
ARTIKEL MODEL KLASIFIKASI PROSIDING...
11
ARTIKEL MODEL KLASIFIKASI PROSIDING BERDASARKAN ABSTRAK UNTUK PENYUSUNAN LETAK SKRIPSI MENURUT BIDANG KAJIAN Oleh: ANGGA CAHYO PRADIKDO 14.1.03.03.0096 Dibimbing oleh : 1. Erna Daniati M.Kom 2. Teguh Andriyanto S.T, M.Cs PROGRAM STUDI SISTEM INFORMASI FAKULTAS TEKNIK UNIVERSITAS NUSANTARA PGRI KEDIRI 2018
Transcript of ARTIKEL MODEL KLASIFIKASI PROSIDING...

ARTIKEL
MODEL KLASIFIKASI PROSIDING BERDASARKAN ABSTRAK
UNTUK PENYUSUNAN LETAK SKRIPSI
MENURUT BIDANG KAJIAN
Oleh:
ANGGA CAHYO PRADIKDO
14.1.03.03.0096
Dibimbing oleh :
1. Erna Daniati M.Kom
2. Teguh Andriyanto S.T, M.Cs
PROGRAM STUDI SISTEM INFORMASI
FAKULTAS TEKNIK
UNIVERSITAS NUSANTARA PGRI KEDIRI
2018


Artikel Skripsi
Universitas Nusantara PGRI Kediri
Angga Cahyo Pradikdo | 14.1.03.03.0096 Teknik – Sistem Informasi
simki.unpkediri.ac.id || 2||
MODEL KLASIFIKASI PROSIDING BERDASARKAN ABSTRAK
UNTUK PENYUSUNAN LETAK SKRIPSI
MENURUT BIDANG KAJIAN
Angga Cahyo Pradikdo
14.1.03.03.0096
Fak Teknik – Prodi Sistem Informasi
Email : [email protected]
Erna Daniati, M.Kom dan Teguh Andriyanto S.T, M.Cs
UNIVERSITAS NUSANTARA PGRI KEDIRI
ABSTRAK
Penelitian ini dilatar belakangi hasil pengamatan pada dokumen skripsi di Program Studi Sistem
Informasi Universitas Nusantara PGRI Kediri. Penulis menemukan suatu masalah yang layak untuk
diteliti yaitu dokumen penelitian ilmiah atau skripsi sebagian besar masih belum tertata dan belum
ada pengklasifikasian dokumen penelitian ilmiah atau skripsi sesuai bidang kajian, yang dapat
memudahkan mahasiswa ketika ingin mencari referensi dari skripsi. Penelitian dikerjakan
menggunakan penelitian Action Research menerapkan 10 siklus, didukung dengan teknik
pemprosesan Text Mining dan menggunakan Algoritma naive bayes sebagai perhitungan untuk
mencari probabilitas dokumen.Hasil pengujian 10 siklus menghasilkan 3 pengetahuan model
klasifikasi terbaik antara lain : Berdasarkan Confusion Matrik . Berdasarkan cross validation dan
Model terbaik dengan berdasarkan 2 pengujian validasi cross validation dan confusion matrik
berdasarkan selisih terkecil dengan nilai tertinggi ialah siklus ke 2 dengan selisih 0,33%. Berdasarkan
hasil pengujian, penulis menerapkan pada jurnal skipsi sebagai penjawab dari rumusan masalah di
peneitian ini.
KATA KUNCI :
Text Mining, Algoritma, Naive Bayes Classifier, Prosiding, Klasifikasi, Tata Letak,
Skripsi.
I. LATAR BELAKANG
Perkembangan teknologi telah
membuat banyak informasi. Informasi-
informasi tersebut tertuang dalam bentuk
dokumen terutama dokumen digital.
Semakin banyak informasi yang ada maka
semakin banyak dokumen-dokumen yang
digunakan, untuk dapat mengorganisir
informasi-informasi tersebut dengan
mudah, maka dibutuhkan klasifikasi
dokumen secara otomatis.
Dokumen teks dalam bentuk digital
telah berkembang sangat pesat salah satu
dari dokumen teks ialah prosiding, dapat
dikatakan prosiding memiliki kekhususan
topik dan merupakan hasil dari konferensi
ilmiah, maka prosiding dapat diandaikan
seperti makalah-makalah seminar yang

Artikel Skripsi
Universitas Nusantara PGRI Kediri
Angga Cahyo Pradikdo | 14.1.03.03.0096 Teknik – Sistem Informasi
simki.unpkediri.ac.id || 3||
dikumpulkan kemudian diterbitkan.
Prosiding biasanya didistribusikan dalam
volume cetak atau elektronik, sebelum
konferensi dibuka atau setelah
ditutup. Prosesi biasanya berisi kontribusi
yang dibuat oleh para periset di konferensi
tersebut. Prosiding adalah catatan tertulis
dari karya yang dipresentasikan kepada
sesama peneliti di banyak bidang. Kualitas
makalah biasanya dipastikan dengan
meminta orang luar membaca surat kabar
sebelum diterima dalam persidangan.
Kebutuhan akan informasi terkait
pemrosesan data berupa nominal maupun
numerik yang semakin meningkat juga
menjadi faktor penting yang melatar
belakangi penulis membuat suatu
penelitian dengan memanfaatkan dokumen
prosiding sebagai bahan penelitian untuk
melakukan klasifikasi prosiding, dengan
tujuan untuk mengekstrak himpunan
dokumen yang tidak terstruktur ke dalam
kategori-kategori yang menggambarkan isi
dokumen. Pengklasifikasian dokumen
menjadi hal yang sangat penting untuk
mengorganisasikan dokumen sehingga
dapat memudahkan pencarian dan
menghemat tenaga dan waktu dalam
pencarian suatu dokumen.
Model klasifikasi bertujuan untuk
menemukan suatu pola atau pengetahuan
yang bermanfaat dan dapat digunakan
terkait dengan data terstruktur maupun
tidak terstruktur, disini penulis
memanfaatkan model klasifikasi data tidak
terstruktur untuk penyusunan letak skripsi
sesuai bidang kajian. Dimana skripsi
merupakan data yang tidak terstruktur,
karena pada dasarnya data tidak terstruktur
ialah teks, file, video, email, presentasi
power point dan pesan suara. Skripsi
merupakan data tidak terstruktur karena
berbentuk teks yang dapat berupa tipe
apapun tanpa mengikuti format, aturan
atau alur tertentu.
Penyusunan merupakan salah satu
kegiatan untuk membuat proses pencarian
dan pengelompokan menjadi lebih
terstruktur, disini penulis ingin melakukan
penyusunan letak terhadap skripsi sesuai
bidang kajian yang mana skripsi memiliki
beberapa kategori bidang kajian yang
berbeda sehingga dengan penyusunan letak
skripsi ini diharapakan skripsi dapat
tersusun dan terklasifikasi dengan baik
yang bermanfaat bagi penelitian untuk
mencari bahan referensi untuk penelitian.
Penyusunan tata letak menjadi
permasalahan yang serius apabila terkait
dengan dokumen. Dengan tata letak,
penyusunan akan menjadi lebih teroganisir
akan tetapi dalam penyusunan tata letak
dokumen butuh proses pengkategorian atau
pengklasifikasian supaya dokumen mudah
di susun dan di letakan di tempat yang
seharusnya, dengan melakukan observasi

Artikel Skripsi
Universitas Nusantara PGRI Kediri
Angga Cahyo Pradikdo | 14.1.03.03.0096 Teknik – Sistem Informasi
simki.unpkediri.ac.id || 4||
atau pengamatan penulis menemukan suatu
masalah pada Program Studi Sistem
Informasi Universitas Nusantara PGRI
Kediri, yang layak untuk diteliti yaitu
dokumen penelitian ilmiah atau skripsi
sebagian besar masih belum tertata dan
belum ada pengklasifikasian dokumen
penelitian ilmiah atau skripsi sesuai bidang
kajian, yang dapat memudahkan
mahasiswa ketika ingin mencari referensi
dari skripsi.
Sesuai dengan dokumen digital
Prosiding Seminar Nasional Teknologi
Informasi dan Multimedia 2017 STMIK
AMIKOM Yogyakarta, pada 4 Februari
2017, Penulis mendapatkan ide untuk
melakukan penelitian text mining dengan
menggunakan sampel Prosiding Seminar
Nasional Teknologi Informasi dan
Multimedia 2017 STMIK AMIKOM
Yogyakarta untuk membuat “MODEL
KLASIFIKASI PROSIDING
BERDASARKAN ABSTRAK UNTUK
PENYUSUNAN LETAK SKRIPSI
MENURUT BIDANG KAJIAN” dimana
skripsi memiliki kategori bidang kajian
yang berbeda. Dengan harapan model
klasifikasi ini nantinya dapat sesuai untuk
penyusunan tata letak skripsi sesuai bidang
kajian di Program Studi Sistem Informasi
Universitas Nusantara PGRI Kediri
II. METODE
Menurut (Kao & Poteet, 2007) text
mining adalah penemuan dan ekstraksi
pengetahuan yang menarik dan tidak
sepele dari teks bebas atau tidak
terstruktur. Ini mencakup segala sesuatu
mulai dari pengambilan informasi yaitu
pengambilan dokumen atau pengambilan
situs web) untuk klasifikasi dan
pengelompokkan teks, untuk (agak lebih
baru) entitas, relasi, dan ekstraksi
peristiwa.
Metode Naive Bayes Classifier
(NBC) menempuh dua tahap dalam proses
klasifikasi teks, yaitu tahap pelatihan dan
tahap klasifikasi. Pada tahap pelatihan
dilakukan proses analisis terhadap sampel
dokumen berupa pemilihan vocabulary,
yaitu kata yang mungkin muncul dalam
koleksi dokumen sampel yang sedapat
mungkin dapat menjadi representasi
dokumen. Selanjutnya adalah penentuan
probabilitas prior bagi tiap kategori
berdasarkan sampel dokumen. Pada tahap
klasifikasi ditentukan nilai kategori dari
suatu dokumen berdasarkan term yang
muncul dalam dokumen yang diklasifikasi.
Klasifikasi NBC dilakukan dengan
cara mencari probabilitas dari kategori Vj
dan kata-kata dalam dokumen dengan
rumus :

Artikel Skripsi
Universitas Nusantara PGRI Kediri
Angga Cahyo Pradikdo | 14.1.03.03.0096 Teknik – Sistem Informasi
simki.unpkediri.ac.id || 5||
Vmap =
argmaxvjϵvP(Vj) ∏ Pi (ai|Vj)...
(2.6)
𝑃(𝑉𝑗) =𝑑𝑜𝑐𝑠𝑗
𝐶𝑜𝑛𝑡𝑜ℎ ............(2.7)
𝑃(𝑊𝑘|𝑉𝑗) =𝑛𝑘+1
𝑛+|𝑣𝑜𝑐𝑎𝑏𝑢𝑙𝑎𝑟𝑦| (2.8)
Confusion matrix melakukan pengujian
untuk memperkirakan obyek yang benar
dan salah.
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 =𝑇𝑃+𝑇𝑁
TP+TN+FP+FN...(2.9)
Sensitivitas dan spesifitas tidak
memberikan informasi untuk nilai
diagnosa yang benar. Maka perlu adanya
Precision untuk menghitung ketepatan
antara informasi yang diminta dengan
jawaban yang di berikan sistem dengan
rumus :
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 =𝑇𝑃
TP+FP....(2.10)
Dan membutuhkan Recall untuk
menilai tingkat keberhasilan sistem dalam
menemukan kembali sebuah informasi
dengan rumus :
𝑅𝑒𝑐𝑎𝑙𝑙 =𝑇𝑃
TP+FN....(2.11)
Tingkat kesalahan diperoleh dari
persamaan
𝑇𝑖𝑛𝑔𝑘𝑎𝑡 𝑘𝑒𝑠𝑎𝑙𝑎ℎ𝑎𝑛 =
𝐹𝑁
TP+FN+FP+TN.....(2.12)
Keterangan Rumus (2.9), (2.10), (2.11),
(2.12) :
TP = true positif yang diklasifikasikan
positif.
TN = true negatif yang diklasifikasikan
negatif.
FP = false positif yang diklasifikasikan
negatif.
FN = false negatif yang diklasifikasikan
positif. (Zaki & JR, 2014)
3.3. Metode Analisis Data
1. Data Selection
a) Data yang digunakan dalam
penelitian ini ialah dokumen
prosiding STMIK AMIKOM
Yogyakarta.
b) Dokumen prosiding tersebut
merupakan kumpulan dari
jurnal-jurnal penelitian yang
memiliki beberapa atribut
“judul, abstrak, latar belakang,
landasan teori, metode penelitian
dan memiliki kategori class
bidang teknik” di dalam
penelitian ini menggunakan
“abstrak” sebagai atribut
penelitian.
c) Periode data yang digunakan
yaitu 4 Februari 2017.
d) Jumlah data yang digunakan
dalam teknik analisa ialah 203
dokumen.
2. Pre processing
Tahapan dari pemrosesan awal
dokumen yang dilakukan ialah :

Artikel Skripsi
Universitas Nusantara PGRI Kediri
Angga Cahyo Pradikdo | 14.1.03.03.0096 Teknik – Sistem Informasi
simki.unpkediri.ac.id || 6||
a) Case Folding ( Merubah huruf
menjadi lowercase )
b) Tokenize ( Merubah kalimat
menjadi kata-kata dan
menghilangkan tanda baca dan
angka )
3. Tranformation
Tahapan setelah Pre
processing menggubah data
menjadi model yang dapat
digunakan dalam penelitian.
a) Stemming ( Merubah kata
menjadi kata dasar sesuai
Kamus Besar Bahasa Indonesia
)
b) Filtering ( Menyaring kata-kata
penting hasil dari tokenize )
tahap filtering dapat
menggunakan teknik Stopword
( Penghapusan kata
penghubung seperti di, ke, dll )
dan Token Filtering
(Mengambil kata berdasarkan
kecocokan antara keluaran kata
dengan list yang digunakan).
c) Pembobotan kata dengan
Term Frequency
4. Evaluasi dan Interpretasi
Berikut ini merupakan
langkah-langkah yang akan di
kerjakan di dalam penelitian
untuk membuat suatu model
klasifikasi :
a) Cross Validation
Setiap kelas pada kelompok
data harus diwakili dalam
proporsi yang tepat antara
training dan data testing. Data
dibagi secara acak pada
masing-masing kelas dengan
perbandingan yang sama.
Untuk mengurangi bias yang
disebabkan oleh sampel
tertentu, seluruh proses training
dan testing di ulangi beberapa
kali dengan sampel yang
berbeda. Tingkat kesalahan
pada iterasi yang berbeda akan
dihitung rata-ratanya untuk
menghasilkan error rate secara
keseluruhan. Model yang
memberikan rata-rata
kesalahan terkecil adalah
model yang terbaik. (Zaki &
JR, 2014)
b) Confusion Matrix
Confusion matrix
melakukan pengujian untuk
memperkirakan obyek yang
benar dan salah. Dengan
menggunakan rumus (2.9) ,
(2.10) , (2.11) , (2.12)
Pengujian evaluasi untuk
mengukur akurasi dari model-
model yang diteliti
Artikel Skripsi
Universitas Nusantara PGRI Kediri
Angga Cahyo Pradikdo | 14.1.03.03.0096 Teknik – Sistem Informasi
simki.unpkediri.ac.id || 7||
menggunakan software RapidMiner.
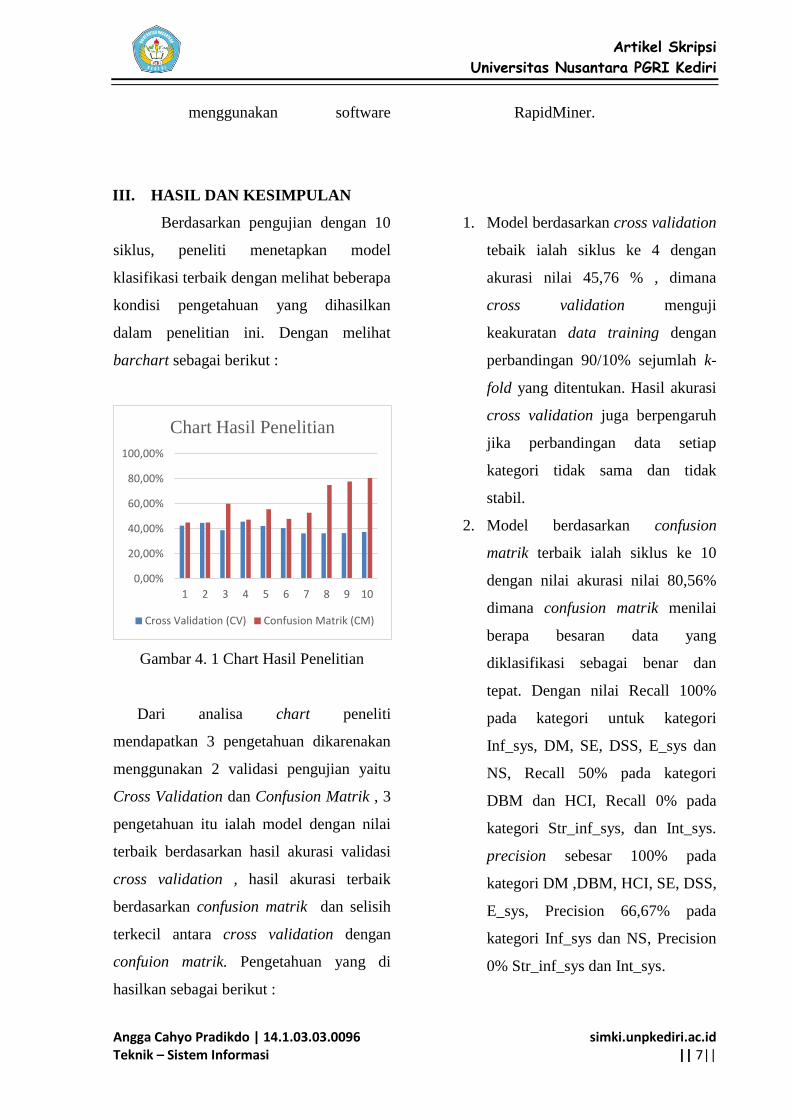
III. HASIL DAN KESIMPULAN
Berdasarkan pengujian dengan 10
siklus, peneliti menetapkan model
klasifikasi terbaik dengan melihat beberapa
kondisi pengetahuan yang dihasilkan
dalam penelitian ini. Dengan melihat
barchart sebagai berikut :
Gambar 4. 1 Chart Hasil Penelitian
Dari analisa chart peneliti
mendapatkan 3 pengetahuan dikarenakan
menggunakan 2 validasi pengujian yaitu
Cross Validation dan Confusion Matrik , 3
pengetahuan itu ialah model dengan nilai
terbaik berdasarkan hasil akurasi validasi
cross validation , hasil akurasi terbaik
berdasarkan confusion matrik dan selisih
terkecil antara cross validation dengan
confuion matrik. Pengetahuan yang di
hasilkan sebagai berikut :
1. Model berdasarkan cross validation
tebaik ialah siklus ke 4 dengan
akurasi nilai 45,76 % , dimana
cross validation menguji
keakuratan data training dengan
perbandingan 90/10% sejumlah k-
fold yang ditentukan. Hasil akurasi
cross validation juga berpengaruh
jika perbandingan data setiap
kategori tidak sama dan tidak
stabil.
2. Model berdasarkan confusion
matrik terbaik ialah siklus ke 10
dengan nilai akurasi nilai 80,56%
dimana confusion matrik menilai
berapa besaran data yang
diklasifikasi sebagai benar dan
tepat. Dengan nilai Recall 100%
pada kategori untuk kategori
Inf_sys, DM, SE, DSS, E_sys dan
NS, Recall 50% pada kategori
DBM dan HCI, Recall 0% pada
kategori Str_inf_sys, dan Int_sys.
precision sebesar 100% pada
kategori DM ,DBM, HCI, SE, DSS,
E_sys, Precision 66,67% pada
kategori Inf_sys dan NS, Precision
0% Str_inf_sys dan Int_sys.
0,00%
20,00%
40,00%
60,00%
80,00%
100,00%
1 2 3 4 5 6 7 8 9 10
Chart Hasil Penelitian
Cross Validation (CV) Confusion Matrik (CM)

Artikel Skripsi
Universitas Nusantara PGRI Kediri
Angga Cahyo Pradikdo | 14.1.03.03.0096 Teknik – Sistem Informasi
simki.unpkediri.ac.id || 8||
3. Model terbaik berdasarkan 2
pengujian validasi cross validation
dan confusion matrik berdasarkan
selisih terkecil dengan nilai
tertinggi ialah siklus ke 2 dengan
selisih 0,33%.
IV. PENUTUP
KESIMPULAN
1. Dengan memanfaatkan data
prosiding STMIK AMIKOM
Yogyakarta 2017 dan teknik text
mining diantaranya prepocesing
dan trasformation dengan
didukung dengan algoritma naive
bayes sebagai proses untuk
menghitung nilai probabiliitas
tertinggi sebagai proses klasifikasi
yang akan digunakan untuk
menguji beberapa pengujian untuk
menghasilkan model terbaik
supaya tata letak skripsi dapat
tertata dan teroganisir.
2. Dari hasil pengujian 10 siklus
menghasilkan 3 pengetahuan
model klasifikasi terbaik antara
lain : berdasarkan Confusion
Matrik , berdasarkan cross
validation dan Model terbaik
berdasarkan 2 pengujian validasi
cross validation dan confusion
matrik berdasarkan selisih terkecil
dengan nilai tertinggi ialah siklus
ke 2 dengan selisih 0,33%. telah
diterapkan di tabel 4.5, 4.6, dan
4.7 berhasil mendapatkan prediksi
klasifikasi sebagai pembantu
supaya dokumen skripsi dapat
tertata dan teroganisir sesuai
bidang kajian supaya dapat
membantu mahasiswa untuk
mencari referensi dari skripsi di
program studi Sistem Informasi
Universitas Nusantara PGRI
Kedir
SARAN
1. Penelitian selanjutnya dapat
ditambah Jumlah dokumen yang
dijadikan data training dan
memperhatikan kestabilan jumlah
data perkategori jika menggunakan
kategori multilabel .
2. Penelitian ini dapat dikembangkan
dengan menggunakan Software lain
untuk membandingkan hasil seperti
WEKA ataupun software yang lain.
V. DAFTAR PUSTAKA
Amborowati, A., Setiaji, B., Utama, H.,
Fatkhurohman, A., Hartatik, & Wulansari,

Artikel Skripsi
Universitas Nusantara PGRI Kediri
Angga Cahyo Pradikdo | 14.1.03.03.0096 Teknik – Sistem Informasi
simki.unpkediri.ac.id || 9||
B. (2017). Prosiding Seminar Nasional
Teknologi Informasi dan Multimedia 2017.
Yogyakarta: Panitia Semnasteknomedia.
C, D. A., Baskoro, D. A., Ambarwati, L.,
& Wicaksana, W. S. (2013). Belajar Data
Mining dengan RapidMiner. Jakarta.
Daniati, E. (2012). Klasifikasi Jenis
Bimbingan Dan Konseling Siswa SMKN 1
Kediri Menggunakan Naive Bayes
Classifier Dan Nearest Neighbor.
Nusantara of Engginering (NoE)/Vol.
1/No. 2/ISSN: 2355-6684, 22-27.
Feldman, R., & Sanger, J. (2007). The Text
Mining HandBook Advanced Approaches
in Analyzing Unstructured Data.
Cambridge: Cambridge University Press.
Hamzah, A. (2012). Prosiding Seminar
Nasional Aplikasi Sains & Teknologi
(SNAST) Periode III. KLASIFIKASI TEKS
DENGAN NAÏVE BAYES CLASSIFIER
(NBC) UNTUK PENGELOMPOKAN
TEKS BERITA DAN ABSTRACT
AKADEMIS, 269-277.
Hasibuan, Z. A. (2007). Metodologi
Penelitian Pada Bidang Ilmu Komputer
dan Teknologi Informasi. Depok: Fasilkom
Universitas Indonesia.
Heizer, J., & Render, B. (2009).
Manajemen Operasi Buku 1 Edisi 9.
Jakarta: Salemba.
Kao, A., & Poteet, S. R. (2007). Natural
Language Processing and Text Mining.
Washington: Springer.
Kurniawan, B., Effendi, S., & Sitompul, O.
S. (2012). JURNAL DUNIA
TEKNOLOGI INFORMASI Vol. 1, No. 1.
Klasifikasi Konten Berita Dengan Metode
Text Mining, 14-19.
LPPM. (2017). prosiding. Diambil kembali
dari http://lppm.stimaimmi.ac.id:
http://lppm.stimaimmi.ac.id/pengabdian-
masyarakat/prosiding/
Lumbanraja, F. R. (2013). Kumpulan
Makalah Seminar Semirata. Sistem
Pencarian Data Teks dengan
Menggunakan Metode Klasifikasi
Rocchio(Studi Kasus:Dokumen Teks
Skripsi), 217-224.
Ma’arif, M. R. (2016). JISKa, Vol. 1, No.
2. PERBANDINGAN NAÏVE BAYES
CLASSIFIER DAN SUPPORT VECTOR
MACHINE UNTUK KLASIFIKASI
JUDUL ARTIKEL, 90 – 93.
Mulyatiningsing, E. (2011). Riset Terapan
Bidang Pendidikan dan teknik.
Yogyakarta: UNY Press.
Rodiyansyah, S. F., & Winarko, E. (2013).
IJCCS, Vol.7, No.1. Klasifikasi Posting
Twitter Kemacetan Lalu Lintas Kota
Bandung Menggunakan Naive Bayesian
Classification, 13-22.
Srivastava, A. N., & Sahami, M. (2009).
Text Mining Classification,Clustering, and
Applications. USA: CRC Press.
Yusra, Olivita, D., & Vitriani, Y. (2016).
Jurnal Sains, Teknologi dan Industri, Vol.

Artikel Skripsi
Universitas Nusantara PGRI Kediri
Angga Cahyo Pradikdo | 14.1.03.03.0096 Teknik – Sistem Informasi
simki.unpkediri.ac.id || 10||
14, No. 1. Perbandingan Klasifikasi Tugas
Akhir Mahasiswa Jurusan Teknik
Informatika Menggunakan Metode Naïve
Bayes Classifier dan K-Nearest Neighbor,
79 - 85.
Zaki, M. J., & JR, W. M. (2014). Data
Mining and Analysis. New York:
Cambridge University Press.




















