
Cara pengujian cepat test formalin pada makanan dengan Test Kit Formalin Easy Test
Upload
virginia-majestica-septrianneCategory
view
57download
1
BAB I
PENDAHULUAN
Latar belakang masalah
Disadari atau tidak, statistika telah banyak digunakan dalam
kehidupan sehari-hari. Terutama dalam dunia penelitian atau riset, di mana
pun dilakukan, bukan saja telah mendapat manfaat yang baik dari statistika
tetapi sering harus menggunakannya. Guna mengetahui apakah cara yang
baru ditemukan lebih baik daripada cara lama, melalui riset yang dilakukan di
laboratorium atau penelitian yang dilakukan di lapangan, perlu diadakan
penilaian dengan statistika. Statistika mampu untuk menentukan apakah
faktor yang satu dipengaruhi atau mempengaruhi faktor lainnya.
Apakah yang dimaksudkan dengan statistika? Penggunaan istilah
statistika berakar dari istilah dalam bahasa Latin modern “statisticum
collegium” (dewan negara) dan bahasa Italia “statista” (negarawan atau
politikus). Gottfried Achenwall (1749) menggunakan Statistik dalam bahasa
Jerman untuk pertama kalinya sebagai nama bagi kegiatan analisis data
kenegaraan, dengan mengartikannya sebagai "ilmu tentang negara” (state).
Pada awal abad ke-19 telah terjadi pergeseran arti menjadi "ilmu mengenai
pengumpulan dan klasifikasi data". Sir John Sinclair memperkenalkan nama
Statistics dan pengertian ini ke dalam bahasa Inggris. Jadi, statistika secara
8

prinsip mula-mula hanya mengurus data yang dipakai lembaga-lembaga
administratif dan pemerintahan. Pengumpulan data terus berlanjut,
khususnya melalui sensus yang dilakukan secara teratur untuk memberi
informasi kependudukan yang berubah setiap saat.
Statistika menurut Yule dan Kendall dalam bukunya “An Introduction
to The Theory of Statistics” adalah....”statistics as a quantitative data affected
to a marked extent by a multiplicity of causes, and statistical method as
methods specially adapted to the elucidation of quantitative data affected by a
multiplicity of causes’. Sedangkan menurut P. Armitage dalam bukunya yang
berjudul “Statistical Methods in Medical Research”.... statistics as the
discipline concerned with the treatment of numerical data derived from groups
of individuals”. Saat ini pengertian statistika secara sederhana yang cukup
sering digunakan adalah pengetahuan yang berhubungan dengan cara-cara
pengumpulan data, pengolahan atau penganalisisannya dan penarikan
kesimpulan berdasarkan kumpulan data dan penganalisisan yang dilakukan.
Singkatnya, statistika adalah ilmu yang berkenaan dengan data.
Istilah 'statistika' (bahasa Inggris: statistics) berbeda dengan 'statistik'
(statistic). Statistika merupakan ilmu yang berkenaan dengan data, sedang
statistik adalah data, informasi, atau hasil penerapan algoritma statistika pada
suatu data. Statistika pada prinsipnya terbagi menjadi dua yaitu statistika
deskriptif yang terdiri dari:
9

a. pengumpulan data
b. pengolahan data
c. penyajian data menggunakan tabel-tabel atau grafik
d. analisis data, perhitungan nilai tengah, variasi, rata-rata dan rasio;
sehingga data mentah lebih mudah “dibaca” dan lebih bermakna dan
statistika inferensial atau statistika induktif yaitu berupa penarikan kesimpulan
ciri-ciri populasi berdasarkan teori estimasi dan uji hipotesis, melakukan
prediksi observasi masa depan, atau membuat permodelan hubungan
(korelasi, regresi, ANOVA, deret waktu). Antara keduanya memiliki
perbedaan yang jelas dimana statistika deskriptif dibuat berdasarkan hasil
observasi yang nyata, sedangkan statistika inferensial berdasarkan suatu
perkiraan untuk menggambarkan ciri-ciri populasi yang seringkali tidak
diketahui.
Selain itu juga dikenal adanya statistika kesehatan dan statistika
kedokteran. Statistika kesehatan merupakan kumpulan keterangan berbentuk
angka yang berhubungan dengan masalah kesehatan masyarakat. Manfaat
dengan adanya statistika kesehatan antara lain:
menentukan ada dan besarnya masalah kesehatan masyarakat
menentukan prioritas masalah dan memilih alternatif pemecahan
masalah kesehatan secara efisien
membuat perencanaan program kesehatan
10

mengadakan evaluasi pelaksanaan program kesehatan
dokumentasi untuk mengadakan perbandingan di masa yang akan
datang
mengadakan penelitian masalah kesehatan yang belum diketahui
atau menguji kebenaran suatu masalah kesehatan
memberi penerangan tentang kesehatan pada masyarakat.
Statistika kedokteran adalah penerapan teori statistik yang dinyatakan dalam
bentuk angka yang berhubungan dengan masalah kedokteran. Dengan
adanya statistika kedokteran, kita dapat memperoleh informasi yang
berhubungan dengan masalah kedokteran seperti angka kematian akibat
penyakit tertentu, juga dapat membantu guna mengadakan penelitian tentang
efektifitas, efisiensi dan keamanan suatu obat baru atau suatu prosedur
pengobatan.
Bila kita berbicara mengenai statistika selalu ada kaitannya dengan
data. Data sendiri adalah sekumpulan keterangan hasil pengukuran atau
penghitungan yang dinyatakan dalam bentuk angka, baik yang belum
disusun atau telah disusun dalam bentuk tabel. Ada macam-macam data
yang dikenal yakni:
1. data kuantitatif dan data kualitatif
Data kuantitatif adalah data yang dinyatakan dalam bentuk angka
yang dihasilkan dari suatu pengukuran misalnya kadar Hb. Angka
11

yang dihasilkan dapat berupa bilangan pecahan/desimal, atau berupa
bilangan bulat. Hal yang paling ditonjolkan adalah jumlahnya. Data
kuantitatif dibedakan menjadi dua yaitu skala interval dan skala rasio.
Ciri khas dari tipe data dengan skala interval adalah memiliki
kemampuan mengklasifikasikan dan membentuk tingkatan dan tidak
adanya nilai nol mutlak. Artinya, angka nol yang digunakan bukan
berarti tidak ada. Contoh: Derajat suhu. Di dalam skala Celcius
misalnya, Nol derajat Celcius bukan berarti tidak ada suhu. Nol derajat
itu memiliki suhu, hanya saja dilambangkan dengan nol. Selain itu,
jarak antar setiap angka yang digunakan adalah sama. Pada data
dengan skala rasio angka nol dianggap mutlak. Contoh: data berat
badan (kg). Angka Nol kg berarti memang tidak ada berat.
Data kualitatif adalah data yang menjelaskan tentang sifat,
misalnya baik-buruk, jenis kelamin, agama. Data inipun terbagi
menjadi dua yaitu data nominal atau disebut juga data kategori dan
data ordinal. Data nominal digunakan untuk mengklasifikasikan
informasi/data. Contoh:Data jenis kelamin = Laki-laki dan Perempuan.
Sedangkan data ordinal digunakan untuk mengklasifikasikan serta
memiliki tingkatan. Tipe data ordinal lebih tinggi dari Nominal karena
kemampuannya untuk membentuk tingkatan. Contoh:Jabatan di dalam
perusahaan = karyawan, manager, direktur utama.
12

2. data primer dan data sekunder
Data primer ialah data yang diperoleh dari hasil pengumpulan
sendiri, diolah, dianalisis serta dipublikasikan sendiri. Sedangkan data
sekunder adalah data yang diperoleh dari hasil penelitian orang lain.
3. data diskrit dan data kontinyu
Data diskrit adalah data yang dihasilkan dari perhitungan, dapat
berupa data frekuensi atau data kategori. Data kontinyu ialah data
yang dihasilkan dari pengukuran dan dapat berupa bilangan bulat atau
desimal tergantung alat ukur yang digunakan, misalnya tinggi badan.
Data diskrit lebih mudah untuk dianalisis tetapi informasi yang
dihasilkan menjadi kurang teliti bila dibandingkan dengan data
kontinyu.
Guna memperoleh informasi yang lebih mendalam, maka data yang
telah diolah haruslah dianalisis lebih lanjut. Beberapa cara analisis data yang
cukup sering digunakan dalam statistika antara lain teori estimasi dan uji
hipotesis. Teori estimasi digunakan untuk menaksir ciri-ciri tertentu suatu
populasi, melalui parameternya, seperti rata-rata, proporsi dan jumlah ciri
tertentu. Data yang digunakan biasanya data kuantitatif. Dalam bidang
kedokteran, teori estimasi digunakan untuk menaksir banyaknya suatu
penyakit atau menaksir prognosis penyakit tertentu. Dalam bidang kesehatan
masyarakat, teori estimasi digunakan untuk menaksir keadaan kesehatan
13

penduduk suatu wilayah atau jumlah kunjungan puskesmas dan lain-lain. Uji
hipotesis membandingkan nilai statistik sampel dengan nilai hipotesis. Data
kuantitatif maupun kualitatif dapat diuji dengan cara ini disesuaikan dengan
keinginan peneliti.
Rumusan masalah
Setelah kita mengenal apa itu statistika beserta cakupannya di atas,
timbul pertanyaan bagaimana aplikasinya dalam penelitian kesehatan
masyarakat mengingat cukup banyaknya permasalahan kesehatan
masyarakat yang dijumpai dan harus segera ditangani. Tulisan berikut akan
membahas bagaimana strategi analisis data kategori dalam penelitian
kesehatan masyarakat. Kita akan membahas mengenai analisis chi square
sebagai strategi tepat guna menganalisis data kategori dalam penelitian
masyarakat. Penelitian dalam bidang kesehatan masyarakat maupun dalam
bidang kedokteran sering menghasilkan dua variabel di mana masing-masing
variabel terdiri dari berbagai golongan atau kategori, misalnya; tingkat
beratnya penyakit, tingkat pendidikan, dan lain-lain. Dari hasil penelitian di
atas, kita ingin mengetahui apakah terdapat hubungan antara dua variabel
atau apakah dua variabel tersebut bersifat independen atau bersifat
dependen. Guna menjawab pertanyaan di atas kita menggunakan analisis chi
square.
14

BAB II
PEMBAHASAN
Data kategori
Data kategori atau disebut juga data nominal merupakan data yang
bersifat kualitatif. Data kategori merupakan data yang paling sederhana yang
terdiri dari jenis-jenis pengamatan yang tidak berurutan, terbagi dua ini atau
itu. Para ahli matematika menyebutnya sebagai pembagian dengan skala 0-
1, seperti golongan darah, jenis kelamin atau jenis pekerjaan.
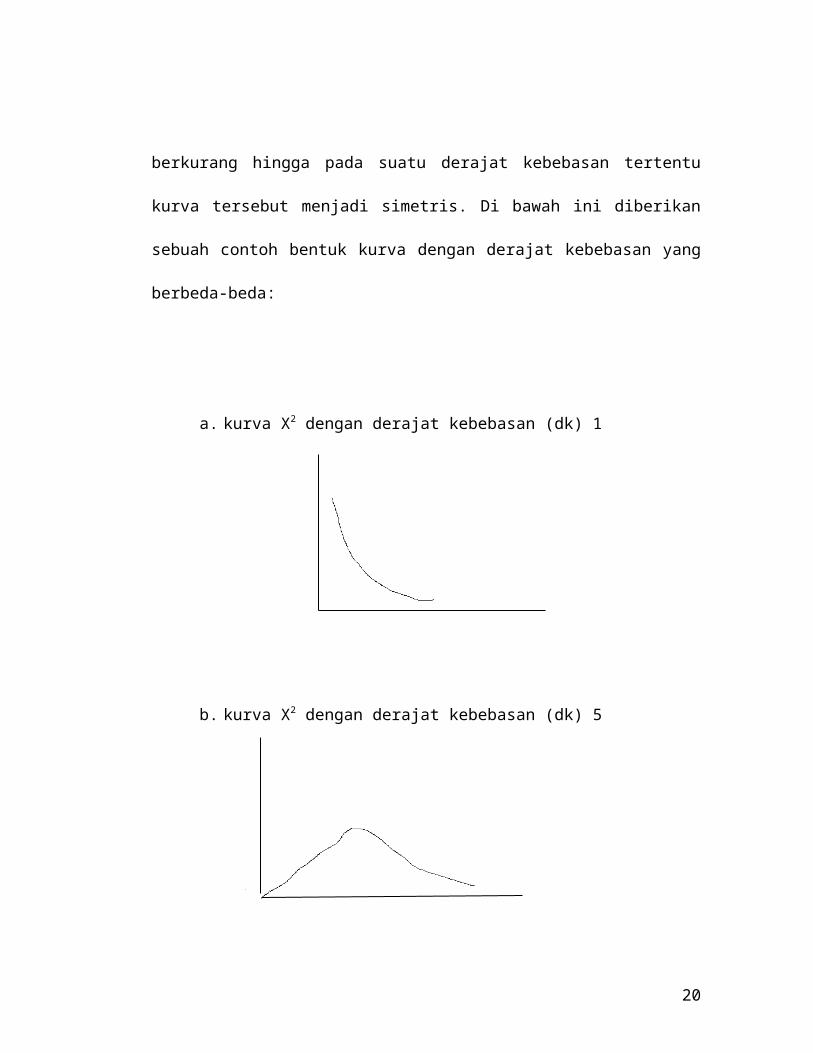
Analisis Chi Square
Distribusi chi square merupakan distribusi sampling dengan variabel
random yang mendekati kontinyu dengan kurva miring ke kanan. Pendekatan
ini makin baik pada sampel yang cukup besar, dan kemiringan kurva
distribusi chi square dipengaruhi oleh besarnya derajat kebebasan yaitu
makin besar derajat kebebasan, kemiringan akan berkurang hingga pada
suatu derajat kebebasan tertentu kurva tersebut menjadi simetris. Di bawah
ini diberikan sebuah contoh bentuk kurva dengan derajat kebebasan yang
berbeda-beda:
15

a. kurva X2 dengan derajat kebebasan (dk) 1
b. kurva X2 dengan derajat kebebasan (dk) 5
c. kurva X2 dengan derajat kebebasan (dk) 10
16

Uji chi square digunakan untuk mengetahui apakah ada perbedaan
atau tidak di antara lebih dari 2 proporsi sampel. Perhitungan didasarkan atas
frekuensi observasi (fo) dan frekuensi yang diharapkan (fe).
Dalam menggunakan chi square untuk keperluan pengujian hipotesis
diperlukan beberapa ketentuan, antara lain:
a. pengamatan harus bersifat independen.
Ini berarti bahwa jawaban sebuah subyek tidak mempunyai pengaruh
terhadap jawaban subyek lain atau sebuah subyek hanya boleh sekali
digunakan dalam analisa.
b. chi square hanya dapat digunakan pada data
frekuensi/kategori/nominal (data kualitatif).
c. jumlah frekuensi yang diharapakan harus sama dengan jumlah
frekuensi pengamatan yang sebenarnya.
d. pada derajat kebebasan 1, tidak boleh terdapat nilai ekspektasi
kurang dari 5, kecuali dengan koreksi Yates.
Bila derajat kebebasan cukup besar, adanya satu angka 5 pada nilai
ekspekatsi tidak akan banyak mempengaruhi hasil yang diinginkan atau
bila terdapat nilai 5 pada ekspektasi dapat digabungkan pada nilai
ekspektasi yang lain, tetapi bila hal ini dilakukan akan mempengaruhi
hasil penelitian atau informasi yang diperoleh akan berkurang.
17

e. bila pada tabel 2×2 dijumpai nilai kurang dari 5, gunakan nilai Fisher
Exact.
f. bila pada tabel 2×2 tidak ada nilai <5, sebaiknya digunakan uji
continuity correction (koreksi Yates).
g. untuk tabelnya yang lebih dari 2×2 misalnya 3×2 atau 3×3 digunakan
uji Pearson Chi-square.
h. sampel sebaiknya cukup besar.
Dalam statistik inferensial kegunaan chi square cukup banyak antara
lain pengujian hipotesis untuk kesamaan beberapa proporsi, estimasi deviasi,
dan pengujian independensi. Selain digunakan untuk tes data kualitatif atau
binomial, juga dapat dipakai untuk tes terhadap data multinominal serta dapat
menjawab pertanyaan “apakah ada atau tidak ada asosiasi antara suatu
variabel dengan outcomes?”.
Pengujian hipotesis untuk kesamaan beberapa proporsi dengan Chi
square
Bila kita memperoleh beberapa proporsi, misalnya: P1, P2, P3, P4,
P5,....Pk dengan event-event atau kategori-kategori X1, X2, X3, X4, X5,....Xk
yang bersifat independen. Kita ingin mengetahui apakah perbedaan proporsi
hasil pengamatan memang berbeda atau disebabkan karena faktor kebetulan
18

saja. Guna mengetahui hal ini, kita membandingkan hasil pengamatan
terhadap hasil yang diharapkan dengan rumus:
X2 =
Nilai ekspektasi (E) dapat dihitung dengan mengalikan besarnya
sampel dengan proporsi hasil pengamatan masing-masing. (O = observasi, E
= ekspektasi)
E1 = nP1, E2 = nP2 ..... Ek = nPk
Hipotesis yang akan diuji:
H0 : P = P1 = P2 = P3 = ......Pk
Ha : P ≠ P1 = P2 = P3 = .......Pk atau P1, P2, P3 ......Pk tidak semuanya sama.
Derajat kebebasan adalah banyaknya kategori dikurangi 1 (dk = k – 1).
Kriteria penerimaan hipotesis ialah bila X2 hasil perhitungan lebih kecil
dari X2 yang terdapat dalam tabel dengan dk = k – 1 dan derajat kemaknaan
α.
19
Contoh 1 :
Dinyatakan status gizi anak balita di daerah X mempunyai
perbandingan yang sama yaitu gizi baik = gizi sedang = gizi kurang = gizi
buruk. Untuk mengetahui apakah pernyataan tersebut dapat dipercaya,
dilakukan penelitian dengan mengambil sampel random sebanyak 100 anak
balita di daerah tersebut dan diperoleh hasil sebagai berikut : 30 anak
dengan gizi baik, 35 anak dengan gizi sedang, 20 anak dengan gizi kurang,
dan 15 anak dengan gizi buruk. Pengujian dilakukan dengan derajat
kemaknaan 5%.
Jawab :
H0 : p = p1 = p2 = p3 = p4
Ha : p ≠ p1 = p2 = p3 = p4 atau antara p1, p2, p3, p4 tidak semuanya
sama.
Diketahui : n = 100 (besarnya sampel)
α = 0,05
Observasi : 30 35 20 15
Ekspektasi : (n x p) → p = 0,25
E1 = 100 x 0,25 = 25
E2 = 100 x 0,25 = 25
E3 = 100 x 0,25 = 25
E4 = 100 x 0,25 = 25
20

Dapat dibuat tabel sebagai berikut:
Gizi baik Gizi sedang Gizi kurang Gizi buruk
Observasi 30 35 20 15
Ekspektasi 25 25 25 25
X2 =
X2 = + + +
X2 = 1 + 4 + 1 + 4
X2 = 10
X2 pada α 0,05 dan dk3 = 7,815 (dk = 4-1)
Kriteria penerimaan bila chi square hasil perhitungan lebih kecil dari
chi square yang terdapat dalam tabel pada α 0,05 dan dk3. Hasil perhitungan
di atas menunjukkan lebih besar. Hal ini berarti bahwa hipotesis ditolak atau
terdapat perbedaan yang bermakna antara perbandingan status gizi anak
balita di daerah tersebut. Kesimpulan: perbandingan status gizi anak balita
daerah X tidak sama.
Contoh 2 :
Dari hasil penelitian tentang status gizi balita sebelumnya di suatu
daerah secara antropometris dibagi dalam kategori baik, sedang, kurang, dan
buruk dengan perbandingan 5 : 4 : 2 : 1. Kini dilakukan penelitian dengan
21

mengambil sampel sebanyak 90 balita dan diperoleh 30 anak dengan gizi
baik, 40 anak dengan gizi sedang, 10 anak dengan gizi kurang dan 5 anak
dengan gizi buruk. Permasalahannya apakah perbandingan status gizi hasil
penelitian sebelumnya dapat dipercaya. Pengujian dilakukan pada derajat
kemaknaan 5%.
Jawab :
H0 : p = 5 : 4 : 2 : 1
Ha : p ≠ 5 : 4 : 2 : 1
α = 0,05
Berdasarkan perbandingan di atas hasil penelitian ini mempunyai
ekspektasi sebagai berikut:
p1 (gizi baik) = 5/12 x 90 = 37
p2 (gizi sedang) = 4/12 x 90 = 30
p3 (gizi kurang) = 2/12 x 90 = 15
p4 (gizi buruk) = 1/12 x 90 = 8
Dapat dibuat tabel sebagai berikut:
Gizi baik Gizi sedang Gizi kurang Gizi buruk
Observasi 30 40 10 5
Ekspektasi 37 30 15 8
X2 =
22

X2 = + + +
X2 = 1,32 + 3,33 + 1,67 + 1,13
X2 = 7,45
dk = 4 – 1
= 3
α = 0,05
X2 = 7,815
Dari hasil perhitungan X2 di atas diperoleh nilai X2 lebih kecil daripada
nilai X2 tabel. Berarti hipotesis nol diterima pada α 0,05 atau tidak terdapat
perbedaan yang bermakna antara proporsi status gizi yang lalu dengan hasil
penelitian yang kini dilakukan. Kesimpulan: proporsi status gizi balita daerah
tersebut dapat dipercaya.
Pengujian chi square pada data binominal
Apabila k = 2 yaitu bila data yang akan diuji merupakan data binominal
di mana probabilitas terjadinya sesuatu adalah p dan proporsi lain adalah q.
Pengujian dilakukan dengan mengambil sampel sebesar n, maka dalam
sampel n tersebut akan terdapat x event yang dikehendaki dan n-x event
yang tidak dikehendaki sedangkan frekuensi yang diharapkan untuk event
yang diinginkan adalah np dan frekuensi yang tidak diinginkan adalah nq.
Maka rumusnya adalah:
23

X2 =
Namun rumus tersebut tidak dapat digunakan karena distribusi
binominal merupakan distribusi diskrit. Untuk menggunakan tabel distribusi X2
pada rumus di atas harus dilakukan koreksi agar distribusi menjadi kontinyu
yang disebut koreksi kontinyuitas (Yates’ correction) dan rumusnya menjadi:
X2 =
Dalam hal ini selisih x dan np digunakan nilai absolut agar tidak
mendapatkan nilai yang negatif. Hipotesis yang digunakan ialah:
H0 : p = p yang diketahui nilainya.
Ha : p ≠ p yang tidak diketahui nilainya.
Kriteria penerimaan hipotesis nol : bila chi square hasil perhitungan
lebih kecil dari chi square yang terdapat dalam tabel dengan dk = 1 dan
derajat kemaknaan α.
Contoh 1:
24

Dinyatakan bahwa penderita yang dirawat di bagian Anak 40% adalah
wanita dan 60% adalah laki-laki. Ingin diuji apakah pernyataan tersebut dapat
dipercaya pada derajat kemaknaan 5%. Untuk keperluan ini diambil sampel
random sebanyak 50 anak yang dirawat di bagian Anak dan diperoleh hasil
27 anak wanita dan 23 anak laki-laki.
Jawab :
H0 : p = 0,4
Ha : p ≠ 0,4
α = 0,05
Hasil Observasi (x) : wanita = 27; laki-laki = 23.
Nilai Ekspektasi (np) dapat dihitung sebagai berikut:
Wanita : 0,4 x 50 = 20
Laki-laki : 0,6 x 50 = 30
X2 =
X2 =
X2 =
X2 = 3,52
X2 α 0,05; dk = 1 = 6,63
25

Hasil perhitungan menunjukkan lebih kecil dari nilai tabel. Jadi,
hipotesis diterima pada α 0,05.
Kesimpulan: proporsi penderita wanita yang dirawat di bagian Anak
adalah 0,4 atau pernyataan bahwa penderita yang dirawat di bagian Anak
40% adalah wanita dapat dipercaya.
Yates’ correction berlaku untuk:
- tabel 2 x 2
- nilai ekspektasi lebih kecil dari 5
- derajat kebebasan = 1
- sampel kecil
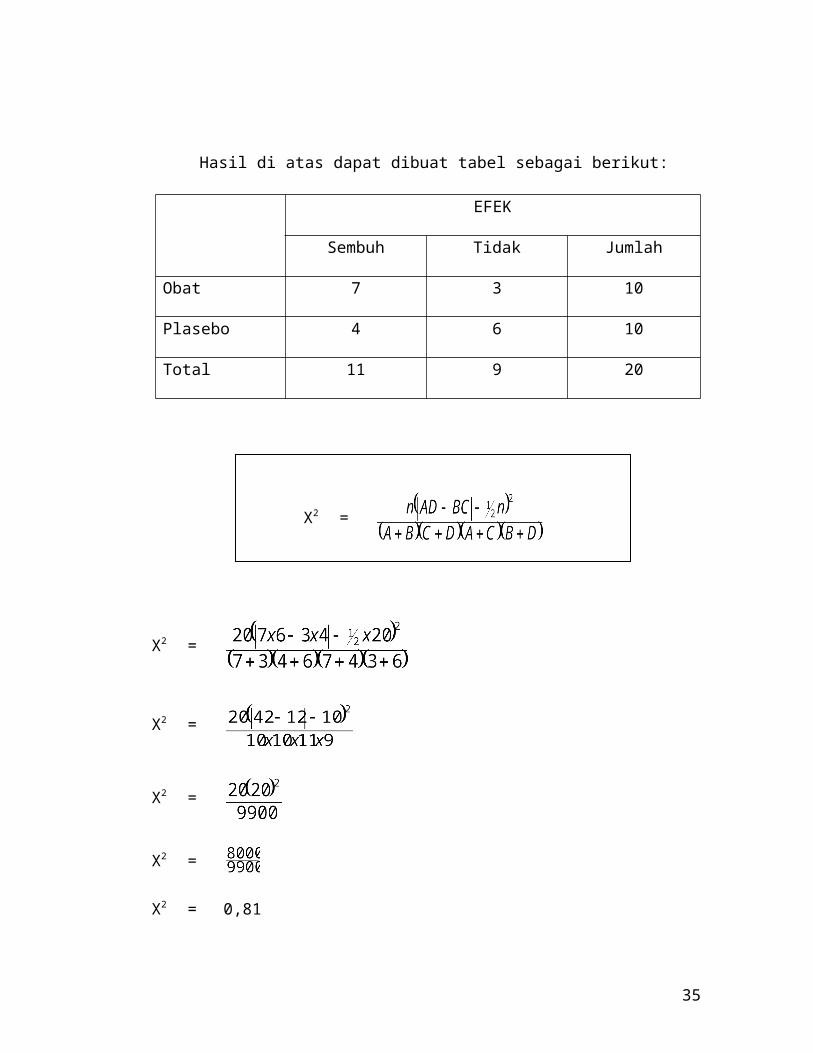
Contoh 2:
Seseorang ingin meneliti efek semacam obat untuk influenza. Pada
penelitian ini diambil 2 kelompok penderita influenza masing-masing terdiri
dari 10 orang. Kelompok pertama diberi obat sedangkan kelompok kedua
diberikan plasebo. Setelah tiga hari ternyata dari kelompok I, 7 orang sembuh
dan 3 orang tidak sembuh, sedangkan dari kelompok II terdapat 4 orang
sembuh dan 6 orang tidak sembuh. Penelitian ini dilakukan pada derajat
kemaknaan 0,05.
Jawab :
H0 : obat = plasebo
26

Ha : obat ≠ plasebo
α = 0,05
Hasil di atas dapat dibuat tabel sebagai berikut:
EFEK
Sembuh Tidak Jumlah
Obat 7 3 10
Plasebo 4 6 10
Total 11 9 20
X2 =
X2 =
X2 =
X2 =
X2 =
X2 = 0,81
27

X2 α 0,05; dk = 1 = 3,84.
Dari hasil di atas ternyata nilai X2 perhitungan lebih kecil daripada nilai
tabel atau hipotesis diterima. Kesimpulan: obat tersebut tidak mempunyai
efek terhadap influenza.
Menguji kesamaan rata-rata Poisson
Misalkan ada k (k ≥ 2) buah distribusi Poisson dengan parameter λ1,
λ2, λ3,..... λk. Akan diuji pasangan hipotesis:
H0 : λ1 = λ2 = λ3 = ...... = λk
Ha : λ1 ≠ λ2 ≠ λ3 ≠ ...... ≠ λk
Dari setiap populasi diambil sebuah sampel acak, berukuran n1 dari
populasi kesatu, n2 dari populasi kedua dan seterusnya berukuran nk dari
populasi ke-k. Untuk tiap sampel dihitung banyak peristiwa yang mengikuti
distribusi Poisson. Jika banyak peristiwa ini dinyatakan dengan x1, x2,....., xk,
maka rata-ratanya:
x =
28

Statistik yang digunakan untuk menguji hipotesis H0 adalah:
X2 =
Derajat kebebasan (dk) = n – 1.
Contoh 1 :
Lima orang sekretaris bertugas untuk menyalin data ke dalam sebuah
daftar yang telah disediakan. Misalkan bahwa banyaknya salah menyalin
untuk setiap daftar berdistribusi Poisson masing-masing dengan rata-rata λ1,
λ2, λ3, λ4, λ5. Dari hasil salinan tiap sekretaris diambil sampel acak berukuran
empat dan dicatat banyaknya kesalahan dalam tiap daftar. Data ini akan
digunakan untuk menguji hipotesis :
H0 : λ1 = λ2 = λ3= λ4 = λ5
Ha : λ1 ≠ λ2 ≠ λ3 ≠ λ4 ≠ λ5
α = 0,05
Tabelnya sebagai berikut:
Sekretaris Kesalahan tiap daftarBanyaknya kesalahan
(xi)
I 2, 0, 3, 3, 2 10
II 0, 0, 2, 1, 2 5
29

III 1, 1, 2, 3, 2 9
IV 2, 1, 1, 1, 4 9
V 2, 3, 0, 3, 3 11
Jumlah 44
Dari kolom ketiga didapat rata-rata x = 44/5 = 8,8 dan dengan rumus
X2 = diperoleh
X2 = + + + +
X2 = + + + +
X2 =
X2 = 2,36
X2 α 0,05; dk = 4 = 9,49
Ternyata nilai X2 perhitungan lebih kecil daripada nilai X2 tabel. Hal ini
berarti hipotesis nul tidak dapat ditolak, di mana tidak ada perbedaan
banyaknya kesalahan yang dilakukan oleh kelima sekretaris tersebut.
Contoh 2 :
Barang rusak setiap hari yang dihasilkan oleh 3 buah mesin ternyata
berdistribusi Poisson. Pengamatan telah dilakukan selama 6 hari dan terdapat barang
rusak setiap hari dari ketiga mesin tersebut, seperti pada tabel di bawah ini:
30

Mesin Banyak barang rusak tiap hari Jumlah
I 4, 3, 4, 6, 3, 5 25
II 3, 2, 3, 6, 5, 2 21
III 5, 5, 3, 4, 4, 6 27
Total 73
Dapatkah disimpulkan bahwa rata-rata dihasilkannya barang rusak
setiap hari oleh ketiga mesin itu sama besar?
Jawab :
H0 : p1 = p2 = p3
Ha : p1 ≠ p2 ≠ p3
α = 0,05
Rata-rata barang yang rusak ( x ) = 73/3 = 24,3
X2 =
X2 = + +
X2 = + +
X2 =
X2 = 0,768
X2 α 0,05; dk = 2 = 5,991
31

Hasil perhitungan X2 lebih kecil dari nilai tabel. Kesimpulannya
hipotesis nul tidak dapat ditolak yang berarti rata-rata dihasilkannya barang
rusak setiap hari oleh ketiga mesin itu sama besar.
Contoh penerapan strategi analisis data kategori dengan
menggunakan metode Chi Square:
Sebuah penelitian tentang cara kontrasepsi yang ditawarkan pada
calon akseptor terdiri dari IUD, pil dan kondom. Penelitian dilakukan pada 3
desa di suatu daerah yaitu desa X, Y dan Z. Dari penelitian tersebut diperoleh
hasil sebagai berikut:
a. dari 40 orang calon akseptor di desa X ternyata 15 orang memilih
IUD, 15 orang memilih pil dan 10 orang memilih kondom
32

b. dari 30 orang calon akseptor di desa Y ternyata 15 orang memilih
IUD, 9 orang memilih pil dan 6 orag memilih kondom
c. dari 30 orang calon akseptor di desa Z ternyata 12 orang memilih
IUD, 8 orang memilih pil dan 10 orang memilih kondom.
Apakah terdapat hubungan antara pemilihan cara kontrasepsi dengan
lokasi desa. Untuk itu dilakukan pengujian dengan derajat kemaknaan 5%.
Jawab :
H0 : ada hubungan antara pemilihan cara kontrasepsi dengan lokasi
desa
Ha : tidak ada hubungan antara pemilihan cara kontrasepsi dengan
lokasi desa
α = 0,05
X2 =
Desa X : 15 orang memilih IUD
15 orang memilih pil
10 orang memilih kondom
Desa Y : 15 orang memilih IUD
9 orang memilih pil
6 orang memilih kondom
Desa Z : 12 orang memilih IUD
33

8 orang memilih pil
10 orang memilih kondom
Tabel:
DesaJenis kontrasepsi
JumlahIUD Pil Kondom
X 15 15 10 40
Y 15 9 6 30
Z 12 8 10 30
Jumlah 42 32 26 100
Derajat kebebasan = (kolom - 1) (baris - 1)
= (3 – 1) (3 – 1)
= 4
E (expected) masing-masing:
E1 = = 16,8
E2 = = 12,6
E3 = = 12,6
E4 = = 12,8
E5 = = 9,6
E6 = = 9,6
E7 = = 10,4
E8 = = 7,8
E9 = = 7,8
34
O E (O – E) (O – E)2 (O – E)2/E
15 16,8 - 1,8 3,24 0,19
15 12,6 2,4 5,76 0,45
12 12,6 - 0,6 0,36 0,02
15 12,8 2,2 4,84 0,37
9 9,6 - 0,6 0,36 0,0375
8 9,6 - 1,6 2,56 0,26
10 10,4 - 0,4 0,16 0,015
6 7,8 - 1,8 3,24 0,41
10 7,8 2,2 4,84 0,62
Jumlah (X2) 2,3725
Nilai X2 dari tabel chi square dengan derajat kebebasan (dk) 4 adalah
9,488. Hasil perhitungan yang didapat adalah 2,3725 (hasil perhitungan lebih
kecil daripada nilai tabel). Hipotesis nul diterima.
Kesimpulan : dari penelitian tersebut menunjukkan adanya hubungan
antara pemilihan cara kontrasepsi dengan lokasi desa.
35

BAB III
KESIMPULAN
Dari pembahasan di atas, dapat disimpulkan sebagai berikut:
a) Chi square adalah strategi yang tepat guna menganalisis data kategori
dalam penelitian masyarakat, karena penelitian dalam masyarakat
sering menghasilkan dua variabel di mana masing-masing variabel
terdiri dari berbagai golongan atau kategori, misalnya; tingkat beratnya
penyakit, tingkat pendidikan, dan lain-lain. Dan untuk mengetahui
apakah ada hubungan antara dua variabel tersebut hanya dapat
dibuktikan dengan analisis chi square.
b) Distribusi chi square merupakan distribusi sampling dengan variabel
random yang mendekati kontinyu dengan kurva miring ke kanan.
Pendekatan ini makin baik pada sampel yang cukup besar, dan
kemiringan kurva distribusi chi square dipengaruhi oleh besarnya
derajat kebebasan yaitu makin besar derajat kebebasan, kemiringan
akan berkurang hingga pada suatu derajat kebebasan tertentu kurva
tersebut menjadi simetris.
c) Uji chi square digunakan untuk mengetahui apakah ada perbedaan
atau tidak di antara lebih dari 2 proporsi sampel. Perhitungan
36

didasarkan atas frekuensi observasi (fo) dan frekuensi yang
diharapkan (fe) dengan rumus:
X2 =
d) Kriteria penerimaan hipotesis ialah bila X2 hasil perhitungan lebih kecil
dari X2 yang terdapat dalam tabel dengan dk = k – 1 dan derajat
kemaknaan α.
37
Copyright © 2022 FDOKUMEN




















