
BAB 2 LANDASAN TEORI - BINA NUSANTARA | Library &...
52
10 BAB 2 LANDASAN TEORI 2.1 Database Database adalah sekumpulan data yang terhubung secara logikal, dan deskripsi dari data tersebut, yang dapat digunakan oleh banyak user dan dibentuk untuk dapat menghasilkan informasi yang dibutuhkan oleh organisasi (Connolly, 2005, p15). Database adalah sekumpulan data yang tetap (persistent data) yang digunakan oleh sistem aplikasi dari perusahaan (Date, 2000, p10). Database merupakan tempat penyimpanan data yang dapat berukuran besar dan dapat digunakan secara bersama-sama oleh banyak departemen dan user. Sebagai pengganti file-file yang tidak terhubung dan memiliki banyak duplikasi, data-data pada database dibuat terintegrasi dengan jumlah duplikasi yang lebih minimum. Database tidak hanya berisi data operasional organisasi, namun juga berisi deskripsi dari data yang disebut sebagai system catalog atau data dictionary atau meta data (data tentang data) (Connolly, 2005, p15). 2.2 Database Management System (DBMS) DBMS adalah sebuah sistem perangkat lunak yang memungkinkan user untuk mengidentifikasikan, membuat, memelihara dan mengontrol akses ke database (Connolly, 2005, p16). DBMS merupakan perangkat lunak yang berinteraksi dengan program aplikasi yang digunakan user dan database. DBMS menyediakan beberapa fasilitas, yaitu:
Transcript of BAB 2 LANDASAN TEORI - BINA NUSANTARA | Library &...

10
BAB 2 LANDASAN TEORI
2.1 Database
Database adalah sekumpulan data yang terhubung secara logikal, dan
deskripsi dari data tersebut, yang dapat digunakan oleh banyak user dan dibentuk
untuk dapat menghasilkan informasi yang dibutuhkan oleh organisasi (Connolly,
2005, p15). Database adalah sekumpulan data yang tetap (persistent data) yang
digunakan oleh sistem aplikasi dari perusahaan (Date, 2000, p10).
Database merupakan tempat penyimpanan data yang dapat berukuran besar
dan dapat digunakan secara bersama-sama oleh banyak departemen dan user.
Sebagai pengganti file-file yang tidak terhubung dan memiliki banyak duplikasi,
data-data pada database dibuat terintegrasi dengan jumlah duplikasi yang lebih
minimum. Database tidak hanya berisi data operasional organisasi, namun juga
berisi deskripsi dari data yang disebut sebagai system catalog atau data dictionary
atau meta data (data tentang data) (Connolly, 2005, p15).
2.2 Database Management System (DBMS)
DBMS adalah sebuah sistem perangkat lunak yang memungkinkan user
untuk mengidentifikasikan, membuat, memelihara dan mengontrol akses ke
database (Connolly, 2005, p16).
DBMS merupakan perangkat lunak yang berinteraksi dengan program
aplikasi yang digunakan user dan database. DBMS menyediakan beberapa fasilitas,
yaitu:

11
• DBMS mengijinkan user untuk mendefinisikan database melalui Data
Definition Language (DDL).
• DBMS mengijinkan user untuk melakukan insert, update, delete, dan retrieve
terhadap data dari database melalui Data Manipulation Language (DML).
• DBMS menyediakan pengaksesan terkendali terhadap database, yaitu:
Security system yang berfungsi untuk mencegah user yang tidak berhak
mengakses database.
Integrity system yang berfungsi untuk memelihara sifat konsistensi
terhadap data yang disimpan.
Concurrency control system yang berfungsi untuk mengatur akses secara
bersamaan pada database.
Recovery control system yang berfungsi untuk melakukan restoring data ke
kondisi konsisten sebelumnya jika terjadi kegagalan pada perangkat keras
atau perangkat lunak.
User accessible catalog yang berisi deskripsi-deskripsi dari data yang
terdapat pada database (Connolly, 2005, p16).
2.2.1 Komponen DBMS
DBMS memiliki lima komponen utama (Connolly, 2005, p18), yaitu :
• Perangkat keras (Hardware)
DBMS dan aplikasi membutuhkan perangkat keras untuk melakukan
proses running. Perangkat keras yang digunakan dapat bervariasi mulai

12
dari personal computer (PC), mainframe tunggal, sampai komputer-
komputer yang menggunakan jaringan.
• Perangkat lunak (Software)
Komponen perangkat lunak terdiri dari perangkat lunak DBMS itu
sendiri dan program aplikasi , bersama-sama dengan sistem operasi,
termasuk perangkat lunak jaringan jika DBMS digunakan melalui
jaringan. Biasanya program aplikasi ditulis dengan bahasa
pemrograman generasi ketiga (3GL) seperti C, C++, Java, VB, COBOL,
Fortran, Ada, atau Pascal, atau menggunakan bahasa pemrograman
generasi keempat (4GL) seperti SQL digabungkan dengan bahasa
pemrograman generasi ketiga.
• Data
Komponen terpenting dalam lingkungan DBMS adalah data. Data
berperan sebagai jembatan antara komponen mesin dan manusia.
Database terdiri dari data operasional dan meta-data (data tentang data
itu sendiri).
• Prosedur
Prosedur mengacu pada bentuk instruksi dan aturan – aturan yang
menentukan desain dan kegunaan database. Para user sistem dan staff
yang mengatur database membutuhkan prosedur terdokumentasi yang
berisi aturan bagaimana menjalankan sistem.
• People
People merupakan orang-orang yang terkait dengan sistem.

13
2.2.2 Advantages and Disadvantages of DBMSs
Dibandingkan dengan file-based approach, DBMS memiliki jauh lebih banyak
keuntungan. Berikut ini tabel keuntungan dan kerugian penggunaan DBMS.
Advantages Disadvantages
Control of data redundancy Complexity
Data consistency Size
More information from the same amount
of data
Cost of DBMSs
Sharing of data Additional hardware cost
Improved data integrity Cost of conversion
Improved security Performance
Enforcement of standards Higher impact of a failure
Economy of scale
Balance of conflicting requirements
Improved data accessibility and
responsiveness
Increased productivity
Improved maintenance through data
independence
Increased concurrency
Improved backup and recovery services
Tabel 2. 1 Advantages and disadvantages of DBMSs
Sumber : Connoly, 2005, p26

14
2.3 Database Model Relasional
Database model relasional adalah kumpulan dari relations yang telah
mengalami proses normalisasi dan memiliki nama relation yang berbeda
(Connolly, 2005, p74). Dalam terminologi model relasional, dikenal istilah-istilah
seperti relation, attribute, domain, tuple, degree, dan cardinality. Relation adalah
sebuah tabel yang terdiri atas kolom-kolom dan baris-baris. Attribute adalah kolom
yang terdapat dalam sebuah tabel. Domain adalah sekumpulan nilai yang
diperbolehkan untuk satu atau banyak atribut. Tuple adalah sebuah baris atau
record dalam sebuah tabel. Degree adalah jumlah attribute yang terdapat dalam
sebuah tabel. Cardinality adalah jumlah record yang terdapat dalam sebuah tabel
(Connolly, 2005, p72).
Dalam database model relasional tidak boleh terdapat duplicate tuples dalam
sebuah tabel. Karena itu harus ada satu atau lebih attribute yang dapat
mengidentifikasi tuple secara unik. Terminologi yang digunakan dalam hal ini
disebut sebagai relational keys. Superkey adalah sebuah attribute atau sekumpulan
attribute yang mengidentifikasikan sebuah tuple secara unik didalam sebuah tabel.
Namun superkey dapat berisi attribute yang mungkin saja tidak dibutuhkan untuk
mengidentifikasikan sebuah tuple secara unik. Candidate key adalah sebuah
superkey yang memiliki sifat uniqueness dan irreducibility. Primary key adalah
candidate key yang terpilih untuk mengidentifikasikan tuple secara unik di dalam
sebuah tabel. Alternate key adalah candidate key yang tidak terpilih menjadi
primary key. Foreign key adalah sebuah attribute atau sekumpulan attribute

15
didalam sebuah tabel yang terhubung dengan candidate key pada tabel lain
(Connolly, 2005, p78).
Sebuah relation dalam database model relasional memiliki properti sebagai
berikut:
• Setiap relation memiliki nama yang berbeda dengan relation lainnya dalam
sebuah relational schema.
• Setiap cell dari sebuah relation hanya berisi sebuah nilai tunggal.
• Setiap attribute dalam sebuah relation memiliki nama yang berbeda.
• Nilai dari sebuah attribute berasal dari domain yang sama.
• Tidak mempunyai duplicate tuple.
• Urutan attribute dari kiri ke kanan tidak memiliki makna tertentu.
• Urutan tuple dari atas ke bawah tidak memiliki makna tertentu secara teori.
Namun, secara teknis dapat memiliki pengaruh dalam efisiensi proses
pengaksesan tuple. (Connolly, 2005, p77).
Dalam terminologi model relasional, relation dapat juga disebut sebagai
table atau file. Tuple dapat juga disebut sebagai row atau record. Attribute dapat
juga disebut sebagai column atau field (Connolly, 2005, p74).

16
2.4 Concurrency Control
2.4.1 Kebutuhan Akan Concurrency Control
Tujuan utama dalam pengembangan database adalah membuat
banyak user bisa mengakses data secara bersamaan. Pengaksesan data ini
tidak bermasalah jika semua user hanya membaca data dan mereka tidak
mengganggu satu sama lain. Tapi ketika dua user atau lebih mengakses
database secara bersamaan dan salah satu melakukan perubahan terhadap
data, maka hal ini akan dapat menimbulkan adanya data yang tidak
konsisten (inconsistency data).
Untuk mengatasi adanya kemungkinan inconsistency data, maka
dibutuhkan adanya suatu mekanisme yang mengatur jalannya transaksi
yang mengakses data yang sama tersebut. Mekanisme ini dikenal dengan
istilah concurrency control. Concurrency control adalah proses pengaturan
operasi-operasi dalam banyak transaksi yang berjalan secara simultan pada
database tanpa mengganggu operasi pada transaksi lainnya sehingga dapat
menghasilkan data yang konsisten (Connolly, 2005, p577).
Tiga contoh masalah penting yang disebabkan oleh concurrency :
- Masalah lost update
- Masalah uncommitted dependency
- Masalah inconsistent analysis
Untuk mengilustrasikan masalah ini, digunakan sebuah relation
rekening staff bank sederhana yang mengandung saldo rekening balx, baly,

17
dan balz. Dalam konteks ini, digunakan transaksi sebagai unit concurrency
control.
2.4.1.1 Masalah Lost Update
Time T1 T2 balx
T1 begin_transaction 100
T2 Begin_transaction read(balx) 100
T3 read(balx) balx = balx + 100 100
T4 balx = balx - 10 write(balx) 200
T5 write(balx) commit 90
T6 commit 90
Tabel 2. 2 Masalah lost update
Sumber : Connoly, 2005, p578
Penjelasan :
Transaksi T1 dan T2 mulai pada waktu yang hampir bersamaan, dan
keduanya membaca saldo balx sebesar $100. T2 menambah balx $100
menjadi $200 dan menyimpan hasil perubahannya dalam database. Di sisi
lain, transaksi T1 mengurangi copy dari balx $10 menjadi $90 dan
menyimpan nilai ini dalam database, menimpa hasil update sebelumnya

18
dan akhirnya menghilangkan $100 yang telah ditambahkan sebelumnya ke
dalam saldo.
Kehilangan update transaksi T2 dapat dihindari dengan mencegah T1
membaca nilai dari balx sampai update T2 telah selesai.
2.4.1.2 Masalah Uncommitted Dependency (Dirty Read)
Time T3 T4 balx
T1 begin_transaction 100
T2 read(balx) 100
T3 balx = balx + 100 100
T4 begin_transaction write(balx) 200
T5 read(balx) … 200
T6 balx = balx - 10 rollback 100
T7 write(balx) 190
T8 Commit 190
Tabel 2. 3 Masalah uncommitted dependency (dirty read)
Sumber : Connoly, 2005, p578
Penjelasan:
Transaksi T4 mengubah balx menjadi $200 namun T4 membatalkan
transaksi sehingga balx harus dikembalikan ke nilai asalnya, yaitu $100.
Namun, pada waktu itu, transaksi T3 telah membaca nilai baru balx ($200)
dan menggunakan nilai ini sebagai dasar pengurangan $10, sehingga
memberikan saldo yang keliru sebesar $190, yang seharusnya adalah $90.

19
Nilai balx yang dibaca T3 disebut dirty data, yang berasal dari nama
alternatifnya, yaitu masalah dirty read. Balx disebut sebagai dirty data
karena nilainya didapatkan dari transaksi yang belum selesai dan belum
commit (Elmasri, 2000, p635).
Alasan rollback ini tidaklah penting. Mungkin masalahnya adalah
transaksinya gagal (error), mungkin mengurangi rekening yang salah.
Efeknya adalah asumsi T3 yang menganggap update T4 telah berhasil
dijalankan, meskipun selanjutnya perubahannya dibatalkan. Masalah ini
dapat dihindari dengan mencegah T3 membaca balx sampai keputusan telah
dibuat, yaitu commit atau abort transaksi T4.
Dua masalah di atas mengkonsentrasikan pada transaksi yang
mengubah database dan campur tangan mereka bisa membuat database
menjadi corrupt. Namun, transaksi yang hanya membaca database bisa
juga memberikan hasil yang tidak akurat jika mereka diijinkan untuk
membaca hasil bagian dari transaksi yang belum selesai yang secara
bersamaan membaca dan menulis database. Contohnya dijelaskan pada
masalah inconsistent analysis.
2.4.1.3 Masalah Inconsistent Analysis
Time T5 T6 balx baly balz sum
t1 begin_tran 100 50 25
t2 begin_tran Sum=0 100 50 25 0
t3 read(balx) Read(balx) 100 50 25 0

20
t4 balx = balx - 10 Sum=sum+balx 100 50 25 100
t5 write(balx) Read(baly) 90 50 25 100
t6 read(balz) sum=sum+baly 90 50 25 150
t7 balz =balz + 10 90 50 25 150
t8 write(balz) 90 50 35 150
t9 commit read(balz) 90 50 35 150
t10 sum=sum+balz 90 50 35 185
t11 commit 90 50 35 185
Tabel 2. 4 Masalah inconsistent analysis
Sumber : Connoly, 2005, p579
Penjelasan:
Masalah inconsistent analysis muncul ketika sebuah transaksi
membaca beberapa nilai dari database tapi transaksi kedua mengubah
beberapa darinya ketika eksekusi transaksi yang pertama. Contohnya,
sebuah transaksi yang meringkas data pada sebuah database(contohnya,
saldo total) akan mendapat hasil yang tidak akurat jika, ketika berjalan,
transaksi lain sedang mengubah database. Pada contoh diatas, ringkasan
transaksi T6 sedang berjalan secara bersamaan dengan transaksi T5.
Transaksi T6 sedang menjumlahkan saldo rekening x ($100), rekening y
($50), dan rekening z($25). Namun, di tengah jalan, transaksi T5 telah
mentransfer $10 dari balx ke balz, sehingga T6 sekarang mempunyai hasil
yang salah (lebih besar $10). Masalah ini dapat dihindari dengan mencegah

21
transaksi T6 membaca balx dan balz sampai setelah transaksi T5 selesai
mengubah nilai balx dan balz pada database.
2.4.2 Serializability dan Recoverability
Tujuan protokol concurrency control adalah untuk menjadwalkan
transaksi sedemikian rupa sehingga dapat terhindar dari berbagai gangguan,
dan juga mencegah tipe-tipe masalah yang digambarkan pada sesi
sebelumnya. Satu solusi yang jelas adalah mengijinkan hanya satu transaksi
yang berjalan dalam satu waktu. Satu transaksi berstatus commit sebelum
transaksi berikutnya diijinkan mulai. Namun, tujuan dari DBMS multi user
juga untuk memaksimalkan derajat concurrency atau paralelisme dalam
sebuah sistem, sehingga transaksi yang dapat berjalan tanpa mengganggu
satu sama lain dapat berjalan secara paralel. Contohnya, transaksi yang
mengakses bagian berbeda pada database dapat dijadwalkan bersama tanpa
gangguan. Dalam bagian ini, kita memeriksa serializability sebagai sebuah
cara untuk membantu mengidentifikasi eksekusi transaksi tersebut yang
dijamin untuk memastikan konsistensi. Pertama, akan dijelaskan beberapa
definisi.
2.4.2.1 Serializability
Schedule adalah sebuah urutan dari operasi-operasi oleh satu set
transaksi yang jalan bersamaan yang menjaga urutan operasi pada setiap
transaksi individual (Connolly, 2005, p580).

22
Sebuah transaksi mencakup sebuah urutan operasi yang terdiri dari
tindakan membaca dan/atau menulis pada database, diikuti oleh sebuah
tindakan commit atau abort. Sebuah schedule S yang terdiri dari sebuah
urutan operasi dari sekumpulan n transaksi T1, T2, … Tn, bergantung pada
constraint dimana urutan operasi untuk setiap transaksi dilindungi di dalam
schedule tersebut. Jadi, untuk setiap transaksi Ti pada schedule S, urutan
operasi pada Ti harus sama dengan schedule S.
Serial Schedule adalah sebuah schedule di mana operasi dari setiap
transaksi dijalankan secara berurutan tanpa adanya interleaved operations
dari transaksi lainnya (Connolly, 2005, p580). Nonserial Schedule adalah
sebuah schedule di mana operasi-operasi dari satu set concurrent
transactions mengalami interleaved (Connolly, 2005, p580).
Pada sebuah serial schedule, transaksi dijalankan pada urutan
tertentu. Contohnya, jika kita mempunyai dua transaksi T1 dan T2, serial
order akan berupa T1 diikuti oleh T2, atau T2 diikuti oleh T1. Pada eksekusi
serial tidak ada interferensi antara transaksi, karena hanya satu transaksi
yang berjalan pada satu waktu.
Masalah lost update, masalah uncommited dependency (dirty read),
dan masalah inconsistent analysis terjadi karena kurangnya pengaturan
masalah concurrency, yang menyebabkan database menghasilkan data
yang tidak konsisten. Eksekusi serial mencegah terjadinya masalah ini.
Sebuah eksekusi serial tidak akan membuat database menjadi tidak
konsisten.

23
Tujuan serializibility adalah untuk menemukan nonserial schedule
yang mengijinkan transaksi untuk berjalan secara bersamaan tanpa
mengganggu satu sama lain, dan kemudian menghasilkan sebuah database
state yang dapat diproduksi oleh sebuah eksekusi serial.
Jika sekumpulan transaksi berjalan secara bersamaan, bisa
dikatakan bahwa nonserial schedule adalah benar jika memproduksi hasil
yang sama seperti beberapa eksekusi serial lainnya. Schedule seperti itu
disebut serializable (Connolly, 2005, p581). Konsep serializability of
schedules digunakan untuk mengidentifikasi apakah schedule adalah benar
ketika eksekusi transaksi memiliki interleaving pada operasi di dalam
schedule (Elmasri, 2000, p644). Untuk mencegah inkonsistensi dari
transaksi yang mengganggu satu sama lain, penting untuk menjamin
serializability dari transaksi yang jalan bersamaan. Pada serializability,
urutan operasi baca dan tulis itu penting. Berikut ini hal-hal yang perlu
diperhatikan:
• Jika dua transaksi hanya membaca satu item data yang sama, dua
transaksi tersebut tidak mengalami konflik dan urutan menjadi tidak
penting.
• Jika dua transaksi melakukan operasi membaca ataupun menulis pada
item data yang berbeda, dua transaksi tersebut tidak mengalami konflik
dan urutan menjadi tidak penting.
24
• Jika satu transaksi menulis sebuah item data dan transaksi lain baik
membaca ataupun menulis pada item data yang sama, maka urutan
eksekusi itu menjadi penting.
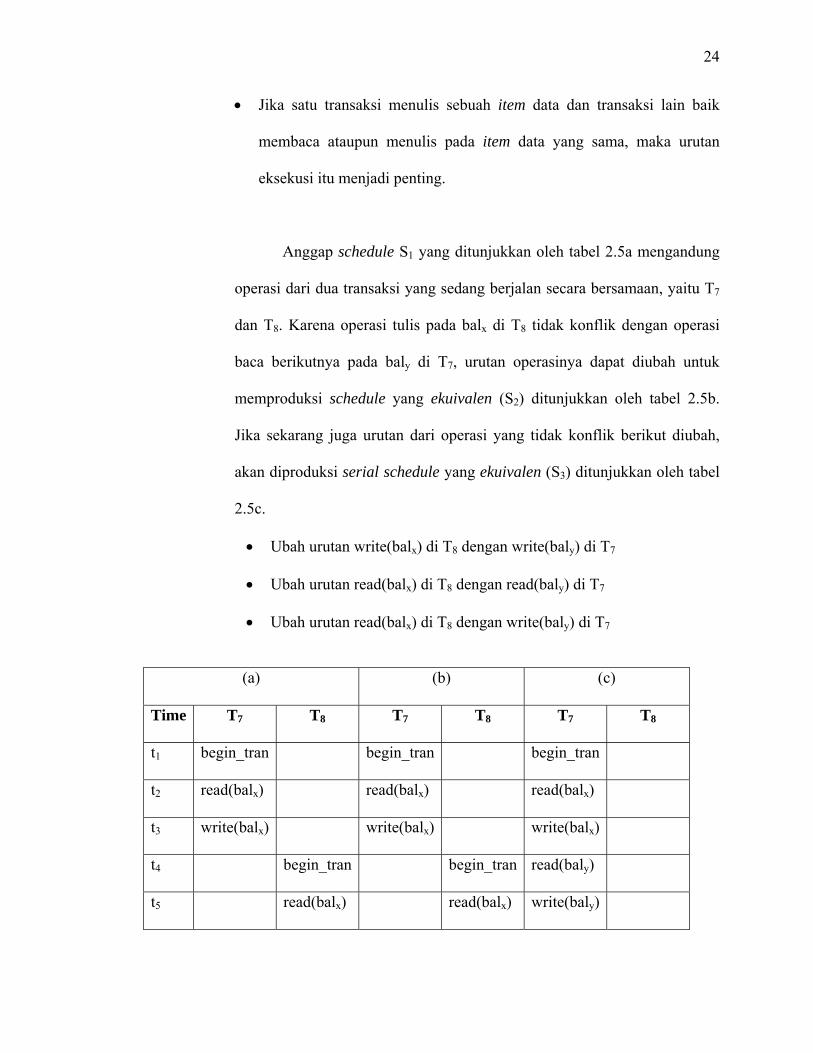
Anggap schedule S1 yang ditunjukkan oleh tabel 2.5a mengandung
operasi dari dua transaksi yang sedang berjalan secara bersamaan, yaitu T7
dan T8. Karena operasi tulis pada balx di T8 tidak konflik dengan operasi
baca berikutnya pada baly di T7, urutan operasinya dapat diubah untuk
memproduksi schedule yang ekuivalen (S2) ditunjukkan oleh tabel 2.5b.
Jika sekarang juga urutan dari operasi yang tidak konflik berikut diubah,
akan diproduksi serial schedule yang ekuivalen (S3) ditunjukkan oleh tabel
2.5c.
• Ubah urutan write(balx) di T8 dengan write(baly) di T7
• Ubah urutan read(balx) di T8 dengan read(baly) di T7
• Ubah urutan read(balx) di T8 dengan write(baly) di T7
(a) (b) (c)
Time T7 T8 T7 T8 T7 T8
t1 begin_tran begin_tran begin_tran
t2 read(balx) read(balx) read(balx)
t3 write(balx) write(balx) write(balx)
t4 begin_tran begin_tran read(baly)
t5 read(balx) read(balx) write(baly)
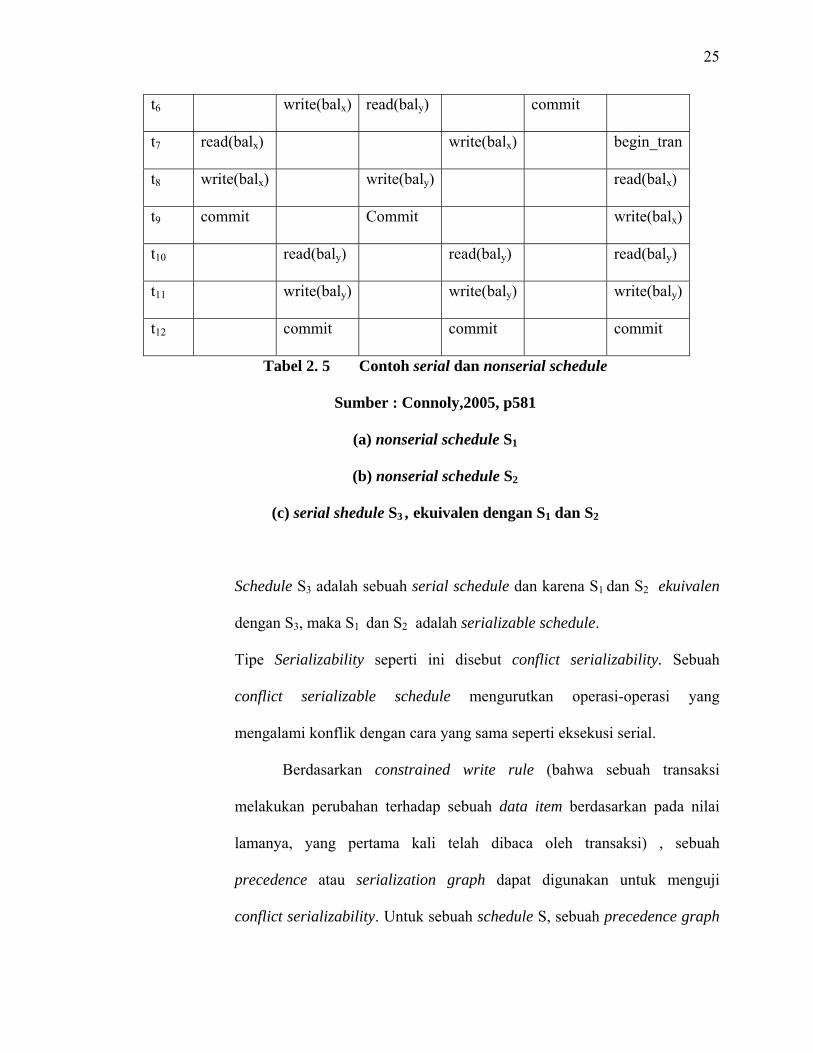
25
t6 write(balx) read(baly) commit
t7 read(balx) write(balx) begin_tran
t8 write(balx) write(baly) read(balx)
t9 commit Commit write(balx)
t10 read(baly) read(baly) read(baly)
t11 write(baly) write(baly) write(baly)
t12 commit commit commit
Tabel 2. 5 Contoh serial dan nonserial schedule
Sumber : Connoly,2005, p581
(a) nonserial schedule S1
(b) nonserial schedule S2
(c) serial shedule S3 , ekuivalen dengan S1 dan S2
Schedule S3 adalah sebuah serial schedule dan karena S1 dan S2 ekuivalen
dengan S3, maka S1 dan S2 adalah serializable schedule.
Tipe Serializability seperti ini disebut conflict serializability. Sebuah
conflict serializable schedule mengurutkan operasi-operasi yang
mengalami konflik dengan cara yang sama seperti eksekusi serial.
Berdasarkan constrained write rule (bahwa sebuah transaksi
melakukan perubahan terhadap sebuah data item berdasarkan pada nilai
lamanya, yang pertama kali telah dibaca oleh transaksi) , sebuah
precedence atau serialization graph dapat digunakan untuk menguji
conflict serializability. Untuk sebuah schedule S, sebuah precedence graph

26
adalah sebuah directed graph G = (N,E) yang berisi sekumpulan node N
dan sekumpulan directed edges E yang dibangun seperti berikut :
• Buat sebuah node untuk setiap transaksi.
• Buat sebuah directed edge Ti -> Tj, jika Tj membaca nilai dari
sebuah item yang telah ditulis oleh Ti.
• Buat sebuah directed edge Ti -> Tj, jika Tj menulis nilai dari sebuah
item yang telah dibaca oleh Ti.
• Buat sebuah directed edge Ti -> Tj, jika Tj menulis nilai dari sebuah
item yang telah ditulis oleh Ti.
Jika sebuah edge Ti -> Tj sudah ada pada precedence graph untuk S, maka
didalam serial schedule S’ yang ekivalen dengan S, Ti harus muncul
sebelum Tj. Jika precedence graph berisi sebuah cycle, maka schedule itu
menjadi tidak conflict serializable.
Perhatikan dua transaksi pada tabel 2.6. Transaksi T9 mentransfer
₤100 dari sebuah rekening dengan saldo balx ke rekening lain dengan saldo
baly, sedangkan T10 menambah saldo dari dua rekening ini sebesar 10%.
Precedence graph untuk schedule ini seperti ditunjukkan oleh gambar 2.1,
mempunyai sebuah cycle, jadi tidak bersifat conflict serializable.
Time T9 T10
t1 begin_transaction
t2 read ( balx )
t3 balx = balx + 100

27
t4 write ( balx ) begin_transaction
t5 read ( balx )
t6 balx = balx* 1.1
t7 write ( balx )
t8 read ( baly )
t9 baly = baly * 1.1
t10 write ( baly )
t11 read( baly ) commit
t12 baly = baly – 100
t13 write ( baly )
t14 Commit
Tabel 2. 6 Dua concurrent update transactions yang tidak conflict-serializable
Sumber: Connoly,2005,p582
Gambar 2. 1 Precedence graph untuk tabel 2.6 menunjukkan sebuah cycle, jadi
tidak conflict-serializable
Sumber : Connoly, 2005, p583
T9 T10
x
y

28
Pada prakteknya, sebuah DBMS tidak menguji serializability dari
sebuah schedule. Hal ini tidak praktis karena interleaving operasi-operasi
dari transaksi-transaksi yang bersamaan ditentukan oleh sistem operasi.
Sebaliknya, pendekatan yang digunakan adalah dengan menggunakan
protokol yang dikenal untuk memproduksi serializable schedule.
2.4.2.2 Recoverability
Serializability mengidentifikasikan schedule yang menjaga
konsistensi database dengan asumsi tidak ada transaksi pada schedule yang
gagal. Jika sebuah transaksi gagal, maka perlu dilakukan proses undo
terhadap efek transaksi. Perhatikan lagi dua transaksi yang digambarkan
pada tabel 2.6. Jika transaksi T9 mengalami rollback, maka akan terjadi
kesalahan data. T10 membaca hasil perubahan data pada T9 dan melakukan
perubahan terhadap nilai balx. Transaksi T10 harus melakukan proses undo
karena membaca nilai balx dari transaksi T9 yang ternyata mengalami
rollback. Schedule seperti ini disebut nonrecoverable schedule yang harus
dihindari. Recoverable schedule adalah sebuah schedule di mana, untuk
setiap transaksi Ti dan Tj, jika Tj membaca sebuah item data yang
sebelumnya ditulis oleh Ti, maka operasi commit dari Ti mendahului
operasi commit dari Tj (Connolly, 2005, p587).

29
2.4.3 Metode Locking
Locking adalah sebuah prosedur yang digunakan untuk
mengendalikan akses bersamaan ke data. Ketika sebuah transaksi sedang
mengakses database, sebuah lock mungkin menolak akses ke transaksi lain
untuk mencegah hasil yang salah (Connolly, 2005, p587).
Metode locking merupakan salah satu pendekatan yang banyak
digunakan untuk menjamin serializability dari sejumlah concurrent
transactions. Ada beberapa teknik locking yang sering digunakan. Dalam
penulisan ini, akan dibahas metode locking dengan menggunakan shared
lock dan exclusive lock.
Sebuah transaksi harus meminta penggunaan shared lock dan
exclusive lock sebelum melakukan akses membaca ataupun menulis
terhadap database. Penggunaan lock ini adalah untuk menjaga konsistensi
data didalam database. Jika sebuah transaksi mempunyai sebuah shared
lock pada sebuah item data, transaksi dapat membaca item data tersebut tapi
tidak dapat mengubahnya (Connolly, 2005, p588). Jika sebuah transaksi
mempunyai sebuah exclusive lock pada sebuah item data, transaksi tersebut
dapat membaca dan mengubah item data (Connolly, 2005, p588).
Read Write
Read Yes No
Write No No
Tabel 2. 7 Lock-compatibilitytables
Sumber : Elmasri, 2000,p676

30
Lock digunakan dengan cara sebagai berikut :
• Transaksi apapun yang membutuhkan akses pada sebuah item data
harus melakukan lock terhadap item tersebut, meminta shared lock
untuk akses membaca saja atau sebuah exclusive lock untuk akses
membaca dan menulis.
• Jika item belum dikunci oleh transaksi lain, lock tersebut akan diberikan
• Jika item sedang dikunci, DBMS menentukan apakah permintaan ini
compatible dengan lock saat ini. Jika diminta shared lock pada sebuah
item yang sudah mempunyai shared lock terpasang padanya,
permintaan lock tersebut akan diijinkan. Selain itu, transaksi harus
menunggu sampai lock yang ada terlepas.
• Sebuah transaksi akan terus memegang lock sampai transaksi tersebut
melepasnya baik pada waktu eksekusi ataupun pada waktu transaksi
tersebut berakhir (abort atau commit). Efek operasi tulis akan terlihat
pada transaksi lain hanya pada waktu exclusive lock telah dilepas.
Two-phase Locking (2PL) merupakan sebuah protokol yang
memperhatikan saat operasi melakukan lock dan unlock di dalam setiap
transaksi. Sebuah transaksi mengikuti protokol two-phase locking jika
semua operasi locking mendahului operasi unlock pertama pada transaksi
(Connolly, 2005, p589).
Sesuai peraturan pada protokol ini, setiap transaksi dapat dibagi ke
dalam dua fase, yaitu growing phase dan shrinking phase. Pada growing

31
phase, transaksi akan mendapatkan semua lock yang dibutuhkan tapi tidak
dapat melepaskan lock apapun. Pada shrinking phase, transaksi akan
melepaskan semua lock yang dipegang tapi tidak bisa mendapatkan lock
baru lainnya. Tidak ada kebutuhan bahwa semua lock didapatkan sekaligus
pada suatu waktu. Secara normal, sebuah transaksi akan mendapatkan lock
untuk menjalankan operasi, dan meminta lock tambahan jika ada operasi
yang membutuhkan lock pada operasi selanjutnya .
Aturan-aturannya adalah sebagai berikut :
• Sebuah transaksi harus mendapatkan sebuah lock pada item sebelum
beroperasi pada item tersebut. Lock tersebut bisa berupa akses membaca
atau menulis, tergantung dari tipe akses yang dibutuhkan.
• Ketika transaksi melepaskan sebuah lock, transaksi tersebut tidak akan
pernah mendapatkan lock baru lainnya.
Berikut akan dibahas bagaimana two-phase locking digunakan
untuk memecahkan tiga masalah concurrency yang telah dibahas
sebelumnya.
2.4.3.1 Mencegah Masalah Lost Update Menggunakan 2PL
Time T1 T2 balx
t1 begin_transaction 100
t2 begin_transaction write_lock(balx) 100
t3 write_lock(balx) read(balx) 100

32
t4 WAIT balx = balx + 100 100
t5 WAIT write(balx) 200
t6 WAIT commit / unlock(balx) 200
t7 read(balx) 200
t8 balx = balx – 10 200
t9 write(balx) 190
t10 commit / unlock(balx) 190
Tabel 2. 8 Mencegah masalah lost update menggunakan 2PL
Sumber : Connoly, 2005, p590
Penjelasan :
Solusi pada masalah lost update ditunjukkan pada tabel 2.8. Untuk
mencegah masalah lost update terjadi, pertama kali T2 meminta dan
mendapatkan sebuah exclusive lock pada balx. Dengan demikian T2 dapat
membaca nilai dari balx, menambah nilainya dengan 100, dan menuliskan
nilai tersebut ke dalam database. Ketika T1 mulai dijalankan, T1 juga akan
meminta sebuah exclusive lock pada balx. Karena exclusive lock untuk balx
sedang digunakan oleh T2, maka permintaan ini tidak langsung disetujui. T1
harus menunggu sampai lock pada balx yang digunakan oleh T2 dilepaskan
yang artinya T1 harus menunggu sampai T2 menyelesaikan semua
operasinya.
33
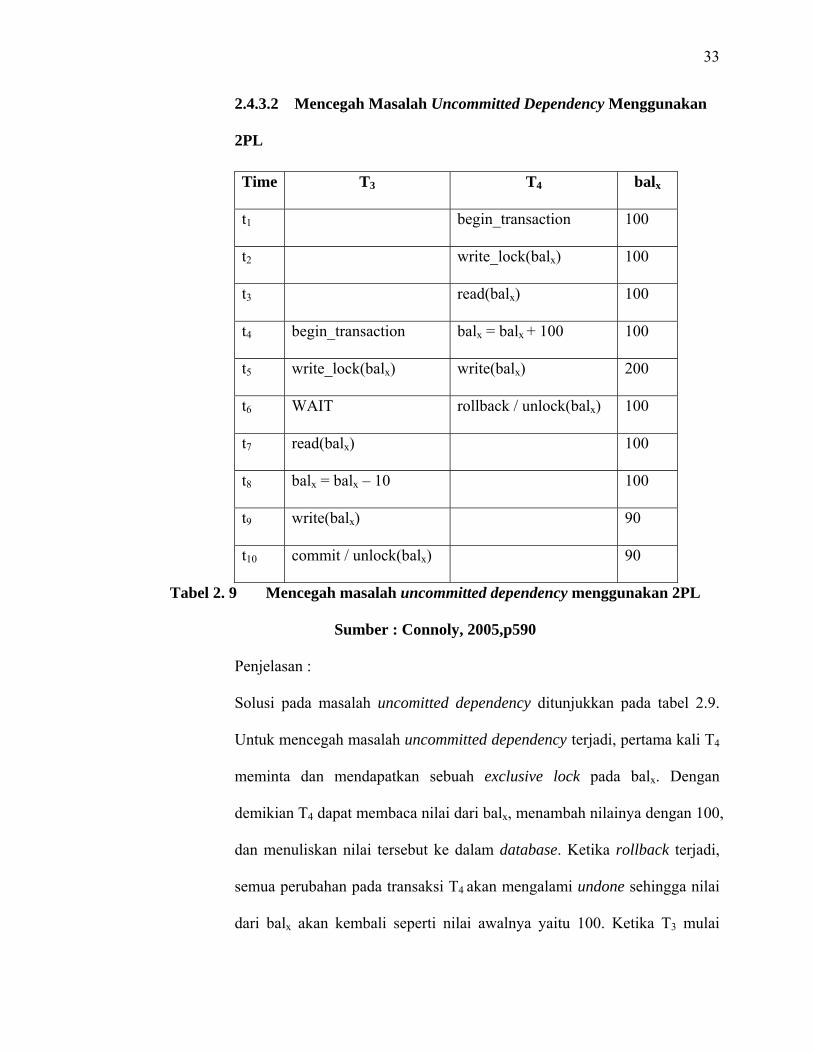
2.4.3.2 Mencegah Masalah Uncommitted Dependency Menggunakan
2PL
Time T3 T4 balx
t1 begin_transaction 100
t2 write_lock(balx) 100
t3 read(balx) 100
t4 begin_transaction balx = balx + 100 100
t5 write_lock(balx) write(balx) 200
t6 WAIT rollback / unlock(balx) 100
t7 read(balx) 100
t8 balx = balx – 10 100
t9 write(balx) 90
t10 commit / unlock(balx) 90
Tabel 2. 9 Mencegah masalah uncommitted dependency menggunakan 2PL
Sumber : Connoly, 2005,p590
Penjelasan :
Solusi pada masalah uncomitted dependency ditunjukkan pada tabel 2.9.
Untuk mencegah masalah uncommitted dependency terjadi, pertama kali T4
meminta dan mendapatkan sebuah exclusive lock pada balx. Dengan
demikian T4 dapat membaca nilai dari balx, menambah nilainya dengan 100,
dan menuliskan nilai tersebut ke dalam database. Ketika rollback terjadi,
semua perubahan pada transaksi T4 akan mengalami undone sehingga nilai
dari balx akan kembali seperti nilai awalnya yaitu 100. Ketika T3 mulai

34
dijalankan, T3 juga akan meminta sebuah exclusive lock pada balx. Karena
exclusive lock untuk balx sedang digunakan oleh T4, maka permintaan ini
tidak langsung disetujui. T3 harus menunggu sampai lock pada balx yang
digunakan oleh T4 dilepaskan dan permintaan akan disetujui setelah proses
rollback pada transaksi T4 selesai dikerjakan.
2.4.3.3 Mencegah Masalah Inconsistent Analysis Menggunakan 2PL
Time T5 T6 balx baly balz sum
t1 begin_tran 100 50 25
t2 begin_tran sum=0 100 50 25 0
t3 write_lock(balx) 100 50 25 0
t4 read(balx) read_lock(balx) 100 50 25 0
t5 balx = balx – 10 WAIT 100 50 25 0
t6 write(balx) WAIT 90 50 25 0
t7 write_lock(balz) WAIT 90 50 25 0
t8 read(balz) WAIT 90 50 25 0
t9 balz =balz + 10 WAIT 90 50 25 0
t10 write(balz) WAIT 90 50 35 0
t11 commit /
unlock(balx,balz)
WAIT 90 50 35 0
t12 read(balx) 90 50 35 0
t13 sum=sum+balx 90 50 35 90

35
t14 read_lock(baly) 90 50 35 90
t15 read(baly) 90 50 35 90
t16 sum=sum+baly 90 50 35 140
t17 read_lock(balz) 90 50 35 140
t18 read(balz) 90 50 35 140
t19 sum=sum+balz 90 50 35 175
t20 commit /
unlock(balx,
baly, balz)
90 50 35 175
Tabel 2. 10 Mencegah masalah inconsistent analysis menggunakan 2PL
Sumber : Connoly,2005, p591
Penjelasan :
Untuk mencegah masalah inconsistent analysis terjadi, pertama kali T5
meminta dan mendapatkan sebuah exclusive lock pada balx. Dengan
demikian T5 dapat membaca nilai dari balx, mengurangi nilainya dengan 10,
dan menuliskan nilai tersebut ke dalam database. Ketika T6 mulai
dijalankan, T6 akan meminta sebuah shared lock pada balx. Karena
exclusive lock untuk balx sedang digunakan oleh T5, maka permintaan ini
tidak langsung disetujui. T6 harus menunggu sampai exclusive lock pada
balx yang digunakan oleh T5 dilepaskan dan permintaan akan disetujui
setelah semua operasi pada transaksi T5 selesai dikerjakan.

36
2.4.4 Deadlock
Deadlock adalah jalan buntu yang dapat terjadi ketika dua atau lebih
transaksi masing-masing menunggu lock yang sedang dipegang oleh
transaksi lainnya untuk dilepas (Connolly, 2005, p594).
Time T17 T18
t1 begin_transaction
t2 write_lock (balx) begin_transaction
t3 read (balx) write_lock (baly)
t4 balx = balx - 10 read (baly)
t5 write (balx) baly = baly + 100
t6 write_lock (baly) write (baly)
t7 WAIT write_lock (balx)
t8 WAIT WAIT
t9 WAIT WAIT
t10 ... WAIT
t11 ... ...
Tabel 2. 11 Contoh deadlock pada dua transaksi
Sumber : Connoly, 2005, p594
Tabel 2.11 menunjukkan dua transaksi T17 dan T18 yang mengalami
deadlock karena masing-masing sedang menunggu transaksi lainnya untuk
melepaskan lock yang sedang dipegang. Pada saat t2, transaksi T17 meminta
dan mendapatkan exclusive lock pada item balx dan pada saat t3 transaksi
T18 mendapatkan exclusive lock pada item baly. Pada saat t6, T17 meminta

37
exclusive lock pada item baly. Karena T18 sedang mengunci baly, maka
transaksi T17 akan menunggu. Sementara itu, pada saat t7, T18 meminta
sebuah exclusive lock pada item balx yang sedang dipegang oleh transaksi
T17. Tidak ada satupun transaksi yang dapat dilanjutkan karena masing-
masing sedang menunggu lock yang tidak dapat dipenuhi sampai transaksi
lainnya selesai. DBMS harus dapat mengetahui adanya deadlock dan
mengatasinya dalam beberapa cara.
Hanya ada satu cara untuk menghancurkan deadlock, yaitu abort
satu atau lebih transaksi. Dengan melakukan abort sebuah transaksi, proses
harus melakukan undo terhadap semua perubahan yang dilakukan oleh
transaksi tersebut. Pada contoh yang ditunjukkan dalam tabel 2.11, proses
abort dapat dilakukan pada transaksi T18. Setelah abort transaksi T18
selesai, semua lock yang dipegang oleh transaksi T18 akan dilepaskan dan
dapat digunakan oleh transaksi T17. Langkah berikutnya, DBMS akan
secara otomatis melakukan restart terhadap transaksi yang telah dibatalkan
tersebut.
Ada tiga teknik umum yang biasa digunakan untuk menangani
deadlock, yaitu timeout, deadlock prevention dan deadlock detection and
recovery. Dengan timeout, transaksi yang meminta lock akan menunggu
selama satu periode waktu tertentu. Dengan menggunakan deadlock
prevention, DBMS akan melihat apakah suatu transaksi akan menyebabkan
deadlock, dan tidak akan mengizinkan deadlock terjadi. Dengan
menggunakan deadlock detection and recovery, DBMS mengizinkan
deadlock terjadi namun mengetahui kejadian deadlock, lalu memecahkan

38
deadlock tersebut. Karena mencegah deadlock lebih susah daripada
menggunakan timeout atau mendeteksi deadlock lalu memecahkannya
ketika deadlock terjadi, sistem umumnya menghindari metode deadlock
prevention.
2.4.4.1 Deadlock Prevention
Salah satu pendekatan untuk mencegah deadlock adalah dengan
mengurutkan transaksi menggunakan transaction timestamps.. Dua
algoritma telah ditemukan oleh Rosenkrantz (1978). Algoritma pertama,
Wait-Die, mengijinkan hanya transaksi yang lebih tua untuk menunggu
yang lebih muda, jika tidak transaksi dibatalkan dan restart dengan
timestamp yang sama, sehingga lama kelamaan transaksi tersebut akan
menjadi transaksi aktif tertua dan tidak akan mati. Algoritma kedua,
Wound-Wait, menggunakan pendekatan simetrikal. Hanya transaksi yang
lebih muda yang dapat menunggu transaksi yang lebih tua. Jika transaksi
yang lebih tua meminta lock yang dipegang oleh transaksi yang lebih muda,
transaksi yang lebih muda digagalkan.
Sebuah variasi dari 2PL, yang disebut sebagai conservative 2PL,
dapat juga digunakan untuk mencegah deadlock. Dengan menggunakan
conservative 2PL, sebuah transaksi mendapatkan semua lock yang
dibutuhkan ketika transaksi dimulai atau transaksi akan menunggu sampai
semua kunci yang dibutuhkan telah tersedia. Protokol ini memiliki
keuntungan yaitu waktu pengaksesan kunci menjadi berkurang karena

39
transaksi tidak pernah ditahan dan bahkan tidak pernah menunggu untuk
mendapatkan lock ketika transaksi sedang dieksekusi. Semua lock harus
didapatkan dan dilepaskan pada satu waktu tertentu. Sehingga, jika sebuah
transaksi gagal mendapatkan sebuah lock, maka transaksi itu harus
melepaskan semua lock yang didapatkannya dan memulai lock process dari
awal lagi. Dalam pandangan nyata, sebuah transaksi mungkin saja tidak
mengetahui lock apa saja yang akan dibutuhkan pada awal transaksi.
Protokol ini tidak digunakan dalam realitas pada DBMS.
2.4.4.2 Deadlock Detection and Recovery
Deadlock detection biasanya ditangani oleh konstruksi wait-for
graph (WFG) yang menunjukkan ketergantungan transaksi, yaitu transaksi
Ti tergantung pada Tj jika transaksi Tj memegang lock pada sebuah item
data yang ditunggu oleh Ti. WFG adalah sebuah directed graph G = (N, E )
yang terdiri atas sekumpulan node N dan sekumpulan directed edge E,
yang dikonstruksi sebagai berikut :
• Buat sebuah node untuk setiap transaksi.
• Buat sebuah directed edge Ti → Tj , jika transaksi Ti menunggu untuk
melakukan lock pada sebuah item yang sedang di-lock oleh Tj.
T1 T2
y
x

40
Gambar 2. 2 WFG dengan sebuah Cycle menunjukkan Deadlock antara 2
transaksi
Sumber : Connoly, 2005, p596
Deadlock terjadi jika dan hanya jika WFG mengandung sebuah
cycle. Gambar di atas menunjukkan WFG yang menunjukkan deadlock
antara dua transaksi. Algoritma dari deadlock detection akan membuat
WFG pada selang waktu tertentu dan mengecek apakah terdapat cycle pada
WFG tersebut. Jika terjadi deadlock, DBMS harus melakukan abort
terhadap salah satu transaksi. Ada beberapa hal yang perlu diperhatikan
dalam hal ini, yaitu :
• Choice of deadlock victim
Logika pemilihan transaksi mana yang mengalami proses abort
mungkin saja membingungkan. Dalam hal ini dapat
dipertimbangkan beberapa hal berikut, yaitu, berapa lama transaksi
telah berjalan. Akan lebih baik jika proses abort dilakukan pada
transaksi yang baru saja dimulai daripada transaksi yang telah
berjalan lebih lama didalam sistem. Pertimbangan berikutnya yaitu
berapa banyak data item yang telah diubah oleh transaksi. Akan
lebih baik jika proses abort dilakukan pada transaksi yang sedikit
melakukan perubahan di dalam database. Pertimbangan berikutnya
yaitu, berapa banyak data item yang masih harus diubah. Akan

41
lebih baik jika proses abort dilakukan pada transaksi yang memiliki
lebih banyak data item untuk diubah didalam database.
• How far to roll a transaction back
Dengan memutuskan terjadinya proses abort pada sebuah transaksi,
maka DBMS akan melakukan rollback terhadap transaksi tersebut.
Salah satu cara untuk mengatasi deadlock dapat dilakukan dengan
melakukan rollback sebagian transaksi yang telah berjalan.
• Avoiding starvation
Starvation terjadi ketika transaksi yang sama selalu terpilih sebagai
victim, dan transaksi tidak pernah berjalan sampai selesai. DBMS
dapat menghindari starvation dengan menyimpan jumlah berapa
kali sebuah transaksi pernah terpilih sebagai victim dan
menggunakan kriteria pemilihan yang berbeda jika jumlah tersebut
telah mencapai angka tertentu.
2.4.4.3 Timeout
Pendekatan sederhana pada pencegahan deadlock adalah
berdasarkan lock timeout. Dengan pendekatan ini, sebuah transaksi yang
meminta sebuah lock akan menunggu hanya sampai periode waktu tertentu
yang didefinisikan sistem. Jika kunci yang diminta tidak didapatkan selama
periode tersebut, maka terjadi request time out pada transaksi tersebut.
Dalam hal ini, DBMS mengasumsikan telah terjadi deadlock, walaupun
mungkin saja deadlock tidak terjadi. Dengan demikian, transaksi tersebut

42
akan mengalami proses abort dan secara otomatis transaksi tersebut akan
mengalami proses restart. Protokol ini merupakan solusi yang umum
digunakan untuk mengatasi deadlock didalam sebuah DBMS. Pada
penulisan skripsi ini, penulis menggunakan mekanisme timeout untuk
mengatasi kemungkinan terjadinya deadlock. Pada aplikasi server, terdapat
menu untuk memilih waktu yang akan digunakan sebagai selang waktu
terjadinya timeout. Jika sebuah transaksi telah berjalan dan menunggu
sebuah lock, maka timer yang menandakan awal waktu menunggu akan
dimulai. Jika transaksi masih menunggu lock sampai selang waktu tersebut
habis, maka terjadi timeout. Transaksi tersebut akan mengalami proses
rollback dan restart dari awal dengan lama waktu menunggu lock yang
dibutuhkan diubah kembali menjadi nol.
2.5 Alat Bantu Perancangan Sistem
Alat bantu perancangan sistem menggunakan UML. UML adalah sebuah
bahasa yang telah menjadi standar dalam industri untuk memvisualisasi,
menspesifikasi, merancang dan mendokumentasi sistem piranti lunak (Booch et al,
1999, p14). UML menawarkan sebuah standar untuk merancang model sebuah
sistem.
2.5.1 Use Case Diagram
Use Case Diagram menggambarkan sekumpulan use case dan aktor
serta hubungannya (Booch et al, 1999, p234). Yang ditekankan adalah
“apa” yang dilakukan terhadap sistem dan bukan “bagaimana”. Sebuah use

43
case menggambarkan interaksi antara aktor dengan sistem. Di bawah ini
dijelaskan bagian use case diagram:
a. Aktor
Aktor adalah segala sesuatu yang melakukan tatap muka dengan
sistem, seperti orang, piranti lunak, piranti keras, atau jaringan
(Schneider dan Winters, 1997, p12). Tiap-tiap aktor menunjukkan
perannya masing-masing.
Notasi aktor dengan nama aktor tersebut dibawahnya:
b. Use case
Use case menggambarkan segala sesuatu yang aktor ingin lakukan
terhadap sistem. Use case harus merupakan “apa” yang yang
dikerjakan piranti, bukan “bagaimana” aplikasi piranti lunak
mengerjakannya. Suatu sistem yang kompleks memiliki banyak use
case, sehingga perlu diorganisasi.
Notasi use case:
Untuk menghubungkan antara aktor dengan use case digunakan
simbol garis yang disebut sebagai relationship.
Pengguna

44
Suatu use case dapat memiliki deskripsi teknik, yaitu: extends, dan
include.
Extends berarti memperluas use case dasar dengan menambah
behavior-behavior baru tanpa mengubah use case dasar itu sendiri.
Titik di mana use case diperluas disebut sebagai extension point.
Sebuah use case dapat meng-include fungsionalitas dari use case lain
sebagai bagian dari proses dalam dirinya. Secara umum diasumsikan
bahwa use case yang di-include akan dipanggil setiap kali use case
yang meng-include dieksekusi secara normal.
Dengan adanya use case diagram maka akan membantu dalam
menyusun kebutuhan sebuah sistem dan mengkomunikasikannya
dengan client.
2.5.2 Class Diagram
Class Diagram menunjukkan entitas yang ada pada sistem dan
bagaimana entitas tersebut saling berhubungan (Booch et al, 1999, p107).
Entitas tersebut memiliki atribut dan perilaku tertentu. Class diagram
memperlihatkan hubungan antarkelas dan penjelasan detail tiap-tiap kelas
di dalam logical view dari suatu sistem. Class tersusun dari tiga bagian,
<<include>>
<<extends>>

45
yaitu nama class, attribute, dan method operasi. Berikut ini adalah contoh
sebuah class :
Gambar 2. 3 Struktur Class
Sumber : Whitten, 2004, p433
2.5.3 Diagram Alir (Flow Chart)
Diagram alir adalah suatu representasi grafis di mana simbol-simbol
digunakan untuk merepresentasikan operasi, data, aliran, logika,
perlengkapan, dan seterusnya. Suatu diagram alir program
mengilustrasikan struktur dan urutan dari operasi sebuah program,
sementara sebuah sistem diagram alir mengilustrasikan komponen-
komponen dan aliran sistem informasi (O’Brien, 2003, pG-8).
Tiga konsep utama dalam pemrograman terstruktur yaitu sequence,
condition, dan repetition (Pressman, 2001, p424). Sequence
mengimplementasikan langkah-langkah proses yang penting dalam
spesifikasi algoritma-algoritma. Condition menyediakan fasilitas untuk
memilih proses berdasarkan logika, dan repetition untuk melakukan proses
perulangan.

46
Firsttask
Nexttask
Else-part Then-part
If-then-elseSequence
Casecondition
Case part
Selection
T
T
T
F
F
F
T
T
FF
RepetitionDo-while Repeat-until
TF
Condition
Gambar 2. 4 Flowchart Constructs
Sumber : Pressman , 2001, p425
2.6 XML
XML adalah sebuah meta-language (bahasa yang digunakan untuk
mendeskripsikan bahasa lain) yang memungkinkan seorang designer membuat
sendiri tag yang menyediakan fungsi yang tidak tersedia dalam HTML (Connolly,
2005, p1073). XML merupakan sebuah versi meta-language yang diturunkan dari
Standard Generalized Markup Language (SGML), yang di desain khusus untuk
dokumen website dan dapat mendukung perancang untuk menciptakan tag sendiri,
yang memiliki kemampuan untuk mendefinisikan, mentransmisikan,
memvalidasikan dan menginterpretasikan data antara aplikasi dan organisasi.
XML dikembangkan oleh World Wide Web Consortium (W3C) yang
didukung sekitar 150 orang anggotanya dan versi 1.0 pertama kali dirilis pada
tahun 1998.

47
Keunggulan yang dimiliki XML antara lain (Connolly, 2005, p1074) :
• Simplicity. XML menggunakan bahasa yang sederhana, mudah
dimengerti oleh manusia dan mesin.
• Open standar and platform / vendor-independent. XML menggunakan
standar terbuka dan tidak tergantung pada platform tertentu.
• Extensibility. XML memungkinkan user untuk mendefinisikan tag
sendiri sehingga dapat dikembangkan sesuai dengan kebutuhan user.
• Reuse. XML memungkinkan libraries dari XML tags untuk dibangun
sekali dan dapat digunakan kembali oleh banyak aplikasi.
• Separation of content and presentation. XML memisahkan antara isi
dan tampilan dari suatu data sesuai dengan pengaturan yang diinginkan.
• Improved load balancing. Data dapat ditampilkan pada browser dengan
baik.
• Support for the integration of data from multiply source. Kemampuan
mengintegrasikan data dari berbagai macam sumber yang berbeda
adalah hal yang sulit dan memakan waktu. XML dapat menggabungkan
data dari banyak sumber yang berbeda dengan cara yang mudah.
• Ability to describe data from a wide variety of applications. XML dapat
digunakan untuk mendeskripsikan data yang terdapat pada aplikasi
yang berbeda.
• More advance search engine. Dengan XML, mesin pencarian akan
mampu untuk menyederhanakan berbagai macam tags.

48
• New opportunities. XML memiliki banyak kelebihan yang dapat
dihadirkan dalam banyak aplikasi teknologi saat ini. Struktur
hirarkisnya cocok untuk kebanyakan tipe dokumen.
Kekurangan-kekurangan XML :
• Parser harus didesain untuk memahami struktur data bersarang yang
berubah-ubah dan harus melakukan pengecekan tambahan untuk
mendeteksi sintaks atau data yang tidak terformat atau terurut dengan
benar.
• Urutan penekanan tombol untuk mengetikkan ekspresi XML pada
keyboard standar komputer seringkali kaku.
XML menggunakan teknologi Document Type Definitions (DTDs) yang
dapat mendefinisikan sintaks yang valid dari dokumen XML.
Contoh bahasa XML :
<?xml version=”1.0” encoding=”UTP-8” standalone=”yes”?>
<?xml:stylesheet type=”text/xsl” href=”staff_list.xsl”?>
<!DOCTYPE STAFFLIST SYSTEM “staff_list.dtd”>
<STAFFLIST>
<STAFF branchNo=”B005”>
<STAFFNO>SL21</ STAFFNO>
<NAME>

49
<FNAME>John</FNAME>
<LNAME>White</LNAME>
</NAME>
<POSITION>Manager</POSITION>
<DOB>1945-10-01</DOB>
<SALARY>30000</SALARY>
</STAFF>
<STAFF branchNo=”B003”>
<STAFFNO>SL37</ STAFFNO>
<NAME>
<FNAME>Ann</FNAME>
<LNAME>Beech</LNAME>
</NAME>
<POSITION>Assistant</POSITION>
<SALARY>12000</SALARY>
</STAFF>
</STAFFLIST>
2.6.1 Deklarasi XML
Sebuah file XML diawali dengan pilihan deklarasi XML, yang
menunjukkan versi XML yang digunakan oleh penulis dalam dokumen,
encoding system yang digunakan dan menentukan apakah ada deklarasi
external markup yang perlu dimasukkan. XML bersifat case-sensitive

50
(huruf kecil tidak sama dengan huruf besar). Artinya tag <price> dan
<Price> merupakan hal yang berbeda.
2.6.2 Elemen XML
Elemen, atau tag, adalah bentuk umum dalam markup. Elemen
pertama pasti adalah sebuah root element, yang dapat terdiri atas banyak
sub elemen lain. Sebuah dokumen XML harus mempunyai satu root
element. Root element contoh diatas adalah <STAFFLIST>. Setiap elemen
diawali dengan tag awal (<STAFF>) dan diakhiri dengan tag akhir
(</STAFF>). Sebuah elemen yang kosong ditunjukan dengan tag :
<EMPTYELEMENT/>.
Tag harus disarangkan dengan benar. Maksudnya adalah satu tag bisa
berada di dalam tag lain (disarangkan), namun tag pembuka dan tag
penutupnya harus berada di antara tag pembuka dan penutup dari tag yang
mengelilinginya. Contoh Tag bersarang:
<STAFF>
<NAME>
<FNAME>Ann</FNAME>
<LNAME>Beech</LNAME>
</NAME>
</STAFF>
Pada contoh tersebut, elemen NAME bersarang di dalam elemen STAFF,
elemen FNAME dan LNAME bersarang di dalam elemen NAME.

51
2.6.3 Atribut XML
Atribut adalah pasangan nama dan nilai yang mendeskripsikan
informasi tentang suatu elemen. Atribut diletakkan dalam tag awal setelah
nama elemen dan nilai atribut ada dalam tanda petik. Contoh : <STAFF
brachNo=”B005”>.
Jika sudah diberikan atribut maka dapat ditunjukkan elemen itu
adalah elemen yang kosong, contoh : <SEX gender=”M”/>
2.6.4 Entity References
Setiap entiti harus memiliki nama yang unik dan penggunaannya
dalam sebuah dokumen XML disebut dengan entity reference. Sebuah
entity reference diawali dengan tanda dan (&) dan diakhiri dengan titik
koma (;). Entity reference adalah karakter yang mengganti illegal character
di XML (http://www.w3schools.com/xml/xml_cdata.asp). Terdapat lima
predefined entity references pada XML, yaitu :
< < less than > > greater than & & ampersand ' ' Apostrophe " " quotation mark
Tabel 2. 12 Predefined entity references pada XML
Sumber : http://www.w3schools.com/xml/xml_cdata.asp

52
2.6.5 Komentar XML
Komentar pada XML menggunakan sintaks sama seperti komentar
pada HTML. Contoh:
<!-- ini adalah komentar -- >
Komentar ini dapat mengandung semua string kecuali ‘--‘.
2.6.6 CDATA Section dan Instruksi Proses
CDATA section memberitahu prosesor XML untuk melewati
karakter markup dan memberikan teks langsung ke aplikasi tanpa
melakukan interpretasi. Instruksi proses dapat digunakan untuk
menyediakan informasi ke sebuah aplikasi. Jika mengandung banyak
karakter < atau &, elemen XML bisa didefinisikan sebagai CDATA.
Contoh (http://www.w3schools.com/xml/xml_cdata.asp):
<script> <![CDATA[ function matchwo(a,b) { if (a < b && a < 0) then { return 1 } else { return 0 } } ]]> </script>
2.6.7 Urutan
Dalam XML urutan elemen sangatlah penting. Jadi, jika urutan elemen
berbeda maka akan dianggap sebagai data yang berbeda. Contoh :
<NAME>
<FNAME>John</FNAME>

53
<LNAME>White</LNAME>
</NAME>
akan berbeda dengan
<NAME>
<LNAME>White</LNAME>
<FNAME>John</FNAME>
</NAME>
Dalam XML urutan atribut tidak terpengaruh.
Contoh :
<NAME FNAME=”John” LNAME=”White”/>
<NAME LNAME=”White” FNAME=”John”/>
Dua elemen diatas akan dianggap sama oleh prosesor XML.
2.7 Parser
Setiap bahasa program mempunyai aturan-aturan yang memberikan
struktur sintaks dari program-program yang terbentuk baik. Sintaks suatu bahasa
program dapat digambarkan oleh notasi tata bahasa bebas konteks (Context-Free
Grammar). Tata bahasa bebas konteks adalah sebuah string yang dibentuk dari
himpunan simbol-simbol. Tata bahasa itu sendiri memberikan keuntungan besar
baik kepada perancang bahasa ataupun penulis kompilator. Keuntungan itu antara
lain :

54
1. Terhadap bahasa program itu sendiri, tata bahasa memberikan penjelasan
sintaks yang jelas dan mudah dimengerti.
2. Dari tata bahasa kelas tertentu, secara otomatis dapat dibentuk parser yang
efisien dan yang dapat menentukan apakah suatu program sumber
menuliskan sintaks dengan benar atau tidak.
3. Dari tata bahasa yang dirancang dengan baik, terbentuk suatu struktur pada
bahasa program yang berguna untuk pengubahan bahasa sumber menjadi
kode objek yang benar dan berguna untuk pendeteksian kesalahan.
4. Bahasa program berkembang dalam suatu periode waktu dengan
menampilkan construct baru dan menyajikan kemampuan tambahan.
Construct-construct ini dapat ditambahkan secara mudah ke dalam suatu
bahasa jika sudah ada implementasi yang berdasarkan deskripsi tata bahasa
dari bahasa itu (Aho, 1986, p157).
Parsing adalah proses menganalisa urutan token dengan tujuan untuk
menentukan struktur tata bahasanya dibandingkan dengan tata bahasa normal
yang diberikan (http://www.wikipedia.com). Proses ini secara formal disebut
analisis sintaks. Parser adalah sebuah program komputer yang menjalankan
tugas ini. Parser adalah sebuah program, biasanya bagian dari sebuah compiler,
yang menerima input dalam bentuk instruksi program sumber secara sekuensial,
perintah-perintah online yang interaktif, tag-tag markup, atau beberapa interface
terdefinisi lainnya, dan memecahkannya menjadi bagian-bagian
(http://www.whatis.com). Sebuah parser bisa juga mengecek apakah semua
input yang diperlukan sudah disediakan dengan lengkap dan sesuai.

55
2.8 Queue
Pada penulisan ini, queue akan digunakan untuk mengimplementasikan
schedule transaksi dan operasi didalamnya. Pada aplikasi ini, sebuah transaksi
dapat terdiri atas satu atau banyak operasi. Semua operasi didalam satu transaksi
akan disimpan ke dalam queue. Setiap operasi akan diproses sesuai prinsip queue.
Sebuah queue adalah sebuah daftar terurut di mana semua penambahan
data dilakukan pada ujung yang satu dan semua penghapusan data dilakukan
pada ujung sebaliknya (Horowitz, 2003, p104). Diberikan sebuah queue Q = (a0 ,
a1, … , an-1 ), a0 adalah elemen depan, an-1 adalah elemen belakang, dan ai+1
berada di belakang ai, 0≤ i ≤ n-1. Batasan pada sebuah queue berlaku jika kita
menambahkan data A, B, C, D , dengan urutan itu, maka A adalah elemen
pertama yang dihapus dari queue. Gambar 2.6 menggambarkan alur kejadian ini.
Karena elemen pertama yang ditambahkan ke dalam queue adalah elemen
pertama yang dihapus, queue juga dikenal sebagai daftar First-In-First-Out
(FIFO).
Gambar 2.6 Menambahkan dan menghapus elemen dalam sebuah queue
(rear = belakang , front = depan)
front
rear
rear
front front
rear
rear front
ABA
CBA
DCBA
DCB
rear
front

56
Representasi queue dalam lokasi sekuensial lebih sulit daripada stack.
Skema paling sederhana adalah menggunakan sebuah array satu dimensi dan dua
variabel, front dan rear. Dari representasi ini, operasi queue pada representasi
sebagai berikut :
Queue CreateQ(max_queue_size)::=
#define MAX_QUEUE_SIZE 100 /*Maximum queue size*/
typedef struct {
int key;
/* other fields */
} element;
element queue[MAX_QUEUE_SIZE];
int rear = -1;
int front = -1;
Boolean IsEmptyQ(queue)::= front == rear
structure Queue is
objects : sebuah daftar terurut terbatas pada nol atau lebih
elemen.
functions:
for all queue Є Queue, item Є element, max_queue_size Є
integer element
Queue CreateQ(max_queue_size) ::=
buat sebuah queue kosong yang ukuran maksimumnya
adalah
max_queue size
Boolean IsFullQ(queue,max_queue_size) ::=

57
if ( jumlah elemen dalam queue == max_queue_size )
return TRUE
else return FALSE
Queue AddQ(queue,item) ::=
if(IsFullQ(queue)) queue_full
else insert item at rear of queue and return queue
Boolean IsEmptyQ(queue) ::=
if ( queue==CreateQ(max_queue_size))
return TRUE
else return FALSE
Element DeleteQ(queue) ::=
if (isEmptyQ(queue)) return
else remove and return the item at front of queue
Tipe data abstrak queue
Boolean IsFullQ(queue) ::= rear == MAX_QUEUE_SIZE-1
Fungsi addq dan deleteq secara struktur mirip dengan add dan delete pada
stack. Stack menggunakan variabel top baik pada add maupun pada delete,
sedangkan queue menggeser posisi rear dalam addq dan front dalam deleteq.
Pemanggilan fungsi umum yaitu addq(&rear,item) ; dan
item=deleteq(&front,rear);. Perhatikan bahwa pemanggilan pada addq
mengirimkan alamat rear. Hal ini dilakukan sehingga modifikasi pada rear
bersifat permanen. Mirip dengan sebelumnya, pemanggilan deleteq mengirimkan
alamat front sehingga modifikasi pada front bersifat permanen. Alamat rear tidak

58
dikirim karena deleteq tidak memodifikasi rear, namun deleteq menggunakan
rear untuk mengecek adanya queue kosong atau tidak (Horowitz, 2003,p107).
Dalam perancangan conccurrency control ini, operasi – operasi yang ada
didalam transaksi akan disimpan dalam sebuah queue. Urutan eksekusi operasi
akan dilakukan sesuai urutan pada queue. Setiap transaksi akan memiliki satu
queue untuk semua operasi didalam transaksi tersebut.
2.9 Multi-User DBMS Architecture
Multi user system adalah sebuah sistem dimana banyak user bisa
mengakses database secara bersamaan (Date, 2000, p6). Untuk pengaksesan
bersamaan ini, dibutuhkan beberapa komputer yang terhubung dalam jaringan
dan berbentuk sebagai clien-server. Jaringan yang digunakan pada aplikasi ini
adalah berupa LAN (Local Area Network).
LAN adalah sebuah jaringan komputer yang dibatasi oleh area geografis
yang relatif kecil dan umumnya dibatasi oleh area lingkungan seperti
perkantoran atau sebuah sekolah (O’Brien, 2003, p189).
Terdapat beberapa multi-user DBMS architecture, yaitu Teleprocessing,
File-Server Architecture, Traditional Two-Tier Client-Server Architecture, dan
Three-Tier Client-Server Architecture (Connolly, 2005, p56). Arsitektur yang
digunakan pada penulisan ini adalah Traditional Two-Tier Client-Server
Architecture. Client-server yang dimaksud adalah sebuah arsitektur dimana
komponen dari perangkat lunak berinteraksi untuk membentuk sebuah sistem.
Pada arsitektur ini terdapat satu atau banyak client yang memerlukan sumber
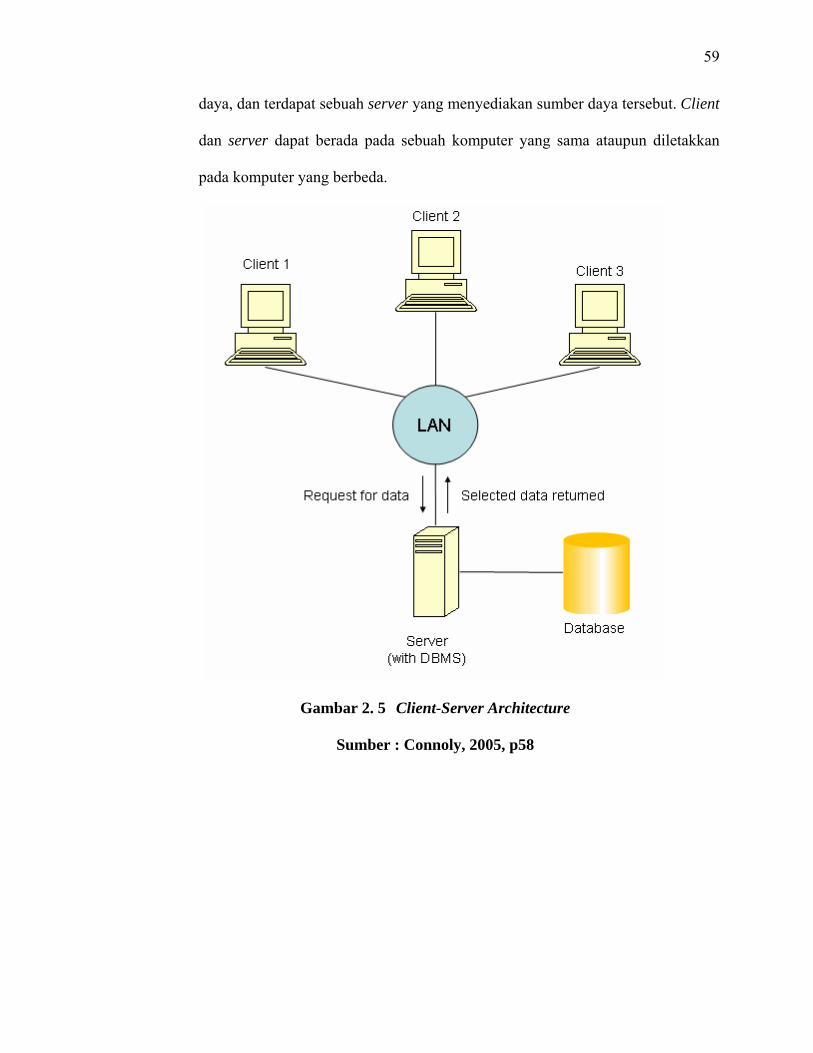
59
daya, dan terdapat sebuah server yang menyediakan sumber daya tersebut. Client
dan server dapat berada pada sebuah komputer yang sama ataupun diletakkan
pada komputer yang berbeda.
Gambar 2. 5 Client-Server Architecture
Sumber : Connoly, 2005, p58

60
Client Server
Menangani User Interface Menerima dan memproses
database request dari banyak
client
Menerima dan mengecek sintaks
dari inputan user
Mengecek authorization
Memproses application logic Memastikan integrity constraint
Menghasilkan database request dan
mengirimkannya kepada server
Memproses Query Processing dan
mengirim response kepada client
Mengirim response kembali kepada
user
Melakukan maintain terhadap
system catalog
Mengatur concurrent database
access
Mengatur recovery control
Tabel 2. 13 Client-server functions
Sumber : Connoly, 2005, p60
Terdapat banyak keuntungan dari tipe arsitektur ini, diantaranya :
- Memungkinkan akses yang lebih luas pada database-database yang ada.
- Meningkatkan kinerja – jika client dan server berada pada komputer yang
berbeda, maka CPU yang berbeda dapat memproses aplikasi-aplikasi secara
paralel. Dengan cara ini juga akan lebih memudahkan untuk mengeset server
machine jika tugasnya hanya untuk melaksanakan database processing.

61
- Biaya hardware dapat dikurangi – hanya server yang memerlukan storage dan
processing power yang cukup untuk menyimpan dan mengatur database.
- Biaya komunikasi dapat dikurangi – aplikasi telah menangani sebagian operasi
pada client dan hanya mengirimkan request untuk database access melalui
jaringan, yang membuat data yang dikirimkan melalui jaringan hanya sedikit.
- Meningkatkan konsistensi – server dapat menangani integrity check, jadi
constraint hanya perlu didefinisikan dan divalidasi pada satu tempat. Hal ini
tentu saja lebih baik dibandingkan masing-masing aplikasi harus melakukan
pengecekan masing-masing.
- Arsitektur ini dapat direpresentasikan pada sistem arsitektur terbuka secara
cukup natural.




















