupakan penduga tak bias bagi , dengan asumsi bahwa dan berdistribusi
simetrik.
Penduga EBLUP pada area contoh ke- dapat dituliskan sebagai:
(∑
∑ )
dengan adalah satuan contoh dan adalah satuan nircontoh, sehingga yang
merupakan nilai dugaan untuk satuan nircontoh dapat dihitung dengan rumus:
Penduga EBLUP pada area nircontoh ke- adalah sebagai berikut:
(∑
)
dengan merupakan nilai dugaan yang dihitung dengan rumus berikut:
Restricted Maximum Likelihood (REML)
Terdapat beberapa metode untuk memperoleh penduga komponen ragam.
Salah satu pendekatannya adalah metode kemungkinan maksimum terbatas atau
Restricted Maximum Likelihood (REML) yang memaksimumkan kombinasi linier
dari . Jika didefinisikan bahwa ( ∑
) dengan ,
maka dapat dinyatakan bahwa:
( ).
Menurut McCullloch dan Searle (2001), fungsi kemungkinan maksimum dari
dapat dituliskan dalam bentuk berikut:
( )
(2)
dengan
( ) . (3)
Pendekatan REML dilakukan dengan mencari solusi persamaan (2) dan (3)
terhadap yang ada di dalam . Metode REML memerlukan anggapan
kenormalan karena persamaan tersebut diturunkan dari sebaran normal.
Analisis Gerombol (Clustering)
Analisis gerombol merupakan teknik peubah ganda yang mempunyai tujuan
utama untuk mengelompokkan objek-objek berdasarkan kemiripan karakteristik
yang dimilikinya (Mattjik dan Sumertajaya 2011). Kemiripan karakteristik antar
objek dapat diukur dengan jarak euclid, jarak mahalanobis, dan ukuran jarak

5
lainnya. Jarak euclid banyak digunakan karena perhitungannya yang sederhana,
yaitu:
( ) √( ) ( )
dengan anggapan bahwa semua peubah diukur dengan skala yang sama. Apabila
terdapat perbedaan skala pengukuran diantara peubah maka harus dilakukan
pembakuan peubah.
Johnson dan Wichern (2007) menjelaskan bahwa terdapat dua pendekatan
dalam metode penggerombolan, yaitu metode berhirarkhi dan metode nirhirakhi.
Metode penggerombolan berhirarkhi dapat dilakukan dengan pendekatan
aglomeratif (penggabungan) maupun divisif (pemisahan). Penggabungan atau
pemisahan antar objek dalam penggerombolan dapat disajikan dalam bentuk
dendogram yang biasanya dijadikan sebagai dasar penentuan banyaknya
gerombol. Metode penggerombolan nirhirarkhi digunakan apabila banyaknya
gerombol yang ingin dibentuk telah ditentukan, yaitu sebanyak k gerombol.
Kendala yang mungkin ditemukan pada proses analisis gerombol di
antaranya adalah pelanggaran asumsi multikolinieritas dan terdapatnya pencilan.
Metode analisis gerombol berhirarkhi k-medoid dapat menjadi salah satu alternatif
untuk mengatasi pencilan. Permasalahan lain yang mungkin ditemukan adalah
apabila penggerombolan dilakukan berdasarkan peubah yang bersifat kategorik,
atau campuran antara peubah kategorik dan numerik. Salah satu pendekatan yang
dapat menangani permasalahan tersebut adalah metode penggerombolan dua
tahap (two step cluster). Selain itu, metode penggerombolan dua tahap juga
mampu menangani penggerombolan pada data yang besar.
3 METODE
Model dasar yang digunakan pada penelitian ini adalah model EBLUP baku,
yang selanjutnya disebut sebagai Model-0. Pemodelan area kecil yang digunakan
pada penelitian ini adalah model level satuan (tipe-B), dengan i dan j masing-
masing menunjukkan area dan satuan pada area contoh, sedangkan dan
masing-masing menunjukkan area dan satuan pada area nircontoh.
a) Model untuk populasi:
b) Model prediksi untuk area contoh:
c) Model prediksi untuk area nircontoh:
dengan menunjukkan nilai respon yang diamati, menunjukkan peubah
penyerta, menunjukkan pengaruh acak area, dan adalah galat penarikan
contoh pada area contoh. Penduga nilai respon yang diamati pada area nircontoh
( ) diperoleh dengan memanfaatkan informasi peubah penyerta pada area
nircontoh ( ) . Model ini menganggap bahwa ( ) dan
( ) . Penelitian dilakukan dengan membangun model baru yang
dikembangkan dari Model-0 tersebut.

6
Pengembangan Model
Pengembangan model dilakukan dengan menambahkan informasi gerombol
ke-k pada Model-0. Penambahan informasi gerombol sebagai bentuk modifikasi
model dasar EBLUP menghasilkan lima model yang diusulkan pada penelitian ini.
Kelima model tersebut memiliki model prediksi yang berbeda-beda, terutama
untuk prediksi pada area nircontoh.
1. Model-1, yaitu modifikasi model EBLUP (Model-0) dengan menambahkan
nilai tengah dari penduga pengaruh acak area masing-masing gerombol pada
model prediksi area nircontoh. Penambahan tersebut dinyatakan sebagai
( )
∑
, dengan merupakan banyaknya area contoh pada
gerombol ke- .
a) Model untuk populasi:
b) Model prediksi untuk area contoh:
c) Model prediksi untuk area nircontoh:
( )
2. Model-2, yaitu modifikasi model EBLUP (model-0) dengan menambah
pengaruh tetap gerombol ke-k (model-1). Pengaruh tetap gerombol
dinyatakan sebagai yang merupakan bentuk penyederhanaan notasi
penduga koefisien peubah dummy untuk gerombol. Sehingga untuk sejumlah
gerombol dapat diuraikan bahwa , dengan
merupakan peubah dummy untuk gerombol dan
merupakan penduga koefisien bagi peubah dummy.
a) Model untuk populasi:
b) Model prediksi untuk area contoh:
c) Model prediksi untuk area nircontoh:
3. Model-3, yaitu kombinasi dari Model-1 dan Model-2.
a) Model untuk populasi:
b) Model prediksi untuk area contoh:
c) Model prediksi untuk area nircontoh:
( )
4. Model-4, yaitu modifikasi Model-1 dengan menambahkan nilai tengah
pengaruh acak peubah penyerta setiap area pada gerombol ke- . Model ini
mengasumsikan sebagai peubah acak, sehingga diperoleh dan yang
merupakan pengaruh acak area ke- dan pengaruh acak peubah pada area

7
ke- . Nilai tengah pengaruh acak area area ke- pada gerombol ke-
dinyatakan sebagai berikut:
( )
∑
Nilai tengah pengaruh acak peubah area ke- pada gerombol ke-
dinyatakan sebagai berikut:
( )
∑
a) Model untuk populasi:
( ) ( )
b) Model prediksi untuk area contoh:
( ) ( )
c) Model prediksi untuk area nircontoh:
( ( )) ( ( ))
5. Model-5, yaitu modifikasi dari Model-4 dengan menambahkan pengaruh
tetap dari gerombol ke- .
a) Model untuk populasi:
( ) ( )
b) Model prediksi untuk area contoh:
( ) ( )
c) Model prediksi untuk area nircontoh:
( ( )) ( ( ))
Model-5 secara diharapkan mampu menghasilkan prediksi dengan akurasi
yang lebih tinggi karena model ini memiliki penambahan komponen yang
paling banyak dibandingkan model-model sebelumnya. Model ini memiliki
tiga komponen tambahan yaitu pengaruh acak area, pengaruh acak peubah
penyerta setiap area, dan pengaruh tetap gerombol sehingga model ini
memiliki titik potong dan kemiringan yang berbeda, mirip seperti Model-4,
namun model ini turut memperhitungkan pengaruh tetap dari setiap gerombol.
Kajian Simulasi
Simulasi dilakukan untuk mengevaluasi kebaikan model yang
dikembangkan. Proses simulasi dilakukan dengan langkah-langkah berikut ini.
1. Membangun populasi yang terdiri dari 40 area, dengan ukuran populasi
masing-masing area berkisar antara 100 hingga 1500 satuan. Populasi
tersebut diasumsikan terdiri dari 5 gerombol. Simulasi ini menggunakan satu
peubah respon dan satu peubah penyerta . Respon yang diamati ( )
merupakan kombinasi linier dari peubah penyerta ( ), pengaruh acak area
( ), dan galat penarikan contoh ( ), dengan menunjukkan area,
menunjukkan satuan, dan menunjukkan gerombol. Hubungan tersebut dapat
dinyatakan dalam model campuran linier berikut:
(4)

8
Parameter pada model (4) memiliki nilai yang berbeda untuk setiap
gerombol ke- . Peubah penyerta dibangkitkan dari sebaran normal
( ) , sedangkan komponen acak dan berasal dari
sebaran tertentu. Beberapa skenario dibangun untuk mengkaji kebaikan
model yang diusulkan pada berbagai kondisi tertentu.
a) Skenario 1, populasi terdiri dari 5 gerombol yang saling terpisah dengan
nilai masing-masing gerombol sebagai berikut:
Tabel 1 Titik potong dan kemiringan pada populasi skenario 1
Gerombol 1 8 2 2 18 5 3 28 8 4 38 11 5 48 14
Populasi ini memiliki heterogenitas antar gerombol yang tinggi. Seluruh
komponen acak pada skenario ini berasal dari sebaran normal, yaitu
( ) dan ( ) sehingga model campuran linier yang
dibangun pada skenario ini akan memenuhi asumsi kenormalan. Skenario
ini dibangun untuk mengkaji kemampuan model pada kondisi populasi
yang ideal, yaitu karakteristik antar gerombol mampu dibedakan dengan
baik dan tidak terdapat gangguan terhadap asumsi kenormalan.
b) Skenario 2, populasi terdiri dari 5 gerombol yang tidak terpisah sempurna
dengan nilai masing-masing gerombol sebagai berikut:
Tabel 2 Titik potong dan kemiringan pada populasi skenario 2
Gerombol 1 8.00 2.00 2 8.90 2.42 3 9.90 3.37 4 11.00 4.11 5 12.20 5.47
Komponen acak pada skenario ini berasal dari sebaran normal, yaitu
( ) dan ( ) . Skenario ini dibangun untuk
mengkaji kemampuan model pada kondisi penggerombolan yang beririsan,
atau heterogenitas antar gerombol yang rendah dan tanpa ada gangguan
terhadap asumsi kenormalan.
c) Skenario 3, populasi terdiri dari 5 gerombol yang terpisah sempurna, yaitu
dengan nilai yang sama dengan skenario 1. Perbedaannya dengan
skenario 1 adalah salah satu komponen acak yang digunakan pada skenario
ini tidak berasal dari sebaran normal. Pengaruh acak area pada skenario ini
dibangkitkan dari sebaran khi-kuadrat ( ) , sedangkan galat penarikan
contoh tetap berasal dari sebaran normal ( ). Skenario ini
dibangun untuk mengkaji kemampuan model pada kondisi dengan
pelanggaran asumsi kenormalan pada komponen pengaruh acak area,

9
dengan mengasumsikan karakteristik antar gerombol mampu dibedakan
dengan baik.
d) Skenario 4, populasi terdiri dari 5 gerombol yang terpisah sempurna, yaitu
dengan nilai yang sama dengan skenario 1. Komponen pengaruh acak
area pada skenario ini berasal dari sebaran normal ( ) , namun
komponen acak galat penarikan contoh pada populasi ini tidak berasal dari
sebaran normal. Galat penarikan contoh berasal dari sebaran khi-kuadrat
( ) . Skenario ini dibangun untuk mengkaji kemampuan model pada
kondisi dengan pelanggaran asumsi kenormalan pada komponen galat
penarikan contoh, dengan mengasumsikan karakteristik antar gerombol
mampu dibedakan dengan baik.
e) Skenario 5, populasi terdiri dari 5 gerombol yang terpisah sempurna, yaitu
dengan nilai yang sama dengan skenario 1. Seluruh komponen acak
pada skenario ini tidak berasal dari sebaran normal melainkan berasal dari
sebaran khi-kuadrat, yaitu ( ) dan ( )
. Skenario ini dibangun
untuk mengkaji kemampuan model pada kondisi dengan pelanggaran
asumsi kenormalan pada seluruh komponen acak, dengan mengasumsikan
karakteristik antar gerombol mampu dibedakan dengan baik.
Langkah-langkah yang dilakukan untuk membangun populasi pada setiap
skenario adalah sebagai berikut:
(i) membangkitkan peubah penyerta ( ) sebanyak
satuan, nilai yang diperoleh pada langkah ini digunakan untuk
seluruh skenario pada proses simulasi,
(ii) membangkitkan pengaruh acak area dan galat penarikan contoh
berdasarkan sebaran tertentu sesuai dengan skenario,
(iii) menghitung nilai peubah respon berdasarkan model (4) dengan
nilai koefisien yang telah ditentukan untuk masing-masing
gerombol sesuai dengan skenario.
2. Mengambil contoh acak dari populasi yang dibangkitkan pada langkah (1),
yaitu sebanyak area contoh yang berasal dari kelima gerombol, sehingga
terdapat area nircontoh (Tabel 3).
Tabel 3 Jumlah area contoh dan nircontoh pada gerombol ke- Gerombol Jumlah Area Contoh Jumlah Area Nircontoh Total Area
1 4 1 5
2 6 2 8
3 8 2 10
4 4 2 6
5 8 3 11
Penarikan contoh acak pada level satuan untuk setiap area contoh dilakukan
secara proporsional dengan ukuran contoh sebesar 3% dari ukuran populasi.
3. Melakukan pemodelan dan menduga nilai tengah area contoh ke-i dan nilai
tengah area nircontoh ke- . Proses ini dilakukan menggunakan model dasar

10
(Model-0) dan kelima model yang diusulkan (Model-1, Model-2, Model-3,
Model-4, dan Model-5).
4. Mengulangi proses pada langkah (2) dan (3) sebanyak B=1000 kali sehingga
dapat dihitung nilai Relative Bias (RB) dan Relative Root Mean Squares
Error (RRMSE) dari hasil pendugaan parameter pada setiap area dengan
rumus sebagai berikut:
( )
∑ .
/
( )
√
∑ ( )
.
5. Mengevaluasi model berdasarkan nilai RB dan RRMSE.
Studi Kasus
Studi kasus pada penelitian ini menggunakan data SUSENAS tahun 2010
dan PODES tahun 2011 yang dikeluarkan oleh Badan Pusat Statistik (BPS).
Peubah yang diamati pada penelitian ini adalah rata-rata pengeluaran per kapita
per bulan untuk kecamatan di wilayah Kota dan Kabupaten Bogor. Data yang
tersedia pada SUSENAS tidak mendukung pendugaan langsung pada tingkat
kecamatan. Hal ini dikarenakan contoh pada tingkat kecamatan berukuran kecil,
bahkan terdapat kecamatan yang tidak disurvei. Model yang dikembangkan pada
penelitian ini digunakan sebagai alternatif untuk mengatasi permasalahan tersebut.
Pemodelan dilakukan dengan memanfaatkan informasi dari peubah yang dipilih
dari data PODES sebagai peubah penyerta.
Proses analisis data PODES dan SUSENAS adalah sebagai berikut:
1. melakukan eksplorasi data, yaitu dengan memeriksa distribusi data yang akan
digunakan, memeriksa peubah-peubah yang berkorelasi kuat terhadap peubah
respon, serta melakukan pemilihan peubah yang mampu membedakan
karakteristik setiap gerombol,
2. melakukan penggerombolan area berdasarkan peubah-peubah yang dipilih dari
data PODES, dengan asumsi bahwa PODES memuat informasi seluruh
anggota populasi hingga di tingkat desa,
3. mengelompokan area berdasarkan gerombol yang terbentuk,
4. melakukan pemodelan dengan model dasar EBLUP dan kelima model yang
dikembangkan,
5. menduga nilai tengah pengeluaran per kapita per bulan setiap kecamatan,
6. mengevaluasi hasil pendugaan dengan membandingkan nilai root mean
squares error (RMSE) dari penduga parameter setiap area,
( ) √ ( )
( ) (
) (
) dengan
(
) ( *
+, *
+ -∑ {
} )
(
) (∑ 2
(
)3
[ ( )
])
11
4 HASIL DAN PEMBAHASAN
Kajian Simulasi
Data pada populasi dibagi menjadi dua, yaitu data contoh dan nircontoh.
Data contoh digunakan untuk membangun enam model prediksi, model dasar
(Model-0) dan model yang diusulkan (Model-1 hingga Model-5). Parameter yang
diamati adalah nilai tengah seluruh area kecil dalam populasi, yaitu area contoh
ke- dan area nircontoh ke- . Model EBLUP baku menghasilkan model prediksi
area nircontoh yang bersifat global, sedangkan model yang diusulkan
menghasilkan model prediksi area nircontoh yang bersifat lokal. Suatu model
dikatakan bersifat global apabila model tersebut berlaku untuk seluruh
pengamatan. Model yang bersifat lokal tidak berlaku untuk seluruh pengamatan,
melainkan bersifat unik untuk level tertentu. Model lokal yang diusulkan pada
penelitian ini bersifat unik untuk masing-masing gerombol.
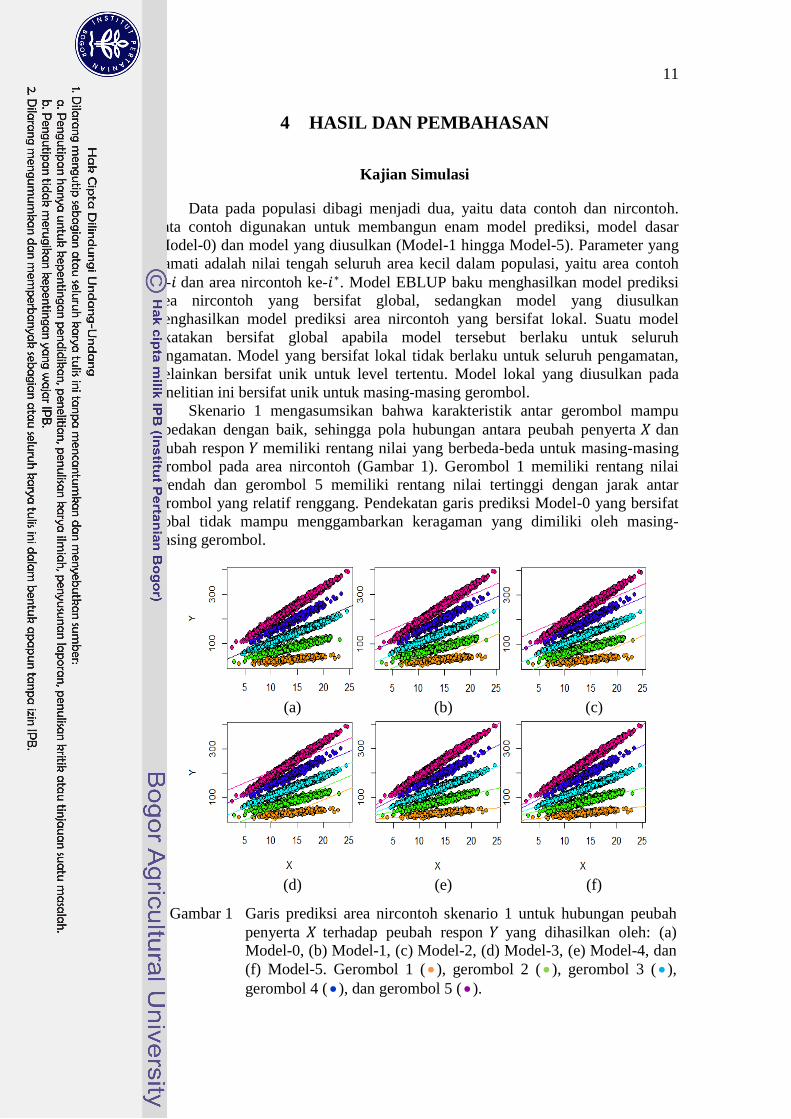
Skenario 1 mengasumsikan bahwa karakteristik antar gerombol mampu
dibedakan dengan baik, sehingga pola hubungan antara peubah penyerta dan
peubah respon memiliki rentang nilai yang berbeda-beda untuk masing-masing
gerombol pada area nircontoh (Gambar 1). Gerombol 1 memiliki rentang nilai
terendah dan gerombol 5 memiliki rentang nilai tertinggi dengan jarak antar
gerombol yang relatif renggang. Pendekatan garis prediksi Model-0 yang bersifat
global tidak mampu menggambarkan keragaman yang dimiliki oleh masing-
masing gerombol.
Gambar 1 Garis prediksi area nircontoh skenario 1 untuk hubungan peubah
penyerta terhadap peubah respon yang dihasilkan oleh: (a)
Model-0, (b) Model-1, (c) Model-2, (d) Model-3, (e) Model-4, dan
(f) Model-5. Gerombol 1 (), gerombol 2 (), gerombol 3 (),
gerombol 4 (), dan gerombol 5 ().
(a) (b) (c)
(d) (e) (f)

12
Model-0 hanya menghasilkan satu garis prediksi area nircontoh (perhatikan
garis berwarna hitam), sedangkan kelima model yang diusulkan menghasilkan
lima garis prediksi area nircontoh, sesuai dengan banyaknya gerombol pada area
tersebut. Model prediksi yang dihasilkan oleh Model-0 mengabaikan pengaruh
acak area sehingga prediksinya diperoleh dari model sintetik yang bersifat global.
Prediksi area nircontoh yang dihasilkan oleh Model-0 akan terdistorsi pada satu
garis prediksi yang bersifat global tersebut (Gambar 1a).
Garis prediksi yang dihasilkan oleh Model-1, Model-2, dan Model-3
memiliki titik potong yang berbeda-beda pada setiap gerombol, namun
kemiringan garis yang dihasilkan tetap sama (Gambar 1b, Gambar 1c, Gambar 1d).
Prediksi area nircontoh dari ketiga model tersebut lebih mampu menghampiri nilai
yang sebenarnya dibandingkan dengan Model-0, dengan asumsi bahwa
penggerombolan yang dilakukan telah mampu membedakan karakteristik antar-
gerombol dengan sangat baik.
Model-4 dan Model-5 merupakan hasil modifikasi titik potong dan
kemiringan dari model EBLUP baku. Kedua model ini mengasumsikan bahwa
peubah penyerta bersifat acak. Garis prediksi area nircontoh yang dihasilkan
kedua model tersebut memiliki titik potong dan kemiringan yang berbeda-beda
pada setiap gerombol (Gambar 1e, Gambar 1f). Kondisi tersebut secara teoritis
memungkinkan agar prediksi yang dihasilkan lebih baik dibandingkan model-
model sebelumnya. Hal ini berlaku pada data dengan kondisi penggerombolan
yang dicerminkan oleh data simulasi ini.
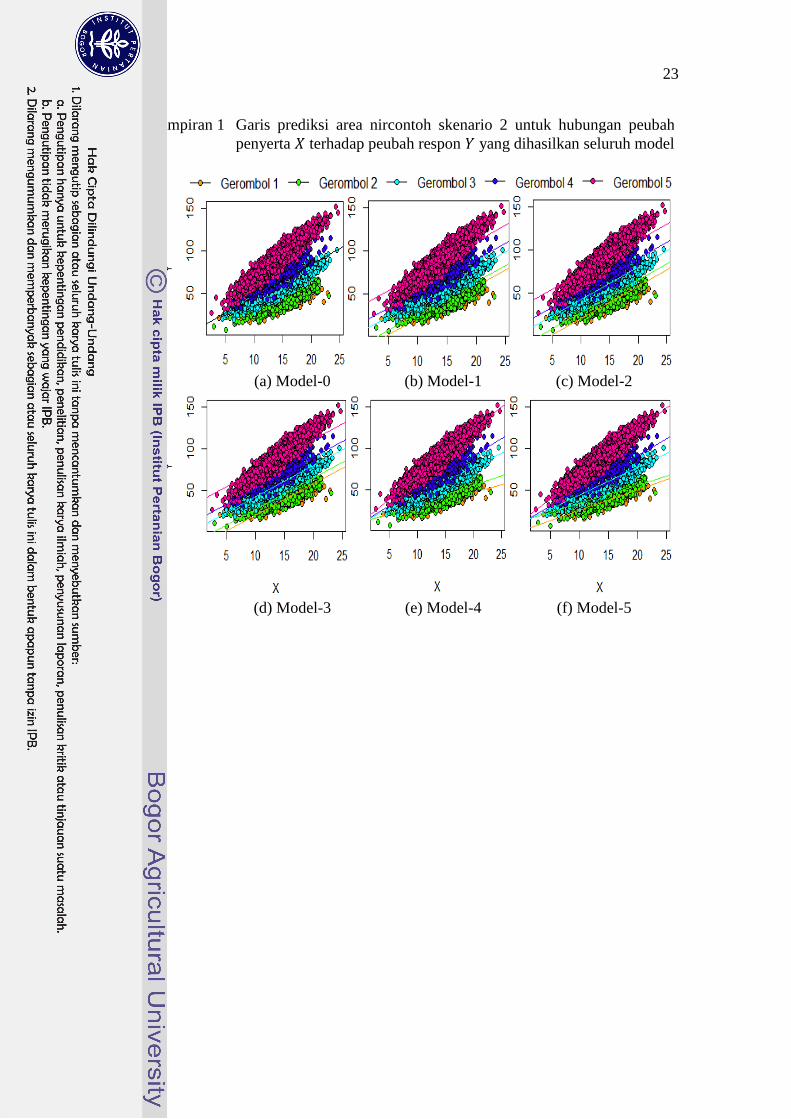
Lampiran 1 hingga Lampiran 4 menunjukkan garis prediksi area nircontoh
skenario 2 hingga skenario 5. Skenario 2 mencerminkan kodisi karakteristik antar
gerombol yang cukup sulit untuk dibedakan sehingga kondisi data menjadi
beririsan antara suatu gerombol dan gerombol lainnya (Lampiran 1). Model-1
menghasilkan garis prediksi area nircontoh yang berhimpit, terutama untuk
gerombol 1 dan gerombol 2, sementara garis prediksi Model-2 dan Model-3
sedikit lebih renggang. Model-4 menunjukkan garis prediksi yang cenderung lebih
mendekati pengamatan area nircontoh yang sebenarnya, jika dibandingkan dengan
Model-5. Selain itu, kuadrat tengah sisaan prediksi area nircontoh Model-4 lebih
kecil dibandingkan dengan Model-5 (Tabel 4). Hal ini mengindikasikan bahwa
penambahan pengaruh tetap gerombol pada model prediksi area nircontoh dengan
asumsi peubah penyerta bersifat acak dapat dinilai kurang tepat pada kondisi
penggerombolan yang beririsan.
Tabel 4 Kuadrat tengah sisaan prediksi area nircontoh
Skenario Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1 387.23 60.29 59.70 59.70 27.41 27.21
2 551.65 54.67 54.27 54.27 37.48 37.52
3 5595.57 177.91 179.73 179.73 26.46 26.69
4 5754.56 169.39 167.88 167.88 14.65 14.60
5 5556.56 154.76 155.67 155.67 2.67 2.67
Skenario 3 hingga skenario 5 mencerminkan data dengan gangguan asumsi
kenormalan pada komponen acak. Skenario 4 mencerminkan kondisi data dengan
galat penarikan contoh yang tidak bersebaran normal. Plot pengamatan area
nircontoh skenario ini menunjukkan pola yang cenderung menjulur ke kanan
(Lampiran 3). Hal ini menunjukkan bahwa pola sebaran komponen acak galat
13
penarikan contoh yang berasal dari sebaran khi-kuadrat mempengaruhi bentuk
sebaran data yang diamati.
Simulasi dengan berbagai skenario secara umum menunjukkan model
prediksi area nircontoh EBLUP baku bersifat global, sementara model yang
diusulkan bersifat lokal. Garis prediksi model yang bersifat lokal lebih mampu
menghampiri pengamatan area nircontoh yang sebenarnya. Hal ini dapat dilihat
berdasarkan plot garis prediksi area nircontoh yang dihasilkan oleh masing-
masing model. Selain itu, nilai kuadrat tengah sisaan dari prediksi area nircontoh
yang diperoleh pada model lokal jauh lebih kecil dibandingkan dengan model
EBLUP baku yang bersifat global (Tabel 4). Kuadrat tengah sisaan dari model
dengan modifikasi titik potong dan kemiringan, yaitu Model-4 dan Model-5,
memiliki nilai yang paling kecil dibandingkan model lain. Hal ini menunjukkan
bahwa kedua model tersebut merupakan model lokal yang paling menghampiri
pengamatan area nircontoh yang sebenarnya.
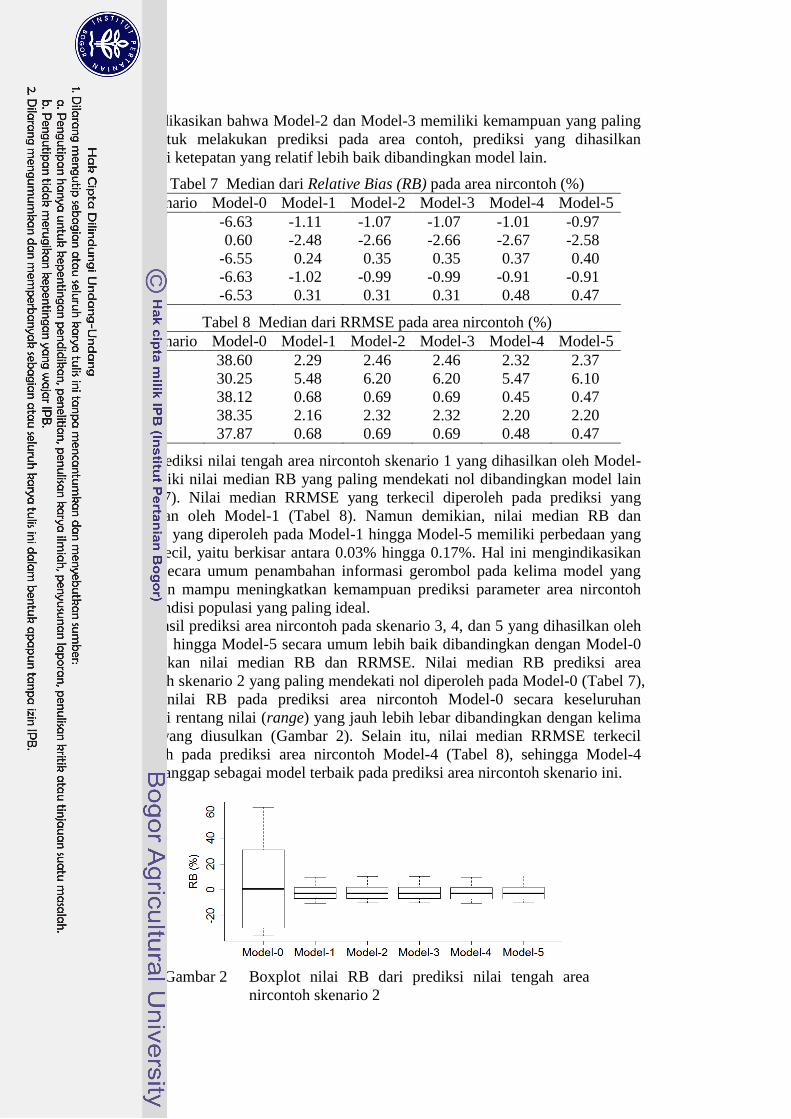
Tabel 5 Median dari Relative Bias (RB) pada area contoh (%)
Skenario Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1 10.56 10.56 0.57 0.57 10.50 0.94
2 7.27 7.27 1.67 1.67 6.67 1.05
3 10.13 10.13 0.20 0.20 9.96 2.04
4 10.49 10.49 0.59 0.59 10.48 0.35
5 10.11 10.11 0.22 0.22 9.94 0.60
Tabel 6 Median dari RRMSE pada area contoh (%)
Skenario Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1 34.32 34.32 1.14 1.14 34.54 11.13
2 25.34 25.34 2.77 2.77 25.53 7.73
3 33.74 33.74 0.66 0.66 33.85 14.40
4 34.18 34.18 1.09 1.09 34.40 6.62
5 33.59 33.59 0.67 0.67 33.69 7.87
Model prediksi EBLUP baku (Model-0) pada area contoh bersifat lokal.
Model tersebut dipengaruhi oleh pengaruh acak area sehingga secara teoritis
model ini sudah memiliki kemampuan prediksi yang cukup baik pada area contoh.
Prediksi yang dihasilkan oleh Model-0 akan memiliki keragaman yang berbeda di
setiap area contoh sehingga hasil yang diperoleh akan mendekati nilai sebenarnya.
Namun demikian, hasil simulasi pada skenario 1 hingga skenario 4
memperlihatkan bahwa Model-0 bukan model terbaik pada prediksi area contoh.
Model-2, Model-3, dan Model-5 menghasilkan prediksi nilai tengah area
contoh dengan kisaran nilai RB dan RRMSE yang jauh lebih kecil dibandingkan
dengan model lain pada semua skenario (Tabel 5 dan Tabel 6). Ketiga model
tersebut merupakan model dengan penambahan informasi gerombol sebagai
pengaruh tetap, sehingga dapat dikatakan bahwa secara umum penambahan
tersebut mampu memperbaiki prediksi area contoh.
Nilai RB dari penduga nilai tengah area contoh Model-2 dan Model-3
memiliki nilai yang paling kecil pada skenario 1, skenario 3, dan skenario 5
(Tabel 5). Nilai RB terkecil pada skenario 2 dan skenario 4 diperoleh pada
prediksi yang dihasilkan oleh Model-5, namun perbedaannya dengan Model-2 dan
Model-3 relatif kecil. Nilai RRMSE yang terkecil pada setiap skenario (Tabel 6)
diperoleh dari prediksi area contoh Model-2 dan Model-3. Hal ini
14
mengindikasikan bahwa Model-2 dan Model-3 memiliki kemampuan yang paling
baik untuk melakukan prediksi pada area contoh, prediksi yang dihasilkan
memiliki ketepatan yang relatif lebih baik dibandingkan model lain.
Tabel 7 Median dari Relative Bias (RB) pada area nircontoh (%)
Skenario Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1 -6.63 -1.11 -1.07 -1.07 -1.01 -0.97
2 0.60 -2.48 -2.66 -2.66 -2.67 -2.58
3 -6.55 0.24 0.35 0.35 0.37 0.40
4 -6.63 -1.02 -0.99 -0.99 -0.91 -0.91
5 -6.53 0.31 0.31 0.31 0.48 0.47
Tabel 8 Median dari RRMSE pada area nircontoh (%)
Skenario Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1 38.60 2.29 2.46 2.46 2.32 2.37
2 30.25 5.48 6.20 6.20 5.47 6.10
3 38.12 0.68 0.69 0.69 0.45 0.47
4 38.35 2.16 2.32 2.32 2.20 2.20
5 37.87 0.68 0.69 0.69 0.48 0.47
Prediksi nilai tengah area nircontoh skenario 1 yang dihasilkan oleh Model-
5 memiliki nilai median RB yang paling mendekati nol dibandingkan model lain
(Tabel 7). Nilai median RRMSE yang terkecil diperoleh pada prediksi yang
dihasilkan oleh Model-1 (Tabel 8). Namun demikian, nilai median RB dan
RRMSE yang diperoleh pada Model-1 hingga Model-5 memiliki perbedaan yang
relatif kecil, yaitu berkisar antara 0.03% hingga 0.17%. Hal ini mengindikasikan
bahwa secara umum penambahan informasi gerombol pada kelima model yang
diusulkan mampu meningkatkan kemampuan prediksi parameter area nircontoh
pada kondisi populasi yang paling ideal.
Hasil prediksi area nircontoh pada skenario 3, 4, dan 5 yang dihasilkan oleh
Model-1 hingga Model-5 secara umum lebih baik dibandingkan dengan Model-0
berdasarkan nilai median RB dan RRMSE. Nilai median RB prediksi area
nircontoh skenario 2 yang paling mendekati nol diperoleh pada Model-0 (Tabel 7),
namun nilai RB pada prediksi area nircontoh Model-0 secara keseluruhan
memiliki rentang nilai (range) yang jauh lebih lebar dibandingkan dengan kelima
model yang diusulkan (Gambar 2). Selain itu, nilai median RRMSE terkecil
diperoleh pada prediksi area nircontoh Model-4 (Tabel 8), sehingga Model-4
dapat dianggap sebagai model terbaik pada prediksi area nircontoh skenario ini.
Gambar 2 Boxplot nilai RB dari prediksi nilai tengah area
nircontoh skenario 2
15
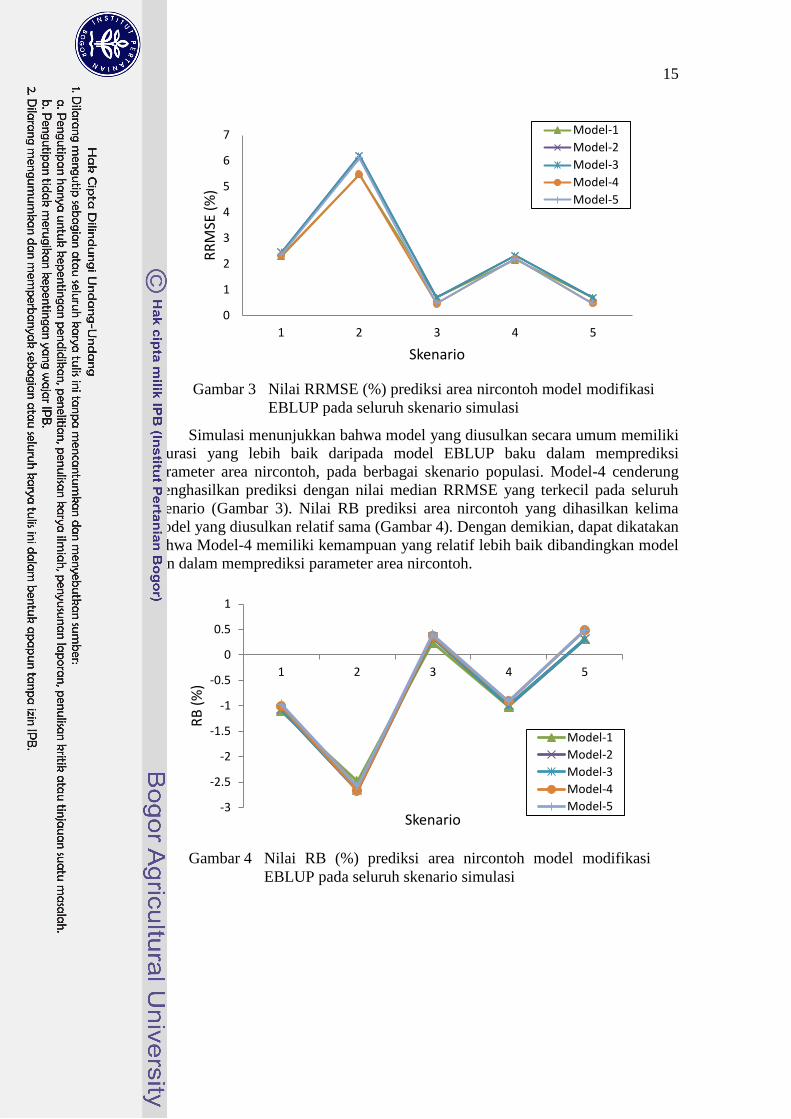
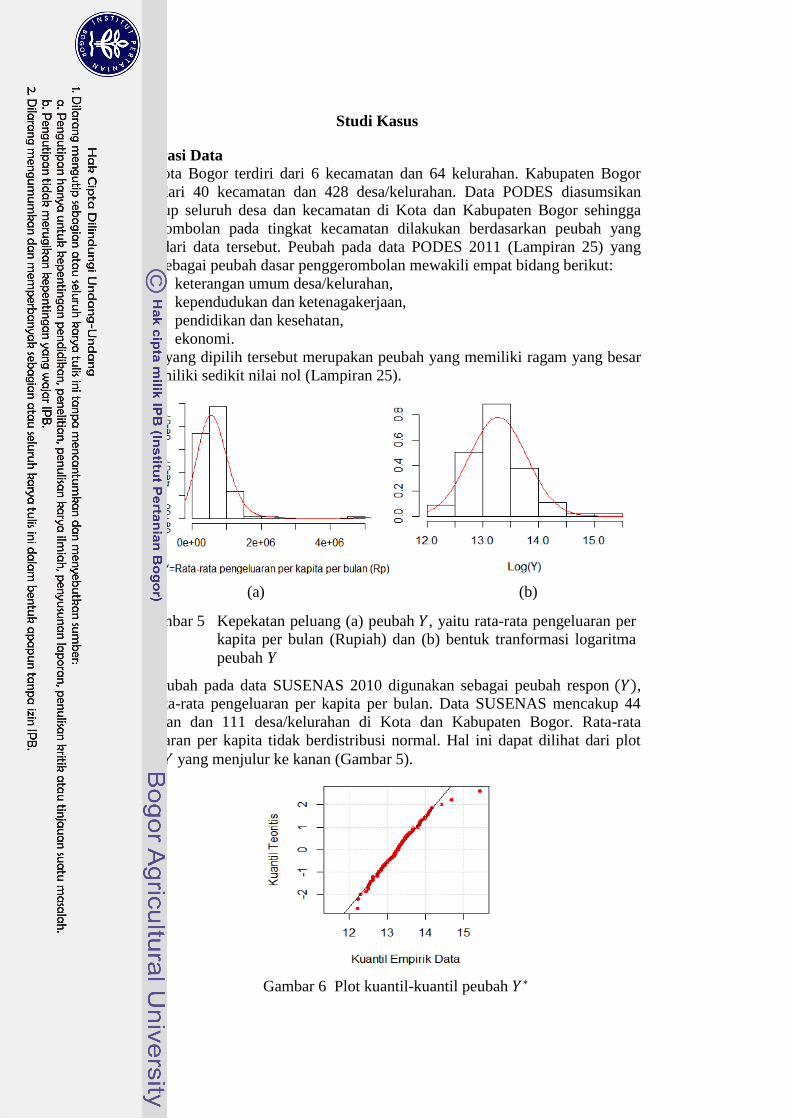
Simulasi menunjukkan bahwa model yang diusulkan secara umum memiliki
akurasi yang lebih baik daripada model EBLUP baku dalam memprediksi
parameter area nircontoh, pada berbagai skenario populasi. Model-4 cenderung
menghasilkan prediksi dengan nilai median RRMSE yang terkecil pada seluruh
skenario (Gambar 3). Nilai RB prediksi area nircontoh yang dihasilkan kelima
model yang diusulkan relatif sama (Gambar 4). Dengan demikian, dapat dikatakan
bahwa Model-4 memiliki kemampuan yang relatif lebih baik dibandingkan model
lain dalam memprediksi parameter area nircontoh.
Gambar 4 Nilai RB (%) prediksi area nircontoh model modifikasi
EBLUP pada seluruh skenario simulasi
-3
-2.5
-2
-1.5
-1
-0.5
0
0.5
1
1 2 3 4 5
RB
(%
)
Skenario
Model-1
Model-2
Model-3
Model-4
Model-5
Gambar 3 Nilai RRMSE (%) prediksi area nircontoh model modifikasi
EBLUP pada seluruh skenario simulasi
0
1
2
3
4
5
6
7
1 2 3 4 5
RR
MSE
(%
)
Skenario
Model-1
Model-2
Model-3
Model-4
Model-5
16
Studi Kasus
Eksplorasi Data
Kota Bogor terdiri dari 6 kecamatan dan 64 kelurahan. Kabupaten Bogor
terdiri dari 40 kecamatan dan 428 desa/kelurahan. Data PODES diasumsikan
mencakup seluruh desa dan kecamatan di Kota dan Kabupaten Bogor sehingga
penggerombolan pada tingkat kecamatan dilakukan berdasarkan peubah yang
dipilih dari data tersebut. Peubah pada data PODES 2011 (Lampiran 25) yang
dipilih sebagai peubah dasar penggerombolan mewakili empat bidang berikut:
1. keterangan umum desa/kelurahan,
2. kependudukan dan ketenagakerjaan,
3. pendidikan dan kesehatan,
4. ekonomi.
Peubah yang dipilih tersebut merupakan peubah yang memiliki ragam yang besar
dan memiliki sedikit nilai nol (Lampiran 25).
Peubah pada data SUSENAS 2010 digunakan sebagai peubah respon ( ),
yaitu rata-rata pengeluaran per kapita per bulan. Data SUSENAS mencakup 44
kecamatan dan 111 desa/kelurahan di Kota dan Kabupaten Bogor. Rata-rata
pengeluaran per kapita tidak berdistribusi normal. Hal ini dapat dilihat dari plot
peubah yang menjulur ke kanan (Gambar 5).
Gambar 6 Plot kuantil-kuantil peubah
Gambar 5 Kepekatan peluang (a) peubah , yaitu rata-rata pengeluaran per
kapita per bulan (Rupiah) dan (b) bentuk tranformasi logaritma
peubah Y
(a) (b)

17
Tabel 9 Uji Kenormalan Anderson-Darling Peubah ( )
AD 9.367 0.506
Nilai-p < 0.005 0.197
Uji kenormalan Anderson-Darling terhadap peubah menghasilkan nilai
signifikansi < 0.005 sehingga pada taraf nyata 5% dapat dikatakan bahwa data
tersebut tidak mengikuti sebaran normal (Tabel 9). Transformasi logaritma
terhadap peubah dilakukan untuk mengatasi ketaknormalan data. Plot kuantil-
kuantil peubah ( ) menunjukkan pola yang mengikuti garis kenormalan
(Gambar 6). Uji kenormalan terhadap hasil transformasi peubah menghasilkan
nilai signifikansi sebesar 0.197, artinya pada taraf nyata 5% hipotesis nol yang
menyatakan bahwa data mengikuti sebaran normal dapat diterima.
Analisis Gerombol
Pembentukan gerombol dilakukan dengan pendekatan analisis gerombol
berhirarki berdasarkan peubah yang dipilih pada tahap eksplorasi data. Jarak yang
digunakan adalah jarak euclid yang mengasumsikan bahwa tidak terdapat
multikolinieritas. Analisis Komponen Utama (AKU) digunakan untuk mengatasi
multikolineritas pada data (Lampiran 26). Analisis gerombol dilakukan
menggunakan seluruh Komponen Utama (KU) untuk mempertahankan seluruh
keragaman data. Analisis gerombol dilakukan dengan metode Ward. Penentuan
gerombol untuk tingkat kecamatan Kota dan Kabupaten Bogor dilakukan
berdasarkan dendogram dengan nilai cutoff pada jarak ketakmiripan 8.20
(Lampiran 27). Penggerombolan tersebut menghasilkan 8 gerombol (Tabel 10).
Tabel 10 Penggerombolan kecamatan di Kota dan Kabupaten Bogor
Gerombol Banyaknya
Anggota
Anggota Gerombol
1 11 Pamijahan, Cigombong, Megamendung, Babakan
Madang, Jonggol, Kemang, Ciseeng, Gunung
Sindur, Rumpin, Cigudeg
2 12 Nanggung, Leuwisadeng, Cibungbulang, Tenjolaya,
Cijeruk, Sukamakmur, Cariu, Tanjungsari, Ranca
Bungur, Sukajaya, Jasinga, Tenjo
3 2 Gunung Putri, Cibinong
4 1 Cisarua
5 6 Parung, Bogor Timur, Bogor Utara, Bogor Tengah,
Bogor Barat, Tanah Sereal
6 6 Dramaga, Ciomas, Tamansari, Caringin, Kelapa
Nunggal, Tajur Halang
7 4 Leuwiliang, Ciampea, Ciawi , Parung Panjang
8 5 Sukaraja, Cileungsi, Citeureup, Bojong Gede,
Bogor Selatan
Karakteristik setiap gerombol dapat dilihat dari statistik rataan peubah dasar
penggerombolan (Lampiran 28). Gerombol 1 dan 2 merupakan kelompok
kecamatan dengan sebagian besar mata pencaharian utama penduduknya adalah
dari sektor pertanian. Gerombol 1 memiliki jumlah sarana kesehatan dan
18
pariwisata yang lebih banyak dibandingkan dengan gerombol 2. Gerombol 2
merupakan kawasan dengan jumlah penduduk yang paling sedikit dibanding
gerombol lain. Gerombol 3 merupakan kawasan yang paling banyak penduduknya,
sehingga kawasan ini juga memiliki sarana pendidikan dan kesehatan yang paling
banyak pula. Sebagian besar mata pencaharian pada gerombol 3 berasal dari
sektor industri. Gerombol 4 merupakan kawasan pariwisata dengan jumlah hotel
dan penginapan yang jauh lebih banyak dibandingkan kawasan lain.
Sebagian besar kecamatan di wilayah kota Bogor termasuk ke dalam
Gerombol 5. Gerombol ini merupakan kawasan dengan persentase keluarga
pertanian paling sedikit. Proporsi jumlah desa/kelurahan dengan sumber mata
pencaharian dari sektor jasa pada gerombol ini mencapai sekitar 50% , jauh lebih
besar dibandingkan dengan gerombol lain. Gerombol 6 merupakan kawasan
dengan rata-rata jumlah industri kecil terbanyak dibandingkan kawasan lain.
Gerombol 7 merupakan kelompok kecamatan dengan proporsi jumlah desa
mencapai 100%, sama halnya dengan gerombol 2, namun persentase keluarga
pertanian pada gerombol 7 lebih sedikit dibandingkan gerombol 2. Jumlah sarana
kesehatan dan pendidikan, serta sarana perekonomian pada gerombol ini juga
lebih banyak daripada gerombol 2. Gerombol 8 merupakan kelompok kecamatan
dengan jumlah koperasi terbanyak dibandingkan gerombol lain.
Pemodelan Small Area Estimation (SAE)
Model area kecil dibangun menggunakan transformasi logaritma dari rata-
rata pengeluaran per kapita per bulan (rupiah) sebagai peubah respon ( ) dan
peubah penyerta ( ) adalah: (1) jumlah minimarket (unit), (2) jumlah poliklinik
(unit), dan (3) sumber mata pencaharian utama sebagian besar penduduk adalah
pertanian atau bukan pertanian. Peubah penyerta dipilih berdasarkan seleksi
dengan metode regresi bertatar atau stepwise (Lampiran 29). Model yang
digunakan adalah model level satuan dengan desa/kelurahan sebagai level satuan
dan kecamatan sebagai level area. Hubungan antara jumlah poliklinik dan
minimarket terhadap peubah menunjukkan pola penggerombolan yang
bercampur (Gambar 7). Kondisi ini relatif mirip dengan kondisi skenario 2 pada
kajian simulasi apabila diasumsikan bahwa hasil penggerombolan sudah tepat.
Gambar 7 Hubungan antara peubah penyerta: (a) jumlah poliklinik (unit) dan
(b) jumlah minimarket (unit) terhadap peubah respon . Gerombol
1 (), gerombol 2 (), gerombol 3 (), gerombol 4 (), gerombol 5
(), gerombol 6 (), gerombol 7 (), dan gerombol 8 ().
(a) (b)

19
Pemodelan area kecil dilakukan dengan menggunakan model EBLUP baku
(Model-0) dan Model-4 yang berdasarkan hasil simulasi dianggap sebagai model
terbaik untuk memprediksi parameter kecamatan nircontoh. Prediksi rata-rata
pengeluaran per kapita per bulan untuk kecamatan di Kota dan Kabupaten Bogor
yang dihasilkan oleh kedua model berbeda-beda, namun masih memiliki
kemiripan pola (Lampiran 31). Prediksi untuk kecamatan yang disurvei (contoh)
adalah sebanyak 44 kecamatan. Seluruh model memprediksi bahwa kecamatan
Gunung Putri memiliki rata-rata pengeluaran per kapita tertinggi dibandingkan
kecamatan lain. Kecamatan yang diprediksi memiliki rata-rata pengeluaran per
kapita terendah adalah kecamatan Nanggung.
Tabel 11 Prediksi rata-rata pengeluaran per kapita dan evaluasi pemodelan pada
kecamatan nircontoh
Kecamatan
nirsampel
Rata-rata pengeluaran per kapita
(ribu rupiah)
Root Mean Squares Error
(ribu rupiah)
Model-0 Model-4 Model-0 Model-4
Leuwisadeng 592.89 586.58 180.884 199.759
Tenjolaya 570.33 559.23 131.250 132.776
Kecamatan yang tidak disurvei (nircontoh) pada studi kasus ini adalah
kecamatan Leuwisadeng dan Tenjolaya. Prediksi rata-rata pengeluaran per kapita
yang dihasilkan kedua model tersebut tidak jauh berbeda (Tabel 11). Prediksi
pada kecamatan nircontoh yang dihasilkan Model-0 memiliki nilai RMSE yang
lebih kecil dibandingkan dengan Model-4. Hal ini menunjukkan bahwa pada studi
kasus ini, Model-0 dapat dikatakan lebih baik dibandingkan dengan Model-4 pada
prediksi kecamatan nircontoh.
Evaluasi model pada studi kasus menunjukkan hasil yang berbeda dengan
simulasi. Perlu digarisbawahi bahwa data simulasi memiliki pola penggerombolan
yang memiliki hubungan linier terhadap peubah respon (Lampiran 1). Data
studi kasus memiliki pola penggerombolan yang cenderung tidak linier terhadap
peubah respon (Gambar 7), jika dibandingkan dengan data simulasi. Hal ini
mungkin disebabkan oleh keragaman di dalam gerombol pada studi kasus yang
relatif besar jika dibandingkan dengan data simulasi. Fenomena ini menunjukkan
kelemahan dari model yang diusulkan pada penelitian ini. Model ini memerlukan
asumsi bahwa penggerombolan mampu membedakan karakteristik antar-area
dengan baik dengan keragaman antar anggota gerombol yang minimum, dan pola
penggerombolan memiliki hubungan yang linier terhadap peubah respon .
Hasil prediksi area nircontoh dengan model-model lain disajikan pada
Lampiran 34. Hasil pemodelan ini menunjukkan bahwa pada prediksi kecamatan
nircontoh, terdapat model dengan penambahan informasi gerombol pada prediksi
area nircontoh menunjukkan akurasi yang lebih baik dibandingkan EBLUP baku,
yaitu Model-1 dan Model-5 (Lampiran 35). Model dengan kompleksitas yang
lebih rendah lebih dianjurkan untuk digunakan pada kasus terapan sehingga
Model-1 dapat dipilih untuk memprediksi parameter area nircontoh pada studi
kasus yang lain. Hal ini didukung oleh hasil kajian simulasi yang menunjukkan
bahwa kemampuan kelima model yang diusulkan hampir sama baiknya dalam
memprediksi parameter area nircontoh, termasuk di dalamnya adalah Model-1.

20
5 SIMPULAN DAN SARAN
Simpulan
Kajian simulasi menunjukkan bahwa secara umum model dengan
penambahan informasi gerombol memiliki kemampuan prediksi yang lebih baik
dibandingkan dengan model EBLUP baku, khususnya pada kasus prediksi area
nircontoh. Model-4 dianggap sebagai model terbaik untuk memprediksi area
nircontoh karena model ini cenderung menghasilkan prediksi dengan nilai
RRMSE terkecil pada berbagai skenario. Studi kasus rata-rata pengeluaran per
kapita tingkat kecamatan di Kota dan Kabupaten Bogor menunjukkan bahwa
prediksi pada kecamatan nircontoh yang dihasilkan Model-0 memiliki nilai
RMSE yang lebih kecil dibandingkan dengan Model-4. Hal ini mungkin
disebabkan oleh keragaman di dalam gerombol pada studi kasus yang relatif besar
sehingga pola penggerombolan cenderung tidak linier terhadap peubah respon,
jika dibandingkan dengan data simulasi. Namun demikian, terdapat model yang
menghasilkan prediksi rata-rata pengeluaran per kapita kecamatan nircontoh
dengan nilai RMSE yang lebih kecil dibandingkan model EBLUP baku, yaitu
Model-1 dan Model-5.
Saran
Mean Squares Error (MSE) yang digunakan pada evaluasi pemodelan pada
penelitian ini masih mengadopsi dari rumus yang sudah ada. Oleh karenanya,
diperlukan pengembangan dalam penguraian MSE bagi penduga yang dihasilkan
oleh model modifikasi EBLUP yang dikembangkan pada penelitian ini. Selain itu,
hasil penelitian ini menunjukkan bahwa penggerombolan memegang peranan
penting dalam menerapkan model yang diusulkan pada studi kasus sehingga
kajian mengenai penggerombolan yang sesuai dengan pemodelan area kecil akan
sangat berguna bagi pengembangan metode yang diusulkan pada penelitian ini.
DAFTAR PUSTAKA
Anisa R, Kurnia A, Indahwati. 2014. Cluster Information of Non-Sampled Area in
Small Area Estimation. IOSR Journal of Mathematics 10(1): 15-19. doi:
10.9790/5728-10121519
Das K, Jiang J, Rao JNK. 2004. Mean Square Error of Empirical Predictor. The
Annals of Statistics 32(2): 818-840. doi: 10.1214/009053604000000201.
Johnson RA, Wichern DW. 2007. Applied Multivariate Statistical Analysis 6th
Edition. London : Prentice-Hall.
Kurnia A. 2009. Prediksi terbaik empirik untuk model transformasi logaritma di
dalam pendugaan area kecil dengan penerapan pada data susenas [disertasi].
Bogor (ID): Program Pasca Sarjana, Institut Pertanian Bogor.

21
Mattjik AA, Sumertajaya IM. 2011. Sidik Peubah Ganda. Bogor: Departemen
Statistika FMIPA-IPB.
McCulloch CE, Searle SR. 2001. Generalized, Linear, and Mixed Models. New
York: John Wiley & Sons.
Rao JNK. 2003. Small Area Estimation. New York: John Wiley & Sons.
Saei A, Chambers R. 2005. Empirical Best Linear Unbiased Prediction for Out of
Sample Area, Working paper M05/03, Southampton Statistical Sciences
Research Institute.


LAMPIRAN

23
(a) Model-0 (b) Model-1 (c) Model-2
(d) Model-3 (e) Model-4 (f) Model-5
Lampiran 1 Garis prediksi area nircontoh skenario 2 untuk hubungan peubah
penyerta terhadap peubah respon yang dihasilkan seluruh model

24
(a) Model-0 (b) Model-1 (c) Model-2
(d) Model-3 (e) Model-4 (f) Model-5
Lampiran 2 Garis prediksi area nircontoh skenario 3 untuk hubungan peubah
penyerta terhadap peubah respon yang dihasilkan seluruh model
25
(a) Model-0 (b) Model-1 (c) Model-2
(d) Model-3 (e) Model-4 (f) Model-5
Lampiran 3 Garis prediksi area nircontoh skenario 4 untuk hubungan peubah
penyerta terhadap peubah respon yang dihasilkan seluruh model
26
(a) Model-0 (b) Model-1 (c) Model-2
(d) Model-3 (e) Model-4 (f) Model-5
Lampiran 4 Garis prediksi area nircontoh skenario 5 untuk hubungan peubah
penyerta terhadap peubah respon yang dihasilkan seluruh model
27
Lampiran 5 Relative Bias (RB) prediksi nilai tengah area contoh pada skenario 1
Area Relative Bias (RB)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1a 337.18 337.18 1.79 1.79 335.17 43.58
1b 341.72 341.72 0.54 0.54 342.86 46.36
1c 371.75 371.75 -0.45 -0.45 372.02 48.60
1e 82.04 82.04 -4.25 -4.25 78.75 3.85
2a 66.10 66.10 0.86 0.86 65.89 9.41
2b 76.34 76.34 1.54 1.54 75.89 11.13
2c 160.18 160.18 6.59 6.59 161.62 28.54
2e 77.88 77.88 -2.44 -2.44 78.29 8.67
2f 71.35 71.35 -2.63 -2.63 71.60 7.37
2h 79.41 79.41 1.37 1.37 78.94 11.30
3a -6.41 -6.41 0.10 0.10 -6.07 -0.34
3b 20.38 20.38 -3.56 -3.56 20.21 -0.49
3c 11.76 11.76 0.58 0.58 12.15 2.46
3e 9.35 9.35 0.68 0.68 9.26 1.85
3f 12.01 12.01 1.92 1.92 11.75 3.05
3g -14.64 -14.64 0.76 0.76 -13.62 0.01
3h 51.18 51.18 -1.08 -1.08 51.31 5.86
3i 12.00 12.00 1.32 1.32 12.16 3.01
4a -17.88 -17.88 -1.22 -1.22 -17.66 -3.28
4b -4.84 -4.84 1.01 1.01 -4.86 0.02
4c -31.17 -31.17 0.95 0.95 -31.28 -3.42
4f -23.80 -23.80 0.74 0.74 -23.47 -2.18
5a -34.71 -34.71 1.05 1.05 -34.89 -3.84
5b -33.92 -33.92 -0.97 -0.97 -34.18 -5.59
5c -27.46 -27.46 0.56 0.56 -27.84 -3.50
5e -35.29 -35.29 -0.98 -0.98 -35.25 -5.47
5g -37.64 -37.64 -0.80 -0.80 -37.60 -5.60
5i -37.71 -37.71 0.32 0.32 -37.85 -4.84
5j -29.33 -29.33 0.95 0.95 -29.22 -2.98
5k -31.23 -31.23 0.09 0.09 -31.53 -4.33
Rataan 47.15 47.15 0.18 0.18 47.08 6.31
Median 10.56 10.56 0.57 0.57 10.50 0.94
28
Lampiran 6 Relative Root Mean Squares Error (RRMSE) prediksi nilai tengah
area contoh pada skenario 1
Area Relative Root Mean Squares Error (RRMSE)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1a 337.18 337.18 7.61 7.61 335.17 104.77
1b 341.72 341.72 7.08 7.08 342.86 107.60
1c 371.76 371.76 7.48 7.48 372.02 116.65
1e 82.10 82.10 7.77 7.77 78.76 23.79
2a 66.11 66.11 1.50 1.50 65.89 21.36
2b 76.34 76.34 1.95 1.95 75.89 24.65
2c 160.19 160.19 6.74 6.74 161.62 53.02
2e 77.89 77.89 2.71 2.71 78.29 25.22
2f 71.35 71.35 2.88 2.88 71.60 22.98
2h 79.41 79.41 1.83 1.83 78.94 25.57
3a 6.42 6.42 0.37 0.37 6.07 2.13
3b 20.39 20.39 3.57 3.57 20.21 6.99
3c 11.77 11.77 0.68 0.68 12.15 4.10
3e 9.35 9.35 0.76 0.76 9.26 3.14
3f 12.02 12.02 1.96 1.96 11.75 4.26
3g 14.68 14.68 0.89 0.89 13.63 4.32
3h 51.18 51.18 1.14 1.14 51.31 16.30
3i 12.01 12.01 1.36 1.36 12.16 4.38
4a 17.89 17.89 1.29 1.29 17.66 5.66
4b 4.85 4.85 1.11 1.11 4.86 1.53
4c 31.17 31.17 1.04 1.04 31.28 9.69
4f 23.80 23.80 0.86 0.86 23.47 7.19
5a 34.71 34.71 1.13 1.13 34.89 11.13
5b 33.92 33.92 1.05 1.05 34.18 11.13
5c 27.46 27.46 0.70 0.70 27.84 8.85
5e 35.29 35.29 1.06 1.06 35.25 11.42
5g 37.64 37.64 0.90 0.90 37.60 12.14
5i 37.71 37.71 0.53 0.53 37.85 12.12
5j 29.33 29.33 1.04 1.04 29.22 9.34
5k 31.23 31.23 0.43 0.43 31.53 10.12
Median 71.56 71.56 2.31 2.31 71.44 22.72
Rataan 34.32 34.32 1.14 1.14 34.54 11.13
29
Lampiran 7 Relative Bias (RB) prediksi nilai tengah area contoh pada skenario 2
Area Relative Bias (RB)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
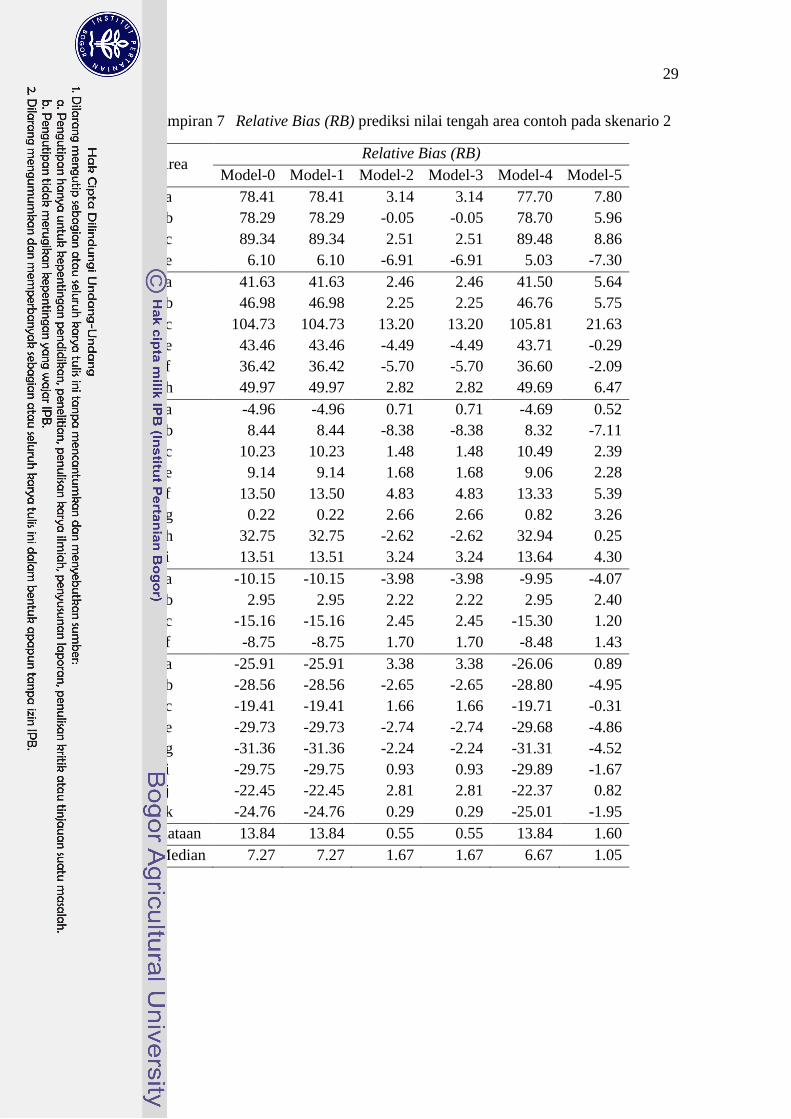
1a 78.41 78.41 3.14 3.14 77.70 7.80
1b 78.29 78.29 -0.05 -0.05 78.70 5.96
1c 89.34 89.34 2.51 2.51 89.48 8.86
1e 6.10 6.10 -6.91 -6.91 5.03 -7.30
2a 41.63 41.63 2.46 2.46 41.50 5.64
2b 46.98 46.98 2.25 2.25 46.76 5.75
2c 104.73 104.73 13.20 13.20 105.81 21.63
2e 43.46 43.46 -4.49 -4.49 43.71 -0.29
2f 36.42 36.42 -5.70 -5.70 36.60 -2.09
2h 49.97 49.97 2.82 2.82 49.69 6.47
3a -4.96 -4.96 0.71 0.71 -4.69 0.52
3b 8.44 8.44 -8.38 -8.38 8.32 -7.11
3c 10.23 10.23 1.48 1.48 10.49 2.39
3e 9.14 9.14 1.68 1.68 9.06 2.28
3f 13.50 13.50 4.83 4.83 13.33 5.39
3g 0.22 0.22 2.66 2.66 0.82 3.26
3h 32.75 32.75 -2.62 -2.62 32.94 0.25
3i 13.51 13.51 3.24 3.24 13.64 4.30
4a -10.15 -10.15 -3.98 -3.98 -9.95 -4.07
4b 2.95 2.95 2.22 2.22 2.95 2.40
4c -15.16 -15.16 2.45 2.45 -15.30 1.20
4f -8.75 -8.75 1.70 1.70 -8.48 1.43
5a -25.91 -25.91 3.38 3.38 -26.06 0.89
5b -28.56 -28.56 -2.65 -2.65 -28.80 -4.95
5c -19.41 -19.41 1.66 1.66 -19.71 -0.31
5e -29.73 -29.73 -2.74 -2.74 -29.68 -4.86
5g -31.36 -31.36 -2.24 -2.24 -31.31 -4.52
5i -29.75 -29.75 0.93 0.93 -29.89 -1.67
5j -22.45 -22.45 2.81 2.81 -22.37 0.82
5k -24.76 -24.76 0.29 0.29 -25.01 -1.95
Rataan 13.84 13.84 0.55 0.55 13.84 1.60
Median 7.27 7.27 1.67 1.67 6.67 1.05
30
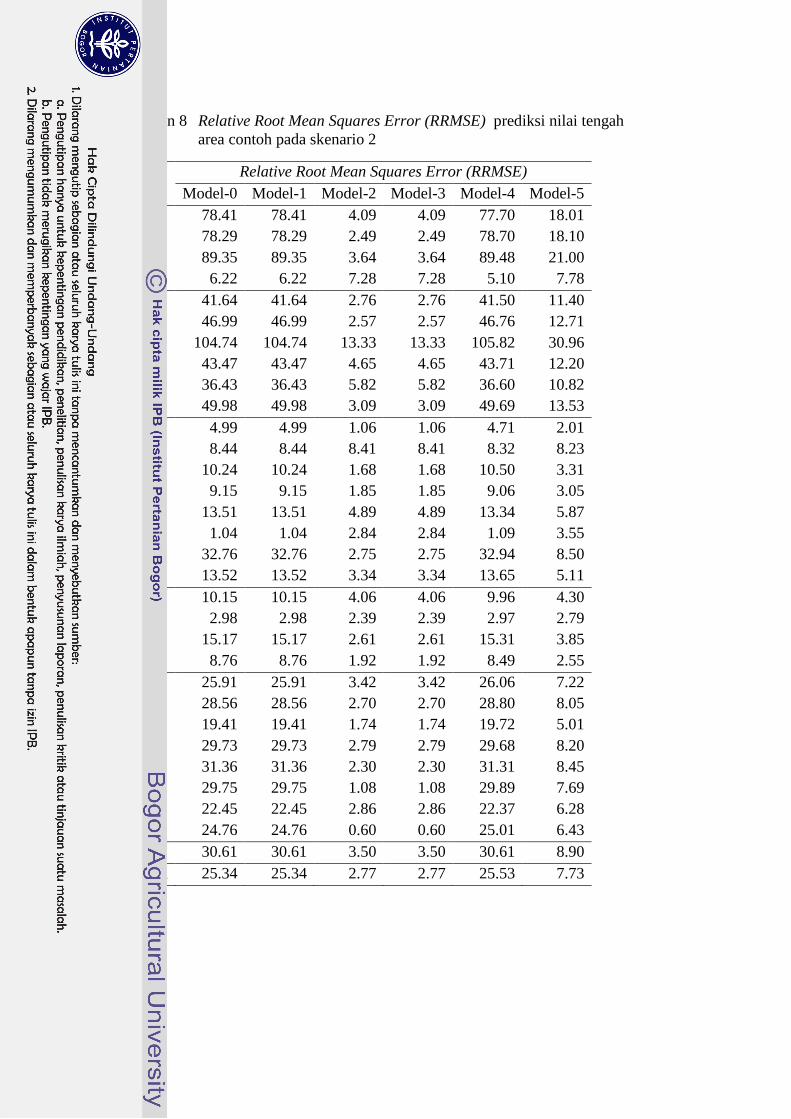
Lampiran 8 Relative Root Mean Squares Error (RRMSE) prediksi nilai tengah
area contoh pada skenario 2
Area Relative Root Mean Squares Error (RRMSE)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1a 78.41 78.41 4.09 4.09 77.70 18.01
1b 78.29 78.29 2.49 2.49 78.70 18.10
1c 89.35 89.35 3.64 3.64 89.48 21.00
1e 6.22 6.22 7.28 7.28 5.10 7.78
2a 41.64 41.64 2.76 2.76 41.50 11.40
2b 46.99 46.99 2.57 2.57 46.76 12.71
2c 104.74 104.74 13.33 13.33 105.82 30.96
2e 43.47 43.47 4.65 4.65 43.71 12.20
2f 36.43 36.43 5.82 5.82 36.60 10.82
2h 49.98 49.98 3.09 3.09 49.69 13.53
3a 4.99 4.99 1.06 1.06 4.71 2.01
3b 8.44 8.44 8.41 8.41 8.32 8.23
3c 10.24 10.24 1.68 1.68 10.50 3.31
3e 9.15 9.15 1.85 1.85 9.06 3.05
3f 13.51 13.51 4.89 4.89 13.34 5.87
3g 1.04 1.04 2.84 2.84 1.09 3.55
3h 32.76 32.76 2.75 2.75 32.94 8.50
3i 13.52 13.52 3.34 3.34 13.65 5.11
4a 10.15 10.15 4.06 4.06 9.96 4.30
4b 2.98 2.98 2.39 2.39 2.97 2.79
4c 15.17 15.17 2.61 2.61 15.31 3.85
4f 8.76 8.76 1.92 1.92 8.49 2.55
5a 25.91 25.91 3.42 3.42 26.06 7.22
5b 28.56 28.56 2.70 2.70 28.80 8.05
5c 19.41 19.41 1.74 1.74 19.72 5.01
5e 29.73 29.73 2.79 2.79 29.68 8.20
5g 31.36 31.36 2.30 2.30 31.31 8.45
5i 29.75 29.75 1.08 1.08 29.89 7.69
5j 22.45 22.45 2.86 2.86 22.37 6.28
5k 24.76 24.76 0.60 0.60 25.01 6.43
Rataan 30.61 30.61 3.50 3.50 30.61 8.90
Median 25.34 25.34 2.77 2.77 25.53 7.73
31
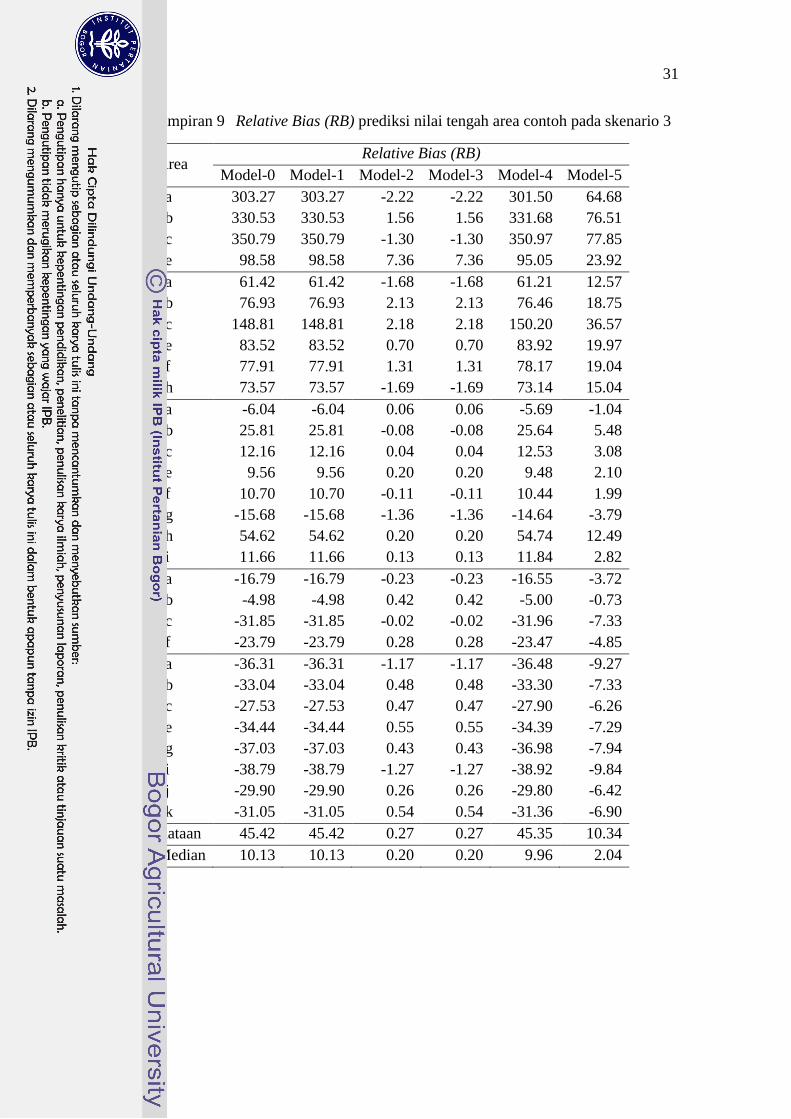
Lampiran 9 Relative Bias (RB) prediksi nilai tengah area contoh pada skenario 3
Area Relative Bias (RB)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1a 303.27 303.27 -2.22 -2.22 301.50 64.68
1b 330.53 330.53 1.56 1.56 331.68 76.51
1c 350.79 350.79 -1.30 -1.30 350.97 77.85
1e 98.58 98.58 7.36 7.36 95.05 23.92
2a 61.42 61.42 -1.68 -1.68 61.21 12.57
2b 76.93 76.93 2.13 2.13 76.46 18.75
2c 148.81 148.81 2.18 2.18 150.20 36.57
2e 83.52 83.52 0.70 0.70 83.92 19.97
2f 77.91 77.91 1.31 1.31 78.17 19.04
2h 73.57 73.57 -1.69 -1.69 73.14 15.04
3a -6.04 -6.04 0.06 0.06 -5.69 -1.04
3b 25.81 25.81 -0.08 -0.08 25.64 5.48
3c 12.16 12.16 0.04 0.04 12.53 3.08
3e 9.56 9.56 0.20 0.20 9.48 2.10
3f 10.70 10.70 -0.11 -0.11 10.44 1.99
3g -15.68 -15.68 -1.36 -1.36 -14.64 -3.79
3h 54.62 54.62 0.20 0.20 54.74 12.49
3i 11.66 11.66 0.13 0.13 11.84 2.82
4a -16.79 -16.79 -0.23 -0.23 -16.55 -3.72
4b -4.98 -4.98 0.42 0.42 -5.00 -0.73
4c -31.85 -31.85 -0.02 -0.02 -31.96 -7.33
4f -23.79 -23.79 0.28 0.28 -23.47 -4.85
5a -36.31 -36.31 -1.17 -1.17 -36.48 -9.27
5b -33.04 -33.04 0.48 0.48 -33.30 -7.33
5c -27.53 -27.53 0.47 0.47 -27.90 -6.26
5e -34.44 -34.44 0.55 0.55 -34.39 -7.29
5g -37.03 -37.03 0.43 0.43 -36.98 -7.94
5i -38.79 -38.79 -1.27 -1.27 -38.92 -9.84
5j -29.90 -29.90 0.26 0.26 -29.80 -6.42
5k -31.05 -31.05 0.54 0.54 -31.36 -6.90
Rataan 45.42 45.42 0.27 0.27 45.35 10.34
Median 10.13 10.13 0.20 0.20 9.96 2.04
32
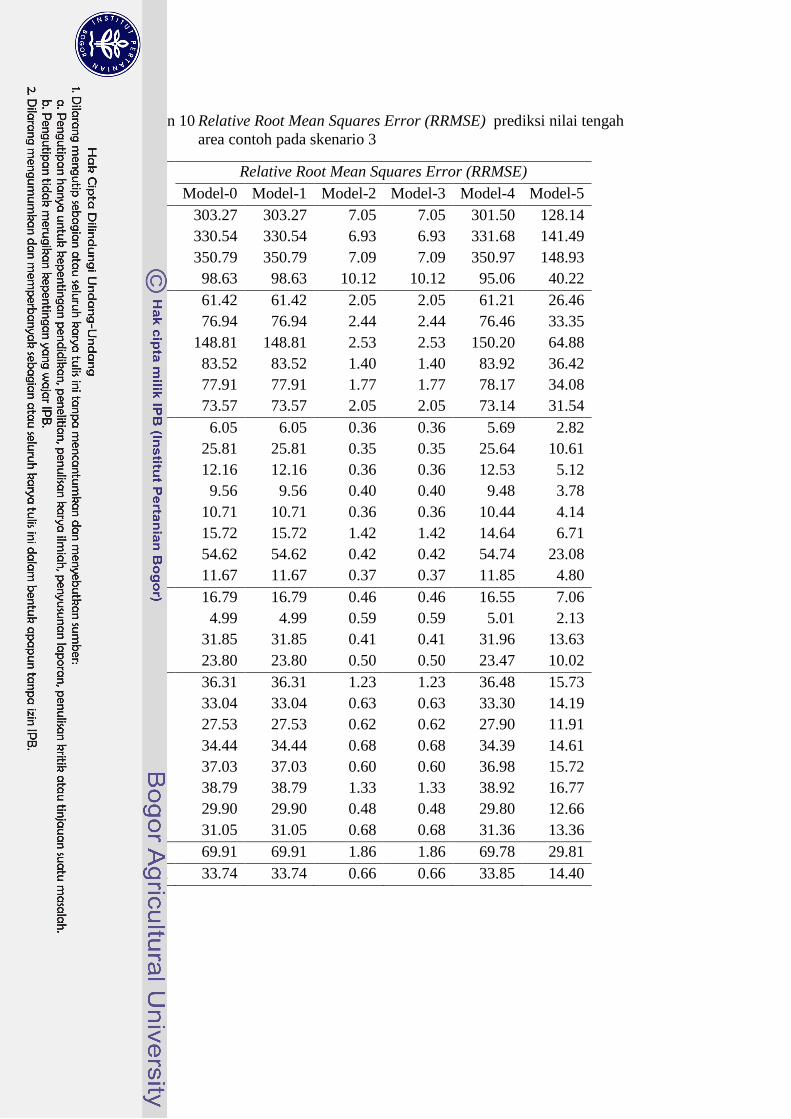
Lampiran 10 Relative Root Mean Squares Error (RRMSE) prediksi nilai tengah
area contoh pada skenario 3
Area Relative Root Mean Squares Error (RRMSE)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1a 303.27 303.27 7.05 7.05 301.50 128.14
1b 330.54 330.54 6.93 6.93 331.68 141.49
1c 350.79 350.79 7.09 7.09 350.97 148.93
1e 98.63 98.63 10.12 10.12 95.06 40.22
2a 61.42 61.42 2.05 2.05 61.21 26.46
2b 76.94 76.94 2.44 2.44 76.46 33.35
2c 148.81 148.81 2.53 2.53 150.20 64.88
2e 83.52 83.52 1.40 1.40 83.92 36.42
2f 77.91 77.91 1.77 1.77 78.17 34.08
2h 73.57 73.57 2.05 2.05 73.14 31.54
3a 6.05 6.05 0.36 0.36 5.69 2.82
3b 25.81 25.81 0.35 0.35 25.64 10.61
3c 12.16 12.16 0.36 0.36 12.53 5.12
3e 9.56 9.56 0.40 0.40 9.48 3.78
3f 10.71 10.71 0.36 0.36 10.44 4.14
3g 15.72 15.72 1.42 1.42 14.64 6.71
3h 54.62 54.62 0.42 0.42 54.74 23.08
3i 11.67 11.67 0.37 0.37 11.85 4.80
4a 16.79 16.79 0.46 0.46 16.55 7.06
4b 4.99 4.99 0.59 0.59 5.01 2.13
4c 31.85 31.85 0.41 0.41 31.96 13.63
4f 23.80 23.80 0.50 0.50 23.47 10.02
5a 36.31 36.31 1.23 1.23 36.48 15.73
5b 33.04 33.04 0.63 0.63 33.30 14.19
5c 27.53 27.53 0.62 0.62 27.90 11.91
5e 34.44 34.44 0.68 0.68 34.39 14.61
5g 37.03 37.03 0.60 0.60 36.98 15.72
5i 38.79 38.79 1.33 1.33 38.92 16.77
5j 29.90 29.90 0.48 0.48 29.80 12.66
5k 31.05 31.05 0.68 0.68 31.36 13.36
Rataan 69.91 69.91 1.86 1.86 69.78 29.81
Median 33.74 33.74 0.66 0.66 33.85 14.40
33
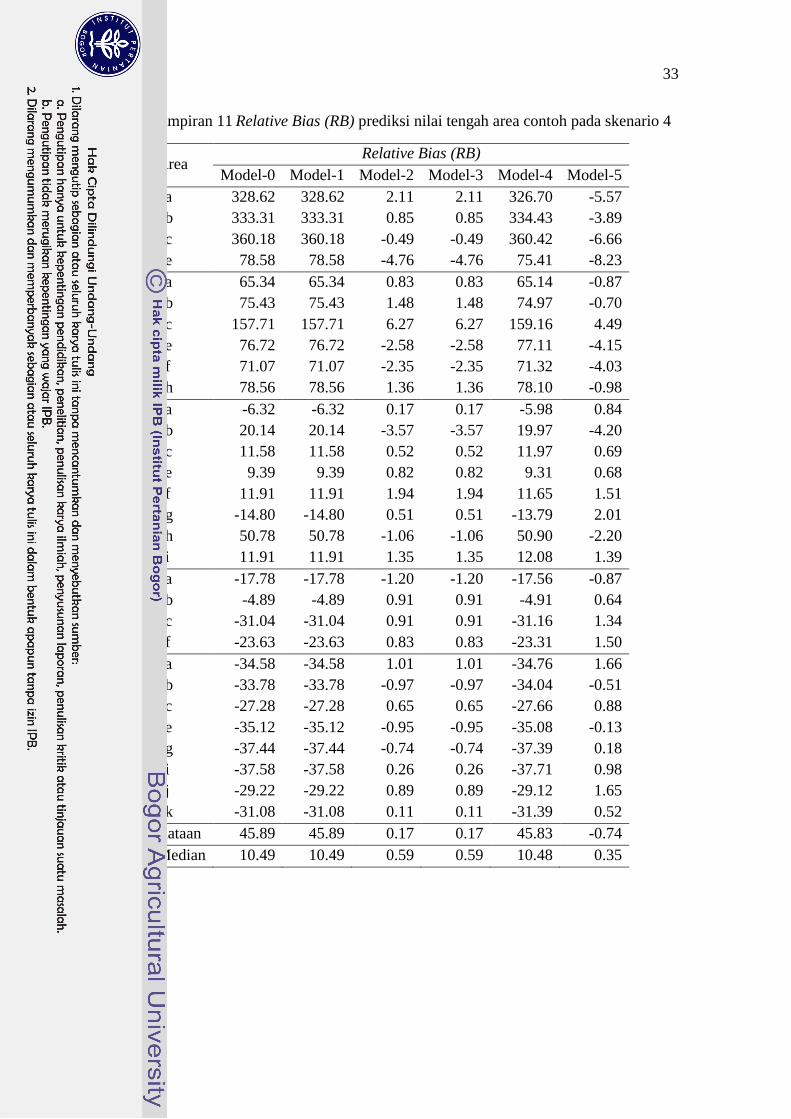
Lampiran 11 Relative Bias (RB) prediksi nilai tengah area contoh pada skenario 4
Area Relative Bias (RB)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1a 328.62 328.62 2.11 2.11 326.70 -5.57
1b 333.31 333.31 0.85 0.85 334.43 -3.89
1c 360.18 360.18 -0.49 -0.49 360.42 -6.66
1e 78.58 78.58 -4.76 -4.76 75.41 -8.23
2a 65.34 65.34 0.83 0.83 65.14 -0.87
2b 75.43 75.43 1.48 1.48 74.97 -0.70
2c 157.71 157.71 6.27 6.27 159.16 4.49
2e 76.72 76.72 -2.58 -2.58 77.11 -4.15
2f 71.07 71.07 -2.35 -2.35 71.32 -4.03
2h 78.56 78.56 1.36 1.36 78.10 -0.98
3a -6.32 -6.32 0.17 0.17 -5.98 0.84
3b 20.14 20.14 -3.57 -3.57 19.97 -4.20
3c 11.58 11.58 0.52 0.52 11.97 0.69
3e 9.39 9.39 0.82 0.82 9.31 0.68
3f 11.91 11.91 1.94 1.94 11.65 1.51
3g -14.80 -14.80 0.51 0.51 -13.79 2.01
3h 50.78 50.78 -1.06 -1.06 50.90 -2.20
3i 11.91 11.91 1.35 1.35 12.08 1.39
4a -17.78 -17.78 -1.20 -1.20 -17.56 -0.87
4b -4.89 -4.89 0.91 0.91 -4.91 0.64
4c -31.04 -31.04 0.91 0.91 -31.16 1.34
4f -23.63 -23.63 0.83 0.83 -23.31 1.50
5a -34.58 -34.58 1.01 1.01 -34.76 1.66
5b -33.78 -33.78 -0.97 -0.97 -34.04 -0.51
5c -27.28 -27.28 0.65 0.65 -27.66 0.88
5e -35.12 -35.12 -0.95 -0.95 -35.08 -0.13
5g -37.44 -37.44 -0.74 -0.74 -37.39 0.18
5i -37.58 -37.58 0.26 0.26 -37.71 0.98
5j -29.22 -29.22 0.89 0.89 -29.12 1.65
5k -31.08 -31.08 0.11 0.11 -31.39 0.52
Rataan 45.89 45.89 0.17 0.17 45.83 -0.74
Median 10.49 10.49 0.59 0.59 10.48 0.35
34
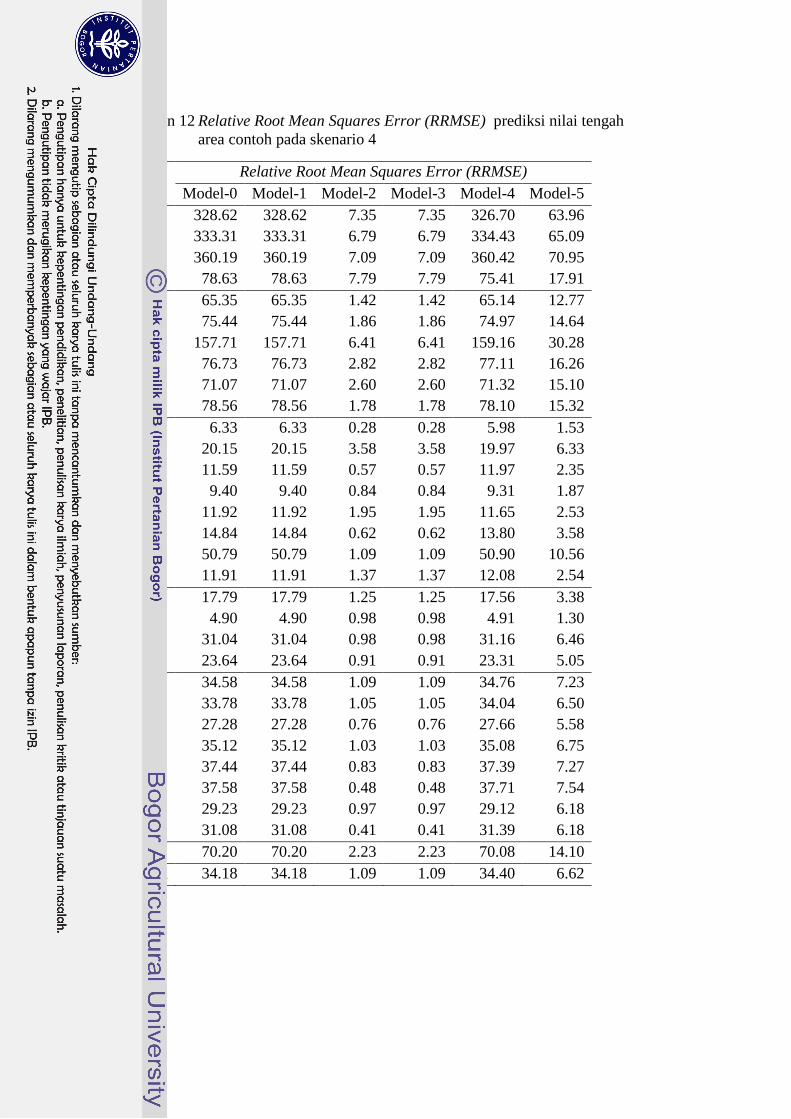
Lampiran 12 Relative Root Mean Squares Error (RRMSE) prediksi nilai tengah
area contoh pada skenario 4
Area Relative Root Mean Squares Error (RRMSE)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1a 328.62 328.62 7.35 7.35 326.70 63.96
1b 333.31 333.31 6.79 6.79 334.43 65.09
1c 360.19 360.19 7.09 7.09 360.42 70.95
1e 78.63 78.63 7.79 7.79 75.41 17.91
2a 65.35 65.35 1.42 1.42 65.14 12.77
2b 75.44 75.44 1.86 1.86 74.97 14.64
2c 157.71 157.71 6.41 6.41 159.16 30.28
2e 76.73 76.73 2.82 2.82 77.11 16.26
2f 71.07 71.07 2.60 2.60 71.32 15.10
2h 78.56 78.56 1.78 1.78 78.10 15.32
3a 6.33 6.33 0.28 0.28 5.98 1.53
3b 20.15 20.15 3.58 3.58 19.97 6.33
3c 11.59 11.59 0.57 0.57 11.97 2.35
3e 9.40 9.40 0.84 0.84 9.31 1.87
3f 11.92 11.92 1.95 1.95 11.65 2.53
3g 14.84 14.84 0.62 0.62 13.80 3.58
3h 50.79 50.79 1.09 1.09 50.90 10.56
3i 11.91 11.91 1.37 1.37 12.08 2.54
4a 17.79 17.79 1.25 1.25 17.56 3.38
4b 4.90 4.90 0.98 0.98 4.91 1.30
4c 31.04 31.04 0.98 0.98 31.16 6.46
4f 23.64 23.64 0.91 0.91 23.31 5.05
5a 34.58 34.58 1.09 1.09 34.76 7.23
5b 33.78 33.78 1.05 1.05 34.04 6.50
5c 27.28 27.28 0.76 0.76 27.66 5.58
5e 35.12 35.12 1.03 1.03 35.08 6.75
5g 37.44 37.44 0.83 0.83 37.39 7.27
5i 37.58 37.58 0.48 0.48 37.71 7.54
5j 29.23 29.23 0.97 0.97 29.12 6.18
5k 31.08 31.08 0.41 0.41 31.39 6.18
Rataan 70.20 70.20 2.23 2.23 70.08 14.10
Median 34.18 34.18 1.09 1.09 34.40 6.62
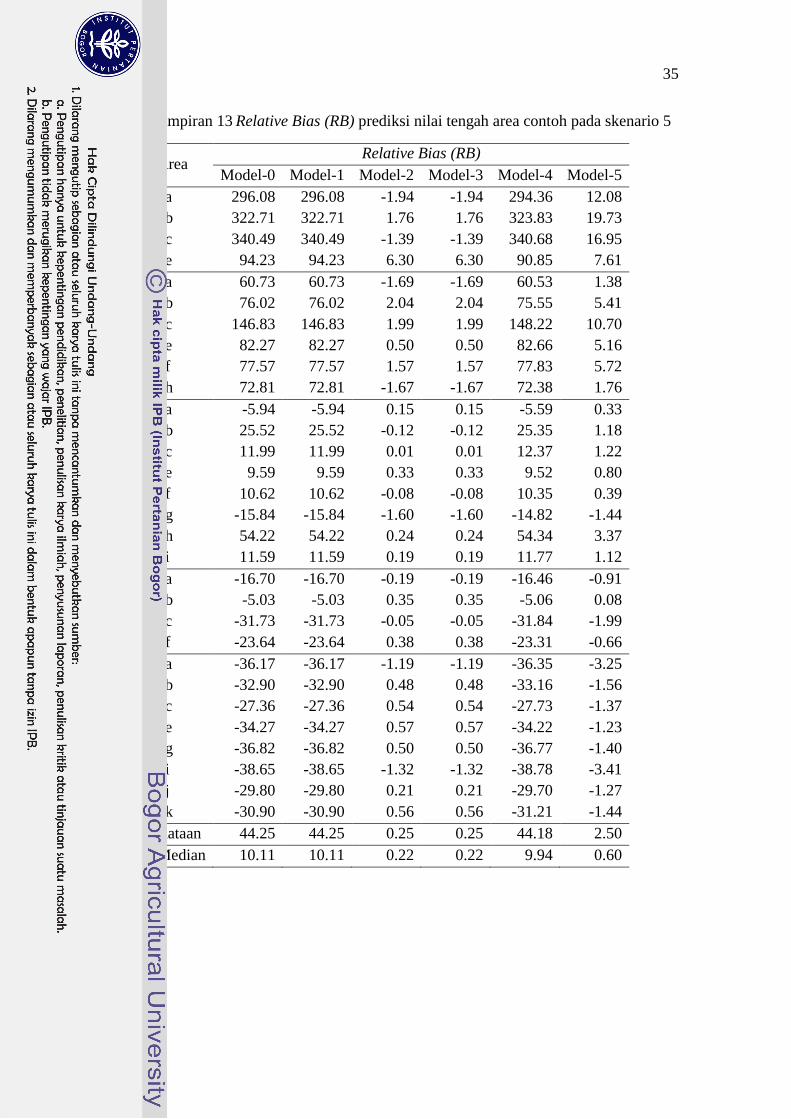
35
Lampiran 13 Relative Bias (RB) prediksi nilai tengah area contoh pada skenario 5
Area Relative Bias (RB)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1a 296.08 296.08 -1.94 -1.94 294.36 12.08
1b 322.71 322.71 1.76 1.76 323.83 19.73
1c 340.49 340.49 -1.39 -1.39 340.68 16.95
1e 94.23 94.23 6.30 6.30 90.85 7.61
2a 60.73 60.73 -1.69 -1.69 60.53 1.38
2b 76.02 76.02 2.04 2.04 75.55 5.41
2c 146.83 146.83 1.99 1.99 148.22 10.70
2e 82.27 82.27 0.50 0.50 82.66 5.16
2f 77.57 77.57 1.57 1.57 77.83 5.72
2h 72.81 72.81 -1.67 -1.67 72.38 1.76
3a -5.94 -5.94 0.15 0.15 -5.59 0.33
3b 25.52 25.52 -0.12 -0.12 25.35 1.18
3c 11.99 11.99 0.01 0.01 12.37 1.22
3e 9.59 9.59 0.33 0.33 9.52 0.80
3f 10.62 10.62 -0.08 -0.08 10.35 0.39
3g -15.84 -15.84 -1.60 -1.60 -14.82 -1.44
3h 54.22 54.22 0.24 0.24 54.34 3.37
3i 11.59 11.59 0.19 0.19 11.77 1.12
4a -16.70 -16.70 -0.19 -0.19 -16.46 -0.91
4b -5.03 -5.03 0.35 0.35 -5.06 0.08
4c -31.73 -31.73 -0.05 -0.05 -31.84 -1.99
4f -23.64 -23.64 0.38 0.38 -23.31 -0.66
5a -36.17 -36.17 -1.19 -1.19 -36.35 -3.25
5b -32.90 -32.90 0.48 0.48 -33.16 -1.56
5c -27.36 -27.36 0.54 0.54 -27.73 -1.37
5e -34.27 -34.27 0.57 0.57 -34.22 -1.23
5g -36.82 -36.82 0.50 0.50 -36.77 -1.40
5i -38.65 -38.65 -1.32 -1.32 -38.78 -3.41
5j -29.80 -29.80 0.21 0.21 -29.70 -1.27
5k -30.90 -30.90 0.56 0.56 -31.21 -1.44
Rataan 44.25 44.25 0.25 0.25 44.18 2.50
Median 10.11 10.11 0.22 0.22 9.94 0.60
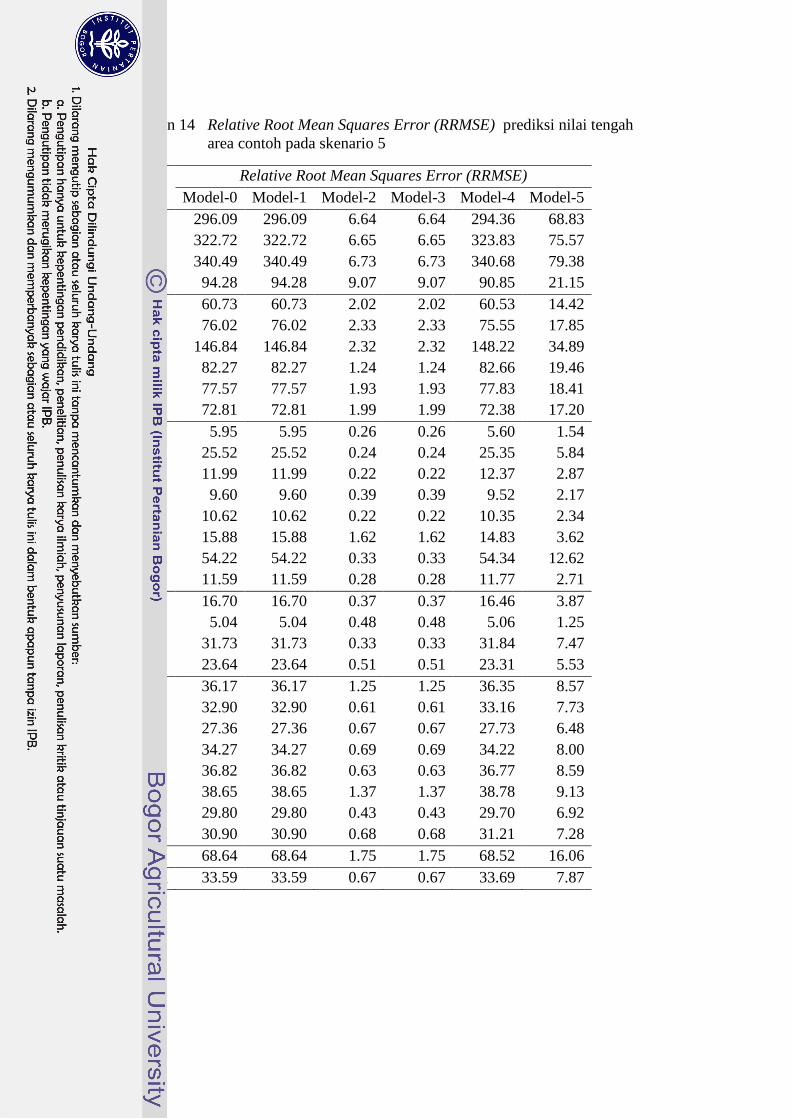
36
Lampiran 14 Relative Root Mean Squares Error (RRMSE) prediksi nilai tengah
area contoh pada skenario 5
Area Relative Root Mean Squares Error (RRMSE)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1a 296.09 296.09 6.64 6.64 294.36 68.83
1b 322.72 322.72 6.65 6.65 323.83 75.57
1c 340.49 340.49 6.73 6.73 340.68 79.38
1e 94.28 94.28 9.07 9.07 90.85 21.15
2a 60.73 60.73 2.02 2.02 60.53 14.42
2b 76.02 76.02 2.33 2.33 75.55 17.85
2c 146.84 146.84 2.32 2.32 148.22 34.89
2e 82.27 82.27 1.24 1.24 82.66 19.46
2f 77.57 77.57 1.93 1.93 77.83 18.41
2h 72.81 72.81 1.99 1.99 72.38 17.20
3a 5.95 5.95 0.26 0.26 5.60 1.54
3b 25.52 25.52 0.24 0.24 25.35 5.84
3c 11.99 11.99 0.22 0.22 12.37 2.87
3e 9.60 9.60 0.39 0.39 9.52 2.17
3f 10.62 10.62 0.22 0.22 10.35 2.34
3g 15.88 15.88 1.62 1.62 14.83 3.62
3h 54.22 54.22 0.33 0.33 54.34 12.62
3i 11.59 11.59 0.28 0.28 11.77 2.71
4a 16.70 16.70 0.37 0.37 16.46 3.87
4b 5.04 5.04 0.48 0.48 5.06 1.25
4c 31.73 31.73 0.33 0.33 31.84 7.47
4f 23.64 23.64 0.51 0.51 23.31 5.53
5a 36.17 36.17 1.25 1.25 36.35 8.57
5b 32.90 32.90 0.61 0.61 33.16 7.73
5c 27.36 27.36 0.67 0.67 27.73 6.48
5e 34.27 34.27 0.69 0.69 34.22 8.00
5g 36.82 36.82 0.63 0.63 36.77 8.59
5i 38.65 38.65 1.37 1.37 38.78 9.13
5j 29.80 29.80 0.43 0.43 29.70 6.92
5k 30.90 30.90 0.68 0.68 31.21 7.28
Rataan 68.64 68.64 1.75 1.75 68.52 16.06
Median 33.59 33.59 0.67 0.67 33.69 7.87
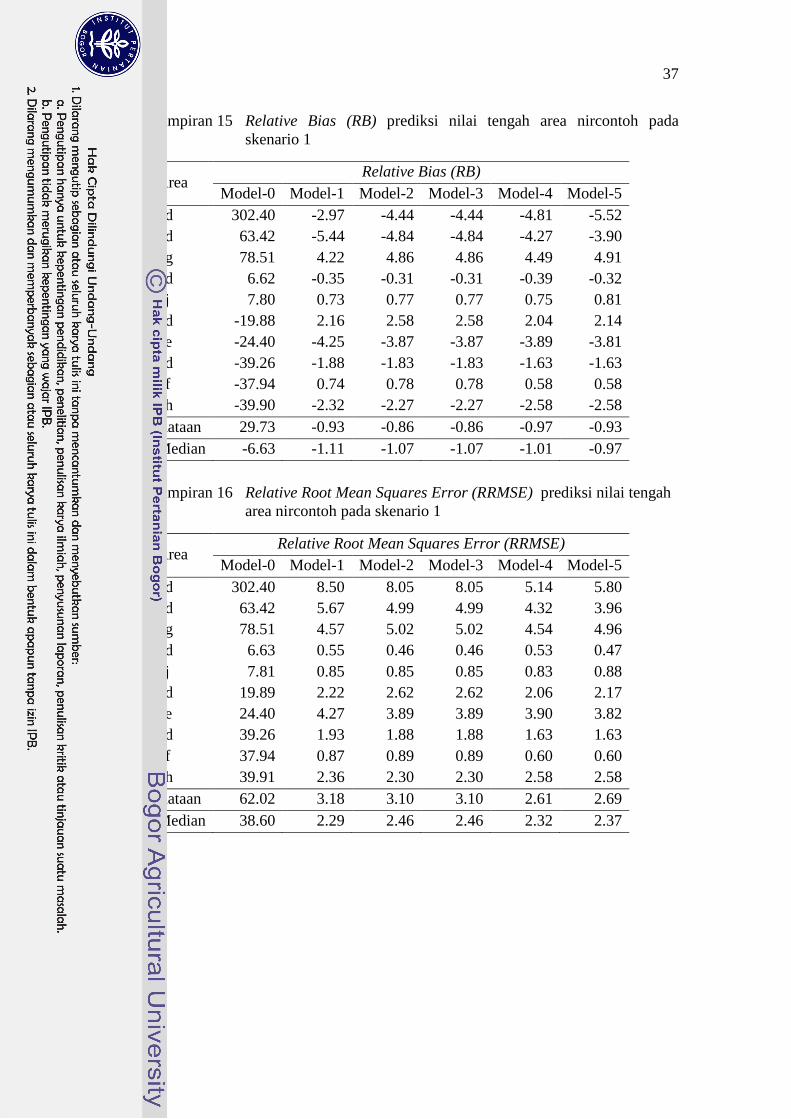
37
Lampiran 15 Relative Bias (RB) prediksi nilai tengah area nircontoh pada
skenario 1
Area Relative Bias (RB)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1d 302.40 -2.97 -4.44 -4.44 -4.81 -5.52
2d 63.42 -5.44 -4.84 -4.84 -4.27 -3.90
2g 78.51 4.22 4.86 4.86 4.49 4.91
3d 6.62 -0.35 -0.31 -0.31 -0.39 -0.32
3j 7.80 0.73 0.77 0.77 0.75 0.81
4d -19.88 2.16 2.58 2.58 2.04 2.14
4e -24.40 -4.25 -3.87 -3.87 -3.89 -3.81
5d -39.26 -1.88 -1.83 -1.83 -1.63 -1.63
5f -37.94 0.74 0.78 0.78 0.58 0.58
5h -39.90 -2.32 -2.27 -2.27 -2.58 -2.58
Rataan 29.73 -0.93 -0.86 -0.86 -0.97 -0.93
Median -6.63 -1.11 -1.07 -1.07 -1.01 -0.97
Lampiran 16 Relative Root Mean Squares Error (RRMSE) prediksi nilai tengah
area nircontoh pada skenario 1
Area Relative Root Mean Squares Error (RRMSE)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1d 302.40 8.50 8.05 8.05 5.14 5.80
2d 63.42 5.67 4.99 4.99 4.32 3.96
2g 78.51 4.57 5.02 5.02 4.54 4.96
3d 6.63 0.55 0.46 0.46 0.53 0.47
3j 7.81 0.85 0.85 0.85 0.83 0.88
4d 19.89 2.22 2.62 2.62 2.06 2.17
4e 24.40 4.27 3.89 3.89 3.90 3.82
5d 39.26 1.93 1.88 1.88 1.63 1.63
5f 37.94 0.87 0.89 0.89 0.60 0.60
5h 39.91 2.36 2.30 2.30 2.58 2.58
Rataan 62.02 3.18 3.10 3.10 2.61 2.69
Median 38.60 2.29 2.46 2.46 2.32 2.37
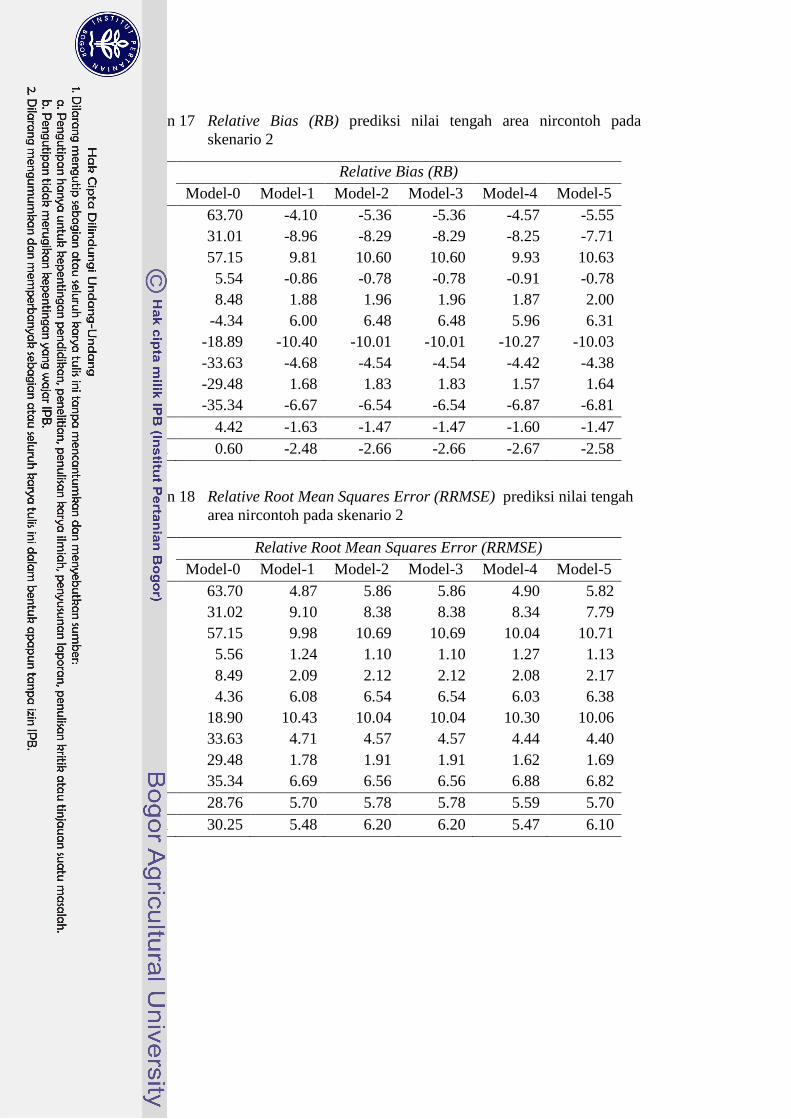
38
Lampiran 17 Relative Bias (RB) prediksi nilai tengah area nircontoh pada
skenario 2
Area Relative Bias (RB)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1d 63.70 -4.10 -5.36 -5.36 -4.57 -5.55
2d 31.01 -8.96 -8.29 -8.29 -8.25 -7.71
2g 57.15 9.81 10.60 10.60 9.93 10.63
3d 5.54 -0.86 -0.78 -0.78 -0.91 -0.78
3j 8.48 1.88 1.96 1.96 1.87 2.00
4d -4.34 6.00 6.48 6.48 5.96 6.31
4e -18.89 -10.40 -10.01 -10.01 -10.27 -10.03
5d -33.63 -4.68 -4.54 -4.54 -4.42 -4.38
5f -29.48 1.68 1.83 1.83 1.57 1.64
5h -35.34 -6.67 -6.54 -6.54 -6.87 -6.81
Rataan 4.42 -1.63 -1.47 -1.47 -1.60 -1.47
Median 0.60 -2.48 -2.66 -2.66 -2.67 -2.58
Lampiran 18 Relative Root Mean Squares Error (RRMSE) prediksi nilai tengah
area nircontoh pada skenario 2
Area Relative Root Mean Squares Error (RRMSE)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1d 63.70 4.87 5.86 5.86 4.90 5.82
2d 31.02 9.10 8.38 8.38 8.34 7.79
2g 57.15 9.98 10.69 10.69 10.04 10.71
3d 5.56 1.24 1.10 1.10 1.27 1.13
3j 8.49 2.09 2.12 2.12 2.08 2.17
4d 4.36 6.08 6.54 6.54 6.03 6.38
4e 18.90 10.43 10.04 10.04 10.30 10.06
5d 33.63 4.71 4.57 4.57 4.44 4.40
5f 29.48 1.78 1.91 1.91 1.62 1.69
5h 35.34 6.69 6.56 6.56 6.88 6.82
Rataan 28.76 5.70 5.78 5.78 5.59 5.70
Median 30.25 5.48 6.20 6.20 5.47 6.10
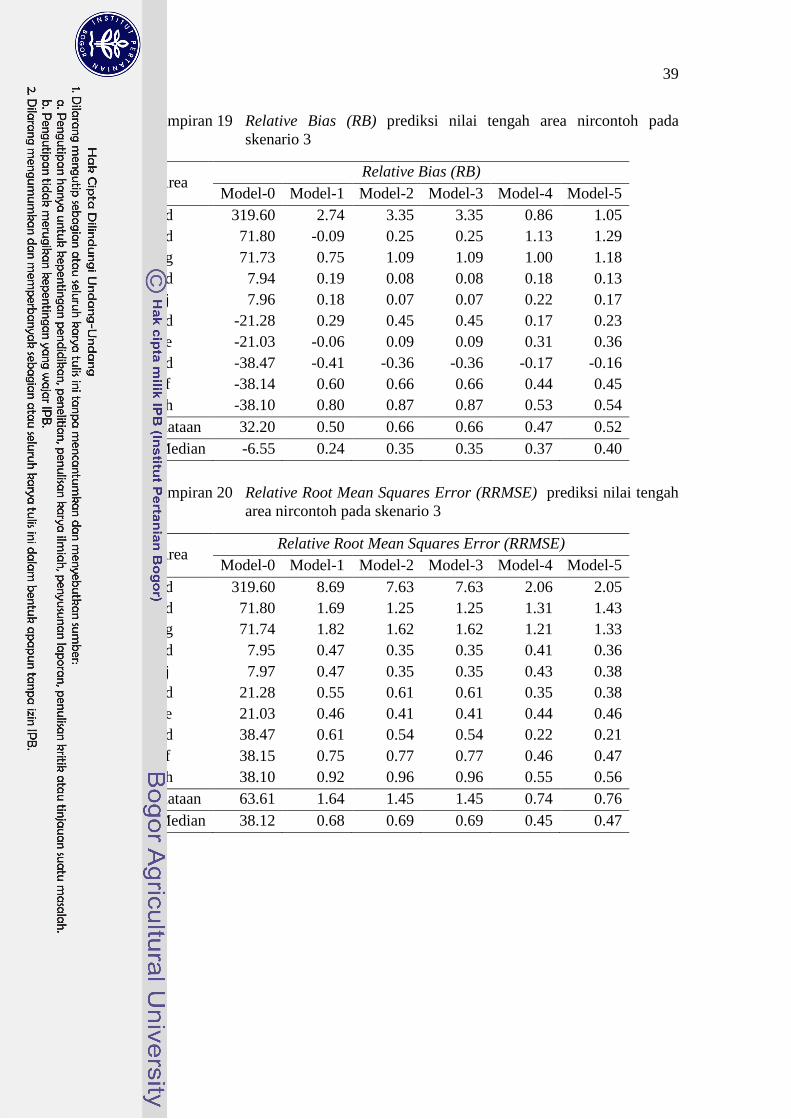
39
Lampiran 19 Relative Bias (RB) prediksi nilai tengah area nircontoh pada
skenario 3
Area Relative Bias (RB)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1d 319.60 2.74 3.35 3.35 0.86 1.05
2d 71.80 -0.09 0.25 0.25 1.13 1.29
2g 71.73 0.75 1.09 1.09 1.00 1.18
3d 7.94 0.19 0.08 0.08 0.18 0.13
3j 7.96 0.18 0.07 0.07 0.22 0.17
4d -21.28 0.29 0.45 0.45 0.17 0.23
4e -21.03 -0.06 0.09 0.09 0.31 0.36
5d -38.47 -0.41 -0.36 -0.36 -0.17 -0.16
5f -38.14 0.60 0.66 0.66 0.44 0.45
5h -38.10 0.80 0.87 0.87 0.53 0.54
Rataan 32.20 0.50 0.66 0.66 0.47 0.52
Median -6.55 0.24 0.35 0.35 0.37 0.40
Lampiran 20 Relative Root Mean Squares Error (RRMSE) prediksi nilai tengah
area nircontoh pada skenario 3
Area Relative Root Mean Squares Error (RRMSE)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1d 319.60 8.69 7.63 7.63 2.06 2.05
2d 71.80 1.69 1.25 1.25 1.31 1.43
2g 71.74 1.82 1.62 1.62 1.21 1.33
3d 7.95 0.47 0.35 0.35 0.41 0.36
3j 7.97 0.47 0.35 0.35 0.43 0.38
4d 21.28 0.55 0.61 0.61 0.35 0.38
4e 21.03 0.46 0.41 0.41 0.44 0.46
5d 38.47 0.61 0.54 0.54 0.22 0.21
5f 38.15 0.75 0.77 0.77 0.46 0.47
5h 38.10 0.92 0.96 0.96 0.55 0.56
Rataan 63.61 1.64 1.45 1.45 0.74 0.76
Median 38.12 0.68 0.69 0.69 0.45 0.47
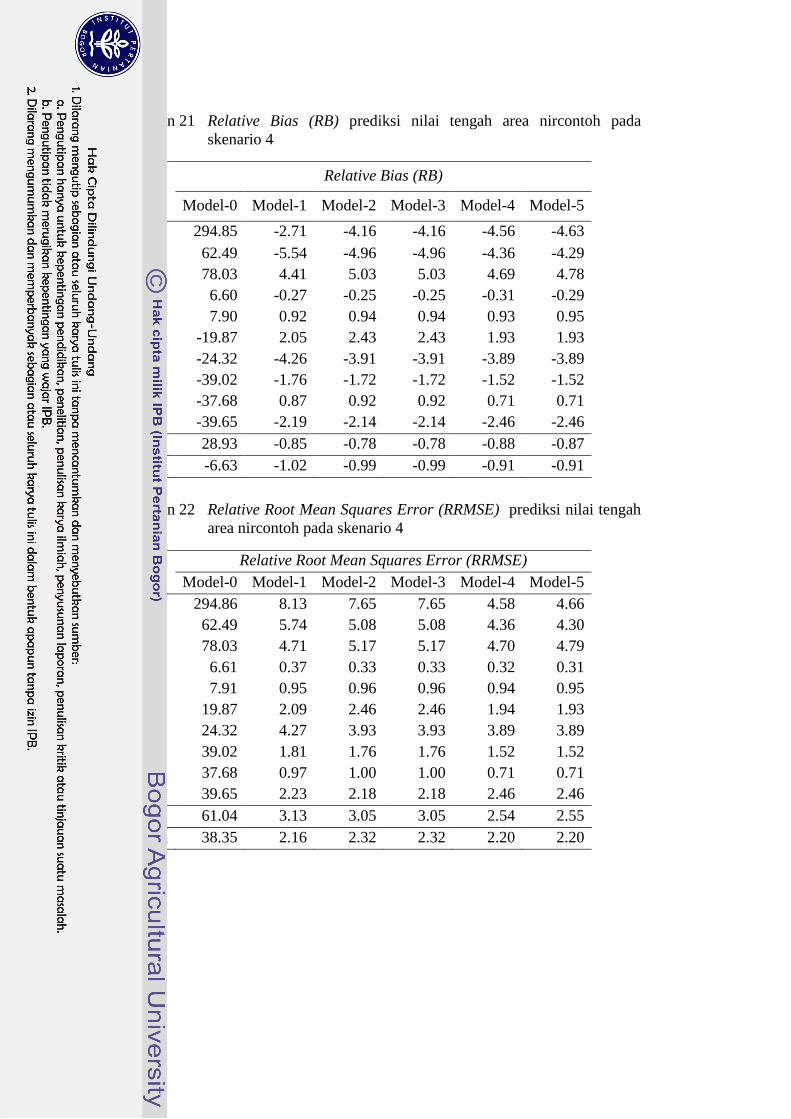
40
Lampiran 21 Relative Bias (RB) prediksi nilai tengah area nircontoh pada
skenario 4
Area Relative Bias (RB)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1d 294.85 -2.71 -4.16 -4.16 -4.56 -4.63
2d 62.49 -5.54 -4.96 -4.96 -4.36 -4.29
2g 78.03 4.41 5.03 5.03 4.69 4.78
3d 6.60 -0.27 -0.25 -0.25 -0.31 -0.29
3j 7.90 0.92 0.94 0.94 0.93 0.95
4d -19.87 2.05 2.43 2.43 1.93 1.93
4e -24.32 -4.26 -3.91 -3.91 -3.89 -3.89
5d -39.02 -1.76 -1.72 -1.72 -1.52 -1.52
5f -37.68 0.87 0.92 0.92 0.71 0.71
5h -39.65 -2.19 -2.14 -2.14 -2.46 -2.46
Rataan 28.93 -0.85 -0.78 -0.78 -0.88 -0.87
Median -6.63 -1.02 -0.99 -0.99 -0.91 -0.91
Lampiran 22 Relative Root Mean Squares Error (RRMSE) prediksi nilai tengah
area nircontoh pada skenario 4
Area Relative Root Mean Squares Error (RRMSE)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1d 294.86 8.13 7.65 7.65 4.58 4.66
2d 62.49 5.74 5.08 5.08 4.36 4.30
2g 78.03 4.71 5.17 5.17 4.70 4.79
3d 6.61 0.37 0.33 0.33 0.32 0.31
3j 7.91 0.95 0.96 0.96 0.94 0.95
4d 19.87 2.09 2.46 2.46 1.94 1.93
4e 24.32 4.27 3.93 3.93 3.89 3.89
5d 39.02 1.81 1.76 1.76 1.52 1.52
5f 37.68 0.97 1.00 1.00 0.71 0.71
5h 39.65 2.23 2.18 2.18 2.46 2.46
Rataan 61.04 3.13 3.05 3.05 2.54 2.55
Median 38.35 2.16 2.32 2.32 2.20 2.20
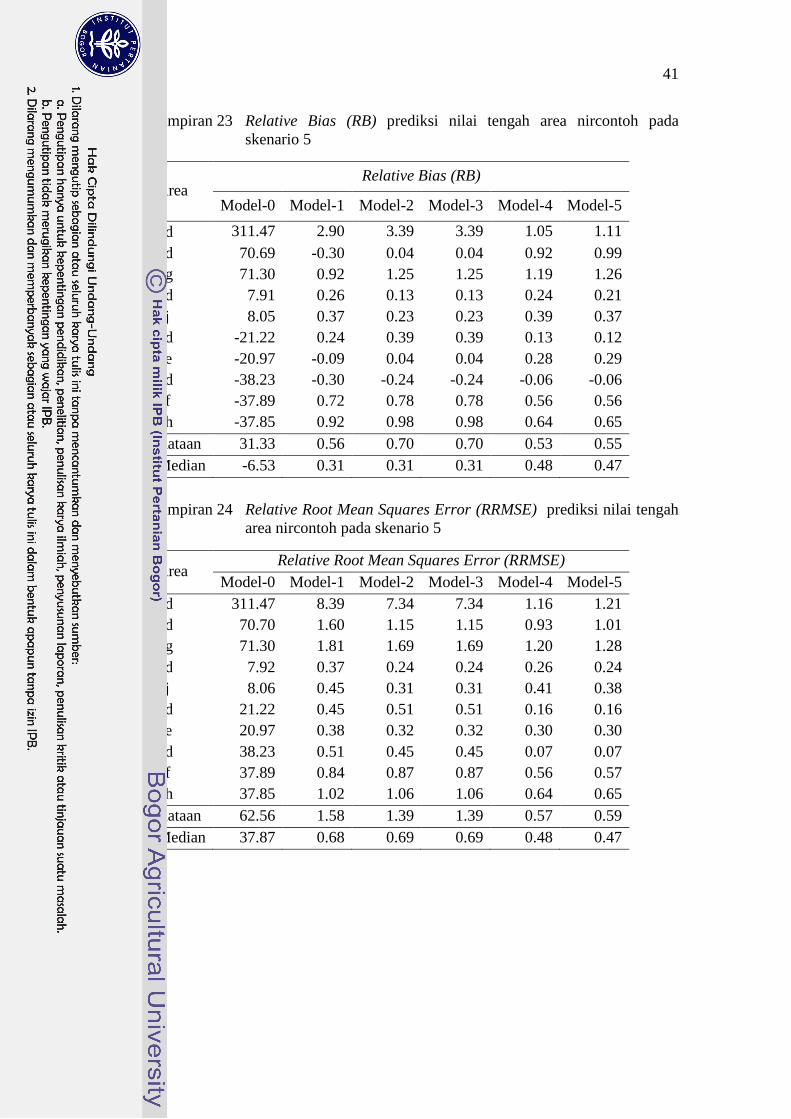
41
Lampiran 23 Relative Bias (RB) prediksi nilai tengah area nircontoh pada
skenario 5
Area Relative Bias (RB)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1d 311.47 2.90 3.39 3.39 1.05 1.11
2d 70.69 -0.30 0.04 0.04 0.92 0.99
2g 71.30 0.92 1.25 1.25 1.19 1.26
3d 7.91 0.26 0.13 0.13 0.24 0.21
3j 8.05 0.37 0.23 0.23 0.39 0.37
4d -21.22 0.24 0.39 0.39 0.13 0.12
4e -20.97 -0.09 0.04 0.04 0.28 0.29
5d -38.23 -0.30 -0.24 -0.24 -0.06 -0.06
5f -37.89 0.72 0.78 0.78 0.56 0.56
5h -37.85 0.92 0.98 0.98 0.64 0.65
Rataan 31.33 0.56 0.70 0.70 0.53 0.55
Median -6.53 0.31 0.31 0.31 0.48 0.47
Lampiran 24 Relative Root Mean Squares Error (RRMSE) prediksi nilai tengah
area nircontoh pada skenario 5
Area Relative Root Mean Squares Error (RRMSE)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
1d 311.47 8.39 7.34 7.34 1.16 1.21
2d 70.70 1.60 1.15 1.15 0.93 1.01
2g 71.30 1.81 1.69 1.69 1.20 1.28
3d 7.92 0.37 0.24 0.24 0.26 0.24
3j 8.06 0.45 0.31 0.31 0.41 0.38
4d 21.22 0.45 0.51 0.51 0.16 0.16
4e 20.97 0.38 0.32 0.32 0.30 0.30
5d 38.23 0.51 0.45 0.45 0.07 0.07
5f 37.89 0.84 0.87 0.87 0.56 0.57
5h 37.85 1.02 1.06 1.06 0.64 0.65
Rataan 62.56 1.58 1.39 1.39 0.57 0.59
Median 37.87 0.68 0.69 0.69 0.48 0.47
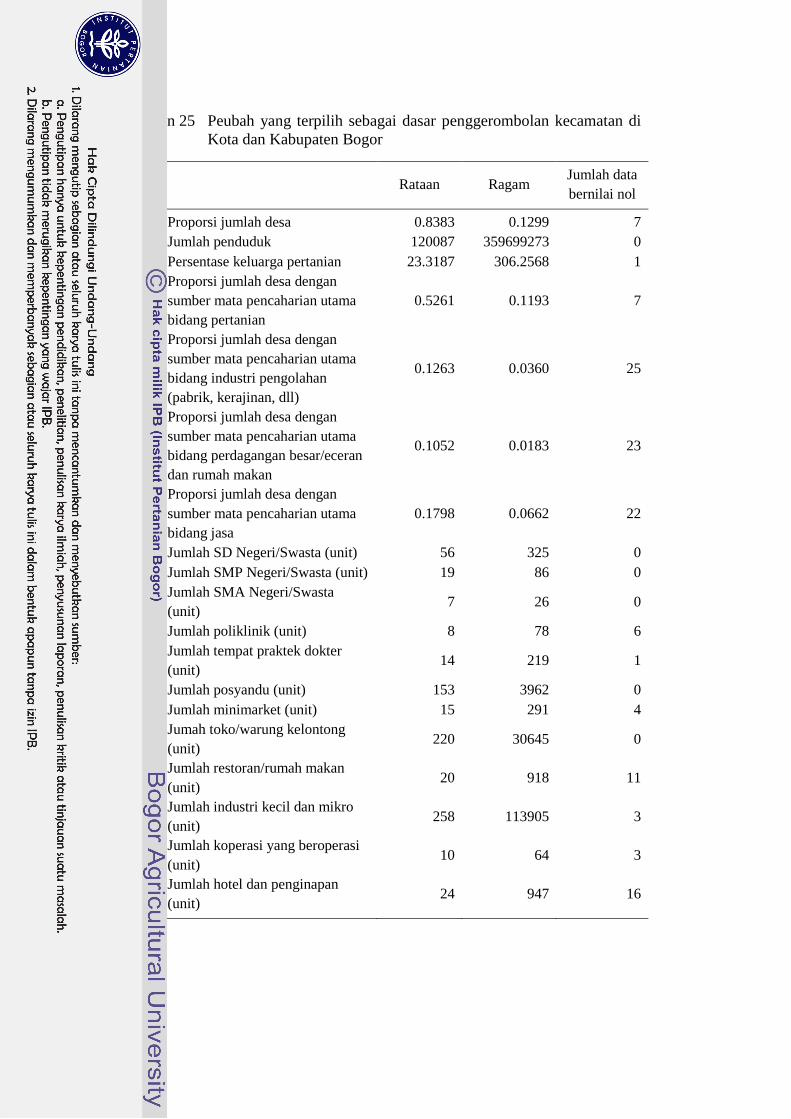
42
Lampiran 25 Peubah yang terpilih sebagai dasar penggerombolan kecamatan di
Kota dan Kabupaten Bogor
Peubah Rataan Ragam Jumlah data
bernilai nol
X1 Proporsi jumlah desa 0.8383 0.1299 7
X2 Jumlah penduduk 120087 359699273 0
X3 Persentase keluarga pertanian 23.3187 306.2568 1
X4
Proporsi jumlah desa dengan
sumber mata pencaharian utama
bidang pertanian
0.5261 0.1193 7
X5
Proporsi jumlah desa dengan
sumber mata pencaharian utama
bidang industri pengolahan
(pabrik, kerajinan, dll)
0.1263 0.0360 25
X6
Proporsi jumlah desa dengan
sumber mata pencaharian utama
bidang perdagangan besar/eceran
dan rumah makan
0.1052 0.0183 23
X7
Proporsi jumlah desa dengan
sumber mata pencaharian utama
bidang jasa
0.1798 0.0662 22
X8 Jumlah SD Negeri/Swasta (unit) 56 325 0
X9 Jumlah SMP Negeri/Swasta (unit) 19 86 0
X10 Jumlah SMA Negeri/Swasta
(unit) 7 26 0
X11 Jumlah poliklinik (unit) 8 78 6
X12 Jumlah tempat praktek dokter
(unit) 14 219 1
X13 Jumlah posyandu (unit) 153 3962 0
X14 Jumlah minimarket (unit) 15 291 4
X15 Jumah toko/warung kelontong
(unit) 220 30645 0
X16 Jumlah restoran/rumah makan
(unit) 20 918 11
X17 Jumlah industri kecil dan mikro
(unit) 258 113905 3
X18 Jumlah koperasi yang beroperasi
(unit) 10 64 3
X19 Jumlah hotel dan penginapan
(unit) 24 947 16
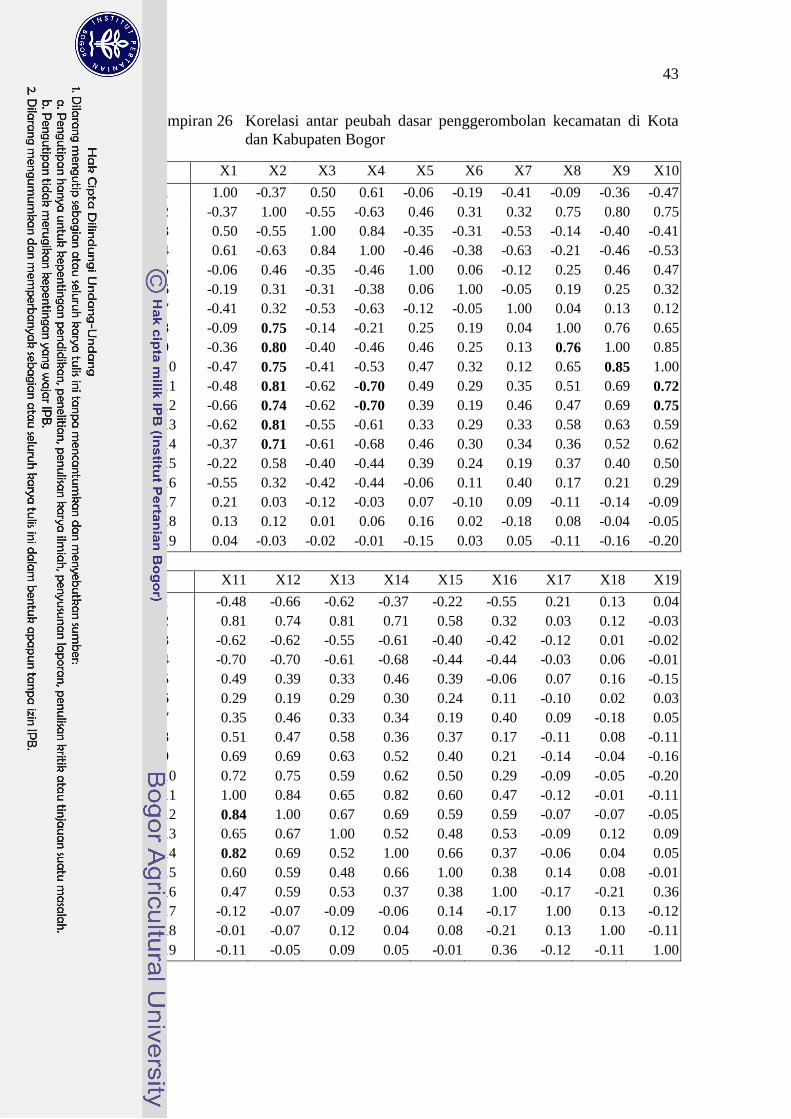
43
Lampiran 26 Korelasi antar peubah dasar penggerombolan kecamatan di Kota
dan Kabupaten Bogor
X1 X2 X3 X4 X5 X6 X7 X8 X9 X10
X1 1.00 -0.37 0.50 0.61 -0.06 -0.19 -0.41 -0.09 -0.36 -0.47
X2 -0.37 1.00 -0.55 -0.63 0.46 0.31 0.32 0.75 0.80 0.75
X3 0.50 -0.55 1.00 0.84 -0.35 -0.31 -0.53 -0.14 -0.40 -0.41
X4 0.61 -0.63 0.84 1.00 -0.46 -0.38 -0.63 -0.21 -0.46 -0.53
X5 -0.06 0.46 -0.35 -0.46 1.00 0.06 -0.12 0.25 0.46 0.47
X6 -0.19 0.31 -0.31 -0.38 0.06 1.00 -0.05 0.19 0.25 0.32
X7 -0.41 0.32 -0.53 -0.63 -0.12 -0.05 1.00 0.04 0.13 0.12
X8 -0.09 0.75 -0.14 -0.21 0.25 0.19 0.04 1.00 0.76 0.65
X9 -0.36 0.80 -0.40 -0.46 0.46 0.25 0.13 0.76 1.00 0.85
X10 -0.47 0.75 -0.41 -0.53 0.47 0.32 0.12 0.65 0.85 1.00
X11 -0.48 0.81 -0.62 -0.70 0.49 0.29 0.35 0.51 0.69 0.72
X12 -0.66 0.74 -0.62 -0.70 0.39 0.19 0.46 0.47 0.69 0.75
X13 -0.62 0.81 -0.55 -0.61 0.33 0.29 0.33 0.58 0.63 0.59
X14 -0.37 0.71 -0.61 -0.68 0.46 0.30 0.34 0.36 0.52 0.62
X15 -0.22 0.58 -0.40 -0.44 0.39 0.24 0.19 0.37 0.40 0.50
X16 -0.55 0.32 -0.42 -0.44 -0.06 0.11 0.40 0.17 0.21 0.29
X17 0.21 0.03 -0.12 -0.03 0.07 -0.10 0.09 -0.11 -0.14 -0.09
X18 0.13 0.12 0.01 0.06 0.16 0.02 -0.18 0.08 -0.04 -0.05
X19 0.04 -0.03 -0.02 -0.01 -0.15 0.03 0.05 -0.11 -0.16 -0.20
X11 X12 X13 X14 X15 X16 X17 X18 X19
X1 -0.48 -0.66 -0.62 -0.37 -0.22 -0.55 0.21 0.13 0.04
X2 0.81 0.74 0.81 0.71 0.58 0.32 0.03 0.12 -0.03
X3 -0.62 -0.62 -0.55 -0.61 -0.40 -0.42 -0.12 0.01 -0.02
X4 -0.70 -0.70 -0.61 -0.68 -0.44 -0.44 -0.03 0.06 -0.01
X5 0.49 0.39 0.33 0.46 0.39 -0.06 0.07 0.16 -0.15
X6 0.29 0.19 0.29 0.30 0.24 0.11 -0.10 0.02 0.03
X7 0.35 0.46 0.33 0.34 0.19 0.40 0.09 -0.18 0.05
X8 0.51 0.47 0.58 0.36 0.37 0.17 -0.11 0.08 -0.11
X9 0.69 0.69 0.63 0.52 0.40 0.21 -0.14 -0.04 -0.16
X10 0.72 0.75 0.59 0.62 0.50 0.29 -0.09 -0.05 -0.20
X11 1.00 0.84 0.65 0.82 0.60 0.47 -0.12 -0.01 -0.11
X12 0.84 1.00 0.67 0.69 0.59 0.59 -0.07 -0.07 -0.05
X13 0.65 0.67 1.00 0.52 0.48 0.53 -0.09 0.12 0.09
X14 0.82 0.69 0.52 1.00 0.66 0.37 -0.06 0.04 0.05
X15 0.60 0.59 0.48 0.66 1.00 0.38 0.14 0.08 -0.01
X16 0.47 0.59 0.53 0.37 0.38 1.00 -0.17 -0.21 0.36
X17 -0.12 -0.07 -0.09 -0.06 0.14 -0.17 1.00 0.13 -0.12
X18 -0.01 -0.07 0.12 0.04 0.08 -0.21 0.13 1.00 -0.11
X19 -0.11 -0.05 0.09 0.05 -0.01 0.36 -0.12 -0.11 1.00
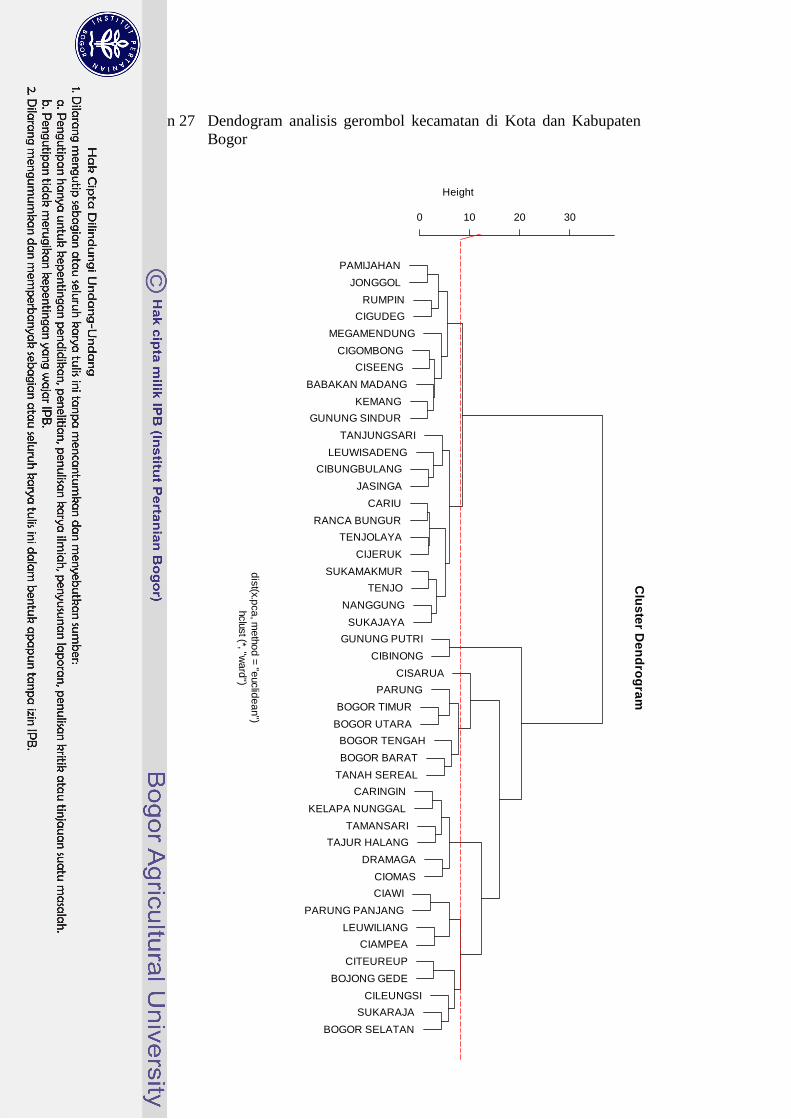
44
Lampiran 27 Dendogram analisis gerombol kecamatan di Kota dan Kabupaten
Bogor
PAMIJAHAN
JONGGOL
RUMPIN
CIGUDEG
MEGAMENDUNG
CIGOMBONG
CISEENG
BABAKAN MADANG
KEMANG
GUNUNG SINDUR
TANJUNGSARI
LEUWISADENG
CIBUNGBULANG
JASINGA
CARIU
RANCA BUNGUR
TENJOLAYA
CIJERUK
SUKAMAKMUR
TENJO
NANGGUNG
SUKAJAYA
GUNUNG PUTRI
CIBINONG
CISARUA
PARUNG
BOGOR TIMUR
BOGOR UTARA
BOGOR TENGAH
BOGOR BARAT
TANAH SEREAL
CARINGIN
KELAPA NUNGGAL
TAMANSARI
TAJUR HALANG
DRAMAGA
CIOMAS
CIAWI
PARUNG PANJANG
LEUWILIANG
CIAMPEA
CITEUREUP
BOJONG GEDE
CILEUNGSI
SUKARAJA
BOGOR SELATAN
0 10 20 30
Clu
ste
r De
nd
rog
ram
hclu
st (*, "w
ard
")
dis
t(x.pca
, me
tho
d =
"euclid
ea
n")
Height
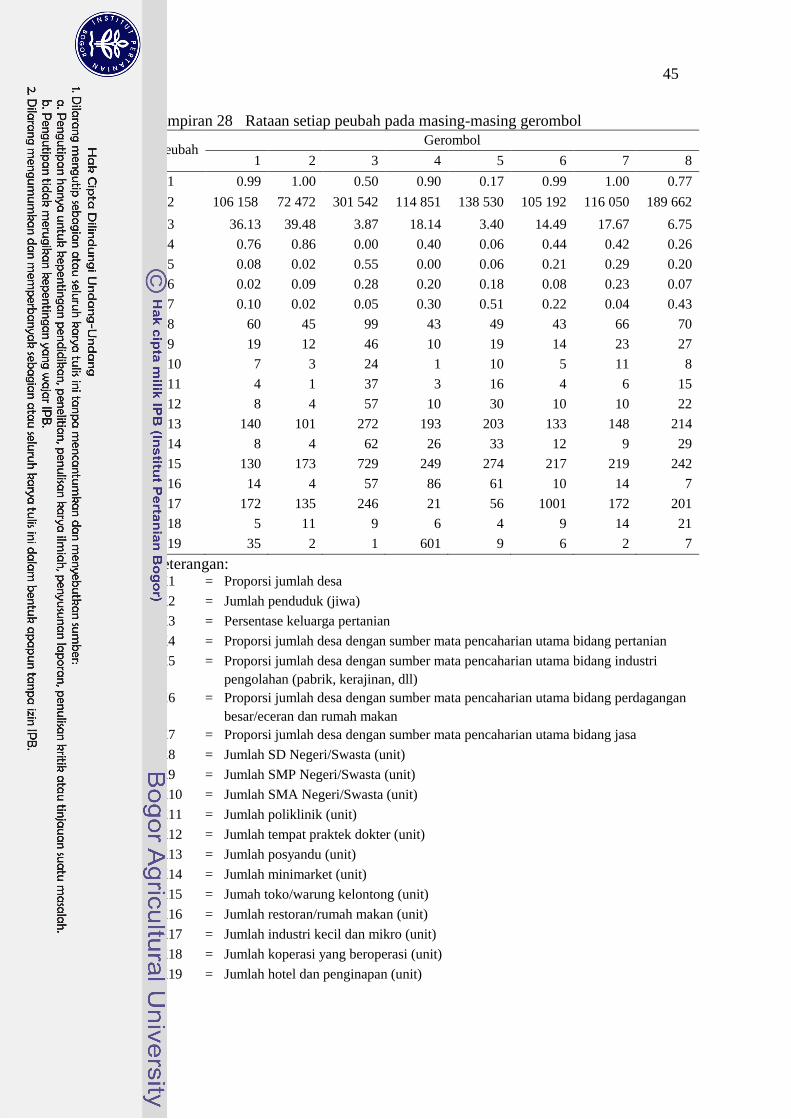
45
Lampiran 28 Rataan setiap peubah pada masing-masing gerombol
Peubah Gerombol
1 2 3 4 5 6 7 8
X1 0.99 1.00 0.50 0.90 0.17 0.99 1.00 0.77
X2 106 158 72 472 301 542 114 851 138 530 105 192 116 050 189 662
X3 36.13 39.48 3.87 18.14 3.40 14.49 17.67 6.75
X4 0.76 0.86 0.00 0.40 0.06 0.44 0.42 0.26
X5 0.08 0.02 0.55 0.00 0.06 0.21 0.29 0.20
X6 0.02 0.09 0.28 0.20 0.18 0.08 0.23 0.07
X7 0.10 0.02 0.05 0.30 0.51 0.22 0.04 0.43
X8 60 45 99 43 49 43 66 70
X9 19 12 46 10 19 14 23 27
X10 7 3 24 1 10 5 11 8
X11 4 1 37 3 16 4 6 15
X12 8 4 57 10 30 10 10 22
X13 140 101 272 193 203 133 148 214
X14 8 4 62 26 33 12 9 29
X15 130 173 729 249 274 217 219 242
X16 14 4 57 86 61 10 14 7
X17 172 135 246 21 56 1001 172 201
X18 5 11 9 6 4 9 14 21
X19 35 2 1 601 9 6 2 7
Keterangan: X1 = Proporsi jumlah desa
X2 = Jumlah penduduk (jiwa)
X3 = Persentase keluarga pertanian
X4 = Proporsi jumlah desa dengan sumber mata pencaharian utama bidang pertanian
X5 = Proporsi jumlah desa dengan sumber mata pencaharian utama bidang industri
pengolahan (pabrik, kerajinan, dll)
X6 = Proporsi jumlah desa dengan sumber mata pencaharian utama bidang perdagangan
besar/eceran dan rumah makan
X7 = Proporsi jumlah desa dengan sumber mata pencaharian utama bidang jasa
X8 = Jumlah SD Negeri/Swasta (unit)
X9 = Jumlah SMP Negeri/Swasta (unit)
X10 = Jumlah SMA Negeri/Swasta (unit)
X11 = Jumlah poliklinik (unit)
X12 = Jumlah tempat praktek dokter (unit)
X13 = Jumlah posyandu (unit)
X14 = Jumlah minimarket (unit)
X15 = Jumah toko/warung kelontong (unit)
X16 = Jumlah restoran/rumah makan (unit)
X17 = Jumlah industri kecil dan mikro (unit)
X18 = Jumlah koperasi yang beroperasi (unit)
X19 = Jumlah hotel dan penginapan (unit)
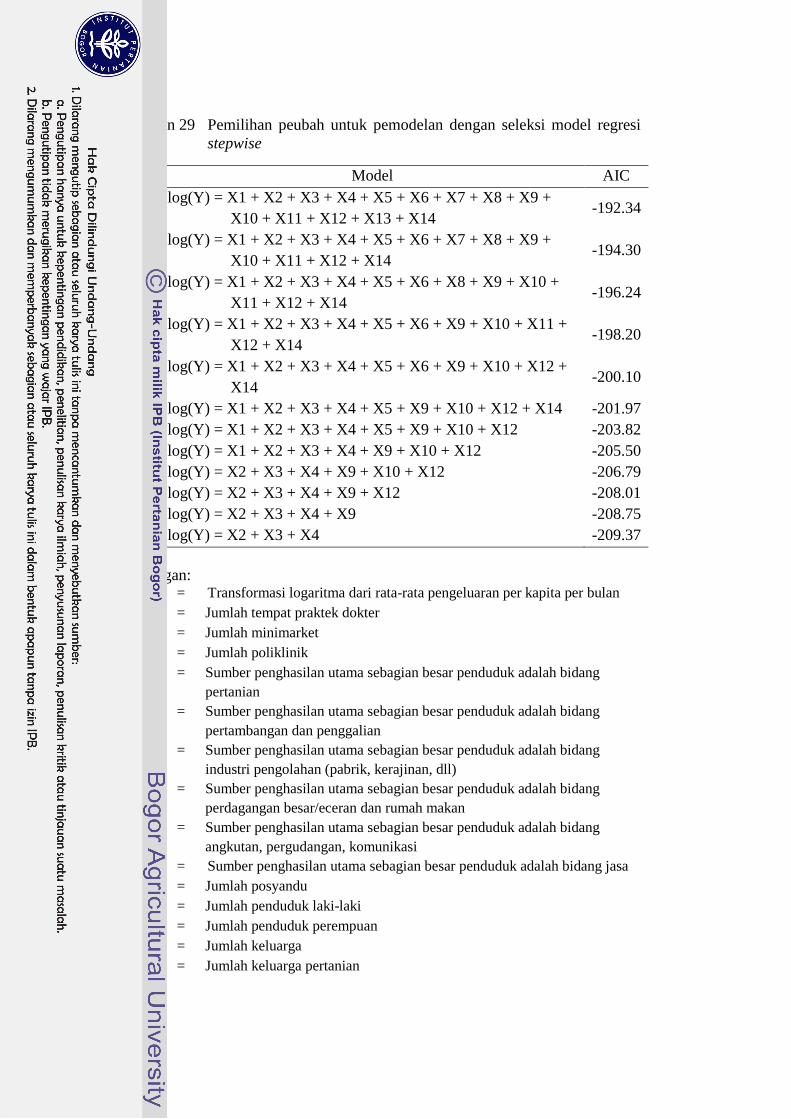
46
Lampiran 29 Pemilihan peubah untuk pemodelan dengan seleksi model regresi
stepwise
Step Model AIC
1 log(Y) = X1 + X2 + X3 + X4 + X5 + X6 + X7 + X8 + X9 +
X10 + X11 + X12 + X13 + X14 -192.34
2 log(Y) = X1 + X2 + X3 + X4 + X5 + X6 + X7 + X8 + X9 +
X10 + X11 + X12 + X14 -194.30
3 log(Y) = X1 + X2 + X3 + X4 + X5 + X6 + X8 + X9 + X10 +
X11 + X12 + X14 -196.24
4 log(Y) = X1 + X2 + X3 + X4 + X5 + X6 + X9 + X10 + X11 +
X12 + X14 -198.20
5 log(Y) = X1 + X2 + X3 + X4 + X5 + X6 + X9 + X10 + X12 +
X14 -200.10
6 log(Y) = X1 + X2 + X3 + X4 + X5 + X9 + X10 + X12 + X14 -201.97
7 log(Y) = X1 + X2 + X3 + X4 + X5 + X9 + X10 + X12 -203.82
8 log(Y) = X1 + X2 + X3 + X4 + X9 + X10 + X12 -205.50
9 log(Y) = X2 + X3 + X4 + X9 + X10 + X12 -206.79
10 log(Y) = X2 + X3 + X4 + X9 + X12 -208.01
11 log(Y) = X2 + X3 + X4 + X9 -208.75
12 log(Y) = X2 + X3 + X4 -209.37
Keterangan: log(Y) = Transformasi logaritma dari rata-rata pengeluaran per kapita per bulan
X1 = Jumlah tempat praktek dokter
X2 = Jumlah minimarket
X3 = Jumlah poliklinik
X4 = Sumber penghasilan utama sebagian besar penduduk adalah bidang
pertanian
X5 = Sumber penghasilan utama sebagian besar penduduk adalah bidang
pertambangan dan penggalian
X6 = Sumber penghasilan utama sebagian besar penduduk adalah bidang
industri pengolahan (pabrik, kerajinan, dll)
X7 = Sumber penghasilan utama sebagian besar penduduk adalah bidang
perdagangan besar/eceran dan rumah makan
X8 = Sumber penghasilan utama sebagian besar penduduk adalah bidang
angkutan, pergudangan, komunikasi
X9 = Sumber penghasilan utama sebagian besar penduduk adalah bidang jasa
X10 = Jumlah posyandu
X11 = Jumlah penduduk laki-laki
X12 = Jumlah penduduk perempuan
X13 = Jumlah keluarga
X14 = Jumlah keluarga pertanian
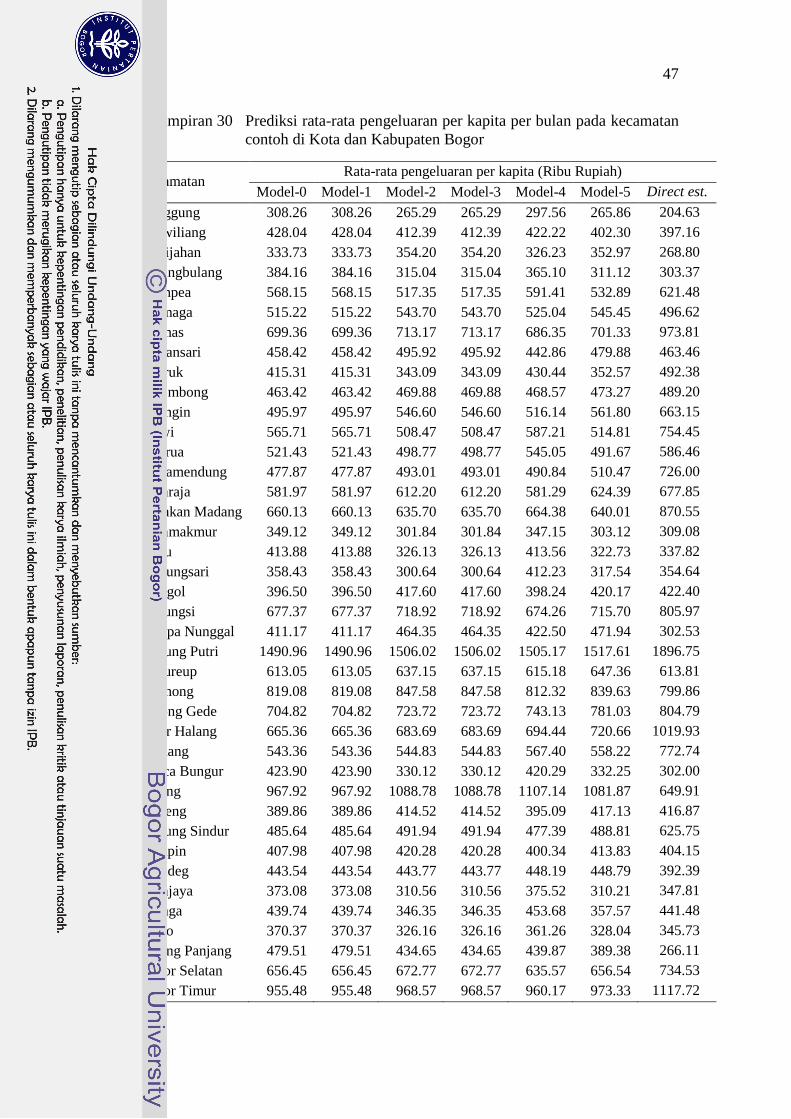
47
Lampiran 30 Prediksi rata-rata pengeluaran per kapita per bulan pada kecamatan
contoh di Kota dan Kabupaten Bogor
Kecamatan Rata-rata pengeluaran per kapita (Ribu Rupiah)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5 Direct est.
Nanggung 308.26 308.26 265.29 265.29 297.56 265.86 204.63
Leuwiliang 428.04 428.04 412.39 412.39 422.22 402.30 397.16
Pamijahan 333.73 333.73 354.20 354.20 326.23 352.97 268.80
Cibungbulang 384.16 384.16 315.04 315.04 365.10 311.12 303.37
Ciampea 568.15 568.15 517.35 517.35 591.41 532.89 621.48
Dramaga 515.22 515.22 543.70 543.70 525.04 545.45 496.62
Ciomas 699.36 699.36 713.17 713.17 686.35 701.33 973.81
Tamansari 458.42 458.42 495.92 495.92 442.86 479.88 463.46
Cijeruk 415.31 415.31 343.09 343.09 430.44 352.57 492.38
Cigombong 463.42 463.42 469.88 469.88 468.57 473.27 489.20
Caringin 495.97 495.97 546.60 546.60 516.14 561.80 663.15
Ciawi 565.71 565.71 508.47 508.47 587.21 514.81 754.45
Cisarua 521.43 521.43 498.77 498.77 545.05 491.67 586.46
Megamendung 477.87 477.87 493.01 493.01 490.84 510.47 726.00
Sukaraja 581.97 581.97 612.20 612.20 581.29 624.39 677.85
Babakan Madang 660.13 660.13 635.70 635.70 664.38 640.01 870.55
Sukamakmur 349.12 349.12 301.84 301.84 347.15 303.12 309.08
Cariu 413.88 413.88 326.13 326.13 413.56 322.73 337.82
Tanjungsari 358.43 358.43 300.64 300.64 412.23 317.54 354.64
Jonggol 396.50 396.50 417.60 417.60 398.24 420.17 422.40
Cileungsi 677.37 677.37 718.92 718.92 674.26 715.70 805.97
Kelapa Nunggal 411.17 411.17 464.35 464.35 422.50 471.94 302.53
Gunung Putri 1490.96 1490.96 1506.02 1506.02 1505.17 1517.61 1896.75
Citeureup 613.05 613.05 637.15 637.15 615.18 647.36 613.81
Cibinong 819.08 819.08 847.58 847.58 812.32 839.63 799.86
Bojong Gede 704.82 704.82 723.72 723.72 743.13 781.03 804.79
Tajur Halang 665.36 665.36 683.69 683.69 694.44 720.66 1019.93
Kemang 543.36 543.36 544.83 544.83 567.40 558.22 772.74
Ranca Bungur 423.90 423.90 330.12 330.12 420.29 332.25 302.00
Parung 967.92 967.92 1088.78 1088.78 1107.14 1081.87 649.91
Ciseeng 389.86 389.86 414.52 414.52 395.09 417.13 416.87
Gunung Sindur 485.64 485.64 491.94 491.94 477.39 488.81 625.75
Rumpin 407.98 407.98 420.28 420.28 400.34 413.83 404.15
Cigudeg 443.54 443.54 443.77 443.77 448.19 448.79 392.39
Sukajaya 373.08 373.08 310.56 310.56 375.52 310.21 347.81
Jasinga 439.74 439.74 346.35 346.35 453.68 357.57 441.48
Tenjo 370.37 370.37 326.16 326.16 361.26 328.04 345.73
Parung Panjang 479.51 479.51 434.65 434.65 439.87 389.38 266.11
Bogor Selatan 656.45 656.45 672.77 672.77 635.57 656.54 734.53
Bogor Timur 955.48 955.48 968.57 968.57 960.17 973.33 1117.72
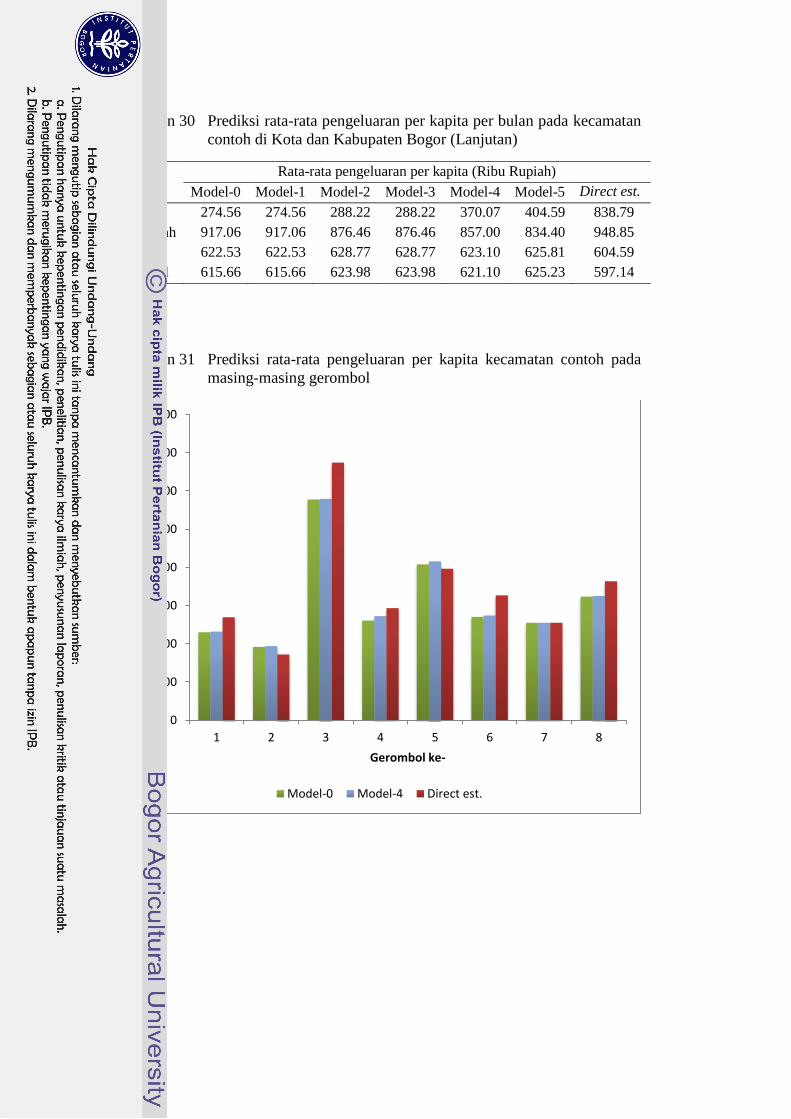
48
Lampiran 30 Prediksi rata-rata pengeluaran per kapita per bulan pada kecamatan
contoh di Kota dan Kabupaten Bogor (Lanjutan)
Kecamatan Rata-rata pengeluaran per kapita (Ribu Rupiah)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5 Direct est.
Bogor Utara 274.56 274.56 288.22 288.22 370.07 404.59 838.79
Bogor Tengah 917.06 917.06 876.46 876.46 857.00 834.40 948.85
Bogor Barat 622.53 622.53 628.77 628.77 623.10 625.81 604.59
Tanah Sereal 615.66 615.66 623.98 623.98 621.10 625.23 597.14
Lampiran 31 Prediksi rata-rata pengeluaran per kapita kecamatan contoh pada
masing-masing gerombol
0
200
400
600
800
1000
1200
1400
1600
1 2 3 4 5 6 7 8
Rat
a-ra
ta p
en
gelu
aran
pe
r ka
pit
a (R
ibu
ru
pia
h)
Gerombol ke-
Model-0 Model-4 Direct est.
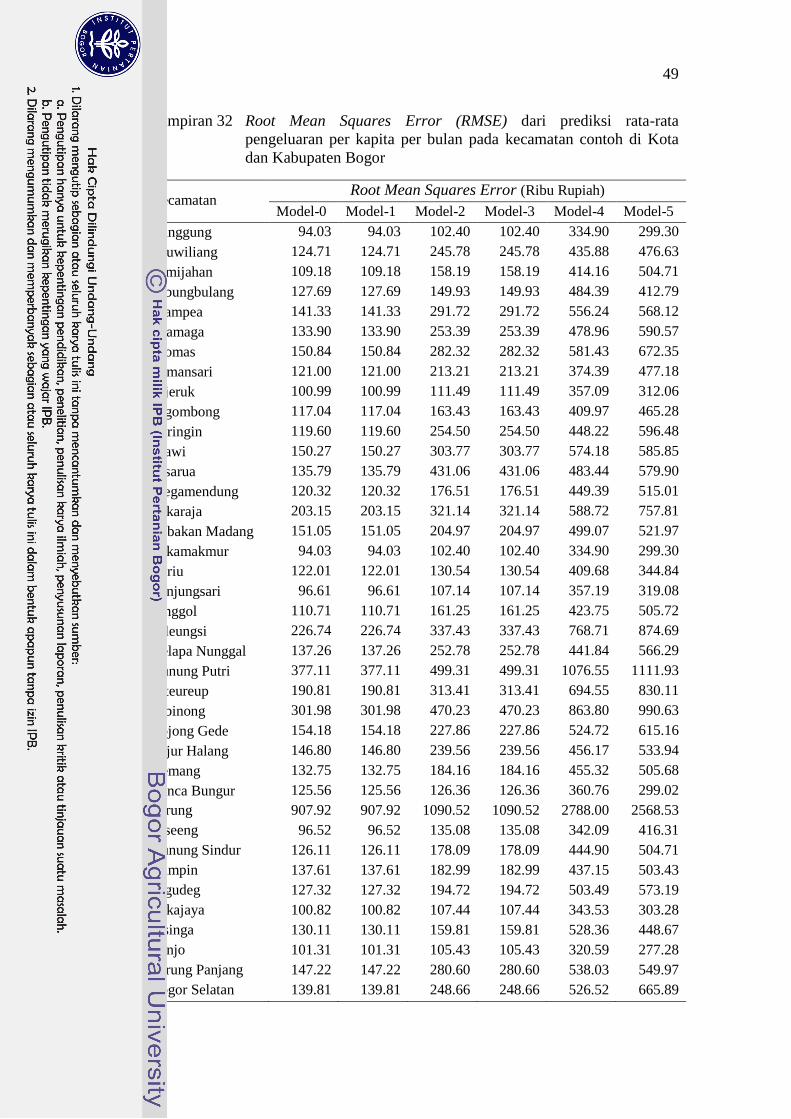
49
Lampiran 32 Root Mean Squares Error (RMSE) dari prediksi rata-rata
pengeluaran per kapita per bulan pada kecamatan contoh di Kota
dan Kabupaten Bogor
Kecamatan Root Mean Squares Error (Ribu Rupiah)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
Nanggung 94.03 94.03 102.40 102.40 334.90 299.30
Leuwiliang 124.71 124.71 245.78 245.78 435.88 476.63
Pamijahan 109.18 109.18 158.19 158.19 414.16 504.71
Cibungbulang 127.69 127.69 149.93 149.93 484.39 412.79
Ciampea 141.33 141.33 291.72 291.72 556.24 568.12
Dramaga 133.90 133.90 253.39 253.39 478.96 590.57
Ciomas 150.84 150.84 282.32 282.32 581.43 672.35
Tamansari 121.00 121.00 213.21 213.21 374.39 477.18
Cijeruk 100.99 100.99 111.49 111.49 357.09 312.06
Cigombong 117.04 117.04 163.43 163.43 409.97 465.28
Caringin 119.60 119.60 254.50 254.50 448.22 596.48
Ciawi 150.27 150.27 303.77 303.77 574.18 585.85
Cisarua 135.79 135.79 431.06 431.06 483.44 579.90
Megamendung 120.32 120.32 176.51 176.51 449.39 515.01
Sukaraja 203.15 203.15 321.14 321.14 588.72 757.81
Babakan Madang 151.05 151.05 204.97 204.97 499.07 521.97
Sukamakmur 94.03 94.03 102.40 102.40 334.90 299.30
Cariu 122.01 122.01 130.54 130.54 409.68 344.84
Tanjungsari 96.61 96.61 107.14 107.14 357.19 319.08
Jonggol 110.71 110.71 161.25 161.25 423.75 505.72
Cileungsi 226.74 226.74 337.43 337.43 768.71 874.69
Kelapa Nunggal 137.26 137.26 252.78 252.78 441.84 566.29
Gunung Putri 377.11 377.11 499.31 499.31 1076.55 1111.93
Citeureup 190.81 190.81 313.41 313.41 694.55 830.11
Cibinong 301.98 301.98 470.23 470.23 863.80 990.63
Bojong Gede 154.18 154.18 227.86 227.86 524.72 615.16
Tajur Halang 146.80 146.80 239.56 239.56 456.17 533.94
Kemang 132.75 132.75 184.16 184.16 455.32 505.68
Ranca Bungur 125.56 125.56 126.36 126.36 360.76 299.02
Parung 907.92 907.92 1090.52 1090.52 2788.00 2568.53
Ciseeng 96.52 96.52 135.08 135.08 342.09 416.31
Gunung Sindur 126.11 126.11 178.09 178.09 444.90 504.71
Rumpin 137.61 137.61 182.99 182.99 437.15 503.43
Cigudeg 127.32 127.32 194.72 194.72 503.49 573.19
Sukajaya 100.82 100.82 107.44 107.44 343.53 303.28
Jasinga 130.11 130.11 159.81 159.81 528.36 448.67
Tenjo 101.31 101.31 105.43 105.43 320.59 277.28
Parung Panjang 147.22 147.22 280.60 280.60 538.03 549.97
Bogor Selatan 139.81 139.81 248.66 248.66 526.52 665.89

50
Lampiran 33 Root Mean Squares Error (RMSE) dari prediksi rata-rata
pengeluaran per kapita per bulan pada kecamatan contoh di Kota
dan Kabupaten Bogor ( Lanjutan )
Kecamatan Root Mean Squares Error (Ribu Rupiah)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
Bogor Timur 213.90 213.90 239.33 239.33 507.42 536.05
Bogor Utara 274.56 274.56 288.22 288.22 370.07 404.59
Bogor Tengah 449.51 449.51 476.94 476.94 900.17 948.01
Bogor Barat 165.64 165.64 227.06 227.06 550.37 631.33
Tanah Sereal 201.30 201.30 233.79 233.79 517.19 560.81
Lampiran 34 Prediksi rata-rata pengeluaran per kapita pada kecamatan nircontoh
menggunakan seluruh model
Kecamatan Rata-rata pengeluaran per kapita (Ribu Rupiah)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
Leuwisadeng 592.89 585.10 404.88 404.88 586.58 405.75
Tenjolaya 570.33 562.84 390.46 390.46 559.23 390.76
Lampiran 35 Evaluasi pemodelan pada kecamatan nircontoh menggunakan
seluruh model
Root Mean Squares Error (Ribu Rupiah)
Model-0 Model-1 Model-2 Model-3 Model-4 Model-5
Leuwisadeng 180.884 168.869 226.855 191.937 199.759 187.673
Tenjolaya 131.250 148.666 163.623 163.083 132.776 125.146

51
RIWAYAT HIDUP
Penulis lahir di Bogor, pada tanggal 14 Februari 1988 dari pasangan
R. Ahmad Rifat dan Siti Salsiah. Pendidikan penulis berawal dari Sekolah Dasar
Negeri Pengadilan III Bogor pada tahun 1994, dan melanjutkan pendidikannya ke
SLTP Negeri 1 Bogor hingga lulus pada tahun 2003. Pada tahun 2003 penulis
melanjutkan pendidikan di SMA Negeri 1 Bogor, dan lulus pada tahun 2006. Pada
tahun yang sama penulis diterima sebagai mahasiswa di Institut Pertanian Bogor
melalui jalur Undangan Seleksi Masuk IPB. Pada tahun kedua di IPB, penulis
memilih program studi Statistika sebagai mayor, dan memilih ilmu konsumen
sebagai minor pada tahun berikutnya. Selama masa perkuliahan, penulis aktif
dalam berbagai kegiatan kepanitiaan yang diselenggarakan oleh Himpunan
Keprofesian Gamma Sigma Beta (GSB), BEM KM, BEM TPB dan BEM FMIPA.
Selain itu penulis juga aktif dalam kegiatan UKM LISES Gentra Kaheman dan
kepengurusan Perguruan Pencak Silat Merpati Putih Kolat IPB.
Pada pertengahan tahun 2009 penulis berkesempatan menjadi asisten mata
kuliah Metode Statistika. Pada Februari-April 2010 penulis melakukan praktek
lapang sebagai research executive assitant di PT. Tempo Inti Media,Tbk. di
Jakarta Barat. Penulis menyelesaikan studi S1 pada Desember 2010 dan bekerja
sebagai analyst di PT. Mediatrac Fractal Collective Intelligence (MFCI) sampai
September 2011. Kemudian penulis melanjutkan studi S2 program studi statistika
di IPB pada tahun yang sama.




















