







Bahasa
Halaman
Hukum


Taming the Elephant
Debanjan MahataDepartment of Information
ScienceUniversity of Arkansas at
Little Rock

Agenda: To get the elephant into your
brains

Overview• The Journey of Hadoop The Elephant
• Hadoop the Elephant Fundas• Story of Sam– How he tamed Hadoop?
• Map and Reduce• Python and the Elephant• Pig

The Characters

Yes This one is too a Love Story
Doug Cutting
Google File System

Birth of An Elephant
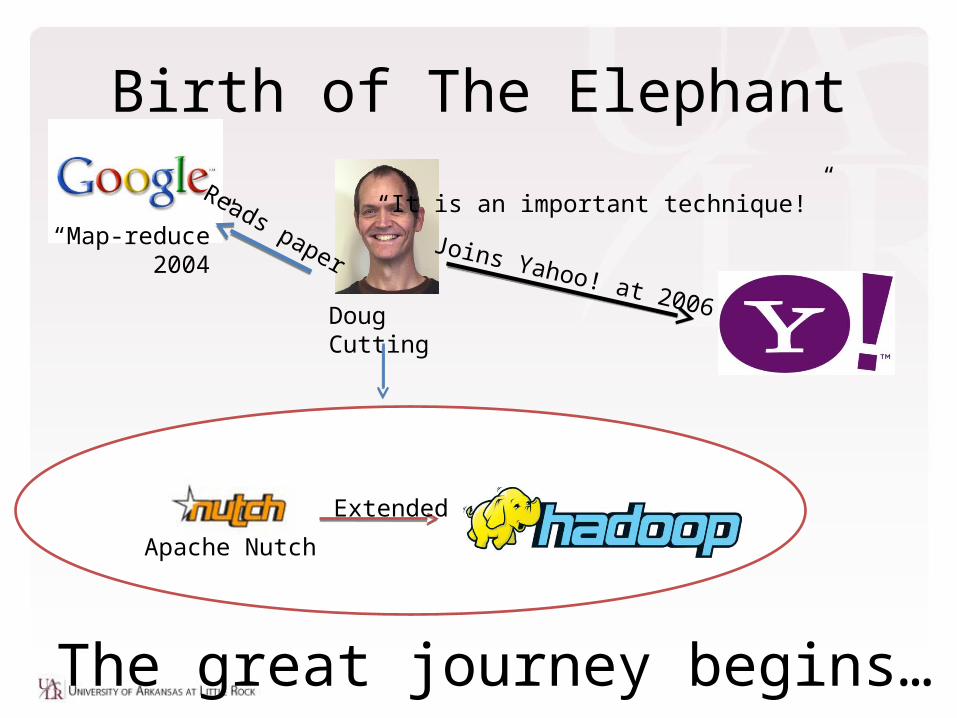
Birth of The Elephant
Apache Nutch
Doug Cutting
“Map-reduce” 2004
“It is an important technique!”Reads paper
Extended
Joins Yahoo! at 2006
The great journey begins…

"The name my kid gave a stuffed yellow elephant. Short, relatively easy to spell and pronounce, meaningless, and not used elsewhere: those are my naming criteria. Kids are good at generating such. Googol is a kid’s term." ---- Doug Cutting, Hadoop project creator
Naming the Elephant

Born to be Scaled• How do you scale up applications?
– Run jobs processing 100’s of terabytes of data
– Takes 11 days to read on 1 computer• Need lots of cheap computers
– Fixes speed problem (15 minutes on 1000 computers), but…
– Reliability problems• In large clusters, computers fail every day• Cluster size is not fixed
• Need common infrastructure– Must be efficient and reliable

• Open Source Apache Project• Hadoop Core includes:
– Distributed File System - distributes data
– Map/Reduce - distributes application• Written in Java• Runs on
– Linux, Mac OS/X, Windows, and Solaris– Commodity hardware
The Environment

Growing Stages• Yahoo! became the primary contributor in 2006

As it Grew• Yahoo! deployed large scale science clusters in 2007.
• Tons of Yahoo! Research papers emerge:– WWW– CIKM– SIGIR– VLDB– ……
• Yahoo! began running major production jobs in 2008.
• Nowadays…
Nowadays…• When you
visit yahoo, you are interacting with data processed with Hadoop!

Nowadays…
Ads Optimizati
on
Content Optimizati
on Search Index
Content Feed
Processing
• When you visit yahoo, you are interacting with data processed with Hadoop!

Nowadays…
Ads Optimizati
on
Content Optimizati
on Search Index
Content Feed
Processing
Machine Learning (e.g. Spam filters)
• When you visit yahoo, you are interacting with data processed with Hadoop!

Nowadays…• Yahoo! has ~20,000 machines running Hadoop• The largest clusters are currently 2000 nodes• Several petabytes of user data (compressed, unreplicated)• Yahoo! runs hundreds of thousands of jobs every month

The Journey of Life Begins

Nowadays…• Who use Hadoop?
• Amazon/A9• AOL• Facebook• Fox interactive media• Google • IBM• New York Times• PowerSet (now Microsoft)• Quantcast• Rackspace/Mailtrust• Veoh• Yahoo!• More at http://wiki.apache.org/hadoop/PoweredBy

A Proud FatherProud Of You My Boy

If You Be friendly With The Elephant

Our own Example
I placed you in Walmart Labs and Amazon.


Clustered Architecture

Hadoop Demystified

HDFSHadoop's Distributed File System is designed to
reliably store very large files across machines in a large cluster. It is inspired by the Google File System. Hadoop DFS stores each file as a sequence of blocks, all blocks in a file except the last block are the same size. Blocks belonging to a file are replicated for fault tolerance. The block size and replication factor are configurable per file. Files in HDFS are "write once" and have strictly one writer at any time.
Hadoop Distributed File System – Goals:• Store large data sets• Cope with hardware failure• Emphasize streaming data access
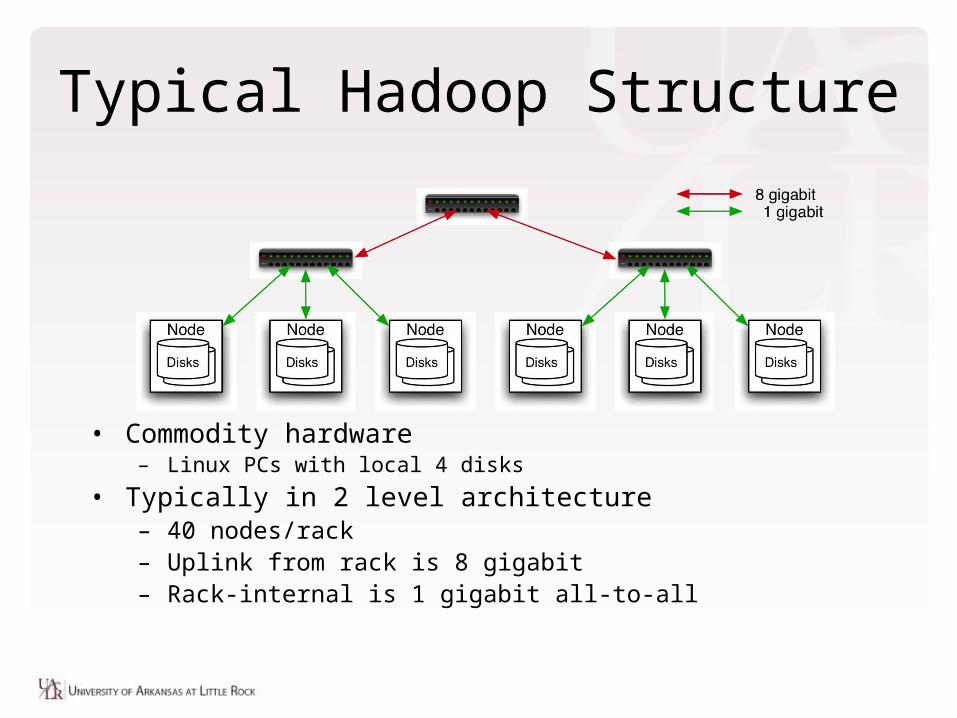
Typical Hadoop Structure
• Commodity hardware– Linux PCs with local 4 disks
• Typically in 2 level architecture– 40 nodes/rack– Uplink from rack is 8 gigabit– Rack-internal is 1 gigabit all-to-all


Hadoop structure• Single namespace for entire cluster
– Managed by a single namenode.– Files are single-writer and append-only.– Optimized for streaming reads of large files.
• Files are broken in to large blocks.– Typically 128 MB– Replicated to several datanodes, for reliability
• Client talks to both namenode and datanodes– Data is not sent through the namenode.– Throughput of file system scales nearly linearly with the number of nodes.
• Access from Java, C, or command line.

Elephant Fundas• Taming the Elephant with Map Reduce
• Courtesy Sam
Believed “an apple a day keeps a doctor away”
Sam’s Mother
Mother
Sam
An Apple

Sam thought of “drinking” the apple
One day
He used a to
cut the and
to make juice.

(map ‘( ))
( )
Sam applied his invention to all the fruits he could find in the fruit basket
Next Day
(reduce ‘( )) Classical Notion of MapReduce in Functional
Programming
A list of values mapped into another list of values, which gets reduced into a single
value

18 Years Later Sam got his first job in JuiceRUs for his talent in making juice
Now, it’s not just one basket but a whole container of fruits
Also, they produce a list of juice types separately
NOT ENOUGH !! But, Sam had just ONE
and ONE
Large data and list of values for output
Wait!
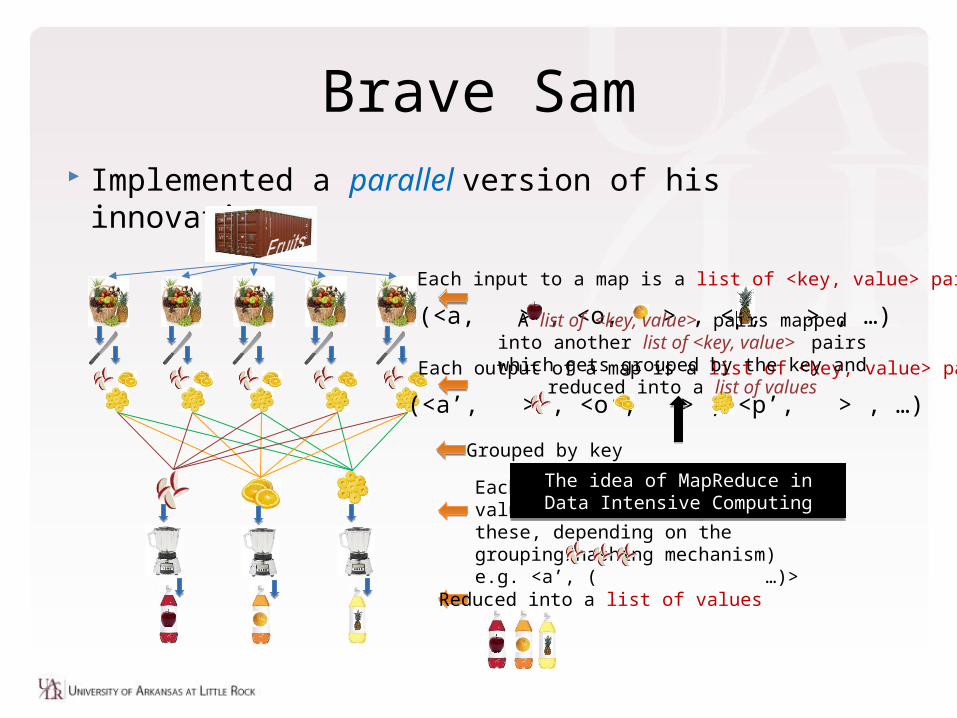
Implemented a parallel version of his innovation
Brave Sam
(<a, > , <o, > , <p, > , …)Each input to a map is a list of <key, value> pairs
Each output of a map is a list of <key, value> pairs
(<a’, > , <o’, > , <p’, > , …)Grouped by keyEach input to a reduce is a <key, value-list> (possibly a list of these, depending on the grouping/hashing mechanism)e.g. <a’, ( …)>
Reduced into a list of values
The idea of MapReduce in Data Intensive Computing
A list of <key, value> pairs mapped into another list of <key, value> pairs which gets grouped by the key and
reduced into a list of values

Sam realized,◦ To create his favorite mix fruit juice he can use a combiner after the reducers
◦ If several <key, value-list> fall into the same group (based on the grouping/hashing algorithm) then use the blender (reducer) separately on each of them
◦ The knife (mapper) and blender (reducer) should not contain residue after use – Side Effect Free
◦ In general reducer should be associative and commutative
Afterwards

Hadoop The Elephant Really Liked Sams’ Fruit
Juice

Applying Sams’ Invention To A Problem Relevant to
Us

Now Utsav Introduces You With Our Star ElephantHey, So All
This For Me. I am really honored.
Thanks a lot.

Python and The Elephant

Python libraries for Hadoop
o Dumboo Hadoopyo Pydoopo Mrjobo Hadoop Streamingo Others

Problems That I Wish To Solve With Hadoop
o Calculating tf_iDf scoreso Calculating feature vectors for large number of documents, blogs, users
o Sorting Indexes to Large Number of Documentso Building a Crawler for collecting event related data from social media
o Building classifierso Entity Resolutiono The list is endless…

Thanks! I Hope You Enjoyed The Elephant
Talk
Top Related
Copyright © 2022 FDOKUMEN

