
APLIKASI SPSS DALAM ANALISIS MULTIVARIATES
135
Transcript of APLIKASI SPSS DALAM ANALISIS MULTIVARIATES


K e a n e k a r a g a m a n H a y a t i | i
APLIKASI SPSS
DALAM ANALISIS MULTIVARIATES

ii| K e a n e k a r a g a m a n H a y a t i
Sanksi pelanggaran pasal 44: Undang-undang No. 7 Tahun 1987 tentang
Perubahan atas Undang-undang No. 6 Tahun 1982 tentang hak cipta.
1. Barang siapa dengan sengaja dan tanpa hak mengumumkan atau
memperbanyak suatu ciptaan atau memberi izin untuk itu dipidana dengan
pidana penjara paling lama 7 (tujuh) tahun dan/atau denda paling banyak
Rp. 100.000.000,- (seratus juta rupiah)
2. Barang siapa dengan sengaja menyiarkan, memamerkan, mengedarkan,
atau menjual kepada umum suatu ciptaan atau barang hasil pelanggaran
hak cipta sebagaimana dimaksud dalam ayat 1 (satu), dipidana dengan
pidana penjara paling lama 5 (Iima) tahun dan/atau denda paling banyak
Rp. 50.000.000,- (lima puluh juta rupiah)

K e a n e k a r a g a m a n H a y a t i | iii
APLIKASI SPSS
DALAM ANALISIS MULTIVARIATES
Penerbit
LPPM Universitas Bung Hatta
2020

iv| K e a n e k a r a g a m a n H a y a t i
Judul:
APLIKASI SPSS DALAM ANALISIS MULTIVARIATES
Penulis: Surya Dharma, Purbo Jadmiko, Elfitra Azliyanti
Sampul: Elfitra Azliyanti
Perwajahan: LPPM Universitas Bung Hatta
Diterbitkan oleh LPPM Universitas Bung Hatta, November 2020
Alamat Penerbit:
Gedung Rektorat Lt.III, Jl, Sumatra Ulak Karang Padang,
Sumbar, Indonesia. Telp. 0751-7051678 Ext.323, Fax. 0751-7055475
Email: [email protected]
Hak Cipta dilindungi Undang-undang
Dilarang mengutip atau memperbanyak sebagian atau seluruh
isi buku ini tanpa izin tertulis penerbit
Isi diluar tanggung jawab percetakan
Cetakan Pertama: November 2020
Perpustakaan Nasional RI: Katalog Dalam Terbitan (KDT)
Surya Dharma, Purbo Jadmiko, Elfitra Azliyanti
APLIKASI SPSS DALAM ANALISIS MULTIVARIATES
Padang: LPPM Universitas Bung Hatta, November 2020
124 Hlm + x; 18,2 cm ISBN: 978-623-93573-9-9

S a m b u t a n R e k t o r | v
SAMBUTAN REKTOR
UNIVERSITAS BUNG HATTA
isi Universitas Bung Hatta adalah menjadikan Universitas Bung Hatta
Bermutu dan terkemuka dengan misi utamanya meningkatkan mutu
sumberdaya manusia yang berada dalam jangkauan funsinya.
Mencermati betapa beratnya tantangan universitas Bung Hatta terhadap dampak
globalisasi, baik yang bersumber dari tuntutan internal dan eksternal dalam
meningkatkan daya saing lulusan perguruan tinggi, maka upaya peningkatan
kualitas lulusan universitas Bung Hatta adalah suatu hal yang harus di lakukan
dengan terencana dan terukur. Untuk mewujudkan hal itu universitas Bung Hatta
melalui lembaga Penelitian dan Pengabdian kepada masyarakat merancang program
kerja dan memberikan dana kepada dosen untuk menulis buku, karena kompetensi
seorang dosen tidak cukup hanya menguasai bidang ilmunya dengan kulaifikasi S2
dan S3 kita di tuntut untuk memahami elemen kompetensi yang bisa di aplikasi
dalam proses pembelajaran. Melakukan riset dan menuangkan dalam bentuk buku.
Saya ingin menyampaikan penghargaan kepada saudara Surya Dharma,
Purbo Jadmiko, Elfitra Azliyanti yang telah menulis buku “APLIKASI SPSS DALAM
ANALISIS MULTIVARIATES”. Harapan saya buku ini akan tetap eksis sebagai
wahana komunikasi bagi kelompok dosen dalam bidang ilmu “Ekonomi dan
Manajemen” sehingga dapat di jadikan sebagai sumber bahan ajar untuk mata
kuliah yang di ampu dan menambah kasanah ilmu pengetahuan mahasiswa.
Tantangan kedepan tentu lebih berat lagi, karena kendala yang sering di
hadapi dalam penulisan buku ini adalah tidak di punyainya hasil-hasil riset yang
bernas. Kesemuanya itu menjadi tantangan kita bersama terutama para dosen di
universitas Bung Hatta.
V

vi| S a m b u t a n R e k t o r
Demikianlah sambutan saya, sekali lagi saya ucapkan selamat atas
penerbitan buku ini. Semoga Tuhan Yang Maha Kuasa meridhoi segala upaya yang
kita perbuat bagi memajukan pendidikan di Universitas Bung Hatta.
Padang, November 2020
Rektor
Prof. Dr. Tafdil Husni, S.E.,M.B.A.

K a t a P e n g a n t a r | vii
KATA PENGANTAR
uji syukur tak terhingga penulis panjatkan kehadirat ALLAH SWT, atas
rahmat dan ridhonya meskipun dalam kondisi pandemik covid-19, penulis
akhirnya mampu menyelesaikan buku: Statistik Multivariate dengan
SPSS.
Penulisan buku ini merupakan momen penting bagi penulis setelah 20 tahun
membina mata kuliah Statistik dan Metode Penelitian di Program Studi Manajemen
FEB Universitas Bung Hatta Padang. Pengalaman dalam membimbing skripsi
mahasiswa, keikutsertaan di berbagai pelatihan analisis statistik dan kegiatan
penelitian−memotivasi penulis untuk menghasilkan sebuah buku yang mudah
dipahami agar pembaca selalu termotivasi untuk mengembangkan pengetahuan
melalui pemanfaatan perkembangan teknologi informasi.
Buku praktikum ini berasal dari modul perkuliahan Analisis Multivariate yang
dibina sejak tahun 2015. Agar bisa dipahami dengan mudah dan aplikati, buku ini
tidak membahas konsep matematis setiap alat analisis. Tiap bab disertai kasus
berupa masalah/pertanyaan penelitian, prosedur analisis secara statistik, tahapan
pengerjaan dengan program aplikasi hingga interprestasi ouput untuk pengambilan
keputusan.
Tiada gading yang tak retak, kesempurnaan hanya milik sang maha pencipta.
Penulis sangat mengharapkan kritik dan saran yang membangun dari seluruh
pembaca melalui: [email protected]. .
Semoga buku ini memberikan manfaat.
Padang, Oktober 2019
Tim Penulis
P

viii| K a t a P e n g a n t a r

D a f t a r I s i | ix
DAFTAR ISI
SAMBUTAN REKTOR UNIVERSITAS BUNG HATTA ......................................... v
KATA PENGANTAR ................................................................................................ vii
DAFTAR ISI ................................................................................................................ ix
BAB 1 PENGENALAN SPSS ........................................................................................ 1
BAB 2 DESKRIPSI VARIABEL BERDASARKAN SKALA PENGUKURAN ........ 11
BAB 3 STATISTIK INFERENSIA ............................................................................... 27
BAB 4 UJI HIPOTESIS KOMPARATIF DATA BERPASANGAN ........................... 43
BAB 5 PENGANTAR ANALISIS MULTIVARIATE (MANOVA) ........................... 51
BAB 6 PENGANTAR ANALISIS DISKRIMINAN .................................................... 55
BAB 7 ANALISIS FAKTOR EKSPLORATORI (EFA) .............................................. 63
BAB 8 ANALISIS FAKTOR CONFIRMATORY
(VALIDITAS KONSTRUK DAN RELIABILITAS) ....................................... 73
BAB 9 PENGANTAR ANALISIS CLUSTER (K-MEAN CLUSTER) ....................... 83
BAB 10 ANALISIS KORELASI DAN REGRESI ......................................................... 93
BAB 11 ANALISIS REGRESI DENGAN VARIABEL PEMODERASI
(SUB-GROUP) .................................................................................................. 99
BAB 12 ANALISIS REGRESI DENGAN VARIABEL PEMODERASI (MRA) ....... 107
BAB 13 ANALISIS REGRESI DENGAN VARIABEL PEMEDIASI
(ANALISIS JALUR) ....................................................................................... 113

x| D a f t a r I s i
P e n g e n a l a n S P S S |1
Bab 1 Pengenalan SPSS
Tujuan Instruksional:
1. Mampu mempersiapkan lembar kerja untuk pengisian data
2. Mampu menentukan tipe variabel yang cocok pada spss berdasarkan skala
pengukuran
3. Mampu membuat coding pada variabel yang berskala nominal dan ordinal
4. Mampu mengimpor data dari file lain menjadi data lembar kerja SPSS
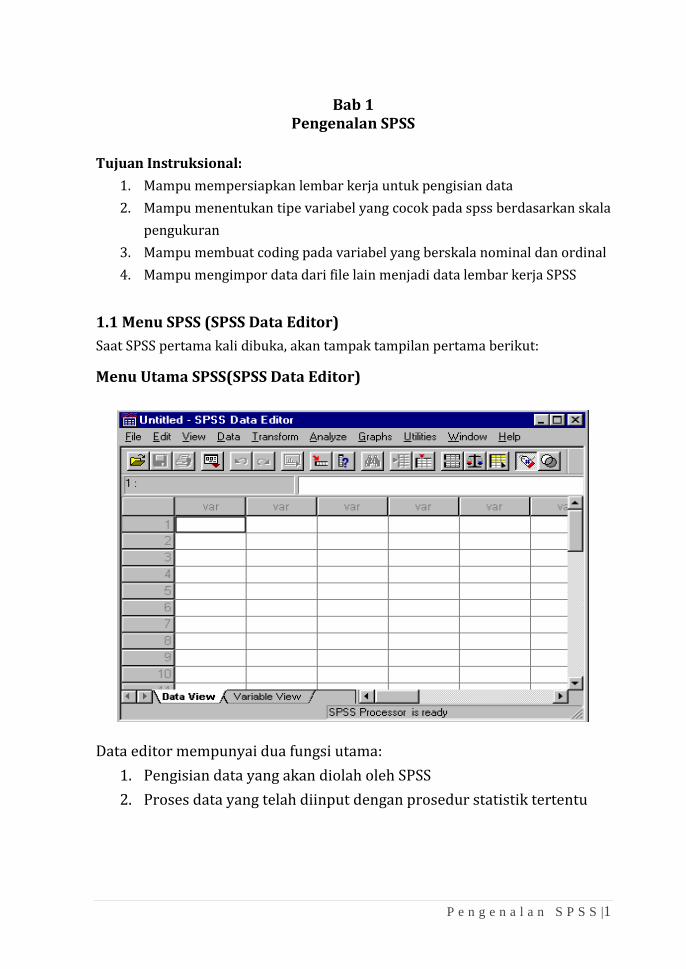
1.1 Menu SPSS (SPSS Data Editor)
Saat SPSS pertama kali dibuka, akan tampak tampilan pertama berikut:
Menu Utama SPSS(SPSS Data Editor)
Data editor mempunyai dua fungsi utama:
1. Pengisian data yang akan diolah oleh SPSS
2. Proses data yang telah diinput dengan prosedur statistik tertentu
2| P e n g e n a l a n S P S S
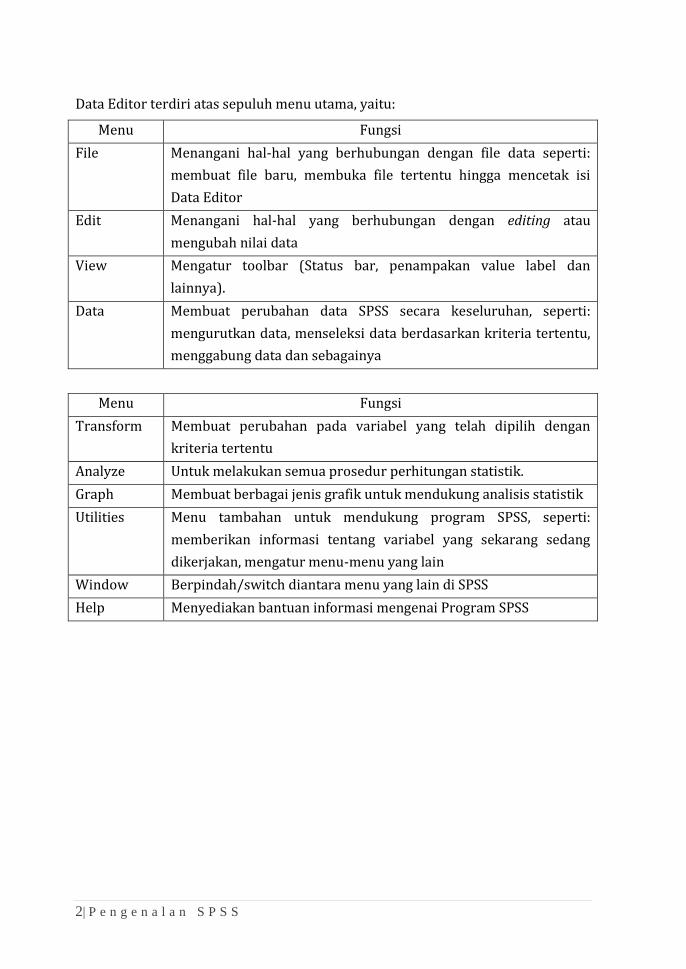
Data Editor terdiri atas sepuluh menu utama, yaitu:
Menu Fungsi
File Menangani hal-hal yang berhubungan dengan file data seperti:
membuat file baru, membuka file tertentu hingga mencetak isi
Data Editor
Edit Menangani hal-hal yang berhubungan dengan editing atau
mengubah nilai data
View Mengatur toolbar (Status bar, penampakan value label dan
lainnya).
Data Membuat perubahan data SPSS secara keseluruhan, seperti:
mengurutkan data, menseleksi data berdasarkan kriteria tertentu,
menggabung data dan sebagainya
Menu Fungsi
Transform Membuat perubahan pada variabel yang telah dipilih dengan
kriteria tertentu
Analyze Untuk melakukan semua prosedur perhitungan statistik.
Graph Membuat berbagai jenis grafik untuk mendukung analisis statistik
Utilities Menu tambahan untuk mendukung program SPSS, seperti:
memberikan informasi tentang variabel yang sekarang sedang
dikerjakan, mengatur menu-menu yang lain
Window Berpindah/switch diantara menu yang lain di SPSS
Help Menyediakan bantuan informasi mengenai Program SPSS
P e n g e n a l a n S P S S |3
Latihan 1
Membuat Variabel dan Mengisi Data
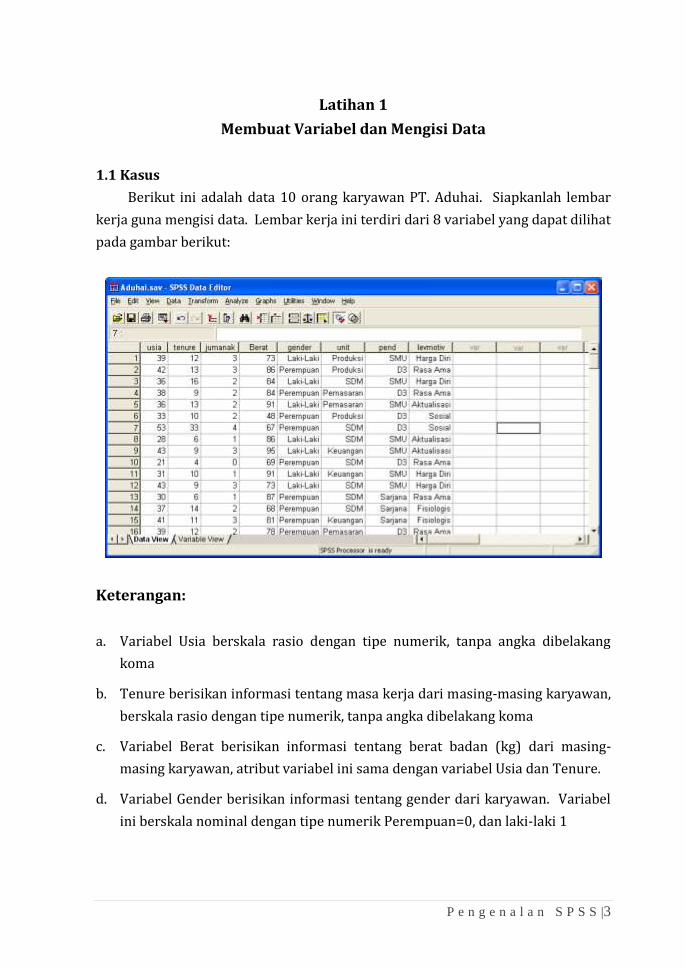
1.1 Kasus
Berikut ini adalah data 10 orang karyawan PT. Aduhai. Siapkanlah lembar
kerja guna mengisi data. Lembar kerja ini terdiri dari 8 variabel yang dapat dilihat
pada gambar berikut:
Keterangan:
a. Variabel Usia berskala rasio dengan tipe numerik, tanpa angka dibelakang
koma
b. Tenure berisikan informasi tentang masa kerja dari masing-masing karyawan,
berskala rasio dengan tipe numerik, tanpa angka dibelakang koma
c. Variabel Berat berisikan informasi tentang berat badan (kg) dari masing-
masing karyawan, atribut variabel ini sama dengan variabel Usia dan Tenure.
d. Variabel Gender berisikan informasi tentang gender dari karyawan. Variabel
ini berskala nominal dengan tipe numerik Perempuan=0, dan laki-laki 1

4| P e n g e n a l a n S P S S
e. Variabel Unit berisikan informasi tentang unit kerja dari masing-masing
karyawan. Variabel ini berskala nominal dengan tipe numerik yang terdiri
dari 4 jenis pilihan yaitu: Pemasaran=1, SDM=2, Produksi=3, dan Keuangan=4
f. Variabel Pend diisi dengan pendidikan terakhir dari masing-masing karyawan.
Variabel ini berskala ordinal dengan tipe numerik yang terdiri dari tiga pilihan
yaitu: Sarjana=3, D3=2, dan SMU=1
g. Variabel Levmotiv berisikan informasi tentang level motivasi dari tiap
karyawan. Variabel ini berskala ordinal dengan tipe numerik. Nilai level
motivasi berkisar dari 1 sampai 5, yaitu: Fisiologis=1, Rasa Aman=2, Sosial=3,
Harga Diri=4, dan Aktualisasi Diri=5.
1.2 Pengerjaan
Saat SPSS diaktifkan, layar yang aktif adalah Data View. Untuk mendefinisikan
atribut dari variabel yang dibuat, layar harus alihkan ke Variabel View dengan
cara mengklik Tab Variabel View. Pengalihan ini juga bisa dilakukan dengan cara
lain, yaitu melalui menu Bar View dengan mengklik menu Variables.
Setelah Tab Variabel Vew aktif, layar akan berubah menjadi seperti yang terlihat
pada gambar berikut:

P e n g e n a l a n S P S S |5
Berbeda dengan tampilan pada tab data view. Pada Tab ini kolom tidak lagi
tampil dengan nama Var, tapi menampilkan atribut dari tiap-tiap variabel. SPSS
secara default akan memberikan nama “var”. Untuk membuat secara spesifik
tentang nama dan atribut variabel, maka Tab Variabel View harus diaktifkan.
1.2.a Variabel Usia, Tenure, Jumanak dan berat
Variabel-Variabel ini berskala rasio dengan type numerik. Pada baris 1
(pertama), yang terlebih dahulu dilakukan adalah mengisi kolom/atribut
Name. Isikan Usia pada kolom name. Tipe variabel ditentukan dengan
cara:
❖ Klik tanda “…” pada pojok kanan, dan pilih numeric. Isikan angka 0
pada Decimal Place, kemudian isikan kolom label dengan “Usia”. Cara
yang sama juga dilakukan untuk variabel Tenure, Jumanak, dan berat.

6| P e n g e n a l a n S P S S
Kolom label digunakan untuk memberikan label pada variabel. SPSS
membatasi hanya 8 karakter untuk nama variabel tanpa spasi, karenanya
informasi lengkap tentang suatu variabel bisa dilakukan melalui label. Pemberian
label ini akan memudahkan user dalam memahami hasil analisis/ouput.
1.2.b Variabel gender, Unit, Pend, LevMot
Statistik digunakan untuk mengolah data kuantitatif, pengisian data dengan
menggunakan string/teks membuat analisis tidak bisa dilakukan. Karenanya
variabel-variabel berskala nominal atau ordinal harus diberikan kode sedemikian
rupa agar data tersebut memiliki pengkodean dalam bentuk angka/numerik.
❖ Ketikkan “gender” kolom name, kemudian aktifkan tanda ... pada kolom type
untuk menentukan type variabel ini. Seperti yang telah dijelaskan
sebelumnya, untuk keperluan pengkodeaan secara kuantitatif, variabel gender
berskala nominal bertype numerik. Oleh sebab itu pilih Numeric pada Tab
Variabel View, Decimal place bisa diabaikan saja, atau isikan dengan 0 jika
tidak memerlukan pecahan desimal.
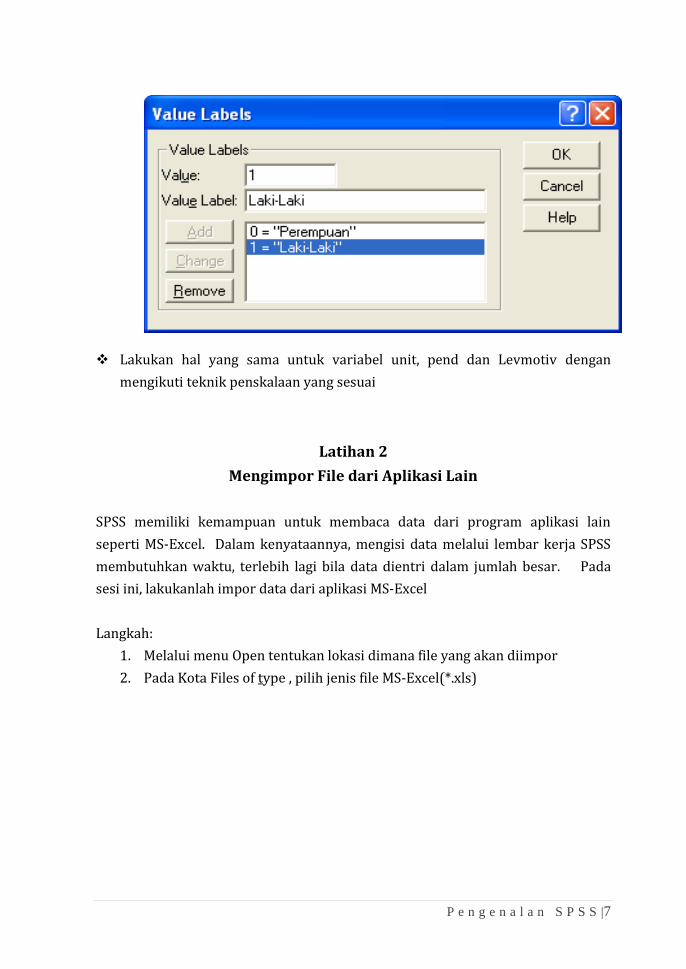
❖ Pada Kolom Values, isikan kode angka yang diinginkan. Pengkodean ini akan
sangat memudahkan karena saat mengisi data kita cukup mengetikkan angka
kode tanpa harus mengetik “Laki-Laki” atau “Perempuan”
P e n g e n a l a n S P S S |7
❖ Lakukan hal yang sama untuk variabel unit, pend dan Levmotiv dengan
mengikuti teknik penskalaan yang sesuai
Latihan 2
Mengimpor File dari Aplikasi Lain
SPSS memiliki kemampuan untuk membaca data dari program aplikasi lain
seperti MS-Excel. Dalam kenyataannya, mengisi data melalui lembar kerja SPSS
membutuhkan waktu, terlebih lagi bila data dientri dalam jumlah besar. Pada
sesi ini, lakukanlah impor data dari aplikasi MS-Excel
Langkah:
1. Melalui menu Open tentukan lokasi dimana file yang akan diimpor
2. Pada Kota Files of type , pilih jenis file MS-Excel(*.xls)
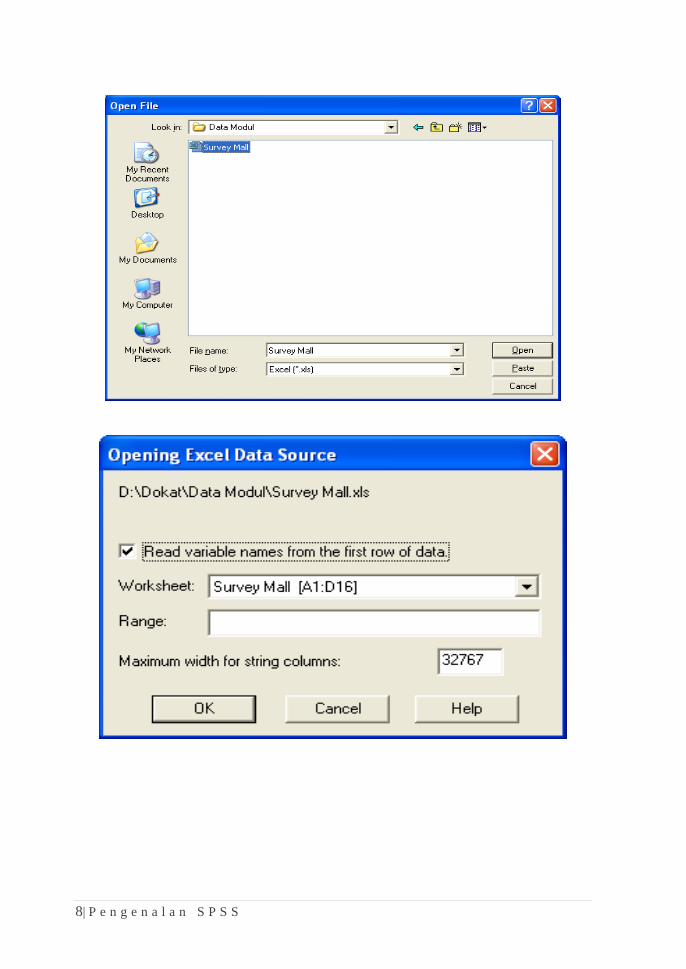
8| P e n g e n a l a n S P S S
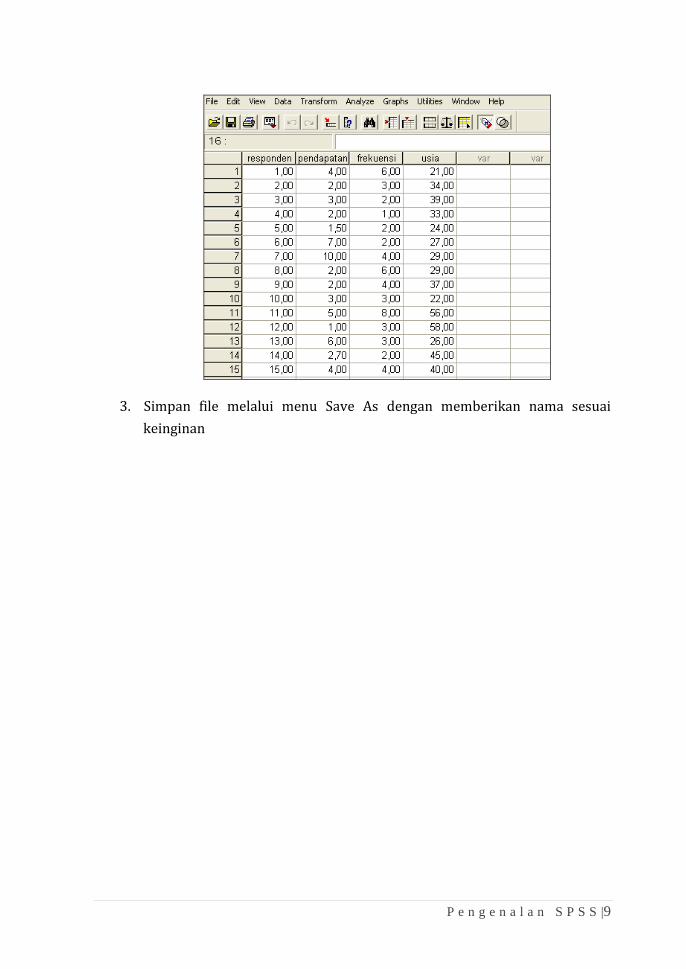
P e n g e n a l a n S P S S |9
3. Simpan file melalui menu Save As dengan memberikan nama sesuai
keinginan

P e n g e n a l a n S P S S |10

D e s k r i p s i V a r i a b e l B e r d a s a r k a n S k a l a P e n g u k u r a n |11
Bab 2
Deksripsi Variabel Berdasarkan Skala Pengukuran
Tujuan Instruksional:
1. Mampu mendeskripsikan variabel berskala nominal dan ordinal
2. Mampu mengeksplorasi data
3. Mampu mendeskripsikan variabel-variabel empiris dan persepsional
(skala interval maupun rasio) dengan melibatkan ukuran-ukuran gejala
pusat, ukuran lokasi, dan dispersi
4. Mampu menguji apakah variabel yang dideskripsikan memiliki distribusi
data yang normal atau tidak
Pengantar:
Statistik deskriptif merupakan metode statistika yang digunakan untuk
menggambarkan data numerik menjadi informasi statistik. Data mentah yang
belum diolah, tidak memberikan manfaat bagi yang menerimanya/pengguna.
Karena itu data harus diolah sedemikian rupa agar dihasilkan informasi statistik
baik berupa tabel ataupun grafik sehingga pengguna dapat memahaminya dengan
mudah. Selain tabel dan grafik, informasi statistik bisa disajikan melalui ukuran-
ukuran statistik. Beberapa ukuran statistik yang sering dipakai adalah:
1. Central tendency seperti: mean, median dan modus
2. Ukuran dispersi seperti standar deviasi dan varian
3. skewness dan kurtosis untuk mengetahui kemencengan/kemenjuluran
data.
2.1 Kasus:
File stres.sav berisikan data penelitian yang dilakukan dengan melibatkan 91
orang responden dengan berbagai latar belakang demografis. Penelitian ini
bertujuan untuk memberikan deskripsi tentang stres kerja yang dirasakan. Stres
kerja diukur dengan mempergunakan kuesioner yang diadopsi dari Kim (1996).
Kuesioner ini terdiri atas 14 pernyataan yang dikelompokkan menjadi 5 dimensi.

12| D e s k r i p s i V a r i a b e l B e r d a s a r k a n S k a l a P e n g u k u r a n
No Item
Pernyataan Dimensi
1 Saya tidak tahu apa yang menjadi tanggung jawab pekerjaan yang saya jalankan
Ambigiuitas Peran 2
Saya tahu dengan pasti apa yang diharapkan instansi dari saya sehubungan dengan pekerjaan yang saya terima
3 Saya mengalami konflik dalam menjalankan berbagai tugas yang diberikan atasan-atasan saya yang berlainan
Konflik Pekerjaan 4
Saya merasakan konflik dari tugas pekerjaan yang dibebankan oleh atasan langsung saya
5 Saya tidak punya cukup waktu untuk menyelesaikan semua pekerjaan saya Beban Pekerjaan
6 Beban tugas saya terlalu berat bagi saya
7 Saya harus bekerja super cepat dalam menyelesaikan pekerjaan saya
8 Saya tidak memiliki ruangan kerja yang memadai untuk menjalankan pekerjaan saya
Ketersediaan Sumber Daya &
Fasilitas
9 Saya memperoleh peralatan kantor yang memadai untuk bekerja
10 Saya mendapatkan dukungan layanan yang cukup untuk melaksanakan pekerjaan saya
11 Saya mengalami kesulitan memperoleh bahan-bahan habis pakai (Seperti: alat tulis) yang saya butuhkan dalam pekerjaan saya
12 Pekerjaan saya jarang membahayakan fisik saya
Tingkat Bahaya Pekerjaan
13 Pekerjaan saya sering menempatkan saya dalam kondisi tidak sehat (fisik maupun batin)
14 Kecelakaan kerja yang serius seringkali terjadi dalam pekerjaan saya
Dengan data yang ada , Anda diminta untuk mendeskipsikan:
1. Secara komprehensif tentang karakteristik demografis responden:
a. Status Menikah dan Status Bekerja Pasangan Menikah
b. Gender, Status Menikah dan Pendidikan
2. Stres Kerja secara keseluruhan
3. Stres kerja berdasarkan karakteristik demografis responden (Gender, Status
Menikah, Pendidikan)

D e s k r i p s i V a r i a b e l B e r d a s a r k a n S k a l a P e n g u k u r a n |13
2.2 Solusi:
Pada sesi ini akan dibahas prosedur Descriptive Statistics dengan sub-menu:
a. Frequencies yang membahas beberapa ukuran statistik deskriptif seperti
mean, median, kuartil, perecentil dan lainnya.
b. Descriptive yang berfungsi untuk mengetahui berbagai ukuran statistik
deskriptif seperti halnya dengan sub-menu Frequencies.
c. Explore untuk memeriksa lebih teliti sekelompok data (deskriptif
komparatif)
d. Crosstabs untuk menyajikan deskripsi data dalam bentuk tabulasi silang
yang terdiri atas baris dan kolom (inferensia atau induktif)
2.2.1 Informasi Demografis Responden (Crosstabs)
Tabulasi silang adalah suatu teknik memperbandingkan dua variabel berskala
non-metric(nominal atau ordinal.
Langkah pengerjaan:
Analyze > Descriptive Statistics > Crosstabs
2.2.1.a Status Menikah dan Status Bekerja Pasangan Menikah
Status Menikah * Pasangan Bekerja Crosstabulation
Count
37 0 37
31 23 54
68 23 91
Tidak Menikah
Menikah
Status Menikah
Total
Tidak Bekerja Bekerja
Pasangan Bekerja
Total

14| D e s k r i p s i V a r i a b e l B e r d a s a r k a n S k a l a P e n g u k u r a n
2.2.1.b Gender vs Status Menikah dan Pendidikan
Crosstabs
Gender * Status Menikah Crosstabulation
Count
22 50 72
15 4 19
37 54 91
Perempuan
Laki-Laki
Gender
Total
Tidak
Menikah Menikah
Status Menikah
Total
Gender * Pendidikan Crosstabulation
Count
18 22 22 10 72
5 6 3 5 19
23 28 25 15 91
Perempuan
Laki-Laki
Gender
Total
SLTA D3 Sarjana
Pasca
Sarjana
Pendidikan
Total
2.2.2 Deskripsi Stres Secara Umum
Data yang tersedia hanya berupa hasil pengukuran melalui item-item
pertanyaan pada kuesioner. Agar bisa dideskripsikan, terlebih dahulu harus
dibuat variabel baru yang merupakan penjumlahan dari ke 14 item pengukuran
D e s k r i p s i V a r i a b e l B e r d a s a r k a n S k a l a P e n g u k u r a n |15
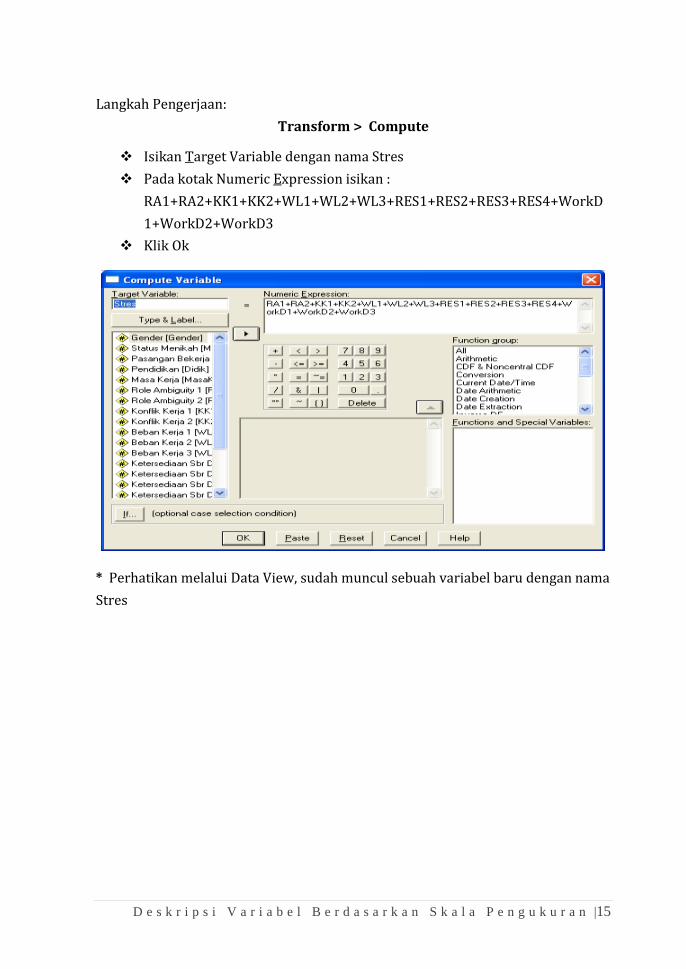
Langkah Pengerjaan:
Transform > Compute
❖ Isikan Target Variable dengan nama Stres
❖ Pada kotak Numeric Expression isikan :
RA1+RA2+KK1+KK2+WL1+WL2+WL3+RES1+RES2+RES3+RES4+WorkD
1+WorkD2+WorkD3
❖ Klik Ok
* Perhatikan melalui Data View, sudah muncul sebuah variabel baru dengan nama
Stres
16| D e s k r i p s i V a r i a b e l B e r d a s a r k a n S k a l a P e n g u k u r a n
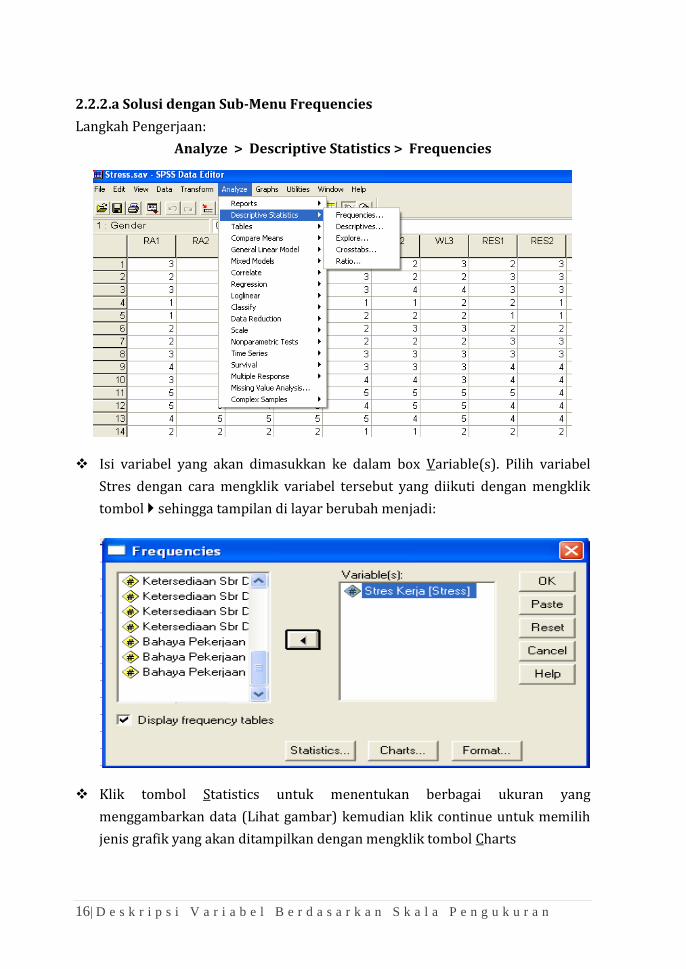
2.2.2.a Solusi dengan Sub-Menu Frequencies
Langkah Pengerjaan:
Analyze > Descriptive Statistics > Frequencies
❖ Isi variabel yang akan dimasukkan ke dalam box Variable(s). Pilih variabel
Stres dengan cara mengklik variabel tersebut yang diikuti dengan mengklik
tombol sehingga tampilan di layar berubah menjadi:
❖ Klik tombol Statistics untuk menentukan berbagai ukuran yang
menggambarkan data (Lihat gambar) kemudian klik continue untuk memilih
jenis grafik yang akan ditampilkan dengan mengklik tombol Charts

D e s k r i p s i V a r i a b e l B e r d a s a r k a n S k a l a P e n g u k u r a n |17
❖ Klik tombol Charts berikan aktifkan Histogram dan With normal curve, klik
continue
Output
Statistics
Stres Kerja
91
0
43,55
47,00
35a
14,875
221,273
-,149
,253
-1,181
,500
49
19
68
3963
34,00
47,00
57,00
Valid
Missing
N
Mean
Median
Mode
Std. Deviation
Variance
Skewness
Std. Error of Skewness
Kurtosis
Std. Error of Kurtosis
Range
Minimum
Maximum
Sum
25
50
75
Percentiles
Multiple modes exis t. The smallest value is showna.
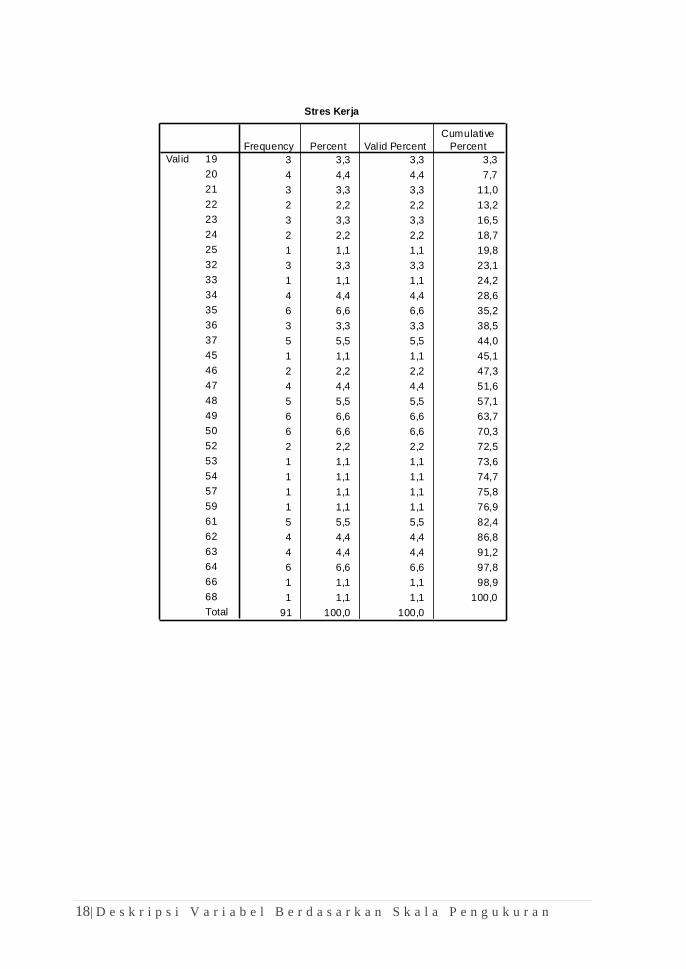
18| D e s k r i p s i V a r i a b e l B e r d a s a r k a n S k a l a P e n g u k u r a n
Stres Kerja
3 3,3 3,3 3,3
4 4,4 4,4 7,7
3 3,3 3,3 11,0
2 2,2 2,2 13,2
3 3,3 3,3 16,5
2 2,2 2,2 18,7
1 1,1 1,1 19,8
3 3,3 3,3 23,1
1 1,1 1,1 24,2
4 4,4 4,4 28,6
6 6,6 6,6 35,2
3 3,3 3,3 38,5
5 5,5 5,5 44,0
1 1,1 1,1 45,1
2 2,2 2,2 47,3
4 4,4 4,4 51,6
5 5,5 5,5 57,1
6 6,6 6,6 63,7
6 6,6 6,6 70,3
2 2,2 2,2 72,5
1 1,1 1,1 73,6
1 1,1 1,1 74,7
1 1,1 1,1 75,8
1 1,1 1,1 76,9
5 5,5 5,5 82,4
4 4,4 4,4 86,8
4 4,4 4,4 91,2
6 6,6 6,6 97,8
1 1,1 1,1 98,9
1 1,1 1,1 100,0
91 100,0 100,0
19
20
21
22
23
24
25
32
33
34
35
36
37
45
46
47
48
49
50
52
53
54
57
59
61
62
63
64
66
68
Total
Valid
Frequency Percent Valid Percent
Cumulative
Percent
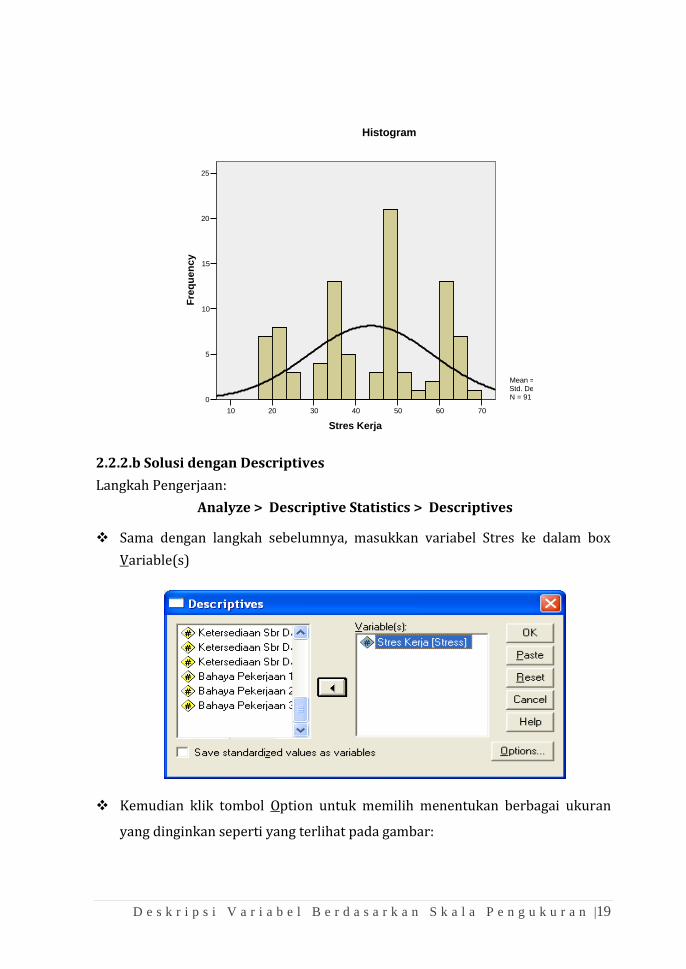
D e s k r i p s i V a r i a b e l B e r d a s a r k a n S k a l a P e n g u k u r a n |19
70605040302010
Stres Kerja
25
20
15
10
5
0
Fre
qu
en
cy
Mean = 43.55Std. Dev. = 14.875N = 91
Histogram
2.2.2.b Solusi dengan Descriptives
Langkah Pengerjaan:
Analyze > Descriptive Statistics > Descriptives
❖ Sama dengan langkah sebelumnya, masukkan variabel Stres ke dalam box
Variable(s)
❖ Kemudian klik tombol Option untuk memilih menentukan berbagai ukuran
yang dinginkan seperti yang terlihat pada gambar:
20| D e s k r i p s i V a r i a b e l B e r d a s a r k a n S k a l a P e n g u k u r a n
Output
Descriptive Statistics
91 49 19 68 43,55 14,875 221,273 -,149 ,253 -1,181 ,500
91
Stres Kerja
Valid N (listwise)
Statis tic Statis tic Statis tic Statis tic Statis tic Statis tic Statis tic Statis tic Std. Error Statis tic Std. Error
N Range Minimum Maximum Mean Std.
DeviationVariance Skewness Kurtosis
2.2.3 Stres kerja berdasarkan karakteristik demografis responden (Gender,
Status Menikah, Pendidikan) dengan Sub-Menu Explore
Langkah Pengerjaan:
Analyze > Descriptive Statistics > Explore
D e s k r i p s i V a r i a b e l B e r d a s a r k a n S k a l a P e n g u k u r a n |21
Explore Gender
Descriptives
40,83 1,799
37,25
44,42
40,69
37,00
232,901
15,261
19
68
49
26
,176 ,283
-1,235 ,559
53,84 1,562
50,56
57,12
53,55
50,00
46,363
6,809
47
66
19
14
,668 ,524
-1,372 1,014
Mean
Lower Bound
Upper Bound
95% Confidence
Interval for Mean
5% Trimmed Mean
Median
Variance
Std. Deviation
Minimum
Maximum
Range
Interquartile Range
Skewness
Kurtosis
Mean
Lower Bound
Upper Bound
95% Confidence
Interval for Mean
5% Trimmed Mean
Median
Variance
Std. Deviation
Minimum
Maximum
Range
Interquartile Range
Skewness
Kurtosis
Gender
Perempuan
Laki-Laki
Stres Kerja
Statis tic Std. Error
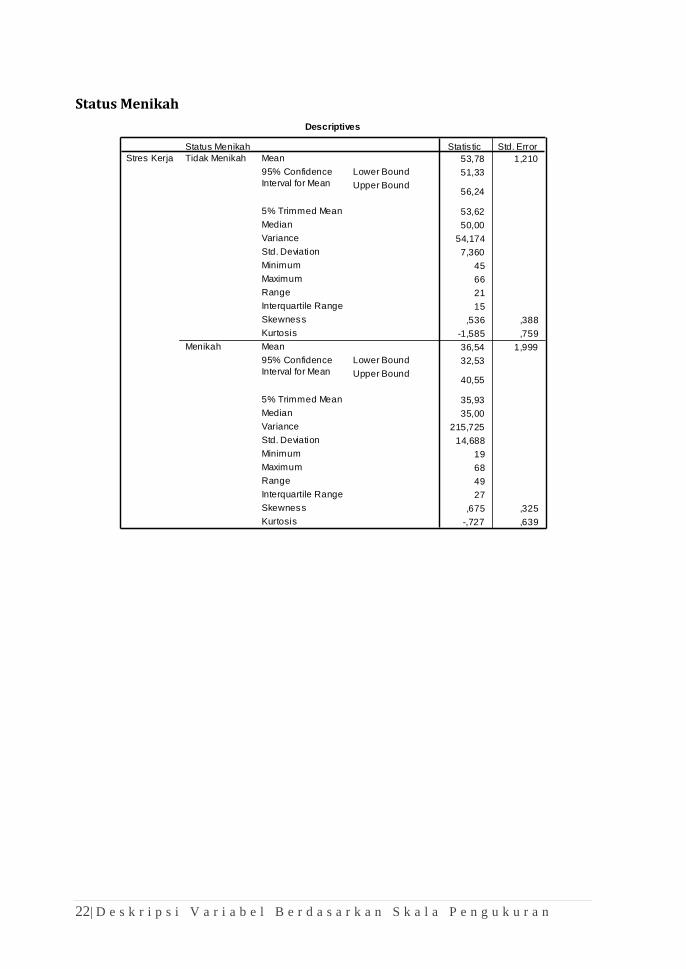
22| D e s k r i p s i V a r i a b e l B e r d a s a r k a n S k a l a P e n g u k u r a n
Status Menikah
Descriptives
53,78 1,210
51,33
56,24
53,62
50,00
54,174
7,360
45
66
21
15
,536 ,388
-1,585 ,759
36,54 1,999
32,53
40,55
35,93
35,00
215,725
14,688
19
68
49
27
,675 ,325
-,727 ,639
Mean
Lower Bound
Upper Bound
95% Confidence
Interval for Mean
5% Trimmed Mean
Median
Variance
Std. Deviation
Minimum
Maximum
Range
Interquartile Range
Skewness
Kurtosis
Mean
Lower Bound
Upper Bound
95% Confidence
Interval for Mean
5% Trimmed Mean
Median
Variance
Std. Deviation
Minimum
Maximum
Range
Interquartile Range
Skewness
Kurtosis
Status Menikah
Tidak Menikah
Menikah
Stres Kerja
Statis tic Std. Error
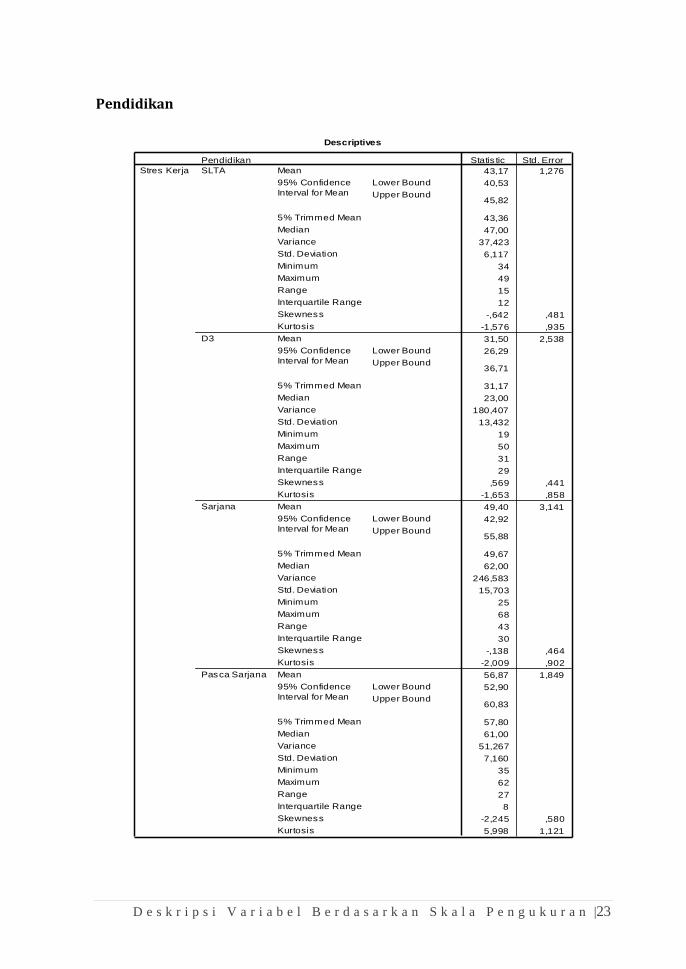
D e s k r i p s i V a r i a b e l B e r d a s a r k a n S k a l a P e n g u k u r a n |23
Pendidikan
Descriptives
43,17 1,276
40,53
45,82
43,36
47,00
37,423
6,117
34
49
15
12
-,642 ,481
-1,576 ,935
31,50 2,538
26,29
36,71
31,17
23,00
180,407
13,432
19
50
31
29
,569 ,441
-1,653 ,858
49,40 3,141
42,92
55,88
49,67
62,00
246,583
15,703
25
68
43
30
-,138 ,464
-2,009 ,902
56,87 1,849
52,90
60,83
57,80
61,00
51,267
7,160
35
62
27
8
-2,245 ,580
5,998 1,121
Mean
Lower Bound
Upper Bound
95% Confidence
Interval for Mean
5% Trimmed Mean
Median
Variance
Std. Deviation
Minimum
Maximum
Range
Interquartile Range
Skewness
Kurtosis
Mean
Lower Bound
Upper Bound
95% Confidence
Interval for Mean
5% Trimmed Mean
Median
Variance
Std. Deviation
Minimum
Maximum
Range
Interquartile Range
Skewness
Kurtosis
Mean
Lower Bound
Upper Bound
95% Confidence
Interval for Mean
5% Trimmed Mean
Median
Variance
Std. Deviation
Minimum
Maximum
Range
Interquartile Range
Skewness
Kurtosis
Mean
Lower Bound
Upper Bound
95% Confidence
Interval for Mean
5% Trimmed Mean
Median
Variance
Std. Deviation
Minimum
Maximum
Range
Interquartile Range
Skewness
Kurtosis
Pendidikan
SLTA
D3
Sarjana
Pasca Sarjana
Stres Kerja
Statis tic Std. Error

24| D e s k r i p s i V a r i a b e l B e r d a s a r k a n S k a l a P e n g u k u r a n
Sebaran Data/Normalitas Distribusi
Pengantar
Rata-rata hitung/mean merupakan ukuran pemusatan utama yang digunakan
sebagai ukuran statistik untuk variabel-variabel berskala metrik (interval dan
rasio). Pada kenyataanya rata-rata hitung sensitif terhadap keberadaan nilai
ekstrim (data dengan nilai terlalu kecil atau terlalu besar), sehingga menimbulkan
bias. Kerenanya, dibutuhkan ukuran sebaran seperti: range/rentang, standar
deviasi hingga varians.
Distribusi normal juga dikenal dengan nama Gauss. Carl Friedrich Gauss
(1777–1855) meneliti tentang terhadap galat/kesalahan dalam pengukuran
berulang pada benda yang sama. Sebaran data akan membentuk distribusi
normal jika jumlah data di atas dan di bawah mean relatif sama, berbentuk kurva
seperti lonceng setangkup yang melebar tak berhingga pada kedua arah positif
dan negatifnya. Dalam bahasa probabilita, peluang untuk mendapatkan suatu
acak nilai pengukuran dengan kisaran 1 standar deviasi diatas maupun dibawah
rata-rata adalah 68,26% seperti gambar berikut:
Cara sederhana dalam mendeteksi apakah sebaran data mengikuti distribusi
normal atau tidak adalah dengan melihat histogram data tersebut. Setiap batang
pada histogram dihubungkan dengan garis sehingga membentuk suatu kurva.
Perhatikan Histogram masa kerja berikut:
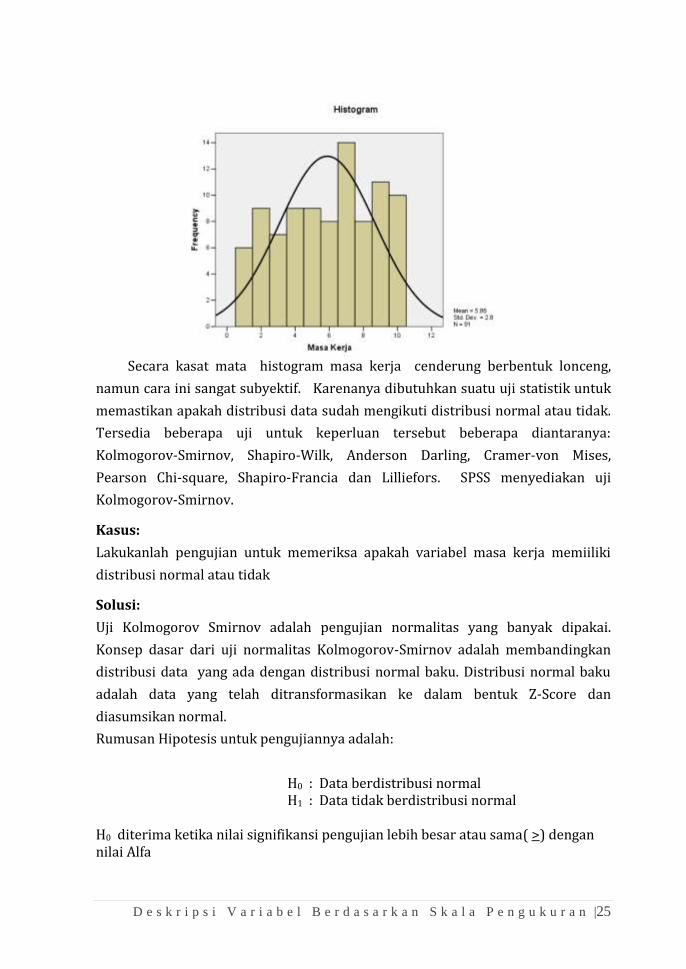
D e s k r i p s i V a r i a b e l B e r d a s a r k a n S k a l a P e n g u k u r a n |25
Secara kasat mata histogram masa kerja cenderung berbentuk lonceng,
namun cara ini sangat subyektif. Karenanya dibutuhkan suatu uji statistik untuk
memastikan apakah distribusi data sudah mengikuti distribusi normal atau tidak.
Tersedia beberapa uji untuk keperluan tersebut beberapa diantaranya:
Kolmogorov-Smirnov, Shapiro-Wilk, Anderson Darling, Cramer-von Mises,
Pearson Chi-square, Shapiro-Francia dan Lilliefors. SPSS menyediakan uji
Kolmogorov-Smirnov.
Kasus:
Lakukanlah pengujian untuk memeriksa apakah variabel masa kerja memiiliki
distribusi normal atau tidak
Solusi:
Uji Kolmogorov Smirnov adalah pengujian normalitas yang banyak dipakai.
Konsep dasar dari uji normalitas Kolmogorov-Smirnov adalah membandingkan
distribusi data yang ada dengan distribusi normal baku. Distribusi normal baku
adalah data yang telah ditransformasikan ke dalam bentuk Z-Score dan
diasumsikan normal.
Rumusan Hipotesis untuk pengujiannya adalah:
H0 : Data berdistribusi normal H1 : Data tidak berdistribusi normal
H0 diterima ketika nilai signifikansi pengujian lebih besar atau sama( >) dengan nilai Alfa

26| D e s k r i p s i V a r i a b e l B e r d a s a r k a n S k a l a P e n g u k u r a n
Langkah Pengerjaan:
Analyze > Nonparametrik Test > 1 Sample K-S
* Masukkan Masa Kerja pada kotak Test Variable List
Output:
One-Sample Kolmogorov-Smirnov Test
91
5,88
2,800
,128
,090
-,128
1,222
,101
N
Mean
Std. Deviation
Normal Parametersa,b
Absolute
Pos itive
Negative
Most Extreme
Differences
Kolmogorov-Smirnov Z
Asymp. Sig. (2-tailed)
Masa Kerja
Test dis tribution is Normal.a.
Calculated from data.b.
Jawaban:
1. Hasil output komputasi One-Sample Kolmogorov-Smirnov Test
menghasilkan nilai signifikasi pengujian (Asymp.Sig) sebesar 0,101. Nilai
tersebut lebih besar 0,05 (Alfa 5%,). Karena itu, H0 yang menyatakan
sebaran data berdistribusi normal harus diterima.

S t a t i s t i k I n f e r e n s i a |27
Bab 3 Statistik Inferensia
Tujuan Instruksional:
1. Mampu melakukan pengujian hipotesis perbedaan rata-rata (variabel berskala
interval dan rasio ) dengan dua atau lebih kelompok melalui:
a. Independent Sample T-test
b. One-Way Anova dengan analisis Post-Hoc
c. General Linear Model Univariate/Two-way Anova
2. Mampu mentransformasi variabel berskala metrik (interval dan rasio) ke
skala yang lebih rendah (ordinal)
3. Mampu melakukan pengujian hipotesis perbedaan variabel berskala nominal
dan ordinal untuk 2 atau lebih kelompok melaui: Uji Chi-Square, Mann-
Whitney-U Test, dan Kruskall Wallis
3.1 Kasus:
Tim seleksi penerimaan mahasiswa ingin melihat apakah terdapat perbedaan
Skor Test Potensi Akademik calon mahasiswa berdasarkan sejumlah karakteristik
individu (jenis SLTA dan Gender). Tim ingin memastikan apakah perbedaan yang
ada tersebut terjadi secara kebetulan atau memang pada hakikatnya
demikian/signifikan. Pada sesi ini Anda diminta untuk menjelaskan apakah:
1. Terdapat perbedaan Skor TPA kerja berdasarkan Gender?
2. Terdapat perbedaan Skor TPA berdasarkan jenis SLTA? jika ya, yang mana
saja yang berbeda?
3. Terdapat perbedaan tingkatan Skor TPA (Tinggi, Sedang dan Rendah )
berdasarkan asal SLTA ?
4. Apakah Asal SLTA dan gender saling berinteraksi dalam kaitannya dengan
skor TPA?
3.2 Solusi:
Tersedia prosedur (Compare Means) dengan beberapa sub-menu yang dapat
digunakan untuk menjawab tiga permasalahan yang diajukan, yaitu:
28| S t a t i s t i k I n f e r e n s i a
a. Sub-Menu Compare Means(Means) digunakan untuk serangkaian statistik
deskriptif suatu variabel berdasarkan pengelompokkan tertentu. Pada
umumnya penggunaan sub-menu ini tidak ada inferensi atau uji terhadap
hipotesis. Namun demikian hal tersebut sangat mungkin dilakukan jika
dibutuhkan.
b. Sub-Menu Compare Means (Independent Samples T-Test) digunakan
untuk mengetahui apakah terdapat perbedaan rata-rata (mean) antara
dua populasi dengan melihat rata-rata dua sampelnya. Pengertian
“independent “ atau “bebas” berarti tidak ada hubungan antara kedua
sampel/populasi yang akan diuji.
c. Sub-Menu Compare Means (One-Way Anova) digunakan untuk
mengetahui apakah ada perbedaan yang signifikan antara rata-rata hitung
tiga kelompok atau lebih. Terdapat tiga asumsi yang harus dipenuhi yaitu:
Populasi/sampel yang diuji berdistribusi normal, memiliki varians yang
sama dan tidak saling berhubungan satu dengan yang lain.
3.2.1 Solusi Untuk Kasus 1 (Sub-Menu Independent Samples T-test)
Langkah Pengerjaan:
Analyze > Compare Means > Independent Samples T-test
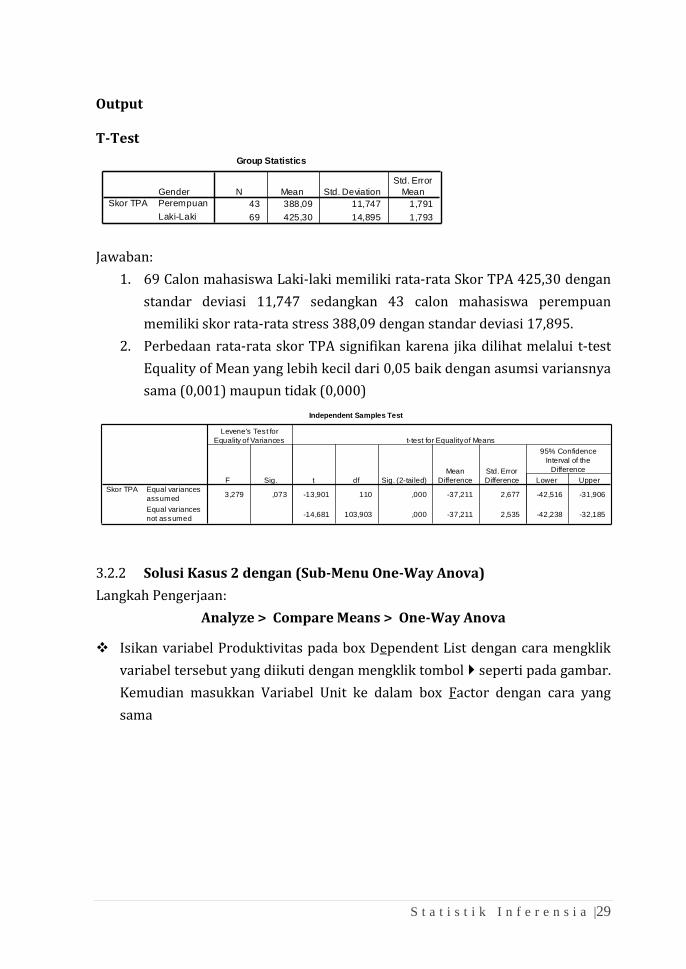
❖ Masukkan variabel Skor TPA pada box Test Variable(s) dan Gender pada
Grouping Variable. Karena peneliti hanya akan memperbandingkan dua
kelompok laki-laki dan perempuan, maka untuk keperluan tersebut harus
diklik tombol Define Groups pada Grouping Variable, lalu isikan 0
(perempuan) untuk Group 1 dan 1 (laki-laki) untuk Group 2
S t a t i s t i k I n f e r e n s i a |29
Output T-Test
Group Statistics
43 388,09 11,747 1,791
69 425,30 14,895 1,793
Gender
Perempuan
Laki-Laki
Skor TPA
N Mean Std. Deviation
Std. Error
Mean
Jawaban:
1. 69 Calon mahasiswa Laki-laki memiliki rata-rata Skor TPA 425,30 dengan
standar deviasi 11,747 sedangkan 43 calon mahasiswa perempuan
memiliki skor rata-rata stress 388,09 dengan standar deviasi 17,895.
2. Perbedaan rata-rata skor TPA signifikan karena jika dilihat melalui t-test
Equality of Mean yang lebih kecil dari 0,05 baik dengan asumsi variansnya
sama (0,001) maupun tidak (0,000)
Independent Samples Test
3,279 ,073 -13,901 110 ,000 -37,211 2,677 -42,516 -31,906
-14,681 103,903 ,000 -37,211 2,535 -42,238 -32,185
Equal variances
assumed
Equal variances
not assumed
Skor TPA
F Sig.
Levene's Test for
Equality of Variances
t df Sig. (2-tai led)
Mean
Difference
Std. Error
Difference Lower Upper
95% Confidence
Interval of the
Difference
t-test for Equality of Means
3.2.2 Solusi Kasus 2 dengan (Sub-Menu One-Way Anova)
Langkah Pengerjaan:
Analyze > Compare Means > One-Way Anova
❖ Isikan variabel Produktivitas pada box Dependent List dengan cara mengklik
variabel tersebut yang diikuti dengan mengklik tombol seperti pada gambar.
Kemudian masukkan Variabel Unit ke dalam box Factor dengan cara yang
sama

30| S t a t i s t i k I n f e r e n s i a
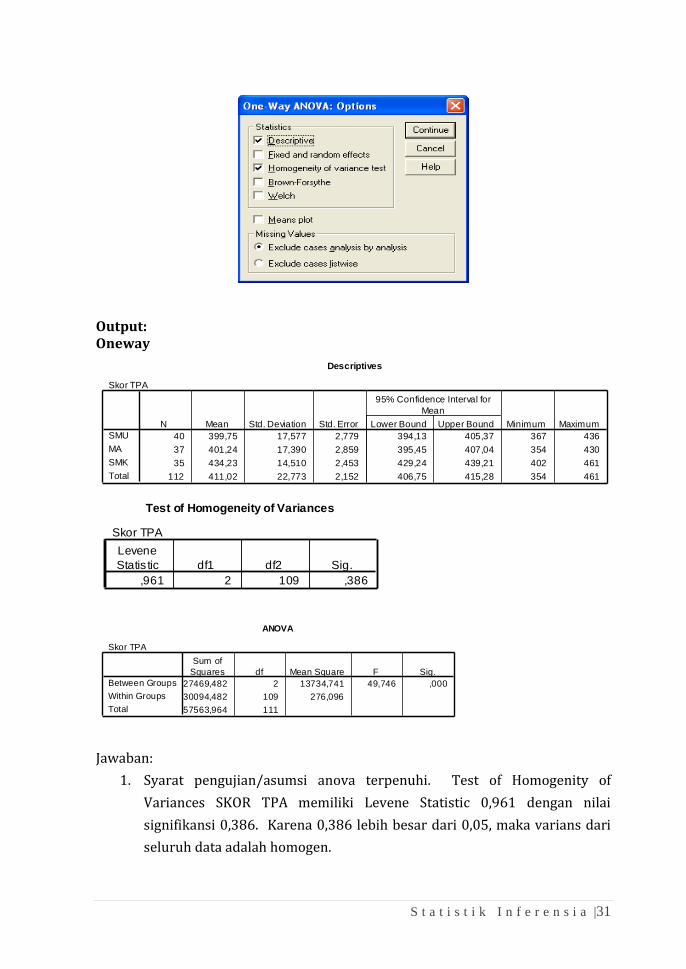
❖ Untuk mengetahui unit mana yang saling berbeda produktivitasnya klik
tombol Post Hoc lalu centang pada box Bonferonni. Sigfinicance level adalah
0,05 (default) kemudian klik continue.
❖ Jika dibutuhkan output deskriptif dari masing-masing kelompok, klik tombol
Options pada sub-menu One-Way Anova lalu beri centang pada box
Descriptive dan Homogenity-of-variance seperti pada gambar berikut:
S t a t i s t i k I n f e r e n s i a |31
Output: Oneway
Descriptives
Skor TPA
40 399,75 17,577 2,779 394,13 405,37 367 436
37 401,24 17,390 2,859 395,45 407,04 354 430
35 434,23 14,510 2,453 429,24 439,21 402 461
112 411,02 22,773 2,152 406,75 415,28 354 461
SMU
MA
SMK
Total
N Mean Std. Deviation Std. Error Lower Bound Upper Bound
95% Confidence Interval for
Mean
Minimum Maximum
Test of Homogeneity of Variances
Skor TPA
,961 2 109 ,386
Levene
Statis tic df1 df2 Sig.
ANOVA
Skor TPA
27469,482 2 13734,741 49,746 ,000
30094,482 109 276,096
57563,964 111
Between Groups
Within Groups
Total
Sum of
Squares df Mean Square F Sig.
Jawaban:
1. Syarat pengujian/asumsi anova terpenuhi. Test of Homogenity of
Variances SKOR TPA memiliki Levene Statistic 0,961 dengan nilai
signifikansi 0,386. Karena 0,386 lebih besar dari 0,05, maka varians dari
seluruh data adalah homogen.
32| S t a t i s t i k I n f e r e n s i a
2. Perbedaan rata-rata antar kelompok Jenis SLTA signifikan, dimana
kelompok SMK memiliki rata-rata skor tertinggi yaitu 434,23 dengan
standar deviasi 14,510
3. Analisis posthoc pada multiple comparisson memperlihatkan perbedaan
rata-rata yang siginifikan antar kelompok adalah: SMU dengan MA
Multiple Comparisons
Dependent Variable: Skor TPA
Bonferroni
-1,493 3,790 1,000 -10,71 7,72
-34,479* 3,846 ,000 -43,83 -25,13
1,493 3,790 1,000 -7,72 10,71
-32,985* 3,918 ,000 -42,51 -23,46
34,479* 3,846 ,000 25,13 43,83
32,985* 3,918 ,000 23,46 42,51
(J) Sekolah Asal
MA
SMK
SMU
SMK
SMU
MA
(I) Sekolah Asal
SMU
MA
SMK
Mean
Difference
(I-J) Std. Error Sig. Lower Bound Upper Bound
95% Confidence Interval
The mean difference is significant at the .05 level.*.
3.2.3.1.a Transformasi ke skala yang lebih rendah
Jika Skor TPA dikatagorikan menjadi tingkatan Tinggi, Sedang dan Rendah,
maka terjadi penurunan skala. Skor TPA kerja yang berskala interval/metrik,
terlebih dahulu harus dirubah/transform menjadi berskala ordinal. Pertanyaan
yang muncul adalah apa yang menjadi kriteria pengkatagorian tersebut?. Cara
yang paling mudah dengan membagi 3 kelas rentang (nilai tertinggi – nilai
terendah)
Descriptive Statistics
112 354 461 411,02 22,773
112
Skor TPA
Valid N (listwise)
N Minimum Maximum Mean Std. Deviation
Rentang : 461 - 354 = 107
Panjang Kelas : 107: 3 = 35,66 => 36
Rendah : < 389
Sedang : 389-425
Tinggi : > 425
S t a t i s t i k I n f e r e n s i a |33
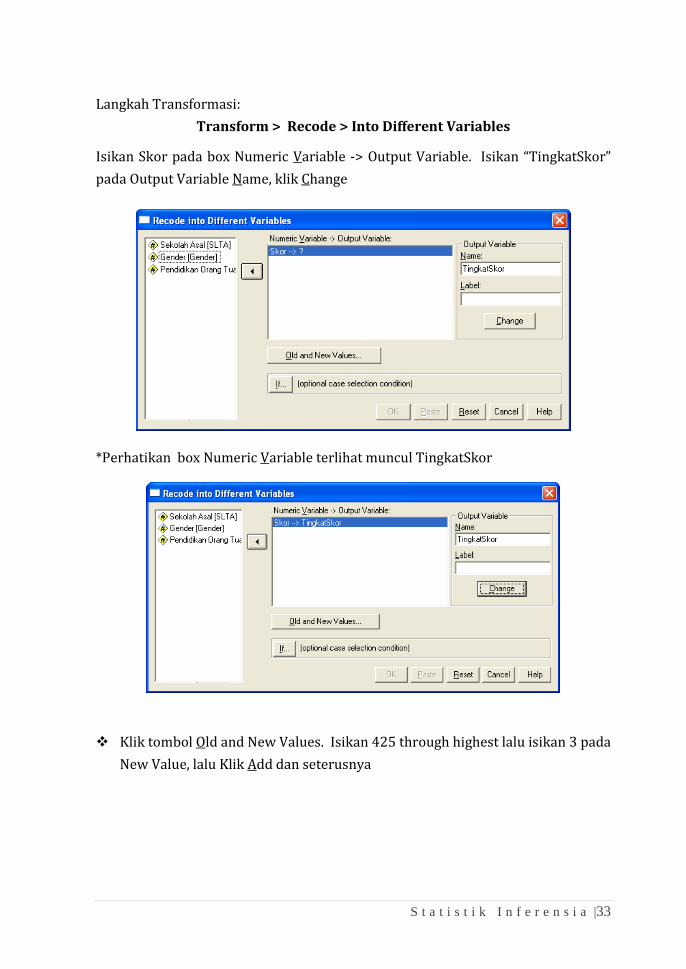
Langkah Transformasi:
Transform > Recode > Into Different Variables
Isikan Skor pada box Numeric Variable -> Output Variable. Isikan “TingkatSkor”
pada Output Variable Name, klik Change
*Perhatikan box Numeric Variable terlihat muncul TingkatSkor
❖ Klik tombol Old and New Values. Isikan 425 through highest lalu isikan 3 pada
New Value, lalu Klik Add dan seterusnya
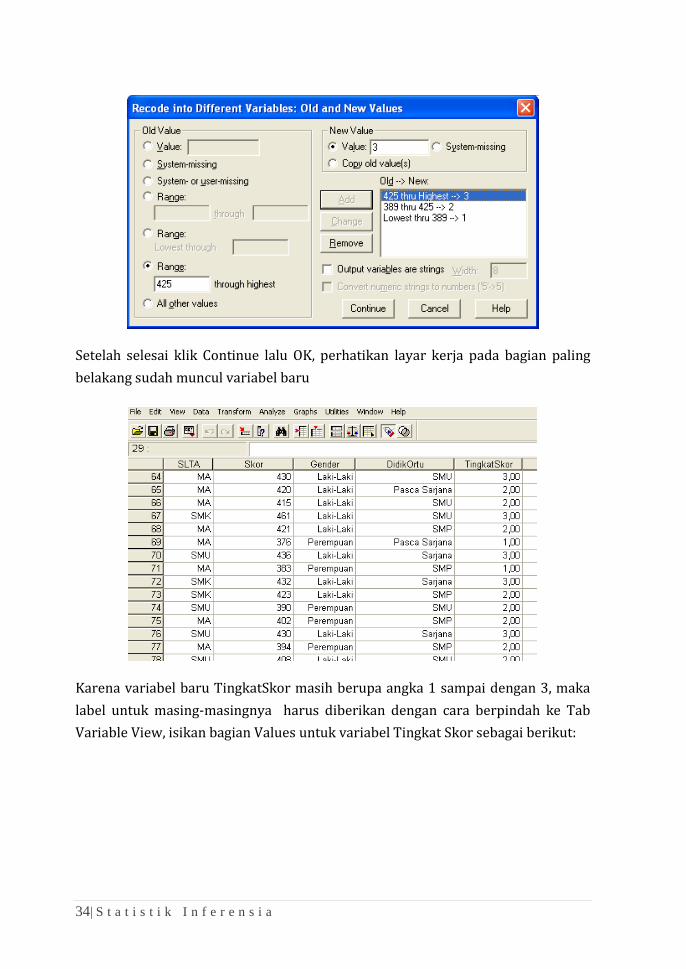
34| S t a t i s t i k I n f e r e n s i a
Setelah selesai klik Continue lalu OK, perhatikan layar kerja pada bagian paling
belakang sudah muncul variabel baru
Karena variabel baru TingkatSkor masih berupa angka 1 sampai dengan 3, maka
label untuk masing-masingnya harus diberikan dengan cara berpindah ke Tab
Variable View, isikan bagian Values untuk variabel Tingkat Skor sebagai berikut:
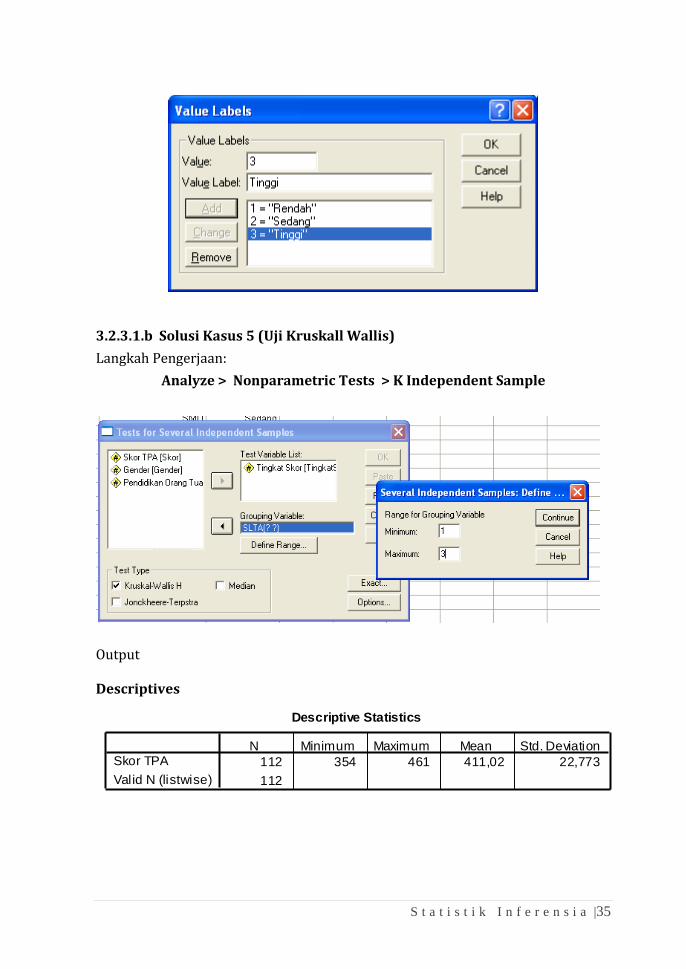
S t a t i s t i k I n f e r e n s i a |35
3.2.3.1.b Solusi Kasus 5 (Uji Kruskall Wallis)
Langkah Pengerjaan:
Analyze > Nonparametric Tests > K Independent Sample
Output Descriptives
Descriptive Statistics
112 354 461 411,02 22,773
112
Skor TPA
Valid N (listwise)
N Minimum Maximum Mean Std. Deviation

36| S t a t i s t i k I n f e r e n s i a
NPar Tests Kruskal-Wallis Test
Ranks
40 45,16
37 42,14
35 84,64
112
Sekolah Asal
SMU
MA
SMK
Total
Tingkat Skor
N Mean Rank
Test Statisticsa,b
47,579
2
,000
Chi-Square
df
Asymp. Sig.
Tingkat Skor
Kruskal Wallis Testa.
Grouping Variable: Sekolah Asalb.
Jawaban:
1. Terdapat perbedaan peringkat /rank Skor TPA yang signfikan
berdasarkan kelompok SLTA. (Asymp.sig 0,000 < 0,05)
3.2.4 Solusi Kasus 3 (Chi-square test)
Uji Chi-Square merupakan uji non-parametrik yang paling luas digunakan.
Uji ini digunakan untuk melihat signifikansi perbedaan data berskala katagorikal
baik ordinal maupun nominal. Pengambilan keputusan dilakukan dengan melihat
signifikasi perbedaan antara data sampel dengan distribusi yang diharapkan.
S t a t i s t i k I n f e r e n s i a |37
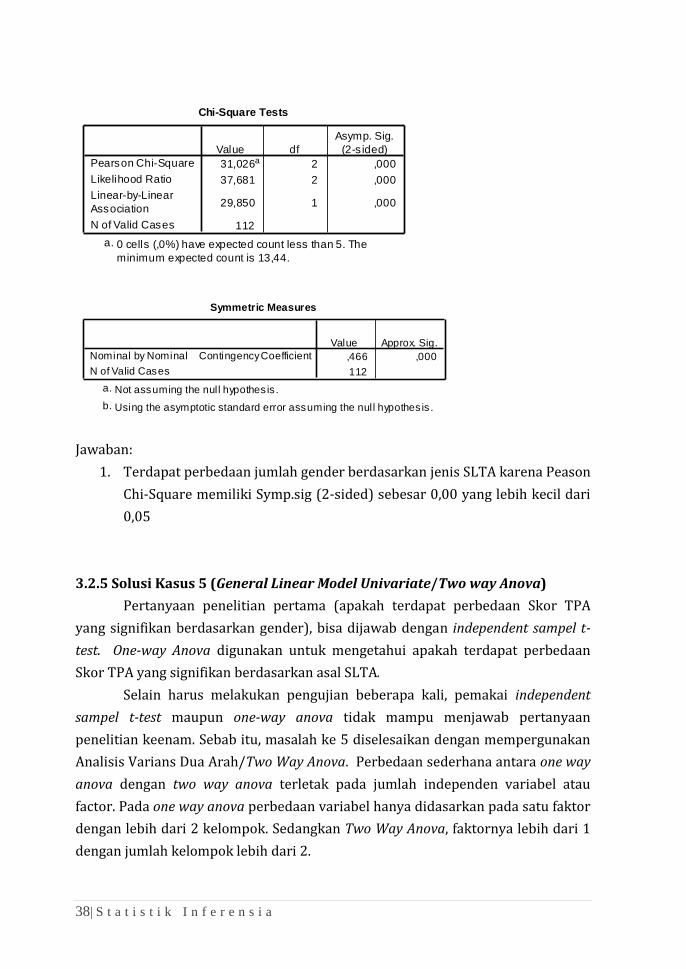
Langkah Pengerjaan:
Analyze > Descriptive Statistics > Crosstabs
Output Crosstabs
Sekolah Asal * Gender Crosstabulation
Count
26 14 40
16 21 37
1 34 35
43 69 112
SMU
MA
SMK
Sekolah
Asal
Total
Perempuan Laki-Laki
Gender
Total
38| S t a t i s t i k I n f e r e n s i a
Chi-Square Tests
31,026a 2 ,000
37,681 2 ,000
29,850 1 ,000
112
Pearson Chi-Square
Likelihood Ratio
Linear-by-Linear
Association
N of Valid Cases
Value df
Asymp. Sig.
(2-s ided)
0 cells (,0%) have expected count less than 5. The
minimum expected count is 13,44.
a.
Symmetric Measures
,466 ,000
112
Contingency CoefficientNominal by Nominal
N of Valid Cases
Value Approx. Sig.
Not assuming the null hypothes is .a.
Using the asymptotic standard error assuming the null hypothes is .b.
Jawaban:
1. Terdapat perbedaan jumlah gender berdasarkan jenis SLTA karena Peason
Chi-Square memiliki Symp.sig (2-sided) sebesar 0,00 yang lebih kecil dari
0,05
3.2.5 Solusi Kasus 5 (General Linear Model Univariate/Two way Anova)
Pertanyaan penelitian pertama (apakah terdapat perbedaan Skor TPA
yang signifikan berdasarkan gender), bisa dijawab dengan independent sampel t-
test. One-way Anova digunakan untuk mengetahui apakah terdapat perbedaan
Skor TPA yang signifikan berdasarkan asal SLTA.
Selain harus melakukan pengujian beberapa kali, pemakai independent
sampel t-test maupun one-way anova tidak mampu menjawab pertanyaan
penelitian keenam. Sebab itu, masalah ke 5 diselesaikan dengan mempergunakan
Analisis Varians Dua Arah/Two Way Anova. Perbedaan sederhana antara one way
anova dengan two way anova terletak pada jumlah independen variabel atau
factor. Pada one way anova perbedaan variabel hanya didasarkan pada satu faktor
dengan lebih dari 2 kelompok. Sedangkan Two Way Anova, faktornya lebih dari 1
dengan jumlah kelompok lebih dari 2.
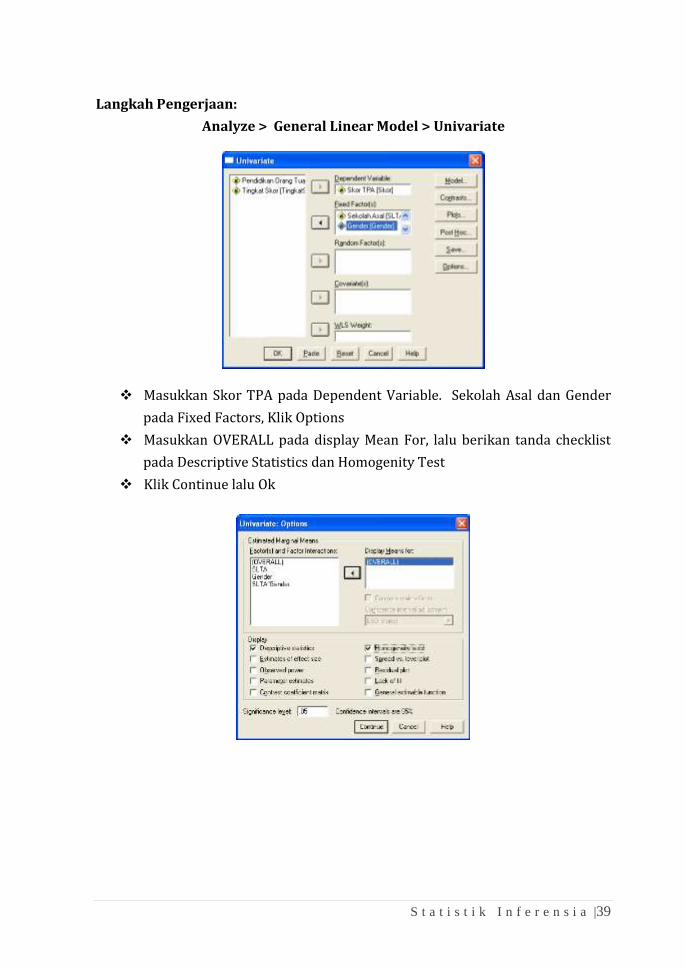
S t a t i s t i k I n f e r e n s i a |39
Langkah Pengerjaan:
Analyze > General Linear Model > Univariate
❖ Masukkan Skor TPA pada Dependent Variable. Sekolah Asal dan Gender
pada Fixed Factors, Klik Options
❖ Masukkan OVERALL pada display Mean For, lalu berikan tanda checklist
pada Descriptive Statistics dan Homogenity Test
❖ Klik Continue lalu Ok
40| S t a t i s t i k I n f e r e n s i a
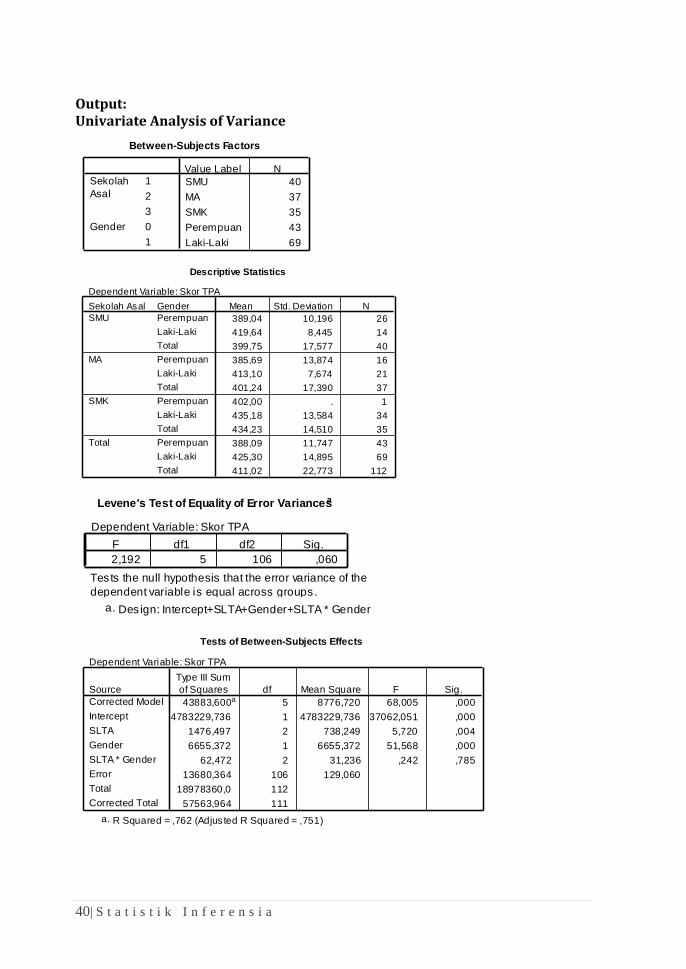
Output: Univariate Analysis of Variance
Between-Subjects Factors
SMU 40
MA 37
SMK 35
Perempuan 43
Laki-Laki 69
1
2
3
Sekolah
Asal
0
1
Gender
Value Label N
Descriptive Statistics
Dependent Variable: Skor TPA
389,04 10,196 26
419,64 8,445 14
399,75 17,577 40
385,69 13,874 16
413,10 7,674 21
401,24 17,390 37
402,00 . 1
435,18 13,584 34
434,23 14,510 35
388,09 11,747 43
425,30 14,895 69
411,02 22,773 112
Gender
Perempuan
Laki-Laki
Total
Perempuan
Laki-Laki
Total
Perempuan
Laki-Laki
Total
Perempuan
Laki-Laki
Total
Sekolah Asal
SMU
MA
SMK
Total
Mean Std. Deviation N
Levene's Test of Equality of Error Variancesa
Dependent Variable: Skor TPA
2,192 5 106 ,060
F df1 df2 Sig.
Tests the null hypothesis that the error variance of the
dependent variable is equal across groups.
Des ign: Intercept+SLTA+Gender+SLTA * Gendera.
Tests of Between-Subjects Effects
Dependent Variable: Skor TPA
43883,600a 5 8776,720 68,005 ,000
4783229,736 1 4783229,736 37062,051 ,000
1476,497 2 738,249 5,720 ,004
6655,372 1 6655,372 51,568 ,000
62,472 2 31,236 ,242 ,785
13680,364 106 129,060
18978360,0 112
57563,964 111
Source
Corrected Model
Intercept
SLTA
Gender
SLTA * Gender
Error
Total
Corrected Total
Type III Sum
of Squares df Mean Square F Sig.
R Squared = ,762 (Adjusted R Squared = ,751)a.

S t a t i s t i k I n f e r e n s i a |41
Estimated Marginal Means
Grand Mean
Dependent Variable: Skor TPA
407,440 2,116 403,244 411,636
Mean Std. Error Lower Bound Upper Bound
95% Confidence Interval
Jawaban:
1. Descriptive Statistics memberikan informasi tentang rata-rata dan standar
deviasi Skor TPA untuk tiap kelompok SLTA yang dipisahkan berdasarkan
gender. Perhitungan Levene’s Test of Equality of Error Variance
mendapatkan nilai sig. sebesar 0,06 yang lebih besar dari 0,05. Dengan
demikian asumsi pengujian dengan ANOVA terpenuhi.
2. Pada output Tests of Between-Subject Effects ditemukan SLTA memiliki
nilai sig sebesar 0,004 yang secara nyata lebih kecil dari 0,05. Dengan
demikian disimpulkan bahwa perbedaan Skor TPA berdasarkan SLTA
adalah signifikan
3. Gender juga memiliki nilai sig yang lebih kecil dari 0,05 yaitu 0,000 yang
bermakna bahwa perbedaan Skor TPA berdasarkan gender juga signifikan
4. Pada bagian interaksi (SLTA * Gender) didapatkan nilai sig sebesar 0,785
yang lebih besar dari 0,05. Dengan demikian bisa disimpulkan bahwa
Jenis SLTA dan gender tidak berinteraksi dalam menghasilkan varians
Skor TPA.

S t a t i s t i k I n f e r e n s i a |42
U j i H i p o t e s i s K o m p a r a t i f D a t a B e r p a s a n g a n |43
Bab 4 Uji Hipotesis Komparatif Data Berpasangan
Tujuan Instruksional:
1. Mampu melakukan pengujian hipotesis perbedaan rata-rata
berpasangan
2. Mampu melakukan pengujian hipotesis perbedaan berpasangan
variabel berskala ordinal
4.1 Kasus
Sebuah Perusahaan memiliki 23 orang karyawan yang baru dilantik sejak 3
tahun yang lalu. Manajemen selalu memantau perkembangan kemampuan
mereka. Tabel berikut memberikan informasi tentang kemampuan bahasa Inggris
mereka ketika sebelum dan dan sesudah mengikuti pelatihan TOEFL.
Selain itu, pada tabel yang sama juga terlihat bagaimana kinerja mereka untuk
setiap tahunnya. Berdasarkan kepada data yang ada, Anda diminta untuk menilai
apakah:

44| U j i H i p o t e s i s K o m p a r a t i f D a t a B e r p a s a n g a n
1. Pelatihan toefl yang diselenggarakan bisa dikatakan efektif?
2. Apakah selalu terjadi peningkatan kinerja mereka dari waktu ke waktu?
4.2 Solusi
4.2.1 Paired sample t-test
Kasus pertama bisa diselesaikan dengan sub menu paired sample t-test. Sub
menu ini digunakan karena hipotesis yang akan diuji satu subyek yang mengalami
dua perlakuan atau menjalani dua pengukuran yang berbeda (Sebelum dan
Sesudah). Asumsi yang harus dipenuhi untuk melaksanakan pengujian adalah
variabel yang akan diuji harus mengikuti distribusi normal (Gunakan uji
Kolmogorov-Smirnov)
One-Sample Kolmogorov-Smirnov Test
23 23
380,70 389,43
16,499 15,353
,168 ,132
,101 ,098
-,168 -,132
,806 ,631
,534 ,821
N
Mean
Std. Deviation
Normal Parametersa,b
Absolute
Pos itive
Negative
Most Extreme
Differences
Kolmogorov-Smirnov Z
Asymp. Sig. (2-tailed)
Skor Toefl
Sblm
Pelatihan
Skor Toefl
Ssdh
Pelatihan
Test dis tribution is Normal.a.
Calculated from data.b.
U j i H i p o t e s i s K o m p a r a t i f D a t a B e r p a s a n g a n |45
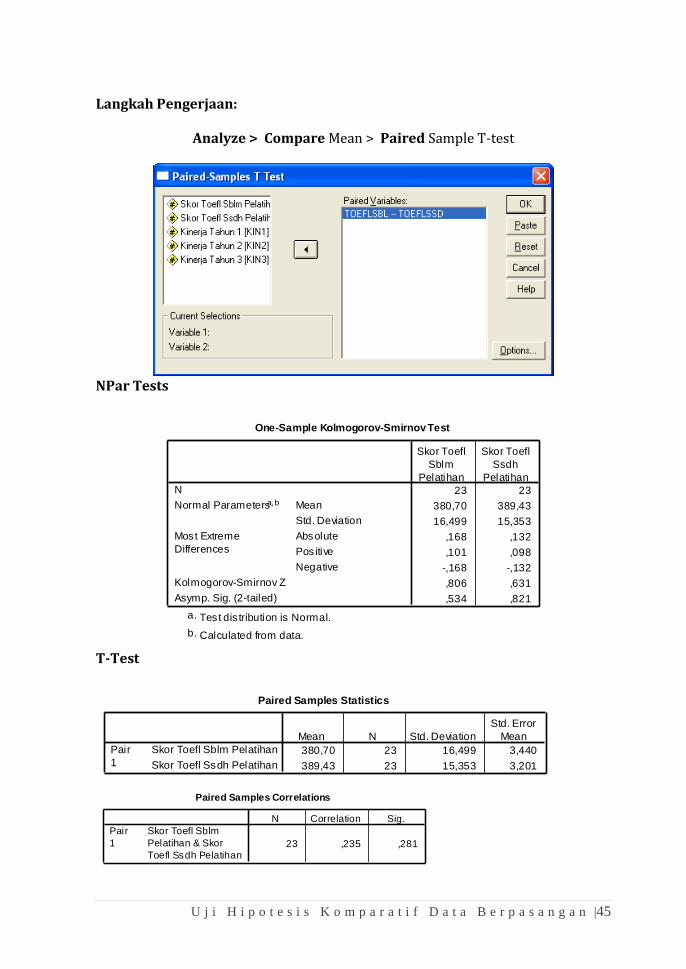
Langkah Pengerjaan:
Analyze > Compare Mean > Paired Sample T-test
NPar Tests
One-Sample Kolmogorov-Smirnov Test
23 23
380,70 389,43
16,499 15,353
,168 ,132
,101 ,098
-,168 -,132
,806 ,631
,534 ,821
N
Mean
Std. Deviation
Normal Parametersa,b
Absolute
Pos itive
Negative
Most Extreme
Differences
Kolmogorov-Smirnov Z
Asymp. Sig. (2-tailed)
Skor Toefl
Sblm
Pelatihan
Skor Toefl
Ssdh
Pelatihan
Test dis tribution is Normal.a.
Calculated from data.b.
T-Test
Paired Samples Statistics
380,70 23 16,499 3,440
389,43 23 15,353 3,201
Skor Toefl Sblm Pelatihan
Skor Toefl Ssdh Pelatihan
Pair
1
Mean N Std. Deviation
Std. Error
Mean
Paired Samples Correlations
23 ,235 ,281
Skor Toefl Sblm
Pelatihan & Skor
Toefl Ssdh Pelatihan
Pair
1
N Correlation Sig.

46| U j i H i p o t e s i s K o m p a r a t i f D a t a B e r p a s a n g a n
Paired Samples Test
-8,739 19,724 4,113 -17,268 -,210 -2,125 22 ,045
Skor Toefl Sblm
Pelatihan - Skor Toefl
Ssdh Pelatihan
Pair
1
Mean Std. Deviation
Std. Error
Mean Lower Upper
95% Confidence
Interval of the
Difference
Paired Differences
t df Sig. (2-tai led)
Jawaban:
1. Rata-rata skor toefl sebelum latihan adalah 380,70 dengan standar deviasi
16,499 sedangkan rata-rata skor toelf sesudah pelatihan 389,43 dengan
sntar deviasi 15,353. Dengan kata lain terjadi peningkatan skor TOEFL
sebesar 8,739 dan standar deviasi 19,724
2. Peningkatan tersebut signifikan karena nilai (sig.two–tailed) sebesar
0,045 lebih kecil dari 0,05
3. Dengan demikian dapat disimpulkan bahwa pelatihan skor tersebut efektif
4.2.2 Pengujian non-parametrik (Wilcoxon Signed Ranks Test atau Sign
Test)
Kasus kedua, hampir mirip dengan kasus pertama. Namun teknik yang
digunakan berbeda, yaitu pengujian non-parametrik (Wilcoxon Signed Ranks
Test atau Sign Test). ini dikarenakan variabel yang akan diuji hipotesisnya
berskala non-metrik. Pengujian dengan Wilcoxon Signed Ranks Test dilakukan
apabila peneliti ingin melakukan pengujian secara parsial (hanya sepasang-
sepasang). Namun jika pengujian dilakukan terhadap lebih dari satu pasang dan
secara serentak/simultan, maka uji non-parametrik yang digunakan adalah
Friedman Test.
U j i H i p o t e s i s K o m p a r a t i f D a t a B e r p a s a n g a n |47
Langkah Pengerjaan:
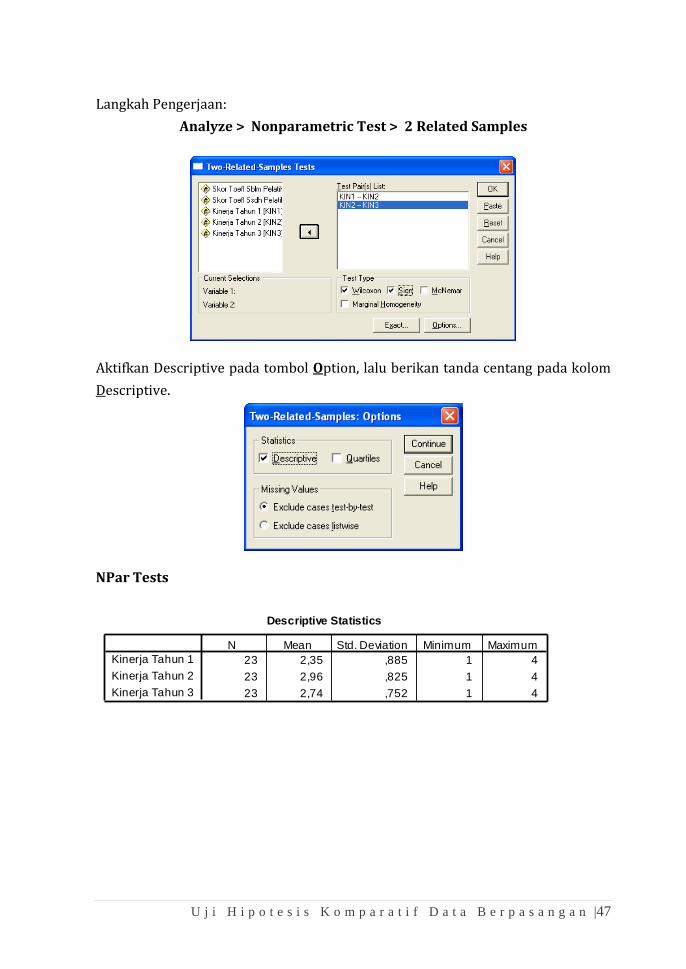
Analyze > Nonparametric Test > 2 Related Samples
Aktifkan Descriptive pada tombol Option, lalu berikan tanda centang pada kolom
Descriptive.
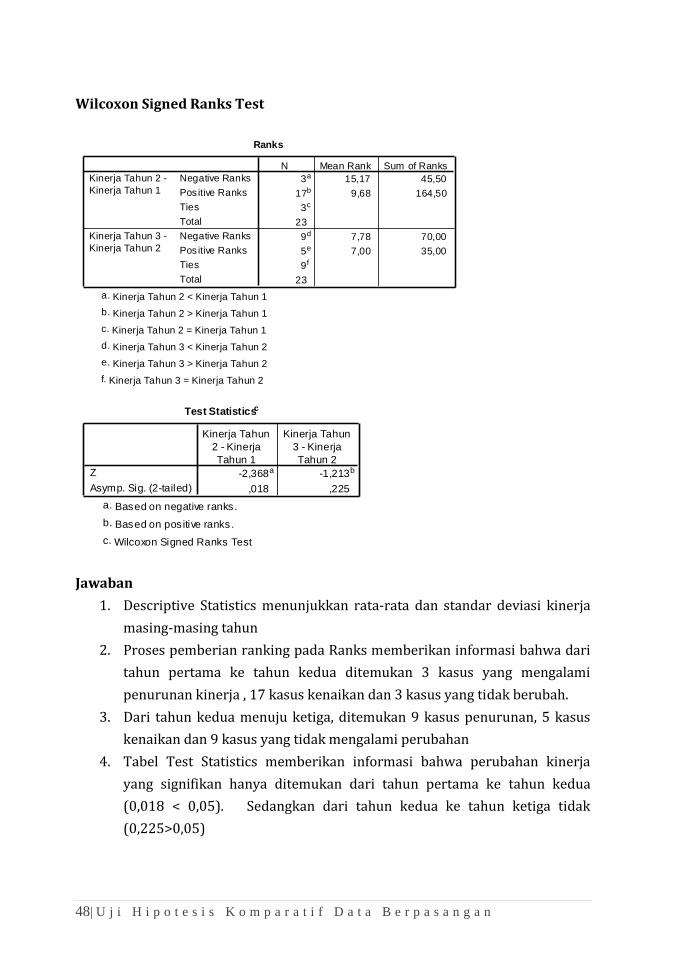
NPar Tests
Descriptive Statistics
23 2,35 ,885 1 4
23 2,96 ,825 1 4
23 2,74 ,752 1 4
Kinerja Tahun 1
Kinerja Tahun 2
Kinerja Tahun 3
N Mean Std. Deviation Minimum Maximum
48| U j i H i p o t e s i s K o m p a r a t i f D a t a B e r p a s a n g a n
Wilcoxon Signed Ranks Test
Ranks
3a 15,17 45,50
17b 9,68 164,50
3c
23
9d 7,78 70,00
5e 7,00 35,00
9f
23
Negative Ranks
Pos itive Ranks
Ties
Total
Negative Ranks
Pos itive Ranks
Ties
Total
Kinerja Tahun 2 -
Kinerja Tahun 1
Kinerja Tahun 3 -
Kinerja Tahun 2
N Mean Rank Sum of Ranks
Kinerja Tahun 2 < Kinerja Tahun 1a.
Kinerja Tahun 2 > Kinerja Tahun 1b.
Kinerja Tahun 2 = Kinerja Tahun 1c.
Kinerja Tahun 3 < Kinerja Tahun 2d.
Kinerja Tahun 3 > Kinerja Tahun 2e.
Kinerja Tahun 3 = Kinerja Tahun 2f.
Test Statisticsc
-2,368a -1,213b
,018 ,225
Z
Asymp. Sig. (2-tailed)
Kinerja Tahun
2 - Kinerja
Tahun 1
Kinerja Tahun
3 - Kinerja
Tahun 2
Based on negative ranks.a.
Based on pos itive ranks.b.
Wilcoxon Signed Ranks Testc.
Jawaban
1. Descriptive Statistics menunjukkan rata-rata dan standar deviasi kinerja
masing-masing tahun
2. Proses pemberian ranking pada Ranks memberikan informasi bahwa dari
tahun pertama ke tahun kedua ditemukan 3 kasus yang mengalami
penurunan kinerja , 17 kasus kenaikan dan 3 kasus yang tidak berubah.
3. Dari tahun kedua menuju ketiga, ditemukan 9 kasus penurunan, 5 kasus
kenaikan dan 9 kasus yang tidak mengalami perubahan
4. Tabel Test Statistics memberikan informasi bahwa perubahan kinerja
yang signifikan hanya ditemukan dari tahun pertama ke tahun kedua
(0,018 < 0,05). Sedangkan dari tahun kedua ke tahun ketiga tidak
(0,225>0,05)

U j i H i p o t e s i s K o m p a r a t i f D a t a B e r p a s a n g a n |49
Sign Test
Frequencies
3
17
3
23
9
5
9
23
Negative Differencesa,b
Pos itive Differencesc,d
Tiese, f
Total
Negative Differencesa,b
Pos itive Differencesc,d
Tiese, f
Total
Kinerja Tahun 2 -
Kinerja Tahun 1
Kinerja Tahun 3 -
Kinerja Tahun 2
N
Kinerja Tahun 2 < Kinerja Tahun 1a.
Kinerja Tahun 3 < Kinerja Tahun 2b.
Kinerja Tahun 2 > Kinerja Tahun 1c.
Kinerja Tahun 3 > Kinerja Tahun 2d.
Kinerja Tahun 2 = Kinerja Tahun 1e.
Kinerja Tahun 3 = Kinerja Tahun 2f.
Test Statisticsb
,003a ,424aExact Sig. (2-tai led)
Kinerja Tahun
2 - Kinerja
Tahun 1
Kinerja Tahun
3 - Kinerja
Tahun 2
Binomial distribution used.a.
Sign Testb.

50| U j i H i p o t e s i s K o m p a r a t i f D a t a B e r p a s a n g a n

P e n g a n t a r A n a l i s i s M u l t i v a r i a t e ( M a n o v a ) |51
Bab 5 Pengantar Analisis Multivariate (Manova)
Tujuan Instruksional
1. Mampu menguji hpotesis perbedaaan rata-rata lebih dari satu variabel
dependen berdasarkan 2 atau lebih lebih kelompok
2. Mampu mengestimasi parameter
3. Mampu memeriksa homogenitas varians tiap variabel berdasarkan
kelompok
5.1 Pengantar
Perbedaan ANOVA dan MANOVA terletak pada banyaknya jumlah variabel
dependennya. Pada MANOVA, jumlah variabel dependennya lebih dari 1 (Skala
rasio atau interval) dan variabel independennya dapat lebih dari satu (Ordinal
atau Nominal). Tujuan dari Manova adalah untuk mengetahui apakah perbedaan
rata-rata kelompok/centroid berbeda signifikan atau tidak. Manova
mengasumsikan setiap variabel dependen memiliki error varians yang sama
untuk setiap grup. Levene’s test digunakan untuk menguji asumsi tersebut .
5.2 Kasus
Sebuah survey dilakukan untuk mengetahui tentang bagaimana masyarakat
menghabiskan waktu mereka. Untuk itu dicatat beberapa variabel penting yaitu:
lama menonton televisi setiap hari (jam), lama membaca majalah atau koran
setiap hari (jam), dan lama mendengar radio setiap hari (jam). Selain itu survey
juga mengelompokkan responden berdasarkan strata pendidikan. Sehubungan
dengan itu, Anda diminta untuk mengetahui :
a. Apakah terdapat perbedaan ketiga variabel berdasarkan tingkat pendidikan
secara bersama-sama?
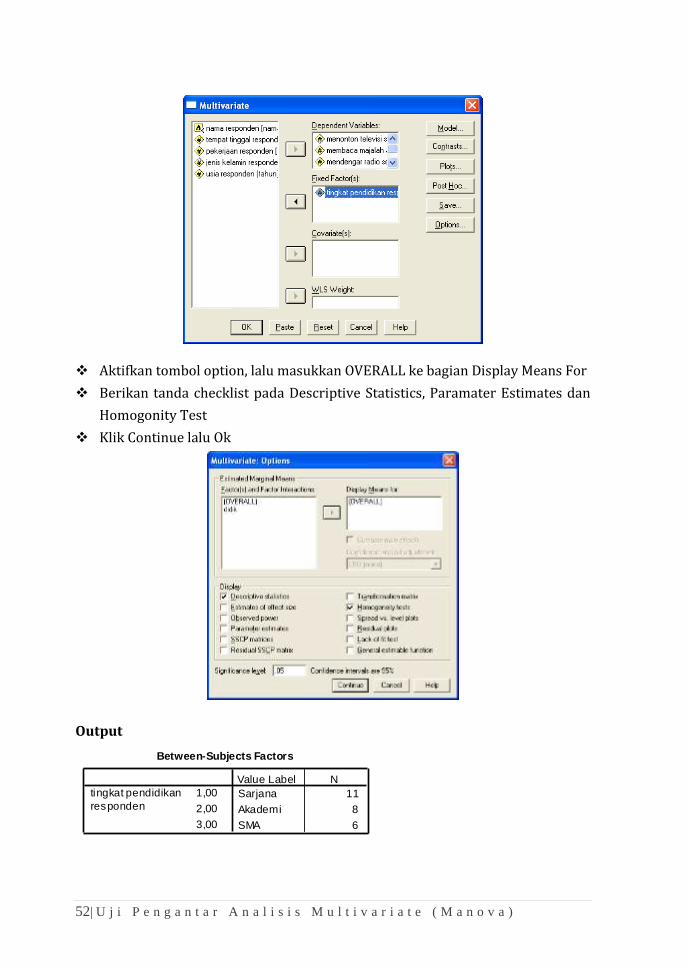
Langkah Pengerjaan:
Analyze > General Linear Model > Multivariate
❖ Masukkan ketiga variabel yang akan diuji ke dalam Dependent Variables
❖ Masukkan Tingkat Pendidikan Responden ke dalam Fixed Factor (s)
52| U j i P e n g a n t a r A n a l i s i s M u l t i v a r i a t e ( M a n o v a )
❖ Aktifkan tombol option, lalu masukkan OVERALL ke bagian Display Means For
❖ Berikan tanda checklist pada Descriptive Statistics, Paramater Estimates dan
Homogonity Test
❖ Klik Continue lalu Ok
Output
Between-Subjects Factors
Sarjana 11
Akademi 8
SMA 6
1,00
2,00
3,00
tingkat pendidikan
responden
Value Label N
P e n g a n t a r A n a l i s i s M u l t i v a r i a t e ( M a n o v a ) |53
Descriptive Statistics
5,2909 1,58774 11
3,5750 1,34137 8
3,8000 1,00995 6
4,3840 1,57101 25
2,9909 ,85259 11
2,6125 ,96279 8
2,2500 1,08766 6
2,6920 ,95478 25
2,0636 ,92333 11
2,1375 ,76893 8
2,1333 ,56095 6
2,1040 ,77108 25
tingkat pendidikan
respondenSarjana
Akademi
SMA
Total
Sarjana
Akademi
SMA
Total
Sarjana
Akademi
SMA
Total
menonton televisi setiap hari (jam)
membaca majalah atau koran setiap hari (jam)
mendengar radio setiap hari (jam)
Mean Std. Deviation N
Box's Test of Equality of Covariance Matricesa
9,249
,598
12
1318,895
,845
Box's M
F
df1
df2
Sig.
Tests the null hypothesis that the observed covariance
matrices of the dependent variables are equal across groups.
Design: Intercept+didika.
Multivariate Testsc
,951 130,764a 3,000 20,000 ,000
,049 130,764a 3,000 20,000 ,000
19,615 130,764a 3,000 20,000 ,000
19,615 130,764a 3,000 20,000 ,000
,361 1,540 6,000 42,000 ,189
,650 1,603a 6,000 40,000 ,172
,522 1,654 6,000 38,000 ,159
,489 3,423b 3,000 21,000 ,036
Pillai's Trace
Wilks ' Lambda
Hotelling's Trace
Roy's Largest Root
Pillai's Trace
Wilks ' Lambda
Hotelling's Trace
Roy's Largest Root
Effect
Intercept
didik
Value F Hypothes is df Error df Sig.
Exact s tatis tica.
The s tatis tic is an upper bound on F that yields a lower bound on the s ignificance level.b.
Des ign: Intercept+didikc.
Levene's Test of Equality of Error Variancesa
,200 2 22 ,820
,911 2 22 ,417
,664 2 22 ,525
menonton televis i setiap hari (jam)
membaca majalah atau koran setiap hari (jam)
mendengar radio setiap hari (jam)
F df1 df2 Sig.
Tests the null hypothes is that the error variance of the dependent variable is equal across groups.
Des ign: Intercept+didika.
54| U j i P e n g a n t a r A n a l i s i s M u l t i v a r i a t e ( M a n o v a )
Tests of Between-Subjects Effects
16,330a 2 8,165 4,187 ,029
2,206b 2 1,103 1,233 ,311
,032c 2 ,016 ,025 ,976
419,329 1 419,329 215,020 ,000
161,213 1 161,213 180,283 ,000
104,883 1 104,883 162,066 ,000
16,330 2 8,165 4,187 ,029
2,206 2 1,103 1,233 ,311
,032 2 ,016 ,025 ,976
42,904 22 1,950
19,673 22 ,894
14,238 22 ,647
539,720 25
203,050 25
124,940 25
59,234 24
21,878 24
14,270 24
Dependent Variable
menonton televisi setiap hari (jam)
membaca majalah atau koran setiap hari (jam)
mendengar radio setiap hari (jam)
menonton televisi setiap hari (jam)
membaca majalah atau koran setiap hari (jam)
mendengar radio setiap hari (jam)
menonton televisi setiap hari (jam)
membaca majalah atau koran setiap hari (jam)
mendengar radio setiap hari (jam)
menonton televisi setiap hari (jam)
membaca majalah atau koran setiap hari (jam)
mendengar radio setiap hari (jam)
menonton televisi setiap hari (jam)
membaca majalah atau koran setiap hari (jam)
mendengar radio setiap hari (jam)
menonton televisi setiap hari (jam)
membaca majalah atau koran setiap hari (jam)
mendengar radio setiap hari (jam)
Source
Corrected Model
Intercept
didik
Error
Total
Corrected Total
Type III Sum
of Squares df Mean Square F Sig.
R Squared = ,276 (Adjusted R Squared = ,210)a.
R Squared = ,101 (Adjusted R Squared = ,019)b.
R Squared = ,002 (Adjusted R Squared = -,088)c.
Grand Mean
4,222 ,288 3,625 4,819
2,618 ,195 2,213 3,022
2,111 ,166 1,768 2,455
Dependent Variable
menonton televis i setiap hari (jam)
membaca majalah atau koran setiap hari (jam)
mendengar radio setiap hari (jam)
Mean Std. Error Lower Bound Upper Bound
95% Confidence Interval
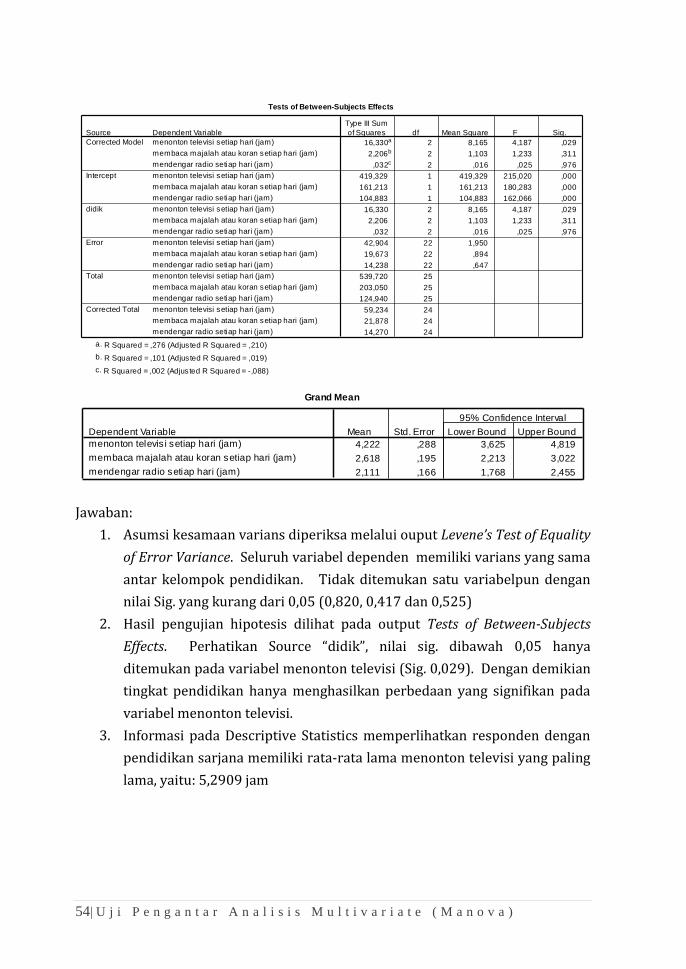
Jawaban:
1. Asumsi kesamaan varians diperiksa melalui ouput Levene’s Test of Equality
of Error Variance. Seluruh variabel dependen memiliki varians yang sama
antar kelompok pendidikan. Tidak ditemukan satu variabelpun dengan
nilai Sig. yang kurang dari 0,05 (0,820, 0,417 dan 0,525)
2. Hasil pengujian hipotesis dilihat pada output Tests of Between-Subjects
Effects. Perhatikan Source “didik”, nilai sig. dibawah 0,05 hanya
ditemukan pada variabel menonton televisi (Sig. 0,029). Dengan demikian
tingkat pendidikan hanya menghasilkan perbedaan yang signifikan pada
variabel menonton televisi.
3. Informasi pada Descriptive Statistics memperlihatkan responden dengan
pendidikan sarjana memiliki rata-rata lama menonton televisi yang paling
lama, yaitu: 5,2909 jam

P e n g a n t a r A n a l i s i s D i s k r i m i n a n |55
Bab 6 Pengantar Analisis Diskriminan
Tujuan Instruksional:
1. Mampu menentukan metode estimasi yang cocok untuk membuat fungsi
diskriminan
2. Mampu Menguji signifikansi dari fungsi diskriminan yang telah terbentuk,
dengan mempergunakan Wilk’s Lambda, Pilai, F test maupun yang lainnya
3. Mampu menguji ketepatan klassifikasi dari fungsi diskriminan, termasuk
mengetahui ketepatan klassifikasi secara individual dengan Casewise
Diagnostics
4. Mampu melakukan interprestasi terhadap fungsi diskriminan
5. Mampu Melakukan uji validasi fungsi diskriminan
6.1 Pengantar
Analisis diskriminan adalah teknik multivariat yang termasuk pada
dependence method, yakni adanya variabel dependen dan variabel independen.
Ciri khusus analisis ini adalah variabel dependen berupa data katagori/nominal
atau ordinal, sedangkan independen variabelnya justru berupa data interval atau
rasio. Hal ini dapat dimodelkan sebagai berikut
Y = X1 + X2 + X3 +……+ Xn
Interval atau Rasio Nominal atau Ordinal
6.1.a Tujuan Analisis Diskriminan:
1. Mengetahui perbedaan yang jelas antar grup pada variabel dependen.
2. Jika ada perbedaan, variabel independen manakah pada fungsi
diskriminan yang membuat perbedaan tersebut.
3. Membuat fungsi atau model diskriminan (yang mirip dengan persamaan
regresi).
4. Melakukan klasifikasi terhadap obyek ke dalam kelompok (grup).
6.1.b Asumsi:
1. Variabel bebas harus terdistribusi normal (adanya normalitas).
2. Matriks kovarians semua variabel bebas harus sama/equal (Box’s M)

56| P e n g a n t a r A n a l i s i s D i s k r i m i n a n
3. Tidak terjadi multikolinearitas (tidak berkorelasi) antar variabel bebas
(Eigen Value harus jauh dari 0)
4. Tidak terdapat data yang ekstrim (outlier).
6.1c. Proses Analisis Diskriminan
1. Memisah variabel-variabel menjadi variabel dependen dan independen
2. Menentukan metode untuk membuat fungsi diskriminan:
a. Simultaneous Estimation, dimana semua variabel dimasukkan
secara bersama-sama dan kemudian dilakukan proses diskriminan
b. Stepwise Estimation, dimana variabel dimasukkan satu persatu ke
dalam model diskriminan. Pada model ini, tetu ada variabel yang
tetap ada pada model, dan ada kemungkinan satu atau lebih
variabel independen yang dibuang dari model
3. Menguji signifikansi dari fungsi diskriminan yang telah terbentuk, dengan
mempergunakan Wilk’s Lambda, Pilai, F test maupun yang lainnya
4. Menguji ketepatan klassifikasi dari fungsi diskriminan, termasuk
mengetahui ketepatan klassifikasi secara individual dengan Casewise
Diagnostics
5. Melakukan interprestasi terhadap fungsi diskriminan
6. Melakukan uji validasi fungsi diskriminan
6.2 Kasus
Seorang analis kredit ingin mengetahui apa variabel-variabel yang dapat
membedakan/mendiskriminasi nasabah yang pernah menunggak pembayaran
cicilan kartu kredit dengan yang tidak pernah. Untuk itu dikumpulkan data 100
nasabah yang melibatkan variabel:
1. Usia
2. Pendapatan
3. Lama menikah
4. Rata-Rata frekuensi menggunakan kartu kredit dalam 1 bulan
P e n g a n t a r A n a l i s i s D i s k r i m i n a n |57
Solusi
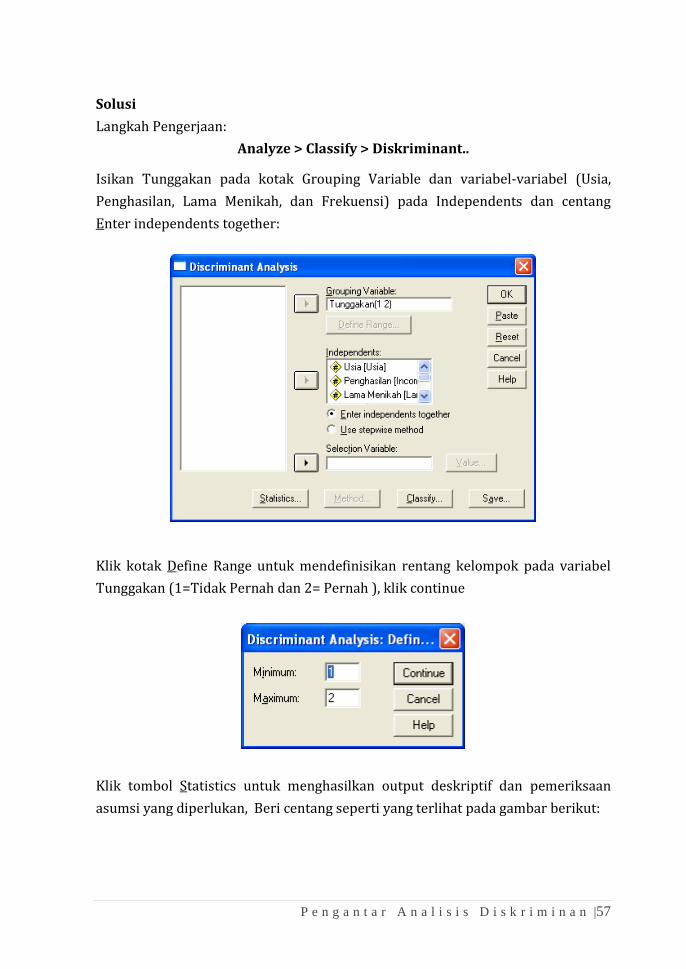
Langkah Pengerjaan:
Analyze > Classify > Diskriminant..
Isikan Tunggakan pada kotak Grouping Variable dan variabel-variabel (Usia,
Penghasilan, Lama Menikah, dan Frekuensi) pada Independents dan centang
Enter independents together:
Klik kotak Define Range untuk mendefinisikan rentang kelompok pada variabel
Tunggakan (1=Tidak Pernah dan 2= Pernah ), klik continue
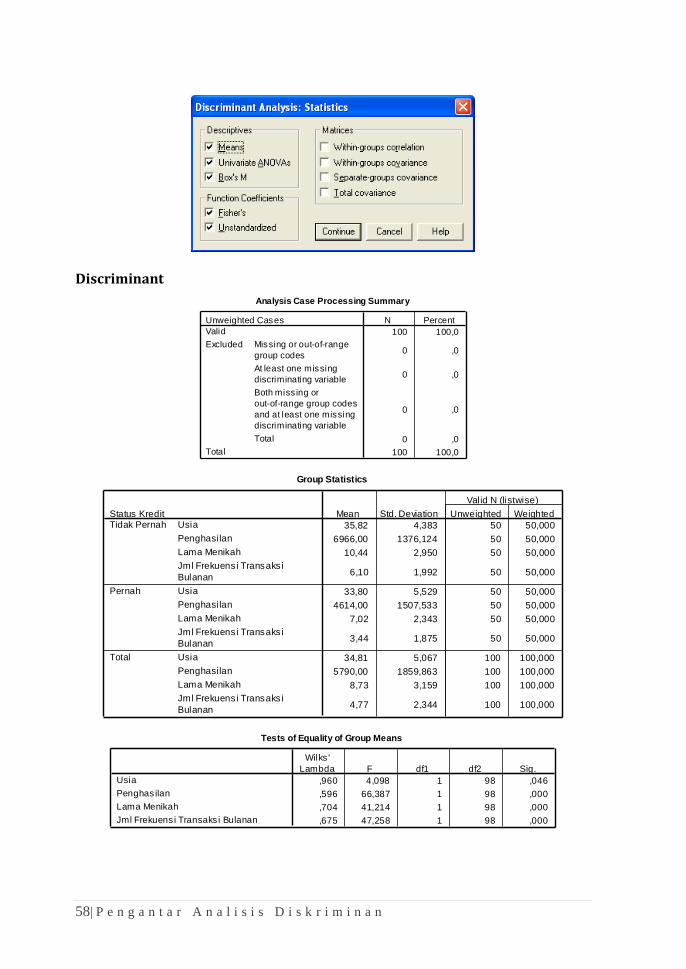
Klik tombol Statistics untuk menghasilkan output deskriptif dan pemeriksaan
asumsi yang diperlukan, Beri centang seperti yang terlihat pada gambar berikut:
58| P e n g a n t a r A n a l i s i s D i s k r i m i n a n
Discriminant
Analysis Case Processing Summary
100 100,0
0 ,0
0 ,0
0 ,0
0 ,0
100 100,0
Unweighted Cases
Valid
Missing or out-of-range
group codes
At least one missing
discriminating variable
Both miss ing or
out-of-range group codes
and at least one missing
discriminating variable
Total
Excluded
Total
N Percent
Group Statistics
35,82 4,383 50 50,000
6966,00 1376,124 50 50,000
10,44 2,950 50 50,000
6,10 1,992 50 50,000
33,80 5,529 50 50,000
4614,00 1507,533 50 50,000
7,02 2,343 50 50,000
3,44 1,875 50 50,000
34,81 5,067 100 100,000
5790,00 1859,863 100 100,000
8,73 3,159 100 100,000
4,77 2,344 100 100,000
Usia
Penghasilan
Lama Menikah
Jml Frekuensi Transaks i
Bulanan
Usia
Penghasilan
Lama Menikah
Jml Frekuensi Transaks i
Bulanan
Usia
Penghasilan
Lama Menikah
Jml Frekuensi Transaks i
Bulanan
Status KreditTidak Pernah
Pernah
Total
Mean Std. Deviation Unweighted Weighted
Valid N (listwise)
Tests of Equality of Group Means
,960 4,098 1 98 ,046
,596 66,387 1 98 ,000
,704 41,214 1 98 ,000
,675 47,258 1 98 ,000
Usia
Penghas ilan
Lama Menikah
Jml Frekuens i Transaks i Bulanan
Wilks '
Lambda F df1 df2 Sig.
P e n g a n t a r A n a l i s i s D i s k r i m i n a n |59
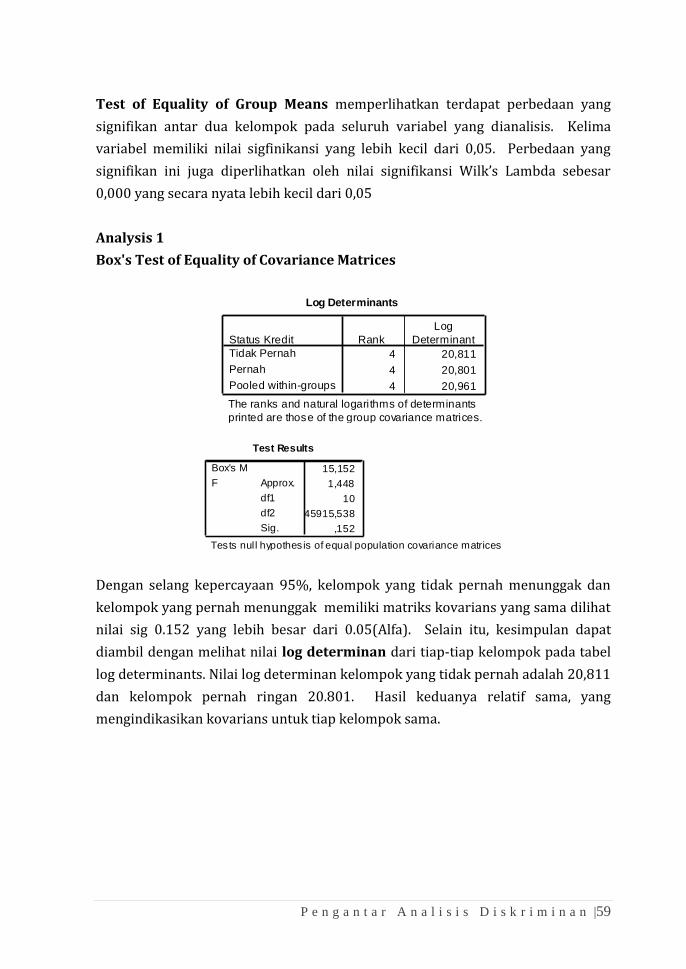
Test of Equality of Group Means memperlihatkan terdapat perbedaan yang
signifikan antar dua kelompok pada seluruh variabel yang dianalisis. Kelima
variabel memiliki nilai sigfinikansi yang lebih kecil dari 0,05. Perbedaan yang
signifikan ini juga diperlihatkan oleh nilai signifikansi Wilk’s Lambda sebesar
0,000 yang secara nyata lebih kecil dari 0,05
Analysis 1
Box's Test of Equality of Covariance Matrices
Log Determinants
4 20,811
4 20,801
4 20,961
Status Kredit
Tidak Pernah
Pernah
Pooled within-groups
Rank
Log
Determinant
The ranks and natural logarithms of determinants
printed are those of the group covariance matrices.
Test Results
15,152
1,448
10
45915,538
,152
Box's M
Approx.
df1
df2
Sig.
F
Tests null hypothes is of equal population covariance matrices.
Dengan selang kepercayaan 95%, kelompok yang tidak pernah menunggak dan
kelompok yang pernah menunggak memiliki matriks kovarians yang sama dilihat
nilai sig 0.152 yang lebih besar dari 0.05(Alfa). Selain itu, kesimpulan dapat
diambil dengan melihat nilai log determinan dari tiap-tiap kelompok pada tabel
log determinants. Nilai log determinan kelompok yang tidak pernah adalah 20,811
dan kelompok pernah ringan 20.801. Hasil keduanya relatif sama, yang
mengindikasikan kovarians untuk tiap kelompok sama.

60| P e n g a n t a r A n a l i s i s D i s k r i m i n a n
Summary of Canonical Discriminant Functions
Eigenvalues
1,708a 100,0 100,0 ,794
Function
1
Eigenvalue % of Variance Cumulative %
Canonical
Correlation
Firs t 1 canonical discriminant functions were used in the
analysis .
a.
Nilai Eigen (eigen value) menunjukkan ada atau tidaknya multikolinearitas
antar variabel bebas. Multikolinearitas akan terjadi bila nilai Eigen mendekati 0
(nol). Berdasarkan hasil pengolahan data didapatkan nilai akar ciri yang menjauhi
nol, yaitu sebesar 1,704. Keadaan ini dapat diartikan bahwa fungsi diskriminan
yang diperoleh cukup baik karena tidak terjadi multikolinearitas di antara
sesama variabel independen.
Nilai canonical correlation. Canonical correlation digunakan untuk
mengukur derajat hubungan antara besarnya variabilitas yang mampu
diterangkan oleh variabel independen terhadap variabel dependen. Dari tabel di
atas, diperoleh nilai canonical correlation sebesar 0,794, bila dikuadratkan
menjadi 0.6304 memiliki arti bahwa artinya 63,04% varians dari variabel
dependen dapat dijelaskan dari model diskriminan yang terbentuk
Wilks' Lambda
,369 95,620 4 ,000
Test of Function(s)
1
Wilks '
Lambda Chi-square df Sig.
Standardized Canonical Discriminant Function Coefficients
,046
,660
,434
,681
Usia
Penghasilan
Lama Menikah
Jml Frekuens i Transaks i Bulanan
1
Function

P e n g a n t a r A n a l i s i s D i s k r i m i n a n |61
Structure Matrix
,630
,531
,496
,156
Penghasilan
Jml Frekuens i Transaks i Bulanan
Lama Menikah
Usia
1
Function
Pooled within-groups correlations between discriminating
variables and s tandardized canonical discriminant functions
Variables ordered by absolute s ize of correlation within function.
Canonical Discriminant Function Coefficients
,009
,000
,163
,352
-6,066
Usia
Penghasilan
Lama Menikah
Jml Frekuensi Transaksi Bulanan
(Constant)
1
Function
Unstandardized coefficients
Tabel canonical discriminant function coefficients menerangkan model
diskriminan yang terbentuk, yaitu :
Y= -6.066+0.352Frekuensi+0.162Lama Menikah+0,000Penghasilan+0,009Usia
Functions at Group Centroids
1,294
-1,294
Status Kredit
Tidak Pernah
Pernah
1
Function
Unstandardized canonical discriminant
functions evaluated at group means
Classification Statistics
Prior Probabilities for Groups
,500 50 50,000
,500 50 50,000
1,000 100 100,000
Status Kredit
Tidak Pernah
Pernah
Total
Prior Unweighted Weighted
Cases Used in Analys is

62| P e n g a n t a r A n a l i s i s D i s k r i m i n a n
Classification Function Coefficients
1,295 1,271
,003 ,002
1,062 ,641
2,034 1,124
-46,565 -30,870
Usia
Penghasilan
Lama Menikah
Jml Frekuensi Transaksi Bulanan
(Constant)
Tidak Pernah Pernah
Status Kredit
Fisher's l inear discriminant functions

A n a l i s i s F a k t o r E x p l o r a t o r i ( E F A ) |63
Bab 7 Analisis Faktor Eksploratori (EFA)
Tujuan Instruksional:
1. Mampu melakukan pemeriksaan asumsi analisis faktor
2. Mampu melakukan proses menurunkan satu atau lebih faktor dari variabel-
variabel yang telah lolos pada uji variabel sebelumnya
3. Mampu memilih metode rotasi yang tepat untuk memperjelas variabel yang
masuk ke dalam suatu faktor
4. Mampu memberi nama dan menginterprestasikan faktor yang terbentuk
7.1 Pengantar
Analisis Faktor merupakan suatu teknik untuk meringkas/summarize
informasi yang ada dalam variabel/atribut asli (awal) menjadi satu set dimensi
baru (factor). Contoh: jika ada 10 atribut yang independen satu dengan yang lain,
dengan analisis faktor mungkin bisa diringkas menjadi 3 kumpulan atribut baru
Kumpulan variabel baru tadi disebut dengan faktor, dimana faktor tersebut tetap
mencerminkan atribut-atribut aslinya. Summarizing dilakukan dengan cara
mengidentifikasi struktur hubungan antar atribut dengan cara melihat korelasi
antar variabel.
Ada beberapa langkah utama yang harus dilakukan untuk melakukan
analisis faktor, yaitu:
1. Menyusun matriks korelasi.
2. Ekstraksi faktor.
3. Merotasi faktor.
4. Menginterpretasikan Faktor.
7.1.1 Menyusun Matriks Korelasi
Dalam analisis faktor, keputusan pertama yang harus diambil adalah
memastikan apakah data yang ada cukup memenuhi syarat. Persyaratan tersebut
diperiksa dengan mencari korelasi matriks antara atribut yang diobservasi. Ada
beberapa ukuran yang bisa digunakan untuk syarat kecukupan data sebagai rule
of thumb yaitu:

64| A n a l i s i s F a k t o r E x p l o r a t o r i ( E F A )
a. Korelasi matriks antar atribut. Tingginya korelasi antar atribut
mengindikasikan bahwa atribut tersebut dapat dikelompokkan ke dalam
sebuah indikator yang bersifat homogen sehingga setiap atibut mampu
membentuk faktor umum atau faktor konstruk. Sebaliknya korelasi yang
rendah antara atribut mengindikasikan bahwa atribut tersebut tidak
homogen sehingga tidak mampu membentuk faktor konstruk.
b. Korelasi parsial: Metode kedua adalah memeriksa korelasi parsial atau
negative anti-image correlations. Dengan kata lain, korelasi antara suatu
atribut dengan dirinya sendiri harus kuat, sementara dengan atribut
justru harus kecil.
c. Kaiser-Meyer Olkin (KMO): Metode ini paling banyak digunakan untuk
melihat syarat kecukupan data untuk analisis faktor. Metode KMO ini
mengukur kecukupan sampling secara menyeluruh dan mengukur
kecukupan sampling untuk setiap atribut. Secara umum jumlah sampel
minimal yang dianjurkan adalah antara 50 sampai 100 sampel, atau
dengan patokan (10:1) dalam arti satu variabel ada 10 sampel.
7.1.2 Ekstraksi faktor
Ekstraksi Faktor adalah suatu metode yang digunakan untuk mereduksi data
dari beberapa atribut untuk menghasilkan faktor yang lebih sedikit yang mampu
menjelaskan korelasi antara atribut yang diobservasi. Ada beberapa metode yang
bisa digunakan untuk melakukan ekstraksi faktor yaitu:
a. Principal Components Analysis: Analisis komponen utama/principal
components analysis) merupakan metode yang paling sederhana di dalam
melakukan ekstraksi faktor. Metode ini membentuk kombinasi linear dari
atribut yang diobservasi. Metode ini merupakan metode yang paling
sederhana dan mudah digunakan dibanding dengan metode lainnya
sehingga sering digunakan.
b. Principal Axis Factoring: Metode ini hampir sama dengan metode principal
components analysis sebelumnya kecuali matriks korelasi diagonal diganti
dengan sebuah estimasi faktor, namun tidak sama dengan principal
components analysis dimana faktor yang awal selalu diberi angka 1.
c. Unweighted Least Square: Metode ini adalah prosedur untuk
meminimumkan jumlah perbedaan yang dikuadratkan antara matriks

A n a l i s i s F a k t o r E x p l o r a t o r i ( E F A ) |65
korelasi yang diobservasi dan yang diproduksi dengan mengabaikan
matriks diagonal dari sejumlah faktor tertentu.
d. Generalized Least Square: Metode ini adalah metode meminimumkan
error sebagaimana metode unweighted least squares. Namun, korelasi
diberi timbangan sebesar keunikan dari indikator (error). Korelasi dari
indikator yang mempunyai error yang besar diberi timbangan yang lebih
kecil dari indikator yang mempunyai error yang kecil.
e. Maximum Likelihood: Adalah suatu prosedur ekstraksi faktor yang
menghasilkan estimasi parameter yang paling mungkin untuk
mendapatkan matriks korelasi observasi jika sampel mempunyai
distribusi normal multivariat.
Ekstraksi faktor menghasilkan suatu matriks yang disebut matriks faktor.
Matriks faktor ini merupakan matriks yang belum dirotasi. Matriks faktor akan
menunjukkan faktor loadings dari masing-masing atribut terhadap terhadap
sediap faktor. Dengan kata lain, Faktor Loadings merupakan skor yang
menunjukkan seberapa besar suatu attribut berkontribusi pada faktor (Young dan
Pearce, 2013)
7.1.3 Merotasi Faktor
Ekstraksi faktor diperoleh, langkah selanjutnya adalah melalukan rotasi
faktor. Rotasi faktor ini diperlukan jika metode ekstraksi faktor belum
menghasilkan komponen faktor utama yang jelas. Artinya terdapat beberapa
atribut yang menghasilkan cross loading sehingga faktor yang dihasilkan belum
mampu merepresentasikan attribut-attribut yang dijelaskan atau malah justru
membingungkan (Young dan Perace, 2013). Atribut tersebut memiliki loading
factors yang tinggi lebih dari satu faktor (Williams et al, 2010)
Tujuan dari rotasi faktor ini agar dapat memperoleh struktur faktor yang
lebih sederhana agar mudah diinterpretasikan. Pada umumnya dalam analisis
faktor, matriks loading faktor yang diperoleh sulit untuk diinterpretasikan, maka
disarankan untuk melakukan rotasi agar faktor yang sudah dirotasi memiliki
sedikit saja atribut dengan nilai muatan mutlak/absolute loading factor yang
besar, sedangkan sisanya kecil atau nol. Pola seperti ini akan memudahkan
interpretasi terhadap faktor yang terbentuk. Progam aplikasi akan
mentransformasi matriks tersebut dengan mengalikan matriks orthogonalnya
sehingga interpretasi yang bermakna menggunakan matriks yang baru itu

66| A n a l i s i s F a k t o r E x p l o r a t o r i ( E F A )
memungkinkan (Johnson and Wichern, 1992). Beberapa metode yang bisa
digunakan adalah:
a. Varimax Method: Adalah metode rotasi orthogonal untuk
meminimalisasi jumlah indikator yang mempunyai factor loading
tinggi pada tiap faktor.
b. Quartimax Method: Merupakan metode rotasi untuk meminimalisasi
jumlah faktor yang digunakan untuk menjelaskan indikator.
c. Equamax Method: Merupakan metode gabungan antara varimax
method yang meminimalkan indikator dan quartimax method yang
meminimalkan faktor.
7.1.4 Interpretasi Faktor
Setelah diperoleh sejumlah faktor yang valid, selanjutnya perlu
diinterprestasikan nama-nama fackor, mengingat faktor merupakan sebuah
konstruk dan sebuah konstruk menjadi berarti kalau dapat diartikan.
Interprestasi faktor dapat dilakukan dengan mengetahui atribut-atribut yang
membentuknya. Interprestasi dilakukan dengan judgment dan bersifat subjektif.
Penamaan faktor bisa berbeda bagi setiap orang.
7.2 Kasus
Direktur sebuah rumah sakit swasta ingin mengetahui, apa faktor yang
mendorong para pasien untuk berkunjung ke rumah sakitnya. Untuk itu diambil
sampel sebanyak 100 orang, yang kemudian diminta pendapatnya tentang atribut-
atribut sebagai berikut:
1. Pelayanan pasien
2. Keluasan area parkir
3. Kebersihan rumah sakit
4. Kecepatan waktu pelayanan
5. Kenyamanan rumah sakit, dan
6. Kelengkapan peralatan medis
Respon diberikan dalam skala likert 5 poin dari 1 (sangat tidak penting) sampai 5
(sangat penting).
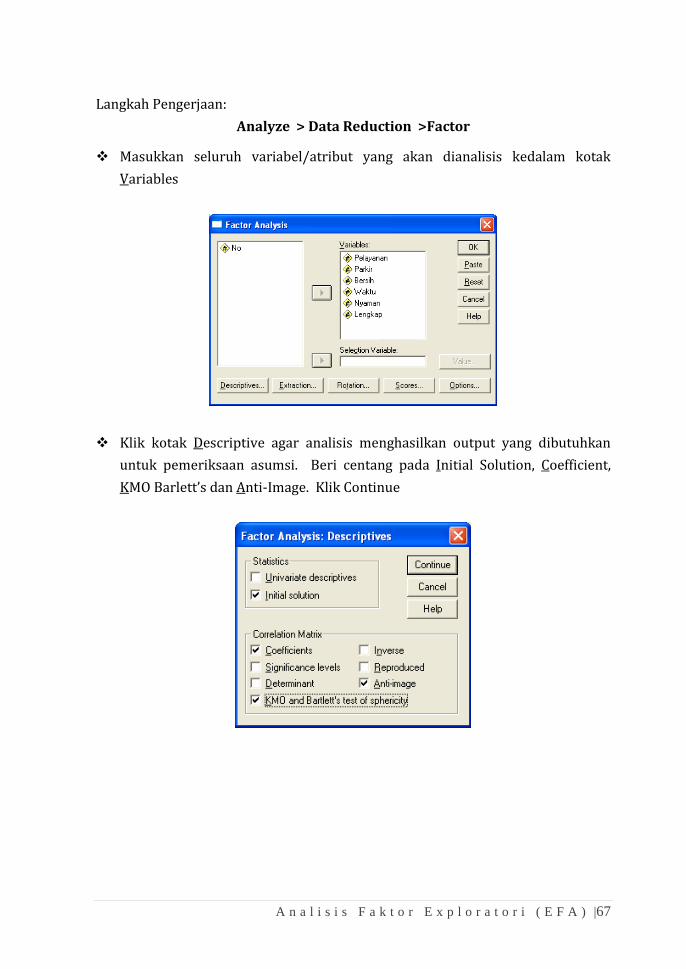
A n a l i s i s F a k t o r E x p l o r a t o r i ( E F A ) |67
Langkah Pengerjaan:
Analyze > Data Reduction >Factor
❖ Masukkan seluruh variabel/atribut yang akan dianalisis kedalam kotak
Variables
❖ Klik kotak Descriptive agar analisis menghasilkan output yang dibutuhkan
untuk pemeriksaan asumsi. Beri centang pada Initial Solution, Coefficient,
KMO Barlett’s dan Anti-Image. Klik Continue

68| A n a l i s i s F a k t o r E x p l o r a t o r i ( E F A )
❖ Klik kotak Extraction, klik Continue
❖ Setelah kembali ke menu Factor Analysis klik kotak Rotation, berikan tanda
centang pada kotak Method untuk Varimax, dan berikan centang pada Loading
plot(s), klik continue
Output:
KMO and Bartlett's Test
,661
99,852
15
,000
Kaiser-Meyer-Olkin Measure of Sampling
Adequacy.
Approx. Chi-Square
df
Sig.
Bartlett's Test of
Sphericity
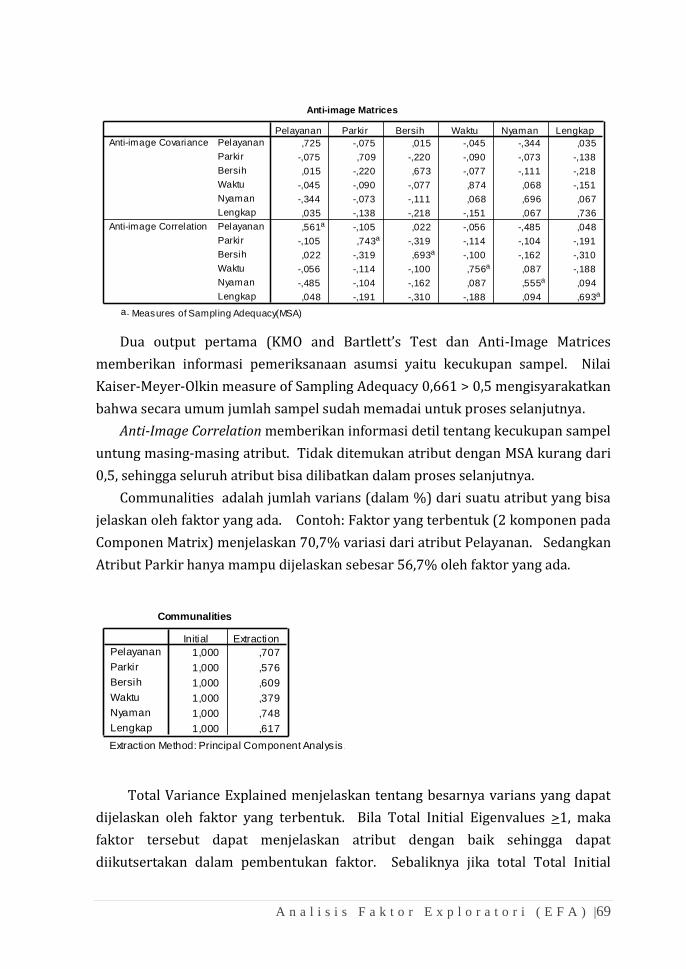
A n a l i s i s F a k t o r E x p l o r a t o r i ( E F A ) |69
Anti-image Matrices
,725 -,075 ,015 -,045 -,344 ,035
-,075 ,709 -,220 -,090 -,073 -,138
,015 -,220 ,673 -,077 -,111 -,218
-,045 -,090 -,077 ,874 ,068 -,151
-,344 -,073 -,111 ,068 ,696 ,067
,035 -,138 -,218 -,151 ,067 ,736
,561a -,105 ,022 -,056 -,485 ,048
-,105 ,743a -,319 -,114 -,104 -,191
,022 -,319 ,693a -,100 -,162 -,310
-,056 -,114 -,100 ,756a ,087 -,188
-,485 -,104 -,162 ,087 ,555a ,094
,048 -,191 -,310 -,188 ,094 ,693a
Pelayanan
Parkir
Bersih
Waktu
Nyaman
Lengkap
Pelayanan
Parkir
Bersih
Waktu
Nyaman
Lengkap
Anti-image Covariance
Anti-image Correlation
Pelayanan Parkir Bersih Waktu Nyaman Lengkap
Measures of Sampling Adequacy(MSA)a.
Dua output pertama (KMO and Bartlett’s Test dan Anti-Image Matrices
memberikan informasi pemeriksanaan asumsi yaitu kecukupan sampel. Nilai
Kaiser-Meyer-Olkin measure of Sampling Adequacy 0,661 > 0,5 mengisyarakatkan
bahwa secara umum jumlah sampel sudah memadai untuk proses selanjutnya.
Anti-Image Correlation memberikan informasi detil tentang kecukupan sampel
untung masing-masing atribut. Tidak ditemukan atribut dengan MSA kurang dari
0,5, sehingga seluruh atribut bisa dilibatkan dalam proses selanjutnya.
Communalities adalah jumlah varians (dalam %) dari suatu atribut yang bisa
jelaskan oleh faktor yang ada. Contoh: Faktor yang terbentuk (2 komponen pada
Componen Matrix) menjelaskan 70,7% variasi dari atribut Pelayanan. Sedangkan
Atribut Parkir hanya mampu dijelaskan sebesar 56,7% oleh faktor yang ada.
Communalities
1,000 ,707
1,000 ,576
1,000 ,609
1,000 ,379
1,000 ,748
1,000 ,617
Pelayanan
Parkir
Bersih
Waktu
Nyaman
Lengkap
Initial Extraction
Extraction Method: Principal Component Analys is .
Total Variance Explained menjelaskan tentang besarnya varians yang dapat
dijelaskan oleh faktor yang terbentuk. Bila Total Initial Eigenvalues >1, maka
faktor tersebut dapat menjelaskan atribut dengan baik sehingga dapat
diikutsertakan dalam pembentukan faktor. Sebaliknya jika total Total Initial
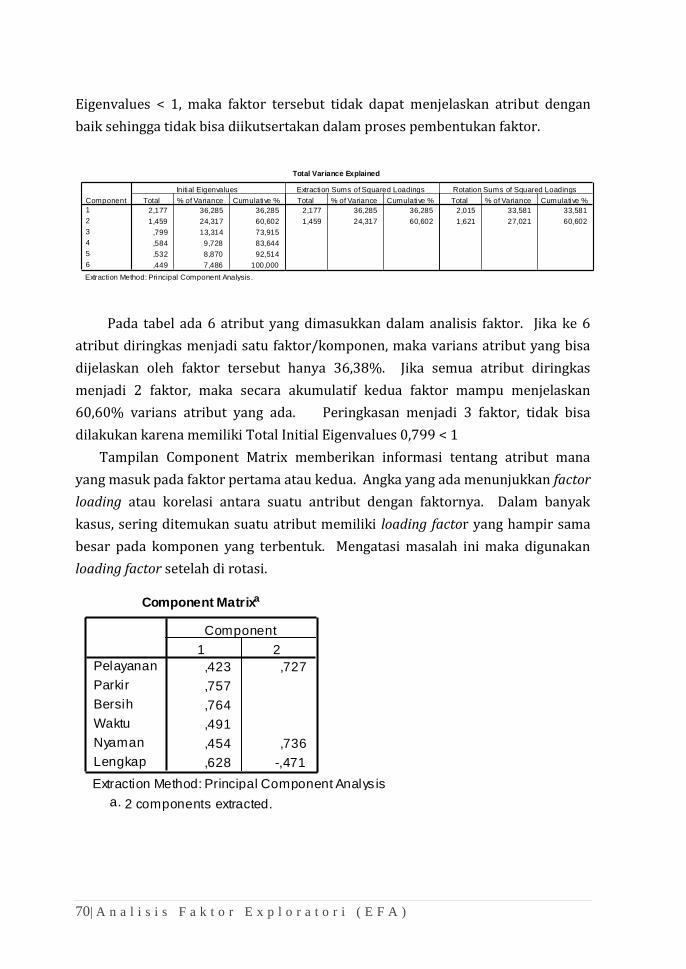
70| A n a l i s i s F a k t o r E x p l o r a t o r i ( E F A )
Eigenvalues < 1, maka faktor tersebut tidak dapat menjelaskan atribut dengan
baik sehingga tidak bisa diikutsertakan dalam proses pembentukan faktor.
Total Variance Explained
2,177 36,285 36,285 2,177 36,285 36,285 2,015 33,581 33,581
1,459 24,317 60,602 1,459 24,317 60,602 1,621 27,021 60,602
,799 13,314 73,915
,584 9,728 83,644
,532 8,870 92,514
,449 7,486 100,000
Component
1
2
3
4
5
6
Total % of Variance Cumulative % Total % of Variance Cumulative % Total % of Variance Cumulative %
Initial Eigenvalues Extraction Sums of Squared Loadings Rotation Sums of Squared Loadings
Extraction Method: Principal Component Analysis .
Pada tabel ada 6 atribut yang dimasukkan dalam analisis faktor. Jika ke 6
atribut diringkas menjadi satu faktor/komponen, maka varians atribut yang bisa
dijelaskan oleh faktor tersebut hanya 36,38%. Jika semua atribut diringkas
menjadi 2 faktor, maka secara akumulatif kedua faktor mampu menjelaskan
60,60% varians atribut yang ada. Peringkasan menjadi 3 faktor, tidak bisa
dilakukan karena memiliki Total Initial Eigenvalues 0,799 < 1
Tampilan Component Matrix memberikan informasi tentang atribut mana
yang masuk pada faktor pertama atau kedua. Angka yang ada menunjukkan factor
loading atau korelasi antara suatu antribut dengan faktornya. Dalam banyak
kasus, sering ditemukan suatu atribut memiliki loading factor yang hampir sama
besar pada komponen yang terbentuk. Mengatasi masalah ini maka digunakan
loading factor setelah di rotasi.
Component Matrixa
,423 ,727
,757
,764
,491
,454 ,736
,628 -,471
Pelayanan
Parkir
Bersih
Waktu
Nyaman
Lengkap
1 2
Component
Extraction Method: Principal Component Analys is .
2 components extracted.a.
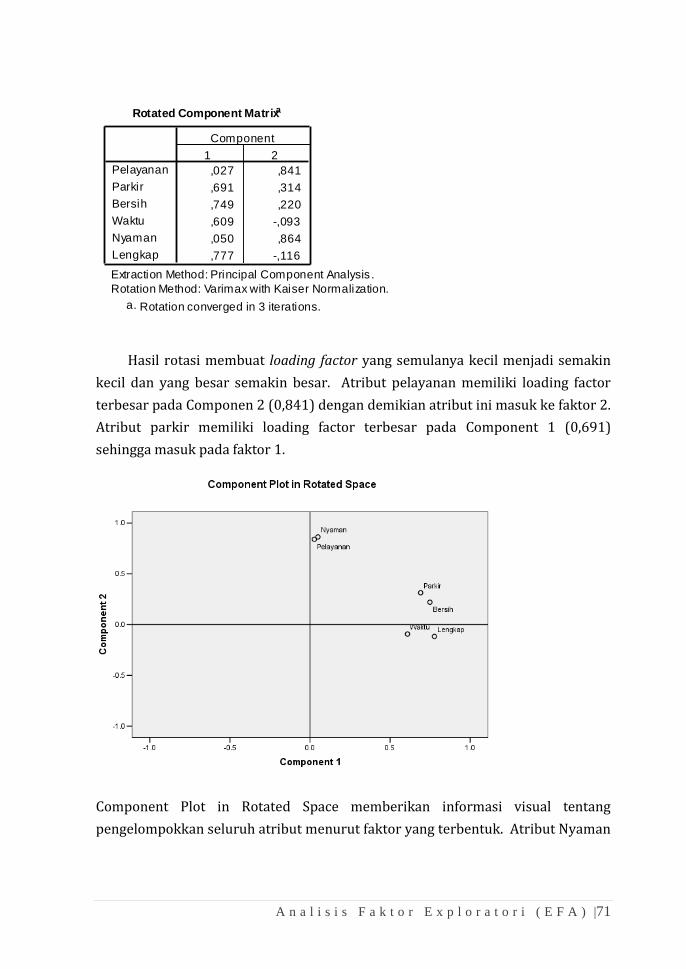
A n a l i s i s F a k t o r E x p l o r a t o r i ( E F A ) |71
Rotated Component Matrixa
,027 ,841
,691 ,314
,749 ,220
,609 -,093
,050 ,864
,777 -,116
Pelayanan
Parkir
Bersih
Waktu
Nyaman
Lengkap
1 2
Component
Extraction Method: Principal Component Analysis .
Rotation Method: Varimax with Kaiser Normalization.
Rotation converged in 3 iterations.a.
Hasil rotasi membuat loading factor yang semulanya kecil menjadi semakin
kecil dan yang besar semakin besar. Atribut pelayanan memiliki loading factor
terbesar pada Componen 2 (0,841) dengan demikian atribut ini masuk ke faktor 2.
Atribut parkir memiliki loading factor terbesar pada Component 1 (0,691)
sehingga masuk pada faktor 1.
Component Plot in Rotated Space memberikan informasi visual tentang
pengelompokkan seluruh atribut menurut faktor yang terbentuk. Atribut Nyaman

72| A n a l i s i s F a k t o r E x p l o r a t o r i ( E F A )
dan Pelayanan mengelompok pada faktor pertama, sedangkan Atribut lainnya
mengelompok pada faktor kedua.
Component Transformation Matrix
,880 ,475
-,475 ,880
Component
1
2
1 2
Extraction Method: Principal Component Analysis .
Rotation Method: Varimax with Kaiser Normalization.
LATIHAN
Persaingan body lotion cukup menarik untuk diperhatikan, body lotion bagi
sebagian wanita sudah menjadi bagian yang tidak terpisahkan dalam kehidupan
sehari-hari. Oleh karena itu perlu dilakukan penelitian mengenai faktor apa saja
yang diperhitungkan seorang konsumen untuk membeli produk body lotion
sehingga produsen mampu menciptakan produk body lotion yang sesuai dengan
ekspektasi konsumen. Untuk menjawab pertanyaan penelitian tersebut,
dilakukan survey terhadap 140 responden dengan menanyakan seberapa penting
atribut-atribut berikut ini:
1. Kekentalan
2. Merk Dikenal/Terkenal
3. Tidak Membuat Alergi
4. Harga Yang Terjangkau
5. Kelembutan Di Kulit
6. Kemasan Yang Menarik
7. Kesesuaian Harga Dengan Mutu
8. Kelembaban
9. Variasi Ukuran Kemasan
10. Pencantuman Komposisi Bahan
11. Variasi Aroma
12. Wangi Yang Lama
13. Reputasi Perusahaan
14. Cepat Menyerap

A n a l i s i s F a k t o r C o n f i r m a t o r y ( V a l i d i t a s K o n s t r u k . . . |73
Bab 8 Analisis Faktor Confirmatory
(Validitas Konstruk dan Reliabilitas)
Tujuan Instruksional:
1. Mampu menggunakan Analisis Faktor untuk mengukur validitas konstruk
2. Mampu menguji item yang valid atau tidak dalam mengukur suatu
konstruk
3. Mampu menguji realibilitas item pertanyaan untuk pengukuran
4. Mampu menghitung Validitas/average variance extracted (AVE).dan
Reliabilitas Konstruk/Composite Reliability (CR)
8.1 Validitas
Latan (2014a: 110) memberikan pengertian validitas sebagai kemampuan
dari instrumen untuk mengukur secara aktual apa yang seharusnya diukur tanpa
kesalahan dalam penarikan kesimpulan dari data. Validitas Konstruk mengukur
sejauh mana item-item pengukuran secara aktual merepresentasikan konstruk
hipotetis yang dirancang untuk diukur oleh sejumlah item pertanyaan (Dahlan,
2014: 183). Teknik yang lazim digunakan untuk hal tersebut adalah dengan
menggunakan Analisis Faktor Konfirmatory/AFK (confirmatory factor
Analysis/CFA).
Asra et al. (2017:110) menjelaskan bahwa tujuan AFK adalah untuk
mengkonfirmasi atau menguji kembali pembentukan konsep atau konstruk yang
telah diformulasikan dalam suatu kerangka teori, atau memerika kembali suatu
model pengukuran yang perumusannya berasal dari suatu teori.
Amir (2015: 135) menjelaskan AFK sebagai metode lanjutan dari analisis
faktor untuk menguji hipotesis dimana yang dihipotesiskan adalah factor
loadingnya. Kemudian CFA dilakukan untuk menguji kecocokan loading yang
terjadi pada matriks yang terbentuk. Dari hasilnya, dapat dilihat sejauh mana
kesesuaian (fit)nya antara faktor loading dari data dengan yang dihasilkan oleh
model. Selain itu juga dijelaskan bahwa factor loading yang bernilai lebih dari 0,4
(absolut) bisa dianggap sebagai angka yang layak. Hair (2010) memberikan
kriteria untuk menentukan factor loading dalam CFA, yaitu:

74| A n a l i s i s F a k t o r C o n f i r m a t o r y ( V a l i d i t a s K o n s t r u k . . .
Factor Loading Jumlah Sampel
0,30 350 0,35 250 0,40 200 0,45 150 0,50 120 0,55 100 0,60 85 0,65 70 0,70 60 0,75 50
8.2 Reliabilitas
Latan (2014b: 97) menjelaskan reliabilitas dari suatu pengukuran
menunjukkan bahwa pengukuran yang dilakukan bebas dari kesalahan atau tanpa
bias dan pengukuran tersebut konsisten dari waktu ke waktu dengan
menggunakan item instrumen yang sama. Salah satu pengujian realibilitas yang
dapat digunakan adalah konsistensi internal dengan menggunakan koefisien
Cronbach Alpha.
Amir (2015:41) menyebutkan bahwa para ahli pengukuran sepakat
mengatakan koefisien Alfa 0,7 diperlukan untuk sebuah skala yang sudah mapan
dan dianggap stabil. Adapun untuk sebuah skala yang masih dalam
pengembangan, koefisien 0,60 dianggap cukup memadai.
8.3. Kasus
Seorang pakar membuat sebuah instrumen untuk mengukur istri ideal
yang menggunakan 4 item pernyataan. Responden diminta mengungkapkan
persetujuan dalam bentuk “sangat tidak setuju” (1), “tidak setuju” (2), “agak
setuju”(3), “Setuju” (4) dan “sangat setuju” (5).
1. Istri saya adalah orang menyenangkan jika di pandang
2. Istri saya selalu patuh atas apapun perintah saya
3. Istri saya adalah orang yang menjaga kehormatan dirinya
sekalipun saya tidak dirumah
4. Istri saya selalu merasa cukup atas segala yang saya berikan
Berdasarkan hasil pilot test terhadap 83 responden, Anda diminta untuk:
1. Menguji Validitas keempat pertanyaan yang ada
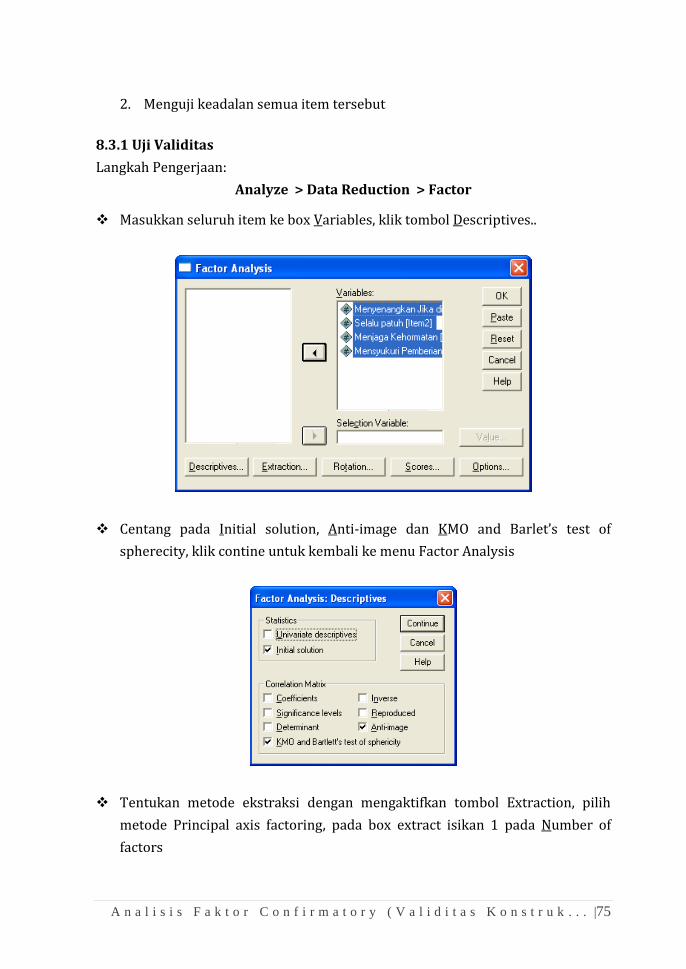
A n a l i s i s F a k t o r C o n f i r m a t o r y ( V a l i d i t a s K o n s t r u k . . . |75
2. Menguji keadalan semua item tersebut
8.3.1 Uji Validitas
Langkah Pengerjaan:
Analyze > Data Reduction > Factor
❖ Masukkan seluruh item ke box Variables, klik tombol Descriptives..
❖ Centang pada Initial solution, Anti-image dan KMO and Barlet’s test of
spherecity, klik contine untuk kembali ke menu Factor Analysis
❖ Tentukan metode ekstraksi dengan mengaktifkan tombol Extraction, pilih
metode Principal axis factoring, pada box extract isikan 1 pada Number of
factors

76| A n a l i s i s F a k t o r C o n f i r m a t o r y ( V a l i d i t a s K o n s t r u k . . .
❖ Clik Continue untuk kembali ke menu Factor Analysis, klik Rotation untuk
menentukan metode rotasi, centang pada Promax
KMO and Bartlett's Test
,699
93,401
6
,000
Kaiser-Meyer-Olkin Measure of Sampling
Adequacy.
Approx. Chi-Square
df
Sig.
Bartlett's Test of
Sphericity
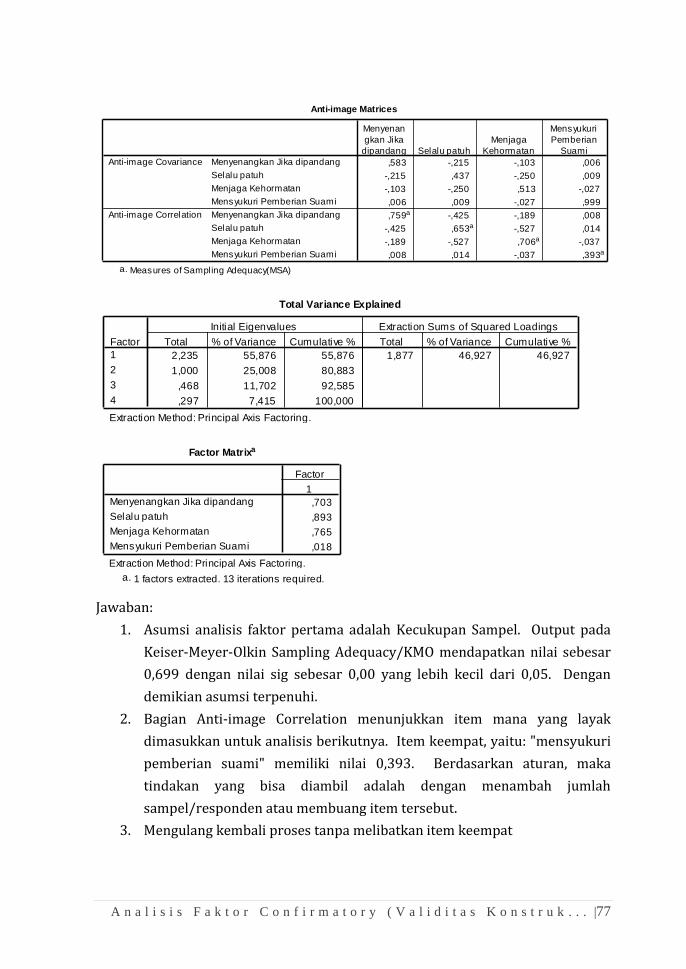
A n a l i s i s F a k t o r C o n f i r m a t o r y ( V a l i d i t a s K o n s t r u k . . . |77
Anti-image Matrices
,583 -,215 -,103 ,006
-,215 ,437 -,250 ,009
-,103 -,250 ,513 -,027
,006 ,009 -,027 ,999
,759a -,425 -,189 ,008
-,425 ,653a -,527 ,014
-,189 -,527 ,706a -,037
,008 ,014 -,037 ,393a
Menyenangkan Jika dipandang
Selalu patuh
Menjaga Kehormatan
Mensyukuri Pemberian Suami
Menyenangkan Jika dipandang
Selalu patuh
Menjaga Kehormatan
Mensyukuri Pemberian Suami
Anti-image Covariance
Anti-image Correlation
Menyenan
gkan Jika
dipandang Selalu patuh
Menjaga
Kehormatan
Mensyukuri
Pemberian
Suami
Measures of Sampling Adequacy(MSA)a.
Total Variance Explained
2,235 55,876 55,876 1,877 46,927 46,927
1,000 25,008 80,883
,468 11,702 92,585
,297 7,415 100,000
Factor
1
2
3
4
Total % of Variance Cumulative % Total % of Variance Cumulative %
Initial Eigenvalues Extraction Sums of Squared Loadings
Extraction Method: Principal Axis Factoring.
Factor Matrixa
,703
,893
,765
,018
Menyenangkan Jika dipandang
Selalu patuh
Menjaga Kehormatan
Mensyukuri Pemberian Suami
1
Factor
Extraction Method: Principal Axis Factoring.
1 factors extracted. 13 iterations required.a.
Jawaban:
1. Asumsi analisis faktor pertama adalah Kecukupan Sampel. Output pada
Keiser-Meyer-Olkin Sampling Adequacy/KMO mendapatkan nilai sebesar
0,699 dengan nilai sig sebesar 0,00 yang lebih kecil dari 0,05. Dengan
demikian asumsi terpenuhi.
2. Bagian Anti-image Correlation menunjukkan item mana yang layak
dimasukkan untuk analisis berikutnya. Item keempat, yaitu: "mensyukuri
pemberian suami" memiliki nilai 0,393. Berdasarkan aturan, maka
tindakan yang bisa diambil adalah dengan menambah jumlah
sampel/responden atau membuang item tersebut.
3. Mengulang kembali proses tanpa melibatkan item keempat
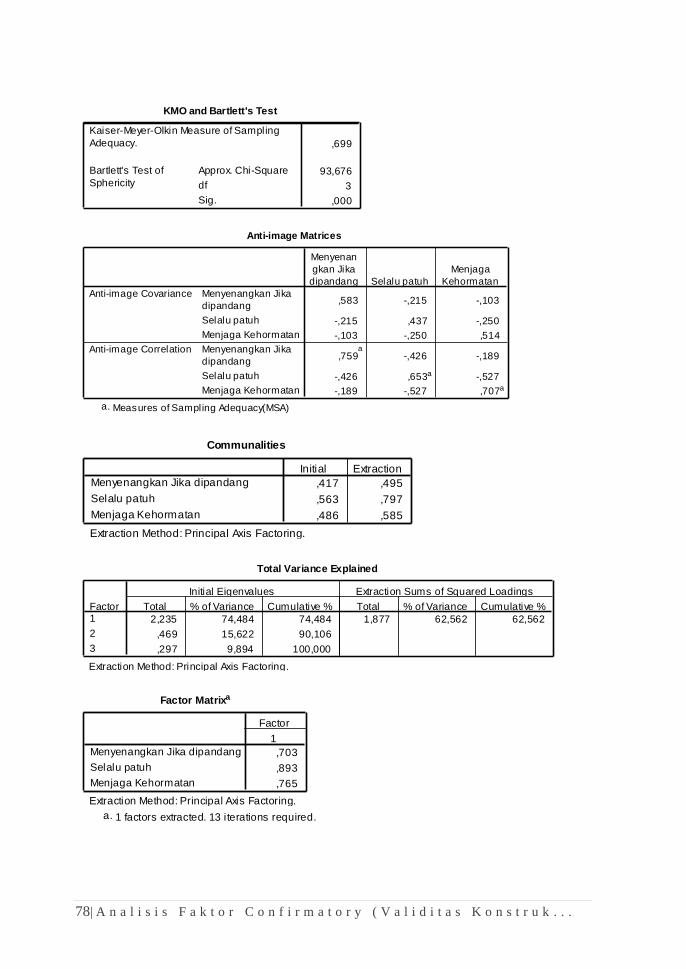
78| A n a l i s i s F a k t o r C o n f i r m a t o r y ( V a l i d i t a s K o n s t r u k . . .
KMO and Bartlett's Test
,699
93,676
3
,000
Kaiser-Meyer-Olkin Measure of Sampling
Adequacy.
Approx. Chi-Square
df
Sig.
Bartlett's Test of
Sphericity
Anti-image Matrices
,583 -,215 -,103
-,215 ,437 -,250
-,103 -,250 ,514
,759a
-,426 -,189
-,426 ,653a -,527
-,189 -,527 ,707a
Menyenangkan Jika
dipandang
Selalu patuh
Menjaga Kehormatan
Menyenangkan Jika
dipandang
Selalu patuh
Menjaga Kehormatan
Anti-image Covariance
Anti-image Correlation
Menyenan
gkan Jika
dipandang Selalu patuh
Menjaga
Kehormatan
Measures of Sampling Adequacy(MSA)a.
Communalities
,417 ,495
,563 ,797
,486 ,585
Menyenangkan Jika dipandang
Selalu patuh
Menjaga Kehormatan
Initial Extraction
Extraction Method: Principal Axis Factoring.
Total Variance Explained
2,235 74,484 74,484 1,877 62,562 62,562
,469 15,622 90,106
,297 9,894 100,000
Factor1
2
3
Total % of Variance Cumulative % Total % of Variance Cumulative %
Initial Eigenvalues Extraction Sums of Squared Loadings
Extraction Method: Principal Axis Factoring.
Factor Matrixa
,703
,893
,765
Menyenangkan Jika dipandang
Selalu patuh
Menjaga Kehormatan
1
Factor
Extraction Method: Principal Axis Factoring.
1 factors extracted. 13 iterations required.a.

A n a l i s i s F a k t o r C o n f i r m a t o r y ( V a l i d i t a s K o n s t r u k . . . |79
Catatan:
1. Setelah item ke empat dibuang, tidak ditemukan satu itempun yang
memiliki kecukupan sampel kurang dari 0,5 (Anti Image Correlation)
2. Factor Matrix memberikan informasi tentang loading factor masing-
masing item, ketiga item valid karena tidak satupun yang memiliki nilai
kurang dari 0,6
8.3.2 Uji Realibilitas
Langkah Pengerjaan:
Analyze > Scale > Reliability Analysis
❖ Masukkan seluruh item yang valid ke dalam box Items. Pilih Alfa pada box
Model dan beri centang pada List item Labels
❖ Klik Statistics, pada box Descriptives for, beri centang item, Scale dan Scale if
item deleted, klik continue
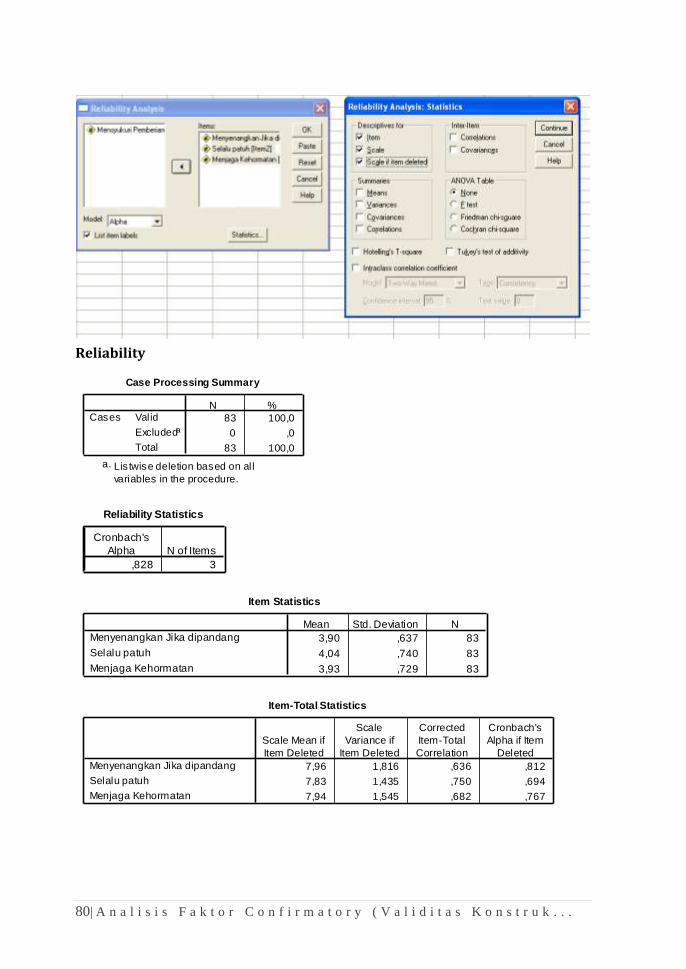
80| A n a l i s i s F a k t o r C o n f i r m a t o r y ( V a l i d i t a s K o n s t r u k . . .
Reliability
Case Processing Summary
83 100,0
0 ,0
83 100,0
Valid
Excludeda
Total
CasesN %
Listwise deletion based on all
variables in the procedure.
a.
Reliability Statistics
,828 3
Cronbach's
Alpha N of Items
Item Statistics
3,90 ,637 83
4,04 ,740 83
3,93 ,729 83
Menyenangkan Jika dipandang
Selalu patuh
Menjaga Kehormatan
Mean Std. Deviation N
Item-Total Statistics
7,96 1,816 ,636 ,812
7,83 1,435 ,750 ,694
7,94 1,545 ,682 ,767
Menyenangkan Jika dipandang
Selalu patuh
Menjaga Kehormatan
Scale Mean if
Item Deleted
Scale
Variance if
Item Deleted
Corrected
Item-Total
Correlation
Cronbach's
Alpha if Item
Deleted

A n a l i s i s F a k t o r C o n f i r m a t o r y ( V a l i d i t a s K o n s t r u k . . . |81
Scale Statistics
11,87 3,311 1,820 3
Mean Variance Std. Deviation N of Item s
Jawaban:
1. Ketiga item memiliki keandalan yang cukup baik, dengan nilai
Crobach’s Alfa 0,828
8.3.3 Penghitungan Validitas dan Reliabilitas Konstruk
0,62ελ
λAVE
2
2
=+
=
( )( )
+
=ελ
λCR
2
2
Item Factor
Loading ()
2 (1-2)
Menyenangkan Jika dipandang 0,70 0,49 0,51 Selalu patuh 0,89 0,80 0,20 Menjaga Kehormatan 0,76 0,58 0,42
Jumlah 2,36 1,88 1,12
0,621,121,88
1,88AVE =
+=
0,836,6896
5,5696
1,125,5696
5,5696
1,122,36
2,36CR
2
2
==+
=+
=
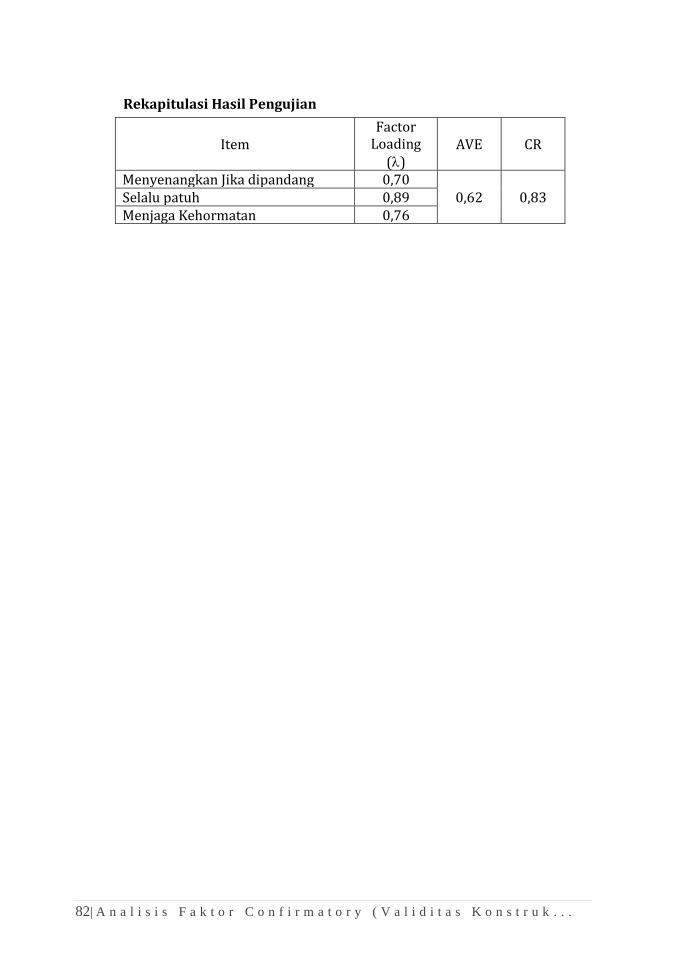
82| A n a l i s i s F a k t o r C o n f i r m a t o r y ( V a l i d i t a s K o n s t r u k . . .
Rekapitulasi Hasil Pengujian
Item Factor
Loading ()
AVE CR
Menyenangkan Jika dipandang 0,70 0,62 0,83 Selalu patuh 0,89
Menjaga Kehormatan 0,76

P e n g a n t a r A n a l i s i s C l u s t e r ( K - m e a n C l u s t e r ) |83
Bab 9 Pengantar Analisis Cluster (K-mean Cluster)
Tujuan Instruksional:
1. Mampu membuat pengelompokkan obyek atas dasar kesamaan
karakteristik yang dimiliki dengan K-mean Kluster
2. Mampu menghitung nilai rata-rata variabel pada cluster yang
terbentuk
3. Mampu memberikan nama kelompok yang cocok atas cluster yang
terbentuk
4. Menguji signifikansi perbedaan variabel berdasarkan kluster yang
terbentuk
9.1 Analisis Cluster
Analisis cluster merupakan teknik multivariat dengan tujuan utama untuk
mengelompokkan sejumlah objek berdasarkan karakteristik yang dimilikinya.
Analisis cluster mengklasifikasi objek sehingga setiap objek yang paling dekat
kesamaannya dengan objek lain berada dalam cluster yang sama. Cluster-cluster
yang terbentuk memiliki homogenitas internal yang tinggi dan heterogenitas
eksternal yang tinggi.
Analisis cluster tidak mengestimasi set vaiabel secara empiris, namun
menggunakan set variabel yang ditentukan oleh peneliti itu sendiri. Fokus dari
analisis cluster adalah membandingkan objek berdasarkan set variabel, hal inilah
yang menyebabkan para ahli mendefinisikan set variabel sebagai tahap kritis
dalam analisis cluster. Set variabel cluster adalah suatu set variabel yang
merepresentasikan karakteristik yang dipakai objek-objek. Bedanya dengan
analisis faktor adalah bahwa analisis cluster terfokus pada pengelompokkan objek
sedangkan analisis faktor terfokus pada kelompok variabel
Solusi analisis cluster bersifat tidak unik, anggota cluster untuk tiap
penyelesaian/solusi tergantung pada beberapa elemen prosedur dan beberapa
solusi yang berbeda dapat diperoleh dengan mengubah satu elemen atau lebih.
Solusi cluster secara keseluruhan bergantung pada variabel-variaabel yang
digunakan sebagai dasar untuk menilai kesamaan. Penambahan atau pengurangan

84| P e n g a n t a r A n a l i s i s C l u s t e r ( K - m e a n C l u s t e r )
variabelvariabel yang relevan dapat mempengaruhi substansi hasi analisisi
cluster.
Cara Kerja Analisis Cluster
Secara garis besar ada tiga hal yang harus terjawab dalam proses kerja analisis
cluster, yaitu :
1. Bagaimana mengukur kesamaan ? Ada tiga ukuran untuk mengukur
kesamaaan antar objek, yaitu ukuran korelasi, ukuran jarak dan ukuran
asosiasi
2. Bagaimana membentuk cluster? Prosedur yang diterapkan harus dapat
mengelompokkan objek-objek yang memiliki kesamaan yang tinggi ke
dalam suatu cluster yang sama.
3. Berapa banyak cluster/kelompok yang akan dibentuk ? Pada prinsipnya
jika jumlah cluster berkurang maka homogenitas dalam cluster secara
otomatis akan menurun.
Tujuan dari Analisis Cluster adalah mengelompokkan obyek berdasarkan
kesamaan karakteristik di antara obyek-obyek tersebut. Dengan demikian, ciri-ciri
suatu cluster yang baik yaitu mepunyai :
1. Homogenitas internal/within cluster: yaitu kesamaan antar anggota dalam
satu cluster.
2. Heterogenitas external/between cluster: yaitu perbedaan antara cluster
yang satu dengan cluster yang lain.
Langkah pengelompokkan dalam analisis cluster mencakup 3 hal berikut :
1. Mengukur kesamaan jarak
2. Membentuk cluster secara hirarkis
3. Menentukan jumlah cluster
Adapun metode pengelompokan dalam analisis cluster meliputi :
1. Metode Hirarkis: pengelompokan dimulai dengan dua atau lebih obyek
dengan kesamaan paling dekat. Kemudian diteruskan pada obyek yang
lain hingga cluster akan membentuk semacam ‘pohon’ dimana terdapat
tingkatan (hirarki) yang jelas antar obyek, dari yang paling mirip hingga
yang paling tidak mirip. Alat yang membantu untuk memperjelas proses
hirarki ini disebut “dendogram”.

P e n g a n t a r A n a l i s i s C l u s t e r ( K - m e a n C l u s t e r ) |85
2. Metode Non-Hirarkis : dimulai dengan menentukan terlebih dahulu
jumlah cluster yang diinginkan (dua, tiga, atau yang lain). Setelah jumlah
cluster ditentukan, maka proses cluster dilakukan dengan tanpa mengikuti
proses hirarki. Metode ini biasa disebut “K-Means Cluster”.
Asumsi yang harus dipenuhi dalam Analisis Cluster yaitu :
1. Sampel harus random
2. Data berkala metrik
3. Jumlah Sampel besar (>200)
9.2 Kasus:
Sebuah Perusahaan ingin mengelompokkan konsumen mereka berdasarkan
profil demografis. Untuk itu dilakukan pendataan dengan melibatkan
sejumlah variabel yaitu:
1. Usia Konsumen (dalam tahun)
2. Jumlah Anak (orang)
3. Income/penghasilan konsumen (dalam Rupiah)
4. Kegiatan konsumen membaca koran setiap minggu (jam)
5. Kegiatan konsumen menonton tv setiap minggu (jam)
6. Jumlah sepeda motor yang dimiliki konsumen (buah)
7. Jumlah mobil yang dimiliki konsumen (buah)
8. Jumlah kartu kredit/ATM yang dimiliki konsumen (buah)
9. Frekuensi pembelian konsumen setiap minggu (kali)
Tahapan Pengerjaan:
9.2.a. Standarisasi Z-Score Variabel untuk menyeragamkan satuan variabel yang
berbeda-beda
Langkah:
Analyze > Descriptive Statistics > Descriptives…
❖ Masukkan seluruh variabel yang menjadi dasar pengelompokkan pada
Box Variables(s),
❖ Centang Options… untuk menampilkan informasi deskriptif yang
dibutuhkan yaitu: mean, std. deviation, Minimum, Maximum
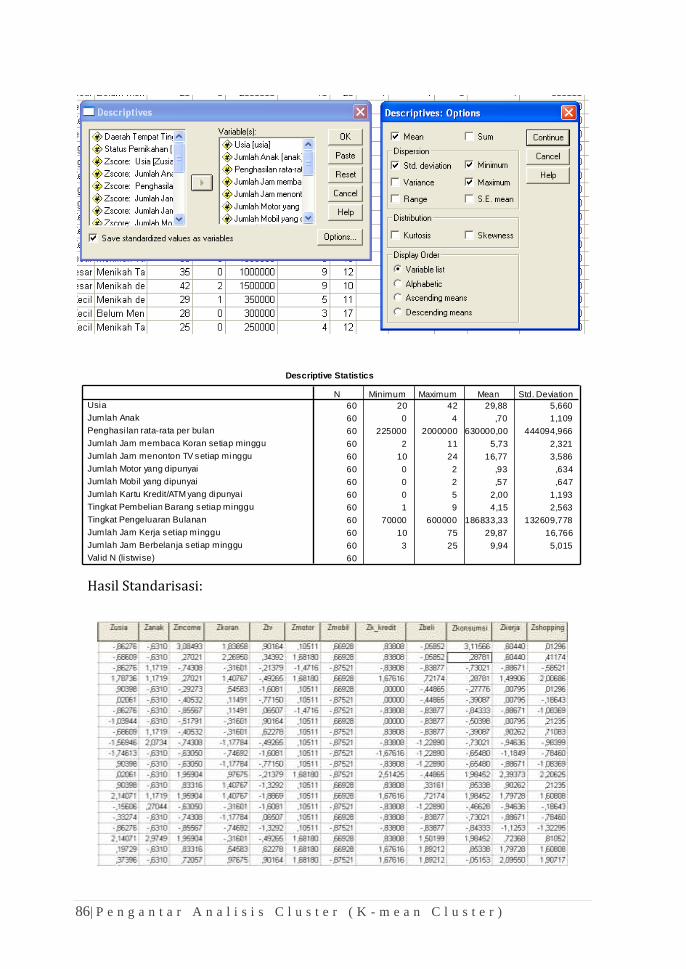
86| P e n g a n t a r A n a l i s i s C l u s t e r ( K - m e a n C l u s t e r )
Descriptive Statistics
60 20 42 29,88 5,660
60 0 4 ,70 1,109
60 225000 2000000 630000,00 444094,966
60 2 11 5,73 2,321
60 10 24 16,77 3,586
60 0 2 ,93 ,634
60 0 2 ,57 ,647
60 0 5 2,00 1,193
60 1 9 4,15 2,563
60 70000 600000 186833,33 132609,778
60 10 75 29,87 16,766
60 3 25 9,94 5,015
60
Usia
Jumlah Anak
Penghasilan rata-rata per bulan
Jumlah Jam membaca Koran setiap minggu
Jumlah Jam menonton TV setiap minggu
Jumlah Motor yang dipunyai
Jumlah Mobil yang dipunyai
Jumlah Kartu Kredit/ATM yang dipunyai
Tingkat Pembelian Barang setiap minggu
Tingkat Pengeluaran Bulanan
Jumlah Jam Kerja setiap minggu
Jumlah Jam Berbelanja setiap minggu
Valid N (listwise)
N Minimum Maximum Mean Std. Deviation
Hasil Standarisasi:
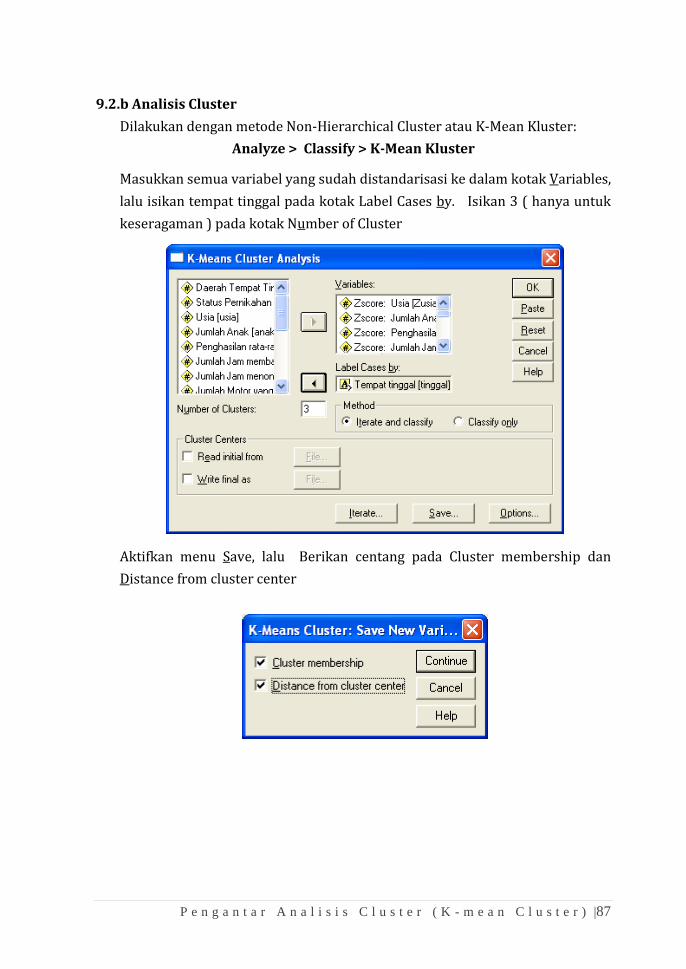
P e n g a n t a r A n a l i s i s C l u s t e r ( K - m e a n C l u s t e r ) |87
9.2.b Analisis Cluster
Dilakukan dengan metode Non-Hierarchical Cluster atau K-Mean Kluster:
Analyze > Classify > K-Mean Kluster
Masukkan semua variabel yang sudah distandarisasi ke dalam kotak Variables,
lalu isikan tempat tinggal pada kotak Label Cases by. Isikan 3 ( hanya untuk
keseragaman ) pada kotak Number of Cluster
Aktifkan menu Save, lalu Berikan centang pada Cluster membership dan
Distance from cluster center
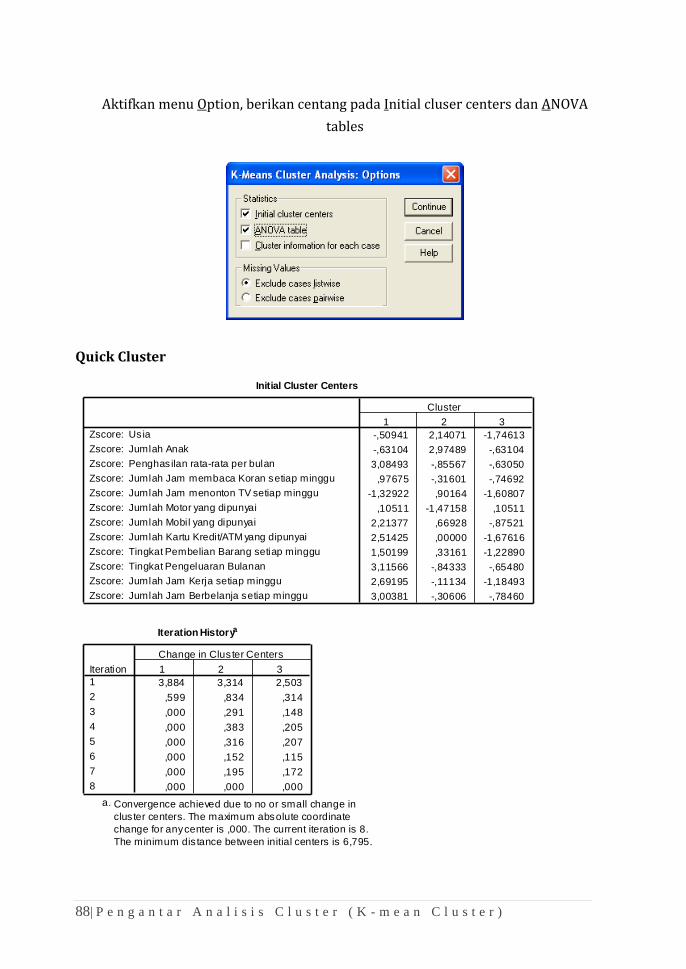
88| P e n g a n t a r A n a l i s i s C l u s t e r ( K - m e a n C l u s t e r )
Aktifkan menu Option, berikan centang pada Initial cluser centers dan ANOVA
tables
Quick Cluster
Initial Cluster Centers
-,50941 2,14071 -1,74613
-,63104 2,97489 -,63104
3,08493 -,85567 -,63050
,97675 -,31601 -,74692
-1,32922 ,90164 -1,60807
,10511 -1,47158 ,10511
2,21377 ,66928 -,87521
2,51425 ,00000 -1,67616
1,50199 ,33161 -1,22890
3,11566 -,84333 -,65480
2,69195 -,11134 -1,18493
3,00381 -,30606 -,78460
Zscore: Us ia
Zscore: Jumlah Anak
Zscore: Penghas ilan rata-rata per bulan
Zscore: Jumlah Jam membaca Koran setiap minggu
Zscore: Jumlah Jam menonton TV setiap minggu
Zscore: Jumlah Motor yang dipunyai
Zscore: Jumlah Mobil yang dipunyai
Zscore: Jumlah Kartu Kredit/ATM yang dipunyai
Zscore: Tingkat Pembelian Barang setiap minggu
Zscore: Tingkat Pengeluaran Bulanan
Zscore: Jumlah Jam Kerja setiap minggu
Zscore: Jumlah Jam Berbelanja setiap minggu
1 2 3
Cluster
Iteration Historya
3,884 3,314 2,503
,599 ,834 ,314
,000 ,291 ,148
,000 ,383 ,205
,000 ,316 ,207
,000 ,152 ,115
,000 ,195 ,172
,000 ,000 ,000
Iteration
1
2
3
4
5
6
7
8
1 2 3
Change in Clus ter Centers
Convergence achieved due to no or small change in
clus ter centers. The maximum absolute coordinate
change for any center is ,000. The current iteration is 8.
The minimum dis tance between initial centers is 6,795.
a.
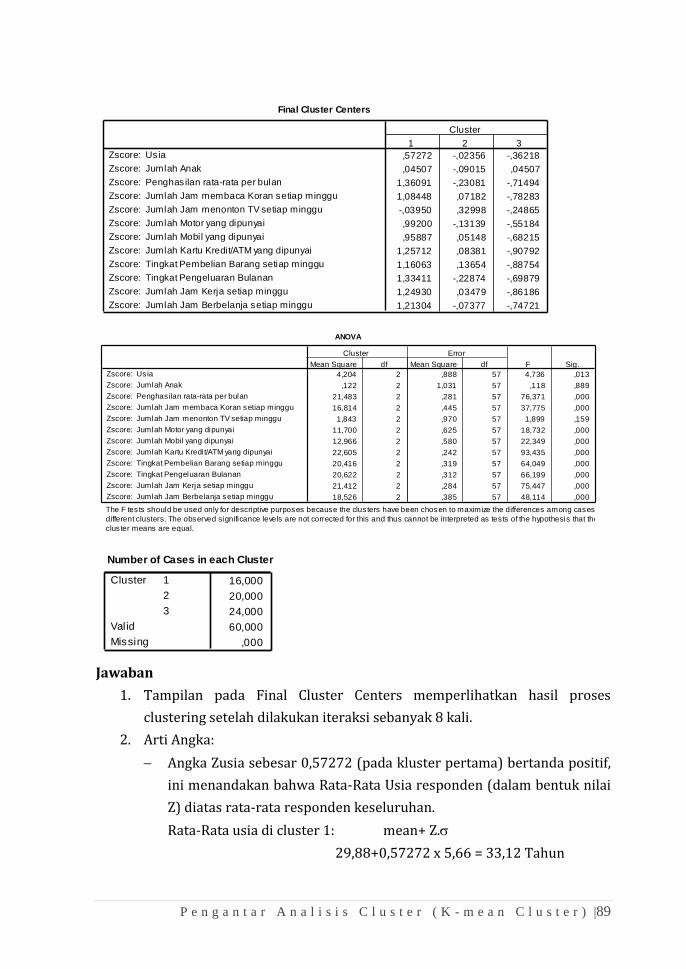
P e n g a n t a r A n a l i s i s C l u s t e r ( K - m e a n C l u s t e r ) |89
Final Cluster Centers
,57272 -,02356 -,36218
,04507 -,09015 ,04507
1,36091 -,23081 -,71494
1,08448 ,07182 -,78283
-,03950 ,32998 -,24865
,99200 -,13139 -,55184
,95887 ,05148 -,68215
1,25712 ,08381 -,90792
1,16063 ,13654 -,88754
1,33411 -,22874 -,69879
1,24930 ,03479 -,86186
1,21304 -,07377 -,74721
Zscore: Us ia
Zscore: Jumlah Anak
Zscore: Penghas ilan rata-rata per bulan
Zscore: Jumlah Jam membaca Koran setiap minggu
Zscore: Jumlah Jam menonton TV setiap minggu
Zscore: Jumlah Motor yang dipunyai
Zscore: Jumlah Mobil yang dipunyai
Zscore: Jumlah Kartu Kredit/ATM yang dipunyai
Zscore: Tingkat Pembelian Barang setiap minggu
Zscore: Tingkat Pengeluaran Bulanan
Zscore: Jumlah Jam Kerja setiap minggu
Zscore: Jumlah Jam Berbelanja setiap minggu
1 2 3
Cluster
ANOVA
4,204 2 ,888 57 4,736 ,013
,122 2 1,031 57 ,118 ,889
21,483 2 ,281 57 76,371 ,000
16,814 2 ,445 57 37,775 ,000
1,843 2 ,970 57 1,899 ,159
11,700 2 ,625 57 18,732 ,000
12,966 2 ,580 57 22,349 ,000
22,605 2 ,242 57 93,435 ,000
20,416 2 ,319 57 64,049 ,000
20,622 2 ,312 57 66,199 ,000
21,412 2 ,284 57 75,447 ,000
18,526 2 ,385 57 48,114 ,000
Zscore: Us ia
Zscore: Jumlah Anak
Zscore: Penghas ilan rata-rata per bulan
Zscore: Jumlah Jam membaca Koran setiap minggu
Zscore: Jumlah Jam menonton TV setiap minggu
Zscore: Jumlah Motor yang dipunyai
Zscore: Jumlah Mobil yang dipunyai
Zscore: Jumlah Kartu Kredit/ATM yang dipunyai
Zscore: Tingkat Pembelian Barang setiap minggu
Zscore: Tingkat Pengeluaran Bulanan
Zscore: Jumlah Jam Kerja setiap minggu
Zscore: Jumlah Jam Berbelanja setiap minggu
Mean Square df
Cluster
Mean Square df
Error
F Sig.
The F tes ts should be used only for descriptive purposes because the clus ters have been chosen to maximize the differences among cases in
different clusters. The observed significance levels are not corrected for this and thus cannot be interpreted as tes ts of the hypothesis that the
cluster means are equal.
Number of Cases in each Cluster
16,000
20,000
24,000
60,000
,000
1
2
3
Cluster
Valid
Missing
Jawaban
1. Tampilan pada Final Cluster Centers memperlihatkan hasil proses
clustering setelah dilakukan iteraksi sebanyak 8 kali.
2. Arti Angka:
− Angka Zusia sebesar 0,57272 (pada kluster pertama) bertanda positif,
ini menandakan bahwa Rata-Rata Usia responden (dalam bentuk nilai
Z) diatas rata-rata responden keseluruhan.
Rata-Rata usia di cluster 1: mean+ Z.
29,88+0,57272 x 5,66 = 33,12 Tahun
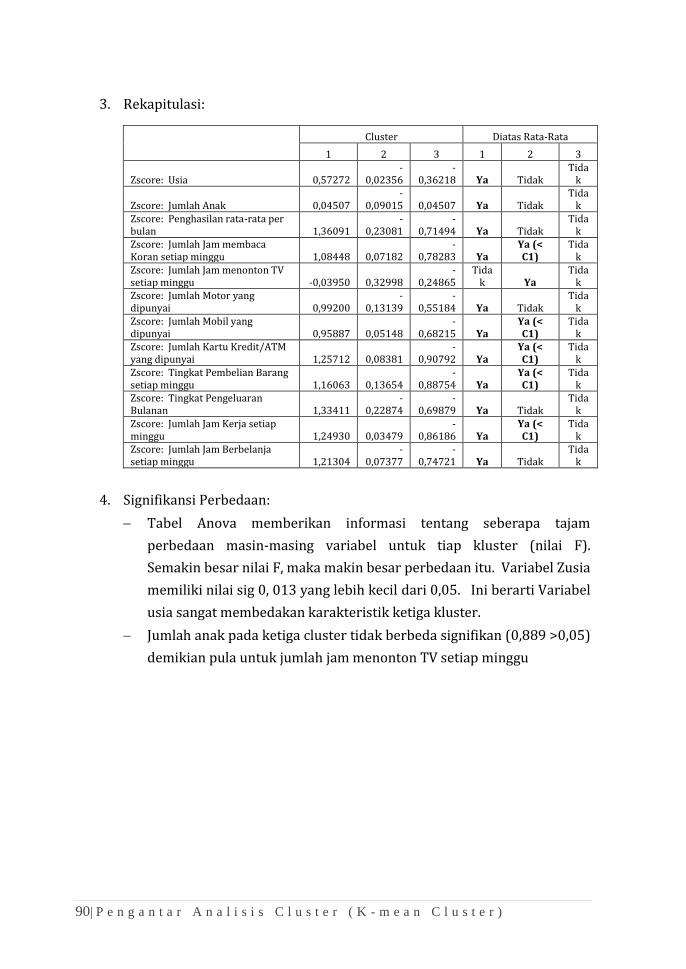
90| P e n g a n t a r A n a l i s i s C l u s t e r ( K - m e a n C l u s t e r )
3. Rekapitulasi:
Cluster Diatas Rata-Rata
1 2 3 1 2 3
Zscore: Usia 0,57272 -
0,02356 -
0,36218 Ya Tidak Tida
k
Zscore: Jumlah Anak 0,04507 -
0,09015 0,04507 Ya Tidak Tida
k Zscore: Penghasilan rata-rata per bulan 1,36091
-0,23081
-0,71494 Ya Tidak
Tidak
Zscore: Jumlah Jam membaca Koran setiap minggu 1,08448 0,07182
-0,78283 Ya
Ya (< C1)
Tidak
Zscore: Jumlah Jam menonton TV setiap minggu -0,03950 0,32998
-0,24865
Tidak Ya
Tidak
Zscore: Jumlah Motor yang dipunyai 0,99200
-0,13139
-0,55184 Ya Tidak
Tidak
Zscore: Jumlah Mobil yang dipunyai 0,95887 0,05148
-0,68215 Ya
Ya (< C1)
Tidak
Zscore: Jumlah Kartu Kredit/ATM yang dipunyai 1,25712 0,08381
-0,90792 Ya
Ya (< C1)
Tidak
Zscore: Tingkat Pembelian Barang setiap minggu 1,16063 0,13654
-0,88754 Ya
Ya (< C1)
Tidak
Zscore: Tingkat Pengeluaran Bulanan 1,33411
-0,22874
-0,69879 Ya Tidak
Tidak
Zscore: Jumlah Jam Kerja setiap minggu 1,24930 0,03479
-0,86186 Ya
Ya (< C1)
Tidak
Zscore: Jumlah Jam Berbelanja setiap minggu 1,21304
-0,07377
-0,74721 Ya Tidak
Tidak
4. Signifikansi Perbedaan:
− Tabel Anova memberikan informasi tentang seberapa tajam
perbedaan masin-masing variabel untuk tiap kluster (nilai F).
Semakin besar nilai F, maka makin besar perbedaan itu. Variabel Zusia
memiliki nilai sig 0, 013 yang lebih kecil dari 0,05. Ini berarti Variabel
usia sangat membedakan karakteristik ketiga kluster.
− Jumlah anak pada ketiga cluster tidak berbeda signifikan (0,889 >0,05)
demikian pula untuk jumlah jam menonton TV setiap minggu
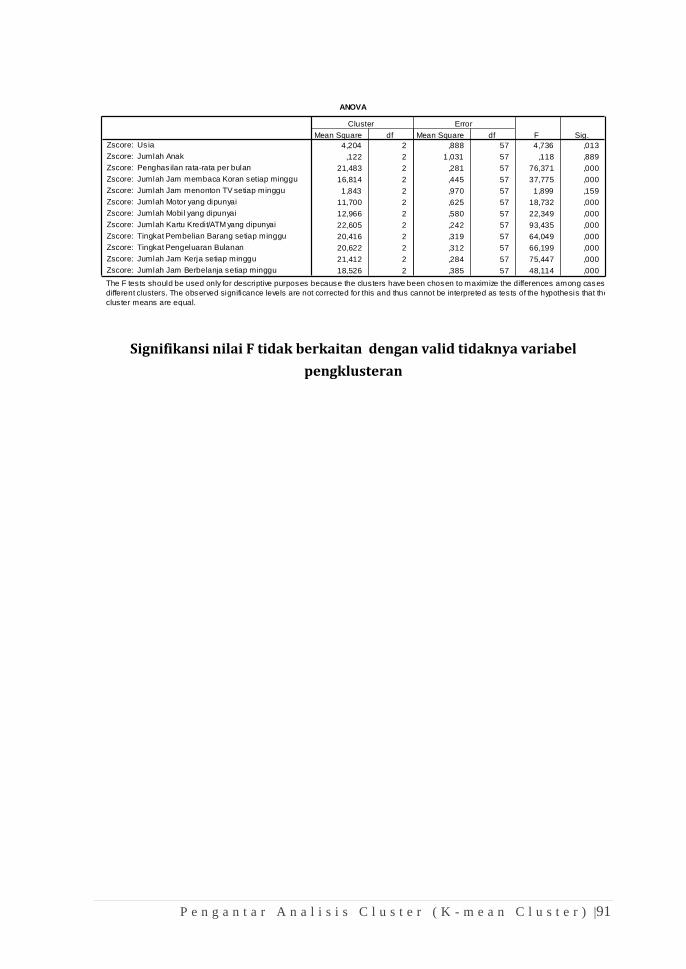
P e n g a n t a r A n a l i s i s C l u s t e r ( K - m e a n C l u s t e r ) |91
ANOVA
4,204 2 ,888 57 4,736 ,013
,122 2 1,031 57 ,118 ,889
21,483 2 ,281 57 76,371 ,000
16,814 2 ,445 57 37,775 ,000
1,843 2 ,970 57 1,899 ,159
11,700 2 ,625 57 18,732 ,000
12,966 2 ,580 57 22,349 ,000
22,605 2 ,242 57 93,435 ,000
20,416 2 ,319 57 64,049 ,000
20,622 2 ,312 57 66,199 ,000
21,412 2 ,284 57 75,447 ,000
18,526 2 ,385 57 48,114 ,000
Zscore: Us ia
Zscore: Jumlah Anak
Zscore: Penghas ilan rata-rata per bulan
Zscore: Jumlah Jam membaca Koran setiap minggu
Zscore: Jumlah Jam menonton TV setiap minggu
Zscore: Jumlah Motor yang dipunyai
Zscore: Jumlah Mobil yang dipunyai
Zscore: Jumlah Kartu Kredit/ATM yang dipunyai
Zscore: Tingkat Pembelian Barang setiap minggu
Zscore: Tingkat Pengeluaran Bulanan
Zscore: Jumlah Jam Kerja setiap minggu
Zscore: Jumlah Jam Berbelanja setiap minggu
Mean Square df
Cluster
Mean Square df
Error
F Sig.
The F tes ts should be used only for descriptive purposes because the clus ters have been chosen to maximize the differences among cases in
different clusters. The observed significance levels are not corrected for this and thus cannot be interpreted as tes ts of the hypothesis that the
cluster means are equal.
Signifikansi nilai F tidak berkaitan dengan valid tidaknya variabel
pengklusteran

P e n g a n t a r A n a l i s i s C l u s t e r ( K - m e a n C l u s t e r ) |92

A n a l i s i s K o r e l a s i d a n R e g r e s i |93
Bab 10
Analisis Korelasi dan Regresi
Tujuan Instruksional:
1. Mampu menjelaskan perbedaan bentuk hubungan simetris, resiprokal dan
kausal
2. Mampu menjelaskan keeratan hubungan simetris bivariate
3. Mampu merumuskan model pengujian dan hipotesis hubungan kausal
4. Mampu menguji hipotesis hubungan kausal
5. Mampu menjelaskan makna dari hubungan kausal yang telah diuji
Analisis regresi sangat berhubungan erat dengan korelasi, sehingga dapat
dikatakan bahwa analisis regresi didasarkan pada korelasi dengan memasukkan
perubahan pada Y relatif akibat perubahan di dalam level X. Latan (2014)
menyimpulkan anali`fssis regresi sebagai teknik analisis statistik yang digunakan
untuk menguji hubungan antara satu atau lebih variabel independen (prediktor)
dengan satu variabel dependen (kriteria).
Analisis ini mempunyai dua tujuan utama yaitu: untuk memprediksi dan
untuk menganalisis hubungan kausal. Dalam memprediksi analisis regresi
digunakan untuk mengembangkan formula untuk melakukan prediksi tentang
variabel dependen. Sedangkan dalam analisis kausal, regresi digunakan untuk
mengatahui apakah variabel independen sesungguhnya berpengaruh terhadap
variabel dependen ataukah tidak dan untuk mengestimasi besarnya pengaruh
tersebut.
Analisis regresi dan korelasi mempunyai keterkaitan. Jika suatu variabel
mempunyai hubungan yang dengan variabel-variabel lain, maka peneliti dapat
mempertimbangkan bahwa variabel-variabel tersebut bisa dipergunakan untuk
memprediksi suatu variabel. Namun jika tidak terdapat hubungan antar variabel,
maka variabel-variabel tersebut juga tidak dapat digunakan untuk memprediksi
keadaan suatu variabel. Dengan kata lain, analisis hanya dapat dan atau
diperlukan jika telah diketahui bahwa ada hubungan yang signifikan antar
variabel yang bersangkutan.
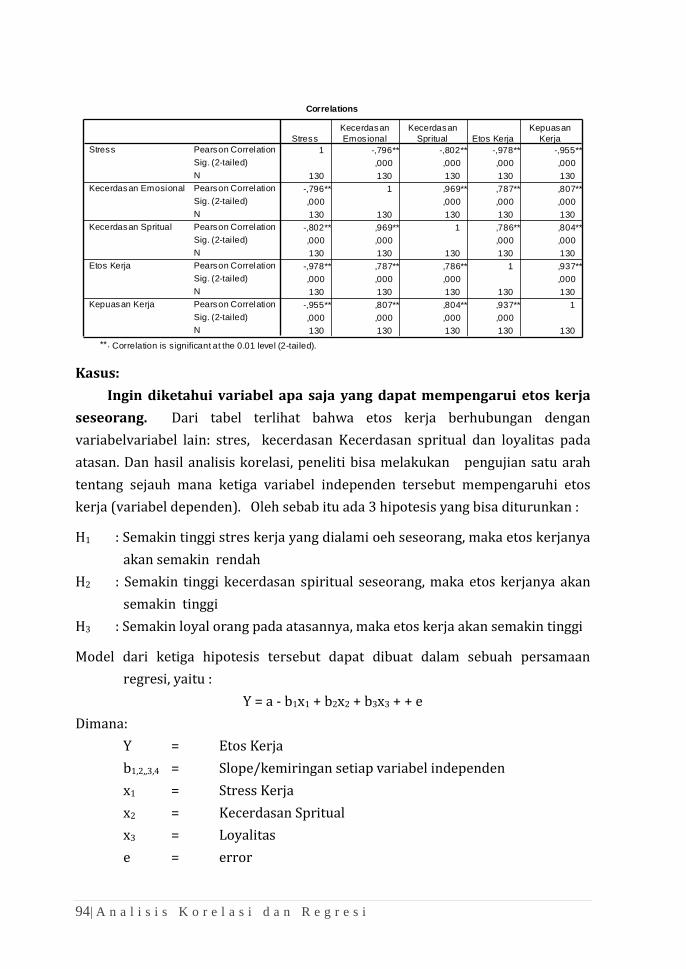
94| A n a l i s i s K o r e l a s i d a n R e g r e s i
Correlations
1 -,796** -,802** -,978** -,955**
,000 ,000 ,000 ,000
130 130 130 130 130
-,796** 1 ,969** ,787** ,807**
,000 ,000 ,000 ,000
130 130 130 130 130
-,802** ,969** 1 ,786** ,804**
,000 ,000 ,000 ,000
130 130 130 130 130
-,978** ,787** ,786** 1 ,937**
,000 ,000 ,000 ,000
130 130 130 130 130
-,955** ,807** ,804** ,937** 1
,000 ,000 ,000 ,000
130 130 130 130 130
Pearson Correlation
Sig. (2-tai led)
N
Pearson Correlation
Sig. (2-tai led)
N
Pearson Correlation
Sig. (2-tai led)
N
Pearson Correlation
Sig. (2-tai led)
N
Pearson Correlation
Sig. (2-tai led)
N
Stress
Kecerdasan Emosional
Kecerdasan Spritual
Etos Kerja
Kepuasan Kerja
Stress
Kecerdasan
Emosional
Kecerdasan
Spritual Etos Kerja
Kepuasan
Kerja
Correlation is s ignificant at the 0.01 level (2-tai led).**.
Kasus:
Ingin diketahui variabel apa saja yang dapat mempengarui etos kerja
seseorang. Dari tabel terlihat bahwa etos kerja berhubungan dengan
variabelvariabel lain: stres, kecerdasan Kecerdasan spritual dan loyalitas pada
atasan. Dan hasil analisis korelasi, peneliti bisa melakukan pengujian satu arah
tentang sejauh mana ketiga variabel independen tersebut mempengaruhi etos
kerja (variabel dependen). Oleh sebab itu ada 3 hipotesis yang bisa diturunkan :
H1 : Semakin tinggi stres kerja yang dialami oeh seseorang, maka etos kerjanya
akan semakin rendah
H2 : Semakin tinggi kecerdasan spiritual seseorang, maka etos kerjanya akan
semakin tinggi
H3 : Semakin loyal orang pada atasannya, maka etos kerja akan semakin tinggi
Model dari ketiga hipotesis tersebut dapat dibuat dalam sebuah persamaan
regresi, yaitu :
Y = a - b1x1 + b2x2 + b3x3 + + e
Dimana:
Y = Etos Kerja
b1,2,,3,4 = Slope/kemiringan setiap variabel independen
x1 = Stress Kerja
x2 = Kecerdasan Spritual
x3 = Loyalitas
e = error
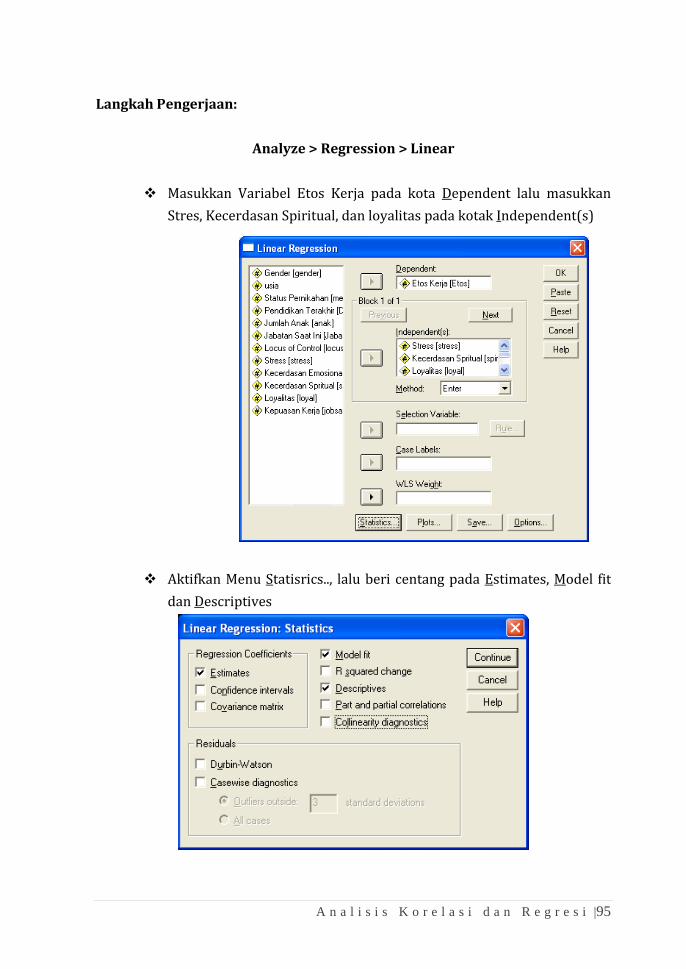
A n a l i s i s K o r e l a s i d a n R e g r e s i |95
Langkah Pengerjaan:
Analyze > Regression > Linear
❖ Masukkan Variabel Etos Kerja pada kota Dependent lalu masukkan
Stres, Kecerdasan Spiritual, dan loyalitas pada kotak Independent(s)
❖ Aktifkan Menu Statisrics.., lalu beri centang pada Estimates, Model fit
dan Descriptives
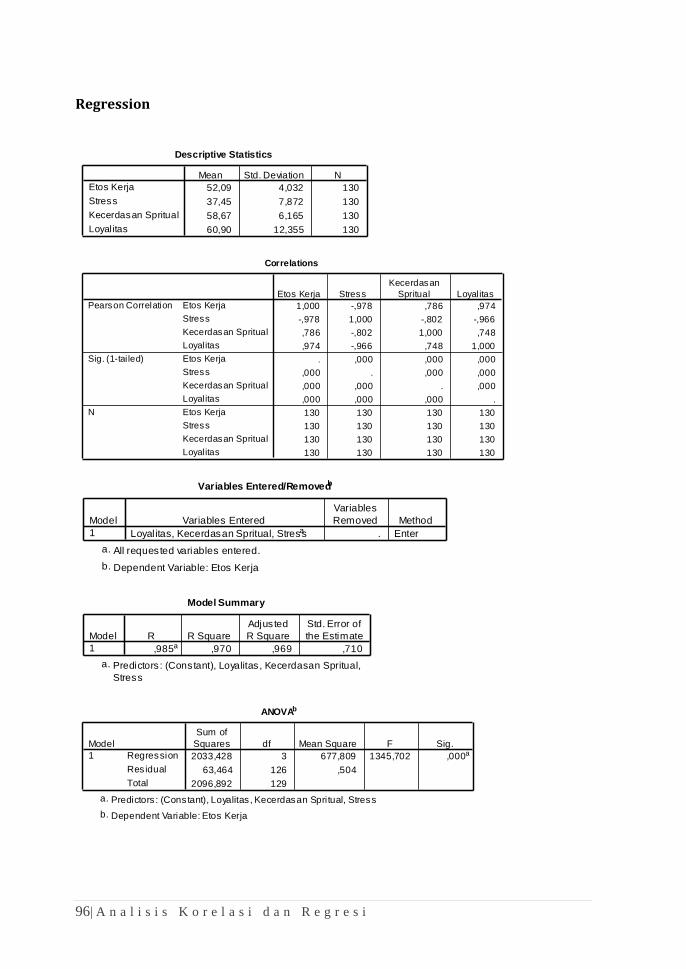
96| A n a l i s i s K o r e l a s i d a n R e g r e s i
Regression
Descriptive Statistics
52,09 4,032 130
37,45 7,872 130
58,67 6,165 130
60,90 12,355 130
Etos Kerja
Stress
Kecerdasan Spritual
Loyalitas
Mean Std. Deviation N
Correlations
1,000 -,978 ,786 ,974
-,978 1,000 -,802 -,966
,786 -,802 1,000 ,748
,974 -,966 ,748 1,000
. ,000 ,000 ,000
,000 . ,000 ,000
,000 ,000 . ,000
,000 ,000 ,000 .
130 130 130 130
130 130 130 130
130 130 130 130
130 130 130 130
Etos Kerja
Stress
Kecerdasan Spritual
Loyalitas
Etos Kerja
Stress
Kecerdasan Spritual
Loyalitas
Etos Kerja
Stress
Kecerdasan Spritual
Loyalitas
Pearson Correlation
Sig. (1-tai led)
N
Etos Kerja Stress
Kecerdasan
Spritual Loyalitas
Variables Entered/Removedb
Loyalitas, Kecerdasan Spritual, Stressa . Enter
Model
1
Variables Entered
Variables
Removed Method
All requested variables entered.a.
Dependent Variable: Etos Kerjab.
Model Summary
,985a ,970 ,969 ,710
Model
1
R R Square
Adjusted
R Square
Std. Error of
the Estimate
Predictors : (Constant), Loyalitas , Kecerdasan Spritual,
Stress
a.
ANOVAb
2033,428 3 677,809 1345,702 ,000a
63,464 126 ,504
2096,892 129
Regression
Residual
Total
Model
1
Sum of
Squares df Mean Square F Sig.
Predictors : (Constant), Loyalitas , Kecerdasan Spritual, Stressa.
Dependent Variable: Etos Kerjab.
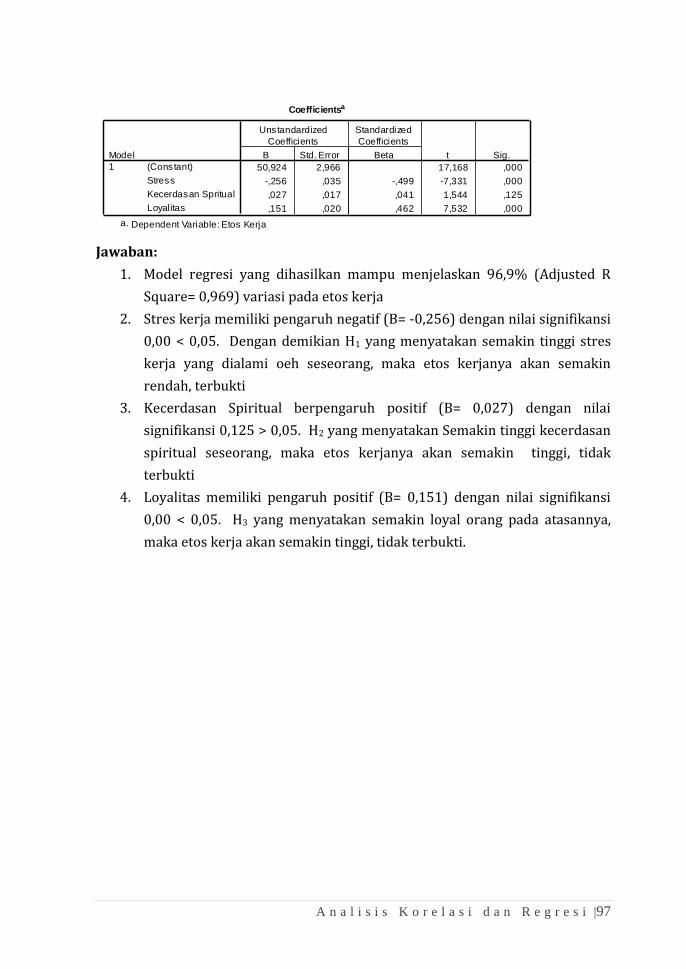
A n a l i s i s K o r e l a s i d a n R e g r e s i |97
Coefficientsa
50,924 2,966 17,168 ,000
-,256 ,035 -,499 -7,331 ,000
,027 ,017 ,041 1,544 ,125
,151 ,020 ,462 7,532 ,000
(Constant)
Stress
Kecerdasan Spritual
Loyalitas
Model
1
B Std. Error
Unstandardized
Coefficients
Beta
Standardized
Coefficients
t Sig.
Dependent Variable: Etos Kerjaa.
Jawaban:
1. Model regresi yang dihasilkan mampu menjelaskan 96,9% (Adjusted R
Square= 0,969) variasi pada etos kerja
2. Stres kerja memiliki pengaruh negatif (B= -0,256) dengan nilai signifikansi
0,00 < 0,05. Dengan demikian H1 yang menyatakan semakin tinggi stres
kerja yang dialami oeh seseorang, maka etos kerjanya akan semakin
rendah, terbukti
3. Kecerdasan Spiritual berpengaruh positif (B= 0,027) dengan nilai
signifikansi 0,125 > 0,05. H2 yang menyatakan Semakin tinggi kecerdasan
spiritual seseorang, maka etos kerjanya akan semakin tinggi, tidak
terbukti
4. Loyalitas memiliki pengaruh positif (B= 0,151) dengan nilai signifikansi
0,00 < 0,05. H3 yang menyatakan semakin loyal orang pada atasannya,
maka etos kerja akan semakin tinggi, tidak terbukti.

A n a l i s i s K o r e l a s i d a n R e g r e s i |98

A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i . . . . |99
Bab 11
Analisis Regresi Dengan Variabel Pemoderasi (Sub-Group)
Tujuan Instruksional:
1. Mampu mendeteksi kapan suatu variabel dapat ditempatkan sebagai
variabel pemoderasi
2. Mampu menguji perbedaan hubungan kausal berdasarkan katagori
3. Mampu menyimpulkan dan memaknai hasil pengujian moderasi dengan
metode sub-group
Dalam kenyataannya tidak hanya terdapat hubungan antara varibel bebas
dengan variabel tergantung, tetapi juga muncul adanya variabel yang ikut
mempengaruhi hubungan antar variabel tersebut yaitu variabel moderasi.
Contoh: Pendapatan akan mempengaruhi konsumsi, namun gaya hidup akan
mempengaruhi hubungan antara pendapatan dengan konsumsi.
Variabel Moderasi adalah variabel yang bersifat memperkuat atau
memperlemah pengaruh variabel penjelas (independen) terhadap variabel
tergantung Salah satu ciri yang penting adalah bahwa variabel ini tidak
dipengaruhi variabel independen
Model Pengujian
Beberapa Metode
1. Sub-Group, dilakukan dengan memecah sampel menjadi dua atau lebih
kelompok berdasarkan yang dihipotesiskan sebagai pemoderasi.
Pemecahan dilakukan berdasarkan nilai rata-rata atau median
2. Uji Interaksi, disebut dengan Moderated Regression Analysis (MRA),
merupakan aplikasi khusus regresi linier berganda dimana dalam
persamaan regresinya mengandung unsur interaksi (perkalian dua atau
lebih variabel independen)

100| A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i . . . .
3. Uji Nilai Selisih Mutlak, dilakukan dengan mencari nilai selisih mutlak dari
variabel independen.
4. Uji Residual, dilakukan dengan menguji pengaruh deviasi dari suatu
model. Fokusnya adalah ketidakcocokan (pack of fit) yang dihasilkan dari
deviasi hubungan antar variabel independen
Kasus
Ingin diketahui apakah gender memoderasi pengaruh pelatihan terhadap
produktivitas
Solusi Dengan Metode Sub-Group
1. Meregresikan X terhadap Y untuk semua sampel untuk mendapatkan sum
square residual/SSR dan diberi simbol SSRT untuk semua sampel
2. Meregresikan X terhadap Y sampel kelompok pertama untuk
mendapatkan SSR1
3. Meregresikan X terhadap Y sampel kelompok kedua untuk mendapatkan
SSR2
4. Hitung SSRG dengan menjumlahkan SSR1 dan SSR2
5. Hitung nilai F
6. Menarik kesimpulan uji moderasi jika nilai F hitung > F tabel, maka
variabel yang digunakan sebagai dasar pembagi kelompok terbukti
sebagai variabel pemoderasi
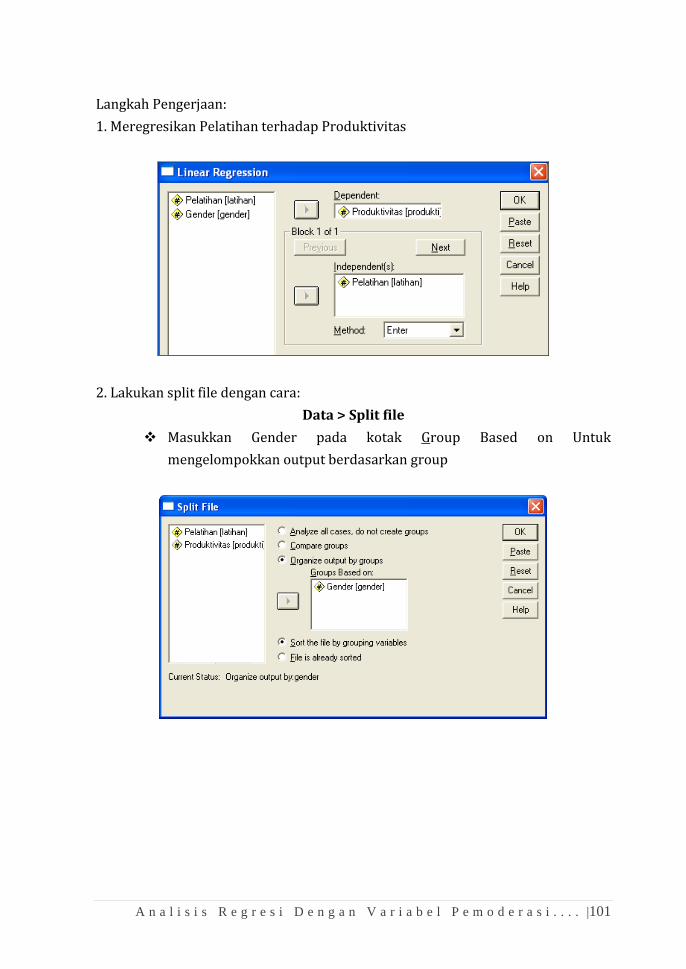
A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i . . . . |101
Langkah Pengerjaan:
1. Meregresikan Pelatihan terhadap Produktivitas
2. Lakukan split file dengan cara:
Data > Split file
❖ Masukkan Gender pada kotak Group Based on Untuk
mengelompokkan output berdasarkan group
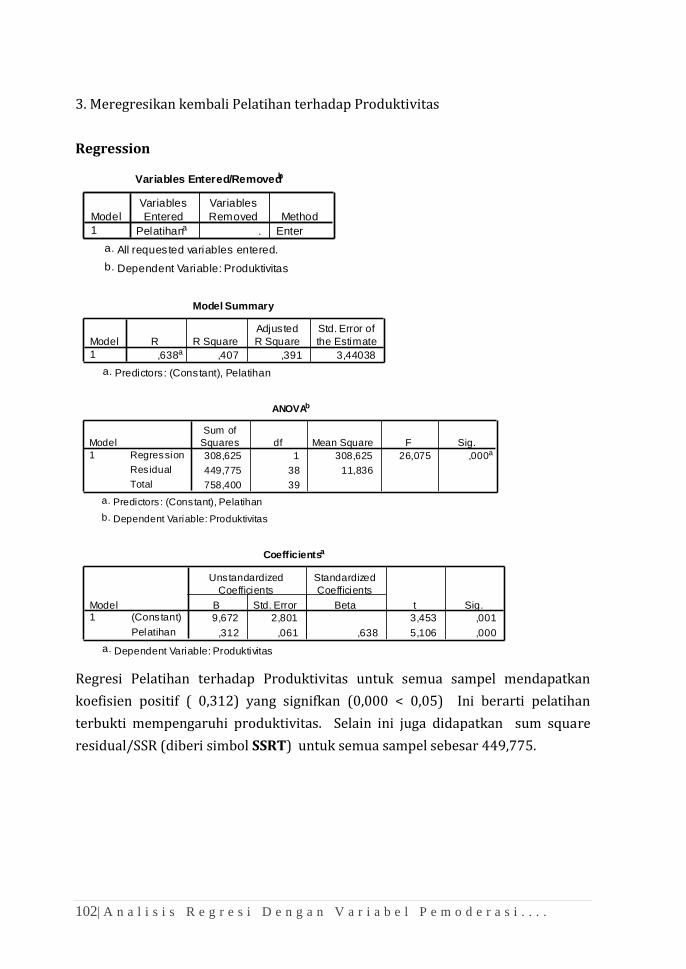
102| A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i . . . .
3. Meregresikan kembali Pelatihan terhadap Produktivitas
Regression
Variables Entered/Removedb
Pelatihana . Enter
Model
1
Variables
Entered
Variables
Removed Method
All requested variables entered.a.
Dependent Variable: Produktivitasb.
Model Summary
,638a ,407 ,391 3,44038
Model
1
R R Square
Adjusted
R Square
Std. Error of
the Estimate
Predictors: (Constant), Pelatihana.
ANOVAb
308,625 1 308,625 26,075 ,000a
449,775 38 11,836
758,400 39
Regression
Residual
Total
Model
1
Sum of
Squares df Mean Square F Sig.
Predictors : (Constant), Pelatihana.
Dependent Variable: Produktivitasb.
Coefficientsa
9,672 2,801 3,453 ,001
,312 ,061 ,638 5,106 ,000
(Constant)
Pelatihan
Model1
B Std. Error
Unstandardized
Coefficients
Beta
Standardized
Coefficients
t Sig.
Dependent Variable: Produktivitasa.
Regresi Pelatihan terhadap Produktivitas untuk semua sampel mendapatkan
koefisien positif ( 0,312) yang signifkan (0,000 < 0,05) Ini berarti pelatihan
terbukti mempengaruhi produktivitas. Selain ini juga didapatkan sum square
residual/SSR (diberi simbol SSRT) untuk semua sampel sebesar 449,775.

A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i . . . . |103
Regression
Gender = Wanita
Variables Entered/Removedb,c
Pelatihana . Enter
Model
1
Variables
Entered
Variables
Removed Method
All requested variables entered.a.
Dependent Variable: Produktivitasb.
Gender = Wanitac.
Model Summaryb
,372a ,138 ,090 2,97482
Model
1
R R Square
Adjusted
R Square
Std. Error of
the Estimate
Predictors : (Constant), Pelatihana.
Gender = Wanitab.
ANOVAb,c
25,508 1 25,508 2,882 ,107a
159,292 18 8,850
184,800 19
Regression
Residual
Total
Model
1
Sum of
Squares df Mean Square F Sig.
Predictors : (Constant), Pelatihana.
Dependent Variable: Produktivitasb.
Gender = Wanitac.
Coefficientsa,b
17,982 3,375 5,327 ,000
,133 ,078 ,372 1,698 ,107
(Constant)
Pelatihan
Model
1
B Std. Error
Unstandardized
Coefficients
Beta
Standardized
Coefficients
t Sig.
Dependent Variable: Produktivitasa.
Gender = Wanitab.
Regresi Pelatihan terhadap Produktivitas untuk semua sampel sampel wanita
koefisien positif ( 0,133) yang tidak signifkan (0,107 > 0,05) dengan sum square
residual 159,292
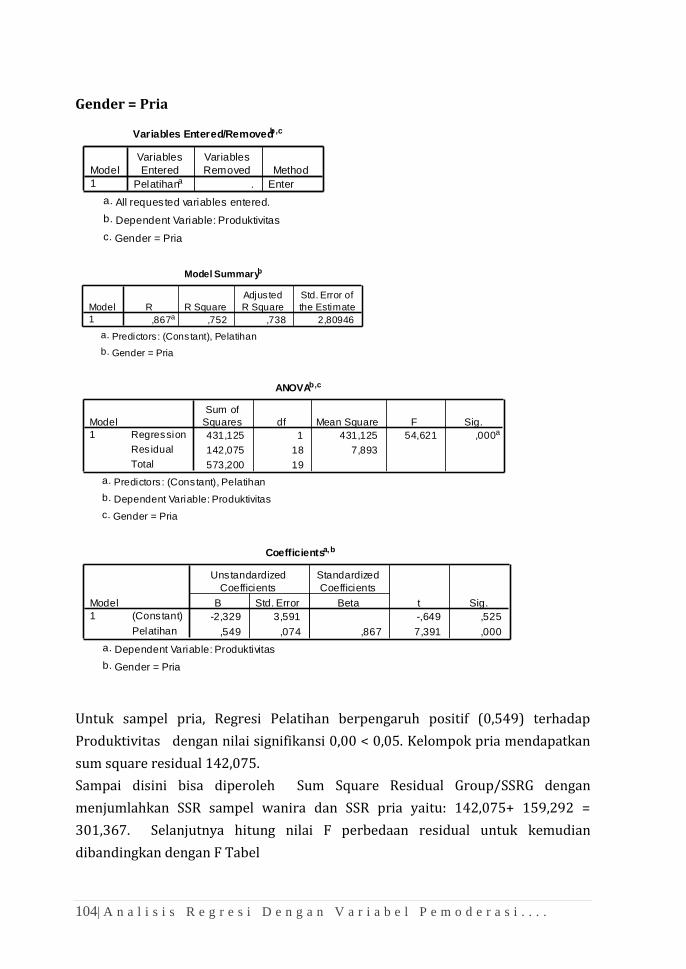
104| A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i . . . .
Gender = Pria
Variables Entered/Removedb,c
Pelatihana . Enter
Model
1
Variables
Entered
Variables
Removed Method
All requested variables entered.a.
Dependent Variable: Produktivitasb.
Gender = Priac.
Model Summaryb
,867a ,752 ,738 2,80946
Model
1
R R Square
Adjusted
R Square
Std. Error of
the Estimate
Predictors : (Constant), Pelatihana.
Gender = Priab.
ANOVAb,c
431,125 1 431,125 54,621 ,000a
142,075 18 7,893
573,200 19
Regression
Residual
Total
Model
1
Sum of
Squares df Mean Square F Sig.
Predictors : (Constant), Pelatihana.
Dependent Variable: Produktivitasb.
Gender = Priac.
Coefficientsa,b
-2,329 3,591 -,649 ,525
,549 ,074 ,867 7,391 ,000
(Constant)
Pelatihan
Model
1
B Std. Error
Unstandardized
Coefficients
Beta
Standardized
Coefficients
t Sig.
Dependent Variable: Produktivitasa.
Gender = Priab.
Untuk sampel pria, Regresi Pelatihan berpengaruh positif (0,549) terhadap
Produktivitas dengan nilai signifikansi 0,00 < 0,05. Kelompok pria mendapatkan
sum square residual 142,075.
Sampai disini bisa diperoleh Sum Square Residual Group/SSRG dengan
menjumlahkan SSR sampel wanira dan SSR pria yaitu: 142,075+ 159,292 =
301,367. Selanjutnya hitung nilai F perbedaan residual untuk kemudian
dibandingkan dengan F Tabel

A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i . . . . |105
Karena nilai F Hitung berada di daerah penolakan (10,834 > 3,259), maka
perbedaan pengaruh antara kelompok wanita dengan pria signifikan. Dengan
demikian bisa disimpulkan bahwa gender memoderasi pengaruh pelatihan
terhadap produktivitas.

A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i . . . . |106

A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i ( M R . . |107
Bab 12
Analisis Regresi Dengan Variabel Pemoderasi (MRA)
Tujuan Instruksional:
1. Mampu merumuskan model pengujian dan hipotesis pengaruh moderasi
2. Mampu menguji hipotesis pengaruh moderasi dengan MRA
3. Mampu menentukan kriteria moderasi berdasarkan aturan yang ada
Variabel moderasi berperanan sebagai variabel dapat memperkuat atau
memperlemah hubungan antara variabel independen dengan variabel dependen.
Apabila variabel moderasi tidak dilibatkan dalam model , maka disebut sebagai
analisis regresi saja, sehingga tanpa adanya variabel moderasi, analisis hubungan
antara variabel prediktor dengan variabel tergantung masih dapat dilakukan.
Dalam analisis regresi moderasi, semua asumsi analisis regresi berlaku, artinya
asumsi-asumsi dalam analisis regresi moderasi sama dengan asumsi-asumsi
dalam analisis regresi. MRA dilakukan dengan cara mengalikan dua atau lebih
variabel bebasnya. Jika hasil perkalian dua varibel bebas tersebut signifikan
maka variabel tersebut memoderasi hubungan antara variabel bebas dan variabel
dependennya.
Tahapan
1. Meregresikan X terhadap Y (Y = a + b1X1+)
2. Meregresikan X dan M terhadap Y (Y = a + b1x1 + b2m+)
Y = Nilai yang diramalkana = Konstansta
b1 = Koefesien regresi untuk variabelprediktor pertama, X1
b2 = Koefesien regresi untuk variabelprediktor kedua (pemoderasi),M
b3 = Koefesien variabel interaksi
X1 = Variabel bebas pertama
M = Variabel bebas kedua (pemoderasi)
X3 = Variabel Interaksi
= Nilai Residu
Y = a + b1X1 + b2M+b3X1M +
Y
X1X1
InteraksiX1
* MInteraksi
X1* M
X2=MX2=M
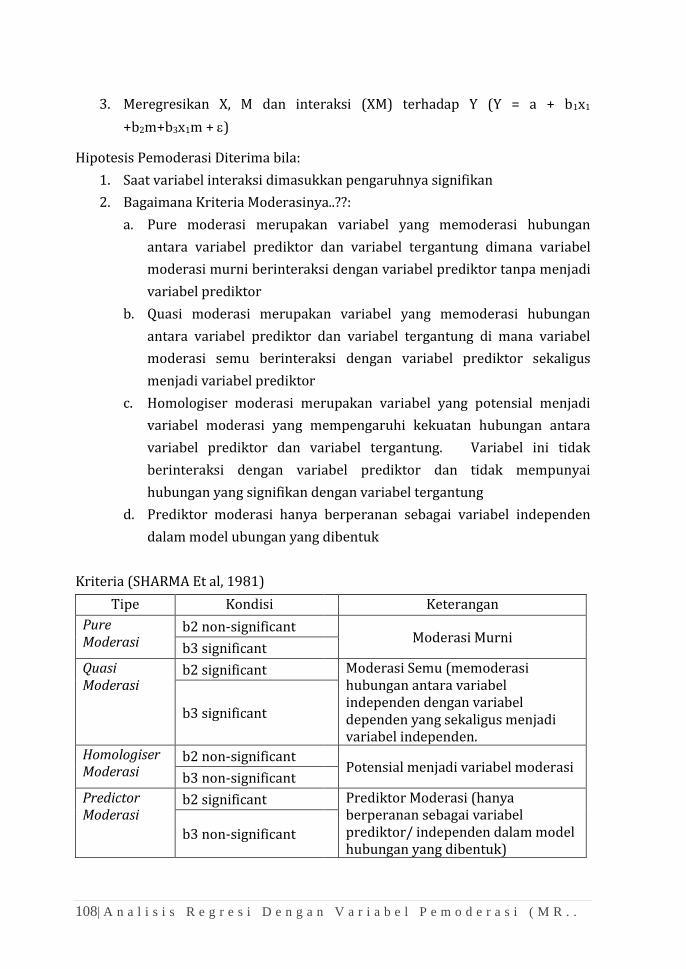
108| A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i ( M R . .
3. Meregresikan X, M dan interaksi (XM) terhadap Y (Y = a + b1x1
+b2m+b3x1m + )
Hipotesis Pemoderasi Diterima bila:
1. Saat variabel interaksi dimasukkan pengaruhnya signifikan
2. Bagaimana Kriteria Moderasinya..??:
a. Pure moderasi merupakan variabel yang memoderasi hubungan
antara variabel prediktor dan variabel tergantung dimana variabel
moderasi murni berinteraksi dengan variabel prediktor tanpa menjadi
variabel prediktor
b. Quasi moderasi merupakan variabel yang memoderasi hubungan
antara variabel prediktor dan variabel tergantung di mana variabel
moderasi semu berinteraksi dengan variabel prediktor sekaligus
menjadi variabel prediktor
c. Homologiser moderasi merupakan variabel yang potensial menjadi
variabel moderasi yang mempengaruhi kekuatan hubungan antara
variabel prediktor dan variabel tergantung. Variabel ini tidak
berinteraksi dengan variabel prediktor dan tidak mempunyai
hubungan yang signifikan dengan variabel tergantung
d. Prediktor moderasi hanya berperanan sebagai variabel independen
dalam model ubungan yang dibentuk
Kriteria (SHARMA Et al, 1981)
Tipe Kondisi Keterangan
Pure Moderasi
b2 non-significant Moderasi Murni
b3 significant
Quasi Moderasi
b2 significant Moderasi Semu (memoderasi hubungan antara variabel independen dengan variabel dependen yang sekaligus menjadi variabel independen.
b3 significant
Homologiser Moderasi
b2 non-significant Potensial menjadi variabel moderasi
b3 non-significant
Predictor Moderasi
b2 significant Prediktor Moderasi (hanya berperanan sebagai variabel prediktor/ independen dalam model hubungan yang dibentuk)
b3 non-significant
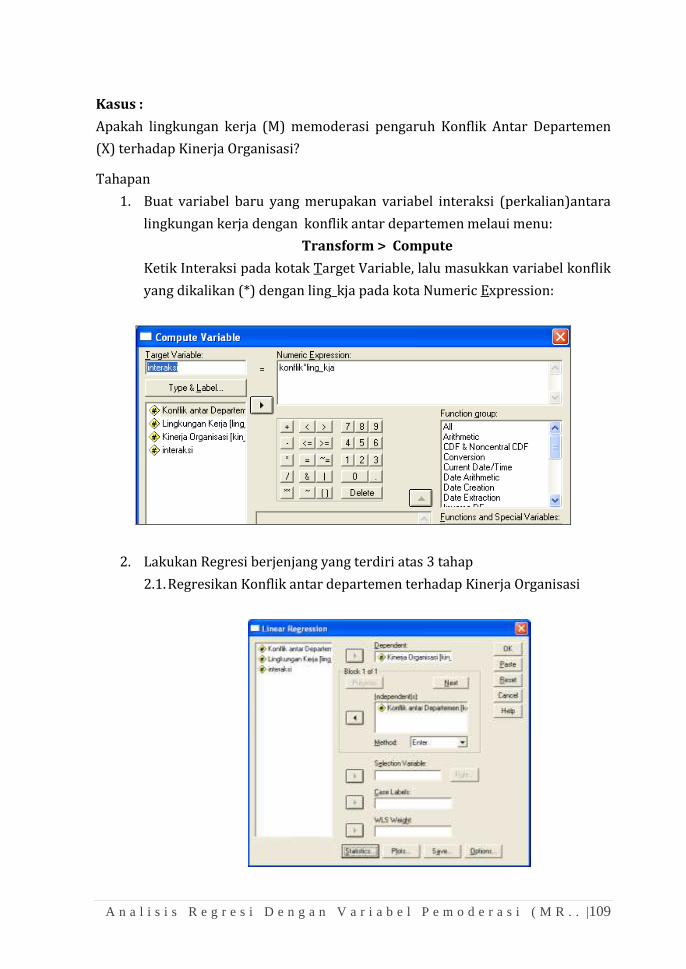
A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i ( M R . . |109
Kasus :
Apakah lingkungan kerja (M) memoderasi pengaruh Konflik Antar Departemen
(X) terhadap Kinerja Organisasi?
Tahapan
1. Buat variabel baru yang merupakan variabel interaksi (perkalian)antara
lingkungan kerja dengan konflik antar departemen melaui menu:
Transform > Compute
Ketik Interaksi pada kotak Target Variable, lalu masukkan variabel konflik
yang dikalikan (*) dengan ling_kja pada kota Numeric Expression:
2. Lakukan Regresi berjenjang yang terdiri atas 3 tahap
2.1. Regresikan Konflik antar departemen terhadap Kinerja Organisasi
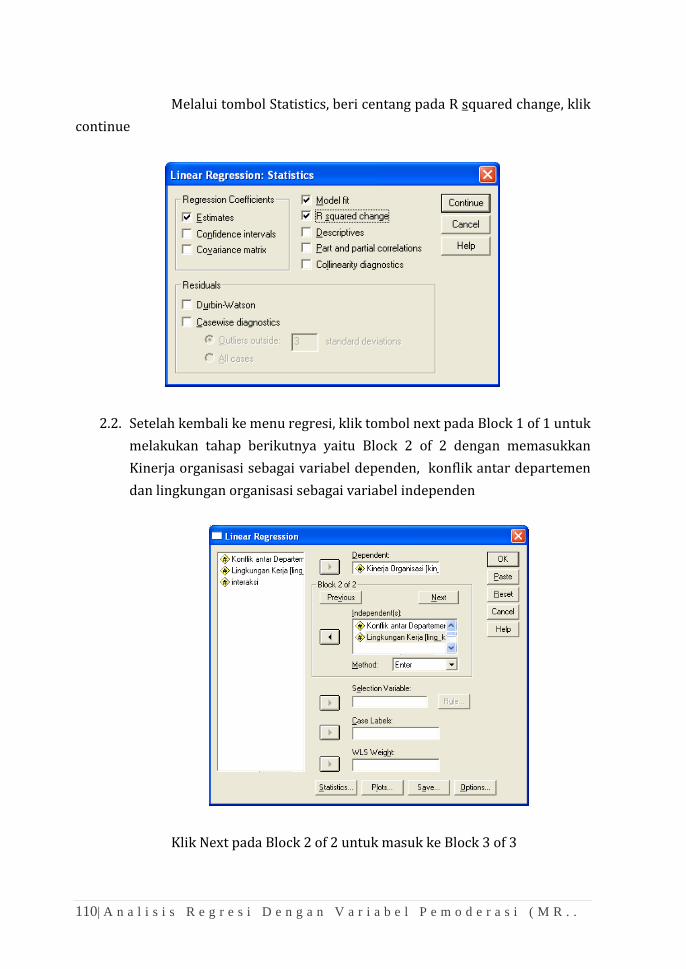
110| A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i ( M R . .
Melalui tombol Statistics, beri centang pada R squared change, klik
continue
2.2. Setelah kembali ke menu regresi, klik tombol next pada Block 1 of 1 untuk
melakukan tahap berikutnya yaitu Block 2 of 2 dengan memasukkan
Kinerja organisasi sebagai variabel dependen, konflik antar departemen
dan lingkungan organisasi sebagai variabel independen
Klik Next pada Block 2 of 2 untuk masuk ke Block 3 of 3
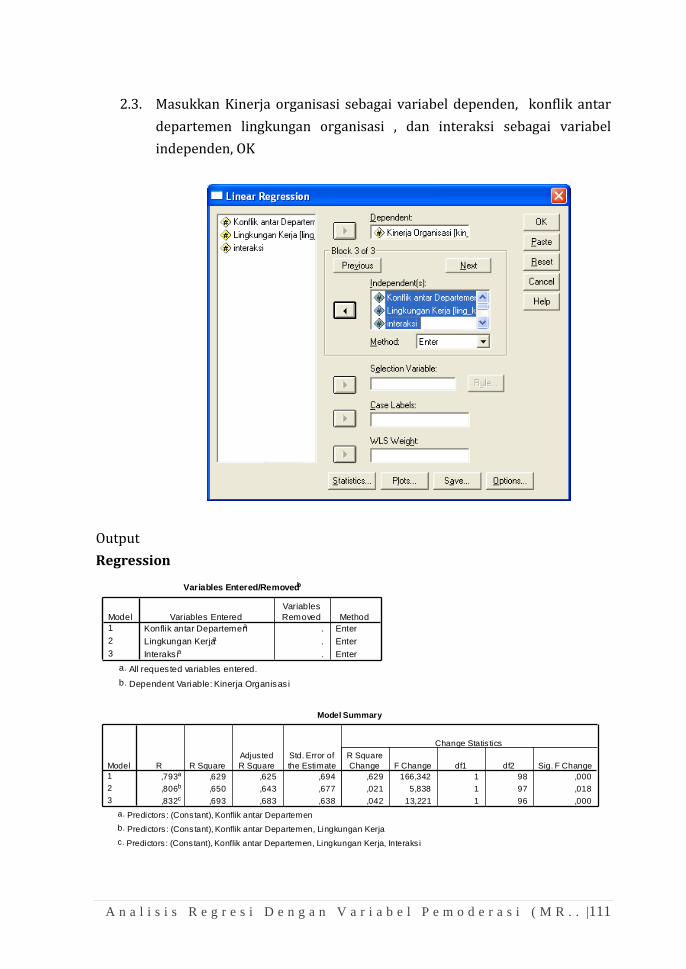
A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i ( M R . . |111
2.3. Masukkan Kinerja organisasi sebagai variabel dependen, konflik antar
departemen lingkungan organisasi , dan interaksi sebagai variabel
independen, OK
Output
Regression
Variables Entered/Removedb
Konflik antar Departemena . Enter
Lingkungan Kerjaa . Enter
Interaks ia . Enter
Model
1
2
3
Variables Entered
Variables
Removed Method
All requested variables entered.a.
Dependent Variable: Kinerja Organisas ib.
Model Summary
,793a ,629 ,625 ,694 ,629 166,342 1 98 ,000
,806b ,650 ,643 ,677 ,021 5,838 1 97 ,018
,832c ,693 ,683 ,638 ,042 13,221 1 96 ,000
Model
1
2
3
R R Square
Adjusted
R Square
Std. Error of
the Estimate
R Square
Change F Change df1 df2 Sig. F Change
Change Statis tics
Predictors : (Constant), Konflik antar Departemena.
Predictors : (Constant), Konflik antar Departemen, Lingkungan Kerjab.
Predictors : (Constant), Konflik antar Departemen, Lingkungan Kerja, Interaks ic.
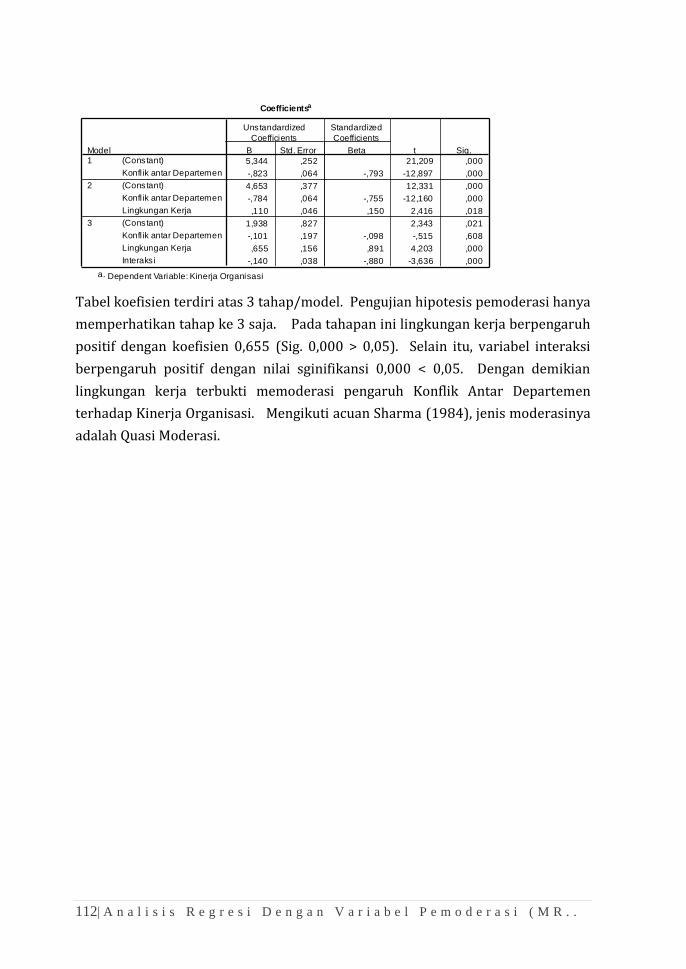
112| A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i ( M R . .
Coefficientsa
5,344 ,252 21,209 ,000
-,823 ,064 -,793 -12,897 ,000
4,653 ,377 12,331 ,000
-,784 ,064 -,755 -12,160 ,000
,110 ,046 ,150 2,416 ,018
1,938 ,827 2,343 ,021
-,101 ,197 -,098 -,515 ,608
,655 ,156 ,891 4,203 ,000
-,140 ,038 -,880 -3,636 ,000
(Constant)
Konfl ik antar Departemen
(Constant)
Konfl ik antar Departemen
Lingkungan Kerja
(Constant)
Konfl ik antar Departemen
Lingkungan Kerja
Interaks i
Model1
2
3
B Std. Error
Unstandardized
Coefficients
Beta
Standardized
Coefficients
t Sig.
Dependent Variable: Kinerja Organisasia.
Tabel koefisien terdiri atas 3 tahap/model. Pengujian hipotesis pemoderasi hanya
memperhatikan tahap ke 3 saja. Pada tahapan ini lingkungan kerja berpengaruh
positif dengan koefisien 0,655 (Sig. 0,000 > 0,05). Selain itu, variabel interaksi
berpengaruh positif dengan nilai sginifikansi 0,000 < 0,05. Dengan demikian
lingkungan kerja terbukti memoderasi pengaruh Konflik Antar Departemen
terhadap Kinerja Organisasi. Mengikuti acuan Sharma (1984), jenis moderasinya
adalah Quasi Moderasi.

A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i ( A n a . . |113
Bab 13
Analisis Regresi Dengan Variabel Pemediasi (Analisis Jalur)
Tujuan Instruksional:
1. Mampu mendeteksi kapan suatu variabel dapat ditempatkan sebagai
variabel mediasi
2. Mampu merumuskan model pengujian dan hipotesis dengan analisis jalur
3. Mampu melakukan pengujian hipotesis dengan metode Kausal-Step dan
Product of Coefficient
4. Mampu menghitung perngaruh langsung dan tidak langsung variabel-
variabel dalam pengujian
Pendahuluan:
Dalam analisis regresi sangat mungkin peneliti menemukan adanya
hubungan tidak langsung antara satu variabel dengan variabel lain. Terdapat satu
variabel yang memperantarai keduanya. Suhu udara bisa saja disimpulkan
mempengaruhi konsumsi bahan bakar mobil, dalam arti semakin tinggi suhu
udara, maka mobil akan semakin boros bahan bakar. Pengaruh tersebut tidaklah
sesederhana itu karena suhu udara tidak serta merta akan mempengaruhi
konsumsi bahan bakar. Sangat logis jika muncul pemikiran bahwa panasnya suhu
udara akan menyebabkan itensitas pemakaian AC semakin tinggi, tingginya
intensitas tersebutlah yang membuat mobil semakin banyak mengkonsumsi
bahan bakar.
Dalam kondisi demikian, maka itensitas pemakaian AC menjadi variabel
mediasi atau intervening. Variabel mediasi adalah variabel yang bersifat menjadi
perantara (mediating) pada pengaruh variabel independen terhadap variabel
dependen. Media tersebut (bisa bersifat partial atau perfect mediation.
Model mediasi memiliki hipotesis bahwa variabel independen
mempengaruhi variabel mediator, dan variabel mediator mempengaruhi variabel
dependen. Mediasi sempurna (perfect mediation) terjadi ketika variabel mediator
dimasukkan dalam persamaan, maka pengaruh variabel independen ke dependen
hilang. Namun jika pengaruhnya berkurang namun tidak sama dengan nol, maka
terjadi mediasi parsial.

114| A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i ( A n a . .
Analisis jalur merupakan suatu teknik untuk menganalisis hubungan sebab
akibat yang terjadi pada regresi berganda jika variabel independennya
mempengaruhi variabel dependen tidak hanya secara langsung, tetapi juga secara
tidak langsung. Hubungan antar variabel dalam analisis jalur ada 2 yaitu :
1. Pengaruh Langsung biasanya digambarkan dengan panah satu arah
dari satu variabel ke variabel lainnya.
2. Pengaruh Tidak Langsung digambarkan dengan panah satu arah pada
satu variabel pada variabel lain, kemudian dari variabel lain panah
satu arah ke variabel berikutnya.
Model Pengujian:
Regresi Tanpa Mediasi
Regresi dengan Mediasi 1
Variabel independen memprediksi M danM memprediksi Y atau:
1. Sebagian variasi X1 bisa memprediksi M dan..
2. Sebagian variasi M bisa memprediksi Y
X1
X2
Y
X1
X2
Y
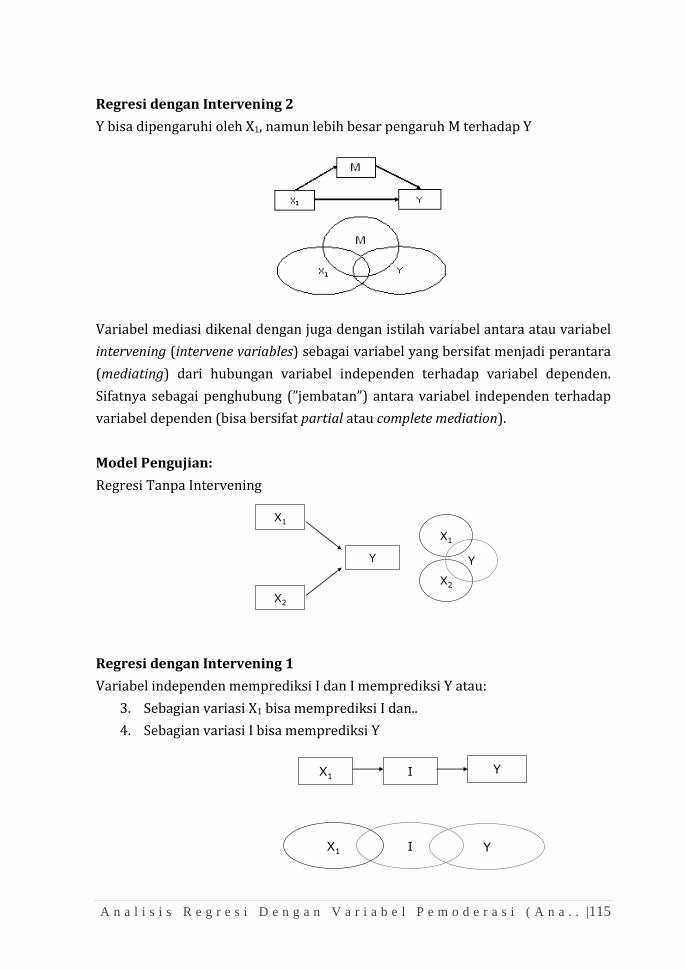
A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i ( A n a . . |115
Regresi dengan Intervening 2
Y bisa dipengaruhi oleh X1, namun lebih besar pengaruh M terhadap Y
Variabel mediasi dikenal dengan juga dengan istilah variabel antara atau variabel
intervening (intervene variables) sebagai variabel yang bersifat menjadi perantara
(mediating) dari hubungan variabel independen terhadap variabel dependen.
Sifatnya sebagai penghubung (”jembatan”) antara variabel independen terhadap
variabel dependen (bisa bersifat partial atau complete mediation).
Model Pengujian:
Regresi Tanpa Intervening
Regresi dengan Intervening 1
Variabel independen memprediksi I dan I memprediksi Y atau:
3. Sebagian variasi X1 bisa memprediksi I dan..
4. Sebagian variasi I bisa memprediksi Y
X1
X2
Y
X1
X2
Y
X1
X1 I Y
I Y

116| A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i ( A n a . .
Regresi dengan Intervening 2
Y bisa dipengaruhi oleh X1, namun lebih besar pengaruh I terhadap Y
Kasus:
Sebuah penelitian dilakukan untuk menganalisis apakah variabel kepuasan
pelanggan (I) memediasi hubungan kausal antara pelayanan (X) terhadap loyalitas
(Y)
Solusi 1 : Metode Kausal Step (Baron dan Kenny,1986)
Langkah & Kriteria:
1. Persamaan 1, pengaruh X terhadap Y, X berpengaruh signifikan terhadap Y
(c≠0)
2. Persamaan 2, pengaruh X terhadap I, X berpengaruh signifikan terhadap I
(a≠0)
3. Persamaan 3, pengaruh X dan I terhadap Y, I berpengaruh signifikan
terhadap Y (b≠0)
4. I adalah :
a. intervening sempurna jika setelah memasukkan I, pengaruh X
terhadap Y menjadi 0 atau tidak signifikan
b. Intervening parsial jika setelah memasukkan I, pengaruh X
terhadap Y menjadi turun tapi tidak menjadi 0 namun masih
signifikan
X1
X1
I
Y
Y
I
Kualitas Layanan Kepuasan Loyalitas
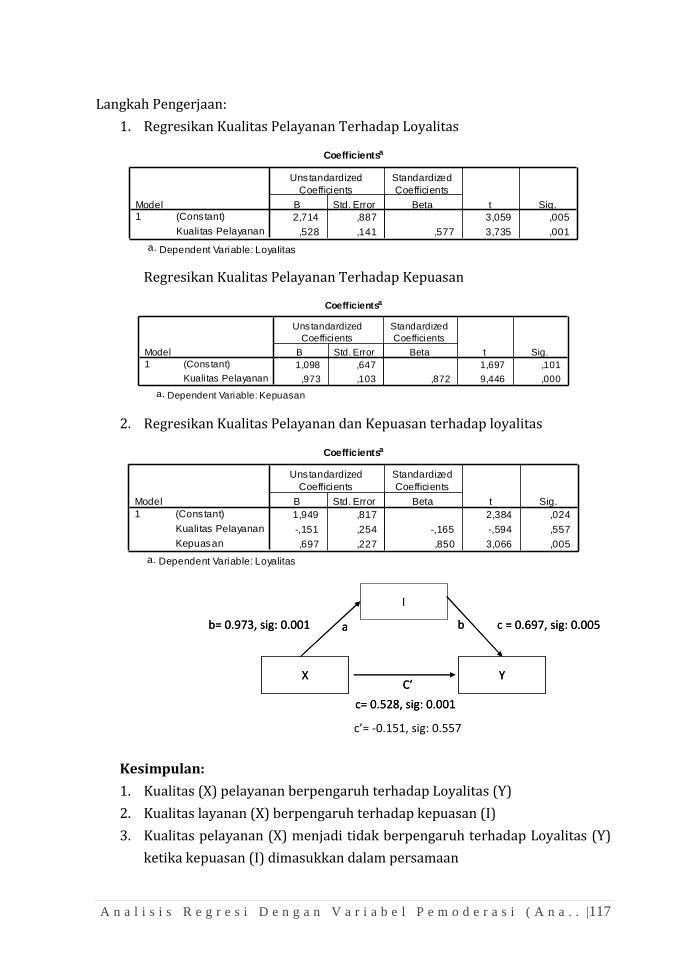
A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i ( A n a . . |117
Langkah Pengerjaan:
1. Regresikan Kualitas Pelayanan Terhadap Loyalitas
Coefficientsa
2,714 ,887 3,059 ,005
,528 ,141 ,577 3,735 ,001
(Constant)
Kualitas Pelayanan
Model1
B Std. Error
Unstandardized
Coefficients
Beta
Standardized
Coefficients
t Sig.
Dependent Variable: Loyalitasa.
Regresikan Kualitas Pelayanan Terhadap Kepuasan
Coefficientsa
1,098 ,647 1,697 ,101
,973 ,103 ,872 9,446 ,000
(Constant)
Kualitas Pelayanan
Model
1
B Std. Error
Unstandardized
Coefficients
Beta
Standardized
Coefficients
t Sig.
Dependent Variable: Kepuasana.
2. Regresikan Kualitas Pelayanan dan Kepuasan terhadap loyalitas
Coefficientsa
1,949 ,817 2,384 ,024
-,151 ,254 -,165 -,594 ,557
,697 ,227 ,850 3,066 ,005
(Constant)
Kualitas Pelayanan
Kepuasan
Model
1
B Std. Error
Unstandardized
Coefficients
Beta
Standardized
Coefficients
t Sig.
Dependent Variable: Loyalitasa.
Kesimpulan:
1. Kualitas (X) pelayanan berpengaruh terhadap Loyalitas (Y)
2. Kualitas layanan (X) berpengaruh terhadap kepuasan (I)
3. Kualitas pelayanan (X) menjadi tidak berpengaruh terhadap Loyalitas (Y)
ketika kepuasan (I) dimasukkan dalam persamaan
X YC’
c= 0.528, sig: 0.001
X YC’
c= 0.528, sig: 0.001
I
ab= 0.973, sig: 0.001 ab= 0.973, sig: 0.001 b c = 0.697, sig: 0.005b c = 0.697, sig: 0.005
c’= -0.151, sig: 0.557

118| A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i ( A n a . .
4. Artinya: kepuasan pelanggan memediasi secara sempurna pengaruh
kualitas pelayanan terhadap loyalitas
Solusi 2 : Metode Product of Coefficient (MacKinnon, Warsi, & Dwyer, 1995)
1. Dilakukan dengan menguji kekuatan pengaruh tidak langsung X terhadap
Y melalui I atau
2. Menguji pengaruh tidak langsung: perkalian pengaruh langsung X
terhadap I (a) dan pengaruh langsung I terhadap Y (b) menjadi ab-
dilakukan berdasarkan rasio antara bc dengan standar error yang akan
menghasilkan nilai statistik
3. Tahapan :
a. Membuat persamaan Regresi X terhadap I untuk mendapatkan
koefisien Regresi (a) dan standar error koefisien regresi (Sa)
b. Membuat persamaan regresi X terhadap Y dengan memasukkan
variabel I untuk mendapatkan koefisien regresi (b ) dan standar error
koefisien regresi (sb)
c. Hitung nilai standar error ab (Sab)
d. Hitung nilai t koefisien ab dengan membagi ab dengan sab
Hasil Tahap 1
Coefficientsa
1,098 ,647 1,697 ,101
,973 ,103 ,872 9,446 ,000
(Constant)
Kualitas Pelayanan
Model
1
B Std. Error
Unstandardized
Coefficients
Beta
Standardized
Coefficients
t Sig.
Dependent Variable: Kepuasana.
222222ab sbsasbasabS ++=
abs
abZ =

A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i ( A n a . . |119
Hasil Tahap 2
Coefficientsa
1,949 ,817 2,384 ,024
-,151 ,254 -,165 -,594 ,557
,697 ,227 ,850 3,066 ,005
(Constant)
Kualitas Pelayanan
Kepuasan
Model
1
B Std. Error
Unstandardized
Coefficients
Beta
Standardized
Coefficients
t Sig.
Dependent Variable: Loyalitasa.
e. Tahap 3: Menghitung nilai standar error ab (Sab) dan menghitung
Hitung nilai t koefisien ab dengan membagi ab dengan sab
Kesimpulan
1. Nilai Z hitung 2,910 lebih besar dari Z tabel pada Alfa 0,05 yaitu 1,96
2. Berarti kepuasan pelanggan memediasi (menjadi variabel intervening)
pengaruh kualitas pelayanan terhadap loyalitas
X Y
I
c
c= -0.151, sig: 0.5571Sc=0.254
c
c= -0.151, sig: 0.5571Sc=0.254
aa= 0.973, sig: 0.001Sa=0.103
aa= 0.973, sig: 0.001Sa=0.103
b b= 0.697, sig: 0.005Sb=0.227
b b= 0.697, sig: 0.005Sb=0.227
222222ab 0,2270,1030,2270,9730,1030,697S ++=
0,0010,0490,005Sab ++= 0,233Sab =
abs
abZ = 2,910
0,233
0,697 x 0,973Z ==
222222ab sbsasbasabS ++=

A n a l i s i s R e g r e s i D e n g a n V a r i a b e l P e m o d e r a s i ( A n a . . |120

R e f e r e n s i |121
Referensi
Amir, Taufiq. 2015. Merancang Kuesioner: Konsep dan Panduan untuk Penelitian
Sikap, Kepribadian & Perilaku, Edisi I. Penerbit: Pranamedia Group, Jakarta.
Asra, Abuzar., dan Rudiansyah. 2013. Statistika Terapan Untuk Pembuat
Kebijakan dan Pengambil Keputusan, edisi kedua. Penerbit: In Media, Bogor
Asra, Abuzar., Utomo, Agung Priyo., Asikin, Munawar., dan Pusponegoro, Novi
Hidayat. 2017. Analisis Multivariabel: Suatu Pengantar. Penerbit: In Media,
Bogor
Baron, R. M., and Kenny, D. A. 1986. The moderator–mediator variable distinction
in social psychological research: Conceptual, strategic, and statistical
considerations. Journal of Personality and Social Psychology, 51(6): 1173–
1182
Breaugh, J. A., & Colihan, J. P. 1994. Measuring facets of job ambiguity: Construct
validity evidence. Journal of Applied Psychology, 79(2), 191–202
Dachlan, Usman. 2014. Panduan Lengkap Structural Equation Modeling
Tingkat Dasar. Penerbit: Lentera Ilmu, Semarang
Dillon, R. W. Dan Goldstein, M. 1984. Multivariate Analysis and Aplications. New
York: John Wiley & Sons, Inc.
Doornik, J. A., and H. Hansen. 2008. An omnibus test for univariate and
multivariate normality. Oxford Bulletin of Economics and Statistics 70: 927–
939
Fornell, C., and Larcker, D. F. 1981. Evaluating Structural Equation Models
with Unobservable Variables and Measurement Error. Journal of
Marketing Research, 18(1): 39 -50
Hair, J. F., Black. W. C., Babin. B. J.; and Anderson. R. E. 2010. Multivariate Data
Analysis, 7th ed. New Jersey: Pearson Prentice Hall
Hu, L., & Bentler, P. M. 1999. Cutoff criteria for fit indexes in covariance structure
analysis: Conventional criteria versus new alternatives. Structural Equation
Modeling, 6: 1–55.

122| R e f e r e n s i
Johnson, R. A., & Wichern, D. W. 1992. Applied multivariate statistical analysis.
Englewood Cliffs, N.J: Prentice Hall.
Kline, Rex B. 2005. Principles and Practice of Structural Equation Modeling,
Second Edition. New York: Guilford Press
Latan, Hengki. 2012. Structural Equation Modelling: Konsep dan Aplikasi
Menggunakan Program Lisrel 9.80. Penerbit: Alfabeta, Bandung
Latan, Hengki. 2014a. Aplikasi Analisis Data Statistik untul Ilmu Sosial Sains
dengan STATA. Penerbit: Alfabeta, Bandung
Latan, Hengki. 2014b. Aplikasi Analisis Data Statistik untul Ilmu Sosial Sains
dengan IBM SPSS. Penerbit: Alfabeta, Bandung
Malhotra, N.K. 2012. Basic Marketing Research : Integration of Social Media,
Fourth Edition. US : Pearson
McLave, James T., Benson. George P., Sinsich, Terry. 2011. Statistik untuk Bisnis
dan Ekonomi, Jiilid 2 edisi 11. Penerbit: Erlangga, Jakarta
Park, H.M. 2008. Univariate Analysis and Normality Test Using SAS, Stata, and SPSS.
Technical Working Paper.
Perrot, Bastien., Bataille,Emmanuelle ., and Hardouin. Jean-Benoit. 2018.
validscale: A Command to Validate Measurement Scales. The Stata Journal,
18(1): 29–50
Raykov, T. 1997. Estimation of composite reliability for congeneric measures.
Applied Psychological Measurement, 21: 173-184.
Razali, Nornadiah Mohd dan Bee Wah Yap. 2011. Power comparisons of Shapiro-
Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling tests. Journal
of Statistical Modeling and Analytics, 2(1): 21-33
Santoso, Singgih. 2006. Seri Solusi Bisnis Berbasis TI: Menggunakan SPSS untuk
Statistik Multivariat. Penerbit: Elex Media Komputindo, Jakarta
Suliyanto, 2011. Ekonometrika Terapan Teori dan Aplikasi dengan SPSS. Penerbit:
CV. Andi Offset, Yogyakarta

R e f e r e n s i |123
Williams, B., Brown, T., Onsman, A. 2010. Journal of Emergency Primary Health
Care (JEPHC), 8(3):1-12
ong, A. G., & Pearce, S. 2013. A beginner’s guide to factor analysis: Focusing on
exploratory factor analysis. Tutorials in Quantitative Methods for Psychology,
9(2): 79–94
Zinbarg, R. E., Revelle, W., Yovel, I. & Li, W. 2005. Cronbach’s a, Revelle’s, b and
McDonalds w: their relations with each other and two alternative
conceptualizations of reliability. Psychometrica, 70(1): 1-11.

124| R e f e r e n s i




















