
Dataminingii p13 Estimation Compatibility Mode1
27
Data Mining II Estimasi Data Mining-2012-a@b 1 Matakuliah Data warehouse Universitas Darma Persada Oleh: Adam AB
-
Upload
dhanawardhana -
Category
Documents
-
view
37 -
download
11
Transcript of Dataminingii p13 Estimation Compatibility Mode1

Data Mining II
Estimasi
Data Mining-2012-a@b 1
Estimasi
Matakuliah Data warehouse
Universitas Darma Persada
Oleh: Adam AB
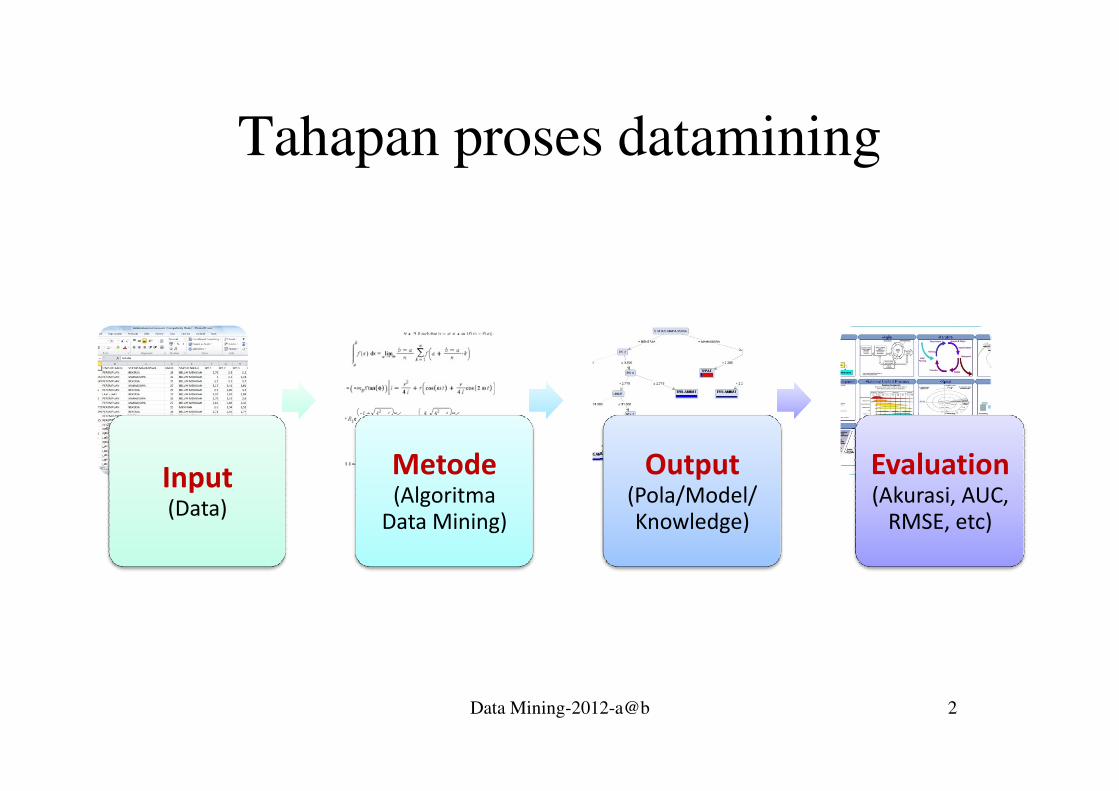
Tahapan proses datamining
Data Mining-2012-a@b 2
Input(Data)
Metode(Algoritma
Data Mining)
Output(Pola/Model/Knowledge)
Evaluation(Akurasi, AUC,
RMSE, etc)

Atribut , Class dan tipe data
• Atribut adalah faktor atau parameter yang
menyebabkan class/label/target terjadi
• Class adalah atribut yang akan dijadikan target,
sering juga disebut dengan label
• Tipe data untuk variabel pada statistik terbagi • Tipe data untuk variabel pada statistik terbagi
menjadi empat: nominal, ordinal, interval, ratio
• Tapi secara praktis, tipe data untuk atribut pada
data mining hanya menggunakan dua:
1. Nominal (Diskrit)
2. Numeric (Kontinyu atau Ordinal)
Data Mining-2012-a@b 3

Metode/Algoritma Data mining
1. Estimation (Estimasi):– Linear Regression, Neural Network, Support Vector Machine, etc
2. Prediction/Forecasting (Prediksi/Peramalan):– Linear Regression, Neural Network, Support Vector Machine, etc
3. Classification (Klasifikasi):
Data Mining-2012-a@b 4
3. Classification (Klasifikasi):– Naive Bayes, K-Nearest Neighbor, C4.5, ID3, CART, Random Forest,
Linear Discriminant Analysis, Neural Network, etc
4. Clustering (Klastering):– K-Means, K-Medoids, Self-Organizing Map (SOM), Fuzzy C-Means, etc
5. Association (Asosiasi):– FP-Growth, A Priori, etc

Output/pola/model/knowledge
1. Formula/Function (Rumus atau Fungsi Regresi)– WAKTU TEMPUH = 0.48 + 0.6 JARAK + 0.34 LAMPU + 0.2
PESANAN
2. Decision Tree (Pohon Keputusan)
3. Rule (Aturan)
Data Mining-2012-a@b 5
3. Rule (Aturan)
– IF ips3=2.8 THEN lulustepatwaktu
4. Cluster (Klaster)
2
2.5
3
Iteration 6
Data Mining-2012-a@b 6
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2
0
0.5
1
1.5
x
y

Refund
Yes No
Splitting Attributes
Data Mining-2012-a@b 7
MarSt
TaxInc
YESNO
NO
NO
Yes No
Single, Divorced
< 80K > 80K

Kriteria Evaluasi dan Validasi
Model• Secara umum pengukuran model data mining
mengacu kepada tiga kriteria: Akurasi
(Accuracy), Kehandalan(Reliability) dan
Kegunaan (Usefulness)
Data Mining-2012-a@b 8
Kegunaan (Usefulness)
• Keseimbangan diantaranya ketiganya diperlukan
karena belum tentu model yang akurat adalah
handal, dan yang handal atau akurat belum tentu
berguna

Kriteria Evaluasi dan Validasi
Model
1. Akurasi adalah ukuran dari seberapa baik model
mengkorelasikan antara hasil dengan atribut dalam data yang
telah disediakan. Terdapat berbagai model akurasi, tetapi
semua model akurasi tergantung pada data yang digunakan
Data Mining-2012-a@b 9
2. Kehandalan adalah ukuran di mana model data mining
diterapkan pada dataset yang berbeda akan menghasilkan
sebuah model data mining dapat diandalkan jika
menghasilkan pola umum sama terlepas dari data testing
yang disediakan
3. Kegunaan mencakup berbagai metrik yang mengukur apakah
model tersebut memberikan informasi yang berguna.

Tool software datamining
• WEKA
• RapidMiner
• DTREG
Data Mining-2012-a@b 10
• Clementine
• Matlab
• R
• SPSS

Data mining-Estimasi
• Estimasi merupakan fungsi minor kedua
dari data mining.
• Suatu misal kita diberi sampel data volume
air isi ulang yang diisi otomatis oleh mesin
Data Mining-2012-a@b 11
air isi ulang yang diisi otomatis oleh mesin
pengisi dengan isi yang bervariasi,
sementara volume yang diharapkan adalah
2000 ml.

Data Mining-Estimasi(lanj)
Data Mining-2012-a@b 12

Data Mining-Estimasi (lanj)
• Berdasarkan data di atas pengisian air pada mesin tidak tepat 2000 ml
• Berapakah volume air pada umumnya di dalam botol yang diisikan?
• Berapa kira-kira volume air yang akan diisi pada
Data Mining-2012-a@b 13
• Berapa kira-kira volume air yang akan diisi pada botol di masa datang bila mesin mengisi (berapa kali) botol tersebut?
• � estimasi/memperkirakan
• Estimasi � estimasi titik
• � setimasi selang

Data Mining-Estimasi (lanj)
• Istilah
• Populasi : objek yang diteliti, dalam hal ini
air minum dalam botol
Data Mining-2012-a@b 14
air minum dalam botol
• Sampel : contoh/cuplikan objek yang
diambil untuk dijadikan penelitian, dalam
hal ini 12 botol minuman.
• Populasi besarnya tidak terbatas

Estimasi Titik
• Estimasi titik : bentuk estimasi yang menghasilkan
satu buah nilai estimasi saja yaitu berupa angka
• Populasi yang terus bertambah , tidak mungkin
bagi kita untuk menghitung mean dan varians.
• Karena itu kita perlu sampel untuk melakukan
Data Mining-2012-a@b 15
• Karena itu kita perlu sampel untuk melakukan
estimasi/perkiraan pada parameter di atas
• Mengapa perkiraan? � sebab bila kita memiliki
perkiraan rata-rata dan varians yang akurat maka
akan banyak pertanyaan yang dapat kita jawab
dengan baik.

Estimasi titik (lanj)
• Cara memperkirakan
• Rata-rata populasi µ dapat diestimasi
dengan rata-rata sampel
• Varians populasi σ2 dapat diestimasi dengan
Data Mining-2012-a@b 16
varians sampel (s2)
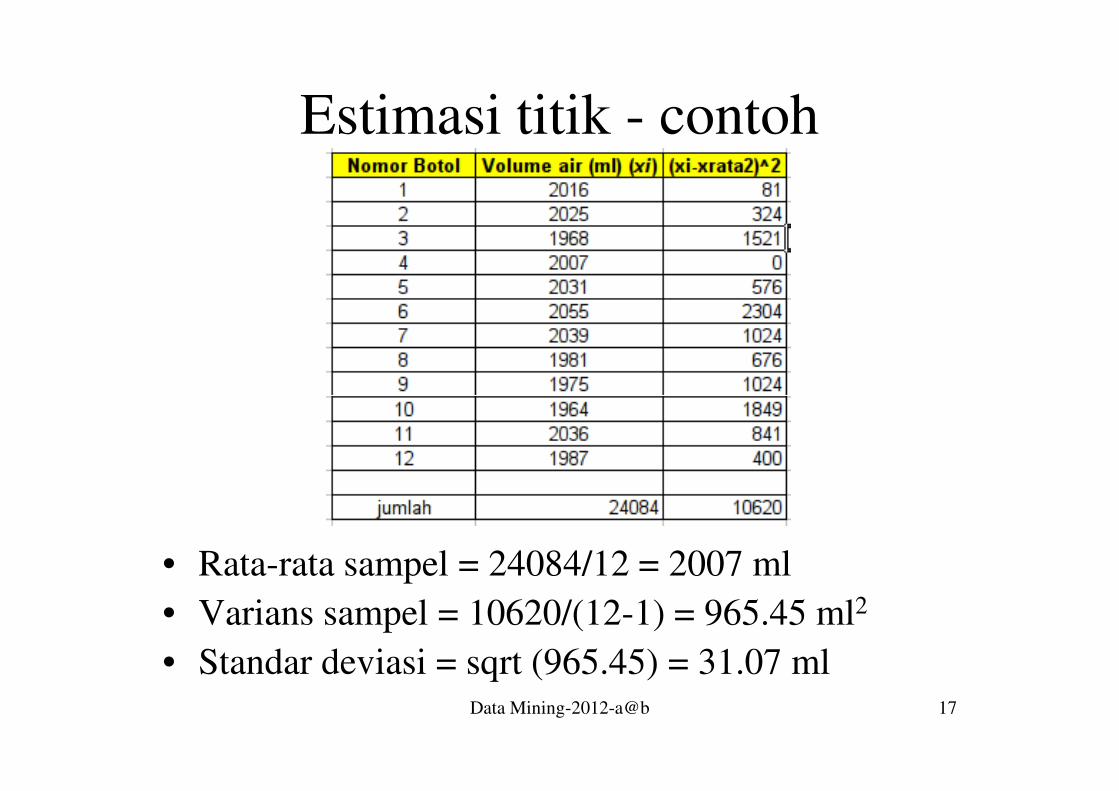
Estimasi titik - contoh
Data Mining-2012-a@b 17
• Rata-rata sampel = 24084/12 = 2007 ml
• Varians sampel = 10620/(12-1) = 965.45 ml2
• Standar deviasi = sqrt (965.45) = 31.07 ml

Estimasi titik - contoh
• Pengetahuan apa yang diperoleh dari
informasi ini?
• � pada umumnya setiap botol akan diisi air
Data Mining-2012-a@b 18
• � pada umumnya setiap botol akan diisi air
sebanyak 2007 ml (rata-rata), dengan
varians sebesar 965.45 ml

Estimasi - selang
• Estimasi titik hanya menghasilkan satu
angka, bagaimana bila diinginkan angka
yang selang agar lebih mengakomodasi
error.
Data Mining-2012-a@b 19
• Menggunakan batas bawah (L) dan batas
atas (U)
• � batas bawah (L) = X - zα /2 . σx
• � batas atas (U) = X + zα /2 . σx
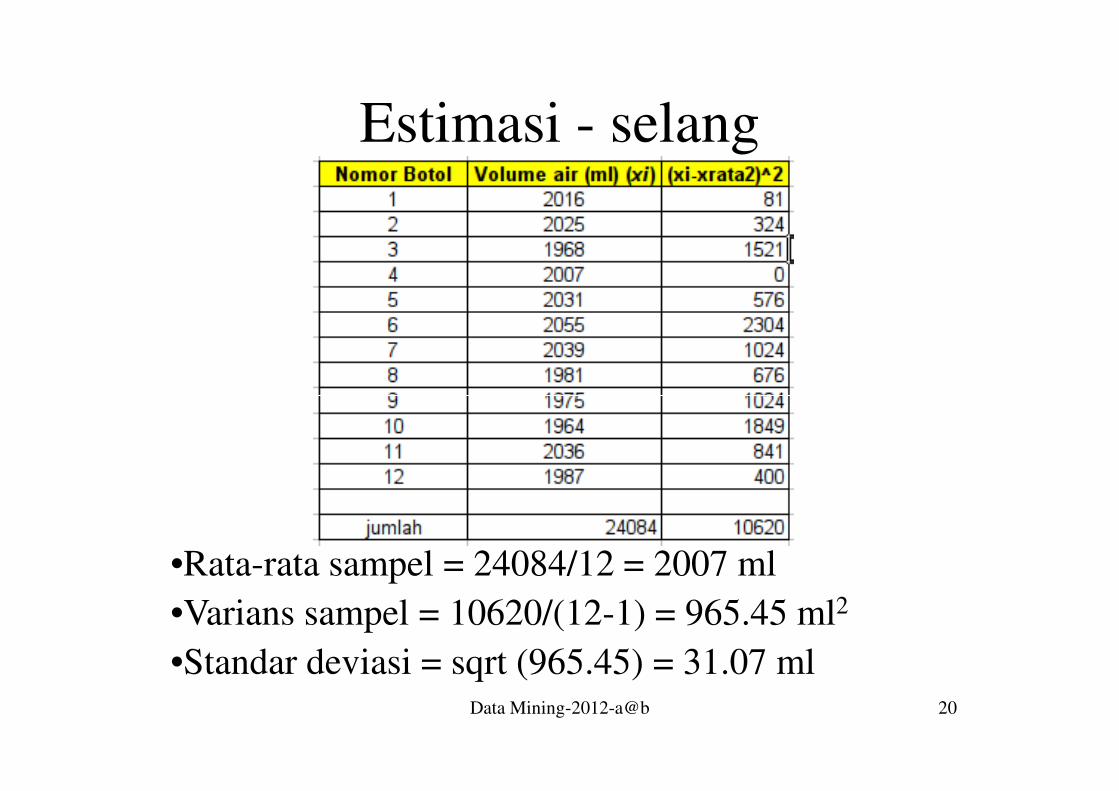
Estimasi - selang
Data Mining-2012-a@b 20
•Rata-rata sampel = 24084/12 = 2007 ml
•Varians sampel = 10620/(12-1) = 965.45 ml2
•Standar deviasi = sqrt (965.45) = 31.07 ml

Estimasi selang (lanj)
• Selang kepercayaan 95%, maka α = 100% -
95% = 5%
• Selang kepercayaan 90% maka α = 10%
• Misal kita gunakan selang kepercayaan 95%
Data Mining-2012-a@b 21
• Misal kita gunakan selang kepercayaan 95%
� α = 5%
• zα /2 = 5/2 = 2.5 % = 0.025
• � lihat tabel distribusi

Estimasi selang (lanj)
Data Mining-2012-a@b 22

Estimasi selang (lanj)
• Nilai 0.024998 ~ 0.0250 terletak dalam
baris 1.9 dan kolom 0.06 sehingga diperoleh
1.9 + 0.06 = 1.96
• � zα /2 batas bawah = - 1.96 (nilai negatif)
Data Mining-2012-a@b 23
• � zα /2 batas atas = 1.96 (nilai positif)
• Tinggal menghitung σx
• σx = σ/sqrt(n) (baca: standar deviasi dibagi akar banyaknya data)

Estimasi selang (lanj)
• σ � standar deviasi � 31.07 ml
• n � banyaknya data � 12 ml
• σx =σ/sqrt(n) � 31.07 / sqrt(12) = 8.97
Data Mining-2012-a@b 24
• σx =σ/sqrt(n) � 31.07 / sqrt(12) = 8.97
• Batas bawah (L) = 2007 – 19.6 (8.97) = 1989.42 ml
• Batas atas (U) = 2007 + 19.6 (8.97) = 2024.58 ml
• Jadi selang kepercayaan 95% berdasarkan sampel
tersebut adalah (1989.42 ; 2024.58 ) ml

Estimasi selang (lanj)
• Pengetahuan apa yang bisa diperoleh dari
pengolahan data di atas?
• � bila kita melakukan prosedur 100 kali
Data Mining-2012-a@b 25
• � bila kita melakukan prosedur 100 kali
maka akan berpeluang untuk mendapatkan
95 buah selang yang benar-benar mencakup
populasi sesungguhnya.

latihan
• Sebuah bagian dari
depnaker bermaksud
memperkirakan besarnya
penghasilan penduduk di
suatu daerah. Lima belas
orang yang telah bekerja
Data Mining-2012-a@b 26
orang yang telah bekerja
diambil secara acak dan
ditanya penghasilan
perbulan. Hasil yang
diperoleh adalah

latihan
1. Perkirakan rata-rata dan varians
penghasilan penduduk daerah tersebut
2. Buatlah selang keyakinan 99%, dan 95%
untuk rata-rata penghasilan. Bandingkan
dari segi intervalnya
Data Mining-2012-a@b 27
dari segi intervalnya




















