
PENGUJIAN PENGENDALIAN DAN PENGUJIAN SUBSTANTIF ATAS TRANSAKSI
Upload
dangnguyetCategory
view
218download
0
Analisis Perbandingan Kinerja Cluster Berbasis Globus dan Alchemi
TESIS
Andrew Fiade0606025411
UNIVERSITAS INDONESIAFAKULTAS ILMU KOMPUTER
PROGRAM MAGISTER ILMU KOMPUTER DEPOK
DESEMBER 2008
Universitas Indonesia

Analisis Perbandingan Kinerja Cluster Berbasis Globus dan Alchemi
TESIS
Diajukan sebagai salah satu syarat untuk memperleh gelar magister ilmu komputer
Andrew Fiade0606025411
UNIVERSITAS INDONESIAFAKULTAS ILMU KOMPUTER
PROGRAM MAGISTER ILMU KOMPUTER DEPOK
DESEMBER 2008
Universitas Indonesia

TESIS ini adalah hasil karya sendiri,
dan semua sumber baik yang dikutip maupun dirujuk
Telah saya nyatakan dengan benar
Nama : Andrew Fiade
NIM : 0606025411
Universitas Indonesia

HALAMAN PENGESAHAN
Thesis ini diajukan oleh :Nama : Andrew FiadeNIM : 0606025411Program Studi : Magister Ilmu KomputerJudul Thesis : Analisa Perbandingan Kinerja Cluster
Berbasis Globus dan Alchemi
Telah berhasil dipertahankan dihadapan Dewan Penguji dan diterima sebagai Bagian persayaratan yang diperlukan untuk memperoleh gelar Magister Komputer pada Program Studi Magister Ilmu KomputerFakultas Ilmu Komputer, Universitas Indonesia
DEWAN PENGUJI
Pembimbing : Pembimbing :Penguji :Penguji :
Ditetapkan di :Tanggal :
Universitas Indonesia

KATA PENGANTAR / UCAPAN TERIMA KASIH
Alhamdulilah dan puji syukur kepada Tuhan Yang Maha Esa, karena berkat atas
rahmat-Nya saya dapat menyelesaikan thesis ini. Penulisan thesis ini dilakukan
dalam rangka memenuhi salah satu syarat untuk mencapai gelar Magister Ilmu
Komputer jurusan Magister Ilmu Komputer pada Fakultas Ilmu Komputer. Saya
menyadari bahwa, tanpa bantuan dan bimbingan dari berbagai pihak, dari masa
perkuliahan sampai pada penyusunan thesis ini, sangatlah sulit bagi saya untuk
menyelesaikan thesis ini. Oleh karea itu, saya mengucapkan terima kasih kepada:
(1) Prof. Drs Heru Suhartanto M.Sc , Ph.D selaku dosen pembimbing yang telah
menyediakan waktu, tenaga dan piikiran untuk mengarahkan saya dalam
penyusunan thesis ini
(2) Drs. Bobby Achirul Awal Nazief , M.Sc., Ph.D. ,selaku dosen pembimbing
yang telah menyediakan waktu, tenaga dan piikiran untuk mengarahkan saya
dalam penyusunan thesis ini
(3) Orang tua dan keluarga saya yang telah memberikan bantuan dukungan
material dan moral
(4) Hardianingsih yang telah memberikan motivasi kepada penulis untuk
menyelesaikan thesis ini
(5) Teman–teman s2 angkatan 2006 yang telah lulus terlebih dahulu,
meninggalkan penulis, dan langsung kembali ke kampung halaman masing-
masing.
(6) Franova anak S1 yang turut serta menyelesaikan tugas akhir dalam lab yang
sama
(7) Pak Widodo dan Pak Broer teman S3 Ilmu Komputer, yang turut serta
langsung maupun tidak langsung dalam diskusi tentang grid computing.
(8) Pak Ismail dan satpam fakultas ilmu computer, yang memberikan kemudahan
dalam menggunakan fasilitas kampus.
Universitas Indonesia

(9) Teman – teman Universitas Mercu Buana khususnya asisten lab informatika,
untuk diskusi ringan dan canda tawa.
(10) Pak Raka Yusuf, Pak Abdusy Syarif dan Pak Kodar, yang memberikan
kesempatan untuk mengajar di mercu buana.
(11) Viny yang memberikan kesempatan mengajar di Universitas Tarumanegara
(12) Nino STTIK meridian yang memberikan waktu untuk mengajar Cisco untuk
memberikan materi kepada penulis.
Akhir kata, saya berharap Tuhan Yang Maha Esa berkenan membalas segala
kebaikan semua pihak yang telah membantu, Semoga thesisi ini membawa manfaat
bagi pengembangan ilmu.
Depok, 2 Desember 2008
Penulis
Universitas Indonesia

HALAMAN PERNYATAAN PERSETUJUAN PUBLIKASI TUGAS AKHIR UNTUK KEPENTINGAN AKADEMIS
Sebagai sivitas akademik Universitas Indonesia, saya yang bertanda tangan dibawah ini:
Nama :NPM :Program Studi :Departemen :Fakultas :Jenis Karya : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Indonesia Hak Bebas Royalti Noneksklusif (Non-exclusive Royalty- Free Right) atas karya ilmiah saya yang berjudul:
Beserta perangkat yang ada (jika diperlukan), Dengan Hak Bebas Royalti Nonekslusif ini Universitas Indonesia berhak menyimpan, mengalihmedia/format-kan, mengelola dalam bentuk pangkalan data (database), merawat, dan memublikasikan tugas akhir saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis/ pencipta dan sebagai pemilik Hak Cipta.
Demikian pertanyaan ini saya buat dengan sebenarnya
Dibuat di: Pada tanggal:
Yang menyatakan
(……………………..)
Universitas Indonesia

Abstract
Universitas Indonesia

ABSTRAK
Nama : Andrew FiadeProgram Studi : Magister Ilmu KomputerJudul :
Thesis ini membahas lingkungan Grid yaitu Globus Toolkit dan Alchemi, keduanya merupakan bagian dari lingkungan grid yang berada dalam lapisan Middleware yang digunakan untuk menjalankan aplikasi grid, pengaturan sumber daya, dapat terhubung dengan lokasi sumber daya yang tersebar secara geografis, serta dapat mendukung aplikasi paralel seperti MPI (Message Passing Interface). Globus Toolkit menggunakan komponen MPICH-G2 untuk menjalankan aplikasi MPI. Globus menyediakan ototentifikasi bagi pengguna, manajemen data, sumber daya dan keamanan data, globus dijalankan di sistem operasi unix, sedangkan Alchemi bekerja dalam lingkungan windows dan mendukung aplikasi dengan arsitektur Framework.NET.
Penelitian ini dilakukan untuk mengetahui kemampuan dari Globus Toolkit dan Alchemi dengan membuat model lingkungan komputasi bagi aplikasi MPI, pengujian dilakukan dengan menggunakan program MPI dengan melakukan beberapa parameter. Hasil yang diperoleh dianalisa dan dibandingkan dengan literatur yang telah dipelajari dan diharapkan dapat menjadi acuan untuk membangun infrastuktur lingkungan grid.
Kata Kunci : Grid, komputasi paralel, globus toolkit, alchemi paralel, alchemi, mpi
Universitas Indonesia

DAFTAR ISI
HALAMAN JUDULLEMBAR PENGESAHANKATA PENGANTARLEMBAR PERSETUJUAN PUBLIKASI KARYA ILMIAHABSTRAKDAFTAR ISIDAFTAR GAMBARDAFTAR LAMPIRAN
1. PENDAHULUAN2. TINJAUAN PUSTAKA3. METODE PENELITIAN4. PEMBAHASAN 5. KESIMPULAN DAN SARAN
DAFTAR REFERENSI
Universitas Indonesia

DAFTAR GAMBAR
Gambar 1.1
Gambar 2.1
Universitas Indonesia

BAB 1PENDAHULUAN
1.1 LATAR BELAKANG
Pemograman aplikasi paralel merupakan hal yang menarik karena ketika
dalam penerapan memerlukan sumber daya dan waktu komputasi. Untuk
menjalankan sebuah aplikasi paralel dapat dilakukan dengan menggunakan beberapa
jumlah komputer yang dilakukan dimasing-masing komputer secara serial kemudian
hasilnya digabungkan. Atau solusi lain yang dapat ditawarkan adalah menggunakan
pemograman paralel, dan untuk mendukung penyebaran aplikasi secara paralel
dilakukan distribusi aplikasi dan dilakukan proses secara bersamaan menggunakan
teknologi Grid. Teknologi grid dapat dikembangkan dengan memanfaatkan jaringan
yang telah tersedia yang kemudian dijadikan sebuah cluster untuk digunakan sebagai
pemroses atau pekerja.
Perkembangan teknologi Grid didukung dengan perkembangan jaringan
komputer yang semakin cepat baik dalam kecepatan data maupun teknologi yang
tersedia. Untuk pendistribusian aplikasi yang dapat dilakukan secara bersamaan oleh
beberapa prosesor dapat mengggunakan pemograman aplikasi paralel, supaya
mendukung pemograman aplikasi paralel maka sumber daya yang digunakan atau
komputer harus mempunyai pustaka yang sama untuk melakukan komunikasi
pengiriman, penerimaan maupun pemrosesan.
Universitas Indonesia

Salah satu pustaka yang menjadi standarisasi dalam aplikasi paralel adalah
MPI (Message Passing Interface). Teknik message passing telah menjadi acuan
dalam membuat program aplikasi paralel. MPI dapat digunakan sebagai pustaka di
bahasa pemograman C, C++, Java, Cobol, Fortran. MPI dapat digunakan di
lingkungan sumber daya yang heterogen dalam arsitektur maupun vendor pembuat
sumber daya yang berbeda. MPI dapat pula menangani masalah keterlambatan data
atau delay yang sering terjadi dalam jaringan komputer dengan menggabungkan
protocol yang telah ada seperti TCP.
Mempertimbangkan pustaka MPI diperlukan dalam pemograman aplikasi
paralel, maka dalam penelitian ini penulis meneliti untuk membandingkan diantara
dua lingkungan Grid yaitu Globus dan Alchemi untuk menjalankan aplikasi paralel
menggunakan MPI, Globus menggunakan MPICH-G2 yaitu mpich yang terintegrasi
dengan Globus. Globus mempunyai komponen dan layanan seperti ototentifikasi
user, keamanan data, manajemen data dan pengaturan sumber daya. Globus bekerja
dalam sistem operasi linux. Alchemi bekerja dalam system operasi windows,
alchemi menggunakan Framework .NET dalam menjalankan aplikasi grid. Bahasa
pemograman yang mendukung Alchemi adalah bahasa pemograman yang
mendukung framework .NET seperti Visual C#, C++, J#.
Untuk mendukung penelitian, maka terdapat beberapa parameter percobaan
yang akan diuji di MPICH-G2 dan di Alchemi. Kemudian dianalisa dari hasil
percobaan. Selanjutnya dibandingkan dari literatur yang penulis pelajari dan rencana
atau usulan dari hasil perbandingan diantara MPICH-G2 dan Alchemi, untuk
pengujian dilakukan dengan 8 prosesor.
1.2 Ruang Lingkup dan Tujuan Penelitian .
Ruang lingkup dan tujuan dari penelitian ini adalah untuk membangun
infrastuktur komputasi Grid dan menjalankan aplikasi MPI baik di linux maupun
di windows, kemudian dapat diketahui kinerja dari kedua infrastruktur grid serta
dapat mengeksplorasi bagaimana cara menjalankan aplikasi MPI, permasalahan
Universitas Indonesia

seputar aplikasi MPI, pembuatan pemograman aplikasi MPI di visual C# dan bahasa
C.
Dengan adanya penelitian ini diharapkan memacu peneliti lain untuk
mengeksplorasi grid di windows atau di linux. dan dapat mempertimbangkan
menggunakan kelebihan Grid untuk melakukan pemograman aplikasi paralel.
1.3 Metodologi Penelitian
Metdologi yang dilakukan untuk penelitian ini yaitu mempelajari dan
mencari literatur mengenai pembangungan infrastuktur di Grid dan MPI, kemudian
menerapkan infrastuktur Grid tersebut, dalam hal ini Globus dan Alchemi.NET,
setelah itu mengintegrasikan MPI dengan globus, diteruskan dengan membuat
aplikasi MPI untuk sistem operasi linux maupun windows dan terakhir uji coba
aplikasi mpi yang dilanjutkan dengan menganalisa hasil percobaan
Beberapa literatur memberikan gambaran alur atau proses yang terjadi pada
saat eksekusi aplikasi MPI dilakukan. Informasi ini akan dibuktikan lagi dengan cara
melakukan uji coba dan observasi atas proses yang terjadi.
1.4 Sistematika Penulisan
Laporan tugas akhir ini memiliki sistematika penulisan sebagai berikut. Bab 2
mengenai lingkungan komputasi Grid dan aplikasi paralel. Bab ini mengenai latar
belakang mengenai lingkungan komputasi Grid secara keseluruhan, arsitektur
alchemi dan arsitektur globus toolkit. Bab 3 mengenai implementasi Message
Passing Interface di MPICH-G2 dan di alchemi. Bab 4 mengenai desain infrastuktur
Grid dan mekanisme menjalankan aplikasi MPI (implementasi di MPICH-G2 dan
Alchemi ) Bab 5 berisi analisa dan hasil dari penujian dan dilanjutkan dengan Bab 6
kesimpulan dan saran yang didapat selama tugas akhir ini dan saran-saran bagi
pengembangan dan penggunaanya berikutnya
Universitas Indonesia

BAB 2GRID COMPUTING
2.1 Grid Computing
Grid adalah " sharing dan koordinasi yang dinamik, dapat tersebar secara geografis,
memiliki sumber daya yang heterogen dan kesemuanya itu dapat di proses,
menjalankan data dan melakukan penyimpanan data" [1]. Istilah heterogen diartikan
sumber daya dapat berbeda di sistem operasi, arsitektur hardware maupun software,
dan lokasi sumber daya dapat berjauhan satu sama lainnya. Istilah geografis
dimaksudkan sumber daya berada ditempat yang berbeda baik secara institusi
maupun secara pengaturan administrasi domain. Perbedaan pengaturan domain
menjadi kendala terutama dalam pengaturan sumber daya.
Teknologi Grid bertujuan untuk mendukung komputasi melalui sumber daya
untuk melewati atau mengantarkan sumber daya di lingkungan pengaturan domain
yang berbeda dan pengaturan ototentifikasi pengguna dalam sebuah instasi sehingga
pengiriman dan pemrosesan job dapat dilakukan walaupun berbeda pengaturan
domain atau pun autentifikasi. Ian Foster dalam bukunya [1] terdapat 3 hal yang
penting untuk menyatakan sebuah lingkungan komputer untuk dikatakan Grid,
yaitu:
1. Dapat mengkoordinasikan sumber daya yang tersebar, Grid dapat mengatur
dan mengintegrasikan sumber daya yang tersebar dan pengguna di domain
kendali yang berbeda. Contoh pengguna yang mengunakan komputer desktop
dengan intrakomputer seperti lab, memiliki perbedaan pengaturan
administrasi walaupun di dalam perusahaan yang sama. Apabila dalam
perusahaan yang berbeda maka factor keamanan, hak akses dan account
menjadi penting, Untuk pengaturan kesemua masalah tersebut telah diatur
Universitas Indonesia

oleh grid dengan membuat kesepakatan dengan komponen local resource
management.
2. Grid menggunakan menggunakan protokol dan antar muka yang standar,
terbuka, dan dapat digunakan untuk berbagai macam hal (general purpose).
Sebuah Grid dibangun menggunakan protokol dan antar muka yang
menangani masalah fundamental seperti otentikasi, otorisasi, pencarian, dan
penggunaan sumber daya.
3. Memberikan quality of service yang tidak trivial. Sebuah Grid
memungkinkan penggunaan sumber daya yang dapat memberikan quality of
service yang berbeda contohnya dalam hal waktu respon, throughput,
ketersediaan sumber daya, keamanan, dan/atau penggunaan beberapa jenis
sumber daya yang sesuai dengan kebutuhan pengguna.
2.2 Infrastruktur lingkungan Grid
Infrastruktur lingkungan grid umumnya tersusun dari empat lapisan (layer) [8][15] seperti
pada gambar 2.1 , yaitu
1. Grid fabric, terdiri dari semua sumber daya tersebar yang bisa diakses melalui
jaringan internet. Sumber daya ini bisa berupa mesin komputer, database, media
penyimpanan data.
2. Core grid middleware atau dikenal pula dengan Grid Services, terdiri dari layanan-
layanan inti seperti layanan manajemen proses jarak jauh, layanan pengaturan
alokasi sumber daya, layanan akses ke media penyimpanan data, dan keamanan.
3. Pengguna-level grid middleware atau Application Toolkit, terdiri dari perangkat
pemrograman dan pengembangan aplikasi dalam lingkungan grid, resource broker
untuk mengatur penggunaan ke sumber daya, dan aplikasi penjadwalan.
4. Grid aplication and portals, terdiri dari aplikasi yang dikembangkan untuk
lingkungan grid menggunakan pustaka tertentu seperti HPC++ dan MPI, serta portal
berbasis web sebagai antar muka bagi pengguna untuk men-submit tugas yang akan
dikerjakan oleh mesin-mesin.
Universitas Indonesia

Gambar 2-1. Arsitektur komponen grid [15]
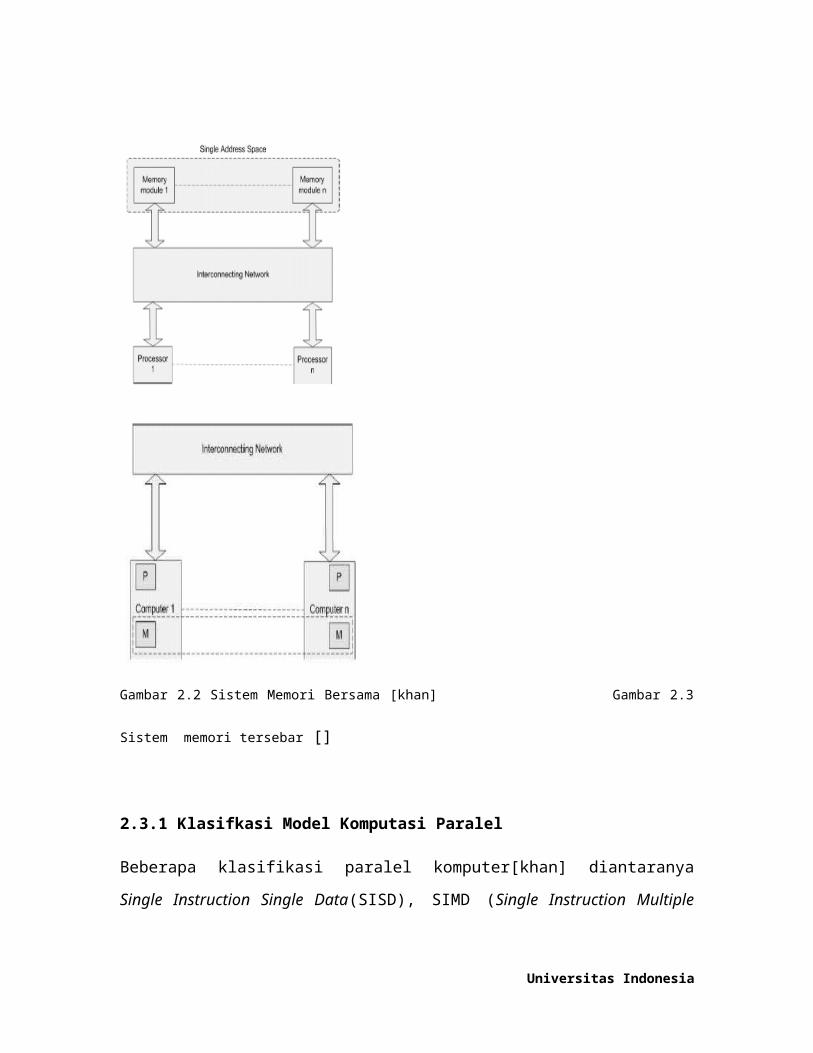
2.3 Model Komputasi Paralel
Komputer Paralel adalah komputer tunggal dengan beberapa internal
prosesor atau beberapa komputer yang dihubungkan oleh suatu interconnection
network[26]. Komputer paralel dapat dikelompokan berdasarkan pengorganisasian
memorinya, ke dalam dua arsitektur dasar yaitu: sistem memori bersama (shared
memory) dan sistem memori tersebar (distributed memory).
Sistem memori bersama, paralel komputer terdiri dari beberapa prosesor yang
terhubung ke satu memori global. Sistem memori bersama menerapkan sistem ruang
pengalamatan tunggal, artinya bahwa setiap sel memori dalam memori global
memiliki alamat yang unik dan alamat ini digunakan oleh setiap prosesor untuk
mengakses isi dari suatu sel memori.
Sistem memori tersebar, paralel komputer terdiri dari beberapa komputer
yang terhubung dengan jaringan. Karena secara fisik memori terpisah (tidak ada
global memori) maka sistem pengalamatan ruang yang digunakan adalah sistem
pengalamatan ruang terpisah. Untuk mengakses data yang ada di komputer lain,
suatu prosesor harus menggunakan mekanisme pertukarana pesan (message passing).
Untuk implementasi sistem memori bersama digunakan program parlalel seperti
OpenMP[] dan sistem memori tersebar menggunkan metode message passing [].
Universitas Indonesia

Ilustrasi sistem memori bersama dan sistem memori tersebar seperti pada gambar
dan
Universitas Indonesia

Gambar 2.2 Sistem Memori Bersama [khan] Gambar 2.3 Sistem memori tersebar []
2.3.1 Klasifkasi Model Komputasi Paralel
Beberapa klasifikasi paralel komputer[khan] diantaranya Single Instruction Single
Data(SISD), SIMD (Single Instruction Multiple Data), Multiple Instruction Single
Data(MISD) dan Multiple Instruction Multiple Data.
Model Single Instruction Single Data Stream (SISD) bukan termasuk model
komputasi paralel, SISD melakukan satu instruksi untuk satu data, dan setiap operasi
instruksi melakukan data element secara tunggal, SISD dibatasi dengan jumlah instruksi
yang dapat dilakukan dalam waktu yang bersamaan. Pengukuran kinerja SISD
menggunakan MIPS (million of instruction per second) atau clock frequensy MHz
(MegaHertz)
Model Single Program Single multiple data adalah model komputasi paralel yang
menerapkan pembuatan poses statis, proses statis yaitu semua proses ditetapkan sebelum
program dijalankan dan sistem akan menjalankan sejumlah proses yang tetap.
Dalam model SPMD, proses yang berbeda disatukan dalam satu program. Untuk
menentukan bagian program mana yang akan dieksekusi oleh suatu proses maka didalam
program terdapat instruksi percabangan.
Universitas Indonesia

Dalam pembuatan proses dinamik, proses-proses baru dapat dibuat pada saat
program paralel sedang berjalan. Proses-proses yang ada juga dapat dihapus. Pembuatan
dan penghapusan pross dapat dilakukan sesuai keadaan, dan jumlah proses yang berjalan
dapat bervariasi sepanjang pengeksekusian. Model pemograman paralel yang
menerapkan pembuatan proses dinamilk adalah multiple program multiple data
(MPMD). Berbeda dengan model SPMD, dalam model MPMD, proses-proses ditiap
prosesor mengeksekusi suatu program utuh yang berbeda
2.3.2 Pemograman Paralel
Terdapat beberapa metode dalam program paralel komputer[] diantaranya
message passing, data paralel, memori bersama, operasi kendali memori, thread, model
kombinasi.
Metode Message passing, setiap prosesor menggunakan memori lokal, dan setiap
prosesor melakukan operasi pertukaran pesan, pengiriman dan penerimaan data, hasil
performa yang ditampilkan berdasarkan tiap-tiap prosesor yang melakukan proses. Untuk
dapat melakukan hubungan antara prosesor maka digunakan pustaka bersama yang secara
eksplisit share informasi antara prosesor, contoh aplikasi MPI.
Metode Data Paralel, setiap proses bekerja dibagian yang berbeda dalam struktur
data yang sama. Umumnya data paralel menggunakan Single Program Multiple Data
atau data yang disebarkan melalui prosesor. Semua pesan diteruskan melalui baris -
baris program yang dbuat oleh programmer. Data paralel merupakan bagian teratas dari
pustaka message passing dengan model data paralel, penulisan program menggunakan
pemograman paralel dan di compile menggunakan compiler paralel. Compiler mengubah
kode program ke bentuk standard dan memanggil pustaka messaga passing untuk
penyebaran ke semua prosesor, contoh aplikasi HPF (High Performance Fortran).
Model memori bersama diterapkan di lingkungan dimana sejumlah prosesor share
ruang memori utamanya. Sistem memori bersama smal scale merujuk kepada arsitektur
memori symentirc multiprosesor (SMP). operasi remote memory, menentukan proses,
sebuah proses diakses ke memory proses lain tanpa partisipasi prosesor lain. Model
thread, proses tunggal mempunyai sejumlah path eksekusi yang berhubungan untuk
Universitas Indonesia

melakukan proses. Kombinasi model merupakan gabungan dari beberapa model yang
telah diuraikan.
Keuntungan menggunakan teknik message passing yaitu dapat menyesuaikan
dengan prosesor yang tersebar dan terkonkesi dengan jaringan, sistem memori bersama
MIMD dapat mengambil keuntungan dari kecepatan data transfer, teknik message
passing memudahkan programer untuk mengatur algoritma parlalel, dan message pasing
salah satu model komputasi paralel dengan unjuk kerja yang baik.
2.4 Arsitektur Alchemi
Alchemi[11] merupakan software framework yang bersifat sumber terbuka,
alchemi dapat mengumpulkan sumber daya melalui jaringan komputer ke dalam bentuk
virtual supercomputer (desktop grid), dan dapat mengembangkan aplikasi untuk
dijalankan di grid
Arsitektur layar alchemi dalam lingkungan grid computing seperti pada gambar 2.
Alchemi menggunakan paradigma program master-worker paralel, yaitu terdapat
komponen yang bersifat independent untuk mengirimkan unit eksekusi paralel ke pekerja
dan mengatur eksekusi tersebut. Unit eksekusi paralel dikenal dengan "grid thread"
berisikan instruksi untuk di eksekusi di node grid. pusat dari komponen dikenal dengan
"Manager".
Aplikasi grid terdiri dari sejumlah grid thread yang berhubungan. aplikasi grid
dan grid thread menggunakan aplikasi kelas .NET atau objek melalui alchemi .NET API.
Ketika sebuah aplikasi ditulis dengan API (Application Programing Interface). Objek
grid thread dikirimkan ke alchemi manager untuk dijalankan oleh grid. atau dapat
menggunakan job yang ditulis dengan sebuah file menggunakan XML. Job dapat
dikirimkan melalui alchemi console atau layanan web Cross-Platform Manager. Kedua
Aplikasi tersebut dapat menterjemahkan kedalam grid thread sebelum dikirimkan ke
manager untuk dijalankan oleh grid
Universitas Indonesia

Gambar 2.4 Arsitektur layar alchemi dalam Lingkungan Grid Enterprise[14]
2.4.1 Komponen Utama Grid Alchemi
Alchemi framework berdasarkan Microsoft .NET. dan Alchemi digunakan pada
hardware yang menggunakan sistem operasi windows. Suatu sistem grid pada framework
Alchemi disusun oleh empat komponen utama. Keempat komponen tersebut adalah [9] :
1. Alchemi Manager - pusat host dengan kemampuan penjadwalan, pada sebuah
sistem grid dibutuhkan minimal satu Manager yang mengkoordinasikan setiap
cluster computer yang terlibat. Fungsi utama dari Manager adalah menjadwalkan
dan menyebarkan thread kepada para eksekutor yang terlibat pada suatu sistem
grid.
2. Alchemi Excecutor- merupakan komponen Alchemi yang memiliki peranan
sebagai pemroses, pengeksekusi dan pelaksana perhitungan bagi thread-thread
yang disebarkan oleh Manager.
3. Alchemi Cross Platform Manager - web service yang berdasarkan Manager
bagian ini merupakan komponen yang berperan sebagai penghubung aktifitas
komunikasi komponen Alchemi dengan non-elemen Alchemi dari grid
4. Alchemi Pengguna - Merupakan bagian alchemi yang bukan bagian inti dari
komponen alchemi namun digunakan dalam mengirimkan job. Secara fisik
sebuah Alchemi Pengguna berupa sebuah komputer yag terhubung pada sistem
Universitas Indonesia

grid. Alchemi Pengguna merupakan komputer yang akan mengirimkan task pada
sistem grid.
Gambar 2.5 Arsitektur Alchemi dan Interaksi Setiap Komponen [14]
Gambar 2.5 menggambarkan hubungan antara empat komponen alchemi, yaitu Manager,
Pengguna, Eksekutor dan CrossPlatformManager. Berikut ini penjelasan masing-masing
komponen:
a. Manager
Komponen Manager mengatur eksekusi aplikasi Grid dan menyediakan layanan yang
berhubungan dengan pengaturan eksekusi thread. Eksekutor mendaftarkan ke Manager
untuk menjaga kondisi bahwa masih terdapat eksekutor di daftar manager. Thread
diterima dari pengguna, kemudian ditempatkan di pool selanjutnya diberikan pengaturan
jadwal untuk di eksekusi dari beragam eksekutor. Prioritas untuk setiap thread dapat
diatur ketika sebelumnya dibuat oleh pengguna, tetapi secara default untuk setiap thread
diberikan prioritas tinggi. Eksekutor akan mengembalikan thread ke manager jika tugas
telah selesai.
b. Eksekutor
Eksekutor menerima thread dari manager dan mengeksekusi thread tersebut.
Eksekutor dapat dikonfigurasi menjadi dedicated, dedicated diantara manager dan
eksekutor terdapat komunikasi dua arah, dimana resource diatur oleh manager,
Universitas Indonesia

sedangkan non-dedicated, resource diatur oleh pengguna menggunakan screen-saver,
saat program screen saver aktif, maka eksekutor aktif. Dalam hal ini non-dedicated
merupakan komunikasi satu arah.
Umumnya non-dedicated digunakan jika hubungan manager dengan eksekutor
melalui jaringan public (internet), sedangkan dedicated jika hubungan manger dan
eksekutor masih dalam satu local area network (LAN).
c. Pengguna
Aplikasi grid dibentuk menggunakan Alchemi API saat dieksekusi oleh
komponen pengguna. Pengguna menyediakan interface aplikasi grid untuk
pengembangan aplikasi. Pengguna mengirim thread ke manager dan mengumpulkan
thread dibalik aplikasi yang dikembangkan melalui Alchemi API.
d. Cross -Platform Manager
Merupakan bagian komponen dari manager, melalui layanan web dan
menggunakan fungsi manager untuk menjalankan alchemi serta mengatur mengeksekusi
dari semua platform untuk menjalankan grid job. Job disubmit melalui manager cross-
platform kemudian diterjemahkan kedalam sebuah format dan disetujui oleh manager,
kemudian akan dijadwalkan seperti halnya menggunakan manager.
2.4.2 Bentuk Konfigurasi
Dalam alchemi terdapat beberapa cara dalam konfigurasi grid, diantaranya
desktop cluster grid, multi-cluster grid (global grid)[9]
a) Cluster (desktop grid)
Skenario seperti pada gambar 3 , terdiri dari satu manager dan banyak eksekutor
yang dikonfigurasi untuk terhubung dengan manager. Satu atau lebih pengguna dapat
mengeksekusi aplikasi di cluster yang terhubung dengan manager.
Universitas Indonesia

Gambar 2.6 Penyebaran Cluster (desktop grid) Gambar 2.7 keterangan symbol
b) Multi cluster
Lingkungan multi-cluster merupakan gabungan dari banyak manager, seperti pada
gambar 5. sama seperti lingkungan cluster single. Beberapa jumlah eksekutor dan owner
dapat terhubung ke manager diantara level dalam hierarki. Eksekutor dan owner dalam
multi-cluster lingkungan dapat terhubung ke manager seperti dalam cluster.
Hal utama dalam melaksanakan multi-cluster di arsitektur alchemi, manager
bertindak sama seperti eksekutor meneruskan ke manager lain, setiap manager pada
setiap level di konfigurasikan untuk terhubung ke level manager yang lebih tinggi yaitu
"intermediate" dan diatur oleh manager dengan level tinggi sebagai "eksekutor" tetapi
ketentuan tersebut tidak berlaku untuk Manager dengan level paling atas.
Misalkan ketika Pengguna telah mengirimkan aplikasi grid ke manager, setiap
manager mempunyai "local" grid thread yang menunggu untuk mengeksekusi. Thread di
berikan prioritas tinggi secara default (kecuali prioritas diubah) dan thread dijadwalkan
dan di eksekusi secara normal oleh manager local eksekutor, eksekutor ini dapat pula
intermediate manager, dimana manager top level memberikan pengaturan. Setelah itu
setelah menerima thread dari manager paling atas kemudian dijadwalkan secara lokal
oleh intermediate manager dengan prioritas dikurangi dan di eksekusi normal oleh
manager local eksekutor.
Dari hal diatas misalkan manager mengiginkan mengalokasi thread ke local
eksekutor ( intermediate) manager dapat lebih dari satu, tetapi tidak ada local thread
menunggu untuk diekseskusi. Dalam hal ini manager sebagai intermediate manager
Universitas Indonesia
dapat meminta thread dari manager top, untuk mengurangi prioritas dan penjadwalan
local.
Dalam kedua kasus maka terjadi pengaruh dalam pengurangan prioritas dari
thread dan hierarki manager dan semakin dekat thread untuk disubmit oleh eksekutor,
prioritas tinggi untuk mengeksekusi, hal ini mengijinkan bagian dari alchemi grid dengan
adminitrative domain (seperti cluster atau multi cluster didalam spesifikasi " AD domain
manager) untuk dishare dengan organisasi lain sehingga dapat dibuat kolaborasi grid
lingkungan tanpa mempengaruhi utilitas dari local Pengguna.
Gambar 2.8 Penyebaran Multi Cluster
2.5 Arsitektur Globus
Globus Toolkit adalah lapisan middleware yang secara de facto menjadi standard
dalam grid computing [3]. Pada susunan layer di sub bab sebelumnya, Globus Toolkit
berperan pada layer core grid middleware. Globus Toolkit memiliki sekumpulan layanan
inti yang digunakan untuk membangun grid dan memungkinkan saling berbagi sumber
daya, managemen data, dan keamanan data dalam area yang terpisah secara batas
geografis. Hingga saat ini, Globus Toolkit telah memiliki layanan keamanan, Data
Management, Execution Management, dan Information Services. Gambar 7 di bawah
memberikan ilustrasi komponen-komponen layanan yang tersedia dalam Globus.
Universitas Indonesia

Gambar 2.9. Arsitektur Komponen layanan Globus Toolkit []
2.5.1 Grid Security Infrastuktur (GSI)
GSI menangani otentifikasi dan otorisasi pengguna, sumber daya, keamanan
pesan dan kemampuan single sign-on (kemampuan otentifkasi dengan diperiksa di satu
sumber daya dapat berlaku untuk sejumlah sumber daya lainnya melalui proses
pemetaan) .
Job tunggal dalam Grid dapat digunakan untuk sumber daya yang besar disetiap
Administrative Domain (AD) yang berbeda dengan aturan dan meknisme kemanan
tersendiri. Untuk pengaturan AD yang berbeda maka diperlukan infrastuktur global dan
menggunakan protokol yang umum digunakan.
Delegasi yang tepat untuk pelayanan pelanggan sangat diperlukan, dan GSI
memnuhi kebutuhan tersebut untuk pengaksesan sumber daya. Seperti pada gambar 4.
salah satu komponen GSI, PKI (Public Key Infrasturktur) untuk credential mengunakan
sertifikasi X.509, sedangkan komponen proxy dan delegation digunakan untuk
keamanan single sing-on. Proxy merupakan certifikasi temporary (umumnya berlaku
secara standar yaitu 12 jam) yang telah di signed oleh pemilik untuk dapat melakukan
Universitas Indonesia

proses kendali untuk ototentifikasi dengan lokasi sumber daya. SSL (Secure Scoket
Layer) digunakan untuk autentifikasi pengguna dan kemanan pesan
Pengguna mendapatkan akses untuk sumber daya Grid berdasarkan identifikasi
subject certificate yang telah di petakan untuk laporan dalam remote mesin yang telah
diatur oleh system administrator.
2.5.2 Globus GRAM
GRAM (Grid Resource Management and Allocation) adalah salah satu komponen
layanan dalam Globus Toolkit untuk melakukan pengiriman (submit), monitor, dan
membatalkan pengerjaan job pada sumber daya komputasi dalam grid. Job adalah
pekerjaan komputasional yang melakukan operasi masukan dan keluaran, dan
berpengaruh terhadap status sumber daya dan sistem berkasnya [4] . Status sumber daya
maksdunya sedang idle, atau sedang digunakan oleh job.
Ada dua versi dari GRAM ini, yaitu yang menggunakan web service, disebut WS
GRAM (Web Service GRAM), dan sedangkan versi sebelumnya disebut pre-WS GRAM.
WS-GRAM (selanjutnya disebut GRAM saja, karena yang diacu dalam penelitian ini
adalah WS-GRAM) menggabungkan layanan dari manajemen job dan local system
adapters dengan layanan lainnya dalam Globus Toolkit untuk mendukung eksekusi job
dengan atau tanpa staging. Staging berguna jika berkas yang diperlukan untuk proses
eksekusi job berada di lokasi mesin lain (staging-in), atau jika berkas hasil eksekusi perlu
diletakkan pada storage tertentu selain pada cluster (staging-out). Untuk melakukan tugas
ini, GRAM bekerja sama dengan GridFTP, komponen layanan lainnya dalam Globus
Toolkit yang bertanggung jawab dalam hal transfer data.
Aktivitas GRAM melibatkan beberapa komponen yang dikelompokkan ke dalam tiga
bagian, yaitu komponen dari Globus Toolkit, komponen dari luar (eksternal), dan
komponen internal. Berikut ini penjelasan masing-masing komponen [4] .
1. Komponen Globus Toolkit untuk GRAM
a. Reliable File Transfer (RFT), beperan saat GRAM melakukan staging
sebelum atau sesudah eksekusi job.
b. GridFTP, berperan dalam transfer data dalam lingkungan grid. Penjelasan
lebih detil tentang GridFTP ini dapat dilihat pada sub-bab berikutnya.
c. Delegation, digunakan oleh client untuk mendelegasikan credential ke
Universitas Indonesia

lingkungan grid untuk digunakan oleh GRAM dan layanan yang lain.
2. Komponen eksternal
a. Local job scheduler berperan dalam membantu GRAM mengatur sumber
daya untuk alokasi job ke compute element (misalnya cluster). Scheduler
paling sederhana yang dimiliki GRAM adalah Fork (pengaturan job standard
pada Unix). Namun, untuk compute elements yang berukuran besar, maka
perlu Local Resource Management System (LRMS) untuk mengontrol
penjadwalan. Contoh LRMS adalah Sun Grid Engine (SGE), Condor, PBS,
LoadLeveler, dan lain-lain.
b. Komponen internal GRAM
c. Scheduler Event Generator (SEG), adalah komponen yang menyediakan
fasilitas bagi GRAM untuk melakukan monitoring. Beberapa modup plugin
dibuat sebagai perantara SEG dengan local scheduler.
d. Fork Starter, adalah program yang berperan untuk memulai dan memonitor
job untuk GRAM yang tidak menggunakan LRMS.
Universitas Indonesia

BAB 3Message Passing Interface
Message Passing Interface merupakan spesifikasi standard yang mengatur bagaimana
cara untuk membuat program aplikasi paralel dengan teknik message passing, mpi dapat
pula didefiniskan sebagai pustaka yang diterapkan untuk teknik message passing. MPI
dapat digunakan di bahasa Fortran, C, C++. Pustaka MPI mempunyai fungsi komunikasi
point to point, yaitu dua prosesor secara bersamaan melakukan operasi data pengiriman
dan penerimaan. fungsi lainnya yaitu fungsi komunikasi kolektif yaitu sekumpulan
prosesor dapat berkomunikasi dengan bermacam cara, seperti: satu proses ke beberapa
proses atau beberapa proses ke satu proses.
3.1 MPICH-G2
MPICH-G2 merupakan [4] implementasi dari standard MPI-1 yang menggunakan
layanan Globus Toolkit untuk menjalankan dilingkungan Grid dan pengaturan aplikasi
yang heterogen. Selama proses berlangsung MPICH-G2 menutupi proses kepada
pengguna seperti pembagian sumber daya, pengiriman dan pembagian tugas dan lain
halnya. Untuk lebih jelasnya terdapat ilustrasi proses MPICH-G2 dalam menjalankan
aplikasi mpi seperti pada gambar [].
Universitas Indonesia

Gambar 3.1 Alur Proses MPICH-G2 [4]
Pada gambar , apabila aplikasi MPICH-G2 dijalankan [7], pengguna diwajibkan
mempunyai kunci public (proxy credential) yang didapatkan dari sistem administrator.
Kunci public (proxy credential) digunakan untuk ototentifikasisd ke setiap sumber daya,
Serta pengguna dapat melihat dan memilih sumber daya untuk proses menggunakan
komponen Monitoring dan Discovery Service (MDS) .
Apabila proses ototenifikasi telah dilalui maka pengguna dapat menggunakan perintah
mpirun untuk melakukan proses komputasi MPI. Proses di MPICH-G2 setelah perintah
mpirun dilaksanakan selanjutnya MPICH-G2 membuat file Resource Specification
Langguange (RSL) yang berisikan identifikasi jumlah sumber daya yang akan digunakan,
memori, lokasi file, aplikasi dan argument pendukung seperti jumlah data. MPICH-G2
selanjutnya memanggil pustaka yang terdapat di Globus yaitu DUROC (Dynamic Update
Request Online Coallocator) dan DUROC menerima informasi dari kode RSL yang telah
dibuat sebelumnya. DUROC kemudian menjadwalkan dan menjalankan aplikasi ke
semua sumber daya yang telah ditentukan.
Pustaka DUROC menggunakan layanan GRAM (Grid Resource Allocation dan
Management) yaitu salah satu komponen dari Globus yang digunakan untuk memulai dan
mengatur sub job ke setiap sumber daya. Untuk setiap sumber daya DUROC
menghasilkan request GRAM ke GRAM Server. Dengan kondisi autentifikasi pengguna
telah didapatkan, autentifikasi pengguna diproses di local scheduler dimasing-masing
sumber daya, Subjob di semua sumber daya terlibat dalam mengeksekusi bagian
program MPI yang dikendalikan oleh DUROC dan dengan bantuan GRAM Server, Hasil
akhirnya DUROC dan pustaka MPICH-G2 menggabungkan semua subjob menjadi satu
job MPI.
MPICH-G2 dapat memilih metode komunikasi terbaik diantara satu atau beberapa dua
proses. Misalkan jika dua proses terletak di sumber daya yang sama, MPICH-G2
menggunakan persediaan sumber daya lokal (jika tersedia) untuk menjalankan
komunikasi diantara mesin dan apabila kedua proses berada di sumber daya yang
berbeda, MPICH-G2 mengunakan Globus Communication (Globus I/O) dan Globus
Data Conversion (Globus DC) untuk komunikasi intermachine (TCP).
Universitas Indonesia

Pelaksanaan program diawasi oleh DUROC dengan bantuan setiap server GRAM di
setiap sumber daya. Saat aplikasi mulai dijalankan, sumber daya di hold, sampai aplikasi
selesai. GRAM memberitahukan ke DUROC setiap perubahan state. Semua perhitungan
di setiap subjob ditahan oleh DUROC dan dilepaskan ketika semua subjob telah mulai
mengeksekusi. Sama halnya, ketika pengguna meminta perberhentian job, DUROC akan
meneruskan ke GRAM dan GRAM memproses mengirimkan pesan untuk segera
diberhentikan semua subjob termasuk proses yang sedang berlangsung.
3.2 Message Passing di Alchemi
Untuk menjalankan aplikasi parlalel dengan mengrunakan teknik Message Passing,
Alchemi menggunakan versi Alchemi parallel [situs alchemi]. Untuk membuat
pemograman di Alchemi menggunakan bahasa pemograman yang mendukung
framework .NET seperti Visual C, C#, J#, Visual Basic .NET.
Fungsi yang tersedia di alchemi untuk message pasing diantaranya[9] :
1) MPI_Init, metode yang digunakan untuk memulai aplikasi MPI
2) MPI_Finalize, metode yang digunakan untuk menyelesaikan aplikasi MPI.
3) MPI_COMM_Size, metode yang digunakan untuk mendapatkan jumlah
prosesor yang aktif yang digunakan untuk eksekusi.
4) MPI_COMM_Rank. Metode yang digunakan untuk memberikan identitas
atau nilai unik kepada setiap prosesor
5) MPI_Send, Metode yang digunakan untuk mengirimkan data ke prosesor
tujuan.
6) MPI_Recv. Metode yang digunakan untuk menerima data dari prosesor asal.
7) MPI_Barrier. Metode yang digunakan untuk batasan sinkronisasi antara
Alchemi Manager dengan Alchemi Eksekutor.
8) MPI_Bcast, metode yang digunakan untuk mengirim data ke semua
prosesor.
Alur kerja proses aplikasi MPI di alchemi dapat terlihat pada gambar
Universitas Indonesia

Gambar 3.2 Flow Diagram Aplikasi Message Passing di Alchemi [9]
Pada gambar 3.2 menjelaskan pengguna mengirimkan aplikasi di komputer desktop,
dengan memberikan jumlah prosesor dan nama aplikasi, kemudian aplikasi menjalankan
fungsi MPI_Init yang diteruskan ke Alchemi Manager, Alchemi Manager akan mencatat
ke dalam tabel proses di database alchemi dengan berisikan nomor proses identitas,
nomor identitas sumber daya, alamat IP dan nomor port pada tiap-tiap komputer yang
menjadi cluster di Alchemi.
Kemudian Alchemi Manager akan mengirimkan subjob data ke setiap Alchemi Eksekutor
dengan menggunakan fungsi MPI_Send, yang selanjutnya Alchemi Eksekutor menerima
subjob dengan fungsi MPI_Recv. Setiap Eksekutor melakukan proses komputasi, setelah
selesai maka subjob dikirimkan kembali ke Alchemi Manager. Hasil dari proses
perhitungan disimpan dalam sebuah file yang terdapat dikomputer pengguna.
Proses pemilihan sumber daya dilakukan secara acak oleh alchemi manager [] dan untuk
setiap proses, alchemi menggunakan penjadwalan FIFS (First in First Serve) untuk
mendapatkan proses komputasi yang maksimal. Pemilihan sumber daya atau eksekutor,
otentifikasi user, penjadwalan aplikasi seluruhnya tersimpan di database alchemi.
Universitas Indonesia

3.2.1 Keamanan di Alchemi
Dalam menjalankan aplikasi di alhemi terdapat dua mekanisme dalam alchemi[16], yaitu
Pengguna yang telah terotentifikasi dapat melakukan kegiatan yang berhubungan
dengan sistem atau sumber daya
Pengguna yang telah terotentifikasi ataupun yang belun terotentifikasi dapat
terlibat dalam penambahan sumber daya.
Dalam gambar 3.3 diuraikan model aturan untuk alchemi
0: alchemi administrator mengatur konfigurasi untuk user, group user, dan hak
akses data, dapat pula ditambahkan pengaturan untuk kontribusi menjadi
eksekutor bagi user untuk terotentifikasi atau tidak terotenfitikasi
2,3,4: manager mengotetinfikasikan user, dan hak yang dapat dilakukan, namun
hal ini tidak berlaku apabila anonymous (user yang tidak terdaftar di database
alchemi) diijinkan terlibat menjadi eksekutor.
Gambar 3.3 Model aturan di Alchemi Gambar 3.4 Hubungan Data di database alchemi
Dalam gambar 3.4 menjelaskan hubungan antara tabel yang berada dalam database
alchemi. Informasi user, group, dan hak akses dikelola database alchemi. Di dalam tabel
grp, user dan prm. Hubungan antara komponen alchemi dengan database alchemi dapat
dijelaskan sebagai berikut:
- ExecuteThread (kegiatan untuk mencatat thread yang berhubungan
dengan ekseskusi aplikasi seperti thread eksekusi, thread untuk hasil
akhir)
Universitas Indonesia

- ManageOwnApp (kegiatan untuk mencatat thread yang berhubungan
dengan aplikasi seperti thread memulai aplikasi, thread untuk
penyelesaian aplikasi)
- ManageAllApp (Kegiatan untuk mencatat thread yang behubungan dengan
keseluruhan aplikasi, seperti daftar semua aplikasi)
- Manage Users (Kegiatan yang berhubungan dengan penambahan user,
group user dan hak akses user)
Gambar 3.5 alur data otentifikasi alchemi
Untuk alur otentifikasi user dapat terlihat pada gambar 3.5, untuk melindungi aplikasi
dari kode yang tidak dikenal, Eksekutor menjalankan grid thread dengan bantuan CAS
(Code Access Security) yang merupakan fungsi dari .NET. CAS merupakan fungsi dari
Framework .NET untuk melindungi aplikasi supaya tetap berada dalam kondisi awal dari
pengaruh kode trojan atau virus ataupun kode program yang tidak dikenal dengan
mempertahankan identitas kode awal. Semua eksekutor menjalankan CAS dengan
AlchemiGridThread yang diberikan hak akses yang terintegrasi dengan .NET Local
Security Policy
Universitas Indonesia

Bab 4
Rancangan dan Mekanisme Percobaan
Pada bagian bab ini, membahas tentang desain dan mekanisme uji coba yang dilakukan
terhadap penggunaan aplikasi berbasis MPI di lingkungan Globus dan Alchemi,
parameter yang digunakan dan analisa dari hasil uji coba.
4.1 Metodologi
Penelitian ini menggunakan pendekatan membangun lingkungan grid sebagai test based,
kemudian melakukan percobaan selanjutnya mendapatkan hasil dan menganalisa dalam
bentuk statsitik. Percobaan dilakukan dalam lingkungan jaringan lokal (LAN) dan
metodologi yang digunakan menggunakan metodologi prototipe, dengan metode
prototipe terdapat beberapa modifikasi yang dilakukan terutama dalam stuktur kode yang
digunakan dalam beberapa parameter uji coba dan untuk mendapatkan unjuk kerja yang
lebih baik,
Linkungan Grid yang digunakan menggunakan empat mesin masing-masing memliki dua
prosesor, sehingga total prosesor yang digunakan sebanyak delapan prosesor. Uji coba
menggunakan software MPICH-G2 dan Alchemi Paralel, informasi secara rinci mengenai
spesifikasi komputer manager dan eksekutor terdapat di tabel 4.1, pada tabel 4.1 memiliki
spesifikasi yang sama untuk kesemua komputer yang digunakan.
Tabel 4.1 Spesifikasi hardware dan software yang digunakan
Arsitektur Mesin Intel X.86
Prosesor Pentium 4 CPU 3.06 GHz
Memori 512 MB
Sistem Operasi Ubuntu dam Windows XP Service Pack 2
Globus Globus versi 4.0.6
MPICH-G2 Integrasi MPI dengan Globus
Alchemi Alchemi Paralel versi 1.05
Universitas Indonesia

Untuk arsitektur lingkungan Grid Alchemi paralel dan MPICH-G2 dapat dilihat di
gambar 4.1 dan gambar 4.2, Satu Mesin digunakan sebagai Manager dan 3 mesin
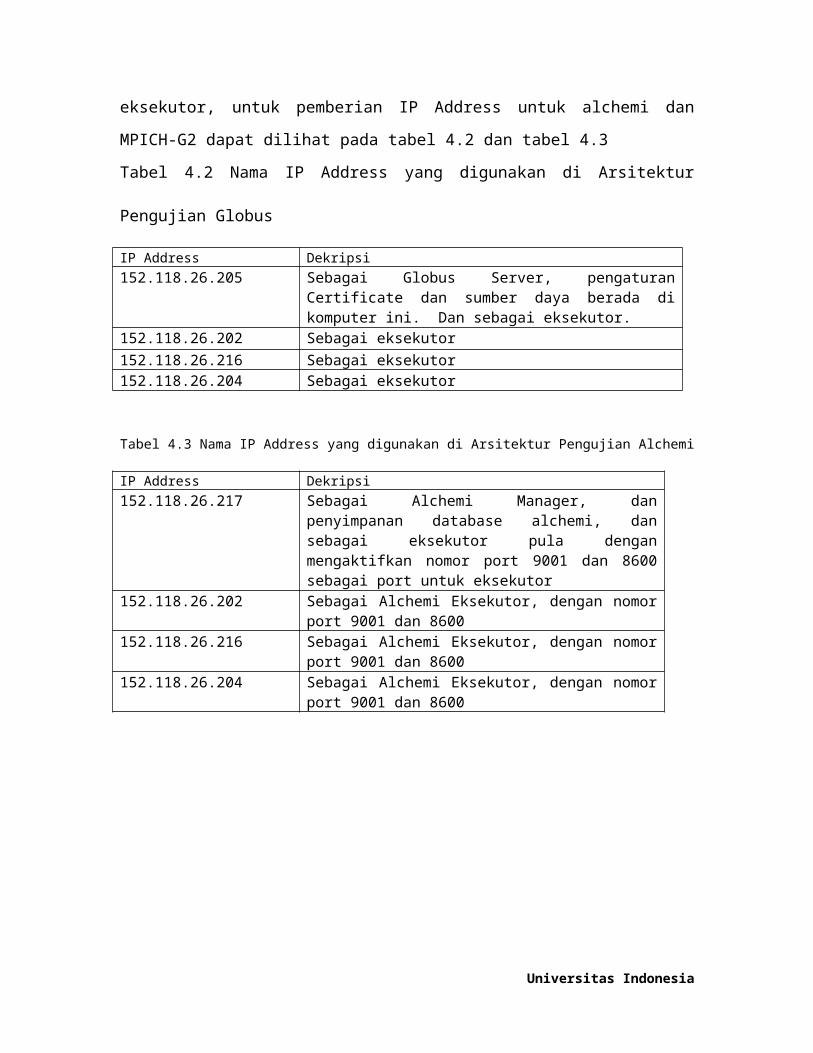
lainnya sebagai eksekutor, untuk pemberian IP Address untuk alchemi dan MPICH-G2
dapat dilihat pada tabel 4.2 dan tabel 4.3
Tabel 4.2 Nama IP Address yang digunakan di Arsitektur Pengujian Globus
IP Address Dekripsi 152.118.26.205 Sebagai Globus Server, pengaturan Certificate dan sumber
daya berada di komputer ini. Dan sebagai eksekutor.152.118.26.202 Sebagai eksekutor152.118.26.216 Sebagai eksekutor152.118.26.204 Sebagai eksekutor
Tabel 4.3 Nama IP Address yang digunakan di Arsitektur Pengujian Alchemi
IP Address Dekripsi 152.118.26.217 Sebagai Alchemi Manager, dan penyimpanan database
alchemi, dan sebagai eksekutor pula dengan mengaktifkan nomor port 9001 dan 8600 sebagai port untuk eksekutor
152.118.26.202 Sebagai Alchemi Eksekutor, dengan nomor port 9001 dan 8600
152.118.26.216 Sebagai Alchemi Eksekutor, dengan nomor port 9001 dan 8600
152.118.26.204 Sebagai Alchemi Eksekutor, dengan nomor port 9001 dan 8600
Universitas Indonesia

Gambar 4.1 Arsitektur Lingkungan Grid MPICH-G2
Gambar 4.2. Arsitektur Lingkungan Grid Alchemi Paralel
Dalam gambar 4.1 dan gambar 4.2 merupakan desain dari lingkungan grid di alchemi
parallel dan MPICH-G2, untuk dapat menjalankan satu mensin menjadi dua prosesor
dalam MPICH-G2 dengan menambahkan daftar nama computer ke file mesin, sedangkan
dalam alchemi dengan menjalankan dua program alchemi eksekutor, namun dibedakan
nmor port untuk alchemi eksekutor.
Universitas Indonesia

4.2 Fungsi MPI
Uji coba menggunakan fungsi-fungsi MPI yang terdapat didalam tabel 4.2, Uji coba ini
untuk mendapatkan batasan maksimal atau overhead yang dapat terjadi di MPICH-G2
dan Alchemi Paralel. Untuk MPICH-G2 uji coba menggunakan bahasa pemograman C
dan untuk Alchemi parallel dalam uji coba menggunakan bahasa Visual C#.
Table 4.3 Fungsi MPI dan Parameter untuk uji coba
Fungsi MPI yang digunakan Paratemer yang digunakanMPI_Send Jumlah Pesan, Jumlah paralel steam, rasio
komputasi, Overhead, Komunikasi Rasio Dalam Komputasi
MPI_Recv Jumlah Pesan, Jumlah paralel steam, rasio komputasi, Overhead, Komunikasi Rasio Dalam Komputasi
MPI_Bcast Jumlah Pesan, Jumlah Prosesor, Komunikasi komputasi rasio
MPI_Gather Jumlah Pesan dan Jumlah Prosesr
Untuk alchemi paralel, tidak memiliki fungsi MPI_Gather, MPI_Gather digunakan untuk
melakukan pengiriman data ke semua eksekutor menggunakan satu perintah. Dalam
Alchemi Paralel fungsi tersebut dapat digantikan dengan melakukan perulangan sebanyak
jumlah prosesor, dan melakukan pengiriman pesan ke tiap prosesor.
4.2.1 Komunikasi Point to Point
Dalam komunikasi point to point, komunikasi dilakukan diantara dua proses, proses yang
satu melakukan operasi kirim (send) dan proses yang lain melakukan operasi terima
(receive).
Dalam mode standar MPI_Send dan MPI_Recv, pesan yang akan dikirim oleh prosesor 0
disalin kesuatu buffer receiver (blok memori) yang dimiliki sistem. Fungsi buffer send
tidak dapat digunakan sampai proses pengiriman selesai oleh prosesor 0, dan prosesor 1
sebagai penerima tidak dapat membaca isi pesan sampai semua pesan diterima.
4.2.2 Komunikasi Kolektif:
Dalam komunikasi kolektif n prosesor berkomunikasi dengan prosesor lainnya. semua
proses mengambil bagian komunikasi diantara proses group yang sama dalam
intrakomunikator object MPI. Program termasuk operasi kolektif dalam penelitian ini
Universitas Indonesia

dibuat skenario master slave dimana semua proses mendapatkan pesan dari satu proses
rank root dan tidak ada interproses komunikasi diantara slave, penelitian ini
membutuhkan waktu untuk menyelesaikan operasi kolektif. Setelah semua selesai
berkomunikasi dan skenario semua waktu di peroleh di prosesor master. Percobaan ini
menggunakan iterasi sebanyak 5 kali, setiap waktu mpi call di hitung untuk penjumlahan
dibagi dengan jumlah yang run. Setelah rata-rata aritmetik ini didapatkan, maka standard
deviation dapat digunakan.
4.3 Parameter
Parameter yang dilakukan untuk uji coba antara lain:
4.4.1 Jumlah Data
Jumlah data yang dapat dikirimkan ke mesin lain, dan uji coba dilakukan di komunikasi
point to point serta komunikasi kolektif, pengiriman jumlah pesan dilakukan secara
bertahap dan meningkat jumlah data yang dapat dikirimkan. Untuk komunikasi point to
point jumlah data yang di uji coba diantara 8 byte sampai 16 Mega byte.
4.4.2 Jumlah Prosesor
Dalam komunikasi kolektif, jumlah prosesor dapat berpengaruh dalam waktu
penyelesaian akhir, aplikasi yang diuji coba dalam komunikasi kolektif seperti perkalian
matrik.
4.4.3 Jumlah Paralel Data Stream
Pengujian dengan melakukan pengiriman data secara jamak ke prosesor, untuk
komunikasi point to point dilakukan pengiriman 2 data sampai 32 data dalam waktu
bersamaan. Untuk komunikasi kolektif dilakukan dengan perbandingan 2, 4 dan 8
prosesor dengan pengiriman data 2 sampai 32 data dalam satu waktu.
Universitas Indonesia

4.4.4 Komunikasi Rasio Dalam Komputasi
Dalam perhitungan komputasi paralel, sangat berpengaruh dalam jumlah data dan
jumlah prosesor untuk komputasi parallel, dalam uji coba ini dilakukan pengujian jumlah
data dan jumlah prosesor yang tepat dalam komputasi parallel
4.4.5 Overhead
Melakukan pengujian untuk mendapatkan hasil batasan yang dapat dilakukan oleh
alchemi parallel dan MPICH-G2 dalam melakukan komputasi, terutama untuk MPICH-
G2 dengan proses yang lebih rumit dalam melakukan komputasi dengan proses GLOBUS
I/O dan otentifikasi SSL.
4.5 Penerapan Aplikasi
Dalam uji coba terdapat beberapa aplikasi yang digunakan dalam uji coba diantaranya:
4.5.1 Aplikasi Ping Pong
Merupakan aplikasi yang digunakan untuk menguji pengiriman dan penerimaan data,
pengujian dengan dua prosesor, data yang dikirimkan mulai dari 8 byte dan 16 Mb,
kemudiaan dibandingkan waktu penyelesaian akhir dari MPiCH-G2 dan Alchemi Paralel.
Pengiriman dan penerimaan data dilakukan dengan satu data dalam satu waktu.
4.5.2 Aplikasi Ping Pong Multi Stream
Berbeda dengan aplikasi Ping Pong sebelumnya, aplikasi ini melakukan pengirirman dan
penerimaan data, namun dalam pengiriman terdapat sejumlah data yang dikirim dalam
satu waktu. Dalam penerapannya dilakukan pengiriman sebanyak n kali dalam jumlah
data yang sama kemudian jumlah data ditingkatkan dan melakukan perulangan sebanyak
n kali. Jumlah loop yang dilakukan mulai dari 2 kali sampai 32 kali dengan penambahan
data dari 8 byte sampai 16 Mega byte.
Universitas Indonesia

4.5.3 Aplikasi Broadcast.
Pengujian untuk melakukan pengiriman secara broadcast dengan melakukan pengiriman
data dari 8 byte hingga 4 mega byte dan dihitung waktu komputasi, jumlah prosesor
mulai dari 2,4, dan 8 prosesor.
dalam percobaan dari 2 prosesor, 4 prosesor dan 8 prosesor.
4.5.4 Perkalian Matrik
Merupakan aplikasi yang menjadi standar dalam pengujian lingkungan grid, berdasarkan
literatur dalam pengujian aplikasi grid, umumnya perkalian matrik selalu menjadi pilihan
dalam percobaan aplikasi grid. Dalam percobaan ini dilakukan pengujian mulai ukuran
matrik 2 x 2 sampai 4096 x 4096
4.5.5 Gaussian Elimination
Merupakan algoritma atau metode untuk menyeleaika pemasalahan persamaan linier.
Dalam percobaan ini, menggunakan persamaan:
E1 : a11x2 + a12x3 = b1
E2: a21x1 + a22x2 + a23x3 = b2
E3 : a31x1 + a32x2 + a33x3 = b3
Dalam algoritma Gaussian Elimination akan dihasilkan nilai x1, x2 dan x3. Jika diberikan
persamaan E1,E2 dan E3 menjadi vector tunggal maka
A.x =b
Dimana koefisien matrik A= [ajk] adalah matrik n x n
Dalam pengujian ini nilai a diberikan nilai acak dan diberikan waktu komputasi sebanyak
n kali atau terdapat persamaan E sebanyak n kali untuk didapatkan setiap nilai x, dan
dihitung kembali waktu komputasinya.
Universitas Indonesia

4.6 Penerapan
4.6.1 Penerapan di MPICH-G2
Untuk menjalankan mpi di lingkungan MPICH-G2, mendaftarakan sertifikasi untuk
proxy dengan menggunakan perintah:
Grid-proxy-init
Perintah Grid-proxy init digunakan untuk mengaktifkan user dengan menggunakan proxy
certificate dengan masa berlaku sertifikasi tersebut secara standar selama 12 jam, untuk
melepaskan kunci sertifikasi proxy dengan menggunakan perintah
Grid-proxy-destroy
Untuk keamanan aplikasi dan pengaturan sumber daya di MPICH-G2 dalam pengiriman
dan penerimaan data, setiap eksekutor melakukan layanan koneksi SSH, untuk
memberikan keleluasaaan Globus Server dalam menjalankan komputasi. Untuk
memudahkan setiap eksekutor atau manager melakukan komputasi tanpa diminta kata
kunci setiap mengakses sumber daya , maka di setiap mesin dapat melakukan perintah
ssh-keygen-d
Perintah ssh-keygen-d untuk membuat kunci public dan untuk mendaftarkan user dalam
authrorized keys menggunakan perintah
cp ~/.ssh/id_dsa.pub ~/.ssh/authorized_keys
4.6.2 Penerapan di Alchemi Manager.
Untuk mengaktifkan MPI dalam alchemi Paralel, yang pertama dilakukan adalah
mengaktifkan alchemi Manager, contoh pada gambar
Universitas Indonesia

Gambar 4.3 Alchemi Manager Aktif
Untuk mengaktifkan alchemi eksekutor seperti pada gambar 4.3, sedangkan apabila
dalam satu mesin ingin menjalankan dua eksekutor maka seperti pada gambar 4.4 dan
gambar 4.5, dengan merubah nomor port standard eksekutor yaitu nomor port 9001
menjadi nomor port yang lain, misalkan nomor port 7000
Universitas Indonesia

Gambar 4.4 Alchemi Eksekutor dengan Port 7000 Gambar 4.5 Alchemi Eksekutor dengan Port
9001
4.6.3 Compile Program
Dalam MPICH-G2, untuk mengcompile program dapat menggunakan mpicc, terdapat
di /MPICH-G2 Location/bin/mpicc. Cara menjalankan dengan perintah:
mpicc pingpong.c –o pinpong
Untuk Alchemi Paralel dengan menjalankan visual studio C# dan kemudian dengan
mengklik Build Solution.
4.6.4 Menjalankan Program MPI
Dalam MPICH-G2, terdapat beberapa cara dalam menjalankan program MPI
diantaranya:
4.6.4.1 Perintah mpirun
Secara standard dapat menggunakan perintah mpirun dengan menjalankan perintah
mpirun –np 2 pingpong –machinefile namamesin
MPICH-G2 menggunakan mesin yang telah ditetapkan dalam sebuah file, dan dapat
diubah berdasarkan keinginan user.
4.6.4.2 Perintah mpirun dengan file RSL
RSL (Resource Spesification Langguange) merupakan penulisan umum untuk merubah
informasi sumber daya [ ]. Informasi yang dapat diberikan di file RSL termasuk nama
Universitas Indonesia

mesin, jumlah mesin, memory, nama aplikasi, jenis job, lokasi aplikasi dan lainya.
Contoh cara membuat file rsl dalam perintah mpirun:
mpirun –dumprsl pingpong.rsl –np 2 pingpong
Perintah diatas digunakan untuk menghasilkan file pingpong.rsl, dilanjutkan dengan
menjalankan perintah
mpirun –globusrsl pingpong.rsl
Contoh file pingpong.rsl
Universitas Indonesia
+( &(resourceManagerContact="riset-c-3208-204")(count=1)(label="subjob 0")(arguments="")(environment=(GLOBUS_DUROC_SUBJOB_INDEX 0)(LD_LIBRARY_PATH /usr/local/globus2/lib/)) (directory="/d")(executable="/d/pingpong"))( &(resourceManagerContact=" riset-c-3208-202")(count=1)(label="subjob 1")(arguments="")(environment=(GLOBUS_DUROC_SUBJOB_INDEX 1)(LD_LIBRARY_PATH /usr/local/globus2/lib/))(directory="/d")(executable="/d/pingpong")

BAB V
Analisa dan Hasil
Pada bagian bab ini membahas analisa dan hasil yang telah dilakukan selama percobaan
yang dilakukan dilingkungan MPICH-G2 dan Alchemi Paralel dari aplikasi yang
sebelumnya dibahas di Bab IV.
5.1 Hasil Pengujian Aplikasi Ping Pong
Berikut beberapa hasil pengujian aplikasi ping pong dengan sekali pengiriman data
Gambar 5.1 Pengujian Aplikasi pingpong-1 Gambar 5.2 pengujian aplikasi pingpong-2
Gambar 5.1 dan gambar 5.2 merupakan hasil dari pengujian aplikasi pingpong dengan
data dari 8 byte sampai 8192 byte dan dilanjutkan dengan 16 Kilo byte sampai 1 Mega
Byte. Dari hasil pengujian antara MPICH-G2 dan Alchemi paralel, waktu yang
dihasilkan kurang dari 1 detik untuk pengujian aplikasi pingpong. Dari literature [khan]
pengujian dilakukan sampai 1 Mega byte dengan asumsi untuk memudahkan dalam
membaca pergerakan data. Untuk mendapatkan hasil yang berbeda maka pengujian
dilakukan dengan menambahkan data dari 2 Mega byte hingga 16 Mega byte, hasil
seperti gambar 5.3
Universitas Indonesia

Gambar 5.3 Hasil pengujian Pingpong-3
Pada Gambar 5.3 terjadi perbedaan dalam jumlah waktu antara MPICH-G2 dan Alchemi
Paralel, untuk informasi rinci dapat dilihat pada table 5.1, pada jumlah data kisaran 8
mega byte dan 16 mega byte waktu penyelesaian antara MPICH-G2 dan Alchemi paralel
berbeda jauh terutama untuk 16 Mega byte waktu tempuh MPICH-G2 lebih besar 3 kali
dari waktu alchemi paralel.
Table 5.1 waktu penyelesaian dalam aplikasi pingpong
data (bytes) Alchemi Paralel MPICH-G22097152 0.381 0.514194304 0.738 1.598388608 1.46 2.6
16777216 2.98 6.7
5.2 Hasil pengujian dengan Aplikasi Ping Pong Multi Stream
Berikut ini beberapa hasil pengujian aplikasi ping pong dengan beberapa data dikirimkan
secara bersamaan. Untuk hasil dalam bab ini ditampilkan data 8192 bytes dan data 2
Mega byte atau 2097152 bytes, untuk hasil pengujian dengan data lainnya terdapat di
dalam lampiran.
Universitas Indonesia

Gambar 5.4 Hasil Pengujian Multi Steam -1 Gambar 5.5 Hasil Pengujian Multi Stream -2
Dari hasil pengujian Multi Stream dengan contoh data berkisar 8192 bytes dan 2097152
bytes dan dilakukan perulangan dari 1 kali hingga 32 kali, waktu penyelesaian MPICH-
G2 lebih besar dari waktu alchemi paralel, ketika data melakukan perulangan dari 1- 4
kali realtif waktu komputasi MPICH-G2 berkisar dibawah 10 detik, namun ketika
perulangan dari 8 kali hingga 32 kali waktu komputasi MPICH-G2 lebih besar 5 hingga 9
kali dari waktu alchemi paralel. Hal ini dapat kemungkinan MPICH-G2 memiliki proses
yang lebih rumit dalam pengaturan dan penjadwalan sumber daya, dengan GLOBUS I/O
pemilihan sumber daya melalui DUROC dan GRAM Server dan otentifikasi keamaman
dengan SSH. Sedangkan alchemi Paralel menggunakan proses yang lebih sederhana
melalui proses pemeriksaan ekskutor dan aplikasi didatabase alchemi selanjutnya
menjalankan aplikasi MPI.
Iinformasi mengenai jumlah waktu yang terdapat pada gambar 5.4 dan 5.5 dapat dilihat
ditabel 5.2
Universitas Indonesia

Table 5.2 Waktu komputasi Multi Stream dengan data 8192 bytes
Jumlah data Alchemi Paralel MPICH-G21 0.015 0.0020142 0.021 0.0224 0.142 0.058 0.074 0.2
16 0.162 0.232 0.34 0.71
Table 5.3 Waktu komputasi Multi Stream dengan data 2097152 bytes
Jumla data Alchemi Paralel MPICH-G21 0.81 0.512 0.754 5.874 1.154 11.78 2.425 51.435
16 6.069 51.43232 12.114 89.9
5.3 Hasil Pengujian dengan aplikasi broadcast.
Aplikasi broadcast sama dengan aplikasi ping pong, dalam aplikasi ini komunikasi
prosesor 0 dengan prosesor eksekutor. Tidak ada komunikasi diantara eksekutor.
Broadcast dengan sejumlah data 4 dan 8 prosesor. Tidak ada komputasi dalam aplikasi
ini, aplikasi melakukan pengiriman data dengan data yang terus meningkat, hasil dapat
dilihat pada gambar 5.6, gambar 5.7, gambar 5.8 dan gambar 5.9
Gambar 5.6 aplikasi Broadcast 4 Prosesor-1 Gambar 5.7 aplikasi Broadcast 4 prosesor -2
Universitas Indonesia

Gambar 5.8 Aplikasi Broadcast 8 Prosesor-1 Gambar 5.9 Aplikasi Broadcast 8 Prosesor-2
Dari hasil broadcast untuk melihat komunikasi antara prosesor 0 (manager) dengan setiap
komputer eksekutor. Dengan laju pertambahan data akan membuat komunikasi
bertambah besar dan dapat terlihat dari setiap gambar hasil pengujian aplikasi broadcast
komunikai yang cukup besar terdapt di MPICH-G2, untuk 4 prosesor, MPICH-G2 waktu
komputasi masih stabil untuk data dari 8 byte hingga 8192 byte. Namun untuk data yang
lebih besar dan jumlah prosesor yang besar waktu komputasi MPICH-G2 bertambah
besar. Sedangkan alchemi paralel relative lebih stabil dengan waktu komputasi paling
besar dibawah 20 detik, hal ini dikarenakan alchemi paralel terintegrasi dengan
Framework .NET dan komunikasi antara dua prosesor diserahkan oleh komunikasi
sisitem operasi windows dan tidak ada autentifiaksi atau keamanan khusus dalam transfer
data
.
Universitas Indonesia
5.4 Hasil pengujian Perkalian Matrik
Untuk pengujian matrik ditampilkan perkalian matrik dari ukuran matrik 64 x 64 sampai
128 x 128, melihat hasil yang diperoleh dari aplikasi ping pong dapat terlihat MPICH-G2
memiliki waktu komputasi yang lebih sedikit unutk alchemi paralel untuk perkalian atara
64 x 64, matrik 128 x 128 dan matrik 256 x 256. Sedangkan untuk perkalian matrik 512
x 512 sampai 2048 x 2048 antara alchemi paralel dan MPICH-G2 dapat dikatakan
cenderung lebih flukuatif (waktu komputasi besar dan waktu komputasi kecil), alchemi
paralel dalam percobaan matrik 512 x 512 dan matrik 1024 x 1024 pada gambar 5.11 dan
5.12, waktu komputasi tidak stabil, untuk 3 dan 5 prosesor waktu yang dbutuhkan lebih
besar nilainya dengan 1 prosesor, dan waktu komputasi lebih baik ketika menggunakan
2,4,6, dan 8 prosesor.
Untuk percobaan matrik dengan ukuran 4096 x 4096 pada MPICH-G2 dengan jumlah
prosesor 1 – 7 prosesor mengalami overhead, overhead dalam hal ini waktu yang
dihasilkan tidak tepat karena bernilai negative, sehingga waktu komputasi tidak valid,
untuk 8 prosesor perkalian matrik 4096 * 4096 tidak terjadi overhead. Namun untuk
alchemi paralel perkalian matrik 4096 x 4096 tidak mengalami overhead, hal ini dapat
dilihat dari hasil aplikasi ping pong dan broadcast alchemi paralel untuk jumlah data
besar dapat melakukan pengiriman dan penerimaan dalam waktu yang lebih sedikit dari
MPICH-G2 untuk hasil perkalian matrik alchemi paralel dapat dilihat pada gambar 5.14
dan untuk perkalian 4096 x 4096 di MPICH-G2 dapat dilihat pada gambar 5.15 .
Dalam implementasinya untuk aplikasi perkalian matrik dialchemi paralel memiliki
hambatan atau tingkat robust/ kehandalan yang rendah, atau untuk kehandalan
menjalankan aplikasi alchemi paralel tidak sebaik dengan MPICH-G2, hal ini
dikarenakan:
Untuk percobaan dengan ukuran data kecil dan jumlah ekskutor besar untuk
melakukan komputasi, alchemi paralel memiliki kendala dalam melakukan
komputasi, dikarenakan penyebaran data yang kecil dan jumlah proseosr besar
kadang ada beberapa prosesor yang seharusnya melakukan komputasi tetapi
dalam keadan diam atau idle, sehingga komputasi tidak selesai, atau pada
Universitas Indonesia

umumnya alchemi manager akan mengeluarkan pesan pop up bahwa aplikasi
tidak dapat dilaksanan. Untuk pemograman message passing jika ada satu mesin
mengalami kesalahan maka seluruh aplikasi tidak dapat dijalankan maka aplikasi
harus dimulai dari awal. Dan berlaku pula untuk alchemi paralel, aplikasi harus
dimulai dari awal.
Ketika aplikasi dihentikan langsung oleh user (di interrupt) maka status aplikasi
di alchemi paralel, belum selesai. Ketika ada aplikasi baru atau aplikasi yang
sama ingin melakukan komputasi, alchemi akan mendahulukan aplikasi dengan
status belum selesai. Karena alchemi menggunakan penjadwalan FCFS (First
Come First Serve) status aplikasi dapat dilihat di database alchemi. Hal ini
berbeda dengan MPICH-G2 jika ada user interrupt aplikasi, maka DUROC akan
mengirimkan status ke GRAM Server bahwa aplikasi di abort atau menggunakan
perintah MPI_Abort untuk membatalkan aplikasi.
Gambar 5.10 Perkalian matrik 64 x 64 Gambar 5.10 Perkalian matrik 128 x 128
Universitas Indonesia

Gambar 5.10 Perkalian matrik 256 x 256 Gambar 5.11 Perkalian matrik 512 x 512
Gambar 5.12 Perkalian matrik 1024 x 1024 Gambar 5.13 Perkalian matrik 2048 x 2048
Universitas Indonesia

Gambar 5.14 matrikalchemi paralel 4096 *4096 Gambar 5.15 Matrik 8 Prosesor
5.5 Hasil Pengujian Gaussian elimination
..
Universitas Indonesia
Copyright © 2022 FDOKUMEN




















